Embed Size (px)
Citation preview

Prof. Dr.-Ing. Wolfgang Lehner 200. Datenbankstammtisch

2
Data Growth
Von 2000 bis 2002 sind mehr Daten generiert worden als in den 40.000 Jahren davor
Von 2004-2005 hat sich diese Datenmenge wiederum vervierfacht
Datenvolumen 2012: 2,5 Zetabytes, d.h. 10x das Datenvolumen von 2006!
Datenvolumen 2020: 100 Zettabytes
Nicht nur Datenvolumen, sondern insbesondere auch Datenvielfalt wächst.
BitKom (2012)
One Minute of Internet
3
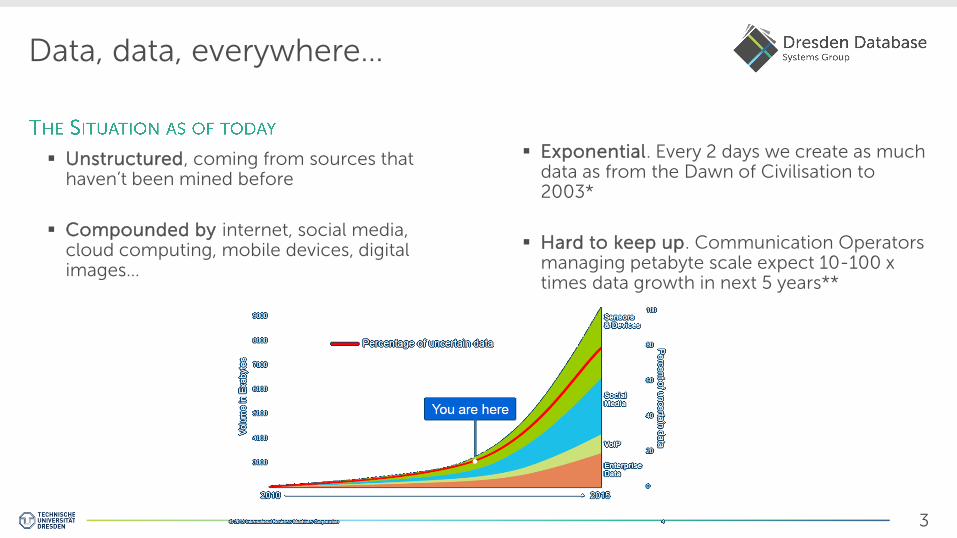
Data, data, everywhere…
Unstructured, coming from sources that haven’t been mined before
Compounded by internet, social media, cloud computing, mobile devices, digital images…
Exponential. Every 2 days we create as much data as from the Dawn of Civilisation to 2003*
Hard to keep up. Communication Operators managing petabyte scale expect 10-100 x times data growth in next 5 years**

4
Generating statistical models out of high volume databases
… this is soooo 2012!

5
Smart Everything
- Smart „things“
- Smart places
- Smart networks
- Smart services
- Smart solutions
„Smart-*“ infrastructure
need to make things Smart…!
Requirements for “Smart Everything”
- Interactive (“tangible”) low latency
- High volume high throughput
6
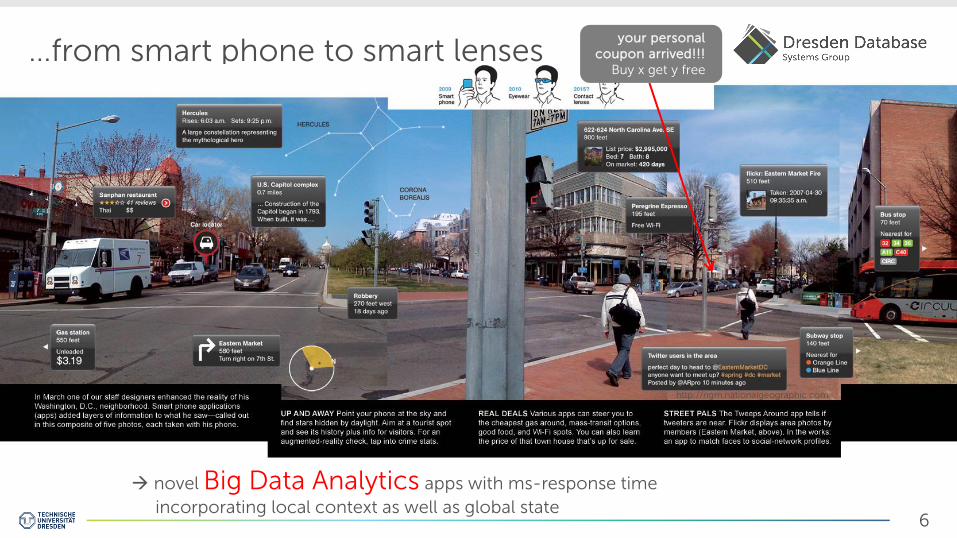
…from smart phone to smart lenses
http://ngm.nationalgeographic.com
novel Big Data Analytics apps with ms-response time
incorporating local context as well as global state
your personal coupon arrived!!!
Buy x get y free

7
Big Computing
First Phase of the next generation HRSK - 7.000 cores
Second Phase (by end of March 2015) - >40.000 cores in total
8
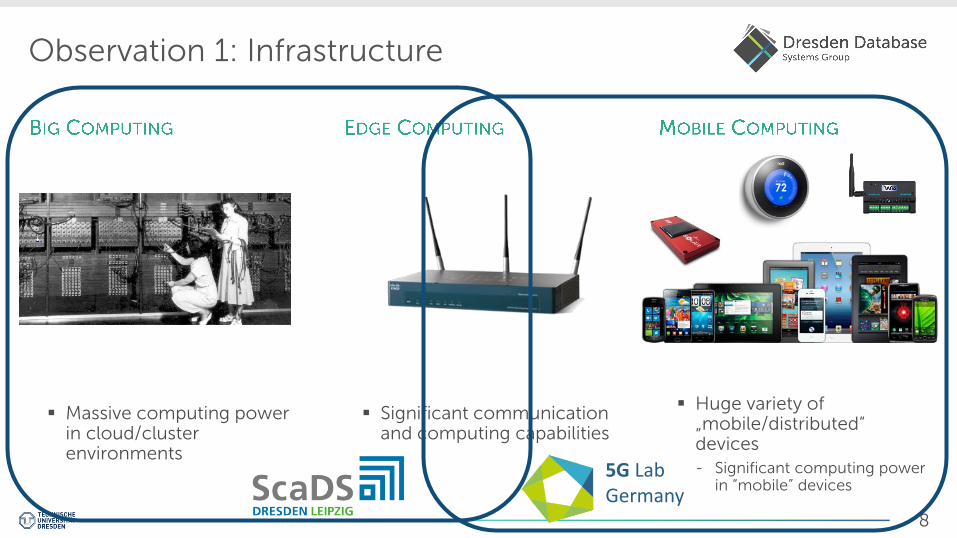
Observation 1: Infrastructure
Massive computing power in cloud/cluster environments
Huge variety of „mobile/distributed“ devices - Significant computing power
in “mobile” devices
Significant communication and computing capabilities
5G Lab Germany
9
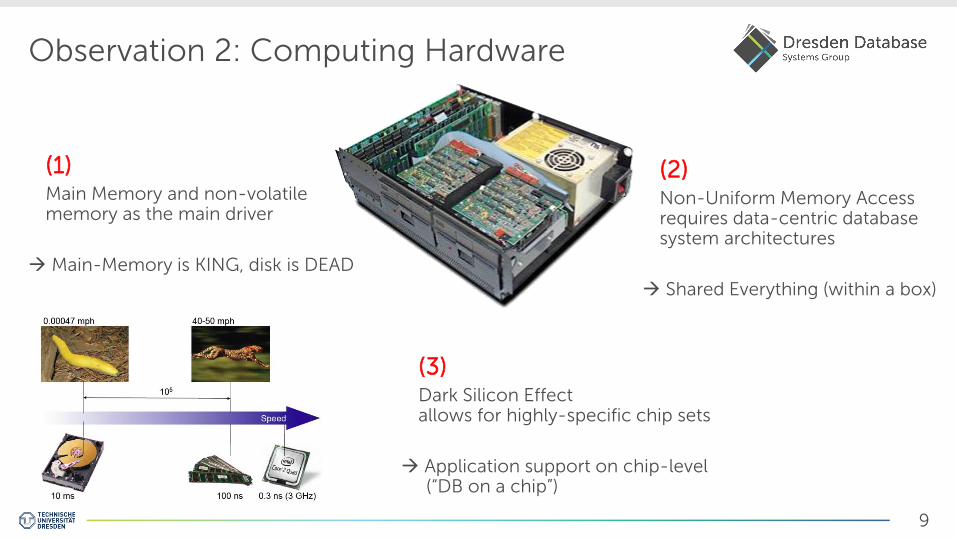
Observation 2: Computing Hardware
(1) Main Memory and non-volatile memory as the main driver
Main-Memory is KING, disk is DEAD
(2) Non-Uniform Memory Access requires data-centric database system architectures
Shared Everything (within a box)
(3) Dark Silicon Effect allows for highly-specific chip sets
Application support on chip-level (“DB on a chip”)
10
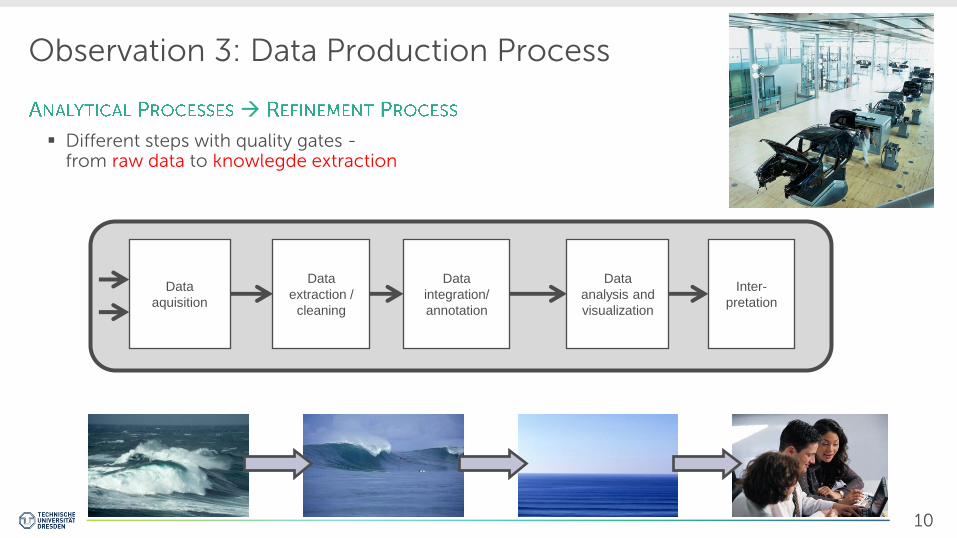
Observation 3: Data Production Process
Different steps with quality gates - from raw data to knowlegde extraction
Data
integration/
annotation
Data
extraction /
cleaning
Data
aquisition
Data
analysis and
visualization
Inter-
pretation
11
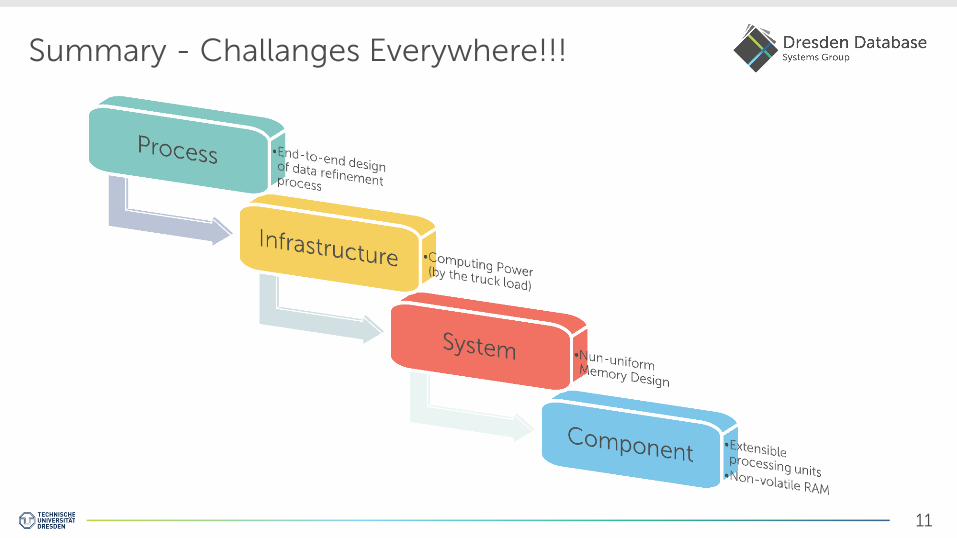
Summary - Challanges Everywhere!!!

Do we have the right database technology?

13
…a plea for specialized DB systems
They are selling “one size fits all“
Which is 30 year old legacy technology that good at nothing Is/Was he right?
(almost 10 years ago!)
14
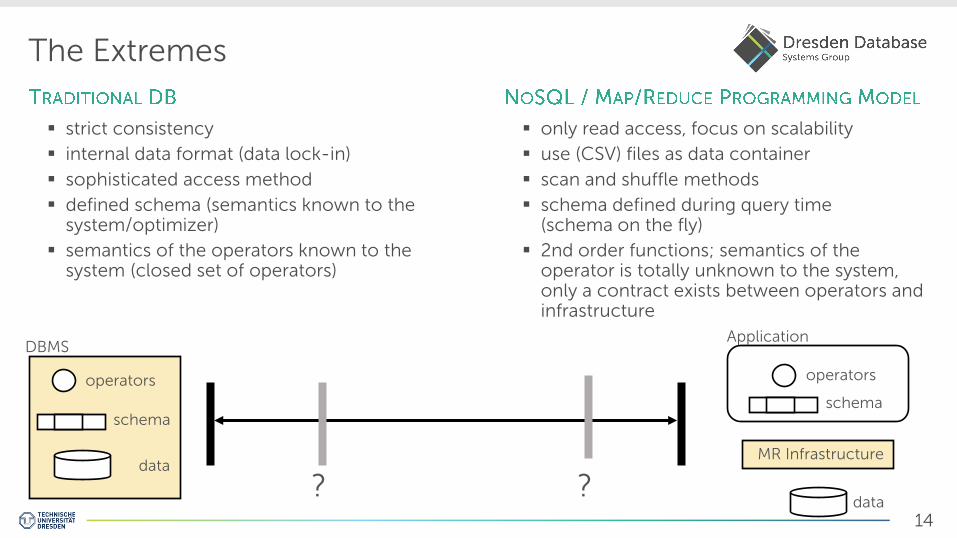
The Extremes
strict consistency
internal data format (data lock-in)
sophisticated access method
defined schema (semantics known to the system/optimizer)
semantics of the operators known to the system (closed set of operators)
only read access, focus on scalability
use (CSV) files as data container
scan and shuffle methods
schema defined during query time (schema on the fly)
2nd order functions; semantics of the operator is totally unknown to the system, only a contract exists between operators and infrastructure
? ?
operators
schema
data
DBMS
data
operators
schema
MR Infrastructure
Application

15
Limits of classical DB systems
perserving consistency in a distributed encironment is costly…
ensure serializability even if the application can ensure no conflicting writes
necessity to put data completely into control of the system (effort to load data into a database system, perform runstats, …)
no native support for regular CSV files
-> optimize time to query
need to follow the „data comes first, schema comes second principle
… with the data model – the tabular model is still very popular (with flexibility)
… with the query model – SQL is just fine (everybody knows SQL)
- NoSQL systems hard to program, e.g. Cassandra 1.0 did not ensure consistency within a row!
- responsibility is left to the application programmer (e.g. store redundant hash codes to compare versions at the application level)
R1 recovery for queries/statements, no easy compensation of loosing a node
16
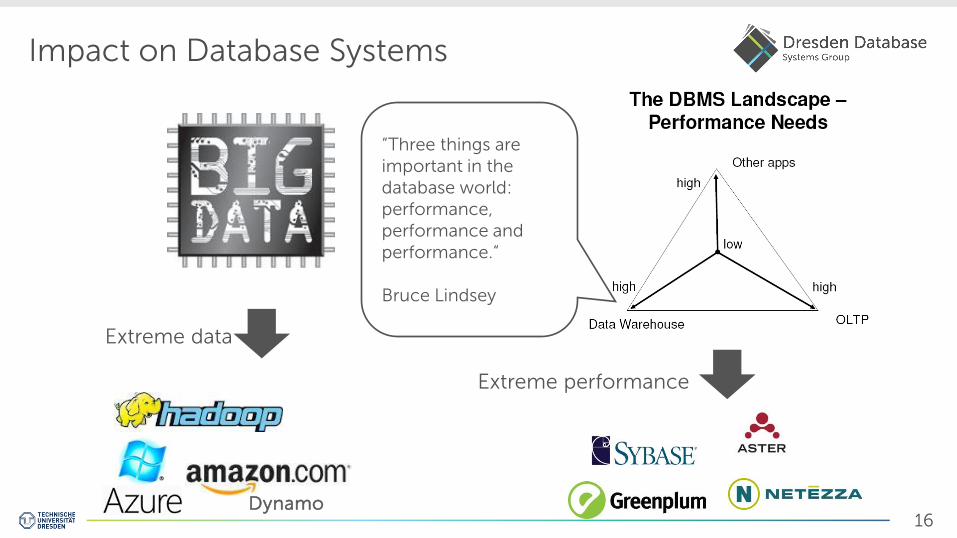
Impact on Database Systems
Extreme data
Extreme performance
Dynamo
“Three things are important in the database world: performance, performance and performance.“ Bruce Lindsey

18
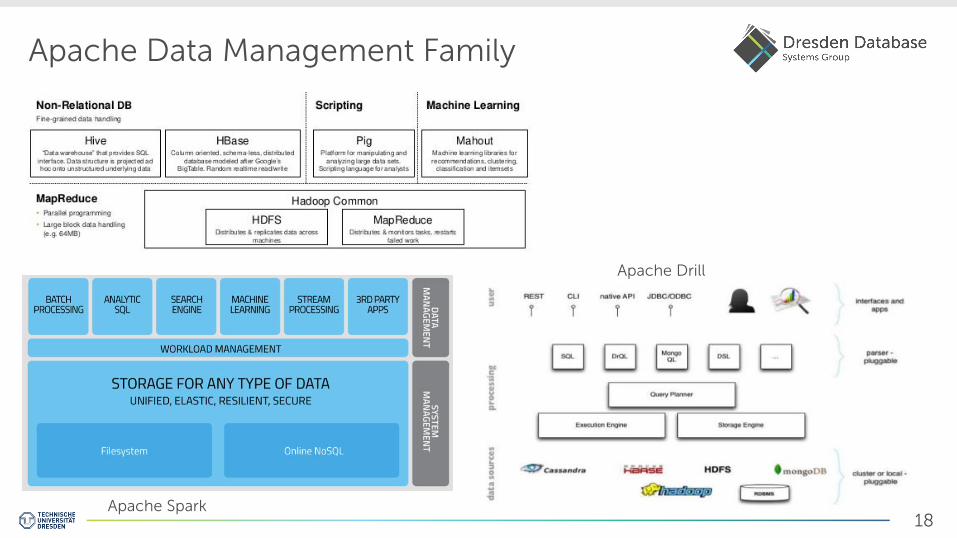
Apache Data Management Family
Apache Spark
Apache Drill
19
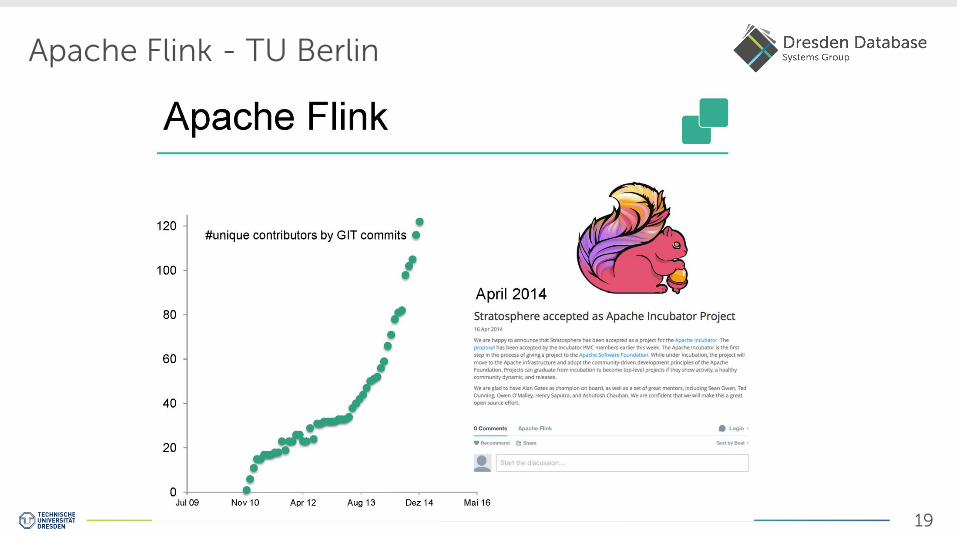
Apache Flink - TU Berlin
20
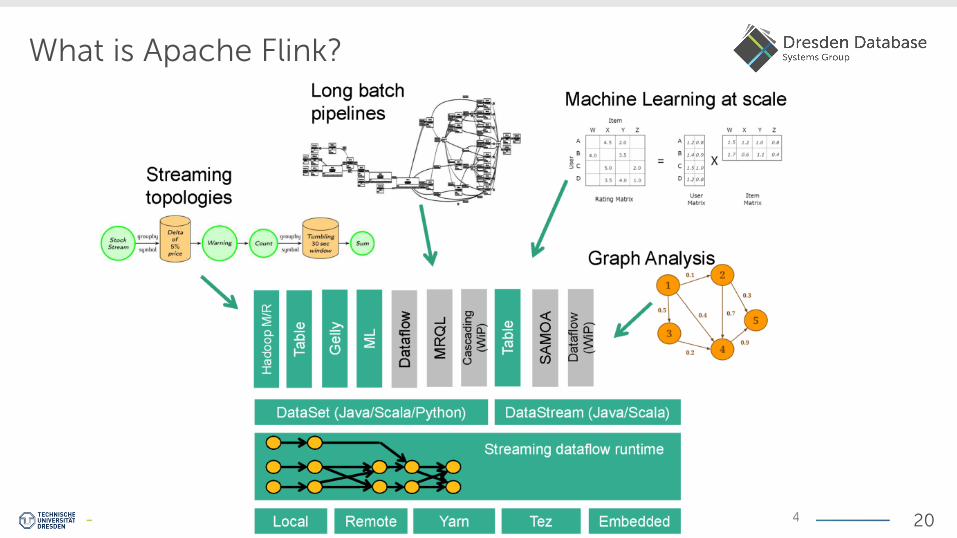
What is Apache Flink?
21
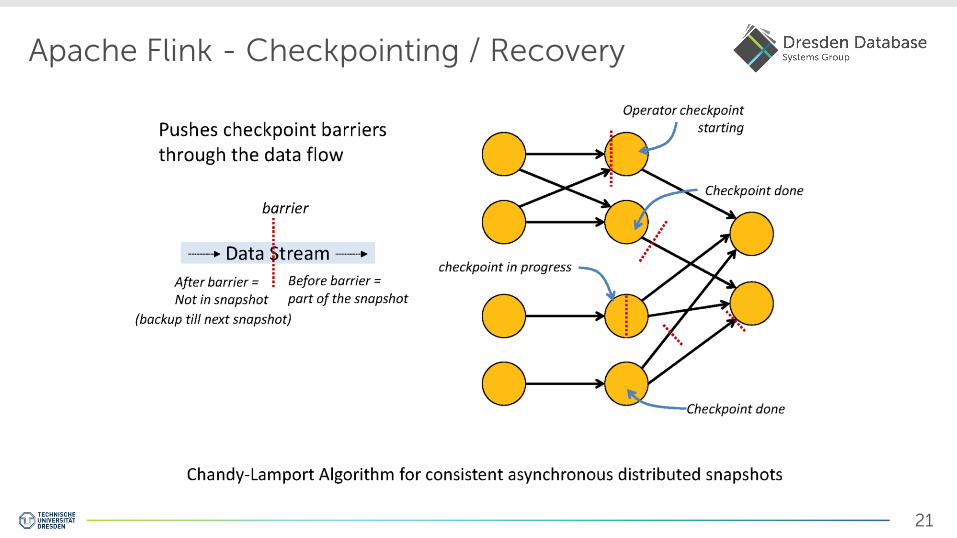
Apache Flink - Checkpointing / Recovery

22
SAP HANA „scale out edition“

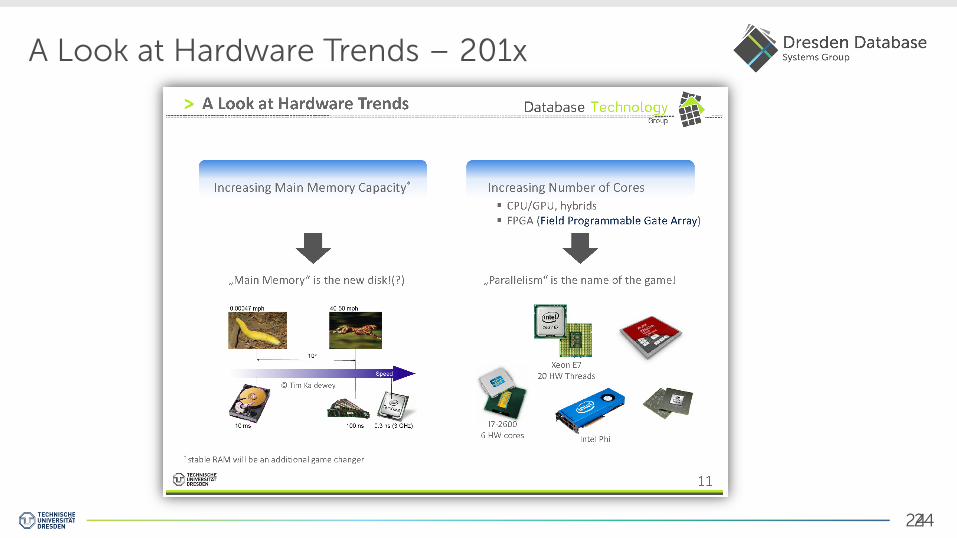
24
A Look at Hardware Trends – 201x
24
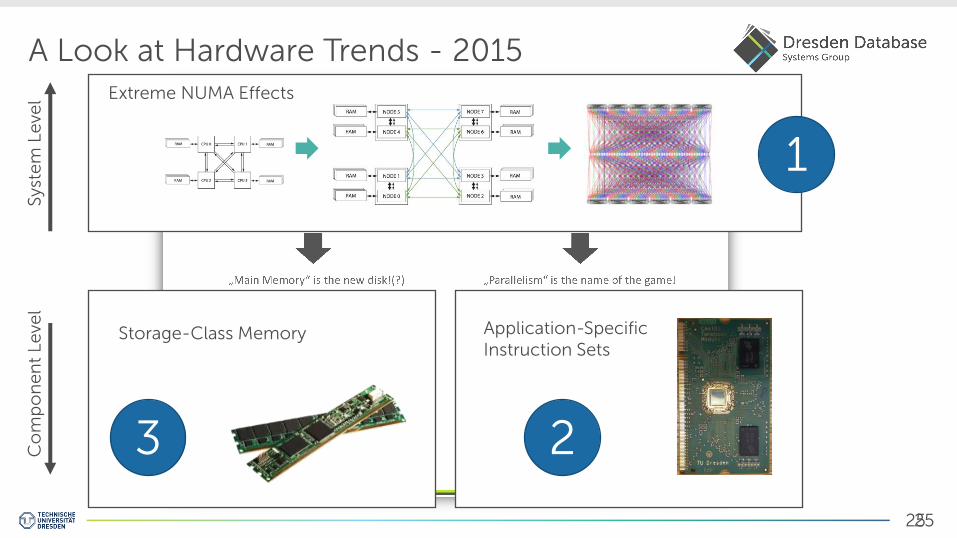
25
A Look at Hardware Trends - 2015
25
Extreme NUMA Effects
Sys
tem
Le
vel
Application-Specific Instruction Sets
Co
mp
on
en
t Le
vel
Storage-Class Memory
1
2 3
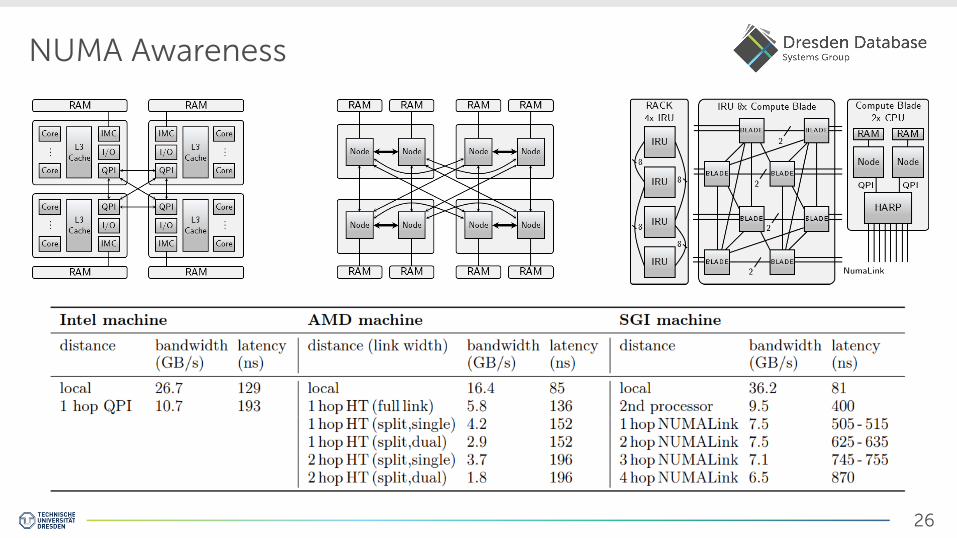
26
NUMA Awareness

27
TA versus Data-oriented Architecture (DORA)
…
Data
…
Data
Indirection
Transactions
Transaction-Oriented Architecture shared-everything
Data-Oriented Architecture mixed shared-everything & shared-
nothing
Lack of scalability
No load balancing & indirection required
Scales on massive parallel systems
Load Balancing and indirection required
Energy proportional by design Not energy proportional by design
Pros & Cons
Challenges
(1) Speed up load balancing indirection to work efficiently for in-memory systems
(2) How to make the data-oriented architecture energy proportional
Well investigated and widely deployed
Which Architecture
? …
Transactions
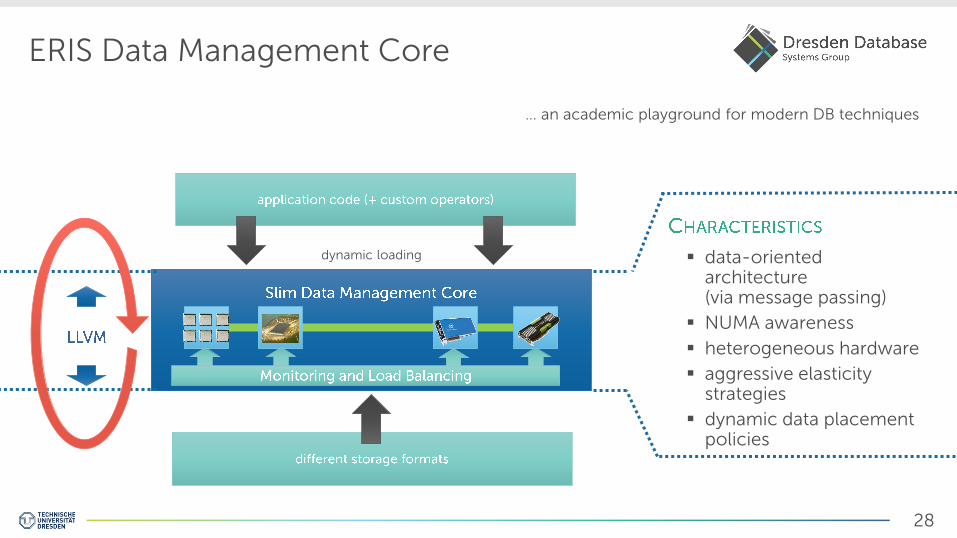
28
ERIS Data Management Core
data-oriented architecture (via message passing)
NUMA awareness
heterogeneous hardware
aggressive elasticity strategies
dynamic data placement policies
dynamic loading
… an academic playground for modern DB techniques
29
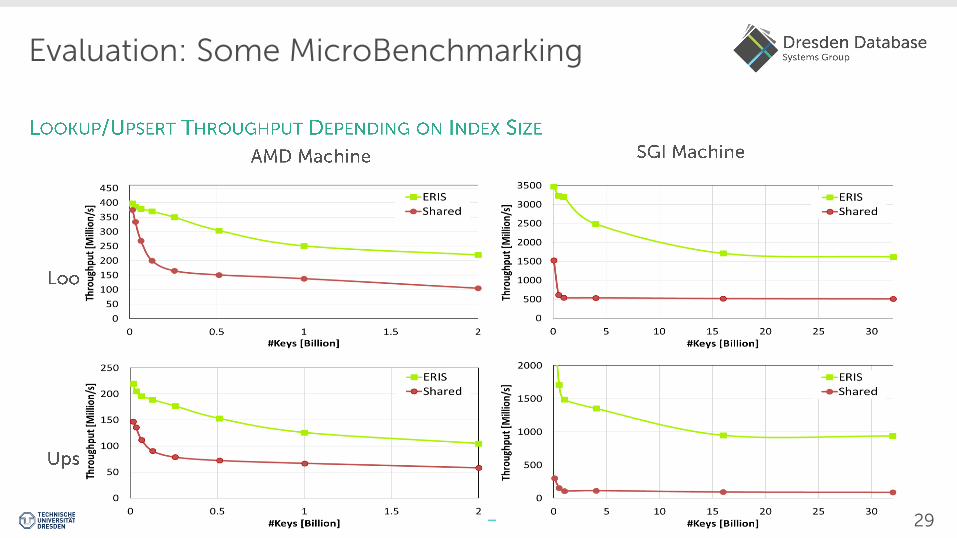
Evaluation: Some MicroBenchmarking
30
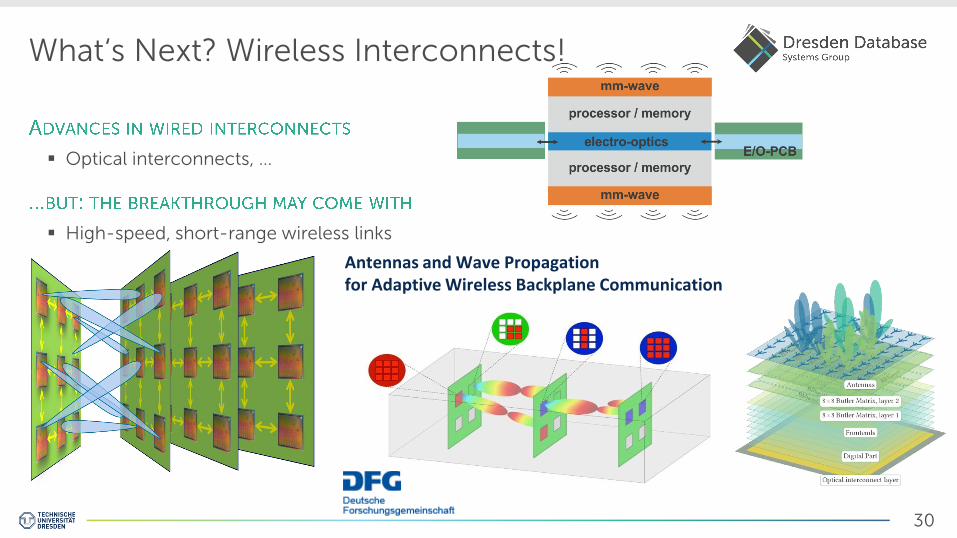
What‘s Next? Wireless Interconnects!
Optical interconnects, …
High-speed, short-range wireless links
Antennas and Wave Propagation for Adaptive Wireless Backplane Communication

31
A Look at Hardware Trends - 2015
31
Extreme NUMA Effects
Sys
tem
Le
vel
Application-Specific Instruction Sets
Co
mp
on
en
t Le
vel
Storage-Class Memory
32
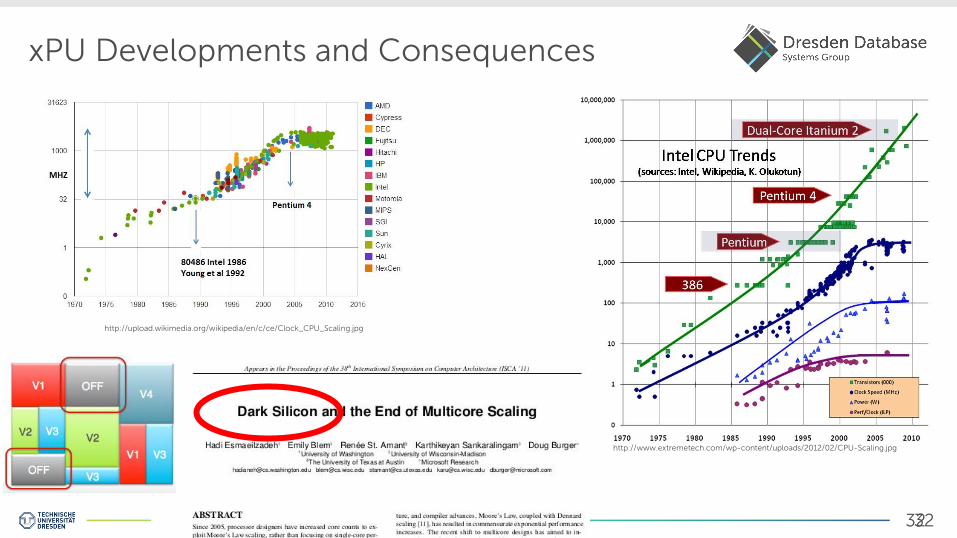
xPU Developments and Consequences
32
http://upload.wikimedia.org/wikipedia/en/c/ce/Clock_CPU_Scaling.jpg
http://www.extremetech.com/wp-content/uploads/2012/02/CPU-Scaling.jpg
33
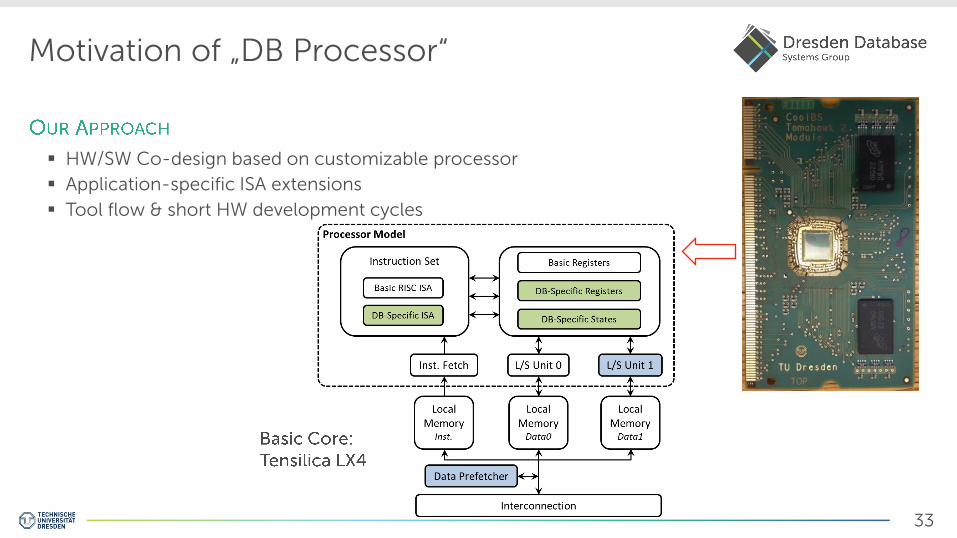
Motivation of „DB Processor“
HW/SW Co-design based on customizable processor
Application-specific ISA extensions
Tool flow & short HW development cycles
35
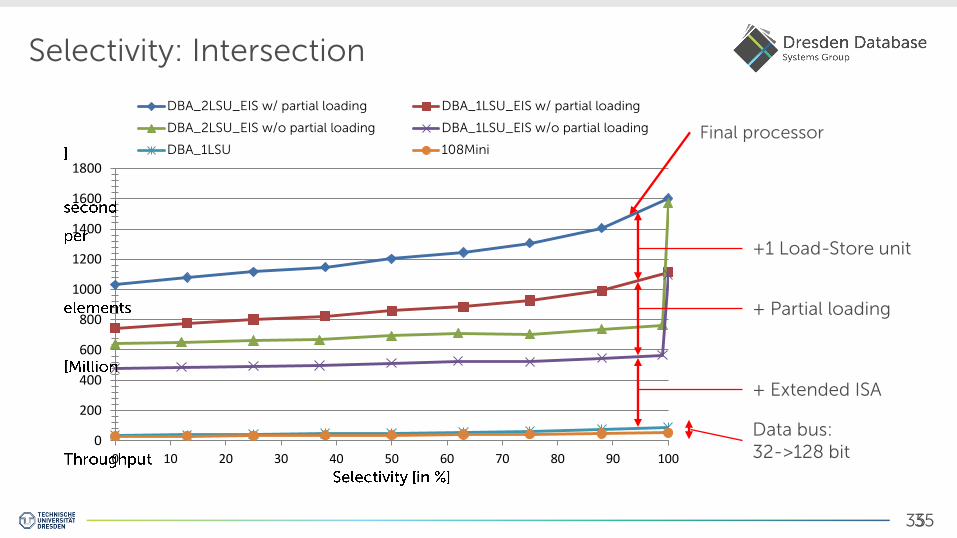
Selectivity: Intersection
35
0
200
400
600
800
1000
1200
1400
1600
1800
0 10 20 30 40 50 60 70 80 90 100
DBA_2LSU_EIS w/ partial loading DBA_1LSU_EIS w/ partial loading
DBA_2LSU_EIS w/o partial loading DBA_1LSU_EIS w/o partial loading
DBA_1LSU 108MiniFinal processor
+1 Load-Store unit
Data bus: 32->128 bit
+ Partial loading
+ Extended ISA
𝑏
36
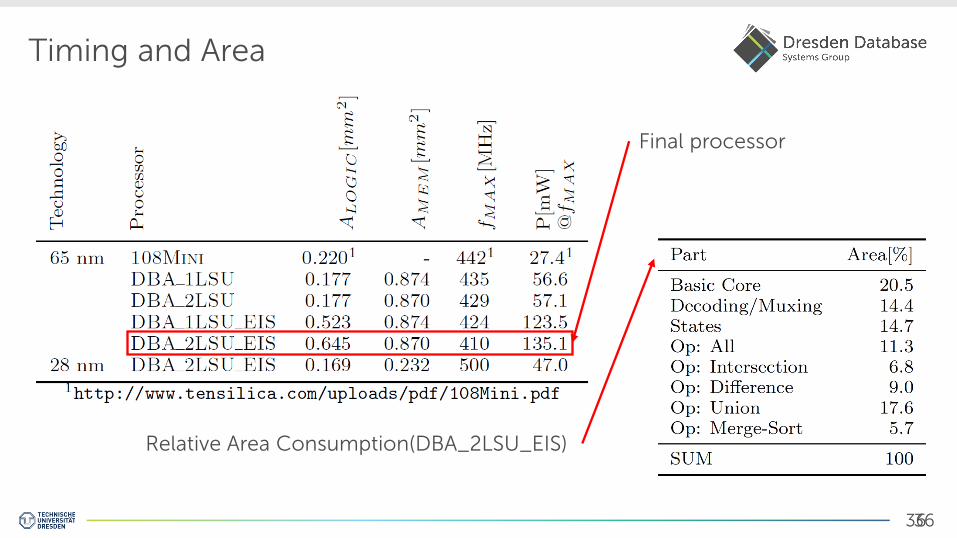
Timing and Area
36
Relative Area Consumption(DBA_2LSU_EIS)
Final processor
37
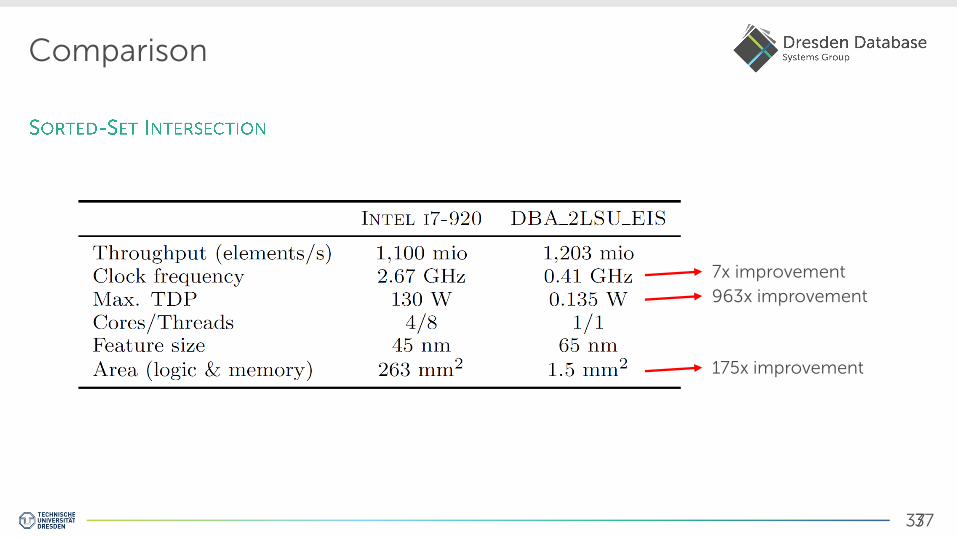
Comparison
37
7x improvement
963x improvement
175x improvement
38
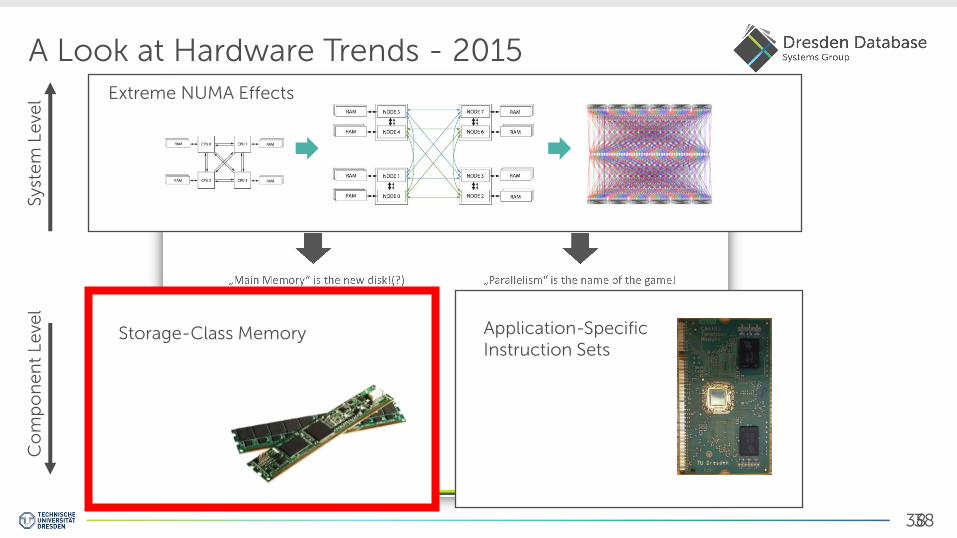
A Look at Hardware Trends - 2015
38
Extreme NUMA Effects
Sys
tem
Le
vel
Application-Specific Instruction Sets
Co
mp
on
en
t Le
vel
Storage-Class Memory
39
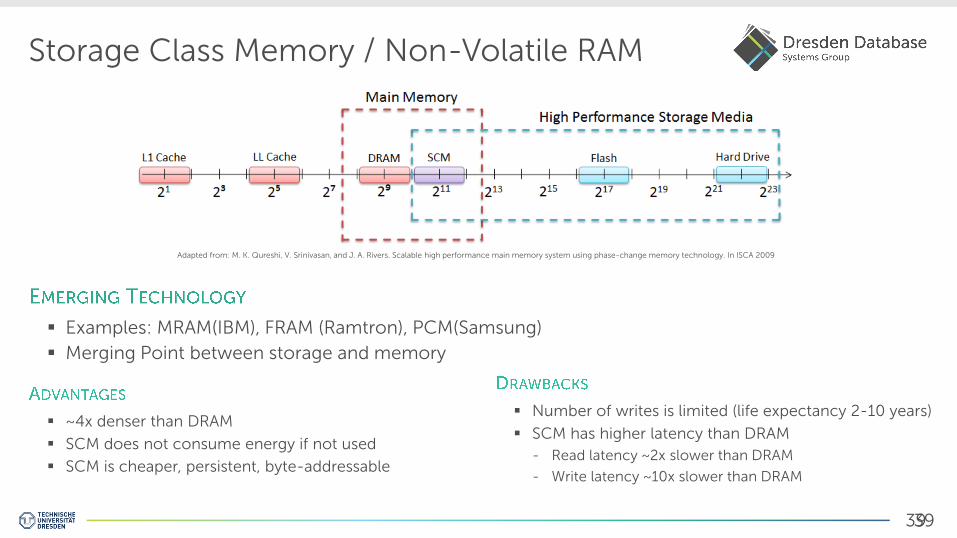
Storage Class Memory / Non-Volatile RAM
Examples: MRAM(IBM), FRAM (Ramtron), PCM(Samsung)
Merging Point between storage and memory
39
Adapted from: M. K. Qureshi, V. Srinivasan, and J. A. Rivers. Scalable high performance main memory system using phase-change memory technology. In ISCA 2009
~4x denser than DRAM
SCM does not consume energy if not used
SCM is cheaper, persistent, byte-addressable
Number of writes is limited (life expectancy 2-10 years)
SCM has higher latency than DRAM
- Read latency ~2x slower than DRAM
- Write latency ~10x slower than DRAM
40
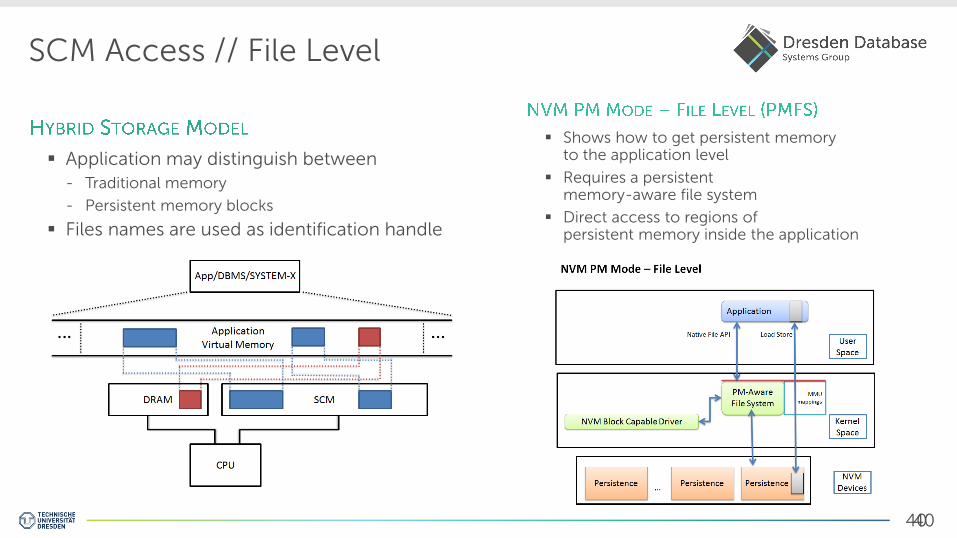
SCM Access // File Level
Application may distinguish between - Traditional memory
- Persistent memory blocks
Files names are used as identification handle
40
Shows how to get persistent memory to the application level
Requires a persistent memory-aware file system
Direct access to regions of persistent memory inside the application
41
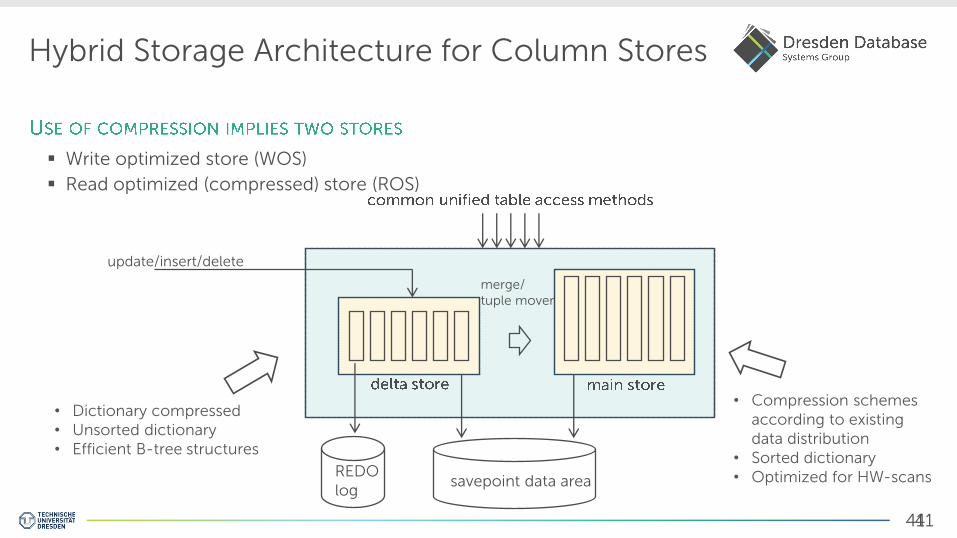
Hybrid Storage Architecture for Column Stores
Write optimized store (WOS)
Read optimized (compressed) store (ROS)
41
update/insert/delete
REDO log
savepoint data area
merge/ tuple mover
• Dictionary compressed • Unsorted dictionary • Efficient B-tree structures
• Compression schemes according to existing data distribution
• Sorted dictionary • Optimized for HW-scans
42
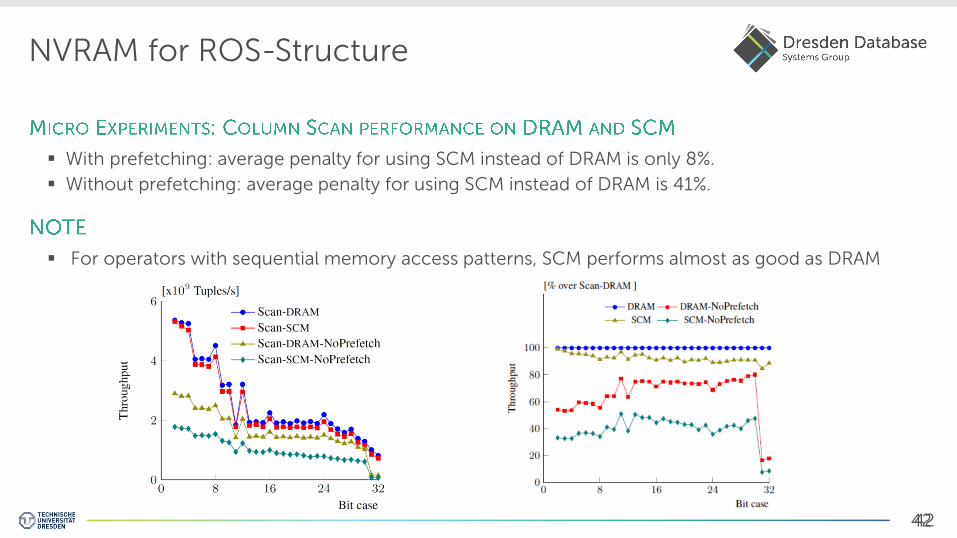
NVRAM for ROS-Structure
With prefetching: average penalty for using SCM instead of DRAM is only 8%.
Without prefetching: average penalty for using SCM instead of DRAM is 41%.
For operators with sequential memory access patterns, SCM performs almost as good as DRAM
42
43
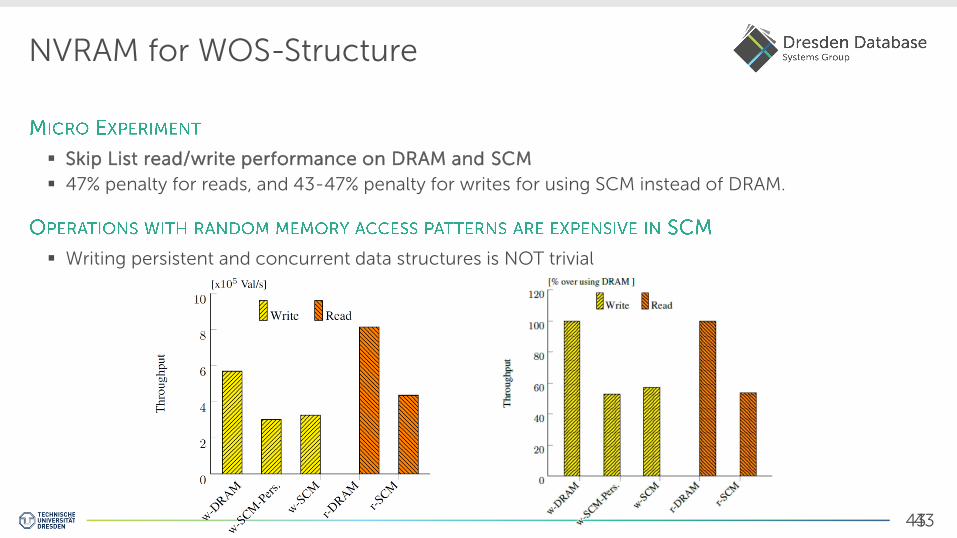
NVRAM for WOS-Structure
Skip List read/write performance on DRAM and SCM
47% penalty for reads, and 43-47% penalty for writes for using SCM instead of DRAM.
Writing persistent and concurrent data structures is NOT trivial
43
44
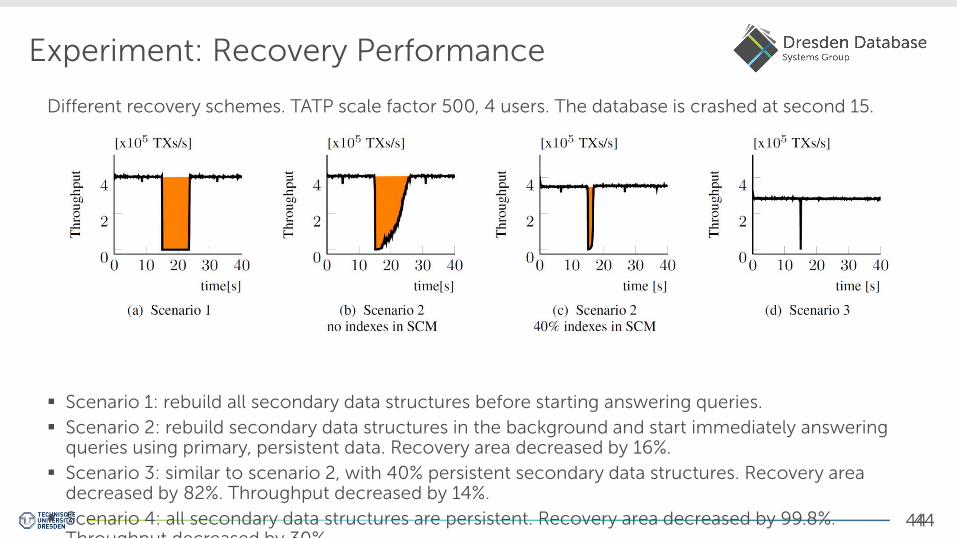
Experiment: Recovery Performance
Different recovery schemes. TATP scale factor 500, 4 users. The database is crashed at second 15.
Scenario 1: rebuild all secondary data structures before starting answering queries.
Scenario 2: rebuild secondary data structures in the background and start immediately answering queries using primary, persistent data. Recovery area decreased by 16%.
Scenario 3: similar to scenario 2, with 40% persistent secondary data structures. Recovery area decreased by 82%. Throughput decreased by 14%.
Scenario 4: all secondary data structures are persistent. Recovery area decreased by 99.8%. Throughput decreased by 30%.
44


46
Summary and Conclusion
In General – Big Data is an enabler! – NOT a final product
Let‘s head for new frontiers!
Significant developments on infrastructure level
Significant developments in the hardware sector - HTM, SCM, etc.
- Heterogenous systems (speclialized cores)
… Big Data is MUCH more than just a lot of data, it‘s all about orchestration, quality control, and interpretation
Prof. Dr.-Ing. Wolfgang Lehner 200. Datenbankstammtisch





























