Embed Size (px)
Citation preview

ETL-Design Optimierung
Tobias Fellner
geboren am 27.01.1979
Dortmund, 04.12.2007

ETL-Design Optimierung Seite 2 von 108
Kurzfassung
Thema dieser Projektarbeit ist die ETL-Design Optimierung. ETL-Design ist die Modellierung von
Datenflüssen und Datentransformationen. Grundlage für eine Optimierung sind Ziele und
Vergleichbarkeit zwischen Designvarianten. Zu diesem Zweck werden in dieser Arbeit, nach einer
Einführung in die zum Verständnis notwendigen Grundlagen, Designziele und darauf wirkende Maße
vorgestellt. Anhand von praktischen Beispielen werden die Zusammenhänge zwischen Maßen und
Zielen nach einem einheitlichen Vorgehen untersucht. Als Modellierungswerkzeug kommt dabei
Informatica PowerCenter 8 Designer zum Einsatz. Nach den praktischen Analysen werden aus den
gewonnenen Erkenntnissen generelle Designempfehlungen im Ergebnisteil der Arbeit vorgestellt. Die
Arbeit schließt mit einer Zusammenfassung sowie einem Ausblick auf Möglichkeiten weiterer
Forschung ab.
Abstract
Subject of this project thesis is ETL-Design optimization. ETL-Design describes the modeling of data
flows and data transformations. Precondition of optimization are knowledge about objectives and
comparability between different approaches. Therefore, after an introduction to the theoretical
fundamentals, objectives and measures are introduced. Then different approaches of optimization are
analyzed in practical examinations. Focus of these analyses are the interdependencies between
measures und objectives. After the practical part, the introduced measures are evaluated. Additionally
based on observations and the gained knowledge general design recommendations are presented in the
conclusion part of this thesis.
Finally, this thesis ends with a summary and an outlook on possible future research.

ETL-Design Optimierung Seite 3 von 108
Markenrechtlicher Hinweis
Die in dieser Arbeit wiedergegebenen Gebrauchsnamen, Handelsnamen, Warenzeichen usw. können
auch ohne besondere Kennzeichnung geschützte Marken sein und als solche den gesetzlichen
Bestimmungen unterliegen.
Sämtliche in dieser Arbeit abgedruckten Bildschirmabzüge unterliegen dem Urheberrecht © des
jeweiligen Herstellers.
Informatica und Informatica PowerCenter sind Marken oder eingetragene Marken der Informatica
Corporation, Redwood /CA United States.
Oracle und Oracle XE sind eingetragene Marken der Oracle Corporation, Redwood Shores/CA United
States.

ETL-Design Optimierung Seite 4 von 108
Inhaltsverzeichnis
Kurzfassung............................................................................................................................................. 2
Abstract ................................................................................................................................................... 2
1 Einleitung ........................................................................................................................................ 7
2 Grundlagen ...................................................................................................................................... 9
2.1 Terminologie ........................................................................................................................... 9
2.2 Einordnung und Bedeutung von ETL Prozessen................................................................... 10
2.2.1 Extraktion ...................................................................................................................... 11
2.2.2 Transformation .............................................................................................................. 12
2.2.3 Laden ............................................................................................................................. 13
2.3 Modellierung von ETL Prozessen mit Informatica Powercenter 8 ....................................... 14
2.3.1 Transformationen in Informatica PowerCenter 8.......................................................... 15
2.3.2 Mappings in Informatica PowerCenter.......................................................................... 18
2.3.3 Mapplets ........................................................................................................................ 19
2.3.4 Sessions ......................................................................................................................... 22
2.3.5 Workflows ..................................................................................................................... 22
3 Designziele und Maße für ETL Prozesse ...................................................................................... 23
3.1 Designziele ............................................................................................................................ 24
3.1.1 Korrektheit..................................................................................................................... 24
3.1.2 Wartbarkeit .................................................................................................................... 24
3.1.3 Wiederverwendbarkeit .................................................................................................. 24
3.1.4 Performance................................................................................................................... 24
3.1.5 Zuverlässigkeit .............................................................................................................. 25
3.1.6 Bewertung der Zielerfüllung ......................................................................................... 25
3.2 Maße...................................................................................................................................... 25
3.2.1 Übersicht ....................................................................................................................... 25
3.2.2 Quantitative Maße ......................................................................................................... 26
3.2.3 Qualitative Maße ........................................................................................................... 27
4 ETL-Design Optimierung.............................................................................................................. 30
4.1 Vorgehensweise..................................................................................................................... 31
4.2 Beispielszenario..................................................................................................................... 32

ETL-Design Optimierung Seite 5 von 108
4.2.1 Datenquellen.................................................................................................................. 32
4.2.2 Zieltabellen.................................................................................................................... 34
4.3 Positionierung von Transformationen ................................................................................... 34
4.3.1 Filtertransformation - Fallbeispiel 1 .............................................................................. 34
4.3.2 Joinertransformation - Fallbeispiel 2............................................................................. 45
4.3.3 Zusammenfassung Positionierung von Transformationen ............................................ 51
4.4 Austauschbarkeit von Transformationen............................................................................... 52
4.4.1 Lookup vs. Join ............................................................................................................. 52
4.4.2 Lookup vs. Join - Fallbeispiel 3 .................................................................................... 53
4.4.3 Lookup vs. Join - Fallbeispiel 4 .................................................................................... 57
4.4.4 Zusammenfassung Lookup vs. Join............................................................................... 64
4.5 Weitere Optimierungsansätze - Fallbeispiel 5....................................................................... 65
4.5.1 Datenquellen.................................................................................................................. 65
4.5.2 Zieltabellen.................................................................................................................... 65
4.5.3 Ausgangsbeispiel........................................................................................................... 67
4.5.4 Variante 1 - Merge and Split ......................................................................................... 72
4.5.5 Variante 2 - Modularisierung ........................................................................................ 79
4.5.6 Variante 3 - Parameter und Sortierungen ...................................................................... 87
5 Ergebnis......................................................................................................................................... 93
5.1 Bewertung der Maße ............................................................................................................. 93
5.1.1 Quantitative Maße ......................................................................................................... 93
5.1.2 Qualitative Maße ........................................................................................................... 95
5.1.3 Zusammenfassung ......................................................................................................... 96
5.2 Klassifizierung von Mappings............................................................................................... 97
5.3 Designempfehlungen............................................................................................................. 97
5.3.1 Wartbarkeit .................................................................................................................... 97
5.3.2 Wiederverwendbarkeit .................................................................................................. 98
5.3.3 Performance................................................................................................................... 99
5.3.4 Zuverlässigkeit .............................................................................................................. 99
6 Zusammenfassung und Ausblick................................................................................................. 101
a. Tabellenverzeichnis..................................................................................................................... 104
b. Abbildungsverzeichnis ................................................................................................................ 106
c. Literaturverzeichnis..................................................................................................................... 107
d. Eidesstattliche Erklärung.........................................................Fehler! Textmarke nicht definiert.

ETL-Design Optimierung Seite 6 von 108

ETL-Design Optimierung Seite 7 von 108
1 Einleitung
ETL steht für Extract, Transform, Load und bezeichnet einen Prozess, mit dem Daten aus
verschiedenen Quellen extrahiert, verarbeitet und anschließend in Zielsysteme transportiert werden.
ETL Prozesse spielen insbesondere in Business Intelligence und in Data Mining Szenarien eine
wichtige Rolle, da sie hier dazu genutzt werden, die zu analysierenden Daten aufzubereiten und zur
Verfügung zu stellen. Hierfür werden Daten aus häufig verteilten, heterogenen, meist operativen
Quellsystemen extrahiert und in Zielsysteme, häufig Data Warehouses, überführt. Neben ihrer
Bedeutung in den genannten Szenarien dienen ETL Prozesse auch der Datenintegration im
Allgemeinen, zum Beispiel bei der Konsolidierung operativer Systeme.
In Data Warehouse Projekten kann die Implementierung von ETL Prozessen bis zu 50% des
Gesamtaufwandes bedeuten (Kurz, 1999, S. 266), andere Schätzungen sprechen sogar von bis zu 80%
(Bange, 2006, S. 64).
Hieraus resultiert, dass Projekterfolge maßgeblich von der Qualität der ETL Prozesse abhängen. Die
Basis bei der Entwicklung von ETL Prozessen stellt dabei das ETL-Design, also die Modellierung von
Datenflüssen und Transformationsregeln dar. Diese Abhängigkeit verdeutlicht die hohe Bedeutung
von gutem ETL-Design. Wodurch gutes Design charakterisiert ist, beziehungsweise wie gutes ETL
Design erreicht wird, ist dabei nicht trivial zu erkennen. Entsprechend stellt es eine Herausforderung
dar, ETL Design zu analysieren, zu vergleichen und zu bewerten.
Während es auf Geschäftsprozessebene umfangreiche Untersuchungen zu ETL Prozessen gibt und aus
diesen verschiedene Vorgehensmodelle hervorgegangen sind1, wurde die Modellierungs- oder
Designebene von ETL Prozessen bisher nicht ausführlich untersucht. Designentscheidungen werden
bei der Modellierung von ETL Prozessen häufig auf Grundlage der Erfahrungen von Entwicklern und
dadurch oft intuitiv gefällt. Hierdurch ist die Qualität starken Schwankungen unterworfen.
Personenunabhängige, kontinuierliche Verbesserung ist schwierig und Fehler werden häufig erst spät
oder gar nicht entdeckt.
Ziel dieser Arbeit ist es, ETL-Design anhand verschiedener Szenarien unter Berücksichtigung von
Zielen und Maßen zu problematisieren, Designvarianten aufzuzeigen und zu bewerten. Auf Basis der
gewonnenen Erkenntnisse sollen Richtlinien für verschiedene, in der Praxis auftretende
Problemstellungen entwickelt werden.
Für das weitere Verständnis werden in Kapitel 2 zunächst theoretische Grundlagen von ETL-
Prozessen vermittelt. Außerdem wird das Werkzeug Informatica PowerCenter 8, mit dem die
Untersuchungen durchgeführt werden, in seiner Funktionsweise vorgestellt.
Anschließend werden in Kapitel 3 Ziele, die beim Design von ETL Prozessen relevant sind,
eingeführt. Neben den Zielen werden quantitative und qualitative Maße vorgestellt, die die Ziele
1 Vergleiche (Kimball, Reeves, Ross, & Thornthwaite, 1998), (Kimball & Caserta, The Data
Warehouse ETL Toolkit, 2004), (Bauer & Günzel, 2004), (Goeken, 2006)

ETL-Design Optimierung Seite 8 von 108
beeinflussen. Sowohl Maße als auch Ziele werden dabei aus verschiedenen Fachbereichen der
Informatik hergeleitet.
Nach der Einführung von Zielen und Maßen wird in Kapitel 4 ein Beispielszenario eingeführt. Anhand
dieses Szenarios werden verschiedene Optimierungsansätze in einzelnen Fallbeispielen untersucht.
Um ihre Vergleichbarkeit sicherzustellen, werden die Analysen nach einem einheitlichen Vorgehen,
das ebenfalls in Kapitel 4 eingeführt wird, durchgeführt. Die Untersuchungen finden dabei auf
Modellierungs- beziehungsweise Designebene statt.
Auf den praktischen Teil der Arbeit und die darin vorgenommenen Untersuchungen anhand von
Beispielen folgen in Kapitel 5 eine Bewertung der eingeführten Maße sowie ein auf den Erkenntnissen
basierender Vorschlag zur Klassifizierung von Mappings. Außerdem werden die in den
Untersuchungen gewonnenen Erfahrungen genutzt, um daraus Empfehlungen für ETL-Design unter
Berücksichtigung der verschiedenen Ziele abzuleiten.
Zum Abschluss der Arbeit werden in Kapitel 6 eine Zusammenfassung der Ergebnisse sowie ein
Ausblick gegeben.

ETL-Design Optimierung Seite 9 von 108
2 Grundlagen
2.1 Terminologie
Im Verlaufe dieser Arbeit werden einige ETL spezifische Begriffe verwendet. Darüber hinaus benutzt
das verwendete Werkzeug Informatica Powercenter 8 zum Teil eine eigene Terminologie. Zum
besseren Verständnis der folgenden Abschnitte werden die wichtigsten Begriffe hier definiert.
• ETL: Extract, Transform, Load
ETL bezeichnet einen Prozess, bei dem Daten aus einer oder mehreren Quellen extrahiert,
verarbeitet bzw. transformiert und anschließend in ein Ziel oder mehrere Ziele geschrieben
werden.
• Quelle: Die zu verarbeitenden Daten können aus einer oder mehreren Quellen verschiedenen
Typs extrahiert werden. In Informatica PowerCenter 8, dem verwendeten Werkzeug, werden
Daten aus einer Quelle in den sogenannten Source Qualifier gelesen und somit in das Mapping
geladen.
• Ziel: Nach der Verarbeitung werden die Daten in ein oder mehrere Ziele, die von
verschiedenem Typ sein können, geschrieben.
• Transformation: Eine Transformation bezeichnet im ETL-Kontext eine Aktivität, die
Manipulationen an Daten bzw. an deren Schema vornimmt. In dieser Arbeit wird, soweit nicht
anders angegeben, davon ausgegangen, dass die Daten in Form eines relationalen Schemas,
also in Tabellenform mit Zeilen und Spalten vorliegen. Die Zeilen beschreiben dabei die
Datentupel, die Spalten deren Attribute.
Zu unterscheiden sind aktive und passive sowie verbundene und nicht verbundene
Transformationen.
Eine aktive Transformation verändert die Anzahl der Zeilen einer Tabelle, dagegen bleibt die
Zeilenanzahl bei passiven Transformationen gleich.
Zu beachten ist, dass sich das Kriterium nur auf die Zeilen bezieht. Eine Transformation, die
die Anzahl der Spalten durch Projektion ändert, die Zeilenanzahl aber unverändert lässt, ist
passiv.
Neben aktiven und passiven gibt es verbundene und nicht verbundene Transformationen als
wesentliche Typen. Eine Transformation wird als verbundene Transformation bezeichnet,
wenn sie über verbundene Ein- und Ausgabeports in den Datenfluss integriert ist. Neben
verbundenen gibt es auch nicht verbundene Transformationen. Diese haben keine direkte
Verbindung zum Datenfluss des Mappings, sondern werden aus anderen Transformationen
aufgerufen.
• Mapping: Eine Menge von Transformationen mit mindestens einer Quelle und einem Ziel
wird als Mapping bezeichnet. In Informatica Powercenter werden innerhalb eines Mappings
Daten aus einer oder mehreren Quellen gelesen, dann optional in weiteren Transformationen
manipuliert und anschließend in ein oder mehrere Ziele geschrieben.
Das Mapping kann hierbei als gerichteter, zyklenfreier Graph gesehen werden. Die einzelnen

ETL-Design Optimierung Seite 10 von 108
Transformationen sind seine Knoten, die Verbindungen zwischen Ports die Kanten (Simitsis,
Vassiliadis, & Sellis, 2005). Die Betrachtung als Graph dient im Verlaufe dieser Arbeit als
Grundlage für die Diskussion verschiedener Qualitätsmerkmale.
• Mapplet: Mapplets sind eine Besonderheit von Informatica Powercenter. Sie bieten die
Möglichkeit, mehrere Transformationen zu einem Modul zusammenzufassen und als eine
Einheit über definierte Ein- und Ausgabetransformationen anzusprechen. Bei sehr
umfangreichen Mappings ist es häufig sinnvoll, zusammengehörige Transformationen in
Mapplets zu kapseln. Hierdurch wird die Übersichtlichkeit erhöht und Wiederverwendung
ermöglicht.
• Session: In Informatica PowerCenter werden einzelne Mappings in Sessions eingebunden, um
diese auszuführen. Für die Session werden die notwendigen Parameter, wie Verbindungen zu
Quell und Zielsystemen, definiert. Außerdem bieten Sessions die Möglichkeit Variablen und
Parameter, die im ETL Prozess genutzt werden, zu definieren. Sessions werden zur
Ausführung in ein Worklet oder einen Workflow integriert.
• Worklet: Ein Worklet fasst mehrere Sessions zu einem Modul zusammen. Als Module lassen
sich Worklets in verschiedenen Workflows wiederverwenden.
• Workflow: Der Workflow ist die höchste logische Ebene in Informatica Powercenter und
bildet einen gesamten ETL Prozess ab. Ein Workflow kann dabei aus 1-n Sessions oder
Worklets und somit aus 1-n Mappings bestehen.
2.2 Einordnung und Bedeutung von ETL Prozessen Das Datenaufkommen in heutigen Unternehmen wächst kontinuierlich, gleichzeitig steigt der Bedarf,
diese Daten in einer unternehmensweiten, einheitlichen Sicht zu analysieren, überproportional zu
diesem Wachstum. Analysen sollen sowohl Erkenntnisse über das operative Geschäft liefern, als auch
entscheidungsunterstützend bei der strategischen Planung und Steuerung helfen. Grundlage für
derartige Analysesysteme bilden häufig Data Warehouse Systeme. In einem Data Warehouse werden
Daten aus allen relevanten Datenquellen eines Unternehmens zusammengeführt und, von den
operativen Daten physikalisch getrennt, in einem einheitlichen Schema vorgehalten. (Inmon, 2002, S.
31)
Die Versorgung eines Data Warehouses findet üblicherweise durch ETL Prozesse statt.
Während eines ETL Prozesses werden zuerst Daten aus Quellsystemen extrahiert. Während der
folgenden Transformationsphase werden Daten bereinigt, verarbeitet und in das Zielschema
transformiert. Anschließend werden während der Ladephase die zuvor extrahierten und
transformierten Daten in das Zielsystem, zum Beispiel ein Data Warehouse geschrieben.
Außer in Data Warehouse Szenarien spielen ETL Prozesse auch bei der Datenintegration im
Allgemeinen eine wichtige Rolle. Sie kommen überall dort zum Einsatz, wo Daten aus verschiedenen
Quellensystemen in andere Datenhaltungssysteme überführt und dabei an neue Anforderungen
angepasst werden müssen.
Grundsätzlich können ETL Prozesse entweder individuell programmiert werden, oder mit Hilfe von
Werkzeugen entwickelt und durchgeführt werden. Im Rahmen dieser Arbeit wird von der Nutzung
eines Werkzeugs, konkret dem Informatica PowerCenter Server 8, ausgegangen.
Durch die hohe Komplexität von ETL Prozessen, ist der Einsatz eines Werkzeugs in den meisten

ETL-Design Optimierung Seite 11 von 108
Fällen sehr empfehlenswert. (Kimball & Caserta, The Data Warehouse ETL Toolkit, 2004, S. 10)
(Kurz, 1999, S. 268)
Nachfolgend wird jede der drei ETL-Phasen näher beschrieben.
2.2.1 Extraktion In der Extraktionsphase werden Daten aus verschiedenen operativen Datenquellen eines
Unternehmens gelesen und in den ETL Arbeitsbereich geladen.
Für ETL Prozesse kommen verschiedene Arten von Datenquellen in Frage. Beispiele sind Textdateien,
relationale Datenbanken und proprietäre Systeme.
Vor der eigentlichen Extraktion müssen die relevanten Quellen und Daten identifiziert und selektiert
werden. Dies sind fachliche Entscheidungen, die von den entsprechenden Abteilungen, in
Zusammenarbeit mit dem ETL-Team, getroffen werden müssen.
Für die Selektion spielen verschiedene Faktoren eine Rolle. So muss zum einen die Verfügbarkeit von
Daten berücksichtigt werden. Bei externen Datenquellen kann diese schwanken und somit nicht immer
auf Dauer gewährleistet werden.
Neben der Verfügbarkeit spielt vor allem die Qualität der Daten bei deren Auswahl eine wichtige
Rolle.
2.2.1.1 Data Profiling Sind die relevanten Daten identifiziert, müssen diese während des sogenannten Data Profilings
analysiert und auf ihre fachliche und technische Qualität überprüft werden.
Nach Bauer und Günzel gibt es 7 Kriterien, anhand derer die Qualität von Daten überprüft werden
kann.
1. Konsistenz: Daten werden als konsistent bezeichnet, wenn sie untereinander, gegenüber den
jeweiligen Metadaten widerspruchsfrei sind.
2. Korrektheit: Bilden Daten die jeweiligen Sachverhalte in der Realität richtig ab, so werden sie als
korrekt bezeichnet.
3. Vollständigkeit: Sind alle benötigten Daten vorhanden, um die jeweiligen Sachverhalte in der
Realität abzubilden, sind diese vollständig.
4. Genauigkeit und Granularität: Dieses Kriterium ist erfüllt, falls die Daten anhand ihrer Ausprägung
unterscheidbar sind und einem geforderten Detaillierungsgrad genügen.
5. Zuverlässigkeit und Glaubwürdigkeit: Um dieses Kriterium zu erfüllen, muss die Herkunft der
Daten nachvollziehbar und vertrauenswürdig sein.
6. Verständlichkeit: Daten werden als verständlich bezeichnet, falls die Bedeutung der Daten für die
Anwender ersichtlich ist.
7. Verwendbarkeit und Relevanz: Nur Daten, die eine entsprechend den anderen 6 Kriterien hohe
Qualität aufweisen und gleichzeitig für die durchzuführenden Analysen relevant sind, werden in das
Data Warehouse überführt.

ETL-Design Optimierung Seite 12 von 108
Mit Hilfe dieser Kriterien können Mindestanforderungen an Datenqualität definiert werden, die zur
Auswahl der Daten erfüllt werden müssen. Zwar können in Phase 2 des ETL Prozesses, der
Transformationsphase, Maßnahmen zur Verbesserung der Datenqualität vorgenommen werden, eine
Verbesserung ist aber nur in bestimmten Fällen und bis zu einem gewissen Maß möglich.
Das Verbesserungspotential der Datenqualität muss dementsprechend bei der Selektion von Daten
berücksichtigt werden. (Bauer & Günzel, 2004, S. 40 ff.)
2.2.1.2 Staging Nach der Selektion der zu extrahierenden Daten werden diese in der Regel in eine sogenannte Staging
Area geladen. Hierbei handelt es sich um einen Arbeitsbereich, in dem alle weiteren Maßnahmen bis
zum Laden vorgenommen werden. Der Vorteil des Zwischenspeicherns der Daten liegt zum einen in
geringeren Sperrzeiten der operativen Systeme begründet. Zum anderen wird durch Staging die
Zuverlässigkeit des Prozesses verbessert. So können ETL Prozesse, bei denen die Daten in einer
Staging Area vorgehalten werden, im Fehlerfall neu gestartet werden, ohne dass erneut auf die Quellen
zugegriffen werden muss. (Kimball & Caserta, The Data Warehouse ETL Toolkit, 2004, S. 29-31)
2.2.2 Transformation Während der Transformationsphase findet die eigentliche Verarbeitung der Daten statt. Dies geschieht
in drei Unterphasen: Der Datenbereinigung, der Schemaintegration und Datentransformation.
2.2.2.1 Datenbereinigung Während der Datenbereinigung werden fehlerhafte Quelldaten behandelt. Dies ist notwendig, da diese
die Ergebnisse der auf den Daten durchgeführten Analysen verfälschen könnten. Außerdem werden
von inkonsistenten Daten Probleme beim späteren Laden verursacht.
Die typischerweise auftretenden Fehler in Quelldaten lassen sich nach (Bauer & Günzel, 2004) in fünf
Klassen unterteilen:
Referenzielle Integrität: Stehen Daten miteinander in einer Fremdschlüsselbeziehung und ist ein Datensatz, auf den verwiesen
wird, nicht vorhanden, liegt eine Verletzung der referenziellen Integrität vor. In einem solchen Fall
kann der fehlende Datensatz entweder ergänzt oder, falls dies nicht möglich ist, der verweisende
Datensatz gelöscht werden.
Fehlerhafte Werte und unzulässige Werte Daten können fehlerhaft in Quellen vorliegen. Dies geschieht zum Beispiel bei der Erfassung durch
Tippfehler oder durch Fehler in den operativen Systemen. Durch Plausibilitätsprüfungen, zum Beispiel
durch den Vergleich mit Referenzdatenquellen und Überprüfung des zulässigen Wertebereichs,
können solche Fehler erkannt und eventuell korrigiert werden. Ist keine automatische Korrektur
möglich, müssen Fehler entweder manuell überprüft und behoben, die betroffenen Daten verworfen
oder die Fehler toleriert werden.
Fehlende Werte und Nullwerte Enthält ein Feld keine Daten, kann dies zwei Ursachen haben. Entweder gibt es zu diesem Feld keinen
Wert in der Realität oder es gibt einen, der aber nicht erfasst wurde. Falls ein Wert nicht erfasst wurde,
kann dieser unter Umständen ergänzt werden. Dies erfordert aber in den meisten Fällen eine manuelle
Prüfung und genaue fachliche Kenntnis der Daten.

ETL-Design Optimierung Seite 13 von 108
Redundanz Redundanzen beziehungsweise Duplikate treten häufig bei Inkonsistenzen auf. In diesem Fall müssen
die Daten untereinander, zum Beispiel mit Hilfe von Zeitstempeln, abgeglichen werden. Erkennung
von Duplikaten und deren Beseitigung ist häufig ein Funktionsmerkmal von ETL-Werkzeugen.
Trotzdem ist die Behandlung von Duplikaten eine große Herausforderung im ETL Kontext.
Unverständliche oder nicht eindeutige Kodierungen In Softwaresystemen werden Daten häufig kodiert gespeichert. Da es keine einheitlichen Standards zur
Kodierung gibt, können Kodierungen in verschiedenen Quellen voneinander abweichen. Ein Beispiel
hierfür sind Angaben zum Geschlecht, die mit m/w, m/f oder 0/1 kodiert werden können. Solche
Konflikte müssen aufgelöst und in eine standardisierte Form überführt werden.
2.2.2.2 Schemaintegration Da die Quelldaten aus verschiedenen operativen Systemen stammen, sind sie oft schemaheterogen.
Für die Integration in das Zielsystem müssen diese jedoch in ein einheitliches Schema überführt
werden. Typische Aufgaben hierbei sind Typkonvertierungen, zum Beispiel verschiedener DATE
Typen, oder die Umwandlung von als Zeichenketten gespeicherten Daten in numerische Werte. Zur
Schemaanpassung werden häufig Metadaten verwendet. Soweit sich die Quellschemata nicht
verändern, sind die Transformationsregeln zur Schemaintegration nach erstmaliger Definition
wiederverwendbar. (Lehner, 2003)
2.2.2.3 Datentransformation Nachdem die Quelldaten bereinigt und Transformationsregeln zur Schemaintegration definiert sind,
können fachlich Transformationen definiert werden, die die Daten den Anforderungen des Zielsystems
entsprechend anpassen und gegebenenfalls erweitern (Lehner, 2003).
Eine typische Anforderung ist die Datenfilterung anhand von Wertebereichen. Außerdem werden
Daten häufig voraggregiert, falls für die Verarbeitung in den Zielsystemen nur eine höhere
Aggregationsstufe benötigt wird. Hierdurch wird der Speicherbedarf in den Zielsystemen zum Teil
drastisch reduziert. Neben diesen Maßnahmen können anhand der bereinigten Daten auch zusätzliche
Attribute aus bestehenden Attributen abgeleitet werden.
Anschließend werden die zuvor definierten Transformationen an den Daten durchgeführt. Die
Transformation findet üblicherweise im Staging Area statt. Nach Durchführung aller
Transformationen folgt die Ladephase.
2.2.3 Laden In der Load- oder Ladephase von ETL Prozessen werden transformierte Daten in Zielsysteme
geschrieben. Dies kann ein Data Warehouse sein, ETL ist jedoch nicht zwangsläufig nur im Data
Warehouse Umfeld anzusiedeln, weswegen auch andere Zielsysteme in Frage kommen. Um das Laden
möglichst performant durchzuführen, werden häufig spezielle Funktionen der Zielsysteme genutzt.
Zum Beispiel bietet sich bei relationalen Datenbanken der sogenannte Bulk Modus an. Hierbei werden
beim Schreiben Protokollfunktionen und Transaktionskontrollen umgangen, wodurch die Leistung
erheblich gesteigert werden kann.
2.2.3.1 Ladestrategien Zur Versorgung eines Data Warehouses sind grundsätzlich drei Ladestrategien denkbar. Diese sind
Initial Load, Full Refresh und Incremental Load.

ETL-Design Optimierung Seite 14 von 108
Mit Initial Load wird das erstmalige Schreiben in die Zielsysteme bezeichnet. Im Data Warehouse
Umfeld werden hierfür alle Tabellen mit den in der Transformationsphase erzeugten Daten bevölkert.
Ein Initial Load findet üblicherweise nur einmal bei der Einführung eines neuen Systems statt.
Full Refresh löscht den Inhalt einer oder mehrerer Zieltabellen und füllt diese mit neuen Daten. Dieses
Verfahren entspricht weitestgehend einem Initial Load, mit dem Unterschied, dass nicht alle Tabellen
des Zielsystems betroffen sein müssen.
Da Full Refresh entsprechend der zu ladenden Datenmenge äußerst aufwendig werden kann, ist
aufgrund der zeitlichen Restriktionen, denen der Ladeprozess unterliegt, das Verfahren eines
Incremental Load häufig sinnvoll. Hierbei werden nur geänderte Daten erneut geschrieben. Dies
reduziert die zu verarbeitende Datenmenge erheblich. Für Incremental Load können Daten in zwei
Klassen unterteilt werden, in neue Daten, die dem Data Warehouse hinzugefügt werden müssen, und
geänderte Daten, für die entsprechend eines Historisierungskonzepts verfahren werden muss.
Im Betrieb eines Data Warehouses wird üblicherweise mit Incremental Load gearbeitet (Bauer &
Günzel, 2004).
2.3 Modellierung von ETL Prozessen mit Informatica Powercenter 8 Zwischen der Modellierung, der Entwicklung und der Durchführung von ETL Prozessen sollen
Brüche vermieden werden. Es soll aus dem Modell direkt in die Entwicklung und zur Wartung und
Weiterentwicklung aus der Entwicklung zurück in das Modell überführt werden können.
Momentan existieren nur sehr wenige Ansätze zur Standardisierung der Modellierung von ETL
Prozessen. Die wenigen, vielversprechenden Ansätze2 werden nicht von ETL Werkzeugen unterstützt,
da die Hersteller hier ihre proprietären Ansätze verfolgen.
In der Praxis bietet es sich daher an, die Modellierung mit dem Werkzeug, in dem die Umsetzung und
der Betrieb der ETL Prozesse realisiert werden sollen, durchzuführen.
Die Entscheidung für ein Werkzeug ist also gleichzeitig eine Entscheidung für die
Modellierungssprache, umgekehrt kann die verwendete Modellierungssprache die Entscheidung für
ein Werkzeug beeinflussen.
Für diese Arbeit wurde Informatica Power Center 8 als ETL Werkzeug gewählt.
Neben einer graphischen Entwicklungsumgebung zum Design von ETL Prozessen bietet es einen
Integrationsserver, um diese auszuführen. Darüber hinaus verfügt Informatica Power Center 8 über ein
sogenanntes Repository. Das Repository ist eine relationale Datenbank, in der alle relevanten
Informationen inklusive Metadaten zu den ETL Prozessen vorgehalten werden. Für Informatica
sprechen insbesondere der große Reifegrad, die hohe Marktdurchdringung und Akzeptanz sowie die
umfassende Konnektivität zu verschiedensten Quell- und Zielsystemen.
In Informatica Power Center 8 existieren verschiedene Betrachtungsebenen für einen ETL Prozess.
Auf höchster Ebene steht der Workflow, welcher einen gesamten ETL Prozess abbildet. Ein Workflow
besteht aus Sessions, die jeweils einzelne Mappings zusammenfassen. Außerdem können mehrere
Sessions zu einem Worklet zusammengefasst werden. Die nächste Ebene unterhalb der Sessionebene
ist die des Mappings. In einem Mapping werden Daten von Quellen durch verschiedene
Transformationen in Ziele transferiert. Ein Mapping ist also eine Menge von Transformationen mit
mindestens einer Quelle und mindestens einem Ziel. Die einzelnen Transformationen leisten hierbei
2 (Vassiliadis, Simitsis, & Skiadopoulus, 2002), (Luján-Mora, Vassiliadis, & Trujillo, 2004)

ETL-Design Optimierung Seite 15 von 108
die notwendige Verarbeitung der Daten, die Transformationsebene stellt gleichzeitig die tiefste
Betrachtungsebene dar.
Nachfolgend werden die Grundlagen zu Transformationen, Mappings, Sessions und Workflows
anhand von Beispielen dargestellt. Hierbei wird nach dem bottom-up Prinzip vorgegangen, es werden
zuerst Transformationen als unterste Betrachtungsebene vorgestellt. Anschließend werden die nächst
höheren Ebenen, Mapping und Mapplet, betrachtet. Abschließend werden Sessions und die darauf
aufbauenden Workflows kurz vorgestellt. Der Betrachtungsschwerpunkt der durchgeführten
Untersuchungen liegt auf den unteren Ebenen, also Transformations-, Mapplet- und Mappingebene.
2.3.1 Transformationen in Informatica PowerCenter 8 Eine Transformation verfügt über Ports, die die Attribute von Daten repräsentieren. Es werden hierbei
Ein- und Ausgabeports getrennt betrachtet. Über die Ein- und Ausgabeports werden Daten
beziehungsweise Attribute zwischen Transformationen weitergeleitet. Neben den Ein- und
Ausgabeports existieren Variablenports, die zur Verarbeitung von Daten innerhalb einer
Transformation genutzt werden.
2.3.1.1 Beispiel einer Transformation Nachfolgend wird eine Transformation inklusive der Ein- und Ausgabeports dargestellt. Als Beispiel
wurde eine EXPRESSION Transformation gewählt.
Abbildung 1 Expression Transformation mit Ein- und Ausgabeports
In Abbildung 1 sind am Beispiel einer EXPRESSION Transformation die verschiedenen Ports zu
erkennen. Von links gelangen Daten über die Inputports SUM_HOURS_PER_PROJECT und
TASK_LOG_COSTCODE in die Transformation. Rechts werden die in der Transformation
berechneten Daten über die Outputports COST_PER_PROJECT, COST_IN_DOLLAR und
COST_IN_FRANKEN zur weiteren Verarbeitung ausgegeben. Variablenports, in diesem Beispiel
FACTOR_COSTCODE, werden auf Mappingebene nicht dargestellt, sondern werden erst beim
Editieren von Transformationen ersichtlich. Folgende Abbildung 2 zeigt dies.

ETL-Design Optimierung Seite 16 von 108
Abbildung 2 Expression Transformation Detailansicht
Für jeden Port werden sein Name, der im relationalen Modell dem Spaltenname entspricht, sein
Datentyp mit Länge und Präzision sowie seine Rolle definiert. Die Rollen können hierbei Eingabe-
Ausgabe- und Variablenports sein. Sie werden in der Detailansicht durch I, O und V definiert und
durch die Checkboxen gewählt. Diese Attribute sind bis auf wenige Ausnahmen für alle
Transformationen gleich. In weiteren Merkmalen unterscheiden sich Transformationen jedoch. In
einer EXPRESSION Transformation, wie sie beispielhaft in der Abbildung dargestellt ist, können für
jeden Port entsprechende Berechnungsanweisungen definiert werden.
2.3.1.2 Transformationstypen Informatica Powercenter 8 bietet Transformationen für viele ETL Anforderungen an. Tabelle 1 bietet
einen Überblick und eine kurze Beschreibung der in Informatica vorhandenen Transformationen. Wo
es zum Verständnis der Beispiele notwendig ist, wird die Funktionsweise einzelner Transformationen
an der Stelle der Verwendung genauer erklärt.
Transformation Typ Kurzbeschreibung
Aggregator aktiv / verbunden Führt Aggregationskalkulationen durch.
Application Source Qualifier
aktiv / verbunden Liest Zeilen aus einer Applikation, z.B. einem ERP System ein.
Custom aktiv oder passiv / verbunden
Ruft eine Prozedur aus einer Shared Library oder DLL auf.
Expression Passiv / verbunden Berechnet Werte.
External Procedure
Passiv /verbunden oder nicht verbunden
Ruft eine Prozedur aus einer Shared Library oder dem Windows COM Layer auf.
Filter aktiv / verbunden Filtert Daten nach dem Prinzip einer Where-Klausel.
Input Passiv / verbunden Definiert die Eingabeports eines Mapplets.

ETL-Design Optimierung Seite 17 von 108
Java Aktiv oder passive / verbunden
Führt benutzerdefinierte Anwendungslogik, die in Java entwickelt wurde, aus. Der Bytecode wird im Informatica PowerCenter Repository gespeichert.
Joiner Aktiv / verbunden Führt Daten aus verschiedenen Datenbanktabellen oder Flatfiles spaltenweise zusammen. Die Daten können aus verschiedenen Quellsystemen stammen.
Lookup Passiv / verbunden oder nicht verbunden
Schlägt Werte in Quellen nach.
Normalizer Aktiv / verbunden Source Qualifier für COBOL Quellen. Kann darüberhinaus zum Normalisieren von Daten aus relationalen oder flachen Quellen verwendet werden.
Output Passiv / verbunden Definiert die Ausgabeports eines Mapplets.
Rank Aktiv / verbunden Beschränkt die Daten auf eine Gruppe von maximal oder minimal Werten.
Router Aktiv /verbunden Teilt den Datenfluss anhand von Bedingungen auf und leitet die Teilströme an verschiedene Transformationen weiter.
Sequence Generator
Passiv / verbunden Generiert Sequenzen, z.B. Primärschlüssel.
Sorter Aktiv / verbunden Sortiert Daten anhand eines Sortierkriteriums.
Source Qualifier Aktiv / verbunden Liest Daten aus relationalen oder flachen Quellen ein.
Stored Procedure
Passiv / verbunden oder nicht verbunden
Ruft eine, in der Datenbank hinterlegte, Stored Procedure auf.
Transaction Control
Aktiv / verbunden Definiert commit und rollback Transaktionen.
Union Aktiv / verbunden Führt Daten aus verschiedenen Datenbanktabellen oder Flatfiles zeilenweise zusammen. Die Daten können aus verschiedenen Quellsystemen stammen.
Update Strategy Aktiv / verbunden Dient im Kontext von Historisierung zur Festlegung, ob Zeilen mit insert, delete, update oder reject verarbeitet werden.
XML Generator Aktiv / verbunden Liest Daten über einen oder mehrere Eingabeports ein und gibt XML über einen Ausgabeport aus.
XML Parser Aktiv / verbunden Liest XML über einen Eingabeport ein und gibt die Daten über einen oder mehrere Ausgabeports aus.
XML Source Qualifier
Aktiv / verbunden Liest Daten aus XML Quellen ein.
Tabelle 1: Übersicht über die Transformationen in Informatica PowerCenter 8 (Informatica, PowerCenter
Transformation Guide, 2006)

ETL-Design Optimierung Seite 18 von 108
Wiederverwendbarkeit von Transformationen Informatica PowerCenter 8 bietet ein Konzept der Wiederverwendbarkeit von Transformationen.
Hierfür wird bei der Erstellung von Transformationen das „reusable“ Merkmal aktiviert. Dies führt
dazu, dass Transformationen in mehreren Mappings verwendet werden können. Die
wiederverwendbare Transformation wird im Repository von Informatica unabhängig von einzelnen
Mappings hinterlegt. Sobald eine solche Transformation in einem Mapping verwendet wird, wird eine
Instanz der Transformation erstellt. Wiederverwendbare Transformationen zeichnen sich vor allem
dadurch aus, dass Änderungen an der Transformation von all ihren Instanzen automatisch
übernommen werden. Standardmäßig ist das Wiederverwendbarkeitsmerkmal für alle
Transformationen aktiviert. Es kann aber für alle Transformationen außer der External Procedure
deaktiviert werden. Grundsätzlich ist die Nutzung von wiederverwendbaren Transformationen
empfehlenswert. Die Auswirkungen von Änderungen auf alle Instanzen einer Transformation können
bei Wartungsarbeiten allerdings auch zu nicht vorhergesehenem Verhalten in anderen Mappings
führen. Bei vorausschauender Anwendung erhöhen sie jedoch sowohl die Wiederverwendbarkeit als
auch die Wartbarkeit. (Informatica, Informatica PowerCenter Designer Guide 8.1, 2006, S. 209)
2.3.2 Mappings in Informatica PowerCenter Innerhalb eines ETL Prozesses durchlaufen Daten einzelne Transformationen. Werden verschiedene
Transformationen zu einem Datenfluss verbunden, stellen diese ein Mapping dar. Hierbei muss ein
Mapping mindestens eine Quelle sowie mindestens ein Ziel aufweisen. Als Quellen und Ziele
kommen in Informatica PowerCenter 8 relationale Tabellen in Datenbanken und flache Dateien in
Frage. Darüber hinaus ist auch Zugriff auf andere Speicherformate, wie zum Beispiel XML oder
Cobol, möglich. Zwischen Quellen und Zielen können beliebig viele Transformationen eingesetzt
werden, in denen die Daten verarbeitet werden.
Innerhalb eines Mappings werden also Daten von Quellen auf Ziele abgebildet und dabei in
Transformationen verarbeitet. Die Daten fließen hierbei immer in eine Richtung von der Quelle zum
Ziel. Der ETL Prozess wird also durch einen gerichteten, azyklischen Graphen beschrieben
(Vassiliadis, Simitsis, & Skiadopoulus, 2002). Das heißt, es sind zwar Aufspaltungen des Datenflusses
möglich, aber keine Umkehrung der Flussrichtung und somit auch keine Schleifen.
Abbildung 3 auf der folgenden Seite zeigt ein einfaches Mapping
Abbildung 3: Einfaches Mapping mit Filter
Das Beispielmapping verfügt über eine Quelle und ein Ziel, in einer FILTER Transformation werden
dabei nur Daten in das Ziel übergeben, für die Start und Ende der Aufgabe im Jahr 2006 lagen.

ETL-Design Optimierung Seite 19 von 108
Die SOURCE QUALIFIER Transformation, die in dem abgebildeten Mapping zu sehen ist, ist eine
Informatica PowerCenter spezifische Transformation. Sie dient dazu, die Daten per SELECT aus
Quellen zu extrahieren und dem Integrationsdienst zur Weiterverarbeitung zu übergeben. Für jede
Quelle wird ein Source Qualifier benötigt. Er kann bereits beim Einlesen einer Quelle in den
Integrationsdienst Operationen, wie zum Beispiel Filterung oder Join durchführen. Die Bedingungen
dafür werden durch eine WHERE Klausel im Source Qualifier definiert. Unter anderem werden die
hieraus entstehenden Potentiale in dieser Arbeit untersucht.
2.3.2.1 Parameter und Variablen Mit Parametern und Variablen wird die Wiederverwendbarkeit von Mappings und den nachfolgend
erläuterten Mapplets verbessert.
Bei Parametern handelt es sich um konstante Werte, auf die während einer Session in
Transformationen zurückgegriffen werden kann. Hierdurch können zum Beispiel Mappings, die sich
strukturell gleichen, aber unterschiedliche Filterbedingungen anwenden, mehrfach mit verschiedenen
Parametern verwendet werden. Ein Parameter wird hierbei für ein Mapping oder Mapplet deklariert
und vor dem Starten einer Session mit einem Wert belegt. Dies kann entweder direkt im Informatica
Mapping- beziehungsweise Mappletdesigner geschehen oder mittels einer Parameterdatei, in der die
Werte hinterlegt werden.
Variablen werden wie Parameter während einer Session in Transformationen einbezogen, um dort eine
höhere Flexibilität und damit Wiederverwendbarkeit zu gewähren. Dies kann zum Beispiel durch
Nutzung einer Variablen für Selektionsbedingungen geschehen. Im Unterschied zu Parametern können
Variablen während einer Session geändert werden. Sie sind also nicht konstant, sondern können in
verschiedenen Durchläufen mit unterschiedlichen Werten belegt werden (Informatica, Informatica
PowerCenter Designer Guide 8.1, 2006).
2.3.3 Mapplets Im Informatica PowerCenter 8 Designer bieten Mapplets die Möglichkeit Mappings zu
modularisieren. Hierdurch können Transformationen, also zusammengehörige Verarbeitungsschritte,
zusammengefasst werden. In komplexen Mappings wird hierdurch die sichtbare Anzahl an
Transformationen verringert. Andererseits wird die Komplexität nicht reduziert, sondern nur durch
Internalisierung verborgen. Wenn sie fachkonzeptionell sinnvoll, also zur Zusammenfassung enger
logischer Gruppen genutzt werden, erhöhen Mapplets jedoch die Übersichtlichkeit. Außerdem sind sie
als modulare Einheiten wiederverwendbar.
Anhand eines Beispiels wird nachfolgend der Einsatz eines Mapplets erläutert. An dieser Stelle soll
dabei nur ein Überblick verschafft werden. Eine Diskussion über den Nutzen und die Risiken findet
später in Kapitel 4 statt. Auch eine Beschreibung des Anwendungsfalls wird später vorgenommen, da
dieses Beispiel wieder verwendet wird.
Im zur Veranschaulichung gewählten Beispiel müssen drei Quellen eingelesen und danach über zwei
JOINER Transformationen zusammengeführt werden. Danach stehen die Daten in der benötigten
Struktur für eine Berechnung der Projektkosten zur Verfügung.

ETL-Design Optimierung Seite 20 von 108
Abbildung 4 zeigt zunächst ein Mapping ohne den Einsatz von Mapplets. Da einzelne Ports für das
Verständnis des Beispiels nicht relevant sind und um die Übersichtlichkeit zu erhöhen, wurde eine
minimierte Darstellung der Transformationen gewählt.
Abbildung 4 Mapping ohne Mapplets
Am Beispiel fällt auf, dass die Transformationen zum Einlesen und Zusammenführen der
Quelltabellen mehr als die Hälfte des gesamten Mappings in Bezug auf die Anzahl der
Transformationen ausmachen. In einem Mapplet können diese Transformationen zu einem Modul
zusammengefasst werden.
Die Zusammenfassung von Transformationen findet mit Hilfe des Mappletsdesigners statt.
Im gewählten Beispiel sind die Quellen, Source Qualifier und Joiner Transformationen, in einem
Mapplet mit der Bezeichnung MLTP_EXTRACT_AND_JOIN_SOURCES zusammengefasst.
Zusätzlich verfügt das Mapplet über eine OUTPUT Transformation. Mapplets können über eine
INPUT und müssen über eine OUTPUT Transformation verfügen. Diese besonderen
Transformationen stellen die Schnittstelle des Mapplets zu dem Mapping, in dem sie genutzt werden,
dar. Da in diesem Beispiel die Quellen in das Mapplet integriert sind, wird keine INPUT
Transformation benötigt. Ziele hingegen lassen sich nicht in Mapplets einbinden, daher ist eine
OUTPUT Transformation immer notwendig. Nachfolgend ist das Mapplet mit den darin enthaltenen
Transformationen dargestellt.

ETL-Design Optimierung Seite 21 von 108
Abbildung 5: Mapplet MLTP_EXTRACT_AND_JOIN_SOURCES
Wird das neu erstellte Mapplet in das Mapping eingebunden, stellt sich das Mapping wie in folgender
Abbildung gezeigt dar.
Abbildung 6 Mapping mit Mapplet
Die Zusammenfassung von der genannten Transformationen reduziert die Gesamtzahl der sichtbaren
Transformationen um die Hälfte.
Wie das Beispiel zeigt, kann der Einsatz von Mapplets die Übersichtlichkeit von ETL Prozessen auf
der Ebene der Mappings erhöhen. Außerdem können Mapplets durch ihre Modularität relativ einfach
wiederverwendet werden.

ETL-Design Optimierung Seite 22 von 108
2.3.4 Sessions Sessions werden mit Task Developer des Workflow Managers von Informatica PowerCenter erstellt.
Eine Session führt immer genau ein Mapping aus und dient als Arbeitseinheit eines Workflows. Neben
dem zugrunde liegenden Mapping werden für eine Session Verbindungen zu den Quell- und
Zielsystemen eingerichtet. Außerdem können innerhalb einer Session Parameter und Variablen
eingesetzt werden. Für jede Session kann die Art der Fehlerbehandlung gewählt werden. Diese reicht
von Ignorieren bis zum Abbrechen des übergeordneten Workflows.
2.3.5 Workflows Der Workflow ist die höchste Ebene des ETL Prozesses in Informatica PowerCenter 8. In ihm werden
eine oder mehrere Sessions ausgeführt. Der Workflow nutzt zur Durchführung des ETL Prozesses den
Integration Service. Außerdem können Workflows über einen Scheduler automatisiert, zeitgesteuert
gestartet werden. Auch für Workflows können unterschiedlich restriktive Arten der Fehlerbehandlung
definiert werden.

ETL-Design Optimierung Seite 23 von 108
3 Designziele und Maße für ETL Prozesse
Im Folgenden wird zunächst eine Liste von denkbaren Designzielen aufgestellt. Danach werden Maße,
die die Ziele beeinflussen, eingeführt.
Da die Gewichtung der einzelnen Ziele stark vom jeweiligen Anwendungskontext abhängt, wird diese
in dieser Arbeit vorerst nicht vorgenommen. Stattdessen werden die Entwicklung der Maße und die
daraus resultierende Zielbeeinflussung anhand verschiedener Beispielen untersucht. Hierdurch
können Zusammenhänge erkannt und daraus Wirkprinzipien abgeleitet werden. Auf Basis der
gewonnenen Erkenntnisse wird im Schlussteil der Arbeit eine Klassifizierung von Mappings
vorgenommen. Diese soll bei der Gewichtung der Ziele in einzelnen Szenarien helfen. Darüber hinaus
werden, ebenfalls im Schlussteil, generelle Empfehlungen für ETL-Design unter Betrachtung der
einzelnen Ziele gegeben.
ETL Designziele Die wesentlichen Ziele, die durch Designentscheidungen beeinflusst werden können, sind:
• Korrektheit
• Wartbarkeit
• Wiederverwendbarkeit
• Performance
• Zuverlässigkeit
Maße Der Erreichungsgrad dieser Ziele wird von verschiedenen quantitativen und qualitativen Maßen
beeinflusst.
Quantitative Maße
• Datenmenge
• Anzahl der Knoten
• Länge
• Komplexität
Qualitative Maße
• Modularität
• Kapselung
• Kohäsion
• Kopplung

ETL-Design Optimierung Seite 24 von 108
3.1 Designziele
3.1.1 Korrektheit
Der Begriff der Korrektheit eines ETL Prozesses wird in dieser Arbeit analog zum Korrektheitsbegriff
in der Softwaretechnik genutzt.
Unter Korrektheit versteht man die Eigenschaft einer Software, die an sie gestellten Spezifikationen zu
erfüllen. Nicht betrachtet wird, ob die Spezifikationen zur Lösung eines fachkonzeptionellen Problems
richtig sind (Liggesmeyer, 2002, S. 7).
Im ETL-Kontext bedeutet Korrektheit, dass die bewirtschaftenden Daten nach Durchführung des ETL
Prozesses vollständig, fehlerfrei, typrichtig, gemäß des spezifizierten Zusammenhangs und Schemas in
den Zielsystemen vorliegen.
Korrektheit ist in ETL Prozessen analog zur Softwaretechnik immer stärkstes Ziel, da fachliche oder
technische Fehler nicht kalkulierbare Probleme nach sich ziehen können.
Dies wird im ETL Kontext insbesondere dadurch verschärft, dass ETL als
Datenbewirtschaftungsprozess häufig die Grundlage für entscheidungsunterstützende Systeme in
unternehmenskritischen Bereichen bildet.
3.1.2 Wartbarkeit Auch Wartbarkeit ist ein aus der Softwaretechnik übernommener Begriff.
Eine hohe Wartbarkeit reduziert den Aufwand für Pflege und Erweiterung einer Software. Hierdurch
werden Kosten gesenkt und eine Weiterentwicklung vereinfacht. Dies steigert in der Regel die
Qualität der Lösungen. Gleichzeitig ist eine gute Wartbarkeit ein wichtiges Kriterium für erfolgreiche
Teamarbeit, da weniger Abstimmungs- und Schulungsaufwand notwendig ist. Dies gilt analog auch
für ETL Prozesse, daher ist auch hier eine hohe Wartbarkeit grundsätzlich erstrebenswert.
3.1.3 Wiederverwendbarkeit Unter Wiederverwendbarkeit versteht man die Möglichkeit ein Softwareprodukt ganz oder teilweise in
weiteren Anwendungsfällen nutzen zu können.
Ein hohes Maß an Wiederverwendbarkeit eines Produkts oder einer Komponente steigert die
Kosteneffizienz bei der Entwicklung zukünftiger Lösungen und kann gleichzeitig bei der
Wiederverwendung ausgereifter Produkte, andere Qualitätsmerkmale, wie die Zuverlässigkeit, positiv
beeinflussen. Dies reduziert zum Beispiel den Aufwand für Validierung und Verifikation stark.
Diese Definition lässt sich in dieser Form auf das Design von ETL Prozessen übertragen.
Das Anstreben einer hohen Wiederverwendbarkeit wird in manchen Fällen den Aufwand für die
initiale Erstellung eines ETL Prozesses erhöhen, dieser Nachteil wird aber vermutlich in den meisten
Fällen von den oben genannten Vorteilen aufgewogen.
3.1.4 Performance Unter Performance wird der Durchsatz bzw. die Durchführungsgeschwindigkeit und damit Dauer
eines ETL Prozesses verstanden.
Im Rahmen von ETL Prozessen ist die Performance häufig ein wichtiges Kriterium.

ETL-Design Optimierung Seite 25 von 108
Während der Extraktion von Daten aus operativen Quellen müssen diese in vielen Fällen gesperrt
werden, wodurch die Arbeit mit diesen Systemen stillsteht. Selbst wenn keine Sperrung der operativen
Systeme erforderlich ist, werden diese durch den Extraktionsprozess stark belastet. Diese Punkte
begründen, warum die Extraktion meistens in einem kleinen Zeitfenster außerhalb der üblichen
Geschäftszeiten stattfinden soll (Bauer & Günzel, 2004).
Neben den Anforderungen der Umgebung ist zu beachten, dass aufgrund der häufig sehr großen
Datenmengen, die in ETL Prozessen verarbeitet werden, diese sehr ressourcenintensiv werden können.
Eine Verbesserung der Leistung kann daher sehr erstrebenswert sein.
Die Leistung von ETL Prozessen wird von vielen Faktoren beeinflusst. In dieser Arbeit sollen nur die
Faktoren betrachtet werden, die durch Designentscheidungen beeinflusst werden können. Die
physikalisch technischen Aspekte, die neben den logisch konzeptionellen eine wichtige Rolle für die
Leistung spielen, sollen hier nicht näher betrachtet werden. Aus diesem Grund wird zur Bewertung der
Performance kein Benchmarking anhand von Durchlaufzeiten eingeführt, sondern lediglich die
Entwicklungstendenz, also ob eine Verbesserung oder Verschlechterung stattgefunden hat, dargestellt.
3.1.5 Zuverlässigkeit Zuverlässigkeit beschreibt die Eigenschaft, unter gleichen Bedingungen reproduzierbar korrekte
Ergebnisse zu erzielen.
Außerdem bezeichnet sie die Fähigkeit eines Systems, bei Erreichen eines unerwarteten Zustands,
etwa durch Fehlbedienung oder Teilausfälle, wieder in einen stabilen Zustand zurückzukehren.
Wichtig für die Bewertung der Zuverlässigkeit ist, ob Fehler bereits bei der Implementierung erkannt
werden können oder erst zur Laufzeit auftreten (Liggesmeyer, 2002, S. 9).
Im Zusammenhang von ETL Prozessen wird Zuverlässigkeit unter anderem durch die Fähigkeit zur
Wiederaufnahme gescheiterter bzw. zur Fortsetzung unterbrochener Prozesse gewährleistet.
3.1.6 Bewertung der Zielerfüllung Um in den folgenden Abschnitten die Auswirkungen von Veränderungen am Design bewerten zu
können, wird die Veränderung der Zielerfüllung anhand einer fünfstelligen Skala dargestellt. Hierbei
findet immer ein Vergleich zwischen dem jeweiligen Ausgangsbeispiel und der jeweilig aktuellen
Variante statt. Die Bewertungsskala ist nachfolgend in einer Tabelle dargestellt
Symbol -- - 0 + ++
Veränderung
gegenüber
Referenz
stark
verschlechtert verschlechtert unverändert verbessert
stark
verbessert
Tabelle 2: Symbolik zur Bewertung der Zielerfüllung
3.2 Maße
3.2.1 Übersicht
Verschiedene Maße beeinflussen die definierten Designziele. In den folgenden Untersuchungen dienen
Sie dazu, Auswirkungen von Veränderungen an Beispielen in einer systematischen Form zu erfassen
und dadurch Vergleichbarkeit zu schaffen.

ETL-Design Optimierung Seite 26 von 108
Zum Teil beeinflussen sich die Maße gegenseitig, so dass es zu Wechselwirkungen kommt.
Die Maße können in zwei Gruppen, quantitative und qualitative, unterteilt werden. Beide Gruppen
unterscheiden sich durch die Art ihrer Erhebung.
Quantitative und qualitative Maße Während sich quantitativen Maße berechnen und in Form eines Messwertes darstellen lassen, müssen
die qualitativen diskutiert und begründet werden. Hierdurch unterliegen qualitativen Maße, im
Gegensatz zu den quantitativen, einer subjektiven Beurteilung. Dementsprechend muss ihre
Ausprägung begründet werden und kann im Einzelfall zur Diskussion stehen.
Quantitative Maße werden in den folgenden Beispielen anhand ihres Messwerts erhoben. Für
qualitative wird eine fünfstellige Bewertungsskala eingeführt, anhand derer die Ausprägung dargestellt
wird. Die Ausprägungen reichen dabei von „sehr schwach“ bis „sehr stark“, wie in der nachfolgenden
Tabelle verdeutlicht wird. Neutral beschreibt dabei eine durchschnittliche Ausprägung.
Symbol n/a n.v. -- - 0 + ++
Ausprägung nicht
erhoben
nicht
vorhanden
sehr
schwach schwach neutral stark sehr stark
Tabelle 3: Ausprägung der qualitativen Einflussfaktoren
Diese Skala bewertet Veränderungen an Maßen nicht, sondern erfasst sie ausschließlich. Welche
Ausprägung sich positiv auf Designziele auswirkt, ist unterschiedlich. So wird beispielsweise im
Allgemeinen eine möglichst starke Kohäsion angestrebt, die Kopplung hingegen sollte möglichst
gering sein. Welchen Einfluss die jeweiligen Ausprägungen haben, wird in den Beispielen für jedes
Designziel diskutiert.
3.2.2 Quantitative Maße
3.2.2.1 Datenmenge Die Datenmenge kann auf mehreren Ebenen betrachtet werden.
Zum einen als Anzahl der Tupel, wobei hier die Breite der Tupel nicht berücksichtigt wird. Diese
Betrachtung ist, bei der Diskussion von Transformationen die die Zeilenanzahl manipulieren,
ausreichend. Eine weitere, genauere Möglichkeit besteht darin, Zeilen und Spalten der Tupel
miteinander zu multiplizieren. Diese Betrachtung liefert eine Kenngröße der tatsächlichen
Datenmenge. Bei der Diskussion von Transformationen, die die Anzahl der Spalten manipulieren,
muss diese Art der Betrachtung gewählt werden.
Zur Bewertung von Optimierungsmaßnahmen muss die Datenmenge auf Transformationsebene
betrachtet werden, das heißt, es wird betrachtet, wie eine Transformation die Datenmenge verändert.
Grundsätzlich ist eine Verringerung der Datenmenge anzustreben. Dies kann beispielsweise durch
Selektionen und Aggregationen, was die Zahl der Tupel verringert, oder durch Projektion, wodurch
nicht benötigte Attribute entfallen, erzielt werden.
Die Datenmenge lässt sich quantitativ erheben:

ETL-Design Optimierung Seite 27 von 108
Da sich in Transformationen häufig nur die Zeilenanzahl ändert, ist zum Aufzeigen der Entwicklung
eine vereinfachte Betrachtung der Datenmenge:
häufig ausreichend. Solange nicht anders angegeben, wird unter Datenmenge die Anzahl der Tupel
verstanden. Beide Varianten der Messgröße stellen nur eine logische Erhebung der Datenmenge dar,
der physikalische Speicherbedarf wird damit nicht berücksichtigt.
3.2.2.2 Anzahl der Knoten Sieht man einen ETL Prozess beziehungsweise ein Mapping als Graphen, kann man die Anzahl der
Knoten innerhalb dieses Graphen betrachten. Innerhalb eines Mappings ist jede Transformation, also
jeder dedizierte Verarbeitungsschritt, ein Knoten. Auf höherer Ebene können auch Mapplets oder
Sessions als Knoten des ETL Prozess-Graphen angesehen werden.
Dieses Maß entspricht der von (Vassiliads, Simitsis, Terrovitis, & Skiadopoulos, 2005) eingeführten
„Size“. Die Bezeichnung Anzahl der Knoten wurde für ein intuitiveres Verständnis gewählt.
3.2.2.3 Komplexität Unter Komplexität wird im ETL Kontext die Anzahl der verbundenen Kanten zwischen den Knoten
verstanden (Vassiliads, Simitsis, Terrovitis, & Skiadopoulos, 2005).
Die Komplexität kann ab der Mappingebene und für alle höheren Betrachtungsebenen untersucht
werden. In Informatica wird die Komplexität durch die Anzahl der verbundenen Ports der einzelnen
Transformationen bestimmt.
3.2.2.4 Länge Die Länge beschreibt nach (Vassiliads, Simitsis, Terrovitis, & Skiadopoulos, 2005) die maximale
Anzahl an Weiterleitungen, die ein Attribut durchläuft.
Die Länge eines Mappings berechnet sich durch die maximale transitive Abhängigkeit eines Attributs
von vorherigen Transformationen.
3.2.3 Qualitative Maße Neben den quantitativen gibt es qualitative Maße zur Formalisierung bestimmter Einflussfaktoren.
Diese werden nachfolgend eingeführt.
3.2.3.1 Modularität Unter Modularität versteht man die Aufteilung von Funktionalität auf Module. Ein Modul stellt dabei
eine in sich geschlossene Einheit dar, die Funktionen über Schnittstellen zur Nutzung bereitstellt.

ETL-Design Optimierung Seite 28 von 108
Wesentlich für ein Modul ist die aus technischer Sicht weitestgehend kontextunabhängige Nutzbarkeit.
Dieses qualitative Maß ist aus der Softwaretechnik abgeleitet, wo Modularität eine wichtige Rolle
spielt (Balzert H. , 1998, S. 572).
3.2.3.2 Kapselung Mit dem Begriff der Modularität geht eng der Begriff der Kapselung einher. Kapselung beschreibt,
wie stark die Funktionalität eines Elements oder eines Moduls nach außen verborgen ist. Zusätzlich
spielt hierbei eine Rolle, wie viele Funktionen innerhalb eines Elements zusammengefasst werden. Zur
Verdeutlichung kann hier das Geheimnisprinzip aus der Softwaretechnik herangezogen werden.
Dieses besagt, dass Funktionen eines Elements innerhalb des selbigen verborgen sein sollen. Die
Details der Implementierung sind also den Nutzern der Funktionen des Elements nicht bekannt
(Balzert H. , 1998, S. 572).
3.2.3.3 Universalität Wie universell ein Element beziehungsweise eine Komponente einsetzbar ist, hängt davon ab, wie
generell sie entwickelt wurde. Das Gegenteil von Universalität ist Spezifität. Ein Element mit hoher
Universalität kann in verschiedenen Szenarien mit geringem Anpassungsaufwand eingesetzt werden,
wohingegen ein spezialisiertes Element üblicherweise nur in einem konkreten Anwendungsfall genutzt
werden kann.
3.2.3.4 Kohäsion Nach (Balzert H. , 1998, S. 474) ist die Kohäsion oder auch Bindung in der Softwaretechnik ein
„qualitatives Maß für die Kompaktheit einer Systemkomponente“. Aus dieser Beschreibung geht
hervor, dass die Kohäsion im Zusammenhang von Modularisierung und Strukturierung eine wichtige
Rolle spielt. Beleuchtungsgegenstand der Kohäsion ist, wie eng die einzelnen Elemente einer
Komponente verbunden sind und wie viele Aufgaben durch sie erledigt werden.
Das Maß der Kohäsion soll in dieser Arbeit aus der Softwaretechnik auf ETL Prozesse und Mappings
übertragen werden und zur Bewertung des Zielerfüllungsgrades dienen. Die Kohäsion spielt
insbesondere bei der Untersuchung von Mapplets eine Rolle, kann aber auch auf
Transformationsebene aufschlussreich sein.
Eine gute, also starke Kohäsion liegt nach (Balzert H. , 1998, S. 474) dann vor, „wenn nur solche
Elemente zu einer Einheit zusammengefasst werden, die auch zusammengehören“. In der Literatur
wird zwischen verschiedenen Arten von Kohäsion unterschieden. Diese reicht in sieben Stufen von der
zufälligen Kohäsion als schwächste bis zur funktionalen Kohäsion als stärkste Form. Letztere liegt
dann vor, „wenn alle Elemente an der Verwirklichung einer einzigen, abgeschlossenen Funktion
beteiligt sind.“ (Balzert H. , 1998, S. 475) Die Art und Stärke der Kohäsion lässt sich laut (Balzert H. ,
1998) nicht automatisch ermitteln. Balzert nennt jedoch Kennzeichen zur Identifikation der
funktionalen Kohäsion. Diese sind:
• Alle Elemente tragen zur Erreichung eines einzelnen, spezifischen Ziels bei.
• Es gibt keine überflüssigen Elemente.
• Die Aufgabe der Komponente lässt sich durch genau ein Verb beschreiben.
• Eine Komponente ist durch eine andere, die den gleichen Zweck erfüllt, aber unterschiedlich
implementiert ist, austauschbar.
• Es liegt eine hohe Kontextunabhängigkeit vor, das heißt, es bestehen einfache Beziehungen zu
anderen Komponenten.

ETL-Design Optimierung Seite 29 von 108
Aus den beschriebenen Merkmalen resultieren nach Balzert folgende Vorteile:
• Hohe Kontextunabhängigkeit
• Geringere Fehleranfälligkeit bei Änderungen
• Geringere Spezialisierung und dadurch hoher Grad an Wiederverwendbarkeit
• Verbesserte Erweiterbarkeit und Wartbarkeit, da sich Änderungen auf isolierte Teile
beschränken. (Balzert H. , 1998, S. 476)
Es liegt die Vermutung nahe, dass diese Kennzeichen und Auswirkungen sich aus der Softwaretechnik
direkt auf die hier durchgeführten Untersuchungen übertragen lassen. In der Auseinandersetzung mit
Beispielen soll diese Vermutung überprüft werden.
3.2.3.5 Kopplung Der Begriff der Kopplung ist eng mit dem der Kohäsion verbunden. Während die Kohäsion die
Aufgabenspezifität der Elemente beschreibt, ist die Kopplung ein qualitatives Maß für die
Schnittstellen zwischen Komponenten. Nach (Balzert H. , 1998, S. 474) ist in der Softwaretechnik
eine ausgeprägte Struktur eines Systems erstrebenswert, da sie zu einem hohen Maß an Einfachheit,
guter Verständlichkeit und leichter Einarbeitung führt. Die Strukturausprägung ist umso größer, „je
stärker die Bindungen der Systemkomponenten im Vergleich zu den Kopplungen zwischen ihnen
sind.“
Diese Forderung und ihre Bedingungen sind vermutlich aus der Softwaretechnik auf die hier
untersuchten ETL Prozesse übertragbar. In den zu behandelnden Beispielen wird dies näher
untersucht.
Zur Bestimmung der Kopplung wird untersucht, wie stark einzelne Elemente Verbindungen
miteinander eingehen. Zu unterscheiden ist dabei zwischen Mappings, die Mapplets verwenden, und
solchen, die nur aus Transformationen bestehen.
Auf Transformationsebene wird die Kopplung durch die ein- beziehungsweise ausgehenden Kanten,
also die verbundenen Ports, bestimmt. Auf dieser Ebene korreliert sie dementsprechend sehr stark mit
der Komplexität. Für Mapplets wird die Anbindung der Ein- und Ausgabetransformationen an das
außenliegende Mapping betrachtet. Innerhalb von Mapplets liegt wiederum Transformationskopplung
vor. Die Transformationskopplung wird auch als intramodulare Kopplung bezeichnet, die zwischen
Mapplets als intermodulare.
In der Softwaretechnik wird angenommen, dass eine schwache Kohäsion zu einer stärkeren Kopplung
führt, sich also bei einer geringeren Spezifikation einzelner Elemente die Anzahl der Verbindungen in
der Regel erhöht. Das würde eine direkte Abhängigkeit dieser Maße bedeuten. Dieser Zusammenhang
soll anhand von Beispielen auf seine Gültigkeit im ETL Kontext überprüft werden.
(Vassiliads, Simitsis, Terrovitis, & Skiadopoulos, 2005) gehen davon aus, dass eine schwächere
Kopplung, vor allem in Verbindung mit stärkerer Kohäsion, zu einer Verbesserung in Bezug auf
Wartbarkeit und Wiederverwendbarkeit führt.

ETL-Design Optimierung Seite 30 von 108
4 ETL-Design Optimierung
Oft ist es möglich, die gleichen fachkonzeptionellen Anforderungen auf verschiedene Weise zu
erfüllen. Um ein optimales Ergebnis zu erreichen, müssen dem Entwickler Alternativen bekannt sein,
und er muss diese für sein Szenario gegeneinander abwägen.
Um Alternativen vergleichbar zu machen, wurden in dieser Arbeit bereits Designziele und darauf
wirkende Maße identifiziert.
Nach (Simitsis, Vassiliadis, & Sellis, 2005) sind bei allen Optimierungsmaßnahmen im Wesentlichen
zwei Punkte zu prüfen:
1. Bleibt die Korrektheit erhalten? Dies ist gegeben, wenn die geänderte Variante aus fachlicher
Sicht äquivalent zur ursprünglichen ist,
2. Werden die angestrebten Ziele durch die Änderungen in höherem Maße erfüllt? Dies ist die
Voraussetzung dafür, dass eine Optimierung stattgefunden hat.
Im Folgenden sollen anhand verschiedener Beispiele typische Szenarien, in denen mehrere
Alternativen möglich sind, vorgestellt, diskutiert und bewertet werden.
Folgende Fälle werden untersucht:
• Positionierung von Transformationen (Swap)
Oft kann eine Transformation an verschiedenen Stellen innerhalb eines Mappings, und damit
innerhalb des Datenflusses, eingebunden werden. Hierbei bieten sich verschiedene Vorgehen
zur Erreichung bestimmter Ziele an. Dieser Ansatz wird von (Vassiliads, Simitsis, Terrovitis,
& Skiadopoulos, 2005) als „Swap“ bezeichnet. Ein besonderer Fall der Umpositionierung ist
die Auslagerung von Funktionalität in die Datenbank. Auch dies wird anhand von Beispielen
diskutiert.
• Austausch von Transformationen
Sollten gleiche Anforderungen unter Nutzung verschiedener Transformationen umsetzbar
sein, muss überprüft werden, welche Transformation am besten geeignet ist sowohl die
Aufgabe zu lösen als auch die vereinbarten Ziele in möglichst großem Maß zu erfüllen.
• Zusammenfassen oder Aufteilen (Merge and Split) Von (Vassiliads, Simitsis, Terrovitis, & Skiadopoulos, 2005) wird der „Merge and Split“
Ansatz eingeführt. Bei dem Optimierungsansatz Zusammenführen (merge) werden
Operationen, die ursprünglich auf mehrere Transformationen verteilt waren, in einer
Transformation zusammengefasst. Im Gegensatz dazu werden bei Aufteilen (split) die in einer
Transformation durchzuführenden Operationen auf mehrere Transformationen verteilt.
• Modularisierung
Mapplets bieten die Möglichkeit Transformationen zu Modulen zusammenzufassen, die

ETL-Design Optimierung Seite 31 von 108
anschließend über Ein- und Ausgabeschnittstellen genutzt werden. Als Module verbergen
Mapplets Implementierungsdetails. Außerdem sind sie wiederverwendbar.
• Parametrisierung
Parameter können in Transformationen dazu eingesetzt werden, Bedingungen dynamisch
festzulegen. Dies wirkt sich meist auf die Universalität und damit auf die
Wiederverwendbarkeit aus.
• Sortierung von Daten Ob und wenn ja welchen Einfluss eine Vorsortierung von Daten hat, wird in einem Beispiel
untersucht.
4.1 Vorgehensweise Nachfolgend wird zuerst ein Beispielszenario vorgestellt. Anhand dieses Szenarios werden
anschließend verschiedene Beispiele und Varianten davon analysiert.
Das Vorgehen dabei folgt jedes Mal dem gleichen Schema.
1) Optimierungsansatz Zuerst wird der zu untersuchende Optimierungsansatz vorgestellt. Dabei werden, wenn diese
schon absehbar sind, Potentiale dieser Ansätze aufgezeigt.
2) Vorstellung verwendeter Transformationen Wo es zum Verständnis notwendig ist, werden die eingesetzten Transformationen in ihrer
Funktionsweise vorgestellt.
3) Ausgangsbeispiel Dann wird eine Ausgangsituation in Form eines konkreten Mappings geschaffen. Anhand dieser
Ausgangssituation wird ein bestimmter Optimierungsaspekt untersucht. Hierbei werden die
fachliche Intension und die daraus resultierenden Rahmenbedingungen des jeweiligen Beispiels
dargestellt.
a) Erfassung der Maße Für jedes Ausgangsmapping werden zuerst die quantitativen Maße erhoben. Anschließend
wird die Ausprägung der qualitativen Maße festgestellt. Aufgrund ihres subjektiven
Charakters wird jede Ausprägung begründet. Nach der Erhebung der Maße im
Ausgangsbeispiel, werden diese zusammengefasst in einer Übersichtstabelle dargestellt.
b) Designziele des Ausgangsbeispiels Für das Ausgangsbeispiel werden Die Designziele nicht ausführlich diskutiert. Es wird nur auf
besondere Auffälligkeiten hingewiesen. Das Ausgangsbeispiel dient mit den dafür erfassten
Maßen als Vergleichsreferenz für weitere Varianten desselben Beispiels.
4) Voraussetzungen der Änderungen Bevor Varianten des Ausgangsbeispiels vorgestellt werden, werden eventuelle, fachliche und
technische, Voraussetzungen für die vorgesehenen Änderungen aufgezeigt.
5) Variante des Ausgangsbeispiels Die Ausgangsvariante wird zur Untersuchung des Optimierungsansatzes in einem Punkt geändert.
a) Erfassung der Maße Für die geänderte Variante werden die Maße erfasst. Dies erfolgt nach dem gleichen Vorgehen
wie im Ausgangsbeispiel.
b) Analyse der Designziele

ETL-Design Optimierung Seite 32 von 108
Auf Grundlage der Maße werden die Auswirkungen der vorgenommen Änderungen für jedes
Ziel diskutiert und bewertet. Als Vergleich dient hierbei die Ausgangsvariante. Jede Analyse
wird mit einer Übersichtstabelle und einer Zusammenfassung abgeschlossen.
6) Untersuchung weiterer Varianten Gegebenenfalls werden in weiteren Varianten die Auswirkungen anderer Änderungen untersucht.
Das Vorgehen entspricht dabei dem der ersten Variante. Jede weitere Variante geht wieder vom
Ausgangsbeispiel aus und zieht dieses zur Bewertung der Ziele heran.
7) Zusammenfassung des Optimierungsansatzes Nach der Vorstellung und Analyse verschiedener Varianten, werden die in den Untersuchungen
gewonnenen Erkenntnisse über den Optimierungsansatz zusammengefasst.
Dieses einheitliche Untersuchungsschema dient für die folgenden Analysen als Schablone. Durch das
systematische Vorgehen wird die Vergleichbarkeit einzelner Analysen gewährleistet. Darüber hinaus
ermöglicht es jederzeit das Vorgehen nachzuvollziehen.
4.2 Beispielszenario Die Untersuchungen der Ziele und der auf sie wirkenden Maße finden anhand von verschiedenen
Beispielen statt.
Alle Beispiele basieren auf der Datenbank des Open Source Programms für Projektmanagement
„dotProject“. Da die Datenbank sehr komplex ist, wird im Rahmen dieser Arbeit nur ein kleiner
Ausschnitt der fachlich besonders interessanten Tabellen und ihrer jeweiligen Attribute verwendet.
Durch diese Vereinfachung wird gewährleistet, dass die Beispiele nachvollziehbar bleiben.
Vor Beginn der Untersuchungen dieser Arbeit wurde die vollständige Datenbank der Anwendung von
MySQL nach Oracle XE 10g migriert. Dies ist unter anderem dadurch begründet, dass für
Verbindungen zu Oracle in Informatica PowerCenter 8 native Treiber zur Verfügung stehen, während
auf MySQL Datenbanken mittels ODBC zugegriffen werden muss. Hierin besteht das Risiko, dass der
ODBC Treiber sich auf Untersuchungen auswirkt und Ergebnisse verfälscht. Alle nachfolgenden
Untersuchungen finden daher auf einer Oracle XE 10g Datenbank statt.
Um die Untersuchungen dieser Arbeit zu unterstützen, wurden sowohl die Schemata einiger Tabellen
als auch die darin enthaltenen Daten manipuliert.
4.2.1 Datenquellen In dotProject werden Projekte, Aufgaben und Aufgabenlogs in separaten Tabellen vorgehalten.
Hierbei beinhalten sie unterschiedlichen Informationsgehalt und stehen zueinander durch
Fremdschlüssel in Beziehung. Bei der Migration auf Oracle wurden die Fremdschlüsselbeziehungen
entfernt. Dies war notwendig, da Oracle für Schlüsselattribute automatisch einen Index erzeugt. Zur
Untersuchung der Auswirkungen eines Indexes musste aber die Möglichkeit geschaffen werden,
diesen zu aktivieren, bzw. zu deaktivieren. Im Rahmen dieser Arbeit kann aber davon ausgegangen
werden, dass sich die Quellen in einem konsistenten Zustand befinden.
4.2.1.1 Aufgabenlogbuch Die Zeiterfassung in dotProject geschieht auf Basis des Aufgabenlogbuchs, dem die Tabelle
TASK_LOG zugrunde liegt. In dieser Tabelle werden geleistete Stunden sowie ein zugehöriger
Kostenfaktor pro Eintrag erfasst. Ein Tupel aus dem Aufgabenlogbuch besitzt jedoch keinen Namen,

ETL-Design Optimierung Seite 33 von 108
sondern wird über eine Fremdschlüsselbeziehung mit dem Attribut TASK_LOG_TASK einer Aufgabe
zugeordnet.
CREATE TABLE task_log_new_1 (
task_log_id INTEGER(11) NOT NULL,
task_log_task INTEGER(11) NOT NULL,
task_log_hours FLOAT NOT NULL,
task_log_costcode VARCHAR(8) NOT NULL,
);
4.2.1.2 Aufgaben Aufgaben werden von der Anwendung in der Tabelle TASKS gespeichert. Eine Aufgabe besitzt eine
ID (TASK_ID), einen Namen (TASK_NAME) und gehört immer zu einem Projekt
(TASK_PROJECT).
CREATE TABLE tasks (
task_id INTEGER(10) NOT NULL,
task_name VARCHAR(255) NOT NULL,
task_project INTEGER(11) NOT NULL,
);
4.2.1.3 Projekte
Einzelne Aufgaben werden in Projekten zusammengefasst. Die Daten eines Projekts werden in der
Tabelle PROJECTS gespeichert. Für jedes Projekt wird die ID (PROJECT_ID) und der Name
(PROJECT_NAME) gespeichert.
CREATE TABLE projects (
project_id INTEGER(11) NOT NULL,
project_name VARCHAR(255) NOT NULL,
);
Die 1:n Beziehung zwischen den Entitäten gestaltet sich wie folgt:
Abbildung 7: Schematische Darstellung der Fremdschlüsselbeziehungen
Zu beachten ist, dass die Fremdschlüsselbeziehungen hier nur die Ausgangssituation der Datenbank
darstellen. Diese wurden aufgrund der geschilderten Indexproblematik entfernt.

ETL-Design Optimierung Seite 34 von 108
4.2.1.4 Datenmenge der Quelltabellen Für die Untersuchung einiger Maße kann die Datenmenge relevant sein. In der Ausgangssituation
waren nur sehr wenige Tupel in der dotProject Datenbank enthalten. Eine geringe Datenmenge lässt
Untersuchungen der Performance ungenau werden, da die Initialisierungsdauer des Integrationsservers
in diesem Fall größer ist als die eigentliche Verarbeitung der Daten. Daher wurden die Daten mittels
eines PL/SQL Scripts künstlich erhöht. Um die Beziehung zwischen den Entitäten zu erhalten, wurden
nur der Tabelle TASK_LOG Tupel hinzugefügt.
Die Tabellen enthalten folgende Anzahl an Tupeln:
Tabelle Anzahl Tupel Tupel * Attribute
TASK_LOG 1098106 4392424
TASKS 133 399
PROJECTS 57 114
Tabelle 4: Datenmengen im Beispielszenario
4.2.2 Zieltabellen In den Beispielen werden die vorgestellten Quelldaten verwendet, um verschiedene Transformationen
durchzuführen. Zum Teil werden zusätzliche Attribute zum Beispiel durch Berechnungen generiert, in
anderen Fällen können Attribute entfallen. Die Zielschemata unterscheiden sich entsprechend
zwischen den verschiedenen Beispielen. Aus diesem Grund werden diese jeweils in den Beispielen
vorgestellt. Grundsätzlich sind alle Ziele Tabellen in einer Oracle XE 10g Datenbank.
4.3 Positionierung von Transformationen Durch eine unterschiedliche Positionierung von Transformationen innerhalb eines Mappings kann der
Erfüllungsgrad der angestrebten Ziele positiv beeinflusst werden.
Anhand von zwei Beispielen in verschiedenen Varianten wird diese Option diskutiert.
4.3.1 Filtertransformation - Fallbeispiel 1 Sollen aus einem ETL Workflow Daten gefiltert werden, steht hierfür in Informatica PowerCenter 8
die Filtertransformation zur Verfügung. Sie funktioniert wie eine where Klausel in einem SQL
Statement, es passieren also diejenigen Daten den Filter, auf die die Filterbedingung zutrifft.
(Informatica, PowerCenter Transformation Guide, 2006, S. 216)
Filtertransformationen können unter bestimmten Voraussetzungen an verschiedenen Stellen in den
Datenfluss eingebunden werden. Neben der expliziten Filtertransformation ist auch eine Filterung im
Source Qualifier, also auf der Datenbank beim Einlesen der Datenquellen, möglich.
Soll die Filterung anhand von Charakteristika der Daten, die sich erst durch andere Transformationen
ergeben, durchgeführt werden, bleibt nur die Möglichkeit einer expliziten Filterung. Dies können
beispielsweise vorangegangene Expression-, Aggregations-, Lookup- oder Joinertransformationen
oder andere sein.
Nachfolgend werden anhand mehrerer Varianten eines Beispiels die Auswirkungen verschiedener
Filterpositionen auf die Maße und die Ziele verdeutlicht. Neben einer Untersuchung der

ETL-Design Optimierung Seite 35 von 108
Auswirkungen verschiedener Positionen einer expliziten Filtertransformation soll auch die Filterung
im Source Qualifier untersucht werden.
4.3.1.1 Fallbeispiel 1 - Positionierung eines Filters Es sollen Daten aus den Tabellen TASK_LOG und TASKS anhand der Bedingung
TASK_LOG.TASK_LOG_TASK = TASKS.TASK_ID per Joinertransformation zusammengeführt
werden und in ein Ziel geschrieben werden. Für das Beispiel sei angenommen, dass aus fachlichen
Gründen eine Filterung der Daten vorgenommen werden soll. Die Filterbedingung des
Ausgangsbeispiels wird durch TASK_LOG.TASK_LOG_HOURS > 5 definiert. Diese Bedingung
bewirkt, dass nur Tupel, in denen mehr als fünf Stunden verbucht sind, den Filter passieren.
Abbildung 8: Fallbeispiel 1 –Ausgangsbeispiel - Filtertransformation
Die Filterbedingung bestimmt die Abhängigkeit von vorausgehenden Transformationen und somit ob,
die Filtertransformation an anderer Position in den Datenfluss einfügt werden kann. In den folgenden
Varianten wird untersucht, wann unterschiedliche Positionen möglich sind und wie diese sich auf die
Maße auswirken. Aus dieser Analyse werden anschließend Schlussfolgerungen auf den jeweiligen
Zielerfüllungsgrad gezogen.
Erhebung der Maße im Ausgangsbeispiel Um eine Vergleichbarkeit der Varianten zu ermöglichen, müssen zuerst die quantitativen und
qualitativen Maße des Fallbeispiels untersucht werden.
Quantitative Maße
Datenmenge
Aus der Tabelle TASK_LOG werden 1098106 Tupel eingelesen, aus der Tabelle TASKS 133. In der
JOINER Transformation werden diese, unter der Joinbedingung TASK_LOG_TASK = TASK_ID,
zusammengeführt, so dass danach alle 1098106 in die Filtertransformation eingehen. Die
Filtertransformation passieren 350 Tupel, die danach in das Ziel geschrieben werden. 1097756 Tupel
werden verworfen, da sie der Filterbedingung widersprechen.
Anzahl der Knoten
Das Referenzbeispiel weist inklusive der Quellen und des Ziels 7 Transformationen auf.
Länge
Im Beispiel durchlaufen alle Tupel das gesamte Mapping. Die maximale Anzahl an Weiterleitungen
beträgt 4.

ETL-Design Optimierung Seite 36 von 108
Komplexität
Die Transformationen sind über 28 Kanten miteinander verbunden, was der Komplexität entspricht.
Qualitative Maße
Modularität
Im Referenzbeispiel ist keine Modularität zu erkennen. Jede Transformation führt exakt eine Aufgabe
aus und es gibt keine Zusammenfassung von Transformationen. Eine Modulbildung findet nicht statt.
Kapselung
Das vorliegende Beispiel weist keine über das Minimalmaß hinausgehende Kapselung auf. Jede
Transformation führt genau eine Operation aus, die anhand ihres Typs und Namens in der Mapping-
Übersicht erkennbar ist.
Universalität
Das Mapping ist sehr spezifisch auf den entsprechenden Anwendungsfall zugeschnitten. Die
Universalität ist also schwach ausgeprägt.
Kohäsion
Durch die fehlende Modularität ist das Mapping bezüglich der Kohäsion wenig aussagekräftig. Die
Kohäsion der einzelnen Transformationen ist aufgrund der eindeutigen Aufgabenspezifität sehr hoch.
Diese soll jedoch nicht explizit betrachtet werden, da Transformationen als das atomare Element
betrachtet werden und Kohäsion erst auf Modulebene sinnvoll analysiert werden kann. In
Ausnahmefällen ist eine Betrachtung bei Transformationen, die mehrere Funktionen in sich vereinen,
möglich und sinnvoll. In diesem Beispiel ist das jedoch nicht der Fall, weswegen die Kohäsion nicht
erhoben wird.
Kopplung
Das Fallbeispiel weist eine starke Kopplung zwischen den Transformationen auf. Intermodulare
Kopplung ist aufgrund der fehlenden Module nicht zu erkennen.
Übersicht über die Maße Die zwei folgenden Tabellen liefern eine Übersicht über die soeben erhobenen Maße. Hierbei werden
zuerst die quantitativen, danach die qualitativen Maße dargestellt.
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
Eingehende Tupel
350
Tupel nach Filter
7 4 28
Tabelle 5: Fallbeispiel 1 - Ausgangsbeispiel - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung

ETL-Design Optimierung Seite 37 von 108
Ausprägung n.v. n.v. - n/a +
Tabelle 6: Fallbeispiel 1 - Ausgangsbeispiel - Qualitative Maße
Untersuchung der Ziele Das vorliegende Ausgangsbeispiel soll für die nächsten Varianten als Referenz dienen. Die
Zielerfüllung wird relativ durch den Vergleich der verschiedenen Varianten bewertet. Es werden also
Verbesserungen beziehungsweise Verschlechterungen aufgezeigt. Entsprechend seiner Funktion als
Referenz wird dieses Beispiel neutral bewertet.
Da Verletzung der Korrektheit alle weiteren Betrachtungen obsolet macht, wird diese immer als erstes
verifiziert. Innerhalb der Übersichtstabellen wird sie nicht explizit dargestellt, da sie im Regelfall
unverletzt sein sollte. Im gegenteiligen Fall wird keine Übersicht über die Ziele dargestellt, sondern
auf die Verletzung der Korrektheit verwiesen.
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausprägung 0 0 0 0
Tabelle 7: Fallbeispiel 1 - Ausgangsbeispiel - Übersicht über die Ziele
4.3.1.2 Voraussetzungen für eine Umpositionierung der Filtertransformation Die Positionsänderung soll zu einem äquivalenten Ergebnis in den Zieltabellen führen, was Bedingung
für das definierte Ziel Korrektheit ist. Dies ist nur unter bestimmten Voraussetzungen gewährleistet.
Drei Fälle beeinflussen hier die Auswahlmöglichkeiten.
1. Die Filterbedingung ist von einer vorausgehenden Transformation abhängig:
• Wenn das in der Filterbedingung zu prüfende Attribut erst in einer Transformation „generiert“
wird, kann die Filtertransformation nicht vor dieser Transformation positioniert werden.
2. Die Filterbedingung ist von der vorherigen Transformation unabhängig:
• Die Filtertransformation kann mit ihrem Vorgänger die Position tauschen und somit früher
ausgeführt werden.
3. Die Filterbedingung ist von keiner Transformation des Mappings abhängig:
• Eine Filterung im Source Qualifier ist möglich. Hierbei werden die Zeilen beim Lesen aus der
Quelle verworfen und gelangen somit gar nicht in das Mapping. Diese Möglichkeit existiert
jedoch nur für relationale Quellen.

ETL-Design Optimierung Seite 38 von 108
4.3.1.3 Variante 1 Als Beispiel für die erste Variation werden wieder beide Tabellen mittels Joinertransformation
zusammengeführt. Die Filtertransformation selektiert alle Tupel, bei denen das Attribut
TASK_LOG.TASK_LOG_HOURS mehr als fünf Stunden geleistete Arbeit aufweist, und lässt diese
den Filter passieren. Die Bedingung ist also die gleiche wie im Ausgangsbeispiel und die
Filtertransformation von der vorhergehenden Joinertransformation unabhängig.
Daraus folgt, dass ein Positionswechsel möglich ist.
In der folgenden Abbildung wird das geänderte Mapping, in dem die Filtertransformation vor der
Joinertransformation stattfindet, dargestellt.
Abbildung 9: Fallbeispiel 1 - Variante 1 - Nach vorne verschobener Filter
Auswirkungen auf die Maße Nachfolgend wird untersucht, inwiefern sich die Maße durch die Manipulationen in der neuen
Variante verändert haben.
Quantitative Maße
Datenmenge
Wie im Ausgangsbeispiel gehen 1098106 Tupel aus TASK_LOG und 133 Tupel aus TASKS in das
Mapping ein. Erneut passieren 350 Tupel den Filter, während 1097756 verworfen werden. Dies
geschieht in der Variante 1 früher, wodurch in der Joinertransformation nur noch 350 Tupel aus
TASK_LOG und 133 aus TASKS also insgesamt 483 Tupel verarbeitet werden.
Anzahl der Knoten
Diese Messgröße wird durch die Veränderungen nicht beeinflusst und beträgt somit weiterhin 7.
Länge
Die Länge bleibt gleich wie im Ausgangsbeispiel, sie beträgt 4.
Komplexität
Die Komplexität wird durch die frühe Filterung leicht reduziert und beträgt jetzt 25. Dies entspricht
einer Reduktion um 3 Kanten.

ETL-Design Optimierung Seite 39 von 108
Qualitative Maße Von den qualitativen Maßen ändert sich nur die Kopplung. Da die Filterung nur noch unter
Einbeziehung der Attribute aus TASK_LOG stattfindet, verringert sich die Kopplung der
Filtertransformation. Da weiterhin alle Attribute jeweils über ein- und ausgehende Ports verbunden
sind, wird die Kopplung mit durchschnittlich (0) bewertet.
Übersicht über die Maße
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106 Eingehende
Tupel
350
Tupel nach Filter
7 4 25
Tabelle 8: Fallbeispiel 1 - Variante 1 - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung n.v. n.v. - n/a 0
Tabelle 9: Fallbeispiel 1 - Variante 1 - Qualitative Maße
Auswirkungen der Alternative auf den Erfüllungsgrad der Ziele Durch die Veränderungen an dem Ausgangsmapping haben sich einige Maße geändert. Dies wirkt
sich auf die Ziele aus, was nachfolgend erläutert und diskutiert werden soll.
Korrektheit
Variante eins und das Ausgangsbeispiel sind bezüglich der Daten die in das Ziel geschrieben werden
äquivalent. Das heißt, das Mapping bleibt durch die neue Position der Filtertransformation fachlich
korrekt. Dies macht eine Betrachtung der weiteren Ziele erforderlich.
Wartbarkeit
Die Wartbarkeit des Mappings wird durch die neue Position des Filters gegenüber dem
Ausgangsmapping nicht wesentlich beeinflusst. Die Verringerung von Komplexität und Kopplung ist
so gering, dass dies die Wartbarkeit nicht verbessert.
Wiederverwendbarkeit
Die Wiederverwendbarkeit wird nicht beeinflusst.
Performance
Durch die frühere Reduktion der Datenmenge wird die Effizienz gesteigert beziehungsweise die
Durchlaufzeit verringert. Da die Joinertransformation sehr aufwendig ist, kann diese Variante deutlich
von der reduzierten Zahl an Tupeln, die in sie eingehen, profitieren.

ETL-Design Optimierung Seite 40 von 108
Zuverlässigkeit
Die Zuverlässigkeit ist im Wesentlichen unbeeinflusst, durch die frühere Filterung werden eventuell
korrupte Daten früher bearbeitet und führen damit zu einem früheren Erkennen von Fehlern.
Außerdem gehen durch die vorgelagerte Filterung weniger Daten in die Joinertransformation ein,
wodurch auch hier die Fehleranfälligkeit reduziert wird. Insgesamt ist die Verbesserung der
Zuverlässigkeit gering.
Übersicht über die Ziele:
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Variante 1 0 0 + +
Tabelle 10: Fallbeispiel 1 - Variante 1 - Zielerfüllung
4.3.1.4 Variante 2 In der zweiten Variante des Beispiels wird wiederum von derselben Anforderung wie in den beiden
vorangegangen Beispielen ausgegangen. Es werden also alle Zeilen, für die weniger als fünf Stunden
Arbeitszeit verbucht sind, ausgefiltert. Die Filterbedingung ist nur von einer der beiden Quellen
abhängig. Da keine weitere Transformation vor der Filterung stattfindet, kann diese im Source
Qualifier durchgeführt werden.
Abbildung 10: Fallbeispiel 1 - Variante 2 - Filterung im Source Qualifier
Statt in einer expliziten Filtertransformation wird in Variante 2 in der Source Qualifier
Transformation, also beim Einlesen der Quelltabelle TASK_LOG gefiltert. Dies geschieht über die
Definition der Filterbedingung in den Optionen des Source Qualifiers. Hierfür nutzt der Source
Qualifier beim Einlesen der Daten aus der Quelltabelle eine where Klausel. Im vorliegenden Beispiel
lautet das dem Source Qualifier zugrunde liegende SQL Statement dementsprechend:

ETL-Design Optimierung Seite 41 von 108
SELECT TASK_LOG.TASK_LOG_ID, TASK_LOG.TASK_LOG_TASK,
TASK_LOG.TASK_LOG_HOURS, TASK_LOG.TASK_LOG_COSTCODE FROM TASK_LOG
WHERE TASK_LOG.TASK_LOG_HOURS > 5
Durch die Verlagerung der Filterung weist das Mapping in dieser Variante bei gleicher Funktionalität
eine Transformation weniger auf. Dass eine Filterung stattfindet, ist nicht mehr direkt erkennbar. Die
Auswirkung auf Maße und Ziele werden nachfolgend dargestellt und diskutiert.
Erhebung der Maße in Variante 2
Quantitative Maße
Datenmenge
In der Quelltabelle TASK_LOG liegen wie in den bereits dargestellten Beispielen 1098106 Zeilen
beziehungsweise Tupel vor. In TASKS sind es wieder 133.
Die Datenmenge wird in der Variante insofern beeinflusst, dass durch die Filterung im Source
Qualifier nur die Tupel eingelesen werden, die den Filter passieren. Dies betrifft wie in den vorherigen
Varianten 350 Tupel. Die anderen 1097756 werden bereits beim Lesen der Quelle durch die WHERE
Klausel verworfen. Es gelangen also nur sehr wenige Tupel überhaupt in das Mapping.
Anzahl der Knoten
Da der Source Qualifier sowohl die Aufgabe des Einlesens als auch die Filterung der Quellen
bearbeitet kann, die Filtertransformation wegfallen. Hierdurch weist Variante 2 eine Transformation
weniger als das Ausgangsbeispiel auf, besteht also aus 6 Knoten.
Länge
Durch den Wegfall eines Knotens wurde die Länge auf 3 reduziert.
Komplexität
Die Komplexität sinkt um 7 Kanten und beträgt nun 21. Auch dies ist auf die eingesparte
Transformation zurückzuführen.
Qualitative Maße
Modularität
Es ist keine ausgeprägte Modularität in der Variante zu erkennen. Der um Filterfunktionen erweiterte
Source Qualifier kann nicht als Modul betrachtet werden, da dieser nicht außerhalb seines Kontextes
verwendet werden kann, sondern immer in Bezug auf die zugehörige Quelle steht.
Kapselung
In Variante 2 ist die Kapselung höher als im Ausgangsbeispiel und als in Variante 1. Ursache ist die
Verlagerung der Filterfunktion in einen der Source Qualifier, der diese Funktionalität nun zusätzlich
zu seiner ursprünglichen Aufgabe, dem Einlesen der Daten, übernimmt. Da diese zusätzliche
Funktionalität von außen nicht erkennbar ist, kann hier von Kapselung gesprochen werden.
Universalität
War die Universalität in den vorherigen Beispielen schon gering, wurde sie durch die Verlegung des
Filters in den Source Qualifier noch weiter reduziert

ETL-Design Optimierung Seite 42 von 108
Dies ist darauf zurückzuführen, dass eine Filterung von Daten im Source Qualifier nur bei relationalen
Quellen möglich ist. Wird die Filterung dagegen erst später in einer expliziten Filtertransformation
durchgeführt, können auch andere Quellen wie zum Beispiel Textdateien verarbeitet werden.
Kohäsion
Die im Source Qualifier durchgeführten Operationen „Einlesen der Quellen“ und „Filtern der Daten“
sind nur durch eine mäßige Kohäsion verbunden. Wie bereits erwähnt, ist die Kohäsion innerhalb von
Transformationen im Gegensatz zur Modulebene nur schlecht zu erfassen. Die Kohäsion dieser
Variante wird in Bezug auf die Mehrfachfunktionalität des Source Qualifiers als schwach gewertet.
Kopplung
Die Kopplung zwischen den Transformationen ist unverändert. Alle Ports sind jeweils einmal
verbunden. Eine Verringerung der Kopplung durch Umpositionierung ist nicht möglich, daher wird für
die Kopplung 0 festgelegt. Intermodulare Kopplung kommt nach wie vor nicht vor.
Übersicht über die Maße
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
Tupel in Quelle
vorhanden
350
Tupel werden
eingelesen
6 3 21
Tabelle 11: Fallbeispiel 1 – Variante 2 - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung n.v. + -- - 0
Tabelle 12: Fallbeispiel 1 – Variante 2 - Qualitative Maße
Auswirkungen auf die Ziele in Variante 2
Korrektheit:
Bei der Verlegung der Filterfunktionalität in den Source Qualifier bleibt die Korrektheit erhalten.
Wartbarkeit:
Die Wartbarkeit wird durch die Kapselung des Filters verschlechtert, da dieser nicht mehr auf den
ersten Blick zu erkennen ist.
Wiederverwendbarkeit:
Da die Filterung im Source Qualifier nur für relationale Quellen möglich ist, ist die Universalität in
dieser Variante schwächer ausgeprägt. Dies verursacht eine geringere Wiederverwendbarkeit.
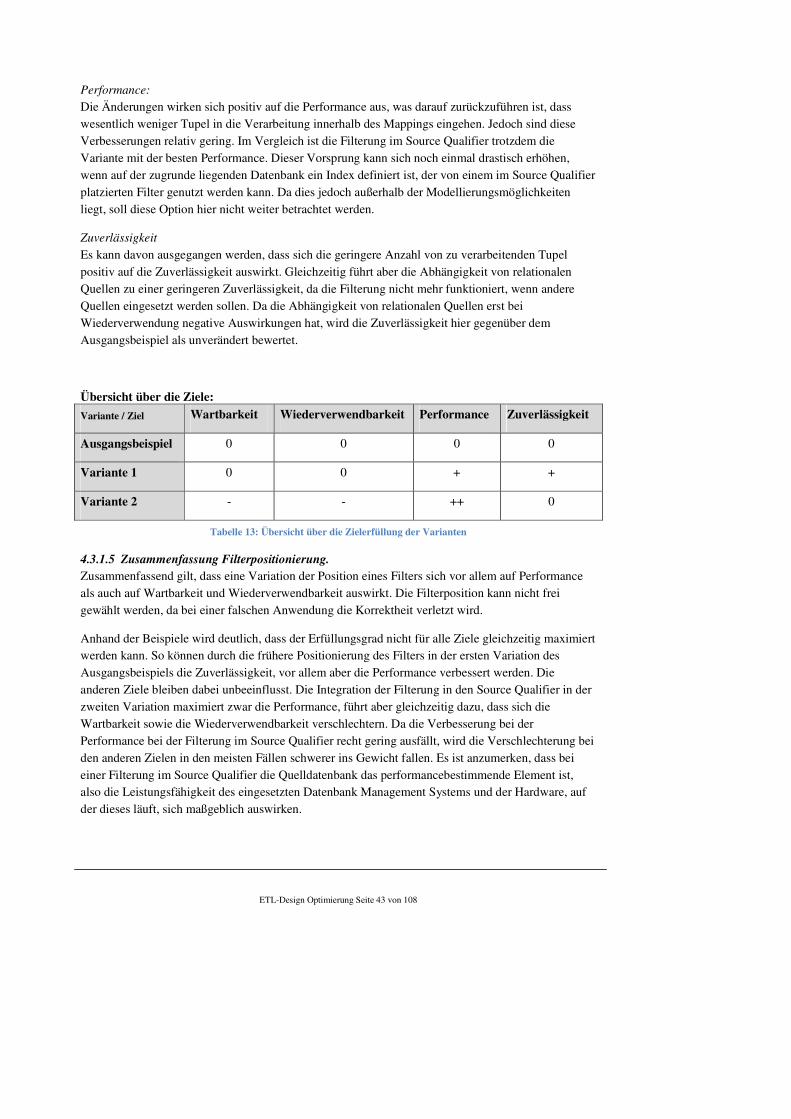
ETL-Design Optimierung Seite 43 von 108
Performance:
Die Änderungen wirken sich positiv auf die Performance aus, was darauf zurückzuführen ist, dass
wesentlich weniger Tupel in die Verarbeitung innerhalb des Mappings eingehen. Jedoch sind diese
Verbesserungen relativ gering. Im Vergleich ist die Filterung im Source Qualifier trotzdem die
Variante mit der besten Performance. Dieser Vorsprung kann sich noch einmal drastisch erhöhen,
wenn auf der zugrunde liegenden Datenbank ein Index definiert ist, der von einem im Source Qualifier
platzierten Filter genutzt werden kann. Da dies jedoch außerhalb der Modellierungsmöglichkeiten
liegt, soll diese Option hier nicht weiter betrachtet werden.
Zuverlässigkeit
Es kann davon ausgegangen werden, dass sich die geringere Anzahl von zu verarbeitenden Tupel
positiv auf die Zuverlässigkeit auswirkt. Gleichzeitig führt aber die Abhängigkeit von relationalen
Quellen zu einer geringeren Zuverlässigkeit, da die Filterung nicht mehr funktioniert, wenn andere
Quellen eingesetzt werden sollen. Da die Abhängigkeit von relationalen Quellen erst bei
Wiederverwendung negative Auswirkungen hat, wird die Zuverlässigkeit hier gegenüber dem
Ausgangsbeispiel als unverändert bewertet.
Übersicht über die Ziele:
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Variante 1 0 0 + +
Variante 2 - - ++ 0
Tabelle 13: Übersicht über die Zielerfüllung der Varianten
4.3.1.5 Zusammenfassung Filterpositionierung. Zusammenfassend gilt, dass eine Variation der Position eines Filters sich vor allem auf Performance
als auch auf Wartbarkeit und Wiederverwendbarkeit auswirkt. Die Filterposition kann nicht frei
gewählt werden, da bei einer falschen Anwendung die Korrektheit verletzt wird.
Anhand der Beispiele wird deutlich, dass der Erfüllungsgrad nicht für alle Ziele gleichzeitig maximiert
werden kann. So können durch die frühere Positionierung des Filters in der ersten Variation des
Ausgangsbeispiels die Zuverlässigkeit, vor allem aber die Performance verbessert werden. Die
anderen Ziele bleiben dabei unbeeinflusst. Die Integration der Filterung in den Source Qualifier in der
zweiten Variation maximiert zwar die Performance, führt aber gleichzeitig dazu, dass sich die
Wartbarkeit sowie die Wiederverwendbarkeit verschlechtern. Da die Verbesserung bei der
Performance bei der Filterung im Source Qualifier recht gering ausfällt, wird die Verschlechterung bei
den anderen Zielen in den meisten Fällen schwerer ins Gewicht fallen. Es ist anzumerken, dass bei
einer Filterung im Source Qualifier die Quelldatenbank das performancebestimmende Element ist,
also die Leistungsfähigkeit des eingesetzten Datenbank Management Systems und der Hardware, auf
der dieses läuft, sich maßgeblich auswirken.

ETL-Design Optimierung Seite 44 von 108
Ein guter Kompromiss zwischen den verschiedenen Zielen ist, eine Filtertransformation so früh wie
möglich in den Datenstrom einzubinden, diese aber nicht in den Source Qualifier auszulagern, sondern
als explizite Transformation beizubehalten.

ETL-Design Optimierung Seite 45 von 108
4.3.2 Joinertransformation - Fallbeispiel 2 Nachdem die Positionierung von Filtertransformationen untersucht wurde, wird nun anhand einer
Joinertransformation überprüft, wie sich dort eine Umpositionierung auswirkt. Zuerst wird jedoch
zum Verständnis die Funktionsweise der Joinertransformation in Informatica PowerCenter 8
dargestellt.
4.3.2.1 Joinertransformationen in Informatica PowerCenter 8 Die Joinertransformation ist eine aktive, verbundene Transformation. Mit ihr können zwei Quellen
zusammengeführt werden, wenn diese in mindestens einem Attribut jeweils übereinstimmende Werte
aufweisen.
Master- und Detailpipeline Informatica unterscheidet bei Joinertransformationen zwischen der Master- und der Detailpipeline. Die
Masterpipeline endet nach der Joinertransformation, während die Detailpipeline bis zum Ziel
weiterläuft. Abbildung 11 stellt dies schematisch dar.
Abbildung 11: Master- und Detailpipeline bei einer Joinertransformation (Informatica, PowerCenter Transformation
Guide, 2006, S. 266)
Aus Performancegründen sollte immer die Quelle mit weniger Zeilen als Master definiert werden.
Dies ist darin begründet, dass jede Zeile der Masterquelle gegen die Zielquelle verglichen wird.
Hierfür wird die Masterquelle vollständig im Speicher vorgehalten. Bei sehr großen Quellen kann der
Speicher unzureichend sein, so dass auf Festplatten ausgelagert werden muss. Dies hat sehr große,
negative Auswirkungen auf die Performance.
Bei der Modellierung im Informatica PowerCenter Designer wird immer die Quelle als Master
gewählt, die als zweite in die Joinertransformation gezogen wird. Die Wahl von Master- und
Detailpipeline sonst keine Wechselwirkung mit anderen Zielen hat, wird sie in allen folgenden
Beispielen beachtet.

ETL-Design Optimierung Seite 46 von 108
Jointypen Ein Join kann auf verschiedene Weise durchgeführt werden. Die Unterschiede beziehen sich dabei
darauf, wie mit Attributen umgegangen wird, bei denen die für die Joinoperation definierte Bedingung
nicht zutrifft. Die Bezeichnungen für die Jointypen weichen in Informatica PowerCenter 8 zum Teil
von den im SQL Standard typischen Bezeichnungen ab. Es gibt vier Typen von Joins.
1. Normal Join: Der Normal Join in Informatica entspricht dem im SQL Standard. Es werden nur
diejenigen Tupel in die neue Tabelle aufgenommen, für die die Joinbedingung zutrifft. Andere
Tupel werden verworfen.
2. Detail outer Join: Entspricht einem Left- beziehungsweise Right outer Join in SQL. Es werden
alle Tupel der Master Quelle behalten, auch wenn die Joinbedingung für ein Tupel nicht
zutrifft. Die davon betroffenen Tupel aus der Detail Quelle werden verworfen
3. Master outer Join: Verhält sich wie ein Detail Outer Join, mit dem Unterschied, dass alle
Tupel der Detail Quelle auch bei nicht Zutreffen der Joinbedingung behalten werden.
Entsprechend werden Tupel der Master Quelle verworfen, wenn für das Tupel die
Joinbedingung nicht erfüllt ist.
4. Full outer Join: Entspricht wiederum dem SQL Standard. Es werden alle Tupel aus beiden
Quellen übernommen, unabhängig von der Erfüllung der Joinbedingung.
Für Joinertransformationen gilt unabhängig von ihrem Typ, dass immer alle Zeilen der Quellen
verarbeitet werden und entsprechend die Joinbedingung für jedes Tupel geprüft wird. Sollte die
Joinbedingung auf mehr als ein Tupel zutreffen, wird jedes dieser Tupel übernommen.
4.3.2.2 Fallbeispiel 2 – Positionierung von Joinertransformationen Zwei Fälle wurden indirekt schon durch die vorherigen Betrachtungen zu Filtertransformationen
beleuchtet; eine Joinertransformation vor und nach einem Filter.
Aus den Betrachtungen zur Filtertransformation lässt sich direkt herleiten, dass, falls im Datenfluss
eines Mappings die Datenmenge reduziert wird, die Joinertransformation erst danach durchgeführt
werden sollte. Hierfür muss im Einzelfall anhand der Join Bedingung geprüft werden, ob dies fachlich
möglich ist.
Wie schon für Filtertransformationen gibt es auch für Joiner die Möglichkeit, diese in den Source
Qualifier zu integrieren. Diese Möglichkeit soll nun auf ihre Auswirkungen untersucht werden.

ETL-Design Optimierung Seite 47 von 108
Beispielszenario Als Ausgangsbeispiel soll dasselbe Mapping wie das in den Betrachtungen zu Filtertransformationen
dargestellte verwendet werden. Da dieses bereits ausführlich beschrieben wurde, sei an dieser Stelle
darauf verwiesen (4.3.1.1) und hier nur noch einmal der Überblick eingefügt.
Abbildung 12: Fallbeispiel 2 – Ausgangsbeispiel – Expliziter Join
4.3.2.3 Voraussetzungen für das Joinen im Source Qualifier
Sollen Quellen statt in einer Joinertransformation bereits im Source Qualifier zusammengeführt
werden, müssen drei Voraussetzungen erfüllt sein:
1. Die Quellen müssen relational sein, es kommen also nur Datenbanktabellen in Frage.
2. Die zu verbindenden Tabellen müssen vom selben Datenbankserver stammen, also über die
selbe Verbindung angesprochen werden.
3. Die in die Joinbedingung eingehenden Attribute müssen bereits in den Datenquellen
vorhanden sein. Werden Attribute erst in Transformationen generiert, können diese vorher
nicht in eine Bedingung einfließen.
Für die folgende Variante sind alle Bedingungen erfüllt.
Standardmäßig werden die Tabellen anhand einer Beziehung zwischen gleichbenannten Attributen, die
in einer Primary Key <-> Foreign Key Beziehung stehen, verknüpft. Besteht eine solche Beziehung in
den Quelltabellen nicht, muss eine selbstdefinierte Verknüpfungsbedingung eingetragen werden. Dies
erfolgt über Eigenschaften der Source Qualifier Transformation. Hier werden äquivalent zu einer
WHERE Klausel die auf Gleichheit zu prüfenden Spalten definiert.

ETL-Design Optimierung Seite 48 von 108
4.3.2.4 Variante 1 Ausgehend von dem bekannten Mapping werden die beiden Source Qualifier sowie die
Joinertransformation entfernt und durch einen Source Qualifier, der eine benutzerdefinierte Join
Bedingung (TASK_LOG_TASK = TASK_ID) enthält, ersetzt. Das Mapping sieht nach den
Veränderungen folgendermaßen aus:
Abbildung 13: Fallbeispiel 2 – Variante 1 – Joinen im Source Qualifier
Quantitative Maße
Datenmenge
In der Quelltabelle TASK_LOG liegen 1098106 und in TASKS 133 Tupel vor. Alle Tupel werden
eingelesen und im Source Qualifier durch Join zusammengeführt.
Anzahl der Knoten
Da keine explizite Joinertransformation und nur noch ein Source Qualifier benötigt werden, sinkt die
Anzahl der Knoten von 7 auf 5.
Länge
Die Länge reduziert sich von 4 auf 3 Weiterleitungen.
Komplexität
In der Variante reduziert sich die Komplexität von 28 auf 21 Kanten.
Qualitative Maße
Modularität
Da die Integration des Joins in den Source Qualifier nicht als Modulbildung angesehen wird, kann im
vorliegenden Beispiel keine solche beobachtet werden.
Kapselung
Durch die Integration von Funktionalität im Source Qualifier ist die Kapselung in der Variante leicht
erhöht.

ETL-Design Optimierung Seite 49 von 108
Universalität
Grundsätzlich müssen Quellen, die in eine Joinoperation im Source Qualifier einbezogen werden,
relational sein und vom selben Datenbankserver stammen. Ein Join über heterogene Quellen ist im
Source Qualifier nicht möglich, sondern muss mittels einer expliziten Joinertransformation
durchgeführt werden. Dementsprechend wirkt sich, ähnlich wie schon bei der Filterung, auch das
Joinen im Source Qualifier negativ auf die Universalität aus.
Kohäsion
Die Source Qualifier Transformation integriert zwei Funktionen, das Auslesen der Quellen und das
Verbinden der enthaltenen Daten mittels Join. Die Kohäsion zwischen diesen Funktionen ist nur
schwach ausgeprägt.
Kopplung
Jeder Port ist jeweils über eine Kante mit einem anderen Port verbunden. Eine Reduzierung zum
Beispiel durch Umpositionierung ist nicht möglich, daher wird die Kopplung mit 0 erhoben.
Übersicht über die Maße
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
Tupel werden
eingelesen und
verarbeitet.
350 Tupel
verbleiben nach
dem Filter
5 3 21
Tabelle 14: Fallbeispiel 2 - Variante 1 - Quantiative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung n.v. + -- - 0
Tabelle 15: Fallbeispiel 2 - Variante 1 - Qualitative Maße
Auswirkungen auf die Ziele in Variante 1
Korrektheit
Die Korrektheit bleibt erhalten, die Veränderungen sind also zulässig.
Wartbarkeit
Wie in den vorangegangenen Beispielen verschlechtert sich die Wartbarkeit durch Kapselung bei
gleichzeitig geringer Kohäsion, da hierdurch das Mapping intransparenter wird. Dieser negative

ETL-Design Optimierung Seite 50 von 108
Einfluss wirkt sich geringer auf die Wartbarkeit aus, als der positive Einfluss der reduzierten
quantitativen Maße. Insgesamt wird die Variante daher bezüglich ihrer Wartbarkeit schlechter
bewertet.
Wiederverwendbarkeit
Da sich die Universalität verringert, verschlechtert sich auch die Wiederverwendbarkeit. Das Mapping
in der veränderten Form setzt relationale Quellen voraus. Der Zugriff auf beide Quellen muss über
eine Verbindung zu einem Datenbankserver stattfinden. Das Mapping in Variante 1 kann
dementsprechend nicht für verteilte Quellen eingesetzt werden.
Performance
Die Veränderungen wirken sich sehr positiv auf die Performance aus. Dies ist darauf zurückzuführen,
dass eine im Source Qualifier implementierte Joinoperation auf der Quelldatenbank durchgeführt wird,
die häufig bessere Performance bietet. Die größte Verbesserung ist zu erzielen, wenn auf der
Quelldatenbank ein Index für die in die Joinbedingung eingehenden Attribute definiert ist. Wenn dies
nicht der Fall ist, fällt die Verbesserung geringer aus. Hieraus geht hervor, dass die Performance für
die jeweilige Infrastruktur zu bewerten ist.
Zuverlässigkeit
Grundsätzlich ist das Ziel Zuverlässigkeit unbeeinträchtigt. Die Fehlerbehandlung kann als
unverändert betrachtet werden, da Fehler, die auf der Datenbank auftreten, ebenso wie Fehler in
expliziten Transformationen in den Logdateien des Workflow Monitors ausgegeben werden. Fehler
werden allerdings frühzeitiger erkannt. Die Auslagerung auf die Datenbank verschiebt
Zuverlässigkeitsanforderungen auf die zugrunde liegenden Systeme. Hierdurch kann sie je nach
eingesetzter Datenbank schwanken. Es wird jedoch davon ausgegangen, das alle Datenbank
Management Systeme bezüglich ihrer Funktionsimplementierung hinreichend zuverlässig sind. Das
Designziel Zuverlässigkeit wird daher als unverändert bewertet.
Übersicht über die Ziele bei der Positionierung von Joinertransformationen:
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Variante 1 - - + 0
Tabelle 16: Fallbeispiel 2 – Vergleich der Zielerfüllung
4.3.2.5 Zusammenfassung Positionierung Joinertransformationen
Join- Operationen können auf verschiedene Weise in den Datenfluss integriert werden. Bereits in den
Betrachtungen zur Filterpositionierung wurde deutlich, dass eine Joinertransformation recht aufwendig
sein kann, so dass diese, falls die Datenmenge im Verlauf eines Mappings reduziert wird, nach dieser
Reduktion eingebunden werden sollte. Hierbei muss jedoch die Korrektheit gewahrt werden, was sich
durch Prüfung der Join-Bedingung sicherstellen lässt. Wie auch Filterung, kann ein Verbund im
Source Qualifier und damit auf der Datenbank durchgeführt werden. Dies unterliegt jedoch
Einschränkungen, da die einbezogenen Quellen relational sein und vom gleichen Datenbankserver
geliefert werden müssen. Falls eine Integration in den Source Qualifier möglich ist, kann sich dies
positiv auf die Performance auswirken. Es muss jedoch die Infrastruktur, und hierbei insbesondere die

ETL-Design Optimierung Seite 51 von 108
regelmäßige Auslastung der Datenbank und Integrationsserver beachtet werden. Die
Verbesserungspotentiale in der Performance werden von Verschlechterungen bei Wartbarkeit und
Wiederverwendbarkeit begleitet. Dementsprechend müssen im Einzelfall die Machbarkeit der Ansätze
geprüft und die Gewichtung der Ziele festgelegt werden.
4.3.3 Zusammenfassung Positionierung von Transformationen Die gezeigten Beispiele bieten nur einen Einblick in die Verbesserungspotentiale, die durch
verschiedene Positionen von Transformationen erschlossen werden können. Grundsätzlich lässt sich
daraus jedoch ableiten, dass sich die deutlichsten Verbesserungen bezüglich des Ziels Performance
erreichen lassen. Einflussstärkstes Maß ist dabei die Datenmenge. Je größer die Reduktion der
Datenmenge, je früher diese innerhalb eines Mappings stattfindet und je aufwendiger die
nachfolgenden Transformationen sind, desto höher sind die erreichbaren Vorteile.
Dieser Ansatz entspricht der klassischen Anfrageoptimierung in Datenbanken. In der Literatur werden
SQL Anfragen zum Teil als Baum betrachtet. Hierbei wird die Anfrage von der Wurzel aus gelesen.
Ein Optimierungsansatz ist es, Selektionen und Projektionen möglichst weit in Richtung der Wurzel
nach unten zu verschieben. Dieses Vorgehen ist eine „algebraische oder
implementierungsunabhängige Optimierung“ (Vossen, 2000, S. 315). Diese Sichtweise lässt sich auf
ETL-Design übertragen und die Ansätze behalten, wie in den Beispielen gezeigt wurde ihre Gültigkeit.
Der Gesichtspunkt der Implementierungsunabhängigkeit stellt den Ansatz als eine besonders geeignete
Form der konzeptionellen Optimierung heraus.
Neben den in den Beispielen gezeigten Transformationen wirken sich Positionsänderungen auch bei
anderen Transformationen aus. Aktive Transformationen sind bezüglich der Positionierung
interessant, insbesondere dann wenn sie die Zeilenanzahl verringern. Beispiele hierfür sind die
gezeigten Filtertransformationen, aber auch Aggregationen, die Tupel anhand bestimmter Kriterien
zusammenfassen beziehungsweise gruppieren. Werden diese früh in den Datenfluss eingebunden,
verringern auch sie die Datenmenge, was die Verarbeitungszeit und den Ressourcenbedarf der
nachfolgenden Transformationen verringert.
Die aufgezeigte Möglichkeit, Funktionalität in den Source Qualifier zu integrieren und damit auf der
Datenbank ausführen zu lassen, kann Verbesserungen der Performance weiter steigern. In den
Beispielen wurde dies anhand von Filter- und Joinertransformationen gezeigt. Gleichzeitig führt die
damit einhergehende Kapselung jedoch in der Regel zu einer Verschlechterung von Wartbarkeit und
Wiederverwendbarkeit, so dass hier eine Entscheidung bezüglich der Zielgewichtung getroffen werden
muss.
Solange die zu verschiebenden Transformationen explizit vorhanden bleiben, sind die
Wechselwirkungen gering, das heißt, die Verbesserungen beim Ziel Performance führen nicht
gleichzeitig zur Verschlechterung anderer Ziele.

ETL-Design Optimierung Seite 52 von 108
4.4 Austauschbarkeit von Transformationen In einigen Fällen können gleiche fachliche Anforderungen an ein Mapping mit Hilfe verschiedener
Transformationen umgesetzt werden. Es besteht die Vermutung, dass die Wahl der „richtigen“
Transformation hierbei große Auswirkungen auf den Erfüllungsgrad der Ziele hat. Nachfolgend sollen
hierzu 3 Beispiele aufgestellt werden, anhand derer die Auswirkungen eines Austauschs von
Transformationen untersucht werden. Als Beispiel wird der Austausch zwischen Lookup- und
Joinertransformation gewählt.
4.4.1 Lookup vs. Join Lookup- und Joinertransformation sind häufig gegeneinander austauschbar. Sowohl mit einer Lookup-
als auch mit einer Joinertransformation können Tupel aus verschiedenen Quellen über eine Bedingung
miteinander verknüpft werden. Die Art der Verknüpfung unterscheidet sie jedoch wesentlich, so dass
im Einzelfall geprüft werden muss, ob ein Austausch aus fachlicher Sicht möglich, und in Bezug auf
die vereinbarten Ziele sinnvoll ist.
4.4.1.1 Joinertransformation Die Joinertransformation wurde bereits bei den Untersuchungen zur Positionierung vorgestellt, daher
sei an dieser Stelle darauf verwiesen. (Abschnitt 4.3.2.1)
4.4.1.2 Lookuptransformation Beim Lookup handelt es sich um eine passive Transformation, er verändert die Zeilenzahl im
Gegensatz zur Joinertransformation also nicht. Lookuptransformationen können sowohl verbunden als
auch unverbunden eingesetzt werden. Sie dienen wie Joinertransformationen dazu, anhand einer
Prüfbedingung eine Quelle durch Daten aus einer anderen zu erweitern.
Wesentlicher Unterschied zur Joinertransformation ist hierbei, dass bei Mehrfachtreffern nur ein Tupel
übernommen wird. Welches dies ist, kann in den Optionen der Transformation bestimmt werden. In
Frage kommen hierbei drei Optionen: Der ersten Wert, der letzten Wert oder der ersten Wert auf den
die Bedingung zutrifft. Alternativ kann im Fall von Mehrfachtreffern ein Fehler gemeldet werden.
Caching Informatica empfiehlt aus Performancegründen für Lookuptransformationen Caching zu nutzen.
Hierbei wird die Lookup-Quelle in den Hauptspeicher des Integrationsservers gelesen und weitere
Abfragen darauf ausgeführt (Informatica, PowerCenter Transformation Guide, 2006, S. 320). Obwohl
dies meistens sinnvoll ist, lohnt sich Caching nicht immer. Ausnahme sind Lookups, die nur sehr
wenige Anfragen durchführen. In diesen Fällen ist der Aufbau des Lookup-Caches aufwändiger als ein
ungecachter Lookup.
Als Standard wird ein statischer Cache genutzt. Dieser behält seinen Inhalt während einer Session. Er
wird bei Ausführung der Lookuptransformation mit dem Einlesen der ersten Zeile aus der Lookup-
Quelle aufgebaut.
Neben dem statischen Cache gibt es den persistenten Cache, der nach einer Session erhalten bleibt und
auf den bei einer erneuten Durchführung zurückgegriffen wird. Dieser kann nur eingesetzt werden,
wenn die Lookup-Quelltabelle statisch ist, also die darin enthaltenen Daten keinen Veränderungen
unterworfen sind.

ETL-Design Optimierung Seite 53 von 108
4.4.2 Lookup vs. Join - Fallbeispiel 3 Die Auswirkungen einer Ersetzung sollen anhand von Beispielen untersucht werden. Hierbei wird das
bereits bei den vorherigen Betrachtungen eingeführte Ausgangsbeispiel herangezogen. In diesem
werden die Quelltabellen TASKS und TASK_LOG mittels einer Joinertransformation verknüpft.
Diese Verknüpfung soll nun mit einer Lookuptransformation durchgeführt werden.
4.4.2.1 Ausgangsbeispiel Zur Erinnerung das Ausgangsbeispiel und die dafür erhobenen Maße:
Abbildung 14: Fallbeispiel 3 – Ausgangsbeispiel
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
Eingehende Tupel
350
Tupel nach Filter
7 4 28
Tabelle 17: Fallbeispiel 3 - Ausgangsbeispiel - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung n.v. n.v. - n/a +
Tabelle 18: Fallbeispiel 3 - Ausgangsbeispiel - Qualitative Maße
4.4.2.2 Voraussetzungen für eine Ersetzung zwischen Lookup und Join Entsprechend dem verschiedenen Verhaltens der beiden Transformationen müssen bestimmte
Bedingungen erfüllt sein, damit sie austauschbar sind, ohne dass dabei die Korrektheit verletzt wird.
Diese Voraussetzungen hängen von der Art der Relation zwischen den beiden betroffenen Tabellen ab.

ETL-Design Optimierung Seite 54 von 108
Bei 1:1 Beziehungen ist ein Austausch immer möglich, bei 1:n muss das Attribut der n-Seite als
Grundlage dienen, das der 1-Seite per Lookup bezogen werden. Stehen die Quellen in einer n:m
Beziehung kann, aufgrund der Behandlung von Mehrfachtreffern, kein Lookup eingesetzt werden.
4.4.2.3 Variante 1 Nun wird das Ausgangsbeispiel dahingehend verändert, dass die Verknüpfung statt durch eine Joiner-
mit einer Lookuptransformation durchgeführt wird. Durch die Änderungen wird nur noch eine
Quelltabelle benötigt, die Daten aus der zweiten Quelle werden durch die Lookuptransformation
bezogen. Da die Tabellen TASKS und TASK_LOG in einer 1:n Beziehung stehen, müssen die Tupel
aus der Tabelle TASK_LOG in die Lookuptransformation eingehen, diejenigen aus TASKS werden
dann mittels Lookup bezogen.
Das Mapping sieht danach folgendermaßen aus:
Abbildung 15: Fallbeispiel 3 – Variante 1 – Lookup statt Join
Erhebung der Maße Um eine Vergleichbarkeit der Varianten zu ermöglichen, müssen zuerst die quantitativen und
qualitativen Maße des Fallbeispiels untersucht werden.
Quantitative Maße
Datenmenge
Die absolute Datenmenge ist gegenüber dem Ausgangsbeispiel unbeeinflusst. Wieder werden 1098106
Tupel aus TASK_LOG bezogen. Die 133 Tupel der Tabelle TASKS werden in dieser Variante aber
erst später, nämlich in der Lookuptransformation bezogen.
Anzahl der Knoten
Die Anzahl der Knoten wird durch die Einsparung einer Quelle und ihres Source Qualifiers von 7 auf
5 reduziert.
Länge
Die maximale Länge beträgt 3, sie wurde also um 1 reduziert.
Komplexität
Durch die Ersetzung der Joinertransformation und insbesondere die daraus resultierende Einsparung
einer Quelle samt Source Qualifier verringert sich die Komplexität von 28 auf 19.

ETL-Design Optimierung Seite 55 von 108
Qualitative Maße
Modularität
Die Modularität ist von den Änderungen nicht beeinflusst. Wie im Ausgangsbeispiel gibt es keine
Module.
Kapselung
Die im Lookup hinterlegte Quelltabelle kann als gekapselt angesehen werden, jedoch ist keine
Funktionalität gekapselt. Die Kapselung wird daher als nicht vorhanden (n.v.) bewertet.
Universalität
Während eine Joinertransformation immer zur Verknüpfung von Tabellen in Frage kommt, ist dies bei
der Lookuptransformation in bestimmten Fällen (n:m Relation) aus bereits erläuterten Gründen nicht
möglich. Bei 1:n Relationen besteht das Risiko eine falsche Reihenfolge beim Lookup zu wählen. Aus
diesen Gründen muss die Universalität dieser Variante als schwach bewertet werden.
Kohäsion
Da in keiner Transformation mehrere Funktionen durchgeführt werden und keine Modulbildung
stattfindet, ist die Betrachtung der Kohäsion obsolet.
Kopplung
Die Kopplung des Mappings wurde, analog zur Komplexität reduziert. Bei Betrachtung der
Lookuptransformation ist zu erkennen, dass seine eingehende Kopplung mit einer Kante sehr gering
ist, die ausgehende mit drei Kanten etwas höher. Die Kopplung des Source Qualifiers ist gestiegen, der
Port TASK_LOG_TASK muss über zwei Kanten mit dem Lookup und dem Filter verbunden werden.
Insgesamt wird die Kopplung als neutral (0) bewertet.
Übersicht über die Maße
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
Eingehende Tupel
350
Tupel nach Filter
5 3 19
Tabelle 19: Fallbeispiel 3 – Variante 1 - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung n.v. n.v. - n/a 0
Tabelle 20: Fallbeispiel 3 – Variante 1 - Qualitative Maße

ETL-Design Optimierung Seite 56 von 108
Auswirkungen auf die Ziele
Korrektheit
Wenn die geschilderten Einschränkungen bezüglich der Reihenfolge beachtet werden, wird die
Korrektheit nicht verletzt. Die Änderungen sind daher zulässig.
Wartbarkeit
Durch die Verwendung einer Lookuptransformation steigt die Übersichtlichkeit. Dies ist darauf
zurückzuführen, dass bei Verwendung einer Lookuptransformation die Anzahl der Knoten und die
Komplexität verringert werden, da hierbei die Quelle des Lookups und ihr Source Qualifier nicht mehr
in das Mapping eingebunden werden müssen.
Daneben wird durch die Verwendung einer Lookuptransformation eine höhere Transparenz erreicht,
da die Art der Beziehung explizit ersichtlich ist. Ein Lookup bildet explizit eine x:1 Beziehung ab.
Eine Joinertransformation enthält im Gegensatz dazu implizit eine 1:1, 1:n oder n:m Beziehung. Um
die Korrektheit nicht zu Verletzen, muss die Richtung der Beziehung bei Wartungsarbeiten
entsprechend berücksichtig werden.
Die Wartbarkeit wird für diese Variante als leicht verbessert bewertet.
Wiederverwendbarkeit
Die Bewertung der Wiederverwendbarkeit erfordert eine fallweise Unterscheidung. Im vorliegenden
Beispiel, dient der Lookup dazu, verschiedene Quellen in großer Breite, das heißt bezüglich vieler
Attribute miteinander zu verknüpfen, wobei gleichzeitig die Relationshierarchie berücksichtigt werden
muss. Hierbei gestaltet sich die Lookuptransformation wenig wiederverwendbar.
Sollen jedoch sehr punktuell zu Tupeln weitere Daten nachgeschlagen werden, zum Beispiel Faktoren
für eine Berechnung in einer Expressiontransformation, kann man hierfür Lookuptransformationen mit
großer Universalität entwickeln. Diese bringen dann eine sehr gute Wiederverwendbarkeit mit sich.
Ein späteres Beispiel wird diese Möglichkeit zeigen (Abschnitt 0).
Für dieses Beispiel wird die Wiederverwendbarkeit als leicht verschlechtert bewertet.
Performance
Der Austausch der Joiner- durch eine Lookuptransformation führt im vorliegenden Beispiel zu einer
schlechteren Performance.
Generell ist die Performance von vielen Faktoren abhängig, was auch in diesem Beispiel deutlich
gezeigt werden kann. Unter bestimmten Bedingungen kann die Performance zugunsten der
Lookuptransformation ausfallen. Aufgrund der komplexen Zusammenhänge muss dies hier auch über
das Beispiel hinaus diskutiert werden.
• Wenn nur wenige Attribute der involvierten Tabellen in die Verknüpfung eingehen, ist
Lookup in der Regel performanter als Join. Dies ist auf die Implementierung der beiden
Transformationen in Informatica zurückzuführen (Informatica, PowerCenter Transformation
Guide, 2006, S. 304).
• Bei Verwendung eines persistenten Caches, ist das Mapping mit einer Lookuptransformation
ab der zweiten Ausführung performanter als das mit einer Joinertransformation. Dies ist damit
zu begründen, dass ein persistenter Cache nur einmal aufgebaut werden muss und danach über
Kommentar [t1]: Wf_filter_after_joiner_many_data: 1:36 Wf:lookup_statt_join_many_data: 1:57

ETL-Design Optimierung Seite 57 von 108
mehrere Sessions hinweg zur Verfügung steht. Es muss geprüft werden, ob ein persistenter
Cache die Korrektheit verletzen kann. Sobald Tabellen, wie im vorliegenden Fall, Änderungen
unterzogen werden, kann kein persistenter Cache verwendet werden, ohne die Korrektheit zu
verletzen.
• Wird für den Lookup kein Cache verwendet, aber im Datenbank Management System ist auf
der Quelltabelle des Lookups ein Index definiert, kann dieser von der Transformation genutzt
werden. In diesem Fall ist die Laufzeit bei Verwendung einer Lookuptransformation geringer
als mit einer expliziten Joinertransformation (Informatica, PowerCenter Transformation
Guide, 2006, S. 297). Im Vergleich mit einem Join im Source Qualifier kann die
Lookuptransformation im beschrieben Fall keine Performanceverbesserung schaffen, da der
Join im Source Qualifier in selbem Maße von einem Index auf der Datenbank profitiert.
Performance hängt immer sehr stark von der Systemumgebung ab. Insbesondere der verfügbare
Hauptspeicher wirkt sich deutlich aus. Daneben muss die Auslastung der Systeme in Bezug auf
Speicher und CPU beachtet werden, falls Datenbank und Integrationsservice auf verschiedenen
Servern laufen. So kann es bei hoher Auslastung des Datenbankservers vorkommen, dass Operationen,
die üblicherweise auf der Datenbank performanter ausgeführt werden, auf dem Informatica
PowerCenter Integrationsserver eine geringere Durchlaufzeit beanspruchen.
Zuverlässigkeit:
Bei Verwendung einer Lookuptransformation zum Verknüpfen der Tabellen bleibt die
Zuverlässigkeit unbeeinflusst. Es ist zu beachten, dass es bei dieser Variante eine zu beachtende
Reihenfolge entlang der relationalen Beziehungen gibt.
Übersicht über die Ziele bei Verwendung eines Lookups in Variante 1
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Variante 1 + - - 0
Tabelle 21: Fallbeispiel 3 – Variante 1 - Zielerfüllung bei Lookup statt Join
4.4.3 Lookup vs. Join - Fallbeispiel 4 Im vorangegangenen Beispiel wurde deutlich, dass die Entscheidung zwischen Lookup und
Joinertransformation sehr schwierig sein kann. Es gibt allerdings auch Fälle, in denen die
Entscheidung aus fachlicher Sicht einfacher gefällt werden kann.
Hierfür wird ein anderes Fallbeispiel herangezogen.
Es sei angenommen, dass auf der Basis der geleisteten Stunden in der Tabelle TASK_LOG
gleichzeitig die Kosten erhoben werden sollen. Jedes Tupel in TASK_LOG weist ein Attribut
COSTCODE auf, das den zugrundeliegenden Stundensatz repräsentiert. Der Kostenfaktor liegt jedoch
nicht in EURO pro Stunde vor, sondern in den Ausprägungen 1 und 2. Diesen Werten müssen
Eurowerte zugewiesen werden. Über eine separate Tabelle, in der die Eurowerte hinterlegt sind, kann
dieser Bezug hergestellt werden. Dies kann entweder über eine Joiner- oder über eine
Lookuptransformation geschehen. Nach der Erhebung des Stundensatzes in EURO können durch

ETL-Design Optimierung Seite 58 von 108
Multiplikation dieses Kostenfaktors mit den geleisteten Stunden die angefallenen Kosten berechnet
werden.
Quelltabellen
Neben der bereits bekannten Tabelle TASK_LOG wurde für das Beispiel eine Tabelle
COSTCODE_EUROVALUE erstellt. In dieser wird den Kostenfaktoren 1 beziehungsweise 2 ein
Stundensatz von 75 beziehungsweise 120 Euro zugewiesen.
COSTCODE_EUROVALUE ist folgendermaßen definiert:
CREATE TABLE COSTCODE_EUROVALUE ( COSTCODE varchar2(8), EUROVALUE number(15,2) );
Zieltabelle
Die Zieltabelle des Mappings TASK_LOG_WITH_COSTS entspricht der Quelltabelle TASK_LOG
erweitert um die Attribute EUROVALUE und TASK_LOG_COST.
CREATE TABLE Task_log_with_costs ( TASK_LOG_ID number(10), TASK_LOG_TASK number(10), TASK_LOG_HOURS number(15,2), TASK_LOG_COSTCODE varchar2(8), EUROVALUE number(10,2), Task_Log_Cost number(15,2) );
Die geschilderte Anforderung kann mittels Joiner- oder Lookuptransformation umgesetzt werden.
Beide Varianten werden nachfolgend dargestellt und anschließend verglichen.

ETL-Design Optimierung Seite 59 von 108
4.4.3.1 Umsetzung mit einer Joinertransformation Die Tabellen TASK_LOG und COSTCODE_EUROVALUE werden in der Joinertransformation unter
der Bedingung TASK_LOG_COSTCODE = COSTCODE zusammengeführt. Danach findet in der
Expressiontransformation die Berechnung der Kosten satt. Anschließend werden die gesamten Daten
in die Zieltabelle TASK_LOG_WITH_COSTS geschrieben.
Abbildung 16: Fallbeispiel 4 – Ausgangsbeispiel - Berechnung der Aufgabenkosten
Erhebung der Maße
Quantitative Maße
Datenmenge
Die Datenmenge in TASK_LOG beträgt unverändert 1098106 Tupel, in COSTCODE_EUROVALUE
liegen 2 Tupel vor. Über die Attribute TASK_LOG.TASK_LOG_COSTCODE und
COSTCODE_EUROVALUE.COSTCODE werden die beiden Tabellen in Beziehung gesetzt. Dabei
wird jedes Tupel aus TASK_LOG mit genau einem aus COSTCODE_EUROVALUE verbunden. Die
Tabellen stehen in einer 1:n Relation zueinander. Da ein Master Outer Join angewandt wird, wird
durch diese Beziehung in der Joinertransformation nur die Anzahl der Spalten erhöht, Tupel bleiben
unverändert 1098106 vorhanden. Diese Zahl bleibt bis in das Ziel unverändert bestehen.
Anzahl der Knoten
Das Mapping besteht aus 7 Knoten.
Länge
Atrribute werden maximal vier Mal weitergeleitet, das Mapping weist also eine Länge von 4 auf.
Komplexität
Die Transformationen des Mappings sind über 23 Kanten verbunden. Dies entspricht der Komplexität.
Qualitative Maße
Modularität
Alle Operationen werden in atomaren Transformationen durchgeführt, Modularität ist nicht
vorhanden.

ETL-Design Optimierung Seite 60 von 108
Kapselung
Es gibt keine verborgene Funktionalität und somit keine Kapselung.
Universalität
Das Mapping weist eine hohe Spezifität für den Anwendungsfall auf.
Kohäsion
Aufgrund der nicht vorhandenen Modularität ist die Kohäsion nicht sinnvoll zu erheben.
Kopplung
Bis auf eine Ausnahme, COSTCODE in der Joinertransformation, sind alle Ports jeweils mit den
nachfolgenden Transformationen verbunden. Die Kopplung wird als neutral erhoben.
Übersicht über die Maße
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
Eingehende Tupel 7 4 23
Tabelle 22: Fallbeispiel 4 – Ausgangsbeispiel - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung n.v. n.v. - n/a 0
Tabelle 23: Fallbeispiel 4 – Ausgangsbeispiel - Qualitative Maße
Auswirkungen auf die Ziele Das vorgestellte Ausgangsbeispiel soll als Referenz für den Vergleich mit einer Lookup-Variante
dienen. Daher werden, um die Vergleichbarkeit zu gewährleisten, die Ziele in der Übersicht alle mit 0
bewertet. In der Diskussion der einzelnen Ziele soll dennoch auf die Besonderheiten des
Ausgangsmappings eingegangen werden.
Korrektheit
Das Mapping führt die geforderten Operationen korrekt durch.
Wartbarkeit
Positiv ist die hohe Transparenz zu werten. Jede Transformation führt genau eine Operation durch, alle
Operationen sind in der Mappingansicht zu erkennen. Für die wenig komplizierten Operationen weist
das Mapping relativ viele Knoten und eine hohe Komplexität auf.

ETL-Design Optimierung Seite 61 von 108
Wiederverwendbarkeit
Das Mapping ist sehr spezifisch auf den Anwendungsfall zugeschnitten und daher schlecht
wiederverwendbar.
Performance
Performance wird erst in der folgenden Variante im Vergleich beurteilt.
Zuverlässigkeit
Das Ausgangsbeispiel lässt keine Zuverlässigkeitsmängel erkennen.
Übersicht über die Ziele
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Tabelle 24: Fallbeispiel 4 – Ausgangsbeispiel – Zielerfüllung
4.4.3.2 Umsetzung mit einer Lookuptransformation Statt beide Quellen einzulesen und anschließend mittels einer Joinertransformation
zusammenzuführen, sollen nun die benötigten Stundensätze über eine Lookuptransformation aus der
Tabelle COSTCODE_EUROVALUE bezogen werden. Anschließend werden wie in der vorherigen
Variante die Kosten in der Expressiontransformation CALCULATE_COSTS berechnet. Die
Auswirkungen, die diese Veränderung mit sich bringt, werden anschließend ausgewertet und
diskutiert.
Abbildung 17: Fallbeispiel 4 – Variante 1 – Umsetzung mit Lookuptransformation
Erhebung der Maße
Quantitative Maße
Datenmenge
Die Datenmenge in TASK_LOG beträgt unverändert 1098106 Tupel, in COSTCODE_EUROVALUE
liegen 2 Tupel vor. Für jedes Tupel aus TASK_LOG wird in der Lookuptransformation das

ETL-Design Optimierung Seite 62 von 108
zusätzliche Attribut EUROVALUE nachgeschlagen. Die Anzahl der Tupel bleibt dabei unverändert,
jedes Tupel wird aber um zwei Attribute, EUROVALUE und TASK_LOG_COST, erweitert.
Anzahl der Knoten
Da die Quelle der Lookuptransformation nicht explizit eingelesen werden muss, reduziert sich die
Anzahl der Knoten von 7 auf 5.
Länge
Auch die Länge kann durch die Veränderungen reduziert werden, und zwar von 4 auf 3.
Komplexität
Die Komplexität kann deutlich reduziert werden. Während die Transformationen im vorangegangenen
Beispiel noch über 23 Kanten verbunden waren, sind es jetzt nur noch 16.
Qualitative Maße
Modularität
Eine Lookuptransformation wird nicht als Modul angesehen, daher ist unverändert keine Modularität
vorhanden.
Kapselung
Die Attribute der Lookup-Quelltabelle sind direkt ersichtlich, daher ist keine Kapselung zu
verzeichnen. Das Mapping ist transparent bezüglich der durchgeführten Operationen.
Universalität
Das Mapping weist eine hohe Spezifität für den Anwendungsfall auf. Allerdings ist es bezüglich der
Quelle der Stundensätze etwas genereller. So ist es relativ einfach möglich, diese Quelle von einer
relationalen Tabelle auf eine flache Textdatei umzustellen.
Kohäsion
Aufgrund der nicht vorhandenen Modularität ist die Kohäsion nicht sinnvoll zu erheben.
Kopplung
Die Lookuptransformation hat aber ein relativ günstiges Verhältnis zwischen eingehender und
ausgehender Kopplung. Der Port TASK_LOG_COSTCODE ist über mehrere ausgehende Kanten
verbunden. Insgesamt wird die Kopplung als neutral erhoben.
Übersicht über die Maße
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
Eingehende Tupel 5 3 16
Tabelle 25: Fallbeispiel 4 – Variante 1 - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung

ETL-Design Optimierung Seite 63 von 108
Ausprägung n.v. n.v. 0 n/a 0
Tabelle 26: Fallbeispiel 4 – Variante 1 - Qualitative Maße
Auswirkungen auf die Ziele Sowohl die quantitativen als auch die qualitativen Maße weisen Veränderungen auf. Die
Auswirkungen auf die vereinbarten Ziele werden nachfolgend dargestellt.
Korrektheit
Fachlich sind beide Varianten des Mappings äquivalent. Die Korrektheit bleibt durch die Verwendung
einer Lookuptransformation statt der Joinertransformation unverletzt.
Wartbarkeit
Alle quantitativen Maße außer der Datenmenge konnten reduziert werden. Hierdurch erhöht sich die
Übersichtlichkeit, was die Wartbarkeit positiv beeinflusst. Darüber hinaus erhöht sich die Universalität
etwas, da die Lookuptransformation einfacher auf verschiedene Quelltypen angepasst werden kann.
Dies verbessert im vorliegenden Beispiel die Wartbarkeit, da die Stundensätze in Euro nicht in der
Originaldatenbank vorlagen, sondern nachträglich eingeführt wurden. Statt einer relationalen Tabelle
hätte entsprechend auch eine Textdatei eingebunden werden können.
Neben den genannten Auswirkungen bleibt die gute Transparenz erhalten. Negative Effekte durch die
richtungsabhängige Relation sind in diesem Fall minimal, da die Beziehung zwischen den Tabellen
auch ohne detaillierte Kenntnis des Datenbankschemas offensichtlich ist.
Wiederverwendbarkeit
Unverändert ist das Mapping recht spezifisch auf den vorliegenden Anwendungsfall zugeschnitten.
Dennoch gibt es eine Verbesserung der Wiederverwendbarkeit. Einen geringen positiven Einfluss auf
hat dabei die bereits dargestellte größere Flexibilität in Bezug auf die Quelle der Stundensätze.
Darüber hinaus kann die Lookuptransformation insofern besser wiederverwendet werden, dass sie die
Lookupquelle integriert. Es müssen als nicht, wie bei einer Joinertransformation, zwei Quellen
verbunden werden, sondern nur eine.
Performance
Auf die Performance wirken sich die Veränderungen positiv aus. Die Laufzeit kann im Vergleich mit
dem Ausgangsbeispiel um ca. 40% reduziert werden. Zur Erhebung der Durchlaufzeit wurde der
Mittelwert von 10 Ausführungen herangezogen, trotzdem sei an dieser Stelle noch einmal auf die recht
geringe Aussagekraft dieses Werts hingewiesen.
Die Verbesserung ist darauf zurückzuführen, dass die Lookupquelle nur sehr wenige Tupel (2)
aufweist und daher der Lookup gegenüber der Joinertransformation effizienter ist.
Zuverlässigkeit
Die Zuverlässigkeit wird durch den Austausch einer Joinertransformation mit einer
Lookuptransformation nicht beeinflusst.

ETL-Design Optimierung Seite 64 von 108
Übersicht über die Ziele
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Variante 1 ++ + + 0
Tabelle 27: Fallbeispiel 4 – Zielerfüllung – Vergleich der Varianten
4.4.4 Zusammenfassung Lookup vs. Join Wie bereits bei der Erhebung der Maße und Untersuchung der Ziele deutlich wurde, ist die
Entscheidung zwischen Lookup und Joinertransformation nicht trivial. Die Auswirkungen von
Veränderungen sind zum Teil gravierend, stehen aber bezüglich der definierten Ziele in Konflikt.
Es gilt zu beachten, dass ein Austausch nur unter bestimmten Voraussetzungen möglich ist. Lookup
und Join unterscheiden sich fachlich dadurch, dass die Lookuptransformation zur Prüfbedingung nur
ein Tupel zurückliefern kann. Die Joinertransformation dagegen überprüft je nach Join-Typ die
Bedingung für alle Tupel und liefert dabei auch Mehrfachtreffer zurück. Dementsprechend können nur
Werte aus Entitäten, die in einer 1:1 oder 1:n Relation stehen, mittels einer Lookuptransformation
bezogen werden. Bei n:m Relationen muss mit der Joinertransformation gearbeitet werden. Bei 1:n
Relation ist es für die Wartbarkeit wichtig, ob Art und gegebenenfalls Richtung der Relation
offensichtlich sind. Dies hängt von den Daten beziehungsweise deren Aussagekraft ab.
Da die zugrundeliegenden Quellen nicht in expliziten Transformationen eingelesen werden müssen
und folglich auch keine Source Qualifier für diese Quellen benötigt werden, reduzieren
Lookuptransformationen quantitative Maße eines Mappings. Insbesondere die Anzahl der Knoten und
die Komplexität sinken in der Regel. Häufig verkürzt sich auch die Länge. Die positiven
Auswirkungen dieser Reduktionen verstärken sich natürlich, wenn an mehr als einer Stelle des
Mappings Daten aus anderen Quellen nachgeschlagen werden müssen, da sich die Einsparungen in
diesem Fall multiplizieren.
Die Lookuptransformation bietet im Gegensatz zur Joinertransformation die Möglichkeit, Daten aus
mehr als zwei Tabellen in einem Verarbeitungsschritt zu verknüpfen. Dies geschieht mittels einer SQL
Override Anweisung in der Lookuptransformation. Weil hierdurch aber massiv Transparenz eingebüßt
wird, ist diese Möglichkeit unter dem Gesichtspunkt der Wartbarkeit als sehr ungünstig zu bewerten.
In Bezug auf das Ziel Performance ist es bei der Frage Lookup vs. Join nicht möglich, eine generelle
Aussage zu treffen. Mehr als von Designentscheidungen hängt die Performance von technischen
Rahmenbedingungen ab. Insbesondere Caching, Art und Struktur der Quellsysteme beziehungsweise
Daten, sowie Ausstattung und Auslastung der Systeme, auf denen die Dienste ausgeführt werden,
beeinflussen die Performance. Beide profitieren stark von vorsortierten Daten, es kann sich jedoch
hierdurch keine Transformation von der anderen abgrenzen. Indizes auf der Datenbank wirken sich bei
Joinoperationen im Source Qualifier und ungecachten Lookups positiv auf die Performance aus.
Laut Informatica ist der Joiner aus Performancegesichtspunkten in der Regel dem Lookup vorzuziehen

ETL-Design Optimierung Seite 65 von 108
(Informatica, PowerCenter Transformation Guide, 2006, S. 318). Die Beispiele haben aber gezeigt,
dass unter bestimmten Bedingungen die Lookuptransformation recht deutliche
Performancevorsprünge vor der Joinertransformation erzielen kann. Welcher Transformation unter
dem Kriterium der Performance der Vorzug zu geben ist, hängt neben den genannten Kriterien von der
Struktur der Daten ab. Sollen zwei Tabellen, die viele Tupel mit jeweils vielen Attributen enthalten,
zusammengeführt werden, ist hierfür die Joinertransformation vorzuziehen. Stammen die zu
beziehenden Daten aus einer in Bezug auf die Zahl der Tupel und deren jeweiligen Attribute sehr
kleinen Tabelle, wird in den meisten Fällen die Lookuptransformation die bessere Performance bieten.
Es ist festzustellen, dass die Entscheidung Lookup vs. Join bezüglich der Performance sehr unscharf
ist. Es ist daher im Einzelfall empfehlenswert, die Auswirkungen auf andere Ziele zu betrachten und
dann entsprechend die Auswirkungen auf die Performance zu überprüfen. Die festgestellten Maße
wirken hierbei entscheidungsunterstützend.
4.5 Weitere Optimierungsansätze - Fallbeispiel 5 Bisher wurden sehr einfache Beispiele vorgestellt, um die Wirkungsweisen verschiedener
Veränderungen an Mappings zu verdeutlichen. Dabei fiel auf, dass für diese einfachen Beispiele
qualitative Maße, insbesondere Modularität, Kohäsion und Kopplung regelmäßig nicht aussagekräftig
untersucht werden konnten. In diesem Abschnitt wird nun ein etwas umfangreicheres Beispiel
eingeführt, an dem sich Auswirkungen auf diese Maße deutlicher zeigen lassen.
Für die Beispiele dienen die bereits vorgestellten Ausschnitte der dotProject Datenbank als Grundlage.
Für das Szenario sollen die anfallenden Kosten eines Projekts berechnet werden. Außerdem soll eine
Umrechnung in verschiedene Währungen anhand von externen Wechselkurstabellen stattfinden.
4.5.1 Datenquellen Für die kommenden Beispiele werden die Tabellen TASK_LOG, TASKS und PROJECTS als Quellen
verwendet. Diese wurden bereits bei der Einführung des Szenarios in Abschnitt 4.2.1 vorgestellt.
Zur Erinnerung sei hier nochmals auf die Beziehung zwischen den Tabellen hingewiesen.
In der Tabelle TASK_LOG werden einzelne Aufgaben mit den dafür angefallenen Stunden und einem
Kostenfaktor gespeichert. Jedes Tupel aus TASK_LOG kann eindeutig einem aus der Tabelle TASKS
zugeordnet werden. In PROJECTS wiederum werden Projekte erfasst. Jedes TUPEL aus TASKS lässt
sich eindeutig einem aus PROJECTS zuordnen. TASKS dient im Beispiel demnach in erster Linie als
Bindeglied zwischen den Teilaufgaben in TASK_LOG und Projekten in PROJECTS.
Im Fallbeispiel müssen Daten aus den drei genannten Tabellen zusammengeführt und aggregiert
werden. Darüber hinaus müssen die Kosten berechnet werden. Diese sollen auf Projektbasis erhoben
werden. Es bieten sich also verschiedene Möglichkeiten an, wo innerhalb eines Mappings diese
Berechnung durchgeführt werden soll. Neben den Kosten in Euro sollen verschiedene
Fremdwährungen berechnet werden. Für das Beispiel werden die Wechselkurse in einer Textdatei
hinterlegt. Diese muss in die Umrechnung einbezogen werden.
Die Ergebnisse, in verschiedenen Währungen, werden in drei verschiedene Zieltabellen geladen.
4.5.2 Zieltabellen Die berechneten Projektkosten sollen jeweils in einer Tabelle pro Währung gespeichert werden. Die
Zieltabellen sehen dabei wie folgt aus:

ETL-Design Optimierung Seite 66 von 108
CREATE TABLE PROJECT_COST_IN_DOLLAR
(
PROJECT_ID number(10),
PROJECT_NAME varchar2(255),
SUM_HOURS_PER_PROJECT number(15,2),
COST_PER_PROJECT number(15,2)
);
Analog dazu gestalten sich die Tabellen für die Währungen Euro und Schweizer Franken:
CREATE TABLE PROJECT_COST_IN_EURO
(
PROJECT_ID number(10),
PROJECT_NAME varchar2(255),
SUM_HOURS_PER_PROJECT number(15,2),
COST_PER_PROJECT number(15,2)
);
CREATE TABLE PROJECT_COST_IN_FRANKEN
(
PROJECT_ID number(10),
PROJECT_NAME varchar2(255),
SUM_HOURS_PER_PROJECT number(15,2),
COST_PER_PROJECT number(15,2)
);
Untersuchung weiterer Optimierungsansätze Bezüglich der oben geschilderten Anforderungen werden verschiedene Designvarianten vergleichen.
Alle Varianten sind fachlich äquivalent und können daher unter Optimierungsgesichtspunkten
miteinander verglichen werden.
Zu Beginn wird, entsprechend des definierten Vorgehens, ein Ausgangsbeispiel eingeführt.
Anschließend werden in Varianten davon Optimierungsansätze untersucht. Dabei wird die
Auswirkung auf die Maße und die Erfüllung der Ziele, im Vergleich mit dem Ausgangsbeispiel,
untersucht beziehungsweise bewertet.

ETL-Design Optimierung Seite 67 von 108
4.5.3 Ausgangsbeispiel
Extraktion und Zusammenführung der benötigten Daten Im Ausgangsbeispiel werden zuerst die drei benötigten Quelltabellen über zwei
Joinertransformationen zusammengeführt.
Hierfür werden die beiden Tabellen TASKS und TASK_LOG anhand der Bedingung
TASK_LOG_TASK = TASK_ID gejoined. Da in der Tabelle TASKS weniger Zeilen vorhanden sind,
bilden ihre Daten die Detailpipeline. Die Tabelle TASK_LOG geht dementsprechend als
Masterpipeline in die Joinertransformation ein.
Im nächsten Schritt werden die zusammengeführten Daten aus der gerade beschriebenen
Joinertransformation in einer weiteren Joinertransformation mit den Daten der Tabelle PROJECTS
verknüpft. Da hierbei wiederum die Tabelle PROJECTS die wenigsten Zeilen liefert, gehen ihre Daten
als Detailpipeline in die Transformation ein und die Ergebnisse der vorherigen Joinertransformation
als Masterpipeline. Die Verknüpfung findet anhand der Bedingung TASK_PROJECT = PROJECT_ID
statt.
Abbildung 18: Fallbeispiel 5 – Ausgangsbeispiel - Zusammenführen der Quellen
Aggregation der geleisteten Stunden Nachdem die benötigten Quelldaten zusammengeführt sind, werden mittels der
Aggregationstransformation SUM_HOURS_PER_PROJECT die geleisteten Stunden pro Projekt
aufsummiert. Dies geschieht mittels der Aggregationsfunktion SUM(TASK_LOG_HOURS) und
einem GROUP BY PROJECT_ID sowie einem GROUP BY COSTCODE. Die Gruppierung nach
COSTCODE wird benötigt, da die darin hinterlegten Faktoren in die folgende Berechnung der Kosten
eingehen sollen.

ETL-Design Optimierung Seite 68 von 108
Abbildung 19 zeigt die Aggregationstransformation
Abbildung 19: Fallbeispiel 5 – Ausgangsbeispiel - Aggregation SUM_HOURS_PER_PROJECT
Berechnung der Kosten Nach der Aggregation wird die Berechnung der Kosten pro Projekt, aufgeteilt nach den
Kostenfaktoren COSTCODE, durchgeführt. Hierfür gehen die Attribute PROJECT_ID,
PROJECT_NAME, SUM_HOURS_PER_PROJECT sowie TASK_LOG_COSTCODE in die
EXPRESSION Transformation CALCULATE_COST ein.
Innerhalb der Transformation wird zuerst der Kostenfaktor ermittelt. Im Beispiel gibt es zwei
Kostenfaktoren, nämlich den Stundensatz für Mitarbeiter in Höhe von EURO 75 und den Stundensatz
für Geschäftsführer von EURO 120. In den Quelldaten wird dies über den Integer 1 für einen
Mitarbeiterstundensatz und 2 für einen Geschäftsführerstundensatz dargestellt. Weitere
Kostenfaktoren gibt es nicht. Die Ableitung des Stundensatzes aus dem in COSTCODE gespeicherten
Wert geschieht unter Nutzung eines Variablenports FACTOR_COSTCODE. Ein Variablenport ist
hierbei ein rein in der Transformation existierender Port, das heißt, er ist nach außen weder über
Eingänge noch über Ausgänge verbunden. Er dient der Berechnung von Werten, die für die
Weiterverarbeitung benötigt werden. Im Beispiel wird auf dem Variablenport FACTOR_COSTCODE
folgende Operation durchgeführt: IIF(TASK_LOG_COSTCODE = '1', 75, 120).
Es wird also abhängig von dem in COSTCODE hinterlegten Wert entweder 75 oder 120 im
Variablenport der jeweiligen Zeile gespeichert.
Danach wird auf den Ausgabeports COST_PER_PROJECT, COST_IN_DOLLAR und
COST_IN_FRANKEN jeweils die Berechnung der Kosten in den entsprechenden Währungen
durchgeführt.
Bei COST_PER_PROJECT sieht die Berechnung dabei folgendermaßen aus:
SUM_HOURS_PER_PROJECT * FACTOR_COSTCODE. Es werden also die aufsummierten
Stunden mit dem Stundensatz, der über den Variablenport geliefert wird, multipliziert.
Für die Berechnungen der Kosten in fremden Währungen wird die Berechnung um einen Faktor, der
dem Umrechnungskurs entspricht, erweitert. Die aktuellen Wechselkurse werden dabei mittels eines
nicht verbundenen Lookups aus einer Textdatei bezogen. Der Aufruf der nicht verbundenen LOOKUP
Transformation geschieht auf dem jeweiligen Port folgendermaßen:
:LKP.LOOKUP_WECHSELKURS('Währung')
Dieser Aufruf wird in die Formel zur Berechnung der Kosten eingebunden. Für beide Währungen gibt

ETL-Design Optimierung Seite 69 von 108
es jeweils einen Ausgabeport, die vollständige Berechnung für die Kosten in Dollar sieht dabei
folgendermaßen aus:
SUM_HOURS_PER_PROJECT * FACTOR_COSTCODE *
:LKP.LOOKUP_WECHSELKURS('Dollar')
Nachdem alle Berechnungen durchgeführt wurden, werden die Attribute PROJECT_ID,
PROJECT_NAME sowie die neu ermittelten Werte COST_PER_PROJECT, COST_IN_DOLLAR
und COST_IN_FRANKEN zur Weiterverarbeitung in der folgenden Transformation
SUM_COST_PER_PROJECT ausgegeben.
Zur Übersicht ist in der folgenden Abbildung die Transformation CALCULATE_COST dargestellt.
Abbildung 20: Fallbeispiel 5 – Ausgangsbeispiel - Expression Transformation CALCULATE_COST
Aggregation der Kosten Nach der Berechnung liegen die Kosten pro Projekt vor. Allerdings sind diese noch nach den beiden
Kostenfaktoren COSTCODE (1,2) separiert. Dies wird nun mit einer weiteren Aggregation behoben.
In dieser Transformation SUM_COST_PER_PROJECT werden die Kosten in den verschiedenen
Währungen sowie die geleisteten Stunden auf Portebene über die Aggregationsfunktion SUM(Port)
aufsummiert und nach der PROJECT_ID gruppiert. Nach erfolgter Aggregation werden die Daten in
die entsprechenden Ziele geschrieben, wie folgende Abbildung zeigt.
Abbildung 21: Fallbeispiel 5 – Ausgangsbeispiel - Aggregation SUM_COST_PER_PROJECT

ETL-Design Optimierung Seite 70 von 108
4.5.3.1 Gesamtübersicht Bevor Varianten des Ausgangsbeispiels vorgestellt werden, soll nun zuerst eine kurze Untersuchung
des vorliegenden Mappings stattfinden. Zur besseren Orientierung ist das vollständige Mapping in
folgender Abbildung dargestellt.
Abbildung 22: Fallbeispiel 5 – Ausgangsbeispiel - Gesamtübersicht
4.5.3.2 Erhebung der Maße des Ausgangsbeispiels
Quantitative Maße Zunächst werden die quantitativen Maße des Ausgangsbeispiels untersucht. Das Mapping ist etwas
komplexer als die vorherigen Beispiele. Informatica PowerCenter 8 bietet eine einfache Möglichkeit
des XML-Exports. Aus einer solchen XML Datei können alle Maße außer Datenmenge und Länge
einfach ermittelt und somit auch für sehr komplexe Mappings erhoben werden.
Datenmenge
Aus der Tabelle TASK_LOG gehen 1098106 Tupel in das Mapping ein. Aus TASK und PROJECTS
jeweils 133 beziehungsweise 57. In der ersten Joinertransformation werden die beiden letzteren zu 133
Tupel zusammengeführt. Anschließend werden in der zweiten Joinertransformation das Ergebnis der
ersten und die Tupel aus TASK_LOG zu 1098106 Zeilen verknüpft. In der ersten Aggregation werden
diese dann auf 72, in der zweiten Aggregation dann nochmal auf 49 Tupel reduziert. Diese
verbleibenden 49 Tupel werden anschließend auf 3 Ziele verteilt.
Anzahl der Knoten
Das Mapping besteht aus 15 Transformationen, was der Anzahl der Knoten entspricht.
Länge
Die maximale Anzahl an Weiterleitungen erfährt das Attribut PROJECT_ID aus der Tabelle
PROJECTS. Diese beträgt 8 und stellt die Länge des Mappings dar.
Komplexität
Die Komplexität, also die Anzahl der Kanten, mit denen die einzelnen Transformationen
untereinander verbunden sind, beträgt 55.
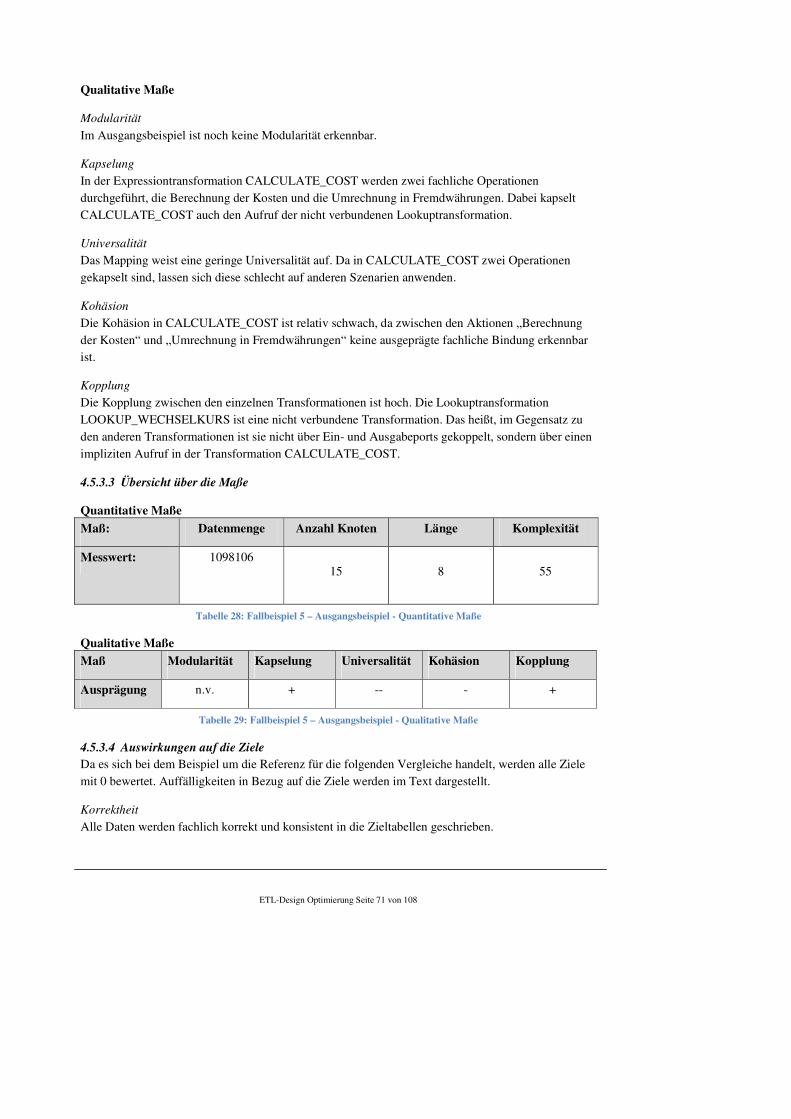
ETL-Design Optimierung Seite 71 von 108
Qualitative Maße
Modularität
Im Ausgangsbeispiel ist noch keine Modularität erkennbar.
Kapselung
In der Expressiontransformation CALCULATE_COST werden zwei fachliche Operationen
durchgeführt, die Berechnung der Kosten und die Umrechnung in Fremdwährungen. Dabei kapselt
CALCULATE_COST auch den Aufruf der nicht verbundenen Lookuptransformation.
Universalität
Das Mapping weist eine geringe Universalität auf. Da in CALCULATE_COST zwei Operationen
gekapselt sind, lassen sich diese schlecht auf anderen Szenarien anwenden.
Kohäsion
Die Kohäsion in CALCULATE_COST ist relativ schwach, da zwischen den Aktionen „Berechnung
der Kosten“ und „Umrechnung in Fremdwährungen“ keine ausgeprägte fachliche Bindung erkennbar
ist.
Kopplung
Die Kopplung zwischen den einzelnen Transformationen ist hoch. Die Lookuptransformation
LOOKUP_WECHSELKURS ist eine nicht verbundene Transformation. Das heißt, im Gegensatz zu
den anderen Transformationen ist sie nicht über Ein- und Ausgabeports gekoppelt, sondern über einen
impliziten Aufruf in der Transformation CALCULATE_COST.
4.5.3.3 Übersicht über die Maße
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
15 8 55
Tabelle 28: Fallbeispiel 5 – Ausgangsbeispiel - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung n.v. + -- - +
Tabelle 29: Fallbeispiel 5 – Ausgangsbeispiel - Qualitative Maße
4.5.3.4 Auswirkungen auf die Ziele Da es sich bei dem Beispiel um die Referenz für die folgenden Vergleiche handelt, werden alle Ziele
mit 0 bewertet. Auffälligkeiten in Bezug auf die Ziele werden im Text dargestellt.
Korrektheit
Alle Daten werden fachlich korrekt und konsistent in die Zieltabellen geschrieben.

ETL-Design Optimierung Seite 72 von 108
Wartbarkeit
Die Wartbarkeit des Mappings ist nicht optimal. Anzahl der Knoten, Länge und Komplexität sind
bezogen auf die gebotene Funktionalität recht hoch. Außerdem werden in CALCULATE_COST
Funktionen gekapselt, zwischen denen eine recht schwache Kohäsion herrscht.
Wiederverwendbarkeit
Das Mapping ist sehr spezifisch auf den Anwendungsfall zugeschnitten und daher schlecht
wiederverwendbar.
Performance
Die Performance wird erst im Vergleich mit den folgenden Varianten bewertet.
Zuverlässigkeit
Das Mapping ist von der Verfügbarkeit der Quellen und der Zielsysteme abhängig. Innerhalb des
Mappings gibt es keine Auffälligkeiten, die sich auf die Zuverlässigkeit auswirken könnten.
4.5.3.5 Zusammenfassung und Übersicht über die Ziele
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Tabelle 30: Fallbeispiel 5 – Ausgangsbeispiel - Zielerfüllung
Auffällig ist in dem vorliegenden Mapping, dass neun von fünfzehn Transformationen dazu benötigt
werden, die für die zu berechnenden Werte erforderlichen Daten zu extrahieren und
zusammenzuführen. Außerdem fällt auf, dass im Abstand von einer Transformation zwei Mal
aggregiert wird. Hier kann vermutet werden, dass diese Redundanz durch eine Zusammenfassung der
beiden Aggregationen behoben werden kann. Dies entspräche einem „Merge and Split“
Optimierungsansatz nach (Vassiliads, Simitsis, Terrovitis, & Skiadopoulos, 2005). In den folgenden
Varianten wird untersucht, ob dies möglich ist und wie sich dies auf das Mapping auswirkt.
In dem entwickelten Mapping muss die Lookup Operation auf jedem der betroffenen Ports für jede
Zeile der eingehenden Daten durchgeführt werden.
4.5.4 Variante 1 - Merge and Split In der ersten Variante des eingeführten Beispiels sollen die Aggregation und die Kalkulation
überarbeitet werden. Dies geschieht auf Grundlage des Ausgangsbeispiels. Dort wurden zuerst in der
Aggregation SUM_HOURS_PER_PROJECT die geleisteten Stunden gruppiert nach PROJECT_ID
und nach dem Kostenfaktor COSTCODE summiert. Danach wurden die aufsummierten Stunden
zusammen mit dem Kostenfaktor in die Berechnung der Kosten einbezogen. Anschließend wurde
durch eine weitere Aggregation SUM_COST_PER_PROJECT die Summe der Kosten diesmal
ausschließlich nach PROJECT_ID gruppiert gebildet. Aufgrund der großen örtlichen und fachlichen
Nähe der beiden Aggregationstransformationen ist die Überlegung einer Zusammenfassung beider
naheliegend. Dieses Vorgehen entspricht dem „Merge and Split“ Ansatz der Optimierungsansätze aus
(Vassiliads, Simitsis, Terrovitis, & Skiadopoulos, 2005), wobei hier ein Merge, also eine
Zusammenfassung durchgeführt wird. Die Zusammenfassung erfordert zusätzlich einen
Positionstausch beziehungsweise „Swap“, da die Kalkulation, die in der Expressiontransformation
CALCULATE_COST vorgenommen wird, dann vor der Aggregation stattfinden muss. Der

ETL-Design Optimierung Seite 73 von 108
Positionstausch oder „Swap“ gehört ebenfalls zu den in (Vassiliads, Simitsis, Terrovitis, &
Skiadopoulos, 2005) beschriebenen Optimierungsmaßnahmen.
In der ersten Variante soll nun überprüft werden, welche Auswirkungen diese Veränderungen auf die
angestrebten Ziele haben.
Ausgangssituation Ausgegangen wird von dem Aggregations- und Kalkulationsabschnitt aus dem Ausgangsbeispiel:
Abbildung 23: Fallbeispiel 5 – Variante 1 - Ausgangssituation mit zwei Aggregationen
Die Anordnung der Transformationen wurde bei der Vorstellung des Ausgangsbeispiels begründet.
Zielsituation der Variante 1 In Variante 1 soll die Zahl der Aggregationen durch Zusammenfassung reduziert werden. Wenn die
Summierung der Stunden und der Kosten in einer Aggregationstransformation berechnet werden
sollen, müssen folglich die Kosten vorher für jeden Eintrag in TASK_LOG.TASK_LOG_HOURS
unter Berücksichtigung des jeweiligen Faktors COSTCODE kalkuliert werden.
Abbildung 24: Fallbeispiel 5 – Variante 1 - Zielsituation mit einer Aggregation

ETL-Design Optimierung Seite 74 von 108
Expressiontransformation Dies erfordert eine Anpassung der Expressiontransformation CALCULATE_COST. Nachfolgend ist
die geänderte Transformation abgebildet.
Abbildung 25: Fallbeispiel 5 – Variante 1 - Kostenkalkulation auf Basis der TASK_LOG Einträge
Wieder enthält die Transformation drei Ausgabeports, COST_PER_TASK_LOG für die Kosten pro
Eintrag in TASK_LOG in Euro sowie COST_IN_DOLLAR und COST_IN_FRANKEN für die
beiden Fremdwährungen.
Die Formel zur Berechnung der Kosten ist in dieser Variante der aus dem Ausgangsbeispiel sehr
ähnlich. Sie unterscheiden sich jedoch darin, dass nicht wie zuvor die bereits aggregierten Stunden zur
Berechnung der Kosten herangezogen werden, sondern diese für jede Zeile auf Basis des Attributs
TASK_LOG_HOURS vorgenommen wird. Hieraus ergibt sich für die Eurowerte die Formel
TASK_LOG_HOURS * FACTOR_COSTCODE
Für die Fremdwährungen wird zusätzlich der Wechselkurs über Aufruf des nicht verbundenen
Lookups als Faktor in die Berechnung einbezogen, woraus sich folgende Formel ergibt:
TASK_LOG_HOURS * FACTOR_COSTCODE * :LKP.LOOKUP_WECHSELKURS('Währung')
Die Expression unterscheidet sich also nur durch das Attribut, das in die Berechnung eingeht. Als
Ergebnis ist jede Zeile der Daten um die Attribute für die Kosten erweitert.
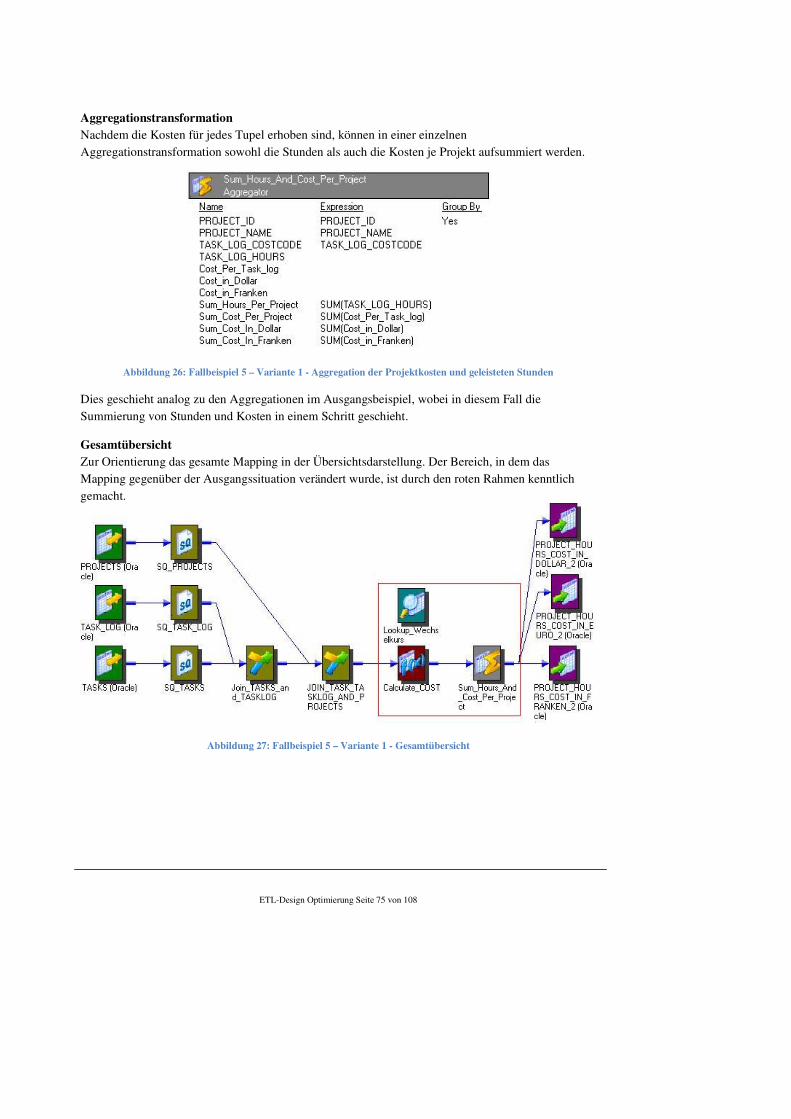
ETL-Design Optimierung Seite 75 von 108
Aggregationstransformation Nachdem die Kosten für jedes Tupel erhoben sind, können in einer einzelnen
Aggregationstransformation sowohl die Stunden als auch die Kosten je Projekt aufsummiert werden.
Abbildung 26: Fallbeispiel 5 – Variante 1 - Aggregation der Projektkosten und geleisteten Stunden
Dies geschieht analog zu den Aggregationen im Ausgangsbeispiel, wobei in diesem Fall die
Summierung von Stunden und Kosten in einem Schritt geschieht.
Gesamtübersicht Zur Orientierung das gesamte Mapping in der Übersichtsdarstellung. Der Bereich, in dem das
Mapping gegenüber der Ausgangssituation verändert wurde, ist durch den roten Rahmen kenntlich
gemacht.
Abbildung 27: Fallbeispiel 5 – Variante 1 - Gesamtübersicht

ETL-Design Optimierung Seite 76 von 108
4.5.4.1 Erhebung der Maße für Variante 1
Quantitative Maße
Datenmenge
Die 57 Tupel aus Projects werden mit den 133 aus TASKS und den 1098106 aus TASK_LOG in 2
Joinertransformationen zusammengeführt. Danach werden 1098106 Tupel weiterverarbeitet. Alle
Zeilen gehen in die Berechnung der Kosten CALCULATE_COST ein. Danach wird die Anzahl der
Zeilen in der Aggregation SUM_HOURS_AND_COST_PER_PROJECT auf 49 reduziert. Die
verbliebenen Tupel werden anschließend in drei Ziele geschrieben.
Anzahl der Knoten
Die Anzahl der Knoten ist von 15 auf 14 um 1 Knoten reduziert.
Länge
Das Attribut mit der bisher größten Anzahl an Weiterleitungen, PROJECT_ID, wurde auch durch die
weggefallene Transformation geleitet. Daher reduziert sich die Länge um 1 auf nun 7.
Komplexität
Durch die Reduktion um eine Transformation wird auch die Komplexität reduziert. Diese beträgt jetzt
44.
Qualitative Maße
Modularität
Bei der Variation werden keine Module erstellt. Daher ist unverändert keine Modularität vorhanden.
Kapselung
Die Expressiontransformation CALCULATE_COST kapselt nach wie vor Funktionalität. Da sich nur
das Attribut, auf dem die Operationen durchgeführt werden, verändert hat, bleibt die Kapselung gleich.
Universalität
Die Änderungen führten zu keiner Verstärkung der Universalität. Genau wie das Ausgangsbeispiel ist
auch diese Variante sehr spezifisch auf den Anwendungsfall abgestimmt.
Kohäsion
CALCULATE_COST zeigt eine schwache Kohäsion bezüglich der enthaltenen Operationen
Kostenberechnung und Währungsumrechnung.
Kopplung
Die einzelnen Transformationen sind stark gekoppelt, intermodulare Kopplung ist nicht erkennbar.

ETL-Design Optimierung Seite 77 von 108
4.5.4.2 Übersicht über die Maße
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
eingehende Tupel
49 nach
Aggregation
14 7 44
Tabelle 31: Fallbeispiel 5 – Variante 1 - Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung n.v. + -- - +
Tabelle 32: Fallbeispiel 5 – Variante 1 - Qualitative Maße
4.5.4.3 Auswirkungen auf die Ziele
Korrektheit
Diese Variante führt die Operationen korrekt durch.
Wartbarkeit
Da sich die Maße nur unwesentlich geändert haben, ist die Wartbarkeit von den Anpassungen
unbeeinflusst. Der minimal positive Einfluss durch die Reduktion quantitativer Maße ist hier
vernachlässigbar.
Wiederverwendbarkeit
Die Variante ist unverändert schlecht bezüglich ihrer Wiederverwendbarkeit.
Performance
Die Reduktion an Knoten und Komplexität lässt vermuten, dass sich die vorgenommenen Änderungen
positiv im Vergleich zum Ausgangsbeispiel auswirken. Für eine genaue Beurteilung müssen allerdings
die durchgeführten Operationen und die jeweilig zu bearbeitenden Daten betrachtet werden.
Beide Beispiele unterscheiden sich dadurch, dass im Ausgangsbeispiel zuerst eine Aggregation auf
Projekte und Kostenfaktor vorgenommen wird und danach auf Basis dieser voraggregierten Daten die
die Kosten berechnet werden. Die Aggregation ist eine aktive Transformation, sie verringert die
Anzahl der Zeilen und damit die Menge der zu verarbeitenden Daten. Im vorliegenden Beispiel
werden 1098106 Tupel aus den Quellen extrahiert. In der angepassten Variante werden für jedes dieser
Tupel die drei notwendigen Berechnungen durchgeführt. Insgesamt wird die Formel zur Berechnung
der Kosten 3294318-mal durchgeführt. Zusätzlich muss für jede dieser Berechnungen per
Lookuptransformation LOOKUP_WECHSELKURS der jeweilige Wechselkurs nachgeschlagen
werden.
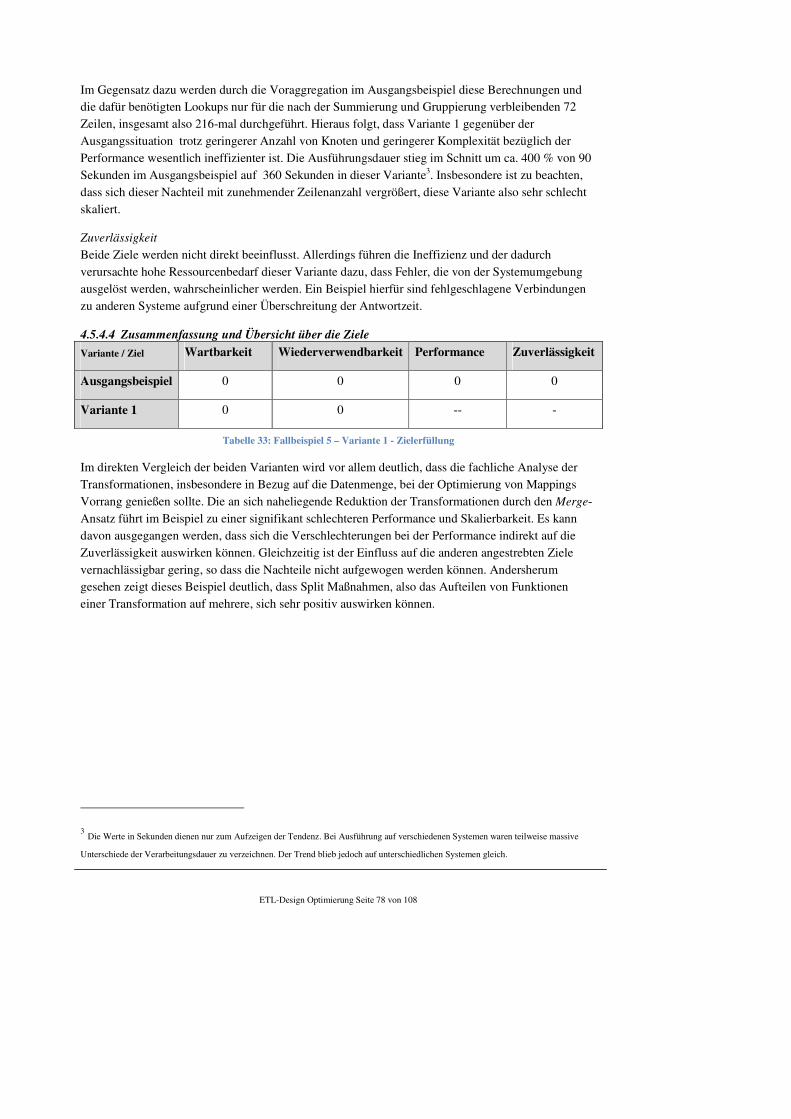
ETL-Design Optimierung Seite 78 von 108
Im Gegensatz dazu werden durch die Voraggregation im Ausgangsbeispiel diese Berechnungen und
die dafür benötigten Lookups nur für die nach der Summierung und Gruppierung verbleibenden 72
Zeilen, insgesamt also 216-mal durchgeführt. Hieraus folgt, dass Variante 1 gegenüber der
Ausgangssituation trotz geringerer Anzahl von Knoten und geringerer Komplexität bezüglich der
Performance wesentlich ineffizienter ist. Die Ausführungsdauer stieg im Schnitt um ca. 400 % von 90
Sekunden im Ausgangsbeispiel auf 360 Sekunden in dieser Variante3. Insbesondere ist zu beachten,
dass sich dieser Nachteil mit zunehmender Zeilenanzahl vergrößert, diese Variante also sehr schlecht
skaliert.
Zuverlässigkeit
Beide Ziele werden nicht direkt beeinflusst. Allerdings führen die Ineffizienz und der dadurch
verursachte hohe Ressourcenbedarf dieser Variante dazu, dass Fehler, die von der Systemumgebung
ausgelöst werden, wahrscheinlicher werden. Ein Beispiel hierfür sind fehlgeschlagene Verbindungen
zu anderen Systeme aufgrund einer Überschreitung der Antwortzeit.
4.5.4.4 Zusammenfassung und Übersicht über die Ziele
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Variante 1 0 0 -- -
Tabelle 33: Fallbeispiel 5 – Variante 1 - Zielerfüllung
Im direkten Vergleich der beiden Varianten wird vor allem deutlich, dass die fachliche Analyse der
Transformationen, insbesondere in Bezug auf die Datenmenge, bei der Optimierung von Mappings
Vorrang genießen sollte. Die an sich naheliegende Reduktion der Transformationen durch den Merge-
Ansatz führt im Beispiel zu einer signifikant schlechteren Performance und Skalierbarkeit. Es kann
davon ausgegangen werden, dass sich die Verschlechterungen bei der Performance indirekt auf die
Zuverlässigkeit auswirken können. Gleichzeitig ist der Einfluss auf die anderen angestrebten Ziele
vernachlässigbar gering, so dass die Nachteile nicht aufgewogen werden können. Andersherum
gesehen zeigt dieses Beispiel deutlich, dass Split Maßnahmen, also das Aufteilen von Funktionen
einer Transformation auf mehrere, sich sehr positiv auswirken können.
3 Die Werte in Sekunden dienen nur zum Aufzeigen der Tendenz. Bei Ausführung auf verschiedenen Systemen waren teilweise massive
Unterschiede der Verarbeitungsdauer zu verzeichnen. Der Trend blieb jedoch auf unterschiedlichen Systemen gleich.

ETL-Design Optimierung Seite 79 von 108
4.5.5 Variante 2 - Modularisierung Im Ausgangsbeispiel und der ersten Variante fiel auf, dass die gravierendsten Veränderungen bei der
Performance auftraten. Die Einflüsse auf andere Designziele waren überwiegend gering. Im Folgenden
wird untersucht, welche Auswirkungen der Einsatz von Mapplets in dem bekannten Beispiel mit sich
bringt. Mapplets bieten die Möglichkeit der Modularisierung, wodurch vermutet werden kann, dass
sich ihr Einsatz auf die Wartbarkeit und Wiederverwendbarkeit auswirkt.
Auf Grundlage des Ausgangsbeispiels werden Transformationen zu Mapplets zusammengefasst und
die resultierenden Auswirkungen untersucht.
In der folgenden Abbildung sind die Transformationen gekennzeichnet, bei denen eine
Zusammenfassung aufgrund der fachlichen Zusammengehörigkeit auf den ersten Blick sinnvoll
erscheint.
Abbildung 28: Fallbeispiel 5 – Variante 2 – potentielle Mapplets
Für die Zusammenfassung von Transformationen zu Mapplets ist zuerst die Frage zu stellen, welche
Transformationen sich zu einer logischen Einheit gruppieren lassen. Grundsätzlich lassen sich alle
Transformationen außer Ziele in Mapplets integrieren.
Mapplet zum Extrahieren und Zusammenführen der Quellen Zuerst werden die Transformationen, die das Extrahieren und Zusammenführen der Quellen
durchführen, im Mapplet MPLT_EXTRACT_AND_JOIN_SOURCES zusammenfassend gekapselt.
Das hierfür verwendete Mapplet ist bereits aus der Einführung von Mapplets in Abschnitt 2.3.3
bekannt.

ETL-Design Optimierung Seite 80 von 108
Aggregation und Kalkulation der Projektkosten Anschließend werden innerhalb des Mapplets
MPLT_CALCULATE_COST_PER_PROJECT_AND_COSTCODE zuerst die Aggregation basierend
auf Project_id und Costcode und danach die Berechnung der Kosten in Euro für die Aggregate
durchgeführt.
Abbildung 29: Fallbeispiel 5 – Variante 2 – Mapplet
MLTP_CALCULATE_COST_PER_PROJECT_AND_COSTCODE zur Vorbereitung der Projektkosten
Die Berechnung der Kosten in Fremdwährungen findet hier nicht mehr innerhalb der Transformation
CALCULATE_COST statt. Stattdessen wird diese in ein eigenes Mapplet verlagert. Es wird also
zusätzlich zur Modularisierung auch eine Split-Optimierung vorgenommen.
Währungsumrechnung Nachdem die Kosten in Euro vorliegen, findet die Umrechnung in die beiden Fremdwährungen
innerhalb des Mapplets MPLT_CURRENCY_CONVERSION statt. Hier geht über die Input
Transformation des Mapplets das zuvor berechnete Attribut COST_PER_PROJECT ein. Innerhalb des
Mapplets werden in einer Expression Transformation die Fremdwährungen durch Bezug des
Wechselkurses mittels eines nicht verbundenen Lookups berechnet.
Abbildung 30: Fallbeispiel 5 – Variante 2 – Mapplet MLTP_CURRENCY_CONVERSION zur Berechnung der
Projektkosten in Fremdwährungen
Die danach folgende Aggregationstransformation SUM_COST_PER_PROJECT lässt sich nicht
sinnvoll einem der Mapplets zuweisen und liegt deshalb nach wie vor als Einzeltransformation vor. In
Ihr werden die Zeilen, die aus fachlichen Gründen momentan noch auf Basis der PROJECT_ID und

ETL-Design Optimierung Seite 81 von 108
des COSTCODE gruppiert sind, erneut aggregiert und diesmal ausschließlich nach der PROJECT_ID
gruppiert. Danach werden die aufbereiteten Daten in die Zieltabellen geschrieben.
Gesamtübersicht Das Ergebnis der Kapselungen ist folgendes Mapping mit den drei beschriebenen Mapplets.
Abbildung 31: Fallbeispiel 5 – Variante 2 – starke Kapselung durch den Einsatz von Mapplets
4.5.5.1 Erhebung der Maße für Variante 2
Quantitative Maße
Datenmenge
Aus TASK_LOG werden 1098106, aus TASKS 133 und aus PROJECTS 57 Zeilen gelesen. Nach dem
Joinen der Daten bleiben 1098106 Zeilen erhalten. Innerhalb des zweiten Mapplets
MPLT_CALCULATE_COST_PER_PROJECT_AND_COSTCODE werden die Daten in der
Aggregation SUM_HOURS_PER_PROJECT auf 72 Zeilen reduziert. Diese 72 Tupel gehen in die
Berechnung der Kosten und die Währungsumrechnung ein. In der Aggregation
SUM_COST_PER_PROJECT werden die Zeilen nochmals reduziert, so dass 49 verbleiben. Diese
werden jeweils in drei Ziele geschrieben.
Anzahl der Knoten
Bei der Verwendung von Mapplets muss deren Eigenschaft Inhalte zu verbergen berücksichtigt
werden. Auf den ersten Blick weist das Mapping in Variante drei 7 Knoten auf. Es müssen aber auch
die Transformationen berücksichtigt werden, die sich innerhalb der Mapplets befinden. Öffnet man die
einzelnen Mapplets und zählt die enthaltenen Transformationen zur Gesamtmenge hinzu, sind 24
Knoten zu zählen. Hierbei werden die Mapplets selbst auch mitgezählt.

ETL-Design Optimierung Seite 82 von 108
Länge
Bei externer Betrachtung ist die Länge 5 für das Attribut PROJECT_ID. Für eine interne Betrachtung
werden die Weiterleitungen innerhalb der Mapplets und die zwischen den Mapplets addiert. Hierbei
ergibt sich für das Attribut PROJECT_ID eine Länge von 11, die sich folgendermaßen
zusammensetzt: Mapplet 1 (MPLT_EXTRACT_AND_JOIN_SOURCES) 3 Weiterleitungen des
Attributs PROJECT_ID. Hinzu kommen 3 Weiterleitungen im zweiten Mapplet
(MPLT_CALCULATE_COST_PER_PROJECT_AND_COSTCODE) sowie 3 zwischen den
zwischen den Mapplets und den nicht in Mapplets gekapselten Transformationen.
Komplexität
Ebenso wie für die anderen quantitativen Maße müssen in der betrachteten Variante die
Besonderheiten von Mapplets beachtet werden. Die Komplexität stellt sich, ohne die innere
Implementierung der Mapplets zu betrachten, mit 23 Kanten als deutlich reduziert dar. Bezieht man
die Kanten innerhalb der Mapplets mit ein, ergibt sich aber eine Komplexität von 64, was eine
signifikante Erhöhung darstellt.
Qualitative Maße
Modularität
Jedes der Mapplets stellt ein Modul dar, die Variante weist also eine hohe Modularität auf.
Kapselung
Die Mapplets verbergen Transformationen und damit Funktionalität. Das erste Mapplet kapselt mit 6
Transformationen am stärksten. Die Mapplets zwei und drei beinhalten jeweils 2 Transformationen.
Insgesamt ist die Kapselung des Mappings bei Verwendung von Mapplets sehr stark.
Universalität
Das dritte Mapplet (CURRENCY_CONVERSION) ist sehr generell. Über eine eingehende
Schnittstelle kann ein numerischer Wert in das Mapplet geleitet werden. Dieses rechnet dann den
eingegebenen Wert in verschiedene Fremdwährungen um. Die innere Implementierung muss dabei
nicht bekannt sein, solange die angebotenen Währungen ausreichen.
Die anderen beiden Mapplets sind fallspezifischer, weisen also eine geringere Universalität auf.
Kohäsion
Die stärkste funktionale Kohäsion weist wiederum das dritte Mapplet auf. Die beiden darin
enthaltenen Transformationen dienen genau einer Funktion, nämlich der Währungsumrechung.
Das zweite Mapplet weist ebenfalls eine recht starke, funktionale Kohäsion auf. Die beiden
enthaltenen Transformationen (Aggregation auf Projektebene und Berechnung der Kosten) dienen der
Berechnung der Projektkosten in Euro. Die Kohäsion ist allerdings nicht so ausgeprägt wie die des
dritten Mapplets, da die starke Kohäsion nur innerhalb des Anwendungskontextes zu beobachten ist.
Die schwächste Kohäsion weist das erste Mapplet zur Zusammenführung der Quellen auf. Zwar
besteht zwischen den Transformationen ein funktionaler Zusammenhang, dies gilt allerdings
ausschließlich in diesem konkreten Beispielkontext.
Kopplung
Auf Transformationsebene ist die Kopplung gegenüber dem Ausgangsbeispiel unverändert.
Auf Mappletebene dagegen lassen sich interessante Auswirkungen auf die Kopplung feststellen. Das

ETL-Design Optimierung Seite 83 von 108
erste Mapplet EXTRACT_AND_JOIN_SOURCES weist mit vier verbundenen Ports eine starke
ausgehende Kopplung auf. Eingehende Kopplung liegt nicht vor, da in dem Mapplet die Quellen
enthalten sind. CALCULATE_COST_PER_PROJECT_AND_COSTCODE ist sowohl eingehend als
auch ausgehend stark gekoppelt. Eingehende und ausgehende Kopplung sind mit jeweils vier
verbundenen Ports gleich. Das Mapplet CURRENCY_CONVERSION besitzt dagegen mit nur einer
eingehenden Kante eine sehr schwache eingehende Kopplung. Die ausgehende Kopplung beträgt im
Beispiel drei. Da sie der Anzahl der berechneten Währungen entspricht, kann diese sich in
verschiedenen Szenarien ändern. Das Verhältnis zwischen eingehender und ausgehender Kopplung ist
für das Mapplet zur Währungsumrechung sehr günstig, da nur ein eingehender Wert benötigt wird, um
daraus viele Werte zu berechnen. Für das gesamte Mapping wird die Kopplung aufgrund dieser
Beobachtungen als neutral gewertet.
4.5.5.2 Übersicht über die Maße Für die Unterscheidung der Betrachtungsebenen mit und ohne der inneren Implementierung der
Mapplets werden in den folgenden Tabellen die Bezeichnungen extern beziehungsweise intern
gewählt.
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
eingehende Tupel
72 nach erster
Aggregation
49 nach zweiter
Aggregation
Extern: 7
Intern: 24 11
Extern: 23
Intern: 64
Tabelle 34: Fallbeispiel 5 – Variante 2 – Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung ++ ++ + + 0
Tabelle 35: Fallbeispiel 5 – Variante 2 – Qualitative Maße
4.5.5.3 Parallelen zur Softwareentwicklung Bevor die Auswirkungen auf die Ziele analysiert werden, soll kurz der Vergleich zwischen ETL
Design beim Einsatz von Mapplets und der Softwaretechnik im Allgemeinen beziehungsweise der
objektorientierten Softwareentwicklung im Speziellen gezogen werden.
Mit Mapplets liegt ein Instrument zur Kapselung und Modularisierung von Mappings vor. Diese
beiden Prinzipien finden sich auch in der Softwaretechnik wieder, wo sie wichtige Kriterien für die
Wartbarkeit und Wiederverwendbarkeit für Software darstellen.

ETL-Design Optimierung Seite 84 von 108
Kapselung in der objektorientierten Programmierung In der objektorientierten Programmierung (OOP) können einem Objekt beziehungsweise seinen
Methoden Parameter übergeben werden, die dann verarbeitet werden. Das Ergebnis wird anschließend
über den Returnwert zurückgegeben. Wichtiges Prinzip in diesem Zusammenhang ist das
Geheimnisprinzip, auch „information hiding“ (Parnas, 1971) genannt. Es besagt, dass auf Attribute
oder Methoden nur über definierte Schnittstellen zugegriffen werden kann. Durch Einhaltung des
Geheimnisprinzips wird verhindert, dass Attribute unerwartet geändert werden oder auf nicht
vorgesehene Weise auf Methoden zugegriffen wird. Außerdem resultiert daraus, dass Klassen
beziehungsweise deren Methoden geändert werden können, ohne dass die Interaktion mit anderen
Klassen davon beeinträchtigt wird (Balzert H. , 2005). Neben diesen positiven Effekten verbessert sich
durch die Modularisierung die Testfähigkeit einer Software. Dementsprechend sind die Hauptvorteile,
die sich in der objektorientierten Programmierung hieraus ergeben, Verbesserung der Wartbarkeit und
Zuverlässigkeit. Zur Beurteilung von Softwarequalität werden unter anderem die Maße Kohäsion und
Kopplung herangezogen. Die Kohäsion beschreibt dabei die Aufgabenspezifität eines Moduls, die
Kopplung die Art, in der die Module über Schnittstellen miteinander verbunden sind. Beide Maße
wurden in Abschnitt 3.2.3 bereits vorgestellt und im gerade gezeigten Beispiel auf Mapplets
übertragen.
Kapselung in Mappings durch Mapplets Mapplets verhalten sich in vielen Punkten ähnlich wie Klassen beziehungsweise die daraus
abgeleiteten Objekte. In ihnen werden Transformationen gekapselt und somit nach außen verborgen.
Ein Mapplet bildet somit ein Modul. Durch die definierten Eingabe- und Ausgabetransformationen,
Input und Output, wird ein Zugriff auf das Mapplets ermöglicht. Im Unterschied zur objektorientierten
Softwareentwicklung bietet ein Mapplet immer nur eine Inputtransformation als Schnittstelle zu allen
im Mapplet enthaltenen Transformationen. Es gibt also keine Möglichkeit, über weitere Schnittstellen
direkt auf einzelne Transformationen innerhalb des Mapplets zuzugreifen. In der OOP wäre dies über
Accessoren möglich. Daraus folgt, dass sich Input- und Outputtransformationen wie als „public“
deklarierte Methoden verhalten. Alle anderen in einem Mapplet enthaltenen Transformationen können
als „private“ betrachtet werden.
Im Umgang mit Mapplets ist es empfehlenswert, eine möglichst hohe Aufgabenspezifität zu verfolgen.
Das heißt, ein Mapplet sollte genau eine, wohldefinierte Aufgabe erfüllen. Hierdurch kann analog zur
Softwaretechnik die Kohäsion möglichst stark gehalten werden. Gleichzeitig sollte auf eine geringe
Kopplung geachtet werden. Bei starker Kohäsion wird die Zahl der Attribute, die in einem Mapplet
verarbeitet werden sollen, überschaubar sein. Hierdurch kann die Zahl der eingehenden Ports
übersichtlich gehalten werden. Zu beachten ist eine Anforderung aktiver Mapplets, also solcher, die
aktive Transformationen enthalten. Für diese gilt, dass alle Attribute, die nach dem Mapplet weiter
verarbeitet werden sollen, durch das Mapplet hindurch geführt werden müssen (Informatica,
PowerCenter Transformation Guide, 2006).
4.5.5.4 Auswirkungen auf die Ziele
Korrektheit
Die eingesetzten Mapplets dienen rein als strukturierende Elemente, durch die das Mapping
Modularität erhält. Innerhalb der Mapplets werden die gleichen Transformationen durchgeführt.
Mapplets wirken sich daher nicht direkt auf die Korrektheit aus.

ETL-Design Optimierung Seite 85 von 108
Wartbarkeit
Mapplets, wie sie in diesem Beispiel zum Einsatz kommen, haben großen Einfluss auf die
Wartbarkeit. Mit ihnen ist eine Strukturierung von Mappings möglich, außerdem verbergen sie
Komplexität. Ob sich Ihr Einsatz positiv oder negativ auf die Wartbarkeit auswirkt, hängt maßgeblich
vom angemessenen Einsatz ab. Der richtige Einsatz lässt sich jedoch nicht objektiv bestimmen,
sondern muss im Einzelfall kritisch hinterfragt werden.
Im gewählten Beispiel wurde bewusst ein übertriebener Einsatz von Mapplets vorgenommen. Daran
kann analysiert werden, wann der Einsatz sinnvoll ist und wann nicht. Es wurde bereits angesprochen,
dass zu einer Verbesserung der Wartbarkeit Mapplets fachlich zusammengehörige Transformationen
kapseln sollten. Im vorliegenden Beispiel sind dies die Datenvorbereitung, die im Mapplet
MPLT_EXTRACT_AND_JOIN_SOURCES stattfindet, die Berechnung der Kosten auf
voraggregierter Ebene im Mapplet
MPLT_CALCULATE_COST_PER_PROJECT_AND_COSTCODE sowie die Währungsumrechung
im Mapplet MPLT_CURRENCY_CONVERSION.
Eine Zusammenfassung von Datenzielen in Mapplets ist in Informatica PowerCenter nicht möglich,
sonst hätte hierdurch das gesamte Mapping auf Mapplets verteilt werden können, so dass auf höchster
Ebene keine Transformationen mehr sichtbar sind.
Aufgrund des überschaubaren Umfangs des Beispiels wird die Übersichtlichkeit durch die
Modularisierung nicht entscheidend verbessert. In der Praxis können die Anforderungen jedoch so
komplex sein, dass sie sich in einfachen Mappings nicht mehr übersichtlich abbilden lassen. In diesem
Falle ist es dringend zu empfehlen, fachkonzeptionelle Aufgaben in Mapplets zu kapseln.
Bei der Findung des richtigen Maßes an fachlicher Kapselung hilft eine Bewertung von Kohäsion und
Kopplung. Liegt zwischen einzelnen Transformationen eine starke Kohäsion vor, sollte die
Zusammenfassung dieser in einem Mapplet auch bei einer nicht kritischen Anzahl an Knoten im
gesamten Mapping erfolgen.
Neben der erhöhten Übersichtlichkeit gibt es die Möglichkeit, durch die Verlagerung von Mappings in
verschiedene Ordner die Zugriffsrechte zu beschränken und somit bei größeren Teams den
Mitgliedern nur Zugriff auf Mapplets, die ihren fachlichen Bereich repräsentieren, zu gewähren.
Hierdurch können bei der Wartung eventuelle Sicherheitsrichtlinien eingehalten werden. Außerdem
wird die Gefahr einer versehentlichen Änderung von Mapplets, für die ein anderes Teammitglied
zuständig ist, verhindert.
Wiederverwendbarkeit
Auch auf die Wiederverwendbarkeit haben Mapplets großen Einfluss. Durch die Zusammenfassung
und Kapselung von Transformationen können häufig wiederkehrende Anwendungsfälle mit einem
Mapplet als Modul hinterlegt werden und so in verschiedenen Szenarien zum Einsatz kommen. Wie
Transformationen können auch Mapplets als „reusable“ deklariert werden. Dies bietet die
Möglichkeit, ein Mapplet in verschiedenen Mappings zu instanziieren. Für Mappletinstanzen gelten
die gleichen Prinzipien wie bei als „reusable“ gekennzeichneten Transformationen. Als Module
können Mapplets die Wiederverwendbarkeit beträchtlich verbessern. Das eingesetzte Mapplet
MPLT_CURRENCY_CONVERSION zum Beispiel kann in dieser Form auch in anderen Mappings,
in denen eine Währungsumrechnung notwendig ist, verwendet werden. Das genannte Mapplet ist
insbesondere aufgrund seiner starken Kohäsion und seiner geringen Kopplung für Wiederverwendung
geeignet. Es wird auf Inputseite nur ein Wert benötigt, der innerhalb des Mapplets umgerechnet

ETL-Design Optimierung Seite 86 von 108
werden soll. Ausgegeben werden nur die umgerechneten Werte in den entsprechenden Währungen.
Die eingehende Kopplung ist also 1, die ausgehende ist dynamisch .
Dies ist ein sehr guter Wert. Vor allem die geringe eingehende Kopplung ist ein Indikator für die
potentiell gute Wiederverwendbarkeit und einfache Wartbarkeit.
Bei dem Mapplet MPLT_CALCULATE_COST_PER_PROJECT_AND_COSTCODE ist eine solch
geringe Kopplung nicht zu erreichen. Da innerhalb des Mapplets eine Aggregation durchgeführt wird,
womit es sich um ein aktives Mapplet handelt, müssen alle Ports durch das Mapplet hindurchgeführt
werden. Auch die Kohäsion ist in diesem Mapplet nicht ganz so stark, da mehrere Aufgaben, nämlich
die Berechnung der Kosten und die Aggregation, durchgeführt werden. Dadurch ist die
Wiederverwendbarkeit dieses Mapplets nicht so hoch wie die des Mapplets
MPLT_CURRENCY_CONVERSION.
Performance
Obwohl Mapplets die quantitativen Maße teilweise recht deutlich negativ beeinflussen, wirkt sich dies
nur unwesentlich auf die Performance aus. Auch das Aufteilen der Berechnungstransformation in zwei
Transformationen, jeweils zur Berechnung und zur Umrechnung, bringt keine Performancenachteile
mit sich.
Zuverlässigkeit
Mapplets als strukturierende Elemente beeinflussen die Zuverlässigkeit nicht.
4.5.5.5 Übersicht über die Ziele und Zusammenfassung
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Variante 1 0 0 -- -
Variante 2 + + 0 0
Tabelle 36: Fallbeispiel 5 – Variante 2 – Zielerfüllung
Variante drei nutzt intensiv das Konzept von Mapplets. Erste Auffälligkeit beim Einsatz von Mapplets
ist, dass die Komplexität stark verborgen wird. Die Zahl der sichtbaren Knoten und Kanten sinkt.
Allerdings wird durch den Einsatz von Mapplets keine echte Reduktion an Knoten und Komplexität
erzielt, sondern das Gegenteil ist der Fall. Durch die zusätzlichen Input und Output Transformationen
und die Mapplets selbst steigen beide Maße deutlich an.
Durch den Einsatz der Mapplets wird das Mapping also technisch komplexer und zugleich deutlich
übersichtlicher. Allerdings ist im Beispiel erkennbar, dass ein übertriebener Einsatz von Mapplets
durch die steigende Intransparenz die Vorteile in Bezug auf die Wartbarkeit verringern oder sogar
ganz aufwiegen kann.
Bemerkenswert ist, dass Mapplets sich bezüglich der Performance als neutral darstellen. Ihr Einsatz
und die damit verbundenen Verbesserungen bezüglich Wartbarkeit und Wiederverwendbarkeit bringen
also keine Wechselwirkung in Bezug auf dieses Ziel mit sich.

ETL-Design Optimierung Seite 87 von 108
4.5.6 Variante 3 - Parameter und Sortierungen In einer letzten Variante des bekannten Beispiels sollen zwei weitere Konzepte untersucht werden.
Zum einen Parameter, die dazu dienen, Transformationen dynamisch an Bedingungen anpassen zu
können. Außerdem soll untersucht werden, welche Auswirkungen eine Sortierung von Daten hat.
Parameter Wie bereits in der Einführung zu Informatica erklärt, dienen Parameter dazu, Werte, die sich häufig
ändern, zur Laufzeit zu definieren. Sie können hierbei in Mapplets, Mappings, Sessions und
Workflows eingesetzt werden. Werden Parameter für ein Mapping definiert, können sie in
Transformationen abgefragt werden. Der jeweils konkrete Wert eines Parameters wird in einer
Parameterdatei eingetragen. Hierbei muss eine Syntax berücksichtigt werden, die im folgenden
Beispiel dargestellt wird.
In diesem Beispiel soll eine Filtertransformation parametrisiert werden, die aus TASK_LOG die Tupel
herausfiltert, die der Filterbedingung nicht entsprechen.
Hierfür wird zuerst für das Mapping ein Parameter unter Angabe seines Namens und Datentyps
festgelegt. Außerdem wird ein Defaultwert für den Parameter definiert. Dieser soll im Beispiel 0 sein.
Abbildung 32: Fallbeispiel 5 - Variante 3 - Filterparameter
Auf diesen Wert kann nun aus Transformationen zugegriffen werden, hier exemplarisch in einer
Filtertransformation. Hierfür wird in der Filterbedingung statt mit einem fixen Wert der Parameter
eingesetzt, so dass die Bedingung für unser Beispiel folgendermaßen aussieht:

ETL-Design Optimierung Seite 88 von 108
TASK_LOG_HOURS > $$Filtercondition
Mit Einsatz dieser Filterbedingung passieren nur noch Tupel, für die die Zahl der geleisteten Stunden
größer als der Filterparameter ist. Der Defaultwert 0 sorgt hierbei dafür, dass vorerst alle Tupel durch
den Filter gelangen. Sollen nun die Tupel restriktiver gefiltert werden und nur noch Tupel, die
beispielsweise TASK_LOG_HOURS > 5 aufweisen, weitergeleitet werden, kann ein neuer Wert in
der Parameterdatei eingetragen werden. Hierfür wird der jeweilige Wert des Parameters in einer
Parameterdatei eingetragen. Diese wird in den Einstellungen der Session, in der das Mapping
durchgeführt wird, referenziert. Die Syntax für das Parameterfile lautet dabei:
[foldername.session_name]
$$ParameterName=ParameterWert4
Im Beispiel dementsprechend:
[dotProject.s_caculate_cost_per_project_14]
$$Filtercondition=5
Die Verwendung eines Parameters macht die Transformation universeller, da nun die Filterbedingung
geändert werden kann, ohne auf das Mapping beziehungsweise den Informatica PowerCenter Designer
zugreifen zu müssen.
Parameter können außer in Transformationen auch für Mapplets, Sessions oder Workflows genutzt
werden.
Sorter Transformation Sortierte Daten können sich laut (Informatica, PowerCenter Transformation Guide, 2006) sehr positiv
auf die Performance verschiedener Transformationen, zum Beispiel Joiner- oder
Aggregationstransformationen, auswirken. Nachfolgend soll dies überprüft werden, indem in das
bekannte Mapping aus Fallbeispiel 5 vor der Aggregation SUM_HOURS_PER_PROJECT eine
Sortertransformation eingefügt wird. Es wird nach dem Attribut PROJECT_ID sortiert.
4 (Informatica, Workflow Administrator Guide 8.1, 2006)

ETL-Design Optimierung Seite 89 von 108
Gesamtübersicht Das Mapping sieht nach den vorgenommenen Änderungen wie in den Abbildungen 33 und 34
dargestellt aus. Da das Mapping zu umfangreich wurde, wird die Darstellung in 2 Abbildungen geteilt.
Abbildung 33: Fallbeispiel 5- Variante 3 - Teilabbildung 1
Abbildung 34: Fallbeispiel 5- Variante 3 - Teilabbildung 2

ETL-Design Optimierung Seite 90 von 108
4.5.6.1 Erhebung der Maße für Variante 3
Quantitative Maße
Datenmenge
Wie in den anderen Varianten werden aus TASK_LOG 1098106, aus TASKS 133 und aus
PROJECTS 57 Zeilen gelesen. Nach dem Joinen der Daten bleiben 1098106 Zeilen erhalten. Den
Filter FILTER_TASK_LOG_HOURS passieren für die Bedingung „TASK_LOG_HOURS > 5“ 350
Tupel, 1097756 werden verworfen. Anschließend reduziert die Aggregation
SUM_HOURS_PER_PROJECT die Zeilen auf 72. In der Aggregation SUM_COST_PER_PROJECT
werden die Zeilen nochmals reduziert, so dass 49 verbleiben. Diese werden jeweils in drei Ziele
geschrieben.
Anzahl der Knoten
Direkt ersichtlich sind 17 Knoten. Innerhalb des Mapplets sind noch einmal 4 Transformationen
integriert. Hieraus ergibt sich eine Gesamtzahl von 21 Knoten.
Länge
Die maximale Zahl an Weiterleitungen erfährt das Attribut PROJECT_ID. Da dieses nicht durch das
Mapplet zur Währungsumrechnung geführt wird, muss diese Ebene nicht betrachtet werden. Durch die
zusätzliche Sortertransformation steigt die Länge des Mappings auf 9.
Komplexität
Die Transformationen sind über 56 direkt ersichtliche so wie 4 im Mapplet verborgene Kanten
verbunden. Hieraus ergibt sich eine Gesamtkomplexität von 60 Kanten.
Qualitative Maße
Modularität
Die Modularität ist zwar nicht mehr so hoch wie in Variante 2, allerdings durch den Einsatz des
Mapplets zur Währungsumrechnung höher als im Ausgangsbeispiel.
Kapselung
Die Kapselung ist deutlich geringer als in Variante 2. Durch den Einsatz des Mapplets ist sie aber
höher als im Ausgangsbeispiel.
Universalität
Zwei Eigenschaften sorgen für eine hohe Universalität dieser Variante. Die Parametrisierung des
Filters und das eingesetzte Mapplet.
Kohäsion
Die Kohäsion des Mapplets MPLT_CURRENCY_CONVERSION wurde bereits in der
vorangegangenen Variante untersucht. Da hier eine Instanz desselben integriert wurde, hat sich an
diesem Maß nichts verändert. Die übrigen Transformationen weisen jeweils nur eine Funktion auf,
was die Betrachtung der Kohäsion an dieser Stelle überflüssig macht.
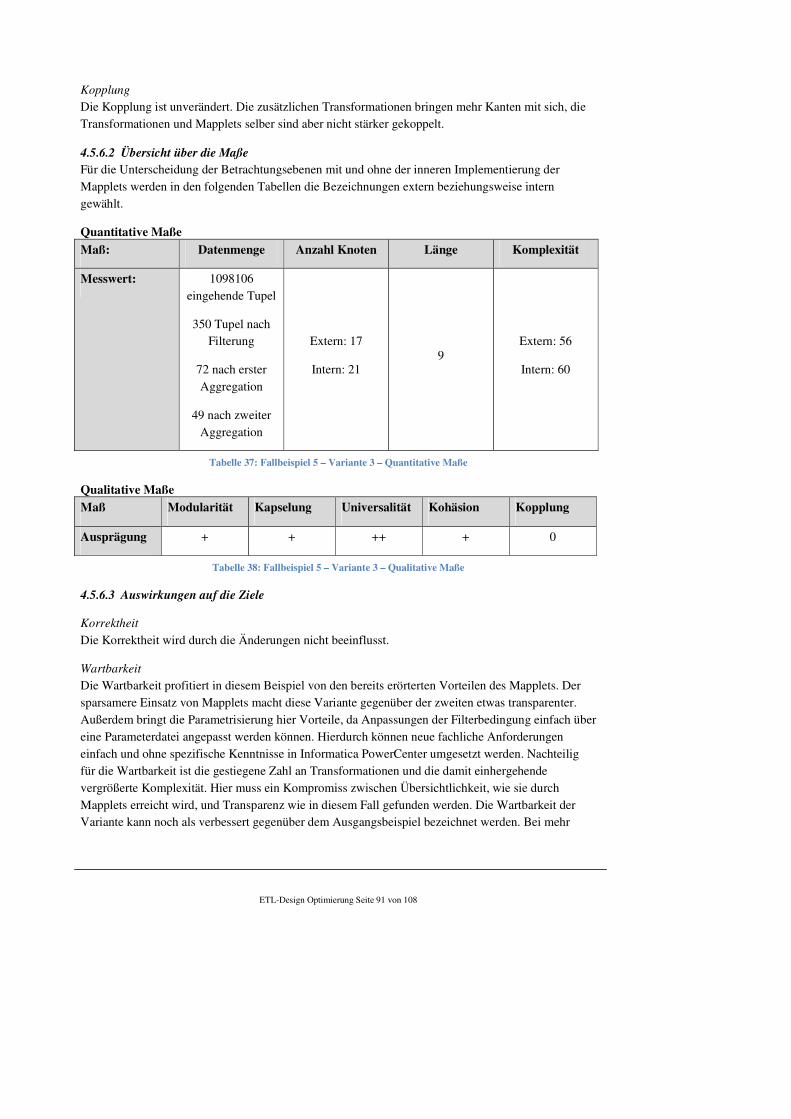
ETL-Design Optimierung Seite 91 von 108
Kopplung
Die Kopplung ist unverändert. Die zusätzlichen Transformationen bringen mehr Kanten mit sich, die
Transformationen und Mapplets selber sind aber nicht stärker gekoppelt.
4.5.6.2 Übersicht über die Maße Für die Unterscheidung der Betrachtungsebenen mit und ohne der inneren Implementierung der
Mapplets werden in den folgenden Tabellen die Bezeichnungen extern beziehungsweise intern
gewählt.
Quantitative Maße
Maß: Datenmenge Anzahl Knoten Länge Komplexität
Messwert: 1098106
eingehende Tupel
350 Tupel nach
Filterung
72 nach erster
Aggregation
49 nach zweiter
Aggregation
Extern: 17
Intern: 21 9
Extern: 56
Intern: 60
Tabelle 37: Fallbeispiel 5 – Variante 3 – Quantitative Maße
Qualitative Maße
Maß Modularität Kapselung Universalität Kohäsion Kopplung
Ausprägung + + ++ + 0
Tabelle 38: Fallbeispiel 5 – Variante 3 – Qualitative Maße
4.5.6.3 Auswirkungen auf die Ziele
Korrektheit
Die Korrektheit wird durch die Änderungen nicht beeinflusst.
Wartbarkeit
Die Wartbarkeit profitiert in diesem Beispiel von den bereits erörterten Vorteilen des Mapplets. Der
sparsamere Einsatz von Mapplets macht diese Variante gegenüber der zweiten etwas transparenter.
Außerdem bringt die Parametrisierung hier Vorteile, da Anpassungen der Filterbedingung einfach über
eine Parameterdatei angepasst werden können. Hierdurch können neue fachliche Anforderungen
einfach und ohne spezifische Kenntnisse in Informatica PowerCenter umgesetzt werden. Nachteilig
für die Wartbarkeit ist die gestiegene Zahl an Transformationen und die damit einhergehende
vergrößerte Komplexität. Hier muss ein Kompromiss zwischen Übersichtlichkeit, wie sie durch
Mapplets erreicht wird, und Transparenz wie in diesem Fall gefunden werden. Die Wartbarkeit der
Variante kann noch als verbessert gegenüber dem Ausgangsbeispiel bezeichnet werden. Bei mehr

ETL-Design Optimierung Seite 92 von 108
Transformationen sollte aber über eine Modularisierung nachgedacht werden, damit die Zahl der
sichtbaren Knoten überschaubar bleibt.
Wiederverwendbarkeit
Die parametrisierte Filterfunktion ist für Szenarien, in denen das gleiche Attribut behandelt wird, gut
wiederverwendbar. Der Vorteil des Mapplets, welches in dieser Variante bereits wiederverwendet
wurde, wurde bereits in Variante 2 geschildert und gilt in diesem Beispiel auch. Damit ist die
Wiederverwendbarkeit dieser Variante sehr hoch.
Performance
Im vorliegenden Mapping sind mit der Filter- und der Sortertransformation zwei Veränderungen, die
Auswirkungen auf die Performance haben, vorgenommen worden. Dass der Filter durch Reduktion
der Daten Performancevorteile bewirkt ist nach den ersten Fallbeispielen bekannt. Allerdings würde
dies auch eine fachliche Änderung des Mappings bedeuten, weswegen die Filtertransformation für die
Messung der Performance aus dem Datenfluss entfernt wurde. Die Untersuchung der Auswirkung
einer Vorsortierung ist dagegen legitim, da diese keine fachlichen Auswirkungen hat. Durch die
Vorsortierung verbessert sich die Performance um ca. 10%. Weitere Verbesserungen sind denkbar,
wenn vor den Joinertransformationen auch Sorter eingefügt würden.
Zuverlässigkeit
Die Zuverlässigkeit wird von den Änderungen in Variante 3 nicht beeinflusst.
4.5.6.4 Übersicht über die Ziele und Zusammenfassung
Variante / Ziel Wartbarkeit Wiederverwendbarkeit Performance Zuverlässigkeit
Ausgangsbeispiel 0 0 0 0
Variante 1 0 0 -- -
Variante 2 + + 0 0
Variante 3 + ++ + 0
Tabelle 39: Fallbeispiel 5 – Variante 3 – Zielerfüllung
Zusammenfassend bringt der Einsatz von Parametern Vorteile in Bezug auf die Wartbarkeit und
Wiederverwendbarkeit, ohne gleichzeitig Wechselwirkungen mit anderen Zielen zu verursachen.
Eine Vorsortierung bewirkt zusätzlich deutliche Performancevorteile, wenn sie vor Transformationen
eingesetzt wird, die von sortierten Daten profitieren. Beispiele hierfür sind Aggregations- und auch
Joinertansformationen. Hierbei ist aber zu beachten, dass Sortierung zusätzliche Knoten erfordert.
Dadurch steigen Komplexität und je nach Attribut auch Länge, worunter die Wartbarkeit leiden kann.

ETL-Design Optimierung Seite 93 von 108
5 Ergebnis
Nachdem Untersuchungen anhand von Beispielen durchgeführt wurden, werden die gewonnenen
Erkenntnisse nachfolgend strukturiert und generalisiert dargestellt. Zunächst werden hierfür die
eingeführten Maße insbesondere bezüglich ihrer Aussagekraft bewertet. Anschließend werden, unter
Berücksichtigung der verschiedenen Ziele, generelle Empfehlungen für ETL Design gegeben.
5.1 Bewertung der Maße Die eingeführten quantitativen und qualitativen Maße unterscheiden sich stark voneinander. Während
sich die quantitativen Maße in Form von Kennzahlen exakt erfassen lassen, beziehen sich die
qualitativen eher auf die logische Struktur von Mappings und sind daher abstrakter. In dieser Arbeit
wurden die Fachbereiche ETL und Softwaretechnik in Beziehung gesetzt. Die quantitativen Maße
wurden zum Großteil aus ETL-spezifischen Quellen, die qualitativen hauptsächlich aus Literatur aus
dem Bereich der Softwaretechnik hergeleitet.
Neben den Maßen wurden Ziele, die bei dem Design von ETL Mappings erstrebenswert sind,
identifiziert. Da es nur sehr wenig Literatur zum Thema Qualität und Ziele von ETL-Design gibt und
die verfügbaren Quellen sich fast ausschließlich mit dem Kriterium Performance befassen, wurden die
weiteren Ziele aus der Softwaretechnik übernommen. In Beispielen wurde anschließend untersucht,
inwieweit sich Änderungen an Mappings auf die Maße auswirken und was diese Auswirkungen
wiederum für die Ziele bedeuteten.
In den Untersuchungen war festzustellen, dass die Maße über unterschiedlich große Aussagekraft
verfügen. Bei den quantitativen Maßen geht von der Datenmenge die größte Aussagekraft aus, das
heißt Änderungen haben hier den deutlichsten Einfluss auf die Ziele. Für die anderen Maße, Anzahl
der Knoten, Länge sowie die Komplexität, konnte in den Beispielen keine so deutliche Beeinflussung
der Zielerreichung beobachtet werden. Es kann angenommen werden, dass sich diese Maße erst in
umfangreicheren Szenarien bei größerer Veränderung deutlicher auswirken.
Nachfolgend werden die Maße im Einzelnen betrachtet.
5.1.1 Quantitative Maße
5.1.1.1 Datenmenge Die Datenmenge hat gravierenden Einfluss auf die Performance. Je weniger Tupel verarbeitet werden
müssen beziehungsweise je weniger Attribute die Tupel aufweisen, desto performanter werden
Transformationen ausgeführt. Besonders deutlich wird dies bei Transformationen, die vor der
Verarbeitung der Daten einen Cache aufbauen. Beispiele hierfür sind Joiner- und
Lookuptransformationen. Die Datenmenge ist in erster Linie fachlich durch die Quellen bestimmt.
Einige Transformationen können diese verringern. Dies geschieht durch Selektion, Projektion und
Aggregation.
Von allen Auswirkungen der quantitativen Maße ist die der Datenmenge auf das Ziel Performance, die
am stärksten ausgeprägte. Wie in den Beispielen gezeigt sollte die Datenmenge daher möglichst früh
reduziert werden.

ETL-Design Optimierung Seite 94 von 108
Neben den Auswirkungen auf die Performance, ist die Datenmenge auch ein wichtiger Indikator für
den Ressourcenbedarf eines ETL Prozesses. Es ist sicherzustellen, dass die Ressourcen des Systems
zum Ausführen des ETL Prozesses ausreichend dimensioniert sind. Bei Informatica PowerCenter, ist
beispielsweise zu beachten, dass bei einigen Transformationen vor der Verarbeitung Caches aufgebaut
werden, in denen Daten zwischengespeichert werden. Diese Caches können sehr groß werden und
haben daher einen entsprechenden Speicherbedarf.
Bezüglich der Datenmenge können Mappings relativ einfach klassifiziert werden, indem die
eingehende der ausgehenden Datenmenge gegenübergestellt wird.
5.1.1.2 Anzahl der Knoten Die Menge der Transformationen stellt die Anzahl der Knoten dar. Durch Zusammenfassung
beziehungsweise Aufteilung von Funktionalität auf eine oder mehrere Transformationen kann die
Anzahl der Knoten verändert werden. Vor den Untersuchungen wurde die Vermutung angestellt, dass
eine minimale Anzahl an Transformationen zu einer bestmöglichen Zielerreichung, insbesondere in
Bezug auf die Performance, führt. In Beispiel 5 Variante 1 wurde gezeigt, dass diese Vermutung nicht
immer richtig ist, sondern die Datenmenge hier entscheidend ist. Wenn durch eine Aufteilung, also
einen Split von Funktionalität, die Datenmenge vor aufwendigen Transformationen reduziert werden
kann, ist diese Möglichkeit sehr empfehlenswert.
In umfangreichen Beispielen kann eine Reduktion der Knoten zu einer Verbesserung der
Übersichtlichkeit führen, insbesondere da sich mit der Zahl der Knoten in der Regel auch die
Komplexität verringert. Dies ist jedoch im Einzelfall kritisch zu beurteilen. Bei einer starken
Zusammenfassung von Funktionalität kann die Transparenz leiden, vor allem dann, wenn zwischen
den zusammengefassten Funktionen eine schwache Kohäsion besteht.
5.1.1.3 Komplexität Häufig kann die Komplexität reduziert werden, indem man Attribute nicht durch alle, sondern nur
durch die Transformationen, in denen sie verarbeitet werden, führt. Hierbei ist zu beachten, dass durch
aktive Transformationen alle Attribute hindurchgeführt werden müssen. Werden Attribute an einer
aktiven Transformation vorbeigeführt, verletzt dies die Korrektheit, da die Zeilenzahl der Attribute die
die aktive Transformation durchlaufen haben und die Zeilenanzahl derer die vorbeigeführt wurden
nicht mehr übereinstimmt. Informatica PowerCenter verhindert dies jedoch automatisch.
Die Komplexität hängt hauptsächlich von der Anzahl der Knoten und ihrer jeweiligen Attribute ab.
Performance wird in erster Linie durch die Art von Transformationen und die Datenmenge bestimmt.
Die Komplexität ist ebenso wie die Anzahl der Knoten zur Beeinflussung der Performance nicht allein
aussagekräftig. In Bezug auf die Wartbarkeit sind deutlichere Zusammenhänge erkennbar, da eine
geringere Komplexität Mappings in der Regel auch übersichtlicher macht. Da bei sehr umfangreichen
Mappings auf das Konzept der Mapplets zurückgegriffen werden sollte, kann die Komplexität
zugunsten einer besseren Übersichtlichkeit in Modulen verborgen und somit die Wartbarkeit gesteigert
werden.
5.1.1.4 Länge Die Länge beschreibt die maximale Anzahl an Weiterleitungen, die ein Attribut in einem Mapping
erfährt. Jede Weiterleitung führt zu einem Verarbeitungsschritt, der mit Aufwand verbunden ist.
Hierdurch wirkt sich die Länge auf die Performance aus. Wie stark diese Beeinflussung ist, kann nicht

ETL-Design Optimierung Seite 95 von 108
anhand der Länge, sondern nur unter Betrachtung der durchgeführten Transformationen bestimmt
werden. Die Weiterleitung von Attributen hat für sich genommen einen vernachlässigbar geringen
Einfluss auf die Performance. Sekundär beeinflusst die Länge auch die Wartbarkeit, da überflüssige
Weiterleitungen die Komplexität erhöhen und somit die Übersichtlichkeit verringern.
5.1.2 Qualitative Maße
5.1.2.1 Modularität
Die Modularität ist als qualitatives Maß nicht sinnvoll in einer Zahl zu erfassen. Stattdessen wird ihre
Ausprägung, wie auch bei den anderen qualitativen Maßen, anhand einer selbst definierten Skala
dargestellt. Erst die Verwendung von Mapplets bringt Modularität mit sich, da diese die
Anforderungen eines Moduls, nämlich Kapselung von Funktionalität und Zugriff auf die Funktionen
über definierte Schnittstellen, erfüllen. Der Einsatz von Mapplets und die damit erwirkte Modularität
wirken sich in hohem Maße auf die Struktur, Übersichtlichkeit, aber auch Transparenz aus. Das
bedeutet, dass Modularität die Wartbarkeit stark beeinflusst. Ob dieser Einfluss positiv oder negativ
ausfällt, hängt von der fachlich sinnvollen Verwendung dieser Möglichkeit ab. Die Zusammenfassung
von Elementen, die untereinander eine schwache Kohäsion aufweisen, wirkt sich negativ auf die
Wartbarkeit aus. In einem solchen Fall kann ein Entwickler die Aufgabe eines Mapplets nicht mehr
ohne weiteres erkennen, sondern muss jedes Mapplet bezüglich seiner inneren Implementierung
untersuchen. Diese Intransparenz macht die Wartung schwieriger.
Neben der Wartbarkeit wirkt sich die Modularität auch maßgeblich auf die Wiederverwendbarkeit aus.
Ein Modul mit starker, funktionaler Kohäsion, geringer (eingehender) Kopplung und hoher
Universalität ist in der Regel gut wiederverwendbar. Durch die Möglichkeit der Instanziierung wird
die Wiederverwendbarkeit dabei zusätzlich positiv beeinflusst.
Direkte Auswirkungen der Modularität auf andere Ziele sind nicht festzustellen.
5.1.2.2 Kapselung Kapselung kann auf Transformations- und Modulebene auftreten. Zwischen Kapselung und
Modularität besteht ein enger Zusammenhang, da Modularität immer zu Kapselung führt oder
umgekehrt Kapselung eine Voraussetzung für Modularität ist. Aufgrund dieses engen
Zusammenhangs gibt es auch bezüglich der Zielbeeinflussung Parallelen zwischen beiden. Durch
Kapselung wird Komplexität verborgen, was sich auf die Wartbarkeit auswirkt. Dies gilt sowohl auf
Transformationsebene als auch auf Mappletebene. Auf beiden Ebenen hängt der Nutzen davon ab,
dass fachlich sinnvoll gekapselt wird. In der Regel hat Kapselung auf Mappletebene eher positive
Einflüsse auf die Wartbarkeit, auf Transformationsebene eher negative.
5.1.2.3 Universalität Universalität ist ein guter Indikator für Wiederverwendbarkeit. Sie hängt zum einen von der Art der
Transformation und der jeweiligen Positionierung ab. Es konnte gezeigt werden, dass eine
Verlagerung von Funktionalität in den Source Qualifier die Universalität in Bezug auf die
verwendbaren Quellen reduziert. Zum anderen werden Transformationen durch die Verwendung von
Parametern oder Variablen universeller.
5.1.2.4 Kohäsion Kohäsion beschreibt die funktionale Bindung zwischen Elementen eines Moduls. Einfacher formuliert
also die fachliche Zusammengehörigkeit. Ihre volle Aussagekraft entwickelt Kohäsion erst, wenn sie

ETL-Design Optimierung Seite 96 von 108
zwischen Transformationen, also auf Modulebene, betrachtet wird. Eine Erhebung der Kohäsion
zwischen den Funktionen innerhalb einer Transformation hat dagegen eine geringere Aussagekraft.
Mit Hilfe der Kohäsion kann die Qualität von Modulen in Bezug auf die Wartbarkeit und
Wiederverwendbarkeit beurteilt werden. Während Modularität und Kapselung sich je nach Auftreten
positiv oder negativ auswirken können, ist möglichst starke Kohäsion durchgängig als positiv zu
bewerten. Sie beeinflusst direkt die Auswirkungsrichtung anderer qualitativer Maße. Obwohl sie als
qualitatives Maß einer gewissen Subjektivität unterliegt und daher schwierig zu erheben ist, ist sie
eines der relevantesten Maße in Bezug auf Wartbarkeit und Wiederverwendbarkeit.
5.1.2.5 Kopplung Als letztes qualitatives Maß bleibt die Kopplung zu beurteilen. Auch sie kann auf
Transformationsebene und auf Mappletebene betrachtet werden. Auf Transformationsebene ist die
Kopplung eng mit der Komplexität verbunden und hat dort eine eher geringere Bedeutung. Große
Aussagekraft zeigt Kopplung erst beim Einsatz von Mapplets. Eine geringe Kopplung wirkt sich
positiv auf die Wartbarkeit und die Wiederverwendbarkeit aus. Hierbei ist die eingehende Kopplung
von größerer Relevanz als die ausgehende.
5.1.3 Zusammenfassung Die einzelnen Maße wirken auf unterschiedliche Ziele. Zum Teil ist die Auswirkungsrichtung auf das
Ziel, also ob eine Verbesserung oder Verschlechterung stattfindet, nicht generell eindeutig von der
Entwicklungsrichtung des Maßes, sondern von den konkreten Bedingungen im Einzelfall abhängig.
Bei den quantitativen Maßen ist die Auswirkung auf die Performance am signifikantesten. Das
einflussreichste Maß ist hierbei die Datenmenge. Die Maße Anzahl der Knoten und Komplexität
wirken sich durch ihren Einfluss auf die Übersichtlichkeit auf die Wartbarkeit aus.
Weiterhin beeinflussen Kapselung und Modularisierung die Transparenz und damit die Wartbarkeit.
Gleichzeitig wird aber auch die Wiederverwendbarkeit von diesen Maßen beeinflusst. Hierbei kann
keine eindeutige Abhängigkeit der Entwicklungsrichtung festgestellt werden. Die
Wiederverwendbarkeit steigt dementsprechend nicht proportional zur Modularität. Der Einfluss der
Länge ist in den vorgestellten Beispielen in der Regel sehr gering.
Universalität zeigt, wie der Name des Maßes vermuten lässt, starke Auswirkungen auf die
Wiederverwendbarkeit.
Bei den qualitativen Maßen sind eine gegenseitige Beeinflussung und eine Hierarchie erkennbar.
Kapselung ist ein Kriterium für Modularität, es besteht also eine einseitige Abhängigkeit zwischen den
Maßen. Kohäsion und Kopplung sind in der Hierarchie tiefer einzustufen und dienen dazu, die
qualitative Auswirkung von Änderungen der Kapselung, insbesondere aber der Modularität zu
bewerten.
Außer Kapselung und Universalität entwickeln die qualitativen Maße ihre volle Aussagekraft erst bei
der Verwendung von Mapplets. Eine Untersuchung von Modularität, Kohäsion und Kopplung ist also
erst auf einer höheren Strukturebene sinnvoll.

ETL-Design Optimierung Seite 97 von 108
5.2 Klassifizierung von Mappings Zur Entscheidung, welche Ziele priorisiert werden sollen, ist es sinnvoll, neben den Anforderungen,
die von außen an das Szenario gestellt werden, das Mapping selber zu klassifizieren.
Nach den Erfahrungen des Autors können drei Grundklassen von Mappings unterschieden werden.
Diese sind nicht scharf voneinander abgegrenzt, sondern gehen teilweise ineinander über. Außerdem
können sie in Kombinationen auftreten.
1. Datenintensive Mappings: Mappings, in denen sehr große Datenmengen verarbeitet werden,
erfordern in der Regel eine besonders gute Performance. In Bezug auf die Datenmenge sollte
zwischen eingehenden und ausgehenden Daten unterschieden werden. Wird die Datenmenge
innerhalb eines Mappings reduziert, ist es sinnvoll, den Faktor dieser Reduktion zu betrachten.
Diese Werte helfen dabei, den Nutzen von Umpositionierungen einzelner Transformationen
abzuschätzen. Je größer die Reduktion der Daten in einer Transformation ist, desto mehr
profitiert die Performance von ihrer frühen Positionierung.
2. Mappings für komplexe Berechnungen: Werden in einem Mapping sehr komplizierte
Berechnungen durchgeführt, ist eine hohe Wiederverwendbarkeit erstrebenswert. Diese kann
beispielsweise dadurch erzielt werden, dass diese Berechnungen in einem
wiederverwendbaren Mapplet eingebettet werden. Sollte dieselbe Berechnung in einem
anderen Szenario erneut benötigt werden, kann darauf zurückgegriffen werden, wodurch der
Entwicklungsaufwand erheblich sinken kann.
3. Mappings zur Verarbeitung kompliziert strukturierter Daten: Werden Daten aus
möglicherweise vielen Quellen nach nicht trivial nachvollziehbaren Kriterien in eine
gemeinsame Struktur überführt, spielt die Wartbarkeit eine wichtige Rolle. Da Mappings mit
der Anzahl der Knoten und steigender Komplexität unübersichtlicher werden, wird es
schwierig, die Strukturen nachzuvollziehen. Im Falle von Wartungsarbeiten können
Zusammenhänge schnell übersehen werden und Mappings dadurch in einen invaliden Zustand
gebracht werden. Noch kritischer ist eine Verletzung der Korrektheit bei der Ausführung, die
durch Änderungen verursacht werden kann und erst zur Laufzeit auftritt.
Durch Zuordnung eines Mappings zu einer oder mehreren dieser Klassen kann eine Gewichtung von
Designzielen vorgenommen werden. Falls die Ziele untereinander in Konflikt stehen, kann durch eine
Klassifizierung ein Ansatz gefunden werden, der den für das jeweilige Szenario besten Kompromiss
darstellt.
5.3 Designempfehlungen Mit Hilfe der definierten Maße und Ziele und unter Berücksichtigung der Untersuchungsergebnisse
dieser Arbeit lassen sich Empfehlungen für das Design von Mappings herleiten. Da in
unterschiedlichen Szenarien verschiedene Ziel verfolgt werden, werden Empfehlungen jeweils für die
Maximierung dieser angegeben. Wenn sich durch Maßnahmen Wechselwirkungen mit anderen Zielen
ergeben, werden diese auch aufgezeigt.
5.3.1 Wartbarkeit Wartbarkeit profitiert von Übersichtlichkeit und Transparenz. Oftmals wird jedoch gleichzeitig mit
einer verbesserten Übersichtlichkeit die Transparenz verringert. Übersichtlichkeit wird durch

ETL-Design Optimierung Seite 98 von 108
Reduzierung der Anzahl der Knoten und Komplexität erzielt. Auch die fachlich sinnvolle
Modularisierung mit Mapplets trägt hierzu bei.
Eine Optimierungsmöglichkeit ohne Wechselwirkungen ist die Komplexität zu senken, indem nur
Ports verbunden werden, die in der jeweiligen Transformation auch verarbeitet werden.
Auch der Austausch einer Transformation durch eine andere kann, durch Reduzierung der Knotenzahl
und der Komplexität, die Übersichtlichkeit und damit die Wartbarkeit verbessern. Hierbei treten zum
Teil aber große Wechselwirkungen mit anderen Zielen auf, wie an den vorgestellten Beispielen zu
erkennen war.
Die Reduzierung der Knotenzahl durch Zusammenfassung mehrerer Transformationen kann auch zu
einer besseren Übersichtlichkeit führen, allerdings muss hier darauf geachtet werden, dass die
Transparenz nicht über Gebühr leidet.
Gleiches gilt für den Einsatz von Mapplets. Diese bringen Struktur in Mappings und unterteilen diese
in kleinere Module. Damit die Wartbarkeit von der gesteigerten Übersichtlichkeit profitiert, muss eine
ausreichende Transparenz sicher gestellt werden. Dies wird erreicht, indem nur Transformationen, die
untereinander eine starke, funktionale Kohäsion aufweisen, in einem Mapplet zusammengefasst
werden.
Wiederverwendung durch Instanziierung von Transformationen kann die Wartbarkeit stark verbessern.
Wird die Reusable-Funktionalität genutzt, müssen mehrfach eingesetzte Transformationen bei
Wartungen nur noch an einer Stelle angepasst werden. Veränderungen wirken sich auf alle Instanzen
aus. Das Arbeiten mit Instanzen birgt jedoch auch Risiken, da die Abhängigkeit der Transformationen
gerade beim mappingübergreifenden Einsatz schnell übersehen werden kann.
Sehr wichtig und ohne Wechselwirkungen irgendeiner Art ist die Einführung und Anwendung von
Namenskonventionen. Bei jeder Transformation und jedem Mapplet sollte die Funktionalität anhand
des Namens erkennbar sein, ohne dass es hierfür bezüglich seiner Implementierung untersucht werden
muss. Insbesondere bei Mapplets trägt eine starke, funktionale Kohäsion dazu bei, dass die Benennung
leichter möglich ist.
5.3.2 Wiederverwendbarkeit Wiederverwendbarkeit wird stark durch das qualitative Maß Universalität beeinflusst.
Verschiedene Transformationen können unterschiedlich universell sein, zum Beispiel in Bezug auf die
damit nutzbaren Quellen. Da häufig für die gleichen Anforderungen unterschiedliche
Transformationen genutzt werden können, kann zur Steigerung der Wiederverwendbarkeit eine
universellere Transformation gewählt werden.
Auch Parameter steigern die Universalität und damit die Wiederverwendbarkeit. Auf Mappingebene
werden durch Parameter beispielsweise Prüfbedingungen universell gehalten. Auf Session und
Workflowebene können Einstellungen wie Dateipfade oder Verbindungsinformationen für Quellen
und Ziele mit Parametern dynamisch gestaltet werden.
In Mapplets können fachliche Aufgaben, die aus mehreren Transformationsschritten bestehen, zu
einem Modul zusammengefasst werden. Dieses kann anschließend in verschiedenen Szenarien

ETL-Design Optimierung Seite 99 von 108
wiederverwendet werden. Besonders positiv wirken sich bei Mapplets eine geringe eingehende
Kopplung bei gleichzeitig starker, funktionaler Kohäsion der integrierten Transformationen aus.
5.3.3 Performance Durch die durchgeführten Untersuchungen wird die Vermutung gestützt, dass Performance in erster
Linie von der Datenmenge und den auf den Daten durchgeführten Operationen abhängt. Außerdem
hängt die Performance in hohem Maß von den technischen Spezifikationen der Laufzeitumgebung ab.
Wann immer es möglich ist, sollte die Datenmenge so früh wie möglich reduziert werden. Dies erfolgt
beispielsweise bei der Selektion in Filtertransformationen und bei Aggregationen. Verbesserungen
können hierbei durch eine Umpositionierung der entsprechenden Transformationen erzielt werden.
Eine weitere Möglichkeit besteht in der Auslagerung von Funktionalität in den Source Qualifier.
Durch diese Maßnahme können teilweise sehr deutliche Verbesserungen der Performance erreicht
werden. Dies hängt jedoch maßgeblich von technischen Rahmenbedingungen wie Nutzung von
Indizes auf Datenbanken und der Ausstattung und Auslastung der beteiligten Systeme ab. Aufgrund
dieser Abhängigkeit kann diese Optimierungsmaßnahme nicht mehr als rein designkonzeptionelle
angesehen werden.
Daneben kann ein Austausch von Transformationen je nach Struktur und Datenausprägung der
zugrunde liegenden Quellen Performanceverbesserungen bringen. Dies wurde in der Betrachtung
Lookup vs. Join exemplarisch gezeigt.
Viele Transformationen profitieren bezüglich der Performance stark von einer Vorsortierung der
Daten. Beispiele hierfür sind Joiner, Lookups und Aggregatoren.
Andere quantitative Maße außer der Datenmenge haben einen sehr viel geringeren Einfluss auf die
Performance. Daraus folgt, dass diese Maße extrem reduziert werden müssen, bevor eine
Verbesserung der Performance festgestellt werden kann. Da eine solche Minimierung der
quantitativen Maße aber meist negative Auswirkungen auf die Wartbarkeit hat, kann dies nicht als
regelmäßiger Optimierungsweg empfohlen werden.
Eine weitere Möglichkeit, die im Rahmen dieser Arbeit nicht getestet werden konnte, stellt die
sogenannte Push Down Optimization dar. Der Integrationsdienst verschiebt dabei Aktivitäten, deren
frühere Ausführung Performanceverbesserungen bringen, zum Beispiel Filter, rückwärts im
Datenstrom in Richtung der Quellen. Vorteil dabei ist, dass Mappings mit einem Fokus auf Ziele wie
Wartbarkeit und Wiederverwendbarkeit entwickelt werden können, während die Performance
nachträglich vom System optimiert wird. Die Push Down Optimization wird zur Laufzeit
vorgenommen, so dass sie in der Modellierung nicht erkennbar ist. In Informatica PowerCenter 8 ist
die Push Down Optimization ein Funktionsmerkmal, für das eine separate Lizenz benötigt wird. Diese
war im Rahmen dieser Arbeit jedoch nicht verfügbar.
5.3.4 Zuverlässigkeit Die Zuverlässigkeit hängt in erster Linie von fachlich richtiger Modellierung ab. Sobald die
Korrektheit gewährleistet ist, wirken sich eher die technischen Rahmenbedingungen auf die
Zuverlässigkeit aus.

ETL-Design Optimierung Seite 100 von 108
In Parameterdateien kann der Zugriff auf benötigte Ressourcen zentral verwaltet werden. Außerdem
können darin Optionen, die bei der Ausführung von Sessions einbezogen werden sollen,
beispielsweise Cachegrößen, definiert werden. Beides kann die Zuverlässigkeit verbessern.
Da die Ausführung einer Session in der Praxis sehr zeitaufwendig werden kann, stellt eine frühe
Erkennung von Fehlern und die damit verlängerte Reaktionszeit im Fehlerfall eine Möglichkeit dar,
die Anforderungen innerhalb des gesetzten Zeitrahmens korrekt zu erfüllen. Unter diesem
Gesichtspunkt ist es sinnvoll, kritische Transformationen, also solche, bei deren Ausführung es mit
höherer Wahrscheinlichkeit zu Fehlern kommen kann, früh in den Datenstrom einzubinden.

ETL-Design Optimierung Seite 101 von 108
6 Zusammenfassung und Ausblick
Ziel dieser Arbeit war es, ETL Design zu problematisieren, relevante Ziele und darauf wirkende Maße
zu identifizieren und verschiedene Designvarianten zu diskutieren.
Nach der Einleitung, in der Ziel, Rahmen und Motivation dieser Arbeit vorgestellt wurden, wurde in
Kapitel 2 eine kurze Einführung in die ETL-Grundlagen gegeben. Hierbei wurden Bestandteile,
Einsatzszenarien und der prinzipielle Ablauf von ETL Prozessen gezeigt. Danach folgte eine
Einführung in Informatica PowerCenter 8, das für die praktischen Untersuchungen dieser Arbeit
verwendete ETL Werkzeug.
Anschließend wurden in Kapitel 3 Designziele und Maße vorgestellt. Die identifizierten Designziele
sind Korrektheit, Wartbarkeit, Wiederverwendbarkeit, Performance und Zuverlässigkeit.
Diese Ziele werden von verschiedenen, quantitativen und qualitativen Maßen beeinflusst. Die
quantitativen werden durch Datenmenge, Anzahl der Knoten, Länge und Komplexität repräsentiert.
Qualitative Maße sind Modularität, Kapselung, Kohäsion und Kopplung.
In Kapitel 4 wurde zuerst ein geeignetes Beispielszenario eingeführt. Darauf folgte die Untersuchung
der sechs Optimierungsansätze:
• Positionstausch
• Austausch von Transformationen
• Zusammenfassen und Aufteilen
• Strukturierung mit Mapplets
• Parametrisierung
• Sortierung von Daten
anhand von Beispielen.
Jede dieser Analysen wurde nach dem zuvor festgelegten, einheitlichen Schema durchgeführt.
Ausgehend von einem Beispiel, wurden verschiedene Varianten desselben vorgestellt und jeweils die
Veränderungen der Maße untersucht. Darauf folgte für jedes Beispiel die Bewertung der aus den
Veränderungen resultierenden Auswirkungen auf die Ziele. Unter Berücksichtigung der
Zusammenhänge zwischen Maßen und Zielen wurde nach Betrachtung der Beispiele jeder
Optimierungsansatz bewertet und sein Nutzen, zum Teil aber auch potentielle Risiken, dargestellt.
Die Untersuchungen zeigten dabei deutlich, dass bei keinem Ansatz von einer generellen
Verbesserung der Zielerfüllung ausgegangen werden kann, sondern jeder Einzelfall unter
Berücksichtigung der zu verarbeitenden Daten betrachtet und der Nutzen von Veränderungen kritisch
überprüft werden muss. Verschärft wird die Notwendigkeit kritischer Betrachtung durch die
Wechselwirkungen zwischen den Maßen. So führte die Verlagerung eines Filters in den Source
Qualifier zu einer Verringerung aller quantitativen Maße, gleichzeitig stieg die Kapselung. Hieraus
resultierte eine Verbesserung der Performance bei gleichzeitiger Verschlechterung von Wartbarkeit
und Wiederverwendbarkeit. Grundsätzlich muss eine Zielgewichtung durch den Entwickler
vorgenommen werden, da die Beispiele zeigten, dass eine zeitgleiche Verbesserung aller Ziele in der
Regel nicht möglich ist. Trotz aller Einschränkungen konnten in den Beispielen zum Teil sehr positive

ETL-Design Optimierung Seite 102 von 108
Auswirkungen der Ansätze nachvollzogen werden. Eine Untersuchung von Szenarien anhand dieser
Ansätze ist also grundsätzlich empfehlenswert.
Um die unterschiedliche Aussagekraft der Maße und ihre zum Teil in Bezug auf die Ziele bestehende
Wechselwirkung weiter zu problematisieren, wurden diese in Kapitel 5 bewertet. Hierbei wurde durch
die Zusammenfassung der zuvor gewonnenen Erkenntnisse ihr Einfluss auf die Ziele dargestellt. Als
das wichtigste quantitative Maß wurde die Datenmenge festgestellt. Sie hat immer einen direkten
Einfluss auf die Performance eines ETL-Prozesses. Die Auswirkung der anderen quantitativen Maße
war nicht eindeutig, so dass deren Auswirkung für jeden Einzelfall betrachtet werden muss. Zwischen
den qualitativen Maßen wurden Abhängigkeiten aufgezeigt. Außerdem wurde als Ergebnis der
Untersuchungen der Beispiele festgestellt, dass einige Maße erst bei Einsatz von Modulen, in den
Beispielen durch Mapplets repräsentiert, sinnvoll erhoben werden können. Kohäsion wurde als eines
der wichtigsten qualitativen Maße identifiziert. Dieses Maß erreicht seine volle Aussagekraft zwar
auch erst bei der Verwendung von Mapplets, erlaubt es dann aber zu bewerten, ob sich Kapselung und
Modularität positiv auf Wartbarkeit und Wiederverwendbarkeit auswirken.
Nach der Bewertung der Maße wurde eine auf den Erkenntnissen dieser Arbeit basierende
Klassifizierung von Mappings vorgestellt. Es wurden drei Klassen festgestellt: Datenintensive,
berechnungsintensive und strukturkomplexe Mappings. Ein Mapping kann durchaus mehreren
verschiedenen Klassen gleichzeitig angehören. Die (anteilige) Zuordnung von Mappings zu den drei
Klassen erleichtert die Zielgewichtung.
Zum Schluss wurden generelle Designempfehlungen, die aus den vorgenommenen Untersuchungen
abgeleitet wurden, ausgesprochen. Aufgrund der Problematik, dass eine gleichzeitige Optimierung
verschiedener Ziele in der Regel nicht möglich ist, wurden Designempfehlungen für jedes einzelne
Ziel getrennt gegeben.
Diese Empfehlungen führen nicht zwangsläufig zu einem optimalen Design, dafür sind die
Zusammenhänge zu komplex. Sie helfen aber dabei, typische Fehler zu vermeiden und somit den
angestrebten Zielen deutlich näher zu kommen.
In der Einleitung wurde festgestellt, dass ETL-Design stark von der Erfahrung und der Intuition der
jeweiligen Entwickler geprägt ist. Vermutlich wird sich dies auch in näherer Zukunft nicht so schnell
ändern, da diesbezüglich der Änderungsdruck nicht groß genug ist. Mit der in dieser Arbeit
vorgestellten Herangehensweise an die Bewertung und Optimierung von ETL-Design wird dazu
beigetragen, dass eine gemeinsame „Sprache“ entsteht, mit der man fachliche Fragen des ETL-
Designs besser diskutieren kann. Dies soll schließlich zu kontinuierlichen Verbesserungen im
Designprozess führen.
Nicht Bestandteil der Untersuchungen dieser Arbeit waren Data Warehouse spezifische Fragen der
Modellierung. Außerdem wurden ETL Prozesse nur auf der Ebene des Designs und die Beispiele nur
anhand des Werkzeugs Informatica PowerCenter 8 untersucht. Sowohl die Untersuchung der in dieser
Arbeit gewonnenen Erkenntnisse in Data Warehouse Szenarien als auch eine Betrachtung unter
Verwendung eines anderen ETL-Werkzeugs können Inhalt weiterer Forschung sein. Da der Rahmen
dieser Arbeit begrenzt war und dadurch nur einige Beispiele untersucht werden konnten, bietet sich
außerdem die Analyse weiterer Beispiele an, um die in dieser Arbeit gewonnenen Erkenntnisse zu

ETL-Design Optimierung Seite 103 von 108
vertiefen und zu festigen. Es ist denkbar, dass dabei weitere Ziele und Maße identifiziert werden
können.
Die Erkenntnisse dieser Arbeit in bestehende Vorgehensmodelle aus dem ETL-Kontext im
Allgemeinen und dem Data Warehouse Kontext im Speziellen zu integrieren und diese
Vorgehensmodelle gegebenenfalls weiterzuentwickeln, ist eine weitere Herausforderung für
zukünftige Forschung.

ETL-Design Optimierung Seite 104 von 108
a. Tabellenverzeichnis
Tabelle 1: Übersicht über die Transformationen in Informatica PowerCenter 8 (Informatica,
PowerCenter Transformation Guide, 2006).......................................................................................... 17
Tabelle 2: Symbolik zur Bewertung der Zielerfüllung........................................................................... 25
Tabelle 3: Ausprägung der qualitativen Einflussfaktoren..................................................................... 26
Tabelle 4: Datenmengen im Beispielszenario ....................................................................................... 34
Tabelle 5: Fallbeispiel 1 - Ausgangsbeispiel - Quantitative Maße ....................................................... 36
Tabelle 6: Fallbeispiel 1 - Ausgangsbeispiel - Qualitative Maße ......................................................... 37
Tabelle 7: Fallbeispiel 1 - Ausgangsbeispiel - Übersicht über die Ziele .............................................. 37
Tabelle 8: Fallbeispiel 1 - Variante 1 - Quantitative Maße .................................................................. 39
Tabelle 9: Fallbeispiel 1 - Variante 1 - Qualitative Maße .................................................................... 39
Tabelle 10: Fallbeispiel 1 - Variante 1 - Zielerfüllung ......................................................................... 40
Tabelle 11: Fallbeispiel 1 – Variante 2 - Quantitative Maße ............................................................... 42
Tabelle 12: Fallbeispiel 1 – Variante 2 - Qualitative Maße ................................................................. 42
Tabelle 13: Übersicht über die Zielerfüllung der Varianten................................................................. 43
Tabelle 14: Fallbeispiel 2 - Variante 1 - Quantiative Maße ................................................................. 49
Tabelle 15: Fallbeispiel 2 - Variante 1 - Qualitative Maße.................................................................. 49
Tabelle 16: Fallbeispiel 2 – Vergleich der Zielerfüllung ...................................................................... 50
Tabelle 17: Fallbeispiel 3 - Ausgangsbeispiel - Quantitative Maße ..................................................... 53
Tabelle 18: Fallbeispiel 3 - Ausgangsbeispiel - Qualitative Maße ....................................................... 53
Tabelle 19: Fallbeispiel 3 – Variante 1 - Quantitative Maße ............................................................... 55
Tabelle 20: Fallbeispiel 3 – Variante 1 - Qualitative Maße ................................................................. 55
Tabelle 21: Fallbeispiel 3 – Variante 1 - Zielerfüllung bei Lookup statt Join ...................................... 57
Tabelle 22: Fallbeispiel 4 – Ausgangsbeispiel - Quantitative Maße .................................................... 60
Tabelle 23: Fallbeispiel 4 – Ausgangsbeispiel - Qualitative Maße ...................................................... 60
Tabelle 24: Fallbeispiel 4 – Ausgangsbeispiel – Zielerfüllung............................................................. 61
Tabelle 25: Fallbeispiel 4 – Variante 1 - Quantitative Maße ............................................................... 62
Tabelle 26: Fallbeispiel 4 – Variante 1 - Qualitative Maße ................................................................. 63
Tabelle 27: Fallbeispiel 4 – Zielerfüllung – Vergleich der Varianten .................................................. 64
Tabelle 28: Fallbeispiel 5 – Ausgangsbeispiel - Quantitative Maße .................................................... 71
Tabelle 29: Fallbeispiel 5 – Ausgangsbeispiel - Qualitative Maße ...................................................... 71
Tabelle 30: Fallbeispiel 5 – Ausgangsbeispiel - Zielerfüllung.............................................................. 72
Tabelle 31: Fallbeispiel 5 – Variante 1 - Quantitative Maße ............................................................... 77
Tabelle 32: Fallbeispiel 5 – Variante 1 - Qualitative Maße ................................................................. 77
Tabelle 33: Fallbeispiel 5 – Variante 1 - Zielerfüllung......................................................................... 78
Tabelle 34: Fallbeispiel 5 – Variante 2 – Quantitative Maße............................................................... 83
Tabelle 35: Fallbeispiel 5 – Variante 2 – Qualitative Maße................................................................. 83
Tabelle 36: Fallbeispiel 5 – Variante 2 – Zielerfüllung........................................................................ 86
Tabelle 37: Fallbeispiel 5 – Variante 3 – Quantitative Maße............................................................... 91
Tabelle 38: Fallbeispiel 5 – Variante 3 – Qualitative Maße................................................................. 91
Tabelle 39: Fallbeispiel 5 – Variante 3 – Zielerfüllung........................................................................ 92

ETL-Design Optimierung Seite 105 von 108

ETL-Design Optimierung Seite 106 von 108
b. Abbildungsverzeichnis
Abbildung 1 Expression Transformation mit Ein- und Ausgabeports................................................... 15
Abbildung 2 Expression Transformation Detailansicht ........................................................................ 16
Abbildung 3: Einfaches Mapping mit Filter.......................................................................................... 18
Abbildung 4 Mapping ohne Mapplets ................................................................................................... 20
Abbildung 5: Mapplet MLTP_EXTRACT_AND_JOIN_SOURCES...................................................... 21
Abbildung 6 Mapping mit Mapplet ....................................................................................................... 21
Abbildung 7: Schematische Darstellung der Fremdschlüsselbeziehungen........................................... 33
Abbildung 8: Fallbeispiel 1 –Ausgangsbeispiel - Filtertransformation................................................ 35
Abbildung 9: Fallbeispiel 1 - Variante 1 - Nach vorne verschobener Filter ........................................ 38
Abbildung 10: Fallbeispiel 1 - Variante 2 - Filterung im Source Qualifier.......................................... 40
Abbildung 11: Master- und Detailpipeline bei einer Joinertransformation (Informatica, PowerCenter
Transformation Guide, 2006, S. 266).................................................................................................... 45
Abbildung 12: Fallbeispiel 2 – Ausgangsbeispiel – Expliziter Join...................................................... 47
Abbildung 13: Fallbeispiel 2 – Variante 1 – Joinen im Source Qualifier............................................. 48
Abbildung 14: Fallbeispiel 3 – Ausgangsbeispiel ................................................................................. 53
Abbildung 15: Fallbeispiel 3 – Variante 1 – Lookup statt Join ............................................................ 54
Abbildung 16: Fallbeispiel 4 – Ausgangsbeispiel - Berechnung der Aufgabenkosten.......................... 59
Abbildung 17: Fallbeispiel 4 – Variante 1 – Umsetzung mit Lookuptransformation ........................... 61
Abbildung 18: Fallbeispiel 5 – Ausgangsbeispiel - Zusammenführen der Quellen .............................. 67
Abbildung 19: Fallbeispiel 5 – Ausgangsbeispiel - Aggregation SUM_HOURS_PER_PROJECT ..... 68
Abbildung 20: Fallbeispiel 5 – Ausgangsbeispiel - Expression Transformation CALCULATE_COST69
Abbildung 21: Fallbeispiel 5 – Ausgangsbeispiel - Aggregation SUM_COST_PER_PROJECT......... 69
Abbildung 22: Fallbeispiel 5 – Ausgangsbeispiel - Gesamtübersicht................................................... 70
Abbildung 23: Fallbeispiel 5 – Variante 1 - Ausgangssituation mit zwei Aggregationen .................... 73
Abbildung 24: Fallbeispiel 5 – Variante 1 - Zielsituation mit einer Aggregation ................................ 73
Abbildung 25: Fallbeispiel 5 – Variante 1 - Kostenkalkulation auf Basis der TASK_LOG Einträge .. 74
Abbildung 26: Fallbeispiel 5 – Variante 1 - Aggregation der Projektkosten und geleisteten Stunden. 75
Abbildung 27: Fallbeispiel 5 – Variante 1 - Gesamtübersicht.............................................................. 75
Abbildung 28: Fallbeispiel 5 – Variante 2 – potentielle Mapplets ....................................................... 79
Abbildung 29: Fallbeispiel 5 – Variante 2 – Mapplet
MLTP_CALCULATE_COST_PER_PROJECT_AND_COSTCODE zur Vorbereitung der Projektkosten
............................................................................................................................................................... 80
Abbildung 30: Fallbeispiel 5 – Variante 2 – Mapplet MLTP_CURRENCY_CONVERSION zur
Berechnung der Projektkosten in Fremdwährungen............................................................................. 80
Abbildung 31: Fallbeispiel 5 – Variante 2 – starke Kapselung durch den Einsatz von Mapplets........ 81
Abbildung 32: Fallbeispiel 5 - Variante 3 - Filterparameter................................................................ 87
Abbildung 33: Fallbeispiel 5- Variante 3 - Teilabbildung 1 ................................................................. 89
Abbildung 34: Fallbeispiel 5- Variante 3 - Teilabbildung 2 ................................................................. 89

ETL-Design Optimierung Seite 107 von 108
c. Literaturverzeichnis
Balzert, H. (2005). Lehrbuch der Objektmodellierung - Analyse und Entwurf mit der UML2 - 2.
Auflage. München: Elsevier GmbH.
Balzert, H. (1998). Lehrbuch der Software-Technik. Heidelberg: Spektrum, Akademischer Verlag.
Bange, C. (2006). Werkzeuge für Business Intelligence. (H. Baars, Hrsg.) HMD Praxis der
Wirtschaftsinformatik - Business & Competitive Intelligence , 247.
Bauer, A., & Günzel, H. (2004). Data-Warehouse Systeme - Architektur, Entwicklung, Anwendung.
Heidelberg: dpunkt.
Goeken, M. (2006). Entwicklung von Data-Warehouse-Systemen Anforderungsmanagement,
Modellierung, Implementierung. Wiesbaden: Deutscher Universitätsverlag | GWV Fachverlage
GmbH.
Informatica, C. (2006). Informatica PowerCenter Designer Guide 8.1. Informatica.
Informatica, C. (2006). PowerCenter Transformation Guide. Redwood / CA, USA.
Informatica, C. (2006). Workflow Administrator Guide 8.1. Informatica.
Inmon, W. (2002). Building the Data Warehouse. New York: John Wiley & Sons Inc.
Kimball, R., & Caserta, J. (2004). The Data Warehouse ETL Toolkit. Indianapolis: Wiley Publishing
Inc.
Kimball, R., Reeves, L., Ross, M., & Thornthwaite, W. (1998). The Data Warehouse Lifecycle
Toolkit. New York: John Wiley & Sons, Inc.
Kurz, A. (1999). Datawarehousing enabling technology. mitp.
Lehner, W. (2003). Datenbanktechnologie für Data-Warehouse Systeme: Konzepte und Methoden.
Heidelberg: dpunkt Verlag.
Liggesmeyer, P. (2002). Softwarequalität: Testen, Analysieren und Verifizieren von Software.
Heidelberg: Spektrum , Akademischer Verlag.
Luján-Mora, S., Vassiliadis, P., & Trujillo, J. (2004). Data Mapping Diagramms for Data Warehouse
Design with UML. Proceedings of the 23rg International Conference on Conceptional Modeling.
Lectures Notes in Computer Science, Springer.
Parnas, D. L. (1971). Information Distribution Aspects of Design Methodology. Ljubljana.
Simitsis, A., Vassiliadis, P., & Sellis, T. (2005). Logical Optimization of ETL Workflows. Athen.

ETL-Design Optimierung Seite 108 von 108
Vassiliadis, P., Simitsis, A., & Skiadopoulus, S. (2002). Modelling ETL Activities as Graphs.
Proceedings of the 4th Int'l Workshop on the Design and Management of Data Warehouses. CEUR
Workshop Proceedings.
Vassiliads, P., Simitsis, A., Terrovitis, M., & Skiadopoulos, S. (2005). Blueprints and Measures for
ETL Workflows. Heidelberg: Springer-Verlag.
Vossen, G. (2000). Datenmodelle, Datenbanksprachen und Datenbankmanagementsyteme 4. Auflage.
München: Oldenbourg Wissenschaftsverlag GmbH.