Embed Size (px)
Citation preview

Statistik mit Stata - 1 -
Übung Statistik I – Statistik mit StataSS07 – 02.07.2007
11. Zusammenhangsanalyse III
Andrea Kummerer (M.A.)
Oec R. I-53
Sprechstunde: n.V.

Statistik mit Stata - 2 -
Überblick
1. Zu Anfang
2. Evaluation
3. Graphisch: Zusammenhang zwischen zwei metrischen Variablen
4. Bivariate lineare Regression
5. Übung Bivariate lineare Regression
6. Besprechung: Inhalt Wiederholungsstunde

Statistik mit Stata - 3 -
1. Zu Anfang• Befehle, die bekannt sein sollten: Update, set memory,
input, use, clear, save, exit, pwd, cd, dir, describe,
codebook, sort, list, help, search, tabulate oneway,
numlabel, mvdecode, mvencode, label, set dp, log using,
log close, log off/on, cmdlog using, cmdlog close,
cmdlog off/on, do, generate, replace, recode, keep, drop,
summarize, tabstat, histogram, graph pie, kdensity,
graph box, set scheme, graph export, robvar, ttest,
iweight (Befehlsoption), tabulate twoway
• Vorbereitung:
1. profile.do ausführen! Ist Stata up-to-date?
2. Heute Verwendung von allbus_ueb4.dta. Wenn also im eigenen Verzeichnis noch nicht vorhanden aus dem Lehre on jeder Lehre Verzeichnis (V) in das eigene Verzeichnis kopieren.

Statistik mit Stata - 4 -
2. Evaluation

Statistik mit Stata - 5 -
3. Graphisch: Zusammenhang zwischen zwei metrischen Variablen• Bei der Untersuchung des Zusammenhangs zwischen
kategorialen Variablen kann man die Variablen in einer Kreuztabelle gegenüberstellen.
• Dies ist im Fall von metrischen Variablen durch die hohe Anzahl möglicher Ausprägungen nicht sinnvoll.
• Bei metrischen Variablen ist ein Scatterplot zur Darstellung sinnvoll. Bsp: Zusammenhang von Arbeitszeit und Einkommen bei westdeutschen Befragten: scatter v381 v207 if v4==1
• Zu beachten: Wie bei Kreuztabellen ist die Darstellung im Scatterplot i.d.R.: die als erklärend aufgefasste Variable wird auf der x-Achse (horizontale Linie), die als abhängig aufgefasste Variable auf der y-Achse abgetragen.
Darstellung auf y-AchseDarstellung auf x-Achse
! iweight-Optionnicht erlaubt !
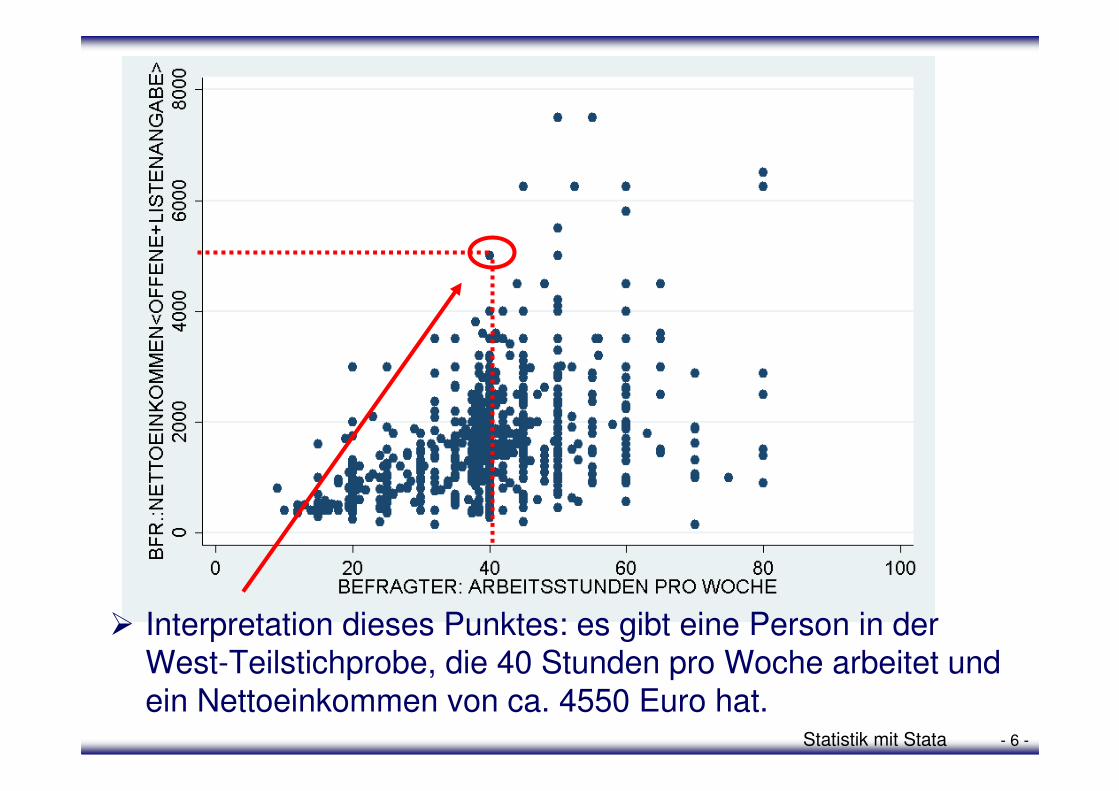
Statistik mit Stata - 6 -
� Interpretation dieses Punktes: es gibt eine Person in der West-Teilstichprobe, die 40 Stunden pro Woche arbeitet und ein Nettoeinkommen von ca. 4550 Euro hat.

Statistik mit Stata - 7 -
• Besteht hier nun ein Zusammenhang?
• Bestünde ein positiver Zusammenhang, so würde man erwarten, dass mit größeren Werten der unabhängigen Variablen auch die abhängige Variable größere Werte annimmt und umgekehrt.
• Im Beispiel der Variablen Einkommen und Arbeitszeit scheint im Fall der westdeutschen Befragten ein solcher Zusammenhang zu bestehen, denn bei höheren Arbeitszeiten wird in der Tendenz auch mehr verdient. Es liegt also eine je-mehr-desto-mehr-Beziehung vor. Allerdings streuen die Werte insbesondere im unteren Bereich der Arbeitsstunden relativ stark.
• Wie stellt sich im Vergleich dazu der Zusammenhang zwischen Einkommen und Arbeitszeit bei ostdeutschen Befragten dar?
• Also: scatter v381 v207 if v4==2
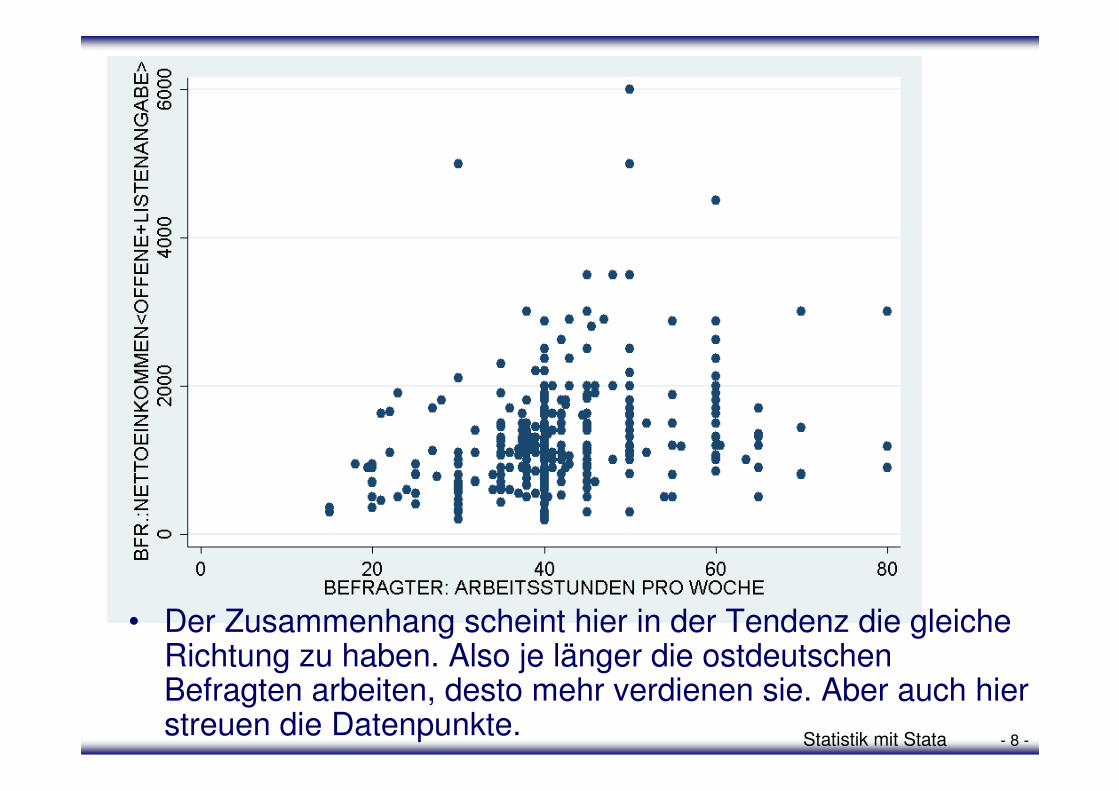
Statistik mit Stata - 8 -
• Der Zusammenhang scheint hier in der Tendenz die gleiche Richtung zu haben. Also je länger die ostdeutschen Befragten arbeiten, desto mehr verdienen sie. Aber auch hier streuen die Datenpunkte.
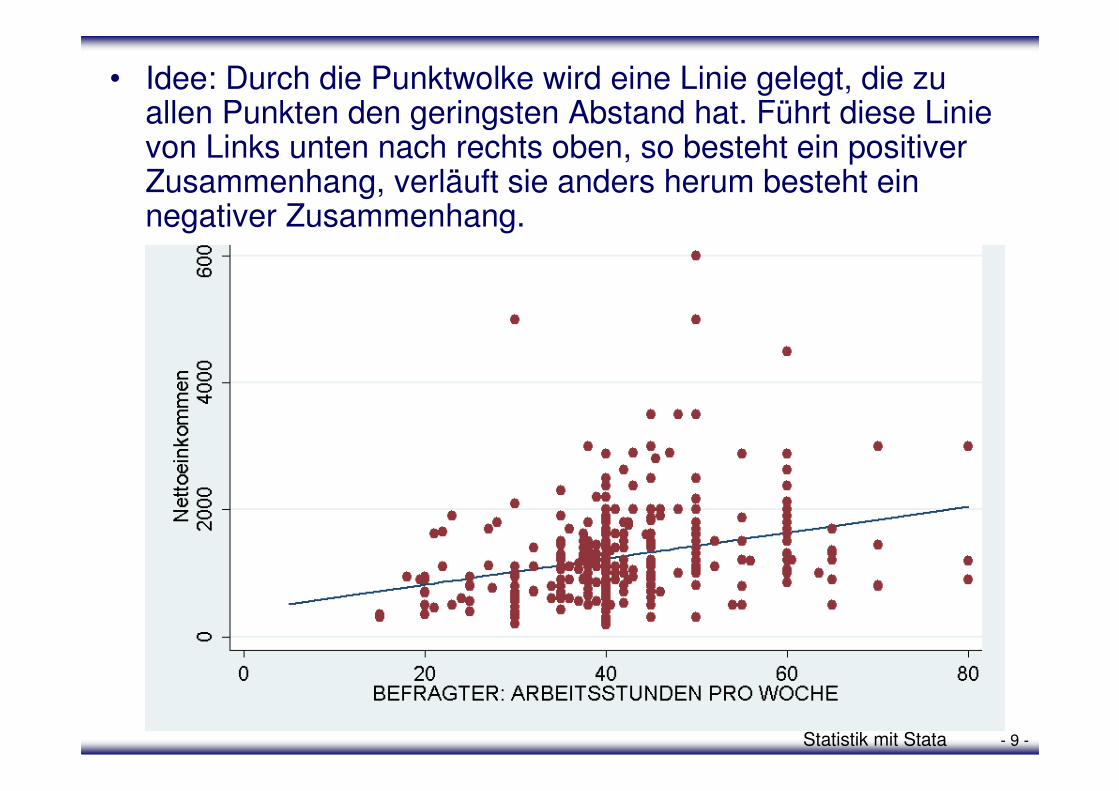
Statistik mit Stata - 9 -
• Idee: Durch die Punktwolke wird eine Linie gelegt, die zu allen Punkten den geringsten Abstand hat. Führt diese Linie von Links unten nach rechts oben, so besteht ein positiver Zusammenhang, verläuft sie anders herum besteht ein negativer Zusammenhang.

Statistik mit Stata - 10 -
• Es besteht hier also ein positiver Zusammenhang: Je länger ein ostdeutscher Befragter arbeitet, desto mehr verdient er.
• Die Linie (die den kleinstmöglichen Abstand zu allen Punkten hat) nennt man Regressionsgerade. Streuen die Punkte sehr weit um diese Gerade ist der Zusammenhang weniger stark, als wenn alle Punkte in der Nähe der Gerade liegen.
• Die je-desto-Beziehung ist dabei desto stärker je größer die Steigung der Geraden ist. Eine flache Gerade bedeutet nämlich, dass sich die Werte auf der y-Achse nur wenig verändern, wenn sich die Werte auf der x-Achse verändern.
• Hinter dieser Interpretation steht die Logik der PRE-Maßeaus der letzten Stunde: Um wie viel verbessert sich die Vorhersage der Werte auf der y-Achse (abhängige Variable), wenn die Werte auf der x-Achse (erklärende Variable) zur Vorhersage herangezogen werden?
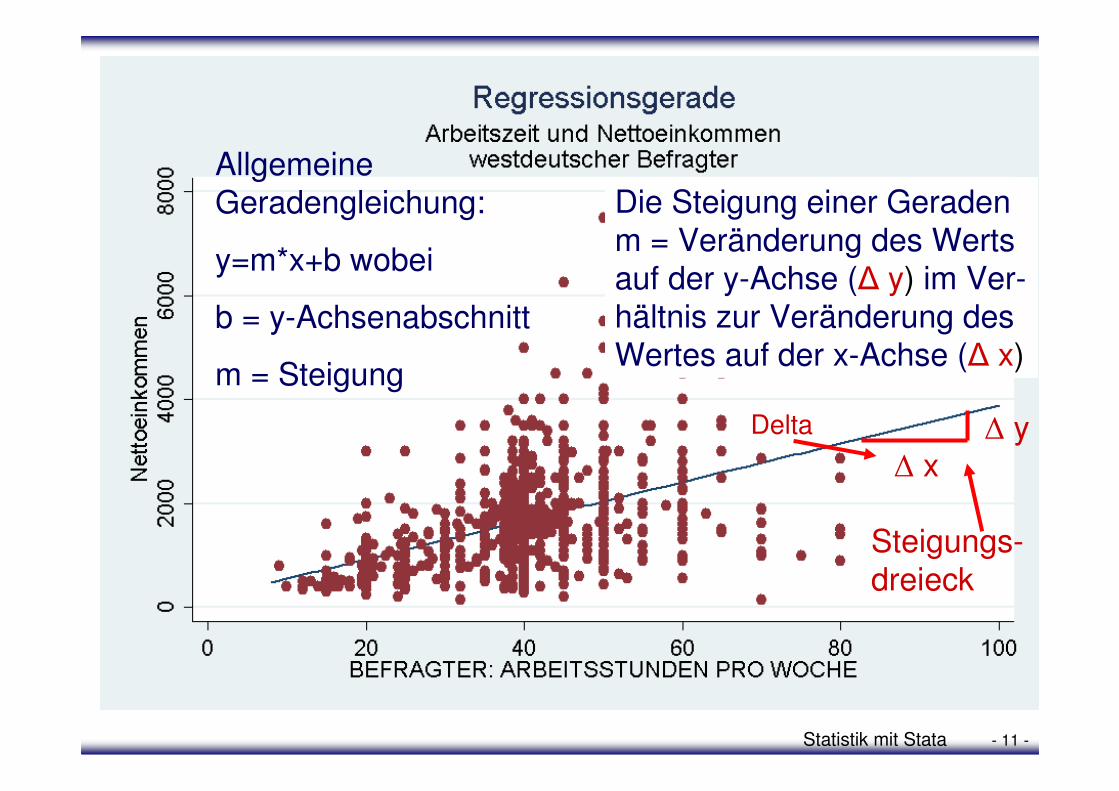
Statistik mit Stata - 11 -
Steigungs-dreieck
Die Steigung einer Geraden m = Veränderung des Werts auf der y-Achse (∆ y) im Ver-hältnis zur Veränderung des Wertes auf der x-Achse (∆ x)
Allgemeine Geradengleichung:
y=m*x+b wobei
b = y-Achsenabschnitt
m = Steigung
∆ x∆ yDelta
Statistik mit Stata - 12 -
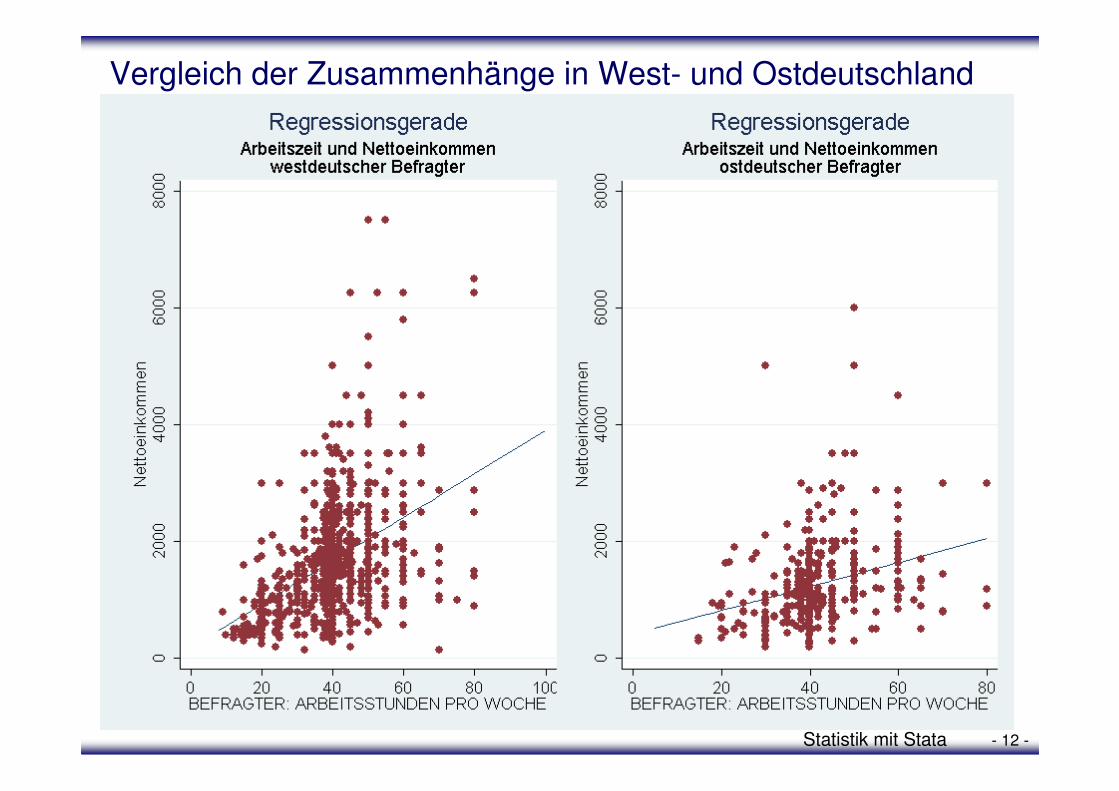
Vergleich der Zusammenhänge in West- und Ostdeutschland

Statistik mit Stata - 13 -
• In der Grafik für den Zusammenhang bei westdeutschen Befragten ist die Steigung der Regressionsgerade größer als in der für Ostdeutschland. Dies verweist auf eine stärker ausgeprägte je-desto-Beziehung.
• Dem gegenüber scheint die Streuung der Datenpunkte um die Regressionsgerade in der westdeutschen Teilstichprobe größer zu sein, als die in der ostdeutschen Teilstichprobe.
• Zusammenfassend scheint der Zusammenhang zwischen Arbeitszeit und Einkommen bei den ostdeutschen stärker zu sein als bei den westdeutschen Befragten. Dafür steigt das Einkommen bei westdeutschen stärker in Abhängigkeit von der steigenden Arbeitszeit als bei ostdeutschen Befragten.
• Aus den Formulierungen wird deutlich, dass ein rein graphisches Vorgehen in der Zusammenhangsanalyse nicht sehr präzise ist.
• Vorgehen, um Zusammenhänge zwischen zwei metrischen Variablen in Zahlen abzubilden: Bivariate lineare Regression

Statistik mit Stata - 14 -
4. Bivariate Lineare Regression
• In der bivariaten linearen Regression wird vereinfacht eine Gerade berechnet, die den geringsten Abstand zu allen Punkten der gemeinsamen Verteilung (also eine Regressionsgerade) hat.
• Gleichzeitig wird bei der linearen Regression mit Stata analysiert, inwiefern die Ergebnisse der Stichprobe auf die Grundgesamtheit verallgemeinerbar sind.
• Stata Befehl:
regress depvar [indepvars] [if] [in] [weight] [, options]
• Beispiel: regress v381 v207 if v4==2
Abhängige Variable Erklärende Variable

Statistik mit Stata - 15 -
Ergebnis:ANOVA-Block
Koeffizienten-Block
Modelfit-Block
• ANOVA: Analysis of Variance
• Im ANOVA-Block finden sich Kennziffern dafür, wie sinnvoll es ist, durch die Punktewolke eine Gerade zu legen.

Statistik mit Stata - 16 -
• Der Modelfil-Block verwertet im Grunde die berechneten Kennwerte aus dem ANOVA-Block.
• Der R-squared (r2)-Wert zeigt an,wie viel der Varianz der abhängigen durch die erklärende Variable erklärt (in bisheriger Terminologie: vorhergesagt) werden kann. In unserem Fall werden also 8,08% der Variation des Einkommens durch die Arbeitszeit erklärt (vgl. Logik der PRE-Maße aus der letzten Stunde).
• Der Root MSE hier sagt aus, dass wir bei der Vorhersage des Einkommens durch die Arbeitszeit durchschnittlich um 658,27 Euro daneben liegen.
• Der F-Wert ist der Wert der Teststatistik für den r2 –Wert.
• Der Wert hinter Prob > F gibt an, wie hoch die Wahrscheinlichkeit ist, dass wir einen r2 –Wert erhalten, wie den hier für unsere Stichprobe ermittelten (Wert der Teststatistik), wenn r2 in der Grundgesamtheit = 0 ist.

Statistik mit Stata - 17 -
• Der Koeffizienten-Block enthält zunächst die Werte für die einzelnen Bestandteile der Regressionsgerade, ist also im Grunde die Regressionsgerade in Zahlen ausgedrückt:
• In der Spalte, die mit Coef überschrieben ist findet sich in der Zeile v207 der Wert der Steigung (m). Diese beträgt hier also 20,52. Erhöht sich also die Arbeitszeit um eine Stunde vergrößert sich das Einkommen der ostdeutschen Befragten laut Regressionsgerade um 20,52 Euro. In der _cons-Zeile ist der y-Achsenabschnitt (b) abgetragen, der hier nicht sinnvoll interpretiert werden kann (daher wird die untere Zeile nicht weiter berücksichtigt). Die Interpretation wäre: Bei einer Arbeitszeit von 0 Stunden verdienen ostdeutsche Befragte durchschnittlich 409,61€.
• Der Std. Err. (Standard Error) gibt die durchschnittliche Abweichung von der Regressionsgerade an.

Statistik mit Stata - 18 -
• Die Angaben in den mit t und P>|t| überschriebenen Spalten enthalten Angaben über einen Hypothesentest hinsichtlich des Wertes der Steigung (m). Getestet wird hier die Nullhypothese, dass bei dem ermittelten Stichprobenwert für m in der Grundgesamtheit m=0 ist (also keine je-desto-Beziehungvorliegt). Unter t findet sich der Wert der Teststatistik. Mit einer Irrtumswahrscheinlichkeit von 5% (Stata-Standard) kann die Nullhypothese verworfen werden, wenn der Wert in der Spalte P>|t| < 0,05.
• Die mit 95% Conf. Interval überschriebene Spalte enthält eine Schätzung über ein Intervall, in dem der Werte der Steigung (m) ausgehend von den Stichprobendaten in der Grund-gesamtheit liegt. Mit einer Wahrscheinlichkeit von 95% enthält das angegebene Konfidenzintervall mit den Grenzen 14,0615 und 26,9758 den Wert der Steigung (m) in der Population.

Statistik mit Stata - 19 -
• Ob die Ergebnisse für eine Stichprobe ermittelten Ergebnisse einer Regression tatsächlich auf die Grundgesamtheit verallgemeinerbar sind, hängt von einigen Annahmen ab, die hier nicht näher erläutert werden. Streng genommen müsste aber vor jeder Interpretation untersucht werden, ob diese Annahmen im vorliegenden Fall zutreffen. Vgl. Kühnel/Krebs (2001): Statistik für die Sozialwissen-schaften, S.424 ff.
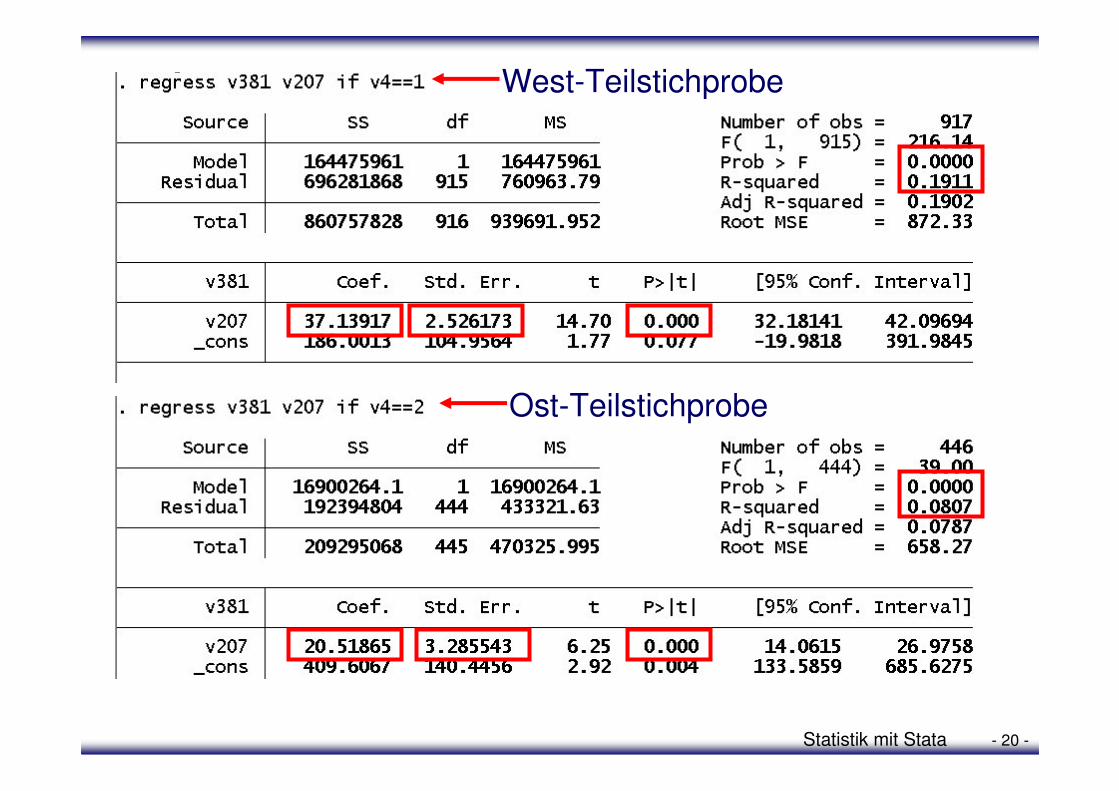
• Regressionen des Einkommens (abhängige Variable) gegen die Arbeitszeit (erklärende Variable) für die west- und die ostdeutsche Teilstichprobe:
regress v381 v207 if v4==1
regress v381 v207 if v4==2
• Interpretation der Ergebnisse:
Statistik mit Stata - 20 -
West-Teilstichprobe
Ost-Teilstichprobe

Statistik mit Stata - 21 -
• Die Steigung der Regressionsgerade ist in der westdeutschen Teilstichprobe mit 37,14 größer als in der ostdeutschen Teilstichprobe mit 20,52 (wie bereits im Scatterplot festgestellt). Erhöht sich die Arbeitszeit um eine Stunde vergrößert sich das Einkommen der westdeutschen Befragten um 16,62 Euro (37,14 - 20,52 =16,62) mehr als das der ostdeutschen.
• Sowohl in der westdeutschen, als auch in der ostdeutschen Teilstichprobe ist der Befund, dass eine je-desto-Beziehungvorliegt mit einer Irrtumswahrscheinlichkeit von 5% auf die jeweilige Population verallgemeinerbar (Die Nullhypothese, dass bei einem Teststatistikwert, wie dem hier jeweils errechneten eine Steigung von m=0 in der jeweiligen Population vorliegt, kann mit einer Irrtumswahrscheinlichkeit von 5% verworfen werden (P>|t| < 0,05).
• Der Standard Error bestätigt den Befund aus dem Vergleich der Scatterplots nicht: Die durchschnittliche Abweichung der Werte von der Regressionsgerade ist in Ostdeutschland

Statistik mit Stata - 22 -
größer als in Westdeutschland. Dies verweist bereits darauf, dass der Zusammenhang in Westdeutschland stärker ist als in Ostdeutschland (die Einkommenswerte also besser aus der Anzahl an Arbeitsstunden vorhersagbar sind).
• Dieses Ergebnis wird durch das Ergebnis des Vergleichs der r2-Werte (Modelfit-Block) der beiden Teilstichproben gestützt. Können in der westdeutschen Teilstichprobe 19,11% der Varianz des Einkommens durch die Anzahl an Arbeits-stunden erklärt (oder vorhergesagt) werden, sind es in der ostdeutschen Teilstichprobe nur 8,07%.
• Sowohl das Ergebnis hinsichtlich r2 in der westdeutschen wie auch in der ostdeutschen Teilstichprobe können mit einer Irrtumswahrscheinlichkeit von 5% auf die jeweiligen Populationen verallgemeinert werden. Dies zeigt jeweils der Wert von 0,000 bei Prob >F. Die Wahrscheinlichkeit, dass bei einem Wert für die Teststatistik, wie er hier vorliegt, der r2-Wert in der Population =0 ist, beträgt in beiden Fällen 0%.

Statistik mit Stata - 23 -
5. Übung Bivariate Lineare Regression
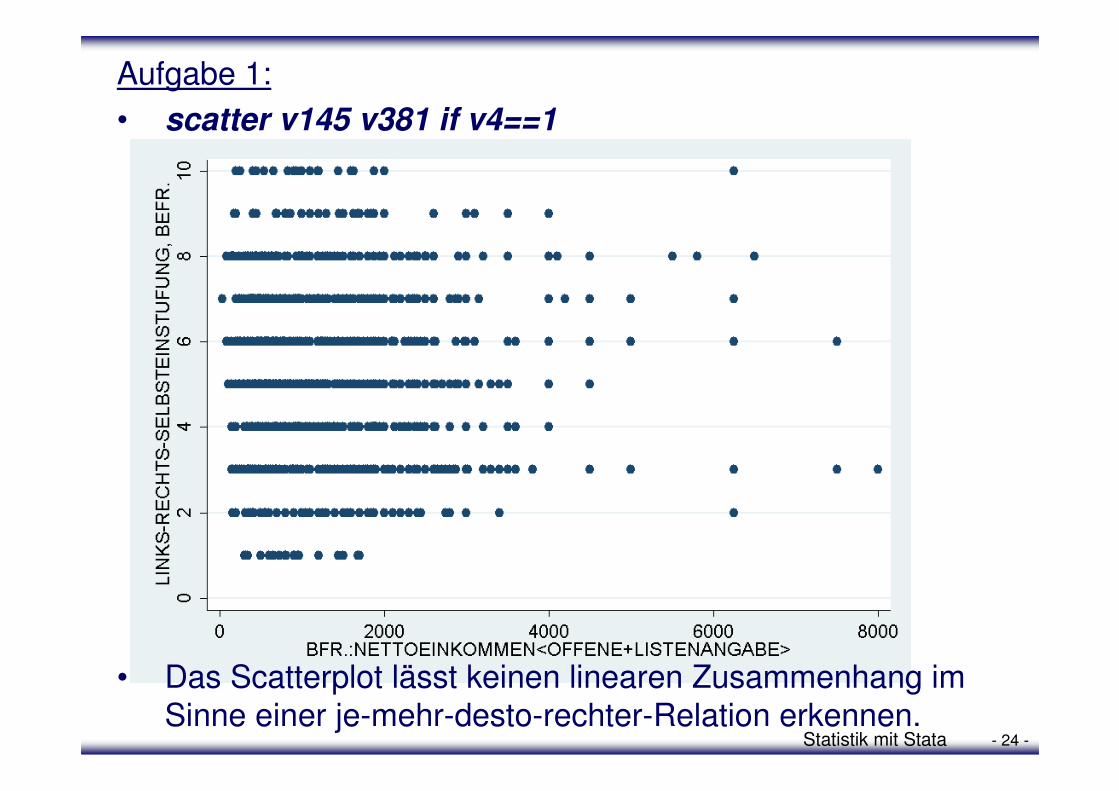
1. Ist in Westdeutschland die Links-Rechts-Selbsteinstufung (v145) abhängig vom Nettoeinkommen (v381) und besteht hier eine je-mehr-desto-rechter-Relation? Erstelle zunächst ein Scatterplot und formuliere daraus resultierend eine Vermutung über den Zusammenhang und seine Richtung. Prüfe deine Vermutung durch Berechnung der Regression.
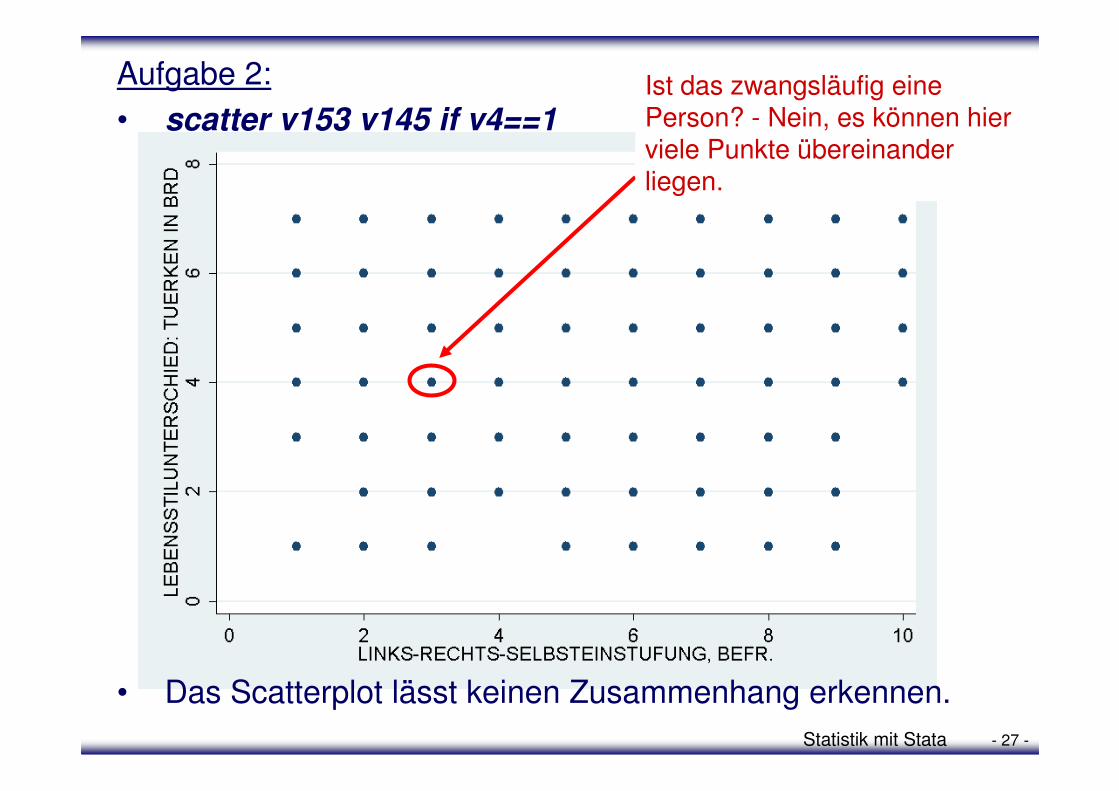
2. Ist der Zusammenhang zwischen der Links-Rechts-Selbsteinstufung (v145) und dem wahrgenommenen Unterschied hinsichtlich des Lebensstils zwischen Türken und Deutschen (v153) in Westdeutschland signifikant? Erstelle ebenfalls zunächst ein Scatterplot und prüfe anschließend deine Vermutung.
Statistik mit Stata - 24 -
• Das Scatterplot lässt keinen linearen Zusammenhang im Sinne einer je-mehr-desto-rechter-Relation erkennen.
Aufgabe 1:
• scatter v145 v381 if v4==1

Statistik mit Stata - 25 -
• Die Steigung der Regressionsgerade ist mit einem Wert von 0,00002 sehr gering. Erhöht sich das Einkommen um einen Euro verändert sich die Links-Rechts-Selbsteinschätzung um 0,00002 Einheiten. Selbst wenn man das Einkommen in 1000er Schritten betrachtet ist die Veränderung in der Links-Rechts-Selbsteinschätzung als gering anzusehen. (Steigt das Einkommen um 1000 Euro sind die Befragten um 0,02 Einheiten rechter eingestellt.
• Da P>|t| > 0,05 kann die Nullhypothese, dass bei einem Teststatistikwert, wie dem hier errechneten eine Steigung

Statistik mit Stata - 26 -
von m=0 in der Population vorliegt mit einer Irrtumswahr-scheinlichkeit von 5% nicht verworfen werden. In der Population liegt also mit einer Irrtumswahrscheinlichkeit von 5% keine je-desto-Beziehung vor.
• Bei einem Wert für die Steigung der Regressionsgerade von 0,00001 ist der vorliegende Standard Error von 0,00005 als groß zu bewerten.
• Der kleine r2-Wert von 0,0001 zeigt, dass in der west-deutschen Teilstichprobe 0,01% der Varianz der Links-Rechts-Selbsteinschätzung durch das Einkommen erklärt werden kann (also im Grunde fast nichts).
• Da der Wert hinter Prob>F >0,05 ist, kann die Nullhypothese, dass bei einem Wert für die Teststatistik wie hier berechnet der r2-Wert in der Grundgesamtheit = 0 ist nicht verworfen werden. Mit einer Irrtumswahrscheinlichkeit von 5% gibt es in der Population keinen Zusammenhang zwischen Einkommen und Links-Rechts-Selbsteinschätzung.
Statistik mit Stata - 27 -
• Das Scatterplot lässt keinen Zusammenhang erkennen.
Aufgabe 2:
• scatter v153 v145 if v4==1Ist das zwangsläufig eine Person? - Nein, es können hier viele Punkte übereinander liegen.

Statistik mit Stata - 28 -
• Die Steigung der Regressionsgerade ist mit einem Wert von 0,11 gering. Erhöht sich der Wert der Links-Rechts-Selbsteinschätzung um 1 Einheit, erhöht sich der Wert der Lebensstilunterschiedsbewertung von Türken um 0,11 Einheit. In der Tendenz wird der Lebensstilunterschied desto größer eingeschätzt, je rechter ein Befragter aus Westdeutschland sich selbst einschätzt, allerdings nur in recht geringem Maße.
• Da P>|t| < 0,05 kann die Nullhypothese, dass bei einem Teststatistikwert, wie dem hier errechneten eine Steigung

Statistik mit Stata - 29 -
von m=0 in der Population vorliegt mit einer Irrtumswahr-scheinlichkeit von 5% verworfen werden. In der Population liegt also mit einer Irrtumswahrscheinlichkeit von 5% eine je-desto-Beziehung vor.
• Relativ zum Wert der Steigung ist der Standard Error von 0,017 als nicht groß zu bewerten.
• Der r2-Wert von 0,019 zeigt, dass in der westdeutschen Teilstichprobe 1,9% der Varianz der Lebensstilunterschieds-einschätzung durch die Links-Rechts-Selbsteinschätzungerklärt werden kann.
• Da der Wert hinter Prob>F <0,05 ist, kann die Nullhypothese, dass bei einem Wert für die Teststatistik wie hier berechnet der r2-Wert in der Grundgesamtheit = 0 ist verworfen werden. Mit einer Irrtumswahrscheinlichkeit von 5% gibt es in der Population einen Zusammenhang zwischen Links-Rechts-Selbsteinschätzung und der Lebensstilunterschieds-einschätzung im Hinblick auf von Türken.

Statistik mit Stata - 30 -
6. Besprechung: Inhalt Wiederholungsstunde

Statistik mit Stata - 31 -
Hausaufgaben:
1. Führe jeden Befehl, den diese Präsentation enthält mindestens einmal aus. Untersuche die verwendeten Befehle dabei auch auf mögliche Unterbefehle und Optionen.
2. Ergänze deine Befehlstabelle um die heute hinzugekommenen Befehle.





























