2016 übermittelten die zuständigen Behörden der Mitgliedsstaaten
mehr als 2.044 Warnungen vor gefährlichen Produkten über das
Schnellwarnsystem der EU. 244 dieser Produkte wurden nachweislich
über das Internet vertrieben. Quelle:
https://ec.europa.eu/germany/news/spielzeug-schuhe-schmuck-mehr-als-2000-gef%C3%A4hrliche-produkte-l%C3%B6sten-eu-weiten-alarm-aus_de
abgerufen am 26.01.2018
Finger weg!Maschinelles Auffinden und Klassifizieren von
risikobehafteten Produkten zur Unterstützung der
Marktüberwachung
Der Onlinehandel wächst. Durch Globalisierung und digitale
Vernetzung ist es möglich, jede Art von Produkt weltweit online zu
vertreiben und zu kaufen. Den europäischen Markt erreichen auf
unterschiedlichen Vertriebswegen eine Fülle von Produkten mit hohen
Qualitätsschwankungen und teilweise gefährlichen Eigenschaften.
Aufgabe der Marktüberwachungsbehörden ist es u. a., im Internet
gehandelte Produkte, von denen ein Risiko für die Verbraucher
ausgeht, aufzufinden und zu verhindern, dass diese auf dem
europäischen Markt verbleiben.
Die Vielzahl der Produkte und die Dynamik des Onlinehandels
erschweren die effiziente Kontrolle des Marktes. Der Einsatz von
Big-Data-Methoden, um gefährliche Produkte automatisch anhand von
Kundenrezensionen zu identifizieren, ist eine Möglichkeit die
Marktüberwachungsbehörden zu unterstützen. Die Nutzung von
Rezensionen bietet sich an, weil in diesen über positive und
negative, aber vor allem über gefährliche Produkteigenschaften
berichtet wird.
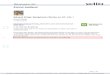
26%
18%
13%7%
5%
31%
Meldungen gefährlicher Produkte nach Produktkategorien 2016
Spielzeuge
Fahrzeuge
Textilien und Kleidung
Elektronische Produkte
Bedarfsgegenstände fürKinder
Wie können Kundenrezensionen…
DatenbasisFür die effiziente und automatische Marküberwachung
mittels Big-Data-Methoden müssen in regelmäßigen Abständen aktuelle
Kundenrezensionen (Daten) beschafft und ausgewertet werden.
Besonders Rezensionen von „neutralen“ Bewertungsportalen, bei denen
Verkäufer oder Hersteller diese nicht manipulieren können (z. B.
durch Löschung von negativen Rezensionen), sind zuverlässig. Auch
die Berücksichtigung von Rezensionen nach einem „verifizierten
Kauf“ hilft gefälschte Rezensionen im Vorfeld auszuschließen.
DatenvorbereitungIm Preprocessing findet eine Vorverarbeitung
der Daten statt. Zunächst werden positive Produktbewertungen (vier
bis fünf Sterne) entfernt. Die verbliebenen Rezensionen werden um
Wörter, die keinen zusätzlichen Informations-gewinn bringen (z. B.
bestimmte oder unbestimmte Artikel), mit einer Stoppwortliste
bereinigt. Mit einem Stemming werden semantisch gleiche Wörter
unter ihrem gemeinsamen Wortstamm zusammengefasst und
aussagekräftiger gemacht. Durch die unveränderten produktbezogen
Daten (Produktbezeichnung, Hersteller, etc.) kann das Produkt
später für Recherchen eindeutig identifiziert werden.
TextrepräsentationDie verwendeten Klassifizierer können die
Semantik der Texte nicht anhand des Sinns einzelner Wörter
verstehen. Deshalb müssen die Texte in eine mathematische Form
„übersetzt“ werden. Mit dieser können daraufhin Wörter verglichen
und einem Kontext zugeordnet werden. In diesem Projekt wurden zwei
gängige Methoden getestet.• Bag of words zählt die Wörter einer
Rezension und
erstellt aus diesen einen Vektor.• Explicit semantic Analysis
nutzt eine vektorielle
Darstellung einer externen Datenbank. Dabei werden für jedes
Wort mehrere Vektoren erstellt. Sie stellen die Entfernung der
Wörter aus der externen Datenbank zu einem Wort dar. Aus diesem
wird ein „Mittelpunkt“ gebildet und dient als Wortvektor.
KlassifikationDie eigentliche Textklassifikation erfolgt über
drei praxiserprobte Verfahren, die parallel getestet werden. Die
Verfahren basieren auf dem Prinzip des maschinellen Lernens, das
unbekannte Datensätze einer bestimmten Klasse zuordnet. Jedoch
benötigt das Verfahren zum „Trainieren“ bereits klassifizierte
Datensätze. Die hier verwendeten Verfahren zur Textklassifizierung
sind
• Support-Vector-Machine (SVM), • datenloses Co-Klassifizieren,•
datenlose hierarchische Klassifizierung.
Sie ordnen die Produkte den Risikoklassen „Mechanische Gefahr“,
„Brandgefahr“, „Chemische Gefahr“ und „Elektrische Gefahr“ zu.
Neben händisch erstellten Trainingsdaten bilden textuelle
Beschreibungen der Risikoklassen die Basis. Sie enthalten erste
„feuernde Ausdrücke“ wie beispielsweise „Brand“.
SortierungUm eine schnellere Interpretation der Ergebnisse zu
ermöglichen, erfolgt eine weitere Sortierung der Daten. Für jede
Risikoklasse wird daher eine interne Prioritätenliste erstellt, in
der die gefährlichste Produkt-kategorie definiert wird.
Kinderspielzeug erhält beispielsweise eine höhere Gewichtung als
Garten-dekoration.
EvaluierungIn einem ersten Testlauf wurden 1.200 Rezensionen
analysiert. Aus diesen Rezensionen konnten 720 Produkte händisch
als potenziell gefährlich identifiziert und einer Risikoklasse
zugeordnet werden. Mit derselben, nun vergleichbaren, Datenbasis
wurde die abschließenden Evaluierung der
Textklassifizierungsverfahren durchgeführt. Der Co-Klassifizierer
erzielte das beste Ergebnis und ordnete 655 Produkte korrekt einer
Risikoklasse zu. Aufbauend auf diesen positiven Ergebnissen erfolgt
die Optimierung der Verfahren, sowie die Anpassung und Erprobung an
weiteren Onlineshop-systemen.
…Unfälle verhindern?
Nachdem beide Klassifizierer auf einer textuellen Beschreibung
der Risikoklassen trainiert wurden, durchlaufen alle
Kundenrezensionen beide Klassifizierer. Eine Klassifikation in die
Risikoklassen erfolgt nur, wenn beide Klassifizierer das Produkt
als risikobehaftet einteilen. Rezensionen, die nur durch einen
Klassifizierer eingeteilt wurden, durchlaufen den Prozess zu einem
späteren Zeitpunkt erneut. Durch die eindeutige Zuteilung werden
gleichzeitig neue Trainingsdaten generiert.
Mit Hilfe einer Baumstruktur, klassifizieren zwei Klassifizierer
auf zwei Ebenen zunächst alle Kundenrezensionen.Die n
vielversprechendsten Rezensionen werden für das weitere Trainieren
genutzt. Nicht eingeteilte Rezensionen durchlaufen den Prozess zu
einem späteren Zeitpunkt erneut. Dieser Vorgang wieder-holt sich,
bis alle Rezensionen klassifiziert werden konnten.
Schematische Darstellung der Co-Klassifizierung
Schematische Darstellung der hierarchischen Klassifizierung
Eine SVM trennt Daten verschiedener Klassen durch eine
Trennebene. Es gibt mehrere mögliche Trennebenen (z. B. Ebenen A
und B). Die SVM versucht dabei den Abstand der Datenklassen (in
diesem Fall Wörter) möglichst groß zu halten. Folglich würde Ebene
A ausgewählt und Ebene B verworfen werden. Neu hinzugefügte Daten
können so möglichst korrekt zugeordnet werden.
Schematische Darstellung der Support-Vector-Machine (SVM)
1 2
D. Schnura1,2
, M. Pendzich2, T. Bleyer
2
441
2
3
5
6
1
2
3
5
6
Foliennummer 1
/ColorImageDict > /JPEG2000ColorACSImageDict >
/JPEG2000ColorImageDict > /AntiAliasGrayImages false
/CropGrayImages true /GrayImageMinResolution 300
/GrayImageMinResolutionPolicy /OK /DownsampleGrayImages true
/GrayImageDownsampleType /Bicubic /GrayImageResolution 300
/GrayImageDepth -1 /GrayImageMinDownsampleDepth 2
/GrayImageDownsampleThreshold 1.50000 /EncodeGrayImages true
/GrayImageFilter /DCTEncode /AutoFilterGrayImages true
/GrayImageAutoFilterStrategy /JPEG /GrayACSImageDict >
/GrayImageDict > /JPEG2000GrayACSImageDict >
/JPEG2000GrayImageDict > /AntiAliasMonoImages false
/CropMonoImages true /MonoImageMinResolution 1200
/MonoImageMinResolutionPolicy /OK /DownsampleMonoImages true
/MonoImageDownsampleType /Bicubic /MonoImageResolution 1200
/MonoImageDepth -1 /MonoImageDownsampleThreshold 1.50000
/EncodeMonoImages true /MonoImageFilter /CCITTFaxEncode
/MonoImageDict > /AllowPSXObjects false /CheckCompliance [ /None
] /PDFX1aCheck false /PDFX3Check false /PDFXCompliantPDFOnly false
/PDFXNoTrimBoxError true /PDFXTrimBoxToMediaBoxOffset [ 0.00000
0.00000 0.00000 0.00000 ] /PDFXSetBleedBoxToMediaBox true
/PDFXBleedBoxToTrimBoxOffset [ 0.00000 0.00000 0.00000 0.00000 ]
/PDFXOutputIntentProfile () /PDFXOutputConditionIdentifier ()
/PDFXOutputCondition () /PDFXRegistryName () /PDFXTrapped
/False
/CreateJDFFile false /Description > /Namespace [ (Adobe)
(Common) (1.0) ] /OtherNamespaces [ > /FormElements false
/GenerateStructure false /IncludeBookmarks false /IncludeHyperlinks
false /IncludeInteractive false /IncludeLayers false
/IncludeProfiles false /MultimediaHandling /UseObjectSettings
/Namespace [ (Adobe) (CreativeSuite) (2.0) ]
/PDFXOutputIntentProfileSelector /DocumentCMYK /PreserveEditing
true /UntaggedCMYKHandling /LeaveUntagged /UntaggedRGBHandling
/UseDocumentProfile /UseDocumentBleed false >> ]>>
setdistillerparams> setpagedevice