Embed Size (px)
Citation preview

FernUniversität in Hagen
Seminarband zum Kurs 1912/19912 im WS 2014/2015
Sicherheit und Privatsphare in
Datenbanksystemen
Prasenzphase: 27-28.02.2015
Betreuer:
Dr. Thomas Behr
Fakultat fur Mathematik und Informatik
Datenbanksysteme fur neue Anwendungen
FernUniversitat in Hagen
58084 Hagen


Zeitplan und Inhaltsverzeichnis
Freitag, 27.02.2015
900 Uhr Vorstellungsrunde
930 Uhr F. Kamfenkel
Einfuhrung
1030 Uhr A. Kounitzky
Verschlusselung
1130 Uhr T. Kontny
Privatssphare messen
1330 Uhr T. Muller
Algorithmen zum Schutz der Privatssphare
1430 Uhr S. Schloßer
Absichtliches Storen von Daten
1530 Uhr S. Nieto-Ernst
Attacken
1630 Uhr D. Zwewdie Ejeta
Spezielle Indexe
Samstag, 28.02.2015
900 Uhr E. Blechschmidt
Location Based Services
1000 Uhr R. Titze
Trajectory Daten
1100 Uhr H. Brieschke
Verbund von Datenbanken
1200 Uhr F. Schlachter
Datenbanken in einer Cloud
1300 Uhr Abschluss


FernUniversität in Hagen
-
Seminar 01912 / 19912 im Wintersemester 2014 / 2015
Sicherheit und Privatsphäre in Datenbanksystemen
Thema 1 Einleitung
Referent: Felix Kamfenkel


Thema 1 - Einleitung Felix Kamfenkel 1
Inhaltsverzeichnis
1) Einleitung .................................................................................................................................... 2
2) Anforderungen an Datenbanken ................................................................................................. 2
3) Discretionary vs. Mandatory Access Control ............................................................................. 4
4) DAC und MAC in unterschiedlichen Datenbank-Arten ............................................................. 7
4.1) Relationale Datenbanken ...................................................................................................... 7
4.1.1) DAC ............................................................................................................................... 7
4.1.2) MAC ............................................................................................................................ 11
4.2) Objektbasierte Datenbanken .............................................................................................. 15
4.2.1) DAC ............................................................................................................................. 16
4.2.2) MAC ............................................................................................................................ 17
4.3) XML-Datenbanken ............................................................................................................. 18
4.4) NoSQL-Datenbanken ......................................................................................................... 19
5) Fazit ........................................................................................................................................... 20
6) Literaturverzeichnis .................................................................................................................. 21

Thema 1 - Einleitung Felix Kamfenkel 2
1) Einleitung
Das weltweite jährlich generierte Datenaufkommen liegt momentan bei ungefähr 8500 Exabyte.
Bereits bis zum Jahr 2020 wird es auf mehr als 40.000 Exabyte angewachsen sein – das ent-
spricht einer Verdoppelung des Volumens ungefähr alle zwei Jahre. Dieser Trend wird sich in
den kommenden Dekaden sogar noch beschleunigen, da im Rahmen der zunehmenden Verbrei-
tung des Internet der Dinge eine Vielzahl von Geräten Sensordaten produzieren wird. Das welt-
weite Informationswachstum1 bleibt somit auf absehbare Zeit hoch (EMC Digital Universe
2014).
Die dabei erzeugten Daten können in aufbereiteter Form durch (Big-Data-)Analysen für Unter-
nehmen wichtige Wettbewerbsvorteile und neue Geschäftsmodelle bedeuten – Daten sind auf
diese Weise „das neue Öl“ (Büst 2013). Um als wertvoller Rohstoff nutzbar sein zu können,
müssen sie jedoch strukturiert gespeichert werden und für die gewünschten Analysen jederzeit
zur Verfügung stehen, was sich nur mittels leistungsfähiger Datenbankmanagementsysteme be-
wältigen lässt.
Die Aufgaben dieser Systeme gehen dabei über die reine Verwaltung des Informationsbestandes
hinaus, da die gespeicherten Informationen immer öfter das Ziel von Kriminellen sind: So hat
sich die Zahl der weltweiten Hacker-Angriffe auf rund 120.000 Stück pro Tag erhöht (PwC
2014). Dies ist umso bedenklicher, da die Sensibilität der gespeicherten Informationen immer
mehr zunimmt, beispielsweise im Rahmen der digitalen Patientenakte oder Bewegungsprofilen
von Personen. Der Schutz der Daten rückt somit bei Datenbankmanagementsystemen immer
stärker in den Fokus. Dieser Schutz beinhaltet nicht nur die Abwehr von illegitimer Nutzung,
sondern auch den Schutz der Privatsphäre der Nutzer bei der legitimen Analyse der Daten und
deren Veröffentlichung im Rahmen normaler Tätigkeiten unterschiedlicher Institutionen. Die
Herstellung von Sicherheit und Privatsphäre in Datenbanken ist somit eine Daueraufgabe von
hoher Wichtigkeit.
2) Anforderungen an Datenbanken
Um den an sie gestellten Anforderungen gerecht zu werden und den Daten-Rohstoff schützen zu
können, müssen Datenbanken eine Reihe von (Grund-)Anforderungen erfüllen. Dabei handelt es
1 Definitorisch korrekt bezeichnen Daten eine zur Verarbeitung bereitstehende Folge von Zeichen. Informationen
entstehen durch die Interpretation der Daten gemäß einer bestimmten Vorschrift zur Deckung eines Informations-
bedarfes (Voß & Gutenschwager 2001: 8ff; Ferstl & Sinz 2006: 131f). Für die vorliegende Ausarbeitung ist der Un-
terschied zwischen den beiden Begriffen jedoch bedeutungslos. Sie werden daher synonym verwendet.

Thema 1 - Einleitung Felix Kamfenkel 3
sich um Vertraulichkeit, Integrität, Verfügbarkeit und Privatheit2 (Bertino & Sandhu 2005;
Bertino et al 1995)3. Nachfolgend werden die vier Eigenschaften kurz charakterisiert und jeweils
einige ihrer wichtigsten Aspekte vorgestellt.
Vertraulichkeit bezeichnet den Schutz von Daten vor unberechtigtem Zugriff. Dazu werden Me-
chanismen benötigt, mit denen man jeden Zugriff auf die gespeicherten Informationen kontrol-
lieren kann. Damit solche Zugriffskontrollmechanismen möglich sind, muss das System zumin-
dest in der Lage sein, seine einzelnen Benutzer zu identifizieren (verschiedene Personen oder
Programme auseinanderzuhalten) und sie zu authentifizieren (sicherzustellen, dass die jeweils
identifizierte Entität auch wirklich diejenige ist, als die sie sich ausgibt). Darüber hinaus fällt
unter die Anforderung der Vertraulichkeit auch die Verschlüsselung von Daten. Diese ist häufig
wünschenswert, da es trotz der Kontrolle der Zugriffe immer noch Personen mit sehr weitrei-
chendem Einblick in die Datenbestände geben kann, beispielsweise Systemadministratoren. Da-
mit die gespeicherten Inhalte auch vor der Kenntnisnahme oder gar einem Missbrauch durch
diese Individuen geschützt sind, werden kryptographische Methoden angewandt.
Der Begriff Integrität bezeichnet im weitesten Sinne die Richtigkeit von Daten, also ihre Voll-
ständigkeit und semantische sowie syntaktische Korrektheit. Um Integrität in einer Datenbank
herstellen und erhalten zu können, ist zum einen wiederum die Zugriffskontrolle relevant, da
sonst jeder Benutzer alle Daten einfach verändern könnte. Zum anderen wird im System eine
Reihe sogenannter Integritätsbedingungen spezifiziert. Dabei handelt es sich um Vorgaben darü-
ber, welche Zustände die in einer Datenbank enthaltenen Elemente annehmen dürfen, damit die
Datenbank konsistent ist. So lassen sich beispielweise Bedingungen für spezifische Werteberei-
che formulieren (etwa, dass ein Rabattsatz nur zwischen 0 und 100 Prozent liegen darf) oder die
Zulässigkeit bestimmter Beziehungen zwischen Datenobjekten sicherstellen. Werden trotzdem
unzutreffende Änderungen durchgeführt, etwa, weil nicht alle Integritätsbedingungen spezifiziert
werden konnten, lässt sich durch die Verwendung digitaler Signaturen zumindest ermitteln, wo-
her die Modifikationen stammen.
Selbstverständlich müssen die gespeicherten Daten jederzeit (oder zumindest ohne großen Auf-
wand) verfügbar sein, um für die Institution, von der sie gespeichert werden, einen Nutzen zu
haben. Diese Verfügbarkeit muss auch dann gegeben sein, wenn mehrere Nutzer parallel auf den
gespeicherten Datenbeständen arbeiten. Die dafür nötige Koordination wird vom Transaktions-
2 Um eine einheitlichere Sprache zu ermöglichen, wurden die in den zu Grunde liegenden englischen Texten ge-
nannten Begriffe ins Deutsche übersetzt. Dies geschah allerdings nur insoweit ein gängiger deutscher Alternativbe-
griff existiert. Begriffe, die durch eine Übersetzung missverständlich oder unnötig umständlich wären, wurden auf
Englisch beibehalten. 3 Die beiden genannten Arbeiten liegen dieser Ausarbeitung als Basistexte zu Grunde. Soweit nicht andere Quellen
angegeben sind, beziehen sich die nachfolgenden Ausführungen immer auf Informationen aus den zwei Basistex-
ten. Es werden daher im Folgenden keine Literaturverweise für diese Texte mehr angegeben.

Thema 1 - Einleitung Felix Kamfenkel 4
management des Systems übernommen. Desweiteren sind für die Verfügbarkeit die Recovery-
Maßnahmen der Datenbank relevant, die dafür sorgen, dass die Informationen auch nach einem
Systemausfall (oder sogar währenddessen) noch zur Verfügung stehen. In einem etwas weiter
gefassten Kontext zählen zur Gewährleistung von Verfügbarkeit zudem sämtliche Maßnahmen,
die zur Abwehr von Denial-of-Service-Attacken und ähnlichen Angriffen dienen.
Von zunehmender Bedeutung ist schließlich die Privatheit von Daten. Obwohl oft synonym ver-
wendet, bezeichnet dieser Begriff nicht dasselbe wie Vertraulichkeit: Techniken zur Vertraulich-
keit können zwar auch zum Schutz der Privatheit eingesetzt werden, zum Beispiel, um den Zu-
griff von Fremden auf Informationen zu blockieren. Zur Herstellung von Privatheit müssen al-
lerdings noch zusätzliche Schritte unternommen werden, da diese auch noch nötig ist, wenn Da-
ten bereits veröffentlicht wurden – und somit nicht mehr vertraulich sind. Geeignete Maßnahmen
sind hier beispielweise die Verfremdung bzw. das absichtliche Stören von Daten während einer
Analyse oder bei einer Publizierung. Generell ist in diesen Fällen wichtig, dass die gesammelten
Informationen nur für Zwecke verwendet werden, zu denen die Betroffenen ihre Zustimmung
erteilt haben. Bei der Privatheit sind somit nicht nur technische Aspekte von Bedeutung, sondern
zudem auch rechtliche.
3) Discretionary vs. Mandatory Access Control
Die nachfolgenden Seiten befassen sich mit dem Aspekt der Vertraulichkeit von Daten, und in
diesem Zusammenhang insbesondere mit der Zugriffskontrolle. Bezüglich dieser gibt es zwei
grundlegend verschiedene Modelle: Discretionary Access Control (DAC) und Mandatory Access
Control (MAC)4. Beide Arten repräsentieren unterschiedliche Ideen der Realisierung eines Zu-
griffsschutzes. Es ist dabei egal, ob ein relationales, ein objektbasiertes5 oder ein NoSQL-
Datenbankmanagementsystem zugrunde gelegt wird, es besteht immer die Wahl zwischen DAC
und MAC. Die Grundideen beider Zugriffsmodelle sind Folgende:
Bei der DAC erfolgt eine Klassifikation der Zugriffsrechte anhand der Benutzer bzw. der Pro-
gramme, die auf die Datenbank zugreifen. Wenn beispielsweise eine Lese-Anfrage für ein be-
stimmtes Element gestellt wird, prüft das System, ob eine Lese-Autorisierung bei diesem Ele-
ment für den nachfragenden Benutzer vorhanden ist. Falls ja, wird der Zugriff erlaubt, falls nein,
wird die Anfrage abgelehnt. Unter einer Autorisierung versteht man dabei eine Berechtigung für
eine bestimmte Zugriffsart auf ein bestimmtes Datenelement für einen bestimmten Benutzer, die 4 Auf Deutsch übersetzt etwa: Benutzerbestimmbare Zugriffskontrolle und Verpflichtende Zugriffskontrolle.
5 Mit dem Ausdruck objektbasiert sind sowohl objektorientierte als auch objektrelationale Datenbankmanage-
mentsysteme gemeint. Siehe dazu auch Abschnitt 4.3.

Thema 1 - Einleitung Felix Kamfenkel 5
dem Datenbankmanagementsystem explizit mitgeteilt werden muss und systemintern dauerhaft
in einer Autorisierungstabelle gespeichert wird.
Bei der DAC gibt das System die Daten somit auf Grund der Tatsache heraus, dass ein bestimm-
tes Subjekt (oder Programm) den Zugriff darauf verlangt. Bei der MAC ist dies nicht der Fall.
Hier ist zwar ebenfalls die Identität des anfragenden Subjekts relevant, allerdings zusätzlich auch
die Identität des angefragten Datenobjekts. Es werden somit nicht nur die aktiven Nachfrager der
Informationen klassifiziert, sondern auch die passiven Entitäten (Relationen, Tupel, etc.), die die
Informationen speichern.
Beiden Parteien werden bei der MAC sogenannte Zugriffsklassen zugeordnet. Im einfachsten
Fall besteht eine Zugriffsklasse aus einer Stufe bzw. einem Level eines hierarchisch geordneten
Satzes von Elementen. So könnte zum Beispiel ein Satz mit den Sicherheitsstufen Streng Ge-
heim, Vertraulich und Öffentlich existieren, und die Zugriffsklasse einer wichtigen Relation als
Streng Geheim festgelegt sein. Diese vertikale Gliederung in Schutzstufen lässt sich durch das
Hinzufügen von nicht hierarchisch geordneten Bereichen zu einem horizontalen und vertikalen
Gitter-Modell erweitern. Den bereits genannten Stufen könnten etwa zusätzlich die Bereiche
Heer, Luftwaffe und Marine zugeordnet sein. Die Zugriffsklasse der wichtigen Relation wäre
dann nicht mehr nur Streng Geheim, sondern zum Beispiel (Streng Geheim, Heer)6.
Eine Zugriffsklasse Z1 dominiert (≥) eine andere Zugriffsklasse Z2, wenn die Sicherheitsstufe
von Z1 höher oder gleich der von Z2 ist, und (im Falle des Gitter-Modells) zusätzlich der Bereich
von Z2 in dem von Z1 enthalten ist. Die Zugriffsklasse (Streng Geheim, Heer) dominiert somit
beispielsweise die Klasse (Vertraulich, Heer), da die Sicherheitsstufe höher ist und die Bereiche
ineinander enthalten bzw. in diesem Fall deckungsgleich sind. Wenn weder Z1 ≥ Z2 noch Z2 ≥ Z1
gilt, sind die Zugriffsklassen nicht vergleichbar. Dies wäre etwa bei (Streng Geheim, Heer) und
(Vertraulich, Marine) der Fall: Obwohl die Sicherheitsstufe der ersten Zugriffsklasse höher ist
als die der zweiten, ist der Bereich Marine nicht in dem Bereich Heer enthalten, und damit eine
der Bedingungen für die Dominanz verletzt.
Die Dominanz-Beziehung zwischen den Zugriffsklassen entscheidet nun darüber, ob ein Zugriff
erfolgen darf oder nicht. In quasi allen Umsetzungen des MAC-Modells gelten dabei zwei Prin-
zipien, die nach ihren Urhebern auch Bell-LaPadula-Prinzipien genannt werden: Erstens darf ein
Daten nachfragendes Subjekt nur Objekte lesen, deren Zugriffsklasse von seiner eigenen domi-
niert wird. Dadurch kann ein Benutzer keine Daten einsehen, die über seiner Sicherheitsfreigabe
liegen (No Read-Up-Prinzip). Zweitens darf ein Subjekt nur die Objekte schreiben, deren Zu-
griffsklasse die Klasse des Subjektes dominiert. Dies macht es für einen Benutzer unmöglich,
6 Die Zugriffsklassen aus dem Beispiel sind durchaus passend, da MAC-Modelle zuerst im Militärbereich Anwen-
dung fanden.

Thema 1 - Einleitung Felix Kamfenkel 6
Daten von einer höheren Sicherheitsstufe in eine niedrigere zu überführen (No Write-Down-
Prinzip). Sind zwei Zugriffsklassen nicht miteinander vergleichbar, ist keinerlei Zugriff möglich,
da zwischen den beiden Klassen ja keine Dominanzbeziehung besteht.
Die Auswirkungen des DAC- und MAC-Modells auf die Sicherheit des Zugriffsschutzes kann
man sich am besten an einem Beispiel verdeutlichen. Dazu sei angenommen, dass ein von einer
fremden Interessengruppe bestochener Saboteur S in einer Abteilung arbeitet, die von einer inte-
geren Managerin M geführt wird. Der Saboteur interessiert sich für eine Tabelle mit wertvollen
Informationen, die der exklusiven Verantwortung der Managerin untersteht. S entwickelt folgen-
de Strategie, um an die gewünschte Tabelle zu kommen: Zunächst erstellt er eine eigene Tabelle,
in der die zu stehlenden Informationen später stehen sollen. An dieser Tabelle vergibt er nicht
nur sich selbst ein Zugriffsrecht, sondern auch der Managerin, wobei diese natürlich nichts von
ihrer neuen Zugriffsmöglichkeit weiß. Im nächsten (etwas schwierigeren) Schritt modifiziert S
eine Anwendung von M und fügt einen Schadcode ein, der die Anwendung zu einem trojani-
schen Pferd macht. Die Schadfunktion der Anwendung besteht darin, die Informationen aus der
Tabelle mit den geheimen Daten auszulesen und in die Kopie-Tabelle zu schreiben.
Unter einem DAC-Modell würde dieser Datendiebstahl funktionieren, da die Anwendung von M
natürlich mit der gleichen Zugriffsklasse arbeitet wie M selbst, und somit auf die Tabelle mit den
sensiblen Informationen zugreifen darf. Da der Managerin ebenso Zugriff auf die Kopie gewährt
wurde, funktioniert auch das Übertragen der Daten problemlos.
Unter einem MAC-Modell hingegen würde der Datenklau nicht funktionieren. Auch hier wäre es
dem trojanischen Pferd zwar möglich, die geheimen Informationen zu lesen. Hier gilt allerdings
das No Write-Down-Prinzip, weshalb die Anwendung die Daten nicht in die Kopie-Tabelle über-
tragen kann: Da S die Tabelle erstellt hat, ist er auch der Eigentümer daran7. Die Tabelle wird bei
einem MAC-Modell deshalb automatisch der Zugriffsklasse des Saboteurs zugeordnet – und da
diese unter der von M liegt, kann die Anwendung der Managerin keine Daten in die Kopie
schreiben.
Der Nachteil der DAC besteht folglich darin, dass keine Kontrolle darüber besteht, wie Daten
verteilt werden, wenn sie, wie hier im Beispiel, einmal von einem zum Zugriff berechtigen Nut-
zer oder Programm extrahiert wurden. MAC-Modelle haben diese Schwäche nicht und sind da-
her generell als sicherer einzustufen8.
7 Üblicherweise ist der Ersteller eines Datenobjekts auch der Eigentümer dieses Objekts.
8 Vorbehaltlich natürlich von Schwächen, die sich durch die konkrete Implementierung ergeben.

Thema 1 - Einleitung Felix Kamfenkel 7
4) DAC und MAC in unterschiedlichen Datenbank-Arten
Nachfolgend werden für unterschiedliche Arten von Datenbanken jeweils wichtige Aspekte von
DAC und MAC vorgestellt. Zunächst werden dabei relationale Systeme besprochen, im An-
schluss objektbasierte. Danach geht das Kapitel auf XML- und NoSQL-Systeme ein. Die Dar-
stellung baut dabei sukzessive aufeinander auf; das bedeutet, dass die für relationale Datenban-
ken erläuterten Eigenheiten grundlegend auch für objektbasierte gelten, sowie das für objektba-
sierte Systeme Gesagte auch für XML und NoSQL Bei jeder Datenbankart kommen allerdings
auf Grund des anderen Datenmodells verschiedene Erweiterungen und Besonderheiten hinzu.
4.1) Relationale Datenbanken
Relationale Datenbanken sind nach wie vor am weitesten verbreitet und weisen deshalb auch den
umfangreichsten Forschungsstand auf. Sowohl für DAC als auch für MAC existiert bei dieser
Datenbankart eine Vielzahl verschiedener Umsetzungen. Die nachfolgenden Absätze sollen un-
abhängig von den konkreten Modellen die grundlegenden Probleme und Anforderungen disku-
tieren, die sich bei DAC und MAC ergeben.
4.1.1) DAC
Eine der ersten DAC-Implementierungen war das Modell des System R. Auch heute noch basie-
ren quasi alle aktuellen Datenbankmanagementsysteme auf diesem ursprünglichen Modell der
Zugriffskontrolle, auch wenn dieses über die Jahre um zahlreiche Erweiterungen ergänzt wurde.
Nachfolgend werden die wichtigsten Aspekte und Features von DAC-Modellen in modernen
relationalen Datenbanken aufgeführt. Dabei geht die Diskussion auf verschiedene Zugriffsmodi,
rollenbasierte und inhaltsbasierte Zugriffskontrolle, Möglichkeiten der Administration von Auto-
risierungen, negative Autorisierungen sowie kontextbasierte Zugriffskontrolle ein.
Eine sehr grundlegende Anforderung ist die Fähigkeit zur Unterscheidung der möglichen Zu-
griffsarten. Die Standardmodi, die bereits im System R vorhanden waren, sind SELECT (Aus-
wahl bestimmter Tupel), INSERT (Einfügen von Tupeln), DELETE (Löschen von Tupeln) und
UPDATE (Änderung von Tupeln). Moderne Datenbanken bieten den Benutzern darüber hinaus
noch weitere Zugriffsarten an, beispielsweise die Verwendung von Triggern (Spezifikation einer
Aktion, die ausgelöst wird, wenn ein bestimmtes Ereignis eintritt), die natürlich ebenfalls kon-
trolliert werden müssen. Nicht alle der genannten Operationen sind dabei auch immer zulässig;

Thema 1 - Einleitung Felix Kamfenkel 8
insbesondere bei der Verwendung von Sichten können sich Einschränkungen ergeben. In diesem
Fall wäre zum Beispiel die Insert-Operation unter Umständen nicht möglich.
Zweitens stellt sich natürlich die Frage, wem man diese unterschiedlichen Arten von Zugriffsbe-
rechtigungen überhaupt erteilen kann. Ursprünglich waren dies lediglich einzelne User oder be-
stimmte im System hinterlegte Gruppen. Durch die Zuordnung eines Benutzers zu einer Gruppe
werden dabei sämtliche zur Gruppe gehörigen Einstellungen auf den jeweiligen Benutzer über-
tragen. Eine besonders wichtige Form der Gruppendefinition und mittlerweile fest etablierte Er-
weiterung in diesem Bereich ist das Rollenkonzept9: Dabei geht man davon aus, dass eine Rolle
bestimmte Funktionen eines Mitarbeiters repräsentiert und mit spezifischen Verantwortlichkeiten
verbunden ist. Die zur Ausführung nötigen Autorisierungen werden dabei der Rolle gewährt,
nicht dem Benutzer.
Damit dieses Konzept funktionieren kann, müssen alle Benutzer gegenüber dem System immer
in einer Rolle auftreten. Die Verwaltung von Autorisierungen wird dann deutlich einfacher, weil
man nicht mehr mit den Zugriffsberechtigungen jedes einzelnen Users umgehen muss, sondern
nur noch mit denen der einzelnen Rollen. Insbesondere Positionswechsel im Unternehmen wer-
den auf diese Weise erleichtert. Die Rollen können zur weiteren Vereinfachung sogar noch hie-
rarchisch gruppiert werden, wodurch eine Vererbung von Autorisierungen ermöglicht wird.
Rollenmodelle unterstützen auch in einer sehr effizienten Weise die Aufgabentrennung im Un-
ternehmen. Diese wird üblicherweise verwendet, um Missbrauch durch Benutzer mit (zu) vielen
Rechten zu verhindern. So wäre es beispielsweise nicht wünschenswert, wenn ein Mitarbeiter,
der das Recht hat, Schecks auszustellen, auch gleichzeitig für die Aufgabe von Bestellungen ver-
antwortlich ist.
Bei der Aufgabentrennung kann zwischen einer statischen und einer dynamischen Variante un-
terschieden werden: Bei statischer Trennung gibt es üblicherweise Einschränkungen bezüglich
der Rollenüberschneidungen. Dabei ist insbesondere wichtig, dass zwei sich gegenseitig aus-
schließende Rollen nicht denselben Benutzer haben dürfen, da sonst das Konzept an sich wir-
kungslos wäre. Bei dynamischer Aufgabentrennung benutzt man ein Session-Konzept, so dass
die Anzahl und Art der Rollen, die ein User annehmen kann, durch die bisherige Verwendung
von Rollen während der aktuellen Session oder früherer Sessions eingeschränkt ist. Eine Session
ist dabei eine atomare Arbeitseinheit, zum Beispiel eine Transaktion. So könnte man etwa ver-
hindern, dass ein User während einer Transaktion zwischen Rollen hin und her springen kann
und sich auf diese Weise mehr Rechte sichern kann, als ihm zustehen. Der Benutzer könnte da-
mit zwar grundsätzlich Mitglied mehrerer konfligierender Rollen sein, allerdings nicht im Rah-
9 Rollenbasierte Zugriffskontrolle wird hier als Unterform der DAC verstanden. Teilweise wird sie allerdings auch als
eigene Form der Zugriffskontrolle eingeordnet (siehe zum Beispiel Lee & Yu 2008: 1).

Thema 1 - Einleitung Felix Kamfenkel 9
men der gleichen Arbeitseinheit.
Drittens ist wichtig, dass Zugriffsberechtigungen anhand des Inhalts der jeweiligen Daten verge-
ben werden können. Hier stellt sich zunächst die Frage, auf welcher Ebene man den Zugriff-
schutz etabliert. Prinzipiell können dies Relationen, Tupel oder einzelne Attribute sein.
Auf Tupelebene könnte man zum Beispiel festlegen, dass Angestellte in der Finanzabteilung nur
Kundenkonten bis zu einer gewissen Höhe einsehen können, weil die Premium-Kunden nur vom
oberen Management betreut werden sollen. Zur Realisierung dieses Vorhabens gibt es prinzipiell
zwei Möglichkeiten: die Erstellung einer Sicht oder die Abfragemodifikation. Im erstgenannten
Fall würden die Mitarbeiter der Finanzabteilung eine Sicht erhalten, die alle größeren Konten
ausblendet. Im letztgenannten Fall würde man mit einer DENY-Anweisung den Zugriff auf Pre-
mium-Konten verbieten. Jeder Anfrage werden dann automatisch die in der Anweisung spezifi-
zierten Verbote in Form einer zusätzlichen Bedingung in der WHERE-Klausel hinzugefügt. Die-
se Modifikation ist natürlich flexibler als die Verwendung von Sichten (zumal auf Sichten nicht
alle Operationen möglich sind), verbraucht allerdings auch mehr Ressourcen, da das System jede
Anfrage umformulieren muss.
Viertens kann man zwischen unterschiedlichen Formen der Administrationsweise von Autorisie-
rungen unterscheiden. Dabei gibt es zwei idealtypische Möglichkeiten, die sich gewissermaßen
an den äußersten Polen eines Spektrums gegenüberstehen: Zum einen kann die Administration
zentralisiert ausgeführt werden. In diesem Fall bestimmen nur wenige Personen (im Extremfall
nur eine) über Vergabe von Autorisierungen; üblicherweise wird es sich dabei um die Daten-
bank- oder Systemadministratoren handeln. Zum anderen ist eine dezentrale Administration
möglich. Diesen Ansatz nennt man auch eigentumsbasierte Administration, da hier die Eigentü-
mer der Daten über die Vergabe von Autorisierungen entscheiden dürfen. Dabei kann das Ver-
gaberecht mittels der GRANT-Option auch delegiert werden.
Soll dieses Recht von einem Benutzer wieder entzogen werden, wird die REVOKE-Operation
verwendet. Üblicherweise soll dann der Zustand wiederhergestellt werden, der vor der Vergabe
des GRANT herrschte. Beispielsweise könnte der Besitzer einer Relation einem anderen Benut-
zer A das Leserecht inklusive der GRANT-Option erteilt haben. A hat danach wiederum einem
weiteren Benutzer B ebenfalls das Leserecht gewährt. Entscheidet sich nun der Besitzer der Re-
lation, Benutzer A die gewährten Rechte wieder zu entziehen, muss auch B seine Zugriffsrechte
verlieren, damit der ursprüngliche Zustand vor der Vergabe aller Rechte an A wiederhergestellt
ist. Da bei diesem Vorgehen eine Kaskade von Rechteentzügen entstehen kann, nennt man diese
Art der REVOKE-Operation auch kaskadierendes REVOKE. Alternativ kann man auch eine
nicht-kaskadierende REVOKE-Operation verwenden. Dabei werden nur dem von der Operation
Betroffenen seine GRANT-Privilegien entzogen, ohne die Ausdehnung auf andere Benutzer, die

Thema 1 - Einleitung Felix Kamfenkel 10
Rechte von dem User erhalten haben. Benutzer B aus dem Beispiel könnte sein Leserecht also
behalten. Inhaltlich wird dabei einfach so getan, als hätte B zu dem Zeitpunkt, als er sein Recht
von A erhalten hat, dieses stattdessen von dem Besitzer der Relation erhalten.
Eine fünfte Möglichkeit der Zugriffskontrolle, die in den meisten Datenbankmanagementsyste-
men vorhanden ist, ist die Vergabe von negativen Autorisierungen. Normalerweise wird bei
DAC-Modellen eine sogenannte Closed-World-Policy angewendet. Dabei wird davon ausgegan-
gen, dass eine nicht vorhandene Autorisierung im System bedeutet, dass auch keine Zugriffbe-
rechtigung besteht. Diese Politik hat den Nachteil, dass ein Benutzer, der bis jetzt noch keinen
Zugriff auf ein Datenelement hat, den Zugriff durchaus irgendwann in der Zukunft unberechtig-
terweise erlangen könnte.
Um diesen Fall zu verhindern, gibt es negative Autorisierungen. Wie der Name bereits erahnen
lässt, spezifiziert man für den betreffenden Benutzer damit explizit das Verbot, auf ein Objekt
zuzugreifen. Damit die negative Autorisierung wirksam sein kann, müssen diese Verbote bei der
Zugriffskontrolle Vorrang haben (Denial-Takes-Precedence-Prinzip). Gilt beispielsweise ein
Leseverbot für einen Benutzer X bei einem bestimmten Datenelement, und ein anderer Benutzer
Y räumt ihm ein Leserrecht darauf ein, gilt weiterhin das Verbot.
Einige DAC-Modelle bieten die Möglichkeit, diese negativen Autorisierungen dennoch zu über-
schreiben. Dazu wird das Konzept der sogenannten More-Specific-Authorization verwendet. Das
bedeutet, dass eine spezifischere Autorisierung eine allgemeinere außer Kraft setzt. Ist der grade
genannte Nutzer X Mitglied einer Gruppe, für die das Leseverbot gilt, und Nutzer Y räumt X
eine benutzerbezogene Leseerlaubnis ein, dann ist die Erlaubnis (nur für den User) spezifischer
als das Verbot (für die ganze Gruppe) und ein Zugriff ist möglich. Sind Erlaubnis und Verbot
nicht vergleichbar, gewinnt natürlich weiterhin das Verbot.
Um bei negativen Autorisierungen nicht jede Zugriffsart (SELECT, INSERT, etc.) einzeln ver-
bieten zu müssen, existiert ein spezieller Null-Zugriffsmodus für negative Autorisierungen, der
alle Zugriffsarten umfasst. Ist für einen Nutzer ein Null-Zugriff bei einer bestimmten Relation
spezifiziert, darf er dort keinen der Zugriffsmodi ausüben.
Schließlich wird sechstens in den meisten DAC-Modellen auch ein kontextbasierter Zugriff an-
geboten, wobei sich dafür verschiedene Kontextfaktoren spezifizieren lassen. Dies kann zum
Beispiel die Zeit sein, indem zeitlich begrenzte oder periodische Zugriffsautorisierungen verge-
ben werden. So könnte in einem Unternehmen als Sicherheitsvorkehrung festgelegt werden, dass
kein Angestellter nachts oder an Wochenenden auf wichtige Dateien zugreifen darf. Da in dieser
Zeit (zumindest üblicherweise) niemand an den Daten arbeitet, ist die Wahrscheinlichkeit näm-
lich hoch, dass der Zugriff gar nicht von einem Angestellten stammt, sondern von einem Angrei-
fer. Neben der Zeit könnte man natürlich auch andere Kontextfaktoren heranziehen, um die Zu-

Thema 1 - Einleitung
griffsentscheidung zu steuern,
spiel auf das Bürogebäude d
Ebenso ist die Spezifikation ei
etwa festgelegt werden, dass e
bank zugreifen darf.
4.1.2) MAC
Die MAC zeichnet sich durch
einem Sicherheitslevel und (op
Datenobjekte als auch User be
Write-Down verfahren.
Es stellt sich dann die Frage,
durchaus gewünscht sein, dass
werden soll, sondern jedem Tu
element (jedem Attributwert) e
sogenannten Multilevel-Relati
sätzliches Klassifikationsattrib
für das Tupel insgesamt ergänz
Abbildung 1 zeigt eine Beispie
den Attributen Name, Abteilu
weils rechts daneben aufgefü
Tupel ist. Der Einfachheit hal
Wie man an der Entität Sam si
eine eigene Klassifizierung z
entspricht dem höchsten Wert
Entität (Galinović & Antončic
Abbildung
Felix Kamfenkel
rn, beispielweise ließe sich der Ort des Zugrif
des Unternehmens oder bestimmte Abteilun
eines bestimmten Kontextes für Applikationen
s ein Programm nur in einem bestimmten Zus
ch die Definition hierarchischer Zugriffsklasse
(optional) einem Bereich bestehen. Mit den Kl
belegt und bei Anfragen nach den Prinzipien
e, welche Dateneinheiten klassifiziert werden
ass nicht einer ganzen Tabelle die gleiche Zugr
Tupel, jedem Attribut (quasi jeder Spalte) ode
eine eigene. In diesen Fällen muss das relatio
lationalmodell erweitert werden. Dazu wird je
ribut zugeordnet und darüber hinaus noch ein
änzt.
piel für eine Datentabelle aus einem Multilevel
ilung und Gehalt. Die zugehörigen Klassifika
eführt, wobei C.Tupel das Klassifikationsattr
alber existieren im Beispiel nur die Zugriffskl
sieht, kann jedem Attribut unabhängig von den
zugeordnet werden. Der Wert des Tupel-Kl
ert (dem Supremum) aus den restlichen Klassif
čic 2007: 128) .
g 1: Beispiel einer Multilevel-Relation und High-Instan
11
riff s im genannten Bei-
ungen darin begrenzen.
en möglich; hier könnte
Zustand auf eine Daten-
ssen aus, die jeweils aus
Klassen werden sowohl
en No Read-Up und No
n sollen. Dabei kann es
ugriffsklasse zugeordnet
der sogar jedem Einzel-
tionale Modell zu einem
jedem Attribut ein zu-
Klassifikationsattribut
el-Relationalmodell mit
ikationsattribute sind je-
ttribut für das gesamte
sklassen Low und High.
den Werten der anderen
Klassifikationsattributes
ssifikationsattributen der
tanz

Thema 1 - Einleitung
In einem Multilevel-Relationalm
eine Relation, die für alle Benutze
Zugriffsklassen unterscheiden. Be
tionsinstanzen, eine Low-Instanz
dass nicht in jeder Instanz alle Tu
jedem Zugriffslevel sind nur die D
niert werden. Die Relationsinstan
erzeugt werden, dass alle Elemen
klassen höher oder nicht vergleich
Für das obige Beispiel bedeutet d
nen, da auf diesem höchsten Zug
gen, dass ein Benutzer mit Siche
Tupel angezeigt bekommen mus
bereits in Abbildung 1 gezeigt ist.
Die nachfolgende Abbildung 2 ze
Tupel vorhanden sein, die Low-A
diesem Zugriffslevel arbeiten, die
muss dabei das als High klassifiz
Up-Bedingung nicht sehen dürfen
rung nur noch als Low klassifizier
ebenfalls auf diese Stufe.
Abbildu
Generell müssen bei Multilevel-
Bildung von Relationsinstanzen m
für jedes Tupel einheitlich klassi
Relationsinstanzen nicht mit dem
durch Null-Werte maskiert sein k
selattribute gleich oder höher sei
manchen Fällen nicht korrekt auf
Felix Kamfenkel
lmodell gibt es zu einem gegebenen Relations
tzer gleich ist, sondern mehrere Relationsinstan
Bei den zwei Klassen Low und High existieren
nz und eine High-Instanz. Der Unterschied zw
Tupel angezeigt werden können, sondern nur ei
ie Daten sichtbar, deren Zugriffsklassen von de
tanzen für eine bestimmte Zugriffsklasse kön
ente in der Multilevel-Relation maskiert werde
ichbar sind.
t dies, dass in der High-Instanz alle Daten ange
ugriffslevel alle anderen dominiert werden. Ma
cherheitsstufe High ja alle Daten lesen darf un
uss. Die High-Instanz ist deshalb die gleiche
ist.
zeigt die Low-Instanz der Multilevel-Relation
Attribute beinhalten – schließlich sollen alle
die für sie lesbaren Attribute auch sehen können
ifizierte Gehalt, das Benutzer dieses Levels we
fen, mit einem Null-Wert maskiert werden. Da
ierte Attribute in dem Tupel enthalten sind, sink
ildung 2: Low-Instanz der Multilevel-Relation
-Relationen zwei Bedingungen erfüllt sein, d
n möglich ist: Zum einen müssen die Werte de
ssifiziert sein. Wäre das nicht der Fall, könnte
em Primärschlüssel auf Tupel zugreifen, da eini
könnten. Zum anderen muss die Zugriffsklass
sein als die des Primärschlüssels. Auch hier kö
auf die Daten zugreifen, da in manchen Relatio
12
onsschema nun nicht
stanzen, die sich nach
ren daher zwei Rela-
zwischen diesen ist,
eine Teilmenge: Auf
der des Levels domi-
önnen somit dadurch
rden, deren Zugriffs-
ngezeigt werden kön-
Man könnte auch sa-
und daher auch alle
he Tabelle, die auch
ion. Hier müssen alle
lle Benutzer, die auf
nen. Beim Tupel Sam
wegen der No Read-
Da nach der Maskie-
inkt C.Tupel für Sam
, damit eine korrekte
des Primärschlüssels
nte man in manchen
inige seiner Attribute
asse der Nichtschlüs-
könnte man sonst in
ationsinstanzen Tupel

Thema 1 - Einleitung
ohne Primärschlüssel auftreten
maskiert werden müsste.
Neben diesen unbedingt einz
sogenannte Polyinstanziierung
tenelemente mit gleichem Nam
es sich sowohl um Relationen
Relationen namens Militärfahr
Öffentlich klassifiziert ist.
Bei Tupeln bedeutet Polyinsta
jedoch mit unterschiedlichen
spielsweise zwei Tupel namen
ist) in beiden Entitäten untersc
in der die bereits bekannte Mul
Bei der Attribut-Polyinstanziie
ein Attribut geben, die jedoch
Klassifizierung des Schlüssels
Fall, die eine gleiche Klassifiz
das Gehalt aufweisen.
Polyinstanziierung kann gener
zer eines niedrigen Levels ein
gleichnamiges Element auf ein
unsichtbare Polyinstanziierung
Felix Kamfenkel
ten würden, wenn dieser auf Grund einer niedr
nzuhaltenden Bedingungen besteht in MAC-
ng zuzulassen. Der Begriff bezeichnet das Au
amen aber verschiedenen Zugriffsklassen. Bei
en, Tupel oder Attribute handeln. So könnte
ahrzeuge geben, wobei die eine als Streng Gehe
stanziierung, dass es Entitäten mit demselben
n Zugriffsklassen des Primärschlüssels gibt. E
ens Ann existieren, wobei der Name (der ja hie
rschiedlich klassifiziert ist. Dieser Fall ist in Ab
ultilevel-Relation um ein zusätzliches Ann-Tu
ziierung kann es schließlich unterschiedlich kl
ch zu einem Tupel mit gleichem Primärschlü
els gehören. Dies ist für die zwei Jerry-Tupel
ifizierung des Namens, aber unterschiedlich kl
Abbildung 3: Polyinstanziierung
erell durch zwei Situationen entstehen: Zum ei
ein Datenelement einfügen will, ohne zu wisse
einem höheren oder nicht vergleichbaren Leve
ung genannt, weil die einfügende Person das
13
edrigeren Zugriffsklasse
-Modellen die Option,
Auftreten mehrerer Da-
ei den Elementen kann
te es zum Beispiel zwei
eheim und die andere als
en Primärschlüsselwert,
Es könnten somit bei-
hier der Primärschlüssel
Abbildung 3 dargestellt,
Tupel erweitert wurde.
klassifizierte Werte für
lüsselwert und gleicher
el aus Abbildung 3 der
klassifizierte Werte für
einen, wenn ein Benut-
ssen, dass es bereits ein
el gibt. Dies wird auch
as konfligierende Tupel

Thema 1 - Einleitung Felix Kamfenkel 14
oder Attribut auf der höheren Ebene wegen des No Read-Up-Prinzips nicht sehen kann10. Zum
anderen kann Polyinstanziierung aber auch unter Kenntnis des Benutzers geschehen, und zwar
dann, wenn er auf einem hohen Level Daten einfügt, die auf einem niedrigeren Level schon vor-
handen sind. Der Benutzer sieht in diesem Fall die betreffenden Daten auf der niedrigeren Stufe,
kann sie aber des No Write-Down-Prinzips nicht selbst verändern. Somit muss er entweder auf
das Einfügen verzichten oder die Polyinstanziierung in Kauf nehmen.
Falls man sich entscheidet, polyinstanziierte Elemente in einem Modell zuzulassen, stellt sich
natürlich die Frage, welche Bedeutung diese Elemente in Bezug auf die reale Welt haben. Übli-
cherweise gilt dabei die Regel, dass polyinstanziierte Tupel verschiedene Entitäten der realen
Welt beschreiben. Das ist hier bei Ann der Fall; gemäß den Einträgen der Multilevel-Relation
gibt es somit zwei Personen dieses Namens, die für das Unternehmen arbeiten. Polyinstanziierte
Werte wiederum beziehen sich auf dieselbe realweltliche Entität. Die beiden Jerry-Tupel aus
Abbildung 3 beschreiben folglich dieselbe Person, wobei Benutzer mit niedriger Sicherheitsfrei-
gabe die Information angezeigt bekommen, Jerry würde 30.000 Euro verdienen. Die Nutzer mit
hoher Freigabe wissen es besser und sehen das tatsächliche Gehalt von 100.000 Euro.
Wie man sieht, ist es durch Polyinstanziierung durchaus möglich, Nutzern auf einem niedrigeren
Level nicht nur die wahren Tatsachen zu verbergen, sondern ihnen sogar bewusst falsche Infor-
mationen zukommen zu lassen und sie damit gewissermaßen auf eine falsche Fährte zu locken.
Die bisher diskutierten Anforderungen bezogen sich auf die Erweiterung des relationalen Mo-
dells zum Multilevel-Relationalmodell. Für die erfolgreiche Umsetzung von MAC in einer Da-
tenbank muss jedoch nicht nur das Datenmodell geändert werden, sondern auch die Systemarchi-
tektur. Andernfalls bleiben unter Umständen Informationskanäle bestehen, die sich potenzielle
Angreifer zunutze machen können, um Informationen von einer höheren zu einer niedrigeren
oder nicht vergleichbaren Sicherheitsstufe zu senden.
Diese Geheimkanäle kann man prinzipiell in die zwei Arten Speicherkanal und Timingkanal
unterteilen: Im ersten Fall werden, wie der Name bereits vermuten lässt, Daten in der Sicher-
heitshierarchie von oben nach unten umgespeichert. Dazu schreibt ein Prozess bzw. eine Trans-
aktion auf dem höheren Niveau in eine Speicherressource, die von einem anderen Prozess auf
einer niedrigeren Ebene ausgelesen werden kann. Im zweiten Fall signalisiert man Informationen
durch das Timing von bestimmten Vorkommnissen. Um solche Timingkanäle sicher vermeiden
zu können, ist es nötig, die Transaktionsalgorithmen des Systems speziell für die MAC abzuän-
dern. 10
Der Benutzer darf natürlich nicht benachrichtigt werden, wenn zu einem von ihm eingefügten Element bereits
ein gleichnamiges mit höherer Klassifikation existiert – schließlich würde man ihn damit ungewollt über die Exis-
tenz des höher klassifizierten Elements in Kenntnis setzen.

Thema 1 - Einleitung Felix Kamfenkel 15
Ein Beispiel ist das bekannte Zwei-Phasen-Sperrprotokoll: Es ist hier möglich, dass eine Trans-
aktion auf einem hohen Level einer mit ihr kooperierenden Transaktion auf einem niedrigen Le-
vel Signale gibt, indem Elemente auf der niedrigeren Ebene bewusst mit Lesesperren belegt
werden. Die Transaktion auf der unteren Ebene kann solche Elemente während der Sperre nicht
schreiben. Über die Dauer der verstreichenden Wartezeit bis zur Freigabe, die von der niedrige-
ren Transaktion gemessen werden kann, lassen sich nun Informationen in der Hierarchie der Zu-
griffsklassen von oben nach unten übertragen.
4.2) Objektbasierte Datenbanken
Unter einer objektbasierten Datenbank wird hier ein System verstanden, das die Prinzipien der
Objektorientierung entweder in ein relationales System integriert (objektrelational), oder ein rein
objektorientiertes Datenmodell verwendet. Zwischen objektorientierten und relationalen Daten-
bankmanagementsystemen bestehen einige wichtige (auch für XML und NoSQL gültige) Unter-
schiede, die sich auf die Realisierung von DAC- und MAC-Modellen auswirken:
So sind erstens die verwalteten Elemente bei objektbasierten Datenbanken deutlich komplexer.
Dabei kann es sich zum Beispiel um Multimedia- oder CAD-Informationen handeln. Diese um-
fangreicheren Datenmodelle verkomplizieren die Zugriffskontrolle, da es natürlich möglich sein
sollte, die erhöhte Komplexität auch auszunutzen und auf die gespeicherten Objekte (sowie ihre
Methoden, Attribute, etc.) flexibel zugreifen zu können.
Zweitens ist auch bei der Spezifikation von Usern eine erhöhte Flexibilität vonnöten, da objekt-
basierte Datenbanken oft bei webbasierten Anwendungen zum Einsatz kommen, die sehr hetero-
gene und dynamische Benutzerpopulationen haben. Das führt dazu, dass sogenannte Teil- bzw.
partielle Identitäten von Benutzern verwendet werden, die zum Beispiel auf (zusätzlichen)
Merkmalen wie Alter oder Nationalität beruhen.
Drittens muss die Zugriffskontrolle für verschiedene Informationsverbreitungsstrategien möglich
sein. Eine solche Strategie bezeichnet die Art, wie Daten einem Benutzer geliefert werden. Nor-
malerweise kommt in Datenbanken eine Pull-Strategie zum Einsatz; das heißt, ein Benutzer oder
ein Programm fragen die Daten beim System ab, die sie haben wollen. Im Internet ist es heutzu-
tage allerdings auch nötig, Informationen im Rahmen einer Push-Strategie ohne vorherige An-
frage zu liefern, beispielsweise bei Newslettern.
Viertens sind im Rahmen der zunehmenden Vernetzung zwischen Unternehmen sehr komplizier-
te Workflows entstanden, an denen oft mehrere verschiedene Firmen beteiligt sind, etwa im Be-
reich des Lieferkettenmanagements. Die dafür nötigen Daten müssen einer ganzen Reihe von
Personen und Programmen offenstehen und gemeinschaftlich verändert werden können. Die Zu-

Thema 1 - Einleitung Felix Kamfenkel 16
griffskontrolle muss in diesem Rahmen dafür sorgen, dass die Festlegungen zum Fluss der Daten
zwischen den Beteiligten eingehalten werden können.
4.2.1) DAC
Wie bereits erwähnt, sind die Datenmodelle in objektbasierten Datenbanken sehr viel komplexer
als in relationalen. Diese Erweiterung hat eine deutlich höhere Granularität der Zugriffsmöglich-
keiten zur Folge. Die Zugriffskontrolle muss hier insbesondere mit Anfragen auf Klassen, In-
stanzen, Attribute und Methoden umgehen können. Dabei stellen sich einige Fragen, deren Lö-
sungen nicht direkt auf der Hand liegen: Beispielsweise könnte ein Benutzer B aus einer Klasse,
die einem anderen Benutzer A gehört, eine Instanz erzeugen. Wem von beiden gehört nun die
Instanz?
Insbesondere die DAC stößt im objektbasierten Kontext schnell an ihre Grenzen, weil nur in den
seltensten Fällen alle Zugriffsmöglichkeiten berücksichtigt und als Autorisierungen im System
gespeichert werden können. Daher behilft man sich damit, zusätzlich auch implizite Autorisie-
rungen zu verwenden, die aus den explizit formulierten Berechtigungen abgeleitet werden. So
könnte beispielsweise die explizite Autorisierung eines Benutzers, lesend auf ein Objekt zuzu-
greifen, bedeuten, dass er auch die implizite Berechtigung hat, alle mit diesem Objekt in Verbin-
dung stehenden Objekte zu lesen. Solche impliziten Autorisierungen werden mittels spezieller
Implikationsregeln abgeleitet, die für Objekte, Subjekte und Zugriffsmodi formuliert werden und
natürlich im System hinterlegt sein müssen.
In der Regel wird die Ableitung impliziter Autorsierungen auf das zu Grunde liegende Datenmo-
dell beschränkt sein bzw. sich an diesem orientieren. Das bedeutet, dass die nicht explizit formu-
lierten Berechtigungen entlang der semantischen Beziehungen der Objekte gefolgert werden.
Prinzipiell sind im Rahmen logikbasierter Zugriffskontrolle allerdings beliebig komplexe Impli-
kationsregeln möglich. Hier existiert eine ganze Reihe unterschiedlicher Modelle (z.B. Purevjii
et al 2005; Coetzee & Eloff 2012). Logikbasierte Ansätze können zudem bei der Verwaltung der
Zugriffskontrollregeln eingesetzt werden (Kolovski 2011).
Die Freiheit, nicht jede Autorisierung einzeln spezifizieren zu müssen, führt zu einer großen
Vereinfachung der Zugriffkontrolle und kann selbstverständlich mit anderen bereits erörterten
Konzepten kombiniert werden. So könnte beispielsweise der Fall eintreten, dass man von 1000
Instanzen einer Klasse lediglich eine einzige schützen möchte. Statt nun 999 einzelne Autorisie-
rungen vergeben zu müssen, reichen zwei Berechtigungen: Eine explizite Autorisierung auf die
Klasse, die sich an alle Instanzen vererbt, und eine negative Autorisierung auf die zu schützende
Instanz.

Thema 1 - Einleitung Felix Kamfenkel 17
Die Möglichkeit impliziter Berechtigungen ergibt sich (in erster Linie) aus der Struktur des je-
weiligen Datenmodells. Eine andere, besonders wichtige Eigenschaft der Objektorientierung, die
Kapselung, lässt sich jedoch auch für die Zugriffskontrolle ausnützen. Kapselung bedeutet, dass
man den Zugriff auf ein Objekt nur über bestimmte Methoden erlaubt und dadurch eine Tren-
nung zwischen seinem Status und seiner Schnittstelle nach außen herstellt. Man versteckt da-
durch die Information, wie bestimmte Funktionalitäten oder Attribute implementiert sind, vor
den Benutzern bzw. Programmen.
Offensichtlich ist dadurch eine sehr effektive Zugriffskontrolle auf das Objekt (und natürlich die
darin gespeicherten Daten) möglich: Die Methoden fungieren als eine Art Schutzschicht, weil
die Benutzer und Programme nicht direkt auf die Werte des Objekts zugreifen können, sondern
immer den Weg über die angebotene Schnittstelle nehmen müssen. Man verlegt durch die Ver-
wendung von Methoden somit im Prinzip einen Teil der Zugriffskontrolllogik in die Daten hin-
ein. Dabei wird auch die Komplexität stark reduziert, da Änderungen eines Objektes für Pro-
gramme transparent sind, solange sich die Schnittstelle (also die Methoden) nicht ändert. An-
dernfalls müsste man die Programme gleich mit umschreiben.
Berechtigungen zum Zugriff müssen dann natürlich auf Methoden vergeben werden. Hier gibt es
unterschiedliche Ansätze; zum Beispiel kann man sogenannte Guard Functions (Wach- oder
Beschützerfunktionen) einsetzen, die vor einem Methodenaufruf immer zuerst aktiviert werden
und prüfen, ob der Zugriff berechtigt ist. Ebenso ist die Verwendung von Proxy-Funktionen
möglich. Dabei handelt es sich um überladene Methoden, die je nach Kontext bzw. Benutzer
eine andere Ausführung (eben einen anderen Proxy) realisieren.
Bei nicht rein objektorientierten, sondern lediglich objektrelationalen Systemen, kann man statt
Methoden auch Stored Procedures (gespeicherte Prozeduren) verwenden. Diese haben zwar in
der Regel keine starke Kapselung, können allerdings trotzdem ähnlich wie Methoden als zusätz-
liche Zugriffskontrollschicht verwendet werden.
4.2.2) MAC
Auch die MAC ist nicht direkt vom relationalen auf den objektbasierten Fall übertragbar. Das
Problem liegt hier vor allem darin, dass die Definition von Subjekt und Objekt nicht eindeutig
ist: Im Falle relationaler Datenbanken sind die Datenobjekte passive Entitäten, die lediglich In-
formationen speichern. Bei den Subjekten handelt es sich um die aktiven Nachfrager dieser In-
formationen, die die Aktionen der Datenbank durch ihre Anfragen anstoßen. Im objektbasierten
Fall sind die Objekte allerdings nicht mehr ausschließlich passiv, da sie nicht nur an sich selbst,

Thema 1 - Einleitung Felix Kamfenkel 18
sondern auch an anderen Objekten Methodenaufrufe durchführen. Die Objekte sind hier somit
sozusagen Subjekt und Objekt zugleich.
Ein naheliegendes Konzept zur Implementierung der MAC im objektbasierten Fall ist ein Nach-
richtenfilter. Da die Kommunikation zwischen allen Objekten über Nachrichten abläuft, kann
man mittels eines Filters relativ einfach kontrollieren, dass keine Inhalte von einem Objekt auf
einem höheren Level an Objekte auf tieferen Levels fließen.
Auch bei der MAC erschwert zudem die Vielfalt der möglichen Beziehungen zwischen Entitäten
die Umsetzung. Man steht hier prinzipiell vor der Entscheidung, ob man sogenannte Single- oder
Multilevel-Modelle implementieren möchte. Im ersten Fall wird festgelegt, dass alle Elemente
eines Objekts (vorwiegend natürlich die Attribute und Methoden) eine Klassifizierung auf der
gleichen Stufe haben müssen. Bei der Multi-Level-Variante darf jedes Element eine unterschied-
liche Zugriffsklasse haben. Die Single-Level-Methode hat den Vorteil, dass sie relativ einfach zu
implementieren ist; die Multi-Level-Variante ist natürlich deutlich komplizierter. Man behilft
sich daher in der Regel damit, dass man ein Pseudo-Multilevel-Modell erzeugt, indem man ein
Objekt mit mehreren Zugriffsklassen auf mehrere Objekte mit jeweils nur einer Zugriffsklasse
abbildet (sogenannter Multilevel Object View Approach).
Dieser Ansatz kann zum Bespiel durch Vererbungshierarchien realisiert werden, in denen die
Objekte mit niedriger Klassifizierung an der Wurzel ansiedelt sind. Davon ausgehend werden
jeweils Unterklassen gebildet, die die niedrig klassifizierten Attribute und Methoden erben und
selbst immer höhere Zugriffsklassen haben. Eine andere Methode ist die Verwendung zusam-
mengesetzter Objekte. Dabei setzt man in einem Objekt mit einer hohen Zugriffsklasse Referen-
zen auf zugehörige Objekte mit niedrigerer Zugriffsklasse.
4.3) XML-Datenbanken
Die Probleme, Anforderungen und Besonderheiten für DAC und MAC in XML-Systemen sind
in hohem Maße ähnlich wie bei objektbasierten Datenbanken. Dies ist leicht nachvollziehbar, da
ein XML-Dokument mit seiner Struktur aus Elementen, (optionalen) Attributen und
Verlinkungen zu anderen Dokumenten stark an miteinander in Beziehung stehende Objekte erin-
nert. Auch XML-Dokumente verfügen zudem über eine hohe Granularität, schließlich muss es
hier möglich sein, Zugriffskontrolle für Attribute, Elemente, Dokumente und sogar Gruppen von
Dokumenten umzusetzen. Der vorwiegend webbasierte Einsatz und die Verwendung in komple-
xen Workflows (meist als Datenaustauschformat) sind weitere Gemeinsamkeiten. Das für ob-
jektbasierte Datenbanken Gesagte ist somit im Kern auch hier zutreffend und die vorgestellten
Techniken können (größtenteils) eingesetzt werden.

Thema 1 - Einleitung Felix Kamfenkel 19
Allerdings gibt es einige Unterschiede, die kurz erwähnt werden sollen: Zum einen gibt es keine
Methoden, die für die Zugriffskontrolle verwendet werden können. Zum anderen werden bei
XML keine Nachrichten zwischen den Dokumenten ausgetauscht, die man mittels eines Filters
überwachen könnte. Drittens ergeben sich durch die Verwendung von Document Type
Descriptions (DTDs) bzw. XMLSchema einige Veränderungen: Durch DTDs können Zugriffs-
kontrollbedingungen für Gruppen von Dokumenten spezifiziert werden. Dabei muss man aller-
dings berücksichtigen, dass nicht unbedingt für jedes Dokument eine DTD oder ein Schema
existieren muss (im Gegensatz zu Instanzen, die immer zu einer Klasse gehören). Falls im Sys-
tem mit einer Closed-World-Policy gearbeitet wird, also zur Zugriffserlaubnis eine Autorisierung
vorhanden sein muss, wäre bei einer Spezifikation der Berechtigungen auf DTD-Ebene unter
Umständen kein Zugriff auf einige Dokumente möglich.
4.4) NoSQL-Datenbanken
NoSQL-Systeme sind in den letzten Jahren immer populärer geworden. Sie vereinen Aspekte aus
allen bisher genannten Datenbank-Arten11; dies gilt auch im Hinblick auf die Anforderungen und
Herausforderungen, die sich bei der Implementierung einer wirkungsvollen Zugriffskontrolle
stellen. Da es bei NoSQL-Systemen kein festes Schema gibt (Sadalage & Fowler 2012), können
prinzipiell die Aspekte aller genannten Datenbank-Arten auftreten.
Allerdings gibt es einen wichtigen Unterschied: Im Gegensatz zu den bisher genannten Daten-
bankarten, zu denen in der Regel vielfältige Umsetzungen der Zugriffskontrolle existieren, steckt
diese in NoSQL-Systemen noch in den Kinderschuhen. Viele Systeme boten bis vor Kurzem
nicht einmal eine Authentifizierung der Benutzer an. Obwohl viele Hersteller mittlerweile nach-
gebessert haben, sind die Möglichkeiten der Zugriffskontrolle nach wie vor sehr beschränkt (sie-
he z.B. MongoDB 2015; Redis 2015).
Dies ist der Tatsache geschuldet, dass NoSQL-Datenbanken in der Regel in ganz spezifischen
Anwendungszusammenhängen eingesetzt werden (wohingegen relationale Systeme eher Univer-
sallösungen sind). Dabei geht man davon aus, dass eine sichere Systemumgebung vorliegt und
somit keine bzw. nur rudimentäre Sicherheitsvorkehrungen nötig sind. Die Zugriffskontrolle
muss daher in der Regel in die Client-Software implementiert werden (Shermin 2013: 3, 49).
11
Die Unterscheidung, zu welcher Art von Datenbank ein System im konkreten Fall zählt, ist nicht immer eindeutig.
So ist beispielsweise eine Vielzahl der NoSQL-Datenbanken objektorientiert und kann daher auch zu diesen Syste-
men gezählt werden. Der Begriff NoSQL bezeichnet allgemein nicht-relationale Datenbanken ohne vordefiniertes
Schema, die SQL nicht als ihre Sprache benutzen, auf Rechner-Clustern laufen und häufig Open-Source-Projekte
sind (Sadalage & Fowler 2012).

Thema 1 - Einleitung Felix Kamfenkel 20
5) Fazit
Bei allen Datenbank-Arten kann die Zugriffskontrolle prinzipiell auf zwei verschiedene Arten
organisiert werden: als DAC und als MAC. Erstere basiert auf der Klassifikation der User, letzte-
re auf der Klassifikation der User und Datenobjekte. Beide bieten je nach Art des Datenmodells
jeweils bestimmte Vor- und Nachteile und haben bestimmte Herausforderungen bei der Imple-
mentierung, wobei von der Grundidee MAC sicherer ist. Obwohl sich die DAC zuerst durchge-
setzt hat und gewissermaßen noch immer eine Art Standard ist, gibt es mittlerweile in fast allen
kommerziellen Datenbankmanagementsystemen (zum Beispiel von Oracle oder IBM) auch
MAC-Implementierungen (IBM 2014; Oracle 2013).
Die Anzahl der Datenbanken wächst rasant, ebenso die Wichtigkeit der darin gespeicherten Da-
ten. Wegen der oft gewaltigen Mengen, die es zu speichern und zu analysieren gilt, ist die Per-
formance der Datenbanken von immer größerer Bedeutung. Die Zugriffskontrolle steht zur die-
ser prinzipiell in einer Tradeoff-Beziehung: Je umfangreicher die Berechtigungsprüfung ausfällt,
desto mehr Ressourcen verbraucht sie natürlich und desto länger dauert ein Zugriff.
Eine Strategie zur Erhöhung der Performance bei großen Datenmengen ist der Einsatz von Sys-
temen, die auf Clustern von Rechnern laufen. Die Anfragen können dann von vielen Servern
parallel bearbeitet werden. Gleichzeitig stellt der Umgang mit den Anfragen eine immer größere
Herausforderung dar, da die Zugriffe auf die Daten aus sehr heterogenen Umfeldern kommen
und zunehmend firmenextern sind. Eine effiziente und effektive Zugriffskontrolle für verteilte
Systeme ist daher von großer Bedeutung.
Performance und die damit in Verbindung stehende Zugriffskontrolle in verteilten Systemen
(insbesondere in NoSQL-Datenbanken) sind somit wichtige Forschungsgebiete der kommenden
Jahre. Weitere aktuelle Forschungsthemen im Bereich Sicherheit und Privatsphäre in Datenban-
ken finden sich in den Beiträgen dieses Seminarbandes.

Thema 1 - Einleitung Felix Kamfenkel 21
6) Literaturverzeichnis
Bertino, Elisa & Sandhu, Ravi S. (2005): Database security – concepts, approaches, and chal-lenges. IEEE Transactions on Dependable and Secure Computing, 2(1). S. 2–19. Bertino, Elisa; Jajodia, Sushil; Samarati, Pierangela (1995): Database security: Research and practice. Information Systems, 20(7). S. 537–556. Büst, René (2013): Daten sind das neue Öl. Daten als Wettbewerbsvorteile in der Cloud verar-beiten. Wirtschaftsinformatik und Management, 2. Springer Gabler Verlag. S. 40–46. Coetzee, Marijke & Eloff, Jan H. P. (2012): An access control framework for web services. In: Information management & computer security, 13(1). S. 29–38. EMC Digital Universe (2014): White Paper. The Digital Universe of Opportunities: Rich Data and the Increasing Value of the Internet of Things. URL: http://idcdocserv.com/1678 (09.01.2015). Ferstl, Otto K.; Sinz, Elmar J. (2006): Grundlagen der Wirtschaftsinformatik. Oldenbourg Verlag: München, Wien. Galinović, Andro & Antončić, Vlatka (2007): Polyinstantiation in Relational Databases with Multilevel Security. Proceedings of the ITI 2007 29th International Conference on Information Technology Interfaces. S. 127–132. IBM (2014): Database Security Guide. URL: http://public.dhe.ibm.com/ps/products/db2/info/vr105/pdf/en_US/DB2Security-db2sece1051.pdf (09.01.2015). Kolovski, Vladimir (2011): Logic-Based Access Control Policy Specification and Management. URL: https://www.cs.umd.edu/sites/default/files/scholarly_papers/VKolovski_1.pdf (09.01.2015). Lee, Dongwon & Yu, Ting (2008): XML Access Control. URL: http://pike.psu.edu/publications/eds07.pdf (09.01.2015). MongoDB (2015): The MongoDB 2.6 Manual. Security. URL: http://docs.mongodb.org/manual/ (09.01.2015). Oracle (2013): Oracle Label Security with Oracle Database 12c. URL: http://www.oracle.com/technetwork/database/options/label-security/label-security-wp-12c-1896140.pdf?ssSourceSiteId=ocomen (09.01.2015). PwC (2014): Managing Cyber Risks in an interconnected World. Key findings from The Global State of Information Security Survey 2015. URL: http://www.pwc.de/de/digitale-transformation/global-state-of-information-security-survey-2015.jhtml (09.01.2015).

Thema 1 - Einleitung Felix Kamfenkel 22
Purevjii, Bat-Odon; Aritsugi, Masayoshi; Imai, Sayaka; Kanamori, Yoshinari; Pancake, Cherri M. (2005): Security Management – Protecting Personal Data with Various Granularities – A Logic-Based Access Control Approach. In: Computational Intelligence and Security. Lecture Notes in Computer Science. Volume 3802. Springer: Berlin. S. 548–553. Redis (2015): Redis Security. URL: http://redis.io/topics/security (09.01.2015). Sadalage, Pramod J. & Fowler, Martin (2012): NoSQL Distilled – A Brief Guide to the World of Polyglot Persistence. Addison-Wesley: Upper Saddle River u.a. Shermin, Motahera (2013): An Access Control Model for NoSQL Databases. University of Western Ontario – Electronic Thesis and Dissertation Repository. Paper 1797.URL: http://ir.lib.uwo.ca/etd/1797/ (09.01.2015). Voß, Stefan; Gutenschwager, Kai (2001): Informationsmanagement. Springer: Berlin u.a.

FernUniversität in Hagen
-
Seminar 01912 / 19912
im Wintersemester 2014/15
„Sicherheit und Privatsphäre in
Datenbanksystemen“
Thema 2
Verschlüsselung
Referentin: Alexandra Kounitzky

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
Inhaltsverzeichnis
1 Einleitung ................................................................................................................................ 1
2 Verschlüsselung ...................................................................................................................... 3
2.1 Klassifizierung der Verschlüsselungsverfahren .............................................................. 3
2.2 Symmetrische Verschlüsselungsverfahren ....................................................................... 4
2.3 Asymmetrische Verschlüsselungsverfahren .................................................................... 4
3 Das RSA-Kryptosystem .......................................................................................................... 5
3.1 Das Public-Key-Verfahren ............................................................................................... 5
3.3 Signaturen ......................................................................................................................... 5
3.4 Das RSA-Verfahren/RSA-Algorithmus ........................................................................... 6
3.5 Gröβen beim RSA-Verfahren ........................................................................................... 7
3.6 Primzahlen ........................................................................................................................ 8
3.7 Beispiel ............................................................................................................................. 8
3.8 Sicherheit des RSA-Verfahrens ....................................................................................... 9
3.9 Aktuell .............................................................................................................................. 9
4 OPES ..................................................................................................................................... 10
4.1 Grundlagen und Konzept ............................................................................................... 10
4.2 Model ............................................................................................................................. 12
4.3 Flatten ............................................................................................................................. 14
4.4 Transform ....................................................................................................................... 14
5 Fazit ....................................................................................................................................... 15
6 Literaturverzeichnis ............................................................................................................... 16

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
1
1 Einleitung
Eine Datenbank ist eine integrierte Ansammlung von Daten, die allen Benutzern eines Anwendungsbereiches als gemeinsame Basis aktueller Information dient [Schlageter (2013, S. 3)]. Das Datenbankmanagementsystem kontrolliert die Datenbank, hierbei können Daten gespeichert, verändert und gelöscht werden, sowie Anfragen an die Datenbank gestellt werden. Um eine Datenbank vertraulich, integer und verfügbar zu halten, werden technische, administrative und physische Kontrollen gefordert. Die Sicherheit von Datenbanken ist deshalb so wichtig, weil private und vertrauliche Informationen wie Kundendaten aus juristischer Sicht geschützt werden müssen. Diese legislativen Maβnahmen bilden die erste Ebene einer sicheren Datenbank. Weiter sind auch organisatorische Maβnahmen zu treffen, die z.B. das Gebäude betreffen. Hierbei geht es um das Bauwerk selbst, sowie die Versorgungsleitungen und den Schutz gegen Blitzeinschlag, Brandgefahr, Vandalismus usw. Auch müssen die Räume (Serverräume, Datenträgerräume) vor unbefugtem Zutritt geschützt werden. Sind diese Voraussetzungen gegeben, kommt eine Identitätskontrolle, wobei sich jeder Benutzer identifizieren muss. Dies kann mit einem Passwort, Chipkarten oder Fingerabdrücken usw. geschehen und wird vom Datenbanksystem übernommen. Hat sich ein Benutzer erfolgreich identifiziert, werden die Daten durch Zugriffskontrollen geschützt. Die Zugriffsbedingungen werden in einer Berechtigungsmatrix gehalten. Die Zugriffsbedingungen können auch wertabhängig (z.B. lohnabhängig) verteilt werden. Als letzte Instanz kommen die kryptographischen Methoden, welche in den folgenden Abschnitten vorgestellt werden.
Abbildung 1 - Die verschiedenen Ebenen des Datenschutzes [Schlageter et al. (2013, S. 4)]

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
2
Im Kapitel zwei wird kurz auf die Verschlüsselung im Allgemeinen eingegangen, unter Berücksichtigung der symmetrischen und asymmetrischen Verschlüsselungsverfahren.
Das dritte Kapitel behandelt das RSA-Verfahren, basierend auf „A Method for Obtaining Digital Signatures and Public-Key Cryptosystems“ von Rivest, Shamit und Adleman [Rivest et al. (1978)].
Bei der Verschlüsselung von Daten in einer Datenbank, kann es zu Problemen kommen. Die Integration von Verschlüsselungstechniken auf Datenbanksystemen verursachen Laufzeitprobleme, denn vor der Verarbeitung der Daten im Rechner, müssen die Daten entschlüsselt werden. Das Problem bei verschlüsselten Daten einer Datenbank liegt darin, dass wenn man bei einer SQL-Anfrage z.B. in einer Spalte einer Tabelle verschlüsselte Informationen hat und ein Vergleichsoperator darauf anwenden möchte, so muss die ganze Tabelle gescannt werden, um die Abfrage zu evaluieren. Denn die Verschlüsselungstechniken berücksichtigen die Reihenfolge nicht und somit können Datenbankindizes wie B-Bäume für Query-Anfragen nicht mehr benutzt werden. Eine mögliche Lösung zu diesem Problem wird im 4. Kapitel betrachtet, wobei das Verschlüsselungsschema OPES zur Sprache kommt, welches auf dem Skript „Order Preserving Encryption for Numeric Data“ von Agrawal, Kiernan, Srikant und Xu beruht [Agrawal et al. (2004)].

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
3
2 Verschlüsselung
Unter Verschlüsselung versteht man aus einem Klartext mit Hilfe eines Verschlüsselungsalgorithmus/Schlüssels einen Geheimtext (cipher text) zu erstellen. Der Entschlüsselung entspricht die umgekehrte Transformation.
Klar-text
Geheim-text
Abbildung 2 – Verschlüsselung
Die Übertragung der verschlüsselten Nachricht kann auf zwei verschiedene Weisen durchgeführt werden. Zum einen gibt es eine Leitungsverschlüsselung, bei der der Absender die Nachricht verschlüsselt und diese an den ersten Empfänger schickt. Dieser entschlüsselt die Nachricht und verschlüsselt sie wieder für den nächsten Empfänger usw. Das Verfahren wird auch Punkt-zu-Punkt-Verschlüsselung genannt und hat den Vorteil, dass nur die beiden direkten Nachbarn sich auf einen Verschlüsselungsalgorithmus, sowie Schlüssel einigen müssen. Hingegen müssen alle Computer in der Kette sicher und vertrauenswürdig sein. Eine andere Methode ist die Ende-zu-Ende-Verschlüsselung bei der der Absender die Nachricht verschlüsselt und diese dann von Computer zu Computer unverändert übertragen wird. Erst der Empfänger entschlüsselt dann die Nachricht.
2.1 Klassifizierung der Verschlüsselungsverfahren 1
2.1.1 Verschlüsselungsoperationen
Bei der Verschlüsselungsoperation wird unterschieden, welche Grundoperation bei der Verschlüsselung angewendet wird, um einen Klartext in einen Geheimtext zu übersetzen. Eine Möglichkeit ist die Ersetzung (substitution). Hierbei wird jedes Zeichen vom Klartext durch ein bestimmtes Zeichen des Geheimtextes ersetzt. Bei der anderen Möglichkeit werden die Zeichen des Klartextes neu angeordnet, sprich ihre Reihenfolge wird verändert. Deshalb nennt man diese Grundoperation Umordnung (transposition).
2.1.2 Verarbeitung des Klartextes
Die Verarbeitung eines Klartextes kann entweder durch Block- oder Stromverschlüsselung stattfinden. Wird der Klartext in Blöcke fester Gröβe eingeteilt, so spricht man von einer Blockverschlüsselung. Der letzte Block wird in der Regel künstlich aufgefüllt, damit auch er der festgelegten Gröβe entspricht. Wird der Klartext hingegen als Folge von Bits betrachtet, so
1 nach [Wohlfeil 2013, S. 53–54]

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
4
wird jedes Klartextzeichen zuerst verschlüsselt und ausgegeben bis das nächste kommt und man spricht von einer Stromverschlüsselung. Dieser Algorithmus wird auch als Online-Algorithmus bezeichnet, denn die Zeichen werden übersetzt, ohne Kenntnis über die Zukunft, sprich der nachfolgenden Zeichen.
2.1.3 Anzahl der Schlüssel
Die dritte Klassifizierung der Verschlüsselungsverfahren beruht auf der Anzahl Schlüssel. Ein symmetrisches Verfahren braucht nur einen Schlüssel, wobei bei einem asymmetrischen zwei benötigt werden. Beide Verfahren werden kurz im nächsten Abschnitt vorgestellt. Ausserdem gibt es noch ein hybrides Verschlüsselungsverfahren, bei welchem zuerst ein geheimer Schlüssel generiert wird, welcher dann mit dem Public-Key-Verfahren verschlüsselt und dem Empfänger übergeben wird. Die Nachricht wird dann symmetrisch mit dem übergebenen Schlüssel verschlüsselt.
2.2 Symmetrische Verschlüsselungsverfahren
Symmetrische Verschlüsselungsverfahren nennt man auch Secret-Key-Verfahren, da der Sender und Empfänger nur einen geheimen Schlüssel austauschen. Sprich, zum Verschlüsselung und Entschlüsseln existiert nur ein Schlüssel. Ein Beispiel:
Cäsar-Chiffre: Dieses Verschlüsselungsverfahren basiert darauf, dass die Klartextzeichen um drei Zeichen im Alphabet verschoben werden. a wird zu d, b zu e usw. Diese Chiffrierung lässt sich sehr einfach berechnen: Chiffre(x) = (x + 3) mod 26
Weiter können symmetrische Verschlüsselungsverfahren in monoalphabetische und polyalphabetische Chiffre unterschieden werden. Im Vergleich zur Cäsar-Chiffre, werden bei den mono- und polyalphabetischen Chiffren die Reihenfolge der Ersetzungszeichen nicht mehr bestimmt (sprich nach dem Alphabet). Bei der monoalphabetischen Chiffre existiert für jedes Klartextzeichen ein Geheimtextzeichen. Der Entzifferung dient z.B. eine Häufigkeitsanalyse. Bei der polyalphabetischen Chiffre wird ein Klartextzeichen nicht immer durch das gleiche Geheimtextzeichen ersetzt – es existiert mehr als ein Geheimtextzeichen für ein Klartextzeichen. Eine weitere Möglichkeit ist die Transpositionsverschlüsselung, die mathematisch auf der Permutation beruht. Man vertauscht hierbei z.B. das erste Zeichen mit dem Fünften, das zweite mit dem Achten usw.
2.3 Asymmetrische Verschlüsselungsverfahren
Die Idee eines asymmetrischen Verschlüsselungsverfahrens kam in den 70er Jahren auf und wurde von Diffie und Hellmann sowie Ralph Merkle entwickelt. Ein bekanntes asymmetrisches Verschlüsselungsverfahren ist das RSA-Verfahren, welches im nächsten Kapitel vorgestellt wird. Es wird auch Public-Key-Verfahren genannt, da Sender und Empfänger je zwei Schlüssel besitzen – einen öffentlichen und einen geheimen.

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
5
3 Das RSA-Kryptosystem
Das RSA-Kryptosystem wurde nach seinen Entdeckern Ronald Rivest, Adi Shamir und Leonard Adleman benannt und 1978 publiziert. Das Verfahren kann zur Verschlüsselung und Erzeugung digitaler Signaturen verwendet werden.
3.1 Das Public-Key-Verfahren
Beim Public-Key-Verfahren brauchen der Absender, sowie der Empfänger zwei zusammengehörende Schlüssel, je zum Ver- und Entschlüsseln. Der Verschlüsselungsschlüssel des Empfängers ist öffentlich. Deshalb nennt man dieses Verfahren auch Public-Key-Verfahren. Der Verschlüsselungsschlüssel entspricht dem Public-Key, sprich dem öffentlichen Schlüssel. Der Schlüssel zum Entschlüsseln einer Nachricht ist hingegen privat. Damit die Sicherheit gegeben ist, gilt es einige Bedingungen zu befolgen. Zum einen darf man den privaten Schlüssel nicht aus dem öffentlichen Schlüssel ableiten können. Zum anderen darf ein Geheimtext nicht mit Hilfe eines öffentlichen Schlüssels entschlüsselt werden können. Somit können alle Benutzer die gleiche Methode anwenden. Die Sicherheit des Verfahrens beruht auf der Sicherheit der Schlüssel.
Bedingungen gemäss [Eckert (2012, S. 248)] : Ausgang der Bedingungen liefert ein kryptografisches System KS bestehend aus M (Nachricht/Message), E (Verschlüsselungsfunktion), D (Entschlüsselungsfunktion), sowie den Schlüsselpaaren KE, KD.
1. Schlüsselpaare (KE, KD) müssen leicht und effizient zu erzeugen sein, wobei KE öffentlich bekannt sein darf. Für alle M gilt D(E(M, KE), KD) = M
2. E und D müssen wie die Schlüsselpaare effizient zu berechnen sein. 3. KD ist nicht aus KE mit vertretbarem Aufwand berechenbar. Die Programmierung der
Entschlüsselung wird durch die Veröffentlichung des Public Keys nicht preisgegeben. 4. Gilt folgende Eigenschaft, so ist das Kryptosystem auch zur Erstellung digitaler
Unterschriften benutzbar. Für alle M gelte: E(D(M, KD), KE) = D(E(M, KE), KD) = M
3.3 Signaturen
Signaturen werden gebraucht, um dem E-Mail-Verkehr eine Unterschrift beizufügen. Für eine Signatur müssen die vier oben genannten Bedingungen erfüllt sein. Als Beispiel nehmen wir die bekannten Figuren Bob und Alice. Bob will Alice eine signierte Nachricht senden.
S = Signatur, M = Nachricht, C = Geheimtext,
DB = Entschlüsselungsschlüssel Bob, DA = Entschlüsselungsschlüssel Alice, EB = Verschlüsselungsschlüssel Bob, EA = Verschlüsselungsschlüssel Alice

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
6
Zuerst muss Bob sich eine Signatur für den Klartext erstellen: S = DB(M)
Dann verschlüsselt Bob die Signatur S mit dem Verschlüsselungsschlüssel von Alice: EA(S)
Die verschlüsselte Signatur sendet Bob an Alice. Er braucht den Klartext nicht mitzuschicken, da dieser bereits in S vorhanden ist.
Alice öffnet nun die verschlüsselte Signatur, sprich den Geheimtext (C). C entschlüsselt sie mit ihrem Entschlüsselungsschlüssel DA, was die Signatur S ergibt: DA(C) = S
Nun weiβ Alice, dass die Nachricht von Bob stammt. Mit Hilfe des Verschlüsselungsschlüssels von Bob kann sie die Nachricht M extrahieren: M = EB(S).
Bob kann nun nicht mehr abstreiten, diese Nachricht geschickt zu haben, denn Alice besitzt das Nachrichten-Unterschrift Paar (M, S). Alice kann die Nachricht hingegen auch nicht verändern, denn sonst müsste sie auch eine Signatur S´ erstellen, wozu sie natürlich ohne den Entschlüsselungsschlüssel von Bob nicht in der Lage ist.
Eine Signatur zeigt die Authentizität einer Nachricht, da nur der Sender seinen privaten Schlüssel kennt und die Nachricht damit „unterschreiben“ kann. Eine mit einer Signatur versehene Nachricht kann später nicht mehr verändert werden – die spezifische Signatur kann nicht für eine andere Nachricht verwendet werden. Zudem ist die signierte Nachricht ein Beweis dafür, von wem die Nachricht stammt. Dies kann nicht widerrufen werden.
3.4 Das RSA-Verfahren/RSA-Algorithmus
Die Nachricht M muss zuerst als Integer zwischen 0 und n-1 dargestellt werden. Dies ist notwendig, denn für die Verschlüsselung muss die Nachricht in numerischer Form vorliegen. Mit diesem Verfahren können nur Nachrichten verschlüsselt werden, die kleiner als n sind, wird eine Nachricht länger, so muss sie in Blöcke geteilt werden. Die Nachricht wird mit dem Verschlüsseln nicht grösser. Der Klartext, sowie der Geheimtext sind Integer zwischen 0 und n-1. Die Nachricht wird damit verschlüsselt, dass man sie in die e-te Potenz modulo n setzt.
C ≡ E(M) ≡ Me (mod n) Verschlüsselung der Nachricht (Klartext) M
D(C) ≡ Cd (mod n) Entschlüsselung des Geheimtextes (ciphertext) C
Untenstehend eine grobe Abfolge der Funktionsweise. Im Unterkapitel 3.8 ist ein Beispiel zu finden:
1. Zuerst wird n (RSA-Modul) erzeugt. Dazu müssen zwei groβe Primzahlen p und q „zufällig“ bestimmt werden. = ∙
2. Im nächsten Schritt wird d bestimmt, so dass a) d ein Integer zwischen 0 und n-1 ist und

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
7
b) d relativ prim, sprich teilerfremd zu φ(n) ist 2, was dem entspricht, dass der ggT( − 1 − 1 , ) = 1 ist. Dies ist bei jeder Primzahl gegeben, welche gröβer ist als max , .
3. Für den öffentlichen Schlüssel fehlt noch e:
Wie d, ist auch e ist ein Integer zwischen 0 und n-1, mit ∙ − 1 − 1 = 1. Anders gesagt, e ist multiplikative Inverse modulo (p – 1)(q – 1) zu d.
Für die Berechnung [Rivest et al. (1978, S. 10)] von e wird der euklidische Algorithmus gebraucht um den ggT von φ(n) und d zu berechnen mit x0 ≡ φ(n), x1 = d, xi+1 ≡ xi-1 (mod xi) bis ein xk gefunden wird, das null ist.
Danach muss der ggT(x0, x1) = xk-1 bestimmt werden. Für jedes xi werden Zahlen ai und bi berechnet, so dass xi = ai * x0 + bi * x1 ist.
Wenn xk-1 = 1 ist, dann ist bk-1 die multiplikative Inverse von x1 (mod x0).
4. Nun entspricht (e, n) dem öffentlichen Schlüssel und 5. (d, n) dem geheimen Schlüssel.
Die Ver- und Entschlüsselung eines Textes kann nun wie oben beschrieben durchgeführt werden. Nimmt man die Formeln von oben zusammen, so gilt ∙ =
Dieses Verfahren kann auch für Signaturen eingesetzt werden, wie im Unterkapitel 3.3 beschrieben: ∙ =
3.5 Gröβen beim RSA-Verfahren
Heutzutage gilt ein Schlüssel von 2048 Bit (617 Dezimalstellen) als sicher. Die Länge des Schlüssels wird an der Anzahl Speicherbits gemessen, die ein Computer braucht, um diesen Wert darzustellen.
Die Gröβe von n wirkt sich direkt auf die Sicherheit des RSA-Verfahrens aus. Je gröβer n ist, desto sicherer ist das Verfahren, denn umso länger ist die Berechnungszeit. Die Faktorisierung von einem 512-Bit RSA-Modul gelang im Jahre 1999. Der Aufwand betrug gut 7 Monate und wurde mit einem Cray C916 Supercomputer, sowie mit über 300 Workstations und PCs erreicht [Eckert (2012, S. 357)].
Die Primzahlen p und q sollten zudem mindestens eine Gröβe einer 100-stelligen Dezimalzahl haben, so dass das Modul n mindestens eine 200-stellige Dezimalzahl wird [Schneier (©1996, S. 467)]. Die Primzahlen sollten aber auch verschieden lang sein, denn gleich lange Primzahlen sind einfacher zu faktorisieren.
2 φ(n) = − 1 − 1 ist die Eulersche Phi-Funktion, welche für eine natürliche Zahl n angibt, wie viele teilerfremde natürliche Zahlen es zu n gibt, die positiv, aber nicht gröβer als n sind.

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
8
3.6 Primzahlen
Die Primzahlen sollen zufällig gewählt werden, unabhängig von der vorherig gewählten Primzahl und alle Primzahlen sollen gleich wahrscheinlich gewählt werden. Am Rechner kann man solche Zufallszahlen hingegen nicht „echt“ simulieren. Also nimmt man eine ungerade Zahl n0 und testet, ob n0, n0 + 2, n0 + 4… eine Primzahl ist. Man entscheidet sich dann für die Primzahl, welche gröβer oder gleich n0 ist. Für diese Aufgabe braucht man einen Primzahltest. Bei solchen Tests wird eine Zahl n getestet. Besteht n den Test nicht, so handelt es sich dabei um eine zusammengesetzt Zahl und somit nicht um eine Primzahl. Besteht n hingegen den Test, so ist noch nicht gegeben, dass n auch wirklich eine Primzahl ist. Hierbei seien folgende Primzahltests erwähnt, die in [Hartlieb und Unger (2014, S. 211–238)] und [Stinson (©1995, S. 133–138)] nachgelesen werden können:
Der Fermat-Test, welcher auf dem kleinen Satz von Fermat beruht Der Solovay-Strassen-Test ist ein Monte-Carlo-Algorithmus. Damit ist gemeint,
dass der Test nur mit einer gewissen Wahrscheinlichkeit eine Aussage trifft. Wiederholt man hingegen den Test, so ist eine Vergröβerung der Wahrscheinlichkeit möglich [Wikipedia: Monte-Carlo-Algorithmus].
Der Rabin-Miller-Test ist wie der Solovay-Strassen-Test ein Monte-Carlo-Algorithmus.
3.7 Beispiel
Nun folgt ein kleines Beispiel, wie man mit dem eben vorgestellten Verschlüsselungsverfahren eine Nachricht verschlüsseln und entschlüsseln kann.
Primzahl p = 29 Primzahl q = 43
Somit wird n = pq berechnet: 9 ∙ 3 = 1
φ(n) = (p – 1)(q – 1) = 1176
Nun muss d gewählt werden, so das gilt ggT(d, φ(n)) = 1 d = 107
Der nächste Schritt berechnet das zu d inverse Element e:
x0 = φ(n) = 1176 a0 = 1 b0 = 0 1176 = 1 ∙ 11 + ∙ 1
x1 = d = 107 a1 = 0 b1 = 1 107 = ∙ 11 + 1 ∙ 1
x2 = x0 mod x1 = 106 a2 = 1 b2 = -10 106 = 1 ∙ 11 + −1 ∙ 1
x3 = x1 mod x2 = 1 a3 = -1 b3 = 11 1 = −1 ∙ 11 + 11 ∙ 1
Nun soll das Wort „Datenbanksystem“ verschlüsselt werden. Mit n = 1247 kann man zwei Buchstaben pro Block kodieren mit A = 00, B = 01 usw…:
0401 2005 1402 0114 1119 2619 2013
e = 11, sprich im binären System = 1011
Die Blöcke werden folgendermaβen verschlüsselt:

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
9
1 = 111 1 = 1 usw…
0401 2005 1402 0114 1119 2619 2013 0741 0469 0234 0098 0302 1242 0742
Die Entschlüsselung geht folgendermaβen: 1 = 11 7 1 = 1 usw…
0741 0469 0234 0098 0302 1242 0742 0401 2005 1402 0114 1119 2619 2013
3.8 Sicherheit des RSA-Verfahrens
Es konnten keine grundlegenden Schwachstellen gefunden werden, doch auch die Sicherheit ist nicht bewiesen. Die Sicherheit basiert darauf, dass eine Faktorisierung (sprich Primfaktorenzerlegung) von groβen Zahlen sehr schwer und aufwändig ist. Natürlich basiert die Sicherheit auch auf der Geheimhaltung der Werte p, q und (p – 1)(q – 1).
Ein Sicherheitsproblem bleibt jedoch bestehen. Die öffentlichen Schlüssel sind für jeden zugänglich. Werden die Primzahlen hingegen groβ genug gewählt, so ist es für einen Angreifer kaum möglich in akzeptabler Zeit die Berechnung des privaten Schlüssels aus dem öffentlichen Schlüssel durchzuführen.
3.9 Aktuell
Das RSA-Verfahren war in den USA patentiert. Inzwischen (seit dem 20.09.2000) ist das Patent abgelaufen. Bei speziellen RSA-Challenges wird versucht, speziell vorgegebene Zahlen zu faktorisieren. Hiermit wird herausgefunden, wie groβ die Schlüssellänge gewählt werden muss, damit das RSA-Verfahren noch als sicher gilt. Diese Challenge existiert seit 1991 und wurde 2007 beendet, als eine 1039-Bit-Zahl (312 Dezimalstellen) erfolgreich faktorisiert wurde. Inzwischen gibt es auch Verfahren, die die gleiche Sicherheit wie die eines RSA-Verfahrens aufweisen, aber mit deutlich geringerer Schlüssellänge auskommen. Die Grundlage solcher Verfahren ist die mathematische Theorie elliptischer Kurven, auf die ich hier nicht weiter eingehe. Es sei verwiesen auf [Hartlieb und Unger (2014, Kurseinheit 6)].

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
10
4 OPES
Order Preserving Encryption Scheme – zu Deutsch ordnungserhaltendes Verschlüsselungsschema wurde entwickelt, um auch die Bereichssuche in verschlüsselten Datenbanken effizient durchführen zu können. Angenommen eine Spalte einer Tabelle enthält verschlüsselte Informationen. Würden diese Informationen bei einer Abfrage (Query) mit einem Vergleichsoperator gebraucht, so bräuchte es bei den existierenden Verschlüsselungstechniken einen gesamten Tabellenscan, denn Datenbankindexe wie B-Bäume können nicht mehr dienen, da die Reihenfolge nicht beibehalten wurde. Dies verursacht erhebliche Leistungseinbuβen.
4.1 Grundlagen und Konzept
Die Grundidee von OPES ist als Input eine vom Benutzer bereitgestellte Zielverteilung zu nehmen und die Klartextwerte in solch einer Weise zu transformieren, dass die Transformation die Reihenfolge beibehält, während die transformierten Werte der Zielverteilung folgen [Agrawal et al. (2004)].
Es wird von einer Datenbank ausgegangen, die aus einzelnen Tabellen besteht, welche ihrerseits aus einer einzigen Spalte bestehen, wobei der Spaltenbereich als Teilmenge von Integer-Werten besteht. Die Klar- und Geheimtextwerte werden folgendermaβen dargestellt:
Klartextwerte (engl. plaintext): P = p1, p2, …, p|p|, pi < pi+1
Geheimtextwerte (engl. ciphertext): C = c1, c2, …, c|p|, ci < ci+1
OPES bietet die Möglichkeit Vergleichsoperatoren bei Abfragen anzuwenden, ohne damit „verknüpfte“ Werte vorher entschlüsseln zu müssen. Tabelle 1 stellt eine Auflistung dar, welche Operatoren anwendbar sind und welche eine Entschlüsselung benötigen.
Entschlüsselung nicht notwendig Entschlüsselung notwendig Gleichheit = SUM Bereich < > AVG MIN, MAX COUNT GROUP BY ORDER BY
Tabelle 1 – Operatoren mit und ohne Entschlüsselung
OPES bietet den Vorteil, dass es sehr einfach in bereits existierende Datenbanksysteme integriert werden kann und dort somit auch die Indexstrukturen beibehalten werden können. Wird ein Wert einer Spalte verändert oder gar ein neuer eingeführt, so kann diese Änderung vorgenommen werden, ohne dass Änderungen in der Verschlüsselung von anderen Daten notwendig sind. Die erhaltenen Resultate von Abfrageprozessen, welche mit OPES verschlüsselt wurden sind sehr genau.
Anfällig für Angriffe ist vor allem das Speicherungssystem der Datenbanksoftware. Ein Angriff kann im Extremfall physisch geschehen, indem das Speichermedium entfernt wird, hingegen

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
11
ist auch ein virtueller Angriff möglich. Der Angreifer kann sich Zugang zu Datenbankdateien verschaffen in dem er den Pfad der Datenbanksoftware umgeht.
Als Voraussetzung dieser Ausarbeitung wird der Datenbanksoftware vertraut um Abfragekonstanten zu verschlüsseln und umgekehrt Abfrageresultate wieder zu entschlüsseln. Ein Gegner kann hingegen keinen Zugang zu Werten des Hauptspeichers einer Datenbanksoftware erlangen. Speicherresidente Daten gelten immer als verschlüsselt.
Im folgenden Abschnitt wird der dazugehörende Algorithmus kurz erläutert:
Von einer benutzerspezifischen Zielverteilung werden zuerst |P| eindeutige Werte generiert und anschliessend in der Tabelle T sortiert. ci = T[i] stellen die verschlüsselten Werte ci von pi dar. Dieser Wert entspricht also dem i-ten Klartextwert in der sortierten Liste von |P| Klartextwerten, welcher verschlüsselt wird in den i-ten Wert der sortierten Liste von |P| Werten, welche von der Zielverteilung vorgegeben wurden. Hier entspricht T dem Verschlüsselungsschüssel, welcher natürlich geheim gehalten werden muss.
Vorteile:
Da die verschlüsselten Werte nur durch die benutzerspezifische Zielverteilung, aber ohne Gebrauch von Informationen der Originalverteilung generiert wurden, werden keine Informationen über die Originalwerte ausser der Reihenfolge preisgegeben. Dies gibt die Sicherheit, dass auch wenn ein Gegner alle verschlüsselten Werte kennt, er trotzdem nicht auf T schliessen kann.
Nachteile:
Trotz aller Vorteile kommen auch Schwächen zum Vorschein. Zum einen ist die Gröβe der Verschlüsselungsschlüssel doppelt so groβ wie die Anzahl der einzelnen Werte der Datenbank. Zum anderen sind Updates nicht ganz unproblematisch. Möchte man einen neuen Wert p hinzufügen, wobei pi < p < pi+1 gilt, so müssen auch alle pj, j > i neu verschlüsselt werden.
4.1.1 Phasen
Vorgehen bei der Verschlüsselung einer gegebenen Datenbank P:
Gegeben sei eine Datenbank P mit Klartextwerten, welche verschlüsselt werden soll. Am Ende wird nur die verschlüsselte Datenbank C auf der Festplatte gespeichert. Damit OPES die Verschlüsselung vornehmen kann, werden alle Klartextwerte benötigt, welche P repräsentieren, sowie eine Datenbank mit Musterwerten der Zielverteilung. Im Zuge der Verschlüsselung wird gleich eine Zusatz-/Hilfsinformation K kreiert, welche dann dem Datenbanksystem der Verschlüsselung von neuen Werten, sowie der Entschlüsselung von kodierten Werten dient. Wie T im letzten Abschnitt, übernimmt hier K die Funktion des geheimen Verschlüsselungsschlüssels.
In [Agrawal et al. (2004, 3.2)] wurde der Arbeitsprozess von OPES in drei Phasen vorgestellt, welche in den Unterkapitel 4.2-4.4 genauer unter die Lupe genommen werden:
1. Model: In der ersten Phase werden der Input sowie die Zielverteilung als stückweis-lineare „Splines“ modelliert.

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
12
2. Flatten: Danach wird die Klartextdatenbank P in eine flache Datenbank3 F transformiert, so dass die Werte in F gleichmässig verteilt werden.
3. Transform: Im letzten Schritt wird die Flat-Datenbank F in eine verschlüsselte (Cipher-) Datenbank C transformiert, so dass die Werte in C gemäss der Zielverteilung verteilt werden. Es gelte im Allgemeinen: pi < pj → fi < fj → ci < cj
4.2 Model
Die Techniken für die Modellierung der Datenverteilung kann grob in drei Kategorien [König und Weikum (1999, S. 425)] aufgeteilt werden.
Die Histogramm-basierte Technik: Histogramme ist die am häufigsten gebrauchte Form für Datensynopsis in der Anwendung und findet vor allem in DB2, Oracle, Microsoft SQL Server und anderen seine Anwendung. Die Werteverteilung bei Histogrammen geschieht durch Annäherung der Gruppierung von Attributwerten in Buckets, sowie der Abschätzung der richtigen Attributwerte. Die Häufigkeit basiert auf der Annahme der gleichmäβigen Verteilung in die Buckets.
Die parametrische Technik: Bei der parametrischen Technik erfolgt die Werteverteilung durch Annäherung und unter Berücksichtigung einer limitierten Anzahl von freien Parametern mit Hilfe einer mathematischen Verteilfunktion. Die Werte für diese Parameter werden so ausgesucht, dass sie zur aktuellen Verteilung passen. Wenn das Modell dann eine passende Verteilung aufweist, ergibt dies eine genaue und kompakte Annäherung.
Die Sampling-Technik: Die Sampling-Technik berechnet ihre Schätzungen durch das Sammeln und Verarbeiten der Zufallsproben von Daten. Eine hohe Genauigkeit und Wahrscheinlichkeit garantieren die Qualität der Schätzung.
Im Folgenden wird von einer Kombination einer Histogramm-basierten, sowie parametrischen Technik ausgegangen. Hierbei werden zuerst die Datenwerte in Buckets verteilt, danach folgt die Modellierung der Verteilung innerhalb jedes Buckets als lineare „Spline“. Unter der Spline versteht man die Linie, die die Dichte von den zwei Endpunkten eines Buckets verbindet. Für die Bestimmung der Anzahl Buckets wird das Minimum Description Length (MDL) Prinzip verwendet, welches von J. Rissanen in [Rissanen (1983)] und [Grünwald (1998)] detailliert beschrieben wird.
Die Bucket-Grenzen werden durch zwei Phasen bestimmt – die Wachstumsphase und die Reduzierungsphase.
3 Eine flache Datenbank bezeichnet eine Datenbank, welche keine komplexen Beziehungen zwischen Entitäten machen kann, wie es relationale Datenbanken haben. Solche flache Datenbanken werden nur für kleine einfache Datenbanken benutzt, wie eine Kontaktliste eines Handys.

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
13
4.2.1 Growth Phase - Wachstumsphase
In der Wachstumsphase ist der Raum rekursiv in feinere Partitionen gesplittet. Jede weitere Partitionierung eines Buckets reduziert die Maximalabweichung der Dichtefunktion innerhalb der neugeformten Buckets im Vergleich zu ihren Elternbuckets.
Gegeben sei ein Bucket [pl, ph) mit h – l – 1 sortierten Punkten pl+1, pl+2,…, ph-1. Festgelegt wird zudem eine Grenze der Anzahl Punkte für die Beendigung der Bucketteilung.
Vorgehen:
1. Eine lineare Spline ist für den gegebenen Bucket zu finden. 2. Für jeden Punkt ps im Bucket ist seinen Erwartungswert zu berechnen, falls die Punkte
gemäβ der durch die lineare Spline modellierte Dichtenverteilung verteilt wurden. 3. Der Bucket wird an dem Punkt gesplittet, welcher die gröβte Abweichung vom
Erwartungswert hat. 4. Die Teilung der Buckets wird dann beendet, wenn die Anzahl von Punkten kleiner als
die vorher festgelegte Grenze ist.
4.2.2 Prune Phase – Reduzierungsphase/Verschmelzung
In der Reduzierungsphase werden einige Buckets reduziert, sprich in gröβere Buckets verschmolzen. Die Idee dahinter ist, die Anzahl der Buckets zu verkleinern, aber gleichzeitig die Werte innerhalb der Buckets nach dem Abbilden gleichmässig verteilt zu haben. Um diese Balance zu erreichen wird wiederum das Minimum Description Length Prinzip von J. Rissanen gebraucht.
Um die Berechnung von lokalen und globalen Vorteilen (benefits) zu verstehen, müssen die Begriffe DataCost und IncrModelCost geklärt werden:
DataCost(p1, p2) = Kosten für die Beschreibung der Daten im Intervall [p1, p2) IncrModelCost = Zunahme der Modellierungskosten wegen der Partitionierung von
einem Bucket in zwei
Für die Reduzierungsphase benötigt man die Berechnung des lokalen, sowie globalen Vorteils.
Als LB wird der lokale Vorteil bezeichnet (engl. local benefit). Er wird bei der Teilung eines Buckets am Punkt ps wie folgt berechnet:
LB(pl, ph) = DataCosdt(pl, ph) – DataCost(pl, ps) – DataCost(ps, ph) – IncrModelCost
Weiter wird der globale Vorteil (GB) berechnet, der bei der Teilung eines Buckets am Punkt ps entsteht und weitere Vorteile von zukünftigen rekursiven Teilungen ermöglicht.
GB(pl, ph) = LB(pl, ph) + GB(pl, ps)+GB(ps, ph)
Ist GB > 0, so wird die Teilung beibehalten und die Buckets werden nicht verschmolzen. In allen anderen Fällen wird die Teilung bei ps und alle anderen Teilungen in [pl, ph) reduziert/verschmolzen. Die Berechnungen erfolgen bottom up, sprich von unten nach oben. Dies induziert lineare Kosten zur Anzahl Teilungen.
Der Grund für die getrennte Behandlung (und nicht der Beendigung der Bucketteilung wenn LB ≤ ) der Wachstums- und Reduzierungsphase liegt darin, dass der Vorteil der Partitionierung erst bei einer feingliedrigen Granularität zum Vorschein kommt und es oft

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
14
vorkommt, dass der lokale Vorteil kleiner Null ist, auch wenn der globale Vorteil weit gröβer als null ist.
4.3 Flatten
In der Flatten-Etappe geht es darum den Klartextbucket B in einen Bucket Bf im abgeflachten Raum so abzubilden, dass die Länge von Bf proportional zur Anzahl Werte in B ist. Dies bewirkt eine Streckung der dichten Klartextbuckets und eine Komprimierung der dünnen Buckets.
Die erste Phase, der Modellierungsphase erbrachte einen Satz von Buckets B1, …, Bm. Für jeden dieser Buckets existiert eine Abbildungsfunktion M, welche durch zwei Parameter charakterisiert wird, einerseits durch den quadratischen Koeffizienten s, andererseits durch den Skalierungsfaktor z. In die Datenstruktur Kf wird wie oben geschrieben, m+1 Bucketgrenzen, m quadratische Koeffizienten und m Skalierungsfaktoren gespeichert. Diese Datenstruktur wird gebraucht um die neuen Klartextwerte zu verflachen (verschlüsseln) und sie allenfalls wieder zu „entflachen“ (entschlüsseln). Dementsprechend nimmt Kf die Funktion des Verschlüsselungsschlüssels ein. Dieser Verschlüsselungsschlüssel wird nur zum Zeitpunkt der initialen Verschlüsselung der Datenbank berechnet und wird danach nicht mehr erneuert, auch nicht, wenn der Datenbank neue Werte übergeben werden. Dies ermöglicht die stufenweise Updatemöglichkeit, die OPES auszeichnet.
Möchte man einen Klartextwert p abflachen, so muss zuerst ein Bucket Bi bestimmt werden, in welchen p fällt. Dies geschieht mit Hilfe der Bucketgrenzen, welche in Kf gespeichert sind. Ist aus dem Flattextwert wieder den Klartextwert herzustellen, so braucht man die Informationen, welche in Kf gespeichert sind, um den flache Bucket Bf
i zu bestimmen, welches angibt, wo der Flatwert f liegt. Auf ihn kann dann die inverse Abbildungsfunktion4 M-1 angewendet werden.
4.4 Transform
Die Transformationsphase spielt sich ähnlich ab, wie die Flatten-Phase. Ist ein gleichmässig verteilter Satz von Flat-Werten gegeben, so ist das Ziel, ihn in eine Zielverteilung abzubilden.
4 −1 = − ± √2+4 wobei z dem Skalierungsfaktor und s dem quadratischen Koeffizienten entspricht
[Agrawal et al. 2004, Punkt 5.5]
Abbildung 3 – Zielverteilung, Schritte 1-3 [Agrawal et al. (2004)]

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
15
1. Als Erstes erfolgt die Berechnung der Buckets, welche für die Transformation der Klartextverteilung in die abgeflachte Verteilung benötigt werden.
2. Die Bucketverteilung in der Zielverteilung wird unabhängig von der Bucketverteilung der Klartextverteilung vorgenommen. Aus der Zielverteilung werden die Buckets für
die abgeflachte Verteilung berechnet. 3. Dann wird die Zielverteilung, sowie die abgeflachte Zielverteilung so skaliert, dass die
Breite der gleichmässigen Verteilung, welche durch Abflachung der skalierten Zielverteilung generiert wurde, gleich der Breite der gleichmässigen Verteilung ist, welche durch Abflachung der Klartextverteilung generiert wurde (Schritt 1).
Durch die Modellierung der Zielverteilung wird ein Satz von Buckets Bt1, …, Bt
k erzeugt. Für jeden Bucket Bt der Länge wt, wird zudem die Abbildungsfunktion Mt und die damit assoziierten Parameter – der quadratische Koeffizient st und der Skalierungsfaktor zt erschaffen.
Die Gröβe des Verschlüsselungsschlüssels K ist abhängig von der Anzahl Buckets, welche für die Partitionierung und Verteilung gebraucht werden. Die gröβte Gröβe liegt bei ca. dreimal der Anzahl von Buckets.
5 Fazit
In dieser Ausarbeitung wurden nach einer kurzen Einführung und Erläuterung der Verschlüsselung die Verschlüsselungsverfahren RSA und OPES behandelt.
Ein Verschlüsselungsverfahren gilt so lange als sicher, bis es gebrochen wurde. Das RSA-Verschlüsselungsverfahren zu knacken ist mindestens so schwierig wie die Faktorisierung von n. Die bekannten Faktorisierungsalgorithmen stammen von Fermat und Legendre. Bis jetzt wurde aber noch kein Algorithmus gefunden, der eine 200-stellige Zahl in einer vernünftigen Zeit faktorisieren kann. Sobald hingegen ein Algorithmus für die Faktorisierung einer x-stelligen Zahl herausgefunden wird, gilt das RSA-Verfahren vermutlich nicht mehr als sicher, denn die Sicherheit des RSA-Verfahrens basiert auf der Schwierigkeit der Faktorisierung von groβen Zahlen.
OPES erlaubt den Gebrauch von Datenbankindizes wie B-Bäume zur Beantwortung von Query-Anfragen mit Vergleichsoperatoren welche direkt an der verschlüsselten numerischen Spalte angewendet werden können. Auch können neue Werte hinzugefügt oder alte Werte verändert werden, ohne eine Änderung in der Verschlüsselung der anderen Werte vornehmen zu müssen. OPES bezieht sich bis jetzt nur auf numerische Daten, was in Zukunft auch auf nicht-numerische Daten mit variabler String-Länge ausgeweitet werden soll.

Sicherheit und Privatsphäre in Datenbanksystemen - Thema 2: Verschlüsselung
16
6 Literaturverzeichnis
Agrawal, Rakesh; Kiernan, Jerry; Srikant, Ramakrishnan; Xu, Yirong (2004): Order Preserving Encryption for Numeric Data.
Eckert, Claudia (2012): IT-Sicherheit. Konzepte, Verfahren, Protokolle. 7., überarb. und erw. Aufl. München: Oldenbourg.
Grünwald, Peter (1998): Introducing the Minimum Description Length Principle.
Hartlieb, Silke; Unger, Luise (2014): Mathematische Grundlagen der Kryptografie: FernUniversität in Hagen.
König, Arnd Christian; Weikum, Gerhard (1999): Combining Histograms and Parametric Curve Fitting for Feedback-Driven Query Result-Size Estimation. In Proc. of the 25th Int'l Conference on Very Large Databases. Edinburgh, Scottland, S. 423–434.
Rissanen, Jorma (1983): A Universal Prior for Integers and Estimations by Minimum Description Length. In: The Annals of Statistics, Institut of Mathematical Statistics (Vol. 11, No. 2), S. 416–431.
Rivest, R. L.; Shamir, A.; Adleman L. (1978): A Method for Obaining Digital Signatures and Public Key Cryptosystems.
Schlageter, Gunter (2013): Datenbanksysteme / Datenbanken I: FernUniversität in Hagen.
Schlageter, Gunter; Wilkes, Wolfgang; Balzer, Michael (2013): Datenbanksysteme / Datenbanken II. Fortgeschrittene Konzepte und Realisierungsaspekte: FernUniversität in Hagen.
Schneier, Bruce (1996): Applied cryptography. Protocols, algorithms, and source code in C. 2nd ed. New York: Wiley.
Stinson, Douglas R. (1995): Cryptography. Theory and practice. Boca Raton: CRC Press (The CRC Press series on discrete mathematics and its applications).
Wikipedia: Monte-Carlo-Algorithmus. Online verfügbar unter http://de.wikipedia.org/wiki/Monte-Carlo-Algorithmus, zuletzt geprüft am 04.01.2015.
Wohlfeil, Stefan (2013): Sicherheit im Internet: FernUniversität in Hagen.

SSeminar
SEM INARABEIT-
„ PRIVATSPHÄRE M ESSEN“ Seminar 1912/ 19912 Sicherheit und Privatsphäre in
Datenbanksystemen, WS 2014/ 2015, Fernuniversität Hagen
Von Thomas Kontny

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
1
INHALT
I.) Einleitung: .................................................................................................................................................... 2
II.) M ulti-Level-Datenbanken / / M ultiple Queries ....................................................................................... 4
III.) Definition des M odells der „k-Anonymität“ sowie Sch wächen des M odells ......................................... 5
1.) Definit ion des M odells ............................................................................................................................ 5
2.) Definit ion QI ............................................................................................................................................ 5
3.) Das k-Anonymitätsmodell: ..................................................................................................................... 6
4.) Schwachstellen und At tackenpotent ial des M odells ............................................................................ 7
IV.) Definition/ Vorgehensweise der Generalisierungs-und Anonymisierungstechniken für Tabellen mit
privaten Attributen .............................................................................................................................................. 9
V.) Definition und Erklärung der Bayes-optimalen Privat sphäre ............................................................... 10
1.) Theorem 1: ............................................................................................................................................ 11
2.) Grenzen der Bayes-opt imalen Privatsphäre........................................................................................ 12
VI.) l-Diversität: Eine praktikable Privatsphären Defini tion ........................................................................ 13
1.) Das l-Diversitätsprinzip ......................................................................................................................... 13
2.) Diversitätsprinzip 2: .............................................................................................................................. 15
Fazit: ................................................................................................................................................................. 18

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
2
I . ) EINLEITUN G:
Die folgende Ausarbeitung beschäftigt sich mit dem Thema „Privatsphäre messen“.
Grundsätzlich ist die Frage zu stellen, warum überhaupt personenbezogene und private Daten veröffentlich werden müssen. Ein grundsätzliches Verbot von Veröffentlichung sensibler Daten, würde dieses Problem anscheinend lösen.
Das erste Problem besteht darin festzustellen, welche Daten privat, vertraulich beziehungsweise sicherheitskritisch sind. Aus der Sicht des Datenhalters können Daten völlig unkritisch sein, jedoch aus der Sicht des Betroffenen (Person, Gruppe, Nation) könnten diese Daten schützenswert sein. Da es in der Regel keine direkte Kommunikation zwischen dem Datenhalter und den weiterführenden Verarbeitern gibt, muss der Datenhalter nach eigenem Ermessen die Entscheidung fällen, welche Daten veröffentlicht werden.
Das andere Problem des Datenhalters liegt darin noch genug Information in den Daten zu belassen, dass diese überhaupt noch interessant für andere sind. Wenn zu viele sensible Informationen entfernt werden, kann die Datei/Tabelle/Datenbank unbrauchbar sein. Aufgrund dieses Qualitätsverlustes werden weitere Statistiken und Auswertungen zwecklos. Falls er kritische Daten veröffentlichen sollte, könnte er die Privatsphäre eines Einzelnen oder die Sicherheit Mehrerer gefährden.1
Eine gängige Praxis für Organisationen liegt darin, für eingehende und ausgehende personenspezifische Daten alle offensichtlichen identifizierenden Attribute („Identifier“) wie Name, Adresse und Telefonnummer zu entfernen. Dies geschieht auf der Annahme, dass Anonymität dadurch erzielt wird, da die Daten anonym aussehen.2
Die übriggebliebene Datei kann jedoch durch Rückidentifizierung mittels Verbindung mit anderen Daten wieder personenbezogen hergestellt werden.
In einer Studie zum U.S. Zensus von 1990 wurde herausgefunden, dass 87% der U.S amerikanischen Bevölkerung (216 Mio. von 248 Mio.) eindeutig durch ihre Postleitzahl(5-stellig), Geschlecht und durch ihr Geburtsdatumzugeordnet werden können. Daten, die diese Attribute enthalten, können daher nicht als anonym bezeichnet werden. Leider werden gerade gesundheitsspezifische Daten in dieser Form häufig veröffentlicht.3
1 Sweeney, Latanya (2002): k-Anonymity: A model for protect ing privacy, Internat ional Journal on Uncertainty, Fuzziness and Knowledge-based systems, S.1. 2 Vgl. ebd., S.2. 3 Vgl. ebd., S.2-3.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
3
Beispiel: GIC Datenbank in Verbindung mit Wählerlisten
Im US-Bundesstaat Massachusetts ist die GROUP INSURANCE COMISSION (GIC) dafür verantwortlich, Krankenversicherungen für Staatsdiener zu erwerben. Zu diesem Zwecke sammelt die GIC patientenspezifische Daten mit annähernd hundert Attributen pro Betroffenen. Dies betrifft circa 130.000 Staatsdiener und ihre Familien, die ebenfalls krankenversichert werden. Da man glaubte, dass diese Daten Anonymität garantieren, wurden Kopien an die Forschung und die Wirtschaft gegeben.
Diese Datei in Verbindung mit der frei verfügbaren Wählerliste von Cambridge Massachusetts, die die Attribute Name; Adresse; Postleitzahl; Geburtsdatumund Geschlecht enthält, kann über die Attribute Postleitzahl, Geburtsdatum sowie Geschlecht verbunden werden. Siehe Abbildung 1.
ABBILDUNG 1
Über diese Verlinkung konnten bestimme Einzelpersonen lokalisiert werden und ihre jeweilige Krankengeschichte, Diagnosen, Medikationen und Heilpläne offenbart werden.
Somit sind hochsensible und private Daten von über 130.000 Menschen in öffentliche Hand geraten.
Als berühmtes Beispiel kann der Gouverneur William Weld genannt werden, dessen Daten ebenfalls in der GIC Datenbank enthalten waren. Er lebt in Cambridge Massachusetts. Laut Wählerliste haben nur 6 Personen sein Geburtsdatum, nur 3 waren männlich und er war der einzige in seinem Postleitzahlengebiet.
Das Beispiel zeigt, wie einfach eine Identifizierung durch mehrere angeblich nicht-identifizierende Attribute möglich ist. Je mehr Personen mit den gleichen Daten in der Datenbank inbegriffen sind, desto schwieriger wird eine Zuordnung. Die Angabe des genauen Geburtsdatums ist natürlich sehr einschränkend, es bleibt zu fragen, ob

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
4
nicht die Angabe des Geburtsjahres bei einer Veröffentlichung der Daten ausreichen würde und die Weiterverwertbarkeit trotzdem nicht maßgeblich einschränkt.4
I I . ) M ULTI -LEVEL-DATENBANKEN / / M ULTIPLE QUERIES
In sogenannte Multi-Level-Datenbanken (MDB –„Multilevel relational database system“) versucht man durch unterschiedliche Sicherheitsniveaus die Daten in unterschiedliche Sicherheitsklassen einzugruppieren und nur den jeweils angemessenen Empfängern freizuschalten. So möchte man garantieren, dass keine sicherheitskritischen Daten an den falschen Adressaten veröffentlicht werden.
Durch Unterdrückung der sensiblen Daten werden alle personenbezogenen sowie rückschlussermöglichenden Daten einfach nicht veröffentlicht. Leider kann dies schlagartig zu Verschlechterung der Datenqualität sowie der Weiterverwendbarkeit für Statistiken und Analysen führen. Die große Herausforderung des Datenhalters liegt darin, so qualitativ hochwertige Daten wie möglich zu liefern, ohne dabei die Anonymität der Einzelnen zu gefährden und diese zu offenbaren.
Die große Schwierigkeit liegt darin, dass es keine messbare Einheit für Privatsphäre gibt, es liegt im Ermessen des Datenhalters was schützenswert ist und was der Öffentlichkeit zugänglich gemacht werden soll. Zumal der Datenhalter auch nicht jeden eventuellen Angriff abschätzen kann, da er nicht o. E. weiß, welche Daten sonst bereits in öffentlicher Hand sind mittels derer eine genaue Zuordnung möglich wäre.
Ebenfalls ist die Verjährung der Daten individuell einschätzbar, wie alt dürfen private Daten sein, damit sie problemlos veröffentlicht werden können?
Da dies nicht eindeutig zu klären ist, sind MDBs kein probates Mittel, um die Privatsphäre zu schützen.
Ähnlich ist die Vorgehensweise bei Mehrfachabfragen aus Datenbanken, die über Assoziation private Informationen offenbaren könnten. Eine Relation R(Arzt, Patient, Medikation) ist unsensibel solange nur die Verbindung „Arzt – Patient“ oder „Arzt-Medikation“ abgefragt wird. Jedoch eine Abfrage „Patient – Medikation“ ist sehr sensibel, da man aufgrund der Medikation leicht auf die zu behandelnde Krankheit schließen kann.
Daher werden sogenannte Abfrage-Restriktionen eingeführt, die bestimmte sensible Abfragemöglichkeiten unterdrücken.
Da es aber aufgrund des immensen Anstiegs an personenrelevanten Daten kaum mehr zu überblicken ist, welche Abfragen über welche Daten Rückschlüsse auf
4 Vgl. ebd., S.2-3.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
5
private, sensible Daten zulassen, ist dies auch kein probates Mittel, um die Privatsphäre zu schützen.5
Die zu Verfügung gestellten Daten sollten daher schon im Vorhinein soweit ausreichend anonymisiert werden, dass auch Mehrfachabfragen keine privaten Daten offenbaren.
I I I . ) DEFIN ITION DES M ODELLS DER „K-ANONYM ITÄT“ SOW IE
SCHW ÄCHEN DES M ODELLS
1.) DEFINITION DES M ODELLS:
Definition 1:
Sei B(A1,..,An) eine Tabelle mit einer endlichen Anzahl von Datensätzen (Tupel). Der gesamte Satz an Attributen von B sei A1,.,An.
Die endgültige zu veröffentlichende Tabelle muss so aufgebaut und anonymisiert sein, dass es nicht möglich ist, durch Hinzuziehen von anderen Datenquellen personenspezifische Informationen zu offenbaren und diese genau einer Person zuzuordnen.
Der Datenhalter muss alle risikoreichen Attribute Ai lokalisieren, die zu einem Rückschluss auf bestimmte Personen benutzt werden könnten. Hierzu gehören nicht nur die offensichtlichen Attribute wie Name, Adresse oder Telefonnummer, sondern auch diese, die in Kombination mit externen Datenquellen als indirekte Identifikationsattribute fungieren können (Geburtsdatum oder Geschlecht). Diese nennen wir „Quasi-Identifizierer“ (kurz: QI).6
2.) DEFINITION QI
Definition 2:
Bezogen auf das vorgestellte Beispiel mit der Wählerliste und der GIC Datei sind die Attribute GebDatum, PLZ, Geschlecht Quasi-Identifizierer.7
Generell: Attribute, die in privaten Datenbanken sowie in öffentlichen Datenbanken erscheinen, sind Kandidaten für QI.
Da es nicht immer eindeutig ist (wie im obigen Fall) welche Attribute als QI benutzt werden können, da der Datenhalter keine vollständige Kenntnis über die vorhandenen externen Daten hat und über deren Verlinkungsmöglichkeiten, ist es
5 Vgl. ebd., S.4-5. 6 Vgl. ebd., S.6. 7 Vgl. ebd., S.7.
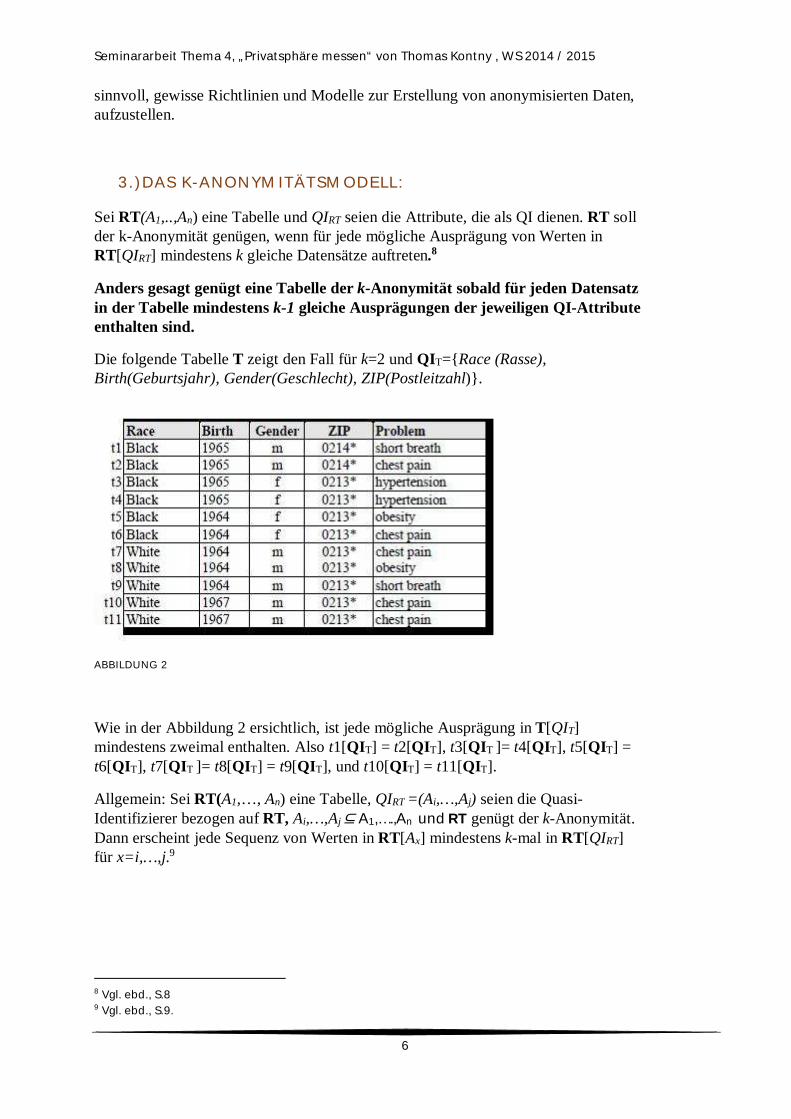
Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
6
sinnvoll, gewisse Richtlinien und Modelle zur Erstellung von anonymisierten Daten, aufzustellen.
3.) DAS K-ANONYM ITÄTSM ODELL:
Sei RT(A1,..,An) eine Tabelle und QIRT seien die Attribute, die als QI dienen. RT soll der k-Anonymität genügen, wenn für jede mögliche Ausprägung von Werten in RT[QIRT] mindestens k gleiche Datensätze auftreten.8
Anders gesagt genügt eine Tabelle der k-Anonymität sobald für jeden Datensatz in der Tabelle mindestens k-1 gleiche Ausprägungen der jeweiligen QI-Attribute enthalten sind.
Die folgende Tabelle T zeigt den Fall für k=2 und QIT=Race (Rasse), Birth(Geburtsjahr), Gender(Geschlecht), ZIP(Postleitzahl).
ABBILDUNG 2
Wie in der Abbildung 2 ersichtlich, ist jede mögliche Ausprägung in T[QIT] mindestens zweimal enthalten. Also t1[QIT] = t2[QIT], t3[QIT ]= t4[QIT], t5[QIT] = t6[QIT], t7[QIT ]= t8[QIT] = t9[QIT], und t10[QIT] = t11[QIT].
Allgemein: Sei RT(A1,…, An) eine Tabelle, QIRT =(Ai,…,Aj) seien die Quasi-Identifizierer bezogen auf RT, Ai,…,Aj ⊆ A1,….,An und RT genügt der k-Anonymität. Dann erscheint jede Sequenz von Werten in RT[Ax] mindestens k-mal in RT[QIRT] für x=i,…,j.9
8 Vgl. ebd., S.8 9 Vgl. ebd., S.9.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
7
4.) SCHW ACHSTELLEN UND ATTACKENPOTENTIAL DES
M ODELLS
a) Unsorted matching attack
Die Schwachstelle auf der die Attacke basiert, ist die Reihenfolge wie die Tupel in der Tabelle organisiert sind. Häufig werden Tabellen nach den jeweiligen Attributen aufsteigend sortiert. Ändert man nun diese Reihenfolge bei der Veröffentlichung der anonymisierten Tabelle nicht und veröffentlich dazu noch eine zweite, die ebenfalls auf der gleichen Ausgangstabelle basiert, kann man diese leicht wieder zusammenfügen, da die Sortierreihenfolge die gleiche ist.10
Lösung: Die veröffentlichten Tabellen sollten zufällig sortiert sein.
Beispiel:
Wie in Abbildung 3 ersichtlich, wurden aus der Ausgangstabelle PT mit den QI=Race,ZIP zwei anonymisierte Tabellen GT1 und GT2 erstellt, die jeweils k=2 genügen. Da die Positionen der Tupel jedoch nicht verändert wurden, kann man diese leicht wieder tabellenübergreifend zusammenfügen und hat die Ausgangstabelle wieder hergestellt.
ABBILDUNG 3
b) Complementary release attack
Da nicht immer alle veröffentlichten Attribute auch QI sein müssen, kann es sein, dass durch unterschiedliche Veröffentlichungen von Untermengen der Basisdatei unterschiedliche Anonymisierungen stattfinden, die jeweils der k-Anonymität entsprechen, jedoch beim Zusammensetzen der jeweiligen veröffentlichten Tabellen über ein anscheinend nicht QI -Attribut die k-Anonymität wieder aufheben. Daher
10 Vgl. ebd., S.10.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
8
müssen alle möglichen Attribute geprüft werden, ob auf diesen eine Verlinkung möglich ist und falls ja, müssen diese als QI deklariert werden.11
c) Temporal Attack
Ähnlich zu b) ist das Problem der zeitlich bedingten Attacke. Da Dateien laufend geändert werden, also Datensätze ergänzt, gelöscht und verändert werden, kann es im zeitlichen Verlauf dazu kommen, dass verschiedene Versionen von veröffentlichten Dateien im Umlauf sind. Diese können ebenfalls wieder für sich k-anonym sein, jedoch in der Verlinkung sensible Daten offenbaren, da über ein Nicht-QI -Attribut verlinkt werden kann, das einzigartig sein könnte.12
Lösung: Daher sollten alle Attribute in die Anonymitätsbetrachtung mit einbezogen werden.
d) Homogenity Attack
Einen anderen Ansatz wählt die Homogenitätsattacke. Falls in der anonymisierten Tabelle das sensible Attribut zu wenige verschiedene Ausprägungen inne hat, und der Parameter k zu klein gewählt wird, besteht eine relativ hohe Wahrscheinlichkeit, dass alle Ausprägungen des sensiblen Attributs gleich sind und keine Anonymisierung stattfindet.
Beispiel: Sei eine Tabelle T mit 60.000 unterschiedlichen Datensätzen enthalten, das sensible Attribut hat in der gesamten Tabelle 3 verschiedene Ausprägungen und ist nicht mit den nicht-sensiblen Attributen verbunden. Wir wählen k = 5, so dass (60.000 / 5) = 12.000 Gruppen entstehen. Da die Wahrscheinlichkeit, dass alle 5
Ausprägungen gleich sind, bei ( ) liegt (=1,23%), kommt es bei insgesamt 148
Gruppen dazu. Das würde bedeuten, dass die privaten Informationen von 740 Personen ungeschützt sind. 13
e) Background Knowledge Attack
Es besteht die Möglichkeit noch zusätzliche Hintergrundinformation zu den vorhandenen hinzuzuziehen aus statistischen Datenbanken, die beispielsweise Wahrscheinlichkeiten von Erkrankungen nach ethnischer Zugehörigkeit, Alter, Berufsgruppe, Jahrgang o.ä. angeben. So kann man über das Ausschlussverfahren,
11 Vgl. ebd., S.11. 12 Vgl. ebd., S.12. 13 M achanavajjhala,A., u.a.(2005): l-diversity: Privacy beyond k-anonymity, ht tp:/ / www.cs.cornell.edu/ ∼mvnak, S2.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
9
die vorhandene Vielfalt der Attributausprägungen des sensiblen Attributs reduzieren und so eventuell eindeutige Zuordnungen herstellen.14
FAZIT: Das Modell der k-Anonymität ist nicht ohne Einschränkung ausreichend, um die eindeutige Zuordnung von sensiblen Attributen zu bestimmten Personen zu verhindern. Eine gewisse Vielfalt von Ausprägungen der sensiblen Attribute ist zusätzlich notwendig.
IV.) DEFIN ITION/ VORGEHEN SW EISE DER GENERALISIERU NGS-U ND
AN ONYM ISIERUNGSTECHN IKEN FÜR TABELLEN M IT PRIVATEN
ATTRIBUTEN
Definition 3: Block-Generalisierung/Anonymisierung:
Ein Block D* = P1,P2,…, ist eine Generalisierung/Anonymsierung des Blocks D wenn ⋃ = D und Pi ∩Pj = ∅ so lange i ≠j. Gegeben sei eine Tabelle T = t1,…,tn mit einer Menge von nicht-sensiblen Attributen N und eine Generalisierung D*N des Bereichs (N), wir konstruieren nun eine Tabelle T* = t1*,….,tn* durch Ersetzung der Werte von ti[N] mit dem anonymisierten Wert DN*( ti[N]), um einen neuen Datensatz (Tupel) ti* zu erhalten.
Das Tupel ti* nennt sich Generalisierung von Tupel ti. Wir benutzen die Notation ti ∗→ti* dass
„ ti* generalisiert/anonymisiert ti“.Ausgeweitet auf die Tabellen bedeutet T T*, dass „T* ist eine Generalisierung von T“.
Typischerweise werden sortierbare Attribute in Intervalle aufgeteilt und kategorisierte Attribute werden in benutzerdefinierte Ebenen aufgeteilt wie z.B. Gemeinden in Städte, Städte zu Regionen und Regionen in Bundesländer.15
Beispiel:
Die Tabelle 1 in Abb.4 ist eine Generalisierung der Tabelle 2. Wir verallgemeinern die Spalte ZipCode (Postleitzahl), indem wir nur die ersten 3 oder 4 Stellen anzeigen. Die Postleitzahlen „1485*“ repräsentieren alle, die mit diesen 4 Stellen beginnen. Das Attribut Age(Alterwird in 3 unterschiedliche Gruppen aufgeteilt <30, zwischen 30 und 40 und >=40. Die Nationalität wird gar nicht angegeben, da hier eine Generalisierung wenig sinnvoll ist.
14 Vgl. ebd., S.2. 15 Vgl. ebd., S.3.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
10
TABELLE 1 (PATIENTENDATEI) TABELLE 2 (4-ANONYM PATIENTENDATEI)
V.) DEFIN ITION U ND ERKLÄRUN G DER BAYES-OPTIM ALEN
PRIVATSPHÄRE
In diesem Abschnitt stellen wir eine Vorstellung von Privatsphäre namens „Bayes-Optimale-Privatsphäre“ dar. Es bezieht die Problematik der Attacke mittels Hintergrundinformationen ein und benutzt die Wahrscheinlichkeitsverteilung über die Attribute sowie Bayesianische Rückschlusstechniken, um auf private Attribute zurückzuführen.
Der Einfachheit halber benutzen wir nur ein mehrdimensionales nichtsensibles Attribut Q für unsere Betrachtung, dessen Werte mittels Anonymisierung von der Grundtabelle T in die anonymisierte Tabelle T* überführt werden. Wir nehmen an, dass T eine einfacher, zufälliger Teilausschnitt einer größeren Population Ω ist. Zum anderen betrachten wir auch nur ein einziges privates Attribut S.
In Bezugnahme auf die Attacke mittels Hintergrundinformationen nehmen wir an, dass der Angreifer teilweise Wissen von sensiblen sowie nichtsensiblen Attributen hat. Im schlimmsten anzunehmenden Fall kennt er die vollständige Verteilung von Q und S, d.h. er kennt die Häufigkeit der jeweiligen Attribute in Ω. Der Angreifer versucht einen bestimmten Datensatz t ∊ T zu finden, der in T* zu einem Datensatz t* generalisiert wurde. Er kennt die nichtsensiblen Attribute des gesuchten Datensatzes t[Q] = q . Das Ziel ist es jetzt mittels des Hintergrundwissens den Wert des sensiblen Attributes t[S] = s herauszufinden.
Bevor er die veröffentlichte Tabelle T* geprüft hat, beruht seine Kenntnis ausschließlich auf seinem Hintergrundwissen bzw. Kenntnis von q und sein Wissen, dass die Information von s irgendwo in T* enthalten ist. Daher gilt folgende Formel:
α(q,s) = Pf (t[S] = s ∣ t[Q] = q)
Nachdem er nun die veröffentlichte Tabelle T* gesichtet hat, hat sich seine Ansicht geändert, da er nun gezielt aufgrund seiner bisherigen Informationen den Suchbereich einschränken kann und je nach Ausprägung der Tabelle das gesuchte Attribut s finden kann.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
11
Daher gilt folgende Formel:
β(q,s,T*) = Pf (t[S] = s ∣ t[Q] = q ∧∃t* ε T*, tt*)
Um nun eine neue Definition von Privatsphäre zu erstellen, müssen die Parameter f (Wahrscheinlichkeit des Attributs) und T* (generalisierte Tabelle von T) gegeben sein. In der nun folgenden Formel wird die bedingte Wahrscheinlichkeit benutzt P (A ∣ B), die die Anzahl der Datensätze als Basis hat die die Bedingung A ∧ B er füllt im Verhältnis zur Anzahl der Datensätze, die nur von Bedingung B er füllt werden.16
1.) THEOREM 1 :
Sei q ein Wer t eines nichtsensiblen Attr ibuts Q in der Grundtabelle T; sei q* ein generalisier ter Wer t von q in der veröffentlichten Tabelle T*; sei s ein möglicher Wer t des sensiblen Attributs; sei n(q*,s‘) die Anzahl der Datensätze t* ∈ T* mit t* [Q] = q und t* [S] = s‘; und sei f(s‘ ∣ q*) die bedingte Wahrscheinlichkeit des sensiblen Attributs s‘ unter der Bedingung, dass das nichtsensible Attribut q aus der Grundtabelle nach T* als q* generalisiert wurde.
( , , ∗) = ( ∗, ) ( ∣ )( ∣ ∗)∑ ( ∗, )∈ ( ∣ )
( ∣ ∗)
Der Bruch setzt die Anzahl der Datensätze eines bestimmten sensiblen Attributs s im Block q* (gewichtet mit der bedingten Wahrscheinlichkeit von s in der Ausgangsdatei q (Anteil Datensätze von s in Grunddatei) zur bedingten Wahrscheinlichkeit von s in q* (Anteil Datensätze von s im Block q*) mit der Summe der Anzahl aller möglichen Ausprägungen von s‘ im Block q*(gewichtet mit der bedingten Wahrscheinlichkeit aller jeweiligen s‘ zur Ausgangdatei q zur bedingten Wahrscheinlichkeit von s‘ im Block q*) ins Verhältnis.
Sind nun gewisse Hintergrundinformationen bei einem Adressaten/Angreifer vorhanden, kann es durch die Veröffentlichung von T* zu zwei kritischen Offenlegungen von privaten Informationen kommen:
Definition 4: (Positive Offenlegung)
Wenn der Adressat mit einer hohen Wahrscheinlichkeit den Wert eines sensiblen Attributs zuordnen kann, weil dieser in einer großen Anzahl n den gleichen Wert im Block q* annimmt und enthalten ist und somit auch die bedingten Wahrscheinlichkeit f ( s ∣ q*) sehr hoch ist, ist der Wert von β(q,s,T*) > 1 –δ (mit δ>0) und es existiert ein t ∈ T so dass t[Q] = q und t[S] = s. Der Bruch von β nimmt im Zähler also nur einen unwesentlich kleineren Wert als im Nenner an, da nur ein geringer Wert im Zähler für ein s‘ ≠ s hinzuaddiert wird. Je größer generell die Wahrscheinlichkeit von s in q bei gleichem f(s∣q*) , desto näher liegt der Wert für β nahe 1. Sprich kommt ein Attribut s sehr häufig in q sowie in q* vor, so nähert sich der Wert für β der 1 an und eine Offenlegung ist sehr wahrscheinlich.
16 Vgl. ebd., S.4.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
12
Definition 5: (Negative Offenlegung)
Wenn im Umkehrschluss der Adressat mit einer hohen Wahrscheinlichkeit einige mögliche Werte eines sensiblen Attributs ausschließen kann (aufgrund seines Hintergrundwissens) dann ergibt sich eine negative Offenlegung wenn β(q,s,T*) < ε (mit ε >0) und es existiert ein t ∈ T so dass t[Q] = q aber t[S] ≠ s. Der Adressat kann dann leicht mittels Ausschlußverfahren das richtige s‘ herausfinden, da er für alle Attribute s‘≠ s die Wahrscheinlichkeit f(s‘∣q) = 0 setzen kann und so nur noch die Ausprägung für s übrig bleibt.
Fazit: Die veröffentlichten Daten sollten dem Adressaten nur unwesentlich mehr Information liefern, als er eh schon durch seine Hintergrundinformation hat. Mit anderen Worten soll es kein großes Delta zwischen der Vorstellung des Adressaten vor bzw. nach Veröffentlichung der generalisierten Daten geben.17
2.) GRENZEN DER BAYES-OPTIM ALEN PRIVATSPHÄRE
Für unsere Betrachtung sind mehr die theoretischen Eigenschaften der „Bayes-optimalen-Privatsphäre“ von Interesse als die wirkliche praktische Umsetzung. Da es einige Schwachstellen gibt, die wie folgt aussehen:
1.) Aufgrund von unzureichendem Wissen des Datenhalters kann er nicht die gesamte Verteilung der sensiblen/nicht-sensiblen Attribute der gesamten Population Ω, aus der T entspringt, kennen (Insufficient Knowledge).
2.) Ebenso ist der Wissensstand des Adressaten/Angreifers nicht komplett bezüglich der sensiblen/nicht-sensiblen Attribute abschätzbar, so dass der Datenhalter nur partiell darauf eingehen kann (Adversary’s Knowledge is Unknown).
3.) Durch Informationsaustausch zwischen Betroffenen und Adressaten kann es zu weiterem Austausch von sensiblen Daten kommen, auf deren Basis der Adressat zu weiteren Schlussfolgerungen kommt, die der Datenhalter ebenfalls nicht abschätzen kann. (Instance-Level Knowledge)
4.) Aufgrund dessen, dass die veröffentlichten Daten mehrere und unterschiedliche Adressaten haben könnten, kann der Datenhalter überhaupt nicht abschätzen, ob er die Daten gegenüber Privatpersonen, Vereinen, Unternehmen oder sogar gegenüber der Einsicht des Staates schützen muss. ( Multiple Adversaries)18
17 Vgl. ebd., S.5. 18 Vgl. ebd., S.5-6.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
13
VI.) L-DIVERSITÄT: EINE PRAKTIKABLE PRIVATSPHÄREN DEFIN I TION
1.) DAS L-DIVERSITÄTSPRINZIP
Gemäß des Theorems kann man berechnen wie die Erwartung des Adressaten/Angreifers ist. Sei q* ein Block aller nicht-sensiblen Attribute, die im generalisierten Tableau zusammengefasst wurden in q*. Wenn wir uns nun den Fall der positiven Offenlegung(„Positive Disclosure“) ansehen, möchte der Adressat/Angreifer den genauen Wert von s ermitteln, sprich t[S] = s. Dies kann nur geschehen wenn die folgende Abschätzung gilt:
∃ ,∀ ≠ , ∗,
( ∣∣ )
( ∣∣ ∗ ) ≪ ( ∗, )
( ∣∣ )
( ∣∣ ∗ )
Diese Bedingung kann zwei verschiedene Ursachen haben. Zum einen kann es an der fehlenden Vielfalt der sensiblen Attribute innerhalb der jeweiligen q*-Blöcke liegen („Lack of Diversity“) und/oder es liegt am fundierten Hintergrundwissen des Adressaten/Angreifers („Strong Background Knowledge“).19
Liegt der erste Fall vor („Lack of Diversity“) dann gilt folgendes: ∀ ≠ , ( ∗, ) ≪ ( ∗, ) Die Anzahl des bestimmten Wertes von s für Attribut S ist überproportional höher als alle anderen s‘ ≠ s.
In diesem Fall haben fast alle Datensätze innerhalb eines Blocks den gleichen Wert s für das sensible Attribut S, somit ist das Ergebnis des Quotienten β(q,d,T*) ≈ 1, da im Nenner (fast) ausschließlich nur die s‘= s summiert werden und damit quasi Gleiche wie im Zähler steht.
Lösung:
Es sollten pro Block ausreichend verschiedene Wert für s enthalten sein in der gleichen Häufigkeit. Ein q*-Block sollte mindestens l ≥ 2verschiedene sensible Attribute enthalten, so dass die l-häufigsten Werte innerhalb des q*-Blocks grob in derselben Häufigkeit auftreten. Man sagt, dass ein q*-Block wohl-repräsentiert bezüglicher l-sensiblen Attributen ist.
Liegt der zweite Fall vor ( „Strong Background Knowledge“) dann gilt folgendes:
19 Vgl. ebd., S.6.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
14
∃ ,( ∣ )
( ∣ ∗)≈ 0
Selbst wenn ein q*-Block ausreichend viele verschiedene Werte für S inne hat in ausreichender Häufigkeit, so kann es sein, dass ein Adressat durch fundiertes Hintergrundwissen einige Ausprägungen s‘ für S ausschließen kann und somit die Menge an Werten von S nachhaltig reduziert.20
Beispiel:
In einer medizinischen Datenbank sucht ein Angreifer die Diagnose für seinen 30jährigen männlichen Nachbarn. Im betreffenden q*-Block sind 5 verschiedene Datensätze enthalten mit 3 verschiedenen Ausprägungen der Diagnosen (Herzinfarkt, Gelbfieber und Krebs). Wenn nun der Angreifer weiß, dass der Nachbar nie in gelbfiebergefährdete Gebiete fährt und auch ein Herzinfarkt aufgrund seines Alters und seiner relativ sportlichen Figur aus der Betrachtung fällt, kommt nur noch eine Krebserkrankung in Betracht. Auch Informationen über Angehörige der betroffenen Person oder direkte Informationen aus Gesprächen können die Vielfalt der S Attribute schnell reduzieren (Instance-Level Knowledge). Wäre der q*-Block eventuell nicht einmal nach dem Geschlecht unterteilt dann wären Diagnosen wie „Brustkrebs“ o.ä. sogar ohne weiteres Wissen auszuschließen.
Wenn wir nun mindestens l verschiedene wohl repräsentierte Ausprägungen in einem q*-Block haben, muss der Angreifer mindestens l-1 maßgebliche Informationen haben, um diese l-1 möglichen Werte von S zu eliminieren.
Leider kann auch bei einem großen l der Datenhalter niemals wissen, wie gut die externen Benutzer seiner Datei informiert sind. Eine 100% Sicherheit gegen Offenbarung von sensiblen Daten ist auch hiermit nicht gewährleistet.
20 Vgl. ebd., S.6.
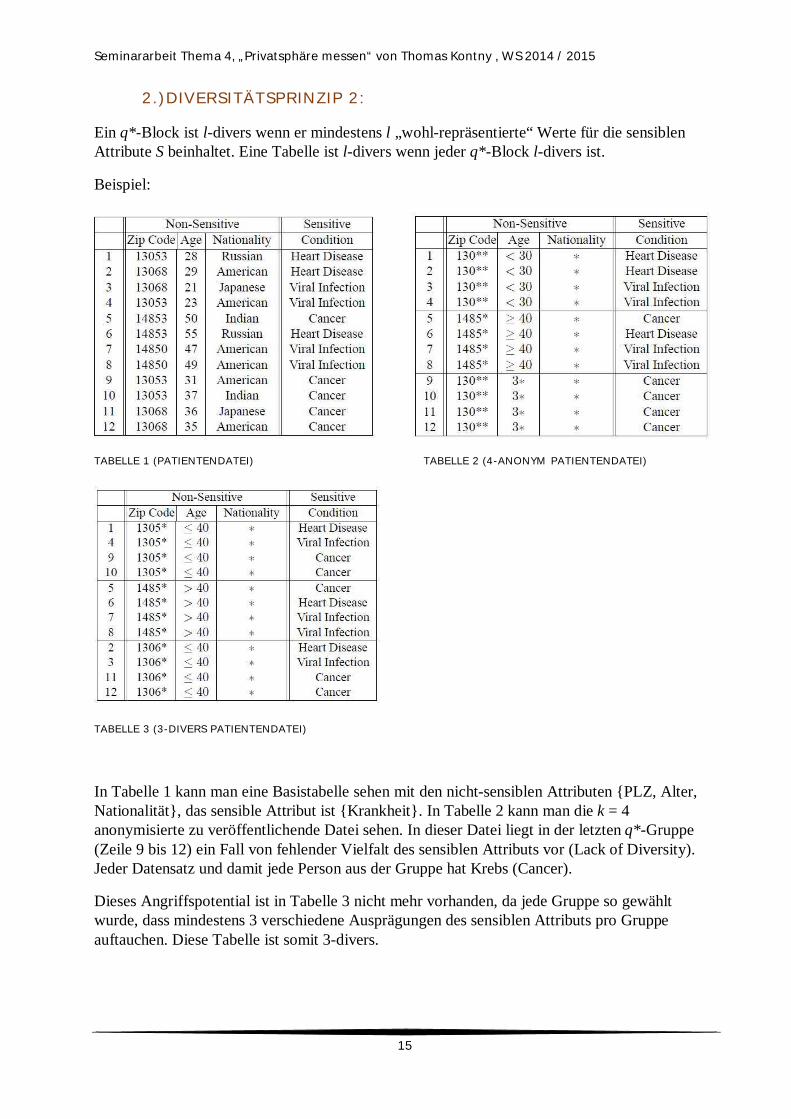
Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
15
2.) DIVERSITÄTSPRINZIP 2 :
Ein q*-Block ist l-divers wenn er mindestens l „wohl-repräsentierte“ Werte für die sensiblen Attribute S beinhaltet. Eine Tabelle ist l-divers wenn jeder q*-Block l-divers ist.
Beispiel:
TABELLE 1 (PATIENTENDATEI) TABELLE 2 (4-ANONYM PATIENTENDATEI)
TABELLE 3 (3-DIVERS PATIENTENDATEI)
In Tabelle 1 kann man eine Basistabelle sehen mit den nicht-sensiblen Attributen PLZ, Alter, Nationalität, das sensible Attribut ist Krankheit. In Tabelle 2 kann man die k = 4 anonymisierte zu veröffentlichende Datei sehen. In dieser Datei liegt in der letzten q*-Gruppe (Zeile 9 bis 12) ein Fall von fehlender Vielfalt des sensiblen Attributs vor (Lack of Diversity). Jeder Datensatz und damit jede Person aus der Gruppe hat Krebs (Cancer).
Dieses Angriffspotential ist in Tabelle 3 nicht mehr vorhanden, da jede Gruppe so gewählt wurde, dass mindestens 3 verschiedene Ausprägungen des sensiblen Attributs pro Gruppe auftauchen. Diese Tabelle ist somit 3-divers.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
16
Bis jetzt ist jedoch nicht genau geklärt, was „wohl-vertreten“ bedeutet, daher die folgenden Definitionen.21
Definition 6.1) (Entropie der L-Diversität):
Eine Tabelle ist Entropie l-divers für jeden Block q* wenn folgendes gilt: − ( ∗, ) log ∗, ≥ log( )∈
Hierbei ist ( ∗, ) = ( ∗, )∑ ( ∗, )∈ der Anteil der Datensätze im q*-Block gleich dem Wert des
bestimmten sensiblen Attributes s im Verhältnis zur Summe aller sensiblen Attribute.
Als Konsequenz dieser Bedingung hat jeder q*-Block mindestens l unterschiedliche Werte für die sensiblen Attribute.
Diese Entropie-Bedingung kann zu strikt sein, wenn einige positive Offenlegungen erlaubt sind (beispielsweise erlaubt eine Klinik die Herausgabe der Information, dass der Patient Herzprobleme hat, weil generell viele Patienten im Krankenhaus diese Probleme haben.) Diese Einschränkung erlaubt es ein neues Prinzip der l-Diversität namens „Rekursive l-Diversität“ zu definieren.
Seien s1,….,sm die möglichen Werte des sensiblen Attributes S im q*-Block. Wir sortieren die Anzahlen n(q*,s1),…, n(q*,sm) in aufsteigender Reihenfolge und benennen die Elemente der resultierenden Sequenz r1,…,rm. Eine Möglichkeit über l-Diversität nachzudenken ist die folgende:
Der Angreifer muss mindestens l-1 mögliche Werte von S eliminieren, um eine positive Offenlegung zu erzwingen. Dies bedeutet, dass er beispielsweise in einer l=2 diversen Tabelle keines der sensiblen Attribute zu häufig auftreten sollte, um eine ungefähre Gleichverteilung der Werte von S zu gewährleisten.
Ein q*-Block ist (c,2)-divers wenn r1 < c(r2+…+r m) ist für eine benutzerspezifische Konstante c. Für l > 2 sagen wir, dass ein q*-Block rekursiver (c,l)- Diversität genügt, wenn wir ein mögliches sensibles Attribut eliminieren können in q* und immer noch einen (c,l-1) diversen Block haben. Diese rekursive Definition kann wie folgt kurz zusammengefasst werden:
21 Vgl. ebd., S.7.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
17
Definition 6.2) Rekursive (c,l)-Diversität:
In einem q*-Block kennzeichnet ri die Anzahl wie oft das i-häufigste sensible Attribut im q*-Block auftaucht. Mit einer gegebenen Konstante c, genügt der q*-Block der rekursiven (c,l)-Diversität falls r1 < (c(rl + r l+1+..+r m). Eine Tabelle T* genügt rekursiver (c,l) Diversität falls jeder q*-Block der l-Diversität genügt.
Nun überlegen wir uns, dass Y die Menge von sensiblen Attributen ist, deren positive Offenlegung erlaubt sei (eventuell weil dieses Attribut sehr häufig vorkommt, beispielsweise die Diagnose „Herzinfarkt“ im Krankenhaus oder weil diese Diagnose unproblematisch ist wie „Patient gesund“). Da wir uns nun über diese Attribute keine Sorgen machen, sei sy das meist häufige sensible Attribut in q*, das nicht in Y ist und sei ry die dazugehörige Häufigkeit. Ein q*-Block genügt dann l-Diversität wenn wir die l-2 häufigsten Werte von S (ohne ry), ohne dass wir dadurch sy zu häufig in der resultierenden Tabelle auftreten lassen.
Also haben wir nach der Entfernung der häufigsten Attribute eine Tabelle die (l-y+1)-divers ist. Dies führt zur folgenden Definition:
Definition 6.3) Positive Offenlegungs-Rekursive (c,l)-Diversität:
Y kennzeichnet die Menge von sensiblen Attributen, für die wir die positive Offenlegung erlauben. In einem gegebenen q*-Block sei der meist häufigste sensible Wert, der nicht in Y ist, der y-te häufigste sensible Wert. Lassen wir r i die Häufigkeit des i- häufigsten sensiblen Wertes im q*-Block sein. Solch ein q*-Block genügt pd (positive disclosure)-rekursiver (c,l)- Diversität wenn eine der beiden folgenden Bedingungen gilt:
≤ − 1 <
≤ − 1 < + Wenn nun ry = 0 ist dann hat der q*-Block nur noch sensible Attribute enthalten, die offengelegt werden können und so sind beide Bedingungen trivial erfüllt. Wenn c > 1 ist, wird die zweite Bedingung zur Bedingung y > l -1 reduziert, weil ry ≤ rl-1. Die zweite Bedingung sagt aus, dass trotz die l-1 häufigsten Werten offengelegt werden können, wir trotzdem nicht wollen, das ry zu häufig auftritt, wenn l-2 davon bereits eliminiert wurden.
Nun kommen wir noch abschließend zur negativen Offenlegung von sensiblen Attributen:
Seien W die Menge der Attribute, für die negative Offenlegung nicht erlaubt ist, sei c2 eine Konstante < 100, die die prozentuelle Häufigkeit in jedem q*-Block von s ε W darlegt.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
18
Definition 6.4) Negative/Positive Offenlegungs-Rekursiv (c1,c2,l)-Diversität:
Sei W die Menge der sensiblen Attribute, die nicht durch negative Offenlegung veröffentlich werden sollen. Eine Tabelle genügt dieser npd (negative/positive disclosure)-rekursiven (c1,c2,l)-Diversität, wenn sie der vorher genannten pd-rekursiven (c1,l)-Diversität genügt und wenn jedes s ε W in mindestens c2 Prozent der Datensätze in q* auftaucht.22
FAZIT:
Ausgehend von der Frage warum man überhaupt private und sensible Daten veröffentlicht, da es ja hundertprozentige Sicherheit geben würde, wenn man sich im allgemeinen juristisch einigen würde, keine personenrelevanten Daten in irgendeiner Form zu veröffentlichen, ist dies in meinen Augen eindeutig zu beantworten:
Da in zahlreichen Bereichen der Forschung wie Gesundheit, Medizin, Soziologie, Psychologie, Technik, Wissenschaft o.ä. auf empirische Daten zurückgegriffen werden muss, um neue Erkenntnisse zu erlangen, ist es unabdingbar auf personenrelevante Daten zurückzugreifen. Da es auch durch Veröffentlichungsverbote nicht gewährleistet wäre, dass diese Daten geschützt sind, wie die andauernden Meldungen von Hackerangriffe und anschließender Veröffentlichung von Kontodaten, Passwortdaten etc. zeigen, ist es vernünftiger, diese Daten freiweilig in bereinigter und anonymisierter Form freizugeben.
So kommen wir zu der Frage welche Daten wirklich schützenswert sind und welche relativ problemlos weitergegeben werden können. Angefangen mit den relativ problemlosen persönlichen Daten wie Adresse, Wohnort und Telefonnummer, die man bei jeder Anmeldung eines Onlineshops,bei SocialMedia-Communities oder Newsgroups angibt und oft sogar hier zu leichtfertig damit ist, sollte dies kein Problem geben, zumal der Informationsgehalt ohne weitere verlinkte Informationen nicht sehr hoch ist. Ein Wählerverzeichnis oder ein Telefonbuch geben ähnliche Auskünfte.
Anders sieht es bei Informationen über die Gesundheit (Krankheitsgeschichte, Behinderungen, Medikation), Geldsituation (Gehalt, Kontostand, Verbindlichkeiten) etc. aus. Wenn Daten dieser Art in einer Tabelle/Datenbank gespeichert sind und zu Forschungszwecken veröffentlicht werden sollen, müssen diese soweit anonymisiert werden, so dass eine direkte Zuordnung einer einzigen Person nicht möglich ist.
Eine nicht praktikable Lösung ist die Unterdrückung von bestimmten Abfragen oder das Setzen von verschiedenen Sicherheitsniveaus, da es sehr schwierig ist einzuschätzen, wer welche Daten sehen darf und welche Daten wie schützenswert sind. Es gibt keine offizielle Maßeinheit für Privatsphäre.
Auch das Löschen von sogenannten Primärschlüsseln wie Name, Sozialversicherungs/Ausweisnummer ist nicht ausreichend, da wie dargestellt über sogenannte Quasi-Identifizierer (QI) und Verlinkung von öffentlichen Daten wie Wählerlisten wieder auf die Einzelperson zurückgeschlossen werden kann.
22 Vgl. ebd., S.8.

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
19
Eine Möglichkeit diese QI zu anonymisieren ist das Prinzip der k-Anonymität. Dadurch ist gewährleistet, dass pro Merkmal ( alle Datensätze, die die gleich Ausprägung der QI haben) mindestens k-verschiedene Datensätze vorhanden sind, also es immer k-1 andere Personen mit den gleichen Quasi-Identifizierern gibt. Dies setzt natürlich voraus, dass man immer weiß, welche die QI sind. Hier liegt meiner Meinung nach die große Schwäche dieses Prinzips. Aufgrund der Nichtkenntnis wer die Empfänger und Bearbeiter der veröffentlichten Datei sind, weiß man auch nicht wie gut deren Hintergrundwissen ist, welche anderen Tabellen/Datenbanken zur Verfügung stehen und wie groß der Wert und auch der Schaden ist, wenn private Daten offenbart werden.
Beispielsweise haben Arbeitgeber/Versicherer und auch Behörden/Ämter großes Interesse daran zu erfahren, wie es um die Gesundheit oder um die wirtschaftliche Situation eines Einzelnen steht und da diese Institution über viele Verbindungen in die Wirtschaft/Forschung verfügen, sind die verlinkbaren Daten sehr breit gestreut. Das kann beispielsweise ein Mitarbeiter eines Krankenhauses oder einer Krankenkasse kaum abschätzen, wenn er nur in diesem Bereich tätig ist. Und wenn das sensible, schützenswerte Attribut pro QI-Block gleich ist oder die Ausprägungen zwar abweichen aber alle sehr kritisch sind ( wie Krankheitsdiagnosen „Krebs“, „Multiple Sklerose“ oder „Depressionen“), kann das alles sehr nachteilig bei Veröffentlichung für den Betroffenen sein. Zynisch gesagt kann sich ein potentieller Arbeitgeber aussuchen, warum er den Bewerber nicht einstellen möchte.
Daher ist das Prinzip der l-Diversität ergänzend zur k-Anonymität sehr hilfreich, da hier der Fokus nicht auf den QI liegt, sondern auf der Qualität des sensiblen Attributs. Der Datenhalter muss gar nicht genau wissen, ob ein Attribut ein QI sein könnte und ob ein Empfänger der anonymisierten Daten durch diese Information unter Einbezug externer Daten hier die einzelne Person bestimmen kann. Solange es gewährleistet ist, dass es mindestens l-verschiedene Ausprägungen des sensiblen Attributs pro Datenblock ( Gruppe der Datensätze mit gleicher Ausprägung der QI) gibt, ist eine eindeutige Aussage über das Individuum nicht möglich. Dies kann natürlich im schlimmsten Falle genauso nachteilig sein, da alle l-unterschiedlichen Attribute nicht problemlos in ihrer Aussage sind, jedoch ist bei groß gewähltem l die Wahrscheinlichkeit geringer.
Die Schwäche des Prinzips liegt ebenfalls darin, dass der Datenhalter nicht den Informationshintergrund des Empfängers kennt, dieser könnte durch Ausschlussverfahren die Diversität nachhaltig reduzieren, jedoch ist dies bei einer wohlverteilten Häufigkeit der Werte des sensiblen Attributs durchaus zu minimieren. Die Abschätzung der Entropie-l-Diversität ist hierzu ein Maß.
Vom Performance-Aspekt sind beide Anonymisierungsmethoden sehr ähnlich, die „l-Diversität“ ist teils sogar noch schneller, daher gibt es auch hier kein Kontra für dieses Prinzip.
Daher ist die Methode der „l-Diversität“ in jedem Fall für Anonymisierungen von der Öffentlichkeit zugänglich gemachten privaten Daten zu empfehlen, da das Grundproblem der genauen Kenntnis des Datenhalters der Verteilung der sensiblen bzw. nicht-sensiblen Attribute, nicht länger nötig ist. Der Datenhalter braucht nicht mehr einzuschätzen, welche

Seminararbeit Thema 4, „ Privatsphäre messen“ von Thomas Kontny , WS 2014 / 2015
20
Hintergrundinformationen die Angreifer haben könnten, solange der Parameter l groß genug gewählt wird.
Es ist in jedem Fall im Sinne des betroffenen Individuums zu handeln und ein genügend großes l zu wählen, so dass trotz jeglicher anderer Informationen nicht auf den Einzelnen zu schließen ist. Dies sollte auch auf die Gefahr hin geschehen, dass die Brauchbarkeit der Daten für den Empfänger dadurch eventuell reduziert werden könnte.
Der Schutz des Einzelnen muss auf jeden Fall hier Priorität haben.
Quellennachweis:
1.)
Sweeney, Latanya (2002): k-Anonymity: A model for protecting privacy, International Journal on Uncertainty, Fuzziness and Knowledge-based Systems.
2.)
Machanavajjhala, Ashwin / Gehrke, Johannes / Kifer, Daniel (2005): l-Diversity: Privacy Beyond k-Anonymity, Journal on Uncertainty, Fuzziness and Knowledge-based Systems.


Seminararbeit
Algorithmen zum Schutz der Privatsphäre
Tobias Müller
10.01.2015
Fakultät für Mathematik und Informatik
FernUniversität in Hagen

Inhaltsverzeichnis
1 Einleitung 3
1.1 Problematik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Algorithmen zum Schutz der Privatsphäre . . . . . . . . . . . . . . . . . . . . 31.3 Anwendungsfälle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 K-Anonymity 5
2.1 Aufwand und optimale K-Anonymisierung . . . . . . . . . . . . . . . . . . . 62.2 Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.3 Bewertung der erreichten Privatsphäre . . . . . . . . . . . . . . . . . . . . . . 10
3 L-Diversity 11
3.1 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2 Schwierigkeit der Sterne-Minimierung . . . . . . . . . . . . . . . . . . . . . . 123.3 Algorithmus: Tupel Minimierung . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3.1 Erste Phase . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.3.2 Zweite Phase . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.3.3 Dritte Phase . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.3.4 Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Resümee 16

1 Einleitung 3
1 Einleitung
Die Privatsphäre ist ein nicht veräußerbares Grundrecht (Art. 2 Abs. 1 i.V.m. Art. 1 Abs. 1 GG),welches jedem Menschen zusteht. Die Sicherstellung dieses Rechtes ist die Aufgabe der staatli-chen Institutionen. Ein gewisses Maß an Anonymität ist zugleich ein wichtiges Element unsererDemokratie. Man bedenke, an dieser Stelle beispielsweise das Wahlgeheimnis. Die Möglich-keit, Informationen ohne Angabe der eigenen Person veröffentlichen zu können, ermöglichtMenschen (neudeutsch Whistleblowern) anonym Skandale an die Öffentlichkeit zu bringen, so-mit besitzt die Anonymität eine Reihe von Vorteilen, die eine moderne und freie Gesellschaftnicht vermissen sollte.
Im Gegenzug hat die Anonymität aber auch Nachteile: Menschen können verleumdet werden,ohne dass das Opfer die Möglichkeit hat, gegen die Behauptungen vorzugehen. Die Politik hatdurch das Bundesdatenschutzgesetz eine Abwägung für beide Seiten getroffen. Das Bundesda-tenschutzgesetz setzt die europäischen Richtlinien (Richtlinie 95/46/EG) zum Datenschutz um.Dieses Gesetzbuch regelt die elektronische Verarbeitung von personenbezogenen Daten.
1.1 Problematik
Bei wenigen Datensätzen ist es noch möglich, diese manuell zu anonymisieren. Für dieses Vor-gehen, wäre z.B. das Weglassen der Buchstaben nach dem ersten Buchstaben zu nennen. AusTobias Müller wird dann Tobias M. Es ist aber offensichtlich, dass selbst dieses einfache Vor-gehen schon keine zufriedenstellenden Ergebnisse liefert, sofern ein weiteres Feld mit demWohnort dieser Person enthalten ist und es nur einen Tobias Müller in diesem Ort gibt. WenigeDatensätze führen bei strenger Beachtung der Gewährleistung der Anonymität schon zu großemAufwand.
Sobald die kleine Dimension verlassen wird und man sich im Bereich von einigen tausendDatensätzen bewegt, ist es zwingend erforderlich, ein systematisches Vorgehen zu definieren.Dieses systematische Vorgehen lässt sich in Form eines Algorithmus formulieren. In Kapitelzwei und drei werden zwei verschiedene Algorithmen, die hierfür verwendet werden können,vorgestellt.
1.2 Algorithmen zum Schutz der Privatsphäre
Es gibt eine Reihe von Algorithmen, deren Ziel die Erreichung eines oder mehrerer Privacy-Kriterien sind. Diese Seminararbeit beschäftigt sich zum Einen mit einem Algorithmus für dieErreichung der K-Anonymity und zum Anderen zur Erreichung der L-Diversity. K-Anonymityund L-Diversity sind Qualitätskriterien für die Bewertung der erreichten Anonymität. Die Qua-litätskriterien unterscheiden sich im Grad der Schwierigkeit, des Informationsverlustes und derStrategie zur Verhinderung der Deanonymisierung eines Individuums. Neben den beiden er-wähnten Kriterien gibt es noch eine Reihe Weiterer. Ein bekannter Vertreter ist die T-Closeness,auf die jedoch nicht näher eingegangen wird.
Im Englischen wird das automatisierte Vorgehen für die Anonymisierung von Daten als "DataMasking" bezeichnet. Weitere semantisch gleiche Bezeichnungen sind: Data Obfuscation, DataSanitization und Data Scrambling. [1]
Nachfolgend sind die häufigsten Methoden aufgezählt, die ein Data Masking realisieren kön-nen:
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

1 Einleitung 4
• Zufällige Namen und BezeichnungenDie reellen Namen werden durch zufällige Namen ersetzt. Dieses Vorgehen kann auf Vor-namen, Nachnamen oder dem vollständigen Namen angewendet werden. Des Weiterenkönnen auch Firmennamen oder Marken durch zufällige Namen ersetzt werden.
• Vermischung von WertenDie vorhandenen Werte können mit anderen Werten aus anderen Zeilen vertauscht wer-den.
• Relative WerteAnstatt der Verwendung von absoluten Zahlenwerten können diese durch relative Werte,die zueinander in Beziehung stehen, ersetzt werden.
• Ersetzung von WertenBestimmte Werte werden durch immer wiederkehrende Ersetzungen ausgetauscht.
• Angabe von WertebereichenDie Originalwerte werden in einem Intervall abgebildet. Beispielsweise könnte das kon-krete Geburtsdatum lediglich durch das entsprechende Jahrzehnt ausgedrückt werden.
1.3 Anwendungsfälle
Die Anwendungsfälle sind thematisch sehr weit: gefächert von der Medizinforschung bis hinzum Verkauf von personenbezogenen Umfragen. Bei der Veröffentlichung von neuen Forschungs-ergebnissen ist es häufig notwendig, die zugrundeliegende Datenbasis mit anzugeben. Eine sol-che Veröffentlichung in Rohform würde jedoch in hohem Maße gegen das geltende Bundesda-tenschutzgesetz verstoßen. Es ist also erforderlich, die Daten so unkenntlich zu machen, dasssie nicht mehr mit einer konkreten Person in Verbindung gebracht werden können. Trotzdemsollen die relevanten Daten so weit wie möglich erhalten bleiben. Beispielsweise macht es fürdie Medizinforschung einen großen Unterschied, ob das Geburtsdatum einer Testperson direktangegeben wird oder in relativ großen Intervallen (z.B. Alter 0-39, Alter 40-79, usw.) veröffent-licht wird. Für die Wirkung eines Medikaments kann das Alter der Person eine entscheidendeEigenschaft sein. Es gilt somit ein Verhältnis zu erschaffen bei dem, zum Einen die Möglichkeitder Identifizierung einer einzelnen Person ausgeschlossen, zum Anderen der Erhalt der relevan-ten Informationen sichergestellt ist.
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller
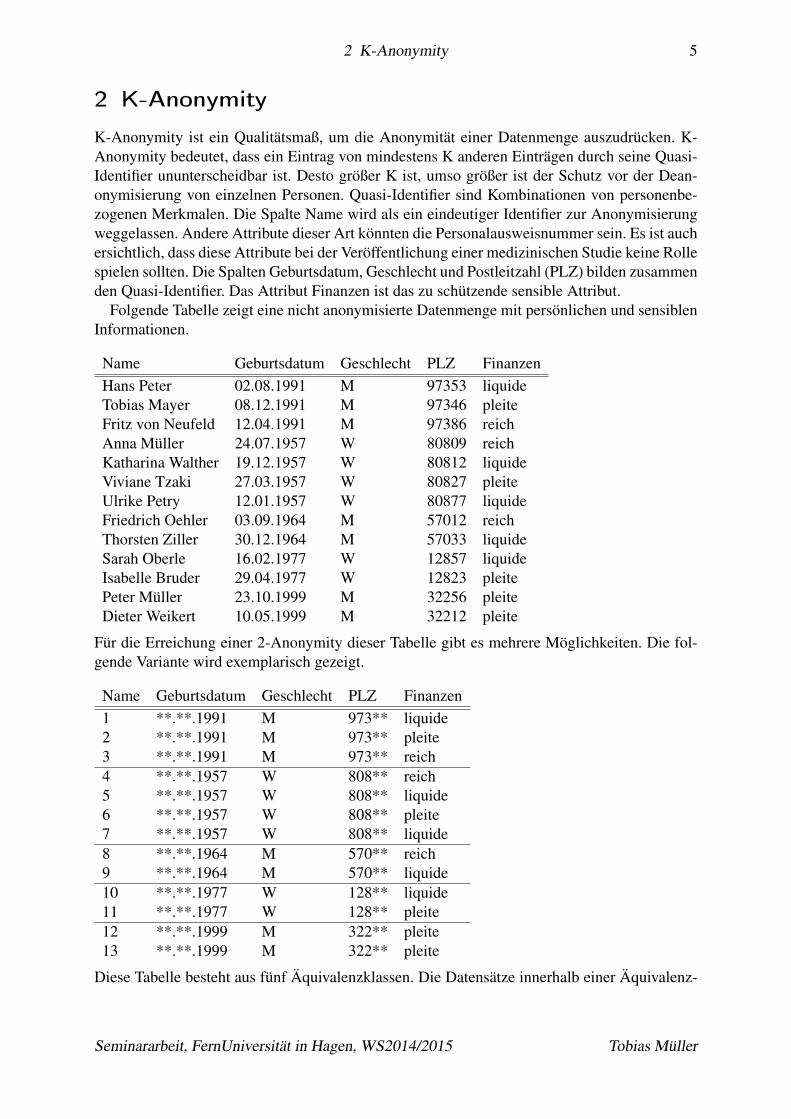
2 K-Anonymity 5
2 K-Anonymity
K-Anonymity ist ein Qualitätsmaß, um die Anonymität einer Datenmenge auszudrücken. K-Anonymity bedeutet, dass ein Eintrag von mindestens K anderen Einträgen durch seine Quasi-Identifier ununterscheidbar ist. Desto größer K ist, umso größer ist der Schutz vor der Dean-onymisierung von einzelnen Personen. Quasi-Identifier sind Kombinationen von personenbe-zogenen Merkmalen. Die Spalte Name wird als ein eindeutiger Identifier zur Anonymisierungweggelassen. Andere Attribute dieser Art könnten die Personalausweisnummer sein. Es ist auchersichtlich, dass diese Attribute bei der Veröffentlichung einer medizinischen Studie keine Rollespielen sollten. Die Spalten Geburtsdatum, Geschlecht und Postleitzahl (PLZ) bilden zusammenden Quasi-Identifier. Das Attribut Finanzen ist das zu schützende sensible Attribut.
Folgende Tabelle zeigt eine nicht anonymisierte Datenmenge mit persönlichen und sensiblenInformationen.
Name Geburtsdatum Geschlecht PLZ Finanzen
Hans Peter 02.08.1991 M 97353 liquideTobias Mayer 08.12.1991 M 97346 pleiteFritz von Neufeld 12.04.1991 M 97386 reichAnna Müller 24.07.1957 W 80809 reichKatharina Walther 19.12.1957 W 80812 liquideViviane Tzaki 27.03.1957 W 80827 pleiteUlrike Petry 12.01.1957 W 80877 liquideFriedrich Oehler 03.09.1964 M 57012 reichThorsten Ziller 30.12.1964 M 57033 liquideSarah Oberle 16.02.1977 W 12857 liquideIsabelle Bruder 29.04.1977 W 12823 pleitePeter Müller 23.10.1999 M 32256 pleiteDieter Weikert 10.05.1999 M 32212 pleite
Für die Erreichung einer 2-Anonymity dieser Tabelle gibt es mehrere Möglichkeiten. Die fol-gende Variante wird exemplarisch gezeigt.
Name Geburtsdatum Geschlecht PLZ Finanzen
1 **.**.1991 M 973** liquide2 **.**.1991 M 973** pleite3 **.**.1991 M 973** reich4 **.**.1957 W 808** reich5 **.**.1957 W 808** liquide6 **.**.1957 W 808** pleite7 **.**.1957 W 808** liquide8 **.**.1964 M 570** reich9 **.**.1964 M 570** liquide10 **.**.1977 W 128** liquide11 **.**.1977 W 128** pleite12 **.**.1999 M 322** pleite13 **.**.1999 M 322** pleite
Diese Tabelle besteht aus fünf Äquivalenzklassen. Die Datensätze innerhalb einer Äquivalenz-
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

2 K-Anonymity 6
klasse unterscheiden sich nicht bezüglich ihres Quasi-Identifiers. Die geringste Datensatzanzahlin einer Äquivalenzklasse beträgt zwei. K ist somit zwei. Es handelt sich um eine 2-Anonymity.
Durch die Veröffentlichung einer Tabelle mit K-Anonymity soll verhindert werden, dass An-greifer ein Indivduum in der Menge einer Äquivalenzklasse identifizieren können. Eine Ver-öffentlichung dieser Tabelle erschwert also die Identifizierung einer Person. Probleme diesesPrivacy-Kriteriums werden im Kapitel 2.3 angesprochen.
Die Erreichung der K-Anonymity kann durch verschiedene Methoden erreicht werden:
• Generalisierung der DatenDie Daten werden allgemeiner ausgedrückt. Beispielsweise könnte das konkrete Altereiner Person durch ein Intervall ausgedrückt werden.
• RauschenDie Informationen können durch Rauschen leicht verfälscht werden.
• Daten vertauschen
• Dummy-Datensätze hinzufügenDurch das Hinzufügen weiterer oft erfundenen Datensätze können homogene Datenmen-gen besser geschützt werden.
• Unterdrücken von DatensätzenDatensätze, welche hohe Kosten bei der Erreichung der K-Anonymität verursachen, kön-nen entfernt werden.
2.1 Aufwand und optimale K-Anonymisierung
Es lässt sich erahnen, dass der Aufwand für die Anonymisierung für größere K-Werte an-steigt, da die Datensätze verstärkt generalisiert werden müssen, um einen gemeinsamen Quasi-Identifier zu erhalten. Der Aufwand beziehungsweise die Kosten der Anonymisierung könnenvereinfacht als der Verlust an Informationen aufgefasst werden. Durch die obige Veränderungist die PLZ beispielsweise nun deutlich unschärfer. Der Informationsgehalt der Daten ist somitgesunken. Ziel eines Algorithmus für die K-Anonymity muss also die Erreichung einer anony-misierten Version mit möglichst geringem Informationsverlust sein. Eine Version mit minima-lem Informationsverlust ist die optimale K-Anonymisierung. "Data Privacy Through Optimalk-Anonymization" stellt zwei Kostenmetriken für die Berechnung der Kosten vor: [BaAg05]
Die disverbibility metric ordnet jedem Tupel einen Strafwert zu. Dieser Wert setzt sich ausder Anzahl der Tupel zusammen, die in der transformierten Tabelle von diesem nicht zu unter-scheiden sind. Wenn ein Tupel sich also in einer Äquivalenzklasse mit h Elementen befindet,so wäre dessen Strafwert gleich h. Wenn dieses Tupel jedoch unterdrückt wird, so wird ihm alsStrafwert die Anzahl der Tupel vom Anfangsdatenset zugewiesen.
Die classification metric sieht keinen Strafpunkt für einen nicht unterdrückten Tupel vor, so-fern dieser zur Mehrheitsklasse innerhalb seiner Äquivalenzklasse gehört. Alle anderen Tupel,welche nicht zur Mehrheitsklasse gehören, erhalten den Wert 1 als Strafpunkt.
Die Kosten werden in beiden Metriken aufsummiert und sind ein Indikator für die Kosteneiner Anonymisierung.
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

2 K-Anonymity 7
2.2 Algorithmus
Das Ziel des Algorithmus ist die Erreichung der K-Anonymity mit möglichst geringen Kosten.Die Lösung mit den geringsten Kosten wird als optimale Lösung bezeichnet. Der Algorithmuszur Suche der optimalen Lösung ist als Suchproblem in einer Potenzmenge realisiert. Es wirdalso jede Teilmenge eines gegebenen Alphabets nach einer Lösung mit den geringsten Kostendurchsucht.
Es werden nun per Suchalgorithmus alle Varianten des Alphabetes durchlaufen. Aus anderenThemenfeldern gibt es eine Reihe von Algorithmen die systematisch diesen Suchbaum (alleTeilmengen der Potenzmenge als Knoten) durchlaufen und auf Basis einer Kostenrechnung ei-ne Unterdrückung von Elementen des Alphabets vornehmen, um das Optimierungsproblem zulösen. Ein bekannter Vertreter ist der OPUS-Algorithmus. Die möglichen Anonymisierungen(Knoten des Graphen) werden nun bezüglich der Kosten getestet. Wenn der Baum vollstän-dig durchlaufen worden ist, kann die Anonymisierung mit den geringsten Kosten verwendetwerden.
Zunächst könnte man glauben, dass jede mögliche Kombination des Alphabets geprüft wer-den müsse. Die Anzahl der Teilmengen einer Menge mit z Elementen ist 2z. Zusammenfassendkann gesagt werden, dass für jeden Knoten die Kosten berechnet werden und falls diese Kostengeringer sind als das bisherige Minimum, bildet dieser Knoten die derzeitig beste Lösung desOptimierungsproblems. Für die Feststellung, ob ein Wert ausgeschlossen werden kann, wirdalso eine Abschätzung gegen die aktuelle unterste Kostengrenze benötigt. Die unterste Kosten-grenze ergibt sich in Abhängigkeit von der Kostenmetrik. Es ist ersichtlich, dass das vollständi-ge Durchlaufen des Baumes z.B. durch Breiten- oder Tiefensuche ziemlich rechenaufwendig ist.Aus diesem Grund wird versucht, bestimmte Kombinationen bezüglich der optimalen Lösungauszuschließen. Realisiert wird dies, indem man versucht, einzelne Werte oder Kombinationendes Alphabets frühzeitig von der Suche auszuschließen. Anfänglich wird versucht, den kom-pletten Knoten zu unterdrücken. Danach werden die noch abzuarbeitenden Werte überprüft. DesWeiteren bedeutet es, dass die Werte in den Kinderknoten auch nicht mehr berücksichtigt wer-den müssen. Das Vorgehen kann daher zu einer signifikanten Einsparung an Rechenzeit führen.Wichtig ist jedoch, dass dieser Ausschluss an Werten nur dann funktioniert, wenn ersichtlichist, dass alle Kombinationen mit diesen Werten nicht zu einer neuen optimalen Kostenbewer-tung führen. Auf die Berechnung der untersten Kostengrenze für die Unterdrückung von Wertenwird an dieser Stelle nicht weiter eingegangen. Es sei auf [BaAg05] Abschnitt 5.2 verwiesen.
Eine weitere Möglichkeit (PRUNE-USELESS-VALUES im Pseudocode) ist die Unterdrückungvon noch zu verarbeitenden Werten für die weitere Spezialisierung eines Knotens. Wenn dieseSpezialisierungen alle kleiner als K sind, ist die einzige Folge davon, dass diese unterdrücktwerden. Dieser Effekt hat keine Auswirkungen auf die, welche nicht unterdrückt bleiben. Es istdaher offensichtlich, dass diese nicht zu einer Verbesserung der Kosten führen.
Der vorgestellte Algorithmus fängt mit der maximal möglichen Anonymisierung der Tabel-le an. Konkret bedeutet dies, dass alle Daten anonymisiert (generalisiert) sind. Beispielsweisewürde das Geburtsdatum in der Tabelle einfach als "*" dargestellt werden. Als Ausgangssitua-tion dient ein Graph, in welchem die möglichen Anonymisierungen als Knoten enthalten sind,und ein Alphabet (z.B. 1,2,3,4,5,6,7,8,9) mit den möglichen Werten. Das Alphabet könnte soübersetzt werden:
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

2 K-Anonymity 8
Nr. Wert
1 Alter: 10 bis 29 Jahre2 Alter: 30 bis 39 Jahre3 Alter: 40 bis 49 Jahre4 Geschlecht: männlich5 Geschlecht: weiblich6 Familienstand: verheiratet7 Familienstand: verwitwet8 Familienstand: geschieden9 Familienstand: ledig
Der gesamte Algorithmus, bestehend aus den Funktionen K-OPTIMIZE und PRUNE, kannwie folgt als Pseudocode formuliert werden. [BaAg05]
K-OPTIMIZE( k, head set H, tail set T, best cost c );; This function returns the lowest cost of any;; anonymization within the sub-tree rooted at;; H that has a cost less than c (if one exists).;; Otherwise, it returns c.T← PRUNE-USELESS-VALUES( H, T )c←MIN( c, COMPUTE-COST( H ))T← PRUNE( H, T, c )T← REORDER-TAIL( H, T )while T is non-empty do
v← the first value in the ordered set THnew← H
⋃v
T← T - v ;; preserve orderingc← K-OPTIMIZE( k, Hnew, T, c )T← PRUNE( H, T, c )
return c
Die Funktion K-OPTIMIZE wird initial mit ( k, /0, ∑all , ∞ ) aufgerufen. Für aktuelle mini-male Kosten c kann ein Wert aus einem anderen Algorithmus verwendet werden, sodass eineobere Grenze zumindest existiert. Alternativ kann auch ein Wert von einer vorherigen Berech-nung mit einem größeren k verwendet werden. Der erste Aufruf realisiert einen Tiefendurchlaufdurch den Baum, welcher aus den Kombinationen des Alphabets besteht. Die Wurzel ist zu-nächst die absolute Generalisierung. Das Head-Set ist eine leere Menge. Konkret bedeutet dies,dass alle Attribute durch "*" ausgedrückt werden. Das Tail-Set beinhaltet die Zahlen, die nochhinzuzufügen sind. Im Falle der Wurzel wären diese alle von 1 bis 9. In der nächsten Ebene(die Kinder der Wurzel) besteht das Head-Set des Knoten jeweils aus einem Element. Das ersteKind hätte beispielsweise den Wert 1, das Zweite den Wert 2, usw. Das Tail-Set des Knotensbeinhaltet nun alle Werte außer dem Wert im Head-Set stehend. In der nächsten Ebene stehennun zwei Werte im Head-Set. Das übrige Vorgehen kann nun analog fortgesetzt werden.
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

2 K-Anonymity 9
Die Funktion REORDER-TAIL bewirkt eine Neuordnung der Tail-Menge. Es wird für dieWerte der Grad der Aufspaltung betrachtet, welcher in der nächsten Ebene des Baumes ent-steht. Die Werte werden absteigend nach diesem Grad sortiert. Diese Strategie hat sich unterEinbeziehung der Kostenmetrik als gute Lösung erwiesen.
PRUNE( k, head set H, tail set T, best cost c );; This function creates and returns a new;; tail set by removing values from T that;; cannot lead to anonymizations with cost;; lower than cif COMPUTE-LOWER-BOUND( k, H, H
⋃T ) ≥ c
then return /0Tnew← Tfor each v in T do
Hnew← H⋃
vif PRUNE( H, Tnew - v, c )
then Tnew← Tnew - vif Tnew 6= T then return PRUNE( H, Tnew, c )else return Tnew
Die Funktion PRUNE ruft sich selbst erneut auf, da durch die Entfernung eines Wertes sichauch die unterste Kostengrenze ändert. Dies macht einen erneuten Aufruf notwendig.
Der Baum wird nun durch den Algorithmus rekursiv im Tiefendurchlauf durchlaufen. DasErgebnis, das nach der Terminierung entsteht, ist die optimale Lösung des Optimierungspro-blems, also die Anonymisierung mit den geringsten Kosten. Der Algorithmus lässt erahnen,dass mit einem geringer werdenden K auch die Performance signifikant sinkt. Die Wahl diesesWertes sollte also mit Bedacht gewählt werden.
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

2 K-Anonymity 10
2.3 Bewertung der erreichten Privatsphäre
Die K-Anonymity ist nur auf den ersten Blick eine gute Lösung. Es gibt mehrere Nachteile derK-Anonymity. [Hauf][MaGe]
Die mehrfache Veröffentlichung der Daten mit unterschiedlichen Versionen der K-Anonymityerlaubt es, die Datensätzen mittels der veränderten Quasi-Identifier miteinander zu verbinden.Da bekannt ist, dass die Person in beiden Tabellen vorhanden sein muss, kann hierdurch mitgeringen Aufwand eine Person identifiziert werden. Vor der Veröffentlichung muss daher eineVorangegangene hinsichtlich der Erhaltung der Anonymität durch die neue Veröffentlichunggeprüft werden. Beispielsweise würde ein Herr Felix Reiter mit bekanntem Quasi-Identifieridentifiziert werden können, sofern die beiden Gruppen, welche durch die Quasi-Identifier ge-geben sind durch ein weiteres Merkmal, welches in beiden Tabellen übereinstimmt, miteinanderverknüpft werden.
Ein weitere Möglichkeit die Anonymität eines Individuums aufzuheben, ist die mehrmaligeVeröffentlichung einer gleich sortierten Tabelle.
Durch die Verwendung von Quasi-Identifiers ist es aber trotzdem möglich, eine Person ausder Datenmenge heraus identifizieren zu können. Hierbei werden externe Datenquellen mit deranonymisierten Tabelle verknüpft. Dies ist nur dann möglich, wenn die Tupel durch ihre Lageverbunden werden können und bestimmte Merkmale in den Tabellen gegeben sind: Zum Einenmüsste die selbe Reihenfolge vorliegen und zum Anderen die selben Personen enthalten sein.Um dies zu erschweren, sollten die k-anonymisierten Tabellen mit unterschiedlichen Reihen-folgen publiziert werden.
Aber auch für den Fall, dass eine Person nicht identifiziert werden kann, muss die K-Anonymitykritisch betrachtet werden. Das Qualitätsmaß an sich bietet nämlich auch Nachteile.
Falls alle Daten homogen sind und bekannt ist, dass ein Individuum sich in den Daten be-findet, kann darauf auf persönliche Attribute geschlossen werden. Diese Attacke wird Homo-genitätsangriff genannt. Eine weitere Attacke bietet die Situation, dass korrelierendes Wissenzur Person dem Angreifer bekannt ist. Der Angreifer kann nun nach dem Ausschlussprinzip diePerson und somit die übrigen Attribute ermitteln.
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

3 L-Diversity 11
3 L-Diversity
Die K-Anonymity besitzt einige Nachteile, welche durch die L-Diversity beseitigt werden sol-len. Die K-Anonmity ist - wie bereits dargelegt - kein absoluter Schutz vor Deanonymisierungder sensitiven Daten. Zum Einen kann versucht werden, die persönlichen (sensitiven) Attri-butwerte vorherzusagen. Zum Anderen kann per Ausschlussverfahren versucht werden, nichtzutreffende Attribute auszuschließen und so die Richtigen zu erraten. Ersteres würde sofortzum Verlust der Anonymität führen. Diese Nachteile sind deswegen unbedingt zu vermeiden.
Grundsätzlich können die Algorithmen in theoretische und heuristische Algorithmen geglie-dert werden. Die theoretischen Algorithmen schaffen bei einem möglichst geringen Informati-onsverlust jedoch meist nur K-Anonymity. Die heuristischen Algorithmen liefern eine deutlichbessere Performance und können mehrere Privacy-Kriterien (L-Diversity, T-Closeness) erfül-len.
Vom Prinzip her ist bei der L-Diversity das Ziel, dass das Wissen über einen Datensatz vorund nach der Veröffentlichung möglichst gering bleiben soll. Das Hintergrundwissen wird alsWahrscheinlichkeitsfunktion über die Attribute modelliert.
Bei der Erreichung der L-Diversity müssen zwei zentrale Problemstellungen gelöst werden.Zum Einen sollen so wenig Attribute wie möglich durch Sterne "*" ersetzt werden müssen, daso der Informationsgehalt abnimmt und relevante Daten verloren gehen können. Diesen Vor-gang kann man auch Generalisierung nennen. Das Gegenteil der Generalisierung ist die Spe-zialisierung. Wenn man beispielsweise lediglich das Geburtsjahr publiziert, dann ist dies dieGenerlisierung des genauen Geburtsdatum (mit Tag und Monat der Geburt). Zum Anderen istdie Anzahl der betroffenen Tupel minimal zu halten. Beide Probleme werden später durch eineKostenmetrik modelliert. Vereinfacht ausgedrückt, bedeuten hohe Kosten einen hohen Verlustan Information.
Es gibt mehrere Ausprägungen bzw. Definitionen der L-Diversity [Hauf]:
• Entropy L-DiversityDie Form setzt voraus, dass jede Äquivalenzklasse, der aus den selben Tupeln besteht,mindestens L verschiedene Werte für das persönliche Merkmal aufweist. Diese Erfor-dernis schützt das Attribut vor einem L-1 Hintergrundwissen. Ein hohes L schützt daherumso mehr.
• Recursive( c, L )-DiversityBei dieser Variante wird die Häufigkeit der Werte beachtet. Keines der Werte darf zuhäufig vorkommen. c gibt an wie die Werte verteilt sind. Konkret bedeutet ein kleines ceine geringe Verteilung der Werte. Ein großes c lässt auf eine hohe Verteilung der Werteschließen. Der Parameter L gibt die Anzahl der Werte an, welche ausgeschlossen werden,bevor ein Wert als zu häufig kategorisiert werden kann.
• Positive Disclosure-Recursive( c, L )-DiversityNicht alle Werte eines sensitiven Attributes haben negative Auswirkungen bei einer Dea-nonymisierung. Beispielsweise könnte der Wert "liquide" als positiver Wert angenommenwerden. Individuen, von denen dieser Wert bekannt ist, müssen nicht mit negativen Aus-wirkungen rechnen. Im Kontext dieser Variante bedeutet dies, dass größere Häufungendieser Werte erlaubt sind.
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

3 L-Diversity 12
• Positive/Negative Disclosure-Recursive( c1, c2, L )-DiversityDurch den zweiten Parameter wird der Anteil der nicht ausschließbaren Werte definiert,die in einer Tupel-Gruppe nicht unterdrückt werden dürfen.
• Multiple Sensitive AttributeDiese Form erlaubt mehrere sensible Attribute. Das Ziel ist letztendlich den Schutz zugewährleisten auch, wenn schon ein anderes sensibles Attribut dem Angreifer bekanntist.
In der nachfolgenden Darstellung werden wir uns auf die Entropy L-Diversity beschränken,da sie am häufigsten Verwendung findet.
3.1 Beispiel
Eine 2-Diversity verlangt, dass maximal 1/2 aller Tupel in der jeweiligen Quasi-Identifier(QI)-Gruppe die selben persönlichen Attribute haben. Die anonymisierte Tabelle aus der Einleitungüber die K-Anonymity würde somit nicht dem Qualitätsmaß der 2-Diversity genügen, da dieQI-Gruppe in Zeile 12 bis 13 mehr als 50% Ähnlichkeit haben.
Die folgende Tabelle würde diese Voraussetzung jedoch erfüllen:
Name Geburtsdatum Geschlecht PLZ Finanzen
1 **.**.1991 M 973** liquide2 **.**.1991 M 973** pleite3 **.**.1991 M 973** reich4 **.**.1957 W 808** reich5 **.**.1957 W 808** liquide6 **.**.1957 W 808** pleite7 **.**.1957 W 808** liquide8 **.**.1964 M 570** reich9 **.**.1964 M 570** liquide10 * W * liquide11 * W * pleite12 **.**.1999 M 322** pleite13 **.**.1999 M 322** reich
Es mussten vier Werte komplett durch Sterne ersetzt werden, da diese Werte nicht besser spezia-lisiert werden konnten, unter Erhaltung der Anforderungen, das alle QI-Gruppen die gleichenWerte haben müssen. Die Generalisierung erstreckt sich über zwei Tupel.
3.2 Schwierigkeit der Sterne-Minimierung
Wie schon angesprochen sollten so wenig Werte wie möglich generalisiert werden. Die Stern-minimierung ist ein NP-Problem. Die Analyse von [XiYi10] zeigt, dass die Berechnung deroptimalen L-Diversity für Werte m≥ l ≥ 3 ein NP-schweres Optimierungsproblem ist, wobei m
die Anzahl der verschiedenen Werte des zu schützenden "sensitive attribute" (SA) ist. In diesemFall wäre das die Spalte Finanzen. Konkret bedeutet dies, dass es eine nicht deterministischeTuringmaschine gibt, welche das Problem in Polynomialzeit lösen kann. [2]
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

3 L-Diversity 13
Der Nachweis hierfür wurde über das dreidimensionale Matching-Problem erbracht. [XiYi10]Man ging dabei von drei gleich großen Dimensionen aus, welche drei disjunkte Mengen anQI-Werte-Tupel enthalten. Auf die Herleitung soll an dieser Stelle nicht weiter eingegangenwerden.
3.3 Algorithmus: Tupel Minimierung
Dieses Kapitel beschäftigt sich mit dem zweiten Problem der Tupel-Minimierung. Es wird einAlgorithmus vorgestellt, welcher mit einer Güte von l arbeitet. Dieser führt zu einer (l ∗ d)-Approximation, wobei d die Anzahl der Attribute des QI-Tupels ist. Diese Grenze nach Obenentsteht durch den ersten l-Diversity-Algorithmus mit einer Worst-Case-Grenze für den Infor-mationsverlust. Der Algorithmus basiert im Vergleich zu anderen Werken auf einer Reihe neu-artiger heuristischen Annahmen, die in der Praxis deutlich bessere Ergebnisse als die Worst-Case-Grenze liefern.
Der Algorithmus ist in drei Phasen organisiert. Ein Tabelle mit sensiblen Informationen wirdin QI-Gruppen organisiert. Die Tupel in diesen Gruppen haben alle die selben QI-Attribute (z.B.Geburtsjahr). Der Algorithmus soll nun so wenig Tupel wie möglich aus diesen QI-Gruppenentfernen. Es müssen am Ende des Algorithmus jedoch folgende Bedingungen erfüllt sein:
1. Alle QI-Gruppen sind l-eligible.
2. Die Menge aller entfernten Tupel sind l-eligible.
„l − eligible“ bedeutet, dass bei gegebenem L und der Tupelmenge S maximal |S|/l denselben SA-Wert haben dürfen.
3.3.1 Erste Phase
In der ersten Phase wird nun geprüft, ob die erste Bedingung erfüllt ist. Falls diese Bedingungerfüllt ist, wird als nächstes geprüft, ob auch die zweite erfüllt ist. Wenn ja, endet der Algorith-mus umgehend.
Der SA-Wert, der am häufigsten in einer QI-Gruppe auftritt, wird als „Pillar“ bezeichnet. Esist durchaus möglich, dass eine Gruppe mehrere Pillar-Werte hat.
Zunächst wird in der ersten Phase für jede QI-Gruppe der Pillar-Wert bestimmt. Es wird nunpro QI-Gruppe ein Tupel mit dem Pillar-Wert entfernt bis die QI-Gruppe die erste Bedingungerfüllt. Es ist aber durchaus möglich, dass eine Gruppe mehrere Pillar-Werte hat. In diesem Fallwird zufällig einer gewählt. Es ist jedoch nicht ausreichend nur Tupel von dem einen Pillar-Wertzu entfernen. Daher ist es erforderlich auch Tupel aus den anderen Pillar-Werten zu entfernenbis die Bedingung erfüllt ist.
Am Ende wird nun noch geprüft, ob die Menge der entfernen Tupel l-eligible ist. Hierfürwird geprüft, ob |R| ≥ l ∗ h(R) gilt. R ist die Menge der entfernten Tupel. „h(R)“ liefert dieAnzahl der Tupel, welche den Pillar-Wert enthalten. Wenn die Gleichung erfüllt ist, endet derAlgorithmus. Andernfalls geht es mit der zweiten Phase weiter.
3.3.2 Zweite Phase
Wenn der Algorithmus in der ersten Phase noch nicht terminiert ist, werden nun in der zweitenPhase Tupel entfernt ohne die erste Bedingung zu verletzten. Der Algorithmus wird terminiert
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

3 L-Diversity 14
sobald die zweite Bedingung erfüllt ist. Wenn dies nicht der Fall ist, geht der Algorithmus indie dritte Phase über.
Das Ziel dieser Phase ist die Erhöhung von |R| und dabei h(R) konstant zu halten, währendTupel aus den QI-Gruppen unter Einhaltung der ersten Bedingung entfernt werden. Die Erhö-hung von |R| wird solange fortgeführt bis die Gleichung |R| ≥ l ∗h(R) erfüllt ist.
Für die weiteren Erklärungen werden zusätzliche Begriffe eingeführt. Nach der ersten Phasemuss für jede QI-Gruppe gelten: |Q| ≥ l ∗ h(Q). Q ist dünn, sofern gilt: |Q| = l ∗ h(Q). Wenn|Q| größer ist, wird Q als dick bezeichnet. Wenn Q einen oder mehrere Pillar-Werte hat, diezugleich Pillar-Werte der Restmenge R sind, wird diese Gruppe als in Konflikt stehende Gruppebezeichnet. Wenn die Gruppe Q sowohl eine dünne als auch eine in Konflikt stehende Gruppeist, wird diese Gruppe als „tot“ bezeichnet. Im anderen Fall ist diese Gruppe „lebend“. ToteGruppen können keine weiteren Tupel verlieren ohne h(R) zu erhöhen oder die erste Bedingungzu verletzen. Ein SA-Wert wird als „lebend“ bezeichnet, sofern es mindestens eine lebende QI-Gruppe gibt, in welcher dieser Wert auftritt.
In jedem Durchlauf wird nun ein lebender SA-Wert v genommen, sodass h(R,v) minimal ist.Es handelt sich also um den Wert, der am wenigsten in den entfernten Tupeln auftritt. Wenn esmehrere dieser Werte gibt, wird einer zufällig aus diesen ausgewählt. Es kann auch passieren,dass kein Wert ausgewählt werden kann. In diesem Fall wird in die dritte Phase übergegangen.Ansonsten wird eine QI-Gruppe betrachtet, in welcher h(Q,v)> 0 gilt. In Abhängigkeit davon,ob Q dick ist, wird aus dieser Gruppe nun ein Tupel mit diesem SA-Wert v entfernt. Wenn Qdünn ist, kann es sich nicht um eine in Konflikt stehende Gruppe handeln. Deswegen kann vonjedem Pillar-Wert ein Tupel entfernt werden. Dieses Vorgehen kann nicht h(R,v) erhöhen. DerAlgorithmus endet nun, sofern R l-eligible ist. Andernfalls findet ein erneuter Durchlauf statt.
3.3.3 Dritte Phase
In dieser Phase werden größere Mengen an Tupeln in der Hoffnung entfernt, dass dies zurErreichung der zweiten Bedingung führt. In den meisten Fällen terminiert der Algorithmusbereits in den ersten beiden Phasen. Nach der zweiten Phase sind alle QI-Gruppen dünn, inKonflikt stehend und es gilt für die R-Menge: |R| < l ∗ h(R). Die zweite Phase hat lediglich|R| erhöht und h(R) konstant gelassen. Da dieses Vorgehen nicht zum Erfolgt gereicht hat, wirdauch zugelassen h(R) zu erhöhen.
Die dritte Phase ist rundenbasiert, wobei jede Runde aus zwei Schritten besteht. Im erstenSchritt werden einige QI-Gruppen als Menge S ausgewählt. Aus diesen Gruppen wird nun je-weils ein Tupel mit den Pillar-Werten entfernt. Im Ergebnis steigt nun h(R) an, ermöglicht aberauch, dass die QI-Gruppen dick werden können. Da sich nun auch die Pillar-Werte von R än-dern, kann es passieren, dass bisher in Konflikt stehende Gruppen nicht mehr in Konflikt stehen.Eine entscheidende Rolle spielt die Wahl der QI-Gruppen für S. Initial wird der Menge P dieMenge der Pillar-Werte von R zugewiesen. C(Q) besteht aus den Pillar-Werten der QI-GruppeQ. Solange P nicht leer ist, wird die QI-Gruppe ausgewählt, die |C(Q)∩P|minimiert. Es wird Pnun diese Menge |C(Q)∩P| zugewiesen. Im zweiten Schritt, werden für jede QI-Gruppe, wel-che nach dem ersten Schritt wieder lebend geworden ist, Tupel entfernt, bis diese wieder tot ist.Wenn die QI-Gruppe dick ist, wird von jedem SA-Wert, welcher nicht ein Pillar von R ist, einTupel entfernt. Im anderen Fall wird zunächst geprüft, ob die Gruppe in Konflikt steht. Wenndies zutrifft, wird die Gruppe nicht weiter bearbeitet. Andernfalls wird von jedem Pillar-Wertaus dieser Gruppe ein Tupel entfernt. Sobald R an irgendeiner Stelle in dieser Phase l-eligible
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

3 L-Diversity 15
wird, terminiert der Algorithmus. Ansonsten wird die nächste Runde durchlaufen.
3.3.4 Bewertung
Die Performance des Algorithmus hängt sehr stark von der Anzahl der verschiedenen QI-Tupelab. Eine hohe Anzahl an QI-Tupeln führt letztlich zu einer hohen Anzahl an QI-Gruppen, derenWerteanzahl mit einer hohen Wahrscheinlichkeit unter l liegt. Es kann daher passieren, dassalle Tupel in die Menge R verschoben werden. Letztlich führt dies zu einer hohen Anzahl anSternen und somit einer hohen Generalisierung der Daten. Diese Gefahr besteht bei QI-Tupelnmit Attributen, die relativ viele verschiedene Werte enthalten, darunter zählt beispielsweise dasGeburtsdatum.
Nichtsdestotrotz zeigt der Algorithmus bei Attributen mit wenigen und mittelvielen Attri-buten eine gute Performance. Als Richtwert für eine gute Performance können Attribute mitweniger oder gleich zwanzig verschiedenen Werten angenommen werden. Andernfalls könnteman beispielsweise beim Geburtsdatum lediglich auf das Geburtsjahr und nicht auf das voll-ständige Datum zurückgreifen.
Je nachdem in welcher Phase der Algorithmus endet, ist die Lösung:
• Erste Phase: optimal
• Zweite Phase: ein additiver Fehler von (l−1) entsteht
• Dritte Phase: ein vielfacher Fehler von l entsteht
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

4 Resümee 16
4 Resümee
Letztlich sind weder die K-Anonymity noch die L-Diversity ein absoluter Garant für die Ge-währleistung der Anonymität eines Individuums. Die K-Anonymity schützt die Daten vor Ver-knüpfung mit den zugehörigen sensiblen Informationen des Individuums. Die L-Diversity ver-hindert durch ein vorausgesetztes Maß an Diversifikation der sensiblen Attribute in den Äqui-valenzklassen die Offenlegung von Attributen durch Erraten oder nach dem Ausschlussprinzip.Beide Gütekriterien für die Anonymität von Daten haben somit ihre Nachteile. Eine Kombina-tion beider Kriterien und deren Verfahren können hingegen zur Erreichung einer hohen Qualitätführen.
Neben den beiden Vorgestellten gibt es noch weitere Erweiterungen. Eines der Bekannterenist die T-Closeness. Es erfordert, dass die Werte der/des sensiblen Attributes in den Äquiva-lenzklassen gleichmäßig über die gesamte Tabelle verteilt sind. Dies bedeutet, dass von einemWert die relative Häufigkeit in einer Äquivalenzklasse nur bis zu einem gewissen Grad von denübrigen relativen Häufigkeiten in den anderen Äquivalenzklassen abweichen darf.
Die vorgestellten Algorithmen für die Erreichung der K-Anonymity und der L-Diversity sindrelativ ausgereift und zeigen in der Praxis eine gute Effizienz zwischen Aufwand und erreichterAnonymisierung.
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller

Literatur 17
Literatur
[BaAg05] Roberto J. Bayardo und Rakesh Agrawal (2005). Data Privacy Through Optimal
k-Anonymization. Proceedings of the 21st International Conference on Data Enginee-ring (ICDE 2005).
[XiYi10] Xiaokui Xiao, Ke Yi und Yufei Tao (2010). The Hardness and Approximation Algo-
rithms for L-Diversity. EDBT 2010, March 22–26, 2010, Lausanne, Switzerland.
[Hauf] Dietmar Hauf, IPD Uni-Karlsruhe. Allgemeine Konzepte K-Anonymity, l-Diversity
and T-Closeness.
[MaGe] Ashwin Machanavajjhala, Johannes Gehrke und Daniel Kifer. L-Diversity: Privacy
Beyond k-Anonymity.
[1] http://de.wikipedia.org/wiki/Data_Masking. Wikipedia - Data Masking;Aufgerufen am 27.12.2014
[2] http://de.wikipedia.org/wiki/NP-Schwere. Wikipedia - NP-Schwere; Aufge-rufen am 27.12.2014
Seminararbeit, FernUniversität in Hagen, WS2014/2015 Tobias Müller


Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
1
FernUniversität in Hagen -
Seminar 01912 im Wintersemester 2014/2015
„Sicherheit und Privatsphäre in
Datenbanksystemen“
Thema 6:
Absichtliches Stören von Daten
Referent: Stephan Schlößer

Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
2
Einleitung
Einführung
Überblick über das Thema
Datenbanken spielen eine wichtige Rolle sowohl in Wissenschaft als auch Wirtschaft. Typischerweise enthalten Datenbanken jeglicher Organisationen sowohl vertrauliche als auch nicht-vertrauliche Daten.
Zielsetzung bei der Datenbankadministration sollte es sein, einen möglichst großen Teil aller Daten zur Entscheidungsfindung und wissenschaftlichen Analyse zur Verfügung zu stellen, ohne dabei in die Privatsphäre von einzelnen Individuen einzugreifen, indem vertrauliche Daten offen gelegt werden.
Dazu können statistische Datenbanksysteme eingesetzt werden, die es für vertrauliche Informationen nur ermöglichen Gesamtstatistiken, wie Mittelwerte, Varianzen oder Korrelationen, abzufragen, ohne dabei einzelne vertrauliche Datensätze offen zu legen.
Um zu verhindern, dass böswillige Abfragen trotzdem einzelne vertrauliche Daten offen legen, sollten die ursprünglichen Daten so verändert werden, dass die Gesamtstatistiken möglichst wenig beeinflusst, die einzelnen vertraulichen Daten aber möglichst stark gestört werden.
Zur Störung von Daten existieren unterschiedliche Verfahren, von denen im Folgenden mehrere vorgestellt und bewertet werden.
Anmerkungen zur Notation
Im Folgenden werden Vektoren (hier in der Regel der Tupel aller Werte eines Attributs einer Datenbank) durch Fettdruck gekennzeichnet.
Außerdem werden folgende Zeichen verwendet:
X Vektor der ursprünglichen vertraulichen Attribute
Y Vektor der gestörten vertraulichen Attribute
S Vektor der nicht-vertraulichen Attribute Vektor der Mittelwerte von Q Kovarianzmatrix zwischen Q und P
Motivation
Motivation zum Stören von Daten
Das reine Beschränken des Zugangs auf Datenbankabfragen von statistischen Kennzahlen für vertrauliche Attribute ist nicht ausreichend zum Schutz vor unerlaubten Enthüllungen. Durch böswillige Abfragen kann ein Nutzer, besonders wenn er ausreichende Kenntnisse der entsprechenden Organisation hat, Zugang zu vertraulichen Daten erhalten.
Z.B. kann bei Kenntnis der Identität des bestbezahlten Mitarbeiters in einer Unternehmensdatenbank dessen Gehalt einfach über eine Abfrage des Maximums der Gehaltswerte ermittelt werden, auch wenn diese als vertraulich behandelt sind.

Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
3
Weiterhin könnte ein Nutzer, durch Kenntnis dass in einem Unternehmen nur ein weiblicher Angestellter arbeitet, alleine durch Abfrage der Mittelwerte von vertraulichen Informationen aller weiblichen Mitarbeiter die genauen Werte bezüglich dieser einen Mitarbeiterin finden.
Es wäre möglich den Zugriff auf statistische Datenbankabfragen zu verbieten, die zu wenige oder sehr viele Datensätze beinhalten. (Restricted Query Set Size) (Tendick und Matloff, 1994)1 Das heißt nur Abfragen zuzulassen die mindestens k und höchstens n-k Datensätze einbeziehen (in einer Datenbank mit n Datensätzen ). Mit steigendem Parameter k steigt dann zwar die Sicherheit, aber es lassen sich auch immer weniger aussagekräftige statistische Abfragen durchführen.
Um möglichst viele Arten von Abfragen zu ermöglichen wurden Methoden entwickelt, die die vertraulichen Daten verändern und jegliche Statistiken werden mit Hilfe dieser veränderten Daten berechnet. (Tendick und Matloff, 1994)1
Anforderungen und potentielle Probleme beim Stören von Daten
Die Veränderung (Störung) der vertraulichen Daten soll so geschehen, dass die erhaltenen Statistiken möglichst gering dadurch beeinflusst werden, die gestörten Daten aber nur wenig auf die ursprünglichen vertraulichen Daten schließen lassen.
Außerdem sollte es auch möglich sein vertrauliche Attribute als Selektionsvariablen in Datenbankabfragen zu verwenden (Confidential Attributes Used for Selection – CAUS), da sonst viele statistische Analysen behindert werden können. (Tendick und Matloff, 1994)1
Durch die Störung der vertraulichen Daten können jedoch, je nach dem auf welche Art sie verändert werden, unterschiedliche Verzerrungen in den erhaltenen Statistiken entstehen, die Ergebnisse und Entscheidungen stark beeinflussen können. Außerdem kann, je nach Grad der Störung, von den gestörten Attributwerten zumindest auf die Größenordnung der ursprünglichen Werte geschlossen werden.
Vorstellung eines Beispiels
Das folgende Beispiel, an dem die unterschiedlichen Methoden zur Datenstörung demonstriert werden, ist einem Paper von Muralidhar, Parsa und Sarathy (1999)2 entnommen.
Es handelt sich dabei um eine beispielhafte Bank, die Daten zu Kunden und ihren Einlagen, in Form von direkten Spareinlagen und außerbörslich gehandelten Geschäften (CDs etc.), in ihrer Datenbank gespeichert hat. Diese Daten sind, aus der Sicht eines Bankmitarbeiters, nicht-vertrauliche Daten.
Zusätzlich hat die Bank jedoch weitere Daten zu Wohneigentum, Aktien/Anleihen und ausstehenden Verbindlichkeiten ihrer Kunden erhoben, um z.B. neue Finanzprodukte gezielter entwickeln oder ihre operationale Strategie mit Hilfe umfangreicherer Informationen planen zu können .
Die Kunden haben diese Informationen unter der Voraussetzung herausgegeben, dass nur aggregierte Informationen verwendet werden und die individuellen Daten für niemanden offen gelegt werden. Es handelt sich dabei also, auch aus der Sicht eines Bankmitarbeiters, um vertrauliche Informationen.
Die Datenbank enthält insgesamt 10.000 Kunden-Datensätze. In Tabelle 1 sind dazu als beispielhafte Gesamtstatistiken wie Mittelwerte, Standardabweichungen und
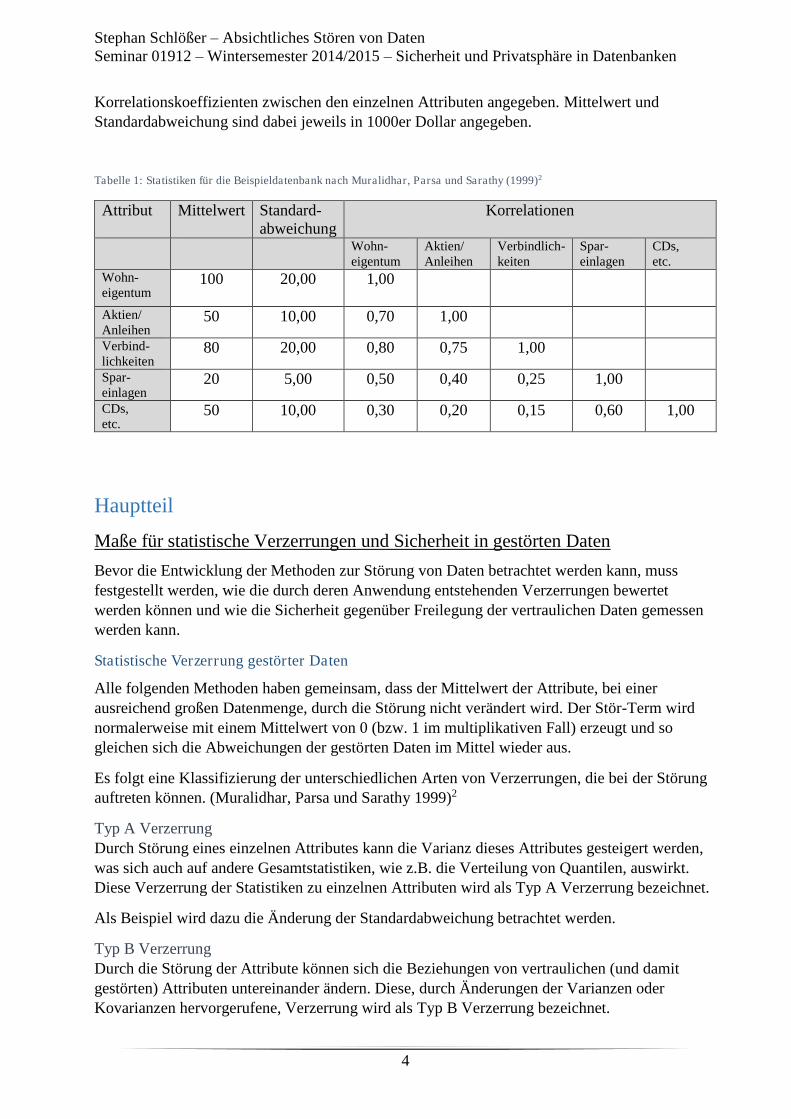
Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
4
Korrelationskoeffizienten zwischen den einzelnen Attributen angegeben. Mittelwert und Standardabweichung sind dabei jeweils in 1000er Dollar angegeben.
Tabelle 1: Statistiken für die Beispieldatenbank nach Muralidhar, Parsa und Sarathy (1999)2
Attribut Mittelwert Standard-abweichung
Korrelationen
Wohn- eigentum
Aktien/ Anleihen
Verbindlich- keiten
Spar-einlagen
CDs, etc.
Wohn- eigentum
100
20,00 1,00
Aktien/ Anleihen
50 10,00 0,70 1,00
Verbind-lichkeiten
80 20,00 0,80 0,75 1,00
Spar-einlagen
20 5,00 0,50 0,40 0,25 1,00
CDs, etc.
50 10,00 0,30 0,20 0,15 0,60 1,00
Hauptteil
Maße für statistische Verzerrungen und Sicherheit in gestörten Daten
Bevor die Entwicklung der Methoden zur Störung von Daten betrachtet werden kann, muss festgestellt werden, wie die durch deren Anwendung entstehenden Verzerrungen bewertet werden können und wie die Sicherheit gegenüber Freilegung der vertraulichen Daten gemessen werden kann.
Statistische Verzerrung gestörter Daten
Alle folgenden Methoden haben gemeinsam, dass der Mittelwert der Attribute, bei einer ausreichend großen Datenmenge, durch die Störung nicht verändert wird. Der Stör-Term wird normalerweise mit einem Mittelwert von 0 (bzw. 1 im multiplikativen Fall) erzeugt und so gleichen sich die Abweichungen der gestörten Daten im Mittel wieder aus.
Es folgt eine Klassifizierung der unterschiedlichen Arten von Verzerrungen, die bei der Störung auftreten können. (Muralidhar, Parsa und Sarathy 1999)2
Typ A Verzerrung Durch Störung eines einzelnen Attributes kann die Varianz dieses Attributes gesteigert werden, was sich auch auf andere Gesamtstatistiken, wie z.B. die Verteilung von Quantilen, auswirkt. Diese Verzerrung der Statistiken zu einzelnen Attributen wird als Typ A Verzerrung bezeichnet.
Als Beispiel wird dazu die Änderung der Standardabweichung betrachtet werden.
Typ B Verzerrung Durch die Störung der Attribute können sich die Beziehungen von vertraulichen (und damit gestörten) Attributen untereinander ändern. Diese, durch Änderungen der Varianzen oder Kovarianzen hervorgerufene, Verzerrung wird als Typ B Verzerrung bezeichnet.

Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
5
Im Beispiel werden dazu die Korrelationskoeffizienten zwischen den vertraulichen Attributen betrachtet.
Typ C Verzerrung Die Störung kann auch zur Veränderung der Beziehungen zwischen vertraulichen (gestörten) und nicht-vertraulichen (nicht-gestörten) Attributen führen. Auch diese Verzerrung hängt mit der Änderung der Varianzen und/oder der Änderung der Kovarianzen zwischen gestörten und nicht-gestörten Attributen zusammen. Sie wird als Typ C Verzerrung bezeichnet.
Im Beispiel werden dazu die Korrelationskoeffizienten zwischen vertraulichen und nicht-vertraulichen Attributen betrachtet.
Typ D Verzerrung Wenn die grundlegende Verteilung der Datenbank keine multivariante Normalverteilung ist und/oder die Störterme nicht multivariant normalverteilt sind, kann die Form der gestörten Datenbank nicht immer vorausgesagt werden. Dadurch können Werte wie Quantile, konditionale Mittelwerte oder Summen verändert sein.
Die Auswirkungen dieser Verzerrungen auf die statistischen Maße sind die gleichen wie bei der Typ A Verzerrung, da jedoch die grundlegende Ursache eine andere ist, wird dies als eigener Fall betrachtet und als Typ D Verzerrung bezeichnet.
Im Beispiel ist die grundlegende Verteilung der Datenbank eine multivariante Normalverteilung und es wird grundsätzlich davon ausgegangen, dass die Störterme auch aus einer multivarianten Normalverteilung erzeugt werden, so dass diese Art von Verzerrung nicht auftritt.
Sicherheit gestörter Daten
Sicherheit von Einzelattributen Die Sicherheit einzelner Attribute wird als die Varianz des Unterschieds zwischen den tatsächlichen Werten X und den gestörten Werten Y berechnet. (Adam und Wortmann, 1989)3
Zur besseren Vergleichbarkeit wird dieser Wert noch mit der Varianz des ursprünglichen Attributes normalisiert: 1 = −
Dieser Wert misst die Sicherheit, die durch die Störung gegeben ist, wenn der originale Attributwert nur aus dem gestörten Attributwert abgeschätzt werden soll.
Sicherheit von Linearkombinationen von Attributen Zusätzlich zur reinen Abschätzung der vertraulichen Attributwerte aus den gestörten Werten, könnten Linearkombinationen der vertraulichen Attributwerte mit Hilfe von Linearkombinationen der beobachteten Werte der gestörten Attribute und der Werte der nicht-vertraulichen Attribute abgeschätzt werden.
Es lässt sich zeigen dass die beobachtete Varianz bei einer solchen Abschätzung von Linearkombinationen vertraulicher Attribute niedriger ist, als im Fall von einzelnen gestörten Attributen. (Tendick, 1991)4

Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
6
Um die Sicherheit gegenüber der Abschätzung von Linearkombinationen zu messen, wird per kanonischer Korrelationsanalyse der maximale Anteil an Varianz λ berechnet, der durch Linearkombinationen von bekannten Attributen (sowohl nicht-vertrauliche, als auch gestörte) für die originalen vertraulichen Attribute erklärt werden kann. (Johnson und Wichern, 1992)5 = 1 −
Für jegliche Linearkombination vertraulicher Attribute bleibt also mindestens ein Anteil der Varianz in Höhe von S2 durch Linearkombinationen beliebiger bekannter Attribute unerklärt.
Evolution der Methoden zur Datenstörung
Im Folgenden wird die Entwicklung der Methoden zur Datenstörung dargestellt und die einzelnen Methoden in Hinsicht auf Sicherheit und statistische Verzerrung bewertet.
Simple Additive Data Perturbation
Die Simple Additive Data Pertubation (SADP) ist die einfachste Form der Additive Data Pertubation Methoden, zu denen alle, bis auf die multiplikative Variante, der im Folgenden vorgestellten Methoden gehören.
Dabei wird ein Stör-Term e zu den ursprünglichen vertraulichen Attributwerten X addiert, um die gestörten Werte Y zu erhalten: = +
Die Verteilung des Stör-Terms hat einen Mittelwert von 0, so dass sich die addierten Werte im Mittel gegenseitig ausgleichen.
Im einfachen Fall der SADP wird jedes Attribut Xi unabhängig von den anderen gestört und einfach eine normalverteilte Zufallsvariable mit Mittelwert 0 und Varianz dXi zum jeweiligen Attributwert addiert. Durch den Parameter d kann der Grad der Störung im konkreten Fall gewählt werden. Mit steigendem d und damit auch steigender Varianz der Stör-Terme steigt die Sicherheit, aber auch der Grad der Verzerrung.
In Tabelle 2 sind die Statistiken der Beispieldatenbank nach Störung per SADP mit d = 1,0 wiedergegeben. (Muralidhar, Parsa und Sarathy, 1999)2
Man kann sehen, dass sich die Mittelwerte nicht geändert haben, jedoch die Standardabweichungen unterschiedlich sind. Es entsteht also eine Typ A Verzerrung. Weiterhin sind die Korrelationen zwischen den vertraulichen Attributen untereinander und zwischen vertraulichen Attributen und nicht-vertraulichen Attributen verändert. Also entsteht eine Typ B und Typ C Verzerrung. Durch die Addition der Stör-Term wurden die Varianzen der Attribute erhöht und die ursprüngliche Korrelationsstruktur verzerrt.
Solange die Stör-Terme multivariant Normalverteilt sind, sind auch die Werte in der neu-entstandenen gestörten Datenbank multivariant normalverteilt und es entsteht keine Typ D Verzerrung.
Die Sicherheit für einzelne Attribute ist mit 1,00 im adäquaten Bereich, jedoch ist die Sicherheit für Linearkombinationen mit 0,26 relativ gering.
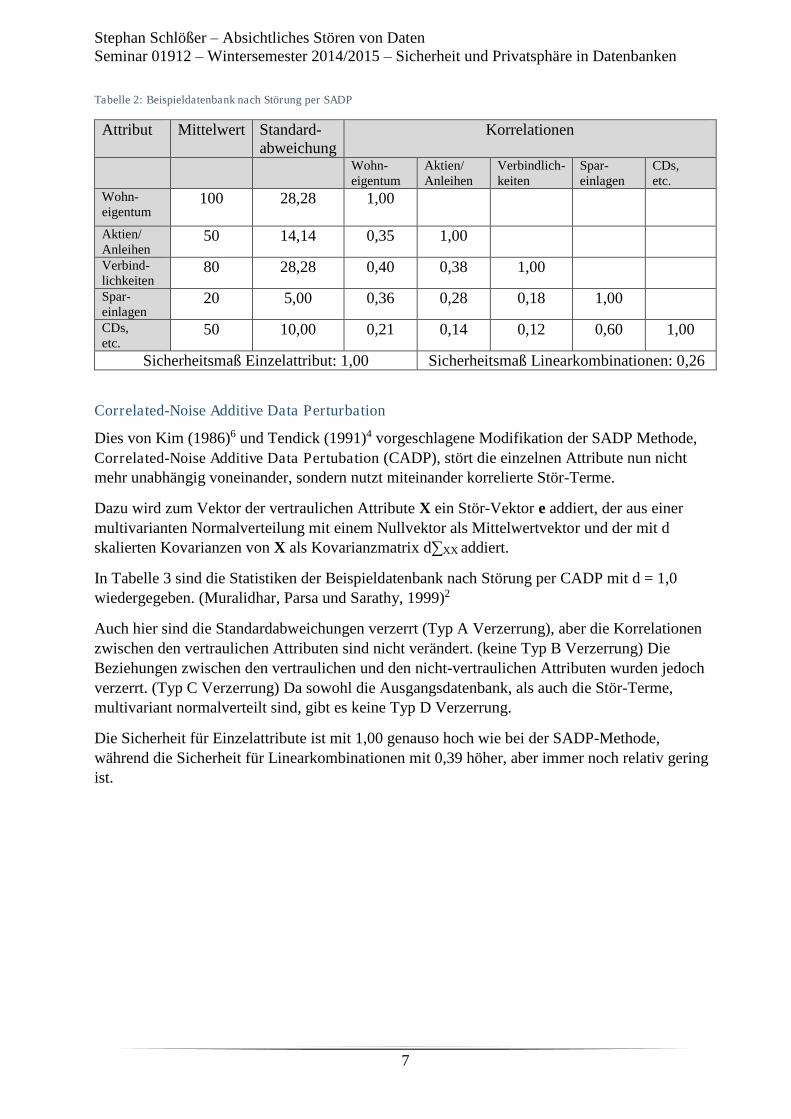
Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
7
Tabelle 2: Beispieldatenbank nach Störung per SADP
Attribut Mittelwert Standard-abweichung
Korrelationen
Wohn- eigentum
Aktien/ Anleihen
Verbindlich- keiten
Spar-einlagen
CDs, etc.
Wohn- eigentum
100
28,28 1,00
Aktien/ Anleihen
50 14,14 0,35 1,00
Verbind-lichkeiten
80 28,28 0,40 0,38 1,00
Spar-einlagen
20 5,00 0,36 0,28 0,18 1,00
CDs, etc.
50 10,00 0,21 0,14 0,12 0,60 1,00
Sicherheitsmaß Einzelattribut: 1,00 Sicherheitsmaß Linearkombinationen: 0,26
Correlated-Noise Additive Data Perturbation
Dies von Kim (1986)6 und Tendick (1991)4 vorgeschlagene Modifikation der SADP Methode, Correlated-Noise Additive Data Pertubation (CADP), stört die einzelnen Attribute nun nicht mehr unabhängig voneinander, sondern nutzt miteinander korrelierte Stör-Terme.
Dazu wird zum Vektor der vertraulichen Attribute X ein Stör-Vektor e addiert, der aus einer multivarianten Normalverteilung mit einem Nullvektor als Mittelwertvektor und der mit d skalierten Kovarianzen von X als Kovarianzmatrix d∑XX addiert.
In Tabelle 3 sind die Statistiken der Beispieldatenbank nach Störung per CADP mit d = 1,0 wiedergegeben. (Muralidhar, Parsa und Sarathy, 1999)2
Auch hier sind die Standardabweichungen verzerrt (Typ A Verzerrung), aber die Korrelationen zwischen den vertraulichen Attributen sind nicht verändert. (keine Typ B Verzerrung) Die Beziehungen zwischen den vertraulichen und den nicht-vertraulichen Attributen wurden jedoch verzerrt. (Typ C Verzerrung) Da sowohl die Ausgangsdatenbank, als auch die Stör-Terme, multivariant normalverteilt sind, gibt es keine Typ D Verzerrung.
Die Sicherheit für Einzelattribute ist mit 1,00 genauso hoch wie bei der SADP-Methode, während die Sicherheit für Linearkombinationen mit 0,39 höher, aber immer noch relativ gering ist.
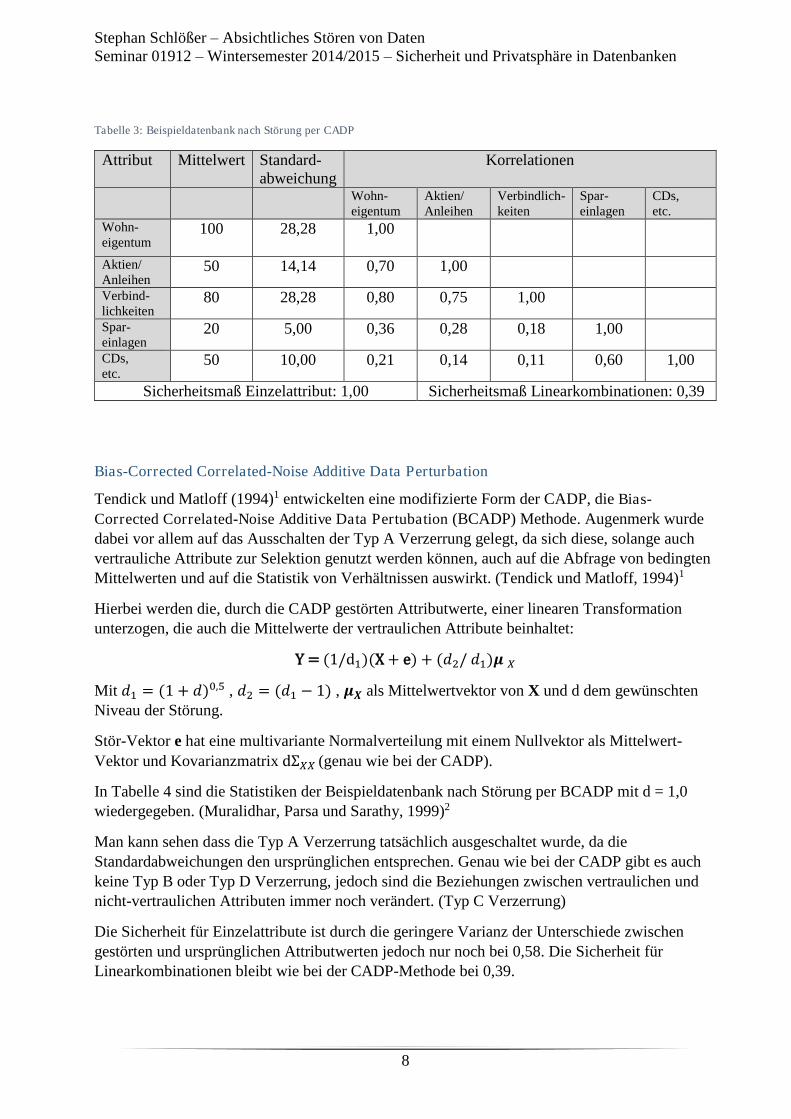
Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
8
Tabelle 3: Beispieldatenbank nach Störung per CADP
Attribut Mittelwert Standard-abweichung
Korrelationen
Wohn- eigentum
Aktien/ Anleihen
Verbindlich- keiten
Spar-einlagen
CDs, etc.
Wohn- eigentum
100
28,28 1,00
Aktien/ Anleihen
50 14,14 0,70 1,00
Verbind-lichkeiten
80 28,28 0,80 0,75 1,00
Spar-einlagen
20 5,00 0,36 0,28 0,18 1,00
CDs, etc.
50 10,00 0,21 0,14 0,11 0,60 1,00
Sicherheitsmaß Einzelattribut: 1,00 Sicherheitsmaß Linearkombinationen: 0,39
Bias-Corrected Correlated-Noise Additive Data Perturbation
Tendick und Matloff (1994)1 entwickelten eine modifizierte Form der CADP, die Bias-Corrected Correlated-Noise Additive Data Pertubation (BCADP) Methode. Augenmerk wurde dabei vor allem auf das Ausschalten der Typ A Verzerrung gelegt, da sich diese, solange auch vertrauliche Attribute zur Selektion genutzt werden können, auch auf die Abfrage von bedingten Mittelwerten und auf die Statistik von Verhältnissen auswirkt. (Tendick und Matloff, 1994)1
Hierbei werden die, durch die CADP gestörten Attributwerte, einer linearen Transformation unterzogen, die auch die Mittelwerte der vertraulichen Attribute beinhaltet: Y = 1/d1 X + e + / 1
Mit 1 = 1 + ,5 , = 1 − 1 , als Mittelwertvektor von X und d dem gewünschten Niveau der Störung.
Stör-Vektor e hat eine multivariante Normalverteilung mit einem Nullvektor als Mittelwert-Vektor und Kovarianzmatrix dΣ (genau wie bei der CADP).
In Tabelle 4 sind die Statistiken der Beispieldatenbank nach Störung per BCADP mit d = 1,0 wiedergegeben. (Muralidhar, Parsa und Sarathy, 1999)2
Man kann sehen dass die Typ A Verzerrung tatsächlich ausgeschaltet wurde, da die Standardabweichungen den ursprünglichen entsprechen. Genau wie bei der CADP gibt es auch keine Typ B oder Typ D Verzerrung, jedoch sind die Beziehungen zwischen vertraulichen und nicht-vertraulichen Attributen immer noch verändert. (Typ C Verzerrung)
Die Sicherheit für Einzelattribute ist durch die geringere Varianz der Unterschiede zwischen gestörten und ursprünglichen Attributwerten jedoch nur noch bei 0,58. Die Sicherheit für Linearkombinationen bleibt wie bei der CADP-Methode bei 0,39.
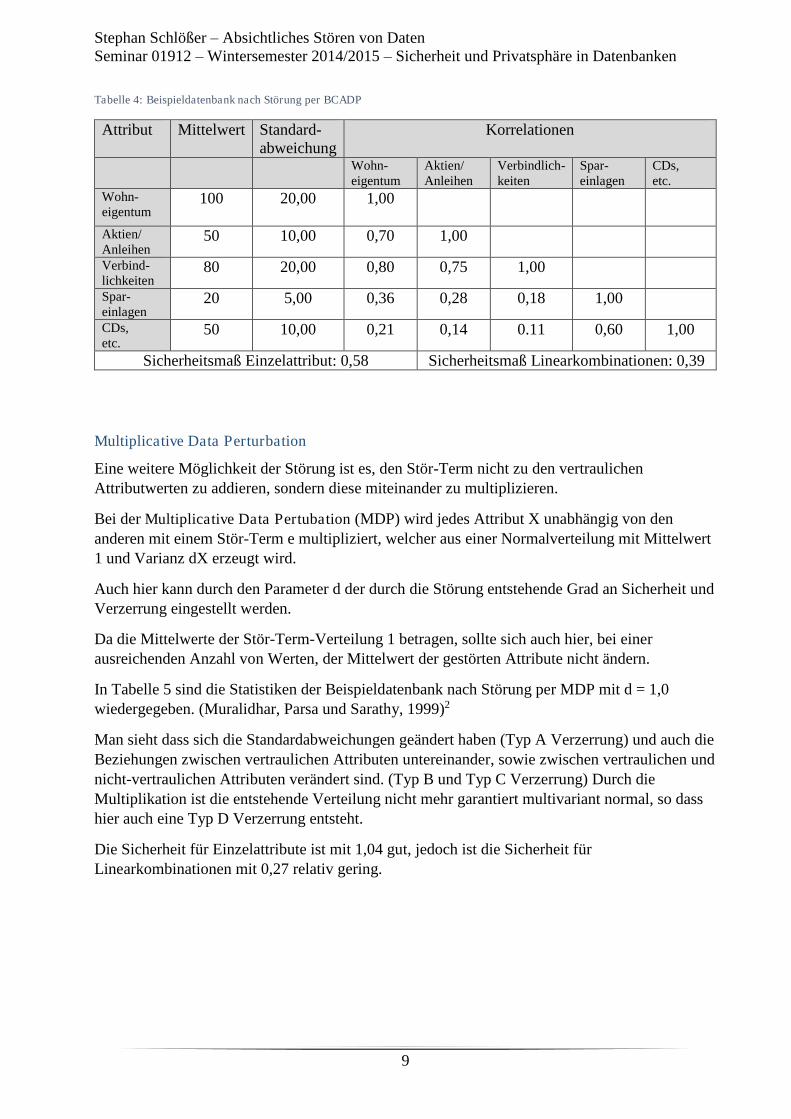
Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
9
Tabelle 4: Beispieldatenbank nach Störung per BCADP
Attribut Mittelwert Standard-abweichung
Korrelationen
Wohn- eigentum
Aktien/ Anleihen
Verbindlich- keiten
Spar-einlagen
CDs, etc.
Wohn- eigentum
100
20,00 1,00
Aktien/ Anleihen
50 10,00 0,70 1,00
Verbind-lichkeiten
80 20,00 0,80 0,75 1,00
Spar-einlagen
20 5,00 0,36 0,28 0,18 1,00
CDs, etc.
50 10,00 0,21 0,14 0.11 0,60 1,00
Sicherheitsmaß Einzelattribut: 0,58 Sicherheitsmaß Linearkombinationen: 0,39
Multiplicative Data Perturbation
Eine weitere Möglichkeit der Störung ist es, den Stör-Term nicht zu den vertraulichen Attributwerten zu addieren, sondern diese miteinander zu multiplizieren.
Bei der Multiplicative Data Pertubation (MDP) wird jedes Attribut X unabhängig von den anderen mit einem Stör-Term e multipliziert, welcher aus einer Normalverteilung mit Mittelwert 1 und Varianz dX erzeugt wird.
Auch hier kann durch den Parameter d der durch die Störung entstehende Grad an Sicherheit und Verzerrung eingestellt werden.
Da die Mittelwerte der Stör-Term-Verteilung 1 betragen, sollte sich auch hier, bei einer ausreichenden Anzahl von Werten, der Mittelwert der gestörten Attribute nicht ändern.
In Tabelle 5 sind die Statistiken der Beispieldatenbank nach Störung per MDP mit d = 1,0 wiedergegeben. (Muralidhar, Parsa und Sarathy, 1999)2
Man sieht dass sich die Standardabweichungen geändert haben (Typ A Verzerrung) und auch die Beziehungen zwischen vertraulichen Attributen untereinander, sowie zwischen vertraulichen und nicht-vertraulichen Attributen verändert sind. (Typ B und Typ C Verzerrung) Durch die Multiplikation ist die entstehende Verteilung nicht mehr garantiert multivariant normal, so dass hier auch eine Typ D Verzerrung entsteht.
Die Sicherheit für Einzelattribute ist mit 1,04 gut, jedoch ist die Sicherheit für Linearkombinationen mit 0,27 relativ gering.
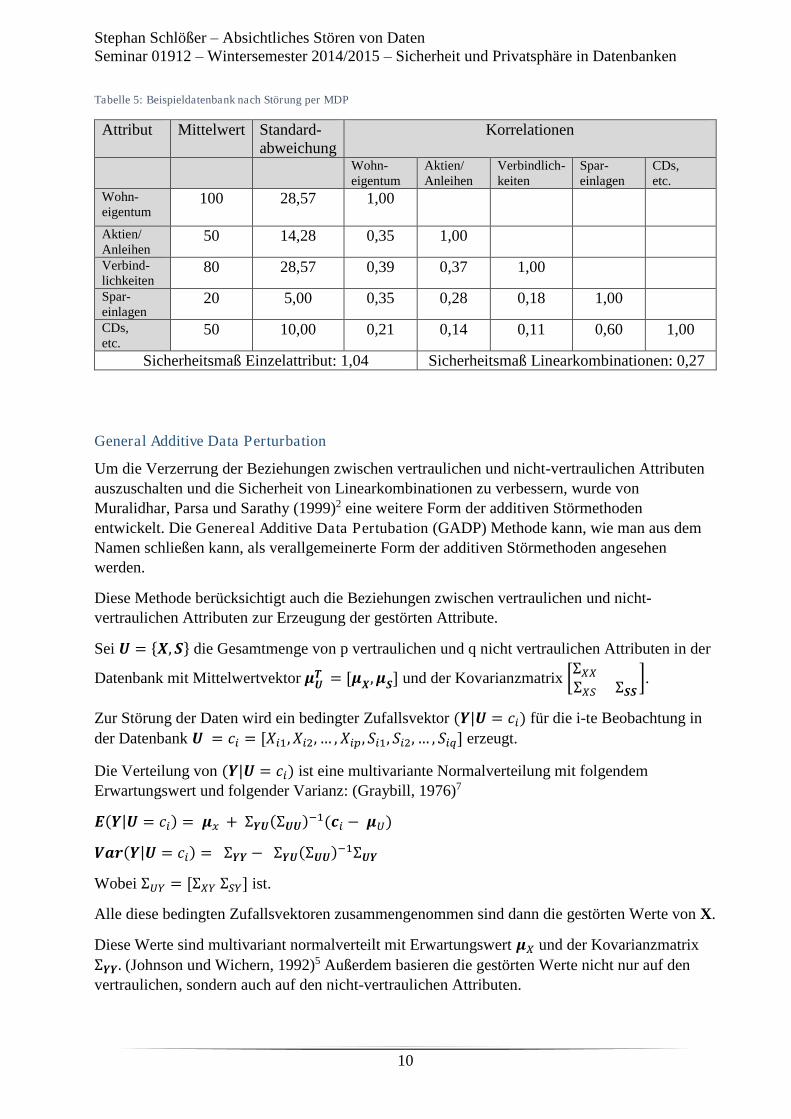
Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
10
Tabelle 5: Beispieldatenbank nach Störung per MDP
Attribut Mittelwert Standard-abweichung
Korrelationen
Wohn- eigentum
Aktien/ Anleihen
Verbindlich- keiten
Spar-einlagen
CDs, etc.
Wohn- eigentum
100
28,57 1,00
Aktien/ Anleihen
50 14,28 0,35 1,00
Verbind-lichkeiten
80 28,57 0,39 0,37 1,00
Spar-einlagen
20 5,00 0,35 0,28 0,18 1,00
CDs, etc.
50 10,00 0,21 0,14 0,11 0,60 1,00
Sicherheitsmaß Einzelattribut: 1,04 Sicherheitsmaß Linearkombinationen: 0,27
General Additive Data Perturbation
Um die Verzerrung der Beziehungen zwischen vertraulichen und nicht-vertraulichen Attributen auszuschalten und die Sicherheit von Linearkombinationen zu verbessern, wurde von Muralidhar, Parsa und Sarathy (1999)2 eine weitere Form der additiven Störmethoden entwickelt. Die Genereal Additive Data Pertubation (GADP) Methode kann, wie man aus dem Namen schließen kann, als verallgemeinerte Form der additiven Störmethoden angesehen werden.
Diese Methode berücksichtigt auch die Beziehungen zwischen vertraulichen und nicht-vertraulichen Attributen zur Erzeugung der gestörten Attribute.
Sei = , die Gesamtmenge von p vertraulichen und q nicht vertraulichen Attributen in der
Datenbank mit Mittelwertvektor = [ , ] und der Kovarianzmatrix [ΣΣ Σ ]. Zur Störung der Daten wird ein bedingter Zufallsvektor | = für die i-te Beobachtung in der Datenbank = = [1, , … , , 1, , … , ] erzeugt.
Die Verteilung von | = ist eine multivariante Normalverteilung mit folgendem Erwartungswert und folgender Varianz: (Graybill, 1976)7 | = = + Σ Σ −1 − | = = Σ − Σ Σ −1Σ
Wobei Σ = [Σ Σ ] ist.
Alle diese bedingten Zufallsvektoren zusammengenommen sind dann die gestörten Werte von X.
Diese Werte sind multivariant normalverteilt mit Erwartungswert und der Kovarianzmatrix Σ . (Johnson und Wichern, 1992)5 Außerdem basieren die gestörten Werte nicht nur auf den vertraulichen, sondern auch auf den nicht-vertraulichen Attributen.

Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
11
Im Gegensatz zu den anderen Störmethoden gibt es hier somit 3 Parameter, die gewählt werden können, um Sicherheit und Verzerrung zu beeinflussen, nämlich die 3 Kovarianzmatrizen Σ , Σ , Σ .
Durch geeignete Wahl der Parameter können durch die GADP alle anderen vorgestellten additiven Methoden der Störung repliziert werden. Z.B. erhält man das gleiche Ergebnis der
Störung wie bei der BCADP, wenn man die Parameter als Σ = Σ , Σ = 11 Σ und Σ = 11 Σ wählt.
Mit günstig gewählten Parametern kann bei der GADP jede Form der zuvor diskutierten Verzerrungen vermieden werden.
Sei ∑G die gesamte Kovarianzmatrix von den vertraulichen Attributen X, den nicht vertraulichen Attributen S und den gestörten vertraulichen Attributen Y.
Σ = [ΣΣ ΣΣ Σ Σ ]
Eine Beobachtung der ungestörten Datenbank würde die Kovarianzmatrix [ΣΣ Σ] ergeben,
während eine Beobachtung nach der Störung die Kovarianzmatrix [ΣΣ Σ ] ergibt.
Setzt man nun die Parameter Σ = ΣXX, Σ = Σ erhält man die Kovarianzmatrix [ΣΣ ΣXX] und man kann erkennen dass die Matrix der transponierten Form der Matrix der ungestörten Datenbank entspricht. Es werden also in diesem Fall genau die gleichen Werte beobachtet und es gibt keine Typ A, B oder C Verzerrung. Solange die Voraussetzung der multivarianten Normalverteilung erfüllt ist, gibt es auch keine Typ D Verzerrung.
Die Wahl des verbleibenden Parameters Σ bleibt dann von der gewünschten Sicherheitsstufe abhängig. Der Parameter kann so gewählt werden, dass die Sicherheit maximiert wird, ohne Verzerrungen einzuführen. Da die nicht-vertraulichen Attribute S immer beobachtet und auch aus ihnen alleine die vertraulichen abgeschätzt werden können, ist die maximale Sicherheit von der Beziehung zwischen X und S abhängig.
Sei der kanonische Korrelationskoeffizient zwischen X und S. Dann kann ein Anteil von der Varianz in Linearkombinationen von X alleine durch Linearkombinationen von S erklärt werden. Also kann nur ein Anteil von 1 − unerklärt bleiben. Diese maximal mögliche Sicherheit kann durch Wahl von Σ = Σ erreicht werden.
In Tabelle 6 sind die Statistiken der Beispieldatenbank nach Störung per GADP mit Σ = Σ , Σ = Σ und Σ = ,35Σ wiedergegeben. (Muralidhar, Parsa und Sarathy, 1999)2
Wie erwartet lässt sich weder Typ A, noch Typ B oder Typ C Verzerrung in den gestörten Daten beobachten.
Die Sicherheit für Einzelattribute ist mit 1,30 gut und die Sicherheit für Linearkombinationen mit 0,65 beim theoretisch höchsten Wert.
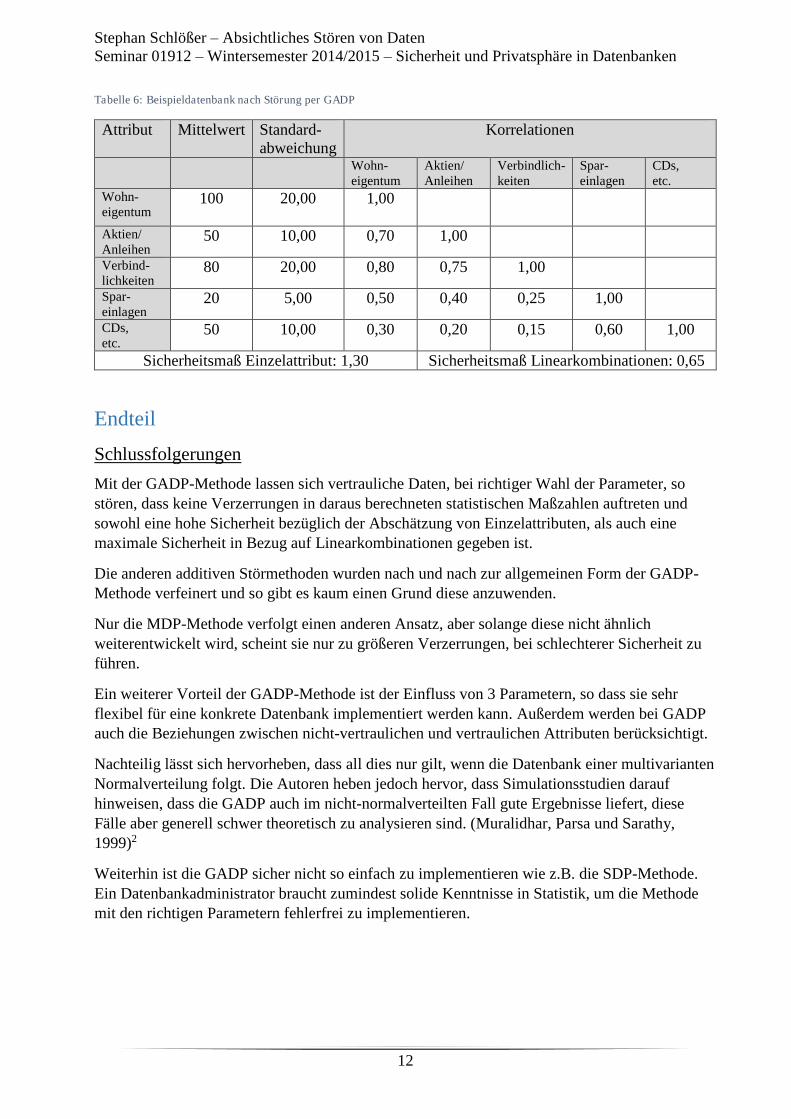
Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
12
Tabelle 6: Beispieldatenbank nach Störung per GADP
Attribut Mittelwert Standard-abweichung
Korrelationen
Wohn- eigentum
Aktien/ Anleihen
Verbindlich- keiten
Spar-einlagen
CDs, etc.
Wohn- eigentum
100
20,00 1,00
Aktien/ Anleihen
50 10,00 0,70 1,00
Verbind-lichkeiten
80 20,00 0,80 0,75 1,00
Spar-einlagen
20 5,00 0,50 0,40 0,25 1,00
CDs, etc.
50 10,00 0,30 0,20 0,15 0,60 1,00
Sicherheitsmaß Einzelattribut: 1,30 Sicherheitsmaß Linearkombinationen: 0,65
Endteil
Schlussfolgerungen
Mit der GADP-Methode lassen sich vertrauliche Daten, bei richtiger Wahl der Parameter, so stören, dass keine Verzerrungen in daraus berechneten statistischen Maßzahlen auftreten und sowohl eine hohe Sicherheit bezüglich der Abschätzung von Einzelattributen, als auch eine maximale Sicherheit in Bezug auf Linearkombinationen gegeben ist.
Die anderen additiven Störmethoden wurden nach und nach zur allgemeinen Form der GADP-Methode verfeinert und so gibt es kaum einen Grund diese anzuwenden.
Nur die MDP-Methode verfolgt einen anderen Ansatz, aber solange diese nicht ähnlich weiterentwickelt wird, scheint sie nur zu größeren Verzerrungen, bei schlechterer Sicherheit zu führen.
Ein weiterer Vorteil der GADP-Methode ist der Einfluss von 3 Parametern, so dass sie sehr flexibel für eine konkrete Datenbank implementiert werden kann. Außerdem werden bei GADP auch die Beziehungen zwischen nicht-vertraulichen und vertraulichen Attributen berücksichtigt.
Nachteilig lässt sich hervorheben, dass all dies nur gilt, wenn die Datenbank einer multivarianten Normalverteilung folgt. Die Autoren heben jedoch hervor, dass Simulationsstudien darauf hinweisen, dass die GADP auch im nicht-normalverteilten Fall gute Ergebnisse liefert, diese Fälle aber generell schwer theoretisch zu analysieren sind. (Muralidhar, Parsa und Sarathy, 1999)2
Weiterhin ist die GADP sicher nicht so einfach zu implementieren wie z.B. die SDP-Methode. Ein Datenbankadministrator braucht zumindest solide Kenntnisse in Statistik, um die Methode mit den richtigen Parametern fehlerfrei zu implementieren.

Stephan Schlößer – Absichtliches Stören von Daten Seminar 01912 – Wintersemester 2014/2015 – Sicherheit und Privatsphäre in Datenbanken
13
Literaturliste
1. Tendick and Matloff, 1994. A Modified Random Pertubation Method for Database Security. ACM Transactions on Database Systems, Vol.19, No.1, March 1994, pp 47-63.
2. Muralidhar, Parsa and Sarathy, 1999. A General Additive Data Pertubation Method for Database Security. Management Science, Vol. 45, No. 10, October 1999, pp. 1399-1415.
3. Adam and Wortmann, 1989. Security control methods for statistical databases: A comparative study. ACM Comput. Surveys 21(4) pp 515-556.
4. Tendick, 1991. Optimal noise addition for preserving confidentiality in multivariate data. J. Statist. Planning and Inference 27(2) pp 341-353.
5. Johnson und Wichern, 1992. Applied Multivariate Statistical Analysis. Prentice-Hall, Englewood Cliffs, NJ.
6. Kim, 1986. A method for limiting disclosure in microdata based on random noise and transformation. ASA Proc. Survey Res. Section 370-374.
7. Graybill, 1976. Theory and Applicatin of the Linear Model. Duxbury Press, North Scituate, MA.


Thema 9: Attacken
Seminar 01912 / 19912
im Wintersemester 2014/2015
Sicherheit und Privatsphäre in Datenbanksystemen
Referent: Stella Nieto-Ernst

1
1 Einführung in die Sicherheitsaspekte Als Informationssicherheit bezeichnet man Eigenschaften von informationsverarbeitenden und -lagernden (technischen oder nicht-technischen) Systemen, die die Schutzziele: Vertraulichkeit, Verfügbarkeit und Integrität sicherstellen. Informationssicherheit dient dem Schutz vor Gefahren bzw. Bedrohungen, der Vermeidung von wirtschaftlichen Schäden und der Minimierung von Risiken. Jedes noch so gut geplante und umgesetzte IT-System kann Schwachstellen besitzen. Sind bestimmte Angriffe zum Umgehen der vorhandenen Sicherheitsvorkehrungen möglich, ist das System verwundbar. Nutzt ein Angreifer eine Schwachstelle oder eine Verwundbarkeit zum Eindringen in ein IT-System, sind die Vertraulichkeit, Datenintegrität und Verfügbarkeit bedroht (englisch: threat). Angriffe auf die Schutzziele bedeuten für Unternehmen Angriffe auf reale Unternehmenswerte, im Regelfall das Abgreifen oder Verändern von unternehmensinternen Informationen. [1]
1.1 Angreifermodelle
Zur Erfassung der möglichen Bedrohungen für ein System ist es zunächst erforderlich, potenzielle Angriffe zu beschreiben. Auf Angreifer muss entsprechend des „Schadenspotentials“ der Angreifer und der „Schutzziele“ des Angegriffenen reagiert werden können. Dazu ist die Analyse der einzelnen Schutzziele und des Angreifermodells notwendig. Um ein möglichst hohes Sicherheitsniveau zu gewährleisten, wird im Angreifermodell grundsätzlich die maximal berücksichtigte Stärke des Angreifers definiert.
1.2 Verschlüsselungsverfahren zum Erreichen der definierten Schutzziele
Es gibt Gründe, die eindeutig dafür sprechen, Datenbanken zu verschlüsseln. Vorsichtsmaßnahmen nach Ermessen reichen nicht aus.
Das Ziel der Verschlüsselung ist es, die Vertraulichkeit von Daten zu erreichen. Bei unverschlüsselten Daten spricht man von Klartext. Dieser wird durch Verschlüsselung in Kryptotext oder Chiffretext überführt. Nur die berechtigten Parteien sollen dann in der Lage sein, den Chiffretext wieder in Klartext zu überführen, also an die Nachricht oder Daten zu gelangen. Die Transformation von Chiffretext zu Klartext wird als Entschlüsselung bezeichnet.
Die Kryptoanalyse (in neueren Publikationen auch Kryptanalyse) bezeichnet im ursprünglichen Sinne das Studium von Methoden und Techniken, um Informationen aus verschlüsselten Texten zu gewinnen. Diese Informationen können sowohl der verwendete Schlüssel als auch der Originaltext sein. Heutzutage bezeichnet der Begriff Kryptoanalyse allgemeiner die Analyse von kryptographischen Verfahren (nicht nur zur Verschlüsselung) mit dem Ziel, diese entweder zu „brechen“, d. h. ihre Schutzfunktion aufzuheben bzw. zu umgehen, oder ihre Sicherheit nachzuweisen und zu quantifizieren. Kryptoanalyse ist damit das „Gegenstück“ zur Kryptographie. Beide sind Teilgebiete der Kryptologie.
In der Kryptologie haben die Begriffe „Entzifferung“ und „Entschlüsselung“ unterschiedliche Bedeutung: Als (befugte) Entschlüsselung bezeichnet man das Verfahren, mit Hilfe des bekannten Schlüssels den Geheimtext wieder in den Klartext zurückzuverwandeln und so die Nachricht lesen zu können. Die (unbefugte) Entzifferung hingegen ist die Kunst, dem Geheimtext ohne Kenntnis des Schlüssels die Nachricht zu entringen. Statt des Verbs „entziffern“ wird in der Kryptanalyse auch der Ausdruck „brechen“ oder umgangssprachlich auch „knacken“ verwendet. [2]

2
2 Motivation der Facharbeit Im ersten Kapitel wurden die wesentlichen Sicherheitsaspekten erläutert, was einen Überblick verschafft bzgl. der Wichtigkeit der Schutzmechanismen. Die Angriffsabwehr bedarf der Kenntnis über möglichen Schwachstellen. Bei Datenbanksystemen stellt die sogenannte „Anfragen-Logdatei“ also das Protokollieren von Anfragen an ein Datenbanksystem einen Schwachpunkt, ein „Leck“, dar, denn daraus kann ein Angreifer Informationen gewinnen.
In dieser Arbeit werden zwei mögliche Angriffsszenarien erläutert:
• Anfragen-Logdatei-Attacke auf verschlüsselte Datenbanken [3]
• Rückschluss- Attacke gegen verschlüsselte Bereichsanfragen in ausgelagerten Datenbanken [4]
3 Anfragen-Logdatei-Attacke auf verschlüsselte Datenbanken [3] In der Literatur gibt es mehr als ein Dutzend vorgeschlagene Mechanismen zum Verschlüsseln von Daten zwecks Geheimhaltung. Ein Datenbanksystem jedoch ist mehr als nur Daten, untrennbarer Aspekt eines Datenbanksystems ist nämlich die Interaktion mit dem Benutzer über Anfragen. Tahmineh Sanamrad und Donald Kossmann entwickelten erstmalig neue Angreifermodelle, die in erster Linie auf den bekannten Angreifermodellen basieren: Angriff bei bekanntem Kryptotext (ciphertext-only attack ), Angriff bei bekanntem Klartext (known-plaintext attack ) und Angriff bei frei wählbarem Klartext (chosen-plaintext attack ). Ziel ihrer Arbeit war, auf Zugriffberechtigten-Angreifer angepasste Modelle vorzustellen, die unabhängig vom eigentlichen Verschlüsselungsschema darauf abzielten, das Datenbanksystem mittels des Spähens der Anfragen-Logdatei zu brechen.
In dem Papier gehen die Autoren von einer Client-Server-Architektur aus, wobei der Client vertrauenswürdig ist, dagegen der Server absolut nicht. Die Autoren gehen auch davon aus, dass eine dünne Verschlüsselungsschicht auf der vertrauenswürdigen Seite oder auf dem Server selbst vorhanden ist. Die Hauptaufgabe dieser Verschlüsselungsschicht ist es, die als Klartext von den Benutzern geschriebenen Anfragen so anzupassen, dass das verschlüsselte Datenbanksystem sie bearbeiten kann. Nach Erhalt der Anfragenergebnisse entschlüsselt die Verschlüsselungsschicht die verschlüsselten Ergebnisse und sendet diese an den Benutzer.
Die Frage ist: Wie sicher sind diese umgeschriebenen Anfragen, die an einen nicht vertrauenswürdigen Datenbank-Server gesendet wurden? Die Verschlüsselungsschicht schreibt die Anfragen gemäß dem Verschlüsselungsschema um, das für die Verschlüsselung der Daten festgelegt wurde. Es gibt dennoch eine Reihe von Beispielen die zeigen, wie die Anfragen selbst als „Leck“ anzusehen sind. Zum Beispiel können manche Anfragen Geheimnisse bezüglich des zugrundeliegenden Verschlüsselungsschemas offenbaren. Außerdem liefert die Anfragen-Logdatei selbst Informationen an den Angreifer, z.B. Zeitstempel, Eingabefrequenz etc.
3.1 Allgemein bekannte Angreifermodelle auf verschlüsselte Daten
Zunächst werden die drei Basis-Angriffsszenarien und deren Notation genauer erläutert. Die neu entwickelten Angreifermodelle werden anschließend mit Hilfe der Methode der Reduktion bewiesen.
Notation Zunächst bezeichnet x einen Klartext aus der Menge der möglichen Klartexte X. Entsprechend bezeichnet y einen Kryptotext aus der Menge aller möglichen Kryptotexte Y.

3
Enc(τ,x) ist die Verschlüsselungsfunktion eines beliebigen Verschlüsselungsschemas. x $← X
bedeutet einfach, dass ein Vektor von Klartexten absolut willkürlich ausgewählt wurde.
Experiment Ein Experiment ist ein probabilistisches System, das mit einem Angreifer A verbunden ist.
Abbildung 1 Ein Experiment tritt in Wechselwirkung mit einem Angreifer und zeigt am Ende, ob der Angreifer Erfolg
hatte oder nicht
Angreifer (Adversary) Ein Angreifer A ist oder hat Zugriff auf einen Algorithmus, der mit einem Experiment interagiert, mit dem Ziel erfolgreich zu sein.
Nutzeffekt (Advantage) Der Nutzeffekt eines Angreifers A, der ein Experiment EXP startet, ist die Erfolgswahrscheinlichkeit von A. Das Experiment gibt eine 1 auf der rechten Schnittstelle aus, wenn es erfolgreich ist. Notation: AdvEXP(A).
3.1.1 Angriff bei bekanntem Kryptotext (ciphertext-only attack CoA )
Wenn ein Angreifer in einem Angriff bei bekanntem Kryptotext erfolgreich ist, bedeutet das, dass folgendes Experiment erfolgreich war:
Experiment 1 : () $← Τ
$← ← (,) $← ()
if x ∈ x then return 1 else return 0
Experiment 1 wählt zufällig mit gleicher Wahrscheinlichkeit einen Vektor mit Klartexten, x. Anschließend verschlüsselt er die Kartexte unter Verwendung der Funktion (, ) um einen
Vektor mit den dazu entsprechenden Kryptotexten y zu erhalten. Der Angreifer erhält y und startet A(y), Der Angreifer ist erfolgreich, wenn der Klartext x, den er zurückgibt in dem Klartext-Vektor x erhalten ist. Notation des Nutzeffekts = ().
3.1.2 Angriff mit bekanntem Klartext (known plaintext attack KPA)
Ununterscheidbarkeit bei einem Angriff mit bekanntem Klartext wird durch folgendes Experiment erfasst:
Experiment 2 : −() $← Τ
$← () ← (,)
(,) $← (). .,∉
$← , ← (,) ′ $← (,, (,),)

4
If ′ ∈ then return 1 else return 0 Der Angreifer A1 wählt zufällig mit gleicher Wahrscheinlichkeit einen Vektor mit Klartexten x. Danach verschlüsselt er die Klartexte unter Verwendung der Funktion (, ) um einen
Vektor mit den dazu entsprechenden Kryptotexten y zu erhalten. Anschließend wählt der Angreifer zufällig zwei Klartexte (1, 2) . . 1, 2∉ und steckt sie in das Experiment. Das Experiment wählt willkürlich einen von beiden ← (,).
D.h. der Angreifer kennt beides x und y bzw. (1, 2) und . Basierend auf und der Information, die er aus x und y gewinnen kann, kann der Angreifer
versuchen, heraus zu finden, welcher der beiden Klartexte(1, 2) entschlüsselt wurde.
Notation des Nutzeffekts = −().
3.1.3 Angriff bei frei wählbarem Klartext (chosen-plaintext attack - CPA )
Ununterscheidbarkeit unter einem Angriff mit bekanntem Klartext wird durch folgendes Experiment erfasst:
Experiment 3 : −() $← Τ ← () ← (,)
(,) ← (). .,∉ $← , ← (,) ′ $← (,, (,),)
If ′ ∈ then return 1 else return 0 Der Angreifer A1 wählt einen Vektor mit Klartexten x. Danach verschlüsselt er die Klartexte unter Verwendung der Funktion (, ) um einen Vektor mit den dazu entsprechenden
Kryptotexten y zu erhalten. Anschließend wählt der Angreifer zwei Klartexte (1, 2) . . 1, 2∉ und steckt sie in das Experiment. Das Experiment wählt willkürlich einen von beiden ← (, ). Also der Angreifer kennt beides x und y bzw. (1, 2) und . Basierend auf und der Information, die er aus x und y gewinnen kann, der Angreifer kann
versuchen, heraus zu finden, welcher der beiden Klartexte(1, 2) entschlüsselt wurde.
Notation des Nutzeffekts = −().
3.2 Einzuführenden Angreifermodelle
3.2.1 Neue benötigte Definitionen
Um neue Zutrittsberechtigter- Angreifermodelle zu definieren werden zusätzliche Funktionen benötigt, die die Anfragenumschreibung erfassen.
Notation. Qx bezeichnet die Menge aller Anfragen, die der Client an die Verschlüsselungsschicht
sendet und Qy die Menge aller umgeschriebenen Anfragen. Dementsprechend wird eine vom
Client gesendete, ursprüngliche Anfrage als qx ∈ Qx bezeichnet und eine an den nicht

5
vertrauenswürdigen Server gesendete, umgeschriebene Anfrage wird als qy ∈ Qy bezeichnet. bezeichnet eine Untermenge von Anfragen aus Qx und dementsprechend ⊆ Qy.
Anfrage (Query). Hier geht es immer um SQL-Anfragen, allerdings können die Zutrittsberechtigter- Angreifermodelle auf andere Anfragentypen angewandt werden.
Anfragebeispiel. Die Relation customer(id,name,age,salary,city) in der verschlüsselten
Datenbank soll betrachtet werden. Folgende Anfrage qx wird von dem Client an den Server gesendet:
SELECT SUM(salary) FROM customer
WHERE city = ‘Zürich‘ and age <= 30
Da die Datenbank verschlüsselt ist, wird die Client-Anfrage durch die Verschlüsselungsschicht abgefangen und so umgeschrieben, dass die Anfrage von der chiffrierten Datenbank abgearbeitet werden kann.
Anfragen-Tokens (Query-Tokens). Diese Tokens sind Teile der Daten in der SQL-Anfrage. Anfragen-Tokens können in Klartext vorhanden sein. Z.B. in dem oberen Beispiel, wären ‘Zürich‘ und 30 Anfragen-Tokens. Anfrage-Tokens können auch als chiffrierter Text verfügbar sein.
Anfrage-Umschreibfunktion (Query Rewrite Function – QRF). Die Anfrage-
Umschreibfunktion ist eine Funktion, die als Eingabe die originale Anfrage qx und das
Verschlüsselungsschema ES hat, und als Ausgabe die umgeschriebene Anfrage qy, also
QRF(ES,qx)=qy. qx wird unterschiedlich umgeschrieben, immer entsprechend dem Verschlüsselungsschema. Zum Beispiel, wenn die Daten in der Datenbank nach dem Verschlüsselungsschema AES verschlüsselt wurden, dann wird aus dem Anfragebeispiel, qx die
ungeschriebene Anfrage qy:
SELECT salary, age FROM customer
WHERE city = EncAES (‚Zurich‘)
Anfrage-Generator (Query Generator – QGen). Der Anfrage-Generator ist eine Funktion, die als Eingabe einen Vektor von Anfragen-Token x in Klartext hat und daraus eine Menge von SQL-Anfragen unter Verwendung der Anfragen-Token x generiert. QGen ist unabhängig vom Verschlüsselungsschema ES, QGen besitzt eine Umkehrfunktion, x = QGen-1(), die als Ausgabe einen Vektor von Anfragen-Token x in Klartext hat.
Abbildung 2 QGen hat als Eingabe einen Vektor von Anfragen-Token x in Klartext und bildet daraus eine Menge
von SQL-Anfragen
Anfrage-Simulator (Query Simulator – QSim ). Parallel zu QGen jedoch in der Kryptotext-Dimension benutzt der Anfrage-Simulator einen Vektor von Anfragen-Token x in Kryptotext y als Eingabe und generiert daraus eine Menge von SQL-Anfragen unter Verwendung der

6
Anfragen-Token y. QSim ist unabhängig des Verschlüsselungsschema ES und darf die Anfrage-Logdatei in Qy verwenden. QGen besitzt eine Umkehrfunktion, y = QGen-1().
Abbildung 3 QSimn hat als Eingabe Anfragen-Token y in Kryptotext, und bildet daraus eine Menge von
umgeschrieben SQL-Anfragen
QGen bzw. QSim sind Funktionen, die ihre Eingaben x bzw. y nicht ändern, sie verpacken diese lediglich in eine SQL-Anfrage.
Abbildung 4 zeigt die oben eingeführten Funktionen. Diese Funktionen werden als Grundlagen für die Entwicklung der neuen Angreifermodelle und Beweise verwendet.
Abbildung 4 Basisfunktionen, die in dem Log-Dateien-Angriff benutzt werden
Tahmineh Sanamrad und Donald Kossmann stellten drei Angreifermodelle vor. Dort wurde bewiesen, dass jedes Angreifermodell auf ein bekanntes Angreifermodell reduziert werden konnte.
Wir definieren den Datenbank-Angreifer A DB: Dieser Angreifer soll Zugriff auf alles haben, was
auf dem Datenbankserver vorhanden ist, also auf den Satz der umgeschriebenen Anfrage Qy, auf die verschlüsselten Daten Y und schließlich auf die verschlüsselten Ergebnismengen, die das Ergebnis der laufenden Qy auf Y sind. Wir gehen auch davon aus, dass das Datenbankschema öffentlich ist, d.h. ein Datenbank-Angreifer kennt die Tabellen, Attribute, Attributtypen, Fremdschlüssel und so weiter.
Beweis durch Reduktion: Wenn A auf B reduzierbar ist, dann kann die Lösung von A nicht schwerer als die Lösung von B sein. Um A zu beweisen reicht es aus, eine effiziente Transformation φ zu finden von der Lösung von Problem B, T auf die Lösung von Problem A, S, z.B. S =φ (T). 3.2.2 Nur Anfrage-Angriff (Query-Only Attack – QoA)
Von einem Nur-Anfrage Angriff (QoA) spricht man, wenn der Datenbank-Angreifer ADB nur Zugriff auf die umgeschriebene Anfrage -Log-Datei hat, nämlich Qy. Der Nutzeffekt eines
Datenbank-Angreifers, ADB, der ein Experiment 4: startet, ist die

7
Erfolgswahrscheinlichkeit von ADB. Das Experiment gibt eine 1 auf der rechten Schnittstelle aus, wenn es erfolgreich ist. () = Pr [() = 1
Das Experiment () ist wie folgt definiert:
Experiment 4 : () $← ← () ← (,)
$← ()
if xt ∈ x then return 1
else return 0 Im Folgenden wird bewiesen, dass der in 3.1.1 vorgestellte „Angriff bei bekanntem Kryptotext (ciphertext-only attack CoA)“ auf einen Nur-Anfrage-Angriff reduziert werden kann. Lemma 1. Gegeben sind ein Verschlüsselungsschema ES und eine Teilmenge von
umgeschriebenen Anfragen ∈ Qy, ES ist mindestens so sicher gegen einen Nur-Anfrage
Angriff wie ES sicher gegen einen Angriff bei bekanntem Kryptotext (ciphertext-only attack CoA) ist. () ≤ ()
Beweis. Sei ES ein beliebiges Verschlüsselungsschema und sei ADB ein Gegner mit einem nicht-trivialen QoA Nutzeffekt gegen ES, dann können wir einen „bei bekanntem Kryptotext“- Angreifer gegen ES konstruieren. Gemäß Definition in dem Experiment 1 für einen solchen Angriff kennt A einen Vektor verschlüsselter Werte, y. A startet QSim (y) um zu simulieren.
Schließlich startet A ADB (). Die Kommunikation von A mit ADB ahmt das QoA-Experiment 4 nach. Offensichtlich ist A effizient, da QSim sublinear zu der Größe seiner Eingabe ist.
3.2.3 Angriff mit bekannter Anfrage (Known-Query Attack - KQA)
Von diesem Angriff spricht man, wenn der Datenbank-Angreifer ADB Zugriff auf eine Anzahl von
(qx, qy) Paaren hat. Zum Beispiel nehmen wir an, qx ist:
SELECT SUM(salary) FROM customer
WHERE city = ’Zurich’ and age <= 30
Und unter Verwendung vom Verschlüsselungsschema ES ist qy :
SELECT salary, age FROM customer WHERE city =EncES(‘Zurich’)
Query-Logdateien versorgen Datenbank-Angreifer zusätzlich mit Informationen bzgl. der Clients, die die Anfragen starten, wie Zeitstempel der Anfrage und deren Frequenz. Ein Angreifer, der Hintergrundwissen über die Business-Logik hat, kann diese zusätzlichen Protokollinformationen

8
verwenden, um die ursprünglichen Anfragen zu erraten, die Clients eingereicht haben. Im Allgemeinen können statistische Angriffe auf Anfragen-Logdateien als KQA klassifiziert werden.
Der Nutzeffekt eines Datenbank-Angreifers, ADB, der ein Experiment 5: −startet, ist die Erfolgswahrscheinlichkeit von ADB, die Umschreibung von zwei Anfragen derselben Struktur (wie in Experiment 5 gezeigt) zu unterscheiden. Das Experiment gibt eine 1 auf der rechten Schnittstelle aus, wenn es erfolgreich ist. −() = Pr [−() = 1
Das Experiment −() ist wie folgt definiert:
Experiment 5 : −() $← ← (,)
(,) $← . .,∉
$← , ← (,) ′ $← (, , (,),)
If ′ ∈ then return 1 else return 0 Lemma 2. Gegeben sind ein Verschlüsselungsschema ES und eine Menge von ursprünglichen
und umgeschrieben Anfragepaaren ( , ), ES ist mindestens so sicher gegen einen Angriff
mit bekannter Anfrage wie ES sicher gegen einen Angriff mit bekanntem Klartext ( known plaintext attack KPA)- s. 3.1.2 -ist. −() ≤ −()
Beweis. Sei ES ein beliebiges Verschlüsselungsschema und sei ADB ein Gegner mit einem nicht-trivialen IND-KQA Nutzeffekt gegen ES, dann können wir einen IND-KPA Angreifer gegen ES konstruieren. Gemäß Definition in dem Experiment 2 für einen solchen Angriff kennt A Klartext/Kryptotext-Paare. A hat außerdem Zugriff auf eine begrenzte QRF, die nur mit
funktioniert. Als erstes startet QGen (x) = und anschließend Q(,) = .
Zusätzlich bekommt A x1, x2 und yb, so dass er = (), = () und = () konstruieren kann.
Schließlich startet A ADB (, , (,),). Die Kommunikation von A mit ADB ahmt das
IND-KPA -Experiment 5 nach. Offensichtlich ist A effizient, da QGen, QRF und QSim linear zu der Größe deren Eingabe sind.
Ununterscheidbarkeit gegen einen Angriff mit bekanntem Klartext kann zu Ununterscheidbarkeit gegen einen Angriff mit bekannter Anfrage reduziert werden, wie Lemma 2 zeigt.

9
3.2.4 Angriff bei frei wählbarer Anfrage (Chosen-Query Attack - CQA)
Von einem solchen Angriff spricht man, wenn der Datenbank-Angreifer, ADB, Zugriff auf eine Anfrage-Umschreibungsfunktion, QRF (ES) hat. Zum Beispiel kann ein Angreifer beliebige Anfragen an die Verschlüsselungsschicht senden und die umgeschriebenen Anfragen auf dem anderen Ende erspähen.
Der Nutzeffekt eines Datenbank-Angreifers, ACQA = (ACQ,ADB), der ein Experiment 6 −startet, ist die Erfolgswahrscheinlichkeit von ACQA. die Umschreibung von zwei selbst ausgewählten Anfragen zu unterscheiden. Das Experiment gibt eine 1 auf der rechten Schnittstellen aus, wenn es erfolgreich ist. −() = Pr [−() = 1
Experiment 6 : −() $← ← (,)
(,) $← () . .,∉
$← , ← (,) ′ $← (, , (,),)
If ′ ∈ then return 1 else return 0
Lemma 3. Gegeben sind ein Verschlüsselungsschema ES und eine Menge von ursprünglichen und
umgeschrieben Anfrage ( , ), wobei , vom Angreifer gewählt wurde, ES ist mindestens
so sicher gegen einen Angriff bei frei wählbarer Anfrage wie ES sicher gegen einen Angriff bei frei wählbarem Klartext (chosen-plaintext attack - CPA ) s.3.1.3 -ist. −() ≤ −()
Beweis. Sei ES ein beliebiges Verschlüsselungsschema und sei ACQA ein Angreifer mit einem nicht-trivialen IND-CQA Nutzeffekt gegen ES, dann können wir einen CPA Angreifer A gegen ES konstruieren. Gemäß Definition in dem Experiment 3 für solchen Angriff kennt A Klartext/Kryptotext-Paare, wobei die Klartexte vom Angreifer gewählt wurden. A hat außerdem Zugriff auf eine vollentwickelte QRF. Als erstes startet QGen (x) = und anschließend Q(,) = .
Zusätzlich bekommt A x1, x2 und yb, so dass der Angreifer( = (), ( = ()
) und ( = () konstruieren kann.
Schließlich startet A ADB (, , (,),). Die Kommunikation von A mit ACQA ahmt das IND-CQA –Experiment nach. Offensichtlich ist A effizient, da QGen, QRF und QSim linear zu der Größe deren Eingabe sind.

10
Ununterscheidbarkeit gegen einen Angriff mit bekanntem Klartext kann zu Ununterscheidbarkeit gegen einen Angriff mit bekannter Anfrage reduziert werden wie Lemma 3 zeigt.
4 Rückschluss- Attacke gegen verschlüsselte Bereichsanfragen in
ausgelagerten Datenbanken [4] Eine Rückschluss-Attacke ist eine Data-Mining-Technik mit dem Zweck Wissen über ein Thema oder eine Datenbank mittels Datenanalyse unrechtmäßig zu gewinnen. Eine Rückschluss-Attacke tritt auf, wenn ein Benutzer in der Lage ist, robuste Informationen über eine Datenbank aus trivialen Informationen zu schließen, ohne direkt darauf zuzugreifen.
Das Datenbank-as-a-Service (DAS) Modell wird in den letzten Jahren als neue Technologie angepriesen. Ausgelagerten Datenbanken auf Remote-Servern ebnen den Weg für den kostengünstigen Know-how-Austausch zwischen Datenbankprofis unter den verschiedenen Organisationen. Allerdings ist eine effektive Anfrageausführung auf einer verschlüsselten Datenbank ein nicht leicht zu lösendes Problem.
Hacigümüs et al. [5] waren die ersten, die die Idee einer verschlüsselten Datenbank vorschlugen, die eine begrenzte Ausführung von SQL-Abfragen in dem Remote-Server unterstützt, ohne die Datenelemente zu entschlüsseln. Seitdem gab es weitere Vorschläge in dieser Richtung, sogenannte Protokolle (protocols), die aber meistens von Bereichsanfragen ausgingen.
Das in der Literatur vorgeschlagen DAS-Modell besteht aus drei Einheiten: dem Benutzer, dem Client und dem Server.
Jede Zeile in der ausgelagerten Datenbank wird einzeln verschlüsselt und Etuple genannt. Es wird angenommen, dass der Remote-Server im DAS-Modell, "ehrlich, aber neugierig" ist. Das heißt, dass der Server nicht vom Protokoll abweichen wird, dennoch ist das Anliegen des Servers so viel Wissen über die verschlüsselten Daten wie möglich zu erfahren. Die Anfragenabarbeitung entspricht der vom Kapitel 3.
Es gibt zwei Hauptansätze, die das Bereichsanfragen unterstützende DAS-Modell umsetzen.
1. Die Precise Query Protocols (PQPs): Diese verwenden ausgefeilte Verschlüsselungstechniken, die dem Server die Ausführung von Bereichsanfragen ermöglichen, ohne die Gefahr von falsch Positiven. Das bedeutet, dass der Server für eine bestimmte verschlüsselte Bereichsanfrage die genaue Menge von Etuples, die die Anfrage erfüllt, zurückgibt.
2. Bucketization: Dieser Ansatz erleichtert die Ausführung von Bereichsanfragen auf Kosten des Wirkungsgrads in Bezug auf die Anzahl von falsch Positiven. In der Tat, im Bucketization-Ansatz wird jedes Anfrage-Attribut in einige zusammenhängende Buckets auf der Grundlage einer Bucketization-Strategie eingeteilt. Bei der Anfragenausführung enthält die Ergebnismenge alle enthaltenden Etuples aus dem Bucket, der dem in der Anfrage angegebenen Bereich entspricht. Diese Vorgehensweise bringt naturgemäß eine gewisse Anzahl an falsch Positiven in der Ergebnismenge in Abhängigkeit von der Bucketbreite.
4.1 Erläuterung der Grundidee anhand eines Beispiels
Die Gefährdung der Offenlegung über ein Zugriffsmuster (Access pattern disclosure) allein stellt keine erhebliche Bedrohung für die allgemeine Datensicherheit eines DAS-Modell dar.

11
Allerdings, wenn die Offenlegung über ein Zugriffsmuster mit hinreichender Menge Hintergrundwissen kombiniert wird, kann diese Gefährdung zu einer erheblichen Verletzung der Privatsphäre führen. In [4] wird diese Behauptung durch Betrachtung des folgenden hypothetischen Szenarios aufgezeigt.
Angenommen eine Bank lagert ihre Datenbank aus Kostengründe aus. Betrachtet man die Tabelle der Konteninhaber kann man die Meinung vertreten, dass die Namen der Konteninhaber an sich nicht als sensible Information anzusehen sind, so dass der Remote-Server (z.B. Mallory) diese Information irgendwie erhalten kann. Selbstredend versucht die Bank sensiblere Informationen (z.B. Kontoguthaben) sicher zu halten. Also werden die Tupel in der Konten-Tabelle verschlüsselt gespeichert. Da jedoch Mallory den Klartext der Verteilung der Namen hat, könnte sie Anfragen und Antworten überwachen, um eine Zuordnung der einzelnen Namen zu den dazu passenden Etuples mit hinreichender Genauigkeit zu schätzen. Da die Tupel verschlüsselt sind, wird Mallory trotzdem immer noch nicht irgendwelche zweckdienliche Informationen erfahren.
Aber, wenn z.B. die Bank einer Behörde bei einem Fall von Geldwäsche helfen muss, wird die Bank bestimmt die Liste der Verdächtigen verschlüsseln, dennoch wird es wahrscheinlich vorkommen, dass die Behörde eine Anfrage nach den Verdächtigen an den Remote-Server sendet. Mallory kann dann die bereits erarbeitete Zuordnung benutzen, um die Liste der Verdächtigen zu erhalten. D.h. eine Zuordnung zwischen nicht empfindlichen Daten und Etuples kann zu einer erheblichen Verletzung der Privatsphäre führen. In [4] wird gezeigt, dass das DAS-Modell Zugriffsmuster offenlegt, die zu einer Gefährdung führen könnten. Die Autoren raten dringlich dazu, die hier besprochenen Protokolle nur dann zu verwendet, wenn die Angreifer keinerlei sonstige Hintergrundwissen über die Klartexte besitzen, und sie somit keine Rückschlüsse ziehen können.
4.2 Angriffsmodell gegen den Precise Query Protocol
Hier werden lediglich Bereichsanfragen berücksichtigt, obgleich das Modell sich auch für Gleichheitsanfragen eignet. Sei R eine Relation mit dem sensiblen Attribut A, die Domäne (vorher definierter Wertebereich) von A ist D, wobei |D| = n, d.h. D hat n diskrete Elemente.
4.2.1 Bedrohungsmodell
Im vorgeschlagenen Modell wird davon ausgegangen, dass der Angreifer (z.B. Mallory) Zugriff auf eine Sequenz von m Bereichsanfragen in der Form, Q = ⟨[s1,f1], [s2,f2],…, [sm,fm],⟩ und die entsprechenden Ergebnisse ⟨E1, E2, …,Em⟩ hat. Außerdem wird angenommen, dass sowohl der Server wie auch der Angreifer "ehrlich, aber neugierig" sind.
Eine weitere Annahme ist, dass Mallory Zugriff auf folgende Hintergrundinformation hat:
1. Der Angreifer kennt (genau oder schätzungsweise) die Klartext-Verteilung von der Spalte A in der ursprünglichen Datenbank.
2. Außerdem kennt der Angreifer die richtigen Bereiche von k Anfragen in Q, wobei k Null sein kann, also die sogenannten „bekannte Anfragen“.
4.2.2 Angriffsmodell
Das Ziel des Angriffes ist es, aus einer Sequenz von m Bereichsanfragen die Werte für s1,…sm
und f1,…,fm aus der Domäne D so genau wie möglich zu schätzen. Das Problem wird als ein nach T (Menge von Beschränkungen) beschränktes Optimierungsproblem auf folgende Weise modelliert:

12
⟨[1, 1], … , [,]⟩∑ (|,[1,1],, ∩ ,| − | − |)2 (1)
4.3 Attacke gegen Bucketization
In diesem Abschnitt wird eine Rückschluss-Attacke gegen den Bucketizationsansatz vorgestellt. Intuitiv kann man davon ausgehen, dass der Bucketizationsansatz robuster gegenüber der Gefährdung der Offenlegung über ein Zugriffsmuster ist. Die Tatsache, dass man die Daten in Buckets aufteilt, fügt naturgemäß eine „Störung“ dem Anfragen-Zugriffmuster hinzu. Interessanterweise, wenn man das Attacke-Ziel leicht ändert, kann man jedoch brauchbare Information aus dem Bucketizationsansatz entdecken.
In der Bucketization wird jede Bereichsanfrage in eine Liste von Buckets umgewandelt und die Bucket-Kennungen werden an den Server im Klartext gesendet. Daher sieht der Angreifer eine Reihe von Bucket-Kennungen und die Menge von Etuples, die für diesen Bucket-Satz zurück erhalten wurde. Es sollte beachtet werden, dass ein Angreifer für diesen Angriff nicht im Voraus die Werte irgendeiner Anfrage kennen darf. Erneut ist die Lösung des obigen Problems eine Approximation und zwar die Schätzung der Bucket-Grenzen. Daher ist die Offenbarung des genauen Anfragenbereiches nicht garantiert. Wenn jedoch die Buckets klein genug sind, kann ein Angreifer immer noch eine sehr gute Annäherung an die tatsächlichen Abfragewerte erhalten.
4.4 Durchgeführte Experimente und Ergebnisse
4.4.1 Experimentanordnung
In [4] werden zwei reale Datenbanken untersucht, die Adult Datenbank aus dem UCI Machine Learning Repository [6] und die North Carolina Voter Datenbank [7]. Hier werde ich aus Platzgründen nur die North Carolina Voter Datenbank berücksichtigen. Diese Datenbank enthält 6190504 Instanzen. Das Anfrage-Attribut ist das Alter, die Domäne ist in diesem Fall [1,100], jedoch gehen die Autoren davon aus, dass auch für größere Domänen die von Ihnen aufgestellten Thesen auch gelten.
Nach Ansicht der Autoren ist das in 4.2 beschriebenes Modell schwer zu bewerkstelligen und der Brute-Force-Ansatz nicht effizient genug. Die Autoren wählten aus empirischen Gründen den Ansatz der simulierten Abkühlung (Simulated Annealing) [8]. Außerdem wurde auch aus Effizienzgründen die Stapelverarbeitung gewählt.
Die Stapelverarbeitung reduziert die Anzahl der erforderlichen bekannten Anfragen, die meisten in diesem Papier berichteten Experimente kommen mit nur 2 bekannten Anfragen aus, auch bei Anfragen mit einer Satzgröße von 100. In der Tat konnte das Modell eine Anfrage mit Satzgröße von 150 mit mehr als 70% Präzision mit nur 2 bekannten Anfragen ermitteln. Die Laufzeit des Angriffs war auch sehr annehmbar. Eine Laufzeit-Verbesserung ist sicherlich auch mit einer parallelen Stapelverarbeitung vorstellbar. Es wurde eine Bewertungsmetrik mit den Toleranzbereichen von 0-Toleranz, 0,1-Toleranz und 0,2-Toleranz definiert.
4.4.2 Ergebnisse
Es handelt sich um eine empirische Evaluation und es gilt die oben definierte Experimentanordnung.
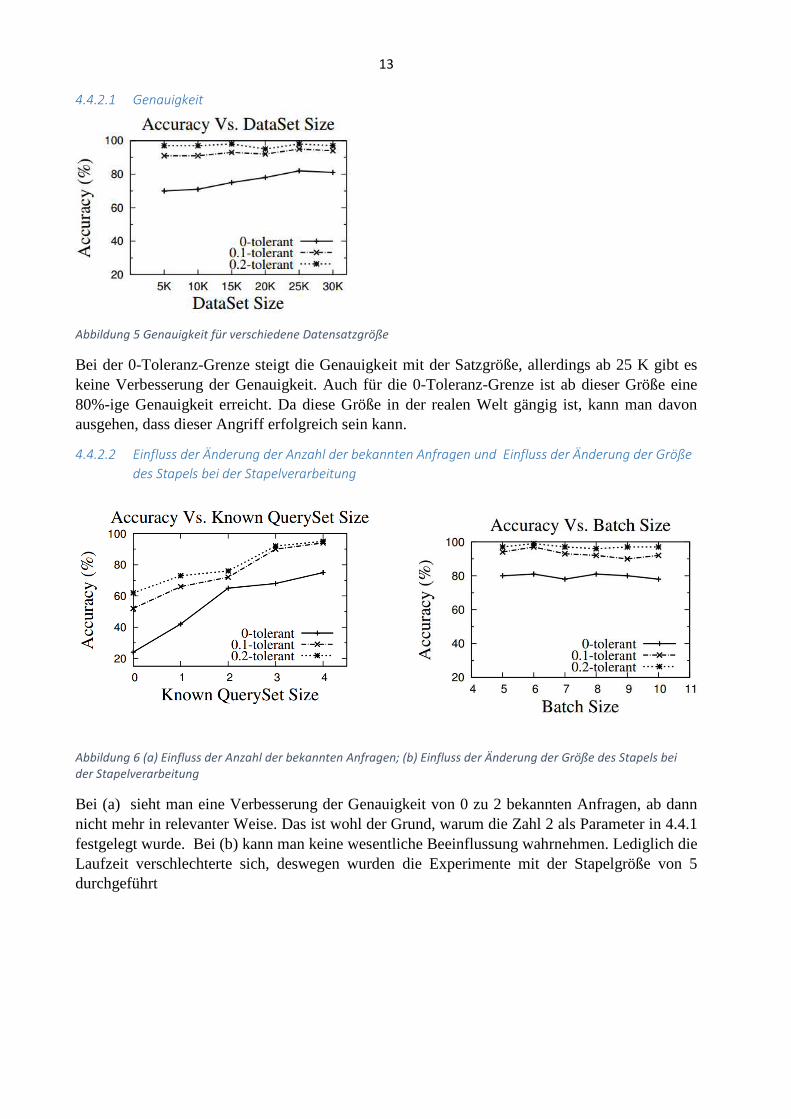
13
4.4.2.1 Genauigkeit
Abbildung 5 Genauigkeit für verschiedene Datensatzgröße
Bei der 0-Toleranz-Grenze steigt die Genauigkeit mit der Satzgröße, allerdings ab 25 K gibt es keine Verbesserung der Genauigkeit. Auch für die 0-Toleranz-Grenze ist ab dieser Größe eine 80%-ige Genauigkeit erreicht. Da diese Größe in der realen Welt gängig ist, kann man davon ausgehen, dass dieser Angriff erfolgreich sein kann.
4.4.2.2 Einfluss der Änderung der Anzahl der bekannten Anfragen und Einfluss der Änderung der Größe
des Stapels bei der Stapelverarbeitung
Abbildung 6 (a) Einfluss der Anzahl der bekannten Anfragen; (b) Einfluss der Änderung der Größe des Stapels bei
der Stapelverarbeitung
Bei (a) sieht man eine Verbesserung der Genauigkeit von 0 zu 2 bekannten Anfragen, ab dann nicht mehr in relevanter Weise. Das ist wohl der Grund, warum die Zahl 2 als Parameter in 4.4.1 festgelegt wurde. Bei (b) kann man keine wesentliche Beeinflussung wahrnehmen. Lediglich die Laufzeit verschlechterte sich, deswegen wurden die Experimente mit der Stapelgröße von 5 durchgeführt
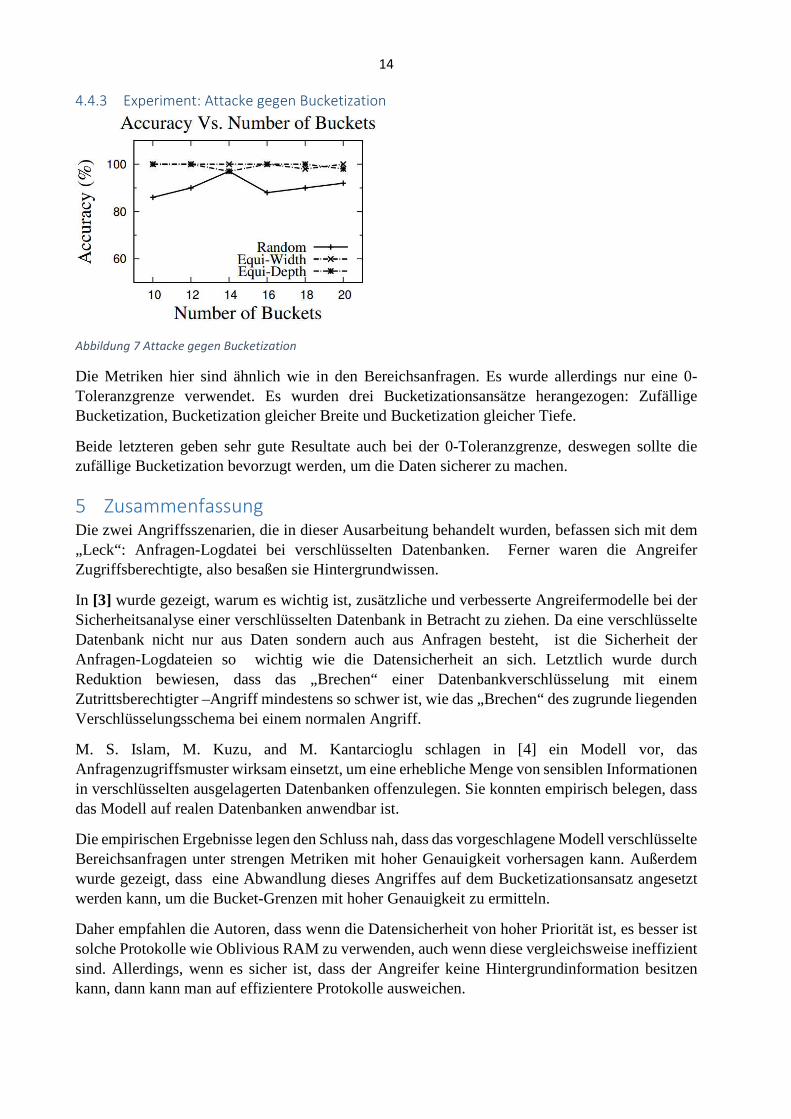
14
4.4.3 Experiment: Attacke gegen Bucketization
Abbildung 7 Attacke gegen Bucketization
Die Metriken hier sind ähnlich wie in den Bereichsanfragen. Es wurde allerdings nur eine 0-Toleranzgrenze verwendet. Es wurden drei Bucketizationsansätze herangezogen: Zufällige Bucketization, Bucketization gleicher Breite und Bucketization gleicher Tiefe.
Beide letzteren geben sehr gute Resultate auch bei der 0-Toleranzgrenze, deswegen sollte die zufällige Bucketization bevorzugt werden, um die Daten sicherer zu machen.
5 Zusammenfassung Die zwei Angriffsszenarien, die in dieser Ausarbeitung behandelt wurden, befassen sich mit dem „Leck“: Anfragen-Logdatei bei verschlüsselten Datenbanken. Ferner waren die Angreifer Zugriffsberechtigte, also besaßen sie Hintergrundwissen.
In [3] wurde gezeigt, warum es wichtig ist, zusätzliche und verbesserte Angreifermodelle bei der Sicherheitsanalyse einer verschlüsselten Datenbank in Betracht zu ziehen. Da eine verschlüsselte Datenbank nicht nur aus Daten sondern auch aus Anfragen besteht, ist die Sicherheit der Anfragen-Logdateien so wichtig wie die Datensicherheit an sich. Letztlich wurde durch Reduktion bewiesen, dass das „Brechen“ einer Datenbankverschlüsselung mit einem Zutrittsberechtigter –Angriff mindestens so schwer ist, wie das „Brechen“ des zugrunde liegenden Verschlüsselungsschema bei einem normalen Angriff .
M. S. Islam, M. Kuzu, and M. Kantarcioglu schlagen in [4] ein Modell vor, das Anfragenzugriffsmuster wirksam einsetzt, um eine erhebliche Menge von sensiblen Informationen in verschlüsselten ausgelagerten Datenbanken offenzulegen. Sie konnten empirisch belegen, dass das Modell auf realen Datenbanken anwendbar ist.
Die empirischen Ergebnisse legen den Schluss nah, dass das vorgeschlagene Modell verschlüsselte Bereichsanfragen unter strengen Metriken mit hoher Genauigkeit vorhersagen kann. Außerdem wurde gezeigt, dass eine Abwandlung dieses Angriffes auf dem Bucketizationsansatz angesetzt werden kann, um die Bucket-Grenzen mit hoher Genauigkeit zu ermitteln.
Daher empfahlen die Autoren, dass wenn die Datensicherheit von hoher Priorität ist, es besser ist solche Protokolle wie Oblivious RAM zu verwenden, auch wenn diese vergleichsweise ineffizient sind. Allerdings, wenn es sicher ist, dass der Angreifer keine Hintergrundinformation besitzen kann, dann kann man auf effizientere Protokolle ausweichen.

15
6 Ausblick Die Modelle in [3] können als Basis für weitere Anstrengungen dienen, die darauf zielen die Anfrage-Logdatei-Sicherheit für alle bestehenden oder bevorstehenden Datenbank-verschlüsselungssystem oder -schemen zu analysieren.
Die Wahrung der Privatsphäre und die Verbesserung der Anfragenperfomance sind zwei stark verknüpfte Herausforderung für ausgelagerte Datenbanken. Zukünftige Arbeiten werden sich sicherlich mit dem Datenkonsistenz-Management in den verschlüsselten Datenbanken beschäftigen.
7 Literaturverzeichnis
[1] „Wikipedia-Informationssicherheit,“ 8 1 2015. [Online]. Available:
http://de.wikipedia.org/wiki/Informationssicherheit.
[2] „Wikipedia-Kryptoanalyse,“ 5 11 2014. [Online]. Available:
http://de.wikipedia.org/wiki/Kryptoanalyse.
[3] T. S. a. D. Kossmann, „Query log attack on encrypted databases,“ In Willem Jonker and Milan
Petkovic, editors, Secure Data Management - 10th VLDB Workshop, p. 95–107, Springer, 2013.
[4] M. K. a. M. K. Mohammad Saiful Islam, „Inference attack against encrypted range queries on
outsourced databases,“ In Elisa Bertino, Ravi S. Sandhu, and Jaehong Park, editors, Fourth ACM
Conference on Data and Application Security and Privacy, CODASPY’14, San Antonio, TX, USA -March
03 - 05, pp. 235-246, 2014.
[5] C. L. a. S. M. H. Hacigümüs B. Iyer, „Executing SQL over encrypted data in the database-service-
provider model,“ SIGMOD, p. 216–227, 2002.
[6] „Adult Data Set. Uci machine learning repository,“ [Online]. Available:
http://archive.ics.uci.edu/ml/datasets/Adult..
[7] „North Carolina Voter Data,“ [Online]. Available: ftp://www.app.sboe.state.nc.us/data.
[8] C. G. a. M. V. S. Kirkpatrick, „Optimization by simulated annealing,“ Science, p. 220:671–679, 1983.

FernUniversität in Hagen
Seminar 01912
Im Wintersemester 2014/2015
Sicherheit und Privatsphäre in
Datenbanksystemen
Abgabe am: 11.01.2015
Thema 11
Spezielle Indexe
Referent: Debru Zewdie Ejeta

Inhaltsverzeichnis I
Inhaltsverzeichnis Abbildungsverzeichnis ...............................................................................................II
1 Einführung ............................................................................................................. 1
1.1 Anonymisierung im Bereich des LBS ............................................................ 1
1.2 Anforderung an die mehrdimensionalen Indexstrukturen .............................. 2
1.3 Anfragetypen bei der mehrdimensionalen Indexstrukturen ........................... 2
2 Problemstellung ..................................................................................................... 5
3 Stand der bisherigen Forschung .......................................................................... 6
3.1 k-Anonymisierung zum Schutz der Privatsphäre der Benutzer ...................... 6
3.2 PIR-basierter Ansatz zum Schutz der Privatsphäre beim LBS ....................... 7
3.3 Anonymisierung mittels Indexstrukturen zum Schutz der Privatsphäre ........ 7
3.3.1 R-Baum basierte Ansätze .................................................................... 7
3.3.2 B+-Baum basierte Ansätze zum Schutz der Privatsphäre bei Nutzung von LBS .............................................................................................. 9
3.3.3 Quad-Tree basierte Ansätze .............................................................. 10
4 Fachliche Würdigung .......................................................................................... 11
4.1 OST-Baum .................................................................................................... 11
4.2 PEB –Baum .................................................................................................. 11
4.3 Der Bob-Baum ............................................................................................... 12
5 Darstellung der Ergebnisse ................................................................................ 14
6 Zusammenfassung ............................................................................................... 16
Anhang ....................................................................................................................... 17
Literaturverzeichnis ................................................................................................. 20

II
Abbildungsverzeichnis
Abbildungsverzeichnis Abbildung 1: R-Baum basierte Datenmodell und dessen Indexstruktur, Seite 8
Abbildung 2: Struktur des OST-Baums, mit eingebetteten Profilinformation, Seite 8
Abbildung 3: Aufbau des B+ Baums mit der Unterscheidung der innere Knoten und Blatt-
knoten, Seite 10
Abbildung 4: Aufbau des Bob-Baums mit der Unterscheidung der innere Knoten und
Blattknoten, Seite 10

1
Einführung
1 Einführung
Um gezielt auf einen bestimmten Datensatz bzw. bestimmte Datensätze in einer großen Daten-
menge der Datenbank effizient zuzugreifen, bedarf es der Verfügbarkeit (einer) geeigneten In-
dexstruktur(en) (IS) auf die Daten, die auch als Zugriffspfade bezeichnet werden können. Im Be-
reich der spatio-temporalen Daten (räumliche-zeitliche Objekten oder auch als Moving Objects
bezeichnet) kommen mehrdimensionale Indexstrukturen zum Einsatz. Im Gegensatz zu den ein-
dimensionalen Indexen, wobei die Indexeinträge über einen einzigen Suchschlüssel aufgebaut
sind, werden die Indexeinträge im mehrdimensionalen Fall durch mehrere Suchschlüssel aufge-
baut. Je nach den zugrundeliegenden Organisationsprinzipien und weiteren charakterisierenden
Eigenschaften können diese mehrdimensionalen Indexstrukturen weiter untergeteilt werden, siehe
auch Tabelle 1 in Abschnitt 4 für eine zusammenfassende Darstellung dieser Eigenschaften.
Während die Suche nach einem oder mehrerer Datensätze von der Verfügbarkeit von IS profitiert
und beschleunigt werden kann, verursachen diese „extra“ Strukturen auch die Verlangsamung der
Wartungsaufgaben des DBMS und erhöhen den Speicherplatzbedarf. Zusätzlich zu dem Einpfle-
gen der Daten im Hauptdatenbestand müssen die entsprechenden Informationen und Einträge auch
in die Indexe eingepflegt werden und es muss extra Speicherplatz dafür reserviert werden.
Im Bereich der Location Based Services (LBS) kommen die Speicherung und Verarbeitung von
mehrdimensionalen Daten zum Einsatz und man benötigt dafür mehrdimensionale IS. Allgemein
folgt der strukturelle Aufbau eines Eintrags einer IS dem Muster: <Suchschlüssel, Zeiger>, wobei
der Zeiger die Adresse bzw. der Identifikator des (der) gesuchten Datensatzes (-sätze) darstellt. Im
Fall der mehrdimensionalen IS bildet der Suchschlüssel eine Menge von Schlüsseln, die als k1, k2,
…, kd für d-dimensionalen Datenraum und d ∈ ℕ und d > 1 dargestellt werden kann. Zusätzlich
zu den Suchschlüsseln und Zeigern kann man auch in Indexeinträge weitere Information einbetten,
wie dies z. B. im Fall der Anonymisierung der Daten durch Einbettung weiterer Information zu-
stande kommen kann. Im Folgenden wird eine kurze Einführung zur Anonymisierung im Bereich
des LBS und zu den allgemeinen Anforderungen an die mehrdimensionalen IS dargestellt.
1.1 Anonymisierung im Bereich des LBS Bei der Benutzung eines LBS ist es entscheidend, dass der Schutz der Privatsphäre des Dienstsu-
chenden gewährleistet wird und dabei die Qualität des Services auch im akzeptablen Bereich ge-
halten wird. Zur Realisierung dieses Ziels werden in der Literatur unterschiedliche Lösungsansätze
und Techniken diskutiert, wie diese in Abschnitt 3 dieser Seminararbeit genauer erläutert werden.
Dabei wird die Lokalität (räumliche wie auch zeitliche) des Dienstsuchenden als sensible Infor-
mation aufgefasst und bei den Bestrebungen zum Schutz der Privatsphäre geht es in erster Linie

2
Einführung
darum, diese Information zu verschleiern, damit diese nicht mehr eindeutig oder zumindest nicht
mehr sehr leicht einer bestimmten Person zugeordnet werden kann. Allgemein kann man Informa-
tionen anonymisieren, indem man durch Hinzufügen von Rauschen, Unterdrückung von Infor-
mationen oder Informationsverallgemeinerung die betroffene Information nicht mehr (leicht)
identifizierbar macht.
1.2 Anforderung an die mehrdimensionalen Indexstrukturen
An die mehrdimensionalen und speziell an die spatio-temporale IS wird die Anforderung gestellt,
dass sie allgemein die folgenden Aufgaben des DBMS unterstützen und dessen Antwortzeit bei
der Aufgabenverarbeitung verkürzen.
Unterstützung und Beschleunigung der relevanten Anfragetypen, siehe Unterabschnitt 1.3 un-
ten.
Da im Bereich der spatio-temporalen Daten und damit auch der LBS, Änderungen der Daten
häufiger sind als bei den entsprechenden statischen Daten, sollen die Updatekosten in Grenzen
gehalten werden bzw. optimal bleiben.
Unterstützung der möglichst weitgehenden Erhaltung der physischen Topologie der Objekte
bei den gespeicherten Daten, z. B. bei Clusterbildung.
Integrationsfähigkeiten in die bestehenden Systeme, wie z. B. das Relationale Datenmodell.
Flexibilität bei neuen Anforderungen, die auch als Erweiterbarkeit bezeichnet werden kann.
Speziell bei LBS sollen die IS den Schutz der Privatsphäre des Benutzers gewährleisten oder
unterstützen.
1.3 Anfragetypen bei der mehrdimensionalen Indexstrukturen Der zu betrachtenden Weltausschnitt wird allgemein als mehrdimensionaler Datenraum D darge-
stellt. Die Objekte werden als Sammlung von N Sätzen des Typs T = (A1, A2, …, An) mit den
Attributen A1 bis An dargestellt und in die Speicherungsstrukturen abgebildet. Jeder Satz wird als
ein geordnetes n-Tupel t = (a1, a2, …, an) dargestellt und die Attribute A1, A2, …, Ak (k≤n) sind
als Schlüssel definiert, spannen also den Suchraum auf. Eine Anfrage Q spezifiziert bis zu k
Schlüssel des Suchraums Qualifikationsbedingungen, die auch als Prädikate bezeichnet werden
können. Dann können die folgenden Anfragetypen unterschieden bzw. definiert werden.
Exakte Anfrage (exact match query), spezifiziert für jeden Schlüssel einen Wert als Q = (A1
= a1) ˄ (A2 = a2) ˄ …˄ (Ak = ak).

3
Einführung
Bereichsanfrage (range query), spezifiziert einen Bereich (also ein Intervall) als ri = (li ≤ai ≤
ui) für jede Schlüsseldimension, also 1 ≤ i ≤ k, und die Query Q = (A1 ∈ r1) ˄…˄ (Ak ∈ rk),
wobei li die untere Grenze und ui die obere Grenze des Intervalls darstellen.
Werden statt allen Schlüssel nur Teilschlüssel in die beiden genannten Anfragetypen spezifi-
ziert, dann wird die Query auch als partielle Anfrage bezeichnet.
Nächster-Nachbar Anfrage (nearest neighbour query), die auch als möglichst ähnliche oder
möglichst nahe an einem gegebenen Objekt definiert werden kann, spezifiziert eine vordefi-
nierte „Distanz“ zum gegebenen Objekt. Dafür muss eine anwendungsspezifische Distanz-
funktion F definiert werden. Gegeben sei weiterhin auch eine Sammlung von Objekten B in
k-dimensionalen Raum, und gesucht werden die nächsten Nachbarn q von Objekt p in B mit
der Bedingung:
(∀ r ∈ B) r ≠ q ⇒ [F r,p ≥ F q, p ] mit q, p ∈ B
Falls die zu betrachtenden Objekte als räumlich ausgedehnte Objekte statt nur als Punkt-Objekte
aufgefasst werden sollen, dann werden diese durch Approximation der Objekte durch einrahmende
Rechtecke bzw. Polygone dargestellt, die auch als bounding box (MAR) bezeichnet werden. Bei
solchen Objekttypen gibt es zwei weitere Anfragetypen, die wie folgt formuliert werden können.
Punktanfrage (point query) die für einen gegebenen Punkt alle ihn enthaltenden Objekte zu-
rückliefert.
Gebietsanfrage (region query), die für ein gegebenes Gebiet alle dies enthaltenden Objekte
zurückliefert.
Soweit die Anfrage zeitbezogen ist, dann gibt es folgende drei weitere Anfragetypen:
Zeitpunktanfrage (time-slice query) die zu einem gegebenen Zeitpunkt alle prädikaterfül-
lende Objekte zurückliefert
Zeitraumanfrage (window query), die zu einem gegebenen Zeitintervall alle prädikaterfül-
lende Objekte zurückliefert
Bewegungsanfrage (moving query), die zu einem gegebenen Zeitintervall alle dem prädi-
katerfüllende Objekte in einem bewegenden Raum (Intervall) zurückliefert.
Im Rahmen dieser Seminararbeit werden anhand einer Literaturauswertung die wichtigsten Eigen-
schaften der IS für spatio-temporalen Daten dargestellt, deren Anwendbarkeit zum Schutz der
Privatsphäre erläutert und ein Vergleich der Effizienz dieser Strukturen mit anderen Techniken
zum Schutz der Privatsphäre vorgenommen. Der restliche Teil dieser Arbeit wird so aufgegliedert,
dass die Problemstellung im Abschnitt zwei nach diesem einführenden Teil im ersten Abschnitt

4
Einführung
folgt, wobei eine formale Definition der Anforderung zum Schutz der Privatsphäre bei der Nut-
zung des LBS dargestellt wird. In Teil drei folgt dann die zusammenfassende Darstellung der bis-
herigen Forschungsergebnisse zu den Themen Spezielle Indexen und Anforderung zum Schutz der
Privatsphäre. Teil vier befasst sich mit der Würdigung der Erfüllung der Anforderung aus Sicht
der theoretischen und praktischen Forschungsberichterstattung zu den genannten Themengebieten.
In Teil fünf wird dann eine vergleichende Darstellung der Ergebnisse aus dieser Seminararbeit
diskutiert. Teil sechs schließt diese Seminararbeit mit einer zusammenfassenden Schlussfolgerung
der Ergebnisse dieser Seminararbeit.

5
Problemstellung
2 Problemstellung
Für eine breitere Akzeptanz der LBS und dessen erfolgreicher Einsatz in breiteren Anwendungs-
gebieten der Wirtschaft und sozio-kulturelles Leben der Gesellschaft, wie z. B. Ermittlung der
nahliegende Sehenswürdigkeiten, Einrichtungen wie Krankenhäuser, Hotels, Arztpraxen und ähn-
liches, Notruf-Situation, Wetterbericht usw. ist es entscheidend, dass bei der Benutzung des ange-
botenen Services der Schutz der Privatsphäre des Dienstsuchenden gewährleistet wird. Die Ver-
folgung des Zieles zum Schutz der Privatsphäre ist dabei zum Teil gegenläufig zum Ziel der Ver-
besserung der Servicequalität und diese beiden Anforderungen sind in Einklang zu bringen
[QUOC11-1, MANL08, JENS04]. Zur Erfüllung dieser Anforderung wurden unterschiedliche
Anonymisierungen der betroffenen (sensiblen) Informationen des Dienstsuchenden vorgeschla-
gen, die durch unterschiedliche Techniken der Daten- bzw. Informationsverallgemeinerung bzw.
–generalisierung, verschleiert (spatio-temporale cloaking oder obfuscation genannt) werden kön-
nen.
Zu den genannten räumlich-zeitlich Verschleierungs- oder Verhüllen durch Areal- und Temporal-
transformationstechniken, zählen auch die hierfür konzipierten Indexierungstechniken. Hierdurch
werden die Lokalität (örtliche und zeitliche) des Dienstsuchenden verschleiert, bevor diese an
dritte Beteiligte, wie z. B. Serviceanbieter, gesendet werden soll. Unter diesen Indexierungstech-
niken können beispielsweise der Bob -Baum, der PEB-Baum, SSTP –Baum und der OST-Baum ge-
nannt werden.
Es gibt auch weitere Anonymisierungstechniken, die ebenfalls durch Informationsverallgemeine-
rung erreicht werden können, wie z. B. k-Anonymisierung [GRUT03] und die auf Informations-
verschlüsselung basierten Private Information Retrieval (PIR) Protokolle [GHIN08].
Im Rahmen dieser Seminararbeit werden die strukturelle Aufbauweise der genannten Indexie-
rungstechniken und deren theoretische Eignung für die Erreichung des gewünschten Grads der
Anonymisierung bei gleichzeitiger Bewahrung der Effizienz der Anfrage- und Wartungsaufgaben
(Query-und Update Processing) des DBMS näher untersucht und gewürdigt. Es wird ein Ver-
gleich hinsichtlich der Erreichung des gesetzten Ziels der Anonymisierung der Privatinformation
durch diese IS mit den anderen (oben erwähnten) Anonymisierungstechniken vorgenommen. Die
Erfüllung der Anforderungen an solche IS zur effizienten Unterstützung der Anfrage- und War-
tungsaufgaben des DBMS und die Gewährleistung des Schutzes der Privatsphäre bei der Nutzung
des LBS werden kritisch gewürdigt.

6
Stand der bisherigen Forschung
3 Stand der bisherigen Forschung
Zum Schutz der Privatsphäre bei der Nutzung von LBS werden in der Literatur unterschiedliche
Lösungsansätze vorgeschlagen und deren Effizienz zur Erfüllung der Anforderung diskutiert.
Diese Lösungsansätze können grob in drei Bereiche unterteilt werden, [QUOC11-1]:
Ansätze mittels der so genannten k-Anonymisierung, welche die Verallgemeinerung der In-
formation mittels der spatio-temporal cloaking unter der Einschaltung eines dritten Dienstan-
bieters vorsieht.
Ansätze mittels der so genannten PIR (Private Information Retrieval), die auf der Verwendung
eines Protokolls basieren.
Ansätze mittels der Benutzung der Indexstrukturen des Datenbanksystems, durch Einbettung
von zusätzlichen Informationen, wie z. B. Privatsphäre-Richtlinien, Sicherheitseinstellung und
ähnliche Profile des Dienstsuchenden, direkt in die Indexstrukturen des DBMS, um diese etwa
den Kontext bewusst (context-aware) zu machen, realisiert werden können [QUOC11-2].
Dabei wird auch als Maß der Erfüllung der Anforderung zum Schutz der Privatsphäre ein Wahr-
scheinlichkeitsmodell herangezogen, das darauf hindeuten soll, in wie fern die Identifizierung
bzw. Rückschluss auf einen bestimmten Benutzer aus der bekanntgemachten Privatinformationen
erschwert werden kann. Im Folgenden werden die ersten zwei Ansätze kurz erläutert und der dritte
Ansatz etwas detaillierter dargestellt.
3.1 k-Anonymisierung zum Schutz der Privatsphäre der Benutzer
Die k-Anonymisierung beruht auf der Verschleierung der privaten Information mittels Verallge-
meinerung der betroffenen Information durch Hinzufügung von zusätzlichen k-1 Daten, wonach
die Daten des Dienstsuchenden nicht mehr von den übrigen k-1 Benutzerinformationen unter-
scheidbar sein soll. k steht dabei für eine Zahl, die vom Dienstsuchenden spezifiziert werden kann
und als Anonymitätsvoraussetzung bezeichnet wird. Der Ablauf dieses Vorgehens wird im Fol-
genden grob skizziert [GRUT03].
Der Benutzer sendet eine Anfrage q an einen (vertrauenswürdigen) Anonymisierungsdienst mit
entsprechenden Privatinformation, der seinerseits dann die Anfrage durch Hinzufügung von wei-
teren k-1 Daten die Information in eine Cloaking-Region CR (verhüllte Region) verallgemeinert
und diese CR statt die ursprüngliche Anfrage an den LBS-Provider schickt. Der Provider wird
dann alle infragekommenden Objekte, die so genannte Points of Interest (POI), an dem Anonymi-
sierungsdienst zurückschicken, der seinerseits dann aus dieser Information die für den ursprüngli-
chen Dienstsuchenden interessierenden Objekte ausfiltert und diese zurückgibt.

7
Stand der bisherigen Forschung
3.2 PIR-basierter Ansatz zum Schutz der Privatsphäre beim LBS Hierbei wird die Erzielung der Anonymität dadurch erreicht, dass die an den Dienstanbieter ge-
sendete Privatinformation des Dienstsuchenden zuerst verschlüsselt und dann übermittelt wird.
Dafür muss auf dem Server und dem Client das dafür benötigte Protokoll installiert sein um diese
Kommunikation zu unterstützen. In [GHIN08] wird beschrieben, dass die erreichte Wahrschein-
lichkeit zum Schutz der Privatsphäre um die Ordnung von 1/U ist, wobei U die Menge der gesam-
ten Nutzer des Dienstes, z. B. die in einem Land registrierte Benutzer, darstellt. Es wird auch in
den genannten Quellen zugegeben, dass die Methode allgemein rechenintensiv ist und für den
praktischen Einsatz auf mobilen Geräten mit beschränkter Rechenkapazität bedenklich sein kann.
3.3 Anonymisierung mittels Indexstrukturen zum Schutz der Privatsphäre
Bei diesem Ansatz wird die Verhüllung der genauen Lokalität durch Vergrößerung des räumlichen
und zeitlichen Raums der Anfragequelle (spatio-temporal cloaking) erreicht. Dabei wird die ge-
naue örtliche und zeitliche Lokalität des Dienstsuchenden durch Vergrößerung verschleiert, um
eine anonyme Benutzung des Services zu gewährleisten. Unter diesem Ansatz kann man die un-
terschiedlichen Indexierungsstrukturen, wie z. B. R-Baum basierte, Quad-Baum basierte und auch
B+-basierte Strukturen, benennen.
3.3.1 R-Baum basierte Ansätze
Unter den Indexstrukturen, die zum Schutz der Privatsphäre eingesetzt werden können und die
nach den Organisationsprinzipien des R-Baums aufgebaut sind, können der TPR*-Baum
[TAOY03], der OST-Baum [QUOC11-2] und der SSTP-Baum [ATLU07] genannt werden. Der
TPR-Baum (Time Parameterized Rectangle-Tree) ist dafür konzipiert, die räumliche Lokalität des
Objektes als Funktion der Zeit darzustellen und damit eine zukunftsorientierte Anfrage (predictive
query) über das gespeicherte Moving Object zu ermöglichen. Statt statischer Positionsdaten über
das betroffene Objekt wird eine lineare Funktion, die die benötigten Information dynamisch er-
mitteln kann, über das Objekt gespeichert, und diese Funktion nimmt als Parameter die Zeit und
die Geschwindigkeit des Objekts. Durch diese Vorgehensweise versucht man den häufig aufzutre-
tenden Updatebedarf des Objektes (einschließlich der Lokalität des Dienstsuchenden) zu minimie-
ren, da das Moving-Objekt häufig seine örtliche Lokalität im Laufe der Zeit ändert. Die modifi-
zierten Indexstrukturen, Abb. 1, werden durch Anpassung der entsprechenden Algorithmen der
Anfrage- und Wartungsaufgaben bedient, siehe auch Anhang.
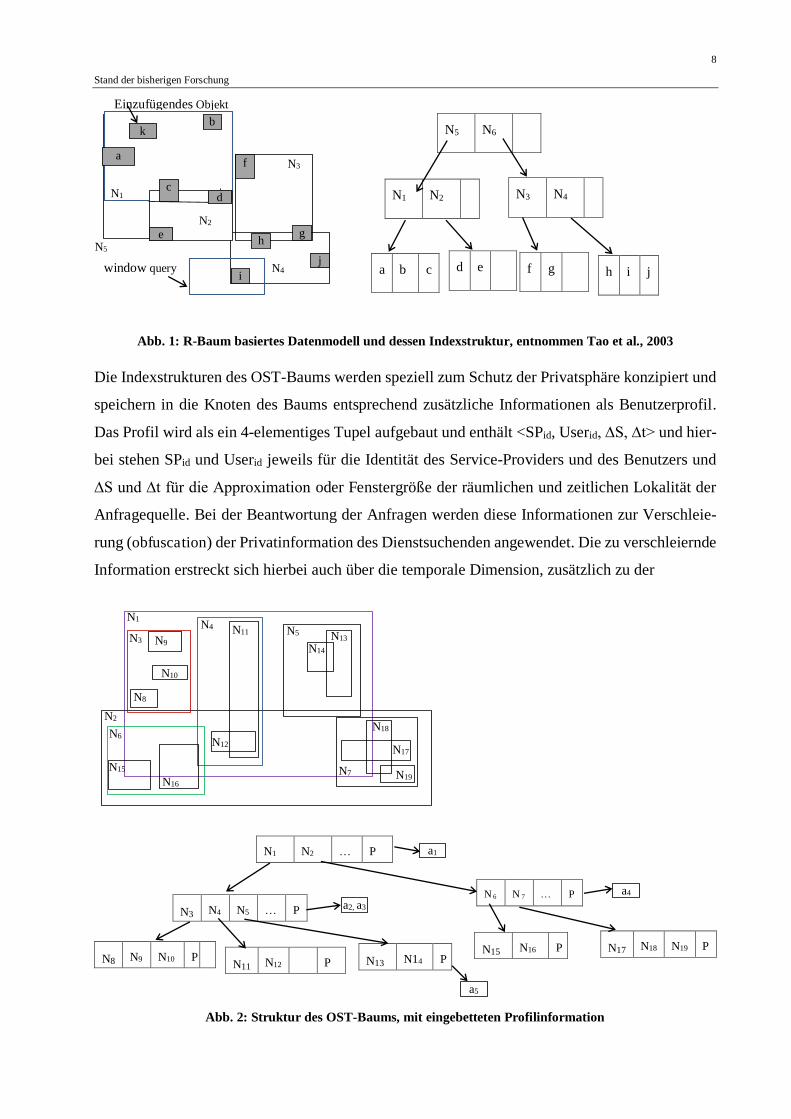
8
Stand der bisherigen Forschung
Abb. 1: R-Baum basiertes Datenmodell und dessen Indexstruktur, entnommen Tao et al., 2003
Die Indexstrukturen des OST-Baums werden speziell zum Schutz der Privatsphäre konzipiert und
speichern in die Knoten des Baums entsprechend zusätzliche Informationen als Benutzerprofil.
Das Profil wird als ein 4-elementiges Tupel aufgebaut und enthält <SPid, Userid, ∆S, ∆t> und hier-
bei stehen SPid und Userid jeweils für die Identität des Service-Providers und des Benutzers und
∆S und ∆t für die Approximation oder Fenstergröße der räumlichen und zeitlichen Lokalität der
Anfragequelle. Bei der Beantwortung der Anfragen werden diese Informationen zur Verschleie-
rung (obfuscation) der Privatinformation des Dienstsuchenden angewendet. Die zu verschleiernde
Information erstreckt sich hierbei auch über die temporale Dimension, zusätzlich zu der
Abb. 2: Struktur des OST-Baums, mit eingebetteten Profilinformation
N5 N6
N1 N2 N3 N4
d e f g h i j a b c
N1 N2 … P
N3 N4 N5 … P N 6 N 7 … P
N17 N18 N19 P N8 N9 N10 P
N15 N16 P N13 N14 P N11 N12 P
N11 N4
N2
N6
N15 N16
N18
N1
N3 N9
N8
N12
N7
N5 N13
N10
N17
N19
N14
a1
a4 a2, a3
a5
N5
a
b k
c d N1
e
i j
f
g h
N3
N2
N4
Einzufügendes Objekt
window query

9
Stand der bisherigen Forschung
räumlichen, und erhöht damit den Anonymisierungsgrad (vgl. auch den Ausdruck für Relevanz in
Abschnitt 5). Die Profil-Informationen können entweder direkt in den Knoten des Baums selbst
untergebracht werden oder extern gespeichert sein und ein Zeiger darauf in den Knoten eingerich-
tet sein, siehe auch Abb. 2 für ein Beispiel [QUOC11-2]. Die Festlegung der Fenstergröße des ∆S
und ∆t wird von den in fragekommenden Dienstanbieters abhängen bzw. entspricht dem Vertrau-
ensgrad des Dienstsuchenden an diesen.
3.3.2 B+-Baum basierte Ansätze zum Schutz der Privatsphäre bei Nutzung von LBS
In [MANL08] wird bemängelt, dass Indexstrukturen auf Basis des R-Baums, wie z. B. der TPR-
Baum oder seine Nachkömmlinge für effiziente Anfragen eingesetzt werden können, aber erhöhte
Updatekosten verursachen und auch nicht leicht in existierende relationale DB-Systeme integriert
werden können. Die als Alternative dafür entwickelte Struktur STRIPES, die auf den Organisati-
onsprinzipien des Quad-Trees aufgebaut ist, kann zwar für effizientere Updatekosten eingesetzt
werden aber sie leidet unter erhöhten Speicherbedarf und kann auch nicht leicht in das relationale
Modell integriert werden. Deshalb wurde als eine bessere Lösung eine Indexstruktur auf Basis des
B+-Baums (Abb. 3) vorgeschlagen und um die temporale Eigenschaft des Objektes zu berücksich-
tigen, wurden die Struktur und die Algorithmen für die Operationen auch entsprechend angepasst,
siehe Anhang für den modifizierten Algorithmus.
Zunächst wurde in dieser Richtung die Indexstruktur des Bx-Baum vorgeschlagen, der sich im
Wesentlichen dadurch vom B+-Baum unterscheidet, dass die Blattknoten Informationen über die
Objektlokalität zum gegebenen Zeitpunkt enthalten, während die inneren Knoten gleich gehalten
werden wie die des B+-Baums. Die Lokalität des Objekts wird als ein Vektorpaar O =(, ) dar-
gestellt, wobei die Position und die Geschwindigkeit des Objekts darstellen, und diese dann
mittels einer so genannten Space-filling curve (Fass-Kurve) als 1-dimensionaler Wert repräsen-
tiert. Dieser Wert wird dann mit dem Zeitintervall des Updates tu kombiniert bzw. verkettet, der
dann in einer 1-dimensionalen Indexstruktur, wie den B+-Baum, indexiert wird. Der Bx-Baum
kann von der strukturellen Effizienz des B+-Baums zwar profitieren, ist aber nicht optimal für
Moving-Objektes angelegt [QUOC11-1]. Deshalb wurde als eine bessere Alternative dafür der
Bdual-Baum vorgeschlagen, der zusätzlich explizit die Objektgeschwindigkeit in seiner Indexstruk-
tur berücksichtigt und deshalb besser für so genannte predictive-query geeignet sein soll. Der Bob-
Baum wurde auf der Grundlage des Bdual-Baums konzipiert und speichert noch weitere Informa-
tion in seinen Knoten, die für die Verschleierung der Privatinformation des Dienstsuchenden beim
LBS dienen sollte [QUOC11-1]. Die Aufbauweise der IS des Bob-Baums ist in Abb.4 angegeben.

10
Stand der bisherigen Forschung
C R1 Z1 R2 Z2 • • • Rp Zp Freier Platz
Zi = Zeiger auf die Söhne, Ri = Referenzschlüssel und k ≤ p≤ 2k
V= Vorgänger, Sj = Schlüssel, Dj = Daten und N= Nachfolger, k* ≤ j≤ 2 k*
Abb 3: Aufbau des B+ Baums mit der Unterscheidung der inneren Knoten-und Blattknoten.
P1 S1 K1 • • • K i-1 Pi Si K i • • • Kq-1 Pq Sq
Abb. 4: Aufbau des Bob-Baums mit der Unterscheidung der inneren Knoten und Blattknoten
3.3.3 Quad-Tree basierte Ansätze
Auf dem Organisationsprinzip des Quad-Tree baut die als STRIPES (a Scalable Trajectory Index
for Predicted Positions in Moving-Object Databases) bezeichnete Indexierungstechnik auf,
[PATE04]. Diese wird durch eine so genannte Dualtransformation des Datenraums aus einem d-
Dimensionen Raum in einem 2d-dimensionalen Raum als Punktobjekte dargestellt, welcher dann
durch Zerlegungsverfahren rekursiv jeweils in 4 untergeordnete Quadranten unterteilt wird. Ein
Knoten enthält neben den Schlüsseln und den Daten vier Zeiger auf die Teilbäume der Quadranten,
welche hier aus Platzgründen nicht wiedergegeben werden können. Charakteristisch für das Orga-
nisationsprinzip des Quad-Trees ist auch, dass dieses keine Einhaltung der Topologie der Daten-
welt ermöglicht und kein Mechanismus zum balancierten Zugriff bereitgestellt wird, [HÄRD01],
siehe auch Tabelle 1 in Abschnitt 4 für eine zusammenfassende Darstellung der Organisations-
prinzipien.
V S1 D 1 S2 D 2 • • • S j D j Fre ie r P la tz N
....:::: ..:: …
Blattknoten
x x xX<=K i Ki-1<=X<=K i Kq-1<=X
K1 Pr1 K i Pri K2 Pr2 Kq-1 Pq-1
Innere Knoten
Innere Knoten
Pnext Blattknoten

11
Fachliche Würdigung
4 Fachliche Würdigung Zur Verbreitung und allgemeiner Akzeptanz von LBS spielt der Schutz der Privatsphäre eine ent-
scheidende Rolle. Zum Schutz der Privatsphäre werden in der Literatur unterschiedliche Lösungs-
ansätze diskutiert, welche auf der k-Anonymisierung der Privatinformation, auf Einbettung von
zusätzlichen Profilinformationen in die Indexstrukturen des DBMS und auf Verschlüsselung
der betroffenen sensiblen Information des Dienstsuchenden beruhen, wie bereits im Teil 3 disku-
tiert wurde.
Im Rahmen dieser Seminararbeit wurde der Ansatz der Verhüllung (spatial-temporal-Cloaking)
mittels der eingesetzten IS des DBMS näher betrachtet. Als Beispiel wurden die Indexstrukturen
auf Basis des Organisationsprinzips des R-Baums, des Quad-Trees und des B+-Baums näher be-
trachtet. Im Folgenden werden beispielhaft der OST-Baum, der PEB-Baum und der Bob-Baum auf
die Erfüllung der gesetzten Anforderung näher untersucht. Die zur erfüllende Anforderung bezieht
sich dabei auf die Gewährleistung des Schutzes der Privatsphäre bei Nutzung des LBS unter
gleichzeitiger Einhaltung der Effizienz bei Anfrage- und Wartungsarbeiten des DBMS.
4.1 OST-Baum
Der OST-Baum (Obfuscating Spatio-Temporal data-Tree) baut auf der Grundlage des TPR-
Baums auf und unterstützt den Schutz der Privatsphäre durch Einbettung zusätzlicher Profilinfor-
mationen des Benutzers als <SPid, Userid, ∆S, ∆t> in die Knoten des Baums, die zu seinen Vorteilen
zählt. Andererseits leidet der OST-Baum auch unter den Einschränkungen der wohl-bekannten R-
Baum Indexstruktur, u. a., die durch die zulässige Überlappung der Datenregionen in den In-
dexstrukturen verursachte Schwierigkeit der Erhaltung der strikten lokalen Ordnungserhaltung
[HÄRD01]. Diese mündet wiederum in die Notwendigkeit der Traversierung mehrerer Pfade bei
der Suche eines gegebenen Datensatzes und damit erhöhten Zugriffsaufwand. Darüber hinaus ver-
ursacht solche Überlappung einen erhöhten Speicherbedarf.
4.2 PEB –Baum
Der PEB-Baum (Policy Embeded Bx-Tree) und der unter 4.3 beschriebene Bob-Baum wurden auf
Grundlage des Bx -Baums, und damit auf Grundlage des allgemeineren B+-Baums, aufgebaut und
enthalten weitere Informationen als die, die im Bx-Baum enthalten sind. Durch Einbettung der so
genannten Location Privacy Policy (LPP), etwa Richtlinien der Lokalitätsprivatsphäre, des Benut-
zers in den Indexstrukturen des Baums ermöglicht der PEB-Baum die Verschleierung der Privat-
information anhand dieser extra Information. Anders als der Bob-Baum und weiteren lokalitätsver-
hüllende Strategien zielt der PEB-Baum auf den Schutz der Privatsphäre gegen eine Gefahr, die

12
Fachliche Würdigung
möglicherweise von anderen Benutzern selbst ausgehen könnte. Durch eine geschickte Kombina-
tion der Information der Privatsphäre mit der Lokalitätsinformationen macht dessen Indexstruktur
die effiziente Anfragebearbeitung und Wartungsarbeiten, die sie vom B+-Baum erbt, möglich.
[LIND11].
Da hierbei der Anfrageverarbeitungsalgorithmus zusätzliche Informationen als die reinen spatio-
temporalen IS auswerten muss, wird dieser auch entsprechend komplexer und verursacht einen
erhöhten Aufwand bei den IO- und CPU-Zeiten. Die Wartungsarbeiten sind aber mit denen des
B+-Baums vergleichbar. Die entsprechenden Bereichsanfragen und nächster Nachbaranfragen sind
auch angepasst, wie in Anhang wieder gegeben wird. Der LPP wird als Tupel wie (role, locr, tint)
aufgebaut, wobei role die Beziehungsart zu weiteren Benutzern, locr die räumliche Region und tint
das Zeitintervall für die Begrenzung beschreiben.
4.3 Der Bob-Baum
Der Bob-Baum wurde auch dafür konzipiert, genauso wie die beiden oben genannten IS, dass die
für den Verschleierungsalgorithmus benötigten Informationen aus Effizienzgründen direkt auf der
Ebene der DB abgelegt sind. Hierbei wird wiederum durch die Einbettung zusätzlicher Informa-
tion für den Schutz der Privatinformation in die IS selbst unter Beibehaltung der effizienten Per-
formanz des B+-Baums die notwendige Verschleierung realisiert. Die IS des Bob-Baums wird
durch die so genannte Eindimensionale Einbettung der mehrdimensionalen Suchschlüssel mittels
der sogenannten space-filling-curve (Fass-Kurve) zur Realisierung der effizienten Anfrage-und
Updatekosten der eindimensionalen Baumstruktur aufgebaut. Dies soll die Nachteile des Organi-
sationsprinzips des R-Baums bzw. seiner Nachkömmlinge, wie TPR-Baum und OST-Baum, ver-
meiden
Allgemein wird ein d-dimensionales Moving-Object (ein Punktobjekt) o zum Zeitpunkt o.tref, Ko-
ordinaten o[1],…, o[d] und Geschwindigkeiten o.v[1], …o.v[d] als 2d-dimensionaler Vektor wie
folgend transformiert.
odual = (o[1](Tref), …, o[d](Tref), o.v[1], …, o.v[d]) wobei o[i](Tref) die ite Koordinate zum Zeitpunkt
Tref (Tref > o.tref) darstellt und gegeben durch o[i](Tref) = o[i] + o.v[i] *(T ref-o.tref). Dieser 2d-di-
mensionale Punkt wird durch die Hilbert-Kurve als 1-dimensionaler Wert dargestellt und dieser
dann mittels B+-Baum indexiert.
Die Anonymisierung wird dabei durch die Einbettung eines 3-tupligen Profils <idsp, iduser, ∆s> in
die Indexstruktur realisiert, wobei idsp und iduser jeweils für die Identität des Serviceproviders und
des Benutzers stehen, und ∆ für die Approximation des Gebiets der Anfragequelle steht. Die
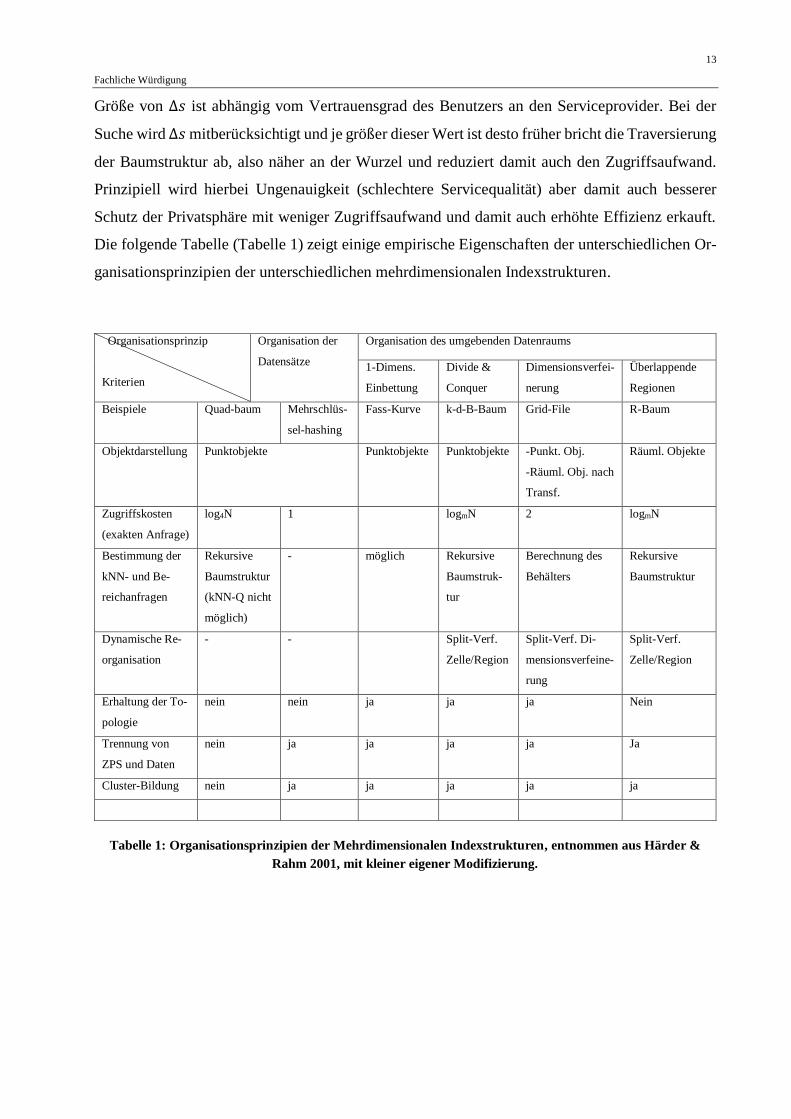
13
Fachliche Würdigung
Größe von ∆ ist abhängig vom Vertrauensgrad des Benutzers an den Serviceprovider. Bei der
Suche wird ∆ mitberücksichtigt und je größer dieser Wert ist desto früher bricht die Traversierung
der Baumstruktur ab, also näher an der Wurzel und reduziert damit auch den Zugriffsaufwand.
Prinzipiell wird hierbei Ungenauigkeit (schlechtere Servicequalität) aber damit auch besserer
Schutz der Privatsphäre mit weniger Zugriffsaufwand und damit auch erhöhte Effizienz erkauft.
Die folgende Tabelle (Tabelle 1) zeigt einige empirische Eigenschaften der unterschiedlichen Or-
ganisationsprinzipien der unterschiedlichen mehrdimensionalen Indexstrukturen.
Organisationsprinzip
Kriterien
Organisation der
Datensätze
Organisation des umgebenden Datenraums
1-Dimens.
Einbettung
Divide &
Conquer
Dimensionsverfei-
nerung
Überlappende
Regionen
Beispiele Quad-baum Mehrschlüs-
sel-hashing
Fass-Kurve k-d-B-Baum Grid-File R-Baum
Objektdarstellung Punktobjekte Punktobjekte Punktobjekte -Punkt. Obj.
-Räuml. Obj. nach
Transf.
Räuml. Objekte
Zugriffskosten
(exakten Anfrage)
log4N 1 logmN 2 logmN
Bestimmung der
kNN- und Be-
reichanfragen
Rekursive
Baumstruktur
(kNN-Q nicht
möglich)
- möglich Rekursive
Baumstruk-
tur
Berechnung des
Behälters
Rekursive
Baumstruktur
Dynamische Re-
organisation
- - Split-Verf.
Zelle/Region
Split-Verf. Di-
mensionsverfeine-
rung
Split-Verf.
Zelle/Region
Erhaltung der To-
pologie
nein nein ja ja ja Nein
Trennung von
ZPS und Daten
nein ja ja ja ja Ja
Cluster-Bildung nein ja ja ja ja ja
Tabelle 1: Organisationsprinzipien der Mehrdimensionalen Indexstrukturen, entnommen aus Härder & Rahm 2001, mit kleiner eigener Modifizierung.

14
Darstellung der Ergebnisse
5 Darstellung der Ergebnisse
Im Laufe dieser Seminararbeit wurden unterschiedliche Möglichkeiten zum Schutz der Pri-
vatsphäre im Bereich der LBS anhand von ausgewählter Literatur aufgezeigt. Insbesondere wur-
den die Techniken der Einbettung von extra Informationen in die IS des DBMS zum Schutz der
Privatsphäre detaillierter erörtert. Zur vergleichenden Darstellung der Effektivität der unterschied-
lichen Anonymisierungstechniken wird nun ein Wahrscheinlichkeitsmodell herangezogen und zu
den Effizienzmerkmalen bei der Anfrage- und Wartungsaufgaben werden die allgemein bekannten
empirischen Eigenschaften, wie z. B. Tabelle 1 in Abschnitt 4, der zugrundeliegenden Organisati-
onsprinzipien der jeweiligen IS betrachtet.
Bei k-Anonymisierung wird die Wahrscheinlichkeit P, dass ein Rückschluss auf eine bestimmte
Person, die möglicherweise hinter der bekanntgemachten Privatinformation stehen könnte, wird
durch P = 1/k gegeben, wobei k-für den Anonymisierungsgrad steht. K kann vom Benutzer je nach
eigenem Bedarf festgelegt werden, aber kann nicht überall unbegrenzt erhöht werden, da diese
allgemein von der Anzahl der angemeldeten Benutzer und weiteren Benutzungsumgebungsmerk-
malen abhängt. Bei dem PIR-basierten Modell wird P durch P = 1/U angegeben, wobei U für die
gesamte Menge der angemeldeten Systembenutzer steht, z. B. die Gesamtanzahl der registrierten
Benutzer in einem Land. Es gilt im Allgemeinen, dass U ≫ k ist. Bei der Verschleierung (obfusca-
tion) anhand der IS des DBMS wird im Allgemeinen eine so genannte Relevanz Ri (relevance) als
Maßstab zum Schutz der Privatsphäre herangezogen. Diese kann wie folgt dargestellt werden:
Ri = ∩ 2∙ wobei Ai, das tatsächliche Gebiet des Benutzers, dessen Genauigkeit allein von der
Bemessungstechnologie abhängt und Af das transformierte (verschleierte) Gebiet darstellen
[ARDA09]. Beim Schutz der Privatsphäre geht es nun darum, Ri möglichst zu verkleinern. Wird
zum räumlichen Aspekt auch der temporale Aspekt für die Verschleierung mit einbezogen, so wird
der obige Ausdruck wie folgt angepasst
Ri = ∩ 2∙ ∙ 1∆ , wobei ∆ das Zeitintervall darstellt.
Zusammenfassend können die bisher gesagten Eigenschaften der Anonymisierungstechniken wie
in die Tabelle 2 überblicksartig dargestellt werden. Die allgemeinen Effizienzeigenschaften der
zugrundliegenden Organisationsprinzipien sind bereits in Tabelle 1 wiedergegeben und können
für einen Vergleich herangezogen werden. Organisationsprinzipien auf Basis der 1-dimensionalen
IS des B+-Baums werden allgemein als effizienter angenommen.
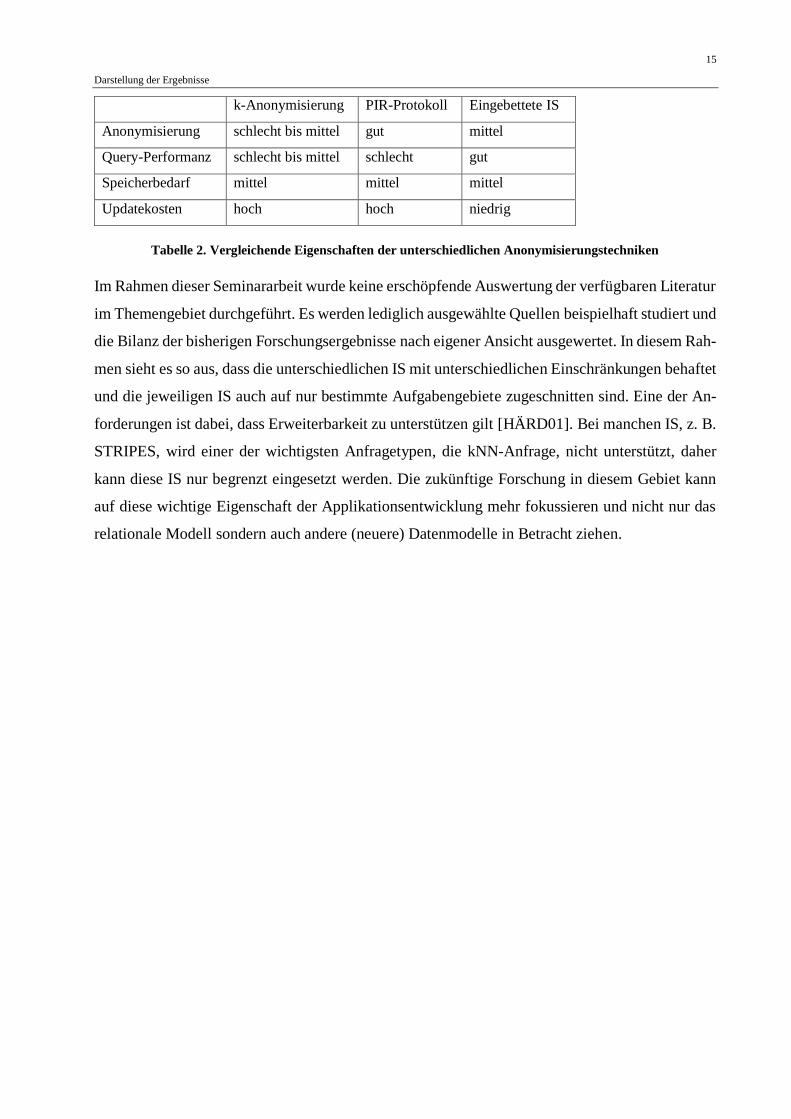
15
Darstellung der Ergebnisse
k-Anonymisierung PIR-Protokoll Eingebettete IS
Anonymisierung schlecht bis mittel gut mittel
Query-Performanz schlecht bis mittel schlecht gut
Speicherbedarf mittel mittel mittel
Updatekosten hoch hoch niedrig
Tabelle 2. Vergleichende Eigenschaften der unterschiedlichen Anonymisierungstechniken
Im Rahmen dieser Seminararbeit wurde keine erschöpfende Auswertung der verfügbaren Literatur
im Themengebiet durchgeführt. Es werden lediglich ausgewählte Quellen beispielhaft studiert und
die Bilanz der bisherigen Forschungsergebnisse nach eigener Ansicht ausgewertet. In diesem Rah-
men sieht es so aus, dass die unterschiedlichen IS mit unterschiedlichen Einschränkungen behaftet
und die jeweiligen IS auch auf nur bestimmte Aufgabengebiete zugeschnitten sind. Eine der An-
forderungen ist dabei, dass Erweiterbarkeit zu unterstützen gilt [HÄRD01]. Bei manchen IS, z. B.
STRIPES, wird einer der wichtigsten Anfragetypen, die kNN-Anfrage, nicht unterstützt, daher
kann diese IS nur begrenzt eingesetzt werden. Die zukünftige Forschung in diesem Gebiet kann
auf diese wichtige Eigenschaft der Applikationsentwicklung mehr fokussieren und nicht nur das
relationale Modell sondern auch andere (neuere) Datenmodelle in Betracht ziehen.

16
Zusammenfassung
6 Zusammenfassung
Bei der Nutzung von LBS wird als entscheidend beachtet, dass der Schutz der Privatsphäre ge-
währleistet wird. Dafür werden unterschiedliche Anonymisierungstechniken vorgeschlagen und
auf deren Effizienz hin untersucht. Bei der Anonymisierung kann man nicht von einer vollständi-
gen Verschleierung der betroffenen Lokalitätsinformation ausgehen, da diese Informationen für
die benötigten Dienste ausgewertet werden müssen. Stattdessen wird allgemein durch Hinzufü-
gung von extra Information die Genauigkeit dieser Informationen absichtlich verschlechtert und
Ungenauigkeiten verschafft. Dies soll die Wiederidentifizierung der betroffenen Person aus der
bekannt gemachten sensiblen Information erschweren, um den Schutz der Privatsphäre zu gewähr-
leisten.
Von den vorgeführten Anonymisierungstechniken kann der Ansatz mittels des PIR-Protokolls als
der effizienteste Mechanismus zum Schutz der Privatsphäre betrachtet werden, da diese die be-
tragsmäßig kleinste Wahrscheinlichkeit verschafft. Andererseits zeigt auch dieser Ansatz ein er-
hebliches Performanz-Defizit bezüglich der weiteren Aufgabenanforderung des DBMS, und damit
ein erhebliches Bedenken für dessen breiteren Einsatz im Bereich der LBS. Der Ansatz mittels der
so genannten k-Anonymisierung zeigte eine bessere Performanz aber der Grad der Anonymisie-
rung ist nicht unbeschränkt, zudem wird der Ansatz bei der so sogenannten Korrelationsattacke
als unzureichend betrachtet. Als bessere Alternative wurden die Anonymisierungstechniken durch
Einbettung von zusätzliche Informationen in die IS des DBMS vorgeschlagen und auf ihre Effizi-
enz untersucht. Aus Sicht der Performanz können solche Strategien als die bessere Alternative
angesehen werden, aber ihre allgemeine Akzeptanz für den Schutz der Privatsphäre unter allen
Benutzungsumgebungen des Dienstes kann nur als bescheiden beschrieben werden. Die einzelnen
Techniken können nur bestimmte Anforderungen besser erfüllen und nicht universell für alle Sze-
narien einsetzbar und damit erfüllen sie nicht eine der wichtigsten Eigenschaft der IS, die Erwei-
terbarkeit, genügend. Dies zeigt sich auch daran, dass bereits eine Fülle von IS in der Literatur
diskutiert wird, und diese sich unterscheiden voneinander nur um bestimmten Aspekte. Dies kann
dazu führen, dass für jeden Anwendungsbereich eine eigene IS zu entwickeln und einzusetzen ist.
Dies wäre auch nicht ganz optimal. Deswegen kann im Rahmen dieser Seminararbeit der Vor-
schlag gemacht werden, dass die Forschung zukünftig die Richtung der Erweiterbarkeit auch eine
geeignete Fokussierung widmet.

17
Anhang
Anhang
A. Bx-tree
1. Der angepasste Algorithmus zur Bereichsanfrage des Bx-Baums
Algorithm Range_query (q, tq) Input : q ist he query range and tq ist he query time.
for j ←0 to n
if partition Tj of the Bx-tree is valid at tq then
q' ←TimeParameterizedRegion(q, tq) //eine Funktion zur Vergrößerung der Anfrage von q //zu q'
calculate start and end points i1, . . . i2m for q'
for k← 1 to m do
locate keaf node containing point i2k-1
repeat
store candidate objects in L
follow the right pointer to the sibling node
until node with point i2k is reached
for each object in L do
if the object’s position at tq is inside q then
add the object to the result_set
return result_set
2. Der angepasste Algorithmus zur Nächste Nachbaranfrage des Bx-Baums
Algorithm kNN_query(q(qx1, qx2), k, tq) Input: a query point q(qx1, qx2), a number k of neighbors, and a query time tq
Construct range Rq1 with q as center and extension rq
R'q1 ← TimeParameterisedRegion(Rq1, tq)
flag ← true //not enough objects i ← 1 //first query region is being searched
while flag
if i = 1 then
find all objects in region R'q1
else
find all objects in region R'qi - R'qi-1
if k objects exist in inscribed circle of R'qi then
flag ← false
else
i ← i + 1
Rqi ← Enlarge (Rqi-1 , rq)

18
Anhang
R'qi ← TimeParameterizedRegion(Rqi, tq)
Return k NNs with respect to q
B. Bob-Baum
Suchalgorithmus
Input : a dual Vekcor of a moving object odual, area of an obfuscated region S
Output : the region that ist area equals S and contains a moving point with a dual vector odual,.
Transform odual into the Hilbert value h.
while (n is not a leaf node) do:
search node n for an entry i such that Ki-1 < h < Ki
if S = Si then
return the region corresponding to the Hilber interval [K i-1-K i].
else if S > Si then
return ExtendCell (Ki-1, Ki, S) //ExtenCell ist ein Algorithmus, der dem Hilbert-Intervall //[K i, Kj] entsprechenden Region durch Hinzufügung von zusätzlichen und zugänglichen Zelle //erweitert, bis diese gleich S groß wird.
else
n ← n ∙.Pi // der ite Zeiger im Knoten n
search leaf node n for an entry (Ki, Pri) with h = Ki
if found then retrieve the user’s exact location
else the search value h is not in the database
C. PEB-Baum
Bereichsuchealgorithmus
Algorithm PRQ (q, tq, uid, friend_list)
Input : R is the query range and tq is the query time, uid is the ID of the user who issues the query, friend_list is the list of users related to uid.
Output : result_list
SVmin ← smallest sequence value in friend_list SVmax ← largest sequence value in friend_list next.timestamp ← 0
more ← true
while more
R ← Enlarge (next_timestamp, R, tq)
ZV _intervals ← ZVconvert(R )
for each (ZVstart; ZVend) in ZV _intervals
StartPnt ← TID ⊕ SVmin ⊕ SVstart
….EndPnt ← TID ⊕ SVmax ⊕ ZVend
current_leaf ← leaf node containing StartPnt

19
Anhang
for each user u in current_leaf do
if u passes location and policy evaluation then
add u to result_list
if current_leaf contains EndPnt then
next_timestamp ← current_timestamp + 1
…..else
current_leaf ← current_leaf.right_sibling
…..if next_timestamp ≥ n ⋁ current_leaf = ⊥ then
more ← false
end while
return result_list

20
Literaturverzeichnis
Literaturverzeichnis
ARDA09 Ardagna, C.A., Cremonini, M., Vimercati, S.D.C., Samarati, P.: An Obfuscation-Based Approach for Protecting Location Privacy. IEEE Transactions on Dependable and Secure Computing Vol. 8, No. 1, Jan-uary-February 2011, 13–27 (2009)
ATLU07 Atluri, V., Shin, H.: Efficient Security Policy Enforcement in a Loca-tion Based Service Environment. In DBSEC, USA, pp. 61-76, 2007.
GHIN08 Ghinita, G., Kalnis, P., Khoshgozaran, A., Shahabi, C., Kian –Lee, T.: Private Queries in Location Based Services: Anonymizers are not Nec-essary. In: Proceedings of the 2008 ACM SIGMOD international con-ference on Management of data, Vancouver, Canada, 2008, pp.121–132.
GRUT03 Gruteser, M., Grunwald, D.: Anonymous Usage of Location Based Services Through Spatial-Temporal Cloaking, in Proc. ACM Mo-biSys, 2003, pp. 31-42
HÄRD01 Datenbanksysteme: Konzepte und Techniken der Implementierung (buch) , 2. Auflage, 2001, Springer, Berlin, pp. 243-295
JENS04 Jensen, C.S., Lin, D., Ooi, B.C.: Query and Update Efficient B + -tree based Indexing of Moving Objects. In: VLDB, Canada, pp. 768–779 (2004)
LIND11 Lin, D., Jensen, C. S., Zhang, R.: A Moving Object Index for Efficient Query Processing with Peer-Wise Location Privacy. In Proc. of the VLDB Endowment 5(1), 2011.
MANL08 Man Lung Yiu, Yufei Tao, and Nikos Mamoulis. The Bdual -tree: in-dexing moving objects by space filling curves in the dual space.VLDB J., 17(3):379–400, 2008.
PATEl04 Patel, J. M., Chen, Y., Chakka, V. P.: STRIPES: An Efficient Index for Predicted Trajectories. In Proc. ACM SIGMOD, International Con-ference on Management of Data. 637–646, 2004.
QUOC11-1 To, Q. C., Dang, T. K., Küng, J.: Bob-tree: An efficient B+-tree based index structure for geographic-aware obfuscation. In Ngoc Thanh Nguyen, Chonggun Kim, and Adam Janiak (editors), Intelligent Infor-mation and Database Systems -Third International Conference, ACI-IDS 2011, Daegu, Korea, April 20-22, 2011, Proceedings, Part I, vol-ume 6591 of Lecture Notes in Computer Science, pages 109–118. Springer, 2011.
QUOC11-2 To, Q.C., Dang, T.K., Küng, J.: OST-tree: An Access Method for Ob-fuscating Spatiotemporal Data in Location-based Services. In: Pro-ceedings of the 4th IFIP International Conference on New Technolo-gies, Mobility and Security (NTMS2011), IEEE Computer Society, Paris, France, 7-10 February, 2011
TAOY03 Tao, Y., Papadias, D., Sun, J.: The TPR*-Tree: An Optimized Spatio-Temporal Access Method for Predictive Queries. In: VLDB, pp. 790–801 (2003).


FernUniversität in Hagen -
Seminar 01912 / 19912 im Wintersemester 2014/2015
„Sicherheit und Privatsphäre in Datenbanken“
Thema 12
Location Based Services
Referent: Enrico Blechschmidt

Thema 12: Location Based Services Seite 2 von 20
Inhaltsverzeichnis
1 Einleitung 3
2 Location Based Services (LBS) 4
2.1 Anwendungsgebiete und Beispiele 4
2.2 Vor- und Nachteile dieser Dienste 6
2.3 Technische Umsetzung 7
3 Privatsphäre und Anonymisierung 8
3.1 Gefährdung der Privatsphäre 8
3.2 Schutz durch Anonymisierung 10
3.3 Geografischer Raum 13
3.4 Verschleierung im Graphen 14
3.5 Anonymisierung durch umgebungsbasierte LBS 15
3.6 Einfluss der Anonymisierung auf die Qualität von LBS 17
4 Fazit und Aussichten 18
Literaturverzeichnis 19

Thema 12: Location Based Services Seite 3 von 20
1 Einleitung
Durch den technischen Fortschritt ist die Verbreitung von Geräten (z. B. Smartphone,
Navigationsgeräten), welche zur präzisen und genauen Ermittlung des aktuellen Aufenthaltsortes
einer Person genutzt werden können, in den letzten Jahren stark angestiegen. Dadurch ist auch
das Angebot sowie die damit verbundenen Möglichkeiten, standortbezogene Dienste (Location
Based Services) bereitzustellen und zu nutzen weiter gewachsen. Neben der aktuellen Position
können durch den Anbieter des Dienstes exakte räumliche und zeitliche Informationen einer
Person erfasst und gesammelt werden. Diese sensiblen und persönlichen Daten können dazu
verwendet werden, die Inhalte, die dem Benutzer geboten werden, immer mehr zu
personalisieren und auf das Verhalten der Person abzustimmen. Gleichzeitig kann von diesen
Informationen auch eine Reihe von Gefahren ausgehen. Durch entsprechende Anonymisierung
der Daten können diese Gefahren jedoch relativiert werden, was sich allerdings auch auf die
Qualität der zur Verfügung gestellten Informationen und Dienste auswirken kann. Um dennoch
eine ausreichende Qualität zu gewährleisten, ist eine entsprechende Balance zwischen Preisgabe
von persönlichen Daten und gewünschter Anonymität zu finden.
In den nachfolgenden Kapiteln wird zunächst allgemein auf „Location Based Services“ (LBS)
(Kapitel 2) eingegangen, wobei mögliche Anwendungsgebiete genannt und anhand von
Beispielen näher erläutert werden. Gleichzeitig wird erklärt, welche Vor- und Nachteile sich für
die Nutzer sowie die Dienstleister dieser Dienste ergeben und wie LBS technisch umgesetzt
werden können.
Anschließend, im Kapitel 3, wird speziell das Thema Privatsphäre und Anonymisierung
aufgegriffen, indem auf die Gefahren für die Privatsphäre eingegangen wird und wie diese durch
Anonymisierung minimiert werden können. Weiterhin wird erläutert, welche Rolle Graphen
sowie deren Verschleierung in Bezug auf LBS spielen und welchen Einfluss die
Anonymisierung auf die Qualität der bereitgestellten Informationen haben kann.

Thema 12: Location Based Services Seite 4 von 20
2 Location Based Services (LBS)
2.1 Anwendungsgebiete und Beispiele
Eine Vielzahl von technischen Geräten ist heutzutage in der Lage, die aktuelle Position seines
Benutzers zu ermitteln und diese an den Anbieter von standortbezogenen Diensten zu senden.
Dadurch ist es möglich, entsprechende Informationen oder Dienstleistungen in Bezug auf den
momentanen Standort abzurufen bzw. zu nutzen. Neben den klassischen GPS-Geräten wie dem
Navigationsgerät sind mittlerweile auch Uhren, Fotokameras und Sportgeräte in der Lage, mit
Hilfe von drahtlosen Netzwerken oder GPS-Empfängern geografische Koordinaten zu
übermitteln und auszuwerten, wodurch auch die Anwendungsgebiete zur Nutzung dieser
Informationen immer neue Formen annehmen.
Neben der Navigation z. B. im Auto können dem Nutzer bei Bedarf sogenannte Points of Interest
(POI), wie Tankstellen, Restaurants oder Sehenswürdigkeiten angezeigt werden.
Aber auch im Bereich des Marketings werden diese Bewegungsdaten zielgerichtet eingesetzt,
um dem Benutzer, in Abhängigkeit seines aktuellen Aufenthaltsorts, für ihn relevante
Informationen zur Verfügung zu stellen oder durch gezielte Marketingaktionen sein
Kaufinteresse anzuregen oder gar erst zu wecken. Neben den bereits erwähnten
Anwendungsgebieten finden LBS u. a. auch in den Bereichen Social-Media, Notrufsysteme
(z. B. Not-Ruf-Apps) und öffentlichen Verkehrsmitteln (z. B. Fahrpläne) Verwendung.
Das vermutlich am häufigsten verwendete Gerät zur Nutzung von standortbezogenen Diensten
ist das Smartphone. Der meist ständige Begleiter verfügt oft über Global Positioning System
(GPS), Field Communication (NFC) oder Wireless LAN (WLAN) und ist so in der Lage, LBS
zu nutzen. Nachfolgend werden einige bekannte Beispiele genannt und kurz erläutert.
Point of Interest
Mit Hilfe von geografischen Standortinformationen können in der Nähe befindliche Objekte
angezeigt werden. Dabei muss es sich nicht immer, wie der Wortlaut eventuell vermuten lässt,
um interessante Punkte handeln, da das Interesse an diesen Punkt je nach benötigter Information
variieren kann. Für jemanden der einen Brief verschicken möchte, ist der nächstgelegene
Briefkasten von größerer Bedeutung, als für jemanden der gerade auf der Suche nach einer
Tankstelle ist (vgl. Openstreetmap).

Thema 12: Location Based Services Seite 5 von 20
Geocaching
Das Geocaching ist eine Art moderne Schatzsuche.
Hierbei werden sogenannte „Caches“ von „Cache-Versteckern“ versteckt und anschließend die
Position des Cache inklusive einiger Hinweise sowie dem Wichtigsten, den Koordinaten des
Cache, in einer der datenbankbasierenden Internetseiten (z. B. Opencaching.de) veröffentlicht.
Mit Hilfe eines GPS-Empfängers und den Koordinaten aus der Datenbank kann man sich
anschließend auf die Suche nach dem „Schatz“ begeben. Ist dieser gefunden, meist eine Dose
mit Logbuch, einem Bleistift sowie Tauschmaterial, trägt man sich in das Logbuch ein und kann
ggf. den Tauschgegenstand durch etwas Neues ersetzen oder einfach dort belassen (vgl.
Geocaching).
Auch heute noch ist Facebook, mit 1.350 Millionen Nutzern, eines der beliebtesten und meist
genutzten Social Networks weltweit (vgl. Statista2). In Deutschland liegt Facebook mit
33,36 Millionen Nutzern weit vor Xing (5,34 Mio.) und Twitter.com (3,83 Mio.) (vgl. Statista).
Dementsprechend groß ist auch das Angebot an immer neuen Funktionen, um immer mehr neue
User zu werben und damit natürlich auch das Interesse als Marketingplattform für Unternehmen
weiter auszubauen.
Facebook bietet zudem eine Reihe von Location Based Services. So kann man z. B. seinen
Freunden bzw. der Öffentlichkeit mitteilen, wo man sich momentan befindet und was man dort
gerade macht oder aber an welchem Ort ein bestimmtes Foto aufgenommen wurde.
Über Facebook Places hat man die Möglichkeit sich aktuelle Informationen (wie beliebte Orte in
der Nähe, Öffnungszeiten usw.) zum derzeitigen Aufenthaltsort anzeigen zulassen. Eine weitere
beliebte Funktion stellt „Freunde in der Nähe“ dar. Ist diese Einstellung aktiviert, werden alle
Freunde die sich in der Nähe aufhalten angezeigt und ggf. sogar benachrichtigt
(vgl. Andreas Pfitzmann/Marit Koehntopp).
Gutschein-Apps
Durch Gutscheine bzw. sogenannte Coupons lassen sich meist einige Euro sparen. Neben
Gutscheinen aus Zeitschriften und Flyern gibt es auch die mobile Variante, bei der man Coupons
direkt auf seinem Smartphone abrufen kann. Je nach Funktionsumfang werden auch hier,
beispielweise bei der App der Firma „GETTINGS“, LBS zur Verfügung gestellt. Auf Basis des
aktuellen Standorts werden eventuelle Vergünstigungen aus den unterschiedlichsten Kategorien
(wie beispielsweise Möbel, Kleidung oder Nahrung) dem Benutzer angezeigt (vgl. Tor).

Thema 12: Location Based Services Seite 6 von 20
2.2 Vor- und Nachteile von Location Based Services
Wie bereits erwähnt ergeben sich aus der Nutzung von Location Based Services eine Menge
Vorteile für den Anwender. Er ist in der Lage jederzeit entsprechende Informationen in Bezug
auf seinen aktuellen Standort in Anspruch zu nehmen und sich so z. B. navigieren zu lassen.
Aber auch in Bezug auf die soziale Komponente kommen diese Services zum Einsatz. Durch
Dienste wie z. B. Facebook hat man die Möglichkeit seinen aktuellen Standort zu offenbaren und
so eventuelle Freunde, die sich in der Nähe aufhalten, zu finden, um sich mit ihnen zu treffen.
Zusätzlich kann man andere teilhaben lassen, welche Orte man bereits besucht hat oder auf
interessante (oder auch nicht interessante) Orte hinzuweisen.
Neben diesen Vorteilen ergeben sich jedoch auch Nachteile, die je nach persönlicher
Einschätzung, mehr oder weniger gravierend sein können.
Gerade marketingbasierende Dienste, die gezielt personalisierte Werbung einsetzen oder die
Inanspruchnahme der bereits erwähnten Coupon-Apps können zum Kauf verleiten. Die
Anwender sollten sich bewusst sein, dass bei jeder Nutzung Daten vom Benutzer an den
Dienstanbieter gesendet werden. Je nach Gerät, Anwendung und Berechtigungen (z. B. bei
Smartphone-Apps) kann dies von einfachen Koordinaten bis hin zu weitaus persönlicheren
Informationen reichen.
Werden die Daten nun zusätzlich vom Dienstanbieter protokolliert und analysiert, lassen sich
eventuell Rückschlüsse auf das Verhalten oder gar auf die Identität der Person ziehen, (vgl.
Marco Gruteser/Dirk Grunwald, Kapitel 1). Je mehr Informationen ein Anbieter über den
Benutzer gesammelt, hat desto gezielter kann er diese einsetzen, um so die Qualität seiner
angeboten Dienste bzw. die Erfolgschance seines Marketings zu erhöhen. Sollte der
Dienstanbieter nun über seine AGBs sogar die Weitergabe der erfassten Daten legitimiert haben,
so steht der Weitergabe oder gar einem Verkauf an Dritte nichts mehr im Wege. In diesem Fall
hätte der Nutzer keinen Überblick mehr, wer alles Zugriff auf die vom Dienstanbieter
gesammelten Daten hat und wozu diese eventuell noch verwendet werden.
Diesen Gefahren sollte man sich zu mindestens bewusst sein, wenn man sich dazu entschließt,
LBS zu nutzen. In Kapitel 3 wird nochmals gezielt auf die Gefährdung der Privatsphäre
eingegangen.

Thema 12: Location Based Services Seite 7 von 20
2.3 Technische Umsetzung von Location Based Services
Die Grundvoraussetzung zur Nutzung von standortbezogenen Diensten ist die Verwendung eines
mobilen Endgerätes, welches in der Lage ist Funksignale zum Beispiel in Form von Global
Positioning System (GPS), Global System for Mobile Communications (GSM), Universal
Mobile Telecommunications System (UMTS), Wireless LAN (WLAN); Bluetooth oder aber
Near Field Communication (NFC) zu senden bzw. zu empfangen.
Entsprechend der verwendeten Technik kann die Genauigkeit von wenigen Millimetern (bei
NFC) bis hin zu einigen Kilometern, z. B. bei der Funkzellenortung (CellID) welche bei GSM
zum Einsatz kommt, variieren (vgl. Goldmedia GmbH Strategy Consulting, Seite 10).
Nachfolgend wird sehr vereinfacht dargestellt wie die Informationsbereitstellung von LBS durch
ein GPS-Signal erfolgt:
Abb. 1: Informationsbereitstellung von LBS durch ein GPS-Signal, Quelle: Goldmedia GmbH
Strategy Consulting Seite, 9

Thema 12: Location Based Services Seite 8 von 20
3 Privatsphäre und Anonymisierung bei der Nutzung von LBS
3.1 Gefährdung der Privatsphäre
Der Schutz der Privatsphäre wird u. a. durch das Persönlichkeitsrecht gemäß Art. 2 Abs. 1 in
Verbindung mit Art. 1 Abs. 1 des Grundgesetzes der BRD definiert (vgl. JuraForum).
Laut Gruteser und Grunwald erfolgt eine Einteilung in zwei Klassen von Gefahren in Bezug auf
Location Based Services. Zum einem die Verletzung der Privatsphäre bei der Kommunikation
(communication privacy) und zum anderen die Bekanntgabe des aktuellen Aufenthaltsortes
(location privacy) einer Person (vgl. Marco Gruteser/Dirk Grunwald, Kapitel 4.1).
Communication privacy
Unter der Annahme, dass der Nutzer des LBS unbekannt also anonym ist, kann der LBS
Anbieter als auch der Angreifer auf das Netzwerk nicht feststellen, wer der eigentliche Absender
einer Nachricht war. Ähnlich wie bei nicht LBS-basierten Web-Diensten gibt es aber ein
Kernproblem und zwar die Standortinformation. Ein Angreifer kann nun versuchen mit Hilfe
einer weiteren anonymen Nachricht und den dazu gehörigen Positionsangaben, diese mit bereits
gesammelten Informationen zu verknüpfen und so festzustellen ob diese Nachricht vom selben
Absender wie die 1. Nachricht versendet wurde.
Angenommen ein Nutzer (S = Subject) sendet eine Nachricht (M =Message) mit seinem
Aufenthaltsort (L = Location) an einen LBS und ein Angreifer (A = Adversary) hat Zugriff auf
diese Information, dann kann dies dazu führen, dass die Anonymität sowie die location privacy
gefährdet ist. Nachfolgend werden 3 mögliche Angriffsszenarien beschrieben:
1. Ortsbezogene Identifikation (Restricted Space Identification):
Falls A weiß, dass eine bestimmte Position zu S gehört, dann lernt A das S in L ist und
S gesendet hat. Wird beispielsweise eine anonyme Nachricht verschickt, so kann der
Angreifer versuchen mit Hilfe der Koordinaten eine Adresse abzuleiten. Über eine
Datenbank, z. B. dem Telefonbuch, kann er nun versuchen herauszubekommen, wer
dort wohnt und weiß so, wer sich vermutlich hinter dieser, ehemals anonymen,
Nachricht verbirgt.

Thema 12: Location Based Services Seite 9 von 20
2. Identifikation durch Überwachung (Observation Identification):
Weiß A, wo sich S momentan aufhält, (L) und findet eine M die von L verschickt
wurde, so weiß A das S diese M geschickt hat.
Beispiel: Der Nutzer hat in einer vorherigen Nachricht seine Identität und seine
momentane Position mitgeteilt und versucht nun vom selben Standort eine anonyme
Nachricht zu verschicken, so kann der Angreifer die 2. Nachricht dem bekannten
Nutzer, anhand der Positionsdaten, zuordnen.
3. Identifikation über Standorterfassung (Location Tracking)
Wenn A weiß, dass S momentan an Position Li und zusätzlich noch weiß das Li zu
einer Reihe von L1, L2 …Ln gehört, dann kann er daraus ableiten, dass S alle Orte
diese Reihe besucht hat.
(vgl. Marco Gruteser/Dirk Grunwald, Kapitel 4.1)
Location privacy
Durch die Benutzung von Location Based Services wird dem Dienstanbieter und/oder Dritten,
der Standort des Benutzers mitgeteilt wird. Nach Duckham und Kulik können sich hierdurch 3
Bereiche von Gefahren ergeben (vgl. Matt Duckham/Lars Kulik, Kapitel 2.1):
1. Location-based „spam“ (ortbezogener Spam):
Der aktuelle Standort könnte von unseriösen Unternehmen dazu verwendet werden
Individuen unaufgefordert mit Produkten oder Dienstleistungen in Abhängigkeit des
momentanen Aufenthaltsortes zu „bombardieren“.
2. Personal wellbeing and safety (persönliches Wohlbefinden und Sicherheit):
Die Information über die derzeitige Position einer Person könnte auch dazu verwendet
werden, um diese beispielsweise zu verfolgen (stalken) oder aber sogar physischen
Schaden zuzuführen.
3. Intrusive inferences (Rückschlüsse):
Durch die Informationen, an welchen Positionen sich eine Person aufhält oder welche
Orte diese besucht, könnten auch Rückschlüsse auf andere personenbezogene Daten,
wie Wohn- und Arbeitsort, Gesundheitszustand oder aber persönliche Vorlieben
gezogen werden.
(vgl. Matt Duckham/Lars Kulik, Kapitel 2.1)

Thema 12: Location Based Services Seite 10 von 20
3.2 Schutz durch Anonymisierung
Ist man innerhalb einer Gruppe von Subjekten nicht identifizierbar, spricht man von Anonymität
(vgl. Andreas Pfitzmann/Marit Koehntopp, Seite 10).
Bei der Benutzung von WEB-Diensten, LBS oder sonstigen Kommunikationsdiensten erfolgt die
Verbindung meist über Identifikationsmerkmale wie IP-Adresse, Rufnummer, Nutzerkennung
oder Geräte-ID. Diese eindeutigen Kennungen lassen sich nun einer Person oder Institution
zuordnen, wodurch der Sachverhalt der Anonymität nicht mehr gewährleistet ist. Es existieren
verschiedene Ansätze, um trotz dieser eindeutigen IDs seine Identität zu verschleiern und so
einen gewissen Grad an Anonymität zu erlangen. Nachfolgend werden 2 dieser Ansätze näher
erläutert.
Onion Routing
Beim Onion Routing, auch besser bekannt unter dem Namen TOR (The Onion Routing), erfolgt
die Kommunikation über mehrere, verschlüsselte „Schichten“ bzw. Stationen (daher auch der
Vergleich mit einer Zwiebel). Diese Schichten werden im TOR-Netzwerk „nodes“ genannt.
Möchte nun ein Nutzer, nachfolgend als Client bezeichnet, anonym, z. B. eine Website aufrufen
oder eine Nachricht versenden, muss zuerst eine Liste der verfügbaren TOR nodes abgerufen
werden. Anschließend wird eine zufällige Route, bestehend aus mindestens 3 nodes, gewählt.
Jeder dieser nodes kennt nur den vorherigen node nicht aber den vorvorherigen oder gar den
ursprünglichen Client. Die Kommunikation zwischen Client und node sowie unterhalb der nodes
erfolgt ausschließlich verschlüsselt. Lediglich die Verbindung zwischen dem letzten node, auch
Exit node genannt, erfolgt unverschlüsselt. Nachdem nun der Exit node die gewünschten
Informationen vom Server erhalten hat, gelangt die Nachricht wieder, auf demselben
verschlüsselten Weg, zurück zum eigentlichen Client. Wurde einmal eine Route aufgebaut, kann
darüber weiter kommuniziert werden. Um einer Überwachung vorzubeugen, wird nach etwa 10
Minuten eine neue Route gewählt, über die dann die Kommunikation erfolgt.
Das Problem am TOR-Netzwerk besteht darin, dass theoretisch jeder solch einen oder sogar
mehrere node(s) betreiben kann. Wählt nun ein Client zufällig genau 3 nodes eines Betreibers,
hat dieser die Möglichkeit, die komplette Route zurückzuverfolgen und so die Identität des
Clients (zu mindestens dessen IP-Adresse) zu ermitteln (vgl. Tor).

Thema 12: Location Based Services Seite 11 von 20
k-Anonymität
Von k-Anonymität wird gesprochen, wenn mindestens k-1 Objekte dieselben Informationen
zugeordnet werden können. Das heißt, je mehr Objekte dieselben Angaben besitzen, umso höher
ist die Menge k-1 und damit auch der Grad der k-Anonymität (vgl. Marco Gruteser/Dirk
Grunwald, Kapitel 5.1).
In Bezug auf LBS kann festgestellt werden, dass je nachdem wie detailliert die Informationen
bezüglich des aktuellen Standortes eines Nutzers vorhanden sind, desto schwieriger wird es, den
Sachverhalt der k-Anonymität herzustellen.
In der Regel werden alle Informationen eines Nutzers in einer Datenbank, genauer gesagt, in
einem Datensatz (tuple) zusammengefasst. Existieren nun mindestens zwei Datensätze mit
identischen Informationen, so sind diese k-anonym, weil die Datensätze nicht von einander
unterscheidbar sind. Durch entsprechende Verallgemeinerung der erfassten Daten kann auch der
Anonymisierungsgrad erhöht werden (vgl. Marco Gruteser/Dirk Grunwald, Kapitel 5.1). Wurden
zum Beispiel die exakten Koordinaten eines LBS Nutzers erfasst, könnten diese anstatt einer
genauen Position auch einem bestimmten Gebiet zugeordnet werden. Zusätzlich wäre es
möglich, statt der exakten Uhrzeit einfach den entsprechenden Tag zu protokollieren. Allein
durch diese Generalisierung ist die Wahrscheinlichkeit, dass sich weitere Personen, die sich an
diesem Tag in diesem Gebiet aufgehalten haben, höher. Daraus ergibt sich wiederrum eine
größere k-1 Menge, wodurch sich auch der Grad der k-Anonymität erhöht.
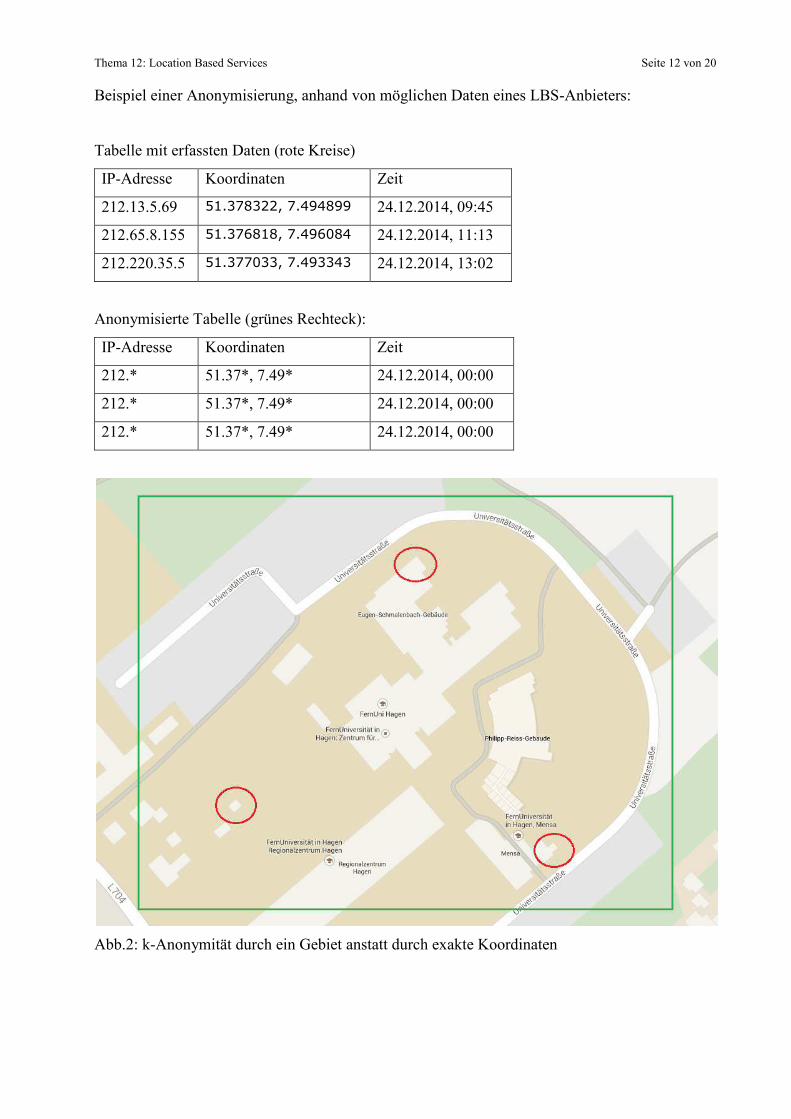
Thema 12: Location Based Services Seite 12 von 20
Beispiel einer Anonymisierung, anhand von möglichen Daten eines LBS-Anbieters:
Tabelle mit erfassten Daten (rote Kreise)
IP-Adresse Koordinaten Zeit
212.13.5.69 51.378322, 7.494899 24.12.2014, 09:45
212.65.8.155 51.376818, 7.496084 24.12.2014, 11:13
212.220.35.5 51.377033, 7.493343 24.12.2014, 13:02
Anonymisierte Tabelle (grünes Rechteck):
IP-Adresse Koordinaten Zeit
212.* 51.37*, 7.49* 24.12.2014, 00:00
212.* 51.37*, 7.49* 24.12.2014, 00:00
212.* 51.37*, 7.49* 24.12.2014, 00:00
Abb.2: k-Anonymität durch ein Gebiet anstatt durch exakte Koordinaten

Thema 12: Location Based Services Seite 13 von 20
3.3 Geografischer Raum
Mit Hilfe von Graphen (G) lassen sich sehr flexible Modelle eines geografischen Raumes
darstellen. Hierbei besteht ein Graph aus mindestens zwei Elementen aus der Menge der
Knoten/Eckpunkte (V für vertices) sowie mindestens einem Element aus der Menge der Kanten
(E für Edges), welche jeweils zwei Punkte aus V verbindet.
Formelle Beschreibung: G = (V, E)
Abb. 3: Beispiel für einen einfachen Graphen
Als Beispiel für Graphen wird oft ein Straßenverkehrsnetz angeführt. Hierbei stellen bestimmte
Orte oder Regionen die Knoten dar und Straßen, als Verbindung zwischen diesen Punkten, die
Kanten. Den in einem Graphen vorhandenen Kanten können zusätzlich, mit Hilfe der Funktion
∶ → ℝ, eine Gewichtung zugeordnet werden. Diese kann zum Beispiel dafür verwendet
werden, um Entfernungen oder Reisezeiten anzugeben (vgl. Matt Duckham/Lars Kulik, Kapitel
5.1).
Früher wurde der geografische Raum meist als Kartesisches Koordinatensystem
(2-Dimensonales Koordinatensystem) abgebildet. Wird der geografische Raum jedoch durch
einen Graphen dargestellt, ergeben sich einige zusätzliche Vorteile:
- Mit Hilfe von Graphen können Einschränkungen bezüglich der Bewegungen, z. B.
durch Straßennetze oder aber einer gegebenen Reisezeit, abgebildet werden.
- Graphen können sowohl im kartesischen Koordinatensystem (z. B. als Vektor-Modell
in räumlichen Datenbanken oder Geoinformationssystemen (GIS)) also auch in
Räumen mit mehr als 2 Dimensionen (z. B. Euklidischer Raum) dargestellt werden.
- Graphen sind rechnerisch effiziente, diskrete Strukturen.
(Vgl. Matt Duckham/Lars Kulik, Kapitel 5.1)

Thema 12: Location Based Services Seite 14 von 20
3.4 Verschleierung in einem Graphen
Ein bestimmter Punkt im geografischen Raum wird mit Hilfe eines Knoten ∈ dargestellt.
Die Verschleierung von wird nun durch eine Menge , eine Anzahl unpräziser Ortsangaben in
Bezug auf , symbolisiert, wobei gilt ∈ und ⊆ . Desweiteren gilt für jedes Element
∈ , dass dieses nicht von zu unterscheiden ist. Weiterhin wird angenommen, dass sich die
Person zu jedem Zeitpunkt an exakt einem dieser Punkte aufhält, der jedoch nicht bekannt ist.
Demzufolge kann der Grad der Privatsphäre, der durch die Ungenauigkeit des momentanen
Aufenthaltsortes zustande kommt, über die Mächtigkeit || (Anzahl der Knoten) der Menge
bestimmt werden. Je größer die Menge ist, desto höher ist auch der Grad der Privatsphäre in
Bezug auf den aktuellen Standort einer Person.
Abb. 4: Beispiel für einen Graphen inklusive Verschleierung
Abbildung 4 zeigt einen Graphen G = (V, E), inklusive der Menge der Verschleierung
= a, c, e, i, m was gleichzeitig den Grad der Privatsphäre || von 5 entspricht. Die Person
muss sich an einem der Punkte von aufhalten.
Es sei noch angemerkt, dass es nicht unbedingt notwendig ist, dass alle Punkte für die
Verschleierung mit dem Graphen G verbunden sind.
(Vgl. Matt Duckham/Lars Kulik, Kapitel 5.2)

Thema 12: Location Based Services Seite 15 von 20
3.5 Anonymisierung durch umgebungsbasierte LBS
Viele standortbezogene Dienste sind in der Lage, sich in der Nähe befindliche Informationen
anzeigen zulassen. Wie bereits erwähnt, können dies beispielsweise Points of Interest (z. B.
Restaurants oder Sehenswürdigkeiten) oder aber wie bei Facebook, sich in der Nähe aufhaltende
Freunde, sein. Die einfachste Möglichkeit hierbei ist die Abfrage in einer Datenbank auf
Grundlage des momentanen Aufenthaltsorts. Entsprechend der Suchanfrage, der momentanen
Koordinaten und mit Hilfe einer kategorisierten Datenbank, können zutreffende Suchergebnisse
bereitgestellt werden. Mögliche Suchanfragen könnten wie folgt lauten:
- Wo finde ich das nächste Fastfood Restaurant?
- Wie weit ist der nächste Briefkasten entfernt?
- Was sind in der Nähe befindliche Sehenswürdigkeiten?
Das Problem hierbei ist jedoch, dass durch die Übermittlung der exakten Koordinaten die
Anonymität in Bezug auf den momentanen Standort nicht mehr gewährleistet ist.
Durch die Nutzung von gewichteten Graphen kann der Zustand der Anonymität jedoch zu einem
gewissen Grad wiederhergestellt werden.
Hierbei werden nicht die momentanen Koordinaten des aktuellen Standorts übermittelt, sondern
lediglich das Gebiet, in dem man sich aufhält (z. B. der Stadtpark). Für dieses Gebiet werden
anschließend entsprechende Suchanfragen durchgeführt und die unterschiedlichen, gewichteten
Graphen mit Hilfe von geeigneten Algorithmen analysiert und anschließend zutreffende
Suchergebnisse selektiert und ausgegeben.
(Vgl. Matt Duckham/Lars Kulik, Kapitel 5.3)
Bei der Wahl der alternativen Positionen sind natürlich etwaige Beschränkungen zu
berücksichtigen, d. h. es dürfen nur diese gewählt, werden bei denen die Suchkriterien auch
weiterhin zutreffen (z. B. Suche nur im Umkreis von 5km).
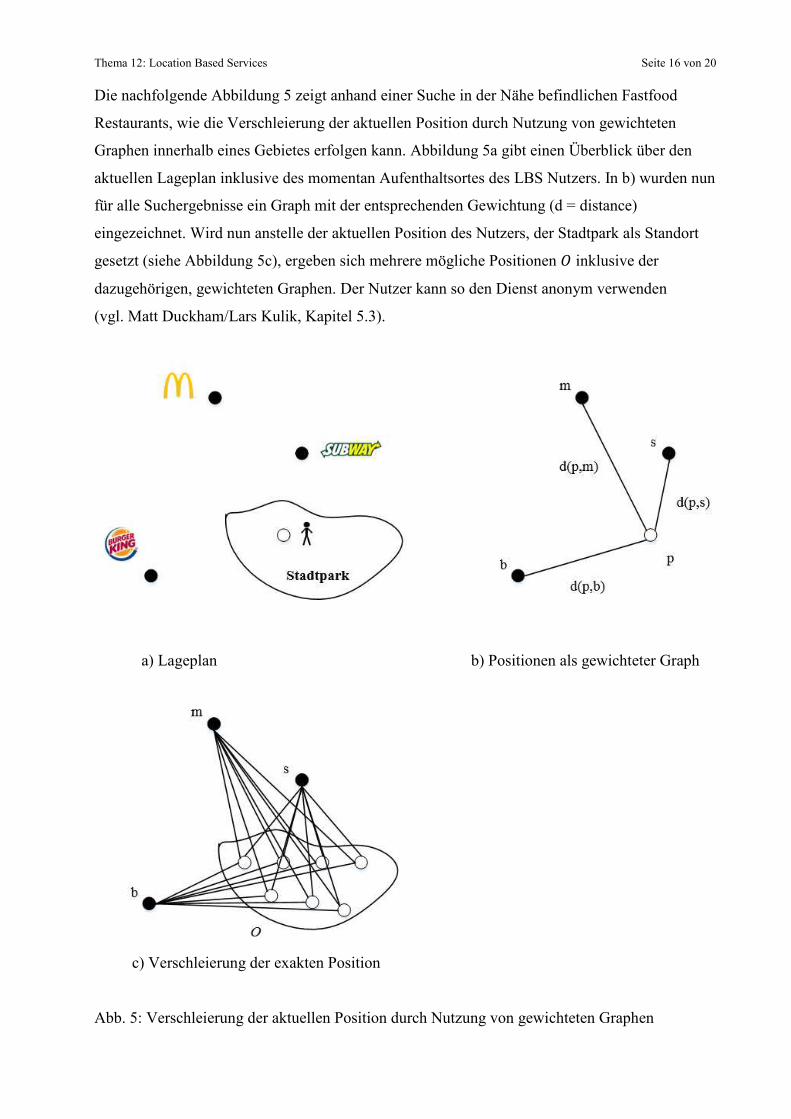
Thema 12: Location Based Services Seite 16 von 20
Die nachfolgende Abbildung 5 zeigt anhand einer Suche in der Nähe befindlichen Fastfood
Restaurants, wie die Verschleierung der aktuellen Position durch Nutzung von gewichteten
Graphen innerhalb eines Gebietes erfolgen kann. Abbildung 5a gibt einen Überblick über den
aktuellen Lageplan inklusive des momentan Aufenthaltsortes des LBS Nutzers. In b) wurden nun
für alle Suchergebnisse ein Graph mit der entsprechenden Gewichtung (d = distance)
eingezeichnet. Wird nun anstelle der aktuellen Position des Nutzers, der Stadtpark als Standort
gesetzt (siehe Abbildung 5c), ergeben sich mehrere mögliche Positionen inklusive der
dazugehörigen, gewichteten Graphen. Der Nutzer kann so den Dienst anonym verwenden
(vgl. Matt Duckham/Lars Kulik, Kapitel 5.3).
a) Lageplan b) Positionen als gewichteter Graph
c) Verschleierung der exakten Position
Abb. 5: Verschleierung der aktuellen Position durch Nutzung von gewichteten Graphen

Thema 12: Location Based Services Seite 17 von 20
3.6 Einfluss der Anonymisierung auf die Qualität von Location Based Services
Wird durch Anonymisierung zum Beispiel die Identität einer Person oder ihr momentaner
Standort verschwiegen, kann dies, je nach Art der Information bzw. des Services oder der
verwendeten Anonymisierung, Einfluss auf die Qualität des Location Based Services haben.
Gerade bei der anonymen Nutzung von umgebungsbasierten LBS können keine genauen
Entfernungen angegeben werden, da dem LBS Anbieter nicht die aktuelle Position sondern
lediglich ein beliebiger Punkt aus dem Gebiet, in dem sich der Benutzer aufhält, mitgeteilt wird.
Durch diese unpräzise Standortinformation kann es passieren, dass es sogar zu einer
Verschiebung bei der Reihenfolge der Ergebnisse kommt, da eventuell ein Ergebnis näher bei
der vermeintlichen Position liegt, als ein 2. Ergebnis welches dem tatsächlichen Aufenthaltsort
am nächsten liegt.
Um dennoch eine akzeptable Mischung zwischen der Preisgabe von persönlichen Daten des
Benutzers (wie z. B. der aktuellen Position) sowie der Qualität des Services zu erhalten, werden
in der Literatur verschiedene Algorithmen erläutert, mit denen auch bei anonymer Nutzung
umgebungsbasierter LBS, mit Hilfe von gewichteten Graphen, gute Ergebnisse erzielt werden
können.
Ein weiteres Merkmal für die Qualität eines Dienstes kann neben den Ergebnissen, die der
Service liefert, auch beispielsweise die Geschwindigkeit, mit der die Ergebnisse zur Verfügung
stehen sowie die Erreichbarkeit sein. Gerade bei der Verwendung des bereits erwähnten „Onion
Routing“ kann dieses Qualitätsmerkmal beeinträchtig sein. Sei es durch die
Geschwindigkeitseinbußen, die durch das Routing über die Clients sowie die Verschlüsselung
entstehen oder gar eventuelle Restriktionen (z. B. durch Internetzensur), die durch den „ Exit
node“ auftreten können.

Thema 12: Location Based Services Seite 18 von 20
4 Fazit und Aussichten
Der Markt von Location Based Services wird sich nach Analysen auch in den nächsten Jahren
weiter rasant entwickeln (Goldmedia GmbH Strategy Consulting, Seite 18). Allein in den letzten
Jahren sind laut der Analyse von Goldmedia die Anbieter von 130 im Jahre 2011 auf 927 im
Jahre 2014 gestiegen (Goldmedia GmbH Strategy Consulting, Seite 13). Tendenz weiter
wachsend.
LBS hält in immer neuen Bereichen Einzug, sei es als Vermittler für private Taxifahrten wie der
zuletzt oft diskutierte Dienst „UBER“ (vgl. Uber) oder aber die neuen Tarife von KFZ-
Versicherungen, bei denen, über eine Art Blackbox, das Fahrverhalten des KFZ-Lenkers
aufgezeichnet und auf Basis dessen der Beitrag zur KFZ-Versicherung berechnet wird
(vgl. Sparkasse).
Durch die weite Verbreitung von Location Based Services steigen auch die Akzeptanz sowie die
Nutzung dieser Dienste. Dadurch wird aber auch die bereitwillige Preisgabe von personen-
bezogenen Daten immer mehr als selbstverständlich angesehen, was von den Anbietern der LBS
natürlich gern gesehen wird. Mit Hilfe dieser Daten sind sie in der Lage, die Angebote noch
besser auf die jeweiligen Nutzer abzustimmen und so die Qualität aber auch die Absatzchancen,
z. B. durch besseres Marketing, weiter zu steigern.
Die Weitergabe von personenbezogenen Daten und sei es „nur“ der aktuelle Standort, hat jedoch
auch negative Folgen. Wie in dieser Arbeit erwähnt, können über Daten der Nutzer eventuell
auch Rückschlüsse auf Identität, Verhalten oder Vorlieben einer Person gezogen werden, was
nicht im Interesse der einzelnen Person liegt bzw. liegen sollte.
Zwar existieren verschiedene Arten der Anonymisierung, jedoch bieten auch diese keinen
100%igen Schutz der Privatsphäre der Benutzer. Sei es durch, ein einfaches Ausschluss-
verfahren, wenn zum Beispiel Daten zwar anonym sind, diese jedoch nur einer einzigen Person
zugeordnet werden können oder aber durch gezielte Angriffe wie in Kapitel 3.1 erwähnt.
Daher sollten Nutzer von Location Based Services immer daran denken, dass ihre
personenbezogenen Daten sowie ihre Privatsphäre durch die Nutzung dieser Dienste gefährdet
sein könnten. Das Recht auf Selbstbestimmung und Privatsphäre sollte auch bei allen
Annehmlichkeiten, die durch LBS bereitgestellt werden, nicht ins Hintertreffen geraten oder gar
vergessen werden.

Thema 12: Location Based Services Seite 19 von 20
Literaturverzeichnis
Andreas Pfitzmann/Marit Koehntopp: Anonymity, unobservability, and pseudonymity — a
proposal for terminology. In Hannes Federrath, editor, Designing Privacy Enhancing
Technologies — Proceedings of the International Workshop on Design Issues in
Anonymity and Unobservability, volume 2009 of LNCS. Springer, 2000.
Facebook: https://de-de.facebook.com/, Abruf am 2014-11-10
Geocaching: Spielregeln, http://www.geocaching.de/index.php/presse/presse-faq,
Abruf am 2014-11-11
Goldmedia GmbH Strategy Consulting: Klaus Goldhammer/Tim Prien/Florian Kerkau/Jan
Schlüter, Location-based Services Monitor 2014
JuraForum: Definition Privatsphäre, http://www.juraforum.de/lexikon/privatsphaere,
Abruf am 2015-01-05
Marco Gruteser/Dirk Grunwald: Anonymous Usage of Location-Based Services Through
Spatial and Temporal Cloaking, veröffentlicht in “Proceedings of the 1st International
Conference on Mobile Systems, Applications and Services”, Seite 31–42, ACM, 2003
Matt Duckham/Lars Kulik: A Formal Model of Obfuscation and Negotiation for Location
Privacy, veröffentlicht in “Pervasive Computing, Third International Conference, 2005”,
Seite 152-170, Springer, 2005
Openstreetmap: Points of interest, http://wiki.openstreetmap.org/wiki/Points_of_interest,
Abruf am 2014-11-10
Sparkasse: S-Drive, ein Telematik-Sicherheits-Services der Sparkasse,
https://www.sparkassen-direkt.de/telematik.html, Abruf am 2015-01-06

Thema 12: Location Based Services Seite 20 von 20
Statista: Das Statistik-Portal, Top 10 Soziale Netzwerke nach der Anzahl der Besucher im
September 2013,
http://de.statista.com/statistik/daten/studie/170467/umfrage/besucherzahlen-sozialer-
netzwerke-in-deutschland/, Abruf am 2014-11-10
Statista2: Das Statistik-Portal, Anzahl der monatlich aktiven Facebook-Nutzer weltweit von
2008 bis zum 3. Quartal 2014 (in Millionen),
http://de.statista.com/statistik/daten/studie/37545/umfrage/anzahl-der-aktiven-nutzer-von-
facebook/, Abruf am 2014-11-10
Tor: Overview, https://www.torproject.org/about/overview.html.en#overview,
Abruf am 2014-12-05
Uber: Privatpersonen als Taxifahrer, https://www.uber.com/, Abruf am 2015-01-06

FernUniversität in Hagen
Anonymisierung und Nutzung von "Trajectory"
Daten
Seminararbeit
Wintersemester 2014/2015
Vorgelegt der Fakultät für Mathematik und Informatik
der FernUniversität in Hagen
Lehrgebiet Datenbanksysteme für neue Anwendungen

Inhaltsverzeichnis I
Inhaltsverzeichnis
Abbildungsverzeichnis II
Abkürzungsverzeichnis III
1 Einleitung 4
2 Grundlagen und Definitionen 5
2.1 Trajektorie Daten 5
2.2 Anonymität 5
2.3 Klassen zur Erhaltung der Privatsphäre 7
3 Anonymisierung von Trajektorien 10
3.1 Methode zur Anonymisierung von Trajektorien 10
3.1.1 Notation und Annahmen 10
3.1.2 Methode zur Anonymisierung von Trajektorien 11
3.1.2.1 Bestimmung der Point Links 12
3.1.2.2 Bildung von anonymisierten Trajektorien mittels Point Matching 14
3.2 Erweiterung der Methode aufgrund qualitativer Aspekte 15
3.3 Rekonstruktion und Nutzbarkeit der anonymisierten Daten 20
4 Fazit und Ausblick 22
5 Anhang 23
5.1 Ergebnis des Berechnungsalgorithmus OPTsigma nach zwei Schleifendurchläufen.
23
5.2 Darstellung des Prozesses „Gruppenbildung der Trajektorien“ – Abbildung 6 24
6 Literaturverzeichnis 25

Abbildungsverzeichnis II
Abbildungsverzeichnis
ABBILDUNG 1: KLASSEN ZUR ERHALTUNG DER PRIVATSPHÄRE 8
ABBILDUNG 2: PROZESS „ANONYMISIEREN VON TRAJEKTORIEN (OPTSIGMA)“ 12
ABBILDUNG 3: BESTIMMUNG DER PL IM 2‐DIMENSIONALEN RAUM 12
ABBILDUNG 4: VERSCHIEDENE „BOUNDING BOXES“ 14
ABBILDUNG 5: POINT MATCHING 14
ABBILDUNG 6: PROZESS „GRUPPENBILDUNG DER TRAJEKTORIEN“ 19
ABBILDUNG 7: PROZESS „GRUPPE VON TRAJEKTORIEN ANONYMISIEREN“ 19
ABBILDUNG 8: GENERIERUNG EINES „SAMPLES“ 20

Abkürzungsverzeichnis III
Abkürzungsverzeichnis
NGO Non Government Organisa-tions/Nichtregierungsorganisationen
QI Quasi-Identifizierer
PL Point Linking
LCM Log cost metric
PM Point Matching
CPU Central Processing Unit
GPS Global Position System
LBS Location based Service
BB Bounding Box
BPMN Business Prozess Model and Notation

Einleitung
1 Einleitung
Aufgrund der weiten Verbreitung und Nutzung von Smartphones
mit ihren Möglichkeiten von CPU-Kapazität, Internetzugang und
GPS-Komponenten ist es möglich, regelmäßig zeitindizierte Geore-
ferenzdaten aufzuzeichnen, zu übertragen und adäquate Dienste zu
nutzen. Auch die Tendenz in der Automobilbranche die Komponen-
ten Reise- bzw. Fahrtdaten und Internet-Fähigkeit zu kombinieren,
um "smarte" Nutzungen zu realisieren, führt zur Möglichkeit Daten
zu erfassen und zu verbreiten.
In den verschiedenen Institutionen (Kommerziell, NGO's, Staaten,
Forschung und Wissenschaft) besteht ein großes Interesse an der
Nutzung dieser erfassten Daten.
Im Gegensatz dazu steht der Bedarf zum Schutz privater Daten
und damit das Vermeiden spezifischer Gefahren, welche durch die
Offenlegung der Daten entstehen können.
Nicht nur die aktuelle Politik beschäftigt sich mit dem Datenschutz
(dpa/heise/Öttinger 2014). Datenschutz ist seit langer Zeit in Bundes-
deutschen- und europäischen Gesetzen festgeschrieben (Bundes-
datenschutzgesetz, Richtlinie 95/46/EG des Europäischen Parla-
ments).
Der Inhalt dieser Arbeit bewegt sich im Spannungsfeld der vielfälti-
gen Nutzung von Raum-Zeitdaten und dem Schutz der Privatsphä-
re.
Dazu wird eine Methode beschrieben, welche die Anonymisierung
von Bewegungsdaten ermöglicht. Zusätzlich soll die Nutzbarkeit der
anonymisierten Daten untersucht werden.

Grundlagen und Definitionen
2 Grundlagen und Definitionen
Innerhalb dieses Kapitels werden die Rahmenbedingungen für die
weiteren Abschnitte geschaffen. Dazu werden Bezeichnungen, De-
finitionen und Grundlagen erläutert.
2.1 Trajektorie Daten
Die vorliegende Arbeit beschäftigt sich mit der Nutzung und Ano-
nymisierung von „trajectory“ Daten. In (Nergiz, et al. 2009) Seite 51
werden trajectory Daten als „sequences of spatio-temporal-points“ mo-
delliert. Damit sind räumliche Punkte in einer zeitlich chronologi-
schen Reihenfolge gemeint. In (Giannotti und Pedreschi 2008) Seite 5 ist
ein „trajectory“ beschrieben als „set of localisation points“. Der zeitliche
Bezug wird zusätzlich durch die Beschreibung des Datentupels in
der Form: (userID, time, cellID, in) genannt. In vorliegender Arbeit ist
ein trajectoy-Datensatz ein Datensatz mit Datentupel in der Form
von Koordinaten und Zeitstempel und wird Trajektorie genannt. Die
Koordinaten beschreiben dabei die Position einer Identität in einem
geeigneten universellen Referenzsystem. Der Zeitstempel ist als
absolute bzw. relative Zeit zu verstehen. Werden relative Zeit-
stempel genutzt, so sind diese chronologisch nur innerhalb des Da-
tensatzes nutzbar.
2.2 Anonymität
Im deutschen Duden (Duden kein Datum) werden als Bedeutungen des
Wortes „Anonym“ sowohl die Ausprägung „ungenannt - ohne Namens-
nennung“ als auch die Ausprägung „unpersönlich - durch Fremdheit ge-
prägt“ aufgeführt. Daraus ableiten kann man, dass durch Anonymi-
tät die Person immer fremd und damit für eine dritte Person nicht
identifizierbar ist.
In (Pfitzmann und Köhntopp 2000) beschreiben die Autoren Anonymität
als einen Zustand, in dem der Einzelne innerhalb einer gegebenen
Menge von Gleichartigen nicht eindeutig identifizierbar ist. Dabei
kann der Zustand sowohl räumlicher als auch zeitlicher Natur sein.

Grundlagen und Definitionen
Auch in (Verykios, Damiani und Gkoulalas-Divanis 2008) ist Anonymität in
dem Sinne spezifiziert, dass die Datensätze mehrerer Person (An-
zahl > 1) in einem spezifischen Zeitintervall und einem räumlichen
Bereich nicht zu unterscheiden sind.
Während der Duden in der zweiten Ausprägung eine absolute Ano-
nymität bzw. Nicht-Identifizierbarkeit definiert, gleichen die beiden
folgenden Definitionen einer „Verschleierung“ der Identität durch
das Verstecken innerhalb einer Gruppe. Für den Datenschutz ist
eine absolute Anonymität erstrebenswert. Vorliegende Arbeit be-
schreibt die Methode eine „relative“ Anonymität zu erzeugen und
folgt damit den Ansätzen von (Nergiz, et al. 2009).
In (Nergiz, et al. 2009) wird bei einer Anonymisierung der Daten nicht
von einer vollkommenen Unkenntlichkeit der Identität geschrieben,
sondern es wird ein Ansatz zur Herstellung einer k-Anonymität be-
schrieben. Damit ist ein Standard gemeint, der die Identifizierung
innerhalb einer Gruppe mit k-1 weiteren Mitgliedern unmöglich
macht.
Die Anonymität gilt in diesem Fall nicht generell, sondern be-
schränkt sich auf die Gruppe mit k-Mitgliedern. Je größer das k,
desto größer die Anonymität (Nergiz und Saygin 2011) Seite 98.
Bei Trajektorien ist dabei eine Besonderheit hervorzuheben: Es
sollten nicht einzelne Datenpunkte anonymisiert werden, sondern
es erfordert die Anonymisierung der Trajektorie als Ganzes. An-
sonsten ist nicht gewährleistet, dass einzelne Datenpunkte als
Quasi-Identifizierer (QI) genutzt werden können (Startpunkt -
Wohnung; Ankunftspunkt – Arbeitsstelle). Ein QI ist eine Kombina-
tion von Attributen, welche ein Individuum implizit identifiziert.
In einem k-anonymisierten Datensatz gibt es für den oder die QI
mehrere Individuen, auf die dieser Schlüssel passt. Bspw. könnte
mit einer Personalnummer eine gewissen Bandbreite zusammenge-
fasst [p1-pn] werden.

Grundlagen und Definitionen
In (Nergiz, et al. 2009) Seite 54 wird beschrieben, dass eine k-
Anonymität vorliegt, wenn man eine vorhandene, ursprünglichen
Trajektorie minimal zu k anderen Trajektorien im anonymisierten
Datensatz zuordnen kann.
(Nergiz, et al. 2009) definiert konkreter, dass ein k-anonymisierter Da-
tensatz T* genau dann die Anonymisierung des originalen Daten-
satzes T ist, wenn gilt:
1. für jede Trajektorie aus der Trajektorie-Menge T* gibt es
mindestens k-1 Trajektorien mit exakt den gleichen Raum-
Zeit-Koordinaten („Set of Points“).
2. Die Trajektorien in T und T* können so sortiert werden, dass
die i-te originäre Trajektorie tri als Teilmenge („subset“) der
anonymisierten Trajektorien tr* die Bedingung erfüllt, dass
die i-te originäre Trajektorie tri auch eine Teilmenge der i-ten
anonymisierten Trajektorie tri* ist.
In der Abbildung 3 im Abschnitt 3.1.2.1 wird gezeigt, dass damit
eine anonymisierte Trajektorie tri* grobgranularer als die originä-
ren Trajektorien tri sein können.
In der oben genannten Definition unter Punkt 2 ist es erforderlich,
dass bei sortierten Trajektorien die originäre Trajektorie eine Teil-
menge der anonymisierten Trajektorien ist oder, wie die Grafik 3
darstellt, in tri* enthalten ist. Damit ist eine Teilmenge im Sinne
von (Nergiz, et al. 2009) eine Trajektorie dann, wenn alle Punkte inner-
halb der anonymisierten Koordinaten bzw. deren Ausdehnung liegt.
2.3 Klassen zur Erhaltung der Privatsphäre
In diesem Abschnitt sollen die möglichen Verfahren zum Schutz
von privaten Daten beschrieben werden. Im Rahmen dieser Arbeit
können die einzelnen Methoden nur kurz erläutert werden. Das
Verfahren der Anonymisierung wird in dem anschließenden Ab-
schnitt ausführlich beschrieben.

Grundlagen und Definitionen
In Anlehnung an (Verykios, Damiani und Gkoulalas-Divanis, Privacy and
Security in Spatiotemporal Data and Trajectories 2008) Seite 215 zeigt die fol-
gende Abbildung Möglichkeiten, um Trajektorie Daten vor unbe-
rechtigtem Zugriff zu schützen und damit die Privatsphäre zu erhal-
ten.
Abbildung 1: Klassen zur Erhaltung der Privatsphäre
In den „policy-based“ Verfahren werden Regelsätze verwendet,
welche den Zugriff auf Daten regelt. Dabei werden für Datenobjek-
te definiert, welche Subjekte welche Operationen durchführen kön-
nen. Die Operationen können Lese-, Schreib- bzw. Löschoperatio-
nen sein. Bei den Subjekten kann es sich um Maschinen oder Per-
sonen handeln. Die Ausgestaltung der „policies“ ist vielfältig vari-
ierbar. So nennt (Verykios, Damiani und Gkoulalas-Divanis 2008) Seite 224
die Möglichkeit, aufgrund des Orts Zugriff zu erlauben oder auch
nicht („location policy“).
Bei den kryptografischen Verfahren werden Daten verschlüsselt.
Damit ist es nur den Instanzen möglich, Daten zu nutzen, die den
jeweiligen Schlüssel besitzen. Innerhalb des Verfahrens können
Klassen zur Erhaltung der Privatsphäre
policy based krypthografische
Verfahren locadon based k‐Anonymität

Grundlagen und Definitionen
auch nur Teile verschlüsselt oder durch einen Hash geschützt wer-
den.
Bei den „location based“ Verfahren wird aufgrund der Position eines
Nutzers von bspw. „Location based Services“ (lbs) entschieden, ob
Daten und in welcher Form diese Daten freigegeben werden. Damit
ähnelt das Verfahren der weiter oben angesprochenen „location po-
licy“. Der Unterschied ist die differenziertere Ausgestaltung. Eine
Abwandlung dieser Verfahren ist es, durch zusätzliche künstliche
Trajektorie die wahre Position bzw. den Trajektorie zu verschleiern.
Das Verfahren der k-Anonymität ist Inhalt dieser Arbeit und die
Methode wird in den folgenden Abschnitten erläutert.

Anonymisierung von Trajektorien
3 Anonymisierung von Trajektorien
In diesem Abschnitt befinden sich die Kerninhalte der Arbeit. Diese
sind die Anonymisierung von Trajektorien, die Analyse der Qualität
der Anonymisierung und die Untersuchung der Nutzung der ano-
nymen Datensätze bzw. der aus der Anonymisierung rekonstruier-
ten Datensätze.
Wie in (Nergiz, et al. 2009) Seite 52 wird dabei von statischen Trajekto-
rien bzw. Daten ausgegangen, welche im Gegensatz zu dynami-
schen Daten nicht laufend „on the fly“ anonymisiert werden müssen.
Diese Annahme ist wesentlich für das Verfahren, das im Folgenden
beschrieben wird.
3.1 Methode zur Anonymisierung von Trajektorien
Es wird das Verfahren beschrieben, welches zur speziellen k-
Anonymität der Datensätze führt.
3.1.1 Notation und Annahmen
Der Raum in dem die Trajektorien aufgezeichnet werden, wird disk-
ret (begrenzt bzw. abzählbar) in ein Gitter mit den Kantenlängen e
x e aufgeteilt und alle Messungen sind in Einheiten dieses Gitters
normalisiert. Die Zeit ist diskret in der Einheit e(t) und ist endlich.
Ein Raum-Zeit-Tupel wird über Interpolation in diskrete Einheiten
des Gitters umgewandelt. Dabei kann die Granularität des Gitters
bzw. der Zeiteinheiten individuell festgelegt werden.
Ein Datensatz T mit Trajektorien tri ist eine Mange von einzelnen
Trajektorien tri und wird beschrieben als T=tr1, tr2, ..., trn.
Eine Trajektorie tri=p1,p2,...,pm ist ein geordneter Satz von
Raum-Zeit-Punkten bzw. –Volumen. Dabei ist die Komponente
Raum bspw. durch eine x-, y- und z-Komponente definiert. Ist die
Granularität des oben beschriebenen Gitters nicht atomar (Kanten-
länge ungleich 1), so sind die einzelnen Koordinaten (xi, yi, zi)
Strecken xi : [xi1-xi2], yi : [yi1-yi2], zi : [zi1-zi2] mit der Kanten-

Anonymisierung von Trajektorien
länge |xi|=|xi1-xi2|, |yi|=|yi1-yi2|, |zi|=|zi1-zi2|und bilden ein
Volumen.
Für die Zeitkomponenten gilt entsprechend ti : [ti1-ti2] und das
Intervall ti hat eine Dauer von |ti|=|ti1-ti2|.
Sind die Kantenlängen und die Zeiträume 1, so sind die Daten-
punkte bzw. die Trajektorie atomar.
Um innerhalb einer Trajektorie auf einen bestimmten Punkt zu
verweisen, wird eine Punktnotation genutzt. So beschreibt tri.pj
den j-ten Punkt in der i-ten Trajektorie.
Der Datenpunkt pk=(xi,yi,zi,ti) beschreibt den Aufenthaltsort eines
Individuums in einem gewissen Zeitintervall, mit einer von der
Granularität des Gitters abhängigen Genauigkeit.
Damit in den folgenden Abschnitten nicht nur die Methode zur Ano-
nymisierung sondern auch die Qualität der Anonymisierung geprüft
werden kann, wird angenommen, dass ein Teil der Trajektorie ei-
nes Individuums bekannt bzw. öffentlich verfügbar ist. Auch dann
soll aufgrund der zusätzlichen anonymisierten Daten nicht auf das
Individuum rückgeschlossen werden können. (Nergiz, et al. 2009) Seite
53 (Vgl. Abschnitt 3.2).
3.1.2 Methode zur Anonymisierung von Trajektorien
In diesem Abschnitt wird die Methode beschrieben, um Trajektorien
zu anonymisieren. Dabei soll, wie in Abschnitt 2.2 definiert, das
Ziel der k-Anonymität erreicht werden.
Das Vorgehen ist als Prozess in der Syntax BPMN 2.0 in Abbildung
2 modelliert. Im Bild ist erkennbar, dass nach dem Start aus einer
Gruppe von Trajektorien genau zwei Trajektorien ausgewählt wer-
den müssen. Der Algorithmus für die Auswahl der zwei Trajektorien
und für die Gruppierung (k Trajektorien als Input) wird im Ab-
schnitt 3.2 beschrieben. Vorerst wird davon ausgegangen, dass es
ein Verfahren gibt, welches die geeigneten Trajektorien sowohl für
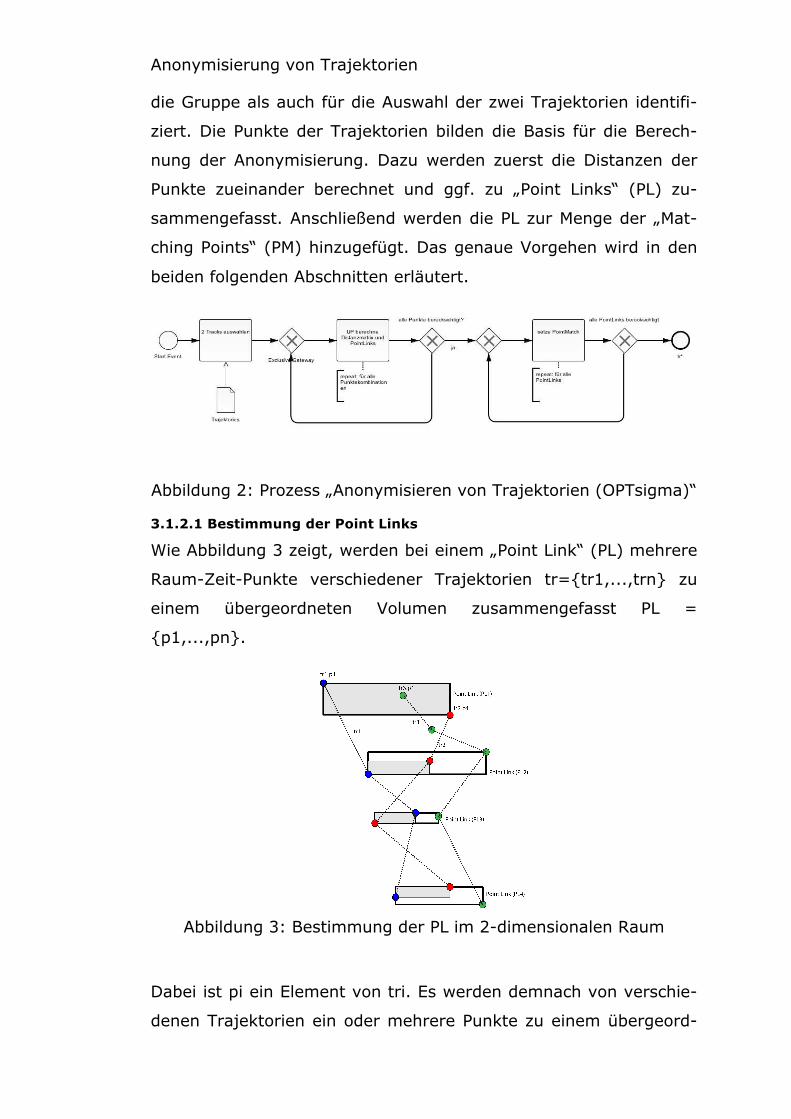
Anonymisierung von Trajektorien
die Gruppe als auch für die Auswahl der zwei Trajektorien identifi-
ziert. Die Punkte der Trajektorien bilden die Basis für die Berech-
nung der Anonymisierung. Dazu werden zuerst die Distanzen der
Punkte zueinander berechnet und ggf. zu „Point Links“ (PL) zu-
sammengefasst. Anschließend werden die PL zur Menge der „Mat-
ching Points“ (PM) hinzugefügt. Das genaue Vorgehen wird in den
beiden folgenden Abschnitten erläutert.
Abbildung 2: Prozess „Anonymisieren von Trajektorien (OPTsigma)“
3.1.2.1 Bestimmung der Point Links
Wie Abbildung 3 zeigt, werden bei einem „Point Link“ (PL) mehrere
Raum-Zeit-Punkte verschiedener Trajektorien tr=tr1,...,trn zu
einem übergeordneten Volumen zusammengefasst PL =
p1,...,pn.
Abbildung 3: Bestimmung der PL im 2-dimensionalen Raum
Dabei ist pi ein Element von tri. Es werden demnach von verschie-
denen Trajektorien ein oder mehrere Punkte zu einem übergeord-

Anonymisierung von Trajektorien
neten Punkt bzw. Fläche/Raum „verlinkt“, der damit eine größere
räumliche bzw. zeitliche Ausdehnung hat als die originären Punkte.
Dabei werden sukzessive weitere Trajektorien zum bestehenden
Ergebnis ergänzt. Erkennbar an den grauen Flächen, welche die
Point Links der Trajektorie tr1 und tr2 darstellen. Die Flächen wer-
den durch die Trajektorie Drei ggf. vergrößert. Dies entspricht einer
Domäne oder Bandbreite einer Anonymisierung in normalen Daten-
banken.
Dieser Umstand ist dann wichtig, wenn es um die Nutzung der
anonymisierten Trajektorien geht und die Ausdehnung der Punkte
ein relevanter Faktor ist. Die Nutzung wird in Abschnitt 3.3 be-
schrieben.
Die „Verlinkung“ kann sowohl im Raum und/oder in der Zeit vorge-
nommen werden. In dieser Arbeit wird die Verknüpfung nur über
den Raum beschrieben.
In folgender Abbildung 4 ist das „Point Linking“ grafisch dargestellt
und entspricht dem Pseudo-Code (OPTsigma Zeile 6-13) aus (Nergiz,
et al. 2009). Im speziellen kann man erkennen, dass für den ersten
Punkt der ersten Trajektorie (tr1.p1) geprüft wird, bei welcher
Kombination mit Punkten der zweiten Trajektorie (tr2.p1,...,tr2.p4)
die geringste räumliche Ausdehnung („Bounding Box“) entsteht.
Die Punkte einer Trajektorie, die mit keinem anderen Punkt „ver-
linkt“ werden können, werden unterdrückt („supressed“). Da im-
mer jeweils ein Punkt der einen Trajektorie mit einem Punkt der
anderen Trajektorie verlinkt wird, geschieht das u.a. bei unter-
schiedlichen Punktezahlen. Im Anhang sind Ergebnisse des Pseudo-
Codes für die ersten zwei Schleifendurchgänge angehängt.

Anonymisierung von Trajektorien
Abbildung 4: verschiedene „Bounding Boxes“
Die Größe der Bounding Box und die Anzahl der unterdrückten
Punkte ist ein Qualitätsmerkmal der Anonymisierung und wird im
Abschnitt 3.2 wieder aufgegriffen. Ziel des Algorithmus ist es, die
Summe aller BB zu minimieren.
3.1.2.2 Bildung von anonymisierten Trajektorien mittels Point Matching
Anschließend werden die in den PL zusammengefassten Punkte zu
einem „Point Matching“ PM = PL1,...,PLm mit bspw. PL2 =
tr1.p2,tr2.p2,tr3.p3 verbunden. Dies ist in folgender Abbildung
dargestellt.
Abbildung 5: Point Matching
Ein PM kann als grobgranularer Trajektorie verstanden werden. Da-
zu muss aber gelten, dass für i<j und alle möglichen k,

Anonymisierung von Trajektorien
PLi.tk1<PLj.tk1. Damit ist realisiert, dass die chronologische Rei-
henfolge der PL erhalten bleibt.
Bei mehr als zwei Trajektorien ist gemäß (Nergiz, et al. 2009) Seite 55
nicht jede Anonymisierung optimal. Es sollte eine Anonymisierung
gefunden werden, welche die „Distanz“ der zur Anonymisierung
genutzten originalen Trajektorien minimiert bzw. eine vorher defi-
nierte Größe nicht überschreitet. Dazu muss das Verfahren erwei-
tert werden.
Im ersten Schritt müssen die geeigneten Gruppen von k Trajektori-
en gebildet werden und diese dann schrittweise mittels des Algo-
rithmus „OPTsigma“ anonymisiert werden. Zur Bildung von Grup-
pen ist in (Nergiz, et al. 2009) der Pseudo-Code TGA beschrieben. Die-
ser wird im Abschnitt 3.2 erläutert.
In diesem Abschnitt wurde ein Verfahren zur Anonymisierung von
zwei Trajektorien beschrieben. Für die Erweiterung der Methode auf
k Trajektorien ist eine Qualitätsbetrachtung und die Spezifikation
zu optimierender Parameter notwendig, da ansonsten willkürlich k
Elemente aus dem Datensatz T zur Anonymisierung genutzt wer-
den könnten. Qualitätsaspekte sind im folgenden Abschnitt be-
schrieben.
3.2 Erweiterung der Methode aufgrund qualitativer
Aspekte
Die qualitative Betrachtung der Methode zur Anonymisierung be-
wegt sich weiterhin im Spannungsfeld zwischen dem Schutz der
Privatsphäre und der optimalen Nutzung der Trajektorien.
Im ersten Teil dieses Abschnitts werden die Aspekte des Daten-
schutzes betrachtet und gegebenenfalls die Methode zur Anonymi-
sierung erweitert. Im zweiten Teil ist die Optimierung für die Nut-
zung der Daten beschrieben. Wie im Abschnitt 3.1 schon angedeu-
tet, ist die optimale Gruppierung der Trajektorien ein wesentliches
Element dieses Teils der Arbeit.

Anonymisierung von Trajektorien
Für den Datenschutz ist in (Nergiz, et al. 2009) Seite 60 eine Schwie-
rigkeit bei der Anonymisierung mit der Methode aus 3.1. genannt.
Die Bildung der BB beinhaltet die Gefahr, dass immer Punkte auf
den Kanten oder sogar in den Eckpunkten liegen. Damit ist eine
Identifizierung potenzieller QI gegeben und muss verhindert wer-
den. Als Lösung wird die Vergrößerung der BB vorgeschlagen. Da-
mit ein potenzieller Angreifer nicht einfach einen immer wiederkeh-
renden Abstand subtrahieren kann, sollte die Vergrößerung zufällig
gewählt werden.
In (Nergiz, et al. 2009) Seite 53 wird die Anonymisierung geprüft, in-
dem zwei Angriffsvektoren wie folgt definiert werden:
1. Angreifer kennt Teile der originären Trajektorien.
2. Angreifer kennt die gesamte Trajektorie und will bspw. bei
„location based service“ (LBS) wissen, ob die Anfrage einer
bestimmten Person zuzuordnen ist.
Für den ersten Angriffsvektor ist es ausreichend, dass für den An-
greifer ausschließlich die anonymisierte Trajektorie sichtbar wird.
Damit kann der bekannte Teil der Trajektorie („Plain Text“) minimal
k Personen zugeordnet werden.
Für den zweiten Angriffsvektor sollte die Abfrage für ein LBS aus
einer zufällig rekonstruierten Trajektorie ausgeführt werden. Diese
unterscheidet sich von der originären Trajektorie und kann damit
einer bestimmten Person nicht zugeordnet werden. Die Rekon-
struktion und die Bildung von „Samples“ ist somit ein wesentliches
Element für die Erhaltung der Privatsphäre und wird in Abschnitt
3.3 erläutert.
Für die Nutzbarkeit der anonymisierten Daten ist die Anforderung
der jeweiligen Anwendung relevant. Aufgrund der Vielzahl von An-
wendungen kann im Rahmen dieser Arbeit nicht auf alle möglichen
Varianten der Anforderungen eingegangen werden.

Anonymisierung von Trajektorien
Somit kann die Frage, ob eine anonymisierte oder rekonstruierte
Trajektorie zu den gleichen Ergebnissen (bei den unterschiedlichen
Anwendungen) führen würde wie die ursprüngliche Trajektorie,
nicht hinreichend geklärt werden.
Dennoch können im Rahmen der Arbeit Aspekte zur Verbesserung
der Anonymisierung untersucht werden. Intuitiv ist eine Anonymi-
sierung nahe (räumlich bzw. zeitlich) an der ursprüngliche Trajek-
torie besser als eine weit entfernte Trajektorie. Sollen also mehr als
zwei Trajektorien anonymisiert werden, müssen die Trajektorien in
geeignete Gruppen eingeteilt werden. Für die qualitative Beschrei-
bung einer k-Anonymisierung eines Datensatzes von n Trajektorien
(n ist vielfaches von k) können dann u.a. die „Point Links“ bzw. die
BB beurteilt werden.
(Nergiz, et al. 2009) Seite 55 beschreibt die Optimierung der Anonymi-
sierung wie folgt.
„Finding the optimal anonymization of two trajectories is the same as
finding the point matching between the two trajectories such that
anonymizing the trajectories through the matching minimizes the log
cost“.
und formuliert dazu auf Seite 53 eine iterative „log cost metric“
(LCM).
!"#(,) =log, ℎ
log(!",!") ,
Formel [1] – Log Cost Metric (LCM)
Die BB berechnet sich gemäß folgender Formel.
∗ = log + log + log
!"#$%∗
Formel [2] – LCM, speziell Berechnung der BB

Anonymisierung von Trajektorien
In Formel 1 werden zwei Fälle beschrieben. Im ersten Fall wird für
alle nicht zuzuordnenden Punkte der Trajektorien das universelle
Volumen gewertet. Dieses ist die maximale Raum- und Zeitaus-
dehnung oder auch die universale Raum-Zeit. Im zweiten Fall wer-
den die konkreten Raum-Zeit-Ausdehnungen und damit die BB der
jeweiligen Punkte berechnet. Die BB berechnet sich nach Formel 2.
In dieser Arbeit wird die Formel aus (Nergiz, et al. 2009) ohne den Pa-
rameter für die Zeit aufgeführt. Dieses Vorgehen verändert die Er-
gebnisse und die daraus abzuleitenden Rückschlüsse nicht.
Für die Distanz von zwei Trajektorien ergibt sich damit folgendes
Ergebnis:
a. Summe aller BB.
b. Zuzüglich der universellen Raum-Zeit pro unterdrückten
Punkt.
Unterdrückt werden Punkt dann, wenn sie bezogen auf die Punkte
der korrespondierenden Trajektorie ungünstig in der Mitte zwischen
zwei günstigeren Punkten liegen.
(Nergiz, et al. 2009) beschreibt auf Seite 62, dass bei den Experimen-
ten zur Gruppierung der Trajektorien diejenigen gruppiert werden,
welche räumlich nahe beieinander liegen und die gleiche Länge ha-
ben. Haben die Trajektorien sehr unterschiedliche Punkteanzahlen
und Abstände würden viele Punkte unterdrückt und die Anonymi-
sierung ist im Sinne der Kosten teuer.
Bei der Bildung der Gruppen sollten demnach die Trajektorien aus-
gewählt werden, welche jeweils die geringste Distanz zueinander
haben. Daraus ergibt sich die Aufgabe, alle Distanzen untereinan-
der zu ermitteln und damit ist ein Aufwand von (n^2-n)/2 Berech-
nungen erforderlich.
In (Nergiz, et al. 2009) Seite 57 wird zur Bestimmung der k Trajektori-
en für die Gruppe G mit der geringsten Distanz zueinander ein
Pseudo-Algorithmus beschrieben, der im folgenden Bild in der

Anonymisierung von Trajektorien
BPMN 2.0 Syntax dargestellt ist (siehe Anhang für eine größere
Darstellung).
Abbildung 6: Prozess „Gruppenbildung der Trajektorien“
Für die Gruppenbildung wird zuerst eine zufällige Trajektorie aus-
gewählt und als Repräsentantin der Gruppe (repG) definiert. An-
schließend wird die Trajektorie mit der geringsten Distanz zu repG
gesucht (Alg. OPTsigma). Die so identifizierte Trajektorie wird der
Gruppe G hinzugefügt. Optional (multiTGA) wird die neue Trajekto-
rie mit repG anonymisiert (OPTsigma) und bildet dann das neue
repG. Der Vorgang der Gruppierung wird solange wiederholt
(repeat), bis die Gesamtzahl der verbleibenden Trajektorien kleiner
k ist.
Die Gruppe der k Trajektorien wird anschließend mit dem (Nergiz, et
al. 2009) Seite 60 Algorithmus „anonTraj“ anonymisiert. Der Pseudo
Code ist als BPMN Modell in folgender Abbildung dargestellt.
Abbildung 7: Prozess „Gruppe von Trajektorien anonymisieren“

Anonymisierung von Trajektorien
3.3 Rekonstruktion und Nutzbarkeit der anonymi-
sierten Daten
Im Abschnitt 3.2. wurde beschrieben, wie k Trajektorien in eine
anonymisierte Trajektorie überführt werden. Diese unterscheidet
sich von den originären Trajektorien durch ihre Granularität. Aus
bspw. atomaren Punkten wurden Volumen bzw. „Bounding Boxes“
(siehe Abbildung 3). Es gibt Anwendungen, die mit diesem gröbe-
ren Input ausreichend gut arbeiten können. Andere Anwendungen
benötigen atomare Trajektorien.
In (Nergiz, et al. 2009) Seite 60 ff. wird zur Bildung atomarer Trajekto-
rien die Rekonstruktion bzw. die Bildung konkreter „Samples“ be-
schrieben. Dabei wird zufällig ein Punkt pro PM ausgewählt, diese
Punkte chronologisch geordnet und zu einer Trajektorie zusam-
mengestellt.
Abbildung 8: Generierung eines „Samples“
In (Nergiz, et al. 2009) Seite 61 Abschnitt 6.2. wird erwähnt, dass die
Wahrscheinlichkeit, aus dem anonymisierten Trajektorie ein
„Sample“ zu generieren, welcher einer originären Trajektorie ent-
spricht, ungleich Null ist. Die Wahrscheinlichkeit berechnet sich wie
folgt.
=1

Anonymisierung von Trajektorien
oder 0, wenn Punkte unterdrückt wurden.
Die Wahrscheinlichkeit ist umgekehrt proportional zur Größe der
BB. Je größer die BB desto unwahrscheinlicher ist es, genau den
richtigen Punkt zufällig auszuwählen. Ist der Punkt der originären
Trajektorien in der Anonymisierung unterdrückt worden, so kann er
auch nicht innerhalb einer Bounding Box liegen und erhöht nicht
die Wahrscheinlichkeit, die originäre Trajektorie zufällig zu rekon-
struieren. Eine gute Anonymisierung maximiert diese Wahrschein-
lichkeit ( (Nergiz, et al. 2009) Seite 61). Dies verdeutlicht erneut das
Spannungsfeld zwischen der Nutzung und dem Schutz der Daten.
In (Nergiz, et al. 2009) Seite 61 wird über die Nutzbarkeit des „Samp-
les“ folgendes geschrieben.
The Success of the anonymization heavily depends on the success of reconstructed da-
ta in explaining the original data.
Für komplexe Datenstrukturen wird in (Nergiz, et al. 2009) Seite 65
Angaben über erklärende Parameter gegeben. In einfachen Daten-
strukturen wären das Mittelwerte und Standardabweichungen mit
denen überprüft werden kann, ob rekonstruierte Daten den originä-
ren Daten entsprechen. Die Überprüfung kann im Rahmen dieser
Arbeit nicht geleistet werden.

Fazit und Ausblick
4 Fazit und Ausblick
In dieser Arbeit wurde eine Methode untersucht, Trajektorien zu
anonymisieren und sowohl die Anforderungen an den Datenschutz
als auch an die weitere Nutzung zu erfüllen. Die vorgestellte Me-
thode führt dabei nicht zu einer grundsätzlichen Anonymität son-
dern erreicht eine sog. k-Anonymität. Dabei war es wesentlich, das
Anonymisierungsverfahren insofern zu optimieren, dass die resul-
tierende und anonymisierte Trajektorie räumlich und/oder zeitlich
nahe an der ursprünglichen Trajektorie liegt. Dazu wurde eine Kos-
tenfunktion definiert, die zu minimieren war.
Ein in dieser Arbeit nicht betrachteter Aspekt ist die Anonymisie-
rung von Trajektorien als laufender Datenfluss (Stream). Viele An-
wendungen nutzen Echtzeit Daten, um bspw. Dienste am lokalen
Ort zur aktuellen Zeit anzubieten. Eine Anonymisierung im nach-
hinein ist für diese Anwendungen nicht geeignet. Für zukünftige
Untersuchungen wäre dies ein interessantes Forschungsgebiet.

Anhang
5 Anhang
5.1 Ergebnis des Berechnungsalgorithmus OPTsig-
ma nach zwei Schleifendurchläufen.
Anhang
5.2 Darstellung des Prozesses „Gruppenbildung der
Trajektorien“ – Abbildung 6

Literaturverzeichnis
6 Literaturverzeichnis
dpa/heise/Öttinger. www.heise.de. 5. 10 2014. http://www.heise.de/newsticker/meldung/Interview-Guenther-Oettinger-verspricht-mehr-Datenschutz-2411705.html (Zugriff am 26. 12 2014).
Duden. Duden. D: D.
Giannotti, Fosca, und Dino Pedreschi. „A Vision of Convergence .“ In Mobility, Data Mining and Privacy, von Fosca Giannotti und Dino Pedreschi, 1-11. Berlin Heidelberg: Springer, 2008.
Nergiz, Mehmet Ercan, Maurizio Atzori, Yücel Saygin, und Baris Güc. „Towards Trajectory Anonymisation: a Generalization-Based Approach.“ http://www.tdp.cat/. 2. 12 2009. http://www.tdp.cat/issues/vol02n01.php (Zugriff am 2. 12 2014).
Nergiz, Mehmet Erkan, und Yücel Saygin. „Condensation-based Methods in Emerging Application Domains.“ In Privacy-Aware
Knowledge Discovery: Novel Applications and New Techniques, von Bonchi Francesco und Ferrari Elena, 89-107. Boca Raton: CRC Press, 2011.
Pfitzmann, A, und M Köhntopp. „Designing Privacy Enhancing Technologies.“ In Designing Privacy Enhancing Technologies, von Hannes Federrath, 1-9. Berkeley: Springer, 2000.
Verykios, V.S., M.L. Damiani, und A. Gkoulalas-Divanis. „Privacy and Security in Spatiotemporal Data and Trajectories.“ In Mobility, Data Mining and Privacy, von Fosca Giannotti und Dino Pedreschi, 213-240. Berlin-Heidelberg: Springer, 2008.



——
Seminar 01912 / 19912
im Wintersemester 2014/2015
„Sicherheit und Privatsphäre
in Datenbanksystemen“
Thema 14
Verbund von Datenbanken
Referent: Heiko Brieschke

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
Inhaltsverzeichnis
1 Allgemeiner Überblick / Zusammenfassung der Basisartikel 31.1 Zugangskontrolle in Datenbankverbünden: Wie rechtliche Fragen die Si-
cherheit prägen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Privatsphäre bewahrende statistische Datenanalyse auf Datenbankver-
bünden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 3-Schichten-Architektur nach dem Beispiel des Information-Queensland-Projektes 52.1 Darstellung und Beschreibung der 3-Schichten-Architektur . . . . . . . . 5
2.1.1 Agenturschicht . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.1.2 Aggregationsschicht . . . . . . . . . . . . . . . . . . . . . . . . . 62.1.3 Benutzerschicht . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Allgemeine Problemstellungen der Datensicherheit innerhalb desInformation-Queensland-Projektes . . . . . . . . . . . . . . . . . . . . . 7
3 Das estnische X-Road-Datenbanksystem 83.1 Datenschutzmechanismen für den Datenaustausch im X-Road-System . 93.2 Sichere Mehrparteien-Berechnungen (SMC) als eine Datenschutz för-
dernde Technik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.3 SHAREMIND - als eine Lösungsarchitektur im X-ROAD-System . . . . 153.4 Praktische Umsetzung von SMC . . . . . . . . . . . . . . . . . . . . . . 16Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
1 Allgemeiner Überblick /Zusammenfassung der Basisartikel
Die Aufgabenbeschreibung des Themas lautete:Sollen Daten, die in verschiedenen Datenbanken gespeichert sind, zusammengefügt
werden, ist es meist nicht zweckmäßig, die Daten in einer neuen Datenbank zu spei-chern, da lokale Anwendungen auf den existierenden Datenbanken weiterlaufen sollen.Vielmehr bleiben die bereits existierenden Datenbanken bestehen und werden um ex-terne Schemata erweitert, die dann im globalen Datenbanksystem zusammengefasstwerden. Anfragen gegen das globale System werden automatisch auf die verschiedenenDatenbanken verteilt und zu einem Gesamtergebnis zusammengefasst. Solche speziel-len Formen von Datenbankarchitekturen erfordern spezielle Sicherheitsmechanismen.
Diese Seminararbeit basiert auf den beiden Basisartikeln [BNC+07] „Zugangskon-trolle in Datenbankverbünden: Wie rechtliche Fragen die Sicherheit prägen“ und[BKL+14] „Privatsphäre bewahrende statistische Datenanalyse auf Datenbankverbün-den“.
Im Folgenden möchte ich mit einer kurzen Darstellung des Inhalts dieser beidenBasisartikel beginnen.
1.1 Zugangskontrolle in Datenbankverbünden: Wierechtliche Fragen die Sicherheit prägen
Dieser Artikel beschreibt ein von der Regierung Queenslands entwickeltes föderiertesDatenbanksystem zur Speicherung georäumlicher Daten. Es werden die wechselseitigenBeziehungen, die zwischen den rechtlichen Gesichtspunkten einerseits und der Infor-mationstechnologie andererseits bestehen und wie diese das architektonische Designund die anschließende Umsetzung von Sicherheitsmaßnahmen bestimmten dargestellt.Zu Beginn des Artikels werden nach einer kurzen Einleitung die Hintergründe des Pro-jektes, der Zweck der Forschung und die angewandte Methodik erläutert. Weiterhinwerden Details der Queensland E-Government-Initiative im Rahmen der australischenGeo-Daten-Entwicklung erklärt. Danach wird ein Überblick über die vorgeschlagenetechnische Architektur gegeben, welche im Rahmen dieser Seminararbeit im Folgendenausführlicher dargestellt wird. Weiter erfolgt in dem Artikel eine Prüfung der rechtli-chen Konzepte, die für die Systemarchitektur und die Aggregation der verschiedenenDaten relevant sind. Dann werden Maßnahmen zur Sicherstellung der Datensicherheit,mit besonderem Schwerpunkt auf die Zugriffskontrolle, beschrieben. Hier wird spezi-ell darauf eingegangen, welchen Einfluss rechtliche Erwägungen auf die Gestaltung
3 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
und Umsetzung der Schutzmaßnahmen haben. Schließlich gibt der Artikel noch einenAusblick auf zukünftige Arbeiten.
1.2 Privatsphäre bewahrende statistischeDatenanalyse auf Datenbankverbünden
Dieser Artikel beschreibt die Implementierung einer sicheren Mehrparteien-Berechnung(secure multi-party computation - SMC) in einem föderierten Datenbanksystem. Eswird die Umsetzung auf zwei realen Plattformen, die Sharemind sichere Mehrparteien-Berechnung und der estnischen X-Road-Datenbanksystem-Plattform beschrieben.Nach einer Einführung in das Thema werden zuerst die Vorteile der Kombinati-on von Daten in einem föderierten Datenbanksystem dargestellt, sowie die betrach-tete X-Road-Systemplattform beschrieben und anschließend verschiedene Kandida-ten für Mikroschutzmechanismen diskutiert. Danach wird die sichere Mehrparteien-Berechnung (SMC) erklärt, eine Privatsphärendefinition für SMC-Anwendungen ge-geben und erklärt, wie dieses in Datenanalysealgorithmen zu erfüllen ist. Dann wirdgezeigt, wie eine föderierte Datenbankumgebung, wie das X-Road-System mit SMCzu kombinieren ist, damit dieses eine sichere Datenanalyseumgebung bietet. Anschlie-ßend wird die Validierung der Notwendigkeit der vorgeschlagenen Lösung durch eineReihe von Interviews mit potenziellen Endkunden dargestellt. Weiter wird das erstePilotprojekt, bei dem die vorgeschlagene Technologie zum Einsatz kommt, beschrie-ben. Abschließend wird die Implementierung statistischer Analysealgorithmen in einerSMC-Umgebung beschrieben und ihre Leistungsfähigkeit mit einer Reihe von Bench-marktests analysiert.
4 von 18
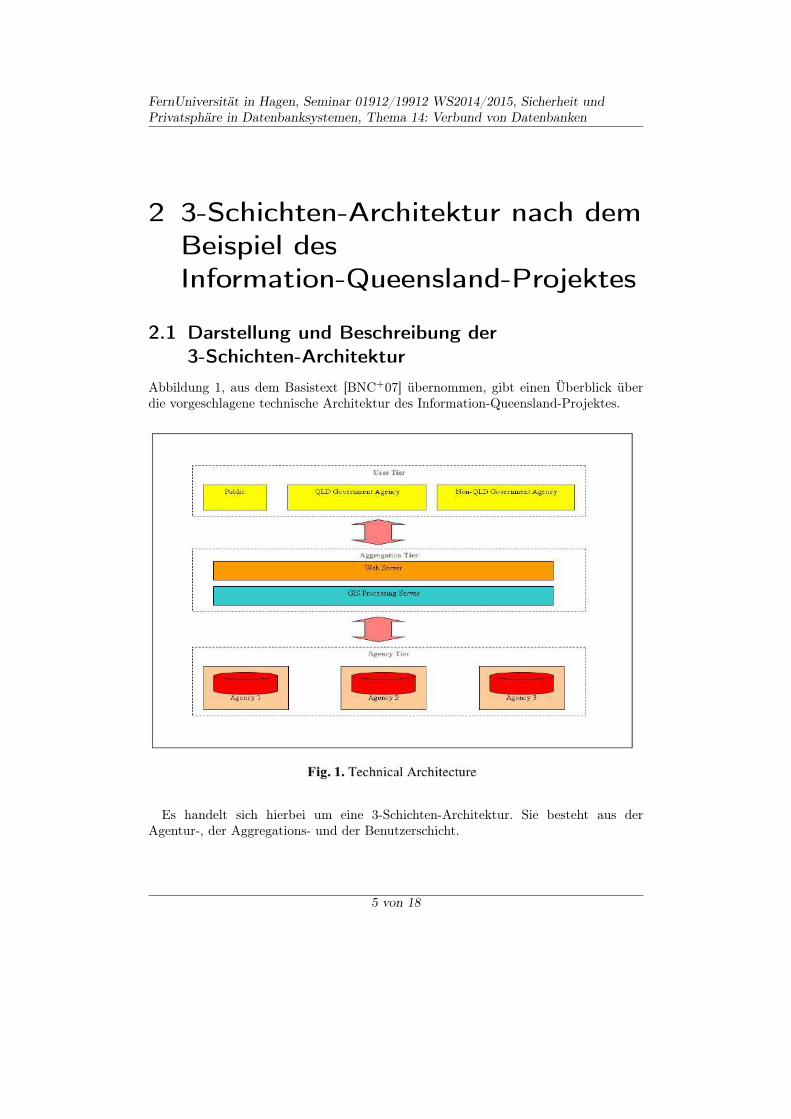
FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
2 3-Schichten-Architektur nach demBeispiel desInformation-Queensland-Projektes
2.1 Darstellung und Beschreibung der3-Schichten-Architektur
Abbildung 1, aus dem Basistext [BNC+07] übernommen, gibt einen Überblick überdie vorgeschlagene technische Architektur des Information-Queensland-Projektes.
Es handelt sich hierbei um eine 3-Schichten-Architektur. Sie besteht aus derAgentur-, der Aggregations- und der Benutzerschicht.
5 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
2.1.1 Agenturschicht
Die unterste Schicht der Architektur bildet die Agenturschicht. In dieser sind al-le an dem System beteiligten lokalen Datenbanken der jeweiligen Behörden ange-siedelt. Jede Behörde ist für die in ihren Datenbanken gespeicherten Daten selbstverantwortlich, sowohl in Hinblick auf die Datenkonsistenz als auch auf die Datensi-cherheit. Jede Behörde entscheidet also selbst, wer auf welche Daten zugreifen darf.Durch diese lokale Datenhaltung ist es ohne Anpassung der bisher verwendeten Zu-gangssoftware und Programme möglich, alle bisherigen rein lokalen Aufgaben unver-ändert weiter zu erfüllen. Zusätzlich kommen jetzt noch weitere Datenanfragen desInformation-Queensland-Systems hinzu. Diese Anfragen werden durch Komponentender über der Agenturschicht liegenden Aggregationsschicht durchgeführt.
2.1.2 Aggregationsschicht
Die Aggregationsschicht bildet die mittlere Schicht der technischen Architektur desInformation-Queensland-Projektes. Sie besteht im Wesentlichen aus einem Web-Serverund einem Datenverarbeitungsserver. Hierbei übernimmt der Webserver die Daten-kommunikation mit den Benutzern des Information-Queensland-Projektes, indem erzum einen die Datenanforderungen der Benutzer entgegennimmt und an den Datenver-arbeitungsserver weiterreicht und zum anderen die vom Datenverarbeitungsserver auf-bereiteten Daten an die Benutzer zurückgibt. Die zentrale Komponente der Aggregati-onsschicht stellt jedoch der Datenverarbeitungsserver dar. Er zerlegt die Benutzeran-fragen in einzelne Datenanforderungen an die verschiedenen Agentur-Datenbanken undsetzt die Einzelantworten der Agentur-Datenbanken zu einem Gesamtergebnis zusam-men, welches dann dem Benutzer zur Verfügung gestellt wird.
Die Aggregationsschicht stellt auf Grundlage der verschiedenen lokalen Datensche-mata der einzelnen Agenturdatenbanken ein globales Datenschema bzw. wie im Ba-sistext bezeichnet ein Datenklassifikationsschema zur Verfügung. Hierbei besteht dieSchwierigkeit und somit mögliche Probleme darin, die teilweise inkonsistenten Daten-klassifikationen der einzelnen Behörden zu harmonisieren.
Eine weitere Aufgabe der Aggregationsschicht ist es, bestimmte Aggregationen vonDaten zu verhindern, deren Veröffentlichung für sich alleine kein Sicherheitsproblemdarstellen, die Kombination dieser Daten aber zu schützenswerten Informationen wer-den, die nicht mehr veröffentlicht werden sollten. Im Basistext wird hierfür als Beispieldie Kombination von Strom- und Wasserversorgungsnetzen in geografischen Kartenangeführt, aus denen dann beispielsweise Informationen hervorgehen, die aus Vertei-digungsgründen geheim bleiben sollten.
2.1.3 Benutzerschicht
Die Benutzerschicht stellt die oberste Schicht in der technischen Architektur desInformation-Queensland-Projektes dar. In ihr sind die Benutzer des Systems ange-siedelt, die unter Verwendung eines Webbrowsers die Möglichkeit haben, Anfragen
6 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
an die Aggregationsschicht zu stellen. Die von der Aggregationsschicht aufbereitetenAntwortdaten werden den Benutzern ebenfalls im Webbrowser angezeigt.
2.2 Allgemeine Problemstellungen derDatensicherheit innerhalb desInformation-Queensland-Projektes
Durch die Aggregierung der Daten der verschiedenen Behörden mussten in dem Ge-samtkonzept verschiedene gemeinsame Problemlösungen zwischen allen teilnehmendenBehörden entschieden und letztlich auch umgesetzt werden, die so, bei der bisherigenrein lokalen Datenhaltung jeder Behörde, nicht vorhanden waren.
Hier sind vor allen Dingen die Autorisierungsrichtlinien zu nennen. Für die ein-zelne Behörde ist es schwierig bis unmöglich zu entscheiden, welche Daten für wenfreigegeben werden, da im Voraus nicht feststellbar ist, zu welchen Endergebnissendie lokalen Daten in der Aggregationsschicht zusammengefasst werden. Andererseits,wenn die Festlegung der Autorisierungsrichtlinien komplett in die Aggregationsschichtverschoben würde, widerspräche dies dem Grundsatz, das jede Behörde selbst für dieSicherheitsrichtlinien ihrer Daten verantwortlich ist. Außerdem wäre in diesem Fallnicht klar, welche Behörde oder Behörden für die Festlegung der Autorisierungsricht-linien verantwortlich ist.
Ein weiteres Problem ist die Festlegung der Stelle an der die Authentifizierung undAutorisierung innerhalb des Information-Queensland-Projektes erfolgen soll. Generellbieten sich hier zwei Stellen an. Zum Ersten bei der Aggregationsschicht und zumZweiten bei der Agenturschicht. Innerhalb der Agenturschicht gibt es nochmals 2 un-terschiedliche Stellen bzw. Möglichkeiten, entweder über Web-Service-Gateways oderbeim direkten Zugang zu den Daten unter Verwendung der in den eingesetzten Daten-banksystemen integrierten Zugriffsschutzmechanismen.
Wird die Autorisierung in der Aggregationsschicht vorgenommen, so müssen dieeinzelnen Behörden ihre Verantwortung hierüber an diese abgeben. Auch ehemals reinlokale Datenzugriffe müssen dann durch die Aggregationsschicht autorisiert werden.Andererseits muss bei der Autorisierung in der Agenturschicht diese in jeder Agenturdurchgeführt werden an die eine Teilabfrage gestellt wird. Dies kann zu entsprechendenLaufzeitverlusten bei der Anfragebearbeitung führen.
7 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
3 Das estnischeX-Road-Datenbanksystem
Im 2. Basisartikel [BKL+14] wird eine sichere Mehrparteienberechnung (secure mul-tiparty computation - SMC) und deren Integration in das estnische X-Road-Systemdargestellt.
Das X-Road-System ist eine plattformunabhängige Datenaustauschschicht. Das Sys-tem sorgt für eine ausreichende Sicherheit bei der Behandlung von Datenbankanfragenund deren Beantwortung. Die X-Road-Infrastruktur besteht aus Soft- und Hardware-komponenten, sowie Organisationsmethoden für die standardisierte Nutzung nationa-ler Datenbanken.
Das X-Road-System hat eine verteilte und redundant ausgelegte Architektur. Somitist auch kein Single Point of Failure vorhanden. Die gesamte Kommunikation läuftüber das öffentliche Internet, ist aber über SSL verschlüsselt. Außerdem wird jede An-frage und Antwort an und von einer Datenbank bilateral authentifiziert, sodass Senderund Empfänger stets bekannt sind. Diese Authentifizierung erfolgt auf Grundlage von
8 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
Zertifikaten, die durch ein Zertifikatszentrum erstellt und anschließend in einem zen-tralen Server abgelegt sind. Dieser zentrale Server erteilt die jeweiligen Zugriffsgeneh-migungen. Dabei kann jede Organisation über eine Schnittstelle zur Administrationdes Sicherheitsservers selbst bestimmen, welche Daten an wen veröffentlicht werdensollen.
Des Weiteren ist jeder Datenbank ein Adapterserver vorgeschaltet. Dieser über-nimmt die Transformation der internen Datenbankschemata in das XML-Format, wel-ches innerhalb des X-Road-Systems zum Informationstransport verwendet wird. An-schließend werden die XML-Nachrichten durch die Security-Server verschlüsselt undvon jeder Anfrage für die spätere Nachweisbarkeit ein Log-Hash zum Zentralservergesendet.
Die technischen Angaben sowie die Übersichtsdarstellung wurden zusätzlich denbeiden Artikeln [httc] und [httd] entnommen.
3.1 Datenschutzmechanismen für denDatenaustausch im X-Road-System
Für den Datenaustausch im X-Road-System bietet dieses seit Anfang 2011 eine Mög-lichkeit, verschiedene Datenbanken ohne Offenlegung der Identität der betroffenen Per-sonen, zu verküpfen. Hierzu wird Pseudonomisierung verwendet. Technisch erfolgt diesdurch eine Verschlüsselung der ID-Codes jeder Person mit einem gemeinsamen sym-metrischen AES-Schlüssel, welcher allerdings über Offline-Mittel, also nicht über dasInternet, X-Road o.ä. verteilt werden muss. Diese Methode bietet zwar einen gewis-sen Grundschutz gegen neugierige Datenanalysten, sie ist aber völlig unzureichendentschlossenen und gezielten Angriffen zu widerstehen. Da die Datenfelder der Daten-sätze nicht verschlüsselt sind, ist es weiterhin möglich, diese mit anderen öffentlichverfügbaren Daten über eine Person (zum Beispiel Geschlecht, Alter, Bildung, Wohn-ort) zu verknüpfen und so auf die Identität der jeweiligen Person zu schließen. Es istsomit praktisch unmöglich auf eine Lösung die auf Pseudonomisierung basiert, eineSicherheitsgarantie der Privatsphäre zu geben.
Aus diesem Grund werden im Basisartikel 2 weitere Mikrodaten-Schutzmechanismenvorgestellt, die k-Anonymität und als Verbesserung dieser die ℓ-diversity.
Das Konzept der k-Anonymität wurde 2002 von Latanya Sweeney mit dem Ziel ver-öffentlicht, wissenschaftliche Daten zu veröffentlichen und dabei garantieren zu können,dass die Individuen, von denen diese Daten handeln, nicht reidentifiziert werden kön-nen, während die Daten selbst weiterhin nutzbar sind. Nach diesem Konzept bietet eineVeröffentlichung von Daten k-Anonymität, wenn die identifizierenden Informationenjedes einzelnen Individuums von mindestens k-1 anderen Individuen ununterscheidbarsind und somit eine korrekte Verknüpfung mit den zugehörigen sensiblen Attributenerschwert wird.[Swe02]
Im folgenden werde ich jetzt das Verfahren zur Erzeugung einer k-anonymen Daten-bank darstellen. Die Informationen hierfür wurden dem Wikipedia-Eintrag [htta] zudiesem Thema mit Stand Dezember 2014 entnommen.
9 von 18
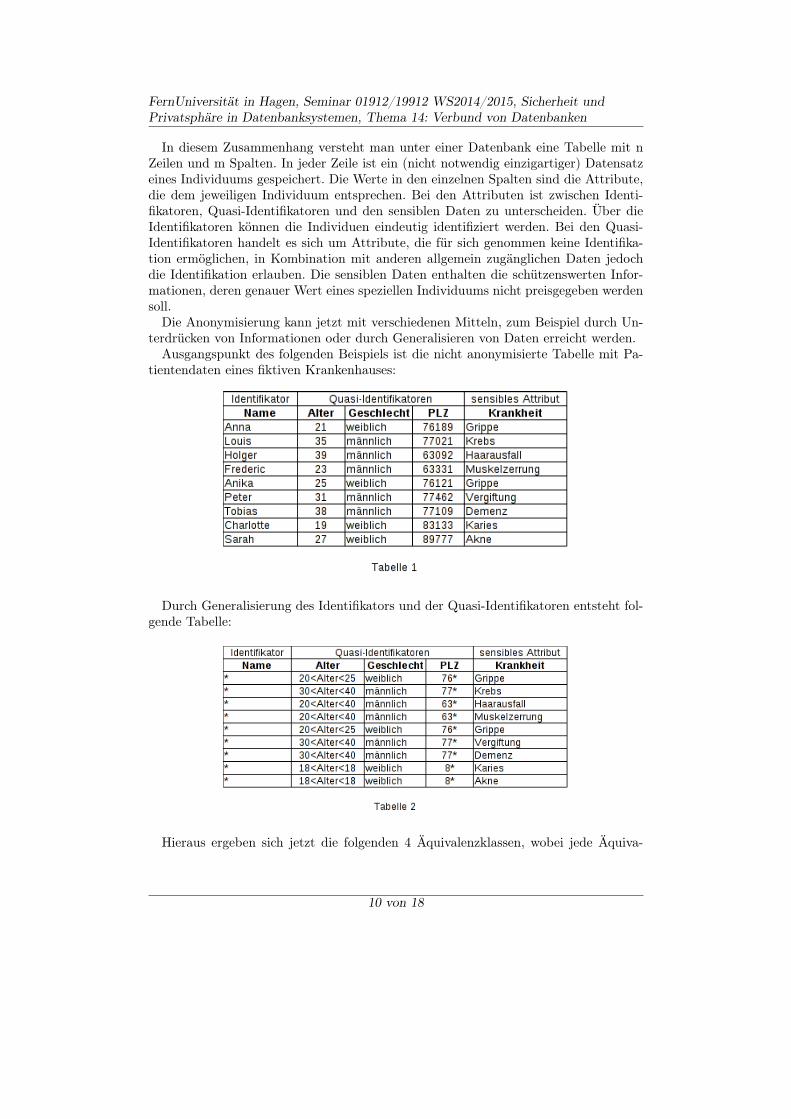
FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
In diesem Zusammenhang versteht man unter einer Datenbank eine Tabelle mit nZeilen und m Spalten. In jeder Zeile ist ein (nicht notwendig einzigartiger) Datensatzeines Individuums gespeichert. Die Werte in den einzelnen Spalten sind die Attribute,die dem jeweiligen Individuum entsprechen. Bei den Attributen ist zwischen Identi-fikatoren, Quasi-Identifikatoren und den sensiblen Daten zu unterscheiden. Über dieIdentifikatoren können die Individuen eindeutig identifiziert werden. Bei den Quasi-Identifikatoren handelt es sich um Attribute, die für sich genommen keine Identifika-tion ermöglichen, in Kombination mit anderen allgemein zugänglichen Daten jedochdie Identifikation erlauben. Die sensiblen Daten enthalten die schützenswerten Infor-mationen, deren genauer Wert eines speziellen Individuums nicht preisgegeben werdensoll.
Die Anonymisierung kann jetzt mit verschiedenen Mitteln, zum Beispiel durch Un-terdrücken von Informationen oder durch Generalisieren von Daten erreicht werden.
Ausgangspunkt des folgenden Beispiels ist die nicht anonymisierte Tabelle mit Pa-tientendaten eines fiktiven Krankenhauses:
Durch Generalisierung des Identifikators und der Quasi-Identifikatoren entsteht fol-gende Tabelle:
Hieraus ergeben sich jetzt die folgenden 4 Äquivalenzklassen, wobei jede Äquiva-
10 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
lenzklasse mindestens 2 Elemente enthält und somit eine 2-Anonymität gewährleistetist.
Das Konzept der k-Anonymität hat aber auch bekannte Mängel, die eine Deanony-misierung ermöglichen könnten. Hierzu zählen zum Beispiel die Homogenitätsattackeund die Hintergrundwissensattacke.
Die nachfolgenden Erklärungen sind dem Artikel [Hau07] entnommen worden. DieHomogenitätsattacke setzt voraus, dass in einer Äquivalenzklasse alle Datensätze iden-tische sensible Daten besitzen. Wenn jetzt ein Angreifer von der Existenz einer Personin dieser Datenbank Kenntnis hat und es ihm möglich ist die Person der entsprechendenÄquivalenzklasse zuzuordnen, erfährt er auch die sensiblen Daten zu dieser Person.
Bei der Hintergrundwissensattacke ist es einem Angreifer eventuell möglich, wenner von der Existenz einer Person in dieser Datenbank weiß und er diese Person derrichtigen Äquivalenzklasse zuordnen kann und er durch das Zusatzwissen verschiedenesensible Attribute für diese Person ausschließen kann, diese Person trotz k-Anonymitäteindeutig zuzuordnen.
Um diese aufgezeigten Schwächen der k-Anonymität zu überwinden, wurde derℓ-Diversity-Ansatz entwickelt. Die folgende Darstellung des ℓ-Diversity-Ansatzes wur-de ebenfalls dem Artikel [Hau07] entnommen.
Bei diesem Ansatz wird die zugrunde liegende Tabelle in sensitive und nicht sen-sitive Attribute unterteilt. Es wird im Folgenden davon ausgegangen, dass alle nichtsensitiven Attribute die Quasi-Identifikatoren bilden und die Tabelle nur ein sensiti-ves Attribut besitzt. Da nun nicht jedes Hintergrundwissen bekannt sein kann, gibtes in der Praxis keinen optimalen Schutz gegen den Ausschluss sensitiver Attribute.ℓ-Diversity bietet daher nur ein Schutzmaß gegen Angriffe, bei denen das sensitiveAttribut vorhergesagt wird. Der Schutz besteht nun darin, das sensitive Attribut, wel-ches mit einer Person in Verbindung steht, in einer Menge von ℓ anderen sensitivenAttributen zu verstecken. Damit müsste ein Angreifer mindestens über ℓ-1 Hinter-grundwissen verfügen, um über Ausschluss der falschen sensitiven Attribute auf dasRichtige schließen zu können.
11 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
3.2 Sichere Mehrparteien-Berechnungen (SMC) alseine Datenschutz fördernde Technik
Secret Sharing (Geheimnisteilung) ist ein Konzept, bei dem ein geheimer Wert untermehreren Parteien aufgeteilt wird. Dadurch ist keine Partei alleine in der Lage dengeheimen Wert zu rekonstruieren. Je nach Verteilschema werden hier einfache underweiterte Verfahren unterschieden. Diese unterscheiden sich dadurch, dass bei deneinfachen Verfahren alle Teilgeheimnisse und bei den erweiterten Verfahren nur eineTeilmenge der Teilgeheimnisse zur Rekonstruktion des Geheimwertes benötigt wer-den. Ein typisches Geheimnis nach diesem Konzept ist der geheime Schlüssel einesRSA-Kryptosystems. Wird dieser auf verschiedene Parteien aufgeteilt, so ist es keinerPartei alleine möglich, Signaturen für dieses Kryptosystem zu erstellen. Andererseitsstellt aber die Kompromittierung eines Teilschlüssels keine Gefahr für das Gesamtsys-tem dar.
Es gibt verschiedene Verfahren wie das Secret Sharing angewendet werden kann. Diefolgende Darstellung eines einfachen Verfahrens wurde dem Wikipediaartikel [httb] mitStand Dezember 2014 zu diesem Thema entnommen und sieht wie folgt aus:
- Gegeben ist der geheime Wert x.
- Jetzt wähle man die Teilgeheimnisse xi mit i ∈ 1, . . . , n sodass gilt:
x = x1 + x2 + . . .+ xn
- Hierbei müssen die xi, i = 2 . . . n Zufallswerte besitzen und x1 wird dann so gewählt,dass die oben angegebene Bedingung erfüllt ist. Da die xi, i = 2 . . . n Zufallswertesind, gilt dies auch für x1.
Eine andere Möglichkeit besteht darin, die Addition im oberen Beispiel durch eineExklusiv-ODER-Verknüpfung ⊕ zu ersetzen. Hierbei gilt dann:
- gegeben ist wieder der geheime Wert x.
- Jetzt wähle man die Teilgeheimnisse xi derart, dass gilt:
x = x1 ⊕ x2 ⊕ . . .⊕ xn
Auch hier ist die Rekonstruktion nur möglich, wenn alle xi, i = 1 . . . n bekannt sind.Neben den einfachen Sharing-Verfahren gibt es auch noch die erweiterten Sharing-
Verfahren. Die meisten Implementierungen dieser Verfahren sind akademische For-schungsimplementierungen, die ein spezielles Problem in einem bestimmten Umfeldlösen und somit als allgemeiner Lösungsansatz nicht brauchbar sind.
Es gibt jedoch auch schon fortgeschrittene Implementierungen mit programmierba-ren Protokoll-Suiten. Im Basisartikel wird hier die Sharemind-Umgebung näher be-trachtet, da diese zum Erstellungszeitpunkt des Artikels diejenige mit der größtenAuswahl an praktischen Funktionen war.
12 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
Die Sharemind-Anwendungsserver sind eine praktische Implementierung sichererMehrparteienberechnungstechnologie, die die Privatsphäre bewahrende Berechnungenauf freigegebenen Geheimdaten erlaubt.
Im Folgenden wird erklärt, wie eine SMC-Bereitstellung auf dem Sharemind-Systemabläuft.
Generell gibt es in einem SMC-System 3 grundlegende Rollen. Diese sind:
- die Eingangspartei I
- die Berechnungspartei C
- die Ergebnispartei R
Die Eingangsparteien sammeln die zu verarbeitenden Daten und senden diese an dasSMC-System. Das SMC-System selbst ist auf den Berechnungsparteien gehostet. Hierwerden aus den verschiedenen Eingabedaten die gewünschten Berechnungen durchge-führt und die Ergebnisse den Ergebnisparteien zur Verfügung gestellt.
Für die Modellierung einer SMC-Anwendung wird jetzt folgende Notation verwen-det: Sei
Ik = (I1, . . . , Ik) die Liste der Eingangsparteien,
Cm = (C1, . . . , Cm) die Liste der Berechnungsparteien und
Rn = (R1, . . . , Rn) die Liste der Ergebnisparteien.
Weiter sei Π ein SMC-Protokoll für die Ausführung einer bestimmten Aufgabe. ImFolgenden bezeichnet ICR eine Partei, die alle 3 Rollen erfüllt, ebenso bezeichnet IC
eine Partei, die die Rollen I und C erfüllt, usw.. Außerdem werden hochgestellte Zah-len (k,m, n ≥ 1) verwendet um darzustellen, dass es mehrere Parteien im System gibt,die die gleiche Rolle ausfüllen. Realen Parteien können nun mehr als eine dieser Rol-len zugewiesen werden. Die Menge I, C,R hat 7 nicht-leere Teilmengen und es gibt27 = 128 Möglichkeiten, diese zu kombinieren. Es sind aber nur die Kombinationeninteressant, in denen alle 3 Rollen vorhanden sind. Somit bleiben noch 128− 16 = 112mögliche Kombinationen. In einer realen Umgebung machen jetzt nicht alle 112 mögli-chen Kombinationen Sinn, aber jede Bereitstellung von SMC kann mithilfe dieser 112Kombinationen dargestellt werden.
Hierauf aufbauend werden im Basisartikel folgende Erwartungen und Definitionenfür den Datenschutz aufgestellt.
Ein SMC-Verfahren Π von Parteien Ik, Cm, Rn bewahrt die Privatsphäre der Ein-gangsparteien, wenn folgende Bedingungen erfüllt sind:
• Quell-Datenschutz:
Bei der Durchführung der Berechnung Π können die Rechenparteienkeine Berechnungsergebnisse mit den Eingangsdaten einer bestimmtenEingangspartei verknüpfen.
13 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
• kryptographischer Datenschutz:
Bei der Durchführung der Berechnung Π lernen die Berechnungspar-teien nichts über die Zwischenwerte, die verwendet werden, um dieErgebnisse zu berechnen. Dies schließt auch die Einzelwerte an denEingängen der Eingangsparteien mit ein, es sei denn, der entsprechen-de Wert gehört zu den erlaubten Ausgabewerten von Π. Eine weitereAusnahme ist, wenn es sich um Eingabedaten bei nur einer vorhande-nen Eingangspartei handelt.
• eingeschränkte Ausgänge:
Bei der Auswertung der Berechnung Π dürfen die Ergebnisparteiennichts über die Zwischenwerte, die zur Berechnung der Ergebnisse ver-wendet wurden, erfahren. Hierin inbegriffen sind auch die Einzelwertein den Eingängen der Eingangsparteien, außer einer dieser Werte istunter den zulässigen Ausgaben der Berechnung Π. Darüber hinauskann eine Ergebnispartei jedoch den Eingangswert seines Eingangs er-fahren, wenn sie gleichzeitig Eingangspartei ist.
• Ausgangs-Datenschutz:
Die Ausgabe der Berechnung Π enthält keinen signifikanten Teil derprivaten Eingabe.
Aus dieser Definition werden im Basisartikel jetzt folgende allgemeine Richtlinienfür die Gestaltung von Privatsphäre bewahrenden Algorithmen dargestellt. Für denQuell-Datenschutz wird verlangt, dass die Berechnungsparteien für keinen Zwischen-wert eine Eingangspartei zuordnen können, die zu diesem beigetragen hat. Dies kannzum Beispiel durch das Mischen der Eingangsdaten erreicht werden.
Kryptographischer Datenschutz wird durch die Verwendung von SMC-Protokollenerreicht, die die Eingabedaten in geschützten Formen (z.B. verschlüsselt) den Be-rechnungsparteien zur Verfügung stellen. Dadurch wird verhindert, dass die Berech-nungsparteien die privaten Eingabedaten selbst rekonstruieren können. Ferner mussder Schutzmechanismus für die privaten Eingabedaten während der gesamten Ausfüh-rung des Algorithmus eingehalten werden, das heißt, die Berechnungsparteien dürfenden Schutzmechanismus zur Durchführung der Berechnung nicht entfernen. Beispie-le geeigneter Techniken hierfür sind zum Beispiel homomorphes Secret Sharing undhomomorphe Verschlüsselung.
Bei den eingeschränkten Ausgängen dürfen die Berechnungsparteien nur die Ergeb-niswerte den Ergebnisparteien veröffentlichen, deren Veröffentlichung durch die Be-rechnung Π erlaubt sind. Alle anderen Ergebniswerte müssen geschützt bleiben. Dar-aus folgt trivialerweise, dass zwischen den Berechnungsparteien nur erlaubte Verfahrenausgeführt werden dürfen. Alle Anfragen der Ergebnisparteien, deren Berechnung nichtzwischen den Berechnungsparteien vereinbart wurden, müssen durch diese abgelehntwerden. In der Praxis überwachen hierfür alle Berechnungsparteien ihre Kopie des aus-zuführenden Codes und wenn sie mit der Ausführung nicht einverstanden sind, kannder Code zurückgewiesen werden. Dies stoppt effektiv das Berechnungsverfahren, da
14 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
der Code von allen beteiligten Berechnungsparteien parallel für die Gesamtberechnungabgearbeitet werden muss.
Der Ausgangs-Datenschutz ist das komplexeste Datenschutzziel und erfordert teil-weise kreative Ansätze. Der komplexeste Teil der Algorithmusentwicklung ist hier dieKontrolle, dass durch den Algorithmus nicht Teile der Eingangswerte über die Aus-gaben veröffentlicht werden. Um dieses Ziel zu erreichen, gibt es viele Möglichkeiten.Als Beispiele werden im Basisartikel die Entropieschätzung der Eingangswerte und diedifferenzielle Privatheit genannt.
Unabhängig von der genauen Vorgehensweise muss der Algorithmusdesigner dasPotenzial der Auswirkungen der Veröffentlichung der Ergebnisse der Berechnung ana-lysieren.
3.3 SHAREMIND - als eine Lösungsarchitektur imX-ROAD-System
Im Folgenden komme ich zur Darstellung aus dem Basisartikel, wie die Sharemind-Architektur in das estnische X-Road-System zu integrieren ist, um eine sichere Mehr-parteienberechnung in föderierten Datenbanken zu ermöglichen. Zuerst müssen dieSMC-Knoten innerhalb des X-Road-Systems bereitgestellt werden. Diese Knoten müs-sen entweder an die X-Road-Sicherheitsserver gekoppelt werden oder es sind eigenstän-dige Server mit einer hohen Netzwerkbandbreite. Eine notwendige Bedingung für dieseSharemind-Knoten ist jedoch, dass sie von unabhängigen Dritten betrieben werden.Dadurch ist eine gewisse Zusammenarbeit der einzelnen Behörden sichergestellt, dadie Realisierung der gewünschten Berechnungen eine Abstimmung der einzelnen Be-hörden, die die Eingangsdaten für die Berechnung in ihren Datenbanken gespeicherthaben, notwendig ist. Aufgrund der notwendigen Abstimmung aller an der Berech-nung beteiligten Behörden ist sichergestellt, dass interne Angreifer keine Möglichkeithaben, selbstständig weitergehende Auswertungen vorzunehmen. Bei einem Außenan-griff, zum Beispiel dem Diebstahl eines einzelnen Sharemind-Knotens, sind die sensi-blen Daten aber ebenfalls nicht gefährdet. Es muss in diesem Fall aber sichergestelltwerden, dass durch die Erlangung noch weiterer sensibler Daten dann nicht doch diesensiblen Informationen offengelegt werden.
Nachdem die dargestellte Sharemind-Infrastruktur eingerichtet ist, erfolgt eine si-chere Mehrparteienberechnung nach folgendem Ablauf.
Wenn die Service-Consumer eine Abfrage erhalten, die die Datenbanken mehrererDienstleister umfasst, so nehmen die Service-Consumer in einem ersten Schritt Kontaktmit den Sicherheitsservern der beteiligten X-Road-Service-Anbieter auf. Die jeweiligenSicherheitsserver leiten die Datenanfrage über das interne Datennetz des jeweiligenAnbieters dann an die Datenbank des Anbieters weiter. Danach werden die Antwort-daten mit Hilfe von Secret Sharing zerlegt und den zuvor bestimmten Sharemind-Rechenparteien zugeleitet. Wenn dies abgeschlossen ist, wird der initiierende Service-Consumer hierüber informiert. Dieser beauftragt seinerseits nun die ausgewählten undmit den Eingangsdaten für die Berechnung versorgten Sharemind-Berechnungsparteien
15 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
die tatsächliche Berechnung auf den übermittelten Eingangsdaten auszuführen. Sobalddie Berechnung abgeschlossen ist, sendet jede beteiligte Sharemind-Berechnungsparteiihre Ergebniswerte zurück an den anfordernden Service-Consumer. Dieser rekonstruiertanschließend aus allen erhaltenen Einzelantworten der Sharmind-Berechnungsparteiendie endgültige Antwort auf die gestellte Anforderung und gibt sie an den Anfordererzurück.
Für jede Berechnungsanforderung müssen die Eingangsdaten geteilt und von al-len beteiligten X-Road-Serviceprovidern auf dieselben Sharemind-Berechnungsparteienverteilt werden. Dies ist eine nicht-triviale Aufgabe. Hierzu können dieX-Road-Serviceprovider eine Präferenzliste der Sharemind-Berechnungsparteien ver-walten, in welcher hinterlegt ist, welchen Sharemind-Berechnungsparteien sie ihre ge-heim genutzten Daten anvertrauen. Nach Empfang einer Berechnungsanfrage durcheinen Service-Consumer müssen sich die beteiligten Serviceprovider über ein gemein-sames Bündel für die Berechnung zu verwendender Sharemind-Berechnungsparteieneinigen. Hierbei kann es dazu kommen, dass die gefundene Schnittmenge an vertrau-enswürdigen Sharemind-Berechnungsparteien nicht groß genug ist. Um diesen Engpasszu vermeiden, wäre es alternativ auch möglich, alle im X-Road-System vorhandenenSharemind-Berechnungsparteien mit der gleichen Vertraulichkeit einzustufen. Dannmüssten die Serviceprovider nur die zu verwendenden Sharemind-Berechnungsparteien,ohne Prioritäten beachten zu müssen, festlegen und die jeweiligen Sicherheitsserver derbeteiligten Dienstleister darüber informieren.
Benötigt ein X-Road-Serviceprovider jetzt mehr Kontrolle über den Berechnungs-prozess, so kann er die Sharemind-Rechenknoten bei sich selbst hosten. Dies gäbeihm auch die Möglichkeit, eine sichere Mehrparteienberechnung zu stoppen, wenn ervermutet, dass hierbei etwas falsch läuft. Allerdings darf dabei nicht außer Acht gelas-sen werden, dass dieser Ansatz der generellen Forderung widerspricht, die Sharemind-Berechnungsparteien durch einen unabhängigen Dritten zu betreiben.
3.4 Praktische Umsetzung von SMC
Bei der praktischen Nutzung der sicheren Mehrparteienberechnung besteht das erstewesentliche Problem darin, zwischen den verschiedenen Serviceprovidern als Eingangs-parteien der sicheren Mehrparteienberechnung ein gemeinsames Datenmodell zu entwi-ckeln, welches auch Schlüsselwerte für die Verknüpfung von Daten von verschiedenenServiceprovidern beinhaltet. Aus Effizienzgründen ist es oft nützlich, die Vorverar-beitung der Daten bei den Eingangsparteien vorzunehmen und anschließend erst dieaufbereiteten Daten an die Berechnungsparteien zu senden. Hierdurch wird der Daten-schutz nicht beeinträchtigt, da die Daten von den Eingangsparteien selbst bearbeitetwerden.
Bei dieser Aufbereitung der Daten kann es jetzt vorkommen, dass einzelne Werte inden Datensätzen fehlen. Um dieses Problem zu beheben, gibt es zwei mögliche Optio-nen. Zum einen ist es möglich einen speziellen Wert einzusetzen, der ausschließlich füreinen nicht vorhandenen Wert steht oder es wird für jedes Attribut des Datensatzesein zusätzliches Attribut geschaffen, in dem dann eine 1, falls der Wert vorhanden,
16 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
und eine 0, falls der Wert nicht vorhanden ist, eingefügt wird.Ähnlich wird auch bei der Filterung der Daten vorgegangen. Hier wird ein Vektor
erzeugt, der für jeden Datensatz, der die gesuchte Bedingung erfüllt, mit 1 belegt wirdund ansonsten mit 0. Sollen jetzt mehrere Filter miteinander kombiniert werden, sobrauchen die zugehörigen Vektoren nur multipliziert zu werden.
Die Verknüpfung von mehreren Tabellen in Sharemind erfolgt über sichereJOIN-Operationen ähnlich dem im X-Road-System verwendeten AES-Blockchiffre.Hierbei werden die Schlüsselwerte der JOIN-Operation zuerst verschlüsselt und dieanschließende JOIN-Operation wird auf den verschlüsselten Klartexten ausgeführt.Der Schlüssel für die Verschlüsselung ist während der JOIN-Operation nicht bekanntund damit ein Entschlüsseln der sensiblen Daten nicht möglich.
17 von 18

FernUniversität in Hagen, Seminar 01912/19912 WS2014/2015, Sicherheit undPrivatsphäre in Datenbanksystemen, Thema 14: Verbund von Datenbanken
Literaturverzeichnis
[BKL+14] Bogdanov, Dan ; Kamm, Liina ; Laur, Sven ; Pruulmann-
Vengerfeldt, Pille ; Talviste, Riivo ; Willemson, Jan: Privacy-Preserving Statistical Data Analysis on Federated Databases. In: Preneel,Bart (Hrsg.) ; Ikonomou, Demosthenes (Hrsg.): Privacy Technologies and
Policy - Second Annual Privacy Forum Bd. 8450, Springer, 2014, S. 30–55
[BNC+07] Burdon, Mark ; Nieto, Juan Manuel G. ; Christensen, Sharon ; Daw-
son, Ed ; W.D.Duncan ; Lane, Bill: Access control in federated databa-ses: How legal issues shape security. In: Wimmer, Maria (Hrsg.) ; Scholl,Hans J. (Hrsg.) ; Grönlund, Ake (Hrsg.): Lecture Notes in Computer
Science, Springer, 2007, S. 228–239
[Hau07] Hauf, Dietmar: Allgemeine Konzepte K-Anonymity, l-Diversity and T-
Closeness , 2007
[htta] k-Anonymität. http://de.wikipedia.org/wiki/K-Anonymit%C3%A4t. –Stand Dezember 2014
[httb] Secret-Sharing. http://de.wikipedia.org/wiki/Secret-Sharing. –Stand Dezember 2014
[httc] X-ROAD FACTSHEET . https://www.ria.ee/public/x_tee/
X-road-factsheet-2014.pdf
[httd] TECHNICAL FACTSHEET . https://www.ria.ee/public/x_tee/
Xroad-technical-factsheet-2014.pdf
[Swe02] Sweeney, Latanya: k-anonymity: A model for protecting privacy. In: Inter-
national Journal of Uncertainty, Fuzziness and Knowledge-Based Systems
10 (2002), Nr. 5, S. 557–570
18 von 18

Seminar 01912/19912
im Wintersemester 2014/2015
Sicherheit und Privatsphäre
in Datenbanksystemen
Thema 15
Datenbanken in einer Cloud
Referent: Florian Schlachter

INHALTSVERZEICHNIS INHALTSVERZEICHNIS
Inhaltsverzeichnis
Abkürzungsverzeichnis 3
I Cloud-Dienste für Datenbanksysteme 4
1 Einführung 4
2 Motivation zur Nutzung von Cloud-Diensten 4
3 Probleme im Vergleich zum konventionellen Betrieb 5
II Mögliche Lösungsansätze 5
4 Verschlüsselung zur Erhöhung des Datenschutzes 6
4.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4.2 Architekturen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
4.2.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
4.2.2 Einsatz eines Proxys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4.2.3 Verzicht des Proxys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4.2.3.1 Metadaten im Client . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4.2.3.2 Metadaten im Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
5 Verhaltensanalyse zur Bekämpfung von Bedrohungen 9
5.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
5.2 Architekturen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
5.2.1 Einsatz von Deep Packet Inspection . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
5.2.2 Analyse von Logfiles mithilfe von IaaS . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
6 Weitere Ansätze 12
6.1 Ansätze für den Cloudbenutzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6.1.1 Transparent Data Encryption (TDE) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6.1.2 Einsatz eines angepassten DBMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6.1.3 Einsatz von Proxys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6.2 Ansätze für den Cloudanbieter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6.2.1 Isolation und Verifikation der Serverumgebung . . . . . . . . . . . . . . . . . . . . . . 13
6.2.2 Einsatz sicherer Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
III Zusammenfassung 13
IV Literaturverzeichnis 15
2

Abkürzungsverzeichnis Abkürzungsverzeichnis
Abkürzungsverzeichnis
AES Advanced Encryption Standard
DS Datenbankserver
ECB Electronic Code Book
ENISA European Union Agency for Network and Information Security
IaaS Infrastructure as a service
IBAS Insider Behavior Analysis Server
NIST National Institute of Standards and Technology
PaaS Platform as a service
SaaS Software as a service
SQL Structured Query Language
3

2 MOTIVATION ZUR NUTZUNG VON CLOUD-DIENSTEN
Teil I
Cloud-Dienste für Datenbanksysteme
1 Einführung
Cloud-Dienste für den privaten als auch den gewerblichen Gebrauch gewannen in den letzten Jahren zunehmend
an Bedeutung. Immer mehr Provider stellen mit ihren Dienstleistungen („Services“) unterschiedlichste Arten
von Ressourcen zur Verfügung, die vom Endkunden nach Bedarf genutzt werden können und in der Regel
nutzungsabhängig abgerechnet werden. Die zu mietenden Ressourcen lassen sich einem der drei vom NIST
definierten Modelle Software, Platform und Infrastructure zuordnen [10] – man spricht daher auch von
Software/Platform/Infrastructure as a Service (SaaS/PaaS/IaaS, vgl. Abb. 1). Kennzeichnend
für alle Modelle ist ein gewisser Grad an Abstraktion sowie die Möglichkeit der einfachen Skalierung.
Abbildung 1: Cloudmodelle1
Computerressourcen (Rechenleistung, Speicher, usw.) in Form eines virtuellen Computers werden im Rahmen
von IaaS, das allgemeinste der drei Modelle, vom Provider zur Verfügung gestellt. Mit IaaS hat der Nutzer
direkten Kontakt mit dem Betriebssystem und steht entsprechend in der Pflicht der Verwaltung des Systems.
PaaS stellt dem Endanwender eine Plattform zur Verfügung, die von der zugrundeliegenden Hardware und
Software abstrahiert und sich ausschließlich auf die auszuführende Anwendungslogik konzentriert. Wird die
Anwendungslogik vom Provider zur Verfügung gestellt, handelt es sich um SaaS. Datenbanksysteme können
von Endnutzern sowohl auf Cloud-Servern betrieben (IaaS) als auch in Form eines Services (Database as a
Service; analog zu PaaS) genutzt werden.
Abhängig von dem Ort der Cloud-Installation wird zwischen Public (Anbieter und Nutzer unterschiedlich),
Hybrid (Mischform Public/Private) und Private Cloud (Anbieter/Nutzer identisch) unterschieden. [10]
Für die vorliegende Ausarbeitung sind insbesondere Public und Hybrid Clouds von Bedeutung, da diese
Formen die gewünschte Datensicherheit negativ beeinflussen.
2 Motivation zur Nutzung von Cloud-Diensten
DBaaS und individuelle Datenbanksysteme auf Cloud-Servern (IaaS) weisen jeweils unterschiedliche Vor-
und Nachteile auf.
IaaS bietet größere Flexibilität, insbesondere mit Blick auf mögliche Modifikationen des eingesetzten Daten-
banksystems. Diese Flexiblität erkauft man sich mit anfallenden Kosten für Administration und Wartung.
Ebenfalls mit Blick auf Skalierungsmöglichkeiten und Hochverfügbarkeit ist der Nutzer üblicherweise auf
1Eigenes Werk.
4

3 PROBLEME IM VERGLEICH ZUM KONVENTIONELLEN BETRIEB
sich alleine gestellt und muss auf die am Markt verfügbaren Datenbanksysteme und ihre Funktionalitä-
ten zurückgreifen. Sofern die Software jedoch horizontal skaliert, lassen sich mit IaaS die notwendigen
Hardwareressourcen schnell erweitern und entsprechend der neuen Anforderungen anpassen.
Anbieter von Databases as a Service hingegen weisen nicht denselben Grad von Flexiblität auf, eliminieren
jedoch die Nachteile von IaaS-Lösungen. So werden üblicherweise keine Fixkosten für eine Wartung und Admi-
nistration der Laufzeitumgebungen und der Datenbanksysteme fällig; stattdessen übernimmt dies der Provider.
Wie für Clouddienste üblich, werden DBaaS-Lösungen regelmäßig nutzungsabhängig abgerechnet.2 Abhängig
von den Zielen und Anwendungszwecken wird zwischen Providern unterschieden, die ihre eigens entwickelten
Datenbanksysteme zur Verfügung stellen und denen, die bekannte und etablierte Datenbanksysteme einsetzen.
Gründe für ein eigenes Datenbanksystem können beispielsweise ein besonderer Anwendungszweck sein oder
die Verbesserung der horizontalen Skalierung auf der eigenen Cloudplattform. Allen Datenbanksystemen ist
gemein, dass diese entweder über eine einfach zu erlernende oder über eine bereits bekannte Schnittstelle (zum
Beispiel SQL) angesprochen werden können. Der Nutzer von DBaaS ist regelmäßig nicht mit Fragestellungen
rund um Hochverfügbarkeit oder Skalierung konfrontiert; stattdessen ist die Sicherstellung dieser Merkmale
Aufgabe des Providers.
IaaS- als auch DBaaS-Anbieter weisen in der Regel eine erhöhte Ausfallsicherheit und Schutz gegen
Datenverluste auf. Insbesondere durch eine automatische Replikation, regelmäßige automatische Backups
und ein automatisiertes Failover der Ressourcen kann so oftmals eine Hochverfügbarkeit der Ressourcen
gewährleistet werden.
Mögliche Kosteneinsparungen, Flexibilität und Skalierungsmöglichkeiten sowie Hochverfügbarkeit sind nach
einer ENISA-Umfrage von Unternehmen die wichtigsten Gründe für eine Nutzung von Clouddiensten. [12]
3 Probleme im Vergleich zum konventionellen Betrieb
Einhergehend mit der Nutzung einer Infrastruktur, die von Dritten betrieben wird und wie es bei Cloud-
Diensten üblich ist, ergibt sich ein Bedarf an Konzepten, um einen hohen Grad an Datensicherheit und
Datenschutz zu gewährleisten. Ein geringerer Datenschutz geht mit dem Überlassen von Daten bei einem
Fremdanbieter automatisch einher. Ohne geeignete Schutzmaßnahmen wären Zugriffe auf die beim Anbieter
hinterlegten Daten durch Mitarbeiter des Diensteanbieters oder durch andere unberechtige Dritter denkbar.
Vertraulichkeit, Datenschutz und Datensicherheit sind zugleich jene Punkte, die Unternehmen im Einsatz
von Clouddiensten besonders wichtig erscheinen. [12]
Kryptographie ist ein Instrument, um die in der Cloud gespeicherten Daten vor Manipulation und unbefugter
Einsicht durch Dritte zu schützen. So weist zum Beispiel Amazon, einer der größten Anbieter von Cloud-
dienstleistungen, in seinen Geschäftsbedingungen darauf hin, Verschlüsselung zum Schutz der eigenen Daten
vor unbefugtem Zugriff einzusetzen. [1]
Um Bedrohungen, die durch Missbrauch von Zugangsdaten entstehen, zu unterbinden oder auf solche schnell
reagieren zu können, lässt sich neben der Kryptographie eine Benutzer-Verhaltensanalyse durchführen. Sie
erlaubt es, ungewöhnliche Muster zu erkennen und zu melden.
Beide Lösungsansätze werden im Folgenden unter Punkt 4 auf der nächsten Seite bzw. Punkt 5 auf Seite 9
detaillierter vorgestellt. Sowohl für Cloudanbieter als auch -nutzer stehen zudem weitere Sicherheitsmaßnahmen
zur Verfügung, die unter Punkt 6 auf Seite 12 übersichtsartig dargestellt werden.
2Üblich ist beispielsweise eine Abrechnung nach genutzter CPU-Zeit und Speicherplatz.
5

4 VERSCHLÜSSELUNG ZUR ERHÖHUNG DES DATENSCHUTZES
Teil II
Mögliche Lösungsansätze
4 Verschlüsselung zur Erhöhung des Datenschutzes
4.1 Grundlagen
Kryptographische Methoden erlauben es, den Datenschutz und die Datensicherheit zu gewährleisten. Ein-
setzbar ist die Kryptographie sowohl für Databases as a Service als auch für IaaS-Lösungen. Um einen
möglichst großen Funktionsumfang der Datenbanksysteme jedoch ausschöpfen zu können, sind sogenannte
homomorphe Verschlüsselungssysteme notwendig, wie nachfolgend ausgeführt wird.
Kryptosysteme eignen sich je nach ihren Eigenschaften und abhängig von der jeweiligen Situation nur
bedingt oder auch gar nicht für die Verschlüsselung von Daten in Cloud-Umgebungen. Grund hierfür ist
insbesondere der Verlust vieler Funktionen des Datenbanksystems. So ist es mit Verschlüsselungssystemen unter
Umständen nicht möglich, Datenbankanfragen/-berechnungen (zum Beispiel der Form select sum(umsatz)
from bestellungen where id >= 150) auf verschlüsselten Daten durchzuführen. Vielmehr wäre es unter
Umständen notwendig, den gesamten Datenbestand an den Client zu übertragen und zunächst lokal zu
entschlüsseln. Die eigentliche Anfrage müsste anschließend auf den nunmehr im Klartext vorliegenden Daten
ausgeführt werden (ineffizient). Um effiziente Datenbankanfragen zu ermöglichen, bedarf es daher Verfahren,
die Anfragen und Berechnungen auf verschlüsselten Daten direkt im Datenbanksystem erlauben. Solche
Verfahren werden unter dem Begriff der homomorphen Verschlüsselungssysteme subsumiert.
Abhängig vom Grad der unterstützten Funktionen seitens des Verschlüsselungsverfahrens, wird zwischen
voll-homomorphen und partiell-homomorphen Verschlüsselungssystemen unterschieden (vgl. Abbildung 2). [2,
S. 43ff.]
Abbildung 2: Homomorphe Verschlüsselungssysteme3
Partiell-homomorphe Verschlüsselungssysteme unterstützen mathematische Operationen (entweder die Multi-
plikation oder die Addition) auf Geheimtext in der Art, dass nach Entschlüsselung des Resultats der Klartext
dem gewünschten Ergebnis entspricht. RSA ist beispielsweise ein partiell-homomorphes Verschlüsselungssys-
tem bezüglich der Multiplikation. [14] Unterstützt ein Verschlüsselungssystem beide Operationen, wird von
3Entnommen aus [2, S. 43].
6

4 VERSCHLÜSSELUNG ZUR ERHÖHUNG DES DATENSCHUTZES 4.2 Architekturen
einem voll-homomorphen Verschlüsselungssystem gesprochen. Voll-homomorphe Verschlüsselungssysteme sind
derzeitig noch Gegenstand intensiver Forschung. Im Jahr 2009 wurde erstmals ein solches System vorgestellt
[7], dessen praktischer Einsatz jedoch weiterhin aufgrund seiner Komplexität und des benötigen Speichers
unmöglich erscheint. [14]
Deterministische Verfahren, zum Beispiel der Advanced Encryption Standard (AES) im ECB4-Modus,
unterstützen auf effiziente Weise den Gleichheitsoperator. Hierzu werden die Nutzdaten, auf denen ein
Vergleich durchgeführt werden soll, in der Clouddatenbank mit AES/ECB verschlüsselt abgelegt. Wird eine
Datenbankanfrage ausgeführt, wird der gesuchte Wert zunächst lokal verschlüsselt (mit demselben Verfahren
und demselben Schlüssel) und als Vergleichswert in die Anfrage eingefügt. Aufgrund der deterministischen
Eigenschaft von AES/ECB führt bei Verwendung des stets identischen Schlüssels ein Klartext stets zum
selben Geheimtext. Deterministische Modi wie ECB sind anfällig für Angriffe, da diese verhältnismäßig
einfach Datenmuster erkennen lassen.
Ordnungserhaltende Verschlüsselungssysteme erlauben es, Anfragen mit Ordnungsrelationen auf verschlüssel-
ten Daten durchzuführen. Eine solche Verschlüsselung ist eine Erweiterung herkömmlicher deterministischer
Verfahren. Eine Analyse der Sicherheit ordnungserhaltener Verschlüsselung wurde in [3] vorgenommen mit
dem Ergebnis, dass solche Verfahren ebenfalls (wie deterministische Verfahren) Informationen über die
zugrundeliegenden Klartextdaten preisgeben könnten.
Die vorgestellten Möglichkeiten zur Verschlüsselung von Daten müssen beim jeweiligen Datenbankdesign
berücksichtigt werden. Für jedes Feld muss ermittelt werden, welche Operationen auf diesem zukünftig
ausgeführt werden sollen. Abhängig hiervon wird man sich entweder für eine nicht-homomorphe (reguläre)
Verschlüsselung, eine deterministische Verschlüsselung (zum Beispiel für Vergleiche, wie es für den Primary
Key einer Tabelle oft der Fall sein kann), eine ordnungserhaltende Verschlüsselung (für Bereichsanfragen)
oder eine partiell-homomorphe Verschlüsselung (für Berechnungen) entscheiden.
Mögliche Softwarearchitekturen für die Anwendung einer solchen Verschlüsselung werden im Folgenden
vorgestellt.
4.2 Architekturen
Die Ausführungen dieses Kapitels basieren, wenn nicht anders angegeben, auf [6].
4.2.1 Grundlagen
Die eingesetzte Architektur sollte darauf abzielen (neben der sicheren Aufbewahrung der Nutzdaten), die
Vorteile von Clouddiensten (insbesondere Verfügbarkeit, Skalierbarkeit und Elastizität) bei gleichzeitig
erlaubtem Direktzugriff durch verschiedene Clients, die geographisch verteilt sein dürfen, nicht einzuschränken.
Einhergehend mit diesen Anforderungen sollte die Architektur konkurrierende Lese- als auch Schreibzugriffe
auf die Daten erlauben.
Metadaten und Encryption engine sind zwei essentielle Komponenten einer jeden Architektur, die im
Folgenden kurz vorgestellt werden.
Um eine Ver- und Entschlüsselung zu ermöglichen, bedarf es sogenannter Metadaten. Diese enthalten
insbesondere die zur Ver- und Entschlüsselung notwendigen Schlüssel und sind immer dann notwendig, wenn
Anfragen an eine verschlüsselte Datenbank gestellt werden. Es ist daher für die Sicherheit kritisch, dass
die Metadaten sicher (zum Beispiel getrennt von der eigentlichen, veschlüsselten Datenbank) aufbewahrt
werden, da anderenfalls ein Zugriff auf die Klartextdaten möglich wird.
4Electronic Code Book
7

4.2 Architekturen 4 VERSCHLÜSSELUNG ZUR ERHÖHUNG DES DATENSCHUTZES
Zuständig für die Verwaltung der Metadaten und deren korrekter Anwendung ist die Encryption engine.
Metadaten und Encryption engine müssen im Herrschaftsbereich des Cloudnutzers liegen; nur so kann
gewährleistet werden, dass der Cloudanbieter keinen Zugriff auf die Klartextdaten erhält (s. o.).
4.2.2 Einsatz eines Proxys
Eine denkbare Architektur wäre der Einsatz eines Proxys (vgl. Abbildung 3). Der Proxy hält die Encryption
engine als auch die Metadaten zentral vor. Alle Clients verbinden sich zu diesem Proxy und führen ihre
Anfragen wie gewohnt aus; der Proxy übernimmt die Kommunikation mit der Clouddatenbank, sorgt für eine
Übersetzung der Anfragen und wendet die Ver-/Entschlüsselung auf die Daten an.
Abbildung 3: Proxy-basierte Architektur5
Diese Architektur führt jedoch mit dem Proxy einen sogenannten Single Point of Failure (SPOF) ein und
widerspricht damit den zunächst vorgestellten Zielen, die Vorteile der Cloud vollständig auszunutzen. Einer
Skalierung dieser Proxy-Architektur stehen Synchronisationsprobleme (bezüglich sich ändernder Metadaten)
entgegen, die es zu lösen gilt. Eine Verlagerung des Proxys in die Cloud scheint zunächst ebenfalls aus oben
genannten Gründen (Metadaten müssen ausschließlich durch den Cloudnutzer lesbar sein) nicht möglich.
Für eine solche architektonische Trennung von dem eigentlichen Client und den im Proxy enthaltenen
Aufgaben spricht hingegen insbesondere, dass sie die Komplexität in den Clients klein hält. Diese können
nahezu unverändert ihre regulären Anfragen an die Datenbank stellen und erhalten vom Proxy den Service
der transparenten Verschlüsselung.
4.2.3 Verzicht des Proxys
4.2.3.1 Metadaten im Client
Um im Vergleich zur zuvor vorgestellten Architektur die Cloudvorteile gänzlich ausnutzen zu können, bietet
es sich an, die Encryption engine und die Metadaten in die Clients zu verschieben. Jeder Client hält
damit beide Komponenten vor (besitzt quasi je einen eigenen Proxy) und verbindet sich eigenständig zur
Clouddatenbank (vgl. Abbildung 4 auf der nächsten Seite).
Diese Architektur leidet jedoch an denselben Skalierungs- und Synchronisationsproblemen wie die Architektur
mittels Proxy: Die Metadaten müssen über alle Clients stets konsistent gehalten werden.
4.2.3.2 Metadaten im Server
Der folgende Architekturvorschlag adressiert das zuletzt verbliebene Problem: Die Synchronisation der
Metadaten. Gelöst wird dieses Problem, indem die Metadaten in die Clouddatenbank verschoben werden.5Entnommen aus [6, S. 182].
8

5 VERHALTENSANALYSE ZUR BEKÄMPFUNG VON BEDROHUNGEN
Um diese weiterhin unter Verschluss zu halten und nur dem Cloudnutzer (bzw. den Clients) zur Verfügung zu
stellen und somit die Sicherheit zu bewahren, werden die Metadaten in der Cloud verschlüsselt. Es bleibt
dem Cloudnutzer überlassen, wie er die Schlüsseldistribution für den Zugriff auf die Metadaten realisiert
(zum Beispiel per Pre-Shared-Key, Schlüsselserver, o. ä.). Diese Architektur ist in Abbildung 5 dargestellt.
Ferretti et al. [6, S. 185ff.] haben gezeigt, dass diese Architektur konsistenzerhaltend bezüglich Modifikationen
der Nutz- und Metadaten ist.
Abbildung 4: Proxy-lose Architektur (Metadaten im Client)6
Abbildung 5: Proxy-lose Architektur (Metadaten verschlüsselt im DBMS)7
5 Verhaltensanalyse zur Bekämpfung von Bedrohungen
5.1 Grundlagen
Während zwar eine Verschlüsselung die Daten vor einer Einsicht unbefugter Dritter schützt, schützt sie
jedoch nicht gegen Bedrohungen, die von autorisierten Benutzern wie (ehemaligen) Mitarbeitern oder
Geschäftspartnern ausgehen. Je mehr Kenntnis ein Angreifer über interne Systeme wie das Datenbanksystem
hat, desto größer stellt sich das Bedrohungspotential dar. Diesen Aspekt haben Chagarlamudi et al. [4]
untersucht und kamen zu dem Schluss, dass Insiderangriffe weitaus bedrohlicher sein können als externe
Angriffe.
Dieser Bedrohungsvektor ist die Motivation für die folgenden Ausführungen, die eine Verhaltensanalyse für
Datenbanksysteme vorschlagen. Die Ausführungen basieren, sofern nicht anders angegeben, auf Moon et al.
6Entnommen aus [6, S. 183].7Entnommen aus [6, S. 184].
9

5.2 Architekturen 5 VERHALTENSANALYSE ZUR BEKÄMPFUNG VON BEDROHUNGEN
[11]. Mittels einer Verhaltensanalyse soll gewöhnliches von ungewöhnlichem Benutzerverhalten abgegrenzt
werden und, sofern ein unübliches Verhalten eines Nutzers erkannt wurde, dieses entsprechend an die zuständige
Instanz (zum Beispiel ein Sicherheitsteam) berichtet werden.
Um die Anwendbarkeit dieser Verhaltensanalyse zu gewährleisten, werden zunächst einige Annahmen getroffen.
Zum einen muss das eingesetzte Datenbanksystem Informationen (zum Beispiel die ausgeführten Anfragen aller
Benutzer) bereitstellen, um diese einer Analyse unterziehen zu können. Dies schließt regelmäßig Databases
as a service-Lösungen aus, die eine solche Schnittstelle und Monitoring nicht zur Verfügung stellen. IaaS
liefert die gewünschte Flexibilität, um die eingesetzte Datenbank an die benötigten Rahmenbedingungen
(Monitoring, Logging) anzupassen.
Während das Verhalten eines Datenbankadministrators (DBA) noch überwacht werden kann, gilt dies für
Systemadministratoren auf Datenbankebene nicht mehr. Es wird daher die Annahme getroffen, dass den
Systemadministratoren vollständig vertraut werden kann.
Eine solche Architektur zur Verhaltensanalyse sollte drei Anforderungen erfüllen. Das System sollte sowohl
in der Lage sein, (1) große Mengen von Logdaten zu analysieren, (2) entsprechend der Auslastung des
Datenbanksystems horizontal nach oben oder nach unten zu skalieren sowie (3) nach Aufforderung unabhängig
von der Größe des aktuellen Logging-Datenbestandes eine geeignete Analyse ausgeben zu können.
5.2 Architekturen
5.2.1 Einsatz von Deep Packet Inspection
Liu and Huang [8] haben einen Ansatz vorgestellt, der explizit auf existierende Datenbankmonitoringtools
verzichtet, da diese unter Umständen zu einer Reduzierung der Datenbankperformance führen können (vgl.
[9]). Stattdessen nutzen sie eine Technik, die unter dem Begriff Deep Packet Inspection (DPI) bekannt
ist. Mit DPI werden ein- und ausgehende Netzwerkpakete außerhalb der Datenbank auf Betriebssystemebene
abgefangen und deren Inhalt (zum Beispiel SQL-Anweisungen) untersucht. DPI erfasst dabei jedoch keine
lokalen Zugriffe auf die Datenbank (da solche keine Netzwerkpakete verursachen), weshalb sich diese Lösung
nur bedingt für das Sammeln von zuverlässigen Loginformationen eignet. Zudem wird keine Lösung vorgestellt,
wie eine solche Architektur in einem verteilten Umfeld skalieren und auf verteilte Systeme angewendet werden
kann.
5.2.2 Analyse von Logfiles mithilfe von IaaS
Eine zweistufige Architektur, die alle drei aufgestellten Anforderungen erfüllt, ist in Abbildung 6 dargestellt
und besteht zum einen aus dem Datenbankserver (DS) und einem Insider Behavior Analysis Server (IBAS), der
für die eigentliche Verhaltensanalyse zuständig ist. Auf dem Datenbankserver ist eine Präprozessorkomponente
für die Überwachung von Logdateien und Veränderungen der Datenbankdateien platziert, die Veränderungen
und Transaktionen an den IBAS übermittelt.
Abbildung 6: High-level Übersicht einer zweistufigen Analysearchitektur8
10

5 VERHALTENSANALYSE ZUR BEKÄMPFUNG VON BEDROHUNGEN 5.2 Architekturen
Der IBAS selbst nimmt die Loginformationen entgegen, wertet sie für den jeweiligen Akteur (Insider) aus und
prüft, ob sich Abweichungen vom bisherigen Verhalten des Akteurs ergeben. Sofern die Anfrage innerhalb einer
Toleranzgrenze liegt, wird das Verhaltensmuster des Akteurs entsprechend aktualisiert. Wird ein abweichendes
Verhalten festgestellt, wird die zuständige organisatorische Einheit (zum Beispiel ein Sicherheitsteam) über
den Vorfall informiert. IBAS besteht aus diversen Komponenten (vgl. Abbildung 7), um sowohl das kurz- als
auch langfristige Verhalten eines Akteurs analysieren zu können.
Abbildung 7: Blick in den Insider behavior analysis server (IBAS)9
Um eine kurzfristige und nahezu in Echtzeit ablaufende Analyse zu ermöglichen, setzt diese Architektur auf
eine In-Memory-Datenbank (IMDB). Die IMDB hält in jedem IBAS eine Datenbasis, um kurzfristige Attacken
zu erkennen. Die Behavior Analysis Component (BAC) analysiert sowohl das kurz- als auch langfristige
Verhalten von Akteuren und meldet entsprechende Abweichungen, die vom Sicherheitsteam über die Behavior
Analysis Display Application (BADA) eingesehen werden können.
Um die Verhaltensanalyse problemlos dem jeweiligen Workload der Datenbanken anpassen zu können und
eine Echtzeitanalyse zu erlauben, wird die Architektur in einer Cloud (in der Regel als Infrastructure as
a service) stationiert. Die einzelnen IBASs werden untereinander mittels Chord koordiniert und verbunden.
Die sich ergebende Struktur wird unter dem Begriff Distributed Insider Behavior Analysis Server (DIBAS)
subsumiert und ist in Abbildung 8 skizziert.
Abbildung 8: Distributed Insider behavior analysis server (DIBAS)10
8Entnommen aus [11, S. 264].9Entnommen aus [11, S. 265].
10Entnommen aus [11, S. 267].
11

6 WEITERE ANSÄTZE
6 Weitere Ansätze
6.1 Ansätze für den Cloudbenutzer
6.1.1 Transparent Data Encryption (TDE)
Transparent Data Encryption (TDE) ist eine Funktion, die insbesondere kommerzielle Anbieter von DBMS
implementieren. Es erlaubt die verschlüsselte Sicherung der Datenbank auf einem unsicheren Speicher und
verhindert somit, dass das Datenbanksystem als Zugriffsebene umgangen wird. Gegenüber dem DBMS
authentifizierte Benutzer können transparent auf die Klartextdaten zugreifen, während Benutzer auf Dateisys-
temebene nur die verschlüsselten Daten einsehen können. [13, 6] TDE ist regelmäßig nur im IaaS-Szenario
anwendbar, da es eine individuelle Konfiguration und ein DBMS mit dieser Funktion benötigt.
6.1.2 Einsatz eines angepassten DBMS
Neben den bereits vorgestellten, nicht-invasiven11 Möglichkeiten zur Wahrung der Datensicherheit wurden
in der Literatur weitere Verfahren vorgestellt, die eine (unter Umständen kostenintensive) Anpassung eines
Datenbanksystems notwendig machen und damit nur im IaaS-Fall zur Anwendung kommen können. Damiani
et al. [5] schlägt beispielsweise die Erweiterung einer verschlüsselten Datenbank um Indizes vor, um Anfragen
auf den verschlüsselten Daten durchführen zu können, und zeigt Verfahren auf, wie diese Indizes effizient und
sicher generiert werden können.
Fraglich ist, inwieweit die Kosten für eine Modifikation des DBMS in Relation zu den potentiellen Einsparungen
durch den Einsatz von Clouddiensten stehen. [6, S. 180]
6.1.3 Einsatz von Proxys
Eine weitere Möglichkeit, ein Datenbanksystem vor unerwünschten oder bedrohlichen Anfragen zu schützen,
ist die Einführung eines Proxys, der jede eingehende Anfrage untersucht und gegebenenfalls an das DBMS
lokal weiterreicht. Ein solcher Ansatz wird beispielsweise von Vitess12 verfolgt. Vitess dient insbesondere
der Skalierung einer MySQL-Datenbankinfrastruktur, implementiert jedoch auch Schutzmechanismen zum
Schutz der Daten und der Server. Die Architektur ist in Abbildung 9 dargestellt.
Der Proxy vttablet nimmt Anfragen entgegen, prüft diese (zum Beispiel auf Anfragen, die zu einer
Überlastung des Datenbanksystems führen könnten) und reicht diese nach der Prüfung an das eigentliche
Datenbanksystem weiter oder lehnt die entsprechende Anfrage ab. Eine direkte Kommunikation mit dem
DBMS unter Umgehung des Proxys ist nicht möglich.
Einsetzbar ist diese Form des Schutzes nur bei Infrastructure as a service-Lösungen, da nur diese die
benötige Flexibilität anbieten.
6.2 Ansätze für den Cloudanbieter
Auch Anbieter von Clouddienstleistungen haben die Möglichkeit, über diverse Ansätze die Sicherheit ihrer
Cloudumgebungen zu erhöhen. Zwei von den Möglichkeiten werden im Folgenden vorgestellt.
11Bei allen vorgestellten Methoden war es bislang nicht notwendig, das DBMS anzupassen.12Ein Softwarepaket, das Google für YouTube entwickelt hat: https://github.com/youtube/vitess (abgerufen am 10. Januar
2015).
12

6 WEITERE ANSÄTZE 6.2 Ansätze für den Cloudanbieter
Abbildung 9: Vitess-Softwarearchitektur13
6.2.1 Isolation und Verifikation der Serverumgebung
Um die Sicherheit von Cloudumgebungen zu erhöhen, bietet sich sowohl eine physische als auch logische
Isolation der zugrundeliegenden Plattform an. Eine physische Isolation kann durch eine geeignete Wahl eines
besonders gesicherten Serverstandortes erfolgen. Striktere organisatorische Richtlinien können hier ebenfalls zur
Missbrauchspräventation eingesetzt werden (zum Beispiel Vier-Augen-Prinzip bei einer Serveradministration).
Eine weitere Isolation kann über den Einsatz virtueller Maschinen erreicht werden.
Ein in der Praxis umgesetztes Beispiel einer besonders isolierten Serverumgebung ist der Service GovCloud
von Amazon, der speziell an die erhöhten Sicherheitsbedürfnisse der US-Regierung und -Behörden angepasst
wurde.14
Neben der Isolation bietet sich als weitere Möglichkeit zur Erhöhung der Sicherheit die Verifikation der
Serverumgebung an. Im Rahmen dessen findet eine Verifikation des Betriebssystemkernels und anderer
Systembestandteilen statt. In der Praxis erscheint diese Lösung jedoch aufgrund der großen Komplexität
praktisch nicht oder nur mit sehr hohen Kosten realisierbar.
6.2.2 Einsatz sicherer Hardware
Ein weiterer denkbarer Weg die Sicherheit in Cloudumgebungen zu erhöhen, wäre der Einsatz besonders
gesicherter Hardware. Sichere Co-/Crypto-Prozessoren oder andere Hardware-Sicherheitsmodule könnten
gegebenenfalls Schlüssel oder andere zu schützende Ressourcen verwalten beziehungsweise kryptographische
Operationen sicher durchführen. Der Einsatz einer solchen Hardware bleibt jedoch aufgrund der hohen Kosten,
Komplexität und limitierten Ressourcen weiterhin Spezialfällen vorbehalten.
13Entnommen https://github.com/youtube/vitess (abgerufen am 11. Januar 2015).14Vgl. https://aws.amazon.com/de/govcloud-us/.
13

Teil III
Zusammenfassung
Die letzten Jahre haben einen eindeutigen Trend gezeigt: Immer mehr Ressourcen werden zentral bei
Cloudanbietern hinterlegt. Unternehmen sehen insbesondere Vorteile wie Kosteneinsparungen, Flexibilität,
Hochverfügbarkeit und Skalierbarkeit. Nichtsdestotrotz steigen mit der Verschiebung der Daten in die Cloud
die Bedenken bezüglich Datenschutz und Datensicherheit.
Mit homomorphen Verschlüsselungssystemen und Benutzer-Verhaltensanalysen stehen erste Instrumente zur
Verfügung, diese Bedenken zu adressieren. Homomorphe Verschlüsselungssysteme erlauben Berechnungen
auf verschlüsselten Daten, ohne diese in der Datenbank entschlüsseln zu müssen. Sie ermöglichen es, Daten-
bankfunktionalitäten zu nutzen, ohne zunächst ganze verschlüsselte Datenbestände zum Client übertragen
zu müssen. Bislang steht jedoch noch kein praxisrelevantes vollhomomorphes Verschlüsselungssystem zur
Verfügung, das beliebige Berechnungen auf verschlüsselten Daten durchführen kann. Vielmehr muss eine
geeignete Verschlüsselung anhand der geplanten Anfragen ausgewählt und im Datenbankschema entsprechend
berücksichtigt werden. Neben partiell-homomorphen Verschlüsselungssystemen stehen sowohl deterministische
als auch ordnungserhaltende Verschlüsselungssysteme mit ihren jeweiligen Vor- und Nachteilen zur Verfügung.
Während eine Datenverschlüsselung nur gegen unautorisierte Zugriffe schützt, ist ein Schutz vor Bedrohungen
durch Insider nicht gegeben. Um potentiell bedrohliche Anfragen gegen ein Datenbanksystem zu ermitteln,
wird eine Verhaltensanalyse je Akteur durchgeführt. Dabei wird anhand typischer Anfragen ein Akteursprofil
erzeugt, gegen das alle zukünftigen Anfragen geprüft werden. Ist eine neue Anfrage untypisch, wird dies
direkt der organisatorisch zuständigen Einheit (zum Beispiel einem Sicherheitsteam) gemeldet. Dieses kann
daraufhin prüfen, inwieweit eine Anfrage zulässig ist und gegebenenfalls notwendige Maßnahmen ergreifen.
Wichtig beim Einsatz von Clouddatenbanken ist eine Analysemöglichkeit, die mit der Größe der Datenbank
skaliert.
Neben den bislang vorgestellten Maßnahmen stehen Cloudnutzer und -betreiber weitere Möglichkeiten
zur Verfügung, die teilweise jedoch nur situationsbezogen eingesetzt werden können. Dem Cloudnutzer
stehen unter anderem der Einsatz eines individuell angepassten Datenbanksystems, der Einsatz eines Proxys
zum Schutz des Datenbanksystems vor gefährlichen Anfragen oder eine transparente Verschlüsselung auf
Dateisystemebene zur Verfügung. Der Cloudbetreiber kann die Sicherheit erhöhen, indem er eine physisch
und logisch isolierte Serverumgebung für seine Cloudplatform schafft oder eine Verifikation des eingesetzten
Softwarestacks vornimmt. Der Einsatz besonders sicherer Hardware wäre denkbar, ist jedoch in der Praxis
auf Sonderfälle beschränkt.
14

LITERATUR
Teil IV
Literaturverzeichnis
Literatur
[1] amazon webservices. AWS customer agreement, 12 2014. URL https://aws.amazon.com/de/
agreement/. Abgerufen am 04.01.2015.
[2] Arvind Arasu, Ken Eguro, Ravi Ramamurthy, and Raghav Kaushik. Querying encrypted data, 4
2013. URL http://research.microsoft.com/pubs/192055/ICDE-tutorial_final.pdf. Abgerufen
am 04.01.2015.
[3] Alexandra Boldyreva, Nathan Chenette, and Adam O’Neill. Order-preserving encryption revisited:
Improved security analysis and alternative solutions. 2011.
[4] M. Chagarlamudi, B. Panda, and Y. Hu. Insider thread in database systems: preventing malicious users’
activities in databases. Sixth International Conference on Information Technology: New Generations
2009, ITNG ’09, 2009.
[5] Ernesto Damiani, S.De Capitanidi Vimercati, Sushil Jajodia, Stefano Paraboschi, and Pierangela Samarati.
Balancing confidentiality and efficiency in untrusted relational dbmss. Proceedings of the 10th ACM
Conference on Computer and Communications Security (CGS), pages 93–102, 2003.
[6] Luca Ferretti, Michele Colajanni, and Mirco Marchetti. Supporting security and consistency for cloud
database. In Y. Xiang et al., editor, CSS 2012, LNCS 7672, pages 179–193. 2012.
[7] Craig Gentry. A fully homomorphic encryption scheme. PhD thesis, Stanford University, 2009.
[8] L. Liu and Q. Huang. A framework for database auditing. Fourth International Conference on Computer
Sciences and Convergence Information Technology 2009, ICCIT ’09, 2009.
[9] Giuseppe Maxia. Mysql 5.4 performance with logging, 04 2009. URL http://datacharmer.blogspot.
de/2009/04/mysql-54-performance-with-logging.html. Abgerufen am 10. Januar 2015.
[10] Peter Mell and Tim Grance. The NIST definition of cloud computing, 7 2009. URL http://www.nist.
gov/itl/cloud/upload/cloud-def-v15.pdf. Abgerufen am 04.01.2015.
[11] Cheolmin Sky Moon, Sam Chung, and Barbara Endicott-Popovsky. A cloud and in-memory based
two-tier architecture of a database protection system from insider attacks. In Y. Kim et al., editor,
WISA 2013, LNCS 8267, pages 260–271. 2014.
[12] European Network and Information Security Agency (ENISA). An SME perspective on
cloud computing, 9 2009. URL http://www.enisa.europa.eu/act/rm/files/deliverables/
cloud-computing-sme-survey/at_download/fullReport. Abgerufen am 04.01.2015.
[13] Oracle Corporation. Encryption and redaction in oracle database 12c with oracle advanced securi-
ty, 06 2013. URL http://www.oracle.com/technetwork/database/options/advanced-security/
advanced-security-wp-12c-1896139.pdf.
[14] Bruce Schneier. Homomorphic encryption breakthrough, 07 2009. URL https://www.schneier.com/
blog/archives/2009/07/homomorphic_enc.html. Abgerufen am 04.01.2015.
15





























