Embed Size (px)
Citation preview

Erste Hilfekasten
für Unicode mit PythonVersion 1.2
Thomas Aglassinger
https://github.com/roskakori/talks/tree/master/pygraz/unicode

Agenda
1.Wozu Unicode?
2.Unicode Zeichenketten in Python 3
3.Encodings
4.Wann Daten (de-)kodieren?
5.Vorhandenes Encoding ermitteln
6.UnicodeError
7.Unicode Zeichenketten in Python 2

Ziele
Die Teilnehmer können...
● ...Texte mit Umlauten in Python verarbeiten.
● ...ein geeignetes Encoding wählen.
● ...die Stärken und Schwächen der wichtigstenEncodings zuordnen.
● ...UnicodeError vermeiden.

Nicht-Themen
● Verstehen der Encodings auf Bit-Ebene→ Wikipedia
● Implementieren eigener Encodings
● Sicherheitsüberlegungen
● http://unicodesnowmanforyou.com/
● '\U0001f4a9'

Wozu Unicode?
● Zur Darstellung und Verarbeitung von Texten
● Deckt die meisten verwendeten Schriftzeichen ab(dz. ca. 110.000 für ca. 100 Schriften)
● Weit verbreitet und unterstützt(Python, XML, Java, .NET, etc)
● Erste publizierte Version: 1991

Unicode ist ein Mapping
● Computer verarbeiten nur Zahlen
● Für Anzeige: Umwandlung der Zahlen inBuchstaben und andere Zeichen
Zeichen DezimalerWert
UnicodeCode Point
A 65 U+0041
ü 252 U+00fc
€ 8364 U+20ac
樹 27193 U+6a39

Hex-Notation

Hex-Notation
U+20ac
● Präfix „U+“ für Unicode Code Point (in Hex)
● Zahlen auf Basis 16 statt 10
● Ziffern 0-9 wie Dezimal, Ziffern a-f = 10-15

Hex-Notation
U+20aceuro_sign = '€'
euro_sign = '\u20ac'
euro_sign = chr(0x20ac) # Python 2: unichr(0x20a0)
euro_sign = chr(2 * 16**3 + 0 * 16**2 + 10 * 16**1 + 12 * 16**0)
euro_sign = chr(8364)
euro_sign = '\N{EURO SIGN}'
import unicodedataeuro_sign = unicodedata.lookup('EURO SIGN')

Unicode Zeichenkettenin Python 3

Unicode Zeichenketten
english_text = 'cheese spaetzle: 10 euro'
german_text = 'Käsespätzle: 10€'german_text = u'Käsespätzle: 10€' # Python 3.3+german_text = 'K\u00e4sesp\u00e4tzle: 10\u20ac'

Encodings

Encodings
● Externe Darstellung von Zeichenketten
● Für Datenaustausch über Dateien,Netzwerkverbindungen etc
● Viele gebräuchliche Encodings älter als Unicode
● Können teilweise nur Teile von Unicode darstellen

Encodings
● Interne Darstellung von Unicode-Zeichen i.d.R. als32 Bit Integer (4 Byte)
● Encodings stellen Zeichenketten i.d.R. als Folge von8 Bit Integers (1 Byte) dar
print('\u20ac'.encode('utf-8')) # euro sign as UTF-8b'\xe2\x82\xac'

UTF-32 (UCS-4, ISO 10646)
● Ordnet jedem Unicode-Zeichen einen 32 Bit Integerzu
● Per Definition zwischen 0 und 0x7fffffff (31 Bit)
● In der Praxis zwischen 0 und 0x0010ffff (21 bit)
● Jedes Zeichen benötigt genau 4 Byte
● Technisch „logischste“ Art der Darstellung
● Interne Darstellung vieler Programmiersprachen

UTF-32 (UCS-4, ISO 10646)
# This code works in Python 2.6+ and 3.3+.import iowith io.open('menu.txt', 'w', encoding='utf-32') as menu_file: menu_file.write(u'Spätzle: 10€')
$ hexdump -C menu.txt
00000000 ff fe 00 00 53 00 00 00 70 00 00 00 e4 00 00 00 |....S...p.......|
00000010 74 00 00 00 7a 00 00 00 6c 00 00 00 65 00 00 00 |t...z...l...e...|
00000020 3a 00 00 00 20 00 00 00 31 00 00 00 30 00 00 00 |:... ...1...0...|
00000030 ac 20 00 00 |. ..|

UTF-32 (UCS-4, ISO 10646)
# This code works in Python 2.6+ and 3.3+.import iowith io.open('menu.txt', 'w', encoding='utf-32') as menu_file: menu_file.write(u'Spätzle: 10€')
$ hexdump -C menu.txt
00000000 ff fe 00 00 53 00 00 00 70 00 00 00 e4 00 00 00 |....S...p.......|
00000010 74 00 00 00 7a 00 00 00 6c 00 00 00 65 00 00 00 |t...z...l...e...|
00000020 3a 00 00 00 20 00 00 00 31 00 00 00 30 00 00 00 |:... ...1...0...|
00000030 ac 20 00 00 |. ..|

UTF-32 (UCS-4, ISO 10646)
● Erfordert vergleichsweise vielSpeicherplatz
● Unterschiedliche Darstellung von 32Bit Integer je nach CPU-Architektur(„endianess“)
● Kann 0-Bytes enthalten→ markiert Ende von Zeichenkettenin C
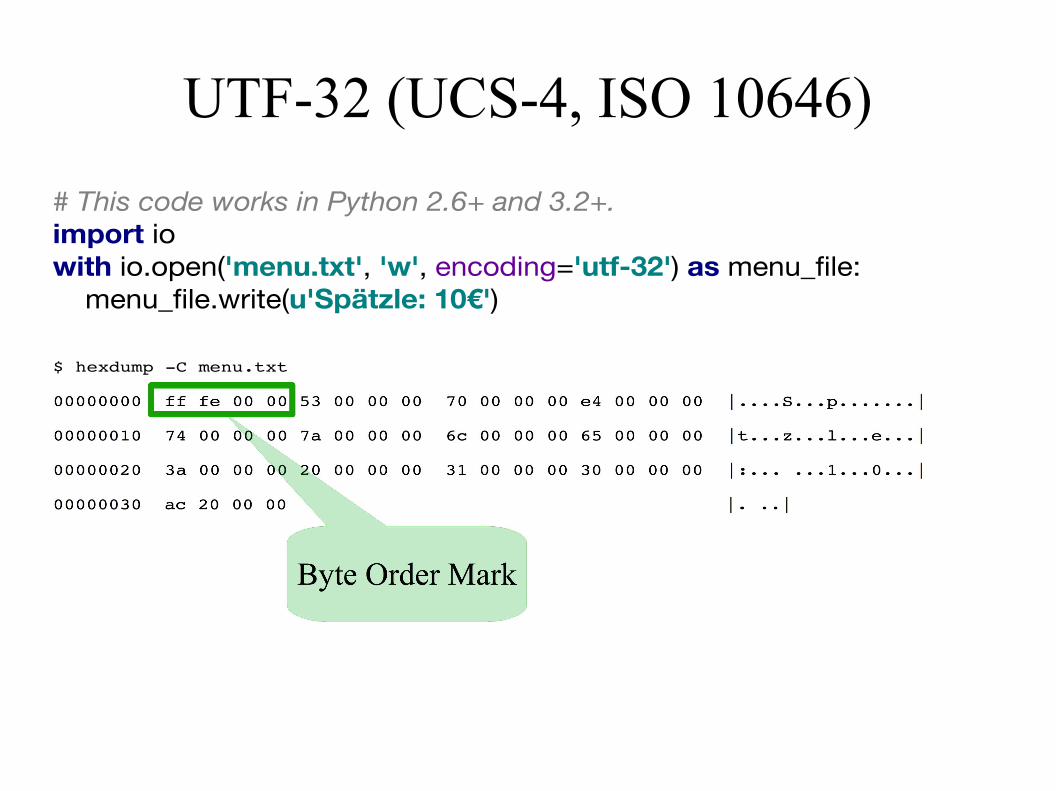
UTF-32 (UCS-4, ISO 10646)
# This code works in Python 2.6+ and 3.2+.import iowith io.open('menu.txt', 'w', encoding='utf-32') as menu_file: menu_file.write(u'Spätzle: 10€')
$ hexdump -C menu.txt

Byte Order Mark
● 0xfeff0000 = „big endian“ (ARM, Motorola)
● 0x0000fffe = „little endian“ (Intel)
● Wenn kein BOM:
– Offiziell: „big endian“ annehmen
– In der Praxis: viele Anwendungen nehmen „littleendian“ an, da dies Windows unter Intel entspricht
– Work around: nach Leerzeichen suchen:0x20000000=big endian, 0x00000020=little endian

Byte Order Mark
● Vorsicht bei string.encode(): BOM wird bei jedemAufruf angehängt>>> 'a'.encode('utf-32') + 'b'.encode('utf-32')b'\xff\xfe\x00\x00a\x00\x00\x00\xff\xfe\x00\x00b\x00\x00\x00'
● Abhilfe: Endianess explizit angeben ('le', 'be'):>>> 'a'.encode('utf-32') + 'b'.encode('utf-32le')b'\xff\xfe\x00\x00a\x00\x00\x00b\x00\x00\x00'
● Kein Problem bei io.open():nur erstes write() schreibtBOM

UTF-16
● Teilt die 4 Byte aus UTF-32 auf in 2 mal 2 Byte
● Nur dann 4 Byte, wenn Code > 0xffff
● „Magic“ zwischen 0xd800 und 0xdfff

UTF-1600000000 ff fe 53 00 70 00 e4 00 74 00 7a 00 6c 00 65 00 |..S.p...t.z.l.e.|
00000010 3a 00 20 00 31 00 30 00 ac 20 |:. .1.0.. |
● Hat BOM
● Kann 0-Bytes enthalten
● Vorteil: für westliche Encodings 50% wenigerPlatzbedarf als UTF-32
● Länge einer Zeichenkette nur mit Dekodierenermittelbar

UCS-2
● Ähnlich UTF-16 aber nur für 0 bis 0xffff (16 Bit)
● „Jugendsünde“ von Unicode, als Chinesisch nochals irrelevant betrachtet wurde
● Nicht verwenden um Datenzu schreiben oder senden
● Weit verbreitet beiAnwendungen, die frühbegannen, Unicode zuunterstützen.

UTF-8
● Wandelt Zeichen um in 1 bis 4 Bytes
● Codes 0 bis 0x7f entsprechen den ASCII-Zeichen
● Codes 0x80 bis 0xff bedeuten, dass mehrere Byteszu verbinden sind, um das eigentliche Zeichen zuerhalten
● „Zusammenbauen“ des eigentlichen Zeichencodesüber Bit-Operationenhttps://en.wikipedia.org/wiki/Utf-8

UTF-8
● Kann 0-Bytes enthalten: 0 bleibt 0.
● Variante: Modified UTF-8 (MUTF-8): wandelt 0 umin 0xc0 0x80 → für C verwendbar
● Speicherbedarf:
– Für englische Texte: 75% geringer als UTF-32
– Für deutsche Texte: ca. 70% geringer als UTF-32

UTF-8
● Kein BOM erforderlich, da sowohl auf big als auchlittle endian das Ergebnis gleich ist
● Aber: BOM 0xefbbbf wird in der Praxis häufigverwendet, um UTF-8 als solchen erkennbar zumachen
● Microsoft Anwendungen ergänzen (Notepad) odererwarten (Compiler) BOM für UTF-8 Texte

UTF-8
● Sehr populär, verwendet für
– Python 3 Quellcodes (sofern nicht anders angegeben)
– XML (sofern nicht anders angegeben)
– Java String Serialization (MUTF-8)
● Verarbeitbar für Software, die eigentlich keinenUnicode unterstützt (zB Lua-Strings)
● Windows Codepage: 65001
● Für ASCII-Texte ident

UTF-8
Diskriminierend: Amerikanerbenötigen weniger Speicherals zB Chinesen
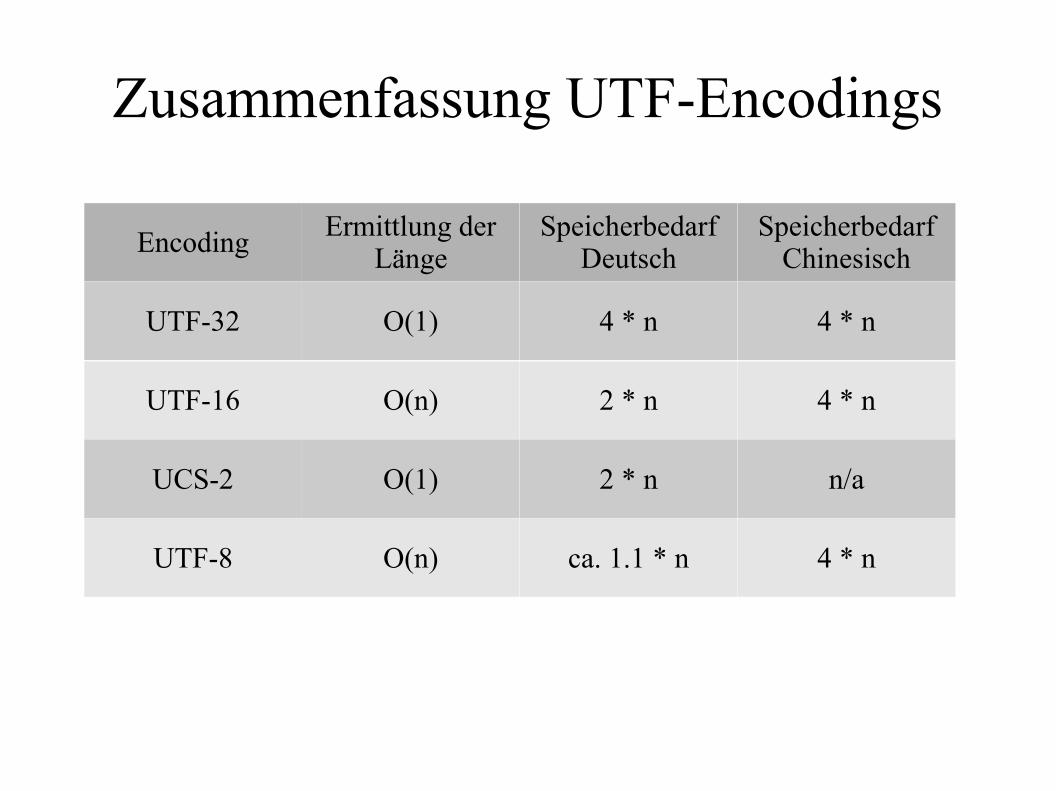
Zusammenfassung UTF-Encodings
EncodingErmittlung der
LängeSpeicherbedarf
DeutschSpeicherbedarf
Chinesisch
UTF-32 O(1) 4 * n 4 * n
UTF-16 O(n) 2 * n 4 * n
UCS-2 O(1) 2 * n n/a
UTF-8 O(n) ca. 1.1 * n 4 * n

8 Bit Encodings
● Aus der Zeit vor Unicode
● Effizient:
– Immer 1 Byte pro Zeichen
– Ermittlung der Länge O(1)

8 Bit Encodings: Herausforderungen
● Umlaute, scharfes S: ä ö ü ß Ä Ö Ü
● Euro: €

ASCII
● „American Standard Code forInformation Interchange“
● Entstanden 1969
● Deckt die Anforderungen derenglischsprachigen Länder zurZeit der Mondlandung ab
https://de.wikipedia.org/wiki/Datei:Apollo11-Aldrin-Ausstieg.jpg

ASCII
● Buchstaben A-Z, Ziffern 0-9, Satzzeichen
● Einige Sonderzeichen wie \, {, }, $ etc
● Steuerzeichen (0x00 bis 0x1f)
● Erfordert nur 7 Bit (Codes 0 bis 0x7f)

ASCII
● Keine Umlaute
● Kein Euro
● Für praktisch alle Anwendungsfälle unbrauchbar
● ASCII-Texte „immer verarbeitbar“
● Oft der Default wenn nicht anders angegeben

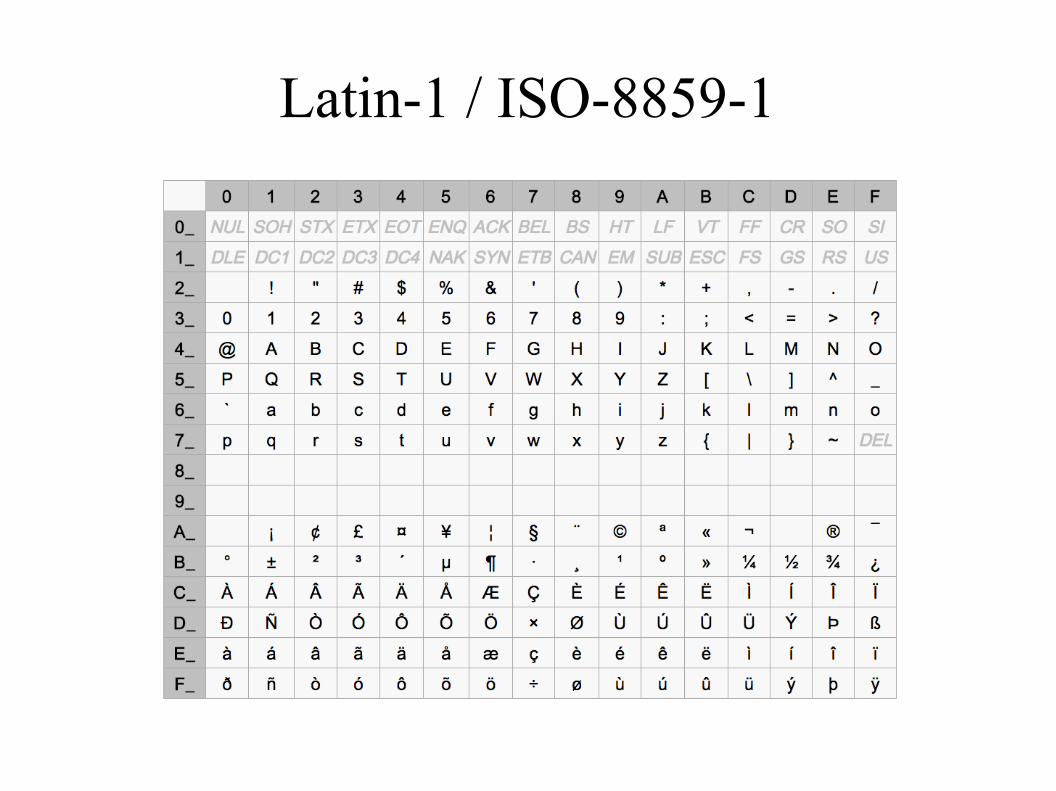
Latin-1 / ISO-8859-1
● Entstanden 1987
● Deckt die Anforderung vielerwesteuropäischen Länder ab als„Never gonna give you up“Nummer 1 war
● Default Encoding für:
– HTML
– Python Quellcodes bis 2.4
https://de.wikipedia.org/wiki/Datei:Rick_Astley-cropped.jpg
Latin-1 / ISO-8859-1

Latin-1 / ISO-8859-1
● 0x00 bis 0x7ff ident mit ASCII
● 0x80 bis 0x9f: unbenutzt - 7 Bit Terminals würdendiese Zeichen in 0x00 bis 0x1f umwandeln →Steuerzeichen→ Chaos
● 0xa0 bis 0xff: diverse regionale Sonderzeichen
● Umlaute
● Kein Euro

Latin-9 / ISO-8859-15
● Entstanden 1999, gleichzeitig mit CounterStrike und der Euro-Einführung
● Weitgehend ident mit Latin-1
● Einige Zeichen umdefiniert, insbesondere:Euro = 0xa4
https://en.wikipedia.org/wiki/File:Counter-Strike_screenshot.png

Latin-9 / ISO-8859-15

Latin-9 / ISO-8859-15
● 0x08 bis 0x9f weiterhin unbenutzt (wegen 7 BitTerminals)
● „nicht ganz“ kompatibel mit Latin-1

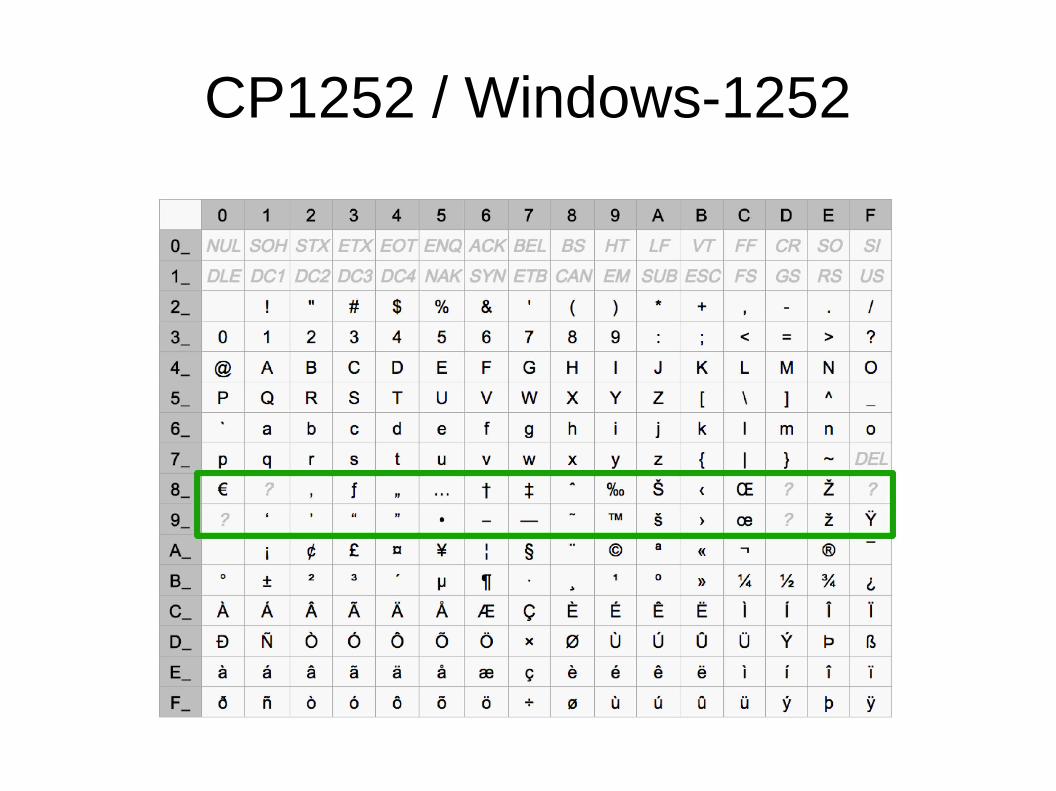
CP1252 / Windows-1252
● Alle Zeichen von Latin-1 mit selbemCode
● Alle zusätzlichen Zeichen von Latin-9mit anderem Code
● Einige weitere Zeichen, insbesondere„smart quotes“
● Oft als „Windows ANSI“ bezeichnet (istaber von Microsoft und nicht vomAmerican National Standard Institute)
https://de.wikipedia.org/wiki/Datei:Vorfenster_additional_window_fenetre_pour_l_hiver.JPG
CP1252 / Windows-1252

CP1252 / Windows-1252
● Umlaute
● Euro = 0x80
● Kann bei Anzeige auf 7 Bit Terminals zuSteuerzeichen führen
● Best practice: Wenn Dokument selbst sagt, dass esLatin-1 ist, dann CP1252 annehmen(zB W3C Recommendation in HTML5)

Zusammenfassung 8 Bit Encodings
Encoding Umlaute? Euro?
ASCII Nein Nein
Latin-1 Ja Nein
Latin-9 Ja Ja, bei 0xa4
CP1252 Ja Ja, bei 0x80

Empfehlungen für deutsche Texte
● Vorzugsweise UTF-8 verwenden
● Wenn 8 Bit Encoding erforderlich, vorzugsweiseCP1252; falls nicht vorhanden, dann Latin-1
● 8 Bit Encodings nur verwenden wenn:
– Anwendung / Protokoll / System Unicode noch nichtunterstützt
– Migration unwirtschaftlich ist
– Speichereffizient kritisch ist

EBCDIC

EBCDIC
● „Extended Binary Coded Decimal InterchangeCode“
● Entstanden um 1963
● Verwendet auf Großrechner
● Nicht verwenden außer externe Daten erfordern es.

CP500
● Zeichen für englische Texte (und einigeSonderzeichen)
● Bedingt Vergleichbar mit ASCII
● Encoding für Dateisystem. Gültige Zeichen inNamen: a-z, 0-9, $, @, TODO; Trennzeichen „.“, „(“und „)“.
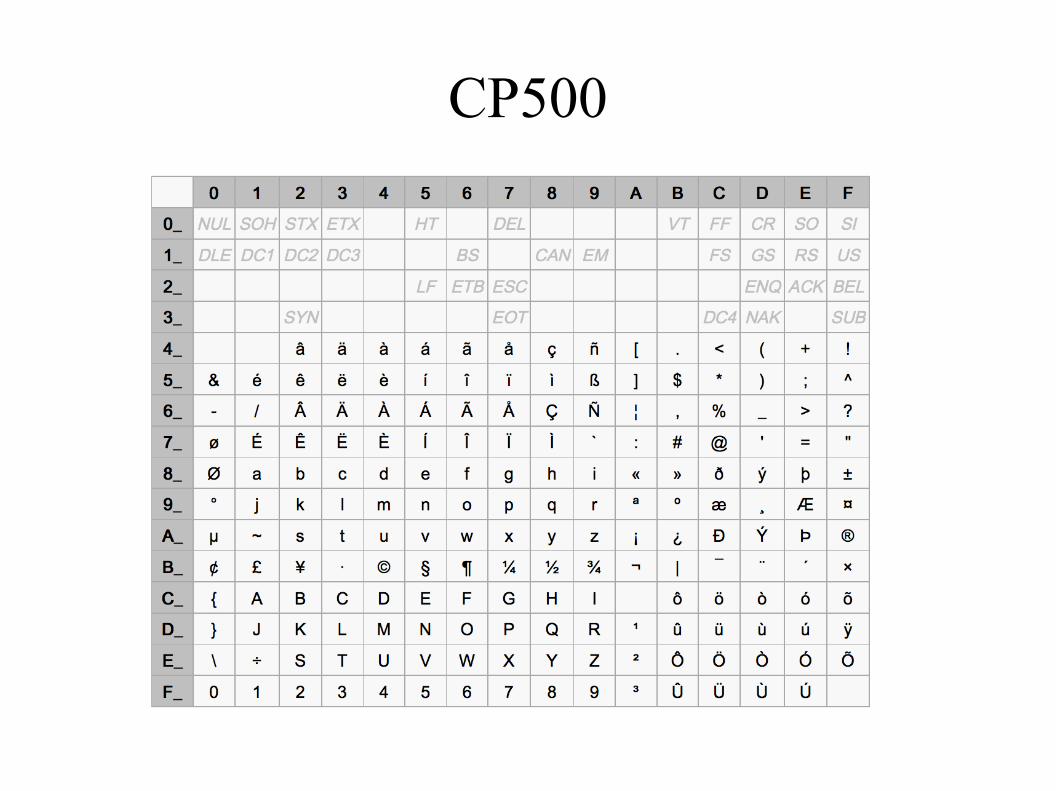
CP500

CP273
● Für westeuropäische Länder
● Vergleichbar mit ISO-8859-1 / Latin-1

CP1141
● Ähnlich CP273 aber mit Euro-Zeichen
● Bedingt vergleichbar mit ISO-8859-15 und CP1252

Empfehlungen für EBCDIC
● Wenn möglich: EBCDIC nicht verwenden
● Für Quelldaten: CP1141
● Für Zieldaten: CP1252
● Für Dateinamen: CP500 (Systemvorgabe)

Wann Datenen-/decoden?
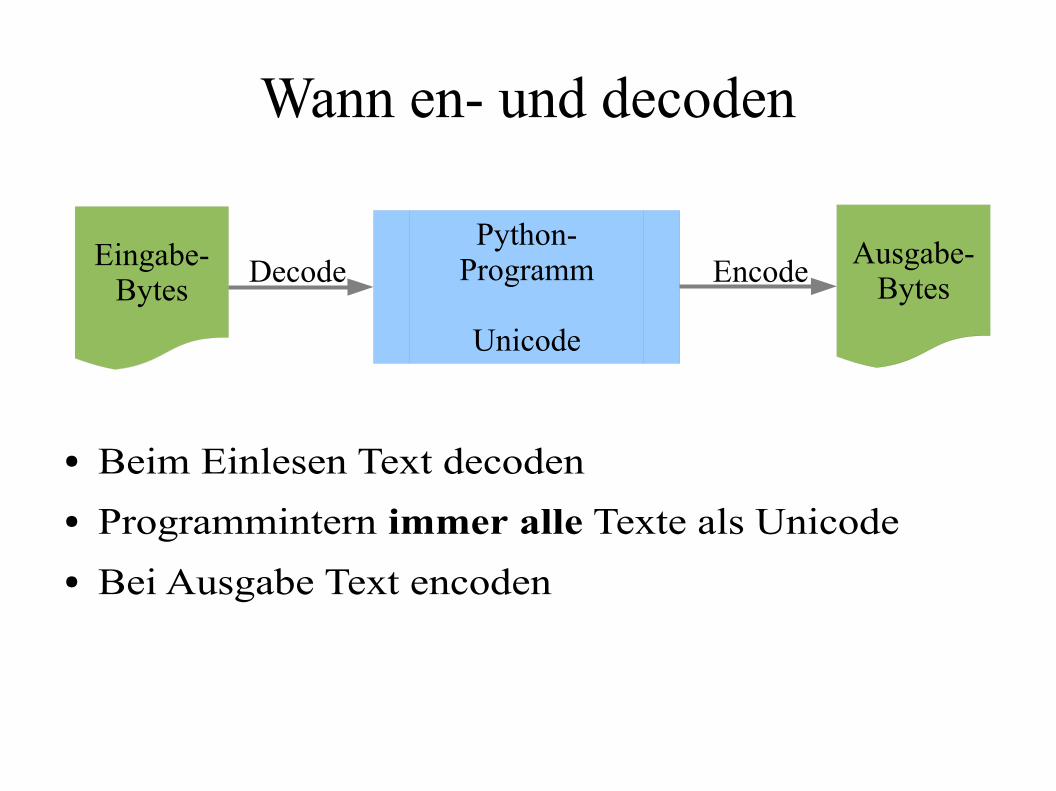
Wann en- und decoden
● Beim Einlesen Text decoden
● Programmintern immer alle Texte als Unicode
● Bei Ausgabe Text encoden
Python-Programm
Unicode
Eingabe-Bytes
Ausgabe-BytesDecode Encode

Ein- und Ausgabe für Text
● io.open(path, mode, encoding=...) # mode='r' oder 'w'
● csv.reader(file, ...) # Nutzt Encoding von filecsv.writer(file, ...)
● xml.etree.ElementTree.parse(path)xml.etree.ElementTree.write( path, encoding=..., xml_declaration=True)
● io.StringIO # ließt / schreibt Unicode String

Ein- und Ausgabe für Byte-Daten
● io.open(path, mode) # mode='rb' oder 'wb'● io.BytesIO # ließt/schreibt Bytes● Kompatibilität: io-Modul ist verfügbar seit Python
2.6+

Python Default Encoding

Python Default Encoding
● Unterschiedliches Ergebnis je nach Python Version,Betriebssystem, Mondphase und Tagesverfassung
● Empfehlung: ignorieren und immer explizitesEncoding nutzen
$ python2.6 -c "import sys; print(sys.getdefaultencoding())"
ascii
$ python3.4 -c "import sys; print(sys.getdefaultencoding())"
utf-8

Encoding für Terminal / Console
● Ähnlich hoffnungslos wie sys.getdefaultencoding()
● Unter Unix / Mac OS X:$ export LC_ALL=en_US.UTF-8
● Unter Windows und cmd.exe:chcp und UTF-8 Hacks wie beschrieben inhttp://stackoverflow.com/questions/878972/
● Print() i.d.R. ok aber nicht notwendigerweise logging-Modul aufsys.stderr, Ein-/Ausgabe mit sys.std*, Pipes, ...
● Unter Python 2 deterministisch praktisch immer kaputt,unter Python 3 je nach Version.

Vorhandenes Encodingermitteln

Eingabe-Encoding
1.Dokumentation – oft einen Versuch wert
2.Beispieldaten analysieren
3.Heuristiken nutzen, zB
– Unicode, Dammit:http://www.crummy.com/software/BeautifulSoup/bs4/doc/#unicode-dammit
– Chardet: https://pypi.python.org/pypi/chardet

Beispieldaten analysieren
● Grundstrategie für deutsche Texte
● Auf BOM prüfen: wenn vorhanden, dann je nachAusprägung UTF-32, UTF-16 oder UTF-8
● Als Hexdump anzeigen und auf Umlaut-ü und Euro-Zeichen prüfen
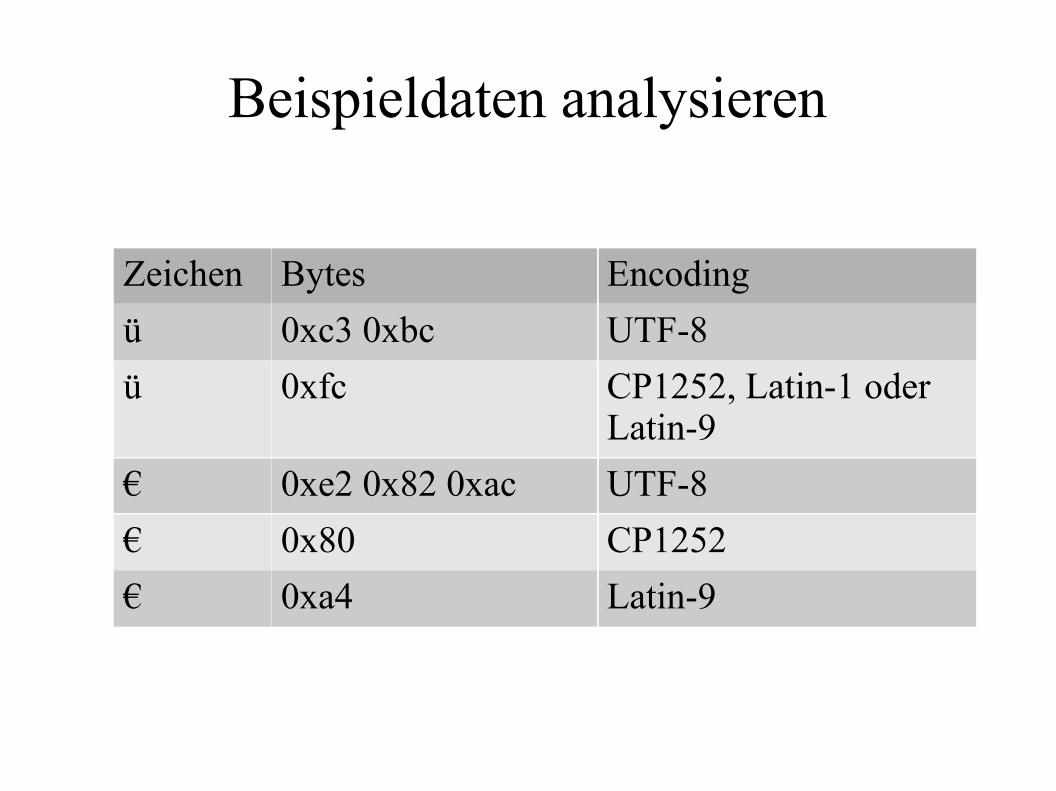
Beispieldaten analysieren
Zeichen Bytes Encoding
ü 0xc3 0xbc UTF-8
ü 0xfc CP1252, Latin-1 oderLatin-9
€ 0xe2 0x82 0xac UTF-8
€ 0x80 CP1252
€ 0xa4 Latin-9

Beispiel 100000000: 46 61 6c 73 63 68 65 73 20 c3 9c 62 65 6e 20 76 |Falsches ..ben v|
0000000f: 6f 6e 20 58 79 6c 6f 70 68 6f 6e 6d 75 73 69 6b |on Xylophonmusik|
0000001f: 20 71 75 c3 a4 6c 74 20 6a 65 64 65 6e 20 67 72 | qu..lt jeden gr|
0000002f: c3 b6 c3 9f 65 72 65 6e 20 5a 77 65 72 67 20 66 |....eren Zwerg f|
0000003f: c3 bc 72 20 e2 82 ac 20 31 30 |..r ... 10|

Beispiel-Pangram
„Falsches Üben von Xylophonmusik quält jedengrößeren Zwerg für € 10“

Beispiel 100000000: 46 61 6c 73 63 68 65 73 20 c3 9c 62 65 6e 20 76 |Falsches ..ben v|
0000000f: 6f 6e 20 58 79 6c 6f 70 68 6f 6e 6d 75 73 69 6b |on Xylophonmusik|
0000001f: 20 71 75 c3 a4 6c 74 20 6a 65 64 65 6e 20 67 72 | qu..lt jeden gr|
0000002f: c3 b6 c3 9f 65 72 65 6e 20 5a 77 65 72 67 20 66 |....eren Zwerg f|
0000003f: c3 bc 72 20 e2 82 ac 20 31 30 |..r ... 10|

Beispiel 200000000: 46 61 6c 73 63 68 65 73 20 dc 62 65 6e 20 76 6f |Falsches .ben vo|
0000000f: 6e 20 58 79 6c 6f 70 68 6f 6e 6d 75 73 69 6b 20 |n Xylophonmusik |
0000001f: 71 75 e4 6c 74 20 6a 65 64 65 6e 20 67 72 f6 df |qu.lt jeden gr..|
0000002f: 65 72 65 6e 20 5a 77 65 72 67 20 66 fc 72 20 80 |eren Zwerg f.r .|
0000003f: 20 31 30 | 10|
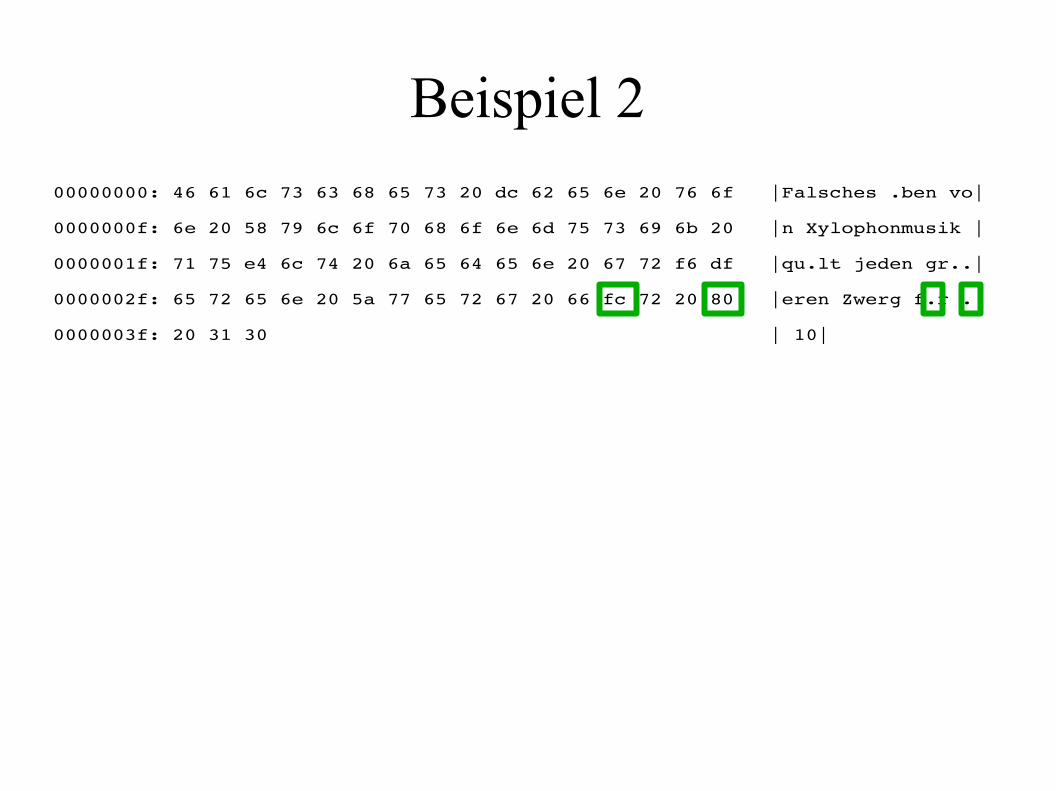
Beispiel 200000000: 46 61 6c 73 63 68 65 73 20 dc 62 65 6e 20 76 6f |Falsches .ben vo|
0000000f: 6e 20 58 79 6c 6f 70 68 6f 6e 6d 75 73 69 6b 20 |n Xylophonmusik |
0000001f: 71 75 e4 6c 74 20 6a 65 64 65 6e 20 67 72 f6 df |qu.lt jeden gr..|
0000002f: 65 72 65 6e 20 5a 77 65 72 67 20 66 fc 72 20 80 |eren Zwerg f.r .|
0000003f: 20 31 30 | 10|

UnicodeError

UnicodeEncodeError
>>> 'Spätzle: 10€'.encode('ascii')
Traceback (most recent call last): File "examples.py", line 78, in <module> 'Spätzle: 10€'.encode('ascii')UnicodeEncodeError: 'ascii' codec can't encode character '\xe4' inposition 2: ordinal not in range(128)
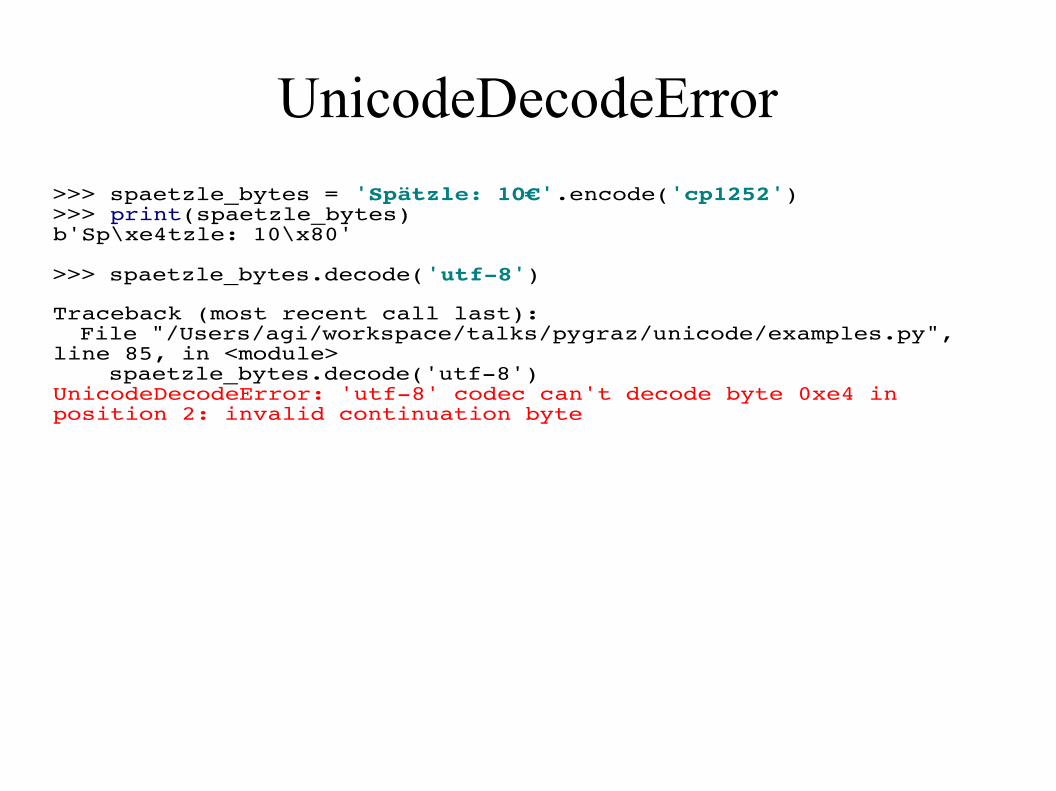
UnicodeDecodeError
>>> spaetzle_bytes = 'Spätzle: 10€'.encode('cp1252')>>> print(spaetzle_bytes)b'Sp\xe4tzle: 10\x80'
>>> spaetzle_bytes.decode('utf-8')
Traceback (most recent call last): File "/Users/agi/workspace/talks/pygraz/unicode/examples.py",line 85, in <module> spaetzle_bytes.decode('utf-8')UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe4 inposition 2: invalid continuation byte

Was tun bei UnicodeError?

Was tun bei UnicodeError?
● Jammern
● Weinen
● Brüllen
● Dinge durch denRaum werfen
● Schoklade essen
● Etc etc etc

UnicodeError vermeiden
● Empfehlungen von vorhin folgen
● Früh decoden
● Intern nur Unicode
● Spät encoden
● Explizites Encodingangeben
J. Robinson, Bomb Queen WMD – Woman of mass destruction, p. 7

Was tun wenn doch UnicodeError?
● Daten vor (De-)Kodieren im Rohformat ausgeben:print('%r' % data)
● errors='replace' setzen und das Ergebnis analysieren
● encodings.cp1252 „verbessern“, so dass jedes Byte(de-)kodierbar ist und das Ergebnis analysieren.
● Alles Workarounds um Fehler zufinden → nach Lösungsfindungwieder abbauen und sauberumsetzen

CP1252 „verbessern“
● Nicht alle Bytes sind mapbar
● Einige mappen auf „undefined“ → UnicodeError
decoding_table = ( '\x00' # 0x00 -> NULL '\x01' # 0x01 -> START OF HEADING '\x02' # 0x02 -> START OF TEXT ... '}' # 0x7D -> RIGHT CURLY BRACKET '~' # 0x7E -> TILDE '\x7f' # 0x7F -> DELETE '\u20ac' # 0x80 -> EURO SIGN '\ufffe' # 0x81 -> UNDEFINED '\u201a' # 0x82 -> SINGLE LOW-9 QUOTATION MARK '\u0192' # 0x83 -> LATIN SMALL LETTER F WITH HOOK '\u201e' # 0x84 -> DOUBLE LOW-9 QUOTATION MARK …)

CP1255 „verbessern“
import codecsfrom encodings import cp1252
decoding_table = ''.join([ code if code != '\ufffe' else chr(index) \ for index, code in enumerate(cp1252.decoding_table)])assert '\ufffe' not in decoding_tablecp1252.decoding_table = decoding_tablecp1252.encoding_table = codecs.charmap_build(decoding_table)
# Führt normalerweise zu UnicodeEncodeError.print('\x81'.encode('cp1252'))

Unicode Normalisierung

Relevanz von Normalisierung
● In vielen Fällen keine Relevanz, insbesondere:
– Daten kommen alle aus dem selben System (zB einezentrale Datenbank)
– Daten werden nur angezeigt oder ausgewertet
● Vor allem dann ein Thema, wenn:
– Datenaustausch mit externen Systemen undunterschiedlichen Plattformen
– Daten werden verglichen

Gleichaussehende Zeichen
Verschiedene Zeichen, die gleich aussehen:
● Großes I: U+0049
● Römische 1: U+2160
>>> print('\u0049')I
>>> print('\u2160')Ⅰ

Verschiedene Darstellungen
Verschiedene Darstellungen des selben Zeichen, zB Umlaut-ä:
● Ein Zeichen: U+00e4
● zusammengesetztes Zeichen: U+0061 U+0308('a' + zwei Punkte darüber)
print_hexdump([code for code in \ unicodedata.normalize('NFC', 'ä').encode('utf-16be')])
00000000: 00 e4 |..|
print_hexdump([code for code in \ unicodedata.normalize('NFD', 'ä').encode('utf-16be')])
00000000: 00 61 03 08 |.a..|

Normalisierung in Filesystem
Keine Einheitlichkeit: Beispiel:with io.open('\u0049.tmp', 'wb'): passwith io.open('\u2160.tmp', 'wb'): pass
Ergebnis mit Mac OS Extended Filesystem:$ ls -1 *.tmpI.tmpⅠ.tmp

Vergleichen mit Normalisierung
● NFC - wenn inhaltlich gleiche Zeichen gleich sein sollen
● NFKC - wenn auch optisch gleiche Zeichen gleich sein sollen(Sicherheitsthema)
● NFD, NFKD – gleiches Ergebnis, aber erfordert unter Umständenmehr Speicher
from unicodedata import normalizeprint(normalize('NFC', '\u00e4') == normalize('NFC', '\u0061\u0308'))# True – umlaut äprint(normalize('NFC', '\u0049') == normalize('NFC', '\u2160'))# False – letter I and Roman number I
print(normalize('NFKC', '\u00e4') == normalize('NFKC', '\u0061\u0308'))# True – umlaut äprint(normalize('NFKC', '\u0049') == normalize('NFKC', '\u2160'))# True – letter I and Roman number I

Empfehlungen zu Normalisierung
● Erst dann zum Problem machen, wenn es eines ist.
● Wenn möglich durchgängig einheitlichnormalisieren (zB NFKC)
● Sonst je Eingangs-/Ausgangsystem beimLesen/Schreiben die erforderliche Normalisierungnutzen
● Bei Dateinamen: abhängig vom Filesystem, fürPython nicht feststellbar (zB NFS).

Unicode Zeichenkettenin Python 2
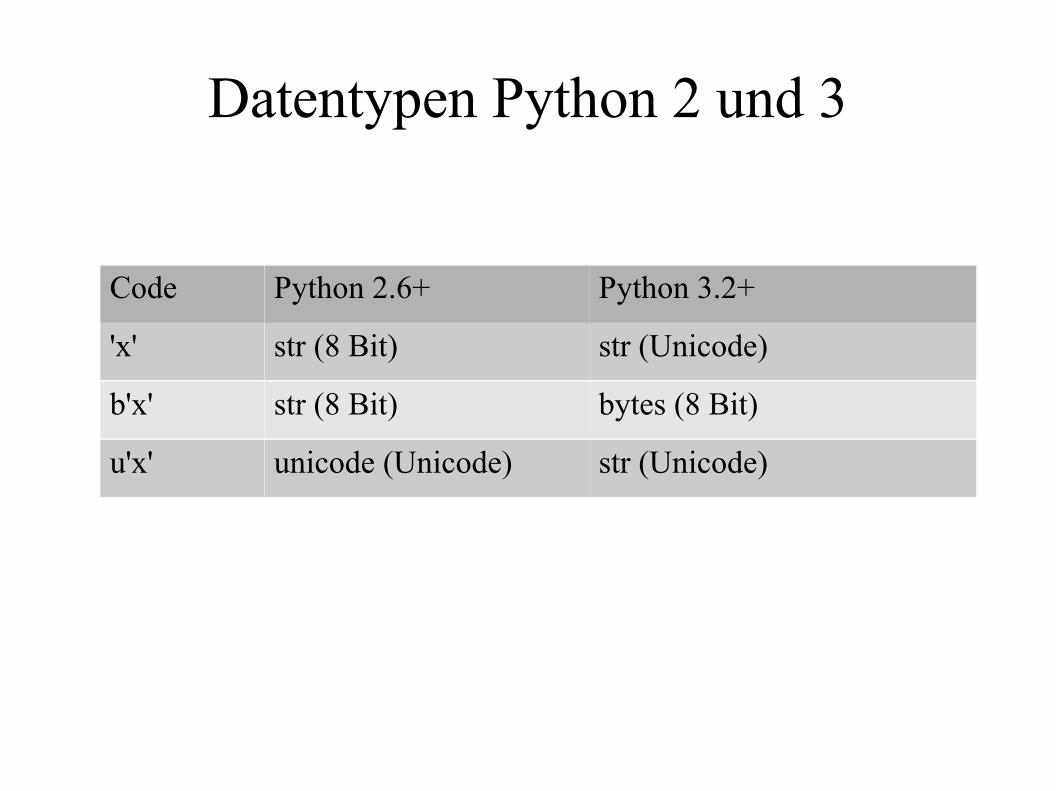
Datentypen Python 2 und 3
Code Python 2.6+ Python 3.2+
'x' str (8 Bit) str (Unicode)
b'x' str (8 Bit) bytes (8 Bit)
u'x' unicode (Unicode) str (Unicode)

Python 2 wie Python 3
● from __future__ import unicode_literals
– '…' entspricht u'...'
● io.open() statt open()
● io.StringIO statt StringIO und cStringIO
● Wo Byte-Strings erforderlich explizit b'...' verwendenBeispiel: csv.reader(file, delimter=b';')
● Aber: manche Unterschiede bleiben bestehen, zB:– str() - unicode()
– __str__ - __unicode__
– chr() – unichr()
– Schmerzlinderung: six.*_types etc → https://pypi.python.org/pypi/six

Unicode in Python 2 und 3
● Ab 2.0: grundsätzlich unterstützt (u'text', codecs undunicodedata Modul)
● Ab 2.5: __future__.unicode_literals Modul
● Ab 2.6: io Modul
● Ab 3.0: durchgängig aber teilweise inkompatibel zuPython 2 unterstützt (kein u'text')
● Ab 3.3: wieder mit u'text'; verbesserte Erkennungfür Terminal-Encoding

Empfehlung
● Wenn möglich Python 3.3+ verwenden
● Sonst: wenn möglich Python 2.6+ verwenden
● Sonst: andere Programmiersprache mit guterUnicode-Implementierung verwenden(zB Java, C#, go, etc)

Zusammenfassung

Zusammenfassung
● Python unterstützt Unicode je nach Version inunterschiedlicher Qualität
● früh decoden, intern alles Unicode, spät encoden
● Encodings
– fix setzen, nicht auf Automatismen hoffen
– ggf. selbst herausfinden mit Hexdump, ü und €
– besonders nützlich: UTF-8, CP1252
● Python 2 Module für Unicode ähnlich Python 3:io, unicode_literals





























