Embed Size (px)
Citation preview

Relevanzbasiertes Preprocessing fürautomatische Theorembeweiser
Mario Frank
25. September 2012

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 2
Agenda
1 TheorembeweiserAnwendungsgebieteGrundlagenGrenzen
2 Überschreiten der Grenzen: PreprocessingVariantenARDE - Axiom Relevance Decision EngineAktueller StandBenchmarks
3 Fazit
4 Ende

Theorembeweiser
25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 4
Anwendungsgebiete
Partielle Lösung der Fragen zurSoftware-/Hardware-Verifikation:Entspricht die Software/Hardware der Spezifikation? Hälteine konkrete Schleife?Medizin:Bei gegebener Menge von Symptomen: WelcheKrankheiten kommen in Betracht?Rechtswissenschaften: SubsumtionWelche der Rechtsnormen sind auf den konkretenSachverhalt anwendbar?

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 5
Grundlagen
Theorembeweiser suchen nach Beweisen für einen Satz miteiner gegebenen Menge von wahren Formeln(Axiome,Hypothesen, Lemmata,...).Ansätze:
1. Beweis durch WiderlegungAnnahme: Satz ist inkorrekt, zeige Unerfüllbarkeit
2. Beweis durch KonstruktionAnnahme: Satz ist korrekt, suche Konstruktion
25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 6
Grundlagen Kalküle
Ein logischer Kalkül ist ein Regelsatz für dieBeweissuche (Analytischer Kalkül, z.B. Resolution,Tableau)Beweiskonstruktion (meist nach Analyse vorgenommen)
Neben dem Ansatz implementieren Theorembeweiser vorallem Kalküle. Manche Kalküle setzen Formeln in speziellenNormalformen, wie Negationsnormalform oder KonjunktiveNormalform, voraus.

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 7
Grundlagen Konnektion
Eine Konnektion ist ein Paar von Prädikaten mit konträrerPolarität, die unifizierbar sind: {p,¬p}.Seien p1 und p2 Prädikate. Diese sind unifizierbar, wenn siedieselbe Anzahl an Argumenten haben und es eineSubstitution gibt, sodass sie gleich werden.

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 8
Beispiel - Tweety-Problem
canFly(tweety)∀X ((bird(X ) ∧ ¬penguin(X ))⇒ canFly(X ))bird(tweety)penguin(tux)cat(meez)
Abbildung: Prädikatenlogische Formelmenge - Tweety-Problem

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 9
Grenzen der Theorembeweiser
Theorembeweiser können nur eine begrenzte Menge anFormeln in einer begrenzten Zeit behandeln. Viele interessanteProbleme enthalten jedoch Tausende oder HunderttausendeFormeln.Gründe für die Grenzen:
1. Speicherverbrauch der Formeln in Normalform2. Rechenaufwand durch Beweissuche bei vielen Formeln
(große Pfad-Anzahl)3. Hoher Zeitaufwand für Normalform-Transformation4. Nutzung von Interpretern (z.B. Prolog)

Überschreiten der Grenzen:Preprocessing

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 11
Preprocessing - Grundlagen
Ein Preprocessor soll die Anzahl der Axiome verringern und dieProbleme (schneller) lösbar machen.Ansätze:
Lexembasiert: State ot the Art (z.B. SinE)Wähle Axiome, die Lexeme teilen. Lexeme sind hierFunktions-/Prädikats-/Konstantennamen.Konnektions-basiert: (z.B. ARDE)Wähle Axiome, die mit dem Problem über Konnektionenverbunden sind.

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 12
Beispiel - Tweety-Problem
1)¬canFly(tweety)2)∀X ((¬bird(X ) ∨ penguin(X )) ∨ canFly(X ))3)bird(tweety)4)penguin(tux)5)cat(meez)
Abbildung: Skolem-Normalform - Tweety-Problem
Lexembasiert: 1,2,3,4Konnektions-basiert:
Iteration 1: 1,2Iteration 2: 1,2,3

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 13
Ansätze, beleuchtet
Lexembasiert:1. Keine Normalform notwendig -> schnell2. Menge kann unvollständig werden3. Betrachtet nicht die Ersetzbarkeit von Variablen
Konnektions-basiert:1. Braucht Negationsnormalform -> langsamer als
lexembasiert2. Axiommenge in Iteration ≥ i vollständig3. Subsumiert Nutzung von Lexemen
25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 14
ARDE - Konzept
Ablauf:1. Transformiere alle Formeln in Skolem-Normalform2. Suche für jedes Prädikat in der aktuellen Formelmenge
eine Konnektion3. Wähle jedes konnektierte Axiom, übergebe aktuell
gewählte Menge und den Satz an den Beweiser4. Weiter bei 2.
Folge: Es baut sich nach und nach ein Konnektionsgraph auf.

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 15
ARDE - technisches
Implementiert in C++ (2500 loc.) und Prolog (200 loc.)Prädikats-Suche via Hash-TabellenStruktur der Formeln wird nicht betrachtet(Konjunktionen/Disjunktionen gehen verloren)Originale der Formeln werden an den Beweiser übergeben-> Jeder Beweiser kann ARDE nutzenNach jeder Iteration wird ein Beweiser-Thread gestartet

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 16
Stärken und Schwächen
Gleichheiten werden (noch) nicht betrachtet -> teilweiseunvollständige MengenStruktur der Formeln wird unzureichend betrachtet -> nochteilweise große MengenLernt Konnektionen und kann diese späterwiederverwendenKann mehrere Hunderttausend Formeln verarbeitenArbeitet zielorientiert

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 17
Tests von leanCoP und E auf aktueller ARDE-Version
Die Wettbewerbs-Probleme wurden nochmals bearbeitet unddie Ausgaben von ARDE an leanCoP 2.2 und E 1.6 (ohneSinE) übergeben.
Klasse AxiomeISA 50-6.000MZR 30-50.000SMO 30.000 - 7.000.000
Tabelle: Problemklassen - übliche Axiomanzahl
25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 18
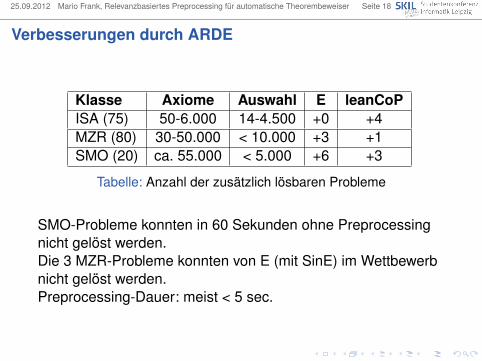
Verbesserungen durch ARDE
Klasse Axiome Auswahl E leanCoPISA (75) 50-6.000 14-4.500 +0 +4MZR (80) 30-50.000 < 10.000 +3 +1SMO (20) ca. 55.000 < 5.000 +6 +3
Tabelle: Anzahl der zusätzlich lösbaren Probleme
SMO-Probleme konnten in 60 Sekunden ohne Preprocessingnicht gelöst werden.Die 3 MZR-Probleme konnten von E (mit SinE) im Wettbewerbnicht gelöst werden.Preprocessing-Dauer: meist < 5 sec.

Fazit

25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 20
Fazit / Weitere Entwicklung
Das Grundkonzept funktioniert, ist aber noch zu schwach.Kommende Features sind:
Behandlung von GleichheitenNutzung der FormelstrukturAnpassung an Modallogik und intuitionistische LogikStärkere Parallelisierung

Ende
25.09.2012 Mario Frank, Relevanzbasiertes Preprocessing für automatische Theorembeweiser Seite 22
Vielen Dank für Ihre Aufmerksamkeit





























