Embed Size (px)
Citation preview

1
Universität Hannover Prof. Dr. L. Hothorn Naturwiss. Fakultät BSc-Modul Biostatistik (3./ 4. Semester)
VARIANZANALYSE ____________________________________
1. MOTIVATION Beispiel: Man möchte wissen, ob fünf verschiedene Erdorten einen Einfluß auf die Löwenzahnstängellänge haben, und wenn ja welche Erdsorten sich signifikant unterscheiden, dabei sollte Erdsorte mit den größten Längen bestimmt werden. Erde Löwen
zahn1 Löwen zahn2
Löwen zahn3
A 32.7 32.3 31.5 B 32.1 29.7 29.1 C 35.7 35.9 - D 36.0 34.2 31.2 E 31.8 28.0 29.2 Der erste Teil der Frage wird mittels ANOVA beantwortet, der zweite Teil konditional mit multiple Mittelwertvergleichen (s. diese Vorlesung)
zahn3

2
2. RATIONALE Zusammenhangsanalyse zwischen Einflußgrößen A, B, C ,...; X1, X2, X3... und Zielgrößen (Endpunkten) Y1,Y2,Y3,.... Schlagworte aus der Lehrbuch-Statistik und veralteter software: Korrelationsanalyse, Regressionsanalyse, Varianzanalyse etc... Korrelationsanalyse (CORR): Zusammenhang zwischen zwei oder mehreren zufälligen Variablen Z1 und Z2 , z.B. Korrelation zwischen Körpergröße und Gewicht bei 14 jährigen Jungen Regressionanalyse (RA): Funktionaler Zusammenhang zwischen einer (oder mehrerer) Zielgröße(n) Yi und einer (oder mehrerer) quantitativer Einflußgrößen Xi , z.B. linearer Zusammenhang zwischen Reaktionsverhalten (in s) und der Alkoholdosis (in mg/kg Körpergewicht) Varianzanalyse (ANOVA): Analyse des Einflusses einer (oder mehrerer) qualitativer Einflußgrößen A, B, C (auch Prüfglieder genannt), in Stufen A1, A2; B1, B2, B3;.., auf eine (oder mehrere) Zielgröße(n) Yi , z.B. Einfluß dreier Gerstensorten (Faktor B: B1, B2, B3) und zweier Düngungsvarianten (Faktor A: A1, A2) auf den Ertrag

3
Dabei: Modell I: Einflußgrößen fest (αi ) die (endlichen) Stufen der Einflußgrößen werden vor dem Versuch bewußt festgelegt Ziel: Schätzung der Effekte und Mittelwert-vergleiche
Modell II: Einflußgrößen zufällig (α i)
die Stufen der Einflußgrößen werden aus der Grundgesamtheit möglicher Stufen zufällig ausgewählt Ziel: Schätzung der Varianzkomponenten und dazugehöriger Konfidenzintervalle
Gemischtes Modell: fest & zufällig
ANOVA: qualitative Einflußgrößen (Faktoren) in Stufen (Modell I)
RA: quantitative Einflußgrößen Skalenumwandlung ist möglich: Dosen: 0, 10, 30 100 ppm ==> Control, low, med., high Düngung: ohne, einmal, mehrfach ==> 0, 1, 2 Eine Zielgröße ==> univariate Analyse Mehrere Zielgrößen ==> multivariate Analyse

4
Ein einheitliches Konzept: Verallgemeinerte lineare Modelle (GLIM) McCullagh/ Nelder (1989) y,... Zielgröße x,... Quantitative Einflußgröße A,... Qualitatitive Einflußgröße Modell Typ y = x1 Einfache lineare Regression
(Korrelation) y = x1 x2 Multiple lineare Regression y = x1 x1*x 1 Polynomiale Regression y1 y2 = x1 x2 Multivariate (multiple) Regression y= A Einfaktorielle VA y= A B Mehr(hier Zwei-)faktorielle VA
(kreuzklassifizierte) (ohne WW) y= A B A*B Mehr(hier Zwei-)faktorielle VA mit WW y= A B⊃A Hierarchische VA y1 y2 = A B Multivariate VA y= A x Einfache Kovarianzanalyse ....... etc.
Und dies ist auch alles (und noch mehr) in einer einheitlichen Software behandelbar, z.B. GLIM oder PROC GLM in SAS, ANOVA in R
5
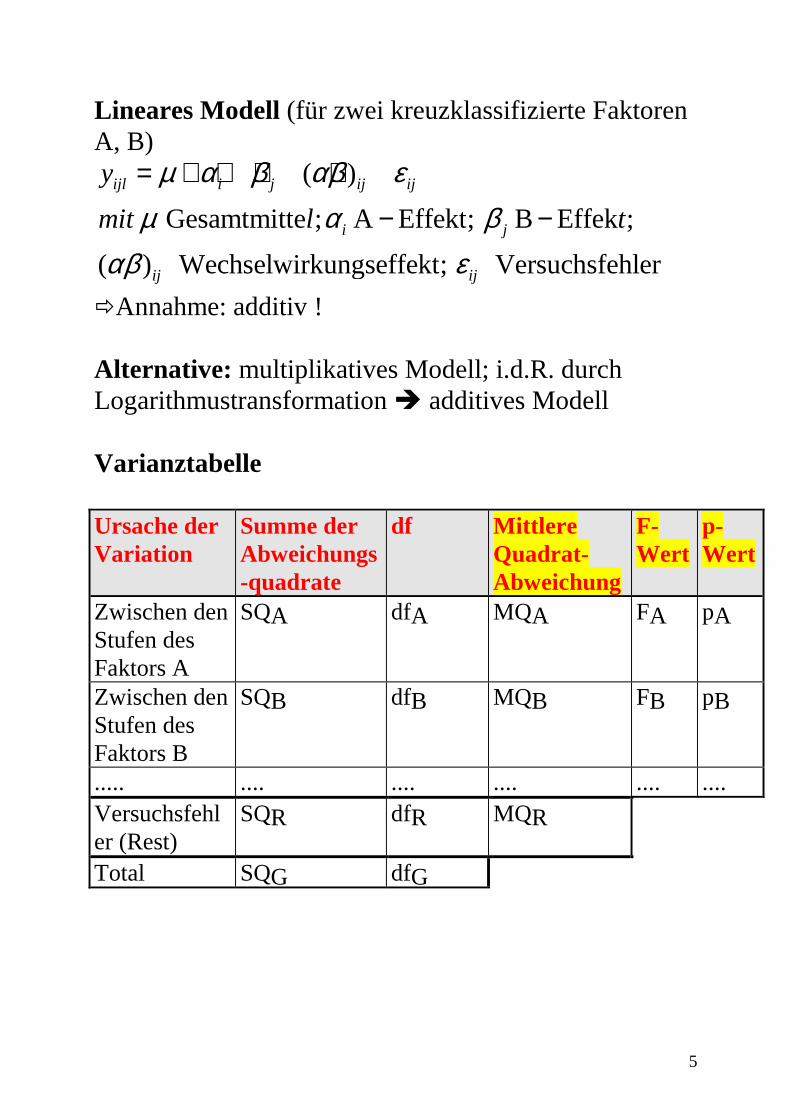
Lineares Modell (für zwei kreuzklassifizierte Faktoren A, B)
( )
Gesamtmitte ; A Effekt; B Effek ;
( ) Wechselwirkungseffekt; Versuchsfehler
ijl i j ij ij
i j
ij ij
y
mit l t
µ α β αβ εµ α β
αβ ε
= + + + +
− −
�Annahme: additiv ! Alternative: multiplikatives Modell; i.d.R. durch Logarithmustransformation � additives Modell Varianztabelle Ursache der Variation
Summe der Abweichungs-quadrate
df Mittlere Quadrat- Abweichung
F-Wert
p-Wert
Zwischen den Stufen des Faktors A
SQA dfA MQA FA pA
Zwischen den Stufen des Faktors B
SQB dfB MQB FB pB
..... .... .... .... .... .... Versuchsfehler (Rest)
SQR dfR MQR
Total SQG dfG
6
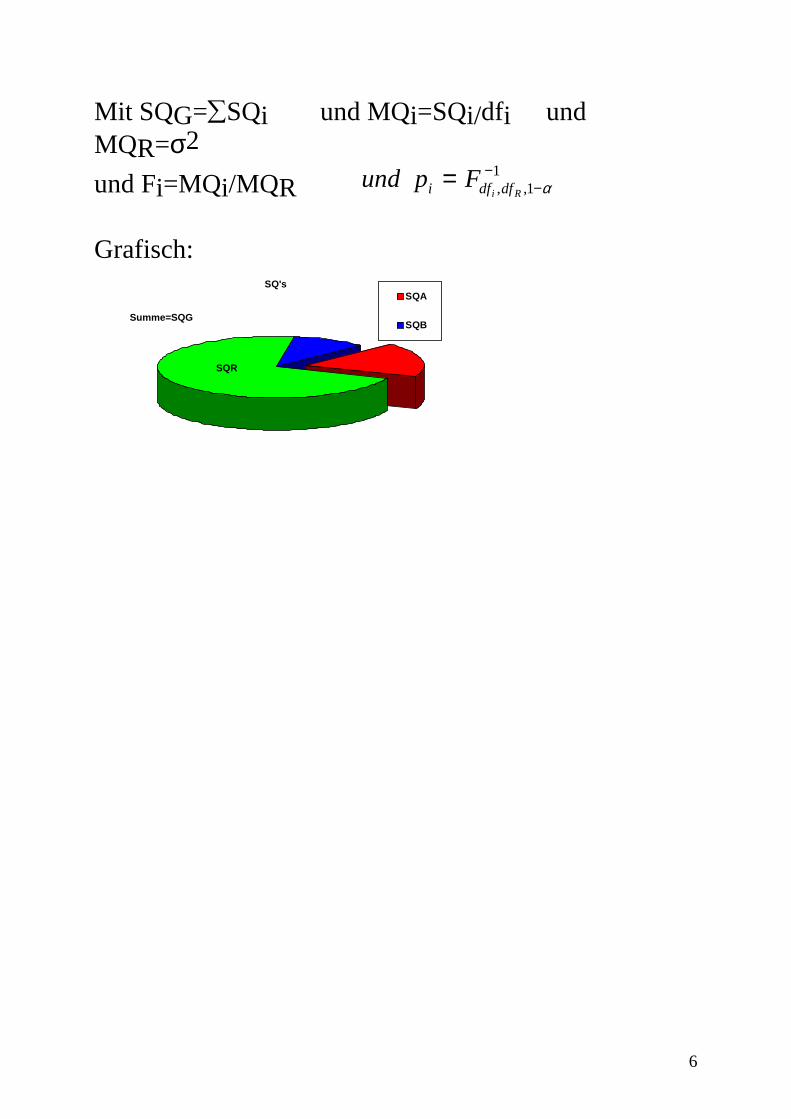
Mit SQG=∑SQi und MQi=SQi/dfi und MQR=σ2
und Fi=MQi/MQR und p Fi df dfi R= −
−, ,1
1α
Grafisch:
SQ'sSQA
SQB
SQR
Summe=SQG

7
3. EINWEGKLASSIFIKATION • unbalanziertes Model I (ungleiche Fallzahlen) • nur ein Faktor A in den Stufen A1, A2,..., Aa • Modell I ... fester Faktor (alternativ zufälliger Faktor) • Annahme eines additiven Modells:
y mit lij i ij i
ij
= + + −
∈ ∈
µ α ε µ αε
Gesamtmitte A Effekt;
Versuchsfehler mit i (1,..,a)und j (1,..., ni
;
)
Ursache der Variation
Summe der Abweichungs Quadrate
df Mittlere Quadrat Abweichung
F-Wert p-Wert
Zwischen den Stufen von A
SQ n Y YA i ii
a
= −=∑ ( ..).
2
1
dfA=a-1
MQA= SQA/(a-1)
FA= MQA/MQR
pA
Versuchs fehler (Rest)
∑∑= =
−=a
iiij
n
jR YySQ
i
1
2.
1
)( dfR=N-a
MQR= SQR/(N-a)
Gesamt ∑∑= =
−=a
iij
n
jG YySQ
i
1
2..
1
)(
dfG=N-1
mit ∑∑∑ ∑= == =
===a
i
n
jij
a
i
n
jij
iii
ii
yN
Yundyn
YundnN1 11 1
.
1..
1

8
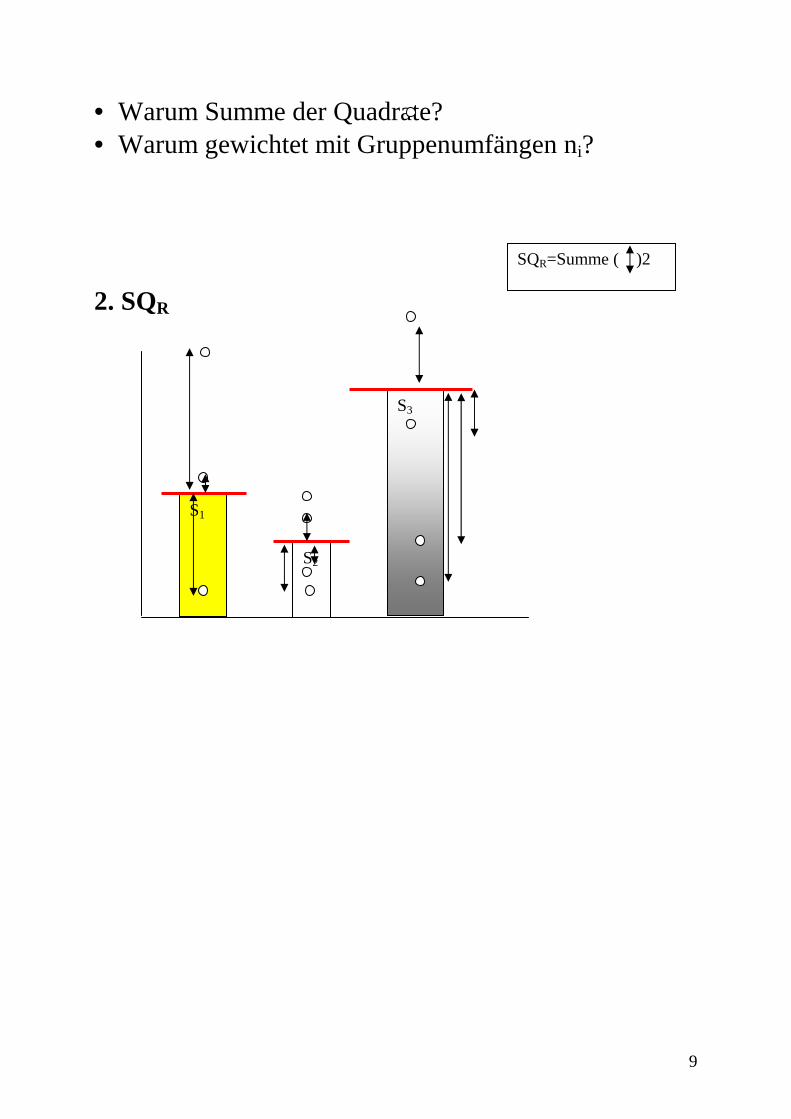
Wie ergeben sich die Freiheitsgrade df? Idee: Zum Schätzen des Parameters geht 1 FG verloren dfA=a-1 dfG=N-1=(∑ni )-1 und: dfR=dfG-dfA=N-1-(a-1)=N-a Rechnung und Denken mit Quadratsummen: ==> erklären Grafische Veranschaulichung der Quadratsummen Beispiel: Einweganlage mit 3 Sorten, mit 3,4 und 5 Wdh. Annahme: die Sorten werden sich dann ‘signifikant’ unterscheiden, wenn die Abweichungen der Sortemittel vom Gesamtmittel groß ist und/oder die Abweichung der Einzelwerte von den Gruppenmitteln gering ist 1. SQA
S1
S2
S3
Gesamtmittel
SQA=n1( )2+n2( )
2+n3( )2
9
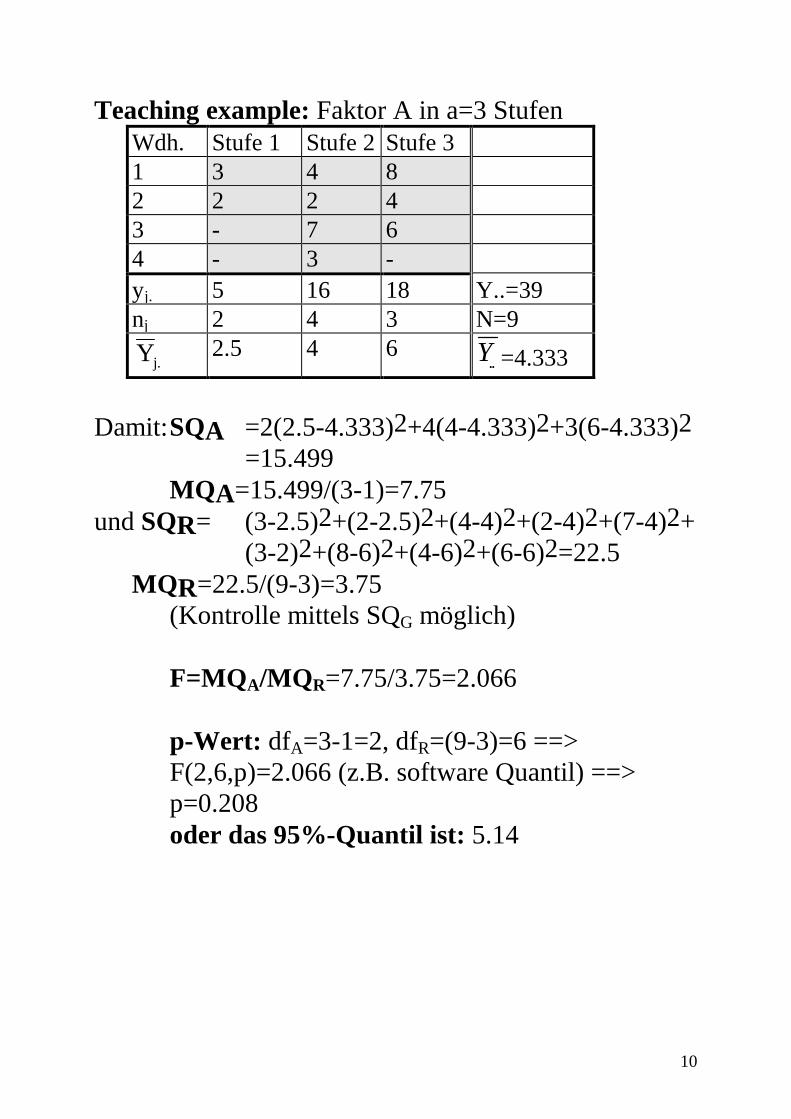
• Warum Summe der Quadrate? • Warum gewichtet mit Gruppenumfängen ni? 2. SQR
S1
S2
S3
SQR=Summe ( )2
10
Teaching example: Faktor A in a=3 Stufen Wdh. Stufe 1 Stufe 2 Stufe 3 1 3 4 8 2 2 2 4 3 - 7 6 4 - 3 - yj. 5 16 18 Y..=39 nj 2 4 3 N=9
Yj. 2.5 4 6 Y.. =4.333
Damit: SQA =2(2.5-4.333)2+4(4-4.333)2+3(6-4.333)2
=15.499 MQA=15.499/(3-1)=7.75 und SQR= (3-2.5)2+(2-2.5)2+(4-4)2+(2-4)2+(7-4)2+
(3-2)2+(8-6)2+(4-6)2+(6-6)2=22.5 MQR=22.5/(9-3)=3.75 (Kontrolle mittels SQG möglich)
F=MQA/MQR=7.75/3.75=2.066 p-Wert: dfA=3-1=2, dfR=(9-3)=6 ==> F(2,6,p)=2.066 (z.B. software Quantil) ==> p=0.208 oder das 95%-Quantil ist: 5.14

11
Varianzanalyse wird generell zweiseitig getestet (einseitig wegen Abw.-Quadrate nicht möglich). � Die Nullhypothese, α=0, oder „alle drei Stufen des Faktors A gehören zu einer Grundgesamtheit“ läßt sich zum Niveau α=0.05 nicht ablehnen Was läßt sich zur Einweganalyse noch sagen ? • Dieser F-Test MQA/MQR stellt einen sog.
Homogenitätstest (Omnibustest) dar (Bezeichnung: „multipler F-Test“). Dies ist aber nicht die Versuchsfrage: man möchte die Unterschiede zwischen den Gruppen wissen, also A1 vs. A2 und A1 vs. A3 usw.
• multiple Vergleiche ==> sehr wichtig ==> siehe
Vorlesung • In der Literatur findet man häufig Kombinationen von
F-Test der Einwegvarianzanalyse und multiplen Tests (zunächst F-Test, wenn dieser signifikant, dann multiple oder Paarvergleiche). Eine solche Vorgehensweise ist statistisch exakt auf Basis des Abschlußtestprinzips, aber i.d.R. kompliziert möglich ==> vor Primitivvarianten sei gewarnt

12
• Fallzahlschätzung ist auch für die
Einwegvarianzanalyse möglich ===> s. spezielle Vorlesung
• Frage: wann ist diese Varianzanalyse (ANOVA ...
analysis of variance) gültig? � sog. ANOVA-Annahmen:
# Gaußverteilung des Fehlerterms # Varianzhomogenität # Unabhängigkeit, z.B. durch Randomisation
erreichbar # Additivität (s. Modellgleichung)
• Zwei Vorgehensweisen: # Vortests auf Gaußverteilung und
Varianzhomogenität # Robustheitsannahmen typisch

13
Test auf Varianzhomogenität: • Typisch in der Literatur: Bartlett-Test � jedoch nicht
robust gegen Abweichung von der Gaußverteilung • Robuste Variante: Levene-Test
i) Transformation in gruppenspezifische Residuals zij=|yij-yi.|
ii) Ein-Weg-ANOVA bezüglich der zij iii) Falls p< 0.05 ⇒ keine homogenen Varianzen
• F-Tests
Fs
si l falls F F Varianzen heterogenil
i
lil df df= ∀ > −
2
2 11 2, , ,
.
α
Vorsicht: Es existieren mehrere F-Tests: i) F-Test der Varianzanalyse F=MQBehandlung/MQR siehe
oben. Dieser ist generell zweiseitig formuliert, dh.
Test Re, ,1Behandlung stdf dfF F α−> �die Hypothesenformulierung lautet: Homogenität vs. Heterogenität
ii) Dagegen kann man F-Tests auf Varianzhomogenität
zweier Gruppen einseitig (ansteigend & abfallend) wie zweiseitig formulieren:
1 2
1 2
21
, ,1 222
.
, ,1
df df
df df
sF einseitig F F
s
oder zweiseitig F F
α
α
−
−
= >
≠

14
• Nichtparametrische Einwegklassifikation Test nach Kruskal- Wallis (1952) (s. Vorlesung nichtparametrische Tests im MSc)
# Varianzanalyse # Einwegklassifikation mit vorgegebener Faktorstruktur library(RODBC) setwd("D:\\Aktuell_D\\data") loew = odbcConnectExcel("loewenz.xls") sqlTables(loew) lo=sqlQuery(loew, 'select * from "Tabelle1$"') odbcCloseAll() attach(lo) anova(lm(Laenge~Erde, data=lo)) # mit notwendiger Definition des qualitativen Faktors blatt = odbcConnectExcel("blatt.xls") sqlTables(blatt) bla=sqlQuery(blatt, 'select * from "Tabelle1$"') odbcCloseAll() attach(bla) # das ist das falsche Regressionsmodell: anstelle qualitativer Faktor ein quantitativer Faktor anova(lm(Uptake~Conc)) bla$Conc <- factor(Conc, labels=c("a","b","c","d","e","f","g","h","i")) detach(bla) attach(bla) summary(Conc) anova(lm(Uptake~Conc))
R-Syntax # Definition einer qualitativen Variablen als qualitativen Faktor bla$Conc <- factor(Conc, labels=c("a","b","c","d","e","f","g","h","i")) detach(bla) attach(bla)

15
4. MEHRWEGKLASSIFIKATION
Hier: Zweiweg-Kreuzklassifikation mit Wechselwirkungsterm (WW) : unbalanziert, Modell I • Zweiweg ... zwei Faktoren A und B, z.B. Sorten und
Düngungsvarianten • Kreuzklassifikation ..... es wird jede Kombination A i
Bj untersucht • unbalanziert .... ungleiche Fallzahlen je Kombination
A1 A2 A3 B1 y11,1
y11,2
y11,3
y12,1
y12,2
y12,3
y12,4
y12,5
y13,1
y13,2
B2 y21,1
y21,2
y21,3
y21,4
y22,1
y22,2
y23,1
y23,2
y23,3
• WW .... die Reihenfolge der Sorten (A) unterscheiden
sich je Stufe der Düngung (B)
16
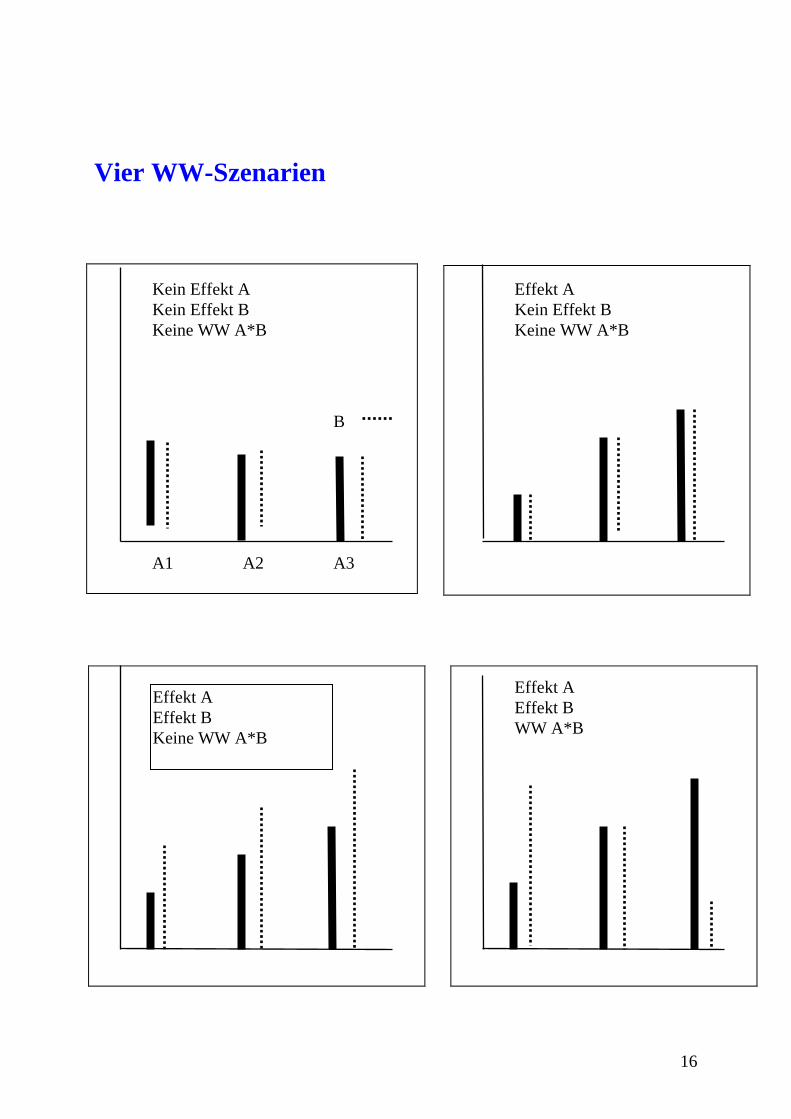
Vier WW -Szenarien
A1 A2 A3
Kein Effekt A Kein Effekt B Keine WW A*B
B
Effekt A Effekt B Keine WW A*B
Effekt A Effekt B WW A*B
Effekt A Kein Effekt B Keine WW A*B

17
Additives Modell:
( )
Gesamtmitte ; A Effekt; B Effek ;
( ) Wechselwirkungseffekt; Versuchsfehler
ijl i j ij ijl
i j
ij ijl
y
mit l t
µ α β αβ εµ α β
αβ ε
= + + + +
− −
Varianztabelle Ursache der Variation
Summe Abw.qua.
Df Mittl. Qu.abw
F-Wert
p-Wert
Zwischen den Stufen A
SQA dfA=a-1 MQA FA pA
Zwischen den Stufen B
SQB dfB=b-1 MQB FB pB
WW A*B SQAB dfAB= (a-1)(b-1)
MQAB FAB pAB
Versuchs fehler (Rest)
SQR dfR=ab(n-1) MQR
Total SQG dfG=N-1 Wie ergeben sich die Freiheitsgrade df? Idee: Zum Schätzen des Parameters geht ein FG verloren dfA=a-1 dfB=b-1 dfAB=(a-1)(b-1) dfG=N-1=∑ni-1 Annahme: balanziert ni=const=n ==> dfG=ab*n-1 und: dfR=dfG-dfA-dfB-dfAB=(ab*n-1)-(a-1)-(b-1)-(a-1)(b-1) =abn-1 -a +1 -b+1-ab +a +b -1=abn -ab=ab(n-1)

18
Urs. SQ df MQ A
SQbn
Y Y NA ii
a
= −=∑
1 2 2
1. ... /
dfA=a-1 MQA= SQA/(a-1)
B SQ
anY Y NB j
j
b
= −=∑
1 2 2
1. . ... /
dfB=b-1 MQB = SQB /(b-1)
WW A*B
SQn
Ybn
Yan
Y Y NAB ij i jjii j
= − − +∑∑∑1 1 12 2 2 2
. .. . . ...,
/ dfAB= (a-1)(b-1)
MQAB = SQAB /(a-1)(b-1)
Rest SQ y
nYR ijk
i j kij
i j
= −∑ ∑2 21
, ,.
,
dfR= ab(n-1)
MQR= SQR/ab(n-1)
Total SQG =... dfG=N-1
Beispiel: Löwenzahnstängellänge in 5 verschiedenen Erdsorten in zwei Jahren beobachtet, unbalanziert, als zweifaktorielle ANOVA mit WW analysiert. Frage warum nicht wiederholtes Messen (repeated measurement), als verbundenes Testproblem? Repeated measurement wäre hier nicht möglich (Löwenzahn stirbt im Winter). Besser: mehrjährige Kultur
Jahr Erde Löwenz.1 Löwenz.2 Löwenz3 1 1 32.7 32.3 31.5 1 2 32.1 29.7 29.1 1 3 35.7 35.9 - 1 4 36.0 34.2 31.2 1 5 31.8 28.0 29.2 2 1 38.2 37.7 31.9 2 2 32.5 31.1 29.7 2 3 37.5 39.5 31.0 2 4 35.8 33.2 31.1

19
2 5 32.9 33.1 35.3
# Zweiweganlage mit Wechselwirkung loew2 = odbcConnectExcel("loew2way.xls") sqlTables(loew2) lo2=sqlQuery(loew2, 'select * from "Tabelle1$"') odbcCloseAll() attach(lo2) lo2$Erde <- factor(Erde,labels=c("i", "ii", "iii", "iv", "v")) lo2$Jahr <- factor(Jahr, labels=c("00", "01")) detach(lo2) attach(lo2) anova(lm(Laenge~Erde + Jahr+Erde*Jahr, data=lo2)) boxplot(Laenge~Erde) boxplot(Laenge~Jahr) boxplot(Laenge~Erde+Jahr) boxplot(Laenge~Jahr+Erde) xbar <- tapply(Laenge,Erde, mean) sd <- tapply(Laenge,Erde, sd) stripchart(Laenge~Erde, "jitter", jit=0.02, pch=16, vert=TRUE) arrows(1:5,xbar+2*sd, 1:5,xbar-2*sd, angle=90, code=3, length=0.1, col="blue") lines(1:5,xbar, pch=4, type="p", cex=2, col="blue") R-Syntax # Grafikelemente stripchart() … jitter arrows(von:bis, wert) lines() # Faktordefinition i) qualitative Variable der ANOVA müssen zuvor als Faktoren definiert werden, falls deren Typ numerisch ist =factor() ii) Definition der Variablen: a+b+a:b (abgekürzt a*b) für kreuzklass. Zweiweganlage mit Wechselwirkung. Aber: b %in% a hierarchische Klassifikation (auch: b/a)

20
Was sagt uns diese Analyse? • Die verschiedenen Erdsorten besitzen einen deutlichen
Einfluß auf die Stängellänge • Es liegt auch ein schwach signifikanter Jahreseinfluß vor • allerdings kann keine WW Erdsorte*Jahr gesichert werden Weil keine sign. WW voliegt, kann der primär interessierende Mittelwertvergleich zwischen den Erdsorten unter Ignorierung des Jahreseinflusses (d.h. gepoolt über beide Jahre) durchgeführt werden. Bei sign. WW muß man die MW-Vergleiche getrennt je Jahr - und damit mit halber Fallzahl! - durchführen. Frage: welche Erdsorte unterscheidet sich � Modul Mittelwertvergleiche
5. LERNZIELE
• Das Prinzip des linearen, additiven Modells der Varianzanalyse
• Das Prinzip der Streuungszerlegung im Modell I, die
Definition der Freiheitsgrade (df), der mittleren quadratischen Abweichungen (MQ), der F-Statistiken und der dazugehörigen p-Werte via F-Verteilung
• Das Prinzip - nicht die Formeln- der Quadratsummen

21
• Vortests auf Varianzinhomogenität • Das Modell der Zweiweganlage; die Interpretation der
Wechselwirkung; die Konsequenzen einer signifikanten WW auf die Mittelwertvergleiche
6. VERNETZUNG
• Blockanlagen • Varianzanalyse im Modell II • Hierarchische Anlagen • Mittelwertvergleiche • Gartenbauliche Versuchsanlagen und deren
Auswertung • zentrale Methodik !!
7. BUCHEMPFEHLUNG
Petersen, R.G. Agriculture field experiments (1994); M. Dekker, New York, S. 35-58
8. ON-LINE LEARNING DASL Projekt: anova http://lib.stat.cmu.edu/DASL/Reference/eesee.html DASL Australien und Nz http://www.statsci.org/data/index.html