Embed Size (px)
Citation preview
1
Angewandte multivariate Statistik mit RLandau 2007Kaarina Foit und Ralf Schäfer
Die vorliegenden Folien sind der zweite Teil einer Vorlesung zumThema multivariate Statistik mit R. Mehrere Einführungen in R findensich auf der Website www.r-project.org und können dort kostenfreiheruntergeladen werden.
2
Page 2
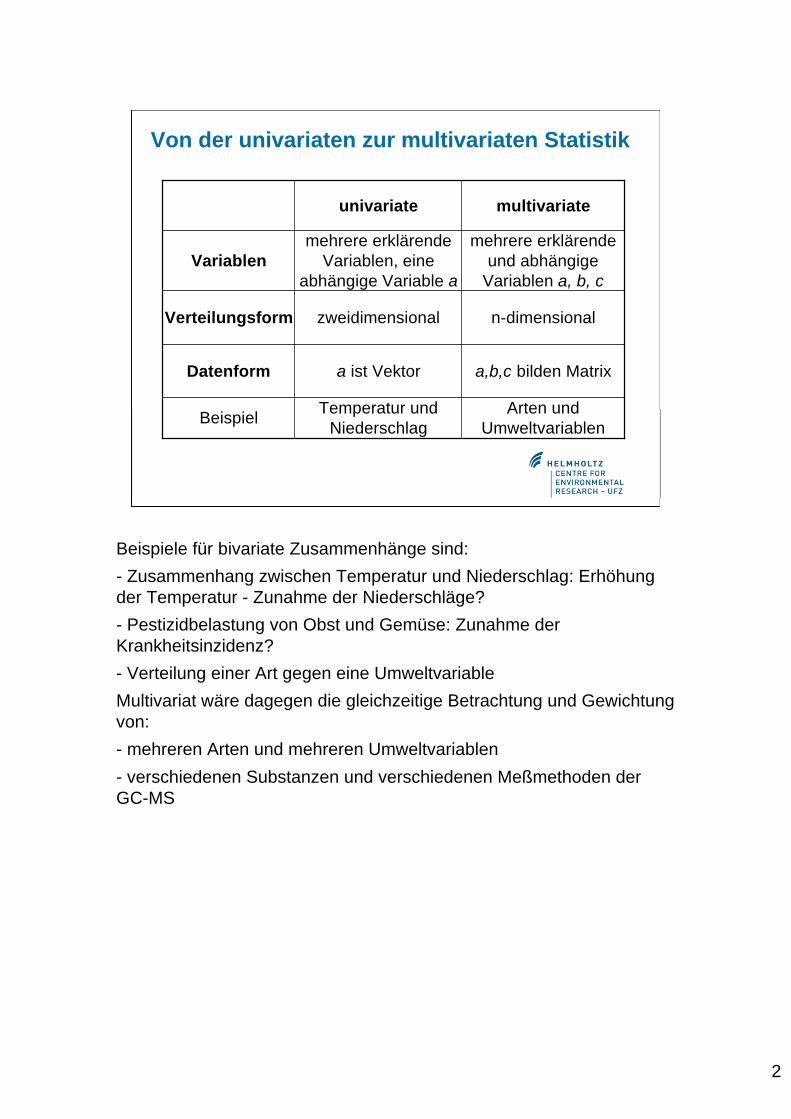
Von der univariaten zur multivariaten Statistik
n-dimensionalzweidimensionalVerteilungsform
mehrere erklärendeund abhängige
Variablen a, b, c
mehrere erklärendeVariablen, eine
abhängige Variable aVariablen
Arten undUmweltvariablen
Temperatur undNiederschlag
Beispiel
a,b,c bilden Matrixa ist VektorDatenform
multivariateunivariate
Beispiele für bivariate Zusammenhänge sind:
- Zusammenhang zwischen Temperatur und Niederschlag: Erhöhungder Temperatur - Zunahme der Niederschläge?
- Pestizidbelastung von Obst und Gemüse: Zunahme derKrankheitsinzidenz?
- Verteilung einer Art gegen eine Umweltvariable
Multivariat wäre dagegen die gleichzeitige Betrachtung und Gewichtungvon:
- mehreren Arten und mehreren Umweltvariablen
- verschiedenen Substanzen und verschiedenen Meßmethoden derGC-MS

3
Page 3
Einige Vorteile multivariater Methoden
Simultane Darstellung von mehreren Dimensionen
Relevanz von erklärenden Variablen für Gemeinschaften,
nicht einzelnen Populationen
Entfernen von “noise” -Variablen (vgl. Flack & Chang 1987)
Größere Power von statistischen Tests durch Aggregation
-Relevanz: Bei der univariaten Statistik wird nur für einzelne Arten dieBedeutung von Umweltvariablen untersucht - es ist fast unmöglich dieErgebnisse für mehrere Arten oder Umweltvariablen zu aggregieren
-zum Entfernen von Noise: Flack und Chang (1987) haben untersuchtwie häufig bei einer Regression ein signifikanter Zusammenhang mitzufällig erzeugten noise variables besteht. Das Resultat war, dass invielen Fällen auch zufällig erzeugte Variablen einen bivariatenZusammenhang mit den zu erklärenden Variablen aufweisen. Dagegenwird zum Beispiel bei „constrained“ multivariaten Methoden nur dieerklärbare Varianz von ausgewählten Umweltvariablen herangezogen,insofern also Rauschen aus dem Datensatz entfernt.
-Die Aggregation erhöht die statistische Stärke der schließendenStatistik (z.B. wird der Unterschied von Messstellen anhand dergesamten Gemeinschaft anstatt von einzelnen Arten untersucht).

4
Page 4
Mathematische Grundlagen
as.matrix()
nrow(), ncol()
+,-,*
a11
K a1n
M O M
am1
L amn
Anzahl der Zeilen und Spalten
Addition, Substraktion und Multiplikation von amn mit bmn
b11
K b1n
M O M
bm1
L bmn
%*% Matrixmultiplikation
t() Matrix transponieren
t(a)%*%b ; crossprod(a,b) at * b
a%*%t(b) ; tcrossprod(a,b) a * bt
-Auch wenn im Rahmen des Kurses schon vorgefertigte Funktionen zurBerechnung eingesetzt werden, soll hier ein kurzer Einblick in dieMathematik gegeben werden, auf der die Berechnung basiert.

5
Page 5
Mathematische Grundlagen
solve()
A1=
1
ad bc
d b
c aA =
a b
c d
A * A1= E
A1* A = E
ist Für
die inverse Matrix für die gilt:
diag() Beispiel: diag(x=1,2,2) erzeugt:
qr()
Wir können mit den hier angegebenen Funktionen und Methoden nichtfür alle Matrizen eine Inverse berechnen! Diese gibt es nur für n*nMatrizen bei denen der Rang = der Anzahl der Zeilen (oder Spalten) ist(bei n*m Matrizen gilt es wenn der Rang = min(n,m) ist, die betrachtenwir hier aber nicht). Das wiederum bedeutet, dass es n unabhängigeLinearkombinationen der Zeilenvektoren geben muss. Die manuelleBerechnung des Ranges kann man z.B. im Bronstein (S.264)nachschlagen. In R wird mit der Funktion qr() u.a. der Rang einer Matrixberechnet, allerdings kommt sie nicht immer zu einem Ergebnis.

6
Page 6
Mathematische Grundlagen
as.matrix()
nrow(), ncol() +,-,*
%*%t()
t(a)%*%b ; crossprod(a,b) a%*%t(b) ; tcrossprod(a,b)
Aufgaben
1. Lesen Sie die Tabellen „Matrix 1“ und „Matrix 2“ alsMatrix ein.
3. Bilden Sie die Inverse der resultierendenMatrizen!
2. Wieviele Reihen und Zeilen haben die Matrizen,die aus der Matrizenmultiplikation resultieren? Wasist ihr Rang?
solve()
diag()qr()

7
Page 7
Klassifikation multivariater Methoden
Datenreduktion und Simplifikation
Sortieren und Gruppieren
Untersuchen von Abhängigkeiten zwischen Variablen
Vorhersage und Hypothesentest
Anhand des Anwendungsbereichs
Beispiele für Anwendungen (die Zahlen beziehen sich auf den Punkt inder Folie).
1. In einer Studie wurden Ernte- und Größendaten für Pflanzen benutzt,um einen Index für die Züchtungswahl zu erstellen
2. Ein Beispiel aus der Klimatologie: Wir können mit multivariatenVerfahren Gruppen von Ländern mit ähnlichen vorhergesagtenVeränderungen an Niederschlag, Meeresspiegel und Temperaturbilden.
3. In Studien werden häufig verschiedene Variablen erhoben undidentifiziert, welche für Veränderungen z.B. in derArtengemeinschaft verantwortlich sind
4. Es gibt Methoden mit denen wir die Zugehörigkeit von neuenMessobjekten zu vorher definierten Gruppen vorhersagen können.Ferner gibt es multivariate Hypothesentests z.B.die Überprüfungauf signifikanten Unterschied von Gemeinschaften ankontaminierten und nicht-kontaminierten Standorten.

8
Page 8
Klassifikation multivariater Methoden
Anhand der Methoden
Multivariate Vergleiche (Zentralmaße usw.)
Multivariate Regression und Korrelation
Klassifikation (Cluster- und Diskriminanzanalysen)
Ordination

9
Page 9
Multivariate Vergleiche: Hotelling
Cu g/kg
9.57.88.48.9Boden b
5.54.23.24.2Boden a
Cu Gehalt von Boden
Vergleich Mittelwert vonzwei Stichproben bzgl.eines Merkmals
H0: 1= 2
63.4
85.9
44.9
78.9
64.3
88.33
55.9
94.0
Fe g/kg
9.57.88.48.9Boden b
5.54.23.24.2Boden a
Cu g/kg
H0: 1 = 2
Vergleich Mittelwert vonzwei Stichproben mit kMerkmalen
Cu und Fe Gehalt von Boden
t.test(), wilcox.test() ... Hotelling‘s T2-Test
-Univariate und multivariate Vergleiche der Zentralmaße laufen analog
-Fettdruck steht für Vektor
-Eine Serie von t-tests ist nicht identisch mit dem Ergebnis desHotelling T2-Tests! (Beachten Sie auch, dass bei einer Reihe von t-testsbezüglich der gleichen Stichprobe die Fehlerwahrscheinlichkeit von0.95 sinkt, und zwar auf 0.95^Anzahl der Tests.

10
Page 10
T2=n1*n
2
n1+ n
2
(Xur
1 X
ur
2 )tS
1(Xur
1 X
ur
2 )
Multivariate Vergleiche: Hotelling
t.test()
Hotelling‘s T2-Test
t =X1
X2
sX1 X2
sX1 X2
=
sX1
2+ s
X 2
2
n mit
„Differenz der Mittelwerte/ Standardfehler der Differenz“
Differenz der Mittelwertvektoren
Inverse der Kovarianzmatrix
Schauen Sie sich zur näheren Erläuterung Exkurs die Datei„Hotelling.R“, in der der Hotelling-Test für R umgesetzt ist. Leider ist derTest noch nicht als Funktion in R implementiert, allerdings kann für denVergleich von 2 Gruppen auch eine Manova durchgeführt werden(siehe weiter unten).
In die Kovarianzmatrix S (die hier aus den Daten geschätzt wird) gehtdie Varianz der beiden Stichproben X1 und X2 ein (vgl. Hartung 1999, S.231)
11
Page 11
Multivariate Vergleiche: Hotelling
Testvoraussetzungen
-die Beobachtungen müssen unabhängig sein-Kovarianzmatrizen gleich-alle Variablen multivariat normalverteilt
Die Testvoraussetzungen sind analog zu univariatenTestvoraussetzungen wie Normalverteilung, Varianzgleichheit usw.

12
Page 12
Multivariate Vergleiche: Voraussetzung
Aufgabe
Sind die Messungen beim Boden multivariatnormalverteilt?
Wie testet man auf multivariate Normalverteilung?
H0: X stammt aus multivariater NVmshapiro.test(){mvnormtest}
Hypothesentest

13
Page 13
Multivariate Vergleiche: Voraussetzungen
Wie testet man auf multivariate Normalverteilung?
Grafisch
chisplot()
Bei Übereinstimmung mit der Normalverteilung sollten diePunkte auf einer Geraden durch den Ursprung liegen.
- Die chisplot-Funktion befindet sich in der Datei Hotelling.R.
- Zur Berechnung: Für die empirischen Daten wird für jede q-dimensionale Beobachtung xi eine generalisierte Abweichung zumgeneralisierten Mittelwert-Vektor der gesamten Stichprobe berechnet.Diese generalisierten Distanzen werden geordnet und mit denQuantilen der Chi-Quadrat-Verteilung verglichen. Bei absoluterÜbereinstimmung sollten sie auf einer Geraden durch den Ursprungliegen.Beispiel: Für den geordneten Vektor ai der Länge n mit denDistanzen (1,2,3,4,5,6,7,8,9,10) ist das Quantil der n Beobachtungenjeweils pi/n = ai da dies der kleinste Wert ist für den gilt: F(i/n) pi/n
-> Was passiert eigentlich bei Abweichung von der Normalverteilung?Auf diese Frage wird im Anschluss an die MANOVA eingegangen.

14
Page 14
Multivariate Vergleiche: MANOVA
........Boden b
Boden c
........Boden d
Cu g/kg
9.57.88.48.9Boden e
5.54.23.24.2Boden a
Cu Gehalt von Boden
Vergleich Mittelwert vonn 2 Stichproben bzgl.eines Merkmals
H0: 1= 2 = ... = n
................Boden b
5.54.23.24.285.978.988.3394.0Boden a
................Boden c
63.4
..
44.9
..
64.3
..
55.9
..
Fe g/kg
9.57.88.48.9Boden e
........Boden d
Cu g/kg
H0: 1 = 2 = ... = n
Vergleich Mittelwert vonn 2 Stichproben mit kMerkmalen
Cu und Fe Gehalt von Boden
aov(), anova() ... manova() ...
-ANOVA und MANOVA ähneln sich stark in der Berechnung (siehe Zar1996). Allerdings können sich die Ergebnisse unterscheiden, wenn mananstatt einer MANOVA, mehrere ANOVAs ausführt. So könnte dieMANOVA signifikante Unterschiede zwischen den Gruppen finden,obwohl die ANOVAs keine finden und umgekehrt (Unterschiede bei denANOVAs für einige erklärende Variablen und keine beim Vergleich derMittelwertvektoren in der MANOVA).
-Beachte: die single-Faktor MANOVA mit 2 Gruppen ist analog zumHotelling T2-Tests, die Ergebnisse sind gleich (F-Wert).

15
Page 15
Multivariate Vergleiche: MANOVAmanova()
Aufgaben
1. Führen Sie eine MANOVA für die Soil-Daten durchund vergleichen Sie die Ergebnisse mit Hotelling‘sT2-Test.
2. Unterteilen Sie die Bodentypen in 4 gleich großeGruppen und wiederholen Sie die MANOVA.
Tip: Beispiel unter summary.manova()
summary.manova() Ergebnisse und Wahl des Tests
summary.aov() Ergebnisse der univariaten ANOVA
Zu Aufgabe 2: Es empfiehlt sich, nicht die Rohdaten zu verändernsondern einen neuen dataframe zu erstellen. Anschließend sollten mitdetach() die variablen des alten Frames aus dem Speicher gelöschtwerden.
Es gibt verschiedene Teststatistiken in der MANOVA. Wilks‘ lambda istzwar am populärsten, viele Autoren empfehlen allerdings Pillai‘s trace,der in R auch als Standardmethode eingestellt ist. Die Statistik nachHotelling-Lawley-Trace sollte verwendet werden, wenn die Variablennicht korrelieren (Zar 1996).
16
Page 16
Multivariate Vergleiche: MANOVA
Voraussetzungen
- die Beobachtungen müssen unabhängig sein- Kovarianzmatrizen gleich- alle Variablen multivariat normalverteilt- Residuen normalverteilt
chisplot(residuals(<your.model>))
-Die MANOVA ist generell robust gegenüber Abweichung von dennotwendigen Testvoraussetzungen. Bezüglich der Kovarianzmatrizengilt, daß wenn die Gruppengröße der zu vergleichenden Stichprobenrelativ gleich ist (größtes n 1.5 * kleinstes n), dann habenUnterschiede zwischen den Kovarianzmatrizen nur geringe Auswirkungauf Pillais Trace. Hotelling-Lawley and Wilks werden mittelmäßig undRoy‘s Kriterium stark beeinflusst (Zar 1996).
--> Was bedeutet in diesem Zusammenhang eigentlich beeinflussen?Nun, wir wollen bei unseren Tests fast immer die Nullhypotheseverwerfen und dabei den Fehler 1.Art (Hypthese abgelehnt, obwohl sierichtig ist) minimieren. Falls die Testvoraussetzungen nicht zutreffen,kann es sein, dass wir annehmen, die Hypothese mit einerSicherheitswahrscheinlichkeit von 5% zu überprüfen (nominal), obwohlsie real höher ist, z.B. 15%.
Eine detaillierte Untersuchung der Auswirkung von Abweichungen vonden Testvoraussetzungen mit Hinweisen für Anwender gibt es vonFinch (2005), der zum Schluß kommt, dass in den meisten Fällen dieparametrische MANOVA das leistungsstärkste Verfahren ist.

17
Page 17
Klassifikation multivariater Methoden
Anhand der Methoden
Multivariate Vergleiche (Zentralmaße usw.)
Multivariate Regression und Korrelation
Klassifikation (Cluster- und Diskriminanzanalysen)
Ordination

18
Page 18
Multivariate Regression und Korrelation
..................
Var 8Var 7Var 6Var 5Var 4Var 3Var 2Var 1Response
..................
..
..
..
..
..
..
..
..
..........
..........
Response1 Response 2
..................
Var 8Var 7Var 6Var 5Var 4Var 3Var 2Var 1Response 3
..................
..
..
..
..
..
..
..
..
..........
..........
Univariate multiple Regression
Multivariate multiple Regression
Yi=
0+
kxi
(k )+ E
ik
Yi
( j )
=0
( j )
+ k
( j )
xi(k )
+ Ei
( j )
k
Aus methodischen Gründen wird die multivariateKorrelation, die auch als kanonischeKorrelationsanalyse bezeichnet wird, später (imZusammenhang mit der kanonischenKorrespondenzanalyse) behandelt.
Das Ergebnis der multivariaten Regression istidentisch mit m univariaten Regressionen (m= Anzahlder abhängigen Variablen bzw. response variablen),aber zusätzlich erhalten wir die Kovarianzmatrix derZufallsfehler und die Möglichkeit globale Hypothesenwie zum Beispiel „Eine erklärende Variable hängt mitkeiner abhängigen Variable zusammen“ zuüberprüfen.

19
Page 19
Multivariate Regression
lm()
Durchführung mit gleichem Befehl wie univariate
aber abhängige Variablen als Matrix!
lm(cbind(,..,..,) ~ ..+..+..)
lm(.. +..+..+.. ~ ..+..+..)
drop1.lml() Überprüfen, ob bestimmte Var global entfernt werden kann
summary.mreg() „nettere“ Variante der summary.lm() Funktion
Die Durchführung einer multivariaten multiplen Regression istinsgesamt identisch mit einer univariaten. Zusätzlich könnenHypothesen für alle Regressionen zusammen überprüft werden, zumBeispiel ob eine Variable niemals signifikant zur Erklärung des Modellsbeiträgt und somit entfernt werden kann.
Eine spezielle Funktion hierfür findet sich auf der Seite der ETH-Zürichvon Werner Stahel und lautet drop1.lml()
http://stat.ethz.ch/teaching/lectures/SS_2006/ams/regr.R (neben einerReihe von anderen Funktionen)
In der Funktion läuft im Endeffekt eine MANOVA für das Modell ab, d.h.die Ergebnisse sind mit einer MANOVA identisch.

20
Page 20
Multivariate Regression
Aufgaben
1. Lassen sich Uran und Aluminium durch Fe und Cuerklären? Welche erklärenden Variablen sind jeweilssignifikant?
2. Erzeugen Sie mit rnorm() eine zusätzlicheerklärende Variable und untersuchen Sie, inwieferndiese Variable signifikanten Erklärungswert hat.Vergleichen Sie dieses Ergebnis mit dem einermanova()!
drop1.mlm() summary.mreg()
Der Code für die Funktionen wird für diesen Kurs bereitgestellt ->Dokument „mvarreg.r“

21
Page 21
Multivariate Regression
- Erwartungswert von Ei = 0
- Zufallsabweichungen haben gleiche
Varianz
- Zufallsabweichungen sind normalverteilt
Modellannahmen
Identifizierbarkeit von
Residuen-plots
Quantil-Residuen-plots
plot.regr()
Die Modellannahmen für den multivariaten Fall sind Generalisierungen der Annahmenfür das univariate Modell. Sie können mit Diagrammen überprüft werden. Dabei dientdie Festlegung der ersten Annahme (Erwartungswert der Residuen = 0) derIdentifizierung der Koeffeizienten (betas), wir brauchen sie nicht näher zu betrachten.Zur Überprüfung der gleichen Varianz der Residuen können wir die Residuen gegendie angepaßten Modellwerte (fitted values) auftragen. Es sollte kein Muster in derVerteilung zu erkennen sein, also z.B. eine Zu- oder Abnahme der Abweichung. Diestandardisierten Residuen werden berechnet, indem die normalen Residuen durchden geschätzten Standardfehler geteilt werden. Sie sind damit genauso skaliert wiedie abhängige Variable und erlauben es, Punkte mit schlechtem Fit zu erkennen (ggf.Ausreißer).
Die Normalverteilung der Residuen lässt sich mit Quantil-Residuenplots überprüfen.
Außerdem interessiert auch, ob vielleicht einzelne Beobachtungen unserererklärenden Variablen einen stärkeren Einfluss haben als andere. Das kann mit demPlotten der Residuen gegen ihren Einfluss (leverage) dargestellt werden. In diesemZusammenhang muß darauf hingewiesen werden, dass einflußreiche Beobachtungennicht zwingend Ausreißer sind. Ausreißer sind Punkte, die nicht gut vom Modellerfasst werden (z.B. erkennbar in residuals vs. Fitted values plots), währendeinflußreiche Beobachtungen einen substantiellen Einfluss auf die Modellparameterhaben. Ein Punkt kann sowohl beides sein als auch nur eines der beiden Merkmaleaufweisen (oder natürlich keines).
Bei der Funktion für den multivariaten Residuen plot.regr() wird neben den üblichenModellprüfdiagrammen noch die Korrelation der verschiedenen Residuen auf dieabhängigen Variablen untersucht. Dafür dienen die Werte der Kovarianzmatrix derZufallsfehler und es lässt sich damit eine partielle Korrelation der abhängigenVariablen überprüfen. Außerdem wird noch ein Quantilplot für diezusammengefassten Residuen des Modells erstellt.
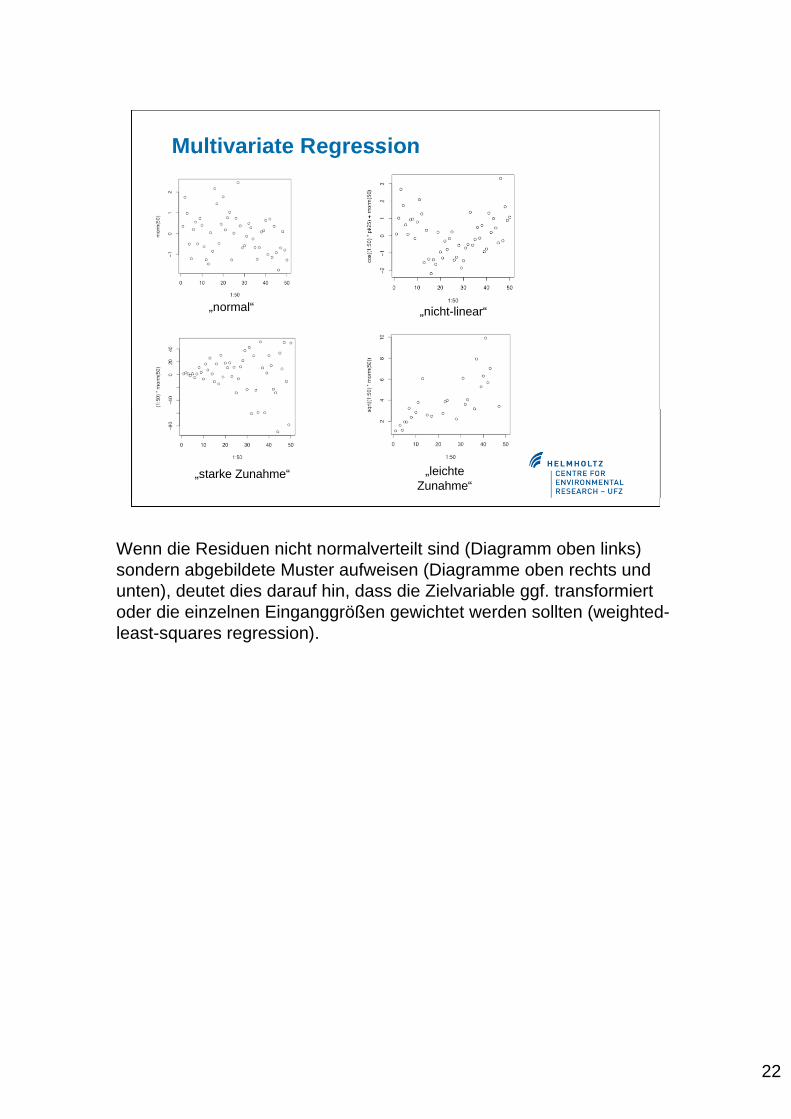
22
Page 22
Multivariate Regression
„normal“
„starke Zunahme“
„nicht-linear“
„leichteZunahme“
Wenn die Residuen nicht normalverteilt sind (Diagramm oben links)sondern abgebildete Muster aufweisen (Diagramme oben rechts undunten), deutet dies darauf hin, dass die Zielvariable ggf. transformiertoder die einzelnen Einganggrößen gewichtet werden sollten (weighted-least-squares regression).

23
Page 23
Klassifikation multivariater Methoden
Anhand der Methoden
Multivariate Vergleiche (Zentralmaße usw.)
Multivariate Regression und Korrelation
Klassifikation (Cluster- und Diskriminanzanalysen)
Ordination
Die bisherigen Abschnitte behandelten multivariate Themen, die großeÄhnlichkeit mit den entsprechenden univariaten Methodenaufwiesen. Die beiden folgenden Abschnitte beschreiten ein neuesTerrain, dass aus der univariaten Statistik nicht vertraut ist.Gleichwohl werden wir einige Techniken (multiple Regression oderANOVA) auch hier wieder antreffen.
Als erstes betrachten wir die Klassifikationsmethoden. Während manbei der Ordination versucht Entitäten entlang eines Gradienten zuplatzieren, ist das Ziel der Clusteranalyse möglichst distinkte,homogene Gruppen aus den Entitäten zu bilden.
Der Abschnitt ist unterteilt in die Cluster- und Diskriminanzanalyse.
Bei der Diskriminanzanalyse beginnen wir a priori mit Gruppen undsuchen Variablen, mit denen die Gruppen unterschieden werdenkönnen, während wir bei der Clusteranalyse nur die Existenz vonGruppen vermuten und diese erst „erstellen“. Es ist möglich, zuersteine Clusteranalyse auszuführen und die aufgestellten Gruppendann als Ausgangspunkt einer Diskriminanzanalyse zu verwenden.

24
Page 24
Clusteranalysen
-Suche nach homogenen Gruppen
-Möglichst großer Unterschied zu anderen Gruppen
Im Diagramm links können wir für den bivariaten Fall distinkte Gruppenerkennen, während das im Diagramm rechts nicht möglich ist.
Beispiele, wo eine Clusteranalyse hilfreich sein könnte:
- Bildung von Ländergruppen anhand der vorhergesagtenAuswirkungen des Klimawandels
- Gruppierung von Stoffen mit ähnlicher Toxizität für einen bestimmtenTestorganismus
Während im bivariaten Fall die Cluster im Scatterplot erkannt werdenkönnen (siehe Diagramm links), empfehlen sich Clusteranalysengerade im multivariaten Fall, da die Visualisierungsmöglichkeit vonmehr als 3 Dimensionen begrenzt ist (allerdings versucht man genaudies mit Ordinationsmehtoden, zu denen wir später kommen).
Natürlich gibt es auch Cluster, die weniger eindeutig sind, eine netteÜbersicht findet sich in Mc Garigal (2000, S. 87).

25
Page 25
Clusteranalysen
-Datenaggregation -> verringern von „noise“
-Identifizieren von Ausreißern
-Beziehung zwischen Variablen visualisieren
Anwendungen
Clusteranalysen können auch verwendet werden, um Ausreißer zuidentifizieren. So könnte das Cluster rechts (blau) auch ohne denMesswert bei 160 cm gebildet werden und dieser Punkt würde dann einCluster mit nur einer einzelnen Beobachtung bilden.
Die Beziehung zwischen Variablen können in einerVariablenclusteranalyse visualisiert werden. Ausgangspunkt ist dieKorrelationsmatrix der Variablen.

26
Page 26
Clusteranalysen
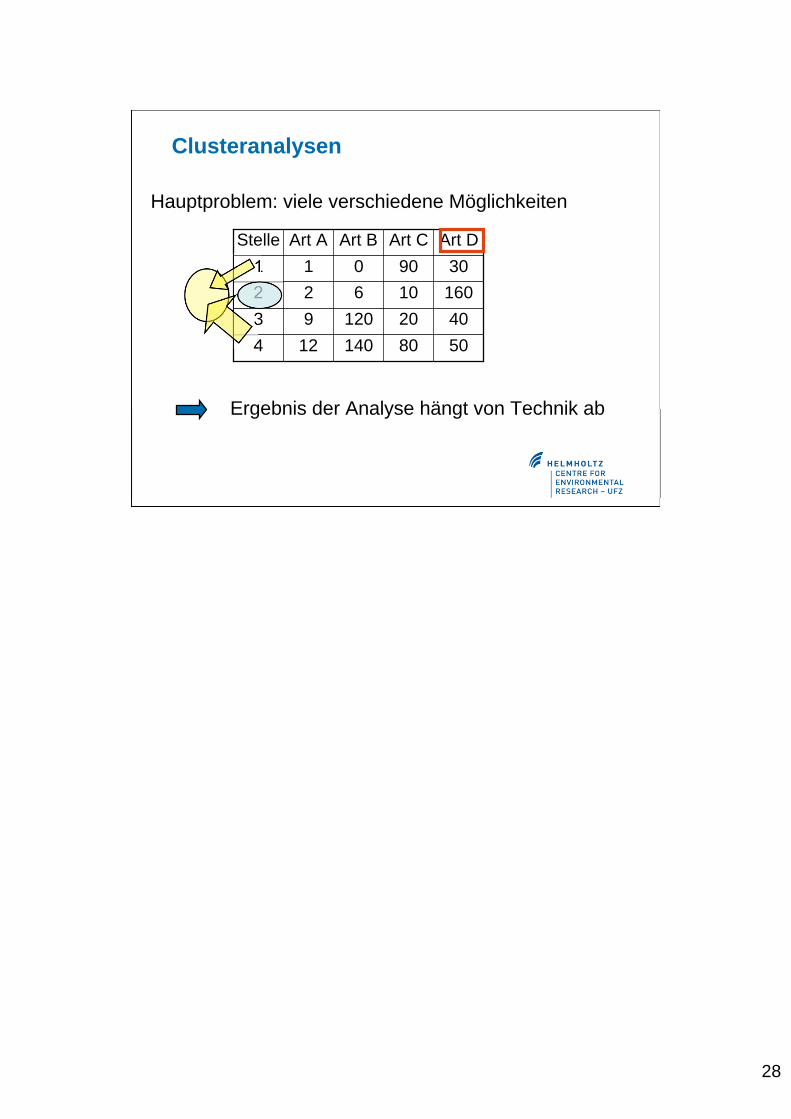
Hauptproblem: viele verschiedene Möglichkeiten
5080140124
402012093
16010622
3090011
Art DArt CArt BArt AStelle
Im folgenden wird das Hauptproblem der Clusteranalyse immultivariaten Fall dargestellt: In Abhängigkeit von der Gewichtung dereinzelnen Variablen, kann man unterschiedliche Cluster bilden.

27
Page 27
Clusteranalysen
Hauptproblem: viele verschiedene Möglichkeiten
5080140124
402012093
16010622
3090011
Art DArt CArt BArt AStelle
28
Page 28
Clusteranalysen
Hauptproblem: viele verschiedene Möglichkeiten
5080140124
402012093
16010622
3090011
Art DArt CArt BArt AStelle
Ergebnis der Analyse hängt von Technik ab

29
Page 29
Clusteranalysen
McGarigal (2000, p.90)
Abbildung aus Mc Garigal (2000, S. 90). Die gestrichelten Pfeileindizieren weniger relevante Techniken für die umweltwissenschaftlicheoder ökologische Clusteranalyse.
Sequential vs. Simultaneous: Bei sequenziellen Methoden werdenrekursive Operationen wiederholt ausgeführt und die Cluster werdenschrittweise gebildet. Bei simultanen Methoden wird in nur einemSchritt die Gruppenzugehörigkeit bestimmt.
Nonhierarchical vs. Hierarchical: Bei nicht-hierarchischen Technikenwerden z.B. k Cluster gebildet, die möglichst homogene Einheitenbeinhalten, während bei hierarchischen Clustern eher der Unterschiedund die Verhältnisse zwischen den Clustern von Interesse sind.

30
Page 30
Clusteranalysen
Gruppenbildung basiert auf Distanz oder Ähnlichkeiten
Distanzmaße:
Euklidische Distanzdij2= (x j1 xi1)
2+ (x j2 xi2 )
2i
j
dij = (xik x jk )2
k=1
n
dij = xik x jkk=1
n
Manhattan Distanz
Bray-Curtis Distanz
dij =
xik x jkk=1
n
(xik + x jk )k=1
n
Das Zusammenfassen von Entitäten zu Gruppen bzw. Clustern beruhtauf der Distanz zwischen den Entitäten. Es gibt viele verschiedeneTechniken, um die Distanz zwischen zwei Entitäten zu bestimmen.
Die euklidische Distanz wird durch die Variablen mit den größtenAbweichungen dominiert. Bei der Manhattan Distanz wird diesesGewicht etwas abgeschwächt. Die Bray-Curtis Distanz reagiert starkauf Extremwerte und hat die schöne Eigenschaft nur Werte zwischen 0und 1 anzunehmen, falls alle Werte für x positiv sind.
Es gibt noch eine ganze Reihe weiterer Distanzmaße auf die hier nichteingegangen werden kann, die aber auch in R implementiert sind. Alswichtige Maße sind noch der Jacquard-Index oder die Canberra-Distanz (eng verbunden mit der Bray-Curtis Distanz) sowie dieMahalanobis-Distanz (Beachte die Ähnlichkeit zur Berechnung vonHotellings T2) zu nennen.
Funktionen für Distanzmaße in R finden sich in den Funktionen: dist(),mahalanobis() und vegdist(){vegan}. Sie sind dort ausführlichbeschrieben. Desweiteren wird eine Funktion zur Berechnung derMahalanobis-Distanz zwischen Matrizen bereitgestellt.

31
Page 31
Clusteranalysen
Visualisierung mit 2 Arten
Art A
Art B
Stelle 1
Stelle 3
Stelle 2
Stelle 4
Distanzen dij zwischen der Stelle 1 und dem Rest
In dem Diagramm wird für den Fall von nur zwei Variablen (Art A undArt B) visualisiert, was die Distanz zwischen den verschiedenenEntitäten (Stellen in diesem Fall) bedeutet.

32
Page 32
Clusteranalysen
Aufgabe
Veranschaulichen Sie sich die Unterschiede in denDistanzmaßen unter Berechnung der Euklidischen,Manhattan, Bray-Curtis und Mahalanobis-Distanz fürfolgende Matrix:
Art
Abundanz
Stelle
Für die Berechnung der Mahalanobis-Distanz wird die Inverse derVarianz-Kovarianz-Matrix benötigt. Wie schon vorher erwähnt, existiertnicht für jede Matrix eine Inverse. Allerdings gibt es die Möglichkeit,Matrizen in andere Matrizen zu überführen, mit denen dann die Inverseberechnet werden kann (Einzelwertzerlegung, bei näherem Interessesiehe http://en.wikipedia.org/wiki/Singular_value_decomposition). Dabeikönnen die Elemente der Inversen allerdings auch negative Werteannehmen, was zu Problemen bei der Berechnung der Mahalanobis-Distanz führt. Deswegen verwenden wir den absoluten Wert derInversen-Matrix.
Bei den Berechnungen fällt auf, daß besonders die euklidische Distanzhohe Unterschiede zwischen den Stellen hervorbringt. Arten mitgeringer Abundanz fallen kaum ins Gewicht, d.h. Art 1 dominiert dieBerechnung der Distanzen zwischen den Stellen. Aus diesem Grundwerden die Variablen bei Verwendung der euklidischen Distanz häufigstandardisiert. Dabei wird der geschätzte Mittelwert abgezogen unddurch die Standardabweichung geteilt. Dies ist in R mit der Funktionscale() implementiert. Desweiteren gibt es die Möglichkeit Distanzenmit dsvdis(){labdsv} zu berechnen und dort Gewichtungen nach Artenvorzunehmen.
Die Mahalanobis-Distanz beruht auf der Kovarianzmatrix und wirddurch Standardisierung der Variablen nicht beeinflusst.

33
Page 33
Clusteranalysen
Hierarchisches Clustering: Agglomerationsmethoden
1. Suchen nach der geringsten Distanz
Abbildung aus Mc Garigal (2000, S. 102)
Die am häufigsten verwendete Methode in der Clusteranalyse ist dashierarchische Clustering mit der Agglomerationsmethode. Bei derAgglomeration bilden am Anfang alle Entitäten ein separates Clusterund werden in Abhängigkeit von ihrer Ähnlichkeit zu größeren Clusternverschmolzen. Im Gegensatz dazu stehen divisive Methoden, die miteinem Gesamtcluster beginnen und daraus neue, kleinere Clusterabspalten.

34
Page 34
Clusteranalysen
Hierarchisches Clustering: Agglomerationsmethoden
2. Berechnung der neuen Distanzen und wiederholen von Schritt 1
Abbildung aus Mc Garigal (2000, S. 102)
Ein wichtiges Unterscheidungsmerkmal beim Clustering stellt dieMethode dar, nach der die neuen Distanzen im Clusterprozess neuberechnet werden.

35
Page 35
Clusteranalysen
Hierarchisches Clustering: Agglomerationsmethoden
Abbildung aus Mc Garigal (2000, S. 106)
Die Methoden lassen sich in 3 Gruppen einteilen:
Space-conserving: die ursprünglichen Distanzen der Entitäten werdenkonserviert -> hohe Korrelation zwischen den ursprünglichen Distanzenund den Distanzen nach der Agglomeration (die sich in derkophenetischen Matrix befinden). Methoden dieser Gruppe werdenverwendet, wenn es darum geht, die Eigenschaften der Eingangsdatenbeizubehalten. (Methoden sind z.B. „Average linkage“ oder „Ward‘s“)
Space-contracting: Bei diesen Methoden werden Entitäten eher zubestehenden Clustern hinzugefügt, auch wenn die Entitäten in denClustern dadurch näher zusammenrücken als es bei denAusgangsdaten der Fall war. Dieses Verfahren ist hilfreich um größereDiskontinuitäten in den Daten zu detektieren. (Mehtode z.B. „Singlelinkage“)
Space-dilating: Bei diesen Methoden werden die Abstände zwischenden Entitäten der Cluster minimiert. Das heißt es werden Cluster mitmöglichst homogenen Mitgliedern gebildet. Das Verfahren kann dazugenutzt werden, um Entitäten mit möglichst ähnlichen Eigenschaftenzusammenzufassen (Methode z.B. „Complete linkage“).

36
Page 36
Clusteranalysen
Single-linkage
Complete-linkage
Average linkage
hclust()
cophenetic()
Ergebnismatrix der Clusterbildung
Clusterfunktion
Visualisieren von Clustern
rect.hclust()
Festlegen von Clustern
cutree()
Abbildung aus Everitt (2005, S. 119)
In R können mit der Funktion hclust() für Dissimilaritätsmatrizen, dievorher mit dist() oder ähnlicher Funktion erzeugt wurden,Clusteranalysen durchgeführt werden. Die Methoden werden jeweilsmit method = „...“ spezifiziert und es stehen folgende Methoden zurAuswahl: „ward", "single", "complete", "average","mcquitty", "median" or "centroid“. Die Methode Ward‘sminimum-variance ähnelt dem average linkage-Verfahren, allerdingswird nicht die mittlere Distanz zwischen den Clustern minimiert,sondern die quadrierte Distanz, gewichtet nach der Clustergröße.Dadurch werden die Clustergrenzen enger gesetzt als bei der „average-linkage“ Methode.

37
Page 37
Clusteranalysen
hclust() cophenetic()
Aufgabe
1. Laden Sie die Daten „varespec“ im vegan-Package und führen Sie folgende Clusteranalysendurch: - single und complete linkage
unter Nutzung der Bray-Curtis undEuklidischen Distanz.
2. Wie hoch sind die Übereinstimmungen zwischenden Eingangs-Distanzmatrizen und denkophenetischen Matrizen?
rect.hclust()
cutree()
plclust()
Mit der Funktion rect.hclust können in bestehenden Clusterplots Clustervisualisiert werden. Dies kann anhand des maximalen Abstands(Entfernung der Cluster) oder durch Festlegen einer definierten Anzahlvon Clustern geschehen. Ähnliches gilt für die Funktion cutree(). Weistman den labels in einem plot mit plclust() das Ergebnis von cutree zu,wird die Zugehörigkeit der einzelnen Entitäten im Plot visualisiert.

38
Page 38
Clusteranalysen
In den Diagrammen sind die Ergebnisse der Clusterlösungen mit demBray-Curtis-Index für die single- (linke Abbildung) und complete linkage(rechte Abbildung) Methode gegenübergestellt. Dabei werden dieUnterschiede zwischen den Methoden deutlich. Wir haben weitentfernte und kleine Cluster beim „complete linkage“ gegenüber großenund nahen Clustern bei der single linkage.-Methode (beachte auch dieSkala!).

39
Page 39
Clusteranalysen
Hierarchisches Clustering: Agglomerationsmethoden
Divise Methode
diana() {cluster}
Clustern von Variablen
varclus() {Hmisc}
Das Hauptargument für das trennende (divisive) Clustering bestehtdarin, dass möglicherweise das Rauschen einzelner Variablen beiAggregation verringert wird. Dieses Argument beruht auf der Annahme,das kleine Distanzen zwischen Entitäten eher auf zufälliges Rauschenzurückzuführen sind, während große Distanzen reale Gradientensignalisieren.
Im Diagramm ist das Ergebnis eines Variablen-Clusterings dargestellt,dass für ca. 30 Umweltvariablen unter Wahl der Spearman-Korrelationals Distanzmaß durchgeführt wurde. Die Funktion varclus befindet sichim Package Hmisc, das Diagramm wird mit der normalen plot()-Funktion erzeugt.

40
Page 40
Clusteranalysen
Nicht-hierarchisches Clustering
Problem:
10685100
690,223,721,118,368,580825
45,232,115,901420
2,375,101315
Anzahl möglicher Partitionenkn
Algorithmus: 1. Aufteilung in k Gruppen2. Bewegen der Einheiten und Veränderung berechnen3. Beste Lösung wählen4. Wiederholen von 2 und 3 bis Clusterkriterium keine
Verbesserung mehr anzeigt
Neben den hierarchischen gibt es auch nicht-hierarchischeClustermethoden, bei denen der Datensatz in eine a priori definierteAnzahl von Gruppen aufgeteilt wird. Diese Methide wird auch als k-Mittelwerte- (k-means) Clustering bezeichnet.
Das größte Problem stellt die hohe Anzahl von möglichen Clustern dar(siehe Tabelle - Kommas zeigen 1000er Stellen an). Als Gütekriteriumfür die bessere Clusterlösung wird am häufigsten die Summe derAbweichungsquadrate (vgl. euklidische Distanz) innerhalb derverschiedenen Cluster verwendet. Da es extrem viele Möglichkeiten derPartitionierung gibt, ist nicht gewährleistet, dass jeweils die besteLösung gefunden wird. Der Algorithmus zum Auffinden dieser Lösungbeginnt mit dem zufälligen Einteilen in die gewünschte Anzahl vonGruppen. Als Ausgangspunkt könnte aber auch das Ergebnis einervorhergehenden hierarchischen Clusteranalyse verwendet werden.
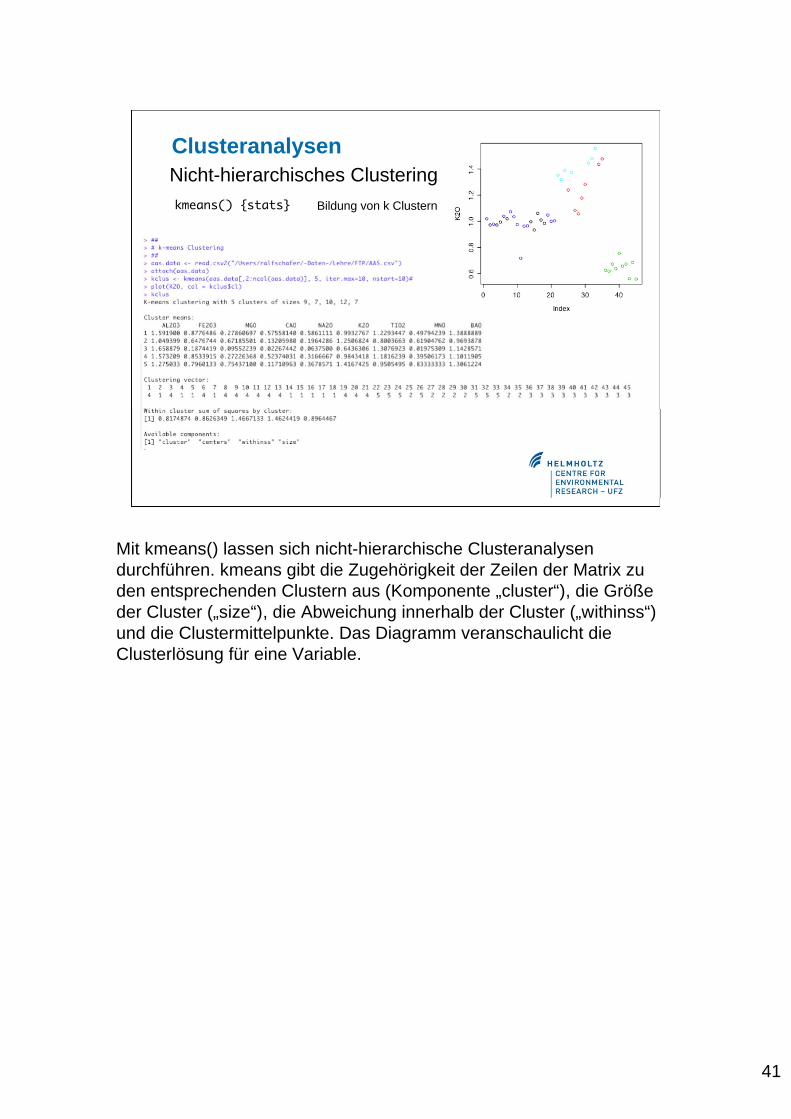
41
Page 41
ClusteranalysenNicht-hierarchisches Clustering
kmeans() {stats} Bildung von k Clustern
Mit kmeans() lassen sich nicht-hierarchische Clusteranalysendurchführen. kmeans gibt die Zugehörigkeit der Zeilen der Matrix zuden entsprechenden Clustern aus (Komponente „cluster“), die Größeder Cluster („size“), die Abweichung innerhalb der Cluster („withinss“)und die Clustermittelpunkte. Das Diagramm veranschaulicht dieClusterlösung für eine Variable.

42
Page 42
Clusteranalysen
Aufgabe
Öffnen Sie die R Datei „Kmeans“ und folgen Sie denAnweisungen im Text. Was ist auf dem Plot zusehen?
Wieviele Cluster sind optimal?
pam() {cluster} Eigene Distanzmatrix kann verwendet werden
clara() {cluster} Große Datensätze
Mclust() {mclust} Modellbasiertes Clustering
Neben der dargestellten Funktion für nicht-hierarchische Clusteranalysen gibt es nochpam(). Hier können eigene Distanzmatrizen verwendet werden und die Funktion istetwas robuster, da sie die Summe der Distanzen minimiert anstelle der quadrierteneuklidischen Abstände. Ferner werden noch neue Grafiken bereitgestellt.
Für große Datensätze sollte die Funktion „clara“ verwendet werden. Was „klein“ und„groß“ ist, hängt von der Anzahl der Variablen und Observationen sowie derRechnerleistung ab.
Die bisher betrachteten Herangehensweisen waren eher heuristisch, es gibt aberauch die Möglichkeit modellbasiert Clusteranalysen vorzunehmen. Darauf kann andieser Stelle nicht näher eingegangen werden, es soll aber auf das Package „mclust“verwiesen werden sowie die Website von Chris Fraley vom Department of Statisticsan der University Washington: http://www.stat.washington.edu/fraley/ Dort finden sichviele Ressourcen zum Thema „modellbasierte Clusteranalysen“, Fraley ist zudemMitautor von R-Packages in diesem Gebiet.

43
Page 43
Clusteranalysen
Bewertung der Ergebnisse
- Daten oder Variablensplitting
- Überprüfen der Clusterlösungen
Nachteile von Clusterverfahren
- Tendenz für bestimmte Cluster (sphärische)
- Beurteilung der Ergebnisse
- „mehr Kunst als Wissenschaft“
Die Clusterlösungen können zum einen visuell als auch mit Hypothesentests überprüftwerden. Visuell haben wir schon den Screeplot kennengelernt. Für dieHypothesentests gibt es unterschiedliche Maße wie das kubische Cluster Kriterium,die pseudo r2 und pseudo F-Statistik. Da diese Maße die multivariateNormalverteilung der Clusterlösungen als Voraussetzung haben, sollten sie nur alsHilfe dienen und nicht als objektives Entscheidungskriterium herangezogen werden(im R Package fpc finden sich Möglichkeiten zur Berechnung dieser Maße).Außerdem beziehen sich die Maße meist auf nur einen Schritt bei der Clusterbildungund sie sind deswegen sehr rechenaufwändig (es werden so lange Cluster gebildet,bis die Nullhypothese, dass die beiden Entitäten ungleich sind, nicht mehr widerlegtwerden kann).
Clustermethoden haben zum Teil Probleme, nicht-sphärische Cluster zu erkennen,deswegen sollten mehrere Methoden parallel für eine Datenanalyse verwendet unddie Robustheit der Resultate kritisch analysiert werden.
Aufgrund der Probleme mit den Indikatoren für die Clusterbewertung bleibt dieAnalyse teilweise subjektiv. Und da schließlich viele Methoden und Funktionen zurVerfügung stehen, kann sie leicht „mißbraucht“ werden und wird z.B. bei McGarigal(2000) mehr als Kunst denn Wissenschaft bezeichnet.
Nichtsdestotrotz ist sie ein sehr wertvolles Werkzeug für die explorativeDatenanalyse.

44
Page 44
Diskriminanzanalysen
Vorhersage von Gruppen anhand von Variablen
Gradient mit max. Varianz zwischen Gruppen und minimal
in Gruppen
Reduziert die Dimensionalität multivariater Datensätze
-> kanonische Funktion
Die Diskriminanzanalyse (DA) hat zum Ziel, die Einteilung von a prioridefinierten Gruppen anhand von Variablen zu erklären (kanonischeDiskriminanzfunktion) - und damit im zweiten Schritt die Zugehörigkeitvon Entitäten anhand der gemessenen Diskriminanzvariablevorhersagen zu können (klassifikatorische Diskriminanzfunktion).
Die a priori definierten Gruppen können natürlich auch das Ergebniseiner Clusteranalyse sein. In der Diskriminanzanalyse würde dannversucht mit Variablen die Klassifikation zu erklären.

45
Page 45
Mathematische Grundlagen II
Idee: Überführen der Matrix mit den beobachtetenVariablen in eine mit linear unabhängigen
a11
K a1n
M O M
am1
L amn
1K 0
M O M
0 Ln
Ziel
Eigenwertproblem: x
r= x
r
Für die Berechnung der Diskriminanzfunktion benötigt man im multivariaten FallDeterminanten, Eigenwerte und Eigenvektoren.
Die Determinante ist eine spezielle Funktion, die jeder n x n Matrix eine eindeutigeZahl zuweist. Wenn die Determinante 0 ist, bedeutet dies, dass mindestens eine Zeileder Matrix nicht linear unabhängig - also redundant ist. Die Determinante erhält manin R mit det().
Über die Lösung des (speziellen) Eigenwertproblems erhält man die Eigenvektorenund Eigenwerte zur Matrix A. Dabei ist wichtig zu erkennen, dass dasEigenwertproblem auch als lineare Abbildung f(x) = lambda*x geschrieben werdenkann und dieser Vektor x dann nur durch den Faktor lambda gestreckt wird für allef(x).
Die Matrix mit den Eigenwerten wird auch als kanonische Form bezeichnet, daherkommt die Bezeichnung für viele Verfahren (kanonische Korrespondenzanalyse,kanonische Korrelation usw.).
Natürlich haben wir es in der Realität selten mit dem Fall zu tun, dass die Matrixquadratisch (n x n) ist. Allerdings gelangt man auch über Singularwert-zerlegung(Spezialfall der Schur-Zerlegung) zu Eigenwerten. Dies ist in R mit svd()implementiert.

46
Page 46
Mathematische Grundlagen II
1 3 1
0 1 2
1 4 1
Beispiel:EW Berechnung
nach Sarrus
33
24 = 0
Charakteristisches Polynom
Eigenwerte: 4; 0 und -1 Matrix der Eigenvektoren:
1 7 2
2 2 1
3 1 1

47
Page 47
Diskriminanzanalyse
z = a1x1+ a
2x2+ ...+ a
qxq
Mehr Variablen:
Abbildung aus Legendre (1998, S. 619)
Das Diagramm beschreibt die Visualisierung einer Diskriminanzanalyseim bivariaten Fall, wo A und B aufgrund von x1 und x2 unterschiedenwerden sollen. Dies gelingt durch die Linearkombination von x1 und x2.Hier wird deutlich, dass die univariate Untersuchung der Trennleistungaufgrund der Variablen in die Irre geführt hätte.
Für mehr Variablen verwendet man die erweiterte Funktion mit qUmweltvariablen und den dazugehörigen Koeffizienten (a).

48
Page 48
Diskriminanzanalyse
1. Schritt: Berechnen der Abweichungsquadratezwischen und innerhalb der Gruppen
Bei der Diskriminanzanalyse geht es darum, die Abweichungenzwischen den Gruppen gegenüber denen innerhalb der Gruppen zumaximieren.
Dabei ist W1 bis Wg die jeweilige Abweichung innerhalb der Gruppeund B ergibt sich aus T - W. Die Abweichungen werden jeweils geteiltdurch die Anzahl der Beobachtungen (n) oder der Gruppen (g).

49
Page 49
Diskriminanzanalyse
2. Schritt: Maximieren von M
M =a 'Aa
a 'Va(V
1A
kI )a
k= 0 (A
kV )a
k= 0
Normalisierung der EV
normalisiertnicht-normalisiert
Von M gelangen wir durch Ableitung der Lagrangefunktion L(lambda, a)nach a zu dem bekannten Eigenwertproblem.
Die berechneten Eigenvektoren werden normalisiert, damit die within-group Abweichungen für alle Eigenvektoren gleich sind (sie hängenansonsten von der Messskala der Variablen ab). Die so normalisiertenEigenvektoren spannen den kanonischen Raum der DA auf.
Abbildungen aus Legendre (1998, 622)

50
Page 50
Diskriminanzanalyse
3. Schritt: Berechnung der Position der Gruppen
z = a1(x1
x1) + a2 (x2 x2 ) + ...+ aq (xq xq )
Kanonische Diskriminanzfunktion
Gruppenzuordnung mit 2 Gruppen:
z >(z1+ z
2)
2; mit z
1> z
2
Nun können wir mit den Eigenvektoren (identisch mit den Koeffizienten a) die Positionder Objekte im kanonischen Raum berechnen. Die Funktion wird kanonischeDiskriminanzfunktion genannt. Kanon stammt aus dem Griechischen und läßt sich inetwas übersetzen als „das grundlegendste zu dem sich ein Objekt ohne Verlust vonallgemeiner Aussagekraft zusammenfassen läßt“.
Die klassifikatorische Diskriminanzfunktion ergibt sich aus ihr, wenn man die nichtzentrierten Werte der Deskriptoren (Umweltvariablen) verwendet. Zu welcher Gruppeein neues Objekt gehört kann entweder grafisch oder mathematisch (scores, Abstandvon den Mittelpunkten der Gruppen o.ä.) geschlossen werden. Im Fall mit 2 Gruppengehört ein neues Objekt zur Gruppe 1, wenn der z-Score größer ist als die Summeder Mittelwerte der z-scores beider Gruppen, dividiert durch 2 (und z1 > z2). Der Fallmit mehreren Gruppen wird hier nicht näher besprochen, die Regel dafür und dieHerleitung findet sich z.B. in Johnson & Wichern (2002, S.628ff).
Die Bewertung der Güte der Diskriminanzfunktion kann anhand der richtigklassifizierten Objekte erfolgen.
Beachte, dass es für jeden Eigenwert einen entsprechenden Eigenvektor und einekanonische Diskriminanzfunktion gibt. Im Fall von nur zwei Variablen oder nur 2-3Gruppen, gibt es jedoch maximal zwei Diskriminanzfunktionen.

51
Page 51
Diskriminanzanalyse
Aufgabe
1. Berechnen Sie die Diskriminanzfunktion für dieBodendaten bzgl. der Gruppierung in Typ 1und 2!
2. Bestimmen Sie die Zugehörigkeit einer neuenProbe!
13769,5127140,5171
UAlNiFeCu
3. Wie hoch ist die Mißklassifizierungsrate?
lda() {MASS}
predict()
predict(your.object, method=„plug-in“)$class
table(...,Type)
Tips:
Bei der Funktion lda() muß nur die Formel eingegeben werden, alleweiteren Funktionen sind für uns in diesem Kurs nicht von Belang.
Bei der Funktion predict() ist es äußerst wichtig, dass die neuen Datenals data.frame mit den Namen der Spalten eingelesen werden.

52
Page 52
Diskriminanzanalyse
Voraussetzungen
- Beobachtungen müssen unabhängig sein
- Kovarianzmatrizen gleich (von allen Gruppen)
- Daten aller Gruppen multivariat normalverteilt
- Variablen nicht multikollinear
- Linearer Gradient der Variablen
- Stichprobengröße: jede Gruppe N 3P
Anmerkungen zum Punkt „Variablen nicht multikollinear“:
Sind Variablen eng korreliert (r > 0.7) oder lassen sich einzelneVariablen als Linearkombination von anderen darstellen, kann darauseine singuläre Matrix folgen, was mathematisch Probleme bereitet.Ferner ist die Interpretation der diskriminatorischen Funktion schwierig,wenn verschiedene Variablen zusammen auf die kanonische Funktionwirken. Eine Möglichkeit mit Kollinearität umzugehen ist, in einerunivariaten ANOVA zu prüfen, welcher F-Wert der betreffendenVariablen am größten ist und die anderen (interkorrelierendenVariablen) aus dem Datensatz zu entfernen.

53
Page 53
Diskriminanzanalyse
1. Test der Variablen auf Unterschiede bezüglich derGruppen (analog zu ANOVA oder MANOVA)
2. Analog zur multiplen Regression wird Zusammenhangzwischen Y (Diskriminante) und mehreren X hergestellt
Ähnlichkeiten zu bisherigen Verfahren:
Probleme der Diskriminanzanalyse
- wichtige Gradienten, die nicht gemessen wurden
- Überprüfung mit neuen Daten
- kein Konsens über Anzahl kanonischer Funktionen
Der Unterschied zur MANOVA besteht darin, dass bei der MANOVA dieNullhypothese: „Alle Gruppen sind gleich“ getestet wird.
Zur Multiplen Regression besteht der Unterschied darin, dass dieabhängige Variable (z) kategorisch ist.
Ob nur die kanonischen Funktionen behalten werden sollten, diesignifikant sind oder nur solche, die eine sachliche Bedeutung haben istumstritten.

54
Page 54
Klassifikation multivariater Methoden
Anhand der Methoden
Multivariate Vergleiche (Zentralmaße usw.)
Multivariate Regression und Korrelation
Klassifikation (Cluster- und Diskriminanzanalysen)
Ordination
Ordinationsverfahren bilden einen der wichtigsten Punkte bei denmultivariaten Verfahren und es gibt eine ganze Reihe vonverschiedenen Techniken. Gemeinsam ist ihnen, dass versuchtwird, die Komplexität oder Beziehungen zwischen den Daten visuellim niedrigdimensionalen Raum darzustellen.

55
Page 55
Ordinationsmethoden: Einleitung
Given the possible choices among these ordinationmethods, it is difficult to determine how much of thevariation attributed to environmental factors is actuallydue to the choice of ordination (Jackson, 1993)
Mit den leistungsfähigen Rechnern und der verfügbaren Software ist esheutzutage recht einfach Ordinationen durchzuführen. Darunterleidet zum Teil aber die Qualität, wenn man mancheVeröffentlichungen anschaut. Das kommt auch daher, dass es keinestrikte Methoden oder Entscheidungsregeln zur Durchführung derAnalysen gibt.

56
Page 56
Ordinationsmethoden: Einleitung
• versuchen wichtige Gradienten aus den Daten zuextrahieren
•„unconstrained“: Extraktion ohne Berücksichtigungvon Variablen außerhalb des Sets
•„constrained“: Extraktion von Gradient der direkt vonVariablen des zweiten Sets abhängt
• Lineare vs. Nicht-lineare Ordination
• Seit 60er-70er Jahre PCA, CA, MDS
• Mitte der 80er „Revolution“ mit CCA
Auch bei der „unconstrained“ Ordination kann im Nachhinein versuchtwerden, Variablen an die Gradienten der Ordination anzupassen.Demgegenüber werden bei der „constrained“ ordination nurGradienten extrahiert, die in beiden Matrizen vorhanden sind.

57
Page 57
Ordinationsmethoden: PCA
Die Mutter aller Ordinationsmethoden....
x1
x2
PCA 1PCA 2
y1= a
1x1+ a
2x2+ ...+ a
qxq
Allgemeine Gleichung für die 1. Achse:
Die PCA kann man sich vorstellen als ein Koordinatensystem dass indie Mitte der Datenpunkte gelegt wird mit linear unabhängigenAchsen. Die Achsen werden dann so lange rotiert, bis die 1. Achsedie maximale Varianz erklärt, die 2. Achse die höchste verbleibendeVarianz usw. Es gibt genauso viele Achsen wie Variablen.
Die Hoffnung dabei ist, dass die ersten Achsen einen großen Anteil derGesamtvarianz erklären. Die Daten werden vor der Analyse zentriert(Mittelwert subtrahiert), um die Interpretation zu erleichtern.
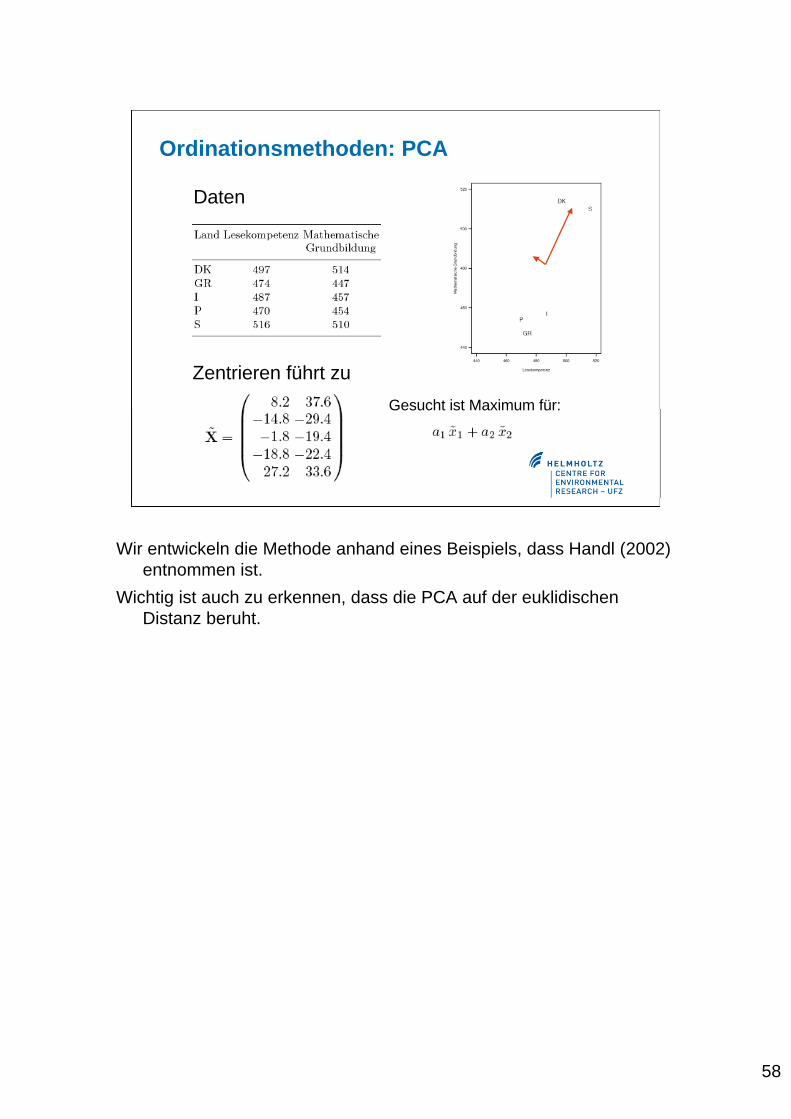
58
Page 58
Ordinationsmethoden: PCA
Daten
Zentrieren führt zu
Gesucht ist Maximum für:
Wir entwickeln die Methode anhand eines Beispiels, dass Handl (2002)entnommen ist.
Wichtig ist auch zu erkennen, dass die PCA auf der euklidischenDistanz beruht.

59
Page 59
Ordinationsmethoden: PCA
Gesucht ist Maximum für:
a1
2+ a
2
2= 1mit
Allgemein:
max(aVar(X)) max(a ' a) mit a 'a = 1
Wir verwenden die Lagrangefunktion:
Die partiellen Ableitungen lauten:
a = a
Die Darstellung hier erfolgt mit der bekannten Varianz-KovarianzmatrixSigma. In der Praxis müssen wir diese Matrix meist schätzen undverwenden S. Werden die Daten vor der Analyse standardisiert(durch Varianz geteilt) rechnet man mit der Korrelationsmatrix R.Standardisieren hat zur Folge, dass alle Variablen mehr oderweniger die gleiche Relevanz bekommen (z.B. sinnvoll fürArtenmatrizen oder wenn die Variablen sehr unterschiedlich skaliertsind).
Da wir die Varianz künstlich beliebig hoch treiben könnten, normierenwir die Koeffizienten der Linearkombination.
Nach einer Reihe von Schritten landen wir wieder bei unseremEigenwertproblem!
60
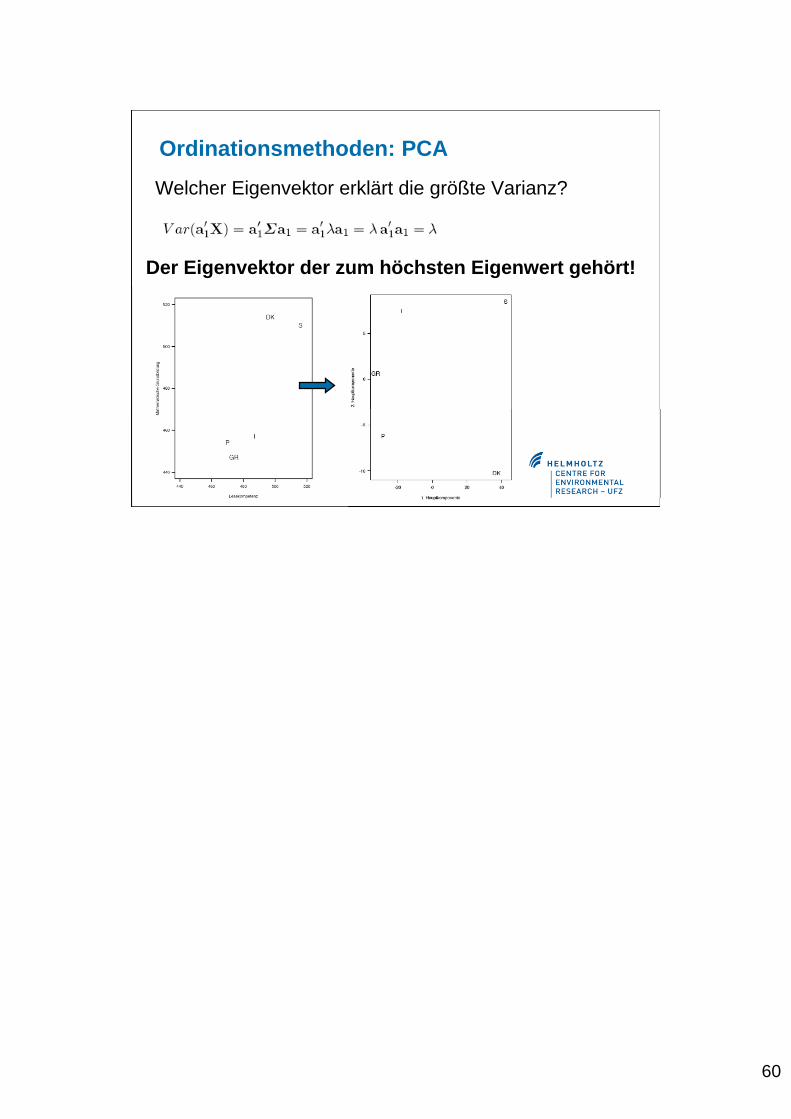
Page 60
Ordinationsmethoden: PCA
Welcher Eigenvektor erklärt die größte Varianz?
Der Eigenvektor der zum höchsten Eigenwert gehört!

61
Page 61
Ordinationsmethoden: PCA
Ladung der Variablen auf den neuen Achsen
- wenn standardisiert Korrelation proportional,ansonsten vom Skalenniveau beeinflusst:
rxi yj
=
aij j
si
und rxi y j
= aij j
nicht-standardisiert standardisiert (da s=1)
verschiedene Methoden um Signifikanz festzustellen:-Faustregeln (±0.3 signifikant, ±0.40 wichtig, 0.5 sehr wichtig-Regeln basierend auf Datensätzen
-Permutationstests
Im Fall, dass wir die standardisierten und zentrierten Variablenverwendet haben (Korrelationsmatrix) ist die Korrelation vonVariablen mit den Hauptkomponentenachsen proportional zumGewicht der einzelnen Variablen auf der jeweiligen Achse.
r: Korrelation zwischen Achse j und Variable X; a = Ladung auf Achse j;lamdba: Eigenwert; s = Standardabweichung von X

62
Page 62
Ordinationsmethoden: PCA
Wieviele Achsen braucht man?
i
i=1
r
j
j=1
p
1. Summenkriterium 2. Mittelwertkriterium
ra1
pi
i=1
p
3. Screeplot 4. Broken-Stick Kriterium
i>1
p
1
ii=1
p
Für das Summenkriterium wird typischerweise ein alpha mit einem Wertzwischen 0.7 und 0.9 gewählt.
Weiterhin kann man auch das Mittelwertkriterium anlegen und nur dieHauptkomponenten verwenden, deren Eigenwert größer als dermittlere Eigenwert ist (bzw. als a * mittlerer Eigenwert).
Ferner haben wir schon den Screeplot im Zusammenhang mit derClusteranalyse kennengelernt.
Die Broken-Stick Methode stellt eine der besten Lösungen dar. DerName leitet sich von der Idee ab, dass wir Punkte (in diesem Falldie Eigenwerte) auf einem virtuellen Stock markieren und schauen,wieviele Punkte sich auf dem Teil i des Stockes vorfinden, wenn erp mal zerbrochen wurde (im vorliegenden Fall die Anzahl derVariablen). Praktisch sollte der i-te Eigenwert größer sein als derWert nach dem Broken-Stick-Modell da er sonst auch zufällig seinkönnte.

63
Page 63
Ordinationsmethoden: PCA
Aufgaben
1. Führen Sie die Befehle in der Datei PCA aus undbetrachten Sie die Ergebnisse!
2. Was ändert sich, wenn man die PCA nicht-skaliertdurchführt?
3. Was ändert sich, wenn man Chicago als Ausreißerentfernt?
Die PCA-Datei wird im Kurs gestellt. Am vorliegenden Beispiel zeigtsich, dass die PCA auch genutzt werden kann, um die Zahl derVariablen vor weiteren Analysen zu verringern. Vorsicht ist jedochgeboten, falls sich die einzelnen Achsen nicht gut interpretierenlassen.
Weitere Befehle um eine PCA durchzuführen gibt es in folgendenPaketen: pca.dudi() {ade4}, pca() {labdsv}, prcomp(), rda(){vegan}
Auf die Unterschiede kann hier nicht näher eingegangen werden.Generell ist aus Gründen mathematischer Präzision prcomp() derFunktion princomp() vorzuziehen, da sie auf dieSingularwertzerlegung für die Eigenwertberechnung zurückgreift.

64
Page 64
Ordinationsmethoden: PCA
Voraussetzungen
- Beobachtungen müssen unabhängig
sein
- multivariate Normalverteilung
- keine gravierenden Ausreißer
- Linearer Gradient der Variablen
- Stichprobengröße: jede Gruppe N 3P
Tests zur Überprüfung der multivariaten Normalverteiung haben wir schonkennengelernt (Quantil-Quantil-plot und den multivariaten Shapiro-Wilk Test).
Ausreißer können die Ergebnisse stark beeinflussen, weil sie zu einer höherenVarianz führen. Allerdings sind nicht alle Ausreißer auf ungewöhnliche Meß- oderUmweltbedingungen zurückzuführen, sondern sie können im Gegenteilökologisch bzw. für die Untersuchung extrem bedeutsam sein. Mac Garigal (2000,S.31) empfehlen in jedem Fall vor einer PCA ein Ausreißer-Screeningdurchzuführen. Entweder indem die Daten zentriert und standardisiert werden(Mittelwert subtrahieren und durch Varianz dividieren), um dann nachBeobachtungen zu suchen, die mehr als 2.5 Einheiten vom Mittelwert entferntsind. Oder durch Betrachten der univariaten Plots für alle Variablen.
Die wichtigste Voraussetzung ist ein linearer Gradient zwischen den Objekten(einzelnen Beobachtungen). Trifft sie nicht zu, kann es zu erheblichen Fehlernkommen (bzgl. Der Position der Beobachtungen). Vergleich hierzu das Beispiel inder Datei „horseshoe.r“ in der anschaulich dargestellt wird, wie sich unimodaleGradienten auf die PCA auswirken. Nicht-Linearität kann überprüft werden, indemman die Scatter-plots aller Hauptkomponenten miteinander betrachtet. Ferner gibtes die Möglichkeit mit anderen Verfahren den Gradienten zu berechnen (dazuwerden wir später noch kommen).
Bei der Stichprobengröße gilt als Richtwert, dass mindestens 3 Mal so vieleBeobachtungen wie Variablen vorhanden sein sollten. Absolutes Minimum ist diegleiche Anzahl von Beobachtungen und Variablen.

65
Page 65
Ordinationsmethoden: PCA
Grenzen der Hauptkomponentenanalyse
- wichtige Gradienten, die nicht gemessen wurden
- Linearität, nur für enge Gradienten in Ökologie
- Zufügen von noise-Variablen erhöht Varianzanteil auf
erster Achse, hat aber keine reale Erklärungskraft
- euklidische Distanz verursacht Verzerrungen bei „double-
zeros“
Die Verzerrung durch die euklidische Distanz spielt insbesondere in derÖkologie eine Rolle: Hier beobachtet man oft nur einige Arten proStelle, alle anderen Arten bekommen die Abundanz 0. Wenn nun anzwei Stellen keine gleichen Arten beobachtet wurden aber diegleichen Arten abwesend waren, sind diese Stellen sich ähnlicher,als andere, die gleiche Arten haben, sich aber in ihren Abundanzenunterschieden. Zum besseren Verständnis sollte man die Datei„double-zeros.r“ ablaufen lassen.

66
Page 66
Ordinationsmethoden: PCA
Verwandte Methoden
Polare Ordination:- Benutzt Dissimilaritätsindex- Platziert alle Entitäten zwischen zwei ausgewählten Polen (möglichst unterschiedlich)- Auch mehrere Achsen möglich- Wenig Voraussetzungen (keine Linearität, Multivariate Normalverteilung)- Subjektive Wahl der Pole wird kritisiert- Weitere Achsen nicht notwendig orthogonal
Faktorenanalyse:- Ähnlich wie PCA aber trennt spezifische und gemeinsame Varianz- Annahme latenter Variablen, die nicht gemessen werden können- mit Latentvariablen die Originalvariablen erklären („Gegenteil“ von PCA)- Stärke: mit wenigen Latentvariablen die Originalvariablen bestimmen- spezifische Varianz wird entfernt, als Rauschen betrachtet- Resultate nicht immer eindeutig, verschiedene Faktorkombinationen denkbar
factanal() {stats}
Die Faktorenanalyse ist insbesondere in der sozialwissenschaftlichenForschung relevant. Dort nimmt sie eine wichtige Stelle ein, hier sollnicht näher auf sie eingegangen werden.

67
Page 67
Ordinationsmethoden: NMDS
Objekte haben Distanzen
Ränge aus Distanzmatrix
Versuch, der Darstellung im niedrigdimensionalenRaum
!0
0.6 0
0.8 0.7 0
1.2 1.3 0.3 0
Nicht-metrische multidimensionale Skalierung wird von Minchin (1987)als die robusteste „unconstrained“ Ordination betrachtet.
Die NMDS beruht auf Distanzmatrizen und umgeht die kritischeAnnahme des linearen Gradienten, indem nur Monotonie gefordertwird bei der Übertragung der Darstellung in denniedrigdimensionalen Raum. Die Dissimilaritätsmatrix kann man mitjedem beliebigen Abstandsmaß berechnet werden, wir haben schoneinige Methoden dafür kennen gelernt.

68
Page 68
Ordinationsmethoden: NMDS
0
1.3 0
0.4 0.6 0
Mathematische Durchführung:
1. Bestimmen der Distanzmatrix aus den Rohdaten2. Bestimmen einer Anfangskonfiguration3. Bestimmen der Distanzmatrix der Konfiguration4. Monotoniebedingung aus Rohdaten-Distanzmatrix überprüfen5. Wenn notwendig Disparitätenmatrix erstellen 6. Beurteilen der Güte der Darstellung
Die Erfüllung der Monotoniebedingung hängt von der Lage der Punkteab. Im Beispiel ist sie erfüllt (rot und blau am weitesten entferntusw.).
Während die metrische multidimensionale Skalierung versucht, dieUnterschiede der Dissimilaritätsmatrix beizubehalten, verzichtet dieNMDS darauf und fokussiert nur darauf, die Ordnung derUnterschiede beizubehalten. In der Regel werden die Ergebnisseder metrischen multidimensionalen Skalierung als Startkonfigurationverwendet.
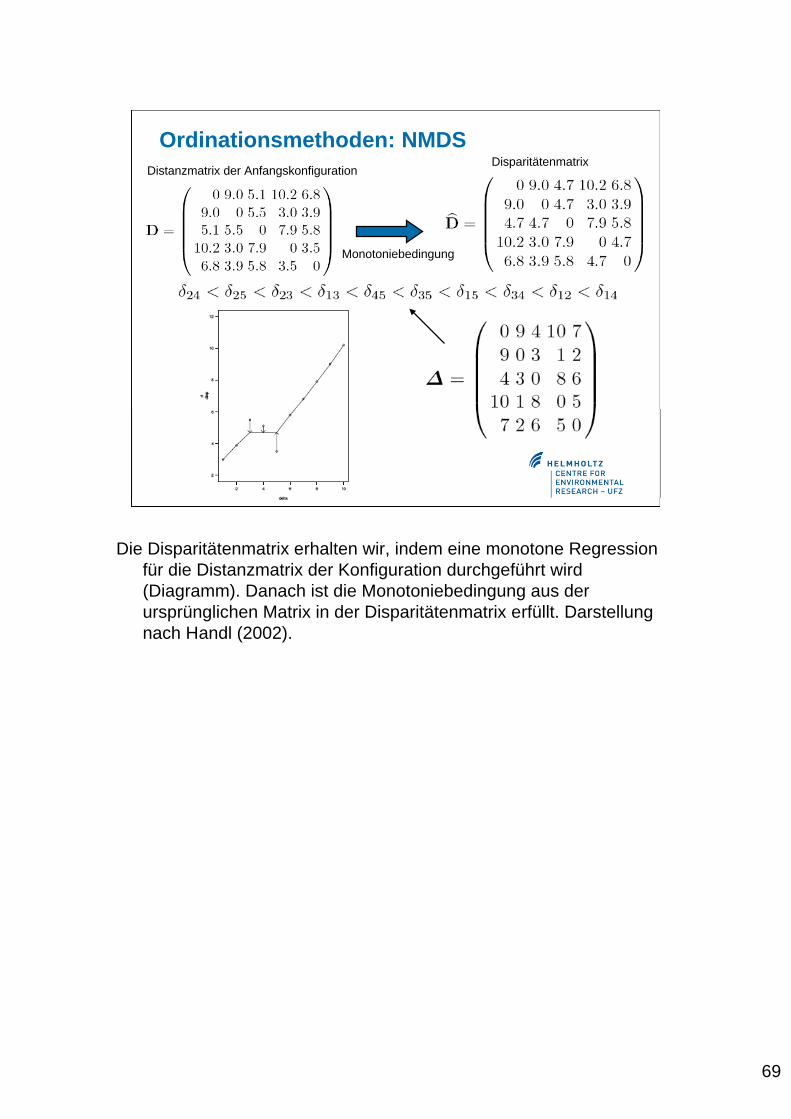
69
Page 69
Ordinationsmethoden: NMDSDistanzmatrix der Anfangskonfiguration
Monotoniebedingung
Disparitätenmatrix
Die Disparitätenmatrix erhalten wir, indem eine monotone Regressionfür die Distanzmatrix der Konfiguration durchgeführt wird(Diagramm). Danach ist die Monotoniebedingung aus derursprünglichen Matrix in der Disparitätenmatrix erfüllt. Darstellungnach Handl (2002).

70
Page 70
Ordinationsmethoden: NMDS
Anpassungsgüte
Umsetzung in R
isoMDS() {MASS}
metaMDS() {vegan} Shotgun-Methode
cmds() {mclust} (Metrische) Multidimensionale Skalierung
Grundfunktion für NMDS
Mit der Anpassungsgüte kann man auch über die Anzahl dernotwendigen Achsen entscheiden. In der bereitgestellten Datei(„nmds.r“) habe ich dazu eine kleine Funktion geschrieben(scree_values). Der Name kommt nicht von ungefähr sondern es istangedacht, die Daten in einen Screeplot einfließen zu lassen.
Die metrische MDS wird auch als Principal Coordinate Analysisbezeichnet.

71
Page 71
Ordinationsmethoden: NMDS
metaMDS() {vegan}Was macht die Shotgun-Methode?
1. Datentransformation
2. Wählt Similaritätsindex (Bray-Curtis)
3. Anpassung, falls zu wenig gleiche Arten vorkommen
4. Mehrere random Starts
5. Zentrieren der Ordination (größte Varianz 1.Achse)
6. Berechnen von WA-Scores
Mehr Infos zur Ordination mit metaMDS gibt es zum einen in derentsprechenden Hilfe und in einem Webdokument von Oksanen:
http://cc.oulu.fi/~jarioksa/opetus/metodi/vegantutor.pdf

72
Page 72
Ordinationsmethoden: NMDS
Aufgaben
1. Benützen Sie die Datei NMDS um eine NMDS mitden Daten (varespec) durchzuführen.
2. Was bedeutet die Skalierung im Diagramm?
3. Laden Sie die „varechem“-Daten, führen Siefolgenden Code aus und erkären Sie, waspassiert!
ef <- envfit( „your-nmds-result“ , varechem, permu=500)plot(ef,p.max=0.01, axis= TRUE,col="black")
4. Was zeigt die Grafik jetzt an? - Interpretieren Siedie Parameter in ef!
In der Datei „varespec.csv“ finden Sie Flechtendaten von 44 Arten an24 Stellen.
Die Funktion envfit versucht Variablen im Datensatz an Gradienten derOrdination anzupassen. Der R^2-Wert ergibt sich aus derKorrelation. Der p-Wert ergibt sich aus der Permutation: Es werdenzufällige Vektoren oder Faktoren erzeugt und der R^2-Wertberechnet. Für die richtigen Vektoren oder Faktoren wird dannverglichen, wie hoch der Anteil derjenigen Vektoren bzw. Faktorenist, die höhere R^2 Werte aufweisen. Bsp.:
500 Permutationen: 5% der R^2-Werte der zufällig erzeugten Vektoren(also 25) größer als 0.4. Dann wären Vektoren mit R^2 > 0.4 aufdem Niveau 0.05 signifikant.

73
Page 73
Ordinationsmethoden: NMDS
Grenzen der NMDS- Ergebnisse abhängig von Startkonfiguration
- Datenverlust durch Rangdaten
- Anzahl der Dimensionen a priori unbekannt
- keine Kausalität aus Fitting von Umweltvariablen
Anwendungen
- Ordination von Unterschieden
- Zusammenhang mit 2. Set von Variablen
- Überprüfung auf Cluster
Permutationstests versuchen zufällige Vektoren an die Datenanzupassen und erzeugen damit Signifikanzgrenzen. Allerdingsfolgt aus der Signifikanz von Variablen nicht notwendig Kausalität.

74
Page 74
Ausblick: Ordination
- populärste Methode zur Zeit- unterstellt unimodale Verteilung der Arten gegenüber Umweltgradient- Mischung aus multipler Regression und Ordination- In R Modellbildung möglich
Kanonische Korrespondenzanalyse (CCA)
cca() {vegan}
- neue, interessante Methode (Yee 2006)- berechnet Reaktion jeder Art gegenüber dem Hauptumweltgradienten- eher „data-driven“ als „model-driven“- Mischung aus GAMs und kanonischer Gauß‘scher Ordination- hohe Rechenleistung benötigt!- in R umgesetzt, allerdings noch nicht allzu komfortabel
Constrained additive Ordination (CAO)
cao() {VGAM}
Aus Zeitgründen konnte im Rahmen dieser Veranstaltung leider nichtmehr auf die CCA eingegangen werden. Eine gute Einführung findetsich in Leps & Smilauer (2003), oder auf höherem Niveau in terBraak & Verdonschot (1995). Die mathematischen Hintergründefinden sich bei Legendre (1998). Die CCA ist für die Ökologie sehrbedeutsam, da aus den Artendaten nur Gradienten extrahiertwerden, die ökologisch bedeutsam sind. Hauptsächlich wird sie mitder Software Canoco durchgeführt, allerdings ist sie auch in Rumgesetzt und eine leicht verständliche Anleitung findet sich imTutorium zum vegan-Package:
http://cc.oulu.fi/~jarioksa/opetus/metodi/vegantutor.pdf
Allerdings beruht die CCA auf Annahmen wie einer unimodalenVerteilung der Arten, die kritisiert werden. Aus dieser Kritik ist dieCAO hervorgegangen, die im Paper von Yee (2006) vorgestellt wird.Diese brandneue Methode ist in R umgesetzt (package VGAM) underlaubt es die Reaktion der Arten auf die Umweltbedingungen zuberechnen sowie eine Ordination durchzuführen. Selbst mit denmodernen Rechnern, kann die Berechnung einige Zeit in Anspruchnehmen (5 Minuten bis mehrere Stunden, je nachModellspezifikation).
Ich habe schon Analysen mit beiden Methoden durchgeführt, werProbleme bei der Umsetzung in R hat, kann sich gerne melden.














