Embed Size (px)
DESCRIPTION
Tabellarische Übersicht über die Grundlagen der Statistik, z.B. für einen Uni-Einführungskurs.
Citation preview

AV gesucht: Leistung bei Test, Reaktionszeit UV gegeben, vom Experimentator teilweise varriert: Geschwisterzahl Experiment willkürliche Manipulation der UV nur bei Experiment sind Kausalschlüsse möglich Randomisierung zufällige Zuordnung der VPersonen zu den UV-Stufen Lose-Ziehen willkürliche Manipulierbarkeit der UV Konfundierung Verfälschung durch Bündelung verschiedener Einflussfaktoren Kohorteneffekt zB Generationsunterschiede (heute alle weniger Kinder) Parallelisierung alle VP haben was gleiches gemeinsam Qualitativ: kategorisch, was?, in Gruppen: Augenfarbe, Geschlecht Nominal: verschieden bezeichnetes ist verschieden: Beruf, Konfession Binär: nur zwei Ausprägungen: mask/fem, bestanden/durchgefallen Ordinal: Rangfolge gut – besser, Schulnoten, Gefahrenstufen Quantitativ: wieviel?, Geschwindigkeit, Gewicht – Zahlen Intervallskala: gleiche Abstände, willkürlicher Nullpunkt: a-b=c-d, Celsius Verhältnisskala: wohldefinierter Nullpunkt, a/b=c/d, Zeit, Gewicht Korellation: Modal: häufigster Wert, nicht automatisch der repräsentativste aber: {1,2,3} alle sind Modalwert Median: der Wert in der Mitte, robust {1,2,3}→2 {1,2,3,4}=2+3/2 Mittelwert/arithm.: informativ, am meisten anwendbar Ausreißeranfällig, muss in den Daten nicht vorkommen: {1,3}→2 Verteilungen: es gibt mehrere Verteilungen zum selben Mittelwert
Interquartil: mittlere 50% der sortierten Daten:
Range: Spannweite: Abstand zwischen größtem und kleinstem Wert
Varianz: s2 = 1/n-1 · Σn
i=0 (xi – x__
)² Euro²
Standardabweichung: s = √Varianz__________
Euro
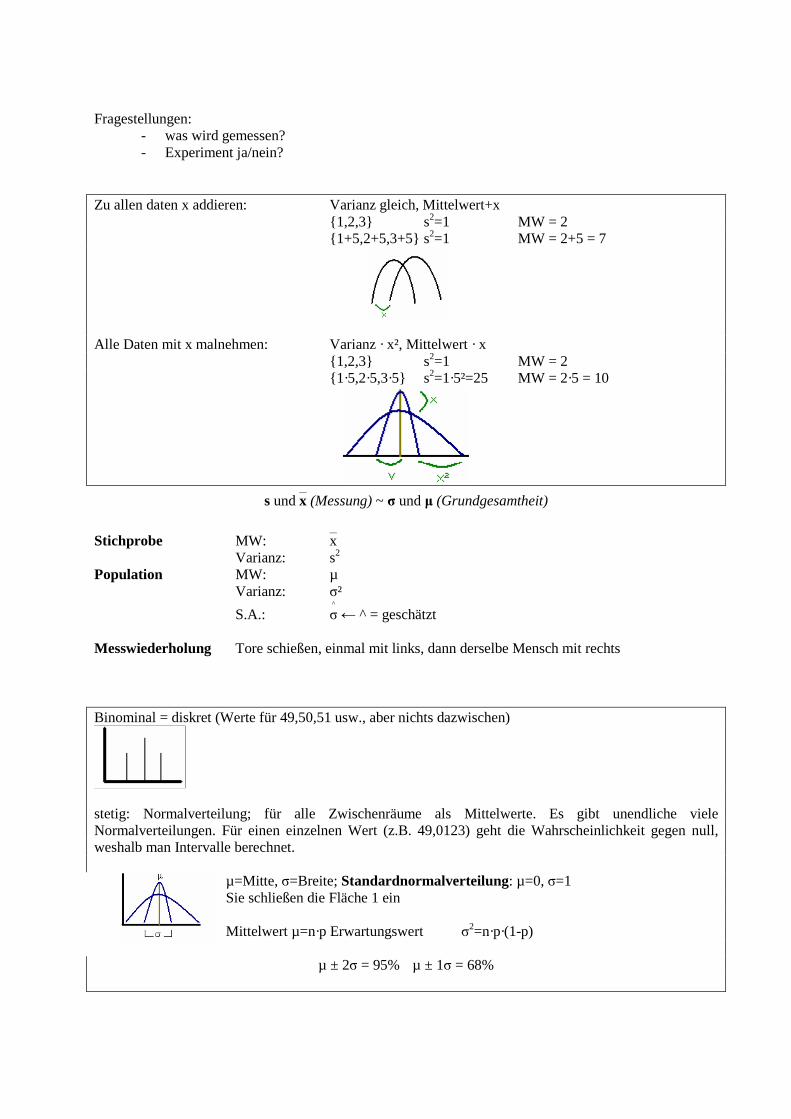
Fragestellungen:
- was wird gemessen? - Experiment ja/nein?
Zu allen daten x addieren: Varianz gleich, Mittelwert+x {1,2,3} s2=1 MW = 2 {1+5,2+5,3+5} s2=1 MW = 2+5 = 7
Alle Daten mit x malnehmen: Varianz · x², Mittelwert · x {1,2,3} s2=1 MW = 2 {1·5,2·5,3·5} s2=1·5²=25 MW = 2·5 = 10
s und x__
(Messung) ~ σ und µ (Grundgesamtheit)
Stichprobe MW: x__
Varianz: s2 Population MW: µ Varianz: σ²
S.A.: σ^
← ^ = geschätzt Messwiederholung Tore schießen, einmal mit links, dann derselbe Mensch mit rechts Binominal = diskret (Werte für 49,50,51 usw., aber nichts dazwischen)
stetig: Normalverteilung; für alle Zwischenräume als Mittelwerte. Es gibt unendliche viele Normalverteilungen. Für einen einzelnen Wert (z.B. 49,0123) geht die Wahrscheinlichkeit gegen null, weshalb man Intervalle berechnet.
µ=Mitte, σ=Breite; Standardnormalverteilung: µ=0, σ=1 Sie schließen die Fläche 1 ein Mittelwert µ=n·p Erwartungswert σ
2=n·p·(1-p)
µ ± 2σ = 95% µ ± 1σ = 68%

Konfidenzintervalle n=Anzahl der Versuchspersonen Konfidenzintervalle für Anteile: (zu 95% in diesem Bereich:)
nppw
wppwp
/)ˆ1(ˆ
2ˆ2ˆ
−=
+<<−
Münze 100mal werfen, p=55%:
w= 05,0100/)55,01(55,0 ≈−
0,55-2·0,55 < p < 0,55+2·0,05 → Die wahre Wahrscheinlichkeit für Kopf liegt mit 95% im Intervall [0,45; 0,68] Konfidenzintervalle für Mittelwerte: (triviales Intervall = uninformativ, z.B. Körpergröße [164, 174]) Bei wenigen VP:
ntxµ
ntx nn
σσ ⋅+<<⋅− −− 11
Ab 30 VP gilt (man kann von der Standardnormalverteilung ausgehen):
nxµ
nx
σσ ⋅+<<⋅− 22
Hypothesentesten Teststatistik = Entscheidungshilfe für oder gegen h0 Nullhypothese stimmt, wenn µB innerhalb der 95% liegt = Annahmebereich der h0.

Unabhängige Stichproben ja nein M 100 150 250 W 110 140 250 210 290 500 h0: p(ja|M)=p(ja|F)=p(ja)
h1: p(ja|M)≠p(ja|F) gestestet wird immer h0, dazu benötigt man p(ja)=0,42 erwartete Häufigkeiten eij: ja nein M e11=n1.·p=105 e12=n1.·(1-p)=145 n1.=250 W e21=n2.·p=105 e12=n2.·(1-p)=145 n2.=250 n.1= n.2=290 n..=500 Vierfelder:
82,0)²(
²2121
21122211 =−
=Χ••••
••
nnnn
nnnnn
Wenn 1 Wert im Innern feststeht, sind alle anderen durch die Randhäufigkeiten ableitbar. χ² sagt: es gibt (k)einen Unterschied, mehr nicht (wo er ist) nur kausal, wenn UV randomisiert t-Test für unabhängige Stichproben
t-Test prüft, ob die Differenz zufällig oder systematisch von 0 abweict.
McNemar + -
+ a c vorher - b d
nachher b/c sind Wechsler p=[(b+c)/2]/Σ

Regression Nur linear:
r→ρ UV: angezogen (ja oder nein) AV: Gewicht N=6 (3 angezogen, 3 ausgezogen) na a
65 64 85 86
s2i
112 110 s2
z s2
i=500 s2
u=1 s2
i >> s2z
Varianz innerhalb Gruppe groß → abhängiges Design
III,II: korr positiv sign cov=sign kor I,IV: korr negativ
sysx
yxr
⋅= ),cov(
durch Standardabw. teilen: normieren
Gründe für Korr:
x→y y→x NICHT KAUSAL df=N-2 h0: kein linearer Zusammenhang
t-Wert soll groß sein
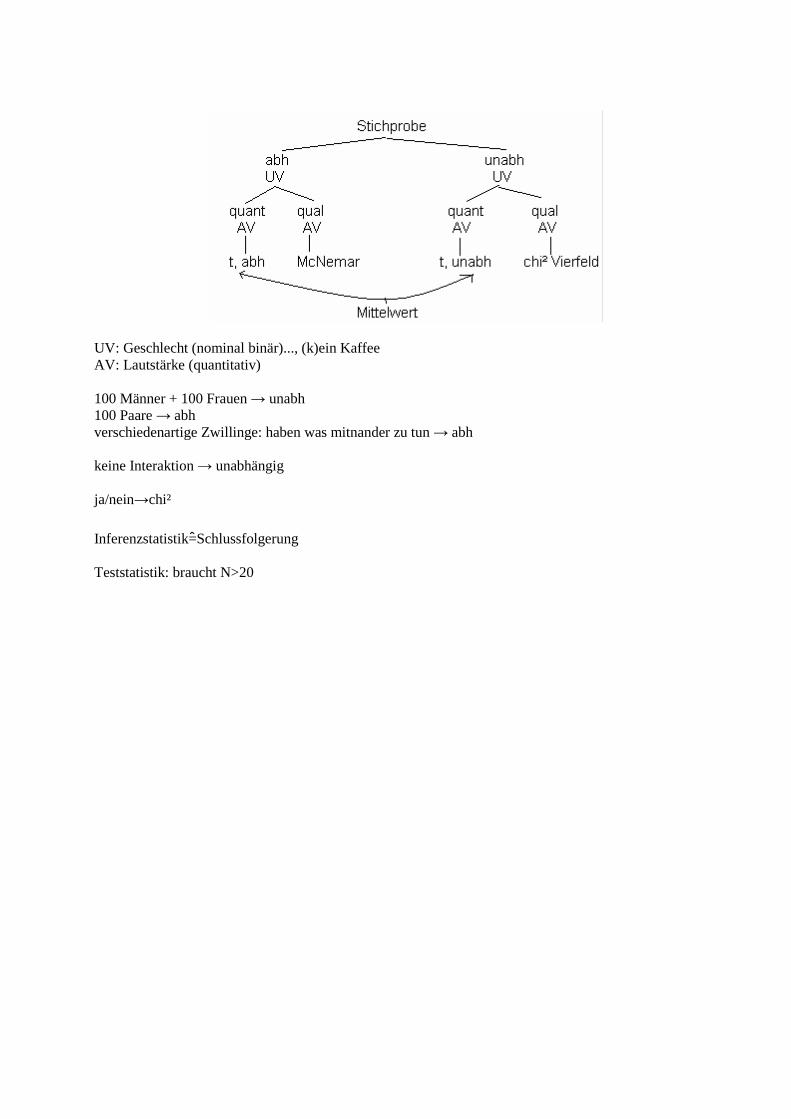
UV: Geschlecht (nominal binär)..., (k)ein Kaffee AV: Lautstärke (quantitativ) 100 Männer + 100 Frauen → unabh 100 Paare → abh verschiedenartige Zwillinge: haben was mitnander zu tun → abh keine Interaktion → unabhängig ja/nein→chi²
Inferenzstatistik=ɵSchlussfolgerung Teststatistik: braucht N>20















![Grundlagen - webdoc.sub.gwdg.dewebdoc.sub.gwdg.de/ebook/diss/2003/fu-berlin/2002/294/grundlagen.pdf · Bahn Wechselwirkung resultieren. ... Sauerstoff durch Luftkontakt [16] und von](https://img.pdfslide.org/doc/110x75/5d51e97088c993c9398b9eb4/grundlagen-bahn-wechselwirkung-resultieren-sauerstoff-durch-luftkontakt.jpg)



![Physikalische Grundlagen.ppt [Kompatibilitätsmodus] Grundlagen.pdf · 1 1 Elektromedizin –Weserlandklinik Prof. Dr.-Ing. Friedrich Ueberle Hochschule für Angewandte Wissenschaften](https://img.pdfslide.org/doc/110x75/5dd0bef9d6be591ccb627e29/physikalische-kompatibilittsmodus-grundlagenpdf-1-1-elektromedizin-aweserlandklinik.jpg)








