Embed Size (px)
Citation preview

Technische Universitat Graz
Institut fur Informationsverarbeitung undComputergestutzte neue Medien
Skript zur Vorlesung506.032, 506.432WS 2002/2003
Multimediale Informationssysteme
DI. Christof Dallermassl
Univ.Ass.DI.Dr. Denis Helic
Version vom 24. November 2004
Inhaltsverzeichnis
1 Inhaltsubersicht 11
1.1 Organisatorisches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.1.1 Ubungsablauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.2 Anderungen im Skript . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2 Internet - das Netz der Netze 16
2.1 Geschichtliche Entwicklung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2 Technische Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Dienste im Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.4 Protokolle im Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3 Informationssysteme 21
3.1 Historisches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Suchmaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2.1 Geschichte von Suchmaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2.2 Einteilung von Suchmaschinen nach Kategorien . . . . . . . . . . . . . . . . . . . . 25
Indexsuchdienste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Katalogsuchdienste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Meta Suchmaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Agents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
Recommendation Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.3 Reihung von Suchergebnissen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.4 Suche nach Multimediadaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3 Brockhaus Multimedial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.3.1 Textdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.3.2 Computergenerierter Kontext . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.3.3 Bilddaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.3.4 Videos und Animationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
Glaserner Mensch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.3.5 Landkarten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.3.6 Weblinks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.3.7 Programming Framework . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
1

INHALTSVERZEICHNIS 2
4 Markup Languages 34
4.1 SGML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.1.1 Struktur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.1.2 Attribute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.1.3 Entities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.1.4 Dokumententypen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.1.5 Probleme von SGML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2 HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2.1 Tags und Entities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2.2 HTML Kommentare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.2.3 HTML Mindesttags . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.2.4 HTML Frames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2.5 Farben in HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2.6 Skripte (Client-seitig) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2.7 Weiterfuhrende Informationen uber HTML . . . . . . . . . . . . . . . . . . . . . . 40
4.3 Style Sheets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.3.1 Einbinden von Style Sheet Definitionen . . . . . . . . . . . . . . . . . . . . . . . . 41
4.3.2 Unterschiedliche Ausgabemedien . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.3.3 Format-Definitionen fur HTML-Tags . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.3.4 CSS Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.4 eXtensible Markup Language (XML) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.4.1 Warum XML und nicht HTML? . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.4.2 Aufbau von XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
XML Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
XML Attribute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
Entities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Document Type Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Schema Definitionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
Processing Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
Namespaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.4.3 Beispiele Vorhandener XML-Definitionen . . . . . . . . . . . . . . . . . . . . . . . 56
4.4.4 Extensible Stylesheet Language (XSL) . . . . . . . . . . . . . . . . . . . . . . . . . 58
Mustervergleich (XPath) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Formatting Objects (FO) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
XML/XSL in the real-world . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.4.5 Weitere Literatur zu XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5 Digital Audio 66
5.1 Digitale Darstellung von Tonen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
5.2 Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.2.1 Wellentheorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
INHALTSVERZEICHNIS 3
5.2.2 MPEG Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
5.2.3 Akustikmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
5.2.4 Mehrkanal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
5.2.5 Weitere Kompressionsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5.2.6 MPEG Layer 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5.2.7 MPEG Layer 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5.2.8 MP3 - MPEG Layer 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.2.9 MPEG2/4 AAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.2.10 MP3 Pro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5.2.11 Ogg Vorbis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5.2.12 TwinVQ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5.2.13 ATRAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.2.14 Dolby AC-3/QDesign . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.2.15 Wave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.2.16 MSAudio - WMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.2.17 Realaudio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.2.18 Literatur zu Digital Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.3 MP3 Hortest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.4 MIDI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
6 Digital Images 78
6.1 Das Auge . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
6.1.1 Farbe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
6.1.2 Richtlinien fur die Verwendung von Farben . . . . . . . . . . . . . . . . . . . . . . 79
6.2 Farbmodelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.2.1 RGB-Farbmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.2.2 CMY-Farbmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.2.3 YUV-Farbmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
6.2.4 YIQ-Farbmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
6.2.5 HSV-Farbmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
6.2.6 Umrechnung zwischen Farbmodellen . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6.3 Rasterbilder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.3.1 Farbe in Rasterbildern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
Gamma-Korrektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
Alpha-Kanal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.4 Datenkompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.4.1 Lauflangenkodierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.4.2 LZW-Codierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
6.4.3 Huffman Codierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.4.4 Verlustfreie JPEG Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.4.5 Verlustbehaftete JPEG Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . 90

INHALTSVERZEICHNIS 4
Progressive Encoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
JPEG Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6.4.6 JPEG 2000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
JPEG2000 Kodierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
6.4.7 Fraktale Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.5 Bildformate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
6.5.1 BMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
6.5.2 TIFF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
6.5.3 GIF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
6.5.4 PNG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
Interlacing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
Datenkompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
6.5.5 JFIF (JPEG) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.5.6 JPEG 2000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.6 Metaformate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.6.1 WMF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.6.2 PICT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.7 Vektorgrafik Formate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.7.1 Postscript . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.7.2 Portable Document Format (PDF) . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
6.7.3 DXF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
6.7.4 SVG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
Anwendung von SVG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
6.8 Digitale Wasserzeichen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
Lowest Bit Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
Texture Block Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
Patchwork Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
Steganografie Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
7 Digital Video 107
7.1 Video und der Mensch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
7.1.1 Wahrnehmung von Bewegung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
7.2 Analoges Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
7.2.1 BAS und FBAS (Composite Video) . . . . . . . . . . . . . . . . . . . . . . . . . . 108
7.2.2 Komponentenvideo (Component Video) . . . . . . . . . . . . . . . . . . . . . . . . 108
7.2.3 Y/C Video (Separiertes Video) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
7.2.4 PAL Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
7.2.5 NTSC Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
7.2.6 High Definition Television (HDTV) . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
7.3 Digitale Videotechnik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
7.3.1 Codecs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
INHALTSVERZEICHNIS 5
Cinepak . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
Indeo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
Microsoft Video-1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
Microsoft RLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
MJPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
7.3.2 Videokompression nach H.261 und H.263 . . . . . . . . . . . . . . . . . . . . . . . 110
H.261 Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
7.3.3 Videokompression nach MPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
MPEG-1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
MPEG-2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
MPEG-4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
MPEG-7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
MPEG-21 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
Windows Media Technologies . . . . . . . . . . . . . . . . . . . . . . . . . . 114
DivX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
MPEG-Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
I-Frame Codierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
P-Frame und B-Frame-Codierung . . . . . . . . . . . . . . . . . . . . . . . . 115
D-Frames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
7.3.4 Video-Dateiformate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Audio-Video-Interleaved Format (AVI) . . . . . . . . . . . . . . . . . . . . . . . . . 116
Quicktime . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
RealVideo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Advanced Streaming Format (ASF) . . . . . . . . . . . . . . . . . . . . . . . . . . 117
7.4 Speichermedium DVD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
7.4.1 Kopierschutzmechanismen der DVD . . . . . . . . . . . . . . . . . . . . . . . . . . 117
7.4.2 Rechtliche Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
7.5 Synchronized Multimedia Integration Language (SMIL) . . . . . . . . . . . . . . . . . . . 118
8 Serverseitige Technologien 122
8.1 Dynamische Generierung von Web-Seiten . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
8.1.1 Common Gateway Interface (CGI) . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
Perl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
8.1.2 Parameterubergabe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
8.1.3 Sicherheitsuberlegungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
8.1.4 Server Side Includes (SSI) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
8.1.5 Servlets und Java Server Pages (JSP) . . . . . . . . . . . . . . . . . . . . . . . . . 125
Java-Servlets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
Java Server Pages (JSP) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Interne Behandlung von JSP . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Installation Servlet/JSP Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128

INHALTSVERZEICHNIS 6
Installation Tomcat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
Installation eigener Java Server Pages . . . . . . . . . . . . . . . . . . . . . 128
Installation eigener Servlets . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
8.1.6 Active Server Pages (ASP) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
8.1.7 in the beginning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
Informationen zu ASP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
8.1.8 PHP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
8.1.9 Cookies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
8.1.10 Session Tracking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
8.2 Distributed Programming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
8.2.1 .NET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
C# . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
SOAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
WebMethod . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
ASP.NET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
8.3 WAP/WML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
8.3.1 WML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
8.3.2 WAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
8.3.3 Installation einer eigenen WAP-Einwahl unter Linux . . . . . . . . . . . . . . . . . 139
mgetty . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
pppd . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
Kannel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
Apache . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
9 Knowledge Management 142
9.1 Die (Informatik) Welt in 100 Jahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
9.1.1 Wie kann irgendwer uber eine so lange Zeit eine vernunftige Prognose machen? . . 142
9.1.2 Die arbeitsteilige Gesellschaft . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
9.1.3 Die wissensteilige Gesellschaft . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
9.1.4 Wissensteilige Gesellschaft oder im Wissen ertrinkende Gesellschaft? . . . . . . . . 145
9.1.5 Technik und Technikspekulationen . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
9.1.6 Wollen wir das alles? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
9.1.7 Zum Autor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
9.2 Active Documents: Concept, Implementation and Applications . . . . . . . . . . . . . . . 148
9.2.1 The notion of active documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
9.2.2 The implementation of active documents . . . . . . . . . . . . . . . . . . . . . . . 149
The heuristic approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
The iconic approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
The linguistic approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
9.2.3 Futher research . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
9.2.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
INHALTSVERZEICHNIS 7
9.2.5 References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
10 Prufungsfragen 153
10.1 Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
10.2 Informationssysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
10.3 Markup Languages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
10.4 Digital Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
10.5 Digital Images . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
10.6 Digital Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
10.7 Serverseitige Technologien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
10.8 Bonus Fragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
A MP3 Hortest 176
B Abkurzungsverzeichnis 180
C Glossar 182
Literaturverzeichnis 184
Index 187

Abbildungsverzeichnis
2.1 Anzahl der Hosts im Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2 EBONE 2000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 hierarchical organisation of domain names . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1 Ted Nelson’s Interfile Communication (1971) . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Screenshot eines Gopher Clients . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3 Sponsored Links bei Suchmaschine ’Overture’ . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4 Suchergebnis ahnlicher Bilder anhand ihrer Struktur . . . . . . . . . . . . . . . . . . . . . 29
3.5 Beispiel des Wissensnetzwerkes (Computergenerierter Kontext) des Multimedialen Brock-hauses (2001) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1 Das Ergebnis des Formatting Object Processors . . . . . . . . . . . . . . . . . . . . . . . . 63
4.2 Internet Explorer 5.0: XML Datei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.3 Internet Explorer 5.0: XSL Datei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.4 Internet Explorer 5.0: XML Datei mit Formatierungen aus XSL Datei . . . . . . . . . . . 65
5.1 Abtastung der Welle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5.2 Abtastung der Welle - zeit und wertdiskret . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5.3 Abtastung der Welle - Quantisierungsfehler . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.4 Aliasing bei zu niederer Abtastfrequenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.5 Akustikmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
6.1 Farbraum des RGB-Modells . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.2 Farbauswahldialog des Bilderbearbeitungsprogrammes Gimp . . . . . . . . . . . . . . . . 81
6.3 Farbmischung bei RGB und CMY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
6.4 Farbraum des CMY-Modells . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6.5 Codebaum fur die Huffman-Codierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.6 Helligkeitsanderung gegenuber Farbtonanderung . . . . . . . . . . . . . . . . . . . . . . . 90
6.7 Zick-Zack-Serialisierung der DCT bei der JPEG-Kompression . . . . . . . . . . . . . . . . 92
6.8 Sehr hohe (1:100) Kompressionsrate bei JPEG . . . . . . . . . . . . . . . . . . . . . . . . 93
6.9 Vergleich JPG mit JPG 2000 bei gleicher Datenrate . . . . . . . . . . . . . . . . . . . . . 94
6.10 JPEG 2000 Regions of Interest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.11 Wavelet Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
8
ABBILDUNGSVERZEICHNIS 9
6.12 JPG 2000 Wavelet Transformation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.13 SVG Grafik ’Stars and Stripes’ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
7.1 I-Frames und P-Frames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
7.2 Anordnung und Beziehung der Frame-Typen bei der MPEG-Kompression . . . . . . . . . 115
7.3 RealPlayer mit SMIL Unterstutzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
8.1 Die Common Language Runtime (CLR) Architektur von .NET . . . . . . . . . . . . . . . 135
8.2 WAP-Einwahl und beteiligte Systeme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139

Tabellenverzeichnis
4.1 Unvollstandige Liste der Entities in HTML . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.1 Werte von Abtastfrequenzen und Samplingraten . . . . . . . . . . . . . . . . . . . . . . . 67
6.1 Kompressionsfaktoren bei verlustbehafteter JPEG-Kompression . . . . . . . . . . . . . . . 90
6.2 Quantisierungstabelle von JPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
6.3 EXIF Daten eines JPEG-Bildes einer digitalen Kamera. . . . . . . . . . . . . . . . . . . . 100
7.1 Datenraten bei H.261 Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
7.2 Kompressionsraten bei MPEG-Frametypen . . . . . . . . . . . . . . . . . . . . . . . . . . 115
7.3 Gruppierung der Frames in MPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
A.1 Musikstucke und ihre Filegrossen im Vergleich zu mp3-komprimierten Dateien . . . . . . . 179
10
Kapitel 1
Inhaltsubersicht
Das Ziel dieser Lehrveranstaltung (LV) ist es, einen Uberblick uber vorhandene Multimediale Informa-tionssysteme und die verwendeten Technologien zu geben. Der Schwerpunkt liegt dabei mehr auf dentechnischen Moglichkeiten und weniger auf der (kunstlerischen) Gestaltung oder dem Inhalt der Infor-mationssysteme.
Verschiedene Technologien, die verwendet werden, um Multimediale Informationssysteme aufzubauen,werden mehr oder weniger detailiert beschrieben, ihre Vor- und Nachteile aufgezeigt und ihre Verwendungerklart. Dazu gehoren auch (einfache) Beispiele, die aufzeigen, wie die jeweiligen Moglichkeiten verwendetwerden konnen bzw. sollen.
Diese LV beschreibt aber auch existierende Informationssysteme und versucht, deren technische Hinter-grunde zu beleuchten. Informationsgewinnung und Knowledge Management gehoren aber ebenfalls zuden behandelten Themen.
1.1 Organisatorisches
Die LV “Multimediale Informationssysteme” wird von Prof. Hermann Maurer1 und Christof Dallermassl2
gehalten.
Eine Anmeldung fur “Multimediale Informationssysteme” ist ab Wintersemester 2001/2002 fur die Vor-lesung als auch fur die Prufung notwendig. Die Prufungsanmeldung ist ausschliesslich am Online Systemder TU-Graz3 moglich.
Fur die Teilnahme an den Konstruktionsubungen ist eine Anmeldung am Online System notwendig! DerAnmeldeschluss und die Ubungsthemen dafur werden in der Vorlesung bekanntgegeben.
Unterlagen, Folien und die aktuellste Version dieses Skripts sind unter http://courses.iicm.edu/mmisim Internet zu finden. Die offizielle Webseite der LV ist im Online System der TU Graz zu finden. Dortwerden auch alle Vorlesungstermine bzw. deren Entfallen aufgelistet.
Die Kommunikation uber diese LV findet hauptsachlich in der Newsgroup news://news.tu-graz.ac.at/tu-graz.lv.mmis auf dem Newsserver der TU-Graz news.tu-graz.ac.at statt.
In diesem Skript wird soweit als moglich auf die deutsche Rechtschreibung Rucksicht genommen. Al-lerdings kann nicht garantiert werden, dass alle Regeln der alten/neuen Rechtschreibung berucksichtigtwerden :-) Der Schreiber dieses Skripts (Christof Dallermassl) bekennt sich der Einfacherheit halber zueinem Gemisch aus neuer, alter und schweizer (ohne ’scharfes s’ (ß)) Rechtschreibung und hofft auf all-gemeines Verstandnis. Der Autor ist jedoch im Allgemeinen froh, etwaige Tipp- oder sonstige Fehlermitgeteilt zu bekommen und bemuht sich, diese schnellstmoglich auszubessern.
[email protected]@iicm.edu3http://online.tu-graz.ac.at
11

KAPITEL 1. INHALTSUBERSICHT 12
1.1.1 Ubungsablauf
In der Ubung sollen Gruppen von StudentInnen (2 bis 4 Personen, in Einzelfallen auch einzeln) einProjekt durchfuhren, das irgendwie mit dem in der Vorlesung vorkommenden Stoff zu tun hat. ImAllgemeinen wird daher ein multimediales Informationssystem zu erstellen sein. Das Ziel der Ubung istes, verschiedene Technologien, die in der Vorlesung ja meist nur kurz angerissen werden konnen, in derPraxis kennenzulernen und das Wissen daruber zu vertiefen.
Wichtig ist jedoch nicht nur die Beschaftigung mit diversen Techniken, sondern auch das Planen desUbungsprojektes. Es muss von jeder Gruppe vor Beginn der Implementierung ein kurzer Projektplanabgegeben werden, in dem
• die Gruppenteilnehmer (Name, Matrikelnummer, email-Adresse),
• eine kurze Beschreibung des Projektes (was wird gemacht) - User Requirements und die darausresultierenden Software Requirements
• eine kurze Beschreibung der verwendeten Technologien (warum wird es so gemacht, wie es geplantist und nicht mit einer ahnlichen Technologie (z.B. warum PHP und nicht JSP)) - grobes SoftwareDesign,
• eine Zeitplanung
enthalten ist.
Die Zeitplanung ist einer der wichtigsten Teile der Projektplanung und nur durch haufige Aufwandsschatz-ungen zu erlernen. Ohne (halbwegs) richtige Zeitplanung ist es unmoglich, ein Projekt zu kalkulieren.Da die Einschatzung, was wie lange brauchen wird, aber nicht aus Buchern erlernt werden kann, sondernhauptsachlich mit Erfahrungswerten arbeitet, sollte dies so oft wie moglich geubt werden, bevor man sichin die freie Wirtschaft wagt.
Eine beispielhafte Projektplanung kann z.B. so aussehen:
Teilnehmer:
Christof Dallermassl, 9031434, [email protected] Blumlinger, 9112345, [email protected]
Thema:
Serverbasiertes Fotoalbum im Web
Beschreibung:
Fotos und ihre Beschreibungen sollen im Web angezeigt werden konnen. Es soll moglichsein, Fotos upzuloaden und Kommentare und Links zu einzelnen Fotos hinzuzufugen. ZumUploaden soll kein Zusatzprogramm ausser einem Webbrowser notig sein. Die Webseitensollen moglichst mit verschiedenen Browsern zusammen arbeiten. Zusatzlich soll es auchmoglich sein, die Bilder auf dem Server leicht zu bearbeiten (Skalieren, Drehen, Spiegeln,evtl. Effekte).
Grobes Design:
Kommentare und Links werden in einer relationalen Datenbank verwaltet. Die Bilder werdeneinfach im Filesystem oder auch in der Datenbank gespeichert. Zur dynamischen Generierungder HTML-Seiten wird Serverseitig PHP verwendet, da diese serverseitige Erweiterung einensehr einfachen Zugriff auf die verwendete Datenbank MySQL erlaubt und es ausserdem eineumfangreiche Bibliothek zur Bildverarbeitung gibt. Zusatzlich ist PHP plattformunabhangig.Alternativ kamen Java Servlets/Java Server Pages in Frage. ASP scheidet wegen der Platt-formabhangigkeit aus.
Zeitplan:
KAPITEL 1. INHALTSUBERSICHT 13
Task DauerInstallation/Konfiguration Apache/PHP/MySQL 5hDesign Webseiten 15hDesign der Datenbank 4hPHP lernen 15hPHP Implementation Anzeige/Upload/Kommentare 30hServerseitige Bildbearbeitung 20hTesten 5hDokumentation 5h
Der Abgabetermin fur diese Projektplanung wird in der Vorlesung bzw. in der Newsgroup bekanntgege-ben.
1.2 Anderungen im Skript
Hier werden Anderungen am Skript dokumentiert, um es dem Leser des Skripts die Entscheidung zuerleichtern, ob sich der Download der neuesten Version bezahlt macht. Die Version des Skripts, die Siegerade in Handen oder Bildschirm halten, wurde am 24. November 2004 erstellt.
Anderungen:
• 19.03.2003 : Kleine Fehler im Kapitel “Markup Languages” und “Digital Video” ausgebessert.Danke an Christina Irk
• 21.01.2003 : Update fur PHP4 Konfiguration (Globale Variablen) - Danke an Edi Haselwanter undeinen Ubungsteilnehmer (Name leider vergessen)
• 13.01.2003 : Kleine Anderungen im Kapitel “Digital Video”
• 02.12.2002: Kleine Anderungen im Kapitel “Digital Bilder”: Kleine Beispiele geandert/dazu. Kur-zer Kommentar zu JPEG dazu (Zick-Zack)
• 25.11.2002: Kleine Anderungen im Kapitel “Digital Audio”: Ogg Vorbis, MP3Pro dazu, kleineDetails dazu
• 18.11.2002: Kleine Anderungen im Kapitel “Server Seitige Erweiterungen”.
• 11.11.2002: Kleine Anderungen im Kapitel “Markup Languages”. XML/CSS hinzugefugt, XHTMLkurz erwahnt. Kleine Umstellung der Reihenfolge (XML Anwendungen mit XSL getauscht).
• 04.11.2002: Kleine Anderungen im Kapitel “Markup Languages”.
• 07.10.2002: Titelseite an neues Semester angepasst, Vorlesungsnummer fur Multimediale Informa-tionsysteme 1 eingefugt.
• 12.07.2002: Neue Prufungsbeispiele und Antworten (Bonusfrage) der letzten Prufung hinzugefugt.Beispiel fur Processing Instructions hinzugefugt. Viele Tippfehler ausgebessert (Danke an MartinPirker).
• 25.06.2002: Link auf freien PHP-Provider hinzugefugt.
• 13.06.2002: Kleine Anderungen im Kapitel “Digital Video”.
• 27.05.2002: Viele Tipp- und Schreibfehler ausgebessert (Danke an Peter Schifferl)
• 21.05.2002: Ab sofort gib es auch die Folien in den papiersparenden Versionen von 4 bzw. 8 Folienpro Seite in verschiedenen Anordnungen. Das Skriptum in 2 pro Seite (aber leider ohne Hyperlinks,d.h. nur zum Drucken).
• 14.05.2002: JSP/Servlet Konfiguration vereinfacht (keine Contexte mehr).
• 02.05.2002: Javascript Beispiel fur Hidden Formfields im Kapitel “Serverseitige Erweiterungen”hinzugefugt. (Danke an Karl Svensson!), PHP-Tutorial-Links hinzugefugt.

KAPITEL 1. INHALTSUBERSICHT 14
• 01.05.2002: Updated Links im Kapitel “Serverseitige Erweiterungen”
• 23.04.2002: Originelle Bonusfragen der Prufung vom 17.04.2002 hinzugefugt.
• 18.04.2002: kleine Tippfehler (Kapitel Knowledge Management) (gefunden von Mario Grunwald),kleine Anderungen im Kapitel Markup-Languages. Abschnitt “Vorhandene XML-Definitionen”hinzugefugt (Beispiele von XML-Standards).
• 21.03.2002: kleinere Tippfehler ausgebessert (Kapitel Markup Languages). Links auf Selfhtml-Seiten upgedated (auf Version 8.0)
• 14.03.2002: Tippfehler im Kapitel Internet entfernt. Ein paar Links bei Informationssystemenhinzugefugt. Gnu Image Find Tool (Suche nach Multimediadaten) hinzugefugt.
• 17.01.2002: Kleine Umstellung bei XSL. XSL manchmal durch XSLT ersetzt.
• 17-19.12.2001: Details zu Processing Instructions hinzugefugt. Literaturverweise aus RFC.bibentfernt (keine Verlinkung innerhalb der RFCs/STDs/FYIs mehr). Details zur Reihung von Such-maschinen hinzugefugt. Korrektur, dass FTP UDP verwendet. Ist falsch! (Sorry!) (Danke anThomas Oberhuber)
• 27.11.2001: Kapitel “Knowledge Management” von Prof. Maurer hinzugefugt.
• 21.11.2001: Originelle Antworten zur Bonusfrage der Prufung am 14.11.2001 hinzugefugt.
• 19.11.2001: Kleine Anderungen im Kapitel “Digitale Bilder”. Info uber JPEG2000 upgedated.
• 05.11.2001: Kleine Umstellungen (u.a. Titel) im Kapitel “Information Server Technologien” (jetzt“Serverseitige Technologien”). Kleine Fehler in Kapitel “Digital Audio” und “Digital Images”ausgebessert (gefunden von Dieter Freismuth).
• 29.10.2001: Kapitel “Markup Sprachen: Kleine Anderungen bei XML/XSL. Beispiel und Screens-hot fur XSLT/FO eingefugt.
• 24.10.2001: Kapitel “Inhaltsubersicht”: Kurze Erklarung zu den Ubungen eingefugt. Beispiel furProjektplanung
• 22.10.2001: Kapitel “Markup Languages”: Beispiele fur verschiedene Media-Typen (print, projec-tion) eingefugt (Danke an Stefan Thalauer).
• 12.10.2001: Kapitel “Internet”: Zahlen von Internet Consortium verwendet, nicht mehr von netsi-zer. Bildformat von pdf auf jpg/png umgestellt, wo vorhanden.
• 09.10.2001: Ein paar Index Eintrage korrigiert.
• 04.10.2001: Ein paar Tippfehler korrigiert und das XML/XSL Beispiel richtig gestellt (gefundenvon Dieter Freismuth).
• 29.09.2001: Ein oder zwei Prufungsfragen dazugeschrieben bzw. leicht geandert.
• 19.09.2001: Viele kleinere Fehler ausgebessert (bemerkt von Erwin Pischler).
• 07.09.2001: Kleine Fehler ausgebessert (bemerkt von Peter Strassnig).
• 24.07.2001: Anderung des PHP-Beispiels (jetzt Verwendung von Standard MySQL PHP Befehlen).
• 05.07.2001: Minimale Anderungen (Tippfehler, Indexfehler)
• 30.05.2001: Kapitel “Digitales Video” ein paar Details dazugefugt, DivX und rechtl. Problemedazu.
• 10.05.2001: Kapitel “Information Server Technologies” Teil uber SSI und .NET hinzugefugt. Tipp-fehler ausgebessert.
• 02.05.2001: Tippfehler aus Kapitel ’Digital Images’ entfernt.
KAPITEL 1. INHALTSUBERSICHT 15
• 05.04.2001: Datenmenge in Tabelle (Digital Audio - Sample Rate, Auflosung, Frequenzband, Da-tenmenge) von kbit auf kB korrigiert.
• 04.04.2001: DVD-Audio Werte korrigiert
• 03.04.2001: Beschreibung von LZW leicht geandert.
• 28.03.2001: in xmltags sind jetzt wieder spaces drin, wenn sie reingehoren.
• 15.03.2001: ein paar Tippfehler ausgebessert
• 07.03.2001: Dateinamen alle umbenannt (mmis_ws2000_ weg - auch die Folien sind jetzt nachThema und nicht mehr nach Datum benannt.)
• 01.02.2001: Index hinzugefugt
• 30.01.2001: Englische Prufungsfragen hinzugefugt.
• 29.01.2001: Kleine Layoutanderungen
• 27.01.2001: Tippfehler und Vannevar Bush’s Artikel-Titel korrigiert und mit Url versehen (imLiteraturverzeichnis).
• 26.01.2001: Prufungsfragen anders gelayoutet, sonst daran nichts geandert.
In der Inhaltsubersicht die “Grobe Inhaltsubersicht” rausgeworfen.
Leichte Layoutanderungen, weil bei Kapitelanfangen Seitenzahl beim Ausdrucken weggeschnittenwurde.
• 24.01.2001: Kapitel Markup Languages/XML: XSL transformiert ein XML-Dokument in ein an-deres XML-Dokument (also evtl. auch in ein HTML-Dokument), aber keinesfalls immer in einHTML-Dokument!
Digital Audio: Abbildung mit Aliasing: Rechter Rand wird jetzt nicht mehr abgeschnitten.
Kurze Erklarung und Bild zu WAP/WML hinzugefugt.
Prufungsfragen hinzugefugt.
Textbreite verandert, Rander verkleinert und alle code-Schnipsel in kleinerer Schrift (ca. 40 Seitengespart).
• 23.01.2001: IPv6 verwendet naturlich Adressen von 128bit Lange (und nicht 129 bit) [KapitelInternet - Das Netz der Netze].
• 22.01.2001: Kapitelweise Titel-Folien eingebaut (in die Folien, NICHT ins Skript!)
• 20.01.2001: Beim Kapitel “Informationssysteme” die Abschnitte “Suchmaschinen” und “BrockhausMultimedia” hinzugefugt.
• 18.01.2001: Den Abschnitt mit den Anderungen und ein Erstellungsdatum auf die Titelseite ein-gefugt. Diesen Abschnitt mit den Anderungen gibt es nun auch als eigenes Dokument zur schnellenUberprufung, ob sich etwas geandert hat. Korrektur von etlichen Schreibfehlern im ganzen Skript.
Kapitel 2
Internet - das Netz der Netze
2.1 Geschichtliche Entwicklung
Im Jahre 1970 begann die ARPA (Advanced Research Projects Agency) damit, Forschungen an weitrei-chenden, ausfallsicheren Netzen zu fordern. 1972 wurde dann die Arbeit von DARPA (Defense AdvancedResearch Projects Agency) weitergefuhrt, da man vor allem im militarischen Bereich auf der Suche nachausfallsicherer, weitraumiger Vernetzung war. Die heute anzutreffende Internet Architektur und die Pro-tokolle bekamen ihre Form gegen Ende der 70er Jahre. Durch die besondere Auslegung des Internetals Packet Switched Network erreichte man die Moglichkeit der Topologie als Maschennetz, bei dem derAusfall eines Knotens noch nicht zum Ausfall des Gesamtnetzes fuhrt, da das Routing auch uber andereKnoten weiter erfolgen kann. Basis fur alle Protokolle im Internet ist TCP/IP (Transmission ControlProtocol/Internet Protocol), an dessen Entwicklung bereits 1979 so viele Organisationen beteiligt wa-ren, sodass DARPA ein informelles Komitee grundete um die Entwicklungen zu koordinieren (ICCB =Internet Control and Configuration Board). Im Jahre 1980 begann, was wir heute als Internet kennen:DARPA stellte die Computer in den Forschungsnetzen auf die neuen TCP/IP Protokolle um. Das AR-PANET, das es als Vernetzung schon gab, wurde schnell zum Kern des neuen Internet. Abgeschlossenwurde die Umstellung auf TCP/IP im Janner 1983. Zur selben Zeit teilte die DCA (Defense Communi-cation Agency) das Internet in zwei getrennte Netzwerke - eines fur militarische Zwecke, eines fur weitereForschung. Der Forschungsteil des Netzes behielt den Namen ARPANET, der militarische Teil, der wiezu erwarten damals der grossere war, bekam den Namen MILNET.
Um nun den Forschungseinrichtungen einen Anreiz zu geben, mit der neuen Technologie zu arbeiten, gabDARPA eine Implementation zu sehr geringen Kosten heraus. Zu dieser Zeit verwendeten die meistenComputer-Science Institute auf Universitaten BSD Unix. So erreichte man durch die Implementationfur Unix auf einen Schlag 90% der universitaren Forschungseinrichtungen im Bereich Computer-Science.Ein weiterer Grund fur die rasche Verbreitung der TCP/IP Technologie war die mangelnde Verfugbarkeitanderer Protokolle fur LANs. Gerade aber LANs waren durch die seit den fruhen 80er Jahren verfugbarebillige Ethernet Technologie sehr stark im Kommen. Damit schlug man also gleich zwei Fliegen mit einerKlappe - man konnte Rechner billig mit Ethernet vernetzen und durch die Verwendung von TCP/IP alsProtokoll kam auch gleich die Moglichkeit dazu, am Internet teilzunehmen.
Das “New Hacker’s Dictionary” [Ray] beschreibt den Grund fur den Erfolg von TCP/IP so:
TCP/IP evolved primarily by actually being used, rather than being handed down from onhigh by a vendor or a heavily-politicized standards committee. Consequently, it (a) works, (b)actually promotes cheap cross-platform connectivity, and (c) annoys the hell out of corporateand governmental empire-builders everywhere.
Als die NSF (National Science Foundation) erkannte, dass Netzwerke bald ein sehr wichtiger Teil derForschung sein wurden, begann sie 1985 um ihre 6 Supercomputer Center herum grossere Netzwerke aufTCP/IP Basis zu installieren. 1986 wurden dann diese Zentren untereinander verbunden und bildetendas NSFNET; weiters wurde das NSFNET auch gleich mit dem ARPANET verbunden.
Bis 1987 waren so hunderte Netzwerke in den Staaten und in Europa mit knapp 20.000 Computern zu
16
KAPITEL 2. INTERNET - DAS NETZ DER NETZE 17
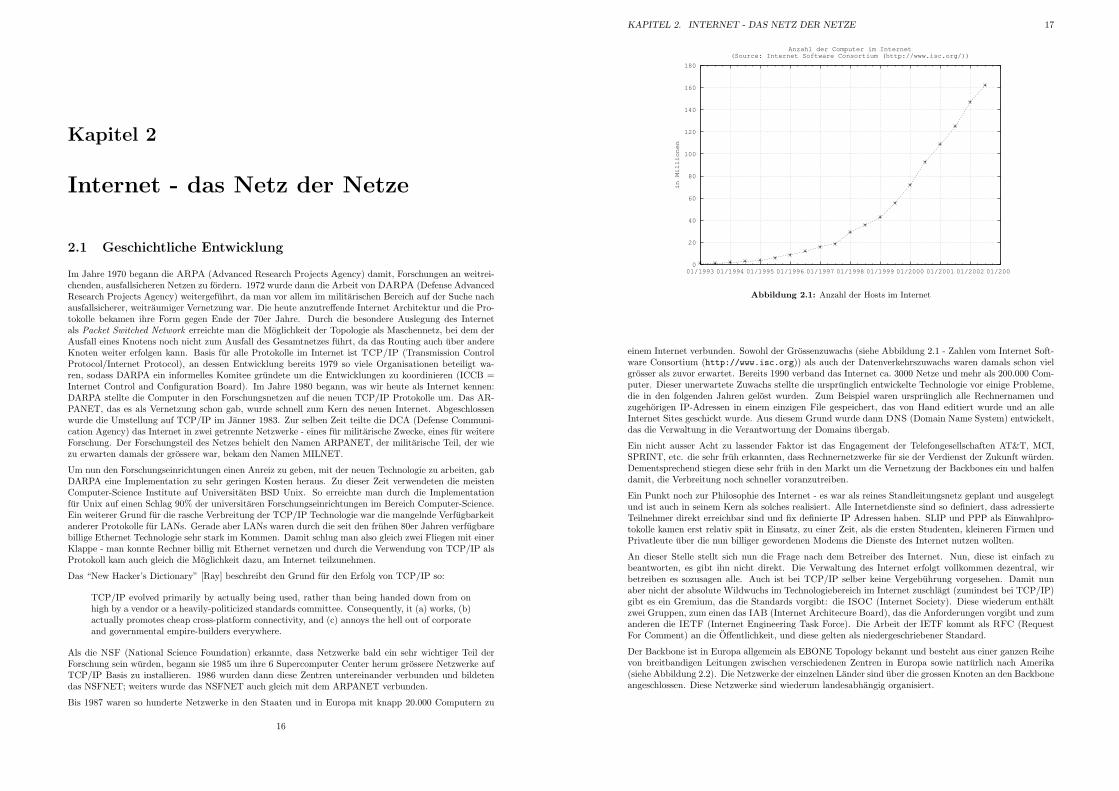
0
20
40
60
80
100
120
140
160
180
01/1993 01/1994 01/1995 01/1996 01/1997 01/1998 01/1999 01/2000 01/2001 01/2002 01/2003
in M
illio
ne
n
Anzahl der Computer im Internet(Source: Internet Software Consortium (http://www.isc.org/))
Abbildung 2.1: Anzahl der Hosts im Internet
einem Internet verbunden. Sowohl der Grossenzuwachs (siehe Abbildung 2.1 - Zahlen vom Internet Soft-ware Consortium (http://www.isc.org)) als auch der Datenverkehrszuwachs waren damals schon vielgrosser als zuvor erwartet. Bereits 1990 verband das Internet ca. 3000 Netze und mehr als 200.000 Com-puter. Dieser unerwartete Zuwachs stellte die ursprunglich entwickelte Technologie vor einige Probleme,die in den folgenden Jahren gelost wurden. Zum Beispiel waren ursprunglich alle Rechnernamen undzugehorigen IP-Adressen in einem einzigen File gespeichert, das von Hand editiert wurde und an alleInternet Sites geschickt wurde. Aus diesem Grund wurde dann DNS (Domain Name System) entwickelt,das die Verwaltung in die Verantwortung der Domains ubergab.
Ein nicht ausser Acht zu lassender Faktor ist das Engagement der Telefongesellschaften AT&T, MCI,SPRINT, etc. die sehr fruh erkannten, dass Rechnernetzwerke fur sie der Verdienst der Zukunft wurden.Dementsprechend stiegen diese sehr fruh in den Markt um die Vernetzung der Backbones ein und halfendamit, die Verbreitung noch schneller voranzutreiben.
Ein Punkt noch zur Philosophie des Internet - es war als reines Standleitungsnetz geplant und ausgelegtund ist auch in seinem Kern als solches realisiert. Alle Internetdienste sind so definiert, dass adressierteTeilnehmer direkt erreichbar sind und fix definierte IP Adressen haben. SLIP und PPP als Einwahlpro-tokolle kamen erst relativ spat in Einsatz, zu einer Zeit, als die ersten Studenten, kleineren Firmen undPrivatleute uber die nun billiger gewordenen Modems die Dienste des Internet nutzen wollten.
An dieser Stelle stellt sich nun die Frage nach dem Betreiber des Internet. Nun, diese ist einfach zubeantworten, es gibt ihn nicht direkt. Die Verwaltung des Internet erfolgt vollkommen dezentral, wirbetreiben es sozusagen alle. Auch ist bei TCP/IP selber keine Vergebuhrung vorgesehen. Damit nunaber nicht der absolute Wildwuchs im Technologiebereich im Internet zuschlagt (zumindest bei TCP/IP)gibt es ein Gremium, das die Standards vorgibt: die ISOC (Internet Society). Diese wiederum enthaltzwei Gruppen, zum einen das IAB (Internet Architecure Board), das die Anforderungen vorgibt und zumanderen die IETF (Internet Engineering Task Force). Die Arbeit der IETF kommt als RFC (RequestFor Comment) an die Offentlichkeit, und diese gelten als niedergeschriebener Standard.
Der Backbone ist in Europa allgemein als EBONE Topology bekannt und besteht aus einer ganzen Reihevon breitbandigen Leitungen zwischen verschiedenen Zentren in Europa sowie naturlich nach Amerika(siehe Abbildung 2.2). Die Netzwerke der einzelnen Lander sind uber die grossen Knoten an den Backboneangeschlossen. Diese Netzwerke sind wiederum landesabhangig organisiert.

KAPITEL 2. INTERNET - DAS NETZ DER NETZE 18
Abbildung 2.2: EBONE 2000
2.2 Technische Grundlagen
Jeder Teilnehmer des Netzes hat eine IP Adresse, die aussagt, in welchem Netzwerk er sich befindetund welcher Rechner er in diesem Netzwerk ist. Diese Kombination ist eindeutig. Es kann keine zweiMaschinen mit der gleichen Adresse im Internet geben. Alle IP Adressen sind 32 Bit (IPv4) lang (IPv6verwendet 128 Bit lange Adressen - Es gibt bei 16 Byte-Adressen 2128 verschiedene Adressen, das sindca. 3 ∗ 1038. Auf der gesamten Erde (Land und Wasserflachen!) konnte man damit 7 ∗ 1023 Rechner proQuadratmeter adressieren.). Adressen werden in einer Punkt-Dezimalzahl Notation geschrieben, d.h. die32-Bit Adressen werden in 4 x 8 Bit Dezimalzahlen durch einen Punkt getrennt geschrieben.
Beispiel: Die Adresse 2166031126 ist binar 10000001000110110000001100010110 (hexadezimal 0x811B0316).Jeweils 8 Bit werden zusammengefasst (10000001.00011011.00000011.00010110) und in der Punkt-Dezimalzahl Notation als 129.27.3.22 geschrieben.
Da diese Zahlen unmoglich zu merken sind, werden einzelnen Rechnern auch Namen (einer oder mehrere)zugewiesen. So hat der oben genannte Rechner den Namen news.tu-graz.ac.at.
Diese Namen sind hierarchisch organisiert (siehe Abbildung 2.3) und werden von vielen Domain NameServern verwaltet.
Das Internet Protokoll ist jedoch von diesen Namen unabhangig und arbeitet immer nur mit den IP-Adressen.
TCP/IP ist das im Internet am meisten benutzte Protokoll und setzt sich aus zwei eigentlich unabhangi-gen Protokollen zusammen:
• IP (Internet Protocol): erzeugt eine Punkt zu Punkt Verbindung, kummert sich um das richtigeRouting der Datenpakete. Unterstutzt aber keine zuverlassigen Verbindungen oder Fehlerkontrolleder Daten.
• TCP (Transmission Control Protocol): baut auf IP auf und stellt eine zuverlassige, virtuelle Punkt
KAPITEL 2. INTERNET - DAS NETZ DER NETZE 19
int com edu gov mil org net jp
�
us nl . . .
acm ieeesun yale ac co oce vu�
jack
�
cs engeng jill
�
keio nec
flitscs cslai linda fluit
cs
pc24robot
Generic Countries
Abbildung 2.3: hierarchical organisation of domain names
zu Punkt Verbindung her. TCP kummert sich um die Wiederanforderung von verlorenen oderdefekten Paketen. Ausserdem konnen Pakete in falscher Reihenfolge oder mehrfach beim Empfangerankommen. TCP behandelt auch diese Fehlerquellen.
Durch die Verwendung von Ports ist es bei TCP (und auch bei UDP) moglich, verschiedene Dienste einesComputers uber das Netzwerk getrennt anzusprechen. So lauscht z.B. ein Web-Server normalerweise aufPort 80, ein Newsserver auf Port 119 oder ein Telnet-Server auf Port 23.
Auf weitere Protokolle, die im Internet verwendet werden (UDP, ICMP, ARP,. . . ), wird hier nicht nahereingegangen, da dies zu weit fuhren wurde. Genaueres kann jedoch im Skript zur Vorlesung ’Datenuber-tragungsprotokolle’1 nachgelesen werden.
2.3 Dienste im Internet
Ursprunglich war das Internet dazu gedacht, eine Moglichkeit zu bieten, auf ’remote’ Rechnern arbeitenzu konnen (☞TELNET). Diese Anwendung wurde aber schon bald von email uberholt. Email ist ubrigensimmer noch der meistgenutzte Dienst des Internet.
Ein weiterer oft benutzter Dienst ist FTP (File Transfer Protocol) der es ermoglicht, Dateien zwischenRechnern zu ubertragen. Schon bald bildeten sich Server im Internet, die eine Vielzahl von Dateien undProgrammen anboten. Suchmaschinen fur Dateien entstanden.
2.4 Protokolle im Internet
Jeder Dienst im Internet verwendet ein eigenes Protokoll, um zwischen dem Client und dem Server Da-ten auszutauschen. Fast alle Protokolle basieren auf TCP/IP, manche auch auf UDP(/IP). Beispiele furDienste, die TCP verwenden, sind POP3 (Post Office Protocol Version 3), ☞TELNET, SMTP (Sim-ple Mail Transfer Protocol), HTTP (HyperText Transfer Protocol). FTP verwendet sogar zwei TCP-Verbindungen. Auf einer werden die Kommandos des Clients und die Antworten des Servers gesendet,wahrend die Daten (upload, download, Verzeichnislisting) auf einer eigenen TCP-Verbindung verschicktwerden.
Viele Streamingprotokolle verwenden UDP, da der Ubertragungsoverhead geringer ist als bei TCP und esz.B. wenig Sinn macht, ein verlorenes Datenpacket einer Telefonverbindung nocheinmal zu senden, wenndas Telefongesprach schon weiter fortgeschritten ist.
Haufig arbeiten viel benutzte Internetdienste mit relativ einfachen, textbasierten Protokollen (z.B. POP3,SMTP, HTTP,...). So ist es meist mit geeigneter Dokumentation relativ einfach, einen (einfachen) Client
1ftp://ftp2.iicm.edu/pub/hkrott/duep/duep.pdf

KAPITEL 2. INTERNET - DAS NETZ DER NETZE 20
oder Server fur ein bestimmtes Protokoll zu implementieren.
Das Senden der Zeichenkette GET / HTTP1.0 gefolgt von einer Leerzeile an einen beliebigen Webserver(Port 80) liefert beispielsweise schon das gewunschte Ergebnis.
Als Grundlage fur fast alle der offenen Protokollstandards dient ein RFC - Dokument. Diese RFCs sindfrei einsehbar und in der Designphase auch von jedermann kommentierbar (wie der Name schon sagt).RFCs sind u.a. auf den entsprechenden Seiten der IETF2 nachlesbar.
Beispiele fur RFCs:
• UDP: RFC 768 ([Pos80])
• TCP: RFC 793 ([Pos81])
• TCP/IP Tutorial: RFC 1180 ([SK91])
• HTTP 1.0 bzw. 1.1: RFC 1945 ([BLFF96] bzw. RFC 2068 ([FGM+97])
• NNTP (Network News Transfer Protocol): RFC 977 ([KL86])
• FTP: RFC 959 ([PR85])
2http://www.ietf.org/rfc.html
Kapitel 3
Informationssysteme
3.1 Historisches
Schon 1945 publizierte Vannevar Bush den Artikel “As We May Think” [Bus45], in dem er eine digitaleBibliothek beschrieb, die wohl heute eher “Knowledge Management System” heissen wurde. In ihr wollteer alle “books, records, and communications” eines Menschen speichern. Ein Index-Device namens memexsollte ahnlich dem menschlichen Gehirn arbeiten und das Auffinden von Daten ermoglichen:
Consider a future device for individual use, which is a sort of mechanized private file andlibrary. It needs a name, and, to coin one at random, “memex” will do. A memex is adevice in which an individual stores all his books, records, and communications, and which ismechanized so that it may be consulted with exceeding speed and flexibility. It is an enlargedintimate supplement to his memory.
Der Begriff Hypertext stammt von Ted Nelson, einem Informationssystem-Pionier. Bereits 1967 be-schrieb er die Anforderungen an ein Hypertext-System namens Xanadu (spater publiziert in LiteraryMachines [Nel92]). Abbildung 3.1 zeigt ein (historisches) Dokument, in dem Ted Nelson Hyperlinksdesignt.
Er verwendete verschiedene Typen von Hyperlinks wie z.B.
• Kommentare
• Lesezeichen
• Fussnoten
• “Hypertext-Sprunge”
Ein weiteres Konzept, das auf Ted Nelson zuruckgeht, ist das der transclusions. Transclusions erlaubenes, Dokumente oder Teile von Dokumenten in andere Dokumente einzubetten, ohne sie zu kopieren. Diesspart redundante Speicherung und garantiert, dass die eingebetteten Dokumente immer auf aktuellemStand sind.
Das Xanadu Projekt ist noch immer in Arbeit (der Start der Implementation war erst in den 90ern).Unter der Url http://www.udanax.com ist der aktuelle Stand der mittlerweile Open-Source Entwicklungzu finden.
Andere Informationssysteme waren z.B. das Hypertext Editing System, das 1967 von van Dam entwickeltund als erstes Hypertext-System auch realisiert wurde. Es unterstutzte
• in-text links
• branches: Menu am Ende eines Segments fur Verzweigungen zu anderen Segmenten
21

KAPITEL 3. INFORMATIONSSYSTEME 22
Abbildung 3.1: Ted Nelson’s Interfile Communication (1971)
• tags: Bemerkungen, die an ein Segment angehangt werden konnten.
1968 entstand NLS (oN-Line System) von Douglas Engelbart, das schon uber 100.000 Artikel enthielt,und sowohl Hyperlinks als auch Struktur kannte. Douglas Engelbart gilt heute als der Erfinder derTextverarbeitung, der Fenstertechnik, der elektronischen Post (email), der heutigen Hypertextsystemeund der Maus. Auf http://sloan.stanford.edu/MouseSite/1968Demo.html stehen einige (ziemlichgeniale) Demonstrationen von Douglas Engelbart als RealVideos zur Verfugung.
Das 1975 von Akscyn geschaffene KMS (Knowledge Management System) war schon ein verteiltes Hyper-media System, das keinen Unterschied zwischen normalen Benutzern und Autoren machte. Informationenwaren in mehreren Hierarchien organisiert und durch Hyperlinks untereinander verknupft. Auch Anno-tationen (Bemerkungen) waren schon moglich.
Das VideoTex-System, das Anfang der 80er Jahre entstand, war ein offentliches System, das auf Telefonund erweiterten TV-Geraten basierte.
Eine Weiterentwicklung davon war BTX (BildschirmTeXt), das ab 1982 von Prof. Maurer und demIICM entwickelt wurde. BTX enthalt uber 20.000 Seiten, die ein sehr weit gestreuten Inhalt hatten. VonEnzyklopadien, uber Spiele bis zu Diskussionsforen und Sex-Angeboten zog sich das Spektrum. Auchwar dies das erste Vorkommen von eCommerce, da bei BTX eine Abrechnung mit dem Konsumentenmoglich war. Ein paar Screenshots (damals hiessen die sicher noch Bildschirmschusse :-) sind im MuseumUnseres Computer Hinterhofs (MUCH))1 zu finden.
Ein weiteres Hypertextsystem war IRIS , das 1985 von Norman Meyrowitz entwickelt wurde. Mehrfen-stertechnik mit eingebauten Editoren (Bearbeitung von Text, Graphik, Bildern, ...), bidirektionale Linksund eine “tracking map”, die die aktuelle Position im Verhaltnis zu Umgebungslinks zeigte, waren dieherausragenden Eigenschaften des Systems.
Als Vorganger zu heutigen Multimediaprasentationswerkzeugen kann man Hypercard nennen (1987 vonBill Atkinson entwickelt). Ein sehr einfaches Benutzerinterface gestattete es relativ einfach, multime-diale Prasentation zu gestalten. Die Informationen waren in “Stapeln” von elektronischen Karten (vgl.“card decks” in WML (WAP) (Abschnitt 8.3) organisiert. Eine Skriptsprache erlaubte auch komplexereOperationen.
1http://much.iicm.edu:88/much/projects/videotex_2/index.htm/
KAPITEL 3. INFORMATIONSSYSTEME 23
WAIS (Wide Area Information Server) startete 1989 als eine gemeinsame Entwicklung von ThinkingMachines, Apple Computer und Dow Jones um Online-Zugriff auf das Wall Street Journal zu realisieren.WAIS bietet Suchfunktionalitat in einem vorher erzeugten Index, einschliesslich Sortierung der Ergebnissenach Wichtigkeit. Die Suchergebnisse konnten danach als Basis fur weitere Suchen verwendet werden,um so eine verfeinerte Suche durchfuhren zu konnen. WAIS ist eine reine Suchmaschine. Es gibt wederHyperlinks noch irgendeine Strukturierung der enthaltenen Informationen.
Gopher wurde ab 1991 als campus-weites Informationsystem an der Universitat von Minnesota verwendet.Es bietet Zugriff auf die enthaltenen Informationen uber eine Menustruktur. Auch wenn der “Informati-onsraum” in Wirklichkeit ein Graph ist (mit Schleifen), prasentiert Gopher eine Baumstruktur. Gopherselbst hat keine Hyperlinks und keine integrierte Suchmaschine, bietet aber gateways zu WAIS.
Abbildung 3.2: Screenshot eines Gopher Clients
Hyper-G (jetzt Hyperwave2) wurde Anfang der 90er am IICM entwickelt und ist ein “multi-user, multi-protocol, structured, hypermedia information system”. Es bietet
• Dokumentenmanagement
• konsistente Links
• Benutzerverwaltung
• Editierfunktionalitat
• und vieles mehr
Trotz der vielen Features, die vor allem bei einer grossen Dokumentenanzahl unersetzbar sind, wurdeHyper-G von einer anderen Informationssystemtechnologie uberholt.
1994 war das Jahr, in dem die Welt ausserhalb der Universitaten das Internet entdeckte. Hypertext undmultimediale Elemente erregten das Aufsehen der Offentlichkeit. Das WWW (World Wide Web) wargeboren. Obwohl dieses System bei weitem nicht das erste Informationsystem war, das Verknupfungenzwischen verschiedenen Inhalten bot, uberholte es alle anderen Systeme mit Uberschallgeschwindigkeit.
Der Grund dafur war, dass sowohl das verwendete Dateiformat (HTML (HyperText Markup Language)),als auch das verwendete Protokoll (HTTP) sehr einfach waren und so von vielen Anwendern/Anbieternimplementiert wurde. HTML wurde aber nicht erst 1994 erfunden. Der Grundstein dafur wurde schonlange vorher bei der Definition von SGML im Speziellen und markup languages im Allgemeinen gelegt.
2http://www.hyperwave.com

KAPITEL 3. INFORMATIONSSYSTEME 24
3.2 Suchmaschinen
Der Siegeszug des WWW brachte es mit sich, dass die Anzahl der Dokumente, auf die zugegriffen wer-den kann, sich in den letzten Jahren explosionsartig vervielfachte. Innerhalb weniger Monate verdoppeltsich der Umfang jeweils und die Anzahl der Dokumente uberschritt anfangs des Jahres 2001 die 2 Mil-liardengrenze. Ahnlich verhalt es sich auch bei den Benutzern: Ungefahr alle 11 Monate verdoppeltsich die Anzahl der Internetbenutzer. Im Jahr 2000 waren geschatzte 142 Millionen Menschen Internet-Teilnehmer. Das Wachstum des WWW lasst das Internet an die Grenzen seiner Funktionalitat stossen,von Effektivitat ganz zu schweigen [For99].
Brauchbare Informationen in diesem Wust an Daten zu finden, ist mittlerweile eine eigene Kunst. Die-ser Abschnitt veranschaulicht die Technik, mit der heutige Suchmaschinen diese Problematik zu losenversuchen.
3.2.1 Geschichte von Suchmaschinen
Als der Abt Hugues de Saint-Cher im Jahre 1240 das erste Stichwortverzeichnis der Bibel aufstellen liess,waren damit 500 Monche beschaftigt. Dabei hat die Bibel in der heute ublichen Druckfassung nur etwa800 Seiten, also knapp 5 MByte. Das World Wide Web, so wird geschatzt, enthalt zur Zeit mehrereMilliarden Seiten beziehungsweise mehrere Tera Bytes an Daten.
Der erste Versuch, ein “Inhaltsverzeichnis” des Internets zu erstellen, hiess Archie. Archie bestand auseinem ‘Datensammler’ (Data Gatherer), der automatisch die Inhaltsverzeichnisse von anonymen ftp-Servern durchsuchte, und einem Retrieval-System, in dem die User mit Suchwortern nach ftp-Dateienrecherchieren konnten. Der Suchdienst, der 1990 an der McGill University in Kanada entwickelt wordenwar, gehorte spatestens ab 1992 zu den gelaufigsten Internet-Tools.
Archie war als Suchwerkzeug fur ftp-Dateien so erfolgreich, dass er die Mitarbeiter des Rechenzentrumsder University of Nevada in Reno 1992 dazu inspirierte, einen ahnlichen Index fur den seinerzeitigenVorlaufer des WWW zu entwickeln, Gopher. Die Gopher-Suchmaschine bekam den Namen Veronica.Veronica ahnelt in vieler Hinsicht schon den heute gangigen, kommerziellen Search Engines: Das Pro-gramm indizierte im Monatsrhythmus alle Gopher-Sites, die beim ‘Mother Gopher’ an der University ofMinnesota angemeldet waren. Veronica erlaubte es, mehrere Suchbegriffe mit Hilfe von booleschen Ope-ratoren zu verknupfen, also den gleichen Befehlen AND, OR und NOT, die auch heute noch die meistenSuchmaschinen einsetzen. Und obwohl die Zahl der zu untersuchenden Dokumente fur heutige Verhalt-nisse einigermassen uberschaubar war (im November 1994 verzeichnete Veronica 15 Millionen Gopher-,ftp- und HTML-Dokumente), wurde schon damals beklagt, dass man als User der unuberschaubaren Zahlvon Dokumenten und den Suchmethoden von Veronica hilflos ausgeliefert sei.
Der erste Such-Robot fur das gerade neu entstehende WWW war der World Wide Web Wanderer, dender MIT-Student Mathew Gray im Fruhjahr 1993 programmiert hatte. Ursprunglich zahlte der Wanderernur Web-Server. Einige Monate spater fugte Michael L. Mauldin, ein Computerwissenschaftler an derCarnegie Mellon University, ein ‘Retrieval Program’ namens ‘Wandex ’ hinzu, um die gesammelten Datendurchsuchen zu konnen. Der Wanderer durchsuchte und katalogisierte von Juni 1993 bis Januar 1996zweimal pro Jahr das Netz.
Im Oktober 1993 entstand Aliweb (kurz fur: Archie-Like Indexing of the Web). Aliweb uberliess einenTeil der Arbeit bei der Katalogisierung den Betreibern von WWW-Servern. Diese mussten fur ihrenServer einen Index erstellen und diesen bei Aliweb anmelden. Aliweb selbst war lediglich ein in Perlgeschriebenes System, das die auf diese Weise zusammengestellten Indizes durchsuchte und sich dabeiauf die Angaben der Server-Betreiber und der Autoren der Seiten verliess.
Im Dezember 1993 gingen fast gleichzeitig drei neue Suchhilfen ans Netz: Jumpstation, World WideWeb Worm und RBSE Spider. Jumpstation und der World Wide Web Worm waren Suchroboter, dieWebsites nach Titel und Header (Jumpstation) beziehungsweise nach Titel und URL (WWW Worm)indizierten. Wer mit diesen beiden Tools suchte, bekam eine Liste von ‘Hits’ ohne weitere Bewertung inder Reihenfolge, in der sie in der Datenbank abgespeichert waren. Der RBSE Spider und der im April1994 an der University of Washington gestartete Webcrawler waren die ersten Search Engines, die nichtbloss eine Aufzahlung von gefundenen Dokumenten lieferten, sondern diese auch nach einem ‘Ranking’sortierten. Webcrawler ist ubrigens der einzige der bisher erwahnten Web-Fahnder, der bis heute uberlebt
KAPITEL 3. INFORMATIONSSYSTEME 25
hat, auch wenn er inzwischen kein Uni-Projekt mehr ist. Mittlerweile hat Excite3 den Webcrawler gekauftund fuhrt ihn als ein Element des Excite Network.
Im Mai 1994 begann Michael Mauldin mit der Arbeit an dem Spider, der unter dem Namen Lycos4 immernoch eine der bekanntesten Suchmaschinen ist. Wie Webcrawler listete auch Lycos seine Suchergebnissenicht einfach nur auf, sondern sortierte sie nach ihrer Relevanz; anders als Webcrawler bewertete Lycosnicht nur die Haufigkeit eines Wortes in einem bestimmten Dokument, sondern auch die ‘word proximity’,also die Nahe von mehreren Suchbegriffen zueinander. Lycos ging am 20. Juli 1994 online.
Wie viele Internet-Einrichtungen sind also auch die Suchmaschinen, die - wie Lycos und Webcrawler heuteals kommerzielles Unternehmen betrieben werden - ein Ergebnis wissenschaftlicher Vorarbeiten an denUniversitaten. Erst 1995, dem Jahr, als das Internet langsam das Bewusstsein einer nicht-akademischenOffentlichkeit erreichte, gingen die ersten Suchmaschinen ans Netz, die Unternehmen mit Gewinnabsichtentwickelt hatten: Infoseek5 startete Anfang 1995; Architex, heute unter dem Namen Excite bekannt,ging im Oktober 1995 online; AltaVista6 startete im Dezember 1995 den regularen Betrieb. WahrendAltaVista als Projekt des Western Research Lab, einer Forschungsabteilung der Computerfirma DigitalEquipment Corporation (DEC) entstand, war es von Anfang an das ‘Business Model’ von Excite undInfoseek angelehnt, sollte sich also durch Anzeigen finanzieren.
Etliche weitere kommerzielle Recherche-Helfer kamen hinzu. Gegenwartig gehoren Search Engines zu denwenigen kommerziellen Angeboten im Internet, die wirklich Profite machen. Anbieter wie Infoseek oderLycos sind an die Borse gegangen, Lycos machte im dritten Quartal 1997 - nach einem Jahr an der Borse -erstmals Gewinne. Google7 meldete kurzlich, dass seit Sommer 2001 wieder schwarze Zahlen geschriebenwerden.
Heutzutage belegt allein der Index einer Search Engine wie Lycos etwa 300 GByte und wird monatlichaktualisiert. Suchmaschinen erlauben auch Benutzern, die nicht englisch sprechen, auf den jeweiligenSprachraum eingeschrankte Suchen durchzufuhren. Die Hersteller bauen ihre Suchmaschinen um Funk-tionen fur immer neue Medientypen aus. Lycos und AltaVista beispielsweise suchen nicht mehr nurnach HTML-Texten, sondern auch nach Bildern, Videos und MP3-Dateien. Ihre Popularitat macht siezu einem zentralen Element im eCommerce: Keine Portal Site kommt mehr ohne Suchmaschine aus.[Bau99]
Google speichert auf seinem Linux Cluster mit mehr als 10.000 Computern uber 2 Milliarden Webseitenund beantwortet pro Tag uber 150 Millionen Anfragen. (Informationen von http://www.google.com/press/highlights.html)
3.2.2 Einteilung von Suchmaschinen nach Kategorien
Suchmaschinen konnen nach der verwendeten Technik in verschiedene Kategorien eingeteilt werden[For99]:
• Indexsuchdienste mittels Spider
• Katalogsuchdienste
• Kombination von Index- und Katalogsuchdiensten
• Metasuchdienste
• Intelligente Agenten
• Recommendation Systems3http://www.excite.com4http://www.lycos.com5http://www.infoseek.com6http://www.altavista.com7http://www.google.com

KAPITEL 3. INFORMATIONSSYSTEME 26
Indexsuchdienste
Hierbei handelt es sich um vollautomatische Suchdienste. Mit Hilfe von sogenannten Robots werden Infor-mationen zusammengetragen und in einer Datenbank gespeichert. Der User kann Suchbegriffe eingeben,mit deren Hilfe dann vom Suchdienst eine Liste zuruckgegeben wird, die nach den Ranking-Kriteriensortiert ist.
Robots, auch Wanderer oder Spiders genannt wandern nicht wirklich durchs Netz, sondern bewegensie sich nur entlang der Hyperlinks fort, indem sie den Dokumenteninhalt verarbeiten und Links ausdem Inhalt extrahieren. Die Suchmaschine fuhrt bei jedem Dokument eine lexikalische Analyse durch,extrahiert inhaltsrelevante Ausdrucke und legt sie in einer Datenbank ab. Meist wird der gesamte Textindiziert (Volltext-Indizierung), oder aber auch nur der Titel plus Headerinformationen und Metatags.
Wie man eine Suchmaschine dazu uberreden kann, die eigene Seite als besonders wichtig einzustufenist ebenfalls eine eigene Wissenschaft ([Len99]): Es kommt vor allem darauf an, nicht moglichst vieleBesucher auf die eigenen Webseite zu locken, sondern gezielt diejenigen anzusprechen, die auch der Inhaltder Seiten interessieren wird.
Mit Zunahme der Komplexitat der einzelnen Seiten wird es fur Robots immer schwerer aus dem Durch-einander von HTML-Frames (viele Suchmaschinen unterstutzen keine Frames und durchsuchen nur den<noframes>-Teil), CSS, JavaScript usw. den wirklichen Inhalt der Seite zu erfassen. Zusatz- (Meta-)Informationen (z.B. <meta name = ’’keywords’’content = ’’Obst, Gemuese, Fruechte’’> oder<meta name = ’’description’’content =’’Der ultimative Obstladen im Internet’’>) werden von Robots be-vorzugt ausgewertet und danach dem Suchenden prasentiert. Naturlich wird auch der Titel der Seite be-sonders bewertet. Seiten, die Informationen nur in graphischer Form prasentieren (Text als Graphik oderFlash, weil der Designer es so will - Google indiziert mittlerweile auch Texte, die in Flash-Anwendungenvorkommen), haben meist das Nachsehen.
Damit ein Roboter der Suchmaschine aber erst einmal auf eine eigene Webseite aufmerksam wird, musser entweder einem Link gefolgt sein, oder die Seite wird bei der Suchmaschine registriert. Bei einerRegistrierung sollte man allerdings keineswegs auf sofortige Ergebnisse hoffen. Wahrend Altavista undFireball8 neue Seiten innerhalb eines ein- oder zweitagigen Zeitraums aufnehmen, kann es bei Lycos schoneinmal vier Wochen dauern. Bei Yahoo9 , einem der wichtigsten Web-Wegweiser, wartet man am langsten- denn dieser Katalog wird komplett von Hand gepflegt.
Katalogsuchdienste
Diese Dienste stehen meist im Zusammenhang mit redaktionell aufgearbeiteten Informationen, es handeltsich um verzeichnisbasierte Suchdienste. Die in der Datenbank eingetragenen Seiten sind von einerRedaktion inhaltlich uberpruft, und alle von den Autoren zur Eintragung angemeldeten Seiten werdenebenfalls uberpruft und kategorisiert. Auf diese Weise kann sichergestellt werden, dass dem Benutzer desSuchdienstes keine inhaltlich falschen Dokumente vorgeschlagen werden. Der Datenumfang ist jedochoft viel geringer als bei den vollautomatischen Suchdiensten. Die Inhalte sind nach Interessensgebietenunterteilt, die ahnlich einer Verzeichnisstruktur angeordnet sind. Diese Form des Suchdienstes bietet demunerfahrenen User einen leichteren Einstieg bzw. oft schnellere Erfolge bei einfachen Suchanforderungen.
Meta Suchmaschinen
Unter Metasuchdiensten versteht man die simultane Nutzung oder Zusammenfassung mehrerer Such-dienste. Es werden nach Eingabe der Suchkriterien automatisierte Abfragen an verschiedene Suchdiensteverschickt und die Ergebnisse dann zusammengefasst. Dies bietet fur den Anwender den Vorteil, sichwiederholte Abfragen bei verschiedenen Anbietern ersparen zu konnen bzw. sich nicht mit der Syntax derverschiedenen Systeme vertraut machen zu mussen. Die speziellen Eigenschaften der einzelnen Anbieter,die im einen oder anderen Fall bei der Suche sehr nutzlich sein konnen, fallen dabei aber grosstenteils weg,d.h. man muss sich mit simplen Suchanfragen zufriedengeben. Ein Beispiel dieser Art von Suchmaschinen
8http://www.fireball.de9http://www.yahoo.com
KAPITEL 3. INFORMATIONSSYSTEME 27
ist Metacrawler10 oder Mamma11.
Agents
Im Zeitalter der zunehmenden Dienstleistungsgesellschaft geht auch das Internet den Weg hin zur personli-cheren Betreuung. Der Gedanke ist ganz einfach: Jeder User hat seine personlichen Interessen und kannnun einen “Agenten” beauftragen, Material zu einem bestimmten Thema zu sammeln. Diese Agentenkonnen ferner die Gewohnheiten der User erforschen, dazulernen und entsprechend handeln. Das Prin-zip der Agenten wird sicher in der Zukunft noch grossen Anklang finden, hat aber den Nachteil, dassim schlimmsten Fall fur jeden User im Internet Unmengen von Nachrichtenpaketen verschickt werden.Schon heute wird uber die Belastung der Datenleitungen durch die vielen Suchdienste, die unaufhorlichdas Netz durchforsten, geklagt. Die Netzwerkbelastung durch eine grosse Verbreitung von Agenten istschwer abzuschatzen.
Recommendation Systems
Man kann sich das System wie folgt vorstellen: Wenn ein Kunde auf der Suche nach einem Buch ist, sokann man ihn einfach fragen, welche Bucher, die er gelesen hat, ihm gefallen haben. Existiert nun eineGruppe von Personen die dieselben Bucher gut fanden, und dieser Gruppe gefielen weitere Bucher, so istes naheliegend, dem Kunden auch diese Bucher vorzuschlagen, und er wird damit hochstwahrscheinlichsehr zufrieden sein. Dieses Prinzip liegt den Recommendation Systems zugrunde und kann naturlichauch auf andere Gegenstande, wie etwa Filme, CDs oder Produkte in einem Katalog angewandt werden.Solche Systeme sind vor allem in Online-Buchhandlungen wie Amazon12 oder ahnlichem zu finden.
3.2.3 Reihung von Suchergebnissen
Die Schwierigkeiten fur aktuelle Suchmaschinen sind nicht so sehr im Auffinden von Informationen zusuchen, sondern eher in der Reihung der Ergebnisse. Das heisst, die besten Treffer sollen zuerst gereihtsein. Da es mittlerweile fast unendlich viele verschiedene Suchmaschinen gibt, verwenden diese auch fastsoviele Algorithmen zur Reihung ihrer Suchergebnisse. Einen Uberblick uber Suchmaschinentechnologienliefert http://searchenginewatch.com/resources/tech.html.
Bei der einfachsten Reihung wird einfach die Anzahl der Worte, die mit der Suchanfrage ubereinstimmt,untersucht. Etwas bessere Ergebnisse liefert schon der Reihungsalgorithmus, der nicht nur das Vorhan-densein bzw. die Haufigkeit, sondern auch die Nahe der Suchworte untereinander bewertet. D.h. eineWebseite, in der die gesuchten Begriffe im gleichen Satz vorkommen bekommt eine bessere Reihung alseine Seite, in der zwar die gesuchten Worte vorkommen, diese aber quer uber den ganzen Text verstreutsind. Zusatzlich ist es immer moglich, Suchbegriffe, die nicht nur einfach im Text, sondern an bevorzugtenPositionen (Titel der Seite oder in Meta-Beschreibungen (Meta-Tags)) vorkommen, hoher zu bewertenund im Suchergebnis nach vorne zu reihen.
Eine etwas fragwurdige Reihungsmethode ist die der sponsored Links. Werbekunden zahlen fur einebessere Reihung bei Suchergebnissen. So ist moglich, fur spezielle Suchworte eine gute Plazierung zukaufen. Google13 hebt diese gekauften Links farblich hervor und schrankt sich auf wenige solcher Linkspro Suchergebnis ein. Die Suchmaschine Overture14 zeigt sogar, wieviel ein Klick auf das Suchergebnisdem Anzeigenkunden kostet (siehe Abbildung 3.3). Eine Suche nach dem Stichwort “Linux” brachteerst um den Platz 50 (auf Seite 2) einen Link zu http://www.linux.org (der erste nichtbezahlte Link),wahrend bei Google obige URL an erster Stelle kommt. Der Nutzen von solchen Reihungen fur denBenutzer ist naturlich sehr fraglich.[SH01]
Als innovativer (zumindest zu dem Zeitpunkt, als er vorgestellt wurde) Ansatz wird hier der Reihungs-algorithmus von Google15[otPC99] vorgestellt: Der sog. PageRank -Algorithmus wurde an der Stanford
10http://www.metacrawler.com11http://www.mamma.com12http://www.amazon.com13http://www.google.com14http://www.overture.com15http://www.google.com/technology/index.html

KAPITEL 3. INFORMATIONSSYSTEME 28
Abbildung 3.3: Die Suchmaschine ’Overture’ zeigt, wieviel ein Klick auf das Suchergebnis den Anzeigenkundenkostet.
University entwickelt und ist immer noch die Grundlage von Google. Hierbei werden vor allem Links, dievon und zu einer Seite zeigen, bewertet. Eine Seite wird dabei als (ge)wichtig eingestuft, wenn viele Linksvon anderen ’(ge)wichtigen’ Seiten einen Link auf diese Seite haben und wenn viele Links von dieser Seiteauf andere ’(ge)wichtige’ Seiten zeigen.
Dieser Prozess muss naturlich iterativ verlaufen, da ja zu Beginn der Suche nach ’(ge)wichtigen’ Seiten,alle Seiten das gleiche ’Gewicht’ haben. Bei jeder Iteration werden Relationen zwischen den Seitenuberpruft und neu bewertet.
Somit werden auch Suchbegriffe einer Seite zugeordnet, die unter Umstanden garnicht auf der betreffendenSeite, wohl aber auf Seiten, die auf diese Seite verweisen, vorkommt. Als Benutzer kann man dies sehen,wenn man sich die von Google gecachte Seite anschaut. Bei einer Suche nach “xml standards dtd” wurdebeispielsweise die URL http://www.oasis-open.org/ gefunden. Bei der Anzeige aus Google’s Cache,kommt folgende Bemerkung zum Vorschein:
These search terms have been highlighted: xml standardsThese terms only appear in links pointing to this page: dtd
Das Wort dtd kommt also auf der gefunden Seite nicht vor, wohl aber in Links auf diese Seite. Anfangdes Jahres 2002 wurde versucht, dieses Verhalten auszunutzen (Details im Internet unter dem Stichwort“Google Bombing”), in der Praxis stellt es aber keine Gefahr fur den Ranking-Algorithmus dar.
Die Verwendung von Frames stellt fur Google ein grosses Problem dar, da einzelne Frameteile meist nichtextra referenziert werden und somit kein expliziter Link zum Inhalt dieses Frameteils verweist und daherder Teil eine schlechtere Bewertung erhalt.
3.2.4 Suche nach Multimediadaten
Bei der Suche nach Multimediadaten, also Bildern oder Musikstucken, ist man zur Zeit noch meistauf die Suche in den Beschreibungen der Daten (Metainformationen) beschrankt. Es gibt nur wenigeSysteme, die wirklich Query by Content erlauben: Anhand von Farb- und Kontrastvergleichen kann manso beispielsweise alle Bilder finden, die ein blauer Himmel ziert. Doch solche Algorithmen sind noch kaumden Kinderschuhen entwachsen. Das Fraunhofer-Institut versucht sich in diese Richtung und versucht dieSuche nach Schablonen ([V.98]). Eine Anwendung ist z.B. das Fingerabdruckarchiv des FBI, das uber 25Millionen Bilder von Fingerabdrucken enthalt. Der Sinn dieser Datenbank ist es, Personen anhand ihrerFingerabdrucke zu identifizieren. Eine andere Anwendung, die in Zukunft grosse Bedeutung erlangenwird, ist die automatische Erkennung von Personen anhand eines Photos. Weitere Anwendungen sindmedizinische Bilddatenbanken, geographische oder Wetter-Karten, Filmarchive, Kunstsammlungen...
KAPITEL 3. INFORMATIONSSYSTEME 29
Abbildung 3.4: Suchergebnis von ahnlichen Bildern anhand ihrer Struktur (Photobook vom MIT). Das gesuchteBild ist links oben, die ahnlichsten Bilder aus der Datenbank nachfolgend von links nach rechts, oben nach unten.
Normalerweise verlangt die automatische Suche nach Bildern ein grosses Wissen von domain-spezifischenMerkmalen (wie z.B. Know-How uber Fingerabdruckmerkmale). Es gibt jedoch auch Projekte, die dieseEinschrankungen zu umgehen suchen. Das Photobook Projekt des MIT16 (siehe auch Abbildung 3.4)versucht, Ahnlichkeiten von Bildern zu finden, indem es nicht die Bilder selbst vergleicht, sondern Merk-male von Bildern heranzieht. Beispielsweise werden Farbe, Struktur und Formen verwendet. DieseEigenschaften werden mit verschiedenen Matching-Algorithmen verglichen (euclidean, mahalanobis, di-vergence, vector space angle, histogram, Fourier peak, wavelet tree distances und lineare Kombinationendieser).
Eine andere Moglichkeit, Bilder nach ihrem Inhalt zu finden, ist das GNU Image Finding Tool17. Diesesnach der GPL (General Public Licence) freie Werkzeug erlaubt die Suche anhand von Beispielbildern.Das Besondere ist jedoch die Moglichkeit, die Suchanfrage iterativ mit der Angabe von positiver odernegativer Relevanz zu verbessern. Dies erlaubt eine genauere Beschreibung des gewunschten Ergebnisses.Ein guter Artikel zu GIFT ist unter [M02] zu finden, der unter anderem auch die Installation beschreibt.
GIFT indiziert alle Bilder und analysiert dabei verschiedene Bildcharakteristika - hauptsachlich Farb- undTexturmerkmale (Farbhistogramm, vorherrschende Farbe in bestimmten Bereichen des Bildes, Musterund Kanten). Eine Online-Demonstation kann unter http://viper.unige.ch probiert werden.
Eine gute Ubersicht uber bestehende Systeme ist ebenfalls auf der zum GIFT Projekt gehorigen Webseite16http://vismod.www.media.mit.edu/vismod/demos/photobook/index.html17http://www.gnu.org/software/gift

KAPITEL 3. INFORMATIONSSYSTEME 30
der Multimedia Retrieval Markup Langauge (MRML)18 zu finden. Ein nicht mehr ganz aktueller Artikelsteht unter http://searchenginewatch.com/sereport/00/12-images.html.
3.3 Brockhaus Multimedial
Der Brockhaus Multimedial dient als Beispiel eines grossen Informationssystems, das viele Bereiche ausdem Themengebiet “Multimediale Informationsysteme” in der Praxis zeigt.
Da die Entwicklung dieses Nachschlagewerks am IICM stattfindet, konnen auch einige Hinweise uber dieinterne Arbeitsweise des Systems gegeben werden.
Der Brockhaus Multimedial 2002 enthalt 98.000 Artikel zu verschiedensten Themen, die aus dem 15bandi-gen Brockhaus, dem Kunst und Kultur Brockhaus, dem Schulerduden uber Sexualitat, dem 6bandigenWerk uber Weltgeschichte, Buchern aus der Reihe “Mensch, Natur, Technik” und anderen stammen.Zusatzlich sind zahlreiche Weblinks, Animationen, Bilder, Filme, Interaktive Anwendungen und Tonbei-spiele enthalten. Die gesamte Datenmenge betragt ungefahr 3GB und wird auf 6 CDs bzw. auf DVDausgeliefert.
3.3.1 Textdaten
Die Texte werden von der Firma Brockhaus zum Grossteil in Form von SGML (Standard GeneralizedMarkup Language)-Dateien geliefert (mehr uber SGML ist in Abschnitt 4.1 zu finden) und am IICM in einproprietares Textformat umgewandelt. Dieses proprietare Format wird aus Effizienzgrunden verwendetund nicht etwa aus Ablehnung von SGML.
Als Beispiel dient der Artikel uber “Leporello” [Bro00]:
Leporello
[nach der langen Liste der Geliebten Don Giovannis, die sein Diener Leporello in Mozarts Operanlegt] das, harmonikaartig gefaltete Landkarten, Prospekte, Bilderbucher oder Ahnliches.
Hier ein Ausschnitt aus der SGML-Version, die von Brockhaus geliefert wird:
<sachart art-id="30899000" typ="norm" verwstw="nein" inhalt="i-nein"><lem><t>Lepor<k>e</k>llo</t></lem><sachkopf>
<ety>[nach der langen Liste der Geliebten Don Giovannis, die seinDiener Leporello in <person><pn>Mozarts</pn></person> Oper anlegt]
</ety><gram>das,</gram>
</sachkopf><artcorp>
<abs>harmonikaartig gefaltete Landkarten, Prospekte, Bilderbücherund Ähnliches.
</abs></artcorp>
</sachart>
Sehr schon ist hier zu erkennen, dass die Informationen mit Hilfe von verschiedenen SGML-Tags inhaltlichgekennzeichnet werden (z.B. <gram> kennzeichnet eine grammatikalische Information, <person> einePerson, ...) und nicht etwa ein Teil des Textes als ’kursiv’ markiert wird. Die Trennung von Inhalt undDarstellung wird hier sehr schon durchgefuhrt.
Die Weiterverarbeitung dieses Artikels fugt interne Daten, wie z.B. eine eindeutige Identifikationsnummer(%ID=30899000%) oder Metainformationen (MIME-Type) hinzu und resultiert in dem (weniger interes-santen und nur der Vollstandigkeit halber aufgefuhrtem) Text:
@1Lepore£ello@0\S{;.FWISSEN;107}@8\\@9@C%ID=30899000%@0[nach der langen Liste der Geliebten Don Giovannis, die sein DienerLeporello in Mozarts Oper anlegt] @2das, @0harmonikaartig gefalteteLandkarten, Prospekte, Bilderbucher und Ahnliches.\\
18http://www.mrml.net
KAPITEL 3. INFORMATIONSSYSTEME 31
Die Texte fur alle Artikel werden blockweise komprimiert und in einer Datei gespeichert. Die Unterteilungin Blocke hat den Vorteil, dass trotz Kompression effizient auf beliebige Stellen innerhalb der Dateizugegriffen werden kann (random access).
Die Offsetwerte, die auf einzelne Artikel in dieser Datei zeigen, werden in mehreren Indizes mit Hilfe einereigenentwickelten Datenbank gespeichert, die mit binaren Baumen sog. b-trees arbeitet. b-trees eignensich hervorragend, um Daten effizient zu speichern und zu suchen, speziell wenn diese auf Festplatte/CD-Rom/etc. gespeichert werden sollen (fur eine genauere Beschreibung von b-trees siehe [MR01] oderhttp://perl.plover.com/BTree/article.html).
Es gibt Index-Dateien fur die Volltextsuche und fur die Suche nach Stichwortern. Der gesamte Textum-fang (komprimiert) belauft sich auf ca. 41MB Daten. Der Volltextindex belegt fast 50MB Speicherplatz.
Aktuelle Daten, die uber das Internet als Update geholt wurden, werden in einem zweiten Satz vonDatenbank plus Indizes abgelegt, die bei Suchen automatisch verwendet werden. Es werden also keineDaten in die originale Datenbank aufgenommen. Der Benutzer merkt von der Aufteilung der Daten inverschiedene Datenbanken aber nichts, mit der Ausnahme, dass er gesondert nach aktualisierten/aktuellenDaten suchen kann.
3.3.2 Computergenerierter Kontext
Der computergenerierte Kontext (auch Wissensnetzwerk genannt) ist eine Neu- und Eigenentwicklungdes IICM und erstmals beim multimedialen Brockhaus im Einsatz. Abbildung 3.5 zeigt einen Screenshotdes Wissensnetzwerkes des Wiedehopfes.
Abbildung 3.5: Beispiel des Wissensnetzwerkes (Computergenerierter Kontext) des Multimedialen Brockhauses(2001)
Wollte ein Lexikonhersteller bisher mehrere Artikel so verlinken, dass sie inhaltlich zusammenpassen,musste ein Heer von Redakteuren dies erledigen. Das Wissensnetzwerk versucht nun, mit Hilfe vonverschiedenen Ahnlichkeitsfunktionen herauszufinden, ob und welche Artikel inhaltlich zusammenpassen.Dazu werden mehrere Kriterien herangezogen:
• Wortahnlichkeit: je mehr Worte in beiden Artikeln vorkommen, desto hoher wird die Wortahnlich-keit eingestuft. Dabei wird jedoch unterschieden, wie hoch das Gewicht der einzelnen Worte ist.Je seltener ein Wort im ganzen Datenbestand vorkommt, desto hoher ist sein Gewicht. Dadurchwerden u.a. Bindeworte (und, oder, ...), Artikel (der, die, das, ...) usw. nicht berucksichtigt. Umdiese Gewichtung berechnen zu konnen, muss zu Beginn ein Worthistogramm erstellt werden, dasdie Haufigkeit jedes Wortes enthalt.
Worte, die im Titel eines Artikels vorkommen, werden auch hoher bewertet, als solche, die nur imText des Artikels enthalten sind.
• (Fein)Klassifikation: jeder Artikel wird von der Brockhausredaktion einem Themengebiet zuge-ordnet. Z.B. existiert eine Klasse Literatur, mit der Unterklasse osterreichische Literatur. DieseThemenklassen werden auch als Vergleichskriterium fur die Ahnlichkeit zweier Artikel herangezo-gen.
• Linkwert: zwei Artikel enthalten gemeinsame Referenzen auf einen dritten Artikel

KAPITEL 3. INFORMATIONSSYSTEME 32
• Medienwert: zwei Artikel verweisen auf gleiche Multimediaobjekte (Bilder, Audioobjekte, ...)
Da die Erstellung der fur diese Vergleiche benotigten Daten (z.B. des Worthistogrammes) sehr viel Com-puterleistung (Zeit und Speicher) benotigt, wird das gesamte Wissensnetzwerk fur alle Brockhaus-Artikelvorgeneriert und nicht dynamisch erzeugt.
Selbst dies ware aber ein Ding der Unmoglichkeit, wenn jeder der knapp 100.000 Artikel mit jedemAnderen verglichen werden musste: Die Anzahl der Vergleiche ware n(n−1)
2 = ca. 5 Milliarden, bei einertheoretischen Vergleichsdauer von 1ms immer noch uber 2 Monate Rechenzeit!
Daher werden fur den Artikelvergleich nur Artikel herangezogen, die ahnliche Worte aufweisen. Dazuwerden zwei Tabellen erstellt: Eine enthalt fur jedes der ca. 300.000 verschiedenen Worte diejenigenArtikel, in denen das Wort vorkommt. Die andere Tabelle enthalt fur jeden Artikel eine Wortliste vonWorten, die insgesamt nicht ofter als 200mal vorkommen durfen. Dadurch kann relativ schnell eine grobeAuswahl an Artikeln getroffen werden, die zu einem Artikel passen konnte (rein durch Vergleichen der’seltenen’ Worte).
In diesem Zusammenhang sei noch ein grosses Problem erwahnt, dass das Erkennen von gleichen Wortenbetrifft: Die deutsche Sprache hat viele Wortformen (gleiches Wort mit verschiedenen Endungen) undzusammengesetzte Worte, die durch einen einfachen Vergleich naturlich nicht gefunden werden konnen.Daher wird (massig erfolgreich) versucht, mit verschiedenen morphologischen Programmen den Wort-stamm zu extrahieren.
Die Erstellung des Wissensnetzwerkes wird von verschiedenen ☞PERL-Skripts erledigt.
3.3.3 Bilddaten
Bilder werden nicht einzeln als Dateien gespeichert, sondern viele zusammen in einer grossen Datenbank(ebenfalls ein b-tree), da bei ca. 13.000 Bildern und vor allem den dazugehorigen Thumbnails viel Spei-cherplatz durch Fragmentierung der CD verschwendet wurde. Jede Datei belegt ja mindestens einenBlock auf der CD und im Schnitt wird ein halber Block pro Datei verschwendet.
Die Bilder selbst sind im JPG-Format oder als Bitmap gespeichert.
3.3.4 Videos und Animationen
Die Videodaten und Animationen (und teilweise auch die Musik) sind als grossteils als Quicktime Moviegespeichert. Dies ist durch lizenzrechtliche Grunde und die einfache Installation des Quicktime Playersbegrundet. Quicktime Videos konnen eine Vielzahl an verschiedenen Datentypen enthalten (siehe auchAbschnitt Quicktime auf Seite 116). So kommen beim Brockhaus gezeichnete (Computer)-Animationen,Videos, aber auch interaktive dreidimensionale Animationen (Quicktime VR) und 360◦ Fotos vor.
Einen Nachteil hat der Quicktime Player aber doch: es ist nicht ganz so einfach, den Player so inein Programm zu integrieren, dass die Player-Oberflache (Buttons, Fortschrittsanzeige, ...) mit derApplikation eine Einheit darstellt und nicht der Quicktime Player als gesondertes Programm (Fenster)erscheint.
Als weitere Formate sind in der Zwischenzeit Flash- oder IPIX-Animationen in Verwendung.
Glaserner Mensch
Eine Sonderrolle bei den Animationen des Brockhaus stellt der Glaserne Mensch (auch Anima genannt)dar: Ein menschlicher Korper kann von allen Seiten interaktiv betrachtet werden. Verschiedene Ansichtenzeigen den nackten Korper, nur die Muskeln, nur Venen, Adern und Nerven, das Knochenskelett odernur inneren Organe. Die jeweilige Ansicht kann gedreht und vergrossert werden.
Was aussieht, wie ein 3D-Modell des Menschen, besteht in Wirklichkeit aus uber 1500 Bilddateien (JPG),die nur sehr geschickt hintereinander dargestellt werden, sodass der Eindruck entsteht, ein wirkliches 3D-Modell vor sich zu haben. Ein Lookup-Table beschreibt dabei, wie die einzelnen Bilder aneinander gereihtwerden mussen, um eine flussige Bewegung zu erzielen.
KAPITEL 3. INFORMATIONSSYSTEME 33
Anima ist eine zugekaufte Applikation der Firma iAS19.
3.3.5 Landkarten
Die Landkarten des Brockhaus bestehen im Grunde genommen aus Bitmap-Grafiken, die mit Ortsinfor-mationen angereichert wurden. Die Bitmaps sind in einem eigenen Format gespeichert, um erstens eineinfaches Auslesen zu verhindern und um die Daten effizient speichern zu konnen.
3.3.6 Weblinks
Es gibt zwei verschiedene Arten von Verbindungen ins Internet:
• Redaktionell erstellte Weblinks, die im Text von Brockhaus geliefert werden.
• Es kann eine Anfrage an verschiedene Suchmaschinen generiert werden. Die Begriffe, nach denengesucht wird, sind mehr oder weniger ein Abfallprodukt der Generierung des Wissensnetzwerkes, dahierbei die “gewichtigsten” Worte (siehe Abschnitt 3.3.2), die einen Artikel beschreiben, gefundenwerden.
3.3.7 Programming Framework
Die Brockhaus-Applikation ist vollstandig in ☞C++ geschrieben und verwendet eine selbstentwickelteOberflache.
19http://www.brainmedia.de

Kapitel 4
Markup Languages
Ein Markup gibt an, wie Text in einem Dokument zu interpretieren ist. Es sind Zusatzinformationen, diezu dem eigentlichen Text eines Dokuments hinzugefugt sind. Das deutsche Wort fur “Markup Langua-ge” ware Auszeichnungssprache, zum leichteren Verstandnis wird jedoch der englische Begriff verwendetwerden.
Markups gibt es in vielen textverarbeitenden Programmen. In LATEX werden z.B. die verschiedenen Teileeines Dokuments damit gekennzeichnet. Dieser Teil des Skriptums wird z.B. von
\chapter{Markup Languages}
eingeleitet. Andere Markups zeigen LATEX, wie es den Text setzen soll (kursiv oder fett), wie groß dieSeite ist, usw. Jede Textverarbeitung schreibt in ihr Dokumentenformat verschiedene “Auszeichnungen”.
Ein “Hello World” Dokument in RTF (Rich Text Format) wird z.B. von Staroffice so geschrieben:
{\rtf1\ansi\deff0{\fonttbl{\f0\froman\fprq2\fcharset0 Times;}}{\colortbl\red0\green0\blue0;\red255\green255\blue255;\red128\green128\blue128;}{\stylesheet{\s1\snext1 Standard;}}{\info{\comment StarWriter}{\vern5690}}\deftab720{\*\pgdsctbl{\pgdsc0\pgdscuse195\pgwsxn12240\pghsxn15840\marglsxn1800\margrsxn1800\margtsxn1440\margbsxn1440\pgdscnxt0 Standard;}}\paperh15840\paperw12240\margl1800\margr1800\margt1440\margb1440\sectd\sbknone\pgwsxn12240\pghsxn15840\marglsxn1800\margrsxn1800\margtsxn1440\margbsxn1440\ftnbj\ftnstart1\ftnrstcont\ftnnar\aenddoc\aftnrstcont\aftnstart1\aftnnrlc\pard\plain \s1 Hello World\par }
Man sieht, dass der Anteil der Formatierungsanweisungen also durchaus hoher sein kann als der Anteilder wirklichen Information.
Die meisten Textverarbeitungen verbergen die Markups vor dem Benutzer, sodass dieser nur in seltenenFallen damit konfrontiert wird (ausser er benutzt LATEX und einen ’normalen’ Texteditor :-).
Verallgemeinerte oder beschreibende Auszeichnungen (generalized or descriptive Markups) folgen einereinfachen Philosophie: sie beschreiben nur die Struktur innerhalb des Dokuments. Das Layout desDokuments wird von anderen Elementen bestimmt; Formatierungsanweisungen sind beispielsweise instyle sheets enthalten.
Ein Beispiel fur eine solche beschreibende Auszeichnung konnte sein (in diesem Fall in SGML-Notation,aber das spielt keine Rolle):
<section><p>this ia a paragraph</p><p>this ia another paragraph</p>
34
KAPITEL 4. MARKUP LANGUAGES 35
<p>this ia a third paragraph</p></section>
Diese Trennung von Inhalt und Darstellung hat grosse Vorteile:
• Konsistenz: Alle Uberschriften, Absatze, Fussnoten, usw. haben das gleiche Layout. Muss z.B.die Schriftgrosse einer Uberschrift geandert werden, wird nur einmal die “Formatvorlage” geandertund sofort nehmen alle Uberschriften die Anderung an.
• Flexibilitat: Verschiedene “style sheets” passen das Dokument einfachst an verschiedene Bedingun-gen an. So ist es z.B. einfach, den Inhalt leicht fur sehschwache Personen anzubieten, indem dieSchriftgrosse einfach auf “riesig” gesetzt wird.
Diese Trennung von Inhalt und Layout wird seit langem gepredigt, aber von den Erzeugern von Doku-menten nur selten eingehalten (sei es, wenn es um die Benutzung der Formatvorlage in Winword geht,oder um HTML/CSS).
4.1 SGML
Als Internationaler Standard ISO8879 [SGM86] wurde 1986 SGML als ein solches “generalized markup”System verabschiedet. Er ist ein Standard fur gerate- und systemunabhangige Beschreibung von Textin elektronischer Form. Wer sich fur historische Details uber SGML interessiert, sei auf die Webseitehttp://www.sgmlsource.com/history/index.htm verwiesen.
SGML bietet ein Markup-Schema, das flexibel und plattformunabhangig ist. Da der Standard abergleichzeitig sehr komplexe Moglichkeiten bietet, waren erstens Programme, die SGML verarbeiten konn-ten, sehr teuer und zweitens setzte sich SGML daher nie wirklich durch. Zusatzlich erlaubte die Definitionvon SGML verschiedene Dinge, die fur Autoren zwar manchmal praktisch waren, aber bei SGML Parsern(☞parse) nur schwer zu implementieren waren (z.B. Weglassen des End-Tags in manchen Fallen).
Trotzdem ist SGML immer noch eine wichtige Grundlage, auf der viele heutige Markup languages auf-bauen (HTML, XML, ...).
Die Markup language definiert,
• welche Markups uberhaupt erlaubt sind,
• welche davon notwendig sind
• wie die Markups vom restlichen Text unterschieden werden und
• welche Bedeutung die verschiedenen Markups haben.
Ein Markup beschreibt zwar die Bedeutung, lasst die Vorgehensweise aber offen. So kennzeichnet dasMarkup “<p>” einen Absatzbeginn, stellt aber das Verhalten frei (Neue Zeile, einrucken, etc.). Da-her kann die Interpretation leicht an unterschiedliche Bedingungen angepasst werden. So kann z.B. einProgramm, das Texte analysiert, alle Literaturangaben einfach weglassen, wahrend ein Formatierungs-programm diese Angaben sammelt und am Ende des Dokuments anhangt.
4.1.1 Struktur
SGML fuhrte das Konzept von Ende-Tags zur Kennzeichnung des Endes fur ein Strukturmelement ein.So wird z.B. ein Absatz der mit dem Tag <p> beginnt, immer von dem Ende-Tag </p> beendet. InSGML-Terminologie ist der Absatz ein Element mit dem Element-Typ “p”.
Das Problem von SGML war allerdings, dass Ende-Tags in manchen Fallen weggelassen werden konnte.Ein Absatz darf beispielsweise nicht innerhalb eines anderen Absatzes vorkommen und so erlaubt SGMLdas Weglassen des End-Tags </p> fur den Fall, dass das Ende des Absatzes zugleich der Anfang einesneuen Absatzes ist.

KAPITEL 4. MARKUP LANGUAGES 36
<p>Hier ist ein Absatz
<p>Und hier kommt ein neuer Absatz. Das fehlende End-Tag stoert SGMLnicht, da Absaetze nicht verschachtelt sein konnen und daher einStart-Tag eindeutig den vorherigen Absatz schliesst.
</p>
Um verschiedene Strukturen zu erhalten, konnen Elemente verschachtelt werden:
<p>Dies ist ein Absatz, der ausserdem noch ein Zitat (quote) enthaelt<q>
dies ist das Zitat</q>hier koennte der Absatz weitergehen...
</p>
4.1.2 Attribute
Fur praktische Anwendungen sind Zusatzinformationen zu Tags oft notwendig. So kann zum Beispiel fureine Notiz ein Typ angegeben werden, der hilft, die Art der Notiz naher zu bestimmen:
<note type="warning">Im Falle eines Notfalles....
</note>
Attribute werden also direkt in das jeweilige Tag geschrieben. Nahere Details zu XML-Attributen folgenin Abschnitt XML Attribute auf Seite 49
4.1.3 Entities
SGML-Dokumente sollen leicht und ohne Verluste von einer Software/Hardware auf eine andere ubert-ragen werden konnen. Daher basiert SGML auf ASCII (American Standard Code for Information In-terchange). Um Buchstaben anderer Zeichensatze oder binare Daten (Musik, Bilder, ...) unterstutzen zukonnen, wurden sog. Entities eingefuhrt. Jede Folge von Zeichen oder Bytes kann als Entity in SGMLkodiert werden. So sind z.B. Umlaute oder Buchstaben mit Akzenten als Entities kodiert (z.B. äfur ’a’).
Um z.B. ein Bild in ein SGML-Dokument einzubinden konnte folgender Code benutzt werden:
<figure entity="figure1">
“Figure1” ist allerdings kein Filename, sondern ein Entity-Name, der irgendwo am Anfang der Dateideklariert werden muss:
<!ENTITY figure1 SYSTEM "fig1.bmp" NDATA BMP>
Auf Details dieser Notation wird hier nicht naher eingegangen, da dieser Abschnitt uber SGML nur alsUberleitung zu anderen Markup-Sprachen wie XML oder HTML verwendet wird.
4.1.4 Dokumententypen
SGML und die meisten von SGML abstammenden Markup-Sprachen unterstutzen verschiedene Doku-mententypen, die formal durch die verschiedenen Bestandteile und deren Struktur beschrieben werden.Diese Information steht in der DTD (Document Type Definition). Ohne eine DTD kann ein SGML-Dokument nicht auf seine syntaktische Richtigkeit uberpruft werden.
Eine DTD legt fest, wie sich Elemente innerhalb eines Dokumentes aufeinander beziehen. Sie stellt aucheine Grammatik (Syntax) fur das Dokument und alle seine Elemente zur Verfugung. Ein Dokument, dassich sowohl an die Markup-Spezifikationen als auch an die Regeln halt, die von seiner DTD umrissen
KAPITEL 4. MARKUP LANGUAGES 37
werden, wird als gultig bezeichnet (im Gegensatz zu einem wohlgeformten Dokument, das sich nur an diedie Markup-Syntaxregeln halt).
Details, wie genau eine DTD aufgebaut wird, sind im Abschnitt Document Type Definition auf Seite 50zu finden.
4.1.5 Probleme von SGML
Die Spezifikation von SGML umfasst uber 500 Seiten (zum Vergleich: die Spezifikation von XML (eX-tensible Markup Language) passt auf 33 Seiten). SGML ist extrem komplex und beinhaltet viele nurselten gebrauchte Features.
SGML unterstutzt tippfaule Dokumentenersteller, indem es erlaubt, dass Tags, die offensichtlich nutzlossind (End-Tag, wenn keine Verschachtelung erlaubt), weggelassen werden konnen. Dies erleichtert dasLesen/Schreiben von SGML-Dokumenten fur Menschen, erschwert aber die Interpretation fur Compu-terprogramme.
4.2 HTML
1990 verwendete Tim Berners-Lee1, britischer Informatiker am Genfer HochenergieforschungszentrumCERN und der Erfinder des Word-Wide-Webs, einige Tags einer SGML-DTD, die am CERN verwendetwurde, fugte die Moglichkeit, Hyperlinks und Bilder einzubinden dazu, und schon war HTML entstanden.
Die anfanglich reine Dokumentenbeschreibungsprache entwickelte sich mangels Alternativen nun auch zueiner Sprache, die das Layout bestimmte. HTML wurde von Netscape und Microsoft ohne Koordinationverwassert und erweitert. Browserinkopatibilitaten machten Web-Designern das Leben schwer.
Das Layout wurde unter Zuhilfenahme von “schmutzigen” Tricks, selbst unter Ausnutzung von Fehlernder Browser, erzeugt. Die Trennung von Inhalt und Darstellung und die Einhaltung des HTML-Standardswurde immer unwichtiger, sodass es heute kaum noch Seiten im WWW gibt, die dem Grundgedankendes Erfinders von HTML entsprechen.
Da das Wissen uber HTML schon sehr verbreitet ist, folgt hier nur ein kurzer Uberblick uber dieGrundzuge dieser Seitenbeschreibungssprache.
HTML ist eine Sammlung plattformunabhangiger Stile, die die verschiedenen Komponenten eines Doku-ments im WWW definieren. Es existiert eine HTML Document Type Definition (DTD), die die erlaubtenTags und Entities definiert.
4.2.1 Tags und Entities
Ein Tag in HTML ist mit spitzen Klammern umgeben (z.B. <p> oder <a>) und tritt meist paarwei-se (Start & End-Tag) auf. Das End-Tag unterscheidet sich durch ersteres durch einen vorgestelltenSchragstrich ’/’. Bei HTML spielt es keine Rolle, ob Tags in Form von Klein- oder Grossbuchstabengeschrieben werden. <H1> ist demnach aquivalent mit <h1>.
Einige wenige “Standalone-Tags” haben kein abschliessendes End-Tag (z.B. das Tag fur den manuellenZeilenumbruch <br>).
Tags konnen Attribute haben, die zusatzliche Angaben enthalten. Viele Browser akzeptieren den Attri-butwert auch ohne doppelte Anfuhrungsstriche:
<h4 align=center>HTML - die Sprache des WWW
</h4>
Dieses Beispiel zeigt eine Uberschrift 4. Ordnung, die zentriert auszugeben ist. Hier sieht man auchschon/schon, wie Inhalt (Uberschrift) mit Darstellung (zentriert) vermischt wurde.
1http://www.w3.org/pub/WWW/People/Berners-Lee/

KAPITEL 4. MARKUP LANGUAGES 38
Tags, die ein Browser nicht kennt, werden normalerweise einfach ignoriert. Dies ist zwar praktisch beimSurfen, aber unpraktisch beim Erstellen von Seiten, da eigene Fehler schwerer auffallen.
Entities beginnen mit einem kaufmannischem ’&’ und schliessen mit Strichpunkt ’;’. Die Unicode-Nummern oder Namen bzw. Abkurzungen fur diese Namen bezeichnen die einzelnen Sonderzeichen.Entities werden hauptsachlich verwendet, um (deutsche) Umlaute bzw. akzentuierte Buchstaben undSonderzeichen zu setzen. Je nach HTML-Version (3.2 oder 4.0) existieren eine ganze Menge davon.Tabelle 4.1 zeigt ein paar davon.
Zeichen Beschreibung Name Unicode ab Versiona a mit Accent grave à à 3.2a a mit Accent acute á á 3.2a a mit Circumflex â â 3.2a a mit Tilde ã ã 3.2a a mit Umlaut ä ä 3.2a a mit Ring å å 3.2A A mit Accent grave À À 3.2...e e mit Accent grave è è 3.2...α alpha α α 4.0...∀ fur alle ∀ ∀ 4.0...
Tabelle 4.1: Unvollstandige Liste der Entities in HTML
Eine ziemlich vollstandige Liste findet sich im entsprechenden Kapitel von SelfHTML2.
Viele Browser “verstehen” mittlerweile auch z.B. die deutschen Umlaute direkt, dies sollte aber nichtdazu verleiten, sie in eine HTML-Seite einzubauen!
4.2.2 HTML Kommentare
HTML beinhaltet die Moglichkeit, an beliebigen Stellen innerhalb einer HTML-Datei Kommentare ein-zufugen. Kommentare werden von WWW-Browsern ignoriert, d.h. bei der Prasentation nicht angezeigt.Kommentare sind z.B. sinnvoll, um interne Angaben zu Autor und Erstelldatum in einer Datei zu plazie-ren, um interne Anmerkungen zu bestimmten Textstellen zu machen, oder um verwendete HTML-Befehleintern auszukommentieren.
<!-- Dieser Text ist ein Kommentar -->
Eine Kommentardeklaration beginnt mit ’<!’ und endet mit ’>. Ein Kommentar selbst beginnt und endetmit ’--’ und darf ’--’ nicht enthalten. D.h. dass verschachtelte Kommentare nicht moglich sind, wohlaber andere HTML-Tags in einem Kommentar.
4.2.3 HTML Mindesttags
Ein HTML-Dokument muss mindestens aus folgenden Tags bestehen:
<html><head>
<title>Titel des Dokuments
</title></head><body>
2http://courses.iicm.edu/mmis/selfhtml80/html/referenz/zeichen.htm
KAPITEL 4. MARKUP LANGUAGES 39
Inhalt des Dokuments</body>
</html>
Der <head>-Teil kann zusatzliche Meta-Informationen enthalten, die z.B. den Autor des Dokumentsausweisen. Diese Information wird vom Browser aber nicht angezeigt (der Inhalt von < title > stehtmeist in der Titelzeile des Browserfensters).
Nur die Teile zwischen dem Start- und dem End-Tag von <body> werden vom Browser interpretiert undangezeigt.
Da es nicht sehr sinnvoll ist, im Rahmen dieses Skriptums alle moglichen HTML-Tags herunterzuleiern(dazu gibt es tausende Bucher und Webseiten - siehe auch Abschnitt 4.2.7), werden hier nur einige wichtigeTechniken beschrieben, die zum Standardwerkzeug von HTML-Programmierern bzw. HTML-Designergehoren.
4.2.4 HTML Frames
Die Erklarungen von SelfHTML sind so gut, dass dem nicht wirklich was hinzuzufugen ist (und es auchnicht viel Sinn macht, es abzuschreiben) siehe SelfHTML Kurs / Frames3
4.2.5 Farben in HTML
Die Farbdefinitionen und deren HTML-Tags sind je nach Browser ziemlich unterschiedlich, die Farbko-dierung selbst folgt jedoch einem einheitlichen Schema:
• durch Angabe der RGB-Werte in Hexadezimalform (RGB = Rot/Grun/Blau) (browserunabhangigund vielseitiger)
• durch Angabe eines Farbnamens (Nur 16 Farbnamen standardisiert, der Rest ist browserabhangig!)
Beispiel fur hexadezimale Kodierungen:
<body bgcolor=#808080> <!-- dunkelgrauer Dateihintergrund --><font color=#990000>roter Text</font><table bgcolor=#00C0C0> <!-- blaugruner Tabellenhintergrund --><hr color=#CC00CC> <!-- violette Trennlinie -->
Jede hexadezimale Farbdefinition ist 6stellig und hat das Schema: #XXXXXX. Die ersten beiden Stellenstellen den Rot-Wert der Farbe dar, die zweiten beiden Stellen den Grun-Wert, und die letzten beidenStellen den Blau-Wert. Die jeweiligen Werte sind naturlich in hexadezimaler Form anzugeben (00 bisFF).
Ein Beispiel fur die Kodierung mit Farbnamen:
<body bgcolor=black> <!-- schwarzer Dateihintergrund --><font color=yellow>gelber Text</font><table bgcolor=aqua> <!-- hellblauer Tabellenhintergrund --><hr color=red> <!-- rote Trennlinie -->
4.2.6 Skripte (Client-seitig)
Normale HTML-Seiten sind, sobald sie einmal beim Client angekommen sind, rein statische Dokumente.D.h. es ist wohl moglich, sie auf der Server-Seite dynamisch zu erzeugen, im Client-Browser konnensie aber nicht mehr verandert werden. Oft ist es jedoch sinnvoll, bestimmte Dinge beim Client zustarten. Es ist beispielsweise viel effizienter, eine einfache Uberprufung von Formularfeldern (z.B. bestehtdie Postleitzahl nur aus Ziffern?) direkt beim Client durchzufuhren, als das ausgefullte Formular zumServer, und bei einem Fehler wieder zum Client zuruck zu schicken.
3http://courses.iicm.edu/mmis/selfhtml80/html/frames/definieren.htm

KAPITEL 4. MARKUP LANGUAGES 40
Diese Skripte werden direkt in den HTML-Code eingebettet und vom Browser ausgefuhrt (interpretiert).Ein einfaches Beispiel4 zeigt eine Interaktion zwischen dem User und dem HTML-Dokument und eineaktive Veranderung des Dokumentes durch die Eingabe des Benutzers:
<html><head>
<title>Text des Titels</title><script language="JavaScript">
<!--UserName = window.prompt("Dein Vorname:","Vorname");
--></script>
</head><body>
<script language="JavaScript"><!--
document.write("<h1>Hallo " + UserName + "!</h1>");-->
</script></body>
</html>
Das daraus resultierende HTML-Dokument enthalt (in meinem Fall) die Zeile ’<h1>Hallo Christof</h1>’.
Mit <script> leitet man einen Skript-Bereich ein. Innerhalb des einleitenden <script>-Tags gibt man mitdem Attribut language an, welche Script-Sprache man innerhalb des Bereichs benutzen mochten. Diegangigste Angabe ist dabei language="JavaScript". Andere denkbare Sprachangaben sind beispiels-weise JScript oder VBScript (beide Microsoft).
Auch hier gehort es zum guten Ton, dem Betrachter der Webseiten eine “Skript-freie” Zone anzubieten.Dies geschieht mit Hilfe des <noscript>-Tags. Manche Surfer benutzen Web-Browser, die keine Skripteausfuhren konnen, andere verbieten aus Sicherheits- oder anderen Grunden die Ausfuhrung von aktivenSkripten in ihrem Browser.
Eine weiterfuhrende Behandlung der Skript-Sprachen wurde den Rahmen dieser Unterlagen sprengen. Essei hier nur kurz auf das Kapitel uber JavaScript von SelfHTML5 verwiesen.
4.2.7 Weiterfuhrende Informationen uber HTML
Als ausfuhrlicher HTML-Kurs mit allen Tipps, Tricks und Features bietet sich SelfHTML6 an. Um denInternetverkehr moglichst gering zu halten und gleichzeitig die Zugriffsgeschwindigkeit zu erhohen, liegtder gesamte Kurs unter http://courses.iicm.edu/mmis/selfhtml80/ bzw. unter ftp://courses.iicm.edu/courses/mmis/selfhtml80.zip als Zip-Datei (7.1MB).
4.3 Style Sheets
Style-Sheets sind eine unmittelbare Erganzung zu HTML7. Es handelt sich dabei um eine Sprache zurDefinition von Formateigenschaften einzelner HTML-Befehle. Mit Hilfe von Style-Sheets kann man bei-spielsweise bestimmen, dass Uberschriften erster Ordnung eine Schriftgrosse von 18 Punkt haben, inder Schriftart Helvetica, aber nicht fett erscheinen, und mit einem Abstand von 1,75 Zentimeter zumdarauffolgenden Absatz versehen werden. Angaben dieser Art sind mit herkommlichem HTML nichtmoglich.
Das ist aber nur der Anfang. Style-Sheets bieten noch viel mehr Moglichkeiten. So kann man belie-bige Bereiche einer HTML-Datei mit einer eigenen Hintergrundfarbe, einem eigenen Hintergrundbild(Wallpaper) oder mit diversen Rahmen versehen. Man kann beliebige Elemente, sei es eine Grafik, einTextabsatz, eine Tabelle oder ein Bereich aus mehreren solcher Elemente, pixelgenau im Anzeigefensterdes WWW-Browsers positionieren. Fur Drucklayouts stehen Befehle zur Definition eines Seitenlayoutsbereit. Fur die akustische Wiedergabe von HTML-Dateien gibt es ein ganzes Arsenal an Befehlen, um
4http://courses.iicm.edu/mmis/selfhtml80/javascript/beispiele/formulareingaben.htm5http://courses.iicm.edu/mmis/selfhtml80/javascript/index.htm6http://www.selfhtml.com7bzw. zu SGML. Da SGML Style Sheets aber wenig Bedeutung haben, werden hier nur HTML Style Sheets behandelt.
KAPITEL 4. MARKUP LANGUAGES 41
kunstliche Sprachausgabesysteme feinzusteuern. Spezielle Filter schliesslich, die derzeit allerdings nochrein Microsoft-spezifisch sind, erlauben Grafik-Effekte bei normalen Texten, die aus Grafikprogrammenwie PhotoShop bekannt sind.
Ein weiteres wichtiges Leistungsmerkmal von Style-Sheets ist es, dass man Style-Definitionen zentralangeben kann. So kann man beispielsweise im Kopf einer HTML-Datei zentrale Definitionen zum Ausse-hen einer Tabellenzelle notieren. Alle Tabellenzellen der entsprechenden HTML-Datei erhalten dann dieFormateigenschaften, die einmal zentral definiert sind. Das spart Kodierarbeit und macht die HTML-Dateien kleiner. Man kann die Style-Sheet-Definitionen sogar in separaten Dateien notieren. SolcheStyle-Sheet-Dateien kann man in beliebig vielen HTML-Dateien referenzieren. Auf diese Weise konnenfur grosse Projekte einheitliche Layouts entworfen werden. Ein paar kleine Anderungen in einer zentralenStyle-Sheet-Datei bewirken so fur hunderte von HTML-Dateien ein neues Layout.
Style-Sheets unterstutzen also erstens die professionelle Gestaltung beim Web-Design, und zweitens helfensie beim Corporate Design fur grosse Projekte oder fur firmenspezifische Layouts.
Es gibt mehrere Sprachen zum Definieren von Style-Sheets (siehe <style type=’’style sheet language’’>in unterem Beispiel). Die bekannteste ist CSS (Cascaded Style Sheet).
Ein erstes Beispiel zeigt, wie Style Angaben in einem HTML-Dokument angegeben werden konnen.
<head><title>Text des Titels</title><style type="text/css">
<!--/* eine Style-Angabe in CSS */body { margin:2cm }h1 { font-size:24pt }-->
</style><style type="text/javascript">
<!--/* eine Style-Angabe in der Netscape eigenen JSSS-Sprache */with(tags.H2){
color = "red";fontSize = "16pt";marginTop = "2cm";
}-->
</style></head>
Wie man sieht, kochen auch hier die grossen Browser-Hersteller ihre eigenen Suppchen. Das W3C hatbisher zwei Standards verabschiedet: CSS1 und CSS2
Netscape 4.x interpretiert fast den vollen Sprachumfang der CSS-Version 1.0 und einen Teil der Befehle derCSS-Version 2.0. Der MS Internet Explorer kennt die CSS-Version 1.0 bereits seit seiner Produktversion3.0. In der Version 4.0 interpretiert er einen Teil der CSS-Version 2.0 und einige spezielle, von Microsofteingefuhrte Style-Sheet-Angaben.
Daraus ergibt sich auch, dass der Einsatz von CSS gut uberlegt werden muss, da dies zwar einige Moglich-keiten bietet, Web-Seiten “aufzupeppen”, ein Benutzer dessen Browser diese Features nicht unterstutzt,wird dann allerdings evtl. gelangweilt oder enttauscht sein.
4.3.1 Einbinden von Style Sheet Definitionen
Die Style Informationen konnen auf verschiedene Arten einem HTML-Dokument zugewiesen werden:
• innerhalb des HTML-Dokumentes
• in einer extra-Datei
Zweiteres hat den unschatzbaren Vorteil, dass sich eine Anderung in einer Datei sofort auf alle einbin-denden Dokumente auswirkt.
Werden beide Moglichkeiten genutzt, uberschreiben die Definitionen in einem HTML-Dokument die Defi-nitionen der externen Datei. So kann man globale Einstellungen treffen, die aber noch je nach Dokumentleicht angepasst werden konnen.

KAPITEL 4. MARKUP LANGUAGES 42
Ein Beispiel fur die Definition innerhalb eines HTML-Dokuments:
<html><head>
<title>Titel der Datei</title><style type="text/css">
<!--/* ... Style-Sheet-Angaben ... */-->
</style></head><body></body>
</html>
Mit Hilfe des <link>-Tags kann eine externe Datei als Style-Sheet eingebunden werden:
<link rel=’’stylesheet’’ type=’’text/css’’ href=’’formate.css’’>
Eine zweite Moglichkeit bietet die selbe Funktionalitat, wird aber nicht von allen Browsern unterstutzt:
...<style type="text/css">
<!--@import url(formate.css);
//--></style>...
Weitere Details entnehme man bitte dem entsprechenden Kapitel von SelfHTML8.
4.3.2 Unterschiedliche Ausgabemedien
Style Sheets unterstutzen unterschiedliche Ausgabemedien. Je nach verwendetem Client, ist es moglich,verschiedene Formatierungen zu erstellen. Diese drei Definitionen im Header des HTML-Dokumentsermoglichen Style-Definitionen aus unterschiedlichen Dateien zu laden:
<link rel=stylesheet media="screen" href="website.css"><link rel=stylesheet media="print" href="printer.css"><link rel=stylesheet media="aural" href="speaker.css">
bzw.
<style type="text/css"><!--@import url(druck.css) print;@import url(multimedia.css) projection, tv;-->
</style>
bzw. direkt in ein externes Style File:
/* allgemeines fuer alle */@media print {/* und hier nur die Style Angaben fuer den Druck */}
Mogliche Medien sind:
• screen fur Style-Sheets, die bei der Bildschirmprasentation wirksam sein sollen.
• print fur Style-Sheets, die bei der Ausgabe uber Drucker wirksam sein sollen. Beispiele finden sichunter
– http://www.telematik.edu/xml/index.xml?style=css: Druckansicht ohne Navigationslei-ste
8http://courses.iicm.edu/mmis/selfhtml80/css/index.htm
KAPITEL 4. MARKUP LANGUAGES 43
– http://courses.iicm.edu/mmis/selfhtml80/css/eigenschaften/printlayouts.htm#size:Ausdruck im Querformat
• aural fur Style-Sheets, die wirksam sein sollen, wenn der Inhalt der HTML-Datei per Sprachausgabeuber Lautsprecher erfolgt.
• projection fur Style-Sheets, die wirksam sein sollen, wenn der Inhalt der HTML-Datei per Dia-projektor oder Overhead-Projektor erfolgt. Ein Beispiel findet sich unter http://www.opera.com/support/operashow/.
• braille fur Style-Sheets, die wirksam sein sollen, wenn der Inhalt der HTML-Datei uber taktileBraille-Medien erfolgt.
• tv fur Style-Sheets, die wirksam sein sollen, wenn der Inhalt der HTML-Datei uber Fernsehtechnikerfolgt.
• handheld fur Style-Sheets, die wirksam sein sollen, wenn der Inhalt der HTML-Datei uber Handys,Palmtops oder ahnliche Gerate mit kleinem Display erfolgt.
• all fur Style-Sheets, die in allen Medientypen wirksam sein sollen.
Zur Zeit werden diese verschiedenen Medien allerdings nicht von allen Browsern unterstutzt (CSS2).
Eine gute Testmoglichkeit bietet der kleine, aber feine Browser Opera9, da er z.B. eine Druckvorschau(Media-Typ print) und einen full-screen Modus (Media-Typ projection) bietet.
4.3.3 Format-Definitionen fur HTML-Tags
Es ist moglich, verschiedene Style-Definitionen fur verschiedene HTML-Tags zu definieren. Diese Style-Angaben werden dann vom Browser immer verwendet, um das HTML-Tag darzustellen. FolgendesBeispiel definiert einen Style fur eine Uberschrift 1. Ordnung (<h1>) und einen fur Text eines Absatzes(<p>) und einen Listeneintrag (< li>):
<style type="text/css"><!--h1 { font-size:48pt; color:#FF0000; font-style:italic; }p,li { font-size:12pt;
line-height:14pt;font-family:Helvetica,Arial;letter-spacing:0.2mm;word-spacing:0.8mm; }
--></style>
Hier sieht man auch, dass Format-Definitionen fur mehrere Tags auf einmal deklariert werden konnen.
Zusatzlich bieten Format-Unterklassen weitere Moglichkeiten, verschiedene Formatierungen auf gleicheHTML-Tags anzuwenden. Das Beispiel von SelfHTML zeigt auf http://courses.iicm.edu/mmis/selfhtml80/css/formate/zentrale.htm, wie Unterklassen definiert und verwendet werden. Das At-tribut “class”, das die Klassenzugehorigkeit bestimmt, ist ein sog. Universalattribut und kann bei allenHTML-Tags verwendet werden. Das folgende Beispiel zeigt auch, wie man ein Navigationsmenu fur denAusdruck (Medientyp “print”) ausblenden kann.
<html><head>
<title>Titel der Datei</title><style type="text/css">
<!--p.normal { font-size:10pt; color:black; }p.gross { font-size:12pt; color:black; }p.klein { font-size:8pt; color:black; }all.rot { color:red; }.blau { color:blue; }
/* do not show menu on print: */
9http://www.opera.com

KAPITEL 4. MARKUP LANGUAGES 44
@media print {.menu {display: none;}
}--></style>
</head><body>
<p class="menu">Navigations Menu: etc.</p>
<p class="normal">Normaler Textabsatz mit Schrift 10 Punkt schwarz</p><p class="gross">Textabsatz mit Schrift 12 Punkt schwarz</p><p class="klein">Textabsatz mit Schrift 8 Punkt schwarz</p><p class="rot">roter Textabsatz</p><address class="rot">roter Absatz fur Adressen</address><blockquote class="blau">blaues Zitat</blockquote>
</body></html>
Eine Unterklasse von all gilt fur alle Tags (das Wort all kann auch weggelassen werden).
Will man das Aussehen eines Tags von der Verschachtelung der HTML-Tags abhangig machen (Wieschaut ein kursiver (< i>) Text aus, wenn er in einer Uberschrift 1. Ordnung (<h1>) verwendet wird?),verwendet man folgende Syntax:
<html><head>
<title>Titel der Datei</title><style type="text/css">
<!--h1 { color:red; }h1 i { color:blue; font-weight:normal; }-->
</style></head><body>
<h1>Wir lernen <i>Style-Sheets</i></h1><p>Wir lernen <i>Style-Sheets</i></p>
</body></html>
Es lassen sich aber auch Formatdefinitionen deklarieren, die keinem bestimmten Tag zugewiesen sind:
<html><head>
<title>Titel der Datei</title><style type="text/css">
<!--p,li,dd,dt,blockquote {
color:red;font-family:Times;margin-top:1cm; margin-left:1cm;
}#fettkursiv { font-weight:bold; font-style:italic; }-->
</style></head><body>
<p id="fettkursiv">Extra-Formatierung
</p><p>
Das ist formatierter Text mit <em id="fettkursiv">Extra-Formatierung</em>
</p></body>
</html>
Diese unabhangigen Definitionen konnen mit dem Universalattribut “id” jedem HTML-Tag zugewiesenwerden. Diese Ids mussen eindeutig fur das ganze Dokument sein (im Gegensatz zu den Definitionen per“class” Attribut, wo ein Klassenname fur mehrere Tags auch verschiedene Formatierungen hervorrufenkann).
Es gibt auch Formatierungen, die nicht von HTML-Tags abhangig sind, bzw. die sich nicht eindeutigdurch ein Tag ausdrucken lassen. Diese heissen “Pseudo”-Formate.
Ein Beispiel ist ein Hyperlink, der verschiedene Zustande haben kann:
<style type="text/css">
KAPITEL 4. MARKUP LANGUAGES 45
a:link { color:#FF0000; font-weight:bold }a:visited { color:#990000; }a:active { color:#0000FF; font-style:italic }
</style>
Die Schlusselworte sind festdefiniert und konnen nicht frei gewahlt werden.
Seit der Version 2.0 der Cascaded Style Sheets gibt es auch die Moglichkeit, Styles abhangig von verwen-deten Attributen zu erstellen:
<html><head><title>Titel der Datei</title>
<style type="text/css"><!--
p { font-weight:bold; font-family:Tahoma,sans-serif; font-size:14pt; }p[align] { color:red; }p[align=center] { color:blue; text-align:left; }td[abbr~=Berlin] { background-color:#FFFF00 }*[lang|=en] { background-color:#FF0000; color:#FFFFFF; }-->
</style></head><body>
<p>Das ist ein Textabsatz, ein stinknormaler.</p><p align="right">Das ist ein Textabsatz, rechts ausgerichtet.</p><p align="center">Das ist ein Textabsatz, zentriert? Wirklich zentriert?</p><table border="1"><tr>
<th>Berlin</th><th>Hamburg</th>
</tr><tr><td abbr="Es folgen Infos zu Berlin">Eine Menge Inhalt zu Berlin</td><td abbr="Es folgen Infos zu Hamburg">Eine Menge Inhalt zu Hamburg</td>
</tr></table><p>
Ein Textabsatz <span lang="fr">avec</span> Text<span lang="en">about</span> einen <span lang="en-US">English man in New York</span>
</p></body>
</html>
Der Hauptnutzen von Style Sheets ist eigentlich die zentrale Definition von Formatangaben. Ab undzu ist es allerdings notwendig, einem HTML-Tag direkt eine Formatangabe ohne zentrale Deklarationzuzuweisen. Mit Hilfe des style-Attributes ist dies bei allen HTML-Tags moglich:
<h1 style="color:red;font-size:36pt;">Heading 1. order</h1>
Beliebige Textabschnitte lassen sich mit dem <span>-Tag formatieren. Dieses Tag hat keine eigeneBedeutung und dient nur zum Definieren von Style-Sheet-Angaben. Es eignet sich besonders dazu, uminnerhalb des Geltungsbereichs anderer HTML-Tags einzelne Zeichen oder Worter anders zu formatieren:
...<body>
<h1>Überschrift 1. Ordnung mit<span style="color:blue;">
blauem Text</span>
</h1><p>
Normaler Textabsatz mit<span style="font-style:italic; color:red;">
rotem kursiven Text</span>
</p></body>...
Ahnlich kann das <div>-Tag verwendet werden. Im Unterschied zu <span> erzwingt <div> aber eineneue Textzeile.

KAPITEL 4. MARKUP LANGUAGES 46
4.3.4 CSS Eigenschaften
Hier soll keine komplette Liste aller Dinge, die man mit CSS beeinflussen kann, stehen, da das denRahmen dieses Skriptes sprengen wurde. Eine vollstandigere Liste findet man wieder mal im Kapitel“Style-Sheet-Angaben” von SelfHTML 10.
Ein Grossteil (vor allem von CSS1) der Formatierungen bezieht sich auf die verwendeten Schriften. Eskonnen fast alle Eigenschaften bestimmt/geandert werden:
• Schriftgrosse (font-size)
• Schriftart (font-family)
• Schriftstil (font-style)
• Schriftvariante (font-variant)
• Schriftgewicht (font-weight)
• Wortabstand (word-spacing)
• Zeichenabstand (letter-spacing)
• Textdekoration (text-decoration)
• Textfarbe (color)
• Textschatten (text-shadow) (CSS2)
Ausserdem ist es moglich, eigene Schriften in eine Web-Seite einzubetten, bzw. diese nachzuladen, fallssie auf dem Computer nicht existiert (CSS2):
<style type="text/css">@font-face { font-family:Kino;
src:local(Kino MT), url(kino.ttf) format(TrueType); }@font-face { font-family:MeineArt;
url(http://www.xy.de/cgi-bin/myfont.pl)format(intellifont) }
</style>
Die erste Deklaration erwartet eine Schrift der “Kino”-Familie. Falls diese Schrift lokal nicht existiert,wird sie von der angegebenen Url geladen. Die zweite Deklaration ladt eine Schrift von der angegebenenUrl und signalisiert, dass diese im Format ’intellifont” ist.
Ein Problem mit diesen Angaben stellen naturlich die verschiedenen Schriftformate dar. Ein Macintoshkann mit einer TrueType-Schrift nicht viel anfangen, braucht sie daher erst garnicht herunterzuladen,kann sie danach naturlich aber auch nicht darstellen.
Weitere Formatangaben beziehen sich auf die Positionierung der Elemente (Abstand zum Rand, Tex-teinruckung, Textausrichtung, etc.) und ermoglichen z.T. eine pixelgenaue Positionierung am Bildschirm.
Eine ganz andere Art von Formatierung beschreiben die Attribute fur die Sprachausgabe. Aus dieserin CSS2 eingefuhrte Moglichkeit, HTML-Dokumente z.B. fur Blinde als gesprochene Worte auszugeben,folgen eine ganze Reihe von Einstellungen (siehe auch http://courses.iicm.edu/mmis/selfhtml80/css/eigenschaften/sprachausgabe.htm):
• Lautstarke (volume)
• Aussprache (speak)
• Pause vor/nach einem Element (pause)
• Hintergrund-Sound (play-during)
10http://courses.iicm.edu/mmis/selfhtml80/css/eigenschaften/index.htm
KAPITEL 4. MARKUP LANGUAGES 47
• Raum-Effekt links/rechts/vorne/hinten (azimuth)
• Sprechgeschwindigkeit (speech-rate)
• Sprechertyp (voice-family)
• etc.
Es ware nicht Microsoft, wenn es nicht auch in Cascaded Style Sheets eine ganze Reihe von eigenenErweiterungen eingebaut hat, die hier nur kurz erwahnt werden sollen:
• Kontrolle uber den Cursor
• Bild-Filter
– Vordergrund/Hintergrund verschmelzen - filter:Alpha()
– Verwisch-Effekt - filter:Blur()
– Transparenzfarbe - filter:Chroma()
– Schattenwurf - filter:DropShadow()
– Spiegeln - filter:FlipH() und filter:FlipV()
– Transparenzmaske filter:Mask()
– etc.
Eine vollstandigere Liste und deren Beschreibungen sind bitte unter http://courses.iicm.edu/mmis/selfhtml80/css/eigenschaften/filter.htm nachzulesen. Es ist aber zu beachten, dass diese Featuresnur vom Internet Explorer >4.0 unterstutzt werden, und eine Verwendung derselben dadurch automatischviele Web-Surfer ausschliesst.
4.4 eXtensible Markup Language (XML)
Die erweiterbare Markup-Sprache XML ist ein Dokumentenverarbeitungsstandard, der vom World-Wide-Web-Konsortium (W3C)11 vorgeschlagen wurde. Obwohl die genauen Spezifikationen noch nicht allefertiggestellt sind, erwarten viele, dass XML und die mit XML verwandten Technologien HTML ersetzenwerden.
4.4.1 Warum XML und nicht HTML?
Die ursprungliche Absicht von HTML war, dass Elemente (Tags) verwendet werden, um Informationlogisch auszuzeichnen (nach ihrer Bedeutung) ohne Rucksicht darauf zu nehmen, wie ein Browser dieseInformation prasentiert. In anderen Worten: Titel, Uberschriften, hervorgehobener Text oder die Kon-taktadresse des Autors sollten in die Elemente < title >, <h1>, <em> (oder <strong>) und <address>gestellt werden. Werden in die Information Elemente wie <font> oder < i> eingemischt um ein gutesLayout zu bekommen, wird es sehr schwierig, die Information bestmoglich an die Gegebenheiten desBenutzers anzupassen.
Der Grund, warum am Besten der Browser entscheidet, wie er z.B. Titel und Uberschriften prasentiert,ist, weil er am meisten uber die Vorlieben und die Umgebung des Benutzers weiss und daher die Lay-outentscheidungen darauf aufbauen kann. Da der Autor der Informationen den Benutzer nicht kennt,kann er naturlich keine Rucksicht darauf nehmen. Beispielsweise kann so ein Benutzer, der schlecht sieht,eine grossere Schrift benutzen.
Leider haben Browserhersteller dieses Konzept entweder nicht verstanden oder beschlossen, es einfach zuignorieren und haben so Standards, die Prasentation und Inhalt zu trennen versuchen, einfach ignoriert.Im Gegenteil - sie erfanden eigene Elemente und Attribute, die nur darauf abzielten, die Prasentation zu
11http://www.w3c.org

KAPITEL 4. MARKUP LANGUAGES 48
bestimmen (wie <font>, <center>, <bgcolor> etc.). Zusatzlich wurden existierende semantische Tagsfur Layoutinformationen missbraucht. So verwendete beispielsweise der HTML-Editor Netscape Golddas Tag <ul>, um Text einzurucken und nicht nur fur Listenelemente.
Dies ist aber nur ein Teil des Problems. Will man unterschiedlichste Informationen sehr prazise beschrei-ben, werden viele unterschiedliche Elemente benotigt, die es in HTML nicht gibt. Ein Chemiker brauchtz.B. viele Elemente, um chemische Formeln zu beschreiben. Ein Maschinenbauer kann damit aber reingarnichts anfangen. Statt dessen wurde er Elemente verwenden, die Maschinenteile beschreiben.
Ein weiteres Problem ist, dass HTML nur sehr wenige Regeln definiert, wie Elemente verschachtelt werdendurfen. Es macht im Allgemeinen wenig Sinn, eine Uberschrift <h2> innerhalb einer Uberschrift <h1>zu verwenden. HTML verbietet dies aber nicht.
1996 begann das W3C einen Standard zu entwickeln, der diese Probleme beseitigen soll. Die XML-Working Group definierte drei Phasen:
1. Definition eines Standards fur die Erstellung von Markup-Sprachen.
2. Entwicklung eines Standards, um Relationen in diesem Markup-Sprachen zu definieren.
3. Entwicklung eines Standards, um die Prasentation dieser Dokumente zu spezifizieren.
4.4.2 Aufbau von XML
XML ist eine vereinfachte Form von SGML, die deren Nachteile vermeiden will, die Vorteile jedochauszunutzen versucht. Die XML-Working Group sieht XML eher als “SGML light” als “HTML++”.
XML erlaubt die Definition eigener Markup-Sprachen und daher auch hochstmogliche Prazision, umInformationen kodieren zu konnen. Dies erlaubt auch Programmen, die diese Informationen verarbeiten,diese besser zu “verstehen”. Als Beispiel konnte ein Dokument dienen, das Kochrezepte enthalt und einerDTD entspricht, die es erlaubt, die verschiedenen Zutaten und Mengen zu definieren. Dieses Dokumentkann so von einem Programm verarbeitet werden, das aus den Zutaten im Kuhlschrank alle moglichenGerichte heraussucht. Sind zusatzliche Informationen uber die Kalorien oder die Preise der Zutatenenthalten, konnen weitere Kriterien angewandt werden, was zu Mittag am Tisch stehen soll.
Dies ist nur moglich, wenn die Applikation die Bedeutung der Informationen wirklich “versteht”. Dasfolgende Beispiel zeigt den Unterschied zwischen einer Markup-Sprache, die nur den Inhalt beschreibtund einer, die es erlaubt, den Inhalt zu interpretieren.
In HTML konnte ein Eintrag einer Adressliste so geschrieben werden:
<p><strong>Christof Dallermassl</strong><br>email:<a href="mailto:[email protected]">[email protected]</a><br><p>
Inffeldg. 16c<br>8010 Graz<br>Tel: +43-316/873-5636<br>Tel: +43-316/873-5699<br>
</p></p>
Die gleiche Information in XML:
<person><name>Dallermassl Christof</name><email>[email protected]</email><address>
<street>Inffeldg. 16c</street><town>8010 Graz</town><tel note="office">+43-316/873-5636</tel><tel note="fax">+43-316/873-5699</tel>
</address></person>
Der Unterschied besteht nun darin, dass die XML-Beschreibung des Eintrags z.B. von einer Suchmaschine,“verstanden” werden kann und somit die Suche nach einer Adresse einfacher und besser beantworten
KAPITEL 4. MARKUP LANGUAGES 49
kann, wahrend sie bei der HTML-Version nur Anhand der Worte vermuten kann, dass es sich um eineAdressbeschreibung handelt. Voraussetzung fur das richtige Interpretieren ist allerdings das Kennen derverwendeten XML-Elemente.
XML Syntax
Bevor hier weiter auf die Verwendung und Details von XML eingegangen wird, soll noch kurz die Syntaxerklart werden.
Die Syntax von XML ist sehr ahnlich zu HTML und SGML, wobei es trotzdem kleine, aber feine Unter-schiede gibt:
• Alle Elemente haben ein End-Tag. Das Weglassen von End-Tags aus Faulheit oder weil es sowiesoimplizit geschlossen wird (<p> in SGML), ist in XML verboten.
• Elemente, die keinen Inhalt haben, konnen (mussen aber nicht) verkurzt geschrieben werden:<img src=’’filename.jpg’’/> anstatt <img src=’’filename.jpg’’></img>. Man beachte den Schragstrich(’/’) vor der schliessenden Spitzklammer!
• Bei Element- und Attributnamen wird zwischen Gross- und Kleinschreibung unterschieden.
• Alle Elemente mussen richtig verschachtelt sein. HTML bzw. die Browser erlauben ja zum TeilKonstrukte wie
<b><i>dieser Text ist fett und kursiv, aber falsch verschachtelt!</b></i>
• Attributwerte mussen immer zwischen Anfuhrungsstrichen stehen. Elemente wie <img src=filename.jpg>sind ungultig und werden vom XML-Parser nicht akzeptiert. Richtig ware <img src=’’filename.jpg’’>.
• Element oder Attributnamen durfen nicht mit “xml” beginnen, weder in Gross- noch in Kleinschrei-bung.
• Doppelpunkte sind in Elementnamen nur erlaubt, um Namensraume zu vergeben (siehe AbschnittNamespaces auf Seite 55).
• Elementnamen durfen keine Leerzeichen enthalten. Zusatzlich durfen sie nicht mit Ziffern beginnen.Dafur sind Umlaute oder Zeichen aus anderen Alphabeten erlaubt (aber nicht sehr empfehlenswert).
XML Attribute
XML Attribute werden normalerweise verwendet, um XML-Elemente naher zu beschreiben oder Zusatz-informationen zu den Elementen zu liefern. Beim aus HTML bekannten Tag <img src=’’filename.jpg’’>ist src ein Attribut zum <img>-Element und liefert die Zusatzinformation, welches Bild eingebundenwerden soll.
Folgendes Beispiel zeigt nicht nur den Gebrauch von Attributen, sondern auch das Dilemma, in demder Autor von XML-Dokumenten ist, da er sich entscheiden muss, ob eine gewisse Information eher alseigenes XML-Element oder lieber als Attribute bei einem XML-Element stehen soll.
Gebrauch eines Attributes, um die Abteilung (department) einer Person anzugeben:
<person department="marketing"><firstname>Anna</firstname><lastname>Smith</lastname>
</person>
Verwendung eines eigenen Elements fur den gleichen Zweck:
<person><department>marketing</department><firstname>Anna</firstname><lastname>Smith</lastname>
</person>

KAPITEL 4. MARKUP LANGUAGES 50
Es gibt keine fixen Regeln, wann Attribute und wann eigene Elemente verwendet werden sollen. DieErfahrung zeigt jedoch, dass Attribute eher vermieden werden sollen:
• Attribute konnen keine Mehrfach-Werte annehmen. Es ist jedoch durchaus erlaubt, mehrmals einElement zu verwenden (z.B. wenn eine Person mehreren Abteilungen zugeordnet ist.).
• Attribute sind nicht erweiterbar (fur zukunftigen Gebrauch). Beispielsweise kann man das Element<adresse> spater durch weitere Elemente wie <strasse>, <ort>, . . . erweitern und somit genauerbeschreiben.
• Attribute konnen keine Strukturen beschreiben (wie Kind-Elemente es konnen).
• Attribut-Werte sind schwerer zu uberprufen (gegen eine DTD).
Manche Informationen sind trotzdem (jede Regel hat ihre Ausnahmen) gut (besser?) in Attributenaufgehoben( z.B. eindeutige Identifikation von Elementen):
<?xml version="1.0"?><messages>
<note id="501">bla, bla, bla,...
</note>
<note id="502">und so weiter und so weiter....
</note></messages>
Entities
Da es nicht wirklich grossartige Unterschiede von XML-Entities zu SGML-Entities gibt, sei hier nur aufAbschnitt 4.1.3 verwiesen.
Document Type Definition
Da es keinen einheitlichen Standard gibt, welche XML-Elemente existieren (das widersprache ja dem Sinnvon XML), kann sich jeder seine eigene Markup Sprache selbst definieren. Eine Moglichkeit, dies zu tun,ist das Erzeugen einer Document Type Definition (DTD).
Eine eigene Markup-Sprache zu definieren ist ziemlich einfach. Das folgende Beispiel zeigt ein XMLDokument, das den Inhalt und den logischen Aufbau eines Buches beschreibt.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><!DOCTYPE book SYSTEM "book.dtd"><book>
<info>this is some info about this book
</info><date>
2000-10-31</date><author>
<name>Christof Dallermassl</name><email>[email protected]</email>
</author><chapter name="the chapter heading">
<section name="Section one"><image src="image1.jpg"/><para>some text abtout Ted Nelson .....</para><para>some info about XML .....</para>
</section><section name="Section two">
....</section>
</chapter></book>
Die Deklaration (<?xml .... ?>) halt mehrere Attribute, die generell ein XML-Dokument beschreiben. Essoll nicht naher auf einzelne Details eingegangen werden, da dies den Rahmen sprengen wurde. Trotzdem
KAPITEL 4. MARKUP LANGUAGES 51
ein paar Anmerkungen: Das encoding Attribut gibt an, mit welchem Zeichensatz das XML-Dokumenterstellt worden ist. Wird hier z.B. ISO-8859-1 verwendet, konnen auch Umlaute verwendet werden. Istder Wert des Attributes standalone ’no’, muss der Parser weitere XML-Dokumente (z.B. eine DTD)laden, um ein gultiges XML-Dokument zu erhalten (bzw. es kann auch eine DTD in der <!DOCTYPE>-Instruktion deklariert werden).
Die <!DOCTYPE>-Instruktion bezeichnet nun den Typ des Dokuments. Das Schlusselwort SYSTEMbedeutet, dass die DTD nur fur die private Nutzung bestimmt ist. Im Gegensatz zu PUBLIC, bei dem dieDTD fur eine weitverbreitete Nutzung gedacht ist.
Welche Elemente nun in der XML-Datei vorkommen durfen, bestimmt die zugehorige Document TypeDefinition. Normaler- und sinnvollerweise wird diese in einer externen Datei definiert (hier book.dtd),es ist aber auch moglich, die DTD direkt in der XML-Datei anzugeben.
<?xml version="1.0"?><!ELEMENT book (info, author, chapter+, date?)><!ELEMENT author (name, email?)><!ELEMENT chapter (section+, para*)><!ELEMENT section (para+, image*)><!ELEMENT image (EMPTY)><!ELEMENT info (#PCDATA)><!ELEMENT date (#PCDATA)><!ELEMENT name (#PCDATA)><!ELEMENT email (#PCDATA)><!ELEMENT para (#PCDATA)>
<![ IGNORE [dieser Teil wird ignoriert!
]]>
<!ATTLIST chapter name CDATA #IMPLIED><!ATTLIST section name CDATA #IMPLIED><!ATTLIST image src CDATA #REQUIRED>
<!ELEMENT name content> definiert, wie das Markup heisst (name) und welche Inhalte (content) eshaben darf. Das angehangte ’+’ bedeutet ’ein- oder mehrmal’, das ’?’ heisst ’null- oder einmal’ und ’*’sagt ’null- oder mehrmal’. Ist kein Zeichen angegeben, darf das Element genau einmal vorkommen.
#PCDATA steht fur normale Buchstaben (Parsed Character Data), die vom XML-Parser geparsed werden(im Gegenteil zu #CDATA, die nicht geparsed werden).
Die Deklaration der gultigen/notwendigen Attribute ist folgendermassen:
<!ATTLIST element-name attribute-name attribute-type default-value>
wobei der Attributtyp #IMPLIED angibt, dass das Argument auch weggelassen werden kann (im Gegenteilzu #REQUIRED).
Da hier die genaue Beschreibung aller moglichen Variationen den Rahmen sprengen wurde, sei hier aufdie Webseite von xml10112 verwiesen, die mehr Einzelheiten auflistet.
Ist es unbedingt notig, eine DTD fur ein XML-Dokument zu schreiben? Nein, nicht unbedingt, aberes ist sehr empfehlenswert, da es ansonsten nicht moglich ist, die high-level Syntax bzw. Semantik desDokuments auf seine Richtigkeit zu uberprufen. Die low-level Syntax wird ja durch die XML-Regelndefiniert, aber welche Elemente wie verschachtelt sein konnen und welche Attribut(werte) sie enthaltendurfen, steht nur in der DTD (Unterschied zwischen valid und wellformed). Fur einen ersten Test ist esallerdings nicht notwendig, eine DTD zu schreiben.
Schema Definitionen
Traditionellerweise werden XML-Sprachen mittels DTDs (siehe Abschnitt Document Type Definition aufSeite 50) definiert. Diese haben aber einige Nachteile: bestimmte syntaktische Beschrankungen sind mitDTDs nicht moglich, die Anzahl der Datentypen ist sehr beschrankt, die Syntax folgt eigenen Regeln undDTDs unterstutzen keine Namespaces (siehe Abschnitt Namespaces auf Seite 55).
12http://www.xml101.com/dtd/

KAPITEL 4. MARKUP LANGUAGES 52
Schemas13 (oder Schemata) sind als Ersatz fur DTDs gedacht und sind selbst im XML-Format geschrie-ben. Das erleichtert die Implementation von Parsern. Die grossen Vorteile von Schemas sind, dass sieviele verschiedene Datentypen unterstutzen und es moglich ist, neue Datentypen zu definieren und einXML-Dokument auch genauestens zu uberprufen, ob diese Richtlinien auch eingehalten wurden.
Dies ist besonders fur Dokumente wichtig, die sehr daten-orientiert sind, da es hier besonders auf einegenaue Uberprufung der Datentypen ankommt. Folgendes Beispiel zeigt den Unterschied zwischen demDaten-orientierten und dem Dokument-orientierten Ansatz:
Daten-orientiert Dokument-orientiert<invoice>
<orderDate>1999-01-21</orderDate><shipDate>1999-01-25</shipDate><billingAddress>
<name>Ashok Malhotra</name><street>123 IBM Ave.</street><city>Hawthorne</city><state>NY</state><zip>10532-0000</zip>
</billingAddress><voice>555-1234</voice><fax>555-4321</fax>
</invoice>
<memo importance=’high’date=’2001-10-23’>
<from>Christof Dallermassl</from><to>Hermann Maurer</to><subject>Latest draft</subject><body>
We need to discuss the latestdraft <important>immediately</important>.Either email me at <email>[email protected]</email>or call <phone>873-5636</phone>
</body></memo>
Das ’Daten-orientierte’ Dokument ist mehr oder weniger eine Datenbank, die verschiedenste Elementeenthalt. Der grosse Vorteil eines XML-Dokumentes gegenuber einer Datenbank ist jedoch, dass das Datei-format von vielen Applikationen gelesen werden kann und nicht auf einen Hersteller (den der Datenbank)oder eine Plattform beschrankt ist und somit leicht weitergegeben werden kann.
Naturlich ist auch bei dem ’Dokument-orienten’ Dokument eine strenge Typen- oder Werteprufung nutz-lich (z.B. bei der Telefonnummer oder dem Datum). Die Frage ist nur, ob sich der Aufwand, ein solchesSchema zu erstellen, immer rechnet. Vor allem, da im Moment kaum Tools, die die Erstellung einesSchemas unterstutzen, erhaltlich sind.
Dies hangt auch damit zusammen, dass die Schema-Spezifikation noch nicht abgeschlossen ist (Ende desReviews war der 15. Oktober 2000) und es daher noch keine gultigen Richtlinien, an die man sich haltenkonnte, gibt. Seit dem 2. Mai 2001 ist die Schema-Spezifikation eine Recommendation und langsamstehen Werkzeuge zur Verfugung.
Folgendes Beispiel ist ein Versuch, ein Schema fur das Buch-Beispiel in Abschnitt Document Type Defi-nition auf Seite 50 zu finden:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="book" type="bookType"/>
<xsd:complexType name="bookType"><xsd:sequence>
<xsd:element name="info" type="xsd:string"/><xsd:element name="author" type="xsd:string"/><xsd:element name="chapter" type="chapterType" minOccurs="1"/><xsd:element name="date" type="xsd:date" minOccurs="0"/>
</xsd:sequence><xsd:attribute name="name" type="xsd:string"/>
</xsd:complexType>
<xsd:complexType name="chapterType"><xsd:sequence>
<xsd:element name="section" type="sectionType" minOccurs="1"/><xsd:element name="para" type="xsd:string" minOccurs="0"/>
</xsd:sequence><xsd:attribute name="name" type="xsd:string"/>
</xsd:complexType>
<xsd:complexType name="sectionType"><xsd:sequence>
<xsd:element name="para" type="xsd:string"/></xsd:sequence><xsd:attribute name="name" type="xsd:string"/>
</xsd:complexType>
13http://www.w3c.org/XML/Schema
KAPITEL 4. MARKUP LANGUAGES 53
Da dieses Beispiel nur die Moglichkeiten ausnutzt, die eine DTD bietet, verbergen sich die Vorteile vonSchemas.
Das Beispiel aus dem Schema-Tutorial des W3C14 ist deutlich komplexer, zeigt dafur ein paar Moglich-keiten der Schemadeklaration.
<?xml version="1.0"?><purchaseOrder orderDate="1999-10-20">
<shipTo country="US"><name>Alice Smith</name><street>123 Maple Street</street><city>Mill Valley</city><state>CA</state><zip>90952</zip>
</shipTo><billTo country="US">
<name>Robert Smith</name><street>8 Oak Avenue</street><city>Old Town</city><state>PA</state><zip>95819</zip>
</billTo><comment>Hurry, my lawn is going wild!</comment><items>
<item partNum="872-AA"><productName>Lawnmower</productName><quantity>1</quantity><USPrice>148.95</USPrice><comment>Confirm this is electric</comment>
</item><item partNum="926-AA">
<productName>Baby Monitor</productName><quantity>1</quantity><USPrice>39.98</USPrice><shipDate>1999-05-21</shipDate>
</item></items>
</purchaseOrder>
Die zugehorige Schemadeklaration:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:annotation><xsd:documentation>
Purchase order schema for Example.com.Copyright 2000 Example.com. All rights reserved.
</xsd:documentation></xsd:annotation>
<xsd:element name="purchaseOrder" type="PurchaseOrderType"/>
<xsd:element name="comment" type="xsd:string"/>
<xsd:complexType name="PurchaseOrderType"><xsd:sequence>
<xsd:element name="shipTo" type="USAddress"/><xsd:element name="billTo" type="USAddress"/><xsd:element ref="comment" minOccurs="0"/><xsd:element name="items" type="Items"/>
</xsd:sequence><xsd:attribute name="orderDate" type="xsd:date"/>
</xsd:complexType>
<xsd:complexType name="USAddress"><xsd:sequence>
<xsd:element name="name" type="xsd:string"/><xsd:element name="street" type="xsd:string"/><xsd:element name="city" type="xsd:string"/><xsd:element name="state" type="xsd:string"/><xsd:element name="zip" type="xsd:decimal"/>
</xsd:sequence><xsd:attribute name="country" type="xsd:NMTOKEN"
use="fixed" value="US"/></xsd:complexType>
<xsd:complexType name="Items"><xsd:sequence>
<xsd:element name="item" minOccurs="0" maxOccurs="unbounded"><xsd:complexType>
14http://www.w3.org/TR/xmlschema-0/

KAPITEL 4. MARKUP LANGUAGES 54
<xsd:sequence><xsd:element name="productName" type="xsd:string"/><xsd:element name="quantity">
<xsd:simpleType><xsd:restriction base="xsd:positiveInteger">
<xsd:maxExclusive value="100"/></xsd:restriction>
</xsd:simpleType></xsd:element><xsd:element name="USPrice" type="xsd:decimal"/><xsd:element ref="comment" minOccurs="0"/><xsd:element name="shipDate" type="xsd:date" minOccurs="0"/>
</xsd:sequence><xsd:attribute name="partNum" type="SKU"/>
</xsd:complexType></xsd:element>
</xsd:sequence></xsd:complexType>
<!-- Stock Keeping Unit, a code for identifying products --><xsd:simpleType name="SKU"><xsd:restriction base="xsd:string"><xsd:pattern value="\d{3}-[A-Z]{2}"/>
</xsd:restriction></xsd:simpleType>
/xsd:schema>
Dieses Beispiel soll nicht dazu dienen, alle Features von XML-Schemas zu erklaren, sondern soll nur einenkurzen Uberblick der Moglichkeiten aufzeigen:
• Die Anzahl und Reihenfolge von Kind-Elementen kann genauer begrenzt werden (minOccurs="0").
• Es gibt vordefinierte Datentypen: xsd:string, xsd:date, xsd:positiveInteger, boolean, recurringDay,etc. (die komplette Liste ist unter http://www.w3.org/TR/xmlschema-0/#CreatDt zu finden)
• Neue Datentypen konnen jederzeit definiert werden (type="SKU").
• Gultige Attributwerte konnen sehr genau (mit Regular Expressions (http://www.w3.org/TR/xmlschema-0/#regexAppendix) eingegrenzt werden
<xsd:pattern value="\d{3}-[A-Z]{2}"/>
• usw.
Wie man sieht, bieten Schemas deutlich mehr Moglichkeiten als DTDs, fallen dafur aber auch deutlichkomplexer aus.
Schemas werden DTDs auch nicht uberall ersetzen, sondern neue Definitionen ermoglichen, die mit DTDsbisher uberhaupt nicht machbar waren. Vor allem ’daten-orientierte’ Dokumente brauchen die Vielfaltder Schemadeklarationen. Und uberall, wo Namespaces verwendet werden mussen, kommt man umSchemas nicht herum, da DTDs mit Namensraumen nicht umgehen konnen.
Processing Instructions
In HTML werden oft Kommentare dazu missbraucht, eigene Erweiterungen einzuschmuggeln (z.B. server-side includes, Browserspezifische Script-Programme, Datenbankabfragen, etc.). Der Vorteil, Kommentarefur diesen Zweck zu benutzen, ist zwar, dass Browser diese Kommandos einfach ignorieren, wenn sie esnicht verstehen. Der Nachteil an dieser Methode ist, wenn alle Kommentare aus dem Dokument entferntwerden, entsteht ein Dokument mit neuem Inhalt (oder auch keinem Inhalt), was ja eigentlich nicht Sinnund Zweck von Kommentaren sein kann.
XML bietet fur solche Zwecke Processing Instructions (PIs) an. PIs stellen einen Mechanismus zurVerfugung, der es erlaubt, Informationen in ein Dokument einzubetten, die nur fur Applikationen undnicht fur den XML-Parser bestimmt sind.
Eine Processing Instructions steht zwischen <? und ?> und muss als erstes Wort eine eindeutige Identi-fikation haben (normalerweise der Name der Applikation oder der Name einer XML-Notation der DTD,die auf die Applikation verweist). IBM verwendet z.B. fur die Bean Markup Language den Namen bmlpi:
KAPITEL 4. MARKUP LANGUAGES 55
z.B. <?bmlpi register demos.calculator.EventSourceText2Int?>
Alles, was hinter dem Namen steht, besteht aus Daten, die fur Applikationen gedacht sind, die Datenmit diesem Identifier (bmlpi) interpretieren wollen. Der XML-Parser ubergibt die Processing Instructionuninterpretiert an jede Applikation.
Wenn nun eine Applikation dieses XML-Dokument parst und auf diese Processing Instruction stosst,kann sie (muss aber nicht) die Argumente der PI auswerten und dementsprechend reagieren. In obigemBeispiel wird wahrscheinlich die Java-Klasse demos.calculator.EventSourceText2Int registriert.
Es ist aber nicht so, dass ein XML-Parser automatisch eine Applikation mit der gegebenen Id sucht unddiese startet! Ob eine PI ausgewertet wird, hangt immer von der Applikation ab, die das Dokument parst.Die Daten, die eine PI enthalt, konnen beliebiger Natur sein (Variablenwerte wie unten, Kommandos wieoben, Zusatzinformationen, . . . ).
XML selbst verwendet auch solche Processing Instructions, darum sind auch Identifikationsnamen, diemit xml beginnen, verboten. Als Beispiel dazu kann die Style-File Deklaration von XML gelten:
<?xml−stylesheet type=’’text/xsl’’href=’’stylefile.xsl ’ ’?>
Diese PI wird beispielsweise vom XSL-Prozessor ausgewertet und der Name des Style-Files herausgelesen.Alle anderen Programme, die dieses XML-Dokument parsen, die aber nichts mit XSL zu tun haben,konnen diese PI einfach ignorieren.
Ein weiteres Beispiel ist das Einbetten von serverseitigem Code (Kapitel 8), z.B. PHP-Code (Abschnitt 8.1.8):hier wird durch die Identifikation php der Applikation, die das Dokument verarbeitet (in diesem Fall demPHP-Interpreter) mitgeteilt, dass PHP-code folgt. Andere Applikationen konnen diese Processing In-struction ignorieren.
<?php$db_host = "was.weiss.ich.net";$db_user = "username";$db_pass = "meinpasswort";$db_name = "meinedb";$my_url = "http://dies.ist.meine.url";
?>
Processing Instructions konnen uberall in einem XML-Dokument stehen (ausgenommen in einem Tagoder einem CDATA-Abschnitt).
Namespaces
Namensraume (namespaces) sind eine Neuerung der XML-Spezifikation. Die Benutzung von Namens-raumen ist in XML nicht notwendig, oft aber sehr nutzlich. Namensraume sind eingefuhrt worden, umdie Eindeutigkeit unter XML-Elementen sicherzustellen. Ein Element <book> wird sicher von vielenXML-Autoren verwendet werden. Welche Elemente oder Attribute aber bei einem <book> vorkommendurfen, wird sich aber von Autor zu Autor unterscheiden. Sobald verschiedene Deklarationen von <book>zusammentreffen, kollidieren sie und das korrekte Zusammenfuhren von Dokumenten ware unmoglich.Namensraume helfen durch die Bereichserweiterung jedes Tags, Elementnamen-Kollisionen zu vermeiden.
Namensraume werden mit dem Attribut xmlns:namespace_id deklariert:
<OReilly:Books xmlns:OReilly="http://www.oreilly.com/">oder<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Falls kein Name (namespace_id) nach dem xmlns-Prafix angegeben wird, wird der Namensraum alsDefault-Namensraum eingestuft und fur alle Elemente innerhalb des definierenden Elements verwendet,die kein eigenes Namensraum-Prafix verwenden.
mit explizitem Namespace mit Default-Namespace<OReilly:Books
xmlns:OReilly="http://www.oreilly.com/"><OReilly:Book>
was weiss ich was fuer ein buch ....</OReilly:Book>
</OReilly:Books>
<Books xmlns="http://www.oreilly.com/"><Book>
was weiss ich was fuer ein buch ....</Book>
</Books>

KAPITEL 4. MARKUP LANGUAGES 56
Ein leerer String als Default-Namespace verhindert, dass ein Default-Namespace innerhalb eines spezifi-schen Elements gesetzt ist.
4.4.3 Beispiele Vorhandener XML-Definitionen
Die Vorteile von XML als universelles Austauschformat kommen naturlich erst zum Tragen, wenn es klardefinierte Element-Satze gibt, die von mehreren Applikationen verstanden werden. Die Liste ist naturlichweit entfernt, vollstandig zu sein, versucht aber die Moglichkeiten und das breite Spektrum von XML zuverdeutlichen:
• eXtensible HyperText Markup Language (XHTML): ist HTML in strikter XML-Syntax geschrieben(Gross/Klein Schreibung, Verschachtelung, etc.). Der Hauptzweck von XHTML ist die leichtereUberprufbarkeit auf gultiges HTML. Die generellen Browserprobleme (verschiedene Interpretationvon HTML-Tags) werden damit wohl nicht gelost werden.
• Scalable Vector Graphics (SVG): siehe Abschnitt 6.7.4
• Die OpenGIS Geographic Markup Language (GML): Geographische Daten konnen so applikati-onsunabhangig gespeichert werden (siehe http://www.opengis.org) und relativ einfach (z.B. mitHilfe von XSLT) in SVG umgewandelt und dargestellt werden.Als Beispiel dient die (sehr kurze) Definition des Flusses Cam (Cambridge):
<River><gml:description>The river that runs through Cambridge.</gml:description><gml:name>Cam</gml:name><gml:centerLineOf>
<gml:LineString srsName="http://www.opengis.net/gml/srs/epsg.xml#4326"><gml:coord><gml:X>0</gml:X><gml:Y>50</gml:Y></gml:coord><gml:coord><gml:X>70</gml:X><gml:Y>60</gml:Y></gml:coord><gml:coord><gml:X>100</gml:X><gml:Y>50</gml:Y></gml:coord>
</gml:LineString></gml:centerLineOf>
</River>
• Docbook bietet eine Moglichkeit, Bucher in XML/SGML zu schreiben. Diese ausgabeformatun-abhangige Textbeschreibung erlaubt es relativ einfach, den Text in verschiedene Formate zu kon-vertieren (HTML, PDF). Details sind unter http://www.oasis-open.org/committees/docbook/zu finden. Eine online-Version des O’Reilly Buches DocBook: The Definitive Guide ist unterhttp://www.docbook.org zu finden. Die Homepage der Entwickler steht unter http://docbook.sourceforge.net.Ein einfaches Beispiel (aus dem O’Reilly Buch entnommen) eines Artikels ist z.B.:
<!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook V3.1//EN"><article>
<artheader><title>My Article</title><author><honorific>Dr</honorific><firstname>Emilio</firstname>
<surname>Lizardo</surname></author></artheader><para> ... </para><sect1><title>On the Possibility of Going Home</title><para> ... </para></sect1><bibliography> ... </bibliography>
</article>
Das docbook-Projekt hat auch eine DTD fur die Erstellung von Webseiten namens website heraus-gebracht. Auf den Downloadseiten von Docbook bei Sourceforge15 ist dieser Teil zu finden. Ein Bei-spiel ist unter http://docbook.sourceforge.net/release/website/example/layout.html zufinden.
• Chemical Markup Language (CML) erlaubt es, chemische Elemente zu beschreiben. Viele Beispieleund Details sind unter http://www.xml-cml.org/ zu finden. Auch dieses XML-Format lasst sicheinfach mit Hilfe von SVG visualisieren.Das Beispiel (von http://www.adobe.com/svg/demos/devtrack/chemical.html) zeigt ein Karo-tinmolekul bzw. eine (SVG) Visualisierung eines Koffeinmolekuls:
15http://sourceforge.net/projects/docbook/
KAPITEL 4. MARKUP LANGUAGES 57
<?xml version="1.0"?><document>
<cml title="carotine" id="cml_carotine_karne"xmlns="x-schema:cml_schema_ie_02.xml">
<molecule title="carotine" id="mol_carotine_karne"><atomArray>
<atom id="carotine_karne_a_1"><float builtin="x2" units="A">17.3280</float><float builtin="y2" units="A">2.0032</float><string builtin="elementType">C</string>
</atom>... many atoms deleted, for space ...
</atomArray><bondArray>
<bond id="carotine_karne_b_1"><string builtin="atomRef">carotine_karne_a_1</string><string builtin="atomRef">carotine_karne_a_2</string><string builtin="order" convention="MDL">2</string>
</bond>... many bonds deleted, for space ...
</bondArray></molecule>
</cml></document>
• Mathematical Markup Language (MathML): Details sind unter http://www.w3.org/Math/ zu fin-den. Die Unterstutzung von MathML ist browsermassig ganz gut.
Als Beispiel (von http://www.zvon.org/HowTo/Output/index.html) dient folgende Formel:∑b
x=1 f(x)
<math xmlns="http://www.w3.org/1998/Math/MathML"><apply>
<sum/><bvar>
<ci> x </ci></bvar><lowlimit>
<ci> a </ci></lowlimit><uplimit>
<ci> b </ci></uplimit><apply>
<fn><ci> f </ci>
</fn><ci> x </ci>
</apply></apply>
</math>
• Synchronized Multimedia Language (SMIL): siehe Abschnitt 7.5
• Voice Markup Language (VoiceXML): Mit VoiceXML kann man Dialogsysteme aufbauen, die sowohlSprachein- als auch -ausgabe unterstutzen. Die Spezifikationen und Beispiele sind unter http://www.w3.org/Voice/ zu finden. Folgendes Beispiel lasst den Benutzer eine Stadt aussuchen:
<field name="city"><prompt>Where do you want to travel to?</prompt><option>Edinburgh</option><option>New York</option><option>London</option><option>Paris</option><option>Stockholm</option></field>
• Election Markup Language (EML): ein Versuch, strukturierte Wahldaten zwischen verschiedenerSoft-, Hardware und Service-Providern austauschen zu konnen (siehe http://xml.coverpages.org/eml.html).
• und viele weitere. . .
Eine lange Liste von XML-Anwendungen kann auf den Webseiten des W3C unter http://www.w3.org/TR/ oder bei xml.com16 unter http://www.xml.com/pub/q/stdlist eingesehen werden.
16http://www.xml.com

KAPITEL 4. MARKUP LANGUAGES 58
4.4.4 Extensible Stylesheet Language (XSL)
Die Spezifikation der erweiterten Stylesheet-Sprache XSL17 ist einer der kompliziertesten Teile der XML-Spezifikation und erst seit dem 15.10.2001 eine Recommendation.
Da bei XML Tags keine bestimmte Bedeutung haben (das Element <table> konnte sowohl eine HTML-Tabelle als auch ein Tisch sein), gibt es keinen Standardweg, ein XML-Dokument anzuzeigen. Es mussalso ein Weg gefunden werden zu beschreiben, wie ein solches Dokument prasentiert werden soll. Einerdieser Wege ist CSS, aber XSL sollte der bevorzugte Mechanismus fur XML sein.
XSL besteht aus zwei Teilen:
• XSLT (XSL Transformations): eine Sprache, um XML-Dokumente zu transformieren.
• XSL-FO (Formatting Objects): eine Methode, um XML-Dokumente zu formatieren. Dieser Teilder Spezifikation ist noch stark im Wandel begriffen. Daher auch nur eine ganz kurze Beschreibungunter Abschnitt Formatting Objects (FO) auf Seite 62.
XSLT ist eine Sprache, die ein XML-Dokument in ein anderes (XML-)Dokument (also evtl. auch in einHTML-Dokument) transformiert, bestimmte Elemente sortiert und filtert und die die Daten danach nochformatiert (z.B. negative Zahlen in Rot).
XML-Dokumente konnen aus verschiedenen Elementen (nodes) bestehen:
• der Dokumentenwurzel (root).
• Elementen
• Text
• Attributen
• Namensraumen
• Processing Instructions
• Kommentaren
Diese Knoten sind intern als Baum organisiert und konnen auch uber diese Baumstruktur angesprochenwerden. Die XSL-Transformationen arbeiten als Eingabe mit einem solchen Baum und das Resultat istwiederum ein solcher Baum.
Die Transformationen drehen sich in erster Linie um so genannte Template Rules. Diese Schablonenenthalten Anweisungen fur den XSLT-Parser, die dieser mit XML-Elementen auffullt und kombiniert.Gewohnlich passen die Regeln nur zu bestimmten Elementen (Knoten im Baum).
Als Beispiel soll hier ein XML-Dokument, das eine Adressliste enthalt, mittels XSLT in HTML (aucheine XML-Art) umgewandelt werden:
<?xml version="1.0"?><addresslist>
<person><name>Dallermassl Christof</name><email>[email protected]</email><address>
<street>Inffeldg. 16c</street><town>8010 Graz</town><tel note="office">+43-316/873-5636</tel><tel note="fax">+43-316/873-5699</tel>
</address><address>
<street>IrgendwoInGrazStr. 43</street><town>8010 Graz</town><tel>+43-316/123456</tel>
</address></person>
17http://www.w3.org/TR/xsl
KAPITEL 4. MARKUP LANGUAGES 59
<person><name>Ablinger Franz</name><address>
<street>Wasweissichwelchestr. 49</street><town>4840 Igendwo_in_OOe</town><tel>+43-7672/987654</tel>
</address></person>
</addresslist>
Das zugehorige XSL-File muss den Namensraum xsl verwenden und ist ebenfalls ein gultiges XML-File:
<?xml version="1.0"?><xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
Als erstes muss naturlich darauf geachtet werden, dass das Ergebnis ein gultiges HTML-Format besitzt:
<xsl:template match="/"><html>
<head></head><body><xsl:apply-templates/>
</body></html>
</xsl:template>
Diese Template-Regel trifft nur auf das root-Element (match="/") zu. XSLT-Kommandos sind immer andem Namensraum xsl zu erkennen. Alle anderen Elemente werden ohne Anderung in den Ausgabebaumbzw. das Ausgabedokument ubernommen. In diesem Fall werden die Elemente <html>, <head> und<body> samt ihren zugehorigen Ende-Tags unverandert ausgegeben. Die Anweisung <xsl:apply−templates/>versucht nun, weitere Templates auf den Eingabebaum anzuwenden:
<xsl:template match="addresslist"><h1>Adressenliste</h1><xsl:apply-templates/>
</xsl:template>
Das Template zum XML-Element <addresslist> schreibt eine Uberschrift und weist den Parser an, weitereTemplates anzuwenden.Das Template fur <person> geht nun endlich auf die Daten los:
<xsl:template match="person"><p><strong>
<xsl:value-of select="name"/></strong><br/><xsl:apply-templates select="email"/><xsl:apply-templates select="address"/>
</p><hr/>
</xsl:template>
<xsl:value−of select=’’name’’> selektiert den Wert (den Text) des Sub-Elements <name> und schreibtihn innerhalb der <strong>-Tags in die Ausgabe. Nach einem Zeilenumbruch (<br> wurde gegen dieSyntaxregeln von XML verstossen, darum wird <br/> verwendet), werden nun weitere Template Regelnangestossen: fur <email> und <address>. Existiert kein Kind-<email>-Element, wird kein Templateangewandt und auch kein Ausgabecode produziert.
Die weiteren Templates sind hoffentlich selbsterklarend und folgen den obigen Mustern:
<xsl:template match="email">email:<a>
<xsl:attribute name="href">mailto:<xsl:value-of select="."/>
</xsl:attribute><xsl:value-of select="."/>
</a><br/>

KAPITEL 4. MARKUP LANGUAGES 60
</xsl:template>
<xsl:template match="address"><p>
<xsl:value-of select="street"/><br/><xsl:value-of select="town"/><br/><xsl:apply-templates select="tel"/>
</p></xsl:template>
<xsl:template match="tel">Tel: <xsl:value-of select="."/><br/>
</xsl:template>
Abschliessend muss naturlich noch das <stylesheet>-Element abgeschlossen werden:
</xsl:stylesheet>
Als XSLT-Prozessor wurde Xalan vom Apache-Projekt18 verwendet. Nach dem Aufruf von
# je nach Ort von Xalan, XALAN_HOME zu setzen:setenv CLASSPATH $XALAN_HOME/xerces.jar:$XALAN_HOME/xalan.jarjava org.apache.xalan.xslt.Process -in addresslist.xml \
-xsl addresslist.xsl -out addresslist.html
entsteht das HTML-Dokument addresslist.html:
<html><head>
<META http-equiv="Content-Type" content="text/html; charset=UTF-8"></head><body>
<h1>Adressenliste</h1><p>
<strong>Christof Dallermassl</strong><br>email:<a href="mailto:[email protected]">[email protected]</a><br><p>
Inffeldg. 16c<br>8010 Graz<br>Tel: +43-316/873-5636<br>Tel: +43-316/873-5699<br>
</p><p>
IrgendwoInGrazStr. 43<br>8010 Graz<br>Tel: +43-316/123456<br>
</p></p>
<hr><p>
<strong>Franz Ablinger</strong><br><p>
Wasweissichwelchestr. 49<br>4840 Igendwo_in_OOe<br>Tel: +43-7672/987654<br>
</p></p><hr>
</body></html>
Der HTML-Code des Dokuments wurde der leichteren Lesbarkeit wegen etwas umformatiert (Einruckung,neue Zeilen, ...), ist aber sonst unverandert und vor allem ein gultiger HTML Code, der von allen Browsernangezeigt werden kann.
Die hier verwendeten Transformationen sind naturlich nur ein kleiner Teil der Features, den XSLT bietet.Ein Feature, das die erweiterten Moglichkeiten zeigt und gut zum Beispiel passt, ist z.B. das Umstellender Reihung (in sortierter Reihenfolge). Der Befehlt < xsl:sort> innerhalb <xsl:apply−templates> bewirkteine Sortierung der Adressliste:
<xsl:template match="addresslist"><h1>Adressenliste</h1><xsl:apply-templates>
<xsl:sort select="name"/></xsl:apply-templates>
</xsl:template>
18http://xml.apache.org/xalan
KAPITEL 4. MARKUP LANGUAGES 61
Ein XSL-Stylesheet wird mit mit folgender Processing Instruction in ein XML-Dokument eingebunden:
<?xml-stylesheet type="text/xsl" href="mystyle.xsl"?>
Mustervergleich (XPath)
Der machtige Mustervergleich (XPath19) von XSL wird in obigem Beispiel nur sehr wenig ausgenutzt. Erwird u.a. verwendet, um im <xsl:template>-Element mit dem match-Attribute einen Knoten im XML-Dokumenten-Baum auszuwahlen. Das verwendete Muster passt auf ein Element, das eine Beziehungzum aktuellen Knoten besitzt. <xsl:template match=’’addresslist/person/email’’> addressiert z.B. das<email>-Element ausgehend vom root-Knoten.
<xsl:template match="person/email">
stimmt nur dem Element <email> uberein, das ein Eltern-Element <person> besitzt.
<xsl:template match="person//tel">
passt jedoch zu jedem <tel>-Element, das einen Vorganger (muss kein direkter sein) <person> hat. Beiobigem Beispiel wurde dieser Ausdruck auf alle <tel>-Elemente auch innerhalb der Adresse zutreffen.
<xsl:template match="person/address/*">
passt auf alle Elemente innerhalb der Adresse einer Person.
<xsl:template match="street | town">
passt auf <street> oder <town>.
<xsl:template match="person/comment()"><xsl:template match="person/pi()">
selektiert alle Kommentare bzw. Processing Instructions innerhalb des <person>-Elements.
Aber nicht nur Elemente, auch Attribute konnen Ziele sein. Es kann z.B. auch nur diejenigen Telefon-nummern selektiert werden, die einen (bestimmten) Attributwert besitzt:
<xsl:template match="tel[@note]">
In diesem Fall werden nur <tel>-Elemente ausgewahlt, die ein note Attribut besitzen.
<xsl:template match="tel[@note=’fax’]">
wahlt nur Telefoneintrage mit note-Attribut und dem Wert “fax” aus.
Der Wert von Attributen wird mit Hilfe des Klammeraffen ’@’ adressiert. Im Beispiel wird das Attributnote mittels @note selektiert und in den HTML-Code in Klammern an die Telefonnummer angefugt.
<xsl:template match="tel">Tel: <xsl:value-of select="."/>(<xsl:value-of select="@note"/>)<br/>
</xsl:template>
Hier alle Elemente von XSL zu erklaren, wurde den Rahmen des Skriptes sprengen, so seien ein paar derweiteren nur noch kurz erwahnt:
• die Fahigkeit, Zahler mitlaufen zu lassen (um z.B. alle Adresseintrage zu numerieren)
• Stringmanipulationen (Zusammenhangen, Ersetzen, ...)
• Erzeugen von Kommentaren oder Processing Instructions (<xsl:comment> und < xsl:pi>)
• etc...19http://www.w3.org/TR/xpath.html

KAPITEL 4. MARKUP LANGUAGES 62
Formatting Objects (FO)
Die zweite Halfte der eXtensible Style Language (XSL) ist die Formatting Language. Diese XML-Applikation wird benutzt, um zu beschreiben, wie der Inhalt gerendert wird, wenn er von einem Le-ser angezeigt wird. Die Spezifikation ist seit 15.10.2001 eine Recommendation. Auch gibt es erst einesehr kleine Anzahl von Applikationen, die mit Formatting Objects umgehen konnen. Darum wird dieBeschreibung hier sehr knapp ausfallen.
FOs bieten ein besseres Layout-Model als CSS, versuchen aber z.T. kompatibel zu CSS zu sein (Eigen-schaftsnamen, etc.).
FOs basieren auf rechteckigen Boxen und Seiten, die nacheinander / nebeneinander gereiht werdenkonnen. Sie erlauben u.a. Text in verschiedenen Formen fliessen zu lassen (von rechts nach links).
Mehr Details findet man im Kapitel der XML-Bibel20.
Das FOP-Projekt von Apache21 ist ein freier Formatting Object Processor, der im Moment die Ausgabe inPDF, MIF, PCL, Postscript, Text, auf einen Drucker und auf den Bildschirm unterstutzt. Die verwendeteVersion von FOP ist 0.20.4.
Folgendes ist ein einfaches “Hello World” FO-Dokument, das nur aus der Deklaration des Seitenlayoutsund vier Blocken besteht:
<?xml version="1.0" encoding="iso-8859-1"?><fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format">??<fo:layout-master-set><!-- layout for the first page -->
<fo:simple-page-master master-name="my_page"page-height="10cm"page-width="15cm"margin-top="1cm"margin-bottom="1cm"margin-left="1.5cm"margin-right="1.5cm">
<fo:region-body margin-top="3cm"/><fo:region-before extent="3cm"/><fo:region-after extent="1.5cm"/></fo:simple-page-master>
</fo:layout-master-set>
<!-- actual layout --><fo:page-sequence master-reference="my_page">
<fo:flow flow-name="xsl-region-body"><fo:block>Hello, world!</fo:block><fo:block font-size="12pt"
font-family="sans-serif"line-height="15pt"space-after.optimum="3pt"text-align="start">
This is the second block in the hello world page.It has a vertical space afterwards.
</fo:block><fo:block>And now there comes the third block! Pay attention!</fo:block><fo:block>
And the fourth and last block in the little Hello World Formatting Objects Example.</fo:block>
</fo:flow></fo:page-sequence>
</fo:root>
Es kann durch einfaches Aufrufen des Shell-Skripts (Unix) bzw. des Batch-Files (Windows) eine PDF-Datei erzeugt werden:
unix:fop.sh hello_world.fo -pdf hello_world.pdfwindows:fop hello_world.fo -pdf hello_world.pdf
Eine gute und ausfuhrliche Einfuhrung in XSL-Formatting Objects kann unter http://www.dpawson.co.uk/xsl/sect3/bk/index.html gefunden werden.
20http://www.ibiblio.org/xml/books/bible/updates/15.html21http://xml.apache.org/fop/
KAPITEL 4. MARKUP LANGUAGES 63
Hello, world!This is the second block in the hello world page. It has a verticalspace afterwards.And now there comes the third block! Pay attention!And the fourth and last block in the little Hello World FormattingObjects Example.
Abbildung 4.1: Das Ergebnis des Formatting Object Processors
Ein nettes Projekt, das ausgehend von HTML-Dokumenten von Word 2000 FO-Dokumente erstellt, istWH2FO22. Auf der Webseite sind auch einige schone Beispiele, die die Machtigkeit von FormattingObjects zeigen.
XML/XSL in the real-world
Im Moment gibt es mehrere Moglichkeiten, XML in Kombination mit XSL zu nutzen:
• Server seitig: Der Server transformiert das XML-Dokument mit Hilfe einer XSL-Datei zu einemHTML-Dokument (evtl. mit CSS). Der User Agent (Browser) stellt dieses HTML Dokument wiegewohnt dar.
• Client seitig mit XSL: Der Server sendet ein XML-Dokument mit dem dazugehorigen XSL Doku-ment an den User Agent. Dieser transformiert wiederum das Ergebnis und stellt es dar. Da imMoment nur der Internet Explorer eine XSL-Transformation unterstutzt, beschrankt sich dieserWeg auf Microsoft-Benutzer.
• Client seitig mit CSS: Der Server liefert ein XML Dokument und ein dazugehoriges CascadedStyle Sheet File aus. Der Browser benutzt diese Information, um die XML Daten darzustellen.Diese Methode wird zumindest vom IE, Opera und Mozilla unterstutzt. Ein Beispiel ist unterhttp://www.w3schools.com/xml/xml_display.asp zu finden. Obwohl dies im Moment die brow-serubergreifendste Moglichkeit ist, XML Dokumente zur Verfugung zu stellen, sollte es sich hier nurum eine Ubergangslosung handeln.
Ein Server, der schon eingesetzt werden kann und viele der obigen Features unterstutzt, ist z.B. Cocoonvom Apache-Projekt23
Weitere nutzliche XML/XSL-Werkzeuge:
• XSLT processor Xalan (Apache Projekt): http://xml.apache.org/xalan
• IBM-XSL-Editor: http://www.alphaworks.ibm.com/tech/xsleditor
• XML-Spy: Osterreichische Entwicklung! http://www.xmlspy.com
• Internet Explorer ab Version 5.0
• Das Kapitel 17 (XSL) der XML-Bible (2.Ed.)24 von Elliot Rusty Harrold ist online lesbar.
22http://wh2fo.sourceforge.net/index.html23http://xml.apache.org/cocoon24http://ibiblio.org/xml/books/bible2/chapters/ch17.html
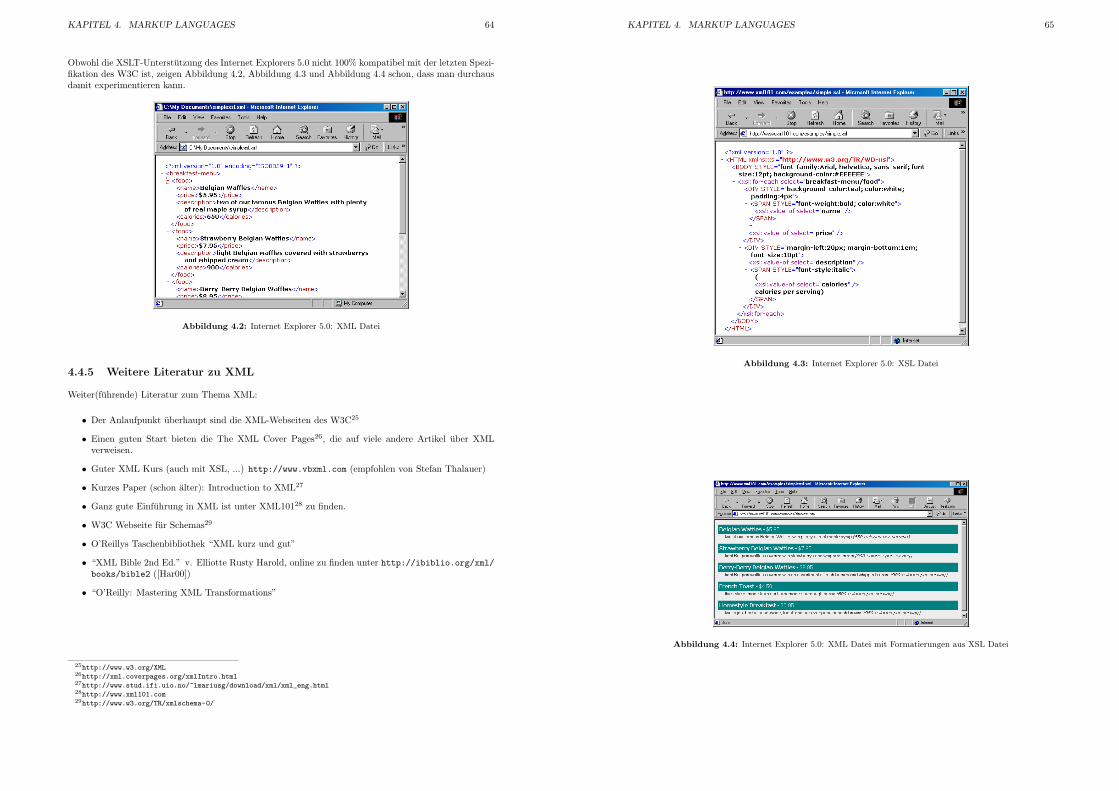
KAPITEL 4. MARKUP LANGUAGES 64
Obwohl die XSLT-Unterstutzung des Internet Explorers 5.0 nicht 100% kompatibel mit der letzten Spezi-fikation des W3C ist, zeigen Abbildung 4.2, Abbildung 4.3 und Abbildung 4.4 schon, dass man durchausdamit experimentieren kann.
Abbildung 4.2: Internet Explorer 5.0: XML Datei
4.4.5 Weitere Literatur zu XML
Weiter(fuhrende) Literatur zum Thema XML:
• Der Anlaufpunkt uberhaupt sind die XML-Webseiten des W3C25
• Einen guten Start bieten die The XML Cover Pages26, die auf viele andere Artikel uber XMLverweisen.
• Guter XML Kurs (auch mit XSL, ...) http://www.vbxml.com (empfohlen von Stefan Thalauer)
• Kurzes Paper (schon alter): Introduction to XML27
• Ganz gute Einfuhrung in XML ist unter XML10128 zu finden.
• W3C Webseite fur Schemas29
• O’Reillys Taschenbibliothek “XML kurz und gut”
• “XML Bible 2nd Ed.” v. Elliotte Rusty Harold, online zu finden unter http://ibiblio.org/xml/books/bible2 ([Har00])
• “O’Reilly: Mastering XML Transformations”
25http://www.w3.org/XML26http://xml.coverpages.org/xmlIntro.html27http://www.stud.ifi.uio.no/~lmariusg/download/xml/xml_eng.html28http://www.xml101.com29http://www.w3.org/TR/xmlschema-0/
KAPITEL 4. MARKUP LANGUAGES 65
Abbildung 4.3: Internet Explorer 5.0: XSL Datei
Abbildung 4.4: Internet Explorer 5.0: XML Datei mit Formatierungen aus XSL Datei
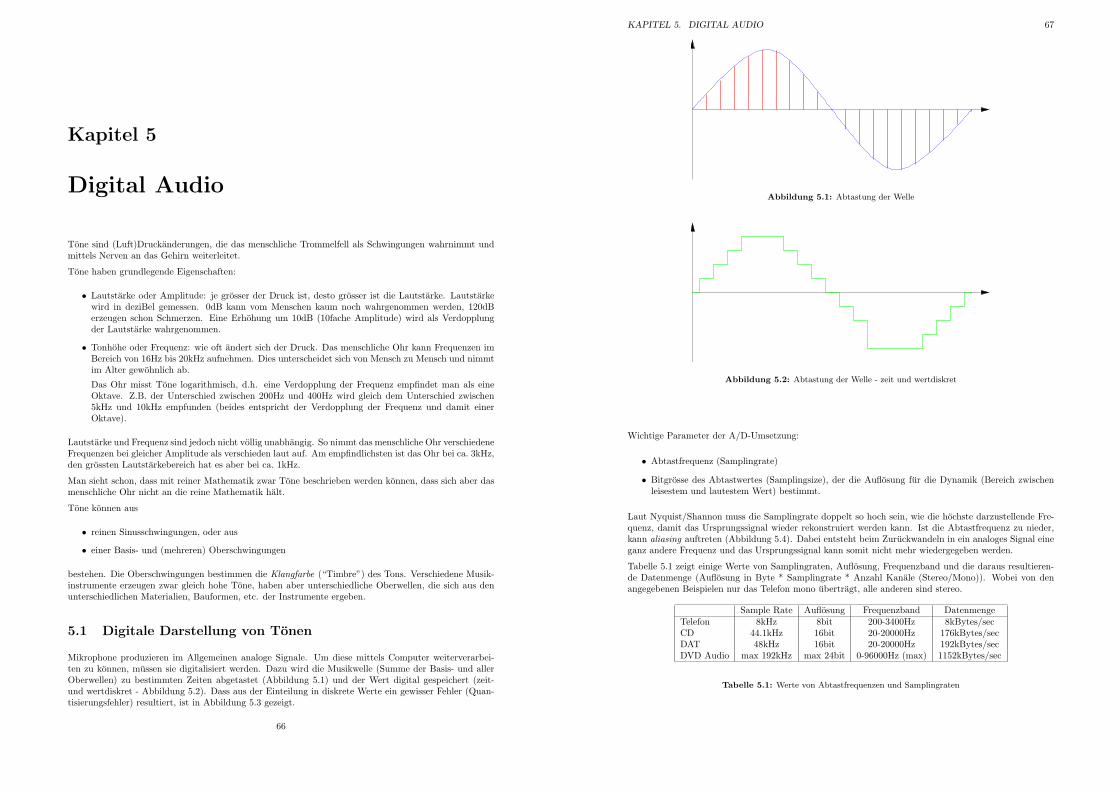
Kapitel 5
Digital Audio
Tone sind (Luft)Druckanderungen, die das menschliche Trommelfell als Schwingungen wahrnimmt undmittels Nerven an das Gehirn weiterleitet.
Tone haben grundlegende Eigenschaften:
• Lautstarke oder Amplitude: je grosser der Druck ist, desto grosser ist die Lautstarke. Lautstarkewird in deziBel gemessen. 0dB kann vom Menschen kaum noch wahrgenommen werden, 120dBerzeugen schon Schmerzen. Eine Erhohung um 10dB (10fache Amplitude) wird als Verdopplungder Lautstarke wahrgenommen.
• Tonhohe oder Frequenz: wie oft andert sich der Druck. Das menschliche Ohr kann Frequenzen imBereich von 16Hz bis 20kHz aufnehmen. Dies unterscheidet sich von Mensch zu Mensch und nimmtim Alter gewohnlich ab.
Das Ohr misst Tone logarithmisch, d.h. eine Verdopplung der Frequenz empfindet man als eineOktave. Z.B. der Unterschied zwischen 200Hz und 400Hz wird gleich dem Unterschied zwischen5kHz und 10kHz empfunden (beides entspricht der Verdopplung der Frequenz und damit einerOktave).
Lautstarke und Frequenz sind jedoch nicht vollig unabhangig. So nimmt das menschliche Ohr verschiedeneFrequenzen bei gleicher Amplitude als verschieden laut auf. Am empfindlichsten ist das Ohr bei ca. 3kHz,den grossten Lautstarkebereich hat es aber bei ca. 1kHz.
Man sieht schon, dass mit reiner Mathematik zwar Tone beschrieben werden konnen, dass sich aber dasmenschliche Ohr nicht an die reine Mathematik halt.
Tone konnen aus
• reinen Sinusschwingungen, oder aus
• einer Basis- und (mehreren) Oberschwingungen
bestehen. Die Oberschwingungen bestimmen die Klangfarbe (“Timbre”) des Tons. Verschiedene Musik-instrumente erzeugen zwar gleich hohe Tone, haben aber unterschiedliche Oberwellen, die sich aus denunterschiedlichen Materialien, Bauformen, etc. der Instrumente ergeben.
5.1 Digitale Darstellung von Tonen
Mikrophone produzieren im Allgemeinen analoge Signale. Um diese mittels Computer weiterverarbei-ten zu konnen, mussen sie digitalisiert werden. Dazu wird die Musikwelle (Summe der Basis- und allerOberwellen) zu bestimmten Zeiten abgetastet (Abbildung 5.1) und der Wert digital gespeichert (zeit-und wertdiskret - Abbildung 5.2). Dass aus der Einteilung in diskrete Werte ein gewisser Fehler (Quan-tisierungsfehler) resultiert, ist in Abbildung 5.3 gezeigt.
66
KAPITEL 5. DIGITAL AUDIO 67
Abbildung 5.1: Abtastung der Welle
Abbildung 5.2: Abtastung der Welle - zeit und wertdiskret
Wichtige Parameter der A/D-Umsetzung:
• Abtastfrequenz (Samplingrate)
• Bitgrosse des Abtastwertes (Samplingsize), der die Auflosung fur die Dynamik (Bereich zwischenleisestem und lautestem Wert) bestimmt.
Laut Nyquist/Shannon muss die Samplingrate doppelt so hoch sein, wie die hochste darzustellende Fre-quenz, damit das Ursprungssignal wieder rekonstruiert werden kann. Ist die Abtastfrequenz zu nieder,kann aliasing auftreten (Abbildung 5.4). Dabei entsteht beim Zuruckwandeln in ein analoges Signal eineganz andere Frequenz und das Ursprungssignal kann somit nicht mehr wiedergegeben werden.
Tabelle 5.1 zeigt einige Werte von Samplingraten, Auflosung, Frequenzband und die daraus resultieren-de Datenmenge (Auflosung in Byte * Samplingrate * Anzahl Kanale (Stereo/Mono)). Wobei von denangegebenen Beispielen nur das Telefon mono ubertragt, alle anderen sind stereo.
Sample Rate Auflosung Frequenzband DatenmengeTelefon 8kHz 8bit 200-3400Hz 8kBytes/secCD 44.1kHz 16bit 20-20000Hz 176kBytes/secDAT 48kHz 16bit 20-20000Hz 192kBytes/secDVD Audio max 192kHz max 24bit 0-96000Hz (max) 1152kBytes/sec
Tabelle 5.1: Werte von Abtastfrequenzen und Samplingraten
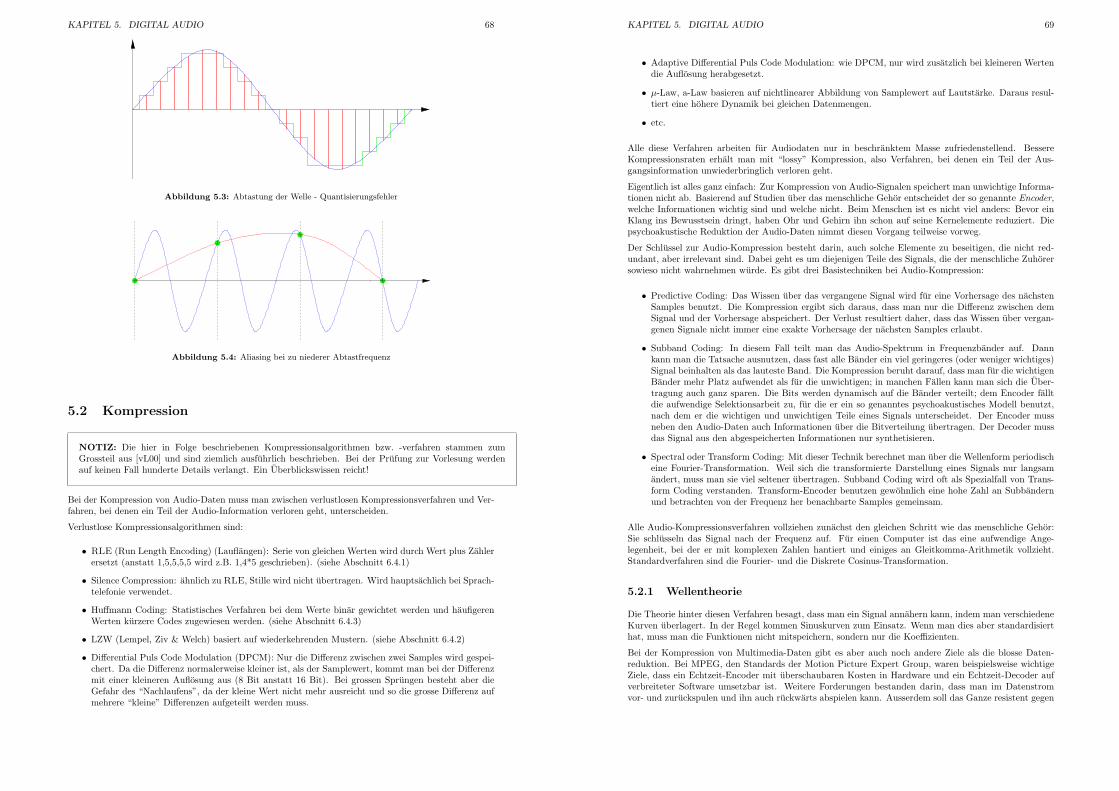
KAPITEL 5. DIGITAL AUDIO 68
Abbildung 5.3: Abtastung der Welle - Quantisierungsfehler
Abbildung 5.4: Aliasing bei zu niederer Abtastfrequenz
5.2 Kompression
NOTIZ: Die hier in Folge beschriebenen Kompressionsalgorithmen bzw. -verfahren stammen zumGrossteil aus [vL00] und sind ziemlich ausfuhrlich beschrieben. Bei der Prufung zur Vorlesung werdenauf keinen Fall hunderte Details verlangt. Ein Uberblickswissen reicht!
Bei der Kompression von Audio-Daten muss man zwischen verlustlosen Kompressionsverfahren und Ver-fahren, bei denen ein Teil der Audio-Information verloren geht, unterscheiden.
Verlustlose Kompressionsalgorithmen sind:
• RLE (Run Length Encoding) (Lauflangen): Serie von gleichen Werten wird durch Wert plus Zahlerersetzt (anstatt 1,5,5,5,5 wird z.B. 1,4*5 geschrieben). (siehe Abschnitt 6.4.1)
• Silence Compression: ahnlich zu RLE, Stille wird nicht ubertragen. Wird hauptsachlich bei Sprach-telefonie verwendet.
• Huffmann Coding: Statistisches Verfahren bei dem Werte binar gewichtet werden und haufigerenWerten kurzere Codes zugewiesen werden. (siehe Abschnitt 6.4.3)
• LZW (Lempel, Ziv & Welch) basiert auf wiederkehrenden Mustern. (siehe Abschnitt 6.4.2)
• Differential Puls Code Modulation (DPCM): Nur die Differenz zwischen zwei Samples wird gespei-chert. Da die Differenz normalerweise kleiner ist, als der Samplewert, kommt man bei der Differenzmit einer kleineren Auflosung aus (8 Bit anstatt 16 Bit). Bei grossen Sprungen besteht aber dieGefahr des “Nachlaufens”, da der kleine Wert nicht mehr ausreicht und so die grosse Differenz aufmehrere “kleine” Differenzen aufgeteilt werden muss.
KAPITEL 5. DIGITAL AUDIO 69
• Adaptive Differential Puls Code Modulation: wie DPCM, nur wird zusatzlich bei kleineren Wertendie Auflosung herabgesetzt.
• µ-Law, a-Law basieren auf nichtlinearer Abbildung von Samplewert auf Lautstarke. Daraus resul-tiert eine hohere Dynamik bei gleichen Datenmengen.
• etc.
Alle diese Verfahren arbeiten fur Audiodaten nur in beschranktem Masse zufriedenstellend. BessereKompressionsraten erhalt man mit “lossy” Kompression, also Verfahren, bei denen ein Teil der Aus-gangsinformation unwiederbringlich verloren geht.
Eigentlich ist alles ganz einfach: Zur Kompression von Audio-Signalen speichert man unwichtige Informa-tionen nicht ab. Basierend auf Studien uber das menschliche Gehor entscheidet der so genannte Encoder,welche Informationen wichtig sind und welche nicht. Beim Menschen ist es nicht viel anders: Bevor einKlang ins Bewusstsein dringt, haben Ohr und Gehirn ihn schon auf seine Kernelemente reduziert. Diepsychoakustische Reduktion der Audio-Daten nimmt diesen Vorgang teilweise vorweg.
Der Schlussel zur Audio-Kompression besteht darin, auch solche Elemente zu beseitigen, die nicht red-undant, aber irrelevant sind. Dabei geht es um diejenigen Teile des Signals, die der menschliche Zuhorersowieso nicht wahrnehmen wurde. Es gibt drei Basistechniken bei Audio-Kompression:
• Predictive Coding: Das Wissen uber das vergangene Signal wird fur eine Vorhersage des nachstenSamples benutzt. Die Kompression ergibt sich daraus, dass man nur die Differenz zwischen demSignal und der Vorhersage abspeichert. Der Verlust resultiert daher, dass das Wissen uber vergan-genen Signale nicht immer eine exakte Vorhersage der nachsten Samples erlaubt.
• Subband Coding: In diesem Fall teilt man das Audio-Spektrum in Frequenzbander auf. Dannkann man die Tatsache ausnutzen, dass fast alle Bander ein viel geringeres (oder weniger wichtiges)Signal beinhalten als das lauteste Band. Die Kompression beruht darauf, dass man fur die wichtigenBander mehr Platz aufwendet als fur die unwichtigen; in manchen Fallen kann man sich die Uber-tragung auch ganz sparen. Die Bits werden dynamisch auf die Bander verteilt; dem Encoder falltdie aufwendige Selektionsarbeit zu, fur die er ein so genanntes psychoakustisches Modell benutzt,nach dem er die wichtigen und unwichtigen Teile eines Signals unterscheidet. Der Encoder mussneben den Audio-Daten auch Informationen uber die Bitverteilung ubertragen. Der Decoder mussdas Signal aus den abgespeicherten Informationen nur synthetisieren.
• Spectral oder Transform Coding: Mit dieser Technik berechnet man uber die Wellenform periodischeine Fourier-Transformation. Weil sich die transformierte Darstellung eines Signals nur langsamandert, muss man sie viel seltener ubertragen. Subband Coding wird oft als Spezialfall von Trans-form Coding verstanden. Transform-Encoder benutzen gewohnlich eine hohe Zahl an Subbandernund betrachten von der Frequenz her benachbarte Samples gemeinsam.
Alle Audio-Kompressionsverfahren vollziehen zunachst den gleichen Schritt wie das menschliche Gehor:Sie schlusseln das Signal nach der Frequenz auf. Fur einen Computer ist das eine aufwendige Ange-legenheit, bei der er mit komplexen Zahlen hantiert und einiges an Gleitkomma-Arithmetik vollzieht.Standardverfahren sind die Fourier- und die Diskrete Cosinus-Transformation.
5.2.1 Wellentheorie
Die Theorie hinter diesen Verfahren besagt, dass man ein Signal annahern kann, indem man verschiedeneKurven uberlagert. In der Regel kommen Sinuskurven zum Einsatz. Wenn man dies aber standardisierthat, muss man die Funktionen nicht mitspeichern, sondern nur die Koeffizienten.
Bei der Kompression von Multimedia-Daten gibt es aber auch noch andere Ziele als die blosse Daten-reduktion. Bei MPEG, den Standards der Motion Picture Expert Group, waren beispielsweise wichtigeZiele, dass ein Echtzeit-Encoder mit uberschaubaren Kosten in Hardware und ein Echtzeit-Decoder aufverbreiteter Software umsetzbar ist. Weitere Forderungen bestanden darin, dass man im Datenstromvor- und zuruckspulen und ihn auch ruckwarts abspielen kann. Ausserdem soll das Ganze resistent gegen
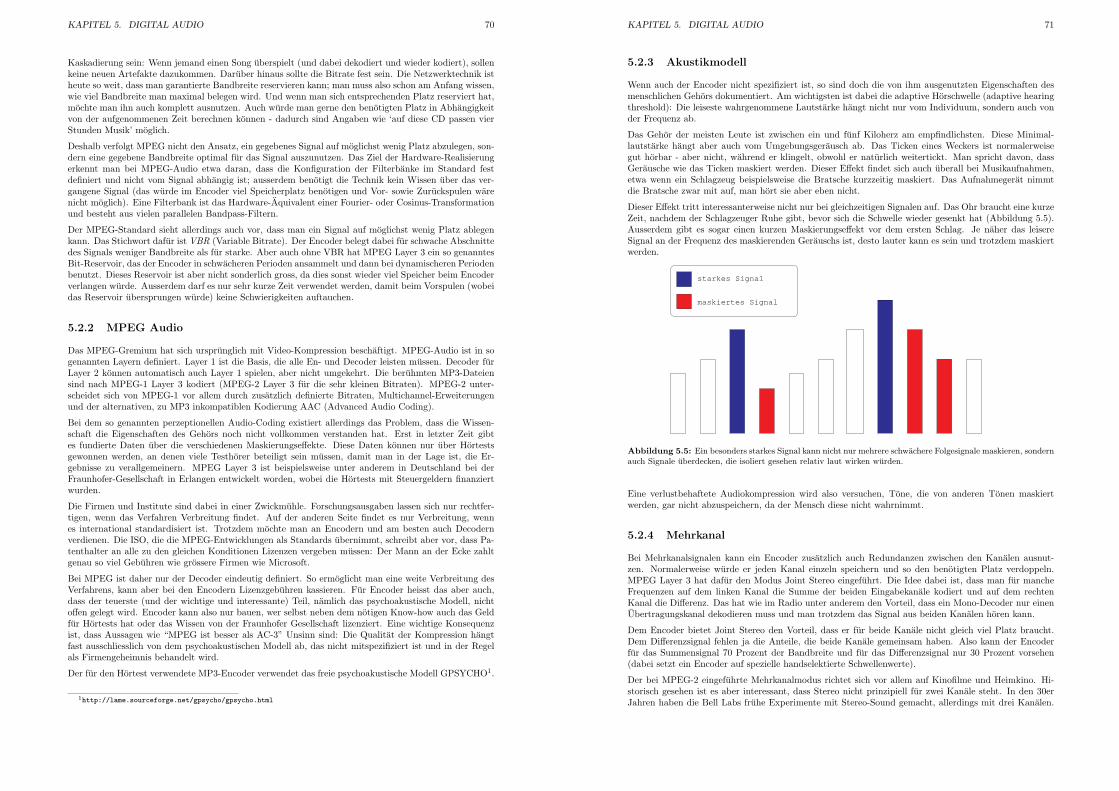
KAPITEL 5. DIGITAL AUDIO 70
Kaskadierung sein: Wenn jemand einen Song uberspielt (und dabei dekodiert und wieder kodiert), sollenkeine neuen Artefakte dazukommen. Daruber hinaus sollte die Bitrate fest sein. Die Netzwerktechnik istheute so weit, dass man garantierte Bandbreite reservieren kann; man muss also schon am Anfang wissen,wie viel Bandbreite man maximal belegen wird. Und wenn man sich entsprechenden Platz reserviert hat,mochte man ihn auch komplett ausnutzen. Auch wurde man gerne den benotigten Platz in Abhangigkeitvon der aufgenommenen Zeit berechnen konnen - dadurch sind Angaben wie ‘auf diese CD passen vierStunden Musik’ moglich.
Deshalb verfolgt MPEG nicht den Ansatz, ein gegebenes Signal auf moglichst wenig Platz abzulegen, son-dern eine gegebene Bandbreite optimal fur das Signal auszunutzen. Das Ziel der Hardware-Realisierungerkennt man bei MPEG-Audio etwa daran, dass die Konfiguration der Filterbanke im Standard festdefiniert und nicht vom Signal abhangig ist; ausserdem benotigt die Technik kein Wissen uber das ver-gangene Signal (das wurde im Encoder viel Speicherplatz benotigen und Vor- sowie Zuruckspulen warenicht moglich). Eine Filterbank ist das Hardware-Aquivalent einer Fourier- oder Cosinus-Transformationund besteht aus vielen parallelen Bandpass-Filtern.
Der MPEG-Standard sieht allerdings auch vor, dass man ein Signal auf moglichst wenig Platz ablegenkann. Das Stichwort dafur ist VBR (Variable Bitrate). Der Encoder belegt dabei fur schwache Abschnittedes Signals weniger Bandbreite als fur starke. Aber auch ohne VBR hat MPEG Layer 3 ein so genanntesBit-Reservoir, das der Encoder in schwacheren Perioden ansammelt und dann bei dynamischeren Periodenbenutzt. Dieses Reservoir ist aber nicht sonderlich gross, da dies sonst wieder viel Speicher beim Encoderverlangen wurde. Ausserdem darf es nur sehr kurze Zeit verwendet werden, damit beim Vorspulen (wobeidas Reservoir ubersprungen wurde) keine Schwierigkeiten auftauchen.
5.2.2 MPEG Audio
Das MPEG-Gremium hat sich ursprunglich mit Video-Kompression beschaftigt. MPEG-Audio ist in sogenannten Layern definiert. Layer 1 ist die Basis, die alle En- und Decoder leisten mussen. Decoder furLayer 2 konnen automatisch auch Layer 1 spielen, aber nicht umgekehrt. Die beruhmten MP3-Dateiensind nach MPEG-1 Layer 3 kodiert (MPEG-2 Layer 3 fur die sehr kleinen Bitraten). MPEG-2 unter-scheidet sich von MPEG-1 vor allem durch zusatzlich definierte Bitraten, Multichannel-Erweiterungenund der alternativen, zu MP3 inkompatiblen Kodierung AAC (Advanced Audio Coding).
Bei dem so genannten perzeptionellen Audio-Coding existiert allerdings das Problem, dass die Wissen-schaft die Eigenschaften des Gehors noch nicht vollkommen verstanden hat. Erst in letzter Zeit gibtes fundierte Daten uber die verschiedenen Maskierungseffekte. Diese Daten konnen nur uber Hortestsgewonnen werden, an denen viele Testhorer beteiligt sein mussen, damit man in der Lage ist, die Er-gebnisse zu verallgemeinern. MPEG Layer 3 ist beispielsweise unter anderem in Deutschland bei derFraunhofer-Gesellschaft in Erlangen entwickelt worden, wobei die Hortests mit Steuergeldern finanziertwurden.
Die Firmen und Institute sind dabei in einer Zwickmuhle. Forschungsausgaben lassen sich nur rechtfer-tigen, wenn das Verfahren Verbreitung findet. Auf der anderen Seite findet es nur Verbreitung, wennes international standardisiert ist. Trotzdem mochte man an Encodern und am besten auch Decodernverdienen. Die ISO, die die MPEG-Entwicklungen als Standards ubernimmt, schreibt aber vor, dass Pa-tenthalter an alle zu den gleichen Konditionen Lizenzen vergeben mussen: Der Mann an der Ecke zahltgenau so viel Gebuhren wie grossere Firmen wie Microsoft.
Bei MPEG ist daher nur der Decoder eindeutig definiert. So ermoglicht man eine weite Verbreitung desVerfahrens, kann aber bei den Encodern Lizenzgebuhren kassieren. Fur Encoder heisst das aber auch,dass der teuerste (und der wichtige und interessante) Teil, namlich das psychoakustische Modell, nichtoffen gelegt wird. Encoder kann also nur bauen, wer selbst neben dem notigen Know-how auch das Geldfur Hortests hat oder das Wissen von der Fraunhofer Gesellschaft lizenziert. Eine wichtige Konsequenzist, dass Aussagen wie “MPEG ist besser als AC-3” Unsinn sind: Die Qualitat der Kompression hangtfast ausschliesslich von dem psychoakustischen Modell ab, das nicht mitspezifiziert ist und in der Regelals Firmengeheimnis behandelt wird.
Der fur den Hortest verwendete MP3-Encoder verwendet das freie psychoakustische Modell GPSYCHO1.
1http://lame.sourceforge.net/gpsycho/gpsycho.html
KAPITEL 5. DIGITAL AUDIO 71
5.2.3 Akustikmodell
Wenn auch der Encoder nicht spezifiziert ist, so sind doch die von ihm ausgenutzten Eigenschaften desmenschlichen Gehors dokumentiert. Am wichtigsten ist dabei die adaptive Horschwelle (adaptive hearingthreshold): Die leiseste wahrgenommene Lautstarke hangt nicht nur vom Individuum, sondern auch vonder Frequenz ab.
Das Gehor der meisten Leute ist zwischen ein und funf Kiloherz am empfindlichsten. Diese Minimal-lautstarke hangt aber auch vom Umgebungsgerausch ab. Das Ticken eines Weckers ist normalerweisegut horbar - aber nicht, wahrend er klingelt, obwohl er naturlich weitertickt. Man spricht davon, dassGerausche wie das Ticken maskiert werden. Dieser Effekt findet sich auch uberall bei Musikaufnahmen,etwa wenn ein Schlagzeug beispielsweise die Bratsche kurzzeitig maskiert. Das Aufnahmegerat nimmtdie Bratsche zwar mit auf, man hort sie aber eben nicht.
Dieser Effekt tritt interessanterweise nicht nur bei gleichzeitigen Signalen auf. Das Ohr braucht eine kurzeZeit, nachdem der Schlagzeuger Ruhe gibt, bevor sich die Schwelle wieder gesenkt hat (Abbildung 5.5).Ausserdem gibt es sogar einen kurzen Maskierungseffekt vor dem ersten Schlag. Je naher das leisereSignal an der Frequenz des maskierenden Gerauschs ist, desto lauter kann es sein und trotzdem maskiertwerden.
starkes Signal
maskiertes Signal
Abbildung 5.5: Ein besonders starkes Signal kann nicht nur mehrere schwachere Folgesignale maskieren, sondernauch Signale uberdecken, die isoliert gesehen relativ laut wirken wurden.
Eine verlustbehaftete Audiokompression wird also versuchen, Tone, die von anderen Tonen maskiertwerden, gar nicht abzuspeichern, da der Mensch diese nicht wahrnimmt.
5.2.4 Mehrkanal
Bei Mehrkanalsignalen kann ein Encoder zusatzlich auch Redundanzen zwischen den Kanalen ausnut-zen. Normalerweise wurde er jeden Kanal einzeln speichern und so den benotigten Platz verdoppeln.MPEG Layer 3 hat dafur den Modus Joint Stereo eingefuhrt. Die Idee dabei ist, dass man fur mancheFrequenzen auf dem linken Kanal die Summe der beiden Eingabekanale kodiert und auf dem rechtenKanal die Differenz. Das hat wie im Radio unter anderem den Vorteil, dass ein Mono-Decoder nur einenUbertragungskanal dekodieren muss und man trotzdem das Signal aus beiden Kanalen horen kann.
Dem Encoder bietet Joint Stereo den Vorteil, dass er fur beide Kanale nicht gleich viel Platz braucht.Dem Differenzsignal fehlen ja die Anteile, die beide Kanale gemeinsam haben. Also kann der Encoderfur das Summensignal 70 Prozent der Bandbreite und fur das Differenzsignal nur 30 Prozent vorsehen(dabei setzt ein Encoder auf spezielle handselektierte Schwellenwerte).
Der bei MPEG-2 eingefuhrte Mehrkanalmodus richtet sich vor allem auf Kinofilme und Heimkino. Hi-storisch gesehen ist es aber interessant, dass Stereo nicht prinzipiell fur zwei Kanale steht. In den 30erJahren haben die Bell Labs fruhe Experimente mit Stereo-Sound gemacht, allerdings mit drei Kanalen.

KAPITEL 5. DIGITAL AUDIO 72
In den Kinos gab es in den 50er Jahren erstmals Stereo, wobei vier bis sieben Kanale gemeint waren.Stereo wurde erst zum Synonym fur zwei Kanale, als es in Form des Plattenspielers die Privathaushalteerreichte. Der Plattenspieler bildete Stereo uber die beiden Seiten der Rille auf der Schallplatte ab undwar deshalb durch die Hardware auf zwei Kanale limitiert.
Die Dolby Labs haben mit dem Dolby-Surround-Verfahren Mehrkanal-Ton im Heim etabliert, der diezusatzlichen Kanale analog im Zweikanal-Signal versteckt. Dolby hat sich schon bei der beruhmtenRauschunterdruckung (etwa Dolby B und Dolby C bei Kassettendecks) mit der Psychoakustik beschaftigt.Anfangs wurde einfach gemessen, welche Teile des Signals Kassetten gewohnlich verrauschen - das Signalhat man dann einfach lauter aufgespielt und beim Abspielen wieder (mit dem Rauschen) leiser gere-gelt. Spater hat Dolby dann auch mit AC1 bis AC3 (inzwischen Dolby Digital genannt) verschiedeneKompressionsverfahren fur Digital-Sound beim Kinofilm entwickelt.
5.2.5 Weitere Kompressionsverfahren
Auch Dolby spezifiziert wie MPEG nicht den Encoder, sondern nur den Decoder und ist damit genau so’offen’ wie MPEG. Das Unternehmen hat allerdings nach eigenen Aussagen doppelt so viele Anwalte wieIngenieure, was moglicherweise einer der Grunde dafur ist, dass bisher niemand ausser Dolby einen AC-3Encoder gebaut hat. AC-3 ist heute im Kino und auf DVDs neben MPEG-2 (allerdings nur Layer 2,nicht AAC) der am haufigsten eingesetzte Standard zur Audio-Kompression. Fur Kinofilme und DVDshaben sich auch 5.1-Kanale durchgesetzt, wobei der Zehntel-Kanal fur Bass-Effekte gedacht ist und sehrwenig Bandbreite hat.
Neben MPEG und AC-3 ist Sonys proprietares MiniDisc-Verfahren ATRAC relativ verbreitet. ATRACkomprimiert immerhin auf ein Funftel der Originalgrosse - dies ist zwar heute nicht mehr sehr viel, aberbei Erscheinen der MiniDisc war dieser Kompressionsfaktor sehr beeindruckend. Ohne ATRAC wurdennur 15 Minuten auf eine MiniDisc passen.
5.2.6 MPEG Layer 1
Der erste Schritt bei MPEG ist die Polyphase-Filterbank, die das Signal in 32 gleich breite Frequenz-Subbander aufteilt. Die Filter sind verhaltnismassig einfach und haben eine gute Zeitauflosung; dieFrequenzauflosung ist ebenfalls recht brauchbar. Bis auf drei Punkte ist das Design ein guter Kompromiss:
• Das Gehor teilt das Signal nicht in gleich breite Subbander auf, sondern sie werden mit steigenderFrequenz exponentiell breiter. Bei den Maskierungseffekten kann man die Subbander des Gehorsbeobachten (von 100 Hz fur tiefe Frequenzen bis 4 kHz fur Hohen), nicht die von MPEG.
• Die Filterbank und die Synthese sind verlustbehaftet. Das ist allerdings nicht horbar.
• Benachbarte Bander haben signifikante Frequenzuberlappung, weil die Filterbanke nicht scharfabschneiden, sondern mit Cosinus approximieren. Ein Ton auf einer Frequenz kann also in zweiSubbandern auftauchen und so die Kompression verschlechtern (Aliasing).
Die Filterbank nimmt je 32 Eingabe-Samples und produziert daraus je ein Sample in jedem der 32Subbander. Ein Layer-1-Frame hat insgesamt 384 Samples, in dem er zwolf Samples aus jedem der 32Subbander gruppiert. Der Encoder befragt das psychoakustische Modell und allokiert dann pro Sample-Gruppe entsprechend Bits. Wenn eine Sample-Gruppe mehr als 0 Bits zugewiesen bekommen hat, wirdauch ein 6-Bit-Skalierungsfaktor mitgespeichert: So kann man den Wertebereich des Quantisierers ver-grossern.
5.2.7 MPEG Layer 2
Layer 2 kodiert die Daten in grosseren Gruppen und schrankt die Bit-Allokationen in mittleren undhohen Subbandern ein, weil diese fur das Gehor nicht so wichtig sind. Die Bit-Allokationsdaten, dieSkalierungsfaktoren und die quantisierten Samples werden kompakter abgelegt. Durch diese Einsparungenkonnen mehr Bits in die Audio-Daten investiert werden.
KAPITEL 5. DIGITAL AUDIO 73
Ein Layer 2 Frame hat 1152 Samples pro Kanal. Es werden nicht Gruppen von zwolf Samples betrachtet,sondern Dreier-Blocke zu je zwolf Samples pro Subband. Die Bits vergibt das Verfahren pro Dreiergruppe,aber es existieren bis zu drei Skalierungsfaktoren. Ausserdem kann Layer 2 drei quantisierte Werte ineinem einzigen, kompakteren Code-Wort ablegen, wenn er drei, funf oder neun Levels fur die Subband-Quantisierung vergeben hat.
5.2.8 MP3 - MPEG Layer 3
MPEG Layer 3 (meist als MP3 bezeichnet) benutzt eine modifizierte diskrete Cosinus-Transformation(MDCT) auf die Ausgabe der Filterbanke und erhoht damit die Auflosung drastisch. Dadurch kann Layer3 auch die Aliasing-Effekte zuruckrechnen - der Decoder muss das allerdings wieder hinzufugen. Layer3 spezifiziert zwei MDCT-Blocklangen: 18 und sechs Samples. Aufeinander folgende Transformations-Fenster uberlappen sich zu 50 Prozent, sodass die Fenster 36 und 12 Samples umfassen. Die langeBlockgrosse ermoglicht eine bessere Frequenzauflosung fur stationare Audio-Signale, wahrend die kurzeBlocklange bessere Zeitauflosung fur transiente impulsartige Signale bietet. Layer 3 definiert Varianten,in welcher Kombination kurze und lange Blocke vorkommen konnen. Der Wechsel zwischen Blocklangenfunktioniert nicht unmittelbar, sondern wird durch einen speziellen langen Block eingeleitet.
Weil MDCT bessere Frequenzauflosung bietet, ist die Zeitauflosung entsprechend schlechter. MDCToperiert auf 12 oder 36 Filterbank-Samples, also ist das effektive Zeitfenster um den Faktor 12 oder 36grosser. Das Quantisierungsrauschen erzeugt also Fehler, die uber dieses grosse Zeitfenster verteilt sind- es ist wahrscheinlicher, dass man sie hort. Bei einem Signal, in dem sich laute und leise Abschnitte inschneller Folge abwechseln, verteilt sich das Rauschen nicht nur auf die lauten Stellen, wo man es wenigerstark horen wurde, sondern auch auf die leisen. Diese Storungen treten gewohnlich als Pre-Echo auf, weildie temporale Maskierung vor einem Signal schwacher (und kurzer) ist als danach.
Neben MDCT hat Layer 3 noch andere Verbesserungen gegenuber fruheren Verfahren:
• Layer 3 kann die Aliasing-Effekte der Filterbank wegrechnen.
• Der Quantisierer potenziert die Eingabe mit 3/4, um die Signal-to-Noise-Ratio gleichmassiger aufden Wertebereich der Quantisierungswerte zu verteilen. Der Decoder muss das naturlich wiederruckgangig machen.
• Die Skalierungsfaktoren werden bei Layer 3 in Bandern zusammengefasst. Ein Band umfasstmehrere MDCT-Koeffizienten und hat ungefahr die Breite der Bander des Gehors. So wird dasQuantisierungsrauschen ahnlich den Konturen der Maskierungsschwelle eingefarbt, damit es keineRausch-Spitzen gibt.
• Layer 3 benutzt einen statischen Huffman-Code fur die quantisierten Samples. Der Encoder sortiertdie 576 Koeffizienten (32 Subbander x 18 MDCT-Koeffizienten) in einer standardisierten Reihen-folge. Dies soll dafur sorgen, dass die hohen Werte von den tiefen Frequenzen am Anfang stehenund die kleinen am Ende. Dann vergibt der Encoder fur die hohen Werte am Anfang lange undfur die kleinen Werte kurze Code-Worter. Die Koeffizienten werden in drei Regionen aufgeteilt, diejeweils eine speziell optimierte Huffman-Tabelle benutzen. Teilweise bildet man hier auch mehrereZahlen auf einen Huffman-Code ab.
• Das Bit-Reservoir ist ebenfalls eine Innovation von Layer 3. Der Encoder darf nur Bits entnehmen,die er vorher in das Reservoir gepackt hat - Kredit wird nicht gegeben.
5.2.9 MPEG2/4 AAC
Die Details von AAC wurden den Rahmen hier bei weitem sprengen. Grundsatzlich teilt AAC dasSignal erst mit einem Polyphase Quadrature Filter (PQF) in vier Subbander, fur die es jeweils einenVerstarkungsfaktor separat ubertragt. Die vier Subbander werden jeweils mit einer MDCT der Lange256 transformiert - fur sehr dynamische Passagen kommt auch eine MDCT-Lange von 32 zum Einsatz.
Die Koeffizienten sagt AAC aber mit einem speziellen Mechanismus fur jedes Frequenzband aus denzwei vorhergehenden Frames vorher. Bei stationaren Signalen erhoht das die Effizienz. Die Differenzen

KAPITEL 5. DIGITAL AUDIO 74
quantisiert das Verfahren nicht-uniform; es benutzt einen von zwolf vordefinierten Huffman-Codes. Einewichtige Neuerung ist das Temporal Noise Shaping (TNS), das auf dynamische Signale zugeschnitten ist.Dabei nutzt man die Beobachtung aus, dass ein Ton in der Frequenzdarstellung wie ein Impuls aussieht.Umgekehrt sieht ein Impuls in der Frequenzdarstellung wie ein tonales Signal aus. Tonale Signale kannman mit einem Linear Predictive Coding (LPC)-Ansatz gut vorhersagen. Es kommt dann ein linearerVorhersager zum Einsatz, um das nachste spektrale Sample zu bestimmen.
Im Zuge von MPEG-4 wurde in AAC noch eine sog. Perceptual Noise Substituion eingebaut. Der Encodercodiert Rauschen nicht mehr, sondern teilt dem Decoder lediglich die Rauschleistung und die Frequenzmit.
MPEG4-AAC gliedert sich in verschiedene Profile, die jeweils verschiedene Techniken ausnutzen. Sounterstutzt QuickTime 6 momentan nur das “Low Complexity” (LC) Profil, wahrend der FrauenhoferCodec Daten fur das “Long Term Prediction” (LPT) Profil erzeugt. Somit kann der QuickTime Playerdiese nicht decodieren.
5.2.10 MP3 Pro
MP3 Pro erweitert und verbessert MP3 bei niedrigeren Bitraten (um 64kBit/s) bei Kompatibilitat zumMP3-Format. Die Kompatibilitat heißt allerdings nicht, dass die verbesserten Fahigkeiten von MP3 Proauch mit einem “normalen” MP3 Decoder genutzt werden konnen.
MP3 Pro versucht mittels Spectral Band Replication (SBR) die bei MP3 verlorenen hoheren Harmonischenzu rekonstruieren. Beim Kodieren wird diese Zusatzinformation in den MP3-Bitstrom eingefugt. SBRverliert bei hoheren Bitraten zunehmend an Wirkung, sodaß bei Bitraten uber 96kBit/s der Einsatzkeinen Sinn mehr macht.
Ein Nachteil des MP3 Pro Formats ist auch, dass es bei keiner Bitrate tatsachliche Transparenz (keinwahrnehmbarer Unterschied zwischen Original und codiertem Stuck) erzeugt. [LZ02]
5.2.11 Ogg Vorbis
Ogg Vorbis ist ein Oberbegriff fur eine Vielzahl von Multimediaformaten der Xiphophorous Foundation2.Das Besondere an Ogg Vorbis ist, dass es sich um ein patent- und lizenzfreies Modell handelt. DerOpen-Source Codec geniesst daher schon aus diesem Grund einen guten Ruf.
Ogg Vorbis liefert aber auch eine sehr gute Tonqualitat. Er ist (lt. [LZ02]) auch der einzige Codec, derbei einer Bitrate von 128kBit/s das Signal erst bei 20kHz beschneidet (bei 64kBit/s immerhin erst bei15,2kHz).
Ogg Vorbis unterstutzt bis zu 255 Kanale und es gibt schon Bestrebungen, Multikanal fur DivX Videoszu nutzen.
Sowohl beim C’t Test [LZ02] als auch bei einem Test der Zeitschrift Chip3, schnitt Ogg Vorbis erstklassigab.
5.2.12 TwinVQ
TwinVQ wurde vom japanischen Telekommunikationskonzern NTT entwickelt und verfolgt einen anderenAnsatz als MPEG. Beide Verfahren wandeln zwar das Signal in die Kurzzeit-Frequenzdarstellung, aberTwinVQ kodiert die Samples dann nicht, sondern betrachtet jeweils Muster aus Samples in Form vonVektoren. Der Encoder greift auf eine Tabelle von Standardmustern zuruck, mit denen er die Eingabe-vektoren vergleicht. Der Index des Vektors, der der Eingabe am nachsten ist, wird dann ubertragen.
Die Artefakte von TwinVQ sind anders als bei MPEG. Es klingt nicht so, als wurde Rauschen dazu-kommen, sondern als wurden Teile des Signals verloren gehen: Es klingt sozusagen ’weichgespult’. BeiSprachubertragung geht dabei gewohnlich unter anderem beispielsweise der Strassenlarm-Teil des Signals
2http://www.xiph.org/3http://www.chip.de/produkte_tests/produkte_tests_8731098.html
KAPITEL 5. DIGITAL AUDIO 75
verloren. Daher ist TwinVQ fur Sprachubertragung und fur sehr kleine Bitraten ausgezeichnet geeignetund wurde in MPEG-4 aufgenommen.
5.2.13 ATRAC
ATRAC steht fur Adaptive Transform Accoustic Coding und ist der von Sony entwickelte Codec fur dieMiniDiscs. Ein ATRAC-Frame hat 512 Samples; die Eingabe wird erstmal mit einem QMF (QuadratureMirror Filter) in drei Subbander unterteilt, die jeweils nochmal mit MDCT aufgeteilt werden: 0 bis 5,5kHz (128 MDCT), 5,5 bis 11 kHz (128 MDCT) und 11 bis 22 kHz (256 MDCT). Es gibt auch einenlangen Block-Modus (11,6 ms) und einen Modus mit drei kurzen Blocken (2,9 ms + 2,9 ms + 1,45 ms).Die Koeffizienten quantisiert ATRAC nach Wortlange und versieht sie mit einem Skalierungsfaktor.
Bei ATRAC schleichen sich bei einer Kaskadierung Artefakte ein. MPEG hingegen hat sich in Hortestsals weitgehend resistent dagegen erwiesen.
5.2.14 Dolby AC-3/QDesign
Dolby AC-3 ist ebenfalls ein psychoakustischer Transformations-Codec, der eine Filterbank mit Aliasing-Kurzung verwendet. Uberlappende Blocke aus 512 Eingabe-Samples wandelt das Verfahren mit einerTransformation zu 256 spektralen Koeffizienten. Die Transformation hat die Eigenschaften von MDCT;die AC-3 Dokumente nennen es allerdings nur TDAC: Dies bedeutet nichts anderes als Time DomainAliasing Cancellation und beschreibt die wichtigste Eigenschaft von MDCT.
Dolby macht zu dem Verfahren keine genaueren Angaben, weil es sich um ein Geschaftsgeheimnis handle,das man nur mit einer Vereinbarung, keine Details zu veroffentlichen, lizenzieren kann. Ahnliches erfahrtman auch von QDesign, Hersteller des Audio-Codec von Apples QuickTime: Anfragen wies die Firmamit dem Hinweis ab, dass es sich bei den technischen Details um ein Geschaftsgeheimnis handle. DieFirma behauptet jedenfalls, ihr psychoakustisches Modell selbst entwickelt zu haben. Leider sind uberden Algorithmus keine Details bekannt; auf der Webseite von QDesign findet man nur die Aussage, dassihr neuer Codec die Audio-Quelle parametrisch erfasst, das Signal in ’relevante Komponenten’ zerlegtund das Ergebnis als Koeffizienten ablegt. Von der Differenz speichert der Encoder ab, wofur er Platzhat.
5.2.15 Wave
Dieses Audioformat (Dateiendung *.wav) von Microsoft und IBM ist Bestandteil der RIFF (ResourceInterchange File Format)-Spezifikation und war ursprunglich nur fur 16-Bit-Stereo und maximal 44.1kHzSample-Frequenz gedacht. Dies hielt die Audioindustrie jedoch nicht davon ab, dieses Format mit 32 Bitund 96kHz zu nutzen. In diesem verlustfreien Format konnen einfach die Daten der PCM-Codierung,aber auch die Codierungsalgorithmen a-Law, µ-Law (Dynamik Kompression) und ADPCM verwendetwerden.
5.2.16 MSAudio - WMA
Microsoft hat innerhalb kurzester Zeit ASF als ein Konkurrenzmodell zu MP3 aus dem Boden gestampft,das sowohl Audio als auch Video enthalten kann. Es ermoglicht Streaming bis zu 160kbit/sec.
Einiges zum Thema MSAudio lasst sich derzeit gar nicht oder nur vage beantworten. So hort man ausansonsten gut unterrichteten Kreisen, Microsoft habe Entwickler extra eingekauft. Die Zeit fur lang-wierige Forschung und Horversuche hatte die Firma wohl nicht. Die dem Perceptual Audio Codingzugrundeliegenden Verfahren sind uberall bestens dokumentiert und veroffentlicht - hier lasst sich frem-des Know-how wunderbar ausschlachten. Dass es sich bei MSAudio nicht um eine revolutionare neueTechnologie handelt, wird schon daran deutlich, dass Microsoft bisher keinerlei Patente angemeldet hat.[CO99]
Die WMA 9 Version von Microsofts Audio Codec kann zusatzlich zu den verlustbehafteten Kompressi-onsarten auch mit einer Verlustlosen aufwarten. Der Player hat allerdings das Problem, dass er nur unter

KAPITEL 5. DIGITAL AUDIO 76
Windows XP lauft.
5.2.17 Realaudio
Dieses Streamingverfahren verwendet ein unbekanntes (Firmengeheimnis) Coding.
Real erweiterte seinen Real-Audio 8 Codec um Surround Eigenschaften, bleibt aber trotzdem abwarts-kompatibel.
Ein Vorteil dieses Formats ist die Verfugbarkeit des Real Players, den es fur alle Betriebssysteme gibt.
In Version 9 hat RealNetworks grosse Teile seines Codes als Open Source (RealNetworks Public SourceLicense (RPSL)) zur Verfugung gestellt. Unter http://www.helixcommunity.org/ finden sich mehrDetails.
5.2.18 Literatur zu Digital Audio
• Ein Grossteil des Wissens in diesem Kapitel stammt aus [vL00] bzw. aus [LZ02].
• Ein ganz guter Artikel uber “Audio Compression” ist unter http://www.cs.sfu.ca/undergrad/CourseMaterials/CMPT479/material/notes/Chap4/Chap4.3/Chap4.3.html zu finden. Vor al-lem ist da eine Beschreibung, wie ein psychoakustisches Modell entwickelt wird, zu finden.
• Fur den MP3-Hortest wurde das Programm “lame” verwendet. http://lame.sourceforge.net/
• eine gute Linksammlung ist auf http://www.mpeg.org/MPEG/links.html zu finden.
5.3 MP3 Hortest
Fur den mp3-Hortest wurden verschiedene Teile von Musikstucken von CD in mp3-Dateien codiert.Ein gute Mischung aus verschiedenen Musikstilen wurde gegenuber einer akademischen Klanganalysebevorzugt.
Eine genaue Auflistung der verwendeten Stucke und wie diese erzeugt wurden, ist in Anhang A zu finden.
5.4 MIDI
Musical Instrument Digital Interface (MIDI) ist kein Soundformat, wie die oben besprochenen, sonderneine Definition von Klangbeschreibungen. Es dient nicht zum Digitialisieren von bestehender Musik,sondern vielmehr zum Produzieren von neuer Musik. Es wurde 1983 von Sythesizerfirmen als seriellerSchnittstellenstandard zum Austausch von Musikdaten definiert. MIDI beschreibt keine Einzelsamples,sondern Daten wie
• Tonhohe
• Lautstarke
• Klangbild
• Anschlagdynamik
• Instrument
• etc.
Generell verfolgt MIDI das Ziel, durch eine standardisierte Beschreibung des Klanges, diesen uberall, auchmit verschiedenen Geraten, reproduzieren zu konnen. Dies ermoglicht eine sehr effiziente Ubertragung
KAPITEL 5. DIGITAL AUDIO 77
(da ja nicht der Klang selbst, sondern nur eine Beschreibung, wie er erzeugt werden kann, ubertragenwerden muss), setzt aber auch voraus, dass alle MIDI-Gerate die verwendeten Klange abspielen konnen.
General MIDI stellt dazu eine Instrumententabelle4 und eine percussion map5 zur Verfugung, die garan-tieren soll, dass alle beteiligten MIDI-Gerate “die gleiche Sprache sprechen”.
MIDI-Gerate kommunizieren mittels Nachrichten. Es gibt zwei Arten von Nachrichten:
• Channel Messages: werden benutzt, um einzelne Kanale anzusprechen, und nicht ein oder mehrerekomplette MIDI-Gerate
• System Messages: tragen nicht Kanal-spezifische Informationen, wie z.B. timing-Signale fur dieSynchronisation oder Setup-Informationen fur ein MIDI-Gerat
Channel Messages enthalten Informationen,
• welche bestimmten Klange ein Instrument abspielen soll,
• dass bestimmte Noten ein- oder ausgeschaltet werden sollen,
• dass der aktuelle Ton oder die aktuelle Note verandert werden soll.
Eine byte-genaue Aufschlusselung der Nachrichten wurde hier den Rahmen sprengen, kann aber unterhttp://www.cs.sfu.ca/CourseCentral/365/li/material/notes/Chap3/Chap3.1/Chap3.1.html ein-gesehen werden.
Eine weitere gute Quelle fur Informationen uber MIDI ist http://www.midi.org, MIDI-Dateien en massekonnen z.B. bei http://www.midi.com gefunden werden.
4http://www.cs.sfu.ca/CourseCentral/365/li/material/notes/Chap3/Chap3.1/instrument.html5http://www.cs.sfu.ca/CourseCentral/365/li/material/notes/Chap3/Chap3.1/percussion.html

Kapitel 6
Digital Images
Da sich ein Grossteil der Erklarungen in diesem Kapitel sowohl auf Bilder als auch auf Grafiken beziehen,wird der Begriff Bilder als Sammelbegriff fur beide verwendet werden.
Bilder gehoren fast zu jeder (multimedialen) Prasentation, sei es im Web, in einem Informationssystemoder bei einer Prasentation. Sie werden zur Informationsvermittlung, zur Erklarung oder einfach alsoptischer Aufputz verwendet und nicht umsonst heisst das Sprichwort “ein Bild sagt mehr als tausendWorte”.
Bilder wurden bereits in der Steinzeit als Kommunikationsmedium (Felszeichnungen) benutzt und geschatzt,da sie ohne viele Erklarungen von vielen Menschen verstanden werden (bei moderner Kunst gilt dies oftnicht mehr :-).
Eine Eigenschaft von Bildern wird jedoch in fast allen Fallen ausgenutzt: Der Mensch ist imstande,innerhalb von sehr kurzer Zeit den Inhalt eines Bildes zu erfassen. Darum ist das Wissen um den Aufbauund Eigenschaften von verschiedenen Bildformaten eine grundlegende Voraussetzung fur den optimalenEinsatz.
6.1 Das Auge
Etwa 126 Millionen Sinneszellen kleiden das Innere des Augapfels aus (das ergibt ca. 400.000 Zellen/mm2)und bilden die Netzhaut (Retina).
Es gibt zwei Arten von Photorezeptoren:
• Stabchen arbeiten bereits bei niedriger Lichtintensitat und dienen daher dem Dammerungssehen(Hell/Dunkel). Ein Auge enthalt ca. 120 Millionen Stabchen.
• Zapfen dienen dem Tages- und Farbsehen. Jeder Mensch hat ca. 6 Millionen Zapfen pro Auge.
In jeder Sekunde werden ca. 20 Bilder uber den Sehnerv an das Gehirn ubermittelt. [Hol00]
6.1.1 Farbe
Das menschliche Auge wandelt elektromagnetische Strahlung einer bestimmten Wellenlange in eine vommenschlichen Gehirn verstandliche Information um. Das Gehirn ordnet dann dieser Information denSinneseindruck Farbe zu.
Gegenstande, die von einer Lichtquelle beleuchtet werden, reflektieren und absorbieren jeweils einen Teildes Lichts. Das fur den Menschen sichtbare Spektrum reicht etwa von 380nm (blau) bis zu 780nm (rot).Verschiedene Arten von Zapfen auf der Netzhaut sind mit verschiedenen lichtempfindlichen Farbstoffenausgestattet [Hen00]:
• rot (ca. 580nm), zu etwa 64% vertreten
78
KAPITEL 6. DIGITAL IMAGES 79
• grun (ca. 545nm), zu etwa 32% vertreten
• blau (ca. 440nm), zu etwa 4% vertreten
Werden alle drei Zapfensorten zu gleichen Teilen angeregt, “sieht” der Mensch Grautone (schwarz bisweiss, je nach Intensitat).
Bevor das Signal jedoch in das Sehzentrum des Gehirns geleitet wird, erfahrt es noch eine Farbveranderungund es werden aus den separaten Signalen fur rot, grun und blau drei neue Signale gebildet.
• Differenzsignal rot - grun zur rot/grun Unterscheidung
• Summensignal rot + grun = gelb = Y zur Gelb- und Helligkeitswahrnehmung - Im Laufe derEvolution hat sich die spektrale Empfindlichkeit der Helligkeitswahrnehmung an die Farbe derSonne angepasst.
• Differenzsignal gelb - blau zur blau/gelb Unterscheidung.
Zunachst noch einige Begriffe, die im Zusammenhang mit Farben immer wieder auftreten:
• Die Helligkeit (brightness) bestimmt, wie intensiv ein visueller Reiz erscheint bzw. wieviel Licht dieFlache abzustrahlen scheint (“dunkel” bis “hell”).
• Farbton (hue) ist das Attribut einer Farbwahrnehmung, das durch Namen wie “rot”, “grun” usw.bezeichnet wird.
• Sattigung (saturation) ermoglicht ein Urteil, wie stark sich ein farbiger Reiz von einem anderenunabhangig von dessen Helligkeit unterscheidet.
6.1.2 Richtlinien fur die Verwendung von Farben
Die bedachte Auswahl der Farben ist bei Informationssystemen sehr wichtig, da verschiedene Farbenauf der einen Seite psychologische Wirkung auf Personen haben, auf der anderen Seite physikalischeGegebenheiten des Auges verschiedenes voraussetzen.
Laut [Hen00] sollen folgende Dinge wegen diverser Eigenschaften des Sehapparates vermieden werden:
• Gleichzeitige Darstellung mehrerer gesattigter Farben aus unterschiedlichen Bereichen des Spek-trums, da dies das Auge ermudet.
• Blauer Text, dunne Linien oder kleine Formen, da im Zentrum der Retina keine blau-sensitivenZapfen zu finden sind.
• Verwendung von rot und grun in der Peripherie grosserer Bilder oder Anzeigen.
• Verwendung von roten Zeichen auf blauem Hintergrund: Beispieltext in Rot
• Verwendung benachbarter Farben, die sich nur im Blauanteil unterscheiden.
• Verwendung von Farbe als alleinigem Unterscheidungsmerkmal bei der Codierung (ca. 9% allerManner sind Farbenblind)
Zu beachten ist weiters:
• Altere Benutzer benotigen eine hohere Lichtintensitat.
• Farbwahrnehmung ist abhangig vom Umgebungslicht.
• Bei gesattigten Farben ist das Auge weniger empfindlich fur Farbtonunterschiede.

KAPITEL 6. DIGITAL IMAGES 80
6.2 Farbmodelle
Der Zweck eines Farbmodells ist immer die bequeme Spezifikation von Farben. Ein Farbmodell enthaltnicht unbedingt alle wahrnehmbaren Farben! Eine gute Einfuhrung in Farbmodelle ist u.a. unter http://www.adobe.com/support/techguides/color/colormodels/rgbcmy.html zu finden.
6.2.1 RGB-Farbmodell
Das RGB (rot-grun-blau) Modell ist das meistverwendete Modell zur Ausgabe auf aktiv lichterzeugendenMedien (z.B. Displays, ...). Die Farbmischung in diesem Modell erfolgt additiv, d.h. die spektralenIntensitaten der einzelnen Lichtkomponenten werden addiert (alle drei Farben zusammen in hochsterIntensitat ergeben weiss - siehe auch Abbildung 6.3).
Abbildung 6.1 zeigt den Farbraum des RGB-Modells, der einen Wurfel mit der Kantenlange 1 darstellt.Grauwerte liegen auf der Hauptdiagonale zwischen schwarz und weiss. Schon experimentieren lasst sichmit den Farbauswahldialogen von Photoshop oder Gimp1, die verschiedene Abbildungen des RGB-Wurfelsauf eine Ebene vorweisen. So lassen sich auch leichter die Zusammenhange zwischen RGB und YUVverstehen (siehe Abbildung 6.2).
blau−Achse
grün−Achse
rot−Achse
schwarz (0,0,0)
rot (1,0,0)
cyan (0,1,1)
magenta (1,0,1)
grün (0,1,0)
blau (0,0,1)
weiss (1,1,1)
gelb (1,1,0)
Abbildung 6.1: Farbraum des RGB-Modells [Hen00]
6.2.2 CMY-Farbmodell
Das CMY (cyan-magenta-yellow) Modell ist das meistverwendete Modell zur Ausgabe auf reflektierendenMedien (z.B. Druckern, ...).
Die Farbmischung erfolgt subtraktiv, d.h. die spektralen Intensitaten der einzelnen Lichtkomponentenwerden entsprechend dem Farbwert von Gegenstanden absorbiert und der Rest reflektiert (aus demweissen Licht entfernt, siehe auch Abbildung 6.3). Grauwerte liegen wiederum auf der Hauptdiagonalen.
Der Farbbereich (color gamut) im CMY-Farbmodell (siehe Abbildung 6.4) ist nicht identisch mit demdes RGB-Modells, d.h. dass im Allgemeinen nicht alle angezeigten Farben auf einem Bildschirm auch aufeinem Farbdrucker druckbar sind!
Viele Drucker fugen zu den drei Farben noch schwarz als vierte Farbe hinzu, um dafur nicht alle dreiFarben zusammenmischen zu mussen (CMYK-Farbmodell).
1http://www.gimp.org
KAPITEL 6. DIGITAL IMAGES 81
Abbildung 6.2: Farbauswahldialog des Bilderbearbeitungsprogrammes Gimp
Abbildung 6.3: Farbmischung bei RGB (links) und CMY Farbmodellen (rechts) [von http://www.adobe.com/
support/techguides/color/colormodels/rgbcmy.html]
6.2.3 YUV-Farbmodell
In diesem Modell erfolgt die Aufspaltung der Bildinformation in ein Helligkeits- und zwei Farbsignale(Blaue und Rote - und ist damit aquivalent zum YCbCr-Farbmodell). Es ist damit abwartskompatibelzum Schwarz-Weiss-Fernsehen. Die Y-Komponente hat den Wertebereich [0,1], die beiden Farbkompo-nenten den Wertebereich [-0.5,0.5].
Das YUV-Farbmodell wird bei PAL-Video verwendet und ist uber die Norm CCIR 601 auch in dieStandardisierung fur Digitales Video eingegangen. Ausserdem wird dieses (oder YIQ) auch bei derverlustbehafteten JPEG-Kompression (Abschnitt 6.4.5) verwendet.
6.2.4 YIQ-Farbmodell
Auch in diesem Modell erfolgt die Aufspaltung der Bildinformation in ein Helligkeits- und zwei Farbsi-gnale. Damit ist es auch abwartskompatibel zum Schwarz-Weiss-Fernsehen. Es wird bei NTSC-Videoverwendet.
6.2.5 HSV-Farbmodell
Das HSV (Hue-Saturation-Value bzw. Farbton, Sattigung, Wert) Modell hat als Farbraum eine sechs-seitige Pyramide, den sogenannten “Hexcone”. Die Projektion der Pyramide entlang der Value-Achseentspricht dem Blick auf den RGB-Farbwurfel (siehe Abbildung 6.1) entlang der Grauwert-Diagonalen.

KAPITEL 6. DIGITAL IMAGES 82
yellow−Achse
magenta−Achse
cyan−Achse
gelb (0,0,1)
weiss (0,0,0)
cyan (1,0,0)
magenta (0,1,0)
grün (1,0,1)
rot (0,1,1)
schwarz (1,1,1)
blau (1,1,0)
Abbildung 6.4: Farbraum des CMY-Modells [Hen00]
Eine sehr gute Simulation (Java-Applet) der verschiedenen Farbmodelle findet sich unter http://www-cg-hci.informatik.uni-oldenburg.de/~pgse96/html/team3/HSV.html.
6.2.6 Umrechnung zwischen Farbmodellen
Alle Formeln dieses Abschnitts stammen aus [Hen00].
Als Basis fur die Umrechnung dient immer das RGB-Modell. Die Beziehung zwischen RGB und CMYist sehr einfach:
(C M Y ) = (1 1 1)− (R GB)
Die Transformation auf die in der Videotechnik verwendeten Formate sind zwar komplizierter, aber immernoch linear:
(Y U V ) = (R G B) ·
0.299 −0.168736 0.5000.587 −0.331264 −0.4186880.114 0.500 −0.081312
Fur Leser mit wenig Erfahrung beim Matrizenrechnen sei hier noch eine kleine Hilfe angegeben:
Die Luminanz (Helligkeit, Grauwert) errechnet sich folgendermassen:Y = 0.299 ∗R + 0.587 ∗G + 0.114 ∗B
Chrominanz 1 (Blaue):U = −0.168736 ∗R− 0.331264 ∗G + 0.5 ∗B
Die Chrominanz 2 (Rote) oder der V-Wert kann somit leicht aus der obiger Matrix berechnet werden. Zubeachten sei aber noch, dass der U- und V-Wert einen Wertebereich von [-0.5,0.5] haben und evtl. nochin einen anderen Wertebereich (in [0,1] bzw. [0,255]) transformiert werden muss.
Fur die Umrechnung in das Farbmodell HSV sind zunachst einige Hilfsgrossen zu bestimmen:
c =√
23R −
√16 (G + B)
s =√
12 (G−B)
m1 = max(R,G,B) m2 = min(R,G,B)
Dabei sind c und s dem Cosinus und Sinus des Farbwinkels proportional, ferner ist die Mehrdeutigkeit
KAPITEL 6. DIGITAL IMAGES 83
der inversen Winkelfunktionen zu berucksichtigen. Der Farbton H ergibt sich daraus als
H = arctan(
sc
)+
{180, wenn c < 0360, wenn s < 0 und c > 0
Die Farbsattigung S ergibt sich dann als
S = m1 −m2
und die Helligkeit V ist
V = m1
6.3 Rasterbilder
Die Digitalisierung von Bilddaten verlauft in der Regel so, dass ein rechteckiges Raster uber das (rechtecki-ge) Bild gelegt wird. Jedem Feld des Rasters (genannt Pixel fur “picture element”) wird ein Helligkeits-oder Farbwert zugeordnet, der der Helligkeit oder Farbe entspricht, die uber das Feld gemittelt wurde.
Wichtige Eigenschaften jedes Bildes sind
• Bildgrosse (Hohe/Breite)
• Farbanzahl/Farbtiefe
– Monochrom (1 Bit)
– Graustufen (z.B. 8 Bit)
– Farbpaletten (z.B. 4-8 Bit)
– Echtfarben (z.B. 15, 16, 24, 32 Bit)
• Kompressionstechniken
– keine
– verlustlos (lossless)
– verlustbehaftet (lossy) - mit mehr oder weniger offensichtlichen Verlusten
6.3.1 Farbe in Rasterbildern
Obwohl die Anzahl der Farben, die das menschliche Auge wahrnehmen kann, durch 19 Bits (ca. 520.000Farben) ausgedruckt werden kann, hat es sich als gunstig erwiesen, die technische Auflosung auf eineganze Anzahl von Bytes aufzurunden (24 Bits). Dies erlaubt die gleichzeitige Darstellung (nicht Wahr-nehmung!) von 16,7 Millionen Farben und erlaubt in jeder beliebigen Farbe Verlaufe, die von Menschenals kontinuierlich angesehen werden. Diese Darstellung wird deshalb als true color bezeichnet.
In den meisten Fallen wird der RGB-Farbraum verwendet und es werden je Grundfarbe 8 Bit Auflosungzur Verfugung gestellt.
In vielen Fallen wird nicht fur jedes Pixel einzeln eine Farbe gespeichert, sondern aus allen in einem Bildvorkommenden Farben wird eine Tabelle gebildet. Fur die entsprechenden Pixel wird dann lediglich einIndex in dieser Farbtabelle gespeichert. Die Grafikformate GIF und TIFF verwenden diese Technik.
Gamma-Korrektur
Jedes Display ist anders und reagiert anders auf Erhohung der Eingangsspannung. Bei Kathodenrohrensteigt die Leuchtkraft nicht linear mit der Eingangspannung, sondern in einer Potenz. Die lineare Um-setzung der binaren Zahlen fuhrt demnach zu einer nichtlinearen Steigerung der Farbintensitat. Um diesauszugleichen, kann eine auf die Hardware abgestimmte Color-LookUp Tabelle eingesetzt werden, die fureine entsprechende Korrektur bei der Darstellung sorgt.

KAPITEL 6. DIGITAL IMAGES 84
Alpha-Kanal
Manche Formate verwenden ein zusatzliches Byte (24 Bit Farbe plus 8 bit Alpha Kanal (also insgesamt32 Bit)) um z.B. Informationen uber die Durchsichtigkeit (Transparenz) des Pixels geben zu konnen. DieVerwendung des Alpha-Kanals ist jedoch nicht standardisiert.
6.4 Datenkompression
Da unkomprimierte Bilddaten sehr gross werden (Hohe * Breite * Farbauflosung in Bytes (nicht Bit!!)),wurden sehr bald Methoden gesucht, diese Datenmenge zu verkleinern. Generell unterscheidet manverlustlose (lossless) und verlustbehaftete (lossy) Algorithmen.
Ein unkomprimiertes Bild der Grosse 1024 x 768 Pixel in 24 Bit Farbtiefe (24 Bit = 3 Bytes) benotigtdaher 1024x768x24bit = 2304KBytes (= 1024x768x24
1024x8 ).
Die verlustfreie Datenkompression sorgt dafur, dass die Codierung des Datenbestandes moglichst dertheoretischen Grenze (dem Informationsgehalt) nahekommt, entfernt aber keine Informationen aus demDatenbestand.
Beispiel: Bilddaten werden in bestimmten Formaten mit 8 Bit/Pixel codiert. Fur ein schwarz/weiss Bildware dies aber eine Verschwendung von 7 Bit/Pixel. Eine verlustfreie Datenkompression wurde hier dieuberflussigen Bits entfernen.
Eine verlustbehaftete Datenkompression ist nur bei Daten moglich, die fur menschliche Sinnesorganebestimmt sind. Aufgrund der Tatigkeit unseres Gehirns kann man bei Bildern, Audio- oder VideodatenInformationen entfernen, ohne dass dies den subjektiven Eindruck verschlechtert.
6.4.1 Lauflangenkodierung
Bei der Lauflangenkodierung (RLE) werden Folgen von Mehrfachsymbolen durch ein Symbol und dieAngabe eines Zahlers ersetzt. Diese sehr einfache Methode ist verlustlos, sehr schnell und einfach, hataber einen sehr niedrigen Wirkungsgrad bei abwechslungsreichem Bildinhalt.
Beispiel: aus den Rohdaten aaaaaaabbcccccccc wird so z.B. 7a 2b 8c. Aus 17 Bytes werden so 6 Bytes(die Leerzeichen dienen nur der besseren Lesbarkeit!).
Bei binaren Datenstromen (schwarz/weiss bzw. 0/1) kann Zusatzliches eingespart werden, indem nur dieAnzahl und nicht mehr der eigentliche Wert ubertragen wird:
Beispiel: aus 0000000011100001111111110000 wird einfach 8 3 4 9 4. Eindeutigkeit wird erreicht,indem der erste ubertragene Wert sich immer auf eine Anzahl von Nullen bezieht (ist daher evtl. Null).
Im schlimmsten Fall kann aber die Lauflangenkodierung die Datenmenge vergrossern, anstatt sie zukomprimieren:
Beispiel: aus abcdefg wird mit der obersten Kompressionsmethode 1a 1b 1c 1d 1e 1f 1g, also eineVerdopplung der Datenmenge.
Dies kann durch z.B. durch escape-codes verhindert werden, indem keine fixen Positionen fur Zahlerverwendet werden, sondern erst durch ein spezielles Zeichen wird ein Byte als Zahler interpretiert.
Beispiel: so kann aus abcdeeeeefffffffg folgendes entstehen: abcd+5e+7fg, wobei hier ’+’ als escape-code verwendet wurde.
Eine etwas andere Methode von RLE wird am Macintosh packbits benannt:
Jede Zeile beginnt mit Zahlerbyte n, gefolgt von einem oder mehreren Datenbytes.
• n = 0 bis 127 : die nachsten n+1 Bytes werden direkt angegeben.
• n = -127 bis -1 : das nachste Byte wird -n+1 mal wiederholt.
• n = -128 : nicht verwendet.
KAPITEL 6. DIGITAL IMAGES 85
Mit dieser Methode, die ubrigens auch beim Bildformat TIFF verwendet wird, liegt die Grosse derkomprimierten Daten im Worst-Case nur mehr geringfugig uber der Originalgrosse.
Trotzalledem ist die Effizienz dieses Verfahrens eher gering und kommt nur bei sehr grossen Blockenvon gleichen Symbolen auf eine gute Kompressionsrate. Lauflangenkodierung wird beim BMP-, PCX-,JPEG- und vor allem beim Fax-Format (nur 2 Farben, schnell, einfach, grosse weisse Flachen) verwendet.
6.4.2 LZW-Codierung
Abraham Lempel und Jakob Ziv entwickelten 1977 den Grundstock dieses Algorithmus (LZ77 und LZ78),der in vielen Text-Kompressionsalgorithmen und Archivierungsprogrammen (z.B. zoo, lha, pkzip oderarj) verwendet wird. Terry Welch (damals bei Unisys) modifizierte 1984 den Algorithmus und so entstandder LZW-Algorithmus, der fur eine Vielzahl von unterschiedlichen Daten verwendet werden kann.
Die verlustlose Kompression nach Lempel-Ziv-Welch (LZW) beruht auf wiederkehrenden Mustern. Die-se Muster bestehen aus Elementen des Grundalphabets und werden ebenso wie diese in eine Tabelle(Worterbuch) eingetragen. Die komprimierte Version eines solchen Abschnittes besteht aus der laufen-den Nummer der entsprechenden Tabellenzeile. Bei wiederholtem Auftreten desselben Abschnittes wirdebenfalls nur der Tabellenverweis geschrieben, ohne dass eine neue Tabellenzeile notwendig ware. DieCodetabelle wird im Laufe der Ubertragung immer langer.
Durch eine geschickte Wahl des Verfahrens fur die Tabelleneintrage und Verzicht auf die maximal moglicheKompressionsrate wird erreicht, dass die fertige Codetabelle nicht ubertragen/gespeichert werden muss,sondern durch den Dekompressionsalgorithmus selbst wieder dynamisch aufgebaut werden kann.
Die Codes haben entweder eine fixe Lange (z.B. bei 8 Bit Daten werden 12 Bit Codes verwendet) odereine variable Lange (bei GIF).
Bei Verwendung der fixen Lange, wird die Tabelle mit dem Grundalphabet gefullt (normalerweise werdenalso die ersten 256 Eintrage des Worterbuches zu Beginn mit den ASCII-Werten von 0 bis 255 gefullt(also ein 1:1 Mapping vom Zeichen zu Wert)). Fur jedes neue Muster wird ein neuer Eintrag in derTabelle gemacht.
Prinzip: Ein neuer Substring wird erzeugt, indem ein neues Zeichen an einen bestehenden Substringangehangt wird. Dieser neue Substring bekommt dann den nachsten freien Code im Worterbuch.
Beispiel: Die Zeichenkette /WED/WE/WEE/WEB soll codiert werden. Das Worterbuch wird zur Initialisierungmit den ASCII-Zeichen von 0 bis 255 gefullt.
char. input code output new code value/W / = <47> <256> = /WE W = <87> <257> = WED E = <69> <258> = ED/ D = <68> <259> = D/
WE <256> <260> = /WE/ E = <69> <261> = E/
WEE <260> <262> = /WEE/W <261> <263> = E/WEB <257> <264> = WEB
B = <66>
Die codierte Zeichenfolge ist also /WED<256>E<260><261><257>B (eigentlich ja <47><87><69><68><256><69><260><261><257><66>).
Beim Decodieren wird nun auch wieder ein Worterbuch aufgebaut:

KAPITEL 6. DIGITAL IMAGES 86
code input char output new code value/ = <47>W = <87> / <256> = /WE = <69> E <257> = WED = <68> D <258> = ED<256> /W <259> = D/
E = <69> E <260> = /WE<260> /WE <261> = E/<261> E/ <262> = /WEE<257> WE <263> = E/W
B = <66> B <264> = WEB
und die ursprungliche Zeichenkette ausgegeben.
Ein weiteres Beispiel stammt aus [Lip97]:
Beispiel: Angenommen, es steht ein Alphabet, bestehend aus vier Zeichen, zur Verfugung: A,B,C,D. DieLZW-Codetabelle wird folgendermassen initialisiert:
LZW-Code Zeichen0 A1 B2 C3 D
Die zu kodierende Zeichenkette lautet ABCABCABCABCD (13 Zeichen).
Das erste Zeichen A kommt naturlich in der Tabelle vor. Deshalb merkt man es sich als Prafix. Dasnachste Zeichen B wird dem Prafix nachgestellt (Suffix) und es entsteht das aktuelle Muster AB. Diesesist in der Codetabelle nicht vorhanden, weshalb ein neuer Eintrag in der Zuordnungstabelle erforderlichwird:
• LZW-Code 4: AB
Nun gibt man den Code <0> fur das Prafix A aus, und B wird zum aktuellen Prafix. Das nachste ZeichenC ergibt mit dem Prafix B das aktuelle Muster BC, das wiederum nicht in der Tabelle vorhanden ist.Die nun erforderlichen Schritte sind:
• LZW-Code 5: BC
• Ausgabe von Code <1> (fur B)
• neues Prafix: C
Das nachste Zeichen ist ein A, das zusammen mit dem Prafix C das Muster CA bildet. Dieses ist in derTabelle wieder nicht vorhanden, was zu folgender Tatigkeit fuhrt:
• LZW-Code 6: CA
• Ausgabe von Code <2> (fur C)
• neues Prafix: A
Das nachste zu betrachtende Muster lautet AB (Prafix A, Suffix B), fur das bereits ein Eintrag in derCodetabelle existiert (LZW-Code 4). Deshalb lautet das neue Prafix jetzt AB. Das nachste Muster ABC(Prafix AB, Suffix C) ist in der Tabelle nicht vorhanden, weshalb wieder eine neuer Eintrag erforderlichwird:
• LZW-Code 7: ABC
• Ausgabe von Code <4> (fur AB)
KAPITEL 6. DIGITAL IMAGES 87
• neues Prafix: C
Hier macht sich der Algorithmus erstmals bezahlt, da zwei Zeichen mit einem Code ausgegeben werdenkonnten.
Als neues Muster ergibt sich CA (Prafix C, Suffix A), das als neues Prafix gemerkt wird, da es in derCodetabelle enthalten ist. Das Muster CAB (Prafix CA, Suffix B) kommt jedoch darin nicht vor:
• LZW-Code 8: CAB
• Ausgabe von Code <6> (fur CA)
• neues Prafix: B
Auch das Muster BC (Prafix B, Suffix C) ist in der Zuordnungstabelle vorhanden. Weiter geht es dannmit BCA (Prafix BC, Suffix A):
• LZW-Code 9: BCA
• Ausgabe von Code <5> (fur BC)
• neues Prafix: A
Das nachste Muster lautet AB, das zum nachsten Prafix wird. Auch ABC ist in der Tabelle schonvorhanden (LZW-Code 7). Beim Muster ABCD (Prafix ABC, Suffix D) wird die Codetabelle wiedererweitert:
• LZW-Code 10: ABCD
• Ausgabe von Code <7> (fur ABC)
• neues Prafix: D
Da nun das Ende der Daten erreicht ist, muss noch der LZW-Code fur das verbleibende Prafix notiertwerden: LZW-Code 3. Insgesamt ergibt sich die Codefolge <0><1><2><4><6><5><7><3>.
Die Dekomprimierung erfolgt im Prinzip analog zur Komprimierung. Da die Codetabelle nicht ubertragenwird, muss sie beim Dekomprimieren neu erzeugt werden. Alles, was man dazu wissen muss, ist, wievieleZeichen (roots) es gibt und wie diese codiert werden. GIF lost dieses Problem auf elegante Weise,indem die LZW-Datengrosse zu Beginn der Bilddaten gespeichert wird. Daraus ergeben sich die ersten2LZW−Datengroesse Eintrage in der Codetabelle. Anschliessend wird jeder LZW-Code decodiert und einneuer Code in der Tabelle erzeugt (Prafix und Suffix). Dieser ergibt sich aus den Zeichen des letztenCodes (Prafix) und dem ersten Zeichen des aktuellen Codes (Suffix). Anschliessend merkt man sichdie ausgegebenen Zeichen, um sie fur den nachsten Code als Prafix zu verwenden. Die nachstehendeTabelle demonstriert die Dekomprimierung des obigen Beispiels. Zu Beginn ist die Codetabelle mit denElementarzeichen A,B,C,D belegt:
Code Char. Output Neuer Code Prafix<0> A A<1> B <4> = AB B<2> C <5> = BC C<4> AB <6> = CA AB<6> CA <7> = ABC CA<5> BC <8> = CAB BC<7> ABC <9> = BCA ABC<3> D <10> = ABCD

KAPITEL 6. DIGITAL IMAGES 88
Wenn die Code-Tabelle voll ist, wird die aktuelle Kompressionsrate uberpruft und bei Bedarf ein CLEAR-Code (z.B. bei GIF 2Code−Size) ausgegeben, der signalisiert, dass das Worterbuch geloscht werden sollum danach ein neues aufzubauen.
Der LZW-Algorithmus wird von den Grafikformaten GIF und TIFF verwendet und liefert Kompressi-onswerte von Faktor 2 bis 3, bei Daten mit vielen ahnlichen Mustern bis zu Faktor 10.
Ein Hauptproblem dieser Kompressionsmethode ist, dass Unisys auf Teile ein Patent hat und so die Be-nutzung lizenzpflichtig ist. Vor allem Compuserves GIF Format verwendet seit 1987 diesen Algorithmus,aber erst 1993 erfuhr Unisys davon und seit 1995 sind alle Programme, die GIF verarbeiten, lizenzpflichtig(eigentlich ist die Implementation des LZW-Algorithmuses lizenzpflichtig). [MvR96]
6.4.3 Huffman Codierung
Bei der Huffman-Codierung werden den Zeichen eines Datenstromes Codes verschiedener Lange zugewie-sen. Dabei erhalten diejenigen Zeichen die kurzesten Codes, die in der Nachricht am haufigsten auftreten.Dieses Prinzip wurde auch schon vor Beginn des Computerzeitalters verwendet: Der am haufigsten inTexten auftretende Buchstabe “e” hat als Morsecode einen einzelnen “Punkt”.
Dieser verlustlose Komprimierungs-Algorithmus wurde schon 1952 erfunden und zeichnet sich dadurchaus, dass die Decodierung sehr schnell geht. Die Codierung (Kompression) erfordert jedoch 2 Durchlaufe:
1. Die relativen Haufigkeiten aller Zeichen muss erfasst und ein Codierungsbaum erstellt werden.
2. Die Daten werden mit Hilfe des Codierungsbaumes codiert.
Beispiel: Die Zeichenkette abbbbccddddddeeeeeee soll codiert werden. Folgende Tabelle gibt Auskunftuber die relativen Haufigkeiten der einzelnen Zeichen.
Zeichen Anzahl pa 1 0.05b 4 0.20c 2 0.10d 6 0.30e 7 0.35
Summe: 20 1.0
Der Codebaum fur diese Verteilung ist in Abbildung 6.5 zu sehen. Er wird nach folgendem Prinziperstellt: Fasse die beiden Gruppen niedrigster Haufigkeit zusammen und addiere ihre Haufigkeit. LinkeAste werden mit “0”, rechte mit “1” codiert (in diesem Beispiel).
0
00
1
11
10
a
0.05 0.10 0.20 0.30 0.35
0.15
0.35
c b d e
0.65
1.0
Abbildung 6.5: Codebaum fur die Huffman-Codierung fur gegebene relative Haufigkeiten einzelner Zeichen
KAPITEL 6. DIGITAL IMAGES 89
Die gegebene Zeichenkette wird demnach mit 000, 01, 01, 01, 01, 001, 001, 10, 10, 10, 10, 10, 10,11, 11, 11, 11, 11, 11, 11 codiert. Der Ergebniscode wurde naturlich mit 8 Bit pro Byte codiert undsomit 00001010, 10100100, 11010101, 01010111, 11111111, 111xxxx ergeben. Die 20 Bytes der Eingabewurden auf nur 6 Byte komprimiert!
Im Allgemeinen komprimiert dieses Verfahren (fur ein verlustloses Verfahren) sehr gut (Faktor 2 bisFaktor 8).
Ein Nachteil des Huffman-Verfahrens ist, dass vor der eigentlichen Codierung / Decodierung die stati-stische Verteilung der Zeichen einer Nachricht bekannt sein muss bzw. die Codetabelle mitgespeichertwerden muss.
Eine Erweiterung des Huffman-Verfahrens, welches diesen Nachteil aufhebt, ist die adaptive Huffman-Codierung. Schlussel zu ihrem Verstandnis ist, dass sowohl Encoder als auch Decoder dieselbe Routinezur Anderung der Baumstruktur benutzen. Die Codetabelle wird im Laufe der Codierung immer “bes-ser”. Der eigentlich verwendete Code kann sich von einem Zeichen zum nachsten komplett andern, dieseVeranderung wird aber beim Decodieren nachvollzogen. Fur spezielle Anwendungen kann auch eine fixeCode-Tabelle festgelegt werden.
Ein weiterer Nachteil des Huffman-Algorithmus ist, dass sich kleine Ubertragungsfehler dramatisch aus-wirken. Schon das Kippen eines Bits kann die Missinterpretation aller nachfolgenden Daten nach sichziehen.
Folgende Bildformate verwenden die Huffman-Codierung:
• TIFF
• TGA
• Lossless JPEG (alternativ zur arithmetischer Komprimierung)
• PNG (in Kombination mit LZ77)
• G3 FAX
6.4.4 Verlustfreie JPEG Kompression
Dieses (weniger gebrauchliche) Kompressionsverfahren wurde 1991 bis 1993 durch die Joint PhotographersExpert Group (JPEG) entwickelt und ist von der CCITT standardisiert worden (ISO-10918). Die JPEG-Kompression von Bilddaten ist farbenblind, d.h. sie muss gegebenenfalls fur jeden Farbkanal eines Bildesseparat durchgefuhrt werden. JPEG ist eigentlich kein Dateiformat, dieses hat vielmehr die AbkurzungJFIF (JPEG File Interchange Format).
Im verlustfreien Modus der JPEG-Kompression werden die einzelnen Pixel eines Bildes aus den benach-barten Pixeln vorhergesagt, und zwar nach einem von 7 moglichen Algorithmen. Dabei wird der Algo-rithmus ausgewahlt, welcher den Vorhersagewert moglichst nahe an die tatsachliche Bildinformation desgesuchten Pixels heranbringt. In den Ausgabestrom wird dann die Nummer des gewahlten Algorithmus,sowie die Differenz zwischen Vorhersagewert und tatsachlichem Datenwert geschrieben.
Nr. Algorithmus0 -1 A2 B3 C4 A + B - C5 A + (B - C)/26 B + (A - C)/27 (A + B)/2
Wobei sich ’A’ auf das Pixel links, ’B’ auf das Pixel oberhalb und ’C’ auf das Pixel links-oberhalb desaktuellen Pixels bezieht.

KAPITEL 6. DIGITAL IMAGES 90
Kompressionsfaktor subjektive Bildqualitat4:1 bis 5:1 mit blossem Auge nicht vom Original unterscheidbar5:1 bis 10:1 exzellente Qualitat10:1 bis 20:1 gute Qualitat20:1 bis 30:1 sichtbare Vergroberung30:1 bis 40:1 “Klotzchengrafik”
Tabelle 6.1: Kompressionsfaktoren bei verlustbehafteter JPEG-Kompression
Durch die Flexibilitat bei der Vorhersage sind die meisten dieser Differenzwerte nahe bei Null, sie konnendarum effizient mit Hilfe z.B. der Huffman-Codierung komprimiert werden. Mit der verlustfreien JPEG-Kompression sind Einsparungen beim Datenvolumen von Bilddaten von bis zu ca. 50% moglich. [Hen00]
6.4.5 Verlustbehaftete JPEG Kompression
In der verlustbehafteten Auspragung basiert das JPEG-Verfahren auf einer speziellen Fourier-Transfor-mation (einer diskreten Cosinus-Transformation), d.h. einer Transformation der Bildinformation in denFrequenzraum. Durch Quantisieren, d.h. Rundung der Fourier-Koeffizienten, werden die hoheren Gliederdieser Transformation und damit die feineren Details der Bildinformation unterdruckt.
Tabelle 6.1 aus [Hen00] zeigt eine Auflistung der erreichbaren Kompressionsfaktoren und die Auswirkun-gen auf die subjektive Bildqualitat.
Die Komprimierung der Grafikdaten mit der verlustbehafteten JPEG Kompression erfolgt in mehrerenSchritten:
1. Datenreduzierung: Das Auge ist nicht in der Lage, so viele Farbdetails zu unterschieden wie Un-terschiede in der Helligkeit (siehe Abbildung 6.6). Das RGB-Farbmodell (Abschnitt 6.2.1) wirddeshalb nach YUV (Abschnitt 6.2.3) oder nach YIQ (Abschnitt 6.2.4) umgewandelt (je nachdem,welcher Literatur man glauben darf), wobei die Farbanteile auf die Halfte (Y:U:V = 2:1:1) oderauf ein Viertel (Y:U:V = 4:1:1) der Auflosung reduziert werden. Bei einer Umwandlung auf 4:1:1stehen fur die Farbinformation (U und V) nur noch 2 Bit fur die Farbanteile (anstatt 8 Bit vor derUmwandlung) zur Verfugung, wahrend fur die Helligkeit (Y) immer noch 8 Bit verwendet werden.Dies ergibt schon eine Datenreduktion von 50%.
Das Bild wird zusatzlich noch in 8x8 Pixel Blocke pro Kanal (Y, U, V) oder nur fur die Luminanz(Y) aufgeteilt. Die weiteren Schritte werden dann jeweils auf solche Makroblocke durchgefuhrt.
Abbildung 6.6: Kleine Anderungen der Helligkeit sind fur das menschliche Auge leichter zu erkennen (kleinesQuadrat links) als kleine Anderungen des Farbtons (kleines Quadrat rechts - fast unsichtbar).
KAPITEL 6. DIGITAL IMAGES 91
2. Diskrete Cosinus-Transformation (DCT): Die DCT basiert auf der Fourier-Transformation, diebeliebige Signale als Uberlagerung von Sinuswellen verschiedener Frequenzen und Amplituden dar-stellt. Aus der ortlichen Verteilung von Pixelwerten in einem Bild entsteht nach der Fourier-Trans-formation eine Frequenz- und Amplitudenverteilung. Grosse, regelmassige Flachen schlagen sichdabei in den niederen Frequenzanteilen nieder, feine Details in den hohen. Der uberwiegende Anteilder visuellen Information eines Bildes mit kontinuierlich verteilten Werten liegt im Bereich niedererFrequenzen.
Fur jeden Makroblock wird die DCT des Helligkeitswertes f(i, j) in den Frequenzraum durchgefuhrt:
F (u, v) =14
7∑i=0
7∑j=0
C(u) · C(v) · f(i, j) · cos(2i + 1)uπ
16· cos
(2j + 1)vπ
16
C(u) = 1√
2wenn u = 0, sonst C(u) = 1
C(v) = 1√2
wenn v = 0, sonst C(v) = 1
Das Ergebnis der DCT ist wiederum ein Satz von 8x8 Koeffizienten je Makroblock, wobei sich dieniederen Frequenzen links oben, die hoheren Frequenzen rechts unten niederschlagen.
3. Quantisierung: Die Quantisierung ist der eigentlich verlustbehaftete Schritt. Aus dem linearenVerlauf der Werte erfolgt die Bildung einer stufenartigen Anordnung, d.h. Division von F (u, v)durch eine Zahl q(u, v) und Rundung der Resultate. Diese Quantisierung ist die Hauptquelle derzunehmenden Ungenauigkeit bei mehrfacher JPEG-Kompression.
FQ(u, v) = round
(F (u, v)q(u, v)
)Dabei ist entweder eine gleichformige Quantisierung moglich (ein q(u, v) fur alle u, v oder es wirdeine Tabelle (Beispielsweise Tabelle 6.2) zugrunde gelegt. Diese Tabelle kann entweder eine Stan-dardtabelle sein, oder eine eigene, die auch in der JFIF-Datei mitgespeichert werden kann. Dabeiwerden meist niedrigere Frequenzen (links oben) weniger geteilt, wahrend die hohen Frequenzen(rechts unten) durch hohere Werte dividiert werden [Kus95]. Je grosser der Quantisierungsfaktor,desto kleiner sind die zu speichernden Werte, die sich somit mit weniger Bits kodieren lassen.
16 11 10 16 24 40 51 6112 12 14 19 26 58 60 5514 13 16 24 40 57 69 5614 17 22 29 51 87 80 6218 22 37 56 68 109 103 7724 35 55 64 81 104 116 9249 64 78 87 103 121 120 10172 92 95 98 112 100 103 99
Tabelle 6.2: Quantisierungstabelle von JPEG [Hen00]
Die standardisierten Quantisiertabellen wurden durch Versuche mit Testpersonen erstellt, bei denenherausgefunden wurde, welche fehlenden Farben/Frequenzen das subjektive Sehen am wenigstenbeeinflussen.
4. Entropie Codierung: Der Fourier-Koeffizient FQ(0, 0) heisst DC-Koeffizient (von directed current,Gleichstrom) und stellt den Gleichanteil dar. Er wird fur alle Kompressionsmodi ubertragen. Ergibt (bezogen auf den jeweiligen Farbkanal) den mittleren Helligkeitswert des Makroblocks wieder.Dieser Wert ist meist ahnlich dem Wert des vorhergehenden 8x8 Makroblocks. Es wird darum nurder Differenzwert zum vorhergehenden 8x8 Makroblock ubertragen.
Die weiteren Fourier-Koeffizienten heissen AC-Koeffizienten (von alternating current, Wechsel-strom). Sie werden nach dem DC-Koeffizienten normalerweise in der sogenannten Zick-Zack-Serialisierung ubertragen (Abbildung 6.7). Dabei erfolgt zunachst eine Lauflangen-Codierung (RLE,

KAPITEL 6. DIGITAL IMAGES 92
i
j
f(i,j)
v
u
F(u,v)
DC
Abbildung 6.7: Zick-Zack-Serialisierung der DCT bei der JPEG-Kompression
Abschnitt 6.4.1), die von der Zick-Zack Reihenfolge profitiert, da so ofters ahnliche Werte direkthintereinander stehen und somit besser komprimiert werden konnen.
Schliesslich werden die dadurch erhaltenen Werte noch entropiecodiert (Huffman-Coding, Lauflangen-kodierung, etc.) . Die evtl. vorhandene Huffman-Tabelle wird zusammen mit der evtl. vorhandenenQuantisierungstabelle im Header der Bilddatei gespeichert.
Das Decoding von JPEG-Daten erfolgt blockweise und fuhrt die inversen Schritte der Kompression inumgekehrter Reihenfolge durch:
• Entropie-Decoding (lt. Huffman-Tabelle)
• Dequantisierung
• Inverse Diskrete Cosinus-Transformation
• Umwandeln in RGB-Werte
Progressive Encoding
Im progressiven Modus werden die Quantisierungswerte nicht blockweise, sondern nach Frequenzen bzw. Fre-quenzbereichen sortiert gespeichert (sog. slices oder scans). Zuerst wird hier der Gleichanteil (DC), dannniedrige Frequenzteile bzw. die wichtigsten Bits der AC-Koeffizienten fur alle Blocke und erst zuletzthohere Frequenzteile ubertragen.
Im hierarchischen Modus wird ein Bild zunachst in grober Auflosung codiert, die nachstfeinere Auflosungwiederum wird nur als Differenz zur groberen ubertragen.
JPEG Eigenschaften
JPEG-Kompression eignet sich sehr gut fur photorealistische Bilder und bietet hierfur sehr gute Kom-pressionsraten (Tabelle 6.1). Harte Ubergange im Bildmaterial bilden Artefakte (siehe Abbildung 6.8)oder werden unscharf. Zusatzlich verringert sich die Qualitat, wenn Bilder ofter hintereinander mit JPEGkomprimiert/dekomprimiert werden. Daher eignen sich Bildformate, die JPEG-Kompression verwenden,nicht fur Bildbearbeitung.
Der Algorithmus ist sehr aufwendig und daher eher langsam.
KAPITEL 6. DIGITAL IMAGES 93
Abbildung 6.8: Sehr hohe (1:100) Kompressionsrate (und zusatzlicher Zoomfaktor) bei JPEG zeigt deutlich die8x8 Makroblocke und lasst die Frequenz-Transformation (und Beschneidung) erahnen (beim Text)
6.4.6 JPEG 2000
1997 begannen die Bemuhungen zur Schaffung eines neuen Standards mit dem Namen JPEG20002.Hauptkritikpunkte am alten JPEG-Standard sind unter anderem die geringe Bildqualitat bei mittlerenund hohen Kompressionsraten, die unbefriedigende progressive Darstellung und die mangelnde Fehler-toleranz bei Online- und Mobilfunk-Anwendungen. Daruber hinaus soll durch eine offene Architekturdes neuen Standards eine Optimierung fur unterschiedliche Anwendungsbereiche ermoglicht werden, zumBeispiel Digitalfotografie, medizinische Bildverarbeitung, Druckvorstufe und Publishing, digitale Bildar-chivierung, mobile Kommunikation, Telefax (auch in Farbe), Satellitenfernerkundung und naturlich dieInternetubertragung.
Der JPEG2000 Standard unterteilt sich in sechs Teile, von denen der erste die Grundfunktionalitat bereitstellt und lizenzfrei ist. Der zweite Teil der Spezifikation stellt einige Erweiterungen zur Verfugung undwurde Ende 2001 fertig gestellt (nicht lizenzfrei). Ein wichtiger weiterer Abschnitt ist Teil 3, der sichdem Speichern von bewegten Bildern widmet: Motion JPEG2000 beruht auf den in Teil 1 festgelegtenVerfahren zum Speichern von stehenden Bildern. Weitere Teile befassen sich mit Konformitatstests,Referenzsoftware und einem Spezialformat fur gemischte Dokumente. [Tri01]
Folgende Anforderungen wurden an den neuen Standard gestellt [BBJ99]:
• hohere Auflosung: JPEG unterstutzte 24 Bit Farbtiefe und eine Bildgrosse von 65535 x 65535 Pixel.JPEG2000 komprimiert Bilder mit bis zu 16384 Komponenten (z.B. Farbkanale) zu jeweils 38 BitTiefe, woebei die Komponenten unterschiedliche Bittiefen haben konnen. Die maximale Grosse derBilder betragt knapp 4.3 Milliarden Pixel (232 − 1) im Quadrat [SMM01].
• bessere Bildqualitat als JPEG bei mittleren und hohen Kompressionsraten. Siehe dazu auch Ab-bildung 6.9
• wahlweise verlustbehaftete oder verlustfreie Kompression
• mehrere Arten der progressiven Ubertragung: auflosungsabhangig, qualitatsabhangig oder positi-onsabhangig (beispielsweise von links oben nach rechts unten)
• Erfassung von Echtfarb-, Graustufen- und Schwarzweissbildern
• Arbeit mit begrenzten Ressourcen (Ubertragungs- oder Speicherkapazitat sowie Arbeitsspeicher)und in Echtzeitumgebungen
• freier Zugriff auf Teilbereiche eines kodierten Bildes2http://www.jpeg.org/JPEG2000.htm

KAPITEL 6. DIGITAL IMAGES 94
Abbildung 6.9: Das linke Bild ist mit JPG bei 0.125 Bits per Pixel komprimiert. Das rechte ist bei gleicherDatenrate mit JPG2000 komprimiert. Man sieht deutlich die schlechtere Qualitat der JPG Kompression [CS01].Bei 8 Bit pro Pixel entspricht 0.125bpp einem Kompressionsfaktor von 1:64.
• Robustheit gegenuber Ubertragungsfehlern. Bei JPG leidet die Bildqualitat dramatisch, wenn Bit-Fehler auftreten.
• Moglichkeit der Definition besonders wichtiger Bildregionen (ROIs, Regions of Interest), die mithoherer Genauigkeit kodiert werden. Abbildung 6.10 zeigt ein Beispiel, in dem das Gesicht derPerson mit hoherer Qualtat gespeichert wurde.
Abbildung 6.10: Bei JPG 2000 ist es moglich, bestimmte Regionen eines Bildes mit hoherer Qualitat zuspeichern[CS01].
• Mitubertragung von Randinformation wie etwa stufenlose Transparenz
• offene Architektur, die Optimierungen auf spezielle Bildklassen erlaubt
• Ruckwartskompatibilitat zu JPEG und Vertraglichkeit mit MPEG-4 sowie bestehenden Fax-Stan-dards
• Unterstutzung von Metadaten, etwa zur Beschreibung der Bildinhalte, sowie von Mechanismen zumSchutz der Eigentums- und Verwertungsrechte
Je nach Anwendung spielen diese Anforderungen wichtigere bzw. unwichtigere Rollen. Fur mobile An-wendungen (Handy, PDA, ...) spielt z.B. die progressive Ubertragung eine wichtige Rolle. Fur satelliten-
KAPITEL 6. DIGITAL IMAGES 95
gestutzte Abtastung der Erdoberflache (Remote Sensing) ist die Robustheit gegenuber Ubertragunsfeh-lern wichtiger. Und im medizinischen Bereich sind Regions of Interest unbedingt von Noten.
Eine engdultige Verabschiedung des neuen Standards ist Ende 2000 geschehen (Final Commitee Draft).JPEG2000 verwendet keine Weiterentwicklung der Diskreten Cosinus Transformation von JPEG, sonderneine ganz neue Technik, die Wavelet Kompression.
JPEG2000 Kodierung
Mit Hilfe des JPEG-Verfahrens sind Kompressionsraten von etwa 1:35 in akzeptabler Bildqualitat zuerreichen. Die Wavelet-Kompression ermoglicht Raten von etwa 1:65. Unter den hier vorgestellten Kom-pressionsverfahren ist dieses sicherlich das mathematisch anspruchsvollste. Die Strategie ist mit JPEGvergleichbar. Es wird versucht, im Bild nicht wahrnehmbare Details zu entfernen. Hierbei wird es jedochnicht komplett in Frequenzkomponenten zerlegt, sondern nach und nach immer grobere Bildstrukturenherausgefiltert.
Die JPG2000 Kodierung teilt sich in 4 Schritte auf [CS01]:
1. Wavelet Transformation
2. Scan Algorithmus
3. Quantisierung
4. Entropie Kodierung
Eine Wavelet-Transformation wandelt das Originalbild in Wavelet-Koeffizienten um, die im Prinzip ver-kleinerte Kopien des Ausgangsbilds beschreiben. Zusatzlich enthalten diese Koeffizienten noch hoch- undtiefpassgefilterte Versionen dieser Bilder.
Abbildung 6.11 zeigt den mathematischen Hintergrund einer Wavelet Transformation. Die Funktionf(x) kann aus gedehnten, gestauchten und verschobenen Kopien seiner selbst dargestellt werden3. Daszugehorige Wavelet g(x) kann aus denselben Basisfunktionen erzeugt werden[BBSS99].
f(x)
g(x)
f(x/2) f(x/2−1/2)
Abbildung 6.11: Die Haar-Funktion f(x) kann durch verkleinerte (und verschobene) Kopien ihrer selbst be-schrieben werden. Das zugehorige Wavelet g(x) wird nun aus der gleichen Basisfunktion konstruiert.
Ein Wavelet-transformiertes Bild besteht sozusagen aus gedehnten, gestauchten und verschobenen Kopienseiner selbst [BBSS99]. Abbildung 6.12 zeigt ein solches Bild.
Die eigentliche Kompression erfolgt im sogenannten Quantisierungsschritt (Rundung). Der bereits ver-abschiedete Teil des Standards (Teil 1) definiert zwei Transformationen: eine ganzzahlig arbeitende furdie verlustlose und eine Gleitkommavariante fur die verlustbehaftete Kompression.
3In der Mathematik wird ein Satz von Funktionen, aus denen andere Funktionen zusammengesetzt werden, als Basisbezeichnet. Die Haar-Basis von 1910 ist eines der einfachsten Beispiele fur eine Wavelet-Funktionenbasis.

KAPITEL 6. DIGITAL IMAGES 96
Abbildung 6.12: Die Wavelet Transformation beruht auf der Tatsache, dass das Signal aus verkleinerten Kopienseiner Selbst dargestellt werden kann[BBSS99].
Anschliessend wird das Ergebnis noch einer Entropie-Codierung (z.B. Run-Length Coding) unterworfen.[Hol00, BBSS99, SMM01]
Bei JPEG fuhrt die Blockbildung zu storenden Mosaikartefakten bei hoher Komprimierung (‘Klotzchen-bilder’), da benachbarte Bildblocke nach der Kodierung nicht mehr nahtlos aneinander passen. Im aktu-ellen JPEG-2000-Vorschlag wird deshalb die Einteilung in Blocke erst nach der Wavelet-Transformationangesetzt. Dadurch konnen die einzelnen Blocke unabhangig voneinander kodiert und dekodiert werden.Abweichungen zwischen den Blocken - etwa durch Datenverlust bei der Ubertragung - treten aber nichtan den Blockkanten auf, sondern werden durch die Wavelet-Transformation geglattet. Dass dies gelingt,verdankt man der Eigenschaft der Wavelet-Transformation, nur die Umgebung eines Pixels zu beachten.[BBJ99]
Mittlerweile existieren verschiedene Programme, die JPEG2000 Dateien codieren/decodieren konnen(u.a. eine Java Implementation einer Universitat von Lausanne4). Andere Links sind auf der Home-page von JPEG20005 angegeben.
6.4.7 Fraktale Kompression
Die verlustbehaftete fraktale Bildkompression basiert auf fraktaler Geometrie. 1988 wiesen MichaelBarnsley und Alan Sloan die Moglichkeit einer solchen Bildkompressionsmethode nach. Die Grundla-ge dafur war die Beobachtung, dass naturliche Objekte oft nicht geraden Linien folgen und keine glattenOberflachen besitzen, mit denen die klassische Geometrie arbeitet. Viele Formen der Natur gehorchender fraktalen Geometrie. Ihre schroffen, scheinbar zufalligen Formen treten im Grossen, wie im Kleinenauf.
Beispiel: Beim Rand einer Wolke treten bei zunehmender Vergrosserung immer wieder die gleichen(gedrehten, gespiegelten) Formen auf.
Dieses Verfahren liefert bis zu einer Kompressionsrate von etwa 1:25 ahnlich gute Ergebnisse wie JPEG.4http://jj2000.epfl.ch5http://www.jpeg.org/JPEG2000.htm
KAPITEL 6. DIGITAL IMAGES 97
Bei hoheren Raten ergeben sich bei JPEG grobe Rasterungen.
Die fraktale Kompression ist sehr zeitaufwendig, die Dekompression eines fraktal komprimierten Bildeserfolgt jedoch sehr schnell.
Zur Zeit existiert noch kein Standardbildformat, das dieses Kompressionsverfahren nutzt. [Hol00]
6.5 Bildformate
Im Folgenden werden einige der bekanntesten Dateiformate fur digitale Rasterbilder vorgestellt. DieEigenschaften des jeweiligen Formats bestimmen oft den Einsatz (z.B. JPEG fur photorealistische Bilder,PNG fur Screenshots, ...).
6.5.1 BMP
Bei dem Bitmap (BMP) Format handelt es sich um eines der einfachsten Formate fur Bilddaten. Es istvor allem in der Windows Welt weit verbreitet.
Als Kompressionsalgorithmus kann RLE (Abschnitt 6.4.1) verwendet werden. Bei Bildern mit 1-, 4- oder8-Bit Farbinformation enthalt der Pixelwert nicht direkt die Farbinformation, sondern einen Index aufdie Farbpalette.
6.5.2 TIFF
Das TIFF-Format wurde bereits 1986 von Aldus Corporation (seit 1994 Adobe) entwickelt. Oberstes Zielwar Portabilitat und Hardwareunabhangigkeit. TIFF ist sehr universell einsetzbar und ist in der Lage,Schwarzweiss-, Grauwert- und Farbbilder inkl. des jeweils verwendeten Farbmodells zu enthalten.
Da es viele Varianten von TIFF-Bildern gibt, kann es ab und zu zu Problemen kommen. Viele Programmeunterstutzen nur einen Teil aller TIFF-Varianten (verschiedene Kompressionsmethoden, etc.).
6.5.3 GIF
GIF wurde von Compuserve 1987 entwickelt (GIF87a) und 1989 verbessert (GIF89a - zu GIF87a kompa-tibel). Vor allem durch die Aufnahme von GIF in die HTML-Spezifikation hat dieses Format ungeheureVerbreitung erlangt. Das Patentproblem (siehe dazu auch The GIF Controversy: A Software Developer’sPerspective6) mit Unisys wegen der Implementation des LZW-Kompressionsalgorithmus (Abschnitt 6.4.2)hat allerdings viele Firmen dazu bewogen, ein anderes Fileformat zu favorisieren. GIF ist dennoch sehrverbreitet und wird fur viele Gelegenheiten (vor allem im Web) immer noch benutzt (u.a. weil es imGegensatz zu JPEG Transparenz und Animationen erlaubt).
GIF unterstutzt eine Farbtabelle von 256 Farben in 24 Bit. D.h. in einem GIF-Bild konnen nur 256verschiedene Farben vorkommen, diese konnen jedoch beliebig aus dem gesamten RGB-Farbraum gewahltwerden.
In eine GIF-Datei konnen mehrere Bilder gespeichert werden, nicht nur eines! Im GIF87a-Format konnendiese Bilder gleichzeitig angezeigt werden. Eine Offsetangabe pro Bild bestimmt das Pixel links/oben, wodieses Bild eingeblendet wird. GIF89a unterstutzt Animationen, indem ein Wert in 1/100sec angegebenwird, wann das nachste Bild dargestellt werden soll.
Das GIF-Format kennt einen interlaced Modus, in welchem die einzelnen Bildzeilen nach Art eines binarenBaums umgeordnet werden. Dies kann benutzt werden, um GIF-Bilder bei der Anzeige zunachst grobgerastert und dann sukzessive verfeinert darzustellen.
Beispiel: Gegeben sei ein Bild von 13 Zeilen. ubertragen werden zuerst die Zeilen 0 und 8. Es folgen dieZeilen 4 und 12, danach 2,6,10 und abschliessend 1,3,5,7,9,11.
6http://cloanto.com/users/mcb/19950127giflzw.html

KAPITEL 6. DIGITAL IMAGES 98
GIF89a unterstutzt transparente Farbe. D.h. ein Eintrag der Farbtabelle wird als transparent gekenn-zeichnet und alle Pixel dieser Farbe erscheinen durchscheinend.
Zusatzlich ermoglicht GIF89a, dass Anwendungen spezifische Informationen im Bildformat abspeichern(Bildbeschreibungstexte, Keywords, ...).
Eine kurze Zusammenfassung der Eigenschaften von GIF:
• LZW-Komprimierung (Patent von Unisys)
• max. 256 Farben zu je 24 Bit
• mehrere Bilder in einer Datei (Animationen)
• interlaced Bildaufbau
• Transparenz
• Texte konnen mitgespeichert werden
6.5.4 PNG
PNG (gesprochen ’ping’) (Portable Networks Graphics) ist ein Dateiformat, das vor allem dazu gedachtist, das GIF-Format wegen des LZW-Patent/Lizenzproblems zu ersetzen. Darum auch die inoffiziellerekursive Abkurzung des Namens PNG zu “PNG’s Not GIF”. PNG wurde als einfaches Dateiformatvom W3C spezifiziert7, das leicht zu implementieren ist, portabel und das alle Eigenschaften von GIFbeherrscht ([ea96] bzw. [MvR96, p.700–719]).
Folgende Aufzahlung zeigt Eigenschaften, die sowohl GIF (GIF89a) als auch PNG besitzen:
• Daten als Datenstrom organisiert
• verlustlose Datenkompression
• Speicherung von Bildern mit Farbtabelle mit bis zu 256 verschiedenen Farben
• progressiver Bildaufbau von interlaced Bildern
• Transparenz (Ein Test, welche Transparenzen ein Browser unterstutzt, ist unter http://entropymine.com/jason/testbed/pngtrans/ zu finden.)
• Moglichkeit benutzerdefinierte Daten zu speichern (keywords, ...)
• Hardware- und Betriebssystemunabhangig
Folgende GIF-Eigenschaften wurden bei PNG verbessert:
• keine Patente, keine Lizenzprobleme
• Schnellerer progressiver Bildaufbau
• Mehr Moglichkeiten, benutzerdefinierte Daten zu speichern
Folgende Features von PNG gibt es bei GIF uberhaupt nicht:
• Speicherung von true-color Bildern mit bis zu 48 Bit pro Pixel (nicht indiziert!)
• Speicherung von grayscale Bilder mit bis zu 16 Bit pro Pixel (nicht indiziert!)
• Alpha Channel
• Gamma Indikator7http://www.w3.org/TR/REC-png
KAPITEL 6. DIGITAL IMAGES 99
• CRC-Prufsumme um Fehler bei der Ubertragung zu entdecken
• Standard Toolkit, um die Implementierung von PNG-Lese- und -Schreib-Routinen zu erleichtern
• Standard Set von Benchmark Bildern, um Implementationen zu testen
Folgende GIF Features wurden in PNG 1.0 nicht spezifiziert:
• Speicherung mehrerer Bilder in einer Datei (wird von MNG (Multi Image Network Graphics)8
ubernommen)
• Animationen
• Zahlung einer Lizenzgebuhr, wenn Software verkauft werden soll, die das PNG-Fileformat lesenoder schreiben kann. D.h. es fallt keine Lizenzgebuhr an (im Gegensatz zu GIF).
Interlacing
PNG Bilder werden typischerweise als Serie von scan-lines gespeichert (von oben nach unten). Zusatz-lich konnen die Bilddaten aber auch in einem speziellem Interlace-Muster gespeichert werden, um eineprogressive Anzeige von niederer zu hoherer Auflosung zu ermoglichen. PNG verwendet ein Schema mitsieben Durchgangen, Adam7 genannt. PNG verwendet die ersten sechs Durchgange, um die geradenZeilennummern (0,2,4,6,8,...) und den letzten, siebten, um die ungeraden Zeilen (1,3,5,7,...) darzustellen.
Die ersten sechs Durchgange ubertragen keine ganzen Zeilen, sondern immer nur bestimmte Pixel proZeile. Die ersten beiden Durchgange enthalten 1/64 der Pixel des Bildes. Die folgenden ubertragen ein1/32, 1/16, 1/8, 1/4 und der letzte schliesslich 1/2 des Bildes (GIF ubertragt 1/8,1/8,1/4,1/2). Ein guterVergleich der beiden Interlacingverfahren ist unter http://www.libpng.org/pub/png/pngintro.html#interlacing zu sehen.
Das Bild selbst wird zuerst in 8x8, dann in 4x8, 4x4, 2x4, 2x2, 1x2 Blocken dargestellt. Der letzteDurchgang fullt die ungeraden Zeilen.
Mit diesem Verfahren kann das menschliche Auge schon nach ca. 30% ubertragener Daten den Inhalt desBildes erkennen (im Gegensatz zu GIF, wo ca 50% benotigt werden).
Durch die Tatsache, dass die Bilddaten von interlaced Bildern nicht in der richtigen geometrischen Anord-nung gespeichert sind (sich aber im Allgemeinen benachbarte Pixel ahneln und damit besser komprimiertwerden konnen), verschlechtert sich die Kompressionsrate bei interlaced Bilden um ca. 10%.
Adam7 Interlacing benutzt untenstehende Tabelle, die uber die nichtkomprimierten Bilddaten gelegt wird(neben- und untereinander wiederholt), um festzustellen, welche Pixel in welchem Durchgang ubertragenwerden mussen.
1 6 4 6 2 6 4 67 7 7 7 7 7 7 75 6 5 6 5 6 5 67 7 7 7 7 7 7 73 6 4 6 3 6 4 67 7 7 7 7 7 7 75 6 5 6 5 6 5 67 7 7 7 7 7 7 7
Datenkompression
PNG speichert Bilder immer komprimiert. Es verwendet eine Vorhersage von Pixeln und komprimiertdie Differenz zwischen dem Pixelwert und der Vorhersage mit einer Variation der Deflate-Komprimier-ungsmethode, die auch im Archivierungsprogramm pkzip verwendet wird. Diese Kompressionsmethodeist gut dokumentiert, frei verfugbar, schnell und auf vielen Plattformen verfugbar.
8http://www.libpng.org/pub/png/pngpic2.html

KAPITEL 6. DIGITAL IMAGES 100
Deflate ist eine Variation des LZ77-Algorithmus von Lempel/Ziv, der aber keine sortierten Hash-Tabellenverwendet und so Patentverletzungen umgeht.
6.5.5 JFIF (JPEG)
Sowohl verlustfrei, als auch die verlustbehaftet JPEG-komprimierten Bilder werden im gleichen Dateifor-mat abgelegt. Dabei werden die drei Teilbilder (scans) des entsprechenden Farbmodells hintereinanderabgespeichert. Die einzelnen Blocke sind die 8x8-Makroblocke der JPEG-Kompression.
Fur Details und Eigenschaften von Bildern, die mit JPEG komprimiert wurden, siehe Abschnitt 6.4.5.
In JPEG Bildern kann in Kombination mit dem EXIF -Format auch Metainformationen gespeichertwerden. Moderne Digitalkameras speichern in diesen Meta-Informationen z.B. die Belichtungszeit, dieBrennweite, Datum und Uhrzeit der Belichtung, etc.
Ein (unvollstandiges) Beispiel von Metadaten, die aus den EXIF-Daten extrahiert werden konnen, zeigtTabelle 6.3.
EXIF-Tag WertCamera make CanonCamera model Canon DIGITAL IXUSDate/Time 2002:05:11 23:06:04Resolution 1152 x 864Flash used YesFocal length 5.4mm (35mm equivalent: 37mm)CCD width 5.23mmExposure time 0.017 s (1/60)Aperture f/2.8Focus dist. 1.02mMetering Mode center weightJpeg process Baseline
Tabelle 6.3: EXIF Daten eines JPEG-Bildes einer digitalen Kamera.
6.5.6 JPEG 2000
Der JPEG2000 Standard definiert gleich mehrere Dateitypen:
• .j2k: farbenblinder JPEG 2000 Datenstrom ohne jegliche Dateiheader.
• .jp2: Kapselt einen JPEG 2000 Datenstrom und fugt Headerinformationen uber das verwendeteFarbmodell und optional Informationen uber Copyright etc. hinzu. Dieses Dateiformat wird vomJPEG 2000 Standard Teil 1 definiert.
• .jpx: Fugt Erweiterungen (JPEG 2000 Standard Teil 2) hinzu. Kann in jp2-Dateien geschriebenwerden. Programme, die die Erweiterungen nicht verstehen, konnen diese einfach ignorieren.
• .mj2: Dieser Dateityp wird fur collections von Bildern verwendet (JPEG 2000 Standard Teil 3).Dies konnen z.B. Videos sein.
• .jpm: unterstutzt mehrere Kompressionsarten und layering (JPEG 2000 Standard Teil 6).
6.6 Metaformate
Metaformatdateien speichern Grafiken als Funktionsaufrufe an das jeweilige Graphiksubsystem des Be-triebssystems. Daher sind diese Dateiformate auch sehr eng mit einem Betriebssystem verbunden. EinVorteil eines solchen Verfahrens ist, dass Metaformatgraphiken sehr schnell aufgebaut werden konnen, da
KAPITEL 6. DIGITAL IMAGES 101
keinerlei Berechnungen/Konvertierungen notig sind, um das Bild aufzubauen. Der schwerwiegende Nach-teil ist jedoch, dass diese Formate sehr plattformspezifisch sind und somit nur fur einen eingeschranktenBenutzerkreis verwendbar sind.
6.6.1 WMF
Windows Meta File (WMF) ist sehr eng mit MS-Windows verbunden. WMF speichert Grafiken als eineFolge von Konstruktionsanweisungen mit den dazu gehorigen Parametern. Die Anweisungen werden unterWindows als Funktionsaufrufe bezeichnet. Diese setzen auf das Graphics Device Interface (GDI) fur dieAusgabe auf die entsprechende Hardware auf. Das GDI enthalt Bibliotheken von grafischen Objektenwie z.B. Kreise, Rechtecke, Ellipsen, ...
6.6.2 PICT
Ein ahnliches Konzept wie WMF verfolgt PICT, das Macintosh-eigene Funktionsaufrufe fur das Grafik-protokoll QuickDraw enthalt.
6.7 Vektorgrafik Formate
Vektorgrafiken bestehen im Unterschied zu Rasterbildern nicht aus Pixeln, sondern aus mathematischexakt definierten Kurven und Linien, die als “Vektoren” bezeichnet werden.
Um solche Kurven zu definieren, sind meist nur wenige Angaben notwendig. Um z.B. eine Linie zudefinieren, mussen nur die Koordinaten des Ausgangspunktes, die Koordinaten des Zielpunktes und dieLinienstarke bekannt sein. Ebenso reichen fur einen Kreis die Koordinaten des Mittelpunktes, sein Radiusund die Linienstarke als Angaben aus.
Vektorgrafiken haben folgende Vorteile gegenuber Rasterbildern:
• Sie sind beliebig skalierbar, d.h. eine Vektorgrafik kann beliebig vergrossert/verkleinert werden,ohne dass es zu Qualitatseinbussen kommt.
• Sie benotigen im Allgemeinen weniger Speicherplatz, da wenige Angaben reichen, um bestimmteFormen darzustellen.
• Sie sind beliebig genau, Auflosung ist kein Thema.
Vektorgrafiken sind ideal zur Speicherung von Bildern, die linienbasierte Informationen oder Elementeenthalten oder leicht in linienbasierte Informationen zu uberfuhren sind (z.B. Text).
Nachteile von Vektorgrafiken sind, dass
• komplexe Bilder mit pixelweise wechselnden Farben (Fotos) nur unter grossem Aufwand gespeichertwerden konnen.
• das Erscheinungsbild vom darstellenden Programm abhangig ist. Die optimale Ausgabequalitat istnaturgemass nur von Vektorausgabegeraten (z.B. Plotter) erreichbar.
6.7.1 Postscript
Postscript wurde 1984 von Adobe entwickelt und ist eigentlich eine Seitenbeschreibungssprache9. Post-script-Dateien sind reine ASCII-Text-Dateien, die den Programmcode enthalten. Eine Linie wird z.B. inPostscript folgendermassen beschrieben (’%’ leitet einen Kommentar ein):
9Eigentlich ist Postscript eine vollwertige Programmiersprache, mit Schleifen, Variablen, ...

KAPITEL 6. DIGITAL IMAGES 102
% Polyline7.500 slwn 1900 2000 m4500 2000 l gs col0 s gr
Wobei die Linie von den Koordinaten (1900,2000) zu dem Punkt (4500,2000) reicht und die FarbeNull hat.
Postscript beschreibt den kompletten Aufbau einer Druck- oder Bildseite, also Text, Vektorgraphik undeingebettete Rasterbilder.
Je nach Version unterstutzt Postscript verschiedene Kompressionsalgorithmen (z.B. Postscript Level 2unterstutzt JPEG Kompression) und verschiedene Farbtiefen (1/4/8/24 Bit).
6.7.2 Portable Document Format (PDF)
PDF von Adobe basiert im wesentlichen auf Postscript (Abschnitt 6.7.1) und ist eigentlich eher einDokumentenformat als ein Bildformat (Ansichtsache!). Die wesentlichen Unterschiede zu Postscript sind:
• Ablage nicht als lesbarer ASCII-Code, sondern zum Teil als komprimierter binarer Byte Code.
• Erweitertes Interface mit dem Betriebssystem (z.B. fur Dateioperationen)
• Ablage von Meta-Informationen fur Copyright, etc. (z.B. eingebaute Kopierschutzfunktionen)
• Hypertextkonzept (Hyperlinks im Dokument und zu anderen Dokumenten (im Web))
6.7.3 DXF
DXF ist ein Format fur vektororientierte Programme und wurde von der Firma Autodesk entwickelt.Daher stammt auch die hauptsachliche Verwendung fur CAD/CAM/CIM. DXF kann im Gegensatz zuvielen anderen Formaten auch dreidimensionale Objekte speichern. Die Anzahl der Farben ist auf 8 Bit(256 Farben) beschrankt und unterstutzt keine Kompression.
Da DXF-Dateien reine Textdateien sind, sind sie relativ leicht von Applikationen zu erzeugen und konnendann von vielen CAD-Programmen importiert werden.
6.7.4 SVG
Das neue Vektor-Grafikformat Scalable Vector Graphics (SVG)10 wurde vom W3C (und Adobe?) ent-wickelt. Dieses Format soll den ersten Vektorbasierten Bild-Standard fur Web-Grafiken bilden.
Einige Eigenschaften von SVG:
• Die Daten werden in einer XML-Datei gespeichert.
• 24 Bit Farbtiefe (true color), Transparenz, Gradienten (Farbverlaufe)
• typographische Features (wie Kerning, “kurvige” Texte, Ligaturen, ...)
• Rasterbilder (JPEG, GIF, ...) konnen eingebettet werden
• Interaktiv: es kann auf Benutzeraktionen reagiert werden (mouse-click, ...)
• Animationen
• Konform zu DOM (Document Object Model). Damit ist es moglich, ein SVG-Bild mit Hilfe vonSkriptsprachen (JavaScript, ...) zu bearbeiten.
10http://www.adobe.com/svg
KAPITEL 6. DIGITAL IMAGES 103
Leider verstehen zur Zeit zumindest die grossen Browser (Netscape, Internet Explorer) das SVG-Formatnoch nicht von selbst. Fur beide gibt es fur Windows-, Mac- und seit 30.11.2001 auch fur Linux-Plattformen ein Plugin, damit SVG-Grafiken angezeigt werden konnen.
Verschiedene Programme konnen SVG bereits exportieren: Adobe Illustrator, CorelDraw mit SVG-Plugin, Gill (Gnome Illustrator)
Unter http://www.w3.org/Graphics/SVG/SVG-Implementations finden sich verschiedene SVG-Imple-mentierungen, u.a. verschiedene Viewer.
Folgender XML-Code beschreibt die amerikanische Flagge (zum besseren Verstandnis des SVG-Codes inAbbildung 6.13 dargestellt) mit drehenden Sternen in SVG-Syntax. Schon sieht man die Definition vonverschiedenen graphischen Elementen und deren Wiederverwendung an verschiedenen Koordinaten. DasXML-Tag <g> dient zur Gruppierung von verschiedenen Elementen.
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 20000303 Stylable//EN"
"http://www.w3.org/TR/2000/03/WD-SVG-20000303/DTD/svg-20000303-stylabl e.dtd" >
<svg viewBox="0 0 1000 600">
<g transform="translate(10 60)">
<defs>
<rect id="red" width="900" height="40" style="fill:#dd0000"/>
<rect id="white" width="900" height="40" style="fill:white"/>
<polygon id="star" style="fill:white;fill-rule:nonzero;"
points="0,-14 8.229,11.326 -13.315,-4.326 13.315,-4.326 -8.229,11.326">
<animateTransform attributeName="transform" type="rotate"
values="0;360" dur="3s" repeatDur="indefinite" />
</polygon>
<g id="6star_row">
<use xlink:href="#star" x="20"/>
<use xlink:href="#star" x="90"/>
<use xlink:href="#star" x="150"/>
<use xlink:href="#star" x="210"/>
<use xlink:href="#star" x="270"/>
<use xlink:href="#star" x="330"/>
</g>
<g id="5star_row">
<use xlink:href="#star" x="60"/>
<use xlink:href="#star" x="120"/>
<use xlink:href="#star" x="180"/>
<use xlink:href="#star" x="240"/>
<use xlink:href="#star" x="300"/>
</g>
</defs>
<use xlink:href="#red"/>
<use xlink:href="#white" y="40"/>
<use xlink:href="#red" y="80"/>
<use xlink:href="#white" y="120"/>
<use xlink:href="#red" y="160"/>
<use xlink:href="#white" y="200"/>
<use xlink:href="#red" y="240"/>
<use xlink:href="#white" y="280"/>
<use xlink:href="#red" y="320"/>
<use xlink:href="#white" y="360"/>
<use xlink:href="#red" y="400"/>
<use xlink:href="#white" y="440"/>
<use xlink:href="#red" y="480"/>
<rect id="bluebox" width="360" height="280" style="fill:#000088"/>
<rect id="border" width="900" height="520"
style="fill:none;stroke:black;stroke-width:0.85"/>
<g transform="translate(4.5 0)">
<use xlink:href="#6star_row" y="20"/>

KAPITEL 6. DIGITAL IMAGES 104
<use xlink:href="#5star_row" y="50"/>
<use xlink:href="#6star_row" y="80"/>
<use xlink:href="#5star_row" y="110"/>
<use xlink:href="#6star_row" y="140"/>
<use xlink:href="#5star_row" y="170"/>
<use xlink:href="#6star_row" y="200"/>
<use xlink:href="#5star_row" y="230"/>
<use xlink:href="#6star_row" y="260"/>
</g>
</g>
</svg>
Abbildung 6.13: SVG Grafik ’Stars and Stripes’
Dieses Beispiel stammt von der Demo-Webseite von Adobe11. Um die Dateien schneller ubertagen zukonnen, sind sie alle gezipped, sodass man den XML-Code erst nach einem gunzip<filename> (unterLinux) oder der Behandlung mit einem entsprechenden Programm unter Windows (Winzip) zu sehenbekommt. Die Plugins der Browser (getestet mit IE) konnen mit gezippten Dateien direkt umgehen.
Anwendung von SVG
Auf der Webseite von Adobe12 sind einige SVG-Beispiele zu finden (u.a. Visualisierung eines Molekuls inder Chemical Markup Language). Ein wichtiger Bereich wird sicher die Darstellung von geographischenDaten. Beispiele dafur finden sich unter anderen unter http://www.academy-computing.com/svgweb.
6.8 Digitale Wasserzeichen
Digitale Wasserzeichen beruhen auf Steganografie: In ansonsten unauffalligen Daten (z.B. Texte, Bilder,Audiodaten, ...) werden zusatzliche Informationen eingebracht. Diese dienen
• der moglichst eindeutigen Identifikation des Empfangers der Daten: Tauchen diese Daten spater ananderer Stelle auf, ist eindeutig bewiesen, dass sie durch den originalen Empfanger weitergegebenwurden (Kopierschutz ) oder gestohlen wurden (Diebstahlsschutz ).
• der eindeutigen Identifikation des Verfassers (Urheberschutz )
11http://www.adobe.com/svg/demos/main.html12http://www.adobe.com/svg
KAPITEL 6. DIGITAL IMAGES 105
Die Entfernung eines digitalen Wasserzeichens aus einem Datenbestand soll grundsatzlich bemerkbar sein- je nach Zielrichtung kann dies von partieller Verfalschung bis zur vollstandigen Unbrauchbarkeit derDaten reichen. [Hen00]
Sichtbare Wasserzeichen dienen der offenen Identifikation von Daten - etwa durch Anbringung einesLogos. Als Beispiel kann die Senderidentifikation in heutigen Fernsehprogrammen herangezogen werden.
Bei Unsichtbaren Wasserzeichen wird ein grosser Teil der Daten geringfugig modifiziert. Beispielsweisewird die Urheberinformationen in digitalen Photos uber das gesamte Bild verteilt und ist damit unsicht-bar.
Unsichtbare digitale Wasserzeichen existieren in verschiedenen Abstufungen der Robustheit. Wenig robu-ste konnen schon durch einfache Transformationen der Daten entfernt werden. Fur Bilddaten sind diesinsbesondere Drehung um kleine Winkel (ca. 0.5 Grad), Glattung oder Beschneiden des Randes.
Bei Audio- oder Videodaten sind wegen der hohen Datenmengen viele robuste Verfahren anwendbar. Sosind Verfahren bekannt, bei welchen das eingebrachte digitale Wasserzeichen auch eine MP3-Codierung“uberlebt”.
Lowest Bit Coding
Bei der Digitalisierung von Multimediadaten kann eine hohere Anzahl von Bits je Sample verwendet wer-den, als der Qualitat und dem Betrachter angemessen sind. In diesen Bits werden geheime Informationengespeichert.
Texture Block Coding
Bei diesem Verfahren werden Bildbereiche ausgeschnitten und an anderer Stelle wieder in das Bild ein-gefugt. Bei hinreichender Ahnlichkeit (grune Wiese, blauer Himmel, etc.) kann diese Modifikation sub-jektiv nicht wahrgenommen werden, identische Bit-Muster konnen aber leicht mit Hilfe des Computersgefunden werden.
Texture Block Coding ist robust gegenuber Veranderungen, die das ganze Bild betreffen (Drehung, Farb-veranderungen, ...).
Patchwork Coding
Bei diesem Verfahren kann nur ein Bit Information in einem Datensatz untergebracht werden: DasWasserzeichen ist also entweder vorhanden oder nicht. Dazu wird eine Konstante C und ein geheimerZahlenwert S, der als Startwert eines genau definierten Pseudozufallszahlengenerators (PZG) dient. DerPZG liefert eine moglichst unzusammenhangende Folge von Zahlen, deren Abfolge aber durch die Wahldes Startwertes eindeutig bestimmt ist. Mit diesem Startwert S und dem PZG werden zwei Pixelkoordi-naten (A und B) eines Bildes berechnet und die Helligkeit des Pixels A um den Wert C verringert, dieHelligkeit des Pixels B und den Wert C vergrossert. Dies wird etwa 10000 mal wiederholt.
Zur Uberprufung des Wasserzeichens werden nun wieder die Koordinaten der Pixelpaare mit Hilfe desStartwertes S und des PZGs wieder berechnet und beobachtet, ob im Mittel uber die 10000 Pixelpaaredie Helligkeitsdifferenz der beiden Pixel 2C ergibt. Ist das so, ist das Wasserzeichen vorhanden, wennnicht ergibt die mittlere Differenz Null.
Eine ausfuhrliche (und mathematisch exaktere) Erklarung findet sich in [Hen00] oder unter http://www.research.ibm.com/journal/sj/mit/sectiona/bender.html.
Steganografie Literatur
• Eine gute Webseite inkl. vieler Links auf Software ist StegoArchive13
13http://www.stegoarchive.com

KAPITEL 6. DIGITAL IMAGES 106
• Eine grosse Linksammlung uber digitale Wasserzeichen ist unter http://view.informatik.uni-leipzig.de/~toelke/Watermark.html zu finden. Dort ist auch der source eines Programmes zu finden, derWasserzeichen in Bilder einfugen/entfernen/uberprufen kann.
• Der Watermarking Webring ist unter http://www.watermarkingworld.org/webring.html zu fin-den.
• Ein Artikel uber aktuelle Steganographieprogramme ist in c’t 9/2001 zu finden ([Wes01]). Kapitel 7
Digital Video
Unter Video wird jegliche Art von Bewegtbildern verstanden. Im Unterschied zur analogen Videotechnikwerden bei der digitalen Videotechnik die Videosignale einer analogen Quelle (Videokamera) digitalisiertund in digitaler Form gespeichert. Digital Video (DV) nimmt die Bilder gleich in digitaler Form auf.Digitale Videotechnik versucht heutzutage die analoge Technik zu verdrangen, die Verarbeitung von digi-talem Videomaterial mit einem PC ist aber nicht ganz unproblematisch: Ein einzelnes Vollbild (Frame)in voller Farbtiefe benotigt bei 800.000 Pixeln (zur Zeit die Standardauflosung von digitalen Videokame-ras) schon 2.4MB. Um eine realistische Bewegtbildfolge zu erhalten, sind 25 bis 30 Bilder pro Sekundenotig. Das fuhrt zu einem Datenstrom von 60MB pro Sekunde! Ein abendfullender Film (120min) wurdeunkomprimiert also 432 Gigabytes an Daten produzieren! Dieses kurze Rechenbeispiel zeigt schon, dassbei digitalem Video die Kompression sehr wichtig ist, will man diese Datenmengen mit ’Standard-PCs’noch irgendwie bewaltigen.
7.1 Video und der Mensch
Das menschliche Auge kann nur relativ langsame visuelle Reize aufnehmen. Schnell aufeinanderfolgendeReize konnen nicht mehr unterschieden werden. Durch hintereinanderfolgende Projektion von Einzel-bildern kann dadurch eine “Scheinbewegung” vorgetauscht werden. Die Grenze fur das Eintreten dieserScheinbewegung liegt bei einer Bildfolge von 16 bis 24 Bildwechseln pro Sekunde.
Der traditionelle Kinofilm basiert auf 24 Bilder pro Sekunde, was aber immer noch zu starkem Flimmernfuhrt. Deshalb wird durch eine Blende jedes Bild nocheinmal bzw. zweimal unterbrochen, sodass 48 bzw.72 Lichtreize pro Sekunde entstehen.
Fur sehr helle Bilder genugt eine Auflosung von 25 Bildern pro Sekunde nicht. Solche Filme flimmernnoch merklich. Daher wurde z.B. beim Fernseher das Zeilensprungverfahren (Interlacing) eingefuhrt: DieBilder werden nicht in ihrer naturlichen Reihenfolge wiedergegeben, sondern in der ersten 1/50 Sekundenur die ungeraden Zeilen, in der nachsten 1/50 Sekunde nur die geraden Zeilen. Dadurch werden 50Bilder mit halber Zeilenzahl erzeugt, die ineinander geschachtelt dargestellt werden und so einigermassenflimmerfrei wirken.
Wirklich flimmerfrei wird das Bild aber erst bei mehr als 75 Bildwechseln pro Sekunde. [Hol00]
Bewegung wird aber nicht nur von Auge erfasst, auch andere Einflussfaktoren spielen ein Rolle.
7.1.1 Wahrnehmung von Bewegung
Der wichtigste psychologische Einfluss auf die Wahrnehmung von Bewegung ist die gegenseitige Be-einflussung benachbarter Lichtsinneszellen auf der Netzhaut des menschlichen Auges. Von erheblicherWichtigkeit ist aber auch die Wahrnehmung von Beschleunigung mittels verschiedener Bogengange imOhr. Diese Bogengange sind mit Flussigkeit gefullt, die bei Beschleunigung durch ihre Massetragheitdafur sorgt, dass Sinneshaare im Ohr umgebogen werden.
107

KAPITEL 7. DIGITAL VIDEO 108
Der Simulation von Bewegungen in multimedialen Umgebungen ist durch die darin fehlende Beschleuni-gungswahrnehmung eine Grenze gesetzt. Wird das menschliche Wahrnehmungssystem raschen optischenBewegungswechseln ausgesetzt, ohne dass eine passende Beschleunigungswahrnehmung existiert (oderumgekehrt), ergibt sich fur die meisten Personen eine heftige Ubelkeit. Beispiel: Lesen beim Autofahren,oder der Besuch eines 3-D Kinos. Eine Vermutung fur diesen Grund ist, dass das Gehirn die Entkopplungsensorischer Inputs als erstes Zeichen fur Vergiftung ansieht, und das spontane Erbrechen von Nahrungsich als evolutionarer Vorteil erwiesen hat.
Ein weiteres Problem bei der Betrachtung von Bewegungen auf einem Bildschirm ist der Wegfall derAkkomodation (der Anpassung der Augenlinse auf unterschiedliche Entfernungen): Hintergrund und Ob-jekt sind scheinbar in gleicher Entfernung angeordnet. Dies ist auch ein Problem bei stereoskopischenAufnahmen, die meist fur eine unnaturliche Entkopplung zwischen Vergenz (Schragstellung der Blickrich-tung beider Augen relativ zueinander) und Akkomodation sorgen und damit bei empfindlichen PersonenUbelkeit erregen. [Hen00]
Jegliche Aufnahme von Bewegung (ob analog oder digital) kann somit nur einen Teil der visuellen Auf-nahme simulieren. Trotzdem haben bewegte Bilder einen wichtigen Platz eingenommen, den sie auch inder digitalen Welt beanspruchen.
7.2 Analoges Video
Um die Eigenschaften von digitalem Video zu verstehen, sollte man auch einiges von analogem Videoverstanden haben.
Das Hauptproblem von analogem Video ist, dass sich die Fehler bei wiederholtem Bearbeiten immerweiter fortpflanzen und sich so die Qualitat immer mehr verschlechtert.
NOTIZ: Die folgenden Videostandards sind nur der Vollstandigkeit halber angefuhrt und werden nuruberblicksmassig bei Prufungen gefragt.
7.2.1 BAS und FBAS (Composite Video)
Am Ende jeder abgetasteter Zeile erfolgt ein Rucksprung auf den Anfang der nachsten Zeile, am Endedes gesamten (Halb-)Bildes der Sprung auf den Anfang des Abtastgerates. Enthalt ein BAS-(Bild, Aus-tastung, Synchronisation)-Signal zusatzlich noch Farbinformation, spricht man von einem FBAS-(Farbe,Bild, Austastung, Synchronisation)-Signal.
7.2.2 Komponentenvideo (Component Video)
Grundlage dieses Videostandards ist ein Farbmodell, in dem jedes der drei Primarsignale getrennt ubert-ragen wird. Je nach Farbmodell sind RGB, YUV oder YIQ die Primarsignale.
7.2.3 Y/C Video (Separiertes Video)
Luminanz/Color-Video ist ein Kompromiss aus FBAS und Component Video. Die beiden Farbsignale(z.B. U und V) werden zu einem gesamten Chrominanz-Signal gemischt, das Luminanzsignal Y wirdseparat ubertragen.
S-VHS und Hi-8 verwendend dieses Modell.
7.2.4 PAL Video
Der im deutschen Sprachraum verwendete Fernsehstandard hat folgende Eigenschaften:
KAPITEL 7. DIGITAL VIDEO 109
• 768 Pixel pro Zeile
• 625 Zeilen pro Bild (Frame) (576 sichtbar)
• 25 Frames pro Sekunden
• Bildseitenverhaltnis von 4:3
• Quadratische Pixel
• Interlaced Modus (zwei Halbbilder mit geraden/ungeraden Zeilen ergeben ein Bild)
7.2.5 NTSC Video
Der amerikanische Fernsehstandard hat folgende Eigenschaften:
• 640 Pixel pro Zeile
• 525 Rasterzeilen (480 sichtbar)
• 29.97 Frames pro Sekunden (diese seltsame Zahl resultiert aus der Tatsache, dass die Trennung vonAudio- und Farbtrager genau auf 4.5 MHz eingestellt wurde)
• Bildseitenverhaltnis von 4:3
• Quadratische Pixel
• Interlaced Modus (zwei Halbbilder mit geraden/ungeraden Zeilen ergeben ein Bild)
• verwendet das YIQ-Farbmodell
7.2.6 High Definition Television (HDTV)
HDTV dient als Sammelbegriff fur verschiedene Formate hochauflosenden Fernsehens. Die in den ver-schiedenen HDTV-Standards definierten Auflosungen und Bildraten werden vermutlich durch die derzei-tige Entwicklung bei digitalen Videostandards obsolet [Hen00], noch bevor sie wirklich auf den Marktkommen.
Die Auflosungen reichen von 1920x1080 (bei einem Seitenverhaltnis von 16:9) bis zu 640x480 (bei 4:3).Die Bildraten sind zwischen 24Hz und 60Hz definiert (sowohl die ’krummen’ NTSC-Frequenzen, als auchdie ’geraden’ PAL-Frequenzen).
7.3 Digitale Videotechnik
Digitale Videotechnik wird wahrscheinlich in der nachsten Zeit die konventionelle analoge Videotechnikablosen, da mehrere Vorteile klar fur die digitale Welt sprechen:
• Direkter Zugriff auf einzelne Bilder
• Keine Verluste beim wiederholten Bearbeiten/Schneiden
Wie schon eingangs erwahnt, ist die Datenmenge, die bei einem digitalen Video anfallt, aber sehr grossund so ist Kompression enorm wichtig.
Fur die Verarbeitung von Multimediadaten hat es sich bewahrt, die dafur benotige Software in mehrereTeile zu spalten und dazwischen Schnittstellen zu standardisieren. Die Arbeitspferde dabei sind Codecs,die Verarbeitung, Umrechnung und das Mixen der Mediastreams ubernehmen. Die einzelnen Teile solltenin der Theorie austauschbar sein, jedoch kann man nicht bei jedem Programm alle fur einen bestimmtenCodec optimalen Einstellungen vornehmen, und nicht jeder Codec kann beliebige Dateiformate schreiben.

KAPITEL 7. DIGITAL VIDEO 110
Auf dem Macintosh ist die unangefochtene Multimediaschnittstelle Apple’s Losung QuickTime. UnterWindows konkurrieren drei Systeme: von Microsoft das alte Video fur Windows und das neuere Direct-Show - und daneben plattformubergreifend Apple QuickTime[DZ01]. Fur Linux gibt es leider noch keineStandards in diese Richtung.
7.3.1 Codecs
Codec steht fur Coder/Decoder und meint die Software oder Hardware, die zur Kompression/Dekompres-sion von Multimediadaten, hauptsachlich Videodaten, verantwortlich ist. Bei lizenzpflichtigen Verfahrensind diese beiden Teile auch manchmal getrennt: der Kompressor ist gebuhrenpflichtig, wahrend derDekompressor frei zuganglich ist.
Codecs spielen also die Rolle von Treibern fur virtuelle oder reale Gerate.
Die wichtigsten Codecs sind Cinepak, Indeo, Video-1, MS-RLE, MJPEG und Codecs nach H.261, H.263und MPEG (siehe Abschnitt 7.3.2 und Abschnitt 7.3.3):
Cinepak Das Verfahren ist mittlerweile von Apple gekauft worden und komprimiert Videodaten, indemwenige vollstandige Bilder (Keyframes) eines Videos in eine grossere Menge von Differenzbildern (DeltaFrames) eingebunden werden. Die Farbtiefe betragt 24 Bit und der typische Kompressionsfaktor ist etwa7:1.
Indeo Wurde von Intel fur den i750-Prozessor entwickelt, es gibt aber auch reine Softwarelosungen.Das Kompressionsverfahren arbeitet mit Makroblocken zu je 4x4 Pixel, ist stark verlustbehaftet undasymetrisch, d.h. die Kompression bedarf eines hoheren Rechenaufwandes als die Dekompression. Dertypische Kompressionsfaktor ist ebenfalls etwa 7:1.
Microsoft Video-1 Entwickelt von MediaVision, mittlerweile von Microsoft gekauft, arbeitet das Ver-fahren mit 8, 16 und 24 Bit Farbtiefe. Der Kompressionsfaktor betragt nur etwa 2:1. Das Verfahren istnur unter Windows verfugbar.
Microsoft RLE Diese Microsoft Eigenentwicklung erlaubt nur 4 oder 8 Bit Farbtiefe. Der typischeKompressionsfaktor ist noch schlechter als bei Video-1.
MJPEG Motion JPEG besteht aus hintereinandergereihten Bildern, die mit JPEG komprimiert wur-den. Der Kompressionsfaktor hangt stark von der verwendeten Qualitat ab und entspricht dem der JPEGKompression (siehe Tabelle 6.1). Ein Nachteil dieses Codecs ist, dass die Einbindung von Audio-Datennicht im MJPEG-Standard definiert ist.
MJPEG Videos werden unter Windows nahezu immer im AVI-Dateiformat und unter Apple im Quicktime-Format abgelegt.
Digitale Videokameras speichern die Videodaten in einem verbesserten MJPEG-Format, das mit einerfixen Datenrate von 3.4MByte/Sekunde arbeitet. Damit kommt man auf 204MB Daten pro Minute oderungefahr 12GB pro Stunde. Der Ton wird mit 16 Bit, 48KHz Stereo (oder 12 Bit, 32kHz, 2x Stereo) imBitstrom mitgespeichert, um Synchronisationsprobleme zu vermeiden.
7.3.2 Videokompression nach H.261 und H.263
H.261 wurde in den Jahren 1984 bis 1990 entwickelt und ermoglicht Video-Conferencing und Video-Telefonie uber ISDN-Leitungen mit einer Bandbreite von 64kbit/sec oder ganzzahligen Vielfachen davon.Entsprechend der Zielanwendung “Kommunikation” wurde spezifiziert, dass Kompression und Dekom-pression zusammen nicht mehr als 150ms Verzogerung bewirken durfen.
Die Bildwechselfrequenz liegt bei 29.97 Frames/Sekunde (30000/1001). Die Auflosung ist entweder352x288 oder 176x144 Pixel. Es treten zwei Arten von Frames auf (siehe auch Abbildung 7.1):
KAPITEL 7. DIGITAL VIDEO 111
• Intraframes (I-Frames) enthalten vollstandige Bilddaten und sind nach JPEG komprimiert.
• Predicted Frames (P-Frames) werden durch Bewegungsvorhersage und Differenzbildung aus denvorhergehenden Frames erzeugt.
P P P PP PI I
Zeit
Abbildung 7.1: I-Frames und P-Frames
Bei H.263 wurden 1996 einige Teile gegenuber H.261 verbessert:
• Verringerte Genauigkeit bei der Bewegungsvorhersage
• Einige Teile des Datenstromes sind optional
• Aushandelbare Parameter zur Leistungssteigerung (z.B. kann auf eine bidirektionale Vorhersageahnlich MPEG umgeschaltet werden)
• Funf verschiedene Auflosungen
• Bildnummerierung mit 8 Bit anstatt mit 5 Bit
Mit diesen Anderungen lassen sich H.263 Datenstrome mit weniger als der halben Datenrate als mitH.261 bei gleichem Inhalt ubertragen.
Eine verbesserte Version von H.263 (H.245) wird vom IP-Telefonie-Standard H.323 benutzt. Mehr Detailsuber H.323 findet man u.a. unter http://www.packetizer.com/iptel/h323/.
H.261 Kompression
Die I-Frames werden im Prinzip nach JPEG komprimiert: Die 16x16 Makroblocke werden in vier 8x8Blocke unterteilt und mit einem festen Wert fur alle Koeffizienten der diskreten Cosinus-Transformationquantisiert.
Fur die P-Frames wird das aktuelle Bild ebenfalls in 16x16 Makroblocke zerlegt. Fur jeden dieser Blockewird im vorhergehenden Bild derjenige Block gesucht, der am besten ubereinstimmt (Best Match-Suche).Der relative Verschiebungsvektor wird in den Ausgabestrom aufgenommen. Die Differenz der beidenMakroblocke wird schliesslich genau wie in der I-Frame-Codierung in das JPEG-Format gewandelt.
Tabelle 7.1 zeigt die Datenraten bei der H.261 Kompression.
7.3.3 Videokompression nach MPEG
Das MPEG-Kompressionsverfahren wurde zuerst 1992 von der Moving Pictures Expert Group vorgestellt.Derzeit gibt es verschiedene Auspragungen des MPEG-Standards:

KAPITEL 7. DIGITAL VIDEO 112
Format Datenrate unkomprimiert Datenrate H.261CIF 352x288x30 36.45Mbit/sec 24xISDN = 1.5Mbit/sQCIF 176x144x30 9.115Mbit/sec 6xISDN = 384kbit/s
Tabelle 7.1: Datenraten bei H.261 Kompression
MPEG-1 (1992) wurde als Standard zur Speicherung von Bildern und Musik auf Datentragern (z.B.CDROM) kreiert. MPEG-1 Layer 3 (mp3) ist ein Quasi-Standard fur hochwertige Audiokompression.
MPEG-1 bietet eine mittlere Bandbreite ≤ 1.892Mbit/sec, davon ca. 1.25Mbit/sec Video. Der Rest wirdauf zwei Audio-Kanale aufgeteilt.
Die Auflosung betragt 360x288 bei 25 Frames/Sekunde (CIF Europa) bzw. 352x240x30 (CIF USA) undunterstutzt kein Interlacing. Trotzdem ist VHS-Aufzeichnung moglich.
Die VideoCD (VCD) basiert auf MPEG-1. Sollte man selbst versuchen, eine VCD herzustellen, mussman beachten, dass das Video als MPEG-1 genau dieser Auflosung und Bildwiederholrate gespeichertwerden muss und 1.15MBit/sec nicht uberschreiten darf. Audio wird auf VCDs im MPEG-1 Layer II mit44100kHz/Stereo und fixen 224kbit/sec gespeichert.[DZ01]
MPEG-2 (1993) ist das bisher am haufigsten angewandte MPEG-Verfahren und erweitert den MPEG-1Standard.
Primares Ziel war es, einen Standard fur digitales Fernsehen mit Datenraten zwischen 2 und 80Mbit/szu schaffen. In MPEG-1 war die Kodierung von “Interlaced” Video (in PAL und NTSC verwendetesZeilensprungverfahren) nicht moglich, MPEG-2 wurde um diese Moglichkeit erweitert. Im Zeilensprung-verfahren kann das Video in Halb- oder in Vollbildern kodiert sein. Fur die Umrechnung von 24 Hz Filmauf 30 Hz NTSC sorgt eine Steuervariable, die das Abspielgerat dazu veranlasst, bestimmte Bilder zuwiederholen. Die Umrechnung von 24Hz Film auf 25Hz PAL unterbleibt, der Film wird einfach mit 25Bildern pro Sekunde abgespielt und dadurch etwas kurzer. MPEG-2 unterstutzt funf Audiokanale undeinen zusatzlichen Tieftonkanal.
Weitere Unterschiede zu MPEG-1 sind unter anderem:
• Best Match-Suche untersucht nicht nur Frames, sondern auch Halbbilder (Fields).
• Frame Grosse kann bis zu 16383x16383 Pixel betragen.
• Nichtlineare Makroblock-Quantisiertabelle
MPEG-2 definiert verschiedene Auflosungen (von MPEG-1 Auflosung bis zu HDTV-Auflosung) und un-terstutzt je nach Auflosung raumliche und/oder zeitliche Skalierbarkeit. Erstere bedeutet, dass derselbeDatenstrom in verschiedenen Auflosungen angezeigt werden kann. Zweitere hilft, den Datenstrom aufVeranderungen der Bandbreite anzupassen. Eine genauere Auflistung, welcher Modus was unterstutzt,ist in [Hen00, S.179] zu finden.
Die Super-VideoCD (SVCD) und die DVD verwenden MPEG-2 als Codec und bietet daher bessereQualitat (hohere Auflosung) als VCD. Viele DVD-Player konnen sowohl VCDs als auch SVCDs abspielen.
MPEG-4 (1999) ist ein universeller Standard fur den Aufbau von Multimedia-Applikationen bis zuhalbsynthetischen VR-Welten aus Texturen und 3D-Objekten. Er umfasst nicht nur die Kompression vonAudio- und Videodaten, sondern auch Sprites, 3D-Welten, Klang- und Sprachsynthese, Bildsynthese ausvorgefertigten Modellen fur Szene und Korper, digitales Fernsehen, mobile Multi-Media, sowie streamingVideo mit virtueller Interaktion. Fur die fortgeschrittenen Teile fehlt es aber noch an passenden Encodern.Die interne Skriptsprache ist Java-Script, die Kommunikation mit dem Player erfolgt uber “MPEG-J”,eine Java-Schnittstelle. [Lov00]
Der sehr komplexe Standard ist zur Integration von PC, TV und Telekommunikation in interaktiveProgramme gedacht. Entsprechende Tools fehlen aber noch. Es sollen die Wunsche von Autoren (fle-xibel fur viele Medien, Rechtsschutz und -verwaltung, bessere Wiederverwertbarkeit), Service-Providern
KAPITEL 7. DIGITAL VIDEO 113
(generischer QoS-Deskriptor fur verschiedene Medien enthalten, vereinfacht die Transporte und der Op-timierung) und Benutzern (hoher Grad an Interaktion) vereint werden. MPEG4 beschreibt:
• die Integration beliebiger Medienobjekte. Dazu zahlen 2D- und 3D-Objekte, Schallquellen, Texte,usw.1, die in einer Baumstruktur organisiert sind und zu komplexeren Objekten zusammengefasstwerden konnen. Die Kompression erfolgt immer fur einzelne Objekte.
• den Zusammenhang dieser Objekte zur Erzeugung einzelner Szenen.
• Multiplex- und Sprachsynchronisationsmechanismen fur ein Transport und die Berucksichtigungvon QoS (Quality of Service).
• Interaktion des Benutzers mit der generierten Szene am Zielort.
In letzter Zeit ist MPEG-4 durch seine hohen Lizenzkosten in die Schlagzeilen geraten. Die Veroffentli-chung von Quicktime 6 wurde lange verzogert, da Apple diese Kosten scheute und abwarten wollte, obein alternativer Codec das Rennen um den Quasi-Internet-Video Standard machen wurde.
MPEG-7 ist seit Dezember 2001 zu grossen Teilen fertig gestellt (6 von 7 Teilen) und hat den Titel“Multimedia Content Description Interface”. MPEG-7 konzentriert sich hauptsachlich darauf, den Inhaltmit Hilfe von XML zu beschreiben, also Informationen uber die Informationen zur Verfugung zu stellenum z.B. Suchen in Multimedia-Dateien zu unterstutzen. Es soll auch moglich sein, mit MPEG-7 Inhalte,die weder visuelle noch Audiodaten enthalten, zu verarbeiten.
MPEG-7 basiert auf folgenden Konzepten [?, GravesMPEG72001]
• Descriptor (D): Beschreibt Daten.
• Description Scheme (DS): Definiert die Struktur der Daten (Descriptors).
• Description Definition Language (DDL): Beschreibt die Sprache, in der Descriptors und DescriptionSchemes spezifiziert sind. DDL basiert auf XML.
Ein kurzes Beispiel aus [?, GravesMPEG72001]eigt die Beschreibung von Metadaten eines Videos:
<Creation><Title>Fawlty Towers</Title><Abstract><FreeTextAnnotation>Communication Problems
</FreeTextAnnotation></Abstract><Creator>BBC</Creator>
</Creation>
Um eine Suche in Multimedialen Daten zu ermoglichen, muss naturlich auch der Inhalt beschriebenwerden. Folgendes Beispiel zeigt, wie eine Szene mit Hilfe von MPEG7 beschrieben wird:
<TextAnnotation><FreeTextAnnotation>Basil attempts to fix the car without success.
</FreeTextAnnotation><StructuredAnnotation><Who>Basil</Who><WhatObject>Car</WhatObject><WhatAction>Fix</WhatAction><Where>Carpark</Where>
</StructuredAnnotation></TextAnnotation>
1Lt. [Hen00] ist MPEG-4 deshalb eher ein Einstieg in die Welt der Virtual Reality als ein Bewegtbild-Standard.

KAPITEL 7. DIGITAL VIDEO 114
Es gibt mehrere Ansatze, wie in solchen Daten gesucht werden kann. Der bekannteste ist XQuery2, eineQuery Language des W3C, die die Suche in XML Daten (und damit auch in in MPEG7) ermoglicht.
MPEG-21 Die Arbeit an diesem Standard wurde erst Mitte des Jahres 2000 begonnen und so gibt esnoch nicht viel daruber zu berichten! MPEG-21 versucht, ein multimediales Framework zu beschreibenund zukunftige Trends fur eine Umgebung vorherzusehen, in der eine Vielzahl von Inhalten unterstutztwerden (auch nicht MPEG-Standards). Erste Ergebnisse werden erst in der naheren oder auch fernerenZukunft erwartet (Die Spanne liegt zwischen Ende 2001 und 2009!).
Ein Schwerpunkt liegt sicher in der Vermarktung von multimedialen Inhalten und so definiert MPEG-21Standards zur Verteilung, Abrechnung, Ubertragung, Beschreibung etc. von digital items (Daten plusMetadaten plus Struktur, wie einzelne Daten miteinander in Verbindung stehen).
Windows Media Technologies Der Windows Media Player ist fur Windows, MacOS, Solaris undeinige auf Windows CE basierende Pocket-PCs verfugbar, der Encoder nur fur Windows. Bei WMA7nannte sich der Codec fur die Videokompression zwar MPEG4, es wurde aber gemutmasst, dass es sicheher um einen reinen MPEG2-Codec mit einigen Zusatzen zur Verhinderung von Mosaiken handelt.Inwieweit sich Microsoft hierbei an den offiziellen MPEG-4 Standard anlehnte, kann nur gemutmasstwerden.
In der zwischenzeit steckt hinter der aktuellen Windows Media Technology ein MPEG4 Codec.
DivX (fur Digital Video Express) war ursprunglich eine gehackte Version des Microsoft MPEG4 V3Codecs aus Windows Media 7 (DivX 3). Er implementiert Video in DVD-Qualitat, der auf dem MPEG-4ISO Standard fur digitale Videokompression basiert und um MP3-codiertes Audio erganzt wurde.
Der grosse Erfolg von DivX bei der Internetgemeinde resultierte in diverse Weiterentwicklungen. FolgendeDivX-Versionen sind im Moment im Umlauf:
• DivX 3.x ist (wahrscheinlich) eben dem oben erwahnten Microsoft Codec “entsprungen” und hat vorallem den Nachteil, dass die Grosse der DivX-Dateien vor dem Codieren nur sehr schwer berechenbarist. Qualitat und Geschwindigkeit ist nach wie vor eine der Starken dieses Codecs.
• DivX 4 ist eine legale (Weiter- bzw. Neu-) Entwicklung der Firma DivX Networks3. Sie ist fur denprivaten Gebrauch frei und wird auch noch weiterentwickelt. DivX 4 unterstutzt Variable Bitraten(VBR) und liefert im Grossen und Ganzen (meistens) eine bessere Qualitat als DivX 3.
• XviD ist eine legale Open Source Entwicklung, die aber zu DivX 3 inkompatibel ist und zur Zeitnoch taglichen Anderungen unterliegt. Trotz alledem, soll Xvid gute Qualitat liefern.
• DivX 5 ist die neueste Version von DivX Networks und verwendet (optional) erstmals eine bidirek-tionale Vorhersage der Frames (siehe auch Abbildung 7.2).
Dieser Kurzuberblick der diversen Codecs stammt von http://www.cselt.it/mpeg/, aus [DZ01] undvon http://www.doom9.org/divx-encoding.htm
MPEG-Kompression
Alle MPEG-Standards verwenden dasselbe Kompressionsverfahren. Die Videodaten liegen in Form vonEinzelbildern (Frames) vor. Es gibt drei Typen von Frames:
• Intraframes (I-Frames) enthalten vollstandige Bilddaten und sind nach JPEG komprimiert. Etwajeder 15. Frame ist ein I-Frame.
• Predicted Frames (P-Frames) werden durch Bewegungsvorhersage und Differenzbildung aus denvorhergehenden Frames erzeugt. Zwischen zwei I-Frames liegen typischerweise drei P-Frames.
2http://www.w3.org/TR/xquery3http://www.divx.com
KAPITEL 7. DIGITAL VIDEO 115
• Bidirectionally Predicted Frames (B-Frames) werden durch eine Bewegungsvorhersage aus demvorhergehenden und dem nachfolgenden I- oder P-Frame erzeugt. Zwischen zwei P-Frames liegentypischerweise zwei bis drei B-Frames.
I B B B P B B BP B B BP B B B I
Zeit
Abbildung 7.2: Anordnung und Beziehung der Frame-Typen bei der MPEG-Kompression
Frame-Typ Grosse KompressionI 92 kByte 7:1P 32 kByte 20:1B 13 kByte 50:1
Mittelwert 26 kByte 25:1
Tabelle 7.2: Kompressionsraten bei MPEG-Frametypen
Die Anordnung und relative Haufigkeit der einzelnen Frames hangt vom verwendeten Codec ab.
Bei MPEG werden die Frames nicht in der Reihenfolge ubertragen, in der sie dargestellt werden. Furpraktische Zwecke hat sich die Darstellungsreihenfolge von Tabelle 7.3 bewahrt. So kann der B-Frameleicht aus dem schon vorher ubertragenen P-Frame berechnet werden.
DarstellungsreihenfolgeBild 1 2 3 4 5 6 7 8 9 10 11 12 13Typ I B B P B B P B B P B B IUbertragungsreihenfolgeBild 1 4 2 3 7 5 6 10 8 9 13 11 12Typ I P B B P B B P B B I B B
GOB GOB GOB GOB
Tabelle 7.3: Gruppierung der Frames in MPEG (GOB = Group of Blocks) [Hen00]
I-Frame Codierung erfolgt genau wie bei H.261 (Abschnitt H.261 Kompression auf Seite 111) be-schrieben, nur werden die erzeugten Daten sofort wieder decodiert, um sie fur die Bewegungsvorhersageim Speicher halten zu konnen.
P-Frame und B-Frame-Codierung Zwischen den I-Frames liegen zunachst P-Frames. Diese sindin 16x16 Pixel grosse Makroblocke eingeteilt. Fur jeden dieser Blocke wird im vorhergehenden I- oderP-Frame in der naheren Umgebung (ca. 10 Pixel in jede Richtung) nach der grosstmoglichen Uberein-stimmung gesucht. Ubertragen wird schliesslich der Verschiebungsvektor aus dieser Bewegungsvorhersagesowie ein Korrekturblock (fast identisch mit H.261, Abschnitt H.261 Kompression).

KAPITEL 7. DIGITAL VIDEO 116
Zwischen den P-Frames wiederum liegen B-Frames, bei denen die Bewegungsvorhersage sowohl aus demvorhergehenden als auch aus dem nachfolgenden I- oder P-Frame gewonnen wird. Die Suche nach derbesten Ubereinstimmung kann auch ergeben, dass diese sich fur eine Mittelung aus vorhergehendem undnachfolgendem P- oder I-Frame ergibt. [Hen00, S.183]
Von entscheidender Bedeutung fur die Qualitat des Codec ist auch die Bestimmung der besten Uberein-stimmung (best match). Verwendet werden die Berechnung der mittleren quadratischen Abweichung oderder mittlere Betrag der Abweichung.
D-Frames sind eine vierte Frame-Kategorie, die ursprunglich fur die Darstellung wahrend eines schnel-len Vor-/Rucklaufes gedacht waren. Diese Bilder sind sehr grob gerastert und lassen sich in etwa mit denDC-Daten (dem Gleichanteil) von JPEG vergleichen.
7.3.4 Video-Dateiformate
Verschiedene Dateiformate konnen durchaus verschiedene Codecs unterstutzen, sodass man keinen direk-ten Schluss aus dem Dateiformat auf den verwendeten Codec ziehen kann.
Audio-Video-Interleaved Format (AVI)
AVI ist von Microsoft mit Video for Windows eingefuhrter Standard, der auf der RIFF-Spezifikationbasiert. AVI-Dateien sind in der Regel komprimiert und verwenden meist Cinepak oder Indeo. Aberauch DivX oder MPEG-4 kann als Codec verwendet werden.
Die Auflosung bei AVI kann grundsatzlich in vollem PAL-Format erfolgen (768x576 Pixel), typische Werteliegen allerdings bei 320x240 bei 24 bis 30 Frames/sec.
Quicktime
Quicktime wurde ursprunglich von Apple entwickelt, wurde aber spater auch auf Windows-Plattformenportiert. Quicktime-Dateien (*.mov) enthalten sowohl Video- als auch Audio-Daten. Quicktime bietetdem Benutzer und dem Programmierer eine Reihe von komplexen Funktionen und unterstutzt auch dasEinbinden von neuen Kompressionsalgorithmen.
Die am meisten verwendeten Codecs in Quicktime-Movies sind der Indeo-Codec und der Cinepak-Codec.Seit Quicktime Version 6 wird auch MPEG-4 unterstutzt.
RealVideo
Dieses Format von Real Networks4 zeichnet sich vor allem dadurch aus, dass es streaming-fahig ist.Diese Eigenschaft wird vor allem ausgenutzt, um Videos ubers Internet zuganglich zu machen. Dabei istnaturlich die verfugbare Bandbreite das grosste Problem.
Bei einem RealVideo-Stream teilen sich Video-Informationen und Audio-Informationen die verfugbareBandbreite. Die Aufteilung kann durchaus je nach Anwendung variieren. So benotigt ein Video mitMusik mehr Anteile fur Audio, als ein Video mit einem Sprecher als Audio-Spur. RealVideo verwendetRealAudio um den Soundtrack zu codieren.
RealVideo komprimiert wie fast alle anderen Video-Codecs verlustbehaftet. Der im Moment verwendeteCodec ist eine Eigenentwicklung namens ’RealVideo 8’ und der Nachfolger des ’Realvideo G2’-Codecs.Eine weitere Methode um die Datenmenge zu reduzieren ist, die Framerate herabzusetzen. RealVideokann beim Codieren die Framerate dynamisch anpassen, je nachdem wie “action-reich” eine Szene ist.Zusatzlich sorgt die Scalable Video Technology (SVT) dafur, dass die Framerate automatisch an diemomentan verfugbare Bandbreite und CPU-Leistung angepasst wird.
4http://www.real.com
KAPITEL 7. DIGITAL VIDEO 117
Eine weitere Technik, die RealVideo verwendet, um die Kompressionsrate zu erhohen, ist es, die Anzahlder verwendeten Farben zu verringern. Pixel mit ahnlichen RGB-Werten werden einfach eliminiert.Dadurch verschwimmt das Bild und Details verschwinden.
RealVideo unterstutzt verschiedene Auflosungen von 176x132 bis zu 640x480 Pixel. Je hoher die Auflosung,desto hoher sind naturlich auch die Anspruche an die Bandbreite!
Die Information dieses Abschnittes stammt von http://service.real.com/help/library/guides/production8/htmfiles/video.htm.
Advanced Streaming Format (ASF)
ASF von Microsoft kann sowohl Audio- (siehe Abschnitt 5.2.16) als auch Video-Daten enthalten. DasDateiformat wird von Microsoft nicht restlos offengelegt, daher ist eine Portierung problematisch. EineIntegration in Videobearbeitungsprogramme sieht Microsoft auch nicht sehr gerne. So existierte eineVirtualDub5-Version, die ASF-Dateien lesen konnte, nur kurze Zeit. WMA (Windows Media Audio)und WMV (Windows Media Video) sind identisch zu ASF (durch Umbenennung einfach erzeugbar).[Lov00, DZ01]
7.4 Speichermedium DVD
Die DVD (Digital Versatile Disc) beruht auf ahnlichen Prinzipien wie die Compact Disc, kann jedochwesentlich mehr Daten aufnehmen (bis zu 16GB). Daher eignet sie sich erstmalig als Medium fur digitaleVideo-Daten (MPEG-2).
Der DVD-Standard ist kein freier Standard und wird vom japanischen DVD-Forum6 kontrolliert. Jeder,der Soft- oder Hardware fur DVDs entwickeln will, muss die aktuelle Version des Standards kaufen(zur Zeit ca. 5000$) und ein NDA (Non Disclosure Agreement) unterzeichnen, das die Weitergabe vonInformationen verbietet.
Darum sind auch nicht viele Informationen erhaltlich, die DVDs betreffen.
Das Verschlusselungsverfahren auf DVDs verwendet einen einfachen DES-ahnlichen Algorithmus, derim August 1999 von einer Crackergruppe geknackt wurde. Nichtsdestotrotz gibt es noch keinen freienDVD-Decoder, da jeder Verbreitungsversuch mit scharfen juridischen Attacken abgewehrt wird.
Weitere Dinge (das Wort ’Informationen’ ware hier ubertrieben) sind auf folgenden Web-Seiten zu finden:
• DVD Copy Control Association7
• OpenDVD8 versucht, Informationen fur Entwickler zur Verfugung zu stellen.
• Das Linux-Video and DVD Projekt (LiViD)9 will eine gemeinsame Grundlage fur Video und DVDunter Linux entwickeln.
7.4.1 Kopierschutzmechanismen der DVD
Etwa ein Viertel der Daten auf einer DVD sind mit CSS (Content Scramble System) verschlusselt.Verfugt der DVD-Player uber einen analogen Ausgang, so muss selbiger uberdies mit einem Macrovision-Kopierschutzsignal ausgestattet sein. Das System sollte in erster Linie Gelegenheitstatern die Moglichkeitzur Duplizierung einer Video-DVD nehmen.
Das DVD-Laufwerk und der Decoder tauschen zuerst die Schlusseldaten uber ein Protokoll zur gegensei-tigen Authentifizierung aus. Zum einen soll dies das Laufwerk davon abhalten, einem nicht lizenzierten
5http://www.virtualdub.org6http://www.dvdforum.com7http://www.dvdcca.org/8http://opendvd.org9http://www.linuxvideo.org/

KAPITEL 7. DIGITAL VIDEO 118
Decoder die Schlusseldaten mitzuteilen. Zum anderen soll sie verhindern, dass man eine gultige Authen-tifizierung aufzeichnet und zu einem spateren Zeitpunkt gegenuber einem echten Decoder erneut abspielt,was ja wieder das Kopieren der DVD erlauben wurde. In diese Berechnung geht ein 40 Bit langer ge-heimer Wert ein, ein so genanntes Shared Secret. Diesen Wert erfahren offiziell nur Lizenznehmer desCSS-Verfahrens, also Hersteller von Decodern und Laufwerken.
Im zweiten Schritt wird nun uber den sicheren Kanal der Disc Key vom Player ausgelesen. Er ist auf derDVD selbst gespeichert, allerdings in einem nur der Firmware zuganglichen Bereich. Der Disc Key istseinerseits chiffriert, und zwar so, dass er sich mit einem von einigen hundert verschiedenen Schlusselndecodieren lasst. Jeder lizenzierte Player hat einen individuellen Schlussel (Player Key), um den DiscKey zu decodieren. Sollte ein solcher je an die Offentlichkeit gelangen, so konnen die Filmherstellerdiesen Player bei der Produktion zukunftiger Titel gezielt sperren. Der fur die eigentliche Dekodierungbenotigte Title Key steckt schliesslich in den Sektor-Headern der verschlusselten Datensektoren. Nur derTitle Key ist erforderlich, um die Videodaten zu entschlusseln, der ganze einleitende Aufwand soll nurseine Geheimhaltung sichern.
Im Zuge der Bemuhungen, fur Linux einen DVD-Player zu schreiben, gelangte im Juli 1999 ein Code-Fragment in die Offentlichkeit, das sowohl das Authentifizierungsverfahren als auch das dazu notwendigeShared Secret enthielt. Damit konnte man DVD-Videos samt deren Schlussel kopieren, aber nicht abspie-len. Den zweiten Teil des Algorithmus sowie einen Player Key entwendeten Hacker aus dem Software-Decoder XingDVD von Xing Labs und implementierten ihn samt einer komfortablen Oberflache in DeCSS,was zu einigem medialem Wirbel fuhrte. Programme wie VobDec knacken die Verschlusselung hingegenuber einen kryptografischen Angriff (durch die damalige US-Exportbeschrankung sind alle Schlussel auf40 Bit Lange beschrankt). Dies ist jedoch auch kein Ausweg aus der rechtlichen Zwickmuhle, da dasVerfahren selbst geschutzt ist. [DZ01]
7.4.2 Rechtliche Probleme
Im Spannungsfeld zwischen kommerziellen Interessen der Unternehmen, Kunstlern und Schauspielern,die auf ihr Copyright pochen und den Rechten sowie der Privatsphare des Kunden ist das letzte Wortnoch nicht gesprochen. Scharf schiessende Rechtsabteilungen von Verwertungsgesellschaften, die gerneauch die Rechtslage zu ihren Gunsten uberziehen und auf Verunsicherung spekulieren, kampfen zwargegen die fortlaufende Entwicklung auf verlorenen Posten, im Einzelfall kann dies jedoch zu kostspieligenStreitigkeiten fuhren.
So fuhrt der DVD-Region-Code schon seit langerem zu einem regelrechten Katz- und Mausspiel zwischenVerscharfungen und Umgehungsprogrammen, die aktuellste Version ist RPC-2 mit “Regional Code En-hancement”. Sie uberpruft bei der Initialisierung, ob der Player auch wirklich auf einen Regionalcodefestgelegt ist und verweigert anderenfalls die Wiedergabe. Hinzu kommt, dass der offentliche Verkauf vonDVDs aus mit einem anderen Region-Code rechtlich nicht erlaubt ist, eine private Verausserung hingegenschon. [Stu01]
Der zweite juristisch umstrittene Punkt ist das Umgehen der DVD-Verschlusselung CSS (Content Scramb-ling System). Prinzipiell ist das Erstellen einer Kopie fur den privaten Gebrauch im Familien- und Freun-deskreis trotz gegensatzlicher Angaben im Vorspann und auf der Hulle erlaubt, auch wenn man dafureinen Kopierschutz a la Makrovision oder CSS uberwinden muss. Ist die Kopiersoftware aber durch einenVerstoss gegen das Gesetz entwickelt worden (durch rechtswidrige Dekompilierung oder Ausspionierungvon Betriebsgeheimnissen, was also beispielsweise fur DeCSS zutrifft), so ist deren Gebrauch rechtswidrig.Allerdings hangt es im Einzelfall davon ab, ob der Benutzer dies arglos oder ”im Wissen der Umstande“tut. [Jae00]
Patentierte oder geheime Verfahren stellen auch fur die Entwickler freier Software nahezu unuberwindbareHurden dar, was besonders bei der Entwicklung eines DVD-Players fur Linux zu Streitigkeiten fuhrte,die bis dato noch nicht entschieden sind.
7.5 Synchronized Multimedia Integration Language (SMIL)
SMIL (Synchronized Multimedia Integration Language) (wie “smile” ausgesprochen) ist eine Entwicklung
KAPITEL 7. DIGITAL VIDEO 119
des W3C (siehe auch SMIL-Spezifikation10 bzw. SMIL Uberblick11) in Zusammenarbeit mit u.a. Real-Networks, Microsoft, Netscape und Philips und dient dem einfachen Verfassen von multimedialen Prasen-tationen im Web.
Ein SMIL-Dokument beschreibt in einer einfachen Sprache, wie verschiedene Medien zu koordinierensind. SMIL folgt der Syntax von XML (siehe Abschnitt 4.4) bzw. HTML.
Diese Beschreibung des multimedialen Inhaltes wird von einem SMIL-Player interpretiert. Dieser regeltnur, in welcher Weise die Media-Clips abzuspielen sind, die Spezifikation enthalt jedoch keine Vorschriftenfur die Formate von Multimedia-Dateien.
SMIL ist ein recht junger Standard. Dementsprechend gibt es noch kaum Software dafur (fur eineListe der Player, die SMIL unterstutzen siehe http://www.w3.org/AudioVideo/). Auch die aktuellenBrowser-Versionen unterstutzen SMIL noch nicht. Gunstig fur die weitere Entwicklung des Standardsist das Engagement der Firma RealNetworks. Die aktuellen Versionen ihres RealPlayers wird neben deneigenen Real-Formaten auch SMIL-Anweisungen abspielen. [Pie98]
Ein schones Beispiel einer Smil-Prasentation kann z.B. unter http://www.dfki.de/imedia/miau/demos/smil_example.html gefunden werden. Hier kann man auch die Einzelteile (Text, Video, Sound) extradownloaden und so die Zusammenhange der verschiedenen Medien naher betrachten.
Abbildung 7.3: RealPlayer mit SMIL Unterstutzung
Als Beispiel, wie verschiedene Multimedia-Daten verknupft werden konnen, kann Abbildung 7.3 dienen.Die dazugehorige SMIL-Datei sieht folgendermassen aus (Beispiel aus dem SMIL Tutorial von Webtech-
10http://www.w3.org/TR/REC-smil/11http://www.w3.org/AudioVideo/

KAPITEL 7. DIGITAL VIDEO 120
niques12):
1 <smil>2 <head>3 <layout>4 <root-layout height="425"5 width="450"6 background-color="black"/>78 <region id="title"9 left="50"10 top="150"11 width="350"12 height="200"/>1314 <region id="full"15 left="0"16 top="0"17 height="425"18 width="450"19 background-color="#602030"/>2021 <region id="video"22 left="200"23 top="200"24 height="180"25 width="240"26 z-index="1"/>27 </layout>28 </head>2930 <body>30 <seq>31 <!-- This img tag displays the title screen -->32 <text src="title.rt"33 type="text/html"34 region="title"35 dur="20s"/>36 <!-- This section displays the animated map with an audio soundtrack -->37 <par>38 <audio src="map_narration.ra"/>39 <img src="map.rp"40 region="full"41 fill="freeze"/>42 </par>43 <!-- This section contains the video-annotated slideshow -->44 <par>45 <img src="slideshow.rp"46 region="full"47 fill="freeze"/>48 <seq>49 <video src="slide_narration_video1.rm"50 region="video"/>51 <audio src="slide_narration_audio1.ra"/>52 <video src="slide_narration_video2.rm"53 region="video"/>54 </seq>55 </par>56 </seq>57 </body>58 </smil>
Das <smil> Dokument teilt sich in einen <head> und einen <body> Teil (vgl. HTML). Im <head>steht die Beschreibung des Aussehens/Layouts und der <body> Bereich enthalt die Timing-Informationund Information uber den Inhalt.
Innerhalb von <seq> und <par> werden die benannten Medien automatisch (sequentiell oder parallel)abgespielt.
SMIL unterstutzt viele verschiedene Medientypen wie Text, Textstream, Bilder, Video, Audio und Ani-mationen.
Ein wichtiges Feature ist das <switch> Tag. Damit konnen verschiedene Optionen eingestellt werden, vondenen der Player dann zur Laufzeit eine auswahlt. So kann aus verschiedenen Medien je nach Sprache,Bildschirmgrosse, Farbtiefe, Bandbreite, etc. ein passendes gewahlt werden. Folgender Ausschnitt bietetz.B. verschiedene Auflosungen, je nach verfugbarer Bandbreite:
12http://www.webtechniques.com/archives/1998/09/bouthillier/
KAPITEL 7. DIGITAL VIDEO 121
1 <par>2 <switch>3 <img src="slideshow_hires.rp" region="full" fill="freeze"
system-bit-rate="20000"/>4 <img src="slideshow_lowres.rp" region="full" fill="freeze"
system-bit-rate="45000"/>5 </switch>6 <audio src="video_narration.ra"/>7 </par>
Ein weiteres SMIL-Tutorial, das mit SMIL erstellt wurde (kein rekursives Problem :-), ist bei “LearnSMIL with a SMIL13” zu finden. Der Java-SMIL-Player SOJA14 sorgt dafur, dass die verwendeten SMILBeispiele direkt betrachtet werden konnen.
13http://www.empirenet.com/~joseram/index.html14http://www.helio.org/products/smil/

Kapitel 8
Serverseitige Technologien
Dieses Kapitel wird einige Techniken vorstellen, die verwendet werden konnen, um Informationsserveraufzubauen. Die ersten Abschnitte dieses Kapitels widmen sich serverseitigen Erweiterungen von Web-Servern, die hauptsachlich dazu verwendet werden, um Web-Seiten dynamisch zu generieren.
8.1 Dynamische Generierung von Web-Seiten
Es gibt mehrere Grunde, warum Web-Seiten dynamisch und nicht statisch sein sollen:
• Die Web-Seiten basieren auf Anfragen von Benutzern, wie z.B. Ergebnisseiten von Suchmaschinenoder der Einkaufswagen bei einem Online-Shop.
• Die Daten andern sich sehr oft, wie z.B. ein Wetterbericht, Schlagzeilen bei Zeitungen.
• Die Web-Seiten enthalten Daten, die aus einer Datenbank stammen (z.B. Preise und Produktbe-zeichnungen von Artikeln eines Geschafts).
Es gibt zahlreiche Moglichkeiten, Webseiten auf dem Server dynamisch zu erzeugen. In den folgendenAbschnitten werden einige vorgestellt.
Ein gemeinsames Problem aller serverseitigen Erweiterungen, die dynamisch Web-Seiten generieren, istmeist, dass Inhalt und Layout mehr oder weniger untrennbar vereint sind. Da jedoch meist verschiedenePersonen oder Gruppen entweder das Layout erstellen oder die Funktionalitat programmieren, muss schonin der Designphase einer dynamisch erzeugten Web-Site geklart werden, wo der Schwerpunkt liegen soll.Sollen nur wenige Teile einer Seite dynamisch generiert werden, bieten sich eher Technologien wie ASP,JSP oder PHP an. Besteht jedoch die Web-Site hauptsachlich aus einer (Java-)Applikation, die nebenbeiWeb-Seiten zur Verfugung stellt, sind eher Servlets vorzuziehen.
Prinzipiell sind aber die meisten Problem mit jeder der vorgestellten (und auch mit vielen anderen)Moglichkeiten losbar. Oft entscheiden aussere Einflusse die Entscheidung, welche Technologie verwendetwird. Oft bestimmen zum Beispiel nicht technische Argumente die Wahl, sondern die Firmenpolitikverlangt, dass ein Produkt der Firma XY (bzw. MS :-) eingesetzt werden muss.
8.1.1 Common Gateway Interface (CGI)
Die Mutter aller dynamischen Webseitengenerierung heisst eindeutig CGI (Common Gateway Interface).CGI entstand zuerst aus dem Wunsch (und der Notwendigkeit), HTML-Formulare auf dem Server aus-zuwerten (siehe auch Abschnitt 8.1.7), die darin enthaltenen Daten irgendwo zu speichern (evtl. in einerDatenbank) und dem Benutzer eine Antwortseite zuruckzuliefern. Eine gute Seite fur den Recherchestartuber CGI im Netz ist http://www.w3.org/CGI/.
122
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 123
Ein CGI-Programm lauft direkt auf dem Web-Server und erzeugt in der Regel HTML-Code, der anden Browser des Benutzers gesendet wird. Dadurch lassen sich relativ einfach dynamische Web-Seitengenerieren.
Die Spezifikation von CGI1 sagt nur, dass CGI-Programme vom Standard-Input lesen und auf Standard-Output schreiben mussen. Dabei ist es egal, in welcher Programmiersprache das CGI-Programm ge-schrieben wurde. Ein gutes Einfuhrungstutorial ist unter http://www.jmarshall.com/easy/cgi/ zufinden.
Somit kann sogar ein Unix-Shell Skript verwendet werden. Als Beispiel dient ein Hello World CGI-Skript :
#!/bin/sh# send http-header and a newline afterwards:echo "Content-Type: text/html"echo ""# send html content:echo "<HTML>"echo " <HEAD>"echo " <TITLE>Hello World CGI</TITLE>"echo " </HEAD>"echo " <BODY>"echo " Hello World ("date "+%T, %d.%m.%Y"echo ")"echo " </BODY>"echo "</HTML>"
Dieses Skript, nachdem es in ein geeignetes Verzeichnis des Web-Servers kopiert wurde (z.B: cgi-bin)oder durch seine Extension dem Webserver verraten hat, dass es ein CGI-Programm ist (.cgi), gibtnun auf Anfrage (naturlich je nach Datum und Uhrzeit) “Hello World (12:05:56, 18.11.2002)” aus. Hiersieht man schon, dass es sehr einfach ist, die Ausgabe von beliebigen Programmen in einer dynamischenWeb-Seite zu verwenden.
Perl
Die Programmiersprache ☞PERL wurde von Larry Wall entwickelt und eignet sich unter anderem be-sonders gut fur Stringmanipulationen aller Arten (Stichwort regular expressions). Daher ist es auch keinWunder, dass viele CGI-Programme in Perl geschrieben wurden/werden. In Perl konnen Parameter, Da-tenbankabfrageergebnisse und andere Programmausgaben einfach (wenn man die z.T. kryptische Syntaxvon Perl einmal verstanden hat :-) analysiert, weiterverarbeitet und in eine HTML-Seite fur die Ausgabeweiterverarbeitet werden.
Mittlerweile existieren mehrere Perl-Bibliotheken, die speziell auf die Probleme mit CGI eingehen: z.B.die cgi-lib2 oder die bei der Standard-Perl Distribution schon enthaltene Perl5 CGI Library CGI.pm3.
Ein einfaches CGI-Programm in plain-Perl (ohne Zusatzbibliotheken), das neben “Hello World” auszuge-ben auch noch die Umgebungsvariable liest, in der die Parameter bei der HTTP-GET Methode ubergebenwerden, ist folgendes:
#!/usr/bin/perl# send http-header and a newline afterwards:print "Content-Type: text/html\n\n";
# send html content:print "<HTML>\n";print " <HEAD>\n";print " <TITLE>Hello World CGI</TITLE>\n";print " </HEAD>\n";print " <BODY>\n";print " Hello World.\n";print " Your QUERY_STRING was ".$ENV{’QUERY_STRING’}."\n";print " </BODY>\n";print "</HTML>\n";
Gute Tutorials uber Perl/CGI findet man unter http://www.comp.leeds.ac.uk/nik/Cgi/start.html,bei den oben erwahnten Perl-CGI-Bibliotheken oder das CGI-Perl-Kapitel von SelfHtml4.
1http://hoohoo.ncsa.uiuc.edu/cgi/interface.html2http://cgi-lib.berkeley.edu/3http://stein.cshl.org/WWW/software/CGI/4http://courses.iicm.edu/mmis/selfhtml80/cgiperl/index.htm

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 124
8.1.2 Parameterubergabe
Jedem serverseitigem Programm (CGI, Servlet, ...) konnen auch Parameter ubergeben werden. Prinzipiellkonnen Anfragen an einen Webserver mittels zweier Request-Methoden gestellt werden:
• HTTP-GET-Methode: Erfolgt der CGI-Aufruf von einem HTML-Formular, das als Methode GETverwendet oder werden die Parameter in der Url codiert, werden diese Parameter (Parameterna-me und Wert) mittels der Umgebungsvariablen QUERY_STRING an das aufgerufene CGI-Programmubergeben. Mehrere Paare [Parametername,Wert] oder mehrere Werte werden durch ’&’ getrennt,Leerzeichen durch ’+’ (bzw. ’%20’) ersetzt. Sonderzeichen werden durch ein vorgestelltes Prozent-zeichen (’%’) und einen ASCII-Hexadezimal-Wert dargestellt.
Ein Url-Aufruf konnte beispielsweise so aussehen:
http://www.google.com/search?sourceid=googlet&q=Abfrage
Damit wird eine Suchabfrage bei der Suchmaschine Google5 ausgelost. In diesem Fall werden zweiPaare [Parametername/Wert] ubergeben: sourceid=googlet und q=Abfrage.
Der Nachteil dieser Methode ist, dass die Gesamtlange der Parameter bzw. der Formulardaten auf1024 Bytes beschrankt ist.
• HTTP-POST-Methode: Bei einem Formular kann als Ubermittlungsmethode auch POST verwendetwerden. In diesem Fall werden alle Formularfelder mit Namen und Wertenim HTTP Header ubertra-gen. Der zugehorige HTML-Code sieht z.B. so aus: <FORM METHOD=”POST”ACTION=”http://www.meinserver.org/cgi−bin/cgitest”>
Dem CGI-Programm werden diese Parameter auf der Standardeingabe (stdin) bereitgestellt. Uberdie Umgebungsvariable CONTENT_LENGTH kann festgestellt werden, wieviele Zeichen gelesen werdenkonnen. Zusatzlich werden noch eine ganze Reihe von Umgebungsvariablen gesetzt, die vom CGI-Programm ausgewertet werden konnen (z.B. DOCUMENT_ROOT, REMOTE_HOST, REFER_URL, REQUEST_METHOD, ...). Eine genaue Liste von auswertbaren Variablen kann im CGI-Standard eingesehenwerden. Eine Testseite, an der man den Unterschied zwischen HTTP-GET und POST sieht, kannunter http://www-scf.usc.edu/~csci351/Special/CGIinC/examples.html ausprobiert werden.
Andere serverseitige Erweiterungen (PHP, ASP, JSP, Servlets, . . . ) verwenden diese Ubergabemetho-den (HTTP-Standard) naturlich ebenso, erleichtern aber die Auswertung der Parameter durch entspre-chende Funktionen bzw. Methoden. Servlets konnen z.B. einfach durch einen Aufruf von request.getParameter(paramName) die Parameternamen samt ihrer Werte auslesen (siehe auch Abschnitt Java-Servlets auf Seite 125).
8.1.3 Sicherheitsuberlegungen
Vom Benutzer ubergebene Parameter konnen ein grosses Sicherheitsrisiko auf einem Web-Server darstellenund mussen daher gut uberpruft werden. Werden namlich diese Eingaben nicht auf ihren Inhalt uberpruftund an weitere Programme als Argumente ubergeben, kann es passieren, dass hochst unliebsame Dingepassieren.
Ein einfaches Beispiel ist eine Benutzereingabe, die danach wieder auf einer HTML-Seite verwendetwerden soll. Gibt nun ein Benutzer ein HTML-Tag anstatt von reinem Text ein und diese Eingabe wirdungepruft wieder in eine HTML-Seite eingebaut, kann das Layout dieser Seite total verandert werden.
Beispiel (harmlos): Anstatt des Namens WolfgangAmadeusMozart wird <B>WolfgangAmadeusMozart</B>eingegeben. Somit erscheint in einem HTML-Dokument der Name ab sofort in Fett, auch wenn das uber-haupt nicht beabsichtigt wurde.
Beispiel (weniger harmlos): Es wird als Name WolfgangAmadeusMozart</BODY></HTML> eingegeben.Ein Browser, der etwas auf den HTML-Standard halt (gibts die?), sieht nach dem Namen das Ende desHTML-Dokuments und zeigt den Rest garnicht mehr an.
Schlimmere Auswirkungen hat eine unkontrollierte Eingabe naturlich, wenn diese in eine Kommandozeileeingebaut wird, und ein externes Programm aufgerufen wird. So kann schon mit einem einfachen “>/
5http://www.google.com
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 125
etc/passwd” (Umleitung der Standard-Ausgabe in die Datei /etc/passwd) diese Datei uberschriebenwerden (naturlich nur, falls das CGI-Programm die entsprechenden Rechte hat). Auf alle Falle konnenevtl. Dateien verandert / geloscht / erzeugt werden oder andere Programme unter der Benutzerkennunggestartet werden, mit der der Web-Server bzw. das CGI-Programm lauft.
Diese Sicherheitsuberlegungen betreffen alle serverseitigen Erweiterungen, die Benutzereingaben verar-beiten, und sind nicht CGI-spezifisch!
8.1.4 Server Side Includes (SSI)
Server Side Includes6 sind heute eher ungebrauchlich (werden aber immer noch von modernen Web-Servern (z.B. Apache) unterstutzt) und werden hier nur der Vollstandigkeit halber erwahnt. Sie werdenvom Web-Server nach SSI-Kommandos geparsed und vor der Auslieferung an den Web-Client ausgefuhrt.Ein SSI-Kommando wird immer in einen HTML-Kommentar verpackt. Dies erlaubt die Verwendung vonHTML-Seiten mit SSI auch von Web-Servern, die SSI nicht beherrschen:
<!--#command tag1="value1" tag2="value2" -->
Es steht nur eine relativ kleine Anzahl von Kommandos zur Verfugung:
• config: stellt verschiedene Parameter ein, die das Parsen der HTML-Seite beeinflussen konnen.
• include: fugt ein anderes Dokument an dieser Stelle ein.
• echo: schreibt die Werte von Variablen in die Ausgabe.
• fsize: schreibt die Grosse der angegebenen Datei in die Ausgabe.
• flastmod: schreibt das letzte Anderungsdatum.
• exec: fuhrt ein externes Programm aus (skript oder CGI-Programm).
Die Kommunikation mit einem externen CGI-Programm erfolgt wie bei CGI uber Umgebungsvariablen,wobei bei SSI noch zusatzliche Variablen definiert wurden (siehe Webseite).
Ein etwas ausfuhrlicheres Tutorial ist auf den Apache Seiten des Include Moduls7 zu finden.
Ein ganz guter Artikel uber SSI ist in c’t 20/2001 ([Len01]) erschienen.
8.1.5 Servlets und Java Server Pages (JSP)
Eine sehr gute Einfuhrung uber JSP (Java Server Pages) und Java-Servlets von Marty Hall8 (JohnHopkins University) findet sich auf http://www.apl.jhu.edu/~hall/java/Servlet-Tutorial/ bzw.in [Hal00].
Anmerkung: “Java Applets” sind Java Programme, die im Web-Browser beim client laufen und habennichts (ausser der Programmiersprache) mit Servlets oder Java Server Pages zu tun!
Java-Servlets
Servlets sind Java-Programme, die auf einem Web-Server laufen und dynamisch Web-Seiten generierenkonnen. Servlets sind somit die Antwort von Sun auf CGI-Programme. Es gibt aber einige Unterschiedevon Servlets gegenuber CGI-Programme:
6http://hoohoo.ncsa.uiuc.edu/docs/tutorials/includes.html7http://httpd.apache.org/docs/mod/mod_include.html8http://www.apl.jhu.edu/~hall/

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 126
• Effizienz: ’Normale’ CGI-Programme werden bei jedem Aufruf vom Web-Server gestartet. Dadurchkann ein ziemlich grosser Overhead durch die oftmalige Initialisierung des Programmes entstehen.Greift das CGI-Programm beispielsweise auf eine Datenbank zu, muss es bei jedem Start eineVerbindung zu der Datenbank aufbauen. Oder es fordern viele Benutzer gleichzeitig eine Seite anund so wird das CGI-Programm mehrmals gestartet. Bei Servlets behandelt eine Java-VM (VirtualMachine) alle Anfragen und startet bei Bedarf einen neuen lightweight Java-Thread und keinenheavyweight Betriebssystemprozess.
Mittlerweile existieren schon verschiedene Techniken, die diese Nachteile von CGI etwas verbessern(z.B. Fast-CGI 9).
• Programmiersprache: Wahrend Java-Servlets logischerweise nur in Java geschrieben werden konnen,kann man ein CGI-Programm in jeder beliebigen Programmiersprache (auch in Java) schreiben.
• Machtigkeit: Servlets konnen einige Dinge, die mit CGI-Programmen nur schwer oder garnichtgelost werden konnen, wie z.B. das Teilen von Daten oder Objekten zwischen mehreren Servlets.Da die Servlet-Engine durchgehend lauft und nicht wie ein CGI-Programm immer von neuemgestartet wird, ist es auch einfacher, Informationen von einer Anfrage zur nachsten weiterzugeben(session-tracking oder caching von fruheren Abfrageergebnissen).
• Portabilitat: Da Java plattformunabhangig ist, sind naturlich auch Servlets unabhangig vom ver-wendeten Betriebssystem. CGI-Programme sind je nach verwendeter Programmiersprache nur mehroder weniger portabel (verschiedene C-Compiler, ...).
Ein Servlet ist eine ganz normale Java-Klasse, die von der abstrakten Klasse javax.servlet.http.HttpServlet ableiten und somit u.a. eine Methode public void doGet(request, response) enthaltenmuss. Diese Methode wird vom Servlet-Server aufgerufen, wenn die entsprechende Seite vom Benutzerangefordert wird (mittels HTTP-GET-request).
Folgender Code kann als Grundlage fur eigene Versuche verwendet werden:
import java.io.∗;import javax.servlet.∗;import javax.servlet.http.∗;
/∗∗∗ Servlet template∗/
public class SomeServlet extends HttpServlet {public void doGet(HttpServletRequest request,
HttpServletResponse response)throws ServletException, IOException {
// Use ”request” to read incomingHTTPheaders (e.g. cookies)// andHTMLform data (e.g. data the user entered and submitted)
// Use ”response” to specify theHTTPresponse line and headers// (e.g. specifying the content type, setting cookies).
PrintWriter out = response.getWriter();// Use ”out” to send content to browser
}}
Fur eine komplette (?) Installationsanleitung siehe Abschnitt Installation eigener Servlets auf Seite 128.
Da es zu weit fuhren wurde, hier alle Einzelheiten und Kniffe der Servlet-Programmierung aufzuzahlen,sei hier wieder auf das Servlet-Tutorial10 verwiesen, das u.a. erklart,
9http://www.fastcgi.com10http://www.apl.jhu.edu/~hall/java/Servlet-Tutorial/
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 127
• wie auf Eingaben von HTML-Forms reagiert werden kann (request.getParameter(paramName))
• wie HTTP-Header ausgelesen werden konnen (request.getHeader(headerName))
• wie Cookies verwendet werden
• wie Sessions ’geTracked’ werden
Eine vollstandige Beschreibung des Servlet-APIs ist unter http://java.sun.com/products/servlet/2.2/javadoc/index.html zu finden.
Java Server Pages (JSP)
Im Gegenzug zu Servlets, die eigene Java-Klassen sind, ist Java Server Pages eine Technologie, beider man statisches HTML mit dynamischen Inhalten mischen kann. Dabei wird Java-Code mit demansonsten statischen HTML-Code vermischt. Bevor eine solche Seite vom Server an den Browser desBenutzers geschickt wird, wird der darin enthaltene Code ausgefuhrt und der dabei entstandene HTML-Code eingefugt.
Ein kurzes Beispiel verdeutlicht dies:
<HTML><HEAD>
<TITLE>JSP-Hello World</TITLE></HEAD><BODY>
Static Hello World<BR><% out.print("Dynamic Hello World :-)<br>"); %>
</BODY></HTML>
Anmerkung: Die Zeilen
• <% out.print("Hello World <BR>"); %>
• <%= "Hello World <BR>" %>
• <% String hello = "Hello World <BR>"; out.print(hello); %>
• <% String hello2 = "Hello World <BR>"; %> <%= hello2 %>
• < jsp:scriptlet > out.print("Hello World <BR>"); </ jsp:scriptlet>
• <jsp:expression> "Hello World <BR>" </jsp:expression>
sind aquivalent. <%= <java-code> %> wird intern zu <% out.print(<java-code>); %> umgesetzt. Diezugehorigen XML-Tags heissen <jsp:expression> und < jsp:scriptlet >.
Interne Behandlung von JSP Samtliche Java Server Pages werden vom JSP-Server beim ersten Auf-ruf in Java-Code umgewandelt und kompiliert. Der Source-Code unseres Hello-World-JSPs liegt z.B. imVerzeichnis <tomcat-dir>/work/localhost_8080%2Fmmis_jsp_example und ist bis auf den etwas seltsa-men Klassennamen (_0002fhello_0005fworld_0002ejsphello_0005fworld_jsp_0) durchaus lesbarerJava-Code:
[...]public void _jspService(HttpServletRequest request,
HttpServletResponse response)throws IOException, ServletException
{[...]response.setContentType("text/html;charset=8859_1");[...]out.write("<HTML>\r\n <HEAD>\r\n <TITLE>JSP-Hello World</TITLE>\r\n </HEAD>\r\n <BODY>\r\n");[...]
}[...]
Man sieht hier sehr schon, dass JSP im Prinzip genau gleich wie Servlets arbeiten und die gleichen Klassenverwenden.

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 128
Installation Servlet/JSP Server
Um Servlets oder JSP versenden zu konnen, muss ein Server installiert werden/sein, der dies unterstutzt.Die Referenzimplementation dafur ist Tomcat11 aus dem Apache12-Projekt. Tomcat kann als eigenstandi-ger Server fur JSP oder Servlets verwendet werden, oder in den Apache Web-Server integriert werden.
Eine Ubersicht uber vorhandene Servlet-Server ist bei eingangs erwahntem Tutorial von Marty Hall imKapitel “Setup”13 zu finden.
Installation Tomcat Die Installation von Tomcat geht ganz einfach von der Hand. Die aktuelleTomcat-Version downloaden und in einem Verzeichnis auspacken. Da die Windows Version nicht getestetwurde, wird hier nur eine Kurzanleitung fur Linux angegeben, die sich prinzipiell aber auf Windows(*.bat-Dateien anstatt *.sh) umlegen lasst (ein kurzer User-Guide findet sich im ausgepackten Tomcat-Verzeichnis unter webapps/tomcat-docs (bzw. unter doc/uguide/tomcat_ug.html bei Version 3.2.1)bzw. unter http://jakarta.apache.org/tomcat/jakarta-tomcat/src/doc/):
# installation in verzeichnis ’/foo’cd /footar xzf <path-to-tomcat-archive>/jakarta-tomcat-4.1.12.tar.gzcd jakarta-tomcat-4.1.12
# make scripts executable (bug in 4.1.12)chmod +x bin/*.sh
# start von tomcat (windows: use bin/startup.bat)bin/startup.sh
# stoppen von tomcat:bin/shutdown.sh
Nach dem Start von Tomcat kann unter http://localhost:8080 (evtl. nur unter http://<hostname>:8080) auf den Tomcatserver zugegriffen werden. Von hier aus konnen auch JSP und Servlet Beispiele,die in der Distribution enthalten sind, ausprobiert und die Dokumentation gelesen werden.
Installation eigener Java Server Pages Um eigene JSP verwenden zu konnen (in diesem Beispielim Verzeichnis <tomcat-dir>/webapps/mmis_jsp, sind folgende Schritte notwendig:
• Obiges hello_world.jsp-Beispiel im Verzeichnis <tomcat-dir>/webapps/ROOT/mmis_jsp kopie-ren/erstellen. Das Verzeichnis <tomcat-dir>/webapps/ROOT/ ist das root-Verzeichnis von Tomcat.(Dieses Verzeichnis erscheint unter der URL http://localhost:8080 im Browser.)
• In einem beliebigen Browser die Seite http://localhost:8080/mmis_jsp bzw. http://localhost:8080/mmis_jsp/hello_world.jsp aufrufen.
Installation eigener Servlets Um eigene Servlets aufrufen zu konnen, mussen folgende Schritte durch-gefuhrt werden:
• Das Root Verzeichnis fur Servlets ist <tomcat-dir>/webapps/ROOT/WEB-INF/classes.
• Erstellen/kopieren eines Servlets in eben diesem/dieses Verzeichnis. Als einfachstes Hello-World-Servlet kann z.B. folgendes verwendet werden (<tomcat-dir>/webapps/ROOT/WEB-INF/classes/HelloWorld.java):
import java.io.IOException;import java.io.PrintWriter;import javax.servlet.ServletException;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;
11http://jakarta.apache.org/tomcat/index.html12http://www.apache.org13http://www.apl.jhu.edu/~hall/java/Servlet-Tutorial/Servlet-Tutorial-Setup.html
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 129
public class HelloWorld extends HttpServlet{
public void doGet(HttpServletRequest request,HttpServletResponse response)
throws IOException, ServletException{
String title = "Hello World";
response.setContentType("text/html");PrintWriter out = response.getWriter();
out.println("<html>");out.println(" <head>");out.println(" <title>" + title + "</title>");out.println(" </head>");out.println(" <body>");out.println(title);out.println(" </body>");out.println("</html>");
}}
• Kompilieren des Servlets im obigen Verzeichnis. Dazu muss der CLASSPATH auf das aktuelle Ver-zeichnis und auf das jar-File, das die Servleterweiterungen enthalt zeigen: CLASSPATH=.:<tomcat-dir>/common/lib/servlet.jar
Unter Windows mussen die Teile des Classpaths naturlich mit ’;’ abgetrennt werden!
• evtl. (bei Tomcat 4.1.12 ganz sicher) muss im Konfigurationsfile web.xml im conf-Verzeichnis derEintrag
<servlet-mapping><servlet-name>invoker</servlet-name><url-pattern>/servlet/*</url-pattern>
</servlet-mapping>
einkommentiert werden. (Entfernen der <!--...--> Zeichen).
Eine Alternative dazu ist das Erzeugen eines neuen Contexts in conf/server.xml, der dann aufein neues Verzeichnis verweist.
• Dieses Servlet ist (evtl. nach Neustart von Tomcat) unter http://localhost:8080/mmis_servlet/servlet/HelloWorld zu erreichen.
Man beachte den servlet-Teil zwischen mmis_servlet und dem Klassennamen und dass kein.class angehangt ist.
8.1.6 Active Server Pages (ASP)
Als Gegenstuck zu Suns Java-basierter serverseitiger Erweiterung stehen Microsofts ASP (Active ServerPages). ASP ist eine Vermischung von HTML und Visual Basic Script. Lt. einem Artikel des MSDN-Magazins14 wird dieses Skript bei jedem Aufruf interpretiert und auf dem Server ausgefuhrt. DasErgebnis wird danach zum Benutzer gesendet.
Die Verwendung von ASP unterscheidet sich kaum von JSP, was allerdings auch wenig erstaunlich ist, daASP hochstwahrscheinlich das Vorbild fur JSP war und Sun durch leichte Erlernbarkeit moglichst vieleEntwickler auf seine Seite ziehen wollte.
Folgendes Beispiel zeigt “Hello World” als ASP:
<html><script language="VBScript" runt="Server">
Sub HelloWorld()Response.Write "Hello World from ASP."
End Sub
14http://msdn.microsoft.com/msdnmag/issues/1000/atlserv/atlserv.asp

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 130
</script><body>
<% HelloWorld %></body>
</html>
Im Grunde genommen ist es eine Geschmackssache bzw. Plattformentscheidung, welche der beiden ServerPages man einsetzen will.
8.1.7 in the beginning
Der folgende Text stammt von http://www.webhostdir.com/guides/asp/in_the_beginning.asp (dar-aus folgt auch die Lobeshymne auf Web Host Directory am siebten Tag):
NOTIZ: Er dient nur der allgemeinen Erheiterung und wird naturlich nicht gepruft :-))
in the beginning was the internet and the internet was bland (unless you liked text) and theinternet was boring (unless you got flamed on the newsgroups).
Thus ended the first (boring) day.
Tim Berners-Lee (God) saw the internet and thought “let there be pages, and let them belinked and let there be colour and graphics”; and there were pages and there was colour andthere were graphics, and God saw the internet and said “now it is a web, and the web isgood”. And the people saw the web and said, “wow, we can use this even if we aren’t particlephysicists” and the people started to use the web and write their own pages (and not all ofthem were students).
Thus ended the second day.
Then the people got restless, “we don’t just want static pages”, they cried; “we want dynamicpages, we want information that changes depending on what we put into our browsers, wewant phone books”, they wailed. God heard the cries and responded with forms, and radiobuttons and text boxes and cgi so that the people would be happy, and the people smiled.The archangel Larry Wall brought forth a perl and said “lo, tho it was not created for thispurpose, see how perl works with cgi” and the people rejoiced.
Thus ended the third day.
Then Bill Gates (The Devil/St. Paul - delete as appropriate) saw the web, and cgi, and perland all the people whose souls weren’t his and said unto himself “damn, I’ll have to rewrite mybook and convince people that I was for the web all along”. And Bill set his pixies to labourlong and hard and produced a browser (Internet Explorer v2), and a web server (InternetInformation Server v1) to demonstrate his conversion, and they weren’t much cop and thepeople did laugh, and some of them threw stones from their Mosaic.
Thus ended the fourth day.
And Bill did wail and gnash his teeth and said to his pixies “work harder and make myproducts work and then give them away”. The pixies worked and toiled and lo, producedInternet Explorer 3 (which was still not much cop) and Internet Information Server v2 (whichwas better). And then Bill looked at the web and said, “lo, on the third day the people wererejoicing because they had cgi and perl and things that I did not provide them with; wouldthey not further rejoice if I was to provide for them the same, only better?” and he set hispixies to work.
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 131
Thus ended the fifth day.
And on the sixth day, active server pages were born. And some of the people scorned, becausethey always scorned Bill; and some of the people scorned because they said Bill had just re-invented what was already there and called it his own; and some people scorned because itwasn’t cross platform (like perl) and only ran on Win95/NT machines. But some of the peoplesaid “hey, we have NT, we have web servers, we have Access and MS SQL Server and we don’twant to learn perl, which is for the bearded unwashed (or UNIX users as they are known).We like Visual Basic and want to do exciting and dynamic things with our web pages”, andthey praised Bill and rejoiced.
Thus ended the sixth day
And on the seventh day, the Web Host Directory was born.
Informationen zu ASP
• Eine ganz gute Einfuhrung in ASP ist das Tutorial von http://www.webhostdir.com/guides/asp/oder http://www.asptutorial.info/.
• Ein Tutorial, das das Zusammenspiel von ASP mit diversen Datenbanken zeigt, ist unter http://asp.papiez.com/tutorials/asp101/ zu finden. Um dieses Tutorial lesen zu konnen, muss mansich (kostenlos) registrieren.
8.1.8 PHP
PHP (PHP Hypertext Processor) ist eine Skriptsprache, die ebenfalls direkt in HTML-Seiten eingebettetwerden kann. Bevor diese HTML-Seite vom Server zum Benutzer gesendet wird, werden diese Befehlevom PHP-Interpreter ausgefuhrt und so eine Web-Seite erzeugt, die vom Browser verstanden wird. DieVerbindung vom Web-Server zum PHP-Interpreter kann auf verschiedene Weise gelost werden:
• Der PHP-Interpreter wird als CGI-Modul verwendet: Diese Methode ist bei jedem Web-Servereinsetzbar, der CGI-Programme ausfuhren kann (praktisch alle “grossen” Web-Server konnen dies),und sehr flexibel. So ist es auch moglich, den Web-Server und den PHP-Interpreter voneinanderunabhangig upzugraden.
Als CGI-Programm bringt der PHP-Interpreter jedoch einen gewissen Overhead mit sich.
• Viel effizienter ist es, den Interpreter als ein Plug-In des Web-Servers zu installieren. Dies wirdbereits fur viele verschiedene Web-Server unterstutzt: Apache, AOLServer, fhttpd, Internet Infor-mation Server, Netscape Server, phttpd, roxen...
• Der Interpreter kann auch als Servlet eingesetzt werden und so evtl. in Kombination mit ApachesJakarta/Tomcat arbeiten [K00].
Es gibt mehrere syntaktische Moglichkeiten, PHP in Web-Seiten einzubauen:
• < ? ... ? >
• <?php ... ?>
• <script language=’’php’’> ... </script>
• <% ... %>
Als einfachstes PHP-Skript dient wiedereinmal ein hello_world.php:

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 132
<html><head>
<title>Example</title></head><body>
<?phpecho "Hi, I’m a PHP script!";
?></body>
</html>
Die Syntax von PHP lehnt sich an Perl, C und Java an und bietet alle bekannten Kontrollstrukturendieser Sprachen. PHP bietet untypisierte Variablen, d.h. obwohl es verschiedene Typen von Variablen gibt(Ganzzahl, Fliesskomma, String, Arrays, ...) mussen sie nicht deklariert werden und Typumwandlungenwerden automatisch vorgenommen.
Variablen werden mit vorangestelltem Dollarzeichen ’$’ geschrieben. PHP-Skripte konnen Paramteruber HTTP-GET und POST erhalten und haben auch Zugriff auf Cookies. Beim Start werden dieseParameter automatisch importiert und stehen als Variable zur Verfugung: Wird also ein PHP-Skript mitder Url http://www.google.com/search?sourceid=googlet&q=Abfrage aufgerufen, stehen dem Skriptsearch die Variablen $client und $q zur Verfugung (Dieses Beispiel dient nur der Demonstation undwill keineswegs andeuten, dass Google mit PHP arbeitet!).
Diese Art der Variablenbelegung ist sicherheitstechnisch etwas zweifelhaft und kann naturlich ausgeschal-tet werden (Stichwort gpc_order bzw. variable_order und register_globals in PHP4 auf einschlagi-gen Web-Seiten15 oder Manuals).
Eine ausfuhrliche Anleitung fur PHP ist das PHP-Manual16, das sowohl die Installation von PHP, als auchdie Programmiersprache selbst beschreibt. Eine weitere gute Beschreibung ist unter www.selfphp3.comzu finden.
Eine besondere Starke von PHP ist die Unterstutzung von vielen verschiedenen Datenbanken (u.a.Adabas-D, mSQL, MySQL, Oracle, Postgres, Slid, Sybase/Sybase-CT, Velocis, dBase-Files, filePro-Dateien, ODBC, ... (Liste17)) und die Einbindung von Datenbankabfragen in Webseiten. Es werdenaber auch ganz andere Techniken unterstutzt, wie z.B. das dynamische Generieren von Bildern18, derZugriff auf Mailserver (SMTP, POP3, IMAP, ...)19 und vieles mehr.
Da die freie Datenbank MySQL20 sehr oft in Verbindung mit PHP bei Web-Sites Verwendung findet, folgtein kurzes Beispiel, wie man mit Hilfe von PHP und einer Datenbank einen Counter fur HTML-Seitenerstellt21. Fur Details zu den php-Funktionen siehe die MySQL Seite des PHP-Manuals22:
<?php$db_host = "was.weiss.ich.net";$db_user = "username";$db_pass = "meinpasswort";$db_name = "meinedb";$my_url = "http://dies.ist.meine.url";
$db_conn = mysql_connect($db_host, $db_user, $db_pass)or die ("\nKeine Verbindung zum Datenbank-Server!<br>\n");
mysql_select_db($db_name, $db_conn)or die ("\nDatenbank auf Server nicht gefunden!<br>\n");
$db_result = mysql_query("SELECT * FROM counter where url = ’$my_url’", $db_conn)or die ("\nDatenbank-Abfrage fehlgeschlagen!<br>\n");
$db_row = mysql_fetch_array($db_result);$hits = $db_row[hits];
$hits++;$db_result = mysql_query("UPDATE counter SET hits = ’$hits’ WHERE url = ’$my_url’", $db_conn)
or die ("\nKonnte Zahlerstand in Datenbank nicht erhohen!<br>\n");
$hits_str = sprintf("Hits von URL ’%s’: %07d", $my_url, $hits);echo $hits_str;@mysql_close($db_conn);
15http://www.intermitto.net/?thema=php&seite=konfig.data16http://www.php.net/manual/17http://www.php.net/manual/en/intro-whatcando.php18http://www.php.net/manual/en/ref.image.php19http://www.php.net/manual/en/ref.imap.php20http://www.mysql.com21Abgeleitet von der MMIS-Ubung SS2001 von Juergen Haeuselhofer, Reinhard Hutter, Michael Mitter und Udo Pichl22http://www.php.net/manual/ref.mysql.php
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 133
?>
PHP-Tutorials sind u.a. hier zu finden:
• PHP fur Anfanger23
• PHP Introductory Tutorial24
• Das PHP4 - Webserver-Programmierung fur Einsteiger25 Buch (auch downloadbar).
• Datenbank, MySQL und PHP26 fuhrt in die Grundlagen von Datenbanken, SQL und PHP ein.
• Ein Pendant zu SelfHtml ist SelfPHP27.
• PHP/MySQL Tutorial28
NOTIZ: Tripod.de (http://www.tripod.lycos.de) bietet gratis 50MB Webspace, PHP (muss aktiviertwerden) und Zugriff auf eine MySQL Datenbank an - Optimal, um fur die Ubung eine PHP-Seite zuerstellen
8.1.9 Cookies
Cookies sind Strings, die vom Web-Server per http an den Web-Browser gesendet werden und dortgespeichert werden. Diese Cookies werden als Teil des HTTP-Headers vom Browser wieder an den Serverubertragen.
Wenn ein Server ein Cookie an einen Browser schickt, kann der Browser dieses Cookie entweder imCache, in seiner Cookie-Datenbank oder in einer Datei nur fur dieses Cookie abspeichern. Cookies habennormalerweise auch ein “Ablaufdatum”. Bei Cache-Cookies wird es auf “Ablaufen bei Beenden desBrowsers” gesetzt; bei Datei-Cookies kann es auf ein beliebiges Datum gesetzt werden. Zusatzlich kannfestgelegt werden, wer das Cookie lesen darf, also welcher Server. Dies wird aber auch vom Server, derdas Cookie schickt, festgelegt.
Cookies erlauben so eine Zustandsspeicherung des Dialoges zwischen Browser und Server, der Web-Surferhat aber kaum inhaltliche Kontrolle uber die bei ihm abgelegten Daten. Kommerzielle Anbieter wertenmittlerweile Cookies aus, um Interessensprofile von Endnutzern zu erstellen.
Oft wird deshalb empfohlen, Cookies entweder auszuschalten oder hochstens nach Bestatigung (da siehterst einmal, wieviele Cookies ubertragen werden!) zu akzeptieren. [Hen00]
8.1.10 Session Tracking
HTTP ist prinzipiell (es gibt auch die andere Variante (HTTP1.1 - Stichwort keepAlive)) ein Protokoll,das fur jeden Request eine neue TCP/IP Verbindung aufbaut. Nachdem dieser Request abgearbeitetist (die Datei vom Server zum Client ubertragen wurde), wird die Verbindung abgebaut. Fur eine neueAnfrage muss erneut eine TCP/IP Verbindung aufgebaut werden.
Diese Tatsache erschwert das sogenannte Session Tracking, also das Verfolgen eines Benutzers uber meh-rere Web-Seiten hinweg. Oft ist es jedoch notwendig zu wissen, welcher Benutzer eine Seite anfordert.Beispielsweise muss ein Online-Shop nach einmaliger Identifikation den Benutzer mitverfolgen, um soimmer den richtigen Wahrenkorb anzubieten.
Egal, welche Technik (ASP, JSP, PHP, ...) man verwendet, das allgegenwartige HTTP-Protokoll bietetnur begrenzte Moglichkeiten zum Session Tracking:
23http://www.skyhome.de/php/24http://www.php.net/tut.php25http://www.galileocomputing.de/openbook/php4/26http://ffm.junetz.de/members/reeg/DSP/27http://www.selfphp.info/index.php28http://hotwired.lycos.com/webmonkey/programming/php/tutorials/tutorial4.html

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 134
• Der Benutzer wird uber Cookies eindeutig identifiziert und bei jedem Seitenaufruf wird ein Cookievom Client zum Server ubertragen, das dem Server mitteilt, welcher Benutzer bzw. welche Sessi-on (ein Benutzer konnte ja mehrmals ’eingeloggt’ sein) vorliegt. Der Web-Server muss nur nochnachschlagen, welcher Cookie-Wert welcher Session entspricht und kann so leicht erkennen, dass einHTTP-Request zu einer bestimmten Session gehort.
Diese Moglichkeit funktioniert auch bei statischen Web-Seiten, da Cookies unabhangig von derWeb-Seite ubertragen werden konnen.
Bei clientseitigen ausgeschalteten Cookies kann diese Technik allerdings nicht angewandt werden.
• Bei Web-Formularen konnen einfach sog. Hidden Fields in der HTML-Seite verborgen werden, derenInhalt fur den Benutzer unsichtbar bleibt und trotzdem fur das serverseitige Skript auswertbar ist:
<INPUT type=”HIDDEN”name=”sessionInfo”value=”username”>
So wird z.B. eine Benutzer/Session-Kennung in jedes ausgelieferte HTML-Dokument verpackt undbeim nachsten Post-Request wieder an den Server zuruckgeliefert (nur bei einem Submit des For-mulars, nicht bei einem normalen Link von der HTML-Seite).
Diese Methode ist unabhangig von Browsereinstellungen und sollte somit eigentlich immer funk-tionieren. Der Nachteil ist allerdings, dass jede ausgelieferte Seite auf einen Benutzer bzw. eineSession zugeschnitten ist. Daher mussen Seiten dieser Art immer dynamisch erzeugt werden, undkonnen daher nicht gecached werden.
Ein weiterer Nachteil dieser Methode ist, dass ein verstecktes Formularfeld naturlich ein Formularvoraussetzt und daher nur eine submit Methode unterstutzt (nur ein Link moglich). Eine Moglich-keit, dies zu umgehen ist folgende, die Javascript verwendet (und von Karl Svensson beigesteuertwurde). Hier wird fur jeden Link eine Javascript-Funktion aufgerufen, die das “submitten” uber-nimmt:
<html>
<head>
<title>Link test</title>
</head>
<script language="JavaScript">
function linkFunc(inURL)
{
Info.action = inURL;
Info.submit();
}
</script>
<body>
<form name="Info" method="get">
<input type="hidden" name="hidden1" value="Kalle">
<input type="hidden" name="hidden2" value="Svensson">
</form>
<a href="javascript:linkFunc(’pelle.htm’)">Pelles page</a>
<a href="javascript:linkFunc(’kalle.htm’)">Kalles page</a>
</body>
</html>
• Eine ahnliche Methode wird verwendet, wenn die Sessionkennung fur einen HTTP-GET-Request indie Url codiert wird, sog. URL-Rewriting (z.B. bei dem Freemailer GMX29: http://www.gmx.net/cgi-bin/folindex/979544435?CUSTOMERNO=1234567). In diesem Fall wird die Kundennummerund eine Session Id in jeder Url mitubergeben. Damit jedoch diese Kundennummer an alle Nach-folgeseiten ubergeben wird, muss an alle Links auf dieser Seite ?CUSTOMERNO=1234567 angehangtwerden. Dies setzt wiederum eine dynamische Seitengenerierung voraus und macht diese Seiten furWeb-Caches untauglich.
Ein guter Artikel betreffend Session-Tracking in PHP4 findet sich unter http://www.dclp-faq.de/ch/ch-version4_session.html, in dem u.a. steht, dass PHP defaultmassig Cookies zum Session-Trackingverwendet.
29http://www.gmx.net
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 135
8.2 Distributed Programming
In diesem Abschnitt wird eine Auswahl an aktuellen Moglichkeiten vorgestellt, wie Applikationen uberNetzwerkgrenzen verteilt werden konnen. Da eine genauere Beschreibung den Raum dieses Skripts beiweitem sprengen wurde, wird nur ein kurzer Uberblick ohne Anspruch auf Vollstandigkeit gegeben.
8.2.1 .NET
Laut Microsoft ist .NET eine “revolutionary new platform, built on open Internet protocols and standards,with tools and services that meld computing and communications in new way”.
Weniger euphorisch gesagt, versucht Microsoft mit .NET eine Konkurrenz zu Java Enterprise Editionaufzubauen, indem eine Moglichkeit geschaffen wird, Applikationen zu erstellen, die
• in verschiedenen Programmiersprachen entwickelt wurden,
• auf verschiedenen Plattformen (z.Zt. nur Windows Plattformen) lauffahig sind,
• miteinander uber das Internet kommunizieren konnen.
Kern der .NET-Plattform ist eine Laufzeitschicht (CLR (Common Language Runtime)), die fur alleSprachen gemeinsam vorgesehen ist, und eine Art Grundgerust fur die Anwendungen darstellt. [Ric00]Die Sprachunabhangigkeit wird durch die Verwendung einer “intermediate language” (MSIL) - also einerArt Bytecode - erreicht. Somit kann in allen Sprachen, fur die ein MSIL-compiler erhaltlich ist, fur .NETentwickelt werden (Abbildung 8.1). Microsoft selbst unterstutzt die Entwicklung dieser Compiler, kannund wird jedoch aus rechtlichen (und marketingtechnischen :-) Grunden keinen Java-Compiler anbieten.
VB
compiler compilercompiler
JIT Compiler
Common Language Runtime
Betriebssystem
C# C++
IL Code
ASM Code
Abbildung 8.1: Die Common Language Runtime (CLR) verarbeitet die intermediate language, die von verschie-denen Compilern erzeugt werden kann.
Das Konzept der ’intermediate language’ ist nicht wirklich neu (schon das altehrwurdige BTX hat einesolche verwendet) und so gibt es auch viele Compiler die verschiedenste Sprachen in den Java-Bytecodeubersetzen (siehe http://grunge.cs.tu-berlin.de/~tolk/vmlanguages.html).
Weitere Infos und Links uber .NET auf der Vorlesungsseite von Dr. Ralph Zeller (Microsoft’s Ex-Universitatsbeauftragen): http://www.ssw.uni-linz.ac.at/Teaching/Lectures/DotNet/
C#
Als neue Sprache und direkten Konkurrenz zu Java entwickelte Microsoft C# (sprich “C sharp” - also“Cis Dur”), die folgende Eigenschaften besitzt:

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 136
• Objekt orientiert, aber keine Mehrfachvererbung, kein Operator-Overloading. Originalzitat auseinem MSDN-Magazin30: “Yeah, yeah. C++ is object oriented. Right. I’ve personally knownpeople who have worked on multiple inheritance for a week, then retired out of frustration to NorthCarolina to clean hog lago.”
• garbage collection
• einfachere Datentypen: keine verschiedenen Typen fur den selben Zwecke (“a char is a char, nota wchar t”). Keine unsigned Typen. Hier liegt aber auch ein Problem bei der Verwendung vonanderen Programmiersprachen, die sehr wohl diese Datentypen unterstutzen, aber bei der Com-pilierung in die (mit C# gemeinsame) MSIL nicht verwendet werden durfen. So ist ein String inVisual Basic gleich einem String in C# gleich einem String in C (den es aber leider nicht gibt :-).
• Versionen fur Libraries (“end of the DLL Hell”).
• Aufrufe zur Windows API oder “alte” DLLs werden unterstutzt. Sollten solche Aufrufe verwendetwerden, ist die Plattformunabhangigkeit naturlich obsolet.
Weitere Infos zu C#:
• http://msdn.microsoft.com/vstudio/nextgen/technology/csharpintro.asp
• http://www.microsoft.com/PressPass/press/2000/jun00/CSharpPR.asp
• http://msdn.microsoft.com/msdnmag/issues/0900/csharp/csharp.asp
SOAP
SOAP (Simple Object Access Protocol) ermoglicht den einfachen Austausch von Informationen zwischenApplikationen uber das Netzwerk. Dies kann ein einfaches Austauschen von Nachrichten sein, oder aberein “remote procedure call”, also ein Aufruf einer Funktion uber Netzwerkgrenzen hinweg.
SOAP kann diese Nachrichten uber HTTP versenden und umgeht somit Probleme mit Firewalls.
SOAP Nachrichten sind in XML kodiert.
Mehr Details uber SOAP auf der Webseite des W3C31 oder unter http://www.iicm.edu/research/seminars/ws_00/pacnik_strohmaier.pdf.
WebMethod
WebMethods erlauben den netzwerktransparenten Zugriff auf Methoden von CLR-Applikationen vonanderen Computern uber ein Netzwerk. Dazu wird einfach ein [Webmethod] Attribut vor den Methoden-namen im Sourcecode gestellt und ab sofort ist diese Methode uber das Netzwerk aufrufbar (mit Hilfevon SOAP).
[WebMethod(Description="ADO.NET WebMethod Example")]public DataSet GetCustomersNew(){[....]}
Das komplette Beispiel findet sich unter http://www.c-sharpcorner.com/database/adovsadonetwebservice.asp.
Prinzipiell ist gegen eine solche Idee nichts einzuwenden, erleichtert es ja die Implementation von ver-teilten Programmen. Der grosse Nachteil32 dieser Methode ist jedoch, dass eine solche WebMethod-Kennzeichnung auch fur andere Programmiersprachen eingefuhrt wurde und damit der Umfang allerSprachen verandert wurde. Dies ist auch einer der Grunde, warum Microsoft Java nicht unterstutzenkann, da Sun eine Anderung der Sprache Java verboten hat.
30http://msdn.microsoft.com/msdnmag/issues/0900/csharp/csharp.asp31http://www.w3.org/TR/SOAP/32Dies ist naturlich nur die personliche Meinung des Autors.
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 137
ASP.NET
ASP.NET unterscheidet sich vom “normalen” ASP hauptsachlich dadurch, dass es nicht nur Visual Basicinnerhalb von ASP-Seiten erlaubt, sondern auch C# oder ahnliche.So bindet folgender Code ein C# Programm in eine ASPX-Seite ein:
<%@page language="C#" src="aux1.cs"%><%assembly Name="aux2.dll" %>
Man beachte, dass kein ausfuhrbares Programm oder eine DLL angegeben wurde, sondern direkt derSource Code, der dann bei Bedarf (wenn der Source ein neueres Anderungsdatum als die erzeugte DLLhat) compiliert und ausgefuhrt wird.
8.3 WAP/WML
8.3.1 WML
WML (Wireless Markup Language) ist die Markup Language fur WAP (Wireless Application Protocol)-Browser (wie HTML fur Web-Browser) und wird ebenfalls via HTTP ubertragen.
Damit der Web-Server WML-Dateien richtig ausliefert, muss dies in der entsprechenden Server-Konfigu-rationsdatei (z.B. bei Apache unter SuSE7.0-Linux in /etc/httpd/httpd/conf) oder in der .htaccess-Datei des Verzeichnisses (falls der Web-Server dies unterstutzt) eingetragen sein:
AddType text/vnd.wap.wml wmlAddType text/vnd.wap.wmlscript wmlsAddType application/vnd.wap.wmlc wmlcAddType application/vnd.wap.wmlscriptc wmlscAddtype image/vnd.wap.wbmp wbmp
Dies setzt die MIME-Types fur die jeweiligen Dateien, sodass der WAP-Browser diese akzeptiert.
Jedes WML-Dokument ist ein gultiges XML-Dokument und muss so alle Anforderungen von XMLerfullen. Ein WML-Dokument besteht aus mehreren Teilen:
• Deck (Stapel): Ein Deck ist am besten mit einer herkommlichen HTML Seite vergleichbar undbesteht aus einer oder mehreren Cards (Karten). Es wird immer ein komplettes Deck auf das WAPGerat geladen, so dass dieses nicht zu groß sein und logisch zusammengehorige Cards enthaltensollte.
Das Deck enthalt ein <wml>-Tag am Anfang (und das abschließende </wml> am Ende), sowie dieMeta-Tags und ggf. fur alle Cards gultige <do>-Elemente.
• Prolog:
<?xml version="1.0" encoding="ISO-8859-1" ?><!DOCTYPE wml PUBLIC "-//WAPFORUM//DTD WML 1.1//EN""http://www.wapforum.org/DTD/wml_1.1.xml">
• WML-Header: Dieser kann Metainformationen enthalten, ahnelt dem HTML-<head>-Tag undwird innerhalb des <wml>-Tags verwendet:
<head><meta name="keywords" content="Stichwort, Suchwort,Schlagwort"/><meta name="description" content="Eine Beschreibung"/><meta name="author" content="Thomas Ziegler"/>
</head>
• Cards: Eine Card (Karte) ist der Teil eines Decks, mit dem der Benutzer navigiert. Er springt alsovon einer <card> zur anderen - die sich entweder auf einem Deck (einer Datei) zusammen oder inunterschiedlichen Dateien befinden.

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 138
<card id="cardid" title="Card Titel"><p>Text auf dieser Karte</p>
</card>
• Verweise lassen sich auf mehrere Arten angeben, die bei HTML gebrauchliche (<a>) wird jedochauch hier akzeptiert.
<a href="http://wml.domain.de/deck.wml/#card">Gehe zu Karte</a>
• Textattribute: werden auch hier unterstutzt und folgen dem HTML-Standard (<em>, < i>, <strong>,...)
• Ein Zeilenumbruch muss in XML-konformer Weise <br/> geschrieben werden. Die Definition vonParagraphen erfolgt wie gehabt mittels <p>. Tabellen sind ebenfalls HTML-konform und werdenmit <table>, <tr>, <td> erstellt. Da XML jedoch sehr streng auf die Syntax achtet, durfen keineEnde-Tags aus Faulheit weggelassen werden!
• Graphiken: Bei WML konnen nur Bilder im WBMP-Format (Wireless Bitmap) verwendet werden.
• Formularfelder werden auch hier unterstutzt (Auswahlfelder, Eingabefelder, ...)
• Tasks losen Aktionen auf einen Event (Card aufgerufen, Verweis angeklickt) aus.
– Mit <go> kann auf eine andere Stelle (Card oder Deck) gesprungen werden:
<go href="http://www.domain.de/deck"/><go href="#card"/>
– <prev/> springt zur vorherigen Stelle.
– <refresh/> ladt die Seite erneut.
– <do> behandelt Events
• Variablen sind eine leistungsfahige Erweiterung der bekannten HTML Funktionalitat. Sie wer-den benutzt, um Statusinformationen oder Benutzereingaben kontextsensitiv von einer Card zurnachsten oder an den Server weiterzugeben. Variablen werden mit dem Dollar-Zeichen ’$’ eingelei-tet. Soll daher ein $-Zeichen im Text verwendet werden, ist $$ zu schreiben.
<p>Wert von T ist $T</p>$(URL:unesc)$(PATH:escape)
Stellt den Text dar und ersetzt $T mit dem Wert der Variable. Mit unesc und escape lasst sichdie Variable URL de- bzw. encodieren.
Die WML-Spezifikation33 und andere Referenzen finden sich auf http://www.wapforum.org. Einegute Einfuhrung, von der auch der WML-Teil dieses Kapitels ubernommen wurde findet sich unterhttp://www.thozie.de/wap/wml.htm. Ein ganz gutes Tutorial ist auch unter http://www.wap-uk.com/Developers/Tutorial.htm zu finden.
8.3.2 WAP
Um nun von einem WAP-Device zu einem Server ein WML-Dokument abfragen zu konnen, werdenmehrere Teile benotigt (siehe auch Abbildung 8.2):
• Das WAP-Gerat muss sich bei einem Einwahlknoten einwahlen und stellt zu diesem eine TCP/IP-Verbindung her. Zwischen WAP-Gerat und dem Einwahlknoten besteht eine ganz normale TCP/IP-Verbindung, wie zwischen einem Computer, der sich uber ein Modem ins Internet einwahlt, unddem Internetprovider, bei dem er sich einwahlt.
33http://www1.wapforum.org/tech/documents/SPEC-WML-19991104.pdf
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 139
• WAP-Gateway: Das WAP-Device spricht nun uber TCP/IP mit Hilfe des Wireless Application Pro-tocol’s mit einer sog. WAP-Gateway, einer Applikation, die die Umsetzung der Anfragen des WAP-Devices auf andere Protokolle erledigt (z.B. HTTP). Die WAP-Einstellungen des WAP-Geratesgeben an, unter welcher IP-Adresse diese WAP-Gateway erreichbar ist.
• Ein Web-Server verwaltet WML-Seiten (sog. Decks) und liefert diese auf Anfrage ganz gleich wieHTML-Seiten per HTTP aus.
wap
WAP−Device Einwahl−knoten
Funkverbindung
PPP
TCP/IP TCP/IP
Web−Server
(TCP/IP)
WAP HTTP
WAP−Gateway
Abbildung 8.2: WAP-Einwahl und beteiligte Systeme: Ein WAP-Device wahlt sich bei einem Einwahlknotenein und baut eine PPP-Verbindung auf. Die WAP-Gateway verwandelt das komprimierte WAP-Protokoll innormales HTTP und requestet bei einem Web-Server die verlangten WML-Dokumente.
8.3.3 Installation einer eigenen WAP-Einwahl unter Linux
In diesem Abschnitt wird die Konfiguration eines eigenen Einwahlsystems fur eine WAP-Einwahl unterLinux beschrieben. Sie ist aus der Projektarbeit von Robert Runggatscher34 entstanden und besteht ausmehreren Teilen:
• mgetty : Ist fur die Einwahl per Modem oder wie hier per ISDN verantwortlich.
• pppd : Ermoglicht die PPP-Verbindung zum WAP-Gerat (Mobiltelefon).
• Kannel35 setzt das WAP-Protokoll, das zwischen dem Einwahlknoten und dem WAP-Gerat gespro-chen wird, auf HTTP um. Hier werden alle Daten komprimiert und zum WAP-Device ubertragen.
• Der Apache Web-Server liefert die WML-Dateien per HTTP aus.
Es wird nicht garantiert, dass folgende Installationsbeschreibung fehlerlos ist und wirklich funktioniert. Essoll jedoch zumindest ein Einblick gegeben werden, welche Teile notig sind und wie diese zusammenspielen.
NOTIZ: Es wird sicherlich keine Installationsanleitung fur irgendwas bei der Prufung gefragt!
mgetty
Installing and configuring mgetty for ISDN providing an automatic startup for ppp. I tried this withmgetty 1.1.21 and 1.1.22.
We made this with an isdn fritz card PCI, the driver was compiled to the kernel, it didn’t work as moduleand we didn’t use the driver for the FRITZ A1 card!
• Extract package34mailto:[email protected]://www.kannel.org

KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 140
• make (maybe you should look at the pathes in the Makefile and change them for your needs, e.g.CONFDIR=$(prefix)/etc/mgetty+sendfax to CONFDIR=/etc/mgetty+sendfax
• make install
• edit the configuration files in $(prefix)/etc/mgetty+sendfax/
– Add the following lines to /etc/inittab:
I0:234:respawn:/usr/local/sbin/mgetty -x 4 -s 38400 /dev/ttyI0
– Add the following lines to $(prefix)/etc/mgetty+sendfax/mgetty.config:
port ttyI0debug 9 #(only for debugging purposes)data-only yport-mode 0660modem-type datainit-chat "" AT&B512&E5666&X0S14=4S19=197&R9600 OKissue-file $(prefix)/etc/mgetty+sendfax/foo.issueautobauding n
– Add the following lines to $(prefix)/etc/mgetty+sendfax/dialin.config
all (allows all numbers a dialin)
– Add the following lines to $(prefix)/etc/mgetty+sendfax/login.config
/AutoPPP/ - root /usr/sbin/pppd file /etc/ppp/wap.conf
The file login.config has to be owned by root.root and have the rights -rw-------
– Provide an empty file $(prefix)/etc/mgetty+sendfax/foo.issue (holds the welcome text)
pppd
• Install the pppd (I didn’t do that because it was already installed)
• Add the following lines to /etc/ppp/wap.conf (same file as given in the $(prefix)/etc/mgetty+sendfax/login.config file)
vjccomp-ac -pc-vjname wap10.1.32.10:10.1.32.1ktuneipcp-accept-localipcp-accept-remotedebugnoauthlockasyncmap 0netmask 255.255.255.255nodetachnoproxyarplcp-echo-interval 30lcp-echo-failure 4idle 600no ipx
Kannel
I made this with the Kannel (www.kannel.org) WAP-Gateway 0.12.1
• ./configure
• make
• makeinstall
KAPITEL 8. SERVERSEITIGE TECHNOLOGIEN 141
• Add the following lines to $(prefix)/kannel/conf/kannel.conf:
group = coreadmin-port = 13000admin-password = wappleradmin-allow-ip = "*.*.*.*"#admin-deny-ip = "127.0.0.1;129.27.153.58"#smsbox-port = 13001wapbox-port = 13002box-allow-ip = "*.*.*.*"#box-allow-ip = "127.0.0.1;129.27.153.58"wdp-interface-name = 129.27.153.58log-file = "/usr/local/kannel/log/bearer_kannel.log"log-level = 0access-log = "/usr/local/kannel/log/kannel.access"unified-prefix = "+43,0043,0"#http-proxy-host = fiicmfw01.tu-graz.ac.at#http-proxy-port = 3128syslog-level = 0
group = wapboxbearerbox-host = localhostlog-file = "$(prefix)/kannel/log/wap_kannel.log"log-level = 0 (for debugging only)
• Running Kannel:
– change to $(prefix)/kannel/bin
– first of all you have to start the bearerbox with th following command:./bearerbox-0.12.1 -v 1 ../conf/kannel.conf
– start the wapbox with th following command:
./wapbox-0.12.1 -v 1 ../conf/kannel.conf
– if you want to start an smsbox too you have to add a sms - group to the kannel.conf file andthen start it by entering (I didn’t tried this at all):
./smsbox-0.12.1 -v 1 ../conf/kannel.conf
Apache
Der Web-Server Apache muss so konfiguriert werden, dass er WML-Dateien richtig erkennt und denMIME-Type richtig setzt. Siehe dazu Abschnitt 8.3.

Kapitel 9
Knowledge Management
In diesem Kapitel finden sich zwei Artikel von Prof. Hermann Maurer1, die einen kurzen Einblick inKnowledge Management geben sollen. Da die Artikel unverandert ubernommen wurden (bis auf mini-male Layoutanderungen (WinWord auf LATEX)) beziehen sich eventuelle Literaturverweise immer auf dieReferenzen, die am Ende des jeweiligen Papers angegeben sind und nicht auf die allgemeine Literaturlisteam Ende des Skriptums.
9.1 Die (Informatik) Welt in 100 Jahren
9.1.1 Wie kann irgendwer uber eine so lange Zeit eine vernunftige Prognosemachen?
Diese Frage stellt sich fast zwangsweise, wenn man den Titel dieses Beitrags liest: kann jemand so naivsein, dass er sich an ein so unmogliches Unterfangen wagt?
Nun, ich bin nicht so einfaltig zu glauben, dass man 100 Jahre in die Zukunft sehen kann. Tatsachlichhalte ich es mit Jaques Hebenstreit, der meint “Jede Vorhersage in der Informatik uber mehr als 20 Jahrekann nur als Science Fiction eingestuft werden”. Und wer sehen will, was alles schief gehen kann, dersoll bitte meinen Beitrag “Prognosen und Thesen? nicht nur zum Schmunzeln” im Informatik SpektrumFebruar 2000 nachlesen!
Warum schreibe ich dann diesen Beitrag trotzdem? Weil ich von einem bisher noch nie explizit ausge-sprochenen Phanomen uberzeugt bin, das tatsachlich mit sehr hoher Wahrscheinlichkeit in 100 Jahrenin voller Entfaltung sichtbar sein wird. Es wird das Leben aller Menschen und alle Regelsysteme derGesellschaft und der Wirtschaft vollig verandern. Bevor ich erklare, was ich meine, muss ich im nachstenAbschnitt aber erst die Basis dafur schaffen.
9.1.2 Die arbeitsteilige Gesellschaft
Wir Menschen sehen uns gerne als Individualisten, die ihr eigenen Ziele und Ideen verfolgen und diealso auch eine gewissen Unabhangigkeit von anderen Menschen haben und schatzen. Dieser Traum derpersonlichen Eigenstandigkeit ist schon, aber entspricht in keiner Weise mehr der Welt in der wir heuteleben.
Geht man weit zuruck, so war das einmal anders. Die Urmenschen lebten in kleinen Gruppen. Sie wardamals von anderen Gruppen, ja selbst von den Mitgliedern des eigenen Stammes weitgehend unabhangig.Wurde damals ein erwachsener Mensch aus einer Gruppe verstossen, so konnte er ohne grossen Verlustan physischer Lebensqualitat weiter leben: er konnte fur sich selbst jagen, sammeln, sich gegen Kalteschutzen, usw.
1mailto:[email protected]
142
KAPITEL 9. KNOWLEDGE MANAGEMENT 143
Im Laufe der Menscheitsentwicklung wurden die Wechselwirkungen zwischen den Menschen immer starker.Der Handel, zuerst lokal, spater weltweit, schaffte hohere Lebensqualitat, aber auch mehr Abhangigkeit,mehr Spezialisierung. Die Verstadterung, spater die Industrialisierung und die Globalisierung schließlichfuhrten zu der Situation die wir heute haben, und die uns oft nicht klar genug bewusst ist: was in derIndustrialisierung als Taylorismus, als Arbeitsspezialiserung beruhmt bzw. beruchtigt wurde, das erlebenwir heute uberall.
Die Menscheit ist in einem unvorstellbaren Mass arbeitsteilig geworden, wie ich mit drei Beispielenerlautere:
Wahrend ich dies schreibe, sitze ich in einem Haus mit vielen Einrichtungsgegenstanden, die ein Heervon speziell ausgebildeten Menschen fur mich geschaffen haben: es geht ja nicht nur um die Baufirmen,die Elektriker, die Installateure, die Mobelfirmen, usw, die unmittelbar sichtbar sind, sondern um derenunzahlige Zuliferanten und Subauftragnehmer, die selbst wieder solche haben, und die alle wieder vonInfrastruktureinrichtungen abhangig sind (Strom, Strassen, Wasser,?.).
Ich trage Kleidung, bei deren Herstellung eine Unzahl von hunderten Spezialisten beteiligt war: alleinam Plastikarmband meiner Uhr haben indirekt sicher hunderte (!) Branchen mitgewirkt: jene, die dieMaschinen zur Erdolgwinnung bauten, das Personal in der technisch-chemischen Industrie das darauseinen Plastikrohstoff erzeugte, die industriellen Schneidereien, die das Band fertigten, die Vertriebswege,die ohne Transportsysteme oder Buchhaltung nicht funktionieren konnten, usw. Wobei hinter so einfachenWorten wie “Transportsystem” ja wieder unzahlige ander Branchen stehen.
Ich trinke eine Tasse Kaffee ohne explizit zu realisieren, wieviele Menschen daran beteiligt waren, sowohlan der Produktion der Tasse als auch an der Produktion dieser braunen heissen Flusigkeit, die ausgerosteten Bohnen gemacht wird, die aus einem anderen Teil der Welt kommen?
Wenn einer von uns heute verstossen wird und auf sich selbst gestellt in der Wildnis (wo es die geradenoch gibt) uberleben will, schafft er dies im Normalfall nicht mehr. Wenn es gelingt, dann nur miteinem dramatisch niedrigerem Komfort. Unsere Gesellschaft ist so arbeitsteilig geworden, so verzahnt,die Menschen sind so von einander abhangig, dass wir uns nicht mehr als Einzellebenwesen sehen konnen,sondern schon viel eher analog zu Ameisen in einem Ameisenhaufen.
Anders formuliert: es gibt das Lebewesen Mensch nicht mehr, sondern das Lebewesen Menschheit: dieMenschen sind nur noch Zellen dieses Lebewesens, die bestimmte Aufgaben ubernommen haben. Diesesneue Lebewesen Menscheit hat anstelle von Muskeln Werkzeuge, Maschinen und Energieversorgungsnetze,anstelle von Blut die globalen Transportsysteme, anstelle von Nerven die weltweiten Kommunikations-,Medien-, Daten- und Computernetzewerke.
Noch anders formuliert: obwohl wir die materiellen Dinge in unserer Umgebung (von der Kleidung zurBehausung, vom Transportmitel zum Essen,?) andauernd und ganz selbstverstandlich benutzen, konnenwir nur ganz wenige davon selbst herstellen: wir haben uns daran gewohnt, dass wir im materiellen Bereichvollstandig auf andere Menschen angewiesen sind, und greifen auf diese Produkte anderer Menschen ohneBedenken jederzeit zu.
Es ist darum so wichtig, dies einmal deutlich zu verstehen, weil die nachsten hundert Jahre etwas Analo-ges bringen werden: die Welt wird nicht nur arbeitsteilig, sie wird auch vollstandig “wissensteilig”: jederMensch wird auf das Wissen anderer Menschen direkt zugreifen mussen und konnen, und dies als Selbst-verstandlichekit betrachten, ohne zu verstehen, wie dieses Wissen in den anderen Menschen entstandenist, und ohne in der Lage zu sein, dieses Wissen selbst zu erarbeiten. Genau wie es die meisten vonuns heute tun, wenn sie ein Auto verwenden: weder wissen sie auch nur annaherend, wie es konstruiertwurde, noch waren sie dazu in der Lage, eines zu bauen.
So wie traditionelle Werkzeuge unserer korperlichen Fahigkeiten vervielfacht haben werden in Zukunft“Wissenswerkzeuge” unserer geistigen Fahigkeiten dramatisch vergrossern, aber gleichzeit auch die ge-genseitige Abhangigkeit!
9.1.3 Die wissensteilige Gesellschaft
Meine Hauptthese ist also, dass die Menschheit in den nachsten 100 Jahren in einem gewaltigen Ausmass“wissenssteilig” werden wird, und dass damit einerseits anstelle des Einzellebewesen Mensch das neueLebewesen Menschheit noch deutlicher als heute sichtbar wird, andererseits die einzelnen Menschen fast

KAPITEL 9. KNOWLEDGE MANAGEMENT 144
wie durch ein grosses “externes Gehirn” gewaltig an mentalen Moglichkeiten gewinnen werden.
Die Weiterentwicklung der Computer bzw. der Informatik wird dabei eine wesentliche Rolle spielen:darauf gehe ich in einem getrennten Abschnitt naher ein. Freilich sollte man die beispielhaften Aussagenin diesem technischeren Abschnitt nur genau als solche sehen: denn ob die dort beschriebenen oder ganzandere Alternativen in 100 Jahren zum Tragen kommen werden, dass kann wirklich niemand vorhersagen.
Meine These aber, dass die Menschheit immer wisssensteiliger wird, die in diesem zentralen Abschnitterlautert wird, diese Prognose wird dem Wind der Zeit eher standhalten, und ist daher auch sehr vielernster zu nehmen.
Rekapitulieren wir noch einmal kurz: die Menschen waren ursprunglich durchaus in der Lage, jeder fursich zu sorgen. Erst durch Phanomene wie Handel, Urbanisierung, Industrialisierung und Globalisierungwurden die Menschen immer mehr von den materiellen Produkten anderer abhangig, besteht heute inden entwickelten Gesellschaften ein unglaubliche starke Abhangigkeit der Menschen voneinander aberauch ein weltweiter Zugriff auf alle Guter: vor 50 Jahren waren Mangos, Bananen, Kiwis usw in Europaeinfach nicht erhaltlich, chinsesische Restaurants eine Seltenheit, oder Handschnitzerein aus Afrika denwenigen Fernreisenden vorbehalten.
Im Bereich “Wissen” ist ein ahnlicher aber langsamerer Prozess verfolgbar, ein Prozess der erst in dennachsten 100 Jahren seinen wirklichen Hohepunkt erreichen wird. Der schon vorher als Beispiel heran-gezogene Urmensch verfugte, jeder einzelne, noch uber das meiste notwendige Wissen. Er vermitteltedieses Wissen auch nicht durch einen formalen Prozess wie “unterrichten” oder “aufschreiben”, sonderneinfach durch “vorzeigen”.
In den allmahlich sich entwickelnden hoheren Kulturen war aber schon bald nicht alles Wissen fur alleverfugbar. Beispielweise wussten die Priester in einigen alten Kulturen sehr viel mehr uber die Astro-nomie als die meisten anderen damaligen Menschen, die Medizinmanner mehr uber Heilkrauter als derDurchschnitt, oder die griechischen Mathematiker mehr uber Geometrie und Logik als ihre Zeitgenossen.Das Wissen begann sich also rasch “aufzuteilen”.
Ein wesentlicher weiterer Schritt in diese Richtung war die Entstehung der Schrift, durch die das Wis-sen einzelner einer grossen Anzahl von Menschen in Gegenwart und Zukunft vermittelbar wurde. DerBuchdruck, und im 20. Jahrhundert dann Bild-, Ton- und Filmedien, schließlich bis hin zu den “neuenMedien” und den Computernetzen, allen voran WWW, trugen dazu bei, dass das wachsende Wissen derMenscheit an immer mehr Orten, aufgeteilt in Milliarden von Bruchstucken, zu finden ist. Jeder einzelneMensch verfugt dabei nur uber einen winzigen Bruchteil des Gesamtwissens. Zusatzlicher Wissenserwerbwar und ist nicht einfach.
Interessant dabei ist aber, und das ist das Entscheidende, dass nicht nur die Zahl der verschiedenartigstund verstreut aufgezeichneten Wissensbruchstucke im Laufe der Zeit, immer mehr wuchs, sondern dass derZugang zum Wissen allmahlich leichter wurde. Unterrichtseinrichtungen wie Schulen und Universitatentrugen dazu bei, Lesen (durch die allgemeine Schulpflicht seit ca. 1800 in Europa weitverbreitet) spielteeine grosse Rolle, aber auch der Zugang zu Buchern wurde einfacher. Musste man vor 400 Jahren vielleichtnoch hunderte Kilometer in eine grosse Klosterbibliothek reiten, mussten sich Leibnitz und Newton nochWochen gedulden um einen Brief vom anderern zu erhalten, entstanden im 20. Jahrhundert zunehmendoffentliche Bibliotheken, ja sind Bucher heute vergleichsweise so billig, dass viele oft gekauft aber nichtgelesen werden: es ist eine Kuriositat unserer Zeit, dass heute mehr Bucher gekauft werden als je zuvor(auch pro Kopf der Bevolkerung) aber deutlich weniger gelesen wird als noch vor 40 Jahren! Medienwie Radio, Fernsehen und seit nicht einmal 20 Jahren das Internet machen den Zugang zu Information(Wissen?) immer einfacher. Die Moglichkeiten, uber moderen Kommunikationsmethoden von Email zuDiskussionsforen oder On-Line Expertenberatung wichtige Wissensbruchstucke zu erhalten, oder durchE-Learning sich grossere Wissensbereiche selbst anzueignen, wachsen standig. Wie wurden heute Newtonund Leibnitz zusammen arbeiten?
Was wir bisher gesehen haben ist noch nicht einmal die Spitze des Eisberges.
Lange vor dem Jahr 2100 werden alle Menschen jederzeit und an jedem Ort auf alles Wissen der Mensch-heit zugreifen konnen, ahnlich wie wir das heute bei materiellen Gutern konnen. Dieser Zugriff wird mitGeraten erfolgen, die stark mit den Menschen integriert sind, und wird sich auf Wissen beziehen dasentweder aus Datenbanken kommt oder aus Dialogen mit Experten entsteht. Das Gehirn des Einzelmen-schen wird nur noch ein vergleichweise winziger Bestandteil eines gewaltigen Wissenvorrates sein, derdurch die Vernetzung aus Milliarden von Menschenhirnen und Datenbanken entsteht. So wie wir heute
KAPITEL 9. KNOWLEDGE MANAGEMENT 145
ohne zu uberlegen in ein Flugzeug einsteigen um etwas Neues zu sehen, werden die Menschen dann inein “Wissensflugzeug” einsteigen, das Ihnen neue Erkenntnisse und Erlebnisse liefert. Lernen, etwa garFaktenlernen, wird etwas sein, das so veraltet ist, wie fur uns Pferdefuhrwerke, die noch vor 100 Jahrendas Hauptverkehrsmittel waren. So wie wir heute Maschinen und Werkzeuge verwenden um Hauser oderComputer zu bauen, einen Staudamm zu errichten oder Holz zu bearbeiten, werden die Menschen in100 Jahren Werkzeuge und Maschinen haben mit denen aus Wissensgrundbausteinen neue Wissengebildeerzeugt werden konnen: nicht alle Menschen werden diese Moglichkeiten ausschopfen, genau so wie auchheute nur ein kleiner Bruchteil bei grossen Vorhaben entscheidend mitmacht. Aber die Potenzierung desWissens durch das Zusammenschalten vieler “Kopfe” und von Computern wird ein unglaublich machtigesLebewesen Menschheit schaffen.
Wie machtig dieses Lebewesen sein wird mag man am besten daran erkennen, was es heute schon erreichthat, im Positiven wie im Negativen: es hat jeden Punkt der Welt zuganglich gemacht, es hat (bildlichgesprochen) mit Mond- und Marssonden erstmals sozusagen ins Weltall gespuckt; es hat gewaltige Pro-duktionskapazitaten in allen Bereichen entwickelt, sonst konnte nicht ein ganz kleiner Prozentsatz derEuropaer alle anderen mit den erforderlichen Lebensmitteln versorgen; dass unsere Wohnungen wohltem-periert sind nehmen wir inzwischen als genauso selbstverstandlich hin wie dass wir uns jederzeit Kleidungoder Essen kaufen oder irgendwohin in die Welt reisen konnen; andererseits hat dieses Lebewesen auchdie Umwelt schwerstens verletzt, ist jederzeit in der Lage sich chemisch, biologisch oder nuklear selbstauszurotten, usw.
Die Wissensvernetzung wird neue Phanomene mit sich bringen, die wir genau so wenig vorhersehenkonnen wie irgendwer bei der Erfindung des Autos hatte prognostizieren konnen, dass ein guter Teil derWirtschaft einmal von Autos abhangen wird, dass Autos die Welt verschmutzen und das Klima andern,dazu fuhren, dass riesige Flachen zuasphaltiert werden, dass Autos mehr Menschen toten als selbst diegrossten Kriege das tun, usw. Die Menschen werden gegen die sicher auch auftretenden negativen Folgender Wissensvernetzung so massiv ankampfen mussen wie wir heute fur z.B. weltweiten Umweltschutzeintreten sollten.
9.1.4 Wissensteilige Gesellschaft oder im Wissen ertrinkende Gesellschaft?
Wahrend ich im Obigen von der Wissensvernetzung schwarme, von der Tatsache, dass Menschen in dennachsten hundert Jahren immer direkter auf alles existierende Wissen zugreifen werden konnen, werdenSkeptiker entgegnen: wir versinken doch schon jetzt in einer Flut unubersehbarer Informationen; eineweitere Vermehrung ist doch wirklich nichts Positives, sondern eine Katastrophe.
Tatsachlich ware eine weiter Ausweitung der unkontrollierbaren Informationsflut, in der das Auffindengewunschter und verlasslicher Information immer schwieriger wird, nicht erstrebenswert. Nur zeich-net sich am Horizont bereits ab, dass die Informationslawine allmahlich gebandigt und strukturiertwerden wird zu sinnvollen, verlasslichen und auf die Person massgeschneiderte Wissenseinheiten. Daswird geschehen uber die starkere Verwendung von Metadaten, von intelligenten Agenten, von vertika-len Suchmaschinen (wo Fachleute Informationen gefiltert und kombiniert haben), von Gigaportalen furdie verschiedensten Anwendungsbereiche, von aktiven Dokumenten, die von sich aus antworten gebenkonnen, uvm. Viel von den angedeuteten Aspekten beginnt man zur Zeit unter dem Begriff “Wissens-mangement” zu subsumieren: erste tastende Bucher zu diesem Thema erscheinen in zunehmender Zahl,Forschungszentren fur diesen Bereich werden gegrundet, wie z.B. das Grazer “KNOW-Center” unter mei-ner wissenschaftlichen Leitung, dessen wisenschaftlicher Direktor Dr. Klaus Tochtermann nicht zufalligaus dem “FAW Ulm” (Forschungsinstitut fur anwendungsorientierte Wissensverarbeitung) kommt.
Wissensmanagement (Knowledge- Management) geht zuruck auf den Stossseufzer vieler Manager: “Wennmeine Mitarbeiter nur wussten, was meine Mitarbeiter wissen, dann waren wir ein viel schlagkraftigeresUnternehmen”. Diese Herausforderung an das Knowledge Management, das gesamte Wissen in denKopfen einer Organisation ( “Corporate Mememory”) allen zur Verfugung zu stellen, ist im “Kleinen”das, was durch die globale Wissensvernetzung in sehr viel grosserem Masstab die Menschheit verandernwird. Dass diese Wissensvernetzung nicht nur ein Traum ist, zeigen die ersten WissensmanagementSysteme wie Hyperwave2 und ihre Module, wie die e-Learning Suite.
Die heutigen Methoden des Wissensmanagement beginnen grosse Organisationen wirtschaftlich zu starken2http://www.hyperwave.de

KAPITEL 9. KNOWLEDGE MANAGEMENT 146
und ihre Zukunft abzusichern: dieser Prozess wird noch Jahrzehnte andauern, die Methoden werden sichstandig verbessern, und allmahlich aus den grossen Organisationen hinausreichen in alle Teile des Lebensder kunftigen Menschheit.
9.1.5 Technik und Technikspekulationen
Eine echte Wissensvernetzung erfordert nicht nur weitere grosse Fortschritte im Bereich Wissensmanage-ment, sondern ist nur moglich, wenn das Wissen jederzeit und an jedem Ort sofort und moglichst direktzur Verfugung steht, d.h. wenn die Verbindung zwischen dem Netz und den Menschen noch sehr vieleinfacher und naturlicher wird, als sie es heute ist.
Ich habe schon vor vielen Jahren den allgegenwartigen Computer prognostiziert: nicht viel grosser als eineKreditkarte, weitaus machtiger als die heutigen schnellsten Computer, mit hoher Ubertragsgeschwindig-keit an weltweite Computernetze mit allen ihren Informationen und Diensten angehangt, in sich vereini-gend die Eigenschaften eines Computers, eines Bildtelefons, eines Radio- und Fernsehgerates, eines Video-und Photapparates, eines Global Positioning Systems, einsetzbar und unverzichtbar als Zahlungsmittel,notwendig als Fuhrer in fremden Gegenden und Stadten, unentbehrlich als Auskunfts- , Buchungs- undKommunikationsgerat, usw.
Die Handys, die wir noch vor 2010 sehen werden und die mit UMTS oder Weiterentwicklungen davonhohe Geschwindigkeit beim Netzzugang ermoglichen werden, werden den beschriebenen allgegenwartigenMinicomputern schon nahe kommen.
Und doch sind solche Uberlegungen naturlich noch sehr konservativ. Die Schirmtechnologie wird sich nichtnur durch faltbare, rollbare, extrem leichte und dunne Farbschirme verbessern, die Schirmtechnolgie wirduberhaupt verschwinden: uber einfache Brillen, die bei den Ohren Stereoton direkt auf die Gehorknochenabgeben (wie das heute bei Horbrillen schon gang und gebe ist) werden Bilder direkt durch die Pupilleauf die Netzhaut projiziert werden, links und rechts naturlich verschiedene, um dreidimensionale Effektezu erlauben.
Die Brille wird aber auch Aufnahmegerat sein, mit einem 500 fach Zoom mit dem man die dann auf demMond entstehenden Gebaude in klaren Nachten sehen wird konnen, mit Infrarot und Lichtverstarkung furklare Sicht bei Nacht und Nebel, mit einer Makrofunktion, damit ich z.B. den Belag auf der Zunge gleichan meinen Arzt, der irgendwo sein mag, ubermitteln kann (und dem ein Computer aus einer Datenbankgleich ahnliche Bilder mit Diagnose und Therapievorschlagen vorlegt). Das bedeutet auch, dass alles wasein Mensch gerade sieht auch beliebigen anderen Menschen zuganglich gemacht werden kann, ja dassvielleicht uberhaupt alles, was ein Mensch je hort oder sieht als eine Art “Supertagebuch” aufgezeichnetwerden wird, das spater nach verschiedensten Kriterien durchsucht werden kann. Naturlich benotigtdas auch die Verwendung neuer Speichermedien. Die heutigen 20 Gigabyte Harddisks, die gerade nocheinen Tag und eine Nacht als Film guter Qualitat aufzeichnen konnten, werden ersetzt werden durchSpeichergerate mit einer millionenfach hoheren Speicherdichte, die dann schon problemlos das ganze 150jahrige Leben von 20 Menschen aufzeichnen konnen. Ist das Science Fiction? Sicher nicht: in den Bio-Nanotechnologielabors wird heute schon an Speicherdichten von 10 Terrabyte pro Quadratzentimentergearbeitet, auf organisch basierenden Mikrokristallen basierend. Ein kreditkartengrosser Speicher die-ser Art wurde dann schon 500 Terrabyte Kapazitat haben, also 25.000 Mal mehr als die 20 GigabyteHarddisks. Und da reden wir von ca. 2020, nicht von heute in 100 Jahren!
Bei der Wissenswiedergabe und Speicherung von Ton, Sprache, Film, dreidimensionalen Szenen etc.zeichnen sich also schon heute ganz wesentliche Umwalzungen ab. Uber taktile und olfaktorische Ausga-begerate wird geforscht: Computer werden in 100 Jahren auch auf diesem Weg mit uns kommunizieren.Die Kommunikationsrichtung Computer- Mensch ist gut absehbar.
Die umgekehrte Richtung ist weniger offensichtlich. Naturlich werden Spracheingabe, Gestenerkennung,Eingabe durch Informationen uber einfache Fingerbewgungen, Computer die horen und sehen und dasErlebte verarbeiten, aber auch subtilere Verfahren eine enorme Rolle spielen. Jeder der unter “Wearables”im WWW sucht wird sich rasch uberzeugen konnen, dass enorm viel im Enststehen ist. Aber noch istirgendwie abzusehen, was sich durchsetzen wird bzw. was die nachsten 100 Jahre an Eingabegeratennoch alles bringen werden.
Insgesamt sind die Benutzerschnittstellen Mensch- Computer darum so schwer vorhersehbar, weil es nichtklar ist, wie weit eine direkte Verbindung der menschlichen Nervenbahnen mit Computern erwunscht ist.
KAPITEL 9. KNOWLEDGE MANAGEMENT 147
Die medizinisch-technische Machbarkeit zeichnet sich am Beispiel der direkten Impulsubergabe an denGehornerv bei tauben Personen ab, oder durch die gedankliche Steuerung von einfachen Bewegungenwie Beinprothesen oder eines Computercursors: wie weit wird die Menschheit bereit sein, eine solchevollstandige Symbiose mit Computern anzunehmen. Werden dafur die nachsten 100 Jahre reichen?Hervorragende Wissenschaftler wie Morawetz, Kurzweil oder Gershenfeld wurden ein klares “Ja” sagen,ja wurden bezweifeln, ober der Mensch als ca. 75 kg schweres Lebewesen uberhaupt noch sinnvoll ist,oder eine noch viel weitergehende Verschmelzung Mensch/Machine nicht die offensichtlichere Zukunftist?
Klar ist, dass die Miniaturiserung von sehr machtigen Computern mit den beschriebenen Benutzerschnitt-stellen und Funktionen so weit gehen wird, dass man sie z.B. einmal in das Loch in einem Zahn wirdeinpflanzen konnen. Die Ubertragung der Signale zu und von den menschlichen Sinnesorganen konntez.B. uber die Leitfahigkeit der menschlichen Haut erfolgen, die Verbindung zu den Datennetzen drahtlos.Die notwendige Energie wird direkt aus der Energie des menschlichen Korpers gewonnen werden: die-ser erzeugt in Ruhestellung ja immerhin 75 Watt. Ein Bruchteil wird fur den Betrieb der notwendigenElektronik genugen.
Ob es dann in 100 Jahren tatsachlich Elektronik sein wird, oder Biochips, oder was ganz anderes, sinddann schon fast “kleine Details”. Werden dann Computer so intelligent wie Menschen sein? Auch dies istletztlich eine eher esoterische Frage: das Lebewesen Menschheit wird eine so starken Symbiose Menschmit Maschine sein, dass die Fahigkeit des ganzen Systems jedenfalls die Fahigkeit jeder Komponente weitubersteigt.
Wieviel vom menschlichen Korper wird in 100 Jahren noch notwendig sein? Wird man biologische Er-satzteillager fur nicht mehr gut funktionierende Organe oder Korperteile verwenden, oder wird fallweisedas schwache Herz durch ein kunstliches, die alten Beine durch eine mechanisch-biologisch-elektronischeVariante, die sehr viel ausdauernder arbeitet, ersetzt werden? Werden wir weiterhin uber zwei organischeAugen die Umwelt optisch aufnehmen, oder werden wir durch eine Unzahl von kleinen Kameras nichtzwei Bilder sondern viele, fasst wie mit den Facettenaugen eines Insekts, in unser Gehirn pumpen wie diesin zahlreichen Versuchen schon heute getan wird? Und wie innig ist das Gehirn oder die daraus hervor-gehenden Nervenstrange mit den weltweiten Computernetzen und damit auch mit anderen menschlichenGehirnen verbunden?
Man kann unzahlige solche Fragen stellen. Antworten darauf konnen nur Spekulationen sein. Ich uberlassesie daher den Verfassern von Science Fiction Literatur. Was aber als einigermassen gesicherte Thesebestehen bleibt ist umwalzend genug um es nochmals zusammen zu fassen: durch die enge Vernetzung vonMenschen und Computernetzen, und die wird sich zwangsweise in den nachsten 100 Jahren in unerhorterWeise weiterentwickeln, entsteht einerseits ein neues Lebewesen Menschheit, wie es ein solches noch niegegeben hat; und wird andererseits jeder Mensch nicht nur Teil dieses Lebewesens, sondern erhalt ausseiner personlichen Sicht heraus eine Erweiterung des eigenen Gehirns in einem gewaltigen Ausmass,durch die direkte Kommunikation mit riesigen Wissensbestanden und anderen Menschen.
9.1.6 Wollen wir das alles?
Viele Menschen sind faustisch: sie leben in einem tieferen Sinn nur dadurch, dass sie etwas erschaffenoder erforschen. So will ich an dieser Stelle Goethe interpretieren. Mao hat Ahnliches aber bescheidenergesagt: wenn er von der Notwendigkeit der dauernden Revolution gesprochen hat, dann meinte er damit,dass es fur die Menschen keinen Stillstand gibt (vielleicht auch keine Fortschritt, was immer das ist),sondern dass Menschen Veranderungen benotigen, um sich zu verwirklichen, um zufrieden zu sein. Aufdie Frage, warum man den Nordpol oder die Berge oder die Planeten “erobern” will, gibt es die klassischeAntwort: weil sie da sind.
All dies spricht dafur, dass vieles von dem was machbar ist, gemacht werden wird: nur grosse und unvor-hersehbare negative Folgen konnen fallweise mogliche Entwicklungen bremsen, andern oder verhindern.Die aufgezeigte wissensteilige Gesellschaft, die Wissensvernetzung ist nicht nur machbar sondern schon imEntstehen. Sie wird in 100 Jahren ein Faktum sein. Dass am Weg dorthin nicht nur technische Problmezu losen sein werden, sondern auch Richtungsanderungen erfolgen konnen und fallweise erfolgen mussenum das menschliche Leben lebenswert zu erhalten, andert das insgesamt entworfene Bild nicht wesentlich.

KAPITEL 9. KNOWLEDGE MANAGEMENT 148
9.1.7 Zum Autor
In Wien geboren, studierte Maurer Mathematik und Informatik in Osterreich und Kanada. Nach einigenAusflugen in die Industrie wurde Maurer Professor fur Informatik, zunachst in Calgary, dann Karlsruhe,dann Graz, mit Gastprofessoren an vielen Stellen der Welt. Autor von uber 500 Publikationen und 14Buchern ist er Mitglied der Finnischen und der Europaischen Akademie der Wissenschaften. Er erhielt furseine Arbeit zahlreiche Auszeichnungen und ist heute als Vorstand zweier Multimedia Institute in Graz,und als wissenschaftlicher Leiter eines im Herbst 2000 gegrundeten Forschungsinstituts fur KnowledgeManagement tatig. Er ist Mitgrunder und Vorsitzender des Aufsichtsrats der Knowledge-ManagementFirma Hyperwave.
9.2 Active Documents: Concept, Implementation and Applica-tions
E. Heirich(Massey University, Palmerston North, NZ,[email protected]
H.Maurer(Graz University of Technology, Graz, [email protected])
Abstract: In this paper we present the notion of “active document”. The basic idea is that in the future,users of documents in any networked system should not just be able to communicate with other users,but also with documents. To put it differently, we believe that communication in networks should beunderstood in a more general sense than it usually is. Although our notion will, at first glance, almostlook like science fiction, we will show that good approximations can indeed be implemented. We concludethis short paper by pointing out a number of important applications of our new concept and mentioncases where it has already been successfully applied.
9.2.1 The notion of active documents
The idea behind active documents is very simple: whenever a user sees some information on the screen ofa networked computer the user can ask (typically by typing) an arbitrary question ... and the documentimmediately provides the relevant answer.
Putting it this way, the notion sounds impossible to implement (how can a document answer any con-ceivable question?), or at least sounds like an idea out of science fiction. However, although the ideacannot be fully implemented it is surprising how well it can be approximated in large scale distributednetworks. The reason for this is that important documents are viewed by a very large number of persons,hence the same questions (albeit in possibly different wordings) come up over and over again. Indeed,experimental data with one of the first users of the Hyperwave eLearning Suite [2, 5, 6] confirms that aftersome 500 to 1000 users new questions come up only exceedingly rarely. Thus, the basic implementationalidea behind active documents is simple: when new documents are added to a server, questions asked areinitially answered by experts, ideally but not necessarily immediately and around the clock. All questionsand answers are recorded in a database. As a new question is asked it is checked whether this questionis semantically equivalent to an earlier one: if so, the system can provide the answer immediately. Asthe number of semantically new questions decreases (and indeed approaches almost zero) the expertsbecome superfluous. In the very rare case that a really new question arises the system might answerapologetically: “This is a very good question. We will forward it to our experts and you will receive ananswer by xxx the latest”.
The crux of the matter is, of course, how is it possible to determine if two questions that may be wordedquite differently are indeed semantically equivalent. How, to just present one example, can any softwarerecognize that the question “Please explain to me how the picture compression techniques GIF, BMP
KAPITEL 9. KNOWLEDGE MANAGEMENT 149
and JPG compare to each other” is really equivalent to “I do not understand the difference between GIF,BMP and JPEG coding”. In the next section we show that this task, as hopeless as it might seem atfirst glance, has indeed both pragmatic and systematic solutions.
9.2.2 The implementation of active documents
The heuristic approach
When a question is asked it is compared with some heuristic algorithm to find an earlier question thatseems to be similar. Similarity can be determined by using a number of techniques that can become quitesophisticated: from comparing if different words match independently of their order ( like GIF and BMPin our example), to the use of synonyms (like JPG and JEPG), to stemming algorithms that take careof the flexion of words, to semantic nets, to syntactic analysis using such nets, a variety of techniques doexist that are surprisingly powerful. A typical example is the “LIKE” operator in the well-known searchengine Verity that is able to identify with a high success rate pieces of text that are likely to have thesame meaning.
In each case, once the system has determined that the question x being asked is likely to be the sameas a question y asked earlier, the system will say “Do you mean y”. It is now up to user to decidewhether indeed the answer to this question y is what is desired or not. If not, the system may offer otheralternatives, but if none satisfies the user, the apology mentioned earlier: “This is a very good question.We will forward it to our experts and you will receive an answer by xxx the latest” will be shown. Astime goes by (in the sense that a document is visited by more and more persons) chances that a questionis asked that is not only identical semantically but is also similar in form decreases, thus reducing theamount of time a human expert has to help out, and hence reducing the number of times a question isnot answered immediately.
The iconic approach
Users ask questions by marking (with the cursor) some part of the screen (a formula, an abbreviation,a picture, etc.): their question refers to information in the marked area. When a question has beenanswered, some icon or highlighting shows to other users that other persons have asked questions concer-ning this piece of information and that experts have answered them. If another user also has a questionconcerning the material at issue, one click suffices to show all questions and answers that have occurredso far. Again, after sufficiently many users the chances are good that all questions of interest have indeedbeen answered.
The iconic approach is clearly particularly easy to implement and has the advantage that semanticallyequivalent questions that are formulated in different ways will not often arise. Also, the advantage of this(and the other techniques relating to active documents) is that feedback is provided to the authors ofdocuments as to where users have questions. After all, this may often mean that some explanation is notclear enough, information is missing, etc., hence allowing the improvement of the documents. The iconicapproach has been sometimes belittled by just saying that this is not more than FAQ’s, and in a wayit is, of course. However, the FAQ’s are not collected in a long unusable list but in a short list directlywhere the problems occur. If that list gets too long, something is likely to be wrong with the document,and the document should be improved.
The linguistic approach
The most satisfying approach to handle active documents would be to develop techniques that actuallyprove the semantic equivalence of questions. Remember, heuristic techniques can only provide guesseswhether two questions are equivalent, they cannot prove their equivalence. Remember also that both theheuristic and iconic approaches use the intelligence of the user to determine whether previously askedquestions are relevant or not.
To actually prove that two pieces of text are semantically equivalent one would require a completeunderstanding of natural language, something still quite elusive. However, we can consider a compromise:

KAPITEL 9. KNOWLEDGE MANAGEMENT 150
rather than allowing a full natural language we restrict our attention to a simplified grammar and to aparticular domain for which an ontology (semantic network) is developed. Clearly, sufficiently restrictingsyntactic possibilities and terms to be used will allow to actually prove the equivalence of pieces of text.This approach has been investigated in the first author’s Ph.D. thesis (for somewhat different purposes[1] ). Attempts to adjust it to the active document situation are currently been carried out [7]. At thispoint in time the restriction on the wording of questions and the domain specificity are serious problems.It seems clear that this technique will not be suitable for the nave user, yet (as we will mention in theapplication section) there may well be situations when this linguistic approach is also useful.
9.2.3 Futher research
Before turning our attention to the application of active documents let us point out that the concept isbeing applied successfully right now, yet there is room for much improvement. In the heuristic approachmentioned, algorithms trying to guess the equivalence of textual pieces still can and should be improvedby incorporating both more powerful semantic networks and more syntactic analysis. Observe that theefforts in this area are, unfortunately, also quite language dependent! In the linguistic approach there aretwo somewhat contradictory aims that one still has to go after: on the one hand, the query syntax shouldbe as natural as possible, on the other hand domain dependence should be reduced and the constructionof the domain specific ontologies should be simplified.
However, there are also other more intrinsic problems with active documents. We have stated that“really new” questions usually do not arise after a document has been used by some 500 to 1000 users.This figure comes from a large eLearning experiment with a multi-national company with some 200.00employees, but is quite unrealistic in other contexts. Typically, the WWW or Intranets also containinformation that changes over time. What we have discussed so far does not handle this situation at all.Just consider a page about skiing in Austria. At some stage someone has asked “How much snow can Icount on” . The answer, whatever it may have been, to exactly the same question is likely to be differentas soon as a day later. It thus seems to appear that the notion of active document is only applicable tofairly static information, and question-answer dialogues should be time-stamped so that they disappearautomatically when they are invalid. Actually, the situation is better than this: an indirect step canalleviate the problems in some situations in a very elegant way. To be specific, the answer to the question“How much snow can I count on” should not be “30 inches” or such but rather “Find information oncurrent skiing conditions under ’snow report’ “ , where ’snow report’ provides a link to another serverthat has indeed up to date information on snow depth, temperatures, etc.
Another fairly deep problem is that the same question may require different answers depending on thecircumstances. Again, an example shows best what can happen. The question “Please explain ISDN”could have as answer “ISDN stands for Integrated Services Digital Networks” and this might be sufficientfor some persons. Others might expect much more than the explanation of what the abbreviation standsfor! Future active documents should probable reply along the lines: “Do you want to know what theabbreviation stands for (choice a), do you want a short technical explanation (choice b), or a fairlydetailed explanation (choice c)”. Clearly this is more work for the experts involved, it tends to blur theborder between simple question and answer situations and eLearning on a broader scale, but it also showsthat our initial claim that persons should be able to really communicate with documents is not that farfetched.
Overall, the deeper one digs into applications of active documents the more does it become apparent thatin a way much of the knowledge that now goes into more clever search engines, into language analysisand intelligent agents will also apply to active documents.
Let us conclude this section by just making sure that two further points are understood: first, activedocuments are not supposed to be restricted to textual questions and textual answers: it is easy to allowarbitrary multimedia activities as answers to questions, and it is certainly conceivable to allow questionsposed in the form of speech input or such, even if this is likely to make the recognition of semanticallyequivalent questions still more complicated; secondly, we have always said that questions are originallyanswered by “experts”. Surely also other users may answer questions being posed, yet somehow the levelof competence of the person answering a question should be known to users. 4 Applications of the notionof active documents
We have encountered the notion of active documents the first time in connection with eLearning experi-
KAPITEL 9. KNOWLEDGE MANAGEMENT 151
ments [5, 2] and have found them to be very useful in this connection. Note that the “critical number” ofusers of the same document (we have quoted 500 - 1000 a number of times) will usually only be reached ifthe courseware at issue is offered on the WWW for a large audience, or in a substantial intranet, but willusually not be reached when using material for e.g. teaching typical university classes. However, even inthis case, the mechanisms described eliminate many duplicate questions and are hence useful even if the“saturation level” is never achieved.
It has become clear over time that the usefulness of active documents goes far beyond eLearning. Indeedwe would like to claim that in the future every WWW or intranet system should assure that ALLdocuments are active. This helps users (who are otherwise frustrated by having to send emails whenthey have questions, often not knowing whom to send them to), eases the support work for those offeringinformation or services, and provides valuable feed-back to the administrators of sites as to where usershave problems.
However, in addition to eLearning there are three other areas where active documents seem to be parti-cularly useful: one is support for software, the other is in connection with help desks, and the third aredigital libraries. Let us elaborate this again by means of examples.
Suppose a company releases a new software product to a large number of (pilot) customers, with thecorresponding documentation on the WWW. In the past, support staff would always receive a stream ofquestions of the type “On page x , line z from the top, in volume y of the documentation it says thatthe SW should act according to w, but it does not. Can you please help?”. Support staff would thenhave to consult volume y, go to page x, count to line z and examine the situation, only to find out thatthis bug had been pointed out many times before, and that the development team was already in theprocess of fixing the bug (or documentation). If each page of the documentation is an active documentthis situation does not occur: after the problem at issue is pointed out the first time, other customershave no need to ask the question any more, helping them and the support staff.
The situation is similar in help-desk situations when customers do not understand a manual or such.There are two interesting additional aspects in this case, however. First, customers may ask the questionnot via an active document on the WWW but by telephone. Help desk staff may, however, now use theactive document to find the answer to this question: after all the question may have been answered by acolleague at some earlier stage. Second, in this case the linguistic approach mentioned could be handy:the domain is limited, and the staff of the support center may well be expected to be able to translatecustomer queries into queries allowed by the linguistic approach. Thus, even a help desk person notcapable of answering a question x, can translate it into x’ for the system, and the system might providethe answer that is then communicated to the user. We have argued in a separate paper [3] that activedocuments will also play a fundamental role in digital libraries in the future, since those libraries will turnmore and more from static information repositories into interactively and collaboratively used centers ofhuman knowledge.
9.2.4 Conclusion
In this paper we have described the new notion of “active document”. We believe that already the firstapplications make it abundantly clear that this notion will play a major role in the intelligent exploitationof information and knowledge in computer networks.
Much research and development remains to be done, yet even with what is available today in e.g. [2]much can be achieved!
9.2.5 References
[1]Heinrich, E., Patrick, J., Kemp, E.: A Flexible Structured Language for the Coding of Human Beha-viour - FSCL, Massey University Department of Information Systems Report 1 (1999)
[2]www.hyperwave.com
[3]Maurer, H: Beyond Classical digital Libraries; Proc. NIT conference, Beijing (2001), to appear.
[4]Lennon, J.: Hypermedia Systems and Applications; Springer Pub. Co., Germany (1997)

KAPITEL 9. KNOWLEDGE MANAGEMENT 152
[5]www.gentle-wbt.com
[6]Maurer, H.: Hyperwave - the Next Generation Web Solution; Addison Wesley Longman (1996)
[7]Maurer, H.: Hyperwave - the Next Generation Web Solution; Addison Wesley Longman (1996)
Kapitel 10
Prufungsfragen
In diesem Teil werden mogliche Prufungsfragen zur Vorlesung vorgestellt. Da der Schreiber aus eige-ner leidvollen Erfahrung weiss, dass Prufungen in einer anderen als seiner Muttersprache nicht geradeeinfacher werden (wer wurde schon vom franzosischen Enlevement des ordures menageres auf “garbagecollection” kommen), wurden alle Fragen so gut als moglich ins Englische ubersetzt.
10.1 Internet
• Wie funktioniert das Namenschema im Internet? Was ist ein Domain Name Service?
How does the naming scheme in the internet work? What is a Domain Name Service?
[07.07.2003] [24.06.2004]
• Ist es moglich, auf einem Rechner verschiedene Server-Dienste (z.B. Mail und WWW) anzubieten?Wie unterscheidet man bei TCP/IP zwischen verschiedenen Diensten auf einem Rechner?
Is it possible to provide different services (e.g. mail and WWW) on one server? How does TCP/IPdistinguish different services on one server?
[27.06.2001] [13.06.2003] [26.05.2004]
• Warum hat sich TCP/IP als Internet-Protokoll durchgesetzt und kein anderes Protokoll? WelcheEigenschaft von TCP/IP macht das Internet relativ unabhangig gegen Ausfalle einzelner Knoten?
Why did TCP/IP win the race as internet-protocol (and no other protocol)? Which quality ofTCP/IP made the internet relatively independent against the breakdown of single nodes?
[31.01.2001] [28.11.2003] [28.04.2004] [11.10.2004]
• Welches Adressierungschema wird im Internet verwendet? Welcher Internet-Dienst ist zustandigfur die Umsetzung von IP-Adressen auf Namen?
Which addressing scheme is used in the internet? Which internet-service is responsible for thetranslation of IP-addresses to names?
[21.03.2001] [03.10.2003] [24.11.2004]
10.2 Informationssysteme
• Sind digitale Bibliotheken eine Erfindung der letzten 10 Jahre? Welche digitalen Bibliothekenkennen Sie und wann sind diese ungefahr entstanden?
Are digital libraries an invention of the past 10 years? Which digital libraries do you know andapproximately when were they invented?
153

KAPITEL 10. PRUFUNGSFRAGEN 154
• Gibt es verschiedene Arten von Hyperlinks? Nennen Sie mindestens drei und erklaren Sie derenAnwendungen.
Are there different types of hyperlinks? Name at least three of them and describe their usage.
• Welche Eigenschaften machten das World-Wide-Web (WWW) so popular? Erklaren Sie die dreiWichtigsten.
Which quality made the World-Wide-Web (WWW) so popular? Describe the three most importantones.
[02.05.2001] [03.10.2003] [23.01.2004] [12.07.2004]
• Ihre 82jahrige Grossmutter hat sich kurzlich einen Computer gekauft und fragt Sie jetzt, welcheSuchmaschine (welchen Typ) Sie ihr empfehlen wurden. Begrunden Sie ihre Empfehlung!
Your 82year old grandmother just bought a computer and asks you, which search engine (whichtype of search engine) you would recommend. Explain your recommendation!
[26.09.2001] [28.11.2003]
• Warum ist es im Internet so schwierig, Informationen zu finden?
Why is it difficult to find information in the internet?
• Wer oder was ist “Veronica”? Welche Moglichkeiten bot Veronica, die es vorher noch nicht gegebenhat.
Who or what is “Veronica”? What previously unknown possibilities did Veronica offer to users?
• Muss sich der Ersteller von Web-Seiten selbst darum kummern, dass seine Seiten von Suchmaschinenindiziert werden? Erklaren Sie Ihre Antwort(en).
Does the creator of web-pages himself has to worry about that his pages are indexed by searchengines? Explain your answer(s).
[21.03.2001]
• Welche Internetdienste machen schon langer Gewinne und wie machen sie dies? Ist dies positiv furdie Benutzer, oder gibt es auch Nachteile?
What kind of internet-services have been making money for some time and how do they do it? Isthis only positive for users, or are there any disadvantages?
• Welche Kategorien von Suchmaschinen gibt es? Erklaren sie deren Grundprinzipien in wenigenSatzen.
What types of search engines are there? Explain the fundamental principles in a few sentences.
[14.11.2001] [03.06.2002] [15.01.2003] [26.05.2004]
• Was unterscheidet einen Indexsuchdiest von einem Katalogsuchdienst? Welchen davon wurden SieIhrer 82jahrigen Grossmutter empfehlen? Warum?
What is the difference of index-based search engines and those based on a catalog? Which onewould you recommend your 82year old grandmother? Why?
[23.01.2002] [09.07.2002] [12.07.2004]
• Was ist ein Robot/Spider? Welche Internettechnologie verwendet einen solchen? Wozu? Was istseine Aufgabe?
What is a robot/spider? Which internet technology is using one of those? What for? What is hisjob?
[17.04.2002] [23.01.2004]
• Welche Schwierigkeiten haben Robots/Spider beim Durchstobern von Webseiten zu meistern? Wel-che Massnahmen kann der Web-Seiten-Gestalter ergreifen, um einem solchen Robot/Spider seineAufgabe zu erleichtern.
What problems are facing robots/spiders when they are collecting data in web-pages? What canbe done by the creator of the web-page to faciliate this task for the robot/spider?
[26.09.2001] [25.09.2002] [16.12.2002]
KAPITEL 10. PRUFUNGSFRAGEN 155
• Erklaren Sie das Prinzip von Meta-Suchmaschinen. Welche Vor- und Nachteile hat eine Suche mitHilfe einer solchen Meta-Suchmaschine?
Explain the principle of meta search engines. Which advantages and disadvantages does searchingwith such a meta search engine have?
[13.06.2003] [24.06.2004]
• Erklaren Sie das Prinzip von Agenten im Zusammenhang mit Suchmaschinen (keine Geheim-dienststories bitte :-)).
Explain the principle of agents in connection with search engines (no crime stories please :-)).
• Wie funktionieren Recommendation Systeme? Wo werden sie hauptsachlich verwendet. Warum?
How does recommendation systems work? Where are they used primarily? Why?
[27.06.2001]
• Welche Moglichkeiten gibt es, Suchergebnisse von Suchmaschinen zu reihen (Ranking)? ErklarenSie eine davon etwas genauer.
Which possibilities are there to rank the search results of search engines? Explain one of thesemethods in detail.
[31.01.2001] [17.12.2001] [06.11.2002] [18.03.2003] [07.07.2003] [28.04.2004]
Bemerkung: Den ersten Teil der Frage nicht vergessen! Fur die volle Punkteanzahl reicht es nicht,z.B. PageRank zu beschreiben. Auch andere Rankingmethoden mussen zumindest erwahnt werden!
• Wie funktioniert das Ranking von Suchergebnissen bei Google? Welche Web-Seiten werden beiGoogle in den Suchergebnissen hoher positioniert?
How does the Google ranking algorithm work? Which Web pages get better ranking in Googlesearch results?
[11.10.2004]
• Warum wurde Google so eine Erfolgsgeschichte? Auf welchen grundliegenden Eigenschaften vomWeb wurde das Google Ranking basiert, um bessere Suchergebnisse zu erzielen?
Why did Google become such a great success? Which are the basic properties of the Web that theGoogle ranking algorithm is based on? How Google makes use of these properties to achieve betterresults ranking?
[24.11.2004]
• Was ist Google Bombing? Kann man damit bessere Positionierung von Web-Seiten in den Sucher-gebnissen bewirken? Wie wird dieses Problem bei anderen Suchmaschinen (Teoma) bewaltigt?
What is Google Bombing? Can yopu achieve better ranking of your Web pages with Googlebombing? How do other search engines (Teoma) solve that problem?
• Welche Moglichkeiten gibt es, nach Multimediadaten (Bildern, Videos, ...) zu suchen? Welchedavon wird hauptsachlich von Suchmaschinen verwendet? Warum?
Which possibilities are there to search for multimedia data (images, videos, ...)? Which one is usedprimarily by search engines? Why?
[02.05.2001]
• Der Computergenerierte Kontext (Wissensnetzwerk) des “Brockhaus Multimedial 2001” verwendetverschiedene Kriterien, um ahnliche Artikel zu finden. Erklaren Sie diese kurz.
The computergenerated context (the knowledge network) of the “Brockhaus Multimedial 2001”uses different criteria to find matching articles. Explain them with a few sentences.
• Welches Problem ergibt sich fur ein Informationssystem beim Speichern von vielen kleinen Dateien(z.B. Bildern und ihren Thumbnails)? Wie lasst sich dieses Problem umgehen?
Which problem does an information system face when storing lots of small files (e.g. images andtheir thumbnails)? How can this be circumvented?

KAPITEL 10. PRUFUNGSFRAGEN 156
10.3 Markup Languages
• Erklaren Sie kurz das Grundprinzip von Markup-Sprachen.
Explain in a few sentences the fundamental principle of markup languages.
[03.10.2003]
• Was beschreiben “Verallgemeinerte oder beschreibende Auszeichnungen (generalized or descriptiveMarkups)”? Nennen Sie die Vorteile dieser Auszeichnung.
What are generalized or descriptive markups describing? Explain the advantages of this kind ofmarkups.
• Was definiert SGML? Was nicht?
What is SGML defining? What doesn’t it define?
• Was sind Entities in HTML/SGML? Wozu werden sie gebraucht?
What are Entities in HTML/SGML? What are they used for?
• Was legt eine Document Type Definition (DTD) fest? Wie bezeichnet man ein SGML-Dokument,das sich an diese DTD halt?
What does a Document Type Definition (DTD) define? How do you call an SGML-document, thatconforms to this DTD?
• Welche Vorteile/Nachteile haben clientseitige Skripte (z.B. JavaScript) gegenuber Serverseitigen(z.B. JSP, PHP, ASP, ...)?
Which advantages/disadvantages have client-side scripts (e.g. JavaScript) in comparison to serverside extensions (e.g. JSP, PHP, ASP, ...)?
• Wozu dienen Cascaded Style Sheets (CSS)? Welche Eigenschaften einer HTML-Seite konnen siebeeinflussen?
What are Cascaded Style Sheets (CSS) for? Which properties of an HTML-page can they influ-ence/change?
[21.03.2001] [13.06.2003] [11.10.2004]
• Muss zum Andern des Layouts von HTML Seiten (z.B. Schriftgrosse von Uberschriften, ...), die mitCascaded Style Sheets (CSS) arbeiten, der HTML-Code der Seite selbst verandert werden? Warumbzw. warum nicht?
You wan to change the layout (e.g. fontsize of headlines, ...) of HTML-pages that are defined withCascaded Style Sheets (CSS). Do you have to change the HTML-code of the page itself? Why?Why not?
[07.07.2003] [26.05.2004]
• Kann man HTML und XML direkt vergleichen? Wo liegen die Haupt-Unterschiede dieser beidenMarkup Sprachen?
Are HTML and XML direktly comparable? Where are the main differences of these two markuplanguages?
[02.05.2001] [15.01.2003] [23.01.2004] [24.06.2004]
• HTML beschreibt ja mehr oder weniger den Aufbau einer Seite. Was sollte XML beschreiben?Wozu dient diese Beschreibung?
HTML describes more or less the structure of a page. What does XML describe? What is thisdescription good for?
[27.06.2001] [17.04.2002] [03.10.2003]
• Beschreiben Sie die Vorteile und Nachteile von XML gegenuber HTML.
Describe the advantages and disadvantages of XML versus HTML.
[26.09.2001] [03.06.2002] [22.05.2003] [12.07.2004]
KAPITEL 10. PRUFUNGSFRAGEN 157
• Wie unterscheidet sich die XML-Syntax von der HTML-Syntax?
Describe the differences between the syntax of HTML and XML.
[28.11.2003] [24.11.2004]
• Erstellen Sie eine (kurze) Adressliste (wie in einem Telefonbuch) in XML und beschreiben Sie anHand dieser die Unterschiede von XML im Vergleich zu HTML.
Create a (short) list of addresses (like in a phone book) in XML and use it to describe the differencesto XML and HTML.
[09.07.2002] [16.12.2002] [07.07.2003] [28.04.2004] [11.10.2004]
• Wozu verwendet man Attribute bei XML? Gibt es eine Regel, wann Daten in ein Attribut und wanneher in ein eigenes Tag zu verpacken sind? Welche Vorteile/Nachteile hat man bei Verwendung vonAttributen gegenuber eigener Tags?
What are attributes used in XML for? Is there a general rule when to use an attribute and when touse a tag for some data? Describe the advantages/disadvantages of the usage of attributes versusthe usage of tags?
[21.03.2001] [23.01.2002] [18.03.2003] [23.01.2004] [24.11.2004]
• Wozu dient eine Document Type Definition (DTD) bei einem XML-Dokument? Muss fur jedesXML-Dokument eine DTD erstellt werden?
What is the Document Type Definition (DTD) of a XML-document used for? Is it necessary tocreate a DTD for every XML-document?
[26.09.2001] [17.04.2002] [28.11.2003] [24.06.2004]
• Welche Moglichkeiten gibt es bei XML festzulegen, welche Tags vorkommen durfen und wie dieseverschachtelt werden konnen? Welche der beiden Moglichkeiten ist ihrer Meinung nach vorzuziehen?Warum?
What possibilities are there to define the allowed tags of an XML-document and how these tagscan be nested? Which one (of the two) would you prefer? Why?
[14.11.2001] [25.09.2002] [22.05.2003]
• Welche Vorteile/Nachteile haben XML-Schemas gegenuber einer Document Type Definition (DTD)?Welche Art von Definition ist machtiger?
What are the advantages/disadvantages of XML-schemas in comparison to a Document Type De-finition (DTD)? What kind of definition is more powerful?
[17.12.2001] [06.11.2002]
• Was sind Processing Instructions bei XML? Wozu werden sie benutzt?
What are Processing Instructions in XML? What are they used for?
[17.12.2001] [09.07.2002]
• Was ist die Extensible Stylesheet Language (XSL)? Wozu wird sie benutzt?
What is the Extensible Stylesheet Language (XSL)? What is it used for?
[31.01.2001] [16.12.2002]
• Welche Moglichkeiten bietet die Extensible Stylesheet Language (XSL) zur Transformation vonXML-Dokumenten?
Which possibilites does the Extensible Stylesheet Language (XSL) provide to transform XML-documents?
• Erklaren Sie kurz die Extensible Stylesheet Language (XSL). Aus welchen Teilen besteht XSL undwozu dienen diese?
Describe the Extensible Stylesheet Language (XSL). What parts is XSL made of and what are theyused for.
[14.11.2001] [03.06.2002] [25.09.2002] [22.05.2003] [26.05.2004]

KAPITEL 10. PRUFUNGSFRAGEN 158
• Wozu wird XPath bei Extensible Stylesheet Language (XSL) verwendet?
What is XPath of Extensible Stylesheet Language (XSL) used for?
[12.07.2004]
• Wie kann die Kombination XML/XSL verwendet werden? Muss eine XSL-Transformation immerauf dem Server erfolgen oder macht sie auch beim Client Sinn? Ist es im Moment sinnvoll, an einenUser Agent (Browser) XML/XSL zu senden?
How can the combination of XML/XSL be used? Must the XSL-transformation always happen onthe server? Does it make any sense to do it on client as well? Does it make any sense to sendXML/XSL to a user agent (browser) at this point of time?
[13.06.2003] [28.04.2004]
10.4 Digital Audio
• Was versteht man beim Digitalisieren (von Audiodaten) unter Aliasing? Welche andere Fehlerquel-len gibt es beim Digitalisieren?
What is meant by Aliasing when digitizing audio-data? What kind of other sources of errors arethere?
[31.01.2001] [26.09.2001] [17.04.2002] [16.12.2002] [13.06.2003] [28.04.2004]
• Beschreiben Sie kurz verlustlose und verlustbehaftete Kompressionsarten fur Audio-Daten. WelcheEffekte werden bei der verlustbehafteten Audiokompression ausgenutzt.
Describe lossless and lossy compression-methods for audio data. Which effects are used for losslessaudioßcompression?
[03.06.2002] [06.11.2002] [22.05.2003] [23.01.2004] [24.11.2004]
• Welche grundlegenden Arten von Kompression von Audiodaten gibt es? Zahlen Sie einige Beispielebeider Arten auf und beschreiben Sie sie kurz.
Which fundamental types of compression of audio-data are there? Give some possibilities of bothtypes and describe them in a few sentences.
[07.07.2003]
• Ein Lied von 3 Minuten Lange wird digitalisert und dann mit MP3 komprimiert. Die Digitalisierungerfolgt mit folgenden Werten: Stereo (2 Kanale), 16bit Auflosung, 44kHz Sampling Rate. DieUmwandlung ins MP3 Format geschieht mit 128kbit/sekunde (konstante Bitrate). Wie gross istdie unkomprimierte Datei, wie gross die komprimierte (in Kilobytes. Zur Einfachheit: 1 Kilobyte= 1000 Bytes)?
A 3 minute song is digitized and converted/compressed to mp3-format. Digitizing is done in stereo(2 channels), 16bit resolution, 44kHz sampling rate. The mp3 compression uses 128kbit/seconds(constant bitrate). What is the file size of the uncompressed, what of the compressed song (inkilobytes). For simplicity use 1 kilo byte = 1000 bytes)?
[18.03.2003] [28.11.2003] [26.05.2004] [11.10.2004]
• Welche Phanomene des menschlichen Gehors werden bei verlustbehafteten Kompressionsalgorith-men von Audiodaten ausgenutzt?
Which phenomena of the human ear are used/exploited by lossy compression algorithms of audio-data?
[21.03.2001] [17.12.2001] [09.07.2002] [15.01.2003] [24.06.2004]
• Kann man sagen, dass ein Kompressionsverfahren fur Audiodaten besser ist als ein anderes? Wa-rum? Warum nicht? Beschreiben Sie kurz, wo das eigentliche Know-How bei verlustbehaftetenKompressionsalgorithmen fur Audiodaten liegt.
KAPITEL 10. PRUFUNGSFRAGEN 159
Is it possible to state that one compression algorithm for audio-data is better than another? Why?Why not? Describe in a few sentences where the ’real’ know-how of lossy compression algorithmsfor audio-data is.
[02.05.2001] [03.10.2003] [12.07.2004]
• Was unterscheidet MIDI von anderen Audio-Formaten? Wozu wird MIDI hauptsachlich verwendet?
What is the main difference between MIDI and other audio-formats? What is MIDI used for mainly?
[27.06.2001] [14.11.2001] [25.09.2002]
10.5 Digital Images
• Welche Eigenschaften des menschlichen Sehapparates (Auge, Signalverarbeitung Auge-Gehirn, ...)gilt es beim Design von Informationssystemen zu beachten? Warum?
Which qualities/properties of the human visual perception (eye, signal processing eye-brain, ...)should be kept in mind when designing information systems? Why?
• Beschreiben Sie kurz die verschiedenen Farbmodelle und deren hauptsachliche Anwendung.
Describe in a few sentences the different color models and their main usage.
[07.07.2003] [28.04.2004]
• Wieviel Speicherplatz benotigt ein digitales unkomprimiertes Rasterbild mindestens? Das Bild hatfolgende Eigenschaften: Breite = 1024 Pixel, Hohe = 768 Pixel, 8 bit Farbtiefe je Farbkanal beiVerwendung des RGB-Farbmodells. Die Grosse ist in KiloBytes (1 kbyte = 1024 bytes) anzugeben.Es muss zumindest eine kurze Formel angegeben werden, anhand derer der Rechengang erkennbarist! Wie verandert sich die Dateigrosse, wenn sowohl Hohe als auch Breite durch 2 dividiert werden?
Calculate the minimal memory consumption of a digital uncompressed raster image. The imagehas the following properties: width = 1024 pixel, height = 768 pixel, 8 bit color depth per channel(RGB color model). The size must be given in kilobytes (1 kbyte = 1024 bytes). There must begiven at least a short formula, so the way of the calculation is visible! How does the file size change,when height and width are divided by 2?
[31.01.2001] [02.05.2001] [14.11.2001] [23.01.2002] [06.11.2002] [22.05.2003] [24.11.2004]
• Beschreiben Sie kurz das Grundprinzip der LZW-Komprimierung. Muss die Code-Tabelle (Worter-buch) mitgespeichert werden? Warum? Warum nicht?
Describe in a few sentences the fundamental principle of the LZW-compression-algorithm. Is itnecessary to store the code-table (dictionary) as well? Why? Why not?
[21.03.2001] [06.11.2002] [03.10.2003] [26.05.2004]
• Beschreiben Sie kurz das Prinzip der Lauflangencodierung (RLE). Welche Probleme konnen beidieser Art von Kodierung enstehen? Wie konnen diese gelost werden?
Describe in a few sentences the fundamental principle of the Run-Length-Encoding (RLE). Whatproblems might occur when using this kind of coding? How can they be solved?
[27.06.2001] [23.01.2002] [23.01.2004]
• Beschreiben Sie kurz das Prinzip der Huffman Codierung. Welche Vorteile und Nachteile hat dieseCodierung?
Describe in a few sentences the fundamental principle of Huffman-Coding. Which advantages/dis-advantages does this coding has?
[31.01.2001] [17.04.2002] [15.01.2003]
• Beschreiben Sie kurz das Prinzip der verlustfreien JPEG-Kompression.
Describe in a few sentences the fundamental principle of the lossless JPEG-compression.
[14.11.2001] [18.03.2003]

KAPITEL 10. PRUFUNGSFRAGEN 160
• Beschreiben Sie kurz das Prinzip der verlustbehafteten JPEG-Kompression (ohne Formeln). Warumwird bei dieser Kompression das YUV (bzw. YIQ) Farbmodell verwendet? Welcher Schritt ist derVerlustbehaftete?
Describe in a few sentences the fundamental principle of the lossy JPEG-compression (no formulasneeded). Why is the YUV (resp. YIQ) color model used in this algorithm? Which part of thealgorithm is ’lossy’?
[26.09.2001] [16.12.2002] [28.11.2003] [28.04.2004] [11.10.2004]
• Fur welche Daten sind verlustbehaftete Kompressionsverfahren ungeeignet bzw. wann konnenkeine verlustbehafteten Kompressionsverfahren eingesetzt werden? Warum?
For which data are lossy compression algorithms not applicable? When can lossy compressionalgorithms not be used? Why?
• Beschreiben Sie die Vor- und Nachteile der verlustbehafteten JPEG-Kompression. Fur welche Bilder(Bildtyp) eignet sich diese gut, fur welche weniger gut? Warum?
Describe the advantages/disadvantages of the lossy JPEG-compression. For what images (type ofimages) is it well usable, for what less usable? Why?
[23.01.2002] [17.04.2002] [18.03.2003] [24.05.2004] [24.06.2004]
• Vergleichen Sie den “alten” JPEG-Standard mit JPEG-2000. Welche Eigenschaften hat JPEG-2000verbessert?
Compare the “old” JPEG-standard with JPEG-2000. Which qualities were improved in JPEG-2000?
[03.06.2002] [09.07.2002]
• Sie mochten ein digitales Photoalbum Ihrer letzten Urlaubsreise ins Web stellen. Welches derfolgenden Graphikformate verwenden Sie: JPG, PNG, GIF, SVG, BMP, TIFF, WMF, Postscript,PDF. Warum? Warum nicht? Geben Sie Begrundungen fur jedes der obigen Dateiformate!
You want to put your digital photoalbum of your last holiday into the web. Which of the followingimage formats (file formats) would you use: JPG, PNG, GIF, SVG, BMP, TIFF, WMF, Postscript,PDF. Why? Why not? Give arguments for each of the given file formats.
[12.07.2004]
• Sie mochten eine Linien-Graphik ins Web stellen. Welches der folgenden Graphikformate verwendenSie: JPG, PNG, GIF, SVG, BMP, TIFF, WMF, Postscript, PDF. Warum? Warum nicht? GebenSie Begrundungen fur jedes der obigen Dateiformate!
You want to put a line-drawing into the web. Which of the following image formats (file formats)would you use: JPG, PNG, GIF, SVG, BMP, TIFF, WMF, Postscript, PDF. Why? Why not?Give arguments for each of the given file formats.
[17.12.2001] [22.05.2003]
• Sie mochten eine Linien-Graphik (3 Farben) in ein Dokument einbinden. Das Dokumentenformatunterstutzt folgende Grafikformate: JPG, PNG, GIF, SVG, BMP, TIFF, WMF, Postscript, PDF.Welches davon verwenden Sie? Warum? Warum nicht? Geben Sie Begrundungen fur jedes derobigen Dateiformate!
You want to put a line-drawing (3 colors) into the document. The document-format supports thefollowing graphic types: JPG, PNG, GIF, SVG, BMP, TIFF, WMF, Postscript, PDF. Which onewould you use? Why? Why not? Give arguments for each of the given file formats.
[03.06.2002] [15.01.2003]
• Welche Vorteile/Nachteile hat das Bildformat Portable Network Graphics (PNG) gegenuber GIF?
Which advantages/disadvantages has the file format Portable Network Graphics (PNG) in compa-rison to GIF?
[25.09.2002] [13.06.2003]
KAPITEL 10. PRUFUNGSFRAGEN 161
• Erklaren Sie kurz, wie beim Bildformat PNG Interlacing funktioniert. Welche Vor- und Nachteilehat die Verwendung von Interlacing (bei PNG)?
Describe in a few sentences how interlacing works in the file format PNG? Which advantages/dis-advantages has the usage of interlacing (of PNG)?
[02.05.2001] [16.12.2002]
• Welche grundlegend verschiedenen Methoden gibt es, Bilder/Graphiken zu speichern? Sind alleunabhangig vom verwendeten Betriebssystem? Fur welche Art von Bildern eignet sich die jeweiligeMethode am besten? Beschreiben Sie kurz die Vor- und Nachteile der jeweiligen Methoden.
Which fundamentally different methods are there to store images/graphics? Are they all indepen-dent of the used operating system? Which method suits which images best? Describe in a fewsentences the advantages/disadvantages of the methods.
• Welche Vor- und Nachteile hat das Vektorformat Scalable Vector Graphics (SVG) gegenuber anderenVektorformaten und welche gegenuber anderen Rasterbildformaten?
Which advantages/disadvantages has the vector format Scalable Vector Graphics (SVG) in compa-rison to other vector formats und which in comparison to other raster image formats?
[27.06.2001]
• Wozu dienen digitale Wasserzeichen und wie funktionieren sie?
What are digital watermarks used for and how do they work?
10.6 Digital Video
• Warum arbeitet das analoge Fernsehen mit 50 Halbbildern pro Sekunde? Wie kommt man auf dieseZahl? Warum Halbbilder?
Why does the analog television work with 50 halfframes per second? Why 50? Why halfframes?
• Welche Vor- und Nachteile hat digitales Video gegenuber analogem Video?
Which advantages/disadvantages has digital video in comparison to analog video?
• Was ist ein Codec und wozu wird er bei digitalem Video verwendet?
What is a Codec and what is it used for in digital video?
[21.03.2001] [03.10.2003] [26.05.2004]
• Fur welchen Zweck wurden die Videokompressionsstandards nach H.261 und H.263 entwickelt.Welche Bedingungen wurden durch diesen Zweck gestellt?
For which purpose were the video-compression-standards H.261 and H.263 developed? Which re-quirements were derived from this purpose?
• Was sind Intraframes, Predicted Frames und Bidirectionally Predicted Frames und wozu dienen sie?
What are Intraframes, Predicted Frames und Bidirectionally Predicted Frames and what are theyused for?
[31.01.2001] [27.06.2001] [23.01.2002] [09.07.2002] [18.03.2003] [24.06.2004] [24.11.2004]
• Werden die Frames bei MPEG Video in der gleichen Reihenfolge ubertragen, in der sie aufgenommenwurden? Warum? Warum nicht? Erklaren Sie auch kurz die verschiedenen Frame-Typen und derenSinn.
Are the frames of MPEG video transmitted in the same order as they are recorded? Why? Whynot? Explain in a few sentences the different frame-types and their usage.
[02.05.2001] [26.09.2001] [03.06.2002] [16.12.2002] [07.07.2003] [12.07.2004]

KAPITEL 10. PRUFUNGSFRAGEN 162
• Welche Unterschiede/Gemeinsamkeiten haben die Videostandards Motion JPEG (MJPEG) undMPEG2? Beschreiben Sie auch die Vor-/Nachteile der jeweiligen Formate.Describe the differences and common things of the video-standards Motion JPEG (MJPEG) andMPEG2. Give advantages/disadvantages of these formats as well.[17.12.2001] [17.04.2002] [25.09.2002] [15.01.2003] [28.11.2003] [11.10.2004]
• Kann von einem Video-Dateiformat auf die verwendete Kompressionsmethode (Codec) geschlos-sen werden, oder ist es moglich, verschiedene Arten von Daten in (verschiedenen) Dateien (z.B.Quicktime-Movie-Dateien) zu speichern?Is it possible to determine the used compression method just by knowing the video-file format or isit possible to store different kinds of data in (different) files (e.g. Quicktime-Movie-files)?
• Beschreiben Sie kurz die grundlegenden Eigenschaften und vor allem die Unterschiede von MPEG-2,MPEG-4 und MPEG-7.Give a short description of the characteristics and especially the differences of MPEG-2, MPEG-4,and MPEG-7.[22.05.2003]
• Wozu dient die Synchronized Multimedia Integration Language (SMIL)? Welche Moglichkeiten bie-tet SMIL?What is the Synchronized Multimedia Integration Language (SMIL) used for? Which possibilitiesdoes SMIL provide?[31.01.2001] [14.11.2001] [06.11.2002] [23.01.2004]
10.7 Serverseitige Technologien
• Welche Vor- und Nachteile haben dynamische gegenuber statischen Webseiten?Which advantages/disadvantages have dynamic web pages in comparison to static ones?
• Eine bestehende Applikation, die in C++ geschrieben ist, soll mit einem Webserver gekoppelt,dynamische Webseiten generieren. Welche Technologie (serverseitige Erweiterung) wahlen Sie undwarum?An already available application (written in C++) should be coupled to a web-server to generatedynamic web-pages. Which technology (server side extension) do you choose? Why?
• Eine bestehende Java (!) Applikation, soll mit einem Webserver gekoppelt, dynamische Webseitengenerieren. Welche Technologie (serverseitige Erweiterung) wahlen Sie und warum?An already available java (!) application should be coupled to a web-server to generate dynamicweb-pages. Which technology (server side extension) do you choose? Why?[26.09.2001] [13.06.2003] [12.07.2004]
• Beschreiben Sie kurz das Grundprinzip und die Vor- und Nachteile von CGI.Describe in a few sentences the fundamental principle and the advantages/disadvantages of CGI.[27.06.2001] [09.07.2002] [07.07.2003] [26.05.2004]
• Ist es moglich, eine in Prolog/Algol68/Pascal geschriebene Anwendung als dynamischer Webseiten-generator einzusetzen? Mit Hilfe welcher Technologie (serverseitige Erweiterung) wurden Sie diesangehen? Warum?Is it possible to use an application that is written in Prolog/Algol68/Pascal to generate dynamicweb pages? Which technology (server side extension) would you choose? Why?
• Welche Methoden gibt es bei HTTP, Parameter (Argumente, Benutzereingaben, ...) an eine ser-verseitige Anwendung zu ubergeben? Welche Vor- und Nachteile haben diese?Which possibilities are there in HTTP to hand over parameters (arguments, user input, ...) to aserverside application? Which advantages/disadvantages do they have?[14.11.2001] [23.01.2002] [06.11.2002] [15.01.2003] [03.10.2003] [24.06.2004]
KAPITEL 10. PRUFUNGSFRAGEN 163
• Ist die Ubergabe von Parametern (Argumenten, Benutzereingaben, ...) an eine serverseitige An-wendung mit irgendwelchen sicherheitsrelevanten Uberlegungen gekoppelt? Auf was mussen Siebesonders achten?
Are there any security concerns to obey when handing parameters (arguments, user input, ...) to aserverside application? What has to be kept in mind?
• Beschreiben Sie kurz die Unterschiede und Gemeinsamkeiten von Java Servlets und Java ServerPages (JSP). Wann entscheiden Sie sich eher fur die eine, wann fur die andere Technologie?
Describe the differences and common features of Java Servlets and Java Server Pages (JSP) in afew sentences. When do you use/prefer the one or the other technology?
[02.05.2001] [18.03.2003] [28.11.2003] [24.11.2004]
• Lassen sich Active Server Pages (ASP) mit Java Server Pages (JSP) vergleichen? Beschreiben Siekurz die Gemeinsamkeiten bzw. Unterschiede.
Is it possible to compare Active Server Pages (ASP) with Java Server Pages (JSP)? Describe thedifferences and common features in a few sentences.
[15.01.2003]
• Lassen sich Active Server Pages (ASP) mit Java Servlets vergleichen? Beschreiben Sie kurz dieGemeinsamkeiten bzw. Unterschiede.
Is it possible to compare Active Server Pages (ASP) with Java Servlets? Describe the differencesand common features in a few sentences.
[31.01.2001] [17.12.2001] [25.09.2002]
• Lasst sich CGI mit Java Servlets vergleichen? Beschreiben Sie kurz die Gemeinsamkeiten bzw.Unterschiede. Wann wurden Sie welche Technologie einsetzen?
Is it possible to compare CGI with Java Servlets? Describe the differences and common featuresin a few sentences. When would you use/prefer the one or the other technology?
[17.04.2002] [03.06.2002] [16.12.2002]
• Sie mochten eine Datenbank in eine dynamische Webseite integrieren (Abfragen und Ausgaben).Welche server-seitige Erweiterung verwenden Sie und warum?
You want to integrate a database in a dynamic web-page (requests and results). Which serversideextension do you use? Why?
[13.06.2003] [28.04.2004]
• Was sind Cookies? Wo werden sie gespeichert? Wozu dienen sie?
What are Cookies? Where are they stored? What are they used for?
[21.03.2001] [23.01.2002] [09.07.2002] [18.03.2003]
• HTTP ist ein Protokoll, das fur jede Anfrage eine neue TCP/IP-Verbindung aufbaut bzw. aufbauenkann. Welche Probleme resultieren daraus fur Betreiber von Webservices und wie konnen diesegelost werden? Beschreiben Sie die grundlegenden Losungsverfahren (low-level) und nicht die, diez.B. von PHP angeboten werden (die aber auch auf den low-level Losungen basieren).
HTTP is a protocol that establishes (may establish) a new TCP/IP connection for every request.Which problems result in this behaviour for web-site providers and how can they be solved? Describethe fundamental solutions (low level) and not the high-level ones provided by e.g. PHP (but thatnevertheless use the low-level methods).
[31.01.2001] [17.12.2001] [25.09.2002] [22.05.2003] [23.01.2004] [11.10.2004]
• Sie mochten WML-Dokumente fur WAP-fahige Gerate anbieten. Welche Teile sind beteiligt, damitIhre Dokumente auf einem WAP-Gerat angezeigt werden konnen? Welche davon mussen Sie selbstzur Verfugung stellen?
You want to provide WML-documents for WAP-devices. Which parts are involved so your docu-ments can be displayed on a WAP-device? Which of those do you have to provide?
[06.11.2002]

KAPITEL 10. PRUFUNGSFRAGEN 164
10.8 Bonus Fragen
Bonus Fragen werden bei Bedarf und Laune als Zusatzfragen eingesetzt und auch bei Bedarf und Launemit Punkten bewertet.
• Bonusfrage: Wie haben Sie ihre Ferien verbracht und was davon wurden Sie im nachsten Jahr nichtwieder tun. ;-)
Bonus Question: How did you spend your holidays and what activity wouldn’t you repeat duringyour next year’s holidays. ;-)
• Beschreiben Sie ein alkoholhaltiges/alkoholfreies Getrank, das besonders gerne wahrend der kaltenJahreszeit im Freien genossen wird.
Describe a drink (with or without alcohol) that is consumed prefereably during the cold season inthe open.
[14.11.2001]
Originelle Antworten:
– (Matthias Ruther): Gluhwein.... Erlauben verlangerte Aufenthalte im Freien in der Winterzeitund haben somit hohen gesundheitlichen Nutzen
– (Klaus Eder):
<xml:document><winter ort="im Freien"><Getraenk><Name>Tee</Name><Preis>25</Preis><Alkohol in %>5<Alkohol in %><Milch>ja</Milch>
</Getraenk></winter>
</xml:document>
– (Rene Vouri): Alkoholhaltiges Getrank: [...] Sehr beliebt bei Studenten und der Kopfwehtabletten-Industrie.Alkoholfreies Getrank: in der Sudoststeiermark geachtet und nur auf dem Schwarzmark erhalt-lich. Bewiesene Einnahmen wird durch soziale Achtung bis hin zum Entzug der sudoststeiri-schen Staatsburgerchaft bestraft.
– (Host Ortmann):
∗ Punsch, Grog oder Gluhwein∗ alle 3 auch in alkoholfreier Form verfugbar (nicht W3C konform!)∗ fuer n ≥ 5 treten extreme Aliasingeffekte auf∗ fuer n ≥ 10 gute Kompression im auditiven Bereich (man hort nur mehr 1
3 )∗ fuer n ≥ 15 garbage collection
– [...] Jagatee (Tee: wurscht war fur einer, Hauptsache viel Rum/Schnaps) [...] (Sandra Wei-tenthaler)
• Bonusfrage: Beschreiben Sie kurz die Unterschiede und Gemeinsamkeiten vom Weihnachtsmannund dem Christkind. Welche “Technologie” wurden Sie fur Ihre Kinder verwenden? Warum? Istes moglich, eine Parallel-Installation durchzufuhren?
Bonus Question: Describe in a few sentences the differences and common features of Santa Clausand the Christkind. Which “technology” would you choose for your own children. Why? Is itpossible to do a parallel-installation?
[17.12.2001]
Originelle Antworten:
KAPITEL 10. PRUFUNGSFRAGEN 165
– (Markus Schwingenschlogl): Der gewichtigeste Unterschied durften wohl der 150kg Vorsprungvom Weihnachtsmann sein.ad Parallelinstallation: [...] seit Windows und Linux auf einem PC laufen ist sowieso gar nichtsmehr unmoglich!
– (Dirk Martin): Beide sind die ersten Versuche, Suchmaschinen fur Kinder zu implementieren.[...] Der Weihnachtsmann hat eine (schone?) graphische Oberflache bekommen.
– (Robert Aschenbrenner): Beides sind serverseitige Erweiterungen fur XMS Seiten. [...] hea-vyweight Process Weihnachtsmann [...]. [...] das laute “HO HO HO” des Weihnachtsmanneswurde das leise Klingeln des Christkindes maskieren.
– (Willibald Krenn): wenn das Christkind mit SGML vergleichbar ware, kann der Weihnachst-mann mit HTML gleichgesetzt werden.
– (Michael Gissing): [...] Der Weihnachtsmann war fruher grun, wurde aber von Coca-Colaaus Marketing-Techniken in rot umgefarbt. [...] Christkind wird vom Weihnachtsmann abergemobbt, sodass am absteigenden Ast.
– (Josef Brunner): Fur meine Kinder (ich hoffe, dass es meine sind) [...]
– (Joachim Reiter): [...] das Christkind ist immer fruher dran, weil der Weihnachtsmann dasReniter verpasst hat.
– (Robert Fritz): [...] CK reitet auf einem Kamel
– (Johannes Gluckshofer): [...] man sieht dauernd besoffene Weihnachtsmanner, die keinen gutenEindruck hinterlassen.
– (Stephan Wagner): Sowohl Weihnachtsmann als auch Christkind sind XMAS-Server [....].Weihachtsmann zeichnet sich durch Plattformunabhangigkeit aus [...].
– (Klaus Stranacher): [...] Eine Abhilfe konnte in Zukunft die open-source Entwicklung “Weih-nachtskind” bringen.
– (Helfried Tschemmernegg): [...] Durch das hohe Alter des Weihnachtsmannes ist mit dessenPensionierung in nachster Zeit zu rechnen. [...]
– (Christian Trenner): [...] fette Weihnachtsmanner qualen sich durch russverschmutzte Kamine[...] Flugverkehr verunsichernden Fortbewegung mithilfe von Rentiergezogenen Schlitten [...]
– (Gerhard Sommer): [...] Das Christkind ist meiner Vorstellung nach ein Tannenbaum, grun,sehr schon geschmuckt und hat einen Weihnachtsstern ganz oben auf der Spitze.
– (Thomas Oberhuber): [...] das Ur-Christkind wurde im Jahre Schnee von der katholischenKirche entwickelt, und drei Jahre spater in der RFC-CK-JS+3 veroffentlicht und empfohlen.[...] Der Weihnachtsmann wurde von einem grossen Getrankehersteller entwickelt [...]. [...]katholische Kirche hat nach eigenen Angaben mehr Juristen als Priester [...]ad Parallelinstallation: unbedingt zuerst den Weihnachtsmann und erst dann das Christkindinstallieren. Denn setzt sich der Weihnachtsmann aufs Christkind, isses weg!!
– (Jari Huttunen): The original versions of these “technologies” originate from Finland (Lap-land). Other products are pirate versions!
• Bonusfrage: Sie stocken bei der Frage nach der Speicherplatz des digitalen Bildes aus Abschnitt 10.5.Was tun Sie? [SCNR]
1. Meine Losung ist 18.874.368bytes, weil ich den Unterschied zwischen Bit und Byte nicht kenneund auch keine Ahnung habe, was das Prefix “kilo” heisst.
2. Ich rufe meinen Bruder/Schwester/Lehrer/Friseur an, der/die war schon immer besser imRechnen
3. Meine Losung ist 1024∗768∗3∗81024∗8 . “Kurzen” und “Einheiten” sind mir Fremdworte.
4. Was ist ein “Farbmodell”?
Bonus Question: You’re stuck at the question for the memory consumption in Abschnitt 10.5.What are you doing? [SCNR]
1. My solution is 18.874.368bytes, because I do not know the difference between bit and byte andI haven’t got the faintest clue, what the prefix “kilo” means.

KAPITEL 10. PRUFUNGSFRAGEN 166
2. I call my brother/sister/teacher/hairdresser, he/she was always better in algebra.3. My solution is 1024∗768∗3∗8
1024∗8 . I don’t know what “cancel” and “unit” means.4. What is a “color model”?
Originelle Antworten:
– (Gunther Laure) Rechnet man das jetzt mit dem Euro immer ganz gleich?– (Helmut Adam) (b) Rufe Prof. Mikolasch an - der wird es uber irgendeine Gaussberechnung
mit mehrdimensionaler Pivotauswahl schon schaffen.– (Harald Auer) (b) [...] Der Telefonjoker fallt mangels Handy aus. Das Saal Publikum kann
auch nicht weiter helfen: statistische Genauigkeit wegen der geringen Anzahl (Anm.: nur 8Prufungsteilnehmer) nicht gegeben).
– (Kevin Krammer) (b) oder (c) Ich verwende den Publikumsjoker.– (Wolfgang Lazian) Eigentlich fehlt hier die Option 50:50 Chance und die Publikumsfrage.
Nachdem aber der Prufungscharacter aufrecht erhalten werden soll, werde ich mal uber meinWAP-Handy meiner 82-jahrige Grossmutter ein SMS schicken. Diese sitzt ja nun Tag undNacht vor dem Blechtrottel [...] um diverse Frage der lieben Bekanntschaft in ihre Suchma-schine einzutippen. [...] Wenn sie nichts findet, soll sie doch mal ihren Nachbarn fragen, derMaurer heisst. Der weiss es sicher.
– (Andreas Schlemmer) Ich frage meine 82 jahrige Oma, die wird die Losung mit Hilfe einesSuchdienstes im Internet finden.
• Bonusfrage: (diesmal rekursiv!) Welche Bonusfrage wurden Sie sich selbst stellen, und wie wurdenSie diese beantworten?
Bonus Question: (recursive!) Which bonus question would you ask yourself and what would youanswer?
Originelle Antworten:
– (Guido Pinkas):
a b x"
x’
x"’
Wenn ich mich im Zustand a befinde und nur durch die Transition x′ (Finden einer Losung zudem in a gestellten Problem) in den Zustand b gelange, wobei ich durch Transtition x′′ (Findeneiner weiteren Losung des Problems) immer noch in Zustand b bin, kann ich dann annehmen,dass ich die Bedingungen erfullt habe um zu Transition x′′′ (Finden eines Beweises fur die inZustand b gewonnenen Losungen) in den Zustand a zu wechseln?Das Modell beinhaltet keinen eindeutigen Endzustand.Q.E.D.
– (Guido Pinkas): Wozu soll ich eine Antwort auf eine Frage geben, wenn ich ja weiss, dass dasStellen dieser Frage die Beantwortung derselben inkludiert?
– (Chen Feng): kompliziertes Chinesisches Schiebespiel, (Anmerkung: zu kompliziert zum Ab-zeichnen, sorry.)
– (Marc Samuelsson): What do you do when in doubt while grading? - Simple, get better grade.– (Gerald Aigner): Was war zuerst da, das Ei oder das Huhn?
function ueberlege{call ueberlege
}
– (Karin Mitteregger): Was ist das hasslichste Tier der Welt und in welchem Format wurdenSie ein Bild davon abspeichern?A: Ein Schabrackentapir und naturlich im JPG-Format bei extrem starker Kompression umdas hassliche Ding verschwinden lassen zu konnen.
KAPITEL 10. PRUFUNGSFRAGEN 167
– (Andreas Klausner): War es wirklich notwendig, zur Beantwortung der Bonusfrage eine neueSeite zu beginnen?Nein, da sie nur der Unterhaltung dient und nur im Zweifelsfall Punkte bringt.
– (Andreas Rath): Meine Bonusfrage ware zu fragen, welche Bonusfragen man sich selbst fragenwurde.Die Antwort auf diese Frage wurde die Frage nach der Frage der Bonusfrage sein.
– (Mario Grunwald, Leonhard Kormann, Mario Polaschegg (gleiche Frage, leicht unterschiedlicheAntwort)):Frage: Welche Bonusfrage wurden Sie sich selbst stellen, und wie wurden Sie diese beantwor-ten?Antwort: Welche Bonusfrage wurden Sie sich selbst stellen, und wie wurden Sie diese beant-worten?Anmerkung: Terminiert wenn
1. Die Frage unverstandlich geworden ist.2. Die Frage anders beantwortet wird (das ist aber nicht sicher).
– (Philip Hofmair): Bonusfrage = Frage nach der Bonusfrage (Frage nach der Bonusfrage)Ich frage mich, wieso fallt mir keine Bonusfrage ein?
• Bonusfrage: (diesmal wieder rekursiv!) Finden Sie diese Bonusfrage sinnvoll?
Bonus Question: (recursive again!) Do you find that this bonus question makes sense?
[03.06.2002]
Originelle Antworten:
– (Wolfgang Auer): Finden Sie! diese Bonusfrage sinnvoll?
– (Florian Eisl:)
Bonusfrage(a){If a = "?" thenBonusfrage(?);
ElseEnd:
}
Bonusfrage ("?");
– (Andreas Gautsch:) Der Sinn einer Frage liegt in der Antwort!
– (Albert Strasser:) Ich nehm die Substitutionsmethode: “Finden Sie diese Finden Sie dieseFinden Sie diese ...” Stack Overflow
– (Martin Moschitz:) Wenn ich die notwendigen Punkte fur die bessere Note mit dieser Antwortbekomme, dann JA. Wenn nicht, dann ist die Antwort NEIN, weil ich mir zumindest einpaar Minuten Gedanken uber die Frage gemacht habe, welche mir dann furs Ausbessern derPrufungsfragen (um die bessere Note zu bekommen) gefehlt haben.
– (Marko Kovacic:)
∗ Finde ich diese Bonusfrage sinnvoll, so finde ich sie sinnvoll.∗ Suche ich diese Bonusfrage sinnvoll und finde sie nicht sinnvoll, so suche ich diese Bonus-
frage sinnlos und finde sie sinnlos.
– (Hanno Rasin-Streden:) Ja, diese Bonusfrage kann sinnvoll aufgefunden werden.
1. Sie ist mit ausrechendem Kontrast gedruckt.2. Das kursiv geschriebene “Bonusfrage” erweckt Aufmerksamkeit, was das Auffinden er-
leichtert.

KAPITEL 10. PRUFUNGSFRAGEN 168
3. Die Bonusfrage ist durchgehend in Deutsch gehalten.4. Sie steht auf der Vorderseite in lesbarer Schriftgroße.
Bonusfrage, die nicht sinnvoll gefunden werden konnen, waren etwa solche in weißer, he-braischer 2-Punkt-Schrift auf der Ruckseite der Prufungsangabe.
– (Thomas Edlinger:) naturlich → wenn man diese Frage in Frage stellen wurde, dann mußteman das auch bei den anderen 8 machen→macht man das, mußte man das bei allen Prufungentun und dann stellt sich die Frage: Ist die Prufung sinnvoll? → Stellt man sich diese Fragekommt man zu: Ist das Fach sinnvoll? → Ist das Studium sinnvoll? ... → Ist das Lebensinnvoll? bzw. Hat das Leben einen Sinn? Oder Was ist der Sinn des Lebens? ...
– (Markus Flohberger:)
function sinnvollbeginprintf("Was tua I do? Wos bringt ma des? Warum ich?");sinnvoll;
end
– (Thomas Trattnigg:) Die Antwort kann immer nur so sinnvoll wie die Frage sein. ;-)
– (Michael Scharnreitner:) Zur Untersuchung deses Problems machen wir uns die Grundeigen-schaften der menschlichen Psyche zunutze, und da explizit die HABGIER.Wir reduzieren (verlustbehaftet, aber fur den Mensch nicht nachvollziehbar) auf:⇒ Bringt diese Frage moglicherweise Punkte?Dieses Problem ist inklusive fertiger Losung in der Prufungs-Ordnungs-Lib gespeichert undliefert⇒ JAals Losung des reduzierten Problems, und somit als Losung des gestellten Problems!
• Bonusfrage: Beschreiben Sie, was und warum Ihr Traumurlaubsziel ist und warum Sie nicht hin-fahren wurden.
Bonus Question: Describe your dream holiday destination and why you would not travel there.
[03.06.2002]
• Bonusfrage: Beschreiben Sie in funf (laut)malerischen Worten eine Ihrer Lieblingstatigkeiten. EineErklarung, um welche Tatigkeit es sich handelt ist nicht unbedingt notwendig :-)
Beispiel: mpffffluck glugg gluggg gluggggg ahhhhhh (Bier aufmachen und trinken).
Bonus Question: Describe in five onomatopoeic words one of your favorite activities. A descriptionof the activity is not compulsory :-)
Example: mpfffluck glugg gluggg glugggg ahhhhh (Open beer and drink it).
[09.07.2002]
Originelle Antworten:
– (Gerhard Zingerle): wosch wusch wich voaam iech wup wup wummp plums grrr (Jonglieren)
– (Martin Halda): hustel sprint hooo wucht hustel (schwitz) - Volleyball spielen (zumindestversuchen)
– (Michael Schmid): bum rap rap tap tap (Firmentur abschließen und gehen)
– (Klaus Schauch): klick knister klick klick grgrgrgr (Fernseher einschalten, zappen, einpennen)
– (Mario Schermann): mp4fluck glu2g glu3g glu5g a6h (Tatigkeit ist lauflangenkodiert)
– (Norbert Thek): click click clikelick click click (Je nach Interpretation, Surfen oder Com-puterspielen - bei zweiterem gehoren noch Explosion, Todesschrei und sonstige Gerauscheeingefugt.)
– (Andreas Martischnig): jajahhh jaajah ohhhh jaaaa aahhh (Wer nun an etwas schweinischesdebkt, mein Gedanke war genau der gleiche.)
KAPITEL 10. PRUFUNGSFRAGEN 169
– (Martina Franke): schlurfschlurf knirsch raschl schnarch KRACH (Das Bett war leider vomXXX-L*tz.)
– (Martin Mayer): pieppiep ssssssss klickklickklick summ!– (Hans Jurgen Gammauf): mhhh schleck schmatz schleck mhhh– (Martin Pirker): gngngngngn knaaaaarz klack-klack aaaaaaahhhhhhh ....... ssssssshhhhhhhh
(Verschlafen, zur Uni hetzen, den Tag brav in der Uni verbringen, den ganzen Tag an dieverpaßte Morgentoilette denken und die Lieblingstatigkeit:∗ gerade noch zuruckhalten∗ Tur Klo∗ zusperren∗ Erleichterung!∗ Nachspulen
Wenn man dringend muß dann auch konnen - unuberboten. OK, vielleicht wars auch ne“Scheiß”frage.....
– (Josef Zehetner): pieppieppiep iiiaakh knacks mmmmmahhhh mmmmhhhhh– (Karl Voit): druck schnurr klick schau freu! (PC einschalten, Booten (zum leichteren Verstand-
nis ist Einlogvorgang außen vor gelassen worden), Mausklick auf Bookmark von Nerd-Clippings(http://www.ash.de/nerdclippings/), Lesen der taglich neu erscheinenden Comics zur He-bung der Moral, falls alle Gags den Weg von der Netzhaut zum emotionalen Teil meinesKleinhirns geschafft haben, lost das zumeist Freude oder Schmunzeln aus)
– (Martin Loitzl): patsch patsch patsch patsch wuuusch (mit viel Anlauf und moglichst großerWasserverdrangung ins Wasser springen und dabei den Applaus/Verargerung der umliegendenBadegaste ernten.)
– (Stephan Weinberger): schrieck gulggulpgilp klink crack schlurf (Martini-Flasche aufschrau-ben, einschenken, Eiswurfel, zerspringt aufgrund therm. Spannungen, do it!)
– (Robert Zohrer): shssssch ..... ssshsssch ..... ssschssch (schlafen)
• Bonusfrage: Gibt es ein Leben vor dem Tod? Nehmen Sie allgemein dazu Stellung und berucksich-tigen Sie das aktuelle Wetter.
Bonus Question: Is there life before death? Discuss this topic in general and take the currentweather into consideration.
[25.09.2002]
Originelle Antworten:
– (Norbert Pramstaller): Die Frage, ob es ein Leben vor dem Tod gibt, sollte man als Katholikmit nein beantworten. Als Katholik glaubt man aber an das Leben nach dem Tod [...]. Nurdie obige Aussage als Techniker zu beantworten ist einfach: Wenn es ein Leben nach demTod gibt, muss es auch ein Leben vor dem Tod geben, also ein geschlossenes System bilden.Kurzum: Katholizismus und Technik - ein totaler Widerspruch! [....]
– (Michael Thonhauser): Ob es ein Leben vor dem Tod gibt ist aus meiner jetzigen Situationheraus mit ja zu beantworten. Zwar ist jetzt ein Bezug zum Wetter schwer herzustellen (viel-leicht hat ja wahrend der letzten 45 Minuten die Sonne zu scheinen begonnen=, aber trotzdemkann ich hierzu anmerken, dass mir vor dieser Prufung bewusst wurde, dass es ein Leben vordem Tod gibt (und zwar durch die Kalte und Nasse auf dem Weg hierher).
– (Christoph Rissner): Wenn man an ein Leben nach dem Tod glaubt, so ist die Gesamtzahlder Leben nach dem Tod viel grosser als jedes Leben vor dem Tod. Daraus schliesse ich: Nein(uabh. vom Wetter)
– (Bernhard Tatzmann): Auf Grund der anhaltenden Regenfalle der letzten Tage ist zur Zeit einLeben vor dem Tod nur in eingeschrankter Form moglich Zu dieser Jahreszeit beschrankt sichdann das Leben vor dem Tod auf Internetsurfen und DVD-Schauen. Vorhanden ist es aber injedem Fall auch wenn man es nicht immer bemerkt, da sich die Menschen dann in ihre Hauserzuruckziehen.Viel offensichtlicher wird es an sonnigen Herbsttagen. Dann strotzt die Stadt nur so von“Leben vor dem Tod”.

KAPITEL 10. PRUFUNGSFRAGEN 170
• Bonusfrage: Welche neue Prufungsfrage sollte bei der nachsten Prufung von Multimediale Infor-mationsysteme gestellt werden?
Bonus Question: Which new question should be asked at the next exam of Multimedia Informa-tionsystems?
[06.11.2002]
Originelle Antworten:
– (Helfried Tschemmernegg): (aus aktuellem Anlass): Beschreibe eine Moglichkeit, die teilweisepolaren Temperaturen in den Horsalen i11 - i13 auf ein angenehmes Niveau zu heben (unterBerucksichtigung extrem begrenzter finanzieller Mittel :-) bzw. beschreibe einen Workaround,um trotz dieser Temperaturen nicht krank zu werden.Ernsthafter: Welches Grundprinzip taucht sowohl bei verlustbehafteter Audio- als auch Bild/Video-Kompression immer wieder auf (Lsg: Beschneiden des Frequenzspektrums)
– (Martin Lechner): Sie haben ein WAP fahiges Handy mit ublicher Bildschirmauflosung (200x 100). Wozu wollen Sie ins Internet?
– (Christoph Mayr): Welche 7 Fragen mochten sie nicht beantworten um mit einer schlechtenAntwort der verbleibenden achten Frage trotzdem die volle Punktezahl zu erreichen?
– (Gerd Wurzer): Ist mir eigentlich wurscht, weil ich hoff, dass i net dabei sein werd. Obawennst scho frogst sprich i mi eineutig dir a lustigere Bonusfrage aus! Woswasi, sowia bildensie die Quersumme der aus allen Ziffern auf dem Angabeblatt bestehende Zahl.Is gor net so wenig, I glaub 117.
– (Christoph Herbst): Bei der Beantwortung dieser Frage werde ich mich wohl zuruckhaltenmussen, um nicht von meinen Komilitonen fur neue Fragen verantwortlich gemacht zu werden.Das konnte ja zur vituellen Steinigung in news.tugraz.flames fuhren und das versuche ich zuvermeiden.
• Bonusfrage: Vergleichen Sie die die Flugeigenschaften von Christkind und Weihnachtsmann. Beruck-sichtigen Sie dabei auch die Gluhweinstandln, die auf dem Weg liegen.
Bonus Question (sorry, very hard to translate this time: Vergleichen Sie die die Flugeigenschaftenvon Christkind und Weihnachtsmann. Berucksichtigen Sie dabei auch die Gluhweinstandln, die aufdem Weg liegen.
[16.12.2002]
Originelle Antworten:
– (Andreas Kresitschnig): Ich glaube, dass das Christkind die besseren Flugeigenschaften hat.
∗ kleiner, beweglicher, ... ist ja noch ein Kind∗ Kinder bekommen nur den Kinderpunsch∗ Christkind ist fur mich weiblich, und Frauen haben sowieso mehr Gefuhl ⇒ auch beim
Fliegen!∗ Ausserdem hat der Weihnachtsmann keine windschlupfrige Kleidung! Das Christkind hat
nur ein Seidenkleid → keinen “Reibungs”Verluste in der Luft.
– (Katrin Amlacher): Unter Berucksichtigung dvon Gluhweinstanden, hat eindeutig der Weih-nachtsmann die besseren Karten. Erstens vertragt er dank seiner Leibesfulle sehr viel desGetranks und zweitens ist der Weihnachtsmann nicht selbst fur die Navigation zustandig. Ermuss nur sicherstellen, dass seine Rentiere nichts zu trinken bekommen. Allerdings konntedie Trefferquote der Schornsteine besorgniserregend sinken. Da das Christkind nur sparlichbekleidet ist, ist eine zusatzliche Warmequelle von Vorteil. Leider ist das Christkind fur dieNavigation selbst verantwortlich, was Baume, Antennen und dergleichen zum ernsthaften Pro-blem machen.
– (Werner Rohrer): Die Flugeigenschaft beim Christkind ist auf jeden Fall besser als beimWeihnachtsmann, bei dem sich der Wind im Bart verfangt. [...] Da ich mich nicht mehrentsinnen kann, ob mehr Weihnachtsmanner oder Christkinder am Gluhweinstand zu findenwaren, werde ich diese Erkundung sofort einholen.
KAPITEL 10. PRUFUNGSFRAGEN 171
– (Christoph Froschl): Aufgrund starten Treibens am 24 in den Einkaufszentren (wo auch dieGluhweinstandln sind) hat der Weihnachtsmann mit seinem uberdiemensionalem Fluggeratsicher Platz- bzw. Parkprobleme. Ich halte das Christkind sowieso fur in der Evolution einenSchritt weiter (siehe Fluggerate, bzw. Sichtbarkeit).
– (Wolfgang Fiedler): Es musste ja heissen “Flugeigenschaften von Christkind und Rentierschlit-ten”, weil der Weihnachtsmann nicht fliegen kann! (Viel zu schwer, grosser Sack (eh klar, wenner nur einmal im Jahr “kommt”! :), keine Flugel, ...)
• Bonusfrage: Was wurde eine Schneeflocke sagen, wenn sie sprechen konnte. Beschreiben Sie imSpeziellen auch die Aussagen von Schneeflocken in Adelboden (z.T. aus Frankreich importiert)nach dem Comeback von Hermann Maier.
Bonus Question: What would a snow flake tell you, if it could speak. Also describe the particularycase of snow flakes in Adelboden (partially imported from France) after the comeback of HermannMaier (world famous Austrian skier, who had a motorcycle accident 22 months ago. In his firstreace yesterday in Adelboden he was 3 seconds behind).
[15.01.2003]
Originelle Antworten:
– (Bernhard Rettenbacher): Ihr konnt mir den Buckel runterrutschen.– (Konrad Lanz): Dieser Tage kommen wir alle unter die Rader und jeder rutscht auf uns herum.
Aber der Hermann ist auch ohne Schnee gerutscht und trotzdem rutscht auch er auf uns herum.Naja, franzosische Schneeflocke musste man sein, da hat man dann seine Ruhe.
– (Carlos Schady): I live in Madrid so if I ever come to meed a snow flake and s/he could talkto me, s/he would say “I’m melting!!!”.
– (Alexander Hubmann): Ich schatze mal wenig. Sie ist ja schliesslich beschaftigt, mit denZahnen zu klappern und zu frieren. Haben ja schliesslich wenig an, die armen Dinger. Undwenn sie sich dann aneinander kuscheln und ihnen endlich warm wird, tauen sie im wahrstenSinne des Wortes auf.
– (Martin Antenreiter): Beim Schneefall: “AAAAHHHHHHH!”, in Adelboden, nachdem Her-mann Maier uber sie gefahren ist: “AUA, AUA, ... merde”.
– (Wolfgang Schriebl):
class Schneeflocke extends MMIS{public void say(){switch(weather_){case(bombastic_freezy):println("Schon ist es auf der Welt zu sein.");break;
case(let_the_water_freeze):println("Naja, gerade noch im Mass.");break;
case(se_big_comeback_or_the_great_herminator):println("Es kann nur einen geben. I’ll be back");break;
}}
}
– (Roland Pierer): “Monsieur Maier? Je ne connais pas Maier! Je prefere Luc Alphaud! MonDieu, les Autrichiens sont victorieux tout les temps.”
– (Johannes Fellner): Eine Schneeflocke zur anderen: “Host in Hermann heit obi schiassn gsegn?I glaub, der wird wieda ganz wie fruha!” - “Is eh gscheida, weil den Sotz ’gemma zu dir oderzu mir’ aus der Raiffeisen-Werbung hot eh kana mehr auskoitn”

KAPITEL 10. PRUFUNGSFRAGEN 172
– (Stefan Achleitner): “Quelle dommage!”
– (Marco Sergio Andrade Leal Camara): From my point of view, it is very good that hte snowflakes do not talk, because there are so many of them, if all would talk, not even our brain-quality of selecting the sound would saves us from getting crazy. Besides that, they wouldalways complain becasue they are falling, because they are stepped over, that someone isthrowsing them, because they lost identity on the gig white, because it’s cold, because it’s hotand they are melting.Hermann Maier did his training in South America, where the snow flakes are speaking spanish.Now he has a big communication problem with the french speaking snow flakes. He has toimprove his snow flake language!
– (Georg Varlamis): Flokke Gotte mit erhobener Faust:
Habe nun, achWolke, Himmel und leider auch SMOGduchaus passiert mit heissem Bemuhnda lieg ich nun, ich arme Flocke,plattgedruckt, von Hermanns Hocke...
Dialog mit Sohn Jacques:
Ich lag nun da, bei Eis und Windgetrennt von Vater Flokkenkindich hatt’ mein’ Knaben wohl im Armer war sehr sicher, es war nicht warm.
Mein Sohn, was birgst du so bang dein Gesichtsiehst Vater du den Hermann nicht?den Hermann Maier mit schiefem Bein?
Mein Sohn, er wirds nur einmal sein- denn musst du, willst du zwei mal fahrensein kleiner 30 - vom Platz, nicht Jahren!
– (Kurt Kostenbauer): Ich mag im nachsten leben eine medizinische Schraube sein.
– (Andreas Nebenfuhr):Schneeflockchen: “Asta Lavista Baby”Herminator: “I’ll be back!”
– (Johannes Rainer): Was gehen mich Ermann Maiar an, diese dreckige Schuft, machen Werbungfur Milka Ice Schokolade, woe er doch genaus wissen, Schokolade aus Fronsee sein viel basser....
• Bonusfrage: Welchen Titel konnte ein wurdiges Nachfolgelied (2004) des heurigen Song-Contest-Lieds von Alf Poier haben?
• Bonus Question: What is missing in the Cultural Capital of Europe 2003 (Graz :-)?
[18.03.2003]
Originelle Antworten:
– (Daniel Blazej): Hansi Hinterseer singt in Pelz-Moonboots “Weil das Tier zahlt”.
– (Christian Kargl): Von 2004 bis 2014 wird O vom Song Contest wegen Beleidigung der Grun-didee ausgeschlossen.
– (Ewald Griesser): Wenn man letzter wird, braucht man sich um ein Nachfolgelied 2004 sowiesokeine Gedanken machen.
– (Florian Heuberger): “84 Jahre auf dem Buckel - surft schon fest mit Googel (!)” (Ahnlichkei-ten mit Ihrer Grossmutter (die ja nicht zu altern scheint1), sind naturlich weder gewollt nochzufallig.
1obwohl 1 12
Jahre zwischen Prufungen war sie immer 82?
KAPITEL 10. PRUFUNGSFRAGEN 173
– (Johann Konrad): ... Es ware mal Zeit fur was typisch osterreichisches! z.Bsp.: Walzerverpackt in Techno oder Rock, oder eine neue Interpretation des Radetzkymarsches :-)
– (MIchael Ebner): Bei einem kuhlen Blonden im Parkhaus ist mir ziemlich egal, was da gesun-gen wird :-)
– (Philipp Berglez): Titel fur Alf Poier: “Stille” oder “Wer wahlt mich”
– (Martin Bachler): Nachstes Jahr muss von allen Interpreten die amerikanische Bundeshymnegesungen werden...
– (Markus Quaritsch): Wir werden mit dem heurigen Lied sicher 2004 nicht Teilnehmer sein.Titel fur den Song-Contest 2005 “Des is da ’Warum die Osterreicher immer letzter werden’Blues” so auf die Art von Hans Sollner vielleicht??
– (Christoph Thumser): Ich hab leider ein Problem, der Name “Alf Poier” sagt mir nichts, daich aber vermute, dass der Name aus der Schlagerszene kommt. Aber ich hab einen Freund,mit dem ich neulich mal gefruhstuckt hab, und der ist ein ziemlicher Folklore-Mensch. Und alser dann die von meiner Mutter selbstgemachte Marmelade gekostet hat, sagte er “Do schmecktma die Sun aussa!”
– (Markus Geigl): Nicht nur den Titel, sondern den ganzen Text hab ich schon im Kopf! Einkleiner Auszug:
Hey Du, Ti Amo!
Strophe:
Es war Sommer, die rote Sonne versank im Meer,ich saß allein und du kamst einfach zu mir her,wie lange hab’ echte Liebe ich vermißt!und wie der Sommerwind hast du mich dann gekußt!
Refrain:
Hey Du, ti amo, ich liebe Dich!Hey Du, ti amo, vergiß mich nicht!Der Sommer mit Dir war so schon!Warum nur, musstet Du gehn?
usw., usf.Dieser Text unterliegt natuerlich noch strengster Geheimhaltung! Außerdem untersteht derdem Urheberecht!
– (Daniel Gander): Ich hatte mir nicht erwartet, dass die Bonusfrage die einzige ist, die ich nichtbeantworten kann. Wie lautet denn der Titel von heuer?
– (Christian Mayrhuber): Nach dem heurigen Song Contest wird von allen teilnehmenden Staa-ten anerkannt, dass dieser sinnlos ist und es gibt keinen Song Contest 2004. ...
– (Gerald Eigenstuhler): “Oh du peinliches Osterreich”
– (Ranub Dalkouhi): Der wohl passendste Titel ob der aktuellen Umwelt und Kriegssituationware: “Weil der Mensch sich verrechnet hat!” (Hoffentlich hab ich mich nicht verrechnet :-)
– (Christian Kirchstatter): ... Wenn wir aber gewinnen wollen, dann mussen wir auf altbewahr-tes mit einem osterreichischen Touch setzen. Udo Jurgens hat schon einmal gewonnen, einesseiner Lieder ist “Griechischer Wein”. Treten wir mit “Wou, ist der steirische Wein gut, WuffWuff” an.
– (Philipp Furnstahl): Liedtitel “Ich muss heim, weil jetzt meine Putzfrau kommt!”Wenig kreativ, aber wahr...
• Bonusfrage: Warum wollen gerade Sie (und sonst niemand) mit Hilfe dieser Bonusfrage Bonus-punkte bekommen?
Bonus Question: Why do you (just you and nobody else) want to get some bonus points for thisbonus question?
[22.05.2003]
Originelle Antworten:

KAPITEL 10. PRUFUNGSFRAGEN 174
– (Hannes Wornig): 8930496
– (Heim Schwarzenbacher): Weil ich weiß, dass ich es bei Armin Assinger bei der Einstiegsfragenicht schaffe um damit auf den heißen Stuhl zu kommen und wenigstens dort 1 Million Euroabzuraumen.
– (Michael Grabner): Sollte ich wirklich punkten, so mochte ich mein Punkte an Alf Poierweitergeben.
– (Florian Fleck): Wenn es wirklich so ist, dass nur eine Person die Vorteile der Bonusfrage ge-nießen wird, dann sollte es nicht ich sein. Ich bin glaube ich zwar schon “Prufungsverzweifelt”,aber es scheint mir im Raum doch noch einige andere zu geben, die noch verzweifelter als ichsind.Außerdem bin ich ein positiv denkender Mensch und hoffe nicht auf die Bonusfrage angewiesenzu sein.
– (Thomas Krajacic): Warum wollen Sie, (und nur Sie) das wissen?
– (Franz Einspieler): Wenn nicht ich, wer dann?
– (Gerald Krammer): In dubio pro reo
– (Wolfgang Wagner): Nach 30min Nachdenken, bin ich zum Schluss gekommen, dass ich so sehreinfallslos und fantasielos bin, mir keine vernunftige Antwort einfallt, und daher Bonuspunkteeigentlich uberhaupt nicht verdiene.Also bleibt nur ein Grund, warum ich vielleicht doch 1-2 Punktchen bekommen sollte: MIT-LEID
– (Bernhard Schutz):
1. Weil ich es diesmal (2ter Versuch fur MMIS) zu 100% ohne Abschreiben und Schummelnprobiert habe.
2. WEil die Punkte sicher wichtig sind fur eine positive Note.3. WEil mich Gunther Laure und Wolfgang Lazian (Telematiker) noch 2 Monate aufziehen,
wenn ich MMIS wieder nicht pack.4. Weil Sowieso.5. Warum “Thanks for the Fish”, ist das so einer, der an der Wand hangt, sich bewegt und
“don’t worry, be happy” singt?
[...]
– (Katharina Seke): Weil unter den Leuten, die hier mit mir im HSi12 sitzen und die MMISPrufung schreiben, keiner soviel Angst vor der Bonusfrage hat wie ich. Da die Bonusfragehauptsachlich Ihrer und meiner Unterhaltung dient, kann ich es trtzdem schaffen mir dasLachen zu verkneifen (harte Arbeit) und nicht wie verruckt am BOden herumzukugeln.Außerdem habe ich Kaffee uber genau diejenigen Seiten des Skriptums geschuttet, auf denenMPEG2, MPEG4 und MPEG7 erklart wurde. Das hat auch noch den Hund meiner Nachbarindazu bewegt, diese Zettel zu fressen. Deshalb konnte ich das nicht lernen und kann nun dieBonuspunkte gut gebrauchen. (Und es ist sicher keiner außer mir so arm!)
– (Stefan Mendel): Weil ich auch Douglas Adams Fan bin.
– (Jurgen Bachler): Weil ich sie nicht mit Fisch bestochen hab (Wie es scheinbar andere Adres-saten getan haben).
– (Helfried Traussnigg): Fallunterscheidung
1. alle anderen sind besser als ich (worst case) → offensichtlich braucht sie dann keinerdringender als ich.
2. alle anderen sind schlechter als ich (best case)p(x) = 0 → irrelevant
– (Reinhold Schmidt): Ich hab fur die Bonusfrage eineinhalb mal so viel Zeit investiert, wie furdie richtigen Fragen.
– (Christian Ropposch): Bonuspunkte fur alle!
– (Christoph Bouvier): Ich glaub ich war als erster fertig! Außerdem hat ganz bestimmt niemandaußer mir das Skriptum gelesen!
KAPITEL 10. PRUFUNGSFRAGEN 175
– (Alexander Gutler):
1.1
∃ Bonusfrage
2.1
∃ Punkt fur die Bewertung der Bonusfrage3. ∀ Student ⊆ Matrikelnummer=”9231666”⇒ #Bonuspunkte++
• Bonusfrage: (diesmal wieder rekursiv!) Bilden Sie eine inoffizielle rekursive Definition fur MMISAbkurzung!
Bonus Question: (recursive again!) Provide an nonoffical recursive definiton for MMIS abbreviati-on!

Anhang A
MP3 Hortest
Fur den mp3-Hortest wurden verschiedene Teile von Musikstucken von CD in mp3-Dateien codiert.Ein gute Mischung aus verschiedenen Musikstilen wurde gegenuber einer akademischen Klanganalysebevorzugt.
Folgende Stucke wurden verwendet:
• Eric Clapton, Unplugged, “Before You Accuse Me”
• Ludwig van Beethoven, Symphonie Nr. 5, “1. AllegRo Con Brio”
• Bill Whelan, Riverdance, “Firedance” (Kastagnetten)
• Ugly Kid Joe, America’s least wanted, “Neighbor”
• Queen, Jazz, “Bicycle Race”
• Klassische Sagen des Altertums, erzahlt von Michael Kohlmeier
• Oscar Peterson, Digital at Montreux, “Soft Winds”
Jedes Stuck wurde als WAV-File auf die Festplatte gerippt und dann mit Hilfe von lame in verschiedenemp3-dateien codiert. Es wurden verschiedene Bitraten, Variable Bit Rate (VBR) und verschiedene Stereo-Varianten (stereo, joint-stereo, force stereo) verwendet. Danach wurden samtliche Stucke mit Hilfe desDiskwriter Plugins des mp3-players XMMS1 ins WAV-Format konvertiert und mit WinOnCD 3.7 alsAudio-CD gebrannt.
Tabelle A.1 zeigt die daraus entstandenen Dateien und ihre Grossen.
Es wurde cdda2wav und lame (Version 3.86) verwendet. Die genaue Commandline geht aus folgendemText hervor:
# ------------------------------------------------------------# oscar peterson, digital in montreux, soft winds (track2)# ripped with:cdda2wav -D 0,3,0 -q -x -H -t 2 -d 42 -O wav oscar_peterson-soft_winds.wav# 256kbit mp3 / joint stereo:lame -h -p -b 256 oscar_peterson-soft_winds.wav oscar_peterson-soft_winds_256kb.mp3# 192kbit mp3 / joint stereo:lame -h -p -b 192 oscar_peterson-soft_winds.wav oscar_peterson-soft_winds_192kb.mp3# 128kbit mp3 / joint stereo:lame -h -p -b 128 oscar_peterson-soft_winds.wav oscar_peterson-soft_winds_128kb.mp3# 64kbit mp3 / joint stereo:lame -h -p -b 64 oscar_peterson-soft_winds.wav oscar_peterson-soft_winds_64kb.mp3# 32kbit mp3 / joint stereo:lame -h -p -b 32 oscar_peterson-soft_winds.wav oscar_peterson-soft_winds_32kb.mp3
# ------------------------------------------------------------# queen, jazz, bicycle racecdda2wav -D 0,3,0 -q -x -H -t 4 -o 6505 -d 50 -O wav queen-bicycle_race.wav
1http://www.xmms.org
176
ANHANG A. MP3 HORTEST 177
# 128kbit mp3, joint stereolame -h -m j -p -b 128 queen-bicycle_race.wav queen-bicycle_race_128kbit_jointstereo.mp3# 128kbit mp3, stereolame -h -m s -p -b 128 queen-bicycle_race.wav queen-bicycle_race_128kbit_stereo.mp3# 128kbit mp3, force stereolame -h -m f -p -b 128 queen-bicycle_race.wav queen-bicycle_race_128kbit_forcestereo.mp3
# 256kbit mp3, stereolame -h -m f -p -b 256 queen-bicycle_race.wav queen-bicycle_race_256kbit_stereo.mp3# 256kbit mp3, joint stereolame -h -m f -p -b 256 queen-bicycle_race.wav queen-bicycle_race_256kbit_jointstereo.mp3
# 32kbit mp3, stereolame -h -m f -p -b 32 queen-bicycle_race.wav queen-bicycle_race_32kbit_stereo.mp3# 32kbit mp3, joint stereolame -h -m f -p -b 32 queen-bicycle_race.wav queen-bicycle_race_32kbit_jointstereo.mp3
# ------------------------------------------------------------# beethoven, symphonie nr.5, 1.satzcdda2wav -D 0,3,0 -q -x -H -t 1 -d 60 -O wav beethoven-symph5.wav
# 256kbit mp3lame -h -h -p -b 256 beethoven-symph5.wav beethoven-symph5_256kbit.mp3# 192kbit mp3lame -h -h -p -b 192 beethoven-symph5.wav beethoven-symph5_192kbit.mp3# 128kbit mp3lame -h -h -p -b 128 beethoven-symph5.wav beethoven-symph5_128kbit.mp3# 64kbit mp3lame -h -h -p -b 64 beethoven-symph5.wav beethoven-symph5_64kbit.mp3# vbr min 64kbit mp3lame -v -p -b 64 beethoven-symph5.wav beethoven-symph5_64kbit_vbr.mp3# vbr min 128kbit mp3lame -v -p -b 128 beethoven-symph5.wav beethoven-symph5_128kbit_vbr.mp3
# ------------------------------------------------------------# riverdance, firedance (kastagnetten)cdda2wav -D 0,3,0 -q -x -H -t 6 -o 10330 -d 52 -O wav riverdance-firedance.wav# 256kbit mp3lame -h -p -b 256 riverdance-firedance.wav riverdance-firedance_256kbit.mp3# 192kbit mp3lame -h -p -b 192 riverdance-firedance.wav riverdance-firedance_192kbit.mp3# 128kbit mp3lame -h -p -b 128 riverdance-firedance.wav riverdance-firedance_128kbit.mp3# 64kbit mp3lame -h -p -b 64 riverdance-firedance.wav riverdance-firedance_64kbit.mp3# 32kbit mp3lame -h -p -b 32 riverdance-firedance.wav riverdance-firedance_32kbit.mp3# 256kbit mp3 vbrlame -v -p -b 256 riverdance-firedance.wav riverdance-firedance_256kbit_vbr.mp3# 192kbit mp3 vbrlame -v -p -b 192 riverdance-firedance.wav riverdance-firedance_192kbit_vbr.mp3# 128kbit mp3 vbrlame -v -p -b 128 riverdance-firedance.wav riverdance-firedance_128kbit_vbr.mp3
# ------------------------------------------------------------# michael kohlmeier, klassische sagen des altertums, track 1cdda2wav -D 0,3,0 -q -x -H -t 1 -o 875 -d 30 -O wav koehlmeier-sagen.wav# 256kbit mp3lame -h -p -b 256 koehlmeier-sagen.wav koehlmeier-sagen_256kbit.mp3# 192kbit mp3lame -h -p -b 192 koehlmeier-sagen.wav koehlmeier-sagen_192kbit.mp3# 128kbit mp3lame -h -p -b 128 koehlmeier-sagen.wav koehlmeier-sagen_128kbit.mp3# 64kbit mp3lame -h -p -b 64 koehlmeier-sagen.wav koehlmeier-sagen_64kbit.mp3# 32kbit mp3lame -h -p -b 32 koehlmeier-sagen.wav koehlmeier-sagen_32kbit.mp3# 192kbit mp3 vbrlame -v -p -b 192 koehlmeier-sagen.wav koehlmeier-sagen_192kbit_vbr.mp3# 128kbit mp3 vbrlame -v -p -b 128 koehlmeier-sagen.wav koehlmeier-sagen_128kbit_vbr.mp3# 64kbit mp3 vbrlame -v -p -b 64 koehlmeier-sagen.wav koehlmeier-sagen_64kbit_vbr.mp3
# ------------------------------------------------------------# ugly kid joe, neighborcdda2wav -D 0,3,0 -q -x -H -t 1 -d 42 -O wav ugly_kid_joe-neighbor.wav# 256kbit mp3lame -h -p -b 256 ugly_kid_joe-neighbor.wav ugly_kid_joe-neighbor_256kbit.mp3# 192kbit mp3lame -h -p -b 192 ugly_kid_joe-neighbor.wav ugly_kid_joe-neighbor_192kbit.mp3# 128kbit mp3lame -h -p -b 128 ugly_kid_joe-neighbor.wav ugly_kid_joe-neighbor_128kbit.mp3# 64kbit mp3lame -h -p -b 64 ugly_kid_joe-neighbor.wav ugly_kid_joe-neighbor_64kbit.mp3

ANHANG A. MP3 HORTEST 178
# ------------------------------------------------------------# eric clapton, unplugged, before you accuse mecdda2wav -D 0,3,0 -q -x -H -t 2 -d 60 -O wav clapton-unplugged-before_you_accuse_me.wav# 256kbitlame -h -p -b 256 clapton-unplugged-before_you_accuse_me.wav clapton-unplugged-before_you_accuse_me_256kbit.mp3# 192kbitlame -h -p -b 192 clapton-unplugged-before_you_accuse_me.wav clapton-unplugged-before_you_accuse_me_192kbit.mp3# 128kbitlame -h -p -b 128 clapton-unplugged-before_you_accuse_me.wav clapton-unplugged-before_you_accuse_me_128kbit.mp3# 64kbitlame -h -p -b 64 clapton-unplugged-before_you_accuse_me.wav clapton-unplugged-before_you_accuse_me_64kbit.mp3
ANHANG A. MP3 HORTEST 179
Nr Titel Dateigrosse01 beethoven-symph5.wav 1058404402 beethoven-symph5 128kbit.mp3 96047003 beethoven-symph5 128kbit vbr.mp3 99672504 beethoven-symph5 192kbit.mp3 144070505 beethoven-symph5 256kbit.mp3 192094006 beethoven-symph5 64kbit.mp3 48002607 beethoven-symph5 64kbit vbr.mp3 91413508 clapton-unplugged-before you accuse me.wav 1058404409 clapton-unplugged-before you accuse me 128kbit.mp3 96047010 clapton-unplugged-before you accuse me 192kbit.mp3 144070511 clapton-unplugged-before you accuse me 256kbit.mp3 192094012 clapton-unplugged-before you accuse me 64kbit.mp3 48002613 koehlmeier-sagen.wav 529204414 koehlmeier-sagen 128kbit.mp3 48065315 koehlmeier-sagen 128kbit vbr.mp3 50797516 koehlmeier-sagen 192kbit.mp3 72097917 koehlmeier-sagen 192kbit vbr.mp3 72021318 koehlmeier-sagen 256kbit.mp3 96130619 koehlmeier-sagen 32kbit.mp3 11995420 koehlmeier-sagen 64kbit.mp3 24011721 koehlmeier-sagen 64kbit vbr.mp3 38856822 oscar peterson-soft winds.wav 740884423 oscar peterson-soft winds 128kb.mp3 67249624 oscar peterson-soft winds 192kb.mp3 100874425 oscar peterson-soft winds 256kb.mp3 134499226 oscar peterson-soft winds 32kb.mp3 16801927 oscar peterson-soft winds 64kb.mp3 33603928 queen-bicycle race.wav 882004429 queen-bicycle race 128kbit forcestereo.mp3 80039130 queen-bicycle race 128kbit jointstereo.mp3 80039131 queen-bicycle race 128kbit stereo.mp3 80039132 queen-bicycle race 256kbit jointstereo.mp3 160078333 queen-bicycle race 256kbit stereo.mp3 160078334 queen-bicycle race 32kbit jointstereo.mp3 19999335 queen-bicycle race 32kbit stereo.mp3 19999336 riverdance-firedance.wav 917284437 riverdance-firedance 128kbit.mp3 83257438 riverdance-firedance 128kbit vbr.mp3 103356639 riverdance-firedance 192kbit.mp3 124886240 riverdance-firedance 192kbit vbr.mp3 131033541 riverdance-firedance 256kbit.mp3 166514942 riverdance-firedance 256kbit vbr.mp3 166436443 riverdance-firedance 32kbit.mp3 20793444 riverdance-firedance 64kbit.mp3 41607845 ugly kid joe-neighbor.wav 740884446 ugly kid joe-neighbor 128kbit.mp3 67249647 ugly kid joe-neighbor 192kbit.mp3 100874448 ugly kid joe-neighbor 256kbit.mp3 134499249 ugly kid joe-neighbor 64kbit.mp3 336039
Tabelle A.1: Musikstucke und ihre Filegrossen im Vergleich zu mp3-komprimierten Dateien

Anhang B
Abkurzungsverzeichnis
ARPA . . . . . . . . Advanced Research Projects Agency
ASCII . . . . . . . . American Standard Code for Information Interchange
ASP . . . . . . . . . . Active Server Pages
CGI . . . . . . . . . . . Common Gateway Interface see also the glossary entry for ☞CGI
CSS . . . . . . . . . . . Cascaded Style Sheet
DARPA . . . . . . . Defense Advanced Research Projects Agency
DNS . . . . . . . . . . Domain Name System see also the glossary entry for ☞DNS
DOM . . . . . . . . . Document Object Model see also the glossary entry for ☞Document Object Model(DOM)
DTD . . . . . . . . . . Document Type Definition
DVD . . . . . . . . . . Digital Versatile Disc
FO . . . . . . . . . . . . Formatting Objects
FTP . . . . . . . . . . File Transfer Protocol see also the glossary entry for ☞FTP
GPL . . . . . . . . . . General Public Licence
HTML . . . . . . . . HyperText Markup Language see also the glossary entry for ☞HTML
HTTP . . . . . . . . HyperText Transfer Protocol see also the glossary entry for ☞HTTP
IAB . . . . . . . . . . . Internet Architecure Board
IETF . . . . . . . . . Internet Engineering Task Force
IP . . . . . . . . . . . . . Internet Protocol see also the glossary entry for ☞IP
ISOC . . . . . . . . . Internet Society
JSP . . . . . . . . . . . Java Server Pages
NDA . . . . . . . . . . Non Disclosure Agreement
NNTP . . . . . . . . Network News Transfer Protocol see also the glossary entry for ☞NNTP
NSF . . . . . . . . . . . National Science Foundation
POP3 . . . . . . . . . Post Office Protocol Version 3 see also the glossary entry for ☞POP3
RFC . . . . . . . . . . Request For Comment
180
ANHANG B. ABKURZUNGSVERZEICHNIS 181
RLE . . . . . . . . . . Run Length Encoding
RTF . . . . . . . . . . Rich Text Format
SGML . . . . . . . . Standard Generalized Markup Language
SMIL . . . . . . . . . Synchronized Multimedia Integration Language
SMTP . . . . . . . . Simple Mail Transfer Protocol see also the glossary entry for ☞SMTP
SOAP . . . . . . . . . Simple Object Access Protocol see also the glossary entry for ☞SOAP
TCP . . . . . . . . . . Transmission Control Protocol see also the glossary entry for ☞TCP
TCP/IP . . . . . . Transmission Control Protocol/Internet Protocol see also the glossary entry for ☞TCP/IP
VM . . . . . . . . . . . Virtual Machine see also the glossary entry for ☞Virtual Machine (VM)
WAIS . . . . . . . . . Wide Area Information Server see also the glossary entry for ☞WAIS
WAP . . . . . . . . . . Wireless Application Protocol
WML . . . . . . . . . Wireless Markup Language
WWW . . . . . . . . World Wide Web see also the glossary entry for ☞WWW
XML . . . . . . . . . . eXtensible Markup Language see also the glossary entry for ☞XML
XSL . . . . . . . . . . . eXtended Stylesheet Language
XSLT . . . . . . . . . XSL Transformations

Anhang C
Glossar
C: A high-level programming language developed by Dennis Ritchie and Brian Kernighan at Bell Labsin the mid 1970s. Although originally designed as a systems programming language, C has provedto be a powerful and flexible language that can be used for a variety of applications, from businessprograms to engineering.
C++: A high-level programming language developed by Bjarne Stroustrup at Bell Labs. C++ addsobject-oriented features to its predecessor ☞C. C++ is one of the most popular programminglanguage for graphical applications, such as those that run in Windows, ☞UNIX, and Macintoshenvironments.
CGI: Common Gateway Interface A specification for transferring information between a World WideWeb server and a CGI program. A CGI program is any program designed to accept and returndata that conforms to the CGI specification. The program could be written in any programminglanguage, including ☞C, ☞PERL, or ☞Java.
DNS: Domain Name System An Internet service that translates domain names into IP addresses.Because domain names are alphabetic, they’re easier to remember. The Internet however, is reallybased on IP addresses. Every time you use a domain name, therefore, a DNS service must translatethe name into the corresponding IP address. For example, the domain name www.example.commight translate to 198.105.232.4.
Document Object Model (DOM): An application programming interface for HTML and XMLdocuments. It defines the logical structure of documents and the way a document is accessed andmanipulated. With the Document Object Model programmers can build documents, navigate theirstructure, and add, modify, or delete elements and content.
FTP: File Transfer Protocol The protocol used on the Internet for sending files.
HTML: HyperText Markup Language The authoring language used to create documents on the WWW.
HTTP: HyperText Transfer Protocol The underlying protocol used by the WWW. HTTP defines howmessages are formatted and transmitted, and what actions Web servers and browsers should take inresponse to various commands. For example, when you enter a URL in your browser, this actuallysends an HTTP command to the Web server directing it to fetch and transmit the requested Webpage.
IP: Internet Protocol IP specifies the format of packets, also called datagrams, and the addressingscheme. Most networks combine IP with a higher-level protocol called TCP, which establishes avirtual connection between a destination and a source. IP by itself is something like the postalsystem. It allows you to address a package and drop it in the system, but there’s no direct linkbetween you and the recipient. TCP/IP, on the other hand, establishes a connection between twohosts so that they can send messages back and forth for a period of time.
182
ANHANG C. GLOSSAR 183
Java: A high-level programming language developed by Sun Microsystems. It is an object-orientedlanguage similar to ☞C++, but simplified to eliminate language features that cause common pro-gramming errors. Java source code files are compiled into a format called bytecode, which canthen be executed by a Java interpreter. Compiled Java code can run on most computers becauseJava interpreters and runtime environments, known as Java Virtual Machines (VMs), exist for mostoperating systems, including UNIX, the Macintosh OS, and Windows.
NNTP: Network News Transfer Protocol The protocol used to post, distribute, and retrieve Usenetmessages.
parse: to analyze (a string of characters) in order to associate groups of characters with the syntacticunits of the underlying grammar.
PERL: Practical Extraction and Report Language A programming language developed by Larry Wall,especially designed for processing text. Because of its strong text processing abilities, Perl hasbecome one of the most popular languages for writing CGI scripts. Perl is an interpretive language,which makes it easy to build and test simple programs.
POP3: Post Office Protocol Version 3 A protocol used to retrieve e-mail from a mail server.
SMTP: Simple Mail Transfer Protocol A protocol for sending e-mail messages between servers
SOAP: Simple Object Access Protocol An XML/HTTP-based protocol to exchange information bet-ween computers. This may vary from the simple exchange of messages to remote procedure calls.Used by Microsoft in .NET.
TCP: Transmission Control Protocol TCP is one of the main protocols in TCP/IP networks. Whereasthe IP protocol deals only with packets, TCP enables two hosts to establish a connection andexchange streams of data. TCP guarantees delivery of data and also guarantees that packets willbe delivered in the same order in which they were sent.
TCP/IP: Transmission Control Protocol/Internet Protocol The suite of communications protocolsused to connect hosts on the Internet.
TELNET: Telnet is a service which allows logging onto a remote computer on the Internet. Telnetprovides a virtual terminal on the remote computer.
UNIX: A popular multi-user, multitasking operating systems developed at Bell Labs in the early 1970s.
Virtual Machine (VM): A self-contained operating environment that behaves as if it is a separatecomputer. For example, Java applets run in a Java Virtual Machine.
WAIS: Wide Area Information Server A distributed information retrieval system.
WWW: World Wide Web A system of Internet servers that support specially formatted documents.The documents are formatted in a language called HTML (HyperText Markup Language) thatsupports links to other documents, as well as graphics, audio, and video files. This means you canjump from one document to another simply by clicking on hot spots. Not all Internet servers arepart of the World Wide Web.
XML: eXtensible Markup Language A specification developed by the W3C1. XML is a pared-downversion of SGML, designed especially for Web documents. It allows designers to create their own cu-stomized tags, enabling the definition, transmission, validation, and interpretation of data betweenapplications and between organizations.
1http://www.w3c.org

Literaturverzeichnis
[Bau99] Tilman Baumgartel. Radarschirme fur den Cyberspace - von Archie bis AltaVista - kurzeGeschichte der Suchmaschinen. c’t, 14:184ff, 1999.
[BBJ99] Wilhelm Berghorn, Tobias Boskamp, and Klaus Jung. Schlanke Bilder - Der zukunftigeBildkompressionsstandard JPEG 2000. c’t, 26, 1999.
[BBSS99] Wilhelm Berhorn, Tobias Boskamp, Steven Schonfeld, and Hans-Georg Stark. Winzig mitWavelets, Aktuelle Verfahren zur Bilddatenkompression. c’t, 26:186–197, 1999.
[BLFF96] T. Berners-Lee, R. Fielding, and H. Frystyk. RFC 1945: Hypertext Transfer Protocol —HTTP/1.0, May 1996. Status: INFORMATIONAL.
[Bro00] Brockhaus, editor. Der Brockhaus multimedial 2001 premium. Bibliographisches Institut &F.A. Brockhaus AG, Mannheim, 2000.
[Bus45] Vannevar Bush. As we may think. The Atlantic Monthly, 176(1):101–108, July 1945. availableonline http://www.theatlantic.com/unbound/flashbks/computer/bushf.htm.
[CO99] Matthias Carstens and Alexander Oberdorster. Frontalangriff, Internet-Audio und -Video:Microsoft contra Apple und MP3. c’t, 10, 1999.
[CS01] C.A. Christopoulos and A.N. Skondras. Jpeg2000 - the next generation still image compressionstandard. Technical report, Ericsson Research Media Lab, April 2001. available online http://www.dsp.toronto.edu/~dsp/JPEG2000/.
[DZ01] Alfred Decker and Markus Zoier. Aktuelle Digitale Videoformate. UE zur Vorlesung Multi-mediale Informationssysteme WS2001, 2000/2001.
[ea96] Mark Adler et al. PNG (Portable Network Graphics) Specification. Technical report, W3C,1996. available online http://www.w3.org/TR/REC-png.
[FGM+97] R. Fielding, J. Gettys, J. Mogul, H. Frystyk, and T. Berners-Lee. RFC 2068: HypertextTransfer Protocol — HTTP/1.1, January 1997. Status: PROPOSED STANDARD.
[For99] Harald Forstinger. Analyse gegenwartiger Suchdienste und Konzepte fur kunftige Wissens-auffindung. Master’s thesis, IICM, Graz University of Technology, June 1999. available onlinehttp://www.iicm.edu/thesis/hforstinger.
[Hal00] Mary Hall. Core Servlets and JavaServer Pages. Sun Microsystems Press/Prentice Hall PTR,1st edition, 2000. see http://www.coreservlets.com or http://www.apl.jhu.edu/~hall/java/Servlet-Tutorial/.
[Har00] Eliotte Rusty Harold. XML Bible. IDG Books Worldwide, 2000. available online http://www.ibiblio.org/xml/books/bible/updates/14.html.
[Hen00] Peter A. Henning. Taschenbuch Multimedia. Fachbuchverlag Leibzig, 2000.
[Hol00] Andreas Holzinger. Basiswissen Multimedia, Band 1. Vogel Verlag, 2000.
[Jae00] S. Jaeger. Legal oder illegal? Der rechtliche Status des DVD-Hackertools. c’t, 14:28, 2000.
184
LITERATURVERZEICHNIS 185
[K00] Kristian Kohntopp. Web-Baukasten - Data Driven Websites mit PHP. Linux-Magazin, 8:114–120, 2000.
[KL86] B. Kantor and P. Lapsley. RFC 977: Network news transfer protocol: A proposed standard forthe stream-based transmission of news, February 1986. Status: PROPOSED STANDARD.
[Kus95] Heiner Kusters. Bilddatenkomprimierung mit JPEG und MPEG. Franzis, 1995.
[Len99] Sven Lennartz. ch bin wichtig! - Promotion-Massnahmen fur suchdienstgerechte Webseiten.c’t, 23:180ff, 1999.
[Len01] Sven Lennartz. Dynamsiche Seiten - Server Side Includes richtig einsetzen. c’t, 20:224–229,2001.
[Lip97] Thomas W. Lipp. Grafikformate. Microsoft Press, 1997.
[Lov00] J. Lovischach. Formen mit Normen - Internet-Standards fur Multimedia - nicht nur online.c’t, 18:115, 2000.
[LZ02] Christoph Laue and Volker Zota. Klangkompresssionen - MP3 und seine designierten Erben.c’t, 19:102 – 109, 2002.
[M02] Henning Mller. Jager des verlorenen Fotos - Das GNU Image Finding Tool fr Linux in derPraxis. c’t, 6:252–257, 2002.
[MR01] Dr. Volker Markl and Frank Ramsak. Universalschlussel - datenbankindexe in mehrerendimensionen. c’t, 01:174–179, 2001.
[MvR96] James D. Murray and William van Ryper. Encyclopedia of Graphics File Formats. O’Reillyand Associates, Inc., 2nd edition, 1996.
[Nel92] Theodor Holm Nelson. Litarary Machines 93.1. Mindful Press, 1992.
[otPC99] Members of the Project Clever. Neue Pfade duch den Internet-Dschungel - Die zweite Gene-ration von Web-Suchmaschinen. Spectrum der Wissenschaft, August 1999.
[Pie98] Claudia Piemont. Ein lacheln furs web - smil-eine sprache fur multimedia-prasentationen imweb. c’t, 20, 1998.
[Pos80] J. Postel. RFC 768: User datagram protocol, August 1980. Status: STANDARD. See alsoSTD0006.
[Pos81] J. Postel. RFC 793: Transmission control protocol, September 1981. See also STD0007.Status: STANDARD.
[PR85] J. Postel and J. K. Reynolds. RFC 959: File transfer protocol, October 1985. ObsoletesRFC0765. Updated by RFC2228 . Status: STANDARD.
[Ray] Eric S. Raymond. The new hacker’s dictionary. available online http://earthspace.net/jargon.
[Ric00] Jeffrey Richter. Microsoft .net framework delivers the platform for an integrated, service-oriented web. MSDN, September 2000. available online: http://msdn.microsoft.com/msdnmag/issues/0900/Framework/Framework.asp.
[SGM86] SGML international standard - iso8879, 1986.
[SH01] Christiane Schulzki-Haddouti. Die suche nach Geld - Suchmaschinen: Platzierung gegenBares. c’t, 25:44, 2001.
[SK91] T. J. Socolofsky and C. J. Kale. RFC 1180: TCP/IP tutorial, January 1991. Status: INFOR-MATIONAL.
[SMM01] Nico Schulz, Simon McPartlin, and Uwe-Erik Martin. Bilderpresse - JPEG2000, Technik undHintergrunde. c’t, 22:186–187, 2001.

LITERATURVERZEICHNIS 186
[Stu01] Ch. Stuecke. DVD-Importe illegal? Der juristische Status auslandischer DVD-Videos inDeutschland. c’t, 01:156, 2001.
[Tri01] Andreas Trinkwalder. Flexibles Leichtgewicht - JPEG2000, Produkte und Marktchancen. c’t,22:180–184, 2001.
[V.98] Roth V. Content-based retrieval form digital video. Technical report, Fraunhofer Institut,1998. available online http://www.igd.fhg.de/igd-a8/publications/OtherSubjects/98_Content-BasedRetrievalFromDigitalVideo.html.
[vL00] Felix von Leitner. Die Kunst des Weglassens, Grundlagen der Audio-Kompression. c’t, 03,2000.
[Wes01] Andreas Westfeld. Unsichtbare Botschaften - Geheime Nachrichten sicher in Bild, Text undTon verstecken. c’t, 09:170–181, 2001.
Index
Aa-Law-Codierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69AAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70, 73Abtastfrequenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67Abtastwert . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67AC-3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72Active Server Pages . . . . . . . . . . . . . . . . . . . . siehe ASPAdam7 Interlacing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99adaptive hearing threshold . . . . . . . . . . . . . . . . . . . . . 71<address> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47Adobe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101, 102ADPCM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Agenten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25, 27Akkomodation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Akustikmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71Aliasing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67, 73Aliweb . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Alpha Kanal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84, 98Altavista . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Amplitude . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66Anima . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33Animation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97, 99Anmeldung
Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11Vorlesung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Apache . . . . . . . . . . . . . . . . . 60, 63, 128, 137, 139, 141Apple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116Archie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24ARPA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16ARPANET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16ASF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75, 117ASP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124, 129
Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131ASP.NET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137Atkinson, Bill . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22ATRAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72, 75Atrribut
vs. Element . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50Attribut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
Mehrfachwert . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50Wert . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
Attribute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . 68, 72Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Augapfel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78Auge . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
Farbsehen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
Auszeichnungssprache . . . . . . siehe Markup SpracheAutodesk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102AVI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110, 116
Bb-trees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31BAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Bernes-Lee, Tim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Bewegung, Wahrnehmung von . . . . . . . . . . . . . . . . 107<bgcolor> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48Bidirectionally Predicted Frame . . . . . . . . . . . . . . 115Bild
digitales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78Format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
Meta- . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100Raster- . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
BildformatVektor- . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
BMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85, 97<body> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38<book> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50<br> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Brightness . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79Brockhaus Multimedial . . . . . . . . . . . . . . . . . . . . . . . . 30
Bilddaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32Computergenerierter Kontext . . . . . . . . . . . . . 31Glaserner Mensch . . . . . . . . . . . . . . . . . . . . . . . . . 32Landkarten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33Programming Framework . . . . . . . . . . . . . . . . . 33Textdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30Videos und Animationen . . . . . . . . . . . . . . . . . . 32Weblinks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
BTX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22Bush, Vannevar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
CC++ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33C# . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135<center> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48CERN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37CGI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122, 125
Sicherheit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124Cinepak . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110, 116CMY . . . . . . . . . . . . . . . . . . . . siehe Farbmodell, CMYCocoon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63Codebaum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88Codec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110, 116Codierung
µ-Law . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69a-Law . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Huffman . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68, 88Lowest Bit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105LZ77 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85LZW . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68, 85Patchwork . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105RLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84Texture Block . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
187
INDEX 188
Codingpredicitve . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Spectral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Subband . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Transform . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
Color Gamut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80Common Gateway Interface . . . . . . . . . . . . siehe CGIComponent Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Composite Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Compuserve . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97Computergenerierter Kontext . . . . . . . . . . . . . . . . . . 31CONTENT LENGTH . . . . . . . . . . . . . . . . . . . . . . . . 124Cookie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127, 133Cookies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133CSS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41, 117
DD-Frame . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116Dallermassl, Christof . . . . . . . . . . . . . . . . . . . . . . . . . . 11DARPA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Dateiformat
Bild . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Deck . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137<department> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49Digitales Bild . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78DivX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114Document Object Model . . . . . . . . . . . . . . . . . . . . . . 102Document Type Definition . . . . . . . . . . . . siehe DTDDOCUMENT ROOT . . . . . . . . . . . . . . . . . . . . . . . . . 124Dokumententyp
Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51SGML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Dolby AC-3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75Dolby-Surround . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72DOM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102Domain Name Service . . . . . . . . . . . . . . . . . . . . . . . . . 18DPCM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68DTD
HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37SGML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
DVD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112, 117Kopierschutz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
DXF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
EEBONE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17Element
leeres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49Name . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49vs. Attribut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Engelbart, Douglas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22Entities
HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37SGML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
escape-codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84Excite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Extensible Stylesheet Language . . . . . . . . siehe XSL
FFarb
-anzahl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83-bereich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80-modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
CMY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80, 82HSV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81RGB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80, 82Umrechnung zwischen verschiedenen . . . . 82YCbCr . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81YIQ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81YUV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81, 82
-sattigung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79-tabelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97-tiefe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83-ton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
Farbe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Rasterbild . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83Verwendung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
FarbmodellYIQ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
Fax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85, 89FBAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Field . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112<firstname> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49Flash . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26<font> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47<form> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124Fourier-Transformation . . . . . . . . . . . . . . . . . . . . . 69, 90Fraktale Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . 96Frame . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
bidirectionally predicted . . . . . . . . . . . . . . . . . 115D- . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116Intra- . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111, 114predicted . . . . . . . . . . . . . . . . . . . . . . . . . . . 111, 114
Frequenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66Frequenzraum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90FTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
GG3-Fax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89Gamma Korrekturk . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83GET-Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124GIF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83, 85, 97, 102GIFT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29Gimp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80Glaserner Mensch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32GNU Image Finding Tool . . . . . . . . . . . . . . . . . . . . . . 29Google . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27, 124, 132Gopher . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23, 24GPSYCHO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
HH.261 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111H.263 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110Horschwelle, adaptive . . . . . . . . . . . . . . . . . . . . . . . . . . 71Halbbilder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107HDTV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109<head> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38Helligkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79Helligkeitswahrnehmung . . . . . . . . . . . . . . . . . . . . . . . 79Hi-8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Hidden Fields . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
INDEX 189
HSV . . . . . . . . . . . . . . . . . . . . . . siehe Farbmodell, HSVHTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23, 35, 37
Entities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Farben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Format Definiation . . . . . . . . . . . . . . . . . . . . . . . 43Frames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Kommentar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38Mindesttags . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38Schrift . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46Script . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Style Sheet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40vs. XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
<html> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38HTTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19, 23
GET-Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . 124POST-Methode . . . . . . . . . . . . . . . . . . . . . . . . . . 124Session Tracking . . . . . . . . . . . . . . . . . . . . . . . . . 133
Hue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79Huffman-Codierung . . . . . . . . . . . . . . . . . 68, 73, 88, 92Hyper-G . . . . . . . . . . . . . . . . . . . . . . . . siehe HyperwaveHypercard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22Hyperlink
Typen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21Hypertext . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21Hyperwave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
IIAB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17IBM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75ICCB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16IETF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17IICM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22, 30<img> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49Indeo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110, 116Indexsuchmaschinen . . . . . . . . . . . . . . . . . . . . . . . 25, 26Informationssysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Geschichte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21Infoseek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Interlacing . . . . . . . . . . . . . . . . . . . . . . . 97, 99, 107, 109Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Dienste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19Geschichte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Protokolle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19Technische Grundlagen . . . . . . . . . . . . . . . . . . . 18
Intraframes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111, 114<invoice> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52IP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . siehe TCP/IPIPv4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18IPv6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18IRIS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22ISDN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
Jj2k . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100Java Server Pages . . . . . . . . . . . . . . . . . . . . . . siehe JSPJava Servlet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124, 125
Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128Javascript . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102JFIF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89, 100Joint Stereo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71jp2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100JPEG . . . . . . . . . . . . . . . . . . . . 81, 85, 89, 90, 102, 110
Bildformat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92Kompressionsalgorithmus . . . . . . . . . . . . . . . . . 90Kompressionsfaktoren . . . . . . . . . . . . . . . . . . . . . 90Progressive Encoding . . . . . . . . . . . . . . . . . . . . . 92Verlustbehaftete Kompression . . . . . . . . . . . . . 90Verlustfreie Kompression . . . . . . . . . . . . . . . . . . 89
JPEG2000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93Bildformat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
jpm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100jpx . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100JSP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124, 125, 127
Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128Interna . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Jumpstation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
KKannel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139, 140Katalogsuchmaschinen . . . . . . . . . . . . . . . . . . . . . 25, 26KMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22Knowledge Management . . . . . . . . . . . . . . . . . . . . . . 142Kommentar
HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38Kompression
Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68fraktale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96H.261 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111MPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114PNG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99verlustbehaftet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69verlustbehaftete JPEG . . . . . . . . . . . . . . . . . . . . 90verlustfreie JPEG . . . . . . . . . . . . . . . . . . . . . . . . . 89Wavelet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
KompressionsfaktorenJPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
L<lastname> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49LATEX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34Lauflangenkodierung . . . . . . . . . . . . . . . 68, 84, 92, 97Lautstarke . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66Lempel, Abraham . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85Leporello . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30<link> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42Lowest Bit Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105Luftdruck . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66Lycos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25LZ77 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85LZW-Codierung . . . . . . . . . . . . . . . . . . . . . . . . 68, 85, 97
MMarkup
generalized, descriptive . . . . . . . . . . . . . . . . . . . 34Markup Sprachen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Maskierungseffekt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71Maurer, Hermann . . . . . . . . . . . . . . . . . . . . . . . . . . 11, 22Memex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21<memo> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52Metabildformat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100Metadaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98Metasuchmaschinen . . . . . . . . . . . . . . . . . . . . . . . . 25, 26Meyrowitz, Norman . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22mgetty . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139

INDEX 190
Microsoft . . . . . . . . . . . . . . . . . . . . 47, 75, 110, 116, 129MIDI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76MILNET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Minidisc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72mj2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100MJPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110MNG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99Modell
psychoakustisches . . . . . . . . . . . . . . . . . . . . . . . . . 70Morsecode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88Mozart, Wolfgang Amadeus . . . . . . . . . . . . . . . . . . . . 30MP3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70, 73
Hortest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76, 176MP3 Pro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74MPEG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114Layer 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72Layer 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72Layer 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73Videokompression . . . . . . . . . . . . . . . . . . . . . . . 111Windows Media Technologies . . . . . . . . . . . . 114
MPEG-1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112MPEG-2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112MPEG-21 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114MPEG-4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112MPEG-7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113MPEG2
AAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73MPEG4
AAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73MSAudio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75µ-Law-Codierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69MySQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
NNamensraum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49, 55Namespace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49, 55Nelson, Ted . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.NET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135NLS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22NSF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16NTSC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109NTSC-Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81Nyquist . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
OOrganisatorisches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
P<p> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35, 43PAL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81, 108Parameterubergabe . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
Sicherheit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124Patchwork Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105PCX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85PDF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102Perl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123<person> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48, 49Photobook . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29Photorezeptoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78PHP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124, 131PICT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
PNG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89, 98POP3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19Portable Document Format . . . . . . . . . . . . . . . . . . . 102POST-Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124Postscript . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101pppd . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139, 140Predicted Frame . . . . . . . . . . . . . . . . . . . . . . . . . 111, 114Predictive Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Processing Instruction . . . . . . . . . . . . . . . . . . . . . . . . . 54Progressive Encoding . . . . . . . . . . . . . . . . . . . . . . . . . . 92Protokolle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19psychoakustisches Modell . . . . . . . . . . . . . . . . . . . . . . 70
QQuantisierung . . . . . . . . . . . . . . . . . . . . . . . . . . 73, 90, 91QUERY STRING . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124Quickdraw . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101Quicktime . . . . . . . . . . . . . . . . . . . . . . . . . . . 32, 110, 116
RRanking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27Rasterbild . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83, 101
Farbe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
RBSE Spider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Realaudio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76Realvideo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116Recommendation Systems . . . . . . . . . . . . . . . . . 25, 27REFER URL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124regular expression . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123REMOTE HOST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124Remove Sensing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95Request for Comment (RFC) . . . . . . . . . . . . . . . . . . 20REQUEST METHOD . . . . . . . . . . . . . . . . . . . . . . . . 124RFC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17RGB . . . . . . . . . . . . . . . . . . . . . siehe Farbmodell, RGBRIFF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75RLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68, 84Robots . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26RTF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34Run-Length-Encoding . . . . . . . . . . . . . . . . . 68, 84, 110
SS-VHS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Sattigung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79Samplingrate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67Samplingsize . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67Saturation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79Scalable Vector Graphics . . . . . . . . . . . . . . . . . . . . . 102Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51<script> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40Sehnerv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78SelfHTML . . . . . . . . . . . . . . . . . . . . . . . . . . 38, 39, 42, 47Servlet . . . . . . . . . . . . . . . . . . . . . . . . . siehe Java ServletSession Tracking . . . . . . . . . . . . . . . . . . . . . . . . . 127, 133SGML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30, 35
Attribute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36Dokumententyp . . . . . . . . . . . . . . . . . . . . . . . . . . . 36Entities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Struktur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
Shannon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
INDEX 191
Silence Compression . . . . . . . . . . . . . . . . . . . . . . . . . . . 68Sinneszellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78Skriptum
Anderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13SMIL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118SMTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19SOAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136Spectral Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Spider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . siehe RobotsStabchen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78Stars and Stripes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103Steganographie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105<style> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41Style Sheet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
Ausgabemedium . . . . . . . . . . . . . . . . . . . . . . . . . . 42Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46Einbinden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Subband Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Suche nach Multimediadaten . . . . . . . . . . . . . . . . . . 28Suchmaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Geschichte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Kategorien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Reihung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26, 27
SVCD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112SVG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102SVT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
TTCP/IP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16, 18, 133
Ports . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19Template Rule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58Texture Block Coding . . . . . . . . . . . . . . . . . . . . . . . . 105TGA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89TIFF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83, 85, 89, 97Timbre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66< title > . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38Tomcat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128Ton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
digitale Darstellung . . . . . . . . . . . . . . . . . . . . . . . 66Tonhohe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66Transclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21TransformCoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Transparenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98Trommelfell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66TwinVQ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
UUbungen
Anmeldung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11Unisys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85URL-Rewriting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
VVariable Bitrate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70VBR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70VCD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112Vektorgrafikformat . . . . . . . . . . . . . . . . . . . . . . . . . . . 101Vergenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Veronica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Verschachtelung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49Video
analog . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
Component . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Composite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Dateiformat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
ASF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117AVI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116Quicktime . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116Realvideo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
digital . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107Mensch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107Y/C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
Video-1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110Video:Codec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110Video:Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . 110VideoTex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22Vorlesung
Anmeldung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11Newsgroup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11Rechtschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . 11Unterlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Anderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
WW3C . . . . . . . . . . . . . 47, 58, 61, 64, 98, 102, 119, 122WAIS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23Wandex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24WAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139Wasserzeichen, digitale . . . . . . . . . . . . . . . . . . . . . . . 104Wave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75Wavelet Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . 95Web-Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123Webcrawler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24WebMethod . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136Welch,Terry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85Wellentheorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69Windows Media Audio . . . . . . . . . . . . . . . . . . . . . . . . . 75Windows Media Technologies . . . . . . . . . . . . . . . . . 114Windows Meta File . . . . . . . . . . . . . . . . . . . . . . . . . . . 101Wireless Application Protocol . . . . . . . . . siehe WAPWireless Markup Language . . . . . . . . . . . siehe WMLWissensnetzwerk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31WMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75WMF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101WML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137<wml> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137World Wide Web . . . . . . . . . . . . . . . . . . . . siehe WWWWorld Wide Web Wanderer . . . . . . . . . . . . . . . . . . . . 24World Wide Web Worm . . . . . . . . . . . . . . . . . . . . . . . 24WWW . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23, 37
dynamische Generierung . . . . . . . . . . . . . . . . . 122
XXalan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60Xanadu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21XHTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56XML . . . . . . . . . . . . . . . . . . . . . . . . . 35, 37, 47, 102, 119
Attribut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48Entities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64Namespace . . . . . . . . . . . . . . . . . . . . . . . . . . . 49, 55Processing Instruction . . . . . . . . . . . . . . . . . . . . 54Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51, 64

INDEX 192
Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49vs. HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47XPath . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61XSL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
XPath . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61XSL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
Formatting Objects . . . . . . . . . . . . . . . . . . . 58, 62Prozessor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60Transformation . . . . . . . . . . . . . . . . . . . . . . . . . . . 58XPath . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
YY/C Video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Yahoo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26YCbCr . . . . . . . . . . . . . . . . . siehe Farbmodell, YCbCrYIQ . . . . . . . . . . . . . . . . . . . . . . . siehe Farbmodell, YIQYUV . . . . . . . . . . . . . . . . . . . . . siehe Farbmodell, YUV
ZZapfen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78Zif, Jakob . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85