Embed Size (px)
Citation preview

Peter Sobe 1
1. Grundlagen der InformatikOrganisation und Architektur von Rechnern
Inhalt Algorithmen, Darstellung mit
Struktogrammen und Programmablaufplänen
Boolesche Algebra / Aussagenlogik
Grundlagen digitaler Systeme
Organisation und Architektur von Rechnern
Zahlensysteme und interne Zahlendarstellung
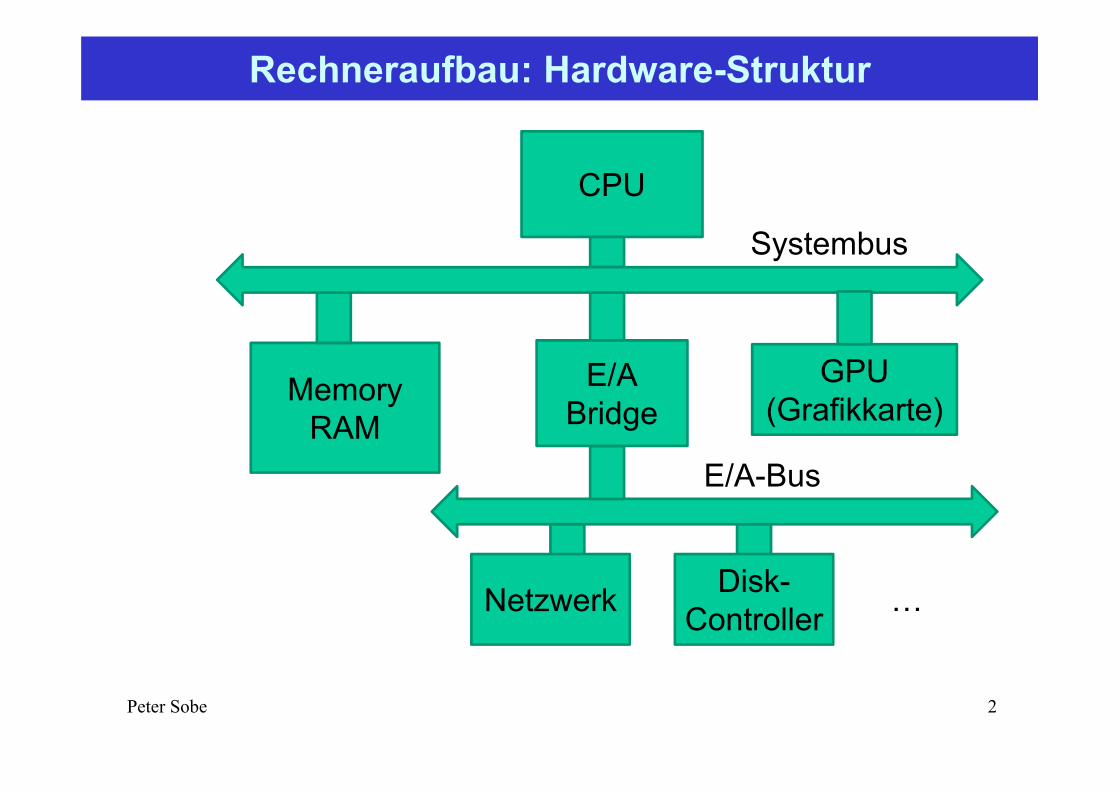
Rechneraufbau: Hardware-Struktur
2Peter Sobe
CPU
MemoryRAM
E/ABridge
Systembus
E/A-Bus
Disk-ControllerNetzwerk
GPU(Grafikkarte)
…
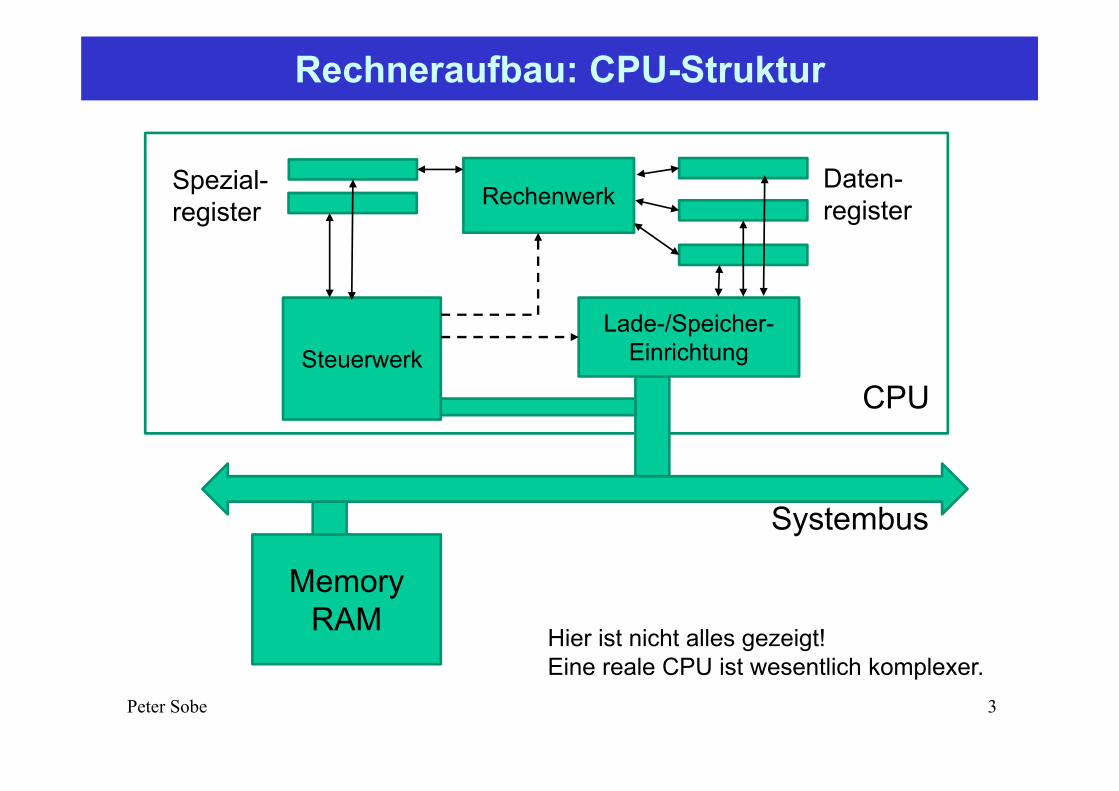
Rechneraufbau: CPU-Struktur
3Peter Sobe
MemoryRAM
Systembus
Hier ist nicht alles gezeigt!Eine reale CPU ist wesentlich komplexer.
Lade-/Speicher-EinrichtungSteuerwerk
RechenwerkDaten-register
Spezial-register
CPU

Schichtenmodell
4Peter Sobe
Strukturierung des Rechensystems (Hardware und Software) inmehrere aufeinander liegende Schichten.
Höhere Schichten benutzen darunter liegende über Schnittstellen
Nur die Schnittstellen sind nach oben sichtbar, die Implementierung der zugehörigen Schicht bleibt verborgen (’information hiding’).
Schichten können ausgetauscht werden (unter Beibehaltung ihrer Schnittstelle), ohne dass die darüber liegenden Schichten geändert werden müssen.
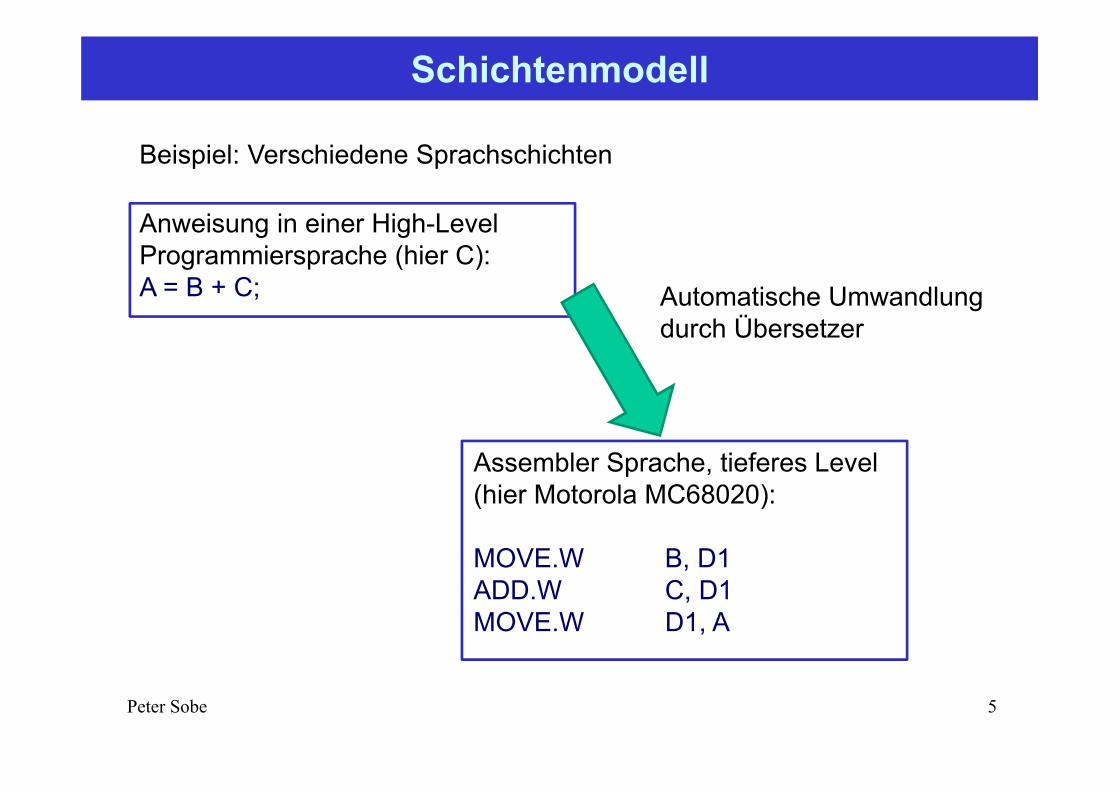
Schichtenmodell
5Peter Sobe
Beispiel: Verschiedene Sprachschichten
Anweisung in einer High-Level Programmiersprache (hier C):A = B + C;
Assembler Sprache, tieferes Level (hier Motorola MC68020):
MOVE.W B, D1ADD.W C, D1MOVE.W D1, A
Automatische Umwandlung durch Übersetzer
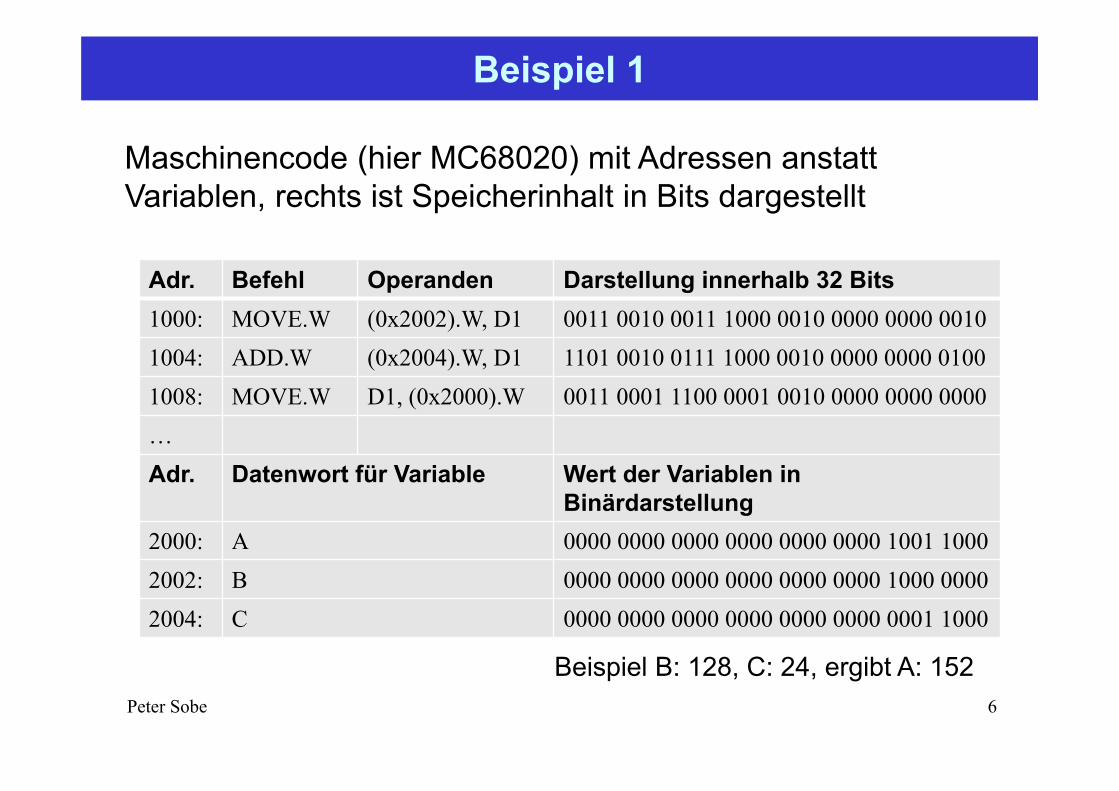
Beispiel 1
6Peter Sobe
Maschinencode (hier MC68020) mit Adressen anstatt Variablen, rechts ist Speicherinhalt in Bits dargestellt
Adr. Befehl Operanden Darstellung innerhalb 32 Bits1000: MOVE.W (0x2002).W, D1 0011 0010 0011 1000 0010 0000 0000 00101004: ADD.W (0x2004).W, D1 1101 0010 0111 1000 0010 0000 0000 01001008: MOVE.W D1, (0x2000).W 0011 0001 1100 0001 0010 0000 0000 0000…Adr. Datenwort für Variable Wert der Variablen in
Binärdarstellung 2000: A 0000 0000 0000 0000 0000 0000 1001 10002002: B 0000 0000 0000 0000 0000 0000 1000 00002004: C 0000 0000 0000 0000 0000 0000 0001 1000
Beispiel B: 128, C: 24, ergibt A: 152
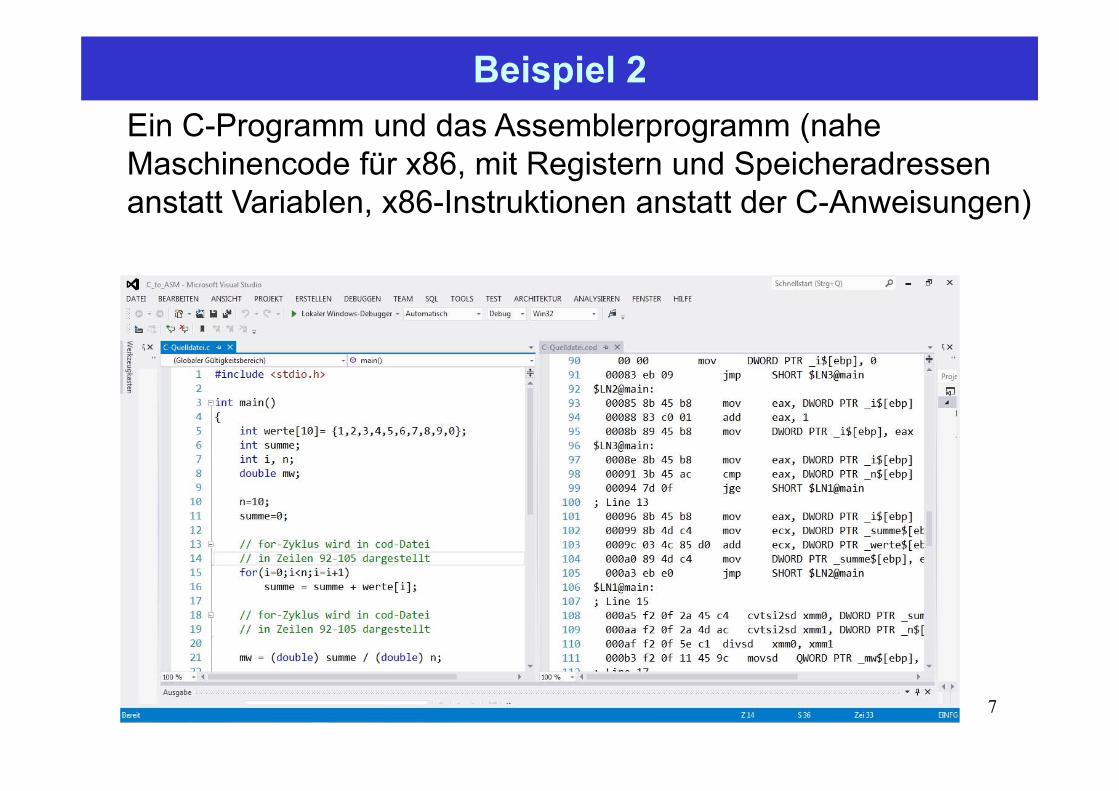
Beispiel 2
7Peter Sobe
Ein C-Programm und das Assemblerprogramm (nahe Maschinencode für x86, mit Registern und Speicheradressen anstatt Variablen, x86-Instruktionen anstatt der C-Anweisungen)
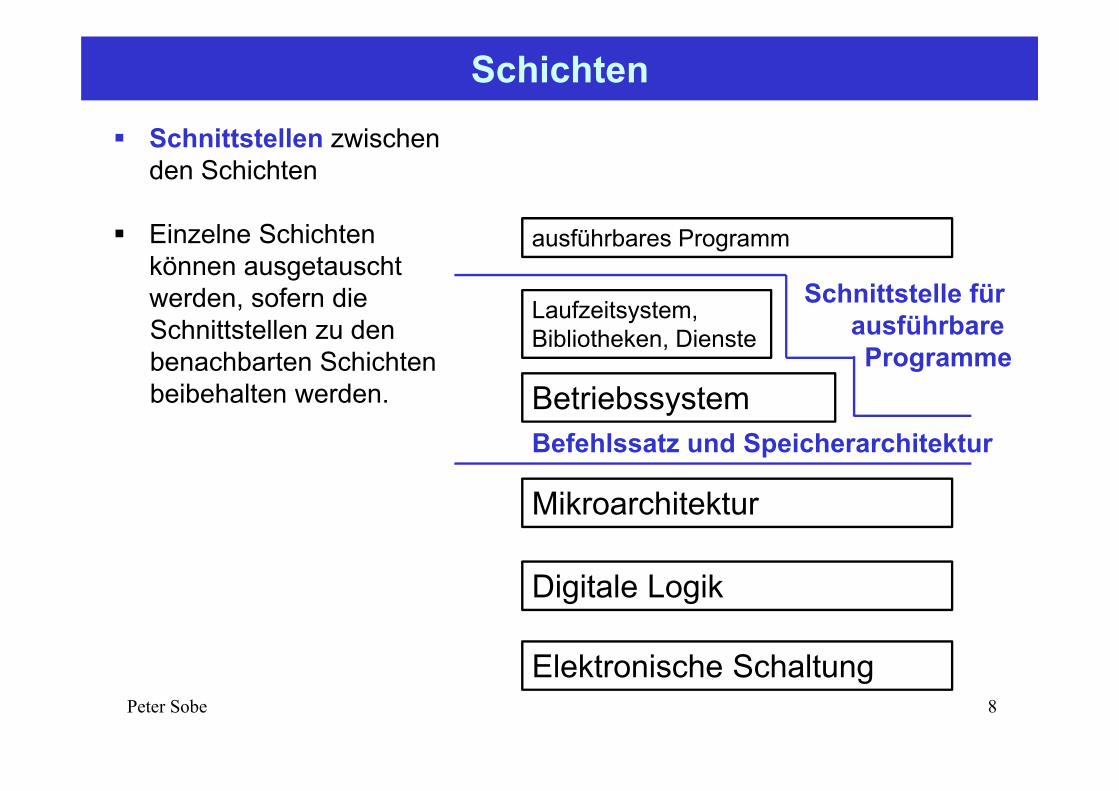
Schichten
8Peter Sobe
Schnittstellen zwischen den Schichten
Einzelne Schichten können ausgetauscht werden, sofern die Schnittstellen zu den benachbarten Schichten beibehalten werden.
Elektronische Schaltung
Digitale Logik
Mikroarchitektur
Befehlssatz und SpeicherarchitekturBetriebssystem
Laufzeitsystem, Bibliotheken, Dienste
ausführbares Programm
Schnittstelle für ausführbare Programme

Architektur und Realisierung
9Peter Sobe
Architektur Betrachtung eines Prozessors ausgehend vom äußeren
Erscheinungsbild legt Art und Weise der Programmierung auf Maschinensprachen-
Ebene fest Definiert Anzahl, Verwendungsmöglichkeiten und Benennung von
Registern (Speicherplätze im Prozessor) Legt Befehle und deren Wirkungsweise fest, Programmiermodell Architekturklassen: von-Neumann, Havard-Architektur, CISC,
RISC, VLIW
Realisierung Interne Wirkungsweisen, verborgen vor dem Programmiermodell Größe und Organisation der Caches Optimierende Techniken, wie z.B. Befehlsphasenpipelining,
Internes Umsortieren von Befehlen

Exkurs: x86-Architektur (1)
10Peter Sobe
Architektur – Betrachtung eines Prozessors ausgehend vom äußeren Erscheinungsbild:
Registersatz: Anzahl der Register, Freiheiten bzw. Beschränkungen bei deren Verwendung
Befehlssatz: Befehlsliste und evtl. verschiedene Varianten der Befehle, wenn unterschiedliche Adressierungsarten zugelassen sind.
Alles andere betrifft die Implementierung und Realisierung.
Die x86-Architektur ist weit verbreitet, in verschiedenen Implementierungen, auch von unterschiedlichen Herstellern(AMD, Intel, Cyrix, u.a.).
Andere ‚Nicht-x86‘-Architekturen: Motorola 68000er, MIPS, PowerPC
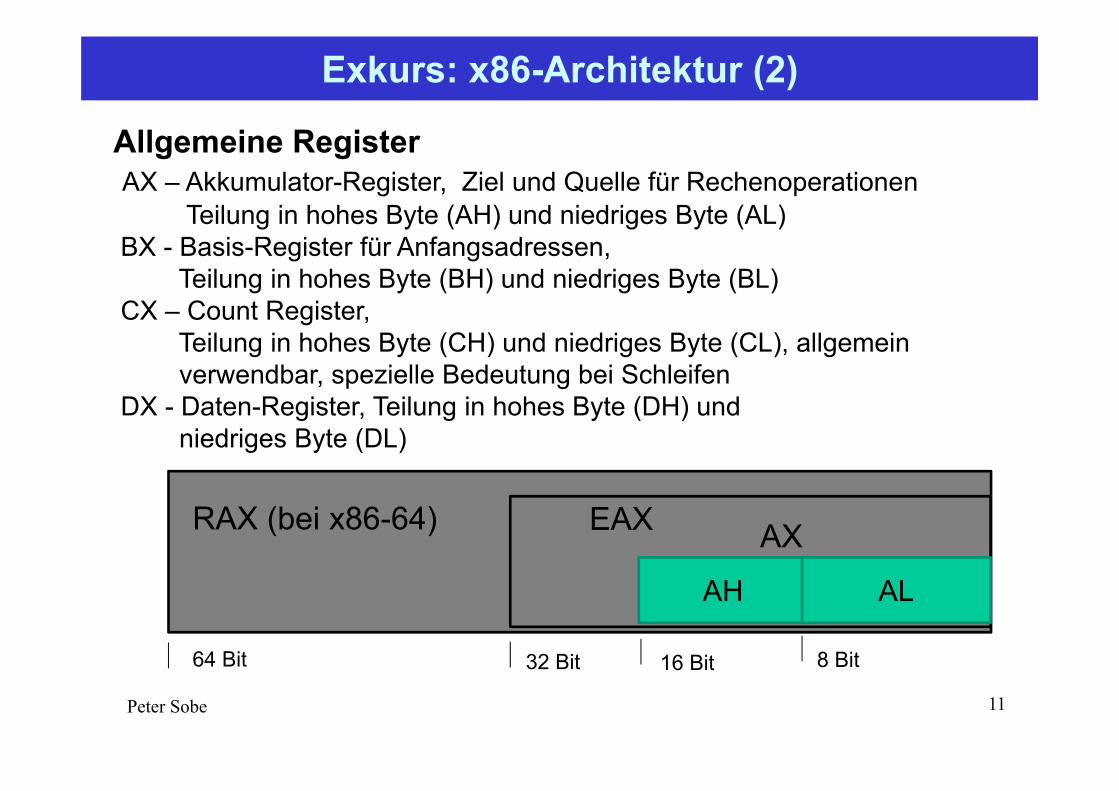
Exkurs: x86-Architektur (2)
Peter Sobe
Allgemeine RegisterAX – Akkumulator-Register, Ziel und Quelle für Rechenoperationen
Teilung in hohes Byte (AH) und niedriges Byte (AL) BX - Basis-Register für Anfangsadressen,
Teilung in hohes Byte (BH) und niedriges Byte (BL) CX – Count Register,
Teilung in hohes Byte (CH) und niedriges Byte (CL), allgemein verwendbar, spezielle Bedeutung bei Schleifen
DX - Daten-Register, Teilung in hohes Byte (DH) und niedriges Byte (DL)
11
AH AL
AXEAX
AH AL
AXEAXRAX (bei x86-64)
8 Bit16 Bit32 Bit64 Bit

Exkurs: x86-Architektur (3)
12Peter Sobe
Pointer-RegisterSP Stack-Pointer: zur Adressierung des Stacks verwendet BP Base-Pointer: zur Adressierung des Stacks verwendet IP Instruction-Pointer: Offset des nächsten Befehls
Index-RegisterSI Source-Index: Unterstützung von Adressierungenesi Quelle (eng: source) für StringoperationenDI Destination-Index: Unterstützung von Adressierungen edi Ziel (eng: destination) für Stringoperationen
Segment-RegisterCS Code-Segment: zeigt auf aktuelles Codesegment DS Daten-Segment: zeigt auf aktuelles Datensegment SS Stack-Segment: zeigt auf aktuelles Stapelsegment ES Extra-Segment: zeigt auf weiteres Datensegment

Exkurs: x86-Architektur (4)
13Peter Sobe
StatusflagsCF Carry-Flag Übertragflag AF Auxiliary Carry-Flag Hilfsübertragflag ZF Zero-Flag NullflagSF Sign-Flag VorzeichenflagPF Parity-Flag ParitätsflagOF Overflow-Flag Überlaufflag
KontrollflagsTF Trap-Flag EinzelschrittflagIF Interrupt Enable-Flag Interruptflag
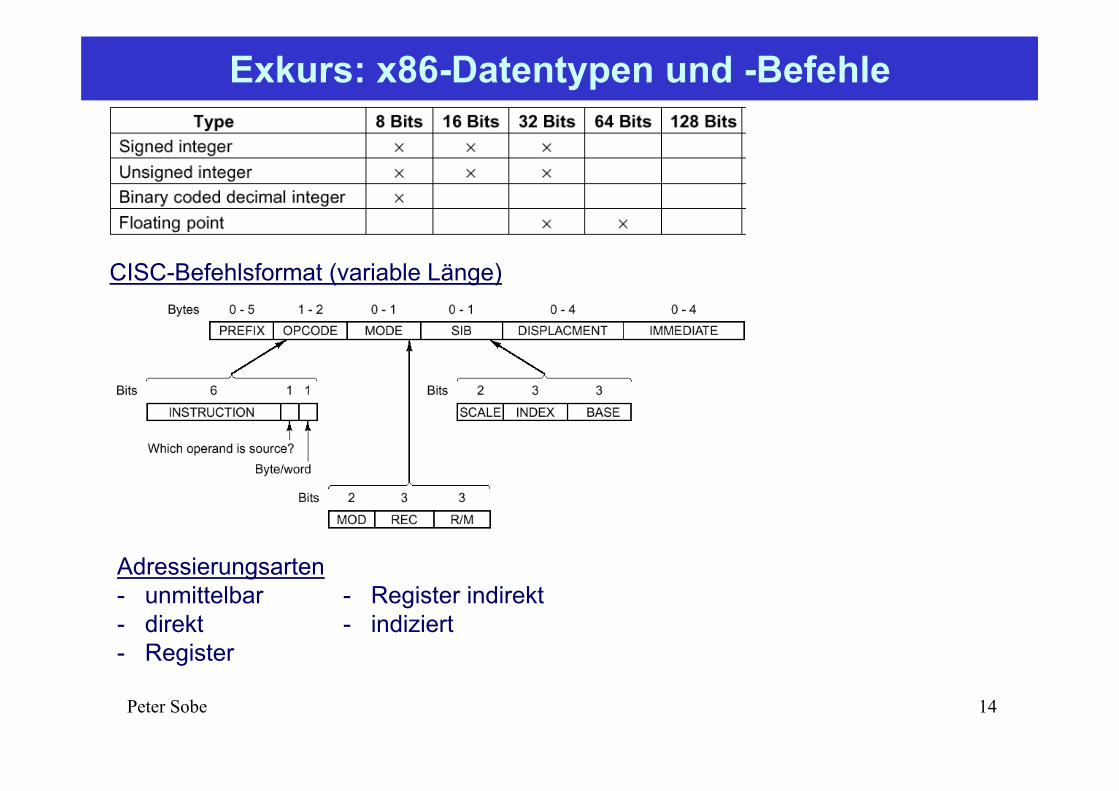
CISC-Befehlsformat (variable Länge)
Adressierungsarten- unmittelbar - Register indirekt- direkt - indiziert- Register
Exkurs: x86-Datentypen und -Befehle
Peter Sobe 14
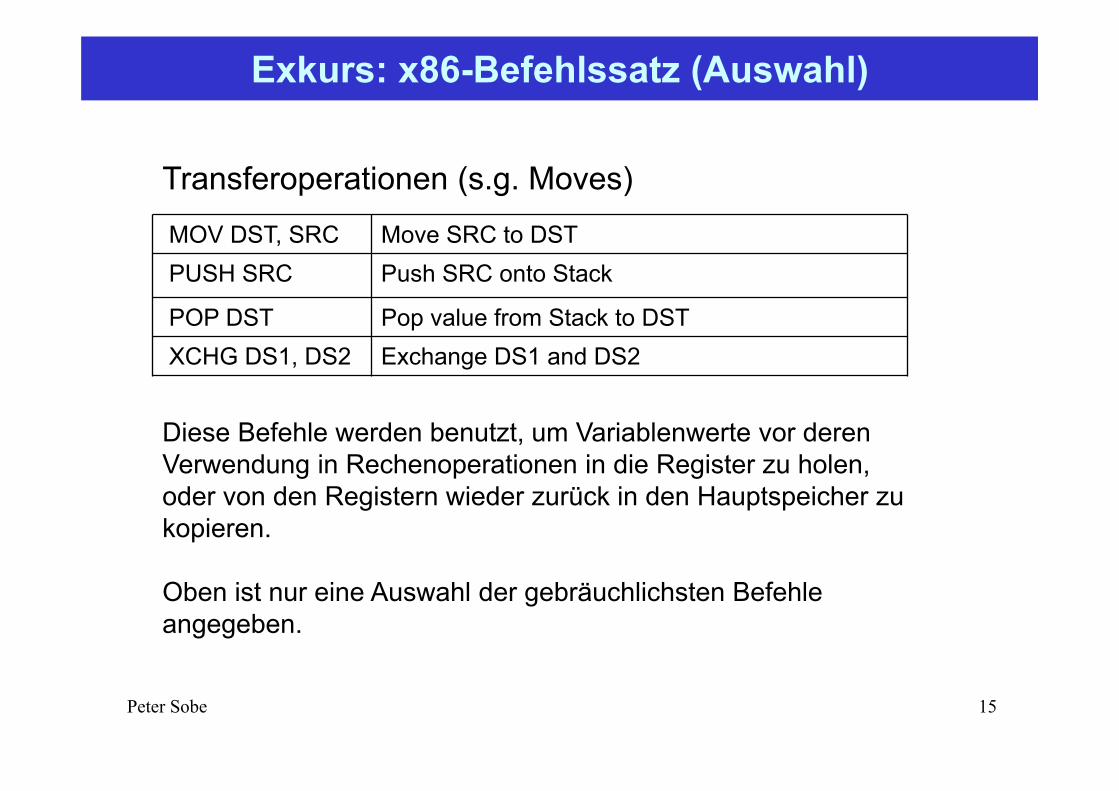
Exkurs: x86-Befehlssatz (Auswahl)
Diese Befehle werden benutzt, um Variablenwerte vor deren Verwendung in Rechenoperationen in die Register zu holen, oder von den Registern wieder zurück in den Hauptspeicher zu kopieren.
Oben ist nur eine Auswahl der gebräuchlichsten Befehle angegeben.
Peter Sobe 15
MOV DST, SRC Move SRC to DSTPUSH SRC Push SRC onto Stack
POP DST Pop value from Stack to DSTXCHG DS1, DS2 Exchange DS1 and DS2
Transferoperationen (s.g. Moves)
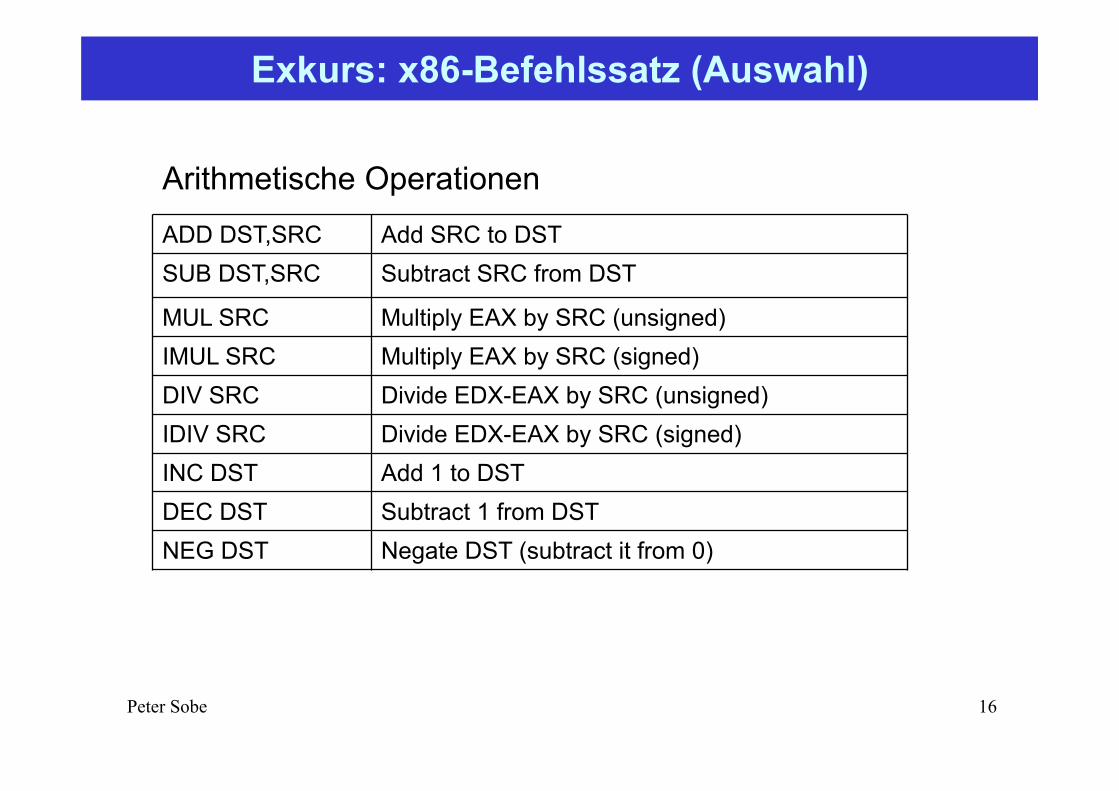
Exkurs: x86-Befehlssatz (Auswahl)
Peter Sobe 16
ADD DST,SRC Add SRC to DSTSUB DST,SRC Subtract SRC from DST
MUL SRC Multiply EAX by SRC (unsigned)IMUL SRC Multiply EAX by SRC (signed)DIV SRC Divide EDX-EAX by SRC (unsigned)IDIV SRC Divide EDX-EAX by SRC (signed)INC DST Add 1 to DSTDEC DST Subtract 1 from DSTNEG DST Negate DST (subtract it from 0)
Arithmetische Operationen

Exkurs: x86-Befehlssatz (Auswahl)
Peter Sobe 17
JMP ADDR Jump to ADDRJxx ADDR Conditional Jump to ADDR
(xx zzum Beispiel NE für ‚NOT Equal‘ als Ergebnis des letzten Vergleichs mit CMP (Compare)
CALL ADDR Call Procedure at ADDRRET Return from ProcedureLOOPxx Loop until Condition is met
Steuerfluss

Exkurs: x86-Befehlssatz (Auswahl)
Peter Sobe 18
AND DST,SRC Boolean AND SRC into DST
OR DST,SRC Boolean OR SRC into DST
XOR DST,SRC Boolean Exclusive OR SRC to DSTNOT DST Replace DST with 1‘s complement
Boolean
SAL/SAR DST,# Shift DST left/right # of BitsSHL/SHR DST,# Shift logical DST left/right # of Bits
ROL/ROR DST,# Rotate DST left/right # of BitsRCL/RCR DST,# Rotate DST through carry # of Bits
Shift/Rotate
TST SRC1,SRC2 Boolean AND Operands, Set Flags CMP SRC1,SRC2 Set Flags based on SRC1-SRC2
Vergleichsoperationen
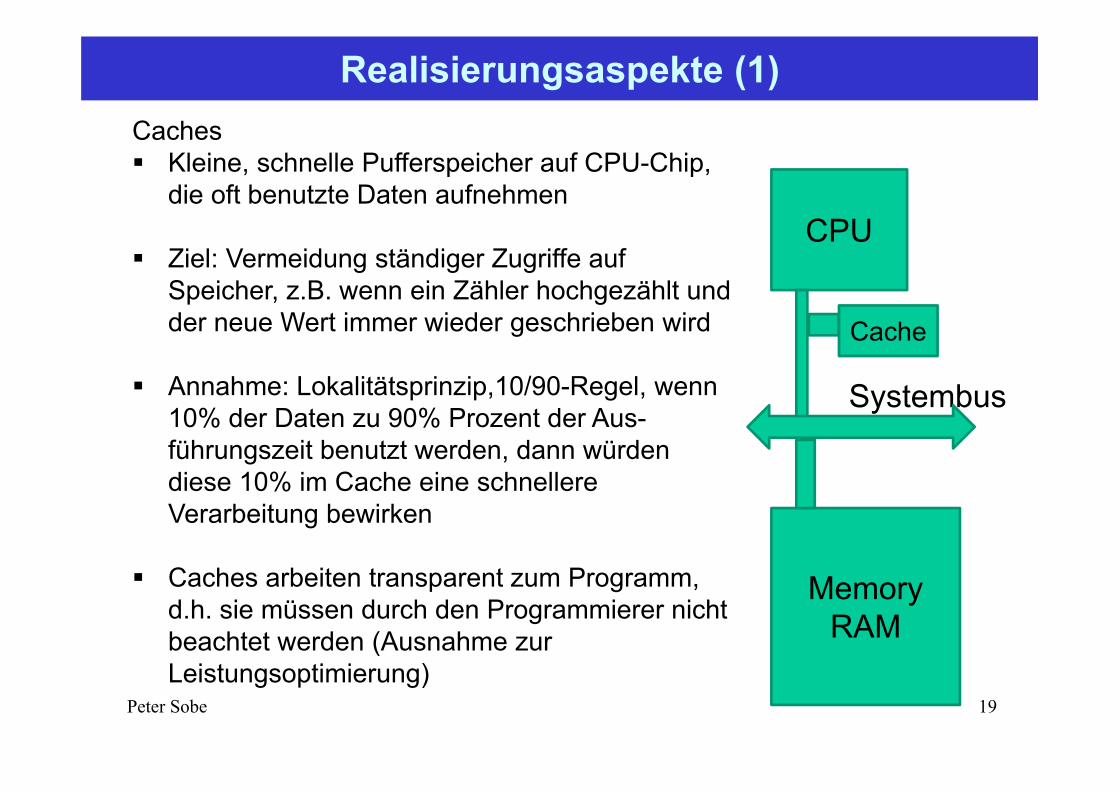
Realisierungsaspekte (1)
Peter Sobe 19
Caches Kleine, schnelle Pufferspeicher auf CPU-Chip,
die oft benutzte Daten aufnehmen
Ziel: Vermeidung ständiger Zugriffe auf Speicher, z.B. wenn ein Zähler hochgezählt und der neue Wert immer wieder geschrieben wird
Annahme: Lokalitätsprinzip,10/90-Regel, wenn 10% der Daten zu 90% Prozent der Aus-führungszeit benutzt werden, dann würden diese 10% im Cache eine schnellere Verarbeitung bewirken
Caches arbeiten transparent zum Programm, d.h. sie müssen durch den Programmierer nicht beachtet werden (Ausnahme zur Leistungsoptimierung)
CPU
MemoryRAM
Cache
Systembus
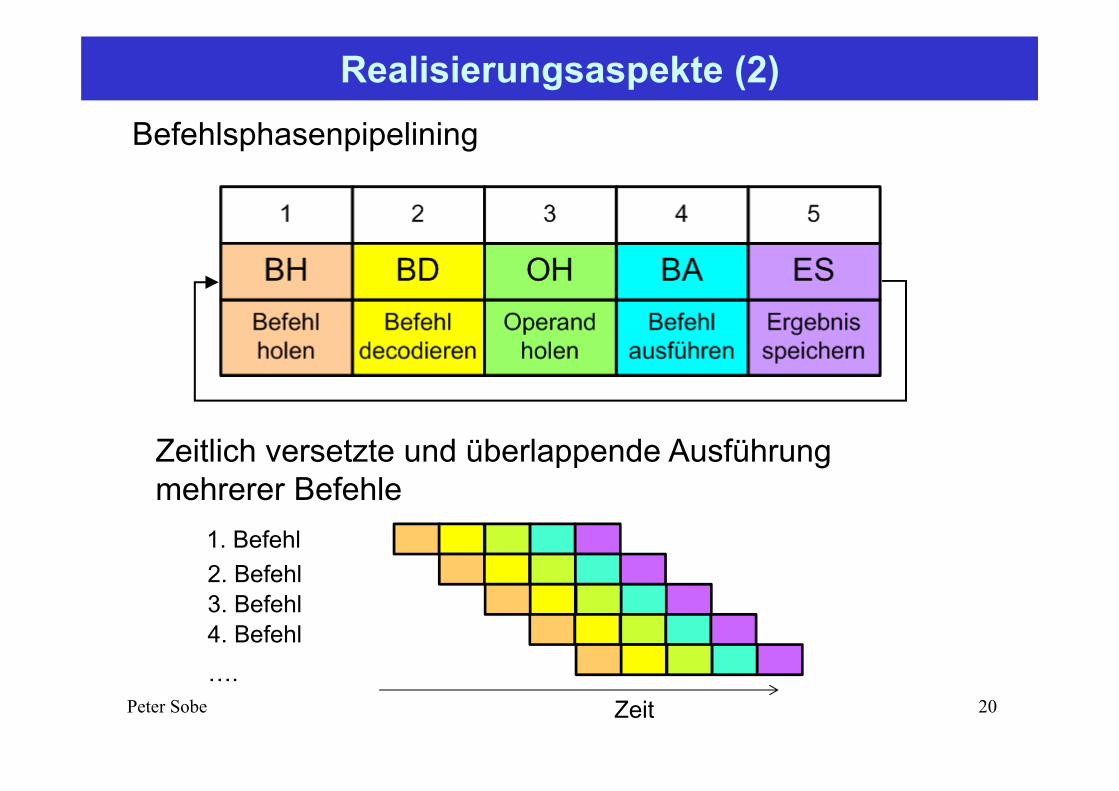
Realisierungsaspekte (2)
Peter Sobe 20
Befehlsphasenpipelining
Zeitlich versetzte und überlappende Ausführung mehrerer Befehle
1. Befehl2. Befehl3. Befehl4. Befehl….
Zeit
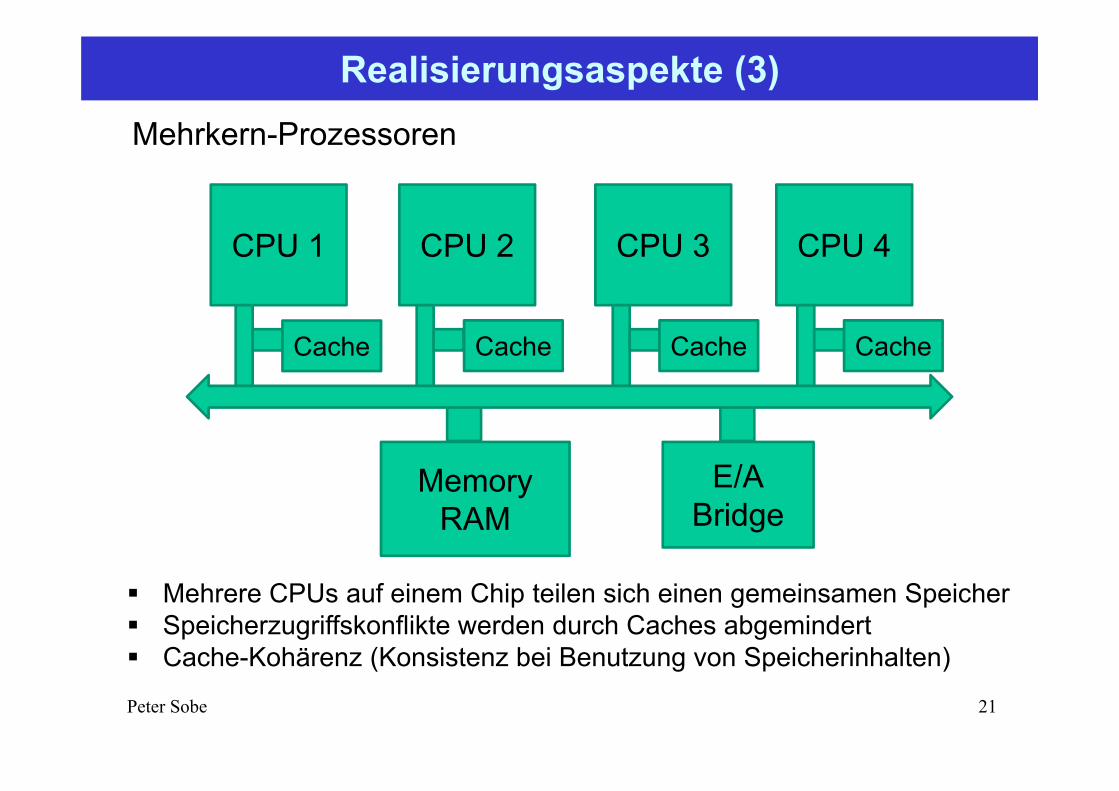
Realisierungsaspekte (3)
Peter Sobe 21
Mehrkern-Prozessoren
CPU 1 CPU 2 CPU 3 CPU 4
MemoryRAM
E/ABridge
Cache Cache Cache Cache
Mehrere CPUs auf einem Chip teilen sich einen gemeinsamen Speicher Speicherzugriffskonflikte werden durch Caches abgemindert Cache-Kohärenz (Konsistenz bei Benutzung von Speicherinhalten)
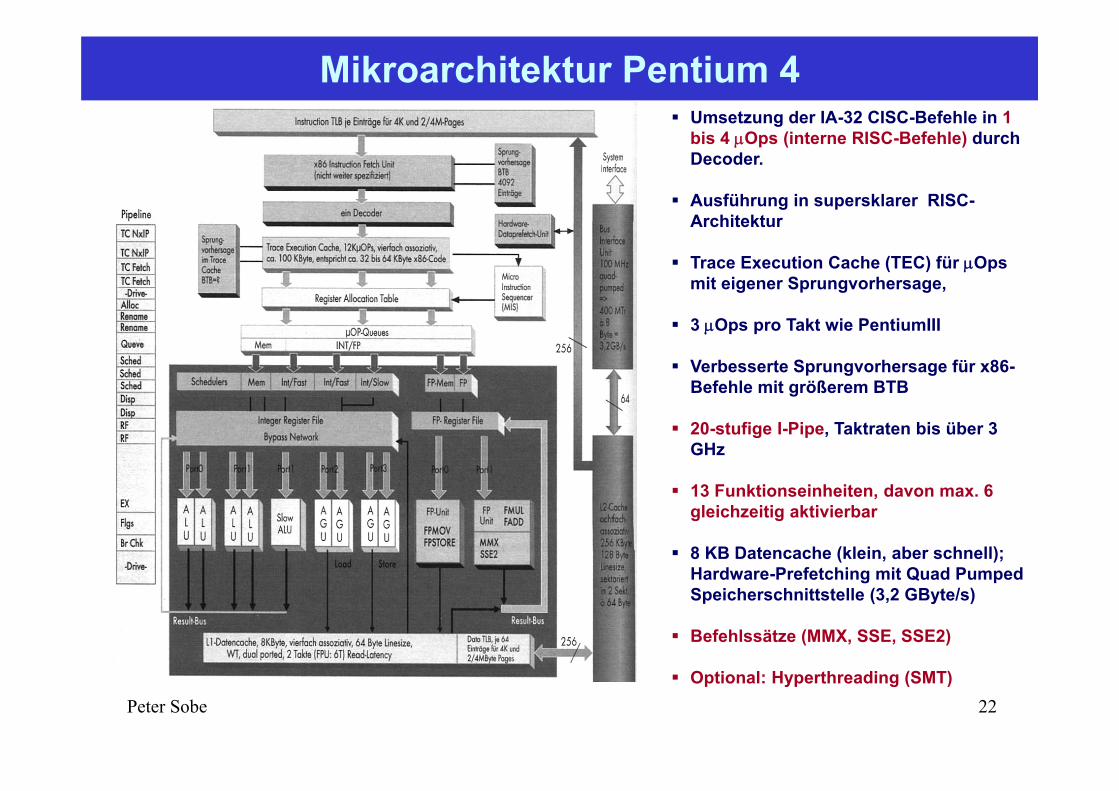
Umsetzung der IA-32 CISC-Befehle in 1 bis 4 Ops (interne RISC-Befehle) durch Decoder.
Ausführung in supersklarer RISC-Architektur
Trace Execution Cache (TEC) für Opsmit eigener Sprungvorhersage,
3 Ops pro Takt wie PentiumIII
Verbesserte Sprungvorhersage für x86-Befehle mit größerem BTB
20-stufige I-Pipe, Taktraten bis über 3 GHz
13 Funktionseinheiten, davon max. 6 gleichzeitig aktivierbar
8 KB Datencache (klein, aber schnell); Hardware-Prefetching mit Quad PumpedSpeicherschnittstelle (3,2 GByte/s)
Befehlssätze (MMX, SSE, SSE2)
Optional: Hyperthreading (SMT)
Mikroarchitektur Pentium 4
22Peter Sobe
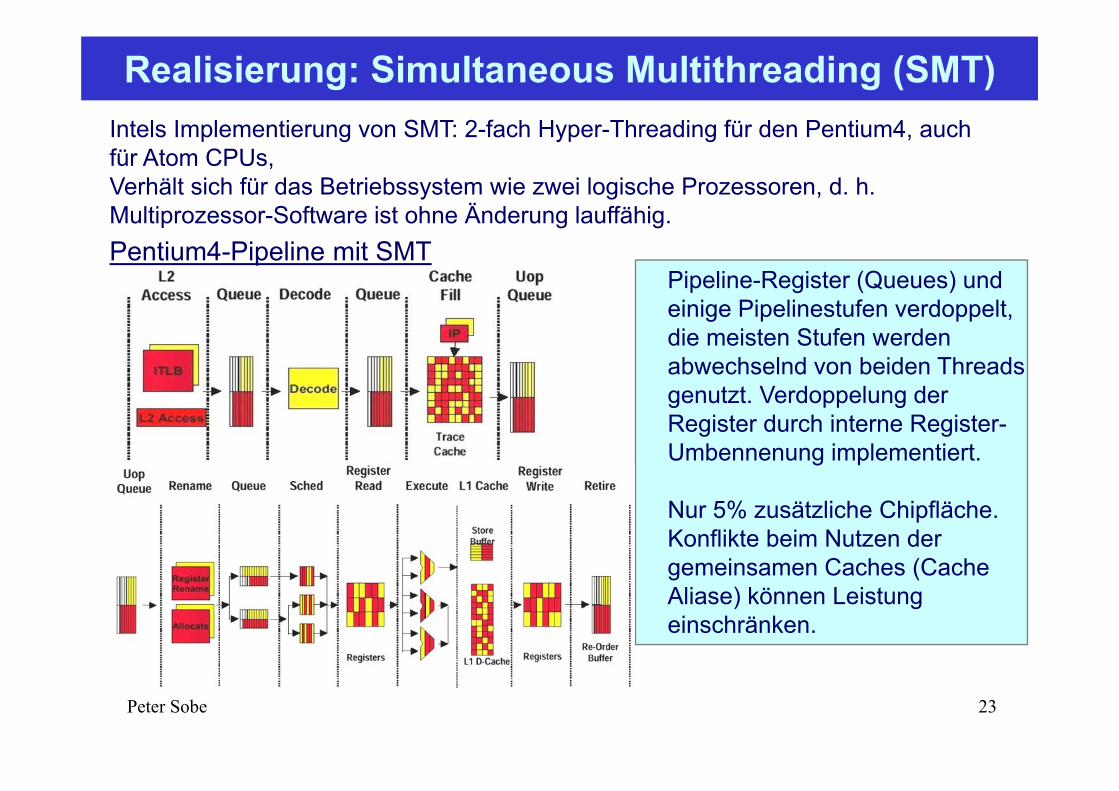
Intels Implementierung von SMT: 2-fach Hyper-Threading für den Pentium4, auch für Atom CPUs, Verhält sich für das Betriebssystem wie zwei logische Prozessoren, d. h. Multiprozessor-Software ist ohne Änderung lauffähig.Pentium4-Pipeline mit SMT
Pipeline-Register (Queues) und einige Pipelinestufen verdoppelt, die meisten Stufen werden abwechselnd von beiden Threads genutzt. Verdoppelung der Register durch interne Register-Umbennenung implementiert.
Nur 5% zusätzliche Chipfläche.Konflikte beim Nutzen der gemeinsamen Caches (Cache Aliase) können Leistung einschränken.
23Peter Sobe
Realisierung: Simultaneous Multithreading (SMT)

Wie benutzen wir Rechner in der Lehrveranstaltung?
Peter Sobe 24
Algorithmen (Programmablaufpläne und C-Programme) werden für hier dargestellte Rechner konzipiert.
Einschränkungen: nur sequentielle Programme (auf einem Prozessorkern)
betrachtet keine Programmierung in Assemblersprachen
(stattdessen in C) auf Realisierungsaspekte (Caches, Pipelining,
Hardware-Threading u.ä.) wird kein Bezug genommen.
Möglichkeiten für weitere Vertiefung








![3a Programmiersprache VB.ppt [Kompatibilitätsmodus]sobe/InfoChem_2016/Vo/3a_Programmierspr... · Die Sprache „Visual Basic“ wird dabei mit gleicher Syntax verwendet. Aber die](https://img.pdfslide.org/doc/110x75/5d532be388c9932e748b56fc/3a-programmiersprache-vbppt-kompatibilitaetsmodus-sobeinfochem2016vo3aprogrammierspr.jpg)

![4 Simulink.ppt [Kompatibilitätsmodus]sobe/InfoMB_Jg13/Vo/4_Simulink.pdf · Simulink ist eine s.g. Toolbox von Matlab Zweck und grundlegende Eigenschaften Mit Simulink werden Modelle](https://img.pdfslide.org/doc/110x75/5a78aee77f8b9a7b698e974c/4-kompatibilittsmodus-sobeinfombjg13vo4simulinkpdfsimulink-ist-eine-sg.jpg)





![3 Simulink.ppt [Kompatibilitätsmodus]sobe/InfoMB_Jg16/Vo/3_Simulink.pdf · Simulink ist eine s.g. Toolbox von Matlab Zweck und grundlegende Eigenschaften Mit Simulink werden Modelle](https://img.pdfslide.org/doc/110x75/5e1a788b99efaa3b8e1db7fb/3-kompatibilittsmodus-sobeinfombjg16vo3simulinkpdf-simulink-ist-eine.jpg)












