Embed Size (px)
Citation preview

DATA MINING RELOADED In 30 Minuten zum eigenen Scraper
Jens Bonerz – SEO CAMPIXX 2016
Hallo ich bin Jens
Off Price GmbH, Leitung Marketing TeamEuropaweiter E-Commerce Händler mit Webshops, Amazon,
Ebay, Adwords, PLA, AMZ PPC, Ebay Ads, Affiliate... Daten ohne Ende!
Und sonst?Berater für datengetriebene E-Commerce Projekte, Amazon Vendor Central,
Datenmigrationen, Datenanalysen, Anti-Scraping Konzepte, Data Mining
Du findest mich bei XING und LinkedIn

Lieblings-Tools
Data AnalyticsSAS, Elastic
Machine LearningGoogle Tensorflow, Caffe
Data MiningPython, Scrapy

Schweizer Messer für Scraping
Scrapy https://github.com/scrapy/scrapy
• Free, open-source, Python• Cookies, Delays, Timeouts, Proxies, User Agents• Paralleles asynchrones Scrapen• Leistungsstarke Selektoren zum Parsen• Datenqualität durch Contracts• Local Crawl Cache• Erweiterbar (z.B PhantomJS)
Scrapy scraped Seiten, bei denen Standardtools wie Scrape Box et al. aussteigen.

Datenanalyse
Elastic http://elastic.io
• Real Time Search & Analytics• Free, open-source, Java, RESTful API• Schnell, invertierter Index über alle Dokumente• Schemalos, kein Datenbankmodell notwendig• Skalierbar, Sharding und Replikation über mehrere Nodes• Scrolling zum speichereffizienten Streamen von Daten• Handling von vielen Hundert Millionen Dokumenten
Durch frei verfügbare Erweiterungen, die perfekte Data Analytics Lösung für Scrapy

Scrapen? Dann wenn es keine API gibt.
• Preise des Wettbewerbs• Sortiment des Wettbewerbs• Kampagnen des Wettbewerbs• Monitoring der eigenen Shops und Angebote• Inhouse-Tools (z.B. Alertsystem für Negativ-
Rezensionen)
Es gibt nichts, was man mit denrichtigen Tools nicht scrapen kann…

Wir scrapen in unseremBeispiel nur einen geringen
Teil der Daten.Weitgehender Konsens bei den Gerichten ist heute (bislang keine umfassende höchstrichterliche Entscheidung), dass – wenn weder wesentliche Teile einer
Datenbank kopiert werden, noch es zur technischen Überlastung der gescrapten Seite kommt – automatisiertes Sammeln von Daten zulässig ist, solange
die Seite rechtlich und technisch frei zugänglich ist.
Lass Dich im Zweifel juristisch beraten, wenn Dein Geschäftsmodell auf Scraping basiert.

LASSET DIE SPIELE BEGINNEN
Mitschreiben nicht nötig. Gib mir Deine Karte nach der Session und Du erhältst die PPT per Mail.
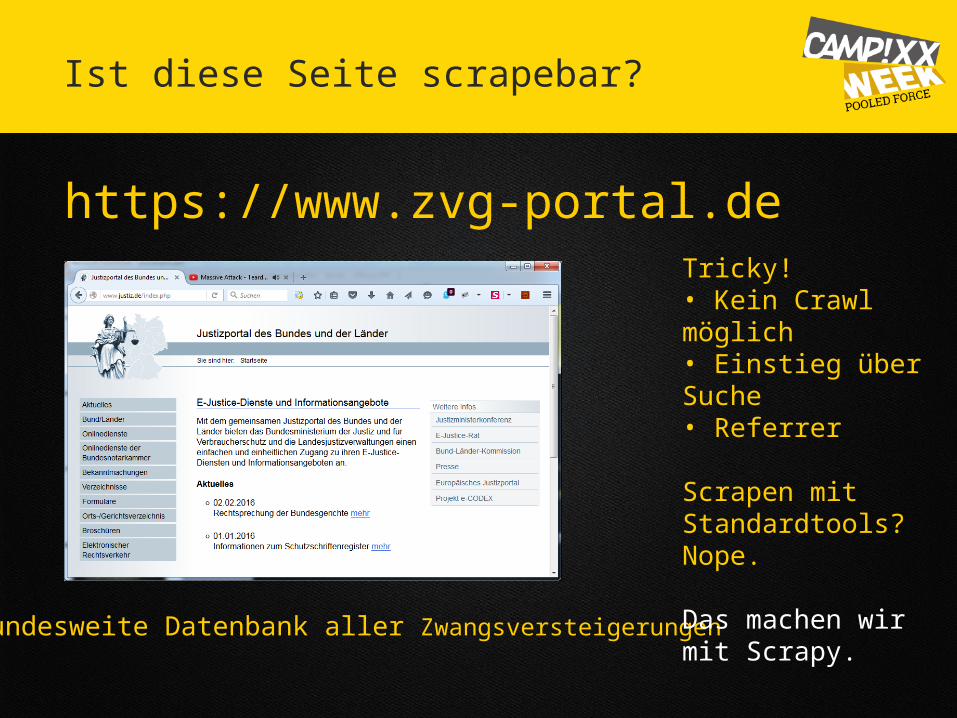
Ist diese Seite scrapebar?
https://www.zvg-portal.de
Bundesweite Datenbank aller Zwangsversteigerungen
Tricky!• Kein Crawl möglich • Einstieg über Suche• Referrer
Scrapen mit Standardtools? Nope.
Das machen wir mit Scrapy.
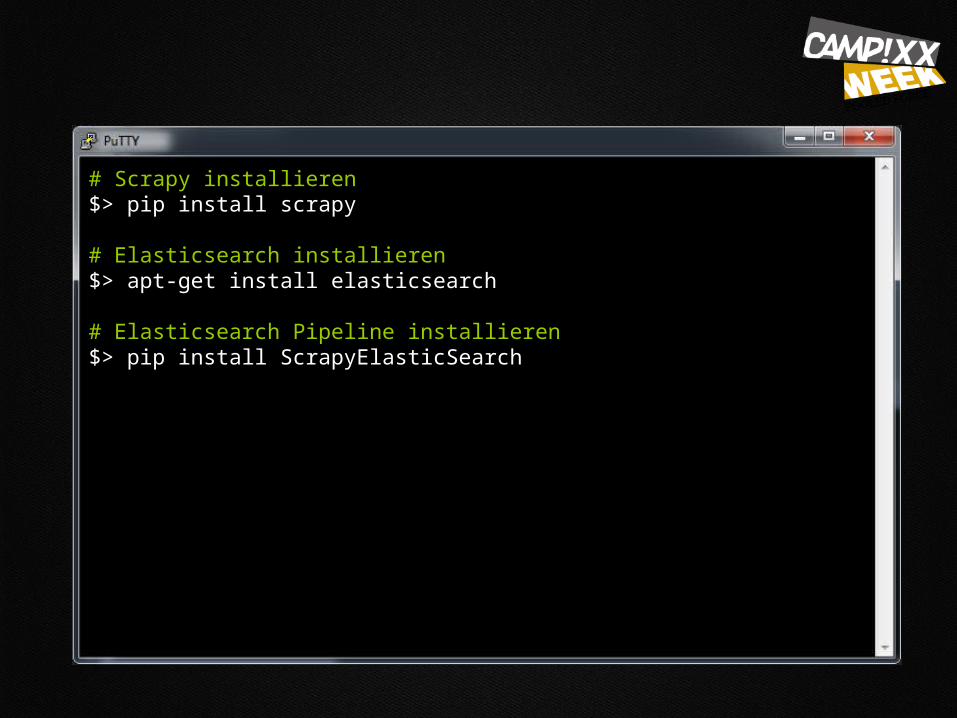
# Scrapy installieren$> pip install scrapy
# Elasticsearch installieren$> apt-get install elasticsearch
# Elasticsearch Pipeline installieren$> pip install ScrapyElasticSearch
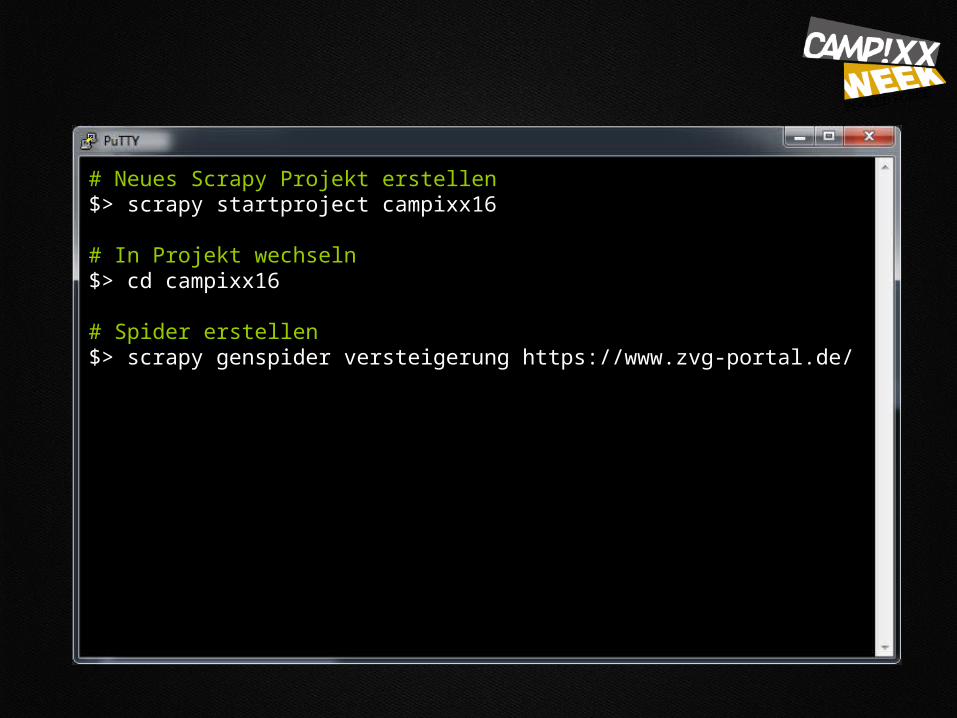
# Neues Scrapy Projekt erstellen $> scrapy startproject campixx16
# In Projekt wechseln $> cd campixx16
# Spider erstellen $> scrapy genspider versteigerung https://www.zvg-portal.de/
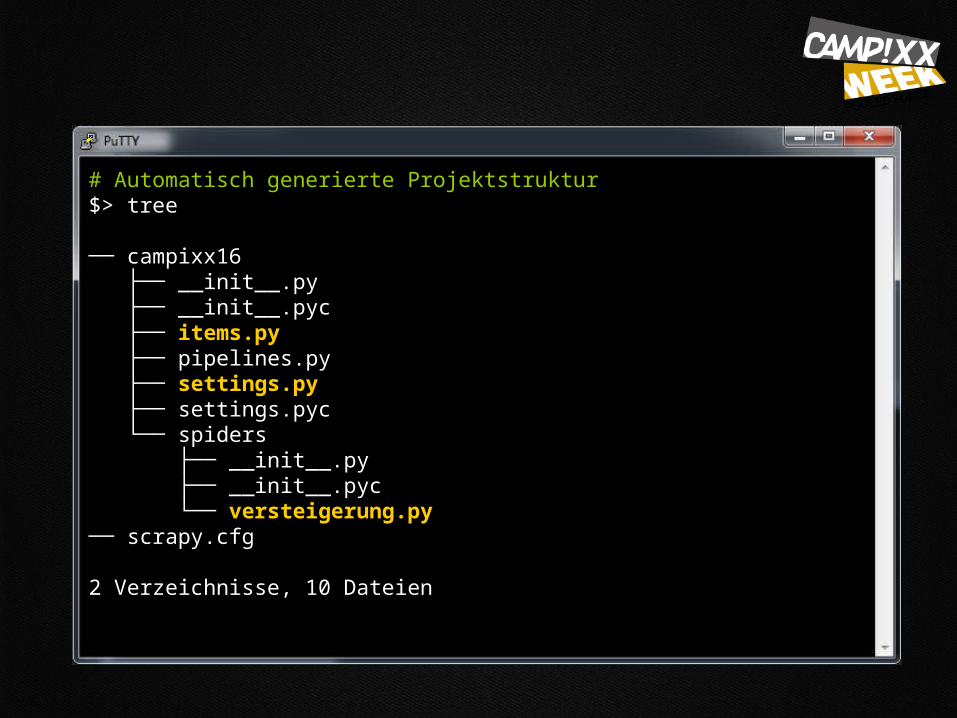
# Automatisch generierte Projektstruktur $> tree
── campixx16 ├── __init__.py ├── __init__.pyc ├── items.py ├── pipelines.py ├── settings.py ├── settings.pyc └── spiders ├── __init__.py ├── __init__.pyc └── versteigerung.py── scrapy.cfg
2 Verzeichnisse, 10 Dateien
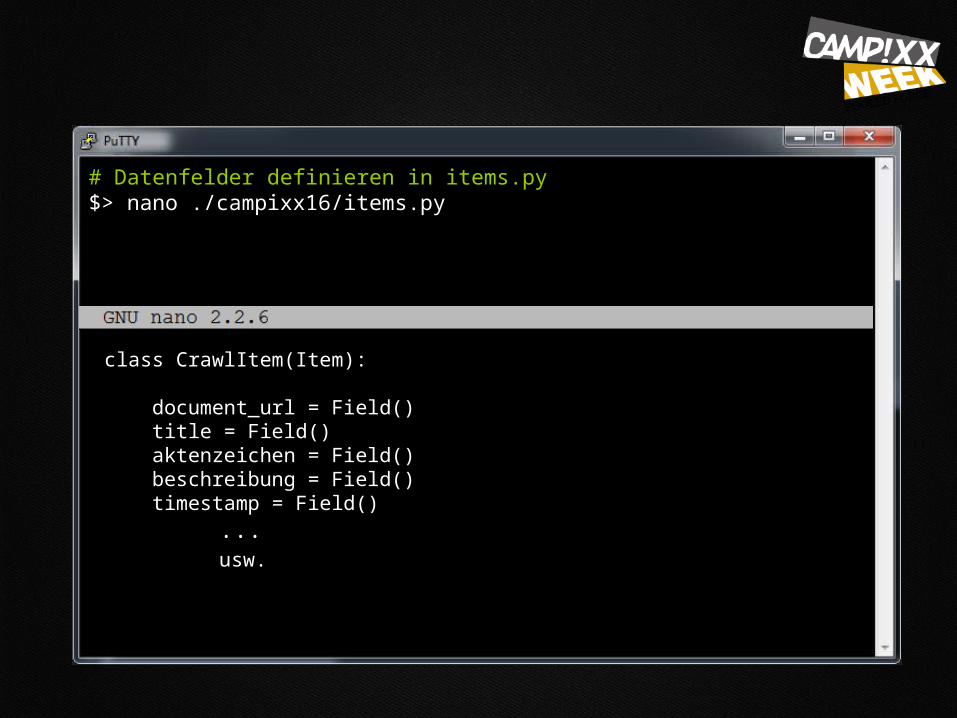
# Datenfelder definieren in items.py $> nano ./campixx16/items.py
class CrawlItem(Item):
document_url = Field() title = Field() aktenzeichen = Field() beschreibung = Field() timestamp = Field() ... usw.
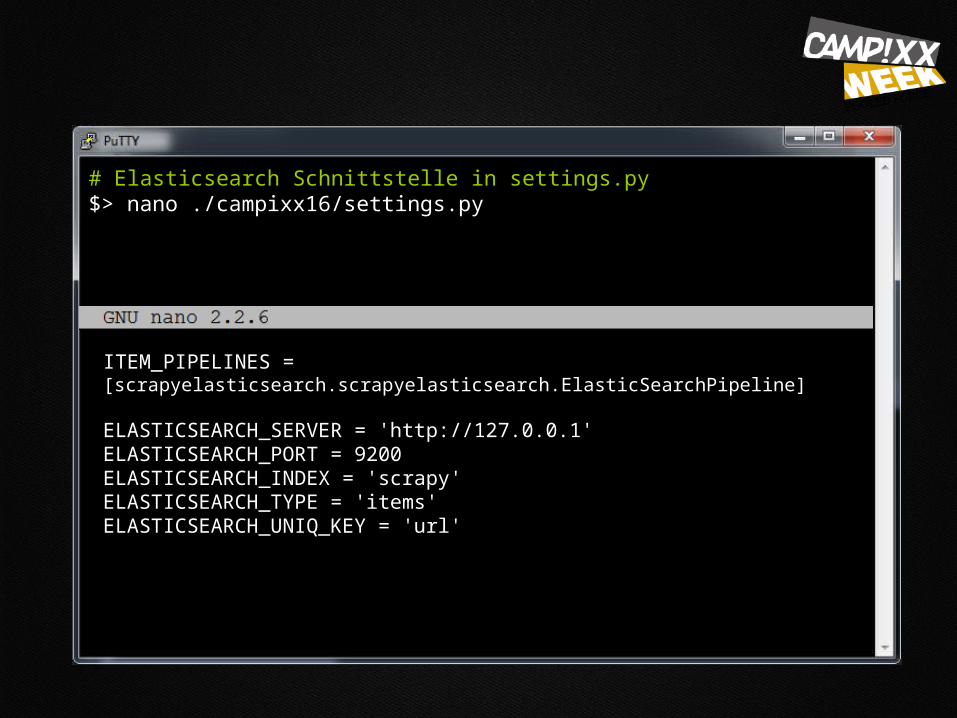
# Elasticsearch Schnittstelle in settings.py $> nano ./campixx16/settings.py
ITEM_PIPELINES = [scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline]
ELASTICSEARCH_SERVER = 'http://127.0.0.1' ELASTICSEARCH_PORT = 9200 ELASTICSEARCH_INDEX = 'scrapy'ELASTICSEARCH_TYPE = 'items'ELASTICSEARCH_UNIQ_KEY = 'url'
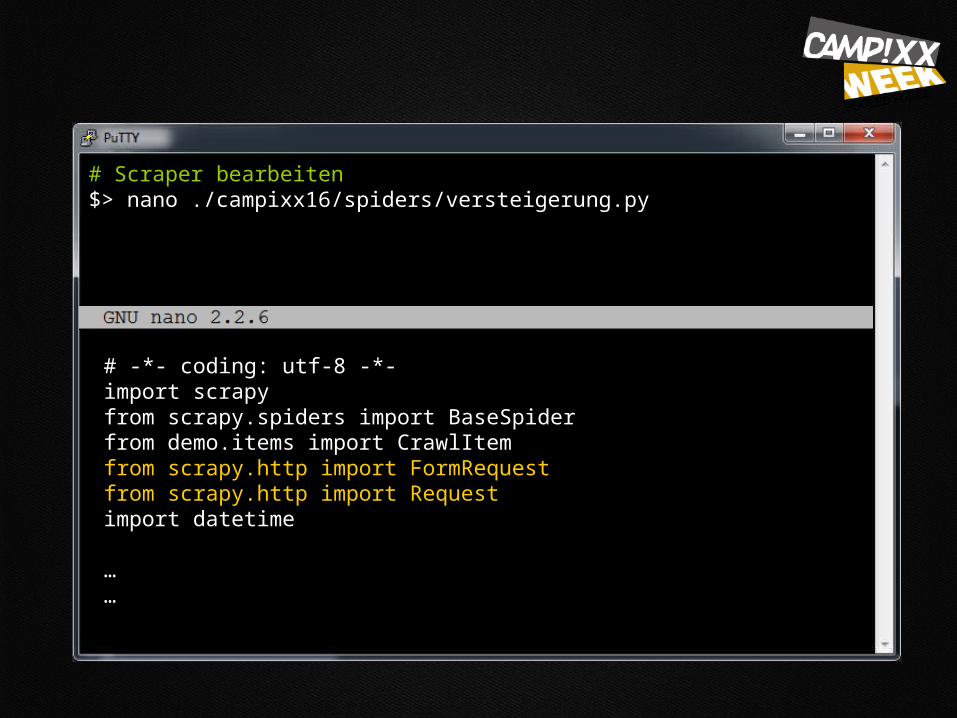
# Scraper bearbeiten $> nano ./campixx16/spiders/versteigerung.py
# -*- coding: utf-8 -*-import scrapyfrom scrapy.spiders import BaseSpiderfrom demo.items import CrawlItemfrom scrapy.http import FormRequestfrom scrapy.http import Requestimport datetime
……
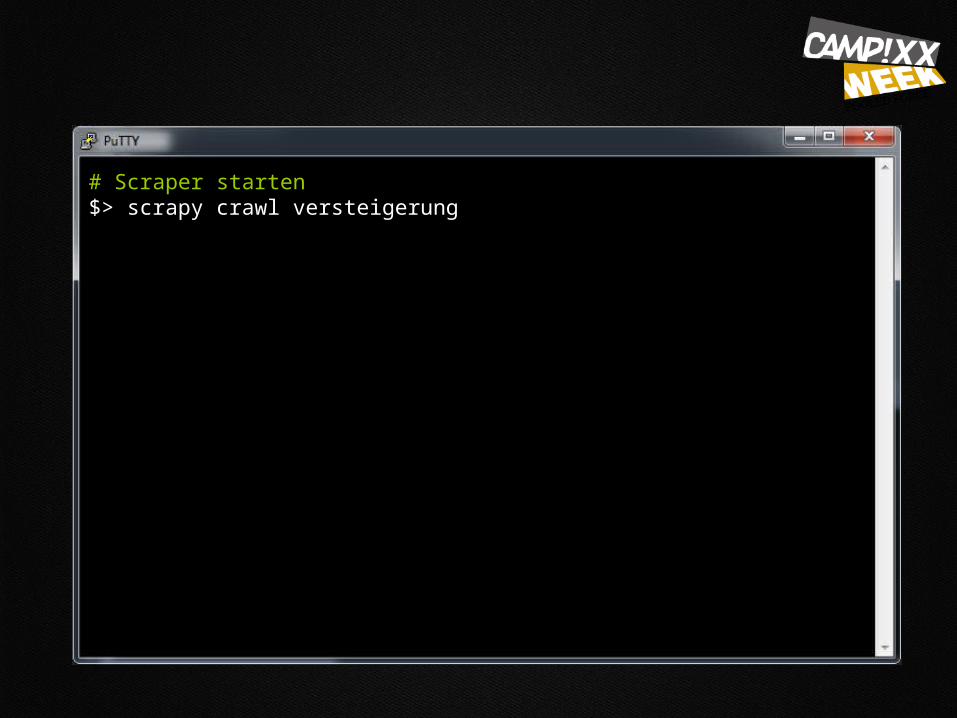
# Scraper starten$> scrapy crawl versteigerung

„If broken it is, fix it you must“
Master Yoda


























![decoding a book - Was ist Buch? [reloaded]](https://img.pdfslide.org/doc/110x75/558df1921a28ab2b438b45c6/decoding-a-book-was-ist-buch-reloaded.jpg)