Einführung in das GPU-Computing mit CUDA
Jörn Dinkla
http://www.dinkla.net
© 2016, Jörn Dinkla, http://www.dinkla.net

GPU-Computing ist überall
Tablet, PC, Cloud, Spielkonsole, Autos …

Jörn Dinkla
Software-Developer und Berater
CUDA seit 2008
Konferenzen + Artikel
Auch
JVM, C++, JavaScript
http://www.dinkla.net

Teil 1: Einführung
Computer-Grafik
GPGPU
GPU-Computing
Frameworks

Computer-Grafik
Vom Modell zum Bild
Tomas Akenine-Mőller © 2002, Quelle: http://www.realtimerendering.com/
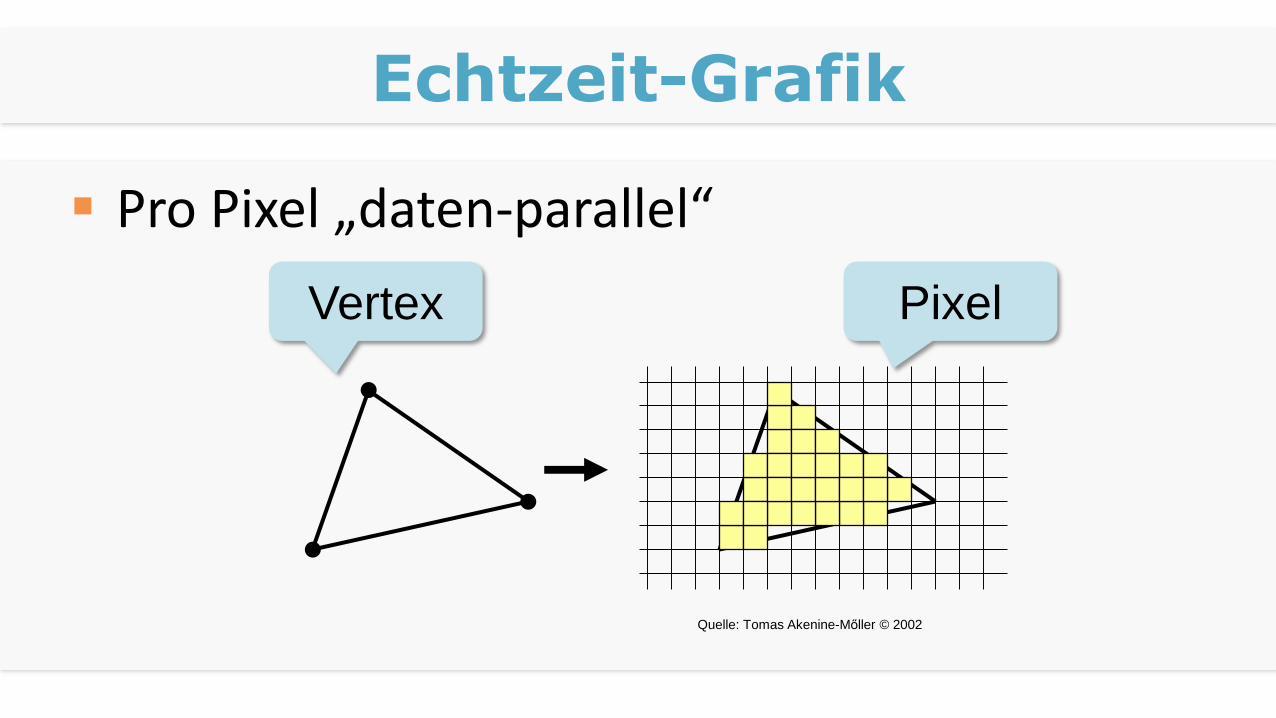
Echtzeit-Grafik
Pro Pixel „daten-parallel“
Quelle: Tomas Akenine-Mőller © 2002
Vertex Pixel

Programmierbare Shader
Ab 2002 HLSL, Cg, GLSL

GPGPU
2003 – 2008
Benutzung der Shader-Sprachen um allgemeine Probleme auf GPUs zu berechnen
Ein „hack“
Generall Purpose computing on GPUs

GPU-Computing
2007 erste Version von CUDA
2008 von OpenCL
2012 C++ AMP von Microsoft
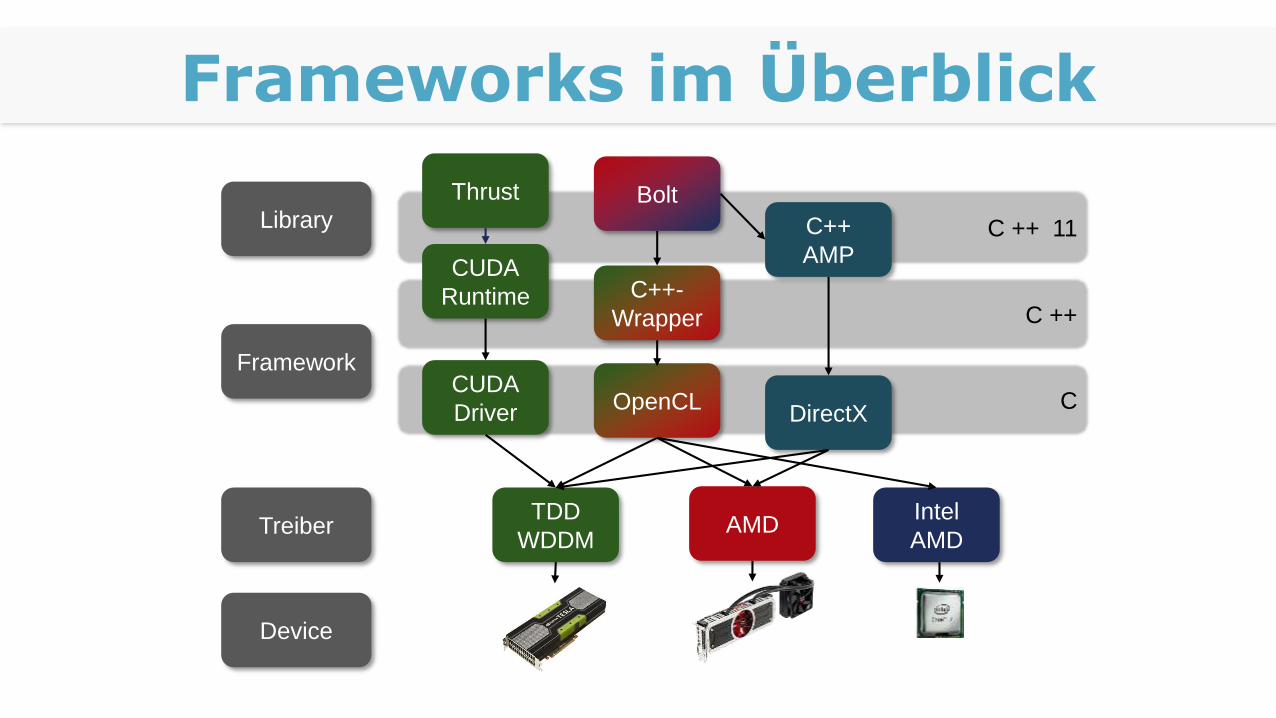
Frameworks im Überblick
C ++ 11
C ++
C
Device
Framework
CUDA
Runtime
C++
AMP
DirectX
AMDTreiberTDD
WDDM
Thrust
C++-
Wrapper
Library
OpenCL
Bolt
Intel
AMD
CUDA
Driver

Vor- und Nachteile
CUDA
+ Verbreitung + C++ 11 - nur NVIDIA
C++ AMP
+ C++ 11 - DirectX - geringe Verbreitung
OpenCL
+ Offen - C99 - Nicht viele Libraries
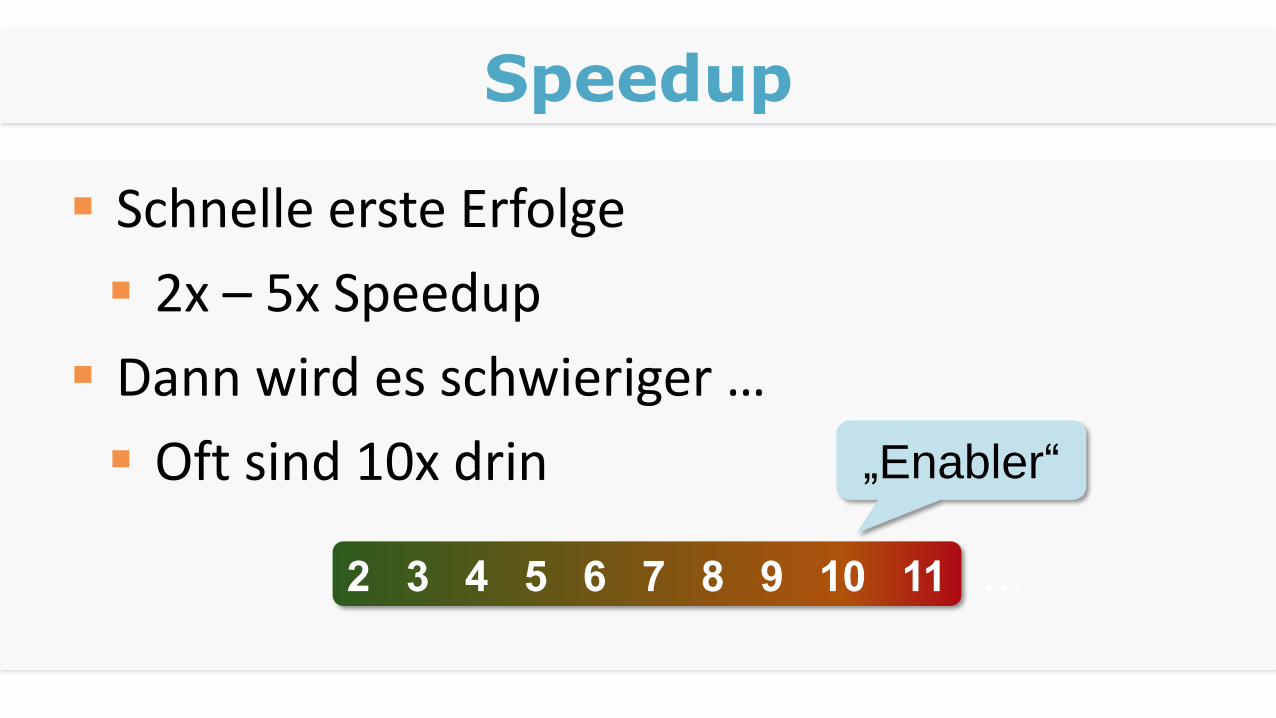
Speedup
Schnelle erste Erfolge
2x – 5x Speedup
Dann wird es schwieriger …
Oft sind 10x drin
2 3 4 5 6 7 8 9 10 11 …
„Enabler“

Teil 2: Parallelität
Warum Parallelität?
Beispiele
Patterns
Map-Reduce

Fortschritt
Schnellere Verarbeitung
Mehr Daten
Höhere Auflösung
Bessere Qualität
Genauigkeit, Fehlertoleranz

Beispiel für Fortschritt
Schneller, Größer, Besser
Höhere Geschwindigkeit
1080p 4K720p576p480p
4k logo: https://en.wikipedia.org/w/index.php?curid=50128124
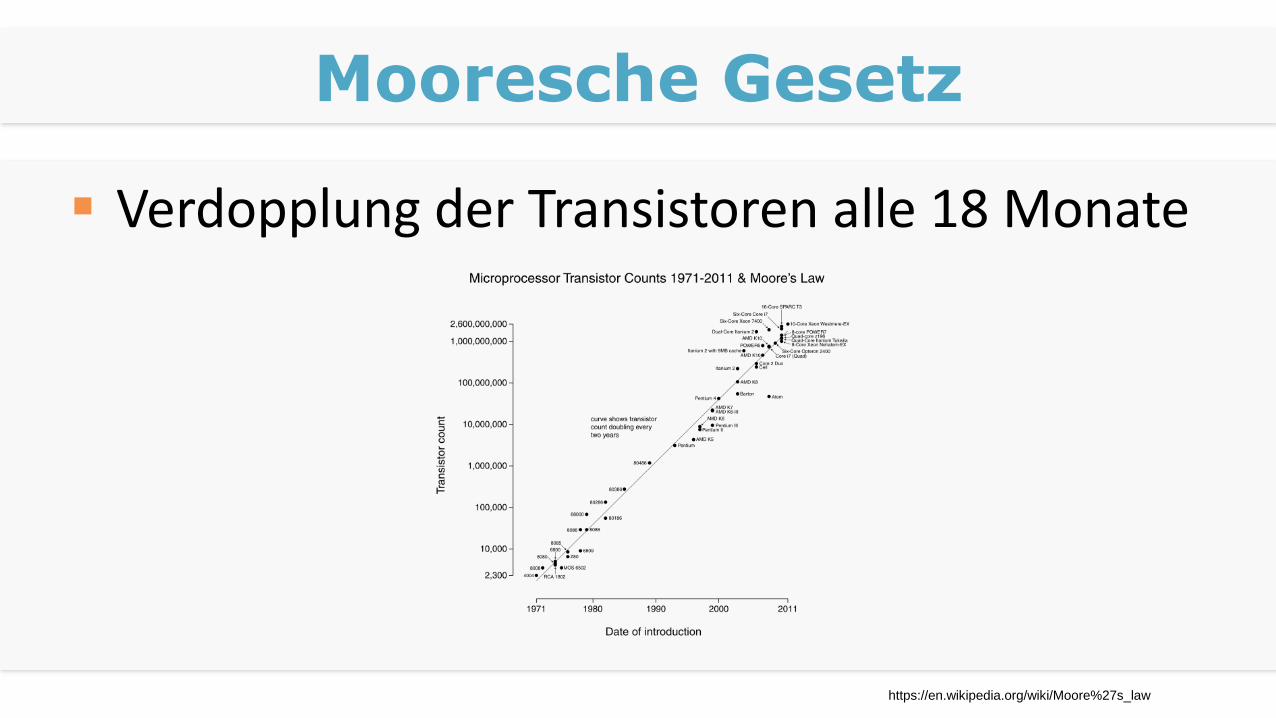
Mooresche Gesetz
Verdopplung der Transistoren alle 18 Monate
https://en.wikipedia.org/wiki/Moore%27s_law
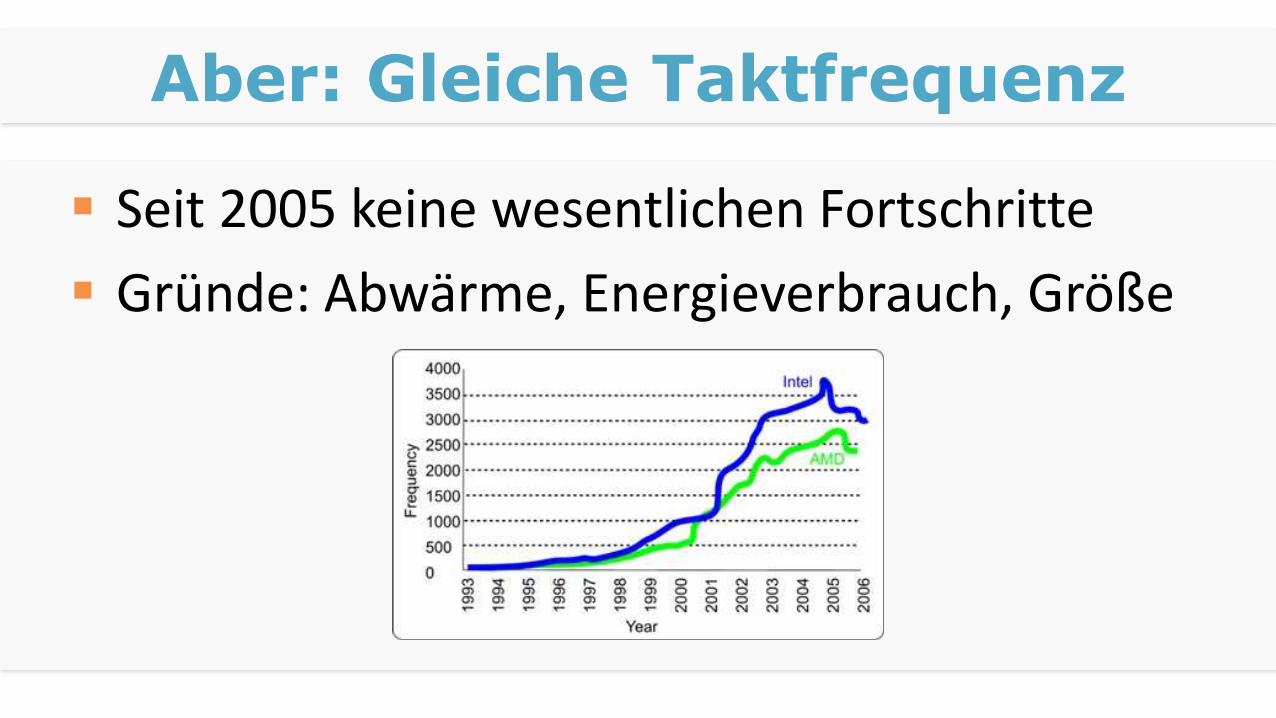
Aber: Gleiche Taktfrequenz
Seit 2005 keine wesentlichen Fortschritte
Gründe: Abwärme, Energieverbrauch, Größe

The Free Lunch is over
Automatischer Fortschritt
Mehr Transistoren, höhere Taktfrequenz
“Abwarten” bei Performance-Problemen
Aber
“The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software” 2005
Siehe http://www.gotw.ca/publications/concurrency-ddj.htm

Concurrency vs. Parallelism
Concurrency = Nebenläufigkeit
Verschiedene Programme
Unterschiedliche Aufgaben
Parallelism = Parallelität
Das gleiche Programm in Teile zerlegt
Gleiche Aufgabe

Aufgabe: Parallelität finden
Erfordert Übung, wird mit der Zeit einfacher
Zerlege einen Algorithmus
In Teile, die unabhängig voneinander berechnet werden können
Minimiere die Abhängigkeiten von Teilen
var

Definition „unabhängig“
Zwei Programmteile sind „unabhängig“,
wenn sie parallel ausgeführt werden können
und die „Semantik“ des Programms gleich bleibt
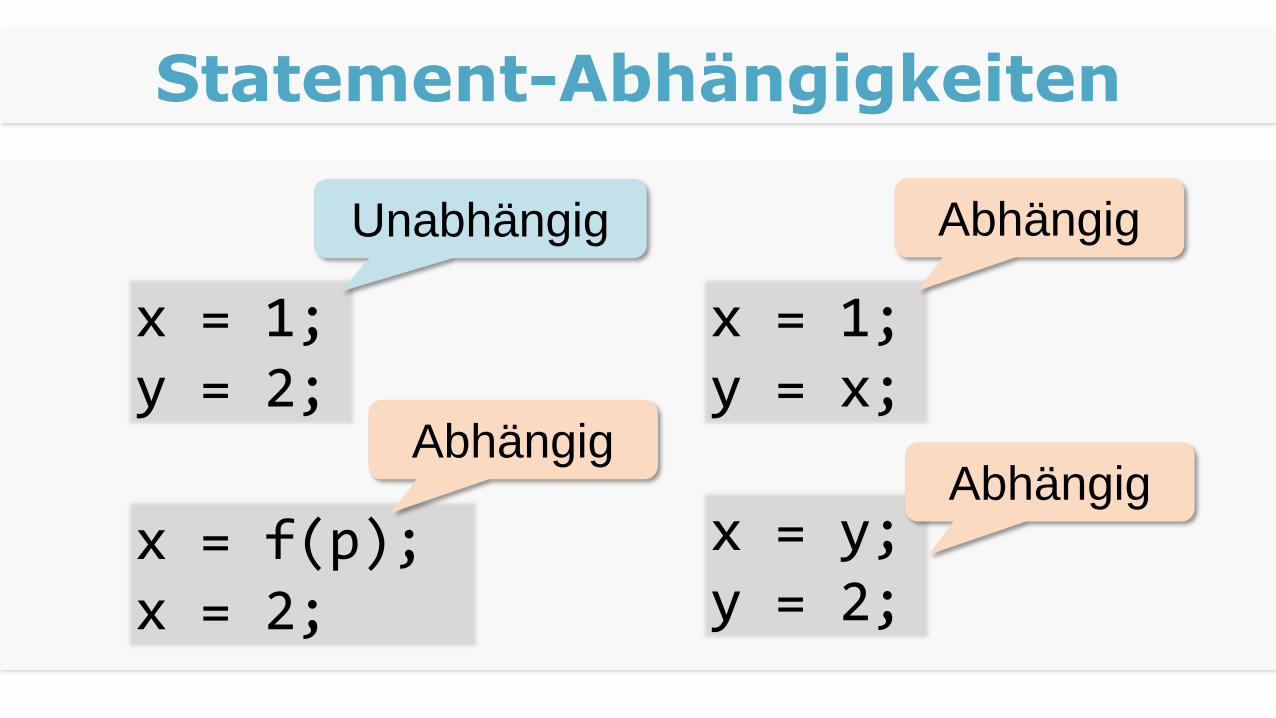
Statement-Abhängigkeiten
x = 1;y = 2;
x = 1;y = x;
x = f(p);x = 2;
x = y;y = 2;
Unabhängig Abhängig
AbhängigAbhängig

Grundregeln
Vermeide
„Shared state“, geteilten Zustand
Synchronisationen
Viele Bücher über das Thema
„Multiprocessor-Programming“
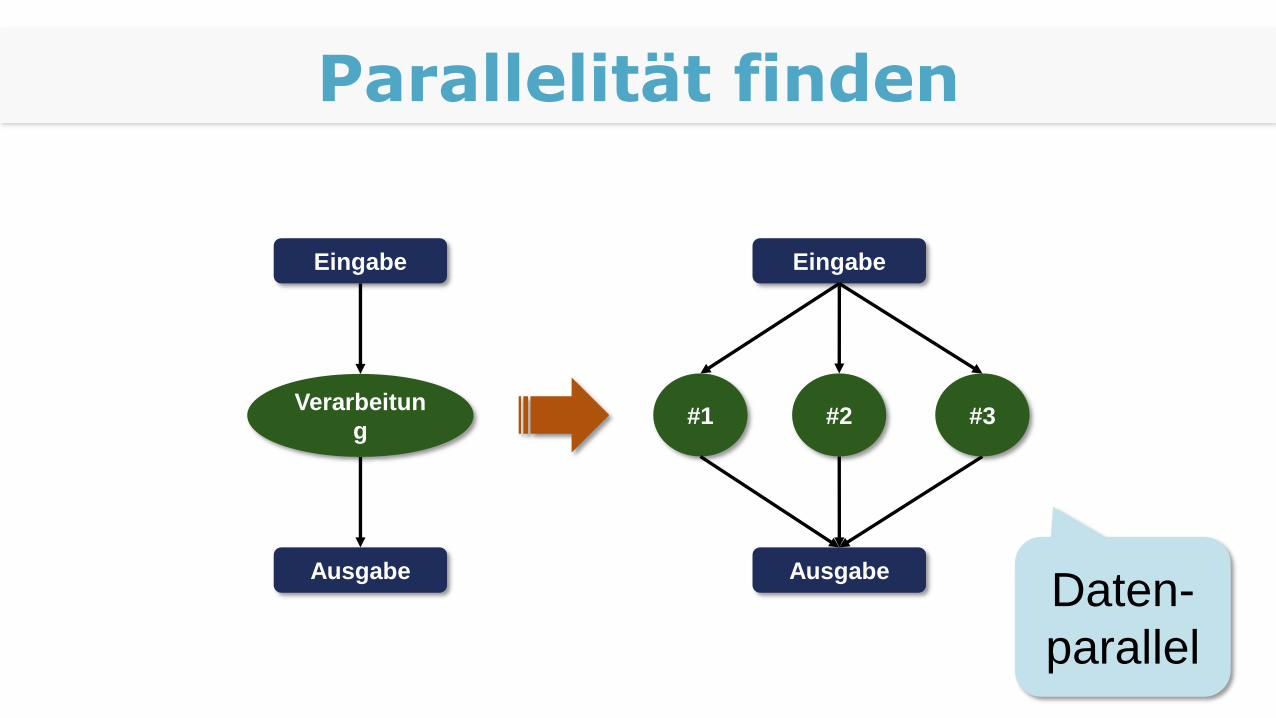
Parallelität finden
Eingabe
Verarbeitun
g
Ausgabe
Eingabe
Ausgabe
#1 #2 #3
Daten-
parallel
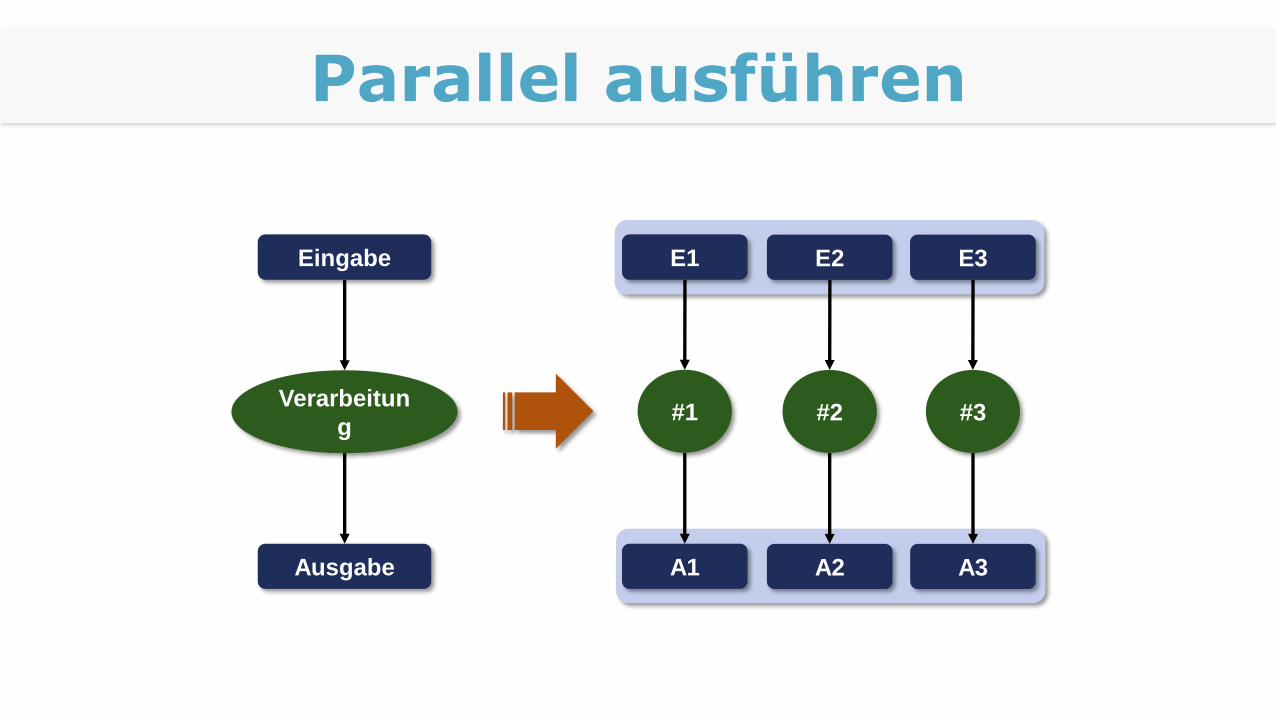
Parallel ausführen
Eingabe
Verarbeitun
g
Ausgabe
E1
A1
#1
E2
A2
#2
E3
A3
#3

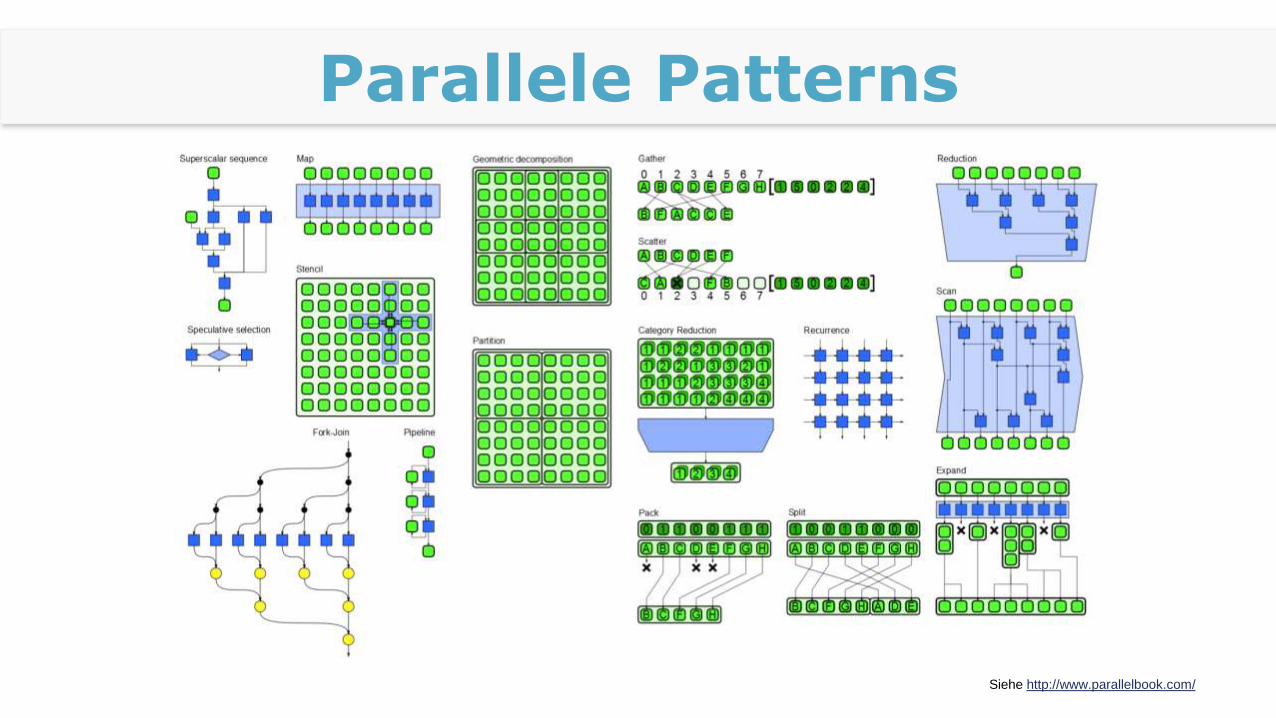
Parallele Patterns
Nicht das Rad neu erfinden
„Structured Parallel Programming“
Michael McCool et. al.
Eher nicht für GPU-Entwickler!
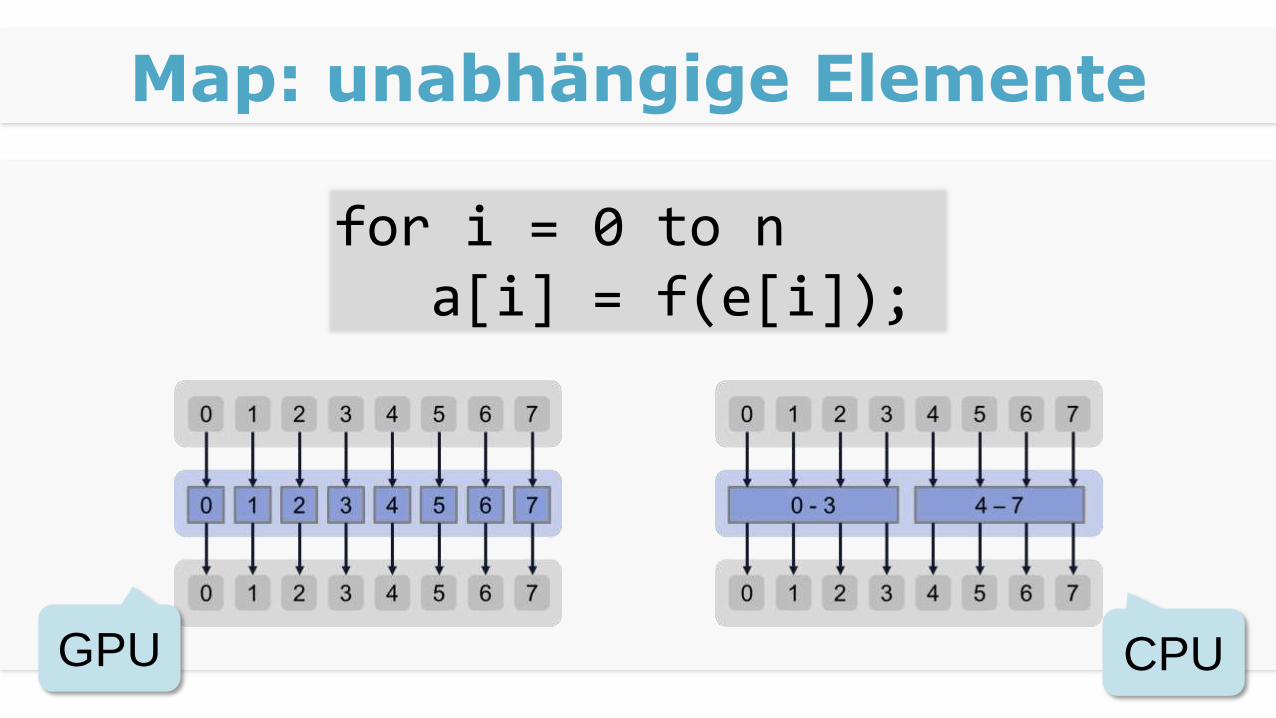
Map: unabhängige Elemente
for i = 0 to n a[i] = f(e[i]);
CPUGPU
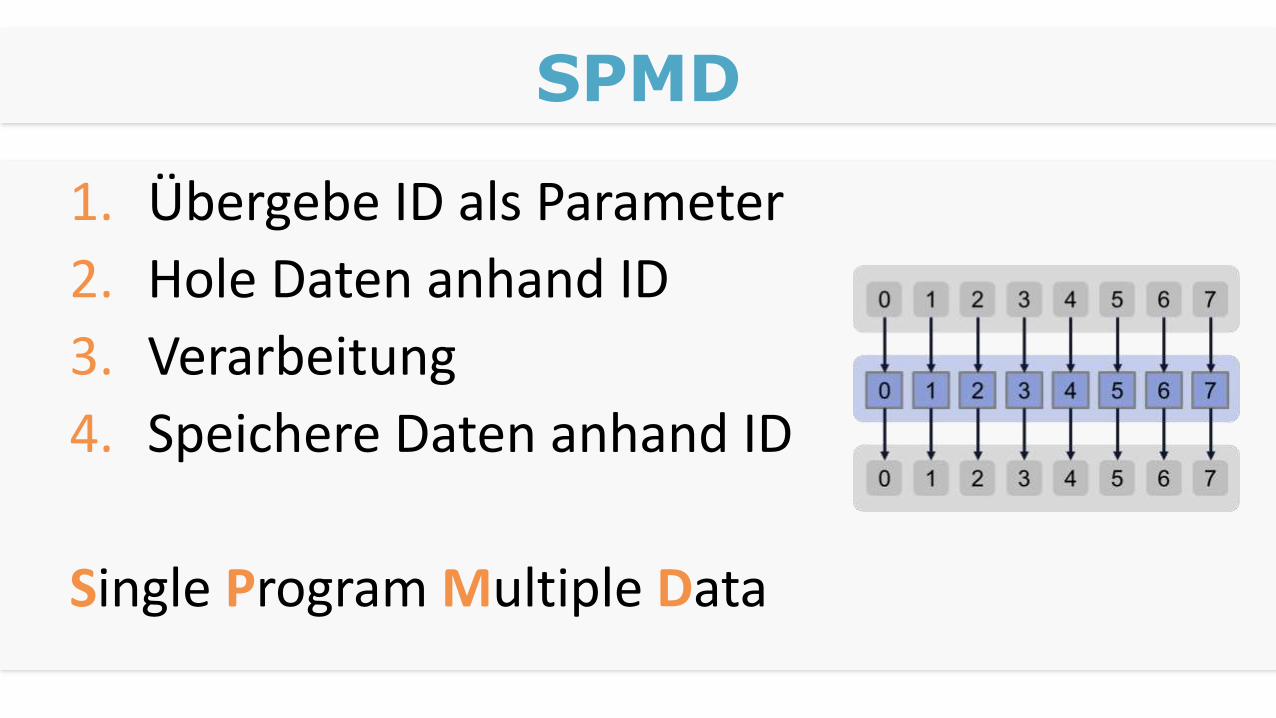
SPMD
1. Übergebe ID als Parameter
2. Hole Daten anhand ID
3. Verarbeitung
4. Speichere Daten anhand ID
Single Program Multiple Data
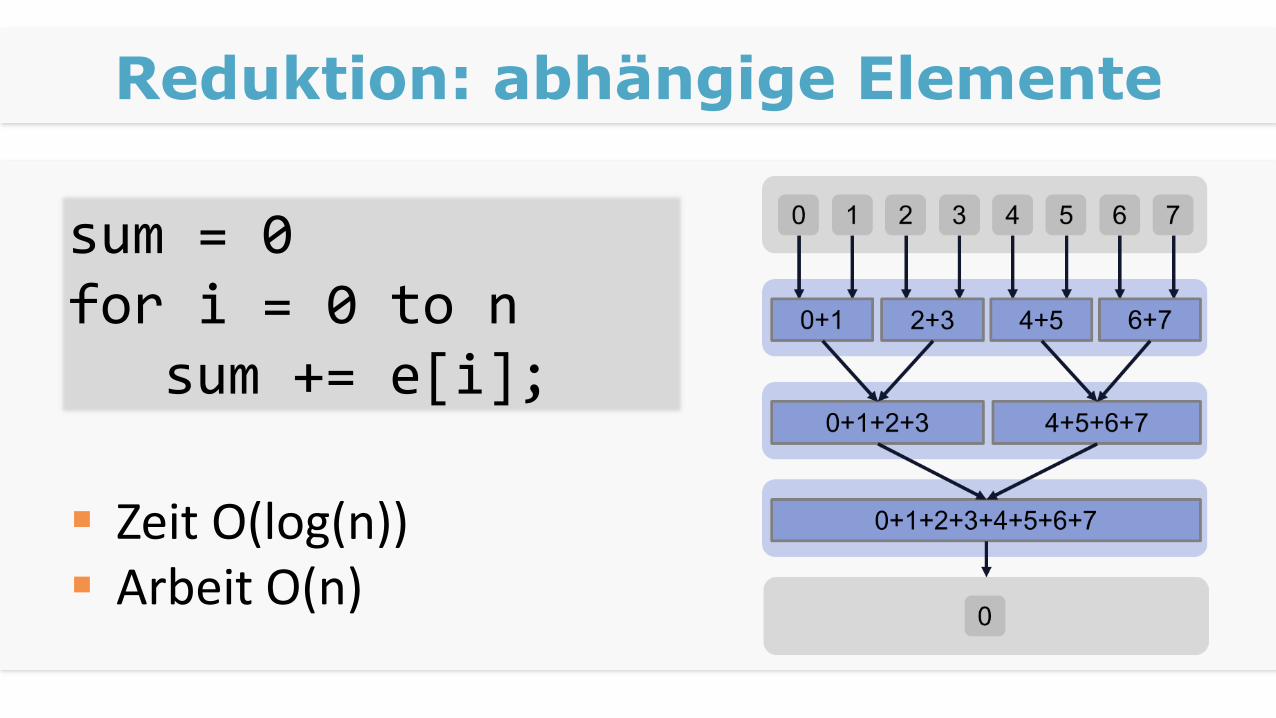
Reduktion: abhängige Elemente
Zeit O(log(n)) Arbeit O(n)
sum = 0for i = 0 to n
sum += e[i];
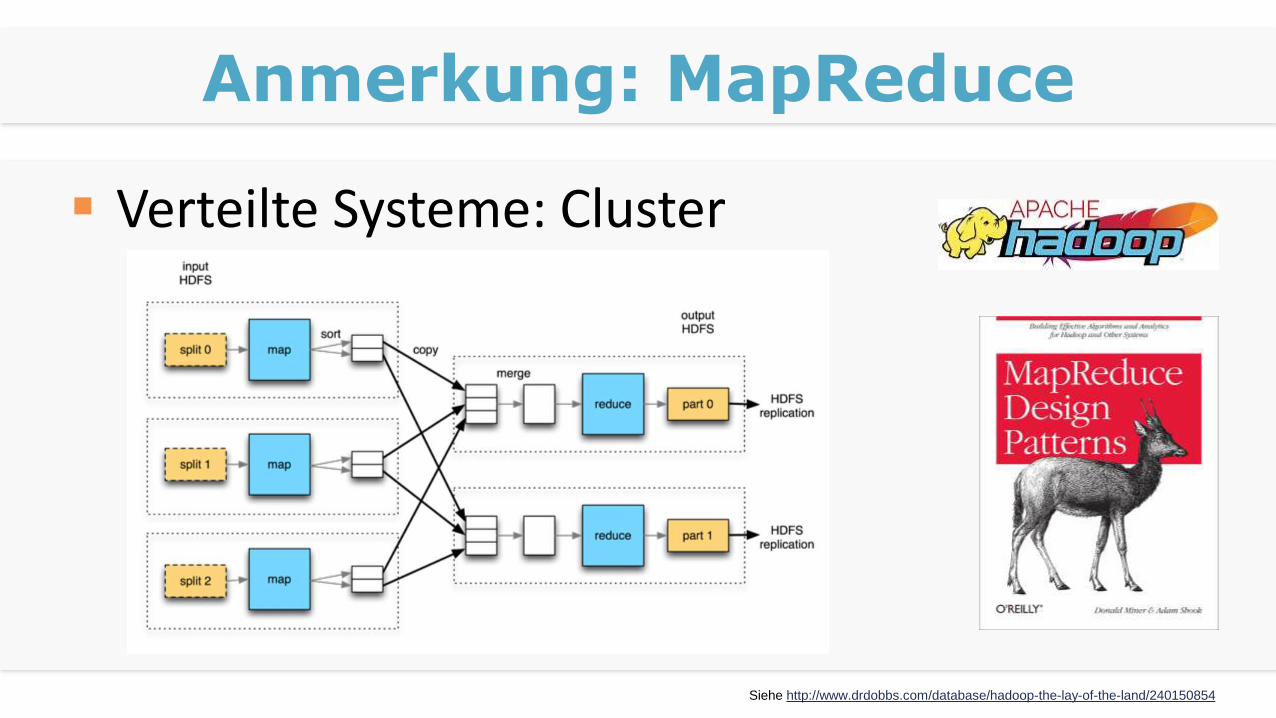
Anmerkung: MapReduce
Verteilte Systeme: Cluster
Siehe http://www.drdobbs.com/database/hadoop-the-lay-of-the-land/240150854
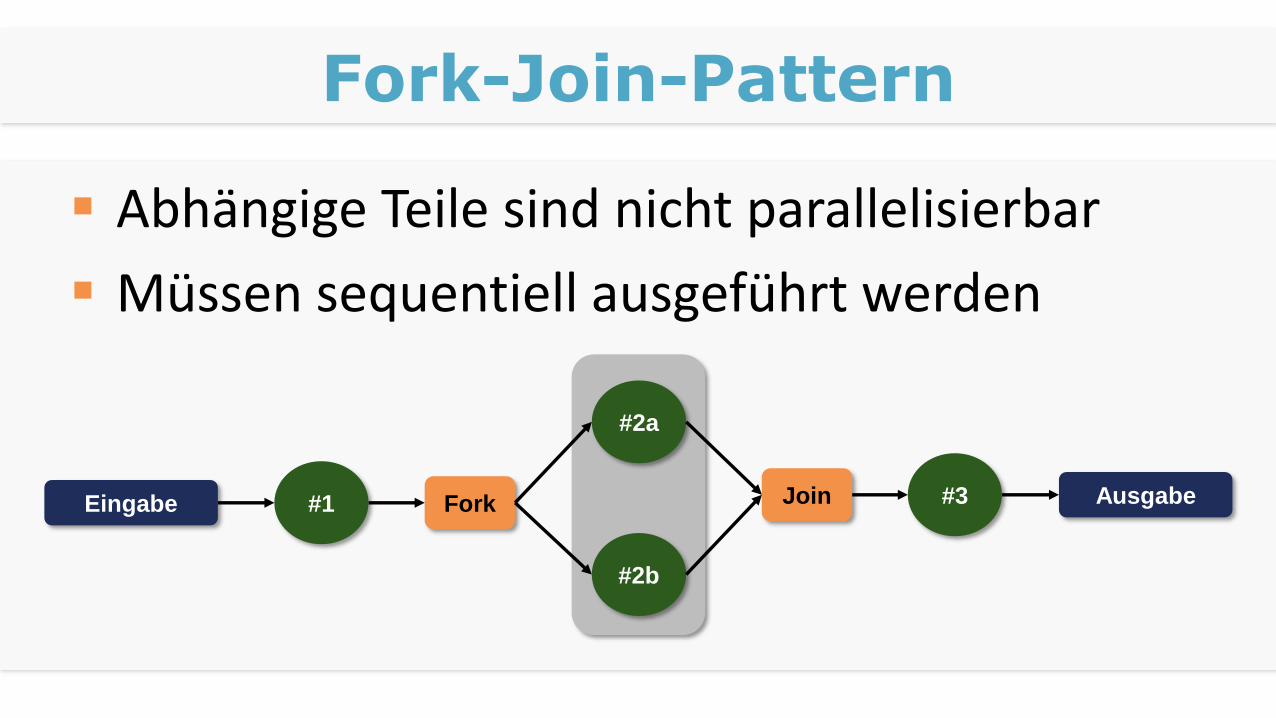
Fork-Join-Pattern
Abhängige Teile sind nicht parallelisierbar
Müssen sequentiell ausgeführt werden
Eingabe
#2a
#2b
#3 AusgabeFork Join#1

Idealer Speedup
Ideal: 100% Parallelisierbarkeit
Speedup S(n) = T(1) / T(n)
Wenn T(1) = 100
dann T(4) = 25 und T(10) = 10
Linearer Speedup
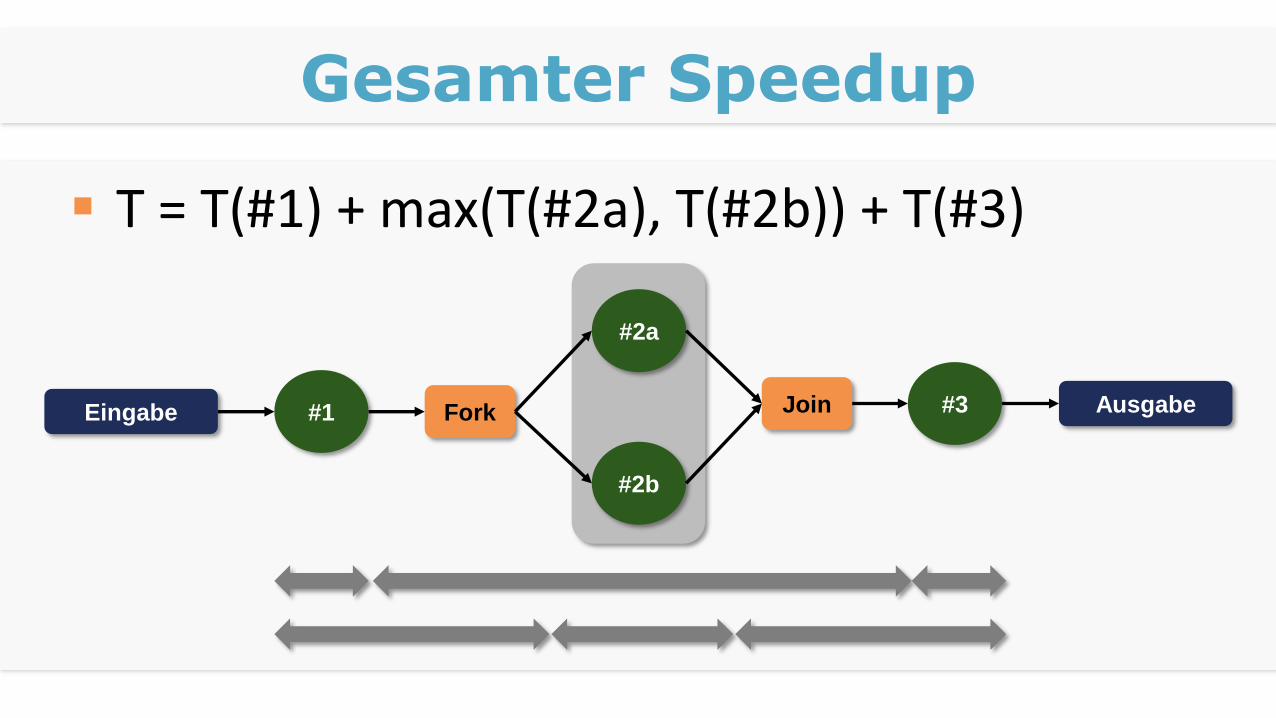
Gesamter Speedup
T = T(#1) + max(T(#2a), T(#2b)) + T(#3)
Eingabe
#2a
#2b
#3 AusgabeFork Join#1

Amdahl‘s Gesetz
Parallelisierbar p, sequentiell (1-p)
T 𝑛 = 1 − 𝑝 ∗ 𝑇 1 +𝑝
𝑛∗ 𝑇(1)
Und damit:
𝑆(𝑛) =𝑇(1)
𝑇(𝑛)=
1
1−𝑝 +𝑝
𝑛
Siehe http://www.drdobbs.com/database/hadoop-the-lay-of-the-land/240150854

Folgerung aus Amdahl
Parallelität maximieren!
Am besten im gesamten System
„Law of diminishing returns“
Viel hilft nicht immer viel

Teil 3: CPU
Architektur CPU
Parallelisierung auf der CPU
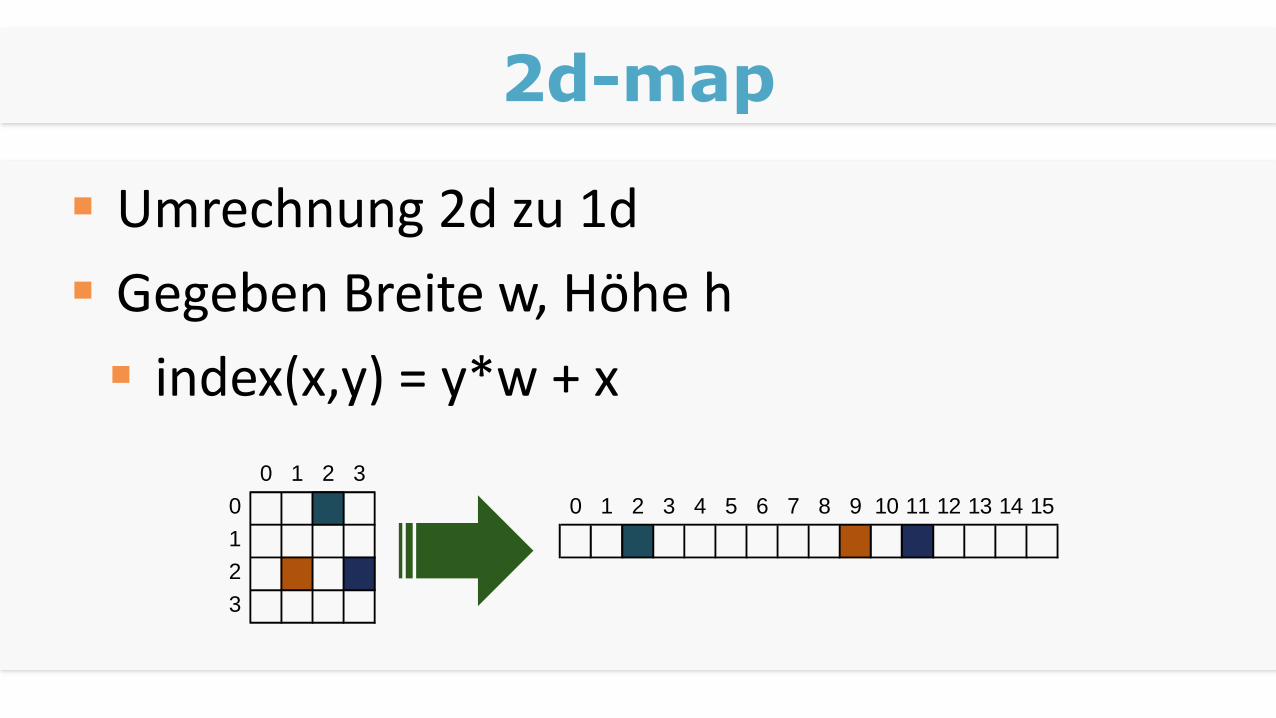
2d-map
Umrechnung 2d zu 1d
Gegeben Breite w, Höhe h
index(x,y) = y*w + x
0 1 2 3
0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
1
2
3
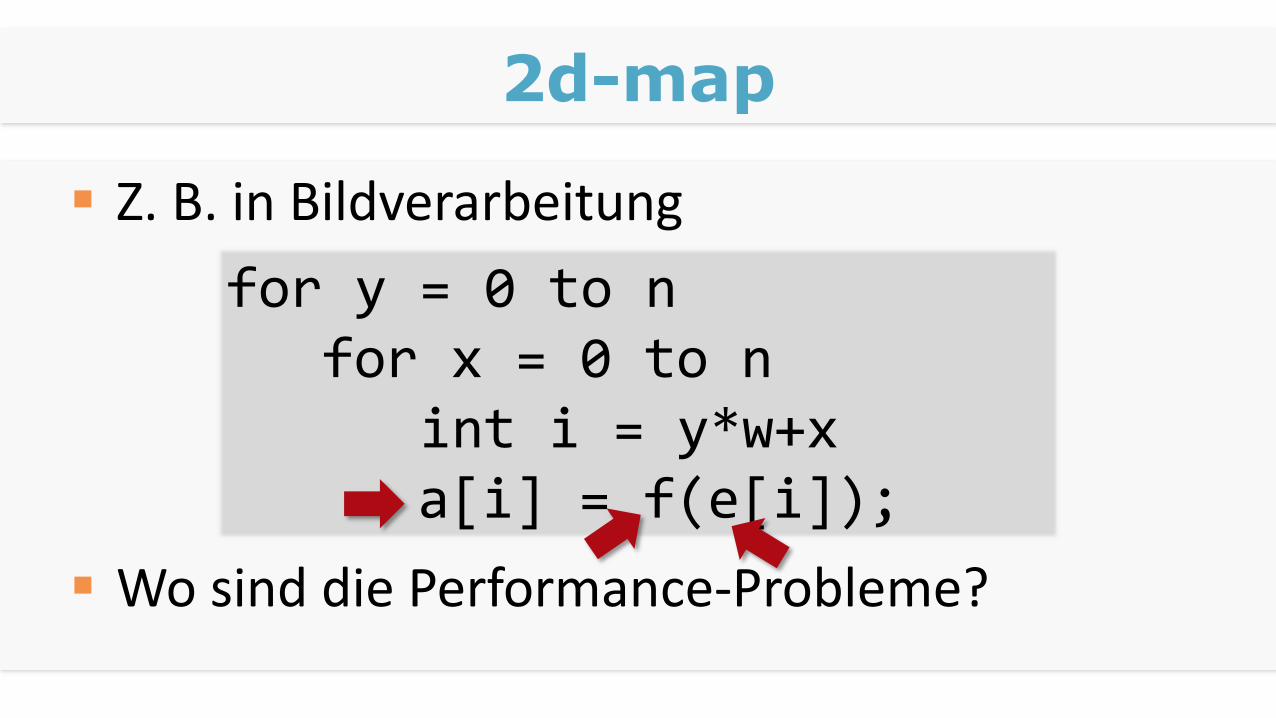
2d-map
Z. B. in Bildverarbeitung
Wo sind die Performance-Probleme?
for y = 0 to n for x = 0 to n
int i = y*w+xa[i] = f(e[i]);

Arithmetische Intensität
Verhältnis Rechnungen zu Speicherzugriffen
𝑎𝑖 =𝑅𝑒𝑐ℎ𝑒𝑛𝑜𝑝𝑒𝑟𝑎𝑡𝑖𝑜𝑛𝑒𝑛
𝑆𝑝𝑒𝑖𝑐ℎ𝑒𝑟𝑧𝑢𝑔𝑟𝑖𝑓𝑓𝑒
Für jeden Speicherzugriff sollte genügend zu rechnen da sein
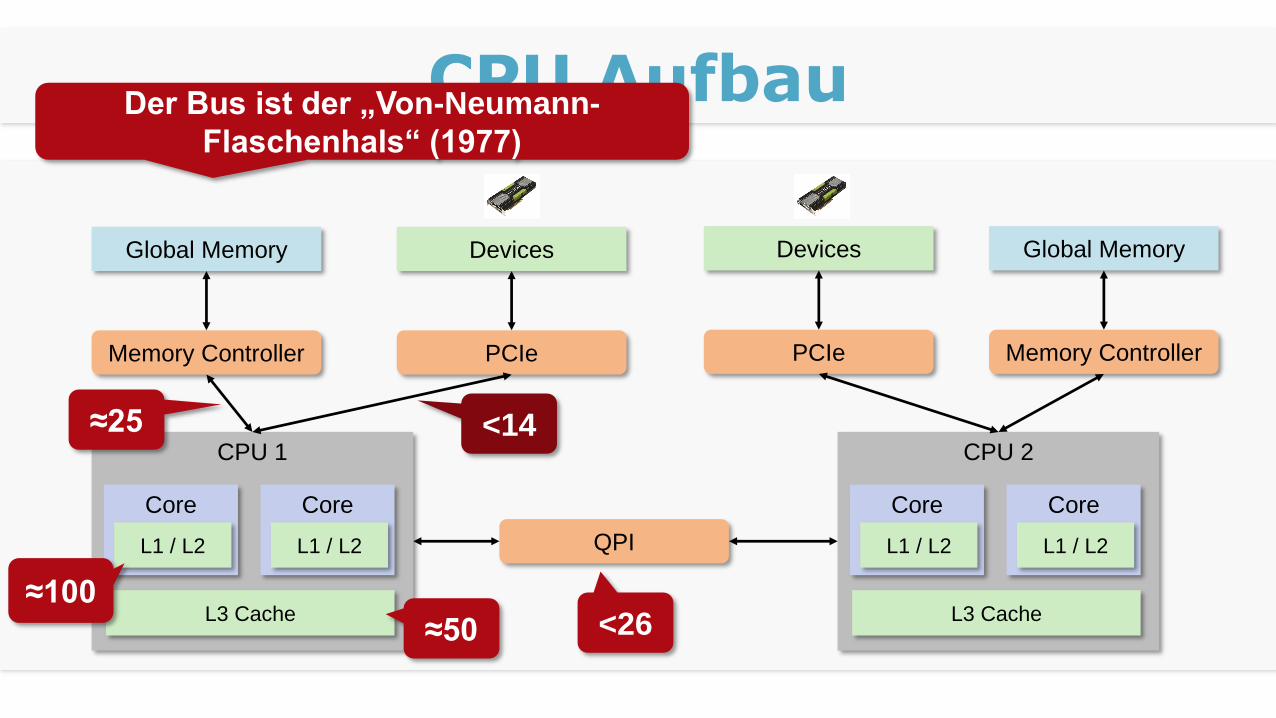
CPU Aufbau
CPU 1
Core
L1 / L2
Core
L1 / L2
L3 Cache
Memory Controller PCIe
Global Memory Devices
CPU 2
Core
L1 / L2
Core
L1 / L2
L3 Cache
QPI
Memory ControllerPCIe
Global MemoryDevices
≈25 <14
<26
Der Bus ist der „Von-Neumann-
Flaschenhals“ (1977)
≈50
≈100
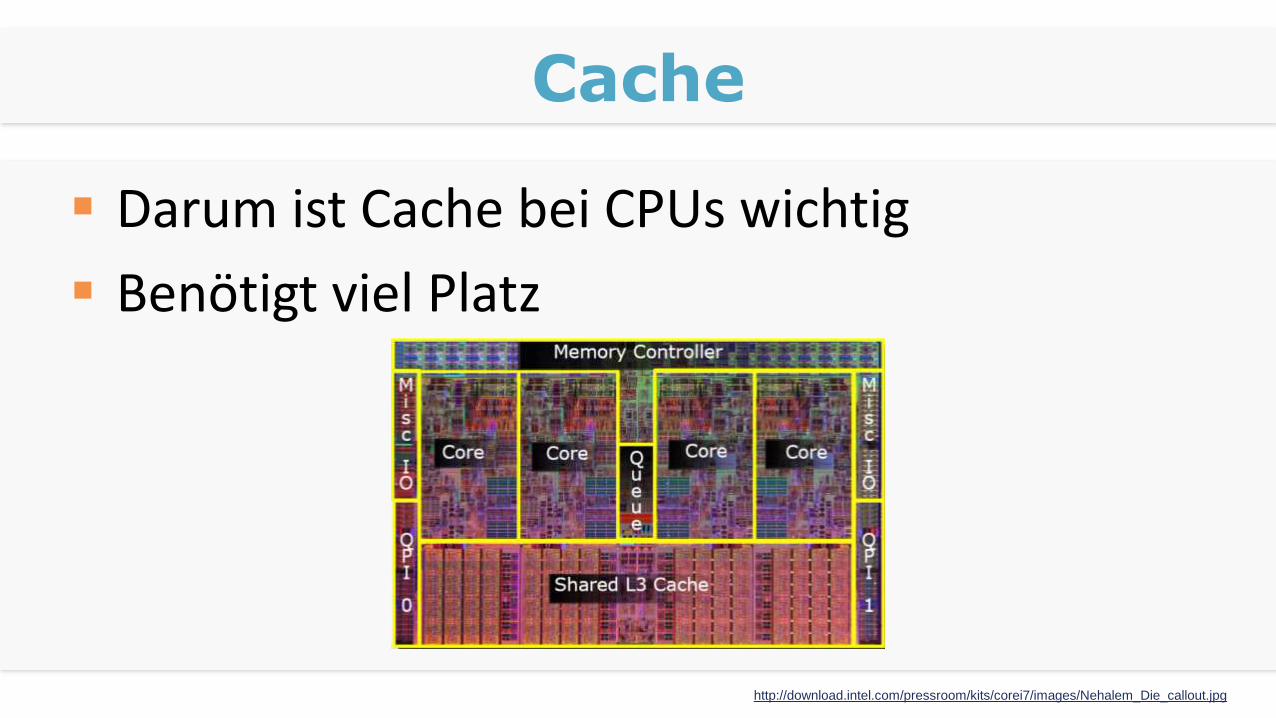
Cache
Darum ist Cache bei CPUs wichtig
Benötigt viel Platz
http://download.intel.com/pressroom/kits/corei7/images/Nehalem_Die_callout.jpg

Cache
Der Cache speichert „lines“ von 64 Bytes
Für x = 0 wird auch x=1 mitgelesen
for y = 0 to n for x = 0 to n
int i = y*w+xa[i] = f(e[i]);

Beispiel: 2d-map

Parallelisierung mit OpenMP

OpenMP
Präprozessor
#pragma omp parallel
Modifiziert Code
Teilt Schleifen auf in mehrere Teile
Thread-Pool, schwergewichtige Threads

OpenMP
Vereinfacht

OpenMP funktioniert, wenn …
Daten-paralleles Problem, wie map
Keine abhängigen Schleifen
Code muss ansonsten umgeformt werden
Benutzt gleiches Memory-Model wie CPU
Daten liegen im gleichen Speicher (NUMA)

OpenMP und ungleiche Last
Wenn Rechenlast ungleich verteilt ist #pragma omp parallel for schedule(dynamic, 1)
Ungleich
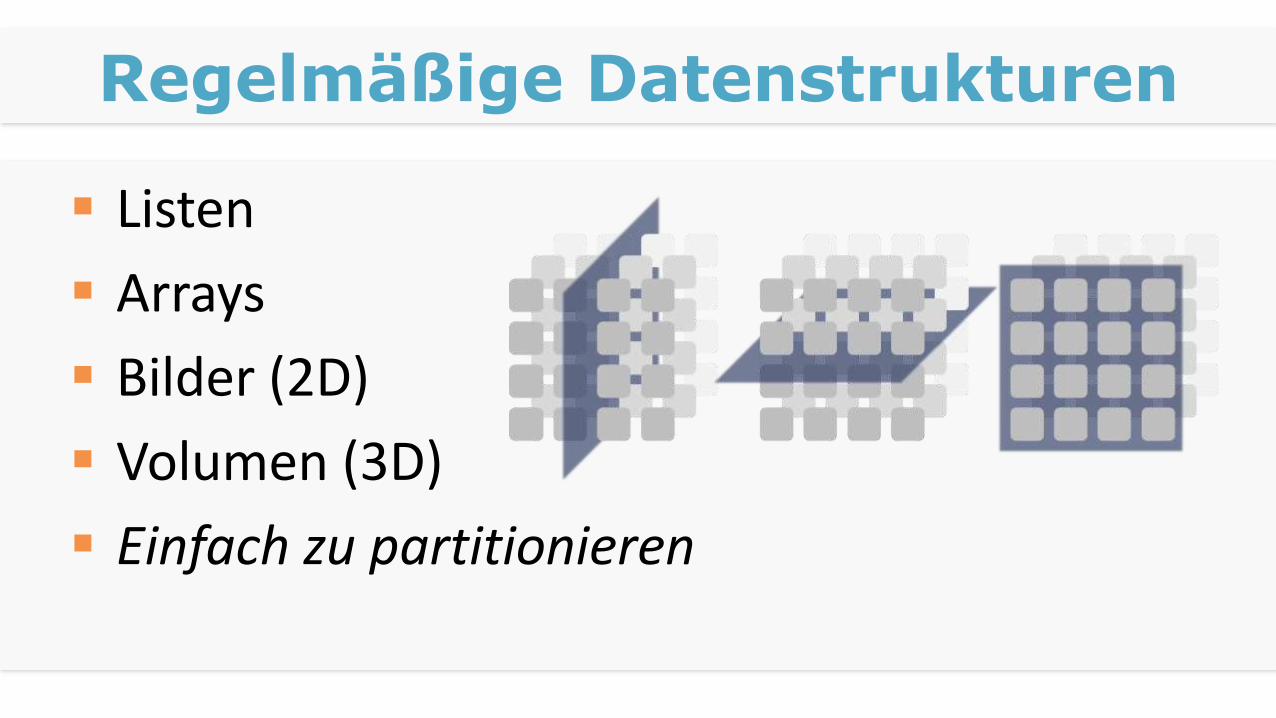
Regelmäßige Datenstrukturen
Listen
Arrays
Bilder (2D)
Volumen (3D)
Einfach zu partitionieren

Unregelmäßige Datenstrukturen
Bäume
Teilbäume
Graphen
Komponenten
Graph Partitioning / Clustering
Im allgemeinen NP-vollständig
Scheduling
Was macht OpenMP, wenn ein Kern schon etwas anderes tut?
Homogen (Gleiche Prozessoren)
Gleiche Arbeit
Heterogen (Unterschiedliche Prozessoren)
Messen und gewichten

Das Programm
Hilfsfunktion
Lambda

Teil 4: Architektur der GPU
Massiv Parallel
Produkte von NVIDIA
Aufbau der GPU

Pascal
60 SMs
á 64 Kerne
3840 Kerne
4 MB Cache
Kern: 32 Bit
https://devblogs.nvidia.com/parallelforall/wp-content/uploads/2016/04/gp100_block_diagram-1-624x368.png

Fermi, Kepler, Maxwell
Weitere Unterschiede … später

Produkte von NVIDIA
GeForce: Spiele-PC
Quadro: Grafik-Workstations
Tegra: Embedded
Tesla: Rechnen

Anzahl der Kerne
Unterschiedliche Anzahl
GeForce 1080
2560 Kerne in 40 SMs
Geforce 1060, 6 MB
1280 Kerne in 20 SMs

Tesla für Rechenzentren
ECC Speicher
Größerer Speicher
Bessere Double-Performance
Kein Monitor-Anschluss
Keine Kühlung

Multi-GPU
Auf normalen Motherboards 2 – 3 Achtung Auslastung PCIe
Spezial-Boards Bis zu 16 GPU pro Knoten
Abhängig von Mainboard, CPU, Chipsatz, PCIe-Controller
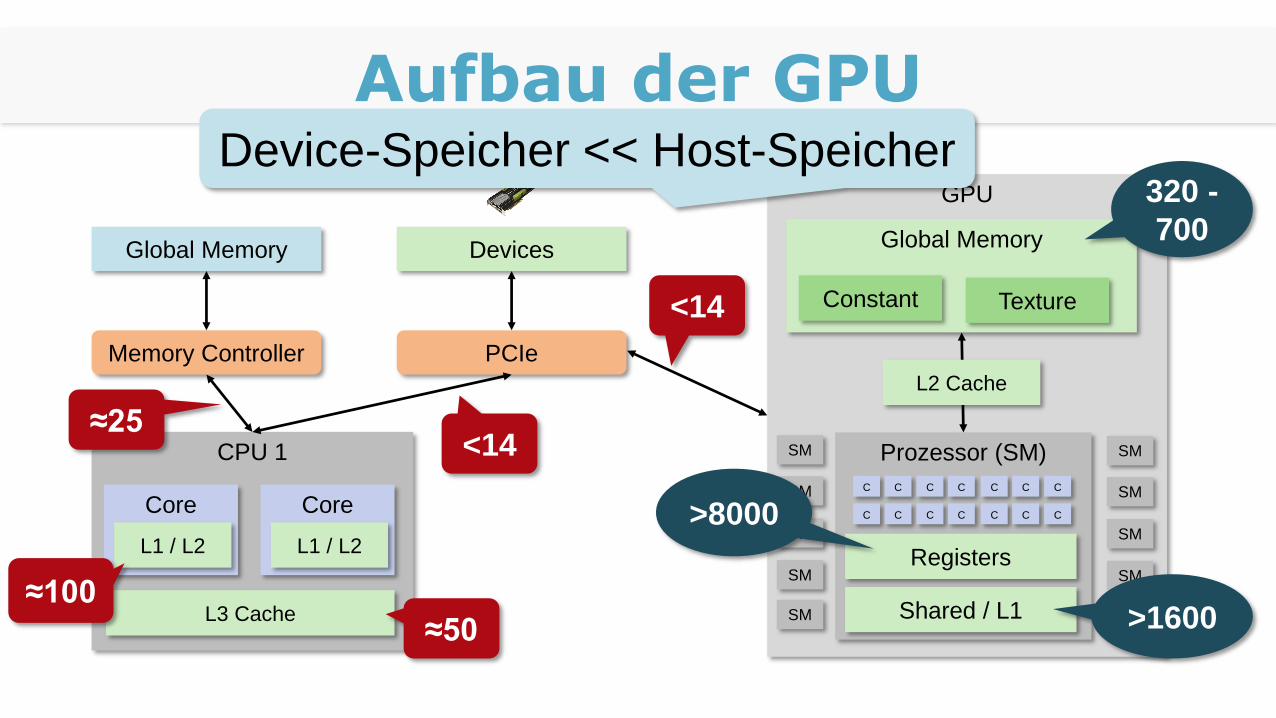
Aufbau der GPU
CPU 1
Core
L1 / L2
Core
L1 / L2
L3 Cache
Memory Controller PCIe
Global Memory Devices
≈25<14
≈50
≈100
<14
GPU
Global Memory
Constant Texture
Prozessor (SM)
Shared / L1
Registers
C
L2 Cache
C
C
C
C
C
C
C
C
C
C
C
C
C
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
>8000
>1600
320 -
700
Device-Speicher << Host-Speicher
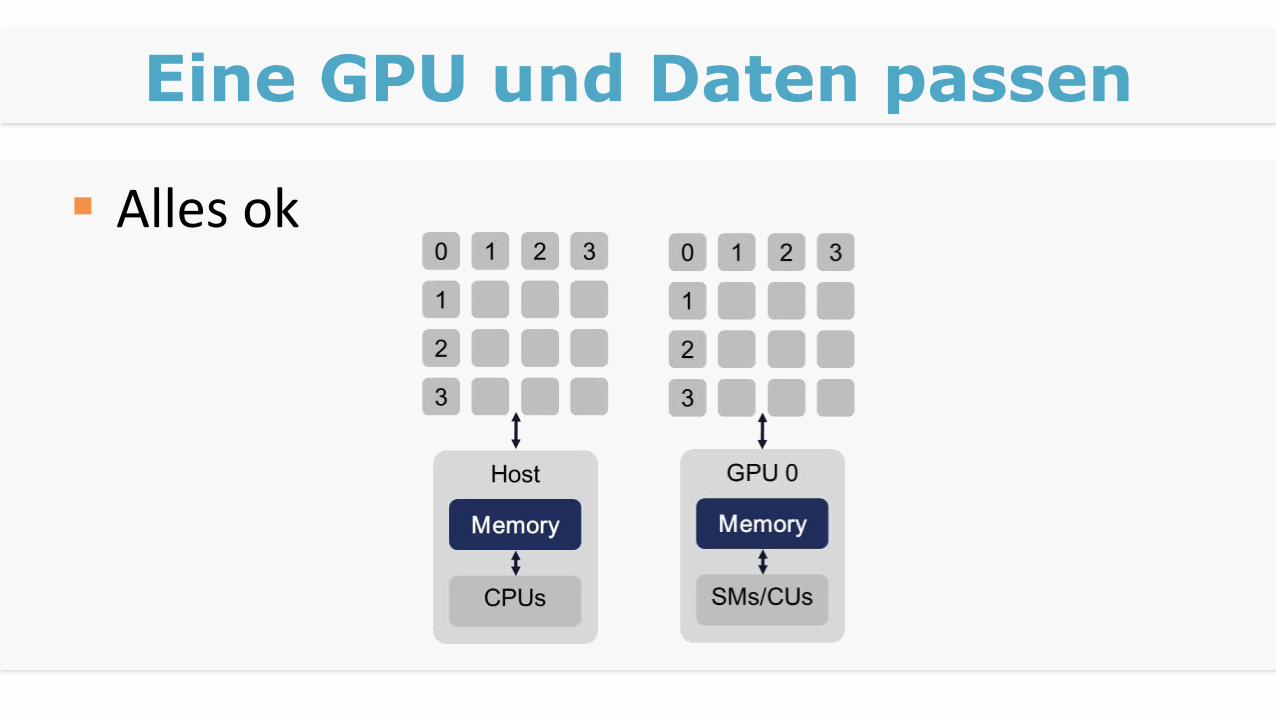
Eine GPU und Daten passen
Alles ok
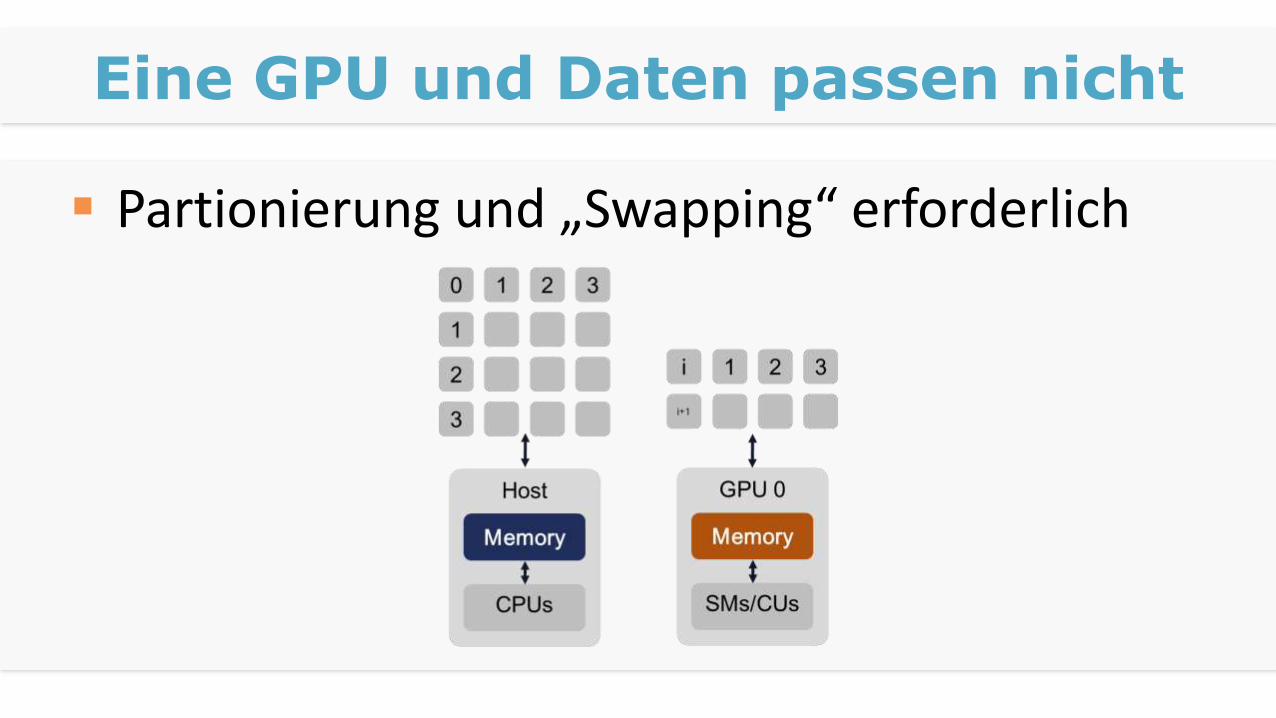
Eine GPU und Daten passen nicht
Partionierung und „Swapping“ erforderlich
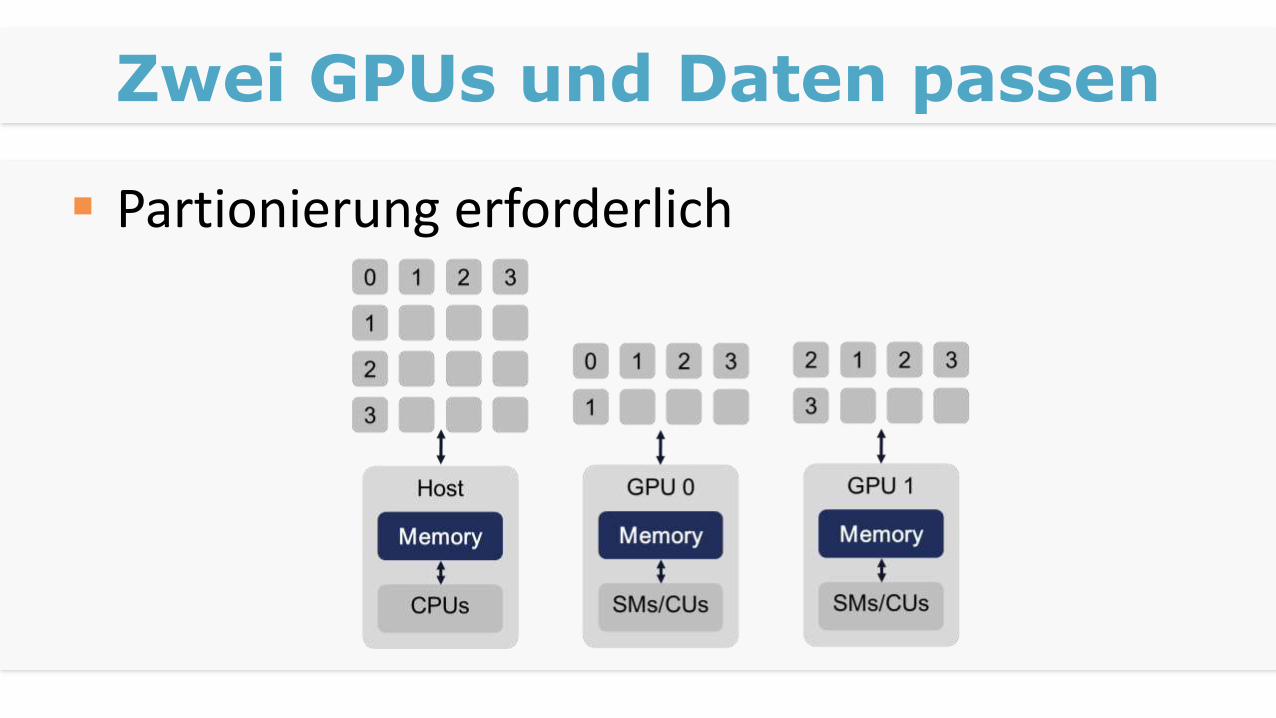
Zwei GPUs und Daten passen
Partionierung erforderlich
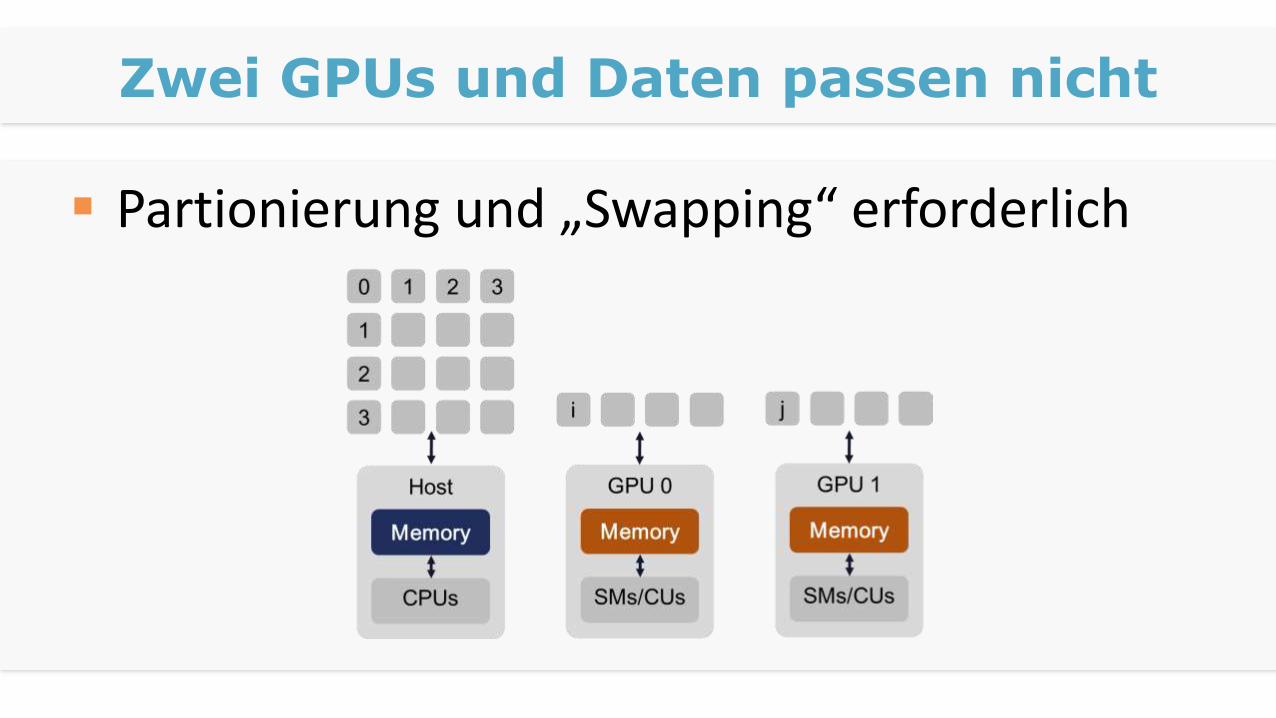
Zwei GPUs und Daten passen nicht
Partionierung und „Swapping“ erforderlich

Unterschiede CPU vs. GPU
Speicher
Aufbau
Größe
Geschwindigkeit
Anzahl der Kerne

Host und Device
Host Der „Kopf“ des Ganzen Management Speicher, Queues, Events
Aufruf von Kerneln Synchronisation
Device Traditionell „reine Arbeitspferde“
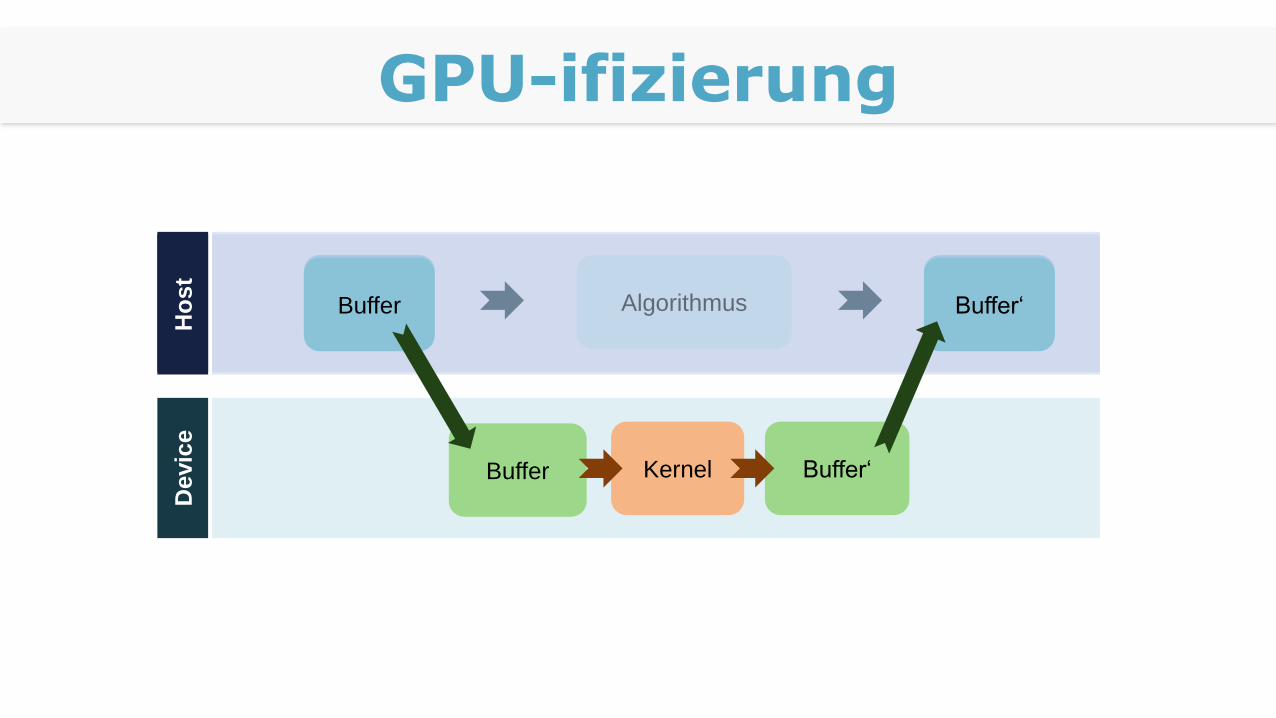
GPU-ifizierung
Ho
st
AlgorithmusBuffer Buffer‘
Ho
st
Buffer Buffer‘
Devic
e
KernelBuffer Buffer‘

Teil 5: Überblick CUDA
Installation
Komponenten
Samples
Bibliotheken

CUDA - Versionen
8.0: Pascal (Unified Memory)
7.5: FP16, C++ GPU Lambas
7.0: C++
6.5: ARM64, __shfl
6.0: Unified Memory, Tegra
https://en.wikipedia.org/wiki/CUDA
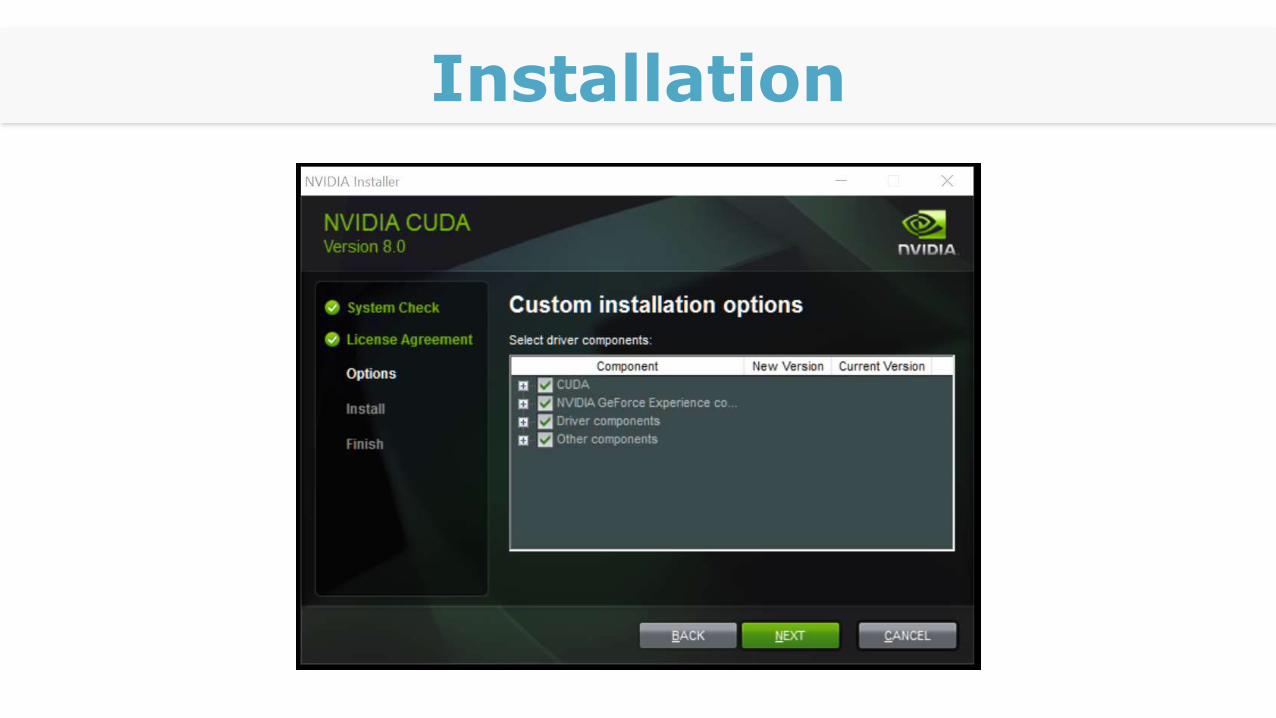
Installation

CUDA
Tools
Samples
VS Integration
Dokumentation
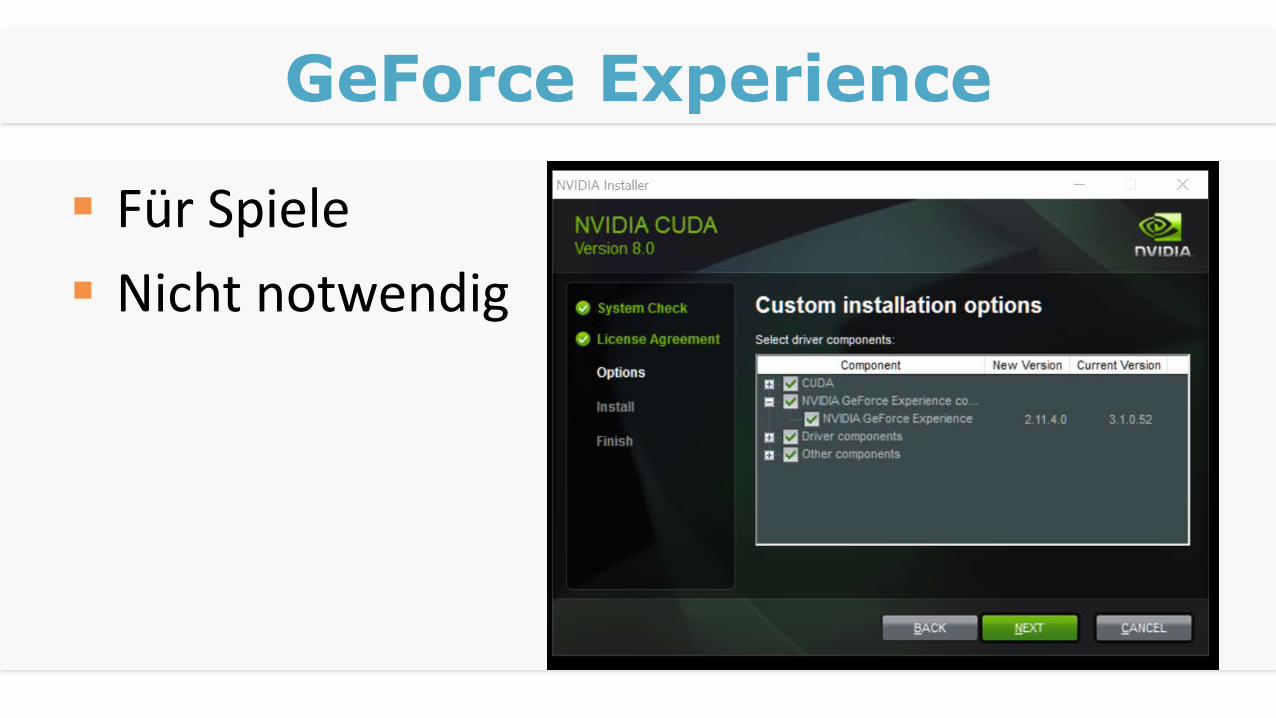
GeForce Experience
Für Spiele
Nicht notwendig
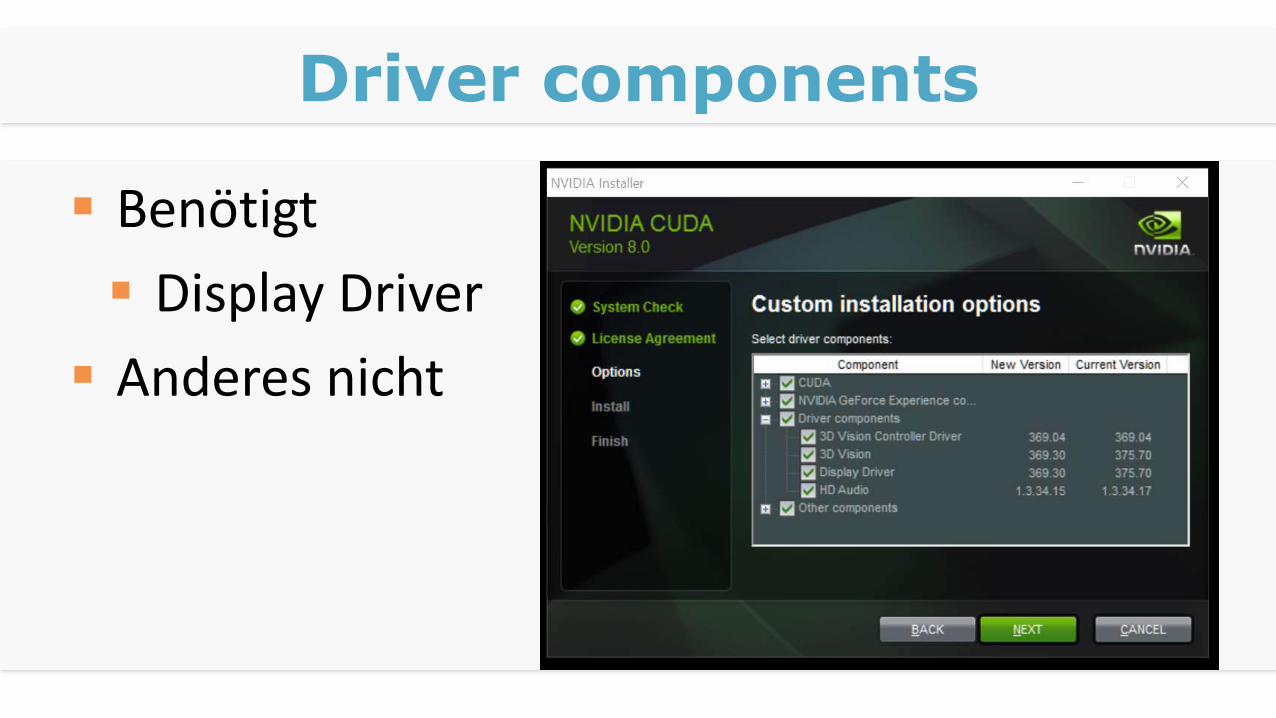
Driver components
Benötigt
Display Driver
Anderes nicht
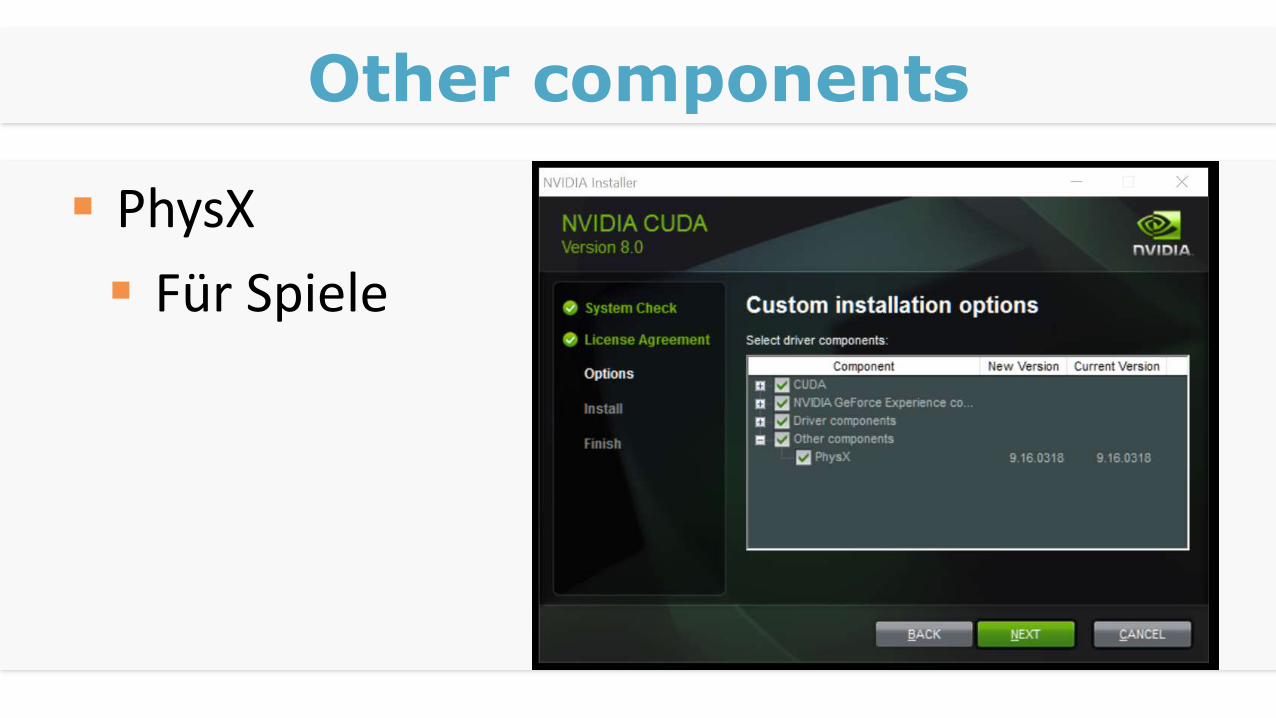
Other components
PhysX
Für Spiele
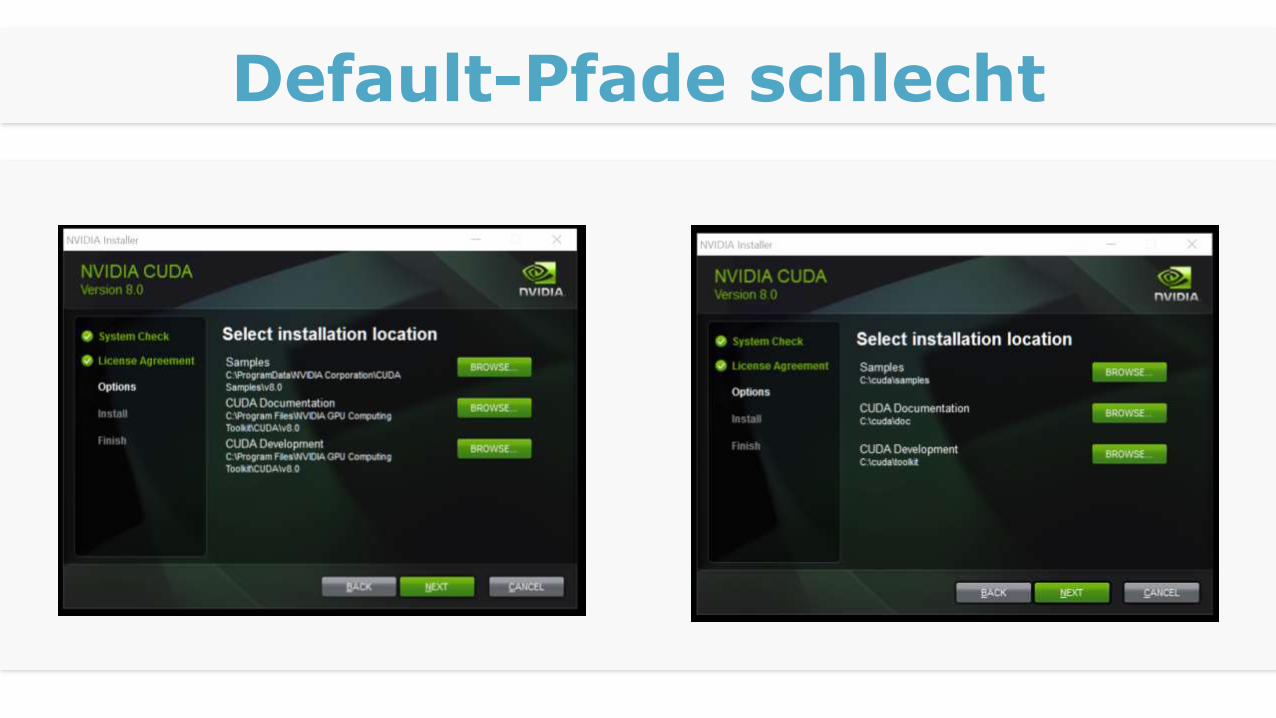
Default-Pfade schlecht
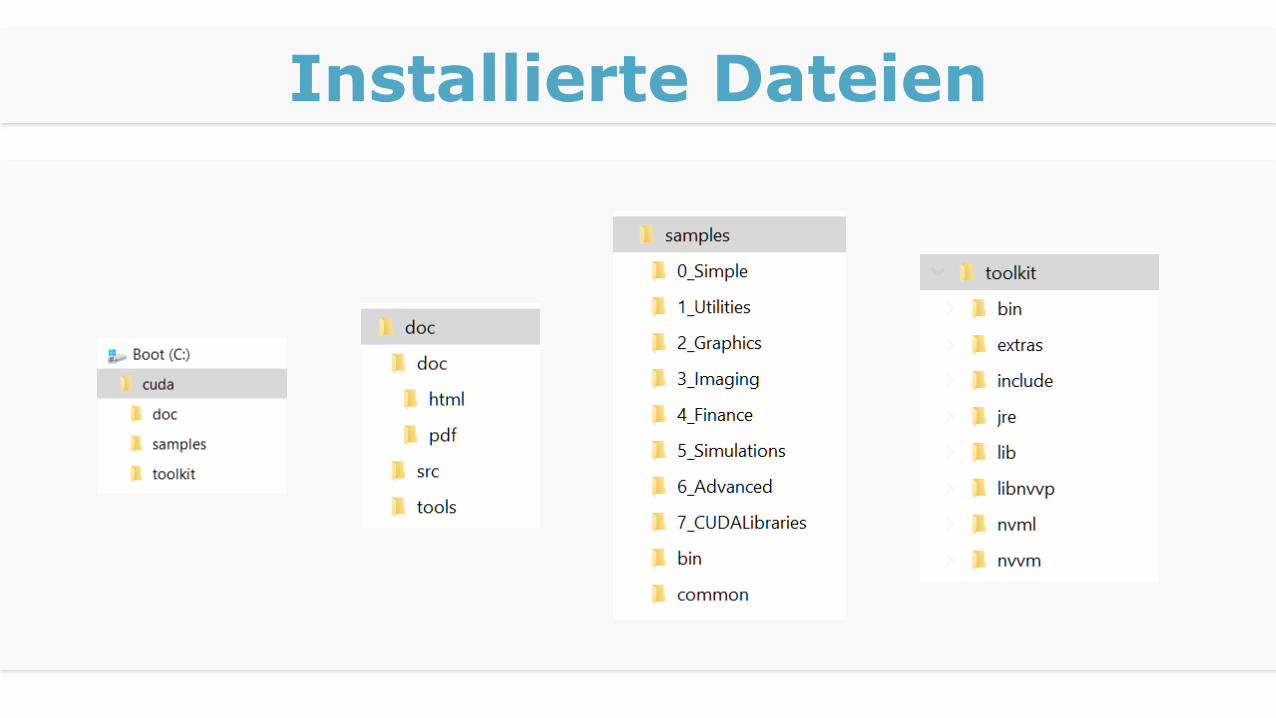
Installierte Dateien
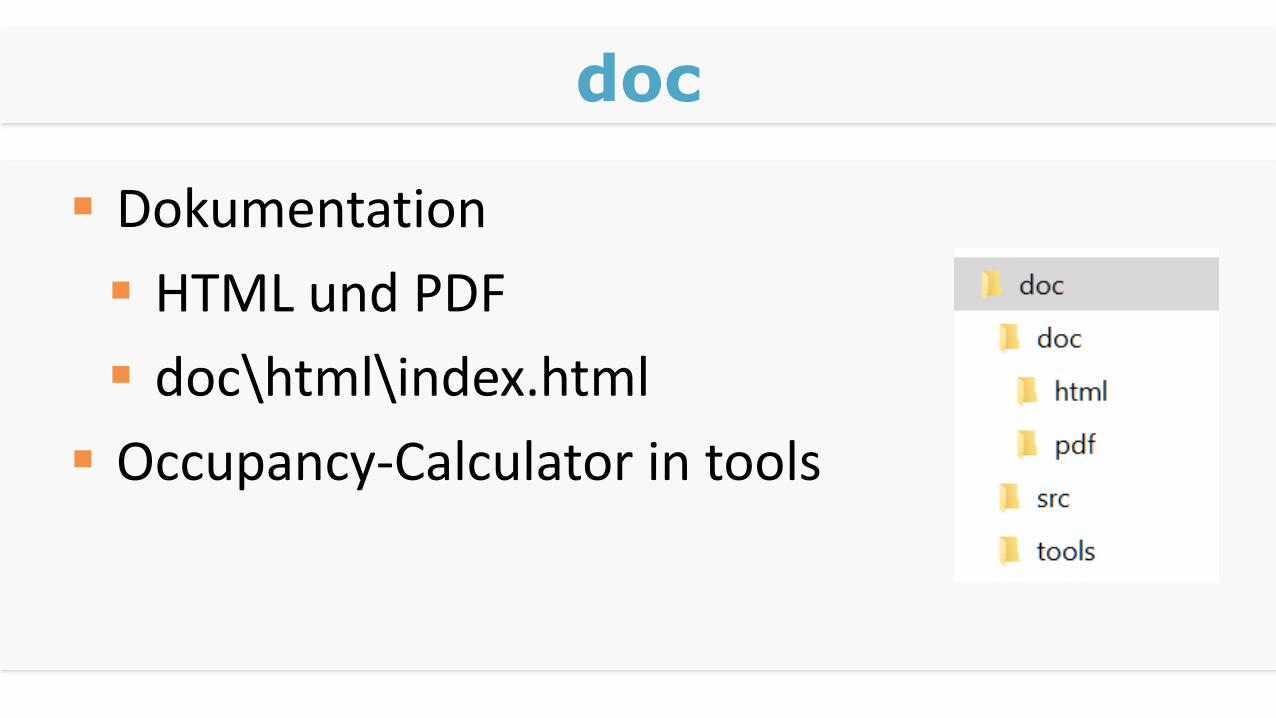
doc
Dokumentation
HTML und PDF
doc\html\index.html
Occupancy-Calculator in tools
CUDA C Programming Guide
CUDA C Best Practices Guide
Samples
155 Beispiele
Anlaufstelle

deviceQuery
Informationen
Anzahl GPUs
Eigenschaften

bandwidthTest
PCIe Bus
„host“
„device“
H2D
D2H
D2D

toolkit
Grundlegende Binaries nvcc compiler nvprof profiler für Kommandozeile nvvp visual profiler
Und weitere für Profis cuda-memcheck.exe nvdisadm.exe nvprune.exe ptxas.exe

Bibliotheken
Mathematische Verfahren
cuBLAS, cuFFT, cuSPARSE, cuSOLVER, NVBLAS
Diverse
cuRAND, nvGRAPH, cuDNN, NPP

Runtime vs. Driver API
CUDA Driver API
Low level, C, ähnlich OpenCL 1.x
CUDA Runtime API
Higher Level, C++
Thrust
Ähnlich STL-Bibliothek

Teil 6: Map mit CUDA
CUDA Grundlagen
Map mit CUDA
Block und Grid
Compute Capability

Methodik
Entwickle
1. „Golden Code“ (sequentiell und korrekt)
2. Parallelisiere auf CPU (*)
3. Transformiere zu GPU-Code
Unit-Tests stellen Korrektheit sicher
(*) Unterschiede CPU-GPU

hello_world.cu
Kernel
Aufruf
Synchronisation
Konfiguration

2d-map-KernelKernel
Template
ID berechnen
Wo ist die for-Schleife?

Aufruf
Aufruf
Synchronisation
Block & Grid

Block
Ein SM hat 64 (Pascal), 128 (Maxwell) oder 192 Kerne (Kepler)
Blockgröße sollte an Hardware (SM) angepasst sein
Typischerweise 32x
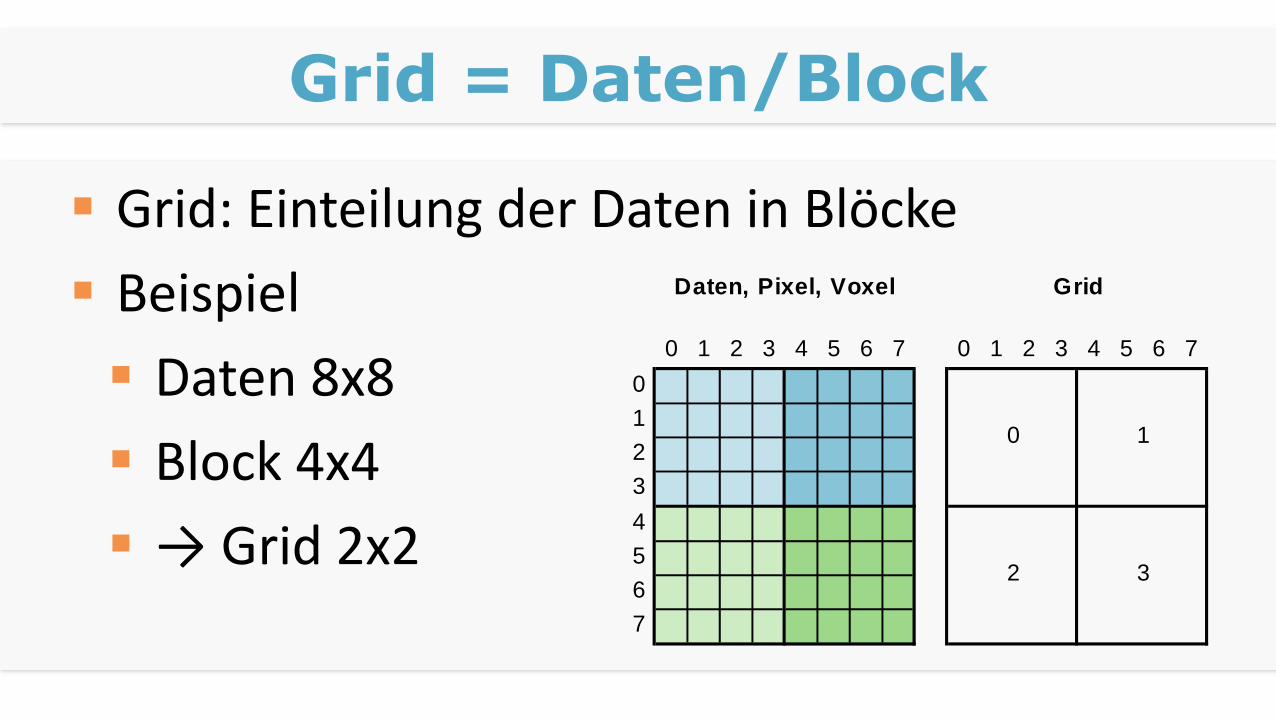
Grid = Daten/Block
Grid: Einteilung der Daten in Blöcke
Beispiel
Daten 8x8
Block 4x4
→ Grid 2x2
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
0
1
2
3
4
5
6
7
0 1
2 3
Daten, Pixel, Voxel Grid
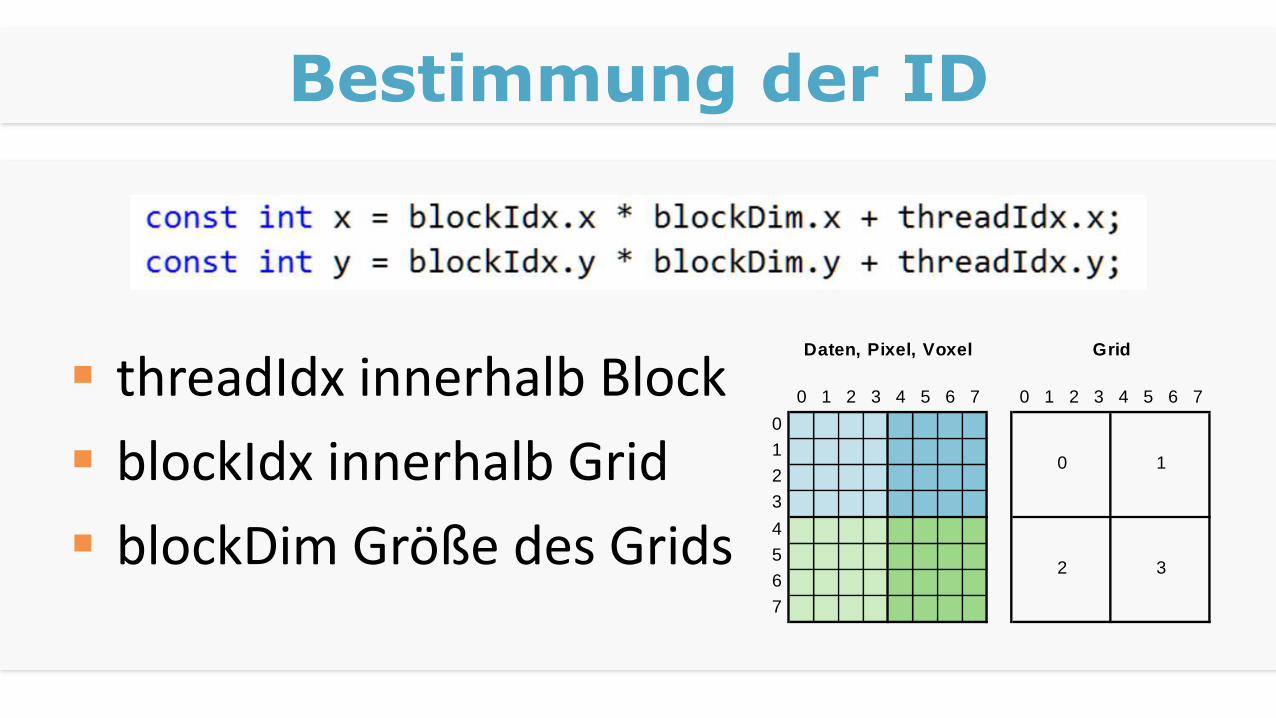
Bestimmung der ID
threadIdx innerhalb Block
blockIdx innerhalb Grid
blockDim Größe des Grids
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
0
1
2
3
4
5
6
7
0 1
2 3
Daten, Pixel, Voxel Grid

Viele, viele Threads
Block & Grid ersetzt die for-Schleifen
Ein dim3(x, y, z) Block besteht aus x*y*z Threads
Ein dim3(X, Y, Z) Grid besteht aus X*Y*Z Blöcken
Insgesamt X*Y*Z*x*y*z Threads
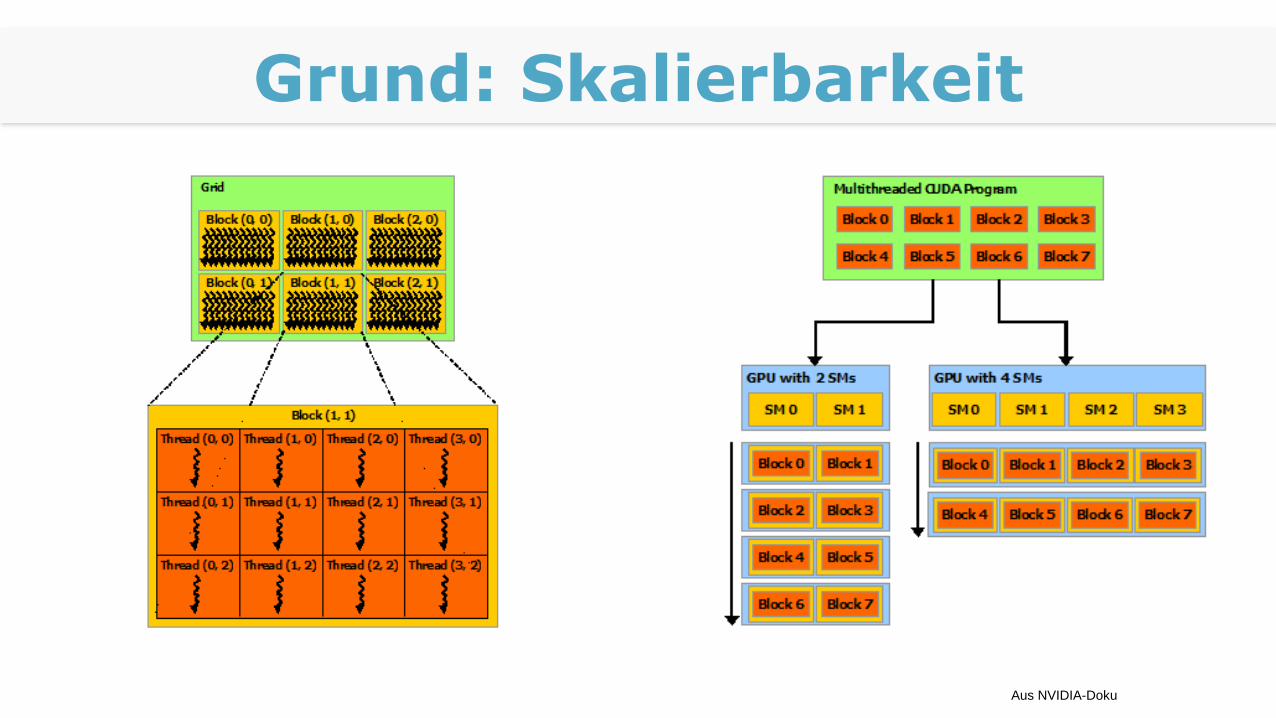
Grund: Skalierbarkeit
Aus NVIDIA-Doku

Stand der Dinge
Wir haben
Kernel
Aufruf des Kernels
Wir benötigen
Speicher auf dem Device
GPU
Global Memory
Constant Texture
Prozessor (SM)
Shared / L1
Registers
C
L2 Cache
C
C
C
C
C
C
C
C
C
C
C
C
C
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM

Speicher allokieren
C/C++ low-level
CUDA

Unified Memory
cudaMallocManaged()
Speicher wird auf Host und Device angelegt
Ab CUDA 8.0 und Pascal-Karte
Beliebige Größe (Swapping automatisch)
Vorher ab CC 3.0
Muss in Device-Speicher passen

… und Pascal-Karte ?
Große Unterschiede zwischen Karten-Generationen: Pascal, Maxwell, Kepler, Fermi
Compute Capability
Zahl Major.Minor, z. B. 3.0, 5.2, 6.0
Kann mit „deviceQuery“ ermittelt werden
Siehe http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities

Compute Capability (CC)
Beispiel
Es gibt mehr,
Das sind nicht alle
Aus https://devblogs.nvidia.com/parallelforall/inside-pascal/

Compute Capability (CC)
2.0 (deprecated) Fermi
3.0, 3.2 Kepler, Unified Memory
3.5 Dynamic Parallelism
5.0, 5.2, 5.3 Maxwell
6.0 Pascal

CC und Code
Problem
Für welche CC schreibt man den Code?
Für die neueste? Das ist am einfachsten!
Aber Kunden mit älteren Karten?
Maintenance-Probleme mit Versionen?

Explizit auch möglich
Anlegen auf Host und Device cudaMallocHost(&ptr, size_t) cudaMalloc(&ptr, size_t)
Kopieren cudaMemcpy(dst, src, sz, dir) dir: H2H, H2D, D2H, D2D
Freigabe mit cudaFree(ptr)

Fehlerbehandlung
Rückgabewert abfragen
Ruiniert die Lesbarkeit!
Makro „drumzurum“

Fehlerbehandlung
Andere Möglichkeit
In Funktion auslagern
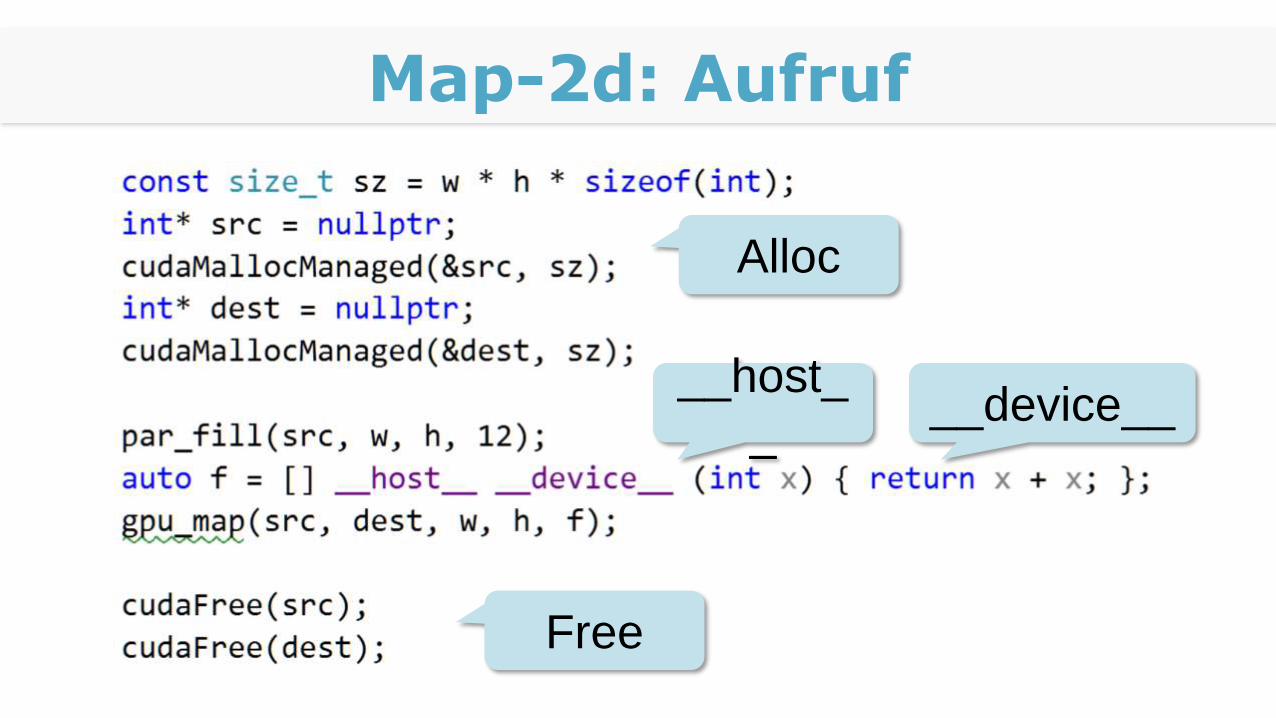
Map-2d: Aufruf
Alloc
Free
__host_
___device__

Teil 7: nvcc und IDEs
Kompilierung
Nvcc
Visual Studio

Compilieren mit nvcc
Präprozessor
Teile Host- und Device-Code
Host-Code wird mit C++ kompiliert
Device-Code wird zu PTX kompiliert (Assembler-Sprache)
Aus PTX wird CUBIN-Binärformat
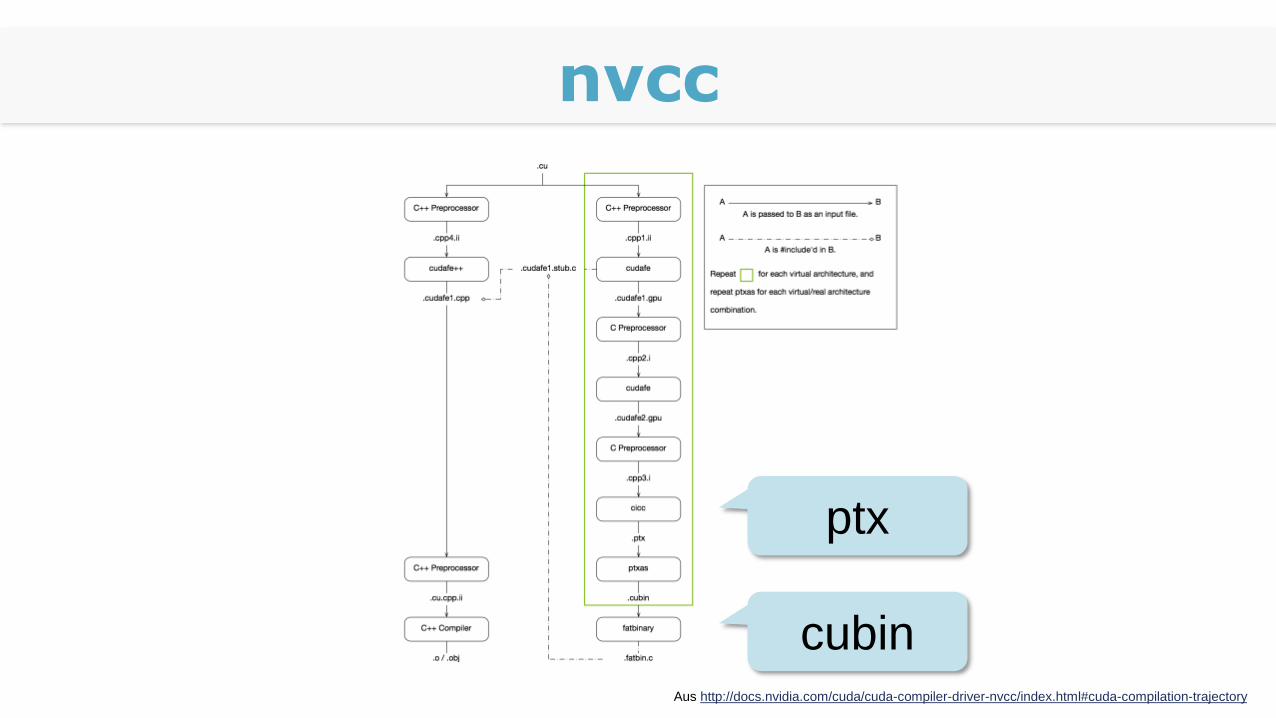
nvcc
Aus http://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html#cuda-compilation-trajectory
ptx
cubin

PTX und Cubin
PTX ist eine Assembler-Sprache
Cubin ist für eine CC kompiliertes PTX
Kompilierung
Offline: mit ptxas
Online: durch Treiber (just-in-time, JIT)

Nvcc erzeugt Exe‘s
Exe nur mit CUBIN
Kleine Datei, aber nur für bestimmte CCs
Exe mit PTX
--fatbin (default)
JIT für alle CCs, auch in Zukunft
PTX sollte in Exe inkludiert werden

nvcc
Typische Kommandozeile
nvcc.exe -gencode=arch=compute_30,code=\"sm_30,compute_30\" -gencode=arch=compute_52,code=\"sm_52,compute_52\" -gencode=arch=compute_60,code=\"sm_60,compute_60\" --use-local-env --cl-version 2015 -ccbin "C:\Program Files (x86)\... \x86_amd64" -I"../gpu-intro/" -IC:\cuda\toolkit\include -IC:\cuda\toolkit\include -G --keep-dir x64\Debug-maxrregcount=0 --machine 64 --compile -cudart static --expt-extended-lambda -g -DWIN32 -DWIN64 -D_DEBUG -D_CONSOLE -D_MBCS -Xcompiler "/EHsc /W3 /nologo/Od /FS /Zi /RTC1 /MDd " -o x64\Debug\gpu_map.cu.obj "C:\workspace-gpu\gpu-intro\map\gpu_map.cu"
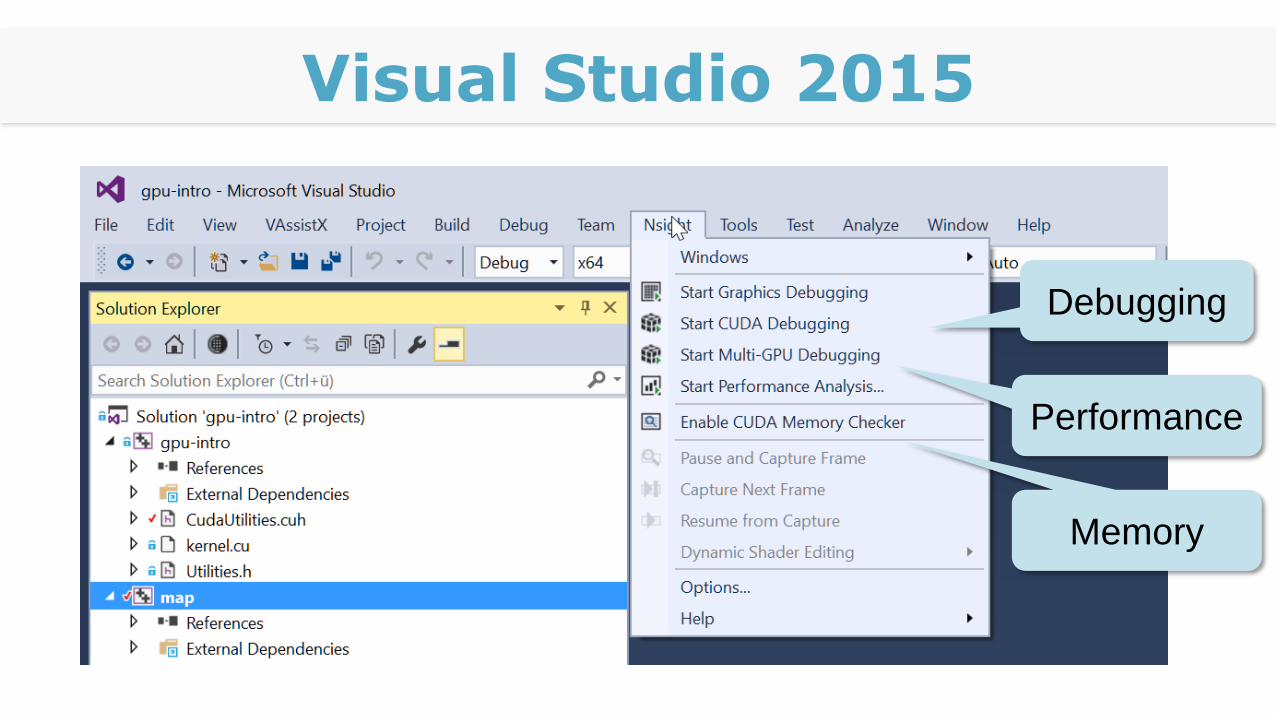
Visual Studio 2015
Debugging
Performance
Memory
Optionen: Common
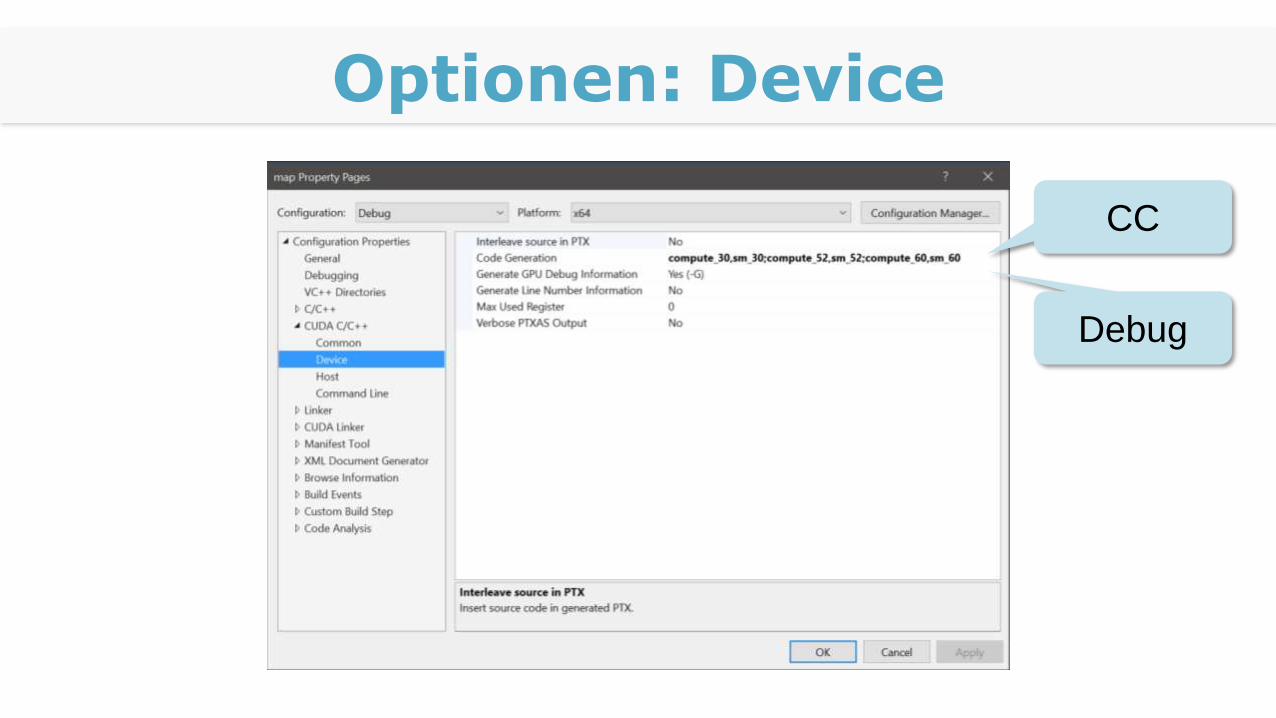
Optionen: Device
CC
Debug
Optionen: Host
Debug
wie C++
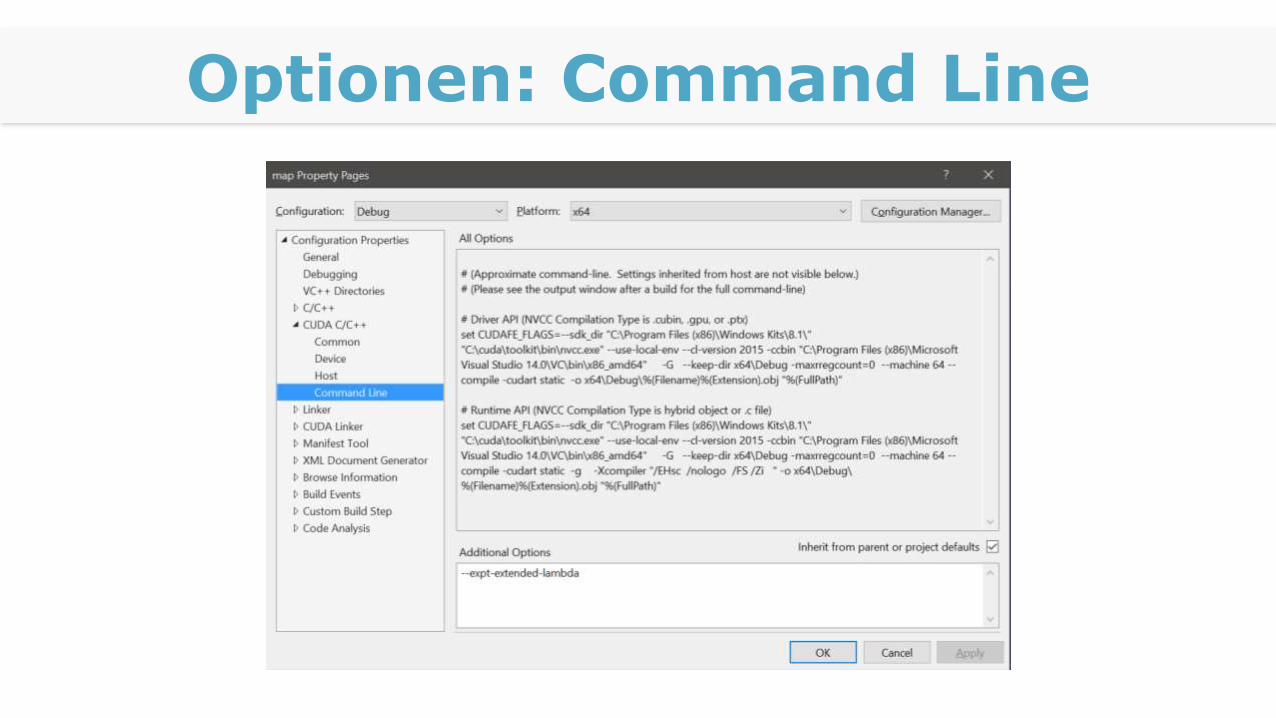
Optionen: Command Line
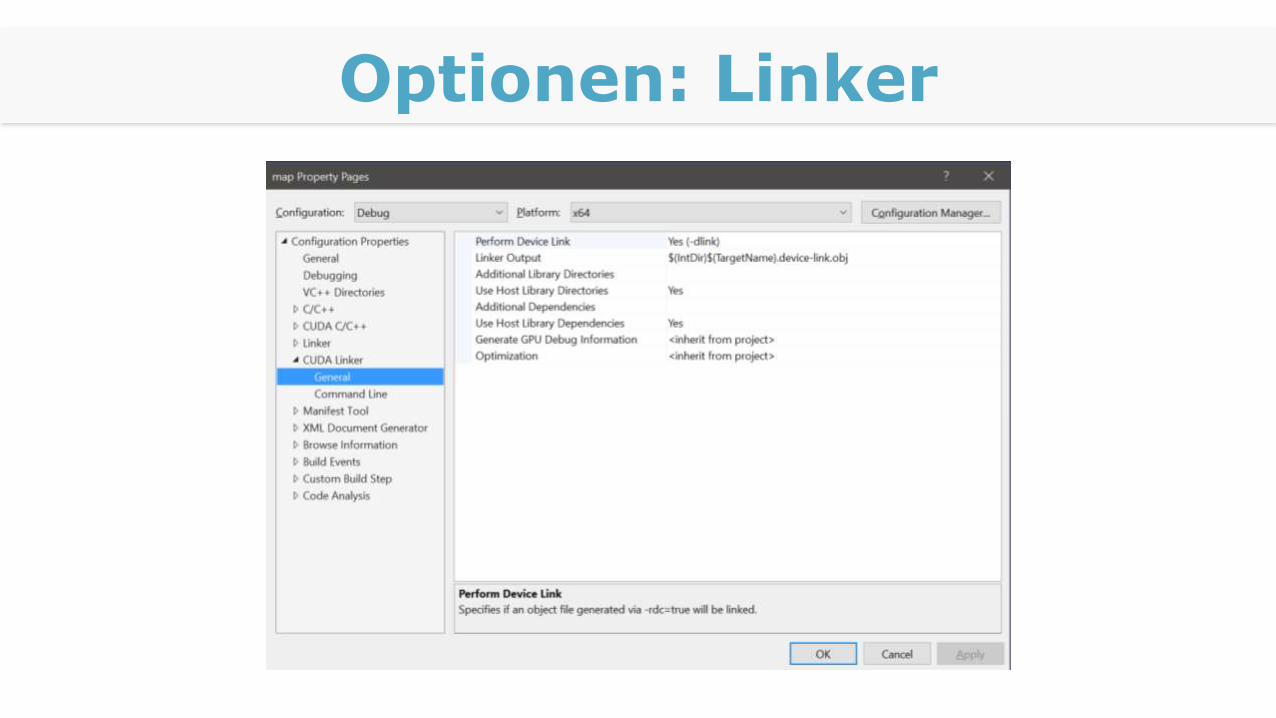
Optionen: Linker
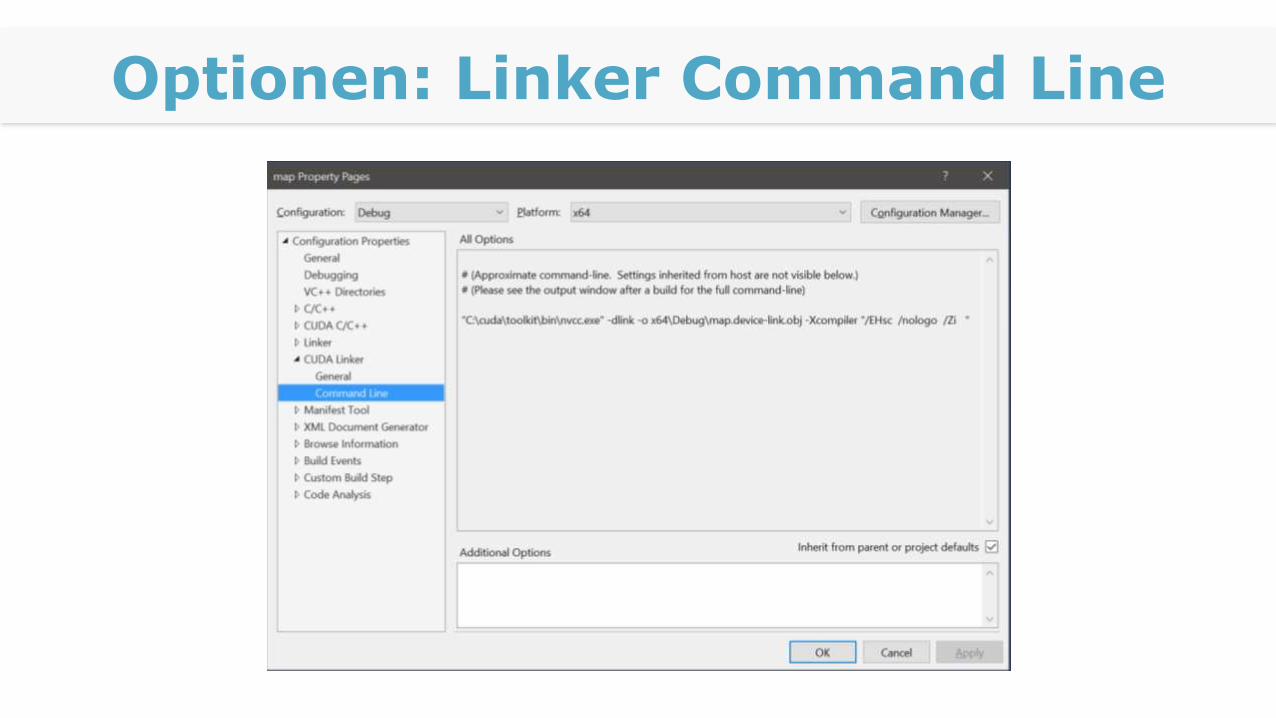
Optionen: Linker Command Line
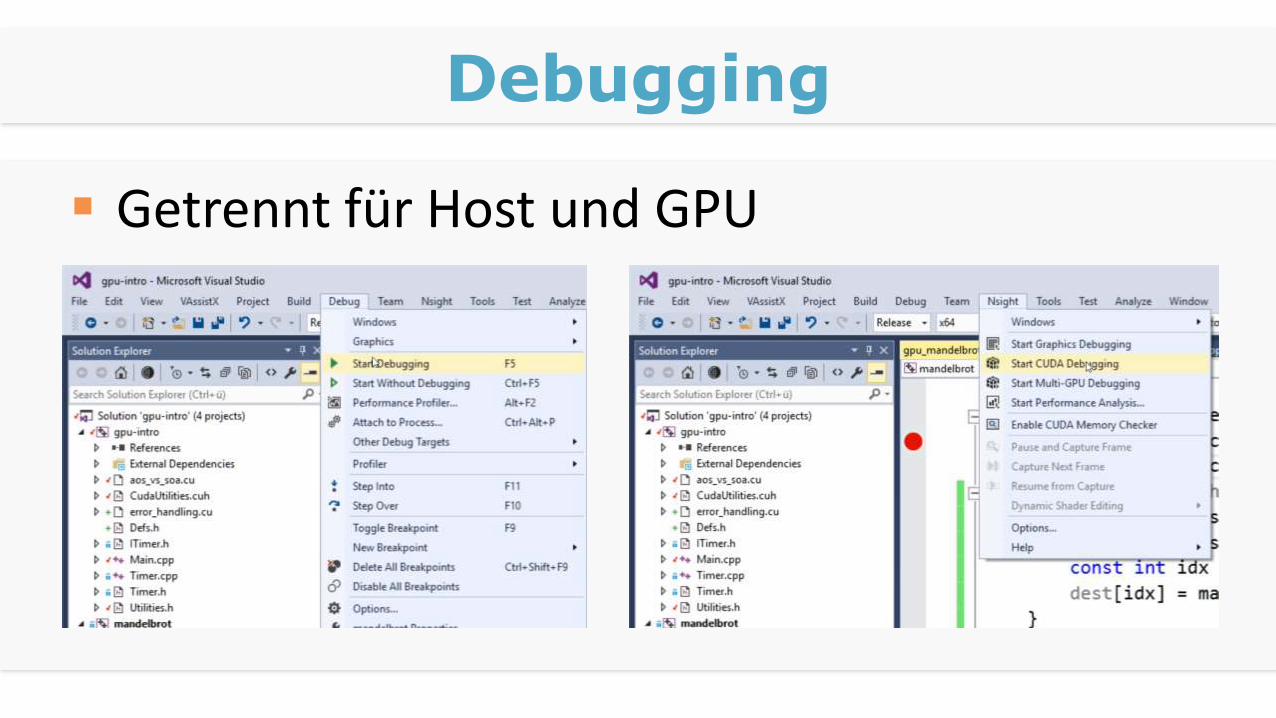
Debugging
Getrennt für Host und GPU

Debugging
Allgemein gilt:
Lieber auf der CPU debuggen
Code-Reuse maximieren
Gemeinsamer CPU und GPU-Code
Unit-Tests für die CPU
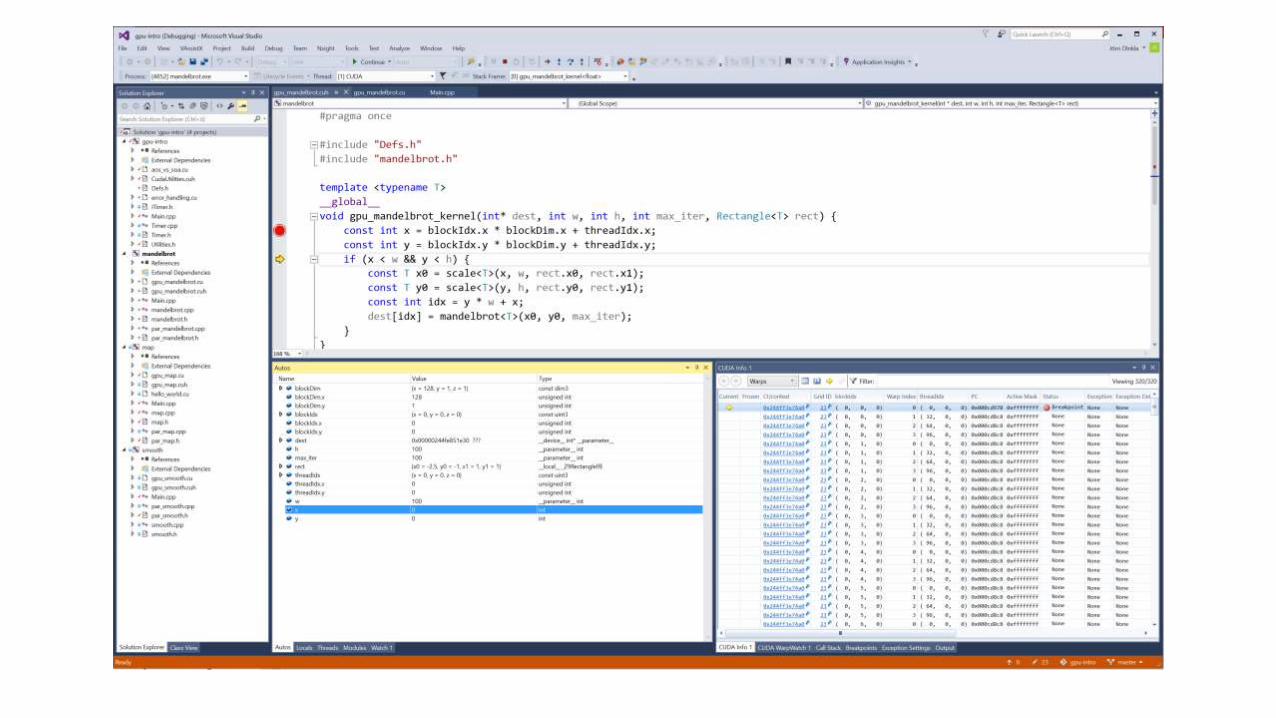
Debugging
Vorsicht bei nur einer GPU-Karte
Gleichzeitig Anzeigen und Debuggen ist oft problematisch

Teil 8: Smoothing
Algorithmus
CPU
GPU-ifizierung

Smoothing
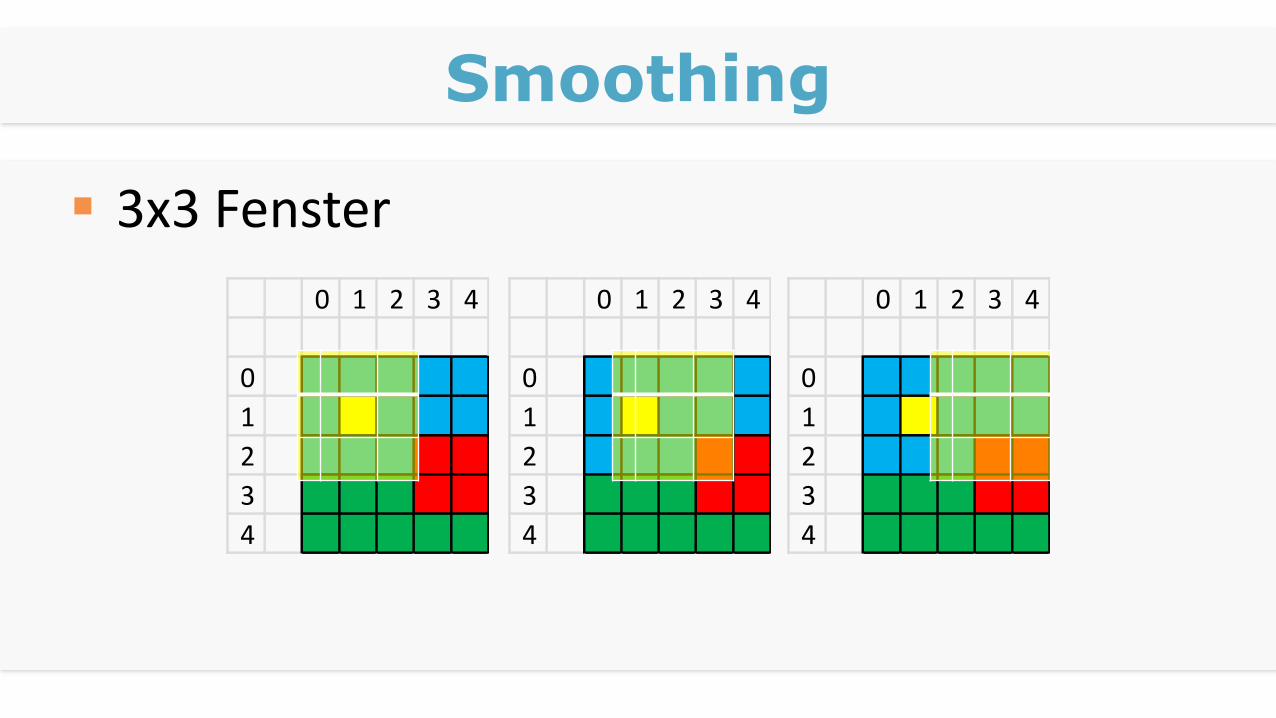
Smoothing
3x3 Fenster
0 1 2 3 4
0
1
2
3
4
0 1 2 3 4
0
1
2
3
4
0 1 2 3 4
0
1
2
3
4
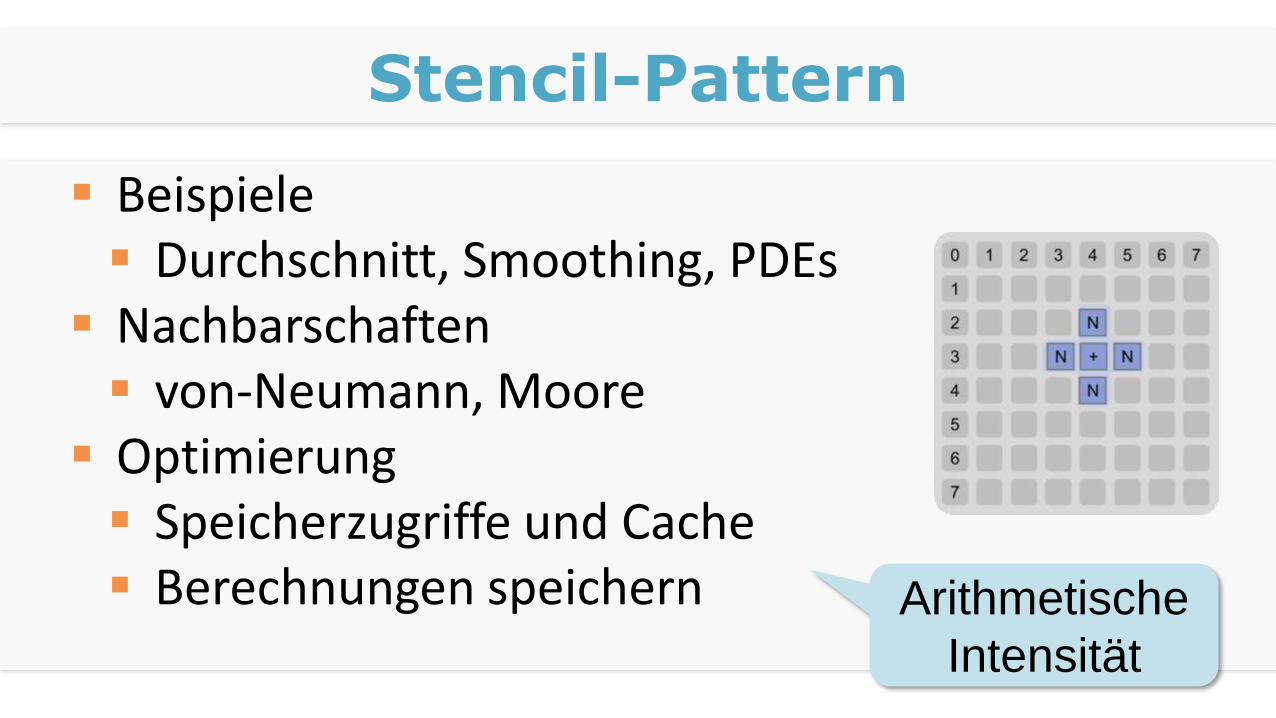
Stencil-Pattern
Beispiele Durchschnitt, Smoothing, PDEs
Nachbarschaften von-Neumann, Moore
Optimierung Speicherzugriffe und Cache Berechnungen speichern Arithmetische
Intensität

Algorithmus
For all pixel at x,y in image
sum = 0, c = 0
For all dx,dy in neighborhood
sum += vol[x+dx, y+dy]
c += 1
vol‘[x,y] = sum / c

Hilfsfunktion

Smooth mit CPU

Beispieldaten
Aus didaktischen Gründen vereinfacht
In Float
Mit RGB analog
Nur Mittelwert, keine gewichtete Summe
Mit Array von Gewichten analog
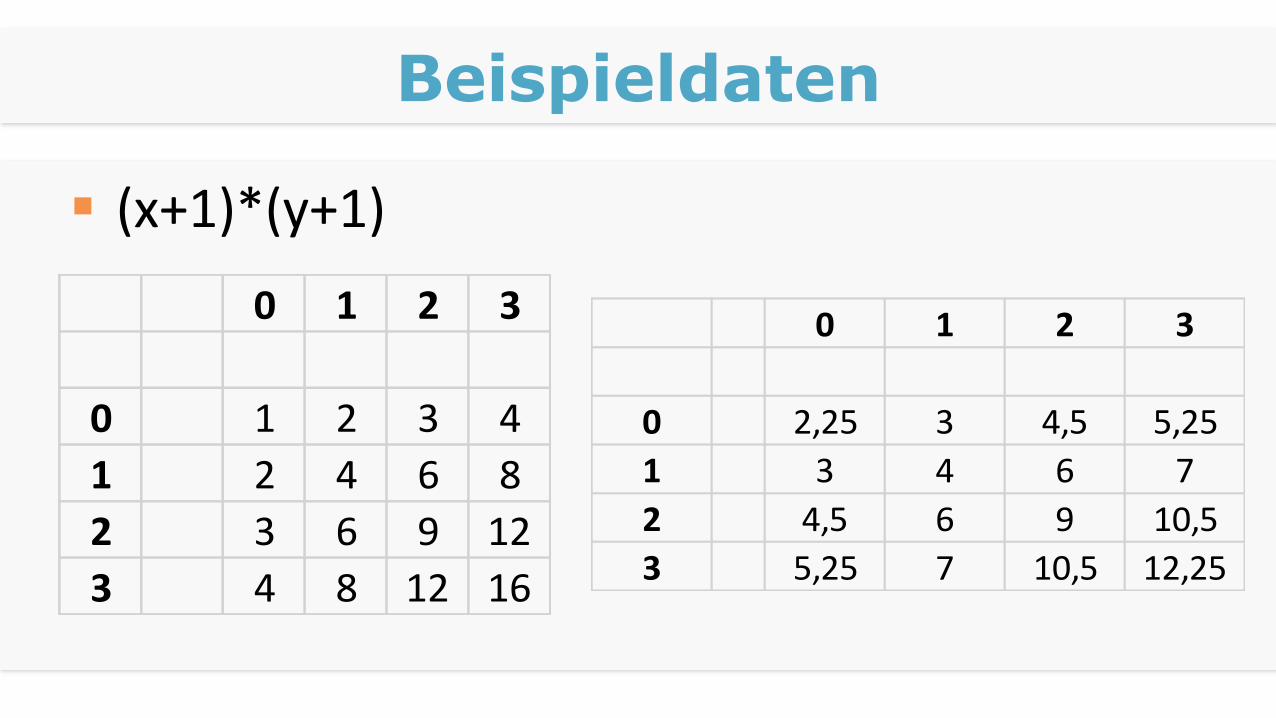
Beispieldaten
(x+1)*(y+1)
0 1 2 3
0 1 2 3 4
1 2 4 6 8
2 3 6 9 12
3 4 8 12 16
0 1 2 3
0 2,25 3 4,5 5,25
1 3 4 6 7
2 4,5 6 9 10,5
3 5,25 7 10,5 12,25

Smoothing mit der GPU
For-Schleifen x,y umformen zu Block&Grid
Kernel schreiben
Kernel-Aufruf schreiben
Code möglichst übernehmen
Erfahrung:
Unterschiedliche Versionen sind schlecht

Minimale Änderungen
Einzige Änderung an smooth()
Wiederverwendbarkeit bei CUDA sehr gut

Kernel

Aufruf des Kernels

Unspecified launch failure
Eine GPU im Rechner …
… und Test mit großen Daten

Windows-Treiber
WDDM (Windows Display Driver Model)
Der normale Treiber, auch für Spieler
Kernel wird nach max. 2 Sekunden abgebrochen von Windows
TCC (nur für Tesla-Karten oder Linux)
Kein Display, keine Beschränkung
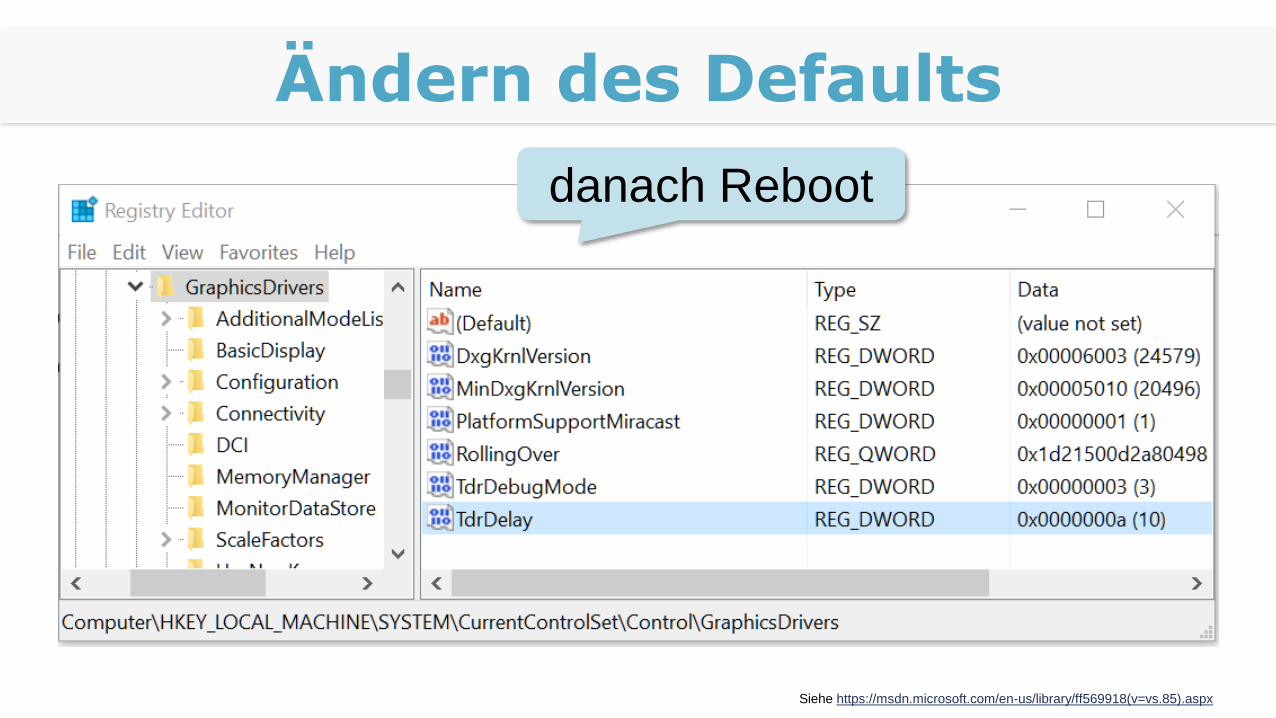
Ändern des Defaults
Siehe https://msdn.microsoft.com/en-us/library/ff569918(v=vs.85).aspx
danach Reboot

Vergleich der Laufzeiten
Das sieht für die GPU nicht gut aus.
Was ist da los?
i7 5930K 4 GHz GTX 1080
w h 1-Thread 12 Threads 128 Block
32768 4096 1908 261 624
32768 12288 5697 772 1853
32768 28672 13283 1761 4279
7,31 3,06 0,42
7,38 3,07 0,42
7,54 3,10 0,41
Speedup

Keine Panik!
Für GPU-Einsteiger normal
Hintergrundwissen erforderlich
GPU darf keine Black-Box mehr sein
Keine automatische Code-Optimierung
Wissen über GPUs erforderlich

Teil 9: CUDA genauer betrachtet
NVVP
Speicher
Kernel und Warps
Occupancy

Profiling allgemein
Nur „Release“-Code profilen
„Debug“-Code ist nicht repräsentativ
Code wird u. U. sehr oft ausgeführt
Keine großen Beispiele verwenden
Auch nicht zu klein

Profiling
nvprof.exe für Kommandozeile
Nsight for Visual Studio
NVVP
Eigene Eclipse-IDE

nvprof
==11816== Profiling result:Time(%) Time Calls Avg Min Max Name73.24% 226.67ms 1 226.67ms 226.67ms 226.67ms void gpu_mandelbrot_kernel<float>(int*, int, int, int, Rectangle<float>)26.76% 82.803ms 1 82.803ms 82.803ms 82.803ms [CUDA memset]
==11816== API calls:Time(%) Time Calls Avg Min Max Name40.80% 327.48ms 1 327.48ms 327.48ms 327.48ms cudaMallocManaged29.10% 233.59ms 1 233.59ms 233.59ms 233.59ms cudaDeviceSynchronize15.69% 125.91ms 1 125.91ms 125.91ms 125.91ms cudaMemset13.48% 108.18ms 1 108.18ms 108.18ms 108.18ms cudaFree0.82% 6.6170ms 1 6.6170ms 6.6170ms 6.6170ms cudaLaunch0.08% 639.91us 91 7.0320us 0ns 346.68us cuDeviceGetAttribute0.02% 148.08us 1 148.08us 148.08us 148.08us cuDeviceGetName0.00% 8.4700us 4 2.1170us 1.1680us 4.3810us cudaGetLastError0.00% 6.4250us 1 6.4250us 6.4250us 6.4250us cuDeviceTotalMem0.00% 6.1330us 4 1.5330us 292ns 4.6730us cudaGetErrorString0.00% 4.6730us 1 4.6730us 4.6730us 4.6730us cudaConfigureCall0.00% 3.5060us 3 1.1680us 292ns 2.3370us cuDeviceGetCount0.00% 2.6290us 5 525ns 292ns 877ns cudaSetupArgument0.00% 1.4600us 3 486ns 292ns 876ns cuDeviceGet
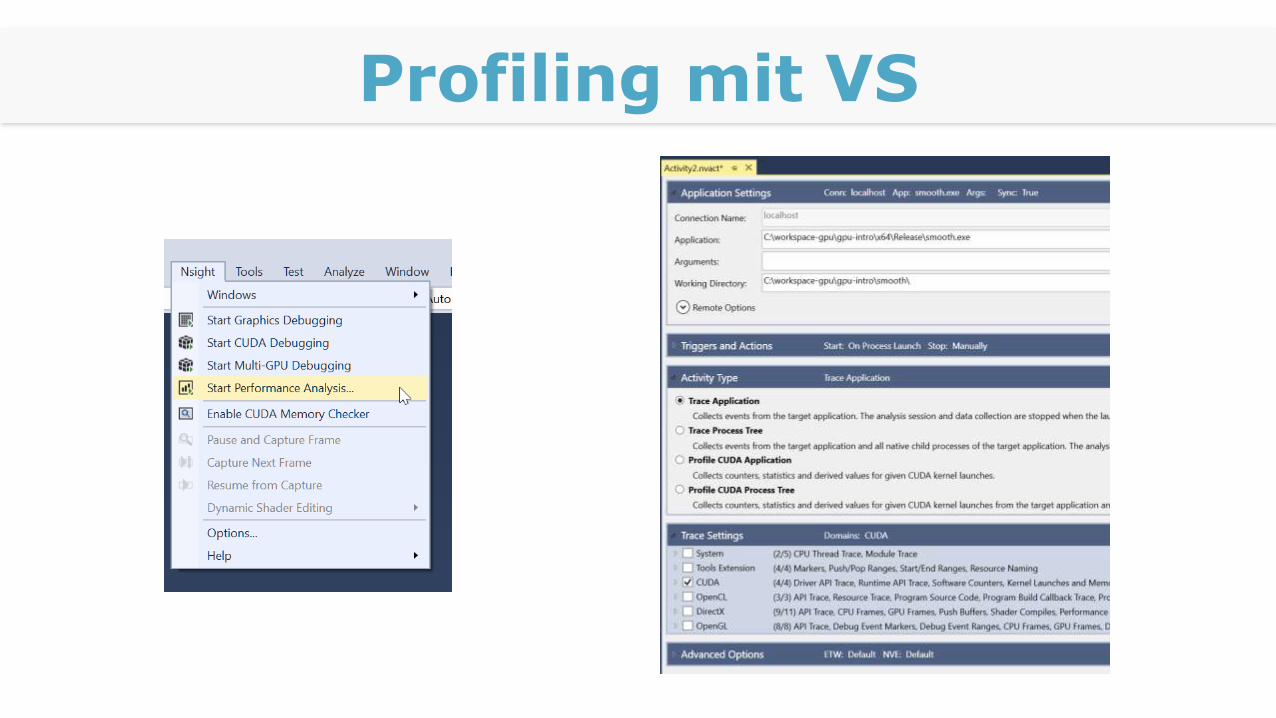
Profiling mit VS
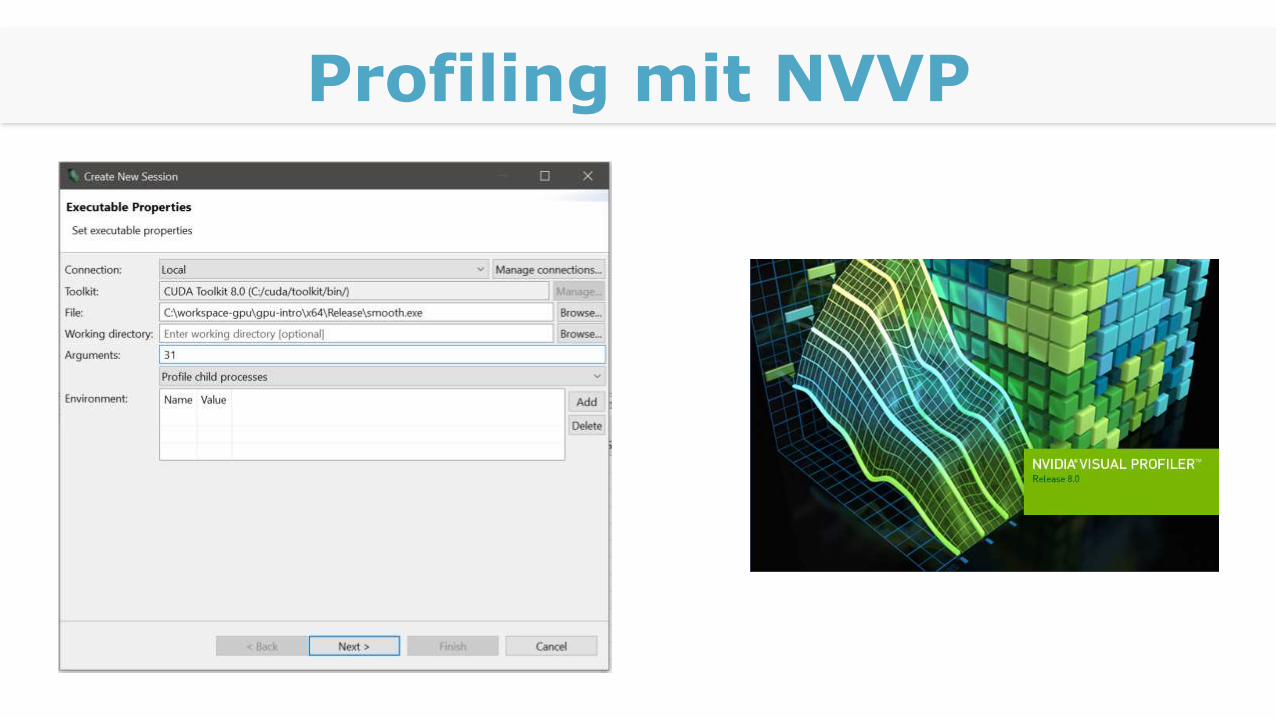
Profiling mit NVVP
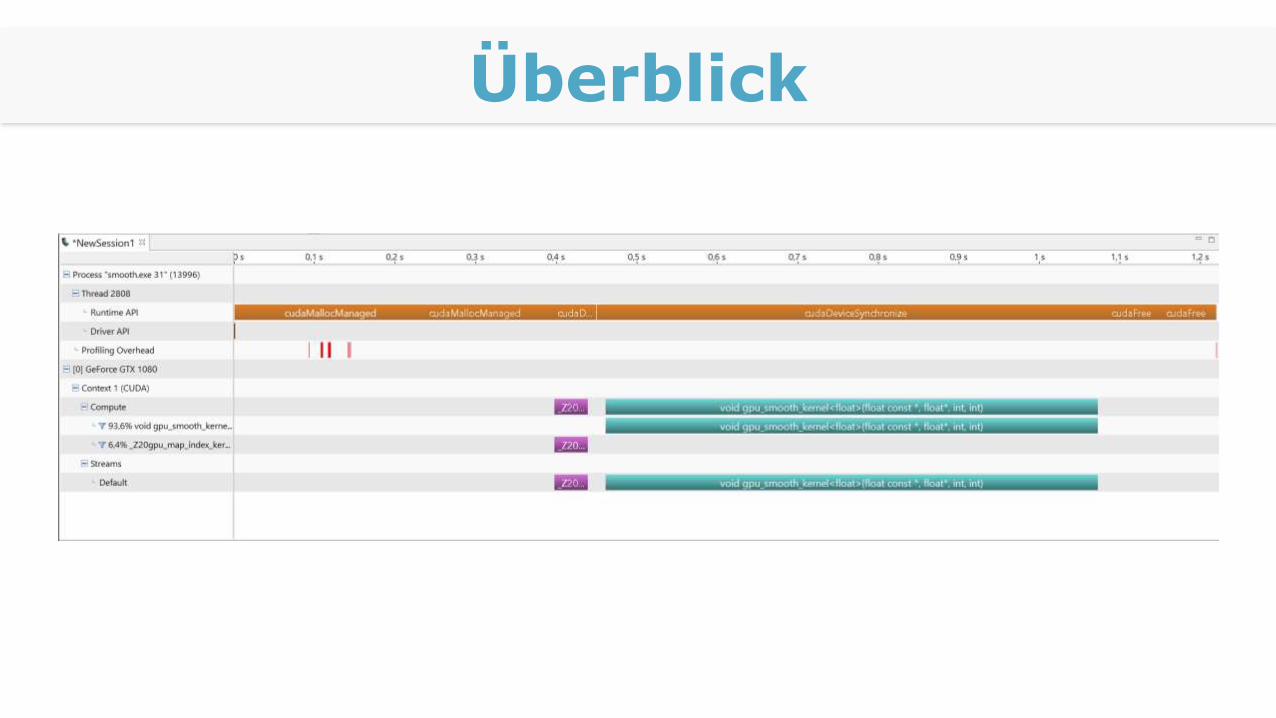
Überblick
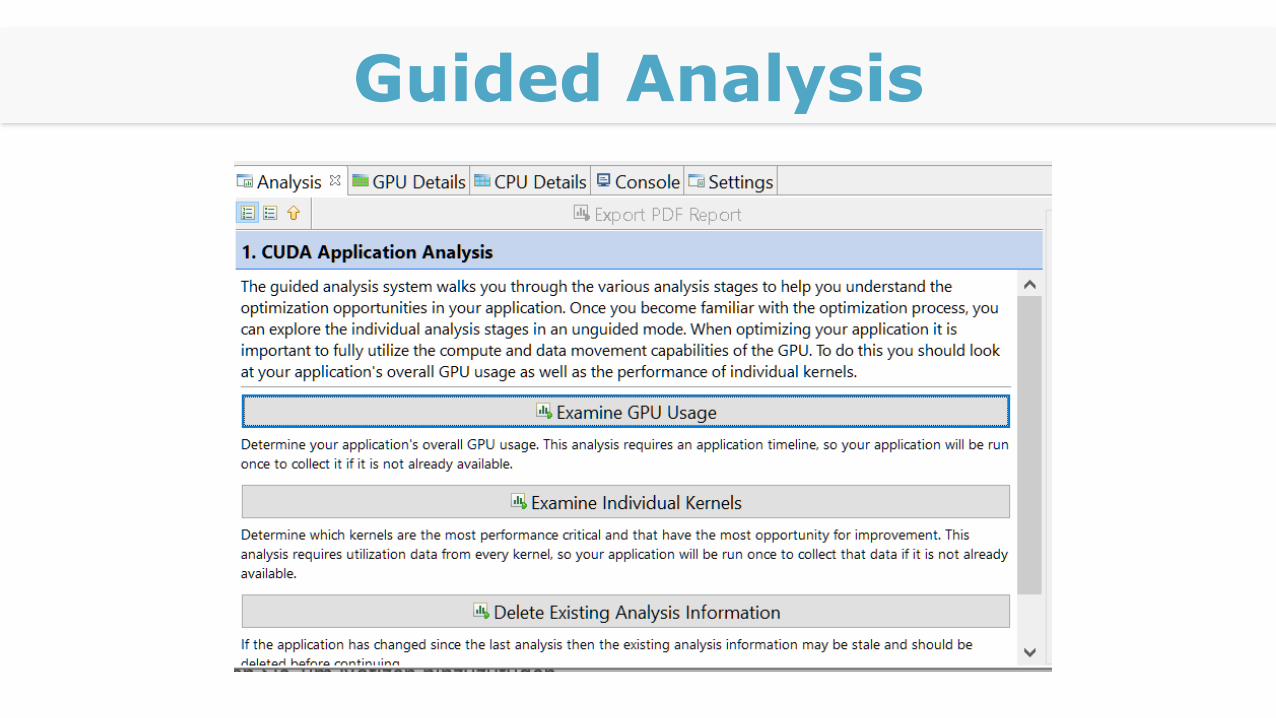
Guided Analysis
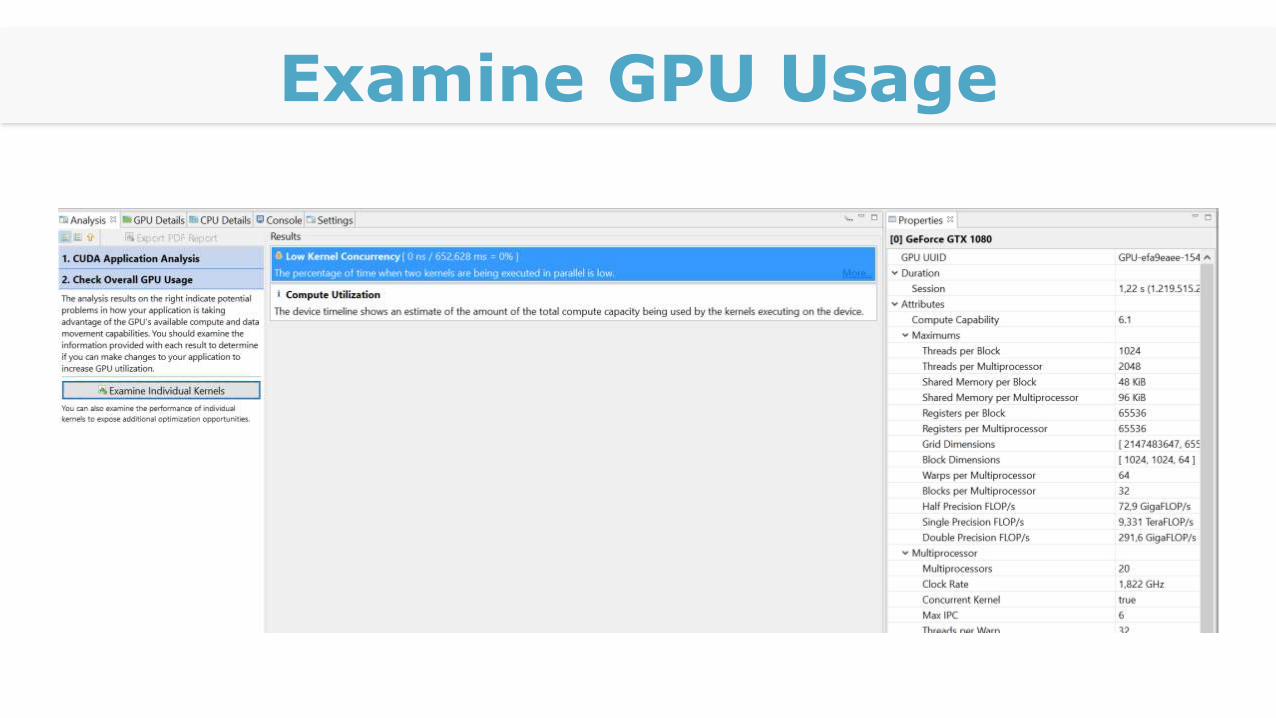
Examine GPU Usage
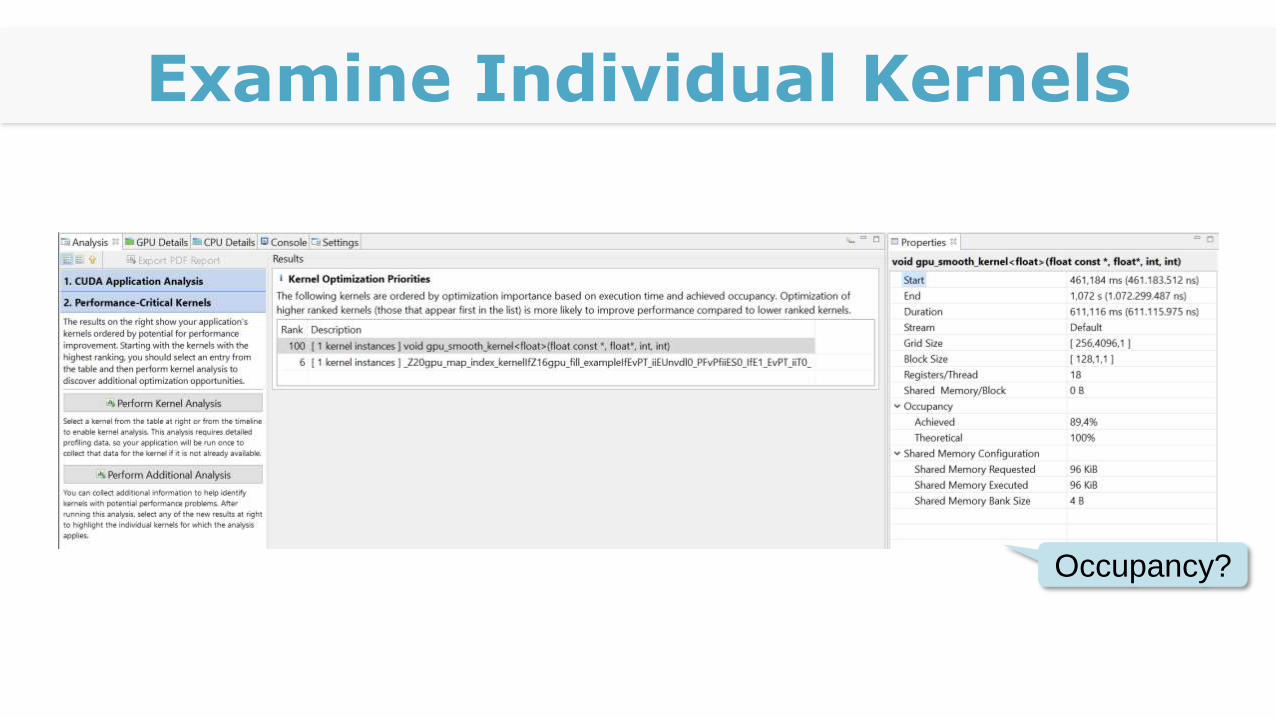
Examine Individual Kernels
Occupancy?

Arten der Auslastung
Computation Bound
Alle Prozessoren 100% ausgelastet
Memory Bound
Bandbreite zum Speicher voll ausgelastet
Latency Bound
Warten auf die Daten
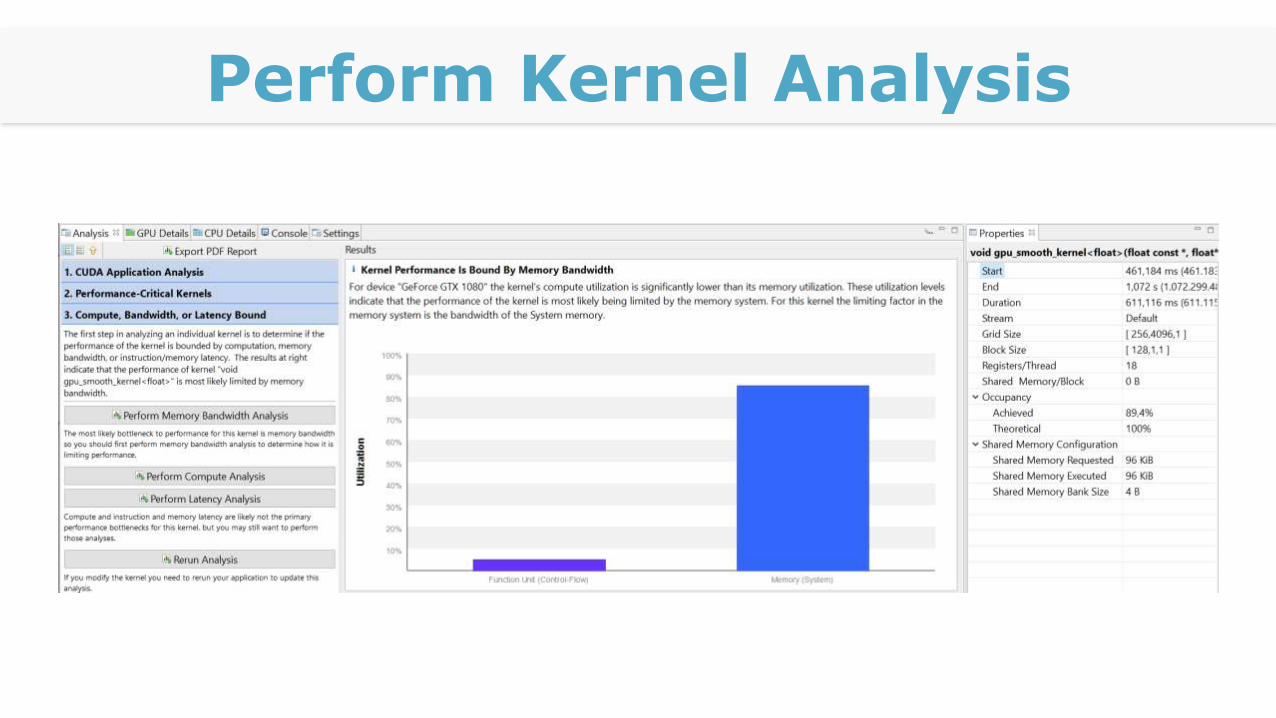
Perform Kernel Analysis

Memory Bandwidth Analysis
Shared
Memory?
Bottleneck PCIe
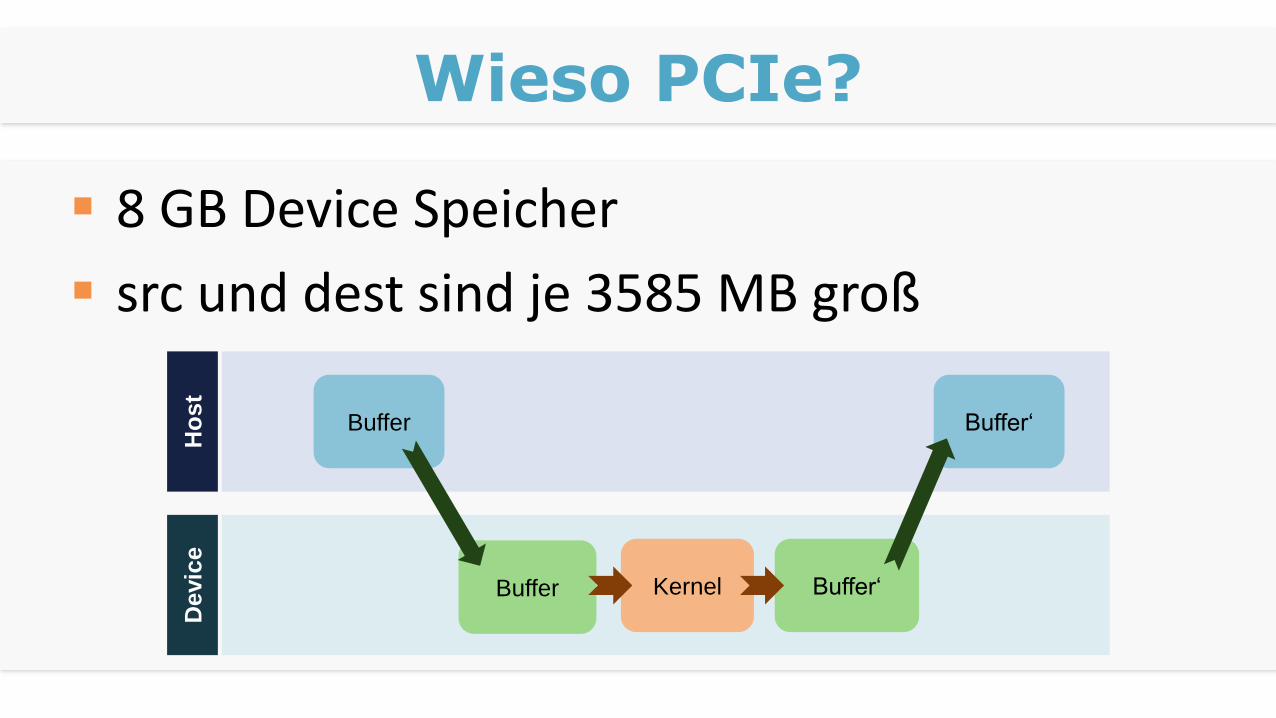
Wieso PCIe?
8 GB Device Speicher
src und dest sind je 3585 MB groß
Ho
st
Buffer Buffer‘
Devic
e
KernelBuffer Buffer‘

Explizit anlegen
cudaMalloc() für Device
cudaMallocHost() für Host
Aber beide passen nicht

Für kleine Buffer schneller
Speedup 10i7 5930K 4 GHz GTX 1080
w h 1-Thread 12 Threads 128 Block
32768 4096 1908 261 186
32768 12288 5697 772 548
32768 28672 13283 1761 error
7,31 10,26 1,40
7,38 10,40 1,41
7,54 error error
SpeedupExplizit schneller
als Unified
Memory
inkl. D2H-
Kopie
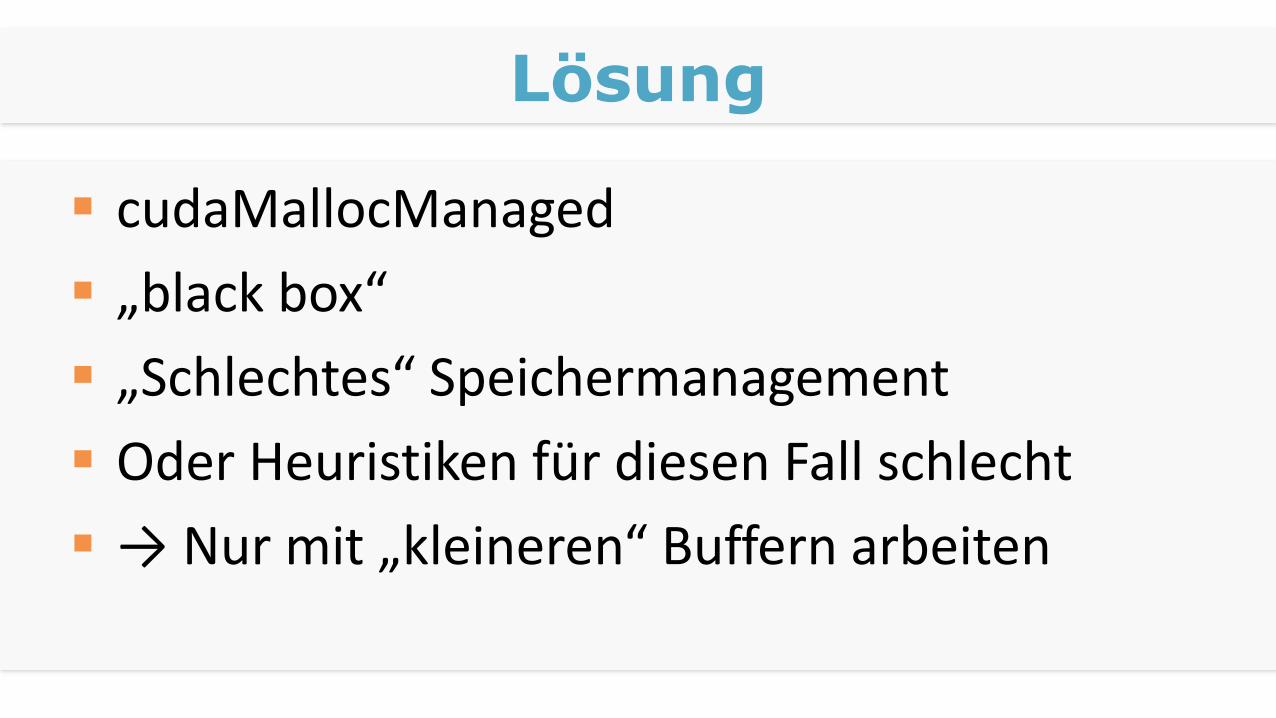
Lösung
cudaMallocManaged
„black box“
„Schlechtes“ Speichermanagement
Oder Heuristiken für diesen Fall schlecht
→ Nur mit „kleineren“ Buffern arbeiten

Mandelbrot
Anzahl der Iterationen bestimmt Farbe
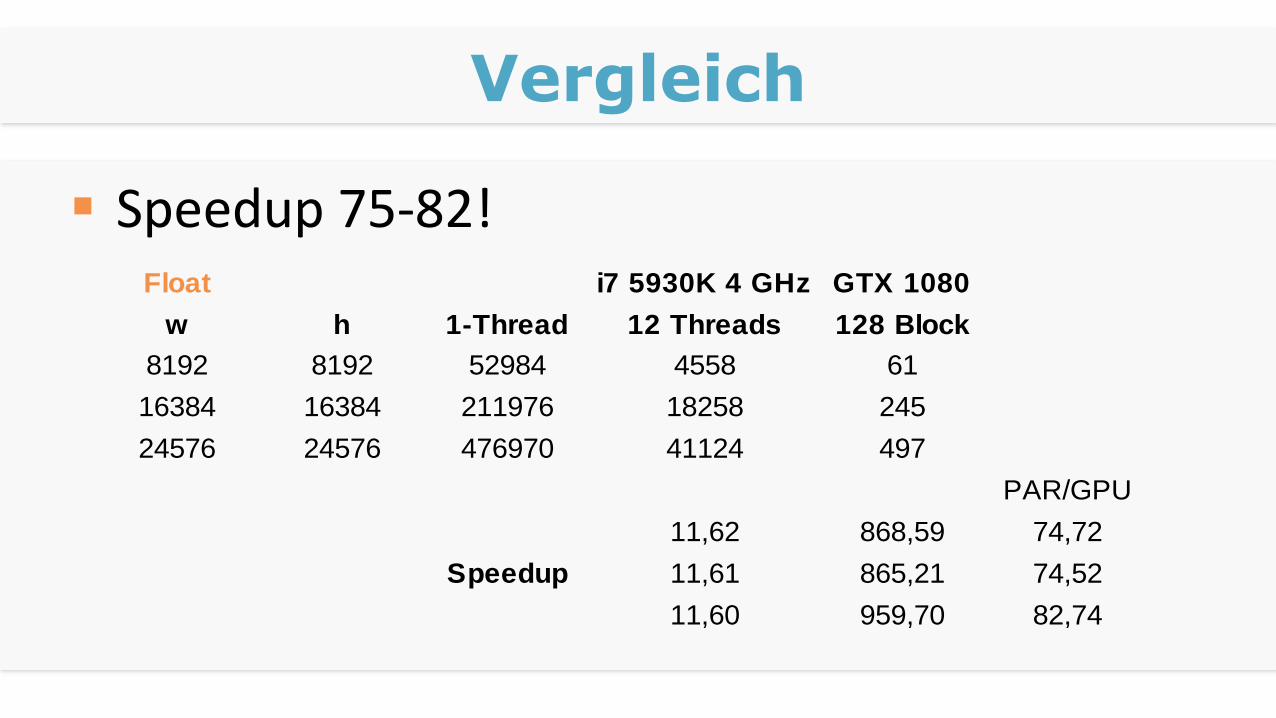
Vergleich
Speedup 75-82!Float i7 5930K 4 GHz GTX 1080
w h 1-Thread 12 Threads 128 Block
8192 8192 52984 4558 61
16384 16384 211976 18258 245
24576 24576 476970 41124 497
PAR/GPU
11,62 868,59 74,72
11,61 865,21 74,52
11,60 959,70 82,74
Speedup
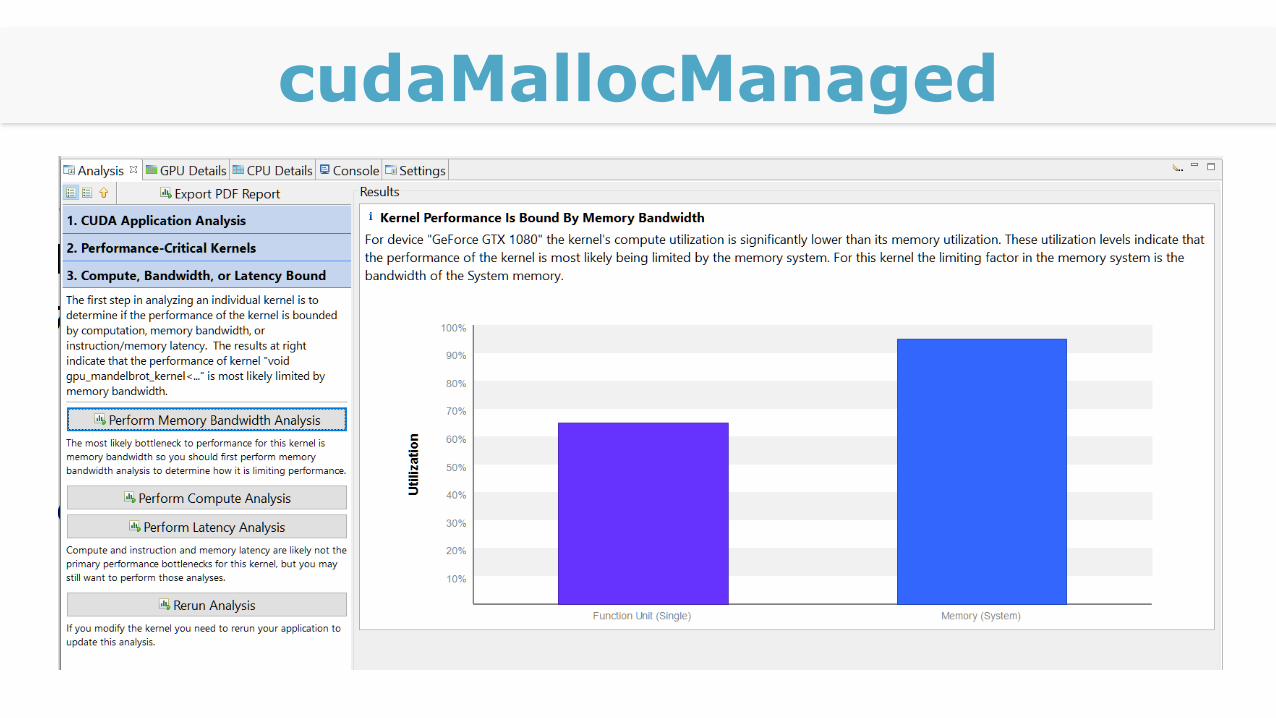
cudaMallocManaged
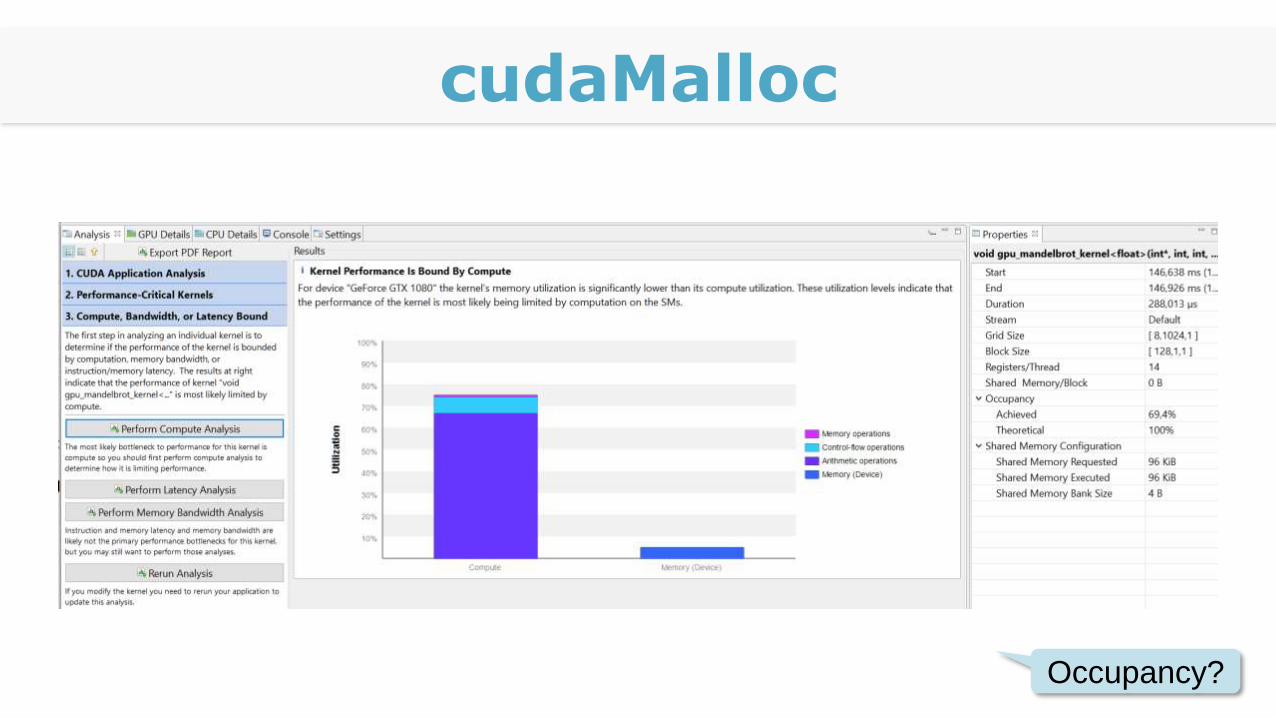
cudaMalloc
Occupancy?
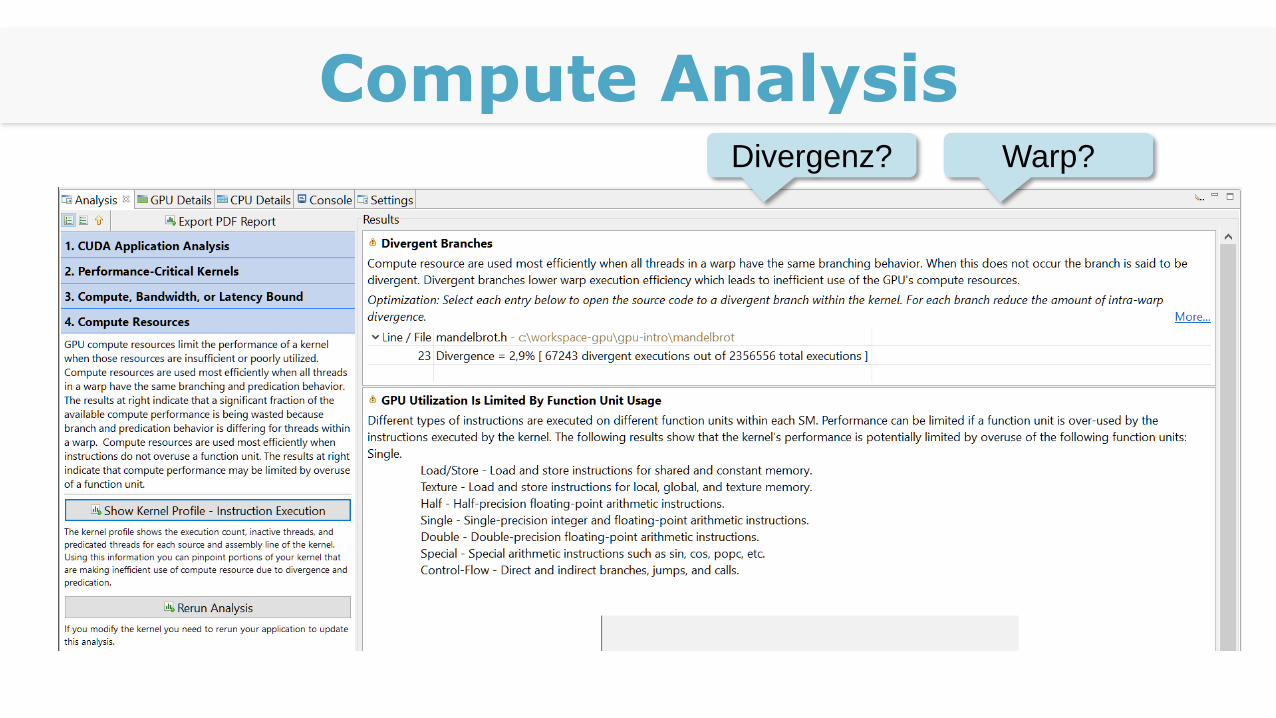
Compute AnalysisDivergenz? Warp?
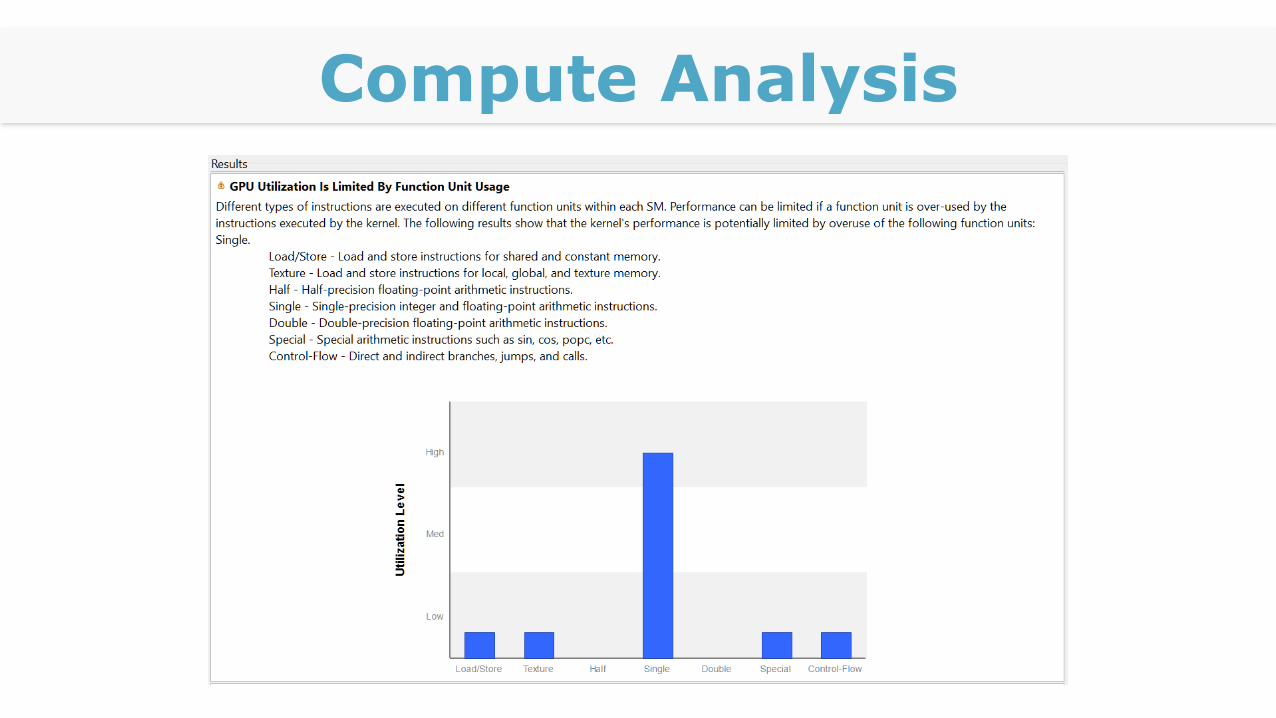
Compute Analysis
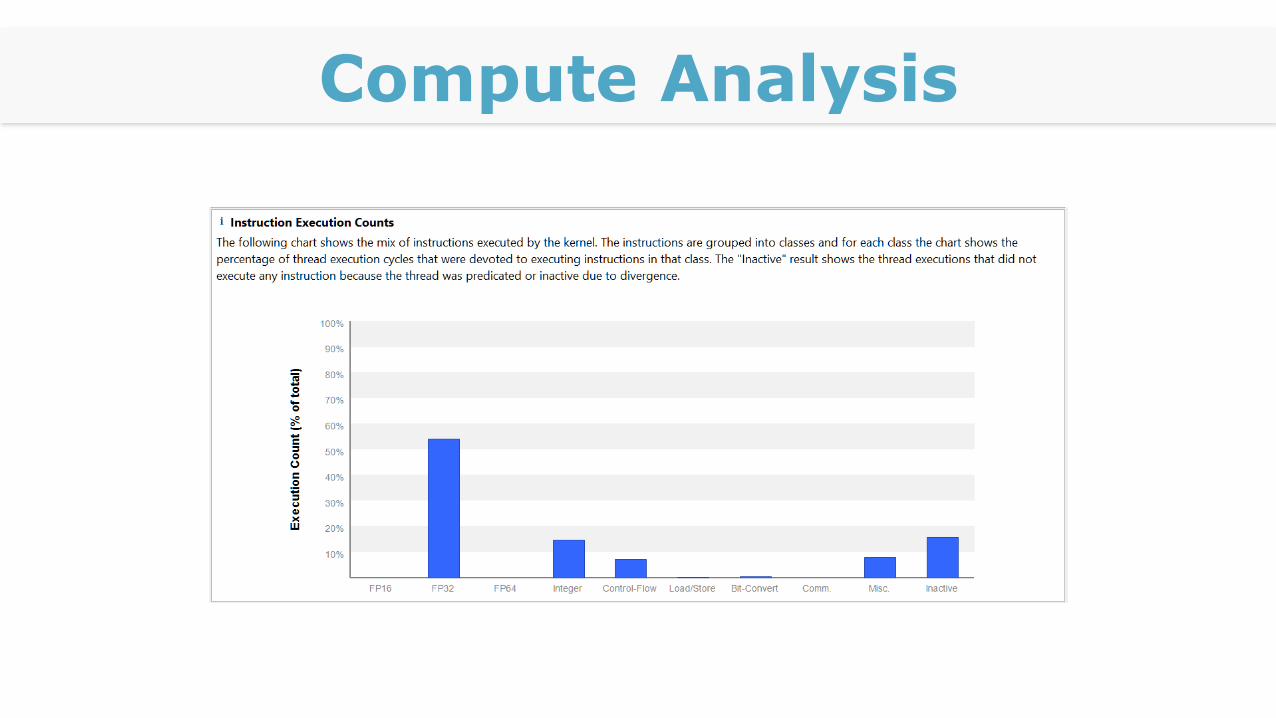
Compute Analysis
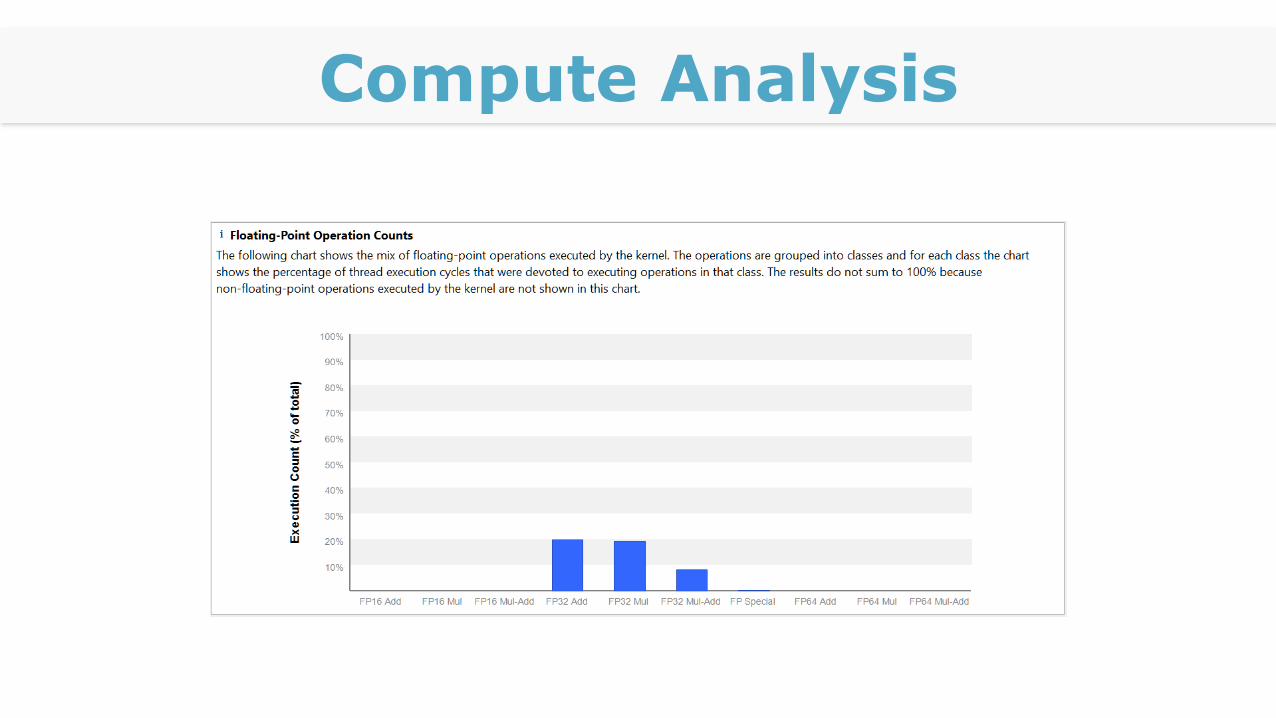
Compute Analysis
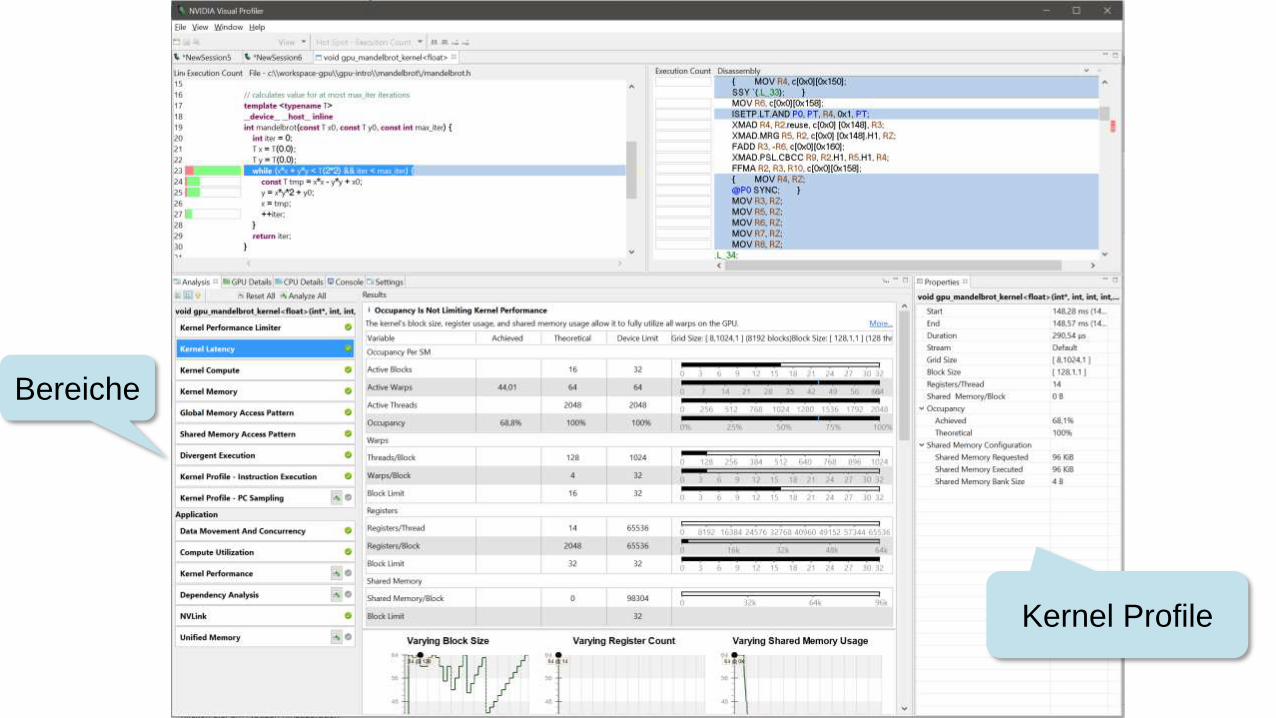
Show Kernel Profile
Kernel Profile
Bereiche

PC Sampling

Kernel-Aufruf
Hat eine SM freie Kapazitäten, wird ihr ein Block zugewiesen
Der Block wird in Warps unterteilt
Ein Warp besteht aus 32 Threads
Kleinste Einheit des Schedulers

Warp = 32 Threads
Ähnlich Vektorrechner
Single Instruction Multiple Threads!
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
f f f f f f f f f f f f f f f f f f f f f f f f f f f f f f f f

Divergenz
Single Instruction Multiple Threads!
Mask-Bit für jeden Thread im Warp
Laufzeit
𝑇 = 𝑇𝑖𝑓 + 𝑇𝑒𝑙𝑠𝑒
Ansonsten (Single-Thread)
𝑇 = max(𝑇𝑖𝑓, 𝑇𝑒𝑙𝑠𝑒)
Die anderen warten …
0 1 2 3
int tid = treadIdx.x;
if (tid < 2) {
call_expensive_function()
} else {
call_expensive_function2()
}
Threads Code

Auswirkung von Divergenz
Wenn divergente Threads vorhanden sind
Kerne sind idle
Wird SM nicht ausgelastet
Berechnung dauert länger als notwendig
Daher Divergenz vermeiden

Warp-Scheduling
Hardware GPU
n SM mit je k Kernen
Software Kernel-Konfiguration
Block-Größe bestimmt Anzahl der Threads
Grid bestimmt Anzahl der Blöcke
Wie kann man GPU möglichst gut auslasten?
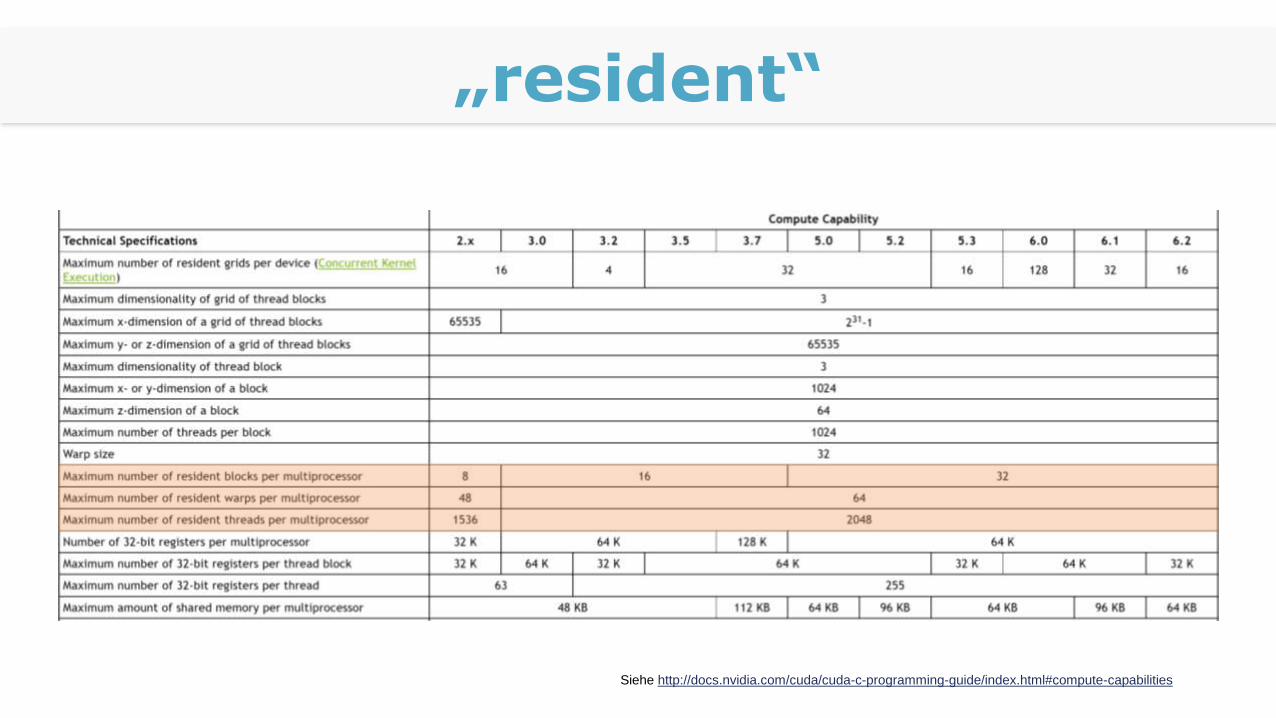
„resident“
Siehe http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities

Resident Warps
Neuere SMs können „gleichzeitig“
32 Blöcke, 64 Warps bzw. 2048 Threads
Ausführbereit halten
Occupancy = Auslastung
W0SM* W1 W2 W3 W4 -- -- -- 5/8
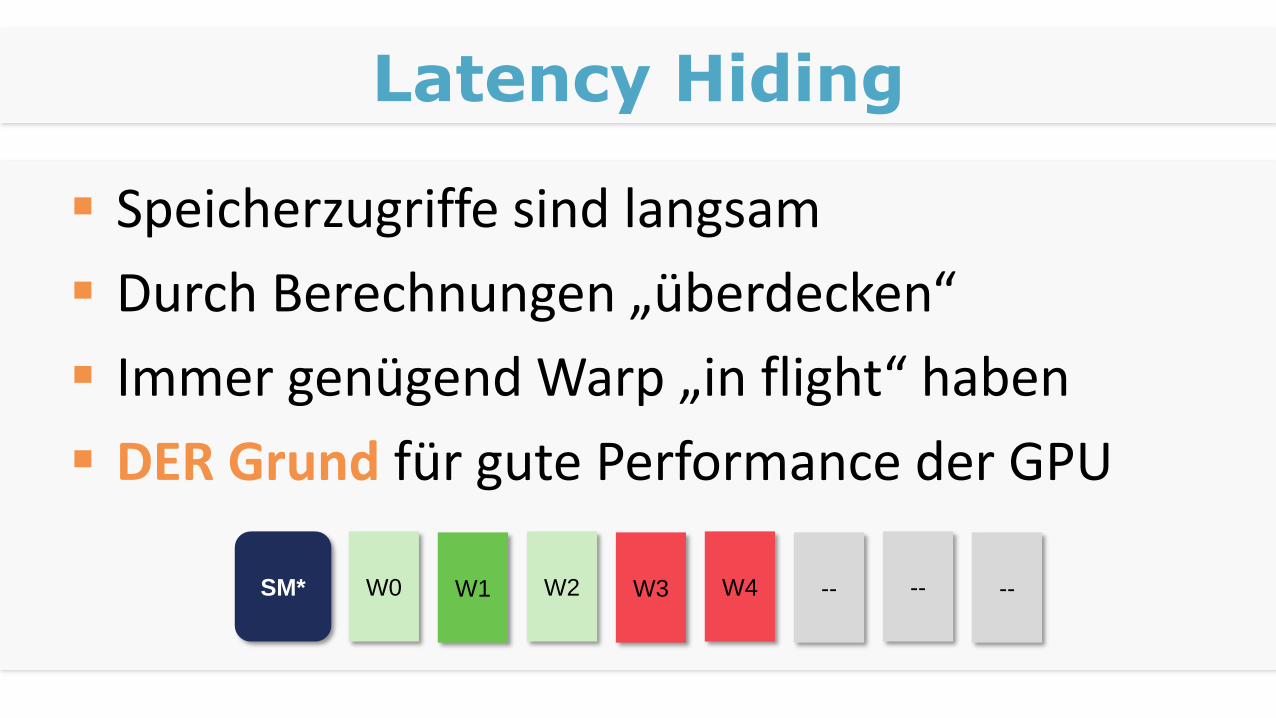
Latency Hiding
Speicherzugriffe sind langsam
Durch Berechnungen „überdecken“
Immer genügend Warp „in flight“ haben
DER Grund für gute Performance der GPU
W0SM* W1 W2 W3 W4 -- -- --
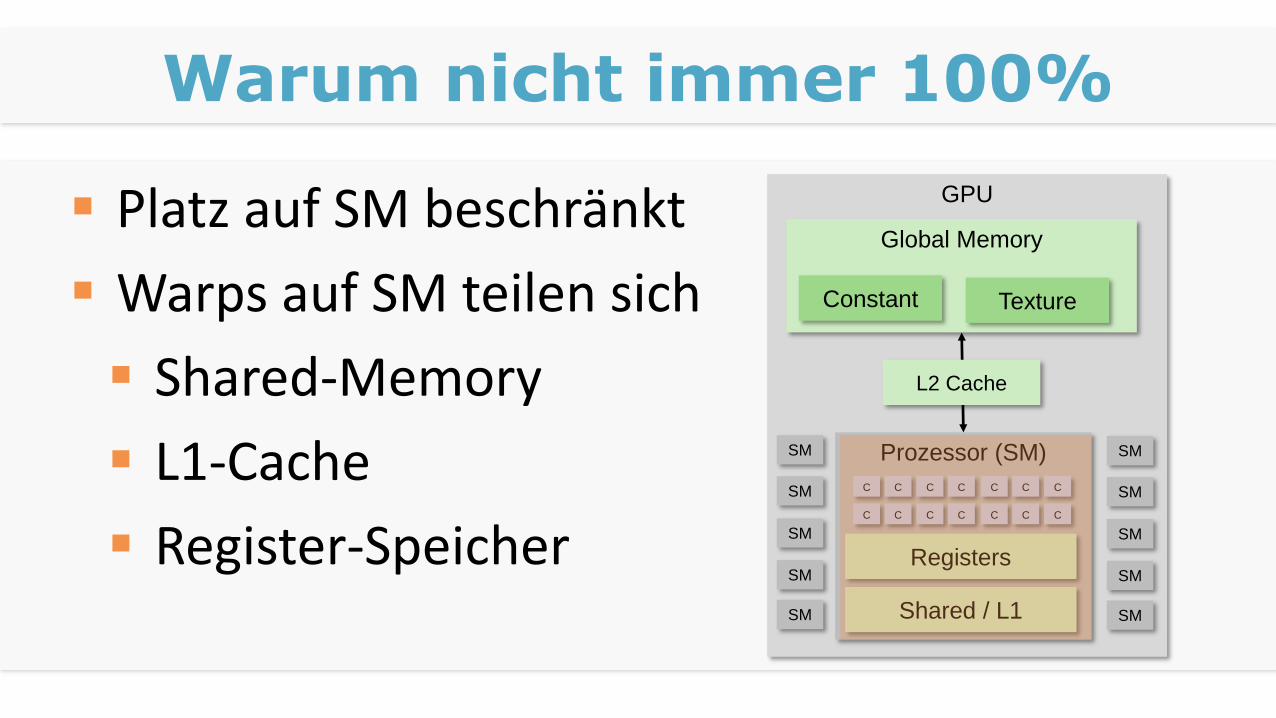
Warum nicht immer 100%
Platz auf SM beschränkt
Warps auf SM teilen sich
Shared-Memory
L1-Cache
Register-Speicher
GPU
Global Memory
Constant Texture
Prozessor (SM)
Shared / L1
Registers
C
L2 Cache
C
C
C
C
C
C
C
C
C
C
C
C
C
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM

Warum nicht immer 100%
Wenn
Kernel sehr viel Register für Variablen benötigt
oder viel Shared-Memory benutzt
dann passen nur weniger „drauf“
Muss für jeden Kernel bestimmt werden

Occupancy ist komplex
Berücksichtige (Werte für CC 3.5) Max Threads pro Block 1024 Max Blocks pro SM 16 Max Warps pro SM 64 Max Threads pro SM 2048 Anzahl 32-bit Register pro SM 64K Max Anzahl Register pro Thread 255 Max Shared Mem pro SM 48 KB Max Shared Mem pro Block 48 KB
Occupancy-Calculator
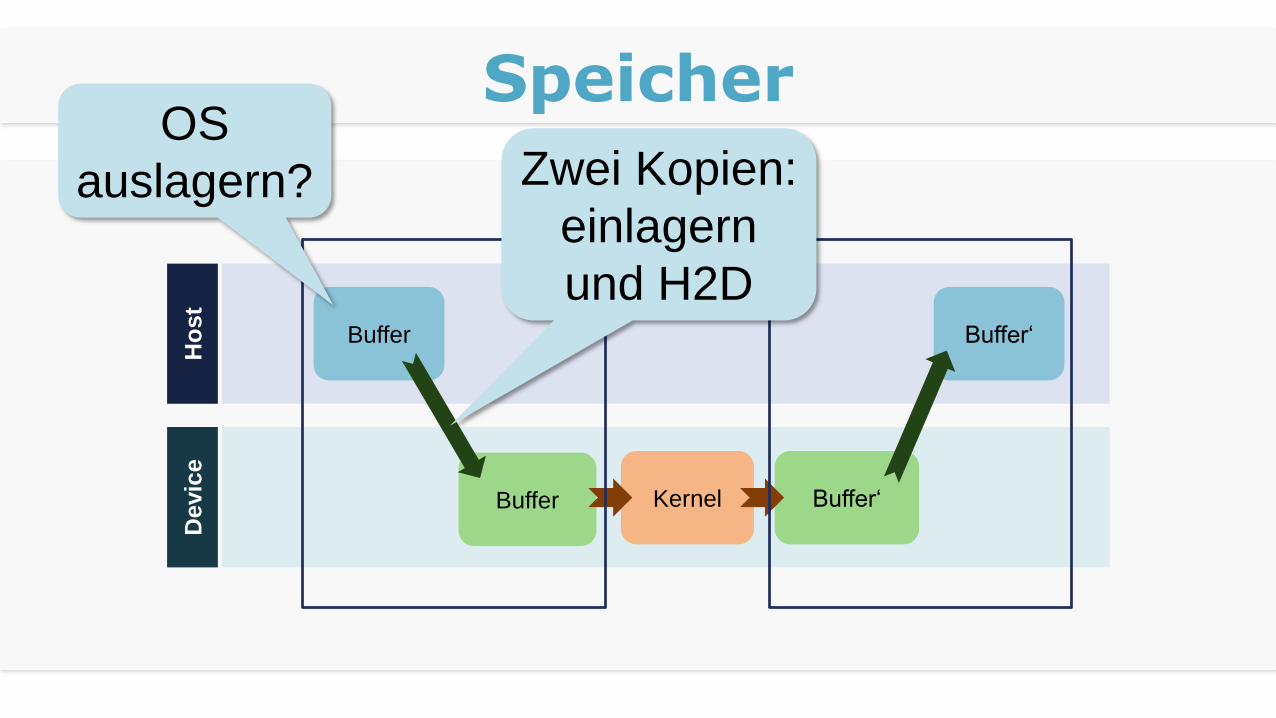
Speicher
Ho
st
Buffer Buffer‘
Devic
e
KernelBuffer Buffer‘
OS
auslagern? Zwei Kopien:
einlagern
und H2D

Arten von Host-Speicher
malloc() „unpinned“
D.h. auslagerbar in den virtuellen Speicher
cudaMallocHost() „pinned“
Virtueller
Speicher
Physikalischer
Speicher
malloc() „pinned“Device
Speicher
knapp

Unterschied CPU vs. GPU
Erstellung eines Threads
Auf CPU „teuer“
Auf GPU „billig“
Occupancy / Over-subscription
Divergenz
Speicher „coalescing“

Teil 10: Optimierung
Bounds
TFLOPS und GB/s

Maximale Rechenleistung
TFLOPS = Anzahl Kerne * Takt * 2 / (1000^2)
2 wegen Fused-Multiply-Add
Beispiel GTX 1080:
2560 * 1607 * 2 = 8.22784 TFLOPS
Beispiel GTX 980:
2048 * 1126 * 2 = 4.612 TFLOPS
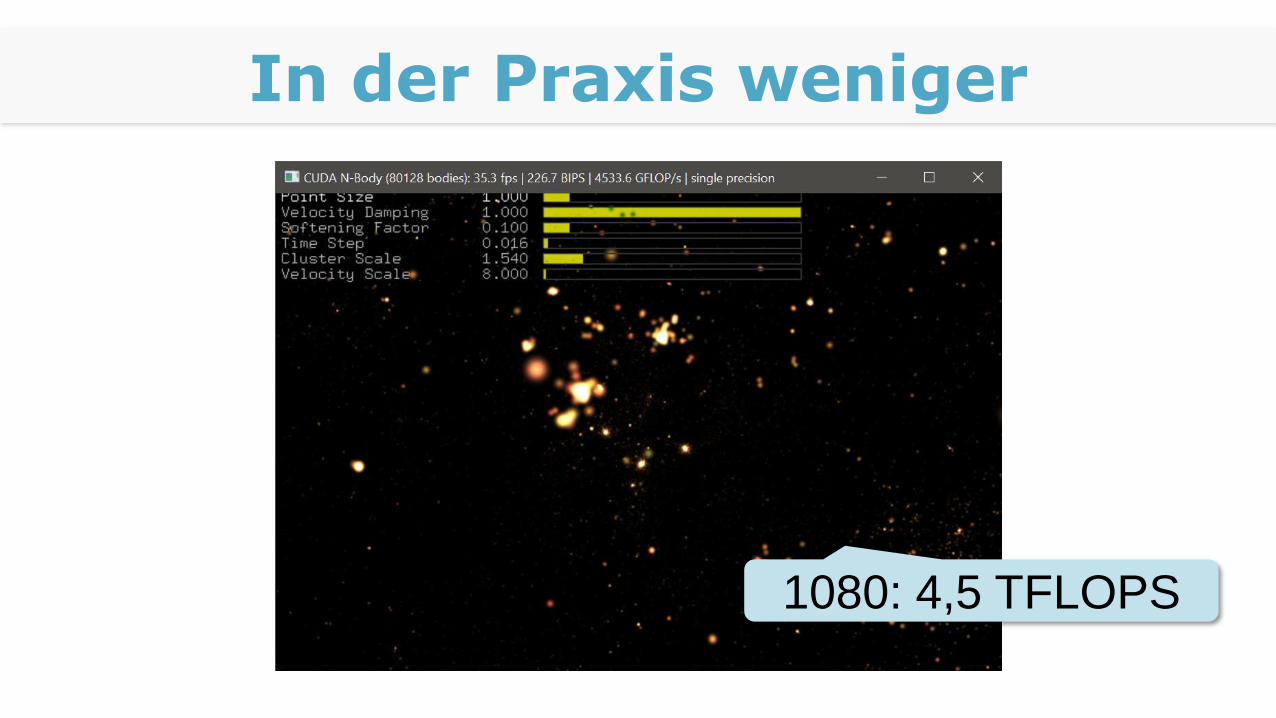
In der Praxis weniger
1080: 4,5 TFLOPS

Maximale Speicherbandbreite
TP = Breite [Byte] * Memory-Takt * x
GDDR3: x = 2, GDDR5: x = 4, GDDR5X: x=8
Beispiel GTX 1080:
256 bit * 1251 / 1024 ≈ 312 GB/s
Beispiel GTX 980:
256 bit * 1753 / 1024 ≈ 219 GB/s

Optimierungspotential
Vergleiche
Maximale Werte …
… mit Werten von Nsight/NVVP

Was optimieren?
Ermittle das Bottleneck mit Profiler
Verwende Amdahls Gesetz für Abschätzung
Siehe https://devblogs.nvidia.com/parallelforall/cuda-8-features-revealed/

Optimierung
Maximiere …
1. Parallelität
2. Speicherdurchsatz
3. Berechnungsdurchsatz

Teil 11: Optimiere Parallelität
Stellen der Parallelität
Streaming
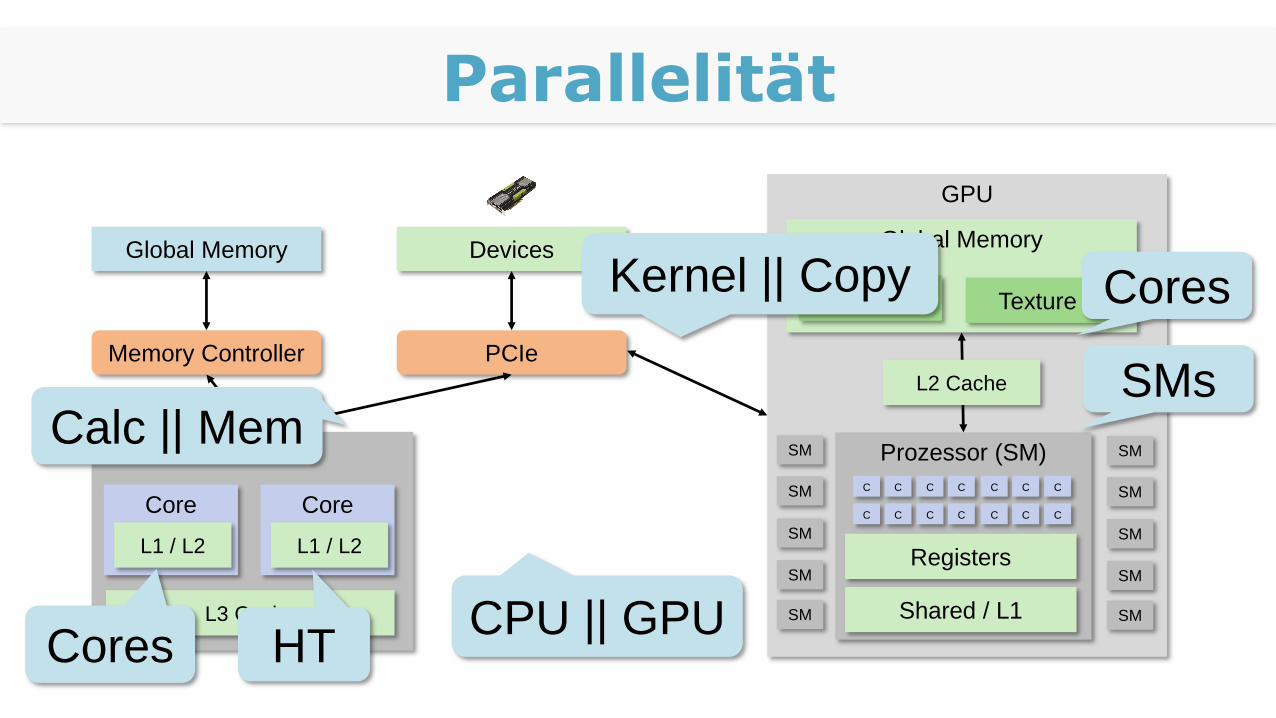
Parallelität
CPU 1
Core
L1 / L2
Core
L1 / L2
L3 Cache
Memory Controller PCIe
Global Memory Devices
GPU
Global Memory
Constant Texture
Prozessor (SM)
Shared / L1
Registers
C
L2 Cache
C
C
C
C
C
C
C
C
C
C
C
C
C
SM
SM
SM
SM
SM
SM
SM
SM
SM
SMCPU || GPUCores
Calc || MemSMs
Cores
HT
Kernel || Copy

Schleifen
Typische Anwendung ist eine Schleife
for all partitions
call kernel 1
call kernel 2
…
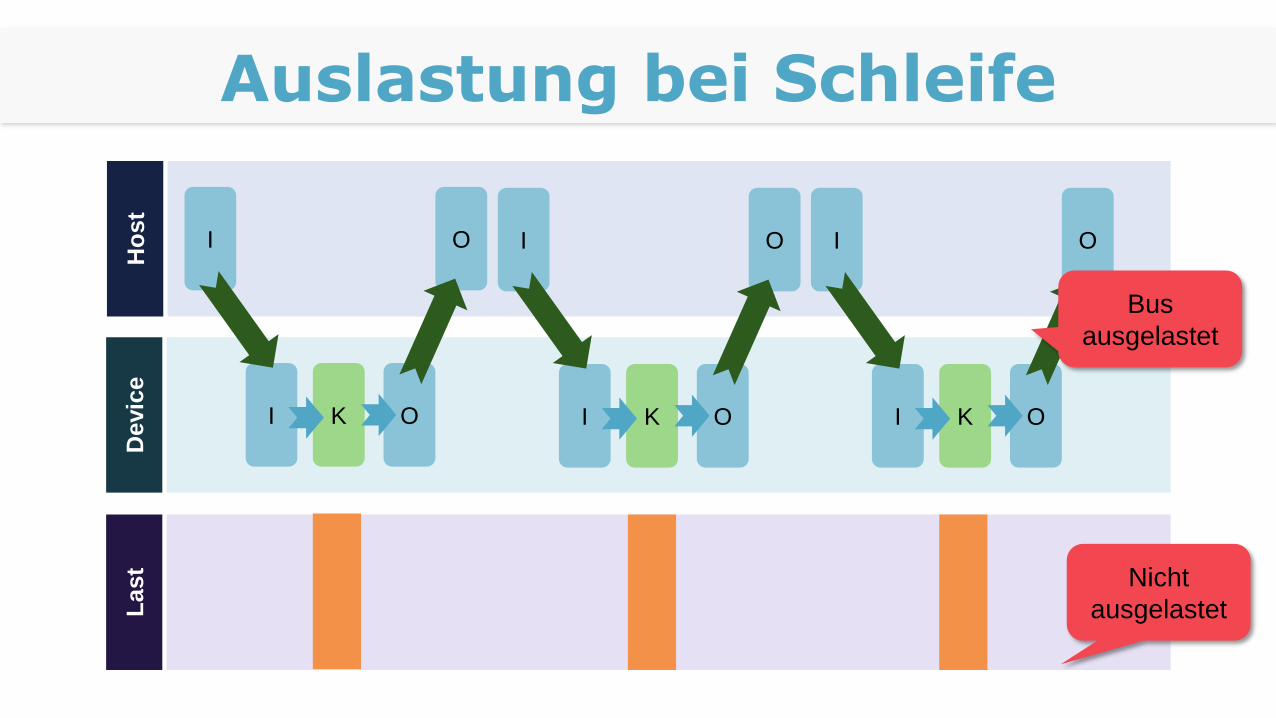
Auslastung bei SchleifeD
evic
eH
ost
I
KI O
O I
KI O
O I
KI O
O
La
st Nicht
ausgelastet
Bus
ausgelastet

Swapping & Streaming
Parallel Für alle „ungeraden“ Partitionen p Kopiere H2D für p in Stream0 Rufe Kernel auf für p in Stream0 Kopiere D2H für p in Stream0
Für alle „geraden“ Partitionen q Kopiere H2D für q in Stream1 Rufe Kernel auf für q in Stream1 Kopiere D2H für q in Stream1
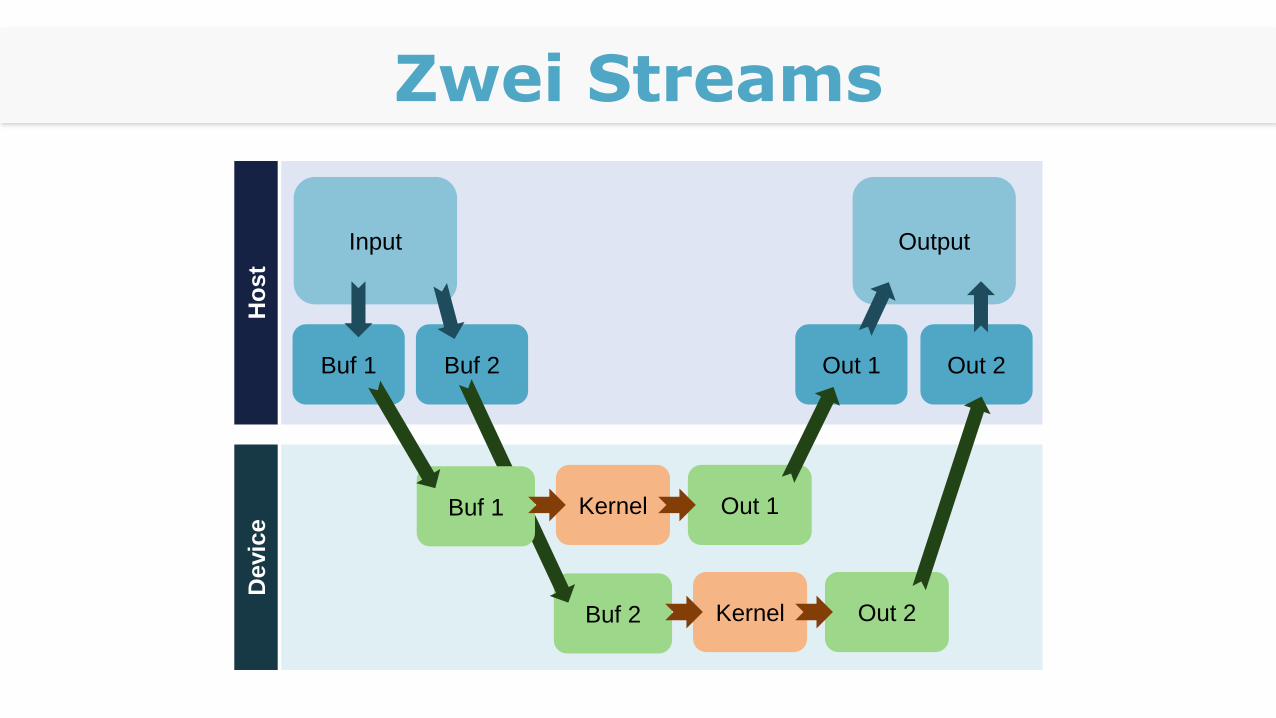
Zwei Streams
Buf 2
Ho
st
Buf 1 Out 2
Devic
e
Kernel Out 1
KernelBuf 2 Out 2
Buf 1
Input Output
Out 1
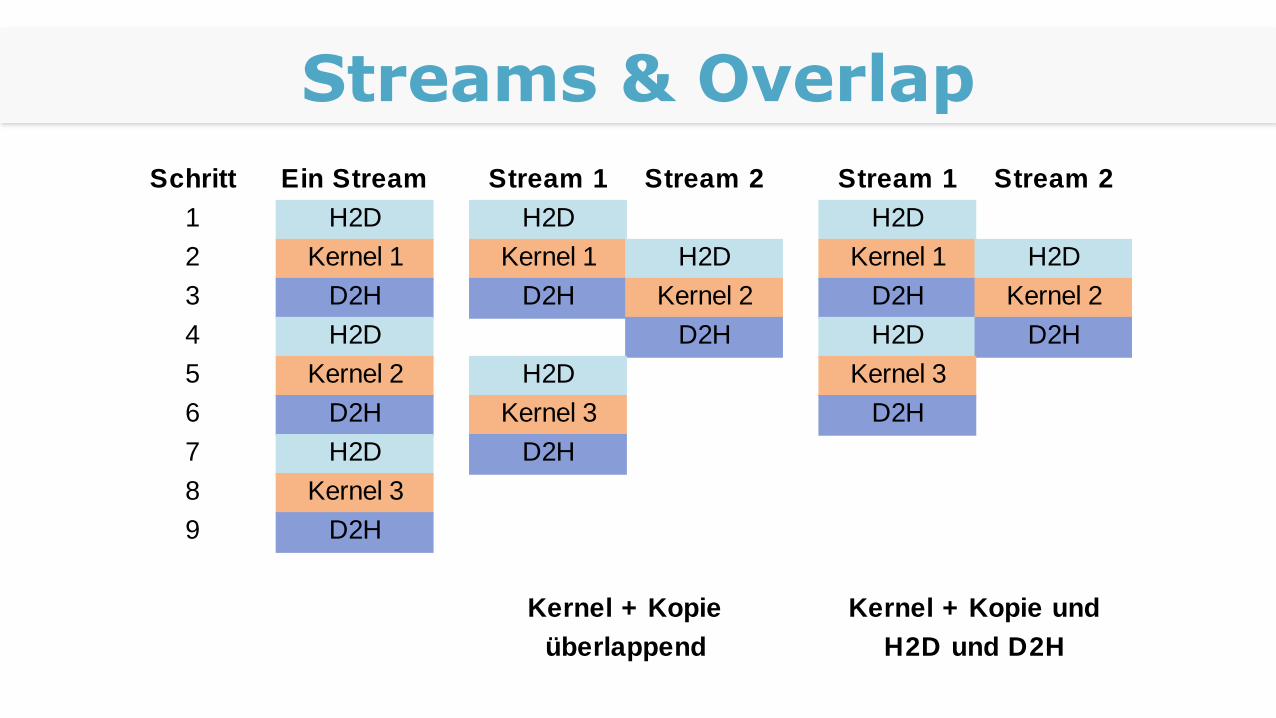
Streams & Overlap
Schritt Ein Stream Stream 1 Stream 2 Stream 1 Stream 2
1 H2D H2D H2D
2 Kernel 1 Kernel 1 H2D Kernel 1 H2D
3 D2H D2H Kernel 2 D2H Kernel 2
4 H2D D2H H2D D2H
5 Kernel 2 H2D Kernel 3
6 D2H Kernel 3 D2H
7 H2D D2H
8 Kernel 3
9 D2H
Kernel + Kopie
überlappend
Kernel + Kopie und
H2D und D2H

Streams mit CUDA
Create src_h, dest_h buffers on host
Create s streams
Create s src_d, dest_s buffers on device
Put all commands into stream
Wait for stream to finish
Destroy everything …

Schleife durch Partitionen
For all partitions p
let s = current stream
Copy async src_h[p] -> src_d[s]
Kernel async (src_d[s], dest_d[s])
Copy async dest_d[s] -> dest[p]
s = (s+1) mod num_streams

Befehle
cudaStreamCreate(s*)
cudaStreamDestory(s)
cudaStreamSynchronize(s)
cudaMemcpyAsync(…, s)
Kernel kernel<<<grid, block, 0, s>>>(…)

Tipp
Vorher immer eine synchrone Version erstellen
100% funktionstüchtig und korrekt
Dann die Synchronisation umsetzen
Asynchronizität ist verwirrend
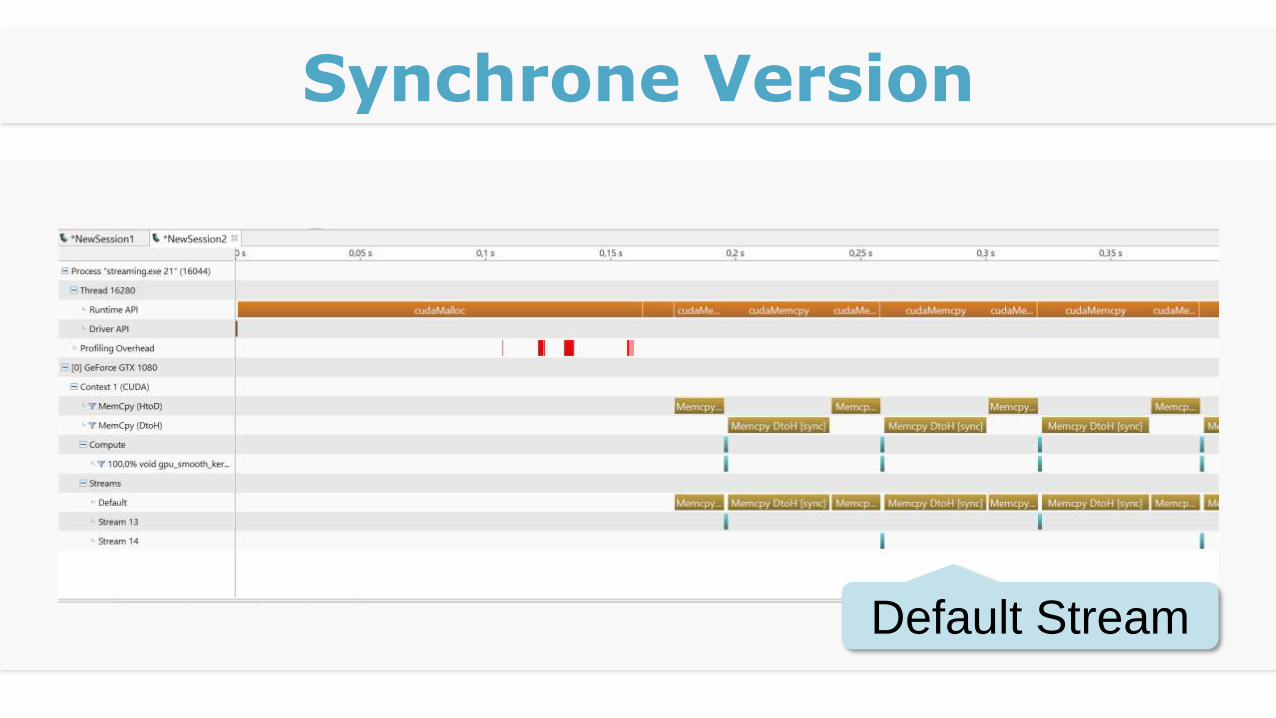
Synchrone Version
Default Stream
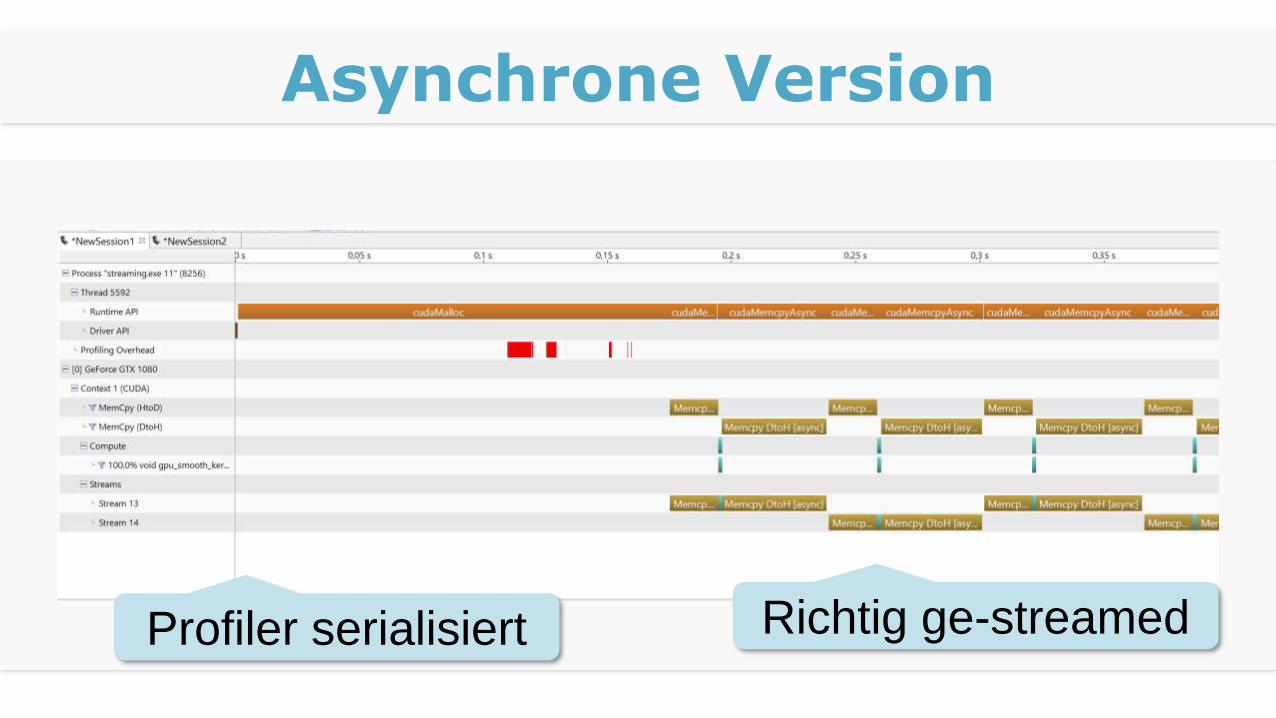
Asynchrone Version
Richtig ge-streamedProfiler serialisiert

Vergleich der Laufzeiten
i7 5930K 4 GHz GTX 1080 GTX 1080
w h 1-Thread 12 Threads 128 Block Streamed
32768 4096 1908 261 186 250
32768 12288 5697 772 548 751
32768 28672 13283 1761 error 1780
7,31 10,26 7,63
7,38 10,40 7,59
7,54 error 7,46
Speedup
Speedup wie CPU
Kleine arith. Intensität
schlecht für GPU

Teil 12: Optimiere Speicher
Coalescing
AoS und SoA
Daten-Lokalität

Speicherzugriffe in einem Warp
Unterschiede zwischen Block
dim3(32,1,1) und dim3(4,8,1) ?

Speicherzugriffe in einem Warp
dim3(32,1,1)
32*float Werte „nebeneinander“
Ein „coalesced“ Zugriff á 128 Byte
dim3(4,8,1)
4*float Werte in 8 Reihen
8 Zugriffe á 16 Byte

Speicherzugriffe in einem Warp
GPU kann Speicherzugriffe innerhalb eines Warps bündeln („coalescing“)
32, 64 und 128 Byte
Auch Alignment beachten

Speicherzugriffe in einem Warp
Also immer „neben“ zugreifen
Nicht „hintereinander“ (wie auf der CPU)
for x .. for y … statt for y … for x
Gut für CPU Gut für GPU

AoS vs. SoA
Array of Structures vs. Structure of Arrays
Siehe Stroustrup, „C++ Prog. Language“, 4th ed., p. 207
mem 0 1 2 3 4 5
AoS value 1 2 3 4 5 6
SoA value 1 3 5 2 4 6
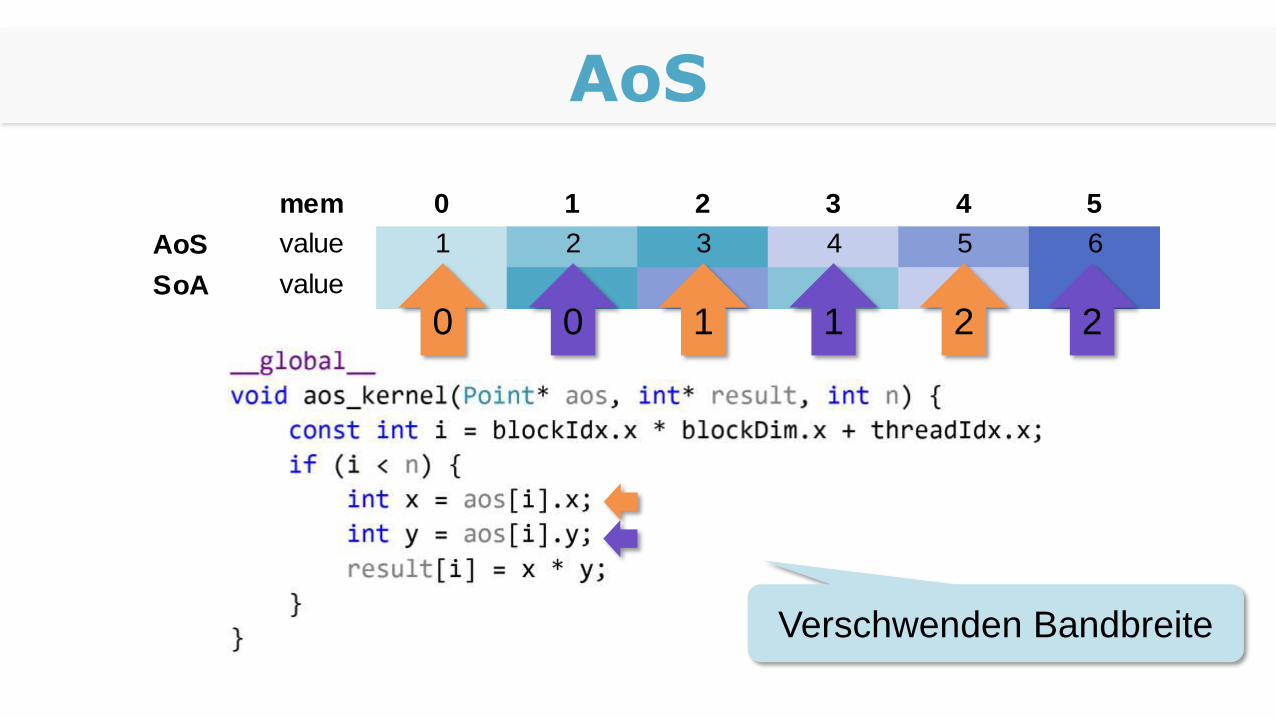
AoS
mem 0 1 2 3 4 5
AoS value 1 2 3 4 5 6
SoA value 1 3 5 2 4 6
0 1 20 1 2
Verschwenden Bandbreite
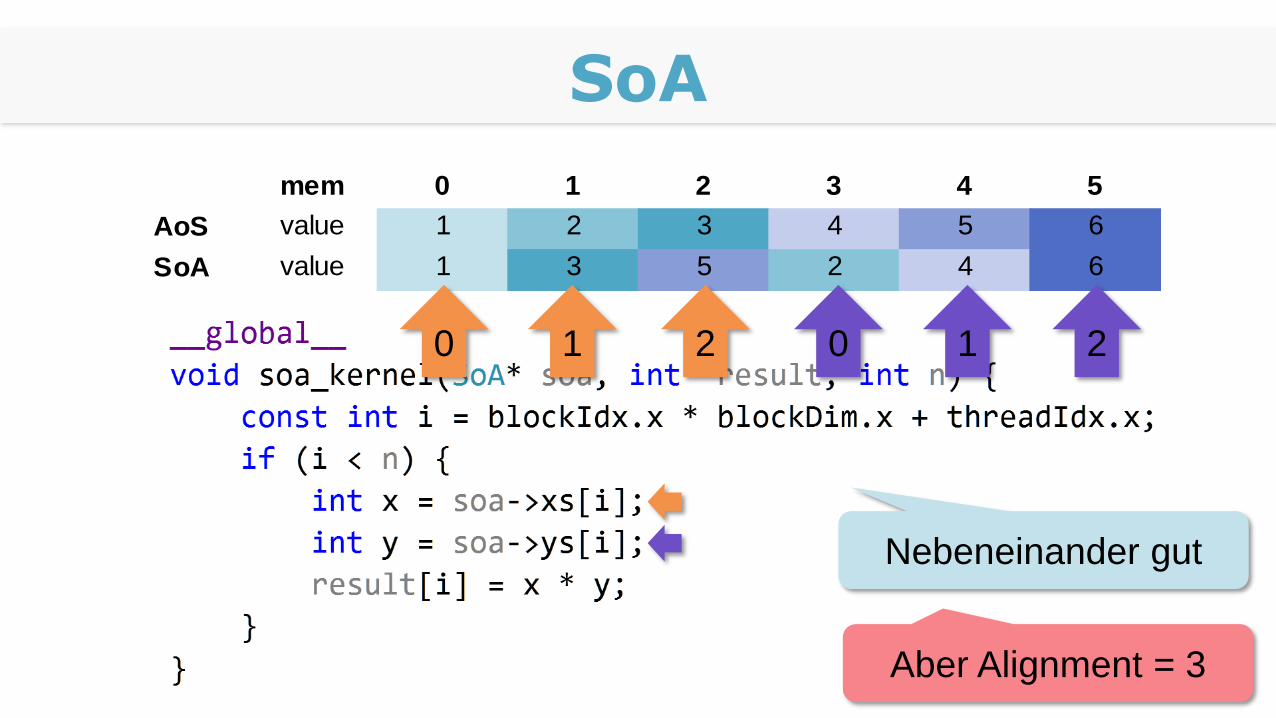
SoA
mem 0 1 2 3 4 5
AoS value 1 2 3 4 5 6
SoA value 1 3 5 2 4 6
0 1 2 0 1 2
Nebeneinander gut
Aber Alignment = 3

Alignment
Alignment erzwingen
sizeof(SoA) == 24, sizeof(SoA2) == 32

AoS vs. SoA
Was ist besser?
Hängt von Zugriffsmuster ab
In der Regel auf der GPU aber SoA
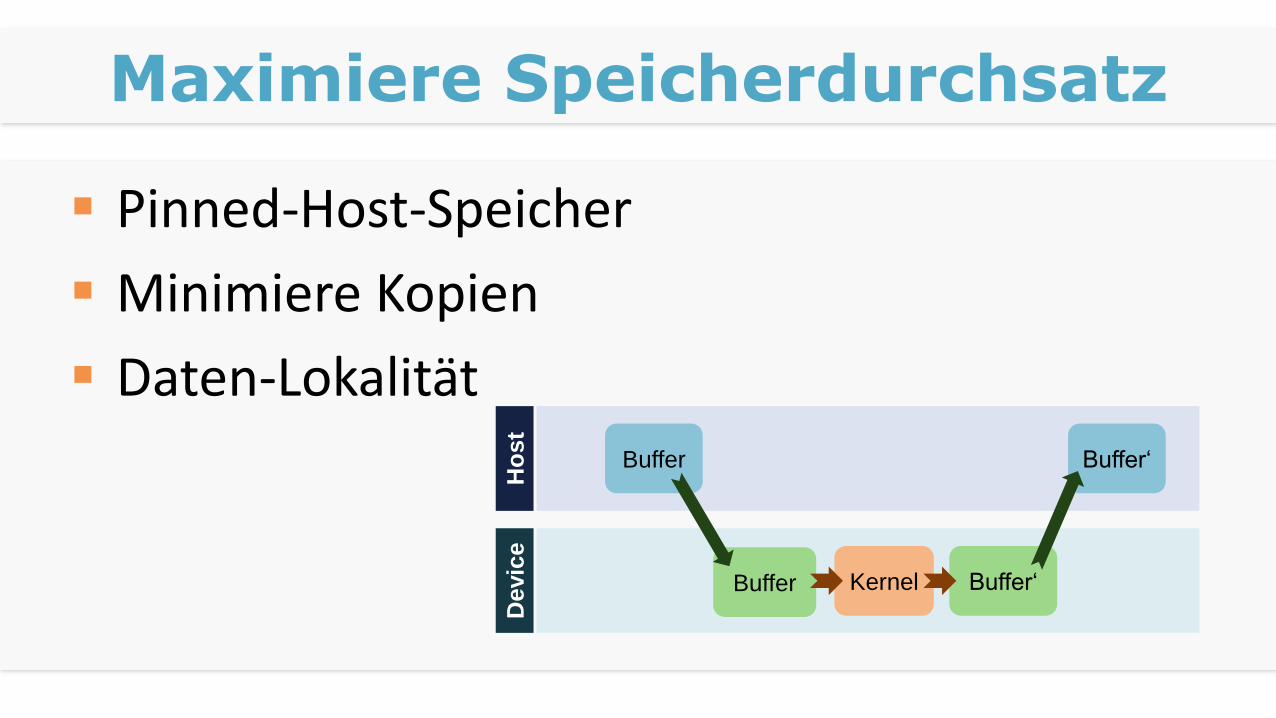
Maximiere Speicherdurchsatz
Pinned-Host-Speicher
Minimiere Kopien
Daten-Lokalität
Ho
st
Buffer Buffer‘
Devic
e
KernelBuffer Buffer‘
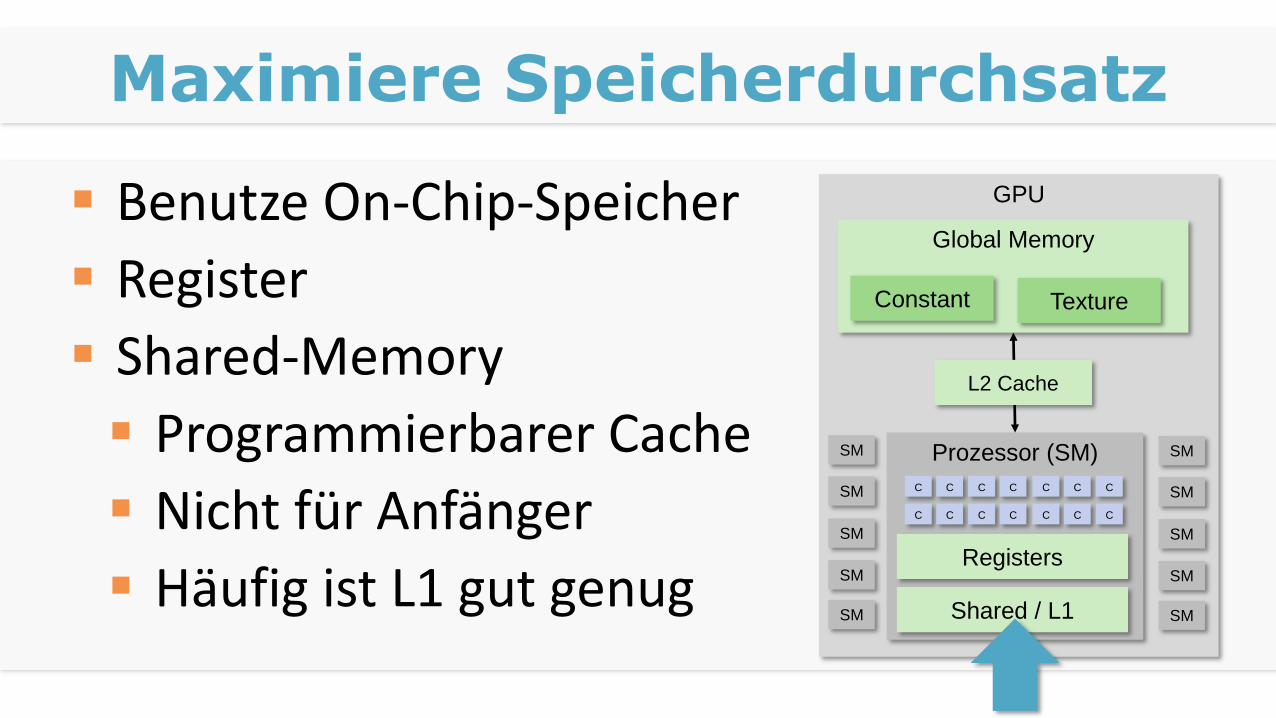
Maximiere Speicherdurchsatz
Benutze On-Chip-Speicher
Register
Shared-Memory
Programmierbarer Cache
Nicht für Anfänger
Häufig ist L1 gut genug
GPU
Global Memory
Constant Texture
Prozessor (SM)
Shared / L1
Registers
C
L2 Cache
C
C
C
C
C
C
C
C
C
C
C
C
C
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM

Teil 13: Optimiere Rechnungsdurchsatz

Berechnungsdurchsatz
Minimiere Divergenz
Berechnen statt Speichern
„do not repeat yourself“ (DRY )
const int i = y*w + x
Aber besser ‚inlinen‘ oder Makro
Fusion von Kerneln

Loop-Unrolling
Interne Parallelität in Kern /Core ausnutzen
Ausfalten von Schleifen fixer Länge
Siehe http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#pragma-unroll

Fast Math
Arithmetik
Präzision vs. Geschwindigkeit
Spezielle Funktionen verfügbar
Siehe http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#maximize-instruction-throughput

Synchronisation
Innerhalb Thread-Block
__syncthreads()
Atomare Zugriffe
atomicAdd()
Speicher
Zwischen Kernel-Aufrufen

Teil 14: Tipps und Tricks

Gleitkommaarithmetik
Ergebnisse von Prozessor zu Prozessor unterschiedlich!
Unterschiedliche Optimizereinstellungen
Können bei C/C++ zu Differenzen führen
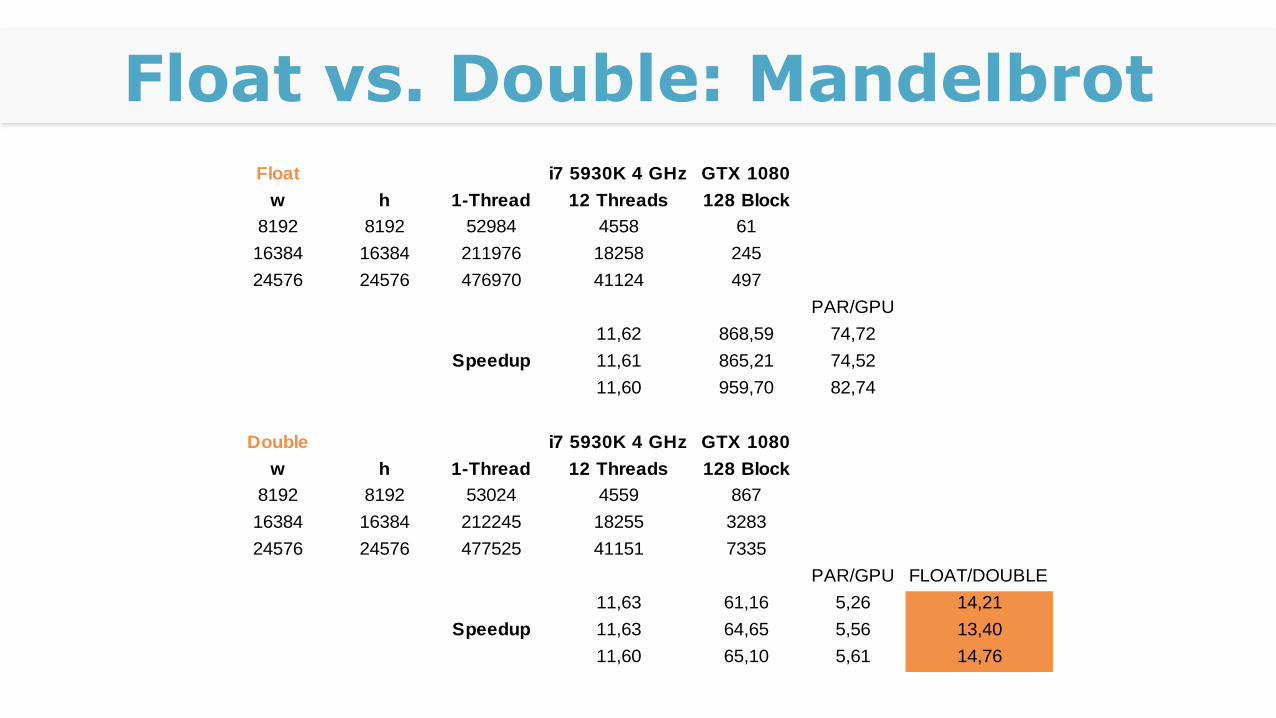
Float vs. Double: Mandelbrot
Float i7 5930K 4 GHz GTX 1080
w h 1-Thread 12 Threads 128 Block
8192 8192 52984 4558 61
16384 16384 211976 18258 245
24576 24576 476970 41124 497
PAR/GPU
11,62 868,59 74,72
11,61 865,21 74,52
11,60 959,70 82,74
Double i7 5930K 4 GHz GTX 1080
w h 1-Thread 12 Threads 128 Block
8192 8192 53024 4559 867
16384 16384 212245 18255 3283
24576 24576 477525 41151 7335
PAR/GPU FLOAT/DOUBLE
11,63 61,16 5,26 14,21
11,63 64,65 5,56 13,40
11,60 65,10 5,61 14,76
Speedup
Speedup

Float vs. Double
Auf CPU ca gleich schnell
Anders bei der GPU
Tesla-Karten ca. 1/2
Statt einem Kern mit 32 bit werden zwei Kerne pro Operation verwendet
Geforce nur 1/8 bis 1/16

Kernel in der Praxis
Aus Wilt „The CUDA Handbook“, S. 218
„Index-
Schlacht“
OptimiertNachteil: Speicherorganisation
fest verdrahtet
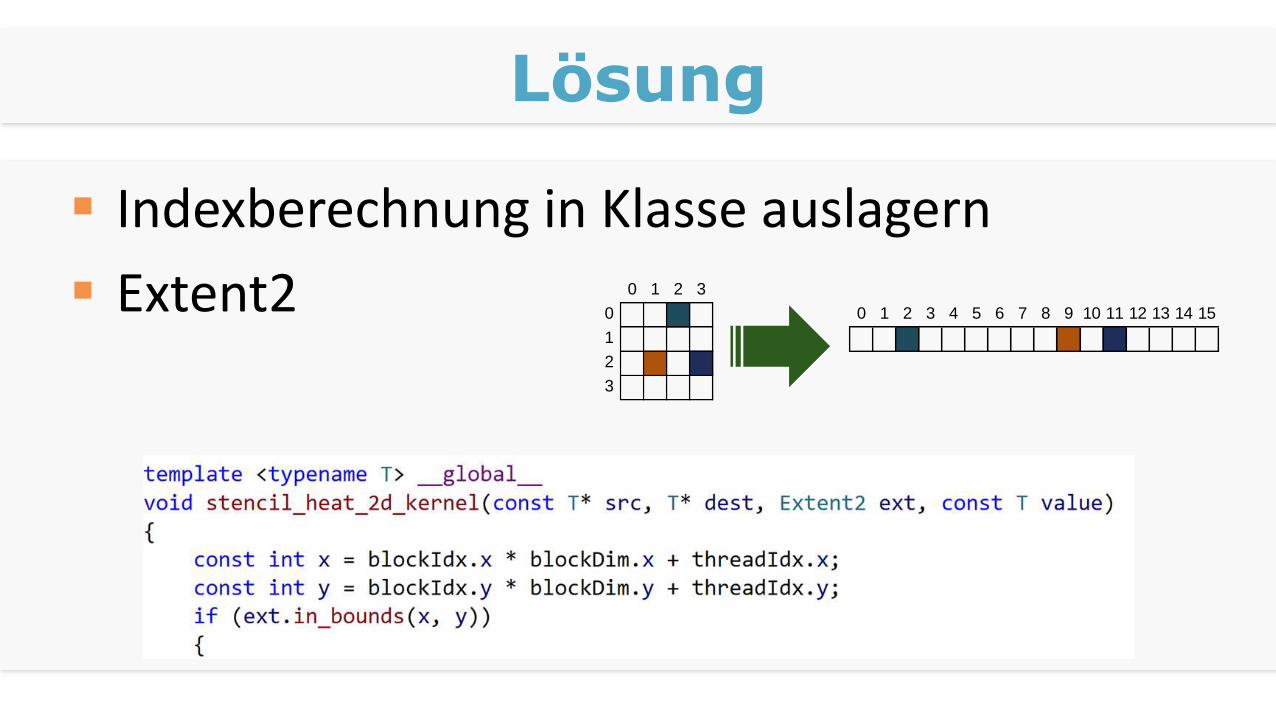
Lösung
Indexberechnung in Klasse auslagern
Extent2 0 1 2 3
0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
1
2
3

Teil 15: Zusammenfassung
Erfolgreiche
GPU-ifizierung

Erfolgreiche GPU-ifizierung
Parallelität muss im Algorithmus vorhanden sein
Immer gegen Golden Code programmieren
Viel gemeinsamer Code (CPU+GPU)

Erfolgreiche GPU-ifizierung
Unterschiedliche Architektur berücksichtigen
Warp, Occupancy, Divergenz
Speicher, Coalescing, Lokalität
Guided Analysis benutzen

Anhang: Literatur und Links
Links
Literatur

Wo Hilfe suchen?
Dokumentation docs.nvidia.com „Programming Guide“ „Best Practices Guide“
Web CudaZone bei nvidia.com Parallel Forall (Blog)

Literatur über CUDA
Einsteiger „CUDA by Example“ Sanders, Kandrot
Fortgeschritten CUDA Programming Cook
CUDA Handbook Wilt

Literatur für Fortgeschrittene
Hwu (Ed.)GPU Computing Gems
Emerald Edition
Hwu (Ed.)GPU Computing Gems
Jade Edition
Recommended