Embed Size (px)
Citation preview

116 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6. Objektver teilung
6.1 Überblick
• Ko-Präsenz Systeme: - in der Regel Client/Server-Architektur, - Klienten übernehmen nur die Darstellung, - ein oder mehrere Server für Konsistenz und Persistenz der Objekte.
• Konsistenz: - Problemstellung, - Daten- und client-zentrierte Konsistenz, - Besonderheiten bei interaktiven 3D Welten.
• Persistenz: - Benutzer ändern die Welt und Ihren Avatar. - Hierbei investieren sie viel Zeit und reales Geld. - Änderungen müssen daher persistent gespeichert werden.
• Zuverlässigkeit: - Fehler dürfen zu keinem Datenverlust führen. - Zu berücksichtigen sind Hardware- und Software-Fehler, sowie Sicherheitsaspekte. - Verbreitete Fehlertoleranz-Strategien setzen hierzu Redundanz und Sicherungspunkte ein.
117 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
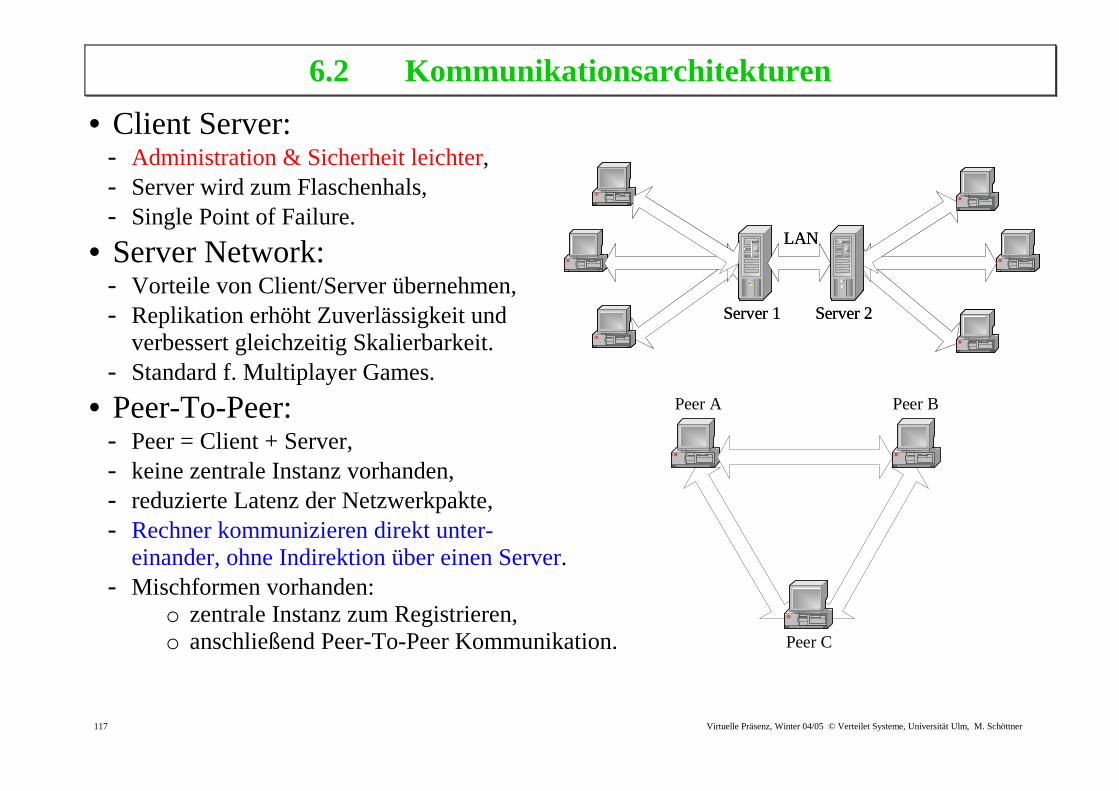
6.2 Kommunikationsarchitekturen
• Client Server: - Administration & Sicherheit leichter, - Server wird zum Flaschenhals, - Single Point of Failure.
• Server Network: - Vorteile von Client/Server übernehmen, - Replikation erhöht Zuverlässigkeit und
verbessert gleichzeitig Skalierbarkeit. - Standard f. Multiplayer Games.
• Peer-To-Peer: - Peer = Client + Server, - keine zentrale Instanz vorhanden, - reduzierte Latenz der Netzwerkpakte, - Rechner kommunizieren direkt unter-
einander, ohne Indirektion über einen Server. - Mischformen vorhanden:
o zentrale Instanz zum Registrieren, o anschließend Peer-To-Peer Kommunikation.
Peer A Peer B
Peer C
Server 1 Server 2
LAN
Server 1 Server 2
LAN
118 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.3 Konsistenz
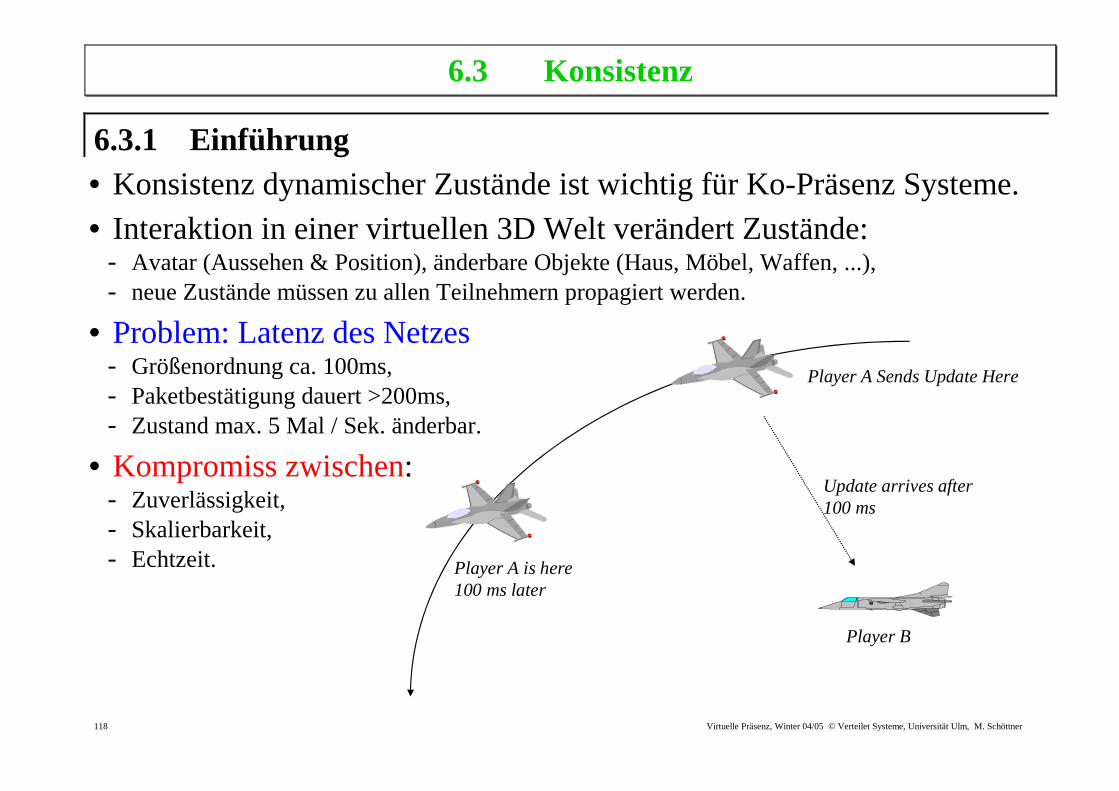
6.3.1 Einführung • Konsistenz dynamischer Zustände ist wichtig für Ko-Präsenz Systeme. • Interaktion in einer virtuellen 3D Welt verändert Zustände:
- Avatar (Aussehen & Position), änderbare Objekte (Haus, Möbel, Waffen, ...), - neue Zustände müssen zu allen Teilnehmern propagiert werden.
• Problem: Latenz des Netzes - Größenordnung ca. 100ms, - Paketbestätigung dauert >200ms, - Zustand max. 5 Mal / Sek. änderbar.
• Kompromiss zwischen: - Zuverlässigkeit, - Skalierbarkeit, - Echtzeit.
Player A Sends Update Here
Player B
Player A is here 100 ms later
Update arrives after 100 ms

119 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.3.2 Lesen und Schreiben im Netz
• Fall A: keine Kopien im Netz (unrepliziert): - ortsfeste oder migrierende Objekte, - Objekt-Eigentümer kann sofort zugreifen, - Kommunikationspartner brauchen etwas länger.
• Fall B: Kopien im Netz (repliziert): - lesen eines Objektes ist sofort möglich, - entweder auf alle Kopien schreiben (update), - oder alle Kopien löschen und nur auf Original schreiben (invalidate).
• Matrixdarstellung: ohne Replikation mit Replikation or tsfeste Seiten, R/W-Operation transpor tieren
Verzögerung für alle, außer für Eigentümer
sofort lesen, überall schreiben, " wr ite update"
migr ierende Speicher teile, lokale Operation
langsam lesen, langsam schreiben, Seitenflattern
aus Cache lesen, Original schreiben, " wr ite invalidate"
• Nach einem "write invalidate" müssen die Seiten von den interessierten Lesern erneut angefordert werden.

120 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.3.3 Konsistenzmodell
• Def.: Der Speicherungsmechanismus garantiert gegenüber den zu-greifenden Prozessen, Regeln nach welchen er die Schreiboperationen sichtbar werden lässt.
• Wahl des Konsistenzmodells ist immer ein Kompromiss: - Je schwächer das Modell, desto geringer sind die Latenzzeiten beim Speicherzugriff. - Je strikter das Konsistenzmodell, desto einfacher ist die Programmierung.
• Daten-zentrierte Modelle: - auf einen verteilten Datenspeicher bezogen, - Teilnehmer verwenden Replikate, - traditioneller Konsistenzbegriff.
• Client-zentrierte Modelle: - seltene und zentrale Aktualisierung der Daten, - Konsistenz aus der Sicht eines Klienten,
o verschied. Klienten dürfen unterschiedl. Sichten haben, o schwächere Konsistenz, als bei daten-zentrierten Modellen.
- z.B. für DNS, Webseiten, ...
121 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
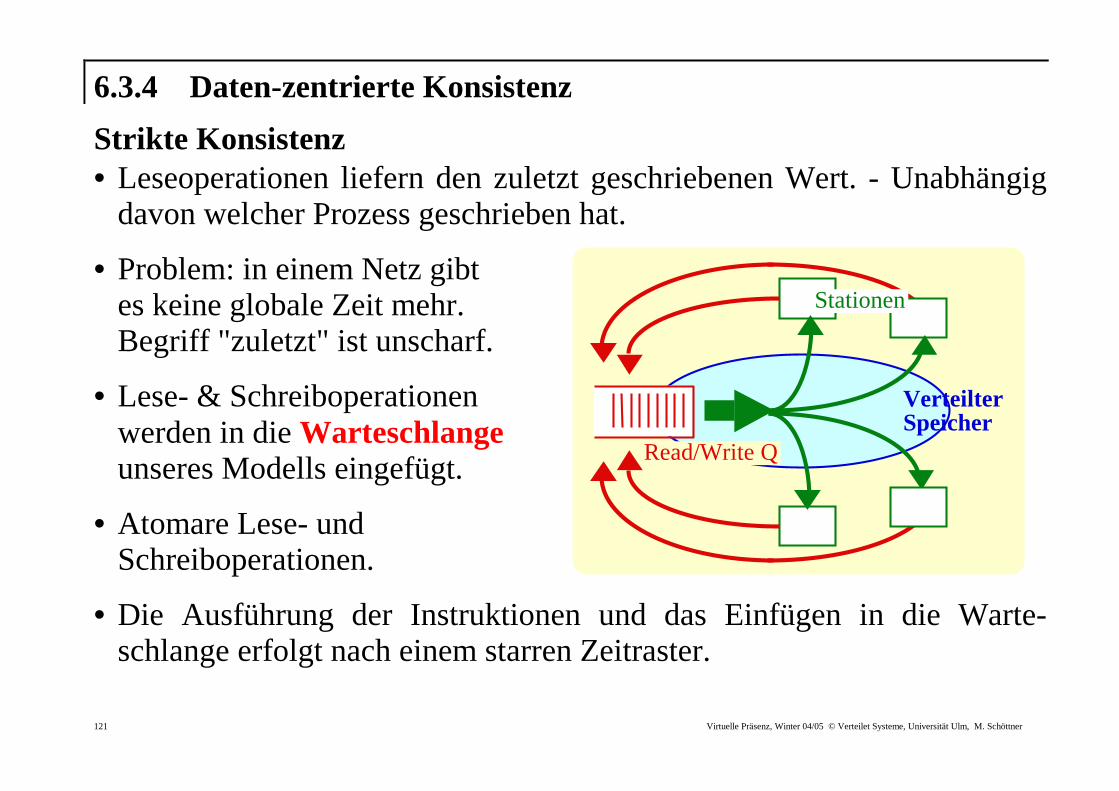
6.3.4 Daten-zentr ier te Konsistenz
Str ikte Konsistenz • Leseoperationen liefern den zuletzt geschriebenen Wert. - Unabhängig
davon welcher Prozess geschrieben hat.
• Problem: in einem Netz gibt es keine globale Zeit mehr. Begriff "zuletzt" ist unscharf.
• Lese- & Schreiboperationen werden in die Warteschlange unseres Modells eingefügt.
• Atomare Lese- und Schreiboperationen.
• Die Ausführung der Instruktionen und das Einfügen in die Warte-schlange erfolgt nach einem starren Zeitraster.
Ver teilter Speicher
Read/Write Q
Stationen
122 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
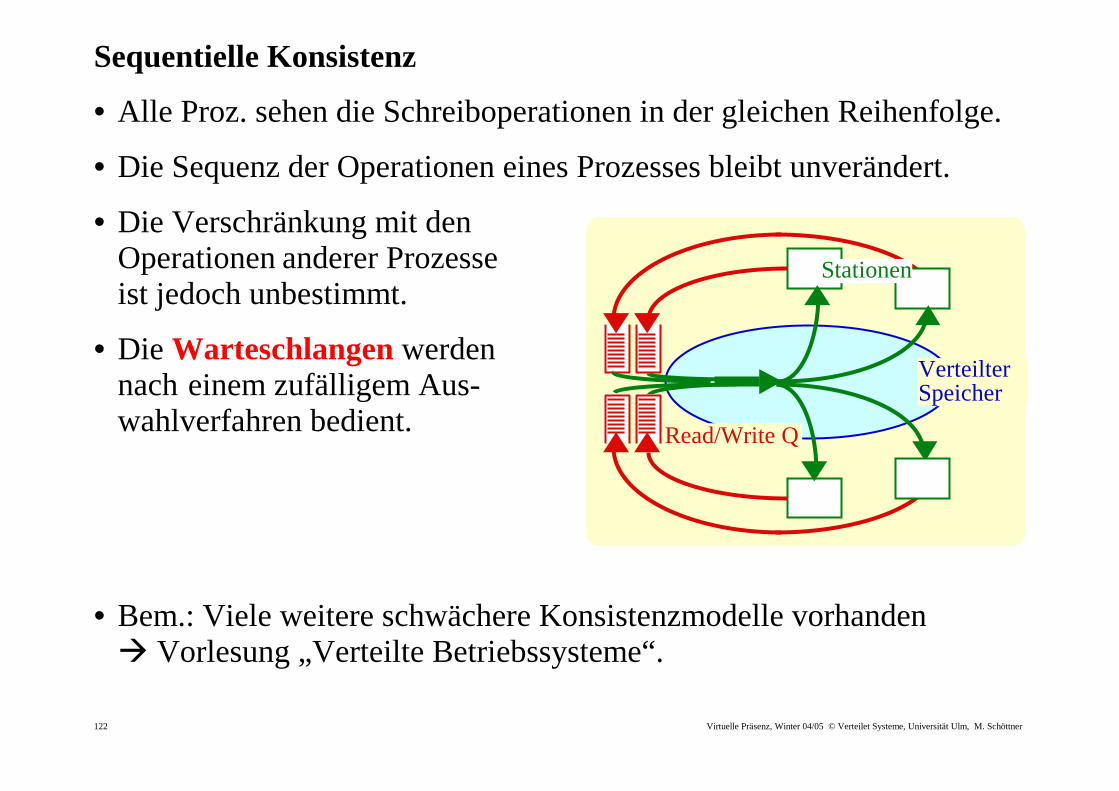
Sequentielle Konsistenz
• Alle Proz. sehen die Schreiboperationen in der gleichen Reihenfolge.
• Die Sequenz der Operationen eines Prozesses bleibt unverändert.
• Die Verschränkung mit den Operationen anderer Prozesse ist jedoch unbestimmt.
• Die Warteschlangen werden nach einem zufälligem Aus- wahlverfahren bedient.
• Bem.: Viele weitere schwächere Konsistenzmodelle vorhanden � Vorlesung „Verteilte Betriebssysteme“ .
Verteilter Speicher
Read/Write Q
Stationen

123 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.3.5 Client-zentr ier te Konsistenz
Eventuelle Konsistenz • Idee: Daten werden letztendlich irgendwann konsistent. • Aktualisierungen setzen sich nach gewisser Zeit durch. • Beispiel: Änderungen von DNS Namen. • Implementierung:
- Push-Modell: Update aller Replikate nach Timeout (periodisch), - Pull-Modell: nach Timeout holen Replikate neue Version (z.B. Webcache).
• Sehr schwaches Konsistenzmodell. • Problem: evt. sieht Klient zwischendurch veraltete Daten.
• Bewertung für Multi-User Welten: - verwendet in Online-Spielen (Doom, Diablo), - unreliable Multicast geeignet für eigene Avatarposition, - bei fremden Objekten muss Eigentümerschaft beachtet werden
� Sperren notwendig, sonst entstehen Inkonsistenzen.

124 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.4 Kohärenz
• Konsistenz: Wann sieht ein anderer Knoten die Änderung? • Kohärenz: Wie sieht ein anderer Knoten die Änderung? • Kohärenzprotokoll: Write-Invalidate
- Updates werden nur bei Lesezugriffen propagiert, - Vorteil: bei Bedarf übertragen � Updates bündelbar, - Nachteil: Lesen ist langsamer, da Daten erst beschafft werden müssen.
• Kohärenzprotokoll: Write-Update - nach jedem Schreibzugriff wird Update an alle Replikate gesendet, - Nachteil: u.U. viele unnötige Datentransfers, - Vorteil: Lesezugriff schneller.
R(X) W(X=4)
R(X)
R(X)
Node-1
Node-2
Node-3
R(X=4)R-Req
invalidate

125 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.5 Zuver lässige Gruppenkommunikation
• Gruppenkommunikation: 1 Sender schickt Nachricht an n Knoten. • Bsp.: Write-Invalidate muss zuverlässig alle Replikate erreichen. • Probl.: im Internet überholen sich Pakete und gehen verloren. • Eigenschaften der Gruppenkommunikation:
- Zuverlässigkeit: Garantie, dass Nachrichten zugestellt werden. - Ordnungsgrad: Vorgaben bzgl. der Reihenfolge der Pakete. - Effizienz: Ethernet bietet HW-Unterstützung für Multicast.
• Implementierung: zuverlässiger atomarer Multicast - atomar (= totale Ordnung): Senderechtvergabe über zirkulierendes Token (z.B. f. seq. Kons.). - Einfacher Ansatz:
o Sender sammelt von jedem Empfänger eine Empfangsbestätigung, o sind alle eingegangen, wird ein „Ende“-Multicast gesendet. o Problem: „Ende“ wieder per Multicast � Quittungen?
- Verbesserung: Negative Acknowledgement o Sender nummeriert alle Multicast-Nachrichten, o Empfänger erkennt somit Lücken zw. eingehenden Nachrichten, o fehlende Nachrichten per negative Ack. nachfordern � Sender muss Historie speichern.
• Problem: Latenz & Skalierbarkeit � viele Protokolle in der Literatur.
126 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.6 Konsistenz in interaktiven 3D Welten
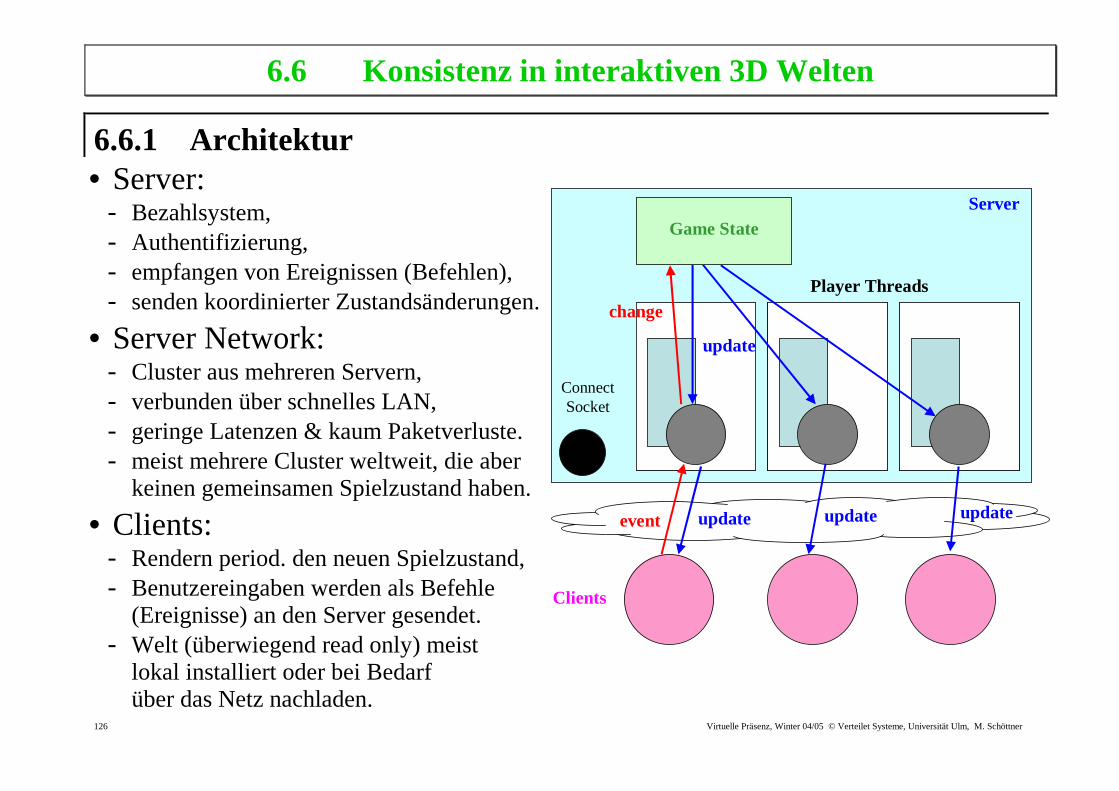
6.6.1 Architektur • Server:
- Bezahlsystem, - Authentifizierung, - empfangen von Ereignissen (Befehlen), - senden koordinierter Zustandsänderungen.
• Server Network: - Cluster aus mehreren Servern, - verbunden über schnelles LAN, - geringe Latenzen & kaum Paketverluste. - meist mehrere Cluster weltweit, die aber
keinen gemeinsamen Spielzustand haben.
• Clients: - Rendern period. den neuen Spielzustand, - Benutzereingaben werden als Befehle
(Ereignisse) an den Server gesendet. - Welt (überwiegend read only) meist
lokal installiert oder bei Bedarf über das Netz nachladen.
Connect Socket
Player Threads
Clients
event
change
update
update update update
Game StateServer

127 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
• Bandbreiten (Quake): Client: 50Kbps, Server: N*50Kbps.
• Latenz: - 33ms für 10.000km bei Lichtgeschwindigkeit. - 100ms entspricht ungefähr der Reaktionszeit des Menschen, - Anforderungen abhängig vom Spiel:
o Rollenspiele weniger empfindlich, o Single-Person Shooter & Rennsimulation ~100ms erwünscht. o 200ms und mehr führen bei diesen Spielen zu wahrnehmbaren Problemen.
• Konsistenz: - Rennspiele haben weniger strenge Anforderungen (Position der Fahrzeuge), - Single-Person Shooter verlangen strenge Konsistenz (Zielgenauigkeit bei Schüssen, ...).

128 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.6.2 Dead Reckoning für Positionszustände • Dead Reckoning = Koppelnavigation:
- Positionsbest. mit Hilfe der alten Position, Fahrtrichtung und Geschwindigkeit. - früher verwendet für Schiffe und Flugzeuge, - hat durch GPS an Bedeutung verloren.
• Idee: Approximierung des echten Zustands. - zwischen Updates wird Zustandsänderung spekulativ berechnet, - seltenere Updates werden zur Korrektur verwendet, - Paketverlust tolerierbar.
• Client-zentriertes Konsistenzmodell.
• Bewertung: - skaliert gut, - geringere Bandbreite, - schwächere Konsistenz, - nur bedingte Genauigkeit, - hektische Bewegungen problematisch, - erlaubt Verzicht auf zuverlässige Gruppenkommunikation.
Predicted Track
Updated Track
Covergence Path
129 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
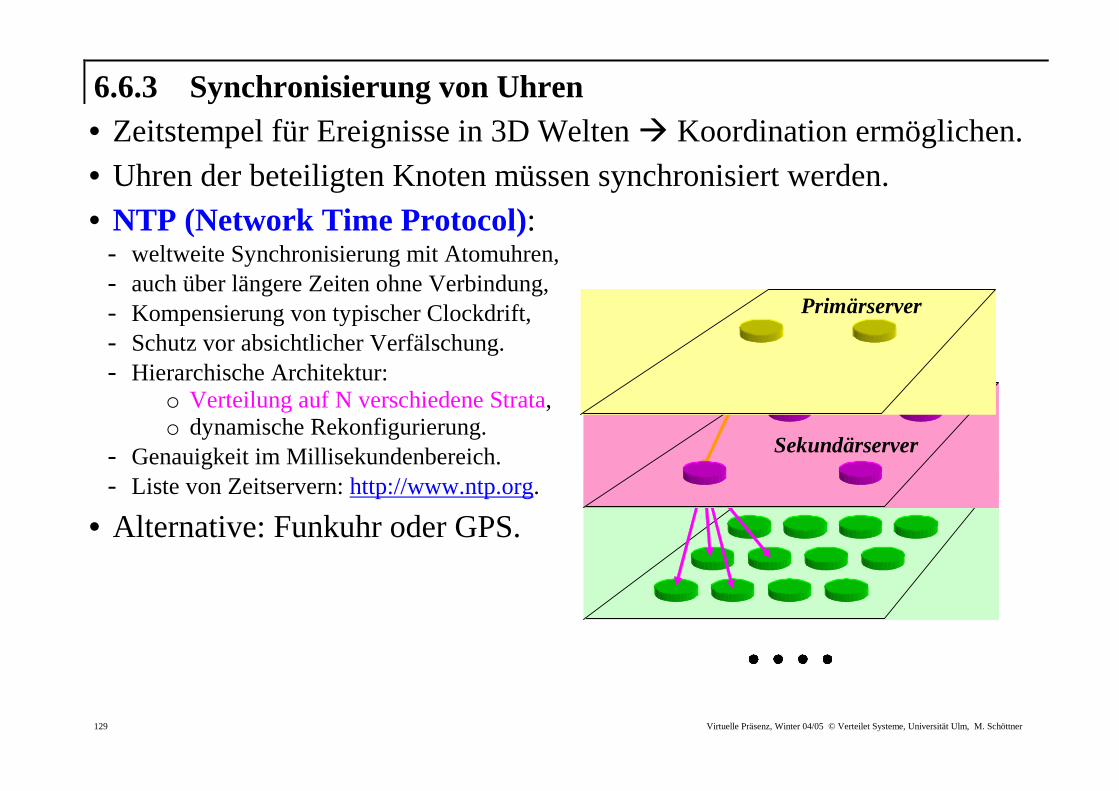
6.6.3 Synchronisierung von Uhren • Zeitstempel für Ereignisse in 3D Welten � Koordination ermöglichen. • Uhren der beteiligten Knoten müssen synchronisiert werden. • NTP (Network Time Protocol):
- weltweite Synchronisierung mit Atomuhren, - auch über längere Zeiten ohne Verbindung, - Kompensierung von typischer Clockdrift, - Schutz vor absichtlicher Verfälschung. - Hierarchische Architektur:
o Verteilung auf N verschiedene Strata, o dynamische Rekonfigurierung.
- Genauigkeit im Millisekundenbereich. - Liste von Zeitservern: http://www.ntp.org.
• Alternative: Funkuhr oder GPS.
Primärserver
Sekundärserver
130 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
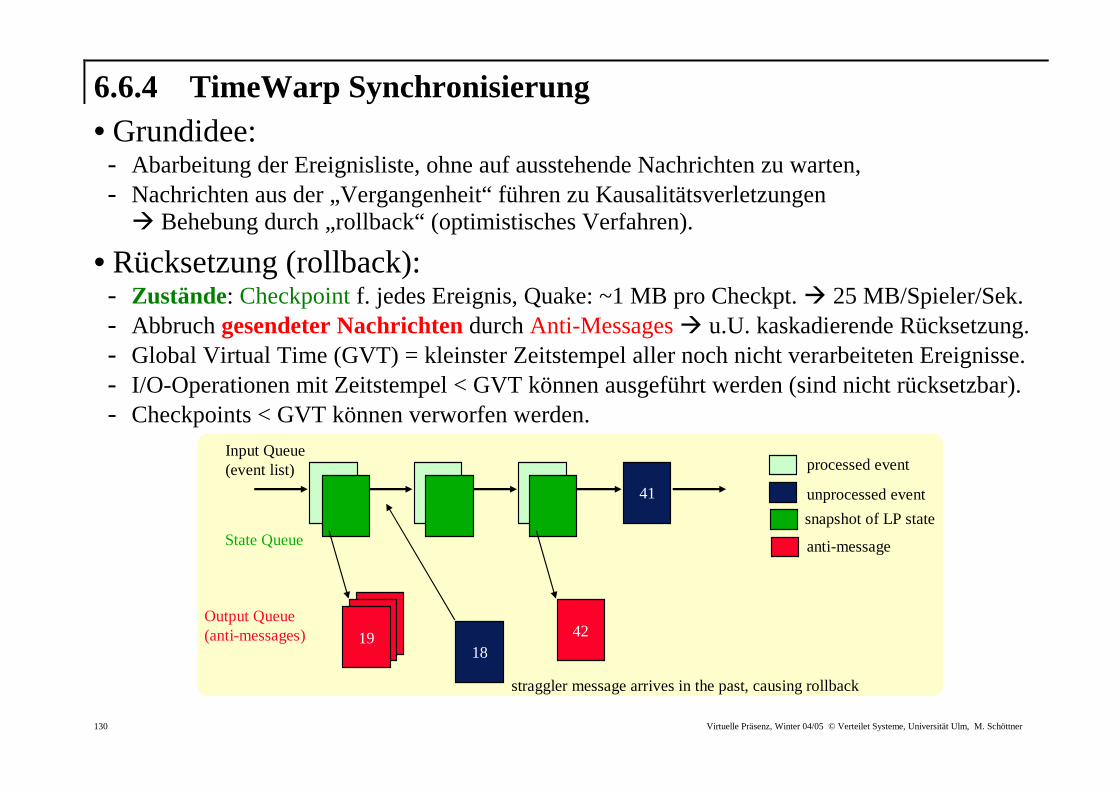
6.6.4 TimeWarp Synchronisierung • Grundidee: - Abarbeitung der Ereignisliste, ohne auf ausstehende Nachrichten zu warten, - Nachrichten aus der „Vergangenheit“ führen zu Kausalitätsverletzungen � Behebung durch „ rollback“ (optimistisches Verfahren).
• Rücksetzung (rollback): - Zustände: Checkpoint f. jedes Ereignis, Quake: ~1 MB pro Checkpt. � 25 MB/Spieler/Sek. - Abbruch gesendeter Nachr ichten durch Anti-Messages � u.U. kaskadierende Rücksetzung. - Global Virtual Time (GVT) = kleinster Zeitstempel aller noch nicht verarbeiteten Ereignisse. - I/O-Operationen mit Zeitstempel < GVT können ausgeführt werden (sind nicht rücksetzbar). - Checkpoints < GVT können verworfen werden.
41
Input Queue(event list)
18
straggler message arrives in the past, causing rollback
12 21 35
processed event
unprocessed event
State Queuesnapshot of LP state
1212Output Queue(anti-messages) 19 42
anti-message
131 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
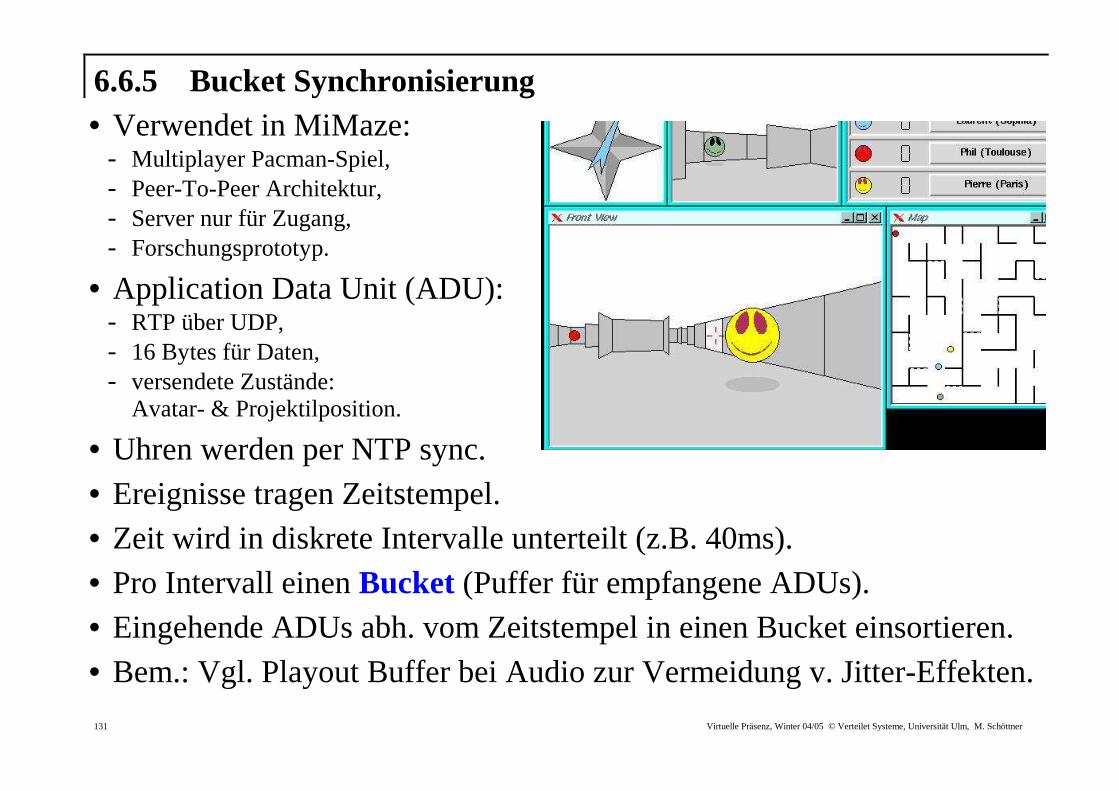
6.6.5 Bucket Synchronisierung • Verwendet in MiMaze:
- Multiplayer Pacman-Spiel, - Peer-To-Peer Architektur, - Server nur für Zugang, - Forschungsprototyp.
• Application Data Unit (ADU): - RTP über UDP, - 16 Bytes für Daten, - versendete Zustände:
Avatar- & Projektilposition.
• Uhren werden per NTP sync.
• Ereignisse tragen Zeitstempel. • Zeit wird in diskrete Intervalle unterteilt (z.B. 40ms).
• Pro Intervall einen Bucket (Puffer für empfangene ADUs). • Eingehende ADUs abh. vom Zeitstempel in einen Bucket einsortieren. • Bem.: Vgl. Playout Buffer bei Audio zur Vermeidung v. Jitter-Effekten.
132 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
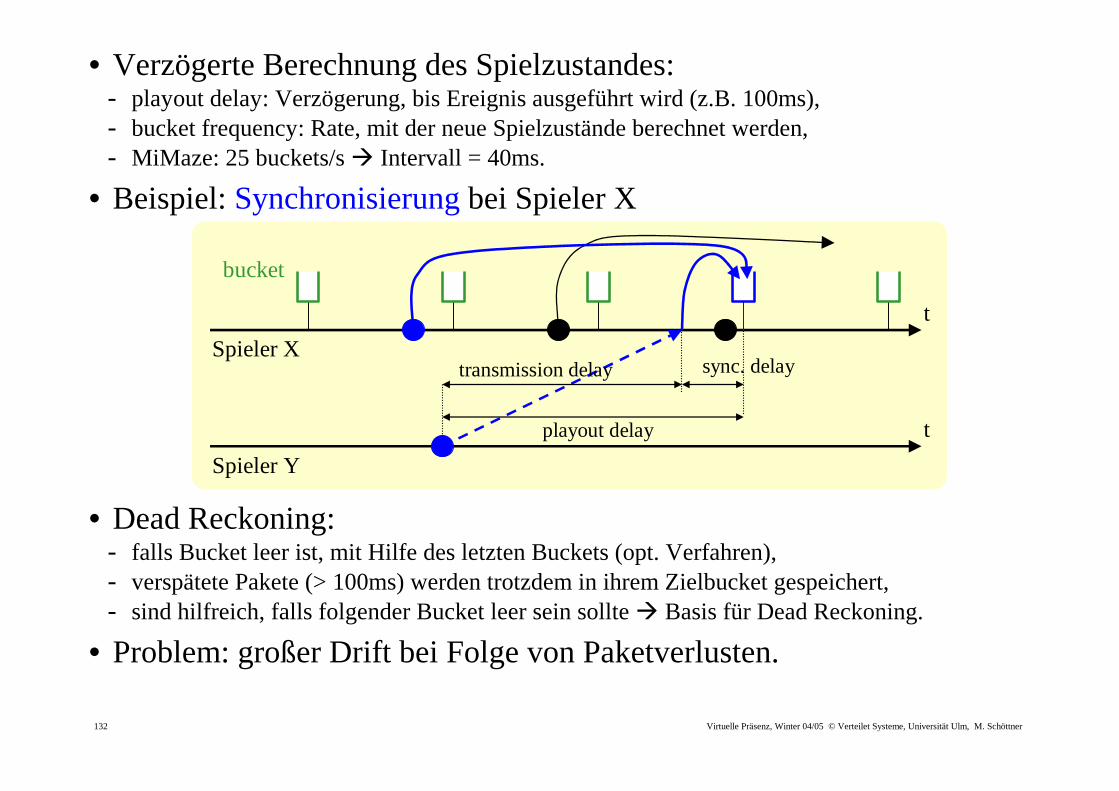
• Verzögerte Berechnung des Spielzustandes: - playout delay: Verzögerung, bis Ereignis ausgeführt wird (z.B. 100ms), - bucket frequency: Rate, mit der neue Spielzustände berechnet werden, - MiMaze: 25 buckets/s � Intervall = 40ms.
• Beispiel: Synchronisierung bei Spieler X
Spieler X
Spieler Y
t
t
bucket
playout delay
transmission delay sync. delay
• Dead Reckoning:
- falls Bucket leer ist, mit Hilfe des letzten Buckets (opt. Verfahren), - verspätete Pakete (> 100ms) werden trotzdem in ihrem Zielbucket gespeichert, - sind hilfreich, falls folgender Bucket leer sein sollte � Basis für Dead Reckoning.
• Problem: großer Drift bei Folge von Paketverlusten.
133 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
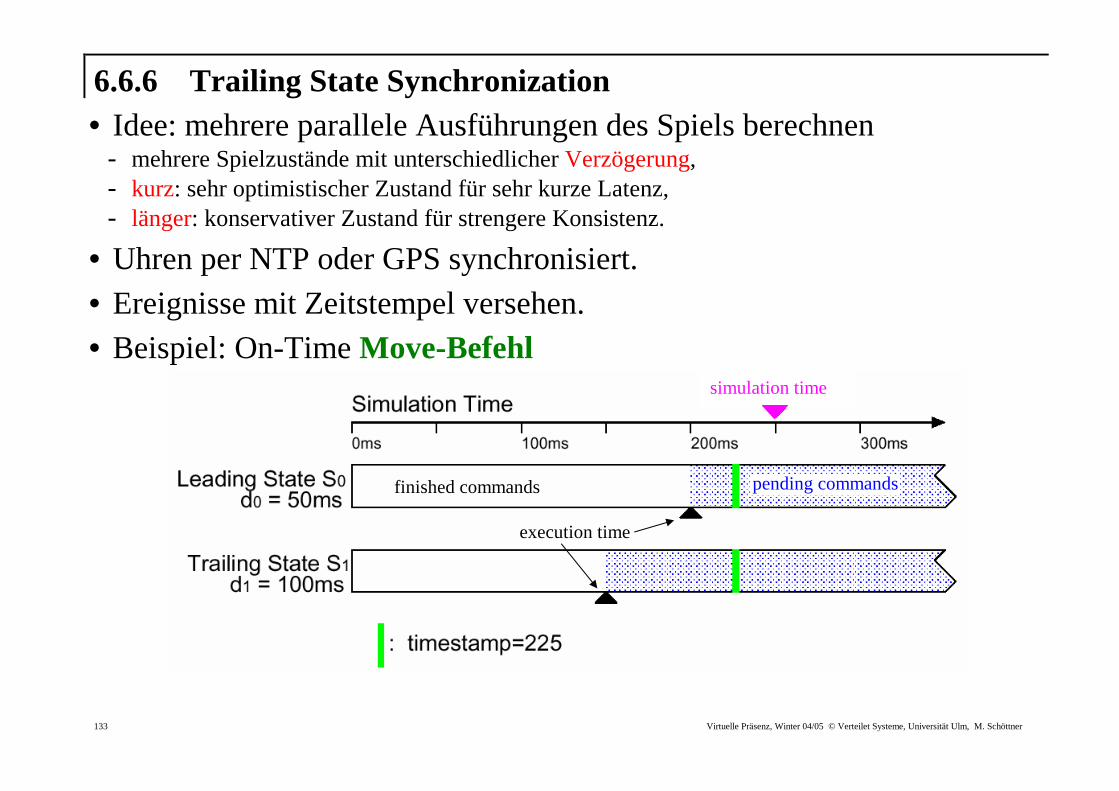
6.6.6 Trailing State Synchronization • Idee: mehrere parallele Ausführungen des Spiels berechnen
- mehrere Spielzustände mit unterschiedlicher Verzögerung, - kurz: sehr optimistischer Zustand für sehr kurze Latenz, - länger: konservativer Zustand für strengere Konsistenz.
• Uhren per NTP oder GPS synchronisiert. • Ereignisse mit Zeitstempel versehen. • Beispiel: On-Time Move-Befehl
simulation time
finished commands pending commands
execution time
134 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
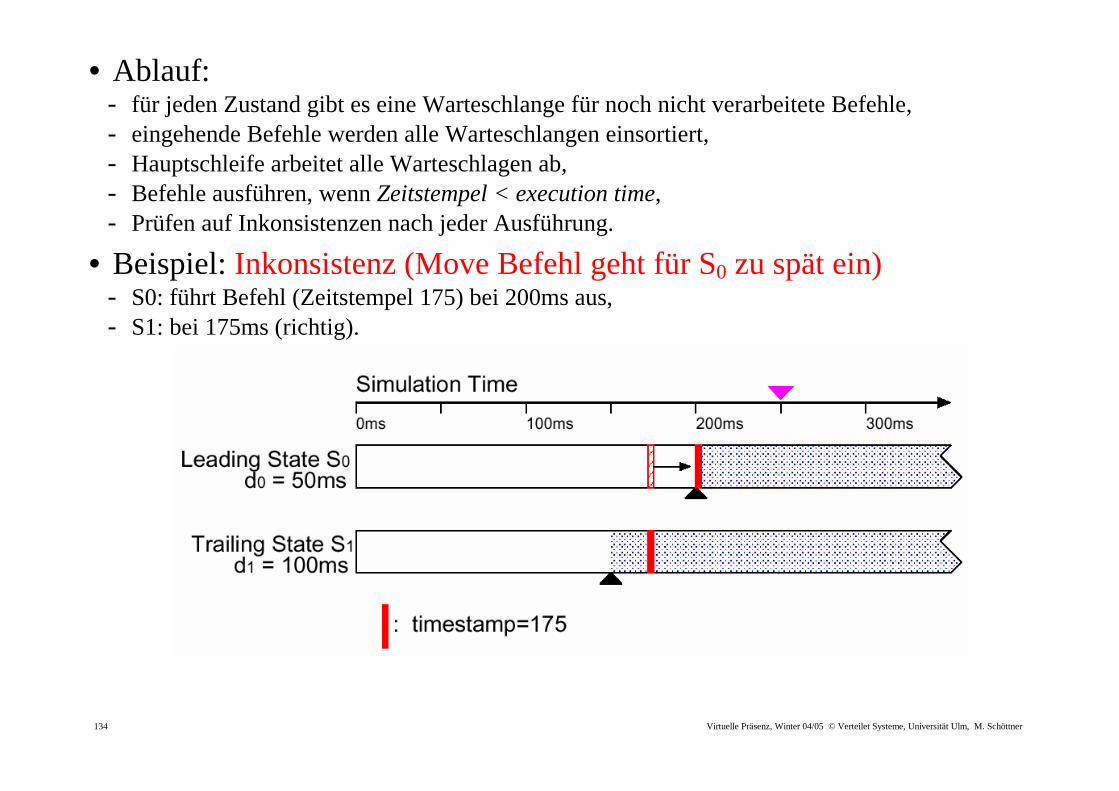
• Ablauf: - für jeden Zustand gibt es eine Warteschlange für noch nicht verarbeitete Befehle, - eingehende Befehle werden alle Warteschlangen einsortiert, - Hauptschleife arbeitet alle Warteschlagen ab, - Befehle ausführen, wenn Zeitstempel < execution time, - Prüfen auf Inkonsistenzen nach jeder Ausführung.
• Beispiel: Inkonsistenz (Move Befehl geht für S0 zu spät ein) - S0: führt Befehl (Zeitstempel 175) bei 200ms aus, - S1: bei 175ms (richtig).
135 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
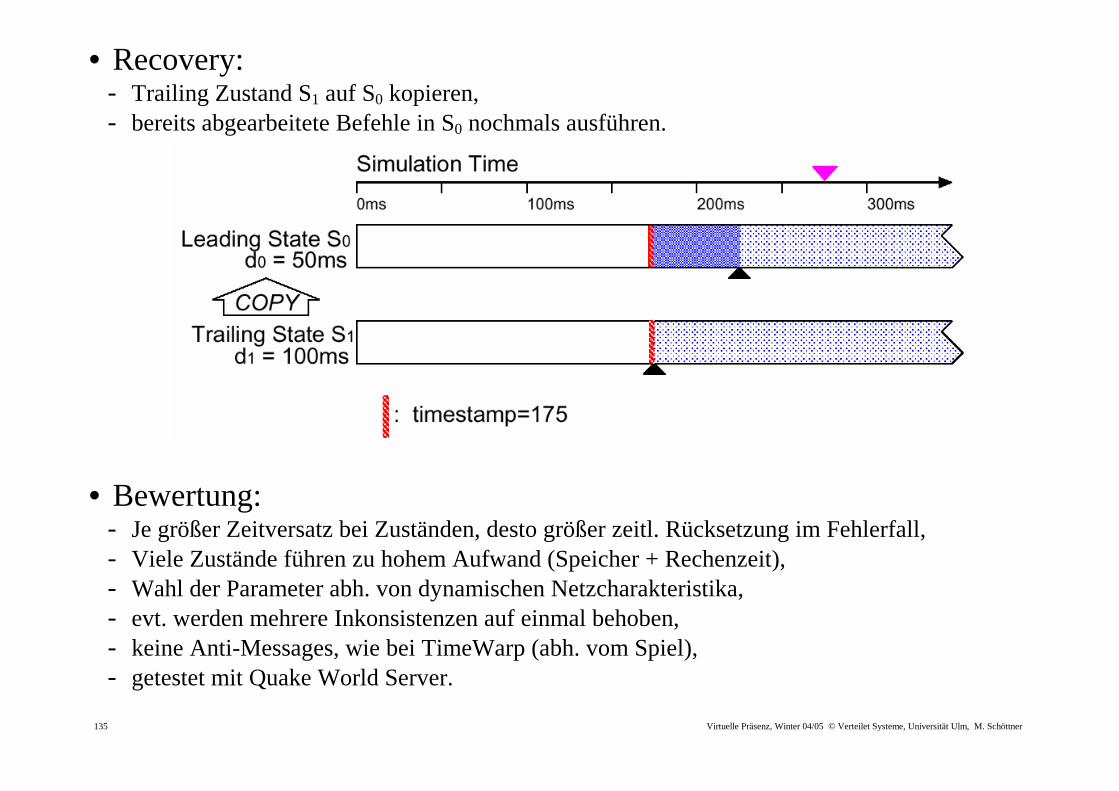
• Recovery: - Trailing Zustand S1 auf S0 kopieren, - bereits abgearbeitete Befehle in S0 nochmals ausführen.
• Bewertung: - Je größer Zeitversatz bei Zuständen, desto größer zeitl. Rücksetzung im Fehlerfall, - Viele Zustände führen zu hohem Aufwand (Speicher + Rechenzeit), - Wahl der Parameter abh. von dynamischen Netzcharakteristika, - evt. werden mehrere Inkonsistenzen auf einmal behoben, - keine Anti-Messages, wie bei TimeWarp (abh. vom Spiel), - getestet mit Quake World Server.
136 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
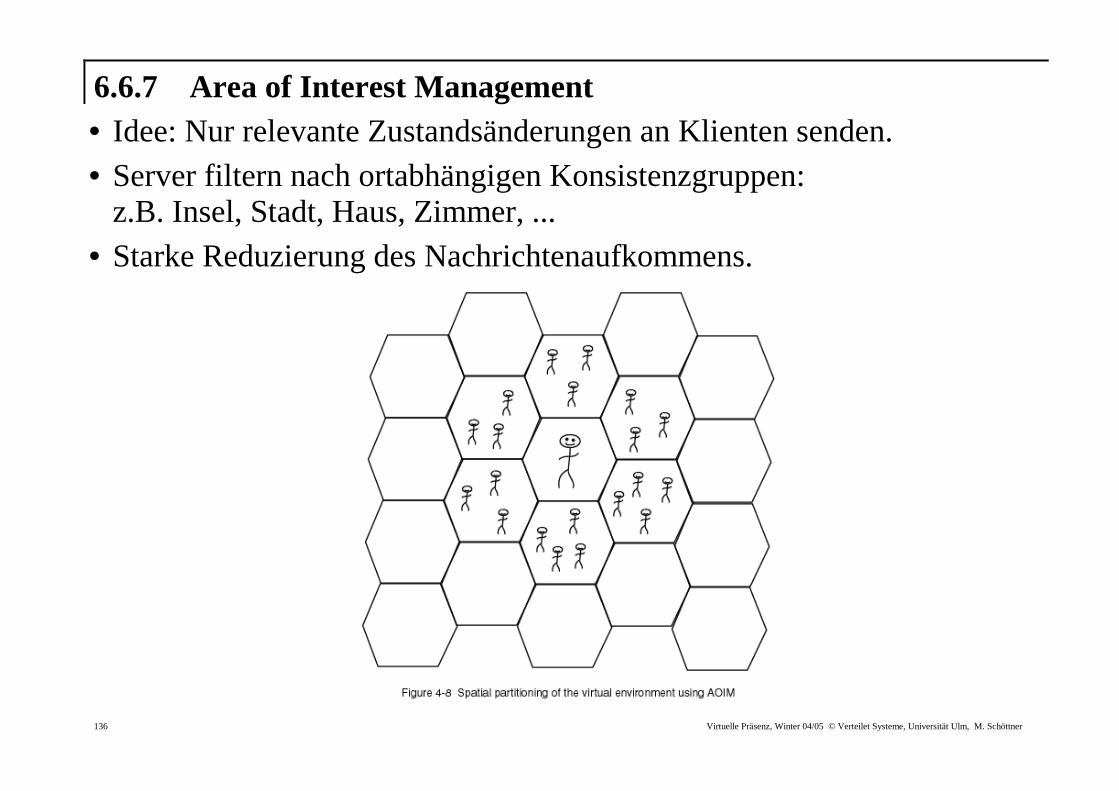
6.6.7 Area of Interest Management • Idee: Nur relevante Zustandsänderungen an Klienten senden. • Server filtern nach ortabhängigen Konsistenzgruppen:
z.B. Insel, Stadt, Haus, Zimmer, ...
• Starke Reduzierung des Nachrichtenaufkommens.

137 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.7 Persistenz
6.7.1 Einführung • Persistenz (Dauerhaftigkeit):
- Definition: Fähigkeit die Lebenszeit von Daten zu verlängern, insbesondere über die Lebenszeit der erzeugenden Einheit hinaus.
- Hierzu werden Daten aus dem flüchtigen Speicher auf Disk gespeichert.
• Ausgangssituation: - sequentieller Zugriff auf Sekundärspeicher, - Datenstrukturen müssen serialisiert werden, - insbesondere Zeiger auf Diskadressen abbilden.
• Bei nur einem Server genügt ein gewöhnliches Dateisystem.
• Bei Server-Clustern werden verteilte Dateisysteme notwendig. - erlauben i.d.R. Lesereplikate, - wodurch wieder die Konsistenzfrage aufgeworfen wird.
• Alternativen zu Dateisystemen: - (verteilte) Datenbanken, - persistente Objektsysteme, - persistenter Verteilter Virtuelle Speicher.

138 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.7.2 Explizite Datenspeicherung • Explizite Datenspeicherung ist die gängige Technik. • Speichern:
- Auswahl der zu speichernden Objekte, - eventuell nicht alle Daten eines Objektes speichern, - Serialisierung der dynamischen Datenstrukturen in eine Datei.
• Laden: - sequentielles Einlesen der Daten, - Wiederaufbau der dyn. Datenstrukturen, - Schreiben der Daten in die erzeugten Objekte.
• Viele teilweise sehr komplexe Dateiformate (z.B. Winword & Acrobat).
• Moderne objekt-orientierte Sprachen (z.B. Java & C++) bieten eine komfortable Serialisierung von Instanzen: - Instanzvariablen werden automatisch in einer Datei gesichert, - Referenzen werden transitiv verfolgt und alle erreichbaren Instanzen mit abgespeichert, - für jede Instanz wird auch die zugehörige Typbeschreibung gespeichert
(Standardklassen z. B. java.lang.String werden in Form einer Pfadangabe berücksichtigt). - aber kein inkrementelles Laden & Speichern möglich (Objekte werden u.U. dupliziert).

139 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
• Beispiel: verkettete Liste in Java abspeichern. - transitive Hülle über alle Instanzen wird auto. gesichert. - Typbeschreibung für benutzdef. K lassen wird ebenfalls abgespeichert.
import java.io.* ;
public class SaveList { public class MyList implements Serializable { static public void main( String[ ] args ) { public String name; MyList ml; public MyList next; FileOutputStream file; ObjectOutputStream oos; public MyList(String s) { name=s; }
ml = new MyList("ms"); } ml.next = new MyList("ps"); ml.next.next = new MyList("abc"); try { file = new FileOutputStream("MyList.txt"); oos= new ObjectOutputStream( file); oos.writeObject( ml ); oos.close(); } catch (Exception e) { }; }}
• Ergebnis:
¬í �sr �MyList
�
æKóƒ·gÐ� �L �namet �Ljava/lang/String;L �nextt �LMyList;xpt �mssq ~ t �pssq ~ t �abcp

140 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.7.3 Implizite Datenspeicherung • Grundidee: Heap des Laufzeitsystems wird persistent gemacht.
- Malcom P. Atkinson, University of Glasgow, PS-Algol (1982), PJama (2000).
• Orthogonale Persistenz: - Der Datenzugriff ist transparent bezüglich der Persistenzeigenschaft. - Die Persistenzeigenschaft ist orthogonal zum Typensystem. - Die Persistenz-Identifikation muß automatisch erfolgen.
• Datenzugriff: - erfolgt beispielsweise durch gewöhnliche Referenzen, - Laufzeitsystem fängt Zugriffe ab und lädt Objekte implizit.
• Typ-Orthogonalität: - alle Instanzen können persistent sein, unabhängig von ihrer Klasse, - damit kein „Serializable“ o.ä. notwendig, wie zum Beispiel in Java.
• Persistenz durch Erreichbarkeit: - nicht alle Objekte müssen persistent sein, - i.d.R. nur transitiv von einer Wurzel aus erreichbare Objekte.
• Vorteile: - Speichertransparenz für den Programmierer. - Zugriffe auf persistente Daten erfolgen ebenfalls unter Kontrolle des Typsystems.
141 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.7.4 Verteilte Datenspeicherung • Verteilte Dateisysteme ermögl. Zugriffe über Rechnergrenzen hinweg. • Zugriffstransparenz:
- Zugriff auf entfernte Dateien erfolgt mit den gleichen Operationen, wie der Zugriff auf lokale Dateien.
- Somit bleibt die Verteilung den Klienten verborgen.
• Ortstransparenz: - Es spielt keine Rolle, an welchem physikalischen Ort eine Datei gespeichert ist. - Dateien können beliebig verlagert werden ohne dass der Benutzer davon betroffen ist.
• Nebenläufigkeitstransparenz: - Keine Inkonsistenzen durch simultane Zugriffe. - Schreibzugriffe sind hierbei aber problematisch. - Meist werden Sperren verwendet, wodurch die Nebenläufigkeitstransparenz verloren geht.
• Fehlertransparenz: - Nach Ausfall eines Clients oder Servers sollte der Dateibetrieb wieder korrekt weiterlaufen.
• Leistungstransparenz: - Verzögerungen eines entfernten Zugriffs sollten gering und unabh. von der akt. Last sein.
Open/Close Read/Write
142 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
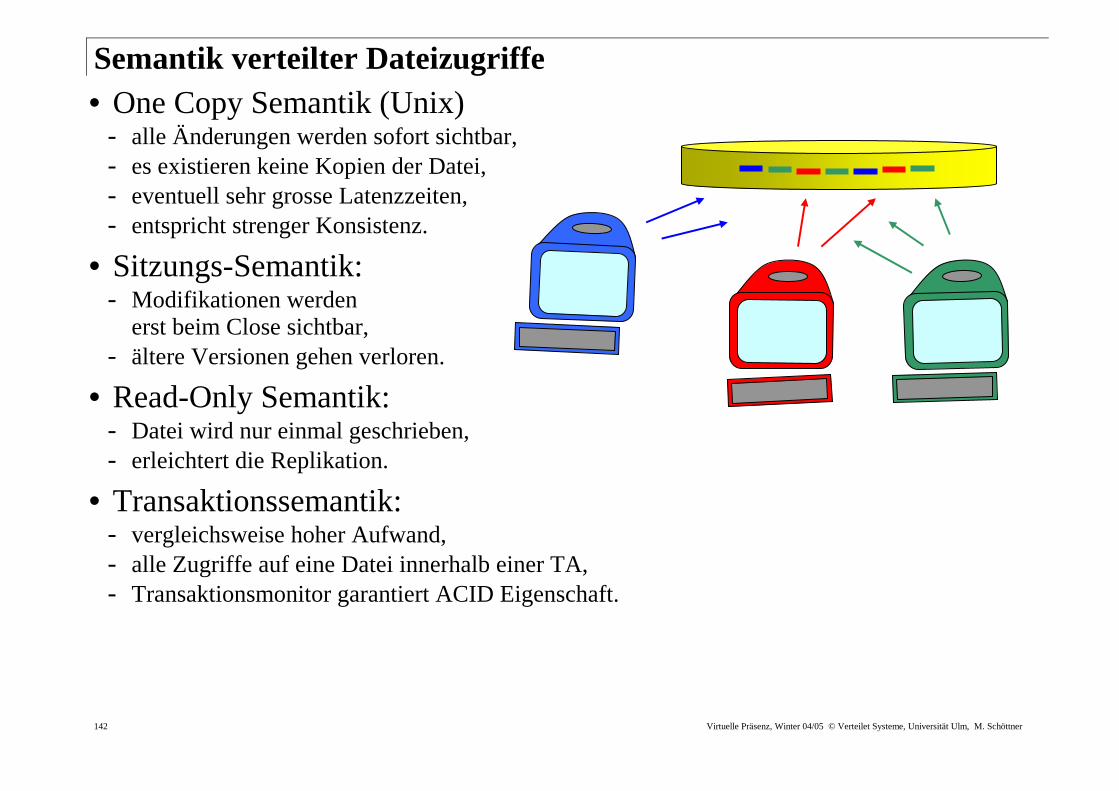
Semantik ver teilter Dateizugr iffe • One Copy Semantik (Unix)
- alle Änderungen werden sofort sichtbar, - es existieren keine Kopien der Datei, - eventuell sehr grosse Latenzzeiten, - entspricht strenger Konsistenz.
• Sitzungs-Semantik: - Modifikationen werden
erst beim Close sichtbar, - ältere Versionen gehen verloren.
• Read-Only Semantik: - Datei wird nur einmal geschrieben, - erleichtert die Replikation.
• Transaktionssemantik: - vergleichsweise hoher Aufwand, - alle Zugriffe auf eine Datei innerhalb einer TA, - Transaktionsmonitor garantiert ACID Eigenschaft.
143 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
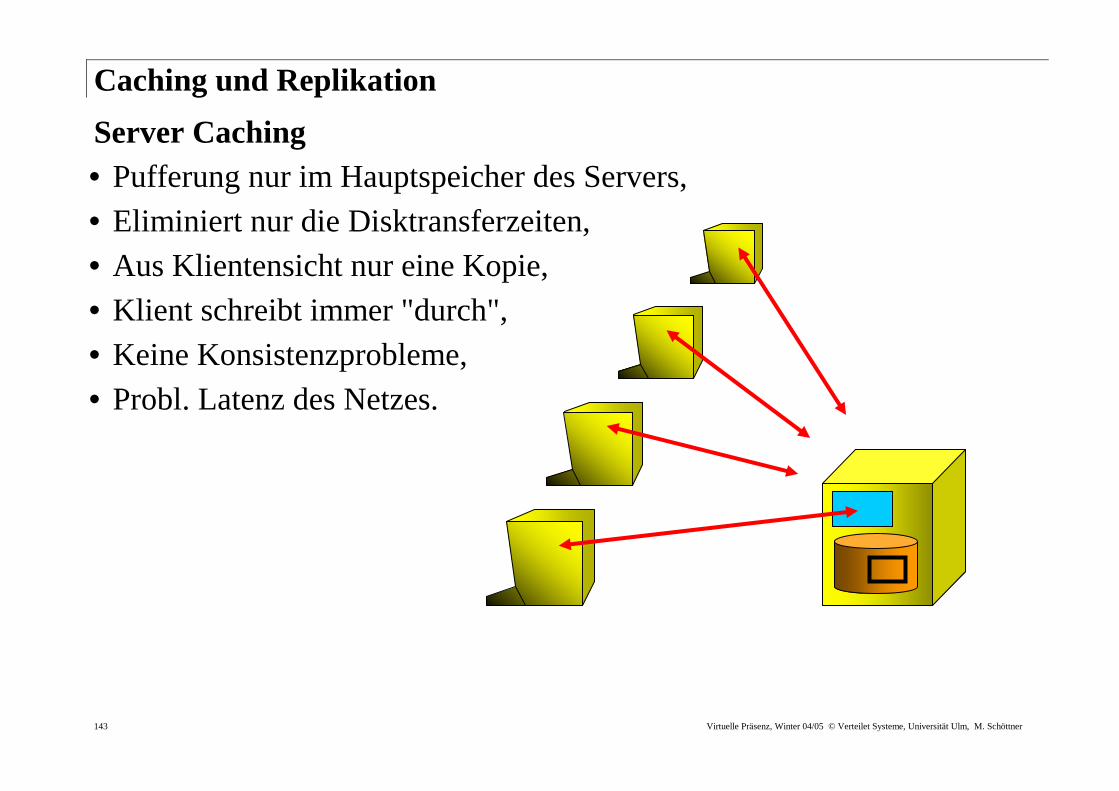
Caching und Replikation
Server Caching • Pufferung nur im Hauptspeicher des Servers, • Eliminiert nur die Disktransferzeiten, • Aus Klientensicht nur eine Kopie, • Klient schreibt immer "durch", • Keine Konsistenzprobleme,
• Probl. Latenz des Netzes.
144 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
KKK ooonnnsssiiisssttteeennnzzzppprrr oootttoookkkooollllll ,,,
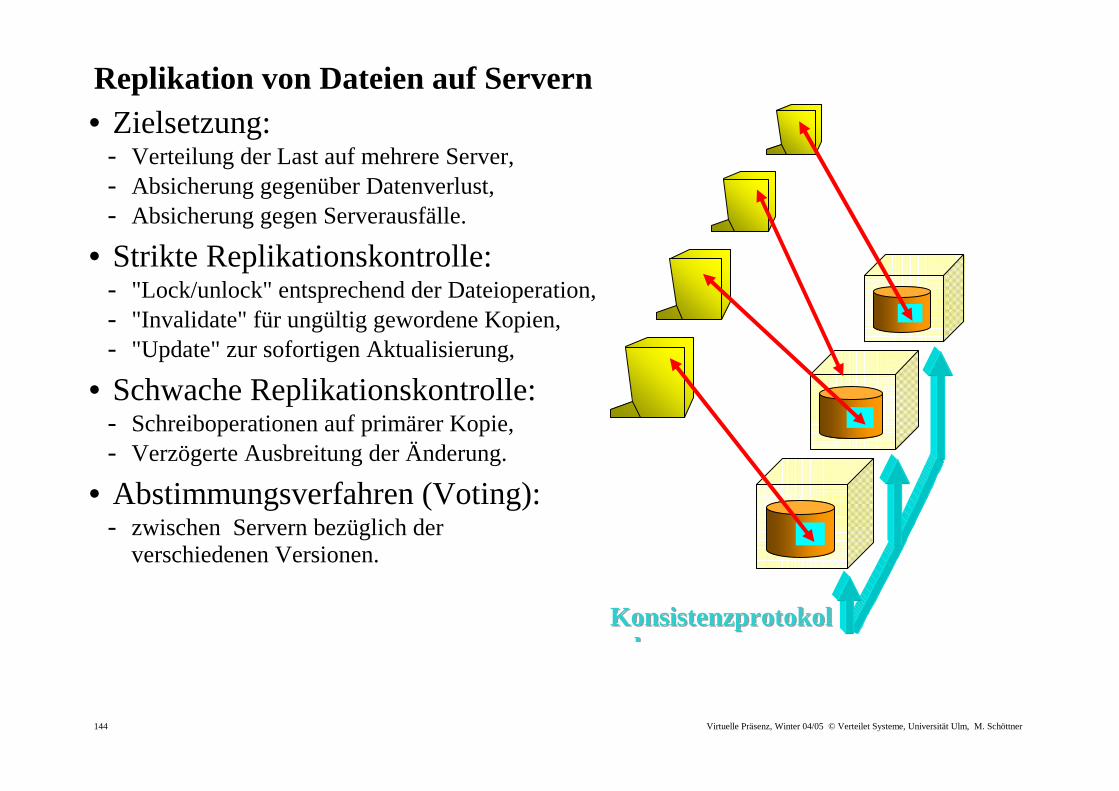
Replikation von Dateien auf Servern • Zielsetzung:
- Verteilung der Last auf mehrere Server, - Absicherung gegenüber Datenverlust, - Absicherung gegen Serverausfälle.
• Strikte Replikationskontrolle: - "Lock/unlock" entsprechend der Dateioperation, - "Invalidate" für ungültig gewordene Kopien, - "Update" zur sofortigen Aktualisierung,
• Schwache Replikationskontrolle: - Schreiboperationen auf primärer Kopie, - Verzögerte Ausbreitung der Änderung.
• Abstimmungsverfahren (Voting): - zwischen Servern bezüglich der
verschiedenen Versionen.
145 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
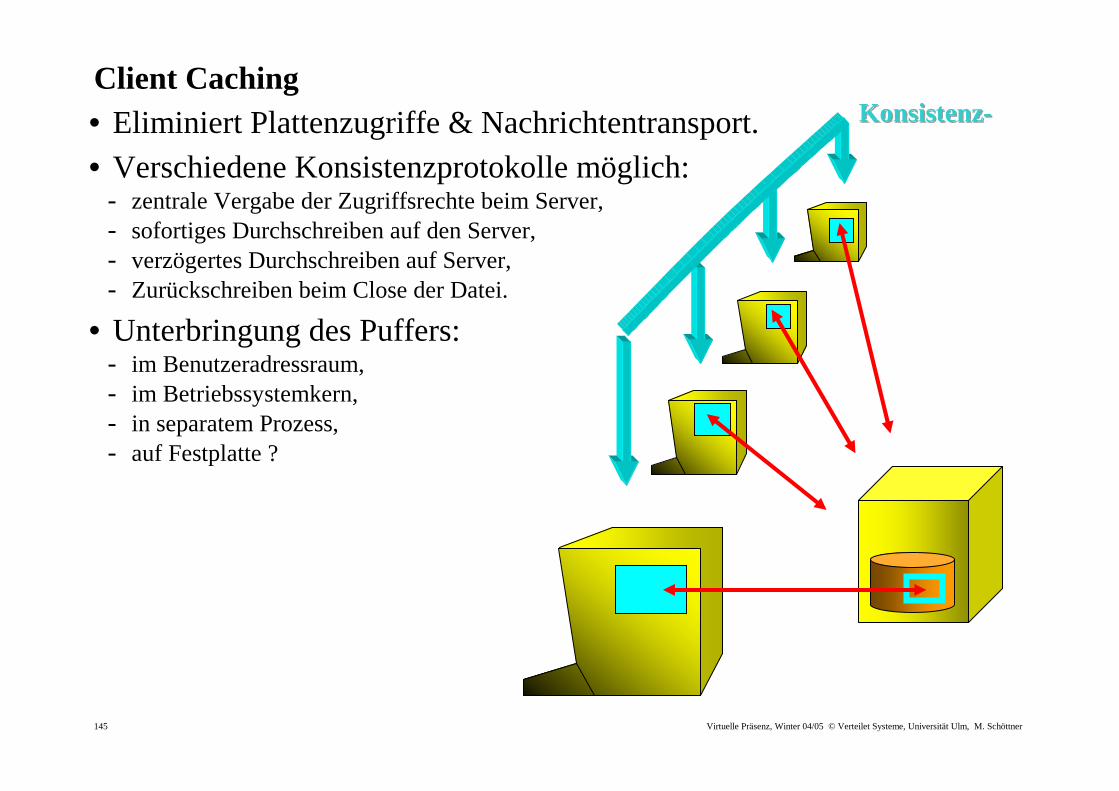
Client Caching • Eliminiert Plattenzugriffe & Nachrichtentransport. • Verschiedene Konsistenzprotokolle möglich:
- zentrale Vergabe der Zugriffsrechte beim Server, - sofortiges Durchschreiben auf den Server, - verzögertes Durchschreiben auf Server, - Zurückschreiben beim Close der Datei.
• Unterbringung des Puffers: - im Benutzeradressraum, - im Betriebssystemkern, - in separatem Prozess, - auf Festplatte ?
KKK ooonnnsssiiisssttteeennnzzz---
ppprrr oootttoookkkooolll lll

146 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
Beispiel: NFS • NFS = Network File System von SUN, 1985.
- Zum Export lokaler Verzeichnisse (verwendet intern RPC). - Klienten für Unix, MacOS und Windows.
• Zugriffstransparenz: - Programme können Zugriffe auf lokale und entfernte Dateien in gleicher Weise durchführen.
• Ortstransparenz: - Dateibaum oder Teile davon werden zum Export angeboten � importierbar durch Klienten. - Klient gibt an, an welcher Stelle im lokalen Verzeichnis das
importierte Dateisystem eingehängt wird (mount point). - Falls bei allen Klienten die gleiche Verzeichnisstruktur
realisiert wird, so ist die Ortstransparenz gegeben.
• Nebenläufigkeitstransparenz: - rudimentäre Sperrmechanismen � nicht gegeben.
• Fehlertransparenz: - bedingt gegeben, NFS-Server (V3) sind zustandslos, V4 jedoch nicht.
• Leistungstransparenz: - Nicht gegeben � hängt von der aktuellen Last ab.
147 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
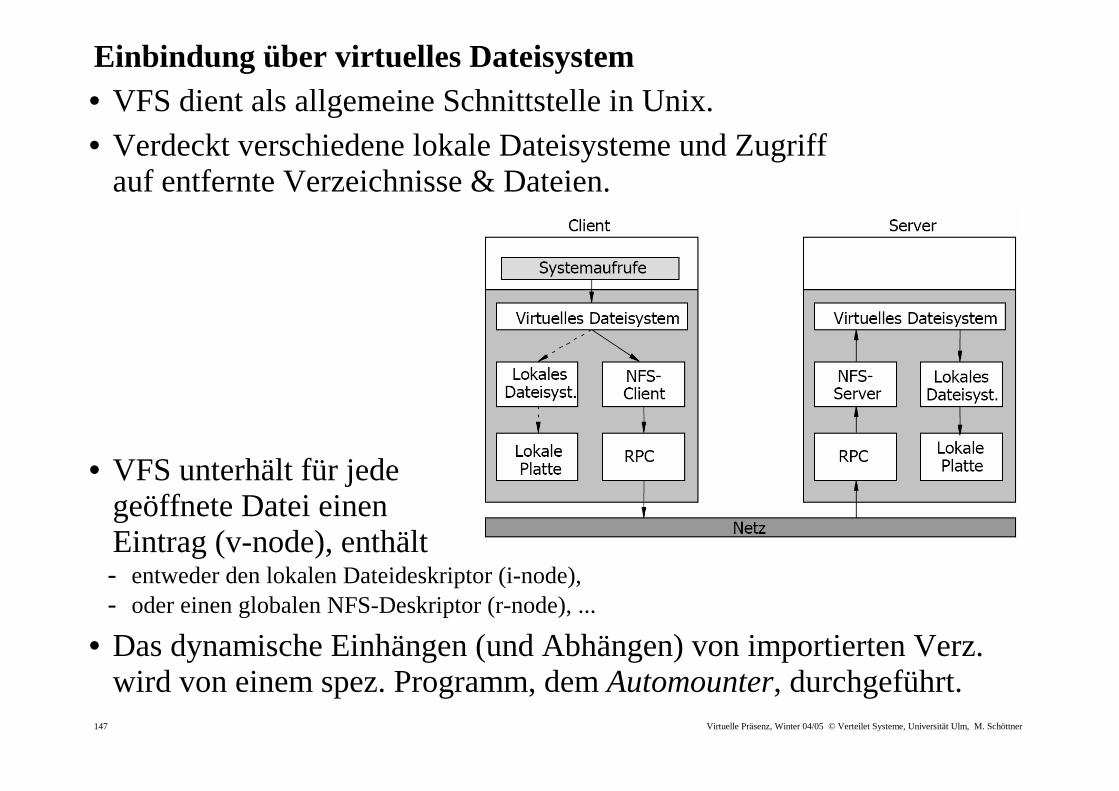
Einbindung über vir tuelles Dateisystem • VFS dient als allgemeine Schnittstelle in Unix. • Verdeckt verschiedene lokale Dateisysteme und Zugriff
auf entfernte Verzeichnisse & Dateien.
• VFS unterhält für jede geöffnete Datei einen Eintrag (v-node), enthält - entweder den lokalen Dateideskriptor (i-node), - oder einen globalen NFS-Deskriptor (r-node), ...
• Das dynamische Einhängen (und Abhängen) von importierten Verz. wird von einem spez. Programm, dem Automounter, durchgeführt.

148 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
NFS-Protokoll • Protokoll (V3) zw. Klient und Server ist zustandslos. � Server merkt sich nichts über Klient � erleichtert Fehlererholung.
• NFS-Server bietet 15 Operationen an, die vom Client aufgerufen werden können, darunter: - lookup(dirfh, name): liefert File-Handle zurück. - read(fh, offset, count): liest bis zu count Zeichen aus Datei fh, Start bei offset. - write(fh, offset, count, data): schreibt count Zeichen in Datei fh, Start bei offset. - Bem.: Nicht vorgesehen sind Dateioperationen wie open oder close, da sie der
Zustandslosigkeit des NFS-Dienstes widersprechen.
Sperren • Sperren für ganze Datei oder nur Teilbereiche.
• Implementierung von Sperren: - in NFS 3: eigener Dienst verwaltet gesperrte Dateien � Klienten müssen Sperrdienst nutzen. - in NFS 4: integriert in NFS-Operationen � nicht mehr zustandslos.
• Probl.: Absturz, während Sperre gehalten wird.
• Fehlererholung aufwendiger � Lösg. Sperren mit Leases.

149 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
Caching • Zugriffe in NFS haben Sitzungssemantik. • Server cachen für die NFS-Klienten transparent
schon gelesene Dateien in ihrem Speicher. • Klienten verwenden Caches, wobei diese nicht mit anderen
Klienten abgeglichen werden, sondern nur mit dem Server: - Ist eine Datei beim Öffnen im Cache des Klienten, so wird der lokale
Zeitstempel mit dem Modifikations-Zeitstempel beim Server verglichen. - Ist Kopie älter, wird sie invalidiert und erneut vom Server heruntergeladen. - Jeder Cacheblock besitzt eine Uhr, die für Dateiblöcke nach 3 Sekunden und
für Verzeichnisse nach 30 Sekunden abläuft � dann beim Server auf Aktualität prüfen. - Beim Schreibzugriff wird der entsprechende Block im Cache als „dirty“ markiert. - Markierte „dirty“ Blöcke werden alle 30 Sekunden zum Server propagiert (sync).

150 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.8 Zuver lässigkeit
6.8.1 Einführung • Ziele von Zuverlässigkeit im Kontext der virtuellen Präsenz:
- kein (großer) Datenverlust im Fehlerfall. - Wiederanlauf sollte möglichst schnell gehen.
• Verwendete Server Cluster: - bieten Hardware- und Software Redundanz, - fällt ein Knoten aus, so kann ein anderer die Arbeit übernehmen. - Knotenausfälle einfach durch periodische Anfragen erkennbar (z.B. Heart-Beat für Linux).
• Fehlertoleranz durch Checkpointing (Sicherungspunkte): - periodisch verteilten Systemzustand auf Disk sichern, - je kürzer Intervall, desto geringer ist Datenverlust, - Wiederanlauf vom letzten Sicherungspunkt aus.
• Verteilter Systemzustand: - gemeinsam genutzte Daten (Welt und Avatare), - lokale Prozesszustände und Nachrichten in Transit � pro Knoten ein Checkpoint. � Checkpoints aller Knoten müssen einen konsistenten Zustand bilden.
• Byzantinische Fehler & Sicherheitsaspekte werden hier nicht betrachtet.
151 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
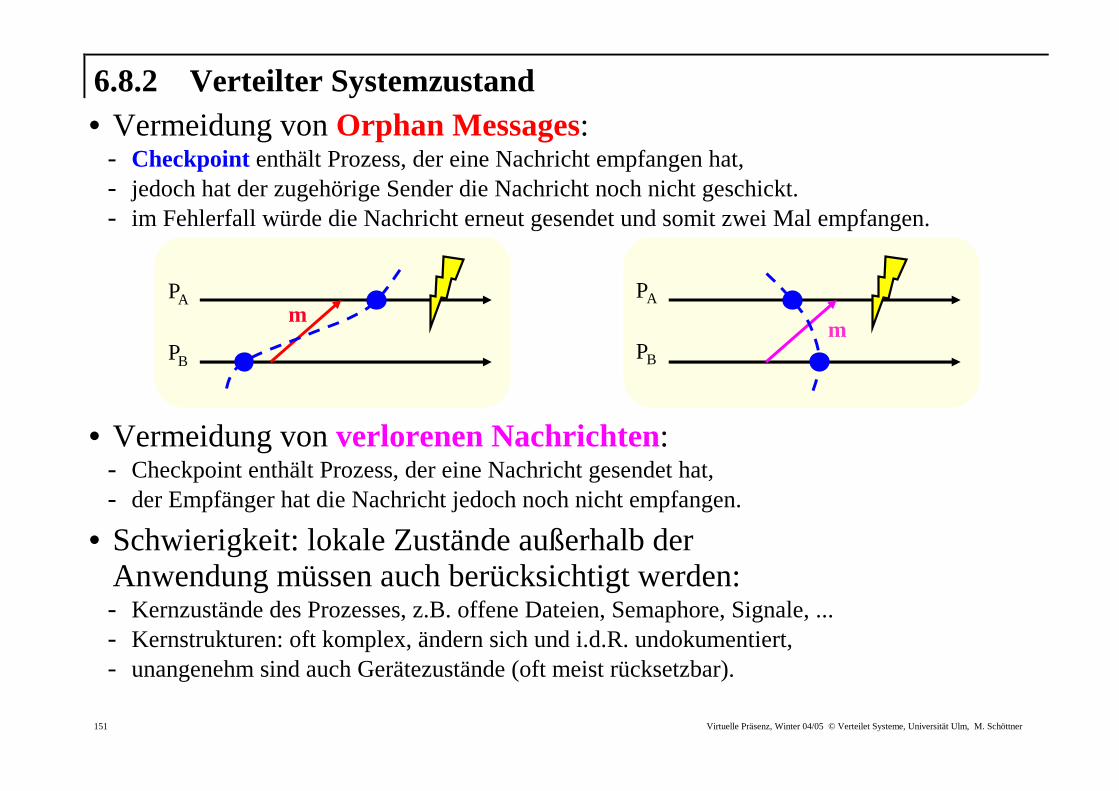
6.8.2 Verteilter Systemzustand • Vermeidung von Orphan Messages:
- Checkpoint enthält Prozess, der eine Nachricht empfangen hat, - jedoch hat der zugehörige Sender die Nachricht noch nicht geschickt. - im Fehlerfall würde die Nachricht erneut gesendet und somit zwei Mal empfangen.
PA
PB
PA
PB
mm
• Vermeidung von ver lorenen Nachr ichten:
- Checkpoint enthält Prozess, der eine Nachricht gesendet hat, - der Empfänger hat die Nachricht jedoch noch nicht empfangen.
• Schwierigkeit: lokale Zustände außerhalb der Anwendung müssen auch berücksichtigt werden: - Kernzustände des Prozesses, z.B. offene Dateien, Semaphore, Signale, ... - Kernstrukturen: oft komplex, ändern sich und i.d.R. undokumentiert, - unangenehm sind auch Gerätezustände (oft meist rücksetzbar).

152 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.8.3 Koordinier tes Checkpointing • Cluster anhalten bis jeder Knoten/Proz. Checkpoint geschrieben hat. • Positiv:
- Relativ einfach zu implementieren. - Es muss immer nur ein Checkpoint gespeichert werden. - Zwischen zwei Checkpoints fällt im normalen Betrieb kein weiterer Aufwand an.
• Negativ: - Checkpointing-Intervall in der Praxis oft groß, z.B. IBM LoadLeveler 15-120min. - erheblicher Zeitaufwand für Koordinierung aller Knoten im Cluster,
• Verfeinerung: Checkpointing nur von abhängigen Prozessen.
6.8.4 Unabhängiges Checkpointing • Jeder Knoten sichert unabhängig von anderen Checkpoints. • Keine Kosten durch Koordination von Knoten bzw. Prozessen.
• Aber u.U. bilden die letzten Checkpoints keinen gültigen Zustand: - Im Fehlerfall muss ein gültiger Zustand berechnet werden. - Hierzu werden evt. auch ältere Sicherungspunkte benötigt. - Jeder Knoten muss somit viele Checkpoints speichern.
153 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
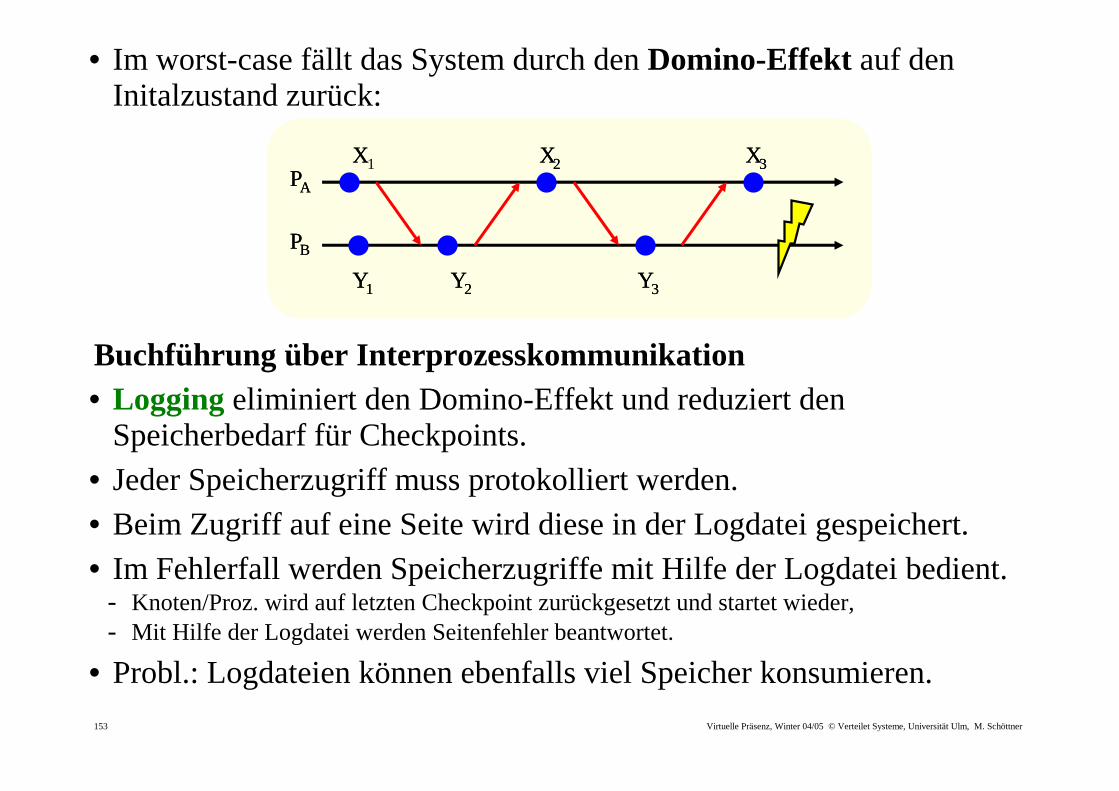
• Im worst-case fällt das System durch den Domino-Effekt auf den Initalzustand zurück:
PA
PB
X1 X2 X3
Y1 Y2 Y3
PA
PB
X X2 X3
Y1 Y2 Y3
Buchführung über Interprozesskommunikation • Logging eliminiert den Domino-Effekt und reduziert den
Speicherbedarf für Checkpoints.
• Jeder Speicherzugriff muss protokolliert werden.
• Beim Zugriff auf eine Seite wird diese in der Logdatei gespeichert. • Im Fehlerfall werden Speicherzugriffe mit Hilfe der Logdatei bedient.
- Knoten/Proz. wird auf letzten Checkpoint zurückgesetzt und startet wieder, - Mit Hilfe der Logdatei werden Seitenfehler beantwortet.
• Probl.: Logdateien können ebenfalls viel Speicher konsumieren.

154 Virtuelle Präsenz, Winter 04/05 © Verteilet Systeme, Universität Ulm, M. Schöttner
6.9 Literatur Verteilte Systeme
Andrew S. Tanenbaum, Maarten van Steen, Pearson Studium, 2003. Networked Virtual Environments: Design and Implementation
Sandeep Singhal & Michael Zyda, Addison-Wesley, 1999. A Distributed Architecture for Multiplayer Interactive Applications on the Internet
Christophe Diot, Laurent Gautier, IEEE Networks magazine, vol. 13, no. 4, July/August 1999. An efficient synchronization mechanism for mirrored game architectures
Eric Cronin, Burton Filstrup, Anthony R. Kurc, Sugih Jamin, 1st Workshop on Network and System Support for Games, Braunschweig, Germany, 2002.
PS-algol: an algol with a persistent heap M. P. Atkinson, K.J. Chrisholm, W.P. Cockshott, ACM Sigplan Notices, Vol. 17, No. 7, 1982.
A Review of the Rationale and Architectures of PJama M. Jordan and M.P. Atkinson, http://research.sun.com/forest/COM.Sun.Labs.Forest.doc.pjama_review.abs.html
Fehlertoleranz und Zuverlässigkeit von Verteilten Systemen Klaus Echtle, Vorlesung, Universität Duisburg/Essen, jährlich.