Embed Size (px)
Citation preview

Einführung in die StochastikWahrscheinlichkeitstheorie und Statistik mit R
Tobias Hell
Skriptum zu den Vorlesungen Stochastik 1 und StatistikUniversität Innsbruck, 2018/19


Vorwort
Die Stochastik als Teilgebiet der Mathematik setzt sich aus den Bereichen Wahrschein-
lichkeitstheorie und Statistik zusammen, so auch dieses zweiteilige Skriptum, es umfasstdie Inhalte der 2013/2014 an der Universität Innsbruck abgehaltenen Vorlesungen Sto-
chastik 1 und Statistik.
Der erste Teil beinhaltet eine Einführung in dieWahrscheinlichkeitstheorie und orientiertsich strukturell sowie an zahlreichen Stellen inhaltlich am englischsprachigen Skriptum[8] und teils an [14]. Des Weiteren dienten abschnittsweise Teile und Aufgaben der Skrip-ten [10, 16, 22] sowie der Bücher [19, 1, 6, 2] als Vorlage.
Im zweiten Teil ndet die Wahrscheinlichkeitstheorie Anwendung in der Statistik. EinigeInhalte dieses Parts sind an die Bücher [4, 20, 17, 5, 9] sowie die beiden Skripten [15, 10]angelehnt, auÿerdem stammen vereinzelt Aufgaben aus diesen Büchern und Skripten.
An einigen Stellen wird die Statistik-Software R verwendet, genauere Informationen, dasManual [21] sowie die Software selbst sind unter
http://www.r-project.org/
frei verfügbar. Programmcode ist in diesem Skriptum stets in grauen Boxen verpackt.
> x=17; y=25;
> x+y
[1] 42
Der Anhang beinhaltet eine kurze Einführung in R, welche sich an [21] orientiert.
Des Weiteren nden sich am Ende einiger Kapitel Schulaufgaben, wovon einige Schul-büchern entnommen sind. Zahlreiche Aufgaben (falls nicht anders angegeben) stammenbeinahe unverändert aus dem unter
https://www.bifie.at/
verfügbaren Aufgabenpool zur Vorbereitung auf die standardisierte Reifeprüfung in Ma-
thematik (Stand: Februar 2013). Es sei betont, dass einige dieser Aufgabenstellungenmeiner Meinung nach unnötig unmathematisch sind und daher sollte man sich mit die-sen Aufgaben besonders kritisch auseinandersetzen.
i

ii
Vielen Dank an Florian Baumgartner, Ingrid Blumthaler, Georg Spielberger, Gregor
Staggl, Florian Stampfer und Alexander Steinicke für beigesteuerte Übungsaufgaben so-wie zahlreiche Anregungen. Insbesondere danke ich Christel Geiÿ für ihre konstruktiveKritik und das Suchen und Finden unzähliger Tippfehler, vor allem in den ersten Ver-sionen des Statistikteils.
Innsbruck, Februar 2013

Inhaltsverzeichnis
I Wahrscheinlichkeitstheorie 1
1. Maÿ- und Wahrscheinlichkeitsräume 31.1. Sigma-Algebren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2. Maÿe und Wahrscheinlichkeitsmaÿe . . . . . . . . . . . . . . . . . . . . . . 121.3. Beispiele diskreter Wahrscheinlichkeitsräume . . . . . . . . . . . . . . . . . 17
1.3.1. Binomialverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.3.2. Hypergeometrische Verteilung . . . . . . . . . . . . . . . . . . . . . 191.3.3. Poisson-Verteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.3.4. Geometrische Verteilung . . . . . . . . . . . . . . . . . . . . . . . . 22
1.4. Bedingte Wahrscheinlichkeiten und Unabhängigkeit . . . . . . . . . . . . . 231.5. Fortsetzung von Maÿen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
1.5.1. Fortsetzungssatz von Carathéodory . . . . . . . . . . . . . . . . . . 291.5.2. Eindeutigkeit von Maÿen . . . . . . . . . . . . . . . . . . . . . . . 331.5.3. Produkträume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 361.5.4. Lebesgue-Maÿ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 441.5.5. Nicht Lebesgue-messbare Mengen . . . . . . . . . . . . . . . . . . . 47
1.6. Beispiele kontinuierlicher Wahrscheinlichkeitsräume . . . . . . . . . . . . . 481.6.1. Gleichverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 481.6.2. Exponentialverteilung . . . . . . . . . . . . . . . . . . . . . . . . . 491.6.3. Normalverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54Schulaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65Kontrollfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
2. Messbare Abbildungen und Zufallsvariable 792.1. Messbare Abbildungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
2.1.1. Eigenschaften messbarer Abbildungen . . . . . . . . . . . . . . . . 852.1.2. Bildmaÿ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
2.2. Verteilung und Verteilungsfunktion . . . . . . . . . . . . . . . . . . . . . . 872.3. Unabhängigkeit von Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . 95Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99Schulaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104Kontrollfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
iii

iv Inhaltsverzeichnis
3. Integration und Erwartungswert 1113.1. Einfache Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1113.2. Konstruktion des Integrals . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
3.2.1. Erster Schritt: Integral einfacher Funktionen . . . . . . . . . . . . . 1123.2.2. Zweiter Schritt: Integral nicht-negativer Funktionen . . . . . . . . . 1133.2.3. Dritter Schritt: Integral messbarer Funktionen . . . . . . . . . . . . 117
3.3. Substitution und Dichten . . . . . . . . . . . . . . . . . . . . . . . . . . . 1213.4. Klassische Sätze der Integrationstheorie . . . . . . . . . . . . . . . . . . . 1243.5. Ungleichungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1333.6. Erwartungswert und Varianz . . . . . . . . . . . . . . . . . . . . . . . . . 1363.7. Gesetze der groÿen Zahlen und zentraler Grenzwertsatz . . . . . . . . . . . 140Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143Schulaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149Kontrollfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
II Statistik 155
4. Einleitung und Überblick 1574.1. Was ist Statistik? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1574.2. Einige Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1584.3. Datenerhebung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1594.4. Stichproben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1604.5. Typische Fragestellungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164Schulaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166Kontrollfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
5. Deskription und Exploration 1695.1. Typen von Merkmalen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1695.2. Empirische Verteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1705.3. Dichten und Histogramme . . . . . . . . . . . . . . . . . . . . . . . . . . . 1735.4. Dichteschätzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1755.5. Statistische Maÿzahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1785.6. Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185Schulaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189Kontrollfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193

Inhaltsverzeichnis v
6. Schätzen 1956.1. Parameterschätzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
6.1.1. Maximum-Likelihood-Prinzip . . . . . . . . . . . . . . . . . . . . . 1976.2. Kondenzschätzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
6.2.1. Kondenzintervall für den Erwartungswert bei bekannter Varianz . 2026.2.2. Statistische Gröÿen normalverteilter Daten . . . . . . . . . . . . . 2046.2.3. Kondenzintervall für den Erwartungswert bei unbekannter Varianz 2096.2.4. Kondenzintervalle für die Varianz . . . . . . . . . . . . . . . . . . 212
Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213Schulaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220Kontrollfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
7. Parametrische Tests 2277.1. Problemstellung und grundlegende Begrie . . . . . . . . . . . . . . . . . 227
7.1.1. Vorgehen bei einem Hypothesentest . . . . . . . . . . . . . . . . . 2297.1.2. Gütefunktion, Macht und p-Wert . . . . . . . . . . . . . . . . . . . 230
7.2. Einstichprobenprobleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2307.2.1. Einfacher Gauÿ-Test . . . . . . . . . . . . . . . . . . . . . . . . . . 2307.2.2. Einfacher t-Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2347.2.3. χ2-Streuungstest . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235
7.3. Zweistichprobenprobleme . . . . . . . . . . . . . . . . . . . . . . . . . . . 2367.3.1. Doppelter Gauÿ-Test . . . . . . . . . . . . . . . . . . . . . . . . . . 2367.3.2. Doppelter t-Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2377.3.3. F -Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2387.3.4. Welch-Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241
7.4. Überblick: Tests für normalverteilte Daten . . . . . . . . . . . . . . . . . . 2427.5. Einfache Varianzanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249Schulaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253Kontrollfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256
8. Nichtparametrische Tests 2598.1. Anpassungstests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
8.1.1. Kolmogorow-Smirnow-Anpassungstests . . . . . . . . . . . . . . . . 2598.1.2. χ2-Anpassungstest . . . . . . . . . . . . . . . . . . . . . . . . . . . 265
8.2. χ2-Unabhängigkeitstest . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2688.3. Vorzeichentest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271
8.3.1. Vorzeichentest für das Einstichprobenproblem . . . . . . . . . . . . 2718.3.2. Vorzeichentest für verbundene Stichproben . . . . . . . . . . . . . . 2738.3.3. Bemerkung zum Vorzeichentest und Rang-Tests . . . . . . . . . . . 275
Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 277

vi Inhaltsverzeichnis
Kontrollfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283
9. Zeitreihen 2859.1. Komponentenmodelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2869.2. Trendbestimmung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287
9.2.1. Globale Regressionsansätze . . . . . . . . . . . . . . . . . . . . . . 2879.2.2. Lokale Ansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287
9.3. Bestimmung der Saison . . . . . . . . . . . . . . . . . . . . . . . . . . . . 288Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 290
A. Eine kurze Einführung in R 291Übungsaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
B. Projektaufgaben 305
C. Antwortschlüssel zu den Kontrollfragen 307

Notation
Es seien Ω eine Menge und A,B ⊂ Ω . Weiters sei I eine beliebige Indexmenge. Wirverwenden die folgenden Bezeichnungen und Schreibweisen.
B P(Ω) := D ⊂ Ω (Potenzmenge von Ω)
B Mit |Ω| bezeichnen wir die Anzahl der Elemente von Ω .
B aii∈I ∈ ΩI . . . über I indizierte Familie von Elementen in Ω
B A ∪B := ω ∈ Ω: ω ∈ A ∨ ω ∈ B (Vereinigung)
B A ∩B := ω ∈ Ω: ω ∈ A ∧ ω ∈ B (Durchschnitt)
B A \B := ω ∈ Ω: ω ∈ A ∧ ω /∈ B (Mengendierenz)
B Ac =: Ω \A := ω ∈ Ω: ω /∈ A (Komplement)
B ∅ = (leere Menge)
B Gilt A ∩B = ∅ , so nennen wir A und B disjunkt.
B Sind A und B disjunkt, so schreiben wir A ]B für die disjunkte Vereinigung.
B N := 1, 2, . . . und N0 := N ∪ 0 (natürliche Zahlen)
B R . . . reelle Zahlen
B Q . . . rationale Zahlen
B χA : Ω→ 0, 1 : χA(ω) :=
1 , ω ∈ A ,0 , ω /∈ A .
(Indikatorfunktion von A)
vii


Teil I
Wahrscheinlichkeitstheorie
1


Kapitel 1
Maÿ- und Wahrscheinlichkeitsräume
Was ein Punkt, ein rechter Winkel, ein Kreis ist, weiÿ ich schon vor der ersten Geo-
metriestunde, ich kann es nur noch nicht präzisieren. Ebenso weiÿ ich schon, was Wahr-
scheinlichkeit ist, ehe ich es definiert habe.H. Freudenthal1
Die Wahrscheinlichkeitstheorie dient der Modellierung zufälliger Phänomene, alsGrundlage dafür wird in diesem Kapitel das Konzept des Wahrscheinlichkeitsraums ein-geführt, welches auf eine Publikation von A. N. Kolmogorow2 im Jahre 1933 zurückgeht.
Ein Wahrscheinlichkeitsraum ist ein Tripel (Ω,F ,P) bestehend aus den folgendendrei Komponenten.
B Die Menge Ω wird als Ergebnismenge oder Menge der Elementarereignissebezeichnet, ein Element ω ∈ Ω als Elementarereignis oder Zustand.
B Bei dem Mengensystem F ⊂ P(Ω) handelt es sich um eine σ-Algebra, welcheman auch den Ereignisraum nennt. Dementsprechend heiÿt eine Menge A ∈ FEreignis, wobei man auch von einer beobachtbaren Teilmenge von Ω spricht.
B DasWahrscheinlichkeitsmaÿ P ordnet jedem Ereignis A ∈ F seine Wahrschein-lichkeit P(A) ∈ [0, 1] zu, welche beschreibt, wie sicher das Ereignis A eintritt.
Mit einem Wahrscheinlichkeitsraum wollen wir ein Zufallsexperiment modellieren, wo-bei es sich dabei um einen zufälligen Vorgang handelt, auf den folgendes zutrit:
B Die Bedingungen, unter denen das Experiment durchgeführt wird, die sogenanntenVersuchsbedingungen, sind genau festgelegt.
B Alle möglichen Ausgänge des Experiments sind im Vorhinein bekannt.
B Das Experiment kann, zumindest theoretisch, beliebig oft unter genau denselbenVersuchsbedingungen wiederholt werden.
Zufallsexperimente können sich wesentlich von etwa den Experimenten der klassischenPhysik unterscheiden, denn dort herrscht das starke Kausalprinzip, nach welchem ähnli-che Ursachen auch ähnliche Wirkungen zur Folge haben. Wirft man beispielsweise einen
1Hans Freudenthal, 19051990, niederländischer Mathematiker und Wissenschaftsdidaktiker2Andrei Nikolajewitsch Kolmogorow, 19031987, russischer Mathematiker
3

4 1. Maÿ- und Wahrscheinlichkeitsräume
Ball mehrmals aus etwa selber Höhe, so wird dieser jedes Mal nach etwa derselben Zeitam Boden aufschlagen, sofern die Versuchsbedingungen bei jeder Durchführung des Ex-periments gleich sind.
Die nachfolgenden Beispiele sollen einen Einblick geben, wie ein Wahrscheinlichkeitsraumzur Modellierung von Zufallsexperimenten verwendet werden kann.
Beispiel 1.1 (Wahrscheinlichkeitsräume)
B Wir betrachten das Zufallsexperiment, welches aus demWurf eines Würfels besteht.Zur Modellierung dieses Experiments wählen wir
Ω := 1, 2, . . . , 6 .Angenommen, jemand würfelt und teilt uns lediglich mit, ob die Augenzahl geradeoder ungerade ist, so können wir nicht entscheiden, ob ein bestimmtes Elementa-rereignis ω ∈ Ω eingetreten ist oder nicht. Dies wird durch die Wahl der σ-Algebra
F := ∅, 1, 3, 5, 2, 4, 6,Ω ⊂ P(Ω)
zum Ausdruck gebracht, F beschreibt also die uns zur Verfügung stehende Infor-mation. Soll es sich um einen fairen Würfel handeln, so werden wir intuitiv dasWahrscheinlichkeitsmaÿ P durch
P (A) :=|A||Ω| =
|A|6
für A ∈ F
denieren. Dann ist die Wahrscheinlichkeit eine gerade Augenzahl zu erhalten
P (2, 4, 6) = 36 = 1
2 .
B Eines der einfachsten Zufallsexperimente ist wohl der Wurf einer Münze. Wir wäh-len
Ω := K,Z ,wobei K für Kopf und Z für Zahl steht. Als geeigneter Ereignisraum dient nun
F := P(Ω) ,
was bedeutet, dass alle möglichen Ereignisse beobachtbar sind. Handelt es sich umeine faire Münze, so würde man vermutlich der Intuition entsprechend P mit
P (K) = P (Z) = 12
wählen. Beispielsweise wäre
Ω := (K,K), (K,Z), (Z,K), (Z,Z)eine mögliche Wahl der Ergebnismenge für den Wurf zweier Münzen.

1. Maÿ- und Wahrscheinlichkeitsräume 5
B Um die zufällige Lebensdauer einer Glühbirne zu modellieren, liegt die Wahl
Ω := [0,∞)
nahe. Was ist in dieser Situation ein sinnvoller Ereignisraum F und welches Wahr-scheinlichkeitsmaÿ P erscheint passend?Diesen Fragen werden wir zu einem späteren Zeitpunkt genau beantworten können,dazu bedarf es jedoch einiger Vorarbeit.
1.1 Sigma-Algebren
Wir wenden uns nun den maÿtheoretischen Grundlagen der Wahrscheinlichkeitstheoriezu. Dabei steht an erster Stelle der Begri der σ-Algebra. Wie bereits eingangs erwähnt,handelt es sich bei einer σ-Algebra um die Menge aller beobachtbaren Ereignisse. Darüberhinaus sind dies die natürlichen Mengensysteme der zufälligen Ereignisse, auf denen Maÿeund somit insbesondere Wahrscheinlichkeitsmaÿe in konsistenter Weise deniert werdenkönnen.
Definition 1.2 (σ-Algebra, Algebra, messbarer Raum)Es sei Ω eine beliebige Menge. Ein Mengensystem F ⊂ P(Ω) wird σ-Algebra auf Ωgenannt, falls die folgenden drei Bedingungen erfüllt sind:
(σ1) Ω ∈ F
(σ2) Ac := Ω \A ∈ F für alle A ∈ F (komplementstabil)
(σ3)⋃∞n=1An ∈ F für alle Folgen An∞n=1 ∈ FN (σ-vereinigungsstabil)
Ein Element A von F wird Ereignis genannt und es tritt ein, falls ω ∈ A , es tritt nichtein, wenn ω /∈ A . Man nennt A ∈ F auch beobachtbar odermessbar. Das Paar (Ω,F)bezeichnet man alsmessbaren Raum. Ein Mengensystem A ⊂ P(Ω) welches (σ1), (σ2)und
(3) A ∪B ∈ A für alle A,B ∈ A (vereinigungsstabil)
erfüllt, wird Algebra auf Ω genannt.
Bemerkung. Es sei F eine σ-Algebra auf Ω .
B Man beachte, dass aufgrund der Komplementstabilität, jede σ-Algebra die leereMenge ∅ enthält. Das unmögliche Ereignis ∅ und das sichere Ereignis Ω sindalso stets beobachtbar.
B Oensichtlich ist F auch eine Algebra auf Ω , denn aus der σ-Vereinigungsstabilitätfolgt die Vereinigungsstabilität, indem man für A,B ∈ F die σ-Vereinigungsstabili-tät auf die Folge An∞n=1 ⊂ F mit A1 = A , A2 = B und An = ∅ für n ∈ 3, 4, . . .anwendet.

6 1. Maÿ- und Wahrscheinlichkeitsräume
B Ist |Ω| <∞ , so gilt
F ist σ-Algebra ⇐⇒ F ist Algebra.
Im Allgemeinen ist jedoch nicht jede Algebra eine σ-Algebra.
B Oftmals werden σ-Algebren und Algebren auch als σ-Körper und Körper be-zeichnet.
Beispiel 1.3 (σ-Algebren)
B Wir beginnen mit den beiden trivialen σ-Algebren. Man überzeugt sich leicht, dasses sich bei der Potenzmenge P(Ω) um eine σ-Algebra handelt. Diese ist bezüglichder Mengeninklusion die gröÿtmögliche σ-Algebra. Die kleinste σ-Algebra lautet∅,Ω .
B Für jede Menge A ⊂ Ω ist ∅, A,Ac,Ω eine σ-Algebra. Nun greifen wir denWurf des Würfels aus Beispiel 1.1 nochmals auf. Die Ergebnismenge lautet dabeiΩ = 1, . . . , 6 und
F = ∅, 1, 3, 5, 2, 4, 6,Ω
ist somit eine σ-Algebra auf Ω . Weiters entspricht dem Würfelergebnis geradeAugenzahl das Ereignis
A := 2, 4, 6 ∈ F .
B Mittels der Ergebnismenge
Ω := (K,K), (K,Z), (Z,K), (Z,Z)
kann das Werfen zweier Münzen modelliert werden, wobei als σ-Algebra die Po-tenzmenge F := P(Ω) gewählt werden kann. Das Ereignis
A := (K,Z), (Z,K), (K,K)
entspricht dem Ausgang mindestens eine Münze fällt auf Kopf des Zufallsexperi-ments.
B Als sinnvolle Ergebnismenge, um die zufällige Lebensdauer einer Glühbirne zu mo-dellieren, haben wir bereits Ω = [0,∞) erkannt. Den Ausgang die Glühbirne funk-tioniert länger als 200 Stunden könnten wir nun durch
A := (200,∞)
ausdrücken. Was ist in diesem Fall jedoch die passende σ-Algebra? Wie wir sehenwerden, ist es jedenfalls nicht die Potenzmenge, diese wäre zu groÿ.

1. Maÿ- und Wahrscheinlichkeitsräume 7
Dass nicht jede Algebra auch eine σ-Algebra ist, wird aus den beiden nachfolgendenBeispielen ersichtlich.
Beispiel 1.4 (Algebra, aber keine σ-Algebra)
B Es sei Ω eine Menge mit |Ω| =∞ . Dann ist
A := A ⊂ Ω: A oder Ac ist endlich
eine Algebra auf Ω , welche nit-konite Algebra auf Ω genannt wird. Diese istjedoch keine σ-Algebra.
B Das Mengensystem
A := (a1, b1] ] . . . ] (an, bn] : n ∈ N ,−∞ ≤ a1 ≤ b1 ≤ . . . ≤ an ≤ bn ≤ ∞ ,
wobei wir für a ∈ R := R ∪ −∞,∞ die Konventionen (a,∞] := (a,∞) und(a, a] := ∅ treen, ist eine Algebra auf R , vgl. Aufgabe (1.9), jedoch handelt essich um keine σ-Algebra, denn
An :=(0, 1− 1
n
]∈ A
für alle n ∈ N , aber
⋃
n∈NAn = (0, 1) /∈ A ,
vgl. Aufgabe (1.18). Auf die Algebra A werden wir bei der Konstruktion desLebesgue-Maÿes wieder treen.
Eine σ-Algebra ist komplementstabil, daher ist die Forderung der σ-Vereinigungsstabili-tät äquivalent zu jener der σ-Schnittstabilität, wie wir im Folgenden zeigen werden. Dazuwird folgender Satz benötigt, dessen Beweis als Übung verbleibt.
Satz 1.5 (De Morgansche3 Regeln)Es sei Ω eine Menge und es bezeichne J eine beliebige Indexmenge. Für eine FamilieAjj∈J von Teilmengen von Ω gilt
( ⋃
j∈JAj
)c
=⋂
j∈JAcj und
( ⋂
j∈JAj
)c
=⋃
j∈JAcj .
Beweis. Aufgabe (1.5).
3Augustus De Morgan, 18061871, englischer Mathematiker

8 1. Maÿ- und Wahrscheinlichkeitsräume
Ein Mengensystem G ⊂ P(Ω) wird σ-schnittstabil genannt, falls
∞⋂
n=1
An ∈ G für alle Folgen An∞n=1 ∈ GN .
Satz 1.6 (σ-∪-stabil ⇔ σ-∩-stabil)Für ein komplementstabiles Mengensystem G ⊂ P(Ω) gilt
G ist σ-vereinigungsstabil ⇐⇒ G ist σ-schnittstabil .
Beweis. Die Aussage folgt direkt aus den De Morganschen Regeln, denn ist bei-spielsweise G ein σ-vereinigungsstabiles Mengensystem, so erhalten wir für die FolgeAn∞n=1 ∈ GN , dass
∞⋂
n=1
An =
( ∞⋃
n=1
Acn
)c
∈ G .
Die andere Richtung zeigt man analog.
Viele σ-Algebren können nicht explizit angegeben werden, jedoch kann man nichtsde-stotrotz in der Praxis sehr gut mit ihnen umgehen. Etwa liefert nachfolgender Satz eineinfaches Verfahren um σ-Algebren zu konstruieren.
Satz 1.7 (Schnitte von σ-Algebren)Es sei Fjj∈J eine Familie von σ-Algebren auf Ω , wobei J 6= ∅ eine beliebige Index-menge bezeichnet. Dann ist
F :=⋂
j∈JFj
ebenfalls eine σ-Algebra auf Ω .
Beweis. Wir weisen die drei denierenden Eigenschaften einer σ-Algebra nach.
(σ1) Da Ω ∈ Fj für alle j ∈ J , ist
Ω ∈⋂
j∈JFj = F .
(σ2) Komplementstabilität: Es sei A ∈ F . Dann ist A ∈ Fj und somit Ac ∈ Fj füralle j ∈ J , woraus unmittelbar Ac ∈ F folgt. Somit ist F komplementstabil.

1. Maÿ- und Wahrscheinlichkeitsräume 9
(σ3) σ-∪-Stabilität: Es sei An∞n=1 eine Folge in F . Für jedes j ∈ J gilt F ⊂ Fj unddaher ist An∞n=1 ∈ FNj , somit gilt
∞⋃
n=1
An ∈ Fj ,
denn Fj ist eine σ-Algebra und daher insbesondere σ-vereinigungsstabil. Dies giltfür alle j ∈ J und somit ist
∞⋃
n=1
An ∈ F ,
folglich auch F σ-vereinigungsstabil.
Damit ist gezeigt, dass der Durchschnitt von σ-Algebren wieder eine σ-Algebra ist.
Bemerkung. Die Vereinigung zweier σ-Algebren ist im Allgemeinen keine σ-Algebra,vgl. Aufgabe (1.11).
Obiger Satz gibt Anlass die von einem Mengensystem erzeugte σ-Algebra zu denieren.
Satz und Definition 1.8 (Erzeugte σ-Algebra)Zu G ⊂ P(Ω) existiert eine bezüglich der Mengeninklusion kleinste σ-Algebra, welche Genthält. Setzt man JG := F ist σ-Algebra auf Ω mit G ⊂ F , so ist diese durch
σ(G) :=⋂
F∈JG
F
gegeben und wird von G erzeugte σ-Algebra genannt. Das Mengensystem G heiÿt dannErzeuger von σ(G) .
Beweis. Die Menge JG ist nicht-leer, denn P(Ω) ist eine σ-Algebra auf Ω , welche Genthält. Nach Satz 1.7 ist somit
σ(G) =⋂
F∈JG
F
eine σ-Algebra und es bleibt noch zu zeigen, dass dies die kleinste ist, welche G enthält.Jede σ-Algebra F mit G ⊂ F liegt in JG und daher gilt σ(G) ⊂ F , was den Beweisvollendet.
Bemerkung. Insbesondere gilt für G1,G2 ⊂ P(Ω) mit G1 ⊂ G2 , dass σ(G1) ⊂ σ(G2) ,siehe Aufgabe (1.12).

10 1. Maÿ- und Wahrscheinlichkeitsräume
Wir sind nun in der Lage eine der wichtigsten σ-Algebren zu konstruieren, die Borel-σ-Algebra auf Rd , wobei d ∈ N . Zuvor jedoch wiederholen wir die Denition oener undabgeschlossener Mengen in Rd .
Definition 1.9(Offene und abgeschlossene Mengen in Rd
)
Eine Menge O ⊂ Rd heiÿt oen in Rd , wenn zu jedem x ∈ O ein ε > 0 existiert, sodass
Bε(x) =y ∈ Rd : ‖x− y‖ < ε
⊂ O ,
wobei ‖·‖ die euklidische Norm auf Rd bezeichnet. Die Menge A ⊂ Rd wird abgeschlos-sen in Rd genannt, wenn ihr Komplement Ac = Rd \A oen ist.
Definition 1.10(Borel4-σ-Algebra auf Rd
)
Die von
GO :=O ⊂ Rd oen
erzeugte σ-Algebra auf Rd wird Borel-σ-Algebra genannt und mit B(Rd)bezeichnet,
ein Element B ∈ B(Rd)als Borel-Menge oder als Borel-messbar.
Bemerkung. Die Borel-σ-Algebra auf Rd wird auch von
GA :=A ⊂ Rd abgeschlossen
erzeugt, es gilt also σ (GA) = σ (GO) = B(Rd). Für A ∈ GA folgt Ac ∈ GO und somit
A ∈ σ (GO) . Daher ist GA ⊂ σ (GO) , dies wiederum impliziert σ (GA) ⊂ σ (GO) . Dieumgekehrte Inklusion zeigt man analog, vgl. Aufgabe (1.17).
Satz 1.11 (Erzeuger der Borel-σ-Algebra)Die folgenden Mengensystem erzeugen B(R) .
GO = O ⊂ R oen , GA = A ⊂ R abgeschlossen ,G1 = (a, b) : a < b , G2 = [a, b] : a < b ,G3 = (a, b] : a < b , G4 = [a, b) : a < b ,G5 = (−∞, x) : x ∈ R , G6 = (−∞, x] : x ∈ R .
Beweis. Die Aussage des Satzes ist auf mehrere Aufgaben verteilt, vgl. (1.17), (1.20) und(1.21).
In vielen Fällen möchte man etwa anstelle der σ-Algebra B(R) auf R eine gleichwertigeσ-Algebra auf beispielsweise dem abgeschlossenen Einheitsintervall [0, 1] betrachten. Wiewir nun sehen werden, kann dies durch die Einschränkung von B(R) auf die Menge [0, 1]erreicht werden.
4Félix Édouard Justin Émile Borel, 18711956, französischer Mathematiker und Politiker

1. Maÿ- und Wahrscheinlichkeitsräume 11
Definition 1.12 (Spur-σ-Algebra)Es sei F eine σ-Algebra auf Ω und A ⊂ Ω . Dann heiÿt
F|A := B ∩A : B ∈ F
Spur-σ-Algebra oder Einschränkung von F auf A .
Zu zeigen, dass es sich bei einer Spur-σ-Algebra tatsächlich um eine σ-Algebra handelt,verbleibt als Übung, vgl. Aufgabe (1.12).
Lemma 1.13 (Spur-σ-Algebra und Erzeuger)Für ein Mengensystem G ⊂ P(Ω) und A ⊂ Ω gilt
σ (B ∩A : B ∈ G) = B ∩A : B ∈ σ(G) .
Beweis. Wir setzen G ∩ A := B ∩A : B ∈ G und σ(G) ∩ A := B ∩A : B ∈ σ(G) .Aus G ⊂ σ(G) folgt G ∩A ⊂ σ(G) ∩A . Da σ(G) ∩A eine σ-Algebra ist, gilt somit
σ(G ∩A) ⊂ σ(G) ∩A .
Wir betrachten das Mengensystem
Σ := B ∈ σ(G) : B ∩A ∈ σ(G ∩A) .
Oenbar ist Σ eine σ-Algebra und somit erhalten wir
σ(G) ⊂ σ(Σ) = Σ ⊂ σ(G) .
Also ist σ(G) = Σ und damit die Aussage gezeigt.
Gegeben sei die Borel-Menge B ∈ B(Rd). Dann wird die Spur-σ-Algebra
B(Rd)∣∣∣B
=A ∩B : A ∈ B
(Rd)
mit B(B) bezeichnet und Borel-σ-Algebra auf B genannt. Des Weiteren gilt nach Lem-ma 1.13
B (B) = σ(B ∩ O : O ⊂ Rd oen
),
vgl. Aufgabe (1.22). Beispielsweise erhält man so B ([0, 1]) , die Borel-σ-Algebra auf demabgeschlossenen Einheitsintervall [0, 1] .

12 1. Maÿ- und Wahrscheinlichkeitsräume
1.2 Maÿe und Wahrscheinlichkeitsmaÿe
In diesem Abschnitt führen wir nun die letzte Komponente eines Wahrscheinlichkeits-raums (Ω,F ,P) ein, das Wahrscheinlichkeitsmaÿ P . Im Weiteren bezeichne F stets eineσ-Algebra auf Ω . Wir führen nun die für die Denition eines Maÿes entscheidende Ei-genschaft ein.
Definition 1.14 (σ-Additivität)Eine Mengenfunktion µ : F → [0,∞] nennt man σ-additiv, wenn
µ
( ∞⊎
n=1
An
)=
∞∑
n=1
µ(An)
für alle Folgen An∞n=1 ∈ FN paarweise disjunkter messbarer Mengen.
Definition 1.15 (Maÿ und Wahrscheinlichkeitsmaÿ)Eine Mengenfunktion µ : F → [0,∞] heiÿt Maÿ auf (Ω,F) , falls
(µ1) µ(∅) = 0 ,
(µ2) µ eine σ-additive Abbildung ist.
Das Tripel (Ω,F , µ) bezeichnet man dann als Maÿraum. Ist P ein Maÿ auf (Ω,F) mit
(P1) P(Ω) = 1 , (P ist normiert)
so nennt man P einWahrscheinlichkeitsmaÿ auf (Ω,F) und das Tripel (Ω,F ,P) einenWahrscheinlichkeitsraum.
Bemerkung. Jedes Maÿ µ ist insbesondere additiv, d. h. für paarweise disjunkte Er-eignisse A1, . . . , An ∈ F , n ∈ N , gilt
µ
(n⊎
i=1
Ai
)=
n∑
i=1
µ(Ai) .
Dies folgt direkt aus der σ-Additivität durch Verwendung der Folge Ai∞i=1 ∈ FN mitAi = ∅ für i > n . Ist auÿerdem Ω endlich, so ist das Maÿ µ genau dann σ-additiv, wennes additiv ist.
Definition 1.16 (Endliche und σ-endliche Maÿe)Ein Maÿ µ auf (Ω,F) heiÿt endlich, falls µ(Ω) < ∞ , und σ-endlich, wenn eine FolgeΩn∞n=1 ∈ FN existiert, sodass
Ω =
∞⋃
n=1
Ωn und µ(Ωn) <∞ für alle n ∈ N .

1. Maÿ- und Wahrscheinlichkeitsräume 13
Oensichtlich ist jedes Wahrscheinlichkeitsmaÿ ein endliches Maÿ, und jedes endliche Maÿinsbesondere σ-endlich. Wir widmen uns nun einigen ersten Eigenschaften von Maÿenbzw. Wahrscheinlichkeitsmaÿen.
Satz 1.17 (Eigenschaften von Wahrscheinlichkeitsmaÿen)Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum. Dann gelten für A,B ∈ F die folgendenAussagen:
(1) B \A ∈ F und P(B \A) = P(B)− P(A ∩B)
(2) P(A ∪B) = P(A) + P(B)− P(A ∩B)
(3) A ⊂ B ⇒ P(A) ≤ P(B) (Monotonie)
(4) P (Ac) = 1− P(A)
(1), (2) und (3) gelten nicht nur für Wahrscheinlichkeitsmaÿe, sondern für beliebige Maÿe.
Beweis. Da B \A = B ∩Ac , vgl. Aufgabe (1.3), ist B \A ∈ F und aus
A ∪B = A ] (B \A) und B = (A ∩B) ] (B \A) ,
vgl. Aufgabe (1.4), und der Additivität von P folgt daher
P(A ∪B) = P(A) + P(B \A) und P(B) = P(A ∩B) + P(B \A) ,
damit sind (1) und (2) gezeigt. Ist nun A ⊂ B , so erhalten wir aus (1)
P(B) = P(A) + P(B \A) ≥ P(A)
und somit (3). Anwendung von (1) führt auf
P(Ac)
= P(Ω \A) = P(Ω)− P(Ω ∩A) = 1− P(A) ,
wobei wir nun erstmals verwendet haben, dass es sich bei P nicht nur um ein Maÿ,sondern um ein Wahrscheinlichkeitsmaÿ handelt.
Bemerkung. Obiger Satz gibt Anlass zu einigen Folgerungen und Denitionen.
B Die Mengenfunktion P : F → [0, 1] ist genau dann ein Wahrscheinlichkeitsmaÿ aufdem messbaren Raum (Ω,F) , wenn
(P1) P(Ω) = 1 ,
(P2) P ist σ-additiv .

14 1. Maÿ- und Wahrscheinlichkeitsräume
B Zu einem Ereignis A ∈ F gibt P(A) ∈ [0, 1] die Wahrscheinlichkeit an, dass Aeintritt. Ist P(A) = 0 , so nennt man A ein fast unmögliches Ereignis, fallsP(A) = 1 gilt, bezeichnet man A als fast sicheres Ereignis, dieses tritt fastsicher ein.
B Ist µ ein Maÿ auf (Ω,F) , so nennt man eine Menge A ∈ F mit µ(A) = 0 auchNullmenge.
B Das Ereignis Ac wird das zu A ∈ F komplementäre Ereignis genannt. NachSatz 1.17 ist die Wahrscheinlichkeit P(A) genau dann bekannt, wenn es die Kom-plementärwahrscheinlichkeit P (Ac) ist, denn P (Ac) = 1 − P(A) . Zu wissenmit welcher Wahrscheinlichkeit ein Ereignis eintritt ist also gleichbedeutend damit,zu wissen mit welcher Wahrscheinlichkeit es nicht eintritt.
Beispiel 1.18 (Dirac5-Maÿe und Zählmaÿe)Es folgen erste Beispiele von Maÿen.
B Es sei F eine σ-Algebra auf Ω und ω0 ∈ Ω fest. Dann wird durch
δω0(A) :=
1 , ω0 ∈ A ,0 , ω0 /∈ A ,
A ∈ F , ein Wahrscheinlichkeitsmaÿ auf (Ω,F) deniert, welches man als Dirac-Maÿ oder Punktmaÿ in ω0 bezeichnet. Die fast sicheren Ereignisse bezüglich δω0
sind dann gerade jene, welche das Elementarereignis ω0 enthalten.
B Insbesondere Linearkombinationen von Dirac-Maÿen sind von groÿer Bedeutung.Betrachten wir beispielsweise den Wurf einer fairen Münze, so kann dieses Zufalls-experiment mittels des Wahrscheinlichkeitsraums
(K,Z,P(K,Z), 1
2δK + 12δZ)
modelliert werden, vgl. Satz 1.19.
B Es sei Ω eine Menge und F := P(Ω) . Das durch
µ(A) := |A| , A ⊂ Ω ,
denierte Maÿ heiÿt Zählmaÿ auf Ω und es gibt an, aus wievielen Elementarereig-nissen sich ein Ereignis zusammensetzt. Es handelt sich hierbei oensichtlich umkein Wahrscheinlichkeitsmaÿ, falls |Ω| ≥ 2 .
Wie bereits aus obigem Beispiel ersichtlich, spielen Linearkombinationen vonWahrschein-lichkeitsmaÿen oft eine wichtige Rolle.
5Paul Adrien Maurice Dirac, 19021984, britischer Physiker und Nobelpreisträger

1. Maÿ- und Wahrscheinlichkeitsräume 15
Satz 1.19 (Linearkombination von Wahrscheinlichkeitsmaÿen)Für n ∈ N seien P1, . . . ,Pn Wahrscheinlichkeitsmaÿe auf (Ω,F) und α1, . . . , αn ≥ 0 mit
n∑
k=1
αk = 1 .
Dann ist die Linearkombination
P :=n∑
k=1
αkPk
ebenfalls ein Wahrscheinlichkeitsmaÿ auf (Ω,F) .
Beweis. Aufgabe (1.24)
Definition 1.20 (Laplace6-Raum)Es sei Ω 6= ∅ eine endliche Menge. Dann wird durch
UΩ(A) :=|A||Ω| für A ⊂ Ω
ein Wahrscheinlichkeitsmaÿ auf (Ω,P(Ω)) deniert. Man nennt UΩ uniforme Ver-teilung oder (diskrete) Gleichverteilung auf Ω und den Wahrscheinlichkeitsraum(Ω,P(Ω),UΩ) Laplace-Raum. Die Gleichverteilung UΩ kann auch als
UΩ =1
|Ω|∑
ω∈Ω
δω
geschrieben werden.
Beispiel 1.21 (Fairer Würfel)Setzen wir Ω := 1, . . . , 6 , so modelliert der Laplace-Raum (Ω,P(Ω),UΩ) den Wurfeines fairen Würfels, denn
UΩ(ω) = 16 für alle ω ∈ Ω
und somit haben alle Elementarereignisse die gleiche Wahrscheinlichkeit einzutreten. Diesbedeutet, alle Augenzahlen sind gleich wahrscheinlich. Die Gleichverteilung auf Ω lässtsich wiederum als
UΩ =1
6
6∑
k=1
δk
6Pierre-Simon Marquis de Laplace, 17491827, französischer Mathematiker und Astronom

16 1. Maÿ- und Wahrscheinlichkeitsräume
darstellen. Dann ist etwa
UΩ (gerade Augenzahl) = UΩ (2, 4, 6) = 12
und
UΩ (keine 6) = 1− UΩ(6) = 56 .
Ohne die jeweiligen Wahrscheinlichkeiten explizit zu berechnen, kann aus 1 ⊂ 1, 3, 5sofort UΩ(1) ≤ UΩ (1, 3, 5) geschlossen werden. Der nachfolgende Satz beinhaltet weitere wichtige Eigenschaften von Maÿen bzw. Wahr-scheinlichkeitsmaÿen. Zuerst legen wir jedoch noch zwei Schreibweisen fest. Für eine FolgeAn∞n=1 ∈ P(Ω)N schreiben wir
An ↑ A , falls A1 ⊂ A2 ⊂ . . . und A =
∞⋃
n=1
An ,
und wir schreiben
An ↓ A , falls A1 ⊃ A2 ⊃ . . . und A =∞⋂
n=1
An .
Satz 1.22 (σ-Subadditivität und Stetigkeit)Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum. Für An∞n=1 ∈ FN gelten die folgendenAussagen:
(1) P
( ∞⋃
n=1
An
)≤∞∑
n=1
P(An) (σ-subadditiv)
(2) Falls An ↑ A , so gilt limn→∞
P(An) = P(A) . (Stetigkeit von unten)
(3) Gilt An ↓ A , dann ist limn→∞
P(An) = P(A) . (Stetigkeit von oben)
(1) und (2) gelten nicht nur für Wahrscheinlichkeitsmaÿe, sondern für beliebige Maÿe.
Beweis. (1) Wir setzen B1 := A1 und Bn := Ac1 ∩ . . .∩Ac
n−1 ∩An für n ∈ 2, 3, . . . . DaBn ⊂ An , ist P(Bn) ≤ P(An) . Auÿerdem gilt Bi ∩Bj = ∅ für i 6= j und somit ist
P
( ∞⋃
n=1
An
)= P
( ∞⊎
n=1
Bn
)=∞∑
n=1
P(Bn) ≤∞∑
n=1
P(An) .
(2) Nun setzen wir B1 := A1 und Bn := An \An−1 für n = 2, 3, . . . und erhalten
∞⋃
n=1
An =
∞⊎
n=1
Bn .

1. Maÿ- und Wahrscheinlichkeitsräume 17
Folglich ist
P
( ∞⋃
n=1
An
)= P
( ∞⊎
n=1
Bn
)= lim
N→∞
N∑
n=1
P(Bn) = limN→∞
P(AN ) .
Aussage (3) ist eine Übung, siehe Aufgabe (1.27).
1.3 Beispiele diskreter Wahrscheinlichkeitsräume
Wir bezeichnen einen Wahrscheinlichkeitsraum (Ω,F ,P) als diskret, wenn Ω höchstensabzählbar ist. Für endliches Ω haben wir bereits den Laplace-Raum (Ω,P(Ω),UΩ) alsBeispiel eines diskreten Wahrscheinlichkeitsraumes kennengelernt, in diesem Abschnittfolgen nun weitere.
1.3.1 Binomialverteilung
Wir führen die Binomialverteilung anhand eines der einfachsten Zufallsexperimente ein,dem Münzwurf.
Problemstellung. Eine Münze falle mit Wahrscheinlichkeit p ∈ (0, 1) auf Kopf undmit Wahrscheinlichkeit 1− p auf Zahl. Was ist für n ∈ N und k ∈ 0, . . . , n die Wahr-scheinlichkeit, dass man bei n-maligem Werfen der Münze k-mal Kopf erhält?
Modellierung. Wir wählen die Ergebnismenge Ω := 0, . . . , n , dies entspricht demgleichzeitigen Werfen n identer Münzen, und die σ-Algebra F := P(Ω) . Für k ∈ Ω gibt
Bn,p (k) :=
(n
k
)pk(1− p)n−k
die Wahrscheinlichkeit an, bei n-maligem Werfen der Münze k-mal Kopf zu erhalten.
Definition 1.23 (Binomialverteilung)Für n ∈ N sei Ω := 0, . . . , n und weiters sei p ∈ (0, 1) . Das Wahrscheinlichkeitsmaÿ
Bn,p :=n∑
k=0
(n
k
)pk(1− p)n−kδk
auf (Ω,P(Ω)) heiÿt Binomialverteilung mit Parametern n , der Anzahl der Versuche,und p , der Erfolgswahrscheinlichkeit.
Dass es sich bei der Binomialverteilung tatsächlich um ein Wahrscheinlichkeitsmaÿ han-delt, folgt aus dem Binomischen7 Lehrsatz, denn
n∑
k=0
(n
k
)pk(1− p)n−k = (p+ (1− p))n = 1 ,
7Giacomo Francesco Alessandro Binomi, 14721483, italienischer Mathematiker

18 1. Maÿ- und Wahrscheinlichkeitsräume
und Satz 1.19.
0 2 4 6 8 100
0.1
0.2
1 3 5 7 9 0 2 4 6 8 100
0.1
0.2
1 3 5 7 9
Abbildung 1.1. Stabdiagramme zur Binomialverteilung B10,p mit p = 1/2 (links) undp = 1/3 (rechts)
Die Linearkombination von Dirac-Maÿen lässt sich sehr gut mittels eines Stabdia-gramms veranschaulichen, vgl. Abbildung 1.1.
Die mehrfache Durchführung eines Zufallsexperiments, welches nur zwei mögliche Aus-gänge zulässt, man spricht hierbei von Erfolg und Misserfolg, nennt man auch Ber-noulli8-Versuch oder Bernoulli-Prozess. Genauer wird das Zufallsexperiment hierbeihöchstens abzählbar oft durchgeführt. Die Binomialverteilung gibt also die Wahrschein-lichkeit an, wie oft sich bei einem endlichen Bernoulli-Versuch Erfolg einstellt. Neben demMünzwurf liefert das Ziehen mit Zurücklegen von Kugeln aus einer Urne ein Beispiel einesBernoulli-Versuchs, vgl. Aufgabe (1.30).
Beispiel 1.24 (Übertragungsrate)Angenommen, es gibt n Kommunikationskanäle zwischen zwei Standorten A und B ,wobei jeder Kanal eine Übertragungsrate von ρ > 0 (z. B. ρ Bits pro Sekunde) besitzt.Werden k der n Kanäle zur Übertragung genutzt, so lautet die Gesamtübertragungsra-te ρk , maximal also nρ . Da jedoch jeder der Kanäle unabhängig voneinander nur mitWahrscheinlichkeit p ∈ (0, 1) funktioniert und dementsprechend mit Wahrscheinlichkeit1 − p versagt, erhält man die zufällige Übertragungsrate R = kρ , k ∈ 0, . . . , n . Wiekann dieses Zufallsexperiment modelliert werden?
Wir wählen die Ergebnismenge
Ω := (ω1, . . . , ωn) : ωi ∈ 0, 1 für i = 1, . . . , n ,
wobei wir ωi = 0 als Versagen des i-ten Kanals interpretieren, ωi = 1 bedeutet, dassdieser funktionsfähig ist. Es bezeichne
Ak := ω ∈ Ω: ω1 + . . .+ ωn = k , k = 0, . . . , n ,
8Jakob I. Bernoulli, 16541705, schweizer Mathematiker und Physiker

1. Maÿ- und Wahrscheinlichkeitsräume 19
das Ereignis, dass k der n Kanäle funktionsfähig sind und n − k ausfallen. Da man fürgewöhnlich nur weiÿ, wieviele der Kanäle ausfallen, jedoch nicht welche, verwenden wirals σ-Algebra
F := σ (Ak : k = 0, . . . , n) .
Dann kann F als die uns zur Verfügung stehende Information nach Durchführung des Zu-fallsexperiments interpretiert werden. Als Wahrscheinlichkeitsmaÿ wählen wir P gegebendurch
P(Ak) :=
(n
k
)pk(1− p)n−k , k = 0, . . . , n .
Identizieren wir Ak mit der natürlichen Zahl k , so entspricht P gerade der Binomial-verteilung mit Parameter p auf 0, . . . , n .
1.3.2 Hypergeometrische Verteilung
Problemstellung. Von insgesamt N Lotterielosen sind G Gewinnlose. Wie hoch istdie Wahrscheinlichkeit, dass k von n gekauften Losen gewinnen?
Modellierung. Wir wählen wiederum Ω := 0, . . . , n , dies entspricht dem gleich-zeitigen Kauf aller n Lose, und F := P(Ω) . Weiters gehen wir davon aus, dass jedeAuswahl von n Losen dieselbe Wahrscheinlichkeit hat, von uns gekauft zu werden. Dannlautet die Wahrscheinlichkeit, dass k Gewinnlose unter den n gekauften Losen sind,
Hn,N,G(k) :=Anzahl der günstigen EreignisseAnzahl der möglichen Ereignisse
=
(Gk
)(N−Gn−k
)(Nn
) .
Definition 1.25 (Hypergeometrische Verteilung)Das Wahrscheinlichkeitsmaÿ
Hn,N,G :=
n∑
k=0
(Gk
)(N−Gn−k
)(Nn
) δk
auf (0, . . . , n,P(0, . . . , n)) nennt man hypergeometrische Verteilung mit Para-metern n,N,G , vgl. Aufgabe (1.29).
1.3.3 Poisson-Verteilung
Problemstellung. Wir greifen den Münzwurf nochmals auf, die Wahrscheinlichkeitfür Kopf sei wiederum p ∈ (0, 1) , jene für Zahl 1 − p . Werfen wir die Münze n-mal, soist
P (k-mal Kopf) =
(n
k
)pk(1− p)n−k .

20 1. Maÿ- und Wahrscheinlichkeitsräume
Was geschieht, wenn wir nun 2n-mal werfen dürfen, sich jedoch die Wahrscheinlichkeitfür Kopf entsprechend halbiert? Oensichtlich wäre dann
P (k-mal Kopf) =
(2n
k
)(p2
)k (1− p
2
)2n−k.
Nun iterieren wir dies, d. h. wir vergröÿern n während wir p entsprechend verkleinernund damit np konstant halten. Was passiert?
Modellierung. Wir wählen Ω := N0 und F := P(Ω) . Es bezeichne pn ∈ (0, 1) dieWahrscheinlichkeit für Kopf bei n-maligem Münzwurf. Aus der Analysis wissen wir, dassfür eine konvergente Folge ann∈N ∈ RN mit limn→∞ an =: x gilt, dass
limn→∞
(1 +
ann
)n= lim
n→∞
(1 +
x
n
)n= ex .
Setzen wir daher λ := limn→∞ npn , so erhalten wir
Bn,pn (k) =
(n
k
)pkn(1− pn)n−k =
npn · (n− 1)pn · . . . · (n− k + 1)pnk!
·(1− npn
n
)n
(1− pn)k
n→∞−→ λk
k!limn→∞
(1− λ
n
)n=λk
k!e−λ =: πλ (k) , k ∈ N0 .
Definition 1.26 (Poisson-Verteilung)Das Wahrscheinlichkeitsmaÿ
πλ :=
∞∑
k=0
λk
k!e−λδk
auf (N0,P(N0)) heiÿt Poisson9-Verteilung mit Parameter λ > 0 .
Um zu zeigen, dass es sich bei(N0, 2
N0 , πλ)tatsächlich um einen Wahrscheinlichkeits-
raum handelt, benötigen wir folgenden Satz.
Satz 1.27 (Reihen von Wahrscheinlichkeitsmaÿen)Es sei αn∞n=1 eine Folge nichtnegativer reeller Zahlen mit
∞∑
n=1
αn = 1
und Pn∞n=1 eine Folge von Wahrscheinlichkeitsmaÿen auf dem messbaren Raum (Ω,F) .Dann ist auch
P :=∞∑
n=1
αnPn
ein Wahrscheinlichkeitsmaÿ auf (Ω,F) .
9Siméon Denis Poisson, 17811840, französischer Mathematiker und Physiker

1. Maÿ- und Wahrscheinlichkeitsräume 21
Beweis. Wir weisen für P die denierten Eigenschaften eines Wahrscheinlichkeitsmaÿesnach.
(P0) Positivität: Oensichtlich gilt P(A) ≥ 0 für alle A ∈ F , da αn ≥ 0 somitαnPn(A) ≥ 0 für alle n ∈ N .
(P1) P ist normiert: Da es sich für jedes n ∈ N bei Pn um ein Wahrscheinlichkeitsmaÿhandelt, ist
P(Ω) =∞∑
n=1
αnPn(Ω) =∞∑
n=1
αn = 1 .
(P2) σ-Additivität: Es sei Ak∞k=1 ∈ FN mit Ai ∩Aj = ∅ für i 6= j . Wir setzen
A :=
∞⊎
k=1
Ak .
Da αnPn(A) ≤ αn für alle n ∈ N , ist∞∑
n=1
αn konvergente Majorante für∞∑
n=1
αnPn(A) .
Somit konvergiert∞∑
n=1
αnPn(A) =∞∑
n=1
∞∑
k=1
αnPn(Ak)
absolut und die Summationsreihenfolge darf vertauscht werden. Dadurch erhaltenwir
P(A) =∞∑
k=1
∞∑
n=1
αnPn(Ak) =∞∑
k=1
P(Ak) .
Damit ist gezeigt, dass P ein Wahrscheinlichkeitsmaÿ auf (Ω,F) ist.
Nach Satz 1.27 handelt es sich somit bei πλ tatsächlich um ein Wahrscheinlichkeitsmaÿauf
(N0, 2
N0), denn
λk
k!e−λ ≥ 0 für alle k ∈ N0
und∞∑
k=0
λk
k!e−λ = eλe−λ = 1 .
Wir haben die Poisson-Verteilung als Grenzwert der Binomialverteilung erhalten, dieshalten wir in folgendem Satz fest.
22 1. Maÿ- und Wahrscheinlichkeitsräume
Satz 1.28 (Poissonscher Grenzwertsatz)Es sei λ > 0 und pnn∈N ∈ (0, 1)N eine Folge von Erfolgswahrscheinlichkeiten mitlimn→∞ npn = λ . Dann gilt für jedes k ∈ N0 , dass
limn→∞
Bn,pn (k) = πλ (k) .
Beispiel 1.29 (Telefonanrufe)Im Schnitt treen in einem Büro innerhalb einer Stunde fünf Telefonanrufe ein. Es be-zeichne N die Anzahl der potentiellen Anrufer zu einer fest gewählten Stunde. Angenom-men, diese N Personen werfen eine Münze, welche mit Wahrscheinlichkeit pN auf Kopffällt, um zu entscheiden, ob sie innerhalb der entsprechenden Stunde anrufen oder nicht.Wirft eine Person Kopf, so ruft diese an. Somit lautet die durchschnittliche Anzahl vonAnrufen in dieser Stunde NpN = 5 . Da N unbekannt ist, jedoch als sehr groÿ angenom-men werden kann, bilden wir den Grenzwert N →∞ und setzen λ := limN→∞NpN = 5 .Für k ∈ N0 gibt dann πλ (k) die Wahrscheinlichkeit an, dass innerhalb einer Stunde kAnrufe eintreen. Weiters ist πλ/2 (k) die Wahrscheinlichkeit, dass k Anrufe innerhalbeiner halben Stunde eingehen.
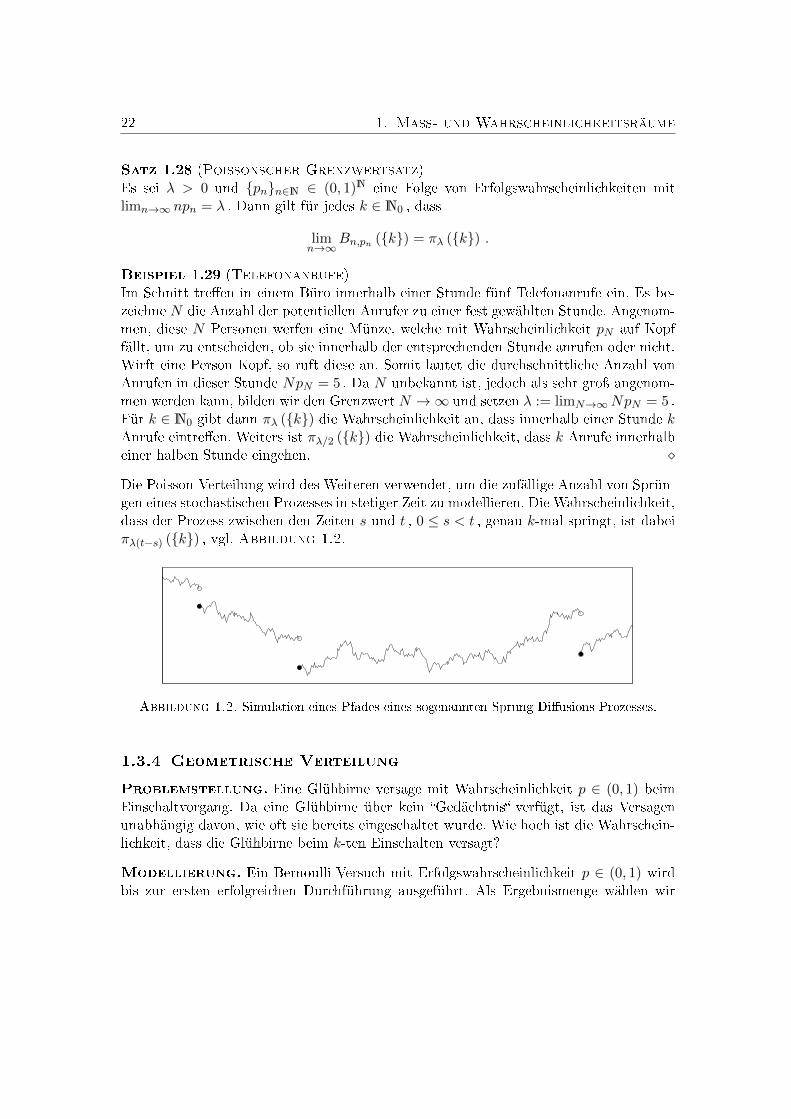
Die Poisson-Verteilung wird des Weiteren verwendet, um die zufällige Anzahl von Sprün-gen eines stochastischen Prozesses in stetiger Zeit zu modellieren. Die Wahrscheinlichkeit,dass der Prozess zwischen den Zeiten s und t , 0 ≤ s < t , genau k-mal springt, ist dabeiπλ(t−s) (k) , vgl. Abbildung 1.2.
Abbildung 1.2. Simulation eines Pfades eines sogenannten Sprung-Diusions-Prozesses.
1.3.4 Geometrische Verteilung
Problemstellung. Eine Glühbirne versage mit Wahrscheinlichkeit p ∈ (0, 1) beimEinschaltvorgang. Da eine Glühbirne über kein Gedächtnis verfügt, ist das Versagenunabhängig davon, wie oft sie bereits eingeschaltet wurde. Wie hoch ist die Wahrschein-lichkeit, dass die Glühbirne beim k-ten Einschalten versagt?
Modellierung. Ein Bernoulli-Versuch mit Erfolgswahrscheinlichkeit p ∈ (0, 1) wirdbis zur ersten erfolgreichen Durchführung ausgeführt. Als Ergebnismenge wählen wir

1. Maÿ- und Wahrscheinlichkeitsräume 23
Ω := N0 , die σ-Algebra laute F := P(Ω) . Dann gibt ω ∈ Ω die Anzahl der Fehlversuchedes Experiments an, bevor dieses das erste Mal glückt. Im Fall einer Glühbirne, versagtdiese also beim (ω + 1)-ten Einschaltvorgang. Wir erhalten
P (kein Misserfolg) = p und P (ein Misserfolg) = (1− p)pund folglich
P (k Misserfolge) = (1− p)kp für k ∈ N0 .
Die Wahrscheinlichkeit, dass die Glühbirne k Einschaltvorgänge überlebt bevor sie ver-sagt lautet somit
gp (k) := (1− p)kp .Definition 1.30 (Geometrische Verteilung)Das Wahrscheinlichkeitsmaÿ
gp :=∞∑
k=0
(1− p)kpδk
auf (N0,P(N0)) heiÿt geometrische Verteilungmit Parameter p ∈ (0, 1) , vgl. Aufgabe(1.36).
1.4 Bedingte Wahrscheinlichkeiten und Unabhängig-
keit
In diesem Abschnitt bezeichne (Ω,F ,P) stets einen Wahrscheinlichkeitsraum. Für einEreignis A ∈ F stellen wir uns nun die Frage, inwiefern das Eintreten eines EreignissesB ∈ F jenes von A beeinusst. Dies kann mittels der bedingten Wahrscheinlichkeitausgedrückt werden. Dazu folgendes Beispiel.
Beispiel 1.31 Wir modellieren den Wurf eines fairen Würfels mittels des Laplace-Raums (Ω,F ,P) , wobei Ω = 1, . . . , 6 . Weiters betrachten wir die Ereignisse
A := ω ∈ Ω: ω ≤ 3 und B := ω ∈ Ω: ω gerade .Oensichtlich ist P(A) = P(B) = 1/2 . Was ist nun aber die Wahrscheinlichkeit, dass Aeintritt, wenn wir bereits wissen, dass B eintreten wird? Definition 1.32 (Bedingte Wahrscheinlichkeit)Es seien A,B ∈ F zwei Ereignisse, wobei P(B) > 0 . Dann heiÿt
P(A|B) :=P(A ∩B)
P(B)
bedingte Wahrscheinlichkeit von A gegeben B .

24 1. Maÿ- und Wahrscheinlichkeitsräume
Bemerkung. Es seien wiederum A,B ∈ F mit P(B) > 0 .
B Man bezeichnet P(A|B) auch alsWahrscheinlichkeit von A unter der Bedin-gung B .
B Bei P( · |B) handelt es sich um ein Wahrscheinlichkeitsmaÿ auf (Ω,F) , vgl. Aufga-be (1.43).
B Im Fall, dass P(B) = 0 , setzen wir im Weiteren P(A|B) := 0 .
Oftmals sind nur gewisse bedingte Wahrscheinlichkeiten bekannt und unter gewissenVoraussetzungen kann daraus die Wahrscheinlichkeit des interessierenden Ereignisses be-rechnet werden.
Satz 1.33 (Satz von der totalen Wahrscheinlichkeit)Es seien I eine abzählbare Indexmenge und Bii∈I ∈ FI eine Familie paarweiser dis-junkter Ereignisse mit
P
(⊎
i∈IBi
)= 1 .
Für jedes Ereignis A ∈ F gilt dann
P(A) =∑
i∈IP(A|Bi)P(Bi) .
Beweis. Aus der σ-Additivität von P folgt
P(A) = P
(⊎
i∈I(A ∩Bi)
)=∑
i∈IP (A ∩Bi) =
∑
i∈IP(A|Bi)P(Bi) .
Aus dem Satz von der totalen Wahrscheinlichkeit folgern wir nun nachfolgendenSatz, der auch als Bayes'sche10 Formel bekannt ist.
Satz 1.34 (Satz von Bayes)Es seien wiederum I eine abzählbare Indexmenge und Bii∈I ∈ FI eine Familie paarwei-ser disjunkter Ereignisse mit P
(⊎i∈I Bi
)= 1 . Für jedes Ereignis A ∈ F mit P(A) > 0
und alle k ∈ I gilt dann
P(Bk|A) =P(A|Bk)P(Bk)∑i∈I P(A|Bi)P(Bi)
.
10Thomas Bayes, ∼17011761, englischer Mathematiker

1. Maÿ- und Wahrscheinlichkeitsräume 25
Beweis. Da
P(Bk|A) =P(Bk ∩A)
P(A)=P(A|Bk)P(Bk)
P(A),
folgt die Aussage aus dem Satz von der totalen Wahrscheinlichkeit durch Ein-setzen der entsprechenden Darstellung für P(A) .
Beispiel 1.35 (Falsch-positiver Befund)Ein Bluttest liefere in 95% der Fälle das richtige Ergebnis, wenn die Krankheit, auf diegetestet wird, tatsächlich vorliegt. Es werden jedoch 1% der Personen ohne diese Krank-heit falsch-positiv getestet. Auÿerdem leiden nur 0.5% der Bevölkerung tatsächlich ander Krankheit. Wie hoch ist die Wahrscheinlichkeit, dass eine Person mit positivem Tes-tergebnis auch wirklich erkrankt ist?
Es wird nun eine zufällig ausgewählte Person getestet. Wir betrachten die Ereignisse
A := der Test ist positiv und B := die Person ist erkrankt .
Dann gilt
P(A|B) = 0.95 , P(A|Bc
)= 0.01 und P(B) = 0.005 .
Aus der Bayes'schen Formel erhalten wir somit
P(B|A) =P(A|B)P(B)
P(A|B)P(B) + P (A|Bc)P (Bc)≈ 0.32 .
Daher sind etwa 68% der positiven Testergebnisse falsch-positiv. Sind A,B ∈ F zwei Ereignisse mit P(A),P(B) > 0 , so gilt oenbar
P(A|B) = P(A) ⇐⇒ P(B|A) = P(B) ⇐⇒ P(A ∩B) = P(A)P(B) .
In diesem Fall beeinussen sich die beiden Ereignisse also nicht gegenseitig. Daher sagtman, dass A ∈ F und B ∈ F unabhängig sind, falls
P(A ∩B) = P(A)P(B) .
Den fundamentalen Begri der Unabhängigkeit erweitern wir in nachfolgender Denitionauf beliebige Familien von Ereignissen.
Definition 1.36 (Unabhängigkeit von Ereignissen)Es sei I eine beliebige Indexmenge. Die Familie Aii∈I ∈ FI von Ereignissen heiÿt(stochastisch) unabhängig, wenn für alle endlichen Teilmengen J ⊂ I gilt, dass
P
( ⋂
j∈JAj
)=∏
j∈JP (Aj) .

26 1. Maÿ- und Wahrscheinlichkeitsräume
Beispiel 1.37 (Unabhängigkeit von Würfelereignissen)Wir betrachten den Laplace-Raum (Ω,F ,P) mit Ω = 1, . . . , 62 , P = UΩ ist also dieGleichverteilung auf Ω . Dieser Wahrscheinlichkeitsraum modelliert den Wurf zweier fairerWürfel, wobei wir davon ausgehen, dass die beiden Würfel voneinander unterschiedenwerden können. Wir nehmen daher an, dass ein Würfel rot und der andere blau ist. Trittdas Elementarereignis ω = (ω1, ω2) ∈ Ω ein, so zeigt der rote Würfel die Augenzahl ω1
und der blaue ω2 . Nun betrachten wir die Ereignisse
R6 := ω ∈ Ω: ω1 = 6 . . . Augenzahl 6 mit rotem Würfel,
B6 := ω ∈ Ω: ω2 = 6 . . . Augenzahl 6 mit blauem Würfel,
Bg := ω ∈ Ω: ω2 ∈ 2, 4, 6 . . . gerade Augenzahl mit blauem Würfel,
B(1,2,3) := ω ∈ Ω: ω2 ∈ 1, 2, 3 . . . Augenzahl 1,2 oder 3 mit blauem Würfel,
S7 := ω ∈ Ω: ω1 + ω2 = 7 . . . Augensumme beider Würfel ist 7,
S5 := ω ∈ Ω: ω1 + ω2 = 5 . . . Augensumme beider Würfel ist 5.
Die Ereignisse R6 und B6 sind voneinander unabhängig, denn
136 = P(R6 ∩B6) = P(R6) · P(B6) = 1
6 · 16 .
Dies ist wenig überraschend, denn schlieÿlich gehen wir davon aus, dass die Würfel ein-ander nicht beeinussen. Daher sind auch alle Ereignisse AR und AB gegeben durch
AR = A1 × 1, . . . , 6 und AB = 1, . . . , 6 ×A2
mit A1, A2 ⊂ 1, . . . , 6 voneinander unabhängig. Da
P(S7 ∩R6) = P(S7) · P(R6) ,
sind weiters auch S7 und R6 unabhängig. Zwar ist
P(Bg ∩B(1,2,3) ∩ S5
)= P(Bg)P(B(1,2,3))P(S5) = 1
36 ,
jedoch
P(Bg ∩B(1,2,3)
)6= P (Bg)P
(B(1,2,3)
).
Somit sind die Ereignisse Bg , B(1,2,3) und S5 nicht voneinander unabhängig.
Bemerkung. Um die Unabhängigkeit dreier Ereignisse A1, A2, A3 zu zeigen, genügtes weder nur die paarweise Unabhängigkeit, d. h.
P (Ai ∩Aj) = P(Ai)P(Aj) für alle i, j ∈ 1, 2, 3 mit i 6= j , (B2)

1. Maÿ- und Wahrscheinlichkeitsräume 27
noch nur
P (A1 ∩A2 ∩A3) = P(A1)P(A2)P(A3) (B3)
nachzuweisen, vgl. Aufgabe (1.42) und Beispiel 1.37. Es muss sowohl Bedingung (B2)als auch (B3) erfüllt sein. Dies gilt natürlich dementsprechend für die Unabhängigkeiteiner beliebigen Anzahl von Ereignissen.
Sind A,B ∈ F unabhängige Ereignisse, so sind auch ihre Komplemente Ac und Bc
unabhängig, denn
P(Ac ∩Bc
)= P
((A ∪B)c
)= 1− P(A ∪B) = 1 + P(A ∩B)− P(A)− P(B) =
= 1 + P(A)P(B)− P(A)− P(B) = (1− P(A)) (1− P(B)) =
= P(Ac)P(Bc).
Da weiters
P(A ∩Bc
)= P (A \B) = P(A)− P(A ∩B) = P(A)− P(A)P(B) = P(A)P
(Bc),
sind auch A und Bc unabhängig. Im folgenden Satz verallgemeinern wir diese Beobach-tungen auf beliebige Familien von Ereignissen.
Satz 1.38 (Unabhängigkeit von Komplementärereignissen)Es sei Aii∈I ∈ FI eine Familie von Ereignissen, wobei I eine beliebige Indexmenge
bezeichne. Setzt man B(0)i := Ai und B
(1)i := Ac
i für i ∈ I , so sind die drei folgendenAussagen äquivalent:
(1) Die Familie Aii∈I ist unabhängig.
(2) Es existiert ein α ∈ 0, 1I , sodassB
(αi)i
i∈I
unabhängig ist.
(3) Für alle α ∈ 0, 1I istB
(αi)i
i∈I
unabhängig.
Beweis. Aufgabe (1.39).
Als Anwendung zu obigem Satz beweisen wir nun die Eulersche Primzahlformel.
Beispiel 1.39 (Eulersche11 Primzahlformel)Die Riemannsche12 Zetafunktion ist durch die Reihe
ζ(s) :=
∞∑
n=1
1
nsfür s > 1
11Leonhard Euler, 17071783, schweizer Mathematiker12Georg Friedrich Bernhard Riemann, 18261866, deutscher Mathematiker

28 1. Maÿ- und Wahrscheinlichkeitsräume
gegeben. Bezeichnen wir mit
P := p ∈ N : p ist Primzahl
die Menge aller Primzahlen, so besagt die Eulersche Primzahlformel, dass
ζ(s) =∏
p∈P
(1− 1
ps
)−1
für s > 1 .
Wir beweisen diese Darstellung, indem wir für festes s > 1 den Wahrscheinlichkeitsraum(Ω,F ,P) mit
Ω := N , F := P(N) und P :=1
ζ(s)
∞∑
n=1
1
nsδn
betrachten. Man beachte, dass es sich nach Satz 1.27 bei P tatsächlich um ein Wahr-scheinlichkeitsmaÿ handelt. Für n ∈ N sei Pn := p ∈ P : p ≤ n und für p ∈ P setzenwir pN := pn : n ∈ N . Dann ist pNp∈P unabhängig, denn für k ∈ N und paarweiseverschiedene p1, . . . , pk ∈ P ist
k⋂
i=1
(piN) = (p1 · . . . · pk)N
und somit
P
(k⋂
i=1
(piN)
)=
∞∑
n=1
P (p1 · . . . · pkn) =1
ζ(s)(p1 · . . . · pk)−s
∞∑
n=1
1
ns=
= p−s1 · . . . · p−sk =k∏
i=1
P(piN) .
Aus der Unabhängigkeit von (pN)cp∈P , siehe Satz 1.38, folgt nun
1
ζ(s)= P (1) = P
⋂
p∈P(pN)c
=
=[P ist stetig von oben
]= lim
n→∞P
⋂
p∈Pn
(pN)c
=
= limn→∞
∏
p∈Pn
(1− P(pN)) =∏
p∈P
(1− 1
ps
),
womit die behauptete Produktdarstellung gezeigt ist.

1. Maÿ- und Wahrscheinlichkeitsräume 29
1.5 Fortsetzung von Maÿen
In diesem Abschnitt werden wir Maÿe konstruieren, indem wir diese zuerst auf einemeinfachen Mengensystem denieren und dann auf eine von diesemMengensystem erzeugteσ-Algebra fortsetzen.
Beispiel 1.40 (Konstruktion des Lebesgue-Maÿes auf R)Wir betrachten die Algebra
A := (a1, b1] ] . . . ] (an, bn] : n ∈ N ,−∞ ≤ a1 ≤ b1 ≤ . . . ≤ an ≤ bn ≤ ∞
auf R und denieren eine Mengenfunktion λ0 : A → [0,∞] vermöge
λ0 ((a1, b1] ] . . . ] (an, bn]) :=n∑
i=1
(bi − ai) .
Kann λ0 zu einem Maÿ auf σ(A) = B(R) fortgesetzt werden? Wie wir sehen werden, istdiese Frage mit Ja zu beantworten, das resultierende und eindeutig bestimmte Maÿ λheiÿt Lebesgue13-Maÿ auf (R,B(R)) .
1.5.1 Fortsetzungssatz von Carathéodory
Es sei Ω eine beliebige Menge.
Definition 1.41 (Äuÿeres Maÿ)Eine Mengenfunktion µ∗ : P(Ω)→ [0,∞] nennt man äuÿeres Maÿ auf Ω , wenn
(µ∗1) µ∗(∅) = 0 ,
(µ∗2) µ∗(A) ≤ µ∗(B) für A ⊂ B ⊂ Ω , (monoton)
(µ∗3) µ∗ (⋃∞n=1An) ≤∑∞n=1 µ
∗(An) für alle Folgen An∞n=1 ∈ P(Ω)N . (σ-subadditiv)
Eine Teilmenge A ⊂ Ω heiÿt µ∗-messbar, wenn
µ∗(C) = µ∗(C ∩A) + µ∗(C \A)
für alle C ⊂ Ω .
Bemerkung. Es bezeichne µ∗ ein äuÿeres Maÿ auf Ω .
B Die Bezeichnung äuÿeres Maÿ kann anfangs etwas irreführend sein, es handelt sichim Allgemeinen um kein Maÿ.
13Henri Léon Lebesgue, 18751941, französischer Mathematiker

30 1. Maÿ- und Wahrscheinlichkeitsräume
B Um die µ∗-Messbarkeit einer Menge A ⊂ Ω nachzuweisen, genügt es zu zeigen, dass
µ∗(C) ≥ µ∗(C ∩A) + µ∗(C \A)
für alle C ⊂ Ω mit µ∗(C) <∞ , vgl. Aufgabe (1.49).
Satz 1.42 (Einschränkung eines äuÿeren Maÿes)Es sei µ∗ ein äuÿeres Maÿ auf Ω . Dann ist
Σ := A ⊂ Ω: A ist µ∗-messbar
eine σ-Algebra auf Ω und die Einschränkung µ := µ∗|Σ ein Maÿ auf (Ω,Σ) .
Beweis. Wir weisen für Σ die denierenden Eigenschaften einer σ-Algebra nach.
(σ1) Oensichtlich ist Ω ∈ Σ , denn
µ∗(C) = µ∗(C ∩ Ω) + µ∗(C \ Ω)
für alle C ⊂ Ω .
(σ2) Komplementstabilität: Es sei A ∈ Σ . Für C ⊂ Ω ist
µ∗(C) = µ∗(C ∩A) + µ∗(C \A) = µ∗(C \Ac
)+ µ∗
(C ∩Ac
)
und somit auch Ac µ∗-messbar.
(σ3) σ-∪-Stabilität: Das Mengensystem Σ ist eine Algebra auf Ω , vgl. Aufgabe (1.50).Nun sei An∞n=1 ∈ ΣN und o. B. d.A. Ai ∩ Aj = ∅ für i 6= j . Wir setzen nunB :=
⊎∞n=1An und Bk :=
⊎kn=1An für k ∈ 2, 3, . . . . Dann gilt für alle k = 2, 3, . . .
und C ⊂ Ω , dass
µ∗(C ∩Bk) = µ∗(C ∩Bk ∩Ak) + µ∗((C ∩Bk) \Ak) = µ∗(C ∩Ak) + µ∗(C ∩Bk−1)
und daher folgt
µ∗(C) = µ∗(C ∩Bk) + µ∗(C \Bk) =
k∑
n=1
µ∗(C ∩An) + µ∗(C \Bk) .
Da µ∗(C \Bk) ≥ µ∗(C \B) , erhalten wir daher
µ∗(C) ≥∞∑
n=1
µ∗(C ∩An) + µ∗(C \B) ≥ µ∗(C ∩B) + µ∗(C \B) ≥ µ∗(C) (∗)
und somit B =⋃∞n=1An ∈ Σ .

1. Maÿ- und Wahrscheinlichkeitsräume 31
Es bleibt die σ-Additivität von µ∗ auf Σ zu zeigen. Dies folgt jedoch direkt aus (∗), indemman C := B setzt, und somit ist (Ω,Σ, µ) ein Maÿraum, wobei µ = µ∗|Σ .
Definition 1.43 (Prämaÿ)Es seien A eine Algebra auf Ω und µ0 : A → [0,∞] eine Mengenfunktion mit µ0(∅) = 0 .Man nennt µ0 Prämaÿ auf A , falls für alle Folgen An∞n=1 ∈ AN paarweise disjunkterMengen mit
⊎∞n=1An ∈ A gilt, dass
µ0
( ∞⊎
n=1
An
)=∞∑
n=1
µ0(An) . (σ-additiv auf A)
Das Prämaÿ µ0 heiÿt endlich, falls µ0(Ω) < ∞ . Man nennt µ0 auÿerdem σ-endlich,wenn eine Folge Ωn∞n=1 ∈ AN existiert, sodass
Ω =∞⋃
n=1
Ωn und µ0(Ωn) <∞ für alle n ∈ N .
Satz 1.44 (Fortsetzungssatz von Carathéodory14)Es sei A eine Algebra auf Ω und µ0 ein Prämaÿ auf A . Dann existiert ein Maÿ µ aufF := σ (A) mit µ0 = µ|A . Für σ-endliches µ0 ist auÿerdem µ eindeutig bestimmt. Mannennt in diesem Fall das Maÿ µ die Fortsetzung von µ0 auf F .
Beweis. Der Beweis erfolgt in drei Schritten.
Schritt 1: Im ersten Beweisschritt zeigen wir, dass durch
µ∗(A) := inf
∞∑
n=1
µ0(An) : An∞n=1 ∈ AN mit A ⊂∞⋃
n=1
An
für A ⊂ Ω
ein äuÿeres Maÿ auf Ω deniert wird.
(µ∗1) Oenbar gilt µ∗(∅) = 0 .
(µ∗2) Monotonie: Dies ist oensichtlich.
(µ∗3) σ-Subadditivität: Für An∞n=1 ∈ P(Ω)N setzen wir A :=⋃∞n=1An . Weiters
wählen wir zu gegebenem ε > 0 für n ∈ N eine Folge Bnk∞k=1 ∈ AN mit
An ⊂∞⋃
k=1
Bnk und∞∑
k=1
µ0 (Bnk) ≤ µ∗(An) + 2−nε .
14Constantin Carathéodory, 18731950, deutscher Mathematiker griechischer Abstammung

32 1. Maÿ- und Wahrscheinlichkeitsräume
Dann ist
µ∗(A) ≤∞∑
n,k=1
µ0 (Bnk) ≤∞∑
n=1
µ∗(An) + ε
und damit die σ-Subadditivität von µ∗ gezeigt.
Schritt 2: Es sei wiederum
Σ := A ⊂ Ω: A ist µ∗-messbar
die σ-Algebra der µ∗-messbaren Mengen. Wir zeigen, dass das Maÿ µ∗|Σ eine Erweiterungvon µ0 ist, d. h. A ⊂ Σ und µ∗|A = µ0 .
Für A ∈ A gilt µ∗(A) ≤ µ0(A) und daher zeigen wir noch , dass µ0(A) ≤ µ∗(A) . Es seiBn∞n=1 ∈ AN eine Folge paarweise disjunkter Mengen mit A ⊂ ⊎∞n=1Bn . Für n ∈ Nsetzen wir An := A ∩Bn . Dann ist A =
⊎∞n=1An und es folgt
µ0(A) =∞∑
n=1
µ0(An) ≤∞∑
n=1
µ0(Bn).
Dies impliziert µ0(A) ≤ µ∗(A) und damit µ∗|A = µ0 .
Es bleibt noch die µ∗-Messbarkeit von A ∈ A zu zeigen. Es sei C ⊂ Ω mit µ∗(C) < ∞ .Wähle zu ε > 0 eine Folge Bn∞n=1 ∈ AN mit
C ⊂∞⋃
n=1
Bn und∞∑
n=1
µ0(Bn) ≤ µ∗(C) + ε .
Aus µ0(Bn ∩A) + µ0(Bn \A) = µ0(Bn) folgt dann
∞∑
n=1
µ0(Bn ∩A) +∞∑
n=1
µ0(Bn \A) ≤ µ∗(C) + ε .
Da weiters C ∩A ⊂ ⋃∞n=1(Bn∩A) und C \A ⊂ ⋃∞n=1(Bn \A) , impliziert obige Abschät-zung
µ∗(C ∩A) + µ∗(C \A) ≤ µ∗(C) + ε
und somit A ⊂ Σ .
Schritt 3: Es bleibt noch die Eindeutigkeit der Fortsetzung für σ-endliches µ0 zu zeigen.Es sei dazu µ ein Maÿ auf F = σ (A) ⊂ Σ mit µ|A = µ0 . Wir zeigen, dass µ = µ∗|F .

1. Maÿ- und Wahrscheinlichkeitsräume 33
Es sei A ∈ F . Für An∞n=1 ∈ AN mit A ⊂ ⋃∞n=1An gilt
µ(A) ≤∞∑
n=1
µ(An) =
∞∑
n=1
µ0(An) .
Dies zeigt, dass µ ≤ µ∗ auf F . Das Prämaÿ µ0 ist σ-endlich und daher existiert eineFolge Ωn∞n=1 ∈ AN paarweise disjunkter Mengen mit
µ0(Ωn) <∞ für alle n ∈ N und Ω =
∞⊎
n=1
Ωn .
Für n ∈ N sind Ωn ∩A,Ωn \A ∈ F und daher gilt
µ(Ωn ∩A) ≤ µ∗(Ωn ∩A) und µ(Ωn \A) ≤ µ∗(Ωn \A) .
Nun folgt aus
µ(Ωn ∩A) + µ(Ωn \A) = µ(Ωn) = µ∗(Ωn) = µ∗(Ωn ∩A) + µ∗(Ωn \A)
und µ(Ωn) < ∞ , dass µ(Ωn ∩ A) = µ∗(Ωn ∩ A) . Summation über n liefert schlieÿlichµ(A) = µ∗(A) .
Bemerkung. Die Fortsetzung eines σ-endlichen Prämaÿes µ0 auf der Algebra A zueinem Maÿ µ auf der σ-Algebra F = σ (A) lässt sich wie folgt skizzieren:
µ0 Prämaÿ auf A Satz 1.44−−−−−−−→ µ∗ äuÿeres Maÿ auf ΩSatz 1.42−−−−−−−→ µ Maÿ auf F
1.5.2 Eindeutigkeit von Maÿen
Viele Maÿe sind bereits durch Vorgabe auf deutlich kleineren Mengensystemen als Alge-bren eindeutig bestimmt. Im Folgenden bezeichne Ω eine beliebige Menge.
Definition 1.45 (π-System und λ-System)Das Mengensystem P ⊂ P(Ω) heiÿt π-System, gegeben dass
A ∩B ∈ P für alle A,B ∈ P . (schnittstabil)
Das Mengensystem L ⊂ P(Ω) heiÿt λ-System oder auch Dynkin15-System, wenn
(λ1) Ω ∈ L ,
(λ2) B \A ∈ L für alle A,B ∈ L mit A ⊂ B ,
15Eugene Dynkin, geboren 1924, russischer Mathematiker

34 1. Maÿ- und Wahrscheinlichkeitsräume
(λ3)⊎n∈NAn ∈ L für alle Folgen Ann∈N ∈ LN paarweise disjunkter Mengen.
Satz und Definition 1.46 (Erzeugtes λ-System)Es sei Ljj∈J eine Familie von λ-Systemen auf Ω , wobei J eine beliebige Indexmengebezeichnet. Dann ist
⋂
j∈JLj
ebenfalls eine λ-System. Zu G ⊂ P(Ω) existiert ein kleinstes λ-System, welches G enthält.Setzt man JG := L ist λ-System auf Ω mit G ⊂ L , so ist dieses durch
λ(G) :=⋂
L∈JG
L
gegeben und wird von G erzeugtes λ-System genannt.
Beweis. Der Beweis erfolgt analog zu jenem für σ-Algebren.
Bemerkung. Für ein Mengensystem G ⊂ P(Ω) gilt oenbar stets λ(G) ⊂ σ(G) .
Lemma 1.47 (Schnittstabiles λ-System)Ist L ⊂ P(Ω) ein λ-System, so gilt
L ist π-System ⇐⇒ L ist σ-Algebra.
Beweis. ⇐: Diese Richtung ist oensichtlich.
⇒: Wir weisen für L die denierenden Eigenschaften einer σ-Algebra nach.
(σ1) Dass Ω ∈ L , ist klar.
(σ2) Komplementstabilität: Es sei A ∈ L . Da L ein λ-System ist, folgt aus A ⊂Ω ∈ L und Eigenschaft (λ2) , dass Ac = Ω \A ∈ L .
(σ3) σ-∪-Stabilität: Für A,B ∈ L gilt nach Voraussetzung, dass A ∩ B ∈ L und daA∩B ⊂ A , folgt A \B = A \ (A∩B) ∈ L . Da L dierenzenstabil ist, existiert zuAn∞n=1 ∈ LN eine Folge Bn∞n=1 ∈ LN paarweise disjunkter Mengen mit
∞⋃
n=1
An =
∞⊎
n=1
Bn ∈ L .
Somit ist L eine σ-Algebra.
Satz 1.48 (π-λ-Theorem von Dynkin)Es sei P ⊂ P(Ω) ein π-System. Dann gilt σ (P) = λ (P) .

1. Maÿ- und Wahrscheinlichkeitsräume 35
Beweis. ⊃: Diese Inklusion ist klar.
⊂: Es ist zu zeigen, dass λ (P) eine σ-Algebra ist. Nach Lemma 1.47 genügt es nach-zuweisen, dass λ (P) ein π-System ist. Für B ∈ λ (P) sei
λB := A ∈ λ (P) : A ∩B ∈ λ (P) .
Es genügt zu zeigen, dass
λ (P) ⊂ λB für alle B ∈ λ (P) .
Wir weisen zuerst für jedes P ∈ λ (P) für λP die denierenden Eigenschaften eines λ-Systems nach.
(λ1) Oensichtlich ist Ω ∩ P = P ∈ λ (P) , also Ω ∈ λP .
(λ2) Für A,B ∈ λP mit A ⊂ B ist (B \A) ∩ P = (B ∩ P ) \ (A ∩ P ) ∈ λ (P) .
(λ3) Es sei An∞n=1 ∈ λNP eine Folge paarweise disjunkter Mengen. Dann ist( ∞⊎
n=1
An
)∩ P =
∞⊎
n=1
(An ∩ P ) ∈ λ (P) .
Nach Voraussetzung ist für alle A ∈ P auch A ∩ P ∈ P , daher P ⊂ λP und somitλ(P) ⊂ λP für alle P ∈ P . Hieraus folgt, dass B ∩ P ∈ λ(P) für alle P ∈ P undB ∈ λ(P) . Schlieÿlich gilt P ∈ λB für jedes B ∈ λ(P) , also ist P ⊂ λB für alleB ∈ λ(P) . Damit ist die Aussage des Satzes gezeigt.
Satz 1.49 (Eindeutigkeit und erzeugendes π-System)Es sei (Ω,F , µ) ein Maÿraum und P ⊂ F ein π-System mit σ (P) = F . Weiters existiereeine Folge Ωn∞n=1 ∈ PN mit Ω1 ⊂ Ω2 ⊂ . . . und
∞⋃
n=1
Ωn = Ω und µ(Ωn) <∞ für alle n ∈ N .
Dann ist µ durch die Werte µ(A) , A ∈ P , eindeutig bestimmt. Ist µ ein Wahrscheinlich-keitsmaÿ, so gilt die Aussage auch ohne die Existenz der Folge Ωn∞n=1 vorauszusetzen.
Beweis. Es sei µ ein weiteres σ-endliches Maÿ auf (Ω,F) mit
µ(P ) = µ(P ) für alle P ∈ P .
Für P ∈ P mit µ(P ) <∞ betrachten wir das Mengensystem
λP := A ∈ F : µ(A ∩ P ) = µ(A ∩ P )
und zeigen, dass es ein λ-System ist.

36 1. Maÿ- und Wahrscheinlichkeitsräume
(λ1) Oensichtlich ist Ω ∈ λP .
(λ2) Es seien A,B ∈ λP mit B ⊂ A . Dann ist
µ ((A \B) ∩ P ) = µ(A ∩ P )− µ(B ∩ P ) =
= µ(A ∩ P )− µ(B ∩ P ) = µ ((A \B) ∩ P ) .
Folglich ist A \B ∈ λP .
(λ3) Es sei An∞n=1 ∈ λNP eine Folge paarweise disjunkter Mengen und A :=⊎∞n=1An .
Wir erhalten
µ(A ∩ P ) =
∞∑
n=1
µ(An ∩ P ) =
∞∑
n=1
µ(An ∩ P ) = µ(A ∩ P ) ,
daher ist A ∈ λP .
Für alle A ∈ F und jedes P ∈ P mit µ(P ) <∞ gilt somit µ(A ∩ P ) = µ(A ∩ P ) . Da µund µ von unten stetig sind, erhalten wir für A ∈ F die gewünschte Identität
µ(A) = limn→∞
µ(A ∩ Ωn) = limn→∞
µ(A ∩ Ωn) = µ(A) .
Für den Fall, dass µ ein Wahrscheinlichkeitsmaÿ ist, wähle P = P ∪Ω als erzeugendesπ-System und beachte, dass der Wert µ(Ω) = 1 bekannt ist. Man wählt nun die durchΩn := Ω , n ∈ N , denierte konstante Folge.
1.5.3 Produkträume
In diesem Abschnitt wenden wir uns der Konstruktion von Produkten von Maÿräumenzu.
Beispiel 1.50 (Mehrmaliges Würfeln)Wir betrachten den Laplace-Raum (Ω,F ,P) mit Ω = 1, . . . , 6 , dieser modelliert denWurf eines fairen Würfels. Wie kann aus (Ω,F ,P) ein Wahrscheinlichkeitsraum konstru-iert werden, welcher das zweimalige Würfeln modelliert, also die zweimalige Durchfüh-rung des von (Ω,F ,P) beschriebenen Zufallsexperiments?
Als Ergebnismenge wählt man natürlich Ω × Ω , als σ-Algebra P(Ω × Ω) und das ent-sprechende Maÿ P2 deniert man durch
P2 (A1 ×A2) := P(A1)P(A2) , A1 ×A2 ⊂ Ω× Ω .
Nun wird unendlich oft gewürfelt. Mit welchem Wahrscheinlichkeitsraum kann dies mo-delliert werden?

1. Maÿ- und Wahrscheinlichkeitsräume 37
Zu zwei gegebenen σ-endlichen Maÿräumen (Ω1,F1, µ1) und (Ω2,F2, µ2) werden wir nunden Produktraum
(Ω1 × Ω2,F1 ⊗F2, µ1 ⊗ µ2)
denieren. Die Produkt-σ-Algebra von F1 und F2 ist gegeben durch
F1 ⊗F2 := σ (A1 ×A2 : A1 ∈ F1, A2 ∈ F2) .
Nun betrachten wir die Algebra
A :=
n⊎
k=1
(A
(k)1 ×A
(k)2
): n ∈ N,
(A
(k)1 , A
(k)2
)nk=1∈ (F1 ×F2)n pw. disj.
.
Diese Algebra erzeugt F1 ⊗F2 , es gilt also σ (A) = F1 ⊗F2 . Weiters denieren wir dieMengenfunktion µ0 : A → [0,∞] vermöge
µ0
(n⊎
k=1
(A
(k)1 ×A
(k)2
)):=
n∑
k=1
µ1
(A
(k)1
)µ2
(A
(k)2
),
wobei wir stets die Konvention 0 · ∞ := 0 treen.
Satz und Definition 1.51 (Produktmaÿraum)Das Mengensystem A ist eine Algebra und die Mengenfunktion µ0 wohldeniert undein σ-endliches Prämaÿ auf A . Nach dem Fortsetzungssatz von Carathéodorykann somit µ0 eindeutig zu einem Maÿ auf F1⊗F2 fortgesetzt werden. Dieses Maÿ heiÿtProduktmaÿ von µ1 und µ2 und wird mit µ1 ⊗ µ2 bezeichnet. Der Maÿraum
(Ω1 × Ω2,F1 ⊗F2, µ1 ⊗ µ2)
heiÿt Produktmaÿraum.
Beweis. µ0 ist wohldefiniert: Es sei A ∈ A mit
A =(A
(1)1 ×A
(1)2
)] . . . ]
(A
(n)1 ×A(n)
2
)=(B
(1)1 ×B(1)
2
)] . . . ]
(B
(m)1 ×B(m)
2
),
wobei(A
(k)1 , A
(k)2
)nk=1
,(B
(k)1 , B
(k)2
)mk=1⊂ F1 ×F2
jeweils paarweise disjunkt seien. Nun wählen wir
C(1)1 , . . . , C
(N1)1 ⊂ Ω1 und C
(1)2 , . . . , C
(N2)2 ⊂ Ω2

38 1. Maÿ- und Wahrscheinlichkeitsräume
mit
Ω1 =
N1⊎
k=1
C(k)1 und Ω2 =
N2⊎
k=1
C(k)2 ,
sodass jede der Mengen A(1)1 , . . . , A
(n)1 , B
(1)1 , . . . , B
(m)1 als disjunkte Vereinigung von Men-
gen ausC
(1)1 , . . . , C
(N1)1
und alle Mengen A
(1)2 , . . . , A
(n)2 , B
(1)2 , . . . , B
(m)2 als disjunkte
Vereinigung von Mengen ausC
(1)2 , . . . , C
(N2)2
geschrieben werden können. Dann exis-
tiert eine Indexmenge I ⊂ 1, . . . , N1 × 1, . . . , N2 mit
A =⊎
(k,l)∈I
(C
(k)1 × C(l)
2
).
Da µ1 und µ2 Maÿe sind, folgt nun
n∑
k=1
µ1
(A
(k)1
)µ2
(A
(k)2
)=∑
(k,l)∈I
µ1
(C
(k)1
)µ2
(C
(l)2
)=
m∑
l=1
µ1
(B
(l)1
)µ2
(B
(l)2
).
µ0 ist σ-endlich: Da µ1 und µ2 jeweils σ-endlich sind, gibt es Folgen
Ω(1)m
∞m=1
∈ FN1und
Ω
(2)n
∞n=1∈ FN2 mit
Ω1 =
∞⋃
m=1
Ω(1)m und µ1
(Ω(1)m
)<∞ für alle m ∈ N
sowie
Ω2 =∞⋃
n=1
Ω(2)n und µ2
(Ω(2)n
)<∞ für alle n ∈ N .
Für m,n ∈ N setze Ωm,n := Ω(1)m × Ω
(2)n ∈ A . Dann ist
Ω1 × Ω2 =
∞⋃
m,n=1
Ωm,n und µ0(Ωm,n) <∞ für alle m,n ∈ N .
Somit ist µ0 also σ-endlich.
µ0 ist σ-additiv: Es genügt für Ai, A(k)i ∈ Fi , i = 1, 2 und k ∈ N , mit
A1 ×A2 =
∞⊎
k=1
(A
(k)1 ×A
(k)2
)

1. Maÿ- und Wahrscheinlichkeitsräume 39
zu zeigen, dass
µ1(A1)µ2(A2) ≤∞∑
k=1
µ1
(A
(k)1
)µ2
(A
(k)2
),
denn die umgekehrte Ungleichung kann leicht mittels der Partitionen bewiesen werden,die wir verwendet haben, um die Wohldeniertheit von µ0 zu zeigen. Es sei nun
ϕ(ω1) :=
∞∑
n=1
χA
(n)1
(ω1)µ2
(A
(n)2
)und ϕN (ω1) :=
N∑
n=1
χA
(n)1
(ω1)µ2
(A
(n)2
)
für ω1 ∈ Ω1 und N ∈ N . Für N →∞ gilt
ϕN (ω1) ↑ ϕ(ω1) = χA1(ω1)µ2 (A2) .
Es sei nun ε ∈ (0, 1) und
BNε := ω1 ∈ Ω1 : (1− ε)µ2(A2) ≤ ϕN (ω1) ∈ F1
für N ∈ N . Die FolgeBNε
N∈N ist aufsteigend und da
⋃N∈NB
Nε = A1 , folgt
(1− ε)µ1(A1)µ2(A2) = limN→∞
(1− ε)µ1
(BNε
)µ2(A2) .
Da (1− ε)µ2(A2) ≤ ϕN (ω1) für alle ω1 ∈ BNε , erhält man
(1− ε)µ2(A2)µ1
(BNε
)≤
N∑
k=1
µ1
(A
(k)1
)µ2
(A
(k)2
)
und somit schlieÿlich
limN→∞
(1− ε)µ1
(BNε
)µ2(A2) ≤
∞∑
k=1
µ1
(A
(k)1
)µ2
(A
(k)2
).
A ist eine Algebra: Dies zu zeigen, verbleibt als Übung.
Bemerkung. Sind (Ω1,F1,P1) und (Ω2,F2,P2) zwei Wahrscheinlichkeitsräume, sonennt man entsprechend
(Ω1 × Ω2,F1 ⊗F2,P1 ⊗ P2)
den Produktwahrscheinlichkeitsraum und P1 ⊗ P2 das Produktwahrscheinlich-keitsmaÿ von P1 und P2 .

40 1. Maÿ- und Wahrscheinlichkeitsräume
Beispiel 1.52 (Zweimaliger Münzwurf)Es seien (Ω1,F1,P1) := (Ω2,F2,P2) :=
(0, 1,P(0, 1), 1
2δ0 + 12δ1
). Dann ist
P1 ⊗ P2 = 14δ(0,0) + 1
4δ(0,1) + 14δ(1,0) + 1
4δ(1,1) = U0,1 ⊗ U0,1 .
Um zu sehen, dass es bei der Bildung von Produkträumen mehrerer Maÿräume nicht aufdie Reihenfolge ankommt, benötigen wir folgendes Lemma.
Lemma 1.53 Für zwei Mengensysteme G1 ⊂ P(Ω1) und G2 ⊂ P(Ω2) gilt
σ (A1 ×A2 : A1 ∈ G1, A2 ∈ G2) = σ(G1)⊗ σ(G2) .
Beweis. Wir setzen F := σ (A1 ×A2 : A1 ∈ G1, A2 ∈ G2) . Oensichtlich gilt
F ⊂ σ(G1)⊗ σ(G2) ,
es bleibt also noch die umgekehrte Inklusion zu zeigen. Wir zeigen dazu, dass
A1 × Ω2 : A1 ∈ σ(G1) = σ (A1 × Ω2 : A1 ∈ G1) .
Wie man sich leicht überzeugt, ist A1 × Ω2 : A1 ∈ σ(G1) eine σ-Algebra auf Ω1 × Ω2 ,also gilt
σ (A1 × Ω2 : A1 ∈ G1) ⊂ A1 × Ω2 : A1 ∈ σ(G1) .Das Mengensystem
Σ := A1 ∈ σ(G1) : A1 × Ω2 ∈ σ (A1 × Ω2 : A1 ∈ G1)
ist eine σ-Algebra auf Ω1 und daher folgt aus G1 ⊂ Σ ⊂ σ(G1) , dass Σ = σ(G1) . Folglichist
A1 × Ω2 : A1 ∈ σ(G1) ⊂ σ (A1 × Ω2 : A1 ∈ G1) .Aus
A1 × Ω2 : A1 ∈ σ(G1) = σ (A1 × Ω2 : A1 ∈ G1) ⊂ F
und
Ω1 ×A2 : A2 ∈ σ(G2) = σ (Ω1 ×A2 : A2 ∈ G2) ⊂ F
dies zeigt man analog folgt nun für A1 ∈ σ(G1) und A2 ∈ σ(G2) , dass
A1 ×A2 = (A1 × Ω2) ∩ (Ω1 ×A2) ∈ F .
Schlieÿlich vollendet die Inklusionskette
A1 ×A2 : A1 ∈ σ(G1), A2 ∈ σ(G2) ⊂ F ⊂ σ(G1)⊗ σ(G2)
den Beweis.

1. Maÿ- und Wahrscheinlichkeitsräume 41
Es sei nun ein weiterer σ-endlicher Maÿraum (Ω3,F3, µ3) gegebenen. Nach Lemma 1.53ist
(F1 ⊗F2)⊗F3 = F1 ⊗ (F2 ⊗F3) .
Des Weiteren gilt
(µ1 ⊗ µ2)⊗ µ3 = µ1 ⊗ (µ2 ⊗ µ3) ,
da die beiden Maÿe auf dem π-System
A1 ×A2 ×A3 : A1 ∈ F1, A2 ∈ F2, A3 ∈ F3
übereinstimmen und somit nach Satz 1.49 unter Verwendung der σ-Endlichkeit dereinzelnen Maÿe gleich sind. Das Produkt der σ-endlichen Maÿräume
(Ω1,F1, µ1), . . . , (Ωd,Fd, µd) , wobei d ∈ N ,
wird daher iterativ konstruiert und dann mit
(Ω1 × . . .× Ωd,F1 ⊗ . . .⊗Fd, µ1 ⊗ . . .⊗ µd)
bezeichnet. Für das d-fache Produkt des σ-endlichen Maÿraums (Ω,F , µ) schreiben wirkurz
(Ωd,F⊗d, µ⊗d
).
Beispiel 1.54 (Produkt von Borel-σ-Algebren)Für d ∈ N ist B
(Rd)
= B(R)⊗d , siehe Aufgabe (1.51).
Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum. Wir konstruieren nun den Produktraum
(ΩN,F⊗N,P⊗N
).
Dazu betrachten wir das π-System der Zylindermengen
P := A1 × . . .×An × Ω× Ω× . . . : n ∈ N , A1, . . . , An ∈ F
und setzenF⊗N := σ(P) .
Auf der Algebra
A :=
n⊎
i=1
Pi : n ∈ N , P1, . . . , Pn ∈ P paarweise disjunkt

42 1. Maÿ- und Wahrscheinlichkeitsräume
denieren wir das Prämaÿ P0 durch
P0 (A1 × . . .×An × Ω× Ω× . . .) :=n∏
k=1
P(Ak) für A1, . . . , An ∈ F .
Mittels des Fortsetzungssatzes von Carathéodory setzen wir P0 zu einem eindeu-tig bestimmten Wahrscheinlichkeitsmaÿ auf F⊗N fort und bezeichnen dieses mit P⊗N .
Beispiel 1.55 (Bernoulli-Maÿ)Wir wollen nun einen Bernoulli-Versuch mit N ∈ N möglichen Ausgängen und unendlichvielen Wiederholungen modellieren. Eine einzige Durchführung werde durch den Laplace-Raum (Ω,P(Ω),P) beschrieben, wobei Ω = ω1, . . . , ωN . Es ist also
P =1
|Ω|∑
ω∈Ω
δω .
Dann modelliert (ΩN,F⊗N,P⊗N
)
den Bernoulli-Versuch und diesem Fall nennt man das Wahrscheinlichkeitsmaÿ P⊗N
Bernoulli-Maÿ.
Für Ω = 1, . . . , 6 modelliert der eben konstruierte Wahrscheinlichkeitsraum das Zu-fallsexperiment unendlich oft würfeln.
Würfeln wir mit einem Würfel unendlich oft, wie hoch ist die Wahrscheinlichkeit, dassunendlich oft, also immer wieder, eine Sechs geworfen wird? Diese Wahrscheinlichkeitsollte natürlich Eins sein, ansonsten gäbe es einen letzten Wurf, bei dem eine Sechs fälltund danach würde nie wieder eine auftreten. Um das eben Beschriebene zu formalisieren,benötigen wir folgende Denition.
Definition 1.56 (Limes inferior und Limes superior von Mengen)Gegeben sei die Folge An∞n=1 ∈ P(Ω)N . Dann nennt man
lim infn→∞
An :=∞⋃
n=1
∞⋂
m=n
Am bzw. lim supn→∞
An :=∞⋂
n=1
∞⋃
m=n
Am
Limes inferior bzw. Limes superior der Folge An∞n=1 .
Bemerkung. Es sei An∞n=1 ∈ FN eine Folge von Ereignissen.
B Wir schreiben auch
A∗ := lim infn→∞
An und A∗ := lim supn→∞
An .

1. Maÿ- und Wahrscheinlichkeitsräume 43
B Da Limes inferior und Limes superior durch das Bilden abzählbarer Vereinigungenund Durchschnitte entstehen, gilt
lim infn→∞
An ∈ F und lim supn→∞
An ∈ F .
B Es ist
A∗ = ω ∈ Ω: |n ∈ N : ω /∈ An| <∞ ,A∗ = ω ∈ Ω: |n ∈ N : ω ∈ An| =∞ .
Der Limes inferior ist also jenes Ereignis, dass ab einem gewissen Index alle Aneintreten, während der Limes superior jenes Ereignis ist, dass unendlich viele derAn eintreten.
B Insbesondere gilt A∗ ⊂ A∗ .
Beispiel 1.57 (Unendlich oft Sechs)Wir betrachten den Wahrscheinlichkeitsraum
(Ω,F ,P) :=(1, . . . , 6N,P(1, . . . , 6)⊗N,U⊗N1,...,6
).
Für n ∈ N denieren wir das Ereignis
An := ω ∈ Ω: ωn = 6 . . . Sechs beim n-ten Wurf.
Dann ist A∗ = lim supn→∞An jenes Ereignis, dass bei unendlich vielen Würfen eineSechs auftritt. Was ist P (A∗) ?
Es bezeichne (Ω,F ,P) einen beliebigen Wahrscheinlichkeitsraum.
Satz 1.58 (Lemma von Borel-Cantelli16)Es sei An∞n=1 ∈ FN eine Folge von Ereignissen.
(1) Gilt∑∞
n=1P(An) <∞ , so ist P(A∗) = 0 .
(2) Ist An∞n=1 unabhängig und∑∞
n=1P(An) =∞ , so gilt P(A∗) = 1 .
Beweis. (1) Da P stetig von oben und σ-subadditiv ist, folgt
P(A∗) = P
( ∞⋂
n=1
∞⋃
m=n
Am
)= lim
n→∞P
( ∞⋃
m=n
Am
)≤ lim
n→∞
∞∑
m=n
P(Am) = 0 .
16Francesco Paolo Cantelli, 18751966, italienischer Mathematiker

44 1. Maÿ- und Wahrscheinlichkeitsräume
(2) Man überzeugt sich leicht, dass log(1− x) ≤ −x für x ∈ [0, 1] , wobei log(0) := −∞ .Da P stetig von unten ist, führen die De Morganschen Regeln auf
P ((A∗)c) = P
( ∞⋃
n=1
∞⋂
m=n
Acm
)= lim
n→∞P
( ∞⋂
m=n
Acm
).
Für jedes n ∈ N erhalten wir jedoch
P
( ∞⋂
m=n
Acm
)=
∞∏
m=n
(1− P(Am)) =
= exp
( ∞∑
m=n
log (1− P(Am))
)≤ exp
(−∞∑
m=n
P(Am)
)= 0 .
Beispiel 1.59 (Anwendungen zum Lemma von Borel-Cantelli)Wir greifenBeispiel 1.57 nochmals auf und bestimmen nun P (A∗) . Die Familie An∞n=1
von Ereignissen ist unabhängig, denn für eine endliche Indexmenge I ⊂ N gilt
P
(⋂
i∈IAi
)= P
(6|I| × 1, . . . , 6 × 1, . . . , 6 × . . .
)=(
16
)|I|=∏
i∈IP(Ai) .
Nach dem Lemma von Borel-Cantelli folgt daher aus
∞∑
n=1
P(An) =∞∑
n=1
1
6=∞ ,
dass P(A∗) = 1 .
Nun werfen wir den Würfel nur ein einziges Mal, wählen also den Laplace-Raum (Ω,F ,P)mit Ω = 1, . . . , 6 , und setzen An := 6 für jedes n ∈ N . Dann ist
∑∞n=1P(An) =∞ ,
jedoch P(A∗) = 1/6 . Dies zeigt, dass die Unabhängigkeit in Teil (2) des Lemmas vonBorel-Cantelli im Allgemeinen eine notwendige Voraussetzung ist.
1.5.4 Lebesgue-Maÿ
Mittels des Fortsetzungssatzes von Carathéodory wollen wir nun das Lebesgue-Maÿ auf Rd konstruieren. Dazu greifen wir Beispiel 1.40 auf und betrachten daherwiederum die Algebra
A = (a1, b1] ] . . . ] (an, bn] : n ∈ N ,−∞ ≤ a1 ≤ b1 ≤ . . . ≤ an ≤ bn ≤ ∞auf R und die Mengenfunktion λ0 : A → [0,∞] gegeben durch
λ0 ((a1, b1] ] . . . ] (an, bn]) =
n∑
i=1
(bi − ai) .

1. Maÿ- und Wahrscheinlichkeitsräume 45
Wir zeigen nun, dass λ0 ein σ-endliches Prämaÿ auf A ist. Da λ0(∅) = 0 , widmen wir unsder σ-Additivität. Es genügt zu zeigen, dass für a < b und paarweise disjunkte Intervalle(an, bn] , n ∈ N und an < bn , mit
(a, b] =∞⊎
n=1
(an, bn]
gilt, dass
λ0 ((a, b]) = b− a =∞∑
n=1
(bn − an) . (∗)
Es sei ε > 0 . Da
[a+ ε, b] ⊂∞⋃
n=1
(an, bn +
ε
2n
),
folgt aus dem Überdeckungssatz von Heine17-Borel, dass eine endliche Indexmen-ge I(ε) ⊂ N existiert, sodass
[a+ ε, b] ⊂⋃
n∈I(ε)
(an, bn] ∪(bn, bn +
ε
2n
).
Damit erhalten wir
b− a− ε ≤∑
n∈I(ε)
((bn − an) +
ε
2n
)≤∞∑
n=1
(bn − an) + ε .
Bilden des Grenzwertes ε ↓ 0 führt nun auf
b− a ≤∞∑
n=1
(bn − an) .
Da b− a ≥∑Nn=1(bn − an) für alle N ∈ N , ist somit (∗) gezeigt.
Setzen wir Ωn := (−n, n] ∈ A für n ∈ N , so gilt
R =
∞⋃
n=1
Ωn und λ0(Ωn) = 2n <∞ für alle n ∈ N .
Dies zeigt die σ-Endlichkeit von λ0 .
17Heinrich Eduard Heine, 18211881, deutscher Mathematiker

46 1. Maÿ- und Wahrscheinlichkeitsräume
Bei λ0 handelt es sich also um ein σ-endliches Prämaÿ auf der Algebra A . Nach demFortsetzungssatz von Carathéodory existiert daher eine eindeutige Fortsetzungλ auf σ (A) = B(R) . Das Maÿ λ heiÿt Lebesgue-Maÿ auf (R,B(R)) .
Es sei nun d ∈ N . Für das Produktmaÿ λ⊗d auf(Rd,B(Rd)
)schreiben wir auch λd oder
kurz wiederum λ . Das Maÿ λd nennt man entsprechend Lebesgue-Maÿ auf(Rd,B(Rd)
).
Wir fassen die bisherigen Überlegungen zu folgendem Satz zusammen.
Satz 1.60(Lebesgue-Maÿ auf Rd
)
Es existiert ein eindeutig bestimmtes Maÿ λd auf(Rd,B(Rd)
)mit
λd ((a1, b1]× . . .× (ad, bd]) =d∏
i=1
(bi − ai)
für alle a1 < b1, . . . , ad < bd , dieses wird Lebesgue-Maÿ auf(Rd,B(Rd)
)genannt.
Beweis. Es genügt den Fall d = 1 zu betrachten. Das Lebesgue-Maÿ λ auf (R,B(R))besitzt die geforderte Eigenschaft und daher genügt es die Eindeutigkeit von λ zu zeigen.Dazu betrachten wir das Mengensystem
P := (a, b] : a < b ∪ ∅ ,
welches B(R) erzeugt. Es sei nun µ ein weiteres Maÿ auf (R,B(R)) mit µ|P = λ|P .
Variante 1: Oensichtlich stimmen dann µ und λ auch auf der Algebra A aus Bei-spiel 1.40 überein. Somit folgt aus dem Fortsetzungssatz von Carathéodory,dass µ = λ auf σ (A) = B(R) .
Variante 2: Das Mengensystem P ist ein π-System. Da Ωn := (−n, n] ∈ P , n ∈ N ,eine aufsteigende Folge mit
∞⋃
n=1
Ωn = R und λ(Ωn) <∞ für alle n ∈ N
deniert, sind die Voraussetzungen von Satz 1.49 erfüllt. Damit folgt die Eindeutigkeitvon λ .
Bemerkung. Das Prämaÿ λ0 auf A kann nach dem Beweis des Fortsetzungssatzesvon Carathéodory sogar auf die dort konstruierte σ-Algebra Σ ⊃ B(R) fortgesetztwerden. Wir bezeichnen diese σ-Algebra mit B(R) und nennen eine Menge B ∈ B(R)Lebesgue-messbar. Man kann unter Verwendung des Auswahlaxioms zeigen, dass
B(R) B(R) P(R) .

1. Maÿ- und Wahrscheinlichkeitsräume 47
1.5.5 Nicht Lebesgue-messbare Mengen
Zur Konstruktion einer nicht Lebesgue-messbaren Menge werden wir das Auswahlaxi-om benötigen.
Axiom 1.61 (Auswahlaxiom)Es sei I eine nicht leere Indexmenge und Mii∈I eine Familie nicht leerer Mengen. Dannexistiert eine auf I denierte Auswahlfunktion
ϕ : i 7→ mi ∈Mi .
Akzeptiert man das Auswahlaxiom, so kann die Menge ϕ(i) : i ∈ I gebildet werden,welche entsteht, indem für jedes i ∈ I genau ein Element mi ∈Mi ausgewählt wird.
Mittels des Auswahlaxioms konstruieren wir nun eine nicht Lebesgue-messbare Menge,eine sogenannte Vitali18-Menge.
Satz 1.62 (Satz von Vitali)Es existiert eine nicht Lebesgue-messbare Menge V ⊂ [0, 1] .
Beweis. Wir denieren vermöge
x ∼ y :⇐⇒ x− y ∈ Q für x, y ∈ Reine Äquivalenzrelation auf R . Man beachte, dass alle Äquivalenzklassen bezüglich ∼dicht in R liegen. Nach dem Auswahlaxiom kann die Menge V ⊂ [0, 1] gebildet werden,welche jeweils genau ein Element jeder Äquivalenzklasse bezüglich ∼ enthält. Wir setzenR := Q ∩ [−1, 1] und denieren für r ∈ R die Menge
Vr := V + r = v + r : v ∈ V .Dann ist
A :=⊎
r∈RVr
eine abzählbare Vereinigung paarweise disjunkter Mengen mit
[0, 1] ⊂ A ⊂ [−1, 2] .
Angenommen, V wäre Lebesgue-messbar. Dann ist auch Vr für jedes r ∈ R messbarund somit insbesondere A . Das Lebesgue-Maÿ λ ist translationsinvariant, daher giltλ(V ) = λ(Vr) für alle r ∈ R . Aus
λ(A) =∑
r∈Rλ(V )
folgt λ(A) ∈ 0,∞ . Dies ist aber oenbar nicht möglich, da [0, 1] ⊂ A ⊂ [−1, 2] . Alsoist V nicht Lebesgue-messbar.
18Giuseppe Vitali, 18751932, italienischer Mathematiker

48 1. Maÿ- und Wahrscheinlichkeitsräume
Bemerkung. Vitali-Mengen werden auch als Vitali-Monster bezeichnet. Zur Kon-struktion weiterer nicht Lebesgue-messbarer Mengen sei auf [12] verwiesen.
1.6 Beispiele kontinuierlicher Wahrscheinlichkeits-
räume
Im Fall eines kontinuierlichen Wahrscheinlichkeitsraums (Ω,F ,P) , ist Ω überabzähl-bar und im Gegensatz zu diskreten Wahrscheinlichkeitsräumen nun in den meisten Fällendie Potenzmenge keine geeignete σ-Algebra, auf der sinnvolle Wahrscheinlichkeitsmaÿedeniert werden können. Wir werden nun drei wichtige Beispiele kontinuierlicher Wahr-scheinlichkeitsräume kennenlernen.
1.6.1 Gleichverteilung
Problemstellung. Auf dem Kreis mit Mittelpunkt im Ursprung und Radius r > 0wird zufällig ein Punkt P gewählt. Wie wahrscheinlich ist es, dass der Abstand von Pzum Punkt Q = (r, 0) gröÿer gleich dem Kreisradius ist?
Modellierung. Den Punkt P zufällig zu wählen bedeutet, einen Winkel α ∈ [0, 2π)zufällig zu wählen. Daher setzen wir Ω := [0, 2π) . Da jeder Winkel α ∈ Ω gleich wahr-scheinlich sein soll, fordern wir vom gesuchten Wahrscheinlichkeitsmaÿ UΩ , dass
UΩ ((a, b]) = UΩ (α ∈ Ω: α ∈ (a, b]) = b−a2π für alle 0 ≤ a ≤ b < 2π .
Da somit insbesondere alle Intervalle (a, b] messbar sein müssen, wählen wir als σ-AlgebraB ([0, 2π)) . Das gesuchte Wahrscheinlichkeitsmaÿ ist folglich durch
U[0,2π) := 12π λ |B([0,2π))
gegeben, wobei λ wiederum das Lebesgue-Maÿ auf (R,B(R)) bezeichnet. Man nenntU[0,2π) die Gleichverteilung auf [0, 2π) .
Wir berechnen nun noch die gesuchte Wahrscheinlichkeit. Es bezeichne PQ den Abstandzwischen P und Q . Da
PQ ≥ r ⇐⇒ α ∈[π3 ,
5π3
],
erhalten wir
U[0,2π) (Abstand ≥ Radius) = U[0,2π)
([π3 ,
5π3
])= 4π/3
2π = 23 .
Definition 1.63 (Kontinuierliche Gleichverteilung)Es sei I ⊂ R ein beschränktes Intervall. Das Wahrscheinlichkeitsmaÿ
UI :=λ |B(I)
λ(I)

1. Maÿ- und Wahrscheinlichkeitsräume 49
auf (I,B(I)) wird (kontinuierliche) Gleichverteilung oder uniforme Verteilung aufI genannt.
Bemerkung. Beachte, dass für jedes Elementarereignis ω ∈ I gilt, dass UI (ω) = 0 .
Beispiel 1.64 (Zufälliger Punkt)Mittels des Wahrscheinlichkeitsraums ([0, 1],B([0, 1]), λ) wird das zufällige Auswähleneines Punktes aus dem Intervall [0, 1] modelliert. Weiters sei s > 1 und für jedes n ∈ Nein Intervall An = [an, bn] ⊂ [0, 1] mit bn − an = n−s gegeben. Da
∞∑
n=1
λ(An) =∞∑
n=1
1
ns<∞ ,
folgt aus dem Lemma von Borel-Cantelli λ(A∗) = 0 , also liegt ein zufällig ausge-wählter Punkt aus [0, 1] fast sicher in nur endlich vielen der Intervalle An .
1.6.2 Exponentialverteilung
Problemstellung. Eine Sekretärin empfängt im Durchschnitt λ = 3 Anrufe proStunde an ihrem Arbeitsplatz. Sie erscheint pünktlich um 8 Uhr zur Arbeit, t1 und t2mit 0 ≤ t1 < t2 bezeichnen jeweils die vergangene Zeit in Stunden seit Arbeitsbeginn.Wie wahrscheinlich ist es, dass der erste Anruf im Zeitintervall (t1, t2] eingeht?
Modellierung. Es bezeichne µλ das gesuchte Wahrscheinlichkeitsmaÿ auf (R,B(R)) ,wir werden es anschlieÿend mit dem Namen Exponentialverteilung versehen. Wie bereitsbei Einführung der Poisson-Verteilung besprochen, ist
µλ (in der ersten Stunde kein Anruf) = µλ ((1,∞)) = πλ (0) = e−λ .
Entsprechend erhalten wir
µλ (in den ersten t1 Stunden kein Anruf) = µλ ((t1,∞)) = πλt1 (0) = e−λt1
und somit
µλ (erster Anruf zwischen t1 und t1 Stunden) = µλ ((t1, t2]) =
= µλ ((t1,∞) \ (t2,∞)) = µλ ((t1,∞))− µλ ((t2,∞)) =
= e−λt1 − e−λt2 =
ˆ t2
t1
λe−λt dt .
Es bezeichne H die Heaviside19-Funktion, welche durch
H(t) :=
0 , t < 0 ,
1 , t ≥ 0 ,
19Oliver Heaviside, 18501925, britischer Mathematiker und Physiker
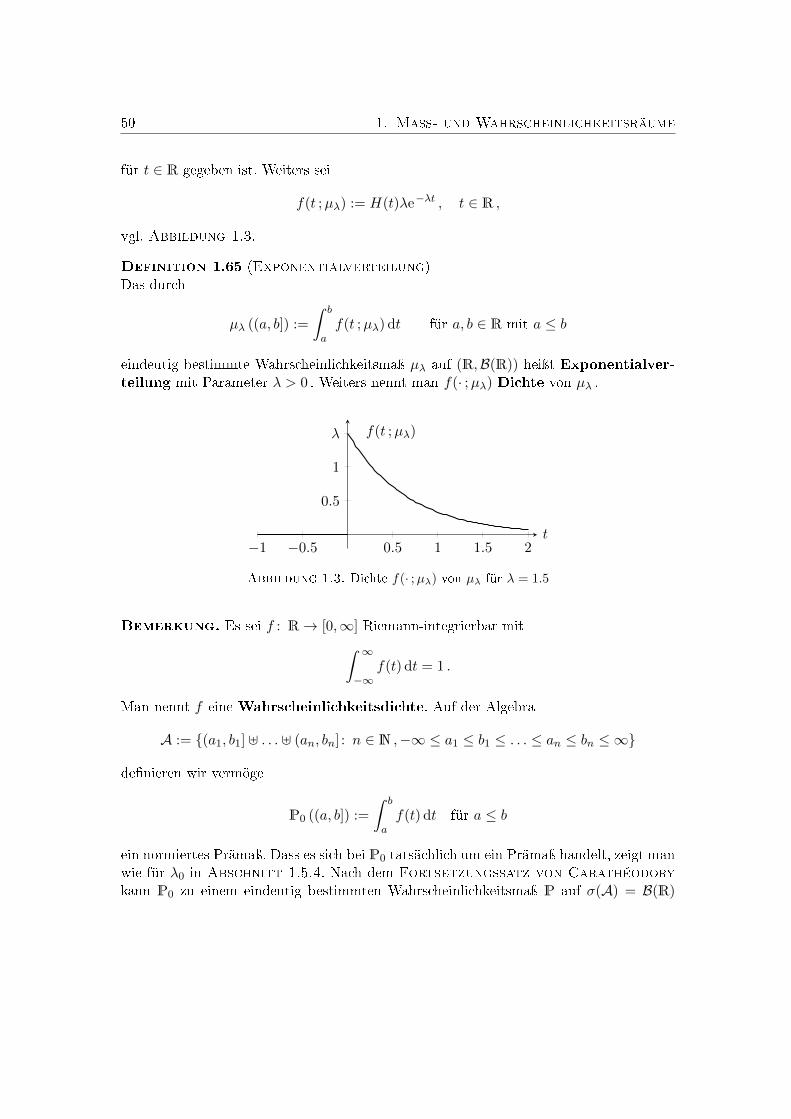
50 1. Maÿ- und Wahrscheinlichkeitsräume
für t ∈ R gegeben ist. Weiters sei
f(t ;µλ) := H(t)λe−λt , t ∈ R ,
vgl. Abbildung 1.3.
Definition 1.65 (Exponentialverteilung)Das durch
µλ ((a, b]) :=
ˆ b
af(t ;µλ) dt für a, b ∈ R mit a ≤ b
eindeutig bestimmte Wahrscheinlichkeitsmaÿ µλ auf (R,B(R)) heiÿt Exponentialver-teilung mit Parameter λ > 0 . Weiters nennt man f(· ;µλ) Dichte von µλ .
−1 −0.5 0.5 1 1.5 2
0.5
1
λ
t
f(t ;µλ)
Abbildung 1.3. Dichte f(· ;µλ) von µλ für λ = 1.5
Bemerkung. Es sei f : R→ [0,∞] Riemann-integrierbar mit
ˆ ∞−∞
f(t) dt = 1 .
Man nennt f eine Wahrscheinlichkeitsdichte. Auf der Algebra
A := (a1, b1] ] . . . ] (an, bn] : n ∈ N ,−∞ ≤ a1 ≤ b1 ≤ . . . ≤ an ≤ bn ≤ ∞
denieren wir vermöge
P0 ((a, b]) :=
ˆ b
af(t) dt für a ≤ b
ein normiertes Prämaÿ. Dass es sich bei P0 tatsächlich um ein Prämaÿ handelt, zeigt manwie für λ0 in Abschnitt 1.5.4. Nach dem Fortsetzungssatz von Carathéodorykann P0 zu einem eindeutig bestimmten Wahrscheinlichkeitsmaÿ P auf σ(A) = B(R)

1. Maÿ- und Wahrscheinlichkeitsräume 51
fortgesetzt werden.
Zur Konstruktion der Exponentialverteilung µλ bleibt also zu überprüfen, dassˆ ∞−∞
f(t ;µλ) dt = 1 .
Dies ist aber oensichtlich erfüllt.
Die Exponentialverteilung wird häug verwendet, um zufällige Wartezeiten zu modellie-ren. Beispielsweise werden auf diese Weise die Eintrittszeiten von Schäden, für die eineVersicherung aufkommen muss, modelliert. Ein anderes Beispiel liefert die Modellierungder zufälligen Lebensdauer von Atomen beim radioaktiven Zerfall.
1.6.3 Normalverteilung
Beispiel 1.66 (100-maliges Würfeln)Wie wahrscheinlich ist es, dass unter n = 100 Würfen mit einem Würfel zwischen 12 und22 Sechser auftreten? Diese Wahrscheinlichkeit können wir explizit berechnen, sie ist
Bn,p (12, . . . , 22) =22∑
k=12
(100
k
)(1
6
)k (5
6
)100−k≈ 0.859 ,
wobei p = 1/6 . Man könnte sich diese mühsame Rechnung durch Approximation mittelsder Poisson-Verteilung ersparen, jedoch ist die Näherung in diesem Fall nicht sehr gut,denn p ist nicht klein genug. Setzen wir λ := np = 100/6 , so erhalten wir nämlich
πλ (12, . . . , 22) =22∑
k=12
λk
k!e−λ ≈ 0.821 .
Wie lässt sich Bn,p für n→∞ bei festem p approximieren?
Für µ ∈ R und σ > 0 denieren wir die Gauÿsche20 Glockenkurve
f(· ;Nµ,σ2
): R→ (0,∞) : t 7→ 1√
2πσ2e−(t−µ)2/(2σ2) ,
vgl. Abbildung 1.4.
Definition 1.67 (Normalverteilung)Das durch
Nµ,σ2 ((a, b]) :=
ˆ b
af(t ;Nµ,σ2
)dt für a, b ∈ R mit a ≤ b
20Johann Carl Friedrich Gauÿ, 17771855, deutscher Mathematiker und Physiker
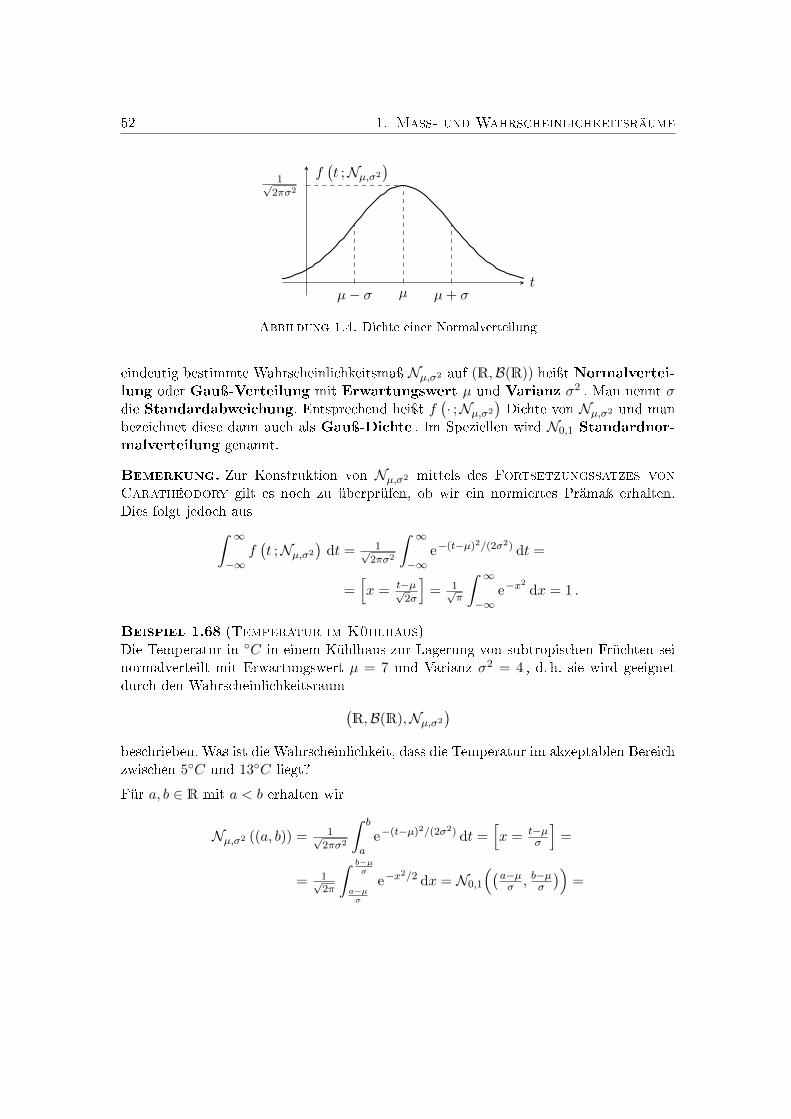
52 1. Maÿ- und Wahrscheinlichkeitsräume
µ− σ µ µ+ σ
1√2πσ2
t
f(t ;Nµ,σ2
)
Abbildung 1.4. Dichte einer Normalverteilung
eindeutig bestimmte Wahrscheinlichkeitsmaÿ Nµ,σ2 auf (R,B(R)) heiÿt Normalvertei-lung oder Gauÿ-Verteilung mit Erwartungswert µ und Varianz σ2 . Man nennt σdie Standardabweichung. Entsprechend heiÿt f
(· ;Nµ,σ2
)Dichte von Nµ,σ2 und man
bezeichnet diese dann auch als Gauÿ-Dichte . Im Speziellen wird N0,1 Standardnor-malverteilung genannt.
Bemerkung. Zur Konstruktion von Nµ,σ2 mittels des Fortsetzungssatzes vonCarathéodory gilt es noch zu überprüfen, ob wir ein normiertes Prämaÿ erhalten.Dies folgt jedoch aus
ˆ ∞−∞
f(t ;Nµ,σ2
)dt = 1√
2πσ2
ˆ ∞−∞
e−(t−µ)2/(2σ2) dt =
=[x = t−µ√
2σ
]= 1√
π
ˆ ∞−∞
e−x2
dx = 1 .
Beispiel 1.68 (Temperatur im Kühlhaus)Die Temperatur in C in einem Kühlhaus zur Lagerung von subtropischen Früchten seinormalverteilt mit Erwartungswert µ = 7 und Varianz σ2 = 4 , d. h. sie wird geeignetdurch den Wahrscheinlichkeitsraum
(R,B(R),Nµ,σ2
)
beschrieben. Was ist die Wahrscheinlichkeit, dass die Temperatur im akzeptablen Bereichzwischen 5C und 13C liegt?
Für a, b ∈ R mit a < b erhalten wir
Nµ,σ2 ((a, b)) = 1√2πσ2
ˆ b
ae−(t−µ)2/(2σ2) dt =
[x = t−µ
σ
]=
= 1√2π
ˆ b−µσ
a−µσ
e−x2/2 dx = N0,1
((a−µσ , b−µσ
))=

1. Maÿ- und Wahrscheinlichkeitsräume 53
= N0,1
((−∞, b−µσ
])−N0,1
((−∞, a−µσ
])=
= Φ(b−µσ
)− Φ
(a−µσ
),
wobei Φ gegeben durch
Φ(x) :=
ˆ x
−∞f (t ;N0,1) dt = 1√
2π
ˆ x
−∞e−t
2/2 dt , x ∈ R ,
die Verteilungsfunktion der Standardnormalverteilung bezeichnet, welche wir im nächstenKapitel genauer besprechen werden. Die Funktionswerte von Φ sind für positive Argu-mente tabelliert. Für x < 0 verwendet man, dass Φ(x) = 1−Φ(−x) , vgl. Aufgabe (1.60).Unter Verwendung einer solchen Tabelle oder mit entsprechender Computerunterstüt-zung erhalten wir für das eingangs geschilderte Beispiel
N7,4 ((5, 13)) = Φ(
13−7√4
)− Φ
(5−7√
4
)= Φ(3)− Φ(−1) = Φ(3) + Φ(1)− 1 ≈ 0.84
für die Wahrscheinlichkeit, dass die Temperatur zwischen 5C und 13C liegt.
Die Normalverteilung ist von zentraler Bedeutung, nicht zuletzt aufgrund des Zentra-len Grenzwertsatzes, den wir später formulieren werden. Ein Spezialfall dieses Satzesist der nachfolgende, welcher eine Antwort auf die in Beispiel 1.66 aufgeworfene Fragegibt, vgl. Abbildung 1.5.
Satz 1.69 (Grenzwertsatz von de Moivre21-Laplace)Es sei p ∈ (0, 1) und q := 1− p . Setzen wir µ := np und σ2 := npq , so existiert für jedesk ∈ N0 ein Restglied Rn(k)n∈N ∈ RN mit limn→∞Rn(k) = 0 und
Bn,p (k) = f(k ;Nµ,σ2
)(1 +Rn(k)) .
Beweis. Es sei auf [19, Abschnitt I.6] bzw. [11, S. 223] verwiesen.
Eine Vorstufe des obigen Grenzwertsatzes wurde bereits um ca. 1700 von Jakob Bernoullibewiesen, diesen nannte er selbst das Goldene Theorem .
Satz 1.70 (Goldenes Theorem von Jakob Bernoulli)
Es sei p ∈ (0, 1) und q := 1− p . Weiters sei C > 0 und K(n, k) :=∣∣∣k−np√
npq
∣∣∣ für n ∈ N und
k ∈ N0 . Setzen wir µ := np und σ2 := npq , so gilt
limn,k→∞
K(n,k)≤C
Bn,p (k)f(k ;Nµ,σ2
) = 1 .
21Abraham de Moivre, 16671754, französischer Mathematiker
54 1. Maÿ- und Wahrscheinlichkeitsräume
0 2 4 6 8 10
0
0.1
0.2
1 3 5 7 9
Abbildung 1.5. Vergleich der Binomialverteilung B10,1/2 mit der Gauÿ-Dichte f(· ;N5,5/2
)
Übungsaufgaben
(1.1) Kombinatorische Grundlagen: Gegeben sei eine Urne mit n ∈ N Kugeln,welche mit 1, . . . , n durchnummeriert sind. Weiters sei k ∈ 1, . . . , n .(a) Wieviele Möglichkeiten gibt es, k Kugeln mit Zurücklegen zu ziehen?
(b) Was ist die Anzahl der Möglichkeiten, k Kugeln ohne Zurücklegen zu ziehen?
Begründen Sie jeweils Ihr Ergebnis.
(1.2) Operationen auf Bild- und Urbildmengen I: Gegeben seien zwei MengenΩ und Σ , beliebige Indexmengen I und J und zwei Mengen A ⊂ Ω und B ⊂ Σsowie eine Abbildung f : Ω → Σ und Familien von Teilmengen Aii∈I ∈ P(Ω)I
und Bjj∈J ∈ P(Σ)J . Beweisen Sie die folgenden Aussagen.
(a) f(⋃
i∈I Ai)
=⋃i∈I f(Ai)
(b) f(⋂
i∈I Ai)⊂ ⋂i∈I f(Ai)
(c) f−1(⋃
j∈J Bj
)=⋃j∈J f
−1(Bj)
(d) f−1(⋂
j∈J Bj
)=⋂j∈J f
−1(Bj)
(e) f−1(Bc) = (f−1(B))c
Notation:
B⋃i∈I Ai := ω ∈ Ω: ∃ i ∈ I : ω ∈ Ai (Vereinigung)
B⋂i∈I Ai := ω ∈ Ω: ∀ i ∈ I : ω ∈ Ai (Durchschnitt)
B f(A) := f(ω) : ω ∈ A (Bildmenge von A unter f)
B f−1(B) := ω ∈ Ω: f(ω) ∈ B (Urbildmenge von B unter f)
B Ac := ω ∈ Ω: ω /∈ A und Bc := σ ∈ Σ: σ /∈ B (Komplement)

1. Maÿ- und Wahrscheinlichkeitsräume 55
Bemerkung: Für zwei Mengen C,D ⊂ Ω gilt
C = D ⇐⇒ (ω ∈ C ⇔ ω ∈ D) und C ⊂ D ⇐⇒ (ω ∈ C ⇒ ω ∈ D) .
(1.3) Darstellung der Mengendifferenz: Es seien A,B ⊂ Ω . Zeigen Sie, dassA \B = A ∩Bc . Fertigen Sie weiters ein entsprechendes Mengendiagramm an.
(1.4) Darstellung als disjunkte Vereinigung: Zeigen Sie, dass für zwei MengenA und B stets
(a) A ∪B = A ] (B \A)
(b) B = (A ∩B) ] (B \A)
gilt. Fertigen Sie wiederum entsprechende Mengendiagramme an.
(1.5) De Morgansche Regeln: Beweisen Sie die formulierten De MorganschenRegeln, also Satz 1.5
(1.6) Mächtigkeit der Potenzmenge: Zeigen Sie für eine endliche Menge Ω auf zweiVarianten, dass |P(Ω)| = 2|Ω| .
(a) Betrachten Sie die Menge A := 0, 1|Ω| und begründen Sie, dass |A| =|P(Ω)| .
(b) Bestimmen Sie für k ∈ 0, . . . , |Ω| die Anzahl der k-elementigen Teilmengenvon Ω , vgl. Aufgabe (1.1). Wie bestimmt man dadurch |P(Ω)| ?
(1.7) Es seien m,n ∈ N . Zeigen und interpretieren Sie die Vandermondesche Iden-tität, nach welcher für k ∈ N0 mit k ≤ m+ n gilt, dass
k∑
j=0
(m
j
)(n
k − j
)=
(m+ n
k
).
Hinweis: (x+ 1)m(x+ 1)n = (x+ 1)m+n, Koezientenvergleich
(1.8) Es seien E,F,G drei Ereignisse. Finden Sie einen Ausdruck für das Ereignis, dassvon E,F,G
(a) nur F eintritt,
(b) sowohl E als auch F , aber nicht G eintritt,
(c) mindestens eines der Ereignisse eintritt,
(d) mindestens zwei Ereignisse eintreten,
(e) alle drei Ereignisse eintreten,
(f) keines der Ereignisse eintritt,

56 1. Maÿ- und Wahrscheinlichkeitsräume
(g) höchstens ein Ereignis eintritt,
(h) höchstens zwei Ereignisse eintreten.
Ein Beispiel für (a) ist etwa Ec ∩ F ∩Gc .
(1.9) Zeigen Sie, dass es sich bei dem MengensystemA aus Beispiel 1.4 um eine Algebraauf R handelt.
(1.10) Ist
G = A ⊂ R : A oder Ac ist abzählbar
(a) eine Algebra?
(b) eine σ-Algebra?
(1.11) Geben Sie zwei σ-Algebren an, deren Vereinigung keine σ-Algebra ist.
(1.12) Es seien Ω eine beliebige Menge und G1,G2 ⊂ P(Ω) mit G1 ⊂ G2 . Zeigen Sie, dass
σ : G ⊂ P(Ω) → F ist σ-Algebra auf Ω : G 7→ σ (G)
inklusionserhaltend ist, d. h. dass σ (G1) ⊂ σ (G2) gilt.
(1.13) Wieviele Elemente enthält die kleinste σ-Algebra auf Ω = [0, 1] , welche die MengenA1 =
[0, 1
2
)und A2 =
14
enthält? Geben Sie die σ-Algebra explizit an.
(1.14) Spur-σ-Algebra: Es sei F eine σ-Algebra auf Ω und A ⊂ Ω . Zeigen Sie, dass essich bei
F|A = B ∩A : B ∈ F
um eine σ-Algebra handelt. Gilt F|A ⊂ F ?
(1.15) Symmetrische Differenzen: Es sei Ω eine beliebige Menge. Man nennt
A∆B := (A \B) ∪ (B \A)
die symmetrische Dierenz von A und B . Zeigen Sie:
(a) A∆B = (A ∪B) \ (A ∩B)
(b) Eine σ-Algebra F auf Ω ist bezüglich der symmetrischen Dierenzen abge-schlossen, d. h.
∆F := A∆B : A,B ∈ F = F .

1. Maÿ- und Wahrscheinlichkeitsräume 57
(c) Sind F1 und F2 zwei σ-Algebren auf Ω , dann ist auch ihre symmetrischeDierenz
F1∆F2 := A∆B : A ∈ F1, B ∈ F2
eine σ-Algebra.
(1.16) Es seien A1, A2, ..., An ⊂ Ω paarweise disjunkt mit Ω =⊎nk=1Ak .
(a) Man zeige, dass zu B ∈ σ (A1, A2, ..., An) eine Indexmenge I ⊂ 1, . . . , nexistiert, sodass
B =⊎
k∈IAk .
Hinweis: Zeigt man, dass
F =
⊎
k∈IAk : I ⊂ 1, . . . , n
eine σ-Algebra ist, so folgt die Inklusion σ (A1, A2, . . . , An) ⊂ F aus derDenition von σ (A1, A2, . . . , An) .
(b) Wieviele Elemente enthält σ(A1, A2, ..., An) ?
(1.17) Man zeige, dass σ (GA) = B(Rd), wobei GA =
A ⊂ Rd abgeschlossen
.
(1.18) Beweisen Sie, dass
⋃
n∈N
(0, 1− 1
n
]= (0, 1) .
(1.19) Es sei O ⊂ R oen. Zeigen Sie, dass O die Vereinigung abzählbar vieler oenerIntervalle ist.
(1.20) Es sei
GI := (a, b) : a < b .
Verwenden Sie Aufgabe (1.19) um zu zeigen, dass σ (GI) = B(R) .
(1.21) Wir betrachten die Mengensysteme
G1 := (a, b] : a < b und G2 := (−∞, x] : x ∈ R .
Zeigen Sie, dass σ (G1) = σ (G2) = B(R) .

58 1. Maÿ- und Wahrscheinlichkeitsräume
(1.22) Gegeben sei die Borel-Menge B ∈ B(Rd). Zeigen Sie, dass
B (B) = σ(B ∩ O : O ⊂ Rd oen
).
(1.23) Geben Sie einen Wahrscheinlichkeitsraum (Ω,F ,P) und Ereignisse A,B ∈ F an,anhand derer Sie die Identitäten
P(A \B) = P(A)− P(A ∩B) und P(A ∪B) + P(A ∩B) = P(A) + P(B)
veranschaulichen.
(1.24) Beweisen Sie Satz 1.19.
(1.25) Augensumme: Betrachten Sie zwei faire Würfel mit den Augenzahlen 1, 2, . . . , 6 .Modellieren Sie den Wurf beider Würfel mittels eines geeigneten Wahrscheinlich-keitsraums. Mit welcher Wahrscheinlichkeit ist die Augensumme m ∈ 2, . . . , 12 ?
(1.26) Reise nach Jerusalem einmal anders: Es seien n ≥ 3 Sitzplätze in
(a) einem Kreis
(b) einer Reihe
angeordnet. Die Sitzplätze werden zufällig an n Personen vergeben, jede Sitzplatz-verteilung sei gleich wahrscheinlich. Modellieren Sie dieses Zufallsexperiment mit-tels eines geeigneten Wahrscheinlichkeitsraums. Ist die Wahrscheinlichkeit, dasszwei bestimmte Personen nebeneinander sitzen, im Fall (a) oder (b) höher? Wiehoch ist die jeweilige Wahrscheinlichkeit?
(1.27) Stetigkeit von oben: Beweisen Sie, dass ein Wahrscheinlichkeitsmaÿ stetig vonoben ist.
(1.28) Multiple-Choice: Bei einem Multiple-Choice-Test stehen bei jeder der 13 Fra-gen drei Antwortmöglichkeiten, wobei jeweils nur eine richtig ist. Zum positivenBestehen müssen mindestens sechs Fragen richtig beantwortet werden. Ein etwasunvorbereiteter Prüing beschlieÿt, bei jeder Frage zufällig eine der drei Antwort-möglichkeiten anzukreuzen. Mit welcher Wahrscheinlichkeit besteht er die Prüfung?
(1.29) Hypergeometrische Verteilung: Zeigen Sie, dass es sich bei der hypergeome-trischen Verteilung tatsächlich um ein Wahrscheinlichkeitsmaÿ handelt.
(1.30) Ziehen mit und ohne Zurücklegen: Gegeben sei eine Urne mit N Kugeln,davon seien W weiÿ und N −W schwarz.
(a) Es werden n Kugeln mit Zurücklegen gezogen. Modellieren Sie dieses Zufalls-experiment mittels eines geeigneten Wahrscheinlichkeitsraums und bestimmenSie die Wahrscheinlichkeit, k weiÿe Kugeln zu ziehen. Warum handelt es sichhierbei um ein Bernoulli-Experiment?

1. Maÿ- und Wahrscheinlichkeitsräume 59
(b) Nun werden n Kugeln ohne Zurücklegen gezogen. Wie lautet das entsprechen-de Modell und was ist nun die Wahrscheinlichkeit, k weiÿe Kugeln zu ziehen?Handelt es sich hierbei ebenfalls um ein Bernoulli-Experiment?
(1.31) Vergleich diskreter Verteilungen: Veranschaulichen und vergleichen Sie dieBinomialverteilung, hypergeometrische Verteilung, Poisson-Verteilung und geome-trische Verteilung für geeignete Parameter mittels Stabdiagrammen.
(1.32) Diskreter Wahrscheinlichkeitsraum: Es sei Ω höchstens abzählbar. Gegebensei der diskrete Wahrscheinlichkeitsraum (Ω,P(Ω),P) . Zeigen Sie, dass
P =∑
ω∈Ω
pωδω ,
wobei pω = P (ω) für ω ∈ Ω .
(1.33) Faschingskrapfen: In einer Bäckerei wurden 50 Faschingskrapfen gebacken, dajedoch die Marillenmarmeladebefüllungsmaschine sonderbare Laute von sich gege-ben hat, beschlieÿt der Bäckermeister, die Erzeugnisse zu testen also zu verkosten.Was er nicht weiÿ: Tatsächlich litt die Maschine unter Marmeladenverstopfung und10 der 50 erzeugten Krapfen konnten nicht befüllt werden. Der Meister lässt seineLehrlinge 10 zufällig ausgewählte Krapfen testen. Wie hoch ist die Wahrschein-lichkeit, dass die Lehrlinge
(a) genau zwei
(b) keinen
(c) alle 10
Krapfen ohne Füllung bekommen? Wie hoch ist die Wahrscheinlichkeit, dass unter20 Krapfen genau 4 ohne Füllung sind? Geben Sie den zur Modellierung diesesZufallsexperiments verwendeten Wahrscheinlichkeitsraum an.
(1.34) Supermarkt: In einer Filiale einer Supermarktkette kauft im Schnitt alle dreiMinuten ein Kunde ein. Was ist die Wahrscheinlichkeit, dass
(a) in einer Stunde 15 Kunden
(b) in 20 Minuten 5 Kunden
einkaufen? Geben Sie den zur Modellierung verwendeten Wahrscheinlichkeitsrauman.
(1.35) Das klassische Geburtstagsproblem: Wie hoch ist die Wahrscheinlichkeit,dass mindestens zwei von n der Studierenden im Stochastik-Proseminar am selbenTag Geburtstag haben? Man nehme dabei an, das Jahr habe 365 Tage und alleTage sind als Geburtstag gleich wahrscheinlich.

60 1. Maÿ- und Wahrscheinlichkeitsräume
(1.36) Geometrische Verteilung: Zeigen Sie für p ∈ (0, 1) , dass die geometrischeVerteilung gp ein Wahrscheinlichkeitsmaÿ auf (N0,P(N0)) ist.
(1.37) Türproblem: Nach einer durchzechten Nacht kommt ein Mann in etwas ange-trunkenem Zustand an seine Haustür. Er hat N für ihn in seiner Verfassung unun-terscheidbare Schlüssel in seiner Tasche und beschlieÿt zu versuchen, die Haustürefolgendermaÿen zu önen: Er nimmt einen Schlüssel aus seiner Tasche, sperrt die-ser nicht, so legt er ihn wieder zu den anderen. Dies wiederholt er so lange, bisdie Tür sich önet. Was ist die Wahrscheinlichkeit, dass er höchstens k Versuchebenötigt, um sein Haus zu betreten? Geben Sie den zur Modellierung verwendetenWahrscheinlichkeitsraum an.
(1.38) Negative Binomialverteilung: BeimWürfeln mit einem fairen Würfel soll manmöglichst oft eine Sechs würfeln, muss aber abbrechen, sobald man insgesamt n ∈ Nmal keine Sechs gewürfelt hat. Man modelliere dieses Zufallsexperiment mit einemgeeigneten Wahrscheinlichkeitsraum und berechne für k ∈ N0 die Wahrscheinlich-keit, dass man nach n Fehlversuchen, k-mal eine Sechs gewürfelt hat.
(1.39) Beweisen Sie Satz 1.38.
(1.40) Stromkreis: Gegeben sei folgender Schaltplan:
Ω := ω1,ω2,ω3,ω4, F := 2Ω
P(ω) =1
4, ∀ω ∈ Ω.
A := ω1,ω2, B := ω1,ω3 C := ω1,ω4A, B, C
(Ω,F , P) A ∈ F P(A) ∈ 0, 1.A B ∈ F
(Ω,F , P) A ∈ F , P(A) > 0.B1, . . . , Bn ∈ F Ω Bi ∩ Bj = ∅ i = jn
i=1 Bi = Ω. P(Bj) > 0 j = 1, . . . , n,
P(Bj |A) =P(A|Bj)P(Bj)n
k=1 P(A|Bk)P(Bk).
(Ω,F , P) A1, . . . An ∈ F
Ac1, A2, . . . , An
Ac1, . . . , A
cn
(Ω,F , P) A1, . . . , An ∈ F
P n
i=1
Ai
= 1 − P(Ac
1) · . . . · P(Acn).
Jeder der Schalter A,B,C,D,E ist unabhängig voneinander mit Wahrscheinlichkeitp ∈ (0, 1) geönet und demzufolge mit Wahrscheinlichkeit 1− p geschlossen.(a) Wie wahrscheinlich ist es, dass alle Schalter geschlossen sind?
(b) Mit welcher Wahrscheinlichkeit ieÿt Strom?
Geben Sie den zur Modellierung dieses Zufallsexperiments verwendeten Wahr-scheinlichkeitsraum an.
(1.41) Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum und A ∈ F ein fast sicheres oder fastunmögliches Ereignis, d. h. P(A) ∈ 0, 1 . Man zeige, dass A von jedem EreignisB ∈ F unabhängig ist.
(1.42) Geben Sie einen Wahrscheinlichkeitsraum und drei Ereignisse A,B,C an, sodassA,B,C paarweise unabhängig, jedoch nicht unabhängig sind.

1. Maÿ- und Wahrscheinlichkeitsräume 61
(1.43) Bedingte Wahrscheinlichkeit: Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraumund B ∈ F mit P(B) > 0 . Zeigen Sie, dass P( · |B) ein Wahrscheinlichkeitsmaÿauf (Ω,F) ist.
(1.44) Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum und n ∈ N . Des Weiteren seienA1, . . . , An ∈ F voneinander unabhängige Ereignisse. Zeigen Sie, dass für alleI ⊂ 1, . . . , n gilt, dass
P
(⋃
i∈IAi
)= 1−
∏
i∈IP(Aci
).
(1.45) Monty-Hall22-Dilemma: Bei einer Quizshow kann der Kandidat zwischen dreiToren, hinter denen sich der mögliche Gewinn verbirgt, wählen. Hinter zwei Torenbenden sich Nieten, während hinter dem dritten Tor ein Auto auf seinen Gewin-ner wartet. Der Kandidat muss sich am Anfang für eines der drei Tore entscheiden.Daraufhin önet der Moderator ein Tor, das der Kandidat nicht gewählt hat undhinter dem sich eine Niete bendet. Der Kandidat kann sich nun zwischen den zweiverbleibenden Toren entscheiden. Soll der Kandidat sein bereits gewähltes Tor be-halten oder auf das andere Tor wechseln, um seine Gewinnchancen zu maximieren?Wie hoch sind jeweils die Gewinnwahrscheinlichkeiten?
(1.46) CSI: Innsbruck: Die Innsbrucker Polizeizentrale nimmt Anrufe von den RevierenMariahilf, Pradl und Bahnhof entgegen. Die Zentrale bekommt im Durchschnittpro Tag vom Revier Pradl dreimal so viele und vom Revier Bahnhof viermal so vieleAnrufe weitergeleitet wie vom Revier Mariahilf. In der Regel wird von Mariahilf ineinem von 10000, von Pradl in einem von 5000 und von Bahnhof in einem von 4000Anrufen ein Kapitalverbrechen gemeldet. Der Zentrale wird ein Mord gemeldet. Mitwelcher Wahrscheinlichkeit wurde von Pradl angerufen?
(1.47) Trickreiche Münzen: Wir betrachten zehn Münzen, wobei die Wahrscheinlich-keit, dass man beim Wurf der k-ten Münze Kopf erhält, gleich k/10 ist. Es wirdzufällig eine der zehn Münzen ausgewählt. Was ist unter der Bedingung Kopf zuerhalten die bedingte Wahrscheinlichkeit, dass die fünfte Münze ausgewählt wird?
(1.48) Konsens: Ein Parlament setzt sich aus zwei Parteien zusammen. Mit einem Anteilvon p ∈ (0, 1) ist die konservative Partei vertreten, mit einem Anteil von (1 − p)die liberale. Mitglieder der konservativen Partei stimmen bei jedem Abstimmungs-durchgang gleich ab, während jedes Mitglied der liberalen Partei mit Wahrschein-lichkeit q ∈ (0, 1) seine Meinung von einem Durchgang auf den nächsten ändert.Man beobachtet nun einen Abgeordneten und weiÿ, dass er bereits zweimal gleich
22Monty Hall, geboren 1921, Moderator der Spieleshow Let's Make a Deal

62 1. Maÿ- und Wahrscheinlichkeitsräume
abgestimmt hat. Wie groÿ ist die Wahrscheinlichkeit, dass er beim nächsten Malwieder gleich stimmt?
(1.49) Es sei µ∗ ein äuÿeres Maÿ auf Ω . Zeigen Sie: Die Menge A ⊂ Ω ist genau dannµ∗-messbar, wenn
µ∗(C) ≥ µ∗(C ∩A) + µ∗(C \A)
für alle C ⊂ Ω mit µ∗(C) <∞ .
(1.50) Beweisen Sie, dass das Mengensystem Σ aus Satz 1.42 eine Algebra auf Ω ist.
(1.51) Beweisen Sie die Aussage in Beispiel 1.54.
(1.52) Mengenoperationen auf Produkten: Es seien Ω1 und Ω2 zwei beliebige Men-gen sowie A1, B1 ⊂ Ω1 und A2, B2 ⊂ Ω2 .
(a) Zeigen Sie, dass (A1 ×A2) ∩ (B1 ×B2) = (A1 ∩B1)× (A2 ∩B2) .
(b) Warum gilt (A1 × A2) ∪ (B1 × B2) = (A1 ∪ B1)× (A2 ∪ B2) im Allgemeinennicht?
(c) Begründen Sie, warum auch (A1×A2)c = Ac1×Ac
2 im Allgemeinen nicht gilt?
(1.53) Es sei Ω eine beliebige Menge und An∞n=1 ∈ P(Ω)N eine monotone Folge vonTeilmengen, d. h. entweder ist
A1 ⊂ A2 ⊂ . . . oder A1 ⊃ A2 ⊃ . . .
erfüllt. Zeigen Sie, dass lim infn→∞An = lim supn→∞An .
(1.54) Zeitlich intensives Würfelspiel: Zu Beginn des Spiels geben wir uns eineFolge kn∞n=1 ∈ 1, . . . , 6N vor, der weitere Spielablauf lautet wie folgt : Im n-tenDurchgang, n ∈ N , würfeln wir kn-mal mit einem fairen Würfel. Wir gewinnen denDurchgang, wenn wir in allen kn Würfen eine Sechs würfeln. Zeigen Sie, dass
(a) die Wahrscheinlichkeit unendlich oft zu gewinnen genau dann gleich 1 ist,wenn
∞∑
n=1
(1
6
)kn=∞ .
(b) die Wahrscheinlichkeit unendlich oft zu verlieren immer 1 ist.
(1.55) Es sei Q ∩ (0, 1) = x1, x2, . . . . Stimmt es, dass
(0, 1) ⊂∞⋃
n=1
(xn − 1
4n , xn + 14n
)?

1. Maÿ- und Wahrscheinlichkeitsräume 63
(1.56) Cantor-Menge: Es sei Cn∞n=0 die durch
C0 := [0, 1] und Cn := Cn−1
3 ∪(
23 + Cn−1
3
), n ∈ N ,
rekursiv denierte Folge von Teilmengen von [0, 1] , wobeiCn−1
3 :=x3 : x ∈ Cn−1
und 2
3 + Cn−1
3 :=
2+x3 : x ∈ Cn−1
.
Man entfernt also aus dem Intervall [0, 1] das mittlere oene Drittel, dann wiederumaus den verbleibenden Stücken das mittlere oene Drittel und setzt diesen Vorgangiterativ fort, vgl. http://de.wikipedia.org/wiki/Cantor-Menge. Es sei
C :=
∞⋂
n=0
Cn ,
diese Menge ist als Cantor23-Menge oder Cantorsches Diskontinuum be-kannt. Zeige, dass C eine Borel-Menge mit λ(C) = 0 ist.Bemerkung : C ist überabzählbar.
(1.57) Smith-Volterra-Cantor-Menge:Wir betrachten die Folge Sn∞n=0 von Men-gen, wobei diese rekursiv durch
S0 := [0, 1] , S1 := S0 \(
38 ,
58
), S2 := S1 \
((532 ,
732
)∪(
2532 ,
2732
)), . . .
gegeben ist. Man entfernt also aus [0, 1] das mittlere oene Viertel, dann aus denverbliebenen Teilen jeweils in der Mitte das oene Intervall der Länge 1/16, aus denvier verbliebenen Teilen weiters jeweils ein oenes Intervall der Länge 1/64 und soweiter, vgl. http://en.wikipedia.org/wiki/Smith-Volterra-Cantor_Set. Nunsei
S :=∞⋂
n=0
Sn .
die sogenannte Smith24-Volterra25-Cantor-Menge. Zeige, dass S eine Borel-Menge mit λ(S) = 1/2 ist.
(1.58) Gedächtnislosigkeit der Exponentialverteilung: Die zufällige Lebensdau-er einer Glühbirne wir als exponentialverteilt angenommen, d. h sie wird für einλ > 0 mittels des Wahrscheinlichkeitsraums (R,B(R), µλ) modelliert. Für a, b ≥ 0bezeichne C das Ereignis, dass die Glühbirne länger als b + a Stunden hält, undA das Ereignis, dass sie nicht in den ersten a Stunden versagt. Was ist die Wahr-scheinlichkeit von C gegeben dem Ereignis B , dass die Glühbirne bereits b Stundengehalten hat? Zeigen Sie, dass µλ(C|B) = µλ(A) .
23Georg Ferdinand Ludwig Philipp Cantor, 18451918, deutscher Mathematiker24Henry John Stephen Smith, 18261883, englischer Mathematiker25Vito Volterra, 18601940, italienischer Mathematiker und Physiker

64 1. Maÿ- und Wahrscheinlichkeitsräume
(1.59) Es sei µ ∈ R und σ > 0 . Führen Sie für die Gauÿ-Dichte f(· ;Nµ,σ2
)eine Kur-
vendiskussion durch. (Extrema, Wendepunkte, Monotoniebereiche, asymptotischesVerhalten, ...)
(1.60) Symmetrie von Φ: Zeigen Sie, dass Φ(−x) = 1− Φ(x) für alle x ∈ R .
(1.61) Schokoladenfabrik: In einer Fabrik werden maschinell Schokoladentafeln her-gestellt. Auf dem Etikett einer jeden Tafel wird ein Gewicht von 200 g angegeben.Aus Erfahrung weiÿ man, dass das Gewicht normalverteilt ist und zwar mit Erwar-tungswert µ = 198 und Standardabweichung σ = 3 . Der kleine Charlie darf sichbei einer Führung durch die Schokoladenfabrik eine Tafel aussuchen. Nun hot ernatürlich auf besonders viel Schokolade.
(a) Wie hoch ist die Wahrscheinlichkeit, dass seine Schokoladentafel mehr als205 g wiegt?
(b) Mit welcher Wahrscheinlichkeit, wiegt die Tafel zwischen 195 g und 200 g?

1. Maÿ- und Wahrscheinlichkeitsräume 65
Schulaufgaben
Die nachfolgenden Aufgaben stammen, sofern keine weiteren Angaben gemacht werden,von https://www.bifie.at/ (Stand: Februar 2013).
(S1.1) Reihenfolge: Für eine Abfolge von fünf verschiedenen Bildern gibt es nur einerichtige Reihung. Diese Bilder werden gemischt und ohne sie anzusehen in einerReihe aufgelegt.
Wie groÿ ist die Wahrscheinlichkeit dafür, dass die richtige Reihenfolge erscheint?
(S1.2) Münzwurf: Eine Münze wird drei Mal geworfen. Z steht für Zahl, W für Wap-pen.
(a) Gib alle möglichen Ausfälle (z. B. ZWZ) an.
(b) Gib alle Ausfälle an, die zu folgenden Ereignissen E1, E2, E3 gehören:
Ereignis Ausfälle
E1 genau zweimal Zahl
E2 mindestens zweimal Zahl
E3 niemals Zahl
(c) Beschreibe die Gegenereignisse E′1, E′2, E
′3 der Ereignisse aus (b) verbal und
gib ihre Wahrscheinlichkeiten P(E′1), P(E′2) und P(E′3) an:
verbal Wahrscheinlichkeit
E′1 P(E′1) =
E′2 P(E′2) =
E′3 P(E′3) =
(S1.3) Augensumme: Zwei Würfel werden geworfen und die Augensumme wird ermit-telt.
Untersuche, ob das Ereignis Augensumme 6 oder Augensumme 9 wahrschein-licher ist.
(S1.4) Wahrscheinlichkeit eines Defekts: Eine Maschine besteht aus den dreiBauteilen A, B und C. Diese haben die im nachstehenden Modell eingetragenenDefekthäugkeiten. Eine Maschine ist defekt, wenn mindestens ein Bauteil defektist.

66 1. Maÿ- und Wahrscheinlichkeitsräume
Berechnen Sie die Wahrscheinlichkeit, dass bei einer defekten Maschine zwei odermehr Bauteile defekt sind!
(S1.5) Sehr Gut: Ein Schüler rechnet bei jedem Test mit einer Wahrscheinlichkeit von20% für die Note Sehr Gut. Wie schaut in diesem Fall bei 8 Tests die Sehr Gut-Verteilung aus? Berechne also die Wahrscheinlichkeiten für 0, 1, 2, . . . , 8 sehr guteBeurteilungen.(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 246, Nr. 6.13)
(S1.6) Ausschuss: In einer Fertigungsabteilung ist bekannt, dass im Schnitt jedes 200.Stück Ausschuss ist. Wie groÿ ist die Wahrscheinlichkeit (Näherung durch einePoisson-Verteilung), dass in einer Tagesproduktion von 1000 Stück
(a) mindestens ein Stück,
(b) höchstens 5 Stück Ausschuss ist?
(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 246, Nr. 6.23)
(S1.7) Dreimäderlhaus: Die Wahrscheinlichkeit unter 3 Kindern 3 Mädchen zu haben(Dreimäderlhaus) beträgt 11.6 %.
Wie groÿ ist die Wahrscheinlichkeit, beim vierten Kind einen Buben zu bekom-men?
(S1.8) 6 aus 45: Seit 1986 wird in Österreich das Lotto-Spiel 6 aus 45 veranstaltet.Dabei werden bei jeder Ziehung aus den Zahlen 1 bis 45 sechs Zahlen zufälligausgewählt. Angenommen, jemand gibt bei einer Spielrunde genau einen Tippab, d. h. er kreuzt (natürlich vor der Ziehung) auf dem Spielschein sechs Zahlenan.

1. Maÿ- und Wahrscheinlichkeitsräume 67
(a) Wie groÿ ist die Wahrscheinlichkeit für diesen Spieler bei der Ziehung 6Richtige zu tippen?
(b) In Deutschland werden beim Lotto 6 aus 49 Zahlen gezogen. Wo ist dieWahrscheinlichkeit für 6 Richtige gröÿer, in Deutschland oder in Österreich?Begründe deine Entscheidung.
(S1.9) Binomialverteilung: Kreuzen Sie jene Situation(en) an, die mit Hilfe der Bi-nomialverteilung modelliert werden kann/können!
In der Kantine eines Betriebs essen 80 Personen. Am Montag werden einvegetarisches Gericht und drei weitere Menüs angeboten. Erfahrungsgemäÿwählt jede vierte Person das vegetarische Gericht. Es werden 20 vegetarischeGerichte vorbereitet. Wie groÿ ist die Wahrscheinlichkeit, dass diese nichtausreichen?
Bei einer Lieferung von 20 Mobiltelefonen sind fünf defekt. Es werden dreiGeräte gleichzeitig entnommen und getestet. Mit welcher Wahrscheinlichkeitsind mindestens zwei davon defekt?
In einer Klasse müssen die Schüler/innen bei der Überprüfung der Bildungs-standards auf einem anonymen Fragebogen ihr Geschlecht (m, w) ankreuzen.In der Klasse sind 16 Schülerinnen und 12 Schüler. Fünf Personen haben aufdem Fragebogen das Geschlecht nicht angekreuzt. Mit welcher Wahrschein-lichkeit benden sich drei Schüler unter den fünf Personen?
Ein Groÿhändler erhält eine Lieferung von 2 000 Mobiltelefonen, von denenerfahrungsgemäÿ 5 % defekt sind. Mit welcher Wahrscheinlichkeit bendensich 80 bis 90 defekte Geräte in der Lieferung?
In einer Klinik werden 500 kranke Personen mit einem bestimmten Medi-kament behandelt. Die Wahrscheinlichkeit, dass schwere Nebenwirkungenauftreten, beträgt 0.001. Wie groÿ ist die Wahrscheinlichkeit, dass bei mehrals zwei Personen schwere Nebenwirkungen auftreten?
(S1.10) Gewinnspiel: Frau König betreut bei einem Schulfest ein Gewinnspiel, bei demKugeln aus einer Urne gezogen werden. Die Urne enthält Kugeln, die entwederdie Aufschrift +2, +5 oder -7 tragen.
Eine Kugel mit der Aufschrift -7 wird mit der Wahrscheinlichkeit 0.4 gezogen.Eine Kugel mit der Aufschrift +2 wird mit derselben Wahrscheinlichkeit gezogenwie eine Kugel mit der Aufschrift +5.
(a) Gib ein Beispiel an, wie die Urne bestückt sein könnte.
(b) Ein Spiel besteht darin, dass zwei Mal nacheinander eine Kugel mit Zurück-legen gezogen und ihre Zahl notiert wird. Dann werden die beiden Zahlen

68 1. Maÿ- und Wahrscheinlichkeitsräume
addiert. Ist die Summe S positiv, erhält der Spieler S Euro ausbezahlt. Istdie Summe S negativ, hat der Spieler verloren und muss diesen Betrag anFrau König bezahlen. Bestimme die Wahrscheinlichkeit, dass der Spieler beieinem Spiel gewinnt.
(S1.11) Kaubonbons: Bei einem Kindergeburtstagsfest seiner Tochter Isabella gibt Wer-ner 30 Kaubonbons verschiedener Geschmacksrichtungen in einen undurchsichti-gen Beutel.
Es gibt 5 Bonbons mit Erdbeer-, 5 mit Kirsch-, 10 mit Zitronen-, 8 mit Orangen-und nur 2 mit Himbeergeschmack.
Isabella liebt Erdbeer- und Zitronengeschmack und hasst Kirschgeschmack. Sienimmt ohne Hinschauen mit einem Gri drei Bonbons. Wie groÿ ist die Wahr-scheinlichkeit, dass unter den drei gezogenen Bonbons
(a) alle drei Erdbeer- oder Zitronengeschmack haben?
(b) mindestens eines Kirschgeschmack hat?
(c) beide Himbeerbonbons dabei sind?
(S1.12) Pearl-Index: Der Pearl-Index ist eine Maÿzahl für die Sicherheit von Verhü-tungsmethoden. Er gibt an, wie viele Schwangerschaften eintreten, wenn 100 Frau-en bzw. deren Partner ein Jahr lang eine bestimmte Verhütungsmethode nutzen.
Der Pearl-Index für die Pille beträgt ca. 0.5 (je nach Studie 0.1 bis 0.9). DerPearl-Index für das Kondom beträgt ca. 7 (je nach Studie 2 bis 12).
Eine Vortragende behauptet, dass bei der Kombination beider Methoden, alsobei Einnahme der Pille und gleichzeitiger Verwendung von Kondomen, pro Jahrim Schnitt ca. 3 bis 4 von 10000 Frauen schwanger werden.
Entscheide, ob die Behauptung der Vortragenden korrekt ist und begründe deineEntscheidung.
(S1.13) Wählen: In einer Bevölkerungsgruppe werden folgende Ereignisse untersucht:
Ereignis E1 lautet hat eine höhere Schulbildung.
Ereignis E2 lautet wählt die Partei A.
Erkläre folgende Symbole mit Worten:

1. Maÿ- und Wahrscheinlichkeitsräume 69
symbolische Schreibweise Bedeutung in Worten
P(E1)
P(E1 ∩ E2)
P(E2|E1)
P(E2)
P(E1|E2)
(S1.14) Batterienkauf: Ein Betrieb stellt Batterien für grakfähige Taschenrechnerher. Der Ausschussanteil beträgt 4%. Ausschussstücke treten unabhängig vonein-ander auf.
Ernst kauft vier Batterien, die in diesem Betrieb hergestellt wurden.
Er behauptet, die Wahrscheinlichkeit, dass alle vier Batterien kaputt sind, seikleiner als die Wahrscheinlichkeit im Lotto 6 aus 45 mit einem Tipp einen Sech-ser zu erzielen.
Ist diese Behauptung richtig oder falsch? Begründe deine Antwort!
(Einen Sechser zu tippen bedeutet, dass man aus den Zahlen 1 bis 45 von sechszufällig gezogenen Zahlen alle errät.)
(S1.15) Ausschussquote: Ein Versandhaus wird von einer Firma mit Artikeln für Haus-haltselektronik beliefert, bei denen von einer Ausschussquote von p = 0.06 aus-gegangen wird.
(a) Eine Lieferung umfasst 200 Stück. Wie groÿ ist die Wahrscheinlichkeit, dasssich in der Lieferung kein defekter Artikel bendet?
(b) Nachdem die ersten 50 Stück der Ware verkauft worden sind, werden fünf alsdefekt reklamiert. Wie groÿ ist die Wahrscheinlichkeit, dass sich fünf defekteArtikel unter den ersten 50 benden?
(S1.16) Schulball: In einer Schule werden für die Erönung des Schulballes Paare ge-sucht, die Walzer tanzen können.
Von den Schülerinnen und Schülern der Maturaklassen können 18 % Linkswalzer(und selbstverständlich auch Rechtswalzer) und 60 % nur Rechtswalzer tanzen,der Rest sind Nichttänzer.
Der Prozentsatz an Burschen von den Linkswalzerkönnern/könnerinnen beträgt30%, von den Rechtswalzerkönnern/könnerinnen 45% und von den Nichttän-zern/tänzerinnen 65%.
a) Stelle den Text grasch dar (z.B. durch ein Baumdiagramm).

70 1. Maÿ- und Wahrscheinlichkeitsräume
In den Aufgaben b) bis e) wird ein Schüler/eine Schülerin zufällig ausgewählt.Formuliere die Wahrscheinlichkeiten der gesuchten Ereignisse zuerst allgemeindurch Symbole und verwende dabei für die Ereignisse die unten angegebenenAbkürzungen. Berechne danach die Wahrscheinlichkeiten und trage beides in dernachstehenden Tabelle ein.
B . . . Bursch, M . . .Mädchen, L . . . Links- und Rechtswalzerkönner/innen,R . . . nur Rechtswalzerkönner/innen, N . . . Nichttänzer/innen
b) Wie groÿ ist die Wahrscheinlichkeit unter den Linkswalzerkönnern/könne-rinnen ein Mädchen zu nden?
c) Wie groÿ ist die Wahrscheinlichkeit in den Maturaklassen einen Burschenzu nden, der Linkswalzer tanzen kann?
d) Wie groÿ ist die Wahrscheinlichkeit in den Maturaklassen einen Burschenzu nden, der Walzer tanzen kann?
e) Wie groÿ ist die Wahrscheinlichkeit in den Maturaklassen einen Burschenauszuwählen?
allgemein Rechnung
b)
c)
d)
e)
(S1.17) Blumen: Eine Blumenhandlung bezieht wöchentlich 600 Rosen. 200 Stück stam-men aus der Gärtnerei A, 300 Stück aus dem Gartenbaubetrieb B und der Restaus der Gärtnerei C. Aus Erfahrung weiÿ man, dass zirka 3 % der Rosen vomBetrieb A, 2 % der Rosen vom Betrieb B und 5 % der Rosen vom Betrieb Cverwelkt ankommen und zum Verkauf nicht geeignet sind.
(a) Wie viele der wöchentlich gelieferten Rosen sind im Durchschnitt zum Ver-kauf nicht geeignet?
(b) Mit welcher Wahrscheinlichkeit stammt eine verwelkte Rose von der Gärt-nerei B?
Dokumentiere jeweils den Lösungsweg.
(S1.18) Führerscheinprüfung: Eine Fahrschule hat eine Erfolgsquote von 75%, d. h.dass 75% der Kandidatinnen und Kandidaten die Führerscheinprüfung auf An-hieb schaen. Wie groÿ ist die Wahrscheinlichkeit, dass bei 300 antretenden Prüf-lingen

1. Maÿ- und Wahrscheinlichkeitsräume 71
(a) mehr als 230,
(b) höchstens 210,
(c) genau 220
die Fahrprüfung auf Anhieb schaen?
Dokumentiere den Lösungsweg.
(S1.19) Golfclub: Von den Mitgliedern eines Golfclubs sind 70 % der Männer und 5 %der Frauen gröÿer als 1.75m. Insgesamt sind 65 % der Mitglieder Männer.
(a) Mit welcher Wahrscheinlichkeit ist ein Clubmitglied, das höchstens 1.75mgroÿ ist, eine Frau?
(b) Mit welcher Wahrscheinlichkeit ist ein Clubmitglied, das gröÿer als 1.75mist, ein Mann?
(Malle et al.: Mathematik verstehen, Österreichischer Bundesverlag Schulbuch, 1. Auage, 2010,
S. 268, Nr. 14.85)
(S1.20) Drehteile: Zwei MaschinenM1 undM2 fertigen Drehteile der gleichen Art. Fürderen Durchmesser ist ein Toleranzbereich (250.0± 2.0) mm vorgeschrieben. DieDurchmesser können in guter Näherung als normalverteilt angesehen werden undzwar bei M1 mit µ1 = 249.0 mm und σ1 = 1.0 mm, bei M2 mit µ2 = 249.5 mmund σ2 = 1.5 mm. Welche Maschine hat den höheren Ausschussanteil?(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 261, Nr. 6.45)
(S1.21) Äpfel: Äpfel sind hinsichtlich ihrer Masse annähernd normalverteilt mit µ =200g und σ = 50g.
Äpfel, die weniger als 150g wiegen, werden als zu klein nicht als Speiseobst zumVerkauf zugelassen.
Die übrigen Äpfel werden in die Kategorien Standard und Extragroÿ so ein-geteilt, dass der Anteil von beiden gleich groÿ ist.
Bei welcher Masse liegt die Grenze zwischen Standard und Extragroÿ?
(S1.22) Körpergröÿe: Die Körpergröÿe von Schülerinnen und Schülern einer bestimm-ten Schule sei annähernd normalverteilt mit dem Mittelwert µ = 160cm.
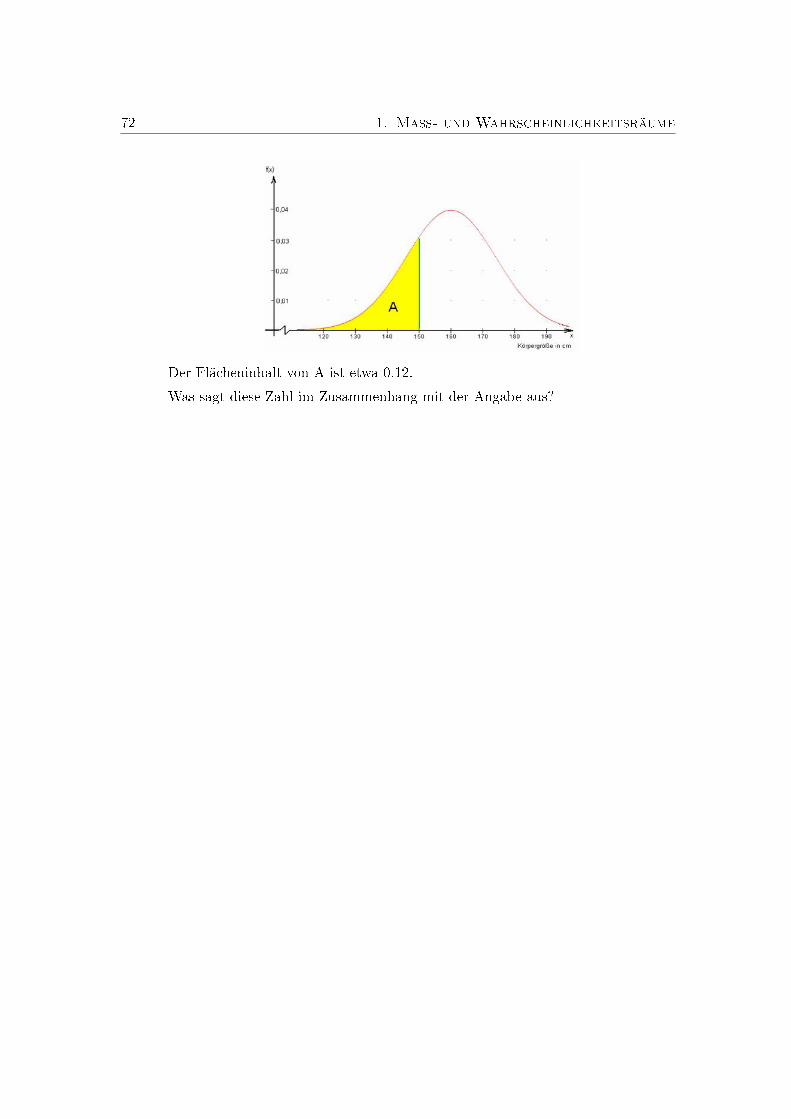
72 1. Maÿ- und Wahrscheinlichkeitsräume
Der Flächeninhalt von A ist etwa 0.12.
Was sagt diese Zahl im Zusammenhang mit der Angabe aus?

1. Maÿ- und Wahrscheinlichkeitsräume 73
Kontrollfragen
1.1 Es seien Ω eine beliebige Menge und A,B ⊂ Ω . Welche der folgenden Aussagensind wahr?
A ∪B = (A \B) ] (B \A) ] (A ∩B)
A ∩B = (A \B) ] (B \A)
A = (B \A) ] (A ∩B)
A = (A \B) ] (A ∩B)
1.2 Es sei Ω = 1, 2, 3, 4 . Welche der folgenden Mengensysteme sind σ-Algebren aufder Menge Ω ?
∅,Ω ∅,Ω, 1, 2, 3, 1, 2, 3, 2, 3, 4, 1, 4 P(Ω)
∅, 1, 2, 3, 4
1.3 Es sei Ω eine beliebige Menge. Unter welchen der folgenden Bedingungen ist Feine σ-Algebra auf Ω ?
i. Ω ∈ Fii. F ist komplementstabil
iii. F ist σ-∩-stabil i. ∅ ∈ F
ii. F ist komplementstabil
iii. F ist ∪-stabil i. F ist Algebra auf Ω
ii. F ist σ-∩-stabil i. Ω ∈ F
ii. F ist σ-∩-stabiliii. F ist σ-∪-stabil
1.4 Es sei Ω = [0, 1] und F = σ([
0, 12
),
34
). Welche der folgenden Aussagen sind
wahr?
(
34 , 1]∈ F
(
12 , 1]\
34
∈ F
[
12 , 1]\
34
∈ F

74 1. Maÿ- und Wahrscheinlichkeitsräume
|F| = 8
1.5 Es sei Ω = 1, . . . , 62 . Ein Elementarereignis (ω1, ω2) ∈ Ω wird als Ergebnis desWerfens zweier Würfel interpretiert, wobei ω1 die Augenzahl des ersten Würfelsangibt und ω2 jene des zweiten Würfels. Sei nun
F = σ ((ω1, ω2) ∈ Ω: ω1 + ω2 = 3) .
Welche der folgenden Ereignisse sind bezüglich F beobachtbar?
Die Augensumme der beiden Würfel ist gleich 3.
Der erste Würfel fällt auf 1, der zweite Würfel auf 2.
Die Augensumme der beiden Würfel ist nicht gleich 3.
Die Augensumme der beiden Würfel ist gleich 4.
1.6 Es sei Ω eine beliebige Menge und F eine σ-Algebra auf Ω . Welche der folgendenAussagen sind wahr?
∀A,B,C ∈ F : A ∩Bc ∪ C ∈ F ∀A,B ∈ F : A \Bc ∈ F Axx∈Q ⊂ F =⇒
⋃
x∈QAx ∈ F
Axx∈[0,1] ⊂ F =⇒⋃
x∈[0,1]
Ax ∈ F
1.7 Es sei Ω = R , G = x : x ∈ R und F = σ(G) . Welche der folgenden Aussagensind wahr?
F ist keine σ-Algebra auf R
F = B(R)
F = A ⊂ R : A oder Ac ist abzählbar F = A ⊂ R : A ist abzählbar
1.8 Es sei Ω eine beliebige Menge und F ⊂ P(Ω) . Welche der folgenden Aussagensind wahr?
F σ-Algebra ⇒ F Algebra
F Algebra ⇒ F σ-Algebra
Ist |Ω| <∞ , so gilt
F σ-Algebra ⇐⇒ F Algebra.

1. Maÿ- und Wahrscheinlichkeitsräume 75
Ist |F| abzählbar, so gilt
F σ-Algebra ⇐⇒ F Algebra.
1.9 Es sei (Ω,F , µ) ein Maÿraum. Welche der folgenden Aussagen sind wahr?
∀A,B ∈ F mit A ∩B = ∅ : µ(A ∩B) = µ(A) + µ(B)
∀A,B ∈ F mit A ∩B = ∅ : µ(A ∪B) = µ(A) + µ(B)
∀A,B ∈ F mit A ∩B = ∅ : µ(A ∪B) = µ(A)µ(B)
Ist Axx∈Q∩[0,1] ⊂ F eine beliebige Familie paarweise disjunkter Mengen,so gilt
⊎
x∈Q∩[0,1]
Ax ∈ F und µ
⊎
x∈Q∩[0,1]
Ax
=
∑
x∈Q∩[0,1]
µ(Ax) .
1.10 Gegeben sei der messbare Raum (Ω,F) und die Mengenfunktion P : F → [0, 1] .Welche der folgenden Aussagen sind wahr?
Ist |F| <∞ , so gilt
P ist σ-additiv ⇐⇒ P ist additiv.
P ist Wahrscheinlichkeitsmaÿ ⇐⇒ P ist Maÿ und P(∅) = 1
P ist Wahrscheinlichkeitsmaÿ ⇐⇒ P ist Maÿ und P(Ω) = 1
P ist Wahrscheinlichkeitsmaÿ ⇐⇒ P ist σ-additiv und P(Ω) = 1
1.11 Es seien (Ω,F ,P) ein Wahrscheinlichkeitsraum und A,B ∈ F . Welche der fol-genden Aussagen sind wahr?
P(A) = 0⇒ P(A ∩B) = 0
P(A) = 0⇒ P(A ∪B) = P(B)
P(A) = 1⇒ P(A ∩B) = P(B)
P(A) = 1⇒ P(A ∪B) = 1
1.12 Es sei (Ω,F) ein messbarer Raum. Welche der folgenden Aussagen sind wahr?
Für ω1, ω2, ω3 ∈ Ω ist
P = 16δω1 + 1
3δω2 + 12δω3
ein Wahrscheinlichkeitsmaÿ auf (Ω,F) .

76 1. Maÿ- und Wahrscheinlichkeitsräume
Für ω1, ω2 ∈ Ω ist
µ = 110δω1 + 3
5δω2
ein Maÿ auf (Ω,F) , aber kein Wahrscheinlichkeitsmaÿ.
Sind P1 und P2 Wahrscheinlichkeitsmaÿe auf (Ω,F) , so ist auch die SummeP = P1 + P2 ein Wahrscheinlichkeitsmaÿ auf (Ω,F) .
Sind P1, P2 und P3 Wahrscheinlichkeitsmaÿe auf (Ω,F) , so ist auch die
P = 3P1 − 4P2 + 2P3
ein Wahrscheinlichkeitsmaÿ auf (Ω,F) .
1.13 Es sei (Ω,F ,P) der Laplace-Raum zu Ω = 1, . . . , 62 . Welche der folgendenAussagen sind wahr?
∀ω ∈ Ω: P(ω) = 0
∀ω ∈ Ω: P(ω) = 136
∀ω ∈ Ω: P(ω) = 16
P =1
36
∑
ω∈Ω
δω
1.14 Es sei (Ω,F ,P) wiederum der Laplace-Raum zu Ω = 1, . . . , 62 . Welche derfolgenden Aussagen sind wahr?
∀ω ∈ Ω: P(ω) = P ((ω1, ω2) ∈ Ω: ω1 + ω2 = 2) P ((ω1, ω2) ∈ Ω: ω1 + ω2 gerade) = 1
4
P ((ω1, ω2) ∈ Ω: ω1 · ω2 ungerade) = 14
P ((ω1, ω2) ∈ Ω: 2ω1 + ω2 = 6) = 118
1.15 Es bezeichne λ das Lebesgue-Maÿ auf (R,B(R)) .Welche der folgenden Aussagensind wahr?
∀x ∈ R : λ(x) = 0
∀x ∈ R : λ(x) > 0
Es ist λ(Q) = 0 und λ ([0, 3] \Q) = 3 .
Für alle a < b gilt λ ([a, b]) = b− a .
1.16 Es bezeichne λ das Lebesgue-Maÿ auf (R,B(R)) . Für n ∈ N sei weiters
An =[0, 1 + 1
2n
], Bn =
[n, n+ 1
2n
]und Cn =
(0, 1− 1
2n
).
Welche der folgenden Aussagen sind wahr?

1. Maÿ- und Wahrscheinlichkeitsräume 77
limn→∞
λ(An) = 1 , limn→∞
λ(Bn) = 0 , limn→∞
λ(Cn) = 1 .
limn→∞
λ(An) = 2 , limn→∞
λ(Bn) = 1 , limn→∞
λ(Cn) = 1 .
λ
( ∞⋂
n=1
An
)= 1 , λ
( ∞⋃
n=1
Bn
)=∞ , λ
( ∞⋃
n=1
Cn
)= 1 .
λ
( ∞⋂
n=1
An
)= 1 , λ
( ∞⋃
n=1
Bn
)= 1 , λ
( ∞⋃
n=1
Cn
)= 1 .
1.17 Es sei (Ω,F ,P) der Laplace-Raum zu Ω = 1, . . . , 62 . Ein Elementarereignis(ω1, ω2) ∈ Ω wird als Ergebnis des Werfens zweier Würfel interpretiert, wobei ω1
die Augenzahl des ersten Würfels angibt und ω2 jene des zweiten Würfels. Weitersbezeichne A1 das Ereignis, dass die Augensumme der beiden Würfel gleich 5 ist,und A2 das Ereignis, dass der erste Würfel eine ungerade Augenzahl zeigt.Welcheder folgenden Aussagen sind wahr?
P(A1) = 16 und P(A2) = 1
2 .
P(A1) = 19 und P(A2) = 1
2 .
A1 und A2 sind nicht unabhängig.
A1 und A2 sind unabhängig.
1.18 Es seien (Ω1,F1,P1) und (Ω2,F2,P2) zwei Wahrscheinlichkeitsräume und
(Ω1 × Ω2,F1 ⊗F2,P1 ⊗ P2)
ihr Produktwahrscheinlichkeitsraum. Welche der folgenden Aussagen sind wahr?
Für alle A ∈ F1 ⊗F2 ist (P1 ⊗ P2) (A) = P1(A)P2(A) .
Ist A1 ∈ F1 und A2 ∈ F2 , so gilt (P1 ⊗ P2) (A1 ×A2) = P1(A1)P2(A2) .
Ist A1 ∈ F1 und A2 ∈ F2 , so gilt (P1 ⊗ P2) (A1 ×A2) = P1(A1) +P2(A2) .
Ist Ω1 = Ω2 = 0, 1 , F1 = F2 = 20,1 und P1 = P2 = 12δ0 + 1
2δ1 , so gilt
P1 ⊗ P2 = 14δ(0,0) + 1
4δ(0,1) + 14δ(1,0) + 1
4δ(1,1) .


Kapitel 2
Messbare Abbildungen und Zufallsvariable
In diesem Kapitel führen wir den fundamentalen Begri der messbaren Abbildung ein.In vielen Fällen werden wir eine solche Funktion als sogenannte Zufallsvariable auassen,welche eine zufällige Beobachtung beschreibt. Im Anschluss werden wir die Eigenschaftensolcher Abbildungen genauer untersuchen.
2.1 Messbare Abbildungen
Ist (Ω,F ,P) ein Wahrscheinlichkeitsraum, so spielen Abbildungen der Form X : Ω→ R
eine wesentliche Rolle zur Modellierung zufälliger Phänomene. Um die Beobachtbar-keit der beschriebenen Vorgänge sicherzustellen, muss die Messbarkeit solcher Abbil-dungen verlangt werden.
Beispiel 2.1 (Kühlhaus-Check)Wir greifen Beispiel 1.68 nochmals auf, betrachten also den Wahrscheinlichkeitsraum
(Ω,F ,P) =(R,B(R),Nµ,σ2
)
für µ = 7 und σ2 = 4 . Wir interessieren uns wiederum dafür, wann die Temperaturim akzeptablen Bereich zwischen 5C und 13C liegt, also im Intervall (5, 13) . Daherdenieren wir die Funktion
X : Ω→ R : ω 7→ χ(5,13)(ω) =
1 , ω ∈ (5, 13) ,
0 , ω /∈ (5, 13) .
Die Abbildung X gibt also an, ob die Temperatur akzeptabel ist oder nicht. Um dieWahrscheinlichkeit zu bestimmen, dass X = 1 bzw. X = 0 eintritt, muss
ω ∈ Ω: X(ω) = 1 = X−1 (1) ∈ F und ω ∈ Ω: X(ω) = 0 = X−1 (0) ∈ F
gelten. Dies ist hier oensichtlich der Fall, denn
X−1 (1) = (5, 13) ∈ B(R) und und X−1 (0) = (−∞, 5] ] [13,∞) ∈ B(R) .
Wie bereits in Beispiel 1.68 geschehen, können wir daher die jeweilige Wahrscheinlich-keit berechnen und erhalten
P(X = 1) := Nµ,σ2
(X−1 (1)
)≈ 0.84
79

80 2. Messbare Abbildungen und Zufallsvariable
und
P(X = 0) := Nµ,σ2
(X−1 (0)
)= 1− P(X = 1) ≈ 0.16 .
Entscheidend ist also die Forderung der Messbarkeit gewisser Urbilder unter X .
Wir interessieren uns nun für Abbildungen, die eine ganz bestimmte mathematischeStruktur erhalten.
Definition 2.2 (Messbare Abbildungen)Es seien (ΩD,FD) und (ΩB,FB) zwei messbare Räume. Eine Abbildung X : ΩD → ΩB
heiÿt (FD,FB)-messbar, falls
∀AB ∈ FB : X−1(AB) ∈ FD .
Bemerkung.
B Ist klar, welche σ-Algebren auf ΩD und ΩB gewählt sind, so nennt man eine(FD,FB)-messbare Abbildung auch einfach nur messbar.
B Für eine Abbildung zwischen messbaren Räumen ist auch die Schreibweise
X : (ΩD,FD)→ (ΩB,FB)
üblich.
B Für AB ∈ FB schreiben wir X ∈ AB := X−1(AB) .
B Ist µ ein Maÿ auf (ΩD,FD) , so setzen wir µ(X ∈ AB) := µ (X ∈ AB) .
B Im Fall dass FD = P(Ω) , ist jede Abbildung X : ΩD → ΩB messbar, da dannoensichtlich X−1(AB) ∈ FD für alle AB ∈ FB .
Zufallsvariable sind spezielle messbare Abbildungen.
Definition 2.3 (Zufallsvariable)Ist (Ω,F ,P) ein Wahrscheinlichkeitsraum, so nennt man eine (F ,B(R))-messbare Abbil-dung X : Ω→ R auch eine (reellwertige) Zufallsvariable.
Bemerkung. Ist (Ω,F) ein messbarer Raum, dann nennen wir X : Ω → R messbar,falls es sich bei X um eine (F ,B(R))-messbare Abbildung handelt.
Beispiel 2.4 (Augensumme)Wir betrachten das Zufallsexperiment, das aus dem Werfen zweier Würfel besteht. Daherwählen wir Ω := 1, . . . , 62 und F := P(Ω) . Dann ist
X : Ω→ R : ω = (ω1, ω2) 7→ ω1 + ω2

2. Messbare Abbildungen und Zufallsvariable 81
eine Zufallsvariable, denn für alle B ∈ B(R) ist X−1(B) ⊂ Ω . Sie gibt die Augensummeder beiden Würfel wieder. Wählen wir als Wahrscheinlichkeitsmaÿ P := UΩ die Gleich-verteilung auf Ω , so ist beispielsweise
P (Augensumme 4) = P(X = 4) = P ((1, 3), (2, 2), (3, 1)) = 336 = 1
12 .
Denieren wir die Zufallsvariablen X1, X2 : Ω→ R durch X1(ω) := ω1 und X2(ω) := ω2
für ω ∈ Ω , so erhalten wir auÿerdem
P (Augensumme ist gerade) = P (X ∈ 2, 4, . . . , 12) =
= P (X1, X2 ∈ 2, 4, 6) + P (X1, X2 ∈ 1, 3, 5) = 12 · 1
2 + 12 · 1
2 = 12 .
Hierbei wurde explizit nachgerechnet, dass
P (X1, X2 ∈ 2, 4, 6) = P (X1 ∈ 2, 4, 6)P (X2 ∈ 2, 4, 6)und
P (X1, X2 ∈ 1, 3, 5) = P (X1 ∈ 1, 3, 5)P (X2 ∈ 1, 3, 5) .Dies folgt aus der Unabhängigkeit der Zufallsvariablen X1 und X2 , welche wir jedocherst zu einem späteren Zeitpunkt einführen werden. Für viele Abbildungen X : (ΩD,FD) → (ΩB,FB) zwischen zwei messbaren Räumen istes schwierig bis unmöglich die Bedingung
X−1(AB) = X ∈ AB ∈ FD für alle AB ∈ FB
explizit nachzuweisen. Wie wir sehen werden, ist dies in den meisten Fällen aber auchnicht notwendig. Dazu beobachten wir zuerst, dass sich zu einer Abbildung mit Wertenin einem messbaren Raum eine zugehörige σ-Algebra denieren lässt.
Satz und Definition 2.5 (Erzeugte σ-Algebra)
(1) Gegeben seien ein messbarer Raum (ΩB,FB) und eine Abbildung X : ΩD → ΩB .Das Urbild
X−1(FB) :=X−1(AB) : AB ∈ FB
ist die kleinste σ-Algebra auf ΩD , bezüglich der X messbar ist. Man bezeichnetdann σ(X) := X−1(FB) als die von X erzeugte σ-Algebra auf ΩD .
(2) Es bezeichne I eine beliebige Indexmenge und für jedes i ∈ I sei (Ωi,Fi) einmessbarer Raum sowie Xi : ΩD → Ωi eine beliebige Abbildung. Dann heiÿt
σ (Xi : i ∈ I) := σ
(⋃
i∈IX−1i (Fi)
)
die von Xii∈I erzeugte σ-Algebra auf ΩD . Diese ist die kleinste σ-Algebra, fürwelche alle Xi messbar sind.

82 2. Messbare Abbildungen und Zufallsvariable
Beweis. Wir überprüfen, dass es sich bei X−1(FB) um eine σ-Algebra auf ΩD handelt.
(σ1) Aus X−1(ΩB) = ΩD folgt ΩD ∈ X−1(FB) .
(σ2) Komplementstabilität: Da zu AD ∈ X−1(FB) ein AB ∈ FB mit X−1(AB) = AD
existiert , erhalten wir
AcD
= ΩD \X−1(AB) = X−1 (ΩB \AB) = X−1 (AcB) ∈ X−1(FB) .
(σ3) σ-∪-Stabilität: Zu An∞n=1 ∈(X−1(FB)
)Nexistiert eine Folge Bn∞n=1 ∈ FNB
mit X−1(Bn) = An für alle n ∈ N . Folglich ist
∞⋃
n=1
An =∞⋃
n=1
X−1(Bn) = X−1
( ∞⋃
n=1
Bn
)∈ X−1(FB) .
Oensichtlich ist X−1(FB) die kleinste σ-Algebra, bezüglich der X messbar ist.
Der nächste Satz zeigt, dass es genügt, die Messbarkeitsbedingung auf einem Erzeugerder σ-Algebra im Bildraum zu überprüfen.
Satz 2.6 (Erzeuger und Messbarkeit)Für GB ⊂ P(ΩB) gilt σ
(X−1(GB)
)= X−1 (σ(GB)) und damit
X ist (FD, σ (GB))-messbar ⇐⇒ ∀AB ∈ GB : X−1(AB) ∈ FD .
Beweis. Es gilt X−1 (GB) ⊂ X−1 (σ (GB)) und somit σ(X−1 (GB)
)⊂ X−1 (σ (GB)) . Um
die umgekehrte Inklusion zu zeigen, weisen wir nach, dass
Σ :=B ∈ σ (GB) : X−1(B) ∈ σ
(X−1 (GB)
)
eine σ-Algebra auf ΩB ist.
(σ1) Oensichtlich ist ΩB ∈ Σ .
(σ2) Komplementstabilität: Für B ∈ Σ ist
X−1 (Bc) =(X−1(B)
)c ∈ σ(X−1 (GB)
)
und somit Bc ∈ Σ .
(σ3) σ-∪-Stabilität: Für jede Folge Bn∞n=1 ∈ ΣN gilt
X−1
( ∞⋃
n=1
Bn
)=∞⋃
n=1
X−1(Bn) ∈ σ(X−1 (GB)
)
und daher⋃∞n=1Bn ∈ Σ .

2. Messbare Abbildungen und Zufallsvariable 83
Aus GB ⊂ Σ folgern wir Σ = σ (GB) und damit die Aussage.
Bemerkung. Speziell für σ (GB) = FB gilt
X ist (FD,FB)-messbar ⇐⇒ X−1 (GB) ⊂ FD .
Beispiel 2.7 (Kriterium für Messbarkeit)Ist (Ω,F) ein messbarer Raum und X : Ω→ R eine Abbildung, so gilt
X ist messbar ⇐⇒ ∀ a < b : X−1 ((a, b)) ∈ F .Dies folgt aus Satz 2.6 durch Betrachtung des Mengensystems P := (a, b) : a < b ,welches B(R) erzeugt, es ist also σ (P) = B(R) . Beispiel 2.8 (Messbarkeit einer Indikatorfunktion)Es sei (Ω,F) ein messbarer Raum und A ⊂ Ω . Wir betrachten die IndikatorfunktionχA : Ω→ R . Dann gilt
χA ist messbar ⇐⇒ A ∈ F .
⇒: Ist χA messbar, so ist A = χ−1A (1) ∈ F .
⇐: Es sei nun A ∈ F . Wir betrachten a, b ∈ R mit a < b und untersuchen alle viermöglichen Fälle.
(1) 0, 1 /∈ (a, b): χ−1A ((a, b)) = ∅ ∈ F
(2) 1 ∈ (a, b) und 0 /∈ (a, b): χ−1A ((a, b)) = A ∈ F
(3) 0 ∈ (a, b) und 1 /∈ (a, b): χ−1A ((a, b)) = Ac ∈ F
(4) 0, 1 ∈ (a, b): χ−1A ((a, b)) = Ω ∈ F
Somit ist χA nach Beispiel 2.7 messbar. Beispiel 2.9 (Diskrete messbare Abbildungen)Es sei (Ω,F) ein messbarer Raum . Eine Abbildung X : Ω→ R mit X(Ω) = x1, x2, . . .ist genau dann messbar, wenn
∀n ∈ N : X−1 (xn) ∈ F .Denn zu jeder Borel-Menge B ∈ B(R) existiert in dieser Situation eine IndexmengeIB ⊂ N mit
X−1(B) =⋃
n∈IB
X−1 (xn) .
Für A ⊂ Ω erhalten wir aus dieser Überlegung direkt
χA ist messbar ⇐⇒ χ−1A (1) = A ∈ F und χ−1
A (0) = Ac ∈ F⇐⇒ A ∈ F .

84 2. Messbare Abbildungen und Zufallsvariable
Für d ∈ N wird eine(B(Rd),B(R)
)-messbare Funktion Borel-messbar oder Borel-
Funktion genannt. Wir zeigen nun, dass stetige Funktionen Borel-messbar sind.
Lemma 2.10 (stetig ⇒ Borel-messbar)Eine stetige Funktion X : Rd → R ist Borel-messbar.
Beweis. Nach Beispiel 2.7 genügt es zu zeigen, dass X−1 ((a, b)) ∈ Bd(R) für alle a < b .Es sei also a < b . Nun ist X aber stetig und somit X−1 ((a, b)) oen in Rd . Da B(Rd)alle oenen Mengen enthält, folgt somit X−1 ((a, b)) ∈ B(Rd) .
Beispiel 2.11 (Metallscheiben)In einer Fabrik werden maschinell Scheiben aus Metall ausgestanzt. Man weiÿ, dass derzufällige Radius der Scheiben in cm näherungsweise normalverteilt ist und zwar mit Er-wartungswert µ = 5 und Standardabweichung σ = 0.1 . Eine Metallscheibe gilt als zuklein, wenn ihr Flächeninhalt kleiner 71 cm2 ist. Mit welcher Wahrscheinlichkeit ist eineausgestanzte Metallscheibe zu klein?
Wir wählen den Wahrscheinlichkeitsraum (R,B(R),P) mit P = Nµ,σ2 . Es wird eineKreisscheibe mit Mittelpunkt im Ursprung und zufälligem Radius r gewählt. Dann ist
A : R→ R : r 7→ πr2
Borel-messbar, dennA ist stetig. Die ZufallsvariableA gibt den Flächeninhalt der entspre-chenden zufällig gewählten Kreisscheibe an. Nun berechnen wir die Wahrscheinlichkeit,dass die Fläche der Kreisscheibe kleiner A0 = 71 ist. Aus
A(r) < A0 ⇐⇒ |r| <√
A0π
erhalten wir
P (Fläche kleiner A0) = Nµ,σ2
((−√
A0π ,√
A0π
))≈ 0.00694 ≈ 7% .
Die Hintereinanderausführung messbarer Abbildungen ist messbar, dies ist Gegenstanddes folgenden Satzes.
Satz 2.12 (Komposition messbarer Abbildungen)Es seien (Ω1,F1) , (Ω2,F2) und (Ω3,F3) messbare Räume. Weiters sei X : Ω1 → Ω2
eine (F1,F2)-messbare Abbildung und Y : Ω2 → Ω3 sei (F2,F3)-messbar. Dann ist dieHintereinanderausführung
Y X : Ω1 → Ω3 : ω1 7→ (Y X)(ω1) = Y (X(ω1))
eine (F1,F3)-messbare Abbildung.
Beweis. Aufgabe (2.3).

2. Messbare Abbildungen und Zufallsvariable 85
2.1.1 Eigenschaften messbarer Abbildungen
In diesem Abschnitt sei (Ω,F) stets ein messbarer Raum und d ∈ N eine natürliche Zahl.
Satz 2.13 (Koordinatenabbildungen)Gegeben seien die Abbildungen X1, . . . , Xd : Ω→ R und
X : Ω→ Rd : ω 7→ (X1(ω), . . . , Xd(ω)) .
Dann gilt:
X ist(F ,B
(Rd))-messbar ⇐⇒ X1, . . . , Xd sind (F ,B(R))-messbar
Beweis. ⇒: Für i = 1, . . . , d ist die i-te Projektion
πi : Rd → R : (x1, . . . , xd) 7→ xi
stetig und somit Borel-messbar. Folglich ist für jedes i = 1, . . . , d auch Xi = πi Xmessbar.
⇐: Es seien a1, . . . , ad ∈ R . Dann ist
X−1 ((−∞, a1]× . . .× (−∞, ad]) =d⋂
i=1
X−1i ((−∞, ai]) ∈ F
und somit X messbar.
Für nachfolgenden Satz vereinbaren wir die Konvention x0 := 0 für x ∈ R .
Satz 2.14 (Summe, Produkt und Quotient messbarer Abbildungen)Es seien X,Y : Ω→ R messbar. Dann sind auch die Abbildungen
X + Y , X · Y und X/Y
messbar.
Beweis. Die Abbildung
m : R×R→ R : (x, y) 7→ x · y
ist stetig und somit eine Borel-Funktion. Weiters ist die Funktion
(X,Y ) : Ω→ R×R : ω 7→ (X(ω), Y (ω))
messbar und daher nach Satz 2.12 die Hintereinanderausführung m (X,Y ) = X · Y .Analog zeigt man, dass X + Y messbar ist, vgl. Aufgabe (2.14).

86 2. Messbare Abbildungen und Zufallsvariable
Um zu zeigen, dass X/Y messbar ist, betrachten wir die Funktion
h : R→ R : x 7→
1/x , x 6= 0 ,
0 , x = 0 .
Dann ist X/Y = X · (h Y ) . Daher genügt es, die Messbarkeit von h zu zeigen.Oensichtlich ist h|R\0 stetig. Für jede oene Menge U ⊂ R ist auch U \ 0 of-
fen und daher h−1 (U \ 0) ∈ B(R) . Da h−1 (0) = 0 , erhalten wir schlieÿlichh−1(U) = h−1 (U \ 0) ∪ (U ∩ 0) ∈ B(R) .
Zur Untersuchung des Inmums und des Supremums messbarer Abbildungen ist es zweck-mäÿig, den Bildbereich von R auf R := R ∪ −∞,∞ zu erweitern.
Wir denieren die erweiterte Borel-σ-Algebra
B(R)
:= σ(
[−∞, x) : x ∈ R)
.
Für eine Abbildung X : Ω→ R gilt dann
X ist(F ,B
(R))-messbar ⇐⇒ ∀B ∈ B
(R)
: X−1(B) ∈ F⇐⇒ ∀x ∈ R : X−1 ([−∞, x)) ∈ F .
Wir bezeichnen X : Ω → R wiederum als messbar, wenn X eine(F ,B
(R))-messbare
Abbildung ist.
Satz 2.15 (inf, sup, lim inf, lim sup messbarer Abbildungen)IstXn : Ω→ R
n∈N eine Folge messbarer Abbildungen, so sind auch die Abbildungen
infn∈N
Xn , supn∈N
Xn , lim infn→∞
Xn , und lim supn→∞
Xn
messbar.
Beweis. Oenbar gilt für jedes x ∈ R , dass
(infn∈N
Xn
)−1
([−∞, x)) =
∞⋃
n=1
X−1n ([−∞, x)) ∈ F
und folglich ist infn∈NXn messbar. Analog zeigt man die Messbarkeit von supn∈NXn ,siehe Aufgabe (2.15) .
Nun denieren wir für n ∈ N die messbaren Abbildung Yn := infm≥nXm . Dann ist auchsupn∈N Yn = lim infn→∞Xn messbar. Wiederum analog zeigt man, dass lim supn→∞Xn
messbar ist, vgl. Aufgabe (2.15).

2. Messbare Abbildungen und Zufallsvariable 87
Bemerkung. Existiert für alle ω ∈ Ω der Grenzwert X(ω) := limn→∞
Xn(ω) in R , so ist
X = limn→∞
Xn = lim supn→∞
Xn = lim infn→∞
Xn
und daher auch die Grenzfunktion X : Ω→ R eine messbare Abbildung.
2.1.2 Bildmaÿ
Wir machen nun eine wichtige Beobachtung: Eine messbare Abbildung transportiert einMaÿ von einem messbaren Raum zum anderen.
Satz und Definition 2.16 (Bildmaÿ)Es seien (ΩD,FD) und (ΩB,FB) messbare Räume. Weiters sei µ ein Maÿ auf (ΩD,FD)und X : ΩD → ΩB eine (FD,FB)-messbare Abbildung. Das Maÿ
µ X−1 : FB → [0,∞] : AB 7→ µ(X−1(AB)
)
auf (ΩB,FB) heiÿt Bildmaÿ von µ unter X . Ist P = µ ein Wahrscheinlichkeitsmaÿ, soauch P X−1 .
Beweis. Wir zeigen, dass µ X−1 ein Maÿ auf (ΩB,FB) ist.
(µ1) Es ist(µ X−1
)(∅) = µ
(X−1(∅)
)= µ(∅) = 0 .
(µ2) σ-Additivität: Für eine Folge Bn∞n=1 ∈ FNB paarweise disjunkter Mengen gilt
(µ X−1
)( ∞⊎
n=1
Bn
)= µ
( ∞⊎
n=1
X−1(Bn)
)=
=∞∑
n=1
µ(X−1(Bn)
)=∞∑
n=1
(µ X−1
)(Bn) .
Somit ist µ X−1 ein Maÿ. Gilt zusätzlich für P = µ , dass P(ΩD) = 1 , so erhalten wir(P X−1
)(ΩB) = P
(X−1(ΩB)
)= P(ΩD) = 1
und damit ist auch P X−1 ein Wahrscheinlichkeitsmaÿ.
2.2 Verteilung und Verteilungsfunktion
Die Wahrscheinlichkeit, dass eine Zufallsvariable Werte in einer bestimmten Borel-Mengeannimmt, deniert ein Wahrscheinlichkeitsmaÿ auf B(R) , die Verteilung der Zufallsva-riablen. Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum.

88 2. Messbare Abbildungen und Zufallsvariable
Definition 2.17 (Verteilung einer Zufallsvariablen)Ist die Abbildung X : Ω → R eine Zufallsvariable, so heiÿt ihr Bildmaÿ PX := P X−1
Verteilung von X .
Bemerkung.
B Ist P = PX , so schreibt man X ∼ P und nennt X dann P -verteilt.
B Zwei Zufallsvariablen X,Y : Ω→ R heiÿen identisch verteilt , falls PX = PY . In
diesem Fall schreiben wir XD= Y .
Beispiel 2.18 (Simulation eines Münzwurfs)Wir wollen den Wurf einer Münze mittels eines Zufallszahlengenerators simulieren. Diegenerierte Zufallszahl sei annähernd gleichverteilt auf [0, 1] , d. h. wir wählen den Wahr-scheinlichkeitsraum
([0, 1],B ([0, 1]) ,U[0,1]
). Für p ∈ (0, 1) betrachten wir die Abbildung
X : [0, 1]→ R : ω 7→ χ[0,p)(ω) .
Da [0, p) ∈ B ([0, 1]) , ist X nach Beispiel 2.8 eine Zufallsvariable. Es ist
PX (1) = λ ([0, p)) = p und PX (0) = λ ([p, 1]) = 1− p ,
folglich
PX = (1− p)δ0 + pδ1 = B1,p .
Die Zufallsvariable X bzw. die Verteilung PX modelliert daher den Wurf einer Münze.
Wie wir sehen werden, ist die Verteilung einer Zufallsvariablen X eindeutig durch eineFunktion FX : R→ [0, 1] bestimmt, der sogenannten Verteilungsfunktion von X .
Definition und Satz 2.19 (Verteilungsfunktion)Es sei X : Ω→ R eine Zufallsvariable. Die Funktion
FX : R→ [0, 1] : x 7→ P (X ≤ x) = PX ((−∞, x])
heiÿt Verteilungsfunktion von X bzw. PX . Diese hat folgende Eigenschaften:
(F1) FX ist monoton wachsend
(F2) FX ist rechtsseitig stetig
(F3) limx→−∞
FX(x) = 0 und limx→∞
FX(x) = 1

2. Messbare Abbildungen und Zufallsvariable 89
Beweis. (F1) Für x1 ≤ x2 ist (−∞, x1] ⊂ (−∞, x2] und daher
FX(x1) = PX ((−∞, x1]) ≤ PX ((−∞, x2]) = FX(x2) .
(F2) Es sei x ∈ R und xn∞n=1 ∈ RN eine monotone Folge mit xn ↓ x für n→∞ . Danngilt
FX(x) = PX ((−∞, x]) = PX
( ∞⋂
n=1
(−∞, xn]
)= lim
n→∞PX ((−∞, xn]) = lim
n→∞FX(xn) ,
da PX stetig von oben ist.
(F3) Es sei xn∞n=1 ∈ RN eine monotone Folge mit xn → ∞ für n → ∞ . UnterVerwendung der Stetigkeit von unten des Maÿes PX erhalten wir
limn→∞
FX(xn) = limn→∞
PX ((−∞, xn]) = PX
( ∞⋃
n=1
(−∞, xn]
)= PX(R) = 1 .
Zu zeigen, dass limx→−∞
FX(x) = 0 , verbleibt als Übung, siehe Aufgabe (2.10).
ImWeiteren werden wir ein Wahrscheinlichkeitsmaÿ P auf (R,B(R)) auch eine Verteilungnennen und die zugehörige Verteilungsfunktion
R→ [0, 1] : x 7→ P ((−∞, x])
mit FP bezeichnen.
Satz 2.20 (Verteilung ↔ Verteilungsfunktion)Es seien P1 und P2 Verteilungen und FP1 und FP2 die zugehörigen Verteilungsfunktionen.Dann gilt
P1 = P2 ⇐⇒ FP1 = FP2 .
Beweis. ⇒: Diese Richtung ist oensichtlich.
⇐: Es gelte FP1 = FP2 . Dann stimmen P1 und P2 auf dem Mengensystem
P := (−∞, x] : x ∈ Rüberein, welches B(R) erzeugt.
Variante 1: Wir betrachten wiederum die Algebra A aus Beispiel 1.40. Für a < b ist
P1 ((a, b]) = P1 ((−∞, b] \ (−∞, a]) = P1 ((−∞, b])− P1 ((−∞, a]) = P2 ((a, b])
und somit stimmen P1 und P2 auf A überein. Der Fortsetzungssatz von Carathéo-dory impliziert daher P1 = P2 auf σ (A) = B(R) .
Variante 2: Da P ein π-System mit σ(P) = B(R) ist, folgt die Aussage direkt ausSatz 1.49.

90 2. Messbare Abbildungen und Zufallsvariable
Beispiel 2.21 (Verteilungsfunktion einer Summe von Dirac-Maÿen)Für n ∈ N seien α1, . . . , αn ≥ 0 mit
∑ni=1 αi = 1 und x1, . . . , xn ∈ R . Wir betrachten
die Verteilung
P :=
n∑
i=1
αiδxi .
Dann ist die zugehörige Verteilungsfunktion durch
FP (x) =
n∑
i=1
αiχ(−∞,x](xi) =
n∑
i=1
αiχ[xi,∞)(x) , x ∈ R ,
gegeben.
Jede Funktion F : R→ [0, 1] mit den Eigenschaften (F1), (F2) und (F3) aus Satz 2.19bezeichnen wir als Verteilungsfunktion. Wir zeigen nun, dass es zu jeder Verteilungsfunk-tion F einen Wahrscheinlichkeitsraum (Ω,F ,P) gibt, auf welchem eine ZufallsvariableX : Ω→ R mit FX = F existiert.
Satz 2.22 (Verteilung → Zufallsvariable)Gegeben sei die Verteilungsfunktion F : R → [0, 1] . Wir wählen den Wahrscheinlich-keitsraum ((0, 1),B ((0, 1)) , λ) . Dann existiert eine Zufallsvariable X : (0, 1) → R mitFX = F .
Beweis. Wir denieren die Rechtsinverse G von F vermöge
G(t) := inf x ∈ R : F (x) ≥ t für t ∈ (0, 1) .
Für x ∈ R und t ∈ (0, 1) gilt
G(t) ≤ x ⇐⇒ t ≤ F (x) .
Insbesondere ist daher t ∈ (0, 1) : G(t) ≤ x = (0, F (x)] ∩ (0, 1) , folglich
G : (0, 1)→ R
eine (B ((0, 1)) ,B(R))-messbare Abbildung und
λ (t ∈ (0, 1) : G(t) ≤ x) = F (x) .
Somit ist X := G die gewünschte Zufallsvariable.

2. Messbare Abbildungen und Zufallsvariable 91
Beispiel 2.23 (Wahrscheinlichkeitsdichte)Eine Riemann-integrierbare Funktion f : R→ [0,∞) mitˆ ∞
−∞f(t) dt = 1
bezeichnen wir als Wahrscheinlichkeitsdichte. Oensichtlich ist zu einer Wahrschein-lichkeitsdichte f durch
F (x) :=
ˆ x
−∞f(t) dt , x ∈ R ,
eine Verteilungsfunktion gegeben. Ist X : Ω→ R eine Zufallsvariable mit
FX(x) =
ˆ x
−∞f(t) dt
für alle x ∈ R , so nennt man fX := f auch Dichte von X bzw. FX . Man beachte, dassnatürlich bei weitem nicht alle Zufallsvariablen eine Dichte besitzen.
Gilt beispielsweise für µ ∈ R und σ > 0 , dass X ∼ Nµ,σ2 , so ist die Gauÿsche Glocken-kurve gegeben durch
fX(t) = f(t ;Nµ,σ2
)= 1√
2πσ2e−(t−µ)2/(2σ2) , t ∈ R ,
eine Dichte von X . Es folgen nun einige Bespiele diskreter Verteilungen, also von Verteilungen, die sich alsSumme bzw. Reihe von Punktmaÿen schreiben lassen. Eine Verteilung P wird somit alsdiskret bezeichnet, falls es eine abzählbare Menge B ∈ B(R) mit P (B) = 1 gibt.
Beispiel 2.24 (Einige diskrete Verteilungen)Es bezeichne (Ω,F ,P) einen Wahrscheinlichkeitsraum.
B Es sei p ∈ (0, 1) . Weiters sei n ∈ N und X : Ω→ R eine Zufallsvariable mit
P(X = k) =
(n
k
)pk(1− p)n−k für alle k ∈ 0, . . . , n .
Dann ist
PX =n∑
k=0
(n
k
)pk(1− p)n−kδk = Bn,p
und man nennt X binomialverteilt mit Parametern n und p . Weiters ist diezugehörige Verteilungsfunktion durch
FBn,p(x) =
n∑
k=0
(n
k
)pk(1− p)n−kχ[k,∞)(x) , x ∈ R ,

92 2. Messbare Abbildungen und Zufallsvariable
gegeben. Etwa wird das n-malige Werfen einer Münze mittels der ZufallsvariablenX bzw. mit Bn,p beschrieben.
Ist speziell P(X = 1) = p und P(X = 0) = 1− p, folglichPX = (1− p)δ0 + pδ1 = B1,p ,
so nennt man X Bernoulli-verteilt. Die zugehörige Verteilungsfunktion ist ent-sprechend durch
FB1,p(x) = (1− p)χ[0,1)(x) + χ[1,∞)(x) , x ∈ R ,gegeben, vgl. Abbildung 2.1.
0 1
1− p
1
x
FB1,p(x)
Abbildung 2.1. Verteilungsfunktion der Bernoulli-Verteilung
Eine Bernoulli-verteilte Zufallsvariable bzw. die Bernoulli-Verteilung modelliert bei-spielsweise den Wurf einer Münze.
B Ist X : Ω → R eine Zufallsvariable und existieren ein n ∈ N und paarweise ver-schiedene x1, . . . , xn ∈ R mit
PX =1
n
n∑
i=1
δxi = Ux1,...,xn ,
so heiÿt X gleichverteilt auf x1, . . . , xn . Ist n = 6 und x1 = 1, . . . , x6 =6 , so dient die auf 1, . . . , 6 gleichverteilte Zufallsvariable X zum Beispiel derModellierung eines fairen Würfels.
B Besitzt die Zufallsvariable X : Ω→ R die Verteilung
PX =
n∑
k=0
(Gk
)(N−Gn−k
)(Nn
) δk = Hn,N,G ,
so nennt man X hypergeometrisch verteilt. Mittels der hypergeometrischenVerteilung kann etwa das Ziehen ohne Zurücklegen von Kugeln aus einer Urnemodelliert werden.

2. Messbare Abbildungen und Zufallsvariable 93
B Es sei λ > 0 und X : Ω→ R eine Zufallsvariable mit
P(X = k) =λk
k!e−λ = πλ (k) für alle k ∈ N0 .
Dann ist
PX =
∞∑
k=0
λk
k!e−λδk = πλ
und X heiÿt Poisson-verteilt. Die Poisson-Verteilung wird unter anderem ver-wendet, um die Anzahl zufällig auftretender Ereignisse zu modellieren.
B Es sei p ∈ (0, 1) . Die Zufallsvariable X : Ω → R heiÿt geometrisch verteilt,wenn
PX =∞∑
k=0
(1− p)kpδk = gp .
Beispielsweise modelliert eine geometrisch verteilte Zufallsvariable die zufällige An-zahl der Einschaltvorgänge, welche eine Glühbirne übersteht, bevor sie versagt.
Im Gegensatz zu diskreten Verteilungen kommt man bei kontinuierlichen Verteilungennun nicht mehr mit Punktmaÿen aus.
Beispiel 2.25 (Einige kontinuierliche Verteilungen)Es sei (Ω,F ,P) wiederum ein Wahrscheinlichkeitsraum. Weiters sei X : Ω → R eineZufallsvariable.
B Ist I ⊂ R ein beschränktes Intervall und
PX(B) =λ(B ∩ I)
λ(I)= UI(B) für alle B ∈ B(R) ,
so nennt man X gleichverteilt auf I . Ist a < b und I = [a, b] , so ist die zugehörigeVerteilungsfunktion für x ∈ R durch
FUI (x) = x−ab−aχI(x) + χ(b,∞)(x) =
0 , x < a ,x−ab−a , x ∈ I ,1 , x > b ,
gegeben, vgl. Abbildung 2.2. Weiters ist die Funktion fX = 1b−aχI eine Dichte
von X .
Mittels der auf I gleichverteilten Zufallsvariablen X modelliert man das zufälli-ge Auswählen einer Zahl im Intervall I .

94 2. Messbare Abbildungen und Zufallsvariable
1
a bx
FUI (x)
Abbildung 2.2. Verteilungsfunktion einer kontinuierlichen Gleichverteilung
B Gilt für ein λ > 0 und für alle x ∈ R , dass
FX(x) =
ˆ x
−∞f (t ;µλ) dt = H(x)
ˆ x
0λe−λt dt = H(x)
(1− e−λx
)= Fµλ(x) ,
so ist PX = µλ und man nennt X exponentialverteilt mit Parameter λ .
−1 −0.5 0.5 1 1.5 2 2.5 3
0.5
1
x
Fµλ(x)
Abbildung 2.3. Verteilungsfunktion von µλ für λ = 1.5
Mittels der Exponentialverteilung können unter anderem zufällige Wartezeiten mo-delliert werden.
B Existieren µ ∈ R und σ > 0 mit
FX(x) =
ˆ x
−∞f(t ;Nµ,σ2
)dt = 1√
2πσ2
ˆ x
−∞e−(t−µ)2/(2σ2) dt = FNµ,σ2 (x)
für alle x ∈ R , so ist PX = Nµ,σ2 und X heiÿt normalverteilt.
Viele in der Natur auftretenden Zufallsgröÿen werden als normalverteilt angenom-men. In vielen Fällen werden auch zufällige Mess- oder Produktionsfehler mittelseiner Normalverteilung modelliert.

2. Messbare Abbildungen und Zufallsvariable 95
−3 −2 −1 1 2 3
0.5
1
x
FN0,1(x)
Abbildung 2.4. Verteilungsfunktion der Standardnormalverteilung
2.3 Unabhängigkeit von Zufallsvariablen
Wir führen nun den Begri der Unabhängigkeit von Zufallsvariablen ein. Im Weiterenbezeichne (Ω,F ,P) einen Wahrscheinlichkeitsraum und I eine beliebige Indexmenge.
Definition 2.26 (Unabhängigkeit von Zufallsvariablen)Die Familie Xi : Ω→ Ri∈I von Zufallsvariablen heiÿt unabhängig, wenn für jedeendliche Menge J ⊂ I und alle Bjj∈J ∈ B(R)J gilt, dass
P (Xj ∈ Bj : j ∈ J) =∏
j∈JP (Xj ∈ Bj) .
Bemerkung.
B Es sei n ∈ N . Die Zufallsvariablen X1, . . . , Xn : Ω→ R sind genau dann unabhän-gig, wenn für alle Borel-Mengen B1, . . . , Bn ∈ B(R) gilt, dass
P (X1 ∈ B1, . . . , Xn ∈ Bn) =
n∏
i=1
P (Xi ∈ Bi) .
B Ist die Familie Xii∈I von Zufallsvariablen unabhängig und identisch verteilt, soschreiben wir Xii∈I u.i.v. (englisch: i.i.d. für independent and identically dis-tributed).
Beispiel 2.27 (Summe Bernoulli-verteilter Zufallsvariablen)Es seien n ∈ N , p ∈ (0, 1) und X1, . . . , Xn u.i.v. Zufallsvariablen und zwar mit Bernoulli-Verteilung PX1 = B1,p . Die Zufallsvariablen X1, . . . , Xn beschreiben das voneinanderunabhängige Werfen n identer Münzen. Wir denieren nun die Zufallsvariable
X :=n∑
i=1
Xi

96 2. Messbare Abbildungen und Zufallsvariable
und wollen die Verteilung PX bestimmen. Es ist P (X ∈ 0, . . . , n) = 1 und daher genügtes P(X = k) für k = 0, . . . , n zu berechnen. Für k ∈ 0, . . . , n ist
P(X = k) = P
(n∑
i=1
Xi = k
)=
(n
k
)P (X1 = 1, . . . , Xk = 1, Xk+1 = 0, . . . , Xn = 0) =
=
(n
k
)P(X1 = 1)kP(X1 = 0)n−k =
(n
k
)pk(1− p)n−k = Bn,p (k) .
Daher ist PX = Bn,p , also X binomialverteilt mit Parametern n und p . Beispiel 2.28 (Unabhängigkeit diskreter Zufallsvariablen)Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum, αk∞k=1 ∈ RN eine Folge und n ∈ N .Weiters seien
X1, . . . , Xn : Ω→ R
Zufallsvariablen mit Xi(Ω) = α1, α2, . . . für i = 1, . . . , n . Dann sind X1, . . . , Xn genaudann unabhängig, wenn
∀x1, . . . , xn ∈ α1, α2, . . . : P(X1 = x1, . . . , Xn = xn) =
n∏
i=1
P(Xi = xi) ,
vgl. Aufgabe (2.19). Wir wollen nun die Unabhängigkeit von Zufallsvariablen über Verteilungen bzw. Vertei-lungsfunktionen charakterisieren. Dazu benötigen wir folgende Denition.
Definition 2.29 (Gemeinsame Verteilung und Verteilungsfunktion)Es seien n ∈ N und X1, . . . , Xn : Ω → R Zufallsvariablen. Das WahrscheinlichkeitsmaÿP(X1,...,Xn) auf (Rn,B (Rn)) sei für B ∈ B (Rn) durch
P(X1,...,Xn)(B) := P ((X1, . . . , Xn) ∈ B)
gegeben. Dann heiÿt P(X1,...,Xn) gemeinsame Verteilung von X1, . . . , Xn bzw. Ver-teilung des Zufallsvektors (X1, . . . , Xn) . Die Funktion
F(X1,...,Xn) : Rn → [0, 1]
x 7→ P(X1,...,Xn) ((−∞, x1]× . . .× (−∞, xn]) = P (X1 ≤ x1, . . . , Xn ≤ xn)
nennt man gemeinsame Verteilungsfunktion von X1, . . . , Xn bzw. Verteilungs-funktion des Zufallsvektors (X1, . . . , Xn) .
Satz 2.30 (Unabhängigkeit und gemeinsame Verteilung)Es sei n ∈ N . Weiters seien X1, . . . , Xn : Ω → R Zufallsvariablen. Dann sind folgendeAussagen äquivalent:

2. Messbare Abbildungen und Zufallsvariable 97
(1) X1, . . . , Xn sind unabhängig
(2) P(X1,...,Xn) = PX1 ⊗ . . .⊗ PXn(3) F(X1,...,Xn)(x) = FX1(x1) · . . . · FXn(xn) für alle x ∈ Rn
Beweis. (1)⇒(2): Da X1, . . . , Xn unabhängig sind, gilt für alle B1, . . . , Bn ∈ B(R) , dass
P(X1,...,Xn)(B1 × . . .×Bn) = P (X1 ∈ B1, . . . , Xn ∈ Bn) =
=
n∏
i=1
P (Xi ∈ Bi) = (PX1 ⊗ . . .⊗ PXn) (B1 × . . .×Bn) .
Da das Mengensystem
P := B1 × . . .×Bn : B1, . . . , Bn ∈ B(R)
ein π-System mit σ(P) = B (Rn) ist, folgt die Aussage aus Satz 1.49.
(1)⇐(2): Diese Richtung ist oensichtlich.
(2)⇔(3): Eine Richtung dieser Äquivalenz ist klar, die andere erhält man durch Verwen-dung des π-Systems
P := (−∞, x1]× . . .× (−∞, xn] : x1, . . . , xn ∈ R ,
welches B(Rn) erzeugt, und Satz 1.49.
Bemerkung. Definition 2.29 und Satz 2.30 lassen sich auf beliebige FamilienXii∈I von Zufallsvariablen erweitern, indem man jeweils endliche Teilmengen J ⊂ Ibetrachtet.
Oftmals möchte man unabhängige Zufallsvariablen gruppieren.
Satz 2.31 (Gruppierung unabhängiger Zufallsvariablen)Es sei Xk : Ω→ R∞k=1 eine Folge unabhängiger Zufallsvariablen, di∞i=1 ∈ NN eineFolge natürlicher Zahlen und gi : R
di → R eine Borel-Funktion für jedes i ∈ N . Füri ∈ N setzen wir di :=
∑i−1j=1 dj und denieren die Zufallsvariable
Yi := gi
(Xdi+1, . . . , Xdi+di
).
Dann ist auch Yi∞i=1 eine Folge unabhängiger Zufallsvariablen.
Beweis. Es seien n ∈ N und B1, . . . , Bn ∈ B(R) . Zu zeigen ist, dass
P(Yi ∈ Bi : i = 1, . . . , n) =n∏
i=1
P(Yi ∈ Bi) .

98 2. Messbare Abbildungen und Zufallsvariable
Man beachte, dass aufgrund der Unabhängigkeit
P(X1,...,Xdn+1
) = P(X1,...,Xd1) ⊗ . . .⊗ P(Xdn+1,...,Xdn+dn)
gilt und somit ist
P(Yi ∈ Bi : i = 1, . . . , n) = P((Xdi+1, . . . , Xdi+di
)∈ g−1
i (Bi) : i = 1, . . . , n)
=
= P(X1,...,Xdn+1
) (g−11 (B1)× . . .× g−1
n (Bn))
=
=
n∏
i=1
P(Xdi+1,...,Xdi+di
) (g−1i (Bi)
)=
=
n∏
i=1
P((Xdi+1, . . . , Xdi+di
)∈ g−1
i (Bi))
=
=
n∏
i=1
P(Yi ∈ Bi) .
Beispiel 2.32 (Unabhängiges Würfeln)Wir betrachten den Laplace-Raum (Ω,F ,P) mit Ω = 1, . . . , 65 , P = UΩ ist alsodie Gleichverteilung auf Ω . Dieser Wahrscheinlichkeitsraum modelliert die voneinanderunabhängigen Würfe mit fünf Würfeln. Oensichtlich sind die Projektionen
Xk : Ω→ R : ω 7→ ωk , k = 1, . . . , 5 ,
voneinander unabhängige Zufallsvariable. Die Zufallsvariable Xk gibt die Augenzahl desk-ten Würfels an. Nach Satz 2.31 sind dann beispielsweise auch
Y1 = X1 ·X2 und Y2 = X3 +X4 +X5
voneinander unabhängige Zufallsvariablen. Genauso sind
Y1 = eX1·sinX2 , Y2 = cos(3X2
3
)und Y3 = |X4 −X5|
voneinander unabhängige Zufallsvariablen.

2. Messbare Abbildungen und Zufallsvariable 99
Übungsaufgaben
(2.1) Operationen auf Bild- und Urbildmengen II: Gegeben seien eine Abbil-dung f : Ω → Σ , A,A1, A2 ⊂ Ω und B,B1, B2 ⊂ Σ . Beweisen Sie die folgendenAussagen.
(a) A1 ⊂ A2 ⇒ f(A1) ⊂ f(A2)
(b) B1 ⊂ B2 ⇒ f−1(B1) ⊂ f−1(B2)
(c) (f |A)−1(B) = A ∩ f−1(B)
(d) f−1(f(A)) ⊃ A . Ist f injektiv, so gilt die Gleichheit.
(e) f(f−1(B)) ⊂ B . Ist f surjektiv, so gilt die Gleichheit.
(2.2) Rechnen mit Indikatorfunktionen: Sei Ω eine beliebige Menge. Zeigen Siefür A,B ⊂ Ω folgende Identitäten:
(a) χ∅ ≡ 0
(b) χΩ ≡ 1
(c) χA · χB = χA∩B
(d) χA = 1− χcA
(e) χA + χB = χA∪B + χA · χB(2.3) Komposition messbarer Abbildungen: Beweisen Sie Satz 2.12.
(2.4) Gegeben sei der messbare Raum (Ω,F) mit Ω = [0, 1] und F =∅,Ω, [0, 1
4), [14 , 1]
.
Welche der folgenden Funktionen auf [0, 1] sind Zufallsvariablen?
(a) χ[0.25,1]
(b)[x 7→ x2
]
(c) −χ[0,0.5] + χ[0.25,0.5]
(d)√
7χ[0,0.25] + 4χ[0.25,1]
(e) [x 7→ 5]
(2.5) Wir betrachten den Wahrscheinlichkeitsraum ((0, 1),B ((0, 1)) , λ) , wobei λ das Le-besguemaÿ bezeichnet. Bestimmen Sie das Bildmaÿ der Zufallsvariablen
X : (0, 1)→ R ,
wobei
(a) X = χ[0,0.25] + χ[0.75,1] ,
(b) X(x) = x ,

100 2. Messbare Abbildungen und Zufallsvariable
(c) X(x) = 14 ,
(d) X = 14χ(0,1)\Q ,
(e) X(x) = − lnxγ mit γ > 0 .
(2.6) Ermitteln Sie die jeweilige Verteilungsfunktion FX in Aufgabe (2.5).
(2.7) Es sei X : R → R : x 7→ |x| . Zeigen Sie, dass eine Borel-messbare FunktionY : R→ R genau dann bezüglich σ(X) = X−1 (B(R)) messbar ist, wenn Y geradeist.
(2.8) Es seien (Ω,F , µ) ein Maÿraum und X,Y : Ω→ R Abbildungen, wobei X messbarsei. Zeigen Sie, dass aus der Messbarkeit von X 6= Y und µ (X 6= Y ) = 0 imAllgemeinen nicht folgt, dass Y messbar ist.
(2.9) Es sei f : R → R dierenzierbar. Zeigen Sie, dass die Ableitung f ′ eine Borel-Funktion ist.
(2.10) Vollenden Sie den Beweis von Satz 2.19.
(2.11) Bestimmen Sie für nachfolgende Verteilungsfunktionen die zugehörigen Verteilun-gen.
(a) F (x) =
0 , x < 15 ,
13 ,
15 ≤ x < 2
5 ,1 , x ≥ 2
5 .(b) F (x) =
0 , x < 0 ,12x , 0 ≤ x < 1
5 ,12x+ 1
6 ,15 ≤ x < 2
5 ,12x+ 1
2 ,25 ≤ x < 1 ,
1 , x ≥ 1 .
(2.12) Mensch ärgere dich nicht über den Start: Bestimmen Sie die Vertei-lungsfunktion FX der Zufallsvariablen X , welche beim Spiel Mensch ärgere dichnicht die Anzahl der bis zum Start notwendigen Würfe mit einem fairen Würfelbeschreibt.
(2.13) Roulette I: Beim Roulette wird eine der 37 Zahlen 0, 1, 2, . . . , 36 mit Wahr-scheinlichkeit 1/37 ausgespielt. Drei Spieler setzen jeweils einen weiÿen Jeton nachfolgenden Strategien:
Spieler 1 setzt immer auf die Zahl 1 .
Spieler 2 setzt auf die Kolonne 1, 2, . . . , 12 .Spieler 3 setzt auf Impair, d. h. auf die ungeraden Zahlen 1, 3, . . . , 35 .
Die Zufallsvariablen X1, X2, X3 beschreiben den Reingewinn der Spieler 1,2,3 inweiÿen Jetons.Wird die Zahl 1 ausgespielt, so erhält Spieler 1 den 36-fachen Einsatz. Nach Abzugseines Einsatzes verbleibt somit ein Reingewinn von 35 weiÿen Jetons. Wird die

2. Messbare Abbildungen und Zufallsvariable 101
Zahl 1 nicht ausgespielt, so verliert Spieler 1 seinen Einsatz.Tritt das Ereignis D = 1, 2, . . . , 12 ein, so wird Spieler 2 der dreifache Einsatzausbezahlt, andernfalls verliert er seinen Einsatz.Für Spieler 3, welcher auf eine einfache Chance spielt, gibt es eine Sonderrege-lung: Wird eine ungerade Zahl ausgespielt, so bekommt er den doppelten Einsatzausbezahlt, falls jedoch die 0 erscheint, bekommt er den halben Einsatz zurück.Ansonsten verliert er seinen Einsatz.Bestimmen Sie jeweils die Verteilung und die Verteilungsfunktion der Zufallsvaria-blen X1, X2, X3 .
(2.14) Vollenden Sie den Beweis von Satz 2.14, indem Sie zeigen, dass auch X + Ymessbar ist.
(2.15) Ergänzen Sie die ausgelassenen Beweisschritte im Beweis von Satz 2.15. ZeigenSie also, dass supn∈NXn und lim supn→∞Xn messbar sind.
(2.16) Es sei (Ω,F) ein messbarer Raum. Zeigen und beantworten Sie:
(a) Ist X : Ω→ R messbar, so sind auch
X+ := maxX, 0 , X− := max−X, 0 und |X| = X+ +X−
messbar.
(b) Die AbbildungX : Ω→ R ist genau dann messbar, wennX+ undX− messbarsind.
(c) Es sei |X| : Ω→ R messbar. Folgt daraus die Messbarkeit von X ?
(2.17) Stetige Verteilungsfunktion: Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraumund X : Ω → R eine Zufallsvariable. Zeigen Sie, dass die VerteilungsfunktionFX : R→ R genau dann stetig ist, wenn
P (X = x) = 0 für alle x ∈ R .
(2.18) Multinomial- und verallgemeinerte hypergeometrische Verteilung:Gegeben sei eine Urne mit N = B1 +. . .+Bk Kugeln in k unterschiedlichen Farben,wobei Bi die Anzahl der Kugeln in der Farbe i = 1, . . . , k bezeichnet. BestimmenSie die Wahrscheinlichkeit, dass unter n
(a) mit Zurücklegen
(b) ohne Zurücklegen
gezogenen Kugeln, genau bi Kugeln von jeder Farbe i = 1, . . . , k sind.
(2.19) Unabhängigkeit diskreter Zufallsvariablen: Zeigen Sie die Aussage inBeispiel 2.28.

102 2. Messbare Abbildungen und Zufallsvariable
(2.20) Summe unabhängiger binomialverteilter Zufallsvariablen: Es seien(Ω,F ,P) ein Wahrscheinlichkeitsraum, n1, n2 ∈ N und p ∈ (0, 1) . Die Zufalls-variablen X1, X2 : Ω → R seien unabhängig mit PX1 = Bn1,p und PX2 = Bn2,p .Bestimmen Sie die Verteilung der Summe X = X1 +X2 .
(2.21) Klassenfahrt: Die 15 Schüler einer Schulklasse dürfen abstimmen, ob ihre Klas-senfahrt nach Rom oder Paris gehen soll. Der k-te Schüler entscheidet sich unab-hängig von den anderen mit Wahrscheinlichkeit pk ∈ (0, 1) für Paris. Wie groÿ istdie Wahrscheinlichkeit, dass höchstens drei Schüler für Paris stimmen?
(2.22) Würfelspiel: Zwei Personen spielen folgendes Spiel: Ein Spieler hat drei roteWürfel, der andere einen schwarzen Würfel. Der Spieler mit dem schwarzen Würfelgewinnt die Runde, wenn seine Augenzahl gröÿer gleich der höchsten Augenzahlder roten Würfel ist. Wie groÿ ist die Wahrscheinlichkeit, dass der Spieler mit demschwarzen Würfel die Runde gewinnt?
(2.23) In den Teich: Ein Frosch springt in Richtung eines groÿen Teichs. Jeder Sprungbringt ihn entweder 1m oder 2m näher ans Wasser. Die Wahrscheinlichkeit für einen1m-Sprung ist p ∈ (0, 1) , jene für einen 2m-Sprung q = (1− p) . Die Sprünge seienvoneinander unabhängig. Sei pn(j) die Wahrscheinlichkeit, dass der Frosch denTeich nach j Sprüngen das erste Mal erreicht, wenn er (n − 1
2)m entfernt startet.Bestimmen Sie p2(2) .
(2.24) Im Wald: Anhand folgenden Beispiels soll gezeigt werden, dass die Summe unab-hängiger Poisson-verteilter Zufallsvariablen wieder Poisson-verteilt ist.
Die Anzahl f der Fichten in einem Waldstück sei Poisson-verteilt mit Parameterλf > 0 , während die Anzahl b der Birken im selben Waldstück als Poisson-verteiltmit Parameter λb > 0 angenommen wird. Bestimmen sie die Verteilung von Fich-ten und Birken, also die Verteilung der Zufallsvariablen f + b , unter der Annahme,dass f und b unabhängig sind.Hinweis: P(f + b = k) =
∑ki=0P(f = i, b = k − i) für k ∈ N0
(2.25) Christkindlmarkt: Zwei Freunde vereinbaren, sich zwischen 18:00 Uhr und19:00 Uhr am Christkindlmarkt zum Glühweintrinken zu treen. Da der Verkehrwie immer kaum vorherzusehen ist, kommen beide zufällig (gleichverteilt) zwischen18:00 Uhr und 19:00 Uhr am vereinbarten Trepunkt an.
(a) Beide sind bereit, bis zu 20 Minuten auf den jeweils anderen zu warten. Dadie Kälte aber ohne Glühwein kaum zu ertragen ist, geht der Wartende nachAblauf der Zeit wieder nach Hause, sollte der andere nicht auftauchen.
(b) Einer der beiden hat nur einen dünnen Pullover an, daher wird ihm bereitsnach 5 Minuten zu kalt und er geht wieder. Der andere ist angemessen geklei-det, er wartet bis zu 20 Minuten.

2. Messbare Abbildungen und Zufallsvariable 103
Wie groÿ ist jeweils die Wahrscheinlichkeit, dass sich beide treen?
(2.26) Roulette II: Beim Roulette setzt ein Spieler jeweils einen weiÿen Jeton auf dieKolonne 1, 2, . . . , 12 und einen auf Impair, also auf die ungeraden Zahlen. SeineReingewinne werden durch die Zufallsvariablen X,Y beschrieben, also durch denZufallsvektor (X,Y ) . Bestimme die Verteilungsfunktion von (X,Y ) .
(2.27) Minimum unabhängiger exponentialverteilter Zufallsvariablen: Esseien X1, . . . , Xn unabhängige, exponentialverteilte Zufallsvariablen mit Parame-tern λ1, . . . , λn > 0 . Zeigen Sie, dass X := minX1, . . . , Xn eine Zufallsvariableist und bestimmen Sie die Verteilung PX .
(2.28) Dichte und Verteilungsfunktion: Bestimmen Sie c ∈ R so, dass die Funktion
fX : R→ R : x 7→
12 + cx für 0 ≤ x ≤ 1 ,
0 sonst,
Dichte einer Zufallsvariablen X ist und ermitteln Sie FX . Berechnen Sie weitersdie Verteilungsfunktion und eine Dichte der Zufallsvariablen Y := 4X − 1 .
(2.29) Substitutionsregel für Dichten: Es sei X eine reellwertige Zufallsvariablemit Dichte fX . Weiters sei α > 0 und β ∈ R . Zeigen Sie, dass die ZufallsvariableY := αX + β die für t ∈ R durch
fY (t) = 1αfX
(t−βα
)
gegebene Dichte besitzt.
(2.30) Intelligent?: Der Intelligenzquotient (IQ) einer bestimmten Bevölkerungsschichtsei N100,152-verteilt. Man bestimme c > 0 so, dass eine aus dieser Bevölkerungs-schicht zufällig ausgewählte Person mit Wahrscheinlichkeit 0.3 einen IQ von min-destens c besitzt.Hinweis: Φ(x) = 0.7 ⇐⇒ x ≈ 0, 525

104 2. Messbare Abbildungen und Zufallsvariable
Schulaufgaben
Die nachfolgenden Aufgaben stammen, sofern keine weiteren Angaben gemacht werden,von https://www.bifie.at/ (Stand: Februar 2013).
(S2.1) Multiple Choice 2: Bei einem Aufnahmetest werden vier Fragen mit je dreiAntwortmöglichkeiten gestellt, wobei jeweils genau eine Antwort richtig ist.
Der Kandidat kreuzt rein zufällig jeweils eine Antwort an. Die Zufallsvariable Xgibt die Anzahl der richtigen Antworten an.
(a) Um welche Art der Wahrscheinlichkeitsverteilung der Zufallsvariablen Xhandelt es sich? Begründe deine Antwort.
(b) Wie groÿ ist die Wahrscheinlichkeit, mindestens zwei Antworten richtig an-zukreuzen?
(S2.2) Versandhaus: Ein Versandhaus wird von einer Firma mit Artikeln für Haus-haltselektronik beliefert, bei denen von einer Ausschussquote von p = 0.06 aus-gegangen wird. Eine Lieferung umfasst 200 Stück.
Die Zufallsgröÿe X beschreibe die Anzahl defekter Artikel in einer Lieferung.
Begründe, warum die Zufallsvariable X binomialverteilt ist.
(S2.3) Normalverteilung: Eine Zufallsvariable X ist normalverteilt mit dem Erwar-tungswert µ und der Standardabweichung σ.
N1 N2 N3 N4
In den Graphen N1, N2, N3, N4 entsprechen den blau markierten Flächen Wahr-scheinlichkeiten. Kreuze an, welche der unten stehenden Wahrscheinlichkeitsaus-sagen sie abbilden.
2. Messbare Abbildungen und Zufallsvariable 105
N1 N2 N3 N4 keiner der Graphen
P(X ≤ a)
P(X ≥ a)
P(X ≤ b)
1− P(X ≤ a)
1− P(X ≤ b)
1− P(µ− a ≤ X ≤ µ+ a)
P(a ≤ X ≤ b)
2P(X < µ− a)
2P(X < b)− 1
P(X ≤ b)− P(X ≤ a)
(S2.4) Binomialverteilung: Eine Binomialverteilung der Zufallsvariablen X mit denParametern p und n wird mit der Formel
P(X = k) =
(n
k
)pk(1− p)n−k , k ≤ n ,
beschrieben.
(a) Unter welchen Bedingungen ist eine Zufallsvariable X binomialverteilt? Er-kläre die Bedeutung der Variablen n und p in der Formel.
(b) Eine Maschine erzeugt Glühbirnen mit einem Ausschussanteil von 1%. Be-rechne die Wahrscheinlichkeit, dass von 6000 Glühbirnen 60 bis 75 Stückschadhaft sind. Dokumentiere deinen Lösungsweg.
(S2.5) Aufnahmetest: Eine Universität führt für die angemeldeten Bewerber/inneneinen Aufnahmetest durch. Dabei werden zehn Multiple-Choice-Fragen gestellt,wobei jede Frage vier Antwortmöglichkeiten hat. Nur eine davon ist richtig. Wermindestens acht Fragen richtig beantwortet, wird sicher aufgenommen. Wer allezehn Fragen richtig beantwortet, erhält zusätzlich ein Leistungsstipendium. DieErsteller/innen dieses Tests geben die Wahrscheinlichkeit, bei zufälligem Ankreu-zen aller Fragen aufgenommen zu werden, mit 0.04158 % an. Nehmen Sie an, dassKandidat K alle Antworten völlig zufällig ankreuzt.
(a) Nennen Sie zwei Kriterien, warum die Anzahl der richtig beantworteten Fra-gen unter den vorliegenden Angaben binomialverteilt ist! Geben Sie zweimögliche Gründe an, warum in der Realität das Modell der Binomialvertei-lung hier eigentlich nicht anwendbar ist!

106 2. Messbare Abbildungen und Zufallsvariable
(b) Geben Sie die Wahrscheinlichkeit an, dass Kandidat K nicht aufgenommenwird! Berechnen Sie die Wahrscheinlichkeit, dass Kandidat K ein Leistungs-stipendium erhält!
(c) Um zu argumentieren, dass die Strategie des zufälligen Ankreuzens nichtaufgeht, wird die Anzahl der Kandidatinnen und Kandidaten ermittelt, dieauf diese Weise zum Test antreten müssten, damit mit mindestens 90%igerWahrscheinlichkeit zumindest eine/einer von ihnen aufgenommen wird.Kreuzen Sie die beiden zutreenden Ungleichungen an, die geeignet sind,diese Anzahl zu ermitteln.
1−(n0
)· 0.00041580 · 0.9995842n ≥ 0.90
1−(n0
)· 0.0004158n · 0.99958420 ≥ 0.90
1−(n1
)· 0.00041580 · 0.9995842n ≥ 0.90
0.9995842n ≤ 0.10
0.0004158n ≤ 0.10
Denieren Sie dazu auch die verwendete Zufallsvariable und geben Sie derenWahrscheinlichkeit p an.
(S2.6) Binomial- und Normalverteilung: Eine Maschine erzeugt Glühbirnen miteinem Ausschussanteil von 1%.
(a) Eine Binomialverteilung der Zufallsvariablen X mit den Parametern p undn wird mit der Formel
P(X = k) =
(n
k
)pk(1− p)n−k , k ≤ n ,
beschrieben. Berechne die Wahrscheinlichkeit, dass von 6000 Glühbirnen 60bis 75 Stück schadhaft sind. Dokumentiere deinen Lösungsweg.
(b) Berechne diese Wahrscheinlichkeit mittels Normalverteilung und vergleichedas Ergebnis mit dem aus (a).
(S2.7) Blutgruppen 1: Nach Karl Landsteiner (1868-1943) unterscheidet man die vierBlutgruppen 0, A, B und AB, die in einer bestimmten Region folgende Verteilunghat:
Blutgruppe 0 A B AB
Anteil 37% 41% 15% 7%
a) Angenommen alle 23 Personen einer Maturaklasse spenden alle Blut. Wel-ches Modell ist geeignet, die Wahrscheinlichkeiten, dass unter den Spen-der/innen mindestens zwei die Blutgruppe A bzw. mehr als 10 und höchstens12 die Blutgruppe 0 haben, zu berechnen? Begründe deine Entscheidung.

2. Messbare Abbildungen und Zufallsvariable 107
b) Mit welchem Modell berechnet man die Wahrscheinlichkeit, dass unter 10000Personen mehr als 3650 Personen die Blutgruppe 0 haben?
c) Die Zufallsvariable X beschreibt die Anzahl der Personen mit BlutgruppeAB aus 10000 untersuchten Menschen.
Was versteht man unter P(µ− ε ≤ X ≤ µ+ ε) = 0.90?
(S2.8) Blutgruppen 2: Nach Karl Landsteiner (1868-1943) unterscheidet man die vierBlutgruppen 0, A, B und AB, die in einer bestimmten Region folgende Verteilunghat:
Blutgruppe 0 A B AB
Anteil 37% 41% 15% 7%
a) 23 Personen einer Maturaklasse spenden Blut. Berechne die Wahrscheinlich-keiten, dass unter den Spender/innen
(i) mindestens zwei die Blutgruppe A haben,
(ii) mehr als 10 und höchstens 12 die Blutgruppe 0 haben.
b) Wie viele Personen müssten Blut spenden, wenn mit einer Wahrscheinlich-keit von mehr als 95% mindestens eine Person die seltene Blutgruppe ABhat?
c) Berechne die Wahrscheinlichkeit, dass unter 10000 Personen mehr als 3650Personen die Blutgruppe 0 haben.
d) Die Zufallsvariable X beschreibt die Anzahl der Personen mit BlutgruppeAB aus 10000 untersuchten Menschen.
Berechne: P(µ− ε ≤ X ≤ µ+ ε) = 0.95
Beschreibe das Ergebnis mit eigenen Worten.

108 2. Messbare Abbildungen und Zufallsvariable
Kontrollfragen
2.1 Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum und X : Ω → R eine Abbildung.Welche der folgenden Aussagen sind wahr?
X ist Zufallsvariable ⇐⇒ ∀B ∈ B(R) : X−1(B) ∈ B(R)
X ist Zufallsvariable ⇐⇒ ∀x ∈ R : X−1 ((−∞, x]) ∈ F Ist X(Ω) = x1, x2, . . . , so gilt
X ist Zufallsvariable ⇐⇒ ∀n ∈ N : X−1 (xn) ∈ F .
X ist Zufallsvariable ⇐⇒ ∀x ∈ R : X−1 (x) ∈ F
2.2 Es sei Ω = (0, π) und X : Ω → R : ω 7→ sinω . Welche der Folgenden Aussagensind wahr?
X ist Borel-messbar.
X ist(X−1(B(R)),B(R)
)-messbar.
IstF =
∅,(0, π2
],(π2 , π
),Ω,
so ist X eine (F ,B(R))-messbare Funktion.
Ist F = P(Ω) und F ′ eine beliebige σ-Algebra auf R , so ist X eine (F ,F ′)-messbare Abbildung.
2.3 Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum und A ∈ F . Weiters sei
X = 7χA − 5 .
Welche der folgenden Aussagen sind wahr?
PX = P(A)δ2 + (1− P(A))δ−5
PX = P(A)δ2 + P(Ac)δ−5
FX = P(A)χ[2,∞) + P(Ac)χ[−5,∞)
FX = P(A)χ[7,∞) + P(Ac)χ[−5,∞)
2.4 Es sei (Ω,F ,P) der Laplace-Raum zu Ω = 1, 2, 3 . Weiters seien die Zufallsva-riablen
X : Ω→ R : ω 7→ ω
und Y = X2 gegeben. Welche der folgenden Aussagen sind wahr?
X und Y sind unabhängig.

2. Messbare Abbildungen und Zufallsvariable 109
PX = 13(δ1 + δ2 + δ3) und PY = 1
3(δ1 + δ4 + δ9)
FX = 13
(χ[1,∞) + χ[2,∞) + χ[3,∞)
)und FY = 1
3
(χ[1,∞) + χ[4,∞) + χ[9,∞)
)
PX+Y = 13(δ2 + δ6 + δ12)
2.5 Gegeben sei der Wahrscheinlichkeitsraum
([0, 1],B([0, 1]), λ)
und die Zufallsvariablen
X = 14 und Y = χ[0,3/4] + χ[1/2,1] .
Welche der folgenden Aussagen sind wahr?
PX = 0 und PY = 34δ1 + 1
4δ2
PX = δ14und PY = 3
4δ1 + 14δ2
FX = χ(1/4,∞) und FY = 34χ(1,∞) + 1
4χ(2,∞)
FX = χ[1/4,∞) und FY = 34χ[1,2) + χ[2,∞)
2.6 Gegeben seien die Abbildungen
F : R→ R : x 7→ 12χ[1,3)(x) + 1
2(x− 2)χ[2,3)(x) + χ[3,∞)(x)
und
P : B(R)→ R : B 7→ 12δ1(B) + 1
2λ ((2, 3) ∩B) .
Welche der folgenden Aussagen sind wahr?
F ist eine Verteilungsfunktion und P eine Verteilung.
F ist eine Verteilungsfunktion, aber P keine Verteilung.
FP = F
FP 6= F
2.7 Es seiX : Ω→ R eine Zufallsvariable auf demWahrscheinlichkeitsraum (Ω,F ,P)mit X ∼ N7,4 . Weiters bezeichne Φ die Verteilungsfunktion der Standardnormal-verteilung. Welche der folgenden Aussagen sind wahr?
P(11 ≤ X ≤ 13) = Φ(3)− Φ(2)
Die Zufallsvariable
Y =X − 7
2
ist standardnormalverteilt.

110 2. Messbare Abbildungen und Zufallsvariable
Die Zufallsvariable
Y =X − 7
4
ist standardnormalverteilt.
P(11 ≤ X ≤ 13) = N7,4([11, 13])
2.8 Gegeben seien die Zufallsvariablen X1, X2 : Ω→ R mit
P(X1,X2) = 14δ(0,0) + 1
4δ(1,0) + 14δ(0,1) + 1
4δ(1,1) .
Welche der folgenden Aussagen sind wahr?
X1 und X2 sind unabhängig.
P(X1,X2) = PX1 ⊗ PX2
X1 und X2 sind nicht unabhängig.
∀x1, x2 ∈ R : F(X1,X2)(x1, x2) = FX1(x1)FX2(x2)

Kapitel 3
Integration und Erwartungswert
In diesem Kapitel werden wir das Integral reellwertiger messbarer Funktionen einführenund dessen grundlegende Eigenschaften studieren. Insbesondere wird uns dies erlauben,den Erwartungswert und die Varianz von Zufallsvariablen zu denieren.
3.1 Einfache Funktionen
In diesem Abschnitt zeigen wir, dass jede messbare Funktion der monotone Grenzwerteinfacher Funktionen ist. Es bezeichne (Ω,F) einen messbaren Raum.
Definition 3.1 (Einfache Funktionen)Eine Abbildung X : Ω → R heiÿt einfache Funktion, wenn ein n ∈ N und paarweisedisjunkte messbare Mengen A1, . . . , An ∈ F sowie α1, . . . , αn ∈ R existieren, sodass
X =
n∑
i=1
αiχAi .
Bemerkung. Nach Beispiel 2.8 und Satz 2.14 ist eine einfache Funktion insbeson-dere messbar.
Beispiel 3.2 (Messbare Abbildung mit endlich vielen Funktionswerten)Nimmt die messbare Abbildung X : Ω → R nur endlich viele Werte an, so ist dieseeine einfache Funktion. Wir nehmen also an, dass X(Ω) = α1, . . . , αn mit paarweiseverschiedenen α1, . . . , αn ∈ R . Für i = 1, . . . , n setzen wir Ai := X−1 (αi) . Dann sindA1, . . . , An ∈ F paarweise disjunkt und
X =n∑
i=1
αiχAi
ist die gesuchte Darstellung.
Wir zeigen nun, dass eine nichtnegative messbare Abbildung der monotone Grenzwertnichtnegativer einfacher Funktionen ist. Im Weiteren bezeichne
E+ := E+(Ω,F) :=
n∑
i=1
αiχAi : n ∈ N , α1, . . . , αn > 0 , A1, . . . , An ∈ F p.w. disjunkt
111

112 3. Integration und Erwartungswert
die Menge der nichtnegativen einfachen Funktionen und
L+ := L+(Ω,F) := X : Ω→ [0,∞] messbar
die Menge der nicht-negativen messbaren Funktionen.
Lemma 3.3 Für eine Abbildung X : Ω→ [0,∞] gilt
X ∈ L+ ⇐⇒ ∃Xn∞n=1 ∈ EN+ : Xn ↑ X .
Beweis. ⇐: Diese Richtung folgt direkt aus Satz 2.15.
⇒: Für n ∈ N setze etwa Xn := min 2−nb2nXc, n .
Obiges Lemma wird im weiteren Verlauf dieses Kapitels noch des Öfteren zum Einsatzkommen.
3.2 Konstruktion des Integrals
Im Folgenden bezeichne (Ω,F , µ) stets einen Maÿraum. Als ersten Schritt werden wirdas Integral auf der Menge der nichtnegativen einfachen Funktionen
E+ =
n∑
i=1
αiχAi : n ∈ N , α1, . . . , αn > 0 , A1, . . . , An ∈ F p.w. disjunkt
denieren.
3.2.1 Erster Schritt: Integral einfacher Funktionen
Für X ∈ E+ mit Darstellung X =∑n
i=1 αiχAi denieren wir das Integral von Xbezüglich µ durch
ˆX dµ :=
n∑
i=1
αi µ(Ai) .
Wir müssen nun sicherstellen, dass diese Denition unabhängig von der gewählten Dar-stellung der einfachen Funktion X ist. Es sei X =
∑mj=1 βjχBj eine weitere Darstellung.
Es gilt zu zeigen, dass
n∑
i=1
αi µ(Ai) =m∑
j=1
βj µ(Bj) .

3. Integration und Erwartungswert 113
Betrachte dazu die Durchschnitte Ai ∩ Bj , i = 1, . . . , n , j = 1, . . . ,m . Im Fall, dassAi ∩Bj 6= ∅ , ist X|Ai∩Bj = αi = βj . Weiters gilt, dass
Ai ⊂m⊎
j=1
Bj und Bj ⊂n⊎
i=1
Ai .
Aus diesen Überlegungen folgt nun
n∑
i=1
αi µ(Ai) =
n∑
i=1
αi µ
m⊎
j=1
Ai ∩Bj
=
n∑
i=1
m∑
j=1
αi µ (Ai ∩Bj) =
=m∑
j=1
n∑
i=1
βj µ (Ai ∩Bj) =m∑
j=1
βj µ
(n⊎
i=1
Ai ∩Bj)
=
=
m∑
j=1
βj µ(Bj) .
Somit ist die Abbildung
E+ → [0,∞] : X =
n∑
i=1
αiχAi 7→ˆX dµ =
n∑
i=1
αi µ(Ai)
wohldeniert.
Im Weiteren verwenden wir stets die Konvention 0 · ∞ := 0 .
Lemma 3.4 (Eigenschaften des Integrals auf E+)Für X,Y ∈ E+ und α ≥ 0 gelten folgende Aussagen:
(1) Es gilt X + αY ∈ E+ undˆ
(X + αY ) dµ =
ˆX dµ+ α
ˆY dµ . (Linearität)
(2) Ist X ≤ Y , so gilt´X dµ ≤
´Y dµ . (Monotonie)
Beweis. Aufgabe (3.1).
3.2.2 Zweiter Schritt: Integral nicht-negativer Funktionen
Nun setzen wir das auf E+ denierte Integral auf die Menge der nichtnegativen messbarenFunktionen
L+ = X : Ω→ [0,∞] messbar

114 3. Integration und Erwartungswert
fort. Für X ∈ L+ denieren wir das Integral von X bezüglich µ durchˆX dµ := sup
ˆY dµ : Y ∈ E+ , Y ≤ X
.
Für X ∈ E+ stimmt die obige Denition des Integrals oenbar mit der bisherigen auf E+
überein und somit haben wir das Integral von E+ auf L+ fortgesetzt. Weiters schreibenwir auch ˆ
X dµ =:
ˆΩX dµ =:
ˆΩX(ω) dµ(ω)
für das Integral von X ∈ L+ bezüglich µ .
Sind X,Y : Ω → R zwei messbare Funktionen, so schreiben wir auÿerdem X = Y fastüberall (kurz: f. ü.), falls µ(X 6= Y ) = 0 . Analog werden etwa X ≤ Y f. ü. und X ≥ Yf. ü. deniert.
Lemma 3.5 (Eigenschaften des Integrals auf L+)Für X,Y ∈ L+ und α ≥ 0 gelten folgende Aussagen:
(1) X ≤ Y f. ü. =⇒´X dµ ≤
´Y dµ (Monotonie)
(2)´
(X + αY ) dµ =´X dµ+ α
´Y dµ (Linearität)
(3) X = 0 f. ü. ⇐⇒´X dµ = 0
(4)´X dµ <∞ =⇒ X <∞ f. ü.
Beweis. (1) Diese Aussage ergibt sich unmittelbar aus der Denition des Integrals.
(2) Nach Lemma 3.3 existieren Folgen Xn∞n=1 und Yn∞n=1 in E+ mit Xn ↑ X undYn ↑ Y . Insbesondere ist dann Xn+αYn∞n=1 ∈ EN+ eine Folge mit Xn+αYn ↑ X+αY .Aus dem Satz von der monotonen Konvergenz, also Satz 3.6, für dessen Beweiswir nur (1) verwenden werden, folgt nunˆ
(X + αY ) dµ = limn→∞
ˆ(Xn + αYn) dµ = lim
n→∞
ˆXn dµ+ α lim
n→∞
ˆYn dµ =
=
ˆX dµ+ α
ˆY dµ
und damit die Linearität des Integrals.
(3) ⇒: Diese Richtung folgt aus (1).
⇐: Es giltX ≥ 1
n
↑ X > 0 . Für jedes n ∈ N folgt aus
0 =
ˆX dµ ≥
ˆ1
nχ
X≥ 1n
dµ =µ(X ≥ 1
n
)
n,

3. Integration und Erwartungswert 115
dass µ(X ≥ 1
n
)= 0 und somit µ(X > 0) = 0 .
(4) Für jedes n ∈ N gilt 1nXχX≥n ≥ χX≥n und daher ist
µ(X =∞) =
ˆχX=∞ dµ ≤
ˆχX≥n dµ ≤ 1
n
ˆXχX≥n dµ ≤ 1
n
ˆX dµ→ 0
für n→∞ .
Bemerkung. Insbesondere gilt für X,Y ∈ L+ , dass
X = Y fast überall =⇒ˆX dµ =
ˆY dµ .
Satz 3.6 (Satz von der monotonen Konvergenz, Beppo Levi1)Ist X ∈ L+ und Xn∞n=1 ∈ LN+ eine Folge mit Xn ↑ X fast überall, so gilt
limn→∞
ˆXn dµ =
ˆX dµ .
Beweis. Es sei N ∈ F eine Nullmenge, sodass Xn ↑ X auf N c . Aus der Monotonie folgt
limn→∞
ˆXn dµ = sup
n∈N
ˆχN cXn dµ ≤
ˆχN cX dµ =
ˆX dµ
und daher bleibt zu zeigen, dass supn∈N´Xn dµ ≥
´X dµ . Es sei dazu Y ∈ E+ mit
Y ≤ X und Darstellung Y =∑M
i=1 αi χAi . Zu ε > 0 und n ∈ N betrachte die Menge
Bεn := ω ∈ N c : Xn(ω) ≥ (1− ε)Y (ω) ∈ F .
Aus Xn ↑ X ≥ Y auf N c folgt Bεn ↑ N c für n→∞ . Somit ist
ˆXn dµ =
ˆχN cXn dµ ≥
ˆ(1− ε)Y χBεn dµ =
M∑
i=1
(1− ε)αi µ (Ai ∩Bεn)
→M∑
i=1
(1− ε)αi µ(Ai) = (1− ε)ˆY dµ
für n→∞ .
Korollar 3.7 (Vertauschen von Reihe und Integral)Für Xn∞n=1 ∈ LN+ gilt
ˆ ∞∑
n=1
Xn dµ =∞∑
n=1
ˆXn dµ .
1Beppo Levi, 18751961, italienischer Mathematiker

116 3. Integration und Erwartungswert
Beweis. Setze S :=∑∞
n=1Xn und SN :=∑N
n=1Xn für N ∈ N . Beachte nun, dassSN∞N=1 ∈ LN+ und SN ↑ S . Aufgrund der Linearität und der monotonen Konvergenzdes Integrals auf L+ folgt daher
∞∑
n=1
ˆXn dµ = lim
N→∞
ˆSN dµ =
ˆS dµ =
ˆ ∞∑
n=1
Xn dµ .
Ist (Ω,F ,P) ein Wahrscheinlichkeitsraum und X ∈ L+ , so nennt man
EX :=
ˆΩX dP
den Erwartungswert von X . Auÿerdem schreiben wir im Fall, dass ein Wahrschein-lichkeitsmaÿ zugrunde liegt, stets fast sicher (kurz: f.s.) anstelle von fast überall.
Beispiel 3.8 (Erwartungswerte diskreter Verteilungen)Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum und X ∈ L+ mit Verteilung PX . Dannnennt man EPX := EX den Erwartungswert der Verteilung PX . Wie wir sehen wer-den, ist die Denition des Erwartungswertes einer Verteilung unabhängig von der Wahldes Wahrscheinlichkeitsraumes und der Zufallsvariablen, vgl. Lemma 3.20. In nachfol-gender Tabelle sind die Erwartungswerte einiger diskreter Verteilungen aufgelistet.
PX EPX Verteilung
Bn,p np Binomialverteilung
Hn,N,G nGN Hypergeometrische Verteilung
πλ λ Poisson-Verteilung
gp1−pp Geometrische Verteilung
Exemplarisch berechnen wir den Erwartungswert der Poisson-Verteilung. Dazu wählenwir einen Wahrscheinlichkeitsraum (Ω,F ,P) und X ∈ L+ mit PX = πλ . Nun folgt ausP(X ∈ N0) = 1 , dass
X =
∞∑
k=0
kχX=k fast sicher.
Somit erhalten wir
Eπλ = EX =
ˆX dP =
∞∑
k=0
ˆkχX=k dP =
∞∑
k=0
kP(X = k) = e−λ∞∑
k=0
kλk
k!= λ .

3. Integration und Erwartungswert 117
3.2.3 Dritter Schritt: Integral messbarer Funktionen
Ist X : Ω→ R messbar, so sind auch
X+ := maxX, 0 und X− := max−X, 0
messbar, es gilt alsoX+, X− ∈ L+ . Weiters lässt sichX in seinen positiven und negativenAnteil zerlegen, d. h.
X = X+ −X− .
Aus X+ ≤ |X| und X− ≤ |X| folgt aufgrund der Monotonie des Integrals auf L+ , dassˆX+ dµ ≤
ˆ|X|dµ und
ˆX− dµ ≤
ˆ|X| dµ .
Insbesondere folgt daher aus´|X| dµ <∞ , dass
´X+ dµ <∞ und
´X− dµ <∞ . Diese
Beobachtungen geben Anlass zu folgender Denition des Integrals messbarer Funktionen.
Definition 3.9 (Integral messbarer Funktionen)
(1) Eine messbare Funktion X : Ω → R heiÿt µ-integrierbar, wenn´|X| dµ < ∞ .
Für die Menge der µ-integrierbaren Funktionen schreiben wir
L1(µ) := L1(Ω,F , µ) :=
X : Ω→ R messbar :
ˆ|X|dµ <∞
.
(2) Für X ∈ L1(µ) ist das Integral von X bezüglich µ durchˆX dµ :=
ˆX+ dµ−
ˆX− dµ
gegeben.
(3) Ist X : Ω → R messbar mit´X+ dµ < ∞ und/oder
´X− dµ < ∞ , so denieren
wir das Integral von X bezüglich µ wie in (2) , wobei nun die Werte ∞ und −∞zugelassen sind. In diesem Fall sagen wir, dass das Integral von X bezüglich µexistiert.
Bemerkung.
B Für A ∈ F und X ∈ L1(µ) setzen wirˆAX dµ :=
ˆχAX dµ .

118 3. Integration und Erwartungswert
B Es sei A ∈ F und X : A → R eine bezüglich F|A messbare Abbildung. Dann istdie durch
(χAX)(ω) :=
X(ω) , ω ∈ A ,0 , ω /∈ A ,
für ω ∈ Ω denierte Funktion messbar bezüglich F . Ist χAX ∈ L1(µ) , so setzenwir wiederum ˆ
AX dµ :=
ˆχAX dµ .
Beispiel 3.10 (Lebesgue-Integral auf Rd)Wir betrachten nun das Lebesgue-Maÿ λ auf
B(Rd) =B ⊂ Rd Lebesgue-messbar
.
Man beachte, dass B(Rd) B(Rd) . Eine Funktion X ∈ L1(Rd,B(Rd), λ
)nennt man
Lebesgue-integrierbar und entsprechendˆX dλ
das Lebesgue-Integral von X . Bemerkung. (Zusammenhang: Riemann-Integral und Lebesgue-Integral)Jede absolut Riemann-integrierbare Funktion X : R→ R ist Lebesgue-integrierbar undˆ ∞
−∞X(x) dx =
ˆR
X(x) dλ(x) .
Beispiel 3.11 (Dirichletsche Sprungfunktion)Die Dirichletsche Sprungfunktion X : [0, 1] → R : ω 7→ χQ(ω) ist bekanntlich nichtRiemann-integrierbar, jedoch ist diese Lebesgue-integrierbar undˆ
[0,1]X dλ =
ˆχ[0,1]∩Q dλ = λ([0, 1] ∩Q) = 0 .
Lemma 3.12 (Linearität des Integrals bezüglich des Maÿes)Es seien µ1 und µ2 zwei Maÿe auf dem messbarern Raum (Ω,F) und α1, α2 > 0 . Weiterssei µ := α1µ1 + α2µ2 und X : Ω→ R eine Abbildung. Dann gilt
X ∈ L1(µ) ⇐⇒ X ∈ L1(µ1) ∩ L1(µ2)
und im Fall der Integrierbarkeit istˆX dµ = α1
ˆX dµ1 + α2
ˆX dµ2 .

3. Integration und Erwartungswert 119
Beweis. Um die Linearität auf L+ zu zeigen, genügt es X = χA , A ∈ F , zu betrachten.Dies ist eine Folgerung aus der monotonen Konvergenz des Integrals auf L+ und derTatsache, dass jede Funktion in L+ der monotone Grenzwert von Funktionen in E+ ist.Es sei also X = χA mit A ∈ F . In diesem Fall erhalten wir jedoch unmittelbar
ˆχA dµ = µ(A) = α1µ1(A) + α2µ2(A) = α1
ˆχA dµ1 + α2
ˆχA dµ2 .
Da somit die Linearität bezüglich des Maÿes auf L+ gezeigt ist, erhalten wir unmittelbardie Aussage über die Integrierbarkeit von X . Zerlegt man X ∈ L1(µ) in Positiv- undNegativ-Anteil, ergibt sich nun die gewünschte Aussage über das Integral.
Bemerkung. Ist µn∞n=1 eine Folge von Maÿen auf (Ω,F) und αn∞n=1 ∈ (0,∞)N ,so kann obiges Lemma auf µ :=
∑∞n=1 αnµn erweitert werden, um im Fall der Integrier-
barkeitˆX dµ =
∞∑
n=1
αn
ˆX dµn
zu erhalten.
Beispiel 3.13 (Erwartungswert der Gleichverteilung)Für a < b bestimmen wir nun den Erwartungswert der Gleichverteilung auf [a, b] , alsoder Verteilung U[a,b] . Wir betrachten den Wahrscheinlichkeitsraum
([a, b],B([a, b]),U[a,b]
)
und die auf [a, b] gleichverteilte Zufallsvariable X : [a, b]→ R : ω 7→ ω . Dann ist
EU[a,b] =
ˆ[a,b]
X(ω) dU[a,b](ω) =1
b− a
ˆ[a,b]
ω dλ(ω) =1
b− a
ˆ b
ax dx =
a+ b
2.
Satz 3.14 (Eigenschaften des Integrals auf L1)Es seien X,Y ∈ L1(µ) .
(1) Gilt X ≤ Y fast überall, dann ist´X dµ ≤
´Y dµ . (Monotonie)
(2) Für α ∈ R ist X + αY ∈ L1(µ) undˆ
(X + αY ) dµ =
ˆX dµ+ α
ˆY dµ . (Linearität)
(3)∣∣´ X dµ
∣∣ ≤´|X|dµ . (Dreiecksungleichung)
(4) Ist Z : Ω→ R messbar und Z = X fast überall, so ist auch Z ∈ L1(µ) undˆX dµ =
ˆZ dµ .

120 3. Integration und Erwartungswert
Beweis. (1) Da X+ ≤ Y + und X− ≥ Y − fast überall, folgt aufgrund der Monotonie desIntegrals auf L+ , dass
ˆX+ dµ ≤
ˆY + dµ und
ˆX− dµ ≥
ˆY − dµ .
Daher istˆX dµ =
ˆX+ dµ−
ˆX− dµ ≤
ˆY + dµ−
ˆY − dµ =
ˆY dµ .
(2) Aus |X + αY | ≤ |X|+ |α||Y | folgt X + αY ∈ L1(µ) . Da
ˆ(−X) dµ =
ˆ(−X)+ dµ−
ˆ(−X)− dµ =
ˆX− dµ−
ˆX+ dµ = −
ˆX dµ ,
genügt es α ≥ 0 zu betrachten und in diesem Fall erhält man die Aussage direkt aus
(X + αY )+ − (X + αY )− = X + αY = X+ −X− + αY + − αY − .
(3) Da X ≤ |X| und −X ≤ |X| , folgt die Aussage aus (1) und (2).
(4) Aus Z = X fast überall folgt Z+ = X+ und Z− = X− fast überall und damitunmittelbar die Aussage.
Ist (Ω,F ,P) ein Wahrscheinlichkeitsraum und X ∈ L1(P) , so nennt man
EX :=
ˆΩX(ω) dP(ω)
wiederum Erwartungswert von X .
Beispiel 3.15 (Integration bezüglich eines Dirac-Maÿes)Zu einer nicht leeren Menge Ω und einem festen ω0 ∈ Ω betrachten wir den Wahrschein-lichkeitsraum (Ω,P(Ω), δω0) . Dann ist jede Funktion X : Ω → R integrierbar bezüglichδω0 , da |X| = |X(ω0)|χω0 fast sicher und daher
ˆΩ|X| dδω0 =
ˆΩ|X(ω0)|χω0 dδω0 = |X(ω0)| <∞ .
Entsprechend erhalten wir
EX =
ˆΩX dδω0 = X(ω0) .

3. Integration und Erwartungswert 121
Beispiel 3.16 (Absolute Konvergenz und Integrierbarkeit)Für Ω := N wählen wir die σ-Algebra F := P(N) und das Maÿ µ :=
∑∞n=1 δn . Dann gilt
für die Abbildung X : N→ R , dass
X ist µ-integrierbar ⇐⇒ˆN
|X| dµ =
∞∑
n=1
|X(n)| <∞ .
Im Falle der absoluten Konvergenz der Reihe∑∞
n=1X(n) ist also
ˆN
X dµ =∞∑
n=1
X(n) .
Beispiel 3.17 (Integration in diskreten Maÿräumen)Gegeben sei der Maÿraum (Ω,P(Ω), µ) mit abzählbarem Ω und
µ =∑
ω∈Ω
αωδω ,
wobei αω ≥ 0 für jedes ω ∈ Ω . Dann gilt für eine Abbildung X : Ω→ R , dass
X ∈ L1(µ) ⇐⇒∑
ω∈Ω
αω|X(ω)| <∞ .
Im Fall der Integrierbarkeit erhalten wirˆX dµ =
∑
ω∈Ω
αωX(ω) .
3.3 Substitution und Dichten
Zur praktischen Berechnung des Integrals einer messbaren Funktion benötigt man häugnachfolgende Substitutionsformel.
Satz 3.18 (Substitutionsformel)Es seien (ΩD,FD) und (ΩB,FB) messbare Räume. Weiters sei µ ein Maÿ auf (ΩD,FD) ,die Abbildung X : ΩD → ΩB messbar. Für eine messbare Funktion g : ΩB → R ist dann
g ∈ L1(µ X−1
)⇐⇒ g X ∈ L1(µ)
und im Fall der Integrierbarkeit gilt für AB ∈ FB , dassˆAB
g d(µ X−1
)=
ˆX−1(AB)
(g X) dµ .

122 3. Integration und Erwartungswert
Beweis. Schritt 1: Wir setzen g := χABg . Dann ist
ˆAB
g d(µ X−1
)=
ˆΩB
g d(µ X−1)
und im Falle der Integrierbarkeit giltˆX−1(AB)
(g X) dµ =
ˆΩD
(g X) dµ .
Schritt 2: Nach dem ersten Beweisschritt können wir annehmen, dass AB = ΩB . Auf-grund der monotonen Konvergenz des Integrals auf L+ und da jede Funktion in L+ dermonotone Grenzwert von Funktionen in E+ ist, genügt es für B ∈ FB zu zeigen, dass
ˆΩB
χB d(µ X−1
)=
ˆΩD
χB X dµ .
Nun ist jedochˆ
ΩB
χB d(µ X−1
)=(µ X−1
)(B) = µ
(X−1(B)
)=
ˆΩD
χX−1(B) dµ =
ˆΩD
χBX dµ .
Korollar 3.19 (Erwartungswert und Verteilung)Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum, g : R → R eine Borel-messbare Funktionund X : Ω→ R eine Zufallsvariable. Dann gilt
g ∈ L1(PX) ⇐⇒ g X ∈ L1(P)
und im Fall der Integrierbarkeit ist
E g(X) =
ˆΩg (X(ω)) dP(ω) =
ˆR
g(x) dPX(x) .
Beweis. Die Aussage ist eine unmittelbare Folgerung aus Satz 3.18.
Bemerkung.
B Ist P eine Verteilung mit´R|x|dP (x) <∞ , so nennen wir P integrierbar und
EP :=
ˆR
x dP (x)
Erwartungswert der Verteilung P .

3. Integration und Erwartungswert 123
B Ist (X1, . . . , Xn) ein Zufallsvektor, so gilt für eine Borel-Funktion g : Rn → R , dass
g(X1, . . . , Xn) ∈ L1(P) ⇐⇒ g ∈ L1(P(X1,...,Xn)
)
und im Fall der Integrierbarkeit ist
Eg(X1, . . . , Xn) =
ˆRng(x1, . . . , xn) dP(X1,...,Xn)(x1, . . . , xn) .
Lemma 3.20 (Gleiche Verteilungen ⇒ gleiche Erwartungswerte)Es seien (Ω1,F1,P1) und (Ω2,F2,P2) Wahrscheinlichkeitsräume sowie X ∈ L1(P1) undY ∈ L1(P2) . Dann gilt
PX = PY =⇒ EP1X = EP2Y ,
wobei EP1X =´
Ω1X dP1 und EP2Y =
´Ω2Y dP2 .
Beweis. Es gelte PX = PY . Dann ist
EP1X =
ˆΩ1
X(ω1) dP1(ω1) =
ˆR
x dPX(x) =
=
ˆR
x dPY (x) =
ˆΩ2
Y (ω2) dP2(ω2) = EP2Y .
Definition 3.21 (Dichte einer Verteilung bezüglich λ)Es sei P eine Verteilung mit Verteilungsfunktion FP . Eine Lebesgue-integrierbare Funk-tion f : R→ [0,∞) mit
FP (x) =
ˆ(−∞,x]
f(t) dλ(t) für alle x ∈ R
heiÿt Dichte von FP bzw. Dichte der Verteilung P bezüglich λ .
Bemerkung. Eine Lebesgue-integrierbare Funktion f : R → [0,∞) ist genau dannDichte der Verteilung P bezüglich des Lebesgue-Maÿes , wenn
P (B) =
ˆBf(t) dλ(t) für alle B ∈ B(R) .
Beispiel 3.22 Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum und X : Ω → R eine Zu-fallsvariable. Weiters sei fX : R → [0,∞) Dichte von PX bezüglich λ und g : R → R
Borel-messbar. Ist gfX ∈ L1(λ) , so gilt
Eg(X) =
ˆR
g(t)fX(t) dλ(t) .

124 3. Integration und Erwartungswert
Beispiel 3.23 (Erwartungswerte kontinuierlicher Verteilungen)In nachfolgender Tabelle sind die Erwartungswerte einiger kontinuierlicher Verteilungenaufgelistet.
P EP Verteilung
U[a,b]a+b
2 Gleichverteilung auf [a, b]
µλ1λ Exponentialverteilung
Nµ,σ2 µ Normalverteilung
Wir bestimmen den Erwartungswert der Exponentialverteilung mit Parameter λ > 0 .Es ist
Eµλ =
ˆR
x dµλ(x) =
ˆ ∞−∞
tf(t ;µλ) dt =
=
ˆ ∞0
tλe−λt dt =[partielle Integration
]= 1
λ .
3.4 Klassische Sätze der Integrationstheorie
In diesem Abschnitt widmen wir uns einigen grundlegenden Sätzen der Integrationstheo-rie. Es bezeichne (Ω,F , µ) stets einen Maÿraum.
Satz 3.24 (Lemma von Fatou2)Es sei X ∈ L1(µ) und
Xn : Ω→ R
∞n=1
eine Folge messbarer Funktionen mit |Xn| ≤ Xfast überall für alle n ∈ N . Dann sind lim supn→∞Xn und lim infn→∞Xn integrierbarund ˆ
lim infn→∞
Xn dµ ≤ lim infn→∞
ˆXn dµ ≤ lim sup
n→∞
ˆXn dµ ≤
ˆlim supn→∞
Xn dµ .
Beweis. Wir zeigen lediglich die erste Ungleichung, denn die zweite folgt direkt aus derDenition des Limes superior und des Limes inferior und die dritte lässt sich analog zurersten beweisen. Für k ∈ N setzen wir
Yk := infn≥k
Xn .
Dann gilt Yk ↑ lim infn→∞Xn ,
|Yk| ≤ X fast überall für k ∈ N und∣∣∣lim infn→∞
Xn
∣∣∣ ≤ X fast überall.
2Pierre Fatou, 18781929, französischer Mathematiker

3. Integration und Erwartungswert 125
Daher folgt aus dem Satz von der monotonen Konvergenzˆ
lim infn→∞
Xn dµ = limk→∞
ˆYk dµ = lim
k→∞
ˆinfn≥k
Xn dµ ≤
≤ limk→∞
infn≥k
ˆXn dµ = lim inf
n→∞
ˆXn dµ .
Satz 3.25 (Satz von der majorisierten Konvergenz, Lebesgue)Es sei X : Ω→ R messbar und
Xn : Ω→ R
∞n=1
eine Folge messbarer Funktionen mitlimn→∞Xn = X fast überall . Weiters sei Y ∈ L1(µ) mit |Xn| ≤ Y fast überall für allen ∈ N . Dann ist X ∈ L1(µ) und
limn→∞
ˆXn dµ =
ˆX dµ .
Beweis. Nach dem Lemma von Fatou istˆX dµ =
ˆlim infn→∞
Xn dµ ≤ lim infn→∞
ˆXn dµ ≤
≤ lim supn→∞
ˆXn dµ ≤
ˆlim supn→∞
Xn dµ =
ˆX dµ .
Als Anwendung des obigen Satzes betrachten wir nun parameterabhängige Integrale. Esbezeichne λ das Lebesgue-Maÿ auf B(Rd) .
Satz 3.26 (Parameterintegrale)Es sei D ⊂ Rm und f : Rd ×D → R eine Funktion mit
∀ y ∈ D : [x 7→ f(x, y)] ∈ L1(λ) .
Wir betrachten die Abbildung
F : D → R : y 7→ˆRdf(x, y) dλ(x) .
(1) Für y0 ∈ D gelte:
(i) Die Funktion [y 7→ f(x, y)] ist stetig in y0 für fast alle x ∈ Rd .(ii) ∃ g ∈ L1(λ) ∀ y ∈ D : |f(·, y)| ≤ g f. ü.Dann ist F stetig in y0 .
(2) Es sei D eine Umgebung von y0 ∈ D und für j ∈ 1, . . . ,m gelte:(i) Die Funktion [y 7→ f(x, y)] ist für fast alle x ∈ Rd in y0 partiell nach yj
dierenzierbar.

126 3. Integration und Erwartungswert
(ii) ∃ g ∈ L1(λ) ∀ y ∈ D :∣∣(∂yjf)(·, y)
∣∣ ≤ g f. ü.Dann ist F in y0 nach yj partiell dierenzierbar und
(∂yjF )(y0) =
ˆRd
(∂yj )f(x, y0) dλ(x) ,
wobei wir für jene x ∈ Rd , in denen [y 7→ f(x, y)] in y0 nicht partiell nach yjdierenzierbar ist, (∂yjf)(x, y0) := 0 setzen.
Beweis. (1) Es sei yn∞n=1 ∈ DN eine Folge mit limn→∞ yn = y0 . Für n ∈ N und x ∈ Rdsetzen wir Xn(x) := f(x, yn) . Dann ist für alle n ∈ N nach Voraussetzung Xn ∈ L1(λ) .Es sei N ⊂ Rd eine Lebesgue-Nullmenge, sodass [y 7→ f(x, y)] für alle x ∈ Rd \N stetigin y0 ist. Setze
X := f(·, y0)χN c .
Dann ist limn→∞Xn = X fast überall und
∀n ∈ N : |Xn| ≤ g f. ü.
Daher folgt aus dem Satz von der majorisierten Konvergenz
limn→∞
F (yn) = limn→∞
ˆRdf(x, yn) dλ(x) = lim
n→∞
ˆRdXn dλ =
ˆRdX dλ = F (y0) .
(2) Es bezeichne ej ∈ Rm den j-ten Standardbasisvektor und N ⊂ Rd eine Lebesgue-Nullmenge, sodass [y 7→ f(x, y)] für alle x ∈ Rd \N in y0 partiell nach yj dierenzierbarist. Weiters sei hn∞n=1 ∈ RN eine Nullfolge mit y0 + hnej ∈ D und hn > 0 für allen ∈ N . Setze
Xn :=f(·, y0 + hnej)− f(·, y0)
hnχN c und X := (∂yjf)(·, y0)χN c .
Dann ist limn→∞Xn = X und für n ∈ N sowie x ∈ N c folgt aus dem Mittelwertsatz
|Xn(x)| =∣∣(∂yj )f(x, y0 + ϑej)
∣∣ ≤ g(x) ,
wobei ϑ ∈ (0, hn) . Daher erhalten wir nach dem Satz von der majorisierten Kon-vergenz
ˆRd
(∂yjf)(x, y0) dλ(x) =
ˆRdX dλ = lim
n→∞
ˆRdXn dλ =
= limn→∞
F (y0 + hnej)− F (y0)
hn= (∂yjF )(y0) .

3. Integration und Erwartungswert 127
Beispiel 3.27 (Gauÿ-Integral)Wir zeigen ˆ ∞
−∞e−x
2dx =
√π .
Dazu betrachten wir die Funktionen
f : [0, 1]× [0,∞)→ R : (x, t) 7→ e−(1+x2)t2
1 + x2
und
F : [0,∞)→ R : t 7→ˆ 1
0f(x, t) dx .
Wie man mittels Satz 3.26 leicht nachprüft, ist F stetig auf [0,∞) und dierenzierbarauf (0,∞) . Auÿerdem gilt
F ′(t) =
ˆ 1
0∂tf(x, t) dx = −2t
ˆ 1
0e−(1+x2)t2 dx =
[z = tx, dz = t dx
]=
= −2e−t2
ˆ t
0e−z
2dz .
Des Weiteren ist ˆ t
0F ′(τ) dτ = F (t)− F (0) = F (t)− π
4
undˆ t
0F ′(τ) dτ =
ˆ t
0
(−2e−τ
2
ˆ τ
0e−z
2dz
)dτ = −
(ˆ t
0e−z
2dz
)2
.
Damit erhalten wir
π
4− F (t) =
(ˆ t
0e−z
2dz
)2
und da limt→∞ F (t) = 0 , ist schlieÿlichˆ ∞
0e−z
2dz =
√π
2.
Aus der Tatsache, dass die Funktion[z 7→ e−z
2]gerade ist, ergibt sich das gewünschte
Resultat ˆ ∞−∞
e−z2
dz =√π .

128 3. Integration und Erwartungswert
Wir werden nun zeigen, dass sich unter entsprechenden Voraussetzungen Integrale be-züglich Produktmaÿen als iterierte Integrale schreiben lassen. Dazu benötigen wir jedochetwas Vorarbeit.
Definition 3.28 (Monotone Klasse)Ein MengensystemM⊂ P(Ω) heiÿt monotone Klasse auf Ω , wenn für jede monotoneFolge An∞n=1 ∈MN mit An ↑ A oder An ↓ A gilt, dass A ∈M .
Bemerkung.
B Jede σ-Algebra ist eine monotone Klasse.
B Der Durchschnitt monotoner Klassen ist wieder eine monotone Klasse. Wir bezeich-nen mit M(G) die kleinste monotone Klasse, welche das Mengensystem G ⊂ P(Ω)enthält.
Satz 3.29 (Satz über monotone Klassen)Es sei A ⊂ P(Ω) eine Algebra auf Ω . Dann ist M(A) = σ(A) .
Beweis. Wir zeigen zuerst, dassM := M(A) eine Algebra ist.
(1) Oensichtlich ist Ω ∈M .
(2) Komplementstabilität: Wir zeigen, dass
Mc := A ∈M : Ac ∈M
eine monotone Klasse ist. Es sei An∞n=1 ∈ (Mc)N mit An ↑ A . Da A ∈ M undAcn ↓ Ac , folgt Ac ∈M . Im Fall, dass An ↓ A , erhält man analog Ac ∈M , also istMc eine monotone Klasse. Nun folgt aus A ⊂Mc ⊂M die KomplementstabilitätvonM .
(3) ∩-Stabilität: Für A ∈M setzen wir
MA := B ∈M : A ∩B ∈M .
Oensichtlich istMA eine monotone Klasse. Es sei nun A ∈ A . Da es sich bei Aum eine Algebra handelt, gilt A ⊂ MA ⊂ M und somit MA = M . Für B ∈ Mist
A ∈MB ⇐⇒ B ∈MA =M
und daher A ⊂MB . Folglich gilt für jedes B ∈M , dassMB =M und dies zeigtdie ∩-Stabilität vonM .

3. Integration und Erwartungswert 129
Also ist die monotone Klasse M eine Algebra, wir zeigen, dass M dann bereits eineσ-Algebra ist. Für Ai∞i=1 ∈MN und n ∈ N setzen wir Bn :=
⋃ni=1Ai ∈M . Dann gilt
Bn ↑∞⋃
i=1
Ai
und somit⋃∞i=1Ai ∈M . Folglich istM eine σ-Algebra. Da eine σ-Algebra insbesondere
eine monotone Klasse ist, gilt A ⊂M(A) ⊂ σ(A) , womit die Aussage gezeigt ist.
Satz 3.30 (Satz von Fubini3-Tonelli4)Gegeben seien die σ-endlichen Maÿräume (Ω1,F1, µ1) und (Ω2,F2, µ2) sowie
X ∈ L+(Ω1 × Ω2,F1 ⊗F2) .
Dann gilt[ω1 7→
ˆΩ2
X(ω1, ω2) dµ2(ω2)
]∈ L+(Ω1,F1) ,
[ω2 7→
ˆΩ1
X(ω1, ω2) dµ1(ω1)
]∈ L+(Ω2,F2)
undˆ
Ω1×Ω2
X(ω1, ω2) d(µ1 ⊗ µ2)(ω1, ω2) =
ˆΩ1
(ˆΩ2
X(ω1, ω2) dµ2(ω2)
)dµ1(ω1) =
=
ˆΩ2
(ˆΩ1
X(ω1, ω2) dµ1(ω1)
)dµ2(ω2) .
Beweis. Schritt 1: Als erstes zeigen wir für festes ω1 ∈ Ω1, dass die Abbildung
Xω1 : Ω2 → [0,∞] : ω2 7→ X(ω1, ω2)
messbar bezüglich F2 ist. Da jede nicht-negative messbare Funktion der Grenzwert ein-facher Funktionen ist, genügt es die Aussage für X = χA mit A ∈ F1 ⊗ F2 zu zeigen.Dazu genügt es zu zeigen, dass
Aω1 := ω2 ∈ Ω2 : (ω1, ω2) ∈ A
für jedes A ∈ F1 ⊗F2 in F2 liegt. Hierfür betrachten wir die Menge
Fω1 := A ∈ F1 ⊗F2 : Aω1 ∈ F2 .3Guido Fubini, 18791943, italienischer Mathematiker4Leonida Tonelli, 18851946, italienischer Mathematiker

130 3. Integration und Erwartungswert
und zeigen Fω1 = F1 ⊗F2 . Beachte, dass A1 ×A2 ∈ Fω1 für alle A1 ∈ F1 und A2 ∈ F2 .Auÿerdem ist Fω1 eine σ-Algebra und daher folgt Fω1 = F1 ⊗F2 .
Schritt 2: Wir zeigen, dass die Abbildung
Ω1 → [0,∞] : ω1 7→ˆ
Ω2
Xω1(ω2) dµ2(ω2)
messbar bezüglich F1 ist. Da jede nicht-negative messbare Funktion der monotone Grenz-wert einfacher Funktionen ist, genügt es aufgrund der monotonen Konvergenz desIntegrals auf L+ die Aussage für X = χA mit A ∈ F1 ⊗ F2 zu zeigen. Dazu betrachtenwir die Menge
M :=
A ∈ F1 ⊗F2 :
[ω1 7→
ˆΩ2
χA(ω1, ω2) dµ2(ω2)
]ist messbar bezüglich F1
und zeigen, dassM = F1 ⊗F2 . Für A1 ∈ F1 und A2 ∈ F2 giltˆ
Ω2
χA1×A2(ω1, ω2) dµ2(ω2) = χA1(ω1)
ˆΩ2
χA2(ω2) dµ2(ω2) .
Daher enthältM die Algebra
A :=
n⊎
k=1
(A
(k)1 ×A
(k)2
): n ∈ N,
(A
(k)1 , A
(k)2
)nk=1∈ (F1 ×F2)n pw. disj.
.
Aus der monotonen Konvergenz des Integrals folgt auÿerdem, dass es sich bei Mum eine monotone Klasse handelt. Nach dem Satz über monotone Klassen gilt
F1 ⊗F2 = σ(A) = M(A) ⊂M ⊂ F1 ⊗F2
und daher istM = F1 ⊗F2 .
Schritt 3: Im letzten Schritt zeigen wir, dassˆ
Ω1×Ω2
X(ω1, ω2) d(µ1 ⊗ µ2)(ω1, ω2) =
ˆΩ1
(ˆΩ2
X(ω1, ω2) dµ2(ω2)
)dµ1(ω1) .
Aufgrund der monotonen Konvergenz des Integrals auf L+ genügt es wiederum dieAussage für X = χA mit A ∈ F1 ⊗ F2 zu zeigen. Dazu denieren wir die Mengenfunk-tionen µ und µ durch
µ(A) :=
ˆΩ1×Ω2
χA(ω1, ω2) d(µ1 ⊗ µ2)(ω1, ω2) ,
µ(A) :=
ˆΩ1
(ˆΩ2
χA(ω1, ω2) dµ2(ω2)
)dµ1(ω1)

3. Integration und Erwartungswert 131
für A ∈ F1⊗F2 . Oenbar handelt es sich bei µ und µ um σ-endliche Maÿe auf F1⊗F2 .Für das π-System
P := A1 ×A2 : A1 ∈ F1, A2 ∈ F2
gilt σ(P) = F1 ⊗ F2 und µ|P = µ|P . Nach Satz 1.49 ist daher µ = µ und damit dieAussage des Satzes gezeigt.
Beispiel 3.31 (Dichte eines Zufallsvektors und Unabhängigkeit)Es sei n ∈ N . Weiters seien X1, . . . , Xn : Ω → R Zufallsvariablen auf dem Wahrschein-lichkeitsraum (Ω,F ,P) . Eine Lebesgue-integrierbare Funktion f(X1,...,Xn) : Rn → [0,∞)mit
F(X1,...,Xn)(x) =
ˆ(−∞,x1]×...×(−∞,xn]
f(X1,...,Xn)(t1, . . . , tn) dλn(t1, . . . , tn)
für alle x ∈ Rn nennt man Dichte des n-dimensionalen Zufallsvektors (X1, . . . , Xn)bezüglich des Lebesgue-Maÿes. Nach dem Satz von Fubini-Tonelli ist
F(X1,...,Xn)(x) =
ˆ(−∞,x1]
. . .
ˆ(−∞,xn]
f(X1,...,Xd)(t1, . . . , tn) dλ(tn) . . . dλ(t1) .
Ist die Dichte f(X1,...,Xn) stetig und haben auch X1, . . . , Xn stetige Dichten fX1 , . . . , fXnbezüglich des Lebesgue-Maÿes, so sind X1, . . . , Xn nach Satz 2.30 und dem Hauptsatzder Integral- und Differentialrechnung genau dann unabhängig, wenn
f(X1,...,Xn)(x) =
n∏
i=1
fXi(xi) für all x ∈ Rn .
Beispiel 3.32 (Mehrdimensionale Normalverteilung)Es sei n ∈ N , µ ∈ Rn und Σ ∈ Rn×n eine positiv denite und symmetrische Matrix.Besitzt der Zufallsvektor X = (X1, . . . , Xn) die Dichte
fX(t) = det(2πΣ)−1/2 exp(−1
2(t− µ)TΣ−1(t− µ)), t ∈ Rn ,
so ist PX =: Nµ,Σ die n-dimensionale Normalverteilung mit Erwartungswert µ undKovarianz Σ .
Satz 3.33 (Satz von Fubini)Die Maÿräume (Ω1,F1, µ1) und (Ω2,F2, µ2) seien σ-endlich und
X ∈ L1(Ω1 × Ω2,F1 ⊗F2, µ1 ⊗ µ2) .
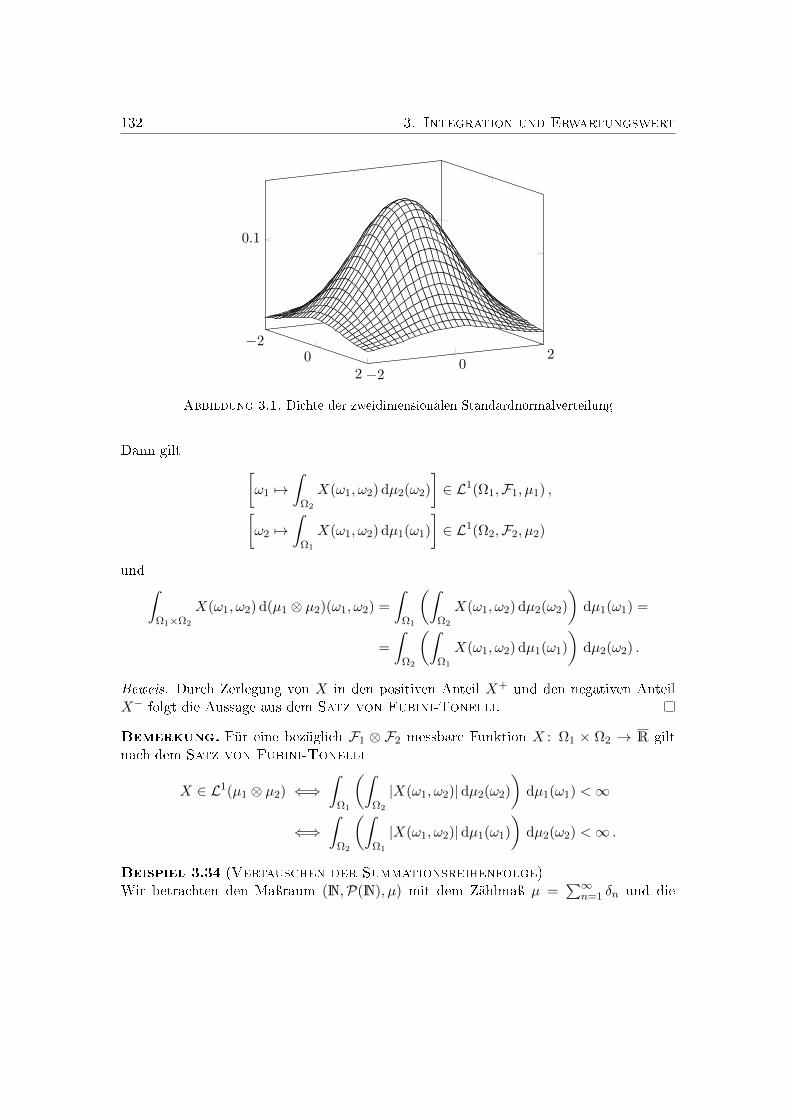
132 3. Integration und Erwartungswert
−20
2 −20
2
0.1
Abbildung 3.1. Dichte der zweidimensionalen Standardnormalverteilung
Dann gilt[ω1 7→
ˆΩ2
X(ω1, ω2) dµ2(ω2)
]∈ L1(Ω1,F1, µ1) ,
[ω2 7→
ˆΩ1
X(ω1, ω2) dµ1(ω1)
]∈ L1(Ω2,F2, µ2)
undˆ
Ω1×Ω2
X(ω1, ω2) d(µ1 ⊗ µ2)(ω1, ω2) =
ˆΩ1
(ˆΩ2
X(ω1, ω2) dµ2(ω2)
)dµ1(ω1) =
=
ˆΩ2
(ˆΩ1
X(ω1, ω2) dµ1(ω1)
)dµ2(ω2) .
Beweis. Durch Zerlegung von X in den positiven Anteil X+ und den negativen AnteilX− folgt die Aussage aus dem Satz von Fubini-Tonelli.
Bemerkung. Für eine bezüglich F1 ⊗ F2 messbare Funktion X : Ω1 × Ω2 → R giltnach dem Satz von Fubini-Tonelli
X ∈ L1(µ1 ⊗ µ2) ⇐⇒ˆ
Ω1
(ˆΩ2
|X(ω1, ω2)| dµ2(ω2)
)dµ1(ω1) <∞
⇐⇒ˆ
Ω2
(ˆΩ1
|X(ω1, ω2)| dµ1(ω1)
)dµ2(ω2) <∞ .
Beispiel 3.34 (Vertauschen der Summationsreihenfolge)Wir betrachten den Maÿraum (N,P(N), µ) mit dem Zählmaÿ µ =
∑∞n=1 δn und die

3. Integration und Erwartungswert 133
Abbildung
X : N×N→ R .
Ist X ≥ 0 , so gilt nach dem Satz von Fubini-Tonelli
∞∑
m=1
∞∑
n=1
X(m,n) =
ˆN
(ˆN
X(m,n) dµ(m)
)dµ(n) =
=
ˆN
(ˆN
X(m,n) dµ(n)
)dµ(m) =
∞∑
n=1
∞∑
m=1
X(m,n) .
Obige Gleichheit gilt nach dem Satz von Fubini auch für X : N×N→ R mit
∞∑
m=1
∞∑
n=1
|X(m,n)| <∞ bzw.∞∑
n=1
∞∑
m=1
|X(m,n)| <∞ ,
also für X ∈ L1(µ⊗2) .
3.5 Ungleichungen
In diesem Abschnitt werden einige grundlegende Ungleichungen mit weitreichenden Kon-sequenzen vorgestellt.
Definition 3.35 (Konvexe und konkave Funktionen)Eine Funktion f : R→ R heiÿt konvex, wenn
∀λ ∈ [0, 1]∀x, y ∈ R : f (λx+ (1− λ)y) ≤ λf(x) + (1− λ)f(y) .
Man nennt f konkav, falls −f konvex ist.
Bemerkung. Konvexe und konkave Funktionen sind stetig und somit insbesondereBorel-messbar.
Satz 3.36 (Jensen5-Ungleichung)Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum, f : R→ R konvex und X ∈ L1(P) . Danngilt
f(EX) ≤ Ef(X) .
Beweis. Setze x0 = EX und wähle a, b ∈ R mit
ax0 + b = f(x0) und ax+ b ≤ f(x) für alle x ∈ R .Dann ist
f(EX) = aEX + b = E(aX + b) ≤ Ef(X) .
5Johan Ludwig William Valdemar Jensen, 18591925, dänischer Mathematiker

134 3. Integration und Erwartungswert
Beispiel 3.37 Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum und X ∈ L1(P) .
B Da x 7→ |x| konvex ist, erhalten wir aus der Jensen-Ungleichung die Dreiecks-ungleichung
|EX| ≤ E|X| .
B Für p ∈ [1,∞) ist x 7→ |x|p konvex und folglich liefert die Jensen-Ungleichung
(E|X|)p ≤ E|X|p .
Im Weiteren bezeichne (Ω,F , µ) einen Maÿraum. Für p ∈ [1,∞) setzen wir
Lp(Ω,F , µ) := Lp(µ) :=
X : Ω→ R messbar :
ˆ|X|p dµ <∞
und
‖X‖p :=
(ˆ|X|p dµ
)1/p
für X ∈ Lp(µ) .
Im Speziellen nennt man eine Funktion X ∈ L2(µ) quadratisch integrierbar.
Bemerkung. Für p ∈ [1,∞) ist ‖ · ‖p keine Norm auf Lp(µ) , sondern nur eine Halb-norm, d. h.
(i) ∀X ∈ Lp(µ)∀λ ∈ R : ‖λX‖p = |λ|‖X‖p , (Absolute Homogenität)
(ii) ∀X,Y ∈ Lp(µ) : ‖X + Y ‖p ≤ ‖X‖p + ‖Y ‖p . (Dreiecksungleichung)
Satz 3.38 (Hölder6-Ungleichung)Es seien p, q ∈ (1,∞) mit 1
p + 1q = 1 sowie X ∈ Lp(µ) und Y ∈ Lq(µ) . Dann ist
XY ∈ L1(µ) und
‖XY ‖1 ≤ ‖X‖p‖Y ‖q .
Beweis. Aus ‖X‖p = 0 oder ‖Y ‖q = 0 , folgt XY = 0 fast überall und daher ‖XY ‖1 = 0 .Daher können wir annehmen, dass ‖X‖p > 0 und ‖Y ‖q > 0 . Nun setzen wir
X =X
‖X‖pund Y =
Y
‖Y ‖q.
6Otto Hölder, 18591937, deutscher Mathematiker

3. Integration und Erwartungswert 135
Es seien x, y > 0 und a, b > 0 mit a+ b = 1. Da der Logarithmus eine konkave Funktionist, erhalten wir
log(ax+ by) ≥ a log x+ b log y = log(xayb
).
Folglich gilt
xayb ≤ ax+ by
für alle x, y ≥ 0 und a, b > 0 mit a+ b = 1 . Nun setzen wir x =∣∣X∣∣p , y =
∣∣Y∣∣q , a = 1
p
und b = 1q und erhalten
∥∥XY∥∥
1≤ 1
p + 1q = 1 .
Da∥∥XY
∥∥1
=‖XY ‖1‖X‖p‖Y ‖q
,
ist damit die Aussage gezeigt.
Korollar 3.39 Ist µ endlich, so gilt Lp1(µ) ⊂ Lp2(µ) für p1 ≥ p2 ≥ 1 .
Beweis. Aufgabe (3.24).
Korollar 3.40 (Cauchy7-Schwarz8-Ungleichung)Sind X,Y ∈ L2(µ) , so ist XY ∈ L1(µ) und
‖XY ‖1 ≤ ‖X‖2‖Y ‖2 .Beweis. Dies ist gerade die Hölder-Ungleichung für p = q = 2 .
Wir zeigen nun für ‖ · ‖p die Dreiecksungleichung, wobei p ∈ [1,∞) .
Satz 3.41 (Minkowski9-Ungleichung)Es sei p ∈ [1,∞) und X,Y ∈ Lp(µ) . Dann ist X + Y ∈ Lp(µ) und
‖X + Y ‖p ≤ ‖X‖p + ‖Y ‖p .Beweis. Für p = 1 ist die Aussage klar, wir betrachten den Fall p ∈ (1,∞) . Dann erhaltenwir für q ∈ (1,∞) mit 1
p + 1q = 1 durch Anwendung der Hölder-Ungleichung
‖X + Y ‖pp =
ˆΩ|X + Y |︸ ︷︷ ︸≤|X|+|Y |
|X + Y |p−1 dµ ≤∥∥X|X + Y |p−1
∥∥1
+∥∥Y |X + Y |p−1
∥∥1≤
≤ (‖X‖p + ‖Y ‖p)∥∥|X + Y |p−1
∥∥q
= (‖X‖p + ‖Y ‖p) ‖X + Y ‖p−1p
und damit die Aussage.7Augustin-Louis Cauchy, 17891857, französischer Mathematiker8Karl Hermann Amandus Schwarz, 18431921, deutscher Mathematiker9Hermann Minkowski, 18641909, deutscher Mathematiker

136 3. Integration und Erwartungswert
3.6 Erwartungswert und Varianz
Es sei X : Ω → R eine Zufallsvariable auf dem Wahrscheinlichkeitsraum (Ω,F ,P) . IstX+ ∈ L1(P) und/oder X− ∈ L1(P) , so heiÿt
EX :=
ˆX dP =
ˆX+ dP−
ˆX− dP
Erwartungswert von X . Dann ist EX ∈ [−∞,∞] und wir sagen, dass der Erwar-tungswert von X existiert .
Bemerkung. Natürlich übertragen sich sämtliche Eigenschaften und Sätze, welche wirfür das Integral kennengelernt haben, auf den Erwartungswert.
Definition 3.42 (Varianz und Standardabweichung)Es sei X ∈ L1(P) . Man nennt
Var(X) := E(X − EX)2
Varianz von X und σX :=√
Var(X) Standardabweichung von X .
Bemerkung.
B Für X,Y ∈ L1(P) gilt im Allgemeinen nicht Var(X + Y ) = Var(X) + Var(Y ) .
B Ist X ∈ L1(P) und α ∈ R , so gilt Var(αX) = α2 Var(X) .
Eine erste Interpretation der Varianz liefert folgende Ungleichung.
Lemma 3.43 (Tschebyschow10-Ungleichung)Es sei X ∈ L1(P) . Dann gilt
P (|X − EX| ≥ ε) ≤ Var(X)
ε2für alle ε > 0 .
Beweis. Wir setzen Y := |X − EX| und erhalten
Var(X) = EY 2 ≥ EY 2χY 2≥ε2 ≥ ε2EχY 2≥ε2 = ε2P(Y 2 ≥ ε2) = ε2P(Y ≥ ε) .
Für die Varianz erhalten wir folgende Formel.
Lemma 3.44 (Steinersche11 Formel, Verschiebungssatz)Für X ∈ L1(P) gilt
Var(X) = EX2 − (EX)2 .
10Pafnuti Lwowitsch Tschebyschow, 18211894, russischer Mathematiker11Jakob Steiner, 17961863, schweizer Mathematiker

3. Integration und Erwartungswert 137
Beweis. Es ist
Var(X) = E(X − EX)2 = EX2 − 2E(XEX) + (EX)2 = EX2 − (EX)2 .
Bemerkung. Nach obigem Lemma is
Var(X) <∞ ⇐⇒ X ∈ L2(P) .
Definition 3.45 (Momente)Es sei X : Ω→ R messbar, P eine Verteilung und n ∈ N .
(1) E|X|n heiÿt n-tes absolutes Moment von X .
(2) Im Falle der Existenz heiÿt EXn das n-te Moment von X .
(3) Man nenntˆR
|x|n dP (x)
n-tes absolutes Moment der Verteilung P .
(4) Entsprechend heiÿtˆR
xn dP (x)
das n-te Moment der Verteilung P , sofern dieses existiert.
Der Erwartungswert einer Verteilung ist also gerade ihr erstes Moment. Die Varianz einerVerteilung steht mit dem zweiten Moment in Zusammenhang.
Es sei X ∈ L1(P) mit Verteilung PX . Dann ist die Varianz von X durch
Var(X) =
ˆR
(x− EX)2 dPX(x)
gegeben. Für eine integrierbare Verteilung P setzt man entsprechend
Var(P ) :=
ˆR
(x− EP )2 dP (x)
und nennt Var(P ) Varianz der Verteilung P . Entsprechend der Steinerschen For-mel ist
Var(P ) =
ˆR
x2 dP (x)− (EP )2 .

138 3. Integration und Erwartungswert
Beispiel 3.46 (Varianzen bekannter Verteilungen)In nachfolgender Tabelle sind die Varianzen einiger bekannter Verteilungen aufgelistet.
P Var(P ) Verteilung
Bn,p np(1− p) Binomialverteilung
Hn,N,G nGNN−GN
N−nN−1 Hypergeometrische Verteilung
πλ λ Poisson-Verteilung
gp1p2− 1
p Geometrische Verteilung
U[a,b](b−a)2
12 Gleichverteilung auf [a, b]
µλ1λ2
Exponentialverteilung
Nµ,σ2 σ2 Normalverteilung
Als Beispiel berechnen wir für λ > 0 die Varianz der Exponentialverteilung. Da Eµλ = 1λ ,
ist
Var(µλ) =
ˆR
x2 dµλ(x)− 1
λ2=
ˆ ∞0
t2λe−λt dt− 1
λ2=[partielle Integration
]=
1
λ2.
Definition 3.47 (Kovarianz und Korrelation)Es seien X,Y ∈ L2(P) .
(1) Man nennt
Cov(X,Y ) := E [(X − EX)(Y − EY )]
Kovarianz von X und Y .
(2) Die Zufallsvariablen X und Y heiÿen unkorreliert, falls Cov(X,Y ) = 0 , andern-falls korreliert.
Bemerkung. SindX,Y ∈ L2(P) , so folgt aus derCauchy-Schwarz-Ungleichung,dass X, Y und XY integrierbar sind und da
Cov(X,Y ) = EXY − EXEY ,
ist die Denition der Kovarianz sinnvoll. Auÿerdem folgt aus dieser Darstellung der Ko-varianz, dass
X und Y unkorreliert ⇐⇒ EXY = EXEY .

3. Integration und Erwartungswert 139
Lemma 3.48 (unabhängig ⇒ unkorreliert)Es seien X,Y ∈ L2(P) unabhängige Zufallsvariablen. Dann sind X und Y unkorreliert.
Beweis. Variante 1: Aus der Cauchy-Schwarz-Ungleichung folgt XY ∈ L1(P) .Daher erhalten wir durch Anwendung des Satzes von Fubini
EXY =
ˆΩX(ω)Y (ω) dP(ω) =
ˆR2
xy dP(X,Y )(x, y) =
ˆR2
xy d(PX ⊗ PY )(x, y) =
=
(ˆR
x dPX(x)
)(ˆR
y dPY (y)
)= EXEY .
Variante 2: (1) Wir betrachten zuerst den Fall, dass X,Y ∈ E+ . Sei also
X =
n∑
i=1
αiχAi und Y =
m∑
j=1
βjχBj .
Dann ist
EXY =∑
i,j
αiβjP(Ai ∩Bj) =[Ai und Bj unabhängig
]=
=∑
i,j
αiβjP(Ai)P(Bj) = EXEY .
(2) Es seien nun X,Y ∈ L+ . Wähle Folgen Xn∞n=1 ∈ EN+ und Yn∞n=1 ∈ EN+ mitXn ↑ X und Yn ↑ Y und erhalte
EXY = E limn→∞
XnYn = limn→∞
EXnYn = limn→∞
EXnEYn = EXEY .
(3) Im letzten Schritt seien nun X,Y ∈ L2(P) . Dann ist XY ∈ L1(P) und aus derUnabhängigkeit von X und Y folgt, dass X+ und X− unabhängig von Y + und Y − sind.Daher gilt
EXY = E(X+ −X−)(Y + − Y −) =
= EX+EY + − EX−EY + − EX+EY − + EX−EY − = EXEY .
Beachte, dass unkorrelierte Zufallsvariablen im Allgemeinen nicht unabhängig sind, vgl.Aufgabe (3.25).
Lemma 3.49 Es seien X,Y ∈ L2(P) . Dann gilt
Var(X + Y ) = Var(X) + Var(Y ) ⇐⇒ X und Y unkorreliert .
Beweis. Aus der Darstellung
Var(X + Y ) = E [(X − EX) + (Y − EY )]2 =
= E(X − EX)2 + E(Y − EY )2 + 2E(X − EX)(Y − EY ) =
= Var(X) + Var(Y ) + 2 Cov(X,Y )
erhält man unmittelbar die Aussage.

140 3. Integration und Erwartungswert
3.7 Gesetze der groÿen Zahlen und zentraler Grenz-
wertsatz
Die beiden nachfolgenden Sätze geben Anlass zur Interpretation des Erwartungswertesals Mittelwert. Es bezeichne (Ω,F ,P) einen Wahrscheinlichkeitsraum.
Satz 3.50 (Schwaches Gesetz der groÿen Zahlen)Es sei Xn∞n=1 ∈ L2(P)N eine Folge unabhängiger Zufallsvariablen mit
EXn = EX1 und Var(Xn) = Var(X1) für alle n ∈ N .
Dann gilt
1
n
n∑
i=1
XiP−→ EX1 , (Konvergenz in Wahrscheinlichkeit)
d. h.
∀ ε > 0: limn→∞
P
(∣∣∣∣∣1
n
n∑
i=1
Xi − EX1
∣∣∣∣∣ > ε
)= 0 .
Beweis. Setzen wir Y := 1n
∑ni=1Xi − EX1 , so erhalten wir aus der Tschebyschow-
Ungleichung
P(|Y | > ε) ≤ Var(Y )
ε2=
Var(X1)
nε2→ 0
für n→∞ .
Eine stärkere Form der Konvergenz liefert folgender Satz.
Satz 3.51 (Starkes Gesetz der groÿen Zahlen)Für eine u.i.v. Folge Xn∞n=1 ∈ L1(P)N von Zufallsvariablen gilt
1
n
n∑
i=1
Xif. s.−→ EX1 für n→∞ , (fast sichere Konvergenz)
d. h. P(limn→∞
1n
∑ni=1Xi = EX1
)= 1 .
Beweis. Es wird auf [19, S. 391] verwiesen.
Bemerkung.
B Gilt limn→∞1n
∑ni=1Xi = EX1 auf A ∈ F mit P(A) = 1 , so folgt für die Verteilung
der Zufallsvariablen X := limn→∞ χA1n
∑ni=1Xi aus dem starken Gesetz der
groÿen Zahlen PX = δEX1 .

3. Integration und Erwartungswert 141
B Die fast sichere Konvergenz impliziert die Konvergenz in Wahrscheinlichkeit, dieUmkehrung gilt im Allgemeinen jedoch nicht.
Beispiel 3.52 (Monte-Carlo-Simulation)Es sei f : [0, 1] → [0, 1] eine Lebesgue-integrierbare Funktion. Wir wollen nun mit pro-babilistischen Methoden das Integral
´[0,1] f(x) dλ(x) näherungsweise bestimmen. Dazu
seien Xi∞i=1 und Yi∞i=1 voneinander unabhängige Folgen u.i.v. Zufallsvariablen mitPX1 = PY1 = U[0,1] . Setze
Zi := χYi≤f(Xi) für i ∈ N .
Dann ist die Folge Zi∞i=1 ebenfalls u.i.v. und
EZ1 =
ˆ[0,1]
f(x) dλ(x) .
Aus dem starken Gesetz der groÿen Zahlen folgt somit
1
n
n∑
i=1
Zif. s.−→ˆ
[0,1]f(x) dλ(x) .
Man simuliert daher für n ∈ N Realisierungen xi := Xi(ω) und yi := Yi(ω) und berechnetzi := Zi(ω) für i = 1, . . . , n . Dann approximiert man das gesuchte Integral durch
1
n
n∑
i=1
zi ≈ˆ
[0,1]f(x) dλ(x) .
Beispielsweise erhält man für f(x) =√
1− x2 eine Näherung an π/4 , vgl. Abbil-dung 3.2.
0 10
1
Abbildung 3.2. Monte-Carlo-Simulation für f(x) =√
1− x2 , x ∈ [0, 1] .
Der nachfolgende Satz ist unter anderem für die Statistik von zentraler Bedeutung unddaher sei er an dieser Stelle erwähnt.

142 3. Integration und Erwartungswert
Satz 3.53 (Zentraler Grenzwertsatz)Es sei Xn∞n=1 ∈ L2(P)N eine Folge u.i.v. Zufallsvariablen und Z eine standardnormal-verteilte Zufallsvariable. Setzt man µ := EX1 und σ2 := Var(X1) > 0 sowie
Zn :=1√nσ
n∑
i=1
(Xi − µ) für n ∈ N ,
so gilt
ZnD−→ Z (Konvergenz in Verteilung)
für n→∞ , d.h.
limn→∞
FZn(x) = Φ(x) für alle x ∈ R ,
wobei Φ = FZ die Verteilungsfunktion der Standardnormalverteilung bezeichnet.
Beweis. Siehe [19, S. 326].

3. Integration und Erwartungswert 143
Übungsaufgaben
(3.1) Monotonie und Linearität des Integrals auf E+: Beweisen Sie Lemma 3.4.
(3.2) Integration bezüglich Dirac-Maÿen: Gegeben sei das Wahrscheinlichkeits-maÿ
P = 13δ2 + 2
3δ3
auf (R,B(R)) .
(a) Bestimmen Sie den Erwartungswert der Zufallsvariablen X = 4χ2 + 9χ3 .
(b) Berechnen Sie nun den Erwartungswert von
Y : R→ R : ω 7→ ω2 .
(3.3) Erwarteter Würfelgewinn: Gegeben sei der Laplace-Raum (Ω,F ,P) , wobeiΩ = 1, . . . , 62 . Weiters sei
X : Ω→ R : (ω1, ω2) 7→ |ω1 + ω2 − 7| .
Warum ist X ∈ E+ ? Bestimmen Sie EX und interpretieren Sie das Ergebnis.
(3.4) Integration bezüglich des Lebesgue-Maÿes: Es bezeichne λ das Lebesgue-Maÿ auf (R,B(R)) . Berechnen Sie das Integral von
(a) X = 2χ[1,3] + 3χ[−7,−5) + 4χ42
(b) Y =∑n
k=1 kχ[k,k+1) , n ∈ N ,
bezüglich λ .
(3.5) Erwartungswert der Binomialverteilung und hypergeometrischenVerteilung: Berechnen Sie den Erwartungswert der
(a) Binomialverteilung
(b) hypergeometrischen Verteilung
in Analogie zu Beispiel 3.8.
(3.6) Erwartungswert der geometrischen Verteilung: Bestimmen Sie den Er-wartungswert der geometrischen Verteilung, vgl. Beispiel 3.8.
(3.7) Erwartete Gewinne beim Roulette: Berechnen Sie die Erwartungswerte derZufallsvariablen X1, X2, X3 aus Aufgabe (2.13).
(3.8) Erwartungswert bezüglich unterschiedlicher Wahrscheinlichkeits-räume: Berechnen Sie für den Wahrscheinlichkeitsraum

144 3. Integration und Erwartungswert
(a) ([0, 5],B([0, 5]),Pa) mit Pa = U[0,5]
(b) ([0,∞),B([0,∞)),Pb) , wobei Pb = 15δ1 + 1
2δ2 + 310δ3 ,
(c) ([0, 5],B([0, 5]),Pc) mit Pc = 12Pa + 1
2Pb
den Erwartungswert der Zufallsvariablen X = 2χ(2,5] − 3χ[1,3] + 3χ3 .
(3.9) Poisson-verteilte Zufallsvariable: Gegeben sei der Wahrscheinlichkeitsraum([0, 1],B([0, 1]), λ) und die Zufallsvariable
X :=
∞∑
k=0
kχ[ak−1,ak) ,
wobei a−1 = 0 , λ > 0 und
ak =k∑
`=0
λ`
`!e−λ für k ∈ N0 .
Bestimmen Sie PX .
(3.10) Integral bezüglich des Lebesgue-Maÿes: Betrachten Sie den messbarenRaum ([0, 1],B([0, 1])) und die Funktion
X : [0, 1]→ [0,∞] : x 7→
1 , x ∈ [0, 1] \Q ,1x , x ∈ [0, 1] ∩Q ,
wobei hier X(0) =∞ gesetzt wird. Zeigen Sie, dass X messbar ist, und bestimmenSie das Integral von X bezüglich λ .
(3.11) Jahrmarkt: An einem Jahrmarktstand erhält man gegen 1 Euro Einsatz beimWerfen zweier fairer Würfel 10 Euro, falls beide Würfel auf Sechs fallen, und 2Euro, wenn einer der beiden Würfel eine Sechs zeigt.
Es beschreibe X den Reingewinn bei diesem Würfelspiel. Bestimmen Sie den Er-wartungswert und die Varianz von X . Kann der Standbetreiber über lange Sichtmit einem Gewinn rechnen und falls dies der Fall ist, welchen Gewinn macht er imSchnitt pro Spiel?
(3.12) Risiko von Roulette-Strategien: Berechnen Sie die Varianzen der Zufallsva-riablen X1, X2, X3 aus Aufgabe (2.13). Welche Strategie ist am risikoreichsten?
(3.13) Randdichten: Der Zufallsvektor (X,Y ) besitze die für x, y ∈ R durch
f(X,Y )(x, y) =
x+ y , für 0 ≤ x, y ≤ 1 ,
0 , sonst,
gegebene Dichte. Bestimmen Sie F(X,Y ) und die Dichten fX und fY von X und Y ,die sogenannten Randdichten. Sind X und Y unabhängig?

3. Integration und Erwartungswert 145
(3.14) Leibniz-Reihe: Auf dem messbaren Raum (N0,P(N0)) betrachten Sie das Zähl-maÿ µ =
∑∞n=0 δn und die Abbildung
X : N0 → R : n 7→ (−1)n
2n+ 1.
Zeigen Sie, dass X nicht µ-integrierbar ist. Existiert dennoch das Integral von Xbezüglich µ ?
(3.15) Umordnung absolut konvergenter Reihen: Zeigen Sie mit dem Satz vonLebesgue, dass eine absolut konvergente Reihe umgeordnet werden kann. Verwen-den Sie dazu den Maÿraum (N,P(N), µ) mit dem Zählmaÿ µ =
∑∞n=1 δn .
(3.16) Verwenden Sie den Satz von Lebesgue, um
log 2 =
ˆ 1
0
dx
1 + x=
ˆ 1
0
∞∑
k=0
(−x)k dx =
∞∑
k=0
ˆ 1
0(−x)k dx =
∞∑
k=0
(−1)k
k + 1
zu rechtfertigen.
(3.17) Es sei Ω = [0, 1] und Xn(x) = nxn für x ∈ Ω und n ∈ N . Zeigen Sie, dassXn → 0 fast überall bezüglich λ , aber
´[0,1]Xn dλ→ 1 . Warum ist der Satz von
Lebesgue hier nicht anwendbar?
(3.18) Es sei y > 0 . Zeigen Sieˆ ∞
0
dx
x2 + y2=
π
2y.
Verwenden Sie den Satz von Lebesgue, um unter dem Integral zu dierenzierenund schlieÿen Sie damit induktivˆ ∞
0
dx
(x2 + y2)n=
π
2y2n−1· 1 · 3 · . . . · (2n− 3)
2 · 4 · . . . · (2n− 2).
(3.19) Parameterintegral: Gegeben sei der Wahrscheinlichkeitsraum (R,B(R),N0,1)und für t ∈ R die Zufallsvariable
Xt : R→ R : ω 7→ cos
(ω
1 + t2
).
(a) Man zeige, dass Xt für jedes t ∈ R integrierbar ist.
(b) Zeigen Sie, dass die Abbildung
R→ R : t 7→ EXt
stetig ist, und berechnen Sie die Grenzwerte limt→∞EXt und limt→−∞EXt .

146 3. Integration und Erwartungswert
(c) Weisen Sie nach, dass [t 7→ EXt] dierenzierbar auf ganz R ist.
(3.20) Zylindervolumen: Für R > 0 betrachten Sie die Kreisscheibe
BR :=
(x, y) ∈ R2 : x2 + y2 ≤ R2.
(a) Zeigen Sie, dass BR ∈ B(R2) .
(b) Berechnen Sie für h > 0 das Integral von X := hχBR bezüglich λ2 und inter-pretieren Sie das Ergebnis.
Hinweis: Verwenden Sie den Satz von Fubini, um zu zeigen, dass λ2(BR) = R2π .
(3.21) Es seienX eine auf [0, π] und Y eine auf [0, 1] gleichverteilte Zufallsvariable. WeitersseienX und Y unabhängig. Berechnen Sie die Erwartungswerte der ZufallsvariablenX2Y und X cos(XY ) .
(3.22) Fragwürdige Würfelspiele: Es kann zwischen den folgenden zwei Würfelspie-len mit drei fairen Würfeln gewählt werden, wobei der Einsatz jeweils 50 Centbeträgt.
Spiel 1: Das Produkt der Augenzahlen wird in Cents ausbezahlt.
Spiel 2: Man erhält das Fünache der Augensumme in Cents.
Welches Spiel würden Sie spielen?
(3.23) Gegeben sei der Wahrscheinlichkeitsraum (R,B(R), µλ) , λ > 0 , und die Zufallsva-riable X : R→ R : ω 7→ e−γω , γ ∈ R . Bestimmen Sie EX .
(3.24) Beweisen Sie Korollar 3.39.
(3.25) Unkorreliert 6⇒ unabhängig: Gegeben sei der Wahrscheinlichkeitsraum
(Ω,F ,P) = ([0, 1],B([0, 1]), λ)
und die Zufallsvariablen
X = χ[0,
12
] und Y = χ[14 ,
12
] + 2χ[78 ,1] .
(a) Zeigen Sie, dass EXY = EXEY .
(b) Sind X und Y unabhängig?
(3.26) Verschwindende Varianz: Es sei X : Ω→ R eine integrierbare Zufallsvariableauf dem Wahrscheinlichkeitsraum (Ω,F ,P) . Zeigen Sie:
Var(X) = 0 ⇐⇒ X = EX fast sicher

3. Integration und Erwartungswert 147
(3.27) Ticketkontrolle: Die Wahrscheinlichkeit, dass im Bus die Tickets kontrolliertwerden, sei p = 0.1 . Günther fährt täglich mit dem Bus zur Schule.
(a) Wie groÿ ist die Wahrscheinlichkeit, dass er nach n ∈ N Tagen zum erstenMal kontrolliert wird?
(b) Sei nun p ∈ (0, 1) beliebig. Berechne den Erwartungswert und die Varianz,dass Günther nach n ∈ N Tagen zum ersten Mal kontrolliert wird.
(3.28) Es seiX eine Zufallsvariable auf demWahrscheinlichkeitsraum (Ω,F ,P) mit Erwar-tungswert EX = 50 und Varianz Var(X) = 5 . Schätzen Sie die Wahrscheinlichkeit
P (|X − 50| ≥ 10)
nach oben mittels der Tschebyschow-Ungleichung ab.
(3.29) Es seiX eine Zufallsvariable auf demWahrscheinlichkeitsraum (Ω,F ,P) mit Erwar-tungswert EX = 10 und Varianz Var(X) = 0.45 . Auÿerdem gelte X(Ω) ⊂ [0, 12] .Schätzen Sie P(X ≤ 7) nach oben mittels der Tschebyschow-Ungleichung ab.
(3.30) Es sei (Ω,F ,P) ein Wahrscheinlichkeitsraum. Die ZufallsvariablenX1, . . . , Xn seienu.i.v. und quadratisch integrierbar.
(a) Berechnen Sie den Erwartungswert und die Varianz von X := 1n
∑ni=1Xn .
(b) Weiters sei nun α ∈ (0, 1) . Wie groÿ muss n mindestens sein, damit
P(|X − EX1| ≥ α
)≤ 1− α ?
(3.31) Wie oft muss eine faire Münze mindestens geworfen werden, damit mit einer Wahr-scheinlichkeit von mindestens 0.95 die Zufallsvariable, welche den Prozentsatz jenerWürfe angibt, welche auf Kopf gefallen sind, von 0.5 um höchstens
(a) 0.01
(b) 0.001
abweicht?
(3.32) Getriebeschaden: Die mittlere Lebensdauer in Stunden eines Maschinenteilsbetrage 50 und die Varianz sei 900. Fällt das Maschinenteil aus, so wird dieses sofortdurch ein gleichwertiges ersetzt. Wieviele Reserveteile werden benötigt, sodass miteiner Wahrscheinlichkeit von 0.95 die Maschine mindestens 5000 Stunden läuft?
(3.33) Varianz der Binomialverteilung: Berechnen Sie für n ∈ N und p ∈ (0, 1) dieVarianz der Binomialverteilung Bn,p .
(3.34) Varianz der Poisson-Verteilung: Berechnen Sie für λ > 0 die Varianz derPoisson-Verteilung πλ .

148 3. Integration und Erwartungswert
(3.35) Varianz der geometrischen Verteilung: Berechnen Sie für p ∈ (0, 1) dieVarianz der geometrischen Verteilung gp .
(3.36) Varianz der kontinuierlichen Gleichverteilung: Berechnen Sie die Vari-anz der Gleichverteilung auf [a, b] für a < b .
(3.37) Erwartungswert und Varianz der Normalverteilung: Es sei µ ∈ R undσ > 0 . Bestimmen Sie den Erwartungswert und die Varianz der NormalverteilungNµ,σ2 .
(3.38) Momente der Exponentialverteilung: Berechnen Sie für n ∈ N das n-teMoment der Exponentialverteilung mit Parameter λ > 0 .

3. Integration und Erwartungswert 149
Schulaufgaben
Die nachfolgenden Aufgaben stammen, sofern keine weiteren Angaben gemacht werden,von https://www.bifie.at/ (Stand: Februar 2013).
(S3.1) Multiple Choice 1: Bei einem Aufnahmetest werden vier Fragen mit je dreiAntwortmöglichkeiten gestellt, wobei jeweils genau eine Antwort richtig ist. DerKandidat kreuzt rein zufällig jeweils eine Antwort an. Die Zufallsvariable X gibtdie Anzahl der richtigen Antworten an.
(a) Um welche Art der Wahrscheinlichkeitsverteilung der Zufallsvariablen Xhandelt es sich? Begründe deine Antwort.
(b) Stelle die Verteilung von X grasch dar. Bestimme den Erwartungswert unddie Standardabweichung von X.
(c) Wie groÿ ist die Wahrscheinlichkeit, mindestens zwei Antworten richtig an-zukreuzen?
(S3.2) Spielrunde: Eine Spielrunde besteht aus 9 Personen. Jede dieser Personen kommtmit einer Wahrscheinlichkeit von 75 % zu den wöchentlichen Treen.
Aus Erfahrung weiÿ man, dass das Treen mehr als zwei Stunden dauert, wennmindestens zwei Drittel der Personen anwesend sind.
Unter den 9 Personen sind vier etwas streitlustiger. Wenn zwei dieser streitlusti-geren Personen anwesend sind, kommt es beim Treen mit Sicherheit zum Streit.
(a) Wie viele Personen kann man durchschnittlich bei einem Treen erwarten?
(b) Wie hoch ist die Wahrscheinlichkeit, dass das nächste Treen mehr als zweiStunden dauert?
(c) Wie hoch ist die Wahrscheinlichkeit, dass es zu einem Streit kommt?
(S3.3) Fertigung mit gleichbleibendem Auschussanteil: Eine Fertigung vonStanzteilen läuft mit dem gleichbleibenden Auschussanteil p = 4% . Wie groÿist die Wahrscheinlichkeit, unter n = 50 hintereinander entnommen Einheiten
(a) genau 0
(b) genau 2
(c) höchstens 2
(d) mindestens 2
fehlerhafte Einheiten vorzunden? Wie groÿ ist der Ewartungswert µ der fehler-haften Einheiten?(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 243, Bsp. 6.5)

150 3. Integration und Erwartungswert
(S3.4) Defekte Dichtungen: In einer Schachtel benden sich 25 einwandfreie und4 defekte Dichtungen. Man entnimmt zufällig drei Dichtungen. Wie groÿ ist derErwartungswert der Anzahl defekter Dichtungen unter den drei entnommenenDichtungen?(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 240, Nr. 6.3)

3. Integration und Erwartungswert 151
Kontrollfragen
3.1 Es sei X die Anzahl jener n ∈ N Würfe, bei denen eine faire Münze auf Kopffällt. Welche der folgenden Aussagen sind wahr?
EX = 12
EX = n2
P(X = k) =(nk
)für k = 0, . . . , n
PX = Bn,1/2
3.2 Gegeben sei die Funktion
f : R→ R : t 7→ 2tχ[0,1](t) .
Welche der folgenden Aussagen sind wahr?
Die durch
F (x) :=
ˆ(−∞,x]
f(t) dλ(t) für x ∈ R
auf R denierte Funktion ist eine Verteilungsfunktion.
Ist X eine Zufallsvariable mit Dichte f bezüglich des Lebesgue-Maÿes λ , sogilt EX = 1 .
Ist X eine Zufallsvariable mit Dichte f bezüglich des Lebesgue-Maÿes λ , sogilt EX = 2
3 .
Ist X eine Zufallsvariable mit Dichte f bezüglich des Lebesgue-Maÿes λ , sogilt EX2 = 1
2 .
3.3 Gegeben seien der Wahrscheinlichkeitsraum (R,B(R),P) mit
P = 12δ0 + 1
2δ1
und die Abbildungen
X : R→ R : ω 7→ 1
ω2und Y : R→ R : ω 7→ 1
1 + ω2,
wobei 1/0 :=∞ . Welche der folgenden Aussagen sind wahr?
X ∈ L1(P) und Y ∈ L1(P)
X ∈ L+ und Y ∈ L+
EX = 12 und EY = 3
4
EX =∞ und EY = 34

152 3. Integration und Erwartungswert
3.4 Es sei
f : R×R : (x, t) 7→ e−x2
cos(
x1+t2
)
und
F : R→ R : t 7→ˆR
f(x, t) dλ(x) .
Welche der folgenden Aussagen sind wahr?
F ist dierenzierbar
F ist nicht stetig
limt→−∞ F (t) =√π
limt→∞ F (t) = 1
3.5 Die Wartezeit X in Minuten an einer Supermarktkasse sei exponentialverteilt mitParameter λ = 1
2 . Welche der folgenden Aussagen sind wahr?
Die durchschnittliche Wartezeit beträgt eine halbe Minute.
Die durchschnittliche Wartezeit beträgt zwei Minuten.
Die Wahrscheinlichkeit, dass man weniger als zwei Minuten wartet, lautete−1
e .
Die Wahrscheinlichkeit, dass man weniger als zwei Minuten wartet, lautet1e .
3.6 Es seien (Ω,F ,P) ein Wahrscheinlichkeitsraum und X,Y ∈ L2(P) . Welche derfolgenden Aussagen sind wahr?
Var(X + Y ) = Var(X) + Var(Y )
Var(XY ) = EX2EY 2 − (EX)2(EY )2
Sind X und Y unabhängig, so gilt Var(XY ) = EX2EY 2 − (EX)2(EY )2 .
Sind X und Y unkorreliert, so gilt Var(XY ) = EX2EY 2 − (EX)2(EY )2 .
3.7 Gegeben sei der Wahrscheinlichkeitsraum
([0, 1],B([0, 1]), 1
2δ0 + 12δ1
)
und die durchX(ω) := ω und Y (ω) := χ(1/2,1](ω)
für ω ∈ Ω denierten Zufallsvariablen. Welche der folgenden Aussagen sind wahr?
X und Y sind unkorreliert
X und Y sind unabhängig

3. Integration und Erwartungswert 153
EX = EY = EXY = 12
EX = EY = 12 und EXY = 1
4
3.8 Gegeben sei der Wahrscheinlichkeitsraum (Ω,F ,P) mit
P =
∞∑
n=1
αnδωn ,
wobei ωn∞n=1 ∈ ΩN und αn∞n=1 ∈ [0,∞)N , sodass∑∞
n=1 αn = 1 . Weiter seiX : Ω→ R messbar. Welche der folgenden Aussagen sind wahr?
X ∈ L1(P) ⇐⇒ ∑∞n=1 αnX(ωn) <∞
X ∈ L1(P) ⇐⇒ ∑∞n=1 αn|X(ωn)| <∞
Ist X ∈ L+ , so gilt EX =∑∞
n=1 αnX(ωn) .
Ist X ∈ L2(P) , so gilt Var(X) =∑∞
n=1 αnX2(ωn)− (
∑∞n=1 αnX(ωn))2 .


Teil II
Statistik
155


Kapitel 4
Einleitung und Überblick
Ich traue einer Statistik nie es sei denn, ich habe sie selbst gefälscht.
W. Churchill1
4.1 Was ist Statistik?
Da es sich bei Statistik2 um ein sehr umfangreiches Fachgebiet mit breit gefächertenAnwendungsbereichen handelt, ist es schwierig, eine genaue Denition des Begris Sta-tistik zu geben. Sehr allgemein gesprochen beschäftigt sich die Statistik zum einen mitMethoden zur Erhebung, Zusammenfassung, Darstellung und Analyse von Da-ten, zum anderen mit Methoden zum Ziehen von Schlüssen auf Grundlage von Daten.
Eine mögliche Einteilung der Statistik liefern die folgenden Teilgebiete.
1. Deskriptive Statistik
- Beschreibende und graphische Aufbereitung und geeignete Zusammenfassungvon Daten
- Datenvalidierung
- Keine formalen Rückschlüsse über die Daten hinausgehend
2. Explorative Statistik
- Aunden von Gesetzmäÿigkeiten in den Daten
- Kann zu neuen Fragestellungen und Hypothesen führen
- Einsatz bei undenierter Fragestellung
- Ebenfalls keine Rückschlüsse über die Daten hinausgehend
- Es können sich deutliche Hinweise für bestimmte Forschungshypothesen erge-ben (empirische Evidenz)
3. Induktive Statistik
- Wahrscheinlichkeitstheoretische Schlussfolgerungen
1Sir Winston Leonard Spencer-Churchill, 18741965, britischer Premierminister und Nobelpreisträger2Statistik stammt vom lat. statisticum, den Staat betreend.
157

158 4. Einleitung und Überblick
- Schätzen unbekannter Parameter
- Testen von Hypothesen
- Ist das verwendete Modell der Wirklichkeit hinreichend gut angepasst?
- Wird oftmals als mathematische Statistik bezeichnet
4.2 Einige Beispiele
Es folgen nun einige Beispiele, welche in nachfolgenden Kapiteln wieder aufgegrien wer-den.
Beispiel 6.6 (Rückfangmethode)Um die unbekannte Anzahl von N Fischen in einem Teich zu schätzen, werden zuerstF1 Fische gefangen und mit roter Farbe markiert. Nach einiger Zeit werden dann erneutF2 < F1 Fische gefangen und es werden darunter r rot markierte Fische gezählt. Wielässt sich nun die Gesamtanzahl N der Fische im Teich schätzen?
Beispiel 6.7 (Rote Ampel)Student T. fährt immer mit dem Fahrrad zur Uni, auf dem Weg muss er häug an einerAmpel halten. Die letzten n = 8 Wartezeiten in Sekunden betrugen
x1 = 49, x2 = 54, x3 = 49, x4 = 37, x5 = 43, x6 = 28, x7 = 55, x8 = 21 .
Wie kann ausgehend vom obigen Datensatz die Dauer der Rotphase geschätzt werden?
Beispiel 7.12 (Im Wirtshaus)In einem Wirtshaus wechseln sich die Wirtin und der Wirt regelmäÿig hinter dem Tresenab. Bei einigen Wirtshausbesuchern ist der Eindruck entstanden, dass die Wirtin dasBierglas deutlich voller füllt als der Wirt. Ein kritischer Kunde hat sich über einigeAbende hinweg den Füllstand des Bierglases in Millilitern notiert, die Ergebnisse sind innachfolgender Tabelle zu nden.
Füllstand Wirtin 563 537 508 516 515 550 551 509 553 545
Füllstand Wirt 519 516 521 518 526 523 507 520 515 523
Wie kann getestet werden, ob der durchschnittliche Füllstand der Wirtin von dem desWirtes abweicht?

4. Einleitung und Überblick 159
Beispiel 8.7 (Benfordsches Gesetz)Nach dem Benfordschen Gesetz sollte die Zahl i ∈ 1, . . . , 9 mit etwa Wahrschein-lichkeit
pi = log10
i+ 1
i
als führende Zier bei Zahlen in einer Billianz auftreten. Im Fall, dass die Verteilung derAnfangsziern zu stark von der zu erwartenden abweicht, sollte die Billianz vermutlicheiner genaueren Prüfung unterzogen werden.Wie kann man für eine vorliegende Billanz überprüfen, ob die Häugkeiten der Anfangs-ziern in Übereinstimmung mit dem Benfordschen Gesetz stehen?
Beispiel 8.14 (Müllabfuhr)Die für einen kleineren Stadtteil zuständige Müllabfuhr kann zwei Routen wählen, umden Müll abzuholen, und möchte wissen, ob diese beiden Routen im Bezug auf die Fahrt-zeit als gleichwertig anzusehen sind oder nicht. Elf Arbeitstage wurde die erste Routegefahren, neun weitere die zweite Route. Die folgende Tabelle enthält die Fahrtzeiten inMinuten.
1 2 3 4 5 6 7 8 9 10 11
Route 1 52.5 59.7 58.6 46.1 47.4 45.7 55.6 48.7 52.4 47.2 45.2
Route 2 65.9 66.1 63.2 52.0 49.6 52.1 52.6 51.7 61.6
Wie testet man, ob die beiden Routen als gleichwertig betrachtet werden können?
4.3 Datenerhebung
Anhand eines Beispiels führen wir nun einige Begrie ein, welche bei einer Datenerhe-bung, etwa mittels einer Umfrage, gebräuchlich sind.
Beispiel 4.1 (Volksbefragung)Anfang 2013 kam es zu einer Volksbefragung betreend die Frage, ob die Wehrpicht inÖsterreich abgeschat werden soll oder nicht. Ein gewisser Anteil der wahlberechtigtenStaatsbürger machte von ihrem Wahlrecht nicht Gebrauch, enthielt sich also der Stimme.Die übrigen entscheiden sich entweder für oder gegen die Abschaung der Wehrpicht,einige wählten ungültig. Durch bloÿes Abzählen wurde dann der Ausgang der Befragungeruiert.Vor der Volksbefragung wollte man jedoch bereits Tendenzen feststellen und daher wur-den Umfragen durchgeführt. Bei einer solchen Umfrage ist es natürlich nur möglich, einengeringen Anteil der Wahlberechtigten zu befragen. Nach welchen Kriterien sollte man beieiner solchen Umfrage die befragten Bürger auswählen?

160 4. Einleitung und Überblick
Um repräsentative Umfragewerte zu erzielen, würde man intuitiv meinen, die Personensollten möglichst zufällig ausgewählt werden.
An einer Menge gewisser Objekte möchte man eine interessierende Gröÿe beobachten,ein sogenanntes (interessierendes) Merkmal. In der Statistik nennt man die untersuch-ten Objekte auch statistische Einheiten, die Menge der statistischen Einheiten wirdGrundgesamtheit oder Population genannt. Jene Teilmenge der Grundgesamtheit,auf welcher das interessierende Merkmal tatsächlich erhoben wird, heiÿt untersuchteTeilgesamtheit oder Teilpopulation, ist dies die gesamte Grundgesamtheit, so sprichtman von einer Vollerhebung. Weiters werden die Werte, welche ein Merkmal annimmt,Ausprägungen genannt. Es ergeben sich die folgenden Entsprechungen am Beispiel derVolksbefragung aus Beispiel 4.1.
Grundgesamtheit: Menge aller wahlberechtigten Staatsbürger
Untersuchte Teilgesamtheit: Menge der Wahlberechtigten, welche an der Um-frage teilnehmen
Interessierendes Merkmal: Antwort auf die Frage nach der Abschaung derWehrpicht
Vollerhebung: Tatsächliche Volksbefragung
Ausprägungen: Ja, Nein, Ungültig oder Enthalten
Wir werden sehen, dass ein Merkmal einer Zufallsvariablen entspricht, an deren Vertei-lung man interessiert ist.
4.4 Stichproben
Wir wenden uns nun dem stochastischen Modell zu, welches eine der einfachsten Artender Datenerhebung in idealisierter Form beschreibt. Dazu führen wir zwei wesentlicheBegrie ein, jenen der Stichprobe und jenen der Realisierung einer Stichprobe.
Definition 4.2 (Stichproben und Realisierungen)Es seien (Ω,F ,P) ein Wahrscheinlichkeitsraum , X1, . . . , Xn : Ω → R u.i.v. Zufallsva-riablen und P eine Verteilung. Falls PX1 = P , so nennt man X1, . . . , Xn eine (unab-hängige) Stichprobe vom Umfang n zur Verteilung P . Für ein festes ω ∈ Ω setzenwir xi := Xi(ω) , i = 1, . . . , n . Dann heiÿt x1, . . . , xn Realisierung der StichprobeX1, . . . , Xn .
Bemerkung.
B Eine Realisierung einer Stichprobe nennt man auch Datensatz oder Messreihe.

4. Einleitung und Überblick 161
B Ist X eine Zufallsvariable, so nennt man eine Stichprobe X1, . . . , Xn zur VerteilungPX auch Stichprobe zu X .
B Für eine Verteilung P bezeichnet man eine Folge Xn∞n=1 u.i.v. Zufallsvariablenmit PX1 = P ebenfalls als Stichprobe zu P .
Interpretation. Die Stichprobe X1, . . . , Xn beschreibt die n Ergebnisse, welche sichaus n unabhängigen und identisch ablaufenden Wiederholungen eines Zufallsexperimentsergeben. Führt man das Experiment tatsächlich n-mal durch, liefert dies die Wertex1, . . . , xn , welche als Realisierung dieser Stichprobe aufgefasst werden.
In R erhält man beispielsweise eine Realisierung einer normalverteilten Stichprobe wiefolgt.
> x=rnorm(10,mean=9,sd=2)
> x
[1] 7.747092 9.367287 7.328743 12.190562 9.659016
[6] 7.359063 9.974858 10.476649 10.151563 8.389223
Das Konzept der Stichprobe beschreibt eine Umfrage wie in Beispiel 4.1 nur in idea-lisierter Form. Eigentlich werden n Personen (zufällig) aus der Menge aller N Wahlbe-rechtigten ausgewählt. Dies kann durch folgendes Zufallsexperiment beschrieben werden:Alle wahlberechtigten Staatsbürger erhalten eine Nummer von 1 bis N . Diese werdenauf Kugeln geschrieben, die Kugeln in eine Urne geworfen, durchgemischt und ohne Zu-rücklegen gezogen. Die noch nicht gezogenen Kugeln sollen bei jeder Ziehung die gleicheWahrscheinlichkeit haben, ausgewählt zu werden.Das entsprechende Zufallsexperiment, welches einer Stichprobe zugrundeliegt, entsprichtjedoch dem Ziehen mit Zurücklegen.Ist die Anzahl N aller Wahlberechtigten im Vergleich zur Anzahl n der ausgewähltenPersonen entsprechend groÿ, so ist der Unterschied zwischen dem Ziehen mit und ohneZurücklegen jedoch verschwindend gering, vgl. Aufgabe (4.3). Es wird also nicht exaktdie Realität beschrieben, man erhält jedoch ein wesentlich einfacheres Modell.
Beispiel 4.3 (Münzwurf)Es sei p ∈ (0, 1) . Wir modellieren den Wurf einer nicht zwingend fairen Münze mittelsdes Wahrscheinlichkeitsraums (G,G, µ) , wobei
G = 0, 1 , G = P(G) und µ = pδ0 + (1− p)δ1 .
Beispielsweise steht 0 für Kopf und 1 für Zahl. Dann ist die Identität
X : G→ R : x 7→ x

162 4. Einleitung und Überblick
eine Zufallsvariable, welche den Ausgang beimWurf der Münze beschreibt. Als Verteilungvon X erhalten wir das Wahrscheinlichkeitsmaÿ
PX = pδ0 + (1− p)δ1
auf B(R) , also die Bernoulli-Verteilung mit Parameter p . Wir möchten nun n unab-hängige und identisch ablaufende Wiederholungen dieses Münzwurfs modellieren. Dazusetzen wir
Ω := 0, 1n, F := P(Ω) und P := µ⊗n.
Es kann leicht nachgeprüft werden, dass die Zufallsvariablen
Xi : Ω→ R : ω = (ω1, . . . , ωn) 7→ X(ωi) , i = 1, . . . , n ,
eine Stichprobe X1, . . . , Xn zur Verteilung PX bilden, vgl. Aufgabe (4.2). Eine typischeFragestellung wäre nun, wie man zuverlässig testet, ob die Münze fair ist, d. h. obp = 1/2 gilt. Bemerkung. In der Praxis ist der zugrundeliegende Wahrscheinlichkeitsraum unbe-kannt und somit auch die Verteilung der beobachteten Zufallsgröÿe. Durch die Realisie-rung einer Stichprobe möchte man die unbekannte Verteilung möglichst gut approximie-ren.
4.5 Typische Fragestellungen
Die typischen Fragestellungen der Wahrscheinlichkeitstheorie unterscheiden sich häugvon jenen der Statistik wie die nachfolgenden zwei Beispiele zeigen.
Beispiel 4.4 (Typische Fragestellung der Wahrscheinlichkeitstheorie)Die Verteilung P sei bekannt.Fragestellung: Wie verhält sich eine Realisierung x1, . . . , xn einer Stichprobe X1, . . . , Xn
zu P ?Beispiel: Ist P integrierbar mit Erwartungswert EP , was kann über das Stichproben-mittel
X(n) :=1
n
n∑
i=1
Xi
ausgesagt werden? Eine mögliche Antwort liefert das Starke Gesetz der groÿenZahlen, nach welchem das Stichprobenmittel fast sicher gegen EP konvergiert, also
X(n) → EP f.s. für n→∞ ,
d.h. P(limn→∞X(n) = EP
)= 1 .

4. Einleitung und Überblick 163
Beispiel 4.5 (Typische Fragestellung der Statistik)Die Verteilung P sei unbekannt, jedoch eine Realisierung x1, . . . , xn der StichprobeX1, . . . , Xn zu P gegeben .Fragestellung: Was kann über die Verteilung P geschlossen werden?Beispiel: Was ist EP ? Es erscheint naheliegend EP durch die Realisierung
x(n) :=1
n
n∑
i=1
xi
des Stichprobenmittels X(n) zu schätzen.
Aus dem nachfolgenden in R realisierten Beispiel lässt sich bereits erahnen, dass sichmit Erhöhung des Stichprobenumfangs n die Schätzung des Erwartungswertes durch dasStichprobenmittel entsprechend verbessert.
> nseq = (25*1:5)^2
> nseq
[1] 625 2500 5625 10000 15625
> for(n in nseq)x=runif(n,0,84);print(mean(x))
[1] 41.04197
[1] 42.23961
[1] 41.92266
[1] 42.29085
[1] 42.08269

164 4. Einleitung und Überblick
Übungsaufgaben
(4.1) Identische Verteilung, unterschiedliche Wahrscheinlichkeitsräume:Gegeben sei der Wahrscheinlichkeitsraum ([0, 1],B([0, 1]), λ) , wobei λ das Lebes-guemaÿ auf [0, 1] bezeichne. Erklären Sie, warum
f : [0, 1]→ R : ω 7→
0 , ω ∈ [0, p) ,
1 , ω ∈ [p, 1] ,
den Münzwurf aus Beispiel 4.3 beschreibt und zeigen Sie, dass f dieselbe Vertei-lung besitzt, wie die im Beispiel denierte Zufallsvariable X .
(4.2) Konstruktion einer Stichprobe: Zeigen Sie, dass es sich bei den Zufallsva-riablen X1, . . . , Xn , welche in Beispiel 4.3 deniert wurden, tatsächlich um eineStichprobe handelt. Wenden Sie die beschriebene Konstruktion einer Stichprobe aufein Merkmal an, welches auf einer endlichen Grundgesamtheit gegeben ist. Dabeisoll jede statistische Einheit mit der gleichen Wahrscheinlichkeit gezogen werden,es soll sich also um eine sogenannte einfache Zufallsstichprobe handeln.
(4.3) Ziehen mit und ohne Zurücklegen: Gegeben sei eine Urne mit N Kugeln,davon seien W weiÿ und N −W schwarz.
(a) Es werden n Kugeln mit Zurücklegen gezogen. Zeigen Sie, dass die Wahr-scheinlichkeit, k weiÿe Kugeln zu ziehen,
Bn,p(k) =
(n
k
)pk(1− p)n−k , p =
W
N, (Binomialverteilung)
beträgt.
(b) Zeigen Sie, wenn n Kugeln ohne Zurücklegen gezogen werden, so ist die Wahr-scheinlichkeit, k weiÿe Kugeln zu ziehen
Hn,N,W (k) =
(Wk
)(N−Wn−k
)(Nn
) . (Hypergeometrische Verteilung)
(c) Für festes n und p beweise man, dass
limN→∞WN→p
Hn,N,W = Bn,p .
Bemerkung: Ist N im Vergleich zu n groÿ, so ist also Hn,N,W ≈ Bn,WN.

4. Einleitung und Überblick 165
(d) In einer Kiste benden sich 500 Kugeln, 75 weiÿe, 425 schwarze. Beim Schüt-teln der Kiste fallen 10 Kugeln heraus. Wie wahrscheinlich ist es, dass genau3 weiÿe Kugeln darunter sind? Berechnen Sie die Wahrscheinlichkeit exaktmittels der hypergeometrischen Verteilung und vergleichen Sie das Ergebnismit der Näherung durch die Binomialverteilung.
(4.4) Erwartungswert, Varianz, Bildmaÿ: Bestimmen Sie einen geeigneten Wahr-scheinlichkeitsraum, Zufallsvariable und ihr Bildmaÿ, den Erwartungswert und dieVarianz der folgenden Situation: Aus einer Geldtasche, in der sich ein 5e-, ein 200e-und drei 500e- Scheine benden, werden zufällig drei Scheine (ohne zurücklegen)gezogen. Betrachtet wird die gezogene Geldsumme.

166 4. Einleitung und Überblick
Schulaufgaben
(S4.1) Preisverteilung: Bei einer Veranstaltung sollen unter 25 Personen fünf Preiseverlost werden. In einer Urne benden sich die 25 Namenskärtchen der Teilneh-merinnen und Teilnehmer. Beschreibe den Ablauf der Gewinnermittlung wenn
a) jede Person mehr als einen Preis erhalten kann,
b) jede Person höchstens einen Preis erhalten kann
und gib das jeweils zu Grunde liegende mathematische Modell an.(https://www.bifie.at/, Stand: Februar 2013)
(S4.2) Fehlerhafte Einheiten: In einem Prüos von 20 Einheiten sind drei Einheitenfehlerhaft. Jemand entnimmt eine Zufallsstichprobe von 5 Einheiten. Berechneden Erwartungswert für die Anzahl fehlerhafter Einheiten der Stichprobe und dieWahrscheinlichkeiten für alle möglichen Anzahlen fehlerhafter Einheiten in einersolchen Stichprobe.(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 240, Nr. 6.1)

4. Einleitung und Überblick 167
Kontrollfragen
4.1 Das Schätzen eines unbekannten Verteilungsparameters, etwa des Erwartungs-werts, fällt in den Bereich der
deskriptiven Statistik,
explorativen Statistik,
deskriptiven und explorativen Statistik,
induktiven Statistik.
4.2 Bei der PISA-Studie 2012 mussten 5000 Schülerinnen und Schüler des Jahrgangs1996 aus österreichischen Schulen ihre Kompetenzen in Mathematik unter Beweisstellen. Welche der folgenden Aussagen treen auf diese Datenerhebung zu?
Die Grundgesamtheit ist die Menge aller Schülerinnen und Schüler des Jahr-gangs 1996.
Eine Schülerin bzw. ein Schüler des Jahrgangs 1996 ist eine statistische Ein-heit.
Es handelt sich um eine Vollerhebung.
Die untersuchte Teilgesamtheit ist die Menge der 5000 getesteten Schülerin-nen und Schüler.
4.3 Es seien X1, . . . , Xn : Ω→ R identisch verteilte Zufallsvariable auf einem Wahr-scheinlichkeitsraum (Ω,F ,P) . Unter welchen der folgenden Annahmen handeltes sich bei X1, . . . , Xn um eine Stichprobe zur Verteilung B1,p = (1− p)δ0 + pδ1
mit p ∈ (0, 1) ?
P(X1 = 0) = 1− p und P(X1 = 1) = p
X1, . . . , Xn sind unabhängig, P(X1 = 0) = 1− p und P(X1 = 1) = p
PX1 = B1,p
P(X1,...,Xn) = (B1,p)⊗n


Kapitel 5
Deskription und Exploration
Der Ausgangspunkt der deskriptiven und explorativen Statistik ist ein Datensatz
x1, . . . , xn ,
wobei n ∈ N den Stichprobenumfang bezeichnet. Die deskriptive Statistik dient derübersichtlichen Darstellung dieser Daten und ihrer Eigenschaften, während die explora-tive Statistik Methoden zum Aunden von Strukturen zur Verfügung stellt. Eine klareGrenze zwischen diesen beiden Teilgebieten der Statistik kann nicht gezogen werden, daeine übersichtliche Darstellung der Daten immer auch zum Aunden von Gesetzmäÿig-keiten hilfreich sein wird.
5.1 Typen von Merkmalen
Wir teilen nun Merkmale nach unterschiedlichen Gesichtspunkten ein. Diese Unterteilungist insofern wichtig, da manche statistische Verfahren für bestimmte Merkmalstypen zuunsinnigen Ergebnissen führen.
Diskrete und stetige Merkmale
Von einem diskreten Merkmal spricht man, wenn die Anzahl der Ausprägungen ab-zählbar ist, also endlich oder abzählbar unendlich. Nimmt das Merkmal hingegen alleWerte eines Intervalls an, so spricht man von einem stetigen Merkmal.
Diskretes Merkmal: Anzahl der Ausprägungen ist abzählbar
Stetiges Merkmal: Alle Werte eines Intervalls werden angenommen
In diesem Kontext hat der Begri der Stetigkeit eines Merkmal nichts mit der Stetigkeitals Abbildung zu tun und kann daher etwas irreführend sein.Typische Beispiele für diskrete Merkmale sind die Parteizugehörigkeit oder die Anzahlder Würfe mit einem Würfel, bis man eine Sechs erhält. Die Körpergröÿe hingegen istein stetiges Merkmal.Oftmals wird ein stetiges Merkmal zu einem diskreten Merkmal gemacht, indem eineEinteilung in Klassen vollzogen wird, etwa aus datenschutzrechtlichen Gründen. Befragtman beispielsweise Personen zu ihrem Einkommen, so könnte aufgrund einer genauenAngabe des Bruttoeinkommens in Euro auf eine einzelne Person rückgeschlossen werden.
169

170 5. Deskription und Exploration
Nominale, ordinale, zirkuläre und reelle Merkmale
Eine andere Unterteilung von Merkmalen erfolgt aufgrund der Struktur des Wertebe-reichs. Zur Einteilung stellt man fest, ob ein Abstandsbegri und/oder eine Ordnungsrela-tion auf dem Wertebereich des Merkmals gegeben ist, vgl. Tabelle 5.1. Die zugehörigenMerkmale mit den entsprechenden Eigenschaften werden nominal, ordinal, zirkulärund reell genannt. Merkmale, auf deren Wertebereich ein Abstandsbegri deniert ist,also zirkuläre und reelle Merkmale, werden auch metrisch genannt.
Merkmalstyp Abstandsbegri Ordnungsrelation Beispiel
nominal nein nein Parteizugehörigkeit
ordinal nein ja Schulnoten
zirkulär ja nein Uhrzeit
reell ja ja Gewicht einer Person
Tabelle 5.1. Einteilung von Merkmalen aufgrund der Struktur des Wertebereichs
Zu beachten gilt es, dass gewisse Berechnungen für bestimmte Merkmalstypen a prio-ri nicht sinnvoll sind, beispielsweise das Addieren von Schulnoten. Berechnet man aufdiesem Weg den Notendurchschnitt, lässt sich das Ergebnis jedoch durchaus sinnvollinterpretieren, insbesondere als statistische Maÿzahl.
5.2 Empirische Verteilung
Wir führen nun die Begrie der empirischen Verteilung und der empirischen Verteilungs-funktion ein und geben einen ersten Einblick in den Zusammenhang mit Verteilung undVerteilungsfunktion. ImWeiteren gehen wir davon aus, dass ein Datensatz x1, . . . , xn ∈ Rvorliegt.
Definition 5.1 (Empirische Verteilung)Das Wahrscheinlichkeitsmaÿ
Pn( · ;x1, . . . , xn) : B(R)→ [0, 1] : B 7→ 1
n
n∑
i=1
δxi(B)
heiÿt empirische Verteilung zu x1, . . . , xn .
Wenn klar ist, dass es sich um die empirische Verteilung zu x1, . . . , xn handelt, so be-zeichnen wir diese der Einfachheit halber mit Pn . Es lässt sich leicht zeigen, dass Pn

5. Deskription und Exploration 171
tatsächlich ein Wahrscheinlichkeitsmaÿ ist, siehe Aufgabe (5.2). Weiters gilt oensicht-lich
Pn(B) =#i ∈ 1, . . . , n : xi ∈ B
n
für B ∈ B(R) . Man bezeichnet Pn(B) auch als relative Häugkeit von B .
Ist Xn∞n=1 eine Stichprobe zur Verteilung P , so folgt für B ∈ B(R) aus dem StarkenGesetz der groÿen Zahlen
Pn(B ;X1, . . . , Xn) =1
n
n∑
i=1
χB(Xi)f.s.−→ EχB(X1) = P (B) für n→∞ ,
da χB(X1), . . . , χB(Xn) u.i.v. sind, vgl. Aufgabe (5.3).
Die empirische Entsprechung der Verteilung ist die empirische Verteilung, nun denierenwir das empirische Pendant der Verteilungsfunktion.
Definition 5.2 (Empirische Verteilungsfunktion)Die zur empirischen Verteilung Pn zu x1, . . . , xn gehörige Verteilungsfunktion
Fn( · ;x1, . . . , xn) : R→ [0, 1] : x 7→ Pn ((−∞, x]) =1
n
n∑
i=1
χ(−∞,x](xi)
heiÿt empirische Verteilungsfunktion zu x1, . . . , xn .
Ist wiederum klar, dass es sich um die empirische Verteilungsfunktion zu x1, . . . , xn han-delt, wird diese mit Fn bezeichnet. Weiters gilt
Fn(x) =#i ∈ 1, . . . , n : xi ≤ x
n.
> x=rnorm (10)
> Fn=ecdf(x)
> plot(Fn ,main="Empirische Verteilungsfunktion")
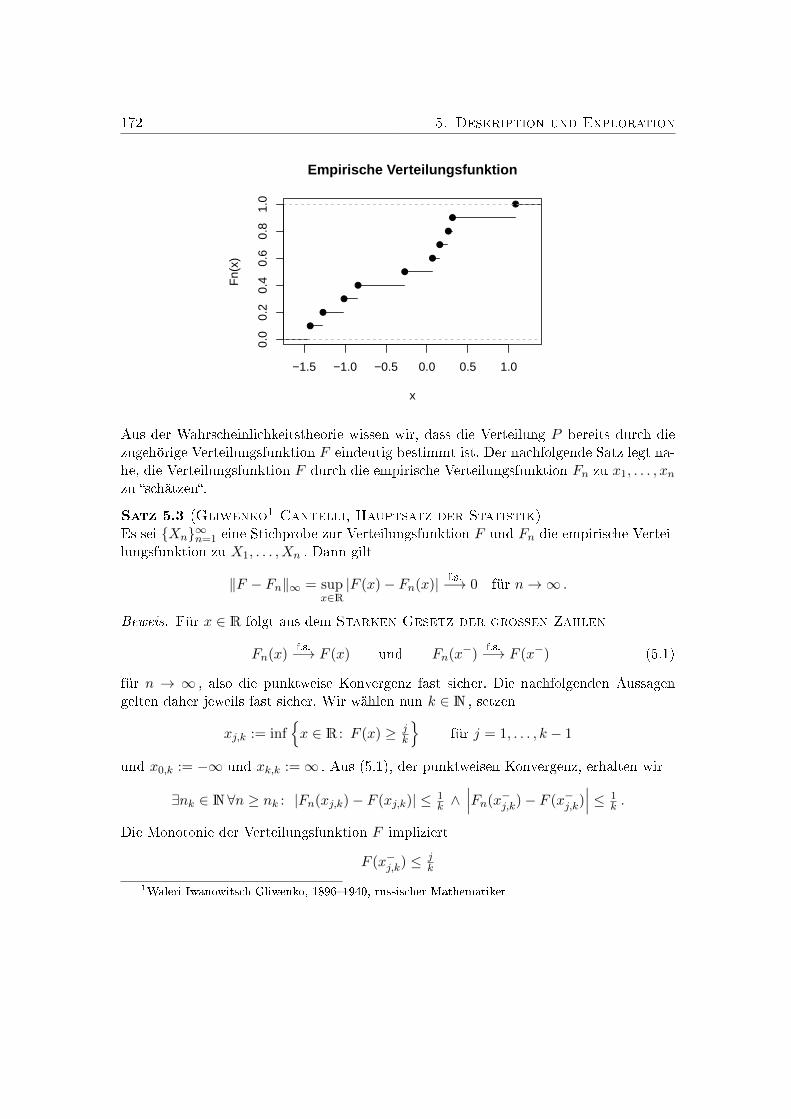
172 5. Deskription und Exploration
−1.5 −1.0 −0.5 0.0 0.5 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Empirische Verteilungsfunktion
x
Fn(
x)
Aus der Wahrscheinlichkeitstheorie wissen wir, dass die Verteilung P bereits durch diezugehörige Verteilungsfunktion F eindeutig bestimmt ist. Der nachfolgende Satz legt na-he, die Verteilungsfunktion F durch die empirische Verteilungsfunktion Fn zu x1, . . . , xnzu schätzen.
Satz 5.3 (Gliwenko1-Cantelli, Hauptsatz der Statistik)Es sei Xn∞n=1 eine Stichprobe zur Verteilungsfunktion F und Fn die empirische Vertei-lungsfunktion zu X1, . . . , Xn . Dann gilt
‖F − Fn‖∞ = supx∈R|F (x)− Fn(x)| f.s.−→ 0 für n→∞ .
Beweis. Für x ∈ R folgt aus dem Starken Gesetz der groÿen Zahlen
Fn(x)f.s.−→ F (x) und Fn(x−)
f.s.−→ F (x−) (5.1)
für n → ∞ , also die punktweise Konvergenz fast sicher. Die nachfolgenden Aussagengelten daher jeweils fast sicher. Wir wählen nun k ∈ N , setzen
xj,k := infx ∈ R : F (x) ≥ j
k
für j = 1, . . . , k − 1
und x0,k := −∞ und xk,k :=∞ . Aus (5.1), der punktweisen Konvergenz, erhalten wir
∃nk ∈ N ∀n ≥ nk : |Fn(xj,k)− F (xj,k)| ≤ 1k ∧
∣∣∣Fn(x−j,k)− F (x−j,k)∣∣∣ ≤ 1
k .
Die Monotonie der Verteilungsfunktion F impliziert
F (x−j,k) ≤ jk
1Waleri Iwanowitsch Gliwenko, 18961940, russischer Mathematiker

5. Deskription und Exploration 173
und daher ist
F (x−j,k)− F (xj−1,k) ≤ 1k .
Für x ∈ [xj−1,k, xj,k) gilt nun weiters
Fn(x) ≤ Fn(x−j,k) ≤ F (x−j,k) + 1k ≤ F (xj−1,k) + 2
k ≤ F (x) + 2k
und
Fn(x) ≥ Fn(xj−1,k) ≥ F (xj−1,k)− 1k ≥ F (x−j,k)− 2
k ≥ F (x)− 2k .
Damit ist gezeigt, dass
∀ k ≥ 1 ∃ nk ∈ N ∀n ≥ nk : supx∈R|F (x)− Fn(x)| ≤ 2
k f.s.
und damit die Aussage des Satzes bewiesen.
Bemerkung. Die empirische Verteilungsfunktion Fn konvergiert nach dem Satz vonGliwenko-Cantelli also fast sicher gleichmäÿig gegen die Verteilungsfunktion F .
5.3 Dichten und Histogramme
Ziel dieses Abschnitts ist es, die Verteilung eines Merkmals durch den gegebenen Da-tensatz x1, . . . , xn graphisch zu beschreiben. Zur graphischen Beschreibung von Dichtenanhand der Daten verwendet man häug sogenannte Histogramme.
Histogramme
Wir gehen davon aus, dass der Datensatz x1, . . . , xn ∈ R in geordneter Form vorliegt,d.h.
x1 ≤ . . . ≤ xn .
Diese Anordnung hat natürlich nur für ordinale und reelle Merkmale eine inhaltliche Be-deutung. Wir unterteilen nun das Intervall [c, d) ⊃ [x1, xn] , c < d , in paarweise disjunkteIntervalle I1, . . . , Ik , welche als Klassen bezeichnet werden. Für alle j = 1, . . . , k sei da-bei Ij = [aj−1, aj) mit a0 = c , ak = d und aj−1 < aj . Damit erhalten wir eine disjunkteZerlegung
[c, d) =k⊎
j=1
Ij .

174 5. Deskription und Exploration
Das zu dieser Zerlegung und dem Datensatz x1, . . . , xn gehörige Histogramm ist danndurch die Abbildung
R→ R : x 7→k∑
j=1
njnλ(Ij)
χIj (x) =
k∑
j=1
Pn(Ij)
λ(Ij)χIj (x)
gegeben, wobei
nj := #i ∈ 1, . . . , n : xi ∈ Ij .
Der Flächeninhalt der Rechtecke Ij ×[0,
njnλ(Ij)
]ist oensichtlich
njnλ(Ij)
λ(Ij) =njn
= Pn(Ij) ,
also gerade die relative Häugkeit der Datenpunkte im entsprechenden Intervall.
Häug wird eine entsprechende äquidistante Zerlegung des Intervalls [c, d) ⊃ [x1, xn]gewählt. Für die Anzahl der Klassen gibt es einige Faustregeln wie etwa k =
√n .
Beispiel 5.4 (Baumhöhe)Zunächst laden wir aus dem Datensatz trees wie folgt die Höhe von 31 gefällten Bäumeneiner bestimmten Art.
> trees.height=trees$Height
> trees.height
[1] 70 65 63 72 81 83 66 75 80 75 79 76 76 69 75 74 85 86 71
64 78 80 74 72 77
[26] 81 82 80 80 80 87
> summary(trees.height)
Min. 1st Qu. Median Mean 3rd Qu. Max.
63 72 76 76 80 87
Mittels des Befehls hist erzeugen wir nun ein Histogramm und lassen uns anschlieÿenddie automatisch gewählte Zerlegung ausgeben.
> trees.HG=hist(trees.height ,freq=FALSE)
> trees.HG$breaks
[1] 60 65 70 75 80 85 90
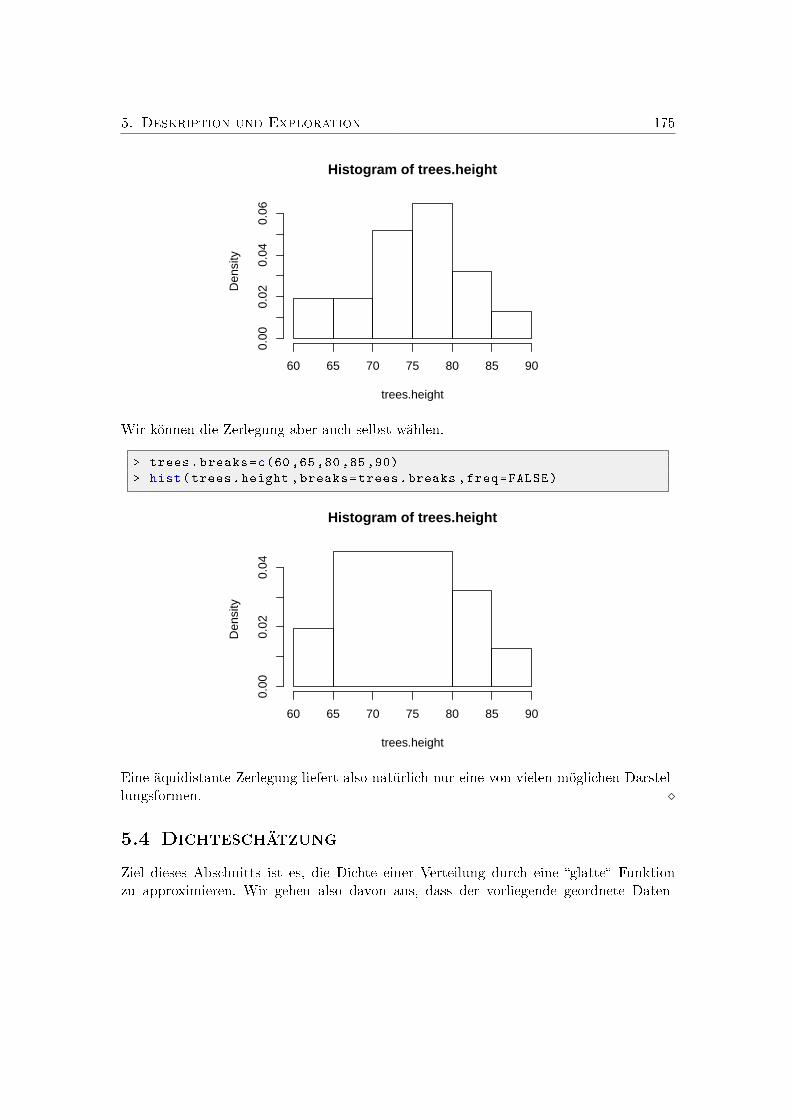
5. Deskription und Exploration 175
Histogram of trees.height
trees.height
Den
sity
60 65 70 75 80 85 90
0.00
0.02
0.04
0.06
Wir können die Zerlegung aber auch selbst wählen.
> trees.breaks=c(60 ,65 ,80 ,85 ,90)
> hist(trees.height ,breaks=trees.breaks ,freq=FALSE)
Histogram of trees.height
trees.height
Den
sity
60 65 70 75 80 85 90
0.00
0.02
0.04
Eine äquidistante Zerlegung liefert also natürlich nur eine von vielen möglichen Darstel-lungsformen.
5.4 Dichteschätzung
Ziel dieses Abschnitts ist es, die Dichte einer Verteilung durch eine glatte Funktionzu approximieren. Wir gehen also davon aus, dass der vorliegende geordnete Daten-

176 5. Deskription und Exploration
satz x1, . . . , xn von einer Stichprobe stammt, deren Verteilung eine Dichte bezüglich desLebesgue-Maÿes besitzt.
Als Vorstufe führen wir das gleitende Histogramm ein. Es sei dazu h > 0 fest gewählt.Analog zum Histogramm wird der Funktionswert durch
fh(x) :=# i ∈ 1, . . . , n : xi ∈ [x− h, x+ h]
n · 2h =1
nh
n∑
i=1
1
2χ[x−h,x+h](xi)
für x ∈ R berechnet. Mittels des Kerns
KN : R→ R : u 7→ 12χ[−1,1](u) ,
welcher als naiver Kern bezeichnet wird, schreibt sich der erhaltene Funktionswert als
fh(x) =1
nh
n∑
i=1
KN
(x− xih
).
Oensichtlich ist KN selbst eine Dichte und somit auch fh . Ein Kern ist also eine vorge-gebene Wahrscheinlichkeitsdichte. Mittels des unstetigen naiven Kerns erhält man jedochnoch keine glatte Approximation. Daher verwenden wir anstelle des naiven Kerns bei-spielsweise den durch
KG(u) :=1√2π
e−u2/2 , u ∈ R ,
gegebenen Gauÿ-Kern oder den Epanechnikov-Kern
KE(u) := 34(1− u2)χ[−1,1] , u ∈ R .
Die für einen Kern K und die Bandbreite h > 0 durch
fh(x) :=1
nh
n∑
i=1
K
(x− xih
)
gegebene Funktion nennt manKern-Dichteschätzer und diese ist natürlich eine Dichte,vgl. Aufgabe (5.11).
Beispiel 5.5 (Insektensprays)Wir wollen die Wirksamkeit von zwei der Insektensprays im Datensatz InsectSprays
miteinander vergleichen.
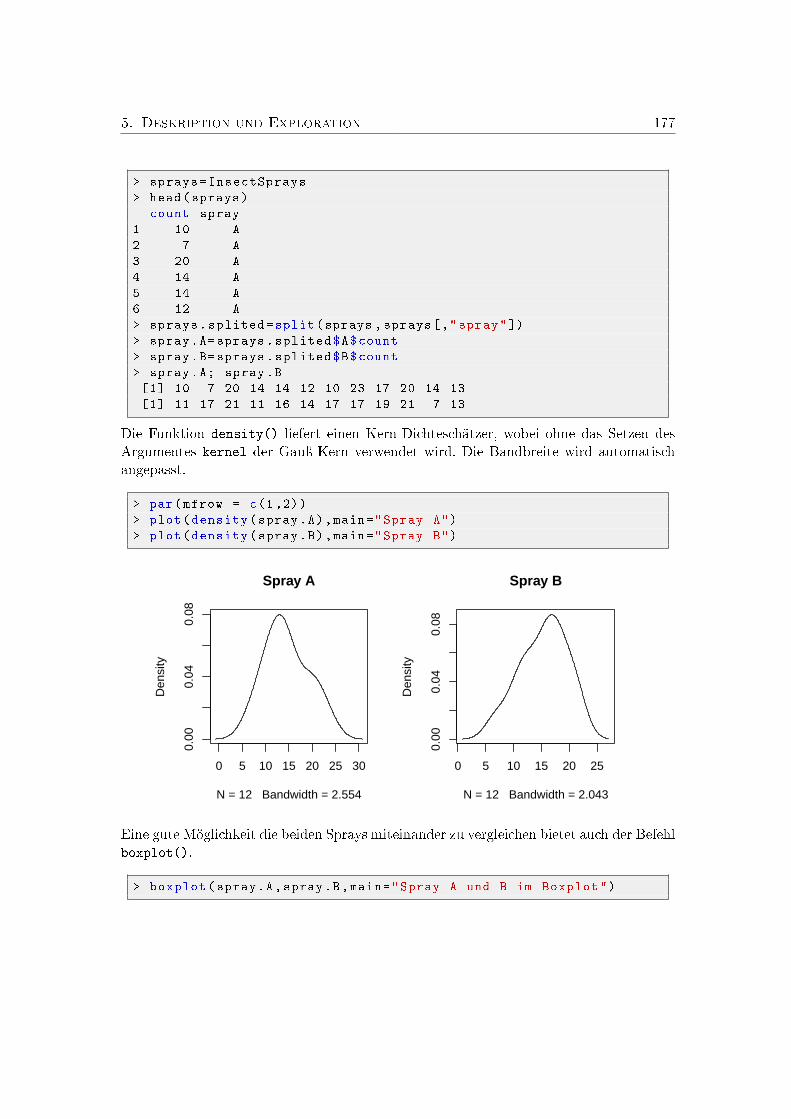
5. Deskription und Exploration 177
> sprays=InsectSprays
> head(sprays)
count spray
1 10 A
2 7 A
3 20 A
4 14 A
5 14 A
6 12 A
> sprays.splited=split(sprays ,sprays[,"spray"])
> spray.A=sprays.splited$A$count
> spray.B=sprays.splited$B$count
> spray.A; spray.B
[1] 10 7 20 14 14 12 10 23 17 20 14 13
[1] 11 17 21 11 16 14 17 17 19 21 7 13
Die Funktion density() liefert einen Kern-Dichteschätzer, wobei ohne das Setzen desArgumentes kernel der Gauÿ-Kern verwendet wird. Die Bandbreite wird automatischangepasst.
> par(mfrow = c(1,2))
> plot(density(spray.A),main="Spray A")
> plot(density(spray.B),main="Spray B")
0 5 10 15 20 25 30
0.00
0.04
0.08
Spray A
N = 12 Bandwidth = 2.554
Den
sity
0 5 10 15 20 25
0.00
0.04
0.08
Spray B
N = 12 Bandwidth = 2.043
Den
sity
Eine gute Möglichkeit die beiden Sprays miteinander zu vergleichen bietet auch der Befehlboxplot().
> boxplot(spray.A,spray.B,main="Spray A und B im Boxplot")

178 5. Deskription und Exploration
1015
20
Spray A und B im Boxplot
Die in einem Boxplot dargestellten Gröÿen werden im nächsten Abschnitt eingeführt.
5.5 Statistische Maÿzahlen
Wir werden nun im Folgenden einige statistische Maÿzahlen einführen. Ausgangspunktist wiederum ein geordneter Datensatz x1, . . . , xn .
Lagemaÿe
Lagemaÿe beschreiben das Zentrum einer Verteilung. Ein Beispiel eines Lagemaÿes istder empirische Mittelwert
x(n) :=1
n
n∑
i=1
xi .
Oftmals wird dieser auch einfach alsMittel bezeichnet. Man beachte, dass der empirischeMittelwert a priori nur für reelle Merkmale sinnvoll deniert ist. Weiters minimiert erdie Summe der quadratischen Abweichungen, d.h.
n∑
i=1
(xi − x(n)
)2 ≤n∑
i=1
(xi − x)2 für alle x 6= x(n) ,
vgl. Aufgabe (5.14). Daraus lässt sich erkennen, dass der empirische Mittelwert sehrstark von Ausreiÿern beeinusst werden kann. Stabiler unter Ausreiÿern verhält sich der(empirische) Median
x(n) :=
xn+1
2, n ungerade,
12(xn
2+ xn
2+1) , n gerade,

5. Deskription und Exploration 179
denn dieser minimiert die Summe der absoluten Abweichungen, d.h.
n∑
i=1
∣∣xi − x(n)
∣∣ ≤n∑
i=1
|xi − x| für alle x 6= x(n) ,
vgl. Aufgabe (5.15). Man beachte bei der Denition des Medians, dass es sich bei x1, . . . , xnum einen geordneten Datensatz handelt.
In R wird der empirische Mittelwert bzw. der Median mittels mean() bzw. median()berechnet.
> x=rnorm (100)
> mean(x);median(x)
[1] 0.1418632
[1] 0.2386723
> mean(x^9);median(x^9)
[1] 61.31929
[1] 2.753051e-06
Weitere wichtige Lagemaÿe sind die sogenannten Quantile. Für α ∈ [0, 1] nennt manxα ∈ R ein α-Quantil, wenn mindestens ein Anteil α der Daten x1, . . . , xn einen Wertkleiner oder gleich xα und mindestens ein Anteil 1−α einen Wert gröÿer gleich xα besitzt.Man beachte, dass Quantile im Allgemeinen nicht eindeutig sind. Ein 25%-Quantil, 50%-Quantil bzw. 75%-Quantil wird auch als unteres oder 1. Quartil, 2. Quartil bzw.oberes oder 3. Quartil bezeichnet. Oensichtlich ist der Median gerade ein 2. Quartil.Den Abstand zwischen oberem und unterem Quartil nennt man Interquartilsabstand.
> quantile(rivers , probs = 0.5)
50%
425
> median(rivers)
[1] 425
Eine praktische Zusammenfassung der wichtigsten Lagemaÿe liefert summary().
> summary(rivers)
Min. 1st Qu. Median Mean 3rd Qu. Max.
135.0 310.0 425.0 591.2 680.0 3710.0
Eine graphische Darstellung dieser Werte bietet einBoxplot. Dieser eignet sich besondersgut, wie bereits in Beispiel 5.5 geschehen, um mehrere Datensätze miteinander zuvergleichen. Dabei gibt die Linie in der Mitte des Rechtecks den Wert des Medians an, die

180 5. Deskription und Exploration
untere Kante des Rechtecks das untere Quartil, die obere das obere Quartil. Die Stricheam Ende der strichlierten vertikalen Linie kennzeichnen das Minimum bzw. Maximumohne Ausreiÿer. Als Ausreiÿer werden Datenpunkte bezeichnet, die mehr als das 1.5-fache des Interquartilsabstands entfernt vom oberem oder unterem Quartil liegen. Diesewerden separat als Kreise eingezeichnet.
Streumaÿe
Die empirische Varianz
s2(n) :=
1
n− 1
n∑
i=1
(xi − x(n)
)2
beschreibt, wie stark die Daten um den empirischen Mittelwert schwanken. Die Mittelungdurch n− 1 anstatt durch n können wir vorerst wie folgt erklären: Da
n∑
i=1
(xi − x(n)
)= 0 ,
wird beispielsweise die Abweichung xn−x(n) durch die restlichen n− 1 festgelegt. Dahervariieren nur n− 1 Abweichungen und man mittelt daher indem man durch die Anzahln− 1 der sogenannten Freiheitsgrade dividiert.
Weitere Streumaÿe sind die empirische Standardabweichung oder Streuung
s(n) =
√√√√ 1
n− 1
n∑
i=1
(xi − x(n)
)2,
der empirische Variationskoezient
V(n) :=s(n)
x(n)
und die empirische Spannweite
r(n) := xn − x1 ,
wobei wiederum x1 ≤ . . . ≤ xn .> var(rivers) #Empirische Varianz
[1] 243908.4
> sd(rivers);sqrt(var(rivers)) #Streuung
[1] 493.8708
[1] 493.8708
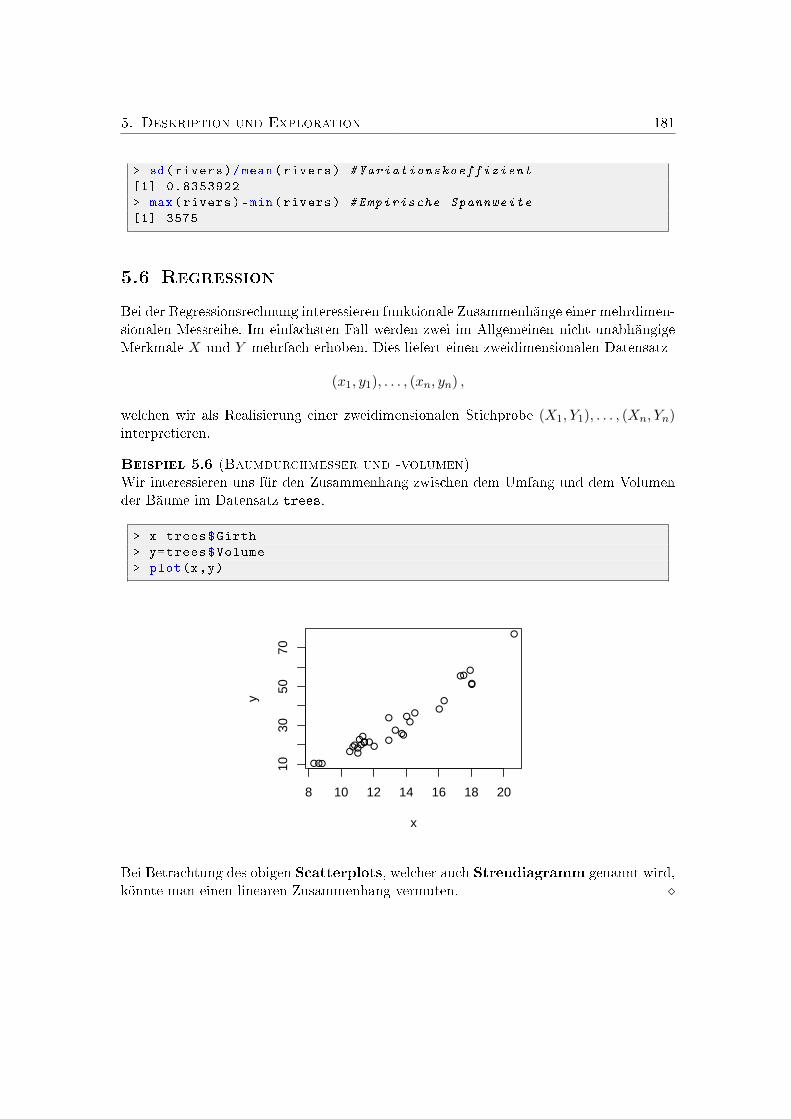
5. Deskription und Exploration 181
> sd(rivers)/mean(rivers) #Variationskoeffizient
[1] 0.8353922
> max(rivers)-min(rivers) #Empirische Spannweite
[1] 3575
5.6 Regression
Bei der Regressionsrechnung interessieren funktionale Zusammenhänge einer mehrdimen-sionalen Messreihe. Im einfachsten Fall werden zwei im Allgemeinen nicht unabhängigeMerkmale X und Y mehrfach erhoben. Dies liefert einen zweidimensionalen Datensatz
(x1, y1), . . . , (xn, yn) ,
welchen wir als Realisierung einer zweidimensionalen Stichprobe (X1, Y1), . . . , (Xn, Yn)interpretieren.
Beispiel 5.6 (Baumdurchmesser und -volumen)Wir interessieren uns für den Zusammenhang zwischen dem Umfang und dem Volumender Bäume im Datensatz trees.
> x=trees$Girth
> y=trees$Volume
> plot(x,y)
8 10 12 14 16 18 20
1030
5070
x
y
Bei Betrachtung des obigen Scatterplots, welcher auch Streudiagramm genannt wird,könnte man einen linearen Zusammenhang vermuten.

182 5. Deskription und Exploration
Bei der linearen Regression wird ein funktionaler Zusammenhang der Form
y = ax+ b
angenommen. Im Allgemeinen wird es natürlich nicht möglich sein yi = axi + b für allei = 1, . . . , n zu erfüllen. Die Konstanten a, b ∈ R sollen nun so bestimmt werden, dassdieses Modell möglichst gut den gegebenen Daten (x1, y1), . . . , (xn, yn) angepasst ist,d.h. die Datenpunkten der Geraden möglichst nahe liegen.
Eine Möglichkeit eine solche Gerade zu bestimmen bietet das Prinzip der kleinstenFehler-Quadrate. Dabei wird die Summe der quadratischen Abstände der Datenpunktezu den zugehörigen Werten auf der Geraden minimiert, also
f(a, b) =n∑
i=1
(yi − (axi + b))2 → min .
Die Gerade, welche man dadurch erhält, wird Regressionsgerade genannt. Eine einfa-che Rechnung, vgl. Aufgabe (5.17), führt auf
a =
∑ni=1(xi − x)(yi − y)∑n
i=1(xi − x)2und b = y − ax ,
wobei
x :=1
n
n∑
i=1
xi und y :=1
n
n∑
i=1
yi .
Um die Steigung a interpretieren zu können, benötigen wir folgende Denition.
Definition 5.7 (Empirische Kovarianz)Die Maÿzahl
sx,y :=1
n− 1
n∑
i=1
(xi − x)(yi − y)
wird empirische Kovarianz der zweidimensionalen Messreihe (x1, y1), . . . , (xn, yn) ge-nannt.
Es bezeichne s2x die empirische Varianz von x1, . . . , xn . Dann können die Koezienten
der Regressionsgerade
y = ax+ b
als
a =sx,ys2x
und b = y − ax

5. Deskription und Exploration 183
geschrieben werden. Die empirische Kovarianz gibt also das Vorzeichen der Steigung derRegressionsgeraden an.
Um die Stärke des linearen Zusammenhangs zu messen, bedarf es einer weiteren De-nition.
Definition 5.8 (Korrelationskoeffizient und empirische Korrelation)Für zwei quadratisch integrierbare Zufallsvariablen X und Y mit positiver Varianz nenntman
ρ(X,Y ) :=Cov(X,Y )√
Var(X)√
Var(Y )
den Korrelationskoezienten, sein empirisches Pendant
rx,y :=sx,ysx · sy
empirische Korrelation nach Pearson2.
Da
f(a, b) =n∑
i=1
(yi − (axi + b))2 = (n− 1)s2y(1− r2
x,y) ,
vgl. Aufgabe (5.18), liegen genau dann alle Datenpunkte (x1, y1), . . . , (xn, yn) auf derRegressionsgerade, wenn |rx,y| = 1 . Oenbar gilt |rx,y| ≤ 1 . Daraus wird ersichtlich,dass die empirische Korrelation ein Maÿ für den linearen Zusammenhang ist.
Beispiel 5.9 (Fortsetzung von Beispiel 5.6)In R wird die Regressionsgerade mittels lm() bestimmt, die empirische Korrelation er-halten wir durch cor().
> x=trees$Girth
> y=trees$Volume
> cor(x,y)
[1] 0.9671194
> plot(x,y)
> rg=lm(y~x)
> rg
Call:
lm(formula = y ~ x)
2Karl Pearson, 18571936, britischer Mathematiker und Philosoph
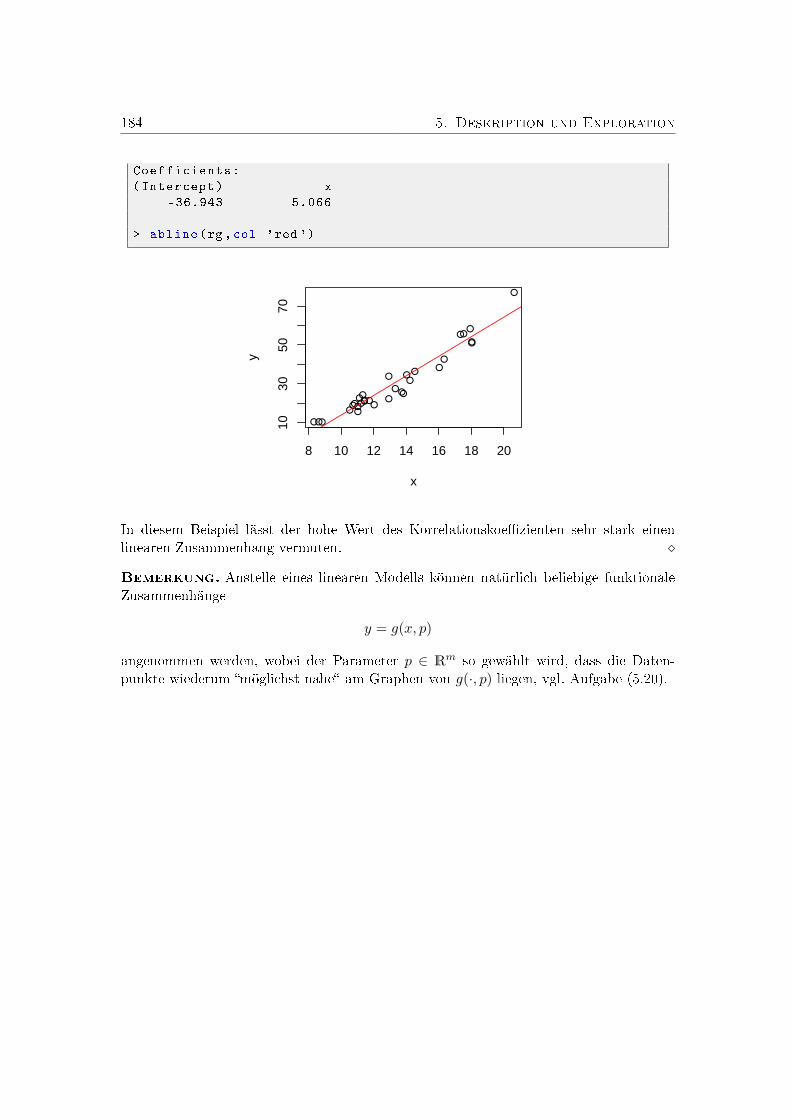
184 5. Deskription und Exploration
Coefficients:
(Intercept) x
-36.943 5.066
> abline(rg ,col='red ')
8 10 12 14 16 18 20
1030
5070
x
y
In diesem Beispiel lässt der hohe Wert des Korrelationskoezienten sehr stark einenlinearen Zusammenhang vermuten.
Bemerkung. Anstelle eines linearen Modells können natürlich beliebige funktionaleZusammenhänge
y = g(x, p)
angenommen werden, wobei der Parameter p ∈ Rm so gewählt wird, dass die Daten-punkte wiederum möglichst nahe am Graphen von g(·, p) liegen, vgl. Aufgabe (5.20).

5. Deskription und Exploration 185
Übungsaufgaben
(5.1) Fragebogenauswertung: Importieren Sie den Datensatz janein.txt. (Die-sen nden Sie unter http://tobiashell.com.) Erstellen Sie eine Grak, die dieabsolute Anzahl der Nein- (0) und Ja-Antworten (1) darstellt und eine zweite,bei der die relativen Häugkeiten dargestellt sind. Beschriften Sie insbesondere diey-Achse.
(5.2) Empirische Verteilung: Zeigen Sie, dass die empirische Verteilung zu x1, . . . , xnein Wahrscheinlichkeitsmaÿ auf B(R) ist, es sich also um eine Verteilung handelt.
(5.3) Es seien X1, . . . , Xn u.i.v. und B ∈ B(R) . Zeigen Sie, dass
χB(X1), . . . , χB(Xn) u.i.v.
(5.4) Empirische Verteilungsfunktion einer normalverteilten Stichprobe:Erzeugen Sie in R ein Plotfenster mit folgenden zwei Plots untereinander und sinn-vollen Beschriftungen:
(a) Plotten Sie die empirische Verteilungsfunktion einer Realisierung einer stan-dardnormalverteilten Stichprobe vom Umfang 10 sowie (im selben Plot inroter Farbe) die Verteilungsfungsfunktion der Standardnormalverteilung.
(b) Wiederholen Sie dasselbe für einen Stichprobenumfang von 100.
Nützliche Befehle: ecdf(), par(mfrow=c()), lines()
(5.5) Histogramm: Erstellen Sie für das Merkmal temp der beiden Datensätze beaver1und beaver2 in einem Plotfenster die zwei Histogramme. Nutzen Sie die Möglich-keit die Anzahl der Klassen zu steuern. Beschreiben Sie die Unterschiede der beidenHistogramme.Für ein besseres Verständnis, was ein Histogramme darstellt, erzeugen sie eine Rea-lisierung einer standardnormalverteilten Stichprobe vom Umfang 5000 und plottenSie ein Histogramm der Daten.
(5.6) Gegeben sei der Datensatz
x1 = 2, x2 = 5, x3 = −2, x4 = 3, x5 = 2 .
Plotten Sie in R die zugehörige empirische Verteilungsfunktion F5 und bestimmenSie P5 . Berechnen Sie weiters den Erwartungswert von P5 .
(5.7) Empirische Verteilungsfunktion einer normalverteilten Stichprobe:Erzeugen Sie in R ein Plotfenster mit folgenden zwei Plots untereinander und sinn-vollen Beschriftungen:

186 5. Deskription und Exploration
(a) Plotten Sie die empirische Verteilungsfunktion einer Realisierung einer stan-dardnormalverteilten Stichprobe vom Umfang 10 sowie (im selben Plot inroter Farbe) die Verteilungsfungsfunktion der Standardnormalverteilung.
(b) Wiederholen Sie dasselbe für einen Stichprobenumfang von 100.
Speichern Sie das Ergebnis als PDF-Datei.
(5.8) Burger: Ein Fast-Food-Kette beschlieÿt in der eigenen Facebook-Gruppe eineUmfrage zu machen, um herauszunden, welcher der beliebteste Burger ist. Dabeistehen fünf Burger zur Auswahl. Jeder Teilnehmer bzw. jede Teilnehmerin kanneinen Burger auswählen und darf nur einmal an der Umfrage teilnehmen. DasUmfrageergebnis lautet wie folgt:
5, 4, 4, 1, 1, 4, 5, 3, 2, 4, 3, 3, 3, 2, 1, 3, 4, 1, 4, 2, 3, 5, 4, 4, 2, 3, 4, 2, 3, 3
Sind die Burger gleich beliebt?
Beantworten Sie dies Fragen (noch) nicht, aber geben Sie an, wie Sie die gege-benen Werte stochastisch modellieren und was mögliche statische Fragestellungenin Zusammenhang mit der Aufgabenstellung sind. Klassizieren Sie insbesonderedas/die Merkmal/e.
(5.9) Exponentialverteilung empirische Verteilungsfunktion: Generieren Sieeine Realisierungen einer exponentialverteilten Stichprobe mit Parameter 2 vomUmfang 1000 . Erzeugen Sie die empirische Verteilungsfunktion Fn für die ersten50, ersten 100, ersten 500, alle 1000 Werte und bestimmen Sie jeweils in R denAbstand
‖Fn − F‖∞ ,
wobei F die Verteilungsfunktion der entsprechenden Exponentialverteilung bezeich-net. Erstellen Sie insbesondere eine Grak mit den vier Graphen der empirischenVerteilungsfunktionen jeweils gemeinsam mit dem Graphen von F . Im jeweiligenTitel soll der Abstand angeführt sein.Hinweis: Recherchieren Sie für Letzteres den Befehl paste .
(5.10) Erwartungswert und Varianz der empirischen Verteilungsfunktion:Gegeben sei eine Stichprobe X1, . . . , Xn zur Verteilung P . Bestimme Sie für festesx ∈ R Erwartungswert und Varianz von
Fn(x ;X1, . . . , Xn) .
(5.11) Man zeige:
(a) KG und KE sind Wahrscheinichkeitsdichten.

5. Deskription und Exploration 187
(b) Es sei x0 ∈ R und h > 0 . Ist K ein Kern, so ist
x 7→ 1
hK
(x− x0
h
)
eine Wahrscheinlichkeitsdichte.
(c) Ein Kern-Dichteschätzer ist eine Wahrscheinlichkeitsdichte.
(5.12) Kern-Dichteschätzer: Führen Sie folgenden R-Code aus. Fügen Sie nun selb-ständig weitere Kerne hinzu und überlegen Sie sich Kriterien für einen gutenKern.
x = rnorm (50)
# Kern
K = function(t) if (t>=0 && t<=1) 4*t^3 else 0
par(mfrow=c(1,2))
s = seq ( -0.5 ,1.5 ,0.01)
plot(s,sapply(s,K),type="l",xlab="x",ylab="K(x)",main="Kern")
# Kerndichteschaetzer
h=0.1
myfh = function(y) n=length(x); return (1/n/h*sum(sapply ((y-x)/
h,K)))
t =seq(-3,3,0.01)
plot(t,sapply(t,myfh),type="l",xlab="x",ylab="f_h(x)",main="
Kerndichteschaetzer")
lines(density(x,kernel="epanechnikov"),col="red")
lines(density(x,kernel="gaussian"),col="blue")
points(x,0*x,pch =20)
(5.13) Insektensprays: Vergleichen Sie die Insektensprays im Datensatz InsectSpraysin Analogie zu Beispiel 5.5. Verwenden Sie weiters den Epanechnikov-Kern zurKern-Dichteschätzung und vergleichen Sie die Resultate zu unterschiedlich gesetz-ten Bandbreiten.
(5.14) Zeigen Sie, dass der empirische Mittelwert die Summe der quadratischen Abwei-chungen minimiert.
(5.15) Zeige Sie, dass der Median die Summe der absoluten Abweichungen minimiert.
(5.16) Zahnwachstum: Vergleichen Sie das Zahnwachstum der Meerschweinchen im Da-tensatz ToothGrowth mit Hilfe eines Boxplots. Verwenden und erklären Sie die

188 5. Deskription und Exploration
Befehle qqnorm und qqline und interpretieren Sie die entsprechenden Plots fürden obigen Datensatz.
(5.17) Gegeben sei eine Messreihe (x1, y1), . . . , (xn, yn) . Zeigen Sie durch Minimierungvon
f(a, b) =n∑
i=1
(yi − (axi + b))2 ,
dass die Koezienten der zugehörigen Regressionsgerade y = ax+ b durch
a =sx,ys2x
und b = y − ax
gegeben sind.
(5.18) Zeigen Sie für a und b wie in Aufgabe (5.17), dass
n∑
i=1
(yi − (axi + b))2 = (n− 1)s2y(1− r2
x,y) .
(5.19) Korrelationskoeffizient und empirischer Korrelation: Zeigen Sie, dass
(a) ρ(X,Y ) ∈ [−1, 1] für quadratisch integrierbare Zufallsvariablen X und Y mitpositiver Varianz ,
(b) rx,y ∈ [−1, 1] für einen Datensatz (x1, y1), . . . , (xn, yn) ∈ R2 , sofern sx, sy >0 .
(5.20) Regressionsparabel: Gegeben sei die Messreihe
(x1, y1), . . . , (xn, yn) .
Passen Sie eine Parabel
y = a+ bx+ cx2
durch Minimierung von
F (a, b, c) =
n∑
i=1
(yi − (a+ bxi + cx2
i ))2
den Daten an. Bestimmen Sie eine solche Parabel für die Höhe und den Durchmesserder Bäume im Datensatz trees.

5. Deskription und Exploration 189
Schulaufgaben
Die nachfolgenden Aufgaben stammen, sofern keine weiteren Angaben gemacht werden,von https://www.bifie.at/ (Stand: Februar 2013).
(S5.1) Einkindfamilien: Ein Vortragender interpretiert die untenstehende Tabelle mitfolgenden Worten:
Sie sehen, dass in dieser Wohnsiedlung 50 % aller Kinder ohne Geschwister auf-wachsen.
Entscheide, ob die Interpretation des Vortragenden korrekt ist und begründe deineEntscheidung.
Anzahl der Kinder Anzahl derpro Wohnung Wohnungen
0 3
1 15
2 6
3 3
4 2
5 1
Tabelle. Ergebnis einer Untersuchung zur Gröÿe der Familien in einer Wohnsied-lung mit 30 Wohnungen.
(S5.2) Tagesumsätze: Die Tagesumsätze (in e) eines Restaurants für eine bestimmteWoche sind in folgendem Diagramm angegeben:

190 5. Deskription und Exploration
(a) Um wie viel wird am Samstag mehr als am Montag umgesetzt?
(b) Wie groÿ ist der durchschnittliche Tagesumsatz in dieser Woche?
(S5.3) Arbeitslose:
Tabelle. Stand: Oktober 2000; Quelle: Bundesministerium f. Wirtschaft und Arbeit,
Presseabteilung
In oben stehender Tabelle sind die Arbeitslosenzahlen für Österreich getrenntnach Altersklassen und Geschlecht aufgelistet.
(a) Sind unter den jungen Arbeitslosen (bis unter 25 Jahre) mehr Männer alsFrauen? Gib die entsprechenden Werte an.
(b) Betrachte die Altersgruppen der 30- bis unter 40-Jährigen und der 40- bisunter 50-Jährigen: In welcher dieser Altersgruppen ist der auf die jeweiligeAltersgruppe bezogene Prozentsatz der weiblichen Arbeitslosen höher?
(c) Von allen Arbeitslosen wird eine Person zufällig ausgewählt. Mit welcherWahrscheinlichkeit ist diese Person jünger als 19 und männlich?
(S5.4) Histogramm erstellen: Bei einer LKW-Kontrolle wurde bei 50 Fahrzeugeneine Überladung festgestellt. Zur Festlegung des Strafrahmens wurde die Überla-dung der einzelnen Fahrzeuge in der folgenden Tabelle festgehalten.
Überladung (in kg) Anzahl der LKW
<1000 14
1000 bis 2000 24
2000 bis 3000 8
3000 bis 4000 4
Zeichnen Sie ein Histogramm der Daten.

5. Deskription und Exploration 191
(S5.5) Spendenaktion: An einer Spendenaktion beteiligten sich fünfhundert Personen.Durchschnittlich wurde ein Betrag von EUR 20, gegeben. Kann man aus diesenInformationen den Gesamtbetrag der Spende ermitteln?
(S5.6) Boxplot: Ein Kastenschaubild zeigt die Studiendauer in Semestern für eine tech-nische Studienrichtung.
(a) Lies die Quartile ab.q1 = q2 = q3 =
(b) Sind die folgenden Aussagen wahr oder falsch? Kreuze an!
Die Spannweite beträgt 10 Semester.
25% der Studierenden studieren höchstens 14 Semester lang.
Es gibt Studierende, die ihr Studium erst nach 10 Jahren beenden.
50% der Studierenden benötigen für den Abschluss des Studiums zwi-schen 13 und 17 Semestern.
1/4 der Studierenden benötigt für den Abschluss des Studiums mindes-tens 17 Semester.
Die Streuung der Werte im ersten Viertel ist am geringsten.
(S5.7) Boxplot zeichnen: Eine Tankstellenkette hat in den Shops von Filialen dieUmsatzzahlen eines Tiefkühlprodukts jeweils über einen Zeitraum von 15 Wochenbeobachtet und der Gröÿe nach festgehalten.
Umsatzzahlen: 12, 12, 12, 12, 18, 18, 18, 18, 18, 23, 23, 23, 23, 23, 24
Zeichnen Sie den entsprechenden Boxplot und tragen Sie die angegebenen Kenn-zahlen unter der Grak ein!
192 5. Deskription und Exploration
(S5.8) Sportwettbewerb 1: 150 Grazer und 170 Wiener Schülerinnen nahmen aneinem Sportbewerb teil.
Der Vergleich der Listen der Hochsprungergebnisse ergibt einen für beide gleichenMittelwert von 1.05 m und eine empirische Standardabweichung für die Grazervon 0.22 m und für die Wiener von 0.3 m.
Entscheide, welche der folgenden Aussagen aus den gegebenen Daten geschlossenwerden können.
(a) Beide Listen haben den gleichen Median.
(b) Der Mittelwert repräsentiert die Leistungen der Grazer Schülerinnen besserals die der Wiener.
(c) Die Standardabweichung der Grazerinnen ist auf Grund der geringeren Teil-nehmeranzahl kleiner als die der Wienerinnen.
(d) Von den Sprunghöhen (gemessen in m) der Wienerinnen liegt kein Wertauÿerhalb des Intervalls [0.45, 1.65] .
(S5.9) Zwei Merkmale mit gegensinnigem Zusammenhang: Die Messung zwei-er Merkmale x und y an 8 Einheiten ergab folgende Wertepaare (xi, yi):
Nr. Gröÿe x Gröÿe y Nr. Gröÿe x Gröÿe y
1 10 6 5 40 2
2 20 3 6 50 3
3 30 6 7 60 2
4 40 4 8 70 3
Gesucht ist eine graphische Darstellung der Gröÿen x und y der Stichprobe. Liegtzwischen den beiden Gröÿen irgendeine Tendenz vor?(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 319, Bsp. 8.3)

5. Deskription und Exploration 193
Kontrollfragen
5.1 Die Studierenden einer Statistikvorlesung werden hinsichtlich ihres Alters in Jah-ren und ihrer Körpergröÿe befragt. Welche der folgenden Aussagen sind zutref-fend?
Beim Alter handelt es sich um ein diskretes Merkmal, die Körpergröÿe stelltein stetiges Merkmal dar.
Sowohl Alter als auch Körpergröÿe sind stetige Merkmale.
Alter und Körpergröÿe sind reelle Merkmale.
Das Alter ist ein ordinales und die Körpergröÿe ein reelles Merkmal.
5.2 Beim zwölfmaligen Würfeln traten folgende Augenzahlen auf:
x1 = 4 , x2 = 3 , x3 = 6 , x4 = 6 , x5 = 4 , x6 = 4 ,
x7 = 4 , x8 = 2 , x9 = 2 , x10 = 3 , x11 = 2 , x12 = 6 .
Es sei
P12 =1
m
n∑
k=1
pkδk
Für welche m,n, p1, . . . , pn ist P12 die empirische Verteilung zu x1, . . . , x12 ?
Für m = 6 , n = 6 und
p1 = . . . = p6 = 1 .
Es ist m = 1 , n = 6 und
p1 = . . . = p6 = 16 .
Für m = 12 , n = 6 und
p1 = 0 , p2 = 3 , p3 = 2 , p4 = 4 , p5 = 0 , p6 = 3 .
Für m = 1 , n = 6 und
p1 = 0 , p2 = 312 , p3 = 2
12 , p4 = 412 , p5 = 0 , p6 = 3
12 .
5.3 Es sei Xn∞n=1 eine Stichprobe zur Verteilung P . Für n ∈ N bezeichne auÿer-dem Pn die empirische Verteilung und Fn die empirische Verteilungsfunktion zuX1, . . . , Xn . Welche der folgenden Aussagen sind wahr?

194 5. Deskription und Exploration
∀B ∈ B(R) : Pn(B)f.s.−→ P (B)
∀x ∈ R : Fn(x)→ FP (x)
Fn → FP fast sicher gleichmäÿig auf R
∀x ∈ R : Fn(x−)f.s.−→ FP (x−)
5.4 Welche der folgenden Aussagen sind wahr?
Der Flächeninhalt der bei einem Histogramm auftretenden Rechtecke istgleich der entsprechenden absoluten Häugkeiten.
Der Flächeninhalt der bei einem Histogramm auftretenden Rechtecke istgleich der entsprechenden relativen Häugkeiten.
Die bei einem Histogramm gebildeten Klassen I1, . . . , Ik müssen nicht zwin-gend paarweise disjunkt sein.
Die bei einem Histogramm gebildeten Klassen I1, . . . , Ik müssen disjunktsein.
5.5 Gegeben sei der Datensatz x1, . . . , xn ∈ R . Welche der folgenden Aussagen sindwahr?
x(n) = x(n)
x(n) 6= x(n)
Die empirische Standardabweichung ist stets kleiner gleich der empirischenVarianz.
Zu α = 1 ist das α-Quantil von x1, . . . , xn eindeutig.
5.6 Es sei (x1, y1), . . . , (xn, yn) ∈ R2 eine Realisierung der zweidimensionalen Stich-probe (X1, Y1), . . . , (Xn, Yn) . Welche der folgenden Aussagen sind wahr?
Sind X1 und Y2 unabhängig, so liegt keiner der Punkte (xi, yi) , i = 1, . . . , n ,auf der zugehörigen Regressionsgeraden.
Sind X1 und Y2 unkorreliert, so liegt keiner der Punkte (xi, yi) , i = 1, . . . , n ,auf der zugehörigen Regressionsgeraden.
Gilt für die empirische Korrelation |rx,y| = 1 , so liegen alle Punkte (xi, yi) ,i = 1, . . . , n , auf der zugehörigen Regressionsgeraden.
Gilt für die empirische Korrelation rx,y = 0 , so liegt keiner der Punkte(xi, yi) , i = 1, . . . , n , auf der zugehörigen Regressionsgeraden.

Kapitel 6
Schätzen
In diesem Kapitel werden Verfahren vorgestellt, mit deren Hilfe man ausgehend von einerRealisierung einer Stichprobe mit unbekannter Verteilung Kennzahlen oder Parametereines angenommenen Verteilungsmodells schätzen kann.
6.1 Parameterschätzung
Ausgangspunkt ist eine Realisierung x1, . . . , xn einer Stichprobe X1, . . . , Xn zu einerunbekannten Verteilung P . Es sei jedoch bekannt, dass die Verteilung aus einer vorge-gebenen Menge von Verteilungen stammt, d. h.
P ∈ Pϑ : ϑ ∈ Θ .
Daher gilt für ein ϑ0 ∈ Θ, dass
P = Pϑ0 ,
die Verteilung hängt also von einem ϑ0 ∈ Θ ab, welches die Verteilung eindeutig be-stimmt.
Beispiel 6.1 (Münzwurf)Gegeben sei eine Stichprobe zu einer B1,p-Verteilung. Wir wählen naheliegenderweise denParameter ϑ gleich dem Erwartungswert p der Verteilung und setzen Θ := [0, 1] . Gegeben sei weiters die Funktion
g : Θ→ R : ϑ 7→ g(ϑ) ,
welche den vom Verteilungsparameter abhängigen zu schätzenden Wert angibt. Gesuchtist nun eine Schätzfunktion
Tn : Rn → R ,
mit deren Hilfe g(ϑ0) ausgehend vom Datensatz x1, . . . , xn durch Tn(x1, . . . , xn) geschätztwerden kann. Die Funktion Tn wird auch Schätzstatistik genannt.
Beispiel 6.2 (Varianz einer Normalverteilung)Gegeben sei eine Stichprobe X1, . . . , Xn zu einer Normalverteilung mit unbekanntemErwartungswert µ0 und unbekannter Varianz σ2
0 . In diesem Fall setzen wir
ϑ := (µ, σ) ∈ Θ := R× (0,∞)
195

196 6. Schätzen
und Pϑ ist die Normalverteilung mit Erwartungswert µ und Varianz σ2 . Interessiert mansich nun für die Varianz der Verteilung der Stichprobe, so gibt
g : Θ→ R : (µ, σ) 7→ σ2
den zu schätzenden Parameter an.
Wir denieren nun zwei wünschenswerte Eigenschaften von Schätzfunktionen.
Definition 6.3 (Erwartungstreue und konsistente Schätzfunktionen)
(1) Die Schätzstatistik Tn heiÿt erwartungstreue Schätzung von g(ϑ) , falls für alleϑ ∈ Θ und alle Stichproben X1, . . . , Xn zu Pϑ gilt, dass
ETn(X1, . . . , Xn) = g(ϑ) .
(2) Eine Folge (Tn)n∈N von Schätzfunktionen heiÿt konsistente Schätzung von g(ϑ) ,falls für alle ϑ ∈ Θ und für alle Stichproben Xn∞n=1 zu Pϑ gilt, dass
limn→∞
Tn(X1, . . . , Xn)f.s.= g(ϑ) .
Schätzproblem 1. Wie schätzt man den Erwartungswert der Verteilung der Stich-
probe?
Eine naheliegende Schätzung des Erwartungswertes ist natürlich der empirische Mittel-wert, also
Tn(x1, . . . , xn) = x(n) .
Diese Schätzung ist erwartungstreu und konsistent, vgl. Aufgabe (6.1).
Schätzproblem 2. Wie schätzt man die Varianz der Verteilung der Stichprobe?
Da die Varianz durch
Var(X1) = E(X1 − EX1)2
gegeben ist, erscheint es naheliegend, sie durch
1
n
n∑
i=1
(Xi − EX1)2

6. Schätzen 197
zu schätzen. Nun ist jedoch EX1 unbekannt und man schätzt daher EX1 wiederum durchdas Stichprobenmittel. Somit ergibt sich als Schätzfunktion
Tn(x1, . . . , xn) =1
n
n∑
i=1
(xi − x(n))2 .
Diese Schätzung ist konsistent, vgl. Aufgabe (6.2). Sie ist jedoch nicht erwartungstreu,denn
ETn(X1, . . . , Xn) = E
1
n
n∑
i=1
X2i −
(1
n
n∑
i=1
Xi
)2 =
= EX21 −
1
n2
n∑
i,j=1
EXiXj =
= EX21 −
1
nEX2
1 −1
n2
n∑
i,j=1
i 6=j
EXiXj =
=
(1− 1
n
)EX2
1 −(
1− 1
n
)(EX1)2 =
=n− 1
nVar(X1) .
Hieraus folgt, dass die empirische Varianz
s2(n) =
n
n− 1Tn(x1, . . . , xn) =
1
n− 1
n∑
i=1
(xi − x(n))2
eine erwartungstreue und konsistente Schätzung für die Varianz ist.
6.1.1 Maximum-Likelihood-Prinzip
Wir kommen nun zu einer systematischen Methode zur Konstruktion von Schätzern. ImFolgenden sei X1, . . . , Xn eine Stichprobe zur unbekannten Verteilung Pϑ .
Diskrete Verteilung.Wir nehmen an, dass es sich für jedes ϑ ∈ Θ bei Pϑ um einediskrete Verteilung handelt, also eine abzählbare Borel-Menge B ∈ B(R) mit Pϑ(B) = 1existiert.
Beispiel 6.4 (Eisessen am Nachmittag)Eine Eisdiele interessiert sich für die Anzahl der Kunden, welche im August währendder Nachmittagszeit, d. h. zwischen 14.00 Uhr und 17.30 Uhr, ein Eis kaufen. Geht mandavon aus, dass im Einzugsbereich der Eisdiele insgesamt N Kunden leben, welche sich

198 6. Schätzen
unbeeinusst voneinander mit Wahrscheinlichkeit p ∈ (0, 1) entscheiden, um die Nach-mittagszeit ein Eis essen zu gehen, so ist es naheliegend, die zufällige Anzahl der Kundendurch eine Binomialverteilung mit Parametern N und p zu modellieren. Da N hier groÿsein wird, bietet es sich an, diese Binomialverteilung durch eine Poisson-Verteilung mitParameter λ = Np zu approximieren, vgl. Aufgabe (6.4). Wir nehmen also an, die AnzahlX der Kunden zur Nachmittagszeit ist πλ-verteilt , d. h. für k ∈ N0 gilt
PX(k) =λk
k!e−λ .
In den vergangen n = 8 Tagen kamen während der Nachmittagszeit
x1 = 36, x2 = 39, x3 = 24, x4 = 9, x5 = 15, x6 = 13, x7 = 35, x8 = 21
Kunden. Wie schätzt man nun λ durch x1, . . . , x8 ?
Da man für jedes ϑ ∈ Θ ein anderes Verteilungsmodell erhält, besteht die Idee beimMaximum-Likelihood1-Prinzip darin, jenes ϑ ∈ Θ als Schätzer zu wählen, für dasdie Wahrscheinlichkeit
P (X1 = x1, . . . , Xn = xn)
maximal wird. Man wählt also jenes ϑ ∈ Θ , für welches die Wahrscheinlichkeit, dassx1, . . . , xn eine Realisierung der Stichprobe X1, . . . , Xn zur Verteilung Pϑ ist, maximalwird.
Aus der Unabhängigkeit der X1, . . . , Xn folgt
P (X1 = x1, . . . , Xn = xn) = P⊗nϑ ((x1, . . . , xn)) =
n∏
i=1
Pϑ(xi) =: L(ϑ;x1, . . . , xn) ,
wobei L( · ;x1, . . . , xn) Likelihood-Funktion genannt wird. Man verwendet bei derMaximum-Likelihood-Methode nun
ϑ(x1, . . . , xn) := arg maxϑ∈Θ
L(ϑ;x1, . . . , xn)
als Schätzer, sofern die rechte Seite existiert und eindeutig ist.
Beispiel 6.5 (Fortsetzung von Beispiel 6.4)In diesem Fall lautet die Likelihood-Funktion
L(λ;x1, . . . , xn) =n∏
i=1
λxi
xi!e−λ = e−nλ
n∏
i=1
λxi
xi!.
1Jean-Claude Van Likelihood, 19001945, japanischer Ornithologe

6. Schätzen 199
Anstatt der Likelihood-Funktion maximieren wir die logarithmierte Likelihood-Funktion
logL(λ;x1, . . . , xn) = −nλ+ log λn∑
i=1
xi −n∑
i=1
log(xi!) .
Wie man leicht sieht, ergibt sich somit als Schätzer
λ(x1, . . . , xn) = x(n) ,
also gerade der empirische Mittelwert. Damit erhält man aufgrund des Datensatzes ausBeispiel 6.4
λ(x1, . . . , x8) = 24
als Schätzung für λ .
Beispiel 6.6 (Rückfangmethode)Wir wollen nun die unbekannte Anzahl von N Fischen in einem Teich mittels der Rück-fangmethode schätzen. Dazu werden zuerst F1 Fische gefangen und mit roter Farbemarkiert. Nach einiger Zeit werden dann erneut F2 < F1 Fische gefangen und es werdendarunter r rot markierte Fische gezählt. Es sei R jene Zufallsvariable, welche die Anzahlder rot markierten Fische im zweiten Fang angibt. Dann gilt
P(R = r) = HF2,N,F1(r) =
(F1
r
)(N−F1
F2−r)
(NF2
) ,
R ist also hypergeometrisch verteilt. Unter Zuhilfenahme von R bestimmen wir nun denMaximum-Likelihood-Schätzer N für die Anzahl N der Fische im Teich, indem wir dieLikelihood-Funktion L(N ; r) = P(R = r) maximieren und zwar für die konkreten Daten
F1 = 500, F2 = 250 und r = 17 .
> F1=500; F2 =250; r=17; N=F1:1e5
> L=dhyper(r,F1 ,N-F1 ,F2)
> N[which.max(L)]
[1] 7352
Kontinuierliche Verteilung. Nun nehmen wir an, dass für jedes ϑ ∈ Θ die Ver-teilung Pϑ eine Dichte fϑ : R→ [0,∞) bezüglich des Lebesgue-Maÿes besitzt.
Da in dieser Situation
P⊗nϑ ((x1, . . . , xn)) = 0

200 6. Schätzen
für alle x1, . . . , xn ∈ R , ist es natürlich nicht sinnvoll, ϑ durch Maximierung dieser Wahr-scheinlichkeit zu schätzen. Stattdessen nimmt man vereinfacht die Wahrscheinlichkeit,dass die beobachteten Werte tatsächlich eine Realisierung der Stichprobe X1, . . . , Xn zuPϑ sind, als direkt proportional zu den Werten der Dichte fϑ an den Datenpunkten anund deniert in diesem Fall die Likelihood-Funktion durch
L(ϑ;x1, . . . , xn) :=
n∏
i=1
fϑ(xi) .
Der Maximum-Likelihood-Schätzer ist dann wiederum durch
ϑ(x1, . . . , xn) := arg maxϑ∈Θ
L(ϑ;x1, . . . , xn)
gegeben, sofern die rechte Seite existiert und eindeutig ist.
Beispiel 6.7 (Rote Ampel)Student T. fährt immer mit dem Fahrrad zur Uni, auf dem Weg muss er häug an einerAmpel halten. Die letzten n = 8 Wartezeiten in Sekunden betrugen
x1 = 49, x2 = 54, x3 = 49, x4 = 37, x5 = 43, x6 = 28, x7 = 55, x8 = 21 .
Es bezeichne t > 0 die Dauer der Rotphase in Sekunden. Die zufällige Wartezeit wirdals gleichverteilt auf dem Intervall [0, t] angenommen. Wie kann ausgehend vom obigenDatensatz die Dauer t der Rotphase geschätzt werden?
Die Gleichverteilung U[0,t] besitzt die Dichte
ft = 1tχ[0,t] .
Wir maximieren daher die Likelihood-Funktion
L(t) =n∏
i=1
ft(xi) =n∏
i=1
1
tχ[0,t](xi) =
t−n , t ≥ maxx1, . . . , xn ,0 , t < maxx1, . . . , xn ,
und erhalten somit als Schätzer
t = maxx1, . . . , xn .
Damit ergibt sich für obige Daten t = 55 .

6. Schätzen 201
6.2 Konfidenzschätzung
Eine Punktschätzung liefert natürlich im Allgemeinen nicht exakt den zu schätzendenWert g(ϑ0) und daher erscheint es sinnvoll, die Genauigkeit des Schätzverfahrens mit an-zugeben. Für die Genauigkeit eines erwartungstreuen Schätzers ist etwa dessen Standard-abweichung ein sinnvolles Maÿ. In vielen Fällen wird jedoch im Vorhinein kein Hinweisauf die Genauigkeit gegeben sein. Bei einer Kondenzschätzung wird nun die Genauigkeitdes Schätzverfahrens direkt in die Schätzung miteinbezogen.
Wie im vorherigen Abschnitt nehmen wir an, dass die Verteilung der gegebenen Stich-probe aus einer Menge Pϑ : ϑ ∈ Θ von Verteilungen stammt.
Ziel einer Kondenzschätzung ist es, mittels einer Stichprobe X1, . . . , Xn zu Pϑ0 einezufällige Menge
I(X1, . . . , Xn) ⊂ R
zu konstruieren, welche g(ϑ0) mit hoher Wahrscheinlichkeit enthält. In den Fällen, welchewir betrachten werden, wird es sich hierbei stets um ein Intervall handeln. Dabei wärezweifelsohne wünschenswert, wenn
B die Wahrscheinlichkeit P (g(ϑ0) ∈ I(X1, . . . , Xn)) möglichst groÿ wäre und
B die Menge I(X1, . . . , Xn) möglichst klein.
Diese beiden Eigenschaften werden natürlich nur bis zu einem gewissen Grad miteinandervereinbar sein.
Definition 6.8 (Konfidenzintervall)Es sei α ∈ (0, 1) . Ein Intervall Iα(X1, . . . , Xn) ⊂ R heiÿt Kondenzintervall zumKondenzniveau 1 − α , wenn für alle ϑ ∈ Θ und für alle Stichproben X1, . . . , Xn zuPϑ gilt, dass
P (g(ϑ) ∈ Iα(X1, . . . , Xn)) ≥ 1− α .
Zur Berechnung von Kondenzintervallen werden wir sogenannte Quantile verwenden.
Definition 6.9 (Quantilfunktion und Quantil)Es sei P eine Verteilung mit Verteilungsfunktion FP . Dann nennt man die durch
GP (α) := minx ∈ R : FP (x) ≥ α
für α ∈ (0, 1) denierte Abbildung dieQuantilfunktion der Verteilung P . Des Weiterennennt man für α ∈ (0, 1) den Wert GP (α) das α-Quantil von P .
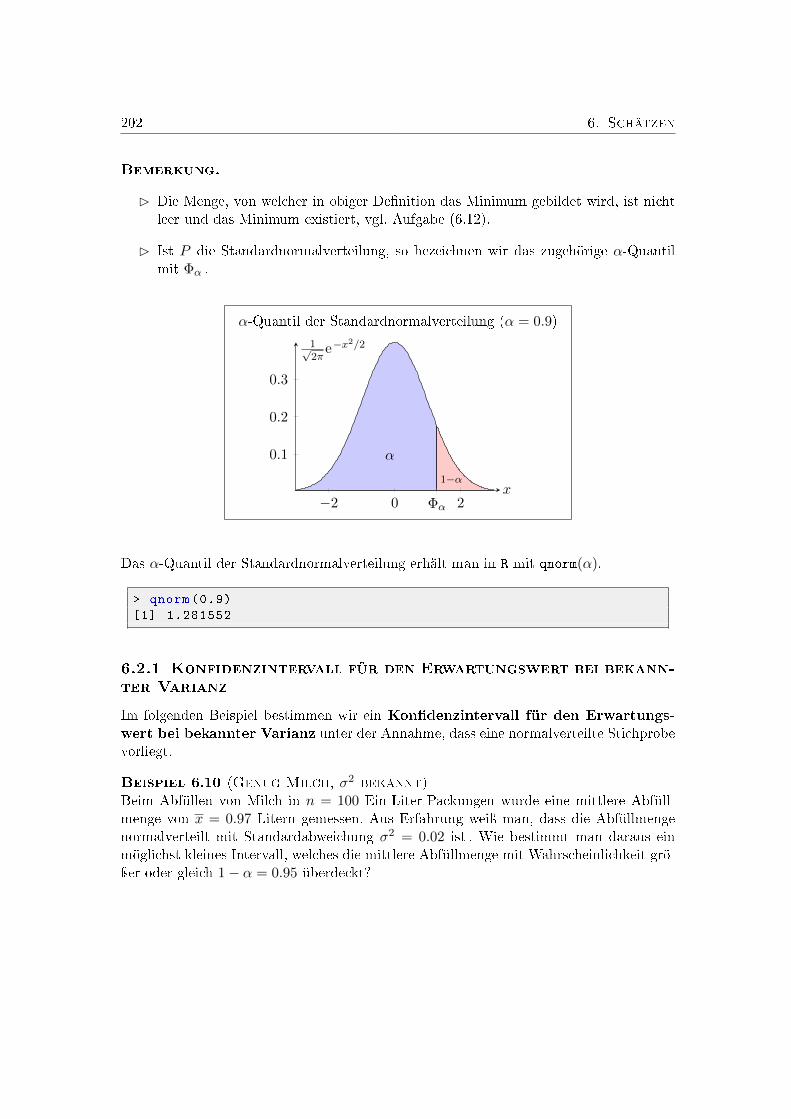
202 6. Schätzen
Bemerkung.
B Die Menge, von welcher in obiger Denition das Minimum gebildet wird, ist nichtleer und das Minimum existiert, vgl. Aufgabe (6.12).
B Ist P die Standardnormalverteilung, so bezeichnen wir das zugehörige α-Quantilmit Φα .
1−α
α
−2 0 2
0.1
0.2
0.3
Φα
x
1√2π
e−x2/2
α-Quantil der Standardnormalverteilung (α = 0.9)
Das α-Quantil der Standardnormalverteilung erhält man in R mit qnorm(α).
> qnorm (0.9)
[1] 1.281552
6.2.1 Konfidenzintervall für den Erwartungswert bei bekann-
ter Varianz
Im folgenden Beispiel bestimmen wir ein Kondenzintervall für den Erwartungs-wert bei bekannter Varianz unter der Annahme, dass eine normalverteilte Stichprobevorliegt.
Beispiel 6.10 (Genug Milch, σ2 bekannt)Beim Abfüllen von Milch in n = 100 Ein-Liter-Packungen wurde eine mittlere Abfüll-menge von x = 0.97 Litern gemessen. Aus Erfahrung weiÿ man, dass die Abfüllmengenormalverteilt mit Standardabweichung σ2 = 0.02 ist . Wie bestimmt man daraus einmöglichst kleines Intervall, welches die mittlere Abfüllmenge mit Wahrscheinlichkeit grö-ÿer oder gleich 1− α = 0.95 überdeckt?

6. Schätzen 203
Es sei X1, . . . , Xn eine N (µ, σ2)-verteilte Stichprobe, wobei der Erwartungswert µ ∈ Runbekannt ist. Dann ist die Zufallsvariable
Z :=1√nσ
n∑
i=1
(Xi − µ)
standardnormalverteilt, vgl. Aufgabe (6.17) bzw. Satz 6.14. Man beachte, dass die Zu-fallsvariable Z zwar vom unbekannten Parameter µ abhängt, jedoch nicht ihre VerteilungPZ . Man nennt daher Z einen stochastischen Pivot. Nun gilt
P(|Z| ≤ Φ1−α/2
)= Φ
(Φ1−α/2
)− Φ
(−Φ1−α/2
)= 1− α ,
wobei Φ wiederum die Verteilungsfunktion der Standardnormalverteilung bezeichnet.Weiters ist
|Z| ≤ Φ1−α/2 ⇐⇒ X − σ√n
Φ1−α/2 ≤ µ ≤ X +σ√n
Φ1−α/2
und daher erhalten wir
Iα(X1, . . . , Xn) =
[X − σ√
nΦ1−α/2 , X +
σ√n
Φ1−α/2
]
als Kondenzintervall zum Kondenzniveau 1− α .Somit ist
Iα ≈ [0.9423, 0.9977]
ein Kondenzintervall für die am Anfang des Beispiels gegebenen Daten. Man beachte,dass 1 /∈ Iα . Die mittlere Abfüllmenge entspricht vermutlich also nicht der Angabe aufder Packung.
Bemerkung. Nach dem Zentralen Grenzwertsatz gilt
limn→∞
1√nσ
n∑
i=1
(Xi − µ) ∼ N0,1 .
Daher ist für einen groÿen Stichprobenumfang n der verwendete stochastische Pivotannährend standardnormalverteilt und man erhält selbst für nicht normalverteilte Datenein approximatives Kondenzintervall.

204 6. Schätzen
6.2.2 Statistische Gröÿen normalverteilter Daten
Die Annahme, dass im vorangegangen Beispiel die Varianz bekannt sei, ist unrealistisch.Um unter anderem ein Kondenzintervall für den Erwartungswert auch bei unbekannterVarianz zu bestimmen, benötigen wir zuerst einige Resultate über die Verteilung vonGröÿen, welche sich aus normalverteilten Daten ableiten lassen.
Definition 6.11 (χ2-Verteilung und t-Verteilung)Es sei X1, . . . , Xn eine standardnormalverteilte Stichprobe.
(1) Die Verteilung der Zufallsvariablen
n∑
i=1
X2i
heiÿt Chi-Quadrat-Verteilung mit n Freiheitsgraden (kurz: χ2n-Verteilung).
(2) Es seien X und Y unabhängige Zufallsvariable mit X ∼ N (0, 1) und Y ∼ χ2n. Dann
heiÿt die Verteilung der Zufallsvariablen
X√Y/n
Student2-t-Verteilung mit n Freiheitsgraden (kurz: tn-Verteilung).
Die folgenden beiden Lemmata dienen der Vorbereitung auf Satz 6.14 und Satz 6.15.
Lemma 6.12 (Zufallsvektor mit unabhängigen Komponenten und Dichten)Es seien X und Y unabhängige Zufallsvariablen mit zugehörigen Dichten fX und fYbezüglich des Lebesgue-Maÿes. Dann besitzt der Zufallsvektor (X,Y ) die Dichte
f(X,Y ) = fX ⊗ fY
bezüglich λ2 .
Beweis. Es seien x, y ∈ R . Die Aussage folgt direkt aus
F(X,Y )(x, y) =[X und Y unabhängig
]= FX(x)FY (y) =
=
ˆ
(−∞,x]×(−∞,y]
fX(s)fY (t) dλ2(s, t) ,
wobei die letzte Gleichheit nach dem Satz von Fubini-Tonelli gilt.
2William Sealy Gosset, 18761937, englischer Statistiker, publizierte unter dem Pseudonym Student

6. Schätzen 205
Lemma 6.13 Es seien Y1, . . . , Yn unabhängige standardnormalverteilte Zufallsvariableund A ∈ Rn×n eine orthogonale Matrix, d. h. ATA = I . Setzt man
Z1...Zn
:= A
Y1...Yn
,
so sind Z1, . . . , Zn ebenfalls unabhängig und standardnormalverteilt.
Beweis. Es seien z1, . . . , zn ∈ R. Für
I := (−∞, z1]× . . .× (−∞, zn] ,
Y := [Y1, . . . , Yn]T und Z := [Z1, . . . , Zn]T gilt
FZ(z1, . . . , zn) = P(Z ∈ I) = P(Y ∈ ATI
)=
ˆATI
fY (y) dλ(y) =[y = ATx
]=
=
ˆIfY
(ATx
)| detAT|︸ ︷︷ ︸
=1
dλ(x) =[fY (ATx) = fY (x)
]=
=
ˆIfY (x) dλ(x)
und damit ist die Aussage des Lemmas gezeigt.
Der nächste Satz zeigt auf, welche statistischen Gröÿen die in Definition 6.11 einge-führten Verteilungen besitzen. Für eine Stichprobe X1, . . . , Xn bezeichne im Folgendenstets
X :=1
n
n∑
i=1
Xi bzw. S2 :=1
n− 1
n∑
i=1
(Xi −X)2
das Stichprobenmittel bzw. die Stichprobenvarianz.
Satz 6.14 (Eigenschaften und Verteilungen statistischer Gröÿen)Es sei X1, . . . , Xn eine N (µ, σ2)-verteilte Stichprobe. Dann gilt:
(1) X und S2 sind unabhängig
(2) X ist N (µ, σ2/n)-verteilt
(3) n−1σ2 S
2 ist χ2n−1-verteilt
(4) X−µS
√n ist tn−1-verteilt

206 6. Schätzen
Beweis. Für i = 1, . . . , n setzen wir
Yi :=Xi − µσ
,
dann ist Y1, . . . , Yn eine standardnormalverteilte Stichprobe. Wir wählen nun eine ortho-gonale Matrix A mit erster Zeile
A1− = 1√n
[1, . . . , 1]
und setzen
Z =
Z1...Zn
:= AY ,
wobei Y = [Y1, . . . , Yn]T . Nach Lemma 6.13 ist auch Z1, . . . , Zn eine standardnormal-verteilt Stichprobe. Oensichtlich gilt
n∑
i=1
Z2i = ‖Z‖22 = ‖Y ‖22 =
n∑
i=1
Y 2i . (?)
Auÿerdem ist
X =σ
n
n∑
i=1
Yi + µ =σ√nA1−Y + µ =
=σ√nZ1 + µ
und
S2 =1
n− 1
n∑
i=1
(Xi −X)2 =σ2
n− 1
(n∑
i=1
Y 2i − nY
2
)=
=σ2
n− 1
n∑
i=1
Y 2i −
(1√n
n∑
i=1
Yi
)2 (?)
=σ2
n− 1
(n∑
i=1
Z2i − Z2
1
)=
=σ2
n− 1
n∑
i=2
Z2i ,
woraus sich die Behauptungen leicht ableiten lassen.
Wie in nachfolgendem Satz gezeigt wird, besitzen die χ2-Verteilung und die t-VerteilungDichten bezüglich des Lebesgue-Maÿes.

6. Schätzen 207
Satz 6.15 (Dichte der χ2-Verteilung und der t-Verteilung)Es sei n ∈ N .
(1) Die χ2n-Verteilung hat die Dichte
f(x ;χ2
n
)= H(x)
xn/2−1e−x/2
2n/2Γ(n2
) , x ∈ R ,
wobei Γ die Eulersche Gammafunktion bezeichnet.
(2) Die tn-Verteilung hat die Dichte
f (x ; tn) =Γ(n+1
2
)√nπΓ
(n2
)(
1 +x2
n
)−(n+1)/2
, x ∈ R .
Beweis. Man erhält die Dichten durch Übergang auf die jeweiligen Bildmaÿe.
(1) Sei X1, . . . , Xn eine standardnormalverteilte Stichprobe, dann ist
Z :=
n∑
i=1
X2i ∼ χ2
n .
Oensichtlich ist FZ(t) = 0 für t ≤ 0 . Für t > 0 gilt
FZ(t) = P(X2
1 + . . .+X2n ≤ t
)=
= P(X1,...,Xn)
(z ∈ Rn : ‖z‖22 ≤ t
)=
=
ˆ‖z‖2≤√t
f(X1,...,Xn)(z) dλ(z) =
= (2π)−n/2ˆ‖z‖2≤√t
e−‖z‖22/2 dλ(z) =
[Kugelkoordinaten
]=
= (2π)−n/2∣∣Sn−1
∣∣ˆ √t
0rn−1e−r
2/2 dr =
[∣∣Sn−1
∣∣ =2πn/2
Γ(n/2)
]=
=2
2n/2Γ(n/2)
ˆ √t0
rn−1e−r2/2 dr =
[x = r2
]=
=
ˆ t
0
xn/2−1e−x/2
2n/2Γ(n/2)dx ,
womit die Behauptung gezeigt ist.
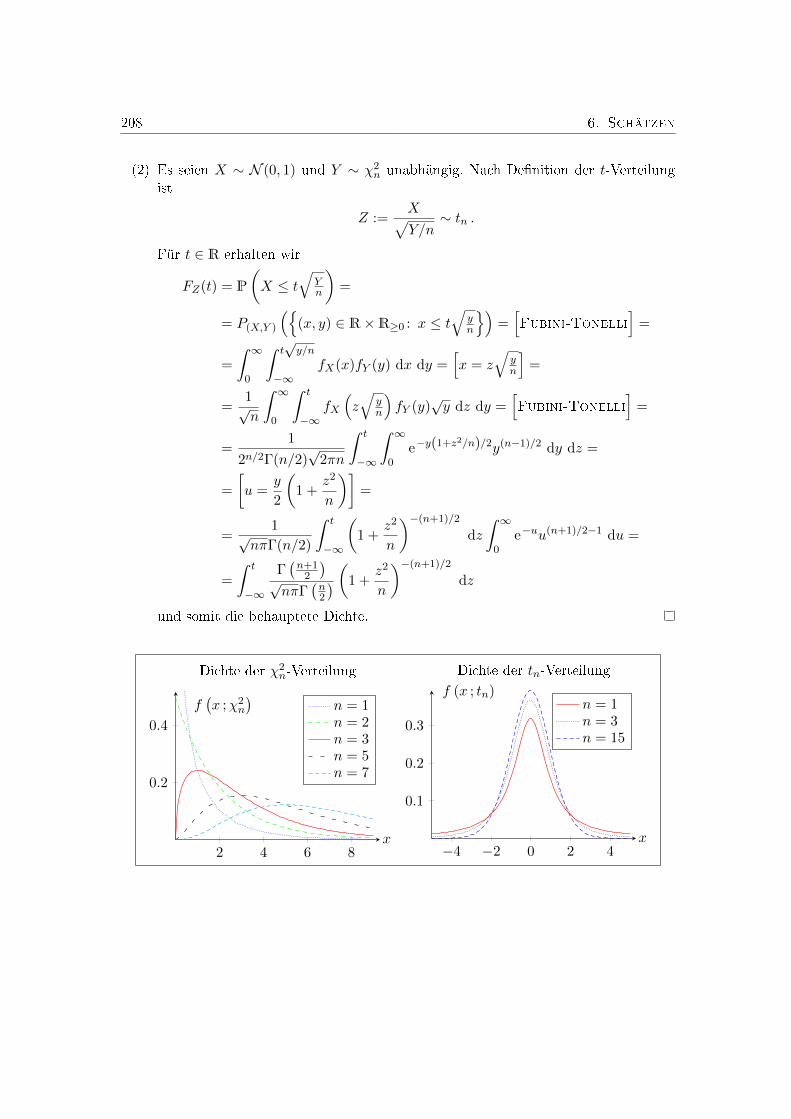
208 6. Schätzen
(2) Es seien X ∼ N (0, 1) und Y ∼ χ2n unabhängig. Nach Denition der t-Verteilung
ist
Z :=X√Y/n
∼ tn .
Für t ∈ R erhalten wir
FZ(t) = P
(X ≤ t
√Yn
)=
= P(X,Y )
((x, y) ∈ R×R≥0 : x ≤ t
√yn
)=[Fubini-Tonelli
]=
=
ˆ ∞0
ˆ t√y/n
−∞fX(x)fY (y) dx dy =
[x = z
√yn
]=
=1√n
ˆ ∞0
ˆ t
−∞fX
(z√
yn
)fY (y)
√y dz dy =
[Fubini-Tonelli
]=
=1
2n/2Γ(n/2)√
2πn
ˆ t
−∞
ˆ ∞0
e−y(1+z2/n)/2y(n−1)/2 dy dz =
=
[u =
y
2
(1 +
z2
n
)]=
=1√
nπΓ(n/2)
ˆ t
−∞
(1 +
z2
n
)−(n+1)/2
dz
ˆ ∞0
e−uu(n+1)/2−1 du =
=
ˆ t
−∞
Γ(n+1
2
)√nπΓ
(n2
)(
1 +z2
n
)−(n+1)/2
dz
und somit die behauptete Dichte.
2 4 6 8
0.2
0.4
x
f(x ;χ2
n
)Dichte der χ2
n-Verteilung
n = 1n = 2n = 3n = 5n = 7
−4 −2 0 2 4
0.1
0.2
0.3
x
f (x ; tn)
Dichte der tn-Verteilung
n = 1n = 3n = 15

6. Schätzen 209
6.2.3 Konfidenzintervall für den Erwartungswert bei unbe-
kannter Varianz
Wir greifen Beispiel 6.10 nochmals auf und bestimmen nun ein Kondenzintervallfür den Erwartungswert bei unbekannter Varianz.
Beispiel 6.16 (Genug Milch, σ2 unbekannt)Dieses Mal sei die Varianz unbekannt, wir schätzen diese durch die Stichprobenvarianz
S2 =1
n− 1
n∑
i=1
(Xi −X
)2.
Nach Satz 6.14 ist
S2 ∼ σ2
n− 1χ2n−1
und damit folgt aus der Unabhängigkeit von X und S2 , dass
Z :=X − µS
√n ∼ tn−1 .
Aufgrund der Symmetrie der stetigen Dichte der t-Verteilung ist
Pµ(|Z| ≤ tn−1;1−α/2
)= 1− α ,
wobei tn−1;1−α/2 das (1−α/2)-Quantil der tn−1-Verteilung bezeichnet. Umformungen inAnalogie zu Beispiel 6.10 führen auf das Kondenzintervall
Iα(X1, . . . , Xn) =
[X − tn−1;1−α/2
S√n,X + tn−1;1−α/2
S√n
].
Wir nehmen nun an, dass in Beispiel 6.10 s2 = 0.02 gemessen wurde. Zusammen mitden restlichen Daten
x = 0.97 , n = 100 und α = 0.05
erhält man dann das Kondenzintervall
Iα ≈ [0.9419, 0.9981] .
> x.mean =0.97;s=sqrt (0.02);n=100; alpha =0.05
> breite=qt(1-alpha/2,n-1)*s/sqrt(n)
> c(x.mean -breite ,x.mean+breite)
[1] 0.9419389 0.9980611
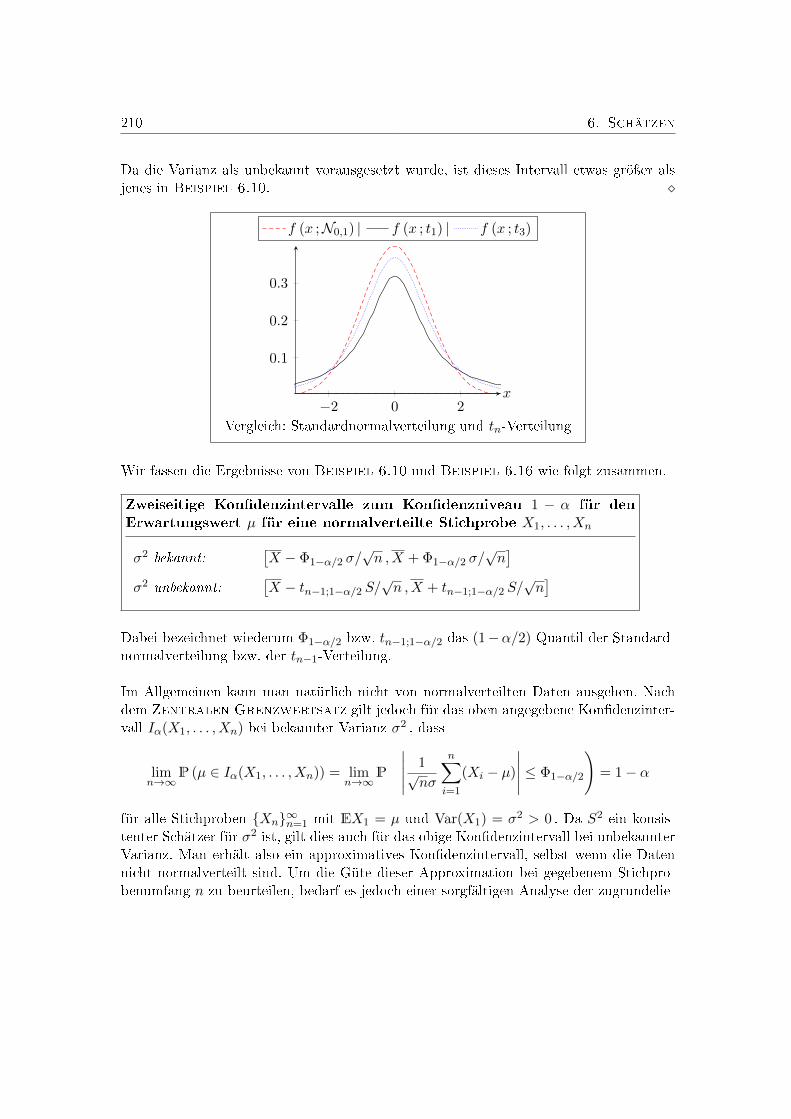
210 6. Schätzen
Da die Varianz als unbekannt vorausgesetzt wurde, ist dieses Intervall etwas gröÿer alsjenes in Beispiel 6.10.
−2 0 2
0.1
0.2
0.3
x
Vergleich: Standardnormalverteilung und tn-Verteilung
f (x ;N0,1) | f (x ; t1) | f (x ; t3)
Wir fassen die Ergebnisse von Beispiel 6.10 und Beispiel 6.16 wie folgt zusammen.
Zweiseitige Kondenzintervalle zum Kondenzniveau 1 − α für denErwartungswert µ für eine normalverteilte Stichprobe X1, . . . , Xn
σ2 bekannt:[X − Φ1−α/2 σ/
√n ,X + Φ1−α/2 σ/
√n]
σ2 unbekannt:[X − tn−1;1−α/2 S/
√n ,X + tn−1;1−α/2 S/
√n]
Dabei bezeichnet wiederum Φ1−α/2 bzw. tn−1;1−α/2 das (1−α/2)-Quantil der Standard-normalverteilung bzw. der tn−1-Verteilung.
Im Allgemeinen kann man natürlich nicht von normalverteilten Daten ausgehen. Nachdem Zentralen Grenzwertsatz gilt jedoch für das oben angegebene Kondenzinter-vall Iα(X1, . . . , Xn) bei bekannter Varianz σ2 , dass
limn→∞
P (µ ∈ Iα(X1, . . . , Xn)) = limn→∞
P
(∣∣∣∣∣1√nσ
n∑
i=1
(Xi − µ)
∣∣∣∣∣ ≤ Φ1−α/2
)= 1− α
für alle Stichproben Xn∞n=1 mit EX1 = µ und Var(X1) = σ2 > 0 . Da S2 ein konsis-tenter Schätzer für σ2 ist, gilt dies auch für das obige Kondenzintervall bei unbekannterVarianz. Man erhält also ein approximatives Kondenzintervall, selbst wenn die Datennicht normalverteilt sind. Um die Güte dieser Approximation bei gegebenem Stichpro-benumfang n zu beurteilen, bedarf es jedoch einer sorgfältigen Analyse der zugrundelie-

6. Schätzen 211
genden Verteilung. In vielen Fällen wird man jedoch auf andere Verfahren zurückgreifen.
Weiters erkennt man an den obigen Beispielen das Prinzip, nach dem häug Kondenz-intervalle konstruiert werden:
[Punktschätzer±Quantil · Standardabweichung des Punktschätzers
]
Bemerkung. Die Konstruktion einseitiger Kondenzintervalle erfolgt analog zur Be-stimmung zweiseitiger Kondenzintervalle, vgl. Aufgabe (6.18).
Beispiel 6.17 (Konfidenzschätzung einer Binomialwahrscheinlichkeit)Ein Eier-Produzent sieht sich dem Vorwurf ausgesetzt, dass seine Eier mit Salmonellenbelastet sind. Um den Anteil der inzierten Eier abzuschätzen, wurden n = 100 Stückauf Salmonellen getestet, dabei el der Test in drei Fällen tatsächlich positiv aus. Manbestimme ein approximatives Kondenzintervall zum Kondenzniveau 1 − α = 0.95 fürden Anteil der mit Salmonellen belasteten Eier.
Es sei X1, . . . , Xn eine B1,p-verteilte Stichprobe. Wie wir bereits wissen, ist
p = X
ein erwartungstreuer und konsistenter Schätzer für p . Da
Var(p) =p(1− p)
n,
schätzen wir die Varianz durch
σ2 =p(1− p)
n.
Die Verteilung von
Z :=p− p√p(1− p)
√n
wird für einen genügend groÿen Stichprobenumfang n gut durch die Standardnormalver-teilung approximiert. Als Faustregel gilt, dass die Bedingung
np(1− p) ≥ 9
erfüllt sein sollte. Damit ist
P
(p− Φ1−α/2
√p(1− p)
n≤ p ≤ p+ Φ1−α/2
√p(1− p)
n
)≈ 1− α

212 6. Schätzen
und wir erhalten somit für p das approximative Kondenzintervall
Iα(X1, . . . , Xn) =
[p− Φ1−α/2
√p(1− p)
n, p+ Φ1−α/2
√p(1− p)
n
].
Es ergibt sich
Iα ≈ [−0.003, 0.063]
für die am Anfang des Beispiels gegebenen Daten.
6.2.4 Konfidenzintervalle für die Varianz
Wir kommen nun zur Konstruktion von Kondenzintervallen für die Varianz.
Beispiel 6.18 (Zweiseitiges Konfidenzintervall für die Varianz)Es seiX1, . . . , Xn eine normalverteilte Stichprobe mit Var(X1) = σ2 > 0 . Nach Satz 6.14ist
Z :=1
σ2
n∑
i=1
(Xi −X
)2
χ2n−1-verteilt. Bezeichne χ
2n−1;α/2 bzw. χ2
n−1;1−α/2 das α/2-Quantil bzw. das (1 − α/2)-
Quantil der χ2n−1-Verteilung. Dann ist
Pσ
(χ2n−1;α/2 ≤ Z ≤ χ2
n−1;1−α/2
)= 1− α
und somit
Pσ
(σ2 ∈
[∑ni=1
(Xi −X
)2
χ2n−1;1−α/2
,
∑ni=1
(Xi −X
)2
χ2n−1;α/2
])= 1− α ,
damit ein Kondenzintervall für σ2 bestimmt.
Kondenzintervalle zum Kondenzniveau 1 − α für die Varianz σ2 beinormalverteilter Stichprobe X1, . . . , Xn
Zweiseitig:[∑n
i=1
(Xi −X
)2/χ2
n−1;1−α/2 ,∑n
i=1
(Xi −X
)2/χ2
n−1;α/2
]
Einseitig:[0,∑n
i=1
(Xi −X
)2/χ2
n−1;α
]
Die Konstruktion eines einseitigen Kondenzintervalls für die Varianz verläuft in völligerAnalogie zu Beispiel 6.18, vgl. Aufgabe (6.20).

6. Schätzen 213
Übungsaufgaben
(6.1) Zeigen Sie, dass das Stichprobenmittel
Tn(X1, . . . , Xn) =1
n
n∑
i=1
Xi
ein erwartungstreuer und konsistenter Schätzer für den Erwartungswert der Stich-probe X1, . . . , Xn ist.
(6.2) Zeigen Sie, dass
Tn(X1, . . . , Xn) =1
n
n∑
i=1
(Xi −X(n))2
eine konsistente Schätzung für die Varianz der Stichprobe X1, . . . , Xn ist.
(6.3) Sei X1, . . . , Xn eine Stichprobe zur Gleichverteilung auf [ϑ, 2ϑ] , d.h. X1 besitzt dieDichte
fϑ : R→ [0,∞) : x 7→
1ϑ , x ∈ [ϑ, 2ϑ] ,
0 , sonst.
(a) Zeigen Sie, dass der Schätzer
Tn(X1, . . . , Xn) =2
3n
n∑
i=1
Xi
ein erwartungstreuer Schätzer für ϑ ist.
(b) Ist der Schätzer auch konsistent?
(6.4) Es seien λ > 0 und (pn)n∈N ∈ [0, 1]N mit
limn→∞
npn = λ .
Für festes k ∈ N zeige man, dass
limn→∞
Bn,pn(k) =λk
k!e−λ = πλ(k) .
(6.5) Gute Birne: Die Lebensdauer einer Glühbirne hängt lediglich von der Anzahl derEin- und Ausschaltvorgänge ab. Die Wahrscheinlichkeit, dass eine Glühbirne beimk-ten Einschaltvorgang ausfällt, sei
pk−1(1− p) ,

214 6. Schätzen
wobei p ∈ (0, 1) . Die Güte eines Glühbirnentyps steht in direktem Zusammenhangmit p und soll dadurch bestimmt werden, dass n Glühbirnen solange ein- undausgeschaltet werden, bis diese alle versagen. Eine solcher Test ergab die Wertex1, . . . , xn ∈ N , wobei die i-te Glühbirne beim xi-ten Einschaltvorgang ausgefallenist.
Bestimmen Sie durch Anwendung des Maximum-Likelihood-Prinzips eine Schät-zung für p .
(6.6) Unzuverlässige Theaterbesucher: Ein Theaterbetreiber möchte wissen, wel-cher Anteil der reservierten Karten im Schnitt auch tatsächlich gekauft wird. Dazubezeichne X die Anzahl der gekauften reservierten Karten. Zu einer Auührungwerden stets n = 200 Karten reserviert. Wir nehmen an, dass jede einzelne Person,die eine Karte reserviert hat, unbeeinusst von den anderen Personen die Kartemit Wahrscheinlichkeit p ∈ [0, 1] kauft. Dann ist X ∼ Bn,p .Bei den letzen 12 Auührungen wurden
x1 = 109, x2 = 151, x3 = 104, x4 = 132, x5 = 149, x6 = 143,
x7 = 113, x8 = 144, x9 = 98, x10 = 127, x11 = 149, x12 = 124
der n = 200 reservierten Karten gekauft.
Konstruieren Sie mit Hilfe des Maximum-Likelihood-Prinzips ausgehend von diesemDatensatz eine Schätzung für p und überprüfen Sie das Ergebnis durch Maximie-rung der Likelihood-Funktion in R.
(6.7) German tank problem: Im Zweiten Weltkrieg wurden die deutschen Panzermit aufsteigenden Seriennummern versehen. Diese wurden von den Alliierten be-nutzt um die Gröÿe der gegnerischen Streitmacht zu schätzen. Wir modellierendiesen Sachverhalt folgendermaÿen: Die Stichprobe X1, . . . , Xn repräsentiere n Se-riennummern gesichteter, deutscher Panzer. Bei einer Gesamtanzahl vonN Panzernnehmen wir an, dass die Stichprobe gleichverteilt auf 1, . . . , N ist. Was ist derMaximum-Likelihood-Schätzer für N ? Zeigen Sie durch eine geeignete Wahl von nund N , dass dieser Schätzer im Allgemeinen nicht erwartungstreu ist.
(6.8) Wirtschaftswissenschaftler W. möchte die Dauer von Arbeitslosigkeit modellieren.Dazu beschreibt er diese durch eine Exponentialverteilung mit Parameter λ > 0 ,d. h. die Dauer X von Arbeitslosigkeit hat die Dichte
f(x) = H(x)λe−λx ,
wobei H die Heaviside-Funktion bezeichnet. Zur Schätzung des unbekannten Pa-rameters λ > 0 , bekommt er vom Arbeitsamt für vier zufällig herausgegrieneArbeitslose die Information, dass diese
x1 = 12, x2 = 2, x3 = 18, x4 = 8

6. Schätzen 215
Monate nach Verlust ihres bisherigen Arbeitsplatzes eine neue Arbeitsstelle gefun-den haben.
(a) Konstruieren Sie den Maximum-Likelihood-Schätzer für λ .
(b) Zeige Sie, dass
Tn(X1, . . . , Xn) =n∑ni=1Xi
ein konsistenter Schätzer ist.
(6.9) Die Dichte der Rayleigh-Verteilung ist für λ > 0 gegeben durch
f(x) =
xe−x2
2λ
λ, x ≥ 0 ,
0 , x < 0 .
Berechnen Sie den Maximum-Likelhood-Schätzer für den Verteilungsparameter λ.
(6.10) Pareto3-Verteilung: Für ξ > 0 und λ > 0 betrachten wir die Dichte
f : R→ R : x 7→
λξλ
xλ+1 , x ≥ ξ0 , x < ξ .
Die unbekannten Parameter ξ und λ sollen mittels der Daten x1, . . . , xn geschätztwerden.
(a) Zeigen Sie, dass ξ = mini=1,...,n
xi der Maximum-Likelihood-Schätzer für ξ ist.
(b) Bestimmen Sie den Maximum-Likelihood-Schätzer λ für λ .
(c) Importieren Sie den Datensatz staedte.txt. (Diesen nden Sie unter http://tobiashell.com.) Berechnen Sie ξ und λ . Plotten Sie anschlieÿend einHistogramm der Daten (Klassenbreite 105) und die Dichte f .
(6.11) Es sei x1, . . . , xn eine Realisierung der N (µ, σ2)-verteilten Stichprobe X1, . . . , Xn ,wobei µ und σ unbekannt seien. Bestimmen Sie durch Anwendung des Maximum-Likelihood-Prinzips eine Schätzung für ϑ = (µ, σ2) .
(6.12) Es sei F eine Verteilungsfunktion und α ∈ (0, 1) . Zeigen Sie, dass die Menge
x ∈ R : F (x) ≥ α
nicht leer ist und ihr Minimum existiert.
3Vilfredo Federico Pareto, 18481923, italienischer Ingenieur, Ökonom und Soziologe

216 6. Schätzen
(6.13) Schreiben Sie eine R-Funktion, welche das Kondenzintervall zum Kondenzniveau1 − α für den Erwartungswert bei bekannter Varianz für normalverteilte Datenberechnet.
(6.14) Dichte der Summe von Zufallsvariablen: Die Zufallsvariablen X und Y mitzugehörigen Dichten fX und fY seien unabhängig. Zeigen Sie, dass die SummeZ = X + Y die Dichte
fZ = fX ∗ fY
besitzt, wobei (fX ∗ fY )(z) =´RfX(t)fY (z − t) dt .
(6.15) Zeigen Sie, dass die Summe unabhängiger normalverteilter Zufallsvariablen wieder-um normalverteilt ist.
Hinweis: Verwenden Sie Aufgabe (6.14).
(6.16) In nachfolgender Tabelle ndet sich das Ergebnis der Erhebung des Merkmals Kör-pergröÿe bei den Spielern der Basketballteams GHP Bamberg und Bayer Giants
Leverkusen sowie bei den Spielern der Fuÿballmannschaft SV Werder Bremen.
Team n min max x s
Bamberg 16 185 211 199.06 7.047
Leverkusen 14 175 210 196.00 9.782
Bremen 23 178 195 187.52 5.239
Berechnen Sie für jedes Team 95%-Kondenzintervalle für die mittlere Körpergröÿeder Spieler und interpretieren Sie das Ergebnis.
(6.17) Es sei X1, . . . , Xn eine N (µ, σ2)-verteilte Stichprobe. Zeigen Sie ohne Verwendungvon Satz 6.14, dass
Z :=1√nσ
n∑
i=1
(Xi − µ)
standardnormalverteilt ist.
(6.18) Gegeben sei eine normalverteilte Stichprobe X1, . . . , Xn . Bestimmen Sie eine obereSchranke zum Kondenzniveau 1− α für den Erwartungswert, d. h. ein Konden-zintervall der Form (−∞, b] ,(a) bei bekannter Varianz,
(b) bei unbekannter Varianz.

6. Schätzen 217
(6.19) Abwaschkrise: Um zu entscheiden, wer den Abwasch erledigen muss, wirft einPärchen nach jedem Essen eine Münze. Zeigt die Münze Kopf, so muss er sichum den Abwasch kümmern, bei Zahl ist sie an der Reihe. Nach n = 142 Würfenist die Münze 53 mal auf Kopf gefallen. Bestimmen Sie ein approximatives 95%-Kondenzintervall für die Wahrscheinlichkeit, dass die Münze auf Kopf fällt, undinterpretieren Sie das Ergebnis.
(6.20) Konstruieren Sie aus einer normalverteilten Stichprobe einseitige Kondenzinter-valle für die Varianz.
(6.21) Konstruieren Sie in R normalverteilte Stichproben (z. B. zu N (5, 4)) von steigen-dem Stichprobenumfang zwischen 5 und 4000 . Plotten Sie in geeigneter Weise diezugehörigen Kondenzintervalle zum Niveau 1−α = 0.9 (z. B. mittels der FunktionplotCI aus dem package plotrix)
(a) bei bekannter Varianz
(b) bei unbekannter Varianz
und vergleichen Sie die Intervallgröÿen.
(6.22) Der Lebenskünstler Detlev hat in Panama eine alte Buslinie mit nur einem Lini-enbus erworben. Diese durchquert in wöchentlicher Routine einmal den Dschungel.Zur Berechnung der Kosten stellt er folgende Überlegungen an: Die AbweichungenX in der Ankunftszeit des Busses seien normalverteilt mit µ = 0 und σ2 = 1 (inTagen). Diese Informationen hat Detlev von dem Busfahrer bekommen, der dieStrecke vorher befahren hat. Die Kosten eines zu frühen oder zu späten Eintreenssteigen mit der Gröÿe der Abweichung gemäÿ 50X2$.
(a) Mit welchen Kosten aufgrund von Unpünktlichkeit muss bei einer Fahrt miteiner Wahrscheinlichkeit von 0.75 gerechnet werden.
(b) Mit welcher Wahrscheinlichkeit können zusätzliche Kosten von mehr als 250$ausgeschlossen werden.
(c) Wie groÿ ist die Wahrscheinlichkeit, dass bei wöchentlichen Fahrten die ge-samten Extra-Kosten in einem halben Jahr (n = 26) höchstens etwa 2100$und in einem Jahr (n = 52) höchstens 3100$ betragen, wenn man annimmtdie Fahrten in verschiedenen Wochen seien voneinander unabhängig?
(6.23) Die Abweichung X der planmäÿigen Ankunftszeiten der Stubaier-Straÿenbahnlinieseien t10-verteilt (in Minuten).
(a) Wie groÿ ist die Wahrscheinlichkeit, dass eine Straÿenbahn maximal 0.7 Mi-nuten von der fahrplanmäÿígen Ankunftszeit abweicht?
(b) Zu welchem Zeitpunkt sollte man spätestens zur Haltestelle gehen, wenn manzu 90% die Straÿenbahn um 15:32 erreichen will?

218 6. Schätzen
(c) In welchem (symmetrischen) Bereich bewegen sich 90% der Ankunftszeitender Straÿenbahn?
(d) Wie sehen die Ergebnisse der Aufgaben a) - c) aus, wenn man annimmt, dieAnkunftszeiten seien standardnormalverteilt?
(6.24) Zahnwachstum, revisited:Vergleichen Sie die Auswirkung der Menge von Vitamin-C-Gaben an Meerschweinchen auf ihr Zahnwachstum im Datensatz ToothGrowth
in R mittels Kondenzintervallen zu den Kondenzniveaus α = 0.1, 0.05, 0.01 . Stel-len Sie die Ergebnisse mit Hilfe des Befehls plotCI dar und interpretieren Sie dasErgebnis. Welche Annahmen stecken hinter der Vorgehensweise (Verteilung etc.)?
(6.25) Maximale Schneehöhen: Die maximale Schneehöhe eines Jahres bei einer Mess-station folgen einer vorgegebenen Verteilung P mit stetiger VerteilungsfunktionFP . Die Zufallsvariable Z(j) bezeichne die maximale Schneehöhe im j-ten Beobach-tungsjahr. Wir nehmen an, die maximalen Schneehöhen verschiedener Jahre seienunabhängig und identisch verteilt und betrachten die Stichprobe Z(1), . . . , Z(n) fürn ∈ N . Die maximale Schneehöhe bis zum Jahr j ist dann
Zj := maxZ(1), . . . , Z(j) .
(a) Wie lautet die Verteilung von Zj und wie hängen FZj und FZ(i) = FP zusam-men?
(b) Es bezeichne Pp das p-Quantil der Verteilung P für p ∈ (0, 1) . Berechnen Siedas entsprechende Quantil der Verteilung von Zj .
(c) Für die Verteilung von Extremwerten (z. B. der Z(j)) hat sich die Gumbel4-Verteilung als geeignet erwiesen. Ihre Verteilungsfunktion für β > 0 undµ ∈ R ist druch
F (x) = e−e−β−1(x−µ)
für x ∈ R gegeben. Berechnen Sie die Quantilfunktion Q(p) zu F .
(6.26) Pareto-Verteilung II: Der Datensatz badhealth.csv (zu nden auf http:
//tobiashell.com) besteht aus einer Liste von Personen verschiedenen Alters, ih-rem subjektiven Gesundheitszustand (0... gesund, 1... krank) und der Anzahl ihrerArztbesuche im Untersuchungszeitraum. Wir betrachten die Anzahl der Arztbesu-che jener Personen, die im Untersuchungszeitraum mindestens einmal einen Arztaufgesucht haben und untersuchen die Anzahl der Arztbesuche in Abhängigkeitvom Gesundheitszustand (0 oder 1). Wir nehmen an, diese seien Pareto-verteilt(siehe Blatt 7) mit noch zu bestimmenden Parametern.
4Emil Julius Gumbel, 18911966, deutsch-amerikanischer Mathematiker

6. Schätzen 219
(a) Bestimmen Sie mit den bereits konstruierten Maximum-Likelihood-Schätzerndie Parameter λi und ξi für i = 1, 2 für Gesunde bzw. Kranke mit Hilfe von R.
(b) Stellen Sie (relative) Histogramme der Arztbesuche und die entsprechendenDichten der Paretoverteilungen dar.
(6.27) Importieren Sie den Datensatz Fishing.csv (zu nden auf http://tobiashell.com) und betrachten Sie die Merkmale mode und income. Ersteres beschreibt dieArt des Fischfangs (charter, boat, pier oder beach) und zweiteres den Gewinn.
(a) Vergleichen Sie die Auswirkung von (mindestens) zwei Fangmethoden auf denGewinn mittels Kondenzintervallen zu den Kondenzniveaus α = 0.1, 0.05, 0.01.
(b) Stellen Sie die Ergebnisse mit Hilfe des Befehls plotCI dar und interpretierenSie das Ergebnis.
(c) Welche statistischen Grundannahmen stecken hinter der Vorgangsweise undsind diese gerechtfertigt?
(6.28) Importieren Sie den Datensatz schneehoehe.csv (zu nden auf http://tobiashell.com), in welchem die maximalen Schneehöhen eines Jahres bei der Messstelle Achen-kirch über mehrere Jahre hinweg aufgezeichnet wurden. Wir verwenden die Gumbel-Verteilung mit Parameter µ und β für die Verteilung der Schneehöhen. Für dieseerhalten wir eine Schätzung mittels
β =
√6
π· S und µ = X − γ · β,
wobei S die Wurzel aus der Stichprobenvarianz und γ die Euler-Mascheroni-Konstante
(in R mit -digamma(1)) bezeichnet.Berechnen Sie Schneehöhen hj , j = 1, . . . , 100 so, dass mit Wahrscheinlichkeitp = 0.01 das Maximum der Schneehöhen aus j Jahren gröÿer oder gleich hj ist.
(6.29) χ2-Verteilung: Es sei X1, . . . , Xn eine standardnormalverteilte Stichprobe. Be-rechnen Sie die Wahrscheinlichkeit, dass der Zufallsvektor X = (X1, . . . , Xn) in dieeuklidische Einheitskugel fällt, also P(‖X‖2 ≤ 1) .

220 6. Schätzen
Schulaufgaben
Die nachfolgenden Aufgaben stammen, sofern keine weiteren Angaben gemacht werden,von https://www.bifie.at/ (Stand: Februar 2013).
(S6.1) Schwarzfahrer/innen: In einer Stadt fahren täglich ungefähr 30000 Personenmit der Straÿenbahn. Durchschnittlich werden täglich 1000 Personen kontrol-liert, ob sie einen gültigen Fahrschein besitzen. Dabei wird festgestellt, dass 60der kontrollierten Personen keinen gültigen Fahrschein haben. Jede/r ertappteSchwarzfahrer/in muss EUR 40, Strafe bezahlen und einen Fahrschein lösen.
Wie hoch ist der durchschnittliche Verlust für die Verkehrsbetriebe durch Schwarz-fahrer/innen in einem Jahr (365 Tage), wenn ein Fahrschein EUR 1,50 kostet?
(S6.2) Quantile: Bestimme die p-Quantile up der standardisierten Normalverteilung(u-Verteilung) für
(a) p = 0.5 , (b) p = 0.6 , (c) p = 0.9 , (d) p = 0.975 , (e) p = 0.1 , (f) p = 0.025 .
(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 261, Nr. 6.39)
(S6.3) Würfeln: Ein Würfel wird 30-mal geworfen. Gib ein Intervall [xun, xob] an, indem die Anzahl x der Sechserwürfe mit einer Wahrscheinlichkeit von 90% liegt.Dabei sollen die Anzahlen unter xun sowie über xob zusammengenommen jeweilshöchstens gleich 5% betragen.(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 246, Nr. 6.23)
(S6.4) Wahl: Bei einer Befragung von 2000 zufällig ausgewählten wahlberechtigten Per-sonen geben 14 % an, dass sie bei der nächsten Wahl für die Partei Alternati-ves Leben stimmen werden. Aufgrund dieses Ergebnisses gibt ein Meinungsfor-schungsinstitut an, dass die Partei mit 12 % bis 16 % der Stimmen rechnen kann.
Mit welcher Sicherheit kann man diese Behauptung aufstellen?
(S6.5) Wellen: Bei Fertigung von Wellen erwies sich deren Durchmesser normalverteiltmit µ = 231.0 mm und σ = 1.0 mm. Für den Durchmesser ist ein Höchstwertvon 232.5mm vorgeschrieben.
(a) Welcher Anteil übersteigt den Höchstwert?
(b) Welchen Wert darf die Standardabweichung σ höchstens haben, sodass beiµ = 231.00 mm der Überschreitungsanteil höchstens 0.5% ist?
(c) Ermittle bei σ = 0.1 mm jenen symmetrisch um µ gelegenen Bereich, in denerwartungsgemäÿ 99% der Durchmesserwerte aller Wellen fallen!

6. Schätzen 221
(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 262, Nr. 6.48)
(S6.6) Dosiermenge: Für eine Dosiermenge gilt ein oberer Grenzwert von 20.15 g. DieDosiermenge kann als normalverteilt mit µ = 20.00 g und σ = 0.05 g angesehenwerden.
(a) Wie groÿ ist der Überschreitungsanteil?
(b) Wie groÿ darf (bei unverändertem µ) die Standardabweichung σ höchstenssein, wenn der Überschreitungsanteil 2% nicht übersteigen darf?
(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 262, Nr. 6.51)
(S6.7) Vertrauensbereiche bei unterschiedlichen Vertrauensniveaus: Auseiner Fertigung mit gleichbleibender Auschussrate wird eine Zufallsstichprobe desUmfangs n = 80 entnommen; darunter werden x = 4 fehlerhafte Einheiten ge-funden. Ermittle den zweiseitigen Vertrauensbereich für die Ausschussrate p derFertigung zum Vertrauensniveau 1− α gleich
(a) 90% , (b) 95% , (c) 99% .
(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 274, Bsp. 7.1)
(S6.8) Vertrauensbereiche bei unterschiedlichem Stichprobenumfang: Er-mittle den zweiseitigen Vertrauensbereich für die konstante Ausschussrate p einerFertigung zum Vertrauensniveau 1 − α = 95% , wenn eine Zufallsstichprobe desUmfangs
(a) n = 80 entnommen wird, darunter x = 4 fehlerhafte Einheiten,
(b) n = 320, darunter x = 16 fehlerhafte Einheiten.
(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 274, Bsp. 7.2)
(S6.9) Vertrauensbereich für p Näherung durch die Normalverteilung:Aus einem gröÿeren Prüos wird eine Zufallsstichprobe von n = 1200 Einheitenentnommen; davon erweisen sich x = 30 fehlerhaft. Ermittle den zweiseitigen99%-Vertrauensbereich für den Fehleranteil p im Prüos.(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 275, Bsp. 7.3)
(S6.10) Notwendiger Stichprobenumfang für Vertrauensbereich für µ: EinLängenmaÿ ist normalverteilt mit σ = 0.2 mm. Eine Stichprobe des Umfangsn = 25 ergab x = 20.4 mm.

222 6. Schätzen
(a) Ermittle den 95%-Vertrauensbereich für µ .
(b) Für welchen Stichprobenumfang besitzt der 99%-Vertrauensbereich für µ diegleiche Länge wie jener aus (a)?
(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 283, Bsp. 7.8)
(S6.11) Section Control: Der Begri Section Control (Abschnittskontrolle) bezeich-net ein System zur Überwachung von Tempolimits im Straÿenverkehr, bei demnicht die Geschwindigkeit an einem bestimmten Punkt gemessen wird, sonderndie Durchschnittsgeschwindigkeit über eine längere Strecke. Dies geschieht mit-hilfe von zwei Überkopfkontrollpunkten, die mit Kameras ausgestattet sind. DasFahrzeug wird sowohl beim ersten als auch beim zweiten Kontrollpunkt fotogra-ert. Die zulässige Höchstgeschwindigkeit bei einer bestimmten Abschnittskon-trolle beträgt 100 km/h. Da die Polizei eine Toleranz kleiner 3 km/h gewährt,löst die Section Control bei 103 km/h aus. Lenker/innen von Fahrzeugen, diedieses Limit erreichen oder überschreiten, machen sich strafbar und werden imFolgenden als Temposünder bezeichnet. Eine Stichprobe der Durchschnittsge-schwindigkeiten von zehn Fahrzeugen ist in der nachfolgenden Tabelle aufgelistetund im abgebildeten Boxplot dargestellt.
v in km/h 88 113 93 98 121 98 90 98 105 129
(a) Bestimmen Sie den arithmetischen Mittelwert x und die empirische Stan-dardabweichung s der Durchschnittsgeschwindigkeiten in der Stichprobe!
Kreuzen Sie die zutreende(n) Aussage(n) zur Standardabweichung an!
Die Standardabweichung ist ein Maÿ für die mittlere Streuung um denarithmetischen Mittelwert.
Die Standardabweichung ist immer ca. ein Zehntel des arithmetischenMittelwerts.
Die Varianz ist die quadrierte Standardabweichung.

6. Schätzen 223
Im Intervall [x− s, x+ s] der obigen Stichprobe liegen ca. 60% bis 80%der Werte.
Die Standardabweichung ist der Mittelwert der Abweichungen von x.
(b) Bestimmen Sie aus dem Boxplot (Kastenschaubild) der Stichprobe den Me-dian sowie das obere und untere Quartil! Geben Sie an, welche zwei Streu-maÿe aus dem Boxplot ablesbar sind! Bestimmen Sie auch deren Werte!
(c) Es wird angenommen, dass die Zufallsvariable die Anzahl der Temposünderunter zehn zufällig ausgewählten Fahrzeuglenkern angibt.
Kreuzen Sie die zwei nicht zutreenden Aussagen an und begründen Sieanschlieÿend, warum diese Aussagen nicht zutreen!
Die Zufallsvariable kann den Wert 0 annehmen.
Die Standardabweichung der Zufallsvariablen ist näherungsweise gleichder empirischen Varianz der Variablenwerte von sehr vielen Stichprobenvom Umfang 10.
Die absolute Häugkeitsverteilung der Variablenwerte von sehr vielenStichproben vom Umfang 10 ist näherungsweise gleich der Wahrschein-lichkeitsverteilung dieser Variablenwerte.
Der Erwartungswert der Zufallsvariable ist näherungsweise der arithme-tische Mittelwert der Variablen bei sehr vielen Stichproben vom Umfang10.
Die Wahrscheinlichkeitsverteilung ordnet jedem Wert der Zufallsvaria-blen genau eine Wahrscheinlichkeit zu.
(d) Die Erfahrung zeigt, dass die Wahrscheinlichkeit, ein zufällig ausgewähltesFahrzeug mit einer Durchschnittsgeschwindigkeit von mindestens 103 km/hzu erfassen, 14 % betragt. Berechnen Sie den Erwartungswert µ und dieStandardabweichung σ der Temposünder unter fünfzig zufällig ausgewähltenFahrzeuglenkern! Berechnen Sie, wie groÿ die Wahrscheinlichkeit ist, dassdie Anzahl der Temposünder unter fünfzig Fahrzeuglenkern innerhalb dereinfachen Standardabweichung um den Erwartungswert, d. h. im Intervall[µ− σ, µ+ σ] liegt!

224 6. Schätzen
Kontrollfragen
6.1 Es sei X1, . . . , Xn eine Stichprobe zur Verteilung P . Weiters sei f : R→ R stetig,f(X1) integrierbar und
Tn(X1, . . . , Xn) =1
n
n∑
i=1
f(Xi) .
Welche der folgenden Aussagen sind wahr?
Tn ist erwartungstreuer Schätzer für Ef(X1) .
Tn ist ein konsistenter Schätzer für Ef(X1) .
Tn ist erwartungstreuer Schätzer für f(EX1) .
Tn ist konsistenter Schätzer für f(EX1) .
6.2 Im Allgemeinen ist ein Maximum-Likelihood-Schätzer
erwartungstreu,
konsistent,
nicht zwingend erwartungstreu,
nicht zwingend konsistent.
6.3 Es sei P eine Verteilung und α ∈ (0, 1) . Das α-Quantil von P
ist stets eindeutig,
ist im Allgemeinen nicht eindeutig,
liegt im Intervall (0, 1) ,
ist gleich F−1P (α) , sofern FP invertierbar ist.
6.4 Es sei X1, . . . , Xn eine Stichprobe zur integrierbaren Verteilung P . Des Weiterensei Iα(X1, . . . , Xn) ein Kondenzintervall für EP zum Kondenzniveau 1 − α ,wobei α ∈ (0, 1) . Welche der folgenden Aussagen sind wahr?
P (EP ∈ Iα(X1, . . . , Xn)) = 1− α P (EP ∈ Iα(X1, . . . , Xn)) ≥ 1− α P (EP ∈ Iα(X1, . . . , Xn)) ≤ α P (EP /∈ Iα(X1, . . . , Xn)) ≤ α
6.5 Es seien X und Y zwei Zufallsvariablen mit Dichten fX und fY bezüglich desLebesgue-Maÿes. Welche der folgenden Aussagen sind wahr?
Der Zufallsvektor (X,Y ) besitzt die Dichte fX ⊗ fY .

6. Schätzen 225
Der Zufallsvektor (X,Y ) besitzt die Dichte fX ∗ fY .
Sind X und Y unabhängig, so besitzt die Zufallsvariable Z = X + Y dieDichte fX ∗ fY .
Sind X und Y unabhängig, so besitzt die Zufallsvariable Z = X + Y dieDichte fX ⊗ fY .
6.6 Es seiX1, . . . , Xn eine normalverteilte Stichprobe. Welche der folgenden Aussagensind wahr?
Die Zufallsvariable
Z =
n∑
i=1
αiXi ,
wobei α1, . . . , αn ∈ R , ist normalverteilt.
Ist A ∈ Rn×n eine orthogonale Matrix, so ist Z1, . . . , Zn eine standardnor-malverteilte Stichprobe, wobei [Z1, . . . , Zn]T = A[X1, . . . , Xn]T .
Für jede Matrix A ∈ Rn×n gilt, dass die Zufallsvariablen Z1, . . . , Zn unab-hängig sind, wobei [Z1, . . . , Zn]T = A[X1, . . . , Xn]T .
Ist X1 ∼ N0,1 und A ∈ Rn×n orthogonal, so ist Z1, . . . , Zn eine standard-normalverteilte Stichprobe, wobei [Z1, . . . , Zn]T = A[X1, . . . , Xn]T .


Kapitel 7
Parametrische Tests
Es werden nun einige statistische Verfahren zum Testen von Hypothesen vorgestellt, so-genannte Hypothesentests. Da wir in diesem Kapitel die Klasse der Verteilungen starkeinschränken, in der Regel werden wir von normalverteilten Daten ausgehen, sprechen wirvon parametrischen Tests. Die Problemstellung und die grundlegenden Begrie sindjedoch dieselben für nichtparametrische Tests, wovon einige in Kapitel 8 präsentiertwerden.
7.1 Problemstellung und grundlegende Begriffe
Ausgangspunkt eines Hypothesentests ist eine zu testende Hypothese, die sogenannteNullhypothese H0 , und eine Alternativhypothese H1 .
Bei einem Einstichprobenproblem liegen Daten aus einer einzelnen StichprobeX1, . . . , Xn vor, während bei einem Zweistichprobenproblem Daten aus zwei Stich-proben X1, . . . , XnX und Y1, . . . , YnY gegeben sind.
Beispiel 7.1 (Qualitätskontrolle, Einstichprobenproblem)Ein Kekshersteller vermutet Unregelmäÿigkeiten in seiner Produktion. Zur Qualitätskon-trolle entnimmt er zufällig 75 Kekspackungen und bestimmt deren Gewicht. Wie kannzuverlässig getestet werden, ob das mittlere Gewicht µ signikant vom vorgegebenenGewicht µ0 abweicht?
Beispiel 7.2 (Zuckerpäckchen, Zweistichprobenproblem)In einer Zuckerranerie wird maschinell Zucker verpackt. Dazu sind zwei Maschinenim Einsatz, welche unabhängig voneinander den Zucker in Päckchen verpacken. Getes-tet werden soll, ob beide Maschinen Zuckerpäckchen mit demselben mittleren Gewichtproduzieren.
Wir gehen wie im vorigen Kapiteln davon aus, die Verteilung der Stichprobe(n) stammeaus einer vorgegebenen Klasse
Pϑ : ϑ ∈ Θ
von Verteilungen. Den Parameterbereich Θ zerlegen wir disjunkt in der Form
Θ = Θ0 ]Θ1 ,
227

228 7. Parametrische Tests
sodass
H0 : ϑ ∈ Θ0 und H1 : ϑ ∈ Θ1 .
Durch einen Hypothesentest wird auf Grundlage der Daten unter Vorgabe einer Irrtums-wahrscheinlichkeit α , z. B. α = 0.05 , entschieden, ob H0 plausibel ist oder nicht, d. h.ob die Nullhypothese beibehalten oder verworfen wird. Die Irrtumswahrscheinlichkeitbezeichnet man auch als Signikanzniveau.
Dabei können zwei Fehler auftreten. Wird die Nullhypothese verworfen, obwohl diesewahr ist, so spricht man vom Fehler 1. Art. Die Wahrscheinlichkeit, den Fehler 1. Artzu begehen, soll dabei kleiner gleich der vorgegebenen Irrtumswahrscheinlichkeit α sein,d. h.
P (H0 wird abgelehnt|H0 wahr) ≤ α .
Beim Fehler 2. Art wird hingegen die Nullhypothese H0 beibehalten, obwohl diesefalsch ist.
H0 wahr H0 falsch
H0 verwerfen Fehler 1. Art Richtige Entscheidung
H0 annehmen Richtige Entscheidung Fehler 2. Art
Beispiel 7.3 (Gefangenendilemma)Zwei Personen, A und B, werden verdächtigt, gemeinsam eine Straftat begangen zu ha-ben. Sie werden getrennt voneinander befragt. Gesteht A bzw. B die Tat, so beträgt dasStrafmaÿ 3 Jahre für A bzw. B. Sollte jedoch einer der beiden gestehen und der ande-re nicht, so erhält der Ungeständige 10 Jahre Haft. Schweigen beide, so müssen sie ausMangel an Beweisen freigesprochen werden. A formuliert folgende Hypothesen:
H0 : B gesteht, H1 : B schweigt.
Wenn A die Nullhypothese H0 für richtig hält, so gesteht er, andernfalls schweigt er. Innachfolgender Tabelle sind die möglichen Entscheidungen und Konsequenzen aufgelistet.
B gesteht B schweigt
A schweigt 10 Jahre für A, 3 für B Freispruch
A gesteht 3 Jahre für A, 3 für B 3 Jahre für A, 10 für B

7. Parametrische Tests 229
Die Nullhypothese wurde also so gewählt, dass der Fehler 1. Art die schlimmeren Aus-wirkungen für A als der Fehler 2. Art hat. Des Weiteren unterscheiden wir zwischen einseitigen und zweiseitigen Testproblemen.Die folgende Tabelle listet die möglichen Situationen für einen unbekannten Parameterϑ und einen festen Wert ϑ0 auf.
H0 H1
ϑ = ϑ0 ϑ 6= ϑ0 Zweiseitiges Testproblem
ϑ ≥ ϑ0 ϑ < ϑ0 Einseitiges Testproblem
ϑ ≤ ϑ0 ϑ > ϑ0 Einseitiges Testproblem
7.1.1 Vorgehen bei einem Hypothesentest
Bezeichnen X1, . . . , Xn die Stichprobenvariablen, so kann das Vorgehen bei einem Hypo-thesentest wie folgt dargestellt werden.
(1) Verteilungsannahme über die Stichprobe(n)
(2) Formulierung der Nullhypothese und der Alternativhypothese
(3) Vorgabe des Signikanzniveaus α
(4) Konstruktion einer geeigneten Teststatistik
T : Rn → R ,
wobei die Verteilung von T (X1, . . . , Xn) für ϑ = ϑ0 bekannt sein muss
(5) Bestimmung eines kritischen Bereichs K ⊂ R , sodass PT (K) ≤ α unter H0
(6) Berechnung der Realisierung τ := T (x1, . . . , xn) der Teststatistik mittels der gege-benen Daten x1, . . . , xn
(7) Testentscheidung:
τ ∈ K : H0 verwerfen ⇒ H1 ist statistisch signikant
τ /∈ K : H0 beibehalten ⇒ H1 ist nicht statistisch signikant
Bemerkung. Mit (5) wird ein Hypothesentest stets so konstruiert, dass die Wahr-scheinlichkeit
P(T ∈ K|H0 wahr) = P(H0 verwerfen|H0 wahr)
den Fehler 1. Art zu begehen durch die Irrtumswahrscheinlichkeit α nach oben beschränktist.

230 7. Parametrische Tests
7.1.2 Gütefunktion, Macht und p-Wert
Die Funktion
g : Θ→ [0, 1]
ϑ 7→ Pϑ (T (X1, . . . , Xn) ∈ K)
heiÿt Gütefunktion des Tests. Sie gibt die Wahrscheinlichkeit an, die Nullhypothese zuverwerfen. Für ϑ ∈ Θ0 gilt
g(ϑ) = Pϑ (H0 wird verworfen|H0 wahr) =: Fehlerwahrscheinlichkeit 1. Art
und für ϑ ∈ Θ1 ist
1− g(ϑ) = Pϑ (H0 wird beibehalten|H0 falsch) =: Fehlerwahrscheinlichkeit 2. Art .
Ist 1−β die Fehlerwahrscheinlichkeit 2. Art, so heiÿt βMacht des Tests oderTeststärke.
Der p-Wert oder die Überschreitungswahrscheinlichkeit p eines Tests ist das gröÿteSignikanzniveau, für welches die Nullhypothese H0 gerade noch beibehalten werdenkann, unter der Annahme, dass diese wahr ist. Ist also Kγ der kritische Bereich zumSignikanzniveau γ ∈ (0, 1) und τ die Realisierung der Teststatistik, so gilt
p = supγ ∈ (0, 1) : τ /∈ Kγ .
Ist α das vorgegebene Signikanzniveau, so kann mittels des p-Werts p die Testentschei-dung wie folgt formuliert werden:
α ≤ p : H0 beibehalten
α > p : H0 verwerfen
7.2 Einstichprobenprobleme
Es werden nun drei Tests vorgestellt, welche auf einer einzelnen Stichprobe basieren.
7.2.1 Einfacher Gauÿ-Test
Der einfache Gauÿ-Test dient zur Überprüfung, ob der unbekannte Erwartungswert µeiner N(µ, σ2)-verteilten Stichprobe mit einem vorgegebenem Wert µ0 übereinstimmtbzw. diesen unter- oder überschreitet. Dabei sei die Varianz σ2 > 0 bekannt.
(1) Verteilungsannahme: X1, . . . , Xn sei eine N (µ, σ2)-verteilte Stichprobe.
(2) Festlegung der Hypothesen:

7. Parametrische Tests 231
H0 H1
µ = µ0 µ 6= µ0 zweiseitig
µ ≥ µ0 µ < µ0 einseitig
µ ≤ µ0 µ > µ0 einseitig
(3) Vorgabe des Signikanzniveaus α: Die Irrtumswahrscheinlichkeit wird in der Regelα := 0.05 gewählt.
(4) Konstruktion der Teststatistik: Der unbekannte Erwartungswert µ wird durch dasStichprobenmittel geschätzt, also durch
Xµ=µ0∼ N (µ0, σ
2/n) .
Als Teststatistik verwendet man den stochastischen Pivot
T (X1, . . . , Xn) =X − µ0
σ
√n
µ=µ0∼ N (0, 1) .
(5) Kritischer Bereich: Den kritischen Bereich K erhalten wir als Komplement desjeweiligen Kondenzintervalls zum Kondenzniveau 1− α .
H0 H1 Kritischer Bereich K
µ = µ0 µ 6= µ0
(−∞,Φα/2
)∪(Φ1−α/2 ,∞
)
µ ≥ µ0 µ < µ0 (−∞,Φα)
µ ≤ µ0 µ > µ0 (Φ1−α ,∞)
(6) Realisierung der Teststatistik: Aus einer Realisierung x1, . . . , xn der Stichprobe wird
τ = T (x1, . . . , xn) =x− µ0
σ
√n
berechnet.
(7) Testentscheidung: Liegt τ im kritischen Bereich K , so wird die Nullhypothese ver-worfen, ansonsten beibehalten.
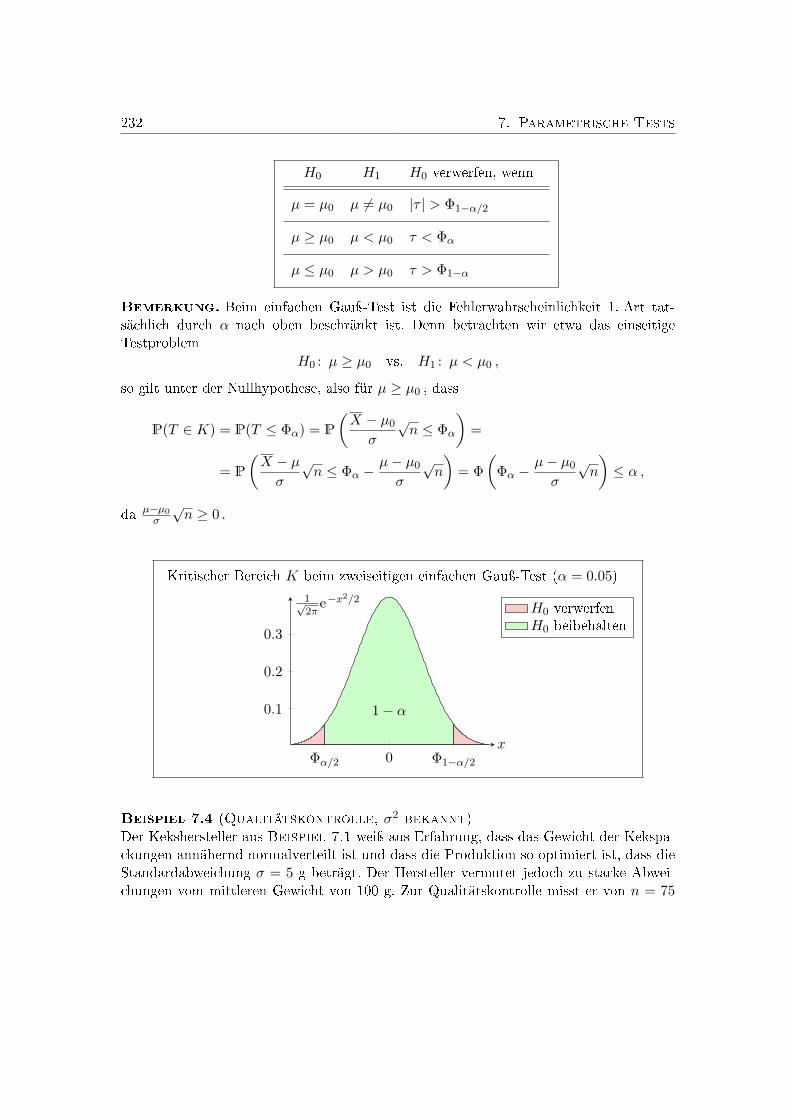
232 7. Parametrische Tests
H0 H1 H0 verwerfen, wenn
µ = µ0 µ 6= µ0 |τ | > Φ1−α/2
µ ≥ µ0 µ < µ0 τ < Φα
µ ≤ µ0 µ > µ0 τ > Φ1−α
Bemerkung. Beim einfachen Gauÿ-Test ist die Fehlerwahrscheinlichkeit 1. Art tat-sächlich durch α nach oben beschränkt ist. Denn betrachten wir etwa das einseitigeTestproblem
H0 : µ ≥ µ0 vs. H1 : µ < µ0 ,
so gilt unter der Nullhypothese, also für µ ≥ µ0 , dass
P(T ∈ K) = P(T ≤ Φα) = P
(X − µ0
σ
√n ≤ Φα
)=
= P
(X − µσ
√n ≤ Φα −
µ− µ0
σ
√n
)= Φ
(Φα −
µ− µ0
σ
√n
)≤ α ,
da µ−µ0σ
√n ≥ 0 .
1− α
0
0.1
0.2
0.3
Φα/2 Φ1−α/2x
1√2π
e−x2/2
Kritischer Bereich K beim zweiseitigen einfachen Gauÿ-Test (α = 0.05)
H0 verwerfenH0 beibehalten
Beispiel 7.4 (Qualitätskontrolle, σ2 bekannt)Der Kekshersteller aus Beispiel 7.1 weiÿ aus Erfahrung, dass das Gewicht der Kekspa-ckungen annähernd normalverteilt ist und dass die Produktion so optimiert ist, dass dieStandardabweichung σ = 5 g beträgt. Der Hersteller vermutet jedoch zu starke Abwei-chungen vom mittleren Gewicht von 100 g. Zur Qualitätskontrolle misst er von n = 75
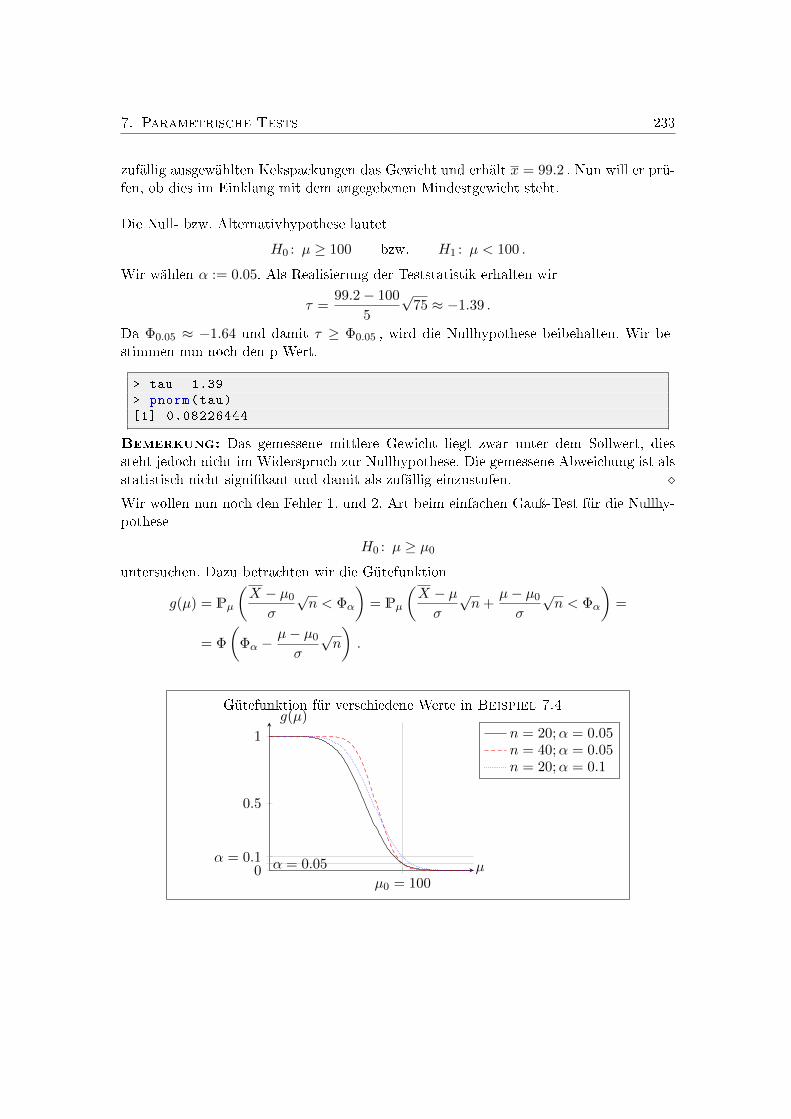
7. Parametrische Tests 233
zufällig ausgewählten Kekspackungen das Gewicht und erhält x = 99.2 . Nun will er prü-fen, ob dies im Einklang mit dem angegebenen Mindestgewicht steht.
Die Null- bzw. Alternativhypothese lautet
H0 : µ ≥ 100 bzw. H1 : µ < 100 .
Wir wählen α := 0.05. Als Realisierung der Teststatistik erhalten wir
τ =99.2− 100
5
√75 ≈ −1.39 .
Da Φ0.05 ≈ −1.64 und damit τ ≥ Φ0.05 , wird die Nullhypothese beibehalten. Wir be-stimmen nun noch den p-Wert.
> tau =-1.39
> pnorm(tau)
[1] 0.08226444
Bemerkung: Das gemessene mittlere Gewicht liegt zwar unter dem Sollwert, diessteht jedoch nicht im Widerspruch zur Nullhypothese. Die gemessene Abweichung ist alsstatistisch nicht signikant und damit als zufällig einzustufen. Wir wollen nun noch den Fehler 1. und 2. Art beim einfachen Gauÿ-Test für die Nullhy-pothese
H0 : µ ≥ µ0
untersuchen. Dazu betrachten wir die Gütefunktion
g(µ) = Pµ
(X − µ0
σ
√n < Φα
)= Pµ
(X − µσ
√n+
µ− µ0
σ
√n < Φα
)=
= Φ
(Φα −
µ− µ0
σ
√n
).
0
0.5
1
µ0 = 100
α = 0.1 α = 0.05 µ
g(µ)Gütefunktion für verschiedene Werte in Beispiel 7.4
n = 20;α = 0.05n = 40;α = 0.05n = 20;α = 0.1

234 7. Parametrische Tests
Man kann anhand dieses Beispiels die folgenden Eigenschaften der Gütefunktion einesTests erkennen.
Eigenschaften der Gütefunktion eines statistischen Tests.
Die Macht eines Tests wird gröÿer, wenn
- der Stichprobenumfang n wächst,
- das Signikanzniveau α wächst.
7.2.2 Einfacher t-Test
Getestet werden soll der Erwartungswert einer Normalverteilung bei unbekannter Va-rianz. Der einfache t-Test verläuft analog zum einfachen Gauÿ-Test, als Teststatistikverwendet man jedoch
T (X1, . . . , Xn) =X − µ0
S
√n
µ=µ0∼ tn−1 .
Es ergeben sich die folgenden Testentscheidungen, wobei τ wiederum die Realisierungder Teststatistik T bezeichne.
H0 H1 H0 verwerfen, wenn
µ = µ0 µ 6= µ0 |τ | > tn−1;1−α/2
µ ≥ µ0 µ < µ0 τ < tn−1;α
µ ≤ µ0 µ > µ0 τ > tn−1;1−α
Beispiel 7.5 (Qualitätskontrolle, σ2 unbekannt)Wir greifen Beispiel 7.4 nochmals auf. Aufgrund eines neuen Herstellungsverfahrenssei die Varianz jedoch dieses Mal unbekannt. Für n = 75 Kekspackungen wurde nunx = 98.9 und s = 5.2 gemessen. Wir wählen
H0 : µ = 100
als Nullhypothese und geben uns abermals α := 0.05 vor. Die Berechnung der Realisie-rung der Teststatistik ergibt
τ =98.9− 100
5.2
√75 ≈ −1.83 .
Da |τ | ≤ 1.99 ≈ t74;0.975 , wird H0 beibehalten. Bemerkung. In R wird der t-Test mittels t.test() auf einen Datensatz angewandt.

7. Parametrische Tests 235
7.2.3 χ2-Streuungstest
Soll eine normalverteilte Stichprobe hinsichtlich ihrer Varianz getestet werden, so wirdder χ2-Streuungstest verwendet. Sei X1, . . . , Xn eine N (µ, σ2)-verteilte Stichprobe, derErwartungswert µ muss nicht bekannt sein. Weiters sei σ2
0 > 0 vorgegeben.
Festlegung der Hypothesen:
H0 H1
σ2 = σ20 σ2 6= σ2
0 zweiseitig
σ2 ≥ σ20 σ2 < σ2
0 einseitig
σ2 ≤ σ20 σ2 > σ2
0 einseitig
Als Teststatistik verwendet man
T (X1, . . . , Xn) =n− 1
σ20
S2 =1
σ20
n∑
i=1
(Xi −X)2 .
Nach Satz 6.14 ist
Tσ2=σ2
0∼ χ2n−1 .
Bezeichnet τ die Realisierung der Teststatistik T , so erhält man die folgenden Testent-scheidungen.
H0 H1 H0 verwerfen, wenn
σ2 = σ20 σ2 6= σ2
0 τ > χ2n−1;1−α/2 oder τ < χ2
n−1;α/2
σ2 ≥ σ20 σ2 < σ2
0 τ < χ2n−1;α
σ2 ≤ σ20 σ2 > σ2
0 τ > χ2n−1;1−α
Beispiel 7.6 (Keksproduktion)Es soll nun getestet werden, ob die Abweichung vom Durchschnittsgewicht bei dem inBeispiel 7.5 beschriebenen neuen Herstellungsverfahren signikant gröÿer geworden ist.Wir wollen also
H0 : σ2 ≤ σ20 gegen H1 : σ2 > σ2
0

236 7. Parametrische Tests
testen, wobei σ0 = 5 . Für n = 75 Packungen wurde s = 5.2 gemessen. Als Signikanzni-veau wählen wir α := 0.05 und für die Realisierung der Teststatistik erhalten wir
τ =n− 1
σ20
s2 ≈ 80.04 .
Da χ274;0.95 ≈ 95.08 , ist τ < χ2
74;0.95 und somit wird die Nullhypothese beibehalten.
7.3 Zweistichprobenprobleme
Es werden nun einige Testverfahren für Zweistichprobenprobleme vorgestellt. Gegebenseien zwei Stichproben
X1, . . . , XnX und Y1, . . . , YnY .
Getestet werden soll, ob gewisse Verteilungsparameter der beiden Stichproben überein-stimmen.
Beispiel 7.7 (Medikamentenstudie)Im Rahmen einer Studie soll die Wirksamkeit eines Medikamentes überprüft werden.Dazu werden die Überlebenszeiten x1, . . . , xnX der Studiengruppe sowie die Überlebens-zeiten y1, . . . , ynY der Kontrollgruppe ermittelt. Durch Vergleich der Überlebenszeitensoll festgestellt werden, ob die Einnahme des neuen Medikaments die Überlebenszeitsignikant gesteigert hat oder nicht.
7.3.1 Doppelter Gauÿ-Test
Der doppelte Gauÿ-Test dient dem Vergleich der Erwartungswerte zweier normalverteilterStichproben bei gleicher und bekannter Varianz. Gegeben sei also eineN (µX , σ
2)-verteilteStichprobe
X1, . . . , XnX
und eine N (µY , σ2)-verteilte Stichprobe
Y1, . . . , YnY ,
wobei die Varianz σ2 > 0 der voneinander unabhängigen Stichproben bekannt sei.
Festlegung der Hypothesen:
H0 H1
µX = µY µX 6= µY zweiseitig
µX ≤ µY µX > µY einseitig

7. Parametrische Tests 237
Für die Teststatistik
T (X1, . . . , XnX , Y1, . . . , YnY ) =X − Y
σ√
1nX
+ 1nY
gilt
TµX=µY∼ N (0, 1) ,
vgl. Aufgabe (7.9). Bezeichne wiederum τ die Realisierung der Teststatistik T . ZumSignikanzniveau α erhalten wir die folgenden Testentscheidungen.
H0 H1 H0 verwerfen, wenn
µX = µY µX 6= µY |τ | > Φ1−α/2
µX ≤ µY µX > µY τ > Φ1−α
7.3.2 Doppelter t-Test
Der doppelte t-Test verläuft analog zum doppelten Gauÿ-Test, nur wird nun die Varianznicht als bekannt vorausgesetzt. Gegeben sei also wiederum eine N (µX , σ
2)-verteilteStichprobe
X1, . . . , XnX
und eine N (µY , σ2)-verteilte Stichprobe
Y1, . . . , YnY ,
wobei dieses Mal die Varianz σ2 > 0 der voneinander unabhängigen Stichproben unbe-kannt sei.
Festlegung der Hypothesen:
H0 H1
µX = µY µX 6= µY zweiseitig
µX ≤ µY µX > µY einseitig

238 7. Parametrische Tests
Die Varianz σ2 wird nun durch die sogenannte gepoolte Stichprobenvarianz
S2p :=
∑nXi=1(Xi −X)2 +
∑nYi=1(Yi − Y )2
nX + nY − 2
geschätzt, es handelt sich hierbei um einen erwartungstreuen und konsistenten Schätzerfür die Varianz σ2 , vgl. Aufgabe (7.10). Für die Teststatistik
T (X1, . . . , XnX , Y1, . . . , YnY ) =X − Y
Sp
√1nX
+ 1nY
gilt, dass
TµX=µY∼ tnX+nY −2 .
Dies führt auf die folgenden Testentscheidungen.
H0 H1 H0 verwerfen, wenn
µX = µY µX 6= µY |τ | > tnX+nY −2;1−α/2
µX ≤ µY µX > µY τ > tnX+nY −2;1−α
7.3.3 F -Test
Der F -Test dient zur Überprüfung, ob sich die Varianzen zweier unabhängiger normal-verteilter Stichproben unterscheiden oder nicht. Sei also X1, . . . , XnX eine N (µX , σ
2X)-
verteilte Stichprobe und Y1, . . . , YnY eine N (µY , σ2Y )-verteilte Stichprobe. Weiters seien
X1, . . . , XnX , Y1, . . . , YnY unabhängig und die Erwartungswerte und Varianzen der Stich-proben unbekannt.
Festlegung der Hypothesen:
H0 H1
σ2X = σ2
Y σ2X 6= σ2
Y zweiseitig
σ2X ≤ σ2
Y σ2X > σ2
Y einseitig
Es stellt sich nun die Frage, nach der Wahl der Teststatistik und nach deren Verteilung.

7. Parametrische Tests 239
Definition 7.8 (F -Verteilung)Es seienm,n ∈ N undX,Y zwei unabhängige Zufallsvariablen mitX ∼ χ2
m und Y ∼ χ2n .
Die Verteilung der Zufallsvariablen
X/m
Y/n
heiÿt Fisher1-Verteilung mit m und n Freiheitsgraden (kurz: Fm,n-Verteilung).
Satz 7.9 (Verteilung des Varianzenquotienten)Sind X1, . . . , XnX , Y1, . . . , YnY unabhängige normalverteilte Zufallsvariable, wobei es sichbei X1, . . . , XnX um eine N (µX , σ
2)-verteilte und bei Y1, . . . , YnY um eine N (µY , σ2)-
verteilte Stichprobe handle, so bezeichnen wir die zugehörigen Stichprobenvarianzen mit
S2X :=
1
nX − 1
nX∑
i=1
(Xi −X)2 und S2Y :=
1
nY − 1
nY∑
i=1
(Yi − Y )2 .
Dann ist der Varianzenquotient
S2X
S2Y
=
1nX−1
(nX−1σ2 S2
X
)
1nY −1
(nY −1σ2 S2
Y
)
FnX−1,nY −1-verteilt.
Beweis. Folgt unmittelbar aus Satz 6.14.
Satz 7.10 (Dichte der F -Verteilung)Die Fm,n-Verteilung besitzt bezüglich des Lebesgue-Maÿes die Dichte
f(x ;Fm,n) = H(x)mm/2nn/2xm/2−1
(mx+ n)(m+n)/2B(m2 ,
n2
) , x ∈ R ,
wobei B die Eulersche Betafunktion bezeichnet.
Beweis. Aufgabe (7.13).
Als Teststatistik wird nun also der Variationskoezient
T (X1, . . . , XnX , Y1, . . . , YnY ) =S2X
S2Y
σ2X=σ2
Y∼ FnX−1,nY −1
gewählt. Die Testentscheidungen lauten damit wie folgt:
1Ronald Aylmer Fisher, 18901962, englischer Statistiker, Biologe und Evolutionstheoretiker

240 7. Parametrische Tests
H0 H1 H0 verwerfen, falls
σ2X = σ2
Y σ2X 6= σ2
Y τ > FnX−1,nY −1;1−α/2 oder τ < FnX−1,nY −1;α/2
σ2X ≤ σ2
Y σ2X > σ2
Y τ > FnX−1,nY −1;1−α
Beispiel 7.11 (Vitamin C und Zähne)Einigen Meerschweinchen im Datensatz ToothGrowth wurde täglich 1 mg Vitamin C ver-abreicht, entweder direkt als Ascorbinsäure (Gruppe 1) oder über Orangensaft (Gruppe2). Nach einiger Zeit wurden die Zähne der Meerschweinchen vermessen und es ergabensich folgende Längen in Millimeter:
Gruppe 1 16.5 16.5 15.2 17.3 22.5 17.3 13.6 14.5 18.8 15.5
Gruppe 2 19.7 23.3 23.6 26.4 20.0 25.2 25.8 21.2 14.5 27.3
Es stellt sich nun die Frage, ob die Art der Verabreichung des Vitamins einen Einussauf das Zahnwachstum hat.
Wir überprüfen zuerst mittels des F -Tests, ob die Varianzen als gleich angenommenwerden können.
> TG=ToothGrowth
> Gruppe1=TG$len[TG$supp=="VC" & TG$dose ==1.0]
> Gruppe2=TG$len[TG$supp=="OJ" & TG$dose ==1.0]
> var.test(Gruppe1 ,Gruppe2)
F test to compare two variances
data: Gruppe1 and Gruppe2 F = 0.4136 , num df = 9, denom df =
9, p-value =
0.2046 alternative hypothesis: true ratio of variances is not
equal to 1 95
percent confidence interval:
0.1027411 1.6652923
sample estimates: ratio of variances
0.413635
Die Varianzen können wir also als gleich annehmen und den doppelten t-Test zum Signi-kanzniveau α = 0.05 anwenden, um zu überprüfen, ob die Länge der Zähne im Mittelals gleich anzusehen ist.
> t.test(Gruppe1 ,Gruppe2 ,var.equal=TRUE)

7. Parametrische Tests 241
Two Sample t-test
data: Gruppe1 and Gruppe2 t = -4.0328, df = 18, p-value =
0.0007807
alternative hypothesis: true difference in means is not equal
to 0 95 percent
confidence interval:
-9.019308 -2.840692
sample estimates: mean of x mean of y
16.77 22.70
Die Hypothese der gleichen Erwartungswerte wird verworfen, es besteht also zwischenden beiden Gruppen ein signikanter Unterschied bezüglich der Länge der Zähne. Setztman bei t.test() das Argument var.equal nicht auf TRUE, so wird der Welch-Testangewandt, welchen wir im nachfolgenden Abschnitt kennenlernen werden.
7.3.4 Welch-Test
Es sei wiederum X1, . . . , XnX eine N (µX , σ2X)-verteilte Stichprobe und Y1, . . . , YnY eine
N(µY , σ2Y )-verteilte Stichprobe sowie X1, . . . , XnX , Y1, . . . , YnY unabhängig. Weiters sei-
en die Erwartungswerte und Varianzen der Stichproben unbekannt.
Beim Welch-Test soll
H0 : µX = µY gegen H1 : µX 6= µY
getestet werden, wobei angenommen wird, dass
σ2X 6= σ2
Y .
Dieses Testproblem nennt sich das Behrens-Fisher-Problem. Als Teststatistik wird
T (X1, . . . , XnX , Y1, . . . , YnY ) =X − Y√S2XnX
+S2YnY
verwendet, die sogenannte Behrens-Fisher-Testgröÿe. Diese ist unter der Nullhypo-these annähernd t-verteilt mit
n =
(s2X/nX + s2
Y /nY)2
(s2X/nX)2
nX−1 +(s2Y /nY )2
nY −1
Freiheitsgraden. Somit wird die Nullhypothese verworfen, falls
|τ | > tn;1−α/2 .

242 7. Parametrische Tests
Beispiel 7.12 (Im Wirtshaus)In einem Wirtshaus wechseln sich die Wirtin und der Wirt regelmäÿig hinter dem Tresenab. Bei einigen Wirtshausbesuchern ist der Eindruck entstanden, dass die Wirtin dasBierglas deutlich voller füllt als der Wirt. Ein kritischer Kunde hat sich über einigeAbende hinweg den Füllstand des Bierglases in Millilitern notiert, die Ergebnisse sind innachfolgender Tabelle zu nden.
Füllstand Wirtin 563 537 508 516 515 550 551 509 553 545
Füllstand Wirt 519 516 521 518 526 523 507 520 515 523
Getestet werden soll, ob der durchschnittliche Füllstand der Wirtin von dem des Wirtessignikant abweicht, vgl. Aufgabe (7.14).
7.4 Überblick: Tests für normalverteilte Daten
Die nachfolgende Tabelle fasst die bisher vorgestellten Tests für normalverteilte Datennochmals zusammen.
H0 Varianz(en) Test
µ = µ0 bekannt Einfacher Gauÿ-Test
µ = µ0 unbekannt Einfacher t-Test
σ2 = σ20 χ2-Streuungstest
µX = µY σ2X = σ2
Y , bekannt Doppelter Gauÿ-Test
µX = µY σ2X = σ2
Y , unbekannt Doppelter t-Test
σ2X = σ2
Y F -Test
µX = µY σ2X 6= σ2
Y , unbekannt Welch-Test
Ein exzellenter Test, um auf eine Normalverteilung zu testen, ist der Shapiro-Wilk-Test, vgl. [18]. Dieser wird durch shapiro.test() aufgerufen.
> x=rnorm (25,2,3)
> shapiro.test(x)
Shapiro -Wilk normality test
data: x W = 0.9832 , p-value = 0.9404

7. Parametrische Tests 243
7.5 Einfache Varianzanalyse
Beim doppelten t-Test wurden zwei unabhängige normalverteilte Stichproben hinsichtlichihrer Erwartungswerte miteinander verglichen. Die Erweiterung auf mehrere unabhängigeStichproben bietet die einfache Varianzanalyse.
Beispiel 7.13 (Puls und Rauchen)Untersucht werden soll die Abhängigkeit des Pulses vom Rauchverhalten, wobei dasRauchverhalten in die vier Kategorien R1, . . . , R4 eingeteilt wird. Dabei steht R1 fürNichtraucher, R2 für Gelegenheitsraucher, R3 für regelmäÿige Raucher und R4 für Ket-tenraucher. Es bezeichne x(j)
i den gemessenen Ruhepuls der i-ten Person mit Rauchver-halten Rj , wobei i = 1, . . . , nj ∈ N . Festgestellt werden soll, ob sich das Rauchverhaltensignikant auf den Ruhepuls auswirkt. Gegeben seien k sogenannte Faktorstufen
X(1)1 , . . . , X(1)
n1, . . . , X
(k)1 , . . . , X(k)
nk,
die Faktorstufen sind voneinander unabhängige Stichproben vom Umfang n1, . . . , nk . Au-ÿerdem gehen wir davon aus, dass alle Faktorstufen normalverteilt mit derselben Varianzσ2 sind, der Erwartungswert sich jedoch in den einzelnen Faktorstufen unterscheidenkann, d.h.
X(j)1 , . . . , X(j)
nj ∼ N(µj , σ
2)
für j = 1, . . . , k . Getestet werden soll
H0 : µ1 = . . . = µk gegen H1 : ¬H0 .
Da wir nur einen Einussfaktor betrachten, sprechen wir im Folgenden von der einfak-toriellen Varianzanalyse. Die Idee dabei ist, zwei unterschiedliche Varianzschätzer zubetrachten, welche bei Gültigkeit von H1 mehr voneinander abweichen als bei Gültigkeitvon H0 .
Wir setzen
X(j)
:=1
nj
nj∑
i=1
X(j)i und X :=
1
n
k∑
j=1
nj∑
i=1
X(j)i ,
wobei n :=∑k
j=1 nj . Als ersten Varianzschätzer betrachtet man die Abweichungen der
X(j)vom Gesamtmittel X, also
S21 :=
1
k − 1
k∑
j=1
nj
(X
(j) −X)2
.

244 7. Parametrische Tests
Beim zweiten Varianzschätzer wird zuerst die Varianz der einzelnen Stichproben durch
S2X(j) :=
1
nj − 1
nj∑
i=1
(X
(j)i −X
(j))2
geschätzt und anschlieÿend die Gesamtvarianz mittels
S22 :=
1
n− kk∑
j=1
(nj − 1)S2X(j) .
Die beiden Varianzschätzer S21 und S2
2 unterscheiden sich nun wie folgt: Bei Gültigkeitvon H0 ist S2
1 ein erwartungstreuer Schätzer für die Varianz σ2 , während es sich bei S22
sowohl unter H0 als auch H1 um einen erwartungstreuen Schätzer für die Varianz σ2
handelt, vgl. Aufgabe (7.16).
Als Teststatistik verwenden wir daher den Quotienten der beiden Varianzschätzer
T(X
(1)1 , . . . , X(k)
nk
)=S2
1
S22
.
Der nachfolgende Satz gibt Aufschluss über die Verteilung dieser Teststatistik unter derNullhypothese.
Satz 7.14 (Verteilung und Unabhängigkeit der Varianzschätzer)Die folgende Aussagen gelten bei Gültigkeit von H0 .
(1) k−1σ2 S
21 ist χ2
k−1-verteilt
(2) n−kσ2 S
22 ist χ2
n−k-verteilt
(3) S21 und S2
2 sind unabhängig
Beweis. Bei Gültigkeit der Nullhypothese gilt µ1 = . . . = µk =: µ und somit
X(j)i ∼ N (µ, σ2) , j = 1, . . . , k , i = 1, . . . , nj .
Folglich ist
Y(j)i :=
X(j)i − µσ
∼ N (0, 1) .
Wir setzen
Y :=[Y
(1)1 , . . . , Y (1)
n1, . . . , Y
(k)1 , . . . , Y (k)
nk
]T

7. Parametrische Tests 245
und wählen eine orthogonale Matrix A ∈ Rn×n , sodass
Aj := Aj− =[a
(j)11 , . . . , a
(j)1n1, . . . , a
(j)k1 , . . . , a
(j)knk
]für j = 1, . . . , k ,
wobei
a(j)il =
δij√nj, i = 1, . . . , k , l = 1, . . . , ni .
Nach Lemma 6.13 sind die Komponenten von
Z := AY
unabhängig und standardnormalverteilt. Für j = 1, . . . , k gilt auÿerdem
Zj =
√nj
σ
(X
(j) − µ)
und damit
n− kσ2
S22 =
1
σ2
k∑
j=1
nj∑
i=1
(X
(j)i −X
(j))2
=k∑
j=1
nj∑
i=1
(X
(j)i − µσ
− X(j) − µσ
)2
=
=k∑
j=1
nj∑
i=1
(Y
(j)i − 1
√njZj
)2
=
∥∥∥∥∥∥Y −
k∑
j=1
ZjATj
∥∥∥∥∥∥
2
2
.
Da des Weiteren
Y = ATZ =n∑
j=1
ZjATj ,
gilt
n− kσ2
S22 =
∥∥∥∥∥∥
n∑
j=k+1
ZjATj
∥∥∥∥∥∥
2
2
=
n∑
j=k+1
Z2j
und somit (2).
Zusätzlich haben wir gezeigt, dass S22 = S2
2(Zk+1, . . . , Zn) . Aus
X(j)
=σ√njZj + µ , j = 1, . . . , k ,

246 7. Parametrische Tests
und
X =1
n
k∑
j=1
njX(j)
folgt S21 = S2
1(Z1, . . . , Zk) und damit (3).
Da
k − 1
σ2S2
1 =1
σ2
k∑
j=1
nj
(X
(j))2− nX2
=
k∑
j=1
Z2j −
k∑
j=1
√njnZj
2
,
wählen wir eine orthogonale Matrix A ∈ Rk×k mit erster Zeile
A1− =
[√n1
n, . . . ,
√nkn
]
und setzen
U := A[Z1, . . . , Zk
]T.
Dann ist
k − 1
σ2S2
1 =k∑
j=2
U2j
und somit auch (1) gezeigt.
Nach Satz 7.14 ist also
S21
S22
H0∼ Fk−1,n−k .
Die Testentscheidung zum Signikanzniveau α lautet daher H0 abzulehnen, falls
τ = T(x
(1)1 , . . . , x(k)
nk
)> Fk−1,n−k;1−α .
Beispiel 7.15 (Fortsetzung von Beispiel 7.13)Der im Paket MASS enthaltene Datensatz survey enthält die in Beispiel 7.13 geschilder-ten Merkmale Pulse und Smoke. Um einen Überblick über die Datenlage zu bekommen,fertigen wir zuerst einen Boxplot an.
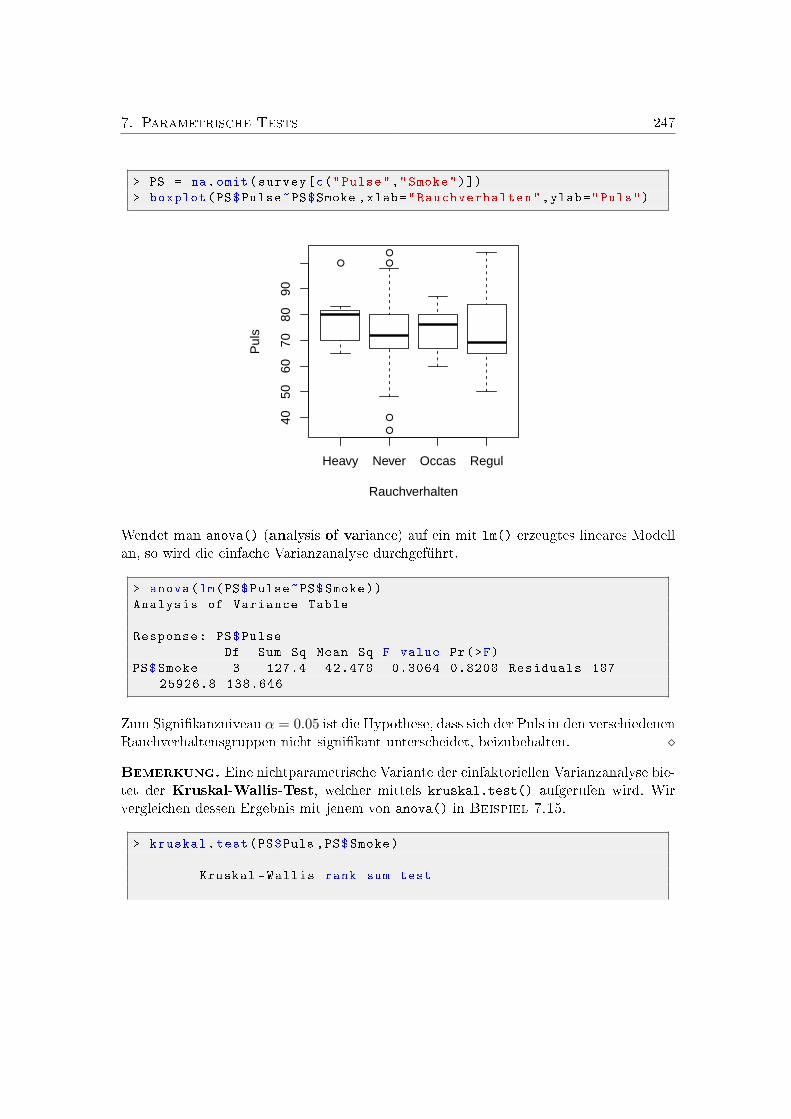
7. Parametrische Tests 247
> PS = na.omit(survey[c("Pulse","Smoke")])
> boxplot(PS$Pulse~PS$Smoke ,xlab="Rauchverhalten",ylab="Puls")
Heavy Never Occas Regul
4050
6070
8090
Rauchverhalten
Pul
s
Wendet man anova() (analysis of variance) auf ein mit lm() erzeugtes lineares Modellan, so wird die einfache Varianzanalyse durchgeführt.
> anova(lm(PS$Pulse~PS$Smoke))
Analysis of Variance Table
Response: PS$Pulse
Df Sum Sq Mean Sq F value Pr(>F)
PS$Smoke 3 127.4 42.478 0.3064 0.8208 Residuals 187
25926.8 138.646
Zum Signikanzniveau α = 0.05 ist die Hypothese, dass sich der Puls in den verschiedenenRauchverhaltensgruppen nicht signikant unterscheidet, beizubehalten.
Bemerkung. Eine nichtparametrische Variante der einfaktoriellen Varianzanalyse bie-tet der Kruskal-Wallis-Test, welcher mittels kruskal.test() aufgerufen wird. Wirvergleichen dessen Ergebnis mit jenem von anova() in Beispiel 7.15.
> kruskal.test(PS$Puls ,PS$Smoke)
Kruskal -Wallis rank sum test

248 7. Parametrische Tests
data: PS$Puls and PS$Smoke Kruskal -Wallis chi -squared =
0.8787 , df = 3,
p-value = 0.8306
Abermals wird die Nullhypothese zum Signikanzniveau α = 0.05 beibehalten. Der hö-here p-Wert erklärt sich dadurch, dass nun keine Verteilungsannahmen getroen wurden.Die Macht dieses Tests ist daher deutlich geringer.

7. Parametrische Tests 249
Übungsaufgaben
(7.1) Fehler 1. und 2. Art: Die Körpergröÿen der Mitglieder (groesse.csv auf http://tobiashell.com) eines Kegelvereins werden normalverteilt mit Standardabwei-chung σ = 12 angenommen. Wir interessieren uns für den Erwartungswert µ .
(a) Formulieren Sie eine zweiseitige Nullhypothese über den Erwartungswert undberechnen Sie den kritischen Bereich für den entsprechenden stochastischenPivot zum Signikanzniveau α = 0, 05 .
(b) Berechnen Sie eine Realisierung der Teststatistik mit dem gegebenen Daten-satz und treen Sie die Testentscheidung.
(c) Plotten Sie in R die zugehörige Gütefunktion.
(7.2) Keksfabrik: Der Kekshersteller aus Beispiel 7.1 misst x(75) = 98.08 . Die Pro-duktion ist so optimiert, dass die Standardabweichung σ = 2 g beträgt. Der Her-steller vermutet jedoch zu starke Abweichungen vom mittleren Gewicht von 100 g.Das Gewicht ist annähernd normalverteilt.
(a) Formulieren Sie die Hypothesen für einen zweiseitigen Test für das mittlereGewicht µ .
(b) Welchen Test würden Sie anwenden und warum?
(c) Führen Sie den gewählten Test für α = 0.05 durch.
(d) Wie müssten die Hypothesen lauten, wenn man zeigen wollte, dass das mittlereGewicht weniger als 100 g beträgt?
(e) Führen Sie auch diesen einseitigen Test für α = 0.05 durch.
(7.3) Pulsfrequenz: In einer Studie wurde die Pulsfrequenz von n = 53 8-9-jährigenJungen gemessen. Es ergab sich eine mittlere Pulsfrequenz von 86.7 Schlägen/Mi-nute. Langjährige Erfahrungen haben gezeigt, dass die Pulsfrequenz normalverteiltist mit Mittelwert µ und Standardabweichung σ = 10.3 Schläge/Minute. Zu testenist die Hypothese
H0 : µ ≥ 90 gegen H1 : µ < 90 .
Berechnen Sie zu den obigen Daten den p-Wert und interpretieren Sie das Ergebnis.
(7.4) Berechnen Sie die Gütefunktion des zweiseitigen einfachen Gauÿ-Tests und skizzie-ren Sie diese.
(7.5) Tortenkontrolle: Eine Firma liefert tiefgefrorene Torten an Supermärkte. Beidem in Kilogramm angegebenen Gewicht der Torten handle es sich um ein an-nähernd normalverteiltes Merkmal. Die Varianz σ2 = 0.01 sei als Erfahrungswert

250 7. Parametrische Tests
bekannt. Das angegebene Mindestgewicht beträgt µ0 = 2 kg. Zur Qualitätskontrol-le wurde von n = 20 zufällig ausgewählten Torten das Gewicht bestimmt, es ergabsich x = 1.97 . Testen Sie zum Signikanzniveau α = 0.05 , ob dies im Einklang mitdem angegebenen Mindestgewicht steht.
(7.6) Faule Eier: Das Durchschnittsgewicht von Eiern einer bestimmten Güteklasse seimit µ = 78 g angegeben, das Gewicht der Eier normalverteilt. Ein misstrauischerKunde kauft 60 Eier und berechnet das mittlere Gewicht x = 72.1 g und dieempirische Standardabweichung s = 6.2 g. Steht dieses Ergebnis im Einklang zuder angegebenen Güteklasse?
(7.7) Tortenkontrolle II: Wir greifen Aufgabe (7.5) nochmals auf. Aufgrund einesneuen Herstellungsverfahrens sei die Varianz jedoch dieses Mal unbekannt. Fürn = 20 Torten wurde nun x = 1.967 und s = 0.093 gemessen. Testen Sie aber-mals zum Signikanzniveau α = 0.05 , ob dies im Einklang mit dem angegebenenMindestgewicht steht.
(7.8) Tortenkontrolle III: Testen Sie zum Signikanzniveau α = 0.05 , ob die Ab-weichung vom Durchschnittsgewicht bei dem in Aufgabe (7.7) beschriebenen neuenHerstellungsverfahren signikant gröÿer geworden ist.
(7.9) Zeigen Sie, dass die beim doppelten Gauÿ-Test verwendete Teststatistik unter derNullhypothese standardnormalverteilt ist.
(7.10) Zeigen Sie, dass die beim doppelten t-Test auftretende gepoolte StichprobenvarianzS2p ein erwartungstreuer und konsistenter Schätzer für die Varianz der Stichproben
ist.
(7.11) Masttierfütterung: In einer landwirtschaftlichen Versuchsanstalt erhielten 9von 21 Masttieren (Gruppe 1) Grünfutterzumischung, während die übrigen 12 Tiere(Gruppe 2) ausschlieÿlich mit Mastfutter gefüttert wurden. Die folgende Tabellezeigt die Gewichtszunahme der Tiere in kg nach einer bestimmten Zeit.
Gruppe 1 7.0 11.8 10.1 8.5 10.7 13.2 9.4 7.9 11.1
Gruppe 2 13.4 14.6 10.4 11.9 12.7 16.1 10.7 8.3 13.2 10.3 11.3 12.9
Testen Sie, ob zwischen den beiden Gruppe ein signikanter Unterschied in derGewichtszunahme besteht.
(7.12) Cholesterin: Eine Gruppe von Personen hat sich über einen bestimmten Zeit-raum nach einer bestimmten Diät ernährt. Unterscheiden sich die Cholesterinwertesignikant?

7. Parametrische Tests 251
Rindeisch 241 261 238 248 225 227 237 235
Schweineeisch 245 199 191 160 208 174 225 174 168 165
(a) Modellieren Sie den Sachverhalt stochastisch.
(b) Welche Darstellungsmöglichkeiten aus der deskriptiven Statistik bieten sichan? Nutzen Sie diese um die Daten darzustellen.
(c) Entscheiden Sie die Frage in der Aufgabenstellung.
(7.13) Beweisen Sie Satz 7.10.
(7.14) Führen Sie den doppelten t-Test und den Welch-Test für Beispiel 7.12 durch undvergleichen Sie die Ergebnisse. Was ergibt der F -Test?
(7.15) Mail-Server: Weicht die Häugkeit der ankommenden E-Mails an einem Servervon jenen der ausgehenden signikant ab?
Ein 157 210 302 128 212 200 157 227 297 281 312 276
Aus 340 170 150 185 183 277 169 264 213 222 298
(a) Modellieren Sie den Sachverhalt.
(b) Welche Darstellungsmöglichkeiten aus der deskriptiven Statistik bieten sichan? Nutzen Sie diese um die Daten darzustellen.
(c) Entscheiden Sie die Frage in der Aufgabenstellung.
(7.16) Erwartungstreue Varianzschätzer: Zeigen Sie, dass S21 bei Gültigkeit von
H0 ein erwartungstreuer Schätzer für die Varianz σ2 ist, während es sich bei S22
sowohl unter H0 als auch H1 um einen erwartungstreuen Schätzer für die Varianzσ2 handelt.
(7.17) Düngemittel: Die folgende Tabelle enthält die Erträge von 20 Feldern, welchemit vier verschiedenen Düngemitteln bzw. gar nicht gedüngt wurden.
Düngemittel Ertrag
keines 66 68 42 56
D1 60 35 51 69
D2 64 79 72 82
D3 97 99 64 91
D4 90 79 87 71

252 7. Parametrische Tests
Überprüfen Sie mit dem entsprechenden Test, ob die unterschiedlichen Düngemittelim Mittel gleiche Erträge liefern.

7. Parametrische Tests 253
Schulaufgaben
Die nachfolgenden Aufgaben stammen, sofern keine weiteren Angaben gemacht werden,von https://www.bifie.at/ (Stand: Februar 2013).
(S7.1) Hypothesentest 1: An einer Schule wird eine neue Unterrichtsmethode er-probt, wodurch die Leistungen von Schüler/innen verbessert werden sollen. Umdie Erfolge dieser neuen Methode zu überprüfen, testet man die Schüler/innen.Dazu verwendet man einen Test, für den die Ergebnisse aus früheren Jahren be-kannt sind.
Stelle dazu Null- und Alternativhypothese auf und beschreibe den Fehler 1. undden Fehler 2. Art.
(S7.2) Hypothesentest 2: Bei einem Signikanztest wurde die Nullhypothese auf dem1%-Signikanzniveau verworfen.
Stelle fest, welche der folgenden Aussagen richtig bzw. falsch sind und begründedeine Entscheidung.
(a) Die Nullhypothese ist falsch.
(b) Die Alternativhypothese ist wahr.
(c) Mit einer Wahrscheinlichkeit von 99% gilt die Alternativhypothese.
(d) Man lehnt die Nullhypothese ab und nimmt eine Fehlerwahrscheinlichkeitvon 1% in Kauf.
(S7.3) Annehmen oder Verwerfen einer Behauptung über p: Ein Betrieb stelltbesonders geformte Gläser für die Pharmaindustrie her. Dabei kommt es im-mer wieder vor, dass ein Glas in Bruch geht. Der Bruchanteil beträgt nahezugleichbleibend 4%. Nach einem längeren Stillstand wird die Produktion wiederaufgenommen. Dabei wird die Behauptung angezweifelt, dass der Bruchanteil ge-genüber dem früheren Wert p = 4% gleichgeblieben ist. Zur Klärung entnimmtman der wieder angelaufenen Fertigung eine Stichprobe. Wie ist zu urteilen, wennman
(a) bei 40 Gläsern 4 Brüche,
(b) bei 100 Gläsern 10 Brüche
feststellt? Verwende ein Vertrauensniveau von 95 %.(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 275, Bsp. 7.4)
(S7.4) Hypothesentest 3: Eine Firma erhält regelmäÿig Lieferungen von Früchten.Der Lieferant behauptet, dass höchstens 5% der Früchte verdorben sind. Die Fir-ma vermutet, dass dieser Anteil höher ist und möchte dies durch eine Stichprobe

254 7. Parametrische Tests
vom Umfang 20 überprüfen. Die Firma beschlieÿt, die Behauptung des Lieferan-ten zu verwerfen, wenn sie mindestens 3 verdorbene Früchte in der Stichprobendet.
(a) Ermittle die Irrtumswahrscheinlichkeit.
(b) Kann die Firma die Behauptung des Lieferanten mit hinreichender Zuver-lässigkeit verwerfen?
Begründe deine Antwort!
(S7.5) Hypothesentest 4: Ein Blumenhändler erhält regelmäÿig Lieferungen von Blu-men aus Holland. Der Lieferant behauptet, dass höchstens 5% der geliefertenBlumen zum Verkauf nicht geeignet sind. Der Blumenhändler entnimmt jederLieferung eine Stichprobe von 20 Blumen.
Wie kann anhand dieser Stichprobe auf dem 5%-Niveau entschieden werden, obdie Angabe des Lieferanten stimmt, und daher die Lieferung anzunehmen ist?
(S7.6) Reissfestigkeit: Ein Betrieb stellt eine bestimmte Drahtart her, dessen Reiss-festigkeit aufgrund langer Beobachtung als normalverteilt mit µ0 = 58.8 N be-trachtet werden kann. Durch ein neues Herstellungsverfahren erwartet man eineVergröÿerung der Reissfestigkeit. Zur Klärung entnimmt man eine Stichprobevom Umfang n = 80, aus der sich x = 61.5 N und s = 6.8 N ergibt. Bestätigtdies die Erwartung bei einem Signikanzniveau von 5%?(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 296, Nr. 7.41)
(S7.7) Motoren: Nach Auskunft einer Lieferrma ist die mittlere Leistung der von ihrhergestellten Motoren normalverteilt mit Mittelwert 2.8 kW und der Standard-abweichung von 0.15 kW.
(a) Man berechne für einen Stichprobenumfang n = 20 und eine Aussagewahr-scheinlichkeit von
(i) 95%
(ii) 99%
einen zweiseitigen Zufallsstreubereich für die Abweichung vom Soll-Wert.
(b) Die ersten 20 gelieferten Motoren wurden hinsichtlich ihrer Leistung über-prüft: Man hat in dieser Stichprobe eine durchschnittliche Leistung von 2.73kW festgestellt. Liegt eine signikante (Anm. α = 0.05) bzw. hochsigini-kante (Anm. α = 0.01) Abweichung vom Soll-Wert vor?
(c) Man berechne für eine Aussagewahrscheinlichkeit von
(i) 95%
(ii) 99%

7. Parametrische Tests 255
und einer tatsächlichen mittleren Leistung in der Grundgesamtheit von 2.73kW die Wahrscheinlichkeit, beim Testen einer Stichprobe vom Umfangn = 20 den Fehler 2. Art zu begehen.
(Schalk et al.: Mathematik 4, Reniets Verlag, 2. Auage, 1992, S. 143, Nr. 6)
(S7.8) F-Test: Zwei Abfüllautomaten unterschiedlicher Art werden zur Abfüllung vonMinearlwasser in 1-Liter-Flaschen eingesetzt. In beiden Fällen kann die Füllmengenormalverteilt angenommen werden. Um die Gleichmäÿigkeit (anders gesagt: dieStreuung) der Füllmenge zu prüfen, wurde die Füllmenge von jeweils 10 an denbeiden Automaten abgefüllten Flaschen gemessen. Es ergab sich (Füllmengen inml):
Automat 1: 1008 1004 1001 1012 1002 1004 1006 999 1009 996
Automat 2: 995 992 998 1000 995 1002 1004 997 999 1002
Lassen die beiden Stichproben auf einen Unterschied der beiden Automaten be-züglich der Streuung der Abfüllmenge schlieÿen? Das Signikanzniveau betrage5 %.(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 303, Bsp. 7.16)
(S7.9) Varianzanalyse: Es soll untersucht werden, ob der Lernerfolg (gemessen inmaximal 20 Punkten) in vier gleichartigen Gruppen von Personen von der an-gewandten Unterrichtsmethode abhängt. Dabei sollen a = 4 verschiedene Un-terrichtsmethoden zum Einsatz kommen. Für jede dieser Methoden wird zufälligeine Gruppe n = 6 Personen ausgewählt. Dabei ergab sich:
Gruppe Lernerfolg yij in Punkten
1 6 12 8 4 10 8
2 7 1 5 3 8 6
3 12 5 8 14 10 11
4 9 12 5 10 7 11
Kann daraus bei einem Signikanzniveau α = 5% ein Einuss der Unterrichts-methode auf den Lernerfolg abgeleitet werden?(Timischl; Kaiser : Ingenieur-Mathematik 4, E. Dorner Verlag, 3. Auage, 2005, S. 313, Bsp. 7.19)

256 7. Parametrische Tests
Kontrollfragen
7.1 Bei einem statistischen Test sollte stets
das Signikanzniveau erst nach Berechnung des p-Wertes gewählt werden,
der p-Wert erst nach Wahl des Signikanzniveaus bestimmt werden,
das Signikanzniveau stets gleich dem p-Wert gewählt werden,
der p-Wert gleich dem Signikanzniveau gesetzt werden.
7.2 Die Macht eines Tests wächst, wenn
der Stichprobenumfang zunimmt,
die Fehlerwahrscheinlichkeit 2. Art gröÿer wird,
die Irrtumswahrscheinlichkeit verkleinert wird,
die Irrtumswahrscheinlichkeit vergröÿert wird.
7.3 Um den doppelten t-Test anzuwenden, müssen die beiden vorliegenden Stichpro-ben
voneinander unabhängig sein,
normalverteilt sein,
dieselbe Varianz haben,
unterschiedliche Varianzen besitzen.
7.4 Um den Welch-Test anzuwenden,
muss die verwendete Teststatistik unter der Nullhypothese t-verteilt sein,
müssen die Varianzen der beiden vorliegenden Stichproben bekannt sein,
müssen die Erwartungswerte der beiden vorliegenden Stichproben bekanntsein,
müssen die Varianzen der beiden vorliegenden Stichproben unterschiedlichsein.
7.5 Mit dem F -Test können zwei unabhängige und normalverteilte Stichproben auf
gleiche Erwartungswerte
gleiche Standardabweichungen
gleiche Varianzen
sowohl gleiche Erwartungswerte als auch gleiche Standardabweichungen
getestet werden.

7. Parametrische Tests 257
7.6 Bei der einfachen Varianzanalyse müssen die vorliegenden Stichproben
voneinander unabhängig sein,
normalverteilt sein,
gleiche Erwartungswerte haben,
gleiche Varianzen besitzen.


Kapitel 8
Nichtparametrische Tests
In Kapitel 7 wurden ausschlieÿlich parametrische Tests betrachtet, d. h. es wurden Ver-teilungsannahmen getroen. Die in diesem Kapitel vorgestellten nichtparametrischenTests kommen ohne derartige Annahmen aus.
8.1 Anpassungstests
Wir werden nun Tests kennenlernen, mit denen überprüft werden kann, ob eine Stich-probe eine vermutete Verteilung besitzt bzw. ob zwei unabhängige Stichproben dieselbeVerteilung besitzen. Solche Tests werden Anpassungstests genannt.
8.1.1 Kolmogorow-Smirnow-Anpassungstests
In diesem Abschnitt werden zwei verschiedene Varianten des Kolmogorow-Smirnow1-Anpassungstests für das entsprechende Ein- und Zweistichprobenproblem vorgestellt.
Testen auf vorgegebene Verteilung
Gegeben sei eine Stichprobe X1, . . . , Xn zur Verteilungsfunktion F und die Verteilungs-funktion F0 der unterstellten Verteilung. Wir wollen
H0 : F = F0 gegen H1 : F 6= F0
testen. Wie wir bereits wissen, approximiert die empirische Verteilungsfunktion
Fn(t ;X1, . . . , Xn) =1
n
n∑
i=1
χ(−∞,t](Xi) ,
welche wir im Folgenden kurz mit Fn bezeichnen, die unbekannte Verteilungsfunktion F .Genauer gilt nach dem Satz von Gliwenko-Cantelli
‖F − Fn‖∞ = supt∈R|F (t)− Fn(t)| f.s.−→ 0 für n→∞ .
Als Teststatistik verwendet man daher den sogenannten Kolmogorow-Abstand
T (X1, . . . , Xn) = ‖F0 − Fn‖∞1Wladimir Iwanowitsch Smirnow, 18871974
259

260 8. Nichtparametrische Tests
und verwirft H0 , falls τ = T (x1, . . . , xn) einen kritischen Wert überschreitet. Die Frageist nun, wie dieser kritische Wert bei Vorgabe des Signikanzniveaus α berechnet wird.Dazu benötigen wir den folgenden Satz.
Satz 8.1 (Verteilung des Kolmogorow-Abstands)Es sei X1, . . . , Xn eine Stichprobe mit stetiger Verteilungsfunktion F . Dann hängt dieVerteilung des Kolmogorow-Abstands ‖F − Fn‖∞ nicht von F ab.
Beweis. Der Beweis erfolgt in drei Schritten.
Schritt 1: Es sei X eine Zufallsvariable mit stetiger Verteilungsfunktion F . Wir zeigen,dass F (X) auf [0, 1] gleichverteilt ist. Dazu betrachten wir für u ∈ (0, 1) die Funktion
G(u) := mint ∈ R : F (t) ≥ u , (Rechtsinverse)
welche die folgenden Eigenschaften hat.
(1) G ist monoton wachsend, denn aus u1 ≥ u2 folgt
t ∈ R : F (t) ≥ u1 ⊂ t ∈ R : F (t) ≥ u2
und daher ist G(u1) ≥ G(u2) .
(2) Es ist F (G(u)) = u für alle u ∈ (0, 1) .Oensichtlich ist F (G(u)) ≥ u . Angenommen es gelte F (G(u)) > u . Aufgrund derStetigkeit von F können wir ein ε > 0 nden, sodass
F (G(u)− ε) ≥ u .
Da G monoton wachsend ist und G(F (t)) ≤ t , folgt der Widerspruch
G(u)− ε ≥ G(u) .
Somit ist F (G(u)) = u .
(3) Für alle u ∈ (0, 1) und alle x ∈ R gilt
G(u) ≤ x ⇐⇒ u ≤ F (x) ,
eine unmittelbare Folgerung aus (1) und (2).
Für u ∈ (0, 1) folgt unter Verwendung der obigen Eigenschaften
P (F (X) ≥ u) = P (X ≥ G(u)) = 1− P (X ≤ G(u)) = 1− F (G(u)) =
= 1− u .

8. Nichtparametrische Tests 261
Oensichtlich gilt
P (F (X) ≤ x) = 0 für x ≤ 0
und
P (F (X) ≤ x) = 1 für x ≥ 1 ,
also erhalten wir insgesamt
P (F (X) ≤ x) =
0 , x ≤ 0 ,
x , x ∈ (0, 1) ,
1 , x ≥ 1 .
Somit ist F (X) auf [0, 1] gleichverteilt.
Schritt 2: Für alle t ∈ R gilt
Xi ≤ t f.s.⇐⇒ F (Xi) ≤ F (t) .
Dies folgt aus der Monotonie von F und dem ersten Beweisschritt, da
F (t) = P(Xi ≤ t) ≤ P (F (Xi) ≤ F (t)) = F (t) .
Schritt 3: Die Behauptung des Satzes folgt nun aus den vorangegangen Schritten desBeweises. Es ist
‖F − Fn‖∞ = supt∈R
∣∣∣∣∣F (t)− 1
n
n∑
i=1
χ(−∞,t](Xi)
∣∣∣∣∣ =
f.s.= sup
t∈R
∣∣∣∣∣F (t)− 1
n
n∑
i=1
χ(−∞,F (t)](F (Xi))
∣∣∣∣∣ =
= supu∈[0,1]
∣∣∣∣∣u−1
n
n∑
i=1
χ(−∞,u](F (Xi))
∣∣∣∣∣
und daher hängt die Verteilung von ‖F − Fn‖∞ nur von der Verteilung von
F (X1), . . . , F (Xn)
ab, also nach dem ersten Beweisschritt nicht von F .
Nach Satz 8.1 kann bei stetiger Verteilungsfunktion F0 das (1− α)-Quantil von
supu∈[0,1]
∣∣∣∣∣u−1
n
n∑
i=1
χ(−∞,u](Gi)
∣∣∣∣∣ =: Gn

262 8. Nichtparametrische Tests
als kritischer Wert gewählt werden, wobei G1, . . . , Gn eine auf [0, 1] gleichverteilte Stich-probe bezeichnet. Dieses (1−α)-Quantil, welches wir mit Gn;1−α bezeichnen, kann mittelsSimulation näherungsweise bestimmt werden bzw. ist vertafelt. Somit lautet die Testent-scheidung
H0 : F = F0 zu verwerfen, falls τ = ‖F0 − Fn( · ;x1, . . . , xn)‖∞ > Gn;1−α .
Testen mittels asymptotischer Verteilung
Es sei F0 wiederum als stetig vorausgesetzt. Der folgende Satz liefert eine weitere Mög-lichkeit zum Testen auf eine vorgegebene Verteilung.
Satz 8.2 (Asymptotische Verteilung, Kolmogorow)Ist Xn∞n=1 eine Stichprobe mit stetiger Verteilungsfunktion F und t ∈ R , so gilt
limn→∞
P
(‖F − Fn‖∞ ≤
t√n
)= K(t)
mit der Kolmogorowschen Verteilungsfunktion
K(t) :=
(1− 2
∞∑
k=1
(−1)k−1e−2k2t2
)χ[0,∞)(t) .
Es gilt also
limn→∞
√n‖F − Fn‖∞ ∼ Z
für eine Zufallsvariable Z mit Verteilungsfunktion K .
Beweis. [7, Abschnitt 10.2]
Satz 8.2 motiviert folgenden Test, bei welchem
H0 : F = F0 verworfen wird, falls τ >K1−α√
n,
wobei K1−α das (1− α)-Quantil der Verteilung zur Verteilungsfunktion K bezeichnet.
Beispiel 8.3 (Puls)Getestet werden soll, ob das im Datensatz survey aus dem Paket MASS vorhandeneMerkmal Pulse, welches bei Studierenden einer Statistikvorlesung erhoben wurde, alsNµ,σ2-verteilt angenommen werden kann, wobei µ = 74 und σ = 12 .

8. Nichtparametrische Tests 263
Die in der Nullhypothese unterstellte Verteilungsfunktion ist durch
F0(x) =1√
2πσ2
ˆ x
−∞e−(t−µ)2/(2σ2) dt
für x ∈ R gegeben. Wir testen mittels des Kolmogorow-Smirnow-Tests
H0 : F = F0 gegen H1 : F 6= F0
zum Signikanzniveau α = 0.05 .
> Pulse=na.omit(survey$Pulse)
> ks.test(Pulse ,"pnorm",mean=74,sd=12)
One -sample Kolmogorov -Smirnov test
data: Pulse D = 0.0696 , p-value = 0.3103 alternative
hypothesis: two -sided
Warning message: In ks.test(Pulse , "pnorm", mean = 74, sd =
12) :
cannot compute correct p-values with ties
Der p-Wert ist gröÿer als das gewählte Signikanzniveau, daher wird H0 beibehalten. Dieobige Warnmeldung kommt dadurch zu Stande, dass manche Werte mehrfach auftreten,man spricht hier von Bindungen (englisch: ties). Dies steht allerdings im Widerspruchzur Annahme, dass die zugrundeliegende Verteilungsfunktion stetig ist. Daher wird derp-Wert nur näherungsweise bestimmt. Da in diesem Fall jedoch davon auszugehen ist,dass die auftretenden Bindungen lediglich durch Runden entstanden sind, sollte der Ap-proximationsfehler vernachlässigbar sein.
Testen auf gleiche Verteilungen
Wir betrachten nun das zugehörige Zweistichprobenproblem. Gegeben seien zwei vonein-ander unabhängige Stichproben
X1, . . . , XnX und Y1, . . . , YnY
mit stetigen Verteilungsfunktionen FX und FY . Getestet werden soll
H0 : FX = FY gegen H1 : FX 6= FY .
Es erscheint naheliegend, als Teststatistik
T (X1, . . . , XnX , Y1, . . . , YnY ) =∥∥FXnX − F
YnY
∥∥∞

264 8. Nichtparametrische Tests
zu verwenden, wobei FXnX bzw. F YnY die zur Stichprobe X1, . . . , XnX bzw. Y1, . . . , YnYgehörige empirische Verteilungsfunktion bezeichnet. Aus dem Beweis von Satz 8.1 gehtdirekt hervor, dass
∥∥FXnX − FYnY
∥∥∞
H0∼ supu∈[0,1]
∣∣∣∣∣1
nX
nX∑
i=1
χ(−∞,u]
(G
(1)i
)− 1
nY
nY∑
i=1
χ(−∞,u]
(G
(2)i
)∣∣∣∣∣ =: GnX ,nY
für unabhängige und auf [0, 1] gleichverteilte Zufallsvariable
G(1)1 , . . . , G(1)
nX, G
(2)1 , . . . , G(2)
nY.
Bezeichne GnX ,nY ;1−α das (1− α)-Quantil von GnX ,nY und
τ =∥∥FXnX ( · ;x1, . . . , xnX )− F YnY ( · ; y1, . . . , ynY )
∥∥∞
die Realisierung der Teststatistik. Dann lautet die Testentscheidung
H0 : FX = FY zu verwerfen, falls τ > GnX ,nY ;1−α .
Der nachfolgende Satz liefert den zum Kolmogorow-Smirnow-Test analogen Test für dasZweistichprobenproblem.
Satz 8.4 (Asymptotische Verteilung, Zweistichprobenproblem)Sei t ∈ R . Dann ist
limnX ,nY→∞
P
(∥∥FXnX − FYnY
∥∥∞ ≤
t√N
)= K(t) ,
wobei
N =nXnYnX + nY
und K die in Satz 8.2 denierte Kolmogorowsche Verteilungsfunktion bezeichnet.
Beweis. [3, S. 119]
Es wird also
H0 : FX = FY verworfen, falls τ >K1−α√N
,
wobei wiederum K1−α das (1 − α)-Quantil der Verteilung zur Verteilungsfunktion Kbezeichnet.

8. Nichtparametrische Tests 265
8.1.2 χ2-Anpassungstest
Für eine gegebene Verteilungsfunktion F0 soll wieder
H0 : F = F0 gegen H1 : F 6= F0
getestet werden. Im Gegensatz zum Kolmogorow-Smirnow-Anpassungstest sei nun jedochnicht vorausgesetzt, dass die Verteilungsfunktionen stetig sind. Wir wählen eine disjunkteZerlegung
R =
k⊎
i=1
Bi ,
B1, . . . , Bk ∈ B(R) seien paarweise disjunkt. Wir bezeichnen mit P0 die Verteilung mitFP0 = F0 . Für i = 1, . . . , k setzen wir
p0i := P0(Bi) und pi := PX1(Bi)
und testen anstelle der ursprünglichen Hypothesen
H0 : (p1, . . . , pk) = (p01, . . . , p
0k) gegen H1 : (p1, . . . , pk) 6= (p0
1, . . . , p0k) .
Es sei Ni jene Zufallsvariable, welche die Anzahl der X1, . . . , Xn angibt, welche einenWert in Bi annehmen, also
Ni :=n∑
j=1
χBi(Xj) .
Dann gilt
Ni ∼ Bn,pi ,
vgl. Aufgabe (8.4). Man beachte, dass ENiH0= np0
i .
Als Teststatistik verwenden wir nun
T (X1, . . . , Xn) =k∑
i=1
(Ni − np0i )
2
np0i
.
Der nachfolgende Satz trit eine Aussage über die asymptotische Verteilung dieser Test-statistik unter der Nullhypothese.

266 8. Nichtparametrische Tests
Satz 8.5 (Asymptotische Verteilung, χ2-Anpassungstest)Es sei Ni ∼ Bn,pi-verteilt für i = 1, . . . , k . Dann gilt
limn→∞
k∑
i=1
(Ni − npi)2
npi∼ χ2
k−1 .
Beweis. [15, S. 88]
Satz 8.5 motiviert den χ2-Anpassungstest, bei welchem zum Signikanzniveau α dieNullhypothese
H0 : (p1, . . . , pk) = (p01, . . . , p
0k)
verworfen wird, falls
τ = T (x1, . . . , xn) > χ2k−1;1−α .
Bemerkung. Als Faustregel gilt, dass beim χ2-Anpassungstest die Bedingung
np0i ≥ 5
für jedes i = 1, . . . , k erfüllt sein sollte.
Beispiel 8.6 (Fairer Würfel?)Beim Spiel Mensch ärgere dich nicht wird der Gegenspieler verdächtigt, einen gezinktenWürfel zu verwenden. Daher hat der misstrauische Kontrahent die letzten n = 60 Würfeseines Gegenspielers notiert, die Häugkeiten der Augenzahlen sind in folgender Tabelleaufgelistet.
Augenzahl 1 2 3 4 5 6
Häugkeit 5 7 10 7 12 19
Es soll getestet werden, ob es sich tatsächlich um einen unfairen Würfel handelt.
Wir testen zum Signikanzniveau α = 0.05 mittels des χ2-Anpassungstests
H0 : p1 = . . . = p6 = 16 gegen H1 : ∃ i ∈ 1, . . . , 6 : pi 6= 1
6 .
Es sei Ni jene Zufallsvariable, welche angibt, wie viele der Würfe Xj die Augenzahl iergeben. Zur praktischen Berechnung der Realisierung der Teststatistik verwenden wir,dass
T (X1, . . . , Xn) =
k∑
i=1
(Ni − np0i )
2
np0i
=
k∑
i=1
N2i
np0i
− n ,

8. Nichtparametrische Tests 267
vgl. Aufgabe (8.6), und erhalten für obige Daten
τ ≈ 12.8 .
Da somit
τ > χ25;0.95 ≈ 11.07 ,
handelt es sich vermutlich um einen gezinkten Würfel.
> y=c(5,7,10,7,12,19)
> p0=rep(1/6,6)
> chisq.test(y,p=p0)
Chi -squared test for given probabilities
data: y
X-squared = 12.8, df = 5, p-value = 0.02533
Beispiel 8.7 (Benfordsches Gesetz)Das Benfordsche Gesetz beschreibt mit welchen Häugkeiten führende Ziern auf-treten, beispielsweise bei Geldbeträgen in der Buchhaltung. Diese Gesetzmäÿigkeit wurdebereits 1881 von S. Newcomb2 entdeckt, damals fand sie allerdings keinerlei Beachtung.Erst durch die Wiederentdeckung durch F. Benford3 im Jahr 1938 wurde der prakti-sche Nutzen der beschriebenen Gesetzmäÿigkeit erkannt. Unterstellt wird die Benford-Verteilung, nach welcher die Zahl i ∈ 1, . . . , 9 mit Wahrscheinlichkeit
pi = log10
i+ 1
i
als führende Zier auftritt, vgl. Abbildung 8.1. Für eine vorliegende Billianz bezeichnexi die absolute Häugkeit der Anfangszier i , wobei i = 1, . . . , 9 . Man kann dann mitdem χ2-Anpassungstest überprüfen, ob dies in Übereinstimmung mit dem Benford-schen Gesetz steht. Die Nullhypothese lautet also
H0 : ∀ i = 1, . . . , 9:xiN
= pi ,
wobei N =∑9
i=1 xi . Sollte die Nullhypothese abgelehnt werden, wäre es vermutlichangebracht, die Billianz einer genaueren Prüfung zu unterziehen.
2Simon Newcomb, 18351909, kanadisch-amerikanischer Astronom und Mathematiker3Frank Benford, 18831948, amerikanischer Elektroingenieur und Physiker

268 8. Nichtparametrische Tests
2 4 6 8
0.1
0.2
0.3
1 3 5 7 9
Abbildung 8.1. Stabdiagramm zur Benford-Verteilung
8.2 χ2-Unabhängigkeitstest
Für einen Zufallsvektor (X,Y ) soll überprüft werden, ob die Komponenten X und Yvoneinander unabhängig sind. Analog zum χ2-Anpassungstest wird der Wertebereichvon X bzw. Y disjunkt in Bx
1 , . . . , Bxkx
bzw. By1 , . . . , B
yky
zerlegt. Für i = 1, . . . , kx undj = 1, . . . , ky setzen wir
pij := P(X ∈ Bx
i , Y ∈ Byj
),
pxi := P(X ∈ Bx
i
)=
ky∑
j=1
pij und pyj := P(Y ∈ By
j
)=
kx∑
i=1
pij .
Sind X und Y unabhängig, so gilt oenbar
pij = pxi pyj .
Als Nullhypothese wählen wir daher
H0 : ∀ i = 1, . . . , kx ∀ j = 1, . . . , ky : pij = pxi pyj .
Es sei (X1, Y1), . . . , (Xn, Yn) eine Stichprobe zu (X,Y ) und Nij jene Zufallsvariable, wel-che angibt, wieviele Stichprobenwerte in Bx
i ×Byj angenommen werden, also die absolute
Häugkeit
Nij :=n∑
m=1
χBxi ×Byj(Xm, Ym) .
Weiters denieren wir
Nxi :=
ky∑
j=1
Nij und Nyj :=
kx∑
i=1
Nij .

8. Nichtparametrische Tests 269
Dann ist die relative Häugkeit 1nNij ein Schätzer für pij und 1
nNxi bzw. 1
nNyj ein Schät-
zer für pxi bzw. pyj . Daher ist zu erwarten, dass bei Gültigkeit der Nullhypothese dieTeststatistik
T ((X1, Y1), . . . , (Xn, Yn)) =
kx∑
i=1
ky∑
j=1
(nNij −Nx
i Nyj
)2
nNxi N
yj
kleine Werte annimmt.
Satz 8.8 (Asymptotische Verteilung, χ2-Unabhängigkeitstest)Es gilt
limn→∞
kx∑
i=1
ky∑
j=1
(nNij −Nx
i Nyj
)2
nNxi N
yj
H0∼ χ2(kx−1)(ky−1) .
Beweis. [23, S. 91]
Bezeichne τ die Realisierung der Teststatistik T . Dann wird H0 zum Signikanzniveauα verworfen, falls
τ > χ2(kx−1)(ky−1);1−α .
Zur Durchführung des χ2-Unabhängigkeitstests empehlt es sich, eine sogenannte Kon-tingenztafel zu verwenden. Es sei (x1, y1), . . . , (xn, yn) eine Realisierung der Stichprobeund nij die zugehörige Realisierung von Nij . Durch Berechnung der absoluten Häug-keiten und der jeweiligen Zeilen- und Spaltensummen erhalten wir die folgende Tabelle.
HHHHHHxy
By1 . . . By
ky
Bx1 n11 . . . n1ky nx1...
......
...
Bxkx
nkx1 . . . nkxky nxkx
ny1 . . . nyky n
Dabei bezeichnet nxi bzw. nyj die entsprechende Realisierung von N
xi bzw. Ny
j .
Beispiel 8.9 (Augen- und Haarfarbe)Wir wollen anhand des Datensatzes HairEyeColor untersuchen, ob es einen signikantenZusammenhang zwischen der Augen- und der Haarfarbe gibt. Die bei Studierenden einerStatistikvorlesung erhobenen Daten sind in folgender Kontingenztafel zusammengefasst.

270 8. Nichtparametrische Tests
XXXXXXXXXXXHaareAugen
braun blau braun-grün grün
schwarz 68 20 15 5 108
braun 119 84 54 29 286
rot 26 17 14 14 71
blond 7 94 10 16 127
220 215 93 64 592
Wir wenden den χ2-Unabhängigkeitstest zum Signikanzniveau α = 0.05 an, wobei dieRechenarbeit R überlassen wird.
> HairEye = apply(HairEyeColor ,c(1,2), sum)
> chisq.test(HairEye)
Pearson 's Chi -squared test
data: HairEye
X-squared = 138.2898 , df = 9, p-value < 2.2e-16
Der p-Wert ist somit kleiner als das gewählte Signikanzniveau, die Nullhypothese daherzu verwerfen. Es gibt also einen signikanten Zusammenhang zwischen der Augen- undder Haarfarbe. Besteht die Kontingenztafel nur aus vier Feldern, so spricht man von einer Vierfelder-tafel. In diesem Fall ist also kx = ky = 2 und die Verteilung der Teststatistik kann unterder Nullhypothese leicht exakt bestimmt werden, sie ist dann nämlich hypergeometrischverteilt. Dies führt auf den exakten Test nach Fisher, vgl. Aufgabe (8.14).
Beispiel 8.10 (Schreibhand und Geschlecht)Im Datensatz survey aus dem Paket MASS wurden bei Studierenden einer Statistikvor-lesung die Merkmale Schreibhand und Geschlecht erhoben. Es liegt die folgende Vierfel-dertafel vor.
`````````````GeschlechtSchreibhand
Links Rechts
Weiblich 7 110
Männlich 10 108
Wir wenden den exakten Test nach Fisher zum Niveau α = 0.05 an, um zu testen, ob einsignikanter Zusammenhang zwischen der Schreibhand und dem Geschlecht besteht.

8. Nichtparametrische Tests 271
> fisher.test(table(survey[c("Sex","W.Hnd")]))
Fisher 's Exact Test for Count Data
data: table(survey[c("Sex", "W.Hnd")])
p-value = 0.6158
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.2140244 2.0876656
sample estimates:
odds ratio
0.6883665
Die Nullhypothese wird beibehalten, es besteht also kein signikanter Zusammenhangzwischen der Händigkeit und dem Geschlecht.
8.3 Vorzeichentest
Der Vorzeichentest dient zur Überprüfung der Lage, genauer des Medians.
8.3.1 Vorzeichentest für das Einstichprobenproblem
Gegeben sei eine Stichprobe X1, . . . , Xn mit stetiger Verteilungsfunktion. Getestet wer-den soll, ob der Median der Stichprobe gleich einem vorgegebenen Wert ist, also
H0 : X = m gegen H1 : X 6= m
für einen vorgegebenen Wert m ∈ R , wobei
X := minx ∈ R : FX1(x) = 1
2
.
Für i = 1, . . . , n setzen wir
Di := Xi −m.
Da die zugrundeliegende Verteilungsfunktion als stetig angenommen wird, lautet dieNullhypothese
H0 : ∀ i = 1, . . . , n : P(Di > 0) = P(Di < 0) = 12 .
Es sei nun
A :=
n∑
i=1
χ(0,∞)(Di) ,

272 8. Nichtparametrische Tests
dies ist also die Anzahl jener Xi , welche gröÿer als m sind. Oensichtlich gilt
AH0∼ Bn,1/2
und daher
EAH0=
n
2.
Bezeichne a die zugehörige Realisierung von A . Zum Signikanzniveau α lautet dann dieTestentscheidung H0 abzulehnen, falls
a < B(n)α/2 oder a > n−B(n)
α/2 ,
wobei B(n)α/2 das (α/2)-Quantil der Bn,1/2-Verteilung bezeichnet.
Beispiel 8.11 (Einstiegsgehalt)Wir interessieren uns dafür, wie es um die Einstiegsgehälter der 50 Chemiker im Daten-satz Chemist aus dem Paket BSDA bestellt ist. Getestet werden soll zum Niveau α = 0.05 ,ob der Median bei m = 40700 liegt.
> x=Chemist$salary
> n=length(x)
> n
[1] 50
> m=40700
> alpha =0.05
> a=length(x[x>m])
> a
[1] 15
> qbinom(alpha/2,n,1/2)
[1] 18
Es liegen also zu viele Gehälter unter m , der Median unterscheidet sich signikant von40700 . Wir berechnen noch den p-Wert.
> 2*pbinom(a,n,1/2) # p-Wert
[1] 0.006600448
Der Vorzeichentest ist im Paket BSDA zu nden, er wird mittels SIGN.test() aufgerufen.Wir vergleichen unser Ergebnis.
> SIGN.test(x,md=m)

8. Nichtparametrische Tests 273
One -sample Sign -Test
data: x
s = 15, p-value = 0.0066
alternative hypothesis: true median is not equal to 40700
95 percent confidence interval:
39344.21 40455.79
sample estimates:
median of x
39945
Conf.Level L.E.pt U.E.pt
Lower Achieved CI 0.9351 39400.00 40400.00
Interpolated CI 0.9500 39344.21 40455.79
Upper Achieved CI 0.9672 39280.00 40520.00
8.3.2 Vorzeichentest für verbundene Stichproben
Wir wollen nun den Vorzeichentest auf das entsprechende Zweistichprobenproblem er-weitern.
Beispiel 8.12 (Neues Maschinenteil)Eine Firma stellt Maschinen zum Abfüllen von Fruchtsäften her. Kürzlich wurde ein neuesMaschinenteil entwickelt, dass den Abfüllvorgang optimieren soll. Dieses neue Maschi-nenteil soll mit dem Vorgängermodell verglichen werden. Dazu wurden zuerst bei 16 mitdem alten Maschinenteil ausgestatteten Maschinen die durchschnittliche Abfüllmenge ge-messen. Anschlieÿend wurden die Maschinen mit dem neuen Maschinenteil ausgestattetund abermals wurde die mittlere Abfüllmenge bestimmt. Die Ergebnisse in Milliliternsind in folgender Tabelle aufgelistet.
Maschine Teil 1 Teil 2 Maschine Teil 1 Teil 2
1 771 681 9 722 755
2 725 752 10 754 699
3 721 737 11 758 675
4 703 716 12 735 692
5 755 678 13 755 733
6 721 726 14 702 696
7 778 677 15 761 742
8 705 676 16 757 745

274 8. Nichtparametrische Tests
Getestet werden soll, ob die beiden Maschinenteile hinsichtlich der Abfüllmenge als gleich-wertig angesehen werden können.
Gegeben sei die zweidimensionale Stichprobe (X1, Y1), . . . , (Xn, Yn) . Wir setzen
Di := Xi − Yi für i = 1, . . . , n
und nehmen an, dass D1, . . . , Dn eine Stichprobe mit stetiger Verteilungsfunktion ist.Getestet werden soll
H0 : P(Di > 0) = P(Di < 0) = 12 gegen H1 : P(Di > 0) 6= P(Di < 0) .
Den Vorzeichentest für dieses Zweistichprobenproblem erhält man also indem man denVorzeichentest für das Einstichprobenproblem auf D1, . . . , Dn anwendet.
Beispiel 8.13 (Fortsetzung von Beispiel 8.12)Wir überlassen die Rechenarbeit R.
> x=scan()
1: 771 725 721 703 755 721 778 705 722 754 758 735 755 702 761
757
17:
Read 16 items
> y=scan()
1: 681 752 737 716 678 726 677 676 755 699 675 692 733 696 742
745
17:
Read 16 items
> d=x-y
> a=length(d[d>0])
> a
[1] 11
> 2*pbinom (16-a,16,1/2) # p-Wert
[1] 0.2101135
Laut dem Vorzeichentest zum Niveau α = 0.05 besteht also kein signikanter Unterschiedzwischen den beiden Maschinenteilen. Dasselbe Ergebnis liefert SIGN.test() direkt aufx und y angewandt.
> SIGN.test(x,y)
Dependent -samples Sign -Test
data: x and y
S = 11, p-value = 0.2101

8. Nichtparametrische Tests 275
alternative hypothesis: true median difference is not equal to
0
95 percent confidence interval:
-8.861978 65.620440
sample estimates:
median of x-y
20.5
Conf.Level L.E.pt U.E.pt
Lower Achieved CI 0.9232 -5.000 55.0000
Interpolated CI 0.9500 -8.862 65.6204
Upper Achieved CI 0.9787 -13.000 77.0000
8.3.3 Bemerkung zum Vorzeichentest und Rang-Tests
An Beispiel 8.12 erkennt man einen Mangel am Vorzeichentest: Die Abstände zwischenden Abfüllmengen gehen nicht in den Test ein, lediglich ihre Vorzeichen. Beim Wilco-xon4-Vorzeichen-Rang-Test wird dies berücksichtigt, für Genaueres sei auf [17, S. 166]verwiesen. In R wird dieser Test mittels wilcox.test(...,paired=TRUE) durchgeführt.Wir vergleichen lediglich das Ergebnis dieses Tests für Beispiel 8.13 ohne auf weitereDetails einzugehen.
> wilcox.test(x,y,paired=TRUE)
Wilcoxon signed rank test
data: x and y
V = 108, p-value = 0.03864
alternative hypothesis: true location shift is not equal to 0
Der p-Wert liegt also deutlich unter jenem, den wir mit dem Vorzeichentest erhalten ha-ben. Zum Signikanzniveau α = 0.05 wird die Nullhypothese nun verworfen.Es sei hier noch der Wilcoxon-Rangsummen-Test erwähnt, mit welchem zwei nichtverbundene Stichproben hinsichtlich der Lage verglichen werden können, vergleiche Auf-gabe (8.17). Dieser ist auch unter den Namen Wilcoxon-Mann-Whitney-Test undU-Test bekannt. Wir demonstrieren diesen Test anhand des folgenden Beispiels.
Beispiel 8.14 (Müllabfuhr)Die für einen kleineren Stadtteil zuständige Müllabfuhr kann zwei Routen wählen, umden Müll abzuholen, und möchte wissen, ob diese beiden Routen im Bezug auf die Fahrt-zeit als gleichwertig anzusehen sind oder nicht. Elf Arbeitstage wurde die erste Route
4Frank Wilcoxon, 18921965, amerikanischer Chemiker

276 8. Nichtparametrische Tests
gefahren, neun weitere die zweite Route. Die folgende Tabelle enthält die Fahrtzeiten inMinuten.
1 2 3 4 5 6 7 8 9 10 11
Route 1 52.5 59.7 58.6 46.1 47.4 45.7 55.6 48.7 52.4 47.2 45.2
Route 2 65.9 66.1 63.2 52.0 49.6 52.1 52.6 51.7 61.6
Wir wenden den Wilcoxon-Rangsummen-Test zum Signikanzniveau α = 0.05 an.
> Route1=c(52.5 ,59.7 ,58.6 ,46.1 ,47.4 ,45.7 ,55.6 ,48.7 ,52.4 ,
47.2 ,45.2)
> Route2=c(65.9 ,66.1 ,63.2 ,52.0 ,49.6 ,52.1 ,52.6 ,51.7 ,61.6)
> wilcox.test(Route1 ,Route2)
Wilcoxon rank sum test
data: Route1 and Route2
W = 23, p-value = 0.04645
alternative hypothesis: true location shift is not equal to 0
Die beiden Routen sind also nicht als gleichwertig zu betrachten.

8. Nichtparametrische Tests 277
Übungsaufgaben
(8.1) Benzinverbrauch: Die Messung des Benzinverbrauchs in Liter pro 100 Kilometervon n = 10 Autos eines bestimmten Typs ergab die Werte
10.8, 11.3, 10.4, 9.8, 10.0, 10.6, 11.0, 10.5, 9.5, 11.2 .
Testen Sie, ob der Benzinverbrauch N (10, 1)-verteilt ist.
(8.2) Generieren Sie in R 30 χ21-verteilte und N (1, 2)-verteilte Pseudozufallszahlen und
testen Sie anschlieÿend mit dem Kolmogorow-Smirnow-Test, ob diese Realisierun-gen aus einer normalverteilten Stichprobe stammen. Vergleichen Sie das Ergebnismit jenem des Shapiro-Wilk-Tests.
(8.3) Affige Reaktionszeit: Im Zuge einer Studie wurde die Reaktionszeit auf einenbestimmten Reiz bei männlichen und weiblichen Aen gemessen.
Reaktionszeit 1 2 3 4 5 6 7 8 9 10
männlich 3.7 4.9 5.1 6.2 7.4 4.4 5.3 1.7 2.9
weiblich 4.5 5.1 6.2 7.3 8.7 4.2 3.3 8.9 2.6 4.8
Testen Sie, ob die Reaktionszeit der männlichen und jene der weiblichen Aendieselbe Verteilung besitzen.
(8.4) Gegeben sei eine Stichprobe X1, . . . , Xn und B ∈ B(R) . Zeigen Sie, dass
N =
n∑
j=1
χB(Xj)
Bn,p-verteilt ist, wobei p = PX1(B) .
(8.5) Zeigen Sie, dass der beim χ2-Anpassungstest auftretende Zufallsvektor (N1, . . . , Nk)multinomialverteilt ist, d. h. für alle i1, . . . , ik ∈ N mit i1 + . . .+ ik = n gilt
P(N1,...,Nk) ((i1, . . . , ik)) =n!
i1! · . . . · ik!pi11 · . . . · pikk .
(8.6) Zeigen Sie, dass für die beim χ2-Anpassungstest verwendete Teststatistik
T (X1, . . . , Xn) =
k∑
i=1
(Yi − np0i )
2
np0i
=k∑
i=1
Y 2i
np0i
− n
gilt.
278 8. Nichtparametrische Tests
(8.7) Kreuzungsversuche: Mendel5 erhielt bei einem seiner Kreuzungsversuche mitErbsen das folgende Ergebnis.
Ausprägung rund gelb rund grün kantig gelb kantig grün
Häugkeit 315 108 101 32
Überprüfen Sie seine Hypothese, dass die vier Ausprägungen im Verhältnis 9 : 3 :3 : 1 stehen.
(8.8) Geburtentrend: In einer Entbindungsstation ergaben sich für die einzelnen Mo-nate eines Jahres die folgenden Geburtenhäugkeiten.
Monat Jan. Feb. Mär. Apr. Mai Jun. Jul. Aug. Sep. Okt. Nov. Dez.
Geburten 119 116 121 125 129 140 138 136 124 127 115 113
Testen Sie die Hypothese der Gleichverteilung der Geburten auf die einzelnen Mo-nate dieses Jahres.
(8.9) Fibonacci-Zahlen und das Benfordsche Gesetz: Testen Sie, ob die Ver-teilung der Anfangsziern der ersten 30 Fibonacci-Zahlen dem BenfordschenGesetz genügt.
(8.10) Sterbezahlen: Die Anzahl der monatlichen Sterbefälle in Italien (erste Zeile)und Schweden (zweite Zeilge) des Jahres 2010 ist in nachfolgender Tabelle gegeben.Untersuchen Sie, ob die Sterbefälle
(a) auf die Monate gleichverteilt sind,
(b) in Italien und Schweden identisch verteilt sind.
1 2 3 4 5 6 7 8 9 10 11 12
51983 51039 53897 48382 45981 45591 49074 46097 44303 47583 49840 53718
8552 7313 8064 7505 7302 6854 7254 7010 7082 7454 7450 8602
(8.11) Schädlingsbefall: Für n = 100 Apfelbäume wurde der Grad des Schädlings-befalls festgestellt. Unter diesen Apfelbäumen sind drei verschiedene Sorten. DasErgebnis ist in folgender Kontingenztafel zusammengefasst.
5Gregor Mendel, 18221884, altösterreichischer Mönch und Naturforscher
8. Nichtparametrische Tests 279
PPPPPPPPPSorteBefall
gering mittel stark
A 22 6 2 30
B 11 12 7 30
C 17 12 11 40
50 30 20 100
Testen Sie, ob der Grad des Schädlingsbefalls in Zusammenhang mit der Apfelsortesteht.
(8.12) Herzinfarktquote In einer Studie nahmen Ärzte über 5 Jahre hinweg entwe-der regelmäÿig Aspirin oder ein Placebo, ohne zu wissen zu welcher Gruppe siegehörten. Gezählt wurde in jeder Gruppe die Anzahl der Personen, welche einenHerzinfarkt erlitten haben. Es liegt die folgende Vierfeldertafel vor.
XXXXXXXXXXXGruppeInfarkt
Ja Nein
Placebo 189 10845
Aspirin 104 10933
Testen Sie, ob die Herzinfarktquote in Zusammenhang mit der Einnahme von Aspi-rin steht.
(8.13) Unfälle und Alter: Besteht ein Zusammenhang zwischen dem Alter eines Au-tofahrers und der Anzahl der Unfälle, in die er im Laufe eines Jahres verwickeltist? Die folgende Kontingenztafel zeigt das Ergebnis einer Untersuchung zu dieserFragestellung.
XXXXXXXXXXXAlterUnfälle
0 1 2 ≥ 3
1829 748 74 31 9 862
3039 821 60 25 10 916
4049 786 51 22 6 865
5059 720 66 16 5 807
≥ 60 672 50 15 7 744
3747 301 109 37 4194
Beantworten Sie obige Fragestellung für diese Daten mit dem entsprechenden Test.

280 8. Nichtparametrische Tests
(8.14) Exakter Test nach Fisher: Gegeben seien die Zeilen- und Spaltensummen nx1 ,nx2 , n
y1, n
y2 einer 2× 2-Kontingenztafel über n Beobachtungen. Begründen Sie, dass
die Zufallsvariable N11 hypergeometrisch verteilt ist, wenn angenommen wird, dassjede Aufteilung der n Beobachtungen, welche die gegebenen Zeilen- und Spalten-summen erfüllt, gleich wahrscheinlich ist.
Beim Fisher-Test wird die Nullhypothese (Unabhängigkeit der beiden betrach-teten Merkmale) verworfen, falls die Wahrscheinlichkeit, dass N11 in der obigenSituation den beobachteten Wert n11 oder einen extremeren annimmt, kleiner alsdas Signikanzniveau α ist. Genauer:
B Einseitiger Test: H0 ablehnen, falls P(N11 ≥ n11) < α .
B Zweiseitiger Test: H0 ablehnen, falls
P(N11 ∈ k ∈ N; P(N11 = k) ≤ P(N11 = n11)) < α .
Testen Sie für die durch6 4
2 12
gegebene Kontingenztafel die Unabhängigkeitshypothese und vergleichen Sie dasErgebnis mit dem Resultat von fischer.test in R.
(8.15) Winterreifen: Eine Reifenrma hat für einen neuen Winterreifen zwei Proleentwickelt, für welche die Gleichwertigkeit hinsichtlich der Bremswirkung bei tro-ckener Fahrbahn überprüft werden soll. Dazu wurden 16 Testfahrzeuge zuerst mitReifen der ersten Prolsorte bestückt und anschlieÿend bei gleicher Geschwindig-keit der Bremsweg gemessen, daraufhin wurde dasselbe mit den Reifen der zweitenProlsorte wiederholt. Die Ergebnisse sind in folgender Tabelle aufgelistet.
Fahrzeug Sorte 1 Sorte 2 Fahrzeug Sorte 1 Sorte 2
1 44.6 44.7 9 50.7 52.2
2 55.0 54.8 10 49.2 50.6
3 52.5 55.6 11 47.3 46.1
4 50.2 55.2 12 50.1 52.3
5 45.2 45.6 13 51.6 53.9
6 46.0 47.7 14 48.7 47.1
7 52.0 53.0 15 54.2 57.2
8 50.2 49.9 16 46.1 52.7
Testen Sie zum Niveau α = 0.05 mittels des

8. Nichtparametrische Tests 281
(a) Vorzeichentests,
(b) Wilcoxon-Vorzeichen-Rang-Tests,
ob ein signikanter Unterschied zwischen den beiden Prolsorten besteht.
(8.16) Routenwahl: Ein Mathematiker wohnt am Rande einer Groÿstadt und arbeitetam Mathematischen Institut in der Innenstadt. Es gibt zwei Möglichkeiten, mit öf-fentlichen Verkehrsmitteln zu fahren. Die erste Route lautet wie folgt: Mit dem Buszur U-Bahn und dann mit der U-Bahn zu einer Station im Stadtzentrum, von dortaus zu Fuÿ zum Institut. Die zweite Route: Mit dem Bus zur Straÿenbahnstationund anschlieÿend mit der Straÿenbahn direkt zum Institut.
Überprüft werden soll, ob die beiden Routen gleichwertig sind, also ob die Summevon Geh-, Warte- und Fahrtzeiten für beide Routen in etwa übereinstimmt. Dazuhat der Mathematiker 12 Arbeitstage hintereinander die erste Route und 11 diezweite genommen und jeweils die Zeit gestoppt. Die folgende Tabelle enthält dieZeiten in Minuten.
1 2 3 4 5 6 7 8 9 10 11 12
Route 1 22.1 27.2 21.6 25.5 20.6 21.3 28.5 28.0 21.1 31.5 21.8 20.3
Route 2 25.9 24.7 24.8 23.2 27.3 22.2 23.8 25.4 27.7 24.2 24.5
Testen Sie, ob die beiden Routen als gleichwertig anzusehen sind.
(8.17) Wilcoxon-Rangsummen-Test:Wir betrachten die zwei unabhängigen Stichpro-ben X1, . . . , Xn und Y1, . . . , Ym mit stetigen Verteilungsfunktionen FX1 und FY1 .Getestet werden soll
H0 : P(X1 > Y1) = 12 gegen H1 : P(X1 > Y1) 6= 1
2 .
Wir denieren die Zufallsvariablen
Zij :=
1 , Xi > Yj ,
0 , sonst ,
für i = 1, . . . , n und j = 1, . . . ,m und betrachten die Teststatistik
U :=
n∑
i=1
m∑
j=1
Zij .
(a) Die Zufallsvariable
RX :=
n∑
k=1
n∑
i=1
χ(−∞,Xk](Xi) +
m∑
j=1
χ(−∞,Xk](Yj)

282 8. Nichtparametrische Tests
wird als Summe der Ränge von X1, . . . , Xn bezeichnet. Zeigen Sie, dass
U = RX − n(n+ 1)
2.
(b) WerdenX1, . . . , Xn, Y1, . . . , Ym
der Gröÿe nach angeordnet, so ist unter H0 jede mögliche Reihenfolge gleichwahrscheinlich. Bestimmen Sie die Verteilung von U unter H0 für n = 3 undm = 4 . Kontrollieren das Ergebnis mit Hilfe der R-Funktion dwilcox(k,n,m),welche die Wahrscheinlichkeit, dass U = k unter H0 ist, berechnet.
(c) Die Nullhypothese wird verworfen, falls die Wahrscheinlichkeit, dass die Test-statistik U den beobachteten Wert oder einen mindestens so extremen an-nimmt, unter H0 kleiner als die Irrtumswahrscheinlichkeit α ist. Wie lässtsich dies (unter Ausnutzung von Symmetrien) exakt ausdrücken?
(d) Lösen Sie Aufgabe (8.16) ohne Verwendung von wilcox.test (die Funktionendwilcox und pwilcox können verwendet werden).
(e) Für groÿe Stichprobenumfänge n und m kann die Verteilung von U durch eineNormalverteilung mit Erwartungswert nm/2 und Varianz nm(n+m+ 1)/12approximiert werden. Lösen Sie Aufgabe (8.16) mit Hilfe dieser Approximati-on.
(f) Vergleichen Sie Ihre Ergebnisse mit denen von wilcox.test.

8. Nichtparametrische Tests 283
Kontrollfragen
8.1 Welche der folgenden Aussagen treen auf den Kolmogorow-Smirnow-Anpassungs-test zu?
Es handelt sich um einen parametrischen Test.
Es handelt sich um einen nichtparametrischen Test.
Es kann getestet werden, ob eine Poisson-Verteilung vorliegt.
Es kann getestet werden, ob eine χ2-Verteilung vorliegt.
8.2 Um mit dem χ2-Anpassungstest auf eine vorgegebene Verteilung zu testen, mussdie vorliegende Stichprobe
eine stetige Verteilungsfunktion besitzen,
diskret verteilt sein,
eine Dichte bezüglich des Lebesgue-Maÿes besitzen,
diskret oder kontinuierlich gleichverteilt sein.
8.3 Welche der folgenden Aussagen treen auf den Vorzeichentest zu?
Es handelt sich um einen nichtparametrischen Test.
Er dient der Überprüfung des Erwartungswertes.
Er dient der Überprüfung des Medians.
Die verwendete Teststatistik ist beim zweiseitigen Testproblem unter derNullhypothese binomialverteilt.


Kapitel 9
Zeitreihen
Wird ein interessierendes Merkmal zu mehreren aufeinanderfolgenden Zeitpunkten er-hoben, so erhält man eine sogenannte Zeitreihe. Eines der wohl bekanntesten Beispieleeiner Zeitreihe ist etwa der zeitliche Verlauf eines Aktienindex.
> DAX = EuStockMarkets [,1]
> plot.ts(DAX ,ylab="DAX",main="Zeitlicher Verlauf des deutschen
Aktienindex DAX")
Zeitlicher Verlauf des deutschen Aktienindex DAX
Time
DA
X
1992 1993 1994 1995 1996 1997 1998
2000
4000
6000
In diesem Kapitel werden wir Zeitreihen näher analysieren. Doch zuerst muss geklärtwerden, was wir genau unter einer Zeitreihe verstehen. Im Weiteren bezeichne wiederum(Ω,F ,P) stets einen Wahrscheinlichkeitsraum.
Definition 9.1 (Stochastischer Prozess und Zeitreihe)Es sei Xt : Ω→ Rt∈N eine Folge von Zufallsvariablen. Dann nennt man Xtt∈N einenstochastischen Prozess in diskreter Zeit. Eine Realisierung xtt∈N von Xtt∈Nwird als Zeitreihe bezeichnet.
Beispiel 9.2 (Weiÿes Rauschen)Es sei σ > 0 . Man nennt den stochastischen Prozess Xtt∈N ∈ L2(P)N weiÿes Rau-schen, falls
(1) EXt = 0 und Var(Xt) = σ2 für alle t ∈ N ,
(2) Xs und Xt unkorreliert sind für alle s, t ∈ N mit s 6= t .
285

286 9. Zeitreihen
Ist speziell Xtt∈N eine Folge von N0,σ2-verteilten unabhängigen Zufallsvariablen, sospricht man von Gauÿschem weiÿen Rauschen. Bemerkung. Man beachte, dass eine Zeitreihe eine einzige Realsierung des zugrunde-liegenden stochastischen Prozesses ist, welcher in vielen Fällen nicht mehrfach erhobenwerden kann. Auÿerdem liegen in der Praxis natürlich nur die ersten N ∈ N Folgengliedereiner Zeitreihe vor, welche wir dann wiederum als Zeitreihe bezeichnen.
9.1 Komponentenmodelle
Ein wichtiges Ziel der Zeitreihenanalyse ist es, eine gegebene Zeitreihe in mehrere Kompo-nenten zu zerlegen, wie etwa in eine Trend- und Saisionkompenente sowie einen zufälligenAnteil. Dafür muss ein entsprechendes Modell unterstellt werden.
Beim additiven Trend-Saison-Modell wird angenommen, dass sich der einer Zeitreihezugrundeliegende stochastische Prozess Xtt∈N in der Form
Xt = Tt + St + Zt , t ∈ N ,
zerlegen lässt, wobei die Trendkomponente Ttt∈N ∈ RN und die Saisonkompo-nente Stt∈N ∈ RN reellwertige Folgen sind, während es sich bei der zufälligen Kom-ponente Zt : Ω→ Rt∈N um einen stochastischen Prozess in diskreter Zeit handelt.
B Der Trend beschreibt das langfristige, systematische Verhalten der Zeitreihe, etwalineares oder exponentielles Wachstum.
B Die Saison hingegen spiegelt zeitlich bedingte, sich wiederholende Schwankungenwieder.
B Der zufällige Anteil der Zeitreihe entspricht all jenen Einüssen, die weder mittelsdes Trends noch durch die Saison erklärt werden können.
Oftmals nehmen mit wachsendem Trend sowohl die Ausschläge und die Streuung dersaisonalen als auch der zufälligen Eekte um den Trend zu. Diese Situation ist im ad-ditiven Trend-Saison-Modells nicht mit inbegrien. Daher unterstellt man oftmals einenZusammenhang der Form
Xt = Tt · St · Zt , t ∈ N ,
und spricht von einemmultiplikativen Trend-Saison-Modell. Sofern alle Komponen-ten positiv sind, kann das multiplikative Saison-Trend-Modell durch Logarithmieren aufdas additive zurückgeführt, denn
logXt = log Tt + logSt + logZt , t ∈ N .
Daher werden wir im Weiteren stets ein additives Trend-Saison-Modell unterstellen.

9. Zeitreihen 287
9.2 Trendbestimmung
Zur Bestimmung des Trends gibt es zahlreiche Ansätze, wir werden im Folgenden lediglichzwei kennenlernen.
9.2.1 Globale Regressionsansätze
Eine Möglichkeit den Trend zu modellieren, besteht im Ansetzen eines funktionalen Zu-sammenhangs der Form
Tt = g(t, p) , t = 1, . . . , N ,
wobei es den Parameter p ∈ Rm dann mittels des Prinzips der kleinstens Fehlerquadratezu bestimmen gilt, d. h. man minimiert
N∑
t=1
(xt − Tt)2 .
Wählt man den Ansatz
Tt = at+ b , t = 1, . . . , N ,
mit a, b ∈ R , so führt dies gerade auf die entsprechende Regressionsgerade.
9.2.2 Lokale Ansätze
Glättet man eine Zeitreihe entsprechend durch ein lokales Mittel, so sollten dadurch dieSaisonkomponente sowie der zufällige Anteil weitestgehend entfernt werden. Beispiels-weise kann der Trend mittels der gleitenden Durchschnitte
Tt =1
2q + 1
q∑
s=−qxt+s , t = q + 1, . . . , N − q ,
der Ordnung 2q + 1 geschätzt werden. Um die Werte am Rand zu schätzen existierenverschiedenste Verfahren, auf welche wir an dieser Stelle nicht näher eignehen.
> q=100
> trend = filter(DAX , filter = rep(1, (2 * q + 1))/(2 * q + 1))
> ts.plot(DAX ,trend ,col=c("black","red"),main="Schaetzung des
Trends f\"ur den Aktienindex DAX")
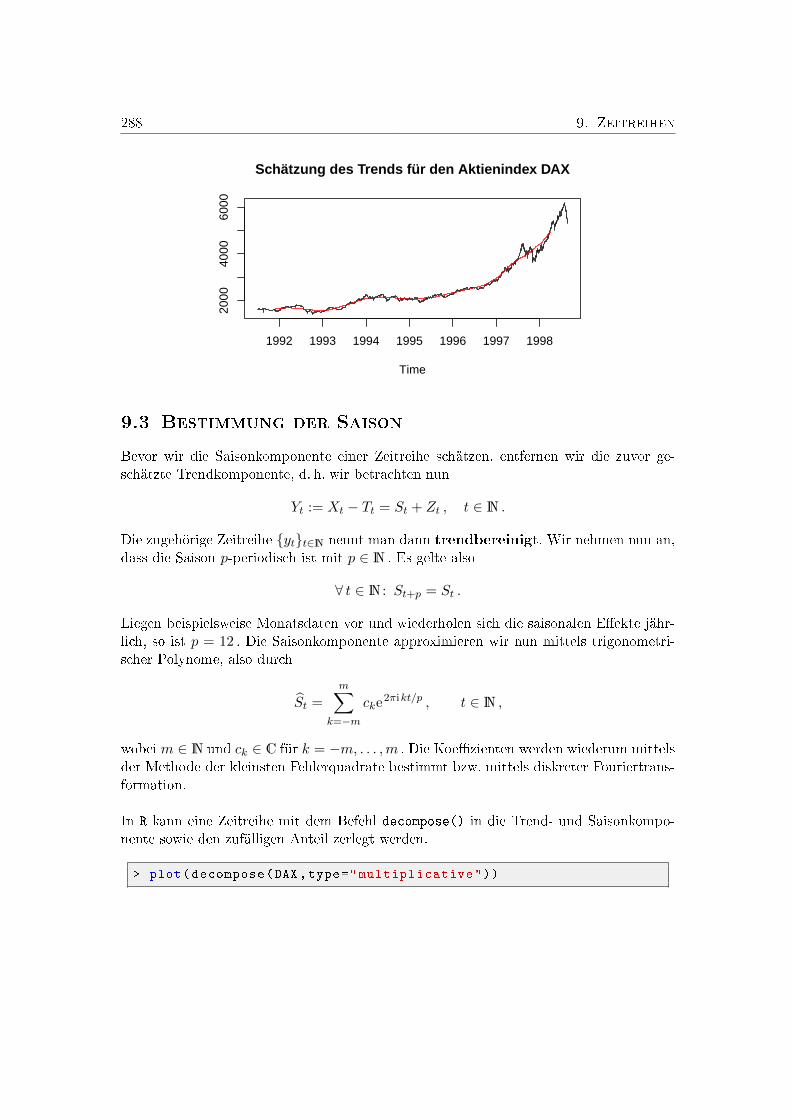
288 9. Zeitreihen
Schätzung des Trends für den Aktienindex DAX
Time
1992 1993 1994 1995 1996 1997 1998
2000
4000
6000
9.3 Bestimmung der Saison
Bevor wir die Saisonkomponente einer Zeitreihe schätzen, entfernen wir die zuvor ge-schätzte Trendkomponente, d. h. wir betrachten nun
Yt := Xt − Tt = St + Zt , t ∈ N .
Die zugehörige Zeitreihe ytt∈N nennt man dann trendbereinigt. Wir nehmen nun an,dass die Saison p-periodisch ist mit p ∈ N . Es gelte also
∀ t ∈ N : St+p = St .
Liegen beispielsweise Monatsdaten vor und wiederholen sich die saisonalen Eekte jähr-lich, so ist p = 12 . Die Saisonkomponente approximieren wir nun mittels trigonometri-scher Polynome, also durch
St =m∑
k=−mcke
2πikt/p , t ∈ N ,
wobeim ∈ N und ck ∈ C für k = −m, . . . ,m . Die Koezienten werden wiederum mittelsder Methode der kleinsten Fehlerquadrate bestimmt bzw. mittels diskreter Fouriertrans-formation.
In R kann eine Zeitreihe mit dem Befehl decompose() in die Trend- und Saisonkompo-nente sowie den zufälligen Anteil zerlegt werden.
> plot(decompose(DAX ,type="multiplicative"))
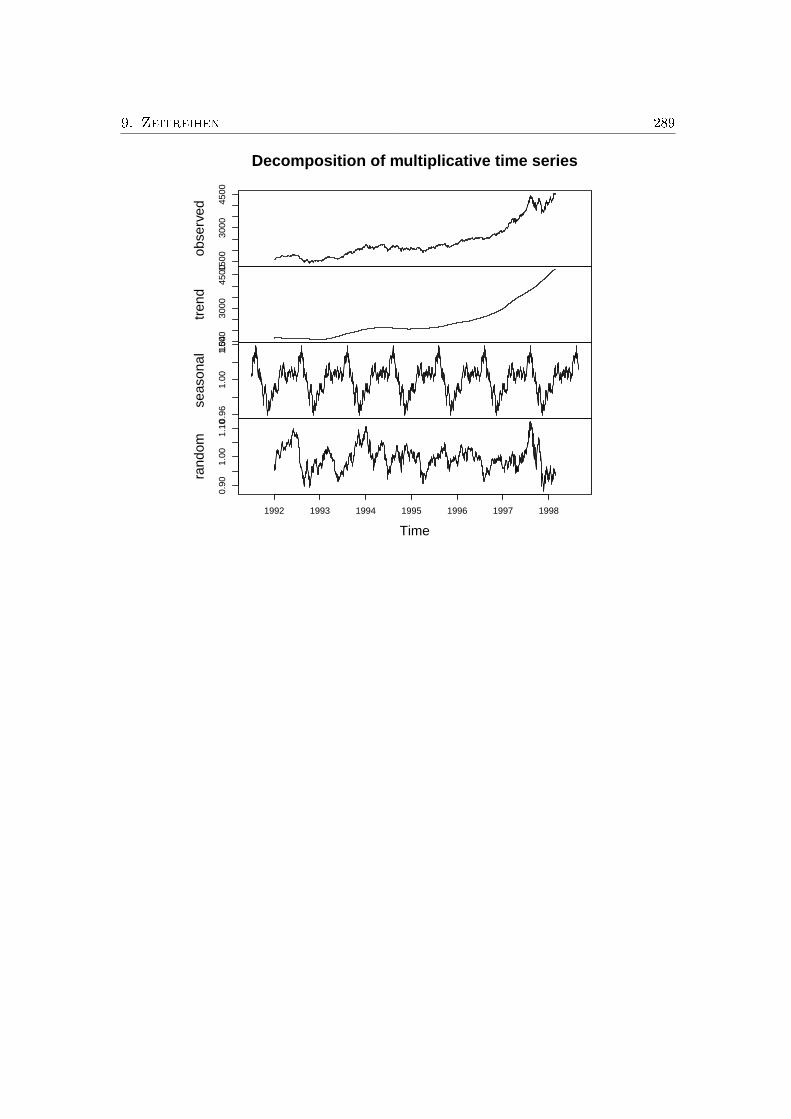
9. Zeitreihen 289
1500
3000
4500
obse
rved
1500
3000
4500
tren
d
0.96
1.00
1.04
seas
onal
0.90
1.00
1.10
1992 1993 1994 1995 1996 1997 1998
rand
om
Time
Decomposition of multiplicative time series

290 9. Zeitreihen
Übungsaufgaben
Die Datensätze zu den folgenden Aufgaben nden Sie unter http://tobiashell.com.
(9.1) Lesen Sie die Zeitreihe aus tempjun.csv ein. Bestimmen mit Hilfe des Befehlesaggregate.ts() eine Zeitreihe mit den Stundenmitteln. Bestimmen Sie weitersdie Trendkurve, die durch die Berechnung der gleitenden Durchschnitte entstehtfür verschiedene q. Plotten Sie abschlieÿend alle Zeitreihen und beschreiben Sie dieAbhängigkeit von q.
(9.2) Betrachten Sie den folgenden Ausschnitt einer Zeitreihe
7.51, 7.42, 6.76, 5.89, 5.95, 5.35, 5.51, 6.13, 6.45, 6.51, 6.92,
6.95, 6.77, 6.86, 6.95, 6.66, 6.26, 6.18, 6.07, 6.52, 6.52, 6.71
und bestimmen Sie den gleitenden 3er- und 11er-Durchschnitt. Anstelle gleitenderDurchschnitte können zur Glättung einer Zeitreihe auch gleitende Mediane verwen-det werden, die analog deniert sind. Berechnen Sie die entsprechende gleitendenMediane. Zeichnen Sie die Zeitreihe zusammen mit Ihren Resultaten.
(9.3) Exponentielle Glättung: Wir betrachten den folgenden rekursiven Filter, deraus einer gegebenen Zeitreihe x1, . . . , xn eine neue Reihe y1, . . . , yn erzeugt, dabeisie b ∈ (0, 1):
y1 := x1, yt+1 := (1− b)xt + byt, t = 1, . . . n− 1. (?)
Zeigen Sie, dass man (?) erhält indem man den sogenannten einfachen rekursivenFilter y0 := 0 , yt := zt+ byt−1 , t = 1, . . . , n , wobei z1, . . . , zn gegeben sind, auf diespezielle Zeitreihe
z1 = x1, z2 = (1− b)x1, . . . , zn = (1− b)xn−1
anwendet.
Wenden Sie für drei verschieden b ∈ (0, 1) die exponentielle Glättung auf die Datenin nachttirol.csv (Anzahl der Nächtigungen in Tirol von 1974 bis 2008) wie folgtan:
B Berechnen Sie zunächst die Zeitreihe z1, . . . , zn .
B Verwenden Sie anschlieÿend den R-Befehl
filter(z, filter = b, method = "recursive").
Erklären Sie die Funktionsweise des Befehles filter und diskutieren Sie die Ab-hängigkeit von b .

Anhang A
Eine kurze Einführung in R
Das Statistikprogramm R steht unter
http://www.r-project.org/
zum kostenlosen Download zur Verfügung, zahlreiche Manuals sowie weitere Informatio-nen zur Software sind ebenfalls dort zu nden. An dieser Stelle wird lediglich eine kurzeEinführung in den grundlegenden Umgang mit R gegeben.
Zuweisungen. Es gibt drei Möglichkeiten einem R-Objekt einen Wert zuzuweisen: Mit=, mit <- oder mit assign().
> x=17
> y<-25
> assign("z" ,42)
> x; y; z
[1] 17
[1] 25
[1] 42
Hilfe. Benötigt man Hilfe zu einem R-Befehl, so kann man dem Befehl einfach einFragezeichen voranstellen und gelangt so auf die entsprechende Hilfeseite. Möchte manbeispielsweise mehr über die Funktion assign() wissen, so kommt man etwa mit ?assignauf die gewünschte Hilfeseite.
Elementare Rechenoperationen.Man kann R natürlich auch wie einen Taschen-rechner verwenden.
> x=17; y=25
> x+y; x-y; x*y; x/y; sqrt(y); x^2
[1] 42
[1] -8
[1] 425
[1] 0.68
[1] 5
[1] 289
Vektoren. Zur Eingabe von Vektoren dient die Funktion c().
291

292 A. Eine kurze Einführung in R
> x=c(1,1,2,3,5,8,13,21,34,55,89)
> x
[1] 1 1 2 3 5 8 13 21 34 55 89
Eine weitere und in einigen Fällen sehr angenehme Möglichkeit einen Vektor zu erzeugen,bietet die Funktion scan().
> x=scan()
1: 1 1 2 3 5
6: 8 13
8: 21 34 55 89
12:
Read 11 items
> x
[1] 1 1 2 3 5 8 13 21 34 55 89
Die Komponenten eines Vektors müssen nicht zwingend aus numerischen Werten beste-hen.
> y=c("Jacqueline","Kevin","Chantal")
> y
[1] "Jacqueline" "Kevin" "Chantal"
Häug verwendete Zahlenfolgen können mit einem Doppelpunkt erzeugt werden.
> 3:10
[1] 3 4 5 6 7 8 9 10
> 2*6:9
[1] 12 14 16 18
> 10:3
[1] 10 9 8 7 6 5 4 3
Für speziellere Zahlenfolgen kann man die Funktion seq() verwenden.
> seq (7)
[1] 1 2 3 4 5 6 7
> seq (7,13)
[1] 7 8 9 10 11 12 13
> seq(7,13,2)
[1] 7 9 11 13
> seq(9,5,-0.5)
[1] 9.0 8.5 8.0 7.5 7.0 6.5 6.0 5.5 5.0
> seq(length =10,from=-2,by=0.1)
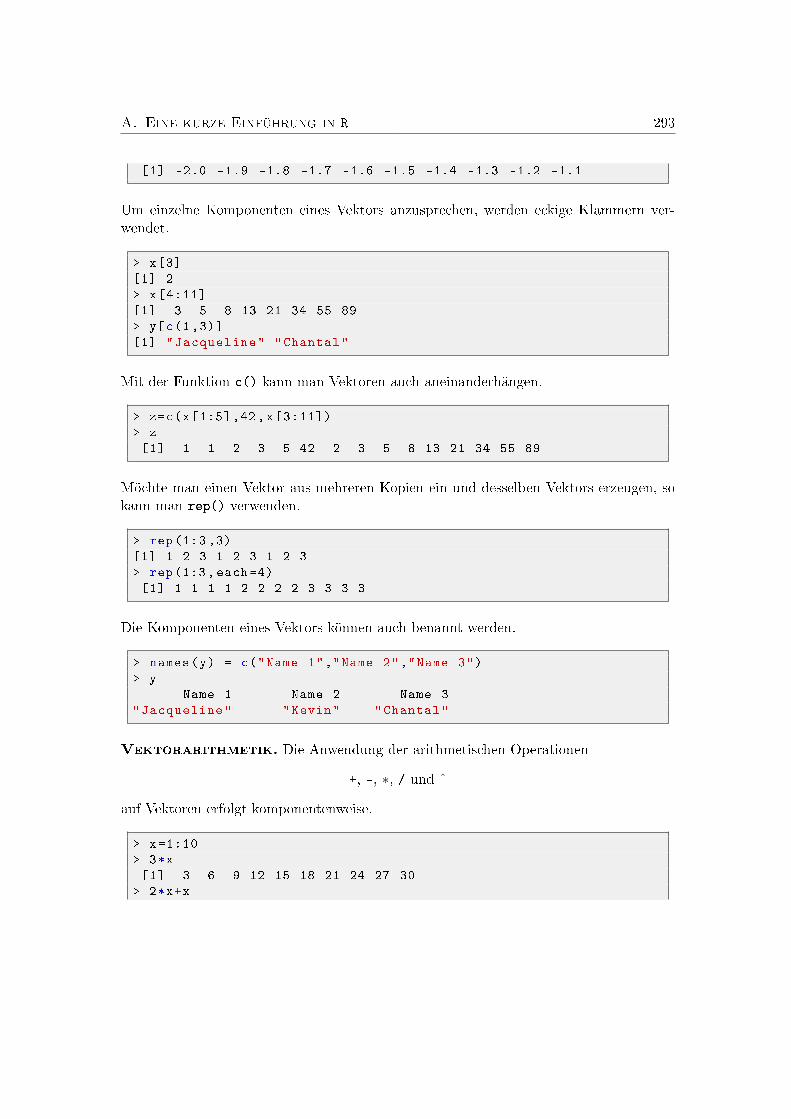
A. Eine kurze Einführung in R 293
[1] -2.0 -1.9 -1.8 -1.7 -1.6 -1.5 -1.4 -1.3 -1.2 -1.1
Um einzelne Komponenten eines Vektors anzusprechen, werden eckige Klammern ver-wendet.
> x[3]
[1] 2
> x[4:11]
[1] 3 5 8 13 21 34 55 89
> y[c(1,3)]
[1] "Jacqueline" "Chantal"
Mit der Funktion c() kann man Vektoren auch aneinanderhängen.
> z=c(x[1:5],42 ,x[3:11])
> z
[1] 1 1 2 3 5 42 2 3 5 8 13 21 34 55 89
Möchte man einen Vektor aus mehreren Kopien ein und desselben Vektors erzeugen, sokann man rep() verwenden.
> rep (1:3 ,3)
[1] 1 2 3 1 2 3 1 2 3
> rep(1:3, each =4)
[1] 1 1 1 1 2 2 2 2 3 3 3 3
Die Komponenten eines Vektors können auch benannt werden.
> names(y) = c("Name 1","Name 2","Name 3")
> y
Name 1 Name 2 Name 3
"Jacqueline" "Kevin" "Chantal"
Vektorarithmetik. Die Anwendung der arithmetischen Operationen
+, -, ∗, / und ˆ
auf Vektoren erfolgt komponentenweise.
> x=1:10
> 3*x
[1] 3 6 9 12 15 18 21 24 27 30
> 2*x+x

294 A. Eine kurze Einführung in R
[1] 3 6 9 12 15 18 21 24 27 30
> x^2
[1] 1 4 9 16 25 36 49 64 81 100
In R stehen natürlich die üblichen elementaren Funktionen
exp(), sin(), cos(), tan(), log(), usw.
zur Verfügung, die Anwendung auf Vektoren erfolgt ebenfalls komponentenweise.
> exp (1:5)
[1] 2.718282 7.389056 20.085537 54.598150 148.413159
Weitere nützliche Funktionen im Zusammenhang mit Vektoren sind
min(), max(), length() und sum(),
wobei die jeweilige Funktionsweise selbsterklärend sein dürfte.
> x=7:12
> min(x); max(x); length(x); sum(x)
[1] 7
[1] 12
[1] 6
[1] 57
Logische Vektoren. Durch die logischen Operationen
==, !=, <, <=, > und >=
erhält man logische Vektoren.
> x=5:13
> x<8
[1] TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
Dem logischen und entspricht &, dem logischen oder entspricht |. Den negierten logi-schen Vektor erhält man durch Verwendung eines Ausrufezeichens.
> x<11 & x>7
[1] FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE FALSE
> x<7 | x>9
[1] TRUE TRUE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
> x!=8; !x==8
[1] TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUE TRUE
[1] TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUE TRUE

A. Eine kurze Einführung in R 295
Mittels eines logischen Vektors können gezielt jene Komponenten eines Vektors ausge-wählt werden, welche eine bestimmte Bedingung erfüllen.
> x[x>10]
[1] 11 12 13
Faktoren. Die Funktion factor() gruppiert die Komponenten eines Vektors, welcherAusprägungen eines diskreten Merkmals enthält.
> x = c("blau","gelb","blau","rot","blau","blau","rot","rot")
> factor(x)
[1] blau gelb blau rot blau blau rot rot
Levels: blau gelb rot
Wendet man die Funktion summary() auf einen faktorisierten Vektor an, so werden dieabsoluten Häugkeiten der Ausprägungen ausgegeben.
> summary(factor(x))
blau gelb rot
4 1 3
Um die Stufen eines Faktors auszugeben, kann die Funktion levels() verwendet werden.Auÿerdem können mit dieser Funktion die Stufen umbenannt werden.
> x.factor = factor(x)
> levels(x.factor)
[1] "blau" "gelb" "rot"
> levels(x.factor) = c(1,2,3)
> x.factor
[1] 1 2 1 3 1 1 3 3
Levels: 1 2 3
Matrizen. Verwendet man die Funktion matrix() um aus einem Vektor eine Matrixzu erzeugen, so ist darauf zu achten, dass ohne das Setzen von byrow=TRUE, die Elementeder Matrix spaltenweise aus dem Vektor eingelesen werden.
> A = matrix (1:9,3, byrow=TRUE)
> A
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9

296 A. Eine kurze Einführung in R
Transponiert wird eine Matrix mit t().
> t(A)
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
Insbesondere bei der händischen Eingabe von Matrizen erweist sich die Funktion scan()
als nützlich.
> A = matrix(scan() ,3,byrow=TRUE)
1: 1 2 3
4: 4 5 6
7: 7 8 9
10:
Read 9 items
> A
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
Wie bereits bei Vektoren, können die Elemente einer Matrix eckigen Klammern ange-sprochen werden.
> A[2:3 ,1:2];
[,1] [,2]
[1,] 4 5
[2,] 7 8
> A[,2]
[1] 2 5 8
Arrays. Eine Matrix ist ein zweidimensionaler Array. Höherdimensionale Arrays kön-nen in R mit array() erzeugt werden.
> A = array (1:20,c(2,5,2))
> A
, , 1
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
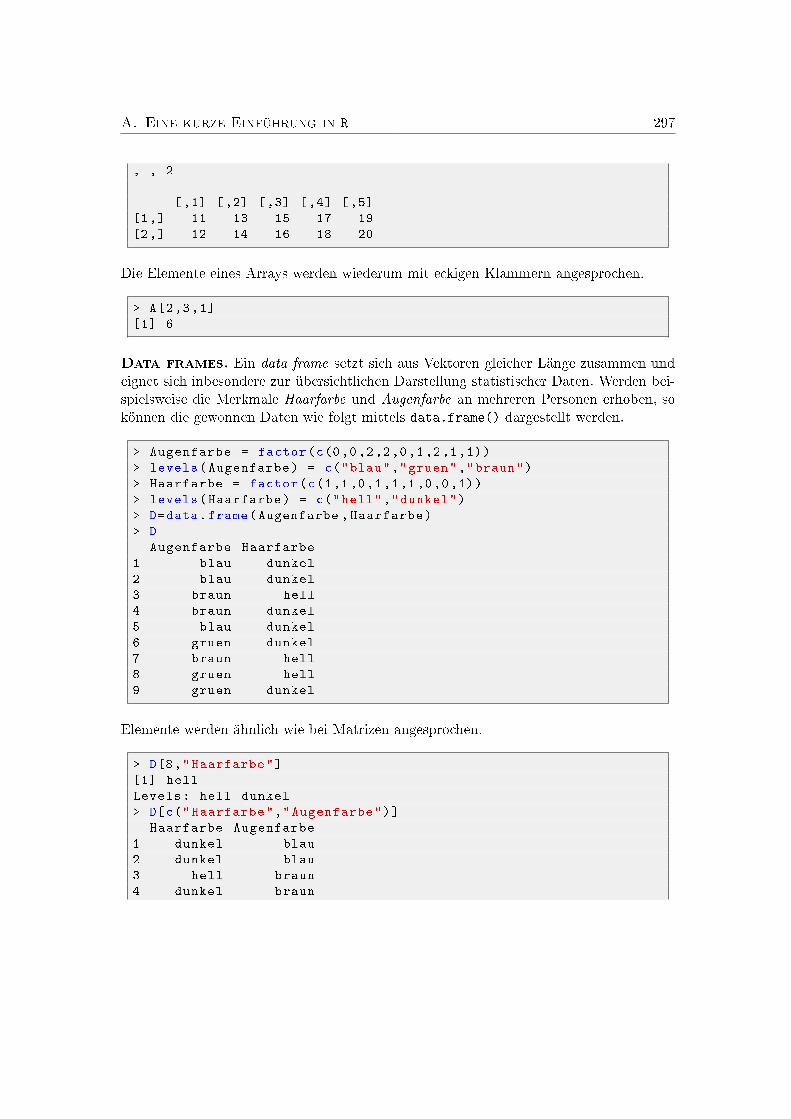
A. Eine kurze Einführung in R 297
, , 2
[,1] [,2] [,3] [,4] [,5]
[1,] 11 13 15 17 19
[2,] 12 14 16 18 20
Die Elemente eines Arrays werden wiederum mit eckigen Klammern angesprochen.
> A[2,3,1]
[1] 6
Data frames. Ein data frame setzt sich aus Vektoren gleicher Länge zusammen undeignet sich inbesondere zur übersichtlichen Darstellung statistischer Daten. Werden bei-spielsweise die Merkmale Haarfarbe und Augenfarbe an mehreren Personen erhoben, sokönnen die gewonnen Daten wie folgt mittels data.frame() dargestellt werden.
> Augenfarbe = factor(c(0,0,2,2,0,1,2,1,1))
> levels(Augenfarbe) = c("blau","gruen","braun")
> Haarfarbe = factor(c(1,1,0,1,1,1,0,0,1))
> levels(Haarfarbe) = c("hell","dunkel")
> D=data.frame(Augenfarbe ,Haarfarbe)
> D
Augenfarbe Haarfarbe
1 blau dunkel
2 blau dunkel
3 braun hell
4 braun dunkel
5 blau dunkel
6 gruen dunkel
7 braun hell
8 gruen hell
9 gruen dunkel
Elemente werden ähnlich wie bei Matrizen angesprochen.
> D[8,"Haarfarbe"]
[1] hell
Levels: hell dunkel
> D[c("Haarfarbe","Augenfarbe")]
Haarfarbe Augenfarbe
1 dunkel blau
2 dunkel blau
3 hell braun
4 dunkel braun

298 A. Eine kurze Einführung in R
5 dunkel blau
6 dunkel gruen
7 hell braun
8 hell gruen
9 dunkel gruen
Es sei noch erwähnt, dass sich data frames mittels read.table() aus Dateien auslesenlassen. Für Genaueres verweisen wir auf die R-Hilfe.
Datensätze und Pakete. In R gibt es eine groÿe Anzahl an Beispieldatensätzen.Eine Liste der im standardmäÿig installierten Paket datasets verfügbaren Datensätzeerhält man mit data(). Ein Beispiel eines solchen Datensatzes ist trees, hierbei handeltes sich um einen data frame. Genauere Informationen zum Datensatz erhält man auf derentsprechenden Hilfeseite, also durch ?trees. Einen Überblick über den Datensatz kannman sich mit head() bzw. tail() verschaen.
> head(trees)
Girth Height Volume
1 8.3 70 10.3
2 8.6 65 10.3
3 8.8 63 10.2
4 10.5 72 16.4
5 10.7 81 18.8
6 10.8 83 19.7
> tail(trees)
Girth Height Volume
26 17.3 81 55.4
27 17.5 82 55.7
28 17.9 80 58.3
29 18.0 80 51.5
30 18.0 80 51.0
31 20.6 87 77.0
Durch das Laden eines Paketes mittels library() werden meist neben vielen weiterenBeispieldatensätze auch für das Paket spezische Funktionen verfügbar. Mit
data(package = .packages(all.available = TRUE))
erhält man eine Liste der Datensätze aus sämtlichen geladenen Paketen.
Verteilungen und Pseudozufallszahlen. Die nachfolgende Tabelle enthälteinige der in R standardmäÿig zur Verfügung stehenden Verteilungen.

A. Eine kurze Einführung in R 299
Verteilung R-Name
Binomialverteilung binom
Chi-Quadrat-Verteilung chisq
Exponentialverteilung exp
Fisher-Verteilung f
Geometrische Verteilung geom
Hypergeometrische Verteilung hyper
Negative Binomialverteilung nbinom
Normalverteilung norm
Poisson-Verteilung pois
Student-t-Verteilung t
Gleichverteilung (kontinuierlich) unif
Jede Verteilung kann mit den Präxen d, p, q und r versehen werden. So erhält manetwa die Funktionswerte der Gauÿ-Dichte einer Normalverteilung mit dnorm(), währendpnorm() die Funktionswerte der zugehörigen Verteilungsfunktion liefert. Mit qnorm()
werden die Quantile einer Normalverteilung berechnet. Um Pseudozufallszahlen aus einerNormalverteilung zu generieren, verwendet man rnorm().
> rnorm(5,mean=42,sd=17)
[1] 36.15336 17.99194 29.04603 51.24752 34.34276
Plots. Sind x und y zwei Vektoren gleicher Länge, so erzeugt plot(x,y) einen Scat-terplot.
> x=rnorm (1000); y=rnorm (1000)
> plot(x,y)
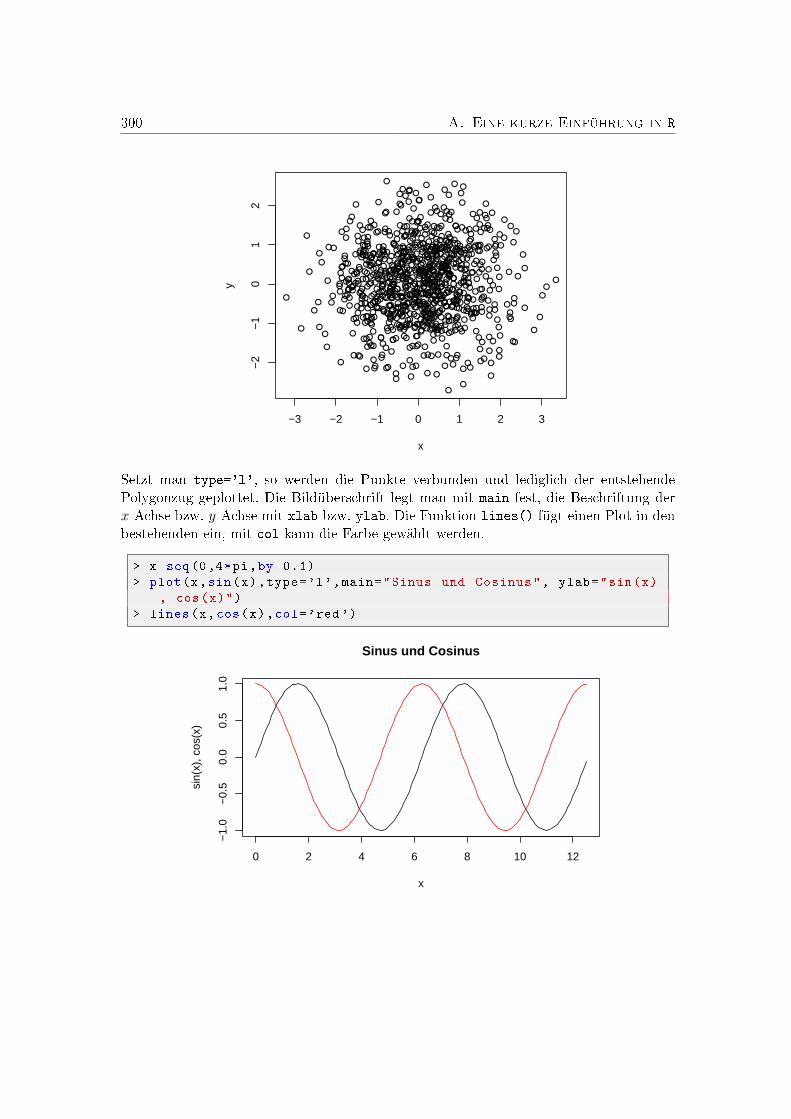
300 A. Eine kurze Einführung in R
−3 −2 −1 0 1 2 3
−2
−1
01
2
x
y
Setzt man type='l', so werden die Punkte verbunden und lediglich der entstehendePolygonzug geplottet. Die Bildüberschrift legt man mit main fest, die Beschriftung derx-Achse bzw. y-Achse mit xlab bzw. ylab. Die Funktion lines() fügt einen Plot in denbestehenden ein, mit col kann die Farbe gewählt werden.
> x=seq(0,4*pi ,by =0.1)
> plot(x,sin(x),type='l',main="Sinus und Cosinus", ylab="sin(x)
, cos(x)")
> lines(x,cos(x),col='red ')
0 2 4 6 8 10 12
−1.
0−
0.5
0.0
0.5
1.0
Sinus und Cosinus
x
sin(
x), c
os(x
)
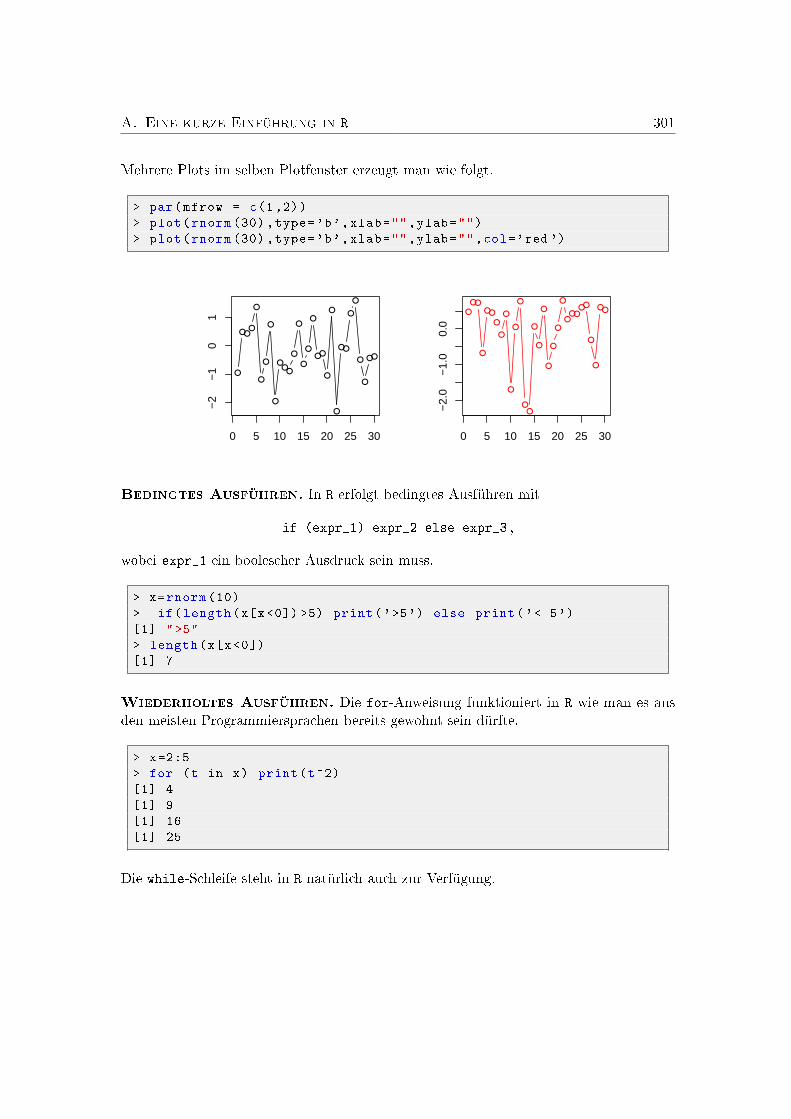
A. Eine kurze Einführung in R 301
Mehrere Plots im selben Plotfenster erzeugt man wie folgt.
> par(mfrow = c(1,2))
> plot(rnorm (30),type='b',xlab="",ylab="")
> plot(rnorm (30),type='b',xlab="",ylab="",col='red ')
0 5 10 15 20 25 30
−2
−1
01
0 5 10 15 20 25 30−
2.0
−1.
00.
0
Bedingtes Ausführen. In R erfolgt bedingtes Ausführen mit
if (expr_1) expr_2 else expr_3 ,
wobei expr_1 ein boolescher Ausdruck sein muss.
> x=rnorm (10)
> if(length(x[x<0]) >5) print('>5') else print('<=5')
[1] ">5"
> length(x[x<0])
[1] 7
Wiederholtes Ausführen. Die for-Anweisung funktioniert in R wie man es ausden meisten Programmiersprachen bereits gewohnt sein dürfte.
> x=2:5
> for (t in x) print(t^2)
[1] 4
[1] 9
[1] 16
[1] 25
Die while-Schleife steht in R natürlich auch zur Verfügung.

302 A. Eine kurze Einführung in R
> x=0
> while(x<3)x=x+1; print(x)
[1] 1
[1] 2
[1] 3
Schlieÿlich kann zum wiederholten Ausführen auch noch repeat verwendet werden.
> repeatx=x+1; print(x); if(x>3) break
[1] 1
[1] 2
[1] 3
[1] 4
Funktionen. Mit function() können eigene Funktionen geschrieben werden. Bei-spielsweise bildet nachfolgende Funktion die Summe der Elemente eines Vektors.
> summe=function(x) y=0; for(t in x) y=y+t; y
> summe (1:42)
[1] 903
Dasselbe Ergebnis liefert die bereits vorhandene Funktion sum(). Dennoch kontrollierenwir unser Ergebnis unter Zuhilfenahme einer wohlbekannten Formel.
> n=42
> n*(n+1)/2
[1] 903

A. Eine kurze Einführung in R 303
Übungsaufgaben
Lösen Sie folgende Aufgaben in R.
(A.1) Erstellen Sie für n ∈ N die Vektoren
x =(1, 1
2 , . . . ,1n
)und y =
(1, 1− 1
n , . . . ,1n
).
Berechnen Sie anschlieÿend
x :=1
n
n∑
i=1
xi , y :=1
n
n∑
i=1
yi und sxy :=1
n− 1
n∑
i=1
(xi − x)(yi − y) .
(A.2) Denieren Sie einen Vektor x , der die Werte der Spalte Height aus dem Datensatztrees enthält. Runden Sie die Werte von x auf die Zehnerstelle und geben Sieanschlieÿend die Anzahl von jedem Typ aus.
(A.3) Plotten Sie die Kurve, die durch die folgende Parametrisierung gegeben ist:
t 7→[
sin(2t)cos(2t)
], t ∈ [0, 2π) .
Speichern Sie das Ergebnis als PDF-Datei.
(A.4) Erstellen Sie einen Datensatz, der für zehn Orte die Meereshöhe, die aktuelle Tem-peratur sowie die Information, ob es in der letzten Stunde geregnet hat oder nicht,enthält. (Als Quelle können Sie beispielsweise http://www.zamg.ac.at verwen-den.) Verwenden Sie die Eingabe 0, falls es nicht geregnet hat, und 1, falls es ge-regnet hat. In der Tabelle soll dann schlieÿlich kein Regen bzw. Regen stehen.Erstellen Sie sodann einen weiteren Datensatz, der nur jeden zweiten Ort sowie nurdie Informationen zu Temperatur und Regen enthält.
(A.5) Stellen Sie den Zusammenhang zwischen den Seehöhen und Temperaturen aus dervorigen Aufgabe graphisch dar.
(A.6) Schneiden Sie beim Datensatz pressure alle Einträge mit pressure kleiner 100 abund plotten Sie die verbleibenden Daten in einem temperature-pressure-Diagramm.
(A.7) Schreiben Sie eine Funktion, die in Abhängigkeit von n ∈ N eine Liste mit denersten n Fibonacci-Zahlen ausgibt. Berechnen Sie die Summe der ersten 10 sowieder ersten 20 Fibonacci-Zahlen.
(A.8) Ordnen Sie den Datensatz beaver1 nach der Spalte time und erstellen Sie ein time-temperature-Diagramm. Fügen Sie dem geordneten Datensatz eine weitere SpalteFieber hinzu, welche die Ausprägungen ja bzw. nein beinhaltet, abhängig davon,ob die Temperatur gröÿer bzw. kleiner gleich 37 Grad Celsius beträgt.


Anhang B
Projektaufgaben
P.1 Zuckerrohrkrankheit: Machen Sie sich mit dem Datensatz cane aus demPackage boot vertraut. Gibt es statistisch signikante Unterschiede der relativenkranken Triebe zwischen den einzelnen Blöcken (A,B,C,D) ? Wenn ja, welche?
P.2 Hauskatzen: Machen Sie sich mit dem Datensatz cats aus dem Package MASS
vertraut. Gibt es statistisch signikante Unterschiede der Körpermasse bzw. derHerzmassen zwischen Katzen und Katern? Gibt es einen Zusammenhang zwischenKörpermasse und Herzmassen bei den einzelnen Tieren?
P.3 Altersheim: Machen Sie sich mit dem Datensatz channing aus dem Packa-ge boot vertraut. Untersuchen Sie für die Personen die im Altersheim verstorbensind, ob es statistisch signikante Unterschiede der Aufenthaltszeit zwischen Män-ner und Frauen gibt.Zusatz: Was lässt sich über die Verteilung der Aufenthaltszeiten aussagen?
P.4 Medikamentenvergleich: Machen Sie sich mit dem Datensatz CrohnD ausdem Package robustbase vertraut. Gibt es statistisch signikante Unterschiededer unerwünschten Eekten (adverse events) zwischen den drei Behandlungsme-thoden?Zusatz: Formulieren Sie weitere Fragestellungen.
P.5 Persönlichkeitsstruktur: Machen Sie sich mit dem Datensatz Cowles ausdem Package car vertraut. Gibt es statistisch signikante Unterschiede von Ex-traversion bzw. Neurotizismus zwischen Männern und Frauen? Gibt es einen Zu-sammenhang zwischen Extraversion und Neurotizismus?
P.6 Kriminalität: Machen Sie sich mit dem Datensatz Freedman aus dem Packagecar vertraut. Gibt es statistisch signikante Unterschiede der relativen Krimina-lität (Verbrechen pro Einwohner) zwischen Städten mit mehr als 700 000 undjenen mit weniger Einwohnern? Untersuche zusätzlich, ob es einen Zusammen-hang zwischen farbiger Bevölkerung und Kriminalität gibt.
P.7 Einwanderung: Machen Sie sich mit dem Datensatz Greene aus dem Packagecar vertraut. Gibt es statistisch signikante Unterschiede der Richterentschei-dung zwischen den einzelnen Richtern? Gibt es einen Zusammenhang zwischendie Sprache des Verfahrens und der Richterentscheidung.
305

306 B. Projektaufgaben
P.8 Arthritis:Machen Sie sich mit dem Datensatz Arthritis aus dem Package vcdvertraut. Gibt es statistisch signikante Unterschiede zwischen der Genesung vonPatienten, die mit dem Wirksto bzw. dem Placebo behandelt wurden? Gibt eseinen Zusammenhang oder Unterschiede zwischen Alter und/oder Geschlecht derPatienten?
P.9 Space Shuttle Fehler:Machen Sie sich mit dem Datensatz SpaceShuttle ausdem Package vcd vertraut. Gibt es statistisch signikante Unterschiede hinsicht-lich der Fehleranfälligkeit der Space Shuttles bei unterschiedlichen Temperaturen?Ist eine zeitliche Verbesserung der Fehler zu beobachten?
P.10 Scheidungen: Machen Sie sich mit dem Datensatz BrokenMarriage aus demPackage vcd vertraut. Gibt es statistisch signikante Unterschiede bei der Schei-dungsrate abhängig von der sozialen Stellung? Sind hier Unterschiede zwischenden Geschlechtern festzustellen?
P.11 Friend or Foe:Machen Sie sich mit dem Datensatz FriendFoe aus dem PackageEcdat vertraut. Gibt es statistisch signikante Unterschiede bei der Höhe desGewinns abhängig von der Entscheidung der Kandidaten. Welche Entscheidungerzielte höhere Gewinne?
P.12 Klassengröÿe: Machen Sie sich mit dem Datensatz Star aus dem PackageEcdat vertraut. Gibt es statistisch signikante Unterschiede beim Abschneiden inMathematik abhängig von der Klassengröÿe?
P.13 Wissenschaftliche Artikel:Machen Sie sich mit dem Datensatz bioChemistsaus dem Package pscl vertraut. Gibt es statistisch signikante Unterschiede beider Anzahl der veröentlichten Artikel abhängig vom Geschlecht der Studenten?Inwieweit beeinusst die Anzahle der veröentlichten Artikel des Betreuers (men-tor) jene der Studenten?
P.14 Filmbewertungen:Machen Sie sich mit dem Datensatz movies aus dem Packa-ge ggplot2 vertraut. Gibt es statistisch signikante Unterschiede bei der Bewer-tung von Filmen abhängig davon, welchem Genre (z. B. Actionlm, Dokumentar-lm, . . .) die Filme angehören. Vergleichen Sie zwei ausgewählte Genres genauer.
P.15 Speiseeiskonsum:Machen Sie sich mit dem Datensatz Icecream aus dem Packa-ge Ecdat vertraut. Untersuchen Sie den Einuss des Preises und der Temperaturauf die Menge des konsumierten Eises.

Anhang C
Antwortschlüssel zu den Kontrollfragen
I Wahrscheinlichkeitstheorie
Kapitel 1
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
1.10
1.11
1.12
1.13
1.14
1.15
1.16
1.17
1.18
Kapitel 2
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
Kapitel 3
3.1
3.2
3.3
3.4
3.5
3.6
3.7
3.8
307

308 C. Antwortschlüssel zu den Kontrollfragen
II Statistik
Kapitel 4
4.1 4.2 4.3
Kapitel 5
5.1
5.2
5.3
5.4
5.5
5.6
Kapitel 6
6.1
6.2
6.3
6.4
6.5
6.6
Kapitel 7
7.1
7.2
7.3
7.4
7.5
7.6
Kapitel 8
8.1 8.2 8.3

Index
abgeschlossene Menge, 10additiv, 12additiven Trend-Saison-Modell, 286Aktienindex, 285Algebra, 5Alternativhypothese, 227ANOVA, siehe VarianzanalyseAusprägung, 160Auswahlaxiom, 47
Bandbreite, 176Bedingte Wahrscheinlichkeit, 23Behrens-Fisher
-Problem, 241-Testgröÿe, 241
Benfordsches Gesetz, 267beobachtbare Menge, 5Bereichsschätzung, 201Bernoulli
-Maÿ, 42-Prozess, 18-Versuch, 18
Bildmaÿ, 87Bindung, 263Borel
-σ-Algebra, 10einer Borel-Menge, 11
-Funktion, 84-Menge, 10-messbare Abbildung, 84-messbare Menge, 10
Boxplot, 179
Cantor-Menge, 63charakteristische Funktion, siehe Indika-
torfunktion
Datenerhebung, 159Datensatz, 160DAX, 285De Morgansche Regeln, 7Dichte
bezüglich des Lebesgue-Maÿes, 123der χ2-Verteilung, 207der F -Verteilung, 239der t-Verteilung, 207der Exponentialverteilung, 50der Normalverteilung, 52Dichteschätzung, 175eines Zufallsvektors, 131Gauÿ-Dichte, 52
Dirac-Maÿ, 14Dirichletsche Sprungfunktion, 118diskrete Verteilung, 91
einfache Funktion, 111Einschränkung
einer σ-Algebra, 11eines äuÿeren Maÿes, 30
Einstichprobenproblem, 227, 230empirische
Korrelation, 183Kovarianz, 182Spannweite, 180Standardabweichung, 180Varianz, 180Verteilung, 170Verteilungsfunktion, 171
empirischerMittelwert, 178Variationskoezient, 180
Ereignis, 5fast sicheres, 14
309

310 Index
fast unmögliches, 14komplementäres, 14sicheres, 5unmögliches, 5
Erwartungswertnicht-negativer Zufallsvariablen, 116einer Verteilung, 116, 122integrierbarer Funktionen, 120messbarer Abbildungen, 136
erweiterte Borel-σ-Algebra, 86Erzeuger einer σ-Algebra, 9erzeugte σ-Algebra, 9, 81erzeugte monotone Klasse, 128erzeugtes λ-System, 34Eulersche Primzahlformel, 27
Faktorstufen, 243fast überall (f.ü.), 114fast sicher (f.s.), 116Fehler
1. Art, 2282. Art, 228
Fehlerwahrscheinlichkeit1. Art, 2302. Art, 230
nit-konite Algebra, 7Fortsetzung eines Prämaÿes, 31Fortsetzungssatz von Carathéodory, 31
Gütefunktion, 230Gauÿsche Glockenkurve, 51Gauÿsches weiÿen Rauschen, 286Gegenhypothese, siehe Alternativhypo-
theseGesetze der groÿen Zahlen, 140gleitender Durchschnitt, 287Goldenes Theorem, 53Grenzwertsatz
Poissonscher, 22von de Moivre-Laplace, 53zentraler, 142
Grundgesamtheit, 160
Halbnorm, 134Hauptsatz der Statistik, 172Heaviside-Funktion, 49Histogramm, 174
gleitendes Histogramm, 176
Indikatorfunktion, 83Integral
einfacher Funktionen, 112messbarer Funktionen, 117nicht-negativer messbaren Funktio-
nen, 113integrierbar, 117Interquartilsabstand, 179Irrtumswahrscheinlichkeit, 228
Kern, 176Epanechnikov-Kern, 176Gauÿ-Kern, 176naiver Kern, 176
Kern-Dichteschätzer, 176Kolmogorow-Abstand, 259Kolmogorowsche Verteilungsfunktion, 262Komplementärwahrscheinlichkeit, 14komplementstabil, 5Komponentenmodell, 286Kondenz
-intervall, 201-niveau, 201
konkave Funktion, 133Kontingenztafel, 269konvexe Funktion, 133Korrelation, 138Korrelationskoezient, 183korreliert, 138Kovarianz, 138kritischer Bereich, 229
Lambda-System, 33Laplace-Raum, 15

Index 311
Lebesgue-Integral, 118-Maÿ, 29, 44-integrierbar, 118-messbare Menge, 46
Lemma vonBorel-Cantelli, 43Fatou, 124
Likelihood-Funktion, 198Limes inferior, 42Limes superior, 42lineare Regression, 182
Maximum-Likelihood-Methode, 198-Prinzip, 197, 198-Schätzer, 200
Maÿ, 12σ-endlich, 12Äuÿeres Maÿ, 29endlich, 12
Maÿraum, 12Maÿzahl, 178Median, 178Mehrdimensionale Normalverteilung, 131Merkmal, 160
diskret, 169metrisch, 170nominal, 170ordinal, 170reell, 170stetig, 169zirkulär, 170
messbar bezüglich eines äuÿeren Maÿes,29
messbareAbbildung, 80Menge, 5
messbarer Raum, 5Messreihe, 160Mittel, 178
Mittelwert, 140Momente, 137
absolutes Moment, 137einer Verteilung, 137
monoton, 29monotone Klasse, 128multiplikativen Trend-Saison-Modell, 286
Nullhypothese, 227Nullmenge, 14
oene Menge, 10
p-Wert, 230Parameterintegral, 125Parameterschätzung, 195Pareto-Verteilung, 215Pi-Lambda-Theorem von Dynkin, 34Pi-System, 33Population, 160
Teilpopulation, 160Prämaÿ, 31Prinzip der kleinsten Fehler-Quadrate, 182Produkt
-σ-Algebra, 37-maÿ, 37-maÿraum, 37-wahrscheinlichkeitsmaÿ, 39-wahrscheinlichkeitsraum, 39
Punktmaÿ, 14Punktschätzungsiehe Parameterschätzung
195
quadratisch integrierbar, 134Qualitätskontrolle, 232, 234Quantil, 179, 201
-funktion, 201Quartil, 179
R-Befehlearray(), 296assign(), 291

312 Index
c(), 291data(), 298data.frame(), 297dnorm(), 299factor(), 295for, 301function(), 302head(), 298if, 301length(), 294levels(), 295library(), 298lines(), 300matrix(), 295max(), 294min(), 294plot(), 299pnorm(), 299qnorm(), 299read.table(), 298rep(), 293repeat, 302rnorm(), 299scan(), 292, 296sum(), 294summary(), 295t(), 296tail(), 298while, 301
Rückfangmethode, 199Randdichte, 144Rayleigh1-Verteilung, englischer Physiker,
215Realisierung, 160Rechtsinverse, 90, 260Regression, 181Regressionsgerade, 182relative Häugkeit, 171, 174
1John William Strutt, 3. Baron Rayleigh,18241919
Saisonkomponente, 286Satz über monotone Klassen, 128Satz von
Bayes, 24der majorisierten Konvergenz, 125der monotonen Konvergenz, 115der totalen Wahrscheinlichkeit, 24Fubini, 131Fubini-Tonelli, 129Gliwenko-Cantelli, 172Lebesgue, 125Levi, 115Vitali, 47
Scatterplot, 181Schätzfunktion
seeSchätzstatistik, 195Schätzstatistik, 195
erwartungstreu, 196konsistent, 196
Schwaches Gesetz der groÿen Zahlen, 140sigma
-additiv, 12-schnittstabil, 8-subadditiv, 16, 29-vereinigungsstabil, 5
Sigma-Algebra, 5Signikanzniveau, siehe Irrtumswahrschein-
lichkeitSmith-Volterra-Cantor-Menge, 63Spur-σ-Algebra, 11Stabdiagramm, 18Standardabweichung, 136Starkes Gesetz der groÿen Zahlen, 140Statistik
deskriptive Statistik, 157explorative Statistik, 157induktive Statistik, 157
statistische Einheit, 160Steinersche Formel, 136, 137Stetigkeit
von oben, 16

Index 313
von unten, 16Stichprobe, 160
einfache Stichprobe, 164Stichprobenmittel, 162, 205Stichprobenvarianz, 205Umfang, 160
stochastischer Pivot, 203Stochastischer Prozess, 285stochastisches Modell, 160Streudiagramm, 181Streumaÿe, 180Streuung, 180Substitutionsformel, 121Symmetrische Dierenz, 56
Teilgesamtheit, 160Test
F -Test, 238χ2-Anpassungstest, 265, 266χ2-Streuungstest, 235χ2-Unabhängigkeitstest, 268t-Testdoppelt, 237einfach, 234
Anpassungstest, 259einseitiger Test, 229exakter Test nach Fisher, 270Gauÿ-Testdoppelt, 236einfach, 230
Hypothesentest, 227Kolmogorow-Smirnow-Anpassungstest,
259Kruskal-Wallis-Test, 247Macht, 230nichtparametrischer Test, 259parametrischer Test, 227Teststatistik, 229Vorzeichentest, 271, 273Welch-Test, 241Wilcoxon-Rangsummen-Test, 275
Wilcoxon-Vorzeichen-Rang-Test, 275zweiseitger Test, 229
Trend-Saison-Modell, 286Trendbestimmung, 287Trendkomponente, 286
unabhängig und identisch verteilt (u.i.v.),95
Unabhängigkeitpaarweise Unabhängigkeit, 26von Ereignissen, 25von Komplementärereignissen, 27von Zufallsvariablen, 95
UngleichungCauchy-Schwarz-Ungleichung, 135Hölder-Ungleichung, 134Jensen-Ungleichung, 133Minkoswki-Ungleichung, 135Tschebyschow-Ungleichung, 136
unkorreliert, 138
Varianz, 136einer Verteilung, 137
Varianzanalyse, 243Verteilung, 88
Bernoulli-Verteilung, 92Binomialverteilung, 17, 91Chi-Quadrat-Verteilung, 204diskrete Gleichverteilung, 15, 92Exponentialverteilung, 50, 94Fisher-Verteilung, 239geometrische Verteilung, 23, 93hypergeometrische Verteilung, 19, 92kontinuierliche Gleichverteilung, 48,
93negative Binomialverteilung, 60Normalverteilung, 51, 94Poisson-Verteilung, 20, 93Standardnormalverteilung, 52Student-t-Verteilung, 204uniforme Verteilung, 15, 49

314 Index
Verteilungsfunktion, 88Vierfeldertafel, 270Vitali-Menge, 47Vollerhebung, 160
Wahrscheinlichkeitsdichte, 50, 91Wahrscheinlichkeitsmaÿ, 12Wahrscheinlichkeitsraum, 12
diskreter, 17kontinuierlicher, 48
Wahrscheinlichkeitstheorie, 3Weiÿes Rauschen, 285
Zählmaÿ, 14Zeitreihe, 285Zetafunktion, 27Zufallsexperiment, 3Zufallsvariable, 80Zweistichprobenproblem, 227, 236Zylindermengen, 41

Literaturverzeichnis
[1] Bauer, H.: Wahrscheinlichkeitstheorie. Fünfte Auage. Walter de Gruyter & Co.,2002
[2] Bosch, K.: Elementare Einführung in die Wahrscheinlichkeitsrechnung. Elfte Auf-lage. Vieweg+Teubner, 2011
[3] Büning, H. ; Trenkler, G.: Nichtparametrische statistische Methoden. ZweiteAuage. Walter de Gruyter, 1994
[4] Eckle-Kohler, J. ; Kohler, M.: Eine Einführung in die Statistik und ihre An-
wendungen. Springer-Verlag, 2009
[5] Fahrmeir, L. ; Künstler, R. ; Pigeot, I. ; Tutz, G.: Statistik, Der Weg zur
Datenanalyse. Fünfte Auage. Springer-Verlag, 2004
[6] Fritzsche, K.: Grundkurs Analysis 2. Springer Spektrum, 2006
[7] Gänssler, P. ; Stute, W.: Wahrscheinlichkeitstheorie. Springer, 1977
[8] Geiÿ, C. ; Geiÿ, S.: An introduction to probability theory. Vorlesungsskriptum,University of Jyväskylä, 2009
[9] Groÿ, J.: Grundlegende Statistik mit R. Vieweg+Teubner, 2010
[10] Helmberg, G. ; Wagner, P.: Wahrscheinlichkeitslehre und Statistik. Vorlesungs-skriptum, Universität Innsbruck, Wintersemester 2002/03
[11] Henze, N.: Stochastik für Einsteiger. Neunte Auage. Springer Vieweg, 2011
[12] Herrlich, H.: Axiom of Choice. Springer Berlin / Heidelberg, 2006
[13] Kersting, G. ; Wakolbinger, A.: Elementare Stochastik. Zweite Auage. Sprin-ger Basel, 2010
[14] Klenke, A.: Wahrscheinlichkeitstheorie. Zweite Auage. Springer Berlin / Heidel-berg, 2008
[15] Kohler, M.: Mathematische Statistik, Skriptum zur Vorlesung. TU Darmstadt,Wintersemester 2010/11
[16] Lang, U.: Maÿ und Integral. Vorlesungsskriptum, ETH Zürich, Sommersemester2005
315

316 Literaturverzeichnis
[17] Lehn, J. ; Wegmann, H.: Einführung in die Statistik. Fünfte Auage. B. G.Teubner, 2006
[18] Shapiro, S. ; Wilk, M.: An analysis of variance test for normality: Complete
samples. In: Biometrika 52 (1965)
[19] Shiryaev, A. N.: Probability. Zweite Auage. Springer New York, 1996
[20] Toutenburg, H. ; Schomaker, M. ;Wiÿmann, M. ; Heumann, C.: Arbeitsbuchzur deskriptiven und induktiven Statistik. Zweite Auage. Springer-Verlag, 2009
[21] Venables, W. ; Smith, D. ; R Core Team: An Introduction to R. Version 2.15.1(22.6.2012). URL: http://cran.r-project.org/doc/manuals/R-intro.pdf
[22] Wagner, P.: Maÿ- und Integrationstheorie. Vorlesungsskriptum, Universität Inns-bruck, Sommersemester 2004
[23] Witting, H. ; Nölle, G.: Angewandte mathematische Statistik. Optimale nite
und asymptotische Verfahren. B. G. Teubner, 1970









![05.02.20081 Wiederholung Einführung in die Wahrscheinlichkeitstheorie Wahrscheinlichkeitsraum Ergebnismenge = { ! 1, ! 2,…} mit ! 2 Pr[ ! ]=1. Berechnung](https://img.pdfslide.org/doc/110x75/55204d6149795902118b47b4/050220081-wiederholung-einfuehrung-in-die-wahrscheinlichkeitstheorie-wahrscheinlichkeitsraum-ergebnismenge-1-2-mit-2-pr-1-berechnung.jpg)