Embed Size (px)
Citation preview

4. Implemen*erung von IR-‐Systemen

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Rückblick✦ IR-‐Modelle bieten formale Repräsenta/on von Anfragen und
Dokumenten und bes*mmen welche Dokumente zu einer Anfrage in welcher Rangfolge zurückgeliefert werden
✦ Boolesches Retrieval und Vektorraum-‐Modell als tendenziell heuris*sche Ansätze
✦ Probabilis/sches IR und Language Models als theore*sch fundierte probabilis*sche Ansätze
✦ Latent Seman/c Indexing als theore*sch fundierter algebraischer aber nur bedingt prak*kabler Ansatz
2

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Mo*va*on
✦ Wie implemen*ert man ein IR-‐System, welches die gemäß verwendeten IR-‐Modells zu einer Anfrage zurückzuliefernden Dokumente möglichst effizient findet?
3
Premature optimizationis the root of all evil
[Donald E. Knuth]

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Inhalt
(1) Architektur eines IR-‐Systems
(2) Inver*erter Index
(3) Sta*sche Indexierung
(4) Anfragebearbeitung und -‐op*mierung
(5) Kompression
(6) Caching
(7) Dynamische Indexierung
(8) Verteile IR-‐Systeme
4

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
4.1 Architektur eines IR-‐Systems
5
Anfragebearbeitung
Anfrage Ergebnis
Indexe Sta*s*ken
Cache
Indexierung(sta/sch & dynamisch)
Dokumentensammlung
+ -‐Einfügen & Löschen

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Aktuelle Hardware✦ Hauptspeicher
✦ Typische Kapazität 8 GB✦ Zugriffszeit (latency) 10 ns = 10 x 10-‐9 s ✦ Datenübertragungsrate (bandwidth) 10 GB/s
✦ Sekundärspeicher (Magnetspeicher)✦ Typische Kapazität 1 TB ✦ Zugriffszeit (latency oder seek 4me) 5 ms = 5 x 10-‐3 s✦ Datenübertragungsrate (bandwidth) 125 MB/s
✦ Sekundärspeicher (Solid State)✦ Typische Kapazität 256 GB✦ Zugriffszeit (latency) 100 μs = 100 x 10-‐6 s✦ Datenübertragungsrate (bandwidth) 250 MB/s
6
© Uncle Saihul@flickr
©brutalSoCal@flickr
© Andreas@flickr

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Hardwaretrends✦ Geschwindigkeit von CPUs wächst weiterhin schneller als
Bandbreite von magne*schem Sekundärspeicher2000 – 2010: CPU (> 50x) vs. HDD (< 2x)
✦ Mehrere Kerne (mul4 core) pro CPU stan schnelleren CPUs enhalten ihr volles Poten*al bei paralleler Programmierung
✦ Grafikprozessoren (GPUs) werden für allgemeine massiv parallele Berechnungen zweckenhremdet
✦ Netzwerkbandbreite nimmt weiter zu, so dass es immer anrak*ver wird, auf den Hauptspeicher eines enhernten Rechners anstelle auf lokalen Sekundärspeicher zuzugreifen
7

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
4.2 Inver/erter Index
✦ Inver/erter Index (inverted index) besteht aus✦ Wörterbuch (dic4onary) mit allen bekannten Termen✦ Indexlisten (pos4ng lists) mit Informa*onen zu Termvorkommen
✦ Wörterbuch wird meist im Hauptspeicher gehalten
✦ Indexlisten werden meist auf Sekundärspeicher abgelegt
8
georgeclooney
d1 d4 d6 d9 d11 d34 d66 d89
d4 d5 d7 d9 d13 d14 d34 d99
Wörterbuch
Indexlisten

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Indexeinträge✦ Indexlisten enthalten Indexeinträge (pos4ngs), deren Inhalt
vom verwendeten IR-‐Modell bzw. Art der Anfragen abhängt
✦ Boolesches Retrieval benö*gt nur eine Dokumentennummer (document iden4fier)
✦ b.idf-‐Varianten benö*gten zusätzlich die Term-‐Häufigkeit !t,d oder vorberechneten Wert (score contribu4on) !t,d x idfd
✦ Phrasen-‐Anfragen benö*gen die Posi*onen (offsets), an denen der Term im Dokument vorkommt
9
did
did !t,d did !t,d x idfd
did {12, 46, 78, 98}

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Sor*erung der Indexlisten✦ Sor/erung der Indexlisten (d.h. Reihenfolge der enthaltenen
Indexeinträge) hängt vom verwendeten Verfahren zur Anfragebearbeitung ab und beeinflusst ihre Komprimierbarkeit
✦ nach Dokumentennummer (document-‐ordered)
z.B. sinnvoll wenn Anfrage konjunk*v interpre*ert wird
✦ nach Wert (z.B. Term-‐Häufigkeit) (score-‐ordered)
z.B. sinnvoll für effiziente Top-‐k Anfragebearbeitung
10
d2 4 d5 2 d8 7 d12 1 d55 1
d2 4 d5 2d8 7 d12 1 d55 1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Wörterbuch✦ Wörterbuch enthält für jeden Term einen Verweis (pointer)
auf die zugehörige Indexliste und evtl. zusätzliche Informa/onen (z.B. die Dokumenten-‐Häufigkeit dft)
✦ Anfragebearbeitung schlägt zuerst die Anfrageterme im Wörterbuch nach und greiq dann, minels der erminelten Verweise, auf die entsprechenden Indexlisten zu
✦ Wie kann das Wörterbuch so im Hauptspeicher implemen*ert werden, dass dieses Nachschlagen effizient möglich ist?
11
Term t dft Verweisauto 6 7,765car 12 2,098devil 9 8,755

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Hash-‐basiertes Wörterbuch✦ Implemen*erung minels Hashtabelle mit Verkefung
h(car) = 0h(auto) = 2h(insurance) = m
✦ Nachschlagen eines Terms t in Zeitkomplexität O(1) (erwartet) durch Berechnen seines Hashwertes h(t) und lineare Suche in der verkeneten Liste an dieser Posi*on
✦ Keine Präfix-‐, Infix-‐ oder Suffixsuche (z.B. sea*, fa*us, *logy)
12
0
1
2
3
m
car 12 2098 devil 9 8755
auto 6 7765 wild 12 2765
/ger 10 1762
insurance 3 7762

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Sor*er-‐basiertes Wörterbuch✦ Implemen*erung minels mehrerer sor*erter Arrays
✦ Nachschlagen eines Terms t in Zeitkomplexität O(log |V|) durch binäre Suche auf den Arrays P und T
✦ Unterstützt Präfixsuche (z.B. sea*) und kann erweitert werden, so dass Infix-‐ und Suffixsuche (z.B. fa*us und *logy) möglich ist
13
a u t o c a r d e v i l i n s u r a …
0 4 7 12 …
7,765 …2,098 8,755 7,762
6 12 9 3 …
T(erme)
P(osi/on)
DF
V(erweise)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
4.3 Sta/sche Indexierung✦ Wie kann man eine sta/sche Dokumentensammlung
indexieren, d.h., einen inver/erten Index dafür erstellen?
✦ Beim Einlesen (Tokenisieren & Normalisieren) der Dokumente sieht man Termvorkommen pro Dokument (token stream)
✦ Zum Erstellen des inver*erten Index müssen Termvorkommen pro Term erminelt werden
✦ Termvorkommen müssen also neu sor/ert (inver*ert) werden14
d1 the d1 world d1 has d3 brand d3 new d3 world
the d1 world d1has d1brand d3 new d1 world d3

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Naïve Indexierung✦ Für sehr kleine Dokumentensammlungen kann man alle
Termvorkommen im Hauptspeicher halten und dort sor*eren
✦ Frage: Wie groß darf eine Dokumentensammlung sein, damit dieser Ansatz mit 2 GB Hauptspeicher noch prak*kabel ist?
Lösung: 33,554 Dokumente
✦ Dokumentensammlungen passen i.d.R. nicht in Hauptspeicher!
✦ Verfahren zur Indexierung sor/eren Termvorkommen daher unter Zuhilfenahme von Sekundärspeicher (external memory)
15
term did 32 Bytes~
∅ Dokumentenlänge ~ 2,000 Terme

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Wahlfreie Zugriffe (random access) sind auf Sekundärspeicher
deutlich teurer als sequen/elle Zugriffe (sequen4al access)
✦ Generelles Vorgehen zum Sor/eren mit Sekundärspeicher
Schrin 1: Erstelle sor/erte Teilfolgen (runs) mit Quicksort, deren Länge vom verfügbaren Hauptspeicher M bes*mmt wird, und speichere diese auf Sekundärspeicher ab
Schrin 2: Verschmelze jeweils F sor*erte Teilfolgen und speichere Ergebnis als neue Teilfolge auf Sekundärspeicher ab
Wiederhole Schrin 2 bis nur noch eine Folge übrig ist
16
Mergesort

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
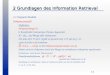
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
R1,0
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
R1,0 R1,1
�logF N/M�
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
R1,0 R1,1 R1,2
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
R1,0 R1,1 R1,2 R1,3
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
N/M/FR1,0 R1,1 R1,2 R1,3
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
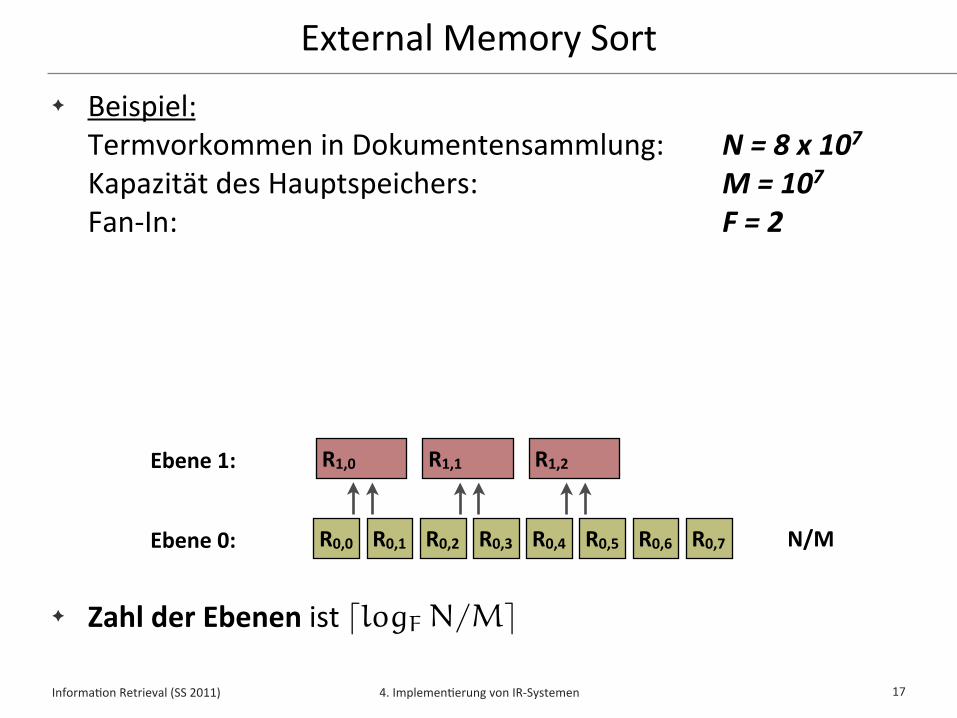
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 2:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
N/M/FR1,0 R1,1 R1,2 R1,3
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 2:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
N/M/FR1,0 R1,1 R1,2 R1,3
R2,0
�logF N/M�
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 2:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
N/M/FR1,0 R1,1 R1,2 R1,3
R2,0 R2,1
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 2:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
N/M/F
N/M/F2
R1,0 R1,1 R1,2 R1,3
R2,0 R2,1
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 2:
Ebene 3:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
N/M/F
N/M/F2
R1,0 R1,1 R1,2 R1,3
R2,0 R2,1
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 2:
Ebene 3:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
N/M/F
N/M/F2
R1,0 R1,1 R1,2 R1,3
R2,0 R2,1
R3,0
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
External Memory Sort✦ Beispiel:
Termvorkommen in Dokumentensammlung: N = 8 x 107 Kapazität des Hauptspeichers: M = 107Fan-‐In: F = 2
✦ Zahl der Ebenen ist
17
Ebene 1:
Ebene 2:
Ebene 3:
Ebene 0: R0,0 R0,1 R0,2 R0,3 R0,4 R0,5 R0,6 R0,7 N/M
N/M/F
N/M/F2
N/M/F3
R1,0 R1,1 R1,2 R1,3
R2,0 R2,1
R3,0
�logF N/M�

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Indexierung mit External Memory Sort✦ Verfahren zur Indexierung können danach unterschieden
werden, ob sie einen (single pass) oder mehrere (mul4 pass)Durchläufe über die Dokumentensammlung benö*gen
✦ Blocked Sort-‐Based Indexing (BBSI)✦ Erstelle Wörterbuch mit term → /d in einem ersten Durchlauf✦ Erstelle sor/erte Teilfolgen von Termvorkommen ( did, /d ) als
Ebene 0 von External Memory Sort in zweitem Durchlauf
✦ Single-‐Pass In-‐Memory Indexing (SPIMI)✦ Erstelle in einem einzigen Durchlauf entsprechend verfügbaren
Hauptspeichers Teilindexe (Wörterbuch + Indexlisten), welche dann analog zu External Memory Sort verschmolzen werden
18

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
4.4 Anfragebearbeitung und -‐op/mierung✦ IR-‐Modelle aus Kapitel 3 lassen sich wie folgt abstrahieren
✦ Beobachtungen:✦ Es müssen nur Anfrageterme betrachtet werden✦ idf-‐Gewicht widf (t) hängt nur vom Anfrageterm t ab✦ h-‐Gewicht w! (t,d) hängt von Anfrageterm t und Dokument d ab
✦ Wie kann man, mit Hilfe eines inver*erten Index effizient✦ den Wert w(q,d) für alle Dokumente ermineln?✦ die Top-‐k Dokumente mit den höchsten Werten w(q,d) bes*mmen?
19
w(q, d) =�
t∈q
widf(t) ·wtf(t, d)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
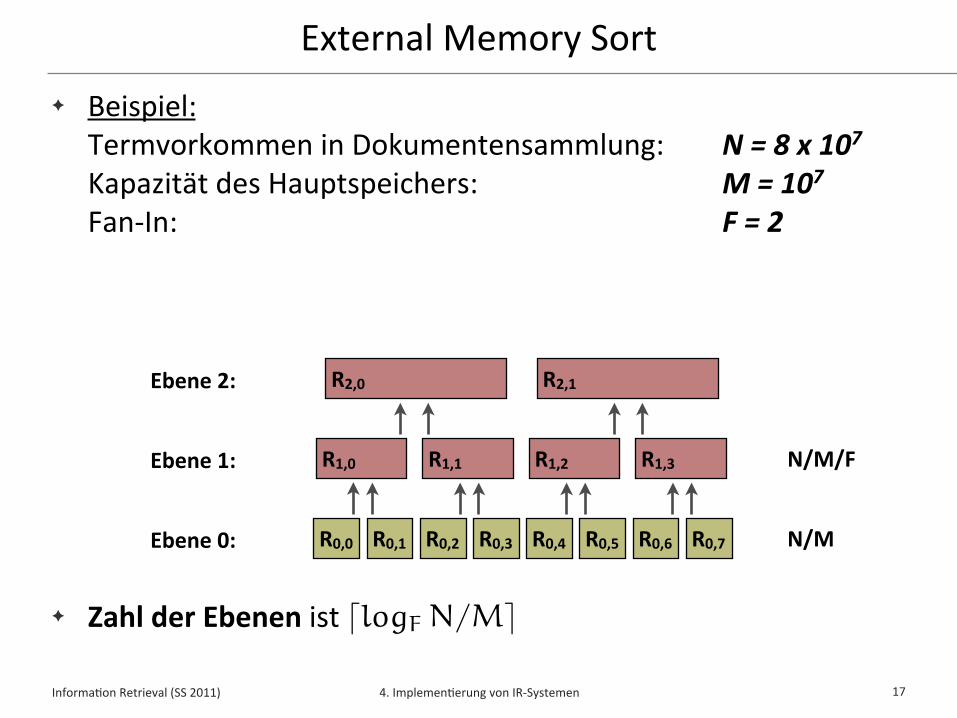
Term-‐at-‐a-‐Time (TAAT)✦ Term-‐at-‐a-‐Time liest Indexlisten der Anfrageterme sukzessive
✦ Die Sor/erung der Indexlisten spielt hierbei keine Rolle
✦ Für jedes Dokument d wird ein Akkumulator (accumulator)verwaltet, in dem sukzessive der Wert w(q,d) aggregiert wird
✦ Zu jedem Zeitpunkt wird ein einziger Anfrageterm t betrachtet und sein Beitrag widf (t) * w! (t,d) für alle Dokumente erminelt
✦ Die Top-‐k Dokumente mit höchstem Wert w(q,d) können z.B. mit Hilfe einer Priority Queue erminelt werden, nachdem die Indexlisten für alle Anfrageterme gelesen wurden
20

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐at-‐a-‐Time Pseudo-‐Code
21
A ← new HashMap() // Akkumulatorenforeach term t in query q
Lt ← InvertedIndex.getIndexList( t ) // Indexliste für twidf ← InvertedIndex.getIDF( t ) // idf-Gewicht für tforeach posting ( d, wtf ) in Lt
A[ d ] ← A[ d ] + widf * wtf
R ← new SizeConstrainedPriorityQueue( k ) // Top-k Ergebnisseforeach document d in A R.add( A[ d ], d )
return R

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐at-‐a-‐Time
22
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐at-‐a-‐Time
22
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐at-‐a-‐Time
22
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
A
d2 0.8d5 0.4d8 1.4d12 0.2d55 0.2
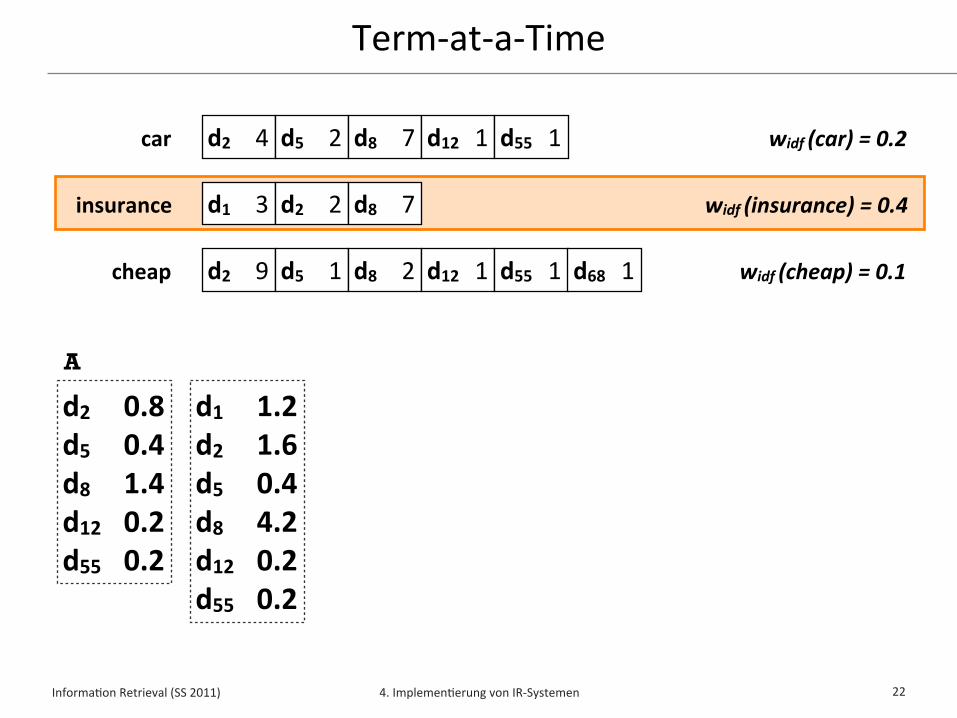
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐at-‐a-‐Time
22
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
A
d2 0.8d5 0.4d8 1.4d12 0.2d55 0.2
d1 1.2d2 1.6d5 0.4d8 4.2d12 0.2d55 0.2

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐at-‐a-‐Time
22
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
A
d2 0.8d5 0.4d8 1.4d12 0.2d55 0.2
d1 1.2d2 1.6d5 0.4d8 4.2d12 0.2d55 0.2
d1 1.2d2 2.5d5 0.5d8 4.4d12 0.3d55 0.3d68 0.2

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐at-‐a-‐Time
22
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
A
d2 0.8d5 0.4d8 1.4d12 0.2d55 0.2
d1 1.2d2 1.6d5 0.4d8 4.2d12 0.2d55 0.2
d1 1.2d2 2.5d5 0.5d8 4.4d12 0.3d55 0.3d68 0.2

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐at-‐a-‐Time
22
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
A
d2 0.8d5 0.4d8 1.4d12 0.2d55 0.2
d1 1.2d2 1.6d5 0.4d8 4.2d12 0.2d55 0.2
d1 1.2d2 2.5d5 0.5d8 4.4d12 0.3d55 0.3d68 0.2
d8 4.4d2 2.5d1 1.2
R (k = 3)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
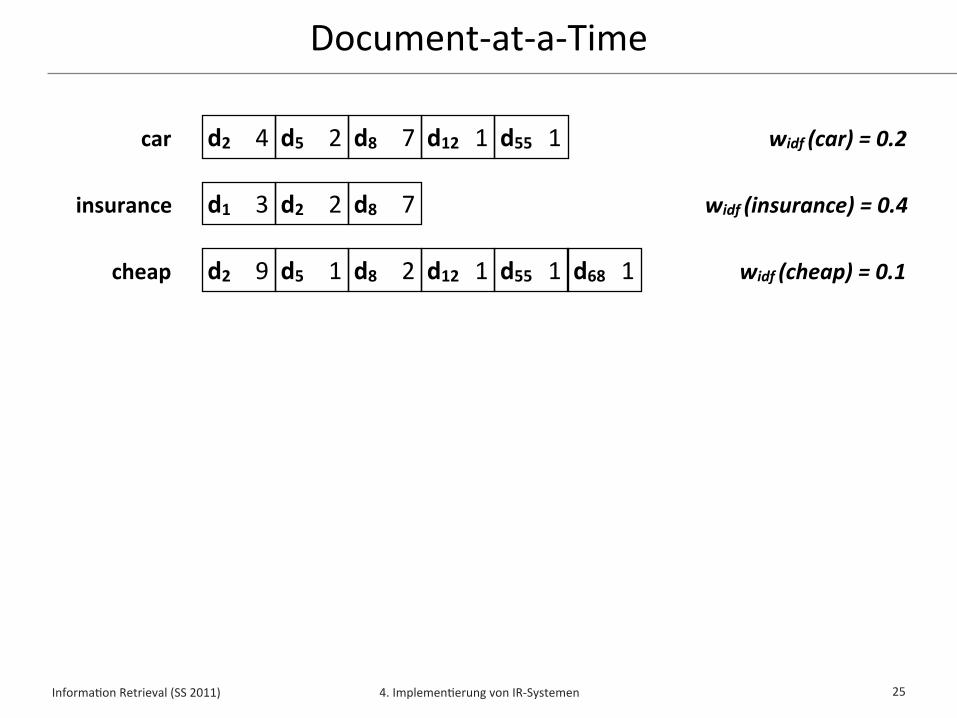
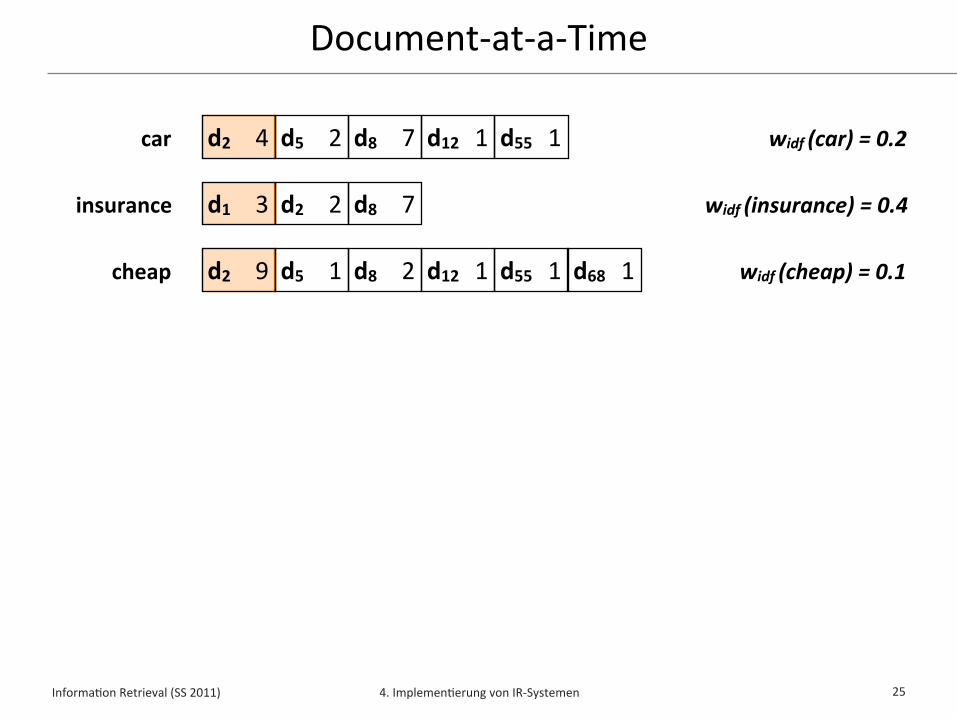
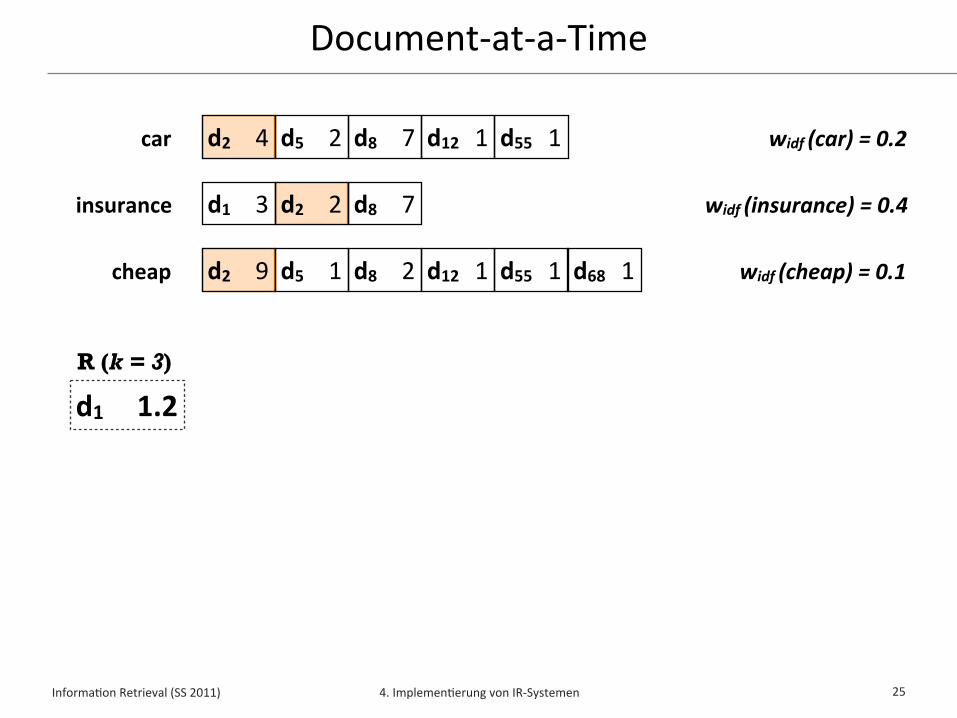
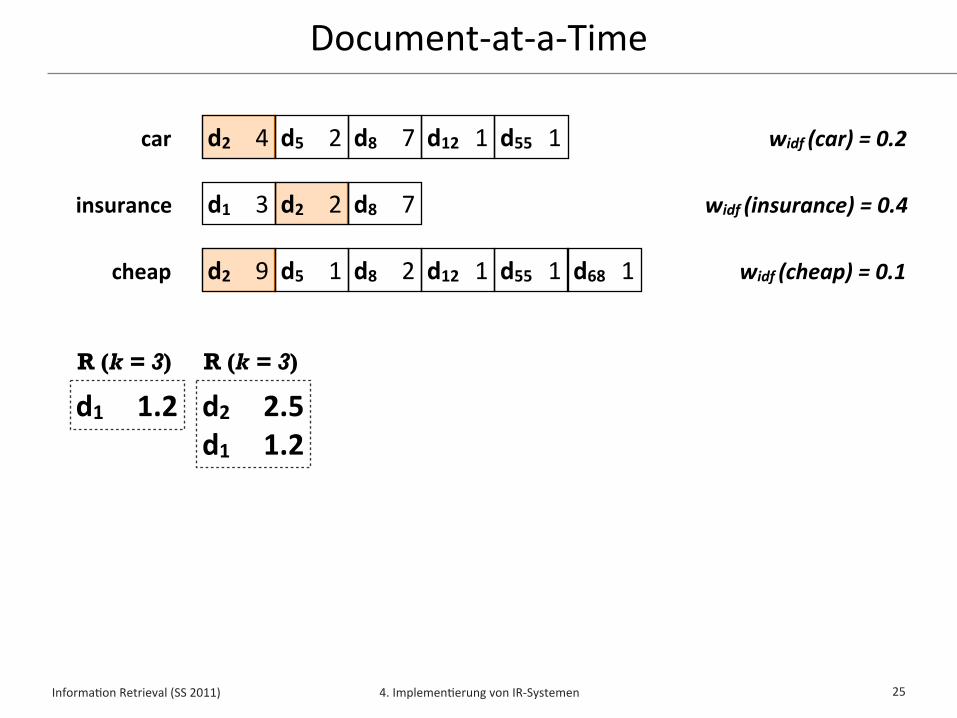
Document-‐at-‐a-‐Time (DAAT)✦ Document-‐at-‐a-‐Time liest Indexlisten für Anfrageterme parallel
✦ Indexlisten sind hierbei nach Dokumentennummer sor/ert
✦ Zu jedem Zeitpunkt wird ein einziges Dokument d betrachtet und sein Wert w(q,d) aus allen Indexlisten aggregiert
✦ Sobald der Wert w(q,d) für das Dokument d erminelt wurde, kann entschieden werden, ob es in die Top-‐k gehört
✦ Die Top-‐k Dokumente mit höchstem Wert w(q,d) können damit während des Lesens der Indexlisten erminelt werden
23

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time Pseudo-‐Code
24
L ← new ArrayList() // IndexlistenIDF ← new HashMap() // idf-Gewichte foreach term t in query q L[ t ] ← InvertedIndex.getIndexList( t ) IDF[ t ] ← InvertedIndex.getIDF( t )
R ← new SizeConstrainedPriorityQueue( k ) // Top-k Ergebnisseforeach document d in ascending order of identifier w ← 0.0 foreach term t in query q if ( L[ t ] points to document d ) then ( d, wtf ) ← L[ t ].read() w ← w + (wtf * IDF[ t ]) L[ t ].movePast( d ) R.add( w, d ) return R
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
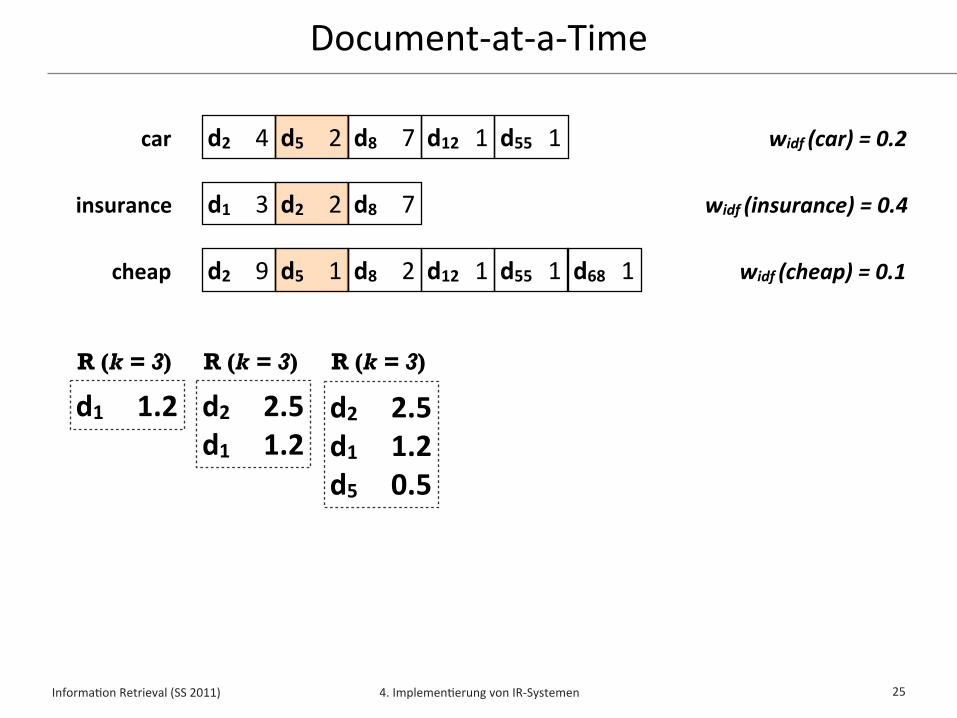
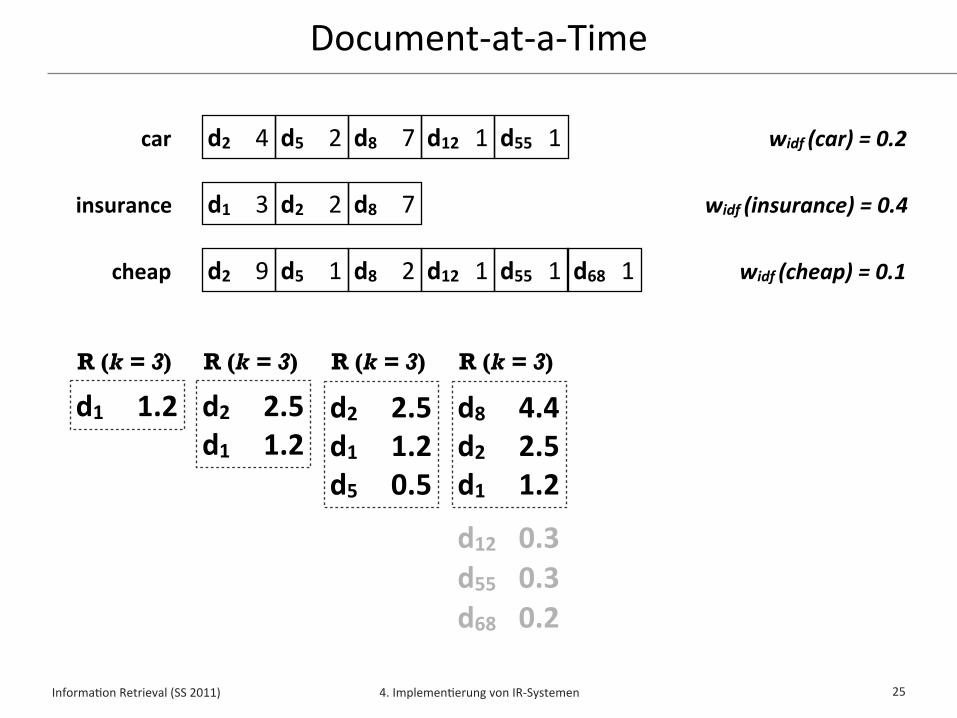
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)
d2 2.5d1 1.2d5 0.5
R (k = 3)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)
d2 2.5d1 1.2d5 0.5
R (k = 3)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)
d2 2.5d1 1.2d5 0.5
R (k = 3)
d8 4.4d2 2.5d1 1.2
R (k = 3)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)
d2 2.5d1 1.2d5 0.5
R (k = 3)
d8 4.4d2 2.5d1 1.2
R (k = 3)
d12 0.3

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)
d2 2.5d1 1.2d5 0.5
R (k = 3)
d8 4.4d2 2.5d1 1.2
R (k = 3)
d12 0.3d55 0.3

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)
d2 2.5d1 1.2d5 0.5
R (k = 3)
d8 4.4d2 2.5d1 1.2
R (k = 3)
d12 0.3d55 0.3d68 0.2
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Document-‐at-‐a-‐Time
25
d2 4 d5 2 d8 7 d12 1 d55 1
d1 3 d2 2 d8 7
d2 9 d5 1 d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d1 1.2R (k = 3)
d2 2.5d1 1.2
R (k = 3)
d2 2.5d1 1.2d5 0.5
R (k = 3)
d8 4.4d2 2.5d1 1.2
R (k = 3)
d12 0.3d55 0.3d68 0.2

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA✦ Wie kann man die Anfragebearbeitung frühzei/g beenden
(d.h. ohne Indexlisten vollständig zu lesen) und dennoch die korrekten Top-‐k Dokumenten finden?
✦ Ein Algorithmus hierzu ist NRA (No Random Accesses) aus der Familie der Threshold-‐Algorithmen (TA) von Fagin et al.
✦ NRA ist ein allgemeines Verfahren, welches für alle monotonen Aggrega/onsfunk/onen f anwendbar ist
✦ Man kann zeigen, dass NRA instanz-‐op/mal (instance op4mal) unter allen Indexlisten sequen*ell lesenden Verfahren ist
26
∀ i : xi ≤ yi ⇒ f(x) ≤ f(y)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA✦ NRA liest Indexlisten für Anfrageterme parallel
✦ Indexlisten sind hierbei absteigend nach Wert sor/ert
✦ NRA verwaltet während des Lesens der Indexlisten✦ eine momentane Top-‐k der besten Dokumente, deren Wert
w(q,d) bereits vollständig erminelt wurde✦ eine Menge von Kandidaten C, die noch nicht in allen Indexlisten
gesehen wurden und für die w(q,d) damit noch unvollständig ist✦ Schwellwert (threshold) für Einzug in die momentane Top-‐k✦ Schranken (bounds) für die Werte w(q,d) von Kandidaten und
bisher unbekannten Dokumenten✦ für jeden Kandidaten d die Menge seen(d) der Indexlisten, in
denen er bereits gesehen wurde27

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA
✦ mink Kleinster Wert w(q,d) in der momentanen Top-‐k
Hier: mink = 4.4
28
d2 4 d5 2d8 7 d12 1 d55 1
d1 3 d2 2d8 7
d2 9 d5 1d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d8 4.4R (k = 1 )
d2 1.7 {car, insurance}d1 1.2 {insurance}
C

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA
✦ high(t) Zuletzt gesehener Wert in Indexliste für Term t
Hier: high(car) = 4 high(insurance) = 3 high(cheap) = 2
29
d2 4 d5 2d8 7 d12 1 d55 1
d1 3 d2 2d8 7
d2 9 d5 1d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d8 4.4R (k = 1 )
d2 1.7 {car, insurance}d1 1.2 {insurance}
C

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA
✦ worst(d) Untere Schranke für aggregierten Wert von Kandidat dHier: worst(d1) = 1.2 worst(d2) = 1.7
30
d2 4 d5 2d8 7 d12 1 d55 1
d1 3 d2 2d8 7
d2 9 d5 1d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d8 4.4R (k = 1 )
d2 1.7 {car, insurance}d1 1.2 {insurance}
C

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA
✦ best(d) Obere Schranke für aggregierten Wert von Kandidat dHier: best(d1 ) = worst(d1 ) + 0.2 * 4 + 0.1 * 2 = 2.2 best(d2 ) = worst(d2 ) + 0.1 * 2 = 1.9
31
d2 4 d5 2d8 7 d12 1 d55 1
d1 3 d2 2d8 7
d2 9 d5 1d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d8 4.4R (k = 1 )
d2 1.7 {car, insurance}d1 1.2 {insurance}
C

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA
✦ unseen Obere Schranke für aggregierten Wert bisher unbekannten DokumentsHier: unseen = 0.2 * 4 + 0.4 * 3 + 0.1 * 2 = 2.2
32
d2 4 d5 2d8 7 d12 1 d55 1
d1 3 d2 2d8 7
d2 9 d5 1d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d8 4.4R (k = 1 )
d2 1.7 {car, insurance}d1 1.2 {insurance}
C

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA✦ NRA verwendet also folgende Schwellwerte und Schranken
✦ high(t) zuletzt gesehener Wert in Indexliste für Term t als obere Schranke für bisher nicht gesehene Werte
✦ mink niedrigster aggregierter Wert in der momentanen Top-‐k✦ worst(d) untere Schranke für aggregierten Wert von Dokument d
✦ best(d) obere Schranke für aggregierten Wert von Dokument d
✦ unseen untere Schranke für aggregierten Wert bisher unbekannten Dokumentes
33
�
t∈ seen(d)
widf(t) ·wtf(t, d)
worst(d) +�
t∈q\seen(d)
widf(t) · high(t)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA✦ NRA nutzt folgende Beobachtungen aus um festzustellen, ob
es die Anfragebearbeitung einstellen kann✦ Sobald unseen ≤ mink gilt, kann es kein bisher unbekanntes
Dokument in die Top-‐k schaffen✦ Sobald für einen Kandidaten best( d ) ≤ mink gilt, kann es dieses
Dokument nicht mehr in die Top-‐k schaffen
✦ Kann es kein unbekanntes Dokument und kein Kandidat mehr in die Top-‐k schaffen, so ist diese endgül*g und NRA kann die Anfragebearbeitung einstellen
34

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Top-‐k Anfragebearbeitung mit NRA
✦ Ist man an der Top-‐1 interessiert, kann NRA an diesem Punkt die Anfragebearbeitung einstellen, da weder d2 noch d1 noch bisher unbekannte Dokumente besser als d8 werden können
35
d2 4 d5 2d8 7 d12 1 d55 1
d1 3 d2 2d8 7
d2 9 d5 1d8 2 d12 1 d55 1
car
insurance
cheap d68 1
widf (car) = 0.2
widf (insurance) = 0.4
widf (cheap) = 0.1
d8 4.4R (k = 1 )
d2 1.7 {car, insurance}d1 1.2 {insurance}
C

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
NRA Pseudo-‐Code
36
R ← new SizeConstrainedPriorityQueue( k ) // Top-kC ← new HashMap() // Kandidaten
L ← new ArrayList() // IndexlistenIDF ← new HashMap() // idf-Gewichte foreach term t in query q
L[ t ] ← InvertedIndex.getIndexList( t )IDF[ t ] ← InvertedIndex.getIDF( t )
while !finished()foreach term t in query q // Lese Indexlisten Round-Robin
( d, wtf ) ← L[ t ].read() c ← C.getOrCreateCandidate( d )c.updateScore( t, wtf * IDF[ t ] )
if c.isEvaluated() then R.add( c.best( ), c )
C.remove( c )
return R
boolean finished()finished ← true foreach candidate c in C
if c.best() > mink thenfinished ← falsebreak
finished ← finished ∧ unseen > mink return finished

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
4.5 Kompression✦ Kompressionsverfahren bes*mmen kompakte Repräsenta/on,
die weniger Speicherplatz als die Rohdaten benö*gt
✦ Man unterscheidet verlustbehauete Kompressionsverfahren (z.B. JPEG) und verlusbreie Kompressionsverfahren (z.B. GIF)
✦ Vorteile durch Anwendung von Kompression in IR-‐System✦ Geringerer Speicherbedarf für die Speicherung von Indexlisten✦ Höhere Cache-‐Effek/vität, da mehr Daten gecacht werden können✦ Performanz-‐Gewinn, da es auf moderner Hardware oq schneller
ist, Daten komprimiert zu lesen und dann zu dekomprimieren
✦ Kein effizientes IR-‐System ohne Kompression!37

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Kompression des Inver*erten Index✦ Wörterbuch und Indexlisten werden separat komprimiert
✦ Komprimierung von Indexlisten basierend auf folgenden Ideen✦ Verwende weniger Speicher, um kleine Zahlen zu repräsen*eren ✦ Nutze aus, dass Indexlisten eine bekannte Sor/erung haben
✦ Beispiel: Naïve Repräsenta*on einer Indexliste mit 32-‐bit Dokumentennummern und 32-‐bit Term-‐Häufigkeiten
Insgesamt: 256 bit = 32 bytes38
d2 19 d5 7 d8 250 d130 30
00000000 00000000 00000000 00000010 00000000 00000000 00000000 00010011 …

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Variable-‐Byte Codes✦ Variable-‐Byte Encoding verwendet pro Byte
✦ das höchstwer*ge Bit als Forsetzungs-‐Bit (con4nua4on bit)✦ die übrigens sieben Bits als “Nutzlast” (payload)
✦ Zahl n wird binär im “Nutzlast”-‐Teil der Bytes repräsen*ert
✦ Fortsetzungs-‐Bit gibt an, ob nächstes Byte auch zu n gehört
✦ Man benö*gt⎣ msb(n) / 7 ⎦+ 1 Bytes zur Repräsenta*on der Zahl n, mit msb(n) =⎣ log2 n ⎦als höchstwer*gem Bit
39
7 6 5 4 3 2 1 0
payloadcon*nua*on bit

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Variable-‐Byte Codes✦ Beispiel: Die Zahl 4711 hat folgende 32-‐bit Binärdarstellung
Mit Variable-‐Byte Encoding erhält man
und benö*gt zwei staf vier Bytes zu ihrer Repräsenta*on
✦ Beispiel: Repräsenta*on einer Indexliste
Insgesamt: 10 Bytes
40
00000000 00000000 00010010 01100111
00100100 11100111
d2 19 d5 7 d8 250 d130 30
00000010 00010011 00000101 00000111 00001000 0000000111111010 …

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Gap Encoding✦ Indexlisten haben eine bekannte und einheitliche Sor/erung
✦ Sind Indexlisten nach Dokumentennummern sor*ert, bilden die Dokumentennummern eine monoton steigende Folge
✦ Gap Encoding speichert für die zweite und folgenden Dokumentennummern nur die Differenz zum Vorgänger (gap)
✦ Diese Differenzen sind kleinere Zahlen als die ursprünglichen Dokumentennummern und lassen sich somit kompakter repräsen/eren (z.B. mit Variable-‐Byte Codes)
41
�n1, n2, n3, . . . � → �n1, (n2 − n1), (n3 − n2), . . . �

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Gap Encoding✦ Beispiel: Indexliste
wird repräsen*ert als
bei Verwendung von Variable-‐Byte Encoding erhält man
Insgesamt: 9 Bytes
42
d2 19 d5 7 d8 250 d130 30
00000010 00010011 00000011 00000111 00000011 0000000111111010 …
2 19 3 7 3 250 122 30

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Gamma Codes✦ Variable-‐Byte Encoding repräsen*ert Zahl als Folge ganzer
Bytes, d.h., pro Zahl wird mindestens ein Byte verwendet
✦ Effek/vere Speicherausnutzung möglich durch Repräsenta*on auf Bit-‐Ebene, d.h., Zahl wird als Folge von Bits dargestellt
✦ Unär-‐Encoding repräsen*ert Zahl n als Folge von n 1-‐Bits gefolgt von einem 0-‐Bit (z.B. 8 = 111111110)
✦ γ-‐Encoding repräsen*ert Zahl n in zwei Komponenten✦ Länge gibt höchstwer*ges Bit msb(n) =⎣ log2 n ⎦in Unär-‐Code an
✦ Offset gibt Wert n -‐ 2 msb(n) in Binär-‐Code an
43

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Gamma Codes✦ Beispiel: Die Zahl 4711 hat folgende 32-‐bit Binärdarstellung
mit γ-‐Encoding erhält man
✦ γ-‐Encoding repräsen*ert die Zahl n mit 2 x⎣log2 n⎦+ 1 Bits
✦ γ-‐Codes sind präfixfrei, d.h. Folge von γ-‐Codes kann eindeu*g interpre*ert werden und es sind keine Trennzeichen nö*g
✦ Repräsenta*on durch γ-‐Codes ist höchstens konstanten Faktor (< 3 ) von einer op/malen Repräsenta/on enhernt
44
00000000 00000000 00010010 01100111
1111111111110Länge: 001001100111Offset:

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Gamma Codes✦ Beispiel: Repräsenta*on einer Indexliste
mit γ-‐Codes (ohne Gap-‐Encoding)
Insgesamt: 76 Bit (10 Byte)
45
d2 19 d5 7 d8 250 d130 30
10 0 11110 0011 110 01 110 11 1110 000 …11111110 1111010

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
4.6 Caching✦ Caching hält Daten für schnellen Zugriff im Hauptspeicher vor
und reduziert dadurch die Antwortzeiten eines IR-‐Systems
✦ Drei Ebenen von Daten, für die Caching sinnvoll sein kann:
✦ Anfrageergebnisse, damit häufige Anfragen ohne weitere Bearbeitung direkt beantwortet werden können
✦ Teilergebnisse, damit Anfragen mit häufig angefragten Kombina/onen von Termen schneller bearbeitet werden können
✦ Indexlisten, damit Anfragen mit häufig angefragten Termen schneller bearbeitet werden können
46

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Caching Strategien✦ Caching-‐Strategie (caching policy) entscheidet für gegebene
Kapazität, welche Elemente im Cache gehalten werden
✦ Universelle Caching-‐Strategien sind:
✦ Least Recently Used (LRU) scha} Platz für neues Element, indem es das am längsten unbenutzte Element enhernt
✦ Least Frequently Used (LFU) scha} Platz für neues Element, indem es das am seltensten benutzte Element enhernt
✦ Kostenbasierte Caching-‐Strategien vergleichen Kosten (z.B. Größe des Ergebnis) mit erwartetem Nutzen (z.B. Häufigkeit der Anfrage * Anzahl gelesener Pos4ngs ihrer Bearbeitung)
47

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Caching in der Praxis✦ Häufigkeitsverteilung der Anfragen in realen IR-‐Systemen lässt
sich oq durch eine Zipf-‐Verteilung beschreiben
✦ Es gibt aber eine große Zahl von Anfragen, die nur einmal vorkommen und daher nicht vom Caching profi*eren können
✦ Analyse eines Query-‐Logs von yahoo.co.uk über ein Jahr hinweg [2] zeigt, dass 88% der Anfragen nur einmal gestellt wurden. Diese machen 44% des Anfrage-‐Volumes aus.
✦ Cache-‐Hit Ra/o als Prozentsatz der Anfragen, die aus dem Cache beantwortet werden können in der Praxis < 50%
48
f(q) = c · i−α α ≈ 1mit

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
4.7 Dynamische Indexierung✦ Interessante Dokumentensammlungen sind meist dynamisch
✦ The New York Times – ca. 250 neue Ar/kel pro Tag
✦ World Wide Web – ca. 8% neue Webseiten pro Woche – ca. 80% der Webseiten nach einem Jahr verschwunden [8]
✦ twiner – ca. 45 Millionen neue Tweets pro Tag
✦ Wie kann man einen inver/erten Index anpassen, wenn sich die zugrundeliegende Dokumentensammlung verändert?
49

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Naïver Ansatz✦ Ein naïver Ansatz könnte sein, für jedes neue, geänderte oder
gelöschte Dokument die betroffenen Indexlisten anzupassen
✦ Dies ist kein prak/kabler Ansatz u.a. aus folgenden Gründen
✦ Indexlisten liegen auf magne*schem Sekundärspeicher und haben damit eine Zugriffszeit von ca. 5 ms (d.h. für 1,000 Terme = 0.5 s)
✦ Sor*erung der Indexlisten soll erhalten bleiben, d.h. man muss die gesamte Indexliste lesen und in veränderter Form schreiben
✦ Größe der Indexlisten ändert sich, so dass es zu Fragmen*erung und/oder erhöhtem Platzbedarf des Index kommt
50

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Re-‐Indexierung✦ Regelmäßige Re-‐Indexierung (d.h. vollständiger Neuau�au
des inver*erten Index) ist prak*kable Lösung
✦ für kleine oder wenig dynamische Dokumentensammlungen
✦ wenn veraltete Anfrageergebnisse akzeptabel sind
✦ Nachteile der regelmäßigen Re-‐Indexierung sind
✦ Ineffizienz – beim Neuau�au werden auch die unveränderten Dokumente erneut eingelesen und verarbeitet
✦ Speicherbedarf – während des Neuau�aus exis*eren i.d.R. sowohl der alte als auch der neue unfer*ge Index
51

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
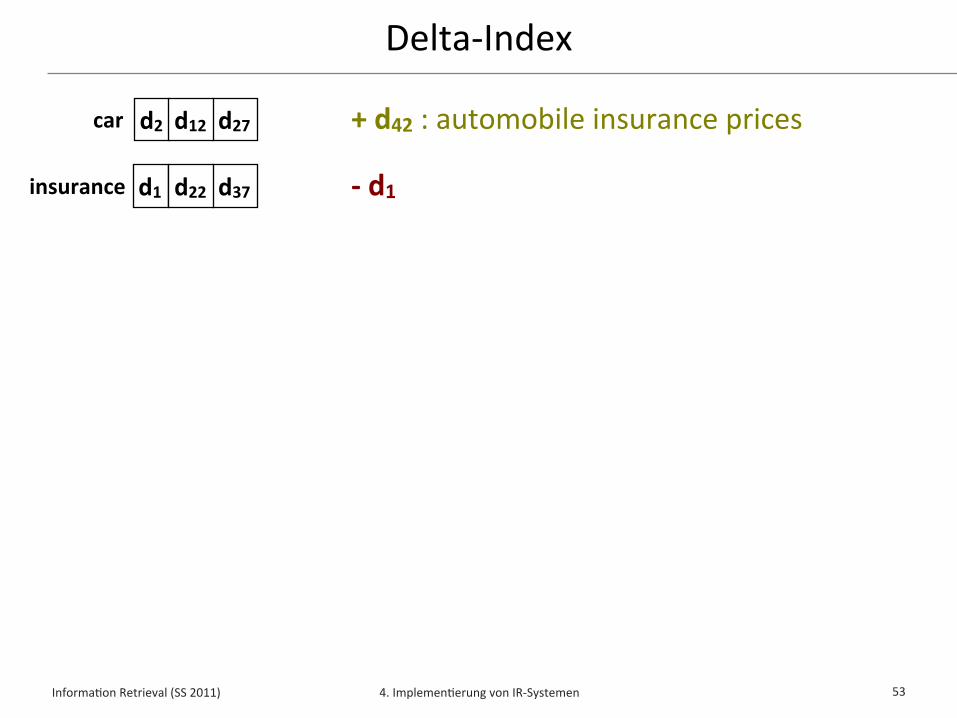
Delta-‐Index✦ Idee: Indexiere Veränderungen der Dokumentensammlung
✦ Neue und geänderte Dokumente werden in einem zusätzlichen inver*erten Index im Hauptspeicher indexiert
✦ Gelöschte Dokumente werden in einer Liste vermerkt
✦ Während der Anfragebearbeitung werden für jeden Anfrageterm die Indexlisten aus Haupt-‐ und Delta-‐Index verschmolzen und dabei gelöschte Dokumente ausgefiltert
✦ Konsolidierung des Haupt-‐Index durch “Einschmelzen” des Delta-‐Index in regelmäßigen Abständen oder nach Bedarf
52
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Delta-‐Index
53
d2 d27d12car
d1 d37d22insurance
+ d42 : automobile insurance prices
-‐ d1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Delta-‐Index
53
d2 d27d12car
d1 d37d22insurance
+ d42 : automobile insurance prices
-‐ d1
d2 d27d12car
d1 d37d22insurance
d42automobile
d42insurance
d42prices
DELETIONS
Haupt-‐Index Delta-‐Index
d1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Delta-‐Index
53
d2 d27d12car
d1 d37d22insurance
+ d42 : automobile insurance prices
-‐ d1
d2 d27d12car
d1 d37d22insurance
d42automobile
d42insurance
d42prices
DELETIONS
Haupt-‐Index Delta-‐Index
d1
insurance d37 d42d1 d22

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Delta-‐Index✦ Beim bisherigen Ansatz werden Haupt-‐ und Delta-‐Index bis zu
T/n mal miteinander verschmolzen bei Kapazität des Delta-‐Index von n und Gesamtzahl T von Indexeinträgen
✦ Jedes Verschmelzen liest und schreibt bis zu T Indexeinträge
✦ Zeitkomplexität zum Au�au des inver*erten Index damit in
✦ Wie kann man verhindern, dass Indexeinträge bei jedem Verschmelzen gelesen und geschrieben werden?
54
O( T2/n)
Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
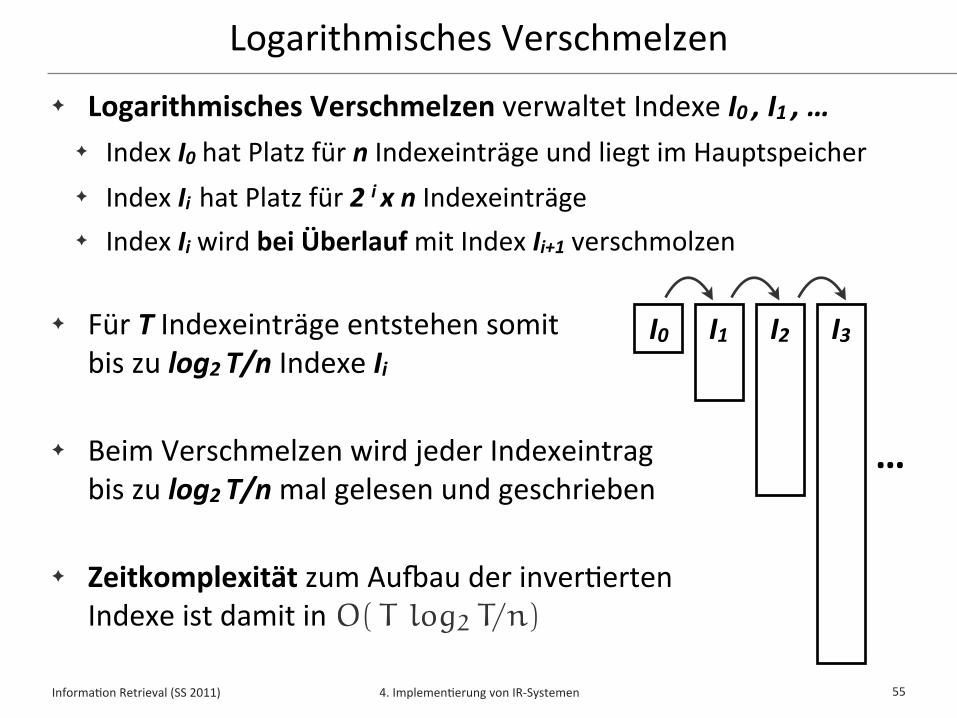
Logarithmisches Verschmelzen✦ Logarithmisches Verschmelzen verwaltet Indexe I0 , I1 , …
✦ Index I0 hat Platz für n Indexeinträge und liegt im Hauptspeicher✦ Index Ii hat Platz für 2 i x n Indexeinträge✦ Index Ii wird bei Überlauf mit Index Ii+1 verschmolzen
✦ Für T Indexeinträge entstehen somitbis zu log2 T/n Indexe Ii
✦ Beim Verschmelzen wird jeder Indexeintrag bis zu log2 T/n mal gelesen und geschrieben
✦ Zeitkomplexität zum Au�au der inver*ertenIndexe ist damit in
55
I0 I1 I2 I3
…
O( T log2 T/n)

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Logarithmisches Verschmelzen✦ Logarithmisches Verschmelzen ist ein effizienter Ansatz zur
dynamischen Indexierung, der auch in der Praxis (z.B. in Apache Lucene) zum Einsatz kommt
✦ Ein Nachteil des logarithmischen Verschmelzens ist, dass zur Anfragebearbeitung für jeden Anfrageterm bis zu log2 T/n Indexlisten betrachtet werden müssen
✦ Die Idee hinter logarithmischen Verschmelzen findet sich auch in anderen log-‐strukturierten Daten-‐ und Indexstrukturen z.B. Binomial Heap, LSM-‐Tree und LHAM
56

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
4.8 Verteilte IR-‐Systeme✦ Verwendung eines Clusters mehrerer Rechner z.B. sinnvoll
✦ für große Dokumentenkollek/onen (z.B. World Wide Web)✦ um die Zeit zum Au~au des inver/erten Index zu reduzieren✦ bei hoher Anfragelast (z.B. Suche in populärer Website)
✦ Welche Möglichkeiten gibt es, einen inver*erten Index verteilt auf mehreren Rechnern abzulegen?
✦ Wie kann man mehrere Rechner dazu verwenden, einen inver*erten Index schneller aufzubauen?
57

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Cluster✦ Cluster von m ähnlich ausgestafeten Rechnern aus, die
miteinander über ein schnelles Netzwerk verbunden sind
✦ Man unterscheidet folgende Arten von Rechner-‐Knoten✦ Master – verteilt und koordiniert Aufgaben✦ Slaves – führt vom Master zugeteilte Aufgaben aus
✦ Andere Arten von Verbünden mehrerer Rechner sind z.B.✦ Grid – loser jedoch koordinierter Zusammenschluss mehrerer
heterogener geographisch verteilter Rechner✦ Peer-‐to-‐Peer – loser unkoordinierter Zusammenschluss mehrerer
heterogener, geographisch verteilter gleichberech*gter Rechner
58

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Verteilter Inver*erter Index
✦ Inver*erter Index kann entlang zwei Dimensionen par//oniert und auf mehrere Rechner-‐Knoten verteilt werden
✦ Term-‐par//onierter inver/erter Index – jeder Rechner-‐Knoten speichert inver*erten Index für eine Teilmenge der Terme
✦ Dokument-‐par//onierter inver/erter Index – jeder Rechner-‐Knoten speichert inver*erten Index für Teilmenge der Dokumente
59
d1 d2 d3 d4 d5
car 10 2 5 2 0auto 2 0 0 0 5
insurance 10 0 5 0 5has 1 2 2 1 1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Verteilter Inver*erter Index
✦ Inver*erter Index kann entlang zwei Dimensionen par//oniert und auf mehrere Rechner-‐Knoten verteilt werden
✦ Term-‐par//onierter inver/erter Index – jeder Rechner-‐Knoten speichert inver*erten Index für eine Teilmenge der Terme
✦ Dokument-‐par//onierter inver/erter Index – jeder Rechner-‐Knoten speichert inver*erten Index für Teilmenge der Dokumente
59
d1 d2 d3 d4 d5
car 10 2 5 2 0auto 2 0 0 0 5
insurance 10 0 5 0 5has 1 2 2 1 1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Verteilter Inver*erter Index
✦ Inver*erter Index kann entlang zwei Dimensionen par//oniert und auf mehrere Rechner-‐Knoten verteilt werden
✦ Term-‐par//onierter inver/erter Index – jeder Rechner-‐Knoten speichert inver*erten Index für eine Teilmenge der Terme
✦ Dokument-‐par//onierter inver/erter Index – jeder Rechner-‐Knoten speichert inver*erten Index für Teilmenge der Dokumente
59
d1 d2 d3 d4 d5
car 10 2 5 2 0auto 2 0 0 0 5
insurance 10 0 5 0 5has 1 2 2 1 1

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Term-‐Par**onierter Inver*erter Index✦ Slaves halten inver*erte Indexe für Teilmengen von Termen
✦ Master bearbeitet Anfragen, indem er für jeden der Anfrageterme die Indexliste vom zuständigen Slave anfordert
✦ Vorteil:✦ Master kommuniziert zur Anfragebearbeitung mit wenigen Slaves
✦ Nachteil:✦ fällt ein Slave aus, so können Anfragen nicht mehr bearbeitet
werden, wenn sie Terme dieses Slaves beinhalten
60

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Dokument-‐Par**onierter Inver*erter Index✦ Slaves halten inver*erten Index für Teilmenge der Dokumente
✦ Anfrage wird von allen Slaves bearbeitet und deren lokale Ergebnisse vom Master in ein globales Ergebnis kombiniert
✦ Vorteil:✦ fällt ein Slave aus, so können weiterhin alle Anfragen bearbeitet
werden, es fehlen lediglich einige Ergebnisse
✦ Nachteil:✦ Master kommuniziert zur Anfragebearbeitung mit allen Slaves
61

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Verteilte Indexierung✦ Indexierung einer Dokumentensammlung ist parallelisierbar
✦ Einlesen und Tokenisieren verschiedener Dokumente ist unabhängig voneinander – kann somit ohne Probleme parallel auf verschiedenen Rechnern sta�inden
✦ Sor/eren der Wortvorkommen verschiedener Terme ist unabhängig voneinander – kann somit ohne Probleme parallel auf verschiedenen Rechnern sta�inden
✦ MapReduce ist ein von Google entwickelter Ansatz zur parallelen Verarbeitung sehr großer Datenmengenauf einem Cluster gewöhnlicher (commodity) Rechner
62

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
MapReduce als System✦ MapReduce unterscheidet zwei Arten von Rechner-‐Knoten
✦ Master (JobTracker) koordiniert Bearbeitung eines Jobs✦ Slaves (TaskTracker) führen Teilberechnungen (tasks) durch
✦ MapReduce verwendet ein verteiltes Dateisystem, welches Dateien in großen Blöcken (> 64 MB) speichert und Replikas dieser Blöcke auf mehreren Rechner-‐Knoten (> 2) speichert
✦ Stärke von MapReduce ist seine Toleranz für Rechner-‐Ausfälle, da der Master fehlende Teilberechnungen erneut starten kann
✦ Apache Hadoop ist eine verbreitete Open-‐Source Implemen*erung des verteilten Dateisystems und MapReduce
63

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
MapReduce zur Problemlösung✦ MapReduce erzwingt Problemlösung mifels zwei Funk/onen,
die aus der funk*onalen Programmierung entliehen sind:
✦ map() erhält Eingabe und gibt eine Menge von Schlüssel-‐Wert-‐Paaren < K1 , V1 > aus
✦ reduce() erhält als Eingabe Schlüssel-‐Wertliste-‐Paare < K1 , List<V1> > in Reihenfolge des Schlüssels K1 und gibt Schlüssel-‐Wert-‐Paare < K2 , V2 > aus
✦ Zwischen map() und reduce() findet im Verborgenen eine Gruppierung und Sor/erung (shuffle) der Schlüssel-‐Wert-‐Paare < K1, V1 > anhand des Schlüssels K1 stan
64

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
WordCount in MapReduce✦ Problem: Berechne für jeden Term t seine Häufigkeit cft
in der Dokumentensammlung, verwende hierzu m Rechner
65
!"#$ %&'()$ *)+',)$
!"#"
!"$"
%"#"
%"&"
-$
.$
-$
.$
-$
-$
.$
.$
+-/"'()"*+,-."/012$"314"5+&67"18)0"'()"9:;<"=1>"
+0/"'()"*+,-."/012$"=1>"5+&67"18)0"'()"9:;<"314"
?'()@"=#A"?*+,-.@"=#A""?/012$@"=#A"B"
?'()@"=CA"?*+,-.@"=CA""?/012$@"=CA"B"
314"D"E=#@"=CF"*+,-."D"E=#@"=CF"B"
/012$"D"E=#@"=CF"=1>"D"E=#@"=CF"B"
1'2-/"314"D"C"*+,-."D"C"B"""
1'20/"/012$"D"C"=1>"D"C"B"""
map( document d )foreach term t in document d
emit < t, d >
reduce( term t, list of integers l )emit < t, l.length() >

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Indexierung in MapReduce✦ Problem: Erstelle inver*erten Index, der für jeden Term t eine
dokument-‐sor*erte Indexliste mit Term-‐Häufigkeiten enthält. Verwende hier zu m Rechner
66
map( document d )foreach term t in document d
emit < t, < d, tft,d >>
reduce( term t, list of document-frequency pairs l )L ← new IndexList()l.sortByDocumentIdentifier()foreach document-frequency pair < d, tft,d > in l
L.add(new Posting( d, tft,d ))emit < t, L >

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
MapReduce Skalierbarkeit✦ MapReduce bietet einen Rahmen, um Probleme parallel auf
einer sehr großen Zahl von Rechner bearbeiten zu können
✦ Im Idealfall erreicht man hierbei lineare Skalierbarkeit, d.h. eine Verdopplung der Zahl von Rechnern führt zu einer Halbierung der benö/gten Zeit zur Lösung des Problems
✦ Für Probleme mit einfacher Struktur (z.B. WordCount und Indexierung) erreicht man diese lineare Skalierung (linear scale-‐out) in der Praxis
67

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Zusammenfassung✦ Inver/erter Index als wich*ge Indexstruktur im IR
✦ External Memory Sort als Schlüssel zur effizienten Indexierung
✦ Anfragebearbeitung auf dokument-‐sor*erten Indexlisten (TAAT + DAAT) und wert-‐sor*erten Indexlisten (NRA)
✦ Kompression von Indexlisten wich*g für kurze Antwortzeiten
✦ Dynamische Indexierung mit logarithmischem Verschmelzen
✦ Verteile IR-‐Systeme auf Clustern mehrerer Rechner zur schnelleren Indexierung und Anfragebearbeitung
68

Informa*on Retrieval (SS 2011) 4. Implemen*erung von IR-‐Systemen
Quellen & Literatur[1] R. Baeza-‐Yates and B. Ribeiro-‐Neto: Modern Informa4on Retrieval, Addison-‐Wesley, 2011[2] R. Baeza-‐Yates, A. Gionis, F. Junqueira, V. Murdock, V. Plachouras, F. Silvestri: The Impact of Caching on Search Engines, SIGIR 2007.[3] S. Büncher, C. L. A. Clake and G. V. Cormack: Informa4on Retrieval,
MIT Press, 2010.[4] T. H. Cormen, C. Stein, C. E. Leiserson and R. L. Rivest: Introduc4on to Algorithms B & T, 2001.[5] W. B. Croq, D. Metzler and T. Strohman: Search Engines Addison-‐Wesley, 2010. (Kapitel 5)[6] R. Fagin, A. Lotem and M. Naor: Op4mal Aggrega4on Algorithms for Middleware, Journal of Computer and System Sciences 66(4), 2003.[7] C. D. Manning, P. Raghavan and H. Schütze: IntroducVon to InformaVon Retrieval, Cambridge University Press, 2008. (Kapitel 4 + 5 + 6 + 7)[8] N. Ntoulas, J. Cho and C. Olston: What’s new on the Web: The Evolu4on of the Web from a Search Engine Perspec4ve, WWW 2004[9] I. H. Winen, A. Moffat and T. C. Bell: Managing Gigabytes, Morgan Kaufmann Publishing, 1999.[10] J. Zobel and A. Moffat: Inverted Files for Text Search Engines, ACM Compu*ng Surveys 38(2), 2006.
69