Embed Size (px)
Citation preview

Künstliche IntelligenzText Mining
Stephan Schwiebert
Sommersemester 2010
Sprachliche Informationsverarbeitung
Institut für Linguistik
Universität zu Köln

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Likelihood
Zwei Hypothesen:
Unabhängigkeit: P(w
2|w
1) = p = P(w
2|←w
1)
Abhängigkeit:P(w
2|w
1) = p
1 != p
2 = P(w
2|←w
1)

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Likelihood
Zwei Hypothesen:
Unabhängigkeit: P(w
2|w
1) = p = P(w
2|←w
1)
Abhängigkeit:P(w
2|w
1) = p
1 != p
2 = P(w
2|←w
1)
c2
Np =
c12
c1
p1=
c2 - c
12
N - c1
p2=
cx = |w
x|

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Likelihood
Zwei Hypothesen:
Unabhängigkeit: P(w
2|w
1) = p = P(w
2|←w
1)
Abhängigkeit:P(w
2|w
1) = p
1 != p
2 = P(w
2|←w
1)
c2
Np =
c12
c1
p1=
c2 - c
12
N - c1
p2=
cx = |w
x|

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Likelihood

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Trigramm, Tetragramm, n-Gramm
Bisher wurden nur Wortpaare untersucht - sinnvoller wäre es aber, auch Trigramme oder allgemein n-Gramme zu untersuchen, um Phrasen wie „Universität zu Köln“ oder „Bundeskanzlerin Dr. Angela Merkel“ zu finden.
Die vorgestellten Verfahren lassen sich prinzipiell anpassen, allerdings nimmt die Anzahl generierter n-Gramme
exponentiell zu tauchen relevante n-Gramme i.d.R. zu selten auf
(Sparse Data Problem)

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Literatur
Manning, Schütze 1999: Foundations of Statistical Natural Language Processing

Dokumentklassifikation

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Information Retrieval
IR is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).(Manning et al., 2008, S.1)

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Beispiel: Suchmaschine

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Beispiel: Suchmaschine
Naiver Ansatz:
Suche in allen Dokumenten nach den zu findenden Wörtern, Gewichte die Dokumente nach Anzahl der Fundstellen.

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Beispiel: Suchmaschine
Naiver Ansatz:
Suche in allen Dokumenten nach den zu findenden Wörtern, Gewichte die Dokumente nach Anzahl der Fundstellen.
Nachteile:
Langsam Größere Dokumente werden bevorzugt Keine erweiterten Anfragen („Ähnliche
Dokumente“) möglich.

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Term-Dokument-Matrix
Manning et al: S. 4

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Term-Dokument-Matrix
Nachteil: Sehr bzw. zu groß.
Beispielkorpus enthält ca. 130.000 unterschiedliche Wörter, ca. 4000 Dokumente -> Matrix enthält 520.000.000 Zellen.
Wie ließe sich das Verfahren verbessern? Welche Beobachtungen lassen sich an einer TD-Matrix machen?

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Invertierter Index
Manning et al: S. 7

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Term Frequency
tf(t,d) : Häufigkeit des Vorkommens von Term t in Dokument d.

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Term Frequency
tf(t,d) : Häufigkeit des Vorkommens von Term t in Dokument d.
Genügt alleine nicht, denn nicht alle Terme sind gleich wichtig. Auf jeder Seite des Java-Seminars taucht das Wort „Java“ auf - offensichtlich ist dies kein gutes Entscheidungsmerkmal (in diesem Kontext).

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Corpus Frequency
c(t): Anzahl der Vorkommen des Terms t im Korpus.

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Corpus Frequency
c(t): Anzahl der Vorkommen des Terms t im Korpus.
Zu generell - evtl. kommt ein Wort in einem Teil der Dokumente sehr häufig vor, in einem anderen Teil jedoch gar nicht - in diesem Fall wäre es ein gutes Entscheidungsmerkmal, würde jedoch durch c(t) nicht erkannt.

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Document Frequency
c(t): Anzahl der Vorkommen des Terms t im Korpus.
Zu generell - evtl. kommt ein Wort in einem Teil der Dokumente sehr häufig vor, in einem anderen Teil jedoch gar nicht - in diesem Fall wäre es ein gutes Entscheidungsmerkmal, würde jedoch durch c(t) nicht erkannt.
Deshalb:df(t): Anzahl der Dokumente, die Term t enthalten.

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Inverse Document Frequency
idf(t): log
N: Anzahl aller Dokumente im Korpus
N
df(t)

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Inverse Document Frequency
idf(t): log
N: Anzahl aller Dokumente im Korpus
idf(t) ist hoch, wenn t nur in wenigen Dokumenten vorkommt niedrig, wenn t in vielen Dokumenten vorkommt am niedrigsten, wenn t in allen Dokumenten vorkommt
N
df(t)

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
TF-IDF
tf-idf (t,d): tf(t,d) * idf(t)

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
TF-IDF
tf-idf (t,d): tf(t,d) * idf(t)
idf(t): log
tf(t,d): Häufigkeit des Vorkommens von Term t in Dokument d.
N: Anzahl der Dokumente
N
df(t)

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
TF-IDF
tf-idf (t,d): tf(t,d) * idf(t)
Wert ist hoch, wenn t häufig in einer kleinen Zahl von Dokumenten
vorkommt niedriger, wenn t seltener in einem Dokument vorkommt,
oder in vielen Dokumenten am niedrigsten, wenn t in (fast) allen Dokumenten
vorkommt.
Gute Berechnung der „Relevanz“ eines Terms. -> Beispiel 1

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Suchmaschine
Wie ließe sich ein einfaches Ranking für einen Suchalgorithmus implementieren, der nach mehreren Termen sucht?

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Suchmaschine
Wie ließe sich ein einfaches Ranking für einen Suchalgorithmus implementieren, der nach mehreren Termen sucht?
Addition der TF-IDF-Werte für jedes Dokument (ggf. Abbrechen, wenn Term nicht auftaucht)
-> Beispiel 2

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Suchmaschine
Wie ließe sich eine Suche nach „ähnlichen Dokumenten“ implementieren?
Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
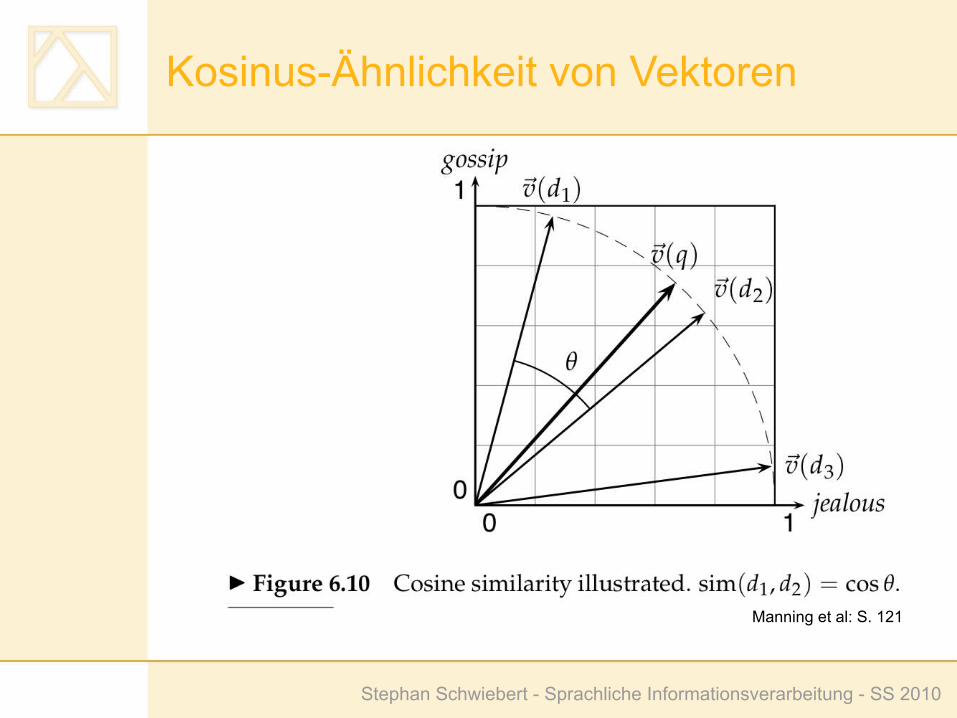
Kosinus-Ähnlichkeit von Vektoren
Manning et al: S. 121

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Kosinus-Ähnlichkeit von Vektoren
=
Beispiel 3

Stephan Schwiebert - Sprachliche Informationsverarbeitung - SS 2010
Literatur
Manning et al., 2009: An Introduction to Information Retrieval. online unter http://nlp.stanford.edu/IR-book/information-retrieval-book.html.