Embed Size (px)
Citation preview

Universitat TubingenWilhelm-Schickard-InstitutArbeitsbereich Diskrete MathematikLeitung: Prof. Dr. Peter HauckVorlesung WS 2008/2009Stand: 16. Oktober 2009
Kryptologie und Datensicherheit
Die Vorlesung wurde fur Diplom- und Masterstudie-rende mit 4 SWS, fur Bachelorstudierende mit 3 SWSgehalten.Die Teile, die fur die Bachelorstudierenden entfallen,sind im Inhaltsverzeichnis mit (∗) gekenntzeichnet.
Herstellung der TeX-Fassung des Vorlesungsskripts: Jurgen SommerUberarbeitung: Jonas Bochtler

Inhaltsverzeichnis
1 Grundbegriffe 12
2 Klassische symmetrische Verschlusselungsverfahren 17
2.A Monoalphabetische Substitutionschiffren . . . . . . . . . . . . 18
2.1 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2 Kryptoanalyse monoalphabetischer Substitutionschiffren . . . 20
2.3 Homophone Chiffren . . . . . . . . . . . . . . . . . . . . . . . 25
2.B Polyalphabetische Verschlusselungen . . . . . . . . . . . . . . 27
2.4 Beispiel: Vigenere-Chiffre . . . . . . . . . . . . . . . . . . . . . 27
2.5 Beispiel: ENIGMA . . . . . . . . . . . . . . . . . . . . . . . . 30
2.6 Kryptoanalyse periodischer polyalphabetischerVerschlusselungen . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.7 Kasiski-Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.8 Friedman-Test . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.9 Nichtperiodische polyalphabetische Verschlusselungen . . . . 41
3 Perfekte Sicherheit von Chiffrierverfahren 43
3.1 Definition (Perfekte Sicherheit) . . . . . . . . . . . . . . . . . 43
3.2 Satz (Shannon, 1949) . . . . . . . . . . . . . . . . . . . . . . . 44
3.3 Satz (Perfekte Sicherheit des One-time-pads) . . . . . . . . . . 45
4 Symmetrische Blockchiffren 46
4.1 Lineare Algebra uber kommutativen Ringen . . . . . . . . . . 47
4.2 Affine Blockchiffren . . . . . . . . . . . . . . . . . . . . . . . . 49
4.3 Kryptoanalyse affiner Blockchiffren . . . . . . . . . . . . . . . 51
2

4.4 Hintereinanderausfuhrung von Blockchiffren, Diffusion undKonfusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.5 Feistel-Chiffren . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.6 Der ’Data Encryption Standard’ DES . . . . . . . . . . . . . 57
4.6.1 Rundenschlusselerzeugung . . . . . . . . . . . . . . . . 59
4.6.2 Beschreibung der Verschlusselungsfunktion fKi. . . . . 60
4.6.3 Sicherheit des DES . . . . . . . . . . . . . . . . . . . . 63
4.6.4 Effizienz der DES-Verschlusselung . . . . . . . . . . . . 69
(∗) 4.7 Differentielle Kryptoanalyse am Beispiel des DES . . . . . . . 69
4.8 Endliche Korper . . . . . . . . . . . . . . . . . . . . . . . . . . 79
4.9 Der Advanced Encryption Standard (AES)Das Rijndael-Verfahren . . . . . . . . . . . . . . . . . . . . . . 82
4.10 Andere Blockchiffren . . . . . . . . . . . . . . . . . . . . . . . 90
5 Betriebsarten von Blockchiffren 92
5.1 Electronic Codebook Mode (ECB Mode) . . . . . . . . . . . . 92
5.2 Cipherblock Chaining Mode (CBC Mode) . . . . . . . . . . . 92
5.3 Cipher Feedback Mode (CFB Mode) . . . . . . . . . . . . . . 94
5.4 Output Feedback Mode (OFB Mode) . . . . . . . . . . . . . 96
6 Stromchiffren 97
6.1 Synchrone Stromchiffren . . . . . . . . . . . . . . . . . . . . . 97
6.2 Selbstsynchronisierende Stromchiffren . . . . . . . . . . . . . . 98
6.3 Schieberegister . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.4 Lineare Schieberegister . . . . . . . . . . . . . . . . . . . . . . 101
6.5 Eigenschaften von linearen Schieberegistern . . . . . . . . . . 102
6.6 Lineare Komplexitat . . . . . . . . . . . . . . . . . . . . . . . 104
3

6.6.1 Satz (Charakterisierung der linearen Komplexitat) . . . 105
6.6.2 Satz (Rekonstruktion des LSR aus Folgestuck) . . . . . 106
6.7 Schieberegister zur Schlusselstromerzeugung . . . . . . . . . . 107
6.8 Spezielle Stromchiffren . . . . . . . . . . . . . . . . . . . . . . 110
(∗) 7 Kryptographisch sichere Pseudozufallsfolgen - Generatorenund Einwegfunktionen 111
7.1 Wahrscheinlichkeitstheoretische Bezeichnungen . . . . . . . . . 112
7.2 Definition (Kryptographisch sicherer Pseudozufallsfolgen-Generator) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
7.3 Bedeutung von Definition 7.2 . . . . . . . . . . . . . . . . . . 114
7.4 Definition (Next-Bit-Tests) . . . . . . . . . . . . . . . . . . . . 116
7.5 Bedeutung von Definition 7.4 . . . . . . . . . . . . . . . . . . 116
7.6 Satz (Yao; 1982) . . . . . . . . . . . . . . . . . . . . . . . . . 117
7.7 Definition (Einwegfunktion) . . . . . . . . . . . . . . . . . . . 118
7.8 Bedeutung von Definition 7.7 . . . . . . . . . . . . . . . . . . 119
7.9 Satz (Hastad, Impagliazzo, Levin, Luby; 1999) . . . . . . . . . 119
7.10 Die Frage nach der Existenz von Einwegfunktionen . . . . . . 123
8 Public-Key-Kryptographie 125
8.1 Die Grundidee . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
8.2 Modulare Potenzen und das RSA-Verfahren . . . . . . . . . . 126
8.3 Lemma (Satz von Euler) . . . . . . . . . . . . . . . . . . . . . 127
8.4 Satz (Eigenschaften der RSA-Funktionen) . . . . . . . . . . . 127
8.5 Bemerkung (schnelles Potenzieren) . . . . . . . . . . . . . . . 128
8.6 RSA-Verfahren (Basisversion) . . . . . . . . . . . . . . . . . . 129
8.7 Bemerkung (Bestimmung von e und d) . . . . . . . . . . . . . 129
4

8.8 Beispiel zur RSA-Verschusselung . . . . . . . . . . . . . . . . 130
8.9 Verwendung von RSA als Blockchiffre . . . . . . . . . . . . . . 131
8.10 Sicherheit des RSA-Verfahrens . . . . . . . . . . . . . . . . . . 132
8.11 Effizienz des RSA-Verfahrens . . . . . . . . . . . . . . . . . . 139
8.12 Bestimmung großer Primzahlen . . . . . . . . . . . . . . . . . 139
8.13 Diskreter Logarithmus . . . . . . . . . . . . . . . . . . . . . . 143
8.14 Bestimmung von p und g . . . . . . . . . . . . . . . . . . . . . 145
8.15 Sicherheit des Diffie-Hellman-Verfahrens . . . . . . . . . . . . 146
8.16 Das ElGamal-Verschlusselungsverfahren . . . . . . . . . . . . . 147
8.17 Effizienz des ElGamal-Verfahrens . . . . . . . . . . . . . . . . 148
8.18 Sicherheit des ElGamal-Verfahrens . . . . . . . . . . . . . . . 148
8.19 Erweiterungen der Diffie-Hellman und ElGamal-Verfahren . . 149
8.20 Modulare Quadratwurzeln . . . . . . . . . . . . . . . . . . . . 150
8.21 Das Public-Key-Verfahren von Rabin . . . . . . . . . . . . . . 152
8.22 Der Blum-Blum-Shub Pseudozufallsfolgengenerator . . . . . . 153
9 Digitale Signaturen und kryptographische Hashfunktionen 154
9.1 Grundidee digitaler Signaturen . . . . . . . . . . . . . . . . . 154
9.2 Signaturschema (vereinfachte Form) . . . . . . . . . . . . . . . 154
9.3 Definition (Hashfunktion) . . . . . . . . . . . . . . . . . . . . 155
9.4 Signaturschema mit Hashfunktion . . . . . . . . . . . . . . . . 156
9.5 Definition (kryptographische Hashfunktion) . . . . . . . . . . 156
9.6 Satz (Kollisionsresistenz und Einwegeigenschaft) . . . . . . . . 157
9.7 Satz (Geburtstagsparadox) . . . . . . . . . . . . . . . . . . . . 158
9.8 Geburtstagsattacke . . . . . . . . . . . . . . . . . . . . . . . . 159
5

9.9 Serielles Hashing mit Kompressionsfunktionen . . . . . . . . . 159
9.10 Konstruktion von Kompressionsfunktionen unter Verwendungvon Blockchiffren . . . . . . . . . . . . . . . . . . . . . . . . . 160
9.11 Spezielle Hashfunktionen . . . . . . . . . . . . . . . . . . . . . 161
9.12 RSA-Signatur . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
9.13 ElGamal-Signatur . . . . . . . . . . . . . . . . . . . . . . . . . 163
9.14 Sicherheit der ElGamal-Signatur . . . . . . . . . . . . . . . . . 165
9.15 Der Digital Signature Algorithm (DSA) . . . . . . . . . . . . . 167
9.16 Message Authentication Codes (MAC) . . . . . . . . . . . . . 167
9.17 Konstruktionsmoglichkeiten von MACs . . . . . . . . . . . . . 168
10 Authentifizierung und Zero-Knowledge-Beweise 169
10.1 Passworter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
10.2 Challenge-Response-Authentifizierung . . . . . . . . . . . . . . 170
10.3 Zero-Knowledge-Beweise . . . . . . . . . . . . . . . . . . . . . 171
10.4 Das Fiat-Shamir-Verfahren (Fiat, Shamir, 1986) . . . . . . . . 172
10.5 Formalisierung der Zero-Knowledge-Eigenschaft . . . . . . . . 173
(∗) 11 Anonymitat 175
11.1 MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
11.2 Blinde Signaturen . . . . . . . . . . . . . . . . . . . . . . . . . 177
11.3 Anwendung: Elektronische Munzen . . . . . . . . . . . . . . . 178
(∗) 12 Secret Sharing Schemes 180
12.1 Definition (Zugriffsstruktur) . . . . . . . . . . . . . . . . . . . 180
12.2 Definition (Secret Sharing Schemes) . . . . . . . . . . . . . . . 180
12.3 Definition (Schwellenwertsystem) . . . . . . . . . . . . . . . . 181
6

12.4 Shamirs Konstruktion eines perfekten Schwellenwertsystems . 181
12.5 Definition (monotone Zugriffsstruktur) . . . . . . . . . . . . . 183
12.6 Monotone Secret Sharing Schemes nach Simmons . . . . . . . 183
7

Abbildungsverzeichnis
1 Grundschema einer Verschlusselung zwischen Alice und Bob . 12
2 Die Teildisziplinen Kryptographie und Kryptoanalyse . . . . . 14
3 Strom- vs Block-, Substitutions- vs Transpositionschiffre . . . 17
4 Zuordnung bei homophoner Substitutionschiffre . . . . . . . . 25
5 Glattung der Buchstabenhaufigkeiten bei Vigenere-Verschlusselung . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6 Schematischer Signallaufplan ENIGMA . . . . . . . . . . . . . 31
7 Schematischer Ablauf einer Feistel-Chiffrierung . . . . . . . . . 54
8 Rundenschlusselerzeugung . . . . . . . . . . . . . . . . . . . . 59
9 Schematische Darstellung der Berechnung von fK(R) . . . . . 63
10 Transformationen . . . . . . . . . . . . . . . . . . . . . . . . . 83
11 Schematischer Ablauf des Rijndael-Verfahrens . . . . . . . . . 84
12 Verschlusselung selbstsynchronisierender Stromchiffren . . . . 98
13 Entschlusselung selbstsynchronisierender Stromchiffren . . . . 98
14 Ruckgekoppeltes Schieberegister . . . . . . . . . . . . . . . . . 100
15 Binares lineares Schieberegister der Lange n . . . . . . . . . . 101
16 Nichtlineare Kombination von linearen Schieberegistern . . . . 108
17 Nichtlineare Filtergeneratoren . . . . . . . . . . . . . . . . . . 109
18 Stop-and-Go-Generator . . . . . . . . . . . . . . . . . . . . . . 109
8

Tabellenverzeichnis
1 Haufigkeitsverteilung der Buchstaben in deutschsprachigenTexten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2 Haufigste Digramme in deutschsprachigen Texten . . . . . . . 21
3 Exemplarische Zeichenfolgeabstande, Ermittlung v. d nachKasiski . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4 Teiltexte 1-5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5 Die 8 S-Boxen des DES, reprasentiert durch acht 4×16 Matrizen 62
6 Output-Differenzen der S-Box S1 fur Input-Differenz B′ =(010100) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
7 Anzahl der verschiedenen Output-Differenzen der S-Box S1 beiInput-Differenz (010100) . . . . . . . . . . . . . . . . . . . . . 71
8 Input-/Output-Differenzen bei S-Box S1 . . . . . . . . . . . . 73
9

Einleitung
Kryptologie: Wissenschaft von der sicheren Ubermittlung (oder Speicherung)von Daten.
Ubermittlung erfolgt uber Kanale: Kupferleitung, Glasfaser, drahtlose Kom-munikation, etc.
Folgende Beeintrachtigungen sind moglich:
• zufallige Storungen
• systematische (physikalisch bedingte Storungen)
• passive Beeintrachtigungen (Abhoren von Telefongesprachen, Lesen vonMails, Speichermedien)
• aktive Beeinflussung (Verandern von Daten, Nachrichten)
Die ersten beiden Punkte sind Thema der Codierungstheorie und der Signal-verarbeitung. Die letzten beiden betreffen die Kryptologie.
Praktisch alle kryptologischen Verfahren haben die Aufgabe, eine (oder meh-rere) der folgenden funf Anforderungen an die Ubermittlung bzw. Speiche-rung von Nachrichten zu gewahrleisten:
• Geheimhaltung (Lesen der Nachricht fur Unbefugte unmoglich bzw.schwierig zu machen)
• Authentifizierung (Identitatsbeweis einer Person oder eines Rechnersgegenuber einer anderen (Teilnehmerauthentizitat) oder Nachweis desUrsprungs einer Nachricht (Nachrichtenauthentizitat))
• Integritat (Nachricht darf wahrend ihrer Ubermittlung nicht (von Un-befugten) verandert werden, ohne dass dies bemerkt wird.)
• Verbindlichkeit (Der Sender kann spater nicht leugnen, die Nachrichtabgeschickt zu haben)
• Anonymitat (In manchen Situationen soll der Sender oder Empfangeranonym bleiben)
10

Fruher: Vor allem Geheimhaltung wichtig; hauptsachlich im militarischenBereich; Bsp.: Strategische Bedeutung der legendaren Chiffriermaschi-ne ENIGMA wahrend des 2. Weltkrieges; fuhrende Beteiligung AlanTurings am Brechen der Verschlusselung.
Heute: Zivile Anwendungen noch wichtiger, insbesondere wegen des enormenWachstums netzgestutzter Kommunikation (Internet).
Inhalt der Vorlesung
• Symmetrische Verschlusselungsverfahren
• Asymmetrische Verschlusselungsverfahren (Public Key Systeme)
• Theoretische Grundlagen: Kryptographisch sichere Pseudozufallsfolgen-generatoren, Einwegfunktionen, kryptologische Hash-Funktionen
• Digitale Signaturen und Authentifizierung
• Zero-Knowledge-Verfahren
• Multiparty-Protokolle
• Anonymitat
11

1 Grundbegriffe
Klartext (plaintext)Zeichenfolge über Alphabet R
Geheimtext, Chiffretext(ciphertext), Kryptogramm: Zeichenfolge über Alphabet S (ggf. R=S)
Klartext
SchlüsselVerschlüsselungChiffrierung(encryption)
SchlüsselEntschlüsselungDechiffrierung(decryption)
Sender(Alice)
Empfänger(Bob)
Abbildung 1: Grundschema einer Verschlusselung zwischen Alice und Bob
Die Verschlusselung geschieht mit einem Verschlusselungsverfahren, Chif-frieralgorithmus.
Die Verschlusselung eines Klartextes durch diesen Algorithmus erfolgt mitHilfe eines Schlussels ke (key, encryption key).
Das Verschlusselungsverfahren ist dann eine Funktion E, die jedem beliebi-gen Klartext m (message) einen Chiffretext c in Abhangigkeit vom Chiffrier-schlussel ke zuordnet:
c = E(m, ke)
Dabei muss gelten: Fur jeden Schlussel ke ist
E(m1, ke) 6= E(m2, ke) falls m1 6= m2,
d.h. E(., ke) ist injektiv; sonst konnte man nicht eindeutig entschlusseln.
Schlussel sind ebenfalls Zeichenfolgen (Passwort, Geheimzahl, Bitfolge . . . ).Die Entschlusselung des Chiffretextes c erfolgt dann mit einem zum Ver-schlusselungsverfahren gehorenden Entschlusselungsverfahren mit Hilfe einesDechiffrierschlussels kd (decryption key), der von ke abhangt.
12

Entschlusselungsfunktion D:
D(c, kd) = m
[Haufig schreiben wir auch Eke(m) statt E(m, ke) und Dkd(c) statt D(c, kd).]
Ist kd = ke (oder lasst sich kd leicht aus ke bestimmen), so spricht man vonsymmetrischen Verschlusselungsverfahren. Ist kd aus ke nicht oder nur mitsehr großem Aufwand berechenbar, so kann man ke auch offentlich machen:asymmetrische Verschlusselungsverfahren oder Public-Key-Verfahren.
Die Gesamtheit aus Verschlusselungsverfahren und aller Schlussel wird Kryp-tosystem genannt.
Beispiel:R = S = 0, 1, . . . , 25Verfahren: Verschiebeschiffre (Shift Cipher)Verschlusselung: x ∈ R, x→ x + i mod 26 fur ein i ∈ 0, 1, . . . , 25Schlussel: iEntschlusselung: x→ x− i mod 26(Symmetrisches Verfahren)Ist m = k1 . . . kr, ki ∈ R,so E(m, i) = ((k1 + i) mod 26) . . . ((kr + i) mod 26) = l1 . . . lr = cD(C, i) = ((l1 − i) mod 26) . . . ((lr − i) mod 26) = m.
(Caesarchiffre: i = 3)
Ein Verschlusselungsverfahren beinhaltet i. Allg. sehr viele verschiedene Ver-schlusselungsmoglichkeiten, die jeweils durch einen Schlussel festgelegt sind.
Kommunikationspartner mussen sich grundsatzlich uber das Verschlusse-lungsverfahren einigen und vor der Ubertragung die Schlussel vereinbaren(entfallt bei Public-Key-Verfahren).
Geheimgehalten werden muss der Schlussel kd (d.h. bei symmetrischen Ver-fahren der gemeinsame Schlussel). Das Verfahren lasst sich i. Allg. nichtgeheimhalten (und sollte auch nicht geheimgehalten werden).
Kerkhoff’sches Prinzip:Die Sicherheit eines Verschlusselungsverfahrens darf nur von der Geheim-haltung des Schlussels abhangen, nicht jedoch von der Geheimhaltung desAlgorithmus.
13

Bei symmetrischen Verschlusselungsverfahren muss daher der Schlussel k(=ke = kd) auf sicherem Weg ubermittelt werden.
Weshalb dann nicht gleich die ganze Nachricht auf sicherem Wege ubermit-teln?
• Nachricht lang, Schlussel kurz
• Zeitpunkt der Schlusselubergabe ist frei wahlbar.
• Mehrere Nachrichten konnen mit gleichem Schlussel verschlusselt wer-den.
Mit Hilfe der Public-Key-Verfahren (asymmetrische Verfahren) hat man dieMoglichkeit, die Schlussel ohne Gefahr auszutauschen.
Beispiel:Biryukov, Shamir und Wagner haben 1999 den Verschlusselungsalgorithmus(A5) geknackt, der GSM-Handy-Telefonate auf der Funkstrecke zur Mobil-telefon-Basisstation schutzt. GSM-Association hat den Algorithmus geheim-gehalten (GSM-Group Special Mobile Standard fur Funktelefone).
Kryptologie
Kryptoanalyse
beschäftigt sich mitdem Entwurf von Ver-schlüsselungsverfahren
Kryptographie
untersucht, wie Ver-schlüsselungsverfahren zu brechen sind
Abbildung 2: Die Teildisziplinen Kryptographie und Kryptoanalyse
Heute wird haufig der Begriff”Kryptographie” synonym mit
”Kryptologie”
verwendet.
Die Kryptoanalyse pruft, wie schwer ein Kryptosystem zu knacken ist. Hin-sichtlich der Schwere eines Angriffs konnen folgende qualitative Unterschei-dungen in absteigender Reihenfolge getroffen werden:
• Vollstandiges Aufbrechen:Schlussel kd wird gefunden. Dann kann jede Nachricht, die mit demzugehorigen Schlussel ke verschlusselt wurde, entschlusselt werden.
14

• Globale Deduktion:Finden einer zu D(., kd) aquivalenten Funktion ohne Kenntnis des Schlus-sels (ggf. nur fur gewisse ke).
• Lokale Deduktion:Finden des Klartextes fur nur einen abgefangenen Chiffretext.
Wichtige Arten von Angriffen:(Angreifer heisst oft Mallory (malicious) - aktiv, oder Eve (eavesdropper,Lauscher) - passiv.)
• Ciphertext-Only-Attack:Der Kryptoanalytiker verfugt uber eine bestimmte Menge Chiffretext.
• Known-Plaintext-Attack:Der Kryptoanalytiker kennt zusatzlich den zum Chiffretext gehorendenKlartext.
• Chosen-Plaintext-Attack:Der Kryptoanalytiker kann einen beliebigen Klartext vorgeben und hatdie Moglichkeit, den zugehorigen Chiffretext zu erhalten (relevant v.a.bei Public-Key-Systemen).
• Chosen-Ciphertext-Attack:Kryptoanalytiker kann bel. Chiffretext vorgeben und erhalt zug. Klar-text. Aus dieser Kenntnis versucht er dann, kd zu bestimmen, oder zueinem anderen Chiffretext den Klartext zu erhalten.
Daneben: Angriffe, die auf physikalisch-technischen Gegebenheiten der Kom-munikation beruhen. Oder Angriffe durch Gewalt, Bestechung, Erpressung.Diese Angriffe sind oft sehr wirkungsvoll. Der Besitzer des Schlussels stellt(neben fehlerhaften Implementierungen von Verschlusselungsverfahren) diegroßte Sicherheitsgefahr dar.
Ein Angriff, bei dem alle moglichen Schlussel durchprobiert werden, heisstBrute-Force-Angriff.
Daher: Menge der Schlussel sollte moglichst groß sein (d.h. Schlussellangemuss genugend groß sein!)
Unterschied zwischen sicheren und uneingeschrankt sicheren Kryptosyste-men:
15

• Uneingeschrankt sicher:Auch bei Kenntnis von beliebig viel Chiffretext kann (beweisbar!) nichtgenug Information gewonnen werden, um daraus den Klartext oder denSchlussel zu rekonstruieren (theoretisch sicher).
• Sicher:Aufwand zur Entschlusselung ist mit vertretbaren Kosten, Speicher-kapazitat, Zeitdauer zu groß (komplexitatstheoretisch sicher oder auchnur praktisch sicher beim Stand der jetzigen Kenntnis).
Beispiel:Schlussellange 128 Bit. 2128 ≈ 2, 5 · 1038 Schlussel.Seien 1012 Schlussel pro Sekunde testbar.Ang. 50 % der Schlussel mussen getestet werden.Aufwand: 1, 25 · 1026 Sek. ≈ 4 · 1018 Jahre.Rechenzeit dauert etwa 400 Millionen mal langer als das Alter des Univer-sums (≈ 1010 Jahre).Demgegenuber:Schlussellange 56 Bit (z.B. DES, s. Kap. 4.6). 256 ≈ 7, 2 · 1016 Schlussel.Aufwand: 3, 6 · 104 Sek. = 10 Stunden.
16

2 Klassische symmetrische Verschlusselungs-
verfahren
Klassisch: Verfahren vor 1970
Es gibt zwei Typen von Unterscheidungen symmetrischer Verschlusselungs-verfahren:
1. Unterscheidung:
2. Unterscheidung:
Stromchiffren (stream ciphers)
Transpositionschiffren
Blockchiffren (block ciphers)
SubstitutionschiffrenPermutationschiffren
in Verbindungmit
Abbildung 3: Strom- vs Block-, Substitutions- vs Transpositionschiffre
Stromchiffre:Jedes Zeichen (oder jeder kurze Block) des Klartextes wird einzeln ver-schlusselt.
Blockchiffre:Klartext wird in Blocke einer festen (i.a. nicht zu kleinen) Lange n zerlegt,und jeder Block wird einzeln verschlusselt. (Es gibt auch Verfahren mit va-riabler Blocklange.)
Stromchiffren lassen sich nach dieser Definition als Blockchiffren mit derLange 1 auffassen. In der Regel spricht man aber nur von Blockchiffren,wenn die Blocke großere Lange haben.
Daruber hinaus sind Stromchiffren in der Regel dadurch gekennzeichnet, dassaus einem Ausgangsschlussel k ein Schlusselstrom ki, k2, . . . erzeugt wird,wobei in einem Klartext m = m1m2 . . . dann m1 mit k1, m2 mit k2, . . .verschlusselt wird.
Zweite Unterscheidungsmoglichkeit symmetrischer Verfahren:
Substitutionschiffre:Jedes Zeichen des Klartextes wird durch ein Zeichen des Geheimtextalpha-bets ersetzt, die Position bleibt unverandert. Substitutionschiffren kommensowohl als Stromchiffren als auch als Blockchiffren vor.
Transpositionschiffre:Der Klartext wird in Blocke zerlegt, und die Zeichen innerhalb des Blocks
17

werden permutiert. Zeichen bleiben also unverandert, Positionen werden ver-andert. Transpositionschiffren sind in der Regel Blockchiffren. (Es gibt al-lerdings auch Transpositionschiffren, die ohne Blockzerlegung den gesamtenKlartext permutieren.)
Substitutionschiffren und Transpositionschiffren sind die Urtypen symmetri-scher Verfahren. Es gibt Verallgemeinerungen, die sich keiner dieser beidenTypen mehr zuordnen lassen, und Kombinationen dieser beiden Typen.
Wir behandeln in diesem Kapitel zwei Typen von Substitutionschiffren, nam-lich monoalphabetische und polyalphabetische Substitutionen. Auf Transpo-sitionschiffren werden wir kurz in Kapitel 4 uber symmetrische Blockchiffreneingehen. Stromchiffren sind Gegenstand von Kapitel 6.
2.A Monoalphabetische Substitutionschiffren
Eine Substitutionschiffre heißt monoalphabetisch, wenn jedes Klartextzeichenaus R immer auf dasselbe Chiffretextzeichen aus S abgebildet wird und dieseZuordnung injektiv ist.
Wir nehmen der Einfachheit halber R = S an (keine wesentliche Einschran-kung).
|R| = n (z.B. n = 26, naturlichsprachiges Alphabet)
Chiffrierverfahren:Anwendung einer Permutation σ von R auf die Buchstaben des Klartextes:
m1 . . .mk → σ(m1) . . . σ(mk) Schlussel: Permutation σ
Also gibt es z.B. 26! ≈ 4 · 1026 monoalphabetische Chiffrierungen uber demnaturlichen Alphabet R = a, b, . . . , z (bzw. R = 0, 1, . . . , 25).
Sei R = 0, 1, . . . , n− 1.Haufig wird nicht die gesamte Schlusselmenge benutzt.
18

2.1 Beispiele
(a) Verschiebechiffre1:
m→ m + i mod n
n verschiedene Schlussel (namlich alle i ∈ 0, 1, . . . , n− 1.)
(b) Affine Chiffren:
Affine Chiffren sind eine Verallgemeinerung von Verschiebechiffren:
m→ am + b mod n, a, b ∈ 0, 1, . . . , n− 1Diese Zuordnung ist bijektiv, falls ggT(a, n) = 1.
Dann existiert namlich a′ ∈ 0, . . . , n−1 mit aa′ ≡ 1 (mod n), und dieZuordnung m→ a′m−a′b mod n ist die Inverse zu m→ am+ b mod n(m→ am + b mod n→ a′(am + b)− a′b mod n = m).Wie bestimmt man a′, das multiplikative Inverse mod n zu a?Erweiterter Euklidischer Algorithmus (s.u.) liefert s, t ∈ Z mit as +nt = 1, da ggT(a, n) = 1. Dann 1 = as mod n = a(s mod n), d.h.a′ = s mod n.
Die Umkehrung gilt ebenfalls, d.h. m → am + b mod n bijektiv ⇔ggT(a, n) = 1.
Damit hat man ϕ(n) Moglichkeiten fur a und insgesamt n·ϕ(n) Schlus-sel (a, b). (ϕ ist die Eulersche ϕ-Funktion, d.h. fur n ∈ N ist ϕ(n) =|i ∈ N : 1 ≤ i ≤ n, ggT(i, n) = 1|.)n = 26 : 12 · 26 = 312 Schlussel
Beispiel:R= 0 ,1 ,. . .25x
xxxxcodiere
R= a,b ,. . . z m→ 7m + 12 mod 26
TEXTcodiere−−−−→ 19, 4, 23, 19
chiffriere−−−−−−→ 15, 14, 17, 15decodiere−−−−−→ PORP
Wir geben hier zur Wiederholung den erweiterten Euklidischen Algo-rithmus an:
1s. Kap. 1
19

Eingabe: a, b ∈ N, a > b.
(1) x := a,s1 := 1,t1 := 0,
y := bs2 := 0,t2 := 1,
s := 0t := 1
(2) Solange x mod y 6= 0 wiederhole:g :=x div y,s := s1 − gs2,
r := x mod y,t := t1 − gt2,
s1 := s2,x := y,
s2 := s,y := r.
t1 := t2, t2 := t
Ausgabe: y (= ggT(a, b))s, t (y = sa + tb)
2.2 Kryptoanalyse monoalphabetischer Substitutions-
chiffren
Monoalphabetische Verschlusselungen naturlichsprachiger Texte sind krypto-logisch nicht sicher, selbst unter der schwachsten Annahme einer Ciphertext-only-attack.
Dies liegt an der charakteristischen Haufigkeitsverteilung der Buchstabenin naturlichsprachigen Texten. Diese Haufigkeitsverteilung insgesamt andertsich bei monoalphabetischen Verfahren nicht (es andert sich nur die Haufig-keit der einzelnen Buchstaben), und das erlaubt in der Regel die Rekonstruk-tion der Klartexte schon aus Chiffretexten mit ca. 500 Buchstaben.
Noch einfacher ist die Analyse bei Verschiebe- oder allgemeiner affinen Chif-fren: Hier genugt die Identifikation eines bzw. zweier Buchstaben, um denSchlussel zu knacken.
Die Kryptoanalyse monoalphabetischer Substitutionschiffren beruht auf derHaufigkeitsanalyse von Chiffretextzeichen bzw. -digrammen (Digramm: Paaraufeinander folgender Zeichen).
Naturliche Sprachen haben eine charakteristische Haufigkeitsverteilung vonBuchstaben und Digrammen (siehe Tabellen 1 u. 2).
20
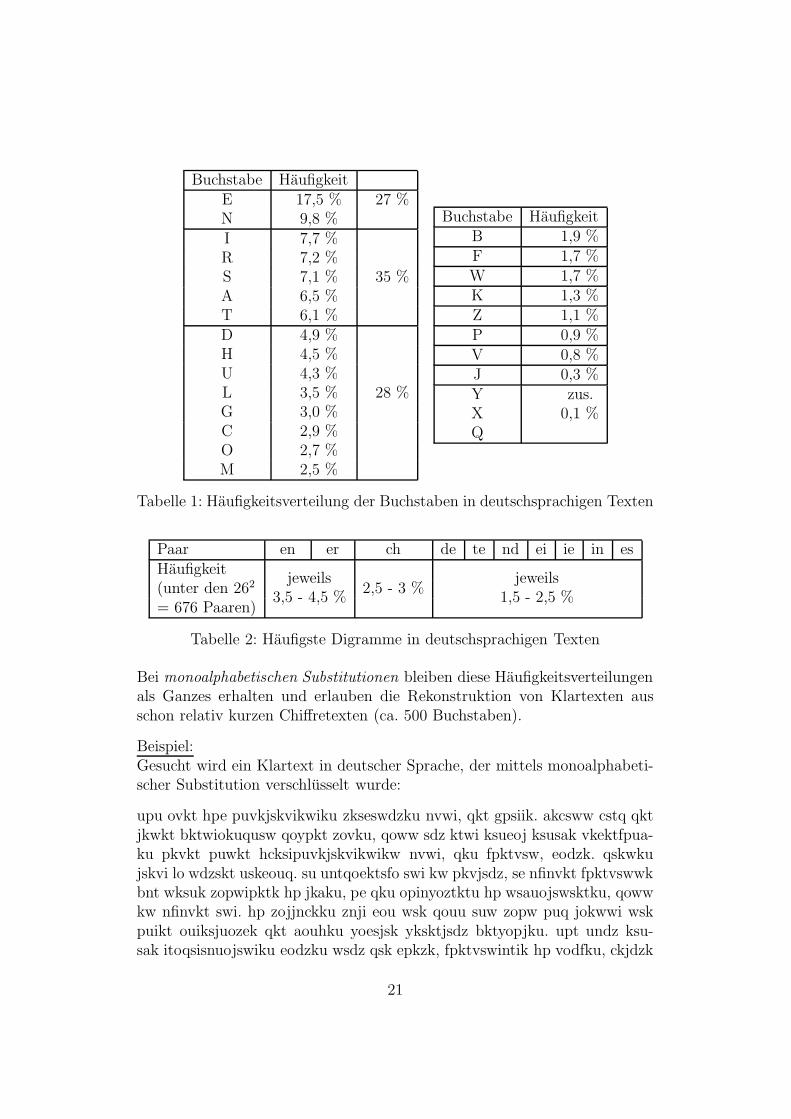
Buchstabe HaufigkeitE 17,5 % 27 %N 9,8 %I 7,7 %R 7,2 %S 7,1 % 35 %A 6,5 %T 6,1 %D 4,9 %H 4,5 %U 4,3 %L 3,5 % 28 %G 3,0 %C 2,9 %O 2,7 %M 2,5 %
Buchstabe HaufigkeitB 1,9 %F 1,7 %W 1,7 %K 1,3 %Z 1,1 %P 0,9 %V 0,8 %J 0,3 %Y zus.X 0,1 %Q
Tabelle 1: Haufigkeitsverteilung der Buchstaben in deutschsprachigen Texten
Paar en er ch de te nd ei ie in esHaufigkeit(unter den 262 jeweils
2,5 - 3 %jeweils
= 676 Paaren)3,5 - 4,5 % 1,5 - 2,5 %
Tabelle 2: Haufigste Digramme in deutschsprachigen Texten
Bei monoalphabetischen Substitutionen bleiben diese Haufigkeitsverteilungenals Ganzes erhalten und erlauben die Rekonstruktion von Klartexten ausschon relativ kurzen Chiffretexten (ca. 500 Buchstaben).
Beispiel:Gesucht wird ein Klartext in deutscher Sprache, der mittels monoalphabeti-scher Substitution verschlusselt wurde:
upu ovkt hpe puvkjskvikwiku zkseswdzku nvwi, qkt gpsiik. akcsww cstq qktjkwkt bktwiokuqusw qoypkt zovku, qoww sdz ktwi ksueoj ksusak vkektfpua-ku pkvkt puwkt hcksipuvkjskvikwikw nvwi, qku fpktvsw, eodzk. qskwkujskvi lo wdzskt uskeouq. su untqoektsfo swi kw pkvjsdz, se nfinvkt fpktvswwkbnt wksuk zopwipktk hp jkaku, pe qku opinyoztktu hp wsauojswsktku, qowwkw nfinvkt swi. hp zojjnckku znji eou wsk qouu suw zopw puq jokwwi wskpuikt ouiksjuozek qkt aouhku yoesjsk yksktjsdz bktyopjku. upt undz ksu-sak itoqsisnuojswiku eodzku wsdz qsk epkzk, fpktvswintik hp vodfku, ckjdzk
21
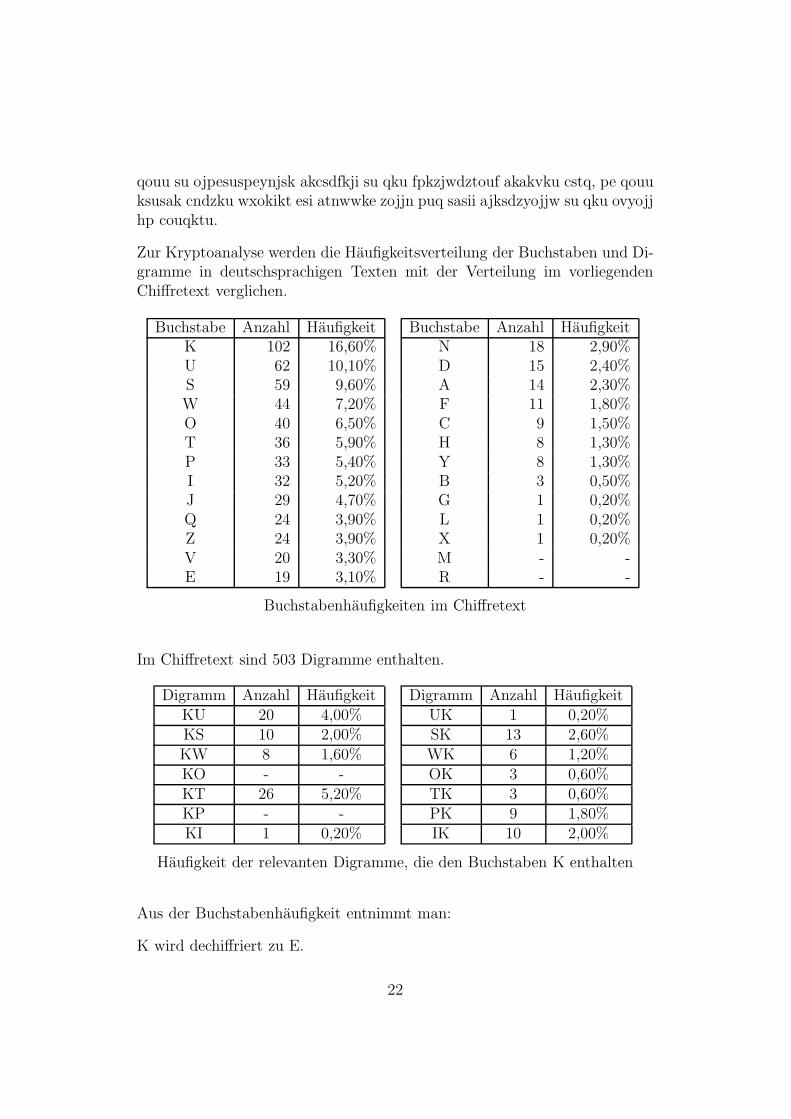
qouu su ojpesuspeynjsk akcsdfkji su qku fpkzjwdztouf akakvku cstq, pe qouuksusak cndzku wxokikt esi atnwwke zojjn puq sasii ajksdzyojjw su qku ovyojjhp couqktu.
Zur Kryptoanalyse werden die Haufigkeitsverteilung der Buchstaben und Di-gramme in deutschsprachigen Texten mit der Verteilung im vorliegendenChiffretext verglichen.
Buchstabe Anzahl Haufigkeit Buchstabe Anzahl HaufigkeitK 102 16,60% N 18 2,90%U 62 10,10% D 15 2,40%S 59 9,60% A 14 2,30%W 44 7,20% F 11 1,80%O 40 6,50% C 9 1,50%T 36 5,90% H 8 1,30%P 33 5,40% Y 8 1,30%I 32 5,20% B 3 0,50%J 29 4,70% G 1 0,20%Q 24 3,90% L 1 0,20%Z 24 3,90% X 1 0,20%V 20 3,30% M - -E 19 3,10% R - -
Buchstabenhaufigkeiten im Chiffretext
Im Chiffretext sind 503 Digramme enthalten.
Digramm Anzahl HaufigkeitKU 20 4,00%KS 10 2,00%KW 8 1,60%KO - -KT 26 5,20%KP - -KI 1 0,20%
Digramm Anzahl HaufigkeitUK 1 0,20%SK 13 2,60%WK 6 1,20%OK 3 0,60%TK 3 0,60%PK 9 1,80%IK 10 2,00%
Haufigkeit der relevanten Digramme, die den Buchstaben K enthalten
Aus der Buchstabenhaufigkeit entnimmt man:
K wird dechiffriert zu E.
22

Ferner zeigt sich, dass sehr wahrscheinlich U oder S zu N dechiffriert wird.Da bei den Digrammen KU doppelt so haufig vorkommt wie KS, nehmen wiran:
U wird dechiffriert zu N.
Unter allen relevanten Digrammen, die K enthalten, treten einzig im Paar(KS,SK) beide Digramme mit einer Haufigkeit von jeweils mindestens 2 %auf. Es ist daher plausibel anzunehmen:
S wird dechiffriert zu I.
Aus der Digrammhaufigkeit von KT ergibt sich:
T wird dechiffriert zu R.
Ersetzt man im Chiffretext die Chiffretextbuchstaben k,u,s,t durch die ihnenvermutlich zugeordneten Klartextbuchstaben E,N,I,R, so ergibt sich:
NpN ovER hpe pNvEjIEviEwiEN zEIeIwdzEN nvwi, qER gpIiiE. aEcIwwcIRq qER jEwER bERwioENqNIw qoypER zovEN, qoww Idz ERwi EINeojEINIaE vEeERfpNaEN pEvER pNwER hcEIipNvEjIEviEwiEw nvwi, qENfpERvIw, eodzE. qIEwEN jIEvi lo wdzIER NIEeoNq. IN NnRqoeERIfo IwiEw pEvjIdz, Ie nfinvER fpERvIwwE bnR wEINE zopwipERE hp jEaEN, peqEN opinyozRERN hp wIaNojIwIEREN, qoww Ew nfinvER Iwi. hp zojjn-cEEN znji eoN wIE qoNN INw zopw pNq joEwwi wIE pNiER oNiEIjNozeEqER aoNhEN yoeIjIE yEIERjIdz bERyopjEN. NpR Nndz EINIaE iRoqIi-InNojIwiEN eodzEN wIdz qIE epEzE, fpERvIwinRiE hp vodfEN, cEjdzEqoNN IN ojpeINIpeynjIE aEcIdfEji IN qEN fpEzjwdzRoNf aEaEvEN cIRq,pe qoNN EINIaE cndzEN wxoEiER eIi aRnwwEe zojjn pNq IaIii ajEIdzyo-jjw IN qEN ovyojj hp coNqERN.
Nun ergeben sich unmittelbar weitere Ersetzungen:
P wird dechiffriert zu U, W wird dechiffriert zu S, O wird dechiffriert zu A,etc.
Es ist dann einfach, die vollstandige Dechiffrierung vorzunehmen:
Chiffretext KlartextA GB VC WD CE M
Chiffretext KlartextF KG QH ZI TJ L
23
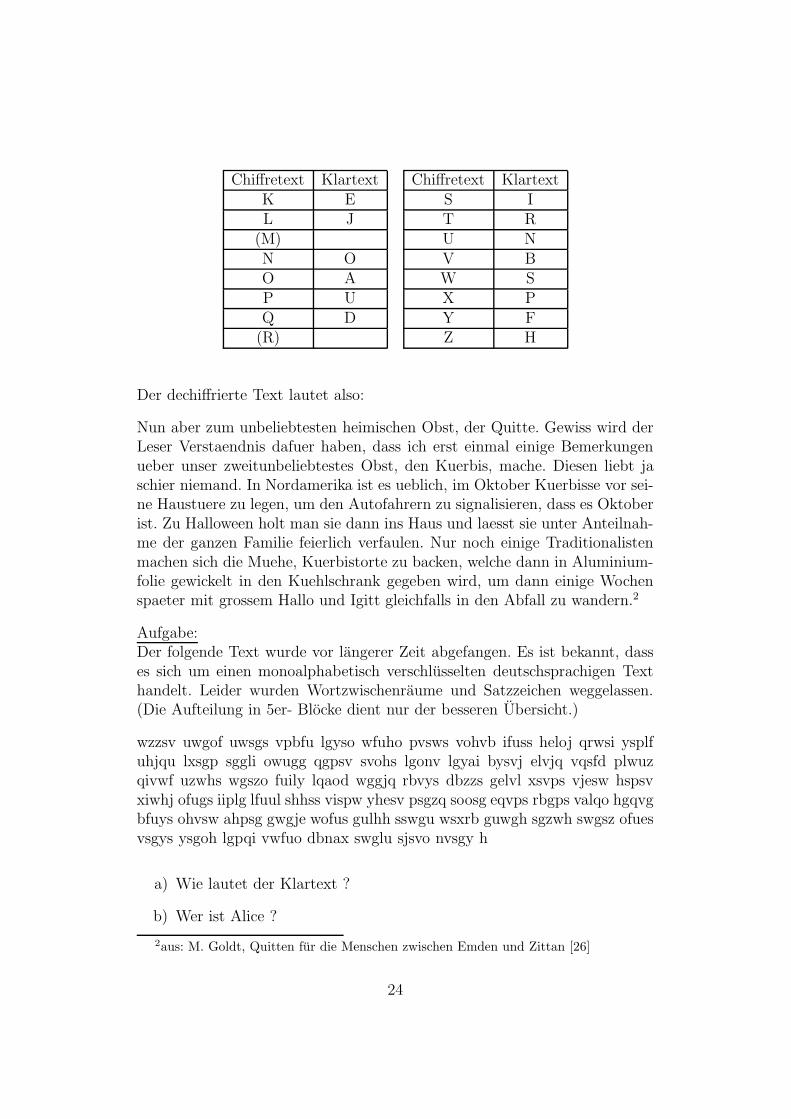
Chiffretext KlartextK EL J
(M)N OO AP UQ D
(R)
Chiffretext KlartextS IT RU NV BW SX PY FZ H
Der dechiffrierte Text lautet also:
Nun aber zum unbeliebtesten heimischen Obst, der Quitte. Gewiss wird derLeser Verstaendnis dafuer haben, dass ich erst einmal einige Bemerkungenueber unser zweitunbeliebtestes Obst, den Kuerbis, mache. Diesen liebt jaschier niemand. In Nordamerika ist es ueblich, im Oktober Kuerbisse vor sei-ne Haustuere zu legen, um den Autofahrern zu signalisieren, dass es Oktoberist. Zu Halloween holt man sie dann ins Haus und laesst sie unter Anteilnah-me der ganzen Familie feierlich verfaulen. Nur noch einige Traditionalistenmachen sich die Muehe, Kuerbistorte zu backen, welche dann in Aluminium-folie gewickelt in den Kuehlschrank gegeben wird, um dann einige Wochenspaeter mit grossem Hallo und Igitt gleichfalls in den Abfall zu wandern.2
Aufgabe:Der folgende Text wurde vor langerer Zeit abgefangen. Es ist bekannt, dasses sich um einen monoalphabetisch verschlusselten deutschsprachigen Texthandelt. Leider wurden Wortzwischenraume und Satzzeichen weggelassen.(Die Aufteilung in 5er- Blocke dient nur der besseren Ubersicht.)
wzzsv uwgof uwsgs vpbfu lgyso wfuho pvsws vohvb ifuss heloj qrwsi ysplfuhjqu lxsgp sggli owugg qgpsv svohs lgonv lgyai bysvj elvjq vqsfd plwuzqivwf uzwhs wgszo fuily lqaod wggjq rbvys dbzzs gelvl xsvps vjesw hspsvxiwhj ofugs iiplg lfuul shhss vispw yhesv psgzq soosg eqvps rbgps valqo hgqvgbfuys ohvsw ahpsg gwgje wofus gulhh sswgu wsxrb guwgh sgzwh swgsz ofuesvsgys ysgoh lgpqi vwfuo dbnax swglu sjsvo nvsgy h
a) Wie lautet der Klartext ?
b) Wer ist Alice ?
2aus: M. Goldt, Quitten fur die Menschen zwischen Emden und Zittan [26]
24

2.3 Homophone Chiffren
Homophone Substitutionschiffren lassen sich als spezielle polyalphabetischeChiffren auffassen, also solche, in denen nicht jeder Klartextbuchstabe jeweilsauf denselben Chiffretextbuchstaben abgebildet wird.
Homophone Chiffren wurden entwickelt, um den Nachteil der charakteristi-schen Haufigkeitsverteilung bei monoalphabetischen Chiffren zu beheben.
Homophone Substitutionschiffre:
Abb. f , die jedem Klartextbuchstaben r ∈ R eine Teilmenge f(r) ⊆ S desChiffretextalphabets zuordnet.
Forderung: r1, r2 ∈ R, r1 6= r2, so f(r1) ∩ f(r2) = ∅
r rr1 2 n
f(r ) f(r )f(r )2 n1
..
..
. ...
... ..
.
.
..
....
. .
.
..
..
.
..
.
.
Abbildung 4: Zuordnung bei homophoner Substitutionschiffre
Verfahren: Ein Klartext m = r1r2 . . . wird chiffriert in c = c1c2 . . .,wobei ci zufallig aus f(ri) gewahlt wird.Schlussel: Abb. f , d.h. f(r)|r ∈ R(Dieses Verfahren wurde schon um 1400 in Italien verwendet.)
Vorteil der homophonen Substitution:Die Haufigkeitsverteilung der Klartextbuchstaben wird zerstort.
Ist r ∈ R und p(r) die Haufigkeit, in der r im Klartext auftaucht, wahlt manf(r) so groß, dass
p(r)
|f(r)| ≈ c Konstante, unabhangig von r
Man benotigt dazu ein großes Alphabet S.
25

In einem Chiffretext treten dann alle Buchstaben aus ∪r∈R
f(r) etwa gleich
oft auf. Damit ist keine direkte Haufigkeitsanalyse mehr moglich. Dennochwerden auch hier z.B. Digramme zur Kryptoanalyse verwendet.
Wir machen dies an einem Beispiel klar:Angenommen die homophone Substitution f eines deutschsprachigen Texteswurde so gewahlt, dass im Chiffretext alle Buchstaben mit etwa gleicherHaufigkeit vorkommen.
D.h. |f(Buchstabe)| ∼ Haufigkeit des Buchstabens in Texten der deutschenSprache.
Ist z.B. |f(c)| = α ∈ N, so folgt aus der Haufigkeit von e, n, r, h in deutsch-sprachigen Texten, dass annahernd Folgendes gilt:
|f(e)| = 6α, |f(n)| = 3, 5α, |f(r)| = 2, 5α, |f(h)| = 1, 5α
Das Digramm ’en’ wird also auf 21α2 viele Arten als Digramm eines Buchsta-ben aus f(e) und eines aus f(n) chiffriert, und bei zufalliger Auswahl tretendiese Digramme im Chiffretext etwa gleich haufig auf.
Dagegen wird das Digramm ’ch’ nur auf 1, 5α2 viele Arten chiffriert. Da’en’ im Klartext etwa 4% aller Digramme ausmacht und ’ch’ etwa 2, 75%,tritt jetzt jedes Digramm im Chiffretext, welchen ’en’ verschlusselt, mit einerHaufigkeit von 4
21% ≈ 0, 2% auf. Jedes Digramm im Chiffretext, welches ’ch’
verschlusselt, tritt dagegen mit einer Haufigkeit von 2,751,5
% ≈ 1, 8% auf. Keineanderen Digramme im Chiffretext treten mit einer derartig hohen Haufigkeitauf (Digramme, die ’nd’ verschlusseln, sind die zweit haufigsten). Auf dieseWeise lassen sich die Mengen f(c) und f(h) bestimmen. Der Grund hierfurist also, dass die Einzelhaufigkeiten von ’c’ und ’h’ relativ gering, die Di-grammhaufigkeit von ’ch’ aber relativ hoch ist, wahrend bei allen anderenhaufigen Digrammen auch die Haufigkeit wenigstens eines beteiligten Buch-stabens relativ hoch ist.
Mit ahnlichen Methoden der Digrammanalyse (und geschicktem Raten) las-sen sich auch die Teilmengen des Chiffretextalphabets B, die anderen Klar-textbuchstaben zugeordnet sind, ermitteln.
Allerdings: Man benotigt deutlich langere Chiffretexte fur diese Analysenals es bei Texten der Fall ist, die mittels monoalphabetischer Substitutionverschlusselt wurden.
26

2.B Polyalphabetische Verschlusselungen
Bei polyalphabetischen Verschlusselungen wird ein Klartextzeichen durchverschiedene Chiffretextzeichen verschlusselt, und ein und dasselbe Chiffre-textzeichen kann fur verschiedene Klartextzeichen stehen (in Abhangigkeitvon ihrer Position im Text).
Sei R das Klartextalphabet,S0, . . . , Sd−1 Chiffretextalphabete.
fj : R→ Sj bijektive Abbildungen (j = 0, . . . , d− 1) undh: N→ 0, . . . , d− 1 (i.d.R. h(x) = x mod d)
Klartext m = r1 . . . rt (ri ∈ R) wird verschlusselt inChiffretext c = fh(1)(r1) fh(2)(r2) . . . fh(t)(rt).
Schlussel = h, f0, . . . , fd−1
Man sagt: h erzeugt den Schlusselstrom fh(1), fh(2), . . .
Eine solche Chiffrierung heißt polyalphabetische Substitution (im engeren Sin-ne). Es handelt sich um eine Stromchiffre. Sie ist also eine Folge von mo-noalphabetischen Substitutionen mit wechselnden Schlusseln, die durch dieAuswahlfunktion h bestimmt werden.
Ist h(x) = x mod d, so wiederholen sich die Schlussel nach jeweils d ver-schlusselten Klartextzeichen. Man nennt die Chiffre dann periodisch. Dannsind f0, . . . , fd−1 die Schlussel, die periodisch angewendet werden.
Annahme fur diesen Abschnitt: R = S0 = S1 = . . . = Sd−1
2.4 Beispiel: Vigenere-Chiffre 3
R = 0, 1, . . . , n− 1 (z.B. n = 26)h(x) = x mod dfj(r) = (r + kj) mod n, kj ∈ R fest (jedes einzelne fj Verschiebechiffre)
Schlussel: k0, . . . kd−1
Man nennt kok1 . . . kd−1 auch Schlusselwort.Insgesamt gibt es also nd verschiedene Schlusselworte.
3nach Blaise de Vigenere, 1523-1596;franzosischer Diplomat, veroffentlichte die nach ihm benannte Chiffre 1586. Die Chiffrewar aber vorher schon bekannt (um 1500): Johannes Trithemius, Giovanni Battista DellaPorta
27

konkretes Beispiel:
R = 0, 1, . . . , 25 (Codierung von A, B, C, . . . , Z)
Schlusselwort:
KRYPTOcodiert−−−−→ 10, 17, 24, 15, 19, 14 (d = 6)
Klartext:
KOMMEMORGENNICHTcodiert−−−−→ 10, 14, 12, 12, 4, 12, 14, 17, 6, 4, 13, 13, 8, 2, 7, 19
Die periodische Addition (modulo 26) des Schlusselworts wird meist in fol-gender Weise geschrieben:
Schlusselwort
fortlaufenderKlartext inZeilen derLange d = 6
-
:
-
XX
XXXz
10 17 24 15 19 14
10 14 12 12 4 1220 5 10 1 23 014 17 6 4 13 1324 8 4 19 6 18 2 7 19
18 19 5 8
XX
XXXy
9
fortlaufenderChiffretextin Zeilen derLange d = 6
Decodiert: UFKBXAYIETGBSTFI
Beachte: Es ist die Regel, dass der gleiche Chiffretextbuchstabe fur verschie-dene Klartextbuchstaben steht (z.B. 1 fur 12 und 13). Ebenso wird ein undderselbe Klartextbuchstabe i.Allg. in verschiedene Chiffretextbuchstaben ver-schlusselt (z.B. 12 in 0, 1, 10).
Polyalphabetische Substitutionen fuhren i.Allg. zur Glattung der Buchstaben-haufigkeiten. Wir machen dies am Beispiel der Vigenere-Chiffre von Seite 27plausibel, indem wir den Chiffretextbuchstaben I analysieren:
Hat das Schlusselwort d′ ≤ d verschiedene Buchstaben, so kann jeder Chif-fretextbuchstabe aus d′ verschiedenen Klartextbuchstaben entstehen.
Chiffretextbuchstabe 8∧= I
28
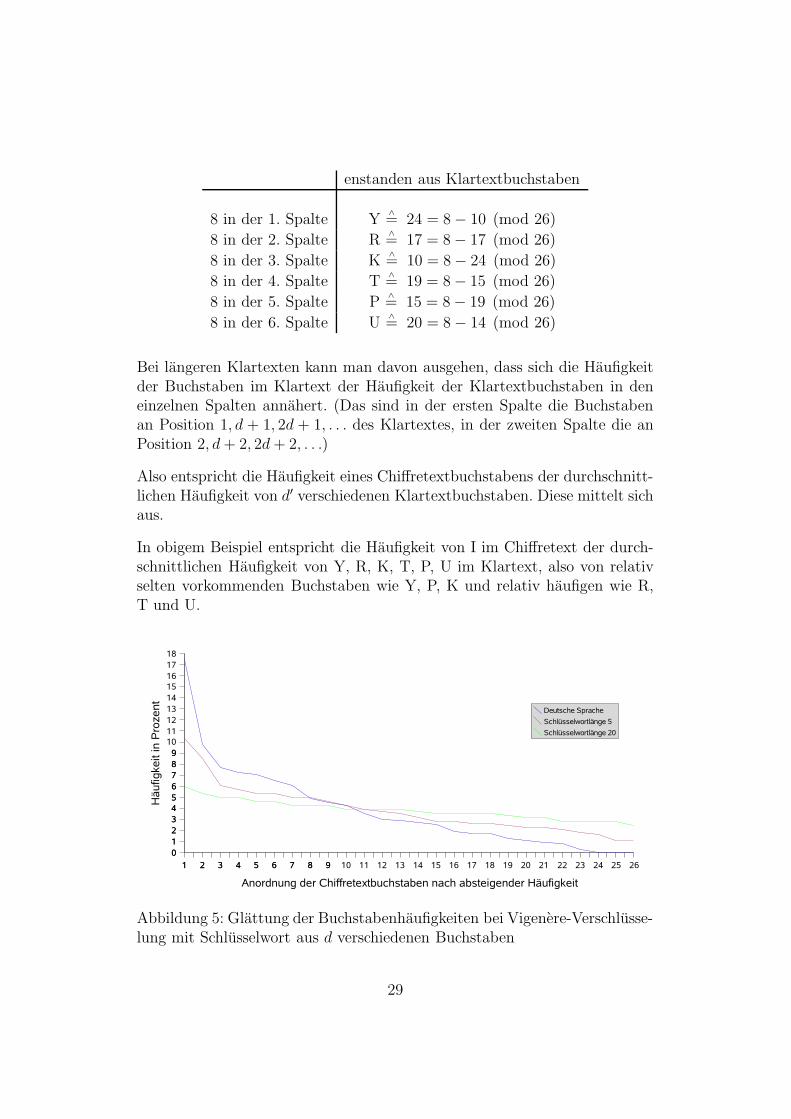
enstanden aus Klartextbuchstaben
8 in der 1. Spalte Y∧= 24 = 8− 10 (mod 26)
8 in der 2. Spalte R∧= 17 = 8− 17 (mod 26)
8 in der 3. Spalte K∧= 10 = 8− 24 (mod 26)
8 in der 4. Spalte T∧= 19 = 8− 15 (mod 26)
8 in der 5. Spalte P∧= 15 = 8− 19 (mod 26)
8 in der 6. Spalte U∧= 20 = 8− 14 (mod 26)
Bei langeren Klartexten kann man davon ausgehen, dass sich die Haufigkeitder Buchstaben im Klartext der Haufigkeit der Klartextbuchstaben in deneinzelnen Spalten annahert. (Das sind in der ersten Spalte die Buchstabenan Position 1, d + 1, 2d + 1, . . . des Klartextes, in der zweiten Spalte die anPosition 2, d + 2, 2d + 2, . . .)
Also entspricht die Haufigkeit eines Chiffretextbuchstabens der durchschnitt-lichen Haufigkeit von d′ verschiedenen Klartextbuchstaben. Diese mittelt sichaus.
In obigem Beispiel entspricht die Haufigkeit von I im Chiffretext der durch-schnittlichen Haufigkeit von Y, R, K, T, P, U im Klartext, also von relativselten vorkommenden Buchstaben wie Y, P, K und relativ haufigen wie R,T und U.
Abbildung 5: Glattung der Buchstabenhaufigkeiten bei Vigenere-Verschlusse-lung mit Schlusselwort aus d verschiedenen Buchstaben
29

Zur Kryptoanalyse periodischer polyalphabetischer Verschlusselungen ist eszunachst notwendig, die Periodenlange d (also bei Vigenere-Chiffren dieSchlusselwortlange) zu bestimmen. Wie das moglich ist, werden wir im nachs-ten Abschnitt beleuchten.
Ist d bekannt, so sind d monoalphabetische Substitutionschiffren zu ent-schlusseln. Dies geht, falls Chiffretexte genugend groß (im Vergleich zur Pe-riodenlange d) sind, wie in 2.2 beschrieben. Bei der Vigenere-Chiffre sinddie zu entschlusselnden, monoalphabetisch verschlusselten Texte die in je-der Spalte. Sie beruhen auf Verschiebechiffren und sind deshalb besonderseinfach zu knacken. Man beachte jedoch: Die Klartexte in den Spalten sindkeine sinnvollen Texte (diese ergeben sich zeilenweise).
Bevor wir auf die Kryptoanalyse periodischer polyalphabetische Verschlusse-lungen eingehen, sei ein historisches Beispiel vorgestellt:
2.5 Beispiel: ENIGMA
Chiffriermaschine, von der deutschen Wehrmacht im 2. Weltkrieg eingesetzt,die 1920 von Arthur Scherbius zunachst fur den zivilen Bereich entwickeltwurde. Sie beruht auf polyalphabetischer Verschlusselung.
Funktionsprinzip:
• Der Klartext wird uber eine Tastatur eingegeben, die mittels elektri-scher Kontakte Signale an das Steckbrett weiter gibt.
• Auf dem Steckbrett kann jede Permutation, die aus 5 (disjunkten) 2erZyklen besteht, geschaltet werden (andere Versionen wurden ebenfallskonstruiert). Damit existieren
(26
2
)(24
2
)(22
2
)(20
2
)(18
2
)≈ 6 · 1011 Steckbrettmoglichkeiten.
• Auf jeder Walze ist eine Permutation verdrahtet. Nach Eingabe einesZeichens dreht sich die 1. Walze um eine Position, so dass eine neuePermutation entsteht. Nach 26 Drehschritten geht sie wieder in ihreursprungliche Position und die 2. Walze dreht sich um eine Position.Nach 26 Drehschritten der 2. Walze beginnt die 3. Walze sich um einePosition zu drehen. (Auch andere Versionen mit 4 und 5 Walzen)
30

• Der Reflektor ist eine fest verdrahtete Permutation von 13 disjunkten2er Zyklen.
• Auf dem Ruckweg werden die Permutationen der 3., 2., 1. Walze noch-mals durchlaufen. Dadurch wird kein Klartextzeichen auf sich abgebil-det.(Das stellte sich als Schwachpunkt heraus.)Periodenlange: 26 · 26 · 26 = 17576
• Die Ausgabe erfolgt uber ein leuchtendes Buchstabenlampchen.
Steckbrett 1. Walze Reflektor3. Walze2. Walze
Abbildung 6: Schematischer Signallaufplan ENIGMA
Je nach Steckbrettverschaltung und Ausgangsstellung der Walzen gibt es da-mit 17576 ·602350749000 ≈ 1, 06 ·1017 viele Schlussel. Diese wurden zunachstalle drei Monate, dann jeden Tag, dann alle acht Stunden gewechselt. Bei dergroßen Periodenlange (in der Regel großer als die Klartextlange) waren dieanschließend dargestellten kryptoanalytischen Verfahren nicht anwendbar.
Dennoch wurde die ENIGMA-Verschlusselung durch die Gruppe von Rejew-ski in Polen geknackt und danach von den Briten durch die Gruppe um AlanTuring in Bletchley Park. (Entwicklung der BOMB - erster elektromagneti-scher Computer, spater COLOSSUS - erster programmierbarer Computer)4
2.6 Kryptoanalyse periodischer polyalphabetischer Ver-schlusselungen
Bei der Kryptoanalyse sind zwei Schritte erforderlich:
a) Bestimmung der Periode d
b) Kryptoanalyse der monoalphabetisch verschlusselten Teiltexte, die durchdie Buchstaben des Chiffretextes gegeben sind, die an der Stelle
4Einzelheiten hierzu in den Werken von Bauer und Kahn [5], [6], [7], [31], [32] oder inder Turing-Biographie von A. Hodges [29]
31

1, d + 1, 2d + 1, . . .2, d + 2, 2d + 2, . . ....d, 2d, 3d, . . .stehen.
Ist der Chiffretext genugend lang, so lasst sich der zweite Schritt wie in2.2 behandeln. Insbesondere bei Vigenere-Verschlusselungen, wo die mono-alphabetischen Verschlusselungen Verschiebechiffren sind, ist dies besonderseinfach.
Wir kummern uns also jetzt um den ersten Schritt, wie man die Periode dbestimmen kann.
Vermutet man, dass ein kleines d gewahlt wurde, kann man folgendermaßenvorgehen:
Man teste nacheinander d = 1, 2, . . . solange, bis sich in den Teiltexten ausSchritt 2 eine Haufigkeitsverteilung ergibt, die der Haufigkeitsverteilung einesnaturlichsprachigen (etwa deutschen) Textes entspricht. Ist der Chiffretextim Vergleich zur Periodenlange genugend groß und ist d relativ klein, so funk-tioniert diese Methode (insbesondere mit Computerunterstutzung) gut. Beieiner falschen Wahl von d entstehen Teiltexte mit Haufigkeitsverteilungen,die in der Regel deutlich glatter sind als die Haufigkeitsverteilung in einemnaturlichsprachigen Text.5
Die nachsten beiden Methoden geben Hinweise auf die Große von d undkonnen sinnvoll in Kombination mit Methode 1 eingesetzt werden.
2.7 Kasiski-Test
Der Kasiski6-Test beruht auf folgender Uberlegung:
Wiederholt sich eine Zeichenfolge im Klartext mit einem Abstand, der einVielfaches der Periodenlange ist, so werden diese Zeichenfolgen gleich ver-schlusselt, so dass sich Wiederholungen von Zeichenfolgen im Chiffretext er-geben, deren Abstand ein Vielfaches der Periodenlange ist.
5Visualisierungen dieses Verfahrens sind daher oft hilfreich. Siehe z.B. http://math.ucsd.edu/~crypto/ (Java Applet)
6Diese Methode stammt in Ansatzen von dem englischen Mathematiker und OkonomCharles Babbage (1792-1871) aus dem Jahr 1854. Sie wurde 1863 von dem preußischenMajor Friedrich Kasiski (1805- 1881) veroffentlicht.
32
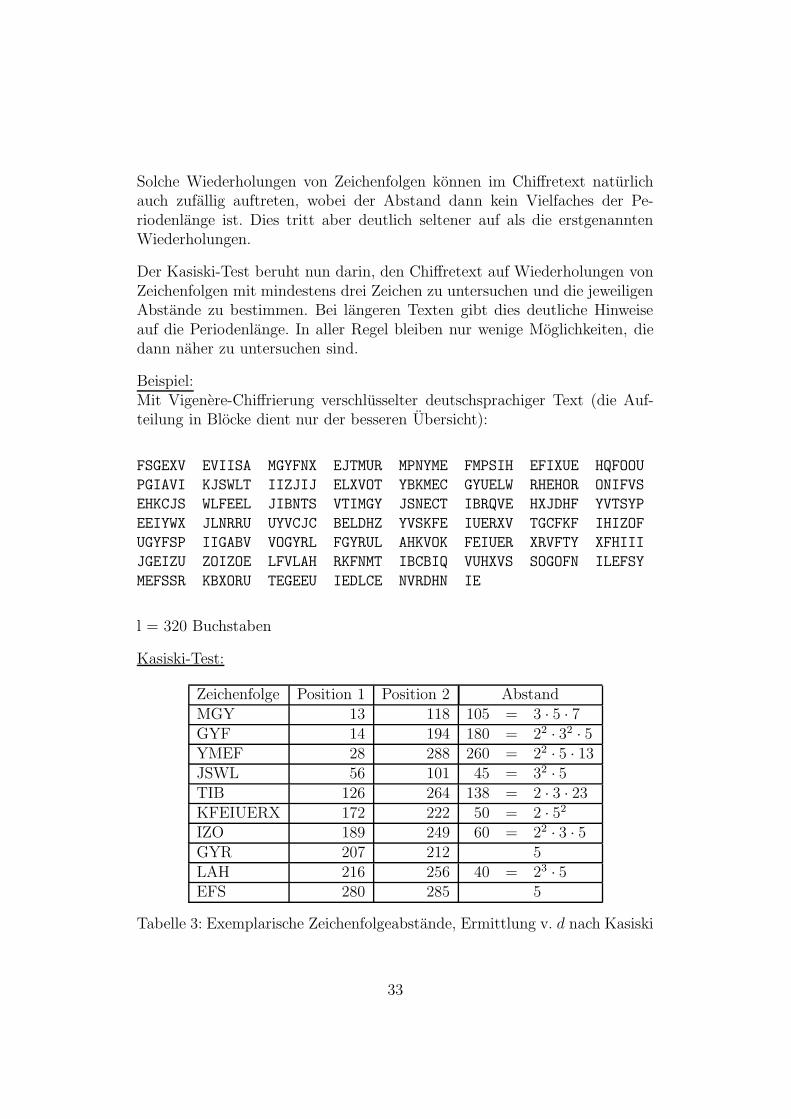
Solche Wiederholungen von Zeichenfolgen konnen im Chiffretext naturlichauch zufallig auftreten, wobei der Abstand dann kein Vielfaches der Pe-riodenlange ist. Dies tritt aber deutlich seltener auf als die erstgenanntenWiederholungen.
Der Kasiski-Test beruht nun darin, den Chiffretext auf Wiederholungen vonZeichenfolgen mit mindestens drei Zeichen zu untersuchen und die jeweiligenAbstande zu bestimmen. Bei langeren Texten gibt dies deutliche Hinweiseauf die Periodenlange. In aller Regel bleiben nur wenige Moglichkeiten, diedann naher zu untersuchen sind.
Beispiel:Mit Vigenere-Chiffrierung verschlusselter deutschsprachiger Text (die Auf-teilung in Blocke dient nur der besseren Ubersicht):
FSGEXV EVIISA MGYFNX EJTMUR MPNYME FMPSIH EFIXUE HQFOOU
PGIAVI KJSWLT IIZJIJ ELXVOT YBKMEC GYUELW RHEHOR ONIFVS
EHKCJS WLFEEL JIBNTS VTIMGY JSNECT IBRQVE HXJDHF YVTSYP
EEIYWX JLNRRU UYVCJC BELDHZ YVSKFE IUERXV TGCFKF IHIZOF
UGYFSP IIGABV VOGYRL FGYRUL AHKVOK FEIUER XRVFTY XFHIII
JGEIZU ZOIZOE LFVLAH RKFNMT IBCBIQ VUHXVS SOGOFN ILEFSY
MEFSSR KBXORU TEGEEU IEDLCE NVRDHN IE
l = 320 Buchstaben
Kasiski-Test:
Zeichenfolge Position 1 Position 2 AbstandMGY 13 118 105 = 3 · 5 · 7GYF 14 194 180 = 22 · 32 · 5YMEF 28 288 260 = 22 · 5 · 13JSWL 56 101 45 = 32 · 5TIB 126 264 138 = 2 · 3 · 23KFEIUERX 172 222 50 = 2 · 52
IZO 189 249 60 = 22 · 3 · 5GYR 207 212 5LAH 216 256 40 = 23 · 5EFS 280 285 5
Tabelle 3: Exemplarische Zeichenfolgeabstande, Ermittlung v. d nach Kasiski
33

Da die lange Zeichenfolge KFEIUERX mit großer Wahrscheinlichkeit sichnicht zufallig wiederholt, kann man davon ausgehen, dass die Schlusselwort-lange ein Teiler von 50 ist. Da 5 in neun Fallen die auftretenden Abstandeteilt, 2 aber nur in sechs Fallen (und 25 uberhaupt nur in einem Fall), ist esplausibel anzunehmen, dass das Schlusselwort Lange d = 5 hat. Die Zeichen-folge TIB hatte sich dann als einzige zufallig wiederholt.
2.8 Friedman-Test
Zentral fur den Friedman7-Test (1922) ist der sog. Koinzidenzindex.
Koinzidenzindex κ(m) einer Zeichenfolge m uber einem Alphabet R (|R| = n)ist die Wahrscheinlichkeit, dass an zwei zufalligen Positionen des Textes dieZeichen gleich sind.
Sei R = r1, . . . , rn. Sei l die Lange der Zeichenfolge m und li die Haufigkeitdes Auftretens von ri in m.
Also: l =n∑
i=1
li
Gesamtzahl aller (ungeordneten) Paare von Positionen in m ist(
l2
)= l(l−1)
2.
Gesamtzahl aller (ungeordneten) Paare von Positionen mit gleichen Zeichen
istn∑
i=1
(li2
)=
n∑i=1
li(li−1)2
.
Die Wahrscheinlichkeit, dass an zwei zufallig gewahlten Positionen in m dergleiche Buchstabe steht, ist also:
κ(m) =
n∑i=1
li(li − 1)
l(l − 1)
Ist l groß und setzen wir pi = lil
fur die Wahrscheinlichkeit des Auftretens
des Zeichens ri, so gilt: κ(m) ≈n∑
i=1
p2i .
(Tatsachlich istn∑
i=1
p2i die Wahrscheinlichkeit, an zwei (nicht notwendig ver-
schiedenen!) zufallig gewahlten Positionen ein gleiches Zeichen zu finden.
7William Frederic Friedman (1891-1969) hat statistische Methoden in die Kryptologieeingefuhrt.
34

Durch leichte Umformungen in der Definition von κ(m) zeigt man
κ(m) =
n∑i=1
p2i
1− 1l
− 1
l − 1≈
l groß
n∑i=1
p2i .)
Wir nehmen jetzt n = 26 an, R = 0, 1, . . . , 25 als Codierung fur A, . . . ,Z.
In langen deutschsprachigen Texten m ist κ(m) ≈ κd := 0, 0762 (ergibt sichaus den Buchstabenhaufigkeiten in deutschen Texten).
Fur lange Texte m mit l1 = l2 = . . . l26 (Zufallstexte) gilt: κ(m) ≈ κz :=26∑i=1
( 126
)2 = 126≈ 0, 0385.
Also: In deutschsprachigen Texten treten gleiche Buchstaben an zwei zufallig(unabhangig) gewahlten Positionen etwa doppelt so haufig auf wie in zufalligerzeugten Texten.(zum Vergleich: κengl ≈ 0, 0669, κruss ≈ 0, 0561, κholl ≈ 0, 0798)
Was hilft der Koinzidenzindex zur Bestimmung der Periode d einer polyal-phabetischen Verschlusselung?
Zerlege den Chiffretext c in die d monoalphabetisch verschlusselten Teiltexte:(Pos. 1, d + 1, 2d + 1, . . . Pos. 2, d + 2, 2d + 2, . . . Pos. d, 2d, 3d, . . .)
Wir nehmen an, dass diese verschieden monoalphabetisch verschlusselt wur-den. (Bei Vigenere bedeutet dies, dass das Schlusselwort aus lauter verschie-denen Buchstaben besteht.) Wahlt man zwei Positionen innerhalb eines sol-chen Teiltextes, so ist die Wahrscheinlichkeit fur zwei gleiche Buchstaben≈ κd = 0, 0762. Wahlt man zwei Positionen, die in verschiedenen Teiltextenliegen, so ist die Wahrscheinlichkeit fur zwei gleiche Buchstaben annahernddie eines Zufallstextes, also ≈ κz = 0, 0385.
[Anmerkung: Letztere Aussage trifft nur zu, wenn die Permutationen, die diemonoalphabetischen Substitutionen bewirken, die Haufigkeit jedes Buchsta-ben insgesamt gleichmaßig verteilen, d.h. fur jedes r ∈ R soll gelten:
1
|M |∑
σ∈M
p(σ−1(r)) ≈ 1
26,
35

wobei M die Menge der auftretenden Permutationen und p(x) fur x ∈ R dierelative Haufigkeit des Buchstabens x in (langen) deutschsprachigen Textenbezeichnet.
Begrundung:Sei M = σ1, . . . , σd, also |M | = d. Die Wahrscheinlichkeit fur zwei gleicheBuchstaben in zwei zufallig gewahlten Positionen in verschiedenen Teiltextenist:
1
d(d− 1)
∑
r∈R
(d∑
i,j=1
p(σ−1i (r))p(σ−1
j (r))−d∑
i=1
p(σ−1i (r))2)
=1
d(d− 1)
∑
r∈R
((∑
i
p(σ−1i (r)) ·
∑
j
p(σ−1j (r))−
∑
i
p(σ−1i (r))2)
≈V or.
1
d(d− 1)
∑
r∈R
(d · 1
26· d · 1
26−∑
i
p(σ−1i (r))2)
=1
d(d− 1)[d2
26−∑
i
∑
r∈R
p(σ−1i (r))2]
=1
d(d− 1)[d2
26−∑
i
∑
r∈R
p(r)2
︸ ︷︷ ︸≈κd≈ 2
26
]
≈ 1
d(d− 1)[d2
26− 2d
26] =
d− 2
d− 1· 1
26≈ 1
26fur große d. ]
Sei nun l die Lange des Chiffretextes c, sein Koinzidenzindex κ(c). Da es dTeiltexte mit je etwa l
dZeichen gibt, gibt es insgesamt ungefahr
1
2· l
d(l
d− 1) · d =
l(l − d)
2d
(ungeordnete) Paare von Positionen in c innerhalb der Teiltexte und
1
2· l︸︷︷︸
Anz. Mogl.an 1. Pos.
· ( l − l
d︸ ︷︷ ︸Anz. Mogl.an 2. Pos.
) =l2(d− 1)
2d
(ungeordnete) Paare von Positionen in c aus verschiedenen Teiltexten. DieZahl der (ungeordneten) Paare von Positionen innerhalb c mit gleichen Buch-staben ist danach ungefahr:
36

l(l − d)
2d· 0, 0762 +
l2(d− 1)
2d· 0, 0385
Dividiert man durch die Gesamtzahl l(l−1)2
aller (ungeordneten) Paare, soerhalt man eine Approximation von κ(c):
κ(c) ≈ l − d
(l − 1)d· 0, 0762 +
l(d− 1)
(l − 1)d· 0, 0385
Diese”Gleichung “ laßt sich nach d auflosen. Es ergibt sich
d ≈ 0, 0377l
(l − 1)κ(c)− 0, 0385l + 0, 0762
Da sich
κ(c) =
26∑i=1
li(li − 1)
l(l − 1), li = Anzahl des Buchstabens ri in c,
berechnen lasst, erhalt man damit eine Abschatzung fur d. Diese Abschatzunggibt jedenfalls die Großenordnung von d an und kann mit den beiden anderenMethoden zur Bestimmung von d kombiniert werden.
Beispiel:Wir verwenden wieder den Text von Seite 33 und bestimmen die Haufigkeits-verteilung der Buchstaben.
Haufigkeitsverteilung der Buchstaben:
Buchstabe Anzahl rel.l1 − l9 Haufigkeit
A 5 1,60%B 8 2,50%C 8 2,50%D 4 1,30%E 32 10,00%F 22 6,90%G 13 4,10%H 14 4,40%I 30 9,40%
37
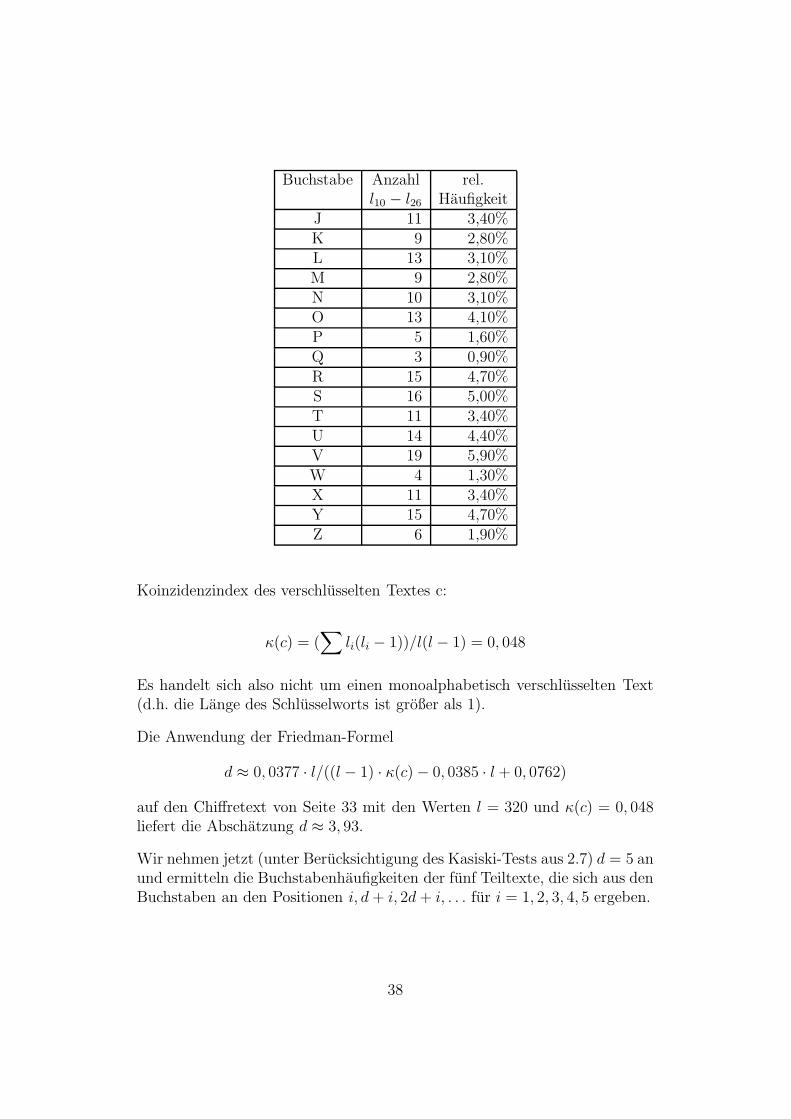
Buchstabe Anzahl rel.l10 − l26 Haufigkeit
J 11 3,40%K 9 2,80%L 13 3,10%M 9 2,80%N 10 3,10%O 13 4,10%P 5 1,60%Q 3 0,90%R 15 4,70%S 16 5,00%T 11 3,40%U 14 4,40%V 19 5,90%W 4 1,30%X 11 3,40%Y 15 4,70%Z 6 1,90%
Koinzidenzindex des verschlusselten Textes c:
κ(c) = (∑
li(li − 1))/l(l − 1) = 0, 048
Es handelt sich also nicht um einen monoalphabetisch verschlusselten Text(d.h. die Lange des Schlusselworts ist großer als 1).
Die Anwendung der Friedman-Formel
d ≈ 0, 0377 · l/((l − 1) · κ(c)− 0, 0385 · l + 0, 0762)
auf den Chiffretext von Seite 33 mit den Werten l = 320 und κ(c) = 0, 048liefert die Abschatzung d ≈ 3, 93.
Wir nehmen jetzt (unter Berucksichtigung des Kasiski-Tests aus 2.7) d = 5 anund ermitteln die Buchstabenhaufigkeiten der funf Teiltexte, die sich aus denBuchstaben an den Positionen i, d + i, 2d + i, . . . fur i = 1, 2, 3, 4, 5 ergeben.
38

Tabelle 4: Teiltexte 1-5
Da der Gesamttext mit Vigenere-Chiffrierung verschlusselt wurde, entstan-den die Teiltexte durch Verschiebe-Chiffren aus den entsprechenden Teiltex-ten des Klartextes.
Teiltext 1: Offenbar steht F fur den Klartextbuchstaben E. Verschiebungum 1
∧= B.
Teiltext 2: Aus der Haufigkeit von E entnimmt man, dass hier keine Ver-schiebung, d.h. Verschiebung um 0
∧= A vorliegt. (Ist das der Fall, so
kommt allerdings der in deutschen Texten relativ haufige Buchstabe Rin dem zweiten Klartextstuck uberhaupt nicht vor.)
Teiltext 3: Dieser Teiltext hat keine typische Haufigkeitsverteilung. Kandi-daten fur den Klartextbuchstaben E sind die Chiffretextbuchstaben Hoder Y. Im ersten Fall wurde Q fur N stehen, d.h. der zweithaufigsteBuchstabe in deutschen Texten wurde in diesem Klartextstuck nichtauftauchen. Die Wahl von Y fur E ist plausibler. Dann Verschiebungum 20
∧= U.
Teiltext 4: Offenbar steht I fur den Klartextbuchstaben E. Verschiebungum 4
∧= E.
39

Teiltext 5: Am wahrscheinlichsten ist, dass V fur den KlartextbuchstabenE steht. Verschiebung um 17
∧= R.
Demnach ist das Schlusselwort BAUER und der Klartext lautet (mit Satz-zeichen):
Es mag ueberraschen, dass man von einem vorgelegten monoal-phabetisch chiffrierten Text leichter sagen kann, ob er englischoder franzoesisch ist, als ihn zu entschluesseln. Dies gilt natuer-lich auch fuer Klartext: es gibt ein einfaches Verfahren, genuegendlangen Klartext auf Zugehoerigkeit zu einer bekannten Sprachezu untersuchen, ohne seine Syntax oder Semantik zu betrachten.(Aus: F.L.Bauer, Entzifferte Geheimnisse [5])
Aufgabe:Der folgende Chiffretext entstand durch polyalphabetische periodische Ver-schlusselung eines deutschsprachigen Texts. Versuchen Sie ihn zu entschlus-seln.
GQGOEQ RYZOEJ DJGBGT OPCBDJ WAHYHT WPCYHT FYZCWF DLVRJG WBCJDG
XYGDHJ OYZEHY GOVVIT XOKVHT ULRIFI MBWPTW MMVGVI REXGWZ OXTPHN
RYGPTW GTCRHT FYZCWF DLVRJZ PYYUDJ HEYOAF RYZFPF GLCFBO OYWYWC
CVCLET CTEHVI YOUUWT HLCHVI DORIFF WYHGZH XVCMWC CBRTOJ OPIBEZ
WMROCV NCVRWA MBRKTZ SEZVTT UMCRIT OBLSTA DMCJUC CLVOUZ GLKSUF
MJXIFZ WYEFUF ZYXVZT BYGDPT XOCRGH GKZOTW RYZEDG DWVRCF RYZREC
CTRIFF GOVOOT UCRVBL YOYMDG DVCADQ RZTRET YPXOAT XGKDBV UYGFDZ
DQWCBS OTUPKY GQXNWT HMCJFT OPXOTW UEHVDZ TEGRKH XMKJJK DYZDDQ
XYGBWT NEYRDF FECRQT UEVLQT XYGBDJ WAHYHT WPCYJT WWCHVI GTIHUF
TICRTT XZTRQG SLTCEF GORREL HYZJDT HYGGHI GEVLQT XJCFZG QKCRGT
BYGPTV UBVRQZ DYEYDB GPJAEN ZBAOAW GOAOTQ REGRGG UXEHVI GQGCEL
GQGOCJ OPCRUG DJKVWV XEVLBJ OBIDPT XOCRQG GSCHQT XPVNDJ QKCLUZ
EGTGBE OBCHTH XMCGBT HYPKTG GTCRXT RYGLEL HPAOAW GOXHDQ OAHVQK
UAHDPE SLREWT UBCJVI HJCJUT HZCGBT OLVRJZ NYJAEQ OPWOTW MTKRJT
CQGBDJ D
40

2.9 Nichtperiodische polyalphabetische Verschlusse-lungen
Nichtperiodische polyalphabetische Verschlusselungsverfahren, auch Lauftext-verschlusselungen genannt, erfullen die Eigenschaft
Lange Schlusselfolge ≥ Lange Klartext.
Man bezeichnet sie auch als Vernam-Chiffren8, insbesondere wenn das Al-phabet 0, 1 zugrunde liegt.
Wird eine Vigenere-Chiffre mit genugend langem ’Schlusselwort’gewahlt (d.h.Lange Schlusseltext ≥ Lange Klartext), so bestehen kryptoanalytische Mog-lichkeiten, falls das Schlusselwort ein sinnvoller Text ist (z.B. fortlaufenderText eines Buches; als auszutauschenden Schlussel benotigt man dann nurSeite, Zeile und Position des ersten Schlusselwortbuchstabens in der Zei-le). Dies beruht auf einer Beobachtung des Kryptologen William Friedman(1891 – 1969), dass in diesem Fall ein hoher Anteil der Geheimtextbuch-staben durch Addition haufig auftretender Klartextbuchstaben mit haufigauftretenden Schlusseltextbuchstaben entsteht.9
In jedem Fall sollten daher bei Lauftextverschlusselungen durch Addition vonSchlusseltexten Zufallsfolgen von Buchstaben als Schlusseltexte genommenwerden.10
Bei der Wahl von Zufallsfolgen als Schlusseltexte lassen sich tatsachlich theo-retisch sichere Kryptosysteme konstruieren.
Zur Verdeutlichung dieser Tatsache nehmen wir an, dass alle Nachrichtenbinar kodiert sind, d.h. R = 0, 1, und der ’Schlusseltext’ ebenfalls eine Fol-ge von Bits ist. Die Verschlusselung erfolgt dann durch stellenweise Additionmodulo 2 (XOR,⊕) von Klartextbits und Schlusseltextbits.
Ist der Schlusseltext eine echte Zufallsfolge, so nennt man dieses VerfahrenOne-time-pad.
Was heißt Zufallsfolge von Bits?
8nach G. Vernam (AT&T)9siehe z.B. Bauer [5]
10Auf die Problematik der Erzeugung von Zufallsfolgen werden wir an spaterer Stelleeingehen.
41

Von einer Folge (von Nullen oder Einsen) zu sagen, sie sei eine Zufallsfolge,ist eigentlich sinnlos. Entscheidend ist vielmehr, wie sie erzeugt wurde.
Eine Zufallsfolge (an)n∈N oder (an)n=1,...,m, an ∈ 0, 1, ist eine Folge vonWerten unabhangiger, gleichverteilter binarer Zufallsvariablen, also der Out-put einer binaren symmetrischen Quelle. D.h. jedes an ist mit Wahrschein-
lichkeit 12
gleich 0 oder 1; der Wert jedes an ist unabhangig von den Wertenvon a1, . . . , an−1 (Munzwurf).
Das One-time-pad ist (unter gewissen Voraussetzungen) perfekt sicher. Washeißt das? Diese Frage behandeln wir im nachsten Kapitel.
42

3 Perfekte Sicherheit von Chiffrierverfahren
Gegeben sei ein Chiffrierverfahren und eine Verschlusselungsfunktion E.
M sei die Menge aller moglichen Klartexte; M sei endlich.
K sei die Menge aller moglichen Schlussel des Verfahrens; K sei endlich.
C sei die Menge aller moglichen Chiffretexte, d.h. C = c : ∃x ∈ M, k ∈K mit E(x, k) = c.
Fur Klartexte gebe es eine Wahrscheinlichkeitsverteilung prM . Schlussel wer-den unabhangig von den Klartexten entsprechend einer Wahrscheinlichkeits-verteilung prK gewahlt.
Dann haben wir eine Wahrscheinlichkeitsverteilung auf M ×K:
pr(x, k) = prM(x)prK(k) fur x ∈M, k ∈ K.
Wir setzenpr(x) := pr((x, k) : k ∈ K) = prM(x) und
pr(k) := pr((x, k) : x ∈M) = prK(k).
Fur einen Chiffretext c ∈ C setzen wir
pr(c) := pr((x, k) : x ∈M, k ∈ K, E(x, k) = c),
die Wahrscheinlichkeit, dass c als Chiffretext bei einer Verschlusselung er-scheint.
3.1 Definition (Perfekte Sicherheit)
Ein Chiffrierverfahren heißt perfekt sicher, wenn fur jeden Klartext m undjeden Chiffretext c gilt:
pr(m|c) = pr(m).
Bedeutung:pr(m) ist wie oben die a-priori-Wahrscheinlichkeit fur Klartext m.
pr(m|c) ist die a-posterio-Wahrscheinlichkeit fur Klartext m, wenn man weiß,dass der Chiffretext c ist.
43

Dies ist eine bedingte Wahrscheinlichkeit:
pr(m|c) =pr(“m und c“)
pr(c)
=pr((m, k) : k ∈ K ∩ (x, k) : x ∈M, k ∈ K, E(x, k) = c)
pr(c)
=pr((m, k) : k ∈ K, E(m, k) = c)
pr(c)
Beispiel: Verschiebechiffre: m = HALLO, c = XRYTY. Dann pr(m|c) = 0.
Bedingung fur perfekte Sicherheit besagt:Wenn ich c kenne, ist die Wahrscheinlichkeit dafur, dass m der zugehorigeKlartext ist genauso groß wie sie es war, bevor ich c kannte. Kenntnis von cmacht keinen Klartext wahrscheinlicher oder unwahrscheinlicher.
Satz von Bayes: Perfekte Sicherheit ⇔ pr(c) = pr(c|m) ∀m ∀ c, Wahrschein-lichkeit von c ist unabhangig vom Klartext.
3.2 Satz (Shannon11, 1949)
Die Bezeichnungen seien wie oben gewahlt.Ist prK die Gleichverteilung auf K und existiert zu jedem Klartext m undjedem Chiffretext c genau ein Schlussel k ∈ K mit E(m, k) = c, so ist dasVerschlusselungsverfahren perfekt sicher.(Ist prM(m) > 0 ∀m ∈M und |K| = |C|, C die Menge aller Chiffretexte, sogilt auch die Umkehrung.)
Beweis:Fur jeden Klartext m und jeden Schlusseltext c gibt es genau einen Schlusselk = k(m, c) mit E(m, k) = c.
pr(m|c) =Bayes
pr(m)pr(c|m)
pr(c)=
pr(m) 1|K|∑
x∈M
pr(x) pr(k(x, c))︸ ︷︷ ︸1|K|
=pr(m)∑
x∈M
pr(x)= pr(m).
11Claude Shannon, 1916 - 2001, u.a. MIT
44

Ist das One-time-pad perfekt sicher? Nicht, wenn wir beliebige (ggf. nachoben beschrankte) Langen von Klartexten zulassen; denn ist l(m) 6= l(c),so ist pr(m|c) = 0, egal welche Wahrscheinlichkeit m hatte. Halten wir dieKlartextlange aber fest, so gilt perfekte Sicherheit.
3.3 Satz (Perfekte Sicherheit des One-time-pads)
Sei n ∈ N. Sei En : 0, 1n → 0, 1n das Verschlusselungsverfahren mit demOne-time-pad, d.h. M ⊆ 0, 1n, K = 0, 1n = C.Wird bei der Verschlusselung von Klartexten immer ein Schlussel (aufs Neue)gleichverteilt zufallig gewahlt, so ist das One-time-pad perfekt sicher.
Beweis:Das folgt sofort aus 3.2.
Wichtig: Schlussel darf nur einmal verwendet werden!
Wird ein Schlussel zweimal verwendet,
m1 ⊕ k = c1
m2 ⊕ k = c2 ,
so ist c1⊕c2 = m1⊕m2; dies ist eine Vernam-Verschlusselung eines sinnvollenTextes (m1) mit einem sinnvollen Text (m2), Ergebnis c1 ⊕ c2 bekannt. Diesliefert Angriffsmoglichkeiten (siehe 2.9).
Außerdem:Bei Mehrfachverwendung des Schlussels k wird das System bei einem Known-plaintext-Angriff sofort gebrochen: Ist m ⊕ k = c, m, c bekannt, so auchk = m⊕ c bekannt.
45

4 Symmetrische Blockchiffren
Wir betrachten im Folgenden Blockchiffren uber einem Alphabet R (Klar-textalphabet = Chiffretextalphabet = R). Klartexte sind Folgen von Zeichenaus R, im wichtigen Fall R = Z2 = 0, 1 also Bitfolgen (z.B. durch Codie-rung mit ASCII-Code entstanden). Eine solche Zeichenfolge wird in Blockeeiner festen Lange n zerlegt. Diese Blocke werden verschlusselt.
Wir betrachten zunachst die Situation, dass zwei gleiche Blocke des Klartex-tes auch gleich verschlusselt werden (d.h. dies entspricht einer monoalphabe-tischen Substitution uber dem Alphabet Rn). Es gibt andere Betriebsartenvon Blockchiffren, bei denen die Verschlusselung eines Blocks von der Ver-schlusselung der vorangehenden Blocke abhangt (also von seiner Position imText; vgl. polyalphabetische Verschlusselungen). Auf diese Betriebsarten vonBlockchiffren werden wir spater eingehen.
Wir beschranken uns fur den Moment auf R = Z2 und nehmen ferner an, dassBlocke der Lange n uber Z2 wieder in Blocke der Lange n uber Z2 verschlusseltwerden (was haufig der Fall ist). Dann gibt es also (2n)! Blockchiffren (mitBlocken der Lange n uber Z2), namlich alle Permutationen der 2n Blocke derLange n.
Wenn man alle diese Permutationen der 2n moglichen Klartextblocke uber Z2
zur Verschlusselung zulasst, so besteht die Schlusselmenge aus allen (2n)! die-ser Permutationen. Die Codierung einer Permutation (also eines Schlussels)erfordert dann mindestens s Bits, wobei 2s−1 ≤ (2n)! < 2s.
Nach der Stirling-Approximation ist (2n)! ≈√
π · 2n+1 (2n
e)2n
, also
s ≈ log2(√
π · 2n+1 · (2n
e)2n
)
= 12(n + 1) + 1
2log2π + 2n · (n− log2 e)
≈ 12(n + 2) + 2n · (n− 1, 44)
[ Die ubliche Codierung eines Schlussels (= Permutation der 2n Blocke) ware,die Permutation so anzugeben, dass zunachst das Bild des Blockes (0, . . . , 0)
←n→angegeben wird (n Bits), dann das Bild des Blockes (0, . . . , 0, 1), . . ., schließ-lich das Bild des Blockes (1, . . . , 1). Dies erfordert n · 2n Bits. ]
Bei der in der Praxis ublichen Blocklange von n = 64 oder n = 128 (odersogar mehr) sind solche Schlussellangen naturlich illusorisch.
Beispiel: n = 64Schlussellange: s = 264 ·26 = 270 ≈ 1021 Bits; die etwas scharfere Abschatzung
46

mit der Stirling-Approximation liefert eine Schlussellange von ≈ 1, 95 · 269
Bits, also keine entscheidende Verbesserung.Zur Speicherung eines Schlussels werden ca. 700 Millionen Festplatten miteiner Kapazitat von je 200 GByte benotigt.
Daher beschrankt man sich in der Praxis auf kleine Teilmengen von Blockchif-fren, fur die die Schlussel (also die Permutationen) mit geringer Bitlange co-diert werden konnen. Wir geben im Folgenden ein erstes Beispiel an, namlichaffin-lineare Chiffren. Sie beruhen, wie viele andere Chiffren auch, auf Al-phabeten, die kommutative Ringe sind. Dies hat den Vorteil, dass man dieElemente des Alphabets addieren und multiplizieren kann. Bei den affinenSubstitutionschiffren in 2.1(b) haben wir hiervon schon Gebrauch gemacht.Die affinen Blockchiffren, die wir jetzt behandeln, sind eine Verallgemeine-rung (von “Blocken“ der Lange 1 auf Blocke der Lange n ∈ N). Sie beruhenauf Operationen, die aus der linearen Algebra bekannt sind, nur dass die dortauftretenden Korper auch kommutative Ringe sein konnen. Wir stellen daherzunachst einmal die wesentlichen Hilfsmittel aus der linearen Algebra uberkommutativen Ringen zusammen, wobei wir auf Beweise verzichten.
4.1 Lineare Algebra uber kommutativen Ringen
Im folgenden sei R immer ein kommutativer Ring mit 1. D.h. R erfullt alleAxiome eines Korpers, nur mussen die von 0 verschiedenen Elemente von Rnicht notwendig ein Inverses bezuglich der Multiplikation besitzen. DiejenigenElemente, die ein multiplikatives Inverses besitzen, nennt man Einheiten vonR. Die Menge aller Einheiten des Rings R bezeichnet man mit R∗.
Beispiele:
a) Z ist kommutativer Ring mit 1. Die Einheiten sind 1 und −1, alsoZ∗ = 1,−1.
b) Sei n eine naturliche Zahl.Zn = 0, . . . , n − 1 ist der Ring der ganzen Zahlen modulo n. Manaddiert und multipliziert modulo n: Addition (Multiplikation) wie inZ, dann Division durch n mit Rest r, 0 ≤ r ≤ n− 1; der Rest ist dasErgebnis der Addition (Multiplikation) in Zn. Das additive Inverse voni ist also n− i.
Welches sind die Einheiten in Zn?
47

Das haben wir schon in 2.1(b) uberlegt:a Einheit in Zn ⇔ ggT(a, n) = 1Z.B.: Einheiten in Z10: Z∗10 = 1, 3, 7, 9Ist n = p eine Primzahl, so sind alle von 0 verschiedenen Elemente Einheiten:Zp ist Korper.
Die Berechnung der multiplikativen Inversen der Einheiten in Z∗n geschiehtz.B. mit dem erweiterten Euklidischen Algorithmus, wie in 2.1(b) beschrie-ben.
Wie uber Korpern kann man uber Ringen Vektoren und Matrizen bilden:
Rn = (r1, . . . , rn)|ri ∈ R
R(n,k) =
r11 . . . r1k...
...rn1 . . . rnk
| rij ∈ R
. Also: Rn = R(1,n)
Matrizenaddition und -multiplikation wie uber Korpern.
Ebenso kann man die Determinante einer quadratischen Matrix berechnen:
n = 1 : A = (a11) = (a) : det(a) = a
n > 1 : A ∈ R(n,n) : det A =n∑
j=1
(−1)i+j aij det Ai,j ∈ R(Entwicklung nach der i-ten Zeile)
Ai,j entsteht aus A durch Streichen der i-ten Zeile und j-ten Spalte.
Ebenso:
det A =n∑
i=1
(−1)i+j aij det Ai,j (Entwicklung nach der j-ten Spalte)
Beispiel: R = Z6
A =
0 2 51 3 14 3 1
Rechne uber Z, reduziere dann modulo 6.
48

det A = 0 · det
(3 13 1
)− 2 · det
(1 14 1
)+ 5 · det
(1 34 3
)
= −2 · (1− 4) + 5 · (3− 12) = 6− 45 = −39 ≡ 3 (mod 6)det A = 3 (in Z6)
Wann besitzt eine Matrix A ∈ R(n,n) eine Inverse A−1?
Forderung:
A · A−1 = A−1 · A = En =
1 0. . .
0 1
Kriterium: A ∈ R(n,n) besitzt Inverse ⇔ det A ist Einheit in R.
Setzt man bij = (−1)i+j det Aj,i, Aj,i wie oben, B = (bij),so gilt A−1 = (det A)−1 · B.
Beispiel: R = Z6
a) Die obige 3 × 3-Matrix ist nicht invertierbar, da det A = 3, und 3 istkeine Einheit in Z6.
b) A =
(1 33 2
)2− 9 = −7 ≡ 5 (mod 6) ,
d.h. det A = 5 und A ist invertierbar in R(2,2).
(det A)−1 = 5 (denn 5 · 5 mod 6 = 1)
A−1 = 5 ·(
2 −3−3 1
)= 5 ·
(2 33 1
)=
(4 33 5
)
4.2 Affine Blockchiffren
Klartexte seien codiert uber einem Alphabet Zk fur ein k ∈ N. Klartextewerden zerlegt in Blocke der Lange n, d.h. in Elemente aus Zn
k . Die Blockewerden einzeln in derselben Weise verschlusselt:
Eine affine Blockchiffre ordnet jedem v = (r1, . . . , rn) ∈ Znk das Element
vA + b ∈ Znk zu, wobei A ∈ Z(n,n)
k , b ∈ Znk . Schlussel ist das Paar (A, b).
Damit die Chiffrierung v 7→ vA+b injektiv ist, muss die Matrix A in Z(n,n)k in-
vertierbar sein, d.h. det A muss eine Einheit in Zk sein (also ggT(det A, k) = 1).
49

Die Dechiffrierung von w = vA + b erfolgt dann durch
v = (w − b)A−1.
Wird der Schlusselraum eingeschrankt auf alle (A, b) mit b = 0 (v 7→ vA,A Schlussel), so spricht man von linearen Blockchiffren. Sie werden auchHill-Chiffren genannt.12
Beachte:Ist v = (r1, . . . , rn), vA + b = (s1, . . . , sn), so hangt jedes si in der Regel vonallen r1, . . . , rn ab. Es handelt sich bei affinen Blockchiffren also nicht umSubstitutionschiffren, die jedes Element des Alphabets Zk einzeln substituie-ren.
Beispiel: R = Z6, n = 2
Wir wahlen A =
(1 33 2
)aus dem zweiten Beispiel am Ende von 4.1. A ist
in Z(2,2)6 invertierbar, A−1 =
(4 33 5
). Sei b = (3, 5).
Verschlusselung des Klartextblockes v = (1, 2):
vA + b = (1, 2)
(1 33 2
)+ (3, 5) = (1, 1) + (3, 5) = (4, 0) = w.
Entschlusselung:
(w − b)A−1 = ((4, 0)− (3, 5))
(4 33 5
)= (1, 1)
(4 33 5
)= (1, 2) = v.
Wie groß ist die Anzahl der Schlussel bei linearen Blockchiffren?Beispiel: R = Z2, n = 64Schlussel A 64× 64 -Matrix uber Z2 mit Determinante 1Schlussellange: 642 = 212 = 4096 Bits(falls man die Matrix als 64× 64 -array speichert.)Anzahl der Schlussel: |GL(64, 2)| = (264 − 1)(264 − 2) . . . (264 − 263)≈ 0, 29 · 24096
[Winzig im Vergleich zu 264! ≈ 2264·62,56 ≈ 21021, der Anzahl aller Blockchiffren
der Lange 64.]
Einige spezielle Chiffrierverfahren lassen sich als affine Blockchiffren auffas-sen:
12Lester S. Hill (1891-1961), 1929
50

Beispiele:
a) Die Vigenere-Chiffre ist eine affine Blockchiffre uber Z26. Als Schlusselwerden samtliche (En, b), b ∈ Zn
26 verwendet:
v 7→ v + b (b ist das”Schlusselwort“,
n ist die Periode der Vigenere-Chiffre.)
b) Zu Beginn von Kapitel 2 hatten wir sog. (Block-) Transpositionschiffrenerwahnt. Der Schlussel ist eine Permutation σ auf 1, . . . , n. Ein Block(r1, . . . , rn) wird verschlusselt zu (rσ(1), . . . , rσ(n)). Diese Chiffren lassensich als lineare Blockchiffren auffassen:Sei Pσ = (pij) die folgende Permutationsmatrix.
pij =
0 fur i 6= σ(j)1 fur i = σ(j)
Dann ist (r1, . . . , rn)Pσ = (rσ(1), . . . , rσ(n))
P−1σ = Pσ−1 (gilt uber jedem Ring R, z.B. R = Z26)
4.3 Kryptoanalyse affiner Blockchiffren
Die Kryptoanalyse affiner Blockchiffren kann bei einem Ciphertext-only-An-griff schwierig sein. Bei einem Known-Plaintext-Angriff sind sie jedoch leichtzu knacken:
Ausgangssituation: Schlussel (A, b) ist festgelegt worden, A ∈ Z(n,n)k , b ∈ Zn
k .
Verschlusselungsfunktion: v 7→ vA + b, v ∈ Znk
Angreifer will (A, b) bestimmen.
Wir gehen davon aus, dass er n + 1 Klartextblocke v0, . . . , vn und die zu-gehorigen chiffrierten Blocke w0, . . . , wn kennt.
Wir nehmen an, dass det
v1 − v0...
vn − v0
eine Einheit in Zk ist.
(Das passiert haufig, da ϕ(k) = k · ∏p Primzahl
p|k
p−1p≥ k
6 ln(ln(k))fur k ≥ 5 nach
einem Satz von Rosser und Schoenfeld; uberdies ist limk→∞
ϕ(k)k1−δ = ∞ fur jedes
51

δ > 0.Bei einem Chosen-Plaintext-Angriff kann man naturlich sicherstellen, dassdie angegebene Determinante eine Einheit ist.)
Setze V =
v1 − v0...
vn − v0
, W =
w1 − w0...
wn − w0
∈ Z(n,n)
k
Dann gilt: V A = W . Da det V eine Einheit in Zk ist, existiert V −1.
Es folgt:A = V −1W und b = w0 − v0A
(Ist die Chiffre sogar linear, so benotigt man nur v1, . . . , vn und bestimmt awie oben (mit v0 = w0 = 0).)
Beispiel:Ang.: Blocklange n = 2, k = 26Angenommen wir wissen, dass der Klartext HERBST in den ChiffretextNEBLIG verschlusselt wurde.
D.h.:7 4 17 1 18 19 −→ 13 4 1 11 8 6v0 v1 v2 w0 w1 w2
V =
(v1 − v0
v2 − v0
)=
(10 2311 15
)W =
(w1 − w0
w2 − w0
)=
(14 721 2
)
10 · 15− 23 · 11 = 150− 253 = −103 ≡ 1 (mod 26), det V = 1 in Z26
V −1 =
(15 −23−11 10
)=
(15 315 10
)
A = V −1W
=
(15 315 10
)(14 721 2
)=
(210 + 63 105 + 6210 + 210 105 + 20
)=
(13 74 21
)
b = w0 − v0A = (13, 4)− (7, 4)
(13 74 21
)= (13, 4)− (107, 133) = (10, 1)
Test:
v1A + b = (17, 1)
(13 74 21
)+ (10, 1) = (225, 140) + (10, 1) = (1, 11) = w1
v2A + b = (18, 19)
(13 74 21
)+ (10, 1) = (310, 525) + (10, 1) = (8, 6) = w2
52

4.4 Hintereinanderausfuhrung von Blockchiffren, Dif-fusion und Konfusion
Die Sicherheit von Blockchiffren kann erhoht werden, indem mehrere Block-chiffren hintereinander ausgefuhrt werden (Produkt von Blockchiffren, Uber-chiffrierung). Wichtig dabei ist, dass die Hintereinanderausfuhrung zwei-er Blockchiffren nicht wieder eine Blockchiffre derselben Art ist (Gruppen-eigenschaft darf nicht erfullt sein). Z.B. ist die Hintereinanderausfuhrungzweier affiner oder linearer Blockchiffren wieder eine affine oder lineare Block-chiffre; hier bringt die Hintereinanderausfuhrung nichts.
Ziel solcher Hintereinanderschachtelungen ist es u.a., zwei Eigenschaften vonBlockchiffren sicherzustellen, die Claude Shannon in einer seiner grundlegen-den Arbeiten zur Kryptographie 1949 als wesentlich fur die Sicherheit von(Block-)Chiffren formuliert hat:
Diffusion:Statistische Auffalligkeiten (Haufigkeiten von Einzelzeichen etc.) eines Klar-textes sollen im Chiffretext “verwischt“ werden. Dies bedeutet, dass jedesZeichen eines Chiffretextblockes von mehreren Zeichen des Klartextblockesabhangen soll und umgekehrt soll jede Anderung eines Zeichens des Klar-textblockes Anderungen von mehreren Zeichen im Chiffretextblock zur Folgehaben (bei gleichem Schlussel).
Konfusion:Aus statistischen Eigenschaften des Chiffretextes soll nicht in einfacher Weiseauf den verwendeten Schlussel zu schließen sein. Insbesondere soll jedes Zei-chen eines Chiffretextblockes von mehreren Zeichen des Schlussels abhangen.
Beispiel:Lineare Chiffren: v → vA, n× n-Matrix A als Schlussel.Lineare Chiffren haben die Eigenschaft der Diffusion.Konfusion: Chiffretextbit an Stelle i hangt von allen Eintragen der i-tenSpalte von A ab (schwache Form der Konfusion).
Wir vermerken an dieser Stelle, dass in der Literatur die Begriffe “Diffusion“und “Konfusion“ nicht immer einheitlich verwendet werden.
Eine der wichtigsten Typen von Blockchiffren, die durch Hintereinander-schachtelungen mehrerer einfacherer Blockchiffren entstehen, behandeln wirim folgenden Abschnitt.
53

4.5 Feistel-Chiffren
Feistel-Chiffren sind benannt nach dem IBM-Ingenieur Horst Feistel (1915-1990), der 1971 einen Chiffrieralgorithmus namens LUCIFER entwickelte,welcher als Vorlaufer des DES (Data Encryption Standard) anzusehen ist.Das typische Konstruktionsprinzip von LUCIFER ist in der Definition vonFeistel-Chiffren beinhaltet. Auf den DES werden wir im nachsten bzw. uber-nachsten Abschnitt eingehen.
Feistel-Chiffren realisieren den Vorschlag Shannons, alter-Klartextblock
v
0R
K
f
0
1
L1
R
K
f+
1
2
L2
R2
L
+
Lr-1
R
K
f+
r-1
r
Lr
Rr
Chiffretextblock
E (v)k
Abbildung 7:Schematischer Ab-lauf einer Feistel-Chiffrierung
nierende Folgen von Block-Substitutionen und Transposi-tionen zur Diffusions- und Konfusionserzeugung zu ver-wenden, und beruhen außerdem auf der Idee, aus einem(kurzen) Ausgangsschlussel eine Folge von Schlusseln furdie Substitutionen zu erzeugen.
Zutaten fur eine Feistel-Chiffre:Eine MengeK der moglichen sogenannten Rundenschlusselund zu jedem K ∈ K eine Funktion fK : Zt
2 → Zt2.
Konstruktion der Feistel-Chiffre (zur gegebenen Block-chiffre):Feistel-Chiffre ist Blockchiffre uber Z2, Blocklange 2t.Festlegung einer Rundenzahl r ≥ 1 und eines Schlussel-raums KF (i. Allg. KF 6= K).
Wahl einer Methode, die aus einem Schlussel k ∈ KF eineFolge K1, . . .Kr ∈ K von Rundenschlusseln erzeugt.13
Verschlusselungsfunktion Ek (zum Schlussel k ∈ KF) derFeistel-Chiffre:
Sei v ein Klartextblock der Lange 2t (d.h. v ∈ Z2t2 ).
Teile v in zwei Halften der Lange t auf:
v = (L0 , R0)↑ ↑
linke Halfte rechte Halfte
Konstruiere eine Folge (Li, Ri), i = 1, . . . , r − 1 nach fol-gender Vorschrift:
(Li, Ri) = (Ri−1, Li−1 ⊕ fKi(Ri−1))
13Wie eine solche Methode realisiert werden kann, sehen wir im nachsten Abschnitt.
54

[Also:
(Li−1, Ri−1)
Substitution des linken Teil-blocks durch Addition des
”Schlusselworts“ fKi
(Ri−1)−−−−−−−−−−−−−−−−−−→ (Li−1 ⊕ fKi(Ri−1), Ri−1)
Transposition(Vertauschen derbeiden Teilblocke)−−−−−−−−−−−−→ (Ri−1, Li−1 ⊕ fKi
(Ri−1)) = (Li, Ri) ]
Schließlich in der r-ten Runde:
(Lr, Rr) = (Lr−1 ⊕ fKr(Rr−1), Rr−1)
[Hier keine Transposition mehr.]
Ek(v) = (Lr, Rr), Chiffretextblock
Entschlusselung:Wie Verschlusselung, nur mit der Schlusselfolge (Kr, Kr−1, . . . , K1).
Begrundung: Wir setzen L′0 = Lr, R′0 = Rr, K
′i = Kr+1−i, i = 1, . . . , r.
Wir verschlusseln (L′0, R′0) mit der Folge (K ′1, . . . , K
′r) und betrachten die
Zwischenresultate (L′i, R′i), i = 1, . . . , r.
1. Runde:
(L′1, R′1) = (R′0, L
′0 ⊕ fK ′1
(R′0)) = (Rr, Lr ⊕ fKr(Rr))
= (Rr−1︸︷︷︸Rr
, Lr−1 ⊕ fKr(Rr−1)︸ ︷︷ ︸Lr
⊕ fKr(Rr−1︸︷︷︸Rr
) = (Rr−1, Lr−1)
︸ ︷︷ ︸(0,...0)←−t−→
2. Runde:
(L′2, R′2) = (R′1, L
′1 ⊕ fK ′2
(R′1)) = (Lr−1, Rr−1 ⊕ fKr−1(Lr−1))
= (Rr−2︸︷︷︸Lr−1
, Lr−2 ⊕ fKr−1(Rr−2)︸ ︷︷ ︸Rr−1
⊕ fKr−1(Rr−2︸︷︷︸Lr−1
)) = (Rr−2, Lr−2)
Am Ende der (r − 1)-ten Runde hat man dann:
55

(L′r−1, R′r−1) = (R1, L1)
r-te Runde:
(L′r, R′r) = (L′r−1 ⊕ fK ′r(R
′r−1), R
′r−1) = (R1 ⊕ fK1(L1), L1)
= (L0 ⊕ fK1(R0)︸ ︷︷ ︸=R1
⊕fK1( R0︸︷︷︸L1
), R0︸︷︷︸L1
) = (L0, R0) = v
Bemerkung:Die Rechnung zur Entschlusselung zeigt, dass jede Verschlusselungsfunkti-on Ek : Z2t
2 → Z2t2 einer Feistel-Chiffre (und auch jede Rundenfunktion
(Li−1, Ri−1) → (Li, Ri)) bijektiv ist, gleichgultig, ob die fKibijektiv sind
oder nicht. Damit hat man naturlich eine große Anzahl an Wahlmoglichkei-ten fur die Substitutionsfunktionen fKi
.
Beachte:Man muss bei Feistel-Chiffren dafur sorgen, dass nicht alle Substitutionen(Li−1, Ri−1) → (Li−1 ⊕ fKi
(Ri−1), Ri−1) affin (oder sogar linear) sind, dennsonst ist die gesamte Feistel-Chiffre affin (bzw. linear) (Transpositionen sindlinear nach Beispiel b) auf Seite 51). Dies bedeutet, dass nicht alle Ri−1 →fKi
(Ri−1) affin sind. Denn:
IstfKi
(Ri−1) = Ri−1Ai + bi, Ai ∈ Z(t,t)2 , bi ∈ Zt
2,
so ist
(Li−1 ⊕ fKi(Ri−1), Ri−1) = (Li−1, Ri−1) ·
1 ...1
0
Ai
1 ...1
+ (bi, 0, . . . 0
←−t−→).
56

4.6 Der ’Data Encryption Standard’ DES
Bemerkungen zur Historie:
15.5.1973 Ausschreibung des NBS (National Bureau of Standards,heute NIST, National Institute of Standards and Technolo-gy) fur einen standardisierten kryptologischen Algorithmus;keine geeigneten Kandidaten.
27.8.1974 Zweite Ausschreibung;einziger akzeptabler Vorschlag kommt von IBM, ist eineWeiterentwicklung von LUCIFER.
1974/75 Begutachtung des Verfahrens durch die NSA (National Se-curity Agency), es werden Modifikationen und insbesondereeine Uberarbeitung der Substitutionen vorgenommen.Geruchte: Wurden dadurch Hinterturen von IBM-Mitarbeitern verhindert? Oder etwa eigene Hintertureneingebaut?Entwurfskriterien wurden als “geheim“ eingestuft.Ferner: Reduktion der Schlussellange gegenuber LUCIFERvon 128 Bit auf 56 Bit!
17.3.1975 Veroffentlichung von Einzelheiten des Algorithmus1976 Zwei Workshops des NBS zur Evaluation15.1.1977 Als DES in der FIPS (Federal Information Processing Stan-
dards) Publ. 46 veroffentlicht.15.7.1977 Standard tritt in Kraft.1978 Uberprufung durch ein Komitee des US-Senats;
nur Zusammenfassung veroffentlicht: DES frei von mathe-matischen und statistischen Schwachen.
1982, 1987,1992, 1997
5-jahrige Uberprufungen, jeweils Verlangerung des Stan-dards um 5 Jahre
1990 Biham, Shamir: Differentielle Kryptoanalyse1994 Coppersmith (aus dem IBM-Entwicklerteam) publiziert
Einzelheiten uber die Entwurfskriterien des DES.1993 Fur 1 Mio US-Dollar lasst sich ein Computer bauen, der den
gesamten Schlusselraum in 7 Stunden durchsucht; daher inder Folgezeit verstarkte Verwendung des Triple-DES.
26.5.2002 DES wird durch AES ersetzt.
DES ist (leicht modifizierte) Feistel-Chiffre. Klartextblocke und Chiffretext-blocke bestehen aus 64 Bits.
Ein Schlussel k hat 56 Bits, wird aber als 64-Bit-String beschrieben; die Bits
57

an den Positionen 8, 16, 24, . . . , 64 werden so gewahlt, dass die 8 Teilblocke zu8 Bits jeweils - gemaß FIPS-Standard - ungerade Anzahl von Einsen enthalten(fehlerentdeckende Codierung). Damit gibt es 256 ≈ 7, 2 · 1016 verschiedeneSchlussel.Rundenschlussel Ki haben jeweils 48 Bits.
Die Modifikation des DES im Vergleich zu reiner Feistel-Chiffre besteht darin,dass der Klartextblock zunachst einer festen Eingangspermutation IP (initi-al permutation) unterworfen wird, dann eine Feistel-Chiffre mit 16 Rundendurchgefuhrt wird und schließlich eine Schlusspermutation IP−1 (Inverse derEingangspermutation) angewandt wird.
Eingangspermutation IP 14
58 50 42 34 26 18 10 260 52 44 36 28 20 12 462 54 46 38 30 22 14 664 56 48 40 32 24 16 857 49 41 33 25 17 9 159 51 43 35 27 19 11 361 53 45 37 29 21 13 563 55 47 39 31 23 15 7
Schlusspermutation IP−1
40 8 48 16 56 24 64 3239 7 47 15 55 23 63 3138 6 46 14 54 22 62 3037 5 45 13 53 21 61 2936 4 44 12 52 20 60 2835 3 43 11 51 19 59 2734 2 42 10 50 18 58 2633 1 41 9 49 17 57 25
IP und IP−1 haben keine kryptologische Bedeutung.
Zur Beschreibung des DES fehlen jetzt nur noch
1. Erzeugung der Rundenschlussel2. Angabe der fK
14Diese und folgende Tabellen sind zeilenweise von links oben nach rechts unten zulesen. Steht eine Zahl z an der Position i, so heißt das, dass das Bit an der Position z imEingabestring auf die Position i im Ausgabestring abgebildet wird.
58

4.6.1 Rundenschlusselerzeugung
Sei k ∈ Z642 der DES-Schlussel (mit den Parity-Bits wie oben beschrieben).
Zu Beginn wird k durch eine Schlusselpermutation auf einen 56-Bit-Stringverkurzt. (Man spricht von Permutation, da die 8 Parity-Bits von k an derStelle 8, 16, . . . 64 unberucksichtigt bleiben und die ubrigen 56 Positionenpermutiert werden.)
Dieser 56-Bit-String wird in 2 28-Bit Halften geteilt: (C0, D0).
In Runde i (i = 1, . . . , 16) werden aus Ci−1, Di−1 ∈ Z282 neue Ci, Di ∈ Z28
2
erzeugt, aus diesen wird dann der Rundenschlussel Ki ∈ Z482 erzeugt.
Def. zunachst vi fur 1 ≤ i ≤
Eingabe Runde 1:
Schlüssel-permutation
Eingabe Runde i:
DC 00
i-1 DC i-1
zykl. Linksshift um v Stelleni
zykl. Linksshift um v Stelleni
k
K
Kompres-sionsabb.
Eingabe Runde i+1:
562
562
642
482 fKi
i DC i
562
i
i DC i
Abbildung 8: Rundenschlusselerzeugung
16 durch
vi =
1 fur i = 1, 2, 9, 162 sonst
Ci entsteht aus Ci−1 durch zy-klischen Linksshift um vi Stel-len. Di entsteht aus Di−1 inder gleichen Weise.
(Also: In Runde 1, 2, 9 und16 Linksshift um eine Stelle,in den ubrigen Runden Links-shift um zwei.)
Auf (Ci, Di) ∈ Z562 wird eine
Kompressionsabbildung ange-wandt, die aus (Ci, Di) denRundenschlussel Ki ∈ Z48
2 her-stellt. [Die Kompressionsabbil-dung wahlt 48 der 56 Bits von(Ci, Di) aus und permutiertdiese.]
59

Schlusselpermutation57 49 41 33 25 17 9 158 50 42 34 26 18 10 259 51 43 35 27 19 11 360 52 44 36 63 55 47 3931 23 15 7 62 54 46 3830 22 14 6 61 53 45 3729 21 13 5 28 20 12 4
Kompressionsabbildung14 17 11 24 1 5 3 2815 6 21 10 23 19 12 426 8 16 7 27 20 13 241 52 31 37 47 55 30 4051 45 33 48 44 49 39 5634 53 46 42 50 36 29 32
4.6.2 Beschreibung der Verschlusselungsfunktion fKi
Wie bei jeder Feistelchiffre wird aus der Ausgabe (Li−1, Ri−1) ∈ Z642 der
(i−1)-ten Runde die Ausgabe (Li, Ri) ∈ Z642 der i-ten Runde erhalten durch:
Li = Ri−1
Ri = Li−1 ⊕ fKi(Ri−1)
[Ausnahme Runde 16; dort R16 = R15, L16 = L15 ⊕ fK16(R15).]
Sei also R ∈ Z322 , K ∈ Z48
2 ein Rundenschlussel. (Wir lassen den Rundenindexder besseren Ubersichtlichkeit wegen jetzt weg.)
1. Schritt:Anwendung der Expansionsabbildunge : Z32
2 → Z482 :
R→ e(R)
Expansionsabbildung32 1 2 3 4 54 5 6 7 8 98 9 10 11 12 1312 13 14 15 16 1716 17 18 19 20 2120 21 22 23 24 2524 25 26 27 28 2928 29 30 31 32 1
2. Schritt:Schlusseladdition: e(R)⊕K = (B1, B2, . . . , B8) ∈ Z48
2
Bj ∈ Z62, j = 1, . . . , 8
3. Schritt:8 S-Boxen S1, . . . , S8. Jede S-Box besteht aus vier Zeilen, jede der Zeilenenthalt die Zahlen 0, 1, . . . , 15 in einer gewissen Reihenfolge.Bj ist Input fur die S-Box Sj . Ist Bj = (b1b2b3b4b5b6), so wird durch b1b6 dieZeile von Sj festgelegt: b1b6 ist die Binardarstellung einer Zahl a ∈ 0, 1, 2, 3.Wahle die (a + 1)-te Zeile von Si. b2b3b4b5 legt den Eintrag in der gewahlten
60
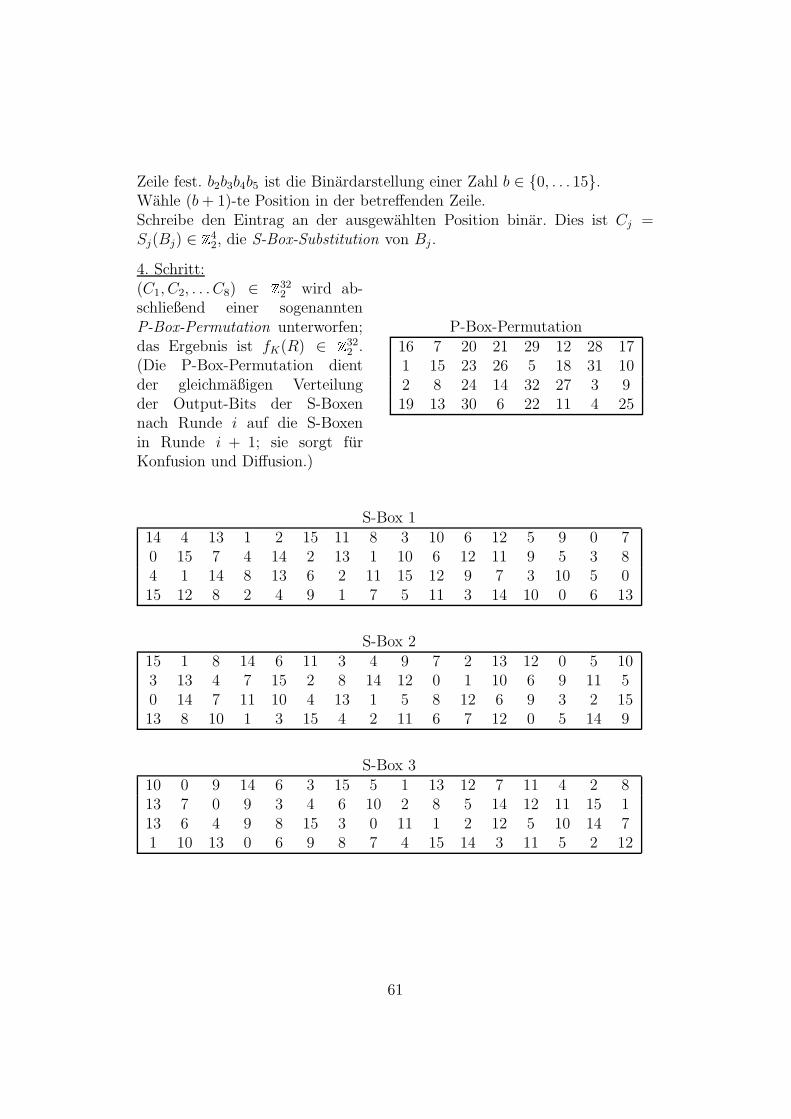
Zeile fest. b2b3b4b5 ist die Binardarstellung einer Zahl b ∈ 0, . . . 15.Wahle (b + 1)-te Position in der betreffenden Zeile.Schreibe den Eintrag an der ausgewahlten Position binar. Dies ist Cj =Sj(Bj) ∈ Z4
2, die S-Box-Substitution von Bj .
4. Schritt:(C1, C2, . . . C8) ∈ Z32
2 wird ab-schließend einer sogenanntenP-Box-Permutation unterworfen;das Ergebnis ist fK(R) ∈ Z32
2 .(Die P-Box-Permutation dientder gleichmaßigen Verteilungder Output-Bits der S-Boxennach Runde i auf die S-Boxenin Runde i + 1; sie sorgt furKonfusion und Diffusion.)
P-Box-Permutation16 7 20 21 29 12 28 171 15 23 26 5 18 31 102 8 24 14 32 27 3 919 13 30 6 22 11 4 25
S-Box 114 4 13 1 2 15 11 8 3 10 6 12 5 9 0 70 15 7 4 14 2 13 1 10 6 12 11 9 5 3 84 1 14 8 13 6 2 11 15 12 9 7 3 10 5 015 12 8 2 4 9 1 7 5 11 3 14 10 0 6 13
S-Box 215 1 8 14 6 11 3 4 9 7 2 13 12 0 5 103 13 4 7 15 2 8 14 12 0 1 10 6 9 11 50 14 7 11 10 4 13 1 5 8 12 6 9 3 2 1513 8 10 1 3 15 4 2 11 6 7 12 0 5 14 9
S-Box 310 0 9 14 6 3 15 5 1 13 12 7 11 4 2 813 7 0 9 3 4 6 10 2 8 5 14 12 11 15 113 6 4 9 8 15 3 0 11 1 2 12 5 10 14 71 10 13 0 6 9 8 7 4 15 14 3 11 5 2 12
61

S-Box 47 13 14 3 0 6 9 10 1 2 8 5 11 12 4 1513 8 11 5 6 15 0 3 4 7 2 12 1 10 14 910 6 9 0 12 11 7 13 15 1 3 14 5 2 8 43 15 0 6 10 1 13 8 9 4 5 11 12 7 2 14
S-Box 52 12 4 1 7 10 11 6 8 5 3 15 13 0 14 914 11 2 12 4 7 13 1 5 0 15 10 3 9 8 64 2 1 11 10 13 7 8 15 9 12 5 6 3 0 1411 8 12 7 1 14 2 13 6 15 0 9 10 4 5 3
S-Box 612 1 10 15 9 2 6 8 0 13 3 4 14 7 5 1110 15 4 2 7 12 9 5 6 1 13 14 0 11 3 89 14 15 5 2 8 12 3 7 0 4 10 1 13 11 64 3 2 12 9 5 15 10 11 14 1 7 6 0 8 13
S-Box 74 11 2 14 15 0 8 13 3 12 9 7 5 10 6 113 0 11 7 4 9 1 10 14 3 5 12 2 15 8 61 4 11 13 12 3 7 14 10 15 6 8 0 5 9 26 11 13 8 1 4 10 7 9 5 0 15 14 2 3 12
S-Box 813 2 8 4 6 15 11 1 10 9 3 14 5 0 12 71 15 13 8 10 3 7 4 12 5 6 11 0 14 9 27 11 4 1 9 12 14 2 0 6 10 13 15 3 5 82 1 14 7 4 10 8 13 15 12 9 0 3 5 6 11
Tabelle 5: Die 8 S-Boxen des DES, reprasentiert durch acht 4× 16 Matrizen
Die Substitutionsfunktionen fK im DES sind nicht bijektiv, was, wie in 4.5erwahnt, keinen Einfluss auf die Bijektivitat der Gesamtverschlusselungs-funktion Ek hat. Es ist relativ einfach, Beispiele R 6= R′ mit fK(R) = fK(R′)zu konstruieren (Ubungsaufgabe).
62
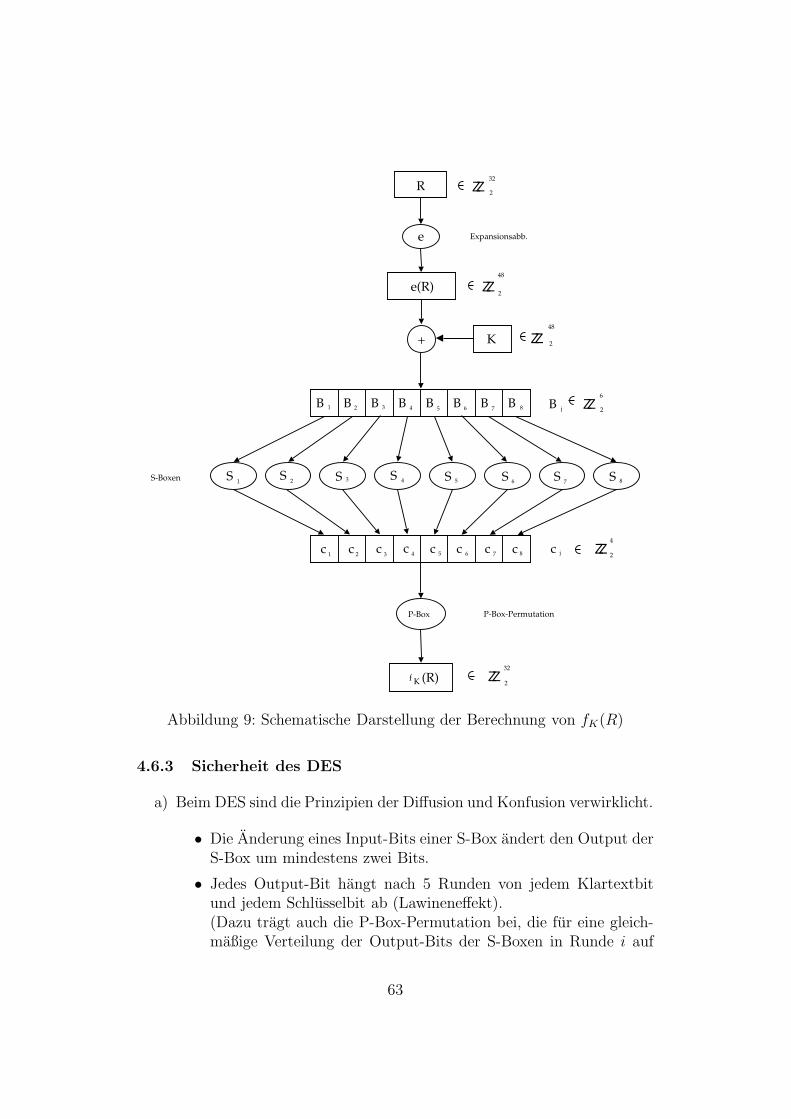
R
B
(R)
P-Box-Permutation
j
654
3
2
e
e(R)
+
Expansionsabb.
K
BBBBBBB B8
7
51 2
3
3 4
4 6
7
7
8
SSSSSS S S1 2 5 6 8
ccccccc c1
c j
P-Box
S-Boxen
48
2
48
2
32
2
ZZ
ZZ
ZZ
ZZ
2
32
2
ZZ
ZZ4
2
6
f K
Abbildung 9: Schematische Darstellung der Berechnung von fK(R)
4.6.3 Sicherheit des DES
a) Beim DES sind die Prinzipien der Diffusion und Konfusion verwirklicht.
• Die Anderung eines Input-Bits einer S-Box andert den Output derS-Box um mindestens zwei Bits.
• Jedes Output-Bit hangt nach 5 Runden von jedem Klartextbitund jedem Schlusselbit ab (Lawineneffekt).(Dazu tragt auch die P-Box-Permutation bei, die fur eine gleich-maßige Verteilung der Output-Bits der S-Boxen in Runde i auf
63

die S-Boxen in Runde i + 1 sorgt.)
Wir verdeutlichen dies an einem Beispiel:
Diffusion bei DES
Klartext 100000000 00000000 00000000 0000000000000000 00000000 00000000 00000000
Klartext 200000000 00000000 00000000 0000000000000000 00000000 00000000 00000001
Schlussel00000001 00100011 01000101 0110011110001001 10101011 11001101 11101111
Chiffretext 111010101 11010100 01001111 1111011100100000 01101000 00111101 00001101
Chiffretext 211110000 10001100 01010111 0010000010010101 10010011 11111110 10110011
Unterschiede an 36 Stellen.
Anzahl der unterschiedlichen Bits bei der Verschlusselung der Klartext-blocke 1 und 2 nach den einzelnen DES-Runden:
zu Beginn 1Nach Runde 1 1 Nach Runde 9 40Nach Runde 2 7 Nach Runde 10 34Nach Runde 3 18 Nach Runde 11 31Nach Runde 4 25 Nach Runde 12 34Nach Runde 5 26 Nach Runde 13 34Nach Runde 6 29 Nach Runde 14 31Nach Runde 7 32 Nach Runde 15 32Nach Runde 8 37 Nach Runde 16 36
64

Konfusion bei DES
Klartext (wie oben Klartext 1)00000000 00000000 00000000 0000000000000000 00000000 00000000 00000000
Schlussel 1 (wie oben)00000001 00100011 01000101 0110011110001001 10101011 11001101 11101111
Schlussel 200000001 00100011 01000101 0110011110001001 10101011 11001101 11101100
Verschlusselung des Klartextesmit Schlussel 1
111010101 11010100 01001111 1111011100100000 01101000 00111101 00001101
Verschlusselung des Klartextesmit Schlussel 2
11101010 00111011 00101011 0100101011101001 00110110 00010111 10000111
Unterschiede an 37 Stellen.
Anzahl der unterschiedlichen Bits bei der Verschlusselung des Klartext-blockes mit den Schlusseln 1 und 2 nach den einzelnen DES-Runden:
Nach Runde 1 2 Nach Runde 9 35Nach Runde 2 12 Nach Runde 10 30Nach Runde 3 24 Nach Runde 11 34Nach Runde 4 28 Nach Runde 12 39Nach Runde 5 29 Nach Runde 13 37Nach Runde 6 33 Nach Runde 14 31Nach Runde 7 34 Nach Runde 15 36Nach Runde 8 37 Nach Runde 16 37
b) Das Design des DES erfordert Rundenschlussel mit 48 Bits. Diese hatteman auch mit einem 48-Bit-Master-Key erzeugen konnen. Das wareaber schon damals unsicher gewesen ( 1
256Aufwand zum Durchsuchen
des gesamten Schlusselraums!). Man hatte solche Rundenschlussel aberauch aus langeren Master-Keys erzeugen konnen. Damit hatte man die
65

Sicherheit erhohen konnen. Dies wurde aber 1975 nicht fur notwendig(oder wunschenswert) gehalten.Als der DES spater hard- und softwaremaßig weit verbreitet war, wareine solche Anderung schwierig. Man entschied sich daher dann fur einvollig neues Verfahren (AES).
c) Bei vollstandiger Durchsuchung des Schlusselraums mussen im schlimm-sten Fall (bei einem Ciphertext-Only-Angriff) 256 Schlussel ausprobiertwerden. Der DES hat jedoch folgende Symmetrieeigenschaft:
Sei m ein Klartextblock, k ein Schlussel, c = Ek(m) der durch DESverschlusselte Block. Bezeichnet man mit m, k, c die zu m, k und ckomplementaren Blocke (Nullen und Einsen vertauschen), so gilt c =Ek(m). Dies fuhrt zu folgendem Angriff, bei dem nur 255 Schlussel zutesten sind, wenn fur einen Klartext m sowohl c = Ek(m) als auch c∗ =Ek(m) bekannt sind (z.B. bei einem Chosen-Plaintext-Angriff). Mantestet dann 255 Schlussel, wobei nie ein Schlussel und sein Komplementgetestet werden (z.B. alle Schlussel mit 0 als erstem Bit). Erhalt manein k mit Ek(m) = c, so ist (sehr wahrscheinlich) k = k; erhalt man ein
k mit Ek(m) = c∗, so ist (sehr wahrscheinlich) k = ¯k.
d) Zur Zeit der Einfuhrung des DES (1975) war eine vollstandige Schlussel-suche kaum denkbar. Dennoch zeigten W. Diffie und M. Hellman ineiner Arbeit 1977, dass es moglich ist, fur 20 Millionen US-$ eine Ma-schine zu bauen, die einen DES-Schlussel innerhalb eines Tages ermit-teln wurde. (Kritik von Diffie und Hellman: Kurze Schlussellange von56 Bits)
1997: RSA Data Security bot 10.000 US-$ demjenigen, der zuerst einenDES-chiffrierten Text knacken wurde. Nach funf Monaten wurde derSchlussel von R. Vesper ermittelt. Methode: Tausende uber das Internetverbundene Rechner arbeiteten zusammen. (25 % des Schlusselraumsmussten durchsucht werden.)
1998: Zweites DES-Challenge durch RSA Data Security. Nach 39 Tagenwurde der Schlussel von Distributed Computing Technologies ermittelt(81 % des Schlusselraums wurden durchsucht).
1998/1999: DES-Cracker von Electronic Frontier Foundation (EEF):1536 parallel arbeitende spezielle Chips (40 MHz). Benotigt im Schnittviereinhalb Tage, um DES-Schlussel zu ermitteln.15
15Einzelheiten siehe Trappe und Washington [46], S. 118-122
66

e) Es gibt vier sog. schwache Schlussel beim DES. Sie haben die Ei-genschaft, dass alle erzeugten Rundenschlussel gleich sind. Die schwa-chen Schlussel sind: (00000001)8, (11111110)8, (00011111)4(00001110)4,(11100000)4(11110001)4
Fur diese schwachen Schlussel gilt: Ek(Ek(m)) = mSchwache Schlussel mussen vermieden werden. Außerdem gibt es insge-samt 12 Schlussel, die nur zwei verschiedene Rundenschlussel erzeugen.Diese heißen semischwache Schlussel und sollten ebenfalls vermiedenwerden. Diese 12 Schlussel lassen sich in 6 Paare (k1, k2) aufteilen, sodass Ek1(Ek2(m)) = m.
f) Keine der S-Boxen beschreibt eine (affin-) lineare Funktion, ebensowe-nig wie das gesamte DES als (affin-) lineare Funktion (bei gegebenemSchlussel) beschrieben werden kann. Der DES ist also gegen die einfa-chen Angriffe, die bei (affin-) linearen Blockchiffren moglich sind, sicher.
Auch gegen kryptoanalytische Angriffe, die darauf beruhen, das Ver-schlusselungsverfahren (bei festem Schlussel) durch eine lineare Funk-tion zu approximieren – sogenannte lineare Kryptoanalyse (Known-Plaintext-Angriff)16 – erwies sich DES als ausreichend sicher: Fur das16-Runden DES werden 243 Klartext-Chiffretextblockpaare benotigt,um mit dieser Methode den Schlussel zu bestimmen17. Allerdings istsie besser als differentielle Kryptoanalyse (die wir in 4.10 behandeln)und vollstandige Durchsuchung des Schlusselraums. Man beachte: 243
Blockpaare entsprechen ca. 140 TByte, das ist in etwa der Inhalt von200 Millionen Buchern.
Beachte: Die Methode der linearen Kryptoanalyse war den Designernvon DES (im Gegensatz zur differentiellen Kryptoanalyse) nicht be-kannt. Die S-Boxen sind bezuglich linearer Kryptoanalyse nicht opti-miert.
g) Jedes Chiffretextverfahren, das die Gruppeneigenschaft besitzt, wo alsodie Hintereinanderausfuhrung zweier Verschlusselungen mit den Schlus-seln k1, k2 einer Verschlusselung mit einem Schlussel k3 entspricht, hateine gewisse innere Symmetrie, die fur kryptoanalytische Angriffe nutz-bar gemacht werden kann. Das DES hat jedoch nicht diese Eigenschaft,d.h. fur die Schlussel k1, k2 ist i.a. Ek1 Ek2 6= Ek3 fur alle Schlussel k3.
16M. Mitsui; Linear cryptoanalysis method for DES cipher, Adv. in Cryptology-EUROCRYPT ’93, Springer LNCS 765, 1994, S. 386-397.
17vgl. [40]
67

Die 256 DES -Verschlusselungsfunktionen erzeugen also eine großereGruppe (innerhalb der Gruppe S264 aller Permutationen der 264 Blockeder Lange 64 uber Z2). Tatsachlich folgt aus Arbeiten von Coppers-mith (1992) und Campbell/Wiener (1993), dass die von den DES-Verschlusselungsfunktionen erzeugte Gruppe mindestens Ordnung 1, 94·102499 hat. (Beachte: |S264 | = (264)! > 10(1020).)
h) Aufgrund von g) kann man die Sicherheit des DES erhohen, indem man(mit verschiedenen Schlusseln) einen Klartext mehrmals chiffriert. Al-lerdings bringt doppelte DES-Verschlusselung kaum mehr Sicherheit.Tatsachlich hat der Schlusselraum jetzt zwar die Große 2112, aber mankann ein Schlusselpaar (k1, k2) mit 257 einfachen DES-Verschlusselun-gen ermitteln (mit einem enormen Aufwand an Speicherplatz). Diesgeschieht mit Hilfe des sog. Meet-in-the-Middle Angriffs, der fur alleMehrfachhintereinanderausfuhrungen symmetrischer Verschlusselungs-verfahren funktioniert.
Wir beschreiben ihn kurz:Angenommen: Eve kennt Klartext m und doppelt chiffrierten Textc = Ek1(Ek2(m)). Sie will (k1, k2) bestimmen.
Sie berechnet und speichert alle Ek(m) fur alle Schlussel k. Dann be-rechnet und speichert sie alle Dk(c).(Dk(c) = Entschlusselung von c; bei DES: verwende die durch k er-zeugten Rundenschlussel k1, . . . k16 in umgekehreter Reihenfolge.)
Dann vergleicht sie die beiden Listen. Ist Ek2(m) = Dk1(c), so istEk1(Ek2(m)) = c. Erhalt man mehrere mogliche Paare (k1, k2), so wahleweiteres Klartext-Chiffretextpaar und teste, welches der Schlusselpaare(k1, k2) den Klartext auf den Chiffretext abbildet.
Bei N Schlusseln (N = 256 bei DES) sind also 2N Berechnungen er-forderlich (+N2 Vergleiche durchzufuhren). Dies ist deutlich wenigeraufwandig als N2 Berechnungen fur vollstandige Schlusselsuche. Derbenotigte Speicherplatz ist allerdings extrem groß.18
i) Aufgrund von h) wird zur Erhohung der Sicherheit in der Praxis oftdas Triple-DES benutzt.
Zwei typische Varianten:Ek1 Ek2 Ek3 fur drei Schlussel k1, k2, k3
Ek1 Dk2 Ek1 fur zwei Schlussel k1, k2
(Bei k1 = k2 hat man wieder das einfache DES.)
18Fur Uberlegungen zum Time-Space-Tradeoff vgl. Stinson [45]
68

Meet-in-the-Middle Angriff erfordert jetzt etwa 2113 Berechnungen, undder benotigte Speicherplatz ist exorbitant.
4.6.4 Effizienz der DES-Verschlusselung
Bei Software-Implementation ist (abhangig vom jeweils verwendeten Com-piler) eine Verschlusselungsrate von ca. 100 Mbit/sec moglich. Hardware-Implementationen sind ca. um einen Faktor 10 schneller.
(∗) 4.7 Differentielle Kryptoanalyse am Beispiel des DES
a) Die Differentielle Kryptoanalyse ist ein Chosen-Plaintext-Angriff, der vonE. Biham und A. Shamir 1990 vorgestellt wurde ([11], [12]), aber offenbarden Entwicklern des DES schon bekannt war (siehe [18]19). Wir stellen dasVerfahren zunachst fur den DES mit wenigen Runden vor (ohne IP, IP−1)und zeigen dann, wie es auf großere Rundenzahlen ausgedehnt werden kann.
Wir beschreiben zunachst die Grunduberlegung.Da affin-lineare Chiffren leicht zu brechen sind (vgl. 4.3), enthalt der DESnicht-lineare Anteile. In jeder Runde ist die einzige Nichtlinearitat (bis aufdie Rundenschlusseladdition - diese ist aber affin) in den S-Boxen enthalten,d.h. im Allgemeinen gilt
Si(B ⊕ B∗) 6= Si(B)⊕ Si(B∗).
Dennoch ist die Betrachtung der binaren Summen (=binaren Differenzen)B ⊕ B∗ sinnvoll. Der Grund ist folgender: In einer Runde des DES ist derRundenschlussel K fur den Angreifer die einzige Unbekannte. Kennt er denInput R ∈ Z32
2 (vgl. Abbildung 9, S. 63), so auch E = e(R), aber nichtE⊕K, und daher auch nicht den Input fur die S-Boxen, die P-Box, die nachsteRunde. Betrachtet man jedoch Inputs R, R∗ und deren “Differenz“ R⊕R∗, sokennt man e(R)⊕e(R∗) = e(R⊕R∗) und e(R)⊕K⊕e(R∗)⊕K = e(R)⊕e(R∗),d.h. fur die Differenz spielt die Schlusseladdition keine Rolle.
Also:R⊕ R∗ bekannt ⇔ Bi ⊕B∗i , i = 1, . . . , 8 bekannt
(Bi, B∗i Input von S-Box Si)
(α)
19online unter http://www.research.ibm.com/journal/rd/383/coppersmith.pdf
69

Da S-Boxen nichtlinear sind, kann gleiche Eingabedifferenz zu verschiedenenAusgabedifferenzen fuhren, d.h. durch Bi ⊕B∗i ist Si(Bi)⊕ Si(B
∗i ) = ci ⊕ c∗i
nicht festgelegt.
Im Anschluss an die S-Boxen gilt wieder:
ci ⊕ c∗i , i = 1, . . . , 8 bekannt ⇔ fK(R)⊕ fK(R∗)(= P (C)⊕ P (C∗)= P (C ⊕ C∗)) bekannt
(β)
(C = (c1, . . . , c8), C∗ = (c∗1, . . . , c
∗8))
Damit:Bei Betrachtung der Differenzen R⊕R∗ beim Durchgang durch eine Rundeist einzig der Ubergang
Bi ⊕ B∗i → ci ⊕ c∗i , i = 1, . . . , 8
nicht eindeutig festgelegt. Bi ⊕ B∗i heißt Input-Differenz fur die S-Box Si,ci ⊕ c∗i = Si(Bi)⊕ Si(B
∗i ) heißt Output-Differenz der S-Box Si.
Beachte: Es gibt 64 mogliche Input-Differenzen, aber nur 16 mogliche Output-Differenzen.
Man untersucht nun fur jede S-Box Si den Zusammenhang zwischen Input-Differenzen und Output-Differenzen. Sei B′ ∈ Z6
2 eine vorgegebene Input-Differenz. Es gibt 64 Paare (B, B∗) ∈ Z6
2×Z62 mit Differenz B′: B⊕B∗ = B′,
namlich alle (B, B ⊕ B′), B ∈ Z62. (Fur B′ 6= 0 sind das 32 verschiedene
ungeordnete Paare, denn (B ⊕ B′)⊕ B′ = B.)
Wir geben exemplarisch eine solche Tabelle fur die S-Box S1 an mit B′ =(010100).
B B∗ S1(B)⊕ S1(B∗)
(000000) (010100) (1110)⊕ (0110) = (1000)(000001) (010101) (0000)⊕ (1100) = (1100)(000010) (010110) (0100)⊕ (1100) = (1000)(000011) (010111) (1111)⊕ (1011) = (0100)(000100) (010000) (1101)⊕ (0011) = (1110)(000101) (010001) (0111)⊕ (1010) = (1101)(000110) (010010) (0001)⊕ (1010) = (1011)(000111) (010011) (0100)⊕ (0110) = (0010)(001000) (011100) (0010)⊕ (0000) = (0010)(001001) (011101) (1110)⊕ (0011) = (1101)(001010) (011110) (1111)⊕ (0111) = (1000)(001011) (011111) (0010)⊕ (1000) = (1010)
70

(001100) (011000) (1011)⊕ (0101) = (1110)(001101) (011001) (1101)⊕ (1001) = (0100)(001110) (011010) (1000)⊕ (1001) = (0001)(001111) (011011) (0001)⊕ (0101) = (0100)(100000) (110100) (0100)⊕ (1001) = (1101)(100001) (110101) (1111)⊕ (0011) = (1100)(100010) (110110) (0001)⊕ (0111) = (0110)(100011) (110111) (1100)⊕ (1110) = (0010)(100100) (110000) (1110)⊕ (1111) = (0001)(100101) (110001) (1000)⊕ (0101) = (1101)(100110) (110010) (1000)⊕ (1100) = (0100)(100111) (110011) (0010)⊕ (1011) = (1001)(101000) (111100) (1101)⊕ (0101) = (1000)(101001) (111101) (0100)⊕ (0110) = (0010)(101010) (111110) (0110)⊕ (0000) = (0110)(101011) (111111) (1001)⊕ (1101) = (0100)(101100) (111000) (0010)⊕ (0011) = (0001)(101101) (111001) (0001)⊕ (1010) = (1011)(101110) (111010) (1011)⊕ (1010) = (0001)(101111) (111011) (0111)⊕ (0000) = (0111)
(+ 32 weitere Paare, wobei Rolle von B, B∗ vertauscht;Output-Differenzen analog)
Tabelle 6: Output-Differenzen der S-Box S1 fur Input-Differenz B′ =(010100)
(0000) 0 (1000) 8(0001) 8 (1001) 2(0010) 8 (1010) 2(0011) 0 (1011) 4(0100) 10 (1100) 4(0101) 0 (1101) 8(0110) 4 (1110) 4(0111) 2 (1111) 0
Tabelle 7: Anzahl der verschiedenen Output-Differenzen der S-Box S1 beiInput-Differenz (010100)
Waren die S-Boxen linear, so wurde in den 64 Paaren mit gleicher Input-Differenz (im obigen Beispiel (010100)) jeweils die gleiche Output-Differenz
71

auftreten. Die Nichtlinearitat ware am großten, wenn zu gegebener Input-Differenz jedes c′ ∈ Z4
2 gleich oft (also 4 mal) als Output-Differenz auftretenwurde.
Dies ist aber im obigen Beispiel nicht der Fall. Die Diskrepanz von derGleichverteilung aller moglichen Output-Differenzen ist fur manche Input-Differenzen großer, fur manche geringer. In der folgenden Tabelle ist fur dieS-Box S1 angegeben, wie sich fur jede Input-Differenz die Anzahl der Output-Differenzen verteilt.
Input- Output-Differenz (Hexadezimal)Differenz 0 1 2 3 4 5 6 7 8 9 A B C D E F000000 64 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0000001 0 0 0 6 0 2 4 4 0 10 12 4 10 6 2 4000010 0 0 0 8 0 4 4 4 0 6 8 6 12 6 4 2000011 14 4 2 2 10 6 4 2 6 4 4 0 2 2 2 0000100 0 0 0 6 0 10 10 6 0 4 6 4 2 8 6 2000101 4 8 6 2 2 4 4 2 0 4 4 0 12 2 4 6000110 0 4 2 4 8 2 6 2 8 4 4 2 4 2 0 12000111 2 4 10 4 0 4 8 4 2 4 8 2 2 2 4 4001000 0 0 0 12 0 8 8 4 0 6 2 8 8 2 2 4001001 10 2 4 0 2 4 6 0 2 2 8 0 10 0 2 12001010 0 8 6 2 2 8 6 0 6 4 6 0 4 0 2 10001011 2 4 0 10 2 2 4 0 2 6 2 6 6 4 2 12001100 0 0 0 8 0 6 6 0 0 6 6 4 6 6 14 2001101 6 6 4 8 4 8 2 6 0 6 4 6 0 2 0 2001110 0 4 8 8 6 6 4 0 6 6 4 0 0 4 0 8001111 2 0 2 4 4 6 4 2 4 8 2 2 2 6 8 8010000 0 0 0 0 0 0 2 14 0 6 6 12 4 6 8 6010001 6 8 2 4 6 4 8 6 4 0 6 6 0 4 0 0010010 0 8 4 2 6 6 4 6 6 4 2 6 6 0 4 0010011 2 4 4 6 2 0 4 6 2 0 6 8 4 6 4 6010100 0 8 8 0 10 0 4 2 8 2 2 4 4 8 4 0010101 0 4 6 4 2 2 4 10 6 2 0 10 0 4 6 4010110 0 8 10 8 0 2 2 6 10 2 0 2 0 6 2 6010111 4 4 6 0 10 6 0 2 4 4 4 6 6 6 2 0011000 0 6 6 0 8 4 2 2 2 4 6 8 6 6 2 2011001 2 6 2 4 0 8 4 6 10 4 0 4 2 8 4 0011010 0 6 4 0 4 6 6 6 6 2 2 0 4 4 6 8011011 4 4 2 4 10 6 6 4 6 2 2 4 2 2 4 2
72

011100 0 10 10 6 6 0 0 12 6 4 0 0 2 4 4 0011101 4 2 4 0 8 0 0 2 10 0 2 6 6 6 14 0011110 0 2 6 0 14 2 0 0 6 4 10 8 2 2 6 2011111 2 4 10 6 2 2 2 8 6 8 0 0 0 4 6 4100000 0 0 0 10 0 12 8 2 0 6 4 4 4 2 0 12100001 0 4 2 4 4 8 10 0 4 4 10 0 4 0 2 8100010 10 4 6 2 2 8 2 2 2 2 6 0 4 0 4 10100011 0 4 4 8 0 2 6 0 6 6 2 10 2 4 0 10100100 12 0 0 2 2 2 2 0 14 14 2 0 2 6 2 4100101 6 4 4 12 4 4 4 10 2 2 2 0 4 2 2 2100110 0 0 4 10 10 10 2 4 0 4 6 4 4 4 2 0100111 10 4 2 0 2 4 2 0 4 8 0 4 8 8 4 4101000 12 2 2 8 2 6 12 0 0 2 6 0 4 0 6 2101001 4 2 2 10 0 2 4 0 0 14 10 2 4 6 0 4101010 4 2 4 6 0 2 8 2 2 14 2 6 2 6 2 2101011 12 2 2 2 4 6 6 2 0 2 6 2 6 0 8 4101100 4 2 2 4 0 2 10 4 2 2 4 8 8 4 2 6101101 6 2 6 2 8 4 4 4 2 4 6 0 8 2 0 6101110 6 6 2 2 0 2 4 6 4 0 6 2 12 2 6 4101111 2 2 2 2 2 6 8 8 2 4 4 6 8 2 4 2110000 0 4 6 0 12 6 2 2 8 2 4 4 6 2 2 4110001 4 8 2 10 2 2 2 2 6 0 0 2 2 4 10 8110010 4 2 6 4 4 2 2 4 6 6 4 8 2 2 8 0110011 4 4 6 2 10 8 4 2 4 0 2 2 4 6 2 4110100 0 8 16 6 2 0 0 12 6 0 0 0 0 8 0 6110101 2 2 4 0 8 0 0 0 14 4 6 8 0 2 14 0110110 2 6 2 2 8 0 2 2 4 2 6 8 6 4 10 0110111 2 2 12 4 2 4 4 10 4 4 2 6 0 2 2 4111000 0 6 2 2 2 0 2 2 4 6 4 4 4 6 10 10111001 6 2 2 4 12 6 4 8 4 0 2 4 2 4 4 0111010 6 4 6 4 6 8 0 6 2 2 6 2 2 6 4 0111011 2 6 4 0 0 2 4 6 4 6 8 6 4 4 6 2111100 0 10 4 0 12 0 4 2 6 0 4 12 4 4 2 0111101 0 8 6 2 2 6 0 8 4 4 0 4 0 12 4 4111110 4 8 2 2 2 4 4 14 4 2 0 2 0 8 4 4111111 4 8 4 2 4 0 2 4 4 2 4 8 8 6 2 2
Tabelle 8: Input-/Output-Differenzen bei S-Box S1
Die differentielle Kryptoanalyse beruht darauf, dass fur jede S-Box bei man-chen Input-Differenzen gewisse Output-Differenzen besonders haufig auftre-
73

ten; die S-Box verhalt sich fur solche Input-Differenzen “etwas linearer“.
Dazu muss fur jede S-Box und jede Input-Differenz eine Tabelle entsprechendTabelle 6 erstellt werden (insgesamt 8 · 26 = 512 Tabellen).
Wir zeigen jetzt, wie die differentielle Kryptoanalyse funktioniert und be-trachten dazu zunachst einmal den DES mit wenigen Runden, weil hier dieSituation noch uberschaubar ist.
b) Analyse einer DES-Runde
Hier spielt die Abweichung der Output-Differenzen von der Gleichverteilung(bei gegebener Input-Differenz) noch keine Rolle.
Der Chosen-Plaintext-Angriff versucht aus der Kenntnis von (R, fK(R)),(R∗, fK(R∗)), . . . auf den Rundenschlussel K zu schließen. Was man dazubenotigt ist die Kenntnis von R, R∗ und von fK(R)⊕ fK(R∗) (evtl. fur me-here Paare (R, R∗)).
Bekannt sind R, R∗, also auch
(1) e(R) = (e1, . . . , e8) und e(R∗) = (e∗1, . . . , e∗8)
Außerdem
(2) B1 ⊕ B∗1(= e1 ⊕ e∗1)
, . . . , B8 ⊕ B∗8(= e8 ⊕ e∗8)
(nach (α))
(aber nicht B1, . . . , B8, B∗1 , . . . , B
∗8)
und
(3) c1 ⊕ c∗1, . . . , c8 ⊕ c∗8 (nach (β))
Der Rundenschlussel sei K = (k1, . . . , k8), ki ∈ Z62.
Es ist
(4) ki = ei ⊕ Bi = e∗i ⊕B∗i , i = 1, . . . , 8(da Bi = ei ⊕ ki, B∗i = e∗i ⊕ ki)
74

Betrachte i = 1:
B′1 := B1 ⊕ B∗1 bekannt.Das Paar (B1, B
∗1) taucht in der Tabelle fur S1 zur Input-Differenz B′1 auf.
Daher kennt man alle Moglichkeiten fur (B1, B∗1) mit Output-Differenz c1 ⊕
c∗1 =: c′1.
Damit erhalt man fur jedes mogliche B1 einen Kandidaten e1↑
bekannt
⊕ B1 fur den
Teilschlussel k1 (bei e∗1 ⊕ B∗1 ergibt sich dasselbe).
Damit sind die Moglichkeiten fur die ersten 6 Bit von K (das ist k1) einge-schrankt.
Beispiel:Angenommen R = (00101∗ . . .∗1), R∗ = (10001∗ . . .∗1) und c1⊕c∗1 = (0110).
Danne1 = (100101), e∗1 = (110001)B1 ⊕ B∗1 = e1 ⊕ e∗1 = (010100) Input-Differenzc1 ⊕ c∗1 = (0110) Output-Differenz
Der Tabelle 6 entnimmt man:
Moglichkeiten fur (B1, B∗1) : (100010),
(110110),(101010),(111110),
(110110)(100010)(111110)(101010)
Kandidaten fur k1 : e1 ⊕ B1 = (000111)(010011)(001111)(011011)
einer davon istder richtige k1
Von 26 = 64 Kandidaten fur k1 sind nur 4 Moglichkeiten geblieben.
Wiederholt man das fur ein anderes Paar R, R∗, so erhalt man eine weitereKandidatenmenge fur k1, die ebenfalls den richtigen k1 enthalt. Nach wenigenVersuchen hat man im Allgemeinen nur noch eine Moglichkeit fur k1.
Fortsetzung Beispiel:
Angenommen R = (01001∗ . . .∗1), R∗ = (00000∗ . . .∗1) und c1⊕ c∗1 = (0001).
Danne1 = (101001), e∗1 = (100000)B1 ⊕ B∗1 = e1 ⊕ e∗1 = (001001)
75

Nur 2 Moglichkeiten fur (B1, B∗1) : (111010),(110011),
[(110011)(111010)
]
Kandidaten fur k1 : e1 ⊕ B1 = (010011)(011010)
← nur dieser tauchtauch oben auf
Also: k1 = (010011).
Dasselbe fuhrt man fur k2, . . . , k8 durch. Dann ist der Rundenschlussel Kbestimmt.
c) Analyse des DES mit 3 Runden
Man wahlt Klartexte (L0, R0) und (L∗0, R∗0) mit R0 =
0 R
K
0
1
L 1 R
K
+
1
2
L 2 R 2
L
+
K
+
L R3 3
3
R∗0, die zu (L3, R3) bzw. (L∗3, R∗3) verschlusselt werden.
Ziel ist die Bestimmung des 56-Bit-Schlussels k, aus demK1, K2 und K3 entstehen.
Tatsachlich benotigt man zur Bestimmung von K3 (dasist das erste Ziel) nur die Kenntnis von L0⊕L∗0, L3⊕L∗3,R3, R∗3 und dass R0 = R∗0 (der Wert von R0 wird nichtbenotigt).
Nun gilt:
L3 = L2 ⊕ fK3(R2) = R1 ⊕ fK3(R2)
= L0 ⊕ fK1(R0)⊕ fK3(R2)
und analog
L∗3 = L∗0 ⊕ fK1(R∗0)⊕ fK3(R
∗2).
Dann folgt (da R0 = R∗0):
L3 ⊕ L∗3︸ ︷︷ ︸=: L′3bekannt
= L0 ⊕ L∗0︸ ︷︷ ︸=: L′0bekannt
⊕fK3(R2)⊕ fK3(R∗2)
Damit ist fK3(R2)⊕ fK3(R∗2) bekannt und R2 = R3, R∗2 = R∗3 sind bekannt.
Die Analyse einer DES-Runde wie in b) (angewandt auf die 3. Runde) liefertjetzt den Schlussel K3. (Dazu benotigt man geeignete R2, R
∗2; daher ver-
wendet man viele (L0, R0), (L∗0, R∗0), um geeignete R2 = R3, R∗2 = R∗3 zu
erhalten.)
76

Vom 56-Bit-Schlussel k sind damit (durch K3) 48 Bit bestimmt. Die restlichen8 Bit erhalt man durch 256 Versuche, indem man testet, wann (L0, R0) auf(L3, R3) abgebildet wird.
d) Analyse des DES mit 4 Runden
Hier kommen nun die Nicht-Gleichverteilungen der Output-Differenzen derS-Boxen bei gegebener Input-Differenz zum Tragen. Daher ist jetzt die Wahlvon Klartextblocken mit geeigneten Differenzen wichtig. Wir demonstrierendas Verfahren mit solch einer geeigneten Wahl.
Wahle (L0, R0) und (L∗0, R∗0) so, dass
-
-
R0 ⊕ R∗0L0 ⊕ L∗0
=
=
(0100 . . . . . . . . . . . . 0000)
(0 . . . 0 1↑23
0 . . . 0 1↑31
0 . . . 0)
e(R0)⊕ e(R∗0) = (0010000 . . . 0 . . . 0 . . . 0)
Input-Differenzen fur S-Boxen in der 1. Runde:
S1 : (001000)Si : (000000), i = 2, . . . 8.
Tabelle der Output-Differenzen von S1 bei Input-Differenz (001000) :Mit Wahrscheinlichkeit 12
64= 3
16(relativ groß) ist Output-Differenz (0011).
Bei allen Si, i = 2, . . . 8: Output-Differenz (0000).
Anwendung P-Box Permutation:fK1(R0) ⊕ fK1(R
∗0) hat mit Wahrscheinlichkeit 3
16an den Stellen 23 und 31
eine Eins, sonst Nullen. (An den Stellen 9, 17, 23, 31 stehen die Eintrage derOutput-Differenz von S1.)
Nach Addition von L0⊕L∗0 ergibt sich daher, dass R1⊕R∗1 = (0, . . . , 0) (d.h.R1 = R∗1) mit Wahrscheinlichkeit 3
16gilt.
Jede andere Kombination als 0011 an den Stellen 9, 17, 23, 31 tritt mitgeringerer Wahrscheinlichkeit auf. (An den Stellen 6= 9, 17, 23, 31 stehen injedem Fall Nullen.)
Auch mit anderer Input-Differenz R0 ⊕ R∗0 und dazu passend gewahltenL0 ⊕ L∗0 kann man mit ahnlichen Wahrscheinlichkeiten R1 ⊕R∗1 = (0, . . . , 0)erhalten.
77

Wendet man mit solchen Klartextblocken die 3-Runden-Kryptoanalyse aufdie Runden 2, 3, 4 an (beachte: L1 = R0, L∗1 = R∗0, L4, L∗4, R4, R∗4 be-kannt) [dort wird vorausgesetzt, dass R1 = R∗1, was in ca. 3
16der Falle
zutrifft], so erhalten wir Kandidatenmengen, die in etwa 316
der Falle denrichtigen Rundenschlussel K4 enthalten. In den ubrigen 13
16der Falle liefert
die 3-Runden-Kryptoanalyse irgendwelche Kandidatenmengen von zufalligen48-Bit-Strings.
Daher: Bei genugend vielen Versuchen tritt K4 deutlich haufiger auf als alleubrigen 48-Bit-Strings und wird erkannt.
e) Differentielle Kryptoanalyse bei großeren Rundenzahlen
Man gibt gewisse L′0, R′0, . . . , L
′t, R
′t vor und berechnet Wahrscheinlichkeiten
pi folgendermaßen:
Falls nach Runde i−1 zwei Blocke (Li−1, Ri−1), (L∗i−1, R∗i−1) mit Li−1⊕L∗i−1 =
L′i−1 und Ri−1 ⊕ R∗i−1 = R′i−1 in Runde i verschlusselt werden, so ist dieWahrscheinlichkeit, dass
Li ⊕ L∗i = L′i und Ri ⊕ R∗i = R′i
gilt, gerade pi.
Die Liste L′0, R′0, L
′1, R
′1, p1, . . . , L
′t, R
′t, pt heißt t-Runden-Charakteristik.
Sind die pi unabhangig voneinander (nicht streng erfullt, da Rundenschlusselnicht voneinander unabhangig), so ist
∏ti=1 pi die Wahrscheinlichkeit, dass
aus L′0, R′0 am Ende L′t, R
′t entsteht.
Wahle bei Rundenzahl r eine (r − 3)-Runden-Charakteristik mit moglichsthohem p =
∏r−3i=1 pi und wende 3-Runden-Kryptoanalyse auf die letzten 3
Runden an.
Macht man das mit sehr vielen Klartext-Chiffretext-Paaren, sollte der letz-te Rundenschlussel in den Kandidatenmengen haufiger auftauchen als dieubrigen 48-Bit-Strings.
Beachte: Je großer r, desto kleiner p, also umso mehr Paare erforderlich.
Bei r = 16 ist differentielle Kryptoanalyse nicht (wesentlich) effektiver alsvollstandige Schlusselsuche. Dies zeigt auch, dass das Design der S-Boxenund die Rundenanzahl von den Entwicklern der DES aufgrund der Kenntnisder differentiellen Kryptoanalyse gewahlt wurde (vgl. [18]).
78

(Mit geeigneten Verbesserungen benotigt man 247 gewahlte Klartexte; diesist besser als 255 Versuche bei vollstandiger Schlusselsuche.)
Weitere Einzelheiten: [13], [27, Kapitel 3.4]20, [40, Kapitel 5].
Zur Beschreibung des AES benotigen wir einige Hilfsmittel uber endlicheKorper.
4.8 Endliche Korper
a) Ein KorperK ist ein kommutativer Ring mit Eins, in dem jedes Elementb 6= 0 ein Inverses b−1 bezuglich der Multiplikation besitzt.
b) Ist |K| endlich, so ist |K| = pa, p eine Primzahl. Dann ist 1 + . . . + 1←− p −→
=
0.
c) Zu jeder Primzahlpotenz gibt es genau einen Korper dieser Ordnung(bis auf Isomorphie).
d) Fur einen endlichen Korper K ist die multiplikative Gruppe K∗ =K \ 0 zyklisch. D.h. es existiert ein Element g ∈ K∗ mit K∗ =< g >= g0 = 1, g1, g2, . . . , gn−1, wobei n = |K∗| = |K| − 1. Esist gn = 1.
e) Fur |K| = p ist K ∼= Zp.
f) Konstruktion von Korpern der Ordnung pa, a > 1 (Bezeichnung: Fpa):
Sei m(x) ∈ Zp[x] ein (uber Zp) irreduzibles Polynom vom Grad a.
Ein Korper mit pa Elementen ist dann Fpa = Polynome in Zp[x] vomGrad < a, versehen mit der ublichen Addition. Die Multiplikation ⊙geschieht wie ublich, mit anschließender Reduktion mod m(x); dabeiliefert die Reduktion eines Polynoms a(x) (mod m(x)) den Rest r(x)bei der Division von a(x) durch m(x): Ist also a(x) = q(x) · m(x) +r(x), Grad r(x) < Grad m(x) (wobei Grad 0 = −1), dann ist r(x) =a(x) mod m(x).
20dort werden auch Design-Prinzipien fur S-Boxen angegeben: Kapitel 3.6
79

Beispiel: Konstruktion von F28 :
m(x) = x8 + x4 + x3 + x + 1 ist irreduzibel uber Z2.
(x6 + x4 + x2 + x + 1)⊙ (x7 + x + 1)
= x13 + x11 + x9 + x8 + x7 + x7 + x5 + x3 + x2 + x +
+ x6 + x4 + x2 + x + 1 mod m(x)
= x13 + x11 + x9 + x8 + x6 + x5 + x4 + x3 + 1 mod m(x)
Wie oben geschildert ist x13+x11+x9+x8+x6+x5+x4+x3+1 mod m(x)der Rest bei der Division durch m(x). Also rechne:
(x13+x11+x9 + x8 + x6+x5+x4 + x3+1) : (x8 + x4 + x3 + x + 1)x13 +x9 + x8 + x6+x5 = x5 + x3
x11 +x4 + x3+1 Rest x7 + x6 + 1x11 +x7 + x6 +x4 + x3+1
x7 + x6 +1
Damit ist insgesamt:
(x6 + x4 + x2 + x + 1)⊙ (x7 + x + 1) = x7 + x6 + 1
Oft schreibt man die Elemente aus Fpa auch als a-Tupel uber Zp :ba−1x
a−1 + . . . b1x+b0 ↔ (ba−1, . . . b1, b0). Addition dann komponenten-weise, Multiplikation nach obiger Regel.
Also in F82 (mit obigem m(x)):
(0, 1, 0, 1, 0, 1, 1, 1)⊙ (1, 0, 0, 0, 0, 0, 1, 1) = (1, 1, 0, 0, 0, 0, 0, 1)
Beachte:Wahlt man ein anderes irreduzibles Polynom m(x) vom Grad a, soist das Ergebnis der Multiplikation (mod m(x)) zweier Polynome vomGrad ≤ a−1 ein anderes. Die entstehenden Korper sind aber isomorph.
g) Die multiplikativen Inversen eines Elements 6= 0 in Fpa bestimmt manmit dem erweiterten Euklidischen Algorithmus in Zp[x]. Dieser wird imFolgenden vorgestellt.
Fur zwei Polynome a(x), 0 6= b(x) ∈ Zp[x] berechnet der erweiter-te Euklidische Algorithmus ggT (a(x), b(x)) und bestimmt Polynomeu(x) und v(x) mit ggT (a(x), b(x)) = u(x)a(x) + v(x)b(x). Dabei istggT (a(x), b(x)) normiert (d.h. der hochste Koeffizient ist 1).
80

Zur verwendeten Schreibweise:Ist bei der Division mit Rest a(x) = q(x) · b(x) + r(x), Grad r(x) <Grad b(x), so schreibe q(x) = a(x) div b(x), und wie oben r(x) =a(x) mod b(x).
Der erweiterte Euklidische Algorithmus in Zp[x] gliedert sich nun wiefolgt:
Gegeben seien a(x), b(x) 6= 0, wobei Grad a(x) ≥ Grad b(x) gelte.
(1) Setzes(x) := a(x), t(x) := b(x),u1(x) := 1, u2(x) := 0, u(x) := 0,v1(x) := 0, v2(x) := 1, v(x) := 1
(2) Solange s(x) mod t(x) 6= 0, wiederhole:q(x) := s(x) div t(x), r(x) := s(x) mod t(x)u(x) := u1(x)− q(x)u2(x), v(x) := v1(x)− q(x)v2(x)u1(x) := u2(x), u2(x) := u(x)v1(x) := v2(x), v2(x) := v(x)s(x) := t(x), t(x) := r(x)
(3) Sei a der hochste Koeffizient 6= 0 von t(x).
t(x) := t(x)a
, u(x) := u(x)a
, v(x) := v(x)a
Ausgabe:t(x) (ggT (a(x), b(x)))u(x), v(x) (t(x) = u(x)a(x) + v(x)b(x))
Beispiel:
(m(x) =)a(x) = x8 + x4 + x3 + x + 1 , b(x) = x7 + x6 + x3 + x + 1in Z2[x]
s(x) t(x) u1(x) u2(x) u(x) v1(x) v2(x) v(x)
x8 + x4 + x3 + x + 1 x7 + x6 + x3 + x + 1 1 0 0 0 1 1
x7 + x6 + x3 + x + 1 x6 + x2 + x 0 1 1 1 x + 1 x + 1
x6 + x2 + x 1 1 x + 1 x + 1 x + 1 x2 x2
x8 + x4 + x3 + x + 1 : x7 + x6 + x3 + x + 1 = x + 1 Rest x6 + x2 + x
x7 + x6 + x3 + x + 1 : x6 + x2 + x = x + 1 Rest 1
Also istggT (a(x), b(x)) = 1
81

und gilt
1 = (x + 1) · (x8 + x4 + x3 + x + 1) + x2 · (x7 + x6 + x3 + x + 1) (∗)
Sei nun F28 wie in f) wieder mit m(x) = a(x) = x8 + x4 + x3 + x + 1gebildet. Fur die Polynome x2 und x7 + x6 + x3 + x + 1 bedeutet dieGleichung (∗) dann
x2 ⊙ (x7 + x6 + x3 + x + 1) = 1.
Als Element von F28 ist also x2 das multiplikative Inverse von x7 +x6 +x3 + x + 1 (und umgekehrt).In der Tupelschreibweise: (11001011)−1 = (00000100).
Bei der Konstruktion von Fpa ist das Polynom m(x) irreduzibel, je-des Polynom 0 6= b(x) ∈ Fpa ist daher teilerfremd zu m(x) (d.h.ggT (m(x), b(x)) = 1). In der eben beschriebenen Weise lasst sich da-her mit dem erweiterten Euklidischen Algorithmus das multiplikativeInverse von b(x) in Fpa bestimmen.
4.9 Der Advanced Encryption Standard (AES) - DasRijndael-Verfahren
a) 1997: US-Standardisierungsbehorde NIST (National Institute of Standardsand Technology) startet offentliche Ausschreibung fur Nachfolgeverfahren desDES.
Anforderungen: offentlich, lizenzfrei, weltweit verfugbar, schneller als TRIPLE-DES. Blocklange mind. 128 Bit, variable Schlussellangen von 128, 192, 256Bit.
1998: 15 AES-Kandidaten werden eingereicht (darunter ’Magenta’, DeutscheTelekom) und begutachtet.
1999: Auswahl von 5 Algorithmen fur die letzte Runde:
• Twofish (s. 4.10)
• RC6 (s. 4.10)
• MARS (IBM, D. Coppersmith)21
21http://domino.research.ibm.com/comm/research_projects.nsf/pages/
security.mars.html
82

• Serpent (R. Anderson, E. Biham, L. Knudsen; 32-Runden Feistel-Chiffre,DES-ahnlich)22
• Rijndael (J. Daemen, V. Rijmen)
2000: Wahl von Rijndael als neuen AES (vor Twofish und Serpent)
Mai 2002: AES (Rijndael) wird zum Federal Information Processing Standard(FIPS 197) in den USA.
b) Rijndael ist eine iterierte Blockchiffre, aber keine Feistel-Chiffre. Es han-delt sich um ein sogenanntes Substitutions-Permutations-Netzwerk (SP-Netz-werk). Blocklange b und Schlussellange k konnen unabhangig voneinander aufeinen der Werte 128, 192, 256 Bit gesetzt werden. Die Zahl der Runden r istabhangig von diesen Werten 10, 12 oder 14.
Im FIPS-Standard ist b = 128, k = 128, r = 10.(Wir verwenden im Folgenden auch diese Parameter.)
Der Ablauf des Rijndael-Verfahrens ist auf Seite 84 skizziert. Die Zwischen-ergebnisse S0, S1, . . . , S9 werden in Rijndael Zustande (states) genannt.
Jede Runde, bis auf die zehnte, besteht aus drei Transformationen (s. Abb.10):
Runde i
entfällt für
i = 10
S
K
S
+ i
i-1
i
MixColumns
SubBytes
ShiftRows
Abbildung 10: Transformatio-nen
SubBytes-Transformation: Nichtlinea-re Transformation; dient dem Schutz gegendifferentielle und lineare Kryptoanalyse.
ShiftRows-Transformation: Dient derDiffusion.
MixColumns-Transformation: Dientebenfalls der Diffusion.
In Runde 10 werden nur die SubBytes-Trans-formation und die ShiftRows-Transformationvorgenommen.
Die Schlusseladdition (bin.Add.,XOR) Add-RoundKey wird vor der ersten Runde und injeder Runde jeweils nach den oben genanntenTransformationen durchgefuhrt.
22http://www.cl.cam.ac.uk/~rja14/serpent.html
83
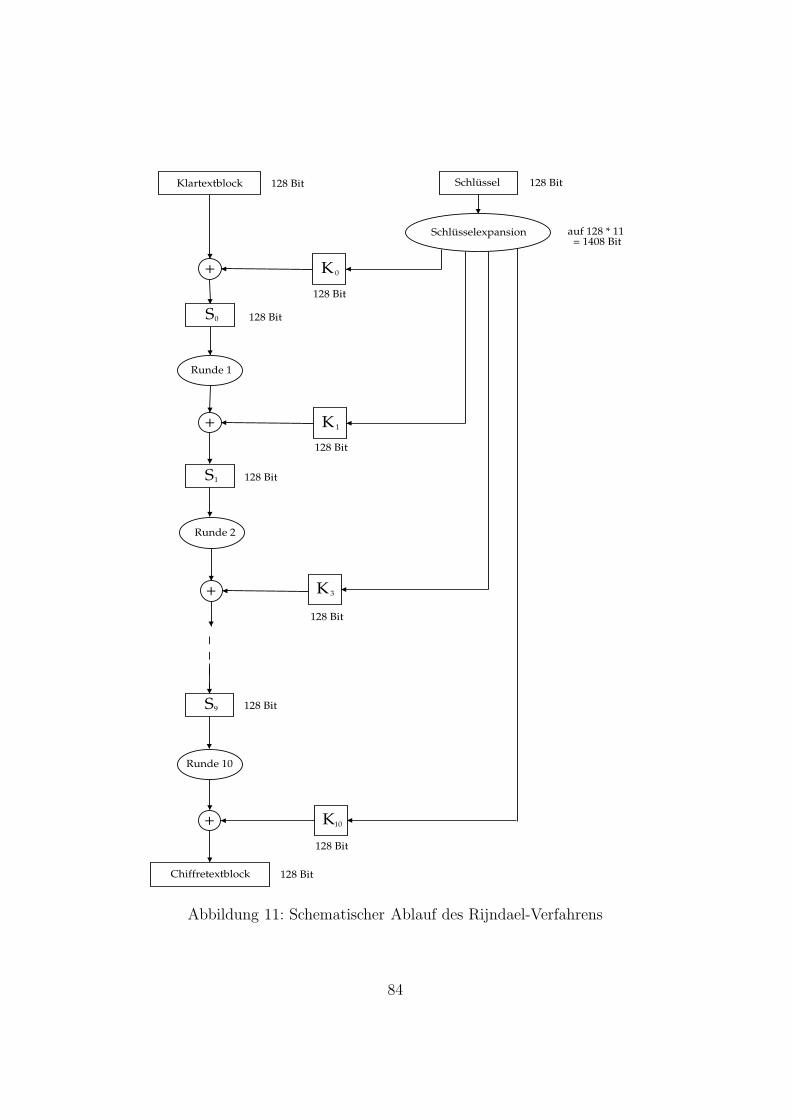
+
Klartextblock Schlüssel
Schlüsselexpansion
Runde 1
Runde 2
S1
K 1
128 Bit
128 Bit
+
128 Bit
K 0
S0
128 Bit
128 Bit
auf 128 * 11 = 1408 Bit
128 Bit
+
Runde 10
S9
K10
Chiffretextblock
128 Bit
128 Bit
128 Bit
+ K 3
128 Bit
Abbildung 11: Schematischer Ablauf des Rijndael-Verfahrens
84

Dass vor der ersten und nach der letzten Runde eine Schlusseladdition durch-gefuhrt wird, bezeichnet man als Whitening. Dies erschwert einen Known-Plaintext-Angriff, da dem Angreifer der Input der ersten Runde und derOutput der letzten Runde unbekannt sind. Die Schlusseladdition vor der er-sten Runde sorgt außerdem dafur, dass Auffalligkeiten im Klartext verwischtwerden.
c) Wir beschreiben nun die drei Transformationen SubBytes, ShiftRows undMixColumns und danach die Rundenschlusselerzeugung.
Zunachst aber zwei Vorbemerkungen:Die Klar- und Chiffretextblocke und samtliche Zustande in Rijndael werdenals 4x4 Matrizen geschrieben, wobei jeder Eintrag aij ein Byte, d.h. einen8-Bit-String ist:
a00 a01 a02 a03
a10 a11 a12 a13
a20 a21 a22 a23
a33 a31 a32 a33
Die Bytes sind spaltenweise ein- und auszulesen, d.h. der Block hat die Form:a00a10a21a20a01 . . . a33
An einigen Stellen muss man Bytes (d.h. 8-Bit-Strings) als Elemente in F28
auffassen: (b7b6 . . . b0) ↔ b7x7 + b6x
6 + . . . + b0. Addition entspricht XOR,Multiplikation Korpermultiplikation. In Rijndael ist F28 bezuglich des irre-duziblen Polynoms x8 + x4 + x3 + x + 1 gegeben.
d) SubBytes-Transformation
Eingabe:
Zustand Si =
b00 . . . b03...
...b30 . . . b33
, bij Bytes
Jedes Byte bij wird einzeln verandert; dies liefert eine neue 4× 4-Matrix, dieAusgabe der SubBytes-Transformation.
Sei g = b7b6 . . . b0 ein Byte.Die SubBytes-Transformation umfasst zwei Schritte:
1. Schritt: Fasse g als Element in F28 auf und berechne g−1 in F28 , fallsg 6= 00 . . . 0. Falls g = 00 . . . 0, so bleibt g ungeandert.
85

2. Schritt: Fasse das nach dem ersten Schritt erzeugte Byte c7c6 . . . c0 alsBit-Folge (also Element in Z8
2) auf und unterwerfe es der folgenden affinenTransformation des Z8
2:
1 0 0 0 1 1 1 11 1 0 0 0 1 1 11 1 1 0 0 0 1 11 1 1 1 0 0 0 11 1 1 1 1 0 0 00 1 1 1 1 1 0 00 0 1 1 1 1 1 00 0 0 1 1 1 1 1
c0
c1
c2
c3
c4
c5
c6
c7
+
11000110
=
d0
d1
d2
d3
d4
d5
d6
d7
d7d6d5d4d3d2d1d0 ist dann das Ergebnis der SubBytes-Transformation vong = b7b6 . . . b0.
Bsp.:g = (11001011) g−1 = (00000100) (siehe S. 82)
1 0 0 0 1 1 1 11 1 0 0 0 1 1 11 1 1 0 0 0 1 11 1 1 1 0 0 0 11 1 1 1 1 0 0 00 1 1 1 1 1 0 00 0 1 1 1 1 1 00 0 0 1 1 1 1 1
00100000
+
11000110
=
11111000
Also: (11001011)→ (00011111)
In Rijndael ist die SubBytes-Transformation durch eine S-Box beschrieben.Die S-Box ist eine 16×16 Matrix, deren Eintrage die Zahlen von 0 bis 255 (ineiner gewissen Reihenfolge) sind. Ein Byte b7 . . . b0 bestimmt durch b7b6b5b4
die Zeile und durch b3b2b1b0 die Spalte (Zeilen u. Spalten mit 0, . . . 15 num-meriert). Der Eintrag an der entsprechenden Stelle ist die Zahl, die binarcodiert die SubBytes-Transformation von b7 . . . b0 angibt. (Schneller als je-desmal Inverse und affine Transformation zu berechnen.)
In SubBytes wird durch g → g−1 die Nichtlinearitat (uber F2) sicherge-stellt. Die Einfachheit dieser Abbildung konnte ggf. kryptoanalytische An-griffe ermoglichen; daher ist eine affine Abbildung nachgeschaltet. Sie dient
86

auch der Konfusion und Diffusion und sorgt dafur, dass der Output von Sub-Bytes nie mit dem Input oder dem Komplement des Inputs ubereinstimmt(Byte-weise).
e) ShiftRows-Transformation
Jede der vier Zeilen der 4×4-Matrix, die man nach SubBytes erhalt, werdenzyklisch verschoben:Die 1. Zeile bleibt unverandert, die 2. Zeile wird um eine Stelle nach links,die 3. Zeile um zwei Stellen nach links und die 4. Zeile um drei Stellen nachlinks verschoben.
f) MixColumns-Transformation
Jedes der Bytes in der Input 4×4-Matrix wird als Element in F28 aufgefasst.Diese 4× 4-Matrix wird von links mit
x x + 1 1 11 x x + 1 11 1 x x + 1
x + 1 1 1 x
multipliziert, wobei x ↔ 00000010 und 1 ↔ 00000001 gilt. Ist ci die i-teSpalte der Inputmatrix, di die i-te Spalte der Outputmatrix, so ist
di =
x x + 1 1 11 x x + 1 11 1 x x + 1
x + 1 1 1 x
· ci.
Die Matrizenmultiplikation erfolgt uber F28 .
g) Schlusselerzeugung
Ausgangsschlussel hat 128 Bit. Er wird als 4× 4-Matrix von Bytes geschrie-ben, spaltenweise zu lesen. Seien w(0), w(1), w(2), w(3) diese Spalten. Es wer-den 40 weitere Spalten a vier Bytes definiert.Sei w(i− 1) schon definiert.Ist i 6≡ 0 (mod 4), so w(i) = w(i− 4)⊕ w(i− 1) (d.h. die 4 Eintrage jeweilsXOR-verknupfen).Ist i ≡ 0 (mod 4) , so w(i) = w(i− 4)⊕ T (w(i− 1)),wobei T folgende Transformation ist:
Sei w(i− 1) =
abcd
, a, b, c, d Bytes.
87

Wende auf b, c, d, a die SubBytes-Transformation an.Dies liefert vier Bytes, e, f, g, h.Berechne r(i) = (00000010)
i−44 in F28 (beachte i ≡ 0 (mod 4))
Dann T (w(i− 1)) =
e⊕ r(i)fgh
Der Rundenschlussel Ki besteht dann aus der 4× 4-Matrix(w(4i), w(4i + 1), w(4i + 2), w(4i + 3)), i = 0, 1, . . . , 10.
h) Entschlusselung
Alle einzelnen Transformationen in Rijndael sind invertierbar. Kehre Algo-rithmus um und ersetze alle Transformationen durch ihre Inverse. (Einzel-heiten: FIPS-Standard 197 oder [40]).
(Die Tatsache, dass alle Einzeltransformationen bijektiv sind, ist typischfur Substitutions-Permutations-Netzwerke; dies unterscheidet sie von Feistel-Chiffren; vgl. Bemerkung am Ende von 4.5.)
Fur Details zu Design und Implementierung von Rijndael siehe [20].Uber generelle Eigenschaften von SP-Netzwerken verweisen wir auf [33].
i) Schnelligkeit
Rijndael ist deutlich schneller als DES (bei Software-Implementierung). Auf1 GHz-Rechner sind Verschlusselungen (abhangig vom C-Compiler) von ca.200 MBit/sec. bis 2 GBit/sec. moglich. Bei Hardware-Implementierung 2GBit/sec. bis 70 GBit/sec.
j) Sicherheit
Nach zwei Runden hat man vollstandige Diffusion: Jedes der 128 Output-Bits nach Runde 2 hangt von jedem der 128 Klartextblockbits ab. Rijndaelist gegen differentielle und lineare Kryptoanalyse sicher. ShiftRows wurdeeingefugt, um gegen zwei relativ neue kryptoanalytische Angriffe (
”truncated
differentials“und”Square-attack“ – ’Square’ war ein Vorlaufer von Rijndael)
sicher zu sein.
Die Schlusselerzeugung mittels SubBytes soll verhindern, dass bei Kenntnisvon Teilen des Schlussels die ubrigen Bits einfach zu ermitteln sind. Außer-dem sorgt dies dafur, dass verschiedene Ausgangsschlussel nie viele Runden-schlussel gemeinsam haben.
88

Nach einigen Jahren der Existenz von Rijndael gibt es mittlerweile einigeneue kryptoanalytische Ansatze gegen das Verfahren.
Eine Idee stammt von Courtois und Pieprzyk (2002). Sie besteht darin, Ri-jndael durch ein uberdefiniertes System quadratischer Gleichungen in meh-reren Variablen zu beschreiben (ca. 8000 Gleichungen in ca. 1600 Variablen).Dieses soll dann (mittels des XL-Algorithmus, extended linearization) in einlineares Gleichungssystem umgewandelt und schließlich gelost werden. Die-se Idee fuhrte auf folgende Kontroverse: Kann man Gleichungssysteme zurBeschreibung des AES finden, welche eine eindeutige Losung haben?
Naheres zum XL-Verfahren und der genannten Kontroverse (speziell Courtoisversus Moh):Courtois: Is AES a secure cipher?
http://www.cryptosystem.net/aes/ und dortige LinksMoh: On the Courtois-Pieprzyk‘s attack on Rijndael (2002)
http://www.usdsi.com/aes.html
siehe auch Crypto-Gram von Bruce Schneier:http://www.schneier.com/crypto-gram-0209.html
http://www.schneier.com/crypto-gram-0210.html
Ein anderer kryptoanalytischer Ansatz gegen Rijndael ist der 2005 von Bern-stein vorgestellte Timing-Angriff. Er beruht darauf, dass die AES-Berech-nungen wesentlich vom Auslesen der Eintrage in großeren Arrays abhangen.Die Table-Lookup-Zeit hangt dabei vom Index des Arrays ab. So sind Ruck-schlusse daruber moglich, was in den L2-Cache (braucht mehr Zeit) und wasin den L1-Cache kommt (braucht weniger Zeit).Fur erfolgreiche Timing-Angriffe wurden 227 Blocke benotigt. Allerdings hatder Angreifer selten die Moglichkeit, so genaue Aussagen uber die CPU-Zeilen zu gewinnen. Daruber hinaus sind AES-Implementierungen mit kon-stanten Zeiten fur die Array-Zugriffe moglich; diese verlangsamen aber dieVerschlusselung.
Nahere Informationen:Bernstein: Cache-timing attacks on AES
http://cr.yp.to/antiforgery/cachetiming-20050414.pdf
Weitere Angriffe beruhen auf Modifikationen der differentiellen Kryptoanaly-se (Boomerang-Attack, Related-Key-Attack) und sind bisher fur AES-Versi-onen mit kleineren als den empfohlenen Rundenzahlen erfolgreich.
89

Als Beispiel sei genannt:M. Gorski, S. Lucks: New Related-Key Boomerang Attacks on AES
http://eprint.iacr.org/2008/438
4.10 Andere Blockchiffren
Neben dem DES und dem AES gibt es eine Reihe weiterer gebrauchlicherBlockchiffren. Wir beschreiben knapp die wichtigsten.
1) IDEAAnfang der 90er Jahre von Xuejia Lai und James Massey entwickelt(IDEA wird auch von PGP verwendet)
Lange Klartext-/Chiffretextblocke 64 BitSchlussellange 128 Bit
Funktionsweise:Aufteilen der 64 Bits eines Klartextblocks auf vier Blocke 16 Bit.Diese vier Blocke werden in acht Runden bearbeitet. In jeder dieserRunden werden aus den vier Eingabeblocken und jeweils sechs Teil-schlusseln der Lange 16 mittels 4 Additionen (modulo 216) und 4 Mul-tiplikationen23 (modulo 216 + 1) die vier Eingabeblocke fur die nachsteRunde erzeugt. Am Ende nochmals je zwei weitere Additionen undMultiplikationen mit 16 Bit-Schlusseln und Zusammensetzen der resul-tierenden 4 Blocke zum Chiffretextblock. IDEA ist keine Feistel-Chiffre.
IDEA hat bisher keine Sicherheitsrisiken aufgewiesen und ist etwa dop-pelt so schnell wie DES.24
2) RC2, RC5, RC6Wichtige Blockverschlusselungsverfahren aus der RC-Familie, entwickeltvon Ron Rivest (vertrieben von RSA Data Security).
RC2 (Anfang der 90’er Jahre entwickelt, 1997 veroffentlicht)Variable Schlussellange (40 Bits bis 1024 Bits), Blocklange 64 Bit, wirdunter anderem im S/MIME-Standard verwendet.25
23genauer: modifizierte Multipliktion modulo 216+1; 0 muss gesondert behandelt werden24Details siehe Schmeh [42], S. 84-85, oder
http://www.informationsuebertragung.ch, Link ‘Algorithmen‘ (mit Applets)25Details: http://www.tools.ietf.org/html/rfc2268
90

RC5 (1995 veroffentlicht)Variable Schlussellange, Klartextblocklange, Rundenzahl (z.B. Klar-textblocklange 32 Bit, Schlussellange 128 Bit, 12 Runden)Kombiniert Add. mod 2w (w = Klartextblocklange), binare Add. XOR,zyklische Shifts (abhangig von Klartextblocken). RC5 scheint gegen dif-ferentielle Kryptoanalyse und lineare Kryptoanalyse sicher zu sein.26
RC6 (1998 veroffentlicht)Erreichte die Auswahlrunde der letzten AES-Kandidaten. Schnell undeinfach zu implementieren. Variable Schlussellangen und Blocklangen.27
3) Blowfish, TwofishBlowfish (1994) und Twofish (1998) sind von B. Schneier entwickelteFeistel-Chiffren.
Blowfish hat variable Schlussellange (bis 448 Bit), S-Boxen sind schlus-selabhangig, 16 Runden, Blocklange 64. Blowfish ist ein schneller undeinfach zu implementiernder Algorithmus (da nur XOR und + von32 Bit-Worten). Gegen Blowfish sind bisher keine erfolgversprechendenAngriffe bekannt.28
Twofish erreichte die Auswahlrunde der letzten funf AES-Kandidaten.Twofish ist Feistel-Chiffre. 8 × 8 S-Boxen, arithmetische Operationenz.T. in F28 .29
4) Weitere gebrauchliche Blockchiffren sind
• CAST (C. Adams, S. Tavares 1990; 1997. Wird auch von PGPverwendet.)30
• MISTY (Fa. Mitsubishi, 1996); Weiterentwicklung: KASUMI (mitA5/3 identisch); wird verwendet fur die symmetrische Verschlusse-lung bei UMTS (Universal Mobile Telecommunication System).31
26Details siehe Menezes, van Oorschott, Vanstone [39], S. 269-270, oderhttp://www.tools.ietf.org/html/rfc2040
27Details: http://citeseer.ist.psu.edu/317403.html28Details: http://www.schneier.com/blowfish.html29Details: http://www.schneier.com/twofish.html30Details: http://tools.ietf.org/html/rfc214431Infos: http://www.3gpp.org/TB/other/algorithms/35202-311.pdf oder Buch von
Schneier [43]
91

5 Betriebsarten von Blockchiffren
Blockchiffren konnen bei der Verschlusselung langerer Klartexte in verschie-denen Weisen eingesetzt werden. Wir beschreiben im Folgenden die wichtig-sten dieser Betriebsarten (’modes of operation’).
Sei also eine Blockchiffre gegeben, die Klartextblocke der Lange n uber Al-phabet R verschlusselt. Schlusselmenge K, k ∈ K, so Ek Verschlusselungs-funktion, Dk Entschlusselungsfunktion.
5.1 Electronic Codebook Mode (ECB Mode)
Beliebig langer Klartext wird in Blocke der Lange n zerlegt. Ggf. Klartexterganzen, dass durch n teilbare Lange entsteht (z.B. zufallige Zeichen amEnde, padding). Chiffrierter Text ist dann Folge der chiffrierten Blocke. (Furfeste Schlussel konnte man eine Tabelle der Klartext-Chiffretext-Paare anle-gen: electronic codebook; daher diese Bezeichnung.)
Probleme:
• Regelmaßigkeiten des Klartextes fuhren zu Regelmaßigkeiten des chif-frierten Textes, denn gleiche Klartextblocke werden immer in gleicheChiffretextblocke verschlusselt. Kann die Kryptoanalyse erleichtern; et-wa wenn Klartextnachrichten immer in der gleichen Weise beginnen(z.B. e-mail).
• Angreifer kann die Nachricht andern, indem er Chiffretext einfugt, dermit dem gleichen Schlussel verschlusselt worden ist; oder er kann dieReihenfolge der Chiffretextblocke andern. Daher sollten z.B. in einerDatenbank die Felder nicht als Block verschlusselt werden.
Man kann die Sicherheit des ECB Mode steigern, wenn Blocke nur teilweiseaus dem Klartext und teilweise aus zufalligen Zeichen gebildet werden.
5.2 Cipherblock Chaining Mode (CBC Mode)
Diese Betriebsart wurde erfunden, um einige der Probleme des ECB Modezu beseitigen.
92

Im CBC Mode hangt die Verschlusselung eines Blocks auch von den vorher-gegangenen Blocken ab (kontextabhangige Verschlusselung).
Es sei R = 0, 1.CBC Mode benotigt festen Initialisierungsvektor IV ∈ 0, 1n
Verschlusselung:Klartextblocke m1, . . . , mt
Setze c0 = IV , cj = Ek(cj−1 ⊕mj).Chiffretextblocke c1, . . . , ct
Entschlusselung:Gegeben c1, . . . ct
Setze c0 = IV .Dann mj = cj−1 ⊕Dk(cj)
Beispiel:n = 5Permutationschiffre b1b2b3b4b5 → bπ(1)bπ(2)bπ(3)bπ(4)bπ(5) (Transpositionschif-fre)Schlusselraum: S5
Sei m = 10100 01110 1100. Padding: Letzten Block zu 11000 erweitern.
Verwende Schlussel k =
(1 2 3 4 53 4 2 5 1
), k−1 =
(1 2 3 4 55 3 1 2 4
).
IV = 11001 = c0
c1 = Ek(c0 ⊕m1) = Ek(01101) = 10110c2 = Ek(c1 ⊕m2) = Ek(11000) = 00101c3 = Ek(c2 ⊕m3) = Ek(11101) = 10111
c = (11001) 10110 00101 10111
Entschlusselung:c0 ⊕Dk(c1) = 11001⊕Dk(10110) = 11001⊕ 01101 = 10100 = m1
Vorteile:Gleiche Klartextblocke in unterschiedlichem Kontext werden i. Allg. verschie-den verschlusselt.
Anderung eines Chiffretextblockes ci fuhrt bei Entschlusselung zu falschemmi und mi+1. Diese sind dann in der Regel unverstandlich, Anderung wirdbemerkt.Andererseits: Tritt eine zufallige Storung in ci bei der Ubertragung auf, so
93

sind nur mi und mi+1 beeinflusst, mi+2, . . . sind wieder korrekt (CBC istselbstsynchronisierend).
Entfernen eines ci fuhrt bei Entschlusselung zu unverstandlichem mi = ci−1⊕Dk(ci+1) anstelle von mi, mi+1 = ci ⊕Dk(ci+1) fehlt, ab mi+2 korrekt.
Einfugen eines c (zwischen ci−1 und ci) fuhrt bei Entschlusselung zu un-verstandlichem mi = ci−1 ⊕Dk(c), neuem unverstandlichem m = c⊕Dk(ci)und danach zu mi+1, . . ..
Wie bei ECB besteht auch bei CBC der Nachteil, dass (ohne Verwendungvon padding) stets abgewartet werden muss, bis ein vollstandiger Block derLange n vorhanden ist, bevor verschlusselt werden kann. CBC ist also v.a.bei Verschlusselungen langer Klartexte gut geeignet.
5.3 Cipher Feedback Mode (CFB Mode)
Hier wieder R = 0, 1.CFB Mode ist eine stromchiffreahnliche Betriebsart von Blockchiffren, dieeine Verschlusselung von Klartexten ermoglicht, ohne abwarten zu mussen,bis ein Block der Lange n vorliegt. Dies ist insbesondere bei interaktiverComputerkommunikation nutzlich.
Der Klartext wird in Blocke p1, p2, . . . der Lange r fur ein festes r mit1 ≤ r ≤ n aufgeteilt (typisch: r = 8). Benotigt wird außerdem ein In-itialisierungsvektor IV ∈ 0, 1n.
Setze I1 = IV .Dann fur j = 1, 2, 3, . . .cj = pj ⊕ Lr(Ek(Ij)) ∈ 0, 1rIj+1 = Rn−r(Ij)|cj ∈ 0, 1n
Dabei bezeichnet Lr(X) die r linksstehenden Bits eines Blocks X der Langen, Rn−r(X) die n− r rechtsstehenden Bits von X.X|Y ist das Hintereinanderschreiben der Strings X und Y .c1, c2, c3, . . . sind die verschlusselten p1, p2, p3, . . . .
Entschlusselung:I1 = IVDann fur j = 1, 2, . . .pj = cj ⊕ Lr(Ek(Ij)) (keine Entschlusselung mit Dk !)
94

Ij+1 = Rn−r(Ij)|cj
(Beachte: cj ⊕ Lr(Ek(Ij)) = pj ⊕ Lr(Ek(Ij))⊕ Lr(Ek(Ij)) = pj)
Beispiel:Sei m wie in 5.2, ebenso Ek.
Weiter sei IV = 11001 = I1 und r = 2.
10↓p1
10↓p2
00↓p3
11↓p4
10↓p5
11↓p6
00↓p7
Ek(I1) = 00111c1 = p1 ⊕ 00 = 10
I2 = 001|10 Ek(I2) = 11000c2 = p2 ⊕ 11 = 01
I3 = 110|01 Ek(I3) = 00111c3 = p3 ⊕ 00 = 00
I4 = 001|00 Ek(I4) = 10000c4 = p4 ⊕ 10 = 01
I5 = 100|01 Ek(I5) = 00011c5 = p5 ⊕ 00 = 10
I6 = 001|10 Ek(I6) = 11000c6 = p6 ⊕ 11 = 00
I7 = 110|00 Ek(I7) = 00101c7 = p7 ⊕ 00 = 00
c1, . . . , c7 : 10 01 00 01 10 00 00
Man sieht an der Beschreibung, dass der CFB Mode wie eine Stromchiffre(auf r-Bit Strings) funktioniert, wobei der Schlusselstrom Lr(Ek(Ij)), j =1, 2, 3, . . . , mittels Blockchiffrierung aus I1 und den vorher verschlusseltenr-Bits erzeugt wird.
CFB Mode ist sehr schnell und kann von Sender und Empfanger fast simultanausgefuhrt werden. Sobald cj vorliegt, kann der Empfanger Ij+1 und dannLr(Ek(Ij+1)) berechnen und dann bei Empfang von cj+1 sofort durch XORpj+1 entschlusseln. Beachte: CFB Mode hangt nur von der Geschwindigkeitder Blockverschlusselung (nicht Entschlusselung) ab.
Ubertragungsfehler oder Anderungen in einem Chiffretextblock wirken sich
95

solange aus, bis der fehlerhafte Block aus Ij herausgeschoben wurde, d.h. aufdie nachsten ⌈n
r⌉ Blocke. CFB ist also auch selbstsynchronisierend.
Das Verhalten bei Einfugen bzw. Entfernen von Chiffretextblocken ist wiebei CBC (mit langerer Auswirkung entsprechend der vorigen Bemerkung).
Da Sender und Empfanger nur uber die Verschlusselungsfunktion Ek verfugenmussen, ist der CFB Mode bei Public-Key-Systemen (siehe spater) nichtanwendbar, denn dort ist Ek als offentlicher Schlussel jedem bekannt. CFBMode wird haufig im Internet eingesetzt.
Spezialfall: r = n, c0 = IV , cj = mj ⊕Ek(cj−1) (vgl. CBC).
5.4 Output Feedback Mode (OFB Mode)
Wieder R = 0, 1.Ahnlich wie CFB, nur Ij+1 = Rn−r(Ij)|Lr(Ek(Ij)).Dann cj = pj ⊕ Lr(Ek(Ij)).
Die Ij hangen nur von k und IV ab und konnen von Sender und Empfangerparallel berechnet werden.
Verschlusselung von pj hangt nur von seiner Position, nicht von den voran-gegangenen Blocken ab.
Anderung eines cj bewirkt nur Anderung bei der Entschlusselung diesesBlockes.
Aber: Wird ein Chiffretextblock entfernt, so werden alle folgenden Chiffre-textblocke falsch entschlusselt. OFB ist nicht selbstsynchronisierend.
OFB ist schnell; wird z.B. zur Verschlusselung gesprochener Sprache in Echt-zeit verwendet.
Spezialfall: r = n.Dann Ij+1 = Ek(Ij), cj = mj ⊕ Ek(Ij) = mj ⊕ Ej
k(I1).
96

6 Stromchiffren
In Abschnitt 2.B hatten wir polyalphabetische Substitutionen, insbesondereLauftextverschlusselungen (z.B. One-Time-Pad) als Beispiele von Stromchif-fren kennengelernt.
Wir wollen jetzt Stromchiffren etwas genauer betrachten. Sie spielten (undspielen) in militarischen Anwendungen eine große Rolle, werden aber auchfur zivile Zwecke haufig verwendet.
Man unterscheidet zwei Typen: synchrone und selbstsynchronisierende Strom-chiffren.
6.1 Synchrone Stromchiffren
Sie sind dadurch gekennzeichnet, dass der Schlusselstrom unabhangig vonKlar- und Chiffretext erzeugt wird.
Beschreibung:Ausgangsschlussel kFunktion zur Erzeugung des Schlusselstroms g(i, k) = ki (i = 0, 1, 2, . . .)Verschlusselungsfunktion E: E(mi, ki) = ci
(verschlusselt Klartextbit resp. Klartextblock mi mit ki zu Chiffretextbitresp. Chiffretextblock ci)
Notwendig:Sender und Empfanger mussen synchronisiert sein. Geht die Sychronisationverloren (z.B. weil Chiffretextbits wahrend der Ubermittlung verloren gehen),so schlagt die Entschlusselung fehl (allerdings tritt sehr viel haufiger dieAnderung eines Bits als ein Verlust auf!).
Fehlerfortpflanzung:Die Anderung eines Chiffretextbits bei der Ubertragung hat keine Auswir-kungen auf die korrekte Entschlusselung der folgenden Bits.
Falls Bits durch binare Addition (XOR) mit Schlusselbits ki verschlusseltwerden (d.h. E(mi, ki) = mi ⊕ ki), so spricht man von binaren additivenStromchiffren (Bsp. One-Time-Pad).
(Synchrone Stromchiffren entsprechen z.B. OFB Mode bei Blockchiffren.)
97
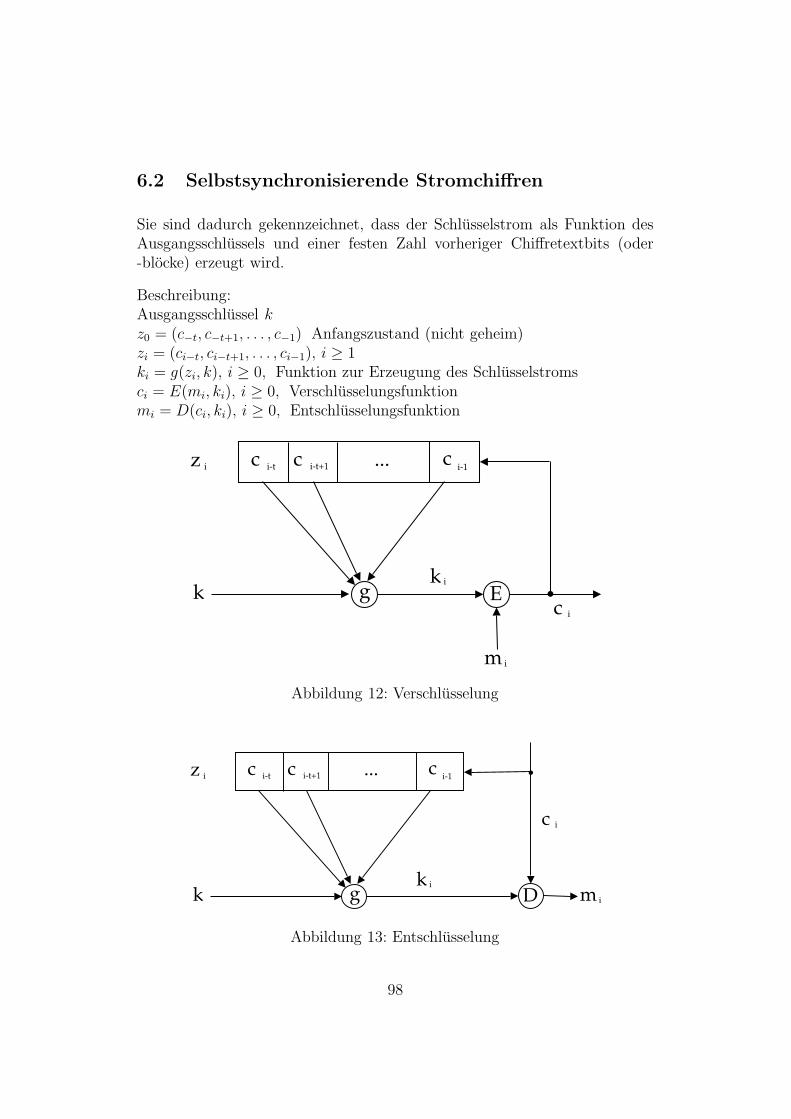
6.2 Selbstsynchronisierende Stromchiffren
Sie sind dadurch gekennzeichnet, dass der Schlusselstrom als Funktion desAusgangsschlussels und einer festen Zahl vorheriger Chiffretextbits (oder-blocke) erzeugt wird.
Beschreibung:Ausgangsschlussel kz0 = (c−t, c−t+1, . . . , c−1) Anfangszustand (nicht geheim)zi = (ci−t, ci−t+1, . . . , ci−1), i ≥ 1ki = g(zi, k), i ≥ 0, Funktion zur Erzeugung des Schlusselstromsci = E(mi, ki), i ≥ 0, Verschlusselungsfunktionmi = D(ci, ki), i ≥ 0, Entschlusselungsfunktion
k
i-1
k i
ic
im
g E
... ci-tciz i-t+1c
.
Abbildung 12: Verschlusselung
k
i-1
k i
ic
img
... ci-tciz i-t+1c
D
.
Abbildung 13: Entschlusselung
98

Typische Vertreter selbstsynchronisierender Stromchiffren sind Blockchiffrenim 1-Bit CFB Mode (d.h. r = 1 im CFB Mode; s. Abschnitt 5.3; die Funktiong wird durch die Blockchiffre realisiert. E ist dann einfach XOR.)
Selbstsynchronisation:Geht ein Chiffretextbit bei der Ubertragung verloren, so synchronisiert sichdas System selber; nur ein Klartextbit geht verloren und t Bits werden falschentschlusselt.
Bsp: t = 2
Verschl.:
. . . m8 m9 m10 m11 m12 m13yk8=g(c6,c7,k)
y·y·
y·y·
yk13=g(c11,c12,k)
. . . c8 c9 c10///︸︷︷︸geht verloren
c11 c12 c13
Entschl.:
. . . c8 c9 c11 c12 c13yk8=g(c6,c7,k)
y·yg(c8,c9,k)
yg(c9,c11,k)
yk13=g(c11,c12,k)
. . . m8 m9 m11 m12 m13
Diese Selbstsynchronisation hat aber auch zur Folge, dass Einfugen und Ent-fernen von Chiffretextbits durch Angreifer schwerer erkannt werden (andersals bei synchronen Stromchiffren).
Fehlerfortpflanzung:Wird ein ci bei der Ubertragung verandert, so wird nur die Entschlusselungder nachsten t Bits ggf. verfalscht, danach wird wieder korrekt entschlusselt.
(Bei synchronen Stromchiffren wird sofort das nachste Bit wieder korrekt ent-schlusselt; daher lassen sich – speziell bei großeren t – absichtliche Anderun-gen von Chiffretextbits durch einen Angreifer bei selbstsynchronisierendenStromchiffren leichter erkennen.)
Sowohl bei synchronen als auch bei selbstsynchronisierenden Stromchiffren istdie Schlusselstromerzeugung (beschrieben durch die Funktion g) die entschei-dende Komponente. In vielen Systemen spielen bei der Schlusselstromerzeu-gung Schieberegister eine wichtige Rolle. Wir geben im Folgenden eine kurzeBeschreibung allgemeiner Schieberegister und wenden uns dann den am ein-fachsten zu implementierenden Typen zu, den linearen Schieberegistern.
99

6.3 Schieberegister
Def.:Ein (ruckgekoppeltes) Schieberegister (feedback shift register) uber dem end-lichen Korper K ist eine Maschine, die aus n Registern R0, . . . , Rn−1 (stages)besteht, die einen Input und eine Output besitzen und ein Element aus Kspeichern konnen; einer Uhr, die den Transport der Daten (= Elemente ausK) kontrolliert; und einer Recheneinheit, die eine fest vorgegebene Funktionf : Kn → K berechnet. n heißt Lange des Schieberegisters.
f (
Output. . . .Verzögerungsglieder
Recheneinheit
, , ... , ) aj-1
aj-2
aj-n
a j-1a j a j-2 a j-n+1 a j-n
R 0R 1R n-1 R n-2
Abbildung 14: Ruckgekoppeltes Schieberegister
Wahrend jeder Zeiteinheit werden folgende Operationen durchgefuhrt:
• Der Inhalt von R0 wird ausgegeben und ist Teil der Output-Folge.
• Der Inhalt von Ri wird an Ri−1 weitergegeben, i = n− 1, . . . , 1.
• Der neue Inhalt von Rn−1 ist aj = f(aj−1, . . . , aj−n), wobei aj−i derfruhere Inhalt von Rn−i ist, i = 1, . . . , n (Ruckkopplung).
Zu Beginn enthalt jedes Si einen Anfangswert ai, i = 0, . . . , n− 1; (a0, . . . , an−1)heißt der Anfangszustand des Schieberegisters.Die Inhalte (aj−n+1, aj−n+2, . . . , aj) der Ri (im (j − n + 1)-ten Zeittakt)j = n + 1, n + 2, . . . heißen die Zustande des Schieberegisters.
Also: Inhalt von
Rn−1 Rn−2 . . . R1 R0
0. Zeittakt an−1 an−2 . . . a1 a0
1. Zeittakt an = f(an−1, . . . , a0) an−1 . . . a2 a1 → Output a0
2. Zeittakt an+1 = f(an, . . . , a1) an . . . a3 a2 → Output a1a0
100

Die Outputfolge ist also eindeutig bestimmt durch den Anfangszustand(a0, . . . , an−1) und die Rekursionsvorschrift aj = f(aj−1, . . . , aj−n).
Schieberegister der Lange n sind also nichts anderes als eine maschinelleVeranschaulichung von Rekursionen (der Ordnung n).
Zu jedem Zeitpunkt befindet sich ein Schieberegister der Lange n in einemvon |K|n moglichen Zustanden.
Daher gibt es Zeitpunkte t1 < t2, in denen sich das Schieberegister im gleichenZustand befindet. Dann stimmt die Outputfolge betrachtet ab Zeitpunkt t1mit der ab Zeitpunkt t2 uberein.
Also:Die Outputfolge eines Schieberegisters ist ab einem aj0 periodisch mit Perioded, d.h. ai = ai+d fur alle i ≥ j0 (d kleinstmoglich).
6.4 Lineare Schieberegister
Def.:Ist in einem Schieberegister der Lange n die Funktion f von der Formf(xn−1, . . . , x0) = cn−1xn−1 + . . . + c0x0 fur feste cn−1, . . . , c0 ∈ K, so heißtdas Schieberegister ein lineares Schieberegister (LSR).(Die ci heißen dann auch Ruckkopplungskoeffizienten.)
Es gilt also: aj =n−1∑i=0
ciaj−n+i fur alle j ≥ n.
Im wichtigsten Fall K = Z2 lasst sich ein lineares Schieberegister also folgen-dermaßen darstellen (binares LSR):
a j
aj-2
c n-2c n-1
XOR-Gatter
a j-1. .Output
i
a j-n+1 a j-n..
c11 c 0
(sind nur dort
erforderlich,
wo c =1)
AND-Gatter
i
R n-1 R n-2 R 1 R 0
Abbildung 15: Binares lineares Schieberegister der Lange n
101

Beispiele:
Sei K = Z2.
a) f(x3, x2, x1, x0) = x2 + x0
Anfangszustand (a0, a1, a2, a3) = (1011)
t R3 R2 R1 R0 Output0 1 1 0 11 0 1 1 0 12 1 0 1 1 03 1 1 0 1 1 ← wie Anfangszustand
Output-Folge ist periodisch mit Periode 3: 101101101 . . .
b) f(x1, x0) = x1 + x0
Anfangszustand (a0, a1) = (10)
t R1 R0 Output0 0 11 1 0 12 1 1 03 0 1 1 ← wie Anfangszustand
Selbe Output-Folge wie in a).
6.5 Eigenschaften von linearen Schieberegistern
a) Bei einem LSR der Lange n gilt:Ist c0 = 0, so stimmt die Output-Folge (bis auf a0) mit der des LSR derLange n−1 uberein, das gegeben ist durch f(xn−2, . . . , x0) = cn−1xn−2+. . . + c1x0) und Anfangszustand (a1, . . . , an−1).
Wir nehmen im Folgenden daher stets c0 6= 0 an. Solche LSR heißendann nicht-singular.
b) Ein (nicht-singulares) LSR ist periodisch (ab a0), d.h. es ex. d mitai = ai+d fur alle i ≥ 0.
[Wahle j minimal mit aj+i = aj+i+d fur alle i ≥ 0.Ang. j > 0. Dann aj−1 6= aj−1+d.Es ist aj−1+n = c0 aj−1 + c1 aj + . . . + cn−1 aj−2+n
102

und aj −1+n︸︷︷︸≥0
= aj−1+n+d = c0aj−1+d + c1 aj+d︸︷︷︸aj
+ . . . + cn−1 aj−2+n+d︸ ︷︷ ︸aj−2+n
.
Also c0 aj−1 = c0 aj−1+d und wegen c0 6= 0 dann aj−1 = aj−1+d, Wider-spruch.]
c) Kommt unter den Zustanden eines LSR einmal (0, . . . , 0) vor, so ver-bleibt das LSR immer im Zustand (0, . . . , 0).
Also nach b): Ein nicht singulares LSR der Lange n mit dem Anfangs-zustand 6= (0, . . . , 0) hat eine Periode ≤ |K|n − 1, im binaren Fall also≤ 2n − 1.
d) Man ist interessiert daran, LSR mit moglichst großer Periode zu kon-struieren. Wir beschranken uns jetzt auf den binaren Fall (der Fallallgemeiner endlicher Korper ist analog).
Es stellt sich heraus, dass es fur jedes n binare LSR gibt, die die Periode2n − 1 haben. Welche sind das?
Dazu betrachtet man das sog. charakteristische Polynom des binarenLSR:
p(t) = c0 + c1t + . . . + cn−1 tn−1 + tn
(Dies ist gerade das charakteristische Polynom der linearen AbbildungZn2 → Zn
2 gegeben durch
0 1 0 . . . 00 0 1 0 . . . 0...
. . .. . .
...0 . . . 0 1 00 . . . 0 1c0 c1 . . . cn−1
x0......
...xn−1
=
x1
...
...
xn−1
c0x0 + . . . + cn−1xn−1
=
x1......
...xn
,
die den Zustandsubergang des binaren LSR beschreibt.)
Man kann zeigen:Genau dann hat das (nicht singulare) binare LSR der Lange n Periode2n − 1 (und das gilt dann fur jeden Anfangszustand 6= (0, . . . , 0)), falls
(1) p(t) irreduzibel
(2) p(t) ∤ tr − 1 fur alle 1 ≤ r < 2n − 1.
[Bemerkung: (1) und (2) bedeuten, dass im Korper F2n , der durch dasirreduzible Polynom p(t) definiert wird (siehe Seite 79), das Element tein erzeugendes Element der zyklischen Gruppe (F2n\0, ·) ist.]
103

Es gilt: Es gibt genau ϕ(2n−1)n
primitive Polynome uber Z2 von Gradn.32
e) Ein binares LSR der Lange n mit primitivem charakteristischen Po-lynom erzeugt fur jeden Anfangszustand 6= (0, . . . , 0) eine periodischeFolge mit Periode 2n−1. Solche Folgen heißen m-Folgen (m = maximalePeriode).
f) m-Folgen haben gewisse statistische Eigenschaften, die sie als Pseudo-zufallsfolgen geeignet erscheinen lassen. Z. B. sind Einsen und Nullen(annahernd) gleich verteilt, ebenso die Paare 00, 01, 10, 11 etc.
Fur kryptographische Zwecke sind sie dennoch nicht tauglich. Aus einerTeilfolge der Lange 2n (deutlich kleiner als die Periode 2n−1) lasst sichnamlich die gesamte Folge ermitteln, wie wir in Kurze sehen werden(Unterkapitel 6.6).
6.6 Lineare Komplexitat
Ist (a0, a1, . . .) eine binare Folge mit Periode d, so gibt es immer mindestensein binares LSR, das diese Folge erzeugt:
Wahle LSR von Lange d, c0 = 1, c1 = . . . = cd−1 = 0Anfangszustand (a0, a1, . . . , ad−1)
[I. Allg. gibt es mehrere: siehe Bsp. von Seite 102]
Man kann zeigen: Ist (a0, a1, . . .) eine binare periodische Folge, so gibt es eineindeutig bestimmtes binares LSR von minimaler Lange n, so dass (a0, a1, . . .)als Outputfolge dieses LSR (mit Anfangszustand (a0, a1, . . . , an−1)) auftritt.
Man sagt auch: n ist die lineare Komplexitat von (a0, a1, . . .).
[Beachte: Erzeugt ein LSR der Lange n eine Folge der Periode 2n− 1, so hatdie Folge lineare Komplexitat n.]
Dieses binare LSR minimaler Lange lasst sich folgendermaßen beschreiben:
Hat (a0, a1, . . .) Periode d, so setze
a(t) = a0 + a1t + . . . + ad−1td−1
32Beweis: z.B. Lidl, Niederreiter [37]
104

und
q(t) =td + 1
ggT(a(t), td + 1)
Ist Grad q(t) = n, so ist p(t) = tnq(1t) (das reziproke Polynom von q) das
charakteristische Polynom des LSR von minimaler Lange (= Grad p(t) = n),das (a0, a1, . . .) erzeugt.33
Es gilt nun:
6.6.1 Satz (Charakterisierung der linearen Komplexitat)
Sei (a0, a1, . . .) eine periodische binare Folge, die von einem LSR der Langen erzeugt wird. Sei außerdem m ∈ N0.Dann sind gleichwertig:
(1) (a0, a1, . . .) hat lineare Komplexitat n
(2) Die n aufeinanderfolgenden ’Zustandsvektoren’
(am, am+1, . . . , am+n−1), . . . , (am+n−1, am+n, . . . , am+2n−2)
der Lange n sind linear unabhangig.
Beweis:
(1) ⇒ (2) : Sei f(x0, . . . , xn−1) =n−1∑i=0
cixi die zum LSR der Lange n, das
(a0, a1, . . .) erzeugt, gehorende Funktion. Setze
C =
0 1 0 . . . 00 0 1 0 . . . 0...
. . .. . .
...0 . . . 0 1 00 . . . 0 1c0 c1 . . . cn−1
und vi =
ai......
...an+i−1
fur i ≥ 0.
Det C = +− c0 und c0 6= 0, da n minimal fur die Erzeugung von (a0, a1, . . .).
Also ist C invertierbar.
33Literatur z.B. Beker, Piper [8]
105

Cmv0 = vm. Daher:
vm, . . . ,vm+n−1 linear unabhangig
⇔ C−mvm︸ ︷︷ ︸= v0
, . . . , C−mvm+n−1︸ ︷︷ ︸= vn−1
linear unabhangig
Angenommen v0, . . . , vn−1 sind linear abhangig.Wahle t ≤ n − 1 minimal mit v0, . . . , vt linear abhangig. Dann existierend0, . . . , dt ∈ Z2 mit d0v0 + . . . + dtvt = 0, dt = 1.
Also: vt =t−1∑j=0
djvj .
Dann gilt fur alle i ≥ 0 : vt+i = Civt =t−1∑j=0
djCivj =
t−1∑j=0
djvj+i.
Daher: at+i =t−1∑j=0
djaj+i fur alle i ≥ 0 (1. Komponente betrachten).
Also wird (a0, a1, . . .) von einem LSR der Lange t ≤ n − 1 erzeugt, Wider-spruch.
(2) ⇒ (1): Angenommen nicht. Sei g(x0, . . . , xr−1) =r−1∑j=0
djxj die Funktion
des kurzesten LSR, das (a0, a1, . . .) erzeugt. Also d0 6= 0.
Es ist ar+i =r−1∑j=0
djaj+i fur alle i ≥ 0. Das bedeutet, dass vm, . . . , vm+r linear
abhangig sind, Widerspruch.
6.6.2 Satz (Rekonstruktion des LSR aus Folgestuck)
Sei (a0, a1, . . .) eine binare periodische Folge der linearen Komplexitat n (alsoPeriode maximal 2n − 1).Dann lasst sich das zugehorige minimale Schieberegister der Lange n ausbeliebigen 2n aufeinanderfolgenden Folgengliedern bestimmen.
Beweis:Bekannt seien ar, ar+1, . . . , ar+2n−1. Seien c0, . . . , cn−1 die Koeffizienten desminimalen LSR, das die Folge erzeugt.
106

Dann ist at+n =n−1∑i=0
ciat+i, t = r, r + 1, . . . , r + n− 1, d.h.
ar+n
...
ar+2n−1
=
ar . . . ar+n−1
ar+1 . . . ar+n...
...ar+n−1 . . . ar+2n−2
︸ ︷︷ ︸=: A
c0
...
cn−1
Die Matrix A ist bekannt und nach 6.6.1 invertierbar.
Damit lasst sich
c0...
cn−1
= A−1
ar+n...
ar+2n−1
bestimmen.
Es bleibt allerdings folgendes Problem:Wenn der Angreifer ein Teilstuck der Schieberegisterfolge kennt, so kanner i. Allg. nicht wissen, ob dieses Teilstuck mindestens Lange 2n, n lineareKomplexitat der Schieberegisterfolge, hat oder nicht. Und selbst wenn dasTeilstuck mindestens Lange 2n besitzt, so kennt er zunachst einmal n nicht.Fur das letztgenannte Problem gibt es jedoch eine Losung:
Man kann auch fur endliche Bitfolgen (a0, . . . , ar) den Begriff der linearenKomplexitat definieren: Dies ist die kleinste Lange eines LSR, dessen Output-Folge mit (a0, . . . , ar) beginnt. Es gibt einen Algorithmus von Berlekamp undMassey, der zu gegebener Bitfolge (a0, . . . , ar) deren lineare Komplexitat mitO(r2) Bit-Operationen bestimmt. Ist also r ≥ 2n, so bestimmt der Berle-kamp-Massey-Algorithmus nach 6.6.2 auch die lineare Komplexitat der ge-samten Schieberegisterfolge und das minimale LSR kann bestimmt werden.34
6.7 Schieberegister zur Schlusselstromerzeugung
Wir hatten in Unterkapitel 6.6 gesehen, dass LSR zur Erzeugung von Schlussel-stromen kaum geeignet sind. Dies ist insbesondere bei additiven binarenStromchiffren der Fall, wo Mallory bei einer Known-Plaintext-Attack beigenugend langem Klartext (Lange ≥ 2·lineare Komplexitat der Schieberegi-sterfolge) durch mi⊕ ci (m1, m2, . . . Klartextfolge, c1, c2, . . . zugehorige Chif-fretextfolge) einen Teil des Schlusselstroms ermitteln kann, der ausreicht, um
34Literatur: Lidl, Niederreiter [37] oder Menezes et al. [39]
107

mit den am Ende von 6.6 beschriebenen Methoden das (minimale) LSR furden gesamten Schlusselstrom zu ermitteln.
Statt LSR konnte man Schieberegister mit einer nicht-linearen Ruckkopp-lungsfunktion f verwenden oder geeignete Konstruktionen mit LSR.
Wir geben einige Beispiele:
a) Nichtlineare Kombination von linearen Schieberegistern
Schlüsselstrom
LSR 1
LSR
LSR 2f
Abbildung 16: Nichtlineare Kombination von linearen Schieberegistern
f ist nicht-lineare Funktion Zk2 → Z2
f muss allerdings sorgfaltig gewahlt werden, um das System gegen so-genannte Korrelationsangriffe sicher zu machen. Diese bestehen dar-in, Zusammenhange (Korrelationen) zwischen dem Schlusselstrom undden Outputfolgen einzelner LSR zu ermitteln (statistische Methoden).Die lineare Komplexitat einer solchen nicht-linearen Kombination kannsehr groß gemacht werden.
b) Nichtlineare Filtergeneratoren
f erzeugt aus den Zustanden des LSR den Schlusselstrom, ist also einenicht-lineare Funktion f : Zn
2 → Z2 (siehe Abbildung 17).
108
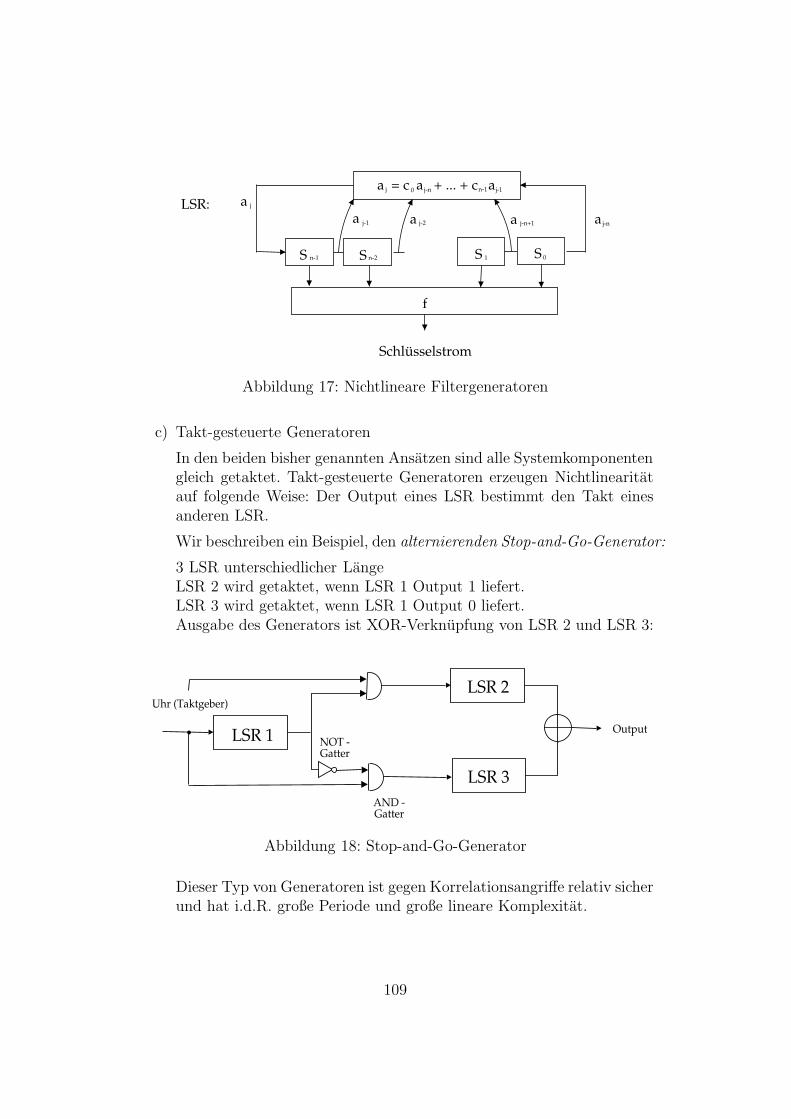
f
a j-1
a j
a j-n+1 a j-n
a = c a + ... + c a j-nj 0 j-1n-1
LSR:
S 1
Schlüsselstrom
a j-2
S n-1 S n-2 S 0
Abbildung 17: Nichtlineare Filtergeneratoren
c) Takt-gesteuerte Generatoren
In den beiden bisher genannten Ansatzen sind alle Systemkomponentengleich getaktet. Takt-gesteuerte Generatoren erzeugen Nichtlinearitatauf folgende Weise: Der Output eines LSR bestimmt den Takt einesanderen LSR.
Wir beschreiben ein Beispiel, den alternierenden Stop-and-Go-Generator:
3 LSR unterschiedlicher LangeLSR 2 wird getaktet, wenn LSR 1 Output 1 liefert.LSR 3 wird getaktet, wenn LSR 1 Output 0 liefert.Ausgabe des Generators ist XOR-Verknupfung von LSR 2 und LSR 3:
LSR 1
LSR 2
LSR 3
Uhr (Taktgeber)
NOT -Gatter
AND -Gatter
Output.
Abbildung 18: Stop-and-Go-Generator
Dieser Typ von Generatoren ist gegen Korrelationsangriffe relativ sicherund hat i.d.R. große Periode und große lineare Komplexitat.
109

6.8 Spezielle Stromchiffren
a) A5-Familie (A5/1, A5/2, A5/3):Beruht auf Takt-gesteuerten Kombinationen von LSR. Eingesetzt etwabei der Verschlusselung von Verbindungen zwischen Handy und Basis-station nach GSM-Standard (wurde zunachst geheimgehalten).A5/1 und A5/2 sind unsicher.
b) SEAL (Software-optimized Encryption Algorithm):Beruht nicht auf LSR. Wurde 1993 von IBM entwickelt.Gilt als sicher.
c) RC 4:Beruht nicht auf LSR. Wurde 1987 von Ron Rivest entwickelt und bis1994 geheimgehalten. Weit verbreitet.Gilt inzwischen nicht mehr als sicher.35
d) Im Rahmen des EU ECRYPT-Netzwerks gab es von 2004 bis 2008das eSTREAM-Projekt, in dem eine Ausschreibung fur Stromchiffrenerfolgte. Das Begutachtungs- und Auswahlverfahren ist inzwischen ab-geschlossen, wobei vier Chiffren fur Software- und drei fur Hardwareim-plementationen am Ende in der engeren Wahl verblieben. Eine Emp-fehlung fur eine dieser Stromchiffren als (EU-)Standard gibt es nochnicht. Dazu sollen noch weitere Analysen abgewartet werden.Naheres unter http://www.ecrypt.eu.org/stream/.
35genauere Beschreibung: Menezes et al. [39], Schmeh [42], Schneier [43]
110

(∗) 7 Kryptographisch sichere Pseudozufallsfol-
gen - Generatoren und Einwegfunktionen
Fur Stromchiffren (aber auch in anderen kryptologischen Zusammenhangen)werden haufig ‘Zufallsfolgen’ von Bits benotigt.
Frage: Was versteht man unter einer Zufallsfolge?
Eine Zufallsfolge stellt man sich vor als Folge von Werten unabhangiger,gleich verteilter Boolescher Zufallsvariablen, d.h. als Output einer Quelle,die mit gleicher Wahrscheinlichkeit Bits 0 und 1 unabhangig von den schonerzeugten Bits ausgibt (binare symmetrische Quelle).
Dann sind aber zwei Bitfolgen gleicher (endl.) Lange gleich wahrscheinlich.Da wir es stets nur mit endlichen Folgen zu tun haben, legt dieser Befundnahe, dass man den Begriff endlicher Zufallsfolgen nicht sinnvoll definierenkann.
Andererseits folgt aus dem Gesetz der großen Zahlen, dass bei genugendlangen Folgen, die von einer binaren symmetrischen Quelle erzeugt werden,z.B. annahernd gleich viele Einsen und Nullen vorkommen oder dass diePaare 00, 01, 10, 11 annahernd gleich oft auftreten, etc.
Darauf beruhen Tests auf Zufalligkeit. Mogliche Vorgehensweisen sind z.B.:
• Moglichst genaue Ubereinstimmung von Merkmalen einer endlichenbinaren Folge mit dem Erwartungswert. Beispiele sind m-Folgen einesLSR (siehe 6.5); sie erfullen die sog. Golomb-Postulate. Diese fordernfur eine Zufallsfolge z.B., dass die Anzahl der Einsen und die Anzahlder Nullen sich um hochstens 1 unterscheiden. Außerdem wird eine ge-naue Ubereinstimmung der Anzahl der sog. runs (maximale Teilfolgenaufeinanderfolgender Einsen/Nullen) gegebener Lange mit dem Erwar-tungswert gefordert, und die Unabhangigkeit der Folgenglieder wirddurch die Konstanz der sog. Autokorrelationsfunktion beschrieben.(Naheres siehe Beker, Piper [8]...)
• Keine extrem hohe Abweichung einzelner Merkmale vom Erwartungs-wert. Dazu fuhrt man statistische Tests durch (z.B. den χ2-Test beimTest auf Haufigkeit von Einsen oder von Paaren).(Naheres siehe z.B. Knuth [34, Chapter 3] oder Menezes et al. [39]...)
In jedem Fall besteht eine gewisse Willkur, welche Eigenschaften man testet.Eine Folge kann viele Tests bestehen, einen weiteren vielleicht nicht.
111

Ein anderer Punkt ist außerdem von Bedeutung:In aller Regel werden ‘Zufallsfolgen’ algorithmisch erzeugt (vgl. Schiebere-gisterfolgen). Was immer man auch unter ‘Zufall’ versteht, eine determini-stische Erzeugung wird man nicht als zufallig ansehen. Aus diesem Grundspricht man in diesem Fall von Pseudozufallsfolgen. Es bleibt aber die Frage,was man unter Pseudozufallsfolgen verstehen soll.
Ein sinnvoller Ansatz, diese Frage anzugehen, ist der folgende:Man testet nicht eine Folge, sondern vergleicht die Verteilung der vom Algo-rithmus produzierten Folgen (einer gewissen Lange) mit der Gleichverteilungauf der Menge dieser Folgen (die von einer binaren symmetrischen Quelleerzeugt wird). Dieser Ansatz liegt auch der Definition von Pseudozufalligkeitin einer fur die Kryptographie geeigneten Weise zu Grunde. Er hat seineWurzeln in der Komplexitatstheorie und wurde in Arbeiten von Goldwas-ser/Micali, Blum/Micali und Yao im Jahr 1982 begrundet.
Grundidee: Die von einem 0-1-Folgen-Generator erzeugte Verteilung von 0-1-Folgen wird als pseudozufallig angesehen, wenn sie sich von der Gleichver-teilung nicht durch einen effizienten Algorithmus unterscheiden lasst.
Effiziente Algorithmen sind Algorithmen, die polynomiale Zeitkomplexitathaben. Neben deterministischen polynomialen Algorithmen betrachten wirauch probabilistische Algorithmen mit polynomialer Zeitkomplexitat.
Probabilistische Algorithmen konnen bei gegebenem Input wahrend der Be-rechnung des Outputs endlich oft Zufallswahlen (Munzwurf) ausfuhren, sodass der nachste Schritt des Algorithmus vom Ausgang dieses Zufallsexperi-ments abhangt. Daher: Bei gleichem Input kann ein probabilistischer Algo-rithmus verschiedene Outputs liefern.
Probabilistische Algorithmen mit polynomialer Zeitkomplexitat sind solche,fur die die Anzahl der Schritte (jeder Munzwurf zahlt als ein Schritt) durchein Polynom in der Lange des Inputs beschrankt ist.
7.1 Wahrscheinlichkeitstheoretische Bezeichnungen
a) Ist p eine Wahrscheinlichkeitsverteilung auf 0, 1n, dem Raum der 0-1-
Folgen der Lange n, so bedeutet xp← 0, 1n, dass Elemente x ∈ 0, 1n
zufallig bezuglich der Wahrscheinlichkeitsverteilung p ausgewahlt wer-den. 0, 1n mit der Gleichverteilung (p(x) = (1
2)n) bezeichnen wir mit
Ωn und schreiben x ← Ωn, wenn Elemente x zufallig und mit gleicherWahrscheinlichkeit aus 0, 1n ausgewahlt werden.
112

b) Ist B: 0, 1n → 0, 1, p eine Wahrscheinlichkeitsverteilung auf0, 1n, so schreiben wir
pr(B(x) = 1| x p← 0, 1n)
fur p(x ∈ 0, 1n| B(x) = 1) =∑
x∈0,1nB(x)=1
p(x).
Also: pr(B(x) = 1| x← Ωn) = |x∈0,1n| B(x)=1|2n
c) Wir haben auch den Fall zu betrachten, dass B keine Funktion (bei unsimmer beschrieben durch einen deterministischen Algorithmus) son-dern ein probabilistischer Algorithmus ist.
In diesem Fall steht pr(B(x) = 1| xp← 0, 1n) fur
∑x∈0,1n
p(x) ·
pr(B(x) = 1), wobei pr(B(x) = 1) die Wahrscheinlichkeit angibt, dassB bei Input x den Wert 1 ausgibt. Diese Wahrscheinlichkeit ist uberdie Gleichverteilung der Zufallswahlen in B gegeben.
Hierzu ein Bemerkung: Bei gegebenem x kann die Anzahl der Zufalls-wahlen vom Ausgang vorheriger Zufallswahlen abhangen. Sie ist aber injedem Fall durch eine Konstante tx beschrankt. Indem ggf. Zufallswah-len zusatzlich durchgefuhrt werden, die keinen Einfluss auf den Ablaufdes Algorithmus haben, wird die Gleichverteilung auf 0, 1tx betrach-tet.
7.2 Definition (Kryptographisch sicherer Pseudozu-
fallsfolgen-Generator)
Ein kryptographisch sicherer Pseudozufallsfolgen-Generator (ks PZG) ist eineFunktion G : 0, 1∗ → 0, 1∗ mit folgenden Eigenschaften:
(1) Es existiert eine Erweiterungsfunktion l : N→ N (d.h. l(n) > n fur allen ∈ N), so dass
G(un) ∈ 0, 1l(n) fur alle un ∈ 0, 1n.
[G entspricht einer Familie von Funktionen 0, 1n → 0, 1l(n), n ∈ N.]
(2) G ist durch einen deterministischen polynomialen Algorithmus bere-chenbar.
113

(3) Fur jeden probabilistischen polynomialen Algorithmus D, der fur jedeendliche 0-1-Folge als Input den Wert 0 oder 1 ausgibt, und jedes po-sitive Polynom P ∈ Z[x] (d.h. P (a) > 0 fur a > 0) gilt fur genugendgroße n:
|pr(D(G(x)) = 1| x← Ωn)− pr(D(z) = 1| z ← Ωl(n))| <1
P (n)
7.3 Bedeutung von Definition 7.2
• Wir identifizieren im Folgenden G mit dem polynomialen Algorithmus,der G berechnet. Der Pseudozufallsfolgen-Generator soll also effizientsein.
• Die Erweiterungsfunktion l beschreibt, dass der Algorithmus G aus 0-1-Folgen der Lange n (den ‘seeds’) 0-1-Folgen der (großeren) Lange l(n)produziert. Beachte: l(n) ist polynomial beschrankt, da G determini-stischer polynomialer Algorithmus.
• Bedeutung von Bedingung (3):Ein Angreifer kann bei Einsatz eines beliebigen probabilistischen po-lynomialen Algorithmus D die von G erzeugte Verteilung G(Ωn) auf0, 1l(n) (bis auf einen vernachlassigbaren Rest) nicht von der Gleich-verteilung auf 0, 1l(n), also Ωl(n), unterscheiden.
Beachte: Naturlich sind G(Ωn) und Ωl(n) Wahrscheinlichkeitsraume mitunterschiedlicher Verteilung, denn G, als deterministischer Algorith-mus, produziert aus den 2n 0-1-Folgen in Ωn nur maximal 2n verschie-dene 0-1-Folgen der Lange l(n). Also haben mindestens (2l(n) − 2n)0-1-Folgen der Lange l(n) unter der durch G erzeugten Wahrschein-lichkeitsverteilung Wahrscheinlichkeit 0. Dieser Unterschied lasst sichentsprechend der Def. mit beschrankten Ressourcen (d.h. probabilisti-schem polynomialem Algorithmus) nicht (d.h. in nicht vernachlassig-barer Weise) aufklaren.
• Ein moglicher Unterscheidungsalgorithmus D1 konnte z.B. folgender-maßen aussehen:
D1 gibt 1 aus, falls Anzahl der Einsen großer als Anzahl der Nullen,sonst 0.Bei Anwendung auf Ωl(n) wird er mit Wahrscheinlichkeit 1
21 oder 0
ausgeben. Wenn es in G(Ωn) eine deutliche Abweichung der Gleichver-teilung von 1 und 0 in den Folgen gibt, so wird D1 das erkennen.
114

Allgemeiner ist jeder statistische Test, der als polynomialer Algorith-mus implementierbar ist (z.B. χ2-Tests), ein moglicher Algorithmus D,gegen den der ks PZG ‘resistent‘ sein muss.
• Mit großerem Aufwand lassen sich G(Ωn) und Ωl(n) unterscheiden, denn|G(Ωn)| ≤ 2n, |Ωl(n)| = 2l(n):
Der Algorithmus DG erzeugt zunachst (mit exponentiellem Aufwand)alle Folgen in G(Ωn) (G ist bekannt) und testet dann, ob z ∈ Ωl(n) inder Liste vorkommt (Ausgabe 1) oder nicht (Ausgabe 0).
Dann
pr(DG(G(x)) = 1| x← Ωn) = 1
pr(DG(z) = 1| z ← Ωl(n)) =|G(Ωn)|
2l(n)≤ 2n
2l(n)
|pr(DG(G(x)) = 1| x← Ωn)− pr(DG(z) =1| z ← Ωl(n))|
≥ 1− 2n
2l(n)≥ 1
2
• Wieso wird in 7.2 nicht etwa die Forderung < 12n gestellt, oder sogar 0?
Weil es dann keinen ks PZG geben wurde! Denn:
Erzeuge eine 2-elementige Teilmenge W ⊆ G(Ωn).
Sei DW (u) =
1 fur u ∈W,
0 sonst.DW ist ein polynomialer Algorithmus.
Dann
pr(DW (G(x)) = 1| x← Ωn) ≥ 2
2n=
1
2n−1
pr(DW (z) = 1| z ← Ωl(n)) =2
2l(n)=
1
2l(n)−1
|pr(DW (G(x)) = 1| x←Ωn)− pr(DW (z) = 1| z ← Ωl(n))|
≥ 1
2n−1− 1
2l(n)−1≥ 1
2n−1− 1
2n=
1
2n
[Selbst wenn G nicht bekannt ist, gibt es einen solchen Algorithmus.Man bildet alle Algorithmen DW mit |W | = 2 und W ⊆ 0, 1l(n) wieoben; von diesen haben solche mit W ⊆ G(Ωn) die oben angegebeneEigenschaft.]
115

• Die Bedingung in 7.2 fur den vernachlassigbaren Rest ‘|pr(. . .)−pr(. . .)|< 1
P (n)’ impliziert, dass diese Bedingung erhalten bleibt, wenn Unter-
scheidungsversuche mit D mit ‘vertretbarem’ Aufwand (d.h. polynomi-al oft) wiederholt werden.
Kryptographisch sichere Pseudozufallsfolgen-Generatoren im obigen Sinnekonnen auch auf andere Weise charakterisiert werden.
Sei dazu G ein deterministischer polynomialer Algorithmus mit Erweite-rungsfunktion l : N → N , der aus 0-1-Folgen der Lange n 0-1-Folgen derLange l(n) erzeugt.
Fur eine 0-1-Folge x, sei G(x)i das i-te Bit der 0-1-Folge G(x).
7.4 Definition (Next-Bit-Tests)
G besteht alle Next-Bit-Tests, falls fur jeden probabilistischen polynomialenAlgorithmus A, der fur jede endliche 0-1-Folge als Input den Wert 0 oder 1ausgibt, und jedes positive Polynom P ∈ Z[x] fur alle genugend großen ngilt:
pr(A(G(x)1G(x)2 . . . G(x)i) = G(x)i+1|x← Ωn) ≤ 1
2+
1
P (n)
fur alle 0 ≤ i < l(n).
7.5 Bedeutung von Definition 7.4
• Der Algorithmus A versucht aus der Kenntnis der ersten i Bits derFolge G(x) das (i + 1)-te Bit von G(x) vorauszusagen.
• G besteht alle Next-Bit-Tests, wenn mit vertretbarem Aufwand (∧= po-
lynomialem probabilistischem Algorithmus) das nachste Bit i.W. nichtbesser bestimmt werden kann als durch Munzwurf (Wahrscheinlichkeit12).
• Wie zu Definition 7.2 kann man sich auch hier uberlegen, dass es nicht-polynomiale Algorithmen A gibt, die fur gewisse Stellen i das nachsteBit mit großerer Wahrscheinlichkeit als 1
2+ 1
P (n)voraussagen konnen.
Ebenso kann man zeigen, dass es immer polynomiale Algorithmen Agibt, die fur gewisse Stellen i das nachste Bit mit Wahrscheinlichkeit≥ 1
2+ 1
2n voraussagen konnen.
116

7.6 Satz (Yao; 1982)
Genau dann ist G ein krytographisch sicherer Pseudozufallsfolgen-Generator,wenn G alle Next-Bit-Tests besteht.
Beweisidee:=⇒ :Wenn G nicht alle Next-Bit-Tests besteht, so gibt es einen probabilistischenAlgorithmus A, ein positives Polynom Q und eine unendliche Teilmenge Kvon N, so dass A fur jedes n ∈ K fur jeweils eine Position in < l(n) aus derKenntnis von G(x)1, . . . , G(x)in das nachste Bit G(x)in+1 mit Wahrschein-lichkeit > 1
2+ 1
Q(n)voraussagen kann. Bei zufalliger Wahl einer Folge aus
Ωl(n) lasst sich deren (in + 1)-tes Bit aber nicht mit Wahrscheinlichkeit > 12
voraussagen.Definiere einen probabilistischen polynomialen Algorithmus D durch
D(z1, . . . , zl(n)) =
1, falls A(z1, . . . , zin) = zin+1
0, sonst
fur (z1, . . . , zl(n)) ∈ 0, 1l(n), n ∈ K. (Fur alle ubrigen Langen von 0, 1-Folgen kann man z.B. D(z1, . . . , zm) = 0 definieren.)Dann ist anschaulich klar (und kann mit etwas Rechnung auch prazise nach-gewiesen werden), dass mit diesem D die Bedingung eines kryptographischsicheren Pseudozufallsfolgen-Generators verletzt ist.⇐= :Ang., G ist kein kryptographisch sicherer Pseudozufallsfolgen-Generator. Dannexistiert ein probabilistischer polynomialer Algorithmus D, ein positives Po-lynom Q(x) und eine unendliche Teilmenge K von N, so dass| pr(D(G(x)) = 1 | x ←− Ωn) − pr(D(z)) = 1 | z ←− Ωl(n) | ≥ 1
Q(n)fur
alle n ∈ K.Sei pi die Gleichverteilung auf 0, 1i, d.h. (0, 1i, pi) = Ωi. Fur jedes n ∈ K
definieren wir jetzt Wahrscheinlichkeitsverteilungen p0, . . . , pl(n) auf 0, 1l(n)
in folgender Weise:
p0((b1, . . . , bl(n))) = pl(n)((b1, . . . , bl(n))) = 12l(n)
p1((b1, . . . , bl(n))) = pr(G(x)1 = b1|x← Ωn) · pl(n)−1(b2, . . . , bl(n)))
p2((b1, . . . , bl(n))) = pr(G(x)1 = b1, G(x)2 = b2|x← Ωn) · pl(n)−2((b3, . . . , bl(n)))...pl(n)((b1, . . . , bl(n))) = pr(G(x)1 = b1, . . . , G(x)l(n) = bl(n)|x← Ωn)
Also: p0 Gleichverteilung auf 0, 1l(n), pl(n) die durch G(Ωn) erzeugte Ver-
117

teilung auf 0, 1l(n). D kann p0 und pl(n) unterscheiden (im obigen Sinne).Sei pr(D(G(x)) = 1 | x ←− Ωn) ≥ pr(D(z) = 1 | z ←− Ωl(n)) (ansonstenbetrachte man im Folgenden die umgekehrten Differenzen).Man sieht dann leicht, dasspr(D(G(x)) = 1 | x←− Ωn) − pr(D(z) = 1 | z ←− Ωl(n)) =∑l(n)−1
j=0 (pr(D(z) = 1 | z pj+1←− 0, 1l(n)) − pr(D(z) = 1 | z pj←− 0, 1l(n))).Also existiert zu jedem n ∈ K ein in, 0 ≤ in < l(n), mit
| pr(D(z) = 1 | zpin+1←− 0, 1l(n)) − pr(D(z) = 1 | z
pin←− 0, 1l(n))| ≥1
Q(n)l(n).
Beachte, dass l(n) durch ein positives Polynom nach oben beschrankt ist, daG ein polynomialer Algorithmus ist.Es folgt, dass D fur z = (G(x)1, . . . , G(x)in , b, bin+2, . . . , bl(n)) mit b =G(x)in+1 den Wert 1 mit nicht-vernachlassigbarer hoherer Wahrscheinlich-keit liefert, als wenn b zufallig (mit Wahrscheinlichkeit 1
2) gewahlt wird.
Damit kann man dann aus D leicht einen probabilistischen polynomialenAlgorithmus A konstruieren, so dass G den Next-Bit-Test bzgl. dieses Algo-rithmus nicht besteht.36
Offen bleibt die Frage: Gibt es kryptographisch sichere Pseudozufallsfolgen-Generatoren? Es stellt sich heraus, dass dies aquivalent zur Existenz soge-nannter Einwegfunktionen ist.
Einwegfunktionen sind Funktionen, die leicht zu berechnen, aber schwierigzu invertieren sind.
7.7 Definition (Einwegfunktion)
Eine Funktion f : 0, 1∗ → 0, 1∗ heißt Einwegfunktion, falls gilt:
(1) Es existiert ein deterministischer polynomialer Algorithmus F , der beiInput x ∈ 0, 1∗ den Wert f(x) ausgibt (d.h. F (x) = f(x)).
(2) Fur jeden probabilistischen polynomialen Algorithmus A und jedes po-sitive Polynom P ∈ Z[x] gilt fur alle genugend großen n:
pr(A(f(x), 1n) ∈ f−1(f(x))︸ ︷︷ ︸Urbild von f(x)
|x← Ωn) <1
P (n)
36Ausfuhrlicher Beweis bei Delfs, Knebl, Introduction to Cryptography [21], Goldreich,Foundations of Cryptography [24] oder Stinson, Cryptography-Theory and Practice [45]
118

[1n bezeichnet einen String aus n Einsen.]
7.8 Bedeutung von Definition 7.7
• Der Hilfs-Input 1n bei A, der die Lange des gewunschten Urbilds angibt,dient dazu, gewisse Funktionen als Einwegfunktionen auszuschließen.Ausgeschlossen werden solche Funktionen f , bei denen die Lange vonf(x) so drastisch gesenkt wird, dass A keine Chance hat, ein Urbild inpolynomialer Zeit in der Große des Inputs f(x) auszugeben.
Bsp:x ∈ 0, 1n, f(x) = Binardarstellung von n (der Lange von x)Dann f(x) ∈ 0, 1⌈log2n⌉
Kein polynomialer Algorithmus kann f(x) invertieren; aber naturlichkann man in polynomialer Zeit in n ein Urbild zu f(x) ∈ 0, 1⌈log2n⌉
hinschreiben, z.B. (0, . . . , 0)←−n−→
.
• Der Algorithmus A, der ein Urbild rat, hat Wahrscheinlichkeit vonmindestens 1
2n , ein richtiges Urbild zu finden. Also kann man die Wahr-scheinlichkeitsschranke 1
P (n)nicht durch 1
2n (oder sogar 0) ersetzen.
• Ein Algorithmus kann sich bis zu einem n0 eine Liste (f(x), x)| Langevon x ≤ n0 erstellen. Fur solche f(x) findet er dann schnell ein Urbild.Daher kann man die Forderung in 7.7 (2) nur fur alle genugend großenn stellen (abhangig vom Algorithmus A und dem Polynom P ).
Einer der wichtigsten Satze der komplexitatstheoretisch orientierten Kryp-tologie, der fruhere Ergebnisse von Blum/Micali, Yao, Goldreich/Krawcyk/Luby verallgemeinert, ist der folgende:
7.9 Satz (Hastad, Impagliazzo, Levin, Luby; 1999)
Genau dann existieren kryptographisch sichere Pseudozufallsfolgen-Genera-toren, wenn Einwegfunktionen existieren.
Der Beweis dieses Satzes ist kompliziert, vor allem die Richtung, wie man ausEinwegfunktionen kryptographisch sichere Pseudozufallsfolgen-Generatorengewinnt.
Wir beschreiben einige wesentliche Punkte:
119

a) Kryptographisch sichere Pseudozufallsfolgen-Generatoren ⇒ Einweg-funktionen:
Wir nehmen der Einfachheit halber an, dass G ein kryptographischsicherer Pseudozufallsfolgen-Generator ist mit Erweiterungsfunktionl(n) = 2n.
Dann definiert man eine Funktion f :⋃
n∈N0, 12n → ⋃n∈N0, 12n
durch f(x, y) = G(x) fur x, y ∈ 0, 1n.Dann erfullt f die Bedingung einer Einwegfunktion:Polynomiale Berechenbarkeit folgt aus der von G.Ang. f ist keine Einwegfunktion. Dann existiert probabilistischer poly-nomialer Algorithmus und positives Polynom Q, so dass
pr(A(f(x), 12n) ∈ f−1(f(x))| x← Ω2n) >1
Q(2n)
fur unendlich viele n.
Man benotigt jetzt einen probabilistischen polynomialen AlgorithmusD, der Ω2n und G(Ωn) ‘unterscheidet’.
Bei Eingabe von α ∈ 0, 12n nutzt D den Algorithmus A. D gibt 1aus, falls A ein Urbild von F zu α findet, sonst 0.
Wegen f(Ω2n) = G(Ωn) [denn fur β ∈ 0, 12n ist
|α ∈ 0, 12n|f(α) = β| = 2n · |γ ∈ 0, 1n|G(γ) = β|] ist
pr(D(G(x)) = 1|x← Ωn) =pr(D(f(z)) = 1|z ← Ω2n) =pr(A(f(z), 12n) ∈ f−1(f(z))|z ← Ω2n) > 1
Q(2n)fur unendlich viele n.
Andererseits gibt es nur maximal 2n viele Elemente in 0, 12n, dieUrbilder unter f haben konnen (denn G hat nur 2n viele Bilder in0, 12n); also wird D nur bei maximal 2n vielen Elementen aus 0, 12n
Wert 1 ausgeben. Also pr(D(z) = 1| z ← Ω2n) ≤ 2n
22n = 12n
Damit: pr(D(G(x)) = 1| x← Ωn)− pr(D(z) = 1| z ← Ω2n)
≥ 1Q(2n)
− 12n ≥ 1
2Q(2n)fur unendlich viele n, Widerspruch.
Man kann schließlich mit einfachen Techniken, auf die hier nicht einge-gangen wird, aus f eine Funktion f ′ : 0, 1∗ → 0, 1∗ konstruieren,die eine Einwegfunktion ist.37
37s. Goldreich [24], S. 36ff.
120

b) Einwegfunktionen⇒ kryptographisch sichere Pseudozufalls-Generator-en:
Zunachst Begriff des Hard-Core-Pradikats einer Einwegfunktion.Bei einer Einwegfunktion f ist es so gut wie nicht moglich, ein Ur-bild x aus y = f(x) mit einem effizienten Algorithmus zu bestim-men. Dennoch tritt oft der Fall auf, dass einzelne Bits von x leichtzu berechnen sind. (Z.B. g Einwegfunktion; fur x = (x1, . . . , xn) seif(x, xn+1) = (g(x), xn+1). Dann f Einweg, aber xn+1 leicht zu bestim-men.) Andererseits konnen bei einer Einwegfunktion nicht alle Bits vonx aus f(x) leicht zu berechnen sein, denn sonst ware x leicht zu be-rechnen. Welche Bits schwierig zu bestimmen sind, konnte allerdingsbei jedem x unterschiedlich sein. Jedenfalls ist es plausibel, dass es einegewisse Boolesche Funktion h : 0, 1∗ → 0, 1 gibt, so dass h(x) ausf(x) im Wesentlichen genauso schwierig zu bestimmen ist wie x, d.h.die Schwierigkeit, x aus f(x) zu bestimmen, manifestiert sich schon ineinem Bit h(x). Dies ist die Idee der Hard-Core-Pradikate.
Def.:Sei h : 0, 1∗ → 0, 1 durch einen deterministischen polynomialenAlgorithmus berechenbar. h heißt Hard-Core-Pradikat einer Funktionf : 0, 1∗ → 0, 1∗, falls fur jeden probabilistischen polynomialenAlgorithmus A (Input Elemente aus 0, 1∗, Output 0 oder 1) undjedes positive Polynom P fur alle genugend großen n gilt:
pr(A(f(x)) = h(x)| x← Ωn) ≤ 1
2+
1
P (n)
Bedeutung:
• Beachte zunachst:
Die Bedingung pr(A(f(x)) = h(x)| x ← Ωn) ≤ 12
+ P (n) und dieentsprechende Bedingung fur den Algorithmus A′ = 1 + A im-plizieren, dass |pr(h(x) = 0| x ← Ωn) − pr(h(x) = 1| x ← Ωn)|vernachlassigbar klein ist, d.h. h verhalt sich fast wie Munzwurfauf Ωn.Daher besagt die Bedeutung von Hard-Core-Pradikaten, dass dieBestimmung von h(x) aus f(x) durch einen effizienten Algorith-mus bis auf einen vernachlassigbaren Rest nicht besser ist als h(x)durch Munzwurf zu ‘raten’.
• Fur die Existenz eines Hard-Core-Pradikats kann es zwei Grundegeben:
121

(a) Informationsverlust von f (d.h. f ist nicht injektiv)z.B. f(z1, . . . , zn) = (0, z2, . . . , zn), h(z1, . . . , zn) = z1
(b) f ist Einwegfunktion
Wir sind am zweiten Fall interessiert.
Tatsachlich kann man zu jeder Einwegfunktion eine eng mit dieser verwandteEinwegfunktion konstruieren, die ein Hard-Core-Pradikat besitzt:
Satz (Goldreich, Levin; 1989)
Sei f : 0, 1∗ → 0, 1∗ eine Einwegfunktion.Definiere g :
⋃n∈N0, 12n → 0, 1∗ durch g(x, y) = (f(x), y), x, y ∈ 0, 1n.
Ist x = (x1, . . . , xn), y = (y1, . . . , yn), so sei h(x, y) =∑
xiyi mod 2.
Dann ist g eine Einwegfunktion und h ist ein Hard-Core-Pradikat fur g.38
[Es ist nicht schwierig, aus g eine Einwegfunktion g : 0, 1∗ → 0, 1∗ zukonstruieren, die ein Hard-Core-Pradikat besitzt.]
Wir konnen also annehmen, dass wir eine Einwegfunktion f mit Hard-Core-Pradikat h vorliegen haben.
Wir beschreiben die Konstruktion eines kryptographisch sicheren Zufallszah-len-Generators jetzt nur fur den Fall, dass f eine bijektive und langenerhal-tende (d.h. x ∈ 0, 1n ⇒ f(x) ∈ 0, 1n fur alle n ∈ N) Einwegfunktionist.
Sei l ein Polynom mit l(n) > n fur alle n.Definiere G auf folgende Weise: Sei s0 ∈ 0, 1n ein Input fur G (seed).Fur j = 1, . . . , l(n) sei sj = f(sj−1).Definiere nun G(s0) = (h(s1), . . . , h(sl(n))) ∈ 0, 1l(n).
Wir zeigen, dass G ein kryptographisch sicherer Pseudozufallsfolgen-Genera-tor ist.Dies beweist man, indem man nachweist, dass G alle Next-Bit-Tests besteht(und zwar von rechts nach links!).
Angenommen, man kann bei zufallig und gleichverteiltem ‘seed‘ s0 ∈ 0, 1nfur unendlich viele n die Bits h(sin) (fur mindestens ein in ∈ 1, . . . , l(n))aus h(sin+1), . . . , h(sl(n)) mit einer Wahrscheinlichkeit > 1
2+ 1
Q(n)(fur ein fe-
stes positives Polynom Q) vorhersagen.
38s. Goldreich [24], S. 66 ff.
122

Wir behaupten nun: Wenn s0 zufallig und gleichverteilt aus 0, 1n gewahltwird, so kann man h(sin) aus f(sin) mit Wahrscheinlichkeit > 1
2+ 1
Q(n)vor-
hersagen:Es sind namlich f(sin) = sin+1, . . . , f(sl(n)−1) = sl(n) aus f(sin) berechenbar.Aus diesen erhalt man h(sin+1), . . . , h(sl(n)) und aus diesen ist nach obigerAnnahme h(sin) mit Wahrscheinlichkeit > 1
2+ 1
Q(n)vorhersagbar.
Da f langenerhaltend und bijektiv ist, gilt dies auch fur f in , d.h. es istf in(0, 1n) = 0, 1n. Daher folgt aus s0 ← Ωn auch sin = f in(s0)← Ωn.Damit widerspricht die vorher bewiesene Aussage der Definition des Hard-Core-Pradikats.
Obige Annahme ist also nicht aufrechtzuhalten, d.h. G besteht alle Next-Bit-Tests (von rechts nach links). Nach dem Satz von Yao (siehe 7.6) ist G daherein kryptographisch sicherer Pseudozufallsfolgen-Generator.
7.10 Die Frage nach der Existenz von Einwegfunktio-nen
Es bleibt die Frage, ob Einwegfunktionen existieren. Dies ist nicht bekannt.
Eine notwendige Bedingung fur die Existenz von Einwegfunktionen ist P 6=NP . (Ob dies gilt, ist eines der beruhmtesten offenen Probleme der Komple-xitatstheorie.)
Sei namlich f eine polynomial berechenbare Funktion. Dann kann man inpolynomialer Zeit entscheiden, ob fur gegebene x und y gilt: f(x) = y. Daherliegt die Berechnung eines Urbilds von y in NP (eine Losung lasst sich inpolynomialer Zeit verifizieren). Ist also P = NP , so lasst sich jede polynomialberechenbare Funktion auch in polynomialer Zeit invertieren, und es gibtkeine Einwegfunktionen.
Tatsachlich ist bei unserer Definition von Einwegfunktionen, in der die Inver-tierung (bis auf einen vernachlassigbaren Rest) auch durch probabilistischepolynomiale Algorithmen unmoglich sein muss, sogar eine weitergehende Be-dingung notwendig, namlich NP * BPP .
BPP steht fur Bounded-Probability Polynomial Time.BPP ist die Klasse aller Sprachen, die von einer probabilistischen, polyno-mial laufzeitbeschrankten Turing-Maschine M (also von einem polynomialprobabilistischen Algorithmus) erkannt werden. Dies bedeutet:
Fur alle x ∈ L : pr(M(x) = 1) ≥ 23
123

Fur alle x 6∈ L : pr(M(x) = 0) ≥ 23
(bounded: Wahrscheinlichkeit wegbeschrankt von 12)
Aquivalent:Ersetze 2
3durch 1− 1
2|x|, |x| = Lange von x.
(sogar 1− 12Q(|x|) , Q ein beliebiges positives Polynom)
Klar: P ⊆ BPP .Also: NP * BPP ⇒ NP 6= P . Nicht bekannt ist auch, ob BPP ⊆ NP .Die obige Forderung verbietet die umgekehrte Inklusion.
P 6= NP bedeutet nur, dass es NP -Probleme gibt, die Instanzen besitzen,die nicht effizient (deterministisch) losbar sind (worst case).
Wir benotigen Funktionen, die im Durchschnitt nicht effizient zu invertierensind. Es ist nicht bekannt, ob aus der Annahme P 6= NP (oder sogar NP *BPP ) die Existenz von Einwegfunktionen folgt. Im nachsten Kapitel werdenwir Kandidaten fur Einwegfunktionen kennenlernen.
124

8 Public-Key-Kryptographie
8.1 Die Grundidee
Die Idee fur Public-Key-Kryptographie stammt von W. Diffie und M.E. Hell-man, dargelegt in der beruhmten Arbeit New Directions in Cryptography [22].
In einem Public-Key-Verschlusselungssystem gibt es keinen gemeinsamen ge-heimen Schlussel, der von zwei Kommunikationspartnern (Alice und Bob)benutzt wird (wie bei den symmetrischen Verfahren).
Stattdessen: Jeder Teilnehmer B hat ein Paar von Schlusseln:
• geheimer Schlussel (private key) GB
• offentlicher Schlussel (public key) PB
GB ist nur B bekannt, PB wird offentlich gemacht. Zu jedem offentlichenSchlussel PB gehort eine Verschlusselungsfunktion EPB
(= E(., PB)). Dieseist auch offentlich bekannt.
Will Alice (A) an Bob (B) eine Nachricht m senden, so verschlusselt A dieNachricht m mit dem offentlichen Schlussel von B
m→ EPB(m) =: c
und sendet c an B.
Ein solches System kann nur sicher sein, wenn zwei Bedingungen erfullt sind:
a) m darf mit realistischem Aufwand nicht aus EPBberechenbar sein: EPB
ist eine injektive Einwegfunktion. (EPBsoll naturlich effizient berechen-
bar sein.)
b) B muss m aus c = EPB(m) effizient berechnen konnen. Dies gelingt mit
Hilfe seines geheimen Schlussels GB. Diese Zusatzinformation ermog-licht eine effiziente Entschlusselung m = DGB
(c) (= E−1PB
(c)).
Injektive Einwegfunktionen, die mit einer Zusatzinformation effizient zu in-vertieren sind, heißen Geheimturfunktionen (oder Fallturfunktionen) (trap-door functions). Bedingungen 1) und 2) implizieren:
125

3) GB darf aus PB nicht effizient berechenbar sein.
Nach 7.10 ist nicht bekannt, ob Einwegfunktionen existieren; dies gilt umsomehr fur Fallturfunktionen.
Dennoch gibt es einige Klassen von Funktionen, die als Kandidaten furFallturfunktionen angesehen werden, da bis heute kein (probabilistischer) po-lynomialer Algorithmus zur Invertierung (in einer nicht vernachlassigbarenAnzahl von Fallen) bekannt ist.
Die wichtigsten Klassen solcher Funktionen und die darauf fußenden Public-Key-Verfahren werden wir im Folgenden besprechen.
Zuvor noch eine Bemerkung:Ein Vorteil von Public-Key-Systemen gegenuber solchen mit symmetrischenVerschlusselungsverfahren ist folgender: Bei n Teilnehmern, die alle geheimmiteinander kommunizieren wollen, muss bei symmetrischen Verfahren jedesPaar von Teilnehmern einen eigenen Schlussel besitzen. Dies erfordert n(n−1)
2
Schlussel; die Anzahl wachst also quadratisch mit der Anzahl der Teilnehmer.Bei Public-Key-Verfahren sind jedoch nur 2n Schlussel (je ein offentlicher undgeheimer pro Teilnehmer) erforderlich; die Anzahl wachst linear.
8.2 Modulare Potenzen und das RSA-Verfahren
1977 stellten R. Rivest, A. Shamir und L. Adleman ein Public-Key-Verfahren(RSA-Verfahren) vor,39 das bis heute zu den popularsten Public-Key-Verfah-ren gehort. Es beruht auf folgender Funktionenklasse, die zur Verschlusselungverwendet wird:
Sei n das Produkt zweier verschiedener Primzahlen p und q und sei e ∈ Nteilerfremd zu ϕ(n).
Def. RSAe,n :=
Zn → Zn
x 7→ xe mod n(modulares Potenzieren).
Falls n fest, schreiben wir RSAe statt RSAe,n.
Man beachte: Es ist ϕ(n) = (p− 1)(q − 1).[Denn die p+ q−1 naturlichen Zahlen i ·p, 1 ≤ i ≤ q−1, j · q, 1 ≤ j ≤ p−1,und n sind die einzigen ≤ n, die nicht teilerfremd zu n sind; also ϕ(n) =n− p− q + 1 = (p− 1)(q − 1).]
39erschienen im Aufsatz On Digital Signatures and Public Key Cryptosystems [2]
126

8.3 Lemma (Satz von Euler)
a) (Satz von Euler) Ist n ∈ N, x ∈ Z, ggT(x, n) = 1, so ist xϕ(n) ≡1 (mod n).[n = p : xp−1 ≡ 1 (mod p) (kleiner Satz von Fermat)]
b) Ist n = pq, p, q verschiedene Primzahlen, und sind a, k ∈ N0, x ∈ Z, soist xkϕ(n)+a ≡ xa (mod n).
Beweis:
a) Ist x mod n = x′, d.h. x = tn + x′, 0 ≤ x′ < n, so ist x ≡ x′ (mod n),also xϕ(n) ≡ (x′)ϕ(n) (mod n). Also ist o.B.d.A. 0 < x < n, d.h. x ∈Z∗n = y ∈ Zn : ggT(y, n) = 1 (Gruppe bezuglich Multiplikation modn), |Z∗n| = ϕ(n).
In jeder endlichen Gruppe G gilt: g|G|︸︷︷︸Potenzierung in G
= e︸︷︷︸neutrales Element
(folgt
aus Satz von Lagrange40). Hier ist also xϕ(n)︸︷︷︸
Potenzierung in Z∗n = 1, d.h. wie
behauptetxϕ(n)︸︷︷︸
Potenzierung in Z ≡ 1 (mod n).
b) Ist p | x, so ist xa ≡ 0 (mod p) und xkϕ(n)+a ≡ 0 (mod p).
Ist p ∤ x, so ist xkϕ(n)+a = xa(xϕ(n))ka)≡ xa (mod p).
Also ist in jedem Fall xkϕ(n)+a ≡ xa(mod p), und analog folgt xkϕ(n)+a ≡xa (mod q). Da p und q verschiedene Primzahlen sind, erhalt man wiebehauptet
xkϕ(n)+a ≡ xa (mod n).
8.4 Satz (Eigenschaften der RSA-Funktionen)
a) Ist e = kϕ(n) + e′, k ∈ N0, 0 ≤ e′ < ϕ(n), so ist RSAe = RSAe′. Alsokann man 0 < e < ϕ(n) wahlen.
b) Unter den Voraussetzungen von 8.2 ist RSAe bijektiv (d.h. eine Per-mutation auf Zn).
40siehe z.B. Buchmann [15, 2.1.1]
127

c) Die inverse Abbildung zu RSAe ist RSAd, wobei d eindeutig bestimmtist durch 0 < d < ϕ(n) und ed ≡ 1 (mod ϕ(n)).
Beweis:
a) Es ist xe = xkϕ(n)+e′ ≡ xe′ (mod n) nach 8.3 b).
b),c) Nach a) ist o.B.d.A. 0 < e < ϕ(n), e ∈ Z∗ϕ(n). Dann existiert genau ein
d ∈ Z∗ϕ(n) mit ed mod ϕ(n) = e⊙ d︸ ︷︷ ︸Multiplikation in Zϕ(n)
= 1, ed = kϕ(n) + 1,
d.h. ed ≡ 1 (mod ϕ(n)) und 0 < d < ϕ(n).(d ist das Inverse zu e in Z∗ϕ(n).)
Sei nun x ∈ Zn. Dann ist
RSAd(RSAe(x)) = (xe)d mod n = xed mod n
= xkϕ(n)+1 mod n8.3 b)= x,
also (RSAe)−1 = RSAd.
8.5 Bemerkung (schnelles Potenzieren)
RSA-Funktionen sind effizient zu berechnen. Man berechnet ae mod n mitder Methode der iterierten Quadrierung:
Schreibe e in Binardarstellung. Sei l = ⌊log2 e⌋ + 1, d.h. e ist l-Bit-Zahl,e = 2l−1el−1 + . . . + 20e0 (ei ∈ 0, 1, el−1 = 1)
= (. . . ((2el−1 + el−2) · 2 + el−3) · 2 + . . . + e1) · 2 + e0
ae = ((. . . ((a2 · ael−2)2 · ael−3)2 . . .)2 · ae1)2 · ae0
Also kann ae in l − 1 Schritten berechnet werden. Jeder Schritt besteht auseiner Quadrierung und gegebenenfalls einer weiteren Multiplikation. Zur Be-rechnung von ae mod n nimmt man nach jeder Quadrierung und ggf. Multi-plikation den Rest modulo n.
128

8.6 RSA-Verfahren (Basisversion)
a) Schlusselerzeugung:a) Wahle große Primzahlen p, q, p 6= q und berechne n = p · q.b) Wahle e mit ggT(e, ϕ(n)) = 1.
offentlicher Schlussel: P = (n, e)
c) Berechne d mit 0 < d < ϕ(n) und ed ≡ 1 (mod ϕ(n)).
Geheimer Schlussel: G
(p, q und ϕ(n) werden ebenfalls geheimgehalten, besser geloscht. NachBestimmung von e und d werden sie nicht mehr benotigt.)
b) Verschlusselung:Wir verschlusseln Zahlen m mit 0 ≤ m < n.Der Klartext m wird mit dem offentlichem Schlussel (n, e) mit Hilfeder RSAe-Funktion verschlusselt:
c = me mod n
(Jeder, der den offentlichen Schlussel eines Teilnehmers kennt, kanndiesem eine verschlusselte Nachricht senden.)
c) Entschlusselung:Entschlusselung mit dem geheimen Schlussel (n, d) und der RSAd-Funktion:
m = cd mod n
Korrektheit der Entschlusselung auf Grund von Satz 8.4 c).
8.7 Bemerkung (Bestimmung von e und d)
a) In der Praxis wird e haufig als kleine Zahl gewahlt, damit die Ver-schlusselung besonders effizient moglich ist. Wegen ggT(e, ϕ(n)) = 1und ϕ(n) = (p− 1)(q − 1), muss e ungerade sein.
Bei Wahl von e = 3 ist z.B. zur Berechnung von me mod n eine Qua-drierung und eine Multiplikation modulo n durchzufuhren. Sehr klei-ne Exponenten e bergen aber gewisse Sicherheitsrisiken (dazu spatermehr).
Daher werden auch gelegentlich Exponenten e der Form 2k + 1 ver-wendet. Hier sind zur Berechnung von me mod n nur k Quadrierungen
129

und eine Multiplikation modulo n erforderlich. Eine typische Wahl iste = 216 + 1 = 65537 (Primzahl).
b) Bestimmung von d:d wird mit Hilfe des erweiterten Euklidischen Algorithmus aus e undϕ(n) bestimmt.
Beachte: ϕ(n) = (p − 1)(q − 1) ist bei Kenntnis von p und q leicht zuberechnen.
(ggT(e, ϕ(n)) = 1. Erweiterter Euklidischer Algorithmus (vgl. 2.1 (b))liefert s, t ∈ Z mit es + ϕ(n)t = 1. Sei s = d + ϕ(n) · u, 0 ≤ d < ϕ(n).Dann ed = es− ϕ(n)eu = 1− ϕ(n)(eu− t) ≡ 1 (mod ϕ(n)).)
8.8 Beispiel zur RSA-Verschusselung
p = 13, q = 23 (unrealistisch klein), n = pq = 299, ϕ(n) = 12 · 22 = 264 =8 · 3 · 11, e = 5 (kleinstmogliches e); offentlicher Schlussel (n, e) = (299, 5).
Bestimmung von d mit ed ≡ 1 (mod ϕ(n)).Erweiterter Euklidischer Algorithmus mit ϕ(n) = 264 und e = 5:
x y s1 s2 s t1 t2 t g r264 5 1 0 0 0 1 1
264 mod 5 = 4 6= 0 5 4 0 1 1 1 −52 −52 52 45 mod 4 = 1 6= 0 4 1 1 −1 −1 −52 53 53 1 1
1 mod 1 = 0
1 =ggT(264, 5) = 264 · (−1) + 5 · 53, d = 53 (ed = 5 · 53 ≡ 1 (mod 264))Geheimer Schlussel d = 53
Der Klartext sei m = 212.
Zur Verschlusselung muss man m5 mod 299 berechnen.
2122 ≡ 44944 ≡ 94 (mod 299)2124 ≡ 942 ≡ 8836 ≡ 165 (mod 299)2125 ≡ 165 · 212 ≡ 34980 ≡ 296 (mod 299)
Verschlusselter Text ist c = 296.
Zur Entschlusselung wird c53 mod 299 berechnet.
130

53 = 25 + 24 + 22 + 20, daher 29653 = ((((2962 · 296)2)2 · 296)2)2 · 296
2962 ≡ (−3)2 ≡ 9 (mod 299)2962 · 296 ≡ 9 · (−3) ≡ −27 (mod 299)(−27)2 ≡ 729 ≡ 131 (mod 299)(−27)4 ≡ 1312 ≡ 17161 ≡ 118 (mod 299)(−27)4 · 296 ≡ 118 · (−3) ≡ −354 ≡ 244 (mod 299)2442 ≡ (−55)2 ≡ 3025 ≡ 35 (mod 299)2444 ≡ 352 ≡ 29 (mod 299)29 · 296 ≡ 8584 ≡ 212 (mod 299)
Die Entschlusselung liefert also wieder den Klartext m = 212.
8.9 Verwendung von RSA als Blockchiffre
Das zugrundeliegende Klartextalphabet R bestehe aus N Zeichen. Diesenwerden die Zahlen 0, 1, . . . , N − 1 zugeordnet.(Typischerweise R = Z2, N = 2)Sei (n, e) der offentliche Schlussel des Teilnehmers B.Setze k = ⌊logN n⌋, d.h. Nk ≤ n < Nk+1.
Ein Klartext (mit Zeichen in 0, 1, . . . N − 1) wird in Blocke der Lange kaufgeteilt, die einzeln verschlusselt werden:m1, . . .mk sei ein solcher Block.
Bilde m =k∑
i=1
miNk−i. (N -adische Zahldarstellung)
Dann: 0 ≤ m ≤ (N − 1)k∑
i=1
Nk−i = Nk − 1 < n
m wird verschlusselt zu c = me mod n.
Schreibe Zahl c wieder zur Basis N . Die N -adische Darstellung von c kannLange k + 1 haben (wenn Nk ≤ c < n).
Chiffretextblock ist dann c = c0c1 . . . ck, 0 ≤ ci ≤ N − 1, d.h. Chiffretext-blocke werden immer in der Lange k+1 dargestellt, evtl. mit fuhrenden Nul-len. Das RSA-Verfahren bildet dann Blocke der Lange k injektiv auf Blockeder Lange k + 1 ab.
In dieser Form kann man das Verfahren wie eine Blockchiffre im ECB-Modeoder im CBC-Mode (mit leichter Modifikation) anwenden.
131

Bsp:
R = 0, a, b, c ↓ ↓ ↓ ↓0 1 2 3
n = 299, e = 5, d = 53 N = 4, k = ⌊log4 299⌋ = 4Zu verschlusselnder Klartextblock: caa0→ 3110
m = 3 · 43 + 1 · 42 + 1 · 4 + 0 · 1 = 192 + 16 + 4 = 212
Verschlusselung: 2125 mod 299. Also c = 296 (siehe Beispiel 8.8)
296 = 1 · 44 + 0 · 43 + 2 · 42 + 2 · 41 + 0 · 40
Also Schlusseltextblock: a0bb0
In der Praxis sind noch weitere Bedingungen fur die RSA-Verschlusselung zubeachten. Gelaufige Standards (z.B. PKCS#1v1.5, PKCS#1v2.1 von RSAData Security Company) operieren auf Byte-Basis und unterscheiden sichvon obiger Beschreibung.Naheres z.B. in Vaudenay [47, 9.3.2 und 9.3.8].
8.10 Sicherheit des RSA-Verfahrens
a) Die Sicherheit des RSA-Verfahrens beruht auf der Annahme, dass dieRSA-Funktionen Einwegfunktionen sind. Nach Definition 7.7 mussenEinwegfunktionen auf 0, 1∗ definiert sein. Daher wird die Einwegfunk-tionsannahme fur die gesamte Familie der RSA-Funktionen gemacht:
Sei Ik = (n, e)|n = p · q, p 6= q Primzahlen, 0 < e < ϕ(n),ggT(e, ϕ(n)) = 1, |n| = k
Sei P (x) ∈ Z[x] ein positives Polynom und A(n, e, y) ein polynomialerprobabilistischer Algorithmus.Dann existiert k0 ∈ N, so dass
pr(A(n, e, y) = RSA−1e (y) | (n, e)← Ik, y ← Z∗n) ≤ 1
Q(k)
fur alle k ≥ k0.
Dabei ist die Gleichverteilung auf Ik und auf Z∗n angenommen, bezuglichderer (n, e) bzw. y zufallig ausgewahlt werden. Dies nennt man dieRSA-Annahme. (Unter dieser Annahme kann man zeigen, dass das
132

niedrigste Bit von x ein Hard-Core-Pradikat fur RSAe(x) ist; siehe z.B.[38, Theorem 9.1, S. 286].)
Wir werden im Folgenden einige Grunde fur die RSA-Annahme benen-nen und außerdem einige Sicherheitsvorkehrungen bei der Wahl vonp, q uns e fur praktische Anwendungen beschreiben.
b) Klar ist, dass die RSAe-Funktionen leicht zu invertieren ist, wenn manden geheimen Schlussel d kennt. Unbekannt ist, ob man zur effizientenInvertierung von RSAe tatsachlich d benotigt.
c) Die Bestimmung des geheimen Schlussels d ist “genauso“ schwierig wiedie Faktorisierung von n. Es gilt namlich:
Satz:
Gibt es fur eines der folgenden Probleme einen polynomialen (probabi-listischen) Algorithmus, so auch fur jedes der anderen:
Gegeben: (n, e), 0 < e < ϕ(n), ggT(e, ϕ(n)) = 1 (n = p · q)(1) Bestimme Faktorisierung von n.(2) Bestimme ϕ(n).(3) Bestimme d mit ed ≡ 1 (mod ϕ(n)).
Beweis:(1) ⇒ (2) Sind p, q mit n = p · q bekannt, so ϕ(n) = (p− 1)(q − 1).(2) ⇒ (3) Sind ϕ(n), e bekannt, so bestimmt man mit dem erweitertenEuklidischen Algorithmus d.(3) ⇒ (1) Zunachst eine Vorbemerkung:Ist G eine endliche Gruppe mit neutralem Element 1G und g ∈ G,so existiert eine kleinste naturliche Zahl c mit gc = 1G. c heißt dieOrdnung von g, c = o(g). Dabei gilt:
1) Es ist o(g) = | < g > |, wobei < g >= 1G, g, g2, . . . , go(g)−1 dievon g erzeugte (zyklische) Untergruppe von G ist. Nach dem Satzvon Lagrange ist o(g) ein Teiler von |G| (vgl. auch Beweis von 8.3a)).
2) Ist gb = 1G, b ∈ N, so ist o(g) ein Teiler von b.
3) Ist o(g) = 2fu, wobei u ungerade ist, und ist z ungerade, so isto(gz) = 2fu′, und u′ teilt u.
Sei nun 2s die großte Zweierpotenz, die ed− 1 teilt, und k =ed− 1
2s .
Ist dann a ∈ Z∗n (d.h. 1 ≤ a ≤ n, ggT(a, n) = 1),so ist o(ak mod n) ∈ 2i|0 ≤ i ≤ s,
133

denn (ak)2s
mod n = aed−1 mod n,da ed− 1 ≡ 0 (mod ϕ(n)) (vgl. Vorbemerkung Punkt 2)).
Fur ein solches a ist naturlich auch a mod p ∈ Z∗p und a mod q ∈ Z∗q .Ang. o(ak mod p) 6= o(ak mod q), o.E. o(ak mod p) > o(ak mod q).Auch die Ordnungen von ak mod p bzw. ak mod q liegen in 2i|0 ≤i ≤ s. Sei o(ak mod q) = 2r. Dann r < s und ak·2r ≡ 1 (mod q), aberak·2r 6≡ 1 (mod p); daher ggT(a2rk − 1, n) = q.
Um also n zu faktorisieren, wahlt man zufallig und gleichverteilta ∈ 1, . . . , n− 1 und berechnet t=ggT(a, n).Ist t > 1, so ist t ein echter Teiler von n, fertig.Ist t = 1, so berechne ggT(a2rk − 1, n), r = 0, . . . , s− 1.Findet man dabei einen Teiler von n, so fertig; wenn nicht, wahlt manein neues a.
Wir werden gleich im Anschluss zeigen, dass gilt:
|a|a ∈ 0, . . . , n− 1, ggT(a, n) = 1, o(ak mod p) 6= o(ak mod q)|≥ (p−1)(q−1)
2(∗)
Daher ist die Wahrscheinlichkeit, ein a mit o(ak mod p) 6= o(ak mod q)– und damit einen echten Teiler von n – zu finden, mindestens 1
2.
Nach l Iterationen ist die Wahrscheinlichkeit also mindestens 1 − 12l ,
einen Teiler von n zu finden; also ist z.B. fur l ≥ log(n) die Wahr-scheinlichkeit mindestens 1 − 1
n. Jede Iteration erfordert wegen s <
log(ed) < log(n2) = 2 log n maximal 2 log n viele ggT-Bestimmungen(die auch polynomial in log n durchfuhrbar sind).
Fur die noch zu beweisende Anzahlaussage (∗) benotigen wir noch:
Chinesischer Restsatz
Seien m1, . . . , mh paarweise teilerfremde naturliche Zahlen und seiena1, . . . , ah ganze Zahlen.
Dann gibt es genau eine Zahl x mit 0 ≤ x ≤h∏
i=1
mi mit x ≡ aj (mod
mj) fur alle j = 1, . . . , h.
Beweis:
Setze m =h∏
i=1
mi und Mj = m/mj fur j = 1, . . . , h.
Dann ist ggT(mj , Mj) = 1 fur j = 1, . . . , h.
Mit dem erweiterten Euklidischen Algorithmus kann man daher naturli-che Zahlen yj bestimmen, so dass yjMj ≡ 1 (modmj) fur alle j =
134

1, . . . , h. Dann folgt auch ajyjMj ≡ aj (modmj) fur j = 1, . . . , h.Da fur i 6= j die Zahl mj ein Teiler von Mi ist, gilt auch aiyiMi ≡0 (mod mj) fur alle i, j = 1, . . . , h, i 6= j.
Setzt man x =h∑
i=1
aiyiMi mod m, so folgt daher x ≡ aj (mod mj) fur
alle j = 1, . . . , h.
Sind x, x′ zwei Losungen mit 0 ≤ x, x′ ≤ m, so ist x ≡ aj ≡ x′ (modmj) fur alle j = 1, . . . , h. Da die mj paarweise teilerfremd sind, folgtdann auch x ≡ x′ (mod m), also x = x′.
Wir beweisen jetzt die noch offen gebliebene Aussage (∗):Z∗p und Z∗q sind zyklische Gruppen der Ordnung p − 1 bzw. q − 1. Seiv ∈ 1, . . . , p − 1 mit < v >= Z∗p (d.h. o(v) = p − 1) und sei w ∈1, . . . , q − 1 mit < w >= Z∗q .Nach dem Chinesischen Restsatz existiert ein x, 1 ≤ x ≤ n = pq mitx ≡ v (mod p) und x ≡ w (mod q). Dann ist also o(x mod p) = p − 1und o(x mod q) = q − 1.
1. Fall: o(xk mod p) > o(xk mod q)Da p − 1 ein Teiler von ϕ(n) und ϕ(n) ein Teiler von ed − 1 ist, isted−1 = (p−1)r fur ein r ∈ N. Es folgt (xk mod p)2s
= (x mod p)k·2s
=(x mod p)ed−1 = (x mod p)(p−1)r = 1. Also ist o(xk mod p) = 2i miti ≤ s. Analog ist o(xk mod q) = 2j mit j < i.
Sei u eine ungerade Zahl in 1, . . . , p − 1 und y ∈ 0, . . . , q − 2.Nach dem Chinesischen Restsatz gibt es ein a, 1 ≤ a < n = pq, mita ≡ hu (mod p) und a ≡ hy (mod q).
Dann ist o(ak mod p) = o(xuk mod p), also o(ak mod p) = o(xk mod p)(siehe Vorbemerkung 3)).
Andererseits ist (ak mod q)2j
= ak·2j
mod q = xyk·2j
mod q = 1, d.h.o(ak mod q) ≤ o(xk mod q) (siehe oben, 2)). Also ist o(ak mod p) >o(ak mod q).
Es ist klar, dass fur jede der (p−1)(q−1)2
moglichen Wahlen von (u, y) diezugehorigen Zahlen a < n paarweise verschieden sind. Damit folgt dieBehauptung in diesem Fall.
2. Fall: o(xk mod p) < o(xk mod q)Analog zum ersten Fall.
3. Fall: o(xk mod p) = o(xk mod q)Wie zu Beginn des ersten Falles sieht man, dass
o(xk mod p) = o(xk mod q) = 2i, i ≤ s.
135

Dabei ist i ≥ 1 (siehe Vorbemerkung 3)), da k ungerade ist und p− 1oder q − 1 gerade ist (in unserem Fall dann sogar beide).
Ist u eine ungerade Zahl in 0, . . . , p − 2 und y eine gerade Zahlin 0, . . . , q − 2, so existiert nach dem Chinesischen Restsatz ein a,1 ≤ a < n = pq, mit a ≡ xu (mod p) und a ≡ xy (mod q). Wie imersten Fall sieht man, dass o(ak mod p) = o(xk mod p).
Andererseits ist (ak mod q)2i−1= (xyk mod q)2i−1
= (xk mod q)y·2i−1=
1, da y gerade und daher 2i ein Teiler von y2i−1 ist.
Also ist o(ak mod q) < o(ak mod p).
Wahlt man u als gerade Zahl in 0, . . . , p − 2 und y als ungeradeZahl in 0, . . . , q−2, so verlauft das Argument analog. Fur jede dieser
insgesamt (p−1)(q−1)2
moglichen Wahlen von (u, y) sind die zugehorigenZahlen a < n verschieden.
Damit ist der Beweis vollstandig.
d) In Folge von c) stellt sich die Frage, wie schnell sich eine Zahl n = p · qfaktorisieren lasst.
Es gibt eine Reihe guter Faktorisierungsalgorithmen, auf die wir aberin dieser Vorlesung nicht eingehen konnen. Keiner von ihnen ist einpolynomialer Algorithmus, und es ist unbekannt, ob Faktorisierung inpolynomialer Zeit moglich ist. Die besten derzeit bekannten Algorith-men (
”Zahlkorpersieb“) haben eine Komplexitat von
O(ec(log n)13 (log log n)
23 ), c geeignete Konstante (c ≤ 3).
Von 1991 bis 2007 veranstaltete die Firma RSA Security die sogenannteRSA-Challenge, bei der große RSA-Zahlen (Produkt zweier Primzah-len) faktorisiert werden sollten. Das letzte Ergebnis war die Faktori-sierung einer 640-Bit-Zahl im November 2005 (Bahr, Boehm, Franke,Kleinjung). Die Rechenzeit auf einem 2,2-GHz-Prozessor betrug 30 Jah-re (tatsachlich wurde die Faktorisierung in funf Monaten auf parallelenRechnern ermittelt).
Zur Zeit gilt eine Bitlange von 1024 Bit fur n als sicher.41
e) Es gibt eine Reihe von Algorithmen, die bei speziellen Eigenschaftenvon p und q schnell eine Faktorisierung liefern. Z.B. sollten p und q nicht
41Naheres uber Faktorisierungsalgorithmen: Buchmann [15], Kapitel 8, Crandall [19]oder Riesel [41]
136

die gleiche Bitlange haben, da ansonsten Algorithmen, die in der Nahevon√
n nach Faktoren suchen, erfolgreich sind. Andererseits sollten pund q beide groß sein. Eine kleine Differenz der Bitlange von p und qist daher die beste Wahl.
Andere Eigenschaften, die haufig gefordert werden:
1. p− q besitzt einen großen Primfaktor, r2. r − 1 besitzt einen großen Primfaktor3. p + 1 besitzt einen großen Primfaktor
(sog. starke Primzahlen)
(analog fur q)
f) Wie vorne erwahnt, wird aus Effizienzgrunden oft ein kleiner Exponente, z.B. e = 3, fur das Verschlusseln verwendet. Das birgt aber eineGefahr in sich, wenn A ein und dieselbe Nachricht an mehrere Benutzermit den offentlichen Schlusseln (n1, 3), (n2, 3), (n3, 3) schickt. Ist m derKlartext, so sendet A
ei = m3 mod ni, i = 1, 2, 3. Wie nehmen m < ni an!
Lauscherin Eve fangt c1, c2, c3 ab. Mit Hilfe des Chinesischen Restsatzesfindet sie ein a, 0 ≤ a < n1 n2 n3, mit
a ≡ c1 (mod n1)a ≡ c2 (mod n2)a ≡ c3 (mod n3)
Dieses a ist eindeutig bestimmt. Wegen m3 < n1n2n3 ist a = m3. Evekann m durch Ziehen der Kubikwurzel aus a erhalten.
Losung: Entweder großere e.Oder: An m wird eine zufallig erzeugte Bitfolge geeigneter Lange (z.B.64 Bit) vor der Chiffrierung angehangt (’Salting’, ’Padding’, Maskie-rung). Fur jedes i muss ein anderer Bitstring gewahlt werden.
g) Auch fur kleine d gibt es Unsicherheiten.Hier gibt es einen Angriff, der auf M.J. Wiener (1990) zuruckgeht.42
Dann kann man durch Kettenbruchzerlegung von
e
n= a0 +
1
a1 + 1a2+ 1
a3+...
42Einzelheiten siehe: Wiener [50]
137

im Fall d < ( n18
)1/4 den geheimen Exponent d schnell ermitteln.
Von D. Boneh, G. Durfee u. Y. Frankel (1998) wurde dieser Angriff aus-gedehnt auf den Fall, dass d < n0,293. Weitere Verbesserungen wurdenspater noch erzielt.
Aus diesem Grund wird gelegentlich empfohlen, bei der Wahl von eund d zunachst d geeignet zu wahlen und daraus e mit dem erweitertenEuklidischen Algorithmus zu bestimmen. (Aus Effizienzgrunden – ewird i.d.R. groß sein – wird dies in der Praxis aber selten gemacht.)
h) Eine weitere Angriffsmoglichkeit beruht auf der Multiplikativitat derRSA-Funktionen:Es gilt (m1m2)
e mod n = me1m
e2 mod n. Das liefert die folgende An-
griffsmoglichkeit bei kleinem m (Boneh, Joax, Nguyen, 2000).
Angenommen Eve weiß, dass m < 2t < n ist (z.B. Passwort, DES-Schlussel). Mit nicht-vernachlassigbarer Wahrscheinlichkeit ist dann
m = m1m2, m1, m2 < 2t2 .
[Hat m z.B. 64 Bit (d.h. m < 264), dann ist die Wahrscheinlichkeit 18%,dass m = m1m2 ist mit m1, m2 jeweils 32-Bit-Zahlen.]
Dann ist
c = me mod n = me1m
e2 mod n = ((me
1 mod n)(me2 mod n)) mod n.
Eve bildet nun die Datenbank 1e, 2e, 3e, . . . , (2t2 )e (alles mod n). Da-
bei seien o.B.d.A. alle ke teilerfremd zu n.Sie bildet auch (1e)−1, (2e)−1, (3e)−1, . . . , ((2
t2 )e)−1 (alles mod n).
Nun testet sie, ob c(ke)−1 mod n = je fur geeignete k, j ∈ 1, . . . , 2 t2.
Dann ist c = jeke mod n, und m = jk (denn RSAe : Zn → Zn istbijektiv, und es sind m, jk < n).(Dies ist ein Meet-in-the-Middle Angriff, vgl. 4.6.)
Wir analysieren die Kosten bei diesem Angriff: Fur den Speicher derDatenbank benotigt man 2
t2 log n Bits. Wenn die Datenbank erstellt
und sortiert ist, ist der Aufwand fur die binare Suche vernachlassigbar(logarithmisch in der Große der Datenbank). Es sind also im Wesentli-chen 2
t2 Multiplikationen durchzufuhren.
Beispiel:DES-Schlussel mit 56 Bit (< 256), n 1024-Bit-Zahl.Dann hat die Datenbank eine Große von 2281024 = 238 Bit (= 32Gigabyte).
138

Falls der DES-Schlussel das Produkt zweier Zahlen < 228 ist, so wird erin 228 Multiplikationen gefunden (anstelle von 256 Exponentiationen).
Losung: Padding-Techniken (vgl. [38, Kapitel 14 und 15]).
i) Angriffe auf Grund von Laufzeiteffekten bei modularer Potenzierung(Paul Kocher, 1995). Moglich, falls physikalischer Zugriff auf Rechner.43
8.11 Effizienz des RSA-Verfahrens
Die aus Sicherheitsgrunden empfohlene Wahl von Zahlen n mit der Bitlangevon 1024 Bit impliziert, dass das RSA-Verfahren zeitaufwandig ist (bei Ver-und mehr noch bei Entschlusselung). Vergleiche dazu die Schlussellange vonDES und AES.
Software-Implementierungen von AES sind derzeit ca. 100 mal schneller alsbei RSA.
Bei Hardware-Implementierungen ist der Geschwindigkeitsunterschied nochgroßer.
Daher wird das RSA-Verfahren haufig nur zur Chiffrierung beim Schlussel-austausch fur symmetrische Verfahren eingesetzt oder bei digitalen Signatu-ren (Hybrid-Verfahren) oder zur Authentifizierung (siehe Kapitel 9, 10).
8.12 Bestimmung großer Primzahlen
a) Zur Schlusselerzeugung beim RSA-Verfahren werden große Primzahlen be-notigt, etwa von Bitlange 500, also in Dezimalstellung ca. 150-stellige Prim-zahlen.
Dazu geht man so vor, dass durch Zufallswahlen Zahlen im gewunschtenGroßenbereich gewahlt werden. Zunachst wird uberpruft, ob eine so gewahlteZahl durch eine kleine Primzahl (z.B. bis 106, Liste) teilbar ist. Wenn diesnicht der Fall ist, wird ein Primzahltest durchgefuhrt (dazu gleich Naheres).Sollte sich herausstellen, dass die gewahlte Zahl keine Primzahl ist, wird eineweitere Zufallswahl durchgefuhrt.
43s. Trappe, Washington [46], S. 143-145 und Ertel [23], S. 84-85
139

Wann kann man dabei erwarten, eine Primzahl gefunden zu haben?Der Primzahlsatz (Hadamard, de la Valle Poussin44, 1896) besagt, dass
π(x) ∼ x
ln(x), π(x) = # Primzahlen ≤ x.
Man kann also erwarten, nach ln(10150) = 150 · ln(10) ≈ 350 Versuchen eine150-stellige Primzahl zu finden, wobei sich diese Anzahl verringert, wenn manz.B. von vorneherein alle geraden Zahlen ausschließt.
(Achtung: Aus dem Primzahlsatz kann man nicht entnehmen, dass in jedemFall zwischen x und x + ln(x) eine Primzahl liegt. Tatsachlich gilt namlichπ(x) > x
ln(x)fur x ≥ 17 und π(x) < 1, 26 · x
ln(x)(Rosser, Schoenfeld), und
hieraus ergibt sich qualitativ nicht viel Besseres als das, was schon das so-genannte Bertrand’sche Postulat (ein bewiesener Satz) besagt, dass namlichzwischen x und 2x eine Primzahl liegt.)
Wie sehen Primzahltests aus?Die naheliegende Probedivision mit allen Zahlen ≤ √n ist zu aufwandig.Sie hat exponentiellen Aufwand bzgl. der Inputlange log(n). Man benotigtschnellere Tests.
b) Fermat-TestEr beruht auf dem kleinen Satz von Fermat (8.3 a)):Ist p eine Primzahl, a ∈ N, ggT(a, p) = 1, so ist ap−1 ≡ 1 (mod p).
Test:Gegeben n. Wahle a ∈ N, a < n.
Ist ggT(a, n) 6= 1, so ist n keine Primzahl.Ist ggT(a, n) = 1, so uberprufe, ob an−1 ≡ 1 (mod n).Wenn nicht, so ist n keine Primzahl.Ansonsten ist keine Aussage moglich.Wiederhole dann den Test mit neuem a.
(Dass nur a < n gewahlt werden, ist keine Einschrankung, da (a + kn)n−1 ≡an−1 (mod n).)
Mit wievielen a muss man den Fermat-Test wiederholen, um bei einer zu-sammengesetzten Zahl herauszufinden, dass sie zusammengesetzt ist?Hier liegt eine Schwache des Fermat-Tests, denn es gibt zusammengesetz-te Zahlen n, so dass an−1 ≡ 1 (modn) fur alle a mit ggT(a, n) = 1 ist.
44vgl. Chandrasekharan [17]
140

Solche Zahlen heißen Carmichael-Zahlen; sie werden vom Fermat-Test nurdann als zusammengesetzt erkannt, wenn man zufallig ein a < n testet mitggT(a, n) 6= 1 (dann hat man sogar schon einen nicht-trivialen Teiler von ngefunden).
Zwar sind Carmichael-Zahlen selten (z.B. gibt es zwischen 1 und 100.000 nur16 Carmichael-Zahlen; 561 ist die kleinste), aber es gibt unendlich viele.45
c) Miller-Rabin-TestUm den Fall der Carmichael-Zahlen auszuschließen, muss man den Fermat-Test verfeinern. Eine solche Verfeinerung stellt der Miller-Rabin-Test dar. Erist auch ein probabilistischer Primzahltest, den wir jetzt kurz vorstellen. Erberuht auf folgender Uberlegung:
Sei p eine ungerade Primzahl, a ∈ N, ggT(a, p) = 1.Sei p− 1 = 2s · t, 2 ∤ t. Klar: s ≥ 1.
Aus ap−1 ≡ 1 (mod p) folgt dann, dass
(a2s−1·t)2 ≡ 1 (mod p).
Anders ausgedruckt: a2s−1·t ist eine Nullstelle des Polynoms x2 − 1 uber Zp.Da Zp ein Korper ist, hat dieses Polynom nur zwei Nullstellen, namlich 1 undp− 1 = −1 mod p, d.h.
a2s−1·t ≡ 1 oder − 1 (mod p).
Ist s− 1 ≥ 1 und ist a2s−1·t ≡ 1 (mod p), so folgt mit demselben Argument
a2s−2·t ≡ 1 oder − 1 (mod p).
So fortfahrend erhalt man:
Entweder ist at ≡ 1 (mod p)oder es existiert ein i, 0 ≤ i ≤ s− 1 mit
a2i·t ≡ −1 (mod p).
Diese Eigenschaft wird nun beim Miller-Rabin-Test fur eine ungerade Zahln (anstelle p) getestet:
45siehe den Beweis von Alford, Granville und Pomerance, [3]
141

Miller-Rabin-Test:Sei n ungerade, n− 1 = 2s · t, 2 ∤ t.Wahle a ∈ 2, 3, . . . , n− 1 zufallig, gleichverteilt.
Ist ggT(a, n) 6= 1, so ist n zusammengesetzt.Ist ggT(a, n) = 1, so berechne at, a2t,. . . , a2s−1·t.Ist at 6≡ 1 (mod n) und a2i·t 6≡ −1 (mod n) fur alle i = 1, . . . , s − 1, so ist nzusammengesetzt.Andernfalls wahle neues a.
Nun kann man zeigen:Ist n zusammengesetzt, n ≥ 3 ungerade, so gibt es in der Menge 1, . . . , n−1hochstens ϕ(n)
4Zahlen a, die zu n teilerfremd sind und fur die der Miller-
Rabin-Test nicht zeigt, dass n zusammengesetzt ist. Die ubrigen mindestens34ϕ(n) zu n teilerfremden Zahlen a nennt man Zeugen gegen die Primzahlei-
genschaft von n. Das bedeutet also, dass beim Miller-Rabin-Test auch jedeCarmichael-Zahl n von vielen zu n teilerfremden a als zusammengesetzt er-kannt wird.
Fuhrt man den Miller-Rabin-Test mit maximal r Iterationen, also verschie-denen Wahlen von a, durch, so ist die Wahrscheinlichkeit, dass man fur eineungerade zusammengesetzte Zahl n nach r Iterationen keinen Zeugen gegendie Primzahleigenschaft von n gefunden hat, nach obiger Bemerkung ≤ 1
4r .
Als probabilistischer Primzahltest wird der Miller-Rabin-Test so angewandt,dass ein geeignetes r fur die Anzahl der Iterationen festgelegt wird. Hat mannach r Wahlen von a keinen Zeugen gegen die Primzahleigenschaft gefunden,so wird
”n ist Primzahl“ausgegeben. Testet man Zahlen n unterhalb einer
Schranke N , so ist die Wahrscheinlichkeit, dass n eine Primzahl ist, wenn derMiller-Rabin-Test dies ausgibt, mindestens 1 − ln(N)
4r . Dies ist eine bedingteWahrscheinlichkeit. Man erhalt die angegebene Abschatzung, wenn man be-nutzt, dass die Anzahl der Primzahlen ≤ N etwa N
ln(N)ist (Primzahlsatz).
In der Praxis wird der Miller-Rabin-Test haufig nur mit sehr wenigen Ite-rationen durchgefuhrt. Der Grund hierfur ist, dass es vermutlich bei einerzusammengesetzten Zahl n sehr viel mehr als 3
4ϕ(n) Zeugen gegen die Prim-
zahleigenschaft gibt. So haben z.B. Damgard, Landrock und Pomerance 1999gezeigt, dass die Wahrscheinlichkeit, eine zusammengesetzte ungerade Zahln ∈ [2499, 2500] bei einem Durchlauf des Miller-Rabin-Tests nicht als zusam-mengesetzt zu erkennen, kleiner als 1
428 ist.
Die Komplexitat eines Durchlaufs des Miller-Rabin-Tests ist O((log(n))3).Bei fester Anzahl r von Iterationen ist der Miller-Rabin-Test also ein proba-
142

bilistischer polynomialer Primzahltest.Um ihn zu einem deterministischen Test zu machen, musste man allerdingsnach obiger Bemerkung mehr als 1
4ϕ(n) Zahlen a testen. Ob schon polynomi-
al (in log(n)) viele Tests genugen, ist unbekannt. Wenn dies der Fall ware, sohatte man mit dem Miller-Rabin-Test einen polynomialen deterministischenPrimzahltest.
Bis vor kurzem war es eine offene Frage, ob es deterministische polynomialeAlgorithmen zur Entscheidung, ob eine Zahl n eine Primzahl ist oder nicht,gibt. Im August 2002 fanden Magrawal, N. Kayal, N. Saxena in Kanpur,Indien eine positive Antwort.
Ihr Algorithmus beruht auf folgender Kennzeichnung von Primzahlen:n prim ⇔ (x + a)n = xn + a in Zn[x] fur alle a mit ggT(a, n) = 1Rechne modulo xr − 1 mit kleinem Grad r.Man braucht dann nur O(poly(log(n))) Paare (r, a) zu testen. Fur Einzelhei-ten verweisen wir auf [28].
Wir betrachten jetzt eine andere wichtige Klasse von Funktionen, die alsKandidaten fur Einwegfunktionen angesehen werden.
8.13 Diskreter Logarithmus
Sei p eine ungerade Primzahl, g eine Primitivwurzel mod p, d.h. Z∗p =< g >=g0 = 1, g, . . . , gp−2 (vgl. 4.8 d)).
Expp,g :
Zp−1 = 0, . . . p− 2 → Z∗px 7→ gx
Inverse:
Logp,g :
Z∗p → Zp−1
y 7→ Logp,g(y). Dies ist der “diskrete“ Logarithmus.
Man kennt bis heute keine polynomialen Algorithmen zur Berechnung vonLogp,g. Die Menge Expp,g gilt daher als Kandidatenfamilie von Einwegfunk-tionen. Dies wird explizit gemacht durch die sogenannte Diskrete-Logarithmus-Annahme.
Sei Ik = (p, g)| |p| = k, p ungerade Primzahl, g Primitivwurzel mod p, k ∈N. Sei P (x) ein positives Polynom und A(p, g, y) ein polynomialer probabili-
143

stischer Algorithmus. Dann existiert k0 ∈ N, so dass
pr(A(p, g, y) = Logp,g(y) | (p, g)← Ik, y ← Z∗p) ≤ 1
P (k)
fur alle k ≥ k0.
Dabei ist die Gleichverteilung auf Ik und auf Z∗p angenommen, bezuglich derer(p, g) und y zufallig ausgewahlt werden.
Die Nutzung des diskreten Logarithmus in der Kryptographie geschah zu-nachst nicht zur Konstruktion eines Verschlusselungsverfahrens, sondern ei-nes Verfahrens zur Schlusselvereinbarung fur symmetrische Verfahren.
Diffie-Hellman-Verfahren (1976, Schlusselvereinbarung)
Situation: Alice und Bob wollen sich auf einen Schlussel K einigen, habenaber nur eine Kommunikationsverbindung zur Verfugung, die abgehort wer-den kann.
Losung: Bob und Alice einigen sich auf eine Primzahl p (p > gewunschterSchlussel K) und eine Primitivwurzel g mod p (2 ≤ g ≤ p − 2). (p und gkonnen offentlich bekannt sein.)
1) Alice wahlt zufallig a ∈ 2, . . . p− 2.Sie berechnet x = ga mod p und sendet x an Bob (a halt sie geheim).
2) Bob wahlt zufallig b ∈ 2, . . . p− 2.Er berechnet y = gb mod p und sendet y an Alice (b halt er geheim).
3) Alice berechnet ya mod p = K.Bob berechnet xb mod p = K.K ist der gemeinsame Schlussel (fur ein symmetrisches Verfahren).
Gultigkeit des Verfahrens:ya ≡ gba ≡ gab ≡ xb (mod p)
Beispiel:p = 17, g = 3(Beachte: 32 = 9 6≡ 1 (mod 17)
34 = 81 ≡ 13 6≡ 1 (mod 17)38 ≡ 132 ≡ −1 (mod 17)316 ≡ 1 (mod 17))
144

Alice wahlt a = 11.311 = (34 · 3)2 · 334 ≡ 13 (mod 17), 34 · 3 ≡ 5 (mod 17), 52 ≡ 8 (mod 17), 52 · 3 ≡ 7 (mod 17)x ≡ 311 ≡ 7 (mod 17)
Bob wahlt b = 4.y = 34 ≡ 13 (mod 17)
Alice: K = ya = 1311 ≡ 4 (mod 17)Bob: K = xb = 74 ≡ 4 (mod 17)K = 4
8.14 Bestimmung von p und g
Zur Bestimmung von Primzahlen, siehe Abschnitt 8.12.Wie bestimmt man Primitivwurzel g modulo p?Ein g ∈ 2, . . . p − 2 ist genau dann eine Primitivwurzel modulo p, wenngp−1 ≡ 1 (mod p), aber gi 6≡ 1 (mod p) fur alle 1 ≤ i < p − 1. Tatsachlichgenugt es zu zeigen, dass g p−1
q6≡ 1 (mod p) fur alle Primteiler q von p − 1.
Sind diese also bekannt, so kann man schnell entscheiden, ob g Primitivwurzelist.
Ohne die Faktorisierung von p − 1 zu kennen, ist kein schnelles Verfahrenbekannt, das testet, ob ein gegebenes g eine Primitivwurzel modulo p ist.
Obwohl es relativ viele Primitivwurzeln modulo p gibt, namlich ϕ(p − 1),und daher Zufallswahlen eine sinnvolle Moglichkeit darstellen, eine solche zufinden, wird man also i.Allg. nicht schnell entscheiden konnen, ob tatsachlicheine Primitivwurzel vorliegt.
Man geht in der Praxis daher haufig folgendermaßen vor:Man wahlt p von der Form 2r + 1, wobei r eine Primzahl ist. Dies geschiehtdurch zufallige Wahl von r, Test auf Primzahleigenschaft und im positivenFall Test, ob 2r + 1 eine Primzahl ist. Die Erfahrung zeigt, dass dieses Vor-gehen meist relativ schnell funktioniert.
Ein solches p hat den Vorteil, dass die Faktorisierung von p−1 = 2r bekanntist. Die Wahrscheinlichkeit, per Zufallswahl eine Primitivwurzel zu finden, istϕ(p−1)
p−1= 1
2r−1
r, also fast 1
2. Man hat bei gewahltem g ∈ Z∗p nur zu testen, ob
g2 6= 1 (d.h. g 6= 1, p−1) und gr 6= 1. Ist dies der Fall, so ist g Primitivwurzelmodulo p.
145

Primzahlen r mit der Eigenschaft, dass auch 2r + 1 eine Primzahl ist, hei-ßen Sophie Germain-Primzahlen (nach Sophie Germain, 1776-1831). Es istunbekannt, ob es unendlich viele Sophie Germain-Primzahlen gibt. Es gibt26.569.515 Sophie Germain-Primzahlen unterhalb 1010. Die großte bekannteSophie Germain-Primzahl ist großer als 2172.000.
8.15 Sicherheit des Diffie-Hellman-Verfahrens
a) Ein Angreifer kennt p, g, x = ga mod p und y = gb mod p. Er willden geheimen Schlussel K = gab mod p berechnen. Die einzig bekannteMethode dafur ist, a aus x oder b aus y zu bestimmen, d.h. diskreteLogarithmen mod p zu berechnen. Es ist aber nicht bekannt, ob dieBerechnung von K tatsachlich aquivalent zur Bestimmung von a oderb ist.
b) Es gibt eine Reihe bekannter Algorithmen zur Bestimmung diskreterLogarithmen. Die besten haben die gleiche Komplexitat (in p) wie diebesten Faktorisierungsalgorithmen (in n). Daher gehen die Empfehlun-gen wie bei RSA dahin, Primzahlen mit 1024 Bit Lange zu wahlen.
c) Ein anderes Risiko beim Diffie-Hellman-Verfahren (wie bei anderenzur Schlusselvereinbarung auch) besteht im sogenannten Man-in-the-middle-Angriff.
Mallory wahlt Exponent c ∈ 0, 1, . . . p− 2.Er fangt ga und gb ab.Er sendet gc an Alice und Bob (die glauben, gb bzw. ga erhalten zuhaben).Alice berechnet KA = gca mod p und Bob berechnet KB = gcb mod p.Sie denken, dies ist ihr gemeinsamer Schlussel.Mallory kann (ga)c = gca und (gb)c = gcb berechnen.
Schickt Alice an Bob eine mit KA verschlusselte Nachricht, so kannMallory sie entschlusseln (denn er kennt KA und KA ist ein Schlusselfur ein symmetrisches Verfahren), lesen, ggf. verandern und mit KB
verschlusselt an Bob schicken. Bob kann die empfangene Nachrichtentschlusseln (er erhalt ja eine mit dem ihm bekannten Schlussel KB
verschlusselte Nachricht) und schopft keinen Verdacht.
Diesem Angriff kann nur durch Authentifizierungsmethoden begegnetwerden, auf die wir in Kapitel 10 zu sprechen kommen.
146

8.16 Das ElGamal-Verschlusselungsverfahren
T. El Gamal (1984)Das ElGamal-Verfahren zur Verschlusselung beruht auf der Sicherheit desDiffie-Hellman-Verfahrens.
Schlusselerzeugung:Alice wahlt Primzahl p und eine Primitivwurzel mod p, g.Sie wahlt zufallig und gleichverteilt a ∈ 2, . . . p− 2.Sie berechnet x = ga mod p.offentlicher Schlussel: (p, g, x)Geheimer Schlussel: a
Verschlusselung:Klartextraum 0, 1, . . . p− 1Bob will Alice den Klartext m senden. Bob wahlt Zufallszahl b ∈ 2, . . . p−2und berechnet y = gb mod p. Dann bestimmt er f = xbm mod p.Chiffretext ist (y, f).
(Beachte: x und y fuhren zu gemeinsamem Schlussel xb mod p = ya modp wie bei Diffie-Hellman. Die Verschlusselung geschieht also gerade durchMultiplikation dieses Schlussels mit m.)
Entschlusselung:Alice hat von Bob Schlusseltext (y, f) erhalten.Sie berechnet (ya)−1 · f mod p.Dies ist der ursprungliche Klartext m.
Korrektheit der Entschlusselung:ya mod p = xb mod p, also (ya)−1f ≡ (ya)−1xb ·m ≡ m (mod p).
Wie berechnet Alice (ya)−1 mod p?Entweder berechnet sie ya mod p und dessen Inverses mit Hilfe des erweiter-ten Euklidischen Algorithmus (vgl. 2.1 b) bzw. 8.7 b)).Oder sie bildet s = p − 1 − a > 0 und berechnet ys. Es ist ysya = yp−1 ≡1 (mod p) nach dem kleinen Satz von Fermat (vgl. 8.3 a)), also ys = (ya)−1.Die zweite Moglichkeit ist i.Allg. die schnellere.
Beispiel:Schlussel von Alice: p=17 , g = 3, a=11x = 311 mod 17 = 7(Siehe Beispiel zum Diffie-Hellman-Verfahren auf S. 144.)offentlicher Schlussel von Alice: (p = 17, g = 3, x = 7)Geheimer Schlussel von Alice: a = 11
147

Bob will Klartext m verschlusselt an Alice senden. m = 10Bob wahlt b = 4.y ≡ 34 (mod 17), also y = 13.f ≡ xbm ≡ 74 · 10 ≡ 4 · 10 ≡ 6 (mod 17)Chiffretext ist (13, 6).
Entschlusselung durch Alice:s = p− 1− a = 5.ysf = 135 · 6 ≡ 13 · 6 ≡ 10 (mod 17).Klartext lautet 10.
8.17 Effizienz des ElGamal-Verfahrens
Zum Verschlusseln sind zwei modulare Exponentiationen modulo p (xb modp, gb mod p) erforderlich. Dabei ist die Großenordnung von p ebenso großwie die Großenordnung von n beim RSA-Verfahren (1024 Bit). RSA benotigtaber nur eine Exponentation. Aber: xb mod p, gb mod p konnen im Vorausberechnet werden und mussen dann nur sicher gespeichert werden (Chip-karte). Voraussetzung ist dabei die Kommunikation mit einem festen Part-ner (z.B. Bank). Dann erfordert die Verschlusselung nur eine Multiplikationmod p (dass b immer gleich gewahlt wird, birgt aber Sicherheitsrisiken, vgl.8.18 b)). Effizienznachteil: Die verschlusselte Nachricht ist doppelt so langwie der Klartext.
8.18 Sicherheit des ElGamal-Verfahrens
a) ElGamal ist genauso schwer zu knacken wie Diffie-Hellman:Ang. Mallory kann ElGamal knacken, d.h. aus (p, g, x) und (y, f) kanner m bestimmen (fur jede Nachricht m).
Dann kann er aus p, g, x = ga mod p, y = gb mod p auch K = gab modp bestimmen:
Er wendet ElGamal-Entschlusselung auf (p, g, x) und (y, 1) an.Er erhalt eine Nachricht m.Er weiß: 1 = gabm mod p. Dann gab ≡ m−1 (mod p).
Umgekehrt: Ang. Mallory kann Diffie-Hellman knacken, d.h. aus Kennt-nis von (p, g, x, y) auf K = gab mod p schließen.Ang. Mallory erhalt ElGamal Chiffretext (y, f) (offentlicher Schlussel(p, g, x)).
148

Er kann K = gab mod p bestimmen. Da f = gab · m mod p, kann erdurch K−1f mod p den Klartext m bestimmen.
b) b sollte bei jeder Verschlusselung neu gewahlt werden. Das so rando-misierte Verschlusselungsverfahren erschwert z.B. die Anwendung sta-tistischer Tests zur Kryptoanalyse.
Es macht auch folgenden Angriff wirkungslos:Ang. Angreifer kennt einen Klartext m und chiffrierten Text (y, f), dermit (p, g, x) und y = gb mod p verschlusselt wurde. Wird zum Ver-schlusseln eines zweiten Klartextes m′ das gleiche b, d.h das gleiche yverwendet, f ′ = xbm′ mod p, so gilt:
f ′f−1 ≡ m′m−1 (mod p)
Damit lasst sich m′ = f ′f−1m mod p ermitteln.
8.19 Erweiterungen der Diffie-Hellman und ElGamal-Verfahren
Die beiden Verfahren lassen sich ubertragen auf andere Gruppen G anstelleZ∗p. Man wahlt dann g ∈ G und hat dann das diskrete Logarithmus-Problemin < g > zu losen. Dazu muss man in G (bzw. der Untergruppe < g >) ef-fizient rechnen konnen, das diskrete Logarithmus-Problem muss aber schwerzu losen sein.
Einen besonders wichtigen Fall stellen die Punktgruppen elliptischer Kurvenuber einem endlichen Korper (Miller 1985; Koblitz 1987) dar. Die entspre-chenden elliptic-curve-cryptosystems werden auch in der Praxis eingesetztund sind offenbar mindestens so sicher wie diejenigen, die auf dem diskretenlogarithmischen Problem in Z∗p beruhen, wobei man mit deutlich kleinerenSchlussellangen auskommt.
[Elliptische Kurven sind die Losungsmengen von Gleichungen der Form y2 =x3 + ax + b (dies ist etwas vereinfacht).Auf diesen Losungsmengen kann man eine Gruppenoperation definieren.46]
Wir besprechen jetzt noch kurz ein Public-Key-Verfahren, das von Rabinstammt und darauf beruht, dass es schwierig ist, Quadratwurzeln modulo
46Einzelheiten siehe z.B. Koblitz [36], Chapter 6 oder Trappe, Washington [46], Chapter15
149

n zu berechnen, wenn n wie im RSA-Verfahren ein Produkt zweier großerPrimzahlen ist.
Wir gehen daher zunachst auf modulare Quadratwurzeln ein. Dies wird auchin Kapitel 10 benotigt.
8.20 Modulare Quadratwurzeln
a) Sei p eine ungerade Primzahl.Die Menge Q = y2 : y ∈ Z∗p ist eine Untergruppe von Z∗p. Da y und−y mod p = p − y das gleiche Quadrat haben, aber y 6= p − y (p un-gerade), ist genau die Halfte der Elemente in Z∗p ein Quadrat (mod p),d.h. |Q| = (p− 1)/2.Das bedeutet, dass ein Element x ∈ Z∗p entweder keine oder zwei Qua-dratwurzeln mod p besitzt.Ist a ein Quadrat in Z∗p, so ist a|Q| = 1 (in Z∗p; folgt aus dem Satz von
Lagrange, vgl. Beweis zu 8.3 a)), d.h. es ist a(p−1)/2 mod p = 1.Ist a kein Quadrat in Z∗p, so ist a(p−1)/2 mod p = p− 1.(Der Grund hierfur ist folgender: Fur jedes a ∈ Z∗p gilt nach dem klei-
nen Satz von Fermat ap−1 = 1 (in Z∗p). Also kann a(p−1)/2 als Nullstelledes Polynoms t2 − 1 ∈ Zp[t] nur die Werte 1 bzw. −1 mod p = p − 1annehmen. Samtliche (p − 1)/2 Elemente a ∈ Q erfullen a(p−1)/2 = 1in Z∗p, sind also Nullstellen des Polynoms t(p−1)/2− 1 ∈ Zp[t]. Da diesesPolynom nicht mehr als (p−1)/2 Nullstellen besitzt, muss fur alle ubri-gen Elemente a ∈ Z∗p, also die Nichtquadrate, a(p−1)/2 mod p = p − 1gelten.)Man kann also leicht entscheiden, ob ein a ∈ Z∗p ein Quadrat ist odernicht.Zur Berechnung von Quadratwurzeln in Z∗p gibt es schnelle (probabili-stische) Algorithmen (siehe z.B. Watjen [48], Kap. 9.2).Fur p ≡ 1 (mod 4) sind allerdings keine deterministischen polynomialenAlgorithmen bekannt. Anders im Fall p ≡ 3 (mod 4), wo die Quadrat-wurzelbestimmung ganz einfach ist. Ist namlich a ein Quadrat, so ist(a(p+1)/4)2 ≡ a(p+1)/2 ≡ a · a(p−1)/2 ≡ a (mod p).
b) Sei nun n = p · q, wobei p 6= q ungerade Primzahlen sind.Dann gilt: Ist a ∈ Z∗n (d.h. ggT(a, n) = 1), so hat a entweder keineQuadratwurzel in Z∗n oder genau vier:Hat a eine Quadratwurzel mod n, so auch mod p und mod q. Seienx1, p− x1 die Quadratwurzeln von a in Z∗p und x2, q − x2 die in Z∗q .
150

Nach dem Chinesischen Restsatz gibt es dann zu jeder Kombinationx ∈ x1, p − x1, x′ ∈ x2, q − x2 ein y ∈ Z∗n mit y ≡ x (mod p) undy ≡ x′ (mod q), und dieses ist auch schnell zu berechnen (siehe 8.10c)).Damit erhalt man vier verschiedene y mit y2 ≡ a (mod p) und y2 ≡ a(mod q), d.h. y2 ≡ a (mod n).Beispiel:n = 21, p = 3, q = 7.Gesucht: Quadratwurzeln aus 16 in Z∗n.4 | p + 1, 4 | q + 1.x1 = 16(3+1)/4 mod 3 = 1, 3− x1 = 2.x2 = 16(7+1)/4 mod 7 = 4, 7− x2 = 3.Viermalige Anwendung des Chinesischen Restsatzes liefert die folgen-den vier Quadratwurzeln von 16 in Z∗21:y1 = 4 (zu x1 = 1 und x2 = 4)y2 = 17 (zu 3− x1 = 2 und 7− x2 = 3)y3 = 11 (zu 3− x1 = 2 und x2 = 4)y4 = 10 (zu x1 = 1 und 7− x2 = 3).(Beachte: y2 = n− y1, y4 = n− y3)
c) Sei wieder n = p · q, wobei p 6= q ungerade Primzahlen sind.Dann ist die Berechnung von Quadratwurzeln mod n genauso schwie-rig, wie die Bestimmung der Faktorisierung von n:Kennt man p und q, so kann man nach a) und b) Quadratwurzeln mo-dulo n effizient berechnen.Umgekehrt:Wahle x ∈ Z∗n zufallig und berechne a = x2 mod n.Bestimme Quadratwurzel y aus a. Ist y = x oder y = n− x, so wahleneues x.Da es vier Quadratwurzeln von a gibt, ist y 6= x, n−x mit Wahrschein-lichkeit 1/2.Durch Iterieren erhalt man also mit beliebig hoher Wahrscheinlich-keit zu einem x und a = x2 mod n eine Quadratwurzel y von a mity 6= x, n− x.Mit einem solchen y kann man die Faktorisierung von n schnell bestim-men:Es ist x2 − y2 ≡ 0 (mod n), d.h. n = p · q|(x− y) · (x + y).n teilt nicht x + y, da wegen x + y < 2n sonst x + y = n folgte, alsoy = n− x, im Widerspruch zur Annahme uber y.n teilt auch nicht x− y, da sonst x = y, ebenfalls im Widerspruch zurAnnahme uber y.
151

Also ist ggT(x + y, n) = p oder q. Da der ggT mit Hilfe des Eu-klidischen Algorithmus schnell zu berechnen ist, erhalt man somit dieFaktorisierung von n.
8.21 Das Public-Key-Verfahren von Rabin
M. Rabin hat 1979 ein Verschlusselungsverfahren vorgeschlagen, das daraufberuht, dass modulares Quadrieren modulo n einfach, das Quadratwurzelzie-hen modulo n aber, falls n Produkt zweier (großer) Primzahlen ist, schwierigist.
Konkret wird bei diesem Verfahren n = p · q gewahlt, wobei p, q ≡ 3 (mod4).Die Abbildung
Quad :
Z∗n → Z∗nx 7→ x2 ist dann ein Kandidat fur eine Einwegfunktion.
(Beachte: Quad ist weder surjektiv noch injektiv, denn ein Quadrat hat im-mer vier Quadratwurzeln.)
Das Verschlusselungsverfahren von Rabin besteht gerade in der Anwendungder Funktion Quad. Der offentliche Schlussel ist n. Nach 8.20 ist das Berech-nen der Quadratwurzeln modulo n (also die Entschlusselung) genauso schwie-rig wie die Faktorisierung von n (beachte Unterschied zum RSA-Verfahren).Kennt man p und q (sie bilden den geheimen Schlussel), so kann man dieQuadratwurzeln von einem y leicht berechnen:
±yp+14 mod p, ±y
q+14 mod q
sind die beiden Quadratwurzeln modulo p bzw. modulo q. Mit dem Chine-sischen Restsatz erhalt man daraus die vier Quadratwurzeln modulo n (vgl.8.20).
[Man muss dann noch sicherstellen, dass der Empfanger erkennen kann, wel-ches die richtige Wurzel ist.47 ]
Wie oben erwahnt ist das Brechen des Rabin-Verfahrens (bei einem Chosen-Plaintext-Angriff) genauso schwierig wie die Bestimmung der Faktorisierungvon n. Gegenuber einem Chosen-Ciphertext-Angriff ist es allerdings unsicher,denn dann kann man bei einem Versuch nach 8.20 c) mit Wahrscheinlichkeit12
die Faktorisierung von n bestimmen.
47Details siehe Buchmann [15], Kapitel 7.4
152

8.22 Der Blum-Blum-Shub Pseudozufallsfolgengene-rator
Wie bei den anderen Kandidaten fur Einwegfunktionen (RSA-Funktionen,Exponentialfunktionen) kann auch Quad verwendet werden, um Pseudozu-fallsfolgen-Generatoren zu konstruieren. Dieser ist besonders popular undwird nach seinen Erfindern Blum-Blum-Shub-Generator (BBS-Generator) ge-nannt48. Entsprechend den Uberlegungen in Kapitel 7.9 benotigt man dazuein Hard-Core-Pradikat fur Quad.
Man kann zeigen, dass das niedrigste Bit von x ein Hard-Core-Pradikat furQuad ist.49
Der BBS-Generator arbeitet daher folgendermaßen:’Initial seed’ x. x0 = x2 mod n.Zufallsfolge b1, b2, . . . erzeugt durch:1) xj = x2
j−1 mod n2) bj = niedrigstes Bit von xj (least significant bit)
48Publikation: Blum, Blum, Shub [14]49siehe z.B. Delfs, Knebel [21], Kapitel 7.3
153

9 Digitale Signaturen und kryptographische
Hashfunktionen
9.1 Grundidee digitaler Signaturen
Die Anforderungen an die digitale Signatur eines elektronischen Dokumentssind die gleichen wie bei gewohnlichen Unterschriften:
Niemand kann ein Dokument mit der Signatur einer Person Asignieren, selbst wenn er Signaturen von A aus anderen Doku-menten kennt.
Daher kann auch A nicht abstreiten, ein Dokument signiert zu haben.Ferner: Signatur lasst sich nicht vom Dokument entfernen.Also: Digitale Signatur muss einen unauflosbaren Zusammenhang zu
• dem Unterzeichner des Dokuments (Identitatseigenschaft) und
• dem signiertem Dokument (Echtheitseigenschaft)
besitzen.
Ferner: Jeder Empfanger muss die digitale Signatur verifizieren konnen (Ve-rifikationseigenschaft).
9.2 Signaturschema (vereinfachte Form)
Jedem Teilnehmer A des Systems wird eine Signaturfunktion sA und eineVerifikationsfunktion vA zugeordnet.sA ist geheim (also nur A bekannt).vA ist offentlich.Aus vA lasst sich sA praktisch nicht bestimmen.
A signiert die Nachricht m folgendermaßen:A berechnet sA(m) und sendet (m, sA(m)).Der Empfanger kann mit vA die Echtheit der Signatur prufen.
Oft: vA ist Umkehrfunktion zu sA, d.h. vA(sA(m)) = m. Aus der Identitatsei-genschaft folgt dann, dass vA eine Einwegfunktion sein muss. Daher werden
154

Signaturschemata haufig mit Mitteln der Public-Key-Kryptographie reali-siert. Beispiele werden wir spater angeben.
Notwendig fur dieses Signaturschema ist ferner, dass das Verzeichnis deroffentlichen Verifikationsfunktion vor Veranderungen durch Unbefugte ge-schutzt ist. Andernfalls konnte ein Betruger die offentliche Verifikationsfunk-tion eines Teilnehmers durch seine eigene ersetzen und dann in dessen NamenSignaturen (mit seiner Signaturfunktion, also der des Betrugers) erzeugen.Dies fuhrt zur Notwendigkeit von Trusted Centers oder Certification Authori-ties (Zertifizierungsstellen), die einen wichtigen Bestandteil der sogenanntenPublic-Key-Infrastruktur darstellen. Hierauf werden wir in dieser Vorlesungnicht eingehen.50
Werden Signaturschemata mit Public-Key-Systemen realisiert, so ist i.Allg.die Signatur sA(m) der Nachricht m ebenso lang wie m. Dies ist nicht sehreffizient. Aus diesem Grund, aber auch aus Sicherheitsgrunden, auf die wirbei den speziellen Signaturverfahren noch eingehen, wird i.Allg. nicht dieNachricht m, sondern ein Hashwert H(m) von m signiert (H offentlich). Wirgehen daher zunachst auf kryptographische Hashfunktionen ein.
9.3 Definition (Hashfunktion)
Sei R ein endliches Alphabet.
Eine Hashfunktion ist eine Abbildung H : R∗ → Rn (n ∈ N fest, R∗ = Mengealler endlichen Strings uber R, Rn = Menge aller Strings der Lange n), dieeffizient (d.h. in polynomialer Zeit) berechenbar ist.
Also: Hashfunktionen sind nie injektiv, d.h. es existieren (unendlich viele)Paare (x, x′) ∈ R∗ ×R∗, x 6= x′, mit H(x) = H(x′).
Beispiel: Quersumme mod 2, R = 0, 1, n = 1
Das oben schon erwahnte Signaturverfahren mit Hashfunktion sieht also fol-gendermaßen aus:
50Naheres dazu z.B. in ausfuhrlicher Darstellung in Mao [38], Schmeh [42], Schwenk [44].Standardwerk: Adams und Lloyd [1], Auszuge unterhttp://www.pkiforum.com/books/adams\_understandingpki.html
155

9.4 Signaturschema mit Hashfunktion
Gegeben sei ein Signaturschema mit Signaturfunktionen sA und offentlichenVerifikationsfunktionen vA (fur jeden Teilnehmer A). Ferner sei eine offentlichbekannte kryptographisch sichere Hashfunktion H gegeben.
A will Nachricht m an B senden und Signatur anfugen. Zur Signatur berech-net A den Hashwert x = H(m) von m. Sie signiert x : sA(x) und sendet(m, sA(x)) an B.
Verifikation der Signatur durch B:B berechnet H(m) = x und verifiziert mit vA, ob sA(x) die Signatur von xist. Ist dies der Fall, wird die Signatur akzeptiert.
Verwendet man Hashfunktionen fur kryptographische Zwecke (speziell furSignaturen), so sind folgende Punkte zu beachten:
- Wenn eine Nachricht m mit dem signierten Hashwert sA(H(m)) von Aversandt wird, so kann jeder Angreifer (mittels vA) H(m) ermitteln.Gelingt es ihm, eine Nachricht m′ zu finden mit H(m) = H(m′), so wird(m′, sA(H(m))) = (m′, sA(H(m′))) vom Empfanger als eine korrekt si-gnierte Nachricht angesehen.
- Angenommen ein Angreifer wahlt y zufallig und berechnet vA(y) = z. DasA(z) = y, kann er behaupten, y sei eine gultige Signatur von A. Gelingtes ihm, eine Nachricht m zu finden mit H(m) = z, so kann er behaupten,dass A die Nachricht m mit sA(z) = y signiert hat.
Dies fuhrt zu Anforderungen an kryptographische Hashfunktionen, die in fol-gender Definition zusammengefasst sind.
9.5 Definition (kryptographische Hashfunktion)
Eine kryptographische Hashfunktion ist eine Hashfunktion, die folgende Be-dingungen erfullt:
(1) H ist eine Einwegfunktion (um Angriffe des zweiten Typs oben zu ver-hindern).
(2) H ist schwach kollisionsresistent, d.h. fur ein gegebenes x ist es nichteffizient moglich (polynomialer Algorithmus), ein x 6= x′ zu finden mitH(x′) = H(x) (um Angriffe des ersten Typs oben zu verhindern).
156

Einer Verscharfung von (2) ist
(2’) H ist stark kollisionsresistent, d.h. es ist nicht effektiv moglich, x 6= x′
zu finden mit H(x) = H(x′).
(Werte von kryptographischen Hashfunktionen werden auch digital finger-prints oder message digests genannt.)
Die Bedingungen (1) und (2) aus obiger Definition sind unabhangig vonein-ander. Das ist in folgendem Satz enthalten:
9.6 Satz (Kollisionsresistenz und Einwegeigenschaft)
a) Ist H stark kollisionsresistent, so ist H schwach kollisionsresistent.
b) Existiert eine schwach bzw. stark kollisionsresistente Hashfunktion, soexistiert auch eine schwach bzw. stark kollisionsresistente Hashfunkti-on, die keine Einwegfunktion ist.
c) Ist H eine schwach kollisionsresistente Hashfunktion, H : R∗ → Rn,und hat jedes x ∈ Rn mindestens zwei Urbilder unter H (typischerFall), so ist H eine Einwegfunktion.
d) Existiert eine Einwegfunktion h : R∗ → Rn, so existiert auch eineEinwegfunktion h : R∗ → Rn, die nicht schwach kollisionsresistent ist.
Beweis:
a) klar.
b) Sei H eine kollisionsresistente Hashfunktion, H : R∗ → Rn.
Definiere h : R∗ → Rn+1 durch h(x) =
1 x falls x Lange n hat,
0 H(x) sonst.
h ist kollisionsresistent, aber fur die Halfte aller y ∈ Rn+1 (die mit 1beginnen) kann man ein Urbild finden.
c) Angenommen es existiert ein probabilistischer polynomialer Algorith-mus A, der mit nicht-vernachlassigbarer Wahrscheinlichkeit zu x einx′ = A(H(x)) liefert mit H(x′) = H(x).Es gilt |H−1(H(x))| ≥ 2, also ist die Wahrscheinlichkeit ≥ 1
2, dass
x′ 6= x ist. Dies fuhrt zu einem probabilistischen polynomialen Algo-rithmus zur Erzeugung von Kollisionen.
157

d) Definiere h(x) =
h(x) falls x mit 1 beginnt,
h(1 x) falls x mit 0 beginnt.
h ist eine Einwegfunktion, aber fur alle x, die mit 10 beginnen (also in14
der Falle), m = 10 m′, ist h(m) = h(0 m′).
Allerdings gilt (vgl. 9.6 d)):
Satz (Roempel, 1990)
Existiert eine Einwegfunktion, so existiert auch eine universelle Hashfunkti-on; diese ist schwach kollisionsresistent.
(Eine universelle Hashfunktion ist eine unendliche Familie Hs : s ∈ Svon Hashfunktionen, zusammen mit einem probabilistischen polynomialenAlgorithmus, der s auswahlt und einem polynomialen Algorithmus, der zugegebenem s ∈ S und x ∈ R∗ den Wert Hs(x) berechnet. Wir werden in 9.16ein ahnliches Konzept behandeln.)
Es ist unbekannt, ob schwach bzw. stark kollisionsresistente Hashfunktionenexistieren.
Wie groß sollte bei einer Hashfunktion die Lange n des Hashwertes gewahltwerden?Naturlich nicht zu groß, denn darin liegt der Sinn von Hashfunktionen. An-dererseits fuhren zu kleine n zu einer Auffalligkeit bezuglich starker Kollisi-onsresistenz.
Dies ist der Ansatzpunkt der sogenannten Geburtstagsattacke, die auf demsogenannten Geburtstagsparadox beruht.
9.7 Satz (Geburtstagsparadox)
Ein Merkmal komme in m verschiedenen Auspragungen vor. Jede Personbesitze genau eine dieser Merkmalsauspragungen.
Ist k ≥ (1+√
1+8m·ln 2)2
≈ 1, 18√
m, so ist die Wahrscheinlichkeit, dass unter kPersonen zwei die gleiche Merkmalsauspragung haben, mindestens 1
2.
(Speziell: Merkmalsauspragung = Geburtstagsdatum, m = 365: Bei 23 Per-sonen ist die Wahrscheinlichkeit mindestens 1
2, dass zwei am gleichen Tag
Geburtstag haben.)
Beweis:Wir beschreiben die Merkmalsauspragungen mit den Zahlen 1, . . . , m und be-
158

trachten den Wahrscheinlichkeitsraum 1, . . .mk mit Gleichverteilung. JedesElementarereignis (g1, . . . gk) ∈ 1, . . .mk hat also die Wahrscheinlichkeit1
mk .Das Elementarereignis (g1, . . . gk) tritt ein, wenn die i-te Person die Merkmals-auspragung gi besitzt.
Wie groß ist die Wahrscheinlichkeit q, dass k Personen alle verschiedeneMerkmalsauspragungen haben?
q =|(gi, . . . gk)| alle gi verschieden|
mk=
k−1∏i=0
(m− i)
mk=
k−1∏
i=0
(1− i
m)
Es ist ex ≥ 1 + x fur alle x ∈ R. Also gilt:
q ≤k−1∏
i=0
e−im = e
−k−1P
i=0
im
= e−k(k−1)
2m
Damit:
e−k(k−1)
2m ≤ 1
2⇔ −k(k − 1)
2m≤ − ln 2⇔ k ≥ 1 +
√1 + 8m · ln 2
2
Daraus folgt die Behauptung des Satzes.
9.8 Geburtstagsattacke
Sei R = Z2. H : Z∗2 → Zn2 Hashfunktion.
Ein Angreifer erzeugt moglichst viele Hashwerte. Diese werden nach Kollisio-nen untersucht. Nach dem Satz ist bei etwas mehr als 2
n2 vielen Hashwerten
die Wahrscheinlichkeit mindestens 12, dass eine Kollision vorliegt. Daran sieht
man, dass z.B. n = 64 keine ausreichende Sicherheit bietet (232 ≈ 4 · 109).
Heutzutage wahlt man fur kryptographische Hashfunktionen mindestens n ≥128, eher sogar n ≥ 160.
Wie konstruiert man Hashfunktionen?
9.9 Serielles Hashing mit Kompressionsfunktionen
Sei k : Rl → Rn, l > n fest, eine Kompressionsfunktion.
159

Konstruktion einer Hashfunktion h : R∗ → Rn:
Der Klartext m wird in Blocke m1, . . . , mt der Lange l − n zerlegt (evtl.Padding). Wahle dann einen Initialisierungsvektor IV =: h0 der Lange n(offentlich bekannt).
Nun berechne: h1 = k(m1, h0)h2 = k(m2, h1)
...ht = k(mt, ht−1) und setze h(m) = ht. Dann gilt:
Satz (Damgard, 1989)
Ist k kollisionsresistent, so auch h.
(Es gibt auch eine Version des parallelen Hashings, siehe z.B. Hardjono, Pie-przyk, Seberry [27], 6.3.)
9.10 Konstruktion von Kompressionsfunktionen unterVerwendung von Blockchiffren
Das Prinzip aus 9.9 wird haufig realisiert durch Kompressionsfunktionen, dieauf Blockchiffren beruhen.
Man kann eine Blockchiffre mit Blocklange n (gleiche Lange von Klartext-und Chiffretextblocken) und Schlussellange s als KompressionsfunktionRs+n → Rn betrachten via
(k, x)︸ ︷︷ ︸∈ Rs+n
→ E(k, x)︸ ︷︷ ︸∈ Rn
= Ek(x),
E die Verschlusselungsfunktion (k ∈ Rs Schlussel, x ∈ Rn).
Diese Kompressionsfunktionen werden entweder direkt wie in 9.9 verwendetoder es werden daraus andere Kompressionsfunktionen abgeleitet. TypischeKonstruktionen sind:
a) hi = Emi(hi−1)
(Rabin-Verfahren)
Hierbei wird der Klartext in Blocke mi der Lange s zerlegt. h0 = IV ∈R ist ein Initialisierungsvektor. Die mi fungieren als Schlussel.
160

[Die Konstruktion hi = Ehi−1(mi) (= E(hi−1, mi)) ist nicht empfehlens-
wert. Hier musste ohnehin s = n sein und falls m die Lange ≤ n hat,so ist h(m) = E(h0, m). In diesem Fall ist m berechenbar, falls E dieVerschlusselungsfunktion eines symmetrischen Verfahrens ist, und h istkeine Einwegfunktion.]
b) hi = Emi(hi−1)⊕ hi−1
(Davis-Meyer-Verfahren)
c) hi = Ehi−1(mi)⊕mi
(Matyas-Meyer-Oseas-Verfahren)
Hier ist s = n und hi−1 ist Schlussel.
d) hi = Ehi−1(mi)⊕ hi−1 ⊕mi
(Miyaguchi-Preneel-Verfahren; auch andere Bezeichnungen.)
Auch hier ist s = n.
9.11 Spezielle Hashfunktionen
Die in der Praxis am haufigsten benutzten kryptographischen Hashfunktio-nen beruhen in der Regel nicht auf Verschlusselungsverfahren, sondern sindspeziell fur kryptographische (insbesondere Signatur-) Zwecke konstruiert.
Sehr verbreitet war lange die Hashfunktion MD4 (Message Digest 4) von RonRivest. Mit Angriffsmethoden, die in den letzten Jahren entwickelt wurden,ist es aber relativ einfach, Kollisionen bei MD4 zu erzeugen.
Weit verbreitet sind derzeit eine Weiterentwicklung von MD4, namlich MD5(1992) und vor allem der von der NSA entwickelte Secure Hash Algorithm,SHA-1 (1992/93). MD5 liefert Hashwerte von 128 Bit, SHA-1 von 160 Bit.51
Beide Hashfunktionen wurden hinsichtlich starker Kollisionsresistenz erfolg-reich angegriffen (Joux; Wang et al. seit 2004). Bei SHA-1 beispielsweisewurden Kollisionen hergestellt mit 269 (ggf. sogar 263) Hashoperationen (an-stelle von 280).52
51Einzelheiten uber die Funktionsweise von SHA-1 u. MD5 siehe z.B. Hardjono, Pie-przyk, Seberry [27], Menezes, van Oorschott, Vanstone [39], Schmeh [42] oder Schneier[43].
52Zu den Angriffen auf MD5 bzw. SHA-1 siehe Hoffman, Schneier,http://www.rfc-archive.org/getrfc.php?rfc=4270 und dortige Links.
161

Das NIST (National Institute of Standards and Technology) hat die Ent-wicklung einer neuen Hashfunktion als Standard angestoßen (ahnlich wie beiAES). Der Sieger soll 2012 feststehen.
Beachte:Anwenden einer Hashfunktion H auf Dokument m liefert keine digitale Si-gnatur. Zwar wird die Echtheitseigenschaft des Dokuments gewahrleistet (daman H(m) aus dem offentlich bekannten H selbst berechnen kann und mitdem gesuchten Hashwert vergleichen kann), nicht aber die Identitatseigen-schaft: Jeder kann H(m) herstellen.
9.12 RSA-Signatur
Vereinfachte Version (ohne Hashfunktion)
Wie bei RSA-Verschlusselung hat jeder Teilnehmer A einen offentlichenSchlussel (n, e) und einen geheimen Schlussel d. Diese werden wie im RSA-Verfahren erzeugt.
Erzeugung der Signatur einer Nachricht m ∈ 0, 1, . . . n− 1:A berechnet s = md mod n. s ist die Signatur von m.A sendet (m, s) an B.
Verifikation durch B:B berechnet se mod n.
Stimmt das Ergebnis mit m uberein, wird die Signatur akzeptiert. Denn Bsieht daran, dass s mit dem geheimen Schlussel von A erzeugt wurde, den nurA kennt. Damit sind Echtheitseigenschaft und Identitatseigenschaft gewahr-leistet. (Bei sprachlichen Nachrichten m wird oft auch nur s = md mod ngesendet; liefert se mod n einen sinnvollen Text, so wird dieser als m akzep-tiert.)
Sicherheit:
• Solange das RSA-Verfahren sicher ist, kann niemand ohne Kenntnisvon d die Signatur s von m erzeugen.
• Die beschriebene einfache Version der RSA-Signatur birgt jedoch dieGefahr der sogenannten existentiellen Falschung (existential forgery):Mallory wahlt s ∈ 0, . . . n − 1 und behauptet, dies sei eine Signatur
162

von Alice. Wer das verifizieren will, berechnet m = se mod n mit demoffentlichen Schlussel von Alice und glaubt, Alice habe m signiert. Inaller Regel wird m ein sinnloser Text sein, aber bei kurzen Mitteilungenvon Zahlenwerten besteht hier eine Gefahr.
• Sind m1, m2 ∈ 0, . . . n − 1 und s1 = md1 mod n und s2 = md
2 mod ndie zugehorigen Signaturen, so kennt man die Signatur von m1m2 (fallsm1m2 < n): (m1m2)
d mod n = s1s2 mod n.
Aus zwei gultigen Signaturen lasst sich eine gultige dritte gewinnen(Multiplikativitat).
Es gibt verschiedene Moglichkeiten, den beiden genannten Gefahren zu be-gegnen. Eine ist die Verwendung von Signaturen eines Hashwertes, die zudemEffizienzvorteile bringt.
RSA-Signatur mit Hashfunktion
Sei m ein beliebiger Text (m ∈ Z∗2). Zur Signatur von m verwendet A offent-lich bekannte, kollisionsresistente Hashfunktion H : Z∗2 → Zm
2 (2m ≤ n, n ausdem RSA-Verfahren) und verfahrt wie in 9.4 beschrieben. Man sieht leicht,dass mit diesem Verfahren die oben genannten Angriffe unmoglich gemachtwerden.
In der Praxis konstruiert man H mit einer kollisionsresistenten Hashfunktion,die z.B. einen 160-Bit-String erzeugt und wendet darauf eine Expansionsfunk-tion an, die den 160-Bit-String auf einen m-Bit-String abbildet.
Einzelheiten sind in einem Public Key Cryptography Standard (PKCS) fest-gelegt, in diesem Fall in PKCS#1. PKCS#1 beschreibt Verfahren der Daten-aufbereitung fur RSA-Verschlusselung und -Signatur. (Die bisher existieren-den PKCS#1 bis PKCS#15 sind von der Firma RSA Security entwickelteStandards, die hauptsachlich Datenformate fur die Public-Key-Kryptogra-phie festlegen.53)
9.13 ElGamal-Signatur
Das ElGamal-Verschlusselungsverfahren ist nicht unmittelbar fur Signatu-ren anwendbar (wie RSA), da die Entschlusselung von einer Zufallswahl desAbsenders abhangt; Entschlusselung und Verschlusselung sind nicht einfach
53Naheres zu diesen Standards in: Schmeh [42]
163

vertauschbar. Das ElGamal-Signaturverfahren muss daher anders konstruiertwerden:
Wie beim ElGamal-Verschlusselungsverfahren hat jeder Teilnehmer A einenoffentlichen Schlussel (p, g, x) und einen geheimen Schlussel a (p Primzahl, gPrimitivwurzel mod p, a ∈ 2, . . . p− 2, x = ga mod p).
Erzeugung der Signatur einer Nachricht m ∈ Z∗2:A benutzt offentlich bekannte kollisionsresistente Hashfunktion H :Z∗2 → 1, 2, . . . p − 2. (Ist H : Z∗2 → Zn
2 , so muss 2n ≤ p − 2 gelten, damitdie Hashwerte als Elemente in 1, 2, . . . p− 2 interpretiert werden konnen.)A wahlt Zufallszahl k ∈ 1, 2, . . . p− 2 mit ggT(k, p− 1) = 1.Sie berechnet r = gk mod p und s = k−1(H(m)− ar) mod (p− 1)(k−1 Inverses von k mod (p− 1).)Signatur sA(m) = (r, s). Gesendet wird (m, sA(m)).
Verifikation durch Empfanger:B kennt offentlichen Schlussel (p, g, x) von A und die Hashfunktion H . Ererhalt von A die signierte Nachricht (m, sA(m)), wobei sA(m) = (r, s).B verifiziert, dass 1 ≤ r ≤ p− 1. Falls dies nicht gilt, wird Signatur zuruck-gewiesen.
Falls 1 ≤ r ≤ p− 1, so uberpruft B, ob xrrs ≡ gH(m) mod p gilt. Wenn ja, soakzeptiert er die Signatur, sonst nicht.
Gultigkeit der Verifikation:
Ist (r, s) wie oben konstruiert worden, so gilt wegen r = gk mod p und s =k−1(H(m)− ar) mod (p− 1):xrrs ≡ gargks ≡ gargH(m)−ar ≡ gH(m) mod p.
Beispiel:p = 17, g = 3, a = 11, x = 311 mod 17, also x = 7.offentlicher Schlussel von A : (p, g, x) = (17, 3, 7)Geheimer Schlussel von A : a = 11
A will Nachricht m mit Hashwert H(m) = 10 signieren.Sie wahlt k ∈ 1, . . . 15 mit ggT(k, 16) = 1.Etwa: k = 13.Berechnung von k−1 mod 16 (mit erweitertem Euklidischen Algorithmus) lie-fert k−1 = 5 (13 · 5 = 65 ≡ 1 mod 16).
r = gk mod p : 313 ≡ 12 mod 17, also r = 12.s = k−1(H(m)− ar) mod (p− 1): 5 · (10− 11 · 12) ≡ 14 mod 16, also s = 14.
164

Signatur von m : (12, 14).
Verifikation durch B:B berechnet aus m den Hashwert H(m) = 10 und bestimmt dann gH(m)
modulo p : 310 ≡ 8 mod 17Dann berechnet er xrrs mod p und vergleicht, ob dies das gleiche Ergebniswie gH(m) mod p liefert (also 8): 712 · 1214 ≡ 13 · 15 ≡ 8 mod 17Signatur wird akzeptiert.
Effizienz des VerfahrensDie Erzeugung der Signatur erfordert eine Anwendung des erweiterten Eukli-dischen Algorithmus zur Bestimmung von k−1 mod p− 1 und eine modulareExponentiation r = gk mod p.
Beide sind als Vorausberechnungen moglich (dann ist aber eine sichere Spei-cherung notwendig, bis eine Nachricht signiert wird). Die aktuelle Signaturerfordert dann nur zwei modulare Multiplikationen, ist also sehr schnell.
Verifikation erfordert drei modulare Exponentiationen (mehr als bei RSA-Signatur).
Eine Beschleunigung ist moglich, indem man die Kongruenz g−H(m)xrrs ≡1 mod p verifiziert und auf der linken Seite moglichst viele Exponentiationensimultan durchfuhrt.
9.14 Sicherheit der ElGamal-Signatur
a) Warum Uberprufung 1 ≤ r ≤ p− 1 ?
Wenn dies nicht geschieht, kann Angreifer Mallory, falls er eine gultigeSignatur (r, s) von A einer Nachricht m kennt, jede andere Nachrichtm′ mit der Signatur von A versehen (sofern ggT(H(m), p− 1) = 1):
Mallory berechnet u = H(m′)H(m)−1 mod (p − 1) und daraus s′ =su mod (p− 1).
Mit Hilfe des Chinesischen Restsatzes berechnet er dann r′ mit1 ≤ r′ ≤ p(p− 1), so dassr′ ≡ ru mod (p− 1) undr′ ≡ r mod p.
Dann ist (r′, s′) eine gultige Signatur (von A) der Nachricht m′ (wennman nicht 1 ≤ r′ ≤ p− 1 uberpruft !):
xr′r′s′ ≡ xr′rs′ ≡ gar′gks′ ≡ gu(ar+ks) ≡ guH(m) ≡ gH(m′) mod p
165

(r′ verletzt den Test 1 ≤ r′ ≤ p − 1: r′ ≡ ru mod (p − 1). Wareru ≡ r mod (p − 1), so H(m′)H(m)−1 ≡ u ≡ 1 mod (p − 1). DannH(m′) = H(m), da 1 ≤ H(m′), H(m) ≤ p − 1. Dies widerspricht derKollisionsresistenz von H . Also: r′ 6≡ r mod (p− 1), aber r′ ≡ r mod p.Daher r′ ≥ p.)
b) Kann Mallory Signatur von A einer Nachricht m falschen, ohne dass era kennt ?
1. Moglichkeit:
Er wahlt r und versucht einen passenden Wert s zu finden. Dann mussxrrs ≡ gH(m) mod p gelten, d.h. er muss den diskreten Logarithmusvon x−rgH(m) zur Basis r modulo p finden. Das ist schwierig.
2. Moglichkeit:
Er wahlt s und versucht einen passenden Wert r zu finden. Dazu musser xrrs ≡ gH(m) mod p nach r
”auflosen“. Hierfur sind keine effizienten
Losungsalgorithmen bekannt, obwohl das Problem nicht direkt mit derBerechnung diskreter Logarithmen zusammenhangt.
Man kennt auch keine effektive Methode, (r, s) ohne Kenntnis von asimultan zu bestimmen, so dass es eine gultige Signatur von m durchA ist.
c) Fur die Sicherheit des ElGamal-Verfahrens ist die Verwendung einerHashfunktion notwendig. Wurde namlich eine Nachricht m direkt si-gniert, so lautet die Verifikationskongruenz
xrrs ≡ gm mod p.
Dann kann man (r, s, m) bestimmen, die diese Kongruenz erfullen; al-lerdings kann man dabei m nicht vorgeben (existentielle Falschung).
Man wahlt u, v ∈ Z, wobei ggT(v, p− 1) = 1.Man setzt r = guxv mod p, s = −rv−1 mod (p − 1) und m = s u mod(p− 1).Dann gilt: xrrs ≡ xrgusxvs ≡ xrgusx−r ≡ gm mod p.
Bei Verwendung von Hashwerten kann man auf diese Weise nur dieSignatur eines Hashwertes erzeugen, aber dann nicht eine zugehori-ge Nachricht zu diesem Hashwert bestimmen (wegen der Einwegeigen-schaft der Hashfunktion).
d) Notwendig fur die Sicherheit der ElGamal-Signatur ist auch, dass beijeder Signatur ein neues k zufallig aus 1, . . . p−2 (mit ggT(k, p−1) =1) gewahlt wird:
166

Angenommen fur die Signatur zweier Nachrichten m1, m2 wird das glei-che k, also auch das gleiche r = gk mod p verwendet.
Seien (r, s1), (r, s2) die beiden Signaturen von m1, m2.Dann s1 − s2 ≡ k−1(H(m1)−H(m2)) mod (p− 1).
Ist ggT(H(m1)−H(m2), p− 1) = 1 (dies ist haufig der Fall), so kannman hieraus k bestimmen (beachte 1 ≤ k ≤ p− 2).
Es ist s1 ≡ k−1(H(m1) − ar) mod (p − 1). Da s1, k, H(m1), r bekanntsind, kann man hieraus den geheimen Schlussel a bestimmen (beachte2 ≤ a ≤ p− 2).
9.15 Der Digital Signature Algorithm (DSA)
Es gibt zahlreiche Varianten des ElGamal-Signatur-Verfahrens. Eine beson-ders effiziente wurde 1991 vom NIST (National Institute of Standards andTechnology) vorgeschlagen und 1994 zum Standard erklart.
DSA arbeitet mit Primzahlen p mit Bitlangen zwischen 512 und 1024 Bit. DieExponentationen erfolgen in einer echten Untergruppe der multiplikativenGruppe von Zp, die Primzahlordnung q hat, q ≈ 2160. Dadurch wird dasVerfahren sehr beschleunigt. Ob dadurch die Sicherheit beeintrachtigt ist, istunbekannt.
Daruberhinaus ist die Parameterwahl beim DSA viel genauer vorgeschriebenals beim ElGamal-Verfahren.54
Wir beschreiben jetzt noch eine Idee, die mit der digitaler Signaturen ver-wandt ist:
9.16 Message Authentication Codes (MAC)
Auch: Schlusselabhangige kryptographische Hashfunktionen.
Dabei hat die Abkurzung MAC nichts mit ‘Media Access Control‘, der Adres-se von Netzgeraten in der OSI-Schicht 2 zu tun. Vielmehr handelt es sich beiden Message Authentication Codes um eine Familie hk : k ∈ K von kryp-tographischen Hashfunktionen. K ist der Schlusselraum.
54Einzelheiten siehe z.B.: Buchmann [15], 11.5
167

Zwei Teilnehmer A und B tauschen den Schlussel k ∈ K aus. A schickt(m, hk(m)). B uberpruft, ob der Hashwert mit dem vereinbarten Schlussel vonA gebildet wurde. Damit kann B uberprufen, ob die Nachricht unverandertist und von A kommt. (Auch Moglichkeit der Datensicherung; Viren!)
Also: MACs haben eine ahnliche Funktion wie die digitale Signatur.
Ihr Vorteil ist, dass sie in der Regel schneller zu berechnen sind. Hashfunktio-nen sind schneller als Public-Key-Verfahren, auf denen haufig digitale Signa-turen beruhen. (Symmetrische Verfahren kann man fur digitale Signaturennicht verwenden.)
Der Nachteil ist aber: A kann abstreiten, (m, hk(m)) gesendet zu haben, dennB hatte dasselbe Paar erzeugen konnen. Also: Nur Nachrichtenauthentizitat,aber Falschungen nicht durch Dritte moglich (wie bei einfachen Hashfunk-tionen).
9.17 Konstruktionsmoglichkeiten von MACs
a) CBC-MACs:
Beruht auf Blockchiffre (der Lange m).
Der Schlussel k der Blockchiffre wird ausgetauscht. Die Nachricht mwird in Blocke m0, . . . , mt der Lange n aufgeteilt. Sender und Empfan-ger einigen sich auf einen Initialisierungsvektor IV = c0, z.B. den Null-string.
CBC-Modus: Ek(ci ⊕mi) = ci+1
ct+1 = Hk(m) ist dann MAC von m.
(Vgl. Konstruktion von Hashfunktionen mit Blockchiffren!)
b) HMAC:
Bellare, Canetti, Krawczyk, 1996.
Gegeben sei: H Hashfunktion (z.B. MD5, SHA-1), 2 Konstanten ipadund opad (Lange abhangig von Schlussellange), k Schlussel.
Berechnet wird HMAC von m durch
H(k ⊕ opad | H(k ⊕ ipad | m)).
Dabei sorgen ipad und opad dafur, dass innerer und außerer Schlusselverschieden sind.
HMAC wird z.B. in TLS-Standard des SSL verwendet.
168

10 Authentifizierung und Zero-Knowledge-
Beweise
Authentifizierung: Nachweis bzw. Uberprufung, dass jemand derjenige ist, derer behauptet zu sein (manchmal wird hierfur auch der Begriff Identifizierunggebraucht).
Forderungen:
- Kein Teilnehmer eines Systems darf sich als jemand anderen ausgebenkonnen.
- Der Verifizierer darf sich nicht als anderer Teilnehmer ausgeben konnen.
Im Wesentlichen gibt es drei Moglichkeiten:
Authentifizierung durch Wissen: A hat eine Information, die nur sie kennt(und ggf. derjenige, gegenuber dem siesich ausweist), also ein Geheimnis.
Authentifizierung durch Besitz: Es wird uberpruft, ob A einen bestimm-ten schwer zu falschenden Gegestand be-sitzt (z.B. Ausweis).
Authentifizierung durch biometrische Merkmale: Z.B. Fingerabdruck
Fur uns ist nur die erste Moglichkeit von Interesse.
10.1 Passworter
Passwort w wird von A ausgewahlt. Im Rechner, gegenuber dem sich A au-thentifizieren muss, ist f(w) gespeichert, f Einwegfunktion. Angreifer konnenin der Regel aus f(w) nicht auf w schließen!
(Diese Methode wird in modifizierter Form z.B. beim Zugang zu UNIX-Systemen verwendet. Allerdings wird dort in der Regel w als Schlussel fur dieVerschlusselung des Nullstrings 0 mit einer schlusselabhangigen Einwegfunk-tion fw verwendet und fw(0) wird gespeichert. Tatsachlich ist das Verfahrennoch etwas aufwandiger. Fur Details sei auf Mao [38], 11.5 verwiesen.)
Wichtig: Passwortverzeichnis (also die f(w) bzw. fw(0)) muss vor unberech-tigten Schreibzugriffen gesichert sein.
169

Gefahren:
• Passwort wird oft unverschlusselt uber unsichere Netze zum Rechnergeschickt, der die Authentifizierung vornimmt.
• Oft werden einfache Passworter w gewahlt. Angreifer berechnen fursolche w die Werte f(w).
Gefahreneindammung durch Einmal-Passworter.
10.2 Challenge-Response-Authentifizierung
Bei diesem Verfahren teilt A demjenigen, gegenuber dem sie sich authentifi-zieren will (etwa B), nicht das Geheimnis mit (wie bei Passwortern). Vielmehrerhalt sie von B eine Aufgabe (’challenge’). die sie nur losen kann, wenn sieein Geheimnis kennt. Die Losung schickt A an B (’response’). B verifiziertdie Losung und erkennt die Identitat von A an, falls die Losung korrekt ist.
Die einfachste Moglichkeit der Realisierung von Challenge-Response-Verfahr-en ist die Verwendung von Verschlusselungsverfahren.
a) Verwendung von symmetrischen Verschlusselungsverfahren
A und B kennen beide den geheimen Schlussel k eines symmetrischen Ver-schlusselungsverfahrens. Will sich A gegenuber B ausweisen, teilt sie das Bmit.B sendet Zufallszahl r an A.A verschlusselt r mit k und sendet c = Ek(r) an B.B entschlusselt c mit k und uberpruft, ob Dk(c) und r ubereinstimmen.Falls ja, so ist die Identitat von A anerkannt, sonst nicht.
Nachteil: B muss k kennen. Bei Verwendung dieses Verfahrens als Zugangs-schutz zu Rechnernetz mussen die geheimen Schlussel sicher gespeichert sein.
(Man kann die Verschlusselungsfunktion auch durch einen MAC ersetzen.)
b) Verwendung von Public-Key-Signaturverfahren
A will sich gegenuber B ausweisen.B sendet Zufallszahl r an A.
170

A signiert r mit ihrem geheimen Schlussel.B verifiziert Signatur mit offentlichem Schlussel von A.
Vorteil: B erfahrt das Geheimnis, also den geheimen Schlussel von A, nicht.Er konnte allerdings durch geeignete Wahl von r ggf. Teilinformationen uberden geheimen Schlussel erhalten.
Gefahren: Ein boswilliger B konnte eine von C mit Hilfe des offentlichenSchlussels von A verschlusselte Nachricht fur A abgefangen haben. Er sendet(statt der Zufallszahl) diese an A. Bei der Authentifizierung durch Signaturentschlusselt A nun diese Nachricht fur B!
Daher sollte nie derselbe Schlussel fur Authentifizierungsverfahren und Nach-richtenverschlusselungen verwendet werden.
10.3 Zero-Knowledge-Beweise
Das Konzept der ’Zero-Knowledge-Proofs’ wurde 1985 von Goldwasser, Mi-cali und Rackoff eingefuhrt.
Wir behandeln hier nur Zero-Knowledge-Verfahren, die sog. interaktive Be-weissysteme sind. Bei interaktiven Beweissystemen wird ein Protokoll zwi-schen Beweiser A und dem Verifizierer B durchgefuhrt.
A kennt ein Geheimnis, B nicht.
Ein solches Protokoll beschreibt Kommunikationsschritte zwischen A und B(Interaktion) und erfullt zwei Kriterien:
1) In dem Protokoll uberzeugt A den Verifizierer B davon, das Geheimniszu kennen.(Durchfuhrbarkeit)
2) Ein Betruger kann das nicht (oder nur mit beliebig geringer Wahr-scheinlichkeit > 0).(Korrektheit)
(Diese Eigenschaften haben auch die Challenge-Response-Systeme.)
Zusatzlich wird jetzt noch die Zero-Knowledge-Eigenschaft gefordert:
3) Der Verifizierer B erfahrt nur, dass A das Geheimnis kennt, aber nichtsweiter (gleichgultig, welche Strategie er anwendet).
171

Wie kann man 3) uberprufen?
Idee: Jede mogliche Interaktion zwischen A und B kann auch ohne Kenntnisdes Geheimnisses von einem Simulator konstruiert werden, ohne dass ein Au-ßenstehender dies von einem echten interaktiven Beweis unterscheiden kann.Wir gehen darauf noch einmal kurz in 10.5 ein.
Wir werden jetzt eine Realisierung eines Zero-Knowledge-Verfahrens kennen-lernen, namlich das sogenannte Fiat-Shamir-Verfahren. Es beruht auf demWurzelziehen modulo einer zusammengesetzten Zahl, das wir schon in 8.20betrachtet haben.
10.4 Das Fiat-Shamir-Verfahren (Fiat, Shamir, 1986)
A wahlt p, q, große Primzahlen, bildet n = p · q.Sie wahlt s ∈ 1, . . . n− 1 zufallig mit ggT(s, n) = 1.Sie berechnet v = s2 mod n. (v, n) ist offentlich, s geheim.(Beachte nach 8.20: s ist nur dann aus n zu bestimmen, wenn man die Fak-torisierung von n kennt.)A beweist B, dass sie eine Quadratwurzel von v modulo n kennt.(A braucht die Faktorisierung von n nicht zu kennen!)
Protokoll:
1) A wahlt zufallig und gleichverteilt r ∈ 1, 2, . . . n − 1. Sie berechnetx = r2 mod n.
2) A sendet x an Verifizierer B.
3) B wahlt zufallig mit Wahrscheinlichkeit 12
ein e ∈ 0, 1 und sendet ean A.(Challenge)
4) Erhalt A den Wert e = 0, so schickt sie r (die Wurzel von x) zuruck.Erhalt A den Wert e = 1, so schickt sie y = rs mod n (also Wurzel vonxv) an B. (Response)
5) B verifiziert, dass r2 ≡ x mod n (im Fall e = 0) bzw. y2 ≡ xv mod n(im Fall e = 1).
(Schritte 1) bis 5) werden wiederholt; jedesmal neues r wahlen!)
172

Analyse:
a) Kennt A das Geheimnis (also s), so kann sie jede der Fragen von Bbeantworten.
b) Ein Betruger kann aus (n, v) das Geheimnis nicht entschlusseln (Qua-dratwurzeln modulo n genauso schwierig wie Faktorisierung von n).
c) Was passiert, wenn ein Betruger trotzdem das Protokoll mit B durch-fuhrt, um sich als A auszuweisen?Er kann nicht beide moglichen Fragen beantworten, denn kennt er rund rs, so auch s. Er hat also nur zwei Moglichkeiten:
• Er wahlt r wie vorgesehen und sendet x = r2 mod n.Sendet B e = 0, so antwortet er r, korrekt.Sendet B e = 1, so kann er nicht antworten.
• Er wahlt y vor und sendet x = y2v−1 mod n.Bei e = 1 kann er jetzt korrekt antworten.Bei e = 0 musste er die Wurzel von v bestimmen. Kann er nicht.
Da er x angeben muss, bevor er e erhalt, kann er mit einer Wahr-scheinlichkeit von 1
2richtig antworten. Nach k Wiederholungen ist die
Wahrscheinlichkeit 12k , dass er immer richtig antwortet.
Bei immer richtiger Antwort ist B mit einer Wahrscheinlichkeit von1− 1
2k uberzeugt, dass A tatsachlich A ist.
10.5 Formalisierung der Zero-Knowledge-Eigenschaft
Wir geben nur die Idee an (am Beispiel des Fiat-Shamir-Verfahrens).
Fur alle s sei Ts die Menge aller moglichen Transkripte von Protokollen,die zwischen einer ehrlichen A (welche also s kennt) und dem Verifizierer Bmoglich sind.
Das Protokoll besitzt die Zero-Knowledge-Eigenschaft, falls folgendes gilt:
Es existiert ein probabilistischer polynomialer Algorithmus S (der ‘Simula-tor‘), der zu jedem s Protokolltranskripte erzeugt. Sei die Menge dieser‘gefalschten‘ Transkripte Fs. Dann ist Ts = Fs und fur alle T ∈ Ts istdie Wahrscheinlichkeit, dass T als Transkript eines interaktiven Protokollszwischen A und B erzeugt wird, gleich der Wahrscheinlichkeit, dass T von S
173

erzeugt wird.(Perfekte Zero-Knowledge-Eigenschaft)
Was macht S bei Fiat-Shamir?
Er wahlt zufallig r und e.Fur e = 0 berechnet er x = r2 mod n und gibt (x, e, r) aus.Fur e = 1 berechnet er x = r2v−1 mod n und gibt (x, e, r) aus.
Naheres siehe Beutelspacher, Neumann, Schwarzpaul [9], Kapitel 16, Gold-reich [24], Kapitel 4, Mao [38], Kapitel 18 oder Watjen [48], Kapitel 11.
174

(∗) 11 Anonymitat
Bei jeder Kommunikation, insbesondere auch im Internet, gibt es verschie-dene Formen von Anonymitat, die in gewissen Situationen wunschenswertsind:
• Senderanonymitat (z.B. bei elektronischen Wahlen)
• Empfangeranonymitat (z.B. bei gewissen Chiffre-Anzeigen)
• Kommunikationsanonymitat (Die Tatsache, dass A und B miteinanderkommunizieren, soll vor den anderen Systemteilnehmern geheim gehal-ten werden.)
Samtliche dieser drei Typen lassen sich bei elektronischer Kommunikationdurch sog. MIXe erreichen. Die Idee geht auf D. Chaum (1981) zuruck.
11.1 MIX
Was macht ein MIX? Dies ist ein Rechner im Netz, der innerhalb eines ge-wissen Zeitintervalls die an ihn gesendeten Nachrichten sammelt, sie in derReihenfolge mischt und sie nach einer gewissen Zeit weitersendet. Der MIXhat einen offentlichen Schlussel EMIX und einen geheimen Schlussel DMIX
zu einem Public-Key-Verfahren.
Wir beschreiben nun, wie mit Hilfe eines MIX verschiedene Formen von An-onymitat realisiert werden konnen.
a) Kommunikationsanonymitat durch MIX
A will B eine Nachricht m senden, diese Kommunikation aber geheim halten.Dies geschieht in folgenden Schritten:
(1) A verschlusselt m zu c = Ek(m), so dass nur B sie entschlusseln kann(z.B. mit dem offentlichen Schlussel von B oder einem gemeinsamenSchlussel eines symmetrischen Verfahrens). Dieser Schritt kann auchentfallen, wenn m nicht geheim gehalten werden muss (insbesonderenicht vor MIX); dann ist c = m.
(2) A bildet (IB, c), wobei IB die Adresse von B ist.
175

(3) A verschlusselt dies mit dem offentlichen Schlussel von MIX,EMIX(IB, c), und sendet dies an MIX.
(4) MIX offnet mit seinem geheimen Schlussel DMIX diese Nachricht underhalt (IB, c).
(5) Da MIX die Adresse IB von B kennt, sendet er c an B.
(6) B entschlusselt c zu m (entfallt, falls c = m).
Die Kommunikationsanonymitat wird gewahrleistet, wenn in einem Zeitraumgenugend viele Nachrichten bei MIX eintreffen. Da er diese wahrend diesesZeitraums sammelt und sie dann in einer anderen Reihenfolge als der ih-res Eingangs (‘Mischen‘) an die jeweiligen Empfanger weitersendet, kannein Angreifer, der diese Sendevorgange beobachtet, nicht feststellen, welcheTeilnehmer miteinander kommunizieren.
b) Kommunikations- und Senderanonymitat durch MIX
Senderanonymitat wird schon durch Protokoll a) geleistet, wenn A keinenHinweis auf seine Identitat in die Nachricht einbaut. B kann dann nicht fest-stellen, von wem die Nachricht kommt. Andererseits kann B dann auch nichtantworten. Diese Moglichkeit lasst sich trotz Senderanonymitat durch dasfolgende Verfahren erreichen:
(1) A sendet EMIX(m, EMIX(IA), IB) an MIX (evtl. auch Ek(m) statt m);dabei ist IA die Adresse von A und EMIX(A) fungiert als anonymeRuckadresse.
(2) MIX offnet mit DMIX diese Nachricht und sendet (m, EMIX(IA)) anB.
(3) B sendet als Antwort EMIX(m′, EMIX(IA)) an MIX.
(4) MIX offnet diese Nachricht und dann EMIX(IA) und sendet m′ an A.
c) Kommunikations- und Empfangeranonymitat durch MIX
B richtet ein ‘Postfach‘ im MIX ein: EMIX(IB). B gibt EMIX(IB) bekannt(senderanonym), ggf. zusammen mit einer Nachricht.Will A an (den anonymen) B eine Nachricht m senden, so sendet erEMIX(m, EMIX(IB)) an MIX. MIX offnet und sendet m an B.
176

d) Vertrauen in MIX
MIX ist die einzige Instanz in obigen Protokollen, die alle Kommunikations-beziehungen rekonstruieren kann. MIX ist also eine Vertrauensinstanz. Dieslasst sich abschwachen durch ein Kaskadenmodell :Es handelt sich hierbei um ein Kommunikationsnetz mit verschiedenenMIXen. A wahlt dann eine Kette (Kaskade) von MIXen, uber die sie ei-ne Nachricht an B schickt. Arbeitet nur ein MIX dieser Kette korrekt, so istdie Kommunikation anonym.
e) Kryptographische Sicherheit eines MIX
Wesentlich bei den dargestellten Verfahren ist, dass das Public-Key-Systemvon MIX (mit dem also EMIX gebildet wird) nicht deterministisch ist; RSAkommt also nicht in Frage, ElGamal jedoch schon. Der Grund ist, dass bei fe-stem offentlichen Schlussel von MIX ein Klartext bei mehrfacher Verschlusse-lung unterschiedlich verschlusselt werden muss. Sonst konnte namlich einAngreifer alle ausgehenden Nachrichten mit EMIX verschlusseln, mit deneingegangenen Nachrichten vergleichen und die Zuordnung rekonstruieren.
MIXe werden z.B. fur elektronische Wahlen eingesetzt; Einzelheiten dazufindet man z.B. in Watjen [48, 10.6].
11.2 Blinde Signaturen
Es gibt Situationen, wo (um Anonymitat zu erreichen) ein Dokument von Bsigniert werden soll, ohne dass B den Inhalt des Dokuments kennt. Moglichist das mit sogenannten blinden Signaturen, ein Konzept, das ebenfalls vonD. Chaum (1981) stammt.Wir beschreiben das Verfahren einer blinden Signatur mit Hilfe des RSA-Verfahrens:
Ziel: A will eine Nachricht m von B signiert erhalten, ohne dass B die Nach-richt m kennt.
B habe offentlichen Schlussel (e, n) und geheimen Schlussel d.
(1) A wahlt zufallig r mit ggT(r, n) = 1 und bildet t = re ·m mod n.
(2) A lasst t von B signieren: td mod n = r ·md mod n.
(3) A bildet r−1 mod n (beachte ggt(r, n) = 1). Dann ist r−1td mod n = md
mod n die Signatur von m durch B.
177

Wenn r zufallig gleichverteilt aus Z∗n gewahlt wird, so ist auch re mod nzufallig gleichverteilt aus Z∗n.B hat also keine Moglichkeit aus der Kenntnis von t = re ·m mod n auf mzu schließen.
11.3 Anwendung: Elektronische Munzen
a) Jedes Munzsystem muss folgende Forderungen erfullen:
1. Jeder muss die Echtheit des Geldes anhand von Sicherheitsmerkmalenverifizieren konnen.
2. Geld muss falschungssicher sein, d.h. es darf nur von einer autorisiertenBank ausgestellt werden konnen.
3. Geldmunzen sind anonym, d.h. sie geben keine Informationen uber denBesitzer preis.
b) Konstruktion eines digitalen Munzsystems (nach D. Chaum, 1985)
Fur jeden Munzwert gibt die Bank B einen offentlichen Schlussel pB (alsobei Verwendung von RSA (e, n)) bekannt und ein sog. ‘Redundanzschema‘.Daten, die nach diesem Redundanzschema gebildet sind und von der Banksigniert sind, sind gultige Munzen zu dem gegebenen Wert.Das Redundanzschema konnte z.B. folgendermaßen aussehen: A wahlt zufal-lig einen String v von gewisser Lange und bildet die Konkatenation m = v|v.m wird von der Bank blind signiert: t = sB(m) (im Fall von RSA also t = md
mod n, wobei d der geheime Schlussel zu (e, n) ist).t ist die Munze.(Vorher muss sich A gegenuber der Bank authentifizieren; die Bank buchtdann den Gegenwert der ausgestellten Munze(n) von ihrem Konto ab.)
Sind die Forderungen 1. - 3. aus a) erfullt?
1. Echtheit: pB(t) = m erfullt das Redundanzschema. Wenn nicht von Bsigniert wurde, wird das nicht der Fall sein.
2. Falschungssicherheit: Niemand kann Munzen selbst herstellen. Manbenotigte dazu ein y, so dass pB(y) (also ye mod n) das Redundanz-schema erfullt. Das lasst sich ohne Kenntnis des geheimen Schlussels
178

der Bank (also d) nicht bewerkstelligen. Man beachte: Es hilft nichts,wenn y das Redundanzschema erfullt; PB(y) = ye mod n wird dasRedundanzschema fast sicher nicht erfullen.
3. Anonymitat: Die Bank B weiß nicht, welche Munze sie an A ausge-geben hat (wegen blinder Signatur). Sie weiß nur, dass sie eine an Aausgegeben hat.
A kann die Munze zur Bezahlung verwenden. Der Empfanger C kann sichvon der Echtheit der Munze uberzeugen. Er reicht sie bei der Bank ein undbekommt den Gegenwert gutgeschrieben.
c) Nachteile des Systems:
Wenn A eine Munze durch die Bank ausgestellt bekommen hat, kann er siebeliebig oft kopieren. Ein Empfanger C kann nicht entscheiden, ob es sichum das Original oder eine Kopie handelt.Er muss daher vor Beendigung der Transaktion mit A bei der Bank nachfra-gen, ob die Munze ein Original ist, d.h. nicht schon einmal eingereicht wurde.Man spricht daher von einem Online-Munzsystem.Dazu benotigt die Bank aber ein Verzeichnis aller eingelosten Munzen, wasmit einem sehr großen Aufwand verbunden ist.
Es gibt auch Offline-Munzsysteme, bei denen die Bank die Identitat von Aaufdecken kann, wenn eine Munze zweimal eingereicht wird.
Ein weiteres Problem ist, dass Geld aus Erpressungen oder Geldwasche nichtzuruckverfolgt werden kann. Um diesem Problem zu begegnen, sind auchgeeignete Verfahren entwickelt worden (z.B. von Frankel, Tsiounis, Yung,1998), auf die wir aber hier nicht weiter eingehen.
179

(∗) 12 Secret Sharing Schemes
Secret Sharing Schemes sind wesentlicher Bestandteil vieler sog. Multipar-ty Computations. Darunter versteht man Verfahren, bei denen eine gewisseAnzahl von Teilnehmern mit ihren Eingaben ein korrektes Ergebnis einer ge-wissen Berechnung erzeugen (dieses Ergebnis kann, je nach Anwendungsfall,den Teilnehmern zumindest teilweise bekannt werden oder auch nicht), aberkein Teilnehmer erfahrt etwas uber die Eingabe der ubrigen Teilnehmer.
Bei Secret Sharing Schemes wird ein Geheimnis auf mehrere Personen verteilt(Teilgeheimnisse), so dass gewisse Teilgruppen der Personen das Geheim-nis rekonstruieren konnen, alle anderen Teilgruppen aber nicht. Ein solchesSzenario hat vielfaltige Anwendungen, z.B. bei Zugangskontrollen, digitalenSignaturen durch mehrere Personen etc.
Die genauere Definition von Secret Sharing Schemes beruht auf dem Begriffder Zugriffsstruktur:
12.1 Definition (Zugriffsstruktur)
Sei T eine Menge von Teilnehmern. Eine Zugriffsstruktur Z auf T ist eineMenge von Teilmengen von T , d.h. Z ⊆ P(T ).Die Teilmengen von T , die in Z liegen, heißen zulassige Konstellationen, dieanderen unzulassige Konstellationen.
Bsp.: T = 1, 2, 3, 4, Z = 1, 2, 1, 3, 4, 2, 3
Wir nehmen im Folgenden o.B.d.A. an, dass jeder Teilnehmer in mindestenseiner zulassigen Konstellation enthalten ist.
Wir geben jetzt eine informelle Definition von Secret Sharing Schemes, die furunsere Zwecke ausreicht. Eine genaue Definition findet man z.B. in Stinson[45, 13.2.2].
12.2 Definition (Secret Sharing Schemes)
Seien T und Z wie in 12.1. Sei g ein Geheimnis. (g stammt in der Regelaus einer Menge von moglichen Geheimnissen, z.B. den moglichen geheimenSchlusseln fur eine digitale Signatur.)
180

In einem Secret Sharing Scheme werden an die Teilnehmer durch eine ver-trauenswurdige Instanz (Dealer) Elemente einer Menge S verteilt (Teilge-heimnisse, shadows), so dass folgende beiden Bedingungen erfullt sind:
(1) Jede zulassige Konstellation von Teilnehmern kann mit Hilfe ihrer Teil-geheimnisse das Geheimnis g bestimmen.
(2) Jede unzulassige Konstellation kann das nicht.
Das Secret Sharing Scheme heißt perfekt, falls jede unzulassige Konstellationmit ihren Teilgeheimnissen soviel uber g erfahrt wie ohne diese.
Wir betrachten zunachst einen wichtigen Spezialfall von Secret Sharing Sche-mes.
12.3 Definition (Schwellenwertsystem)
Sei T eine Menge von Teilnehmern T = 1, . . . , n. Sei k ≤ n.Sei Z die Zugriffsstruktur, die aus allen Teilmengen von T besteht, die min-destens k Teilnehmer enthalten:
Z = U ⊆ T : |U | ≥ k
Ein Secret Sharing Scheme zu dieser Zugriffsstruktur heißt (k, n)-Schwellen-wertsystem (threshold system).
12.4 Shamirs Konstruktion eines perfekten Schwellen-wertsystems
Gegeben sei T mit |T | = n, 2 ≤ k ≤ n.Vorgegeben wird eine große Primzahl p (die das Sicherheitsniveau festlegt;siehe unten). In jedem Fall muss p ≥ n + 1 gelten.Das Geheimnis g sei ein Element aus Zp.Der Dealer wahlt zufallig a1, . . . , ak−1 ∈ Zp, ak−1 6= 0 und bildet
f(x) = g + a1x + · · ·+ ak−1xk−1 ∈ Zp[x],
ein Polynom vom Grad k−1. a1, . . . , ak−1 und naturlich auch g halt er geheim.Der Dealer wahlt ferner zufallig paarweise verschiedene x1, . . . , xn ∈ Z∗p. Diese
181

werden offentlich gemacht. Der Teilnehmer i erhalt als Teilgeheimnis gi =f(xi).
Zur Rekonstruktion von g mussen k Teilnehmer kooperieren, etwa i1, . . . , ik.Durch (xi1 , gi1), . . . , (xik , gik) ist das Polynom f eindeutig bestimmt. Mankann es z.B. durch Lagrange-Interpolation berechnen:
f(x) =k∑
j=1
(x− xi1) · · · (x− xij−1)(x− xij+1
) · · · (x− xik)
(xij − xi1) · · · (xij − xij−1)(xij − xij+1
) · · · (xij − xik)· gij
Dann ist g = f(0). Man kann g naturlich auch direkt berechnen, indem mangleich x = 0 in obige Formel fur f(x) einsetzt:
g =
k∑
j=1
(gij ·
∏
l 6=j
xil
xil − xij
)
(Alle Rechnungen sind in Zp, d.h. mod p durchzufuhren.)
Wenn mehr als k Teilnehmer kooperieren, etwa k, so liefert die Lagrange-Interpolation ebenfalls f , da alle Punkte auf dem Graph von f liegen. Ge-nauer: Sei f das von den k Teilnehmern interpolierte Polynom vom Grad≤ k− 1, so hat f − f Nullstellen xi1 , . . . , xiek
, die paarweise verschieden sind.
Da der Grad des Polynoms f − f hochstens k − 1 ist, ist f − f = 0, d.h.f = f .
k′ < k Teilnehmer konnen g mit hoher Wahrscheinlichkeit nicht bestimmen:Sie interpolieren mit ihren Punkten (xi1 , gi1), . . . , (xik′
, gik′) ein Polynom vom
Grad≤ k′−1. Nun gibt es, wie man mit Hilfe der Vandermonde-Determinantenachrechnen kann, fur jedes h ∈ Zp gleich viele Polynome vom Grad ≤ k′−1,die durch (xi1 , gi1), . . . , (xik′
, gik′) gehen und an der Stelle 0 den Wert h haben.
Werden also (xi1 , gi1), . . . , (xik′, gik′
) zu Beginn gleichverteilt zufallig gewahlt,so ist die Wahrscheinlichkeit 1
p, dass die k′ Teilnehmer das richtige Geheimnis
rekonstruieren. Dies ist dieselbe Wahrscheinlichkeit, ohne Kenntnis der Teil-geheimnisse das Geheimnis zu raten. Das Shamirsche Schwellenwertsystemist also perfekt.
Wir betrachten jetzt noch eine allgemeinere Form von Zugriffsstrukturen,durch die die meisten in Anwendungen auftretenden Falle abgedeckt sind:
182

12.5 Definition (monotone Zugriffsstruktur)
Eine Zugriffsstruktur Z ⊆ P(T ) heißt monoton, falls gilt:Ist U ∈ Z, U ⊆ V ⊆ T , so ist V ∈ Z.
Klar: Zugriffsstrukturen von Schwellenwertsystemen sind monoton, aber derMonotoniebegriff ist naturlich allgemeiner.Auch fur beliebige monotone Zugriffsstrukturen lassen sich Secret SharingSchemes konstruieren. Es gibt eine Vielzahl von Konstruktionsverfahren. Wirbeschreiben hier eines, das Methoden der linearen Algebra benutzt und aufG. Simmons (1991) zuruckgeht.
12.6 Monotone Secret Sharing Schemes nach Simmons
Die Konstruktion von Simmons beruht auf folgendem
Lemma
Sei Y ein d-dimensionaler Vektorraum, v1, . . . , vd eine Basis von Y . Dannexistiert vd+1 ∈ Y , so dass v1, . . . , vi−1, vi+1, . . . , vd+1 eine Basis von Y istfur alle i = 1, . . . , d + 1.
Beweis:Wir zeigen, dass jedes vd+1 =
∑di=1 aivi mit ai 6= 0 fur alle i (also z.B.
vd+1 = v1 + · · ·+ vd) die Behauptung des Lemmas erfullt:Aus Symmetriegrunden genugt es, die Behauptung fur i = 1 zu zeigen.Angenommen, v2, . . . , vd, vd+1 sind linear abhangig. Sei
∑d+1j=2 bjvj = 0, nicht
alle bj = 0. Ware bd+1 = 0, so waren v2, . . . , vd linear abhangig, Widerspruchzur Voraussetzung. Also ist bd+1 6= 0. Dann ist a1v1 + · · · + advd = vd+1 =−∑d
j=2bj
bd+1vj , also a1v1 ∈ 〈v2, . . . , vd〉. Wegen a1 6= 0 ist dann auch v1 ∈
〈v2, . . . , vd〉, ein Widerspruch zur Voraussetzung.Damit ist die Behauptung gezeigt.
Wir beschreiben jetzt das Simmons-Verfahren:
(1) Sei T = t1, . . . , tn die Teilnehmermenge, Z ⊆ P(T ) eine monotoneZugriffsstruktur. Sei
U = P(T ) \ Zdie Menge der unzulassigen Konstellationen,
Umax = U ∈ U : U 6⊆ U ′ fur alle U ′ ∈ U
183

die Menge der maximal unzulassigen Konstellationen. Sei
d = |Umax|, Umax = U1, . . . , Ud.
Sei p eine große Primzahl (p bestimmt das Sicherheitsniveau), V ein(d + 1)-dimensionaler Zp -Vektorraum (V = Zd+1
p ).Wahle in V
– einen 2-dimensionalen Unterraum X; dies ist der (offentlich be-kannte) sog. Geheimnisraum;
– in X einen 1-dimensionalen Unterraum G = 〈w〉, das Geheimnis;
– einen d-dimensionalen Unterraum Y von V mit Y ∩X = G;
– Vektoren y1, . . . , yd in Y , so dass je d Vektoren aus y1, . . . , yd, wlinear unabhangig sind (also eine Basis von Y bilden); dies geht,indem man w zu einer Basis y2, . . . , yd, w von Y erganzt und aufdiese das obige Lemma anwendet, um y1 zu erhalten.
(2) Verteilung der Teilgeheimnisse:Sei t ein beliebiger Teilnehmer aus t1, . . . , tn. Sei
t 6∈ Ui1 , . . . , Uir und t ∈ Uj fur alle j ∈ 1, . . . , d \ i1, . . . , ir.
Dann erhalt t als Teilgeheimnismenge yi1, . . . , yir.(Ggf. erhalt t die leere Menge, wenn er in allen Uj enthalten ist.)
(3) Rekonstruktion (bzw. Versuch der Rekonstruktion) des Geheimnissesdurch eine Menge S von Teilnehmern:Die Teilnehmer aus S bilden den von ihren Vektoren erzeugten Unter-raum und bilden dessen Durchschnitt mit X.
1. Fall: Die Teilnehmermenge S ist zulassig (d.h. S ∈ Z):Dann S 6⊆ Ui fur alle i = 1, . . . , d, denn Teilmengen unzulassiger Men-gen sind unzulassig wegen der Monotonie von Z. Sei i ∈ 1, . . . , d.Dann existiert ein Teilnehmer t in S, t 6∈ Ui. Daher kommt yi unterden Teilgeheimnissen von t vor. Da dies fur alle i gilt (jedes Mal evtl.mit einem anderen Teilnehmer aus S), ist die Menge aller Teilgeheim-nisse der Teilnehmer aus S die Menge y1, . . . , yd.Es ist 〈y1, . . . , yd〉 = Y und Y ∩X = G.Die Teilnehmermenge S kann also das Geheimnis G bestimmen.
2. Fall: Die Teilnehmermenge S ist unzulassig:Dann existiert ein j mit S ⊆ Uj. Also kommt yj nicht unter den Teil-geheimnissen der Teilnehmer in S vor. Folglich ist der von den Teil-nehmern in S mit ihren Teilgeheimnissen erzeugte Unterraum Y0 in
184

〈y1, . . . , yj−1, yj+1, . . . , yd〉 enthalten.Es ist Y0∩X ⊆ Y ∩X = 〈w〉. Angenommen, w ∈ Y0∩X ⊆ 〈y1, . . . , yj−1,yj+1, . . . , yd〉. Dann sind w, y1, . . . , yj−1, yj+1, . . . , yd linear abhangig, imWiderspruch zur Wahl in (1).Folglich ist Y0 ∩ X = 0, und die Teilnehmer aus S erfahren nichtsuber G.Das Secret Sharing Scheme ist also perfekt. Da es p2−1
p−1= p + 1
1-dimensionale Unterraume in X gibt, ist bei zufalliger gleichverteilterWahl des Geheimnisses G die Wahrscheinlichkeit 1
p+1, dieses zu raten.
Beispiel:
Sei T = 1, 2, 3, 4,Z = 2, 4, 1, 2, 4, 1, 3, 4, 2, 3, 4, 1, 2, 3, 4.Z ist monoton.Die maximal unzulassigen Mengen sind U1 = 1, 2, 3, U2 = 1, 4, U3 =3, 4.Also ist d = 3 und V = Z4
p.Sei e1, e2, e3, e4 eine Basis von V, z.B. die kanonische.Wir wahlen als Geheimnisraum X = 〈e1, e2〉 und als Geheimnis G = 〈e1+e2〉.Wir setzen ferner Y = 〈e1 + e2, e3, e4〉.Mit y1 = e1 + e2 + e3 + e4, y2 = e3, y3 = e4 und w = e1 + e2 sind dieBedingungen aus (1) erfullt.Nun werden die Teilgeheimnisse verteilt:1 6∈ U3, also erhalt 1 die Menge e4;2 6∈ U2, U3, also erhalt 2 die Menge e3, e4;3 6∈ U2, also erhalt 3 die Menge e3;4 6∈ U1, also erhalt 4 die Menge e1 + e2 + e3 + e4.
Wir uberprufen jetzt den Rekonstruktionsprozess an zwei Beispielen:
Sei S = 2, 3, 4. S ist also zulassig.Der von 2, 3, 4 mit ihren Teilgeheimnissen erzeugte Unterraum ist
Y0 = 〈e3, e4, e1 + e2 + e3 + e4〉 = 〈e3, e4, e1 + e2〉.Es ist Y0 ∩X = 〈e1 + e2〉 = G. Das Geheimnis wird rekonstruiert.
Sei S = 1, 2, 3. S ist unzulassig.Der von 1, 2, 3 mit ihren Teilgeheimnissen erzeugte Unterraum ist
Y0 = 〈e3, e4〉.Es ist Y0 ∩X = 0, d.h. das Geheimnis wird nicht rekonstruiert.
185

Literatur
[1] Charlisle Adams and Steve Lloyd. Understanding Public-Key Infrastruc-ture. Technology Series. New Riders Publishing, Indianapolis, USA, 2edition, 1999.
[2] Leonard Adleman, Ronald L. Rivest and Adi Shamir. On Digital Signa-tures and Public Key Cryptosystems. MIT Laboratory for ComputerScience Technical Memorandum, (82), April 1977.
[3] William R. Alford, Andrew Granville and Carl Pomerance. There areinfinitely many Carmichael numbers. Annals of Mathematics, (140):703–722, 1994.
[4] Doris Baker and H. X. Mel. Cryptography decrypted. Addison Wesley,Boston, 2001.
[5] Friedrich L. Bauer. Entzifferte Geheimnisse. Springer, 3. Auflage, 2000.
[6] Friedrich L. Bauer. Mathematik besiegte in Polen die unvernunftig ge-brauchte ENIGMA - Teil 1. Informatik Spektrum, 28(6):493–497, 2005.
[7] Friedrich L. Bauer. Mathematik besiegte in Polen die unvernunftig ge-brauchte ENIGMA - Teil 2. Informatik Spektrum, 29(1):53–60, 2006.
[8] Henry Beker and Fred Piper. Cipher Systems: The protection of com-munications. Northwood Books, London, 1982.
[9] Albrecht Beutelspacher, Heike B. Neumann und Thomas Schwarzpaul.Kryptographie in Theorie und Praxis. Vieweg, Braunschweig, 2005.
[10] Albrecht Beutelspacher, Jorg Schwenk und Klaus-Dieter Wolfenstetter.Moderne Verfahren der Kryptologie. Vieweg, Braunschweig, 4. Auflage,2001.
[11] Eli Biham and Adi Shamir. Differential Cryptanalysis of DES-like Cryp-tosystems. Journal of Cryptology, 4(1):3–72, 1991.
[12] Eli Biham and Adi Shamir. Differential Cryptanalysis of the Data En-cryption Standard. Springer, 1993.
[13] Alex Biryukov, Christophe de Canniere and Bart Preneel. An Introduc-tion to Block Cipher Cryptanalysis. Proceedings of the IEEE, 94(2):346–356, 2006.
186

[14] Leonore Blum, Manuel Blum and Mike Shub. A Simple UnpredictableRandom Number Generator. SIAM Journal on Computing, (15):364–383, 1986.
[15] Johannes Buchmann. Einfuhrung in die Kryptographie. Springer, Berlin,2. Auflage, 2001.
[16] Steve Burnett and Stephen Paine. Kryptographie. mitp, Bonn, 2001.
[17] Komaravolu Chandrasekharan. Einfuhrung in die analytische Zahlen-theorie. Lecture notes in mathematics 29, Springer, Berlin, 1966.
[18] Don Coppersmith. The data encryption standard (DES) and its strengthagainst attacks. IBM Journal of Research and Development, 38(3):243–250, 1994.
[19] Richard Crandall and Carl Pomerance. Prime Numbers - A Computa-tional Perspective. Springer, New York, 2001.
[20] Joan Daemen and Vincent Rijmen. The Design of Rijndael. AES - TheAdvanced Encryption Standard. Springer, Berlin, 2002.
[21] Hans Delfs and Helmut Knebl. Introduction to Cryptography. Springer,Berlin, Heidelberg, 2002.
[22] Whitfield Diffie and Martin E. Hellman. New Directions in Cryptogra-phy. IEEE Transactions on Information Theory, 22:644–654, 1976.
[23] Wolfgang Ertel. Angewandte Kryptographie. Fachbuchverl. Leipzig imCarl-Hanser-Verl., Munchen, 2001.
[24] Oded Goldreich. Foundations of Cryptography, Vol. 1 - Basic Tools.Cambridge University Press, Cambridge, 2001.
[25] Oded Goldreich. Foundations of Cryptography, Vol. 2 - Basic Applica-tions. Cambridge University Press, Cambridge, 2004.
[26] Max Goldt. Quitten fur die Menschen zwischen Emden und Zittau.Haffmans Verlag, Zurich, 1993.
[27] Thomas Hardjono, Josef Pieprzyk and Jennifer Seberry. Fundamentalsof Computer Security. Springer, Berlin, 2003.
[28] Peter Hauck. Primzahltests und Faktorisierungsalgorithmen. Vorle-sungsskript, Universitat Tubingen, SS 2007.
187

[29] Andrew Hodges. Alan Turing: the Enigma. Simon Schuster, New York,1983.
[30] Patrick Horster. Kryptologie. Bibliographisches Institut, Mannheim,1985.
[31] David Kahn. The Codebreakers. MacMillan, New York, 1967.
[32] David Kahn. Seizing the Enigma. Houghton Miffin, Boston, 1991.
[33] Jonathan Katz and Yehuda Lindell. Introduction to Modern Cryptogra-phy. Chapman & Hall/CRC, Boca Raton, 2008.
[34] Donald E. Knuth. The Art of Computer Programming, volume 2. Ad-dison Wesley, Reading, Mass., 2 edition, 1998.
[35] Neal Koblitz. A course in number theory and cryptography. Springer,New York, 2 edition, 1994.
[36] Neal Koblitz. Algebraic aspects of cryptography. Springer, Berlin u.a., 2edition, 1999.
[37] Rudolf Lidl and Harald Niederreiter. Introduction to finite fields andtheir applications. Cambridge University Press, Cambridge, 1986.
[38] Wenbo Mao. Modern Cryptography - Theory and Praxis. Prentice Hall,2004.
[39] Alfred J. Menezes, Paul C. van Oorschot and Scott A. Vanstone. Hand-book of Applied Cryptography. CRC Press, London, 1997.[http://www.cacr.math.uwaterloo.ca/hac/].
[40] Michael Miller. Symmetrische Verschlusselungsverfahren. Teubner,Stuttgart/Leipzig/Wiesbaden, 2003.
[41] Hans Riesel. Prime Numbers and computer methods for factorizations.Birkhauser, Boston, 2 edition, 1994.
[42] Klaus Schmeh. Kryptografie und Public-Key-Infrastrukturen im Inter-net. dpunkt, Heidelberg, 2. Auflage, 2001.
[43] Bruce Schneier. Angewandte Kryptographie. Addison Wesley, Bonn u.a.,1997.
[44] Jorg Schwenk. Sicherheit und Kryptographie im Internet. Vieweg, Wies-baden, 2002.
188

[45] Douglas Stinson. Cryptography - Theory and Praxis. Chapman &Hall/CRC, Boca Raton, 3 edition, 2006.
[46] Wade Trappe and Lawrence C. Washington. Introduction to Cryptogra-phy with Coding Theory. Prentice Hall, New Jersey, 2002.
[47] Serge Vaudenay. A Classical Introduction to Cryptography: Applicationsfor Communications Security. Springer, New York, 2006.
[48] Dietmar Watjen. Kryptographie - Grundlagen, Algorithmen, Protokolle.Spektrum Akademischer Verlag, 2004.
[49] Michael Welschenbach. Kryptographie in C und C++. Springer, Berlinu.a., 2. Auflage, 2001.
[50] Michael J. Wiener. Cryptanalysis of short RSA secret exponents. IEEETransactions on Information Theory, 36(3):553–558, 1990.
189





























