Embed Size (px)
Citation preview

Verteilte Algorithmen
Motivation und Einführung
PD Dr.-Ing. Gero Mühl
Kommunikations- und BetriebssystemeFakultät für Elektrotechnik u. InformatikTechnische Universität Berlin

VS / Motivation und EinführungG. Mühl 2
Verteiltes System – Einige Definitionen
“A distributed computing system consists of multiple autonomous processors that do not share primary memory, but cooperate by sending messages over a communication network.”-- Henri Bal
“A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.”-- Leslie Lamport
“A distributed system is a collection of independent computers that appears to its users as a single coherent system”-- Andrew S. Tanenbaum

VS / Motivation und EinführungG. Mühl 3
Verteiltes System – Eigene Definition
> Autonome Rechner, die durch ein Netzwerk lose miteinander verbunden sind und miteinander durch Nachrichtenaustauschkommunizieren, um gemeinsam eine Gesamtfunktionalität zu gewährleisten.

VS / Motivation und EinführungG. Mühl 4
Verteilte Systeme – Abgrenzung
> Rechnernetze> Hier steht die Vernetzung der Rechner im Vordergrund und
nicht die Kooperation der Rechner> Rechnernetze ermöglichen z.B. den Zugang zu einem
entfernten Rechner per SSH
> Parallelrechner> Haben im Gegensatz zu verteilten Systemen einen
gemeinsamen physikalischen Speicher

VS / Motivation und EinführungG. Mühl 5
Verteilte Systeme – Ziele> Leistungsgewinn durch echt nebenläufige Prozesse
> Gemeinsames Knacken eines kryptografischer Schlüssels> Paralleles Suchen nach den Primfaktoren einer großer Zahl
> Erhöhte Funktionalität und Flexibilität durch inkrementelle Erweiterbarkeit> Skalierung des Systems durch Hinzufügen von Rechnern
> Bereitstellung entfernter Daten und Dienste> Zugriff auf mehrere Datenbanken (z.B. Bibliothekskatalog)> Nutzung brachliegender Rechenkapazität (z.B. SETI@home)
> Fehlertoleranz durch Redundanz> Redundante Speicherung von Daten> Primary/Backup Server
(Backup übernimmt bei Ausfall des Primary)

VS / Motivation und EinführungG. Mühl 6
Weitere Gründe für den Einsatz verteilte Systeme
> Wirtschaftlichkeit: Vernetzte PCs haben meist besseres Preis-Leistungsverhältnis als Supercomputer⇒ Anwendung – falls möglich – auf mehrere kleine Rechner
verteilen
> Geschwindigkeit: Falls Anwendung gut parallelisierbar ist, ist eine sonst unerreichbare Leistung möglich> Vgl. auch Grid Computing> Ggf. (dynamische) Lastverteilung beachten

VS / Motivation und EinführungG. Mühl 7
Verteilte Systeme – Eigenschaften und Folgen
> Echt-Nebenläufige Prozesse mit unterschiedlicher Geschwindigkeit Nebenläufigkeit> Vieles Ereignisse passieren gleichzeitig> Abläufe sind nicht reproduzierbar Nichtdeterminismus⇒ Mechanismen zur Koordination und zur Synchronisation von
Aktivitäten (z.B. für exklusiver Zugriff auf Ressourcen)
P1 P2 P3 P1 P2 P3
Ein Prozessor Drei Prozessoren

VS / Motivation und EinführungG. Mühl 8
Verteilte Systeme – Eigenschaften und Folgen
> Kein gemeinsamer primärer Speicher> Kommunikation nur durch Nachrichtenaustausch möglich> Kein Knoten hat globale Sicht auf den Gesamtzustand des
Systems Zustandsverteilung⇒ Mechanismen für eine konsistente Sicht auf den Zustand
notwendig

VS / Motivation und EinführungG. Mühl 9
Verteilte Systeme – Eigenschaften und Folgen
> Nachrichtenlaufzeit ist unbestimmt, meist nicht beschränkt und variiert unvorhersagbar> Beispiel Ethernet: Hier hängt die Nachrichtenlaufzeit stark
von der aktuellen Last des Netzwerks ab
> Langsame Prozesse bzw. Verbindungen können nicht von ausgefallenen unterschieden werden⇒ Keine adäquate Ausfallserkennung möglich

VS / Motivation und EinführungG. Mühl 10
Verteilte Systeme – Eigenschaften und Folgen
> Kommunikation ist fehleranfällig> Nachrichtenverlust, -duplizierung, -verfälschung ist möglich⇒ Mechanismen zur Erkennung und zum Umgang mit
Kommunikationsfehlern
> Kommunikation ist unsicher> Es besteht die Gefahr, dass Nachrichten abgehört, mit
Absicht verfälscht, hinzugefügt oder unterschlagen werden⇒ Sicherheitsmechanismen

VS / Motivation und EinführungG. Mühl 11
Verteilte Systeme – Eigenschaften und Folgen
> Rechner und Netzwerkverbindungen können unabhängig voneinander ausfallen Teilweiser Ausfall möglich> In großen Systemen sind einzelne Ausfälle von Rechnern
oder Netzwerkverbindungen wahrscheinlich> Ein Ausfall sollte nicht das gesamte System lahm legen,
sondern Ausfälle von einzelnen Rechnern oder Netzwerkverbindungen sollten verkraftet werden
⇒ Fehlertoleranzmechanismen notwendig
VS / Motivation und EinführungG. Mühl 12
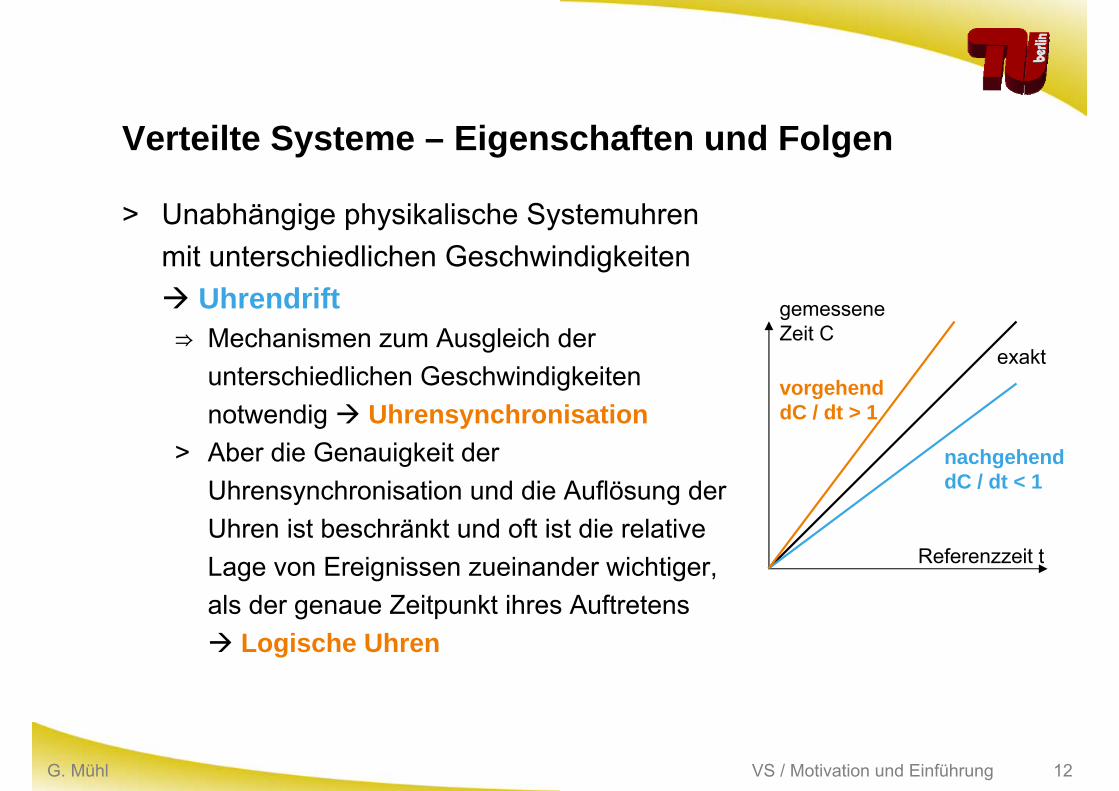
Verteilte Systeme – Eigenschaften und Folgen
> Unabhängige physikalische Systemuhren mit unterschiedlichen Geschwindigkeiten Uhrendrift⇒ Mechanismen zum Ausgleich der
unterschiedlichen Geschwindigkeiten notwendig Uhrensynchronisation
> Aber die Genauigkeit der Uhrensynchronisation und die Auflösung der Uhren ist beschränkt und oft ist die relative Lage von Ereignissen zueinander wichtiger, als der genaue Zeitpunkt ihres Auftretens Logische Uhren
Referenzzeit t
gemesseneZeit C
nachgehenddC / dt < 1
vorgehenddC / dt > 1
exakt

VS / Motivation und EinführungG. Mühl 13
Verteilte Systeme – Eigenschaften und Folgen
> Unterschiedliche administrative Domänen> Für jede Domäne ist ein eigener Administrator zuständig> Zentralisierte Administration in großen Systemen unmöglich⇒ Dezentrale Administration ermöglichen und die
Administration (soweit möglich und sicher) automatisieren
> Komponenten sind heterogen Heterogenität> Interoperabilität zwischen Komponenten schwierig zu
gewährleisten⇒ Schnittstellenstandardisierung notwendig

VS / Motivation und EinführungG. Mühl 14
Verteilten Systeme – Faustregeln für den Entwurf
> System nur verteilen, wenn dies auch gewinnbringend ist; ansonsten lieber eine zentralisierte Lösung umsetzen
> „Central point of failure” vermeiden> Ein Teilausfall sollte nicht das gesamte System lahm legen> Hierfür ist Redundanz notwendig
> Auf Skalierbarkeit achten> Für eine wachsende Anzahl von Beteiligten, sollte die Performance
nicht überproportional sinken> Auf Flaschenhälse achten> Mini-Prototypen lassen keine Rückschlüsse auf die Performanz
eines großen Systems zu> Nur soviel Zugang erlauben, wie für die Ausführung einer
Aufgabe gerade erforderlich ist

VS / Motivation und EinführungG. Mühl 15
Verteilten Systeme - Schlussfolgerungen> Das Entwerfen, Implementieren, Testen und Absichern eines
verteilten Systems ist erheblich aufwendiger als im Falle eines zentralisierten Systems
> Nur bei geeigneter Gestaltung ist ein verteiltes System performanter, skalierbarer und fehlertoleranter sowie vielleichtauch ähnlich sicher wie ein zentralisiertes System
> Voraussetzung hierfür ist das Verständnis der in verteilten Systemen auftretenden Phänomene, der resultierenden Probleme und die Kenntnis möglicher Lösungsansätze für diese
> Gegenstand der Vorlesung sind adäquate Modelle sowie Konzepte und Algorithmen, die zum Verständnis und zur Beherrschung der in verteilten Systemen auftretenden Phänomene beitragen

Beispiele für konzeptionelle Probleme in Verteilten Systemen

VS / Motivation und EinführungG. Mühl 17
Konzeptionelle Probleme in VS
> Verteilte Einigung (Konsens)> Uhrensynchronisation> Detektieren und Auflösen oder Verhindern von Verklemmungen> Kausalitätstreue Beobachtungen> Geheimnisvereinbarung und vertrauliche Datenübertragung
über unsichere Kanäle> Schnappschussproblem> Erkennen der globalen Terminierung> Verteilte Speicherbereinigung> Wechselseitiger Ausschluss> Konsistenzzusicherung bei replizierten Daten> …
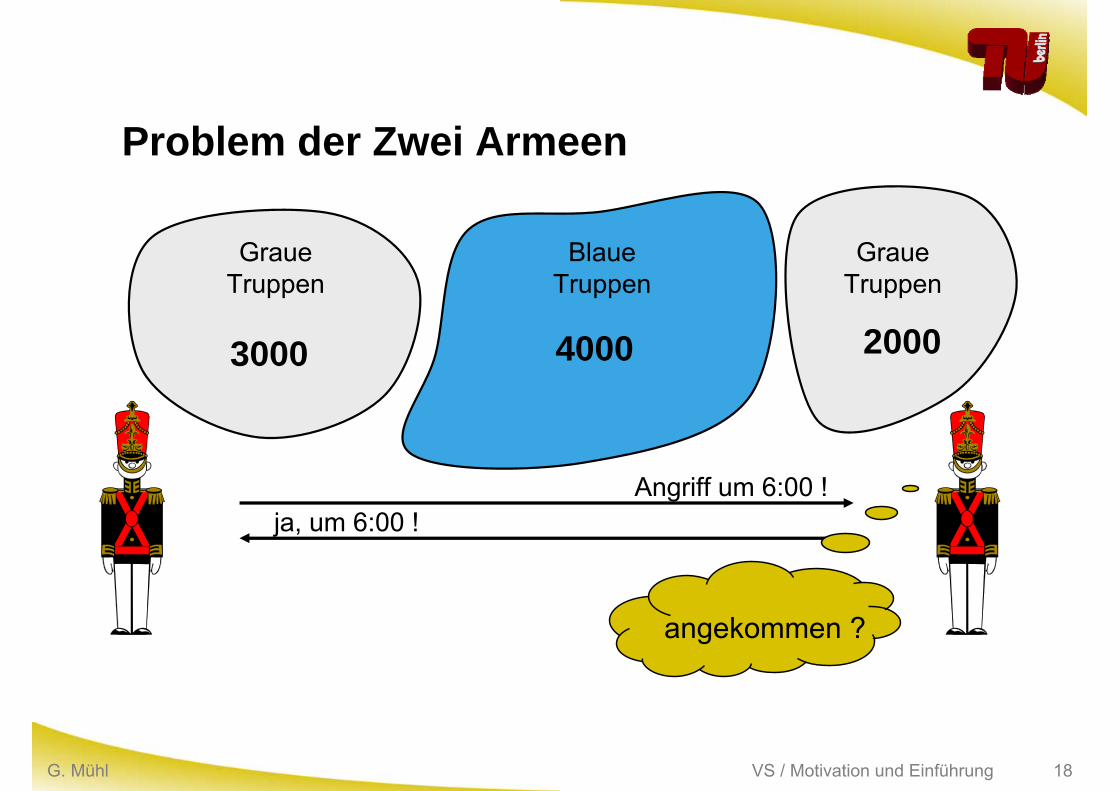
VS / Motivation und EinführungG. Mühl 18
Problem der Zwei Armeen
3000 20004000
Angriff um 6:00 !ja, um 6:00 !
angekommen ?
GraueTruppen
GraueTruppen
BlaueTruppen

VS / Motivation und EinführungG. Mühl 19
Verteiltes make
Rechner, auf dem der Übersetzer läuft
Rechner, auf dem der Editor läuft
104 105 106 107 108 109 110
104 105 106 107 108102 103
Zeit gemäßlokaler Uhr
Zeit gemäßlokaler Uhr
Datei test.class erzeugt
Datei test.java erzeugt
Reale Zeit

VS / Motivation und EinführungG. Mühl 20
Phantom-Deadlocks
B
A
C
t = 1, beobachte B⇒ B wartet auf A
B
A
C
B
A
C
t = 2, beobachte C⇒ C wartet auf B
t = 3, beobachte A⇒ A wartet auf C
B
A
C
Falscher Schluss:zyklischer Wartegraph Verklemmung

VS / Motivation und EinführungG. Mühl 21
Kausal inkonsistente Beobachtungen> Problem: Falsche Schlussfolgerung des Beobachters durch
kausal inkonsistente Beobachtung> Eine unbegründete Pumpenaktivität erhöhte den Druck bis zum
Bersten der Pipeline; daraufhin trat das Öl aus dem Leck aus, was durch den Druckverlust angezeigt wird!
Pumpe Druck-Messer
Leck
Pumpe
Druckmesser
Beobachter
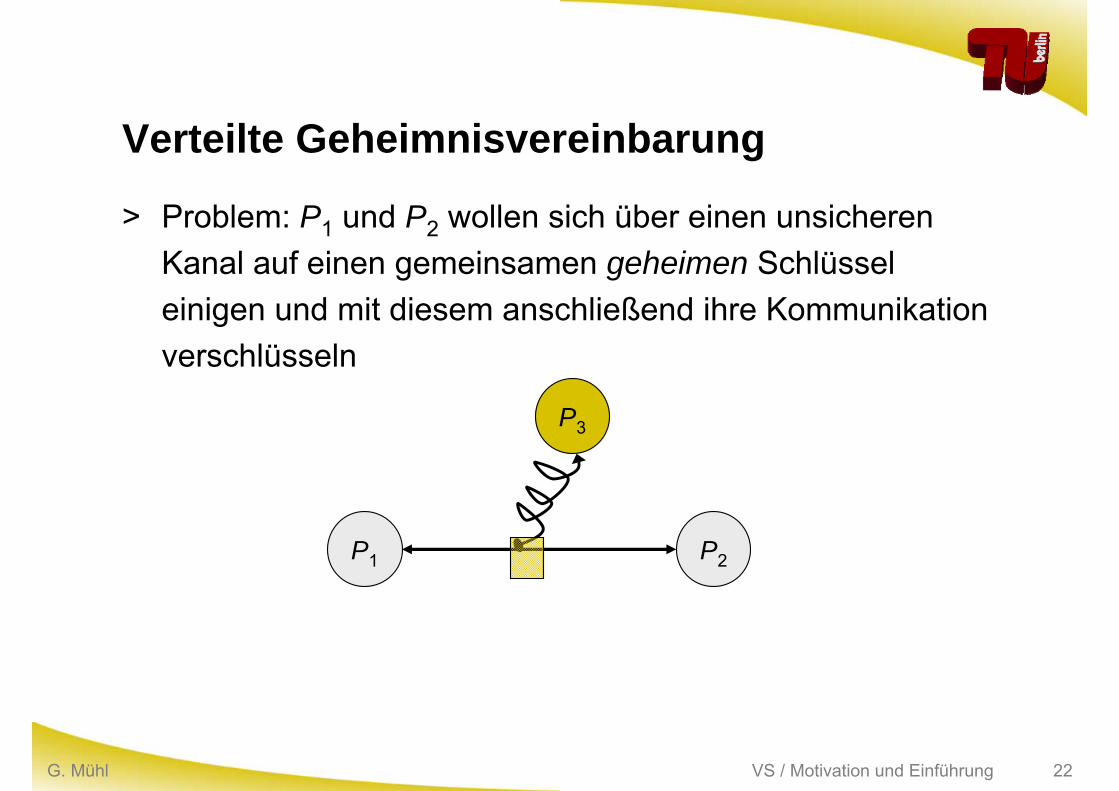
VS / Motivation und EinführungG. Mühl 22
Verteilte Geheimnisvereinbarung
> Problem: P1 und P2 wollen sich über einen unsicheren Kanal auf einen gemeinsamen geheimen Schlüssel einigen und mit diesem anschließend ihre Kommunikation verschlüsseln
P1 P2
P3

Grundlegende Modelle für verteilte Systeme

VS / Motivation und EinführungG. Mühl 24
Verteiltes System – Eine abstrakte Sicht
> Ein verteiltes System ist ein zusammenhängender Graph, bestehend aus einer Menge von Knoten und Kanten> Knoten werden oft auch als Prozesse, Rechner etc. bezeichnet> Kanten werden oft auch als Links, Kanäle etc. bezeichnet
> Die Knoten können über die Kanäle Nachrichten mit ihren jeweiligen direkten Nachbarn austauschen
> Mittels Routing können auch beliebige Knoten kommunizieren

VS / Motivation und EinführungG. Mühl 25
Netzwerk-Topologien
> Topologie ist ein ungerichteter Graph G = (V, E)> Knotenmenge V = {v0,…,vn-1}> Kantenmenge E = {e0, …, em-1}, ei = (vi_1,vi_2)
> Statische vs. dynamische Topologie> Statische: Knoten- und Kantenmenge ändern sich nicht> Dynamische: Knoten- und Kantenmenge können sich mit
der Zeit ändern
Default für die Vorlesung

VS / Motivation und EinführungG. Mühl 26
Spezielle Topologien
> Ring> Anzahl Knoten = Anzahl Kanten (n = m) > E = {(vi, vj) | j = (i + 1) mod n}> Knotengrad (Nachbarn pro Knoten): 2> Knotengrad konstant bei Skalierung> Durchmesser (längster kürzester Pfad) ⌊n / 2⌋
> Baum> Zusammenhängender Graph
ohne Zyklen> m = n - 1

VS / Motivation und EinführungG. Mühl 27
Spezielle Topologien
> Stern> Spezieller Baum mit zentralem Knoten v0
> E = {(v0, vi) | i ≠ 0}> Nachbarn pro Knoten: 1 bzw. n – 1> Durchmesser 2> Nicht (unbegrenzt) skalierbar
> Vollständiger Graph> m = n (n – 1) / 2> E = {(ei_1, ei_2 | i_1 < i_2)> Nachbarn pro Knoten: n – 1> Durchmesser 1> Nicht (unbegrenzt) skalierbar

VS / Motivation und EinführungG. Mühl 28
Gitterstrukturen
> Eigenschaften> Konstanter Knotengrad bei Skalierung> Erweiterbarkeit in kleinen Inkrementen> Gute Unterstützung von Algorithmen mit lokaler
Kommunikationsstruktur (Modellierung physikalischer Prozesse)
4x4-Gitter 4x4-Torus

VS / Motivation und EinführungG. Mühl 29
Vollständige Bäume
> Eigenschaften vollständiger k-närer Baum bzw. X-Baum> h = ⌊logk n⌋ (Logarithmischer Höhe)> Erweiterbar in Potenzen von k> Konstanter Knotengrad bei Skalierung> Knotengrad maximal k + 1 (bzw. maximal k + 3)
Binärbaum Binärer X-Baum

VS / Motivation und EinführungG. Mühl 30
Hyperwürfel
> Hyperwürfel (engl.: Hypercube) = Würfel der Dimension d> Rekursives Konstruktionsprinzip
> Hyperwürfel der Dimension 0: Einzelner Knoten> Hyperwürfel der Dimension d + 1: „Nimm zwei Würfel der
Dimension d und verbinde die korrespondierenden Ecken“
0 1 2 3 4

VS / Motivation und EinführungG. Mühl 31
Eigenschaften von Hyperwürfeln
> Anzahl der Knoten n = 2d
> Anzahl der Kanten m = d 2d−1 Ordnung O(n log n)> Maximale kürzeste Weglänge zwischen zwei Knoten
(tritt auf bei diagonal gegenüberliegende Ecken)d = log n Ordnung O(log n)
> Viele Wegealternativen Fehlertoleranz> Knotengrad = d (nicht konstant bei Skalierung!)> Mittlere Weglänge = d / 2> Einfaches Routing von einzelnen Nachrichten
> XOR von Sende- und Zieladresse (je ein Bitvektor mit d Bits)> Dimensionen, in deren Bits Einsen im Ergebnis stehen
nacheinander abarbeiten. Ist die Reihenfolge hierbei egal?
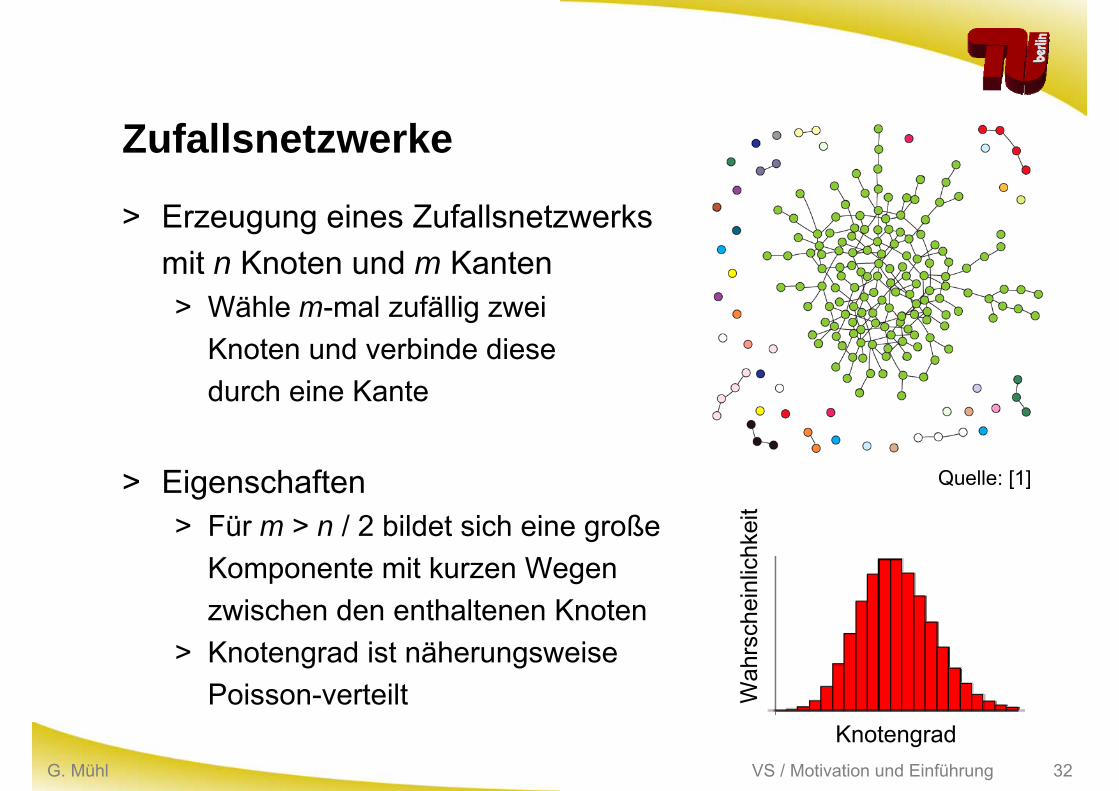
VS / Motivation und EinführungG. Mühl 32
Zufallsnetzwerke
> Erzeugung eines Zufallsnetzwerks mit n Knoten und m Kanten> Wähle m-mal zufällig zwei
Knoten und verbinde diese durch eine Kante
> Eigenschaften> Für m > n / 2 bildet sich eine große
Komponente mit kurzen Wegen zwischen den enthaltenen Knoten
> Knotengrad ist näherungsweise Poisson-verteilt
KnotengradW
ahrs
chei
nlic
hkei
t
Quelle: [1]

VS / Motivation und EinführungG. Mühl 33
Small World-Netzwerke
> Eigenschaften> Hoher Clustering-Koeffizient> Kurze Wege
> Erzeugung nach Watts und Strogatz [2]> Ausgangspunkt ist ein Ring, in welchem
jeder Knoten mit seinen k nächsten Knoten verbunden ist
> Wähle für jede Kante mit Wahrscheinlichkeit p einen neuen, zufälligen Knoten
> Hier: Mittlerer Knotengrad k
Small World
regelmäßig(p = 0)
zufällig(p = 1)

VS / Motivation und EinführungG. Mühl 34
Skalenfreie Topologien
> Eigenschaften zusätzlich zu denen der Small World-Topologien> Verteilung der Anzahl der
Nachbarn folgt P(k) ∼ k -γ⇒ Viele Knoten mit wenigen
Nachbarn⇒ Wenige Knoten (Hubs) mit
vielen Nachbarn> Nah an vielen realen
Netzwerken (z.B. Internet, WWW, soziale Netzwerke) Quelle: [1]
Eingangsgrad der Web-Seiten des WWWs
Quelle: [1]

VS / Motivation und EinführungG. Mühl 35
Skalenfreie Topologien
> Erzeugung durch Preferential Attachment> Start mit einer kleinen Anzahl von Knoten m0
> In jedem Schritt wird ein Knoten hinzugefügt und mit m ≤ m0 anderen Knoten verbunden
> Hierbei wird ein Knoten i mit Grad ki mit der Wahrscheinlichkeit P(ki) = ki / ∑j kj gewählt
> „Die Reichen werden reicher“> Für eine mit diesen Regeln erzeugte Topologie gilt: γ = 3

VS / Motivation und EinführungG. Mühl 36
Kanaleigenschaften (aus Sicht der Prozesse)
> Zuverlässigkeit> Zuverlässig: Jede gesendete Nachricht kommt
genau einmal und unverändert an> Unzuverlässig: Es können Fehler auftreten
> Verlust: Gesendete Nachricht wird nicht empfangen> Duplizierung: Gesendete Nachricht wird mehrfach
empfangen> Verfälschung: Gesendete Nachricht wird verfälscht
empfangen> Hinzufügen: Nicht gesendete Nachricht wird empfangen
> Ordnung> Ungeordnet: Nachrichten können sich überholen> FIFO: Nachrichten können sich nicht überholen
Default für die Vorlesung

VS / Motivation und EinführungG. Mühl 37
Kanaleigenschaften (aus Sicht der Prozesse)
> Kapazität> Unbeschränkt: Beliebig viele Nachrichten im Kanal möglich> Beschränkt: Maximal n Nachrichten gleichzeitig im Kanal
> Bei Überlauf entweder Verwerfen von Nachrichten oder Blockieren bis wieder Platz im Kanal ist
> Richtung> Bidirektional: Senden und Empfangen in beide
Richtungen möglich> Unidirektional: Senden und Empfangen nur in eine
Richtung
Default für die Vorlesung

VS / Motivation und EinführungG. Mühl 38
Kanaleigenschaften (aus Sicht der Prozesse)
> Synchron vs. Asynchron> Asynchron: Das Senden einer Nachricht ist nicht
blockierend> Synchron: Das Senden einer Nachricht ist blockierend
> Der Sender wird blockiert, bis der Empfänger die Nachricht abgenommen hat; Implementierung durch implizite Bestätigung
Default für die Vorlesung
Asynchron Synchron

VS / Motivation und EinführungG. Mühl 39
Verteilter Algorithmus
> Läuft auf den Knoten des Systems in Form von Prozessen> Wir betrachten nur einen Prozess pro Knoten; daher verwenden
wir beide Begriffe oft synonym> Auf verschiedenen Knoten können unterschiedliche Teile des
Algorithmus ablaufen> Die Knoten kommunizieren, indem sie Nachrichten über Kanäle
austauschen

VS / Motivation und EinführungG. Mühl 40
Zustand eines Verteilen Algorithmus
> Jeder Knoten hat einen lokalen Zustand; dieser besteht aus den lokalen Variablen des Algorithmus
> Der Zustand eines Kanals besteht aus den in ihm befindlichen Nachrichten
> Der Zustand eines verteilten Algorithmus besteht aus > den Zuständen der Knoten und > den Zuständen der Kanäle

VS / Motivation und EinführungG. Mühl 41
Verarbeitungsmodell> Berechnungen werden von außen
angestoßen> Initiale Aktion wird beim Start des
Algorithmus zuerst ausgeführt> Danach wartet jeder Prozess passiv
auf den Eingang einer Nachricht> Geht eine Nachricht ein, so wird eine
entsprechende atomare Aktion ausgeführt
> Zwischenzeitlich eintreffende Nachrichten werden gepuffert
> Eine Aktion kann den lokalen Zustand des Prozesses verändern und Nachrichten an andere Prozesse aussenden
passiv
aktiv
Nachrichtempfangen
Aktionausgeführt
Prozess
P1:{Init}
SEND(Ping) TO P2;
P2:{RECEIVE (Ping) from P1}
SEND(Pong) TO P1;

VS / Motivation und EinführungG. Mühl 42
Synchrones Systemmodell
> Die maximale Dauer von Aktionen und die maximale Laufzeit von Nachrichten sind beschränkt und bekannt> Beispiel: Aktionen brauchen keine Zeit, Nachrichten exakt
eine Zeiteinheit. Dann können verteilte Algorithmen in synchronisierten Runden ablaufen
> Im synchronen Modell können Entscheidungen aufgrund des Ablaufs der Zeit getroffen werden können> Beispiel: Wird eine erwartete Nachricht nicht innerhalb der
maximalen Laufzeit empfangen, kann sicher auf einen Fehler (Knotenausfall, Nachrichtenverlust etc.) geschlossen werden

VS / Motivation und EinführungG. Mühl 43
Asynchrones Systemmodell> Aktionen und Nachrichten können beliebig lange dauern bzw.
verzögert werden oder die Schranken sind nicht bekannt
> Aus dem zeitlichen Ablauf (z.B. Timeouts) können keine (sicheren) Informationen gewonnen werden> Beispiel: Wird eine Nachricht nicht vor einem Timeout empfangen,
so gibt es dafür mehrere mögliche Ursachen1. Die Nachrichtlaufzeit ist länger als gewöhnlich2. Die Nachricht ist verloren gegangen3. Der sendende Prozess hat die Nachricht später als normal
abgeschickt4. Der sendende Prozess ist abgestürzt, bevor er die Nachricht
senden konnte

VS / Motivation und EinführungG. Mühl 44
Synchrones vs. Asynchrones Systemmodell
> Algorithmen für Probleme in synchronen Systemen> Oft existieren einfache Algorithmen, diese sind aber meist
nicht direkt oder nur eingeschränkt einsetzbar, da sie unrealistische Annahmen machen
> Algorithmen für Probleme in asynchronen Systemen> Für viele Probleme existieren keine Algorithmen> Wenn sie existieren, sind sie oft komplex und ineffizient> Wenn für ein Problem aber ein Algorithmus existiert, so ist
dieser meist gut einsetzbar

VS / Motivation und EinführungG. Mühl 45
Atommodell> Ist ein teilsynchrones Modell> Unterschied zum asynchronen Modell: Aktionen sind zeitlos> Empfängt ein Prozess eine Nachricht, ändert sich sein lokaler
Zustand entsprechend der Aktion und er kann instantan Nachrichten aussenden
> Zeit-Raum-Diagramm: Graphische Darstellung von (lokalen Ereignisse und) Interaktionen aller Prozessoren
P1
P2
P3
Default für die Vorlesung

VS / Motivation und EinführungG. Mühl 46
Beispiel: Verteilter Maximum-Algorithmus
> Eine Gruppe Philosophen sitzt an einem runden Tisch und will den ältesten unter ihnen bestimmen
> Jeder Philosoph kann aber nur mit seinen beiden Nachbarn kommunizieren
102
72 114
60
84 96

VS / Motivation und EinführungG. Mühl 47
Beispiel: Verteilter Maximum-Algorithmus{INIT}: // wird von jedem Philosophen initial ausgeführt
meinMax := <eigenes Alter>;SEND(<linker Nachbar>, meinMax);SEND(<rechter Nachbar>, meinMax);
{RECEIVE (<linker Nachbar>, nachbarMax)}IF (nachbarMax > meinMax) THEN
meinMax := nachbarMax;SEND(<rechter Nachbar>, meinMax);
ENDIF
{RECEIVE (<rechter Nachbar, nachbarMax)}IF (nachbarMax > meinMax) THEN
meinMax := nachbarMax;SEND(<linker Nachbar>, meinMax);
ENDIF
AtomareAktionen

VS / Motivation und EinführungG. Mühl 48
Beispiel: Verteilter Maximum-Algorithmus
> Aufgrund unterschiedlicher Nachrichtenlaufzeiten können verschiedene Abläufe auftreten
102 114
72
114
60
96
84
114
114
114
11496 102
Terminierung
tempus fugit

VS / Motivation und EinführungG. Mühl 49
Beispiel: Verteilter Maximum-Algorithmus
> Gibt es mehrere mögliche Abläufe zu einer Eingabe?> Führt jeder Ablauf zum korrekten Ergebnis (hier 114)?> Wie viele Nachrichten werden minimal gebraucht und
wann tritt dieser Fall ein?> Wie viele Nachrichten werden maximal oder
durchschnittlich gebraucht? Wovon hängt das ab?> Woher sollen die Philosophen wissen, dass sie den
Algorithmus starten sollen?> Reicht es aus, wenn ein beliebiger Philosoph den
Algorithmus startet?

VS / Motivation und EinführungG. Mühl 50
Beispiel: Verteilter Maximum-Algorithmus
> Terminiert der Algorithmus immer?> Wie lange dauert es minimal, maximal oder
durchschnittlich, bis der Algorithmus terminiert?> Woran erkennt ein einzelner Philosoph die Terminierung?> Was passiert, wenn mehrere Philosophen das gleiche
Alter haben?

VS / Motivation und EinführungG. Mühl 51
Eigenschaften von Algorithmen
> Deterministisch vs. Nichtdeterministisch> Deterministisch: Stets gleicher Ablauf bei gleicher Eingabe> Nichtdeterministisch:
Verschiedene Abläufe bei gleicher Eingabe möglich
> Determiniert vs. nichtdeterminiert> Determiniert: Stets gleiches Ergebnis bei gleicher Eingabe> Nichtdeterminiert:
Unterschiedliche Ergebnisse bei gleicher Eingabe möglich

VS / Motivation und EinführungG. Mühl 52
Eigenschaften von Algorithmen
> Terminierend: Terminieren für jede Eingabe nach endlich vielen Schritten
> Partiell korrekt: Wenn sie terminieren, liefern sie immer das korrekte Ergebnis
> Total korrekt:Sind terminierend und partiell korrekt

VS / Motivation und EinführungG. Mühl 53
Eigenschaften Verteilter Algorithmen
> Sind (bis auf wenige Ausnahmen) nichtdeterministisch> Ursache sind z.B. unvorhersagbare Nachrichtenlaufzeiten
und variierende Ablaufgeschwindigkeiten> Mittels Synchronisationsmechanismen kann
Nichtdeterminismus entgegengewirkt werden, allerdings verringert dies die mögliche Parallelität
> Es gibt sowohl determinierte als auch nichtdeterminierte verteilte Algorithmen

VS / Motivation und EinführungG. Mühl 54
Erwünschte Eigenschaften Verteilter Algorithmen
> Verteilte Algorithmen sollen in der Regel total korrekt sein> Aber nicht für jedes zu lösende Problem gibt es einen total
korrekten Algorithmus; dann hilft oft ein Algorithmus mit abgeschwächten Anforderungen, z.B. bezüglich der Terminierung
> Manche Algorithmen sollen nicht terminieren (z.B. fortlaufende Uhrensynchronisation); dann wird stattdessen oft die Erfüllung anderer Bedingungen (z.B. einer Invariante) verlangt

VS / Motivation und EinführungG. Mühl 55
Zeitkomplexität Verteilter Algorithmen
> Variable Zeitkomplexität> Aktionen zeitlos> Nachrichten benötigen maximal eine Zeiteinheit
> Einheitszeitkomplexität> Aktionen zeitlos> Nachrichten benötigen genau eine Zeiteinheit
> Achtung: Es gilt nicht immer variable Zeitkomplexität ≤ Einheitszeitkomplexität> Grund: Die variable Zeitkomplexität erlaubt Abläufe, welche
die Einheitszeitkomplexität nicht gestattet

VS / Motivation und EinführungG. Mühl 56
Literatur1. S. Strogatz. Exploring complex networks. Nature, 410:268--276, 2001.2. D. Watts and S. Strogatz. Collective Dynamics of 'Small-World' Networks.
Nature, 393:440--442, 1998.





























