Embed Size (px)
Citation preview

University of ZurichDepartment of Informatics
Entwurf und Implementierungeiner Anwendung zurcomputergestütztenDurchführung von klinischenInterviews
Diplomarbeit in Informatikvorgelegt von
Philippe HochstrasserLuzern, Schweiz
Matrikelnummer: 01-919-786
Betreuer: Boris GlavicProf. Dr. Klaus R. Dittrich
Datum der Abgabe: 1. September 2007
University of ZurichDepartment of Informatics (IFI)Binzmühlestrasse 14, CH-8050 Zürich, Switzerland
DIPLOMARBEIT–DatabaseTechnologyResearchGroup,Prof.Dr.KlausR.Dittrich
Hintermann

Diploma ThesisDatabase TechnologyResearch GroupDepartment of Informatics (IFI)University of ZurichBinzmühlestrasse 14, CH-8050 Zürich, SwitzerlandURL: http://www.ifi.unizh.ch/dbtgZusammenfassung
2

Für eine Teilstudie des Nationalen Forschungsschwerpunktes Sesam, welche die Architektur undImplementierung einer Datenbank für die Sesam-Studie zum Ziel hat, wird eine Anwendung benö-
tigt welche standardisierte Interviews durchführen kann. Die bereits bestehende Software DIAXsoll durch die Anwendung ersetzt werden und sich durch zusätzliche Funktionalität von dieser ab-
heben. Im XML-Format definierte Interviews sollen von der Anwendung interpretiert werden kön-nen, sodass diese das Interview durchführen kann und den Interviewer dabei unterstützt. Die so
erhobenen Daten werden exportiert um automatisiert in die Datenbank eingelesen zu werden. Dievorliegende Ausarbeitung beschreibt Probleme sowie deren Lösungsansätze, welche während der
Entwicklung und Implementierung der Anwendung auftraten.
3

Abstract
The national main research topic, the Sesam-Project, has a partial study, which aims to designand implement a Database for the main project, requires an application to accomplish standardi-
zed interviews. The existing software DIAX, needs to be replaced by the application which standsout from the old applikation by implementing additional functionality. Interview-definitions as
XML documents can be read and interpreted by the application, to accomplish the interview andsupporting the interviewer during the talk. The collected data can be exported to be read easily by
the database. The present report describes problems and their resolutions which appeared duringthe design and implementation of the application.
4

Inhaltsverzeichnis
1.Einleitung.........................................................................................................................................7
1.1 Das Sesam-Projekt...................................................................................................................7
1.2 Aufgabenstellung.....................................................................................................................8
2. VerwandteArbeiten......................................................................................................................10
2.1 Überblick Psychodiagnostik..................................................................................................10
2.2 XML.......................................................................................................................................11
2.3 XML Schema - Validierung...................................................................................................12
2.4 Compiler................................................................................................................................14
3. Anforderungen..............................................................................................................................16
3.1 Zusammenfassung..................................................................................................................18
4. Die DIAX-Software......................................................................................................................19
4.1 Die Architektur von DIAX....................................................................................................19
4.2 Die Graphische Benutzeroberfläche......................................................................................20
4.3 Frage-Typen...........................................................................................................................22
4.4 Regeln ...................................................................................................................................26
4.5 Nachteile................................................................................................................................27
4.6 Zusammenfassung..................................................................................................................27
5. Probleme und Lösungsansätze......................................................................................................28
5.1 Architektur.............................................................................................................................285.1.1 Impliziter Compiler-Aufruf............................................................................................285.1.2 Trennung von Software und Definition..........................................................................29
5.2 Format der Interview-Definition............................................................................................295.2.1 Binärformat....................................................................................................................305.2.2 Textformate....................................................................................................................30
5.3 Konstruktion einer Regel-Sprache.........................................................................................315.3.1 Darstellung der Regeln...................................................................................................33
5.4 Zusammenfassung..................................................................................................................34
6. Umsetzung und Implementierung................................................................................................34
6.1 Gestaltung der Benutzeroberfläche........................................................................................35
6.2 Frage-Typen...........................................................................................................................36
5

6.2.1 Alternativen....................................................................................................................366.2.2 Umsetzung......................................................................................................................37
6.3 Regel Sprache........................................................................................................................45
6.4 Daten lesen.............................................................................................................................526.4.1 Interview-Definition.......................................................................................................526.4.2 Interview - Schema.........................................................................................................536.4.3 Parsen.............................................................................................................................54
6.5 Datenmodell...........................................................................................................................566.5.1 Interview........................................................................................................................566.5.2 Regeln ...........................................................................................................................57
6.6 Interview Durchführung.........................................................................................................586.6.1 Visualisierung der Fragen...............................................................................................596.6.2 Übersicht und freie Navigation......................................................................................596.6.3 Tastatursteuerung...........................................................................................................616.6.4 Antworten anzeigen.......................................................................................................626.6.5 Inkonsistenz Lösemodus................................................................................................62
6.7 Export der Antworten............................................................................................................66
6.8 Zusammenfassung..................................................................................................................67
7. Editor............................................................................................................................................68
7.1 Zusammenfassung..................................................................................................................72
8. Weiterführende Ideen...................................................................................................................73
8.1 Ideen zur Verbesserungder Interview-Anwendung...............................................................73
8.2 Ideen zur Verbesserungdes Editors.......................................................................................74
8.3 Algorithmus Konsistenz-Nachweis.......................................................................................758.3.1 Operator-Graphen...........................................................................................................758.3.2 Der Algorithmus.............................................................................................................76
8.4 Zusammenfassung..................................................................................................................79
9. Zusammenfassung........................................................................................................................81
Anhang A : Interview-Schema.........................................................................................................87
Anhang B : UML – Internes Modell.................................................................................................93
Anhang C : Antwort-Export-Schema...............................................................................................94
6

1. EinleitungIn den Abschnitten dieses Kapitels wird der Zusammenhang dieser Ausarbeitung mit der Sesam-
Studie beschrieben, sowie die Aufgabenstellung aufgezeigt.
1.1 Das Sesam-ProjektDas Sesam-Projekt ist einer der Nationalen Forschungsschwerpunkte (NFS). Die NFS werden
durch den Schweizerischen Nationalfonds zur Förderung der wissenschaftlichen Forschung finan-
ziell unterstützt. Der Nationalfonds ist ein Programm zum Zweck der Förderung von langfristig
angelegten Forschungsvorhaben. Zentrale Forschunsthemen sind solche mit strategischer Bedeu-
tung für die schweizerische Wissenschaft, Wirtschaft und Gesellschaft. Finanziert werden die For-
schungsschwerpunkte durch Bundesbeiträge, Eigenmittel der Hochschulen und Drittmittel. Die
einzelnen Projekte werden an Hochschulen oder Forschungsinstitutionen angesiedelt und von dort
aus geleitet, beim Sesam Projekt ist dies die Universität Basel.[NFS]
Sesam steht für ″Swiss Etiological Study of Adjustment and Mental Health″ oder zu deutsch
″Schweizerische ätiologische Studie zur psychischen Gesundheit″. Wobei der Ausdruck ″Atiolo-
gie″ die wissenschaftliche Erforschung von Krankheitsursachen bedeutet. Der Hintergrund der Se-
sam-Studie ist die Aussage der Weltgesundheitsorganisation (WHO), welche besagt dass ″in den
kommenden Jahrzehnten die psychische Gesundheit wesentlich über das Wohlergehen des Einzel-
nen und der Gesellschaft entscheiden. Im Jahr 2020 werden Depressionen die zweithäufigste Ursa-
che schwerer gesundheitlicher Beeinträchtigungen und vorzeitiger Sterblichkeit sein.″[SESAM].
(vgl. Abbildung 1) Gemäss [SESAM] zählen in den Industriestaaten psychische Erkrankungen
(vorallem Depressionen) zu der viert häufigsten Ursache von schwerwiegenden Beeinträchtigun-
gen. So wurden z.B. im Jahr 2002 in der Schweiz 543 Verkehrstote und 1546 Todesfälle durch Sui-
zid verzeichnet. Somit zählen psychische Erkrankungen zu den grössten Herausforderungen des
Schweizer Gesundheitswesens.
Das Sesam-Projekt hat sich zum Ziel gesetzt Faktoren, Einflüsse und Wechselwirkungenwährend
der persönlichen Entwicklung eines Menschen zu untersuchen. Daraus können Rückschlüsse gezo-
gen werden, wie sich einerseits Sachverhalte nachteilig und andererseits Bedingungen positiv auf
die psychische Gesundheit auswirken. Die aus der Studie gewonnenen Erkenntnisse sollen ″eine
Grundlage zur Entwicklung von wirkungsvolleren Massnahmen zur Förderung der psychischen
und physischen Gesundheit bilden″.[SESAM]
7

Um diese Ziele zu erreichen werden in einem Zeitraum von 20 Jahren Daten über die Probanden
und ihre Familien (Eltern und Grosseltern) gesammelt, wobei das Ziel bei 3000 Probanden liegt.
Daten können z.B. Fragebögen, biologische Analysen, genetische Daten, Multimedia- und Se-
quenzdaten sein. Das Sesam-Projekt ist also keine Momentaufnahme sondern eine Langzeit-Stu-
die. VerschiedeneFaktoren von der Kindheit bis ins späte Jugendalter bestimmen, wie sich die
psychische Gesundheit weiterentwickelt und verändert. Durch die 20 Jahre dauernde Begleitung
der Probanden, können Ursachen und deren Auswirkungen auf die Probanden unter Berücksichti-
gung der jeweiligen Lebensumstände vergleichsweise gut untersucht werden. Somit können ″wert-
volle Grundlagen für das Verstehender langfristigen Entwicklung der seelischen Gesundheit″ ge-
wonnen werden.[SESAM]
Neben der Kernstudie werden 13 weitere Teilstudien durchgeführt. Da offensichtlich eine riesige
Datenmenge gesammelt wird, beschäftigt sich eine der Teilstudienmit der Entwicklung der dafür
benötigten Datenbank. Diese Teilstudie wird von Prof. Dr. K. Dittrich vom Institut für Informatik
(ifi) der Universität Zürich geleitet. Das Ziel besteht aus dem Design und der Implementierung ei-
ner Datenbank sowie zusätzlich benötigter Anwendungssoftware, sodass die administrative Arbeit
der Forscher erleichtert werden kann.[SESAM]
1.2 AufgabenstellungZiel dieser Diplomarbeit ist das Design und die Implementierung einer solchen zusätzlichen An-
wendungssoftware. Im Rahmen der Sesam-Studie werden von den Probanden Daten durch Frage-
bögen, insbesondere durch standardisierte Interviews erhoben. Diese zeichnen sich unter anderem
durch eine bestimmte Reihenfolge von definierten Fragen aus und werden im anschliessenden Ka-
pitel genauer beschrieben. Ein solches Interview ist das CIDI (Composite International Diagnostic
8
Abbildung 1: WHO Prognose [SESAM]
Atemwegerkrankungen
Durchfallserkrankungen
Säuglingssterblichkeit
Depressionen
Herz-Kreislauferkrankungen
Herz-Kreislauferkrankungen
Depressionen
Verkehrsunfälle
Hirnschlag
Lungenerkrankungen
1.
2.
3.
4.
5.
1990 2020

Interview), welches zur einfacheren Durchführung und Auswertung computergestützt durchgeführt
werden kann. Die betreffende Software heisst DIAX und wird später noch genauer beschrieben.
Allerdings ist die Verwendungdieses Programmes im Rahmen der Sesam-Studie aus mehreren
Gründen, wie sie in den folgenden Kapiteln beschrieben werden, praktisch nicht möglich.
Die Aufgabe besteht darin eine Anwendungssoftware zu entwickeln, mit dessen Hilfe ein standar-
disiertes Interview durchgeführt werden kann. Die Applikation soll sich an DIAX orientieren und
dem Interviewer entsprechende Unterstützung bei der Durchführung eines Interviews bieten. Die
Applikation soll nicht nur das CIDI, sondern verschiedene Interviews darstellen können. Die durch
die Software erhobenen Daten sollen, in ein Format exportiert werden können, welches leicht in
die Datenbank einzulesen ist. Es ist nicht der Sinn die bestehende Software einfach nur neu zu im-
plementieren, sondern es soll zusätzliche Funktionalität hinzugefügt werden, welche dem Inter-
viewer die Arbeit erleichtert. Ebenso sollen unter anderem die vorhandenen Mängel der bestehen-
den Software vermieden werden.
2. Verwandte ArbeitenIn diesem Kapitel werden für die Ausarbeitung relevante Aspekte von verwandten Arbeiten kurz
erläutert und in einer zusammenfassenden Weise dargestellt. Es handelt sich dabei um Themen, die
9

als Grundlagen für diese Arbeit betrachtet werden und auf denen die folgenden Ausführungen auf-
gebaut sind. Einerseits wird. Um klinische und standardisierte Interviews zu definieren wird in Ab-
schnitt 2.1 ein kurzer Überblick zur Psychodiagnostik gegeben. Die restlichen Abschnitte dieses
Kapitels beschreiben Technologien, welche unter anderem zur Umsetzung der Aufgabenstellung
benutzt wurden. Und werden an dieser Stelle kurz beschrieben, sodass sie als Grundlagen für die
weitere Ausarbeitung dienen.
2.1 Überblick PsychodiagnostikStandardisierte Interviews, wie sie zur Befragung der Probanden im Rahmen des Sesam-Projektes
verwendet werden, gehören zu den klinischen Interviews, welche wiederum Verfahren der Psycho-
diagnostik sind. Um die Begriffe zu erklären wird an dieser Stelle ein kurzer Überblick über die
Psychodiagnostik gegeben und die verwendeten Verfahrenklassifiziert.
Im Rahmen der klinischen Psychologie und Psychotherapie sind die wichtigsten Funktionen der
Psychodiagnostik gemäss [PDIAG] :
● Deskription: Die Erfassung und Beschreibung des Status (aktuelle Probleme, Störungen)
eines Patienten und deren Verlauf (Veränderungender Symptomatik).
● Klassifikation: Zuordnung von Patienten zu diagnostischen Kategorien (eines statistischen
Klassifikationssystems).
● Erklärung: Erfassen von diagnostischen Informationen zu Merkmalen (z.B. biographische
Daten, Persönlichkeitsmerkmale)
● Prognose: Leistet einen Beitrag zur Vorhersagevon Verläufenpsychischer Störungen.
● Evaluation: Wirksamkeitsnachweis und Qualitätssicherung von therapeutischen Interven-
tionen.
Die klinische Psychodiagnostik umfasst verschiedene Verfahren,welche in folgende Klassen un-
terteilt werden(gemäss[PDIAG]):
● Klinisch-psychologische Testverfahren sind wissenschaftliche, standardisierte Tests, wobei
verschiedene Tests unterschieden werden.
• Mehrdimensionale Persönlichkeitsfragebögen (Selbstbeurteilung) mit dem Ziel der Er-
hebung von Persönlichkeitsmerkmalen.
• Klinische Selbstbeurteilungsverfahren (klinische Fragebögen) erleichtern die Erhebung
von selbsteingeschätzten Merkmalen wie z.B subjektive Beschwerden oder die emotio-
nale Befindlichkeit.
10

• Klinische Fremdbeurteilungsverfahren (klinische Ratingskalen) zu denen im weiteren
Sinne auch Symptom-Checklisten, strukturierte und standardisierte Interviews zählen.
• Projektive Verfahrenwelche gemeinsam haben, dass ihnen die Hypothese der Projekti-
on zugrunde liegt. Diese besagt, dass die eigene Wünsche, Triebe, Spannungen (Innen-
welt) auf die Aussenwelt, also andere Personen oder Objekte übertragen werden. Insbe-
sondere dann wenn eine unstrukturierte Aussenwelt vorliegt. [SkriptDiagnostik]
● Checklisten
Diese Klasse stellt diagnostische Instrumente dar, wie sie von Ärzten oder Therapeuten be-
nutzt werden und sind den Fremdbeurteilungsverfahren zugeordnet.
● Klinische Interviews
Klinische Interviews können vielfältig angewendet werden wie z.B. zur Erhebung von bio-
grafischen, anamnestischen Informationen oder Informationen auf der sozialen Ebene. Sie
werden anhand ihres Strukturierungsgrades differenziert und es wird zwischen freien, halb-
strukturierten, strukturierten und standardisierten Interviews unterschieden. Das strukturier-
te Interview zeichnet sich dadurch aus, dass unter anderem die Fragen, deren Reihenfolge
und Sprungregeln zum Auslassen von Fragen festgelegt sind. Ein Interview ist standardi-
siert, wenn der gesamte Prozess der Datenerhebung sowie der Auswertung standardisiert
ist, die Antworten des Befragten kodiert werden. Der individuelle Beurteilungsspielraum
des Diagnostikers wird dadurch stark eingeschränkt. Durch die Standardisierung wird die
computergestützte Auswertung der Daten ermöglicht.
● WeitereVerfahren
In der klinischen Psychodiagnostik existieren noch weitere Verfahren auf die hier nicht
weiter eingegangen wird. Der interessierte Leser sei auf [PDIAG] und die dort angegebe-
nen Referenzen verwiesen.
2.2 XMLXMLwird hier kurz vorgestellt, da es in der entwickelten Anwendung verwendet wird. Über die
Verwendungund wieso dieses Konzept angewandt wurde, wird in einem späteren Kapitel infor-
miert.
Die Extensible Markup Language XML wurde vom W3C (WorldWideWebConsortium) im Jah-
re 1998 standardisiert. XML ist ein Textformat und ermöglicht es strukturierte Daten darzustellen.
Einem Rechner wird durch die Standardisierung erleichtert ein XML-Dokument zu lesen und zu
generieren. Die Tags (durch '<' und '>' umklammerte Wörter), wie sie auch in HTML vorkommen,
11

sind in XML frei definierbar und dienen der Abgrenzung von Daten. Die Tags können durch soge-
nannte Attribute erweitert werden. Die Interpretation der Tagswird der Applikation überlassen,
welche ein XML Dokument liest. Die Tag-Namen sowie die Struktur eines XML-Dokumentes
sind frei definierbar, haben grundsätzlich keine Bedeutung. Als Einschränkung gilt nur, dass die
Tags über die entsprechende Umklammerung verfügen ('<', '>') und dass offene Elemente (durch
ein, dem Start-Tag entsprechendes Tag) geschlossen werden. Im Gegensatz zu HTMLwo gewisse
Strukturen eingehalten werden müssen und definierte Tags existieren, welche eine bestimmte Be-
deutung besitzen, wie z.B. der <br>-Tag, welcher besagt, dass der folgende Text auf einer neuen
Zeile beginnt. In spezialisierten XML-Untersprachen gibt es jedoch sehr wohl definierte Tags,
welche eine bestimmte Bedeutung haben. Beispiele für solche Untersprachen sind XSD (wird im
folgenden Abschnitt behandelt) und SVG[SVG], was zur Beschreibung von 2-dimensionalen Vek-
tor-Graphiken benutzt werden kann. Ein XML Dokument muss syntaktisch fehlerfrei sein, es darf
z.B. bei einem Tag das abschliessende '>' nicht vergessen werden, nur so ist eine fehlerfreie auto-
matische Verarbeitungmöglich.
Ein Vorteilvon XML ist, dass es sowohl für einen Rechner leicht interpretierbar ist, wie auch für
Menschen. Speichert ein Programm Daten auf die Festplatte wird dafür oft ein binäres Format ge-
wählt, was es einem Menschen erschwert diese Daten ohne ein entsprechendes Programm zu le-
sen. Werden die Daten jedoch als Text gespeichert, so können die Daten auch direkt von Menschen
gelesen werden, was die Erstellung, Interpretation und Überprüfung erleichtert.
Da XML standardisiert ist und in einem Dokument die verwendete Zeichen-Kodierung definiert
wird, ist XML plattformunabhängig. Dazu trägt auch das ″escapen″ also die Markierung von spe-
ziellen Zeichen bei. Es existieren zahlreiche Werkzeugewelche das Lesen und Generieren von
XML Dokumenten in verschiedenen Programmiersprachen unterstützen. [W3CXML]
2.3 XML Schema - ValidierungDie am meisten genutzte Schema Sprache zur Validierungvon XML Dokumenten ist die W3C
XML Schema Sprache XSD (XML Schema Definition Language). Sie wurde wie viele andere
Schema Sprachen entwickelt, um die ″Document TypeDefinition Language″ (DTD) zu ersetzen.
Die W3C XML Schema Sprache ist eine XML Sprache, durch die Inhalt und Struktur eines XML
Dokumentes definiert wird.[Bing/Miller] Eine XML Sprache ist eine auf der XML-Technologie
aufbauende Sprache, zu denen unter anderem auch XHTML oder XSL (XSLT) gehören.
Die XSD erlaubt es die Struktur und die Datentypen eines XML-Dokumentes zu definieren. Dazu
werden die Elemente oder Tags eines XML Dokumentes beschrieben. Ein Element eines XML Do-
kumentes muss jeweils einen Namen enthalten und einem Typ zugeschrieben werden. Die Typen
12

werden unterschieden in einfache (vordefinierte) Datentypen und komplexe Datentypen. Einfa-
che Datentypen beschreiben den Inhalt eines Elementes indem definiert wird von welchem Typ
(z.B. int oder string) der Inhalt ist. Die komplexen Datentypen beschreiben die Struktur, also wie
ein Element aufgebaut ist und definiert z.B. Elemente welche in dem beschriebenen Element vor-
kommen. Zusätzlich können die Attribute eines Elementes beschrieben werden, dies geschieht
durch Angabe des verlangten Typs.
Die Struktur eines komplexen Datentyps kann durch die Reihenfolge (sequence) sowie einer mög-
lichen Auswahl (choice) an Elementen beschrieben werden. Weiter lässt sich auch beschreiben ob
ein Element vorkommen muss oder ob es optional ist und wie oft ein ein bestimmtes Element ma-
ximal vorkommen darf. Bei der Attribut-Definition wird festgelegt welche Attribute ein Element
haben kann bzw. haben muss und von welchem (einfachen) Datentyp sie sind. Attribute können,
ähnlich einem Primärschlüssel einer relationalen Datenbank, als eindeutige Referenz definiert wer-
den (id). Der Attributwert darf dadurch innerhalb des Dokumentes nur ein einziges mal erscheinen,
es wird also eine inhaltliche Beschränkung ermöglicht. Den gleichen Zweck erfüllt auch das <uni-
que>-Element, durch das Element-Namen eingeschränkt werden können. Die komplexen Datenty-
pen können abgeleitet sowie eingeschränkt werden, was die Wiederverwendung erleichtert. [XML-
Schema] Für weitere Details und eine genaue Beschreibung der W3C XML Schema Sprache XSD
siehe [XMLSchema].
Ein mit XSD erstelltes Schema kann zur Validierungvon XML-Dokumenten benutzt werden, da-
bei wird das XML-Dokument überprüft, ob es die im Schema beschriebenen Definitionen erfüllt.
Weiter kann ein Schema auch zu Dokumentationszwecken dienen.
Ein XML Dokument welches einem bestimmten Schema entspricht wird oft als Instanz-Dokument
des Schemas bezeichnet. Die objektorientierte Beziehung von Klassen und Objekten kann auf ein
Instanz-Dokument übertragen werden wobei das XML Schema der Klasse und das Instanz-Doku-
ment dem Objekt entspricht. [Bing/Miller] Die Instanz-Dokumente können gegen ein sie definie-
rendes Schema validiert werden. Dabei wird überprüft ob das Dokument den Definitionen des
Schemas entspricht. Somit kann sichergestellt werden, dass das Dokument nur Informationen oder
Daten enthält welche von einem entsprechenden Programm verstanden werden sowie dass sich die
Daten in einer bestimmten Struktur befinden.
Die Vorteilegegenüber der älteren Document Type Definition Language sind die bereits definier-
ten einfachen Datentypen, welche es ermöglichen Werte bezüglich ihres Typs einzuschränken. Die
Fähigkeit Typen zu definieren und diese durch Ableiten des Inhaltes von Elementen und Erweitern
(Objekt-Orientierung), wieder zu verwenden.
13

2.4 CompilerDa bei der Implementierung der Anwendung ein Parser-Generator verwendet wird, soll an dieser
Stelle ein kurzer Überblick über die Funktionsweise eines Compilers zusammenfassend dargestellt
werden.
Die Thematik Compilerbau wird nach [Völler] in vier Teilbereiche aufgeteilt.
● Lexikalische Analyse (Scanner oder Lexer)
● Syntaxanalyse
● Semantikbeschreibung
● Codeerzeugung
Die Nachfolgende Abbildung 2 zeigt diese vier Bereiche im Zusammenhang.
Der Scanner separiert die einzelnen Symbole (Tokens) aus den Zeichen des Quelltextes. Dies er-
folgt durch das Zusammenfassen von einzeilnen Zeichen aus dem Quelltext, sodass sie Tokens
bilden. Diese Folge von Tokens wird dem Parser übergeben der sie dann auf ihre syntaktische
Richtigkeit überprüft. Nach der Prüfung auf syntaktische Korrektheit wird weiter überprüft ob
Kontextbedingungen erfüllt werden wie z.B., dass die alle Identifikatoren deklariert wurden oder
dass die Operatoren in Ausdrücken vom selben (kompatiblen) Typ sind.[Völler]
14
Abbildung 2: 4 Teilbereicheeines Compilers
Scanner
Parser
Übersetzer
Optimierer
Codierer
LexikalischeAnalyse
Syntaxanalyse
Swmantik-beschreibung
Swmantikbeschreibung
Tokens
Abstrakte Syntax
AbstrakteMaschinenbefehle
AbstrakteMaschinenbefehle

3. AnforderungenIn diesem Kapitel werden die Anforderungen an die zu implementierende Software besprochen.
Sie werden aus der Beschreibung des standardisierten, bzw. klinischen Interviews (vgl. Abschnitt
2.1) und der Aufgabestellung abgeleitet. Die Anforderungen beschreiben über welche Funktionali-
tät die Software verfügen muss, um die gestellte Aufgabe zu lösen. Es handelt sich also um eine
allgemeine Beschreibung der zu erstellenden Software und ist ein erster Schritt der Implementie-
rung, wobei einzelne Teilprobleme definiert werden. Mögliche Lösungsansätze sowie die konkre-
ten Lösungen zu den Teilproblemenwerden in den folgenden Kapiteln erläutert und konkretisiert.
Die Applikation soll verschiedene Interview-Typen darstellen können, welche durch entsprechen-
de Interview-Definitionen beschrieben werden. Ein Interview ist strukturiert, Fragen werden in
Sektionen oder Gruppen zusammengefasst, wobei die Gruppen wiederum andere Gruppen enthal-
ten können. Am Anfang sowie am Ende einer Gruppe, soll es die Möglichkeit geben dem Benut-
zer, falls erforderlich, eine Information anzuzeigen. Die Reihenfolge der Fragen ist festgelegt, wo-
bei diese je nach Antworten adaptiv angepasst wird. D.h. durch definierbare Sprungregeln können
Fragen ausgelassen werden. Es soll einer fachlich versierten Person auch ohne Informatik-Kennt-
nisse möglich sein Interview-Definitionen zu erstellen und zu verändern.
Der Benutzer soll eine durch eine entsprechende Visualisierung die Übersicht erhalten wo er sich
im Interview befindet. Dazu soll er frei im Interview navigieren können. Falls dem Probanden
während des Interview eine Antwort zu einer vorhergehenden Frage einfällt oder er diese präzisie-
ren möchte, muss es möglich sein diese Frage direkt anzuwählen. Ein weiterer Punkt welcher die
graphische Benutzeroberfläche betrifft, ist die graphische Trennung des Fragetextes von allfälligen
Kommentartexten. Diese Trennung erlaubt es auch bei Bedarf den Kommentartext auszublenden.
Der Beantwortungsprozess soll über die Tastatur gesteuert werden können, sodass der Interviewer
z.B bei Multiple Choice Fragen die gewünschten Antworten nicht zwingend mit der Maus auswäh-
len muss. Eine Steuerung über die Tastatur macht die Bedienung der Software angenehmer und
schneller für den geübten Benutzer. Die neue Software soll die drei Hauptlandessprachen der
Schweiz (deutsch, französisch und italienisch) unterstützen. Das Interview soll unabhängig von der
Herkunft der Probanden ohne sprachliche Probleme durchgeführt werden kann.
Die Antwort einer Frage muss auf ihren Typ überprüft werden. Es macht z.B. keinen Sinn eine
Buchstabenfolge als Antwort zu geben wenn eine Zahl erwartet wird. Es muss neben der regulären
Antwortmöglichkeit alternative Antwortmöglichkeiten, geben um z.B. zu vermerken, dass der Pro-
band die Antwort verweigert hat. Diese alternativen Antwortmöglichkeiten müssen zudem ein-
schränkbar sein, sodass für jede Frage definiert werden kann welche zur Beantwortung der Frage
15

zur Verfügung stehen. Durch eine Plausibilitätsprüfung soll das Interview als Gesamtes in einem
konsistenten Zustand gehalten werden. Mit ihnen kann vermieden werden, dass widersprüchliche
Antworten gegeben werden. Weiter soll die Plausibilitätsprüfung erlauben, Antworten von einzel-
nen Fragen gezielt einzuschränken. Da je nach Fragestellung bestimmte Antwortwerte keinen Sinn
ergeben. So z.B. macht es keinen Sinn die Frage ″Wie viele Kinder haben Sie ?″ mit Werten < 0 zu
beantworten. Weiter soll auch die Konsistenz von zwei oder mehreren Fragen, welche in einem
Zusammenhang stehen, überprüft werden können. So kann gewährleistet werden, dass sich das In-
terview immer in einem konsistenten Zustand befindet. Tritt ein inkonsistenter Zustand ein, soll
der Benutzer eine entsprechende Hilfestellung erhalten, um das Interview wieder in einen konsis-
tenten Zustand zu überführen.
Die Sprungregeln wie auch die Plausibilitätsprüfung, sollen durch einfach formulierbare Regeln
definiert werden. Sodass sie von einer fachkundigen Person geschrieben und editiert werden kön-
nen. Die Regeln müssen eindeutig sei, dürfen keinen Interpretationsspielraum offen lassen.
Die Antworten sollen codierbar sein, sofern dies Sinnvoll ist. Z.B. haben Multiple Choice fragen
fest definierte Antwortmöglichkeiten, welche dementsprechend codiert werden sollen, andererseits
ist es eher umständlich einen Freitext zu codieren und unter entsprechenden Umständen auch nicht
sinnvoll. Durch die Codierung soll die Auswertung der Antworten erleichtert werden.
Dem Benutzer soll die Möglichkeit geben werden, die Oberfläche seinen Bedürfnissen entspre-
chend anzupassen.
Die Applikation soll auf verschiedenen Plattformen ausgeführt werden können.
16

3.1 ZusammenfassungDie Anforderungen werden zur besseren Übersicht in tabellarischer Form nochmals wiedergege-
ben und zusammengefasst. Da in der vorliegenden Arbeit häufig darauf referenziert wird verein-
facht die Tabelle das Auffinden der entsprechenden Anforderung.
1. Interviews werden durch editierbare Definition beschrieben.2. Interview ist strukturiert.3. Feste Reihenfolge der Fragen.4. Information am Anfang und Ende einer Gruppe möglich.5 Freie Navigation innerhalb eines Interviews6. Visualisierung des Interviews (Übersicht).7. Trennung Frage- und Kommentartext.8. Tastatursteuerung9. Mehrsprachigkeit unterstützen.10. Typenprüfung der Antwort.11. Alternative Antwortmöglichkeiten.12. Plausibilitätsprüfung13. Unterstützung um Inkonsistenz zu beheben.14. Adaptiver Ablauf durch Ablaufregeln15. Regeln in einer einfachen, eindeutigen Sprache.16. Antworten sind codierbar.17. Oberfläche kann angepasst werden.18. Plattformunabhängigkeit.
17

4. Die DIAX-SoftwareDa sich die zu erstellende Applikation an der DIAX Software orientiert, wird diese hier kurz vor-
gestellt. Die Funktionalität wird analysiert und mit den im vorhergehenden Kapitel definierten An-
forderungen verglichen.
DIAX oder DIA-X ist ein computergestütztes standardisiertes Intervewiev, bzw. ein Diagnosesys-
tem welches in zeitlich effizienter Weise die Ableitung von Diagnosen unterstützt. In einem Dialog
werden durch Beantwortung von Fragen Diagnosen nach den Kriterien psychologischer Verfahren
erstellt. Der Interviewer erhält die Fragen und die für diese Frage relevanten Antwortmöglichkei-
ten auf dem Bildschirm präsentiert. Je nach Antwort werden adaptiv weitere Fragen gestellt. Ge-
mäss [AeBlatt18] erfordert die Benutzung von DIAX minimale Vorkenntnisse,keine Computer-
und Programmierkenntnisse. Die Durchführung eines Interviews dauert zwischen 30-90 Minuten.
Danach liefert das Programm einen Output mit den zutreffenden Diagnosen. Über ein zusätzliches
Modul kann eine Übertragung in gängige Datenbankformate vorgenommen werden.[AeBlatt18]
Das DIAX Programm ist also darauf ausgelegt, dass die Fragen durch einen Interviewer dem Pro-
banden gestellt werden und der Interviewer die Antworten im DIAX eingibt.
Die einzelnen Fragen des Interviews sind in so genannte Sektionen (Gruppen) gegliedert. Zu Be-
ginn und am Ende einer Sektion werden zum Teil zusätzliche Informationen über die eben beende-
te oder über die nachfolgende Sektion angezeigt.
4.1 Die Architektur von DIAXEin Nachteil der DIAX Architektur ist, dass ein Programm generiert wird, welches ein bestimmtes
Interview ausführen kann. Jede Änderung am Interview hat eine neu-Kompilierung der Software
zur Folge. Im Rahmen der SESAM-Studie werden neue Interviews entwickelt und diese werden
während der Entwicklung getestet. D.h. in der Entwicklungszeit wird ein Interview ständig verän-
dert. Damit eine Änderung von der Software übernommen wird, muss diese bei jeder Änderung
neu kompiliert werden, um das Interview gegebenfalls testen zu könnnen. Dazu muss beachtet
werden, dass bei diesem Ansatz für jedes Interview ein separates Programm erzeugt wird (zur Illu-
station s. Abbildung 3).
18

Ein weiterer Nachteil welcher sich problematisch auswirkt, dass spezielle C++ Bibliotheken ver-
wendet werden die für die Kompilierung unerlässlich sind. Diese speziellen Bibliotheken wurden,
für eine veraltete Entwicklungsumgebung von Borland entwickelt und wurden nicht mehr aktuali-
siert. Mit anderen Worten die benötigten Bibliotheken sind nicht mehr mit aktuellen Entwicklungs-
umgebungen kompatibel. Die Folge davon ist, dass Änderungen am bestehenden Programm prak-
tisch nicht mehr möglich sind, da die benötigten Komponenten nicht mehr erhältlich sind.
Die Interview-Definition beinhaltet zum Teil auch Code-Fragmente z.B. zur Definition von so ge-
nannten Konsistenzregeln welche in DIAX die Typenprüfung der Antwort übernehmen. Aus die-
sem Fakt resultiert dass die Anforderung 15 (einfache Regelsprache) klar nicht erfüllt wird und die
Anforderung 1 (editierbare Interview-Definition) zum Teil nicht, den nur jemand mit den nötigen
Programmierkenntnissen ist in der Lage eine Veränderungvorzunehmen.
4.2 Die Graphische BenutzeroberflächeDas UI ist in 3 Bereiche unterteilt, im ersten Bereich wird die Frage durch einen Fragetext gestellt,
wobei dort auch Informationen gegeben werden, wie die Frage bei bestimmten Reaktionen des
Probanden beantwortet werden soll (Kommentare). Ein zweiter Bereich stellt das Antwortfeld dar,
in welches die Antworten eingetragen werden. Der dritte Bereich enthält Buttons zur Steuerung
des Interviews. Mit dem ″OK″ Button wird die Antwort bestätigt und es wird die nächste Frage an-
gezeigt. Durch Betätigung des ″zurück″ Buttons gelangt man zur vorherigen Frage zurück, jedoch
nur innerhalb einer Sektion. Ist eine Sektion beendet, kann man nicht mehr in vorangegangene
Sektionen zurück. Somit ist die Anforderung 6 betreffend Navigation nicht vollständig erfüllt, da
nur eine Vorwärts-bzw. Rückwärtsnavigation innerhalb einer Sektion aber keine freie Navigation
möglich ist. Wird eine bereits beantwortete Frage erneut durch die ″zrück-Funtkion″ angezeigt,
wird die gegebene Antwort gelöscht und zwingt somit den Benutzer die Frage erneut auszufüllen.
Es werden noch drei weitere Buttons angezeigt welche alternative Antwortmöglichkeiten anbieten
(Problem, verweigert, weiss nicht). Je nach Frage sind nicht alle alternativen Antwortmöglichkei-
ten verfügbar.
19
Abbildung 3: DIAX - Architektur
Interview-Definition A
Interview-Definition B
Interview-Definition C
Compiler
Interview-ProgrammA
Interview-ProgrammB
Interview-ProgrammC
Programm- Code

Zusätzlich wird in einer Leiste am unteren Fensterrand angezeigt bei welcher Frage man sich in-
nerhalb der Sektion befindet.
In der Folgenden Abbildung ist die DIAX Oberfläche abgebildet, wobei die oben erwähnten Ele-
mente hervorgehoben werden.
Wie aus Abbildung 4 leicht ersichtlich ist erhält der Interviewer abgesehen von der Information
über bereits beantwortete Fragen keinen Überblick über das gesamte Interview. Er weiss nicht wie-
viele Gruppen es gibt, wieviele davon und wieviele Fragen er gesamthaft noch zu bearbeiten hat.
Auch da wird Anforderung 6 diesmal betreffend Visualisierung nicht erfüllt. Ebenfalls nicht erfüllt
wird die Anforderung 9 (Mehrsprachigkeit), da die Software nur in deutscher Ausführung vor-
liegt.
20
Bereich mit Frage-sowieKommentartext
Antwort - BereichButtons - Bereich
Information überbereits beantworteteFragen
Abbildung 4: DIAX – Oberfläche [DIAX]

4.3 Frage-TypenDIAX kennt verschiedene Fragetypen, welche im folgenden kurz vorgestellt und erläutert werden.
Zahlen-FrageAls Antwort wird bei der Zahlen-Frage eine Zahl oder Ziffer erwartet, es ist nicht möglich eine
Buchstabenfolge anzugeben. Zusätzlich wird die unten dargestellte Frage eingeschränkt sodass nur
Werte zwischen 1 und 99 möglich sind.
Datum-FrageDieser Fragetype erwartet eine Datums-Angabe als Antwort. Bei der dargestellten Frage wird
ebenfalls der Wertebereich überprüft. Die Antwort muss zwischen dem 1.1.1900 und 31.12.1990
liegen. Dabei wird die Anwtort auf den entsprechenden Datentyp geprüft, so ist z.B. der 31.2.xxxx
ein ungültige Datum. Für eine zukünftige Forschungsreihe müsste der Wertebereich zwingend ver-
ändert werden, denn Probanden können durchaus nach dem 31.12.1990 geboren sein. Dabei wer-
den die Anforderungen 1 sowie 15 tangiert betreffend einfache Editierbarkeit der Interview-Defi-
nition und der Regeln. Nebenbei ist an dem gezeigten Beispiel eine Einschränkung der alternativen
Antwortmöglichkeiten ersichtlich.
21
Abbildung 5: DIAX Zahlen-Frage [DIAX]

Text-FrageDie Text-Fragewird durch einen Freitext beantwortet. Dabei wird eine definierte Länge des Textes
gefordert, was z.B. verhindert, dass die Antwort in Stichworten gegeben wird. Dies kann je nach
Frage umständlich sein, wie bei der unten abgebildeten Frage. Die Frage nach der beruflichen Tä-
tigkeit kann durch die Berufsbezeichnung beantwortet werden, was allerdings als Antwort nicht
akzeptiert wird.
22
Abbildung 7: DIAX Text-Frage [DIAX]
Abbildung 6: DIAX Datum-Frage [DIAX]

Multiple Choice Frage
Die Multiple Choice Fragen (MC) bieten ihrerseits definierte, auswählbare Antwortmöglichkeiten
an. Es kann nur eine einzige Antwort ausgewählt werden.
Listen – Frage
Aus der dargestellten Liste muss mindestens eine Antworten ausgewählt werden. Es können je-
doch auch mehrere Antworten gleichzeitig ausgewählt werden. Dieser Fragetype ist vom Prinzip
her eine MC-Frage, jedoch mit einer anderen Darstellung.
23
Abbildung 8: DIAX MC-Frage mit einerAntwortmöglichkeit [DIAX]
Abbildung 9: DIAX Listen-Frage [DIAX]

Ja/Nein-Frage
Die Ja/Nein-Frage ist eine spezielle Multiple Choice Frage, wobei nur die Antwortmöglichkeiten
″ja″ oder ″nein″ zur Auswahl stehen. Offensichtlich ist auch hier nur eine Auswahl erlaubt.
Dual-Frage
Die sogenannte Dual-Frage ist eine Frage mit zwei verschiedenen Antworttypen. Sie eignen sich
um Fragen welche ebenfalls zwei separate Fragen beinhalten zu beantworten.
24
Abbildung 11: DIAX Dual-Frage [DIAX]
Abbildung 10: DIAX Ja/Nein-Frage [DIAX]

Mehrfach-Antwort
Die Mehrfach Antwort erlaubt es zu einer Frage mehrere Antworten zu geben. Diese Antwortart
kommt äusserst selten vor und wird dann benutzt wenn die Frage zu verschiedenen Inhalten gleich
lautet. Die Antwort zu den verschiedenen Inhalten kann in einem Fenster beantwortet werden.
Adaptive Frage-Typen
DIAX kennt noch weitere sogenannte adaptive Fragetypen, welche sich abhängig von vorherge-
henden Antworten jeweils unterschiedlich präsentierten. So gibt es Fragen welche vorangegangene
Antworten in ihren Fragetext einbeziehen. Eine weitere Möglichkeit ist auch der Einbezug einer
vorangegangenen Antwort in die Antwortmöglichkeiten (so z.B. bei MC-Fragen).
4.4 RegelnIm DIAX Programm werden zwei Arten von Regeln verwemdet. Die erste Art überprüft die Ant-
wort ob sie dem entsprechenden Antworttyp genügt und entspricht der Datentypprüfung. So wird
der Benutzer darauf hingewiesen wenn er z.B. bei einer Zahlen-Frage einen Text (Buchstaben) in
das Antwortfeld schreibt und darauf die Antwort mit OK bestätigt, dass nur Zahlen als Antwort
akzeptiert werden. Eine Prüfung über mehrere Fragen hinweg, so wie dies in Anforderung 12
(Plausibilitätsprüfung) beschrieben wird, gibt es nicht.
Die zweite Art von Regeln sind die sogenannten Sprungregeln. Je nach Antwort einer Frage wer-
den nachfolgende Fragen durch eine ″GOTO″-Anweisung übersprungen. Die Sprungregeln dienen
der Steuerung des Interview-Ablaufes und sind insofern wichtig, da es unter gegebenen Umstän-
25
Abbildung 12: DIAX Mehrfach-Antwort [DIAX]

den keinen Sinn macht Fragen zu stellen wenn eine bestimmte Frage mit einer bestimmten Ant-
wort beantwortet wurde. Dies soll an folgendem Beispiel aus dem CIDI-Interview erläutert wer-
den. Eine der ersten Fragen der Sektion B welche sich mit Tabakkonsum befasst, lautet ″Haben Sie
schon jemals in Ihrem Leben eine Zigarette geraucht?″ und ist vom Typ Ja/Nein-Frage. Wird diese
Frage mit ″Nein″ beantwortet, macht es offensichtlich keinen Sinn weitere Fragen über das Kon-
sumverhalten von Zigaretten zu stellen.
4.5 NachteileAn dieser Stelle wird ein weiterer Nachteil beschrieben, welcher zu einer Einschränkung bei der
Definition eines Interviews führt. Dieser Nachteil bezieht sich auf die Codierung der Antworten.
Diese ist in DIAX definiert, es ist also nicht möglich Antworten (z.B. einer MC-Frage) frei zu co-
dieren. Bestimmte Codes (1,5 und 6) sind fest mit den Sprungregeln verknüpft, was eine weitere
Einschränkung bedeutet, da die Sprungregeln nicht beliebig definiert werden können. Durch die-
sen Sachverhalt werden gleich mehrere Anforderungen aus Kapitel 3 tangiert. Es werden die Edi-
tierbarkeit (Anforderung 1), die Möglichkeit zu freien Ablaufsgestaltung (14) und die Codierung
(16) eingeschränkt
4.6 ZusammenfassungIn diesem Kapitel wurde die bestehende DIAX-Software kurz vorgestellt. Weiterwurde die Archi-
tektur besprochen und deren Nachteile aufgezeigt. So z.B. muss jedes Interview neu kompiliert
werden, ebenfalls wenn eine Interview-Definition verändert wurde. Durch diesen Ansatz erhält
man für jedes Interview ein eigenes Programm. Ein weiterer Punkt ist, dass die Software spezielle
C-Bibliotheken benötigt welche mit neuen Entwicklungsumgebungen nicht mer kompatibel sind.
Weiter wurde die graphische Benutzeroberfläche mit ihren drei Bereichen (Frage-/Kommentartext,
Antwort-Bereich und Buttons-Bereich) besprochen. Die häufigsten Fragetypen wurden kurz vor-
gestellt und beschrieben. Zuletzt werden die von DIAX implementierten Regeln analysiert, dabei
können zwei Typen unterschieden werden. Der eine Typ überprüft die Antwort auf den betreffen-
den Antworttyp, der andere dient dazu um Fragen mit einer ″GOTO″-Anweisung zu überspringen.
Dadurch dass in DIAX über eine feste Codierung verfügt wird der Benutzer bei der Erstellung ei-
nes Interviews eingeschränkt.
5. Probleme und LösungsansätzeIn diesem Kapitel werden grundsätzliche Fragestellungen betreffend Architektur und Design der
26

Software und ihrer Komponenten diskutiert und zu den jeweiligen Problemstellungen verschiede-
ne Lösungsansätze vorgeschlagen.
An dieser Stelle sei auch erwähnt, dass die Programmiersprache Java [JAVA]für die Implementie-
rung der Applikation gewählt wurde. Somit kann die Anforderung 18 (plattformunabhängigkeit)
erfüllt werden. Zusätzlich kann man auch davon ausgehen, dass Java in den kommenden Jahren
von den Entwicklern die nötige Aufmerksamkeit erhält, sodass anzunehmen ist, dass die in Ab-
schnitt 4.1 beschriebene DIAX-Problematik (betreffend der inkompatiblen C++ Bibliotheken), in
voraussehbarer Zeit nicht eintreten wird.
5.1 ArchitekturIn diesem Abschnitt werden alternative Lösungsansätze zu der in Abschnitt 4.1 vorgestellten Ar-
chitektur der DIAX-Software besprochen. Dabei sollen die genannten Nachteile möglichst vermie-
den werden.
5.1.1 Impliziter Compiler-AufrufUm Änderungen einfacher vorzunehmen zu könne, soll also der explizite Kompiliervorgang weg-
fallen. Dies kann erreicht werden indem beim Start des Programmes zuerst die Interview-Definiti-
on eingelesen wird und dann das Programm selber den Compiler-Aufruf tätigt um anschliessend
die kompilierten Klassen zu benutzen oder gegebenenfalls durch einen erneuten System-Aufruf
eine generierte main-Methode aufruft. Dieser Ansatz gleicht somit demjenigen von DIAX, mit
dem Unterschied, dass das Kompilieren durch die Software selber erledigt wird.
Dies hat zur Folge, dass das Programm benutzerfreundlicher wird, der Benutzer muss sich nicht
mehr selber um das Kompilieren des Codes kümmern. Andererseits ist es nötig, die gesamte Ent-
wicklungsumgebung an den Benutzer zu liefern. Bei Verwendungder Sprache Java wären somit
ein SDK sowie zusätzlich benötigte Bibliotheken fester Bestandteil der Software. Weiter gibt es
nicht mehr für jede Interview-Definition ein separates Programm wie beim DIAX Ansatz. Dieser
Ansatz hat jedoch den Nachteil das bei jedem Programmstart zuerst der Kompilier-Vorgangausge-
27
Abbildung 13: Ansatz mit implizitem Compiler-Aufruf
Interview-Definition A
Interview-Definition B
Interview-Definition CCompiler
Programm- CodeInterview-Programm
A, B oder C

führt werden muss, wobei hier noch Optimierungspotential vorhanden ist, indem nur compiliert
wird wenn die Intervew-Definition gewechselt wird.
5.1.2 Trennung von Software und DefinitionEin dritter Ansatz sieht die komplette Trennung der darstellenden und definierenden Komponenten
vor. Die Software welche ein Interview darstellt und ausführt ist eine eigenständige Komponente
und unabhängig von einer Interview-Definition. Die Programm-Komponente wird ein einziges mal
kompiliert und kann verschiedene Interview-Definitionen einlesen, erhält dadurch sämtliche benö-
tigten Informationen um das Interview darzustellen. Die Vorteiledieses Ansatzes liegen darin, dass
ein kompiliertes Programm vorliegt welches die Interview-Definitionen interpretieren kann. Um
ein Interview zu verändern genügt es eine Änderung von der Definition vorzunehmen. Somit gibt
es auch nur ein einziges Programm für verschiedene Interviews.
Als weiterer Vorteilgegenüber dem Ansatz mit implizitem Compiler-Aufruf gilt im Falle einer un-
gültigen oder fehlerhaften Interview-Definition, da der Benutzer angemessen informiert werden
kann. Im zweiten Ansatz würde eine fehlerhafte Definition zu einer Reihe von Compiler-Fehler-
meldungen führen und einem Benutzer ohne Programmierkenntnisse keine brauchbaren Hinweise-
liefern, wo der oder die Fehler entstanden sind und wie sie zu beheben sind.
5.2 Format der Interview-DefinitionDa die Interview-Definition extern von der Software gehalten werden soll, muss ein Format ge-
wählt werden um die betreffenden Daten speichern zu können. Diese gespeicherten Daten müssen
von der Interview-Anwendung gelesen und interpretiert werden können. Dazu gilt es zu beachten,
dass es unter Umständen sinnvoll ist Interview-Definitionen getrennt von der eigentlichen Anwen-
dung zu erstellen und zu bearbeiten.
Die Interview-Definition soll das gesamte Interview definieren, d.h. die Fragen, Reihenfolge,
Struktur der Sektionen (Gruppen), sowie die Ablauf- und Konsistenzregeln.
28
Abbildung 14: Ansatz der kompletten Trennung
Interview-Definition A
Interview-Definition B
Interview-Definition CCompiler
Programm- Code
Interview-ProgrammA, B oder C

5.2.1 BinärformatDie Programmiersprache Java unterstützt das Lesen und Schreiben von Objekten. Dazu muss aller-
dings zwingend ein entsprechender Editor implementiert werden um Schema-Definitionen zu er-
stellen bzw. zu bearbeiten. Ein Nachteil dieser Möglichkeit ist, dass die gespeicherten Daten ohne
den Editor oder die Interview-Applikation nur schwer zu lesen sind. Ein wirkliches Problem ent-
steht dann wenn ein Interview gepeichert ist und der Code der entsprechenden Klassen verändert
wird. Das bereits erstellte Interview kann unter Umständen nicht mehr gelesen werden und müsste
neu erstellt werden. Als Abhilfe müsste ein Werkzeug implementiert werden, welches ein (mit ei-
ner älteren Version) erstelltes Interview auf die aktuell verwendete Versionüberträgt.
5.2.2 TextformateAls Alternative bieten sich Textformate an, welche es ermöglichen eine Interview-Definition mit
standardisierten Editoren zu bearbeiten und für Menschen gut lesbar sind.
● Reiner Text
Dieses Format hat den Nachteil, dass zuerst eine Sprache für die Interview-Definition ent-
worfen und ein dieser Sprache entsprechender Parser implementiert werden muss. Wird das
Datenmodell des Interviews verändert so muss auch der Parser entsprechend verändert wer-
den. Der Aufwand für die Umsetzung dieses Ansatzes ist somit vergleichsweise hoch. Da
während der Entwicklungszeit mit Anpassungen des Datenmodells und somit auch dessen
Definition zu rechnen ist, scheint dieser Ansatz weniger produktiv zu sein als die im fol-
genden vorgestellten Alternativen.
● Tabelle
Gegenüber dem reinen Textformat hat eine Tabelle den Vorteil, dass z.B. Attribute über
ihre Kolonnen identifiziert und gelesen werden können, was den parsing-Prozess verein-
facht. Durch die Struktur der Tabelle gestaltet sich eine Interview-Definition übersichtlich.
Allerdings hat ein bestimmter Fragetyp auch sämtliche Attribute aller anderen Fragen ob-
wohl sie nicht gebraucht werden, was der Parser bei der Umsetzung in das Datenmodell be-
rücksichtigen muss. Da die unterschiedlichen Fragetypen voraussichtlich auch unterschied-
liche Attribute haben werden, führt dies zu einer breiten Tabelle Bei sämtlichen Attributen ,
die nicht von allen Fragen benötigt werden entstehen leere Felder. Dadurch wird die Über-
sichtlichkeit eingeschränkt. Um dies zu umgehen, ist es denkbar die Fragen gemäss ihren
Typen in verschiedenen spezialisierten Tabellen zu definieren ähnlich den Relationen einer
relationalen Datenbank. Dabei muss allerdings die Struktur des Interviews miteinbezogen
werden. Ein weiterer Nachteil dieser Darstellung ist, dass die Interview-Definition aus
29

mehreren Dokumenten besteht, was die Übersichtlichkeit stark einschränkt.
● XML
Die in den vorhergehenden Ansätzen erwähnten Nachteile werden mit dem Einsatz von
XML zur Interview-Definition aufgehoben. Somit sind Daten, welche als XML-Dokument
gespeichert werden unabhängig von den Klassen welche sie beschreiben.Mit XML können
die Daten strukturiert dargestellt werden und sie sind sowohl für Menschen wie auch Ma-
schinen lesbar. Die Implementierung eines Parsers fällt weg, da die Programmiersprache
Java die entsprechende Unterstützung bereitstellt. Bei Änderungen des Datenmodells muss
der Parser immer noch angepasst werden, jedoch fällt der Aufwand geringer aus als wenn
ein eigener Parser angepasst werden müsste. Somit ist XML, von den besprochenen Ansät-
zen, die ideale Lösung für das Format der Interview-Definitionen.
Durch die Verwendungvon XML zur Definition der Interviews ergibt sich die Notwendigkeit
einen Editor zu implementieren. Da gemäss Anforderung 1 fachlich versierte Personen ohne Infor-
matik-Kenntnisse in der Lage sein sollen Interview-Definitionen zu erstellen. Die Forscher des Se-
sam-Projektes kommen hauptsächlich von der Psychologie und es kann davon ausgegangen wer-
den dass sie nicht über die entsprechenden Kenntnisse verfügen, um ohne weiteres ein XML-Do-
kument zu verfassen oder zu editieren. Um den Forschern die Arbeit mit den Interview-Definitio-
nen zu vereinfachen, wird durch den Einsatz von XML zur Beschreibung der Interviews ein ent-
sprechender Editor benötigt. Dieser wird in Kapitel 7 kurz beschrieben.
5.3 Konstruktion einer Regel-SpracheDie Überprüfung des Daten-Typs von Antworten soll nicht von der Plausibilitätsprüfung bzw.den
Ablaufregeln übernommen werden. Dies würde zu Redundanz in der Interviw-Definition führen,
da diese Überprüfung für jeden Fragetyp immer gleich aussieht. Es macht daher Sinn, dass diese
Aufgabe von der Software übernommen wird. Zudem wird die Prüfung der Antworten bezüglich
des Daten-Typs bei allen Interview-Typen benötigt, was ein weiterer Grund ist diese nicht in die
Interview-Definitionen auszulagern.
Die Plausibilitätsprüfung und die Ablaufregeln dagegen variieren je nach Interview und müssen
daher für jedes Interview spezifisch definiert werden. Die Ablaufregeln haben die Aufgabe dem
Interview die Adaptivität bezüglich des Interview-Ablaufes zu ermöglichen. Der in DIAX umge-
setzte Ansatz Fragen durch eine ″GOTO″-Anweisung zu überspringen, ist mit der Anforderung be-
treffend Navigation nur schwer vereinbar. Denn wird eine Frage übersprungen, ist es durch eine
flexible Navigation möglich zu dieser Frage zurück zu gelangen und diese auszufüllen. Um dies zu
unterbinden muss zusätzlich eine Verwaltungder übersprungenen Fragen eingeführt werden. Ein
30

anderer Ansatz welcher die Verwaltungvon Fragen ebenfalls umsetzt, ist die Einführung eines Zu-
standes für jede Frage. Sämtliche Fragen können den Zustand ″ein″ oder ″aus″ annehmen. Um dies
zu illustrieren wird wieder das Beispiel aus Abschnitt 4.4 verwendet, wobei gefragt wird, ob man
bereits einmal Zigaretten geraucht hat, mit anschliessenden Fragen zum Konsumverhalten. Wird
die Frage mit ″Nein″ beantwortet, werden die Fragen betreffend Konsumverhalten ausgeschaltet
und nicht nur übersprungen. Somit ist es nicht möglich zu einer ausgeschalteten Frage zurückzuge-
hen und diese unnötigerweise zu beantworten, da diese jetzt den Status ″aus″ besitzt und nicht
mehr angezeigt wird. Das beschriebene Verhaltenkann auch durch eine alternative Belegung des
Zustandes herbeigeführt werden. Dazu geht man davon aus, dass die folgenden Fragen über das
Konsumverhalten ausgeschaltet sind, wird die Frage mit ″Ja″ beantwortet, werden sie eingeschal-
tet.
Der Plausibilitätsprüfung fällt die Aufgabe zu die Antwortmöglichkeiten einzuschränken. Dies
kann erreicht werden durch eine Einschränkung des Wertebereiches oder durch Vergleichemit an-
deren Antworten. Somit können zwei Arten von Plausibilitätsprüfungen unterschieden werden.
Diejenigen welche nur den Wertebereich einschränken werden im folgenden Beschränkung ge-
nannt werden. Beschränkungen sollen es durch eine entsprechende Überprüfung unmöglich ma-
chen z.B. eine Frage nach dem Alter des Probanden mit dem Wert 200 zu belegen, welcher offen-
sichtlich falsch ist, ebenso falsch wie eine negative Zahl. Die andere Art der Plausibilitätsprüfung
soll die Konsistenz zwischen verschiedenen Fragen gewährleisten und wird im folgenden als Kon-
sistenzregel bezeichnet. Sind z.B. die Fragen A und B gegeben, kann es Sinn machen die Antwort
der Frage B einzuschränken wenn die Frage Amit einer bestimmten Antwort beantwortet wurde.
Somit lassen sich grundsätzlich drei verschiedene Regeltypen unterscheiden. Die Beschränkung,
welche den Wert einer Antwort einschränkt, die Konsistenzregel, welche Antwortwerte über meh-
rere Fragen in Abhängigkeit von einzelnen Antworten einschränken kann und Ablaufregeln zur
Ablaufsteuerung (ein-, ausschalten von Fragen). Aufgrund ihrer Funktion werden die Regeln je-
doch im folgenden unterschieden in Ablaufregeln und Konsistenzregeln, wobei die Beschränkung
als eine vereinfachte Konsistenzregel betrachtet wird. Ein weiterer Punkt der hier besprochen wird
ist die Regeln dargestellt werden sollen. Dazu werden im folgenden ein paar Beispiel-Regeln als
natürlich-sprachliche Sätze formuliert.
5.3.1 Darstellung der RegelnIn diesem Abschnitt wird nach einer Darstellung für die vorher beschriebenen Regeln gesucht. Ge-
mäss Anforderung 15 müssen die Regeln in einer einfachen Art und Weise definiert werden kön-
nen und dazu eindeutig sein. Ebenso müssen sie durch einen Rechner interpretierbar sein, da sie in
der Interview-Definition beschrieben werden.
31

Wird nach dem Alter des Probanden gefragt (Frage 1) so kann eine mögliche Beschränkung für die
Antwort lauten: ″Die Antwort von Frage 1 muss grösser als 0 sein″ (Regel 1). Die Antwort auf die
Frage nach dem Geburtsdatum (Frage 2) kann beschränkt werden durch: ″Die Antwort der Frage 2
muss zwischen dem 1.1.1900 und 1.1.2040 liegen″ (Regel 2).
Für ein Beispiel einer Konsistenzregel werden die folgenden Fragen vom Typ Ja/Nein-Frage und
Zahlen-Frage eingeführt: ″Haben Sie jemals eine Zigarette geraucht?″ (Frage 3), ″Wie alt waren
sie damals?″(Frage 4). Eine entsprechende Konsistenzregel könnte dem gemäss lauten: ″Wenn
Frage 3 mit ja beantwortet wurde, muss die Antwort von Frage 4 kleiner oder gleich der Antwort
von Frage 1 sein″ (Regel 3). Denn es macht keinen Sinn, dass der Proband in Frage 4 ein Alter an-
gibt welches er noch nicht erreicht hat. Weitermuss dies nur dann überprüft werden wenn die Fra-
ge 3 mit ″Ja″ beantwortet wurde. Es macht offensichtlich auch keinen Sinn die Frage 4 zu stellen
wenn die Frage 3 mit ″Nein″ beantwortet wurde, was sich zusätzlich als Ablaufregel formulieren
lässt: ″Wenn Frage 3 mit ″Nein″ beantwortet wird, dann soll Frage 4 nicht gestellt werden″ (Regel
4).
Es scheint offensichtlich, dass solche ausformulierten Bedingungen durch einen Rechner nur
schwer interpretiert werden können. Deshalb werden die Regeln nachfolgend in einen ″Pseudo-
Code″ umformuliert.
Regel 1 (Beschränkung): ″Frage 1 > 0″
Regel 2(Beschränkung): ″1.1.1990 < Frage 2 <1.1.2040″ oder als Alternative
″ Frage 2 > 1.1.1990 UND Frage 2 < 1.1.2040″
Regel 3 (Konsistenzregel): ″WENN Frage 3 = Ja DANN Frage 4 <= Frage 1″
Regel 4: (Ablaufregel): ″WENN Frage 3 = Nein DANN Frage 4 OFF″
(diese Formulierung setzt voraus, dass sich die Frage 4 in
eingeschaltetem Zustand befindet.)
Um die in Kapitel 3 gemachten Anforderungen betreffend Regeln zu erfüllen und durch die hier
erwähnten Regel-Beispielen sowie deren Umsetzung in ″Pseudo-Code″ macht es Sinn die Regeln
als Aussagen der Logik zu betrachten. Die Aussagen-Logik alleine reicht jedoch nicht aus um die
Regeln zu beschreiben, da die Referenzen variable Werte sind. Ebenfalls besitzen die Beschrän-
kungen und Konsistenzregeln nicht die Aussdrucksstärke der Prädikatenlogik, da Werte -Bereiche
aufgrund der Datenstrukturen, wie sie durch einen Rechner verwendet werden, eingeschränkt sind.
Die Ablaufregeln benötigen ihrerseits eine Formulierung um Fragen ein- bzw. auszuschalten, was
sich nicht direkt durch die Prädikatenlogik beschreiben lässt. Somit kann die zu verwendende Re-
gelsprache als eine Teilmenge der Prädikatenlogik beschrieben werden. Die Regelsprache selber
32

wird in Abschnitt 6.3 des nachfolgenden Kapitels beschrieben und konkretisiert.
5.4 ZusammenfassungZu der in Abschnitt 4.1 vorgestellten DIAX-Architektur wurden Alternativen diskutiert um deren
Nachteile aufzuheben. Eine vorgestellte Lösung ist die des implizieten Compiler-Aufrufes, dabei
wird vor dem Start der eigentlichen Anwendung ein zuerst der Code mit der entsprechenden Inter-
view-Definition kompiliert. Dies geschieht jedoch automatisch, sodass der Benutzer den Compi-
ler-Aufruf nicht explizit vorzunehmen hat. Allerdings mit dem Nachteil, dass die Java-SDK ein
fester Bestandteil der Anwendung wird. Der nächste Ansatz sieht die komplette Trennung von De-
finition und Anwendung vor. Die Definitionen können von der Anwendung gelesen werden, ohne
das ein Kompilier-Vorgangnötig ist. Weiter wurden mögliche Alternativen zum Format der Inter-
view-Definition aufgezeigt. Dabei wurden die Vor-und Nachteile des Binärformates und Textfor-
maten wie Reiner Text, Tabellen und XML besprochen.
Im nächsten Abschnitt wird ein erster Schritt zur Definition der Regelsprache gemacht, wobei die
Regeln auf Grund ihrer Funktion in Ablauf- und Konsistenzregeln unterschieden werden. Die Be-
schränkung kann als vereinfachte Konsistenzregel betrachtet werden. Die Datentyp-Prüfung soll
von der Software realisiert werden und nicht durch Regeln. Durch die Formulierung von Beispiel-
regeln in einem „Pseudo-Code“ wurde erwähnt, dass die zu verwendende Regelsprache als Teil-
menge der Prädikationlogik bezeichnet werden kann.
6. Umsetzung und ImplementierungDieses Kapitel befasst sich sich mit konkreten Problemen, die während der Implementierung auf-
traten sowie mit den betreffenden Lösungen. Weiter wird die Umsetzung der in Kapitel 5 aufge-
zeigten Lösungsansätze beschrieben und konkretisiert. Der Aufbau und der Inhalt der Benutzero-
berfläche wird kurz beschrieben. Die Fragen werden in Typen klassifiziert und vorgestellt, sowie
deren Visualisierungen gezeigt. Darauf wird die Umsetzung von Interview-Definition und ihrem
Schema kurz besprochen. Die in Kapitel 5 gemachten Grundüberlegungen zu den Regeln werden
hier konkretisiert und ausführlich beschrieben. Nachdem also die Interview-Definition inklusive
Regeln festgelegt sind, werden im Falle der Interview-Definition zwei Parser-Möglichkeiten dis-
kutiert und kurz beschrieben wie die Regeln in das interne Modell transformiert werden. Dazu
wird das Modell beschrieben, welches verwendet wird um die Interview-Definition zu modellie-
ren. Weiterwerden ausgewählte Abläufe während dem Betrieb der Anwendung besprochen, wie
die ständig wechselnde Ausprägung der Visualisierung der Fragetypen implementiert wurde. Wel-
che Probleme bei der Umsetzung einer Steuerung der Anwendung über die Tastatur auftraten und
wie sie gelöst wurden, sowie die Hilfestellung funktioniert, welche den Interviewer unterstützt ein
33

Interview aus einem Inkonsistenten Zustand wieder in einen konsistenten zu überführen. Am
Schluss dieses Kapitels wird diskutiert, wie die Antworten exportiert werden.
6.1 Gestaltung der BenutzeroberflächeFür die Implementierung der Benutzeroberfläche wird ausschliesslich SWT [SWTorg] verwendet.
Die Gestaltung wird in einem ähnlichen Stil gehalten wie dies beim DIAX-Programm der Fall ist
und wird in verschiedene Bereiche aufgeteilt. Wie beim Vorgängergibt es einen Bereich der zum
anzeigen des Frage- und Kommentartextes dient. Mit dem Unterschied, dass die Texte graphisch
voneinander getrennt sind und in verschiedenen Komponenten dargestellt werden. Zusätzlich lässt
sich der Kommentartext permanent ausschalten, da ein geübter Benutzer diese nicht mehr benöti-
gen wird. Im Zweifelsfall kann der Kommentar jederzeit wieder eingeschaltet werden. Die Komm-
ponente mit dem Kommentartext ist auch nur dann sichtbar, wenn ein Kommentar definiert wurde.
Ebenfalls bekannt ist der Antwortbereich, der sich je nach Fragetyp in unterschiedlichen Ausprä-
gungen präsentiert. Die Buttons wurden wie gehabt übernommen und dienen dazu die Antworten
zu bestätigen, zurück zur vorherigen Frage zu gelangen (über Gruppengrenzen hinaus) oder eine
der drei alternativen Antworten zu geben. Neu ist ein vierter Bereich, der Informationsbereich,
welcher aus zwei Komponenten besteht. Die obere für Übersicht und Navigation zeigt das gesamte
Interview mit seiner Struktur an. Die einzelnen Gruppen lassen sich aufklappen und wieder
schliessen. Zusätzlich wird durch eine farbliche Markierung der Fragen über ihren Zustand infor-
miert. Die Übersich und Navigationskomponente, welche in diesem Kapitel in Abschnitt 6.6.2 ge-
nauer beschrieben wird, ermöglicht es eine Frage aus der gezeigten Übersicht direkt auszuwählen,
sodass die betreffende Frage daraufhin angezeigt wird und zeigt dem Benutzer die Struktur des In-
terviews an. Die untere Informations-Komponente informiert den Benutzer über den Fortschritt im
Interview. Dabei wird er darüber informiert wieviele (eingeschaltete) Fragen das Interview hat und
wieviele davon er bereits bearbeitet hat. D.h. wieviele in irgendeiner Form beantwortet wurden.
Zusätzlich erhält er auch die Information wieviele Fragen korrekt beantwortet wurden. Weiter wird
angezeigt wieviele Fragen sich in einem inkonsistenten Zustand befinden, sofern dieser Fall ein-
tritt.
34

6.2 Frage-TypenIn diesem Abschnitt werden Alternativen zu der in Abschnitt 4.3 gemachten Klassifizierung der
Fragetypen in DIAX sowie die schlussendliche Umsetzung besprochen.
6.2.1 AlternativenAnstelle von definierten Typenwäre es denkbar, dass die Interview-Definition die Fragen so be-
schreibt, dass keine Typen benötigt werden. Es kann sogar für jede Frage die graphische Umset-
zung in der Interview-Definition beschrieben werden. Allerdings würde dies zu einer hohen und
unnötigen Redundanz führen, wenn jede Frage detailliert beschrieben würde und auch noch deren
graphische Umsetzung definiert wird. Die geschilderte vollumfängliche Beschreibung eines Inter-
35
Kompenente für den Fragetext Kompenente für denKommentartext
Antwortbereich Buttonsbereich
Komponente fürdie Übersicht undfreie Navigation
Informations-Komponente
Abbildung 15: Benutzeroberfläche

views hat neben der erwähnten Redundanz noch weitere Nachteile. Um ein Interview zu definieren
bzw. zu editieren müssen Kenntisse über die graphische Darstellung vorhanden sein. Dies wider-
spricht der impliziten Anforderung, dass eine fachlichkundige Person (ohne Programmierkenntnis-
se) das Erstellen und Editieren einer Interview-Definition vornehmen kann. Zudem macht es kei-
nen Sinn einen vergleichsweise grossen Aufwand für einige wenige Fragen zu betreiben, welche
nur selten verwendet werden. Gemeint sind damit diejenigen Fragen welchesich nicht in die im
folgenden Abschnitt gemachte Klassifizierung einfügen. Die Klassifizierung bietet die Vorteile,
dass unnötige Redundanz in der Interview-Definition durch die Verwendungvon definierten Fra-
ge-Typen vermieden werden kann. Weiter sind fest definierte Fragetypen leichter zu testen und
zeichnen sich durch eine geringere Fehleranfälligkeit aus. Für die Behandlung von seltenen Frage-
typen wird am Schluss des nächsten Abschnittes ebenfalls eine Lösung vorgestellt. Ebenfalls eine
Möglichkeit wäre die Verwendungvon definierten Frage-Typenmit einem zusätzlichen Type, wel-
cher den Frage-Typ, sowie dessen graphische Darstellung definiert. Aber auch hier kann dagegen
argumentiert werden, dass der Implementierungs-Aufwand für diese seltenen Frage-Typen ver-
gleichsweise gross ist in Anbetracht, dass sie nur selten benötigt werden.
6.2.2 UmsetzungFür die Anwendung werden die folgenden Frage-Typen definiert und somit zur Verfügunggestellt.
Text-Fragen
Werden durch einen Freitext beantwortet und dienen dazu solche Fragen zu beantworten bei denen
es nicht möglich ist im voraus alle Antwortmöglichkeiten aufzulisten. Bei der Text-Frage in DIAX
wurde der Freitext insofern eingeschränkt, dass eine Mindestlänge gefordert wird. Auf diese Ein-
schränkung wird verzichtet, sodass es möglich ist eine Text-Frage auch nur durch ein einziges
Wort zu beantworten.
36

Zahlen-Fragen
Erwarten als Antwort die Angabe einer Ziffer oder Zahl. Sie sind den Textfragen ähnlich, jedoch
mit dem Unterschied, dass nur eine Ziffer oder Zahl als Antwort akzeptiert wird, was automatisch
überprüft wird. Somit fällt das Feld für die Antwort verglichen mit der Text-Frage kleiner aus. Im
Unterschied zu der DIAX-Zahlen-Frage wird im Antwortbereich keine Angabe über die erwartete
Masseinheit gegeben (vgl. Abbildung 5). Dies kann jedoch durch einen entsprechenden Kommen-
tar übernommen werden.
37
Abbildung 17: Zahlen-Frage
Abbildung 16: Text-Frage

Datum-Fragen
Wie der Name schon sagt, wird ein Datum als Antwort erwartet. Dabei wird überprüft ob ein gülti-
ges Datum angegeben wurde. Wird. z.B. der 31.2.2000 angegeben wird der Benutzer informiert,
dass es sich bei dem betreffenden Datum um eine ungültige Antwort handelt.
Multiple Choice Fragen (MC-Fragen)
MC-Fragen werden beantwortet indem aus einer vorgegebenen Auswahl die zutreffende Antwort
ausgewählt wird. Die Multiple Choice Fragen können weiter unterteilt werden in:
● MC-Fragen mit einer Antwortmöglichkeit
38
Abbildung 18: Datum-Frage
Abbildung 19: MC-Frage mit einer Antwortmöglichkeit

Bei dieser Unterart der MC-Fragen kann jeweils nur eine einzige Antwortmöglichkeit aus
gewählt werden.
● MC-Fragen mit mehreren Antwortmöglichkeiten werden beantwortet indem eine oder meh-
rere Antwortmöglichkeiten gleichzeitig ausgewählt wird.
● MC-Fragen mit editierbaren Antwortmöglichkeiten
39
Abbildung 20: MC-Frage mit mehrerenAntwortmöglichkeiten
Abbildung 21: MC-Frage mit einem beschreibbarenFeld

Diese Unterart der MC-Fragen ist eine MC-Frage mit einer oder mehreren Antwortmög-
lichkeiten, hat jedoch zusätzlich noch eine oder mehrere beschreibbare Antwortmöglich-
keiten. Dadurch erhält der Benutzer die Möglichkeit während dem Interview eine zusätzli-
che Antwort frei zu definieren, falls die Frage nicht mit den vordefinierten Antwortmög-
lichkeiten beantwortet werden kann.
Die eben gezeigten drei Unterarten werden durch einen einzigen Fragetyp definiert (die MC-Fra-
ge). Die Unterscheidung wird mittels den entsprechenden Attributen in der Interview-Definition
vorgenommen. Die verschiedenen Antwortmöglichkeiten müssen für jede einzelne MC-Frage in
der Interview-Definition definiert werden, da sich diese bei jeder Frage unterscheiden. Zusätzlich
kann für jede Unterart durch eine entsprechendes Attribut definiert werden, ob auch keine Aus-
wahl als Antwort erlaubt ist oder ob zwingend mindestens eine Antwortmöglichkeit ausgewählt
werden muss.
Speziell bei MC-Fragen ist die Codierung , welche auf den Abbildungen zu den MC-Fragen eben-
falls ersichtlich ist. Sie wird wie die Antwortmöglichkeiten über die Interview-Definition für jede
MC-Frage separat festgelegt. Bei der MC-Frage mit editierbaren Antwortmöglichkeiten gibt es
zwei Alternativen zur Code-Generierung, welche auch beide implementiert wurden und durch ent-
sprechende Attribute in der Interview-Definition eingeschaltet werden können. Die erste Alternati-
ve nimmt den Code der untersten definierten Antwort, also der Antwort direkt über der ersten edi-
tierbaren Antwort, und addiert eins dazu. Haben z.b. drei definierte Antworten die Codes 1,3 und 4
(in dieser Reihenfolge von oben nach unten dargestellt) und folgt darauf eine editierbare Antwort-
möglichkeit, erhält sie automatisch den Code 5. Die zweite Möglichkeit besteht darin den editier-
baren Antwortmöglichkeiten einen Code zuzuweisen, wie es bei definierten Antwortmöglichkeiten
der Fall ist.
Ja/Nein-Fragen
Ja/Nein-Fragen sind MC-Fragen mit einer Antwortmöglichkeit und einer Einschränkung der Ant-
wortmöglichkeiten auf ″ja″ und ″nein″.
Ebenfalls möglich wäre die Repräsentation dieses Fragetyps durch eine MC-Frage. Für einen eige-
nen Typ spricht allerdings, dass dieser Fragetyp häufig vorkommt und die Antwortmöglichkeiten
jedesmal neu definiert werden müssen, obwohl sie immer die gleiche Ausprägung (nämlich ″Ja″
und ″Nein″) haben. Dies würde zu unnötiger Redundanz führen, was mit der Einführung eines spe-
ziellen Fragetyps umgangen werden kann.
Auch hier wird eine Codierung der Antwort vorgenommen, im Unterschied zu den MC-Fragen
wird die Codierung der Antworten allerdings in der Interview-Definition global, also für das ge-
40

samte Interview definiert. Denn es kann davon ausgegangen werden dass die Antwort ″Ja″ oder
″Nein″ immer mit dem gleichen Code verschlüsselt wird innerhalb des gleichen Interviews.
Dual-Fragen
Fragen welche zwei verschiedene Antwortarten gleichzeitig anzeigen, bilden ebenfalls einen eige-
nen Fragetyp. Sie dienen zur Beantwortung von Fragen die eigentlich aus zwei Fragen bestehen
wie z.B. ″Beschreiben Sie dieses Erlebnis und geben Sie an wann es stattgefunden hat.″ (Eine
Kombination von Text- und Datum-Frage.) Dabei müssen beide Antworten gegeben werden, die
Antworten stellen keine Alternativen dar. In der folgenden Abbildung 23 ist die Darstellung einer
Dual-Frage abgebildet, welche aus einer Zahlen-Frage und einer MC-Frage besteht.
41
Abbildung 22: Ja/Nein-Frage

Zu den eben genannten sechs Basis-Typen kommen noch zwei referenzierende Typen hinzu. Refe-
renzierende Typen referenzieren die Antworten von vorangegangenen Fragen und sind durch diese
Abhängigkeit dynamische Typen. Differenzieren lassen sich diese Typen durch den Ort der Refe-
renzierung.
Fragen mit Text-Referenz
Dieser Fragetyp referenziert Antworten im Fragetext. Je nachdem wie vorangegangene Fragen be-
antwortet werden, passt sich der Fragetext der betreffenden Frage dynamisch an. Dadurch lassen
sich frühere Antworten wieder aufgreifen und der Fragetext kann sich auf diese beziehen. Im enge-
ren Sinne ist dies kein eigener Fragetyp sondern eine Erweiterung der restlichen Fragetypen, da als
Antwortart jeder andere Fragetyp verwendet werden kann.
Die folgende Abbildung zeigt eine Text-Rerenz-Fragewelche als Basistyp eine Text-Frage hat. Im
Fragetext wird eine MC-Frage mit mehreren Antwortmöglichkeitet referenziert wie sie in Abbil-
dung 20 gezeigt wurde. Die dort gegebenen Antworten, so wie sie in der Abbildung gegeben wer-
den, sind in den Fragetext übernommen worden.
42
Abbildung 23: Dual-Frage

MC-Fragen mit Antwort-Referenz
Dieser referenzierende Type ist eine MC-Frage mit einer oder mehreren Antwortmöglichkeiten
wobei zusätzlich vorangegangene Antworten wieder als Antwortmöglichkeiten adaptiv integriert
werden. In Abbildung 25 wird wieder die Frage aus Abbildung 20 referenziert. Die dort gegebenen
Antworten werden den definierten Antworten (″Antwort x″ und ″Antwort y″) hinzugefügt. Für die
Codierung wird für die erste adaptiv hinzugefügte Antwort der Code der direkt oberhalb liegen-
den Antwortmöglichkeit genommen und um eins erhöht.
43
Abbildung 24: Frage mit Textreferenz
Abbildung 25: MC-Frage mit Antwort-Referenz

Im DIAX treten vereinzelt noch weiter Fragetypen auf (s. Abschnitt 4.3) , für die jedoch nicht se-
parate Fragetype definiert werden, da sie einerseits selten vorkommen und andererseits durch die
oben erwähnten acht Fragetypen darstellbar sind. So z.B. ein Fragetyp welcher die Antwortmög-
lichkeiten in einer Liste präsentiert und man dort eine Antwort auswählen kann (vgl. Abbildung 9).
Dieser Typ entspricht der MC-Frage mit einer Antwortmöglichkeit. Ein weiterer Fragetyp kommt
nach einer MC-Frage mit mehreren Antwortmöglichkeiten und listet die dort gegebenen Antwor-
ten nochmals auf, wobei jeder Antwort ein beschreibbares Feld angehängt wird um dort die Häu-
figkeit der Verwendunganzugeben (der gleiche Fragetyp, jedoch mit anderem Inhalt wurde in Ab-
bildung 12 gezeigt). Diese Frage lässt sich durch mehrere Zahlen-Fragen mit Text-Referenzen dar-
stellen. Dadurch wird zwar das bestehende Interview um neue Fragen ergänzt, was aber den Ab-
lauf aus Sicht des Probanden nicht verändert. Denn bei dem beschriebenen Fragetyp muss der In-
terviewer jede Antwortmöglichkeit vorlesen und die Antwort in das entsprechende Feld eingeben.
Es ist demnach eine Frage die mehrere Fragen enthält und es hat keine Nachteile diese Frage in
mehrere Fragen aufzuteilen. Es entsteht sogar ein Vorteil indem es nicht mehr möglich ist Häufig-
keiten in ein falsches Feld einzutragen, wenn diese spezifische Frage auf mehrere Fragen aufgeteilt
wird.
6.3 Regel SpracheDie Regeln bestehend aus Ablauf- und Konsistenzregeln müssen gemäss Anforderung 15 in einer
eindeutigen und leicht lesbaren Weise definiert werden können , sodass eine fachlich versierte Per-
son die Aussagekraft der Regeln vollständig nutzen kann.
Um einen Überblick zu erhalten was die Regeln ausdrücken sollen, wird im folgenden definiert
aus welchen minimalen Elementen eine Regel besteht.
● Konstanten : konstante Wertewelche Antworten einschränken.
● Referenzen : referenzieren die Antwort einer Frage (variable Werte)
● Vergleichsoperatoren: definieren den Typ einer Bedingung und liefern als Resultat einen
boolschen Wert, abhängig davon ob die Bedingung erfüllt ist. Die Vergleichsoperatoren
vergleichen zwei Werte, wobei dies der Vergleichzwischen einer Konstante und einer Re-
ferenz oder zwischen zwei Referenzen sein kann.
Aus diesen Grundelementen definiert sich die eben erwähnte
● Bedingung : ein übergeordnetes Element welches aus 2 Werten sowie einem Vergleichsope-
rator besteht und seinerseits ein Basiselement für die Regeln ist. Die Struktur der Bedin-
gung wird durch das folgende Beispiel gezeigt, wobei der Ausdruck <Wert x> sowohl
44

eine Konstante wie auch eine Referenz sein kann. Wobei es bezogen auf das Regelsystem
keinen Sinn ergibt, dass beide Werte Konstanten sind.
<Wert 1> Vergleichsoperator <Wert 2>
Die Regeln sollen nur dann überprüft werden, wenn alle variablen Werte der Regel auch tatsäch-
lich mit einem Wert belegt sind, d.h. die Antworten der referenzierten Fragen müssen korrekt be-
antwortet sein. Mit einer korrekten Antwort wird eine Antwort bezeichnet die einen konkreten
Wert hat, welcher vom Datentyp der entsprechenden Frage ist. Fragen welche mit alternativen
Antwortmöglichkeiten beantwortet werden, gelten als nicht korrekt beantwortet. Da sich die Zwe-
cke von Konsistenz- und Ablaufregeln unterscheiden, wird deren Aufbau im folgenden getrennt
betrachtet.
Konsistenzregeln
Der Zweck von Konsistenzregeln besteht darin die Konsistenz des Interviews zu bewahren.
Dabei ist die Beschränkung, welche sich auf nur die Antwort einer Frage bezieht und diese
einschränkt eine vereinfachte Konsistenzregel. Das Konstrukt der Bedingung reicht bereits
aus um einfache bzw. einseitige Beschränkungen zu definieren.
Die Konsistenzregel soll aus einer Vorbedingungund einer Nachbedingung bestehen. Die
Nachbedingung wird nur dann überprüft, wenn die Vorbedingungerfüllt ist. Dadurch erhal-
ten die Regeln eine gewisse Dynamik und können sich so je nach Antwort selber aktivie-
ren. Eine Konsistenzregel ist im Prinzip eine andere Formulierung einer Wenn-DannAus-
sage. (Wenn die Vorbedingungerfüllt ist, dann muss auch die Nachbedingung erfüllt sein.)
Wird die Vorbedingungnicht erfüllt, gilt die Regel als inaktiv und wird nicht beachtet,
ebenso wenn nicht alle referenzierten Antworten mit korrekten Werten belegt werden.
Ablaufregeln
Die Ablaufregeln bestehen wie die Konsistenzregeln aus zwei Teilen. Der erste Teil ist
äquvalent mit der Vorbedingungeiner Konsistenzregel. Die Ablaufregel hat die Aufgabe
das Interview an definierte Antworten zu adaptieren. Dazu werden im zweiten Teil der Ab-
laufregel diejenigen Fragen definiert, welche ein- oder ausgeschaltet werden, sofern die
Vorbedingungerfüllt ist.
6.3.1.1 SchreibweiseZu der gezeigten Rein-Text-Schreibweise am Beispiel einer allgemeinen Bedingung (<Wert 1>
Vergleichsoperator <Wert 2>) gibt es noch Alternativen wie die Darstellung der Regeln
als XML-Elemente. Da XML eine Strukturierung der Regeln ermöglicht, kann auf eine Klamme-
45

rung der Verknüpfungenverzichtet werden. Auch das Lesen und Interpretieren der Regeln durch
einen Rechner wird durch die XML-Darstellung vereinfacht. Da die Regeln jedoch auch von Men-
schen geschrieben werden sollen, die XML nicht kennen, ist die Rein-Text-Schreibweise vorzuzie-
hen (vgl. Anforderungen 1 und 15 betreffend Editierbarkeit der Interview-Definitionen ohne Infor-
matik-Kenntnisse und somit auch der Regeln und einer einfachen Regelsprache).
Im Beispiel der allgemeinen Bedingung wird die Infix-Schreibweise verwendet. Mögliche Alterna-
tiven dazu sind die Prefix- und Postfix-Schreibweise, welche aufgrund ihrer Struktur die Interpre-
tation durch eine Maschine etwas vereinfachen. Da dies wiederum eine Rein-Text-Schreibweise
ist, kann sie auch von Menschen leicht interpretiert werden. Die allgemeine Bedingung wird durch
die Prefix- und Postfix-Schreibweise folgendermassen dargestellt:
Vergleichsoperator <Wert1> <Wert2> (Prefix-Schreibweise)
<Wert1> <Wert2> Vergleichsoperator (Postfix-Schreibweise)
6.3.1.2 Erweiterung der BedingungDie Bedingungselemente beider Regel Typen soll durch UND oder ODER Verknüpfungen er-
weiterbar sein. Die Komplexität der Regeln nimmt durch die Möglichkeit der Verknüpfungen zu,
dafür kann die Aussagekraft einer Regel erhöht werden. Die logische Verknüpfungvon Bedingun-
gen fordert zusätzlich eine Möglichkeit der Priorisierung, bzw. der Strukturierung der logisch ver-
knüpften Bedingungen. Diese Notwendigkeit soll in einem kurzen Beispiel erklärt werden. Gege-
ben sind die Bedingungen A, B und C. Diese werden Verknüpft, sodass der Ausdruck ″AUND B
ODER C″ entsteht. Dieser Ausdruck lässt einen unerwünschten Interpretations-Spielraum offen.
Da es sich bei den logischen Operatoren UND, ODER um binäre Operatoren handelt, muss defi-
niert werden welcher die höhere Priorität besitzt. Nur so erhält der Ausdruck eine eindeutige Aus-
sage. Denn der Ausdruck kann als ″(A UND B) ODER C″ oder ″AUND (B ODER C)″ interpre-
tiert werden wobei die Bedeutung offensichtlich unterschiedlich ist. Um dies zu erreichen gibt es
die Möglichkeit die Priorität wie erwähnt zu definieren, wobei dies wieder zu Einschränkungen
der Aussagekraft führen kann und die Lesbarkeit verschlechtert. Eine andere Möglichkeit welche
die Lesbarkeit erhöht und die Aussagekraft nicht einschränkt, ist die Einführung von Klammern
wie sie im Beispiel verwendet wurden. Durch die Klammerung können mehrere Verknüpfungen
auf die gleiche Ebene gestellt werden und anderen Verknüpfungenunter- oder übergeordnet wer-
den. Eine Priorisierung kann je nach Bedarf eindeutig ausgedrückt werden ohne, wie bereits er-
wähnt, die Aussagekraft zu beeinträchtigen.
6.3.1.3 Positionierung der Regeln in der Interview-DefinitionSomit ist grundsätzlich geklärt welche Elemente im Allgemeinen benötigt werden um die Regeln
46

zu konstruieren. Als nächstes muss die Frage beantwortet werden wie eine Regel in der Interview-
Definition dargestellt werden soll und wo. An dieser Stelle werden zwei Möglichkeiten erläutert
die Regeln in der Definition zu platzieren.
● Zuordnung zu einer Frage
Die Regeln werden direkt Fragen zugeordnet, sind also Bestandteil einer Frage. Da die Zu-
ordnung nicht ziellos vorgenommen werden sollte, sind die folgenden Einschränkungen zu
beachten. Beschränkungen werden zu derjenigen Frage zugeordnet welche sie betreffen.
Die restlichen Regeln werden jeweils der Frage zugeordnet welche in der gegebenen Rei-
henfolge der Fragen zuletzt präsentiert wird. Angenommen eine Konsistenzregel referen-
ziert in ihrer Vor-und Nachbedingung die Fragen 2, 3 und 6, wobei die Ziffern der Reihen-
folge der Fragen entsprechen. Die Regel wird der (zuletzt präsentierten) Frage 6 zugeord-
net. Bei Ablaufregeln müssen nur die Fragereferenzen der Vorbedingungberücksichtigt
werden. Diese Möglichkeit der Zuordnung hat den Vorteil, dass jeweils nur Regeln von be-
reits beantworteten Fragen ausgewertet werden müssen Da sich die Regeln in den jeweils
letzten Fragen befinden, sind alle referenzierten Fragen beantwortet und es muss nur noch
die Korrektheit der Antwort überprüft werden. Die Restlichen Regeln des Interviews, bzw.
die Regeln die den nachfolgenden Fragen zugeordnet wurden müssen nicht betrachtet wer-
den, da sie mit Sicherheit noch nicht beantwortete Referenzen beinhalten.
● globale Regeln
Die zweite Möglichkeit besteht darin, die Regeln in der Interview-Definition in einem se-
paraten ″Abschnitt″ zu definieren und sie somit von den Fragen zu lösen. Durch die Globa-
lisierung innerhalb eines Interviews müssen die Regeln nicht mehr einer Frage zugeordnet
werden, was vor allem das Editieren der Regeln erleichtert. Denn wird eine Regel um eine
Bedingung, mit einer bisher unbekannten Referenz, erweitert , muss sie unter Umständen
einer neuen Frage zugeordnet werden, um die richtige Funktionalität zu gewährleisten. Im
Unterschied zu der vorher beschriebenen Möglichkeit, die Regeln den Fragen zuzuordnen,
müssen bei dieser Alternative jeweils alle Regeln überprüft werden, nachdem eine Frage
beantwortet ist. Diese Überprüfung ordnet die Regeln in aktive und passive Regeln ein,
wobei bei den aktiven sämtliche variablen Wertemit konkreten Werten belegt sind. Die
passiven Regeln sind diejenigen welche variable Werte, also Referenzen auf Fragen haben,
die noch nicht beantwortet wurden oder nicht korrekt beantwortet sind. Was bedeutet, dass
es nur Sinn macht die aktiven Regeln aufzulösen und dadurch zu überprüfen ob sie erfüllt
sind.
47
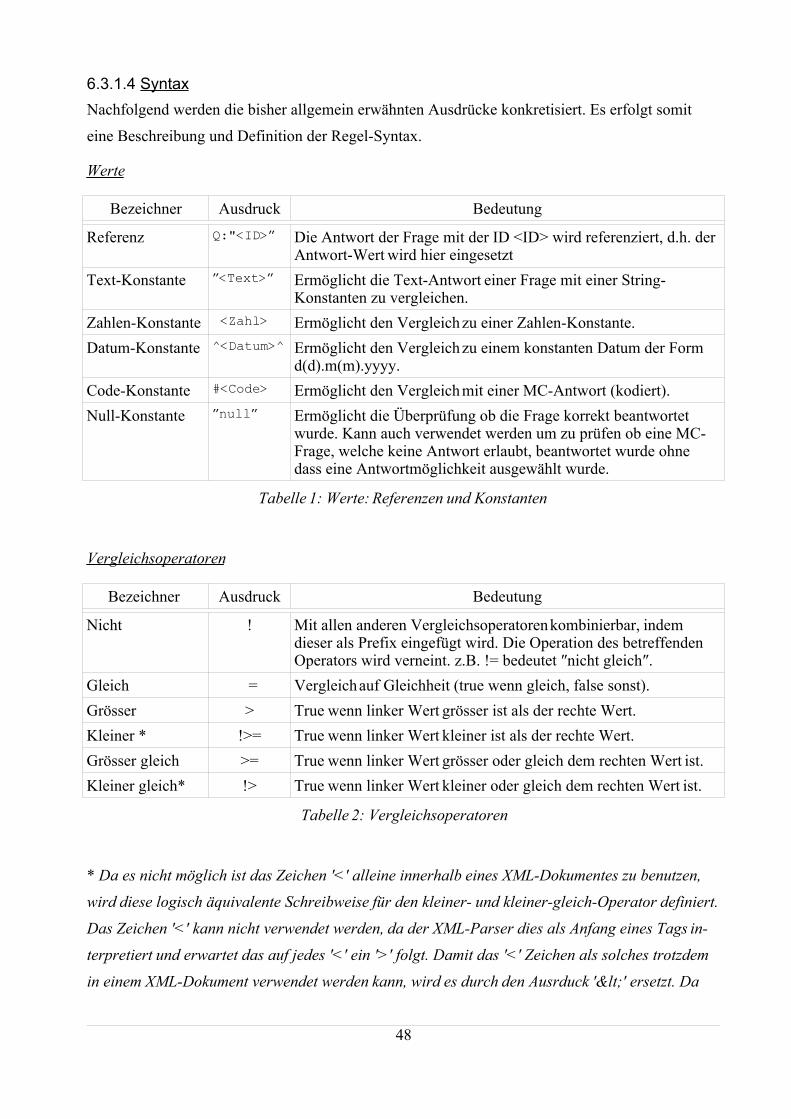
6.3.1.4 SyntaxNachfolgend werden die bisher allgemein erwähnten Ausdrücke konkretisiert. Es erfolgt somit
eine Beschreibung und Definition der Regel-Syntax.
Werte
Bezeichner Ausdruck Bedeutung
Referenz Q:"<ID>″ Die Antwort der Frage mit der ID <ID> wird referenziert, d.h. derAntwort-Wert wird hier eingesetzt
Text-Konstante <Text>″ ″ Ermöglicht die Text-Antwort einer Frage mit einer String-Konstanten zu vergleichen.
Zahlen-Konstante <Zahl> Ermöglicht den Vergleichzu einer Zahlen-Konstante.Datum-Konstante ^<Datum>^ Ermöglicht den Vergleichzu einem konstanten Datum der Form
d(d).m(m).yyyy.Code-Konstante #<Code> Ermöglicht den Vergleichmit einer MC-Antwort (kodiert).Null-Konstante null″ ″ Ermöglicht die Überprüfung ob die Frage korrekt beantwortet
wurde. Kann auch verwendet werden um zu prüfen ob eine MC-Frage, welche keine Antwort erlaubt, beantwortet wurde ohnedass eine Antwortmöglichkeit ausgewählt wurde.
Tabelle 1: Werte: Referenzen und Konstanten
Vergleichsoperatoren
Bezeichner Ausdruck Bedeutung
Nicht ! Mit allen anderen Vergleichsoperatorenkombinierbar, indemdieser als Prefix eingefügt wird. Die Operation des betreffendenOperators wird verneint. z.B. != bedeutet ″nicht gleich″.
Gleich ' = Vergleichauf Gleichheit (true wenn gleich, false sonst).Grösser > True wenn linker Wert grösser ist als der rechte Wert.Kleiner * !>= True wenn linker Wert kleiner ist als der rechte Wert.Grösser gleich >= True wenn linker Wert grösser oder gleich dem rechten Wert ist.Kleiner gleich* !> True wenn linker Wert kleiner oder gleich dem rechten Wert ist.
Tabelle 2: Vergleichsoperatoren
* Da es nicht möglich ist das Zeichen '<' alleine innerhalb eines XML-Dokumentes zu benutzen,wird diese logisch äquivalente Schreibweise für den kleiner- und kleiner-gleich-Operator definiert.
Das Zeichen '<' kann nicht verwendet werden, da der XML-Parser dies als Anfang eines Tags in-terpretiert und erwartet das auf jedes '<' ein '>' folgt. Damit das '<' Zeichen als solches trotzdem
in einem XML-Dokument verwendet werden kann, wird es durch den Ausrduck '<' ersetzt. Da
48
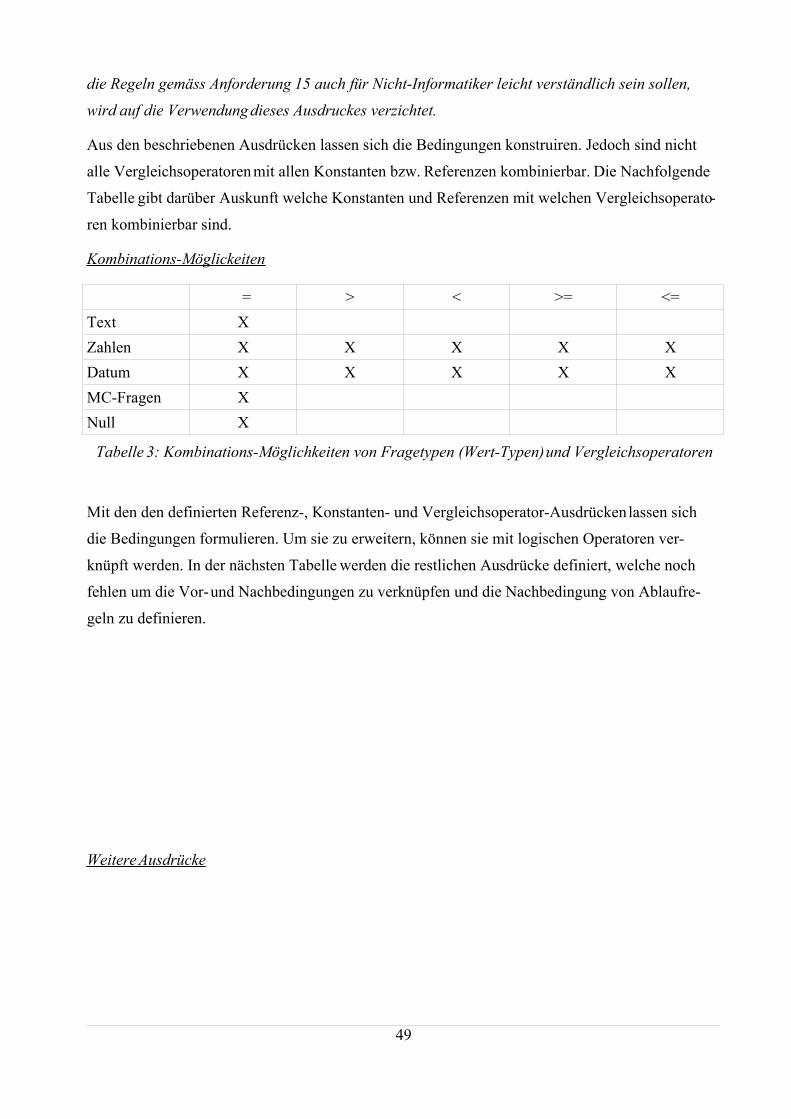
die Regeln gemäss Anforderung 15 auch für Nicht-Informatiker leicht verständlich sein sollen,
wird auf die Verwendungdieses Ausdruckes verzichtet.
Aus den beschriebenen Ausdrücken lassen sich die Bedingungen konstruiren. Jedoch sind nicht
alle Vergleichsoperatorenmit allen Konstanten bzw. Referenzen kombinierbar. Die Nachfolgende
Tabelle gibt darüber Auskunft welche Konstanten und Referenzen mit welchen Vergleichsoperato-
ren kombinierbar sind.
Kombinations-Möglickeiten
' = > < >= <=Text XZahlen X X X X XDatum X X X X XMC-Fragen XNull X
Tabelle 3: Kombinations-Möglichkeiten von Fragetypen (Wert-Typen)und Vergleichsoperatoren
Mit den den definierten Referenz-, Konstanten- und Vergleichsoperator-Ausdrückenlassen sich
die Bedingungen formulieren. Um sie zu erweitern, können sie mit logischen Operatoren ver-
knüpft werden. In der nächsten Tabelle werden die restlichen Ausdrücke definiert, welche noch
fehlen um die Vor-und Nachbedingungen zu verknüpfen und die Nachbedingung von Ablaufre-
geln zu definieren.
WeitereAusdrücke
49

Bezeichner Ausdruck Bedeutung
Logischer ″und″- Operator AND Logische ″und″-Verknüpfungvon Bedingungen.Logischer ″oder″- Operator OR Logische ″oder″-Verknüpfungvon Bedingungen.Trennzeichen Vor-,Nachbedingung
-> Trennt die Vor-von der Nachbedingung. Wirdals der logische ″daraus folgt″- Operatorinterpretiert.
Nachbedingung der Ablaufregel true{<Liste>}false{<Liste>}
<Liste> kann eine oder mehrere Referenzenenthalten. Ist die Vorbedingungerfüllt, werdenalle Fragen der true-Liste eingeschaltet, die derfalse-Liste ausgeschaltet.
Klammerung ( ) Werden logische Operatoren verwendet umBedingungen zu verknüpfen, muss mitKlammern die Struktur der Verknüpfungdefiniert werden.
Endzeichen ; Markiert das Ende einer Regel.
Tabelle 4: WeitereAusdrücke der Regelsprache
6.3.1.5 Allgemeine RegelnDurch die Definition sämtlicher Ausdrücke lassen sich nun die Regeln in einer allgemeinen
Schreibweise ausdrücken.
● Allgemeine Beschränkung (entspricht der allgemeinen Bedingung)
<Wert> Vergleichsoperator <Wert>;
● Erweiterte Allgemeine Beschränkung (erweiterte allgemeine Bedingung)
( <Bedingung> logischer Operator <Bedingung> [logischer Operator
<Bedingung> ...] );
Werden logische Operatoren verwendet muss eine Klammerung vorgenommen werden um
die Struktur zu definieren. Die logischen Operatoren innerhalb einer Klammer müssen im-
mer vom gleichen Typ sein, da sonst nicht-eindeutige Ausdrücke entstehen. Innerhalb einer
Klammer können mehrere logische Verknüpfungenmit dem gleichen logischen Operator
vorgenommen werden.
● Allgemeine Konsistenzregel
<Bedingung> -> <Bedingung>;
Die Vorbedingungwird durch das Trennzeichen '->' von der Nachbedingung getrennt. Da
das Trennzeichen dem logischen ″daraus folgt″ entspricht wird die Regel dementsprechend
interpretiert. In Worten ausgedrückt sagt eine Konsistenzregel folgendes aus: ″Wenn die
50

Vorbedingungerfüllt ist, muss auch die Nachbedingung erfüllt sein.″ Die Vor-und Nachbe-
dingungen können gemäss der erweiterten allgemeinen Bedingung erweitert werden.
● Allgemeine Ablaufregel
<Bedingung> -> true{<Liste>} false{<Liste>};
Auch bei der Ablaufregel kann die Vorbedingungdurch eine erweiterte Bedingung ersetzt
werden. Die Nachbedingung entspricht nicht einer Bedingung sondern enthält zwei Listen,
welche die in den Listen eingetragenen Fragen (ausgedrückt als Referenzen) je nach Liste
entweder ein- oder ausschalten sofern die Vorbedingungerfüllt ist. Die Ablaufregel in Wor-
ten ausgedrückt lautet: ″Wenn die Vorbedingungerfüllt ist, schalte alle Fragen der true-Lis-
te ein, diejenigen der false-Liste aus.″
Die Liste ist ein Ausdrück der Form:
Referenz [Referenz, ...]
6.4 Daten lesenFür die Interview-Definition wurde der in Kapitel 5 beschiebene Ansatz des XML-Formates um-
gesetzt. Die Gründe bzw. die Vorteiledieses Ansatzes wurden ebenfalls in Kapitel 5 besprochen.
Hier wird die konkrete Umsetzung betreffend Interview-Definition, Schema, Regeln und dem Par-
sen von Interview-Definitionen sowie den darin enthaltenen Regeln besprochen.
6.4.1 Interview-DefinitionIn XML können Daten auf verschiedene Weise strukturiert werden, ohne dass die Bedeutung ver-
ändert wird. Es muss also für jedes Datum eine entsprechende Darstellungsart bestimmt werden.
Der Wert eines Datums kann zwischen zwei Tags, also als Inhalt eines Elementes oder als Attribut
eines Tags definiert werden. Ebenfalls besteht die Möglichkeit ein Datum durch erwähnen oder
nicht-erwähnen zu definieren, so kann z.B. ein Datum vom Typ Boolean definiert werden, dass
dass Datum den Wert „true“ hat, wenn es erwähnt wird und sonst „false“. Da ein Interview bereits
eine feste Struktur hat, wurde diese auch in die Interview-Definition übernommen. Dadurch wird
die, für standardisierte Interviews wichtige, Information über die Struktur des Interviews direkt be-
schrieben und muss somit nicht zusätzlich definiert werden. Ein entsprechend versierter Leser des
XML-Dokumentes erhält diese Information ebenfalls direkt vermittelt. Die Struktur des Interviews
wird also durch eine entsprechende Struktur des XML-Dokumentes beschrieben. Es erfolgt somit
auch ein erster Schritt in Richtung internes Datenmodell welches im folgenden Abschnitt genauer
beschrieben wird. Eine Interview-Definition beschreibt genau ein Interview welches Gruppen oder
Fragen enthalten kann. Jede Gruppe kann ihrerseits wieder Gruppen oder Fragen enthalten. Die
51

eben beschriebenen Struktur wird in folgender Abbildung verdeutlicht.
In XML wird dieser Sachverhalt durch eine entsprechende Schachtelung der Elemente (Tags) aus-
gedrückt. Gruppen wie auch Fragen erhalten eine ID, zur eindeutigen Identifizierung. Die ID wird
als Attribut des Gruppe- bzw. Frage-Elementes modelliert. Die Gruppen enthalten weiter ein Ele-
ment für den Gruppentitel. Grundsätzlich enthalten sämtliche Fragetypen die folgenden Elemente:
Fragetext, Kommentartext und optional ein Element um die alternativen Antwortmöglichkeiten
einzeln auszuschalten. Diejenigen Frage-Typen welche noch spezielle Informationen benötigen
wie z.B. die Multiple Choice Fragen mit den definierter definierten Antwortauswahl erhalten diese
wiederum in eigenen Elementen innerhalb des Frage-Elementes.
Die Ablauf- und Konsistenzegeln werden innerhalb des Interview-Elementes durch zwei entspre-
chende Elemente getrennt. Jede Regel wird durch ein separates Element im übergeordneten Regel-
element modelliert.
6.4.2 Interview - SchemaDie XML Technologie erlaubt es Schemata zu schreiben, welche Instanz-Dokumente auf Inhalt
und Struktur überprüfen. In diesem konkreten Fall sind die Instanz-Dokumente die Interview-Defi-
nitionen. Sollte sich beim erstellen einer Interview-Definition ein Fehler einschleichen, wird dies
bei der Validierung anhand des Schemas bemerkt und es wird eine detailierte Fehlermeldung aus-
gegeben wo sich der oder die Fehler ereignet haben. Dies ist vorallem dann sehr hilfreich wenn die
Definition sehr gross wird, denn ohne die betreffenden Informationen wäre es schwer einen Fehler
in einer grossen Definition, was einem langen Dokument entspricht, zu finden.
Im Schema des Interviews werden sämtliche Elemente beschrieben und definiert. Bei den Fragen
wird der angebotene Mechanismus der Vererbunggenutzt. Ein Frage-Basis-Element definiert die-
jenigen Elemente und Attribute welche alle Frage-Typen gemein haben. Also die Elemente Frage-,
Kommentarttext und das optionale Element für das Ausschalten der alternativen Antwortmöglich-
keiten. Desweiteren das Attribut für die eindeutige ID und ein optionales Attribut, das verwendet
werden kann um die Fragen auszuschalten. Sämtliche anderen Fragen mit Ausnahme von Fragen
52
Abbildung 26: Interview - Struktur
Interview Gruppe
Frage
X Y
Bedeutet: X enthält Y

mit Text-Referenz und Doppel-Fragen sind von diesem Basis-Typ abgeleitet und erweitern diesen
entsprechend ihren spezifischen Attributen oder benötigten Elementen. Die beiden Ausnahmen
sind Elemente die ein bzw. zwei Frage-Elemente (Doppel-Fragen) beinhalten. Diese ″Umklamme-
rung″ von Fragen dient lediglich als Information für den Parser, das die eigentlichen Frage-Typen
über eine zusätzliche Funktion verfügen. Das Interview-Schema ist in Anhang A : Interview-Sche-
ma zur genaueren Betrachtung abbgebildet.
6.4.3 Parsen
6.4.3.1 Interview-DefinitionDa Struktur und Inhalt der Interview-Definition bekannt sind, sowie die Regel-Sprache definiert
ist, wird sich dieser Abschnitt mit dem Parsen der Interview-Definition befassen. Java bietet zwei
verschiedene Möglichkeiten ein XML-Dokument zu lesen. Die Sprache unterstützt das ″W3C Ob-
jekt Document Model″ (DOM) und die ″Simple API for XML″ (SAX).
Object Docoment Model (DOM)
W3C DOM ist eine plattform.- und sprachunabhängiges Schnittstelle um auf Inhalt und
Struktur eines Dokumentes dynamisch zuzugreifen und diese zu verändern. DOM ist in die
folgenden drei Teile aufgeteilt: Core, HTML und XML, wobei der Core Teil eine Objekt-
menge auf niedrigem Level anbietet. Diese Objektmenge genügt bereits um ein strukturier-
tes Dokument zu repräsentieren. Die Core Schnittstelle alleine ist somit in der Lage
HTML- oder XML-Dokumente darzustellen. Die HTML- und XML-Spezifikation bieten
eine Schnittstelle auf höherem Level um leichter und direkter auf Typen eines Dokumentes
zugreifen zu können.[XMLDOM]
Simple API for XML (SAX)
SAX unterstützt wie DOM den Zugriff auf Informationen, die in einem XML-Dokument
gespeichert sind. Dabei werden zwei grundsätzlich verschiedene Ansätze verwendet. DOM
erstellt einen Baum aus Knoten welcher der Struktur des Dokumentes entspricht. Der Zu-
griff auf die im Dokument gespeicherten Information erfolgt durch die Interaktion mit den
erstellten Baum, dem hierarchischen Objekt Modell. Die Funktionsweise von SAX besteht
darin einen Stream von Parser-Events zu erstellen. Es ist dann der Applikation überlassen
diese Events zu interpretieren.[XMLSAX]
Für den Definitions-Parser fällt der Entscheid aus den folgenden Gründen auf SAX:
● Grösse des Dokumentes
Gemäss [XMLSAX] soll SAX benutzt werden wenn das XML-Dokument lang ist. Eine In-
53

terview-Definition erreicht schnell mehrere tausend Zeilen. DOM erstellt das Objekt Mo-
dell und benötigt dafür den entsprechenden Speicher.
● DOM Objekt Modell wird nicht benötigt
Einerseits müsste das von DOM erstellte Objekt Modell in das interne Datenmodell über-
führt werden, da es keinen Sinn macht zwei identische Modelle im Speicher zu halten und
so doppelten Speicher zu brauchen. Das DOM-Modell kann nicht direkt verwendet werden,
weil die Objekte nicht über die benötigte Funktionalität verfügen. Diese könnte allerdings
durch Wrapper-Objekte zusätzlich hinzugefügt werden. Da die Interview-Applikation
grundsätzlich keine Änderungen an dem Modell vornimmt (abgesehen von den einzufü-
genden Antworten) ist es nicht nötig das Dokument als DOM-Modell im Speicher zu hal-
ten. Zudem werden die Antworten nicht in dem Dokument gespeichert sonder separat ex-
portiert.
Einzig für einen allfälligen Dokument-Editor würde es Sinn machen das DOM-Modell zu
benutzen, da dort das Dokument selber verändert wird.
6.4.3.2 Schema-ValidierungAls konkreter SAX-Parser wird Xerces verwendet, die betreffende Instanz wird durch die Klasse
XMLReaderFactory zur Verfügunggestellt. Der über die Factory erhaltene Parser kann über so
genannte Features und Properties zusätzlich konfiguriert werden. Es muss dem Parser auch über
ein Feature bekannt gegeben werden, dass das Dokument über ein Schema validiert werden soll.
Ist der Parser richtig konfiguriert, übernimmt dieser die Validierung selbstständig, ohne dass eine
spezifische Implementierung benötigt wird. Weitere Informationen über die zur Verfügung stehen-
den Features und Properties sowie deren Beschreibungen sind in [XercesFEAT]und [Xerce-
sPROP] ersichtlich.
6.4.3.3 RegelnDa die Regeln aus den in Abschnitt 5.3 nicht in XML ausgedrückt werden, sondern in einer Text
Schreibweise, ist es notwendig einen regelspezifischen Parser zu implementieren, welcher die Re-
geln interpretieren kann. Um den Parser effizient zu implementieren wird ein Parser-Generator
verwendet, welcher mit Hilfe einer Grammatik den entsprechenden Code generiert. Es gibt eine
grosse Auswahl an Parser-Generatoren für Java, eine kurze Übersicht und weitere Informationen
zu den verschiedenen Produkten sind in [JavaCompiler] ersichtlich. Verwendetwird der ANTLR
(ANother Tool for Language Recognition) Parser-Generator [antlr], da er bereits während des Stu-
diums für andere Projekte benutzt wurde und die Einarbeitungszeit dadurch auf ein Minimum be-
schränkt werden konnte. In [Bühler] wird eine kurze Evaluation von Parsern vorgenommen, wobei
54

erwähnt wird, dass ANTLR zu den umfangreichsten gehört und über eine gute Dokumentation
verfügt.In einer sogenannten Grammatik wird die oben beschriebene Regelsprache definiert. Die
Grammatik wird dann durch ANTLR compiliert und liefert als Ausgabe die entsprechenden Java-
Klassen, welche einen Lexer und einen Parser implementieren.
6.5 DatenmodellIn den vorangegangenen Abschnitten wurde besprochen wie die Interview-Definition aussieht und
durch welche Parser sie gelesen werden. In diesem Abschnitt wird nun besprochen, was die Parser
als Ausgabe liefern.
6.5.1 InterviewWie in Abschnitt 6.4.3 erwähnt erwähnten Gründen wird nicht ein DOM-Parser verwendet um die
Interview-Definitionen zu parsen und daraus ein Datenmodell zu erstellen, sondern ein SAX-Par-
ser. Das so generierte interne Datenmodell gibt die Interview-Struktur wieder und verfügt über
Methoden um Attribute wie z.B. Fragetext, Gruppentitel, usw. abzufragen. In Anhang B ist das
UML des internen Modells abgebildet und wird im folgenden kurz besprochen. Die Klassen im
Diagramm sind jeweils nur mit den wichtigsten Attributen abgebildet, sämtliche Methoden wurden
nicht berücksichtigt um eine bessere Übersicht zu gewährleisten.
Die Interview-Definition wird durch die Klasse Interview modelliert. Sie enthält eine Instanz vonQuestionGroup, welche die Gruppen des Interviews darstellen. Diese Instanz dient als Wurzel der
Interview-Struktur. Weiter enthält das Interview jeweils eine Instanz der Klassen ConsistencyTreeund SequenceTree, welche für die Organisation der entsprechenden Regeln zuständig sind. Wie aus
dem Diagramm zu erkennen ist, werden die Klassen QuestionGroup und Question von Question-Component abgeleitet. Dabei wird das Design-Pattern Composite umgesetzt, welches den Zweck
erfüllt Hierarchien zu modellieren, wobei sämtliche Objekte der Hierarchie gleich behandelt wer-
den können, was durch eine einheitliche Schnittstelle erreicht wird. Die Klasse Question ist ihrer-
seits wiederum eine abstrakte Klasse und dient als Superklasse für sämtliche Fragetypn-Modelle
welche von Question abgeleitet und als spezialisierte Question-Subklassen bezeichtet werden.
Wird eine Frage beantwortet, erhält die betreffende Question Subklasse eine Instanz der Klasse
Answer, welche die Antwort speichert. Für die Klasse DualQuestion, welche den Dual-Fragetype
modelliert, wird eine spezielle Antwort, die DualAnswer, benötigt, da diese Antwort zwei Antwor-ten enthält. (Eine Antwort für jede Frage der Dual-Frage). DualAnswer erbt von Answer, wobei sie
für jede Antwort über eine separate Instanz von Answer verfügt.
Als alternativen Lösungsansatz, wäre ebenfalls möglich sämtliche Fragetypen in einer einzigen
Klasse zu modellieren, wie dies auch zu Beginn der Implementierung umgesetzt wurde. Die ein-
55

zelnen Fragetypen wurden durch Konstanten definiert. Da jedoch die meisten Fragetypen über ei-
genen Attribute und spezialisierte Implementierungen verfügen wurde die Klasse sehr gross und
unübersichtlich. Somit wurde die in Anhang B gezeigte Umsetzung mit einer abstrakten Super-
klasse, welche die Schnittstellen für sämtliche Fragetypen definiert, vorgezogen.
Die Implementierung der Gruppen durch die Klasse QuestionGroup kann allenfalls vernachlässigt
werden, indem die Fragen (repräsentiert durch die Klasse Question) die Gruppe als Attribut erhal-
ten und somit die Information über die Interview-Struktur speichern. Hier hat sich jedoch gezeigt,
dass die Verwendungder implementierten Gruppe doch Vorteilehat. So z.B. ist es vorteilhaft für
die Implementierung des Navigationsbereiches, wenn das Interview durch Gruppen-Objekte struk-
turiert wird, welche ihre Kind-Objekte speichern.
6.5.2 RegelnDie Regeln, bestehend aus Ablauf- und Konsistenzregeln (implementiert durch SequenceRule und
ConsistencyRule) werden jeweils in einem eigenen Baum zusamengefasst (Implementierung in Se-quenceTree und ConsistencyTree). Wie in Abschnitt 6.4.3 beschrieben wurde, werden die Regeln
von einem Parser gelesen. Dieser erstellt aus den Regeln eine Baumstruktur, welche aus Knoten
besteht. Durch Auflösung der Regeln (immer sofern alle Werte bekannt sind) erhält der Wurzel-
knoten einen boolschen Wert. Die Regeln werden also in einem, aus der Logik bekannten, Binär-
baum dargestellt. In Abbildung 27 ist die Konsistenzregel ″Q:"1" > 0 -> Q:"Q2" != #4 ;″
zur Illustration als Baum dargestellt.
Die einzelnen Regelbäume werden, getrennt nach Ablauf- und Konsistenzregeln, in den ″Tree-
Klassen″ zusammengefasst. Hier wurde wiederum zwischen zwei Alternativen ausgewählt. Diese
werden anhand der Konsistenzregeln erklärt. Da sämtliche Wurzelknoten den Wert ″true″ anneh-
men müssen, um einen konsistenten Zustand zu repräsentieren, können sie zu durch UND-Ver-
knüpfungen zu einem Baum zusamengefasst werden. Dieser enthält dann sämtliche Regeln und re-
56
Abbildung 27: Beispiel eines einzelnenRegelbaumes

präsentiert einen konsistenten Zustand genau dann wenn der Wurzelknoten des zusammenfassen-
den Baumes den Wert ″true″ hat. Die zweite Möglichkeit die einzelnen Regelbäume zusammenzu-
fassen besteht darin sie, bzw. die jeweiligen Wurzelknoten in einem Array abzuspeichern. Es reicht
aus, die Regeln einzeln zu lösen um einen inkonsistenten Zustand zu entdecken. Dieser tritt genau
dann ein, wenn ein oder mehrere Wurzelknoten nach Auflösung den Wert ″false″ besitzen. Eben-
falls vorteilhaft ist, dass die Regeln, welche nicht erfüllt wurden, bereits bekannt sind. Beim
Baum-Ansatz ist nur die Information bekannt, dass ein inkonsistenter Zustand vorliegt (dann wenn
der Wurzelknoten des zusammenfassenden Baumes den Wert ″false″ hat). Um herauszufinden
welche Regeln nun nicht erfüllt sind, muss eine zusätzliche Überprüfung stattfinden.
Bei den Ablaufregeln macht es ebenso keinen Sinn diese in einem Baum zusammenzufassen, da
sie nicht voneinander abhängig sind. Deswegen werden auch sie mit dem Array-Ansatz zusam-
mengefasst.
6.6 Interview DurchführungDieser Abschnitt beschäftigt sich mit Funktionen welche die Arbeit mit der Anwendung erleich-
tern. Es wird beschrieben wie die Fragen visualisiert werden und die freie Navigation vorgestellt,
ebenso die Tastatursteuerung, welche eine schnelle und zielsicherere Navigation auf der Benutze-
roberfläche ermöglicht. Weiter wird auch beschrieben wie sich die Anwendung verhält wenn man
zu einer bereits bearbeiteten Frage zurückkehrt, da sich das Verhalten in diesem Punkt von DIAX
unterscheidet. Eine weiter Hilfe ist der Inkonsistenz-Lösemodus, welcher zum Einsatz kommt
wenn eine Regelverletzung der Konsistenzregeln festgestellt wurde und sich das Interview somit
in einem inkonsistenten Zustand befindet.
6.6.1 Visualisierung der FragenDie einzelnen Komponenten der Benutzeroberfläche, mit Ausnahme des Antwortbereiches, wer-
den nur einmal instanziert. Problematisch ist der Antwortbereich, da dieser je nach gezeigtem Fra-
getyp eine andere visuelle Ausprägung hat. Um dieses Problem zu lösen werden im folgenden Lö-
sungsansätze besprochen.
Die in obigem Abschnitt 6.5.1 beschriebenen, Question-Subklassen des internen Datenmodells,implementieren ebenfalls ihre Darstellung in der Benutzeroberfläche. Über eine entsprechende
Schnittstelle, welche allen spezialisierten Frage-Klassen gemein ist, kann die darstellende Kompo-
nente von der Oberfläche abgerufen werden, um diese darzustellen. Dieser Ansatz widerspricht je-
doch dem MVC-Modell (Model-View-Controler), welches eine Trennung des Modells, also der
Daten von ihrer Darstellung und der kontrollierenden Kompnente verlangt. Da die Question-Sub-
klassen eindeutig der Modell-Komponente zugeschrieben werden.
57

Die umgesetze Lösung implementiert für jeden Fragetyp eine darstellende Klasse. Diese darstel-
lenden Klassen erben zwecks Schnittstellen-Definition von einer allgemeinen ″Antwort-Darstel-
lungs″ Klasse. Die Klasse welche den Antwortbereich darstellt, instanziert jedes mal wenn eine
neue Frage angezeigt werden soll die, dem Fragetype entsprechende, spezialisierte Darstellungs-
Klasse. Die neu erstellten Objekte ersetzen jeweils ihr Vorgängerobjekt.Der Nachteil liegt in der
ständigen Generierung von neuen Objekten, hat aber den Vorteil, dass nicht von jedem Fragetyp
die entsprechende Darstellungs-Klasse im Speicher gehalten wird, was ebenfalls als eine ähnliche
Lösung betrachtet werden kann. Dazu werden sämtliche bekannten darstellenden Klassen instan-
ziert und je nach gezeigtem Fragetyp angezeigt.
6.6.2 Übersicht und freie NavigationDie inAbbildung 28 abgebildete Übersichts- und Navigationskomponente, gibt dem Benutzer eine
Übersicht über die Struktur und den Aufbau des Interviews. Als oberstes Element eines Interviews
wird jeweils das Interview angezeigt, welches entsprechend der verwendeten Interview-Definition
Fragen sowie Gruppen enthält. Die Gruppen lassen sich, wie auch das Interview-Element, beliebig
öffnen und schliessen. Im geöffneten Zustand werden sämtliche untergeordneten Elemente des be-
treffenden Elementes angezeigt. Die jeweils aktuelle Frage, d.h. die Frage welche gerade darge-
stellt wird, wird durch eine Blau-Färbung markiert. Dabei werden jeweils sämtliche übergeordne-
ten Komponenten automatisch geöffnet, sodass der Benutzer die betreffende Frage in der Über-
sichtskomponente sieht. Sämtliche korrekt beantwortete Fragen, also Fragen die mit dem Ok-But-
ton bestätigt wurden, werden grün angezeigt. Fragen welche in einem orangen Farbton erscheinen,
wurden durch eine der alternativen Antwortmöglichkeiten beantwortet. Schwarze Fragen stellen
noch unbearbeitete Fragen dar und solche mit einer Grau-Färbung befinden sich im ausgeschalte-
ten Zustand und können auch nicht angewählt werden.
58

Die freie Navigation wurde so implementiert, dass mit Ausnahme der inaktiven (grauen) Fragen,
eine beliebige Frage durch anklicken ausgewählt werden kann, worauf diese angezeigt wird. Dies
erleichtert die Navigation, da der Benutzer wenn er sich z.B. bei der fünfzigsten Frage befindet
und die Frage zehn nochmals bearbeiten möchte, nicht durch ″dauerklicken″ auf den zurück-But-
ton dahin gelangt, sondern eine schnellere Alternative zur Verfügunghat.
6.6.3 TastatursteuerungDie Tastatursteuerung soll eine Alternative zur Bedienung mit der Maus darstellen. Für einen zügi-
gen Ablauf müssen, die Antwortmöglichkeit und die Buttons ansteuerbar und auswählbar sein. Mit
der Tabulator-Tastekann der Fokus verschoben werden, wobei bei jeder Frage zuerst die Antwort
angesteuert wird. Gibt es mehrere Antwortmöglichkeiten oder Antwortfelder, so erhalten diese der
Reihe nach den Fokus. Danach wechselt der Fokus auf die Buttons, wobei zuerst der OK-Button
markiert wird. Sobald alle Buttons den Fokus einmal erhielten, wechselt er wieder in den Antwort-
bereich zurück. Der Navigationsbereich wird bewusst ausgelassen, da er für den normalen Inter-
view-Ablauf, also das beantworten der Fragen in ihrer festgelegten Reihenfolge, nicht benötigt
wird. Durch drücken der Enter-Tastewird die die mit dem Fokus belegte Komponente ausgewähl,
59
Abbildung 28: Die Navigations-Komponente
Korrekt beantwortete Fragen
Durch einen alternativeAnwtort beantwortete Frage
Ausgeschaltete Frage
Aktuelle Frage
unbearbeitete Fragen
Offene Gruppemit den darinenthaltenenFragen
GeschlosseneGruppen

sofern die Komponente über die eine entsprechende Funktion verfügt (z.B. Buttons). SWT imple-
mentiert den Fokus-Mechanismus selber, sodass er ohne zusätzlichen Code funktioniert. Dabei
werden alle fokusierbaren Komponenten der Reihe nach durchlaufen. Um den Naviagationsbe-
reich wie gewünscht auszulassen werden die ″TraverseEvents″ abgefangen und überprüft welche
Komponente als nächstes den Fokus erhalten soll, ist dies der Navigationsbereich, wird er über-
sprungen.
Da der vom Betriebssystem Windows verwendete Fokus nicht unbedingt auf den ersten Blick er-
kennbar ist, wurde eine Markierung in Form eines Pfeiles implementiert, welcher jeweils auf die
fokussierte Komponente zeigt. Als Beispiele zur Illustration sei hier auf die Abbildungen 19-21
(MC-Fragen) in Abschnitt 6.2 verwiesen, wo der Fokus jeweils im Antwortbereich sichtbar ist.
Dieser Pfeil soll es erleichtern, dass der Fokus auf den ersten Blick hin erkannt wird. Da die An-
wendung ebenfall auf Mac OS laufen soll, tritt folgendes Problem auf. Die SWT-Buttons sind
beim Mac OS nicht fokussierbar, was bedeutet, dass der von SWT zur Verfügunggestellte Fokus-
Mechanismus nicht vollständig die geforderten Zwecke erfüllt. Um dies zu lösen, wurde der beste-
hende Mechanismus erweitert, sodass die Buttons im Buttons-Bereich auch bei Verwendungdes
Mac OS fokusierbar sind. SWT ist somit nicht vollständig plattformunabhängig, wie das von Java
im allgemeinen angenommen wird.
6.6.4 Antworten anzeigenGeht man bei DIAX zu einer bereits beantworteten Frage zurück wird diese zurückgesetzt, bzw.
mit einem ″Default-Wert″ besetzt. Dies hat zur Folge, dass die Frage erneut dem Probanden ge-
stellt und beantwortet werden muss. Um dies wurde in der implementierten Anwendung geändert,
d.h. sofern die Frage korrekt beantwortet wurde, wird die gegebene Antwort angezeigt und durch
erneutes betätigen des OK-Buttons wieder übernommen. Einmal gemachte Angaben gehen da-
durch nicht verloren. Wurde eine Frage allerdings durch eine alternative Antwortmöglichkeit be-
antwortet, muss der Interviewer über die gemachte Auswahl informiert werden. Um dies zu visua-
lisieren wurde die Möglichkeit in Betracht gezogen den betreffenden Button einzufärben. Dies ist
jedoch bei SWT-Buttons in einer plattformunabhängigen Weise nicht möglich. Deswegen wird
eine alternative Visualisierung verwendet, welche wiederum aus einem Pfeil besteht, der auf die
getroffene alternative Antwort zeigt. Dieser zweite Pfeil wird ebenfalls verwendet um anzuzeigen,
dass die Frage Korrekt beantwortet wurde, indem er auf den OK-Button zeigt. Ebenfalls wird der
Fokus auf denjenigen Button gelegt, durch den die Frage zuletzt beantwortet wurde. Für den Inter-
viewer bedeutet dies, dass wenn er zu einer Frage zurückkehrt, durch drücken der Enter-Taste die
Frage, so wie sie beantwortet wurde, erneut beantwortet. In Abbildung 29 wird der Buttons-Be-
reich gezeigt, wie er erscheint wenn zu einer Frage zurückgegangen wird, welche mit ″verweigert″
60

beantwortet wurde.
6.6.5 Inkonsistenz LösemodusWie bereits mehrfach erwähnt wird ein inkonsistenter Zustand erreicht, wenn eine oder mehrere
Konsistenzregeln nicht erfüllt werden. Dies wird dem Benutzer durch eine Information und zusätz-
lich über die Informationskomponente angezeigt, indem die Anzahl der inkonsistenten Fragen an-
gegeben wird. Weiter werden die betreffenden Fragen im Navigationsbereich rot markiert. Dabei
wird in den Inkonsistenz-Lösemodus gewechselt. Solange sich der Benutzer in diesem Modus be-
findet, wird er in der Navigation insofern eingeschränkt, dass er nicht mehr ganz frei durch das In-
terview navigieren kann. Grundsätzlich kann der Benutzer nur noch die inkonsistenten Fragen be-
arbeiten. Er erhält die Möglichkeit, beliebige Fragen anzusehen, jedoch ohne sie bearbeiten zu
können (ausgenommen wie erwähnt, die inkonsistenten Fragen). Wird nicht frei navigiert, werden
nur noch die inkonsistenten Fragen angezeigt. Bevor wieder in den normalen Modus gewechselt
wird, muss die Inkonsistenz gelöst werden. So soll verhindert werden, dass durch das weitere Be-
antworten von Fragen zusätzliche Abhängigkeiten zu den bereits verletzten Regeln entstehen, was
das Lösen der Inkonsistenz zusätzlich erschwert. Um dem Benutzer zu informieren wie er die In-
konsistenz lösen kann, wird im Inkonsistenz-Lösemodus im Informationsbereich ein zusätzliches
Fenster eingeblendet, welches Hilfestellung zu der aktuell gezeigten Frage anzeigt. Im Informati-
ons-Text, welcher zu den Regeln in der Interview-Definition definiert wird, wird die aktuelle Fra-
ge, sofern sie im Text erwähnt wird, blau markiert.
61
Markierung der zuletztgegebenen Antwort
Fokus - Markierung
Abbildung 29: Buttons-Bereich mit Antwort- und Fokus-Markierung

Der verwendete und im folgenden beschriebene Algorithmus ermöglicht es dem Interviewer das
Interview wieder in einen konsistenten Zustand zu überführen. Dazu wird davon ausgegangen,
dass eine Belegung der variablen Werte (Referenzen) existiert, sodass alle Regeln erfüllt werden.
Nur wenn alle aktiven Regeln erfüllt werden, befinden sie sich in einem konsistenten Zustand. Be-
reits eine einzige Regel, die nicht erfüllt ist, führt zu einem inkonsistenten Zustand. Es wird also
vorausgesetzt, dass es innerhalb der unterschiedlichen Möglichkeiten ein Interview auszufüllen,
bzw. die Fragen zu beantworten, mindestens eine existiert, sodass das beantwortete Interviews
sämtliche Regeln erfüllt. Wie diese Voraussetzungdurch einen Algorithmus überprüft werden
kann, wird im anschliessenden Kapitel, Abschnitt 8.3 erläutert.
Tritt ein inkonsistenter Zustand ein, werden zunächst die nicht erfüllten Regeln isoliert betrachtet.
Es sei die MengeM, jene Menge welche sämtliche inkonsistenten Regeln enthält, wobeiM eineTeilmenge sämtlicher Konsistenzregeln ist. Durch die Referenzen der inM enthaltenen Regeln,lassen sich die betroffenen Fragen ermitteln. Diese Fragen werden dem Interviewer der Reihe nach
präsentiert, sodass er die Antworten mit dem Probanden bearbeiten kann. Zur Unterstützung wird
62
Abbildung 30: ErweiterterInformations-Bereich im Inkonsistenz-Lösemodus

im Informations-Bereich der Benutzeroberfläche ein Fenster eingeblendet, welches für jede der
Regeln aus M einen allgemeinen Hilfetext anzeigt, wie die Regeln erfüllt werden. Nach jeder be-arbeiteten Frage werden, wie im normalen Modus, alle Regeln überprüft und die MengeM ange-passt. D.h. Regeln die durch die editierte Frage wieder erfüllt werden, verlassenM und Regelnwelche durch die revidierte Antwort verletzt werden, kommen neu zuM hinzu. Dieser Vorgangwird solange wiederholt, bis sämtliche Regeln erfüllt werden und die Inkonsistenz somit aufgeho-
ben wird. Danach wird wieder in den normalen Modus gewechselt und das Interview kann fortge-
führt werden.
Der verwendete im Inkonsitenz-Lösemodus verwendete Algorithmus funktioniert grundsätzlich
wie eben beschrieben. Anhand der folgenden Überlegung wird beschrieben, wie die Effizienz un-
ter gegebenen Umständen erhöht werden kann. Sei FMenge der inkonsistenten Fragen, wird zu-sätzlich deren Häufigkeit festgehalten, die grösser als 1 sein kann. Z.B. wenn eine Regel ausM diebetreffende Frage mindestens zweimal referenziert oder wenn die Frage in mehreren Regeln (aus
M) referenziert wird. Angenommen F enthält eine Frage ″Frage X″ welche mehrmals durch die inM enthaltenen Regeln referenziert wird. Die Frage hat also eine Häufigkeit > 1, alle anderen Fra-gen in F besitzen die Häufigkeit 1. Falls sich nun die Frage bzw. die Antwort auf ″Frage X″ in ei-nem inkonsistenten Zustand befindet, diese zuerst angezeigt und korrigiert wird, können durch
eine korrigierte Antwort mehrere Regeln auf einen Schlag erfüllt werden. Wenn die Häufigkeiten
nicht beachtet werden, besteht die Möglichkeit, dass im schlechtesten Fall alle Fragen mit Häufig-
keit 1 zuerst angezeigt werden. Wurden diese alle korrekt beantwortet und liegt somit der Fehler
bei ″Frage X″, müssen alle Fragen angezeigt werden bis schliesslich die entscheidende Frage er-
scheint. Dieser Fall wird durch den Algorithmus verhindert, was unter den beschriebenen Umstän-
den als Optimierung gesehen werden kann. Es werden also die Häufigkeiten der Fragen in F er-mittelt, welche besagen wie oft eine Frage durch die inM enhaltenen Regeln referenziert wird.Darauf werden zuerst die Fragen mit den höchsten Häufigkeiten h angezeigt. Wurden alle Fragenmit der Häufigkeit h einmal präsentiert, wird h um eins verringert und alle Fragen mit h-1 werdenangezeigt, sofern welche in F enthalten sind. Die Häufigkeit h wird also schrittweise verringert bissie gleich 0 ist, danach wird sie wieder auf die höchste Häufigkeit gesetzt. Somit müssen nach je-
der bearbeiteten Frage nicht nur die MengemM und F angepasst werden sondern auch die Häufig-keiten der in F enthaltenen Fragen.
Beweis
Unter der Annahme, dass sich für alle variablen Werte aller Konsistenzregeln eines Interviews eine
Belegung finden lässt, sodass sich die Regeln in einem konsistenten Zustand befinden. D.h. alle
Regeln werden durch die Belegung erfüllt, was für Regeln mit Vor-und Nachbedingungen bedeu-
63

tet, dass die Nachbedingung gilt, wenn die Vorbedingungerfüllt ist. Ist die Vorbedingungnicht er-
füllt, gilt die Regel als erfüllt. Denn die Vorbedingungdefiniert die Umstände unter welchen die
Nachbedingung (welche als eigentliche Regel betrachtet werden kann) gelten muss, sofern sie zu-
treffen. Sind die Umstände nicht gegeben, wird die Nachbedingung nicht beachtet, was dem Wahr-
heitswert ″true″ der gesamten Regel entspricht.
Gilt die eben beschriebene Annahme existiert mindestens eine Belegung der variablen Werte wel-
cher in einem konsistenten Zustand resultiert. Die MengeM, der inkonsistenten Regeln ist in je-dem Fall eine Teilmenge aller Regeln des Interviews. Der konsistente Zustand aller Regeln kann
beschrieben werden durch die Aussage, dass die Menge aller Regeln konsistent ist, wenn alle mög-
lichen Teilmengen konsistent sind. Denn wird eine einzige Regel, welche eine Teilmenge aller Re-
geln ist, nicht erfüllt, ist die Menge aller Regeln ebenfalls nicht erfüllt und somit inkonsistent.
Daraus folgt, dass wenn sich alle Teilmengen in einem konsistenten Zustand befinden, die Menge
aller Regeln ebenfalls konsistent ist. Aus dieser Aussage lässt sich der Beweis ableiten, dass es in
jedem Fall möglich ist einen inkonsistenten Zustand einer Teilmenge aller Regeln in einen konsis-
tenten zu überführen, sofern mindestens ein konsistenter Zustand aller Regeln existiert.
Da eine Variablen-Belegung existiert, sodass sämtliche Regeln erfüllt werden und somit konsistent
sind, existiert auch für jede Teilmengemindestens ein konsistenter Zustand (wurde eben gezeigt).
D.h. für jede beliebige MengeM, unter Berücksichtigung der Voraussetzung,existiert in jedemFall eine Variablen-Belegung, sodassM konsistent ist. WennM konsistent ist, ist auch die Mengealler Regeln konsistent, da keine inkonsistenten Regeln mehr existieren.
Um die Bedingung, dass mindestens ein konsistenter Zustand existiert zu überprüfen wird in Ab-
schnitt 8.3 ein Algorithmus beschrieben welcher diese Überprüfung automatisiert.
6.7 Export der AntwortenDie durch das Interview erfassten Antworten werden in einem XML-Dokument gespeichert, wel-
ches durch das in Anhang C abgebildete Schema dokumentiert wird. Es ist offensichtlich, dass es
keinen Sinn macht das gesamte interne Modell zu exportieren, sozusagen eine erweiterte Inter-
view-Definition als XML-Dokument zu speichern. Die Antworten könnten den Frage-Elementen
der Definition hinzugefügt werden. Da der Export der Antworten zum Zweck geschieht, die erho-
benen Daten in die Datenbank zu schreiben, muss dort nicht jedes mal die gesamte Definition ge-
speichert werden, was zu unnötiger Redundanz führen würde. Es reicht somit völlig aus die die
Antworten zu exportieren, allerdings müssen sie eindeutig den gestellten Fragen zugeordnet wer-
den können. Für diese Zuordnung werden die eindeutigen ID's der Fragen verwendet. Ein weiterer
Punkt über den diskutiert werden muss ist, wie alternative Antworten exportiert werden. Dazu gibt
64

es grundsätzlich zwei Möglichkeiten. Erstens, die alternative Antwort wird wie eine normale Ant-
wort in das XML-Dokument geschrieben. Bei der zweiten Möglichkeit wird ein Attribut einge-
führt, welches den Status der Frage speichert.
Die erste Alternative birgt allerdings die Gefahr von Missverständnissen, denn wird eine Frage
z.B. mit ″Problem″ beantwortet ist nicht eindeutig klar, ob jetzt die Frage mit der betreffenden al-
ternativen Antwort beantwortet wurde, oder ob dies die korrekte Antwort ist. Wird die zweite
Möglichkeit verwendet entsteht eine gewisse informative Redundanz in der Datenbank.Wird eine
Frage korrekt beantwortet und zusätzlich noch ein Attribut gespeichert, welches anzeigt, dass der
Antwortstatus korrekt ist, wird pro Datenbankeintrag zweimal die Information gespeichert, dass
die Frage korrekt beantwortet wurde. Trotz diesen Nachteilen wird für den Datenexport diese
Möglichkeit verwendet, da sie den Status einer Antwort eindeutig kennzeichnet.
6.8 ZusammenfassungIn diesem Kapitel wurden mehrere konkrete Probleme und deren Lösungen besprochen. So die
Gestaltung der Benutzeroberfläche, welche in etwa den gleichen Aufbau wie bei DIAX besitzt, al-
lerdings mit verbesserten Eigenschaften, wie die Trennung von Frage- und Kommentartext, sowie
die Möglichkeit den Kommentartext permanent auszuschalten. Die Fragetypen wurden klassifi-
ziert, sodass es eine beschränkte Menge an verfügbaren Fragetypen gibt. Neu ist die Navigations-
komponente, welche innerhalb des gesamten Interviews, die freie Navigation ermöglicht und das
Interview in einem Überblick darstellt. In diesem Überblick wird durch entsprechende Färbung der
Fragen deren aktueller Status vermittelt. Ebenfalls neu ist die Erweiterung der in DIAX vorhande-
nen Informationskomponente.
Die Regelsprache wurde aufgrund der in Abschnitt 5.3 gemachten Grundlagen erweitert und deren
Syntax vollständig beschrieben. Dazu wurden sämtliche Werte und Vergleichsoperatorendefiniert
und beschrieben. In einer allgemeinen Schreibweise wurden sämtliche möglichen Regelkonstrukte
aufgezählt. Die Interview-Definition und das entsprechende Schema wurde kurz beschrieben Da-
bei wurde auch diskutiert, wo die Regeln in einer Interview-Definition definiert werden sollen.
Anschliessend wurde das interne Modell besprochen. D.h. die Modellierung des Interviews, beste-
hend aus Gruppen, Fragen und den Regelbäumen zu den Konsistenz- und Ablaufregeln. Weiter
wurden Mechanismen beschrieben, welche zur Laufzeit angewendet werden. Da der Antwortbe-
reich für jeden Fragetyp angepasst werden muss, wurde die Variante angewendet, welche jeweils
für jede neue Frage ein neues graphisches Objekt instanziert. Die Navigations- und Übersichts-
komponente sowie die Tastatursteuerungwurde ebenfalls beschrieben, dabei wird auf die Proble-
matik hingewiesen, dass SWT nicht vollständig plattformunabhängig ist. Antworten werden nicht
65

mehr zurückgesetzt wie in DIAX, sondern es werden die gegebenen Antworten angezeigt, wenn
eine beantwortete Frage erneut angezeigt wird. Ebenfalls wird die umgesetzte Möglichkeit zur Vi-
sualisierung der gemachten alternativen Antworten beschrieben.
Der Inkonsistenz-Lösemodus wird beschrieben und dessen Funktionsweise erklärt. Dieser soll den
Interviewer unterstützen, wenn ein Interview in einen inkonsistenten gelangt um wieder in einen
konsistenten Zustand zu wechseln. Es wird ebenfalls der Beweis erbracht, dass der verwendete Al-
gorithmus unter den beschriebenen Umständen einen inkonsistenten Zustand eines Interviews in
einen konsistenten überführen kann.Abschliessend wurde beschrieben wie die Antworten expor-
tiert werden um möglichst einfach in die Datenbank einzulesen.
7. EditorUm das erstellen und editieren einer Interview-Definition weiter zu erleichtern wurde ein Editor
implementiert, der es erlaubt Interview-Definitionen zu bearbeiten. So wird es auch Personen er-
möglicht ein Interview zu verändern ohne Kenntnisse über XML zu besitzen. Ein weiterer Vorteil
ist die Übersicht über das gesamte Interview, welche der Editor anbietet und wie bei der Interview-
Anwendung eine schnelle Navigation erlaubt. Ein Vorteil ist es weil eine Frage durch die abgebil-
dete Struktur schnell gefunden wird. Wird in einer Interview-Definition eine Frage gesucht, so
kann dies in Abhängigkeit von der Dokumentgrösse sehr mühsam sein.
Was den Editor anbelangt, wäre es denkbar die Interview-Definition, sofern vorhanden, mit einem
DOM-Parser einzulesen und das erhaltene Modell zu nutzen um Veränderungen vorzunehmen.
Auf diese Möglichkeit wurde allerdings verzichtet, da das interne Modell wie es für die Interview-
Anwendung verwendet wird, über zusätzliche Funktionalitär verfügt welche ebenfalls durch den
Editor genutzt werden kann. Der Editor bearbeitet also das interne Modell, und kann ein solches
von Grund auf neu erstellen.
Bei der Implementierung des Editors wurden zum Teil Komponenten der Interview-Anwendung
wiederverwendet so z.b. die Navigationskomponente. Im Editor wird sie verwendet um die zu edi-
tierenden Gruppen, Fragen oder die Grundeinstellungen des Interviews auszuwählen.
In Abbildung 31 wird die Ansicht zu den Interview Grundeinstellungen gezeigt, welche es erlaubt
eine Beschreibung des Interviews zu erfassen und die globale Codierung der Ja/Nein-Fragen vor-
zunehmen. Zu dieser Ansicht gelangt man wenn wann im Navigationsbereich das oberste Element
(Interview) anwählt. Ebenso werden die entsprechenden Ansichten angezeigt, wenn ein Element in
der Navigationskomponente ausgewählt wird, also Gruppen oder Fragen.
66

Wird eine Gruppe ausgewählt können Titel, dessen Abkürzung und die Start- und Endinformation
editiert werden, welche während des Interviews jeweils zu Beginn und am Ende der betreffenden
Gruppe angezeigt werden. Die ID kann nur editiert werden wenn eine Gruppe neu erstellt wird. In
der folgenden Abbildung wird die Gruppen-Ansicht gezeigt.
67
Abbildung 31: Editor: Interview Grundeinstellungen
Abbildung 32: Editor: Gruppen - Ansicht

Die Fragen werden über eine eigene Ansicht editiert. Diese besteht aus einer Basis-Ansicht (vgl.
Abbildung 33) welche je nach Fragetyp ein weiterschalten zu einer spezifischen Ansicht zulässt.
Dies entspricht dem Aufbau der Fragen, dass jede Frage über gewisse Grundinformationen verfügt
welche in der Basis-Ansicht dargestellt werden. Die je nach Fragetype unterschiedlichen und somit
spezifischen Informationen werden in den entsprechenden spezifischen Ansichten dargestellt. Die
Fragetypen Text-, Zahlen- und Datum-Frage verfügen nur über die Basis-Ansicht, da sie keine
weiteren Informationen benötigen. In der Basis-Ansicht lässt sich der Fragetyp spezifizieren, die
ID (sofern eine Frage neu erstellt wird), der Status der Frage (ob sie ein- oder ausgeschaltet ist) so-
wie den Frage- und Kommentartext. Ebenfalls lassen sich die alternativen Antwortmöglichkeiten
einschränken.
In Abbildung 34 wird eine spezifische Ansicht am Beispiel einer MC-Frage gezeigt. Durch sie
können sämtliche Informationen editiert werden, welche zusätzlich zu den Basis-Information von
dem betreffenden Fragetyp benötigt werden.
68
Abbildung 33: Editor: Ansicht Frage-Basis

Bei dem gezeigten Beispiel sind dies die Antwortoptionen, also ob keine Antwort erlaubt ist und
ob eine oder mehrere Antwortmöglichkeiten ausgewählt werden können. Informationen welche die
Antwortmöglichkeiten beschreiben, den Text der Antwortmöglichkeit sowie den entsprechenden
Code und falls erwünscht zusätzliche editierbare Antwortmöglichkeiten.
Für die Konsistenz- und Ablaufregeln existieren ebenfalls entsprechende Ansichten, welche es er-
lauben Regeln zu editieren oder neu zu erstellen. Die entsprechenden Ansichten werden über einen
Menüpunkt angezeigt. Aus zeitlichen Gründen konnte keine Hifestellung zur Regelgenerierung
implementiert werden, wie sie in Abschnitt 8.2 vorgeschlagen wird. Dies hat zur Folge, dass die
Person welche Veränderungenvornimmt, über genaue Kenntnisse der Regel-Syntax verfügt.
7.1 ZusammenfassungUm das Erstellen und Editieren von Interview-Definitionen zu erleichtern wurde ein Editor imple-
mentiert. Zum Teil wurden Komponenten der Interview-Anwendung wiederverwendet, wie z.B.
die Navigationskomponente. Mit dem Editor können bestehende Interview-Definitionen verändert
oder von Grund auf neu erstellt werden. Für die einzelnen strukturellen Elemente einer Interview-
Definition gibt es entsprechende Ansichten, wie für die Interview-Grundeinstellungen, Gruppen
und die verschiedenen Fragetypen. Sämtliche Fragetypen verfügen über eine Basis-Ansicht. Wer-
den noch zusätzliche Informationen benötigt, in Abhängigkeit vom Fragetyp, werden spezialisierte
Ansichten angezeigt. Auch für die Konsistenz- und Ablaufregeln wurden entsprechende Editier-
69
Abbildung 34: Editor: spezifische Ansicht einer MC-Frage

möglichkeiten implementiert, diese verfügen jedoch über ein Minimum an Funktionalität.
8. Weiterführende IdeenIn diesem Kapitel werden weiterführende Ideen präsentiert, welche aus zeitlichen Gründen nicht
mehr implementiert werden konnten, jedoch zu weiteren Verbesserungender Software führen.
Diese werden nach Applikationen getrennt dargestellt. Ebenfalls wird hier ein Algorithmus präsen-
tiert, welcher automatisch die Erfüllbarkeit der Konsistenzregeln überfprüft.
8.1 Ideen zur Verbesserung der Interview-AnwendungDie Interview-Applikation wird durch eine Konfigurationsdatei konfiguriert. Eine sinnvolle Erwei-
terung ist eine graphische Oberfläche, welche es erlaubt die dort angegebenen Parameter zu verän-
dern. Ob es für sämtliche Parameter sinnvoll ist diese zur Laufzeit zu verändern sei an dieser Stelle
offen gelassen. Für die verschiedenen Schrift-Parameter, welche die Schriftart, -grösse und -typ
definieren, macht es durchaus Sinn diese zur Laufzeit zu verändern und dafür eine entsprechende
graphische Schnittstelle zu implementieren. Die Veränderungenkönnen aufgrund der Implemen-
tierung sofort übernommen und angezeigt werden.
Während der Präsentation der Software bei den Sesam-Forschern, kam der Wunsch auf die Zeit,
welche für die Beantwortung einer Frage benötigt wird, zu messen und festzuhalten. Dies kann
vergleichsweise einfach implementiert werden. Der Zeitraum welcher gemessen werden soll, wird
Eingeschränkt durch den Zeitpunkt, wo die Frage angezeigt wird und den Zeitpunkt, welcher
durch die Betätigung eines Buttons im Buttons-Bereich definiert wird. Die so gemessene Zeit kann
als Attribut der Answer-Klasse übergeben werden. Nun muss nur noch die Export-Methode ange-
passt werden, welche die Tags für den Antwort-Export generiert, sodass die gemessene Zeit eben-
falls gespeichert wird. Eine weitere kleine Anpassung muss noch im Antwort-Export Schema vor-
genommen werden, wo es die entsprechenden Elemente zu definieren gilt.
Ebenfalls sinnvoll, um allfälligen Pannen vorzubeugen, scheint ein Mechanismus welcher in einem
definierbaren Zeitabstand während dem laufenden Interview die Antworten exportiert und somit
speichert. Somit kann vermieden werden, dass im Falle einer Panne (z.B. unbeabsichtigtes schlies-
sen der Interview-Applikation) sämtliche bereits erhobenen Informationen verloren gehen. Ebenso
kann das Interview auch unterbrochen werden, falls der Proband z.B. aus zeitlichen Gründen das
Interview abbrechen muss. Dies setzt jedoch eine weiter Implementierung voraus, welche expor-
tierte Antworten einlesen und das interne Modell anpassen kann, sodass das Interview fortgeführt
werden kann.
Wird in der Konfigurationsdatei das ″default″-Interview auskommentiert erscheint eine Ansicht
70

welche es dem Benutzer erlaubt zwischen sämtlichen Interviews auszuwählen, deren Interview-
Definitionen in einem bestimmten Verzeichnis gespeichert sind. Diese Ansicht soll erweitert wer-
den, sodass zusätzliche Daten wie z.B. die ID des Probanden und des Interviewers angegeben
werden können. Diese zusätzlichen Daten sind Daten, welche ebenfalls in der Datenbank gespei-
chert werden, jedoch getrennt von den exportierten Antworten. Diese Informationen können von
der beschriebenen Ansicht eingelesen und zu einem späteren Zeitpunkt in ein separates XML-Do-
kument exportiert werden. Aus diesen zusätzlichen Daten soll auch ein eindeutiger Dateiname für
den Antwort-Export generiert werden können, damit die Antworten z.B. einem Interview-Typ so-
wie der ID des Probanden eindeutig zugeordnet werden können.
8.2 Ideen zur Verbesserung des EditorsUm es auch einer Person ohne entsprechende Kenntnisse über die Regel-Syntax zu ermöglichen
Regeln zu schreiben, kann eine entsprechende Hilfestellung implementiert werden. Die Idee be-
steht darin, dass eine ″Top-Down″-Strategie verwendet wird um Regeln zu generieren. D.h. die
Struktur der Regel soll von Anfang und während des Erstellungsprozesses sichtbar sein. So kann
der Benutzer im Falle einer Konsistenzregel zu Beginn auswählen, ob es sich um eine Beschrän-
kung oder eine Regel bestehen aus Vor-und Nachbedingung handelt. Entsprechend der getroffenen
Auswahl wird ein Regelgerüst in einem Text-Feld angezeigt. Dazu kann z.B. die allgemeine
Schreibweise verwendet werden, wie sie in Abschnitt gezeigt wurde. Wenn also eine Beschrän-
kung ausgewählt wird, zeigt das Text-Feld folgenden Ausdruck an: <Wert> Vergleichsope-
rator <Wert>;. Je nachdem wo der Benutzer den Cursor innerhalb des Text-Feldes platziert ,
kann er den entsprechenden Ausdruck mit Hilfe einer entsprechenden Ansicht bearbeiten. Der Be-
nutzer soll auch die Möglichkeit erhalten, eine durch den Cursor angewählte Bedingung zu erwei-
tern. Der Allgemeine Ausdruck lässt sich durch diese VorgehensweiseSchritt für Schritt in eine
konkrete Regel umformulieren. Angenommen der Cursor wurde im Text-Feld auf den ersten
<Wert>-Ausdruck platziert. Da ein Wert entweder eine Referenz oder eine Konstante ist, soll der
Benutzer zwischen diesen beiden Möglichkeiten auswählen können. Wählt er die Referenz aus, so
soll er aus einer Liste der bereits bekannten Fragen, die gewünschte Frage auswählen können. Der
Wert-Ausdruckwird darauf durch die entsprechende Referenz ersetzt. Bei der Schrittweisen Gene-
rierung einer Regel so wie sie beschrieben wurde ist darauf zu achten, dass die Auswahlmöglich-
keiten entsprechend eingeschränkt werden. Ist z.B. die ausgewählte Frage eine Text-Frage, darf es
nicht möglich sein einen Vergleichsoperatorwie ″>″ oder ″<=″ auszuwählen, da diese nicht mit
dem Fragetyp kompatibel sind. Ebenso müssen die Konstanten überprüft werden, ob sie dem Fra-
getyp auf der jeweils anderen Seite des Vergleichsoperatorsentsprechen. An dieser Stelle werden
nicht sämtliche möglichen Szenarien durchgegangen, da es sich nur um eine Idee zur erleichterten
71

Regelgeneration handelt. Die Vorgehensweisewurde anhand der Beispiele erklärt und ist auf sämt-
liche Szenarien welche bei der Generierung von Regeln auftauchen übertragbar. Der vorgestellte
Mechanismus stellt eine wesentliche Erleichterung dar für eine Person welche über minimale
Kenntnisse der Regelsyntax verfügt. Allerdings ist eine entsprechende Implementierung mit einem
beträchtlichen Aufwand verbunden da sämtliche Möglichkeiten abgedeckt werden müssen.
Eine Erweiteung welche als notwendig betrachtet wird ist die Möglichkeit in der Navigationskom-
ponente Fragen zu verschieben, was in einer Änderung der Reihenfolge im Interview resultiert.
Auch Gruppen mitsamt ihren untergeordneten Komponenten sollen innerhalb des Interviews ver-
schoben werden können. Ebenfalls ist eine Funktion nötig, welche es ermöglicht eine Frage zu lö-
schen.
Die Diax-Software ermöglicht es dem Anwender bevor das Interview gestartet wird, einzelne
Gruppen auszuwählen, sodass nur deren Fragen im Interview gezeigt werden. Der Editor soll
ebenfalls über diese Möglichkeit verfügen. Dazu soll es möglich sein Gruppen eventuell auch ein-
zelne Fragen in der Navigationskomponente zu markieren und diese in eine neue Interview-Defini-
tion zu exportieren. Diese Funktion macht Sinn, da unter Umständen bei einem Interview-Termin
nicht sämtliche Fragen dem Probanden gestellt werden müssen.
8.3 Algorithmus Konsistenz-NachweisDer in diesem Abschnitt vorgestellte Algorithmus, kann automatisch herausfinden ob es für eine
gegebene Menge von Konsistenzregeln mindestens eine Belegung der variablen Werte gibt, wel-
che einen konsistenten Zustand der Menge beschreibt. Dieser Algorithmus ist eine praktische Er-
gänzung des Editors, sodass die erstellten Regeln automatisch auf ihre Erfüllbarkeit getestet wer-
den können. Für die Beschreibung des Algorithmus werden sogenannte Operator-Graphen benutzt
welche anschliessend definiert werden. Danach erfolgt die Beschreibung des eigentlichen Algo-
rithmus in drei Teilen.
8.3.1 Operator-GraphenOperator-Graphen werden benutzt um die Konsistenzregeln darzustellen. Dazu werden erweiterte
gerichtete Graphen verwendet, welchen gerichteten Graphen als Grundlage dienen. Eine erste Er-
weiterung wird in folgendem Beispiel beschrieben. Als darzustellende Regel wird eine allgemeine
Beschränkung der Form Var > Const (VariablerWert bzw. Referenz > konstanter Wert) ver-
wendet. Die Werte werden als Knoten dargestellt, der Vergleichsoperatorals gerichtete Verbin-
dung, wobei angezeigt wird, dass der Knoten von dem die Verbindungausgeht (hier Var), links
vom betreffenden Vergleichsoperator steht. Der als Senke erscheinende Knoten steht dementspre-
chend auf der rechten Seite des Vergleichsoperator.Die Erweiterung besteht darin, dass die Verbin-
72

dung mit dem Zeichen des Vergleichsoperatorsversehen wird und die dargestellte Bedingung den
Wert ″true″ haben muss. Der Wert ergibt sich durch Auflösung der entsprechenden Bedingung,
mit konkreten Werten. Die eben beschriebene graphischen Darstellung einer Beschränkung ist in
Abbildung 35 ersichtlich.
8.3.2 Der AlgorithmusDer Algorithmus besteht aus drei Teilen. Im ersten Teil wird überprüft ob die Bedingungen mit
boolschen Werten belegt werden können, sodass die Regelmenge konsistent ist. Ist dies der Fall
tritt der zweite Teil in Aktion welcher die Struktur der Regeln überprüft, ob unlösbare Zyklen (s.
betreffenden Abschnitt) vorhanden sind. Im dritten Teil werden die variablen Werte belegt, sodass
die einzelnen Bedingungen die im ersten Teil bestimmten Werte annehmen. Schlägt die Überprü-
fung eines Teiles fehl, sind die Regeln nicht erfüllbar und die verbliebenen Teile müssen nicht
mehr ausgeführt werden.
Erster Teil: suchen der boolschen Belegung für alle Bedingungen
Um die boolsche Belegung für sämtliche Bedingungen zu finden sodass die Regeln konsistent
sind, werden die Regeln der Reihe nach aufgelistet. Alle vorkommenden Beschränkungen erhalten
den Wert ″true″, da sie in nur so erfüllt sind. Gibt es erweiterte Beschränkungen (also durch logi-
sche Operatoren verknüpfte Bedingungen) werden die einzelnen Bedingungen, ebenfalls mit bool-
schen Werten belegt und zwar so, dass die Beschränkung wahr ist.
Die Belegung soll in einer Wahrheitstabelle (vgl. [LogikSkript]) erfolgen, sodass sämtliche mögli-
chen Belegungen daraus ersichtlich sind, dies gilt auch für die noch ausstehenden Konsistzenzre-
geln. Diese werden ebenfalls in mit sämtlichen möglichen Belegungen in die Tabelle eingetragen.
Bestehen allenfalls Vor-und Nachbedingungen ebenfalls aus erweiterten Bedingungen sind diese
wiederum so zu in die Tabelle einzutragen dass sämtliche möglichen Belegungen erfasst werden.
Die so entstandene Tabelle enthält also alle möglichen Belegungen sämtlicher Bedingungen. Nun
werden diejenigen Möglichkeiten gesucht welche sämtliche Regeln erfüllen. D.h. die Beschrän-
kungen müssen alle erfüllt sein, und Konsistenzregeln deren Vorbedingungenerfüllt sind müssen
auch eine erfüllte Nachbedingung aufweisen. Regeln welche eine nicht erfüllte Vorbedingungbe-
sitzen gelten als erfüllt. Hier findet die erste Überprüfung auf Erfüllbarkeit statt. Denn gibt es kei-
73
Abbildung 35: Beschränkung Var> Const alsOperator-Graph
ConstVar>

ne Belegung der einzelnen Bedingungen, sodass alle Regeln erfüllt sind, ist die Menge der Regeln
nicht erfüllbar. Gibt es jedoch mindestens eine Belegung die in einem konsistenten Zustand aller
Regeln resultiert werden diese Möglichkeiten im nächsten Teil einer weiteren Überprüfung unter-
zogen.
Zweiter Teil: Suche nach unlösbaren Zyklen
Für jede Mögliche Belegung aus dem ersten Teil wird nun ein Operator-Graph erstellt, wobei die
Verbindungen, jeweils die betreffenden boolschen Werte zugeordnet werden. Dabei werden die
Operatoren der Verbindungennegiert, falls sie den ″false″Wert erhalten. Da die Verbindungen im
Operator-Graph immer erfüllt sein müssen. Der entstandene Operator-Graph besteht aus mindes-
tens einer Komponente eines Graphen, kann jedoch auch aus mehreren unabhängigen Komponen-
ten bestehen (vgl. [Sedgewick], [Mazzola]). An dieser Stelle kann der Graph noch vereinfacht
werden, indem Knoten welche durch eine Verbindungmit '='-Operator verbunden sind zu einem
Knoten zusammengefasst werden. Da im folgenden mit dem Operator-Graphen gearbeitet wird,
dient dieser Zwischenschritt der Optimierung. Jeder einzelne Teilgraph ist auf das Vorhandensein
eines unlösbaren Zyklus zu überprüfen.
Ein unlösbarer Zyklus ist ein Zyklus welcher mit keiner Belegung der entsprechenden Werten er-
füllt werden kann. Ein Zyklus ist nicht erfüllbar wenn jeweils immer die gleichen Operatoren die
Verbindungen in die gleiche Richtung beschreiben. Dies betrifft jedoch nur die '<' und '>'-Operato-
ren. Ein solcher unlösbarer Zyklus wird lösbar wenn z.B, ein '>'-Operator durch einen '<'-Opera-
tor ersetzt wird oder einer der Operatoren negiert wird.. Bei den '>=' und '<=' -Operatoren besteht
dieses Problem nicht, da Gleichheit erlaubt ist. Ein weiter Fall welcher zu einer nicht lösbaren In-
konsistenz führt, ist die Verbindungzweier Konstanten durch den '='- Operator. Diese Verbindung
kann nicht erfüllt werden, da eine Konstante mit dem Wert X eines betreffenden Typs durch ein
und denselben Knoten im Operator-Graph dargestellt wird. Ein konstanter Knoten mit Wert Y ent-
spricht entweder nicht dem Datentyp von X oder hat einen anderen Wert. In beiden Fällen schlägt
die Überprüfung auf Gleichheit fehl.
In Abbildung 36 wird ein Beispiel eines unlösbaren Zyklus gezeigt, welcher aus den Bedingungen
Var 1 > Const , Const > Var 2 und Var 1 = Var 2 gebildet wird. Ein Zyklus ist
im allgemeinen nicht lösbar, wenn durch das vorher beschriebene Zusammenfassen von Knoten,
welche durch einen '='-Operator verbunden sind, ein Widerspruch ensteht, wie dies ebenfalls in
Abbildung 36 der Fall ist. Denn Var 1, bzw. Var 2 kann nicht gleichzeitig kleiner und grösser
als Const sein. Es ist offensichtlich, dass keine Belegung der variablen WerteVar 1 und Var
2 gefunden werden kann, sodass alle Verbindungenwahr sind.
74

Es muss also jeder Teilgraph auf Zyklen durchsucht werden, dazu kann wie in [Sedgewick] be-
schrieben, ein entsprechend modifizierter Algorithmus zur Tiefensuche herangezogen werden.
Sind Zyklen gefunden worden, müssen sie überprüft werden ob es sich jeweils um lösbare oder
unlösbare Zyklen handelt. Existiert bereits ein einziger unlösbarer Zyklus in einem Teilgraphen
aus einer Zuordnungsmöglichkeit aus dem ersten Teil, so ist diese Zuordnungsmöglichkeit nicht
erfüllbar und wird nicht weiter betrachtet. Gibt es an dieser Stelle keine erfüllbare Zuordnung ist
die Menge der Regeln nicht erfüllbar und der Algorithmus kann abgebrochen werden. Existiert je-
doch mindestens eine Zuordnung aus dem ersten Teil welche keine unslösbaren Zyklen enthält, so
wird mit diesen Zuordnungen im dritten Teil die Belegung der variablen Werte überprüft.
Dritter Teil: suche nach einer Belegung der variablen Werte
In diesem dritten und letzten Teil des Algorithmus werden Belegungen für die variablen Werte,
also die Referenzen gesucht, sodass alle Bedingungen des Operator-Graphen erfüllt werden. Dazu
wird ein Knoten gesucht, welcher nur ausgehende Verbindungenhat und somit als Startknoten
dient. Existiert kein solcher Knoten kann auch ein Knoten mit nur eingehenden Verbindungenge-
sucht werden. Ist ein solcher Knoten ebenfalls nicht auffindbar, handelt es sich um einen lösbaren
Zyklus und es kann ein beliebiger Knoten als Startpunkt verwendet werden.
Als nächstes muss für den Startknoten ermittelt werden welchen Fragetyp er referenziert um einen
entsprechenden Startwert zu setzen. Dies wird auch bei jedem weiteren Referenzknoten nötig sein.
Um das Vorgehenzu beschreiben wird davon ausgegangen, dass es sich bei sämtlichen referenzie-
renden Knoten um Zahlen-Fragen handelt, es können jedoch beliebige Typen sein, es muss jeweils
einfach der Typ angepasst werden. Es wurde also ein Startknoten gefunden welcher nur ausgehen-
de Verbindungenaufweist. Ist es ein referenzierender Knoten, also einer mit einem VariablenWert,
75
Abbildung 36: Beispiel eines unlösbarenZyklus
Const
Var1
Var2
<
>
=

so wird im der Wert 0 gegeben. Im folgenden Schritt werden die Nachbarknoten mit ihren jeweili-
gen, durch die Verbindungdefinierten, Operatoren betrachtet. Ist der Nachbar ebenfalls eine Refe-
renz so wird dieser Abhängig vom Operator ein Wert gegeben welcher die Beziehung erfüllt und
möglichst nah am Wert des Starknotens ist. So z. B. Erhält der Nachbarknoten für den Operator
″>″ den nächstkleineren Wert -1. Angenommen ein weiterer Nachbarknoten des Startknotens ist
ein Knoten mit einer Konstante, welche den Wert 2 hat und die Verbindungausgehend vom Start-
knoten hat den Operator ″>=″. Nun muss der Startknoten angepasst werden und erhält den Wert 2,
da dies dem nächsten Wert entspricht welcher die Bedingung gerade noch erfüllt. Nach einer er-
folgten Anpassung müssen sämtliche bereits angepassten Knoten wieder überprüft werden und ge-
gebenenfalls erneut angepasst werden. Da der erste Nachbarknoten den Wert -1 hat und dieser
kleiner als der Startknoten (2) ist, muss er nich angepasst werden da 2 > -1 korrekt ist.
In Abbildung 37 wird das Beispiel mit noch unbelegten Referenzen-Knoten gezeigt. Mit dem be-
schriebenen Vorgehenkönnen sämtliche variablen Knoten mit Werten belegt werden. Wobei auch
entgegen der Pfeilrichtung vorgegangen werden kann. Für dieses Verfahrenbietet sich eine ent-
sprechend modifizierte Breitensuche (vgl. [Sedgewick] ) an. Ist es nicht möglich eine entsprechen-
de Belegung zu finden, so besteht ein Widerspruch in den Regeln und sie sind nicht erfüllbar.
Wenn jedoch eine wiederspruchsfreie Belegung gefunden wird, so gibt es mindestens eine (näm-
lich genau die gefundene) Belegung der variablen Werte, sodass sich die Regeln in einem konsis-
tenten Zustand befinden.
8.4 ZusammenfassungIn diesem Kapitel wurden Ideen beschrieben, welche die Funktionalität von Interview-Anwendung
und Editor verbessern, jedoch aus zeitlichen Gründen nicht mehr implementiert werden konnten.
Die vorgeschlagenen Verbesserungender Interview-Anwendung sind:
● Die Möglichkeit die Parameter der Konfigurationsdatei graphisch darzustellen und in die-
ser Darstellung zu verändern, insbesondere die Schrift-Parameter.
● Die Zeit erfassen welche der Proband benötigt um eine Frage zu beantworten.
76
Abbildung 37: Illustration zum Beispiel
?
?
2Start-Knoten, referenziertZahlen-Frage
1. Nachbar, referenziertZahlen-Frage
2. Nachbar, KonstanterWertvom Typ Zahl

● Automatische Speicherung der Antworten, sowie die Möglichkeit diese wieder zu lesen.
(Wiederaufnahme eines abgebrochenen Interviews.)
● Implementierung um die Prozessinformationen einzulesen und diese gegebenenfalls zur
Generierung des Dateinamens für das Antwort-Export-Dokument.
● Eine Erweiterung, sodass die Applikation für die Qualitätssicherung verwendet werden
kann. Für die Qualitatssicherung der Interviews, im Rahmen der Sesam-Studie werden die
beantworteten Interviews, durch Personen überprüft. Dazu kann die Interview-Anwendung
verwendet werden. Die Erweiterung muss in der Lage sein die Interview-Definition und
enstpsrechende Antworen aus der Datenbank auszulesen, sodass die Person welche die
Überprüfung vornimmt, das Interview mit den Antworten ansehen und gegebenenfalls
überarbeiten kann.
Als Erweiterungen für den Editor wurden genannt:
● Implementierung einer Hilfestellung, welche die Regel-Generierung vereinfacht und diese
somit auch einer Person ohne vollständigen Kenntnissen der Regel-Syntax ermöglicht.
● Erweiterung der Funktionalität der Navigationskomponente insbesondere das Verschieben
von Fragen und Gruppen innerhalb des Interviews, sowie die Möglichkeit Strukturen zu lö-
schen.
● Erweiterung der Navigationskomponente, sodass markierte Elemente in ein neues Inter-
view exportiert werden können.
Weiter wurde der Algorithmus ausführlich beschrieben welcher die Erfüllbarkeit einer gegebenen
Menge von Konsistenzregeln überprüft. In drei Schritten werden Bedingungen überprüft welche
es unmöglich machen, sämtliche Regeln auszufüllen, sodass sie sich in einem Konsistenten Zu-
stand befinden. Dazu wird überprüft ob es eine Belegung sämtlicher Bedingungen mit boolschen
Werten gibt sodass alle Regeln erfüllt werden. Gibt es mindestens eine solche Belegung werden
für diese Operator-Graphen erstellt. Hier wird überprüft ob unlösbare Zyklen existieren welche es
unmöglich machen die Regeln zu erfüllen. Werden keine solche Zyklen entdeckt, wird im letzten
Schritt eine Belegung der variablen Werte gesucht, sodass die Regeln erfüllt werden. Gelingt dies
so gibt es erwiesener massen mindestens eine Möglichkeit das Interview zu beantworten, sodass es
sich in einem konsistenten Zustand befindet.
9. ZusammenfassungAus der vorliegenden Arbeit resultiert eine Anwendung, welche Interview-Definitionen im XML-
Format lesen und das entsprechende Interview graphisch darstellen und durchführen kann. Die An-
77

wendung ist auf klinische Interviews, bzw. standardisierte Interviews spezialisiert, sodass in der
Definition spezifizierte Regeln überprüft werden können. Mit Hilfe von Konsistenzregeln, können
Antworten entdeckt werden, welche sich im Widerspruch zu anderen Antworten befinden oder
aber den Wertebereich einer Antwort einschränken. Durch Ablaufregeln kann der Interview-Ver-
lauf, in Abhängigkeit der Antworten, adaptiv angepasst werden. Dies wird erreicht indem einzelne
oder mehrere Fragen, je nach Antwort einer bestimmten Frage, ein- bzw. ausgeschaltet werden.
Die durch die Anwendung erhobenen Antworten werden in ein XML-Dokument exportiert, sodass
diese mit geringem Aufwand in eine Datenbank eingelesen werden können. Zusätzlich wurde ein
Editor implementiert, welcher es einer entsprechend instruierten Person ermöglicht Interview-De-
finitionen zu verändern oder neu zu erstellen.
Die Anforderungen an die Interview-Anwendung wurden aus der Definition des standardisierten
Interviews abgeleitet. Die DIAX-Anwendung ist ein Programm welches ebenfalls klinische Inter-
views durchführen kann, aber aus den beschriebenen Gründen nicht im Rahmen des Sesam-Pro-
jektes verwendet werden kann. Die neu im Rahmen dieser Arbeit implementierte Interview-An-
wendung unterscheidet sich unter anderem in den folgenden Punkten von der DIAX-Software.
● Die Interview-Anwendung ist ein kompiliertes Programm, welches Interview-Definitionen
im XML-Format interpretieren kann.
● Konsistenz- und Ablaufregeln können ohne Programmierkenntnisse verfasst werden.
● Die Regeln werden in einer eindeutigen und leicht verständlichen formalen Sprache darge-
stellt.
● Die Interview-Anwendung verfügt über eine definierte Anzahl von Fragetypen. Dadurch
wird man gezwungen andere Typen durch die definierten Typen zu ersetzen, dafür können
ohne über Programmierkenntnisse verfügen zu müssen, Attribute der definierten Fragety-
pen verändert werden.
● Durch die Übersichts- und Navigationskomponente erhält der Benutzer eine Übersicht über
das gesamte Interview und er kann sich darin frei bewegen. Durch eine Farb-Codierung der
Fragen lässt sich der Status einer bestimmten Frage leicht erkennen.
● Die Informationskomponente gibt gut sichtbar Auskunft über den aktuellen Stand des In-
terviews. D.h. es wird angezeigt wieviele Fragen bearbeitet und wieviele korrekt beantwor-
tet wurden. Tritt ein inkonsistenter Zustand ein wird ebenfalls darüber informiert, wieviele
Fragen inkonsistent sind.
● Durch den Inkonsistenz-Lösemechanismus wird der Interviewer bei Auftreten eines inkon-
78

sistenten Zustandes dazu angehalten, die Inkonsistenz zu lösen und wird dazu entsprechend
unterstützt. Dazu werden Hilfstexte angezeigt, welche die inkonsistenten Regeln beschrei-
ben.
● Der Editor, durch den Interview-Definitionen erstellt und verändert werden können, ohne
über entsprechende XML-Kenntnisse zu verfügen.
In dieser Ausarbeitung wurden Probleme, die während der Implementierung auftraten, Lösungsal-
ternativen sowie jeweils die konkrete Lösung beschrieben. In Kapitel 5 Werden allgemeine Pro-
blemstellungen und entsprechende Lösungsmöglichkeiten besprochen, wie die Auswahl einer ge-
eigneten Programmiersprache, die Grundsätzliche Architektur, die das Einlesen von Interview-De-
finitionen ermöglicht, welches Format für die Interview-Definition verwendet werden soll und wie
die Regeln ausgedrückt werden sollen. In Kapitel 6 werden die Ansätze zum Teil weiter konkreti-
siert und es werden weitere Details und Lösungsansätze der Implementierung besprochen. Wie die
Oberfläche gestaltet wurde, weiter die Typen der Fragen klassifiziert und beschrieben. Die Regeln
wurden ausführlich besprochen und deren Syntax beschrieben. Es wurde erklärt wie die Interview-
Definitionen mit den Regeln gelesen werden und das durch den Lese-Prozess erhaltene interne Da-
tenmodell aussieht. Mechanismen die zur Laufzeit verwendet werden, wurden erklärt und be-
schrieben. Also wie die Fragen visualisiert werden, wie die Übersichts- und Navigationskompo-
nente interpretiert und verwendet wird. Die Tastatursteurungwurde beschrieben und ebenfalls was
passiert wenn eine beantwortete Frage erneut angezeigt wird, da sich das Verhaltenvon dem ent-
sprechenden Verhalten in DIAX unterscheidet. Der Inkonsistenz-Lösemodus wurde beschrieben,
und erklärt, sowie der Beweis wurde erbracht, dass unter den gegebenen Umständen ein inkonsis-
tenter Zustand in einen konsistenten überführt werden kann. est Ebenso werden dort spezifische
Probleme und deren Lösungsansätze besprochen. Zuletzt wurde in dem betreffenden Kapitel be-
schrieben wie die Antworten existiert werden und welche Probleme dabei auftreten. Die Funktio-
nalität des Editors wird anschliessend in einem eigenen Kapitel beschrieben. Die Ausarbeitung
wird mit einer Reihe an Ideen abgeschlossen, welche nicht mehr umgesetzt werden konnten, je-
doch zu weiteren Verbesserungender beiden Applikationen führen.
79

Literaturverzeichnis
[AeBlatt18] : Ralf Ott, Computergestützte Diagnoseverfahren für psychische Störungen:Unterstützung für den „klinischen Blick“, Deutsches Ärzteblatt 97, Ausgabe 18 vom 05.05.2000,S. 16-18, http://aerzteblatt.lnsdata.de/pdf/97/18/s16.pdf
[antlr] : Terence Parr , antlr.org, http://www.antlr.org/,Stand: 09.08.2007
[Bing/Miller] : Jian Bing Li, James Miller, Testing the Semantics of W3C XML Schema, 2005,http://ieeexplore.ieee.org/iel5/10076/32335/01510064.pdf
[Bühler] : Marc Bühler, Semesterarbeit: Lernumgebung LogicTraffic ImplementierungeinesParsersund Evaluators für aussagenlogische Formeln, people.inf.ethz.ch/rarnold/theses/LogicTraffic-Parser_report.pdf, Stand:11.08.2007
[DIAX] : DIA-X Interview, Version1.2
[JAVA]: (Sun), The Source for Java Developers, http://java.sun.com/, Stand: März 2007
[JavaCompiler] : Fraunhofer Institut, Compiler Construction with Java,http://catalog.compilertools.net/java.html, Stand: 09.08.2007
[LogikSkript] : (unbekannt), Logik Skript: Was ist Logik?,http://www.ifi.unizh.ch/cl/klenner/lehre/formale_grundlagen/Aussagenlogik.pdf, Stand:25.08.2007
[Mazzola] : Guerino Mazzola, Gérard Milmeister, Jody Weissmann, Comprehensive Mathematicsfor Computer Scientists 1, 2004, Springer, 1. Auflage, ISBN: 3-540-20835-6
[NFS] : Schweizerischer Nationalfonds zur Förderungder wissenschaftlichen Forschung (SNF),Nationale Forschungsschwerpunkte NFS,http://www.snf.ch/D/forschung/Forschungsschwerpunkte/Seiten/default.aspx, Stand: 15.08.2007
[PDIAG] : Schumacher J., Brähler E., Klinische Psychodiagnostik, 2004,http://medpsy.uniklinikum-leipzig.de/pdf/klips_diagn.pdf
[Sedgewick] : Robert Sedgewick, Algorithmen, 2002, Addison-Wesley,2. Auflage, ISBN: 3-8273-7032-9
[SESAM] : sesam, Projekt Homepage, http://www.sesamswiss.ch, Stand: 15.08.2007
[SkriptDiagnostik] : Changiz Mohiyeddini, VorlesungDiagnostik: Diagnostik als Testung,www.psychologie.unizh.ch/klipsypt/lehre/ss04/diagnostik/11.pdf, Stand: 09.08.2007
[SVG] : Chris Lilley, Dean Jackson (W3C), Scalable VectorGraphics (SVG),http://www.w3.org/Graphics/SVG/, Stand: 23.08.2007
[SWTorg] : http://www.eclipse.org/swt/, Stand: Mai 2007
[Völler] : Prof. Dr. Reinhard Völler, Formale Sprachen und Compiler, http://users.informatik.haw-
80

hamburg.de/~voeller/fc/comp/comp.html, Stand: 13.08.2007
[W3CXML] : Bert Bos, W3C: XML in 10 points, http://www.w3.org/XML/1999/XML-in-10-points.html.en, Stand: 01.08.2007
[XercesFEAT] : The Apache Software Foundation, Setting Features,http://xerces.apache.org/xerces2-j/features.html, Stand: 08.08.2007
[XercesPROP] : The Apache Software Foundation, Setting Properties,http://xerces.apache.org/xerces2-j/properties.html, Stand: 08.08.2007
[XMLDOM] : Robin Cover, Technology Reports: W3C Document Object Model (DOM),http://xml.coverpages.org/dom.html, Stand: 08.08.2007
[XMLSAX] : (Autor unbekannt), XML Focus Topics : SAX,http://www.xml.org/xml/resources_focus_sax.shtml, Stand: 08.08.2007
[XMLSchema] : W3C, W3C Recommendation: XML Schema Part 0: Primer Second Edition,http://www.w3.org/TR/xmlschema-0/, Stand: 01.08.2007
81

AbbildungsverzeichnisAbbildung 1: WHO Prognose [SESAM]............................................................................................8Abbildung 2: 4 Teilbereiche eines Compilers..................................................................................14Abbildung 3: DIAX - Architektur....................................................................................................20Abbildung 4: DIAX – Oberfläche [DIAX].......................................................................................21Abbildung 5: DIAX Zahlen-Frage [DIAX]......................................................................................22Abbildung 6: DIAX Datum-Frage [DIAX]......................................................................................23Abbildung 7: DIAX Text-Frage [DIAX]..........................................................................................23Abbildung 8: DIAX MC-Frage mit einer Antwortmöglichkeit [DIAX]..........................................24Abbildung 9: DIAX Listen-Frage [DIAX].......................................................................................24Abbildung 10: DIAX Ja/Nein-Frage [DIAX]...................................................................................25Abbildung 11: DIAX Dual-Frage [DIAX].......................................................................................25Abbildung 12: DIAX Mehrfach-Antwort [DIAX]...........................................................................26Abbildung 13: Ansatz mit implizitem Compiler-Aufruf..................................................................28Abbildung 14: Ansatz der kompletten Trennung.............................................................................29Abbildung 15: Benutzeroberfläche...................................................................................................36Abbildung 16: Text-Frage.................................................................................................................38Abbildung 17: Zahlen-Frage............................................................................................................38Abbildung 18: Datum-Frage.............................................................................................................39Abbildung 19: MC-Frage mit einer Antwortmöglichkeit.................................................................39Abbildung 20: MC-Frage mit mehreren Antwortmöglichkeiten......................................................40Abbildung 21: MC-Frage mit einem beschreibbaren Feld...............................................................40Abbildung 22: Ja/Nein-Frage...........................................................................................................42Abbildung 23: Dual-Frage................................................................................................................43Abbildung 24: Frage mit Textreferenz.............................................................................................44Abbildung 25: MC-Frage mit Antwort-Referenz.............................................................................44Abbildung 26: Interview - Struktur..................................................................................................53Abbildung 27: Beispiel eines einzelnen Regelbaumes.....................................................................58Abbildung 28: Die Navigations-Komponente..................................................................................61Abbildung 29: Buttons-Bereich mit Antwort- und Fokus-Markierung............................................62Abbildung 30: Erweiterter Informations-Bereich im Inkonsistenz-Lösemodus..............................64Abbildung 31: Editor: Interview Grundeinstellungen......................................................................69Abbildung 32: Editor: Gruppen - Ansicht........................................................................................70Abbildung 33: Editor: Ansicht Frage-Basis.....................................................................................71Abbildung 34: Editor: spezifische Ansicht einer MC-Frage............................................................72Abbildung 35: Beschränkung Var> Const als Operator-Graph.......................................................76Abbildung 36: Beispiel eines unlösbaren Zyklus.............................................................................78Abbildung 37: Illustration zum Beispiel..........................................................................................79
82

TabellenverzeichnisTabelle 1: Werte: Referenzen und Konstanten.................................................................................49Tabelle 2: Vergleichsoperatoren........................................................................................................49Tabelle 3: Kombinations-Möglichkeiten von Fragetypen (Wert-Typen)und Vergleichsoperatoren50Tabelle 4: WeitereAusdrücke der Regelsprache..............................................................................51
83

Anhang A : Interview-Schema
<?xml version="1.0" encoding="iso-8859-1"?><xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:annotation><xsd:documentation>
This is the xml scheme for an interview.</xsd:documentation>
</xsd:annotation>
<xsd:element name="InterviewDefinition" type="InterviewDefinitionType"/>
<xsd:complexType name="InterviewDefinitionType"><xsd:sequence>
<xsd:element name="Interview" type="InterviewType"/><xsd:element name="Rules" type="RulesType"/>
</xsd:sequence></xsd:complexType>
<xsd:complexType name="InterviewType"><xsd:sequence>
<xsd:element name="Description" type="LangSelectionType"/><xsd:element name="InterviewType" type="xsd:string"/><xsd:element name="Definitions" type="DefinitionsType"/><xsd:choice minOccurs="1" maxOccurs="unbounded">
<xsd:element name="QuestionGroup"type="QuestionGroupType"/>
<xsd:element name="Question" type="QuestionType"/></xsd:choice>
</xsd:sequence><xsd:attribute name="numberOfQuestions" type="xsd:int"
use="required"/></xsd:complexType>
<xsd:complexType name="DefinitionsType"><xsd:sequence>
<xsd:element name="YesCode" type="CodeDefinitionType"/><xsd:element name="NoCode" type="CodeDefinitionType"/>
</xsd:sequence></xsd:complexType>
<xsd:complexType name="CodeDefinitionType"><xsd:attribute name="value" type="xsd:int"/>
</xsd:complexType>
<xsd:complexType name="QuestionGroupType"><xsd:sequence>
<xsd:element name="Title"type="LangSelectionType"/>
<xsd:element name="shortcut"type="LangSelectionType"/>
<xsd:element name="beginInfo" type="LangSelectionType"minOccurs="0" maxOccurs="1"/>
<xsd:choice minOccurs="1" maxOccurs="unbounded"><xsd:element name="QuestionGroup"
type="QuestionGroupType"/><xsd:choice>
<xsd:element name="TextQuestion"type="TextQuestionType"/>
84

<xsd:element name="NumberQuestion"type="NumberQuestionType"/>
<xsd:element name="SelectionQuestion"type="SelectionQuestionType"/>
<xsd:element name="YesNoQuestion"type="YesNoQuestionType"/>
<xsd:element name="DateQuestion"type="DateQuestionType"/>
<xsd:element name="RefSelectionQuestion"type="RefSelectionQuestionType"/>
<xsd:element name="DualQuestion"type="DualQuestionType"/>
<xsd:element name="TextRefQuestion"type="TextRefQuestionType"/>
</xsd:choice><xsd:element name="endInfo" type="LangSelectionType"
minOccurs="0" maxOccurs="1"/></xsd:sequence><xsd:attribute name="id" type="xsd:ID" use="required"/><xsd:attribute name="enabled" type="xsd:boolean" use="optional"/>
</xsd:complexType>
<xsd:complexType name="TitlesType"><xsd:sequence>
<xsd:element name="Title" type="LangSelectionType"/><xsd:element name="shortcut" type="LangSelectionType"/>
</xsd:sequence></xsd:complexType>
<xsd:complexType name="LangSelectionType"><xsd:sequence>
<xsd:choice minOccurs="1" maxOccurs="3"><xsd:element name="german" type="xsd:string"
minOccurs="0" maxOccurs="1"/><xsd:element name="french" type="xsd:string"
minOccurs="0" maxOccurs="1"/><xsd:element name="italian" type="xsd:string"
minOccurs="0" maxOccurs="1"/></xsd:choice>
</xsd:sequence></xsd:complexType>
<xsd:complexType name="ExclusiveButtonsType"><xsd:sequence>
<xsd:element name="Button" minOccurs="0"maxOccurs="unbounded">
<xsd:complexType><xsd:sequence></xsd:sequence><xsd:attribute name="buttonID" type="xsd:int"/></xsd:complexType>
</xsd:element></xsd:sequence>
</xsd:complexType>
<xsd:complexType name="RulesType"><xsd:sequence>
<xsd:element name="ConsistencyRules"type="ConsistencyRulesType"/>
<xsd:element name="SequenceRules" type="SequenceRulesType"/></xsd:sequence>
85

</xsd:complexType><xsd:complexType name="ConsistencyRulesType">
<xsd:sequence><xsd:element name="ConsistencyRule"
type="ConsistencyRuleType" minOccurs="0"maxOccurs="unbounded"/>
</xsd:sequence></xsd:complexType>
<xsd:complexType name="ConsistencyRuleType"><xsd:sequence>
<xsd:element name="Rule" type="xsd:string" minOccurs="1"maxOccurs="1"/>
<xsd:element name="HelpText" type="LangSelectionType"minOccurs="1" maxOccurs="1"/>
</xsd:sequence></xsd:complexType>
<xsd:complexType name="SequenceRulesType"><xsd:sequence>
<xsd:element name="SequenceRule" type="xsd:string"minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence></xsd:complexType>
<!-- Basic Question --><xsd:complexType name="QuestionType">
<xsd:sequence><xsd:element name="QuestionText" type="LangSelectionType"
minOccurs="1" maxOccurs="1"/><xsd:element name="CommentText" type="LangSelectionType"
minOccurs="0" maxOccurs="1"/><xsd:element name="ExclusiveButtons"
type="ExclusiveButtonsType" minOccurs="0"maxOccurs="1"/>
</xsd:sequence><xsd:attribute name="id" type="xsd:ID" use="required"/><xsd:attribute name="enabled" type="xsd:boolean" use="optional"/>
</xsd:complexType>
<!-- Text Question --><xsd:complexType name="TextQuestionType">
<xsd:complexContent><xsd:extension base="QuestionType"></xsd:extension>
</xsd:complexContent></xsd:complexType>
<!-- Number Question --><xsd:complexType name="NumberQuestionType">
<xsd:complexContent><xsd:extension base="QuestionType"></xsd:extension>
</xsd:complexContent></xsd:complexType>
<!-- Selection Question --><xsd:complexType name="SelectionQuestionType">
<xsd:complexContent><xsd:extension base="QuestionType">
<xsd:sequence>
86

<xsd:element name="SelectionDefinition"type="SelectionDefinitionType"/>
</xsd:sequence><xsd:attribute name="multiselect" type="xsd:boolean"
use="required"/><xsd:attribute name="emptyAllowed" type="xsd:boolean"/>
</xsd:extension></xsd:complexContent>
</xsd:complexType>
<!-- Yes No Question --><xsd:complexType name="YesNoQuestionType">
<xsd:complexContent><xsd:extension base="QuestionType">
<xsd:sequence><xsd:element name="RefAnswer"
type="LangSelectionType"/></xsd:sequence>
</xsd:extension></xsd:complexContent>
</xsd:complexType>
<!-- Date Question --><xsd:complexType name="DateQuestionType">
<xsd:complexContent><xsd:extension base="QuestionType"/>
</xsd:complexContent></xsd:complexType>
<!-- SelectionQuestion that references it answerpossibilities to other answers-->
<xsd:complexType name="RefSelectionQuestionType"><xsd:complexContent>
<xsd:extension base="QuestionType"><xsd:sequence>
<xsd:choice minOccurs="1" maxOccurs="unbounded"><xsd:element name="SelectionDefinition"
type="SelectionDefinitionType"/><xsd:element name="RefSelectionDefinition"
type="RefSelectionDefinitionType"/></xsd:choice>
</xsd:sequence><xsd:attribute name="multiselect" type="xsd:boolean"
use="required"/></xsd:extension>
</xsd:complexContent></xsd:complexType>
<!-- used by SelectionQuestionType--><xsd:complexType name="SelectionDefinitionType">
<xsd:sequence><xsd:choice minOccurs="2" maxOccurs="unbounded">
<xsd:element name="SelectionItem"type="SelectionItemType"/>
</xsd:choice><xsd:choice minOccurs="0" maxOccurs="unbounded">
<xsd:element name="WritableField"type="WritableFieldType"/>
</xsd:choice></xsd:sequence>
</xsd:complexType>
87

<!-- used by RefSelectionQuestionType--><xsd:complexType name="RefSelectionDefinitionType">
<xsd:sequence><xsd:element name="RefSelectionItem"
type="RefSelectionItemType" minOccurs="1"maxOccurs="unbounded"/>
</xsd:sequence></xsd:complexType>
<!-- used by SelectionDefinitionType--><xsd:complexType name="SelectionItemType">
<xsd:attribute name="text" type="xsd:string" use="required"/><xsd:attribute name="textFR" type="xsd:string" use="optional"/><xsd:attribute name="textIT" type="xsd:string" use="optional"/><xsd:attribute name="code" type="xsd:string" use="required"/>
</xsd:complexType>
<xsd:complexType name="WritableFieldType"><xsd:attribute name="auto" type="xsd:boolean" use="optional"/><xsd:attribute name="code" type="xsd:string" use="optional"/>
</xsd:complexType>
<!-- used by RefSelectionDefinitionType--><xsd:complexType name="RefSelectionItemType">
<xsd:attribute name="questionRef" type="xsd:IDREF" use="required"/></xsd:complexType>
<!-- Questions with a (to previous answers) related questiontext -->
<xsd:complexType name="TextRefQuestionType"><xsd:sequence>
<xsd:choice minOccurs="1" maxOccurs="1"><xsd:element name="TextQuestion"
type="TextQuestionType"/><xsd:element name="NumberQuestion"
type="NumberQuestionType"/><xsd:element name="SelectionQuestion"
type="SelectionQuestionType"/><xsd:element name="YesNoQuestion"
type="YesNoQuestionType"/><xsd:element name="DateQuestion"
type="DateQuestionType"/><xsd:element name="RefSelectionQuestion"
type="RefSelectionQuestionType"/><xsd:element name="DualQuestion"
type="DualQuestionType"/></xsd:choice>
</xsd:sequence></xsd:complexType>
<xsd:complexType name="TextRefType"><xsd:attribute name="id" type="xsd:IDREF" use="required"/>
</xsd:complexType>
<!-- Dual Question --><xsd:complexType name="DualQuestionType">
<xsd:sequence><xsd:element name="QuestionText" type="LangSelectionType"
minOccurs="0" maxOccurs="1"/><xsd:element name="CommentText" type="LangSelectionType"
88

minOccurs="0" maxOccurs="1"/><xsd:element name="ExclusiveButtons"
type="ExclusiveButtonsType" minOccurs="0"maxOccurs="1"/>
<xsd:choice minOccurs="2" maxOccurs="2"><xsd:element name="TextQuestion"
type="TextQuestionType"/><xsd:element name="NumberQuestion"
type="NumberQuestionType"/><xsd:element name="SelectionQuestion"
type="SelectionQuestionType"/><xsd:element name="YesNoQuestion"
type="YesNoQuestionType"/><xsd:element name="DateQuestion"
type="DateQuestionType"/><xsd:element name="RefSelectionQuestion"
type="RefSelectionQuestionType"/><xsd:element name="TextRefQuestion"
type="TextRefQuestionType"/></xsd:choice><xsd:element name="RefAnswer" type="LangSelectionType"
minOccurs="0" maxOccurs="1"/></xsd:sequence><xsd:attribute name="enabled" type="xsd:boolean" use="optional"/>
</xsd:complexType>
</xsd:schema>
89
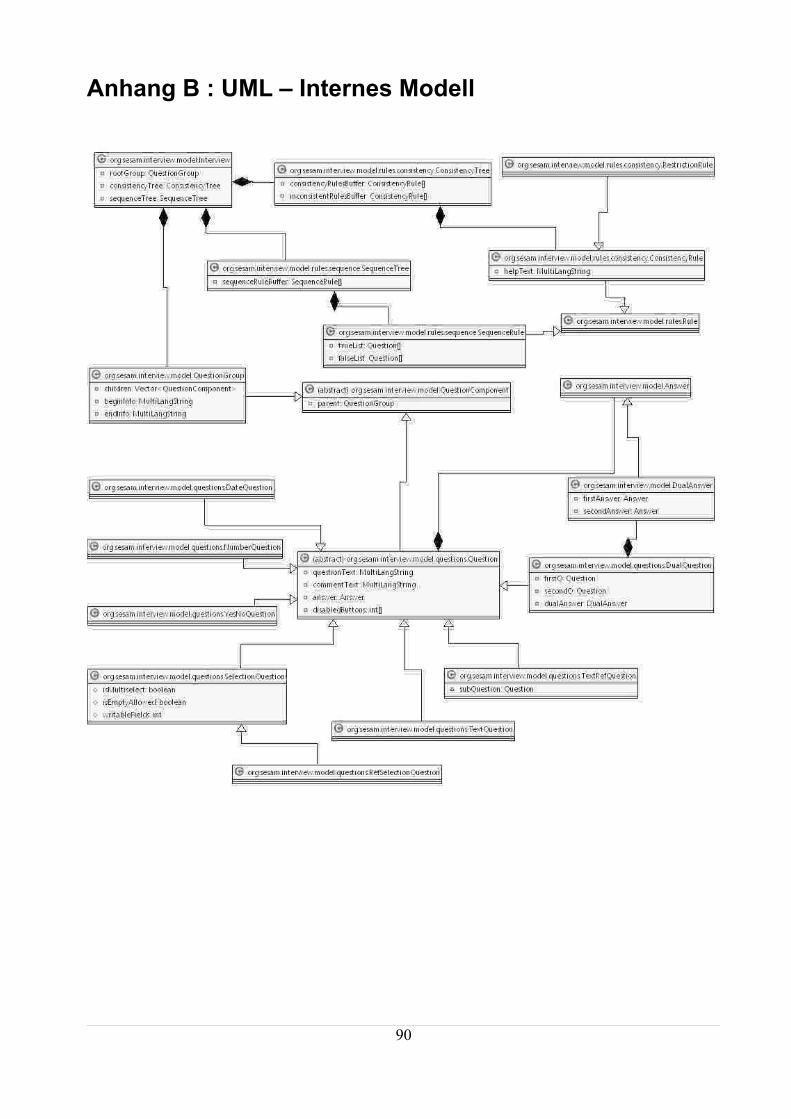
Anhang B : UML – Internes Modell
90

Anhang C : Antwort-Export-Schema
<?xml version="1.0" encoding="iso-8859-1"?><xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:annotation><xsd:documentation>
This is the xml scheme for the answer export.</xsd:documentation>
</xsd:annotation>
<xsd:element name="AnswerExport" type="AnswerExportType"/>
<xsd:complexType name="AnswerExportType"><xsd:sequence>
<xsd:element name="InterviewType" type="xsd:string"/><xsd:element name="InterviewID" type="xsd:string"/><xsd:choice maxOccurs="unbounded" minOccurs="0">
<xsd:element name="Answer" type="AnswerType"/><xsd:element name="DualAnswer" type="DualAnswerType"/>
</xsd:choice></xsd:sequence>
</xsd:complexType>
<xsd:complexType name="AnswerType"><xsd:sequence>
<xsd:element name="AnswerItem" type="xsd:string"minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence><xsd:attribute name="id" type="xsd:ID" use="required"/><xsd:attribute name="type" type="xsd:string" use="required"/><xsd:attribute name="state" type="xsd:string" use="required"/>
</xsd:complexType>
<xsd:complexType name="DualAnswerType"><xsd:sequence>
<xsd:element name="Answer" type="AnswerType"/><xsd:element name="Answer" type="AnswerType"/>
</xsd:sequence></xsd:complexType>
</xsd:schema>
91




























