Embed Size (px)
Citation preview

Universität AugsburgInstitut für InformatikProgrammierung verteilter Systeme
Konzepte und Techniken für dasSemantic WebWS 2007/2008
SeminarbandProf. Dr. Bernhard BauerDipl.-Inf. Wolf FischerDipl.-Inf. Florian LautenbacherDipl.-Inf. Stephan Roser

Vorwort
Im Laufe des Wintersemester 2007 / 2008 fand an der Universität Augsburg dasSeminar ’Konzepte und Techniken für das Semantic Web’ statt. Dieser Bandstellt sämtliche studentischen Arbeiten dieses Seminars dar.Die erste Arbeit, behandelt von Gorana Bralo, gibt eine Einführung in die grund-legenden Prinzipien des Semantik Webs. Weiterhin zeigt sie, in welchen Gebietendas Semantic Web von Bedeutung ist und wo es bereits zu einem verstärktenEinsatz gelangt. In die theoretischen Grundlagen, auf denen das Semantic Webaufbaut, führt Carsten Angeli ein. Seine Arbeit widmet sich dabei insbesondereverschiedenen Beschreibungslogiken und wie diese zur Wissensrepräsentationangewendet werden können. Das Semantic Web wäre jedoch von keinerlei Nutzen,wenn es nicht verschiedene Software zur Inferenz auf Wissensbasen geben würde.Hierzu wurden drei unterschiedliche Reasoning-Techniken und deren Funktions-weisen untersucht: Thomas Eisenbarth widmete sich dem in Jena verwendetenRETE Algorithmus. Anschließend präsentiert Stephanie Siekmann in ihrer Arbeitdas Prinzip, welches in einem der neuesten erhältlichen Reasoner, KAON2, zumEinsatz kommt. Abschließend zeigt Philipp Kretschmer, welche Funktionsweiseeiner der bekanntesten und am weitesten verbreiteten Algorithmen, der TableauxAlgorithmus, besitzt.Um Wissen aus einer Wissensbasis zu erhalten muss es jedoch eine Möglichkeitgeben, diese abzufragen. SPARQL ist die hierfür vom W3C standardisierte Query-Sprache und wird von Alexander Matwin zusammengefasst. Um überhaupt aneine Wissensbasis zu gelangen bedarf es jedoch zuerst der Erstellung der On-tologie. Benedikt Gleich zeigt, welche verschiedenen Methodologien sowie auchPattern im Laufe der Zeit entstanden sind und welche Parallelen sich hierbei zuden entsprechenden Ansätzen im Software Engineering ergeben. Ein Problem,welches sowohl bereits bei der Erstellung als auch generell bei der Verwendungvon Ontologien auftritt, ist, dass für ein und die selbe Domäne häufig verschiedeneOntologien existieren, welche allerdings leicht oder komplett unterschiedlicheSichtwinkel auf den jeweiligen Bereich besitzen. Dennoch ist es manchmal not-wendig, verschiedene Ontologien zu vereinen, um eine größere Wissensbasis zuerhalten. Entsprechende Techniken, wie ein solcher Vorgang bewerkstelligt werdenkann, werden dem Bereich des ’Ontology Mapping’ zugeordnet und von MichaelButhut vorgestellt.Eine Anwendungsdomäne, in der Ontologien heutzutage bereits von größererBedeutung sind, stellen Web Services dar. In diesen werden Ontologien unteranderem dazu verwendet, eine automatische Komposition von verschiedenen WebServices zu erreichen. Welche Techniken dazu verwendet werden können und wieweit der Stand der Forschung ist, fasst Joachim Alpers zusammen. Den Abschlussdes Seminars bildet die Arbeit von Martin Haslinger. Er beschäftigte sich mitder Frage, wie weit die Forschung bei den Themen Proof, Trust und Security imKontext des Semantic Web ist.

III
Die vorgestellten Themen stellen trotz ihres Umfangs jeweils nur eine komprimier-te Übersicht über den aktuellen Stand der Forschung im Semantic Web Umfelddar. Nach wie vor bietet dieser Bereich sehr viele Forschungsfelder, so dass auchin Zukunft mit vielen neuen und interessanten Forschungsresultaten zu rechnenist.
Februar 2008 Die Editoren

Inhaltsverzeichnis
Grundlagen des Semantic Web und Anwendungsgebiete . . . . . . . . . . . . . . . . 1
Theoretische Grundlagen des Semantic Web . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Reasoning: Rete (und Jena) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
Reasoning auf Datalog-Basis (KAON2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Reasoning mit Tableau (anhand von Pellet) . . . . . . . . . . . . . . . . . . . . . . . . . . 70
Die Anfragesprache SPARQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
Ontologie-Methodologien und Ontologie Design . . . . . . . . . . . . . . . . . . . . . . . 105
Ontology Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
Semantic Web Service Composition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
Semantic Web: Proof, Trust und Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164

Grundlagen des Semantic Web undAnwendungsgebiete
Gorana Bralo
Universität [email protected]
Zusammenfassung Semantic Web ist eine neue Web-Technologie, dieals Erweiterung des bestehenden World Wide Web zu sehen ist. Das Zielist dabei die Erweiterung der Funktionalitäten des WWW sowie seineVerbesserung und Optimierung. In Zukunft sollen die Informationen undDaten nicht nur für den Menschen verständlich sein, sondern auch fürMaschinen.
1 Einleitung
Wie sieht das Zeitalter, in dem wir Menschen uns heute befinden — aus infor-mationstechnologischer Sicht betrachtet — eigentlich aus? Jeder hat sicherlichschon einmal darüber nachgedacht und früher oder später realisiert, dass Dinge,die uns vor einigen Jahren noch unmöglich erschienen, heute längst zu unseremAlltag gehören. Betrachten wir einmal das World Wide Web. Kaum jemandkann sich heutzutage das Internet noch wegdenken. Auf der einen Seite bietet esuns überaus viele Möglichkeiten und vereinfacht gleichzeitig in vielerlei Hinsichtunser Leben sowie unsere Kommunikation. Auf der anderen Seite weist es aberauch viele Schwächen und Verbesserungmöglichkeiten auf. Eine der neuen undbahnbrechenden Web-Technologien, die versucht diese Schwächen des WWWauszubessern und neue Funktionalitäten zu bieten, heißt „Semantic Web“. Dochbevor näher auf diese Technologie und ihre Möglichkeiten eingegangen wird, solltezunächst die Frage beantwortet werden, was das Schlagwort „Semantic Web“überhaupt bedeutet und für was es genau steht.
„The Semantic Web is not a separate Web but an extension of the currentone, in which information is given well-defined meaning, better enablingcomputers and people to work in cooperation.“ [?]
Das Semantic Web ist also kein vollkommen neues oder eigenständiges Inter-net, sondern bildet viel mehr eine Erweiterung zu dem schon vorhandenen WorldWide Web. Dabei beseitig es jedoch viele Nachteile des WWW, indem es nebender Syntax auch Semantik integriert. Das Internet enthält einen sehr großenUmfang an Informationen in Form von Dokumenten. Diese Dokumente könnendurchsucht und zur Informationsgewinnung herangezogen werden. Letzteres istjedoch nur durch einen Menschen möglich, denn Maschinen sind nicht in der Lage

2 G. Bralo
diese Daten zu interpretieren und ihnen eine Bedeutung zuzuordnen. Möchteman aber diese Daten effektiv nutzen, so ist es erforderlich die zugrundeliegendeSemantik, also die Bedeutung, zu extrahieren. Sucht ein Nutzer im Internet nacheinem bestimmten Schlüsselwort, z.B. dem Begriff „Golf“, so werden Sucher-gebnisse aus verschiedenen Bereichen zurückgeliefert, so z.B. aus dem Bereich„Auto“ als auch aus dem Bereich „Sport“. Der Nutzer muss nun anschließenddiese Ergebnisse durchsuchen und die für sich relevanten Quellen herausfiltern.Die Suchmaschine ist zwar in der Lage aufgrund des eingegebenen Suchbegriffes,die syntaktisch relevanten Ergebnisse zu suchen, aber nicht zu verstehen nach wasder Nutzer sinngemäß gesucht hat. Maschinen sind also nicht fähig der Syntaxeigenständig Semantik zuzuordnen da ihnen Kontextwissen fehlt.
Genau an diesem Punkt setzt das Konzept des Semantic Web an. Es versuchtmit neuen Technologien einen Lösungsansatz für dieses Problem zu bieten. Infor-mationen sollen in Zukunft nicht nur maschinenlesbar sondern auch maschinen-verständlich sein, d.h. Maschinen sollen in der Lage sein Informationen in ihremKontext zu verstehen. Dadurch könnte die Informationssuche automatisiert undpersonalisiert werden, was bedeuten würde, dass z.B. Suchmaschinen bessere undgezieltere Ergebnisse liefern und dem Menschen gleichzeitig Aufwand ersparenkönnten. Doch nicht nur die Problematik von Suchmaschinen ist ein wichtigerBereich vom Semantic Web. Es hat noch viele weitere wichtige Funktionalitätenund Anwendungsgebiete auf die im weiteren Verlauf noch eingegangen wird. DieVision des Semantic Web besteht also darin einen Lösungsansatz dafür zu bieten,die Interaktion zwischen Maschinen auf einer neuen Ebene zu ermöglichen, aufder die Informationsverarbeitung bzw. -suche noch weitreichender automatisiertwerden kann sowie effektiver und besser wird.
Die Themen der vorliegenden Arbeit sind die Grundlagen und Anwendungsgebietedes Semantic Web. Sie behandelt in einem groben Überblick die zugrundelie-genden Konzepte sowie die Technologien des Semantic Web und versucht dieseanhand von drei Projektbeispielen zu veranschaulichen.
2 Grundlagen des Semantic Web
Damit das Semantic Web funktionieren und die oben genannten Ansprücheerfüllen kann, müssen die Maschinen auf strukturierte Informationen zugreifenkönnen. Die heutzutage vorhandenen Informationen im WWW sind jedochmehr chaotisch als strukturiert vorhanden. Es muss also zunächst eine gewisseStruktur in die Welt der Informationen und ihre Darstellung gebracht werden.Des weiteren müssen entsprechende Regeln definiert werden, wie Maschinen aufdiese Informationen überhaupt zugreifen können. In diesem Kapitel werden daherdie Architektur von Semantic Web und ihre Umsetzung, in Form von Werkzeugen,vorgestellt und im einzelnen kurz erklärt.

Grundlagen des Semantic Web und Anwendungsgebiete 3
2.1 Das SchichtenmodellDas Grundgerüst des Semantic Web bildet das Schichtenmodell. [?] Es wurde vonder WC3 Semantic Web Activity beschrieben und ist in Abbildung 1 dargestellt.Es besteht aus 7 Schichten, die von unten nach oben aufeinander aufbauen.
Abbildung 1. Das Schichtenmodell
2.1.1 URI und Unicode Die unterste Schicht, definiert durch URI und Uni-code, ist wichtig für die Kommunikation zwischen Maschinen. Um Zeichen aufverschiedenen und heterogenen Systemen eindeutig und ohne Informationsvers-lust kodieren und dekodieren zu können, braucht man ein Kodierungsystem, dasplattform- und sprachunabhängig ist. Hier wird daher der Unicode Zeichensatzeingesetzt. [?] Aus demselben Grund werden URIs (Unified Ressource Identi-fier) verwendet. Damit kann eine eindeutige Adressierung von verschiedenenphysikalischen als auch abstrakten Ressourcen gewährleistet werden. Zwei syn-taktisch gleiche Begriffe, mit unterschiedlicher Semantik, können somit durchzwei verschiedene URIs eindeutig referenziert werden. [?]
2.1.2 XML und XML-Schema Die zweite Schicht definiert die einheitlicheFormatierung und Darstellung von Dokumenten mittels XML. Im Gegensatz

4 G. Bralo
zu HTML ist es bei der XML-Technologie möglich die Dokumentenstrukturfür verschiedene Applikationen dynamisch anzupassen und beliebig zu erwei-tern. Ausserdem können mit selbst erstellen Tags Dokumente in bestimmterForm gekennzeichnet werden und dadurch mit Semantik angereichert werden.XML-Schema ist der WC3-Standard, der der Definition von XML-Sprachendient. Namespaces werden definiert, um Namenskonflikte zwischen Dokumentenunterschiedlicher Entwickler zu vermeiden. [?]
2.1.3 RDF und RDF-Schema Das Resource Description Framework (RDF)baut auf der XML-Schicht auf. Sie ist eine plattformunabhängige Beschreibungs-sprache, die dazu dient Beziehungen, d.h. den semantischen Zusammenhang,zwischen Daten zu definieren. Die RDF-Dokumente setzen sich aus drei ver-schiedenen Objekten zusammen, durch die eine solche Beziehung beschriebenwird: Ressourcen, Eigenschaften, Aussagen. Die Ressourcen sind die eigentlichenDokumente. [?]
2.1.4 Ontologie Eine Ontologie definiert formal einen Wissensbereich, indemVerbindungen und Beziehungen zwischen Objekten beschrieben werden. [?] Esgibt drei Bausteine: das Konzept bzw. den Begriff, Relationen zwischen diesenBegriffen sowie Regeln über die Relationen und Begriffe. Hier ein Beispiel zur Ver-anschaulichung: Hat man z.B. die Relationen „Snoopy ist ein Hund“ und „Hundist ein Tier“ und würde eine Maschine nach „Tier“ suchen, so wäre „Snoopy“ einErgebnistreffer. Es wurde zwar nicht nach „Hund“ gesucht, aber durch Ontologienist es eben möglich Informationen, die nicht direkt miteinander verknüpft sind,zusammenzuführen. Ontologien definieren somit das zugrundeliegende Schemaeines Systems. Um dieses konkret darstellen zu können und in die Daten einzubin-den, benötigt man eine sogenannte Ontologiesprache, die OWL (Web OntologyLanguage). [?]
2.1.5 Logic, Proof, Trust
3 Veranschaulichung des Semantic Web Konzeptes anProjektbeispielen
In diesem Abschnitt werden drei Projekte der [?] im Detail vorgestellt. Anhanddieser konkreten Beispiele soll die Funktionsweise und die Idee des Semantic Webveranschaulicht werden.
3.1 Semantic MediaWiki
Das Projekt [?] ist die Realisierung eines Wikisystems der etwas anderen Art. Eswurde von dem Institute AIFB (University of Karlsruhe) mit der Unterstüzungdes FZI Karlsruhe umgesetzt.

Grundlagen des Semantic Web und Anwendungsgebiete 5
3.1.1 Die Idee dahinter Das wohl bekannteste Beispiel eines Wikis ist Wi-kipedia. Heutzutage kennt und nutzt jeder die Online-Enzyklopädie um Wissennachzuschlagen und sich zu informieren. Es entstand aus der Idee heraus, dassjeder Benutzer die Möglichkeit haben soll, an der Bearbeitung und Erstellungvon Beiträgen zu einem Thema mitzuwirken. Das Ziel ist die Erstellung einerumfangreichen Online Enyklopädie, wobei jeder frei entscheiden kann worüber ereinen Artikel verfassen möchte.
„Ein Wiki ist ein webbasiertes System, das das kollaborative Verfassenund Aktualisieren von Webseiten ermöglicht.“ [?]
Das System ist also dezentral organisiert und es liegt an den Benutzern sichgegenseitig zu korrigieren und zu überwachen. Das Prinzip ist klar. Doch wieim ersten Kapitel schon angesprochen, leben wir heute in einer Zeit, in derdas Informationswachstum schnell voranschreitet und die Benutzer schnell denÜberblick verlieren können. Ein Wiki setzt keine Vorkenntnisse einer bestimmtenProgrammiesprache oder ähnlichem voraus um Inhalte zu bearbeiten. Der Benut-zer ist fähig mit einer einfachen Syntax und einem Texteditor, den er aus seinemBrowser heraus aufrufen kann, Veränderungen vorzunehmen. Genauso gibt eskeine festgelegten Regeln wie der Inhalt der Seiten aufgebaut werden muss. JederBenutzer kann dies so umsetzen, wie er möchte.Dieses Konzept, das verschiedene Benutzer eigenständig Webseiten zu verschie-denen Themen erstellen können sowie das Fehlen einer festgelegten Strukturbzgl. des Artikelaufbaus, erfordert bei zunehmenden Informationen eine genauereStrukturierung.
Die Artikel können zwar mit Links zu anderen Artikeln versehen werden umsomit eine Verknüpfung zu erstellen, dennoch ist die Suchfunktion nicht optimal,da nur nach Schlüsselwörtern gesucht werden kann. Fehlt eine Verknüpfungdurch Links, so wird die Suche nach Seiten, die sinngemäß in Verbindung stehenschwierig. Sogenannte Übersichtsseiten versuchen das Problem zu lösen und demNutzer die Suche zu erleichtern. Dabei werden die Inhalte verschiedener Artikelzusammengeführt und zu sogenannten Kategorien zugeordnet. Solche Übersichtenmüssen jedoch manuell erstellt und daher auch manuell gewartet werden, waseinen enormen Zeitaufwand bedeutet.Wie am Anfang dieser Arbeit schon beschrieben, existieren Probleme bei derSuche nach Inhalten, da Maschinen kein Kontextwissen besitzen und damit nichtalle relevanten Inhalten von irrelevanten unterscheiden können. Zudem sind sieauch nicht in der Lage unterschiedliche Begriffe mit derselben Bedeutung zuerkennen. Das sind alles Punkte, die bei dem Durchsuchen von Informationenin einem Wiki ein Problem darstellen. Entweder es werden zu viele Ergebnissezurückgeliefert, oder zu wenige.
Die Idee des Semantic Wiki besteht nun darin, durch Semantik eine Lösungfür diese Probleme zu schaffen. Der wesentliche Unterschied zu einem normalenWiki ist der, das hier bei dem Erstellen von Artikeln Semantik integriert wird

6 G. Bralo
und zwar mit Hilfe von sogenannten Annotationen. Annotationen sind nichtsanderes als Anmerkungen, die dem Inhalt einer Webseite Bedeutung verleihen.Es ist also nicht nur die Darstellung von Inhalten wichtig, sondern auch ihreBedeutung und mögliche Relationen zu anderen Inhalten. Diese Metadaten sindes, die den Maschinen das nötige Kontextwissen liefern, um die Bedeutung derVerknüpfungen verstehen zu können.
3.1.2 Funktionsweise Wie diese Idee konkret umgesetzt ist, soll an einemBeispiel veranschaulicht werden:Als Suchbegriff werden wir „Berlin“ verwenden. Wie in Abbildung 2 zu sehen ist,wird als Ergebnis die entsprechende Seite zurückgeliefert, die Informationen zu"Berlin“ enthält.
Abbildung 2. Das Sucherbenis der Suche nach dem Begriff: „Berlin“
Neben der allgemeinen Beschreibung ist besonders der Bereich „Facts aboutBerlin“ interessant. Dieser Bereich enthält wichtige zusätzliche Angaben bzgl.Berlin, z.B. zu der Einwohnerzahl oder der Fläche mit dem entsprechenden Wert.Alle diese Verweise stellen die Relation zwischen den entsprechenden Artikeln undBerlin dar, in diesem Fall z.B. zwischen den Artikeln Einwohnerzahl bzw. Flächeund dem Artikel Berlin. Um diese Beziehung noch verständlicher zu machen,sehen wir uns die Attributsuche von z.B. dem Attribut „Population“ an. DurchAnklicken des „Lupe“-Symbols neben dem Wert für die „Population“, sehen wirdie in Abbildung 3 dargestellte Ergebnisseite.
Wie man sehr schön erkennen kann, werden hier alle Seiten aufgelistet, diebei dem Attribut „Population“ den Wert „3,391,407“ haben. Hier ist dies nurbei Berlin der Fall. Ausserdem hat man hier die Möglichkeit gezielt nach allenStädten zu suchen, die eine bestimmte Anzahl an Einwohnern haben.Dies verdeutlicht, dass also jede Seite, die eine Stadt beschreibt, ein Attribut

Grundlagen des Semantic Web und Anwendungsgebiete 7
Abbildung 3. Das Ergebnis der Attributsuche für das Attribut „Population“
„Population“ enthält und damit mit ihr in Relation steht. Die Maschine, die nunz.B. alle Stätde mit einer bestimmten Einwohnerzahl suchen soll, ist durch dasKontextwissen, nämlich das die Zahl „3,391,407“ auf der Seite von „Berlin“ die„Population“ beschreibt, in der Lage, alle relevanten Seiten zu durchsuchen undfalls zutreffend als Ergebnis zu liefern, so z.B. die Seite „Berlin“.Als ein weiteres Beispiel wird die „Population“ betrachtet. Wie man sieht, istzusätzlich zur Beschreibung des Attributs „Population“, z.B. der Typ, auch eineAuflistung aller verknüpfen Seiten angezeigt: Seiten mit allen Städten, die diesesAttribut auf ihrer Seite definiert haben. (siehe Abbildung 4)
Abbildung 4. Das Attribut „Population“
Wir können sehen, dass unter anderem auch Berlin aufgeführt ist, mit demWert „3,391,407“. Es werden die gesamten Seiten angezeigt, die mit diesemAttribut in Relation stehen.Im Vergleich zu einem einfachen Wiki, beispielsweise Wikipedia, stellt diese Wiki-Form also eine erhebliche Vereinfachung für die Suche dar, die damit viel breiterund gezielter erfolgen kann. Sucht man nämlich nach dem gleichen Begriff, alsoz.B. „Berlin“, in Wikipedia, dann bekommt man ebenso einen groben Überblicküber die Einwohneranzahl oder auch die Fläche. Möchte man jedoch gezielt

8 G. Bralo
nach bestimmen Einwohnerzahlen oder allgemein nach Städten, mit definiertenEinwohnerzahlen, suchen, ist das nicht automatisiert möglich. Dies muss derBenutzer manuell machen.
3.1.3 Integration von Semantik Der folgende Abschnitt beschäftigt sichmit der Einbindung von Semantik in das Wikisystem. Es wird aufgezeigt aufwelche Weise sich in diesem Fall Ontologien wiederfinden, wie OWL zum Einsatzkommt und Queries verwendet werden.
Wie bereits im ersten Kapitel dieser Arbeit erklärt wird, definiert eine Ontologieeine Wissensbasis, die sich aus drei Bausteinen zusammensetzt:
– Begriffe– Relationen zwischen Begriffen– Regeln bzgl. der Begriffe und Relationen
Aufgrund dieser Wissensbasis ist man in der Lage Informationen und Inhalteals Begriffe zu definieren, Relationen zwischen ihnen herzustellen und somit fürden Zweck der semantischen Anreicherung zu verwenden. Diese drei Bausteinefinden sich demnach auch im Semantic MediaWiki wieder. Um diese konkretumzusetzen bedarf es außerdem einer Ontologiesprache, die in diesem Fall OWLDL ist. Die Abkürzung OWL DL steht für Web Ontologie Language DescriptionLogic. In Abb. 5 sind die wesentlichen Konstrukte dieser Ontologiesprache undihre Umsetzung im Semantic MediaWiki dargestellt:
Abbildung 5. Ontologie im Semantic MediaWiki
Anhand des Artikels „Berlin“ wird die Umsetzung der Ontologie veranschau-licht. Um eine Wissensbasis aufzubauen, definiert man sich zunächst Begriffe, dieman anschließend in Beziehung zueinander stellen kann. Solche Begriffe definiert

Grundlagen des Semantic Web und Anwendungsgebiete 9
man mit Hilfe der Ontologiesprache, die zu diesem Zweck Klassen, Objekte undverschiedene Eigenschaften von Klassen oder Objekten vorsieht. Eine Klasse wirdim Semantic MediaWiki in Form von einer “Category“ definiert. Eine Eigenschafteiner solchen “Category“ wird durch eine “Datatype property“ oder “Objecttypeproperty“ definiert. Diese Konstrukte definieren also die grobe Struktur deszugrundeliegenden Schemas. Konkrete Ausprägungen dieses Schemas sind dannalle Artikel, die zu einer bestimmten „Category“ gehören oder als „Property“gekennzeichnet sind.
Um bei einer Suche nach allen im Wiki existenten Städten auch die Stadt„Berlin“ zurückgeliefert zu bekommen, muss diese also als Stadt gekennzeichnetwerden. Dies erreicht man dadurch, dass man sie der Klasse Stadt zuordnet. InAbb. 6 sieht man den dazugehörigen Code:
Abbildung 6. Zuordnug zur Klasse: City
Durch [[Category::City]] ist der Artikel als „City“ gekennzeichnet. Bei ei-ner entsprechenden Suche nach Städten werden also alle Artikel im SemanticMediaWiki zurückgeliefert, die dieser Kategorie zugeordnet sind. Eine konkre-te Ausprägung wäre daher unser Beispielartikel „Berlin“. Als weiteres Beispielnehmen wir die „Population“. Die zugehörige Ontologiedefinition ist „Datatypeproperty“ und die konkrete Ausprägung in Falle des Artikels „Berlin“ z.B. istder Wert „3,391,407“. Würde man nach allen Einwohnerzahlen suchen, würdenalso all diejenigen Zahlen zurückgeliefert, die mit „Population“ getagged sind.Um also Relationen zwischen verschiedenen Artikeln in einem Wiki herzustellen,muss man sie entsprechend taggen, d.h. im Code mit dem richtigen Verweis derrichtigen Klasse zuordnen bzw. als bestimmte Eigenschaft kennzeichnen.
Für die semantische Suche im Semantic MediaWiki existieren sogenannte Inline-Queries. In Abb. 7 sieht man ein Beispiel für eine solche Inline-Query und dasdazu zurückgelieferte Ergebnis. Diese ermöglichen eine einfache Einbindung inerstellte Seiten und den Zugriff auf diese Suchergebnisse durch mehrere Benutzer.Die Inline-Queries haben eine einfache Syntax. Es existieren vordefinierte Parame-

10 G. Bralo
Abbildung 7. Inline-Query mit dargestelltem Ergebnis
ter für die zurückzuliefernden Argumente sowie Parameter für die Darstellung derSuchergebnisse. Man definiert einfach die Suchkriterien durch die Inline-Queryund bindet diese in die entsprechende Seite ein. Beim Seitenaufruf werden danndie Ergebnisse dargestellt. Die Darstellung der Ergebnisse lässt sich dabei beliebigverändern. Man kann die Daten sortieren oder sogar Templates benutzen, die eserlauben CSS einzubinden oder Bilder anzeigen zu lassen.
3.1.4 Zusammenfassung Das Ziel des Semantic MediaWiki ist demnach dieErweiterung des Wikisystems zu einem System welches nicht nur die Suchenach bestimmten Schlüsselwörtern sondern nach konkreten Fragen erlaubt. Esentstehen also
„kollaborative Wissensmanagement-Systeme, die trotz dezentraler Struk-turen auf einer einheitlichen Wissensbasis beruhen“. [?]
Ausserdem ist das System beliebig erweiterbar ohne dabei auf eine Strukturierungder Daten verzichten zu müssen oder gar den Überblick über die Informationenzu verlieren. Durch die Semantik können auch neu hinzugefügte Daten stets indas Gesamtinformationsnetz integriert und mit anderen Daten verknüpft werden.
3.2 MultimediaN E-Culture demonstrator
Bei dem Projekt [?] handelt es sich um eine Suchanwendung, die auf einerAnsammlung von Informationen und Quellen über Kunst beruht. Es macht dieSuche nach Relationen zwischen Epochen, Malern und Gemälden und somit eineumfangreichere Informationsdarstellung möglich. Realisiert wurde das Projektgemeinsam von mehreren holländischen Universitäten, wie z.B. der Universiteitvan Amsterdam und der Technical University Eindhoven (TU/e).

Grundlagen des Semantic Web und Anwendungsgebiete 11
3.2.1 Die Idee dahinter
„The objective of this project is the development of a set of e-culturedemonstrators providing multimedia access to distributed collections ofcultural heritage objects.“ [?]
Das Ziel des MultimediaN E-Culture demonstrator ist also die Entwicklungeines elektronischen Assistenten, der einen multimedialen Zugriff auf verteilteSammlungen von kulturellem Erbe ermöglicht. Dabei steht die umfangreicheSuche nach bestimmten Informationen und Sachverhalten mit einem höherenGrad an Verknüpfung untereinander im Vordergrund. Wie auch bei dem ers-ten Projektbeispiel des Semantic MediaWiki möchte man auch in diesem Falldie Suche nach konkreten Fragen ermöglichen und nicht nur nach einzelnenSchlüsselwörtern. Es sollen z.B. Fragen zu der Beziehung verschiedener Malerzueinander oder zu der Verbindungen zwischen verschiedenen Epochen dargestelltwerden können. [?] Gezeigt wird also der semantische Informationszugriff sowiedie kontextabhängige Darstellung von Informationen. [?]
Im Rahmen dieses Projektes geht es vor allem um die Suche nach Gemäldenberühmter Maler und verschiedenen Informationen im Bereich der Kunst imAllgemeinen. Wie weiter oben erwähnt, besteht die Wissensbasis dieses Systemsaus verschiedenen Informationen zu Kunstwerken, Malern, sowie Epochen undihren Verbindungen. Die Quellen dieser Informationsbasis bilden verschiedeneMuseen oder anderen Kunstarchive der Niederlande. Um die Vorteile eines sol-chen Systems gegenüber einem System ohne semanatische Integration besserzu erkennen, nimmt man als Gegenbeispiel die Suche mit Google. Google istdie Suchmaschine Nummer eins, wenn es darum geht Informationen zu finden,und besitzt keine semantische Grundlage. Mit der Bildersuche von Google kannman ebenso nach verschiedenen berühmten Gemälden oder Malern suchen. Dergravierendste Unterschied zwischen diesen beiden System ist dabei die Art undWeise der Suche und die zurückgelieferten Suchergebnisse. Sucht man mit derGoogle Bildersuche nach einem bestimmten Stichwort, kann es passieren, dassman entweder überhaupt keine Ergebnisse dazu zurückgeliefert bekommt oderaber viel zu viele. Dabei werden vielleicht auch irrelevante Ergebnisse angezeigt,die im Bezug auf das Suchwort sogar falsch sein können. Mit der Suche desMultimediaN E-Culture demontrator kann dies nicht passieren. Zu jedem Such-begriff werden nur die wirklich relevanten Ergebnisse angezeigt. Gleichzeitig dazuwerden auch die Verbindungen mit anderen Kategorien dargestellt, die für denBenutzer ebenfalls interessant sein könnten. Dadurch gewinnt man einen besserenÜberblick über die Einordnung des gesuchten Begriffes und ist zu grundsätzlichzu einer gezielteren Informationssuche fähig.
Durch Semantik werden auch bei diesem Projekt Beziehungen zwischen den Ob-jekten der Wissensbasis hergestellt und somit ein großes Netz aus Informationenaufgebaut wobei die Suche die Einordnung der Objekte in dieses Netz aufgezeigt.

12 G. Bralo
3.2.2 Funktionsweise Im folgenden Abschnitt wird an einem konkreten Such-beispiel die Funktionsweise des MultimediaN E-Culture demonstrator erklärt.Es gibt zwei Möglichkeiten eine Suche durchzuführen, entweder mit der „BasicSearch“ oder der „Advanced Search“. Zunächst wird die Beispielsuche mit der„Basic Search“ durchgeführt. Gesucht wird nach dem Maler Gustav Klimt. Indas Suchfeld wird „Klimt“ eingegeben. Nach der Eingabe erscheint unter demSuchfeld eine Liste von möglichen Optionen bzw. Vorschlägen, die den Benutzerdirekt auf die entsprechenden Suchseiten weiterleiten (Siehe Abbildung 8). Istder Benutzer auf der Suche nach Bildern von dem Maler Klimt sind und keineErgebnisse angezeigt haben möchte, die z.B. nur in irgendeiner Weise mit Klimtim Zusammenhang stehen, so hat er die Möglichkeit auf „Works created by anartist with matching name on the keyword ’klimt’“ zu klicken und wird direktzur entsprechenden Seite weitergeleitet.
Abbildung 8. Basic Search für den Suchbegriff Klimt
Klickt man stattdesssen auf „Search“ gelangt man zu der Seite, auf der allemöglichen Ergebnisse, die in irgendeinem Zusammenhang mit Klimt stehen,angezeigt werden. Die Suchergebnisse sind kategorisiert. Man sieht die Kategorieder Werke, die von Klimt stammen, aber auch Kategorien, die z.B. bestimmteEpochen enthalten. Die Werke und der Malstil von Klimt gehören demnachdiesen Epochen an und es werden in der Kategorie die Werke von anderenMalern aufgelistet, die somit mit Klimt den Malstil, der charakteristisch für dieseEpochen ist, gemeinsam haben. Des Weiteren wird im unteren Bereich der Seitedie zeitliche Einordnung der Werke der verschiedenen Maler dargestellt, wie manin Abbildung 9 sehen kann.
Klickt man nun in der Kategorie der Werke von Gustav Klimt auf ein konkre-tes Bild, z.B. „The Kiss“, dann gelangt man auf eine Detailseite (Abbildung 10)auf der weitere zusätzliche Informationen zu dem ausgewählten Werk angezeigtwerden. Sie enthält Informationen zum Material des Kunstwerks, zum Entste-hungszeitraum, der Art des Werkes oder auch zur Quelle des Werkes, also woherdie Informationen zu dem Bild stammen. Alle diese Informationen sind dabeidirekt mit dem Kunstwerk verbunden. Dies bedeutet, würde man konkret nachWerken suchen, die in einem bestimmten Zeitraum entstanden sind, so würde

Grundlagen des Semantic Web und Anwendungsgebiete 13
Abbildung 9. Zeitliche Einordnung der Werke
auch dieses Werk aufgelistet werden, falls es denn in den gesuchten Zeitraumfällt.
Abbildung 10. Detailseite zum Werk „The Kiss“
Ausgehend von der Detailseite des Werks „The Kiss“ kann man durch ankli-cken der rot markierten Informationsfelder auf weitere Seiten gelangen, diewiederum entsprechende Informationen zum angeklickten Begriff sowie mit dieserInformation getaggte Werke enthalten. Klickt man z.B. auf den Begriff „gold“, derbei dem Werk „The Kiss“ angibt, das dieses Werk Gold als Materialbestandteilenthält, gelangt man auf eine Seite, die Informationen zu diesem Material angibt.

14 G. Bralo
Ausserdem wird auf der Seite zusätzlich zu den Materialinformationen auch dieKategorie mit entsprechenden Werken, die Gold verwenden, angezeigt. Die „Ad-vanced Search“ funktioniert genauso wie die „Basic Search“, hat zusätzlich abernoch die Möglichkeit die Suchkriterien zu verändern und genauer einzustellen.In Abbildung 11 sieht man die zur Verfügung stehenden Felder der erweitertenSuche.
Abbildung 11. Detailseite zum Werk „The Kiss“
Interessant ist das Feld „Period“. Anhand einer vorgegebenen Tabelle kannder Benutzer eigene sogenannte „Time Queries“ erstellen und damit die Suchenach Werken oder Malern aus bestimmten Zeiträumen suchen, z.B. aus einerbestimmten Zeit, nach oder vor einer bestimmten Zeit. Neben Jahreszahlen kannman auch Abfragen generieren, wie z.B. „his late period“ und ähliches.
Im Vergleich zu der Bildersuche mit Google wird deutlich, dass die Suche indiesem Fall viel gezielter und umfangreicher erfolgen kann. Es werden keineDaten und Informationen doppelt geliefert. Zusätzlich werden, falls gewünscht,viele weiterführende Ergebnisse angezeigt und die Einordnung in das Gesamtnetzsomit viel klarer. [?]
3.2.3 Integration von Semantik
3.2.4 Zusammenfassung Der MultimediaN E-Culture demonstrator ist einSystem, das aufgrund der integrierten Semantik eine bessere Suche und Navigationdurch die Daten im System ermöglicht. Alle Daten sind miteinander verbundenund strukturiert in das System integriert. Man gelangt einfach zu allen Seiten, diedem Benutzer die nötigen Informationen bereitstellen. Ausserdem bieten die vielenOptionen zahlreiche Möglichkeiten die Suchkriterien beliebig zu erweitern und zuverändern. Die Relationen zwischen den Daten stellen dem Benutzer nicht nurdie gesuchten Daten sondern auch alle damit in Zusammenhang stehenden Datenzu Verfügung. Dieses System zeigt in welcher Form Semantik dazu beitragen

Grundlagen des Semantic Web und Anwendungsgebiete 15
kann das Suchen nach Daten zu optimieren und zu vereinfachen, vor allem imHinblick auf Suchmaschinen.
4 Schluss
Diese Seminararbeit wurde nicht abgeschlossen, daher fehlen noch diverse Punkte:Anwendungsgebiete, Zusammenfassung, weitere Beispiele, Literaturverzeichnis,etc.
(Anmerkung der Editoren)

Theoretische Grundlagen des Semantic Web
Carsten Angeli
Universität [email protected]
Zusammenfassung Das Semantic Web baut auf dem Fundament derLogik auf. In dieser Arbeit werden die Grundlagen der Pädikatenlogik undder Beschreibungslogik erklärt, und gezeigt, wie verschiedene Beschrei-bungslogiken in wissensbasierten Systemen zum Einsatz kommen. DieAusdrucksmächtigkeit der vorgestellen Logikklassen SHIQ, SHOIN (D)
und SROIQ(D+) wird im Detail untersucht. Abschließend wird auf dieZusammenhänge zwischen den Logikstufen und den im Semantic Webeingesetzten Ontologiesprachen RDFS, DAML+OIL, OWL DL und OWL1.1 sowie SWRL eingegangen.
1 Einleitung
1.1 Motivation
Die Anzahl der im Internet verfügbaren Webseiten und die Menge der angebote-nen Services wächst stetig an. Bereits im November 2006 ergaben Schätzungen,dass die Zahl der weltweit angebotenen Seiten die Marke von 100 Millionenüberschritten hat[15]. Diese Fülle an Daten und Informationen ist jedoch größ-tenteils unstrukturiert. Die Suche nach Informationen oder Diensten ist dadurchschwierig, da eine Suchmaschine den Volltext eines Dokuments durchsuchen muss,um seinen Inhalt zu ermitteln. Auch Zusammenhänge zwischen verschiedenen Do-kumenten können nur schwer oder gar nicht ermittelt werden. Diese Lücke kannim Semantic Web mit Hilfe von Metadaten, Ontologien und Inferenzmaschinengeschlossen werden.
Die Vision des Semantic Web stammt von Tim Berners-Lee[3]. Er beschreibtes als „an extension of the current Web in which information is given well-definedmeaning, better enabling computers and people to work in cooperation“[4].
Die Informationen liegen im Semantic Web in strukturierter Form vor undkönnen dadurch leichter gefunden und besser genutzt werden. Der Schlüsselhierzu liegt in der Verwendung von Logik, genauer, von Beschreibungslogik.Nur damit ist es möglich, das Inferenzmaschinen automatische Schlüsse überdie Zusammenhänge von Daten ziehen können. In gewisser Weise stellt dasSemantic Web damit das Gegenstück zum Web 2.0 dar: während bei letzteremdie Kommunikation zwischen Menschen in sozialen Netzwerken im Vordergrundsteht, dienen Beschreibungslogik und Ontologien im Semantic Web dazu, dieInteraktion zwischen Maschinen zu verbessern.

Grundlagen Semantic Web 17
1.2 Herausforderungen
Um durch automatisiertes Schlussfolgern möglichst viel Information zu gewinnen,sind ausdrucksstarke Beschreibungslogiken nötig. Ist die Ausdrucksmächtigkeitjedoch zu groß gewählt, so ist die Logik nicht mehr entscheidbar. Ohne terminie-rende und effiziente Inferenz-Algorithmen ist eine Logik nicht für das SemanticWeb geeignet. Daher müssen Logikstufen verwendet werden, die einen gutenKompromiss zwischen Ausdrucksmächtigkeit und Entscheidbarkeit darstellen.
1.3 Ziele und Aufbau der Arbeit
Im Rahmen dieser Arbeit werden die Prädikatenlogik und die Beschreibungslogikals Grundlage des Semantic Web vorgestellt (Kapitel 2). Insbesondere die häufigverwendeten Logikstufen SHIQ(D), SHOIN (D) und SROIQ(D+) werden inKapitel 3 auf ihre Ausdrucksmächtigkeit untersucht. Anschießend werden inKapitel 4 die damit in den verschiedenen Ontologiesprachen möglichen semanti-schen Konstrukte betrachtet. Diese Verbindung von Beschreibungslogiken undOntologiesprachen wird anhand der Sprachen RDFS, DAML+OIL, OWL DLund OWL 1.1 sowie SWRL gezeigt.
2 Grundlagen
Die Bausteine des Semantic Web sind Metadaten, mit denen andere Inhaltebeschrieben werden. Erst die Metadaten machen aus rohen Daten Informationen,indem sie den Inhalt eines Datums mit einer Bedeutung verknüpfen. Gibt manden Metadaten eine syntaktische Struktur und legt die formalen Zusammenhängezwischen den Begriffen fest, so spricht man von einer Ontologie. Nach T. Gruberversteht man darunter eine „explizite formale Spezifikation einer gemeinsamenKonzeptualisierung“[9]. Eine Ontologie ist also die Beschreibung eines Wissensbe-reichs, die den Begriffen aus einer Terminologie eine Bedeutung zuweist und dieZusammenhänge zwischen den Konzepten festlegt. DerZweck einer Ontologie istdie Darstellung von Wissen in einer Form, die logischeSchlüsse über den Inhaltermöglicht.
Um aus den statischen Informationen einer Ontologie neues Wissen zu erschlie-ßen, bedient man sich einer Inferenzmaschine (engl. reasoner). Dabei handeltes sich um ein Softwaresystem, das in der Lage ist, logische Schlussfolgerun-gen auf einer Ontologie zu berechnen. Man erhält dadurch Informationen, dienicht explizit in der Wissensbasis hinterlegt sind, aber durch die semantischenZusammenhänge zu folgern sind1.
Die Voraussetzung dafür ist jedoch, dass die Ontologie, auf der die Inferenz-maschine arbeitet, in einer Sprache fomuliert ist, der eine feste Syntax und eine1 Im Englischen: to entail: nach sich ziehen, zur Folge haben. Daher wird das Problemdes Schließens über eine Ontologie (reasoning problem) auch als „ontologie entailment“bezeichnet.

18 C. Angeli
formelle Logik zu Grunde liegen. Die Logik definiert dabei die Regelnfür dieSchlussfolgerungen und die Gültigkeit von Aussagen.
Fünf Aspekten kommt in der Logik besondere Bedeutung zu (vgl. [7]):
Ausdrucksstärke Welche Formulierungen sind in der Logik möglich,welche Sachverhalte kann sie ausdrücken?
Korrektheit Sind nur gültige Schlussfolgerungen möglich?Vollständigkeit Können alle gültigen Schlussfolgerungen herge-
leitet werden?Entscheidbarkeit Existiert ein terminierender Algorithmus zur Lö-
sung des Problems?Komplexität Welche Resourcen (Rechenleistung, Speicher)
sind zur Berechnung nötig?
Damit begründet die Logik das Fundament des Semantic Web. Von denunterschiedlichen Feldern der Logik sind für das Semantic Web besonders dieGebiete der Prädikatenlogik und der Beschreibungslogik von Interesse.
2.1 Prädikatenlogik
Die Prädikatenlogik (auch: Quantorenlogik) kann in verschiedene Stufen unterteiltund durch Erweiterungen ergänzt werden. In dieser Arbeit werden nur diejenigenBereiche untersucht, die für das Semantic Web von Bedeutung sind. Für eineallgemeinere Betrachtung der Logik sei auf U. Schöning [16] und E. Bergmann[2] verwiesen.
2.2 Prädikatenlogik 1. Stufe
Die Grundlage der meisten Beschreibungslogiken ist die Prädikatenlogik der1. Stufe (engl. first order logic, FOL). Diese Logik umfasst die Verwendungvon Elementen (Variablen), Funktionen, Prädikaten und Quantifikation überElemente, z.B. ∀xP (x) (vergl. [17]).
Sie erweitert damit die Aussagenlogik, die keine Variablen kennt, um Leerstel-len, die besetzt werden können. Besetzt man die Leerstellen, können die Prädikatezu true oder false ausgewertet werden.
Das wichtigste Werkzeug der Prädikatenlogik sind die Quantoren ∃ und ∀.Mit ihnen können Aussagen über eine Anzahl von Elementen gemacht werden.Der Allquantor ∀ bedeutet dabei, dass ein Prädikat für alle Elemente gilt, derExistenzquantor ∃ sagt aus, dass es mindestens ein Element gibt, für das dasPrädikat wahr ist. Die Aussage „alle Raben sind schwarz“ kann damit formalisiertwerden als ∀xRabe(x)→ Schwarz(x).
Die Quantoren können einander auch ersetzen:
∃x verstehtLogik(x)⇐⇒ ¬∀x ¬verstehtLogik(x)∀x verstehtLogik(x)⇐⇒ ¬∃x ¬verstehtLogik(x)
Das zweite Beispiel für die Ersetzung kann gelesen werden als „Jeder verstehtLogik.“ ⇐⇒ „Es existiert keiner, der Logik nicht versteht.“

Grundlagen Semantic Web 19
2.3 Prädikatenlogik höherer Stufe
Eine Erweiterung der Prädikatenlogik 1. Stufe auf Basis des typisierten Lambda-Kalküls ist die Prädikatenlogik höherer Stufe (engl. higher order logic, HOL).Die Grundlagen dafür enwickelte Alonso Church bereits 1940[5]. Im Gegensatzzur Prädikatenlogik 1. Stufe, in der nur über Elemente quantifiziert wird, werdenin HOL auch Existenz- und Allaussagen über Prädikate gemacht. Ein Beispielsoll dies verdeutlichen: In first order logic ist es möglich, über das Prädikat „xist eine gerade Zahl“, kurz G(x), z.B. die Aussage ∃x G(x) („es gibt eine Zahl,die gerade ist“) zu machen. In higher order logic ist es ebenso möglich, Aussagenwie „Es gibt ein Prädikat mit der Eigenschaft: es trifft auf die Zahl x zu“ zuformalisieren: ∃p p(x). p stellt dabei eine Variable dar, die mit einem Prädikaterster Stufe besetzt wird. Bei der Gesamtaussage handelt es sich damit um einPrädikat zweiter Stufe. Diese Quantifizierung über Prädikate kann beliebig tiefverschachtelt werden.
2.4 Beschreibungslogik
Um die Begriffe und das Wissen einer Domäne formell und strukturiert darzustel-len und durch logisches Schließen aus vorhandenem Wissen Neues zu generieren,werden Beschreibungslogiken verwendet. Ihr Vorteil gegenüber der Prädikatenlo-gik ist, dass die Struktur der Informationen erhalten bleibt und dass die Logikentscheidbar wird (Abschnitt 2.4.3). Damit können Ontologien erstellt werden,die die Grundlage für wissensbasierte Systeme wie das Semantic Web darstellen.
Die Bausteine einer Beschreibungslogik sind Objekte (auch bezeichnet alsInstanzen oder Individuen), Konzepte (auch: Klassen) und Rollen. Ein Objektentspricht dabei einer einfachen Konstante. Ein Konzept ist formal betrachtetein einstelliges Prädikat und steht für eine Menge von Objekten. ZweistelligePrädikate werden in der Beschreibungslogik als Rollen bezeichnet. Sie beschreibendie Verbindungen zwischen Objekten.
Dies soll an einem Beispiel veranschaulicht werden. Für die Notation wirdin dieser Arbeit die Konvention verwendet, die auch bei Baader et al. [1] undin den Publikationen von I. Horrocks zum Einsatz kommt: Objekte werden inGroßbuchstaben geschrieben, Konzepte beginnen mit einem Großbuchstaben,Rollen beginnen mit Kleinbuchstaben. Als Schrift wird Sans Serif für Beispielein den Beschreibungslogiken verwendet, Schreibmaschinenschrift wird beiCodebeispielen (RDF, OWL) in Kapitel 4 eingesetzt.
– Objekte: ANNA, TOM, UNI AUGSBURG– Konzepte: Person, Universität, Student ≡ Person u ∃ studiertAn.>– Rollen: studiertAn
Damit lassen sich etwa die folgenden Sachverhalte formalisieren:
– Student(TOM), Student(ANNA)– Universität(UNI AUGSBURG)– studiertAn(TOM, UNI AUGSBURG)

20 C. Angeli
Konzepte lassen sich unterscheiden in atomare und komplexe (zusammengesetzte)Konzepte. Im Beispiel handelt es sich bei Person und Universität um atomareKonzepte, die sich nicht weiter aufteilen lassen. Student bezeichnet ein komplexesKonzept, das auf dem atomaren Konzept Person und der Rolle studiertAn aufbaut.Als besondere Konzepte existiert >, das universelle Konzept und ⊥, das bottom-Konzept. Das universelle Konzept kann für jedes beliebige Konzept stehen, dasbottom-Konzept entspricht der leeren Menge. Dies wird deutlich, wenn mandie Interpretation I betrachtet. Eine Interpretation weist einer Syntax einedefinierte Semantik zu. Nach [1] besteht „eine Interpretation I aus einer nichtleeren Menge ∆I (der Domäne der Interpretation) und einer Interpretations-Funktion, die jedem atomaren Konzept A eine Menge AI ⊆ ∆I zuweist undjeder atomaren Rolle R eine binäre Relation RI ⊆ ∆I ×∆I zuordnet.“Es geltenfolgende Definitionen (nach [1]):
>I = ∆I
⊥I = ∅¬AI = ∆I \AI
(C uD)I = CI ∩DI
(∀R.C)I = a ∈ ∆I | ∀b. (a, b) ∈ RI → b ∈ CI(∃R.>)I = a ∈ ∆I | ∃b. (a, b) ∈ RI
2.4.1 Assertional Box und Terminological Box Bei einer Wissensbasis(engl. knowlege base) werden zwei Bereiche unterschieden: die TBox (terminolo-gical box) und die ABox (assertional box). Die TBox enthält dabei das Wissenüber die Konzepte einer Ontologie und ihre Zusammenhänge. Die ABox dagegenspeichert die Informationen über einzelne Individuen (Objekte) der Konzepte.Auch Zustandsinformationen über das modellierte System werden in der ABoxabgelegt. In Abbildung 1 ist ein Beispiel dazudargestellt.
2.4.2 Open World Assumption vs. Closed World Assumption Bei derModellierung einer Wissensrepräsentation kann man von zwei unterschiedlichenStandpunkten ausgehen, der Closed World Assumption und der Open WorldAssumption. Bei der ersten Annahme geht man davon aus, dass die verwendeteDatenbasis vollständig ist und alles, was nicht explizit als wahr bekannt istoder hergeleitet werden kann, falsch ist. Diese Annahme wird regelmäßig beiDatenbanksystemen verwendet. Betrachtet man beispielsweise die Abfrage nacheinem bestimmten Artikel in der Produktdatenbank eines Unternehmens, so kannman davon ausgehen, dass, falls eine leere Ergebnismenge zurückgeliefert wird,es den Artikel nicht gibt, da alle Artikel in der Produktdatenbank aufgeführtwerden.
In der Prädikatenlogik und auch in der darauf basierenden Beschreibungslogikgilt diese Annahme im Allgemeinen nicht. Damit werden die Möglichkeiten vonInferenzschlüssen eingeschränkt. Jedoch entspricht die Open World Assumption

Grundlagen Semantic Web 21
Abbildung 1. Assertional Box und Terminological Box
eher den Gegebenheiten der wirklichen Welt. Ist in einem WissensbasiertenSystem z.B. hinterlegt TOM ≡ Student u studiertAn.UniAugsburg, und es wirdeine Anfrage gestellt TOM ≡ studiertAn.TUM? so wird das System unter derOpen World Assumption nicht „nein“ antworten, sondern „unbekannt“, denn esist möglich, dass Tom an beiden Universitäten eingeschrieben ist.
2.4.3 Entscheidbarkeit der Beschreibungslogik Im Gegensatz zur Prädi-katenlogik ist die Beschreibungslogik entscheidbar [11]. Dies ist eine wichtigeBedingung, damit automatische Inferenzschlüsse möglich sind. Die Grundlagefür den Beweis der Entscheidbarkeit ist die Erfüllbarkeit von prädikatenlogi-schen Formeln mit (höchstens) zwei Variablen. Auf dieses Problem können alleKonzeptbeschreibungen, die sich auf die in Tabelle 1 aufgeführten Operatoren be-schränken, zurückgeführt werden. Auf die Wiedergabe des vollständigen Beweiseswird hier verzichtet. Er findet sich bei[14].
Tabelle 1. Zulässige Operatoren entscheidbarer Beschreibungslogiken
C tD Vereinigung von KonzeptenC uD Schnitt von Konzepten¬C Negation von Konzepten∀R.C Qualifizierte Allaussagen über Rollen∃R.C Qualifizierte Existenzaussagen über RollenR v S Inklusionsbeziehungen zwischen Rollen (Subsumption)R t S Vereinigung von RollenR u S Schnitt von Rollen¬R Negation von RollenR−1 Komplementbildung über Rollen

22 C. Angeli
Damit ist es möglich, mit Hilfe von Inferenzmaschinen automatisierte Schluss-folgerungen zu ziehen. Dazu existieren unterschiedliche Algorithmen, die jedochin dieser Arbeit nicht betrachtet werden.
3 Ausdrucksstärke von Beschreibungslogiken
Um die Ausdrucksmächtigkeit von Beschreibungslogiken zu definieren, wirdeine Reihe von Buchstaben-Symbolen verwendet. Dabei steht jeder Buchstabefür bestimmte Gesetzmäßigkeiten und Operatoren, die zur Verfügung stehen. InTabelle 2 (Seite 23) wird die Bedeutung der Buchstaben für die Beschreibungslogikaufgelistet, teils auch mit Verweisen auf die damit möglichen Ausdrücke in denin Kapitel 4 beschriebenen Ontologiesprachen.
Die Kombination der Symbole aus Tabelle 2 ergibt die Expressivität einerLogik. Verschiedene Zusammensetzungen sind dabei auch äquivalent, bestimmteKombinationen schließen andere Stufen als Untermenge mit ein.
3.1 FL−
Als Beispiel für die einfachste strukturelle Beschreibungslogik soll hier die Gram-matik von FL− vorgestellt werden. (vgl. [7])
Es wird verwendet:– A für atomare Konzepte– C,D für komplexe Konzepte– R für atomare Rollen
Die Grammatik wird dann beschrieben durch:
C,D → A | C uD | ∀R.C | ∃R
Atomare Konzepte wurden bereits in Abschnitt 2.4 erläutert. Der Schnitt (ent-spricht auch der logischen UND-Verknüpfung) von Konzepten erlaubt die Bildungvon Klassen, deren Elemente gleichzeitig Instanzen aller am Schnitt beteiligtenKonzepte sind. Die Quantoren werden wie folgt verwendet: die universelle Ein-schränkung ∀R.C definiert ein Konzept, das alle Elemente enthält, die Instanzenvon R und des Konzepts C sind. Zum Beispiel lässt sich so ein Konzept anlegenStudentin ≡ ∀ studiertAn.Weiblich. Mit der existenziellen Einschränkung ∃R wirdgarantiert, dass jedes Element mindestens einmal in der Rollenbeziehung R steht.Das Konzept Student lässt sich auf diese Weise als ∃ studiertAn darstellen.
In den folgenden Abschnitten wird die Ausdrucksstärke häufig verwendeterund für das Semantic Web relevanter, Beschreibungslogiken betrachtet.
3.2 ALC und die SH-LogikfamilieDie Grundlage der meisten Beschreibungslogiken ist ALC. Die Abkürzung stehtfür attributive language [with] complement. Zusätzlich zu der im vorigen Ab-schnitt 3.1 vorgestellten Logik FL− kann hier die Negation (bzw. Komple-mentbildung) von Konzepten formuliert werden. Im Gegensatz zur Familie derAL-Logiken gibt das C an, dass auch komplexe Konzepte negiert werden können.

Grundlagen Semantic Web 23
Tabelle 2. Symbolübersicht: Ausdrucksstärke von Beschreibungslogiken
AL steht für attributive language. Dies ist die Basis für die meistenBeschreibungslogiken. Damit sind folgende Operationen möglich:
– Negation atomarer Konzepte: ¬A– Schnitt von Konzepten: C uD– Universelle Einschränkungen durch ∀R.C– Existenzielle Restriktion, limitiert auf atomare Rollen: ∃R
FL− entpricht AL, jedoch ohne atomare NegationFLo weitere Einschränkung von FL−, auch die Verwendung von Existenz-
quantoren wird ausgeschlossenC Negation (Komplementbildung) von komplexen KonzeptenS Abkürzung für ALC mit Transitivität für Rollen (in Kombinationen
mit weiteren Buchstaben verwendet)H Hierarchische Verschachtelung von Rollen, in RDFS ausgedrückt
durch rdfs:subPropertyOfO Nominale Wert für Konzepte. In OWL ausgedrückt durch owl:oneOf,
owl:hasValueI Invertierung von RollenN Beschränkung der Kardinalität (owl:Cardinality,
owl:MaxCardinality)R Reflexivität und Irreflexität; Disjunktheit von Rollen; Axiome, die
Zusammensetzung von Rollen beschreiben (in begrenztem Umfang)Q Qualifizierte Beschränkungen der Kardinalität. In OWL 1.1 ermög-
licht durch Sprachkonstrukte, die die Kardinalität einschränken, unddabei eine Typisierung (spezifischer als owl:thing) zulassen.
U Vereinigung von KonzeptenF Funktionale Rollen („features“), eine Teilmenge der Rollen in RE Gestattet die Verwendung von Existenzquantoren in vollem Umfang,
in OWL: für die durch den Quantor gebundene Variable sind auchandere Werte als owl:thing zulässig.
(D) Erlaubt die Verwendung von Datentypen (z. B. Integer, String) undexpliziten Werten („Text“, 42)
(D+) Es können nicht nur Standard-Datentypen wie in (D) verwendetwerden, auch die Definition eigener Typen ist möglich.

24 C. Angeli
„Um sehr lange Namen für ausdrucksstarke Beschreibungslogiken zu vermei-den, wurde die Abkürzung S für ALCR+ eingeführt.“[1] S entspricht damit ALC,erweitert um Transitivität für Rollen.
Eine einfache Logik, die dies verwendet, ist z. B. SIN , die ALCR+ um dieInvertierung von Rollen erweitert und die Beschränkung der Kardinalität zulässt.Kardinalitätsbeschänkungen können in der Form > nR geschrieben werden.So lässt sich etwa mit > 10.000 studiertAn die Menge der Hochschulen mitmindestens 10.000 Studierenden beschreiben. Dabei muss eine Einschränkungbeachtet werden: die Kardinalitätsbeschränkung ist nur dann für eine Rolle Rzulässig, wenn von R keine transitiven Beziehungen zu Unterrollen existieren.[1].
Ist zusätzlich die hierarchische Verschachtelung von Rollen möglich, so wirddies durch den Buchstaben H ausgedrückt. Die wichtigsten Vertreter der SH-Familie sind die Logiken SHIQ, SHIF und SHOIN , die in den folgendenAbschnitten beschrieben werden.
3.3 SHIQ(D) und SHIN (D)
Die Beschreibungslogik SHIQ(D) ist mächtig genug, um damit Ontologien zuerstellen, auch wenn einige Konstrukte fehlen, die erst von erweiterten Logiken(Abschnitte 3.4 und 3.5) eingeführt werden. Die Sprache OIL (Ontologie InferenceLayer, siehe 4.2) basiert auf dieser Logik.[6]
Die Erweiterung gegenüber der SH-Familie betreffen:
I Invertierung von Rollen: R ∪ R−|R ∈ RQ Qualifizierte Beschränkungen der Kardinalität der Form 6 nR.C und
> nR.C(D) Dieser Zusatz bezieht sich auf die Verwendung von Datentypen. Damit
sind Standard-Datentypen wie Integer oder String möglich. Werden nurdie Logik-Eigenschaften besprochen kann der Zusatz auch weggelassenwerden.
Eine ähnliche Beschreibungslogik ist SHIN (D). Im Gegensatz zu SHIQ(D)
ist aber eine zahlenmäßige Beschränkungen nur in der Form 6 nR.> und > nR.>möglich. Das Top-Konzept > steht dabei für jedes beliebige Konzept und wirdvereinfachend weggelassen (z. B. 6 nR).
3.4 SHOIN (D)
In SHOIN (D) kommt eine weitere Möglichkeit hinzu, Konzepte anzulegen. DasSymbol O beschreibt, dass es erlaubt ist, Konzepte durch nominale Werte zudefinieren, das heißt, es werden alle zulässigen Werte aufgezählt. Ein KonzeptSchwierigkeitsgrad liese sich dann als Schwierigkeitsgrad ≡ leicht, mittel, schwerschreiben. Dies ist besonders nützlich, wenn es keine Möglichkeit gibt, das Konzeptaus anderen Konzepten und Rollen aufzubauen.
Im Gegensatz zu SHIQ(D) ist jedoch nur eine Kardinalitätsbeschränkungohne Qualifizierung möglich (wie schon bei SHIN (D) beschrieben). Die in Ab-schnitt 4.3 vorgestellte Ontologiesprache OWL-DL basiert auf SHOIN (D).

Grundlagen Semantic Web 25
3.5 SROIQ(D+)
Zu den neuesten Entwicklungen auf dem Gebiet der Beschreibungslogik gehört dieLogik SROIQ(D+). Die Grundlagen dazu stammen von Ian Horrocks et al. [12]und wurden 2006 auf der Konferenz Knowledge Representation and Reasoningvorgestellt. Der folgende Abschnitt stützt sich in Teilen auf Inhalte aus [12].
Die Erweiterungen gegenüber SHOIN betreffen die folgenden Bereiche:1. H ⇒ R: zu der hierarchischen Schachtelung von Rollen (H) kommt die
Möglichkeit hinzu, Aussagen über Reflexivität, Irreflexivität, Anitsymmetrieund Disjunktheit von Rollen zu treffen. Im begrenztem Umfang lässt sichauch die Zusammensetzung von Rollen durch Axiome beschreiben.
2. N ⇒ Q: bei einer Beschränkung der Kardinalität ist es auch möglich, eineTypisierung vorzunehmen.
3. (D) ⇒ (D+): Es können nicht nur die Standard-Datentypen wie in (D) verwen-det werden, auch die Definition eigener Typen ist möglich.
Die zusätzlichen Möglichkeiten von SROIQ gegenüber SHOIN werdenim Folgenden sowohl theoretisch vorgestellt, als auch anhand einiger Beispieleveranschaulicht:
Reflexivität Eine Relation ist reflexiv, wenn gilt: ∀a ∈ A : (a, a) ∈ R. Dieskann z. B. auf die Rolle kennt(A,B) angewandt werden, denn jeder kenntsich selbst.
Irreflexivität Für eine irreflexive Relation gilt: ∀a ∈ A : (a, a) 6∈ R. Das istnützlich für die Rollendefinition istGeschwisterVon(A,B), denn keiner zähltals Geschwister für sich selbst.
Antisymmetrie Die Definition für Antisymmetrie lautet: ∀a, b ∈ A : (a, b) ∈R ∧ (b, a) ∈ R⇒ a = b. Die Verwendung ist beispielsweise sinnvoll bei derRolle istTeilvon(A,B).
Disjunktheit Zwei Mengen (hier: Rollen) sind disjunkt, wenn sie kein gemein-sames Element besitzen. Während die Disjunktheit von Konzepten in denmeisten Beschreibungslogiken ausgedrückt werden kann, ist die Disjunkt-heit von Rollen erst in SROIQ möglich. Damit lässt sich beispielsweiseausdrücken, dass die Rollen studiertAn und istProfessorAn disjunkt sind.
Universelle Rolle U Als Gegenstück zu dem bereits in ALC eingeführten uni-versellen Konzept (geschrieben als >), existiert in SROIQ auch eine univer-selle Rolle U , die für jede beliebige Rolle stehen kann.
Komplexe Inklusion von Rollen Axiome der Form RS v R und S R v Rkönnen verwendet werden, um zu definieren, dass eine Rolle eine andere Rollebeinhaltet (subsumiert). Ein Beispiel soll das verdeutlichen: mit dem Axiombesitzt hatBauteil v besitzt und der Tatsache, dass jedes Notebook miteinem Prozessor ausgestattet ist (Notebook v ∃hatBauteil.Prozessor),lässt sich ausdrücken, dass der Besitzer eines Notebooks auch einen Prozessorbesitzt: ∃besitzt.Notebook v ∃besitzt.Prozessor
Lokale Reflexivität In SROIQ kann ein Konzept mit ∃R.Self definiert werden.So lässt sich z. B. das Konzept „Narzist“2 als ∃liebt.Self formalisieren.
2 als Narzist wird eine selbstverliebte Person bezeichnet

26 C. Angeli
Eine weitere Besonderheit der Logik SROIQ ist die Einführung einer RoleBox (kurz RBox). Neben den gleichfalls vorhandenen ABoxen und TBoxen„enthält die RBox alle Statements, die Rollen betreffen“[12]. Formal definiertist die RBox als Menge R = Rh ∪ Ra. Hierbei steht Rh für eine reguläreRollenhierarchie, Ra bezeichnet eine (endliche) Menge von atomaren Rollen.
Bei SROIQ(D+) handelt es sich gegenwärtig um die ausdrucksstärkste Be-schreibungslogik, die entscheidbar ist, und für die (zumindest theoretisch) effizi-ente reasoning-Algorithmen zur Verfügung stehen.
3.6 DLR
Eine Beschreibungslogik, die sich deutlich von den bisher vorgestellten unterschei-det, ist DLR. Die Besonderheit ist, dass die auf AL basierenden Logiken nurbinäre Rollen zulassen. Damit können nur „(. . . ) Beziehungen zwischen [zwei]Konzepten repräsentiert werden, wohingegen in einigen Situationen in der realenWelt der Bedarf besteht, mehr als zwei Objekte in Relation zu setzen.“([1], Kap.5.7) Aus diesem Grund sind in DLR n-stellige Relationen möglich.
Die Grundbausteine sind atomare Konzepte (A) und Rollen (P). Mit derfolgenden Syntax lassen sich n-stellige Konzepte und Rollen erstellen (aus: [1]):
R −→ >n | P | ($i/n : C) | ¬ R | R1 u R2
C −→ >1 | A | ¬C | C1 u C2 | ∃[$i]R | 6 k[$i]R
Dabei gibt n die Stelligkeit der Relation an (2 ≤ n ≤ nmax; nmax beliebig, aberfest). Die Variable $i verweist auf die i-te Komponente der Relation, 1 ≤ i ≤ nmax.
Genau betrachtet stellt DLR eine Erweiterung zu SQI dar, welche diebeschriebenen n-stelligen Relationen einführt. Da DLR jedoch selten in derPraxis Anwendung findet, wird für weitere Details auf [1] verwiesen.

Grundlagen Semantic Web 27
4 Ontologiesprachen
Die im Kapitel 3 vorgestellten Beschreibungslogiken sind die Grundlage für die imSemantic Web verwendeten Ontologiesprachen. Damit lässt sich diesen Sprachendie Ausdrucksmächtigkeit einer bestimmten Logik zuweisen. In den folgendenAbschnitten werden die wichtigsten Sprachen des Semantic Web betrachtet undihre jeweilige Ausdrucksmächtigkeit anhand konkreter Sprachkonstrukte bewertet.
4.1 RDF und RDFS
Das Resource Description Framework (RDF) ist eine der grundlegendsten Spra-chen des Semantic Web. Seit 2004 gehört es zu den Empfehlungen des World WideWeb Consortiums (W3C). Das RDF dient dazu, Resourcen, insbesondere Inter-netseiten, mit Metadaten zu beschreiben. Jedoch ist RDF auf eine Grundmengean Klassen beschränkt, die hauptsächlich dazu geeignet ist, einen Webresourcemit Metadaten wie Autor, Titel, Version oder Erstellungs- und Änderungsdatumanzureichern.
Um eigene Terminologien zu erstellen existiert eine Sprache zur Vokabelde-finition (RDF Vocabulary Description Language), RDF Schema. Damit lassensich einfache Ontologien entwerfen, die Möglichkeiten für automatisches Rea-soning sind jedoch sehr begrenzt. RDFS unterteilt alle Resourcen3 in Klassen.Die Wurzelklasse, auf die sich alle anderen Klassen zurückführen lassen, istrdfs:Resource. Allgemeine Klassen werden durch rdfs:Class beschrieben. FürDatentypen wird rdfs:Datatype verwendet, einfache Literale, wie Integer oderString, fallen in die Klasse rdfs:Literal.
Um eine Ontologie zu erstellen, werden die Klassen zu sogenannten RDF-Tripeln verbunden. Diese Tripel haben dir Form Subjekt-Prädikat-Objekt undkönnen zu komplexen RDF-Graphen kombiniert werden. Die Verbindung zwischenSubjekt und Objekt, also das Prädikat, wird in RDF durch Properties dargestellt.Dabei handelt es sich um binäre Relationen, entsprechend den Rollen in denBeschreibungslogiken. Die Menge der Properties wird ebenfalls zu einer Klassezusammengefasst (rdfs:Property).
Beispiele für Properties in RDF sind etwa rdfs:domain und rdfs:range,mit denen die zulässigen Klassen für Subjekt und Objekt eingeschränkt werden.rdfs:subClassOf und rdfs:subPropertyOf werden benötigt um Hierarchienvon Klassen und Properties zu erstellen, die einander subsumieren. Weitere Detailszur Syntax und Grammatik von RDF und RDFS sind in den Empfehlungen desWorld Wide Web Consortiums4 zu finden.
4.2 DAML+OIL
Diese Ontologiesprache entstand durch die Zusammenführung der Entwicklungvon DAML-ONT und OIL. DAML-ONT wurde vom DARPA, einer Forschungs-einrichtung des US Verteidigungsministeriums, entworfen. DAML steht dabei für3 „Alles, was durch RDF beschrieben wird, wird als Resource bezeichnet.“[18]4 http://www.w3.org/TR/

28 C. Angeli
DARPA Agent Markup Language und wurde 2001 um das Ontologie InferenceLayer OIL5 erweitert. DAMl+OIL wurde entworfen, „um die Struktur einerDomäne abzubilden; es verfolgt dabei einen objekt-orientierten Ansatz, der aufKlassen und Eigenschaften (Rollen) aufbaut.“[10]
Wie bereits in Teil 3.3 beschrieben, entsprechen die Möglichkeiten vonDAML+OIL der Ausdrucksstärke SHIQ(D) bei den Beschreibungslogiken. Aneinem Codebeispiel lässt sich zeigen, wie etwa eine qualifizierte Kardinalitäts-beschränkung (Q) möglich ist. Betrachtet wird der DL-Ausdruck > 10000studiertAn.Universität. Ein ähnliches Beispiel wurde schon in Abschnitt 3.2 ver-wendet, jedoch ohne die Beschränkung auf Universität. In DAML+OIL würde,angelehnt an die RDF-Syntax, folgender Code geschrieben (Ausschnitt):
1 <daml:Restriction daml:minCardinalityQ="10000">2 <daml:onProperty rdf:resource="#studiertAn"/>3 <daml:hasClassQ rdf:resource="#Universitaet"/>4 </daml:Restriction>
Obwohl DAML+OIL bereits viele Möglichkeiten zur Ontologie-Erstellung undzum Reasoning durch Inferenz-Algorithmen bietet, ist DAML+OIL inzwischenvon OWL überholt.
4.3 OWL DL
Bei der Web Ontology Language, kurz (OWL), handelt es sich ebenfalls umeine Spezifikation des W3C. OWL baut direkt auf RDF und RDFS auf undbringt wichtige Erweiterungen ein. Die Sprache kennt drei Ebenen: OWL Lite,OWL DL und OWL Full. Bei OWL Lite handelt es sich um eine eingeschränkteVariante, die sich hauptsächlich für einfache Konzept-Hierarchien mit wenigeneinschränkenden Randbedingungen eignet. Die Ausdrucksstärke von OWL Liteentspricht der in Abschnitt 3.4 vorgestellten Logik SHIF (D). OWL Full hingegenbietet alle syntaktischen Möglichkeiten von RDF an, der Preis ist jedoch, dassdie Entscheidbarkeit verloren geht.
OWL DL (Description Logic) bietet hier den besten Kompromiss: es unter-stützt alle Konstrukte der Logik SHOIN (D), garantiert jedoch Vollständigkeit6
und Entscheidbarkeit7.Ein kurzes Beispiel soll die Modellierungsmöglichkeiten mit OWL DL veran-
schaulichen. Es soll der Ausdruck Student ≡ Person u ∃ studiertAn.Universität ausder Beschreibungslogik in die OWL Syntax übertragen werden.
1 <owl:Class>2 <owl:intersectionOf rdf:parseType="collection">3 <owl:Class rdf:about="#Person"/>5 Selten auch als Ontologie Interchange Language bezeichnet, siehe:
http://www.ontoknowledge.org/oil/oil-faq.html#acronym6 Alle gültigen logischen Folgerungen können berechnet werden.7 Alle Berechnungen terminieren in endlicher Zeit.

Grundlagen Semantic Web 29
4 <owl:Restriction>5 <owl:onProperty rdf:resource="#studiertAn"/>6 <owl:toClass>7 <owl:Class rdf:about="#Universitaet">8 </owl:toClass>9 </owl:Restriction>10 </owl:intersectionOf>11 </owl:Class>
Das Schlüsselwort Class definiert eine Klasse, entsprechend einem Konzeptin den Beschreibungslogiken. Mit owl:intersectionOf in Zeile zwei wird dieSchnittmengenbildung von Klassen formuliert, analog zu „u“ im DL-Statement.Zeile drei nennt die Klasse Person als ersten Teil der Schnittbildung, in Zeile vierwird mit <owl:Restriction> die zweite Klasse des Schnitts deklariert. DieseDeklaration geschieht implizit, in dem alle Klassen zusammengefasst werden,die der Rolle studiertAn im owl:onProperty...-Statement entsprechen. In Zeilesechs und sieben wird schließlich eine weitere Typbeschränkung vorgenommen,die verlangt, dass alle Objekte, die in der Rollenbeziehung stehen, aus der KlasseUniversität stammen müssen.
4.4 OWL 1.1
Bei OWL 1.1 handelt es sich um eine Weiterentwicklung von OWL DL. Eswerden neue Sprachelemente eingführt, die die Ausdrucksstärke deutlich erhöhen.Dabei wurde jedoch darauf geachtet, dass die Entscheidbarkeit erhalten bleibtund effiziente Inferenz-Algorithmen zur Verfügung stehen. Die Expressivitätwird dabei von SHOIN (D) auf SROIQ(D+) erweitert. OWL 1.1 beruht auf dertheoretischen Arbeit von Ian Horrocks et al.[12]. Seit September 2007 gibt esdazu eine Arbeitsgruppe, im Januar 2008 wurden erste detailliertere Dokumentezu OWL 1.1 als „Working Draft“ des W3C veröffentlicht.
4.5 SWRL
Die Semantic Web rule-language SWRL ist eine Kombination aus den Ontolo-giesprachen OWL Lite, OWL DL und der Regelsprache RuleML (Rule MarkupLanguage). Das Ziel von SWRL ist der Entwurf einer Regelsprache für dasSemantic Web.
Für SWRL sind verschiedene Syntax-Varianten definiert, die für unterschied-liche Zwecke gedacht sind: (vgl. [13])
abstrakte Syntax Sie soll für den Menschen lesbar sein und so einen einfachenZugang zum Verständnis der Regeln bieten. Diese Syntax baut auf dererweiterten Backus-Naur Form (EBNF) auf.
konkrete XML Syntax Diese Variante kombiniert die XML-Darstellungenvon OWL und RuleML. Der Vorteil ist hier, dass Ontologie Axiome undRegeln frei kombinert werden können, und dass eine einfache Interoperabilitätzwischen den Werkzeugen gewährleistet ist.

30 C. Angeli
konkrete RDF Syntax Regeln können in SWRL auch durch eine RDF Syntaxbeschrieben werden. Die Verwendung von Variablen in den Regeln über-steigt jedoch die Semantik von RDF. Ob eine entsprechende semantischeErweiterung von RDF möglich ist, ist nicht bekannt.
Werden alle Modellierungsmöglichkeiten von SWRL ausgeschöpft, so sinddie Ontologien nicht mehr entscheidbar. Für die Verwendung mit automatischenInferenz-Systemen muss die Sprache daher eingeschränkt werden. Somit kanneine generelle Mächtigkeit der Sprache nicht angegeben werden. Eine geeigneteEinschränkung von SWRL auf Description Logic Programs8 wird bei [8] gezeigt.
5 Zusammenfassung und Ausblick
Obwohl die Idee für das Semantic Web schon 1998 formuliert wurde ([3]) und dietheoretischen Grundlagen der Beschreibunglogik seit 1940 bekannt sind ([5]), istdie Enwicklung leistungsfähiger Logiken für Ontologien noch immer ein wichtigerGegenstand der Forschung. So baut die aktuell entwickelte, neue Version derWeb Ontologie Language, OWL 1.1, direkt auf den Mitte 2006 veröffentlichtenErgebnissen von I. Horrocks zu der Logik SROIQ ([12]) auf.
Durch die Verbesserung der Beschreibungslogiken, der Ontologiesprachenund der reasoning-Algorithmen ist es möglich, immer größere und komplexereOntologien zu entwerfen und zu verarbeiten. Die theoretischen und technischenGrundlagen für das Semantic Web sind damit gegeben.
Um der Vision von Tim Berners-Lee zum Durchbruch zu verhelfen, ist esnotwendig, die Konzepte und Techniken des Semantic Web auch in der Praxiseinzusetzen. Ein erster Schritt wäre der konsequente Einsatz von Metadaten inInternetseiten, um die Inhalte automatisch zu erfassen.
Die Standards zur Barrierefreiheit von Webseiten unterstützen dieses Ziel.So ist es für barrierefreie Seiten vorgesehen, Bilder immer mit <alt>-Tags zuversehen, die den Inhalt des Bildes beschreiben. Gliedernde <div>-Elementemüssen mit einem Titel versehen werden, der das Thema des Abschnitts geeignetbeschreibt.
Damit diese Metatags auch automatisch verarbeitet werden können reichtes nicht aus, die Syntax durch eine Sprache wie RDFS oder OWL festzulegen.Für eine klar definierte Semantik ist auch eine Ontologie notwendig, die dieBedeutung der Begriffe festsetzt. Für Metadaten, die Dokumente beschreiben,kann etwa die Dublin Core9 Ontologie verwendet werden.
Je mehr von den Möglichkeiten, die Ontologien im Semantic Web bieten,umgesetzt wird, desto besser und leichter können die Angebote im Internetgenutzt werden.
8 Eine andere Art der Wissensrepräsentation als die in dieser Arbeit beschreibeneDescription Logic
9 http://dublincore.org/

Grundlagen Semantic Web 31
Literatur
[1] F. Baader, D. Calvanese, D. L. McGuinness, D. Nardi, and P. F. Patel-Schneider.The Description Logic Handbook: Theory, Implementation, and Applications. Cam-bridge University Press, 2003.
[2] E. Bergmann and H. Noll. Mathematische Logik mit Informatik-Anwendungen.Springer, 1977.
[3] T. Berners-Lee. Semantic web road map. W3C Draft, Sept 1998. http://www.w3.org/DesignIssues/Semantic.html.
[4] T. Berners-Lee, J. Hendler, and O. Lassila. The semantic web. Scientific American,284(5):34–43, 2001.
[5] A. Church. A formulation of the simple theory of types. The Journal of SymbolicLogic, 5(2):56–68, 1940.
[6] S. Decker and I. Horrocks. Knowledge representation on the web. In Proc. Int’lWorkshop on Description Logics (DL2000), 2000.
[7] E. Franconi. Description logic – tutorial course.http://www.inf.unibz.it/~franconi/dl/course/, 2002.
[8] B. N. Grosof, I. Horrocks, R. Volz, and S. Decker. Description logic programs:Combining logic programs with description logic. In Proc. 12th Int’l World WideWeb Conf., May 2003.
[9] T. R. Gruber. A translation approach to portable ontologies. Knowledge Acquisition,5(2):199–220, 1993.
[10] I. Horrocks. DAML+OIL: a description logic for the semantic web. Bull. of theIEEE Computer Society Technical Committee on Data Engineering, 25(1):4–9,2002.
[11] I. Horrocks. Applications of description logics: State of the art and research chal-lenges. Proceedings of the 13th International Conference on Conceptual Structures,pages 87–90, 2005.
[12] I. Horrocks, O. Kutz, and U. Sattler. The even more irresistible SROIQ. In Proc.of the 10th Int. Conf. on Principles of Knowledge Representation and Reasoning(KR 2006), pages 57–67. AAAI Press, 2006.
[13] I. Horrocks, P. F. Patel-Schneider, H. Boley, S. Tabet, B. Grosof, and M. Dean.Swrl: A semantic web rule language combining owl and ruleml. W3C Membersubmission, May 2004. http://www.w3.org/Submission/SWRL/.
[14] B. Nebel and S. Wölfl. Knowledge representation and reasoning – vorlesung, 2005.http://www.informatik.uni-freiburg.de/~ki/teaching/ws0506/krr/vorlesung.html.
[15] F. Rötzer. Neuer rekord: 100 millionen websites weltweit. heise online - News, 01.November 2006.http://www.heise.de/newsticker/meldung/80395.
[16] U. Schöning. Logik für Informatiker. B.I.-Wissenschaftsverlag, 1987.[17] W. Vogler. Logik für informatiker – vorlesungsskript, 2003.[18] Rdf vocabulary description language 1.0: Rdf schema. W3C Recommendation,
2004.http://www.w3.org/TR/rdf-schema/.

Reasoning: Rete (und Jena)
Thomas Eisenbarth
Universität [email protected]
Zusammenfassung Reasoning als Bestandteil des Semantic Webs be-fasst sich mit der von Logik geleiteten, intelligenten Beantwortung von An-fragen und Hinzulernen durch Maschinen. Das Ziel ist es, einen „gesunde-nen Menschenverstand” zu imitieren, indem der Maschine die tatsächlicheBedeutung von Fakten bekannt gemacht wird. Diese Herausforderunggeht mit ernormen Datenmengen einher, auf Basis derer diese Semantikaufgebaut wird. Die Benutzung von trivialen Algorithmen zur Lösungvon Problemen und Anfragen auf den Daten, führt häufig zu einer inak-zeptablen Komplexität in Form von Laufzeit- und/oder Speicherbedarf.Dies wiederum behindert den Einsatz dieser Systeme in der Realität,in der sie beispielsweise in Geschäftsprozessmanagement- und Optimie-rungswerkzeugen Anwendung finden. Als einer der ersten Lösungsansätzeentstand 1974 der Rete-Algorithmus. Dieser ist (in abgewandelter undzumeist optimierter Form) die Grundlage für viele bekannte und sich imEinsatz befindende Expertensysteme.1 Aus diesem Grund ist es sinnvoll,die Hintergründe und Abläufe dieses Algorithmus zu kennen. Wir fassendie Funktionsweise von Rete zusammen und vergleichen diverse konkreteImplementierungen.
1 Einleitung
Eine Fähigkeit der menschlichen Natur ist es, durch Lernen aus vergangenenEntscheidungen und daraus resultierenden Ergebnissen zu lernen. Computerdagegen haben im allgemeinen nicht diese Fähigkeit zu lernen. Um elektronischenGeräten im allgemeinen und Computern im speziellen zum einen dieses Lernenzu ermöglichen und zum anderen Entscheidungen (nach Möglichkeit auch noch)korrekt zu treffen, ist es notwendig, Wissen zu formulieren und den Maschinen zurVerfügung zu stellen. Wie landläufig bekannt ist, haben elektronische Geräte dieEigenschaft, dass man diesen selbst die einfachsten Zusammenhänge umfangreichdarzulegen hat. Dies hat zur Folge, dass die sogenannten Expertensysteme,welche Computer zur Lösung von komplexen Problemen bewegen sollen, mitriesigen Datenmengen als Grundlage umzugehen haben. Auf dieser Basis werdenAlgorithmen verwendet, die aus dem Berg an Daten die für den Anwenderrelevanten heraussuchen und diesem (womöglich in anderer Repräsentation) alsLösung präsentieren. Der einfachste - jedoch leider ebenso inakzeptable - Weg zu1 U.a. Jena, Red Hat’s JBoss Rules, die Haley Ltd. und ILOG-Produktketten basierenauf Rete.[13, 12, 16, 15]

Reasoning: Rete (und Jena) 33
Abbildung 1. Einordnung von Rete im Semantic-Web.
einer solchen Problemfindung wäre der folgende: Der Computer führt Listen überdie Regeln eines solchen Systems und durchläuft diese Listen linear und ohneweitere Strategie zur Suche nach der gewünschten Lösung. Sei r nun die Anzahlder Regeln, p die Durchschnittliche Anzahl an Prämissen für diese Regeln und fdie Anzahl an Fakten, so ist die Komplexität des beschriebenen Systems gleich
O(rfp) (1)
Bei steigender Anzahl an Regelprämissen ist diese Laufzeit zu ungünstig, umdamit ernsthaft arbeiten zu können.
Charles L. Forgy fand im Zuge seiner Arbeit an der Carnegie Mellon Uni-versity heraus, dass herkömmliche Systeme damals bis zu 90% ihrer Laufzeitmit Mustervergleichen (engl. „pattern matching”) beschäftigt waren.[14] Manbenötigt also eine effiziente Vorgehensweise, um schnell an die gewünschten Er-gebnisse zu gelangen. Forgy hat einen Weg vorgestellt, der dies möglich macht:Der Rete-Algorithmus. Im Umfeld des Semantic Web lässt sich Rete als einemögliche Basis von Reasoner-Systemen sehen. In der wohl bekannten Übersicht,die in Abbildung 1 dargestellt ist, kann man Rete damit auf der Ebene der OWLbzw. Rules einordnen.
Im Zuge dieser Arbeit wollen wir in Kapitel 2 zunächst Begrifflichkeiten rundum Reasoning sowie Rete klären und konkrete Beispiele für die verwendetenTermini geben. Anschließend beschreiben wir in Kapitel 3 die einzelnen Schrittedes Algorithmus im Detail und betrachten in Kapitel 4 das Thema Optimierun-gen im originalen Rete sowie Erweiterungen und weitere Verbesserungen vonNachfolgern. In Kapitel 5 betrachten wir den Zusammenhang von Rete und Jenaund die Möglichkeiten des OWL-Reasonings in Jena.

34 T. Eisenbarth
2 Hintergrund und Einführung in Rete
Reasoning-Systeme lassen sich anhand ihrer unterschiedlichen Funktionsweisegrundsätzlich differenzieren: Rückwärts-verkettete2 Algorithmen starten mit ei-ner Menge von Schlussfolgerungen und arbeiten sich rückwärts zum Antezedenzdurch, um zu prüfen, ob Daten vorhanden sind, die auf die gesuchten Schlussre-geln passen. Dafür muss man wissen, nach welchen Zielen man sucht. In einemkriminologischen Expertensystem könnte man beispielsweise untersuchen wollen,ob ein Verdächtiger der Täter eines Verbrechens ist. Ein Indiz bei rückwärtsverketteten Algorithmen das „Ziel” dar, wofür unser System den „Nachweis”sammeln muss: Es wird also versucht, alle Schlussregeln zu finden, die für dieÜberführung des Verdächtigen sorgen. Daraufhin muss gezeigt werden, dass dieVorbedingungen der Schlussregel ebenfalls wahr sind. So werden diese Vorbe-dingungen zum neuen Ziel, die wie beim ursprünglichen Ziel bewiesen werdenmüssen. Das Ergebnis ist entweder die Überführung des Täters in Form einervollständigen, geprüften Kette ausgehend vom Ziel-Knoten. Andernfalls findenwir womöglich keine weiteren Regeln, deren Konklusionen bzw. Aktionen in dieKette passen. Der Verdächtige wäre dann unschuldig.
Die zweite Möglichkeit ist die Nutzung von vorwärts-verketteten Algorithmen.3Im Gegensatz zu rückwärts gerichteten Algorithmen arbeitet das System hierDaten-gesteuert. Es werden also Daten in das System gegeben, die letztendlichentscheiden, ob eine Regel ausgeführt wird oder nicht. Sofern eine Ausführungder Regel(n) stattfindet, können damit wiederum solange neue oder abgeänderteDaten in das System eingespeist werden, bis eine Entscheidung möglich ist.[18]
Charles L. Forgy hat in seiner Dissertation [5] bereits 1979 die Idee seinesAlgorithmus Rete beschrieben und diese in den darauf folgenden Jahren ver-feinert. [8, 6] Rete bezeichnet das lateinische Wort für Netzwerk und wurdeaufgrund der Organisationsform des Graphen gewählt, die ein Rete ausmacht.Die grundsätzliche Überlegung hinter Rete besteht aus folgenden Punkten:– Ein Knoten im Graph repräsentiert eine Vorbedingung.– Der Pfad vom Wurzelknoten zu einem Blatt stellt eine Menge von Vorbedin-
gungen (die gesamte Liste von Vorbedingungen zu einer Aktion).– Rete eliminiert Redundanzen dadurch, dass Knoten mehrfach verwendet
werden (können).– Es werden Teil-Lösungen gespeichert, wenn Fakten verbunden werden. Da-
durch muss nicht das gesamte Netz neu berechnet werden, falls sich Faktenändern.
Diese (und weitere) charakteristischen Eigenschaften werden wir im folgen-den genauer beschreiben. Eine Übersicht über verwendete Termini und derenEinordnung in Rete ist in Abbildung 2 dargestellt.
Grundsätzlich werden bei Rete zwei Arten von Speicher unterschieden: Pro-duktionsspeicher („Production memory”, PM) und Arbeitsspeicher („workingmemory”, WM).2 engl. „Backward-Chaining”3 engl. „Forward-Chaining

Reasoning: Rete (und Jena) 35
Rete: ,,Big Picture''
Arbeitsspeicher (WM)
Working Memory Elements (WMEs):
Abbild der Welt und/oder des Systems selbst
Produktionsspeicher (PM)
Produktionen (,,Regeln'')
(Regelname LHS-->
RHS)
Alpha-Teil
Tests auf Konstanten
Beta-Teil
Joins und Beta-Speicher
Abbildung 2. Rete: Übersicht der Termini als „Big picture”.
2.1 Produktionsspeicher: PM
Der Produktionsspeicher besteht aus Elementen, die ihrerseits wiederum zumeinen als Regelprämissen (auch als Left Hand Side, LHS) und zum anderen als„Right Hand Side” (RHS) bezeichnet werden. Letztere sind zusammengesetzt ausPrämissen und Konklusionen. Zusammengefasst als Einheit nennt man die beidenElemente Produktionen oder Regeln. Die Regel haben folgende Form:
wenn Bedingung, dann Handlung.Im Allgemeinen können die beiden Teile der Regel unterschiedlich interpretiert
werden:
– Als Schlussregel: Wenn Prämisse, dann Konklusion.Diese Form findet beispielsweise in der formalen Logik als Transformationsre-gel in einem Kalkül Anwendung.
– Als Hypothese: Wenn Anhaltspunkt, dann Hypothese.Als Hypothese ist eine Regel beispielsweise aus der Medizin als Diagnosebekannt.
– Als Produktion: Wenn Bedingung, dann Aktion.

36 T. Eisenbarth
Diese Form von Regel finden wir in Produktionssystemen. Auch in Retehaben die Regeln diese Form.
Konkret sehen Produktionen in Rete normalerweise folgendermaßen aus:
Listing 3.1. Schema von Produktionen1 (Name der Regel2 Left -hand -side , LHS: Regelpraemisse(n)3 -->4 Right -hand -side , RHS: Aktion(en)5 )
In den Regelprämissen können Variablen verwendet werden. Diese sind in derLiteratur wie auch in unserer Arbeit von spitzen Klammern umgeben: <x>
Als konsistentes Beispiel in dieser Arbeit wollen wir uns eine Bibliothekvorstellen. Diese hat Bücher im Bestand, die in bestimmten Fachrichtungen(Informatik, Mathematik) einsortiert sind, verliehen werden können und vonVerlagshäusern verlegt werden.
Ein konkretes Beispiel für eine (Produktions-)Regel wäre:
Listing 3.2. Konkrete Beispiel-Produktionen1 (Finde -ausgeliehenes -Buch -einsortiert -in-Informatik -mit -Verlag -Springer2 (<x> ausgeliehen -an <y>)3 (<x> einsortiert -in <z>)4 (<x> verlegt -von Springer)5 -->6 BeliebigeAktion ()7 )
Die RHS mit ihren Aktionen ist für den Rete-Algorithmus zunächst nichtvon Bedeutung, da Rete die Suchfunktionalität, also die LHS, übernimmt. Inkonkreten Implementierungen übernehmen die Suchalgorithmen wie Rete dasFinden einer Lösung. Andere Teile (Module) des Systems werden dann zurAusführung der Regeln verwendet.[3, S.8.] Eine sinnvolle Möglichkeit für Aktionenwäre beispielsweise, neue Fakten in das System zu geben, die auf den Ergebnissenaufbauen, die durch die Auslösung „gelernt” wurden.
2.2 Arbeitsspeicher: WM
Der „Arbeitsspeicher” eines Rete-Netzes besteht aus „Working Memory Elements”(WME). Diese beschreiben als Faktenbasis ein Modell der Realität des Rete undwerden als n-Tupel dargestellt. WMEs zu unserem Beispiel könnten also wie folgtaussehen:
Listing 3.3. Beispiel-WMEs1 w1: (B1 verlegt -von Springer)2 w2: (B1 einsortiert -in Mathematik)3 w3: (B2 verlegt -von Pearson)4 w5: (B2 einsortiert -in Informatik)5 w6: (B2 ausgeliehen -an Thomas)6 w7: (B1 ausgeliehen -an Hans)7 w8: (B3 verlegt -von Pearson)8 w9: (B4 einsortiert -in Informatik)

Reasoning: Rete (und Jena) 37
Wie man sieht, setzen sich einfache WMEs z.B. als Tripel in der Form Objekt,Attribut, Wert zusammen. Die Einschränkung auf die Form des Tripels wird inder Literatur häufig aufgrund der Einfachheit gewählt. Grundsätzlich sind jedochauch andere, komplexere Repräsentationen denkbar. In WMEs sind immer nurKonstanten und keine Variablen erlaubt.
3 Der Rete-Algorithmus
Das Rete selbst ist ein Datenflußgraph, bestehend aus einem „Alpha”- sowieeinem „Beta”-Teil:
3.1 Der Alpha-Teil
Start
verlegt-von ? ausgeliehen-an ?einsortiert-in ?
Mathematik
InformatikPearsonSpringer
Thomas
Hans
WMEs
Geographie
Physik
AM1 AM2 AM3 AM4 AM5 AM6 AM7 AM8
Abbildung 3. Alpha-Teil des Rete-Netzes.
Pro Vorbedingung einer Produktionsregel wird im Alpha-Teil eine Filterregelmit genau dieser Vorbedingung angelegt. Als Tests der Vorbedingungen sind prin-zipiell alle Funktionen vorstellbar, die einen Wahrheitswert (Boolean, true/false)zurückliefern können. Wie an unserem Beispiel zu erkennen ist, sind die aus-zuführenden Tests häufig Gleichheitsfunktionen. Konkrete Implementierungenvon Rete unterstützen jedoch auch andere Funktionen (größer, kleiner, etc.). [3,S.10] Als „Input” in diese Filterregeln werden die WMEs gegeben: Von einemStartknoten aus werden die WMEs gegen die Filterregeln der Vorbedingungen

38 T. Eisenbarth
geprüft. Als Output der Regel speichert Rete alle WMEs, die die Filterregelerfolgreich erfüllen. WMEs, die keine einzige Regel treffen werden verworfen. DieListe an treffenden WMEs werden als Alpha-Speicher („alpha memory”, AM)bezeichnet und im Alpha-Teil des Graphen gespeichert. Rete würde im Beispielals einen konkreten Alpha-Speicher also all diejenigen WMEs hinterlegen, die dieRegel „verlegt-von” erfüllen. Ein weiterer Alpha-Speicher mit den entsprechendpassenden WMEs würde für „einsortiert-in” angelegt. Anschaulich dargestelltwird dies in Abbildung 3.
3.2 Der Beta-Teil
Der Beta-Teil des Rete-Netzes ist optional und besteht aus Knoten, die zweiEingangskanten (veranschaulicht dargestellt als „linke” bzw. „rechte” Eingangs-kante) aufnehmen. Die üebergebenen Objekte heißen „Tokens” und dienen alsDatenhalter z.B. für WMEs oder Listen von WMEs. In einigen Implementie-rungen werden die Token auch für die Alpha-Speicher verwendet. Dort haltendiese jeweils ein einzelnes WME sozusagen als Wrapper. In der Regel ist eineder Eingangskanten durch einen Alpha-Speicher aus dem Alpha-Teil des Netzesbelegt. Die zweite Kante wird durch Vorgänger-Tokens belegt. Der Wurzelknotendes Beta-Netzes ist ein spezieller Knoten: Er gibt keine Informationen an seineNachfolger ab, um einen Einstieg in den Graphen zu ermöglichen. Es gibt mehrereAnsätze dieses Problem zu umgehen: Einige Implementierungen bieten einenAdapter für Alpha-Speicher, andere erlauben es, dass beide Eingangsknotendirekte Alpha-Speicher sind.
Der Beta-Teil ist hauptsächlich zuständig für Join-Operationen, deren Resul-tate wiederum in Tokens gespeichert werden.
Die Verknüpfung der Tokens wird durch eine JOIN-Operation realisiert, wiein 3.4 zu sehen ist.
Listing 3.4. Join-Operation der Beta-Knoten1 X Y Y Z2 ========= ============3 foo 23 23 John4 and 105 bar 42 42 Doe67 Ergebnis eines Join auf beiden Knoten:89 X Y Z
10 ======================11 foo 23 John12 bar 42 Doe
Das Ergebnis der Join-Operationen besteht also aus einer Kombination vonTokens die beispielsweise einige der Produktionsregeln treffen. Dieses Ergebniswird Beta-Speicher. Der grundsätzliche Zweck ist die Speicherung von Referenzenbzw. Listen auf WMEs.
3.2.1 p-Knoten Das Ergebnis der Verknüpfungskette ist eine Liste all derje-nigen WMEs, die auf alle Regeln treffen oder eine leere Liste, sofern kein WME

Reasoning: Rete (und Jena) 39
alle Bedingungen erfüllt. Dieser Verbund von Fakten in Form von Tokens, dieauf einen bestimmten Satz an Produktionsregeln zutreffen wird auch als Kon-fliktmenge (engl. „conflict set”) bezeichnet. Der Token, der das Zutreffen allerProduktionsregeln beschreibt und damit ein Blatt des Baumes darstellt, wirdauch „Terminalknoten” oder „p-Knoten” (Produktions-Knoten) genannt. Fürden Fall dass ein WME mehrere Produktionen erfüllt und dadurch auch mehrereAktionen der RHS ausgeführt werden müssen, befinden sich diese im Konflikt.Als „Agenda” wird diese Liste der Aktionen genannt. In dieser werden Listenauszuführenden und aller (zeitlich) geplanter Aktionen geführt. Zeitlich geplanteAktionen werden ausgeführt, falls sie nach einer gewissen Zeit immer noch wahrsind.[4] Die Agenda kümmert sich auch um die Reihenfolge, in der die Regelnausgeführt werden. Für die Lösung des Problems der Reihenfolge existieren eineReihe von möglichen Ansätzen:[7]– FIFO / LIFO: Die einfachsten und wahrscheinlich bekanntesten Varianten
verwenden die Listenpositionen als Entscheidungsgrundlage. FIFO führt dieältesten Aktionen zuerst aus. LIFO arbeitet wie ein Stack und nimmt dieneuesten Elemente mittels „pop” vom Stack bzw. aus der Liste.
– „Salience” benutzt einen ganzzahligen Wert zum Festlegen der Priorität.Höhere Zahlen bedeuten hierbei höhere Priorität.
– Komplexitätsbasierte Lösungsverfahren nehmen beispielsweise die Anzahlder Prämissen als Maß der Komplexität und setzen komplexere Aktionen andie Spitze der Agenda.Zusammenfassend lässt sich feststellen, dass der Alpha-Teil des Netzes alle
Tests durchführt, die nur ein WME betreffen. Der Beta-Teil ist für alle anderenverantwortlich, in denen zwei oder mehr WMEs vorkommen. Abbildung 4, inAnlehnung an http://en.wikipedia.org/wiki/Image:Rete.JPG, veranschaulichtdies.
3.3 Entfernen von WMEsFakten (also WMEs in der Rete-Welt) ändern sich zwar nicht sehr häufig (zumin-dest im Vergleich zur Frequenz, mit der die Produktionen sich ändern). Dennochmuss man natürlich die Möglichkeit bedenken, dass WMEs entfernt werdenmüssen: Es müssen also alle Einträge im Alpha-Teil sowie im Beta-Teil entferntwerden. Im originalen Rete-Algorithmus hat Forgy das Entfernen von WMEseffektiv gleich realisiert, wie das Hinzufügen von Fakten. Der einzige Unterschiedwar, dass beim Entfernen in den entsprechenden Methoden ein spezielles Flaggesetzt war, mit dem zwischen Hinzufügen und Löschen unterschieden wurde.[3,S.28] Die Methoden, die die Join-Knoten behandeln, verfahren beim Löschengenauso. Der Vorteil besteht darin, dass sowohl das Hinzufügen als auch dasLöschen effektiv mit den gleichen Methoden durchgeführt werden kann.
3.4 Bearbeiten von WMEsWie wir bereits festgestellt haben, ändern sich Fakten im Vergleich zu Anfragenseltener. Dennoch muss man Anpassungen der Faktenbasis vornehmen, beispiels-

40 T. Eisenbarth
Abbildung 4. Das gesamte Rete-Netz
weise wenn man zeitliche Attribute in seinen Fakten hält. „Älter werden” wäreeine typische Operation, bei der ein Attribut nach Ablauf einer Frist inkrementiertwird. Das Bearbeiten von WMEs ist im originalen Rete jedoch nicht vorgesehenund muss über den Umweg realisiert werden, dass das zu bearbeitende WMEentfernt, und ein neues WME eingefügt wird.
3.5 Negierte Prämissen
Neben Tests auf die Existenz von WMEs im Arbeitsspeicher eines Rete möchteman auch überprüfen können, ob sich ein WME nicht im Speicher befindet. DieSyntax zur Darstellung lautet folgendermaßen:
Listing 3.5. Konkrete Beispiel-Produktionen1 (<x> ausgeliehen -an <y>) /* B1 */2 (<x> einsortiert -in <z>) /* B2 */3 -(<x> verlegt -von Springer) /* B3 */

Reasoning: Rete (und Jena) 41
Dieser Ausschnitt einer Produktionsregel trifft dann zu, wenn x ausgeliehenist in y, einsortiert ist in z, und nicht von „Springer” verlegt wurde. In Retebedeutet dies, dass im Beta-Netz ein WME lediglich weiter nach unten im Baumgereicht wird, wenn die Produktionen B1 und B2 zutreffen und x mit der gleichenVariablenbindung nicht auf die Bedingung B3 anspricht.
Negierte Prämissen werden häufig als abgeleitete Beta-Speicher implemen-tiert, die prinzipiell einen identischen Funktionsumfang besitzen und auch Alpha-Speicher als Eingangskanten erhalten. Während bei „normalen” Beta-Speicherndie Ergebnisse des Joins weitergereicht werden, müssen beim negativen die Ergeb-nisse der Joins zwischengespeichert werden. Das Token wird nur weitergegeben,sofern der Zwischenspeicher leer ist. Dies ist der Indikator, dass kein WME imArbeitsspeicher existiert, das die beschriebene negierte Prämisse beinhaltet.
3.6 Hinzufügen und Entfernen der Produktionen
Es wird häufig davon ausgegangen, dass Rete der Hinzufügen oder Entfernenvon Produktionen nicht oder nur durch eine vollständige Neugenerierung desgesamten Rete-Netzes unterstützt. Dieser Trugschluss rührt von der Beschrei-bungssprache OPS5 her, die vom Rete-Erfinder Forgy definiert wurde und dieerste erfolgreich eingesetzte Sprache für ein Expertensystem war. Auf dem Bereichder Modifikation von Produktionen, sprich Hinzufügen und Entfernen hatte OPS5Defizite.[3] Beim Hinzufügen von Produktionen startet man am Startknoten desBeta-Netzes und arbeitet den Weg nach unten und fügt neue Beta Speicher bzw.Tupel ein oder findet ebensolche, die mitverwendet werden können. Ebenso mussder Alpha-Teil des Netzes durch die Wiederverwundung von Knoten oder durchEinfügen angepasst werden.
3.7 Laufzeitverhalten
Obwohl Rete einen deutlichen Vorteil gegenüber primitiven Algorithmen bringt,hat die Original-Variante von Forgy auch Nachteile, von dem man in der Literaturregelmäßig liest: Der hohe Speicherverbrauch. Diese Feststellung gilt zumindestfür die ersten Implementierungen von Rete, bei denen beispielsweise an vielenStellen Kopien der WME-Instanzen angelegt wurden, anstatt mit Zeigern zuarbeiten. Eine zweite Sonderheit betrifft Expertensysteme im allgemeinen: BeiGraphen mit vielen Tausend oder Millionen Einträgen ist es entscheidend, niedas gesamte Netz ablaufen zu müessen. Eine derartige Operation wäre direktproportional zur Größe des Rete-Netzes, was insgesamt zu einer geringen Ska-lierbarkeit führen würde. Denkt man an eine Implementierung von Rete in Javamuss man beispielsweise die Konsequenzen des „Mark & Sweep”-Java GarbageCollectors mit einrechnen, der bei der Skalierbarkeit auch eine Grenze darstellenkönnte. Garbage Collection durchläuft normalerweise alle Objektinstanzen undsucht nach Referenzen auf die untersuchte Instanz. Falls keine Referenz gefundenwird, kann das Objekt zerstört werden. Bei potentiell Millionen von Objektenist die dadurch entstehende Problematik der Skalierbarkeit klar. Die einzigenMöglichkeiten dieses Problem anzugehen bestehen darin, einen intelligenteren

42 T. Eisenbarth
(also spezielleren) Garbage Collector dafür zu verwenden, oder die Verwaltungdes Speichers selbst zu übernehmen. Letzteres ist einfach, nachdem die Lebenszeitder zu verwaltenden Objekte klar definiert ist: Tokens werden dann entfernt,wenn ein WME entfernt wird. Andere bei anderen Objekte, wie beispielsweiseden Produktionsregeln, ist der Lebenszyklus durch das Hinzufügen bzw. Ent-fernen der Produktion klar geregelt. Die Optimierung von Speicherplatz undLaufzeitverhalten war in der Vergangenheit neben Erweiterungen von Rete einesder Forschungsschwerpunkte. Wir wollen diese nun detaillierter betrachten.
4 Optimierungen und Nachfolger des Algorithmus
Die Grundlage des Erfolgs von Rete beruht auf folgenden Eigenschaften: Retespeichert Ergebnisse der letzten Regel-Tests. Dies hat zur Folge, dass lediglichneue Fakten (WMEs) tatsächlich gegen die LHSs getestet und berechnet werdenmüssen. Die Komplexität von Rete ist also etwa O(rfp). Ein Vergleich zu der inder Einleitung genannten, exponentiellen Laufzeit von möglichen anderen Algo-rithmen machen die Vorteile von Rete deutlich. Zwei empirische Beobachtungenvon Forgy bilden die Grundlage für die eingebauten Optimierungen:[9]
– „Temporale Redundanz”:Das Ausführen einer Aktion ändert gewöhnlich nur wenige Fakten.[9]
– Strukturelle Gleichheit:Identische Knoten tauchen häufig auf der LHS auf, es werden also die gleichenPrämissen verwendet.
Diese Tatsachen benutzte Forgy, um Rete anzupassen. Folgende Optimierun-gen sind Bestandteil des originalen Rete-Algorithmus:
4.1 State-saving
Diese Optimierung baut darauf, dass bei Änderungen des Arbeitsspeichers dieErgebnisse der Änderung einmalig in das Rete-Netz eingepflegt (also die Ergeb-nisse berechet) werden. Bei der nächsten Änderung des Arbeitsspeichers bleibendie meisten der vorherigen Modifikationen erhalten. Dadurch spart sich derRete-Algorithmus die Neu-Berechnung der Änderungen.
Diese Optimierung baut auf der Voraussetzung auf, dass sich Fakten (WMEsin Rete) zum einen weniger häufig ändern, als Anfragen gestellt werden. Zumanderen dürfen sich nur überschaubare Teile des gesamten Arbeitsspeichersändern. Sollten die genannten Voraussetzungen in einer Umgebung nicht gelten,wäre dieser Rete-Mechanismus unter Umständen ineffizient.[3]
4.2 Teilen von Knoten
Das Teilen von Knoten findet an mehreren Stellen in Rete statt. Im Alpha-Teil speichert Rete nur einen Alpha-Speicher, sofern mehrere Produktionen diegleichen Regeln haben, anstatt Duplikate zu erstellen. Wenn zwei oder mehr

Reasoning: Rete (und Jena) 43
Produktionen identische Prämissen haben, werden im Beta-Teil die gleichenKnoten dafür verwendet. Durch das Einsetzen eines „Dummy”-Root-Knotensentsteht im Beta-Teil von Rete ein Baum.
4.3 Erweiterungen des Original-Algorithmus
Wie wir im vorherigen Abschnitt erläutert haben, biete der originale Rete-Algorithmus von Forgy Optimierungspotential. In den Jahren nach der erstenVeröffentlichung wurden diverse Erweiterungen und Optimierungen vorgeschla-genen: Viel Energie wurde in den Jahren auf die Optimierung von Rete aufMultiprozessorsysteme verwendet. Obwohl diese Algorithmen schneller zum Zielkommen als die Sequentiellen, bilden die gleichen Algorithmen die Basis. Durchdie hohe Verbreitung von SMP-Systemen (sogar in Consumer-Hardware durchIntel Core2Duo, etc.) in den letzten Jahren, wächst der Einfluss solcher Op-timierungen sicher weiter. Eine (verkürzte) Übersicht weiterer Nachfolger desAlgorithmus sei hier gegeben:[3, S.53]
– „Modify-in-place” erweitert Rete um die Möglichkeit, WMEs direkt zu ändern,ohne den Umweg des Entfernens und Hinzufügens.
– „Scaffolding” ist gedacht für Umgebungen, in denen WMEs häufig gelöschtund wieder hinzugefügt werden. Die Optimierung baut darauf, WMEs als„inaktiv” zu markieren, anstatt diese zu löschen. Bei Wiedereinfügen desgleichen WME wird der Zustand von „inaktiv” auf „aktiv” gesetzt und damitumfangreiche Speicherfunktionen vermieden.
– Eine ganze Reihe von Verbesserungen adressieren die Problematik der Join-Operationen im Beta-Netz: In Umgebungen mit sehr großen Mengen imArbeitsspeicher können die Kreuzprodukte der Joins zu teuer werden. „Col-lection Rete” adressiert diese Problematik.[1]
In den heutigen Anwendungen kommt Rete quasi ausschließlich mit Erweite-rungen und Optimierungen zum Einsatz.
5 Rete und LP-Engine in Jena
Jena ist ein Open Source Java-Framework, um Applikationen für das SemanticWeb zu entwerfen. Es bietet Unterstützung für folgende Techniken:
– Das Ressource Description Framework (RDF) wurde zunächst als Metadaten-Model entworfen und wird heute auch als allgemeine Umgebung benutzt, umInformationen und Ressourcen für das WWW zu beschreiben. Es ist eineEmpfehlung des W3C4. Die genaue Definition was unter einer Ressourcezu verstehen ist, und was damit die Grundlage bildet, was durch RDFbeschrieben wird, ist in RFC 2396 definiert: „A resource can be anything thathas identity. Familiar examples include an electronic document, an image,
4 World Wide Web Consortium

44 T. Eisenbarth
a service (e.g., ’today’s weather report for Los Angeles’), and a collectionof other resources. Not all resources are network ’retrievable’; e.g., humanbeings, corporations, and bound books in a library can also be consideredresources” Diese Ressourcen werden durch Tripel der Form Subjekt-Prädikat-Objekt beschrieben. Das Subjekt ist dabei durch die Ressource festgelegt,das Prädikat und Objekt beschreiben dieses. Ein Beispiel: „Der Himmel hatdie Farbe blau.” Das Subjekt ist „Der Himmel”, Prädikat ist „hat die Farbe”und das Objekt ist „blau”.
– Ressource Description Framework Schema (RDFS) ist eine erweiterbareSprache, die grundlegende Elemente für die Beschreibung von Ontologien alsVokabular bietet. RDFS definiert das Vokabular für eine bestimmte Domäneund ist ebenfalls eine Empfehlung des W3C.
– OWL ist eine Sammlung von Spezifikationen des W3C, um Ontologiendurch eine formale Beschreibungssprache zu erstellen, um die automatisierteVerarbeitung der Daten möglich zu machen. OWL soll diese maschinelleBearbeitung besser unterstützen als XML, RDF, und RDFS.[2] OWL setztsich aus drei Unterklassen von Sprachen zusammen: OWL lite, OWL DL,and OWL Full5
– SPARQL ist eine RDF-Abfragesprache und ist rekursiv definiert als „SPARQLProtocol and RDF Query Language”. SPARQL wurde am 15.02.2008 nacheinem langen Prozess vom W3C standardisiert. Tim Berners-Lee, Direktor desW3C, sagte zur Veröffentlichung des Standards: „Trying to use the SemanticWeb without SPARQL is like trying to use a relational database withoutSQL”. Damit ist die Bedeutung sowie die Einordnung in die Zusammenhängedes Semantic Web als Abfragesprache klar. Das Projekt dppedia.org versuchtdie Inhalte von Wikipedia so zu strukturieren, dass sie mittels SPARQLabgefragt werden können. Derzeit sind Informationen zu 80000 Personen,293000 Orten, 62000 Musikalben und 36000 Filmen erfasst. Eine in SPARQLformulierte Anfrage an diese Datenbank sieht beispielsweise so aus:6
Listing 3.6. Anfrage an dbpedia.org1 PREFIX owl: <http ://www.w3.org /2002/07/ owl#>2 PREFIX xsd: <http ://www.w3.org /2001/ XMLSchema#>3 PREFIX rdfs: <http :// www.w3.org /2000/01/ rdf -schema#>4 PREFIX rdf: <http ://www.w3.org /1999/02/22 -rdf -syntax -ns#>5 PREFIX foaf: <http :// xmlns.com/foaf /0.1/ >6 PREFIX dc: <http :// purl.org/dc/elements /1.1/>7 PREFIX : <http :// dbpedia.org/resource/>8 PREFIX dbpedia2: <http :// dbpedia.org/property/>9 PREFIX dbpedia: <http :// dbpedia.org/>
10 PREFIX skos: <http :// www.w3.org /2004/02/ skos/core#>1112 SELECT ?name ?birth ?description ?person WHERE 13 ?person dbpedia2:birthPlace <http :// dbpedia.org/resource/Berlin > .14 ?person skos:subject15 <http :// dbpedia.org/resource/Category:German_musicians > .16 ?person dbpedia2:birth ?birth .17 ?person foaf:name ?name .
5 Eine ausführliche formelle Beschreibung findet sich in [11]6 Die Anfrage ist ein Beispiel des Projekts, zu finden unter http://wiki.dbpedia.org/-OnlineAccess?v=8hr

Reasoning: Rete (und Jena) 45
18 ?person rdfs:comment ?description .19 FILTER (LANG(? description) = 'de ') .20 21 ORDER BY ?name
Die einzelnen Bestandteile der Anfrage haben folgende Bedeutung:– PREFIX definiert Verkürzungen, damit der eigentliche Query übersichtli-cher bleibt. „owl” steht hier beispielsweise abgekürzt für die URL „http://-www.w3.org/2002/07/owl#”– Variablen werden durch ein vorangestelltes Fragezeichen definiert. DasErgebnis soll in diesem Beispiel also Name, Geburtsdatum, Beschreibung undPerson zurückgeben.– Mittels „birthPlace” und „subject” werden die Bedingungen zur Abfragedefiniert: Ich möchte hier also alle Musiker, die in Berlin geboren wurden alsErgebnis bekommen.– Durch den definierten „FILTER” werden nur diejenigen Resultate zurück-gegeben, die in deutscher Sprache vorliegen. Falls der Filter nicht gesetzt ist,werden auch Ergebnisse in allen anderen Sprachen zurückgegeben, die in derdbpedia hinterlegt sind.Jena wurde von den HP Labs entwickelt und enthält ein Subsystem für
Reasoner. Die Einordnung ist in Abbildung 5 zu sehen. In dieses Subsystem könnenKomponenten als Module integriert werden, um zusätzliche Fakten aus einerBasis zu generieren. Rete ist eine derartige spezielle Reasoner-Implementierung.
Abbildung 5. Aufbau der Inferenz-Komponente von Jena.[13]
5.1 Jena und ReteJena enthält einen allgemeinen Reasoner, der für OWL- und RDFS-Reasoning ge-eignet ist. Der Reasoner unterstützt die Bildung von Schlussfolgerungen, „Forward-” und „Backward-Chaining” und ein hybrides Verfahren, das in Abbildung 6veranschaulicht ist.
Das „Forward-Chaining” in Jena ist doppelt implementiert: Eine ältere Version,die nicht auf Rete basiert, kann in speziellen Umgebungen effizienter sein alsdie Rete-Version. Die Grundlage der zweiten Implementierung bildet der Rete-Algorithmus.

46 T. Eisenbarth
5.2 OWL-Reasoning in Jena
Wie wir in der Einfüehrung zu diesem Kapitel beschrieben haben unterstützt JenaOWL-Reasoning. Genauer bezieht sich die Unterstützung auf OWL/lite. Jenaliefert dazu drei verschiedene Konfigurationen aus: Eine Standard-Konfigurationund zwei kleinere, auf Performance optimierte Versionen. Allerdings ist keinedavon vollständig, was den Funktionsumfang betrifft. Es können jedoch externeReasoner wie Pellet, Racer or FaCT über den DIG-Standard eingebunden werden.7Diese bieten mitunter eine umfangreichere Unterstützung der OWL-Spezifikation.
Eine Einschränkung der OWL-Unterstützung in Jena basiert auf dem grund-legenden Aufbau der Reasoner in Jena. Die Reasoner sind als instanzbasierteSysteme umgesetzt: Sie verwenden Regeln um die „if-” und „only-if”- OWL-Konstrukte auf die Daten zu verbreiten.
Reasoning auf Klassen bedeutet in der Regel Klassenhierachien zu erkennenund auswerten zu können. Da Jena diese Anfragen indirekt löst, nämlich indemzwei prototypische Instanzen der beiden Klassen erstellt und ausgewertet werden,ist der von Jena gewählte Ansatz weniger mächtig als dies von DL-Systemen herbekannt ist. Es werden daher die Konstrukte complementOf und oneOf nichtunterstützt. Beide werden für die Bildung komplexer Klassen benutzt.
Jena ist daher eher für einfache, normale Ontologien geeignet.[13] Die aufPerformance optimierte Konfigurationen des OWL-Reasoners unterstützen dieOWL-Konstrukte „minCardinality” und „someValuesFrom” nicht. Ersteres prüftauf eine bestimmte untere Grenze der Kardinalität. Ein Beispiel veranschaulichtdies:
Listing 3.7. owl:minCardinality1 <owl:Class rdf:ID=" Vintage">2 <rdfs:subClassOf >3 <owl:Restriction >4 <owl:onProperty rdf:resource ="# hasVintageYear "/>5 <owl:cardinality6 rdf:datatype ="&xsd;nonNegativeInteger ">1</owl:cardinality >7 </owl:Restriction >8 </rdfs:subClassOf >9 </owl:Class >
7 DIG ist ein standardisiertes XML-Format, um Description Logic zu formulieren:http://dl.kr.org/dig/
Abbildung 6. Ablauf des Hybrid-Reasoners in Jena.

Reasoning: Rete (und Jena) 47
Die Restriktion legt fest, dass jeder Wein mindestens einen Jahrgang habenmuss. Das OWL-Konstrukt „someValuesFrom” dient ebenfalls der Festlegungvon Restriktionen:
Listing 3.8. owl:someValuesFrom1 <owl:Class rdf:ID="Wine">2 <rdfs:subClassOf rdf:resource ="& food;PotableLiquid" />3 <rdfs:subClassOf >4 <owl:Restriction >5 <owl:onProperty rdf:resource ="# hasMaker" />6 <owl:someValuesFrom rdf:resource ="# Winery" />7 </owl:Restriction >8 </rdfs:subClassOf >9 ...
10 </owl:Class >
Zumindest eines der „hasMaker”-Eigenschaften muss im vorgenannten Beispielauf eine „Winery” verweisen. Die kleinste Konfiguration des Reasoners wirdOWLMicro genannt. Diese Konfiguration kommt dem Funktionsumfang vonRFDS gleich, mit einigen hinzugefügten Axiomen:
– intersectionOf– unionOf– hasValue
OWLMicro erreicht die beschriebene hohe Performance durch das Auslassen derbeschriebenen Kardinalitätsbeschränkungen und Gleichheitsaxiome, und wägtdamit Performance gegen Funktionsumfang zugunsten ersterem ab.[13]
5.3 Tabling in Jena
Die Backward-Chaining-Engine in Jena unterstützt Tabling, was von der Funk-tion an die State-Saving-Optimierung in Rete erinnert: Wenn ein Ziel in dasTabling aufgenommen wird, werden alle bis dahin berechneten Treffer auf diesesZiel gespeichert. Diese Art Cache wird bei künftigen Abfragen benutzt, waszu Performance-Verbesserungen führt. In Jena können alle oder einzelne Zieleeiner Abfrage in diesen Cache eingefügt werden. Die Einträge im Cache lebenunendlich lange; es gibt keinerlei automatisierte Strategien zum Entfernen vonObjekten. Eine reset-Methode ermöglicht es, den Zwischenspeicher zu leeren. BeiHinzufügen oder Entfernen von Statements wird reset automatisch aufgerufenund der Speicher damit geleert. Sofern diese Änderung der Statements nicht odernicht häufig genug vorkommt, um die Speicherauslastung in Grenzen zu halten,muss manuell abgewägt werden, wann der Cache geleert wird.
Zusammengefasst lässt sicht feststellen, dass Jena ein weit entwickeltes Frame-work für ein breites Aufgabenspektrum im Semantic Web ist. Es vereint diverseFunktionen wie Forward- und Backward-Chaining und bietet dank seiner flexiblenArchitektur viele Schnittstellen und Möglichkeiten zur Erweiterung.

48 T. Eisenbarth
6 Zusammenfassung
Wie am Anfang der Arbeit angedeutet, findet Rete heute in vielen AnwendungenEinsatz: Zum Beispiel auch JBoss Rules, ein Open Source Produktionssystem,das auf Geschäftsprozesse und -anwendung ausgerichtet ist, und von Red Hatvertrieben wird. Rules verwendet eine abgewandelte Version von Rete mit demNamen ReteOO, angelehnt an die objektorientierte Optimierung. Ein Blick in dieRegelsprache von JBoss Rules lässt einen eindrucksvollen Schluss auf die Nähezum originalen Rete-Algorithmus zu:
Listing 3.9. Regeln aus JBoss Rules1 import rules.Good;2 import rules.Participant;3 import rules.Negotiation;45 rule "Validity -1"6 when7 Good(\ $good:name)8 Participant(participantName == "Susan",9 goodName == \$good)
10 then11 System.out.println (" Participant is interested in good:"12 +\$good );13 end
Charles Forgy hat mit seiner Arbeit am Rete-Algorithmus einen wichti-gen Grundstein für den heutigen Einsatz in Reasoning- und Pattern-Matching-Systemen und damit für das Semantic Web geschaffen. Die intensive Diskussionseiner Grundlagen in den Folgejahren haben weitere Verbesserungen nach sichgezogen und Rete im Laufe der Zeit zu einem funktionsreichen und hoch op-timierten Suchverfahren ausgebaut. Neben dem praktischen Einsatz in vielenSystemen ist Rete selbst nach über 20 Jahren nach den ersten wissenschaftlichenVeröffentlichungen immer noch ein direktes Forschungsthema, was die Tragweiteder Forschung von Forgy unterstreicht.[10, 17]
Literatur
[1] A. Acharya and M. Tambe. Collection oriented match. In CIKM ’93: Proceedingsof the second international conference on Information and knowledge management,pages 516–526, New York, NY, USA, 1993. ACM.
[2] A. Deborah L. McGuinness (Knowledge Systems Laboratory, Stanford University)Frank van Harmelen (Vrije Universiteit. Owl web ontology language overview, 022004. http://www.w3.org/TR/owl-features/, abgerufen am 16.02.2008.
[3] R. B. Doorenbos. Production matching for large learning systems. PhD thesis,Pittsburgh, PA, USA, 1995.
[4] D. J. R. Engine. Temporal rules. http://legacy.drools.codehaus.org/Temporal+Rules,abgerufen am 19.02.2008.
[5] C. L. Forgy. On the efficient implementation of production systems. PhD thesis,Pittsburgh, PA, USA, 1979.
[6] C. L. Forgy and S. J. Shepard. Rete: a fast match algorithm. AI Expert, 2(1):34–40,1987.

Reasoning: Rete (und Jena) 49
[7] A. Giurca. Some facts about the jboss rule engine, 01 2008.http://oxygen.informatik.tu-cottbus.de/RealRules/?q=node/44, abgerufenam 20.02.2008.
[8] A. Gupta, C. Forgy, A. Newell, and R. Wedig. Parallel algorithms and architecturesfor rule-based systems. In ISCA ’86: Proceedings of the 13th annual internationalsymposium on Computer architecture, pages 28–37, Los Alamitos, CA, USA, 1986.IEEE Computer Society Press.
[9] G. Ingargiola. Cis587:the rete algorith. http://www.cis.temple.edu/ ingargio/-cis587/readings/rete.html, abgerufen am 10.12.2007.
[10] Z. M. K. Mastura Hanafiah. Using rule-based technique in developing the tool forfinding suitable software methodology. Annals of Dentistry (ISSN 0128-7532), 20,No 2, 2007.
[11] F. U. A. Mike Dean, BBN Technologies Guus Schreiber. Owl web ontology languagereference, 02 2004. http://www.w3.org/TR/owl-ref/, abgerufen am 15.02.2008.
[12] I. Red Hat. Jboss rules, 04 2007. http://www.jboss.com/pdf/jboss_rules_fact_sheet_04_07.pdf,abgerufen am 14.02.2008.
[13] D. Reynolds. Jena 2 inference support, 12 2007.http://jena.sourceforge.net/inference/, abgerufen am 12.02.2008.
[14] B. Schneier. The rete matching algorithm, 12 2002.http://www.ddj.com/184405218, abgerufen am 13.12.2007.
[15] D. Selmann. Ilog brms blog, 01 2008. http://blogs.ilog.com/brms/category/jrules/jrulesperformance/,abgerufen am 14.02.2008.
[16] I. The Haley Enterprise, 2001. http://www.haley.com/members/pdf/ReasoningAboutRete++.pdf,abgerufen am 14.02.2008, Registrierung notwendig.
[17] K. Walzer, A. Schill, and A. Löser. Temporal constraints for rule-based eventprocessing. In PIKM ’07: Proceedings of the ACM first Ph.D. workshop in CIKM,pages 93–100, New York, NY, USA, 2007. ACM.
[18] B. Wilson. The ai dictionary, 04 2007. http://www.cse.unsw.edu.au/ billw/ai-dict.html, abgerufen am 14.02.2008.

Reasoning auf Datalog-Basis (KAON2)
Stephanie Siekmann
Universität [email protected]
Zusammenfassung Viele moderne Inferenzsysteme sind auf das Reaso-ning über großen TBoxen optimiert. Jedoch gibt es viele Anwendungen,darunter auch das Datenmanagement im Semantic Web, die nicht haupt-sächlich auf der Überprüfung der Erfüllbarkeit von Konzepten beruhen,sondern auf der Anfragebearbeitung, also der Instanzüberprüfung ingroßen ABoxen. In dieser Arbeit wird ein Reasoningalgorithmus vorge-stellt, der sich dieser Problematik annimmt. Eine SHIQ(D) Wissensbasiswird über fünf Transformationsschritte auf ein disjunktes Datalog Pro-gramm reduziert. Durch diese Transformation ist es möglich, Technikenzur Optimierung der Anfragebearbeitung aus der Datenbankentwicklungauf das Reasoningproblem zu übertragen und so die Performance, geradegegenüber den Tableaux-basierten Konkurrenten, zu verbessern.
1 Einleitung
Im World Wide Web können Fakten zwischen unterschiedlichen Anwendungenausgetauscht und in lesbarer Form aufbereitet werden. Mit dem Aufkommender Web Services wurde dieser Umgang mit Information schon wesentlich er-leichtert, jedoch blieben es weiterhin pure Fakten ohne inhärente Bedeutung.Die Grundidee des Semantic Web ist es, die Fakten mit ihrer Bedeutung zuassoziieren. Hierfür müssen die im Web enthaltene Informationen so formalisiertwerden, dass sie algorithmisch verarbeitet werden können, sie sind also in einermaschinenlesbaren Form festzuhalten.Um dieses Wissen letztendlich auch sinnvoll nutzen zu können, ist das Reasoningeine unverzichtbare Grundlage des Semantic Web. Reasoning bezeichnet dasZiehen von vernünftigen, nachvollziehbaren Schlüssen aus vorhandenem Wissen.Es simuliert im wesentlichen den gesunden Menschenverstand, also das Verstehenund Nutzen der Bedeutung von Fakten. [14]Diese Seminararbeit beschreibt eingangs die Grundlagen der Wissensrepräsen-tation im Semantic Web und zeigt dann die Aufgaben und Bedeutung desReasonings auf. Im Hauptteil wird das Resolutions-basierte ReasoningsystemKAON2 detailliert vorgestellt. Nach einem Einblick in die Historie und die tech-nische Architektur des Systems werden die einzelnen Transformationsschrittedes Reduktionsalgorithmus beschrieben, der eine SHIQ Wissensbasis in eindisjuntives Datalog Programm übersetzt. Im Anschluss daran wird näher auf diemöglichen Techniken zur Optimierung der Anfragebearbeitung auf einer solchenDatenbank eingegangen. Eine Performanceuntersuchung des KAON Algorithmus

Reasoning auf Datalog-Basis (KAON2) 51
schliesst die Arbeit ab. Im Folgenden wird vorausgesetzt, dass der Leser mit denGrundlagen von Ontologien in der Informatik, sowie den Sprachen des SemanticWeb, wie RDF, vertraut ist.
2 Grundlagen des Reasoning
2.1 Wissensrepräsentation im Semantic Web
Die Hauptaufgabe (vgl. 2.2.1) eines Reasoningsystems, auch Inferenzsystem ge-nannt, besteht darin, neues Wissen aus Vorhandenem abzuleiten. Dieser Vorgangwird auch als Schlussfolgern bezeichnet. Aus einer Anzahl von Fakten, den Prä-missen, wird ein neues Faktum, die Konklusion, abgeleitet. Um das Schlussfolgernim Semantic Web zu realisieren muss zunächst das vorhandene Wissen durchsogenannte Wissensrepräsentationssprachen maschinenlesbar formalisiert werden.Reales Wissen wird also in ein formales Modell überführt, das sogenannte Domä-nenmodell. [3]Ein Inferenzsystem verwendet Inferenzregeln zum Ableiten neuen Wissens. DieseRegeln sind Bestandteil eines sogenannten Kalküls, welches die zugrundeliegendenMöglichkeiten zur Manipulation von Formeln genau beschreibt.Die Möglichkeiten eines Inferenzmechanismus hängen stark von der Mächtigkeitder Repräsentationssprache ab. Je ausdrucksstärker die sprachlichen Konstruktesind, desto aufwändiger ist das Schlussfolgern. Eine wichtige Rolle spielt in diesemZusammenhang der Begriff der Entscheidbarkeit1. Das Entscheidbarkeitsproblemeiner Logik tritt in zwei Formen auf. Zum einen als Gültigkeitsproblem in derFrage ob eine gegebene Formel allgemeingültig ist. Zum anderen als Erfüllbar-keitsproblem. Es stellt sich die Frage ob für eine formulierte Semantik überhaupteine Belegung gefunden werden kann, die korrekt und vollständig ist, so dass dasSystem also nur gültige Schlüsse zieht, und für jede Aussage in endlicher Zeitfeststellen kann, ob sie richtig oder falsch ist. Im Folgenden wird deutlich werden,dass man bei der Auswahl der Wissensrepräsentationssprache stets den Spagatzwischen einer möglichst ausdrucksstarken Logik und einer noch handhabbarenKomplexität des Inferenzmechanismus bewältigen muss. [14]
2.1.1 Prädikatenlogik Die Prädikatenlogik stellt eine Erweiterung der Aus-sagenlogik dar. Syntaktisch werden Terme mittels Variablen, Konstanten undFunktionssymbolen, sowie den aus der Aussagenlogik üblichen Junktoren (¬,∧,∨,→,↔) gebildet. Über Relationssymbole stellt man Aussagen über die Beziehungdieser Terme zueinander dar, man formt sog. Atome. Um das volle Potentialder Prädikatenlogik auszuschöpfen kann man noch Quantoren (∃,∀) auf Atomeanwenden um mit solchen sogenannten Formeln die Eigenschaften ganzer Ob-jektmengen zu beschreiben.Bekannte Kalküle für die Prädikatenlogik sind der Hilbertkalkül, der Baumkalkül1 Das klassische Entscheidungsproblem wurde zu Beginn dieses Jahrhundert von Hilbertformuliert. Es war Teil seines formalen Programms zur Lösung der Grundlagenpro-bleme der Mathematik.

52 S. Siekmann
und der Resolutionskalkül. Mit letzterem kann über einen Widerspruchsbeweisgeprüft werden ob eine Formel aus einer Wissensbasis abgeleitet werden kann.Dieses Prinzip wird im Rahmen des KAON2-Reduktionsalgorithmus (vgl. Kapitel3) große Bedeutung erhalten.Die Prädikatenlogik der 1. Stufe, First Order Logic (FOL), ist in seiner klassichenForm sehr ausdrucksstark und daher nur semi-entscheidbar. Das bedeutet, dassman zwar alle wahren Schlüsse in endlicher Zeit finden kann, der Algorithmusaber nicht zwingend terminiert wenn man einen falschen Schluss widerlegen möch-te. Des Weiteren darf die zugrundeliegende Wissensbasis keine Widersprücheenthalten um aus ihr neues Wissen ableiten zu können. [3]
2.1.2 Beschreibungslogik Den Kompromiss zwischen der ausdrucksstarkenPrädikatenlogik der 1. Stufe und der effizienten Inferenz auf der andere Seite stelltdie sog. Beschreibungslogik, engl. description logic (DL), dar. Im Unterschied zurPrädikatenlogik ist sie entscheidbar. Für das Finden aller wahren sowie falschenSchlüsse gibt es also stets ein terminierendes Reasoning-System. DLs erlaubendie Spezifikation von Hierarchien unter Verwendung einer eingeschränkten Mengevon FOL-Formeln. [1]
Abbildung 1. DL-Nomenklatur [2]
ALC (Attributive Language incl. Complement) ist die kleinste, aussagenlogischabgeschlossene Beschreibungslogik. Grundbausteine sind Klassen, auch als Kon-zepte bezeichnet, Rollen, die Attribute bzw. Beziehungen der Klassen beschreiben

Reasoning auf Datalog-Basis (KAON2) 53
und Individuen, also einzelne Instanzen der Klassen. Verfügbare Konstruktorensind Konjunktion, Disjunktion und Negation (u,t,¬), die Quantoren schrän-ken Rollenbereiche ein (∃,∀). Erweiterungen von ALC erlauben zusätzlich dieKardinalitätenrestriktion von Rollen:
– N : Kardinalitäten von Rollen („number restrictions“)– Q: Qualifizierte Rollenbeschränkungen– F : Beschränkung der Kardinalitäten auf 0, 1 oder „beliebig“
DL Nomenklatur Eine Übersicht über mögliche Erweiterungen von ALC findensich in Abbildung 1:Durch die Abbildungsfunktion π sind alle ALC-Aussagen in die Prädikatenlogikübersetzbar, wodurch alle semantischen und logischen Konsequenzen nachvoll-ziehbar werden.
2.1.3 Aufbau der Wissensbasis Franz Baader [1] gibt folgende Defintionfür die Wissensbasis einer Beschreibungslogik:
Description Logics (DL) is the most recent name for a family of know-ledge representation formalisms that represent the knowledge of anapplication domain (the world) by first defining the relevant conceptsof the domain (its terminology), and then using these concepts tospecify properties of objects and individuals occuring in the domain(the world description).
Abbildung 2. Architektur der Wissensbasis

54 S. Siekmann
Die Wissensbasis K = (T,A) unterteilt sich in die T-Box und die A-Box,wie in Abbildung 2 zu sehen ist. Die T-Box enthält das terminologische Wissen,also allgemeingültige Aussagen über Klassen und Rollen, die die Struktur derzu modellierenden Domäne beschreiben. Das assertionale Wissen findet sich inder A-Box, deren Axiome Auskunft über die aktuelle Sitation geben, also denZustand konkreter Instanzen von Klassen beschreiben.
2.1.4 OWL, die Web Ontology Language Aufgrund verschiedener Ansprü-che an Komplexität und Entscheidbarkeit wurden die vom W3C2 spezifiziertenOntologiesprachen modular entworfen. Auf Basis der Beschreibungslogik entstan-den drei Abstufung von OWL, der Web Ontology Language.
Abbildung 3. OWL Varianten [12]
OWL Lite baut syntaktisch auf der RDFS3-Syntax auf, schränkt aber die er-laubte Nutzung und damit die Semantik ein um entscheidbar zu bleiben. DieAusdruckskraft von OWL Lite entspricht der Beschreibungslogik SHIF(D), einerAbschwächung von SHIQ(D), da nur die Kardinalitäten 0, 1 und „beliebig“ er-laubt sind. Reasoning auf einer OWL Lite Wissensbasis ist in ExpTime4 möglich.[14] [5]
OWL DL erhält die Nutzungseinschränkungen von OWL Lite aufrecht und bietetweitergehende Modellierungskonstrukte. OWL DL bietet eine maximale Auswahl2 World Wide Web Consortium - http://www.w3.org/3 RDFS steht für Ressource Description Framework Schema (RDF-Schema) und isteine Auszeichnungssprache die es erlaubt, eine Grammatik sowie Ontologien fürRDF-Aussagen festzulegen und RDF um weitere, komplexe Metadaten zu ergänzen.
4 P ⊆ NP ⊆ PSpace ⊆ ExpTime ⊆ NExpTime

Reasoning auf Datalog-Basis (KAON2) 55
an Konstrukten, die noch entscheidbar ist und NExpTime für das Reasoningbenötigt. OWL DL entspricht der Beschreibungslogik SHOIQ(D). [14] [5]
OWL Full stellt die mächtigste Ausführung von OWL dar. Sämtliche existierendenSprachkonstrukte werden unterstützt womit die volle RDF-Kompatibilität sicher-gestellt ist. OWL Full ist nicht entscheidbar und auch nicht in die Prädikatenlogikübersetzbar. [14] [5]
Abbildung 4. Komplexitätsvergleich [5]
2.1.5 SHIQ Da der KAON2 Algorithmus auf einer Wissensbasis arbeitet,die mittels SHIQ ausgedrückt ist, wird die Syntax und die Semantik dieserBeschreibungslogik an dieser Stelle kurz formal beschrieben. Im Folgenden wirdangenommen, dass A,B Konzeptnamen, a, b Namen von Instanzen und R,Sabstrakte Rollen sind. Eine SHIQ Wissensbasis, kurz SHIQ(KB), besteht ausdrei endlichen Sets aus Axiomen, der RBox, der TBox und der ABox. DerAusdruck |KB| bezeichnet die Größe der Wissensbasis. [8] [9] Eine SHIQ RBox,KBR, kann Axiome der Form S v R enthalten, sofern auch Inv(R) v Inv(S)5
vorkommen. Ebenso können Transitivitätsaxiome Trans(R) in der RBox stehen,wenn diese auch Trans(Inv(R)) enthält. Man bezeichnet eine Rolle R als einfach,wenn von ihr keine transitive Subrolle in KBR vorhanden ist, wenn also formalgilt S v∗ R6 und Trans(S) /∈ KBR. Nichteinfache Rollen werden auch alskomplex bezeichnet. [9] Eine SHIQ TBox, KBT , ist eine endliche Menge vonKonzeptinklusionsaxiomen der Form C v D, wobei C und D Konzeptausdrückesind, die aus Konzeptnamen mittels bekannter Operatoren (vergleiche Abbildung5) gebildet werden. [9] Eine SHIQ ABox, KBA, enthält Axiome der FormA(a),¬A(a), R(a, b),¬S(a, b), a ≈ b und a 6≈ b, wobei S eine einfache Rolle ist.Zu beachten ist, dass negierte Aussagen über einfache Rollen erlaubt sind. EineSHIQ(KB) definiert sich also über ein Tripel (KBR,KBT ,KBA). Die Semantikwird durch Übersetzung in die First Order Logic sichtbar. [9]5 Inv(R) = R−1 also die Inverse von R6 v∗ ist die reflexiv-transitive Ableitung von v

56 S. Siekmann
Abbildung 5. Syntaxvergleich
Die Logik SHIQ− erhält man aus SHIQ indem man Kardinalitätenrestrik-tionen bei einfachen Rollen weiter einschränkt: ≤ n.S.C und ≥ n.S.C DurchVerbot der Transitivitätsaxiome Trans(R) in den RBoxen erhält man die weitereingeschränkte Logik ALCHIQ−, die während des 1. Transformationsschritt3.4.1im Reduktionsalgorithmus von KAON2 relevant wird.
2.2 Reasoning im Semantic Web
2.2.1 Aufgaben der Reasoner Inferenzsysteme unterstützen das SemanticWeb sowohl beim Designen von Ontologien als auch bei der Wissensgewinnung,indem sie implizites Wissen explizit machen. Inferenz wird mittels Subsumption,Klassifikation und Konsistenzüberprüfung realisiert. [3]Bei der Subsumption stellt man sich die Frage welches Konzept Subkonzept einesanderen ist. Ein Konzept A subsumiert ein Konzept B wenn B Teilmenge vonA ist. Das bedeutet, dass B spezieller ist als A. Mit diesem Wissen ist eineEinordnung neuer Konzepte in eine sogenannte Subsumptionshierarchie möglich.Die Klassifikation übernimmt die Eingliederung von neuen Konzepten in einebestehende Ontologie. Man bestimmt für eine Instanz, zu welchem Konzept siegehört. Klassifikation kann durch Subsumption realisiert werden.
2.2.2 Anforderungen an die Reasoner Zur Erfüllung oben genannter Auf-gaben werden an die Reasoner besondere Anforderungen gestellt:

Reasoning auf Datalog-Basis (KAON2) 57
– Korrektheit: Gültigkeit aller vom Reasoner abgeleiteten Aussagen– Vollständigkeit: Finden sämtlicher Konzepte, im Rahmen der Klassifikation,
zu denen eine Instanz zugeordnet ist– Entscheidbarkeit: Entscheidung über die Gültigkeit einer Aussage in endlicher
Zeit– Effizienz: Möglichst effiziente Bearbeitung einer Anfrage
Weitere spezielle Anforderungen lassen sich aufgrund der Eigenschaften desSemantic Web ableiten [3]:– Skalierbarkeit: Das Semantic Web wächst ständig an. Reasoner müssen auch
mit einer sich rasant vergrößernden Wissensbasis umgehen können.– Adaptive Performance: Reasoner müssen mit der hohen Dynamik des Seman-
tic Web umgehen können. Neues Wissen kommt hinzu, anderes verschwindetwieder, das Semantic Web ändert sich permanent.
– Robustheit: Inkonsistenzen wie widersprüchliche Formeln, Ausnahmen odersemantische „broken links“ kommen im WWW sehr häufig vor. Diese dürfendie Funktionsfähigkeit des Inferenzsystems nicht beeinträchtigen.
– Integration verteilten Wissens: Ontologien können eine Vielzahl weitererOntologien, die im gesamten Semantic Web verteilt sind, einbinden. Wissenmuss durch die Reasoner also homogen und konsistent über verschiedeneStandards integriert werden können.
– Verständlichkeit: Da das Semantic Web vor allem normale Nutzer ansprechensoll, ist es entscheident, dass Reasoner einfach und intuitiv bedienbar bleiben.
Viele dieser Anforderungen konkurrieren miteinander, man muss also zwischenihnen abwägen.
3 KAON2
3.1 Historie
Die Bezeichnung KAON steht für „KArlsruhe ONtology and Semantic Web ToolSuite“. Dieses Projekt wurde seit Beginn 2001 an dem Forschungszentrum fürInformatik (FZI) Karlsruhe und dem Institut für angewandte Informatik undformale Beschreibungsverfahren (AIFB) der Universität Karlsruhe entwickelt. Dieerste Version erschien im Jahr 2002 und wurde als Open-Source InfrastructureTool Suite zur Erstellung und Verwaltung von Ontologien veröffentlicht. AufBasis dieses Systems wird nun seit 2005 der Nachfolger KAON2 entwickelt. Dembisherigen Entwickler- und Forschungsteam hat sich die Information ManagementGroup (IMG) der Universität von Manchester angeschlossen, zudem wird dasProjekt teilweise durch die EU7 finanziert. Im Gegensatz zur KAON Toolsuite istKAON2 keine Open Source Software mehr, sondern wird durch die KarlsruherFirma Ontoprise GmbH vertrieben. Eine Nutzung für Forschung und Lehreist allerdings weiterhin kostenlos möglich. Im Gegensatz zu KAON, das alsOntologiesprache RDF(S) verwendet, basiert KAON2 auf OWL-DL. Die beidenSysteme sind also nicht kompatibel. [12]7 EU IST Project DIP 50483

58 S. Siekmann
3.2 Architektur
Abbildung 6. KAON2 Architektur [16]
KAON2 ist ein DL-Reasoner, der SHIQ Wissensbasen bearbeiten kann. DasSystem unterstützt Aufgaben wie die Berechnung der Entscheidbarkeit einerWissensbasis, die Erfüllbarkeit von Konzepten, die Berechnung der Subsumptions-hierarchie und die Bearbeitung von Anfragen, dem sogennanten Query Answering.Abbildung 6 beschreibt den technischen Aufbau der KAON2 Architektur. DieOntology API stellt Dienste zur Manipulation der Ontologie, wie das Hinzufügenvon Axiomen, zur Verfügung. OWL und SWRL8 werden syntaktisch vollständigunterstützt. Definiert von der Description Logic Implementation Group stellt dasDIG Interface ein, von der Programmiersprache des Anwenders unabhängigesInterface dar. Es beinhaltet ein XML Schema für Beschreibungssprachen sowieHTTP als Transferprotokoll. Die Resoning API ermöglicht das Ausführen meh-rerer Reasoning-Tasks. Die zentrale Komponente von KAON2 ist die ReasoningEngine welche auf dem Algorithmus zur Reduktion einer SHIQ Wissensbasiszu einem disjunkten Datalog Programm basiert. Eine detaillierte Beschreibungzu den technischen Aufgaben der einzelnen Subkomponenten finden sich inden Ausführung zu den entsprechenden Transformationsschritten in Abschnitt3.4. Die Ontology Clausification Komponente übernimmt die Übersetzung derTBox einer SHIQ(KB) in ein Set von FOL-Klauseln (Schritt II). Das BasicSuperposition Kalkül zur Saturierung dieser Klauseln ist im Theorem Proverimplementiert (Schritt III). Auch die Elimination der Funktionssymbole (SchrittIV) und die Übersetzung der Klauseln in disjunkte Regeln (Schritt V) findet hierstatt. Die eigentliche Anfragebearbeitung auf der disjunkten Datenbank findet inder Disjunctive Datalog Engine statt. [16] [15]8 Semantic Web Rule Language

Reasoning auf Datalog-Basis (KAON2) 59
3.3 Inferenzmechanismus
Abbildung 7. KAON2 Inferenzmechanismus [11]
Obwohl die Anfragebearbeitung auf A-Boxen im Semantic Web einen enormhohen Stellenwert einnehmen arbeiten viele existierende Inferenzsysteme aufihnen sehr ineffizient. [7] Für die Praxis ist das ABox-Reasoning, also die In-stanzgenerierung, weit wichtiger als das TBox-Reasoning. ResolutionsbasierteVerfahren eignen sich erfahrungsgemäß hervorragend für die Generierung neuer In-stanzen. [11] Das Hauptproblem ist, dass ein Reasoner in der Regel jede möglicheAntwort (a1 . . . an) auf eine Anfrage betrachten muss und zudem für jede Aussagezu überprüfen hat, ob die Negation ¬Q(a1 . . . an) zu einem Widerspruch führt.Dies is offensichtlich sehr ineffizient. Naive Versuche solche Resolutionsbeweiserfür First Order Logiken anzuwenden schlagen fehl. Grund ist, dass die Transfor-mation der gegebenen Wissensbasis in FOL-Klauseln Existenzquantoren erzeugt,die in Funktionssymbolen skolemisiert werden müssen. Die Terminierung einessolchen Algorithmus ist nicht erzwingbar. [4] KAON2 behilft sich der Annahme,dass eine endliche Menge neuer, durch Existenzquantoren erzeugter, Individuenfür das Ziehen aller relevanten Konsequenzen ausreicht.Zunächst wird nur die TBox behandelt. Eine endliche Menge logischer Kon-sequenzen wird aus der Wissensbasis abgeleitet und in ein disjunktes DatalogProgramm transformiert. Konkret wird der Inhalt der TBox mittels des KAON2Reduktionsalgorithmus in funktionsfreie Klauseln transformiert, die anschliessendin eine disjunkte Datenbank geschrieben werden. Eine detaillierte Beschreibungdieses Vorgangs folgt in Kapitel 3.4. Anschliessend wird die ABox dem disjunkti-ven Datalog Programm hinzugefügt. Das eigentliche Query-Answering wird ineinem Konsistenzcheck umgewandelt und mittels standardisierter Methoden fürfunktionsfreie Klauseln auf diesem Datalog Programm ausgeführt. [7] Abbildung7 verdeutlicht diese Zusammenhänge grafisch.

60 S. Siekmann
3.4 Transformationsalgorithmus
Abbildung 8. KAON2 Transformation [6]
In der Welt der deduktiven Datenbanken wurde die optimale Handhabunggroßer Datenmengen bereits intensiv erforscht. Es existieren effiziente queryanswering - Algorithmen. Zudem wurde eine Reihe von hochentwickelten Opti-mierungstechniken wie die join-order optimization (Berücksichtigung von Daten-sets mit Gemeinsamkeiten) und magic-sets (Ignorieren irrelevanter Elemente)erforscht. Auf diese Techniken wird im Rahmen dieser Arbeit in einem eigenenKapitel zur Optimierung 3.5 näher eingegangen.Die Idee der KAON Entwickler war es, sich diese Entwicklungen aus dem Da-tenbankmanagement zu Nutze zu machen. Ziel des KAON2 Verfahrens ist es,die Anfragebearbeitung in OWL durch Wiederverwendung einer disjunktivenDatenbank zu realisieren. Die Wissensbasis eines DL-Systems kann auf eineDatenbank abgebildet werden, da diese dieselbe Grundstruktur beinhalten. Diein einer DL beschriebenen Wissensbasis muss also in eine Datenbank überführtwerden, um eine effiziente Abfragebearbeitung durchzuführen. [8]Der Input des KAON2 Transformationsalgorithmus ist eine SHIQ KnowledgeBase SHIQ(KB), der Output ein disjunktes Datalog Programm DD(KB). DieTranformation findet in 5 Schritten statt:
3.4.1 Elimination der Transitivitätsaxiome Die Wissensbasis liegt zu die-sem Zeitpunkt in SHIQ vor. Wie in Kapitel 2.1 beschrieben, ist diese Logiknoch zu ausdrucksstark um damit Berechnung durchführen zu können. Tran-sitive Rollen stellen ein Problem für die Entscheidung über die Erfüllbarkeit

Reasoning auf Datalog-Basis (KAON2) 61
einer Wissensbasis dar, da sie in ihrer Klauselform keine sog. covering lite-rals9 enthalten. Die Terminierung des Algorithmus wird durch sie gefährdet. [4]Man überführt die Wissenbasis SHIQ(KB) im 1. Schritt der Transformationdurch das Entfernen der transitiven Rollen in eine vollständige vergleichbare inALCHIQ Wissensbasis Ω(KB). [8] Im Folgenden steht das Kürzel NNF (C) fürdie Negations-Normalform eines Konzepts C.
1. Berechnung des sog. concept closure, das kleinstmögliche Set aller relevantenKlauseln. Relevant bedeutet in diesem Zusammenhang, dass alle im Setenthaltenen Klauseln folgende Bedingungen erfüllen:
– Falls C v D ∈ KBT , dann NNF (¬C tD) ∈ clos(KB)– Falls C ≡ D ∈ KBT , dann NNF (¬C tD) ∈ clos(KB) und NNF (¬DtC) ∈ clos(KB)
– Falls C(a) ∈ KBA, dann NNF (C) ∈ clos(KB)– Falls C ∈ clos(KB) und D ein Subkonzept von C ist, dann D ∈ clos(KB)– Falls ≤ nR.C ∈ clos(KB), dann NNF (¬C) ∈ clos(KB)– Falls ∀R.C ∈ clos(KB), S v∗ R, und Trans(S) ∈ KBR, dann ∀S.C ∈clos(KB)
2. Abgleichen der RBox durch Entfernen aller transitiven Axiome:
Ω(KB)R erhält man durch Entfernen aller Trans(R) aus KBR
3. Abgleichen der TBox, indem für jedes Konzept das in clos(KB) enthaltenist ein neues Inklusionsaxiom, das die Transitivität kodiert, eingefügt wird:
Ω(KB)T erhält man durch Hinzufügen eines neuen Inklusionsaxioms∀R.C v ∀S.(∀S.C) für jedes Konzept ∀R.C ∈ clos(KB) und Rolle S, für die
gilt S v∗ R und Trans(S) ∈ KBR
4. Bewahren der initialen ABox:
Ω(KB)A = KBA
Der formale Beweis dafür, dass Ω(KB) vollständig vergleichbar zur ursprüng-lichen Wissensbasis SHIQ(KB) ist und somit gilt, dass wenn SHIQ(KB)entscheidbar ist dies auch für die Wissensbasis nach der Transformation gilt,findet man bei Hustadt, Motik und Sattler (2006)[15].
3.4.2 Überführung in die Klauselnormalform Im zweiten Schritt derTransformation wird die ALCHIQ Wissensbasis in FOL-Klauseln übersetzt. Dieerste Idee hierzu wäre eine direkte Klausalisierung mittels des Mappingoperatorsπ, siehe Tabelle 1, und anschliessender Skolemisierung dieser Klauseln. DieserAnsatz bringt jedoch zwei wesentliche Nachteile mit sich. Zum Einen bestehtdie Gefahr des exponentiellen Wachstums der Wissensbasis aufgrund verschach-telter t und u Verknüpfungen. Des Weiteren kann durch das direkte Mappingdie syntaktische Struktur der Ausgangsdaten zerstört werden, was es schwierig

62 S. Siekmann
Übersetzung von Konzepten in FOLπy(A,X) = A(X)
πy(C uD,X) = πy(C,X) ∧ πy(D,X)πy(¬C,X) = ¬πy(C,X)
πy(∀R.C,X) = ∀y : R(X, y)→ πy(C, y)πy(≥ nS.C,X) = ∃y1, ..., yn :
∧S(X, yi ∧
∧πx(C, yi) ∧
∧yi 6≈ yj
Übersetzung von Axiomen in FOLπ(C v D) = ∀x : πy(C, x)→ πy(D,x)π(R v S) = ∀x, y : R(x, y)→ S(x, y)
π(Trans(R)) = ∀x, y, z : R(x, y) ∧R(y, z)→ R(x, z)π(C(a)) = πy(C, a)
π(R(a, b)) = R(a, b)π(a b) = a b für ∈ ≈, 6≈
Übersetzung der Wissensbasis in FOLπ(R) = ∀x, y : R(x, y)↔ R−(y, x)
π(KB) =∧R∈NR
π(R) ∧∧α∈T∪R∪A π(α)
Tabelle 1. Mapping zu FOL [8]
wenn nicht gar unmöglich macht ein Entscheidungsverfahren für die Klauselnzu finden. [4] Um diese Datenexplosion zu verhindern und die Struktur währendder Prozedur zu erhalten führt man eine sogenannte strukturelle Transformationdurch, auch als Renaming nach Nonnengart und Weidenbach (2001) bekannt.Grob gesagt führt die strukturelle Transformation einen neuen Namen für jedekomplexe Unterformel in π(Ω(KB)) ein. So ersetzt man z.B. ∃P.A v ∀Q.B durcheinen einfacheren Ausdruck ∃P.A v N1 , N2 v ∀Q.B , N11 v N2. Anschliessendführt man auf diesem Datenset eine direkte Klausifikation durch. [6]Ergebnis dieses sogenannten Preprocessing ist ein äquivalentes Klauselset Ξ(KB),dessen enthaltene Klauseln sich in eine der acht folgenden syntaktischen Katego-rien, vergleiche Tabelle 2, einordnen lassen. [9] Für einen Term t bezeichnet P (t)eine Disjunktion der Form (¬)P1(t) ∨ ... ∨ (¬)Pn(t), und P (F (x)) eine Disjunk-tion der Form P1(f1(x)) ∨ ... ∨ Pn(fm(x)). Diese Eigenschaft wird man sich imnachfolgenden Transformationsschritt zu Nutze machen.
3.4.3 Saturieren der Klauseln mittels Basic Superposition Im zentra-len Schritt des Algorithmus saturiert man die Klauseln der R- und der T-Boxmittels eines Resolutionsbasierten Verfahren nach Bachmair, Nieuwenhuis undRobo (1995), dem sogenannten Basic Superposition Kalküls. Die aus der ursprüng-lichen Wissensbasis ableitbare Klauseln, die Inferenzen, werden mit Hilfe derInferenzregeln des Kalküls berechnet. [8] Aus Platzgründen wird auf die Grund-lagen der Resolution hier nicht detailliert eingegangen, sie werden im Folgendenals bekannt vorausgesetzt. Das Kalkül benötigt zwei Parameter. Zum Einen einelexikographische Hierarchie, induziert durch eine Rangordnung >P über allen9 Literale, die alle Variablen einer Klausel enthalten

Reasoning auf Datalog-Basis (KAON2) 63
Klausel-Typen(1) ¬R(x, y) ∨ Inv(R)(y, x)(2) ¬R(x, y) ∨ S(x, y)(3) P f (x) ∨ (R(x), f(x))(4) P f (x) ∨R(f(x), x))(5) P1(x) ∨ P2(f(x)) ∨
∨fi(x) ≈ / 6≈ fi(x)
(6) P1(x) ∨ P2(g(x)) ∨ P3(f(y(x))) ∨∨ti ≈ / 6≈ tj ,
wobei ti und tj in der Form f(g(x)) oder x sind.(7) P1(x) ∨
∨¬R(x, yi) ∨ P2(y) ∨
∨yi ≈ yj
(8) R(a, b) ∨ P (t) ∨∨ti ≈ / 6≈ tj ,
wobei t(i) eine Konstante b oder ein funktionaler Term fi(a) ist.Tabelle 2. ALCHIQ Klausel Typen
Funktionen, Konstanten und Prädikaten der Formeln: f >p c >p p >p ⊥Der zweite Parameter des Kalküls ist eine Entscheidungsfunktion f , die eigen-mächtig ein Set negativer Literale aus jeder Klausel wählt.Die Saturation mittels Basis Superposition ist, wie die Resolution, ein Wider-spruchsverfahren. Wird eine Menge von Schlussfolgerungen bis zur Redundanzerfüllt, sind also alle Inferenzen in N redundant, so ist N unentscheidbar wenn,und nur genau dann wenn, sie die leere Schlussfolgerung enthalten. [15] Die 5Inferenzregeln des Kalküls werden im Folgenden vorgestellt:
1. Positive Superposition
(C ∨ s ≈ t) · ρ (D ∨ w ≈ v) · ρ(C ∨D ∨ w[t]p ≈ v) · θ
wobei σ = MGU(sρ, wρ∣∣ρ) und θ = ρσ(+Nebenbedingungen)
Wählen gleicher Terme um sie in anderen Termen zu ersetzten. Entfernendes entsprechenden Äquivalenzaxioms nach der Vereinigung.
2. Negative Superposition
(C ∨ s ≈ t) · ρ (D ∨ w 6≈ v) · ρ(C ∨D ∨ w[t]p 6≈ v) · θ
wobei σ = MGU(sρ, wρ∣∣ρ) und θ = ρσ(+Nebenbedingungen)
Selbes Vorgehen wie bei der positiven Superposition, nur mit ungleichenAxiomen.
3. Relexive Superposition
(C ∨ s 6≈ t) · ρ(C · θ
wobei σ = MGU(sρ, tρ) und θ = ρσ(+Nebenbedingungen)

64 S. Siekmann
Äquivalenzprädikate werden mit dem Ergebnis ihrer Vereinigung ersetzt.
4. Equality Factoring
(C ∨ s ≈ t ∨ s′ ≈ t′) · ρ(C ∨ t 6≈ t′ ∨ s′ ≈ t′) · θ
wobei σ = MGU(sρ, s′ρ) und θ = ρσ(+Nebenbedingungen)
Eine Menge von Äquivalenzen wird nach Vereinigung der Terme vereinfacht.
5. Geordnete Hyperresolution
(C ∨A) · ρ (D ∨ ¬B) · ρ)(C ∨D) · θ
wobei Ei die Form (Ci ∨Ai) · ρ für 1 ≤ i ≤ n und N die Form(D ∨ ¬B1 ∨ ... ∨ ¬Bn) · ρ hat. σ ist die allgemeingültigste Substitution, wie
Aiθ = Biθ für 1 ≤ i ≤ n.
Das Preprocessing im vorangegangenen Schritt der Transformation 3.4.2 hatsichergestellt, dass die übergebenen Klauseln eine wohl-definierte Struktur haben.Eine Fallunterscheidung gibt Aufschluss über die möglichen Formen einer abge-leiteten Klausel C. Diese gehört entweder einer der 8 syntaktischen Kategorien(vergleiche Tabelle 2) an oder ist redundant. Eine Terminierung des Algorith-mus ist an dieser Stelle also sichergestellt. Der Beweis mittels Induktion überdie Herleitungslänge, sowie kompatible Regeln zur Elimination der Redundanzkönnen bei Hustadt, Motik und Sattler (2004) [15] nachgelesen werden. DieErgebnismenge der saturierten Klauseln wird als Sat(ΓTR) bezeichnet und imfolgenden, vierten Schritt der Transformation weiterverarbeitet.
3.4.4 Entfernen der Funktionssymbole Funktionssymbole innerhalb rekur-siver Regeln gefährden die Terminierung der Anfragebearbeitung. Daher ersetztman funktionale Terme f(a), f(x) in diesem Schritt durch frische Konstantenaf , xf und simuliert die Relation ein einem neuen Prädikat Sf . Zur selben Zeitwerden alle unsicheren, freien Variablen in den Klauseln gebunden. [9] Formaldefiniert man einen Operator λ, der funktionale Terme eliminiert und unsichereVariablen bindet wie folgt [15]:
1. Für jeden Term der Form f(x) in Klausel C wird eine neue Variable xf , dienicht in C vorkommt, eingeführt. Jedes Vorkommen von f(x) wird mit xfersetzt.
2. Jeder funktionale Grundterm f(a) wird mit λ(f(a)) ersetzt.3. Für jede Variable xf die im ersten Schritt eingeführt wurde wird das Literal¬Sf (x, xf ) beigefügt.
4. Falls nach Ausführung der Schritte 1-3 noch Variablen u verbleiben, die ineinem positiven Literal, nicht aber in einem negativen vorkommen, so wird

Reasoning auf Datalog-Basis (KAON2) 65
das Literal ¬HU(x) hinzugefügt. HU steht für Herbrand Universe10 und istein einfacher Trick unsichere Variablen u zu handhaben. Für jedes solche uwird eine Aussage HU(u) in den Rumpf der jeweiligen Klausel eingefügt. [8]
Alle Inferenzschritte des Basic Superposition Kalküls auf dem saturierten Klau-selset Ξ(KB) lassen sich auf diese Weise in FF (KB) überführen und umgekehrt,Ξ(KB) und FF (KB) sind also vollständig vergleichbar.
3.4.5 Transformation in ein disjunktes Datalog Programm Der OutputFF (KB) enthält funktionsfreie Klauseln in denen jede Variable innerhalb einesnegativen Literals vorkommt. Unter diesen Voraussetzungen kann das Klauselsetim letzten Schritt der Transformation sehr einfach in einen disjunktiven Regelsatzumgeschrieben werden, indem man positive Literale in den Kopf der Formel undnegative Literale in den Rumpf der Formel verschiebt. [6] Jede Klausel
A1 ∨ ... ∨An ∨ ¬B1 ∨ ... ∨ ¬Bn
aus FF (KB) wird also nach obigen Regeln in die neue Form umgeschrieben
A1 ∨ ... ∨An ← B1 ∨ ... ∨Bn
mit n,m ≥ 0 und Ai, Bi Atome über Σ.
3.5 Optimierung
Parallel zur Forschung im Bereich der Beschreibungslogiken wurden Technikenzur Optimierung von Anfragebearbeitungen in deduktiven Datenbanken entwi-ckelt. Die Vergleichbarkeit einer Beschreibungslogik wie SHIQ und disjunktivemDatalog ermöglicht die Anwendung bekannter Optimierungstechniken aus derWelt der Datenbanken auf die Reasoning Problematik im Semantic Web. DerKAON2 Reduktionsalgorithmus ermöglicht es, eine SHIQ(KB) in ein disjunkti-ves Datalog Programm umzuschreiben welches dieselben grundlegenden Faktenwie die ursprüngliche Wissensbasis beinhaltet. [15] Auf diese Weise wird ABoxReasoning auf eine Anfragebearbeitung im disjunktiven Datalog reduziert underlaubt Optimierungstechniken anzuwenden die im Folgendem kurz vorgestelltwerden.
Join-Order Optimization stellt eine Kernfunktion deduktiver Datenbanken dar.Die Dauer einer Anfragebearbeitung ist stark von der Reihenfolge abhängig, inder die Tabellen bearbeitet werden. Dieses Optimierungsverfahren berechneteine solche „vorteilhafte“ Reihenfolge, indem Gemeinsamkeiten verschiedenerDatensets berücksichtigt werden. [13]
10 nach dem französischen Mathematiker Jacques Herbrand

66 S. Siekmann
Magic Sets Transformation für disjunktive Datenbanken wurde erstmals 1987von Beeri und Ramakrishnan vorgestellt. Bei einer zielgerichteten Suche werdennur die relevanten ABox Fakten benötigt. So sorgt die Magic Set Transformationdafür, dass nur die relevanten Daten aus der Datenbank gelesen werden müssen.Die Überlegenheit der Top-Down Anfragebearbeitung, bei der sozusagen dieAnfrage die Berechnung leitet, gegenüber dem Bottom-Up Prinzip stellt dieMotivation für diese Optimierungstechnik dar. Dabei wird zu jedem berechnetenPrädikat ein sogenanntes „magisches“ Prädikat, indem die Menge der relevantenFakten berechnet wird, hinzugefügt. Die originalen Regeln werden mit magischenPrädikaten angereichert, so dass die Verarbeitung nicht relevanter Daten vermie-den wird. Grob gesagt wird die Anfrage also derart modifiziert, dass zunächstein Set relevanter Fakten während der Anfrageevaluation erzeugt wird, indemdann die eigentliche Bearbeitung stattfindet. [13][15]
3.6 Performanceuntersuchung
Reasoning auf Wissensbasen, die durch eine ausdrucksstarke Logik beschriebenwerden, stellt ein schwieriges Berechnungsproblem dar. Für das Ableiten einerALC(KB) mit leerer TBox wird im Worst Case PSpace benötigt, Schlussfol-gern aus einer „normalen“ ALC(KB) braucht ExpTime und das Reasoning überSHOIN (KB) NexpTime.[11] Der Worst Case entspricht hier aber nicht demAverage Case und so existieren eine Reihe hochspezialisierter Reasoner die fürbestimmte Aufgaben optimiert wurden und dort effiziente Ergebnisse liefern.Diese Performanceuntersuchung beginnt mit der Laufzeitanalyse der einzelnenTransformations-Schritte des Reduktionsalgorithmus. Danach wird das ABox-sowie das TBox-Reasoning im Vergleich zu anderen Reasoningsystemen analysiert.
Laufzeit des Reduktionsalgorithmus Die Beweise und Herleitungen zu den imFolgenden aufgelisteten Laufzeiten entnimmt der interessierte Leser bitte denArbeiten von Hustadt, Motik und Sattler [8],[16],[10].Der erste Schritt der Transformation, das Entfernen der Transititätsaxiome,findet in polynomialer Zeit zur Größe der Wissensbasis statt. Die darauf folgendestruktureller Transformation zur Erzeugung logischer Klauseln ist ebenfalls poly-nomial. Die Saturation mit Basic Superposition findet in ExpTime statt. Ebensobedarf die Erzeugung funktionsfreier Klauseln exponentieller Größe in |KB|.Die Umwandlung der TBox in ein Datalog-Programm benötigt zusammen alsoExpTime. Diese Behandlung der TBox muss nur ein einziges Mal durchgeführtwerden. Das Datalog Programm kann im Cache gespeichert und für weitereAnfragen wiederverwendet werden. Die eigentliche Anfragebearbeitung, bezie-hungsweise der Konsistenzcheck auf der Datenbank, ist NP vollständig. Zusam-mengefasst verhält sich der Algorithmus worst-case optimal. Die Erfüllbarkeiteiner SHIQ Wissensbasis mittels KAON2 ist NP vollständig.

Reasoning auf Datalog-Basis (KAON2) 67
Die im Folgenden formulierten Aussagen basieren auf Evaluationsergebnis-sen der KAON2 Entwickler, nachzulesen bei Motik und Sattler [16], [15]. Essei erwähnt, dass es schwierig, wenn nicht gar unmöglich ist, die einzelnenReasoning-Algorithmen getrennt von ihrer Implementierung zu untersuchen. DieImplementierungsart dieser komplexen Algorithmen in Kombination mit einerdurchdachten Speicherverwaltung, sowie die Wahl der Implementierungssprachewirken sich deutlich auf die Effiziens eines Reasoningsystems aus.
ABox Reasoning Bei vielen, auf Beschreibungslogiken ausführbaren, Anwen-dungen verhält sich die TBox in Größe und Aufbau relativ stabil, vergleichbarzu einem Datenbank-Schema. Die ABox hingegen varriert stark und kann sehrgroß werden. Aus dieser Motivation heraus haben die KAON2 Entwickler einSystem entworfen, dass auf das Reasoning über großen ABoxen spezialisiert undoptimiert ist. In der Theorie weist das KAON2 System bei der Anfragebearbei-tung großer ABoxen deutlich bessere Ergebnisse auf als seine tableaux-basiertenKonkurrenten auf, da diese in der Regel jedes Element der ABox ungeachtetderer Gemeinsamkeiten und ihrer Relevanz einzeln untersuchen. In der Praxishat sich jedoch gezeigt, dass gerade diese Optimierungstechniken von Nachteilsein können, sofern sie für eine bestimmte Testumgebung suboptimal eingestelltsind. Auf Ontologien die von Haus aus viele Äquivalenzen beinhalten verschwin-det zum Beispiel der positive Effekt der magic set Transformation. Angewandtauf andere Wissensbasen wirkten sich ungünstige Parameter sogar negativ aufdie Bearbeitungszeit des Algorithmus aus. In wieder anderen Testumgebungenmit einfachen TBoxen und sehr großen ABoxen zeigte das KAON2 System dieerhoffte Leistung und glänzte gerade im Vergleich zu Pellet11 und RACER12.Die tableaux-basierten Reasoner zeigten sich von der ansteigenden Datenmengeweitaus mehr beeindruckt als der Inferenzmechanismus der Karlsruher.
TBox Reasoning Beim TBox Resoning erreicht der KAON2 Reasoner nichtdie Performance tableaux-basierter Systeme. Die Ergebnisse schwanken sehrin Abhängigkeit des Aufbaus der TBox. [16] So hat sich gezeigt, dass KAON2auf Ontologien mit zwar komplexen aber dennoch sehr kleinen TBoxen guteErgebnisse liefert. Im Durchschnitt zeichnet sich aber ab, dass der Algorithmusdie Robustheit der tableaux-basierten Systeme nicht erreicht. Für die Entwicklerist das nicht sehr überraschend, lag der Fokus bei der Entwicklung doch ganzklar auf dem Reasoning über großen A-Boxen. Desweiteren wurden für tableaux-basierte Systeme in den letzten Jahren eine Vielzahl von Optimierungstechnikenentwickelt die genau diese Aufgabenstellung behandeln. Auf resolutions-basierteSysteme, wie KAON2, sind diese Verfahren nicht direkt übertragbar. Die KAON2-Entwickler sehen hier erfolgsversprechendes Forschungspotential um auf langeSicht mit anderen Systemen gleichziehen zu können.
11 http://www.mindswap.org/2003/pellet/12 http://www.sts.tu-harburg.de/ r.f.moeller/racer/

68 S. Siekmann
4 Schluss
Bevor die Vision des Semantic Web nutzbar wird, muss eine kritische Masseverfügbarer Inhalte erreicht werden. Im Rahmen dieser Arbeit wurde deutlich,dass es sehr aufwendig ist maschineninterpretierbare Webinhalte zu erstellen. DieFrage stellt sich, ob man genügend Anwender finden wird, die diesen Mehraufwandnicht scheuen. Des Weiteren ist eine einheitliche Standardisierung erforderlichum parallele Entwicklungen nicht kompatibler Systeme zu verhindern. DieserAufgabe nimmt sich das W3C bereits erfolgreich an. Gerade im Bereich derRepräsentations- und Anfragesprachen für semantische Modelle existieren eineReihe verschiedener Ansätze. Ein solches System ist KAON2, das in dieserArbeit vorgestellt wurde. Eine beste Lösung für all die verschiedenen Aufgabendes Reasonings ist nicht in Sicht und so handelt es sich nach wie vor um einhochaktuelles Forschungsgebiet. Richtet man den Blick speziell auf das KAON2System, so kann man aktuellen Veröffentlichungen [10] entnehmen, dass zurZeit zwei Themen im Mittelpunkt der Karlsruher Forschung stehen. Zum Einendie Erweiterung des Basic Superposition Kalküls um Simplifikationsregeln, diegefährliche Klauseln entschärfen und zum Anderen der Versuch algebraischesReasoning direkt in den Resolutionsprozess zu integrieren, wie es beim TableauxKalkül (Haarslev, Timmann, Möller) bereits praktiziert wird.
Literatur
[1] F. Baader, D. Calvanese, D. L. McGuinness, D. Nardi, and P. F. Patel-Schneider,editors. The Description Logic Handbook: Theory, Implementation, and Applicati-ons. Cambridge University Press, 2003.
[2] F. Baader, I. Horrocks, and U. Sattler. Description logics as ontology languagesfor the semantic web, 2003.
[3] S. Balzer. Inferenzsysteme für das Semantic Web. Seminar Semantic Web undInferenzsysteme, Universität Ulm, 2004.
[4] C. Braun. KAON2 Algorithm - Non-tableau reasoning with description logics.Knowledge Representation and Reasoning for the Semantic Web, Seminar, UniKarlsruhe, 2006.
[5] P. Hitzler. Web Ontology Language OWL: Semantik. Vorlesung „IntelligenteSysteme im World Wide Web“, Universität Karlsruhe, 2007.
[6] U. Hustadt and B. Motik. Description Logics and Disjunctive Datalog—TheStory so Far. In I. Horrocks, U. Sattler, and F. Wolter, editors, Proc. of the 2005Int. Workshop on Description Logics (DL 2005), volume 147 of CEUR WorkshopProceedings, Edinburgh, UK, July 26–28 2005.
[7] U. Hustadt, B. Motik, and U. Sattler. Reasoning for Description Logics aroundSHIQ in a Resolution Framework. Technical Report 3-8-04/04, FZI, Germany,2004.
[8] U. Hustadt, B. Motik, and U. Sattler. Reducing SHIQ− Description Logic toDisjunctive Datalog Programs. In D. Dubois, C. A. Welty, and M.-A. Williams,editors, Proc. of the 9th Int. Conference on Pronciples of Knowledge Representationand Reasoning (KR 2004), pages 152–162, Whistler, Canada, June 2–5 2004. AAAIPress.

Reasoning auf Datalog-Basis (KAON2) 69
[9] U. Hustadt, B. Motik, and U. Sattler. A Decomposition Rule for Decision Pro-cedures by Resolution-based Calculi. In F. Baader and A. Voronkov, editors,Proc. of the 11th Int. Conference on Logic for Programming Artificial Intelligenceand Reasoning (LPAR 2004), volume 3452 of LNAI, pages 21–35, Montevideo,Uruguay, March 14–18 2005. Springer.
[10] U. Hustadt, B. Motik, and U. Sattler. Deciding Expressive Description Logics inthe Framework of Resolution. Information & Computation, 2008. To appear.
[11] M. Krötzsch. Practical reasoning with owl and rules. Invited talk at the SemanticWeb Technology Showcase 2007, Vienna, Austria, MAY 2007.
[12] N. Kwekkeboom. Ontologien im Semantic Web am Beispiel der KArlsruhe ON-tology and Semantic Web Infrastructure. Seminar Ägenten im Semantic Web“,Universität Münster, 2007.
[13] A. Maedche and B. Motik. Repräsentations- und Anfragesprachen für Ontologien- eine Übersicht. Datenbank-Spektrum, 6:43–53, 2003.
[14] W. May. Reasoning im und für das Semantic Web. In PGrundlagen von Daten-banken, pages 9–20, 2005.
[15] B. Motik. Reasoning in Description Logics using Resolution and Deductive Da-tabases. PhD thesis, Univesität Karlsruhe (TH), Karlsruhe, Germany, January2006.
[16] B. Motik and U. Sattler. A Comparison of Reasoning Techniques for QueryingLarge Description Logic ABoxes. In M. Hermann and A. Voronkov, editors, Proc.of the 13th Int. Conference on Logic for Programming Artificial Intelligence andReasoning (LPAR 2006), volume 4246 of LNCS, pages 227–241, Phnom Penh,Cambodia, November 13–17 2006. Springer.

Reasoning mit Tableau (anhand von Pellet)
Philipp [email protected]
Universität Augsburg
Zusammenfassung Das Semantic Web versucht Probleme, die beimFinden von Informationen im Internet vorhanden sind, zu beseitigen. InSuchmaschinen ist eine riesige Menge an Informationen auffindbar, obman die gesuchten Informationen in den Suchergebnissen wiederfindet,ist jedoch schwer zu sagen. Selten spiegelt die Trefferliste das gewünschteResultat wieder. Auf der Suche nach einer Bank für seinen Garten, findetder Benutzer im Suchergebniss sowohl Internetadressen, die sich mitseiner Sitzgelegenheit auseinandersetzen, als auch welche die von einemGeldinstitut stammen. Dies zeigt, dass es hilfreich ist, die Suche miteinem semantischen Hintergrund zu ergänzen.Beschreibungslogiken sind in der Lage komplexes Wissen zu repräsen-tieren. Das World Wide Web Consortium (W3C) hat zu diesem Zweckdie Web Ontology Language (OWL) spezifiziert. Der Tableaualgorithmuskann logische Schlussfolgerungen (Reasoning) aus den in der Wissensba-sis (Ontologie) vorhandenen Informationen ziehen. Pellet ist für OWLimplemeniert worden, da bereits existierende Reasoner notwendige Funk-tionen wie Reasoning mit Individuen, XML Schema Datentypen oder„conjunctive ABox queriesnnicht unterstützten.
1 Einführung
Das Internet hat sich zu einem Medium entwickelt, in dem eine schier unendlicheMenge an Informationen publiziert wird. Die Informationen sind so aufbereitet,dass wir Menschen sie interpretieren und verstehen können. Auf der Suchenach einem bestimmten Begriff im Internet zum Beispiel „Müller“ bekommtder Benutzer bei der Suchmaschine Yahoo eine Ergebnismenge mit ungefähr126 Millionen Ergebnissen zurück. Ein Schulabsolvent auf der Suche nach demtraditionsreichen Beruf des Müllers wird selbst nach einigen Seiten feststellen,dass die ersten Resultate immer noch nicht mit seiner Suche übereinstimmen. Erbekommt lediglich Internetseiten großer und kleinerer Unternehmen oder vonFamilien mit diesem Namen angezeigt.
Das Problem ist, dass Suchmaschinen nur die Zeichenketten der einzelnenSeiten mit komplexen Algorithmen analysieren und mit statistischen Wertenaufbereiten können. Im Endeffekt bleibt die Suche aber dennoch Stichwortbasiertund alle Internetseiten, auf denen das Wort „Müller“ vorhanden ist, sind inder Ergebnismenge vorhanden. Für den Benutzer ist es aber sinnvoller, bei derSuche den semantischen Inhalt in den Vordergrund zu holen. So bekommt der

Reasoning mit Tableau (anhand von Pellet) 71
Benutzer eine Ergebnismenge mit Firmen, Familien oder dem Handwerksberufje nach seinem semantischen Wunsch angezeigt. Ziel des Semantic Web ist esdarum, Wege und Methoden zu finden, Informationen so zu repräsentieren, dassMaschinen damit in einer Art und Weise umgehen können, die aus menschlicherSicht nützlich und sinnvoll sind [3].
Beschreibungslogiken sind eine Familie von Sprachen, die Wissen einer Domänerepräsentieren können und es strukturiert und formell abbilden. Logische Forma-lismen bieten auch die Möglichkeit implizites Wissen aus einer Spezifikation zugenerieren und sind außerdem ein Gebiet in dem intensiv geforscht wird. Die Ent-wickler einer Beschreibungslogik müssen auch darauf achten, dass sie die Sprachenicht zu ausdruckststark werden lassen, da ein effizientes Schlussfolgern erschwertwürde. Das W3C standardisierte OWL anhand des Gesichtspunktes, dass für diePraxis ein optimaler Ausgleich zwischen Ausdrucksstärke und Effizienz vorhandensein muss. Dieser Zielkonflikt ist einer der wichtigsten Forschungsansätze auf demGebiet der Beschreibungslogiken.
Tableaualgorithmen ermöglichen automatisches Schlussfolgern und sind be-liebt, weil sie oft eine optimale Worst-Case Komplexität haben und abgeschlossensind [1]. Der Algorithmus zeichnet sich auch dadurch aus, dass er leicht anverschiedene Beschreibungslogiken angepasst werden kann. Der erste Tableaual-gorithmus wurde von Schmidt-Schauß und Smolka 1991 für die BeschreibungslogikALC (Kapitel 2.1) entwickelt. Die vom W3C standardisierte Sprache ist OWL,OWL-Full ist unentscheidbar, aber so ausdrucksstark gewählt, um möglichst vielmit implizitem Wissen arbeiten zu können. OWL-DL ist eine abgeschlosseneTeilsprache von OWL und wurde entwickelt, dass Anfragen immer mit einemterminierenden Algorithmus beantwortet werden können. OWL DL entsprichtder Beschreibungslogik SHOIN(D), die sehr ausdrucksstark und entscheidbar ist[3].
Eine der wenigen hochperfomanten Inferenzmaschinen für OWL ist Pellet. Sieist die einzige, die zum jetzigen Zeitpunkt, alle OWL DL Konzepte unterstützt.Pellet ist Open Source und wurde entwickelt, weil bereits vorhandene Reasonerzwar durchaus hochperfomant sind, aber einige notwendige Eigenschaften nichtunterstützen. Dazu zählen unter anderem, dass der Reasoner nicht von eindeutigenBezeichnern aussgehen soll und mit Individuen umgehen können muss. Pelletselbst ist auch hochperfomant, wie ein Vergleich in der Zusammenfassung zeigenwird.
Das erste Ziel dieser Arbeit ist es, den Tableaualgorithmus vorzustellen, wasin Kapitel 2 abgehandelt wird. Dies geschieht mit der Beschreibungslogik ALC,welche ebenfalls kurz vorgestellt wird (Abschnitt 2.1). Der zweite Hauptpunktist die Inferenzmaschine Pellet in Kapitel 3 und die von ihr implementiertenOptimierungen in Abschnitt 2.3.
2 Tableau
Dieses Kapitel stellt die Semantik und das automatische Schlussfolgern vor. DieSemantik, welche mit der Beschreibungslogik ALC möglich ist, schauen wir uns

72 P. Kretschmer
im nächsten Kapitel an. Sie ist ein Teil der Prädikatenlogik erster Stufe unddie Logik, mit der wir die Funktionsweise des Tableaualgorithmus zuerst ohneund dann mit dem Blockingverfahren kennenlernen. Ein Beispiel veranschaulichtabschließend das Vorgehen des Algorithmus.
2.1 Beschreibungslogik ALC
ALC (Attributive Language with Complements) ist eine einfache Beschreibungslo-gik, die Teile von OWL DL repräsentieren kann. Ihr einfacher und übersichtlicherAufbau ist der Grund, weshalb sie als Beispielsprache für die Vorstellung desTableau gewählt wurde. Als Grundbausteine besitzt sie Klassen, Rollen undIndividuen. Ein Ausdruck der Form
Fussballprofi(OliKahn)
bedeutet, dass das Individuum OliKahn in der Klasse Fußballprofi enthalten ist.Hat man noch eine Klasse Verein, sagt uns das, dass durch die Rolle Mitgliedder Form
Mitglied(OliKahn,BayernMuenchen)
OliKahn ein Mitglied des Vereins BayernMuenchen ist. Unter- und Äquivalenz-klassenbeziehungen werden mit den Standardsymbolen ⊆ und ≡ dargestellt.Komplexe Klassen werden durch Konjunktion ∧ und Disjunktion ∨ und derenVerschachtelung konstruiert. Mit den Quantoren ∀R.C und ∃R.C können auchkomplexe Klassen erzeugt werden. Die Übersetzung in Prädikatenlogik siehtbeispielhaft wie folgt aus:
Fussballprofi ⊆ V ereinsmitglied (ALC)(∀x)(Fussballprofi(x)→ V ereinsmitglied(x)) (Praedikatenlogik)
Fussballprofi ≡ Profifussballer (ALC)(∀x)(Fussballprofi(x)↔ Profifussballer(x)) (Praedikatenlogik)
Eine vollständige Übersetzungstabelle für die Prädikatenlogik erster Stufe ist in[3] zu finden.
Die formale Syntax und Semantik kann in TBoxen und ABoxen unterteiltwerden. ABoxen haben assertionales Wissen der Form C(a) oder R(a, b), für eineKlasse C und Rolle R und den Individuen a und b. Terminologisches Wissenwird in TBoxen dargestellt, welche die Äquivalenz und Unterklassenbeziehungbeinhalten.
Die Aussage,
dass ein Profifussballer (Pf)eine Teilmenge von Mensch (M) geschnitten Vereinsmitglied (Vm)oder Mensch (M) geschnitten nicht Amateur (Am) ist,

Reasoning mit Tableau (anhand von Pellet) 73
wird in ALCPf ⊆ (M ∧ V m) ∨ (M ∧ ¬Am)
und in Prädikatenlogik
(∀x)(Pf(x)→ (M(x) ∧ V m(x)) ∨ (M(x) ∧ ¬Am(x)))
ausgedrückt. Ist logische Konsequenz aus der Aussage, dass der Profifußballerein Mensch ist? Formell besitzt sie die Form
Pf ⊆M
in ALC und in Prädikatenlogik
(∀(x)(Pf(x)→M(x)).
Der Tableau ist ein Algorithmus für logische Schlussfolgerungen, mit dem wirdas überprüfen können.
2.2 Tableauverfahren
Logisches Schlussfolgern aus einer Theorie oder Wissensbasis kann nach [3] immerauf einen Nachweis von Unerfüllbarkeit zurückgeführt werden. Durch die engeVerwandschaft mit der Prädikatenlogik, wäre es denkbar, die Aussagen aus derBeschreibungslogik zuerst zu übersetzen und anschließend mit Algorithmen derPrädikatenlogik auf Unerfüllbarkeit zu prüfen. Außer, dass diese Vorgehensweiseineffizient ist, besteht noch das gravierende Problem, dass die Prädikatenlogikerster Stufe nicht entscheidbar ist. Eigens für Beschreibungslogiken entworfeneAlgorithmen versprechen hier eine bessere Performance.
2.2.1 Naives Tableauverfahren [5] beschreiben die Idee, dass das Testenauf Unterklassenbeziehungen auf das Testen von Erfüllbarkeit reduziert werdenkann. Sie definieren ein Konzept als erfüllbar, wenn es in einer Interpretation einenicht leere Menge verzeichnet wird, andernfalls ist es unerfüllbar. Die Beweise fürUnterklassenbeziehungen und Erfüllbarkeit hängen folgendermaßen zusammen:
(C ⊆ D)⇔ (C ∧ ¬D) ist unerfuellbar [6]
Die Frage aus dem letzten Kapitel, ob der Profifußballer ein Mensch ist, kannman nun beantworten, indem man Pf ⊆M in die Form
(Pf ∧ ¬M)
bringt und mit der vorhandenen Wissensbasis (Pf ⊆ (M ∧ V m) ∨ (M ∧ ¬Am))interpretiert. Der Algorithmus fängt mit einem einzelnen Individuum an undbaut dann nach und nach eine vollständige Interpretation auf. Die Interpretationwird nach den Regeln des Tableaualgorithmus (Tabelle 1) durchgeführt. Wirzeigen, dass mit (Pf ∧¬M) keine vollständig Interpretation möglich ist, wodurch

74 P. Kretschmer
Unerfüllbarkeit bewiesen ist. Das der Profifußballer ein Mensch ist, folgt sofort ausobiger Beziehung. Der Tableauansatz bietet Vorteile wie eine solide theoretischeBasis, optimale Worst Case Effizienz und leichte Anpassbarkeit durch Erweiterungder Regeln [5].
Ein Tableau ist ein Graph, der zu Beginn eine Theorie oder Wissensbasisin Negationsnormalform (NNF) benötigt. NNF wird erreicht indem man alleNegationen mit unter anderem DeMorgan Regeln direkt vor die atomaren Klassenbringt. Dies ist in linearer Zeit für jede in ALC ausgedrückte Wissensbasis möglich[1]. Durch die Reduktion des automatischen Schlussfolgerns auf Unerfüllbarkeitversuchen wir ¬D(a) und D(a), einen Widerspruch, in einer Aussage zu erzeugen.
Bevor wir uns die Tableauregeln formell und das Vorgehen im Konkretenansehen, ein einfaches Beispiel. Die Aussagen
Pf(a) und (¬Pf ∧Am)(a)
erfordern es, dass Pf(a) und ¬Pf(a) und Am(a) gelten müssen, damit dieAussage wahr ist. Offensichtlich können die Aussagen Pf(a) und ¬Pf(a), wie esfür Erfüllbarkeit nötig wäre, gleichzeitig nicht wahr sein. Demnach gibt es keinewie in [5] verlangte nicht leere Menge, die eine Interpretation erfüllt. Auch dievon [6] geforderte vollständige Interpretation ist durch den Widerspruch nichtmöglich.
Die Ersetzungregeln des Tableaualgorithmus für ALC sind in Tabelle 1 darge-stellt und dem Buch von [3] entnommen. Das Tableau ist vollständig verzweigt,wenn man keine der Ersetzungsregeln mehr anwenden kann. Befindet sich ineinem Ast des Tableaus ein Widerspruch, so ist dieser abgeschlossen. Sind alleÄste des Tableaus abgeschlossen, gilt die Wissensbasis, der dem Tableau zugrundeliegt, als unerfüllbar. Kann man keine neuen Elemente zu einem Ast hinzufügenmüssen, wir den Algorithmus an dieser Stelle terminieren und die Wissensbasisist erfüllbar. Grundsätzlich können die Ersetzungsregeln in beliebiger Reihenfolge
Auswahl AktionC(a) ∈W (ABox) Füge C(a) hinzu.R(a, b) ∈W (ABox) Füge R(a, b) hinzu.C ∈W (TBox) Füge C(a) für ein bekanntes Individuum a hinzu.(C ∧D)(a) ∈ A Füge A(a) und D(a) hinzu.(C ∨D)(a) ∈ A Dupliziere den Ast. Füge zum einen C(a) und
zum anderen Ast D(a) hinzu.(∃R.C)(a) ∈ A Füge R(a, b) und C(b) für ein neues Individuum
b hinzu.(∀R.C)(a) ∈ A Falls R(a, b) ∈ A, so füge C(a) hinzu.
Tabelle 1. Tableauersetzungsregeln für ALC; A ist die Aussagenmenge;
auf die Aussagen in der Wissensbasis angewandt werden. Die Komplexität istdann exponentiell in Bezug auf die Zeit. Eine Modifikation schafft es aber den

Reasoning mit Tableau (anhand von Pellet) 75
Algorithmus in polynomieller Zeit zu behandeln, dazu mehr im Kapitel 2.2.3,Komplexität [1].
Dieser Tableaualgorithmus garantiert wegen der Ersetzungregel (∃R.C)(a) ∈A keine Terminierung. Der folgende Abschnitt zeigt, wann ein solches Problemauftritt und wie es gelöst werden kann.
2.2.2 Tableauverfahren mit Blocking Das Problem, dass der Algorithmusnicht immer Terminiert, kommt durch die Regel (∃R.C)(a) ∈ A. An dieser Stellewird verlangt, R(a, b) und C(b) der Menge hinzuzufügen, wobei das Individuum bimmer ein Neues sein muss. Abbildung 1 stellt einen solchen Fall dar (Beispiel aus[4]). Man will anhand der Theorie ¬Person ∨ ∃hasParent.Person nachweisen,
Abbildung 1. Terminierungsproblem
dass Bill keine Person (¬Person(Bill)) ist.Im ersten Schritt wird die Regel für Disjunktion angewandt und zwei Verzwei-
gungen entstehen. Die linke Seite hat durch ¬Person(Bill) einen Widerspruchund ist abgeschlossen. Die rechte Seite zeigt, wie man durch wiederholtes Anwen-den der Regel für das Existenzzeichen in eine Endlosschleife geraten kann. Dieneu hinzugefügten Individuen besitzen keine wesentlichen neuen Informationenund sind unnötig. Wir wenden die Regel in Zukunft nur an, wenn der Zweig andieser Stelle nicht blockiert. Auf diese Weise kann der Algorithmus terminieren.Bleibt noch eine Definition für das Blockieren anzugeben.
Müssen wir die Regel für (∃R.C)(a) ∈ A anwenden, blockiert der Algorithmusan dieser Stelle, falls es ein b gibt, dass
C|C(a) ∈ A ⊆ C|C(b) ∈ A

76 P. Kretschmer
gilt [3].Wendet man diese Definition an, blockiert der Algorithmus bei der Wahl von
∃hasParent.Person(x1), da x1 ⊆ Bill ist. Bill blockt x1 und der Zweig mussnicht weiter untersucht werden.
2.2.3 Komplexität Der Tableaualgorithmus für ALC wie er in Kapitel 2.2.1beschrieben ist, besitzt exponentielle Laufzeit und Speicheranforderungen [1]. Zieleines jeden Algorithmus muss es sein, die Komplexität so gering wie möglich zuhalten. In unserem Fall können die bestehenden Regeln unangetastet bleiben, sindjedoch nicht mehr beliebig hintereinander anwendbar. [1] geben eine Reihenfolgefür das Anwenden der Regeln vor. Man fängt an mit C0 (x0).
1. wendet so lang wie möglich ∧ und ∨ an und sucht Widersprüche;2. danach erzeugt man alle notwendigen ∃ Nachfolger von x0 und wendet die ∀
Regel an;3. Nachfolger werden genauso abgehandelt;
Diese einfache Anpassung drückt uns die Speicherkomplexität in einen polynomi-ellen Rahmen.
2.2.4 Beispiel In diesem Beipiel schauen wir uns den Tableau mit Blocking anund verwenden für unseren Nachweiß eine Aussage, wie sie in jeder Organisationüblich ist, Chef ⊆ ∃hatV orgesetzten.Chef . Der Vorstellung das ein Chef wiedermindestens einen Chef hat, fügen wir noch die Aussage hinzu, dass Knut einEisbaer ist,
Eisbaer(Knut).
Wir versuchen nachzuweisen, dass Knut kein Chef ist, ¬Chef(Knut). Währendder Konstruktion des Tableau verwenden wir Abkürzungen für die Begriffe, siebestehen nur aus dem ersten Buchstaben des korrespondierenden Wortes. Klassenbekommen einen Großbuchstaben, alles andere Kleinbuchstaben.
In die Wissensbasis W werden alle Aussagen in Negationnormalform einge-tragen.
¬C ∨ ∃h.C,E(k), C(k)
Initial haben wir in unserem Tableau nur einen leeren Ast A0, der der leerenMenge entspricht. Im ersten Schritt wählen wir aus W F (k) und erhalten für A0die Menge A1 mit
A1 = E(k) .
Als nächstes Wählen wir C(k) und die Menge
A2 = E(k), C(k)
ersetzt A1. Als neues Element aus der Wissensbasis fehlt in unser Menge noch¬C ∨ ∃h.C. Da es sich hier noch um ein Element der TBox handelt, müssen wir

Reasoning mit Tableau (anhand von Pellet) 77
noch ein bekanntes Individuum hinzufügen. Wir wählen den uns bekannten kaus und das Element gehört jetzt zur ABox Menge.
A3 = E(k), C(k), (¬C ∨ ∃h.C)(k)
Wir wählen als nächstes (¬C ∨ ∃h.C)(k) und wenden die Regel für Disjunktionan. Ab jetzt müssen wir zwei Äste A4,1 und A4,2 betrachten.
A4,1 = E(k), C(k), (¬C ∨ ∃h.C)(k), (∃h.C)(k)A4,2 = E(k), C(k), (¬C ∨ ∃h.C)(k),¬C(k)
Der Ast A4,2 ist abgeschlossen, da er C(k) und ¬C(k) enthält. Wenden wir unsjetzt A4,1 zu, wählen (∃h.C)(k) und ersetzen die Menge durch die neue A5,1. Wiein der Ersetzungsregel vorgesehen, fügen wir die Rollenbeziehung und die KlasseC mit einem neuen Individuum j1 hinzu.
A5,1 = E(k), C(k), (¬C ∨ ∃h.C)(k), (∃h.C)(k), h(k, k1), C(k1) .
Wir wählen als nächstes ¬C ∨ ∃h.C aus W und dazu das bekannte Individuumk1. Dieses Element fügen wir in A5,1 ein und erhalten
A6,1 = A5,1 ∪ (¬C ∨ ∃h.C)(k1) .
Nach der Disjunktionsregel müssen wir den Ast A6,1 wieder teilen und durch
A7,1 = A6,1 ∪ (∃h.C)(k1)A7,2 = A6,1 ∪ ¬C
ersetzen. An dieser Stelle terminiert der Algorithmus, da C(k) und ¬C(k) einWiderspruch in A7,2 ist. Der letzte noch nicht abgeschlossene Ast ist A7,1. Andieser Verzweigung können wir aber auch nicht weitermachen, denn1. keine Auswahl aus der Wissensbasis oder A7,1 bringt ein neues Element ins
Tableau2. bis auf (∃h.C)(k1). Dies wird aber durch k geblockt, weil beide in die KlassenC,¬C ∨ ∃h.C und ∃C gehören.
Wir haben einen Tableau berechnet, der wegen Ast A7,1 nicht abgeschlossen ist.Daraus können wir direkt schließen, dass die Aussage ¬Chef(Knut) nicht ausder Wissensbasis
¬C ∨ ∃h.C,E(k), C(k)gefolgert werden kann. Wir haben gezeigt, dass mit der Wissensbasis es durchausmöglich ist, dass Knut ein Chef ist.
2.3 Implementierung und OptimierungenDie im Folgenden vorgestellten Implementierungs- und Optimierungsverfahrensind ein Teil derer, die Pellet unterstützt. Dazu gehören Lazy Unfolding, Nor-malization and Simplifikation und Semantic Branching, welche für die LogicSHIN(D) implementiert wurden. SHIN(D) entspricht OWL-Lite. Für OWL-DL,was der Logik SHOIN(D) gleichkommt, sind neue Techniken entworfen worden.Wir schauen uns in dieser Arbeit Learning-based Disjunkt Selection an.

78 P. Kretschmer
2.3.1 Lazy Unfolding Lazy unfolding ist ähnlich dem Proxy Pattern, welchesvon [2] als Design Pattern für den Softwareentwurf vorgestellt wurde. Es gehtdarum, dass ein Proxy-Objekt ein Platzhalter für das komplexere Original istund an dessen Stelle steht. Es wird erst dann durch das Original ausgetauscht,wenn das Original tatsächlich benötigt wird.
Lazy unfolding kann man auf zwei verschiedene Arten anwenden. Die Ersteist wie oben beschrieben, wenn ein Konzept für den Algorithmus gebraucht wird,ersetzt man es durch seine Definition. Sei A ≡ D und es wird aus der Menge(A ∧ E) ausgewählt, wird an dieser Stelle A durch D ersetzt. Statt D kann Aauch durch einen komplexeren Wert definiert werden.
Bis jetzt werden unnötige Ersetzungen vermieden, falls schon ein widerspruchs-freier Ast gefunden wurde, oder schon vorher ein Konflikt auftrat. Noch effizienterist es, wenn man nicht den Wert durch seine Definition austauscht, sondern siemit in die Menge aufnimmt. Tritt später noch einmal dieses Konzept auf, mussman dieses nicht auch ersetzen, sondern hat es noch in der Menge und kann denWiderspruch ohne Ersetzen testen. Als Ergänzung zu den Tableauregeln kannman Lazy unfolding ausdrücken wie in Abbildung 2
Abbildung 2. Lazy unfolding Regeln
2.3.2 Normalisierung Normalisation verstärkt den Gewinn der aus Lazyunfolding gezogen werden kann, noch um ein Vielfaches. Die Idee hinter Nor-malisation ist, dass Widersprüchliche nicht atomare Aussagen schnell erkanntwerden. Hat man alle Konzepte in Negationsnormalform gebracht (¬C ∧ ¬D)und analog dazu (C ∨D), sind zwei konträre Aussagen vorhanden. Das Problemist jedoch, dass man erst beide mit den Ersetzungsregeln umformen muss, umdas zu erkennen.
Mit Hilfe der DeMorgan Regeln bringt man komplexe Aussagen in einesyntaktische Normalform. Wichtig ist nicht, ob man ∨ oder ∧ verwendet, sondern

Reasoning mit Tableau (anhand von Pellet) 79
das es einheitlich gemacht wird. Für das Beispiel aus dem letzten Abschnittwählen wir ∨ und formen (¬C ∧¬D) in ¬(C ∨D) um. Jetzt ist der Widerspruchdirekt ersichtlich. Die umgeformten Aussagen liegen aber nicht mehr alle inNegationsnormalform vor.
Wichtig ist es noch die Konjunktionen als Mengen ¬∨C,D und ∨C,D zubetrachten, damit die Reihenfolge der Elemente keine Rolle spielt. Für die LogikALC sind die Funktionen für Normalisierung und Vereinfachung in Abbildung3 zu sehen. An andere ausdrucksstärkere Logiken können wir die Idee durchergänzen der Funktionen anpassen. Ein Beipsiel dafür ist, die ≤ Restriktion aufZahlen in ¬ ≥ umzuformen und ≥ als Norm zu wählen.
Abbildung 3. Normalisierungsfunktionen [6]
Wir können Widersprüche noch schneller erkennen, ohne die Ausrücke expan-dieren zu müssen. Wenn wir ¬∨C,D und ∨C,D durch atomare Konzeptna-men ersetzen, ¬ ∨ C,D ≡ ¬CD und ∨C,D ≡ CD, sind die Widersprüchesofort sichtbar. Unsere Ersetzungen müssen wir von denen in der Originalwissens-basis trennen, um den Benutzer nicht zu verwirren und dem System mitzuteilen,dass es sie nicht klassifiziert werden müssen [6].
Diese Methode ist leicht zu implementieren und für sehr viele Logiken an-wendbar. Im Anschluss an diese Methode sind viele Tests auf Unerfüllbarkeitnicht mehr notwendig, weil die Widersprüche direkt vorliegen. Die veränderteDarstellungsweise erkennt doppelte Einträge wie (C ∨D) und (D ∨ C) in derAussage und reduziert beide auf eine Aussage ∨C,D. Diese Verbesserung führt

80 P. Kretschmer
allerdings auch zu neuen Kosten und kann daher manchmal auch keinen Nutzenoder sogar eine leichte Verschlechterung der Laufzeit bewirken.
2.3.3 Semantic Branching Search In Abschnitt 2.2.1 haben wir das naiveTableauverfahren kennengelernt. Die vorgestellten Regeln basieren auf einer reinsyntaktischen Betrachtung des Problems. Findet man eine Disjunktion vor, mussman den Baum an dieser Stelle aufteilen und beide Seiten weiter verfolgen. Schonan einem kleinen Beispiel wird deutlich, dass unter diesen Umständen der selbeAusdruck mehrmals untersucht werden muss. Die Menge (A ∨B), (A ∨ C)dient als Grundlage für den Test auf Unerfüllbarkeit. Wählt man zuerst (A ∨B)aus, zeigt man A und B. Im weiteren ist es noch nötig, A wegen (A ∨ C) zuzeigen. Ist A ein komplexer Ausdruck verliert man viel Zeit für einen Beweis, denman schon geführt hat.
Man sollte versuchen diese redundanten Test zu vermeiden. Wir erreichendieses Ziel, indem wir die Disjunktion nicht syntaktisch aufteilen, sondern uns einElement aus der noch nicht aufgeteilten Disjunktion herausnehmen, und damitden Baum weiter aufspannen [6]. Wir wählen für einen Ast A und für den Anderen¬A. Beide Äste sind strikt disjunkt und wir führen keine unnötigen Test aus. An-schaulich lässt sich die neue Vorgehensweise so darstellen. Diese Lösung ist durch
Abbildung 4. Semantic Branching
anpassen des weit verbreiteten Davis-Putnam-Logemann-Loveland Verfahren(DPLL) entstanden und hilft Entscheidbarkeit in Problemen zu optimieren.
Durch hinzufügen des negierten Astes sind nur selten stark negative Auswir-kungen aufgefallen, dagegen ist das Verbesserungspotenzial enorm groß. StarkeSynergieeffekte sind bekannt zusammen mit den Vorgehensweisen „Local Simpli-fikation“ und „Heuristic guided search“, die nicht Bestandteil dieser Arbeit sindund in [6] nachgelesen werden können.
2.3.4 Learning Based Disjunkt Selection Kritisch für die Leistung desReasoning-Prozesses sind die Disjunktionen. Eine gute Reihenfolge in der dieDisjunktionen abgearbeitet werden, bringt einen Leistungsschub für das Schluss-folgern. Für das DPLL Verfahren sind einige Verbesserungen gefunden worden,mit denen der Suchbaum möglichst klein gehalten werden kann [7].
Untersucht man Wissensbasen, kommt man oft zu dem Schluss, dass es ansich nur eine sinnvolle Erweiterung des Tableaus gibt. Der Reasoner kann das

Reasoning mit Tableau (anhand von Pellet) 81
Problem aber erst nach einigen Schritten feststellen, was bei teuren Expansionennicht wünschenswert ist. Um keine Leistung zu verschenken, ist die Idee, dassder Algorithmus aus einer schon berechneten Aussage einer Disjunktion lernt.
In [7] wird eine Möglichkeit aufgezeigt, wie man widerspruchsfreie Expansionenfür ähnliche Aussagen wiederverwenden kann. Der Pseudocode in Abbildung 5 istvon ihnen vorgestellt worden und basiert auf der Idee, die Aussagen anhand derAnzahl, der durch sie verursachten Widersprüche zu sortieren. Jetzt ist es einfach,
Abbildung 5. Pseudocode Learning based disjunkt selektion Technik
eine Aussage, die schon einmal einen Widerspruch verursacht hat zu finden. Da esfast unmöglich ist, festzumachen, warum eine Disjunktion erfolgreich expandiertwerden konnte, speichert diese Technik nur die Widersprüche ab. Eine Methodedie im Nachhinein noch alle widerspruchsfreien Vervollständigungen findet undfür den späteren Bedarf bereitstellt, ist aber denkbar [7].
3 Pellet
In Anwendungen des Semantic Web ist es vielmals von großer Bedeutung Schluss-folgerungen ziehen zu können. Diese sollen zudem schnell und vollständig sein.Bevor man mit der Entwicklung von Pellet begann, untersuchte man zuerst schonvorhandene Reasoner heraus, die die Beschreibungslogik von OWL (SHOIN(D))behandeln konnten. Die bekanntesten davon sind FaCT und Racer. Die Leistungder Reasoner war gut, jedoch sind einige für das Semantic Web notwendige Eigen-schaften, wie ABox Reasoning, conjuctive ABOX Queries und Unterstützung vonXML Schema Datentypen, nicht vorhanden. Pellet erfüllt diese Anforderungenund bietet eine gute bis sehr gute Leistung an, wobei es der erste Reasoner ist,der ganz OWL-DL verarbeiten kann.

82 P. Kretschmer
3.1 Basis Dienste
Pellet kann für OWL-DL einen vollständigen Konsistenz- sowie Syntaxtest durch-führen. Als OWL-DL Reasoner sollte Pellet die Standardanforderungen fürlogische Schlussfolgerungen anbieten. Dazu gehören [8]:
– Konsistenztest, der sicherstellt, dass eine Wissensbasis keine widersprüch-lichen Aussagen enthält. Eine ABox wird gegen eine TBox auf Konsistenzgeprüft.
– Konzept Erfüllbarkeit, testet, ob zu einer Klasse Instanzen bestehen können.Wenn nicht, ist durch die Definition einer solchen Instanz die ganze Ontologieunvereinbar.
– Klassifikation, berechnet Klassenbeziehungen und dadurch eine kompletteKlassenhierarchie.
– Realisation, errechnet die direkten Typen für jedes Individuum. Erst nachder Klassifikation möglich, da die direkten Typen im Bezug auf die Klassen-hierarchie beschrieben sind.
Da das Internet ein großes verteiltes System ist, hat man über mancheOntologien die man einbinden muss, keine Kontrolle. So kann es leicht passieren,dass sich das Vokabular der anderen Ontologie mit dem Eigenen überschneidet.Für diesen Fall bietet Pellet drei Lösungsmöglichkeiten an:
– Man kann die verursachende Aussage ignorieren.– Man kann beide verwenden, aber unterschiedlich behandeln.– Die Behandlung der Ontologie zurückweisen.
Anfragen auf Individuuen in den Sprachen SPARQL und RDQL sind „Con-junctive ABox Queries“. Dieser Typ von Anfragen bietet noch wenig Implementie-rungerfahrung, da das Hauptaugenmerk bis jetzt auf dem Reasoning mit Klassenlag. Es ist jedoch anzunehmen, dass sich das in Zukunft ändern wird.
Kein standard Dienst, der aber für die Praxis von großer Bedeutung ist, istdas Debugging. Es ist wichtig semantische Fehler in der Ontologie aufzuspüren.Typischerweise erkennen Reasoner nur Widersprüche und bieten keine Möglichkeitdie Herkunft des Fehlers heraus zu finden. In Pellet gibt es einmal den Ansatz,dass der Fehlerursprung angezeigt wird und zusätzlich die Lösung „axiom tracing“[8]. Sie extrahiert die relevanten Basisaxiome, die den Widerspruch verursachen.
3.2 Architektur und Design
Pellet macht keine eindeutigen Namensannahmen, unterstützt ABox Reasoningund arbeitet mit externen Modulen zusammen, die unter anderem XML Datenty-pen unterstützen. Beeinflusst wurden diese Funktionalitäten durch die Tatsache,dass Pellet speziell als OWL Reasoner gedacht war.
Über Schnittstellen bietet Pellet, dass einen kleinen Kern besitzt, Anschluß-möglichkeiten für Erweiterungen und unterstützt explizit die DIG (DL Imple-mentors Group) Schnittstelle.
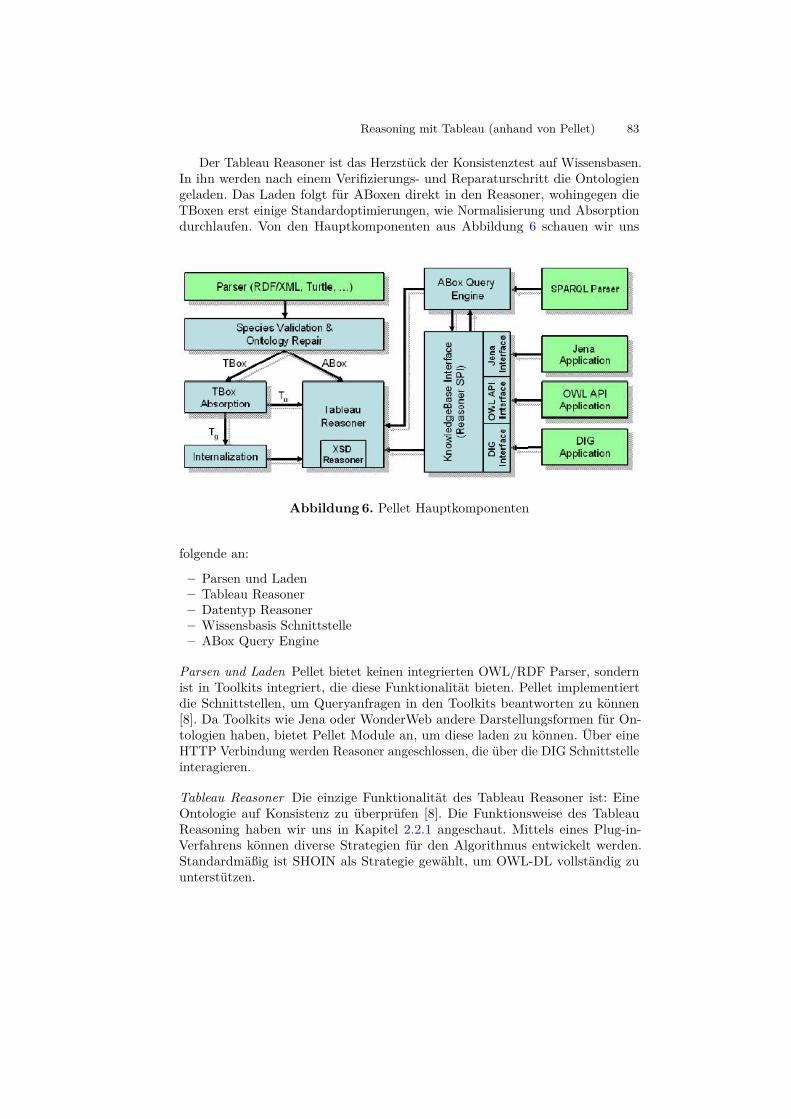
Reasoning mit Tableau (anhand von Pellet) 83
Der Tableau Reasoner ist das Herzstück der Konsistenztest auf Wissensbasen.In ihn werden nach einem Verifizierungs- und Reparaturschritt die Ontologiengeladen. Das Laden folgt für ABoxen direkt in den Reasoner, wohingegen dieTBoxen erst einige Standardoptimierungen, wie Normalisierung und Absorptiondurchlaufen. Von den Hauptkomponenten aus Abbildung 6 schauen wir uns
Abbildung 6. Pellet Hauptkomponenten
folgende an:
– Parsen und Laden– Tableau Reasoner– Datentyp Reasoner– Wissensbasis Schnittstelle– ABox Query Engine
Parsen und Laden Pellet bietet keinen integrierten OWL/RDF Parser, sondernist in Toolkits integriert, die diese Funktionalität bieten. Pellet implementiertdie Schnittstellen, um Queryanfragen in den Toolkits beantworten zu können[8]. Da Toolkits wie Jena oder WonderWeb andere Darstellungsformen für On-tologien haben, bietet Pellet Module an, um diese laden zu können. Über eineHTTP Verbindung werden Reasoner angeschlossen, die über die DIG Schnittstelleinteragieren.
Tableau Reasoner Die einzige Funktionalität des Tableau Reasoner ist: EineOntologie auf Konsistenz zu überprüfen [8]. Die Funktionsweise des TableauReasoning haben wir uns in Kapitel 2.2.1 angeschaut. Mittels eines Plug-in-Verfahrens können diverse Strategien für den Algorithmus entwickelt werden.Standardmäßig ist SHOIN als Strategie gewählt, um OWL-DL vollständig zuunterstützen.

84 P. Kretschmer
Datentypen Reasoner Ein Framework von I.Horrocks und U.Sattler von 2001 istdie Basis für Datentypen Reasoning in Pellet. Es geht in diesem Schritt darum,nicht leere Schnittmengen zwischen Datentypen zu finden, die dann als Konsistentbezeichnet werden.
Wissensbasis Schnittstelle Alle Reasoning Aufgaben können auf einen Wissensba-sis Konsistenztest reduziert werden, wobei man eine geeignete Transformationdurchführen muss [8]. Boolsche Anfragen werden mit Hilfe eines Tests auf Un-erfüllbarkeit und Anfragen die eine Menge als Antwort benötigen auf mehrereKonsistenztest zurückgeführt. Die Wissensbasisschnittstelle bietet die Funktiona-lität solche Queries zu beantworten und setzt auf der Annotated Term (ATerm)Bibliothek auf.
ABox Query Engine Pellet kann Anfragen in SPARQL und RDQL annehmenund transformiert sie in ein internes Format mit dem Modul HP Lab’s ARQ desJena Toolkits. Die ABox Query Engine ist mit dem Tableau Reasoner und derWissensbasis verbunden. Die „Rolling-up“ Technik von Horrocks und Tessaris2002 verwendet die Enginge um Anfragen mit ununterscheidbaren Variablen zuhandhaben. Mehrere Query Engines zusammen beantworten die Anfrage. Die Ers-te analysiert die Anfrage und unterteilt sie gegebenenfalls in mehrere Teilanfragen.Diese werden dann getrennt bearbeitet und am Ende wieder zusammengeführt.
Einige in Pellet implementierte Optimierungen sind in Kapitel 2.3 beschriebenworden. Die Leistung im Vergleich zu anderen Reasonern schauen wir uns in derZusammenfassung an.
4 Zusammenfassung
In dieser Arbeit haben wir uns den Tableaualgorithmus, mit der Beschreibungs-logik ALC angeschaut. Wir haben dabei festgestellt, dass dieser nicht immerterminiert und dass mit Blocking ein Abschluss des Algorithmus immer gewähr-leistet werden kann.
Im Weiteren haben wir Optimierungen des Tableauverfahren kennengelernt,die in Pellet implementiert sind. Abschließend schauen wir uns noch einenLeistungsvergleich zwischen Pellet und anderen hochperfomanten Reasonernan.
Zum Vergleich verwenden wir RacerPro 1.8.2 und FaCT++ 0.99.5. Ausge-schlossen sind „ABox Assertions“, „nominals“ und „qualified number restrictri-ons“, da nicht alle Reasoner diese unterstützen. Die Abbildung 7 zeigt nach obenan der Y-Achse die Zeit in logaritmischer Skala und nach rechts an der X-Achsedie Größe der Ontologien [8]. Wir stellen fest, dass Pellet zwar generell langsamerals beide Konkurenten ist, aber dies in der Praxis nicht so schwer ins Gewichtfallen würde. Für die komplexe Medizinontologie Galen (äußerst rechts) ist Pelletfast zehnmal schneller als FaCT++. Die Leistung von Pellet in einem weiterenTest mit ABox Queries ist im Gegensatz zu RacerPro wesentlich besser.
Die Forscher suchen nach neuen Optimierungen, um eine bessere Performancezu erreichen. Auf diese Weise, hoffen die Forscher in Praxisprojekten größere

Reasoning mit Tableau (anhand von Pellet) 85
Verbreitung zu finden. Ich bin zuversichtlich, dass dies gelingt und der Schulab-solvent auf der Suche nach seinen Traumberuf, effektiv mit semantischer Sucheunterstützt werden kann.
Abbildung 7. Leistungsvergleich Pellet, RacerPro und FaCT++
Literatur
[1] F. Baader and U. Sattler. An overview of tableau algorithms for description logics.2001.
[2] E. Gamma, R. Helm, R. Johnson, and J. Vlissides. Design Patterns: Elements ofReusable Object-Oriented Software. Addison-Wesley, 1995.
[3] P. Hitzler, M. Krötzsch, S. Rudolph, and Y. Sure. Semantic Web. Springer, 2008.[4] P. D. P. Hitzler, D. S. Rudolph, and D. R. Volz. Vorlesung intelligente systeme im
world wide web; web ontology language owl: Semantik. Institut für AngewandteInformatik und Formale Beschreibungsverfahren (AIFB) Universität Karlsruhe(TH), 2007.
[5] B. Hollunder, W. Nutt, and M. Schmidt-Schauß. Subsumption algorithms forconcept description languages. 1990.
[6] I. Horrocks. Implementation and optimization techniques. In Description LogicHandbook, pages 306–346, 2003.
[7] E. Sirin, B. Parsia, and B. C. Grau. From wine to water: Optimizing descriptionlogic reasoning for nominals. 2006.
[8] E. Sirin, B. Parsia, B. C. Grau, A. Kalyanpur, and Y. Katz. Pellet: A practicalowl-dl reasoner. 2005.

Die Anfragesprache SPARQL
Alexander [email protected]
Universität Augsburg
Zusammenfassung Die folgende Arbeit zeigt eine Einführung in SPAR-QL, ihre Sprachkonstrukte, wie man auf die von RDF spezifizierten Datenund Informationen zugreift und den Vergleich zur relationalen Algebra.SPARQL ist die Abkürzung für SPARQL Protocol and RDF QueryLanguage. Nachdem sie beim World Wide Web Consortium (W3C) [8]mehrere Jahre auf der Liste der Candidate Recommandation stand undauch mal wieder verworfen wurde, ist sie aber seit dem 15. Januar 2008 zurendgültigen Recommandation avanciert [6]. SPARQL basiert im Kern aufeinfache RDF Anfragen, deren Komplexität aber durch erweiterte Funk-tionalität, wie zum Beispiel der Konstruktion komplexerer Anfragemusteroder zusätzlicher Filterbedingungen, gesteigert werden kann.
1 Einführung
Im Semantic Web ist es wichtig, einheitliche, offene Standards zu vereinbaren,um Informationen zwischen verschieden Plattformen und Anwendungen aus-zutauschen und in Beziehung setzen zu können. Diese Standards sollten auchdas Ziel der Flexibilität und Erweiterbarkeit erfüllen. Zu diesem Zweck, derSchaffung solcher Standards, hat sich das W3C zusammengeschlossen, welches1994 gegründet wurde. Da es sich bei diesem Consortium um keine anerkannteOrganisation handelt und somit keine festen Standards festlegen darf, handeltes sich bei ihren Arbeiten um sogenannte Recommandations. Empfehlungen,basierend auf Technologien die frei von Patentgebühren sind.
Es wurden bereits wichtige, grundlegende Standards von diesem Consortiumbeschrieben, wie zum Beispiel die Markup- und Meta-Sprache XML (eXtensibleMarkup Language), mit deren Hilfe man eine logische Struktur von Dokumentenfestlegen kann. Auch Spezifikationssprachen wie RDF (Resource DescriptionFramework) und OWL (Web Ontology Language ) sind schon längst als Recom-mandations von der W3C eingestuft.
RDF ist eine allgemeine Sprache zur Beschreibung von Metadaten und struk-turierten Informationen. Es ermöglicht Anwendungen den Austausch von Datenim Web, ohne dabei ihre ursprüngliche Bedeutung zu verlieren.
OWL ist wie RDF auch eine Repräsentationssprache, nur mit dem Unterschiedder höheren Komplexität und Ausdrucksstärke. So ist es hier möglich komplexereSachverhalte und logische Zusammenhänge zu modellieren. Ziel dieser Sprachenist es Informationen auf eine maschinenlesbare Art und Weise zu spezifizieren.

Die Anfragesprache SPARQL 87
Da RDF als Sprache zur Wissensrepräsentation eine der wichtigsten Grundla-gen des Semantic Web darstellt, ist somit der Erfolg des Semantic Web wesentlichabhängig von der Möglichkeit auf eine standardisierte Weise Anfragen auf eineRDF-Datenmenge zu stellen oder generell auf die RDF-Daten zugreifen zu können.Verschiedenste Anfragesprachen, wie zum Beispiel XQuery, RDQL (RDF Que-ry Language, SQL-ähnliche Syntax), SeRQL (Weiterentwickeltung von RDQL)haben sich im Laufe der letzte Jahre entwickelt, doch letztendlich konnte sichkeiner dieser Sprachen durchsetzen. Dies lag nicht nur zuletzt an der teilweisenschwierigen Umsetzung komplexer Semantiken.
Um die Entwicklung eines einheitlichen Standards zu avancieren, wurdeanfang Februar 2004 die RDF Access Working Group von dem W3C gegründet.Es wurden von ihnen Anforderungen einer RDF-Abfragesprache und eine Reihevon Anwendungsfällen für den Zugriff auf RDF-Daten formuliert und könnenin [3] nachgelesen werden. Dabei hat sich über die letzten Jahre SPARQL alsdie geeignete Anfragesprache für RDF herauskristallisiert, die den gestelltenAnforderungen genügte.
Diese Arbeit beginnt mit einer kurzen Einführung in die RDF Syntax, dieals Grundlage für die SPARQL-Anfragen dient. Somit wird der Einstieg in diefolgende komplexere Betrachtung von SPARQL erleichtert. Es wird aufgezeigt,wieso SPARQL es verdient hat als Recommendation eingestuft worden zu sein undwarum SPARQL den geforderten Leistung besser entspricht, als ihre Vorgänger.Danach folgt im Kapitel 3 die Übersetzung von SPARQL in relationale Algebra,welches die formale Semantik beschreibt und den Hauptteil der Arbeit ausmacht.In Kapitel 4 wird die Arbeit um SPARQL-DL, die konjunktive Anfragen zulässt,erweitert. Kapitel 5 gibt eine Zusammenfassung der Arbeit, den Ausblick undden aktuellen Stand von SPARQL wieder.
2 Sprachkonstrukte
2.1 RDF-Graphen und deren Syntax
Das Grundkonzept von RDF ist die Beschreibung von Ressourcen durch eineReihe von Eigenschaften und den zugehörigen Werten, dabei werden Ressourcenin RDF als Entitäten verstanden. Konkrete und abstrakte Gegenstände werdendemzufolge auf Ressourcen abgebildet. Man kann über sie Aussagen treffenund sie untereinander in Beziehung setzen. Als gängige Ressourcen können zumBeispiel Personen, Dokumente, Internetseiten oder reale Dinge, wie die Alpendie als Beispiel während der gesamten Arbeit dienen, verwendet werden. Eine„RDF-Aussage“ besteht somit aus einer Ressource, einer Eigenschaft und ihremWert.
Die genaue Beschreibung der Syntax von RDF-Datenmengen und der Seman-tik kann hier [4] nachgelesen werden. Folgendes Beispiel zeigt einen RDF-Graphenzu drei gegebenen Aussagen. Es dient einerseits der Veranschaulichung mehrererAussagen, andererseits ist das Beispiel eingefügt worden, um in späteren Kapitelndarauf verweisen und zugreifen zu können.

88 A. Matwin
Beispiel 2.1 Aussagen und ihre Darstellung in graphischer Form
„Die Zugspitze hat eine Höhe von 2962 Metern“„Die Zugspitze ist ein Teil der Alpen.“„Die Alpen liegen in Europa.“„Die Zugspitze hat den Namen Zugspitze.“
Abbildung 1. Transformation der Aussagen zu einem RDF-Graphen
Da es nicht immer sinnvoll ist zur Repräsentation von RDF-Daten einenGraphen zu zeichnen, wurde als inoffizielle RDF-Syntax Turtle eingeführt, diedie Beschreibung zulässiger RDF-Graphen zeigt. Natürlich gibt es noch weitereSyntax, um RDF Modelle zu beschreiben, wie XML, N3 oder N-Tripels. Daaber die Anfragesprache SPARQL wie RDF auf der Turtle Syntax basiert, ist esoffensichtlich diese als Standard zu wählen.
Der Graph in Abbildung 1 würde in Turtle wie folgt aussehen:
<http://www.example.org/mountains/Zugspitze><http://www.example.org/mountains/Höhe>„2962 Metern“.
Diese Textdarstellung sieht vor die einzelnen Tripel zeilenweise durch einen Punktgetrennt formal zu notieren. Die Unified Ressource Identifiers (URIs) werdendurch < und > geklammert und Literale in Anführungszeichen gefasst. Die Syn-tax ist bis auf diese Besonderheiten eine direkte Übersetzung des RDF-Graphenin Tripel. Zur Vereinfachung ist es möglich Namensräume zu deklarieren, um dieURIs abzukürzen (wie auch geschehen in Abbildung 1).

Die Anfragesprache SPARQL 89
2.2 SPARQL- Anfragen
In diesem Abschnitt geht es darum zu zeigen wie man speziell auf Informationenin RDF zugreifen kann. Es soll auch aufgezeigt werden, dass im Vergleich zu eineranderen RDF Query Language wie am Anfang beschrieben zum Beispiel XQueryoder RDQL, SPARQL eine weitaus höhere Komplexität bezüglich den Anfragenermöglicht. SPARQL ermöglicht es die Anfragen anhand einiger Kriterien zufiltern, um die Ergebnismenge einzuschränken. So kann zum Beispiel in einemRDF-Dokument nach allen Literalen in deutscher Sprache gesucht werden, wasmit der RDF Query Language RDQL nicht möglich wäre.
2.2.1 Bestandteile einer Anfrage Die SPARQL Anfrage verwendet einenRDF-Graph als Anfragemuster und ist in der Turtle Syntax formuliert. So istein konsistenter Zustand gegenüber dem Description Framework garantiert, derauch seine Daten in der RDF-Tripel Notation abspeichert. Da aber SPARQLgegenüber der RDF-Query Language mehr Komplexität verspricht, führt SPARQLzusätzliche Anfragevariablen ein, um bestimmte Elemente im Anfragegraphenals Ergebnis zu ermitteln. Außerdem kann auch über jede Anfrage, spezielleAusgabeformatierung des Ergebnisses mit angegeben werden.
Eine SPARQL Anfrage basiert auf der Idee des Pattern Matchings. Dies bedeu-tet, dass in einer Anfrage ein Graphmuster beschrieben wird, welches Variablenenthalten kann. Zu diesem Muster werden dann übereinstimmende Teilgraphenaus dem RDF-Graphen bestimmt. Die Variablen werden an die URIs, Literaleoder leere Knoten gebunden und bilden die Lösung der Anfrage.
Beispiel 2.2 Eine Anfrage in SPARQL
PREFIX ex: < http://www.example.org/mountains/>SELECT ?res ?nameWHERE ?res ex:name ?name
Diese Anfrage enthält drei wesentliche Bestandteile PREFIX, SELECT, WHERE.Das Schlüsselwort PREFIX deklariert wie in der Turtle-Notation auch schongezeigt wurde, einen Namensraum. In der SELECT-Klausel, die das Ausgabefor-mat bestimmt, werden alle Lösungen einer Anfrage zurückgeliefert. Die Angabevon Variablennamen nach dem SELECT schränkt das Ergebnis auf diese Attri-bute ein. Es handelt sich um die Bezeichner, für die Rückgabewerte angefordertwurden. Die WHERE-Klausel macht die eigentliche Anfrage aus. In geschweiftenKlammern folgt das Graphmuster, welches die Lösung der Anfrage beschreibt.Sie kann aus einer Kombination von einfachen und komplexen Graphmusternbestehen, welche in den folgenden Abschnitten genauer beschrieben werden.
Demnach liefert die Anfrage aus Beispiel 2.2 als Ergebnis Ressourcen mitdem jeweiligen dazugehörigen Namen. Wendet man diese Anfrage auf den RDFGraphen aus Abbildung 1 an erhält man folgende Lösung:

90 A. Matwin
?res ?namehttp://www.example.org/mountains/Zugspitze Zugspitze
Tabelle 1. Lösung einer Anfrage
2.2.2 Einfache Graphmuster Bei der vorgestellten Anfrage handelt es sichin der WHERE-Klausel um ein einfaches Graphmuster. Dieses Muster bestehtaus Tripeln die eine Turtle-ähnliche Syntax aufweisen. Im Gegensatz zu Turtle,können aber Variablenbezeichner wie zum Beispiel ?res verwendet werden. DieseBezeichner stehen für Platzhalter, die erst nach der Anfrage mit konkreten Wertenaus dem gegebenen Datenbestand gefüllt werden. Das einfache Graphmusterenthält demnach eine Menge von Tripelmustern, in denen anstatt den RDF-Ausdrücken für Subjekt, Prädikat und Objekt Variablen stehen können. Eswerden dann alle Teilgraphen (Tripel) im RDF-Graphen gesucht, die der Anfrageentsprechen und an die Variablen gebunden.
2.2.3 Leere Knoten in SPARQL Im allgemeinen dienen leere Knoten inRDF dazu, Beziehungen zwischen mehr als zwei Ressourcen zu kodieren. Dies wirddurch Hilfsknoten ermöglicht, welche aber lediglich eine strukturelle Funktionbesitzen und nicht auf Ressourcen verweisen, die beschrieben werden sollen. Sokönnen bei der Darstellung von mehrwertigen Prädikaten leere Knoten eingeführtwerden.
Auch bei SPARQL kommen die leeren Knoten auf verschiedene Weise zumEinsatz. Auf der einen Seite können leere Knoten in Anfragen als Subjekteund Objekte vorkommen. Sie können wie Variablen auch bei der Durchführungeiner Anfrage mit Werten des RDF-Graphen belegt werden. Jedoch zählt dieseBelegung nicht zum Ergebnis dazu und eine Auswahl mit SELECT ist auchnicht möglich. Mittels der festgelegten ID eines leeren Knotens kann er öftersinnerhalb eines Graphmusters verwendet werden, jedoch nicht außerhalb inanderen Mustern. Dies muss vor allem bei gruppierten und komplexen Musternberücksichtigt werden. Auf der anderen Seite kann ein leerer Knoten auch wiederim Ergebnis auftauchen. Dies ist dann der Fall wenn der RDF-Graph auch leereKnoten besitzt. Das Vorkommen eines leeren Knotens in der Ergebnismengesichert lediglich die Existenz des entsprechenden Knotens im Anfragegraphen,gibt aber keine Auskunft über dessen Identität wieder. Leere Knoten erhalten inder Ergebnismenge zwar eine ID, doch ist diese komplett unabhängig von derBezeichnung des leeren Knotens im Eingabegrahen. Liefert die Ergebnismengeallerdings mehrere leere Knoten mit der gleichen ID zurück, bedeutet dies, dasssie sich auf das selbe Element im Anfragegraphen beziehen. Dies kann natürlichverschiedene Auswirkungen auf die Vergleichbarkeit von Ergebnissen haben.
2.2.4 Komplexe Graphmuster In SPARQL ist es möglich aus mehrereneinfachen Graphmustern komplexere Muster zu erzeugen, welche man als grup-pierendes Graph-Muster bezeichnet. Dies ermöglicht, bestimmte Bedingungen

Die Anfragesprache SPARQL 91
nur an einen Teil des gesamten Musters zu stellen. So können zum Beispiel einigeTeilmuster optional oder mehrere alternative Muster definiert werden. Dazu ist esnotwendig, einzelne einfache Graphmuster mit Hilfe von geschweiften Klammernvoneinander zu trennen. Diese Aufteilung macht aber nur Sinn, wenn zusätzlicheAusdruckmittel verwendet werden können. SPARQL bietet hier die Möglichkeitvon optionalen Informationen. Das optionale Graphmuster dient den Abfragenvon unvollständigem Wissen, da eventuell Daten nicht vorliegen können. Hierfürmuss dem Graphmuster das Schlüsselwort OPTIONAL vorangestellt werden.Ein optionales Graphmuster (G,O) besteht aus zwei Graphmustern G und O,welches als Lösung entweder eine Lösung von G und O oder nur eine Lösungvon G hat. Im letzteren Fall sind die Variablen von O ungebunden, da sie keinerLösung im RDF-Graphen entsprechen. Das optionale Graphmuster muss folglichnicht bei allen Ergebnissen vorkommen, doch wenn sie vorkommen, tragen siezur zusätzlichen Informationsgewinnnung bei.
Beispiel 2.3 Folgende WHERE-Klausel fragt nach den Namen aller Berge undfalls bekannt dem Datum seiner Erstbesteigung
WHERE ?res ex:name ?name .OPTIONAL?res ex:erstBesteigung ?datum .
Gruppierende Graphmuster finden nicht nur bei optionalen Mustern Verwendung.Sie können auch für verschiedene alternative Muster benutzt werden. Mit demSchlüsselwort UNION lassen sich zwei gruppierende Graphmuster verketten. AlsLösung enthält man die Menge, die entweder zu einem der Graphmuster oder zubeiden paßt. Der Operator UNION kann als Logisches Oder verstanden werden.
Beispiel 2.4 Folgende WHERE-Klausel fragt nach den Namen aller Berge welchesich entweder in den französischen oder deutschen Alpen befinden
WHERE ?res ex:name ?name;
ex:teilvon ex:französischeAlpen.UNION?res ex:name ?name;
ex:teilvon ex:deutscheAlpen.
Abschließend sei noch erwähnt, dass Kombinationen von OPTIONAL- undUNION- Graphmustern möglich und diese auch auf jeweils mehreren Musterngrößer zwei verknüpfbar sind.

92 A. Matwin
2.2.5 Anfragen mit Datenwerten Im Gegensatz zu den anderen Anfra-gesprachen wie zum Beispiel RDQL ist es in SPARQL möglich Anfragen mitDatenwerten zu stellen. Dabei unterscheidet SPARQL in typisierte und unty-pisierte Datenwerte. Liegt ein RDF-Literal in untypisierter Form vor, so kannmittels einer SPARQL-Anfrage ohne Benennung des Typs nach ihm gesuchtwerden. Dabei werden allerdings die Literale mit Typisierung nicht mit in dieErgebnismenge aufgenommen. Enthalten die Literale jedoch einen Datentypoder eine Sprachinformation (zum Beispiel in der Form einer Sprachangabe wie„wert“@de), ist es wichtig dies auch in der Anfrage zu berücksichtigen und dengesuchten Typ mitanzugeben.Eine Anfrage wie
?subjekt <http://example.org/p> "test" .
würde bei folgendem RDF-Dokument
ex:bsp1 ex:p "test" .ex:bsp2 ex:p "test"@de .
nur auf die Daten von bsp1 passen.Diese Eigenschaft ermöglicht es SPARQL mit Hilfe der Angabe des Sprachcodesin der Anfrage, in einem RDF-Graphen nach allen Literalen zum Beispiel indeutscher Sprache zu suchen.
2.2.6 Filter Oft reichen optionale oder alternative Bedingungen nicht aus,wenn zum Beispiel nach Werten in einem bestimmten Bereich gesucht werdensoll, oder nach Literalen in denen ein bestimmtes Wort vorkommt. Ein weiteresProblem das durch die Verwendung von Sprachangaben auftritt ist, dass nichtnach einem Wert gesucht werden kann, wenn man die Sprachangabe nicht kennt.Diese Anfragen können in SPARQL mit Hilfe von verschiedenen Filterbedingun-gen gelöst werden. Sie dienen dem Zweck Ergebnismengen weiter einzuschränken.In dieser Arbeit wird nur ein ein Teil der Filterbedingungen vorgestellt. Einekomplette Auflistung sämtlicher Filter ist in [5] zu finden
Beispiel 2.5 Folgendes Beispiel zeigt, wie man in einer SPARQL Anfrage Fil-terbedingungen einsetzt
WHERE ?res ex:name ?name .OPTIONAL?res ex:erstBesteigung ?datumFILTER (?datum > 1800)
Dieses Beispiel zeigt auf, dass Filter, eingeleitet durch das Schlüsselwort FILTER,auch in gruppierenden Graph-Mustern eingesetzt werden können, auch wenn sie

Die Anfragesprache SPARQL 93
Bestandteile von Optionen oder Alternativen sind. Als Ergebnis dieser Anfrage,werden alle Namen der Berge und falls bekannt nur die Daten ausgegeben, wenndie Erstbesteigung nach 1800 war.
In Beispiel 2.5 wurde der Vergleichsoperator > (größer) als Filterbedingungvorgestellt. Weitere Vergleichsoperatoren wie = (gleich), < (kleiner), <= (kleiner/-gleich), >= (größer/gleich) und != (ungleich) können der Anfrage für Vergleichedienen. Dabei ist zu beachten, dass nur verträgliche Datentypen untereinanderverglichen werden können. Der Vergleich selber Datentypen macht SPARQL keineProbleme, so lassen sich Zeitangaben, numerische Werte, Wörter und getypteWerte ohne Sprachangabe vergleichen.
SPARQL bietet auch die Möglichkeit durch spezielle Operatoren bestimmteBedingungen zu testen oder auf einen Teil des Literals zuzugreifen. Mit Hilfe desOperators LANG(A) wird zum Beispiel der Sprachcode des Literals als Stringzurückgeliefert. Mit dem Operator STR(A) lässt sich ein Literal oder eine URIauf ein String abbilden. Diese unären Operatoren vereinfachen die Abfrage undschränken die Ergebnismenge weiter ein. Ein nützlicher binärer Operator ist derREGEX(A,B) Operator. Er liefert ein true zurück, wenn in der Zeichenkette A,der Ausdruck B gefunden werden kann. So lassen sich zum Beispiel bestimmteLiterale durch die Angabe eines Wortes selektieren.
Durch die booleschen Operationen && (logisches und), || (logisches oder)und ! (logische Negation) können mehrere Filterbedingungen verkettet oder eineBedingung umgedreht werden. Dadurch werden komplexere Anfragen möglichund die Ausdrucksstärke wird erhöht. Abschließend sollen noch die arithmetischenOperatoren kurz erwähnt werden, mit denen man numerische Werte entsprechendberechnen kann. Es stehen hier die vier Grundrechenarten zur Verfügung.
2.2.7 Ausgabeformate Eine SPARQL-Anfrage besteht unter anderem auchaus der Spezifikation einer Ergebnisform. Es wurden in sämtlichen Beispielendie an SQL-angelehnte SELECT-Klausel verwendet, die alle Lösungen einerAnfrage ausgibt. Dies kann jedoch wie bei SQL auch zu Redundanzen führen.Um dem entgegen zu wirken sind weitere Ergebnisformen, wie CONSTRUCT,ASK und DESCRIBE möglich, die alle eine unterschiedliche Ausgabeform haben.Die CONSTRUCT-Klausel kann in Verbindung mit anderen Graphmusterndazu verwendet werden, als Ergebnisform wieder einen neuen generierten RDF-Graphen zu erhalten. Dabei werden die Variablen durch die, entsprechend in derLösung gefundenen URIs oder Werte ersetzt.
Bei Anfragen mit dem Schlüsselwort ASK, kann geprüft werden, ob es für dasangegebene Graphmuster überhaupt eine Lösung im untersuchten RDF-Graphengibt. Bei dieser Wahl der Ergebnisform entfällt die WHERE-Klausel und eintrue oder false wird zurückgeliefert.
Als vierte Ergebnisform ist die DESCRIBE-Klausel zulässig. Es kann hier eineMenge der zu beschreibenden Ressourcen ausgewählt werden. Der Ergebnisformist wiederrum ein RDF-Graph, der die gefundene Lösung beschreibt.

94 A. Matwin
2.2.8 Modifikatoren Trotz der vielen Möglichkeiten Ergebnisse anhand vonFilterbedingungen oder verschiedenen Anfragemustern zu spezialisieren, kann dieresultierende Lösungsmenge immer noch sehr groß sein. Um hier noch eine gewisseStruktur zur ermöglichen, bietet SPARQL Modifikatoren an. Sie ermöglichen dieLösungsmenge anhand von verschieden Kriterien zu sortieren. Auch hier lehntsich SPARQL sehr stark an die SQL-Syntax an wie folgendes Beispiel zeigt.
Beispiel 2.6 Diese Anfrage sortiert die Berge anhand ihrer Höhe
SELECT ?res ?höheWHERE ?res ex:erstBesteigung ?datum .ORDER BY ?datum
Hier werden die Berge aufsteigend nach dem Datum ihrer Besteigung aus-gegeben. Eine absteigende Sortierung kann durch den Zusatz DESC(?datum)erreicht werden. Eine ORDER BY Anweisung kann nur auf eine SELECT An-weisung ausgeführt werden. Über das Schlüsselwort SORT BY kann explizit dieSortierreihenfolge für jede Variable einzeln bestimmt werden.
Um einen Ausschnitt einer Ergebnismenge bei allen Ergebnisformen zu er-halten, werden die Schlüsselwörter LIMIT und OFFSET benötigt. Dabei gibtLIMIT die Anzahl der Ergebnisse an während OFFSET die Stelle angibt, wo mitder LIMIT Zählung begonnen werden soll.
Eine zusätzlich Möglichkeit große Mengen zu reduzieren ist das SchlüsselwortDISTINCT, welches auch nur direkt nach dem SELECT auftreten darf. Esentfernt eventuelle Redundanzen aus der Ergebnismenge.
3 Übersetzung von SPARQL in relationale Algebra
Im vorherigen Kapitel wurde vorgestellt, wie man mit SPARQL als Anfragespra-che auf RDF-Mengen Lösungen finden und die Lösungsmenge durch Filterope-rationen und Ausgabeformen reduzieren kann. Das folgende Kapitel beschreibteine Übersetzung von SPARQL in relationale Algebra, eine formale abstrakteSprache um Anfragen besser analysieren zu können. Wie wichtig die relationaleAlgebra ist, zeigt ihre heutige Verwendung: sie dient als theoretische Grundlagefür Anfragesprachen in relationalen Datenbanken. Es werden Operatoren definiert,die auf Mengen von Relationen anwendbar sind, um so Relationen verknüpfen,filtern oder umbenennen zu können.
Da SPARQL sich auch stark an die relationale Abfragesprache SQL anlehnt,dürfte die Transformation dem einen oder anderen vertraut vorkommen. AlsDatenquelle der SPARQL-Anfragen werden wieder RDF-Dokumente dienen. Soberuht die vorgestellte Algebra auf Operationen von RDF-Relationen. Einigevon ihnen gleichen denen der relationalen Algebra, andere wiederum sind leichtmodifiziert worden, um die SPARQL Semantik beschreiben zu können.
Die Vorteile einer solchen Transformation liegen klar auf der Hand. Aufder einen Seite lassen sich durch die Darstellung von komplexeren Anfragenauf einen Operatorbaum, die Anfragen besser planen oder optimieren. Auf der

Die Anfragesprache SPARQL 95
anderen Seite können durch die Transformationen auf relationale Algebra, schonentwickelte und erprobte Algorithmen angewandt werden. So ist zum Beispiel eineAnwendung des Hill-Climbing Algorithmus nach der Transformation denkbar,um die Anfrage zu optimieren.
Einen vorläufigen Überblick soll folgende Transformation einer SPARQL-Anfragein einen relationalen Operatoraum bringen.Beispiel 3.1 Diese Anfrage liefert Namen von Personen und wenn vorhandenderen Emailadresse
SELECT ?name ?nicknameWHERE ?person rdf:type foaf:Person .?person foaf:name ?name .OPTIONAL ?person foaf:nick ?nickname
π?name,?nickname
:./
./
π?person←?subject
σ ?predicate=rdf:type?object=foaf:Person
Triples
π ?person←?subject?name←?object
σ?predicate=foaf :name
Triples
π ?person←?subject?nickname←?object
σ?predicate=foaf :nick
Triples
3.1 Relationemodell für RDF Terme
Als Erstes wird hier das Relationemodell für RDF Terme definiert, bevor einerelationale Definition von SPARQL gegeben werden kann. Ein RDF Term bestehtwie in Kapitel 2 auch schon erwähnt entweder aus URIs, aus Literalen oderleeren Knoten. Diese Terme sind die Skalare, welche die Werte des hier vorge-stellten Relationenmodell repräsentieren. Auch der Begriff der Anfrage-Variablenkommt uns von SPARQL vertraut vor und wird hier genauso mit einem ? vordem Namen dargestellt. Der Begriff des RDF-Tupels muss noch neu eingeführtwerden. Es handelt sich hier um eine partielle Funktion, welche die Menge derVariablen auf die Menge der Terme abbildet. Ein Tupel könnte wie folgt aussehen:

96 A. Matwin
t =
?person → < http : //example.org/people/Simon >?name → “Simon“?nickname→ “Sam“?age → “23“
Im Unterschied zu den bereits vorgestellten RDF Tripeln, können die Tupelseine beliebige Anzahl von Komponenten beinhalten, die untereinander in keinersemantischen Relation stehen müssen. Dies ist bei den Tripeln natürlich nicht derFall, da die Komponenten Subjekt, Prädikat und Objekt durchaus in Beziehungstehen und dies auch den Sinn eines RDF-Tripel ausmacht. Ein Tupel kann alseine Art Container verstanden werden, der Variablen auf RDF-Terme abbildet. Esstellt jedoch kein Problem dar jedes RDF-Tripel auch als RDF-Tupel, allerdingsohne Semantik, darzustellen. Man spricht dann von einem S/P/O Tupel. Oftwird auch noch in gebundene oder freie Attribute unterschieden, je nachdem obsie in der Tupeldomäne auftreten oder nicht. Unter einem Attribut versteht mandie Variablen, die in einem Tupel vorkommen.
3.1.1 RDF Relationen Um bei mehreren Tupel die Übersicht nicht zu ver-lieren, ist es möglich sie in einer Tabelle anzuordnen, indem die Zeile einemTupel entspricht und die Spalte einem Attribut der durch einen Variablennamendeklariert ist. Man spricht bei so einer Ansammlung von Tupeln, von einer RDFRelation. Eine sinnvolle Wahl von Variablennamen, die zugleich die Überschriftender Spalten sind, lässt Schlussfolgerungen über mögliche Operationen mit anderenRelationen ziehen. Anhand der Attribute von jedem Tupel lassen sich intuitiv die„richtigen“ Überschriften finden. Dabei kann es auch vorkommen, dass bei einemTupel ein Attribut nicht vorkommt und somit ungebunden ist. Dies entspricht inetwa dem NULL bei SQL.Beinhaltet eine Relation die Überschriften ?Subject, ?Prädikat, ?Objekt sprichtman von einer Graph Relation. Diese Relation besitzt nur S/P/O Tupel, die gleichden RDF-Tripeln sind. Daraus folgt, das jeder Graph-Relation ein RDF-Graphzugeordnet werden kann und umgekehrt. In den folgenden Kapiteln werdenallgemeine Operatoren auf RDF-Relationen vorgestellt, die anschließend nochmit SPARQL-spezifischen Semantiken komplettiert werden.
3.1.2 Selektion Bei der Selektion (σ) werden diejenigen Tupel einer Relationausgewählt, die das sogennante Selektionsprädikat erfüllen [2]. Dies lässt sich inSPARQL durch den Schlüsselbegriff FILTER realisieren. Durch die Filter-Klauselwird auch der Wertebereich durch Vergleichsoperatoren eingeschränkt. Es lassensich auch so genannte konstante Attribut-Selektionen durchführen. So kann manzum Beispiel nur Tupel filtern, welche als Prädikat die gleiche URI besitzen.σ?predicate=ex:name(R)

Die Anfragesprache SPARQL 97
3.1.3 Projektion und Umbennung Die Projektion (π) enthält die Mengeder Attributnamen im Subskript [2]. Sie ermöglicht zum Beispiel nur auf dasSubjekt oder das Objekt zu selektieren. Durch den Umbenennungsoperator kannder Varialenname ?subject in ?person geändert werden.π ?person←?subject
?name←?object(R)
3.1.4 Inner Join und Left Outer Join In der regulären relationalen Al-gebra werden mit der Operation Inner Join (./) mehrere Tabellen verbunden,sofern zumindest ein Attribut in beiden Tabellen übereinstimmt. In dem hiervorgestellten Modell gibt es einen kleinen Unterschied. Ein gemeinsames Attributist jedes Attribut, wenn es in beiden Relationen gebunden ist.
Ein Inner Join fasst zwei Tabellen über die gemeinsamen Attribute zusammen.Dabei beinhaltet A Join B alle Kombination eines Tupels von A mit einem Tupelvon B, allerdings ohne die Tupel die keinen Joinpartner im gemeinsamen Attributhaben.
Der Left Outer Join (:./)hingegen nimmt diese Tupel mit auf, und das fehlendeAttribut wird in diesem Tupel zu einem ungebundenen.
?person ?name ?parentex : Simon “Simon“ ex : Peterex : Simon “Simon“ ex : Claudiaex : Tanja “Tanja“
Tabelle 2. Tabelle mit einem ungebundenem Attribut
3.1.5 Union Der Union Operator in dem hier vorgestellten Relationenmodell,ist die Vereinigungsmenge der Tupeln von A mit den Tupeln von B. Dabeibleiben ungebundene Variablen auch in der Lösungsrelation ungebunden. DieAttributsmenge ergibt sich aus der Vereinigung der jeweiligen Attribute beiderRelationen.
3.2 Relationale Definition für SPARQL
Wie schon in Kapitel 2.2.1 beschrieben, besteht eine SPARQL-Anfrage aus einenRDF-Graphen als Anfragemuster. Diese Graphenmuster können einfache, aberauch sehr komplexe Struktur aufweisen. So gibt es die Möglichkeit aus mehrereneinfachen Mustern ein komplexeres Graphmuster zu erstellen, um auf diesemweitere Operationen durchzuführen. Hier seien nochmal die SchlüsselwörterOPTIONAL oder UNION aus Kapitel 2.2.4 erwähnt.
Ziel in diesem Abschnitt wird sein, eine Übersetzung der verschiedenen An-fragemuster von SPARQL-Anfragen in einen Ausdruck, des in Kapitel 3.1 de-finierten Relationenmodells, zu finden. Diese basieren auf einer Reihe von Re-chenoperationen, welche die verschiedenen Ausdrucksmöglichkeiten einer Anfrage

98 A. Matwin
repräsentieren. Unterschieden werden Operatoren, die der Beschreibung einesGraphen-Muster dienen, von jenen, die Modifikatoren der Ergebnismenge aus-drücken. Die hier relevanten Operatoren sind InnerJoin, LeftOuterJoin, Filterund Union. Jeder dieser Operatoren liefert das Ergebnis einer Teilanfrage. Wiediese Teilanfragen in einem komplexen Graphmuster ausgewertet werden, giltes hier zu klären. Das Ergebnis der Übersetzung eines Graphmuster wird auchPattern Relation genannt.
Da die einfachste SPARQL-Anfrage aus einem RDF-Tripel besteht, bildetdieses Tripel auch den Anfang, bevor mit weiteren komplexeren Strukturen, wiegruppierende Graphmuster und Filter fortgesetzt wird.
3.2.1 Tripel - Suchmuster Eine Pattern Relation aus einer einfachen RDF-Tripel Anfrage erhält man durch eine konstante Attribut-Selektion auf daskonkrete Attribut (meist das Prädikat) und durch Projektion und Umbenennungder Variablen.
Beipiel 3.2 Transformation einer einfachen Anfrage eines RDF-Tripel in einerelationale Operation
?person foaf:name ?name
wird in diese relationale Operation übersetzt:
π ?person←?subject?name←?object
(σ?predicate=foaf :name)
3.2.2 Gruppierte Graphmuster, OPTIONAL und FILTER Innerhalbeines gruppierten Muster ist die Reihenfolge der Abarbeitung der einzelnen Musterirrelevant solange sie nicht mit OPTIONAL verbunden sind. Die Übersetzungerfolgt folgendermaßen [7]:
1. Bildung der InnerJoins für alle Tripel-Suchmuster und Vereinigungen (UNI-ON). Dabei spielt hier die Reihenfolge keine Rolle, da der InnerJoin kommu-tativ und assoziativ ist.
2. Bildung des LeftOuterJoin aller optionalen Blöcke (OPTIONAL) mit demResultat aus 1., in der Reihenfolge wie sie in der Anfrage vorkommen. Dabeibildet das optionale Suchmuster die rechte Seite des OuterJoins.
3. Wende jede Werteeinschränkung (FILTER) durch den Selektionsoperator aufdie Ergebnisse aus 2. an.
Beispiel 3.3 Transformation eines gruppierten Musters in einen relationalenAusdruck
p1 . FILTER (p) . OPTIONAL p2 . p3 .

Die Anfragesprache SPARQL 99
wird übersetzt in
σp((p1 ./ p3) :./ p2)
Dabei stehen die Abkürzungen p1, p2, p3 für beliebige einfache Suchmusterin der SPARQL Syntax und wurden der Übersichtlichkeit halber so dargestellt.
3.2.3 UNION UNION bezieht sich nur auf die direkt angrenzenden einfachenoder auch gruppierenden Graphmustern. Relationen werden vereinigt, sobaldeine Relation auf die Anfrage passt. Ihr Relation Pattern wird wie in der Anfrageübersetzt.
3.3 Probleme bei der Übersetzung
Die meisten SPARQL Anfragen könne ohne größere Probleme in relationaleAlgebra übersetzt werden. Allerdings gibt es auch besondere Fälle, die eigensbetrachtet werden müssen. In dieser Arbeit werden zwei wichtige Transformations-probleme angesprochen. Um einen Gesamtüberblick aller Probleme zu bekommen,sei auf [7] verwiesen.
3.3.1 FILTER Variablen Problem FILTER-Ausdrücke in SPARQL könnenbeliebige Variablen benutzen, egal ob die Variablen innerhalb der Teilanfragevorkommen oder in einem anderen Suchmuster außerhalb verwendet werden.Dies würde bei der genauen Übersetzung in einen Operatorbaum einen Fehlerverursachen. Da sich die Selektion nur auf Variablen innerhalb des Unterbaumes,wo sie vorkommt beziehen und nicht auf Variablen außerhalb Einfluss nehmenkann, führt folgendes Beispiel zu einer nicht korrekten Lösung.
Beispiel 3.6 Die Selektion im rechten Unterbaum hat keine Funktion und be-zieht sich nicht auf die Variable im linken Unterbaum:
:./
π ?x←?subject?type←?object
σ?pred=rdf :type
Triples
σ?type=foaf :Person
π ?x←?subject?name←?object
σ?pred=foaf :name
Triples
Um diesem Problem aus dem Weg zu gehen, kann man die Selektionsbedin-gung von FILTER im JOIN formulieren. Dadurch befindet sich die Einschränkung

100 A. Matwin
am Verzweigungsknoten und kann auf beide Unterbäume angewandt werden.Man spricht von einem bedingten JOIN.
Beispiel 3.7 Lösung des FILTER Variablen Problems
:./?type=foaf :Person
π ?x←?subject?type←?object
σ?pred=rdf :type
Triples
π ?x←?subject?name←?object
σ?pred=foaf :name
Triples
3.3.2 Geschachtelte OPTIONS Bei geschachtelten OPTIONS kann dasErgebnis der relationalen Algebra zur SPARQL Semantik unterschiedlich sein.Die SPARQL-Semantik sieht eine Abarbeitung der LeftOuterJoins (OPTIONAL)in der Reihenfolge, wie sie in der Anfrage vorkommen vor. Diese entspricht einerAuswertung im Operatorbaum von links nach rechts. Im Gegensatz dazu steht dieAusführung von unten nach oben beim Operatorbaum der relationalen Algebra.
Dies führt zu einem Problem bei zwei in sich verschachtelten OPTIONALS.Wenn eine Variabel außerhalb der OPTIONAL-Ausführung und in dem innerstenOPTIONAL-Ausdruck, aber nicht in dem zweiten OPTIONAL verwendet wird,kann eine verschiedene Bindung beteiligter Variablen durch eine unterschiedlicheAusführung auftreten.
Dieser exklusive Fall tritt allerdings in der Praxis nicht sehr häufig auf undkann deshalb meist vernachlässigt werden.
4 SPARQL-DL
Die bisherigen SPARQL-Anfragen legten alle eine RDF-Datenmenge zu Grunde.Dies bedeutet, dass im Graphmuster einer Anfrage immer ein, oder bei komplexe-ren Suchmustern, mehrere RDF-Tripel festgelegt waren. Dieses Kapitel erweitertdas Spektrum nicht auf die Suche in RDF-Graphen, sondern wie man auch fürOntologien in Ontologiensprachen wie OWL-DL Anfragen stellen kann. Kom-plexe Ontologien bestehen meist nicht aus einfachen Graphen sondern besitzeneine Vielzahl unterschiedlicher Interpretationen. Ziel wird es sein eine einfacheAnfragesprache zu beschreiben die mit SPARQL einhergeht aber auch OWL-DLunterstützt. SPAQRL-DL macht hier einen Schritt in die richtige Richtung.
Als erstes müssen die syntaktischen Unterschiede von SPARQL und OWL-DLaufgezeigt werden, um eine Sprache zu entwickeln die mehrere flexible Anfragenauf unterschiedlichen Modellen erlaubt [1].

Die Anfragesprache SPARQL 101
4.1 SPARQL Syntax
RDF-Graphen bestehen aus einer Menge von SPO-Tripeln, in der jedes Tripeleine semantische Bedeutung hat. Die Elemente der Tupel können entweder ausleeren Knoten Vbnodes einer URI Vuri oder einem Literal Vlit bestehen. Dies lässtsich formal folgendermaßen festhalten:
(s,p,o) ∈ (Vuri ∪ Vbnodes)× Vuri × (Vuri ∪ Vbnode ∪ Vlit)
4.2 OWL-DL Syntax
Obwohl man bis zu einem gewissen Grad, in den Interpretationen von OWLGraphen erkennen kann, ist die Semantik eine andere. Die Menge der URIsVuri teilt sich in viele verschiedene Teilmengen auf. Formal besteht ein OWL-DLVokabular Vo = (Vcls,Vop,Vdp,Vap,Vind,VD,Vlit) aus einem 7-Tupel. Die Bedeutungdieser Teilmengen und deren Grammatik können in [1] nachgelesen werden.
Eine OWL-Ontologie besteht hauptsächlich aus einer endlichen Menge vonKlassen, Eigenschaften, den Properties und speziellen Axiomen. Klassen undProperties können in komplexe Beziehungen gesetzt werden, die mit Hilfe vonKonstruktoren aus der Logik beschrieben werden.
Es ist leicht erkennbar, dass sich das Vokabular und die Namensräume Vuri derRDF-Datenmenge zum Vokabular der OWL-Ontologie unterscheiden. Es musseine Interpretationsfunktion gefunden werden, die beide Vokabularien verträglichmacht. Als erstes wird eine abstrakte Syntax für SPARQL-DL Anfragen definiert,ihre Semantik beschrieben und anschließend wird die abstrakte Syntax in dasTripelmuster von SPARQL überführt.
4.3 SPARQL-DL Abstract Syntax
Folgendes OWL-DL Vokabular liegt vor: Vo = (Vcls,Vop,Vdp,Vap,Vind,VD,Vlit).Vbnode und Vvar bilden die Mengen der leeren Knoten und Variablen. Eineatomare SPARQL-DL Anfrage q kann eine dieser Formen annehmen:q ← Type(a,C) | PropertyValue(a,p,v) | SameAs(a,b) | DifferentFrom(a,b)|EquivalentClass(C1, C2) | SubClassOf(C1, C2) | DisjointWith(C1, C2)|ComplementOf(C1, C2)| EquivalentProperty(p1, p2) | SubPropertyOf(p1, p2)|InverseOf(p1, p2)| ObjectProperty(p)| DatatypeProperty(p)| Functional(p)|InverseFunctional(p) | Transitive(p) | Symmetric(p) | Annotation(s, pa, o)mit a,b ∈ Vuri∪Vbnode∪Vvar, v ∈ Vuri∪Vlit∪Vbnode∪Vvar, p, q ∈ Vuri∪Vvar, C,D ∈Sc ∪ Vvar, s ∈ Vuri, pa ∈ Vap, o ∈ Vuri ∪ Vlit. Eine allgemeine Anfrage Q setzt sichaus einer endlichen Menge von q-Anfragen zusammen. Diese werden mit einerKonjunktion verbunden und nennt sie deswegen auch eine konjunktive Anfrage.
4.4 SPARQL-DL Semantik
Wie können nun diese atomaren Anfragen interpretiert werden? Die SPARQL-DLSemantik ist ähnlich der OWL-DL Semantik. Es müssen Kriterien spezifiziert

102 A. Matwin
werden unter denen eine Interpretation eine atomare Anfrage erfüllt. Dabei wirdausgegangen, dass leere Knoten in den atomaren Anfragen vorkommen können.
Sei O eine OWL-DL Ontologie mit Vo wie in Kapitel 4.3 definiert und I dieInterpretation von O mit I = (4I , I). Eine atomare Anfrage passt zu Vo , wennalle URIs in der Anfrage ihrem korrekten Typ/Menge zugeordnet sind, zumBeispiel Type(a,C) mit a ∈ Vind und C ∈ Vcls. Eine Durchführung σ überprüftob ein Element aus Vind ∪ Vbnode ∪ Vlit auf ein Element der InterpretationenDomäne 4I überführt werden kann, mit der Bedingung, dass σ(a) = aI wenna ∈ Vind oder a ∈ Vlit.
Eine Interpretation I erfüllt eine Anfrage q hinsichtlich σ, wenn q mit Voübereinstimmt und die entsprechende Bedingung aus Abbildung 2 erfüllt ist.
Eine Interpretation I erfüllt eine Anfrage Q = q1 ∧ q2 ∧ ... ∧ qn bezüglich σwenn auch für alle qi ∈ Q für jedes i=1,....,n I bezüglich σ gilt.
Die Lösung zu einer SPARQL-DL Anfrage Q ist, wenn durch eine Varia-blenüberführung µ der Form Vvar → Vuri ∪ Vlit alle Variablen in Q durch denentsprechenden Wert in µ ersetzt werden können. Die Anfrage µ(Q) ist mit demVokabular von O verträglich und man sagt auch O ist ein Modell von µ(Q).
Abbildung 2. SPARQL-DL Anfrage und die Kriterien der Interpretation [1]
4.5 SPARQL-DL Abstract Syntax in RDF-Graphen
Dieser Abschnitt beschäftigt sich mit der Übersetzung von der SPARQL-DLabstract Syntax in das RDF Tripelmuster. Dabei wird die Funktion T wie in[2] benutzt, welche komplexe Klassenausdrücke in ein oder mehrere RDF Tripelübersetzt. Wenn eine Komponente bei der Übersetzung als Subjekt, Prädikatoder Objekt verwendet wird, bedeutet dies, dass diese Übersetzung einen Teil

Die Anfragesprache SPARQL 103
des Ergebnisses ausmacht. Dieses Element ist dann auch Teil des Tripels. DieÜbersetzung einer SPARQL-DL Anfrage ist die Vereinigung aller RDF-Tripel,die durch die Übersetzung jeder atomaren Query erhalten wurde. Abbildung 3zeigt die Umformungen der Abstract Syntax in RDF-Tripel.
Abbildung 3. Überführung der SPARQL-DL Syntax in RDF-Tripel [1]
5 Zusammenfassung
In dieser Arbeit wurde als erstes ein kleiner Einblick in das Resource DescriptionFramework gegeben, welches als formale Sprache für die Beschreibung sturktu-rierter Daten dient. Um nun auf diesen Datenbestand zugreifen zu können, hatsich letztendlich die Anfragesprache SPARQL durchgesetzt. Es wurden hier diewichtigsten Ausdrucksmittel von SPARQL vorgestellt, zugleich nicht auf jedeAusdrucksform im Detail, im Rahmen der Seminarabeit, eingegangen werdenkonnte. Die verschiedenen Anfragebedingungen in Form von unterschiedlichenGraphmustern und Filtern sowie Modifikatoren und Ausgabeformate haben ge-zeigt, dass SPARQL eine hohe Vielfalt und Komplexität bezüglich dem Zugriffauf spezifizierte Informationen bietet.
Im dritten Kapitel wurde durch die Transformation in relationale Algebradie genaue Semantik der Ausdrucksmittel beschrieben. Ein Relationenmodellund die dazu gehörigen Mengenoperationen für RDF-Terme wurden eingeführtund vorgestellt. Diese Umsetzung von SPARQL-Anfragen in relationale Algebraist nicht nur mit Aufwand verbunden, sondern bringt mehrere Vorteile mit sich.Abgesehen von einer graphisch, verständlicheren und vertraulicheren Darstellungzum Beispiel durch einen Operatorbaum, liegt es nicht fern SPARQL Anfragenauch nach SQL zu übersetzten. Da es momentan immer noch viel mehr SQLServer als SPARQL-Anfrage Server gibt. „Der Übergang von der Industrie-

104 A. Matwin
zur Informationsgesellschaft findet seine wohl markanteste Ausprägung in derrasanten Entwicklung des World Wide Web.“[5] Um nun diese Entwicklungvorwärts zu treiben ist eine Umstrukturierung der Informationen notwendig. DasWeb bietet heutzutage eine unüberschaubare Menge an Informationen, die auf denMenschen ausgerichtet ist. Ziel ist es aber die Bedeutung einer Information nichtnur für den Menschen interpretierbar zu machen sondern auch maschinenlesbar.Dies würde eine semantische Suche ermöglichen. „Das Semantic Web steht fürdie Idee, die Information von vornherein in einer Art und Weise zur Verfügungzu stellen, die deren Verarbeitung durch Maschinen ermöglicht.“[5] Diesen Ansatzverfolgt das World Wide WEB Consortium, welches durch ihre Standards wieden XML und RDF Informationsspezifikationssprachen und nicht zuletzt derAbfragesprache SPARQL den Weg in die Zukunft ebnen.
SPARQL war in letzten Jahren meist nur als Anfragesprache für RDF-Graphengeeignet. Dies hat sich aber in letzter Zeit gewandelt. SPARQL-DL unterstütztnicht mehr nur die RDF-Semantik sondern teilweise auch die Semantik von OWL,wie in Kapitel 4 beschrieben. Sie kann als Sprache aufgefasst werden, die zwischeneiner RDF Anfragesprache und einer reinen Anfragesprache für die DescriptionLogic (DL) liegt. Ziel wird es sein, in nähere Zukunft eine Abfragesprache zugenerieren die sämtliche Ausdrucksformen von SPARQL auch auf komplexereOntologien erlaubt. SPARQL-DL ist schon mal ein Schritt in die richtige Richtung.
Literatur
[1] E.Sirin and B.Parsia. Sparql-dl:sparql query for owl-dl. 2007.[2] F.Patel-Schneider and I.Horrocks. Owl web ontology language, 2004.[3] K.Clark. Rdf data access use cases and requirements, 25-03-2005.[4] P.Hayes. Rdf semantics, 10-02-2004.[5] P.Hitzler, M.Krötzsch, S.Rudolph, and Y.Sure. Semantic Web. Springer-Verlag,
2008.[6] R.Cover. W3c publishes sparql recommendation, 15-01-2008.[7] R.Cyganiak. A relational algebra for sparql. 28-09-2005.[8] W3C. W3c world wide web consortium.

Ontologie-Methodologien und Ontologie Design
Benedikt Gleich
Universität [email protected]
Zusammenfassung Das Design von Ontologien für praktische Anwen-dungen ist eine Aufgabe mit zunehmender Komplexität, so dass eine un-strukturierte und manuelle Entwicklung kaum noch sinnvoll ist. Ontologie-Methodologien liefern strukturierte Vorgehensanweisungen für den Prozessdes Ontology Engineering in seiner Gesamtheit und beziehen dabei auchprojektspezifische Fragestellungen mit ein. Ontologie Design Patternsadressieren dagegen den konkreten Modellierungs-Prozess und bietenhierbei konkrete Anleitungen für wiederkehrende Problemklassen. DaOntologien eine Schlüsseltechnologie für das Semantic Web darstellen,ist auch deren konkrete Syntax (z.B. RDF/OWL) genauso relevant wiees semantische Ähnlichkeiten zu bekannteren Techniken wie UML sind.Da es noch viele praktische Herausforderungen im Ontologie Design gibt,verspricht dieses Forschungsfeld auch langfristig spannende Fragen undAntworten.
1 Einleitung
Ontologien sind ein sehr mächtiges Werkzeug imWissensmanagement und darüberhinaus eine der Schlüsseltechnologien des Semantic Web. Mit ihnen lassen sichnicht nur statische Taxonomien, sondern dynamische Abbilder der realen Welterstellen, aus denen mit Inferenz-Regeln verschiedenste Aussagen abgeleitetwerden können.
Da Ontologien erhebliche Mengen von Wissen akkumulieren sollen, ist ihreEntwicklung ein langwieriger und komplexer Prozess. In dieser Arbeit sollenunter anderem Techniken beschrieben werden, mit denen dieser Entwicklungspro-zess methodisch und strukturiert durchgeführt werden kann. Zusätzlich werdenOntologien gegen andere Modellierungstechniken abgegrenzt und gegenwärtigeHerausforderungen kurz behandelt.
Ontologie-Methodologien liefern Empfehlungen, wie die Entwicklung einerOntologie organisiert werden kann. Zusätzlich findet man in Ontologie DesignPatterns eine Reihe von praktischen Techniken, die bei der Modellierung einzelnerKonzepte hilfreich sind.
Im Folgenden sollen nach einer kurzen Abgrenzung zwischen Ontologien undanderen Modellierungstechniken wie UML verschiedene Ontologie-Methodologiengenauer beschrieben werden. Darauf folgt eine Betrachtung verschiedener On-tology Design Patterns (ODPs). Die Arbeit schließt mit der Untersuchung vonpraktischen Herausforderungen und einer Zusammenfassung.

106 B. Gleich
1.1 Definitionen
Für den Begriff der Ontologie gibt es eine Vielzahl von unterschiedlich intuitivenDefinitionen[2]. Die bekannteste und in gewisser Weise „klassische” Definitionstammt von Thomas Gruber[12]:
„An ontology is an explicit specification of a conceptualization.”
Nicht zuletzt aufgrund ihrer Kürze ist diese Definition nicht besonders in-tuitiv, besonders im Vergleich zu folgender Beschreibung [3], die die einzelnenBestandteile von Ontologien beschreibt:
„An ontology is a hierarchically structured set of concepts describing aspecific domain of knowledge that can be used to create a knowledgebase. An ontology contains concepts, a subsumption hierarchy, arbitra-ry relations between concepts, and axioms. It may also contain otherconstraints and functions.”
2 Unterschiede zwischen Ontologien und UML
Durch den hohen Abstraktionsgrad des Konzeptes von Ontologien gibt es häufigVerwirrung bei der Abgrenzung zu anderen Modellierungs-Techniken wie UMLoder auch zu Wissensrepräsentations-Sprachen wie XML.
Grundsätzlich kann man festhalten, dass Ontologien in der Regel in XML-Dialekten (wie z.B. RDF / OWL) gespeichert und ausgetauscht werden. Abgese-hen davon haben Ontologien eine eigene Semantik, die speziell auf die abstrakte,aber dennoch praktisch einsetzbare Beschreibung von Sachverhalten der realenWelt ausgerichtet ist.
Eine andere Natur hat das Verhältnis zwischen Ontologien und UML Modellenund insbesondere Klassendiagrammen. Letztere können sowohl Code-Klassen inder objektorientierten Programmierung, als auch fachliche Sachverhalte der realenWelt beschreiben. Gerade das entspricht aber in vielen Aspekten dem Konzeptvon Ontologien. In der Tat ist es auch möglich, Übersetzungen zu definieren, mitdenen z.B. in OWL definierte Ontologien nach UML oder auch UML-Modellenach OWL abgebildet werden können [11, 1, 13].
Da es jedoch für die Erstellung von Ontologien inzwischen Tools wie protégégibt, die ähnlich leicht wie UML-Editoren zu bedienen sind, ist der Einsatz vonUML zur Modellierung von Ontologien grundsätzlich vor allem in Ausnahmefälleninteressant.

Ontologie-Methodologien und Ontologie Design 107
3 Ontologie Methodologien
Der Entwurf von Ontologien – das Ontology Engineering – erfährt in den letztenJahren eine Entwicklung, die mit der des Software Engineering vergleichbarist: Beide Bereiche streben ingenieursmäßige, also methodische und planbareEntwicklungsprozesse an.
Ontologie-Methodologien beschäftigen sich mit der grundlegenden Fragestel-lung im Ontology Engineering: Welche Methoden, Aktivitäten und Annahmensind für die Erstellung von Ontologien zu empfehlen?[5]. Die Methodologiendes Ontology Engineering sind sehr heterogen und stark von ihren jeweiligenAnwendungsgebieten abhängig. Daher sollen nach der Vorstellung einer möglichenKlassifizierung einige konkrete Ansätze zur Methodik im Ontology Engineeringgenauer beschrieben werden.
Bei der Betrachtung der verschiedenen Methodologien zeigt sich in der zeitli-chen Entwicklung eine qualitative Veränderung: Während die frühen Methodolo-gien wie Uschold/King oder Grüninger/Fox nur grundlegende und unvollständigeVorgehehensmodelle vorschlagen, liefern fortgeschrittene Varianten wie Methon-tology oder Ontology Development 101 bereits umfassende Empfehlungen fürden gesamten Projektumfang und den Lebenszyklus des Ontology Design. Dahersollen diese im Folgenden als Methodologien der zweiten Generation bezeichnetwerden, während die frühen Methodologien die ersten Generation darstellen. Diedritte Generation wird von Methodologien gebildet, die über das reine OntologyDesign hinaus auch alle anderen Rahmenbedingungen des Ontology Engineeringwie iterative Entwicklung oder Aspekte der Kollaboration einbeziehen.
3.1 Klassifikation
Von Mariano Fernández López werden insgesamt neun verschiedene Kriterienvorgeschlagen[15], mit denen Methodologien zum Design von Ontologien klassifi-ziert werden können:
C1: Einflüsse durch Knowledge Engineering Bereits vor dem breiten Ein-satz von Ontologien gab es Ansätze zum „Wissensmanagement”. Es ist hilf-reich für das Verständnis von Methodologien, sie auf diese Einflüsse hin zuüberprüfen.
C2: Detailgrad der Methodologie Wie detailliert wird das empfohlene Vor-gehen beschrieben? Sind das konkrete Vorgehen und der Einsatz von ToolsBestandteil der Methodologie?
C3: Art und Weise der Formalisierung Wie soll das zu erfassende (seman-tische) Wissen syntaktisch abgebildet werden?
C4: Anwendungsabhängigkeit Gibt es einen konkreten Anwendungsbereich,auf den die Methodologie ausgelegt ist oder findet die Entwicklung abstraktstatt?
C5: Vorgehen zur Auswahl von Konzepten Hier gibt es die grundlegendenKonzepte „bottom-up” (von konkreten zu abstrakten Konzepten), „middle-out” (von den wichtigsten Konzepten zu den abstrakteren und konkreteren)sowie „top-down” (von abstrakten zu konkreten Konzepten).

108 B. Gleich
C6: Empfehlungen zum Lebenszyklus? Wird auf implizite oder expliziteWeise ein bestimmter Lebenszyklus für die zu entwickelnde Ontologie vorge-schlagen, etwa durch Angabe der erwarteten Lebensdauer?
C7: Standardkonformität Bezieht sich die Methodologie auf die im IEEE-Standard 1074-1995 beschriebenen Methoden zur Entwicklung von Software-Produkten?
C8: Empfohlene Techniken Gibt es konkrete Vorschläge, wie bestimmte Ak-tivitäten im Ontology Engineering ausgeführt werden sollen?
C9: Anwendung Welche Ontologien und welche Systeme wurden mit der vor-geschlagenen Methodologie bereits entwickelt?
Obwohl diese Kriterien schon 1999 vorgestellt wurden, stellen sie doch nachwie vor ein hilfreiches Raster zur Analyse der vielen verschiedenen Methodologiendar, die nun im einzelnen kurz vorgestellt werden sollen.
3.2 Methodologien der ersten Generation
3.2.1 Uschold/King Die Methode Uschold/King [17, 15, 5] ist eine der erstenvorgeschlagenen Methodologien. Sie empfiehlt im Wesentlichen vier Phasen:
1. Ermittlung der genauen Zielsetzung2. Entwicklung der Ontologie
(a) Erfassung der Konzepte(b) Kodierung(c) Integration existierender Ontologien
3. Evaluation4. Dokumentation
Dabei werden für die Erfassung der Konzepte (ontology capture) die dreiMethoden top-down, bottom-up und middle-out – jedoch mit Präferenz auf derletzten – vorgeschlagen. Eine der wichtigsten Anwendungen dieser Methodologieist die so genannte Enterprise Ontology, die eine Sammlung wichtiger Begriffe ausdem betriebswirtschaftlichen Umfeld darstellt. Insgesamt geht die Unschold/King-Methode allerdings nur auf wenige Aspekte des Ontology Engineering ein, womitbei ihrer Anwendung viele Fragen offen bleiben.
3.2.2 Grüninger/Fox Die Grüninger/Fox-Methode [10, 15] ist ebenfalls einesehr frühe Methodologie, die sehr stark durch den Einsatz der PrädikatenlogikErster Ordnung geprägt ist. Dabei werden sechs verschiedene Phasen unterschie-den:
1. Erfassung von Motivations-Szenarien Meist ist die Entwicklung von neu-en Ontologien durch Mängel in aktuellen Ontologien oder den Wunsch nachbestimmten Neuerungen motiviert. Diese Motive und insbesondere die erhoff-ten neuen Ergebnisse sollten hier festgehalten werden.

Ontologie-Methodologien und Ontologie Design 109
2. Informelle Formulierung von zentralen Anfragen Diese Fragen (com-petency questions) dienen als Benchmark für die spätere Entwicklung derOntologie. Mit ihnen kann die Terminologie überprüft werden. So zeigt sich,ob Axiome und Definitionen ausreichend sind.
3. Formale Spezifikation der Ontologie Hierfür werden zuerst aus den zen-tralen Anfragen die wichtigsten Begriffe extrahiert, um diese dann in einenFormalismus zu überführen.
4. Spezifizierung von zentralen Anfragen Die bereits informell festgehalte-nen zentralen Anfragen müssen nun formal spezifiziert werden.
5. Spezifizierung von Axiomen und Definitionen Ebenso wie die zentra-len Anfragen müssen auch die Axiome und Definitionen spezifiziert werden,um sie praktisch einsetzen zu können.
6. Definition der Vollständigkeitsbedingungen Die nun spezifizierte Onto-logie kann natürlich nur unter bestimmten Bedingungen vollständige Ant-worten liefern. Diese Bedingungen müssen nun festgehalten werden.
Wiederum fehlen in dieser Methodologie eine Reihe von wichtigen Angaben,etwa zum Lebenszyklus der zu entwickelnden Ontologie oder zu empfehlenswertenTechniken und Tools. Im Gegensatz zur Uschold/King-Methode werden abereventuelle Anwendungen zumindest in den Entwicklungsprozess einbezogen. Insge-samt ist die Uschold/King-Methode heute nur noch für spezielle Anwendungsfällezu empfehlen.
3.3 Methodologien der zweiten Generation
3.3.1 Methontology Während die bisher geschilderten Methodologien derersten Generation angehören, handelt es sich bei Methontology bereits um eineMethodologie der zweiten Generation: Analog zum Software Engineering werdendort nicht nur die Kernaktivitäten der Entwicklung einer Ontologie, wie etwa dieSpezifikation und Konzeptualisierung, sondern auch „Umgebungsbedingungen”wie Lebenszyklen oder konkrete Techniken beschrieben, was auch in Abbildung 1dargestellt ist.
Diese verschieden Aktivitäten des „Ontology Development Process” könnendabei in drei Klassen eingeteilt werden[7, 15]:
Projektmanagement Hierbei sind die klassischen Aktivitäten Planung, Über-wachung und Qualitätssicherung zu nennen, die für die erfolgreiche Entwick-lung einer Ontologie notwendig sind.
Entwicklung Die Entwicklung setzt sich aus den Tätigkeiten Spezifikation, Kon-zeptualisierung, Formalisierung und Implementierung zusammen. Dabei wirdin der Spezifikation beschrieben, warum die Ontologie entwickelt wird undwie bzw. von welchen Nutzern sie benutzt werden soll. Während im Rahmender Konzeptualisierung das vorhandene Wissen strukturiert wird, wird es imRahmen der Formalisierung in ein möglichst automatisiert verarbeitbaresModell transformiert. Nach der Implementierung, in der die Ergebnisse dervorherigen Schritte zu einem System zusammen gesetzt werden, folgt die

110 B. Gleich
Abbildung 1. Bestandteile des Ontologie Design Prozesses von Methontology
Wartungsphase, in der Fehler behoben und neue Anforderungen umgesetztwerden.
Support In den Bereich des Support fallen die Aktivitäten des Ontology Engi-neering, die vor und nach der eigentlichen Entwicklung stattfinden. Dabeisind Aktivitäten wie die Aneignung des notwendigen Wissens (KnowledgeAcquisition), die Evaluation der Ergebnisse oder die Integration eventuellerverwendeter Ontologien zu nennen. Genauso entscheidend ist auch die Doku-mentation der Ergebnisse sowie ein dediziertes Konfigurationsmanagement.
Für die konkrete Entwicklung identifiziert Methontology dabei eine Reihe vonKomponenten[4]:
– Konzepte– Relationen– Instanzen– Konstanten– Attribute– Formale Axiome– Regeln
Diese Komponenten werden überwiegend im üblichen Sinne verwendet. BeiAttributen wird zwischen Instanzattributen und Klassenatributen unterschieden:Erstere beziehen sich auf Eigenschaften von Instanzen (z.B. „Name” bei einerkonkreten Person), während sich Letztere sich auf das (abstrakte) Konzept ansich beziehen und weder vererbt noch in die Instanzen übernommen werden.
Der Unterschied zwischen Axiomen und Regeln besteht darin, dass Axiomeüberwiegend im Sinne von Integritätsbedingungen verwendet werden, die immerwahr sein müssen, während Regeln die Basis für das Reasoning darstellen.
Analog zum Software Engineering ist auch im Ontology Engineering eingezieltes und geplantes Vorgehen unverzichtbar. Daher werden diese Aktivitäten

Ontologie-Methodologien und Ontologie Design 111
durch den Ontology Life Cycle in einen zeitlichen Zusammenhang gesetzt, der inAbbildung 2 illustriert wird.
Abbildung 2. Die Verteilung der einzelnen Tätigkeiten von Methontology
Darüber hinaus stellt Methontology auch Tools wie ODE oder WebODE zurVerfügung, wobei allerdings zusätzlich auch andere Tools verwendbar sind.
Insgesamt präsentiert sich Methontology als durchdachte und umfassendeSammlung von Methoden zur Entwicklung von Ontologien. Die vielen verschie-denen Anwendungen, etwa aus der Rechtswissenschaft [4] oder der Chemie [16],zeigen die vielseitige Anwendbarkeit.
3.3.2 Ontology Development 101 Während die bisher geschilderten Metho-dologien sich überwiegend auf einem relativ abstrakten Niveau bewegen, liefertder Artikel „Ontology Development 101: A Guide to Creating Your First Onto-logy” [19] eine sehr anschauliche und pragmatische Methodologie für OntologieDesign.
Dabei stellen die Autoren ihren Ausführungen einige allgemeine Grundregelnvoran:
– Es gibt keine Patentlösung für Ontologie-Design. Die optimale Methodologiehängt immer von der jeweiligen Anwendung und den erwünschten Ergebnissenab.
– Ontologie-Design ist zwangsläufig ein iterativer Prozess.– Die Konzepte sollten sich möglichst an Objekten und Relationen des Anwen-
dungsbereiches orientieren. Dabei werden Objekte durch Substantive undRelationen durch Verben beschrieben.

112 B. Gleich
Darauf aufbauend wird dort eine konkrete und praxisnahe Vorgehensweisebeschrieben, mit der eine Ontologie für den Anwendungsbereich verschiedenerWeinsorten mit Hilfe des Ontologie-Editors protégé entwickelt werden könnte.Dieses Vorgehensmodell gliedert sich in sieben Schritte:
1. Bestimmung von Anwendungsbereich und Zielsetzung der OntologieAm Anfang sollte festgelegt werden, wofür die Ontologie in welchem Bereichbenutzt werden sollte und welche Arten von Anfragen an sie gestellt werden.Dafür empfehlen die Autoren die bereits geschilderten zentralen Anfragen(competency questions) aus der Grüninger/Fox-Methode. Darüber hinaussollte erwähnt werden, wer die Ontologie warten und benutzen wird.
2. Wiederverwendung überprüfen Nach dem ersten Schritt ist es sehr emp-fehlenswert, zu überprüfen, ob wirklich eine neue Ontologie entwickelt werdenmuss oder ob es nicht bereits eine bestehende Ontologie gibt, die die Anfor-derungen weitgehend erfüllt.
3. Auflistung wichtiger Begriffe Als Grundlage für die nächsten Schritte soll-ten nun alle wichtigen Begriffe des Anwendungsbereiches möglichst vollständigaufgelistet werden, ohne auf etwaige Überschneidungen zu achten.
4. Definition von Klassen und deren Hierarchie Dafür eignen sich die be-reits genannten Methoden top-down, bottom-up oder eine Kombination ausbeidem. Die Hierarchie sollte dabei in der Form „ist ein” („is a”: subsum-tion/subclass) entwickelt werden: Wenn jede Instanz von B eine auch eineInstanz von A ist, dann ist B eine Unterklasse A.
5. Definition von Klassen-Eigenschaften In dieser Phase können meist dieim 3. Schritt erstellten Begriffe, die nicht im 4. Schritt als Klassen verwen-det wurden, herangezogen werden: Höchstwahrscheinlich repräsentieren sieEigenschaften. Dabei sind intrinsische (z.B. Geschmack) und extrinsische(z.B. Name) Eigenschaften zu unterscheiden. Weiterhin können diese sichauf Teile einer Klasse beziehen (z.B. die Flasche eines Weins) oder für eineRelation stehen (z.B. zum Weingut). Eigenschaften werden dabei häufig auchals „Slots” bezeichnet.
6. Definition von „Aspekten” Für die angelegten Slots müssen nun „Aspek-te” definiert werden, die auch als „facets” bezeichnet werden. Diese Beziehensich auf Typisierung, Wertebereich oder Kardinalität. Ein Wein kann bei-spielsweise aus mehreren Rebsorten zusammengesetzt sein.
7. Erstellung von Instanzen Um die erstellte Ontologie nun anzuwenden,müssen konkrete Instanzen erstellt werden, so dass auch die anfangs formu-lierten zentralen Anfragen überprüft werden können.
Das in „Ontology Development 101” geschilderte Vorgehen ist also sehrhilfreich und empfehlenswert für erste praktische Versuche mit Ontologien, wennauch weniger wissenschaftlich als die anderen Methodologien.
3.4 Methodologien der dritten Generation
Im Vergleich zu den bisher geschilderten Methodologien unterscheiden sich dieMethodologien der dritten Generation vor allem dadurch, dass sie über den

Ontologie-Methodologien und Ontologie Design 113
eigentlichen Ontologie-Design-Prozess hinaus gehende Empfehlungen geben. Ins-besondere bilden sie viele aus dem Software Engineering bekannte Techniken aufdie Erstellung von Ontologien ab und vollziehen damit den Schritt vom reinenOntology Design zum Ontology Engineering.
3.4.1 Methodologien und Software Engineering Schon bei Methontolo-gy ist ein deutlicher Bezug zum Software-Engineering anhand der Unterteilungin Management, Entwicklung und Support erkennbar: Während im Projektma-nagement die Kosten, Termine und Qualität miteinander abgeglichen werden,entspricht die Entwicklung in Methontology dem Design und der Implementierungim Software Engineering. Der Support schließlich entspricht im Wesentlichen denPhasen Analyse, Test und Wartung.
Daran zeigt sich, dass Ontologien zwar keine Software-Anwendungen imklassischen Sinne sind, aber grundsätzlich im Rahmen von ähnlichen kontrolliertenund methodischen Prozessen entwickelt werden können und sollten. Dieser Ansatzwird von der Methodologie UPON [18] weiter verfeinert: UPON steht dabei für„Unified Process for Ontology Building”. Der Ansatz besteht also darin, für dieEntwicklung von Ontologien einen iterativen, inkrementellen und an Use-Casesorientierten Prozess einzuführen. Dabei gibt es grundsätzlich fünf verschiedeneAbläufe (Anforderungen, Analyse, Design, Implementierung und Test) sowie injeder Iteration vier Phasen (inception, elaboration, construction und transition).
Auch die Methodologie On-To-Knowledge [23] setzt ihre Schwerpunkte imorganisatorischen Ablauf von Projekten, die durch fünf Phasen gekennzeichnetsind:
– Machbarkeits-Studie– Kick-off– Verfeinerung– Evaluierung– Wartung
Dabei sind die Phasen Verfeinerung und Evaluierung iterativ angelegt. Paral-lelen zu klassischen Software-Entwicklungs-Modellen sind hierbei offensichtlich.
Diese Parallelen zum Software Engineering sind dabei keineswegs weit her-geholt, sondern in den meisten Fällen mit nur geringen Anpassungen direktfür Ontologie-Methodologien anwendbar. Es empfiehlt sich also grundsätzlich,bekannte und bewährte Methoden aus dem Software Engineering für das On-tologie Design anzuwenden – sei es nun durch die Nutzung von dediziertenMethodologien wie UPON oder Methontology oder einfach durch die individuel-le Übertragung von bewährten Praktiken, soweit sie im Ontology Engineeringnützlich sein können.
3.4.2 Kollaborative Methodologien Neben der Anlehnung an Technikendes Software Engineering liegt ein weiterer wesentlicher Aspekt aktueller Metho-dologien in der Betonung des kollaborativen Ansatzes.

114 B. Gleich
Bei genauerer Betrachtung wird schnell klar, dass Ontologien anders als klas-sische Software-Systeme eine noch stärkere Interaktion der Beteiligten erfordern,da eine Arbeitsteilung im Ontologie Design nicht einfach durch die Aufteilung inverschiedene Module realisiert werden kann: Insbesondere muss auch die vertikaleKonsistenz gewährleistet werden, etwa durch die Verwendung einer gemeinsamenBasis-Ontologie.
Genau diesen Ansatz verfolgt die Methodologie DOGMA-MESS (Desi-gning Ontology-Grounded Methods and Applications – A Meaning EvolutionSupport System) [6]: Ontologien werden dabei auf mehreren verschiedenen Ebe-nen verwendet: Es gibt eine permanente Meta-Ontologie, die Begriffe wie Objekt,Prozess oder Akteur definiert. Diese wird durch die „Upper Common Ontology”verfeinert, in welcher ein einzelner Domain-Experte für die gesamte Organisa-tion geltende Ableitungen von der Meta-Ontologie vornimmt. Diese Ontologiewird dann von mehreren verschiedenen Domain-Experten wiederum zu einer„Lower Common Ontology” verfeinert, in der dann schließlich die konkreten undAbteilungs-spezifischen Konzepte und Sachverhalte modelliert werden.
So kann sichergestellt werden, dass parallele Entwicklungen von verschiedenenArbeitsgruppen automatisch ein gewisses Maß an Konsistenz aufweisen, da sieauf einer gemeinsamen Grundlage beruhen. Dabei ist zu erwähnen, dass für jedeOntologie jeweils im Wesentlichen ein Experte zuständig ist; die Zusammenarbeitfindet also vertikal und nicht horizontal oder Ontologie-intern statt. So werdenReibungsverluste vermieden und die Entwicklung von konsistenten Ontologienerleichtert.
Eine ähnliche Struktur beschreibt auch die Methodologie DILIGENT (DIs-tributed, Loosely-controlled and evolvInG Engineering of oNTologies) [20], diefünf Phasen beinhaltet:
1. Entwicklung (build)2. Lokale Anpassung (local adaption)3. Analyse (analysis)4. Bereinigung (revision)5. Lokale Überarbeitung (local update)
Zu Beginn entwickelt eine Gruppe von Domain-Experten, Anwendern undOntologie-Entwicklern eine erste Entwurfsversion der jeweiligen Ontologie. Imnächsten Schritt sind die Anwender frei, die initiale Ontologie für ihren eigenenBedarf anzupassen und zu verändern. Daraus entstehen nun verschiedene undin der Regel auch widersprüchliche lokale Ontologien, die von einem Ausschussmit Vertretern aller beteiligten Parteien regelmäßig analysiert und bereinigtwerden, so dass sich die lokal angepassten Ontologien nicht zu weit auseinanderentwickeln. Ist die Bereinigung durch den Ausschuss erfolgt, müssen die Anwenderihre lokalen Kopien soweit überarbeiten, dass die Konsistenz zur bereinigtenVersion weitestgehend wiederhergestellt wird.
Es zeigt sich also, dass eine pragmatische Ontologie-Methodologie ein de-diziertes Change Management erfordert. Dabei spielt es natürlich eine großeRolle, wie die Beteiligten ihre Änderungswünsche kommunizieren bzw. insgesamt

Ontologie-Methodologien und Ontologie Design 115
miteinander interagieren. Diese Perspektive ist auch kennzeichnend für die Metho-dologie HCOME (Human-Centered Ontology Engineering Methodology) [14].Dort wird explizit zwischen „privaten” und „gemeinsamen” Phasen des Ontolo-gy Engineering entschieden. Beispielsweise wird die Spezifikation grundsätzlichgemeinsam durchgeführt, während die Konzeptualisierung ganz überwiegend inEinzelarbeit erfolgt. Die Details von HCOME können auch aus Abbildung 3entnommen werden.
Abbildung 3. Die Verteilung von privaten und gemeinsamen Aktivitäten inHCOME
Insgesamt liefern die geschilderten kollaborativen Ansätze wertvolle Anre-gungen für die Entwicklung von umfangreichen und praktisch anwendbarenOntologien. Ein semantisches Web kann nur entstehen, wenn eine möglichstgroße Anzahl von Beteiligten im Ontology Engineering vernetzt wird, so dassstatt vieler inkompatibler Ontologien wenige möglichst vereinbare Ontologienentstehen können. Die geschilderten Methodologien rücken dieses Ziel zumindestetwas näher.
3.5 Vergleich und Bestandsaufnahme
Anhand der geschilderten Methodologien lässt sich sehr gut die wissenschaftlicheEntwicklung im Bereich Ontology Engineering nachvollziehen: Waren die erstenbeiden Beispiele (Uschold/King und Grüninger/Fox) noch sehr rudimentäreAnsätze, die heute nur noch in Ausschnitten Anwendung finden, haben die

116 B. Gleich
nachfolgenden Methodologien Methontology und Ontology Development 101bereits einen durchaus ausgereiften Stand erreicht, der im Folgenden durchMethoden wie DILIGENT, HCOME, DOGMA oder UPON nur noch weiterdifferenziert und verfeinert wird.
Dem entsprechend ist auch der Nutzen für konkrete Anwendungen zu sehen:Während Methontology und Ontology Development 101 sich als „Universalwerk-zeug” für die verschiedensten Anwendungen eignen, dabei aber kollaborativeAnsätze nicht einbeziehen, sind DILIGENT, HCOME und DOGMA dann emp-fehlenswert, wenn das Ontology Design in nennenswertem Maßstab mit vielenverschiedenen Beteiligten durchgeführt wird. Ebenso ist der Ansatz von UPONbesonders für große Ontologie-Projekte interessant, an denen eine erheblicheAnzahl an Mitarbeitern dauerhaft beschäftigt ist.
Die nächste große Herausforderung für Ontologie-Methodologien wird darinbestehen, die in der Theorie bereits sehr ausgereiften Techniken auch im prakti-schen Umfeld über rein akademische Experimente oder Feldstudien hinaus zuerproben.
4 Design Patterns
Die vollständig manuelle Entwicklung von Ontologien ist heute nicht mehr prakti-kabel, weshalb Methoden für die effiziente semi-automatische Erstellung benötigtwerden. Ontologie Design Patterns (ODPs) spielen dabei eine wichtige Rolle:„Patterns have proved to be a fruitful way to handle the problem of reuse.” [3]
Grundsätzlich bezeichnen ODPs eine Reihe von Design-Richtlinien: „OD-Ps name, abstract and identify ontological design structures, individual terms,composed larger expressions, and related semantic contexts.” [22]
Um die Vorteile von Design Patterns für Ontologien im praktischen Einsatznutzen zu können, ist angesichts der wachsenden Vielfalt eine Klassifikationvon Ontology Design Patterns sehr hilfreich.
Bisher sind ODPs weitgehend auf bestimmte Spezialgebiete ausgerichtet. [3]schlägt eine allgemeine Klassifikation von Patterns nach verschiedenen Abstraktions-Ebenen vor, die auch in Abbildung 4 illustriert sind:
Application Patterns Ontology Application Patterns beschreiben allgemeineVorgehensweisen, wie die jeweilige Ontologie zu verwenden ist, insbesonderewas ihren Zweck, ihren Kontext und ihre Schnittstellen anbelangt.
Architecture Patterns Ontology Architecture Patterns sollen dagegen helfen,die grobe Struktur von Ontologien zu entwickeln. Insbesondere geht es hierum die Art und Weise der Partitionierung großer und komplexer Ontologien.
Design Patterns Klassische Ontology Design Patterns beschreiben ein allge-meines und wiederholtes Konstrukt in Ontologien. Durch ihre hohe Spezifitätkönnen sie auch in der automatischen oder semi-automatischen Erstellungverwendet werden.
Semantic Patterns Semantic Patterns dienen zur sprachunabhängigen Be-schreibung bestimmter Konzepte (beispielsweise durch Prädikatenlogik).

Ontologie-Methodologien und Ontologie Design 117
Syntactic Patterns Syntactic Patterns beziehen sich auf die Art und Weiseder syntaktischen Notation von Ontologien.
Abbildung 4. Die Hierarchie von ODPs nach Blomqvist
4.1 Design Patterns aus der MolekularbiologieEines der wichtigsten Anwendungsgebiete von ODPs ist die Molekularbiologie, woschon sehr lange mit umfangreichen Ontologien gearbeitet wird [22]. Dort werdeninsgesamt sieben verschiedene grundlegende Design Patterns vorgeschlagen, dieganz überwiegend so abstrakt sind, dass sie ohne Weiteres in anderen Fachgebietenangewendet werden können:
Definition-Encapsulation Dieses ODP erleichtert den Umgang mit verschie-denen Definitionen des selben Begriffes. Anstatt jede Definition einzeln zu

118 B. Gleich
modellieren (und damit die Ontologie sehr unübersichtlich zu machen), kön-nen verschiedene Definitionen durch ein Interface gekapselt werden, so dassdie Benutzer leichter und strukturierter die passende Definition auswählenkönnen.
Expression-Composer Häufig gibt es komplexe Ausdrücke, die sich aus meh-reren einzelnen Komponenten zusammensetzen – in der Molekularbiologiebetrifft dies insbesondere die Namen von komplexen Molekülen. Diese könnenüber einen „Organizer” und einen „ExpressionComposer” aus den einzel-nen Elementen zusammengesetzt werden, womit diese nur einmal abgebildetwerden müssen.
ChainOfExpressions Hier geht es darum, dass verschiedene Konzepte einenbestimmten Kontext erfüllen können. Dieser Sachverhalt lässt sich durch einInterface „Expression” abbilden, das eine Kette von „ConcreteExpressions”enthält.
Terminological Hierarchy Es ist gerade in Ontologien üblich, umfangreichebaumartige Begriffs-Hierarchien aufzubauen. Diese bestehen aus (primitiven)Blättern und (zusammengesetzten) Knoten. Damit der Nutzer bei der Anwen-dung nicht zwischen diesen beiden Fällen unterscheiden muss, werden dieseEigenschaften hinter „TreeComponents” und dem „TreeComposer” gekapselt.
Update-Dependencies Jede „lebendige” Ontologie erfährt regelmäßige Ände-rungen und Verbesserungen. Damit diese nicht die Konsistenz gefährden,kann ein „Dependency-Updater” eingerichtet werden, der benachrichtigtwird, wenn ein ihm zugeordnetes Element verändert wird und daraufhin dienotwendigen Änderungen durchführt.
Interaction-Hider In vielen Fällen verletzten Ontologien die Anforderung dermöglichst geringen Kopplung. Dann bietet es sich an, die Interaktionen einerterminologischen Gruppe hinter einem „InteractionHider” zu kapseln. So kanneine Gruppe von Konzepten geändert werden, ohne dass unkontrollierbareAuswirkungen auf einen ganz anderen Teil der Ontologie auftreten können.
Terminology-Organizer Gerade in der Chemie gibt es eine umfangreiche No-menklatur, in der einzelne Wortbausteine für bestimmte Stoffe stehen. Mo-delliert man komplette Moleküle, ist es möglich, einen „Organizer” zu model-lieren, der den den endgültigen Begriffsnamen aus den einzelnen enthaltenenKonzepten zusammensetzt.
Obwohl dieser Ansatz sehr häufig zitiert wird, finden sich dennoch kaumdirekte Weiterentwicklungen. Allerdings gibt es gegenwärtig wieder zunehmendesInteresse am Thema Ontologie Design Patterns, insbesondere im Rahmen desSemantic Web.
4.2 Design Patterns im Semantic Web
Insbesondere von Aldo Gangemi [8] stammen wertvolle Anregungen zum Einsatzvon Design Patterns im Semantic Web. An erster Stelle ist hier ein Notations-Ansatz für ODPs zu nennen, der sich an dem für Patterns im Software Enginee-ring orientiert und aus folgenden „Slots” besteht:

Ontologie-Methodologien und Ontologie Design 119
– allgemeiner Sachverhalt– beispielhafter Anwendungsfall– Notation bzw. Legende– Herangehensweise (ggf. mit Alternativen)– Bemerkungen– OWL-Code
Damit lassen sich nun eine Reihe von ODPs beschreiben, wobei diese hier ausPlatzgründen nur informell beschrieben werden sollen [8, 9]. Die hervorgehobenenBegriffe stehen dabei für ontologische Konzepte.
Menge-Element Entspricht etwa einer 1-n-Beziehung: Mehrere Instanzen einesKonzepts sind Bestandteil der Instanz eines Oberkonzepts.
Teilnahme Objekte (z.B. Personen) nehmen an Ereignissen (z.B. Veranstaltun-gen) teil. Diese Teilnahme hat einen Zeitindex und eine Dauer.
Vertrag-Umsetzung In einem Vertrag einigen sich in der Regel mehrere Par-teien auf bestimmte Bedingungen, die einen Rechtsgegenstand betreffen. DieUmsetzung des Vertrages erfordert dabei bestimmte Handlungen.
Plan-Ausführung Ein Plan entspringt einer bestimmten Situation und hatein klar definiertes Ziel. Zu seiner Ausführung sind Aufgaben und Rollennotwendig.
4.3 Design Patterns im praktischen Einsatz von OWL
Neben den erwähnten, eher „akademischen” Patterns gibt es noch einige sehrpraktische Probleme im Ontologie-Design, die durch einfache ODPs gelöst werdenkönnen[21]:
Listing 7.1. Attribute in OWL<owl:onProperty>
<owl :Funct iona lProperty rd f : ID=" ha sSp i c i n e s s " /></owl :onProperty>. . .<owl :C la s s rd f : ID=" Sp i c i n e s s ">
<rd f s : subC la s sO f><owl :C la s s rd f : about="#ValuePart i t i on " />
</ rd f s : subC la s sO f><rdfs:comment xml:lang=" en ">A ValuePart i t i on thatd e s c r i b e s only va lue s from Hot , Medium or Mild .</ rdfs:comment>
<ow l : e qu i va l en tC l a s s><owl :C la s s>
<owl:unionOf rd f :parseType=" Co l l e c t i on "><owl :C la s s rd f : about="#Hot " /><owl :C la s s rd f : ID="Medium" /><owl :C la s s rd f : ID="Mild " />

120 B. Gleich
</owl:unionOf></ owl :C la s s>
</ ow l : e qu i va l en tC l a s s></ owl :C la s s>. . .<owl :Funct iona lProperty rd f : about="#hasSp i c i n e s s ">
<rd f s : r a n g e r d f : r e s o u r c e="#Sp i c i n e s s " /><rdfs:comment xml:lang=" en ">A property to be usedwith the Va luePart i t i on − Sp i c i n e s s .</ rdfs:comment><rd f : t y p e r d f : r e s o u r c e=" h t tp : //www.w3 . org /2002/07/ owl#
ObjectProperty " /></ owl :Funct iona lProperty>
Enum-Attribute in OWL In OWL gibt es keinen Unterschied zwischen einerRelation und einem Attribut. Um dennoch eine klare Semantik zu gewähr-leisten, empfiehlt sich die Anwendung eines Patterns: Wie in Listing 7.1beschrieben, wird eine funktionale Eigenschaft „has[Attributname]” angelegt.Zusätzlich wird zur Klasse „ValueType” eine neue Unterklasse „[Attribut-name]ValueType” angelegt. Dieser werden nun die gewünschten Werte alsUnterklassen zugeordnet. Schließlich wird der Wertebereich der anfangs defi-nierten Eigenschaft auf „[Attributname]ValueType” gesetzt.
„Entwirren” von Hierarchien Sehr häufig entstehen in der Anlage von hier-archischen Ontologien keine strikten Bäume, sondern Überschneidungen derForm, dass einzelne „Blätter” zu mehreren verschiedenen Vaterknoten gehö-ren. Um dieses Problem zu lösen müssen alle „überzähligen” Relationen durch„value types” ersetzt werden. Dadurch kann die Zugehörigkeit zu mehreren Va-terknoten durch die Zugehörigkeit zu einem dem „value type” entsprechendenKnoten abgebildet werden.
4.4 Bewertung
OPDs sind wie beschrieben eine wertvolle Technik des Ontologie Design. Aller-dings sind Patterns in der Regel das Resultat der umfangreichen und regelmäßigenAnwendung bestimmter Techniken. Dieser Sachverhalt ist im Ontologie Designbisher eher die Ausnahme: Abgesehen von der Molekularbiologie sind Ontologiennoch in nahezu allen anderen Bereichen ein sehr junges Forschungsfeld. Zwarkönnen auch dort schon einzelne Patterns identifiziert werden, jedoch sind diesenur in den seltensten Fällen Ergebnis umfangreicher praktischer Anwendung,sondern vielmehr das Resultat von überwiegend akademischen Überlegungen.Das Forschungsfeld der ODPs ist also noch stark auf umfassende praktische Er-fahrungen angewiesen, mit deren Hilfe in den nächsten Jahren noch nennenswerteFortschritte erzielt werden können.

Ontologie-Methodologien und Ontologie Design 121
5 Praktische Herausforderungen
5.1 Die Einschränkungen OWL als Ontologie-Sprache
OWL steht für Web Ontology Language und ist ein Standard des W3C [24], derspeziell für die automatisierte Verarbeitung von Ontologien ausgelegt ist. OWLbesteht aus drei Untersprachen mit jeweils steigender Ausdrucksmächtigkeit:OWL Lite, OWL DL und OWL Full.
Im Vergleich zu RDF werden in OWL zusätzliche Sprachkonstrukte eingeführt,mit denen Eigenschaften wie etwa Disjunktheit oder Äquivalenz von Klassen oderKardinalitäten notiert werden können. Allerdings zeichnen sich gerade OWL Liteund OWL DL auch durch die dort gemachten Einschränkungen aus. So sind beiOWL Lite nur die Kardinalitäten 0 und 1 erlaubt. Dadurch wird eine geringeKomplexität erreicht, die die automatische Verarbeitung deutlich erleichtert.
OWL DL (DL steht für Description Logic) stellt hier eine Kompromiss-Lösung dar: Es wird genau die Ausdrucksstärke unterstützt, die noch vollständigentscheidbar ist. Dies geschieht durch die Aufstellung von Bedingungen für dieVerwendung der einzelnen Sprachkonstrukte.
OWL Full besitzt dagegen keine solchen Einschränkungen, womit jedoch dieEntscheidbarkeit nicht mehr gewährleistet ist. Für automatisierte Verarbeitungist OWL Full also – trotz oder gerade wegen seiner großen Ausdrucksmächtigkeit– ungeeignet.
Grundsätzlich findet also immer ein Austausch zwischen Ausdrucksmächtigkeitund Entscheidbarkeit statt – eines der wichtigsten grundlegenden Problemedes Semantic Web. Dennoch konnten mit der Sprachversion 1.1 noch einigeOptimierungen an OWL vorgenommen werden [25]. Hier sind z.B. reflexive,irreflexive, symmetrische und asymmetrische Properties möglich. Ebenso ist esmöglich, Kardinalitäten im Bezug auf bestimmte Konzepte exakt einzuschränken(qualified cardinality restrictions). Ebenso sind in OWL 1.1 benutzerspezifischeDatentypen möglich, die sich an den XML Schema Datentypen orientieren, womitin einer Ontologie neue Datentypen definiert werden können.
5.2 Auf dem Weg zum Semantic Web
Das Semantic Web ist nach wie vor eher eine Vision als eine konkrete Aufgaben-stellung. Das gilt insbesondere für die häufige Vorstellung, das Semantic Webwürde das gegenwärtige World Wide Web vollständig ablösen.
Dass dies aktuell kaum realistisch ist, wird schnell ersichtlich, wenn manbetrachtet, wie neue Informationen im Internet veröffentlicht werden: Es handeltsich in den meisten Fällen um natürlich-sprachlichen Text, der nicht semantischannotiert ist. Sollte das Internet als Ganzes zu einem Semantischen Web wer-den, müssten alle Personen, die bisher Inhalte veröffentlichen, diese semantischannotieren, was zumindest mit den heutigen Technologien kaum denkbar sind.
Eine wesentliche Vorbedingung, die einen breiten Einsatz von semantischerAnnotation überhaupt möglich machen könnte, ist die weitere Entwicklung undAusdifferenzierung von Ontologien. Gerade mit der Entwicklung vieler „kleiner”

122 B. Gleich
Ontologien, die konkrete und begrenzte fachliche Domänen abdecken, ist esdenkbar, dass immer mehr Inhalte sukzessive semantisch angereichert werden –eine Aufgabe, die dann ähnlich wie Programmierung oder Design an „Semantik-Entwickler” übergeben werden könnte.
Damit diese Visionen jedoch zu Realität werden, ist es von entscheidenderBedeutung, ob sich konkrete Anwendungen für die Nutzer von semantischenInhalten ergeben – also im Web insbesondere ob sich semantische Suchmaschinenentwickeln, die dem Nutzer einen erkennbaren Mehrwert bringen. Das ist schongegenwärtig beispielsweise bei Produktkatalogen denkbar, die momentan nochmit ad-hoc-Methoden durchsucht werden.
Abgesehen von der Vision des „großen” Semantischen Web gibt es schonheute viele „kleinere” Semantische Netze, die in bestimmten fachlichen Domänenbereits große Erfolge erzielen und intensiv genutzt werden. Dies ist beispielswei-se in der Molekularbiologie der Fall und auch in anderen Bereichen wie etwader Bibliographie, der Rechtswissenschaft oder bei Produkt-Katalogen gibt esvielversprechende Entwicklungen.
6 Zusammenfassung, Bewertung und Ausblick
In dieser Arbeit wurden verschiedene Methoden und Techniken zur praktischenErstellung von Ontologien behandelt. Während die beschrieben Methodologienbereits einen nennenswerten Reifegrad erreicht haben, sind Ontologie DesignPatterns bisher noch in einem früheren Entwicklungs-Stadium.
Dennoch sind beide Techniken sehr hilfreich beim Design von Ontologien undwerden daher wohl zukünftig an Bedeutung zunehmen. Da Ontologien eine derSchlüsseltechnologien des Semantic Web darstellen, ist es zu erwarten, dass hiernoch umfangreiche weitere Forschungsanstrengungen unternommen werden.
Ontologie-Methodologien und Ontologie-Design sind also zwei Forschungs-felder, die auch zukünftig noch viele wertvolle Erkenntnisse versprechen undwesentlich zur Vision eines oder vieler semantischer Netze betragen.
Literatur
[1] K. Baclawski, M. K. Kokar, P. A. Kogut, L. Hart, J. Smith, W. S. Holmes III,J. Letkowski, and M. L. Aronson. Extending UML to support ontology engineeringfor the semantic Web. Lecture Notes in Computer Science, 2185:342+, 2001.
[2] E. Blomqvist. State of the art: Patterns in ontology engineering, 2005.[3] E. Blomqvist and K. Sandkuhl. Patterns in ontology engineering: Classification of
ontology patterns. In C. S. Chen, J. Filipe, I. Seruca, and J. Cordeiro, editors,ICEIS (3), pages 413–416, 2005.
[4] O. Corcho, M. Fernández, A. Gómez-Pérez, and A. López-Cima. Building legalontologies with methontology and webode. In R. Benjamins, P. Casanovas, J. Breu-ker, and A. Gangemi, editors, Law and the Semantic Web, number 3369 in LNAI,pages 142–157. Springer-Verlag, 2005.

Ontologie-Methodologien und Ontologie Design 123
[5] O. Corcho, M. Fernández-López, and A. Gómez-Pérez. Methodologies, tools andlanguages for building ontologies: where is their meeting point? Data Knowl. Eng.,46(1):41–64, 2003.
[6] A. de Moor, P. D. Leenheer, and R. Meersman. Dogma-mess: A meaning evolutionsupport system for interorganizational ontology engineering. In H. Schärfe, P. Hitz-ler, and P. Øhrstrøm, editors, Proceedings of the 14th International Conference onConceptual Structures (ICCS 2006), volume 4068 of Lecture Notes in ComputerScience, pages 189–202. Springer, 2006.
[7] M. Fernández-López, A. Gómez-Pérez, and N. Juristo. Methontology: from onto-logical art towards ontological engineering. In Proc. Symposium on OntologicalEngineering of AAAI, 1997.
[8] A. Gangemi. Ontology design patterns for semantic web content. In InternationalSemantic Web Conference, pages 262–276, 2005.
[9] A. Gangemi. Ontology design patterns – a primer, with applications and andperspectives. 2006. abgerufen am 23. 02. 2008.
[10] M. Grüninger and M. Fox. The role of competency questions in enterprise engi-neering, 1994.
[11] R. Grønmo, M. C. Jaeger, and H. Hoff. Transformations between UML and OWL-S.In A. Hartman and D. Kreische, editors, Model Driven Architecture – Foundationsand Applications: First European Conference (ECMDA-FA’05), volume 3748 ofLNCS, pages 269–283, Nuremberg, Germany, Nov. 2005. Springer Verlag.
[12] T. R. Gruber. Towards Principles for the Design of Ontologies Used for KnowledgeSharing. In N. Guarino and R. Poli, editors, Formal Ontology in ConceptualAnalysis and Knowledge Representation, Deventer, The Netherlands, 1993. KluwerAcademic Publishers.
[13] G. Guizzardi, G. Wagner, and H. Herre. On the foundations of uml as an ontologyrepresentation language. In EKAW, pages 47–62, 2004.
[14] K. Kotis, G. A. Vouros, and J. P. Alonso. Hcome: A tool-supported methodologyfor engineering living ontologies. In C. Bussler, V. Tannen, and I. Fundulaki,editors, Semantic Web and Databases. Second International Workshop - SWDB2004, volume 3372 of LNCS, pages 155–166, Berlin Heidelberg, Germany, August2004. Springer-Verlag.
[15] M. López. Overview of the methodologies for building ontologies, 1999.[16] M. F. López, A. Gómez-Pérez, J. P. Sierra, and A. P. Sierra. Building a chemi-
cal ontology using methontology and the ontology design environment. IEEEIntelligent Systems, 14(1):37–46, 1999.
[17] M. K. M. Uschold. Towards a methodology for building ontologies, 1995.[18] A. D. Nicola, M. Missikoff, and R. Navigli. A proposal for a unified process for
ontology building: Upon. In DEXA, pages 655–664, 2005.[19] N. F. Noy and D. L. Mcguiness. Ontology development 101: A guide to creating
your first ontology. Technical report, Stanford Knowledge Systems Laboratory,March 2001.
[20] H. S. Pinto, S. Staab, and C. Tempich. Diligent: Towards a fine-grained methodo-logy for distributed, loosely-controlled and evolving engineering of ontologies. InR. L. de Mántaras and L. Saitta, editors, ECAI, pages 393–397. IOS Press, 2004.
[21] A. L. Rector, N. Drummond, M. Horridge, J. Rogers, H. Knublauch, R. Stevens,H. Wang, and C. Wroe. Owl pizzas: Practical experience of teaching owl-dl:Common errors & common patterns. In E. Motta, N. Shadbolt, A. Stutt, andN. Gibbins, editors, EKAW, volume 3257 of Lecture Notes in Computer Science,pages 63–81. Springer, 2004.

124 B. Gleich
[22] J. R. Reich. Onthological design patternsfor the integration of molecular biologicalinformation. In German Conference on Bioinformatics, pages 156–166, 1999.
[23] S. Staab, R. Studer, H.-P. Schnurr, and Y. Sure. Knowledge processes andontologies. IEEE Intelligent Systems, 16(1):26–34, 2001.
[24] W3C. Owl web ontology language – overview, 2004. [abgerufen am 25. 02. 2008].[25] W3C. Owl 1.1 web ontology language – overview, 2007. [abgerufen am 25. 02.
2008].

Ontology Mapping
Michael Buthut
Universität [email protected]
Zusammenfassung Ontologien sind ein wichtiger Bestandteil der Vi-sion des Semantic Web, mit der die Informationen im WWW nicht nurmenschenlesbar, sondern maschinenlesbar werden sollen. Um eine Wis-sensbasis zu erweitern muss eine Ontologie mit einer anderen Ontologieverknüpft werden. Oftmals besitzen Ontologien nicht exakt dieselbe Do-mäne bzw. sie besitzen eine unterschiedliche Sichtweise auf die Domäne,dadurch kann es zu Inkonsistenz des gefolgerten Wissens kommen. DieGründe dafür werden dargestellt und danach werden zwei Ansätze vor-gestellt, wie dennoch zwei Ontologien miteinander verknüpft werdenkönnen. Im letzten Kapitel wird ein Framework vorgestellt mit dem sichverschiedene Ontology Mapping Ansätze einheitlich vergleichen lassen.
1 Einleitung
Heutzutage ist es selbstversändlich Wissen über elektronische Medien zu verbrei-ten oder es sich anzueignen. Allerdings ist es oftmals schwer an das benötigteWissen zu gelangen. Suchmaschinen nähern sich schwer dem subjektivem Opti-mum der Anfrage. Tim Berners-Lee, der Erfinder des WWW, entwurf deshalb dieVision des Semantic Web [1]. Das in elektronischen Medien hinterlegte Wissensollte nicht mehr nur von Menschen lesbar und interpretierbar sein, sondernmaschinenlesbar werden. Dadurch müsste nicht mehr gesucht werden, da allesWissen semantisch erfasst und verlinkt wäre. Probleme stellen sich dabei, wennzwei Wissensbasen miteinander verknüpft werden sollen die nicht dieselbe Sicht-weise auf eine Domäne haben. Bei einer derartigen Verknüpfung darf diese keineInkonsistenzen und damit falsche Annahmen folgern. In dieser Arbeit wird nacheiner Einführung auf zwei unterschiedliche Ansätze eingegangen, wie Ontologien,trotz unterschiedlicher Domäne, miteinander verknüpft werden. Anschließendwerden zwei Konzepte (C-OWL, OWL-DL) zum Austausch der Wissensbasisund deren formale Grundlagen näher behandelt und mit Beispielen illustriert.Nach Erarbeitung der beiden Konzepte wird am Ende noch auf einen Vergleichverschiedener Ansätze im Ontology Mapping eingegangen.
1.1 Ontologien und OWL
Semantische Modelle vereinen in sich die Fähigkeit eine eindeutige Bedeutungjedem Informationselement explizit zu zuordnen. Damit dies erreicht werdenkann, muss ein semantisches Modell drei Anforderungen erfüllen [5].

126 M. Buthut
– Gemeinsame BegrifflichkeitDie Bedeutung von Informationen kann nur unterschieden werden, wenn diebeteiligten Systeme die gleiche Sprache sprechen. Jedes Einzelteil erhält dabeieinen eindeutigen Namen (Symbol). Da unterschiedliche Anwendungsbereicheaber auch unterschiedliche Sichtweisen besitzen, können die Begriffe variieren.
– Beziehungen zwischen DingenEine eindeutige Bennenung der Informationsteile ist aber nicht ausreichend.Eine explizite Semantik ensteht erst mit dem Verständnis über deren Zu-sammenhänge. Die Beziehungen werden dabei als Rollen eines Symbolsrepräsentiert.
– mathematisch fundierte SemantikMathematische Korrektheit ist darüber hinaus auch ein wichtiger Bestandteilsemantischer Modell. Erst dadurch wird eine eindeutige Interpretation derKonstrukte möglich.
Unter einer Ontologie versteht man Modelle die alle drei obige Eigenschaftenbesitzen. Sie dienen der Wissensrepräsentation eines formal definierten Systemsvon Begriffen und Relationen. Man bildet Informationen und deren Zusammen-hang ab. Aber nicht nur deren Zusammenhang wird damit repräsentiert, sondernsie enthalten zusätzlich Inferenz- und Integritätsregeln. Mit diesen Regeln kön-nen aus einer Ontologie heraus Schlüsse gefolgert werden und deren Gültigkeitgewährleistet werden.
Abbildung 1. Beispiel einer Ontologie [5]
In Abbildung 1 wird eine Beispielontologie grafisch dargestellt. Beispielsweiseenthält die Ontologie ein Konzept Person. Peter ist nach dieser Darstellung einePerson. Personen die Artikel geschrieben haben sind Autoren und damit wie-derum Personen. „hat-geschrieben“ ist dabei eine Beziehung zwischen einzelnenElementen. Alex bildet damit eine Instanz des Konzeptes Autor und hat Artikel1geschrieben. Automatisch könnte bei der Beispielontologie das Wissen abgeleitetwerden, dass „hat-geschrieben“ das Inverse zu „hat-Autor“ ist. Um eine solchesWissen automatisch ableiten zu können muss die Bedeutung der verwendeten

Ontology Mapping 127
Symbole mathematisch präzise formuliert sein. Eine dafür entwickelte Spracheist OWL. Unter OWL versteht man die Web Ontology Language, eine Sprachemit der sich Ontologien anhand einer formalen Beschreibungssprache erstellen,veröffentlichen und verteilen lassen. OWL ist eine Spezifikation des W3C, demGremium zur Standardisierung der das World Wide Web betreffenden Techniken[8]. OWL besteht aus drei Untersprachen (OWL Lite, OWL DL, OWL Full) mitzunehmendem Abstraktionsgrad, so dass verschiedene Nutzergruppen, je nachAbstraktionsgrad, damit arbeiten können. In dieser Arbeit werden wir uns aufOWL-DL beschränken. Das Kürzel DL steht für description logic und zeigt damitden Grundgedanken des Ansatzes an. Die OWL DL zugrunde liegende Beschrei-bungslogik ist SHOIN (D), was wiederum eine entscheidbare Untermenge derPrädikatenlogik erster Stufe darstellt.
2 Ontology Mapping
Nach der Vision des Semantic Web werden Ontologien eingesetzt um die seman-tische Beziehung von Objekten widerzuspiegeln. Es soll beispielsweise möglichsein Wissen über eine bestimmte Domäne um Wissen einer anderen Domäne zuerweitern.
2.1 Global as View vs. Local as View
Sollen zwei Parteien miteinander kommunizieren können, müssen beide die gleicheRepräsentation für eine Ontologie haben. Oftmals ist dies aber nur der Idealfall,dass beide Parteien mit der Repräsentation der Ontologien übereinstimmen.Deshalb werden Ontologien gemappt um, die im Normalfall unterschiedlichen,Wissensbasen miteinander zu verbinden. Global as View (GAV) bzw. Localas View (LAV) sind zwei verschiedene Ansätze bzw. Sichtweisen im OntologyMapping.
Definition Global-as-View (GAV): „It is assumed that both onto-logies describe exactly the same set of objects. As a result, semanticrelations are interpreted in the same way as axioms in the ontologies.There are special cases of this assumption, where one ontology is regardedas a ’global schema’ and describes the set of all objects, other ontologiesare assumed to describe subsets of these objects.“ [2]
Definition Local-as-View (LAV): „It is not assumed that ontologiesdescribe the same set of objects. This means that mappings and ontologyaxioms normally have different semantics. There are variations of thisassumption in the sense that sometimes it is assumed that the sets ofobjects are completely disjoint and sometimes they are assumed to overlapeach other.“ [2]

128 M. Buthut
Ein globales Schema vereint dabei alle Objekte aller beteiligten Ontologien. Einebestimmte Ontologie bildet dann eine Untermenge des globalen Schemas. Einglobales Schema ist leichter zu verwenden, aber es beherbergt den Nachteil, dassbei sich ändernden oder wachsenden Datenquellen bzw. Ontologien jedesmal einneues globales Schema erstellt werden muss. Gegenteilig dazu verhält sich LAV.Das ganze wird genau anders herum betrachtet und so werden alle Konzepte derDatenquellen mit Begriffen des zu integrierenden Schemas erzeugt. An dieserStelle erschwert man zwar das ausführen von Anfragen, da dem System explizitbekannt gegeben werden muss wie er die Anfrage mappt. Aber dafür mussnun nicht mehr bei Änderungen der Datenquellen das zu integrierende Schemarekonstruriert werden, sondern nur die Mappings angepasst werden. Bei einerlokalen Sichtweise können Objekte disjunkt zu Objekten in der anderen Ontologiesein. Darüber hinaus können sich die Objekte auch in den Ontologien überlappen.Desweiteren gibt es eine Kombination beider Sichtweisen: Global-Local-as-View(GLAV). Allerdings ist im GLAV Ansatz das korrekte beantworten von Anfragenwenig erforscht, da der Ansatz auch leider alle Schwierigkeiten in sich vereint.Es hat sich in der Praxis bisher gezeigt, dass für Umgebungen in denen sich dieDatenquellen oft ändern der LAV Ansatz besser geeigneter ist.
2.2 Formale Einführung in OWL
Um nun die beiden Ansätze im Folgenden besser verstehen zu können, werdendie formalen Grundlagen für OWL behandelt werden. Eine OWL Ontologiebesteht aus Axiomen, Fakten und einer Referenz wie diese in andere Ontologienimportiert werden kann. In dieser Arbeit wird sich auf OWL-DL beschränkt, dadiese Sprache der SHOIQ(D) Logik entspricht. Eine OWL Ontology ist dannein Paar 〈i, Oi〉, dabei ist i der Index einer Instanz von der Ontology O.
Satz 1 Seien nun C,D,E,F Konzepte und r,s Rollen. Dann können nur folgendeKonzepte in der Ontologie Oi auftreten:
C , i:C , C u D , j:E , C u (j:E) , ∃r.C t D , ∃(j:s).C t (j:F)
Dabei gehört jeder Ausdruck der ohne Index oder mit Index i in Oi auftauchtzu der lokalen Sprache Oi. Fremde Konzepte j 6= i gehören zu der Sprache Oj .Die Konzepte C und D in Satz 1 sind somit lokale Konzepte. Wohingegen E undF fremde Konzepte darstellen. Genauso verhält es sich bei den Rollen r und s.Das bedeutet nun aber das eine Ontologie nur die oben genannten Variantenenthält. Beispielsweise können Konzepte zusammengefügt oder eine Schnittmengebilden. Ein OWL Space bildet dann eine Familie von Ontologien 〈i, Oi〉i∈I .∀i 6= j ist die j-fremde Sprache von Oi in der lokalen Sprache Oj enthalten.Für einen derartigen OWL Space gibt es dann eine Interpretation I. Mit einerInterpretation können dann Ausdrücke auf Korrektheit geprüft werden. Die hierdargestellte Interpretation bildet dabei aber eine globale Sichtweise.

Ontology Mapping 129
Ein Mapping wird als das Bestehen einer sematischen Relation angesehen. Bei-spielsweise werden die beiden Relationen zwischen Ontologien häufig verwendet[3]:
– Equivalence (≡):Equivalence states that the connected elements represent the same aspect ofthe real world according to some equivalence criteria. A very strong form ofequivalence is equality, if the connected elements represent exactly the samereal world object.
– Containment (v,w):Containment states that the element in one ontology represents a more specificaspect of the world than the element in the other ontology. Depending onwhich of the elements is more specific, the containment relation is defined inthe one or in the other direction.
2.3 Beispiele für OWL Mapping und deren GrenzenEs werden nun drei Beispiele behandelt, um auf deren Grenzen beim normalenOWL Mapping einzugehen. Es gibt dabei drei Kategorien in denen das normaleOWL Mapping an seine Grenzen stößt [6]:
– the directionality of information flow: we need to keep track of thesource and the target ontology of a specific piece of information
– local domains: we need to give up the hypothesis that all ontologies areinterpreted in a single global domain
– context mappings: we need to be able to state that two elements (con-cepts,roles, individuals) of two ontologies, though being (extensionally) dif-ferent, are contextually related, for instance because they both refer to thesame object in the world
Beispiel 1 Angenommen zwei Ontologien O1 und O2 wollen zusammenarbeiten.O2 ist dabei eine Erweiterung von O1, somit importiert O2 O1 und fügt einneues Axiom hinzu. Nun sollen die Axiome die zu O2 hinzugefügt werden keineAuswirkungen auf O1 haben. Nun seien A v B und C v D Axiome in O1. O2dagegen enthält ein Axiom B v C. Jetzt wollen wir, dass A v D in O2 aber nichtin O1 gilt.
In normalem OWL Mapping würde ein solches Beispiel nicht umsetzbar sein. DieFolgerung A v D ist eine logische Konsequenz der Anweisungen, die im globalenOWL Space enthalten sind. Beide Ontologien würden also nun davon ausgehen,dass A v D ist. Dies kann aber unter gewissen Umständen zu Fehlinterpretationenführen.
Beispiel 2 Angenommen es gibt eine Ontologie OWCM die zur „worldwide orga-nization on car manufacturing“ gehört. Nun soll diese Ontologie eine „standard“Beschreibung eines Autos beinhalten. Car soll nun eine Instanz dieser Ontologiesein. Die Ontologie OWCM beinhaltet dabei zwei individuelle Konstanten Dieselund Petrol. Zusätzlich soll es noch folgendes Axiom geben:

130 M. Buthut
Car v (∃1)hasEngine. Diesel, Petrol
wobei Diesel 6= Petrol
Das bedeutet nun nichts anderes, als dass ein Auto nur einen Motor haben kannund dieser entweder ein Diesel oder ein Benziner ist. Nun will sich ein Fahr-zeughersteller z.B. Ferrari seine OFerrari mit der Ontologie OWCM verknüpfen.Dann könnte die Verknüpfung so aussehen:
Ferrari v (WCM : car u (∃1) (WCM : hasEngine) . F23, F23)
wobei F23 6= F34i
Ein Ferrari kann dabei nur den Motor F23 oder F34i besitzen. Damit besteht nunaber der Fall, dass die Interpretation des OWL Spaces, der die beiden Ontologienbeinhaltet, zu falschen Aussagen kommt. Denn (F23)IFerrari = (Diesel)IWCModer analog mit F34i. Die Aussage ist damit aber falsch, da Ferrari nur Benzineralso Petrol Motoren verbaut. Die Diversität der einzelnen Domänen der beidenOntologien ist dafür verantwortlich. Beide Domänen besitzen einen anderen Ab-straktionsgrad, so ist die Ontologie Ferrari präziser bei der Motorenbeschreibungals die Ontologie der WCM die nur nach Benzin oder Diesel unterscheidet.
Beispiel 3 Nun sei OFiat eine Ontologie die Sachverhalte aus Sicht des Fahr-zeugherstellers FIAT wiederspiegelt. Dagegen sei nun OSale eine unabhängigeOntolgie die aus Sicht eines Verkäufers deklariert wurde. Beide enthalten nun einKonzept Car, das aber sehr unterschiedlich ist und es damit keinen Sinn machtdas Konzept des jeweils Anderen zu importieren. Somit gehören die Instanzendieser Konzepte auch nicht zum jeweils anderen. Sollen diese beiden Ontologiennun verknüpft werden um evtl. einen Mehrwert aus der anderen Ontologie zuerzeugen, dann ist dies mit OWL nicht möglich. Denn für eine Instanz
Sale : Car ≡ Fiat : Car
impliziert dies
CarISale = CarIFiat
Damit wären die beiden Interpretationen gleich, auch wenn sie das nicht möglich.Mit diesen Beispielen wurde verdeutlicht das OWL in vielen Szenarios Schwierig-keiten bereiten kann. Daher ist es nötig OWL zu erweitern. Es gibt verschiedeneAnsätze und Verfahren um beispielsweise oben genannte Probleme zu lösen. Inden folgenden Kapiteln werden zwei Verfahren für derartige Probleme vorgestellt.
2.4 C-OWLSchaut man sich die Funktionsweise von Ontologien und Context einmal näheran, dann fällt auf, dass sie eigentlich sehr konträre Verhaltensweisen aufweisen.Eine Ontologie ist ein gemeinsames und geteiltes Model der Domänen für allebeteiligten Parteien. Das heißt in anderen Worten, dass jeder die gleiche Sichtauf die Ontologie hat. Wohingegen Context ein lokales Modell ist, dass nichtgeteilt wird und jede beteiligte Partei hat dabei ihre eigene Sicht auf die Daten.

Ontology Mapping 131
2.4.1 Motivation Sowohl Context als auch Ontologien haben beide Stärkenund Schwächen. Die Stärke von Ontologien ist es, dass eben genau diese ge-meinsame und übereinstimmende Sicht auf die Daten vorhanden ist. Somit istder automatische Austausch von Daten erst möglich. Aber dafür ist es teilweiseschwer eine gemeinsame Sicht zu ermitteln. Bei Änderungen muss die gemeinsameOntologie jedesmal neu erzeugt werden. Was eigentlich in einem dynamischenUmfeld, wie z.B. dem World Wide Web schwierig ist. Ein Context ist einfacher zuerstellen, da keine Übereinkunft mit den anderen beteiligten Partnern bestehenmuss. Für den Datenaustausch sollte aber dennoch limitierte Übereinkunft beste-hen. Dies muss aber auch nur für die „relevanten“ Partner gelten. Der Nachteildabei ist, dass es ein gemeinsames Mapping über die Elemente des Contextsgeben muss, um kommunizieren zu können. Für C-OWL wird die Notation füreine Ontologie verwendet und um einige Erweiterungen ergänzt mit denen esmöglich ist die Dinge zu modellieren bei denen eine Ontologie an Ihre Grenzenstößt [6].
2.4.2 Formale Grundlagen von C-OWL und Beispiele Man modifiziertnun die Definition einer Interpretation in OWL. Dabei ist die Hauptidee, dass dieglobale Interpretation aufgesplittet wird. Dann besitzt jede Ontologie ihre eigenelokale Interpretation. Nach [6] wird dazu ein Hole definiert. Ein Hole (H) ist einPaar aus einem nicht leeren Set und einer Funktion. Diese Funktion mappt jedeKonstante von Oi in ein Element der Domäne, jedes Konzept in der gesamtenDomäne und jede Rolle. H erweitert also die Ontologie Oi um eine „angepasste“Interpretation, die jedes Axiomenpaar verifiziert, dass widersprüchlich sein könnte.Zusätzlich muss aber die Erfüllbarkeit gewährleistet bleiben um später desMapping überhaupt ausführen zu können. Eine OWL Interpretation mit Holesfür einen OWL Space ist dann eine Familie lokaler Interpretationen von Oi.Entweder ist es dabei eine Interpretation der Sprache Li auf die Domäne von ioder es ist ein Loch für Li auf der Domäne von i. Somit kann jede Interpretationum die lokale Interpretationsbeschreibung erweitert werden.Ontologien mit Löchern können sich in verschiedenen Ontologien auch verschiedenverhalten. Deshalb können manche Axiome in einer Ontologie erfüllt sein, dafüraber in anderen evtl. nicht. Mit dieser Definition können wir nun untersuchenwas mit Beispiel 1 passiert.
Beispiel 4 Beispiel 1 in C-OWL: Nehmen wir eine Interpretation I =I1, I2 mit Holes an die wie folgt definiert ist:
1. Die Domäne von I1 = a, b, c, d , die Interpretation sind wie folgt:AI1 = a , BI1 = a, b , CI1 = c , DI1 = c, d
2. Die Domäne von I2 = a, b, c, d und I2 = H2, d.h. I2 ist ein Loch
I ist eine Interpretation für den OWL Space der O1 und O2 enthält da ja
1. I1 |= A v B, I1 |= C v D, und I1 6|= A v D2. I2 |= 1 : A v 1 : B, I2 |= 1 : B v 1 : C, und I2 |= 1 : C ⊆ 1 : D und I2 ein Ho-
le ist

132 M. Buthut
Damit ist es nun möglich, dass die Interpretation O2 erfüllt ohne dass in O1A v D gefolgert wird. OWL geht von der Existenz einer einzigen geteiltenDomäne aus. Mit anderen Worten gesagt, dass jede Ontologie Eigenschaften desganzen Universums beschreibt. In den meisten Fällen ist dies aber nicht immerzutreffend, denn eine Ontologie die Autos beschreibt ist nicht dafür gedacht überMedizin zu sprechen. Die Idee in C-OWL ist es lokale Domänen zu schaffen,damit nicht Äpfel mit Birnen verglichen werden. Dabei können sich diese lokalenDomänen überlappen, so dass wir mit dem Fall umgehen können müssen, dasszwei Ontologien auf das selbe Objekt verweisen. Für die OWL Interpretationmit lokalen Domänen wird die Interpretation auf komplexe Konzepte, Rollenund Individuen erweitert. Aufzupassen gilt es wenn j-fremde Konzepte, Rollenund Individuen, die in Oi verwendet werden, als ein Objekt interpretiert werdenkönnten das nicht in der lokalen Domäne von Ii ist. Somit müssen alle fremdenKonzepte, Rollen oder Individuen eingeschränkt werden [6].
Beispiel 5 Beispiel 2 in C-OWL:Sei nun I = IWCM , IFerrari eine Interpretation des OWL Spaces der OWCM
und OFerrari enthält. Die Domäne von WCM enthält dabei zwei Konstantend1 und d2. Diese Kostanten entsprechen den Interpretationen ob ein Auto mitDiesel bzw. Benzin fährt. Die Domäne Ferrari enthalte auch zwei Konstantend1 und d3, die für F23 bzw. F34i stehen. Somit sei nun:
(hasEngine)IWCM = 〈c1, d1〉 , 〈c2, d2〉
wobei c1 und c2 Auto Objekte in beiden Domänen sind.
Dadurch kann verifiziert werden, dass die Axiome in Beispiel 2 von der Inter-pretation erfüllt werden und damit kein Ferrari einen Diesel Motor besitzt. Esstehen nun Konzepte, Rollen und Individuen einer Ontologie und deren Domänelokal zur Verfügung, aber ein Context Mapping erlaubt es festzulegen, dass einebestimmte Eigenschaft zwischen den Elementen zweier verschiedener Ontologienerhalten bleibt. In Beispiel 3 könnte so aufgebaut sein, dass die Klasse Car inder Ontologie OFiat die selben Autos enthält wie die Klasse Car von OSale. Dieskann aber nicht mit lokalen Axiomen in der Ontology realisiert werden. Fürdie Notation von Context Mappings verwendet man Bridge Rules. Diese Rulesbilden den Kern des C-OWL Ansatzes damit keine Inkonsistenzen beim Mappingerzeugt werden.
2.4.3 Bridge Rules
Definition 2 Bridge Rules: Eine Bridge Rule von i zu j kann folgendermaßenformalisiert werden,
i : x v−→ j:y, i:x w−→ j:y, i:x ≡−→ j:y, i:x ⊥−→ j:y, i:x ∗−→ j : y,
dabei können x bzw. y Konzepte, Individuen oder Rollen der Sprachen Li undLj sein.

Ontology Mapping 133
Wenn x und y z.B. Konzepte C und D sind dann bedeutet i : x v−→ j:y nichtsanderes als das das i-lokale Konzept C spezifischer ist als j-lokale Konzept D.Analog dazu impliziert w das D spezifischer als C ist, ⊥ implziert das C undD disjunkt sind, * impliziert Kompatibilität von C und D und ≡ impliziert dasC und D den gleichen Abstraktionsgrad besitzen. Abbildung 2 verdeutlicht dieAnwendung der Bridge Rules und die passenden Mappings an einem grafischenBeispiel.
Abbildung 2. Beispiel eines Mappings mit Bridge Rules von Wine zu Vino [6]
Ein Mapping von zwei Ontologien ist damit eine Reihe von Bridge Rules zwischendiesen. Für einen OWL Space 〈i, Oi〉i∈I ist Mij ein Mapping von Oi zu Ojbestehend aus einer Reihe von Bridge Rules von Oi zu Oj für beliebige i,j. EinMapping ist richtungsgebunden, Mij ist nicht die Umkehrung des Mappings Mji.Die Gegenrichtung könnte dabei zum Beispiel die leere Menge liefern. Gleichzeitigist zu beachten, dass die Importierung von Oi in Oj nicht das gleiche ist wiedas Mapping von Oi zu Oj mit Mij . Die Informationen gehen zwar in beidenFällen von i zu j, aber bei der Importierung kopiert Oj die Informationen ohneAnpassung. Dagegen übersetzt Oj , beim Mapping, die Semantik von Oi in seineeigene lokale Semantik.
Beispiel 6 Beispiel 3 und Beispiel 2 in C-OWL:Beide beschreiben dieselbe Sichtweise von zwei unterschiedlichen Sichtweisen,somit ist
Sale : Car ≡−→ FIAT : Car
Die Domänen Relation von OSale zu OFIAT wäre dann rij (Car)ISale = (Car)IFIAT .Context Mappings können aber auch zur besseren Formalisierung von Beispiel 2eingesetzt werden. Wenn festgelegt werden soll, dass F23 und F34i jeweils BenzinMotoren sind kann dies mit folgenden Bridge Rules formalisiert werden:
WCM : Petrol w−→ Ferrari : F23WCM : Petrol w−→ Ferrari : F34i

134 M. Buthut
Natürlich muss für eine C-OWL in der Praxis auch die Syntax angepasst werden.Deshalb besteht eine Context Ontologie aus einem Paar einer OWL Ontologieund einer Reihe von C-OWL Mappings, wobei jedes Mapping aus einer Reihevon Bridge Rules mit der selben Ziel Ontologie besteht.
2.5 DL safe rules
In diesem Kapitel wird ein globaler Ansatz für ein Ontology Mapping vorgestelltmit dem heterogene Ontologien verknüpft werden sollen. Für weitere Details wirdauf [4] verwiesen.
2.5.1 Motivation Um die Interoperabilität zwischen verschiedenen Anwen-dungen, die unterschiedliche Ontologien besitzen, gewährleisten zu könnnen, musszuerst ein Mapping System formal definiert werden. Im vorherigen Kapitel wurdegezeigt wie C-OWL die Interoperabilität gewährleisten kann. Ein anderer Ansatzist der OWL-DL safe rule Ansatz. Der grundlegende Gedanke dabei basiertauf deduktiven Datenbanksystemen. Dabei wurde Datalog, eine entscheidbarelogische Regelsprache, die ursprünglich für solche Datenbanksysteme entwickeltwurde, mit OWL-DL kombiniert. Als Ergebnis entstand die Semantic Web RuleLanguage (SWRL). Man sieht das Mapping von OWL-DL Ontologien als eineÜbereinstimmung zwischen Anfragen über Ontologien an. OWL bietet nur dieMöglichkeit einfache Mappings zwischen den Elementen auszuführen. Im prakti-schen Einsatz wird aber oft eine komplexere Abfragestruktur als nur Äquivalenzund Zusammenfassung benötigt. Daher wird das Mapping zweier Ontologienmit einer konjunktiven Anfrage (Query) an eine Datenbank repräsentiert. DasMapping selbst wird durch die Übereinstimmung dieser Queries ausgedrückt.Allerdings ist in der Kombination von OWL und SWRL logisches Schließenunentscheidbar. Um dennoch Entscheidbarkeit zu erhalten entwickelte man dieIdee SWRL soweit einzuschränken, dass es entscheidbar wird. Dabei bilden dieDL-safe Rules die notwendigen Einschränkungen. Der hier vorgestellte Ansatzverwendet dabei die globale Sichtweise (GAV) 2.1.
2.5.2 Grundlagen Um ein OWL-DL Mapping System einführen zu kön-nen müssen erst einige Grundlagen wiederholt werden. Zuerst muss der Begriffkonjunktiver Queries über eine SHOIN (D) knowledge base (KB) eingeführtwerden. Nach der Definition für konjunktive Queries [7] hat ein Atom die FormP (s1, . . . , sn) bzw. P (s). P kann dabei entweder eine Variable oder ein Individu-um der KB sein. Ein Atom ist ein Ground-Atom wenn es keine Variablen enthältund ein DL-Atom wenn P ein SHOIN (D) Konzept bzw. eine abstrakte oderkonkrete Rolle ist. Eine konjunktive Query über die KB wird dann als Q (x, y)geschrieben. Dabei repräsentieren x und y eine Reihe von non-distinguishedVariablen (mit Existenzquantor ∃ gebunden).
Definition 3 Eine konjunktive Query Q (x, y) ist dann DL-safe falls jede Varia-ble, die in einem DL-Atom auftaucht, auch in einem Nicht-DL-Atom in Q (x, y)auftaucht.

Ontology Mapping 135
Eine Rolle einer SHOIN (D) KB hat desweiteren die Form H ← Q (x, y). H istdabei ein Atom und Q (x, y) weiterhin die Query.
Definition 4 Eine Rolle ist safe falls jede Variable von H auch in x auftaucht.Eine Rolle ist nur dann DL-safe falls Q (x, y) DL-safe ist.
Mit anderen Worten ist eine Query oder eine Rolle dann DL-safe wenn sie sichauf explizit benannte Indviduen bezieht. Um nun automatisch eine Query ineine DL-safe Query zu transformieren wird für jedes α, das in der KB auftaucht,ein spezielles nicht DL Prädikat O (α) eingeführt [4]. Dieses Prädikat wirddann konjunktiv mit der Query verknüpft, um diese DL-safe zu machen. VieleExistenzquantoren sind aber unnötig und komplizieren die Query. Man kanneine Query oftmals vereinfachen und von unnötigen non-distinguished Variablenbefreien. Dazu verwendet man die Query-Roll-Up Technik [4] um unnötigeVariablen zu entfernen, ohne dabei einen Verlust der Semantik zu erleiden.
2.5.3 Tree-Like Query Parts Komplexere Queries weisen eine Baumstrukturmit einer Wurzel auf. Mit der Query-Roll-Up Technik ist es möglich unnötigeVariablen zu eliminieren in dem die baumartigen Teile einer Query zu einemKonzept reduziert werden. Somit wird die spätere Transformation in DL-safeQueries erleichtert.
Beispiel 7 Angenommen folgende konjunktive Query soll transformiert werden:
∃y, z, w : R (x, y) ∧A (y) ∧ S (y, z) ∧B (z) ∧ T (y, w) ∧ C (w)
Obige Query besitzt eine baumartige Struktur mit der Wurzel x. Die Existenz-quantoren von z und w können dann zum ersten Auftreten von selbigen bewegtwerden:
∃y : R (x, y) ∧A (y) ∧ [∃z : S (y, z) ∧B (z)] ∧ [∃w : T (y, w) ∧ C (w)]
Dies wiederum kann weiter transformiert werden:
∃y : R (x, y) ∧A (y) ∧ ∃S.B (y) ∧ ∃T.C (y)
Nach erneutem Durchlauf erhält man mit Transformation für y:
∃R. [A ∧ ∃S.B ∧ ∃T.C] (x)
Wie man sieht könnten die überflüssigen Variablen y, z und w entfernt werden,indem sie in DL transformiert wurden.
Mit dieser Vorgehensweis ist es möglich einen Algorithmus zu entwerfen mit demdie Anfragen automatisch von einem System umgeformt und anschließend dieAntwort berechnet werden kann. Die Antwort kann dabei nur berechnet werden,falls DL-safety sichergestellt ist, ansonsten wäre die Beantwortung unentscheidbar.

136 M. Buthut
Algorithmus 1 Algorithmus zur Beantwortung von Queries in einemOntology Integration System:
Vorraussetzung ist ein Integrationssystem IS und eine konjunktive Query Q (x, y)
– Roll-Up auf baumartige Teile von Q (x, y)– Roll-Up auf baumartige Teile der Query Mappings inM– Stoppe falls Q (x, y) oder einige Mappings vonM nicht DL-safe sind– Bilde das ganze als deduktives Datalog Programm (DD) ab– Berechne die Antwort von Q (x, y)
Die Query wird mit diesem Algorthmus, nach der Sicherstellung der DL-safety, inein deduktives Datalog Programm abgebildet, da für Datalog effiziente Technikenfür deren Ausführung bekannt sind [4].
2.5.4 Beispiele Mit folgenden Beispielen sollen die angewandten Technikennoch einmal verdeutlicht werden. Für weitere Informationen und Details wirdauf [4] verwiesen. Das Beispiel bezieht sich auf die gewünschte semantischeÜbereinstimmung zweier heterogener Ontologien. Beide Ontologien modellierendabei eine Bibliotheks Domäne. Die Quellontologie S und die Zielontolgie T sindin 3 dargestellt. In der Quellontologie schreibt eine Person Publikationen. DiePublikationen können entweder Artikel oder Thesen sein. In der Zielontologie Tbesitzen Autoren Einträge. Ein Eintrag kann dabei ein Artikel, eine Masterarbeitoder eine Doktorarbeit sein. Sowohl Person als auch Autor besitzen einen Namenund Publikationen sowie Einträge besitzen einen Titel und ein Thema.
Abbildung 3. Quell- und Zielontologie [4]
Nun werden sechs verschiedene Mappings angewendet, um die beiden Ontologienmiteinander zu verknüpfen. Dabei werden die unterschiedlichen Fälle sichtbarund es wird darauf eingangen wie diese mit safe rules abgebildet werden können.Die Mappings sind dazu in Abbildung 4 dargestellt.
Das in Abbildung 5 dargestellte Klassendiagramm verdeutlicht den Zusammhangder Mappings aus Abbildung 4 und den Aufbau der Ontologie .

Ontology Mapping 137
Abbildung 4. Mappings von Quell- auf Zielontologie [4]
Beispiel 8 Mapping m1:Das Mapping m1 in Abbildung 4 bildet die Publikationen samt ihrem Titel aufdie dazugehörigen Einträge der Zielontologie ab. Das sound Mapping lässt sichdann formal als folgende Aussage darstellen:
∀x, y : t : Entry (x) ∧ t : title (x, y)← s : Publications (x) ∧ s : title (x, y)
Dieses Mapping enthält dabei keine unbedeutenden Variablen in Qt,1, die zuerstentfernt werden müssten, und kann somit direkt übersetzt werden. Dennoch ist dasMapping nicht Dl-safe, da beide Variablen x und y nicht in nicht-DL Prädikatenin Qs,1 vorkommen. Durch die Bindung mit dem speziellen nicht-DL Prädikat Okann dieses Mapping aber DL-safe werden.
Abbildung 5. Aufbau der Ontologien und der Beispielmappings [4]

138 M. Buthut
∀x, y : t : Entry (x) ∧ t : title (x, y)← s : Publications (x) ∧ s : title (x, y)∧O (x) ∧ O (y)
Beispiel 9 Mapping m2:Das Mapping m2 bildet die Artikel der Quell Ontologie auf die der Zielontologieab. Daraus ergibt sich direkt folgendes Konzept:
s : Article v t : Article
Beispiel 10 Mapping m3:Das Mapping m3 zeigt die Verwendung eines komplexen Konzepts in einemKonzept Mapping, dabei werden die Konzepte Thesis der Quellontologie auf dieVereinigung der Konzepte PhDThesis und MasterThesis abgebildet:
s : Thesis v (t : MasterThesis t t : PhDThesis)
Das verdeutlicht nun, dass es aufgrund der Ausdrucksstärke der Ontologiesprachees möglich ist Disjunktion in Mappings auszudrücken, obwohl die Query Sprachenur Konjunktionen erlaubt.
Beispiel 11 Mapping m4:Mapping m4 bildet die Eigenschaft Autor der Quellontologie auf die Zielontologieab. Durch ein einfaches Rollen Mapping erhält man:
s : author v t : author
Beispiel 12 Mapping m5:Mapping m5 bildet die Personen die Autoren von Publikationen sind auf Autorender Zielontologie ab. Für eine Query Qs,5 können wir nun die Query Roll-UpTechnik verwenden. Die Query ist baumartig aufgebaut mit der charakterisierendenVariable x als Wurzel. Somit kann diese Query wiederum zu folgender, semantischäquivalenten, Query transformiert werden:
Qs,5 (c) : (∃s : author−.s : Person) (x)
Damit kann nun ein Konzept Mapping angegeben werden:
∃s : author−.s : Person v t : Author
Vergleicht man nun dieses Mapping mit einem DL-safe Mapping, das man ohneQuery Roll-Up erhält, fällt die Varietät beider Mappings auf. Das Mapping inBeispiel 13 bildet nur die Personen, deren Publikationen explizit in der Quel-lontologie benannt sind, auf die Autoren der Zielontologie ab. Dagegen benötigtBeispiel 12 nur die Existenz einer Publikation. Die Publikation muss dabei nichtexplizit benannt sein.
Beispiel 13 Mapping m5 ohne Query Roll-Up:
∀x : t : Author (x)← s : Person (x) ∧ s : author (y, x) ∧ O (x) ∧ O (y)

Ontology Mapping 139
Beispiel 14 Mapping m6:Mapping m6 bildet das Topic einer Publikation auf einen Eintrag in der Zie-lontologie ab. Dabei ist zu beachten, dass Topic ein eigenes Konzept in derQuellontologie ist, wohingegen der Name des Themas in der Zielontolgie alsEigenschaft dargestellt wird. Deshalb ergibt sich folgende Aussage:
∀x, z : t : Entry (x) ∧ t : subject (x, z)← s : Publication (x)∧s : isAbout (x, y) ∧ s : name (y, z)
Auch dieses Mapping ist nicht DL-safe, da weder Qs,6 noch Qt,6 baumartigeQuerys sind. Das Query Roll-Up kann hier also nicht angewendet werden. Umdennoch ein DL-safe Mapping zu erhalten werden wieder die Variablen x, y undz explizit an benamte Individuen gebunden:
∀x, z : t : Entry (x) ∧ t : subject (x, z)← s : Publication (x)∧s : isAbout (x, y) ∧ s : name (y, z) ∧ O (x) ∧ O (y) ∧ O (z)
3 Vergleich verschiedener Ontologie Mapping Ansätze
In den letzten Abschnitten wurden zwei Ansätze für das Ontology Mappingvorgestellt. Darüber hinaus gibt es noch weitere Verfahren um ein Mappingdurchzuführen. In diesem Vergleich werden die unterschiedlichen Ansätze inDistributed First Order Logic (DFOL) übersetzt. Somit erhält man eine gemein-same Ebene auf der die Möglichkeiten bzw. Unterschiede der Ansätze besserdargestellt werden können. Alle hier verglichenen Mapping Ansätze haben dieGemeinsamkeit, dass sie auf der Description Logic (DL) beruhen.
3.1 Einführung in DFOLDFOL ist ein logisches Framework zur Represäntation von verteiltem Wissen [7].Zum einen besteht es aus einer Reihe von first order Theorien und zum anderen auseiner Reihe von Axiomen. Die Axiome beschreiben dabei die Beziehungen zwischenden einzelnen Theorien. Damit können Mapping Sprachen folgendermaßen inDFOL ausgedrückt werden:
3.2 C-OWL im DFOL FrameworkWie bereits in Defintion 2 dargestellt kann eine Bridge Rule von i zu j fünfVarianten aufweisen wobei x und y weiterhin entweder Konzepte, Rollen oderIndividuen bzw. Konstanten sind. Wegen der Erfüllbarkeit der Bridge Ruleskann i : x ≡−→ j:y äquivalent mit der Konjunktion der Mappings i : x v−→ j:yund i : x w−→ j:y dargestellt werden. Desweiteren ist das Mapping i : x ⊥−→ j:ymit i : x v−→ j : ¬y äquivalent. Schließlich ist i : x ∗−→ j : y zu der Negation desgesamten Mappings i : x v−→ j:y äquvivalent. Mit einer Überstzung in DFOLsieht man das selbst die komplerexeren Bridge Rules aus einfacheren aufgebautwerden können. Nur negative Informationen eines Mappings 6 v können nicht inDFOL übersetzt werden [7].

140 M. Buthut
3.3 OIS im DFOL Framework
Ontology Integration Framework (OIS) ist ein alternativer Ansatz für das Ontolo-gy Mapping. Für detaillierte Informationen zu OIS wird auf [7] verwiesen. DiesesFramework verwendet auch unterschiedliche Sichtweisen für die Integration. OIScharakterisiert den globalen, den lokalen und den GLAV Ansatz. Trotz uner-schiedlicher Sichtweisen sind alle drei Ansätze in der semantischen Betrachtunggleich. Mappings werden als Terme einer gemeinschaftlichen Übereinstimmungzwischen einem lokalen und dem globalen Modell beschrieben. Daher gibt es dreiunterschiedliche Formen für eine Übereinstimmung des Mappings:
– I erfüllt 〈x, y, sound〉 insbesondere die lokale Interpretation D, falls alle Tupeldie y in D erfüllen, x in I erfüllen
– 〈x, y, complete〉 insbesondere die lokale Interpretation D, falls keine anderenTupel als die y in D erfüllen, x in I erfüllen
– 〈x, y, exact〉 insbesondere die lokale Interpretation D, falls die Reihe vonTupeln die y in D exakt die Reihe von Tupeln ist die x in I erfüllen
Die dritte Form kann dabei wieder äquivalent mit der Konjunktion der beidenersten Varianten abgebildet werden. Mit anderen Worten ist das exact Mappingdie Konjunktion von sound und complete Mapping. Sound und complete Mappingkönnen wiederum in DFOL übersetzt werden.
3.4 DLII im DFOL Framework
DLII bezeichnet eine DL für Information Integration [7]. Im Gegensatz zu OIS,das die Domänen in eine globale Domäne einbettet, setzt DLII eine partielle Über-lappung der Domänen voraus. Eine Interpretation I assoziiert zu jedem ModellMi eine Domäne 4i. Diese verschiedenen Modelle werden mittels interschemaAussagen verknüpft. Die Erfüllbarkeit der interschema Aussagen sind dabei sodefiniert, dass zwischen extensional und intentional Interpretierungen unterschie-den wird: vext,vint, 6 vext, 6 vint sowie ≡ext,≡int, 6 ≡ext, 6 ≡int. Wiederum kann≡ durch die Konjunktion von v dargestellt werden und anschließend in DFOLübersetzt werden. Dabei erkennt man, dass die extensional Interpretation mitder in OIS übereinstimmt und die intentional Interpretation stimmt dabei mitder Semantik eines Mappings in C-OWL überein.
3.5 Fazit
Der DFOL Ansatz hat zwei wesentliche Vorteile. Man kann durch die Überset-zung auf eine gemeinsame Ebene Reasoning zwischen verschiedenen Frameworksdurchführen. Obwohl DFOL nicht alle Mappings, wie oben beschrieben, überset-zen kann, so deckt es doch die meisten davon ab. Desweiteren kann damit dieAussagekraft der verschiedenen Ansätze auf gleichem Niveau verglichen werden.So bietet zum Beispiel C-OWL nur die Möglichkeit 2-stellige Relationen zwischenKonzepten, Rollen und Individuen zu bilden. DLII und OIS erlauben n-stellige

Ontology Mapping 141
Beziehungen zwischen den Elementen die gemappt werden sollen. Viele ande-re Ansätze erlauben nur positive Verknüpfungen bei einem Mapping. C-OWLbeispielsweise erlaubt aber auch Aussagen darüber, dass zwei Elemente nicht äqui-valent (6 equiv) sind. Auch in Bezug auf die Beziehungen der Domänen lassen sichdie Ansätze unterscheiden. Während bei C-OWL die verwendeten Domänen völligverschieden sein können, werden beispielsweise bei DLII überlappende Domänevorrausgesetzt. In Abbildung 6 werden die Unterschiede und Gemeinsamkeitennochmals zusammengefasst.
Abbildung 6. Vergleich der Mappings nach [7]
Die Aufstellung und die Erkenntnisse, die man bei der Übersetzung in ein ein-heutliches Framework erzielt hat, erleichtern die Auswahl des richtigen MappingAnsatzes. Beispielsweise wird für die Integration einer Datenbank ein Modellgewählt werden, dass n-stellige Beziehungen ermöglicht, denn diese stimmen mitTupeln in relationalen Datenbanken überein.
4 Schluss
Die Verbindung zweier Ontologien kann in vielen Anwendungsfälllen Problemebereiten. Beispielsweise haben zwei Ontologien eine andere Interpretation derSachverhalte. Es wurden zwei unterschiedliche Ansätze vorgestellt wie ein Ontolo-gy Mapping umsetzbar ist, damit dennoch verschiedene Sichtweisen miteinanderverbunden werden können.C-OWL versucht beim Mapping auftretende Problememit sogenannten Bridge Rules zu lösen. Ziel ist es dabei den Vorteil von Contextmit denen einer Ontologie zu verknüpfen. OWL-DL dagegen betrachtet das Pro-blem aus der globalen Sichtweise.Es wurde gezeigt wie die OWL Syntax angepasstwerden kann, um Erfüllbarkeit zu gewährleisten. Damit können die Aussagendann in ein Datalog Programm übersetzt und efiizient ausgewertet werden. Imletzen Kapitel wurde darauf eingegangen wie verschiedene Ansätze auf ihre ge-meinsame Komponente, der Beschreibungslogik 1.Ordnung, reduziert werden,um damit einen Vergleich zu erhalten. Durch die Varietät der Ansätze ist es nichteinfach den passenden Ansatz zu finden, wenn denn kein Vergleich der Ansätzemöglich wäre. Mit den hier vorgestellten Ansätzen wurden die Grundlagen gelegt,damit Maschinen selbstständig Wissensbasen erweitern können. Nächster Schrittist eine Automatisierung für derartige Abläufe.

142 M. Buthut
Literatur
[1] T. Berners-Lee, J. Hendler, and O. Lassila. The semantic web. Scientific American,284(5):34–43, May 2001.
[2] S. Brockmans and P. Haase. A metamodel and uml profile for networked ontologies- a complete reference. Technical report, Universität Karlsruhe (TH), APR 2006.
[3] S. Brockmans, P. Haase, and H. Stuckenschmidt. Formalism-independent specifica-tion of ontology mappings - a metamodeling approach. In R. Meersman, Z. Tari,and et al., editors, OTM 2006 Conferences, LNCS, Montpellier, France, OCT 2006.Springer Verlag.
[4] P. Haase and B. Motik. A mapping system for the integration of owl-dl ontologies.In IHIS ’05: Proceedings of the first international workshop on Interoperability ofheterogeneous information systems, pages 9–16, New York, NY, USA, 2005. ACM.
[5] A. Maedche and B. Motik. Repräsentations- und Anfragesprachen für Ontologien -eine Übersicht. Datenbank-Spektrum, 3(6):43–53, 2003.
[6] P. Bouquet and F. Giunchiglia and F. van Harmelen and L. Serafini and H. Stu-ckenschmidt. Cowl: Contextualizing ontologies, 2003.
[7] L. Serafini, H. Stuckenschmidt, and H. Wache. A formal investigation of mappinglanguage for terminological knowledge. In IJCAI, pages 576–581, 2005.
[8] W3C. Owl web ontology language - overview. http://www.w3.org/TR/owl-features/, Februar 2004.

Semantic Web Service Composition
Joachim [email protected]
WS 2007/08Lehrstuhl Programmierung verteilter Systeme
Prof. Dr. BauerUniversität Augsburg
Zusammenfassung Web Services dienen dem Aufruf von Methoden ineinem verteilten Umfeld. Zur Erweiterung der manuellen Kommunikationzwischen Web Dienst und Benutzer werden Möglichkeiten erforscht, wiedie für eine Planungsaufgabe relevanten und verfügbaren Dienste auf-zufinden und in den Bearbeitungsprozess einzubinden sind. Dieses Zielverfolgt die „Semantic Web Service Composition“. In dieser Seminararbeitsoll aufgezeigt werden, welche Ansätze für diese Art der Kompositionexistieren, wie diese kategorisiert werden können und schließlich soll einAnsatz speziell herausgegriffen und im Detail erläutert werden.
1 Einleitung
Web Services (WS) werden in unternehmensinternen und -übergreifenden ver-teilten Systemen eingebunden. Ein Hauptziel von verteilten Systemen ist es, diejeweiligen Ressourcenstärken der einzelnen Systemteilnehmer, wie bspw. Rechen-leistung oder Speicherplatz, optimal zu nutzen. Damit eine Komponente einesverteilten Systems mit einer anderen kommunizieren kann, müssen definierteSchnittstellen geschaffen werden. Diese geben an, wie Nachrichten gelesen werdenmüssen und welches die übergebenen Parameter sind.Handelt es sich bei der Kommunikation um eine Anforderung bzw. eine Anfragezur Lieferung eines Wertes bzw. einer Datenreihe, so spricht man von einerService-Anfrage. Diese kann über verschiedene Übertragungsmethoden erfolgen,wie bspw. einem entfernten Prozedur- oder Methodenaufruf - Remote ProcedureCall (RPC) bzw. Remote Method Invocation (RMI) . Bei diesem synchronenÜbertragungsprotokoll blockiert der anfragende Client (service requester) solange, bis der angefragte Server (service provider) den Befehl verarbeitet hat undeine Antwort zurückgeliefert hat. Im Fall von RMI wird dabei die Methode einesentfernten Objekts mit ggf. entfernten Referenzen aufgerufen.Neben der Übertragungsart müssen für ein solches Service-System auch dieSchnittstellenbeschreibungen und das Umfeld der Methodeneinbindung definiertwerden. In der Common Object Request Broker Architecture (CORBA) geschiehtdies durch die Interface Definition Language (IDL) zum einen und Object RequestBroker (ORB) zum anderen. Es wird damit ein plattformunabhängiges Systemgeschaffen, in dem Service-Partner über einen Verzeichnisdienst gesucht werden

144 J. Alpers
und anschließend die Verbindungen dynamisch generiert werden können. Einsolches System wird als Service-orientierte Architektur (SOA) bezeichnet.
Ziel einer SOA ist es dem Dienstnutzer die Entwicklung einer vollständigenApplikation zu ersparen und statt dessen Services anzubieten, durch die mansich die gewünschte Funktionalität zusammenstellen kann.Ein menschlicher Benutzer kann über Relevanz eines Web Service bspw. anhandder Signatur relativ problemlos entscheiden. Ziel ist es jedoch die Funktionalitäteines WS auch für eine Maschine-Maschine-Kommunikation interpretierbar zumachen und schließlich die Möglichkeit zu bieten, dass Dienste sich automatischsuchen, auffinden, austauschen und interpretieren können, ohne dass Bedeutung(Semantik) verloren geht (siehe Abbildung 1). Ziel der Semantic Web Service
Abbildung 1. Konstituenten des Internet (Quelle: [9] S.55)
(SWS) -Komposition ist es daher einen Weg zu finden, wie die für ein Planungszielrelevanten und verfügbaren Web Services gefunden werden können und derenAufruf in geordneter und semantisch sinnvoller Form erfolgen kann. So soll esmöglich werden verteilte Dienste zu einer Applikation zu orchestrieren, die jeweilszur Laufzeit neu (dynamisch) zusammensetzbar sind.Die Seminararbeit zeigt in Kapitel 2 die Grundlagen von Web Services und denStand der Forschung auf. Im Anschluss werden Möglichkeiten zur Semantikdefi-nition und zur Festlegung von semantischen Beziehungen festgelegt. Nach einergrundlegenden Erläuterung, wie die SWS-Komposition abläuft, sollen bestimmtePlaner exemplarisch und im fünften Kapitel schließlich der Model-based Planner(MBP) detailliert erläutert werden.
2 Web Services: Stand und Ziel der Technik
2.1 Grundlagen und Standards von Web Services
Web Services sind über standardisierte Schnittstellen zur Verfügung stehendeDienste mit einer wohldefinierten Funktionalität, die mittels der Auszeichnungs-

Semantic Web Service Composition 145
sprache XML beschrieben werden. Für WS können folgende Integrationsaspekteaufgezeigt werden (vgl. [17] S.16):
1. Lose KopplungDies ermöglicht eine dynamische Bindung von Diensten untereinander zurLaufzeit.
2. Universelle NutzbarkeitMit Hilfe von Registern können Dienste im Netz aufgefunden und dortentsprechend ihrer Anwendung beschrieben werden.
3. StandardsprachenWie bereits erwähnt, werden Web Services durch XML-basierte Sprachenbeschrieben. Zwar können die zugrunde liegenden WS-Anwendungen in ande-ren Sprachen implementiert sein, jedoch werden die Schnittstellen einheitlichin XML definiert.
Zur Umsetzung dieser Eigenschaften werden XML-basierte Sprachen einge-setzt, die zur Kommunikation, Beschreibung und Auffindbarkeit von Web Servicesdienen. Weite Verbreitung finden diese Standards im World Wide Web (WWW) ,wo sie auf den gängigen Protokollen HTTP oder TCP aufsetzen. Die wichtigstenKonstituenten und Standards im Bereich von Web Services sind:
1. Simple Object Access Protocol (SOAP)Die eigentliche Anfrage und Ergebnisrückgabe des Dienstes erfolgt in SOAP.Eine SOAP-Nachricht besteht aus einer Verpackung (Envelope), wo derInhalt der Nachricht beschrieben wird, einer Kodierungsinformation, wiedie serialisierten Informationen interpretiert werden müssen und schließlichdie Übertragungsdefinition, wie die Nachricht über RPC übergeben unddargestellt werden soll (vgl. [17] S.18).
2. Universal Description, Discovery and Integration (UDDI)Eine UDDI-Registry setzt sich aus den Einträgen verschiedener UDDI- Betrei-ber zusammen und enthält eindeutige Schlüssel für jeden in ihr aufgelistetenWeb Service. Sie dient dazu WS anhand des Schlüssels zu identifizieren unddurch Beschreibungen für den Nutzer auffindbar zu machen (vgl. [10]).
3. Web Service Definition Language (WSDL)Über WSDL wird beschrieben, welche Daten und Datenformate von einemWS nach Anfrage geliefert werden und wie entsprechende Operationen darauflauten. Die Beschreibung erfolgt in XML, wobei ein Element die Port-Typen,d.h. eine genaue Adresse der Dienst-Ressourcen und ein weiteres die Pa-rameter, die für einen Funktionsaufruf erforderlich sind, definiert (vgl. [3]S.2).
Der Zusammenhang dieser Standards ist Abbildung 2 zu entnehmen: Will einNutzer (Requester) einen Dienst für eine bestimmte Aufgabe über eine WSDL-Definition finden, so wendet er sich an einen Dienstverwalter (Broker), der inseiner UDDI-Registry nach entsprechenden Einträgen sucht und den Nutzer zueinem Anbieter (Provider) verweist. Anschließend kommt der Dienstaufruf überSOAP zwischen Requester und Provider zustande.

146 J. Alpers
Abbildung 2. SOA-Struktur bei Web Services (Quelle: [9] S.54)
2.2 Die Kopplung von Web Services
Die Kopplung von Web Services soll einen Austausch von synchronen oderasynchronen Nachrichten ermöglichen, welche zu einer Kette von Interaktio-nen zusammengefügt werden können und schließlich zu einer abstrakteren undkomplexeren Funktionalität beitragen.
Da diese Kommunikation von Maschine-zu-Maschine erfolgen soll, ist nebender Syntax die Übereinstimmung folgender Kriterien, wie auch bei der Mensch-zu-Mensch-Kommunikation, für eine einwandfreie Interpretation unerlässlich (inAnlehnung an (i.A.) [10] S.45/46):
1. VokabularDas Vokabular bzw. der Zeichenvorrat muss für alle Kommunikationspartnerverständlich sein und die jeweils gleiche Bedeutung aufweisen. Beschreibenmehrere Begriffe des Senders den gleichen Sachverhalt, so müssen dieseSynonyme auch dem Empfänger bekannt sein.
2. Bedeutung (Semantik)Im Umfeld der menschlichen Kommunikation geht die Bedeutung einher mitder Interpretation der Sachverhalte. Dabei wird mit dem transportiertenVokabular ein Konzept verbunden, welches dem Empfänger bekannt sein mussund die Bedeutung der Nachricht dadurch semantisch erschlossen werdenkann.
3. EindeutigkeitInterpretationsfehler treten des weiteren bei Begriffen mit mehreren Bedeu-tungen auf, sog. Homonyme. In diesem Fall kann das System keine eindeutigeSemantik erkennen und die Nachricht nicht verarbeiten. Um das zu vermeiden,wird das Unified Resource Identifier (URI) -Konzept herangezogen. Durchdiese eindeutige Identifikation der Ressourcen kann eine Mehrdeutigkeitvermieden werden.
Durch die Definition dieser Kriterien können die Beziehungen von WS aus-reichend definiert werden, um ein WS-System zu schaffen. Es kann sich dabeium eine hierarchische Gliederung von Web Diensten einer Domäne (Taxonomie)oder um ein domänenübergreifendes Netz von Beziehungen, einer sog. Ontologie,handeln (i.A. [11] S.53).

Semantic Web Service Composition 147
2.3 Motivation für eine „Semantic Web Service Komposition“
Wie in der Einleitung beschrieben, ist es das Ziel einer SOA-Umgebung, dassdurch die Verwendung von Web Services auf die Programmierung einer pro-prietären Anwendung verzichtet werden kann. Statt dessen sollen elementareFunktionen bereit gestellt werden, die je nach Bedarf von den Netzwerkteilneh-mern angefordert werden können (vgl. [3]).Dabei liegt die besondere Herausforderung darin ein dynamisches Binden derWS zur Laufzeit zu ermöglichen. Es muss möglich sein, dass sich der Planer dieKomposition bei jeder Anfrage neu generiert, da die Verfügbarkeit von Dienstenim Internet oft nicht gesichert ist oder neue bzw. veraltete WS identifiziert werdenmüssen.Der Planungsalgorithmus soll anhand von Beschreibungen der WS erkennen,ob diese für das Planungsproblem relevant sind und sie zur Laufzeit einbinden.Daher kommt es zu der Forderung nach aussagekräftigen Beschreibungen undBeschreibungsmodellen, so dass die Ausführungssemantik für Entwickler undPlaner ersichtlich wird (vgl. [6] S.449/450).Die bereits etablierten Standards im Bereich Web Services reichen für eine aus-reichende Beschreibung der Zusammenstellung nicht aus. So kann zwar durchWSDL die syntaktische Form der ausgetauschten Nachrichten definiert werden,aber keine semantische Information über den Zusammenhang mitgeliefert werden.Es ist daher nötig weitere Standards zu definieren, die dem Planer Informationendarüber liefern, wie er bei der Planung zu verfahren hat.Wichtige Fragestellungen hierbei sind:
1. Welches ist der Ausgangszustand und welches der Zielzustand der Planung?2. Nach welchen Kriterien soll die Suche nach geeigneten Web Services durchge-
führt werden?3. Inwiefern kann man von einer „geschlossenen Welt“ ausgehen, bei der alle
Domäneninformationen ersichtlich sind?4. Wie soll verfahren werden, wenn ein atomarer Web Service kein oder ein
unerwartetes Ergebnis zurückliefert (Nichtdeterminismus)?
3 Semantik bei Web Services
3.1 Nutzen und Notwendigkeit von Semantik und Ontologien imWeb
„Die Herausforderung im Umfeld der Service-orientierten Architekturen bestehtdarin, Semantik so eindeutig formulieren zu können, dass menschliche Interpreta-tionsvorgänge verzichtbar werden, ohne Semantik zu verlieren.“ [10]
Um dies zu gewährleisten, muss zum einen die Art der Beziehung von WS-Ressourcen untereinander und zum anderen die Nutzung des domänenspezifischenVokabulars definiert werden. Dabei sind folgende Kriterien zu erfüllen (i.A. [11]S.53):

148 J. Alpers
1. Deklaration von SynonymenWerden identische Inhalte mit unterschiedlichen Namen bezeichnet, so musssichergestellt werden, dass diese untereinander verknüpft sind.
2. Logisches Erschließen von Zusammenhängen und AbstraktionsstufenEs muss für Nutzer eines Dienstes ersichtlich sein, wenn dieser die gleicheFunktionalität bietet wie andere Dienste, die dessen Grundfunktionen einzelnbezeichnen.
3. Erschließen und Zusammenfassen von Grundfunktionalitäten zur Erfüllunggeforderter DiensteDie verwendeten Begriffe sollen dem Nutzer aufzeigen können, wie elementareOperationen zur Definition von komplexeren Diensten genutzt werden können.
3.2 Semantikbeschreibung durch RDFUm Web Services automatisiert miteinander kommunizieren zu lassen, muss esmöglich sein deren Inhalt, sowie deren Wechselwirkungen und Zusammenhängemit anderen Diensten in maschinenauswertbarer Form zu beschreiben. Hierfürwurde das Resource Description Framework (RDF) entwickelt, welches u.a. inXML dargestellt werden kann. Das RDF ermöglicht es durch die folgende Tripel-Darstellung Zusammenhänge zwischen WS-Objekten zu definieren:1. Subjekt (Resource)2. Prädikat (Property)3. Objekt (Resource)
Jedes dieser Elemente wird jeweils durch das Attribut „resource“ definiert,welches auf einen eindeutigen Unified Resource Identifier (URI) verweist. Seman-tische Annotation kann also vereinfacht als die Angabe von Web-Ressourcen(Resource) und deren Eigenschaften (Property) angesehen werden. Wie auchfür die Validierung von XML-Dokumenten wird für die Definition eines Domä-nenvokabulars ein RDFS-Schema (RDFS) verwendet. Über dieses ist es möglichKlassen, Eigenschaften, Domänengrößen (Range) und Dokumentationen derSubjekte (resources) zu beschreiben (vgl. [3] S.3).
Das Vokabular, welches zur Beschreibung dieser Beziehungen verwendet wird,kann in jeder Domäne anders definiert sein, so dass ein Austausch von RDF-Datenzwischen Domänen mangels Interpretierbarkeit wenig sinnvoll erscheint (vgl. [10]S.46/47).Damit ein Kommunikationsnetz von Web Services entsteht, muss daher eineOntologie geschaffen werden, also ein System von Zusammenhängen zwischenverschiedenen WS-Komponenten. Dies garantiert, dass das domäneninterne Vo-kabular auf die gleiche Weise interpretiert werden kann, daher im semantischenWeb eindeutig ist und von Servern als auch von Clients dort abgerufen werdenkann (vgl. [14] S.26 f.). Dafür muss das in RDFS beschriebene domänenspezifischeVokabular anderen Domänen zugänglich gemacht werden. So können zum einenSynonyme der gleichen Abstraktionsstufe aufeinander verweisen (equivalentClass)und zum anderen kann sichergestellt werden, dass Begriffe unterschiedlicherAbstraktionsstufen nicht zusammen verwendet werden (isSubclassOf) (vgl. [11]S.53). Ein Ansatz dies umzusetzen stellt OWL-S dar.

Semantic Web Service Composition 149
3.3 Ontologiegestützte Semantikbeschreibung bei Web Servicesdurch OWL-S
Die Vision im Umfeld von Semantic Web ist eine Welt, in der sich weiterent-wickelnde Service-Ansammlungen und -Vernetzungen so gestaltet sind, dassAgenten und Applikationen miteinander automatisiert kommunizieren können.Ontologien stellen dabei den Basisbaustein für das Semantic Web dar, weil diesedafür sorgen, dass WS-Systeme ohne manuellen Einfluss interpretierbar werden.Ontologien stellen ein abstraktes Modell mit einem klar definierten Konzept unddefinierten Bedingungen dar, in dem sich die Entitäten Domänenwissen teilen(vgl. [5] S.3).
Durch die Web Ontology Language for Services (OWL-S) ist es möglich solcheOntologien zu definieren. OWL-S ist eine von der W3C entwickelte Sprache, umsemantische Web Service-Beschreibungen zu ermöglichen und gilt als Weiterent-wicklung der DARPA Agent Markup Language for Services (DAML-S) . Sie kannwie die anderen WS-Standards in XML deklariert werden (vgl. [5] S.1).
Die Sprache baut auf drei zusammenhängenden „Unter-Ontologien“ auf (vgl.[13]):
1. Profil (Profile)Dieses dient der Beschreibung des WS und dessen Aufgabe. Es hilft dem WSfür Agenten auffindbar zu werden.
2. Prozessmodell (Process Model)Hier wird beschrieben, wie der WS funktioniert. Durch die Angabe, welcheProzesschritte und Vorbedingungen für einen bestimmten Output nötig sind,wird der automatisierte Aufruf und die Einbettung in eine WS-Kompositionermöglicht.
3. Fundament (Grounding)Dieses beschreibt die genutzten Formate und Protokolle des WS und damitdie möglichen Interaktionsformen. Diese Angaben werden normalerweise inWSDL ausgedrückt.
Das Profil und das Prozessmodell müssen so aufeinander abgestimmt sein,dass die im Profil eines Web Service angegebene Funktionalität auch durch dasProzessmodell umgesetzt wird. Dabei gibt es vier zentrale Definitionsbausteine,die in beiden Kategorien beschrieben werden: Input, Output, Vorbedingung(Precondition) und Auswirkungen (Effects).Der Input eines atomaren WS ist der Inhalt einer Nachricht, die ähnlich einemRPC an den Service übergeben wird. Der Output stellt das zurückgelieferteErgebnis dar. Durch Vorbedingungen und Auswirkungen eines Web Service wirdein globaler Status definiert, der vor der Ausführung eingetreten sein muss bzw.danach eintritt.So kann bei einem Online-Kauf mittels Web Services die Gültigkeit einer Kre-ditkarte als Vorbedingung, die Eingabe der Kreditkartennummer als Input, dieAusgabe der Kaufbestätigung als Output und die Auslieferung der Ware an denKäufer als Auswirkung definiert werden. Durch diese Definitionsbausteine wird

150 J. Alpers
es zudem möglich neue Web Services ohne zusätzlichen Programmieraufwand zurLaufzeit aufzufinden und zu benutzen.
Inputs und Outputs werden in XML als Unterklassen der Parameter-Klasseabgebildet, welche wiederum die jeweiligen Datentypen als Oberklasse haben.Im folgenden Code-Beispiel einer OWL-Definition in XML ist zum einen diehierarchische Einordnung von Inputwerten zu sehen und zum anderen die Na-mensraumangaben zu RDF, RDFS und OWL, durch die die entsprechendenSchlüsselwörter definiert werden:
<owl:DatatypeProperty rdf:ID="parameterType"><rdfs:domain rdf:resource="#Parameter"/>
[...]<owl:Class rdf:ID="Parameter">
<rdfs:subClassOf><owl:Restriction>
<owl:onProperty rdf:resource="#parameterType" />[...]<owl:Class rdf:ID="Input">
<rdfs:subClassOf rdf:resource="#Parameter"/></owl:Class>
Für die Beschreibung der Vorbedingungen (Preconditions) und Auswirkungen(Effects) wird die Kodierungssprache offen gelassen. Es kann dabei auf die XML-Annotation zurückgegriffen werden oder bspw. die Planning Domain DefinitionLanguage (PDDL) genutzt werden (vgl. [13]). Da OWL als WWW-Sprachenicht davon ausgehen kann, alle Informationen für Preconditions und Effectszu kennen, verwendet sie im Gegensatz zu formalen Planungsalgorithmen eine„Open-World-Semantics“, bei der fehlende Beschreibungen der Planungsdomänezugelassen sind, jedoch bei AI-Planern für einen Abbruch sorgen können (vgl.[18]).
OWL-S unterscheidet drei Prozessarten bei der Einbindung von WS (vgl. [1]S.6):
– atomare Prozesse, die keine weiteren Unterprozesse beinhalten– simple Prozesse, die nicht direkt aufrufbar sind, sondern hinter denen sich
atomare oder zusammengesetzte WS verbergen– Prozesskompositionen, die Unterprozesse enthalten
Handelt es sich nicht um den Aufruf eines einzelnen, atomaren WS, sondern einersog. Komposition, werden nicht mehr die einzelnen In- und Outputs betrachtet,sondern die Stati, die der Prozess im Laufe der Planung annimmt.
Eine solche Prozesskomposition kann mit Flusskonstruktoren und entspre-chenden atomaren WS beschrieben werden. Wie im Prozessmodell in Abbildung 3zu sehen, hat der Client bei „Amazon.com“ die Auswahl, ob er ein Buch über eineder Suchfunktionen (Autor, Künstler, etc.) finden, seinen Einkaufwagen einsehenoder modifizieren, oder eine Sequenz (Sequence) dieser Aktionen durchführenwill. In letzterem Fall würde also nach einer erfolgreichen Buchsuche dieses in

Semantic Web Service Composition 151
Abbildung 3. Beispiel eines Prozessmodells in OWLS (Quelle: i.A. [14] S.31)
den virtuellen Einkaufswagen gelegt werden. Die Blätter dieser Graphdarstellungsind die atomaren Dienste, deren Beschreibung in WSDL erfolgen kann.
4 Verfahren der Semantic Web Service Komposition
4.1 Funktion und Ablauf der SWS Komposition
Ähnlich wie beim sog. semantischen Prozessmanagement ist es das Ziel der WebService Komposition einen höheren Automatisierungsgrad in der Erstellung undDurchführung von Prozessen zu erreichen.Prinzipiell sind zwei Ansätze bei der konkreten Umsetzung einer Web ServiceKomposition zu unterscheiden:Zum einen bieten Sprachen wie die Business Process Execution Language forWeb Services (BPELWS) die Möglichkeit verteilte Web Services miteinander zuverbinden und zu orchestrieren. Dabei fungiert ein Web Service als steuerndesElement, der u.a. regelt in welcher Reihenfolge Nachrichten eintreffen müssen. Eshandelt sich um eine syntaktische Orchestration. Daher muss auch jeder neueProzess manuell über ein jeweils zu definierendes Interaktionsprotokoll mit demsteuernden WS verbunden werden.Die zweite Möglichkeit wird über einen separaten Planer realisiert, der durchverschiedene Algorithmen den Planungsraum durchsucht und bestimmte WS fürseinen Zweck zusammenstellt. Um zu wissen, welche Services für die jeweiligePlanungsdomäne auszuwählen sind, können durch OWL-S definierte Ontologiengenutzt werden. Dadurch soll sicher gestellt werden, dass jede in einem Pla-nungsablauf einbezogene Domäne (Diskurswelt) die genutzte Terminologie gleichversteht und Mehrdeutigkeiten unterbunden werden (vgl. [8] S.3). Statt einem

152 J. Alpers
zentralen, orchestrierenden Dienst werden bei OWL-S für jeden WS der OntologieVorbedingungen (Preconditions) und Auswirkungen (Postconditions) definiert.Durch diese Parameter wird es einem Planer ermöglicht über ein Top-Down-Vorgehen das Auffinden und die Zusammensetzung von Diensten automatisiertvorzunehmen (vgl. [16] und [3]).
Der Prozess einer automatischen Zusammenstellung von Web Services kann alsabstraktes Modell beschrieben werden, bei dem ein Service Provider verschiedeneWeb Services zur Nutzung bereitstellt, die wiederum ein Service Requester inAnspruch nehmen kann. Die weiteren Komponenten und der Planungsablaufkann wie folgt dargestellt werden (vgl. Abbildung 4):
Abbildung 4. Ablauf der Web Service Komposition (Quelle: [17] S.21)
Der Ablauf der Kompositionsplanung kann im Detail in folgende Phasengegliedert werden (i.A. [17] S.20 f.):
1. Dienst anbieten/ publizierenUm die angebotenen WS bei den Repositories publik zu machen, werden dieBeschreibungsdaten der Dienste bspw. über UDDI zur Verfügung gestellt.Neben der Signatur, also Angaben über Datentypen und Operationen desWeb Service, müssen für eine automatisierte Planung ebenso Informationenüber den Status (State) zur Verfügung stehen, der die Vorbedingungen undEffekte bzw. Nachbedingungen eines Dienstes definiert.
2. ÜbersetzenBei der Kommunikation zwischen Benutzer und Planer muss es ersteremmöglich sein seine Planungsaufgabe möglichst einfach und standardisiertzu beschreiben. Dazu gehören die Angaben, welche Daten der Requesterbenötigt, welche er als Input liefert, in welchem Format sie bereitgestelltwerden und wie diese in Beziehung stehen. Dieses ist mit Hilfe von Meta-Auszeichnungssprachen wie WSDL oder DAML-S möglich.Der Planer selbst benötigt diese Angaben in formalisierter Form, in derjeweiligen Sprache, in der sein Planungsalgorithmus formuliert ist. Dahermuss eine Übersetzung ermöglicht werden, durch die keine semantischenZusammenhänge verloren gehen.

Semantic Web Service Composition 153
3. Erzeugen eines Prozessmodells zur WS-KompositionMit den überlieferten Angaben setzt der Planer aus den atomaren Diensten derService Repository ein Prozessmodell zusammen und gibt dieses zusammenmit der Kontroll- und Datenflussspezifikation an den Übersetzer zurück.
4. Bewertung der KompositionDa es mehrere Web Services geben kann, die ihre Funktionalitäten gleichdefiniert haben, aber für die Planungsaufgabe weniger wertvolle Ergebnisseliefern, wird durch den Evaluator ein Ranking der zurückgelieferten Service-Kompositionen durchgeführt.
5. Ausführung der WS-KompositionBei der Ausführung der gewählten Planungskomposition wird eine Sequenzvon Nachrichtenaus- und eingängen (Data flow) festgelegt, wobei jedes zu-rückgelieferte Web Service-Resultat innerhalb der Planung als Inputwert fürden nächsten atomaren Dienstaufruf dient.
4.2 Planer für SWS Komposition
4.2.1 SHOP 2 Der SHOP2-Planungsalgorithmus ist ein sog. Hierarchical TaskNetwork (HTN) -Planer. HTN-Planern liegt zu Grunde, dass jede Planungsdo-mäne mit Hilfe einer Ansammlung von Methoden und Operatoren definiert wird.Jede Methode beschreibt, wie eine Planungsaufgabe weiter untergliedert werdenkann und gibt eine Ordnung dieser vertikalen Aufrufe vor. Jeder Unterprozessruft rekursiv entsprechende Methoden auf bis die Ebene der primitiven Diensteerreicht ist, die mit den übergebenen Operatoren aufgerufen werden können.Hierarchische Planer sind besonders für den WS-Bereich geeignet, da zum Erstel-len einer Methode nicht der gesamte Aufrufplan der Unterdienste bekannt seinmuss.(vgl. [18] S.3).SHOP2 gibt im Gegensatz zu seinem Vorgänger SHOP keine totale, sonderneine partielle Ordnung beim Aufruf der Unterprozesse vor. Dadurch könnensich Planungsschritte von unterschiedlichen Planungsaufgaben überschneidenund ermöglichen eine flexiblere Gestaltung der Domänenstruktur. SHOP-Planergenerieren ihre Planungsfolgen zudem immer in der Reihenfolge, wie die Dienstespäter auch ausgeführt werden. Auf diese Weise kennt der Planer bei jedemPlanungsschritt den momentanen Status des Systems (vgl. [15] S.379 f.).HTN-Planer sind geeignet für die Planung in vollständig beschriebenen Domä-nen, in denen partiell geordnete Ausführungssequenzen zur Verfügung stehen.Werden nicht die benötigten Methoden und Ausführungspläne zur Verfügunggestellt, kann der Algorithmus keine adäquate Lösung für das Planungsproblemzurückliefern. Er hängt also stark von der Designqualität der Methoden in denDomänen ab (vgl. [12].
4.2.2 OWLS-Xplan Um die Schwäche der HTN-Planer zu übergehen, wurdemit dem OWLS-Xplan der Versuch einer Kombination von HTN- und aktionsba-sierter Planung unternommen.Letztere nutzt wie SHOP2 die Information der Domänenmethoden, jedoch befol-gen zur Ausführung der Planungsaufgabe nicht die hierarchische Untergliederung

154 J. Alpers
in Unterprozesse, sondern bedienen sich der atomaren Dienste, die dort angege-ben werden. Dafür wird OWL-S und PDDL genutzt. Der Planer konvertiert dieService- und Ontologiebeschreibungen, die ihm in OWL-S vorliegen, durch einKonvertierungstool (OWL2PDDL) in PDDL. Als Ergebnis erhält man zum eineneine Domänenbeschreibung mit allen Typen, Prädikaten und Aktionen und zumanderen eine Problembeschreibung, die alle Planungsobjekte, den Ausgangszu-stand und den Zielzustand beschreibt. Diese Informationen nutzt der integrierteAI-Planer von Xplan, um einen Verbindungsgraph zu erstellen, der initialisiertenumerische oder literale Operatoren untereinander verbindet und so den Pla-nungsrahmen vorgibt. Der Planer implementiert eine „Re-Planning“-Komponente,durch die auf Änderungen im globalen Zustand während des Planungsprozessreagiert werden kann (vgl. [12]).
4.2.3 Model-based Planner Der MBP stellt einen Vertreter der Artifici-al Intelligence (AI) -Planer dar und implementiert das „Planning as ModelChecking“-Modell. In diesem werden drei für die Web Service-Komposition wich-tige Anforderungen erfüllt (vgl. [16] S.2):
1. Nichtdeterministische DomänenFür einen Requester ist der Output eines WS nicht immer vorhersehbar bevorer nicht wirklich ausgeführt wurde (z.B. ist bei der Buchung eines Flugticketsnicht sicher, ob diese bestätigt wird).
2. Partielle BeobachtbarkeitDer interne Status von WS ist für externe Anfrager i.d.R. nicht einsehbar,sondern nur die jeweiligen Outputs (z.B. ob noch freie Plätze vorhandensind).
3. Beschreibung komplexer ZieleDie Ziele einer WS-Komposition müssen zeitlichen Bedingungen und Prä-ferenzen angepasst werden können (z.B. soll ein Hotel erst gebucht werden,wenn ein entsprechender Flug reserviert wurde).
Im Gegensatz zu HTN-Planern wie SHOP2 werden bei diesen Planern diePlanungsziele definiert und nicht eine geordnete Abfolge von Unterprozessaufrufenformuliert (vgl. [15] S.380). Der MBP wird im folgenden Kapitel näher erläutert.
5 Beschreibung eines SWS Kompositions-Planer amBeispiel des MBP
5.1 Aufbau und Algorithmen des Planers
Die Planung mit dem MBP ist in zwei Phasen gegliedert:
1. Die Darstellung der Planungsdomäne durch Binary Decision Diagrams (BDD)bzw. NuPDDL.
2. Die Anwendung verschiedener Planungsalgorithmen mit Hilfe eines SymbolicModel Checking (SMC) -Planers.

Semantic Web Service Composition 155
5.1.1 Domänenbeschreibung durch BDDs bzw. NuPDDL Durch Bi-nary Decision Diagrams (BDD) ist es möglich, eine Domäne als nichtdetermi-nistisches Zustandsübergangssystem (state transistion system) in Baumstruk-tur darzustellen. In der BDD-Darstellung werden mehrfach-verwurzelte (multirooted), azyklische, gerichtete Graphen verwendet, durch die binäre Entschei-dungsdiagramme abgebildet werden. Die internen Knoten eines solchen Graphenrepräsentieren die Variablen, über die die Funktion definiert ist. Die Blätterdes Baums nehmen den Wert 1 oder 0 an. Hierbei ist zu erwähnen, dass dieBaumgröße exponential zu der Anzahl enthaltener Variablen ansteigt.Eine Funktion F(X1,X2,X3) kann als Baum dargestellt werden, in dem jederKnoten auf zwei Kindknoten verweist, wobei die Kante entweder gestrichelt(Wert=0) oder durchgezogen (Wert=1) dargestellt wird (siehe Abbildung 5). Diezugehörige Wahrheitstabelle zeigt für F genau die Werte der Baumblätter vonlinks nach rechts gelesen an (vgl. [4] S.293 f.).
Abbildung 5. Beispiel eines BDD-Baums mit Wahrheitstafel ([4] S.293)
Im MBP werden durch die Verwendung einer Einheitstabelle (unique table)isomorphe, also bedeutungsgleiche Graphen und dadurch redundante Knotenvermieden. Eine zweite Tabelle (computed table) speichert die zuletzt durchlaufe-nen Transformationen und erhöht dadurch die Effizienz des Planungsalgorithmus(vgl. [2]).
Beim MBP erfolgte diese Darstellung mit Hilfe der aktionsbasierten Sprache„AR“, die fähig ist auch andere als Wahrheitsvariablen zu verarbeiten, eine serielleKodierung vorgibt und das Planungproblem als endlichen Automaten darstellt.
Neue Versionen des MBP unterstützen statt dessen eine Domänenbeschrei-bung und -validierung in NuPDDL, die an PDDL angelehnt ist. Letztere wirdals Standard in der Deklaration von Inputwerten für AI-Planer gehandhabt undbesitzt starke Parallelen zu DAML-S , welche wiederum als Vorgänger von OWL-Sgehandhabt wird.Wie bei OWL-S bereits erwähnt, stellt es für AI-Planer ein Problem dar mit einer„Open-world assumption“ (OWA) umzugehen, d.h. dass nicht alle Variablen fürdie Planung zur Laufzeit zur Verfügung stehen. Ist dies der Fall, so geht derPlaner von dem Wahrheitswert „False“ der Variablen aus, obwohl nicht sicherist, welchen Wert er besitzt. Diesen Umstand bezeichnet man als „Negation as

156 J. Alpers
Failure“ und er ist besonders für die Planung im dynamischen WWW-Umfeldrelevant (vgl. [17] S.24).Zur Beschreibung von Nichtdeterminismus im Initialzustand und von Aktionsef-fekten wird bei NuPDDL das „oneof“-Schlüsselwort genutzt. Für den AI-Planerwird dabei die „open-world assumption“ auf eine Closed-World Assumption(CWA) reduziert:
(define (domain d) ... (:predicates (P1) (P2) (P3) (P4) (P5) (P6))...)(define (problem p)
....(:init (and (P1) (oneof (and (P2) (P3)) (P4)) (unknown (P5))))(:effect (and (P1) (oneof (and (P2) (P3)) (P4)) (unknown (P5))))
....)
Wie in dem Programmierbeispiel in PDDL zu sehen, kommen nicht alle definier-ten Prädikate der Domäne auch im Planungsproblem vor (hier P6). Für dieseVariablen gilt im Sinne der CWA, dass sie immer den Wert „False“ annehmen.Während P1 immer „True“ sein müsste, müssen entweder P2 und P3 oder aber P4wahr sein. Der Wahrheitswert von P5 ist für das Modell indifferent. Ein gültigesModell des Initialzustands wäre bspw.:
P1=True; P2=True; P3=True; P4=False; P5=True; P6=False
Durch nichtdeterministische Aktionseffekte werden ebenso in dem Programmbei-spiel beschrieben. So könnte ein auf den obigen Intialzsutand folgender Zustandwie folgt lauten:
P1’=True; P2’=True; P3’=True; P4’=P4; P5’=False; P6’=P6
P4 und P6 können die alten Werte beibehalten, da an diese Variablen keineBedingungen geknüpft sind. P5 kann beide Wahrheitswerte annehmen. Es könnenalso alle Zustände eingenommen werden, in denen die obige Formel eingehaltenwird (vgl. [19]).
5.1.2 Planungsdurchführung durch Symbolic Model Checking Sym-bolic Model Checking (SMC) erlaubt es, große, endliche Zustandssysteme übersymbolische Repräsentationstechniken (wie bspw. BDD) zu durchsuchen. DiePlanung wird über endliche Automaten und deren Zustandsübergänge definiert.Um ein effizientes Durchsuchen der Domäne zu gewährleisten, werden Ziele überformalisierte Bedingungen des Planungsverlaufs ausgedrückt. Die Domäne selbstist als Zustandsübergangssystem (state transition system) mit einer endlichenAnzahl von Zuständen, einer endlichen Anzahl von darauf ausführbaren Aktionenund Zustandsübergangsfunktionen repräsentiert. Planer für SMC weisen folgendeCharakteristika auf (vgl. [19], [7] S.403ff.):
1. Die Planungsdomänen stellen nichtdeterministische Zustandsübergangssyste-me dar, in denen eine Aktion von einem Zustand zu mehreren, möglichenZuständen führen kann.

Semantic Web Service Composition 157
2. Durch Formeln der temporalen Logik werden sowohl Zielzustände, also auchzeitlich begrenzte Ziele (temporally extended goals) auf den zu durchlaufendenPlanungspfaden definiert.
3. Pläne können bedingtes und iteratives Verhalten aufweisen.4. Über temporale Formeln können Bedingungen ausgedrückt werden, die den
gesamten Planungspfad über gültig sein müssen.5. Die Suche durch die Modellzustände fungiert über Transformationen der
Zustandsbeschreibungsformeln.
Planung über SMC ist daher darauf ausgelegt unter nichtdeterministischenund nicht vollständig beschriebenen Domänen zu planen, was sie für die Sucheim Bereich der Web Services sehr nützlich macht. Diese Art der Planung istso konzipiert, dass weder der Grad an Unsicherheit im Planungsraum, nochdie zusätzliche Angabe von temporären Zielen die Planer-Performance negativbeeinträchtigen (vgl. GHAL2004 S.404).
5.2 Systematik und Merkmale der Planungsalgorithmen
Der MBP stellt ein Tool zur automatischen Erzeugung von Web Service Kom-positionen dar, welches dem Entwickler verschiedene Planungsmöglichkeiten fürverschiedene Planungsprobleme bietet.Allen Planungsszenarien ist gleich, dass sie in nichtdeterministischen Domänenausgeführt werden können. Nichtdeterminismus in einer (Planungs)-Umgebungzeichnet sich dadurch aus, dass die Ergebnisse eines Planungslaufs nicht vorher-bestimmbar sind und damit nicht reproduzierbar sind.
5.2.1 Planung nach Grad der Beobachtbarkeit Für den Fall der Planungin nichtdeterministischen Domänen können, je nach Umfang an Informationen,die über die Domänen zum Zeitpunkt der Planungsausführung zur Verfügungstehen, drei weitere Planungsdimensionen unterschieden werden (vgl. [2]):
1. Volle Beobachtbarkeit (Full Observability)In diesem Fall geht man davon aus, dass die Planungsdomänen voll einsehbarund zur Laufzeit bekannt sind.
2. partielle Beobachtbarkeit (Partial Observability)Es sind nur Teile der Domäneninformationen zur Laufzeit bekannt.
3. Keine Beobachtbarkeit (Null Observability)Die Domäne ist dem Planer gänzlich unbekannt.
Beobachtbarkeit ist dabei als der Anteil der zur Planung zur Verfügungstehenden Informationen definiert. Je nach Grad der Beobachtbarkeit verwendetder MBP unterschiedliche Planungsalgorithmen. Eine Übersicht über den Aufbauund Ablauf der Planung des MBP ist Abbildung 6 zu entnehmen.
Im Falle der teilweisen Beobachtbarkeit (partial observability) wird die Tie-fensuche favorisiert. Dazu werden vom Nutzer die beobachtbaren Variablen unddie Bedingungen, unter welchen diese beobachtbar sind, in BDD bzw. NuPDDL

158 J. Alpers
Abbildung 6. Aufbau des Model-based Planner
angegeben. Der Ausführungsplan dieser Kategorie besitzt eine Baumstruktur.Die Verzweigungen werden durch die beobachtbaren Variablen vorgegeben.
Kann keine Domäneninformation zur Laufzeit abgerufen werden, bedient mansich des „Conformant Planning“. Diese Planungsart erstellt über eine Breitensucheeine Sequenz von Aktionen, die ohne Kenntnis der Anfangskonditionen immerzum gewünschten Ziel führt. Dafür definiert er zusätzliche Variablen, die zurPlanung benötigt werden.
5.2.2 Planung nach Art der Ausführung Ist eine nichtdeterministischeDomäne vollständig oder teilweise bekannt, kann die Erreichung eines Komposi-tionsziels auf folgende Weise definiert werden (vgl. [2]):
1. Weak PlanningNur manche Ausführungen der Planung führen zum gewünschten Ziel.
2. Strong PlanningFür alle Ausführungsvarianten ist sicher, dass das Planungsziel erreicht wird.
3. Strong Cyclic PlanningEs werden iterativ verschiedene Strategien nach dem Trial-and-Error-Prinzipdurchlaufen. Das Ziel wird in allen Ausführungsfällen erreicht.
Die erzeugten Pläne sind Status-Aktions-Tabellen (state-action tables), in de-nen die auszuführenden Aktionen in Form von Statusmengen dargestellt werden.Weak Planning und Strong Planning nutzen die effizientere Breitensuche, umden Planungsgraphen zu durchlaufen. Dazu geht der Algorithmus vom Zielstatusaus und sucht sich einen Weg zum Initialzustand. Nach jedem Schritt wird ein

Semantic Web Service Composition 159
entsprechender Graph in der Status-Aktions-Tabelle erstellt, der im Falle vonWeak Planning eine Chance hat zum gewünschten Zielzustand zu gelangen undim Falle von Strong Planning die Erreichung garantiert. Dabei wird iterativ jedererreichbare Zustand als neuer Ausgangspunkt und damit als neues Planungszieldefiniert. Strong Cyclic Planning nutzt zwei mögliche Planungsvarianten: Beimglobalen Ansatz wird eine Analyse aller Statusvarianten der Planung vorausge-setzt, wobei sich der lokale Ansatz wie die beiden ersteren Planungsarten überZwischenzustände der Planung weiterhangelt (vgl. [2]).
In der Automatendarstellung der Planungsausführung beschreibt ein gerich-teter Graph durch seine Knoten alle Zustände, die durch eine bestimmte Ver-fahrensweise (Policy) erreicht werden können. Solche Policies sind die möglichenWege von einem Initialstatus zu einem Endstatus zu gelangen. In Abbildung 7ist ein Zustandsübergangssystem zu sehen, in dem es mehrere Möglichkeiten gibtvom Initialstatus s1 zum Zielstatus s4 zu gelangen.
Abbildung 7. Beispiel eines nichtdeterministischen Zustandsübergangssystems
Von s2 aus gesehen gibt es für die Zustandstransition move(l2,l3) zwei nichtde-terministische Zustandsübergangsmöglichkeiten: der Status ändert sich in s3 oderin s5. Der Planungsalgorithmus für Strong Planning garantiert in diesem Beispieldurch seine Policy, dass der Planungsgraph auf jeden Fall zum gewünschten Zielführt, indem er folgende Aktionen beschreibt (i.A. [7]):
(s1,move(l1,l2))(s2,move(l2,l3))(s3,move(l3,l4))(s5,move(l5,l4))
Egal welcher Pfad von s2 aus genommen wird; er erreicht immer Status s4 (inAbbildung 7 durch die blauen und roten Kanten gekennzeichnet).Der zugehörige Algorithmus beginnt beim Zielstatus der Suche und arbeitet sichüber erreichbare Zustände vor zum Anfangsstatus. Er kann in folgende Schrittegegliedert werden (i.A. [7]):

160 J. Alpers
1. Input sind der Zielzustand, der Initialzustand und die möglichen Operationenfür die Domäne, d.h. Tupel mit Angaben über die Vorbedingungen undAuswirkungen einer Aktion.
2. Solange es weitere Zustandsübergänge gibt und der Initialzustand nichterreicht ist, wird folgende Suchroutine (StrongPreImage) rekursiv aufgerufen:– Gegenwärtiger Zustand (PreImage) = Zielzustand– Es werden alle möglichen Zustandsübergänge (Tupel) der gegenwärtigenZustände zu PreImage hinzugefügt und als neue Ausgangszustände definiert.PreImage enthält also immer die Zustand-Tupel, die zum Zielzustand leitenoder zu Zuständen führen, die Teil des Lösungswegs sind.– Im Anschluss werden alle Tupel weggeschnitten, deren Lösungsweg zumZielstatus bereits bekannt ist.
3. Der Algorithmus terminiert, wenn entweder der Initialzustand in der Zu-standsmenge enthalten ist oder keine weiteren Zustände mehr der Policyhinzugefügt werden können.
Der Strong Planning-Algorithmus gewährleistet, dass immer eine Lösunggefunden wird oder gibt eine Fehlermeldung zurück, wenn keine „starke“ Lösungexistiert, also eine, die garantiert zum Zielstatus führt.
Im Fall von Weak Planning wäre der Erfolg eines Planungslaufs nur in determi-nistischen Domänen garantiert, da dieser Plan im Gegensatz zur Strong PlanningMethode nur einen möglichen Pfad für die Zielerreichung angibt, auch wenndieser nur unter bestimmten Bedingungen zum Ziel führt. In deterministischenDomänen würden Strong und Weak Planning zu identischen Ergebnissen führen,da eine Zielerreichung immer sichergestellt ist (vgl. [7]).Für den Graph in Abbildung 7 wäre folgendes ein Beispiel für eine Weak Planning-Verfahrensweise, welche mit den blauen Kanten dargestellt wird:
(s1,move(l1,l2))(s2,move(l2,l3))(s3,move(l3,l4))
Im Gegensatz zur Strong Planning Policy davor wird die Möglichkeit, dassmove(l2,l3) auch zu s5 führen könnte, nicht berücksichtigt, sondern nur ein Wegzum Zielstatus s4 angegeben. Es ist daher nicht sicher, dass s4 auch wirklicherreicht wird, falls der Suchroboter bei Status s5 anlangt.
Der dritte, mögliche Suchalgorithmus im Rahmen des SMC ist das Strong Cy-clic Planning. In diesem Fall wird ein Weg zur Erreichung des Zielstatus gefunden,der durch mehrere Iterationen des Plandurchlaufs in jedem Fall zum Zielstatusführt. Dabei wird davon ausgegangen, dass bei einem nichtdeterministischenZustandsübergang nach einer endlichen Anzahl von Wiederholungen der richtigePfad gewählt wird.In Abbildung 7 stellen die grünen Kanten den Pfad dar, den ein Strong CyclicPlanning-Algorithmus, bei dem Versuch von s1 nach s4 zu gelangen, findenwürde. Durch folgenden Zustandsübergang ist nicht sicher, ob der Zustand bei s1verharren oder ob er sich in s5 ändern würde, also nichtdeterministisch ist:
(s1,move(l1,l4))

Semantic Web Service Composition 161
Durch die Iterationen ist es im Vergleich zum Weak Planning Algorithmussicherer den Zielstatus zumindest nach einer endlichen Anzahl von Versuchenzu erreichen. Weak Planning kann immer auch einen Pfad abbilden, der in derMenge aller möglichen Strong Planning-Verfahren enthalten ist. So könnte imoben aufgeführten Weak Planning-Beispiel auch der selbe Pfad vom Algorithmusgefunden werden, der im Fall von Strong Cyclic Planning gefunden wurde.Strong Planning-Lösungen sind eine Untergruppe der Strong Cyclic Planning-Lösungen, welche wiederum immer Teil aller möglichen Weak Planning-Lösungensind (vgl. [7]).
Die genannten Planungsvorgehensweisen setzen voraus, dass ein ganz bestimm-ter, formulierter Endzustand erreicht werden soll. Es können auch Bedingungenausgedrückt werden, die Auswirkungen auf den Planungsablauf haben. In diesemFall spricht man von zeitlich erweiterten Zielen (temporally extended goals).Hierbei werden statt dem Endzustand die Zustandsänderungen in Form vonSequenzen beobachtet. Ein Beispiel für ein Solches wäre im Bereich der kommerzi-ellen Web Services die Bedingung, ein Hotel erst zu buchen, wenn der gewünschteFlug auch reserviert werden konnte (vgl. [14] S.31). Erweiterte Ziele können beimMBP über die Computation Tree Logic (CTL) ausgedrückt werden.
6 Zusammenfassung und Fazit
Für die Planung von Web Service Kompositionen sind semantische Informationenüber die Dienste für ein sinnvolles Kombinieren unerlässlich. Ohne diese Zusatz-informationen ist es für Planer schwierig die für sie relevanten Web Servicesaufzufinden und deren Terminologie miteinander zu vergleichen. Um Informatio-nen darüber zu erhalten, in welchem Verhältnis Web Dienste zueinander stehen,können durch OWL-S definierte Ontologien genutzt werden. Dadurch kann sichergestellt werden, dass jede in einem Planungsablauf einbezogene Domäne (Diskurs-welt) das genutzte Vokabular gleich versteht und Mehrdeutigkeiten unterbundenwerden. In OWL-S selbst ist es durch die Prozessmodellbeschreibung bereitsmöglich statische Abfolgen bzw. Kompositionen von Diensten zu definieren.
Um für das dynamische WWW eine Möglichkeit der nichtdeterministischenPlanung zur Laufzeit in ggf. nicht vollständig bekannten Domänen zu bieten,können AI-Planer wie der MBP herangezogen werden. Diese planen anhand vonglobalen Stati der Planungsdomäne und ihren Diensten und nicht durch denAustausch einzelner Nachrichten. Für die Anwendung des MBP im Bereich derWS ist zu beachten, dass das Verhalten von Web Diensten über eine Menge vonZuständen im Zustandsübergangsgraphen abgebildet wird. Web Dienste definierenjedoch ihr Verhalten in Abhängigkeit vom fortlaufenden Nachrichtenaustausch,so dass ihr Zustand nur selten bekannt ist.
Alle diese Ansätze der semantischen Web Service Komposition nutzen nebenden normalen Input- und Outputwerten auch Angaben über Vorbedingungenund Auswirkungen, um die semantisch sinnvolle Verknüpfung der Dienste zugewährleisten. Diese Angaben werden in formalisierter Form sowohl von OWL-Sverwendet, als auch in AI-Planern, wo sie durch bedingte Zustände in den entspre-

162 J. Alpers
chenden Automaten dargestellt werden. Die Angaben unterstützen Web ServicePlaner dabei u.a. Bedingungen festzulegen, die über den gesamten Planungsver-lauf gelten sollen. Durch die Weiterentwicklung des MBP und die Möglichkeit dieDomänen in PDDL zu beschreiben, so dass auch externe PDDL-Modelle genutztwerden können, hat zur Kompatibilität mit WS-Standards beigetragen und denAnpassungsaufwand von vorhandenen Daten gesenkt. Auch durch die Möglichkeitder Umwandlung von OWL-S (DAML-S) nach PDDL (vgl. [17]) kann bestehendeWS-Semantik genutzt werden und muss nicht in separater Form für AI-Planerneu definiert werden.
Literatur
[1] u. Beek, Maurice H. ter. A survey on service composition approaches: From industri-al standards to formal methods. Istituto di Scienza e Tecnologie dell’Informazione,Pisa, Italy, 2006.
[2] P. C. A. P. M. R. M. T. P. Bertoli. Mbp: a model based planner. 2001. ITC-IRST,Trento (Italien).
[3] B. Biplav Srivastava and J. Koehler. Web service composition - current soluti-ons and open problems. http://www.isi.edu/info-agents/workshops/icaps2003-p4ws/papers/srivastava-icaps2003-p4ws.pdf, Abgerufen: 14.12.2007, 2003.
[4] R. E. Bryant. Symbolic boolean manipulation with ordered binary-decision dia-grams. School of Computer Science, Carnegie-Mellon University, Pittsburgh„1992.
[5] A. H. Cardoso, Jorge; Sheth. Semantic web services and web process composition.First International Workshop, SWSWPC, San Diego, CA, USA, Springer Verlag„Juli 2004.
[6] J. Eder. Conceptual modeling of web service conversations. Advanced InformationSystems Engineering, Springer Verlag, S.449 - 467, Berlin/Heidelberg, 2003.
[7] M. Ghallab, D. Nau, and P. Traverso. Automated planning - theory and practice.Morgan Kaufmann Publishers, S.403-415, San Fransisco, USA, 2004.
[8] B. Heinrich and F. Lautenbacher. Semantisches prozessmanagement - ein ansatzzur automatisierten planung von prozessmodellen. ehrstuhl für Betriebswirtschafts-lehre, Wirtschaftsinformatik & Financial Engineering; Programmierung verteilterSysteme, Universität Augsburg„ 2007.
[9] M. Jeckle. Semantik, odem einer service-orientierten architektur, 2001.http://www.sigs.de/publications/js/2004/01/dostal_JS_01_04.pdf, Abgerufen:14.12.2007.
[10] M. Jeckle. Semantik und web services: Beschreibung von semantik, 2002.http://www.sigs.de/publications/js/2004/02/dostal_JS_02_04.pdf, Abgerufen:14.12.2007.
[11] M. u. Jeckle. Semantik und web services: Vokabulare und ontologien, 2003.http://www.sigs.de/publications/js/2004/03/dostal_JS_03_04.pdf, Abgerufen:14.12.2007.
[12] A. u. Klutsch, Matthias; Gerber. Semantic web service composition planning withowls-xplan. German Research Center for Artificial Intelligence, Saarbrücken, 2005.
[13] D. E. u. Martin. Owl-s: Semantic markup for web services.http://www.w3.org/Submission/OWL-S/, Abgerufen: 14.02.2008.

Semantic Web Service Composition 163
[14] M. u. Martin, David; Paolucci. Bringing semantics to web services: The owl-sapproach. „Semantic Web Services and Web Process Composition“ Cardoso, Jorge;Sheth ,Amit (Hrsg.), First International Workshop, SWSWPC, San Diego, CA,USA, Springer Verlag, Juli 2004.
[15] D. u. Nau. Shop2: An htn planning system. Journal of Artificial IntelligenceResearch, Ausg. 20 (2003), S.379 - 404, URL: http://www.jair.org/media/1141/live-1141-2152-jair.pdf.
[16] M. Pistore. Ws-gen: A tool for the automated composition of semantic web services.http://iswc2004.semanticweb.org/demos/26/paper.pdf.
[17] J. Rao. Semantic web service composition via logic-based program synthesis.Department of Computer and Information Science, Norwegian University of Scienceand Technology, Trondheim, Norwegen.
[18] B. Sirin, Evren; Parsia. Planning for semantic web services. Computer ScienceDepartment, University of Maryland, 2004.
[19] Website. Mbp:a model based planner. http://sra.itc.it/tools/mbp/index.html,Letztes Update: 16.02.2005, Abgerufen: 14.12.2007.

Semantic Web: Proof, Trust und Security
Martin Haslinger
Universität [email protected]
Zusammenfassung In dieser Seminararbeit sollen die Gesichtspunk-te Sicherheit (Security), Vertrauen (Trust) und Beweisführung (Proof)im Umfeld des Semantic Web betrachtet werden. Es werden allgemeineTechniken, aktuelle Fortschritte und Ansätze zur Spezifikation und Stan-dardisierung dieser Bereiche aufgezeigt. Zu jedem Aspekt wird weiterhinnoch ein Ansatz detaillierter vorgestellt.
1 Einleitung
Semantic Web ist neben Web 2.0 und Ajax eines der meistgenutzten Schlagworteim Bezug auf die Zukunft des Internets. Während sich Ajax auf die Präsentationund Web 2.0 auf die Mensch-Mensch Interaktion beziehen, ist das SemanticWeb zur Verbesserung der Kommunikation zwischen Rechnern, sogenanntenSoftware Agenten, gedacht. Informationen sollen so aufbereitet werden, daß siefür Maschinen den selben Informationsgehalt darstellen wie für den Menschen.Diese Vision von Tim Berner-Lee vom W3C stammt bereits aus dem Jahr1998.[5] Die Softwareagenten sollen nicht nur wie bisher nach Schlagwortenund Zusammenhängen suchen können, sondern die Inhalte des Webs in ihrerBedeutung erfassen. Schließlich sollen von ihnen die Daten über mehrere Quellenhinweg zusammengefasst werden, um inhaltlich korrekte Ergebnisse zu liefern.
Zur Spezifikation von Semantic Web Diensten hat das W3C mit dem SemanticWeb Stack (Abbildung 1) eine mehrschichtige Architektur entworfen. SemantischeWeb Services basieren demnach auf URI[6] bzw. IRI[13] Resourcen und werdenin dem auf XML[8] basierenden RDF[4] beschrieben. Um Abfragen auf denRDF Strukturen zu definieren wird die Sprache SPARQL (SPARQL Protocoland RDF Query Language)[27] verwendet. Regeln für die Behandlung der RDFDaten werden im Rule Interchange Format (RIF)[7] spezifiziert. Das SemanticWeb nutzt für die Verarbeitung Ontologien. Um diese wiederzugeben wird dasauf RDF basierende OWL[23] genutzt. Bevor jedoch Semantic Web Dienstevon Applikationen angesprochen werden, müssen die Daten noch mittels einervereinheitlichten Logik einen Beweis für ihre Richtigkeit anfügen. Die bishererwähnten Bestandteile des Stacks sind gemäß Spezifikation zusätzlich über einCrypto-Verfahren abzusichern. Schließlich sollten noch Informationen bezüglichder Vertrauenswürdigkeit des Inhalts beigefügt werden. Mit dem momentanenStand der Forschung sind noch nicht all diese Schichten vollständig spezifiziertworden. Während für die unteren Schichten inkl. Abfrage, Regelaustausch und
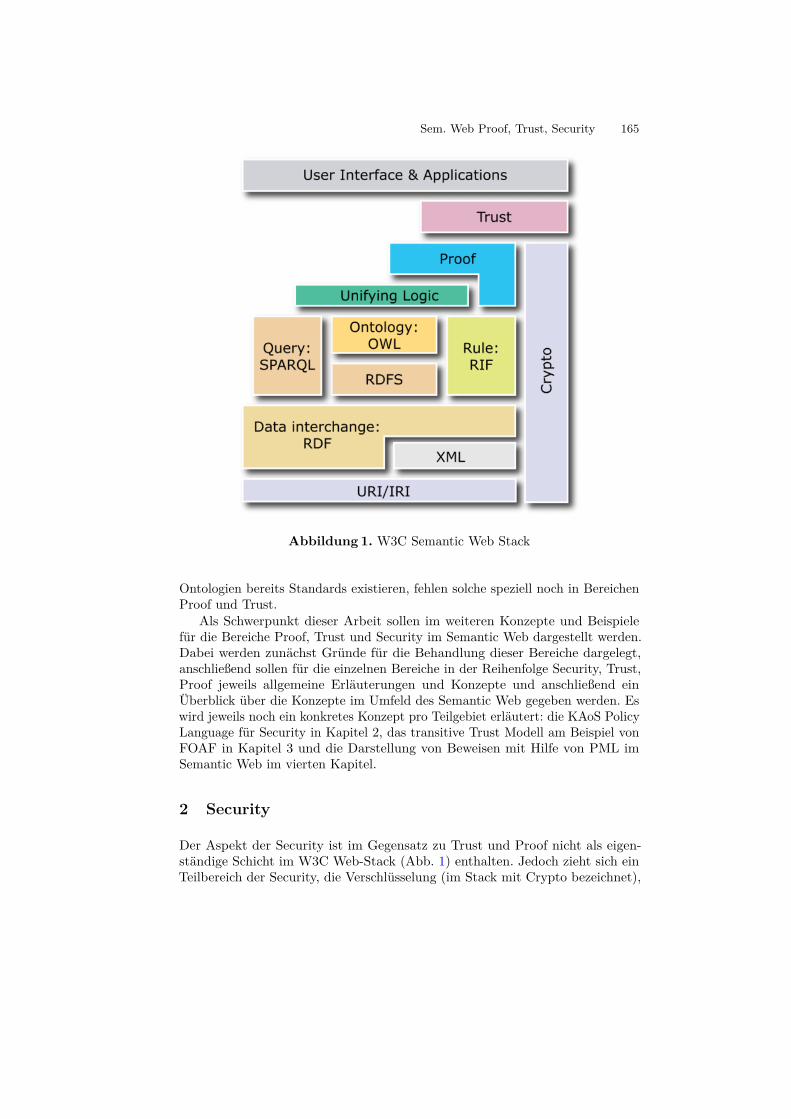
Sem. Web Proof, Trust, Security 165
Abbildung 1. W3C Semantic Web Stack
Ontologien bereits Standards existieren, fehlen solche speziell noch in BereichenProof und Trust.
Als Schwerpunkt dieser Arbeit sollen im weiteren Konzepte und Beispielefür die Bereiche Proof, Trust und Security im Semantic Web dargestellt werden.Dabei werden zunächst Gründe für die Behandlung dieser Bereiche dargelegt,anschließend sollen für die einzelnen Bereiche in der Reihenfolge Security, Trust,Proof jeweils allgemeine Erläuterungen und Konzepte und anschließend einÜberblick über die Konzepte im Umfeld des Semantic Web gegeben werden. Eswird jeweils noch ein konkretes Konzept pro Teilgebiet erläutert: die KAoS PolicyLanguage für Security in Kapitel 2, das transitive Trust Modell am Beispiel vonFOAF in Kapitel 3 und die Darstellung von Beweisen mit Hilfe von PML imSemantic Web im vierten Kapitel.
2 Security
Der Aspekt der Security ist im Gegensatz zu Trust und Proof nicht als eigen-ständige Schicht im W3C Web-Stack (Abb. 1) enthalten. Jedoch zieht sich einTeilbereich der Security, die Verschlüsselung (im Stack mit Crypto bezeichnet),

166 M. Haslinger
von der URI/IRI- bis zur Proof-Schicht fast durch den kompletten Stack. ImUmfeld des Semantic Web ist es also wichtig alle Schichten gleichsam abzusichern,um keine Sicherheitslücken aufzureißen.
Der Gesichtspunkt Security umfasst dabei einen weiten Bereich von Ver-schlüssung und Privacy bis hin zu Autorisierung und Digital Rights Management(DRM). Ein besonderes Augenmerk muss dabei auf die Schichten gelegt wer-den, die nicht in klassischen Webanwendung vorhanden sind, sowie die XMLDatenstrukturen.
2.1 Klassische Security Mechanismen
Einigen dieser Sicherheitsaspekte kann mit bewährten Mitteln begegnet werden,für andere wiederum gibt es aufgrund der fehlenden Berücksichtigung der Seman-tik keine Lösungsansätze aus dem Umfeld des klassischen Web. Zur Absicherungder Daten gegenüber dem unberechtigtem Zugriff Dritter gibt es heutzutage vieleLösungen. Die bekanntesten sind sicherlich die in der E-Mail Kommunikation ein-gesetzten Verfahren OpenPGP[9] und S/MIME[3], sowie das aus dem klassischenWWW bekannte X.509 Public Key Verfahren[19], das bei SSL verschlüsseltenSeiten (HTTPS Protokoll) verwendet wird. Speziell für die Verschlüsselung vonXML Dokumenten gibt es darüber hinaus noch weniger bekannte Methoden, wieXMLEnc.[21][20]
Eine gebräuchliche Methode zur Überprüfung von Zugriffsrechten sind Ac-cess Control Lists (ACL), sie werden heute auf vielen Web Seiten in Form vonhtaccess Dateien und im Betriebssystemumfeld verwendet. Aufgrund ihrer feh-lenden Semantik und Aufwändigkeit sind sie aber für das Semantic Web Umfeldnicht brauchbar. Bessere Ansätze finden sich im Bereich der Web Services mitden OASIS1 Standards Web Service Security (WSS)[1] und Extensible AccessControl Markup Language (XACML)[26], sowie der für XML Dokumente aus-gelegten XML Role-Based Access Control (X-RBAC).[20][22] Aber auch diesetraditionellen Systeme sind nicht geeignet, da sie zumeist einen zentralen Serverbenötigen, die Semantik weiterhin unberücksichtigt lassen und in größeren ver-teilten Systemen nicht skalieren. Auch ist es anzuzweifeln, ob eine Trennung inAuthentifikation und Zugriffskontrolle weiterhin sinnvoll ist.[15][30]
2.2 Semantische Sicherheitsansätze
Während sich traditionelle Ansätze zur Verschlüsselung wie OpenPGP, S/MIMEoder XMLEnc weiterhin nutzen lassen, indem sie einfach eingebettet werden, müs-sen für die Zugriffsverwaltung und Authentifikation neue Möglichkeiten erschloßenwerden. Als spezielle Ansätze für das Semantic Web wurden Kombinationen vonWeb Ontology Language (OWL)[23] und Policy Languages entwickelt. KAoS2
und Rei3 sind zwei der bekannteren Projekte in diesem Gebiet.1 http://www.oasis-open.org/2 http://www.ihmc.us/research/projects/KAoS/3 http://rei.umbc.edu/

Sem. Web Proof, Trust, Security 167
Policies definieren Zugriffsrechte und Regeln, die das Verhalten der System-komponenten dynamisch regulieren. Diese können je nach Policy Sprache auchzur Laufzeit angepaßt werden.. Hierbei können sowohl bestehende Policies ge-ändert, als auch neue Policies und Domänen angelegt werden. Dadurch kanndynamisch reagiert werden anstatt das komplette System im voraus zu planen.Die Verwendung von Semantic Web Ontologien hat dabei sowohl Vor- als auchNachteile. Als Vorteile, die durch die Verwendung von Semantiken entstehen,wären zu nennen:
– Die Modellierung komplexer Regelsysteme wird vereinfacht. Durch die hoheAnzahl an Abstraktionsebenen in den Ontologien wird die Aussagekraftbezüglich des Kontextes erhöht und Änderungen sind leicht vorzunehmen.Neue Konzepte können den Ontologien dabei leicht hinzugefügt werden. Innicht-semantischen Policy Sprachen ist dies nur schwer zu erreichen.
– Durch diese gute Anpassbarkeit eignen sich semantische Policies schließlichauch für eine Wiederverwendung in künftigen Systemen und müssen nicht im-mer von Grund auf neu entstehen. Bestende Policies werden einfach angepaßtund erweitert.
– Ein großer Vorteil von semantischen Policies ist zudem die ihre Analysierbar-keit. Diese ist wichtig für die Entdeckung von Widersprüchen in den Regelnund vereinfacht den Zugang zu den Policy Informationen, wodurch auchdie dynamische Berechnung von Beziehungen zwischen den Policies und derUmgebung möglich werden. Ähnlich wie in Datenbanken kann hierzu gezieltgesucht werden, indem man das Ontologieschema für Abfragen nutzt.
– Die Analysierbarkeit kann desweiteren für die Verifizierung genutzt wer-den und erhöht durch das leichte auffinden bestimmter Teile die Effizienzgegenüber Policies ohne Semantik.
Jedoch entstehen hierbei auch technische Schwierigkeiten:
– Die Erzwingung der Regeln ist ein kritischer Punkt.Policies, die speziell für das Semantic Web entwickelt wurden, sind oftmalsschwer zu integrieren. Grund dafür ist, daß die Spezifikation der Ontologiebasierten Policies von der konkreten Implementierung weit entfernt sein kann.
– In einer heterogenen Umgebung muß eine Übereinkunft über eine gemeinsamverwendete Ontologie getroffen werden.
– Als unbestreitbarer Nachteil muß zudem angemerkt werden, daß die Verwen-dung und Modellierung für den Benutzer nicht leichter wird, sondern dieRegeln im Gegenteil schwerer lesbar und verwaltbar werden. Dies kann aberdurch graphische Oberflächen, welche einem den Umgang mit der konkretenSyntax abnehmen, verbessert werden.[30][28]
Diese Probleme lassen sich zum Teil noch nicht automatisiert lösen. Doch fürdie Autoren von [28] zeigte sich aus Erfahrungen, daß die genannten Vorteile derVerwendung von Semantic Web Ontologien den Nachteilen deutlich überliegen.

168 M. Haslinger
2.3 KAoS Policy Language
Am meisten Erwähnung unter den speziell für das Semantic Web entwickeltenPolicy Languages finden bisher die bereits erwähnten Projekte KAoS und Rei.Die Entwicklung von KAoS begann bereits Mitte der 1990er und dauert bis heutean. Es entwickelte sich aus einer Sammlung plattformunabhängiger Services zurDefinition von Policies über eine Policy Language auf DAML Basis zur heutigenauf OWL basierten Version. Es werden Ontologien zur Beschreibung und Beweis-führung von Domänen genutzt. Diese Domänen können dabei Personen, Agentenund andere computergestützte Akteure sein. KAoS wird in einer Vielzahl vonAnwendungen, wie z.B. Web Services, Mensch-Maschinen Zusammenarbeit inder Raumfahrt oder Kriegsführung, verwendet. KAoS Domain Services stellendie Möglichkeit zur Organisation in Domänen und Subdomänen für Software-komponenten, Personen etc. zur Verfügung. KAoS Policy Services erlauben dieSpezifikationen von Policies innerhalb der Domänen. Dabei wird zwischen Auto-risation, dem Erlauben oder Verbieten bestimmter Vorgänge, und Bedingungen,z.B. der Ausführung einer bestimmter Aktion vor einer anderen, unterschieden.Nennenswert sind, daß KAoS nicht annimmt, daß das Policy gestützte Systemaus homogenen Komponenten besteht. KAoS kann, wie bereits zuvor vorgestellt,Policies dynamisch zur Laufzeit ändern. Das Framework kann auf eine Vielzahlan Plattformen zur Erzwingung der Policies ausgedehnt werden und ist daraufausgelegt anpassbar und robust, auch in Bezug auf Angriffe und Ausfälle, zu sein.
KAoS Policies sind in der aktuellen Version eine Ontologie auf OWL Basis,die sogenannte KAoS Policy Ontologie (KPO). Es existieren momentan mehr als100 Klassen und Attribute in der Basisontologie. Eine Policy ansich ist dabei eineInstanz eines der vier vordefinierten Policy Typen. Komplexe Policies werdendirekt aus diesen Typen zusammengesetzt. Jede spezifizierte Domäne kann sichentweder nach dem demokratischen oder dem tyrannischen Prinzip verhalten. Esist also entweder alles erlaubt, was nicht explizit verboten ist oder alles verboten,was nicht explizit erlaubt wird. Konflikte die zwischen verschiedenen Policiesauftreten versucht KAoS selbstständig zu lösen. Die Algorithmen dazu wurdenals Erweiterung zu Stanfords Java Theorem Prover (JTP)[16] implementiert undin KAoS integriert. Die Lösung der Konflikte erfolgt dabei über Ordnung derPolicies nach Präzedenz und wenn nötig Generierung neuer harmonisierenderRegeln. Das Reasoning wird bei KAoS ebenfalls mithilfe von JTP bewältigt.
In Listing 10.1 ist ein Beispiel analog zu [28] abgebildet.4 Es modelliert folgen-den Sachverhalt in der KAoS Ontologie: „professors are permitted to communicatethe final examination grade to their students using an encrpted communicati-on only after the approval of the institute’s director“[28] Die Spezifikation istzweigeteilt. Der erste (Zeilen 10-31) definiert die Aspekte des regulierten Teilsin einer einzigen OWL Klasse. Informationen zum Policy Management befindensich im zweiten Teil (Zeilen 33-37) und sind damit komplett getrennt. Im erstenTeil werden die drei Restriktionen aufgestellt. In den Zeilen 14-17 wird definiert,daß die Aktion von einem Professor ausgeführt werden muß. Daß der Empfänger4 Das Original Beispiel verwendete noch DAML statt OWL. Es wurde an die neuereKAoS Spezifikation angepaßt.

Sem. Web Proof, Trust, Security 169
ein Student sein muß wird durch eine zweite Restriktion in den Zeilen 19-22bestimmt. Die Bedingung der Zustimmung des Direktors des Institutes ist inden Zeilen 24-27 als weitere Restriktion definiert. Diese Bedingungen sind inder Klasse der auszuführenden Aktion der verschlüsselten Kommunikation (abZeile 10) enthalten. Im zweiten Teil wird schließlich in Zeile 38 die Absenderseite(Subject) als derjenige definiert, der die Einhaltung sicherstellen muß und inZeile 39 die Priorität der Policy auf 10 gesetzt.
Listing 10.1. KAoS Beispiel<?xml version="1.0"?>
2 <rdf:RDF xmlns:rdf="http: //www.w3.org /1999/02/22 -rdf -syntax -ns#"xmlns:rdfs="http: //www.w3.org /2000/01/rdf -schema#"
4 xmlns:owl ="http://www.w3.org /2002/07/ owl#"xmlns:xsd ="http://www.w3.org /2000/10/ XMLSchema#"
6 xmlns:policy="http: // ontology.coginst.uwf.edu/Policy.owl#"xmlns="http: // ontology.coginst.uwf.edu/ExamplePolicies/PolicyExample.owl#"
>8 <owl:Ontology rdf:about="" />
<!-- ..... -->10 <owl:Class rdf:ID="ExaminationGradePolicyAction">
<owl:intersectionOf rdf:parseType="owl:collection">12 <owl:Class rdf:about="http:// ontology.coginst.uwf.edu/Action.owl#
EncryptedCommunicationAction"/>
14 <owl:Restriction ><owl:onProperty rdf:resource="http: // ontology.coginst.uwf.edu/Action.
owl#performedBy"/>16 <owl:toClass rdf:resource="http:// ontology.coginst.uwf.edu/
ActorClasses.owl#AgentProfessors"/></owl:Restriction >
18<owl:Restriction >
20 <owl:onProperty rdf:resource="http: // ontology.coginst.uwf.edu/Action.owl#hasDestination"/>
<owl:toClass rdf:resource="http:// ontology.coginst.uwf.edu/ActorClasses.owl#AgentStudents"/>
22 </owl:Restriction >
24 <owl:Restriction ><owl:onProperty rdf:resource="http: // ontology.coginst.uwf.edu/ Action
.owl#hasApproval"/>26 <owl:toClass rdf:resource="http:// ontology.coginst.uwf.edu/
ActorClasses.owl#AgentInstituteDirector"/></owl:Restriction >
28</owl:Class >
30 </owl:intersectionOf ></owl:Class >
32<policy:PosAuthorizationPolicy rdf:ID="ExaminationGradePolicy">
34 <policy:controls rdf:resource="#ExaminationGradePolicyAction"/><policy:hasSiteOfEnforcement rdf:resource="http:// ontology.coginst.uwf.edu/
Policy.owl#SubjectSite"/>36 <policy:hasPriority >10</policy:hasPriority >
<policy:hasUpdateTimeStamp >446744445544 </policy:hasUpdateTimeStamp >38 </policy:PosAuthorizationPolicy >
Zur einfacheren Administration existiert ein KAoS Policy Administration Tool(KPAT) genanntes Werkzeug. Dadurch wird die bereits erwähnte Benutzerfreund-lichkeit einer semantischen Policy Language hergestellt. Ohne dieses Programmwäre aufgrund der Komplexität wohl nur eine geringe Verbreitung zu erwarten.Es kann sowohl Policies definieren, anzeigen, analysieren, und Konflikte lösen, als
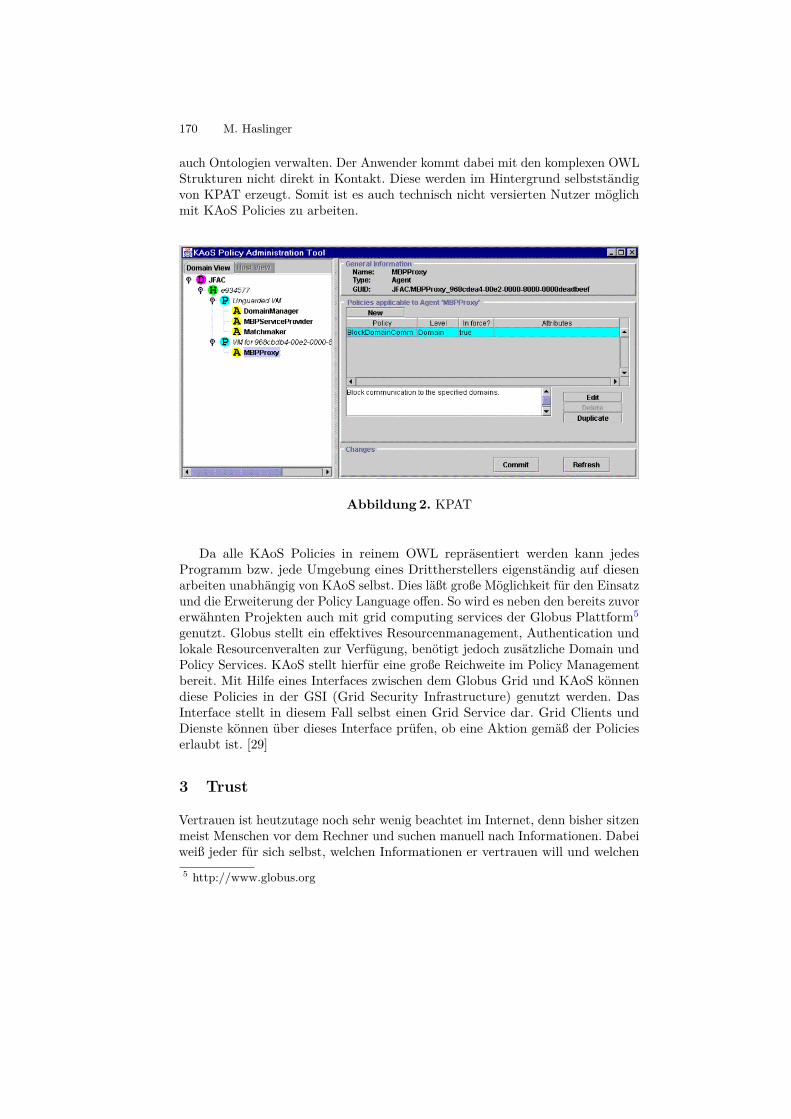
170 M. Haslinger
auch Ontologien verwalten. Der Anwender kommt dabei mit den komplexen OWLStrukturen nicht direkt in Kontakt. Diese werden im Hintergrund selbstständigvon KPAT erzeugt. Somit ist es auch technisch nicht versierten Nutzer möglichmit KAoS Policies zu arbeiten.
Abbildung 2. KPAT
Da alle KAoS Policies in reinem OWL repräsentiert werden kann jedesProgramm bzw. jede Umgebung eines Drittherstellers eigenständig auf diesenarbeiten unabhängig von KAoS selbst. Dies läßt große Möglichkeit für den Einsatzund die Erweiterung der Policy Language offen. So wird es neben den bereits zuvorerwähnten Projekten auch mit grid computing services der Globus Plattform5
genutzt. Globus stellt ein effektives Resourcenmanagement, Authentication undlokale Resourcenveralten zur Verfügung, benötigt jedoch zusätzliche Domain undPolicy Services. KAoS stellt hierfür eine große Reichweite im Policy Managementbereit. Mit Hilfe eines Interfaces zwischen dem Globus Grid und KAoS könnendiese Policies in der GSI (Grid Security Infrastructure) genutzt werden. DasInterface stellt in diesem Fall selbst einen Grid Service dar. Grid Clients undDienste können über dieses Interface prüfen, ob eine Aktion gemäß der Policieserlaubt ist. [29]
3 Trust
Vertrauen ist heutzutage noch sehr wenig beachtet im Internet, denn bisher sitzenmeist Menschen vor dem Rechner und suchen manuell nach Informationen. Dabeiweiß jeder für sich selbst, welchen Informationen er vertrauen will und welchen5 http://www.globus.org

Sem. Web Proof, Trust, Security 171
nicht. Soll diese Aufgabe in Zukunft aber auch von Computer selbstständigbewältigt werden, so muß diesem zunächst Vertrauen und kritischer Umgang mitden erhaltenen Daten beigebracht werden. Vertrauen kann definiert werden alseine subjektive, asymmetrische, transitive, zeit- und kontextabhängige Relation(siehe [11]). Die Ausprägung von Vertrauen kann also als ein Tupel Tα(β, τ, κ)dargestellt werden, das das Vertrauen von α zur Quelle β im Kontext κ zumZeitpunkt τ ausdrückt. Die Umkehrrelation Tβ(α, τ, κ) muß dabei keinesfallsden selben Wert haben oder in irgendeiner Relation dazu stehen. Es würdein der Regel zum Beispiel niemand einem Informatikstudenten Vertrauen fürAussagen über Neurochirurgie als Kontext zusprechen, einem Professor diesesGebietes jedoch sehr wohl. Vertrauen gegenüber anderen kann entweder auseigenen Erfahrungen gebildet werden oder es wird einfach die Meinung andererbzw. die Gesamtmeinung einer Gruppe übernommen (siehe [24]). Zweiteres isterst ab einer großen Anzahl Einzelmeinungen sinnvoll, um eine repräsentativeMeinung einzunehmen, die in vielen Fällen dann durchaus objektiv sein kann.[11]
3.1 Aspekte des Vertrauens
Der Begriff des Vertrauens kann dabei wieder, wie die Sicherheit, in verschiedeneAspekte unterteilt werden (siehe [18]).
– Zunächst gibt es einmal das Vertrauen darin, daß die erhaltenen Informationentatsächlich von der Quelle stammen, die angegeben wird. Im Semantic Webkönnen dafür relativ problemlos die bereits aus klassischen Web Anwendungenbekannten digitalen Signaturen und Zertifikate verwendet werden. Für diesegibt es grundsätzlich zwei verschiedene Ansätze, die sich auch in Kapitel 2.1bei S/MIME bzw. OpenPGP wieder finden.• Ersteres greift eine Hierarchie von Vertrauenswürdigkeit auf und manvertraut letztendlich darauf, daß höhere Stufen nur Vertrauen gegenüberQuellen bzw. Personen aussprechen, die tatsächlich diesen gegenüberbekannt und legitimiert sind.
• Der andere Ansatz, den OpenPGP aufgreift, ist ein sogenanntes Web-of-Trust. Es stützt sich darauf, daß sich das Vertrauen gegenseitig ausge-sprochen und nicht von einer höheren Instanz erteilt wird. Jeder bestätigtalso die ihm direkt bekannten Identitäten.
– Darüber hinaus gibt es noch den bezüglich des Semantic Web interessanterenAspekt des Vertrauens in den Inhalt einer Aussage.Für dieses können grundsätzlich mehrere Zustände unterschieden werden (vgl.[11]):• Vertrauen• Misstrauen• Gleichgültigkeit
Dies kann noch durch einen weiteren Zustand, Unbekannt, erweitert werdenWürde man Vertrauen im Intervall [0,1] skalieren, so wäre Vertrauen 1, Miss-trauen 0, Gleichgültigkeit 0,5 und der zusätzliche Zustand Unbekannt würde

172 M. Haslinger
im Gegensatz zu Gleichgültigkeit wirklich bedeuten, daß man überhauptkeine Einschätzung abgeben kann. Es gibt weitere, meist einfachere, Modellezur Skalierung von Vertrauen, wie z.B. eine simple binäre 1, -1 Skalierungoder eine Abstufung im Ganzzahlbereich [0,10] (siehe [18]).
3.2 Vertrauen im Semantic Web
Im Semantic Web werden nach O’Hara, Alani, Kalfoglou, Shadbolt [25] fünfStrategien zur Vertrauensbildung unterschieden.
– Die optimistische bzw. pessimistische Strategie nehmen grundsätzlich an, daßein Gegenüber vertrauenwürdig bzw. nicht vertrauenswürdig ist bis etwasanderes bewiesen wird. Das Problem an diesem beiden Methoden ist, daßdie Kontextabhängigkeit, der Unterscheidung der Thematiken, nicht gewahrtbleibt und sie dadurch nur bedingt anwendbar sind. Diese Strategien würdenauch zu verhältnismäßig vielen false positives bzw. false negatives führen bisdas System das Vertrauen gegenüber einer Quelle nach dem Trial-and-ErrorVerfahren invertiert. Diese Strategien können also nur auf Fehler reagierenund anschließend die Bewertung der Quelle invertieren. Im untrainiertenGrundzustand sind sie also ziemlich unzuverlässig.
– Die zentralisierte Strategie geht von einer übergeordneten Stelle aus, die daskomplette Vertrauen im Netzwerk speichert. Aufgrund der Heterogenität, derGröße und der Erfahrung, die bisher mit dem Internet gesammelt wurdenist dies aber nicht praktikabel. Allein die Menge der zu speichernden Datensowie die Latenzzeiten würden in größeren Netzen nicht mehr skalieren.
– Nach der investigativen Strategie ist Vertrauen eine Reaktion auf Unsicherheitund wird durch Austausch mit anderen in einem Bayeschen Netzwerk gebildet.Dies geschieht nach ähnlichen Methoden wie in Peer-To-Peer Netzwerken.
– Die letzte und interessanteste (nach [25]) Möglichkeit ist schließlich die Tran-sitivität. Wenn ein Agent A in einem Netz nicht weiß, ob er einem Agenten Gim bezug auf Kontext κ vertrauen kann, werden die A bekannten vertrauens-würdigen Agenten gefragt, ob diese G in bezug auf κ vertrauen. (siehe Abb.3) Diese können wiederum ihnen vertraute Dritte befragen, falls keine direkteRelation existiert. Dabei kann bei jeder transitiven Anfrage eine Gewichtungdes Ergebnisses erfolgen. Dies entspricht dem Prinzip des Knowledge Out-sourcings, da nicht jeder Agent im Netz von allen anderen Kenntnis habenmuß. Praktikabel bleiben also nur die letzten beiden Lösungen.
Ein weiterer möglicher Ansatz zur Verarbeitung von Vertrauen im SemanticWeb findet sich in der Nutzung von Policy Languages, analog zu KAoS im BereichSecurity (siehe 2.3). In [24] wird von Nejdl, Olmedilla und Winslett mit dem vonder University of Illinois at Urbana-Champaign und dem L3S Research Centerder Universität Hannover entwickelten PeerTrust ein Beispiel für einen solchenAnsatz erläutert.

Sem. Web Proof, Trust, Security 173
Abbildung 3. Transitives Vertrauen
3.3 Friend of a Friend (FOAF)
Als in der Praxis bisher am häufigsten angetroffene Strategie wird im weiterennäher auf die Transitivität am Beispiel des Friend of a Friend (FOAF)6 Projekteseingegangen. FOAF ist eine der meist verbreitetsten konkreten Ontologien imSemantic Web und basiert vollständig auf RDF und OWL. Es können bereitsmehr als 1,5 Millionen FOAF Dokumente gefunden werden (siehe [12]).
Mit Hilfe von FOAF lassen sich Informationen über sich selbst, wie z.B. Name,E-Mail, Homepage etc. veröffentlichen. Für das Semantic Web am interessantestenist aber sicherlich die Möglichkeit mittel des Tags foaf:knows Informationenüber bekannte Personen einzufügen und somit ein Social Network zu bilden. InListing 10.2 ist als Beispiel die FOAF Datei eines Max Mustermann inkl. E-Mail,Hompage, Telefonnummer und Infomationen über seinen Arbeitsplatz dargestellt(siehe Zeilen 12-23). Innerhalb des Tags foaf:knows (Zeile 25) ist Beschrieben,daß er Susi Musterfrau kennt und daß ihm ihre E-Mail Adresse und Adressefür weitere Informationen bekannt sind. Mit Hilfe einer Kombination aus Name,E-Mail Adresse, deren SHA1 Prüfsumme und Homepage kann somit jede Personeindeutig identifiziert werden (vgl. [12]).
Unter der Annahme, daß jeder seinen bekannten Personen auch vertraut kanneine Aussage über den Grad des Vertrauen zwischen allen Personen angegebenwerden, indem man die Länge des Pfades zwischen ihnen betrachtet (vgl. [12]).Eine wichtige Rolle spielt hierbei natürlich die maximal akzeptierte Pfadlänge,wodurch die Größe des vertrauenswürdigen Bereiches definiert wird. Wäre diesemaximale Pfadlänge zum Beispiel zwei, so würde man nur Personen trauen, dieman direkt kennt, nicht aber den Bekannten eines Bekannten. Im Beispiel ausAbbildung 3 wäre G für A nur vetrauenswürdig, wenn die maximal akzeptiertePfadlänge mindestens vier ist. Durch Einfügung einer binären Vertrauensrelation1,-1 in die FOAF Ontologie, wie in [18], kann dieses Vertrauensnetzwerk weiter
6 http://www.foaf-project.org/

174 M. Haslinger
verfeinert werden, wodurch man jedem Bekannten vetrauen, aber auch Mißtrauenausprechen kann. Auch die Nutzung einer feiner Abstufung zur Einteilung desVertrauens, wie im vorherigen Abschnitt erläutert, würde das Netzwerk verbes-sern. Das hier vorgestellte Verfahren nutzt also entweder die optimistische oderpessimistische Strategie bezüglich Personen bei denen kein Attribut gesetzt wirdund läßt damit den Kontext außer Acht. Eine Erweiterung um ein zusätzlichesKontextattribut wäre also ebenfalls von Vorteil.
Listing 10.2. FOAF Beispiel<rdf:RDF
2 xmlns:rdf="http: //www.w3.org /1999/02/22 -rdf -syntax -ns#"xmlns:rdfs="http: //www.w3.org /2000/01/rdf -schema#"
4 xmlns:foaf="http: //xmlns.com/foaf /0.1/">
6 <foaf:PersonalProfileDocument rdf:about=""><foaf:maker rdf:resource="#me"/>
8 <foaf:primaryTopic rdf:resource="#me"/></foaf:PersonalProfileDocument >
10<foaf:Person rdf:ID="me">
12 <foaf:name >Max Mustermann </foaf:name ><foaf:title >Herr</foaf:title >
14 <foaf:givenname >Max</foaf:givenname ><foaf:family_name >Mustermann </foaf:family_name >
16 <foaf:nick >Maxi</foaf:nick >
18 <foaf:mbox rdf:resource="mailto:[email protected]"/><foaf:mbox_sha1sum >89 bb3626ceb282eb0ee2df42be487f3 e251db556 </
foaf:mbox_sha1sum >20 <foaf:homepage rdf:resource="http: //www.nowhere.org"/>
<foaf:phone rdf:resource="tel:0123456789"/>22 <foaf:workplaceHomepage rdf:resource="http://www.firma.de"/>
<foaf:workInfoHomepage rdf:resource="http://www.firma.de/mustermann.htm"/>24
<foaf:knows >26 <foaf:Person >
<foaf:name >Susi Musterfrau </foaf:name >28 <foaf:mbox rdf:resource="mailto:[email protected]"/>
<foaf:mbox_sha1sum >4e9a542076c3828885910b94efdbaf95933d7501 </foaf:mbox_sha1sum >
30 <rdfs:seeAlso rdf:resource="http://susi.musterfrau.de"/></foaf:Person >
32 </foaf:knows ></foaf:Person >
34 </rdf:RDF >
4 Proof
Als letztes gilt es sich nun noch dem Bereich der Beweise zu widmen. Im Umfelddes Semantic Web werden diese notwendig, um die Korrektheit hergeleiteterAussagen anzuzeigen. Solange die Informationen von Menschen gesucht undzusammengefaßt werden obliegt es diesem Assoziationen korrekt zu erzeugen. Sokann man aus den beiden Aussagen „Ein Auto ist teuer“und „Ein Porsche ist einAuto“problemlos auf die Tatsache schließen, daß ein Porsche teuer ist. Findet nunaber eine Anwendung im Semantic Web auf die Frage, ob ein Porsche teuer sei,diese beiden Aussagen und schließt korrekt auf das Ergebnis, so muß diese auchbeweisen können, daß dies stimmt, falls keine alleinstehende Aussage darüber

Sem. Web Proof, Trust, Security 175
gefunden werden konnte und das Ergebnis rein durch Schlüsse aus anderenAussagen stammt.
4.1 Beweise für das Semantic Web
Bisher wurde im Bereich des Semantic Web kaum zum Thema Beweise geforscht,weshalb sich die möglichen Methoden derzeit stark in Grenzen halten. AusErfahrung zeigte sich aber bereits, daß es am effizientesten ist allgemeine Beweisermit speziellen, aufgaben- oder umfeldspezifischen zu kombinieren und somit„hybrid reasoning“durchzuführen (siehe [10]). Es gibt zwar viele Programme, diedie benötigten Beweise automatisch erstellen, wichtig ist es jedoch diese in dasSemantic Web einzubetten. Der erzeugte Beweis sollte also in einer Sprache desSemantic Web, vorzugsweise OWL, vorliegen und soweit standardisiert sein, daßer mit den meisten automatischen und manuellen Beweisern interpretierbar bzw.nachprüfbar ist. Ist dies gewährleistet kann jedes beliebige Proof Programm,das dieser Zwischensprache mächtig ist, genutzt werden. Ein weiteres Kriteriumwäre Lesbarkeit für Menschen, um zumindest einzelne Teile eines Beweisennachvollziehen zu können. Da sich Beweise aber durchaus über mehrere Seitenhinziehen können, ist dies nicht unbedingt von höchster Priorität.
Ein Vorschlag für einen solchen OWL Dialekt kommt vom Knowledge SystemsLaboratory der Stanford University. Der Proof Markup Language (PML) genannteAnsatz zur Einbindung von Beweisen setzt vollständig auf OWL. PML ist eineOntologie, die OWL erweitert. Leider ist hier zu erwähnen, daß die meisten bishererwähnten Beispiele für PML nicht mehr aufrufbar sind und das Projekt aktuellnoch am Anfang und wenig verbreitet ist.
4.2 Proof Markup Language (PML)
PML nutzt eine IWBase genannte verteilte Registry von Metadaten und Quellen,die für die Beweise benötigt werden. IWBase ist Teil des Inference Web, dasebenfalls an der Stanford University entwickelt wurde und neben der Registry auchdie Tools für PML bereit stellt. Das unten stehende Beispiel ist der letzte Schritteines längeren PML Beweises und mangels funktionierenden Service zu PMLdirekt aus [10] übernommen. In diesem Schritt wird gefolgert, daß TonysSpecialityden Typ SEAFOOD hat. Zunächst soll aber nun auf die einzelnen Elementeeines in PML dargestellten Beweises eingegangen werden. PML Klassen könnensowohl Beweise als auch provenance information (Herkunftsinformationen) sein.Die Hauptkonstrukte der Beweisdarstellung in PML sind:
– NodeSet7, ein Beweisschritt der als ein Set von Knoten im Beweisbaumangesehen werden kann.• Die Conclusion stellt die Schlußfolgerung des Beweisschrittes dar. Esgibt jeweils genau eine und ist vom Typ Expression.
7 Im weiteren sind PML Konzepte in SansSerif und PML Attribute in Courier undRDF Klassen in Schrägschrift geschrieben.

176 M. Haslinger
• Im Wert hasLanguage wird der Sprachtyp des Beweises angegeben, ihrTyp ist Language. In Beispiel ist als Sprache KIF[17] angegeben.
– Expression repräsentiert einen logischen Ausdruck– InferenceStep stellt die Begründung für die Schlußfolgerung des NodeSet dar.
Sie sind in einer Collection enthalten, die im Attribut isConsequentOf desNodeSet enthalten ist. Er ist eine anonyme OWL Klasse und kann kein bisbeliebig oft in einem Beweisschritt vorkommen. Im Beispiel beschränkt sichdie Anzahl jedoch auf genau einen Schritt. InferenceStep hat wiederrum einigeAttribute, um den Schritt detailliert zu beschreiben.• Die angewandte Regel wird in hasRule dokumentiert. Ihr Typ ist Infe-
renceRule. PML definiert hierfür die vordefinierten Werte Assumption,DirectAssertion und UnregisteredRule. Die möglichen Regeln können aberbeliebig erweitert werden, indem sie in der IWBase registriert werden.
• Der Antezedent wird mittels hasAntecedent angegeben und kann fürden Beweisschritt als Prämisse angesehen werden. Hier kann wiederumeine Collection eingefügt werden, um mehrere Prämissen anzugeben. Jenach Regel kann die Reihenfolge hier von Bedeutung sein. Im Beispielwerden zwei Prämissen verwendet, die mit ihrer URI angegeben werden.• Mit jedem InferenceStep können beliebig Terme Variablen zugewiesen wer-
den. Damit wird eine Substitution in den Prämissen durchgeführt, bevordie Regel des Schritts angewendet wird. Diese Zuweinsungen haben denTyp VariableBinding und werden in der Collection hasVariableMappingannotiert.
• Ebenfalls null bis beliebig oft kann die Collection hasDischargeAssump-tion belegt werden. In ihr werden Expression Ausdrücke dargestellt,die im Beweisschritt verworfen werden.
• Jede Quelle eines Schrittes (PML Typ Source) wird in hasSource einge-tragen und repräsentiert das Originalstatement aus welchem die Schluß-folgerung gewonnen wurde. Dieses Attribut ist eine optionale Collectionund kann damit ebenfalls beliebig viele Quellen beinhalten.
• Die verwendete Engine des Schrittes wird mit Typ InferenceEngine imAttribut hasInferenceEngine angegeben. Im Beispiel ist dies der bereitserwähnte JTP, welches von den Entwickler von PML selbst stammt.
• Der Zeitpunkt der Ausführung des Schritts wird mit Typ dateTime inhasTimeStamp festgehalten. Im Beispiel fehlt dieses Attribut, obwohl esgemäß [10] verpflichtend ist.
Listing 10.3. PML Beispiel<rdf:RDF >
2 <iw:NodeSet rdf:about="http: //.../ tonysns4_0.owl#tonysns4_0"><iw:Conclusion >
4 (|http://www.w3.org /1999/02/22 -rdf -syntax -ns#| ::type|http: //.../ tonys.daml#|::|TonysSpecialty| ?x)
</iw:Conclusion >6 <iw:hasLanguage rdf:resource="http: //.../ registry/LG/KIF.owl#KIF"/>
<iw:isConsequentOf rdf:parseType="Collection">8 <iw:InferenceStep >
<iw:hasRule rdf:resource="http: //.../ registry/DPR/GMP.owl#GMP"/>

Sem. Web Proof, Trust, Security 177
10 <iw:hasInferenceEngine rdf:resource="http: //.../ registry/IE/JTP.owl#JTP" rdf:type="http: //.../ iw.owl#InferenceEngine"/>
<iw:hasAntecedent rdf:parseType="Collection">12 <iw:NodeSet rdf:about="http: //.../ tonysns4_1.owl#tonysns4_1"/>
<iw:NodeSet rdf:about="http: //.../ tonysns4_5.owl#tonysns4_5"/>14 </iw:hasAntecedent >
<iw:hasVariableMapping rdf:parseType="Collection">16 <iw:VariableMapping iw:Variable="?x">
<iw:Term >18 |http: //.../ tonys.daml#|::|SEAFOOD|
</iw:Term >20 </iw:VariableMapping >
</iw:hasVariableMapping >22 </iw:InferenceStep >
</iw:isConsequentOf >24 </iw:NodeSet >
</rdf:RDF >
Im Beispiel wird also ein Beweisschritt dargestellt, der als SchlußfolgerungTonysSpeciality mit SEAFOOD gleichstellt. zu Beginn ist dies noch mit derVariable ?x belegt. Wie bereits erwähnt wird als Sprache des Beweises KIFverwendet und somit ist ?x eine Variable, die gemäß KIF Syntax mit einemFragezeichen beginnen muß. Als Prämissen werden zwei nicht angegebene NodeSetverwendet und als Schritt wird schließlich die Variable ?x mit SEAFOOD belegt.Die dafür angewandte Regel ist GMP, das hier ebenfalls nicht näher spezifiziertist.
Zur Repräsentation der provenance information dient das Element Prove-nanceElement. Sie werden in der IWBase gespeichert. Es ist das oberste Elementder Darstellung und hat wiederum mehrere Attribute:
– Die URI dient der eindeutigen Identifizierung und ist eine Instanz des primi-tiven Typs anyURI
– In der URL wird ein optionaler Verweis auf ein Web Dokument hinterlegt.– Name vom Typ string dient als Kurz- oder Spitzname des Elementes in der
IWBase.– Der Übermittler wird im Attribut Submitter vom Typ Team hinterlegt.– Zudem werden sowohl das Datum der ursprünglichen Registrierung in der
IWBase in DateTimeInitialSubmission,– als auch das der letzten Aktualisierung (DateTimeLastSubmission) benötigt.
Diese sind jeweils vom Typ dateTime.– Optional ist eine Beschreibung in englischer Sprache im Attribut EnglishDes-
cription.
Darüber hinaus gibt es noch spezialisierte Typen von ProvenanceElement:
– Source bezeichnet ein ProvenanceElement, das als Quelle von Originaldatendient. Momenten sind folgende Typen in der IWBase definiert:• InferenceEngine• Ontology• Organization• Person• Publication• Language

178 M. Haslinger
• Team– Eine InferenceRule ist die Beschreibung einer Regel, die auf die Prämissen
angewendet wird. Es wird dabei zwischen den Typen PrimitiveRule undDerivedRule unterschieden.• Eine PrimitiveRule ist mindestens einer InferenceEngine zugewiesen undrepräsentiert eine Regel, wie z.B. Modus Ponens. Diese Regeln könnenin anderen Engines auch als abgeleitete Regeln existieren. Jeder dieserRegeln ist wie zuvor eine Langauge zugewiesen.
• DerivedRule spezifiert eine abgeleitete Regel und benötigt daher derenPML Beweis zur Spezifikation.
Die komplette PML API ist in Java implementiert und unter [2] verfügbar. DieEntwickler vom PML legten ein besonderen Augenmerk darauf die Beweise mittelder Web Infrastruktur portabel zu halten. Ein Teil dazu trägt unteranderemPMLs Unabhängigkeit von einer spezifischen Sprache für Beweise bei. PML trägtmittel Metainformationen und Annahmen über die Manipulation von Daten zurErhöhung des Vertrauens in Semantic Web Anwendungen bei. Durch Integrationin JTP ist auch bereits gelungen eine Referenz für einen Reasoner mit PMLUnterstützung zu stellen. Die IWBase ist für die Aufnahme weiterer ebensooffen wie für die Erweiterung des Regelsatzes und der anderen Bestandteile desSpezifikation.[10] PML ist also ein Vorschlag für eine Beweissprache, die aufgrundihrer Erweiterbarkeit, Offenheit und OWL als Grundlage durchaus potential zueinem Standard für die Proof Schicht des Semantic Web hat.
5 Fazit
Es zeigt sich also, daß die Schichten Proof und Trust des Semantic Web Stack sowiedas Thema Security allgemein eine große Wichtigkeit zukommt. Soll das SemanticWeb in Zukunft von einer Vision zur Realität werden, werden sie unverzichtbarsein, um das Vertrauen der Benutzer in die Sicherheit und Korrektheit derAnwendungen zu gewinnen. Zusammenfassend betrachtet erscheinen die BereicheSicherheit, Vertrauen und Beweisführung aber bisher noch wenig erforscht. EineStandardisierung dieser fehlt sogar noch gänzlich. Für eine Akzeptanz einer zumStandard erkorenen Technik werden aber Dokumentation und Einfachheit bei derImplementierung und Definition unverzichtbar sein. Dies ist bei den vorgestelltenTechniken leider noch nicht erreicht. Lediglich das grafische Tool zur Erzeugungvon KAoS Policies erscheint bereits ein guter Ansatz in Richtung Useability zusein. Dokumentation sind leider rar und oft fehlerhaft. Beispiele oftmals nichtmehr verfügbar oder funktionstüchtig.
Bis zur echten Verwendbarkeit von Sicherheits-, Vertrauens- und Beweismerk-malen in Semantic Web Anwendungen gibt es also noch viel zu tun. Mit demmomentanen Stand der Entwicklung können sie Bereiche nur durch manuelleEingriffe in der Entwicklung abgedeckt werden.

Sem. Web Proof, Trust, Security 179
Literatur
[1] Oasis web services security (wss) tc.[2] Pml api.[3] S/mime working group.[4] D. Beckett and B. McBride. Rdf/xml syntax specification (revised), Februar 2004.[5] T. Berners-Lee. Semantic web roadmap, Oktober 1998.[6] T. Berners-Lee, R. Fielding, and L. Masinter. Uniform resource identifiers (uri):
Generic syntax, August 1998.[7] H. Boley and M. Kifer. Rif basic logic dialect, Oktober 2007.[8] T. Bray, J. Paoli, C. M. Sperberg-McQueen, E. Maler, F. Yergeau, and J. Cowan.
Extensible markup language (xml) 1.1 (second edition, September 2006.[9] J. Callas, L. Donnerhacke, H. Finney, and R. Thayer. Openpgp message format,
November 1998.[10] P. P. da Silva, D. L. McGuinness, and R. Fikes. A proof markup language for
semantic web services. Inf. Syst., 31(4):381–395, 2006.[11] L. Ding, L. Zhou, and T. Finin. Trust based knowledge outsourcing for semantic web
agents. In WI ’03: Proceedings of the 2003 IEEE/WIC International Conferenceon Web Intelligence, page 379, Washington, DC, USA, 2003. IEEE ComputerSociety.
[12] L. Ding, L. Zhou, T. Finin, and A. Joshi. How the semantic web is being used:An analysis of foaf documents. pages 113c–113c, 2005.
[13] M. Duerst and M. Suignard. Internationalized resource identifiers (iris), Januar2005.
[14] D. Fensel, K. P. Sycara, and J. Mylopoulos, editors. The Semantic Web - ISWC2003, Second International Semantic Web Conference, Sanibel Island, FL, USA,October 20-23, 2003, Proceedings, volume 2870 of Lecture Notes in ComputerScience. Springer, 2003.
[15] T. Finin and A. Joshi. Agents, trust, and information access on the semantic web.SIGMOD Rec., 31(4):30–35, 2002.
[16] G. Frank, J. Jenkins, and R. Fikes. Jtp: An object-oriented modular reasoningsystem, Januar 2008.
[17] M. R. Genesereth. Knowledge interchange format (kif).[18] J. Golbeck and J. Hendler. Accuracy of Metrics for Inferring Trust and Reputation
in Semantic Web-Based Social Networks, volume 3257. January 2004.[19] R. Housley, W. Polk, W. Ford, and D. Solo. Internet x.509 public key infrastructure
certificate and certificate revocation list (crl) profile.[20] L. Kagal, T. W. Finin, and A. Joshi. A policy based approach to security for the
semantic web. In Fensel et al. [14], pages 402–418.[21] L. Kagal, M. Paolucci, N. Srinivasan, G. Denker, T. Finin, and K. Sycara. Au-
thorization and privacy for semantic web services. IEEE Intelligent Systems,19(4):50–56, 2004.
[22] G. Klyne. Framework for security and trust standards, Dezember 2002.[23] D. L. McGuinness and F. van Harmelen. Owl web ontology language overview,
Februar 2004.[24] W. Nejdl, D. Olmedilla, and M. Winslett. Peertrust: Automated trust negotiation
for peers on the semantic web. In W. Jonker and M. Petkovic, editors, Secure DataManagement, volume 3178 of Lecture Notes in Computer Science, pages 118–132.Springer, 2004.

180 M. Haslinger
[25] K. O’Hara, H. Alani, Y. Kalfoglou, , and N. Shadbolt. Trust strategies for thesemantic web. In Proc. of the Workshop on Trust, Security, and Reputation onthe Semantic Web, November 2004.
[26] B. Parducci, H. Lockhart, P. Mishra, R. Levinson, and J. B. Clark. Oasis extensibleaccess control markup language (xacml) tc.
[27] E. Prud’hommeaux and A. Seaborne. Sparql query language for rdf, Januar 2008.[28] G. Tonti, J. M. Bradshaw, R. Jeffers, R. Montanari, N. Suri, and A. Uszok.
Semantic web languages for policy representation and reasoning: A comparison ofkaos, rei, and ponder. In Fensel et al. [14], pages 419–437.
[29] A. Uszok, J. M. Bradshaw, and R. Jeffers. Kaos: A policy and domain servicesframework for grid computing and semantic web services. In C. D. Jensen, S. Poslad,and T. Dimitrakos, editors, iTrust, volume 2995 of Lecture Notes in ComputerScience, pages 16–26. Springer, 2004.
[30] A. Uszok, J. M. Bradshaw, M. Johnson, R. Jeffers, A. Tate, J. Dalton, and S. Aitken.Kaos policy management for semantic web services. IEEE Intelligent Systems,19(4):32–41, 2004.