Embed Size (px)
Citation preview

Data Warehousing und Mining: Data Preprocessing – 1Klemens Böhm
Kapitel 6:Data Preprocessing
Data Warehousing und Mining: Data Preprocessing – 2Klemens Böhm
Preprocessing (1)
� Data Cleaning, Data Integration, Data Transformation, Data Reduction,
� Data Cleaning – Daten sind i. Allg.:
� unvollständig – Daten fehlen ganz, oder nur Aggregate sind vorhanden,
� ‚noisy‘ – unkorrekte Attributwerte,
� inkonsistent –unterschiedliche Bezeichnungen im Umlauf;
Unser Thema im folgenden: Duplikateliminierung.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 3Klemens Böhm
Preprocessing (1)
� Data Integration –
� unterschiedliche Bezeichnungen auf der Schemaebene (‚customer-id‘ vs. ‚cust-id‘) und auf der Instanzebene (‚Steffi‘ vs. ‚Stephanie‘),
� Unterschiede auf der semantischen Ebene, z. B. Übernachtungspreis mit/ohne Frühstück.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 4Klemens Böhm
Preprocessing (2)� Data Transformation –
hier: Normalisierung, Aggregierung,
� Data Reduction –Ziel: Deutlich geringeres Datenvolumen mit möglichst geringem Informationsverlust:
� Aggregation und Verallgemeinerungen entlang der Konzepthierarchie,
� Dimensionalitätsreduktion,
� Komprimierung,
� ‚Numerosity Reduction‘ –parametrisierte Modelle, Cluster.
Z. T. gleiche Techniken, die später als Data Mining-Techniken verkauft werden.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 5Klemens Böhm
Gliederung
� Einleitung,
� Duplikatelimination – zwei Ansätze,
� Data Reduction.Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 6Klemens Böhm
Motivation für Duplikateliminierung
� „Real-World Data is Dirty“.
� Doppelte Post im Briefkasten, wer kennt das nicht.
� Wie kann das Data Cleaningeffizient durchgeführt werden?
� Auch Problem für ‚Data Warehousing‘. Warum?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 7Klemens Böhm
Beispiele aus realem Datensatz
SSN Name (First, Initial, Last)
Address
334600443 Lisa Boardman 144 Wars St. 334600443 Lisa Brown 144 Ward St. 525520001 Ramon Bonilla 38 Ward St. 525250001 Raymond Bonilla 38 Ward St. 0 Diana D. Ambrosion 40 Brik Church Av. 0 Diana A. Dambrosion 40 Brick Church Av. 0 Colette Johnen 600 113th St. apt. 5a5 0 John Colette 600 113th St. ap. 585 850982319 Ivette A Keegan 23 Florida Av. 950982319 Yvette A Kegan 23 Florida St.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 8Klemens Böhm
Duplikateliminierung – Beispiele (1)� Deduplication,
� Duplikate, die CiteSeer nicht erkannt hat:
� L. Breiman, L. Friedman, and P. Stone, (1984). Classification and Regression. Wadsworth, Belmont, CA.
� Leo Breiman, Jerome H. Friedman, Richard A. Olshen, and Charles J. Stone. Classificationand Regression Trees. Wadsworth and Brooks/Cole, 1984.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 9Klemens Böhm
Duplikateliminierung – Beispiele (2)
� Zählen der gemeinsamen Worte reicht nicht –dies sind keine Duplikate:
� H. Balakrishnan, S. Seshan, and R. H. Katz, Improving Reliable Transport and HandoffPerformance in Cellular Wireless Networks, ACM Wireless Networks, 1(4), December1995.
� H. Balakrishnan, S. Seshan, E. Amir, R. H. Katz, „Improving TCP/IP Performance overWireless Networks“, Proc. 1st ACM Conf. on Mobile Computing and Networking, November 1995.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 10Klemens Böhm
Ansätze – Vergleich (1)
� Zwei Ansätze, der erste von Hernandez und Stolfo (HS), der zweite von Sarawagi und Bhamidipaty (SB).
� Verschiedene Zielsetzungen:
� HS minimiert Kosten der Berechnungen,
� SB minimiert intellektuellen Aufwand.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 11Klemens Böhm
Ansätze – Vergleich (2)
� Unterschiedliche Ziele bezüglich Ergebnisqualität:
� HS:– ‚Knowledge Base‘ gegeben
(Äquivalenztheorie). – ‚Optimalität des Ergebnisses‘
bezieht sich auf diese Knowledge Base.– Ansatz tauscht Optimalität
des Ergebnisses der Duplikateliminierung, basierend auf Knowledge Base, gegen Beschleunigung.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 12Klemens Böhm
Ansätze – Vergleich (3)� Unterschiedliche Ziele
bezüglich Ergebnisqualität (Forts.):
� SB:– Erweitert die Knowledge Base,– gegeben ein gewisses Maß
an intellektueller Anstrengung, die man bereit ist zu investieren, wie sollte Knowledge Base am besten erweitert werden?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 13Klemens Böhm
HS Ansatz – Übersicht
� Duplikateliminierung – Implementierungsaspekte,
� Problem Statement,
� Äquivalenz,
� Ermitteln von Repräsentanten,
� „Sorted Neigborhood“ Methode,
� Verfeinerungen von „Sorted Neigborhood“,
� Experimente und Ergebnisse.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 14Klemens Böhm
Duplikateliminierung
� Zunächst, „zum Aufwärmen“: Wir wollen Duplikate ‚auf der physischen Ebene‘eliminieren, d. h. identische Records sollen aus Datenbeständen entfernt werden,
� „select distinct * from big_table“
� Wie implementiert man es effizient?Verbesserung, die im folgenden vorgestellt wird, ist recht einfach und ‚klein‘.
� Ziel: Gegenüberstellung Duplikateliminierung auf physischer Ebene – Duplikateliminierung auf logischer Ebene.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 15Klemens Böhm
� Duplikateliminierung ist im wesentlichen Sortieren.
1. Sortieren,2. linearer Scan
mit Vergleich benachbarter Records,3. Schreiben der Records ohne Duplikate.
� I/O Kosten: N·logN + N + N/fN = Anzahl Pages, f = mittlere Anzahl Recordduplikate pro File.
� Strikte Trennung von Sortieren sowie Duplikatelimination ist nicht zwangsläufig, wird im folgenden aufgebrochen.
Naheliegender AnsatzEinleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 16Klemens Böhm
Modifizierter Merge-Sort Algo. (1)� Ziel: Eliminierung der Duplikate
möglichst früh stattfinden lassen, Duplikateliminierung ins Sortieren ‚hineindrücken‘.
� Merge-Sort:
� Aufteilen der Daten in Hälften,
� Jede Hälfte sortieren, mit Merge-Sort(d. h. Verfahren ist rekursiv),
� sortierte Hälften mergen, d. h. zu einer sortierten Liste zusammenfügen,mit gleichzeitiger Duplikateliminierung.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 17Klemens Böhm
Beispiel: Modified Merge-Sort
1,3,5,6,8 1,4,6,7,93,6,7,8, 0,3,4,5,6
0,1,3,4,5 8,9, , ,6,8, , , 1,3,4,6,7
8,5,6,3,1 0,4,3,6,5 3,7,7,6,8 1,4,9,6,7
0,1,3,4,5,6,7,9, , , , , , , , , , ,
Merge-sort & PurgeN·logN + N + N/f
Modified Merge-SortN · logN + N + N/f
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 18Klemens Böhm
Modifizierter Merge-Sort Algo. (2)
� Minimierung von I/O Operationen
� Aufteilen der Daten in n Runs,
� Runs im Hauptspeicher sortieren,
� log n Mergephasenmit gleichzeitiger Duplikateliminierung.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 19Klemens Böhm
Modifizierter Merge-Sort Algo. (3)Bemerkungen:
� Einsparung verglichen mit naiver Methode ist abhängig vom Duplikatshäufigkeit f.
� I/O Reduktion von 7% bei f=2 (uniform verteilte Duplikate).
� Alternative Lösungsansätze existieren(z. B. Hash-basierte).
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 20Klemens Böhm
Data-Cleaning –Merge/Purge Problem (1)
� Jetzt Duplikatelimierung auf logischer Ebene.
� Teilaspekte des Problems:
� Finde äquivalente Datensätze, d. h. Duplikate und „ähnliche“ Records, die die gleiche Instanz beschreiben.
� Wähle Repräsentanten aus.
� Vorgehen: Ähnlichkeit wird durch eine Äquivalenz-Theorie definiert.(Theorie: Menge von Formeln, die gemäß Folgerbarkeit abgeschlossen ist.)
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 21Klemens Böhm
Data-Cleaning –Merge/Purge Problem (2)
� Eigenschaft des im folgenden vorgestellten Ansatzes: Effizienz kann mit Genauigkeit erkauft werden und umgekehrt.
� Hier vorgestellter Ansatz war Grundlage des DataCleanser DataBlades von Informix.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 22Klemens Böhm
Äquivalenz-Theorie
� Regeln zur Beschreibung von Äquivalenz.
� Wahl der Regeln ist problembezogen, Anwendungswissen wird benötigt.
� Regeln reflektieren
� Aufbau der Datensätze,
� Bedeutung der Felder.
� Welche der folgenden Regeln fällt in die erste, welche in die zweite Kategorie?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 23Klemens Böhm
Äquivalenz-Theorie – Beispiel
� equiv_Record(R1,R2):similar_First(R1,R2), equal_Last(R1,R2), similar_ID(R1,R2).
� equiv_Record(R1,R2):similar_Address(R1,R2), similar_ID(R1,R2).
� similar_Address(R1,R2):similar_Street(R1,R2), similar_Street_Num(R1,R2).
� similar_ID(R1,R2): missing_ID(R1,R2).
� similar_ID(R1,R2): equal_ID(R1,R2).
D. h. Definition der Äquivalenz basiert i. Allg. u. a. auf String-Ähnlichkeit.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 24Klemens Böhm
Ähnlichkeit von FeldinhaltenÄhnlichkeit von Feldinhalten kann
durch verschiedene Metriken oder Transformationen definiert werden, z. B.
� phonetische Distanz(Schmidt, Schmitt)
� Rechtschreibdistanz (Küssnacht, Küsnacht)
� Typewriter Distanz (Feller, Geller)
� Kanonisierungen (Bahnhf-Str., Bahnhofstr., Bahnhofstrasse)
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 25Klemens Böhm
Fehlerarten (1)
� Beim Zusammenfassen äquivalenter Records kann
� zuviel zusammengefaßt werden (= False Positive),
� zuwenig zusammengefaßt werden (= Miss),
� Beispiel:
� der Realität entsprechende Clusterung: {R1;R2;R3} {R4;R5} {R6;R7;R8} {R9;R10}
� Ergebnis des Algorithmus: {R1;R2;R3} {R4} {R5} {R6;R7;R8;R9;R10}
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 26Klemens Böhm
Fehlerarten (2)
� Fehlerarten: False Positive, Miss,
� Je nach Verwendungszweck müssen diese Fehler unterschiedlich gewichtet werden.
� Beispiel: Cleaning von Adreßdaten für Werbeversand.
a) Adressaten stört es nicht, wenn sie gleiche Werbung mehrmals erhalten.
b) Adressaten sind sauer und kaufen unser Produkt definitiv nicht.
� In welchem der Fälle sind Misses stoßender?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 27Klemens Böhm
Sorted Neighborhood Methode (1)
� Gegeben Äquivalenztheorie, wie findet man äquivalente Datensätze?
� Mögliches, aber teures Vorgehen: Similarity Join, Nested-Loop.
� Sorted-Neighborhood Methode löst das Problem auch weitgehend, ist aber billiger:
� Durch Sortieren ähnliche Datensätze zusammenbringen,
� Vergleichsoperation nur in der Umgebung des Datensatzes nach Sortierung,
� Berechnung der transitiven Hülle.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 28Klemens Böhm
Algorithmus� Konkateniere die Datensätze,
� erzeuge Schlüssel aus (Teilen der) relevanten Felder,
� sortiere die Daten anhand dieses Schlüssels (Sort),
� schiebe ein Fenster der Größe w über die sortierte Liste und vergleiche ersten Recordmit den folgenden w-1 Records (Merge)(w ist Parameter des Algorithmus),
� berechne transitive Hülle,
� wähle Klassen-Repräsentanten (Purge, vgl. mit einer der folgenden Folien).
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 29Klemens Böhm
Merge – IllustrationEinleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Relation, deren Duplikate erkannt werden sollen(sortiert)
Data Warehousing und Mining: Data Preprocessing – 30Klemens Böhm
Merge – IllustrationEinleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Relation, deren Duplikate erkannt werden sollen(sortiert)
Data Warehousing und Mining: Data Preprocessing – 31Klemens Böhm
Merge – IllustrationEinleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Relation, deren Duplikate erkannt werden sollen(sortiert)
Data Warehousing und Mining: Data Preprocessing – 32Klemens Böhm
Merge – IllustrationEinleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Relation, deren Duplikate erkannt werden sollen(sortiert)

Data Warehousing und Mining: Data Preprocessing – 33Klemens Böhm
Frage zum Algorithmus
� Warum reicht Sortieren allein nicht, warum ist das Fenster vorteilhaft?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 34Klemens Böhm
Aktuelles Fenster
Fenster im nächsten Schritt
ww
Window Scan
� Fenstergröße w beeinflußt Genauigkeit und Rechenaufwand.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 35Klemens Böhm
Anzusprechende Punkte
� Welches Sortierkriterium?
� Tradeoff zwischen Effizienz und Akkuratheit.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 36Klemens Böhm
Data-Cleaning: Schlüsselwahl (1)Schlüsselwahl: Definition des Schlüssels
ist anwendungsspezifisch – „Faustregeln“:
� String aus möglichst viel relevanter Info. bilden.
� Übereinstimmung in signifikanten Stellen bringt Ähnliches zusammen.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 37Klemens Böhm
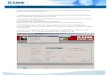
Data-Cleaning: Schlüsselwahl (2)
� Vorsicht mit Nummern: Transpositionen haben großen Einfluß.Manchmal erste drei Buchstaben, manchmal erste drei Konsonanten.
� Beispiel:
First Last Address ID Key
Sal Stolfo 123 First Street 45678987 STLSAL123FRST456
Sal Stolfo 123 First Street 45678987 STLSAL123FRST456 Sal Stolpho 123 First Street 45678987 STLSAL123FRST456 Sal Stiles 123 Forest Street 45654321 STLSAL123FRST456
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 38Klemens Böhm
Transitive Hülle
� Transitivität (a = b und b = c ⇒ a = c) hilft, um äquivalente Datensätze zu erkennen.
� Berechnung der transitiven Hülle: Diverse Rechenmethoden sind in der Literatur bekannt, z. B. direkte Matrix-Methoden.
� Verbesserungen der Trefferquote, aber auch Erhöhung der Anzahl der False Positive Fehler. Warum mehr False Positives?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 39Klemens Böhm
Sorted Neighborhood Methode -Verfeinerungen
� Multipass-Variante,
� inkrementelle „sorted neighborhood“ Methode.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 40Klemens Böhm
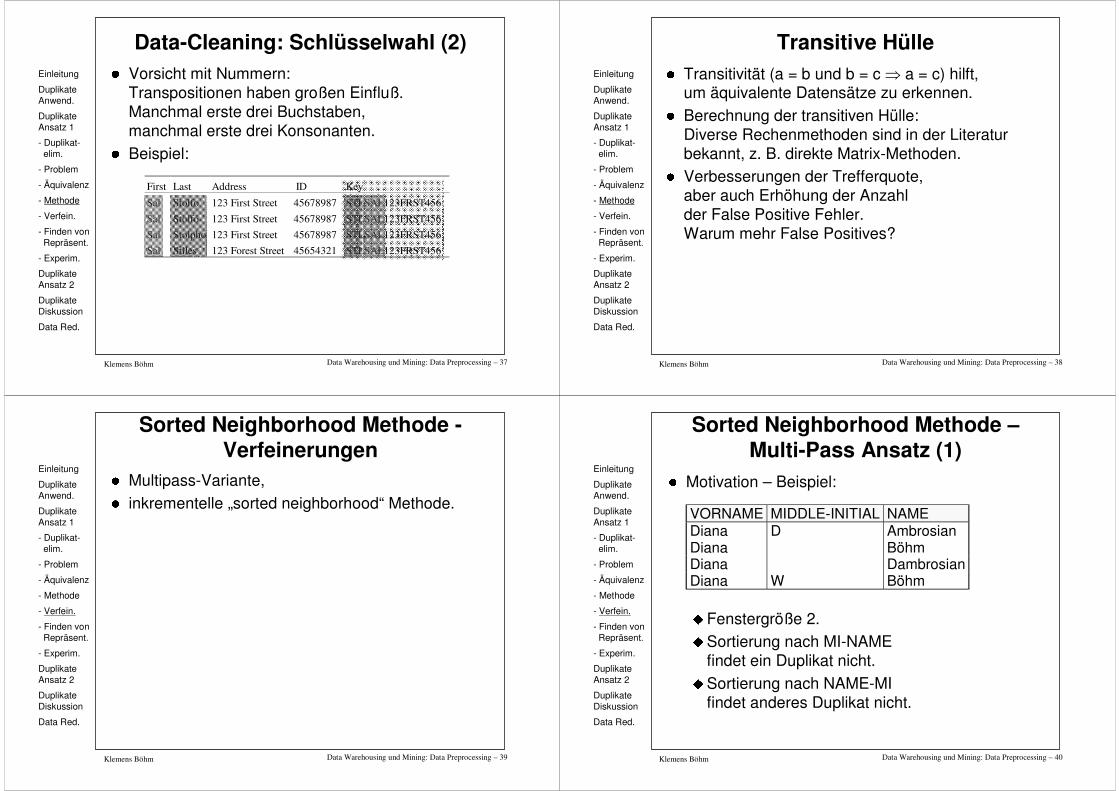
Sorted Neighborhood Methode –Multi-Pass Ansatz (1)
� Motivation – Beispiel:
� Fenstergröße 2.
� Sortierung nach MI-NAME findet ein Duplikat nicht.
� Sortierung nach NAME-MI findet anderes Duplikat nicht.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
VORNAME MIDDLE-INITIAL NAME Diana D Ambrosian Diana Böhm Diana Dambrosian Diana W Böhm
Data Warehousing und Mining: Data Preprocessing – 41Klemens Böhm
Sorted Neighborhood Methode –Multi-Pass Ansatz (2)
� Prinzip:
� Mehrfache Durchführung des Sorted Neighborhood Verfahrens mit unterschiedlichem Sortierschlüssel,
� Berechnung der transitiven Hülle liefert das Gesamtergebnis.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 42Klemens Böhm
Sorted Neighborhood Methode –Multi-Pass Ansatz (3)
� Vorteile:
� Gleiche Genauigkeit (Miss-Rate) kann mit geringerer Fensterbreite erreicht werden. (Offensichtlich. Wieso?)
� Bei gleicher Duplikat-Erkennungsrate, d. h. gleicher Anzahl von Misses, ergeben sich weniger False Positives als mit der Single Pass Methode. (Experimentelles Ergebnis)
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 43Klemens Böhm
Inkrementelle Methode (1)
� Anstelle der vollständigen Menge der Datensätze kann man (im Data Warehouse) mit prime representativesjedes Clusters arbeiten.
� Löschen von Datensätzen
� kann Cluster „auseinanderreißen“(Illustration auf folgender Folie),
� Algorithmus (Menge von Deletes):1. Alle Löschungen durchführen
und IDs der betroffenen Cluster merken,2. Neu-Berechnung der betroffenen Cluster.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 44Klemens Böhm
Inkrementelle Methode (2)� Beispiel: Ralf Duckstein,
Rolf Duckstein, Rolf Dachstein
� Weitere Vornamen: Rene, Rembert, Robert, Roland
� Weitere Nachnamen: Dickel, Dormann
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 45Klemens Böhm
Auswahl von RepräsentantenAuswahlkriterien sind fallabhängig, z. B.
� zufälliges Sample,
� n-letzte Werte, z. B. bei Wohnadressen,
� Generalisierung, z. B. Mittelbildung,
� syntaktisch (längster oder vollständigster Rekord),
� Benutzer-Interface.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
zData Warehousing und Mining: Data Preprocessing – 46Klemens Böhm
Experimentelle Ergebnisse (1)
Datenbasis: 13751 Rekords (7500 Originale, davon 50% mit 1-5 Duplikaten)
Detektierte Duplikate [%]
Hier Ergebnisse mit synthethischen Daten.1 – Last Name, 2 – First Name, 3 – Street Address
1
2
3
Multi-Pass
Multi-Pass
1,2,3
Rechenzeit für Single und MP [s]
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 47Klemens Böhm
Experimentelle Ergebnisse (2) Datenbasis: 1M Records + 423644 Duplikate
Detektierte Duplikate False-Positive
1,2
3
Multi-Pass
0.2%
0
Multi-Pass
123
1 – Last Name, 2 – First Name, 3 – Street AddressIst das
erwartet?
Data Warehousing und Mining: Data Preprocessing – 48Klemens Böhm
Fallbeispiel: Analyse der OCAR Daten
� Datensatz des Office of ChildrenAdministrative Research, U.S.A.,Datenbank über staatliche Zahlungen an Familien und Firmen für Hilfeleistungen an bedürftige Kinder,
� Schiefe Verteilung der Daten: Mehrere Records pro Individuum.
� Auswertungen der Records soll eindeutigen Schlüssel zur Identifizierung der einzelnen Kinder liefern.
� Ziel des Data Cleaning –Datenanalyse, z. B. durchschnittlicher Zeitraum finanzieller Unterstützung.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 49Klemens Böhm
Fallbeispiel: Analyse der OCAR Daten (Forts.)
� OCAR-Behörde hat ein eigenes Kriterium für Äquivalenz: erste vier Buchstaben des Nachnamens und erste drei Buchstaben des Vornamens und Geburtsmonat und -jahr und interne Nummer müssen übereinstimmen.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 50Klemens Böhm
Fallbeispiel: Analyse der OCAR Daten (Forts.)
� Multi-Pass Methode mit folgenden Schlüsseln:
� Nachname, Vorname, Social Sec. Nummer, interne Nummer,
� Vorname, Nachname, Social Sec. Nummer, interne Nummer,
� Interne Nummer, Vorname, Nachname, Social Sec. Nummer.
� Ziel: Vergleich der Ansätze.
� Im folgenden: Vergleich mit OCAR-Kriterium.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 51Klemens Böhm
Ergebnisse mit realen Daten (1)
Possible Misses Possible False-Positives
1 – Last Name, 2 – First Name, 3 – Street Address
1
23
Multi-Pass
1,32
Multi-Pass
Beobachtung: Fenstergröße von untergeordneter Bedeutung.
Data Warehousing und Mining: Data Preprocessing – 52Klemens Böhm
Ergebnisse mit realen Daten (2)� Wie aussagekräftig
sind Kurven auf vorangegangener Folie?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 53Klemens Böhm
Fallbeispiel: Analyse der OCAR Daten (Forts.)
� Fehler kann entweder durch das OCAR-Kriterium oder durch die Multi-Pass Methode zustandekommen.
� Vergleich zufällig ausgewählter Datensätze „von Hand“, z. B. 45,8% der Potential Misses sind Fehler des OCAR-Kriteriums, 27,1% sind Fehler der Multi-Pass Methode.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
- Duplikat-elim.
- Problem
- Äquivalenz
- Methode
- Verfein.
- Finden vonRepräsent.
- Experim.
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
zData Warehousing und Mining: Data Preprocessing – 54Klemens Böhm
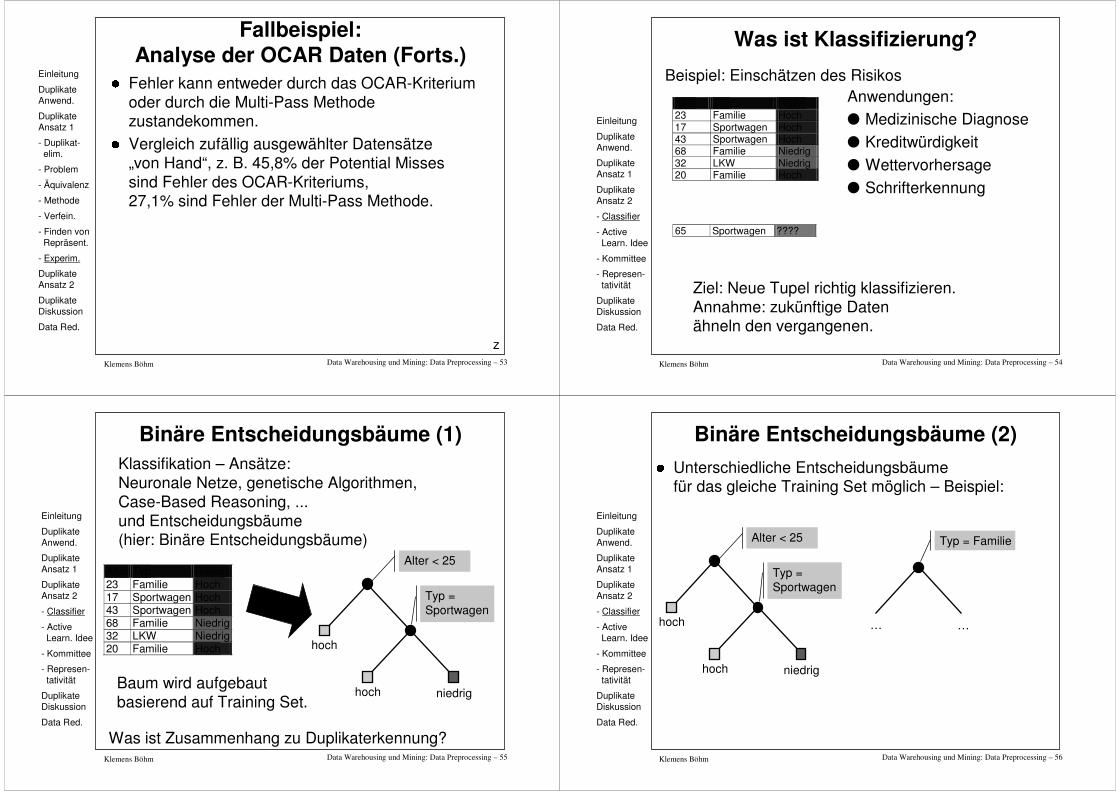
Was ist Klassifizierung?
Beispiel: Einschätzen des Risikos
Alter Typ Risiko 23 Familie Hoch 17 Sportwagen Hoch 43 Sportwagen Hoch 68 Familie Niedrig 32 LKW Niedrig 20 Familie Hoch
65 Sportwagen ????
Anwendungen:l Medizinische Diagnosel Kreditwürdigkeitl Wettervorhersagel Schrifterkennung
Ziel: Neue Tupel richtig klassifizieren.Annahme: zukünftige Daten ähneln den vergangenen.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 55Klemens Böhm
Binäre Entscheidungsbäume (1)Klassifikation – Ansätze: Neuronale Netze, genetische Algorithmen, Case-Based Reasoning, ...und Entscheidungsbäume(hier: Binäre Entscheidungsbäume)
Alter Typ Risiko 23 Familie Hoch 17 Sportwagen Hoch 43 Sportwagen Hoch 68 Familie Niedrig 32 LKW Niedrig 20 Familie Hoch
Alter < 25
Typ = Sportwagen
hoch
hoch niedrigBaum wird aufgebautbasierend auf Training Set.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Was ist Zusammenhang zu Duplikaterkennung?Data Warehousing und Mining: Data Preprocessing – 56Klemens Böhm
Binäre Entscheidungsbäume (2)� Unterschiedliche Entscheidungsbäume
für das gleiche Training Set möglich – Beispiel:
Alter < 25
Typ = Sportwagen
hoch
hoch niedrig
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Typ = Familie
… …
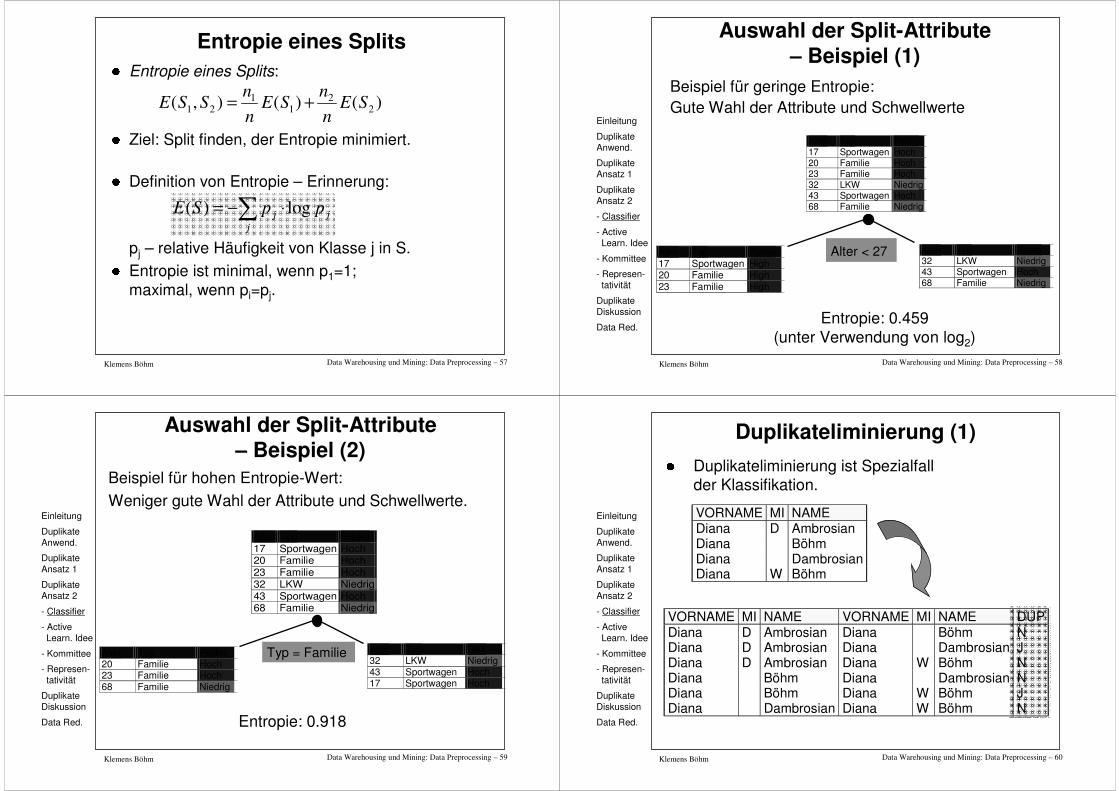
Data Warehousing und Mining: Data Preprocessing – 57Klemens Böhm
Entropie eines Splits
� Entropie eines Splits:
� Ziel: Split finden, der Entropie minimiert.
� Definition von Entropie – Erinnerung:
pj – relative Häufigkeit von Klasse j in S.
� Entropie ist minimal, wenn p1=1; maximal, wenn pi=pj.
)()(),( 22
11
21 SEnn
SEnn
SSE +=
∑ ⋅−=j
jj ppSE log)(
Data Warehousing und Mining: Data Preprocessing – 58Klemens Böhm
Auswahl der Split-Attribute– Beispiel (1)
Beispiel für geringe Entropie: Gute Wahl der Attribute und Schwellwerte
Alter Typ Risiko 17 Sportwagen Hoch 20 Familie Hoch 23 Familie Hoch 32 LKW Niedrig 43 Sportwagen Hoch 68 Familie Niedrig
Alter Typ Risiko 32 LKW Niedrig 43 Sportwagen Hoch 68 Familie Niedrig
Alter Typ Risiko 17 Sportwagen High 20 Familie High 23 Familie High
Alter < 27
Entropie: 0.459(unter Verwendung von log2)
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 59Klemens Böhm
Alter Typ Risiko 17 Sportwagen Hoch 20 Familie Hoch 23 Familie Hoch 32 LKW Niedrig 43 Sportwagen Hoch 68 Familie Niedrig
Beispiel für hohen Entropie-Wert: Weniger gute Wahl der Attribute und Schwellwerte.
Alter Typ Risk 32 LKW Niedrig 43 Sportwagen Hoch 17 Sportwagen Hoch
Alter Typ Risiko 20 Familie Hoch 23 Familie Hoch 68 Familie Niedrig
Typ = Familie
Entropie: 0.918
Auswahl der Split-Attribute– Beispiel (2)
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 60Klemens Böhm
Duplikateliminierung (1)� Duplikateliminierung ist Spezialfall
der Klassifikation.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
VORNAME MI NAME Diana D Ambrosian Diana Böhm Diana Dambrosian Diana W Böhm
VORNAME MI NAME VORNAME MI NAME DUP Diana D Ambrosian Diana Böhm N Diana D Ambrosian Diana Dambrosian J Diana D Ambrosian Diana W Böhm N Diana Böhm Diana Dambrosian N Diana Böhm Diana W Böhm J Diana Dambrosian Diana W Böhm N

Data Warehousing und Mining: Data Preprocessing – 61Klemens Böhm
Duplikateliminierung (2)
� Algorithmen für maschinelles Lernen
� z. B. Classifier,
� Training Set – Menge von Duplikaten und Nicht-Duplikaten,
� zusätzlicher Input: Diverse einfache anwendungsspezifische Funktionen für das Matchingfür die unterschiedlichen Attribute – Beispiele:– Editierdistanz– „abbreviation match“– Zahlenfelder: absolute Differenz.
Text-Felder
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
zData Warehousing und Mining: Data Preprocessing – 62Klemens Böhm
Active Learning – Motivation (1)
� Im Versicherungsbeispiel sind Trainingsdaten verfügbar (Menge der Kunden aus der Vergangenheit).
� Bei Duplikaterkennung, z. B. CiteSeer, ist das nicht so!
� Naiver, für Benutzer anstrengender Ansatz:
� System generiert zufällig Paare von Datenobjekten.
� Benutzer muß für jedes Paar sagen, ob Duplikate oder nicht.
� Ablauf endet, sobald wir gutes Training Set beisammen haben.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 63Klemens Böhm
Active Learning – Motivation (2)
� Problem mit (2): Ermitteln eines Training Set, das den Datenbestand gut abdeckt.
� Idee: System entdeckt ‚schwierige‘ Datenobjekte, d. h. solche, für die erwarteter Informationsgewinn groß.
� Benutzer markiert nur diese von Hand.Vorteil: Er muß nur ein paar Paare markieren, im Gegensatz zur o. g. Vorgehensweise.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Alter Typ Risiko 17 Sportwagen Hoch 23 Familie Hoch 20 Familie Hoch 32 LKW Niedrig 43 Sportwagen Hoch 68 Familie Niedrig
Data Warehousing und Mining: Data Preprocessing – 64Klemens Böhm
Active Learning – Motivation (2)� Problem mit (2): Ermitteln eines Training Set,
das den Datenbestand gut abdeckt.
� Idee: System entdeckt ‚schwierige‘ Datenobjekte, d. h. solche, für die erwarteter Informationsgewinn groß.
� Benutzer markiert nur diese von Hand.Vorteil: Er muß nur ein paar Paare markieren, im Gegensatz zur o. g. Vorgehensweise.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Alter Typ Risiko 17 Sportwagen Hoch 23 Familie Hoch 20 Familie Hoch 32 LKW Niedrig 43 Sportwagen Hoch 68 Familie Niedrig

Data Warehousing und Mining: Data Preprocessing – 65Klemens Böhm
Active Learning – Motivation (3)
� Beispiel: Ich bin Psychologe und möchte herausfinden, wie mutig Sie sind.
� Hierzu habe ich Fragebogen entworfen:
� „Würden Sie vom Stuhl springen?“
� „Würden Sie vom Tisch springen?“
� „Würden Sie aus dem Fenster (1. OG) springen?“
� „Würden Sie aus dem Fenster (2. OG) springen?“
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 66Klemens Böhm
Wie arbeitet Active Learner? (1)
� Objekt ermitteln, für das Classifier am wenigsten sicher ist.
� Beispiel:
� Zwei Klassen: Positiv (P) und negativ (N)
� r hat Koordinate 0, b hat Koordinate 1.r ist negativ, b ist positiv.
Sicher negativ
Sicher positivr bx
0 1
‚region of uncertainty‘
d
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 67Klemens Böhm
Wie arbeitet Active Learner? (2)
� Beispiel (Fortsetzung):
� Wir wollen wissen: Wo ist Schwellenwert zwischen N und P?Wir dürfen für einen Punkt nachschauen. Welchen?
� Annahme: prob(N) (WS, daß Punkt negativ) umgekehrt proportional zum Abstand von r, d. h., prob(N|x)=1-d, prob(P|x)=d
� Information ist ‚d·prob(N)’.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 68Klemens Böhm
Wie arbeitet Active Learner? (3)� Beispiel (Forts.):
� ‚region of uncertainty‘(Bereich zwischen r und b) muß verkleinert werden.
� Erwartete Reduktion istPr(N|x)·d+Pr(P|x)·(1-d)=(1-d)·d+d·(1-d)=2d·(1-d)Maximal für d=0.5.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 69Klemens Böhm
Wie arbeitet Active Learner? (4)
� Beispiel (Forts.):
� Im Beispiel kann ClassifierKlassen vollständig separieren.
� Weiteres Kriterium neben Unsicherheit:Repräsentativität.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
zData Warehousing und Mining: Data Preprocessing – 70Klemens Böhm
Wie bestimmt man Unsicherheit der Vorhersage für ein Datenobjekt? (1)
� Kommittee (Menge) von N Classifiern, alle unterscheiden sich geringfügig voneinander.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 71Klemens Böhm
Wie bestimmt man Unsicherheit der Vorhersage für ein Datenobjekt? (2)
� Eindeutiges Duplikat/Nicht-Duplikat wird von allen Mitgliedern (des Kommittees) gleich vorhergesagt.
� ‚Schwierigere‘ Paare bekommen unterschiedliche Vorhersagen –ins Training Set einfügen.
� Idee funktioniert im Prinzip für alle Arten von Classifiern(regressionsbasiert, Bayes, Entscheidungsbaum).
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 72Klemens Böhm
Wie bestimmt man Unsicherheit der Vorhersage für ein Datenobjekt? (3)
� Experte markiert ein paar zufällig ausgewählte Trainingsdaten von Hand.
� Erstellung des Kommittees.
� Experte kann jetzt die k schwierigsten Elemente von Hand markieren.
� Erstellung eines neuen Kommittees, Ablauf wiederholt sich.
� Wie wählt man k?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
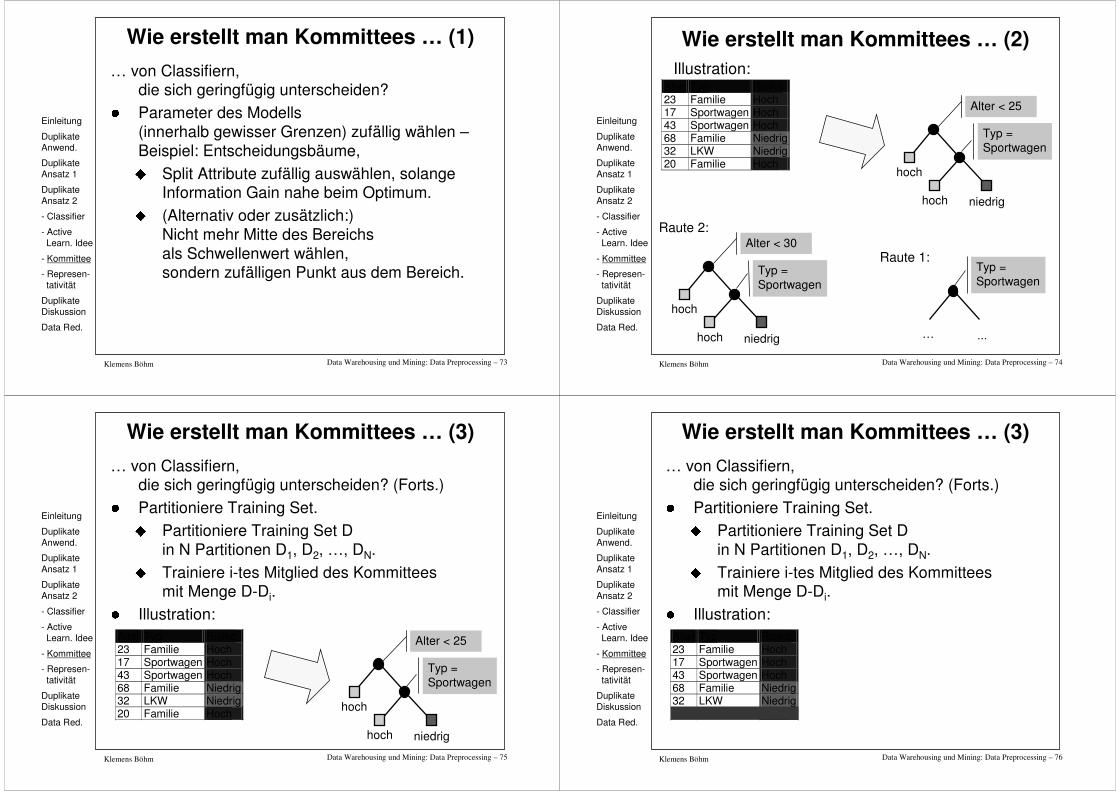
Data Warehousing und Mining: Data Preprocessing – 73Klemens Böhm
Wie erstellt man Kommittees … (1)… von Classifiern,
die sich geringfügig unterscheiden?
� Parameter des Modells (innerhalb gewisser Grenzen) zufällig wählen –Beispiel: Entscheidungsbäume,
� Split Attribute zufällig auswählen, solange Information Gain nahe beim Optimum.
� (Alternativ oder zusätzlich:)Nicht mehr Mitte des Bereichs als Schwellenwert wählen, sondern zufälligen Punkt aus dem Bereich.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 74Klemens Böhm
niedrighoch
Wie erstellt man Kommittees … (2)Illustration:
Alter Typ Risiko 23 Familie Hoch 17 Sportwagen Hoch 43 Sportwagen Hoch 68 Familie Niedrig 32 LKW Niedrig 20 Familie Hoch
Alter < 25
Typ = Sportwagen
hoch
niedrighoch
Alter < 30
Typ = Sportwagen
hoch
...…
Typ = Sportwagen
Raute 2:
Raute 1:
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 75Klemens Böhm
Wie erstellt man Kommittees … (3)… von Classifiern,
die sich geringfügig unterscheiden? (Forts.)
� Partitioniere Training Set.
� Partitioniere Training Set D in N Partitionen D1, D2, …, DN.
� Trainiere i-tes Mitglied des Kommitteesmit Menge D-Di.
� Illustration:
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
niedrighoch
Alter Typ Risiko 23 Familie Hoch 17 Sportwagen Hoch 43 Sportwagen Hoch 68 Familie Niedrig 32 LKW Niedrig 20 Familie Hoch
Alter < 25
Typ = Sportwagen
hoch
Data Warehousing und Mining: Data Preprocessing – 76Klemens Böhm
Wie erstellt man Kommittees … (3)… von Classifiern,
die sich geringfügig unterscheiden? (Forts.)
� Partitioniere Training Set.
� Partitioniere Training Set D in N Partitionen D1, D2, …, DN.
� Trainiere i-tes Mitglied des Kommitteesmit Menge D-Di.
� Illustration:
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Alter Typ Risiko 23 Familie Hoch 17 Sportwagen Hoch 43 Sportwagen Hoch 68 Familie Niedrig 32 LKW Niedrig 20 Familie Hoch

Data Warehousing und Mining: Data Preprocessing – 77Klemens Böhm
Wie erstellt man Kommittees … (3)… von Classifiern,
die sich geringfügig unterscheiden? (Forts.)
� Partitioniere Training Set.
� Partitioniere Training Set D in N Partitionen D1, D2, …, DN.
� Trainiere i-tes Mitglied des Kommitteesmit Menge D-Di.
� Illustration:
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Alter Typ Risiko 23 Familie Hoch 17 Sportwagen Hoch 43 Sportwagen Hoch 68 Familie Niedrig 32 LKW Niedrig 20 Familie Hoch
Data Warehousing und Mining: Data Preprocessing – 78Klemens Böhm
Wie erstellt man Kommittees … (3)… von Classifiern,
die sich geringfügig unterscheiden? (Forts.)
� Partitioniere Training Set.
� Partitioniere Training Set D in N Partitionen D1, D2, …, DN.
� Trainiere i-tes Mitglied des Kommitteesmit Menge D-Di.
� Illustration:
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Alter Typ Risiko 23 Familie Hoch 17 Sportwagen Hoch 43 Sportwagen Hoch 68 Familie Niedrig 32 LKW Niedrig 20 Familie Hoch
Data Warehousing und Mining: Data Preprocessing – 79Klemens Böhm
Wie erstellt man Kommittees … (3)… von Classifiern,
die sich geringfügig unterscheiden? (Forts.)
� Partitionieren der Menge der Attribute.
� Sieht erfolgversprechend aus, wenn Training-Daten ‚sparse‘ sind, aber viele Attribute haben.
� Beschreibung für Entscheidungsbaum:– Baue Entscheidungsbaum auf,– lösche das ‚beste‘ Attribut
aus Attributmenge (d. h. Split-Attribut der Wurzel),
– wiederhole dies, bis keine Attribute mehr vorhanden, oder bis Qualität der Vorhersage deutlich zurückgeht.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 80Klemens Böhm
Wie erstellt man Kommittees?Experimentelle Ergebnisse
� Randomisierung der Parameter des Modells und Partitionierung der Attributmenge führen tendenziell zu hoher Akkuratheit,
� Kommittees können recht klein sein (< 5), ohne daß man bezüglich Akkuratheit verliert.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.

Data Warehousing und Mining: Data Preprocessing – 81Klemens Böhm
Representativität – Motivation
� Realwelt-Daten sind ‚noisy‘.
� Wie stellen wir sicher, daß wir keinen Outlier wählen?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 82Klemens Böhm
Representativität von Datenobjekten (1)Wie kombiniert man Repräsentativität
mit Unsicherheit? Zwei Ansätze:
� Erster Ansatz basiert auf Clustering.
� Repräsentativität eines Datenobjekts –geschätzte Dichte.
� Dimensionen: Beobachtbare Attribute, z. B. Alter.
� Illustration:
Linker Punkt hat höhere Dichte als rechter.
x
xxx x
x
x
xx xxx
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 83Klemens Böhm
Representativität von Datenobjekten (2)Wie kombiniert man Repräsentativität
mit Unsicherheit? Zwei Ansätze:
� Erster Ansatz (Forts.).
� Jedem Punkt einen Score zuordnen: Gewichtete Summe von Dichte und Unsicherheit; n Punkte mit höchstem Score.
� Diverse Parameter.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
Data Warehousing und Mining: Data Preprocessing – 84Klemens Böhm
Representativität von Datenobjekten (3)Wie kombiniert man Repräsentativität
mit Unsicherheit? Zwei Ansätze (Forts.):
� Zweiter Ansatz basiert auf Sampling.
� Kandidaten mit ihrem Unsicherheitswert gewichten.
� n Objekte auswählen(Auswahl-WS = Gewicht).
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
x
xxx x
x
x
xx xxx

Data Warehousing und Mining: Data Preprocessing – 85Klemens Böhm
Wichtigkeit des Themas
� Die einzige Ressource, die uns wirklich wichtig ist, ist unsere Zeit und Energie.
� Alle anderen Ressourcen werden immer billiger;Optimierung diesbezüglich dieser Ressourcentendenziell weniger bedeutsam.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
- Classifier
- ActiveLearn. Idee
- Kommittee
- Represen-tativität
DuplikateDiskussion
Data Red.
zData Warehousing und Mining: Data Preprocessing – 86Klemens Böhm
Vergleich HS – SB
� Betrachtungsebene
� HS: Reduzierung des Rechenaufwands,bzw. Tausch maßvolle Abstriche bei Ergebnisqualität vs. Beschleunigung,
� SB: Minimierung des intellektuellen Aufwands, Ergebnisqualität ist fest. Was ist gemeint?
� Kriterium, ob Duplikate oder nicht
� HS: Distanz,
� SB: Regeln (Entscheidungsbaum),
� Datenvolumen
� HS: Sehr große Datenbestände, für die Join zu teuer ist,
� SB: Kosten des Joins (Aufwand der Mitglieder des Kommittees) werden vernachlässigt.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
z
Data Warehousing und Mining: Data Preprocessing – 87Klemens Böhm
Data Reduction: Sampling
� Sample-Techniken – Alternativen:
� Einfaches Ziehen mit/ohne Zurücklegen,
� Cluster Sample – Beispiel: Datenbank-Tupel von Disk seitenweise einlesen.
� Stratified Sample– Stratum – Partition der Datenbank
gemäß irgendeines Attributs, z. B. Bundesland.
– Sampling nach Bundesländern separat.– Effekt: Auch kleine Bundesländer werden
mit gewünschter Genauigkeit berücksichtigt.
� Kosten abhängig von der Größe des Samples, nicht des Datenbestands.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes
zData Warehousing und Mining: Data Preprocessing – 88Klemens Böhm
Data Reduction� Ziel von Data Reduction:
Weniger relevante Attribute weglassen.
� Beispiel: Starke Korrelation der Attribute Jahreseinkommen und Kontostand.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes

Data Warehousing und Mining: Data Preprocessing – 89Klemens Böhm
Data Reduction: Auswahl von Attributen (1)
� Ziel: Analyse einer Klasse, z. B. Tupel mit Nationalität=‚Schweiz‘oder Geschlecht=‚männlich‘.(D. h. Klassenzugehörigkeit ist bestimmter Wert eines ausgezeichneten Attributs.)
� Problem: I.Allg. ∃ viele Attribute, welche erlauben recht genaue Aussage bezüglich Klassenzugehörigkeit?
� Attribut ist relevant bezüglich einer Klasse. := Werte dieser Attribute erlauben mit hoher Wahrscheinlichkeit Differenzierung zwischen Elementen dieser Klasse und anderer Klassen.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes
Data Warehousing und Mining: Data Preprocessing – 90Klemens Böhm
Data Reduction: Auswahl von Attributen (2)
� Beispiele:
� Kennzeichen wenig relevant, ob KFZ billig oder teuer (d. h. Klasse = ‚Preis-Auto=hoch‘), Automarke dagegen schon.
� Geburtsmonat wenig relevant bezüglich ‚Besserverdiener‘, Geburtsjahr dagegen schon.
� Attribute auswählen, die bezüglich Klasse relevant sind.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes
Data Warehousing und Mining: Data Preprocessing – 91Klemens Böhm
Information Gain (1)
� S – Stichprobe, Menge von Tupeln; ein Attribut bestimmt Klassenzugehörigkeit.s – Anzahl der Samples(Sample = Element der Stichprobe).
� m – Anzahl der Klassen C1, ..., Cm. sj – Anzahl der Samples in Klasse Cj.
� Wie überraschend ist Klassenzugehörigkeit eines Samples? Information Gain:
s
s
s
sssI j
m
j
jm 2
11 log),,( ∑
=
−=K
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes
∑=j
jss
Data Warehousing und Mining: Data Preprocessing – 92Klemens Böhm
Information Gain (2)� Beispiel:
� s1=20, s2=...=sm=0 → Weitere Stichprobe nicht überraschend.
� s1=5, s2=5, ..., sm=5 → maximale Überraschung(analog zum Spiel aus Kapitel 2).
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes

Data Warehousing und Mining: Data Preprocessing – 93Klemens Böhm
Information Gain (3)
� We wollen Klasse vorhersagen.C1=reich, C2=normal, C3=arm.
� Außerdem beobachtbare Attribute.a1=Rolls Royce, a2=Mercedes, a3=VW, a4=Kia
� Ohne Kenntnis des Autos ist Kenntnis des Wohlstands überraschend.
� Auto-Information konkret verfügbar → Grad an Wohlstand weniger überraschend.
� Analog zur Folie von eben können wir Grad der Überraschung quantifizieren.
R.R. M. VW Kia gesamt reich 3 5 2 0 10 normal 0 5 3 2 10 arm 0 1 4 5 10
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes
Data Warehousing und Mining: Data Preprocessing – 94Klemens Böhm
Information Gain (4)
� Attribut A mit Werten {a1, ..., av} ({RR, M, VW, Kia})⇒ S→{S1, ..., Sv}sij – Anzahl der Samples mit Attributwert aiin Klasse Cj. (Cj∈{reich, normal, arm})
� Wie überraschend ist Klasse eines Samples mit Attributwert ai?
� Beispiel: ‚Wie überraschend ist Klassenzugehörigkeit der RR-Fahrer?‘
i
ijm
j i
ijimi s
s
s
sssI 2
11 log),,( ∑
=
−=K
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes
Z. B. „Alle reichen/normalen/armen
RR-Fahrer geteilt durch
alle RR-Fahrer.“
Data Warehousing und Mining: Data Preprocessing – 95Klemens Böhm
Information Gain (5)
Wie überraschend ist Klassenzugehörigkeit, wenn ich Attribut A kenne? (Durchschnitt bilden.)E(A) – Durchschnitt der I(si1, …, sim)
„Durchschnittliches Maß an Überraschung, wenn wir das Auto bereits kennen“
In der Realität wollen wir natürlich möglichst geringe Überraschung.
Wir sind an Attributen interessiert, die uns helfen, die Klasse vorherzusagen.
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes
i
ijm
j i
ijimi s
s
s
sssI 2
11 log),,( ∑
=
−=K
Data Warehousing und Mining: Data Preprocessing – 96Klemens Böhm
Information Gain (6) Information gain: gain(A) = I(s1, s2, ..., sm) – E(A).
Hoher Information Gain heißt: Attribut diskriminiert gut.
Wann ist I(s1, s2, ..., sm) groß?
Wann ist E(A) groß?
Einleitung
DuplikateAnwend.
DuplikateAnsatz 1
DuplikateAnsatz 2
DuplikateDiskussion
Data Red.
- Sampling
- Choice ofAttributes
z

Data Warehousing und Mining: Data Preprocessing – 97Klemens Böhm
Mögliche Prüfungsfragen (1)
� Erläutern Sie die Begriffe Data Cleaning, DataIntegration, Data Transformation, Data Reduction.
� Welche Techniken zur Duplikateliminierung kennen Sie? Was sind die Zielsetzungen der jeweiligen Techniken?
� Wieso braucht man für die Duplikaterkennung eine Äquivalenztheorie?
� Konstruieren Sie ein Beispiel aus dem Anwendungsbereich Medizin, in dem (a) False-Positives (b) Misses sehr störend sind.
� Erläutern Sie die Sorted-Neighborhood Methode. Welche Verfeinerungen kennen Sie?
� Wie wirkt sich die Multi-Pass Verfeinerung aus auf die Zahl der Misses und der False-Positives?
Data Warehousing und Mining: Data Preprocessing – 98Klemens Böhm
Mögliche Prüfungsfragen (2)
� Was sind Repräsentanten im Kontext von Duplikateliminierung?
� Erklären Sie die folgenden Begriffe:
� Klassifikation,
� Active Learning,
� Unsicherheit und Repräsentativität (im Kontext von Active Learning),
� Cluster Sample,
� Stratified Sample,
� Information Gain.
� Wie baut man einen Entscheidungsbaum auf?
� Erklären Sie die Arbeitsweise eines Active Learners.
Data Warehousing und Mining: Data Preprocessing – 99Klemens Böhm
Literatur
M. Hernandez and S. Stolfo. Real-world Data isDirty: Data Cleansing and The Merge/PurgeProblem. Data Mining and Knowledge Discovery2(1): 9-37 (1998)
M. Hernandez and S. Stolfo. The Merge/PurgeProblem for Large Databases. Proceedings of the1995 ACM SIGMOD Conference, May 1995.
D. Bitton and D.J.DeWitt. Duplicate RecordElimination in Large Data Files. ACM Transactionson Database Systems, 8(2):255-265, June 1983.
S. Sarawagi and A. Bhamidipaty. Interactivededuplication using active learning. Proceedings of the Eighth ACM SIGKDD International Conferenceon Knowledge Discovery and Data Mining, 2002.