Embed Size (px)
Citation preview

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Vorlesung 10
Unüberwachtes Lernen II
Martin Giese

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Übersicht
DiskriminanzanalyseLernen spärlicher RepräsentationenNichtnegative MatrixfaktorisierungIndependent Component Analysis (ICA)Lernen von Mannigfaltigkeiten

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
I. Diskriminanzanalyse

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
(z.B. McLachlan & Krishnan, 1996;
Ripley, 1996)Kanonische Variaten
Bekannt auch als Fisher’s lineare Diskriminanten
Ziel: Konstruktion von Richtungen, die günstig für
Klassifikation sind ⇒ Nutzung der Klassenlabel
Gegeben: Daten xi und Zughörigkeit zu g verschiedenen
Klassen
Problem: Finden von Richtungen im Datenraum, die
– Varianz zwischen Klassen maximieren
– Varianz innerhalb der Klassen maximieren

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Kanonische Variaten
Mittelwerte innerhalb einer Klasse µi
Mittelwert aller Klassen:
Kovarianzmatrix zwischen den Klassen:
Kovarianzmatrix innerhalb einer Klasse Σ (hier als gleich
angenommen für alle Klassen)
∑=
=g
iig 1
1 µµ
Ti
g
iig
))((1
11
µµµµC −−−
= ∑=

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Kanonische Variaten
Sei n ein Richtungsvektor, dann definiert y=nTx ein
Merkmal entlang einer Richtung im Datenraum
Eine optimale Merkmalsrichtung ist gegeben durch
die Bedingung
Der Vektor n kann beliebig skaliert werden, z.B. so
dass nTΣn = 1.
nder Klasse innerhalb Varianz Klassenden zwischen Varianzsuparg* =
Σ=
≠ nnCnnn
0nT
T

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Kanonische Variaten
Optimierungsproblem:
minimiere nTCn unter der NB nTΣn = 1
Lagrange-Funktion:
Optimalitätsbedingung:
Normales Eigenvektor-Problem, falls Σ invertierbar; sonst
spezielle numerische Techniken (→ MATLAB; Golub & van Loan,
1989)
)1(),( −Σ+= nnCnnn TTL λλ
0),(=Σ+=
∂∂ nCn
nn λλL
Verallgemeinertes Eigenvektorproblem

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Kanonische Variaten
Nach Bestimmung der “besten Richtung”
Iteration: nächste dazu orthogonale Richtung
finden, usw.
Falls Σ invertierbar ist, wieder einfach die
grössten Singulärwerte nehmen

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
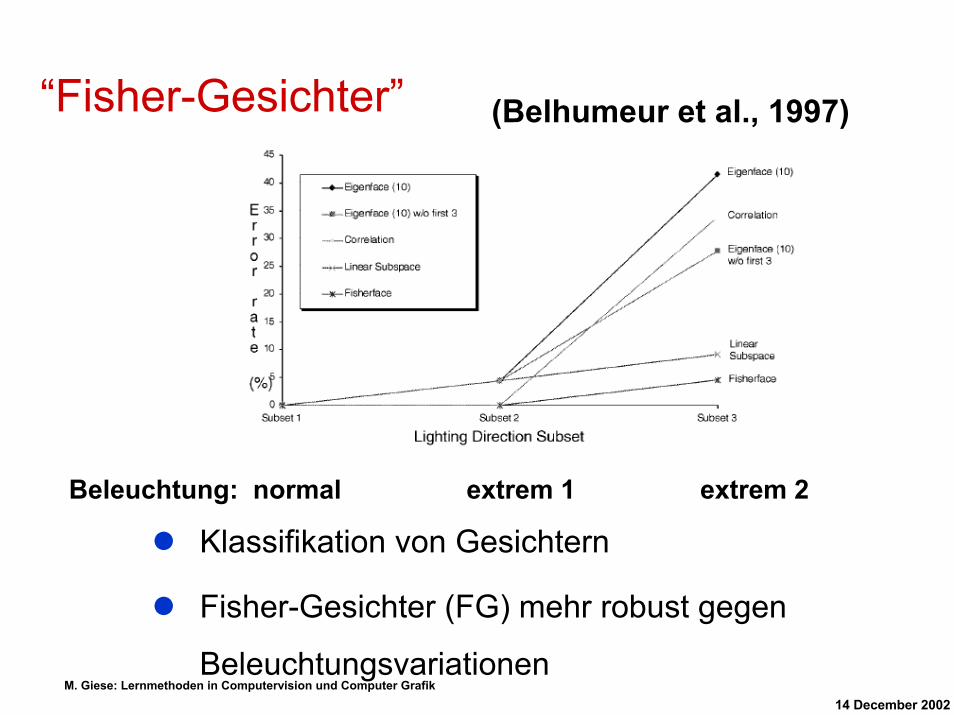
“Fisher-Gesichter” (Belhumeur et al., 1997)
Vergleich: “Eigen-Gesichter” vs. “Fisher-
Gesichter”
Yale + Harvard Gesichtsdatenbasen
Beleuchtungsvariationen, verschiedene
Gesichtsaudrücke, Verdeckungen
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
“Fisher-Gesichter” (Belhumeur et al., 1997)
Beleuchtung: normal extrem 1 extrem 2
Klassifikation von Gesichtern
Fisher-Gesichter (FG) mehr robust gegen
Beleuchtungsvariationen
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
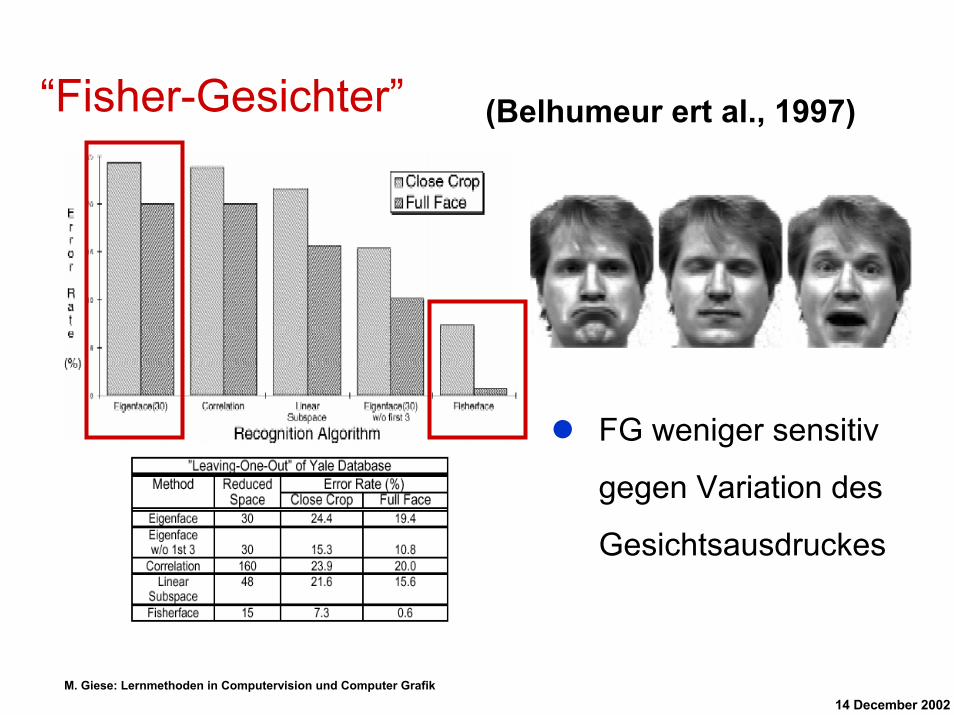
“Fisher-Gesichter” (Belhumeur ert al., 1997)
FG weniger sensitiv
gegen Variation des
Gesichtsausdruckes

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
(Belhumeur et al., 1997)“Fisher-Gesichter”Fisher-Gesicht für
Brillenträger
FG robust gegen Verdeckungen durch Brille
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
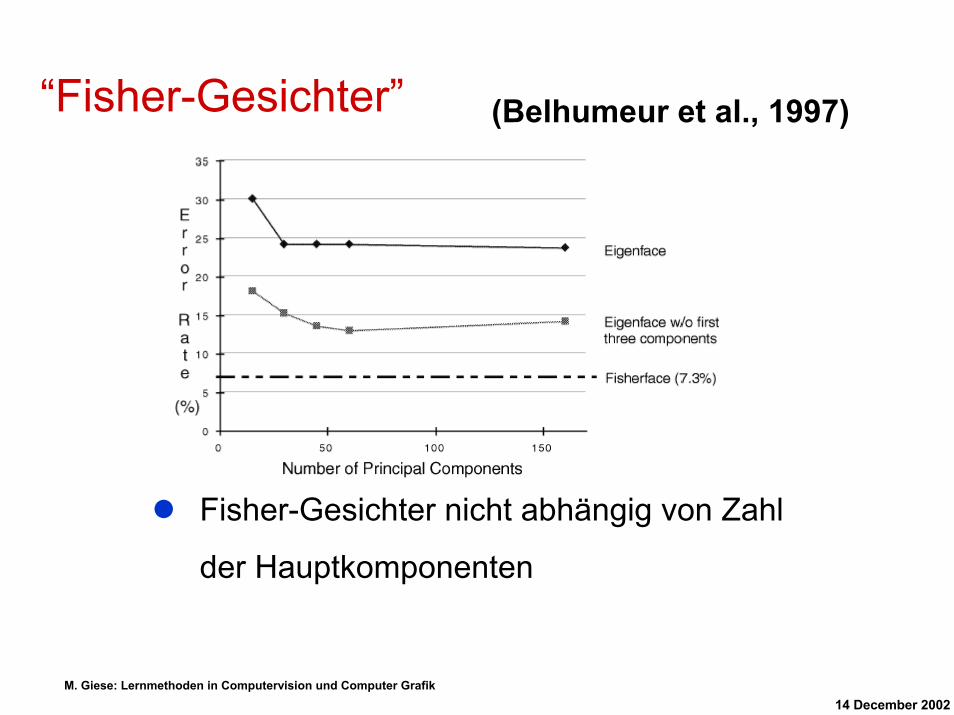
“Fisher-Gesichter” (Belhumeur et al., 1997)
Fisher-Gesichter nicht abhängig von Zahl
der Hauptkomponenten

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
II. Lernen spärlicher Repräsentationen

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Approximation durch Basisfunktionen
Ziel: Repräasentation von Bildern I(x, y) durch
Basisfunktionen gk(x, y)
Bide enspricht Linearkombination der Basisfunktionen:
Gewichte wk werden für jedes Bild neu geschätzt
Basisfindungsproblem: Bestimme die optimalen gk(x, y),
so dass Bilder im Mittel gut approximiert werden.
∑=
=K
kkk yxgwyxI
1
),(),(

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Wörterbuch (dictionary)
Bilder I(x, y) sind Zufallsvariable
Die Funktionen gk(x, y), 1 ≤ k ≤ K, definieren ein
Wörterbuch (dictionary)
Ziel: Wörter sollten vollständigen Code liefern, und einen
Code mit minimaler Redundanz
Annahme: Bilder können durch Kombination weniger
Wörter dargestellt werden (Spärlichkeit)

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Spärlichkeit
Minimale Redundanz:
– gk orthogonal und erklären maximale Varianz;
paarweise dekorrelierte Gewichte:
E{wk wl} = E{wk } E{ wl} für k ≠ l ⇒ PCA
→ nur Statistik 2. Ordnung modellierbar
– Nur wenige Gewichte wk ≠ 0 ⇒ spärliche Kodierung
→ auch Statistik höherer Ordnung modellierbar

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
LernalgorithmusSpärlichkeitsmass: Funktion S(w), die
für grosse w immer langsamer ansteigt
⇒ Lösungen mit vielen kleinen Gewichten bestraft
Minimierung des Kostenfunktionals:
λ bestimmt Trade-off zwischen Spärlichkeit und Approx.
Vgl. Regularisierung !!!
∑∫ ∑==
+−=K
kk
yx
K
kkkK wSyxyxgwyxIggL
1
2
, 11 )(),(d),(),(],...,,[ λw
Approximation Spärlichkeit
)1log()()(
2
2
wwSewS w
+=
−= −

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Lernalgorithmus
Die Bilder I(x, y) und die Gewichte wk sind Zufallsvariable
Minimierung durch stochastischen Gradientenabstieg:
1. Für jedes Bild Optimierung der Gewicht
2. Gemittelt über viele Bilder Optimierung der
Basisfunktionen

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Optimierung der Gewichte
Annahme: Bild I(x, y) konstant
Kostenfunktion kompakt geschrieben:
Zeitliche Änderung in Richtung des Abfalls von L:
mit)('21 wCwbw
w SL+−=
∂∂
−=&
∑∫
∫∫
=
++
−=
K
kk
yx
TT
yx
T
yxK
wSyxyxyx
yxyxyxIyxyxIggL
1,
,
2
,1
)(),(d),(),(
),(d),(),(2),(d),(],...,,[
wggw
gww
),(d),(),(,
yxyxyxIyx∫= gb ),(d),(),(
,
yxyxyxyx
T∫= ggC

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Optimierung nach den Basisfunktionen
Sei das rekonstruierte Bild.
Über die Bilder gemittelte Kostenfunktion:
(langsame) zeitliche Änderung in Richtung des Abfalls von
<L>:
∑∫=
+−=K
kk
yx
wSyxyxIyxIL1
2
,
)(),(d),(ˆ),(
unabhängig von g(x,y)
( )),(ˆ),(2),(
),( yxIyxIwyxg
Lyxg k
kk −−=
∂∂
−=&τ
∑=
=K
kkk yxgwyxI
1
),(ˆ),(ˆ
Zeitkonstante
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
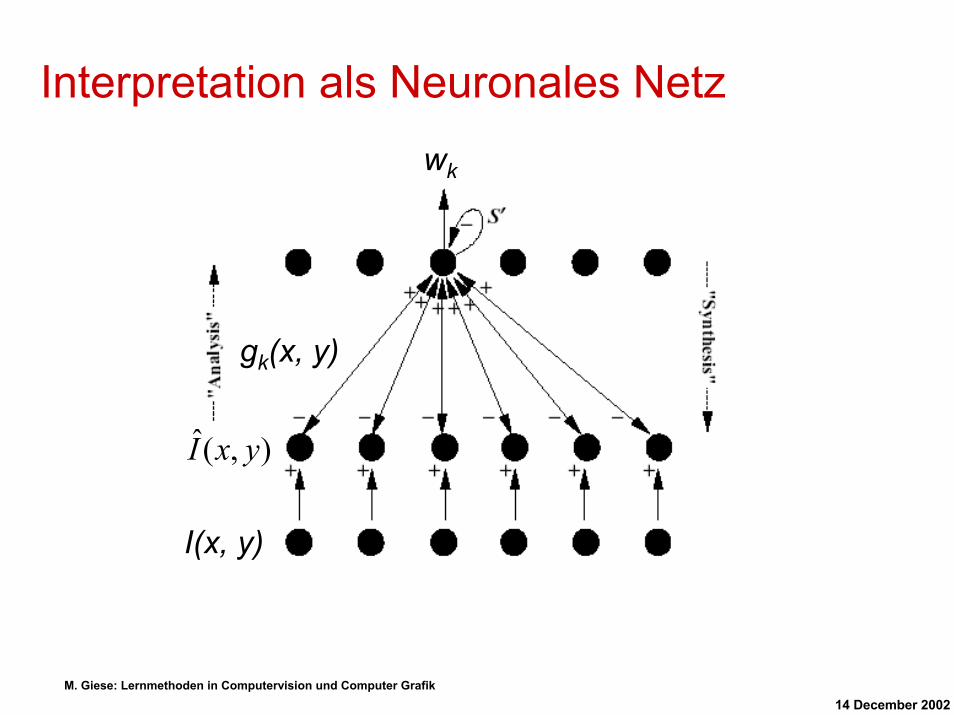
Interpretation als Neuronales Netz
I(x, y)
),(ˆ yxI
gk(x, y)
wk

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
ExperimenteNatürliche Bilder: Land-
schaftsaufnahmen 512 x 512
Pixel
Hohe Ähnlichkeit der lokalen
Bildstatistik
Vorfilterung (pre-whitening)
Unterfenster 12 x 12 Pixel
Zufällig gewählte Ausschnitte
Ca. 200.000 Trainingsbilder

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Spärliche Codierung Lokalisierte Filter (“Rezeptive
Felder”)
Veschiedene Frequenzbänder
Verschiedene Ortslokalisation
Paramter ähnlich kortikalen
Neuronen
„Simple cells“, Visueller Kortex
(Daugman, 1989)
(Olshausen & Field,1996)
),(ˆ yxgk
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
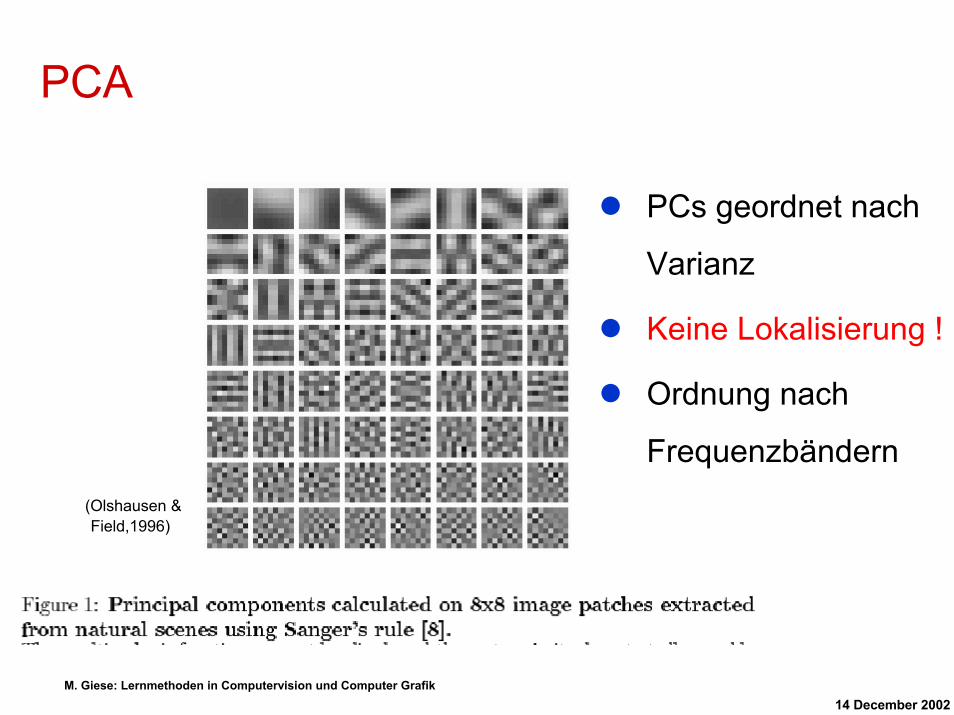
PCA
PCs geordnet nach
Varianz
Keine Lokalisierung !
Ordnung nach
Frequenzbändern(Olshausen & Field,1996)
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
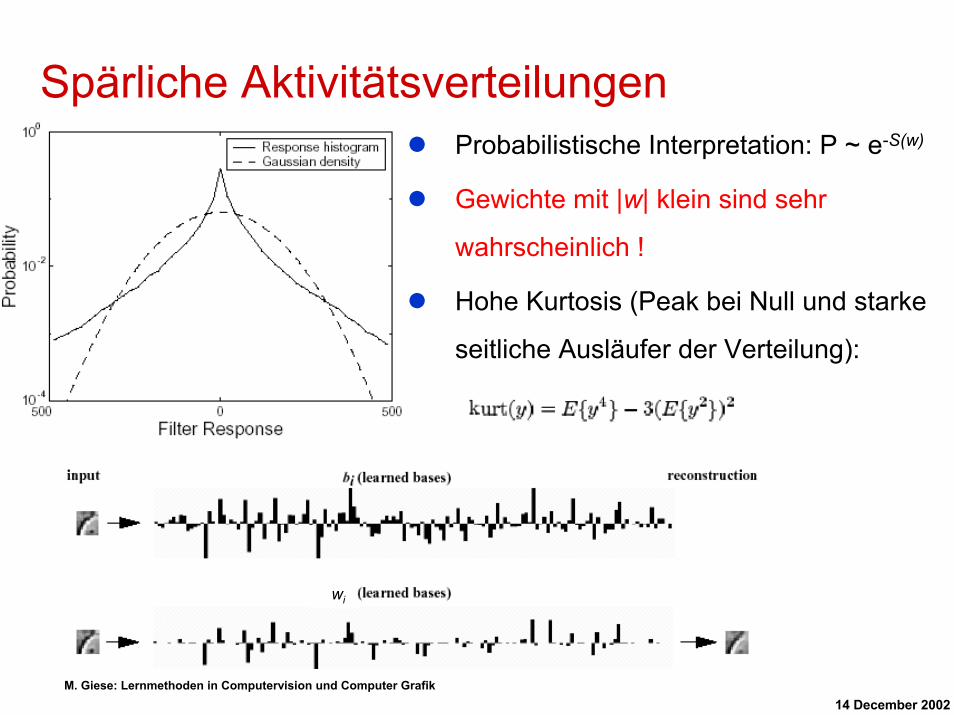
Spärliche AktivitätsverteilungenProbabilistische Interpretation: P ~ e-S(w)
Gewichte mit |w| klein sind sehr
wahrscheinlich !
Hohe Kurtosis (Peak bei Null und starke
seitliche Ausläufer der Verteilung):
wi

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
III. Nichtnegative Matrixfaktorisierung (NMF)

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Viele natürliche Objekte bestehen aus Teilen
Ziel: unüberwachtes Lernen von Teilen
Teile als “Wörterbuch” (Augen, Mund, …)
Bilder I(x, y) repräsentiert durch Basisfunktionen gk(x, y)
Einschränkung: Gewichte nie negativ: wk ≥ 0
Analog zu neuronaler Aktivität
∑=
=K
kkk yxgwyxI
1),(),(
Lernen von Objektteilen

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Matrixfaktorisierung
Gegeben: Datenmatrix X = [x1, …, xL] mit xij ≥ 0
(Helligkeitswerte positiv oder Null)
Ziel: Faktorisierung der Datenmatrix in der Form
X = U W d.h. xi = U wi
GewichteBasisbilder / Prototypen

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
MatrixfaktorisierungDurch verschiedene NB für U und W ergeben sich
verschiedene Lernverfahren:
1. wi Einheitsvektoren ⇒ Vektorquantisierung
2. Spalten von U orthonormal; Zeilen von W orthogonal
⇒ PCA
3. Alle Einträge von U und W nichtnegativ
⇒ Nichtnegative Matrixfaktorisierung
→ Keine Kompensation positiver und negativer
Terme möglich !
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
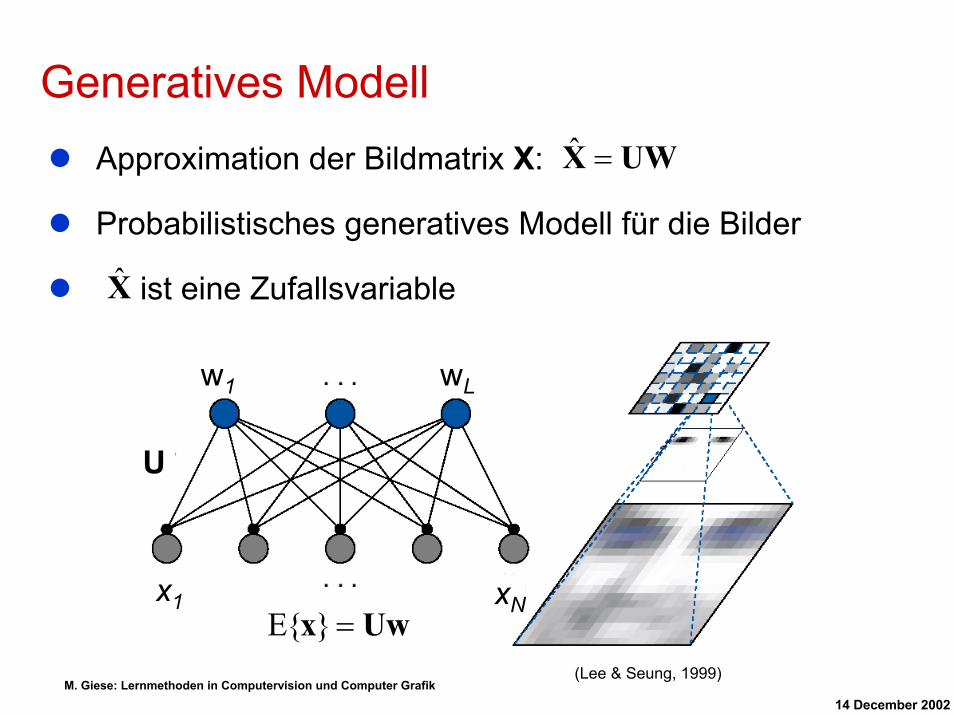
Generatives ModellApproximation der Bildmatrix X:
Probabilistisches generatives Modell für die Bilder
ist eine Zufallsvariable
UWX =ˆ
X
w1 wL
U
x1 xNUwx =}{E
(Lee & Seung, 1999)

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
KostenfunktionOptimales generatives Modell minimiert Abweichung
zwischen X und
Divergenz (unsymmetrische Distanz) zwischen X und :
Entspricht Kullback-Leibler-Divergenz falls
(Verteilung)
Minimierung unter den Nebenbedingungen uij , wij ≥ 0
Annahme poissonverteiltX
∑
+−=
nmmnmn
mn
mnmn xx
xxxD
,
ˆˆ
log)ˆ,( XX
X
1ˆ,,
== ∑∑nm
mnnm
mn xx
X

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
LernalgorithmusIteration mit multiplikativen Updates
Abwechselnd U und W optimiert
Zusätzlicher Normalisierungschritt (sonst unterbestimmt)
Konvergenz kann bewiesen werden ( nimmt
immer ab, es sei denn lokales Minimum erreicht.)
∑←q mq
mqnqmnmn
xwuu
)(UW
∑←q qn
qnqmmnmn
xuww
)(UW
∑←q
qm
mnuu
mnu
)ˆ,( XXD
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
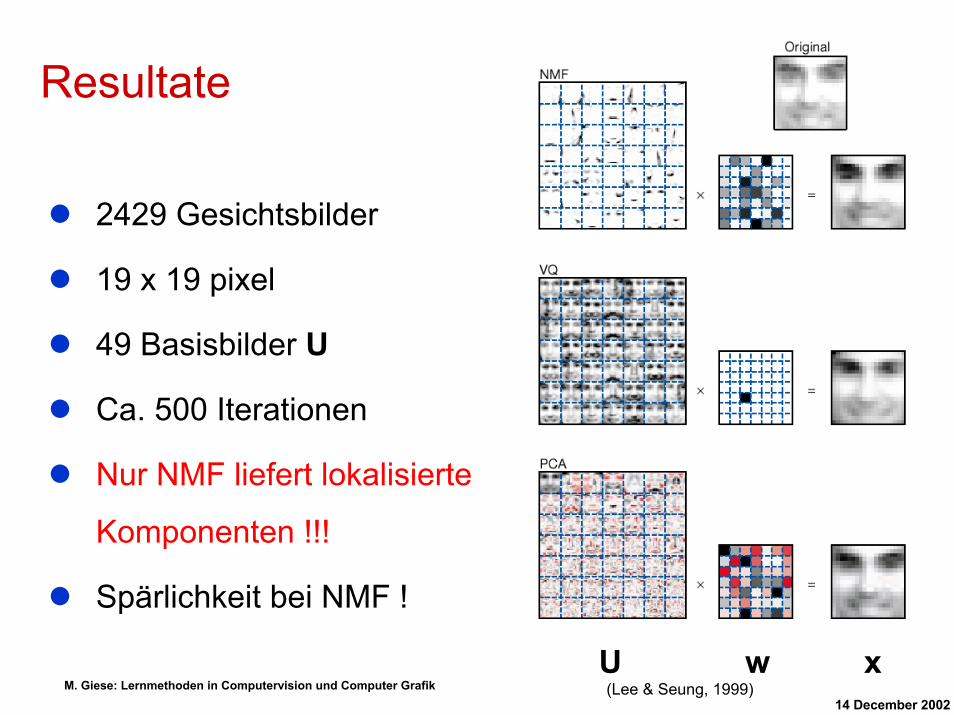
Resultate
2429 Gesichtsbilder
19 x 19 pixel
49 Basisbilder U
Ca. 500 Iterationen
Nur NMF liefert lokalisierte
Komponenten !!!
Spärlichkeit bei NMF !
U w(Lee & Seung, 1999)
x
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
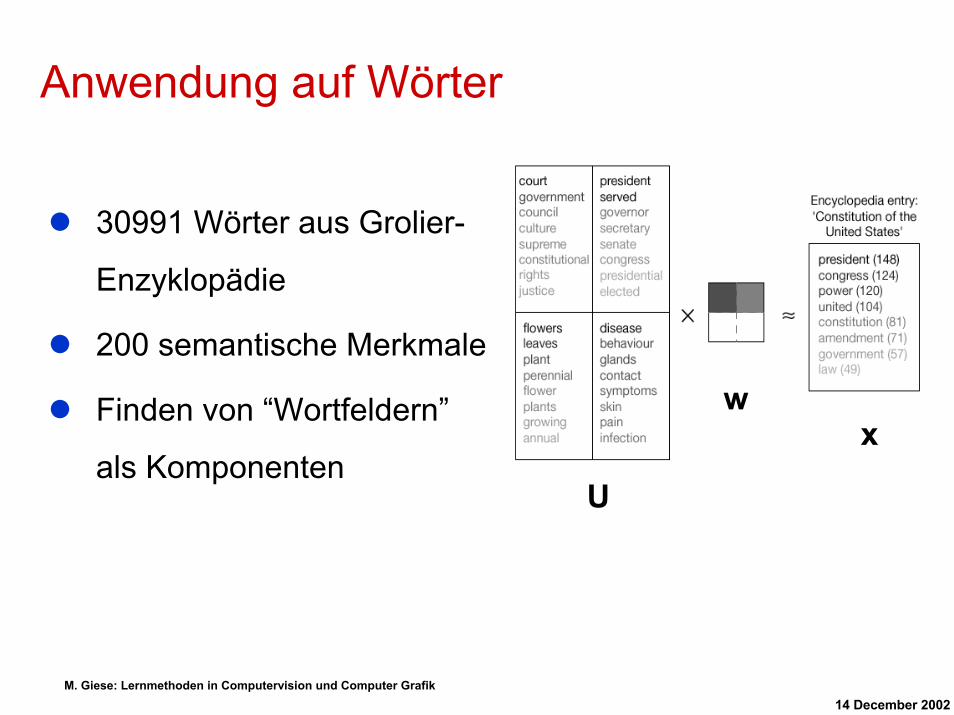
Anwendung auf Wörter
U
wx
30991 Wörter aus Grolier-
Enzyklopädie
200 semantische Merkmale
Finden von “Wortfeldern”
als Komponenten

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
IV. Independent Component Analysis (ICA)

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Problembeschreibung
Generatives Modell: Datenvektoren ergeben sich durch
lineare Überlagerung von Quellensignalen zk:
Annahme: Quellensignale zk statistisch unabhängig, d.h.
Gesucht: Quellensignale z und Mischmatrix W
Wzwx == ∑=
K
kkk z
1
)()()()( 21 Kzpzpzpp ⋅⋅⋅⋅=z
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
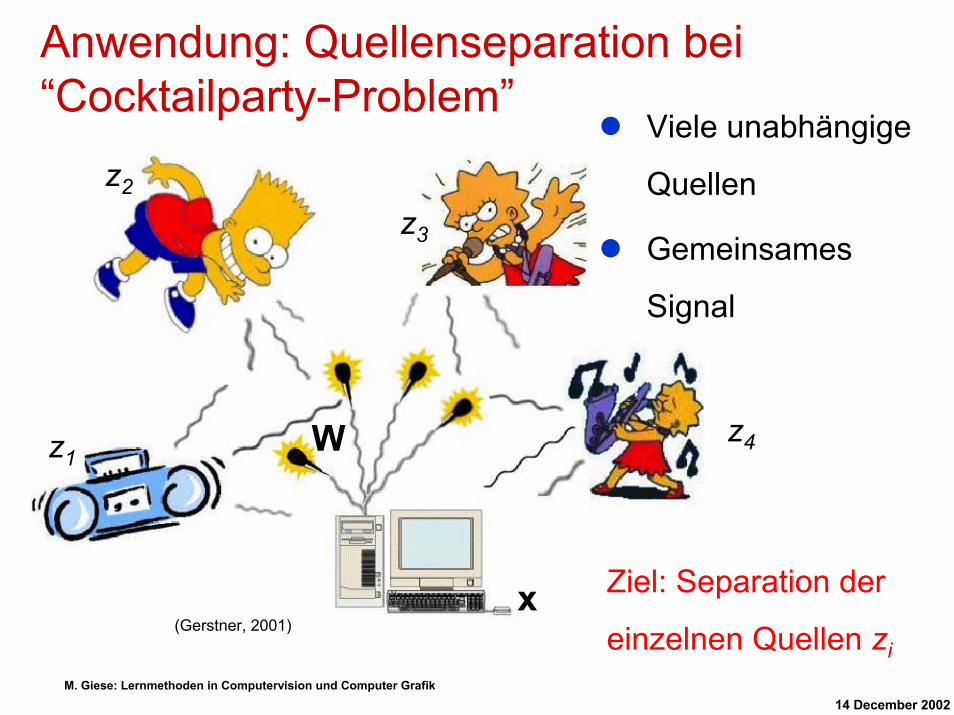
Anwendung: Quellenseparation bei “Cocktailparty-Problem”
Viele unabhängige
Quellen
Gemeinsames
Signal
Ziel: Separation der
einzelnen Quellen zi
z1
z2
z3
z4W
x(Gerstner, 2001)
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
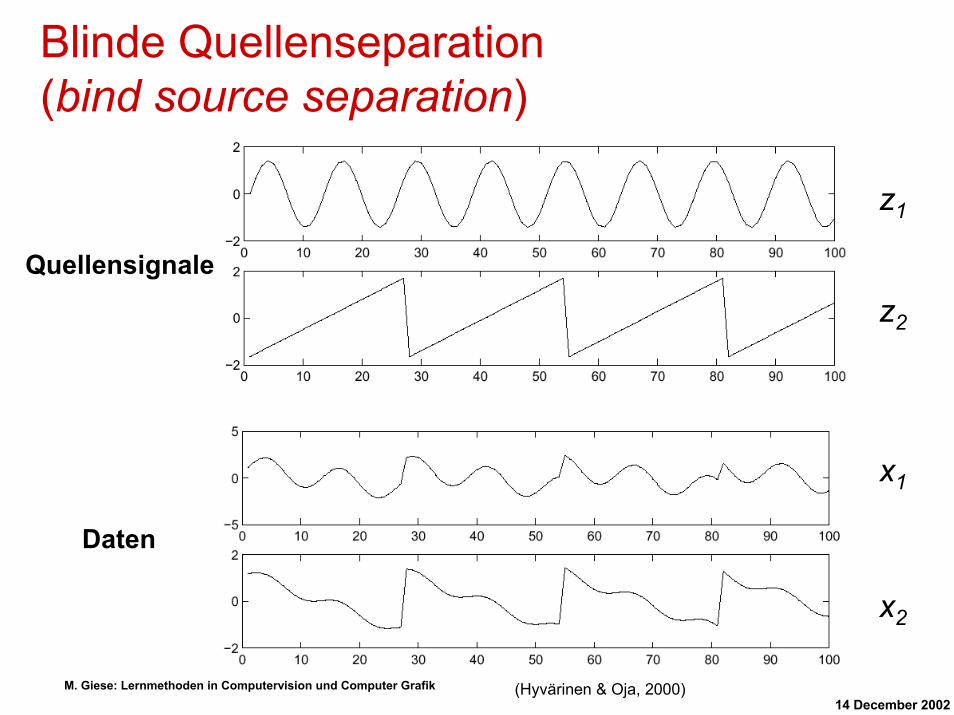
Blinde Quellenseparation (bind source separation)
(Hyvärinen & Oja, 2000)
z1
z2
x2
x1
Quellensignale
Daten
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
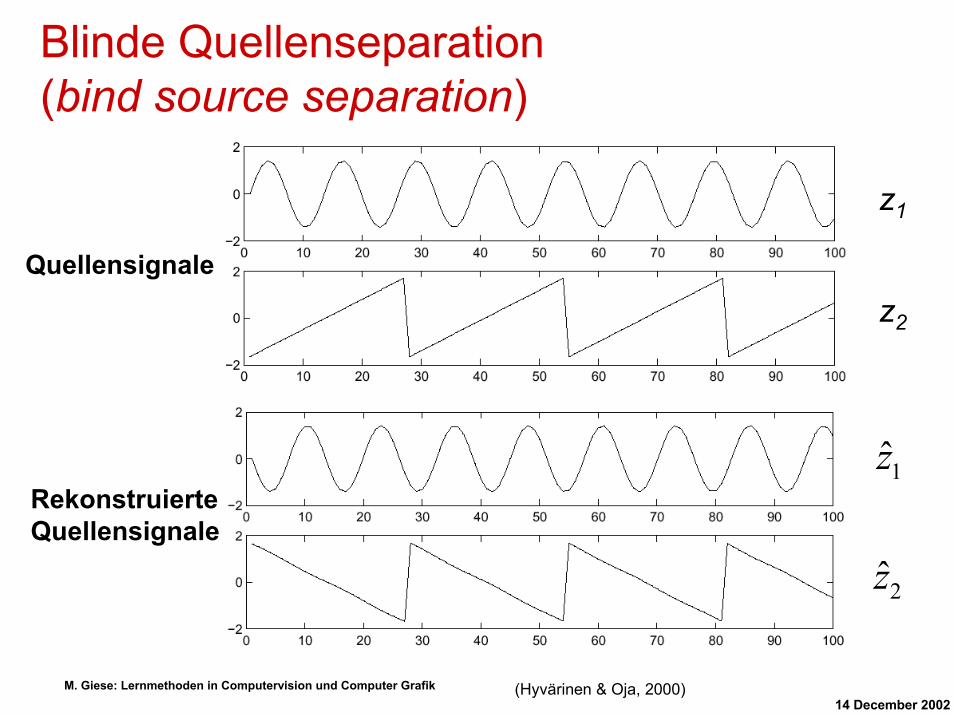
Blinde Quellenseparation (bind source separation)
z1
Quellensignale
z2
Rekonstruierte Quellensignale
1z
2z
(Hyvärinen & Oja, 2000)

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Schätzung der Mischmatrix
Wenn die Mischmatrix W invertierbar ist gilt mit V = W-1
d.h. die Quellen sind ein lineare Transformation der
Signale
Die Mischmatrix V muss geschätzt werden.
Wegen x = Wz ergeben sich folgende Mehrdeutigkeiten:
– Skalierung der zi unbestimmt.
– Die zi können beliebig permutiert werden.
xWVxz 1−==

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Gaussche VerteilungenAnnahme: Daten (durch Abziehen des Mittelwertes und
Skalierung) vorher so transformiert dass sie unkorreliert
sind und Varianz 1 in alle Richtungen haben.
Für zwei Dimensionen folgt:
Vollständige Symmetrie ⇒
keinerlei Information über die Dimensionen zi
⇒ ICA Problem nicht eindeutig lösbar für gausssche
unabhängige Komponenten

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
ICA AlgorithmenIdee: Maximierung der Information über Quellenvariablen
duch Schätzung maximal nicht-gaussscher Variablen zi
Maximierung von Massen für die Unabhängigkeit der zi
Entropie: Information die durch Beobachtung einer
Variablen z erhalten wird:
Maximal falls z gaussverteilt
(Hinweis: Berechnen Sie )
∫−== zzzzz d)(log()()]([)( pppHH
0)()]([
0
≡zz
ppH
δδ

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
ICA AlgorithmenNegentropie: Abweichung von der maximalen Entropie
(zG sei eine gaussche Zufallsvariable mit gleicher
Kovarianzmatrix wie z):
Gemeinsame Information (mutual information):
Differenz der Information, die durch Vektor z und die
einzelnen Komponenten zk übertragen wird:
)()(),...,(1
1 zHzHzzIK
kkK ∑
=
−=
)()()( zzz HHJ G −=

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
ICA AlgorithmenFalls V nichtsingulär ist, gilt wegen z = V x für kleines
Volumen im Wahrscheinlichkeitsraum
mit und |V| = det(V).
Daraus folgt:
1||)()(d)(d||)(d)(d)(
−=⇒
====
VxVxxxxVVxzVxzz
xz
xzzz
pp
ppppdp
Vxz
=∂∂
|)log(|)(|)log(|d)()(log(
d)(|)log(|d)())(log(
d)())(log(d)())(log()(
VxVxxx
zzVzzx
zzVxzzzz
xx
zzx
zzzz
+=+−=
+−=
−=−=
∫∫∫
∫∫
Hpp
ppp
ppppH

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
ICA AlgorithmenEs sei angenommen, dass die Quellenvariablen z
normiert und unkorreliert sind. ⇒ E{zzT} = I ⇒|E{zzT} | = |I| = 1 = | V E{xxT} VT | = |V|2 |E{xxT}|,
d.h. |V| ist konstant bzw. unabhängig von z.
Folgerung:
d.h. der Minimierung der gemeinsamen Information
enspricht eine Maximierung der Negentropie der
einzelnen zk
)const()(),...,(1
1 x+−= ∑=
K
kkK zJzzI

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
ICA Algorithmen
Verschiedene Methoden zur Schätzung von V, z.B.
Maximum-Likelihood (z.B. Pham et al, 1992)
Schneller Algorithmus (“fast ICA”) basierend auf
Approximation der Negentropie (Hyvärinen, 1999):
wobei ξ eine normalverteilte Zufallsvariable mit µ = 0 und
σ = 1 ist. F(z) ist eine sigmoidale oder exponentielle
nichtlineare Funktion.
2)}]({)}({[)( ξFEzFEzJ −∝

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
x2
x1
Daten
z1
z2Quellenvariablen
Einfaches BeispielGleichverteilte
unabhängige
Quellenvariblen z1,2
Bei PCA Vektoren zi
orthogonal
Bei ICA ist Verteilung
Produkt der Marginal-
verteilungen
(Gerstner, 2001)
z1
z2
1z
2z
2z
1z
w1
w2
Hauptkomponenten(PCs)
Gewichtsvektoren der ICA
Rek. Quellenvar.
Daten im KS der PCs

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Lernen natürlicher Bilder
Natürliche Bilder (Bäume, Blätter,
usw.)
Fenster mit 12 x 12 Pixeln
17.595 Traingsbilder
144 Filter gelernt
Lokalisierte rezeptive Felder
(vgl. Olshausen & Field)
(Bell & Sejnowski, 1995)
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
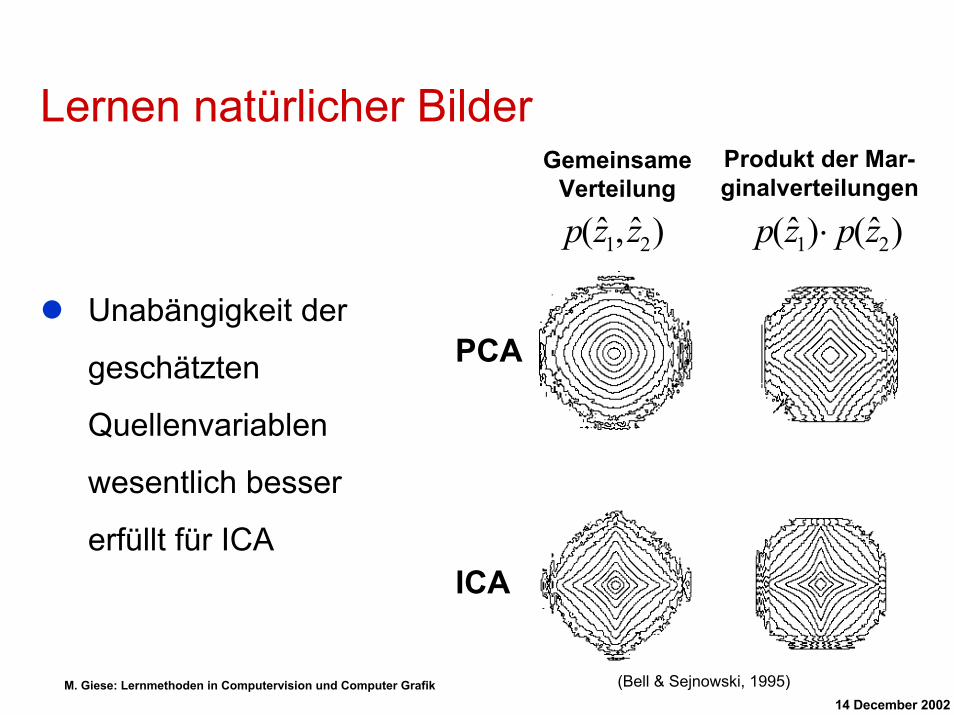
Lernen natürlicher BilderProdukt der Mar-ginalverteilungen
Gemeinsame Verteilung
ICA
)ˆ()ˆ( 21 zpzp ⋅)ˆ,ˆ( 21 zzp
PCA
(Bell & Sejnowski, 1995)
Unabängigkeit der
geschätzten
Quellenvariablen
wesentlich besser
erfüllt für ICA
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Lernen natürlicher Bilder
Ähnliche Studie
(Hyvärinen, 2000)
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
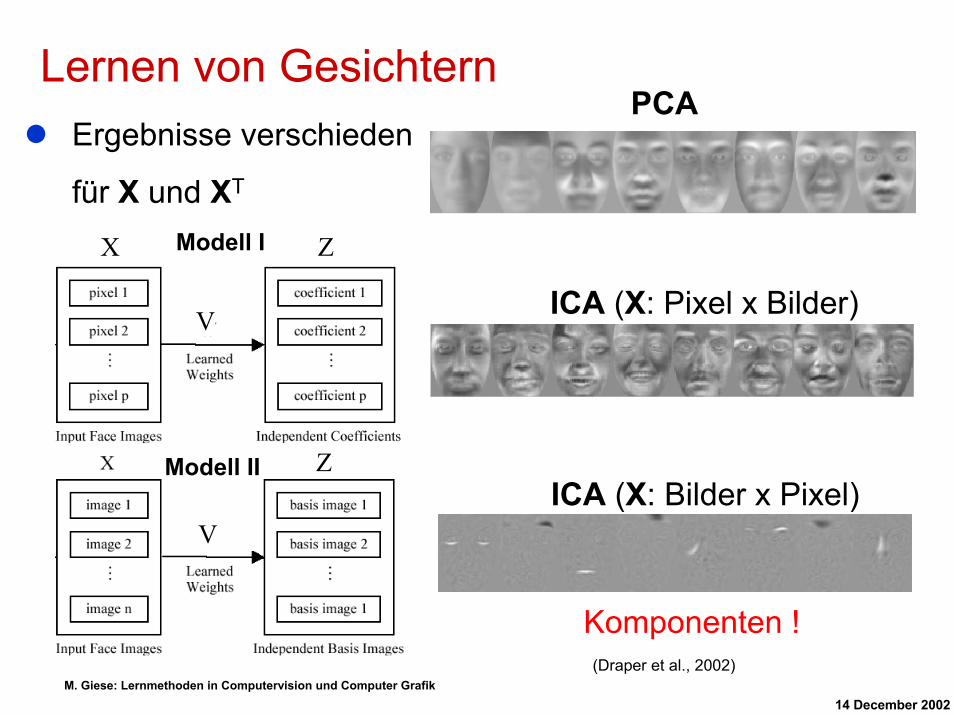
Lernen von GesichternPCA
Ergebnisse verschieden
für X und XT
Z
V
V
ZX Modell I
Modell II
ICA (X: Pixel x Bilder)
ICA (X: Bilder x Pixel)
Komponenten !(Draper et al., 2002)

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
V. Lernen von Mannigfaltigkeiten
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
oo
oo
x1
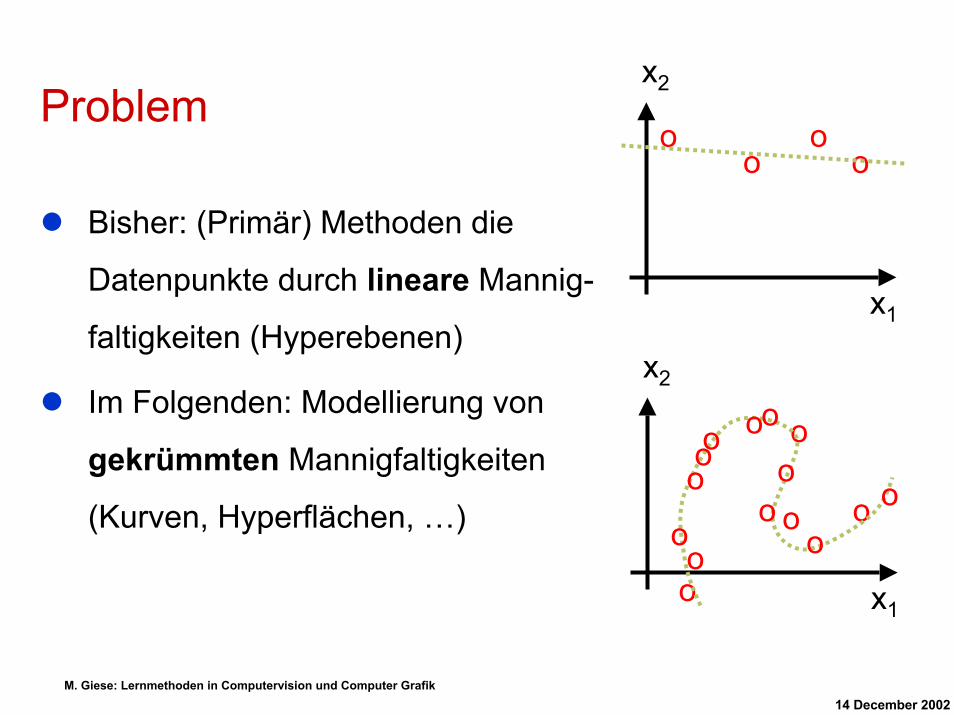
x2Problem
Bisher: (Primär) Methoden die
Datenpunkte durch lineare Mannig-
faltigkeiten (Hyperebenen)
Im Folgenden: Modellierung von
gekrümmten Mannigfaltigkeiten
(Kurven, Hyperflächen, …) o
o
o
o x1
x2
oo
ooo
oo
o
ooo
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
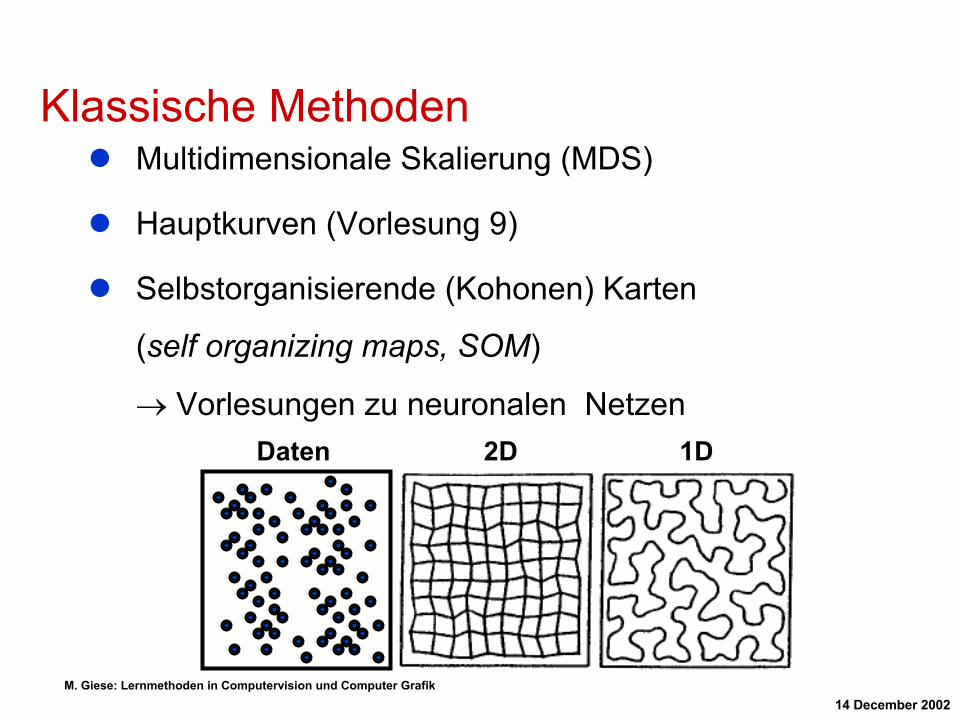
Klassische MethodenMultidimensionale Skalierung (MDS)
Hauptkurven (Vorlesung 9)
Selbstorganisierende (Kohonen) Karten
(self organizing maps, SOM)
→ Vorlesungen zu neuronalen NetzenDaten 2D 1D

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Lokal Lineare Einbettung(local linear embedding, LLE)
Niedrigdimensionale Mannigfaltigkeit eingebettet in
hochdimensionalen Raum
Datenpunkte im hochdimensionalen Raum: xi, 1 ≤ i ≤ l
Koordinaten in der niedrigdimensionalen Mannigfaltigkeit: yi, 1 ≤ i ≤ l
Annahme: Dichte Abtastung der Mannigfaltigkeit durch die
Datenpunkte
(Roweis & Saul, 2000)
x1
x2
x3
x1
x2
x3
y1
y2
Mannigfaltigkeit Datenpunkte Niedrigdim. Man.

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Lokal Lineare Einbettung(local linear embedding, LLE)
Algorithmus zum Lernen der Abbildung x ↔ y:
1. Approximation jedes Datenpunktes durch die Linearkombination
der Nachbarn: Minimierung von
unter den NB:
Symmetrie: Invarianz gegen Translation, Rotation + Skalierung
von Datenpunkt und Nachbarn
2
1 } vonNachbarn{
)( ∑ ∑= ∈
−=l
i ikkiki WE xxW
1} vonNachbarn{ falls 0
=
∉=
∑k
ik
ik
WikW

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Lokal Lineare Einbettung(local linear embedding, LLE)
2. Schätzen der niedrigdimensionalen Mannigfaltigkeit durch
Approximation jedes Datenpunktes durch Übernehmen der
Gewichte Wij : Minimierung von
mit Y = [y1, …, yl] und NB
Lösung: SVD ⇒ Spärliches Eigenwertproblem
⇒ Zwei Kleinste-Quadrate-Schätzungen
2
1 } vonNachbarn{2 )( ∑ ∑
= ∈
−=l
i ikkiki WE yyY
Iyy0y ⋅== ∑∑=
ll
i
Tii
ii
1
und
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
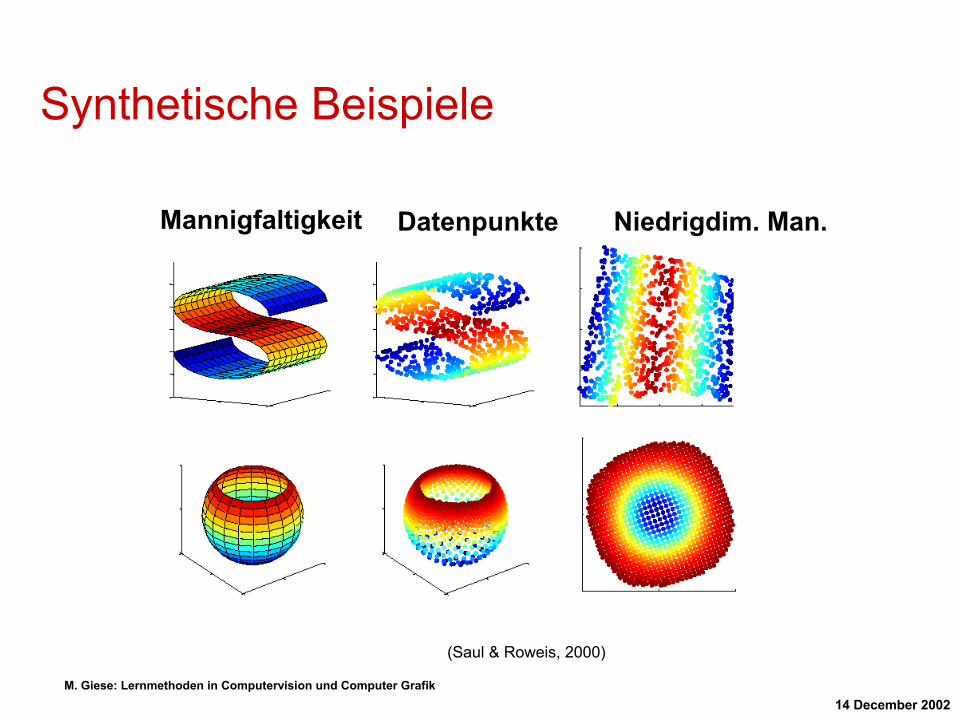
Synthetische Beispiele
Mannigfaltigkeit Datenpunkte Niedrigdim. Man.
(Saul & Roweis, 2000)
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Synthetische Beispiele
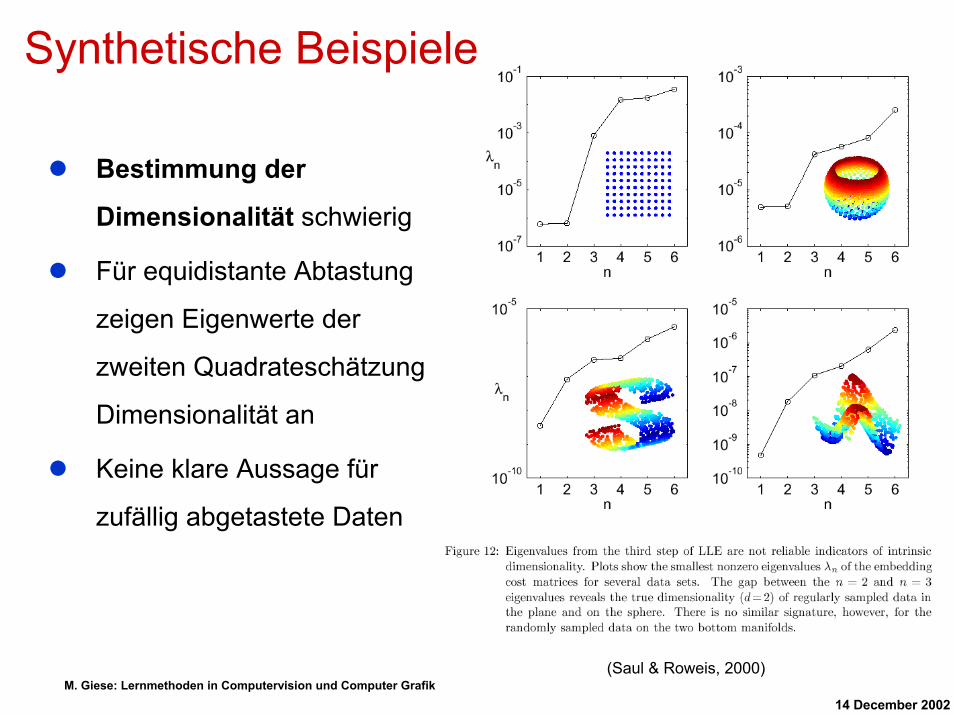
Bestimmung der
Dimensionalität schwierig
Für equidistante Abtastung
zeigen Eigenwerte der
zweiten Quadrateschätzung
Dimensionalität an
Keine klare Aussage für
zufällig abgetastete Daten
(Saul & Roweis, 2000)
M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Ans
icht
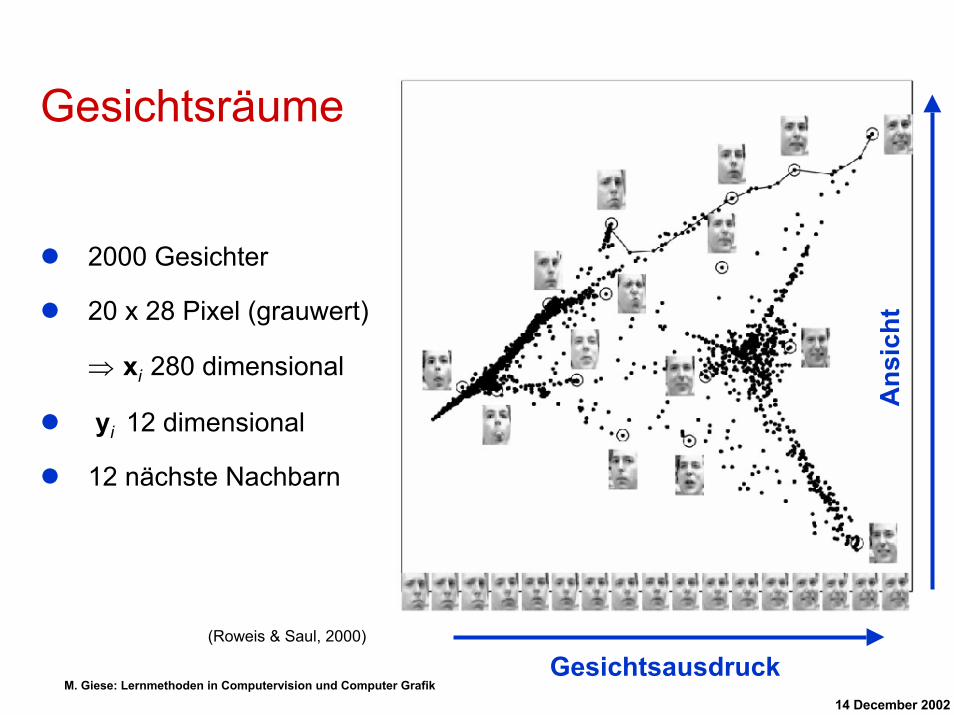
Gesichtsräume
2000 Gesichter
20 x 28 Pixel (grauwert)
⇒ xi 280 dimensional
yi 12 dimensional
12 nächste Nachbarn
(Roweis & Saul, 2000)
Gesichtsausdruck

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Texträume
(Roweis & Saul, 2000)
5000 Wörter
31.000 Artikel
Grolier Enzykopädie
Wortzahlen als Merkmale
20 nächste Nachbarn
Euklidsche Distanz zwischen
Wortzahlvektoren

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
Wichtige Punkte
Fisher-Gesichter / DiskriminanzanalyseSpärliche neuronale CodierungLernen von rezeptiven FeldernNichtnegative MatrixfaktorisierungIndependent Component Analysis und Anwendungen auf BilderLokal lineare Einbettung (LLE)

M. Giese: Lernmethoden in Computervision und Computer Grafik14 December 2002
LiteraturBelhumeur, P.N., Hespanha, J. P. & Kriegman, D.J (1997) Eigenfaces vs. Fisherfaces:
Recognition using class specific linear projection. IEEE Transactions on Pattern Recognition and Machine Intelligence, 19, 711-720.
Bell, A.J.& Sejnowski, T.J. (1995) An information maximisation approach to blind separation and blind deconvolution. Neural Computation, 7, 1129-1159.
Cherkassky, V., Mulier, F. (1998). Learning From Data. John-Wiley & Sons Inc, New York.
Draper, B.A., Baek, K., Bartlett, M.S., and Beveridge, J.R. (2002) Recognizing faces with PCA and ICA. Computer Vision and Image Understanding, (submitted).
Duda, R.O., Hart, P.E., Stork, D.G. (2001). Pattern Classification. John-Wiley & Sons Inc, New York.
Forsyth, D.A. & Ponce, J. (2003). Computer Vision: A modern Approach. Prentice-Hall. Upper Saddle River, NJ.
Hyvärinen, A. & Oja, E. (2000) Independent Component Analysis: A tutorial. Neural Networks, 13, 411-430.
Lee D.D & Seung, H S. (1999) Learning the parts of objects by non-negative matrix factorization. Nature 401, 788-791.
Roweis S.T. & Saul L.K. (2000) Nonlinear dimensionality reduction by local linear embedding. Science 290, 2323-2326.





![Vorlesung: Pädiatrie Infektiologie Teil I · (Microsoft PowerPoint - 1. Vorlesung Infekt.NETZ.ppt [Schreibgesch tzt] [Kompatibilit tsmodus]) Vorlesung Infekt.NETZ.ppt [Schreibgesch](https://img.pdfslide.org/doc/110x75/5d4b913888c99388658b7be4/vorlesung-paediatrie-infektiologie-teil-i-microsoft-powerpoint-1-vorlesung.jpg)























