Embed Size (px)
Citation preview

IMISE-REPORTS Herausgegeben von Professor Dr. Markus Löffler
L. Jansen, M. Boeker, H. Herre, F. Loebe (Eds.)
Ontologies and Data in Life Sciences (ODLS 2014)
Freiburg im Breisgau, October 7-8, 2014 IMISE-REPORT Nr. 1/2014
Medizinische Fakultät

Impressum Herausgeber: Universität Leipzig
Medizinische Fakultät Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE) Härtelstraße 16-18, 04107 Leipzig
Prof. Dr. Markus Löffler
Editoren: Ludger Jansen, Martin Boeker, Heinrich Herre, Frank Loebe Redakteur: Frank Loebe
Kontakt: Telefon: (0341) 97-16100, Fax: (0341) 97-16109 Internet: http://www.imise.uni-leipzig.de
Redaktionsschluss: 02. Oktober 2014
Druck: Inhalt: Universitätsklinikum Leipzig AöR, Bereich 2 - Abteilung Zentrale Vervielfältigung/Formularwesen Einband: Buch- und Offsetdruckerei Herbert Kirsten
Herausgegeben für:
Ontologien in der Biomedizin und den Lebenswissenschaften (OBML), Fachgruppe im Fachbereich Informatik in den Lebenswissenschaften der Gesellschaft für Informatik e.V. (GI), Bonn
Sprecher der Fachgruppe: Prof. Dr. Heinrich Herre, Universität Leipzig Vertreter: Dr. Martin Boeker, Universitätsklinikum Freiburg
Webseite der Fachgruppe: https://wiki.imise.uni-leipzig.de/Gruppen/OBML IMISE 2014 (Report als Sammelband). Das Copyright der Einzelartikel verbleibt bei den Autoren. Alle Rechte vorbehalten. Nachdruck nur mit ausdrücklicher Genehmigung des Herausgebers bzw. der jeweiligen Autoren und mit Quellenangabe gestattet. ISSN 1610-7233

ONTOLOGIES AND DATA IN LIFE SCIENCES (ODLS 2014)
Proceedings of the 6th Workshop of the
GI Workgroup
ONTOLOGIES IN BIOMEDICINE AND LIFE SCIENCES (OBML)
Freiburg im Breisgau, Germany October 7-8, 2014
IMISE, University of Leipzig 2014

ii
Organizers
Martin Boeker (chair) University Medical Center Freiburg Heinrich Herre (speaker, OBML) University of Leipzig Ludger Jansen (program chair) University of Muenster Frank Loebe University of Leipzig
Local Organizer
Martin Boeker University Medical Center Freiburg
Keynote Speaker
Jesualdo Tomás Fernández-Breis University of Murcia, Spain
Program Committee
Ludger Jansen (program chair) University of Muenster Patryk Burek University of Leipzig Georgios V. Gkoutos Aberystwyth University, UK Heinrich Herre University of Leipzig Robert Hoehndorf University of Cambridge, UK Toralf Kirsten University of Leipzig Oliver Kutz Otto von Guericke University Magdeburg Wolfgang Müller HITS gGmbH, Heidelberg Axel Ngonga-Ngomo University of Leipzig Anika Oellrich European Bioinformatics Institute (EBI), Hinxton, UK Dietrich Rebholz-Schuhmann University of Zurich, Switzerland Peter Robinson Charité Berlin Daniel Schober Leibniz Institute of Plant Biochemistry (IPB), Halle Falk Schreiber Leibniz Institute of Plant Genetics and Crop Plant Research (IPK),
Gatersleben Stefan Schulz Medical University of Graz, Austria Aleksandra Sojic Institute of Industrial Technologies and Automation (ITIA-CNR),
Milan, Italy George Tsatsaronis Technical University Dresden Dagmar Waltemath University of Rostock

iii
Authors
Martin Boeker University Medical Center Freiburg Patryk Burek University of Leipzig Vinay K. Chaudhri SRI International, Menlo Park, California, USA Giorgia Contini Institute of Industrial Technologies and Automation (ITIA-CNR),
Milan, Italy Martin Eisenacher Ruhr University Bochum Rita Faria University of Minho, Braga, Portugal Henson Graves Algos Associates, Fort Worth, Texas, USA Niels Grewe University of Rostock Heinrich Herre University of Leipzig Daniel Jacob INRA, University of Bordeaux, France Ludger Jansen University of Muenster Frank Loebe University of Leipzig Gerhard Mayer Ruhr University Bochum Annick Moing INRA, University of Bordeaux, France Steffen Neumann Leibniz Institute of Plant Biochemistry (IPB), Halle Marco Sacco Institute of Industrial Technologies and Automation (ITIA-CNR),
Milan, Italy Reza M. Salek European Bioinformatics Institute (EBI), Hinxton, UK Nico Scherf Technical University Dresden Daniel Schober Leibniz Institute of Plant Biochemistry (IPB), Halle Stefan Schulz Medical University of Graz, Austria Aleksandra Sojic Institute of Industrial Technologies and Automation (ITIA-CNR),
Milan, Italy Walter Terkaj Institute of Industrial Technologies and Automation (ITIA-CNR),
Milan, Italy Alexandr Uciteli University of Leipzig, Germany Michael Wilson University of Alberta, Edmonton, Canada

iv
Preliminary Program as of October 2, 2014
TUESDAY Oct 7, 2014 (13:00 – 13:45) Getting together / Registration / COFFEE
13:45 – 14:00 M. Boeker Welcome Remarks Session 1 14:00 – 14:30 H. Graves Ontology for Molecular Structure 14:30 – 15:00 F. Loebe Entities with Genetic Information: An Initial Perspective from the
Core Theme of Continuity and Change in Biology
15:00 – 15:30 COFFEE
Session 2 15:30 – 16:00 H. Herre OWL Patterns for Modeling the Change over Time Exemplified by
the Cell Tracking Ontology 16:00 – 16:30 L. Jansen Butterflies and Embryos: The Ontology of Temporally Qualified
Continuants
16:30 – 17:00 COFFEE
Session 3 17:00 – 18:00 Update Session
starting 20:00 DINNER
WEDNESDAY Oct 8, 2014 09:00 – 10:00 J. Fernández-Breis From Guidelines to Metrics: Practical Experiences and Community
Directions in Ontology Evaluation (KEYNOTE)
10:00 – 10:30 COFFEE
Session 4 10:30 – 11:00 M. Boeker A Proposal for an Ontology for the Tumor-Node-Metastasis
Classification of Malignant Tumors: a Study on Breast Tumors 11:00 – 11:30 A. Sojic Towards a Teenager Tailored Ontology: Supporting Inference
About the Obesity-Related Health Status
11:30 – 12:00 COFFEE
Session 5 12:00 – 12:30 H. Herre OntoStudyEdit: A New Approach for Ontology-Based Representa-
tion and Management of Metadata in Clinical and Epidemiological Research
12:30 – 13:00 D. Schober Ontology Usage in Omics Standards Initiatives: Pros and Cons of Enriching XML Data Formats with Controlled Vocabulary Terms
13:00 – 14:00 LUNCH
starting 14:00 OBML Workgroup Meeting Closing

v
Table of Contents Paper
ID Nr. of Pages
Keynote Abstract
From Guidelines to Metrics: Practical Experiences and Community Directions in Ontology Evaluation
A 1
Jesualdo Tomás Fernández-Breis
Regular Papers in alphabetic order according to last names of first authors
A Proposal for an Ontology for the Tumor-Node-Metastasis Classification of Malignant Tumors: a Study on Breast Tumors
B 5
Martin Boeker, Rita Faria and Stefan Schulz
OWL Patterns for Modeling the Change over Time Exemplified by the Cell Tracking Ontology
C 5
Patryk Burek, Nico Scherf and Heinrich Herre
Ontology for Molecular Structure D 6
Henson Graves
Butterflies and Embryos: The Ontology of Temporally Qualified Continuants E 5
Ludger Jansen and Niels Grewe
Entities with Genetic Information: An Initial Perspective from the Core Theme of Continuity and Change in Biology
F 6
Frank Loebe and Vinay K. Chaudhri
Ontology Usage in Omics Standards Initiatives: Pros and Cons of Enriching XML Data Formats with Controlled Vocabulary Terms
G 6
Daniel Schober, Michael Wilson, Daniel Jacob, Annick Moing, Gerhard Mayer, Martin Eisenacher, Reza M. Salek and Steffen Neumann
Towards a Teenager Tailored Ontology: Supporting Inference About the Obesity-Related Health Status
H 6
Aleksandra Sojic, Walter Terkaj, Giorgia Contini and Marco Sacco
OntoStudyEdit: A New Approach for Ontology-Based Representation and Management of Metadata in Clinical and Epidemiological Research
I 6
Alexandr Uciteli and Heinrich Herre

From Guidelines to Metrics. Practical Experiences andCommunity Directions in Ontology EvaluationJesualdo Tomas Fernandez-BreisDepartment of Informatics and Systems, Universidad de Murcia, IMIB-Arrixaca, CP 30100 Spain
ABSTRACTMany biomedical ontologies have now been developed, stimulated
by the increasing importance of biomedical ontologies in the scientificcommunity. Most ontology development efforts have required not onlythe participation of ontology engineers but also of domain experts.This should help the veracity of the domain knowledge, but notnecessarily the engineering of the ontology. In fact, the quality ofontologies varies widely due to absent integration of one or more ofsuch expert competencies (d’Aquin and Gangemi (2011)).
Measuring the quality of the resulting ontologies is necessaryin order to monitor to which extent and how good methodologies,practices and guidelines are being applied. In the last years, aseries of techniques and tools have been developed (see, forinstance, Gangemi et al. (2006); Obrst et al. (2007); Vandredic (2010))The Ontology Summit Communique 2013 (Neuhaus et al. (2013))identified that such tools and techniques are not widely used in thedevelopment of ontologies, what can lead to ontologies of poor qualityand, consequently, is an obstacle to the success of ontologies. Someontology construction methods have developed their own method forevaluating their ontologies, but such methods have not been used toevaluate ontologies developed by others. Indeed, there is a lack ofpractical experiences and scientific literature about the application ofgeneral evaluation methods to ontologies created applying differentmethodologies and guidelines.
In the last years, the ISO 25000 Software Product QualityRequirements and Evaluation standard (SQuaRE) ISO25000 (2005)has been adapted to ontology evaluation with the aim of providinga generic framework for objective, reproducible ontology evaluation.This framework, called OQuaRE, proposes the use of metrics toevaluate the quality characteristics of ontologies. OQuaRE has beensuccessfully applied to the evaluation of different types of ontologies(Duque-Ramos et al. (2013); Bennett et al. (2013)) and has beenable to draw conclusions similar to the ones from specific evaluationmethods, like the GoodOD guideline (Boeker et al. (2013); Duque-Ramos et al. (2014)). However, the evaluation by external expertsalso revealed areas of improvement (Duque-Ramos et al. (2013)),including the need for evaluating against clear requirements, which isalso a recommendation of the Ontology Summit Communique 2013.
The evolution from construction guidelines and methodologies toevaluation metrics requires a deep understanding of the possibilities
and limitations of metrics-based evaluation, as well as communityefforts, discussion and agreement. This is one of the big challengesin the ontology engineering field for the next years.Contact: [email protected]; http://webs.um.es/jfernand
Funding: This talk is possible thanks to the InternationalAssociation for Ontologies and its Applications. This researchhas been carried out thanks to the support of Spanish Ministryof Science and Innovation and the FEDER programme throughgrant TIN2010- 21388-C02-02, and thanks to the Fundacion Senecathrough grant 15295/PI/10.
REFERENCESBennett, M., Suarez-Figueroa, M.C., Poveda-Villalon, M., Fernandez-Breis, J.T.,
Duque-Ramos, A., Tartir, S. (2013). Evaluation of OOPS!, OQuaRE and OntoQAfor FIBO Ontologies. Ontology Summit 2013.
Boeker, M., Jansen, L., Grewe, N., Rohl, J., Schober, D., Seddig-Raufie, D., andSchulz, S. (2013). Effects of guideline-based training on the quality of formalontologies: A randomized controlled trial. PLOS One, 8(5), e61425.
d’Aquin, M. and Gangemi, A. (2013). Is there beauty in ontologies?. Applied Ontology3: 165-175.
Duque-Ramos, A., Fernandez-Breis, J. T., Iniesta, M., Dumontier, M., Aranguren,M. E., Schulz, S., Aussenac-Gilles, N., and Stevens, R. (2013) Evaluation of theOQuaRE framework for ontology quality, Expert Systems with Applications, 40(7),2696-2703.
Duque-Ramos, A., Boeker, M., Jansen, L., Schulz, S., Iniesta, M., and Fernandez-Breis, J. T. (2014). Evaluating the good ontology design guideline (GoodOD) withthe ontology quality requirements and evaluation method and metrics (OQuaRE).PLOS One, 9(8), e104463.
Gangemi, A., Catenacci, C., Ciaramita, M., and Lehmann, J. (2006). Modellingontology evaluation and validation. European Semantic Web Conference, pages140–154.
ISO (2005). ISO/IEC 25000:2005, Software Engineering - Software Product QualityRequirements and Evaluation (SQuaRE) - Guide to SQuaRE (ISO/IEC 25000),Geneva, Switzerland: International Organization for Standardization.
Neuhaus, F., Vizedom, A., Baclawski, K., Bennett, M., Dean, M., Denny, M.,Gruninger, M., Hashemi, A., Longstreth, T., Obrst, L., Ray, S., Sriram, R. D.,Schneider, T., Vegetti, M., West, M., and Yim, P. (2013). Towards ontologyevaluation across the life cycle the ontology summit 2013. Applied Ontology, 8(3),179–194.
Obrst, L., Ceusters, W., Mani, I., Ray, S., and Smith, B. (2007). The evaluation ofontologies. In Semantic Web, pages 139–158. Springer US.
Vrandecic, D. (2010). Ontology Evaluation. Ph.D. thesis, Institute of AppliedInformatics and Formal Description Methods AIFB.
1Paper A

A Proposal for an Ontology for the Tumor-Node-MetastasisClassification of Malignant Tumors: a Study on Breast TumorsMartin Boeker 1,*, Rita Faria 1,2, and Stefan Schulz 3
1 : Center for Medical Biometry and Medical Informatics, University Medical Center Freiburg, Germany2 : Department of Informatics, University of Minho, Braga, Portugal3 : Institute of Medical Computer Sciences, Statistics and Documentation, Medical University of Graz, Austria
ABSTRACT
Objectives: To (1) outline an ontology which represents theTumor-Node-Metastasis (TNM) classification for the staging ofmalignant tumors, and (2) to provide a full implementation ofthis TNM ontology for the TNM classification of breast tumors.
Methods: Our TNM ontology uses the Foundational Modelof Anatomy for anatomical entities and BioTopLite 2 as a do-main top-level ontology. The general rules for the TNM systemand the specific TNM classification for breast tumors (ICD-OC50) were represented as described in the literature. Additionalinformation was collected from daily practice in tumor documen-tation in the Comprehensive Cancer Center at the UniversityMedical Center Freiburg, Germany.
Results: The TNM was represented as an information artifactwhich consists of single representational units. Correspondingto every representational unit, tumors and tumor aggregateswere defined. Tumor aggregates consist of the primary tumorand (if existent) of infiltrated regional lymph nodes and distantmetastases. The different codes for T, N, and M are dependenton the location and certain qualities of the primary tumor, theinfiltrated regional lymph nodes and the existence of distantmetastases.
Conclusion: This work presents a first version of the TNM On-tology which represents the TNM system for the description ofthe anatomical extend of malignant tumors which is one of themost important tools in clinical oncology. The presented workis already sufficient to show its representational correctnessand completeness as well as its applicability for classificationof instance data. This work provides a foundation for a TNMOntology.
Contact: [email protected]
1 INTRODUCTION
The clinical and pathological staging of malignant tu-mors is one of the most important procedures in the
*to whom correspondence should be addressed
diagnosis of cancer patients to assess the prognosis ofthe patient and to determine the necessary treatment.The staging procedure compiles several clinical andpathological parameters: the location and the size ofthe primary tumor, the location and the number of theinfiltrated regional lymph nodes, and the existence ofdistant metastases.
By far, the most important system to unambigu-ously code the staging information is the Tumor-Node-Metastasis (TNM) classification (Sobin, Gospodarowicz,and Wittekind 2009) for malignant tumors of the Unionfor International Cancer Control (UICC)1. Despite its im-portance, there has not been developed a version of theTNM in a formal logic based language so far. A formalrepresentation of the TNM classification would provideseveral advantages over its natural language form.
An advantage of a formalized TNM ontology wouldbe the enhanced support for the development and re-finement of the TNM. The taxonomic structure and theaxiomatic description of a formalized TNM would makeexplicit the complex natural language descriptions. Thiswould help decompose the text descriptions into all theirdefining criteria. It would also help detect errors andinconsistencies in the definitions of the TNM stages forthe different tumor entities which frequently occurrede.g. due to overlapping criteria (non-disjoint definitions)or non-exhaustive definitions, which resulted in cases oftumors for which no code was applicable.
Additionally, logical inconsistencies and coding prob-lems due to overcomplexity could be detected earlier bydescription logic reasoning. The TNM ontology couldbe further used for automatic classification of instancedata from clinical databases on a sound and standard-ized logical basis.Advanced retrieval and querying toolswould benefit from the TNM ontology. For these usecases, a formalized TNM version could constitute a uni-fied source for provider of clinical documentation andanalysis tools.
1. http://www.uicc.org
1Paper B

Boeker et al.
With this work we want to close the gap of a missingformal representation by outlining and prototyping aTNM ontology (TNMO).
The objectives of this work are (1) to outline an ontologythat represents the TNM classification for the staging ofmalignant tumors, and (2) to provide a full implementa-tion of this TNM ontology for the TNM classification ofmalignant breast tumors.
1.1 The TNM classification
The UICC published the first edition of the TNM codingsystem of the anatomic extent of disease (EOD) in 1968.Since then, the system has undergone several revisionsand arrived in 2009 at the 7th edition. The objectives ofthe TNM classification are six-fold. It supports treatmentplanning, prediction of outcomes (prognosis), evaluationof treatment results, exchange of information betweendifferent participants in the treatment process, continuingresearch in malignant diseases, and cancer control (Sobin,Gospodarowicz, and Wittekind 2009; Webber et al. 2014)
The TNM coding procedure requires a high degreeof both domain knowledge and experience in tumordocumentation. Even documentation experts frequentlyengage in discussions about how a given case should becoded correctly. This is mainly due to the development ofthe TNM classification as an evolutionary process (Web-ber et al. 2014) which has to account for the huge amountof new scientific insights in tumor prognosis and thedependency of therapeutic effects on tumor stage. Con-trolled by medical experts, TNM’s underlying structurehas become more and more complex over the years.
Dependent on the location of the primary tumor, thethree parts of the code (T, N, and M) represent differentaspects of a tumor. T describes size and sometimes infil-trative level of the primary tumor, N describes infiltratedregional lymph nodes, and M distant metastases. T andN usually provide three to four levels with increasingseverity, viz. T0–T3 and N0–N3, respectively. For thedistant metastases, there is only a binary classificationinto M1 (evidence) an M0 (no evidence).
The results from the clinical assessment have to be accu-rately discerned from the pathological assessment dueto their different meanings and evidence levels. Thisdistinction is symbolized by a prefix c (clinical) and p(pathological) for most primary tumor locations.
Many users of the TNM classification have problemswith the correct coding or – on the other side – withthe interpretation of codes. The classification of thedifferent primary tumor locations differs to the sameextend as the underlying diseases. As a consequence,
even expert coders resp. physicians in one organ systemmight encounter difficulties in the correct application orinterpretation of the TNM to a different organ system.
Besides the complex semantics of the “main” TNM, aseries of additional symbols exists, which might havelargely different meanings in the different tumor loca-tions. Prefixes, suffixes, and certainty factors increasethe confusion, e.g. for carcinoma in situ the suffix “is”has to be used (Tis). With the possibility to always usea code of “X” if the underlying clinical or pathologicalsituation provides incomplete information, inaccurateand incomplete code assignments become widespread(MX for “no statement on metastases possible”).
2 METHODS
Our TNM ontology uses the Foundational Model of Anatomy(Rosse and Mejino Jr. 2003) for anatomical entities and BioTo-pLite 2 as a domain top-level ontology (Beißwanger et al. 2008;Schulz and Boeker 2013) Tailored for the biomedical domainand based on description logics (Baader et al. 2007) BioTopLite2 (BTL2) provides upper-level types both for general categorieslike Material object, Process, Information object, Quality etc.,as well as constraints on all of them, using a set of sixteencanonical relations, partly derived from the OBO Relation On-tology (RO) (Smith et al. 2005) They constrain each categoryby means of a set of general class axioms. It also contains otheraxioms such as relationship chains, as well as existential andvalue restrictions at the level of class definitions. Thus, the build-ing of domain ontologies under BTL2 heavily constrains thefreedom of the ontology engineer, which is fully intended asthis guarantees a higher predictability of the domain ontologiesproduced under BTL2.
The general rules for the TNM system and the specific TNMclassification for Breast Tumors (ICD-O C50) were representedas described in Sobin, Gospodarowicz, and Wittekind (2009)
3 RESULTS
The TNM ontology for breast tumors has the descriptionlogic expressivity of SRI . Beyond the included defini-tions of BioTopLite 2, it consists of 550 axioms, 341logical axioms, and 198 classes. It defines 287 subClas-sOf and 51 EquivalentTo axioms, it does not define ownobject properties.
3.1 Representational units of the TNMO
The representation of the TNM system is decomposedin representational units T, N and M and the locationof the primary tumor. Thus, for every existing codeTn, Nn and Mn in combination with a specific organthere exists one tnmo:RepresentationalUnit which is an
2 Paper B

btl2:InformationObject. E.g. every TNM code for breastcancer is represented by a separate class. In the remain-ing text, the namespace of the TNM ontology is notshown:
MammaryGlandTNM_pN2b subClassOfRepresentationalUnitInTNMForMammaryGlandTumors
These classes are related to their patho-anatomical relataof type PrimaryTumor or TumorAggregate by the relationbtl:represents:
MammaryGlandTNM_pN2b subClassOfRepresentationalUnitInTNMForMammaryGlandTumors andbtl2:represents only
TumorOfMammaryGlandWith-ClinicalDetectedMetastaticInternalLymphNodes-AndWithoutMetastaticAxillaryLymphNodes
3.2 Representation of the primary tumor
The primary tumor is represented as PrimaryTumor, asubclass of PathologicalAnatomicalStructure. The char-acteristics relevant for the representational unit T of theTNM classification system are represented as qualitiesof PrimaryTumor. For breast tumors the length of thetumor, the quality of the tumor pathology (inflammatory,extending to the chest wall, ulcerating), and the qualityof the tumor confinement with respect to neighboring or-gans (confined or invasive) are important. PrimaryTumoris directly related to the corresponding representationalunit:
NonInvasiveTumorOfMammaryGland EquivalentToTumorOfMammaryGland and(btl2:isBearerOf some (Confinement and
(btl2:projectsOnto someConfinedConfinementValueRegion)))
SmallNonInvasiveTMG EquivalentToNonInvasiveTumorOfMammaryGland and(btl2:isBearerOf some (PhysicalLength and
(btl2:projectsOnto someLengthValueBelow2cm)))
SmallNonInvasiveTMG subClassOfbtl2:isRepresentedBy only
(MammaryGlandTNM_T1 orMammaryGlandTNM_pT1)
3.3 Representation of regional lymph nodes
The most complex part of the TNM classification ofmost primary tumor locations is the interpretation ofthe representational unit N, which codes to which ex-tent the primary tumor infiltrated regional lymph nodes.The anatomical structure of the infiltrated lymph nodes
around the mammary gland was modeled according toclinical anatomical conventions:
MetastaticAxillaryMammaryLymphNode subClassOfMetastaticLymphNode and(btl2:includes some
MetastasisOfTumorOfMammaryGland) and(btl2:isIncludedIn some
(LevelIAxillaryLymphNode orLevelIIAxillaryLymphNode orLevelIIIAxillaryLymphNode))
To further differentiate regional lymph node metastasesof breast tumors, the pathological adherence of the lymphnodes to the surrounding tissue has to be considered:
MovableMetastaticLateralAxillaryLymphNode EquivalentToMetastaticAxillaryMammaryLymphNode and(btl2: isBearerOf some
(Adherence and(btl2:projectsOnto some
MovableAdherenceValueRegion)))
The clinical significance of different patterns of infil-trated lymph nodes for prognosis and treatment has led toa complex structure. For the breast, generally only infil-trated lymph nodes around the breast gland on the sameside of the primary tumor (ipsilateral) are consideredto be regional lymph node metastases. To define re-gional lymph node metastases, the aggregate of primarytumor and infiltrated lymph nodes around the breast (Tu-morAggregate) has to be considered as one (composite)entity:
TumorOfMammaryGlandAggregate EquivalentToTumorAggregate and(btl2:hasPart some
TumorOfMammaryGland)
TumorOfMammaryGlandWith-MovableMetastaticAxillaryLymphNodes EquivalentToTumorOfMammaryGlandAggregate and(btl2:hasPart some
MovableMetastaticLateralAxillaryLymphNode)
TumorOfMammaryGlandWith-MovableMetastaticAxillaryLymphNodes subClassOf(TumorOfLeftMammaryGlandWith-
LeftLymphNodesMetastasis orTumorOfRightMammaryGlandWith-
RightLymphNodesMetastasis)
TumorOfLeftMammaryGlandWith-LeftLymphNodesMetastasis EquivalentTo(TumorOfMammaryGlandAggregate and((btl2:hasPart some TumorOfLeftMammaryGland) and(btl2:hasPart some
((AxillaryLymphNode or InfraclavicularLymphNode orInternalLymphNode or SupraclavicularLymphNode) and(btl2:hasPart some Metastasis) and(btl2:isIncludedIn some LeftBodyPortion))))
3Paper B

Boeker et al.
TumorOMammaryGlandWith-MovableMetastaticAxillaryLymphNode
TumorOfLeftMammaryGlandWith-LeftLymphNodeMetastasis
TumorOfRightMammaryGlandWith-RightLymphNodeMetastasis
� InfraclavicularLymphNode
AxillaryLymphNode
SupraclavicularLymphNode
InternalMammaryLymphNode
�
hasPart
Metastasis
LeftBodyPortionisIncludedIn
hasPart
MovableMetastaticLymphNode
MammaryGlandTNM_N1
hasPartisRepresentedBy
only
only
represents
TumorOfLeftMammaryGland
hasPart
TumorOfMammaryGlandTumorOfMammaryGlandAggregatehasPart
MalignantAnatomicalStructureTumorAggregatehasPart
Figure 1. Graph of the patho-anatomical structures which are represented by an N1 representational unit of the TNM for breasttumors.
TumorOfMammaryGlandWith-MovableMetastaticAxillaryLymphNodes subClassOf
(btl2:isRepresentedBy onlyMammaryGlandTNM_N1)
3.4 Representation of distant metastases
For the representational unit M of the TNM classificationsystem the existence of distant metastases is evaluated.Their definition corresponds to the definition of regionalinfiltrated lymph nodes :
TumorOfMammaryGlandWithDistantMetastasis EquivalentToTumorOfMammaryGlandAggregate and(btl2:hasPart some
(Metastases and(not (btl2:isIncludedIn some
(AxillaryLymphNode orInfraclavicularLymphNode orInternalLymphNode orSupraclavicularLymphNode)))))
TumorOfMammaryGlandWithDistantMetastasis subClassOf(btl2:isRepresentedBy only
(MammaryGlandTNM_M1 orMammaryGlandTNM_pM1)
The TNM Ontology for breast tumors can be downloadedfrom http://purl.org/tnmo/tnmo.owl.
4 DISCUSSION
The TNM is a globally accepted system to describe theanatomical extent of malignant tumors (Sobin, Gospo-darowicz, and Wittekind 2009; Webber et al. 2014)Although the TNM is of high importance for the stagingof tumor diseases, to the knowledge of the authors, thereexists no formal representation of the TNM so far. Withthis work, the authors provide a first outline of a TNMontology and a prototypical implementation on the TNMfor breast cancer.
Preliminary work shows that it is possible to classify in-stance data with our ontology. In addition, our examplesalready can serve to make explicit where the semanticsof the breast tumor TNM is difficult to comprehend orambiguous for their clinical users.
Over time, the TNM classification has developed intoa coding system which had to accommodate both thepragmatics of coding and representational accuracy. Theliterature on ambiguities and difficulties of TNM in prac-tice is abundant. The discussion of the TNM for breasttumors illustrates the dilemma of its maintainers (Barrand Baum 1992; Gusterson 2003; Güth et al. 2007) Theyhad to account for the rapid progression of scientificknowledge on tumors and to keep it usable at the sametime: new versions of TNM were already outdated whencompared with new scientific insights. On the other hand,
4 Paper B

it became increasingly complex, with a negative impacton usability by non-expert and expert documentationstaff and physicians.
This study is limited in so far as we provide here a firstversion of the TNM Ontology (TNMO) which has beendeveloped only for a single tumor location (breast tu-mors), which is, however, one of the most complex andbest represented tumor entities in the TNM classificationsystem. Therefore, we believe that this first version isalready as far complete and stable to be transferred toother organ system.
Until now, it has only been possible to preliminarilydemonstrate that it is possible to classify instance datawith the TNMO for breast cancer. A systematic empir-ical evaluation of the completeness, exhaustivity andcorrectness of the TNMO has not been conducted so far.
Due to the nature of the domain and the rich top-levelontology employed, the resources needed to classify theontology are considerable. To circumvent performanceissues with the TNMO, we will provide the TNMO inmodules for different organ systems. Thus, the user canimport only the modules of interest into his applicationcontext.
Future research must evaluate the presented prototypeontology (1) by implementing further tumor locations,and (2) by application in clinical classification and re-trieval scenarios. We will provide the formalization ofTNM for other primary tumor locations in a modularway, so that users can select which part of the TNMOthey would like to use. In this way, we hope to reduce thecomputational resources already needed to a minimum.
In conclusion, this work presents a first version of theTNM ontology (TNMO) which represents the TNMsystem for the description of the anatomical extend ofmalignant tumors which is one of the most importanttools in clinical oncology. The presented work is alreadysufficient to show the representational correctness andcompleteness of the TNMO as well as its applicabilityfor classification of instance data. This work provides afoundation for a TNM ontology.
5 REFERENCES
Baader, Franz, Diego Calvanese, Deborah L. McGuinness, DanieleNardi, and Peter F. Patel-Schneider. 2007. The Description LogicHandbook: Theory, Implementation, and Applications, 2nd Edi-tion. 2. Cambridge University Press.
Barr, L. C. and M. Baum. 1992. “Time to abandon TNM staging ofbreast cancer?” The Lancet, Originally published as Volume 1,Issue 8798, 339 (8798) 915–917.
Beißwanger, Elena, Stefan Schulz, Holger Stenzhorn, and Udo Hahn.2008. “BioTop: An Upper Domain Ontology for the Life Sciences- A Description of its Current Structure, Contents, and Interfacesto OBO Ontologies.” Applied Ontology 3 (4) 205–212. http : / /www.imbi.uni- freiburg.de/ontology/biotop/publications/ao08.pdf.
Gusterson, B. A 2003. “The new TNM classification and micrometas-tases.” The Breast, 8th International Conference on Primary Ther-apy of Early Breast Cancer, St Gallen, Switzerland, 12 (6) 387–390.
Güth, Uwe, Dorothy Jane Huang, Wolfgang Holzgreve, Edward Wight,and Gad Singer. 2007. “T4 breast cancer under closer inspection:A case for revision of the TNM classification.” The Breast 16 (6)625–636.
Rosse, Cornelius and José L.V. Mejino Jr. 2003. “A reference ontologyfor biomedical informatics: the Foundational Model of Anatomy.”Journal of Biomedical Informatics 36 (6) 478–500.
Schulz, Stefan and Martin Boeker. 2013. “BioTopLite: An Upper LevelOntology for the Life Sciences. Evolution, Design and Appli-cation.” In INFORMATIK 2013. Ontologien in den Lebenswis-senschaften. Edited by Hornbach, Matthias, vol. p-220, 1889–1899. Lecture Notes in Informatics. Bonn: Gesellschaft für Infor-matik.
Smith, Barry, Werner Ceusters, Bert Klagges, Jacob Köhler, AnandKumar, Jane Lomax, Chris Mungall, Fabian Neuhaus, Alan L.Rector, and Cornelius Rosse. 2005. “Relations in biomedicalontologies.” Genome Biology 6 (5) R46.
Sobin, Leslie H., Mary K. Gospodarowicz, and Christian Wittekind.2009. TNM Classification of Malignant Tumours. 7. Chichester,West Sussex, UK ; Hoboken, NJ John Wiley & Sons.
Webber, Colleen, Mary Gospodarowicz, Leslie H. Sobin, ChristianWittekind, Frederick L. Greene, Malcolm D. Mason, CarolynCompton, James Brierley, and Patti A Groome. 2014. “Improv-ing the TNM classification: Findings from a 10-year continuousliterature review.” International Journal of Cancer 135 (2) 371–
378.
5Paper B

OWL Patterns for Modeling the Change over Timeexemplified by the Cell Tracking OntologyPatryk Burek 1,∗, Nico Scherf 2 and Heinrich Herre 1∗
1Institute for Medical Informatics, Statistics and Epidemiology, University of Leipzig.2Institute for Medical Informatics and Biometry, TU Dresden.
ABSTRACTIn recent years cell tracking experiments are gaining an increa-
sing interest. The key aspect of developing an ontology suitable forthe annotation of the results of cell tracking experiments is the repre-sentation of cells’ change over time. Yet, there is no golden hammerapproach for modeling the change of enduring objects such as cells.In the current paper we review the Web Ontology Language (OWL)patterns for representing the change of enduring objects.
1 INTRODUCTIONCell tracking is a vital field of research in biology and experimen-tal medicine covering a broad spectrum of analyses, ranging frommigration patterns in cell cultures to comprehensive genealogicalinformation for developing organisms. The experiments use motionpictures of cell cultures. The gained material is analysed manu-ally, automatically or semi-automatically [Scherf et al. (2013)]. In[Burek et al. (2010)] authors reported work in progress on the frame-work for analysing, specifying and annotating results of experimentsand simulations in the field of stem cell research. The core compo-nent of the framework is an ontology formalized in Web OntologyLanguage [W3C OWL Working Group (2012)], which enables theannotation of pictures taken during time lapse experiments with theinformation obtained during analysis.
All information is organized into pedigree-like data structures cal-led cellular genealogies. In a cellular genealogy the founder cellrepresents the root and the progeny is arranged in the branches ofthe tree. In such a framework a cell is perceived as a spatially andtemporally extended object. The existence of such a cell is tempo-rally restricted by the generating division of the paternal cell and bydeath or by the terminating division that generates the descendingdaughters [Burek et al. (2010)]. Cells observed in a cell trackingexperiment are dynamic entities, i.e. they change their location, theirshape, they undergo transformations etc. Therefore, the key requi-rement for an ontology of cellular genealogies is the representationof the change of individual cells over time. In particular,in the cur-rent paper we explore a way for representing the change of shape orlocation of a cell.
In frames of the work on the ontology of cellular genealogies weinvestigated several patterns for the representation of these changes.The current paper reports on those patterns. Although the patternsare discussed in context of cellular genealogies we believe thattheir application is far more generic, since the representation of thechange of quality values is a common challenge in many (if not all)domains. Consider, for instance, the electronic patient record, whichneeds a proper representation of the change of patient’s vital signs.
∗to whom correspondence should be addressed
2 PRELIMINARIES: TERMINOLOGICALCLARIFICATIONS AND PROBLEM STATEMENT
In the current paper we do not make many ontological restrictionson the categories utilized for the development of ontologies. Thebroad spectrum of the top level categories, which can be utilized forknowledge representation in general and for ontology modeling inparticular, can be found in the literature devoted to top level ontolo-gies (e.g. GFO [Herre et al. (2006)], DOLCE [Masolo et al. (2003)],BFO [Spear (2006)]).
The analysis reported in the current paper is based on the follow-ing common-sense assumptions:• Entities such as cells endure through time spans called their
lifetime. We call those enduring entities endurants.
• Endurants such as cells possess characteristics depicting them.Those characteristics, called in the current paper qualities,are expressed in natural and artificial languages by means ofsyntactic elements such as adjectives / adverbs, or attributes/properties, respectively(p. 30, [Herre et al. (2006)]). Exem-plary qualities of cells are shape and location. Qualities havevalues as for instance cell’s shape could take a value of oval orellipse.
• A characteristic can change its value over time. For instance,the shape of a cell can change, i.e the value of a shape qualityat two different time points may differ.
Based on the above assumptions and the terminological clarifica-tions the problem in the current paper can be formulated as follows:How to model in OWL the change of an endurant’s quality valuesover time?
We do not believe that there is a single approach, which worksfor all cases where qualities are modeled in OWL ontologies. Forthis reason, the goal of the current paper is to review the possiblepatterns. Furthermore, these patterns are verified against our specificuse case.
3 PATTERNS FOR MODELING OF QUALITIESIn the current section we review several OWL patterns, which canbe utilized for modeling of the change of quality values of enduringentities. The patterns are depicted with diagrammatic notation. Theexemplary applications of patterns for annotating experiment resultsutilize the Turtle notation [Beckett et al. (2012)].
3.1 Pattern 1: OWL PropertiesFigure 1 presents a straightforward approach for modeling qualitiesin OWL by means of OWL properties. On figure 1 a shape of a cell
1Paper C

Patryk Burek 1,∗, Nico Scherf 2 and Heinrich Herre 14
Fig. 1. Pattern 1: Quality assignment modeled as OWL property.
is modeled by owl:ObjectProperty named has shape, linkinga class cell with a class shape 1.
Utilizing this pattern, an individual cell and its shape can bedefined in turtle notation as follows:
:oval a :Shape .:my_cella :Cell ;:has_shape :oval .
The advantage of pattern 1 is its simplicity and the limited numberof entities used. Unfortunately, the pattern does not allow represen-ting the change of quality value over time as for instance the changeof the shape of a cell from oval to ellipse.
3.2 Pattern 2: Time-indexed OWL PropertiesIn order to support the modeling of the changes of the quality valuesover time one can extend pattern 1 by adding the temporal indexto the value assignment. Figure 2 presents a class cell linked with aclass shape by means of two distinct owl properties: has shape at t1and has shape at t2 denoting that a cell has a shape at a given timet1 and t2, respectively. Utilizing that pattern one can easily modelthe change of the shape of a cell:
:oval a :Shape .:ellipse a :Shape .:my_cell
a :Cell ;:has_shape_at_t1 :oval ;:has_shape_at_t2 :ellipse .
This approach is simple and suites the goal. It works well espe-cially in situations, where the number of time indexes is limited orthere is some idiosyncratic time index, as for instance G2 check-point and Metaphase checkpoint in the cell cycle development. Inthat scenario the change of shape can be modeled simply by meansof two distinct OWL properties: has shape at G2 checkpoint andhas shape at Metaphase checkpoint.
3.3 Patterns 3 and 4: Reified Quality AssignmentUnfortunately, pattern 2 is not applicable to our use case, since incell tracking experiments the number of observations (photos) ishigh and can reach hundreds for a single experiment. Additionally,time indexes are not known upfront. Therefore, the applicationof pattern 2 would require the adjustment of the ontology foreach experiment. Moreover, it would result in hundreds of qualityassignment properties.
1 For the sake of simplicity of the examples presented in the current paperwe model all qualities as OWL classes and their values as instances. Cle-arly, in real life systems the different means can be utilized for that purposestarting e.g. the application of OWL datatype properties for simple types.
Fig. 2. Pattern 2: Quality assignment modeled as time-inexed OWL pro-perty.
Fig. 3. Pattern 3: Quality assignment modeled as time-indexed OWL class.
Fig. 4. Pattern 3 applied for modeling of a cell with multiple qualities.
Pattern 3 depicted on figure 3 overcomes those limitations. Here,in contrast to patterns 1 and 2, a quality assignment is modelednot as owl:ObjectProperty alone but as a combination ofowl:ObjectProperty and owl:Class. An object propertyhas shape links a Cell class with a ShapeAssignment class. Shape-Assignment represents a quality assignment at some time and hastwo properties: has value and at time. The former specifies a valueof a quality i.e. a specific shape, whereas the latter specifies thetemporal location 2 3.
2 For the purpose of the current paper the class Time is considered as anabstraction of the time parameter and no specific time ontology is assumed.In the GFO-like understanding of time the class Time can be consideredeither as time interval or time point/citegfo3 In a slightly different variant of the pattern instead of property has shape ageneric property has quality could be used. The has quality property wouldlink a Cell class not with ShapeAssignment, but with a generic QualityAssi-gnment class. That generalization of the handling of qualities minimizes thenumber of classes and properties needed in case of diverse qualities. How-ever, it does not influence the discussed patterns as such when it comes torepresenting the change of quality value over time. Therefore, in the currentpaper we will not use it.
2 Paper C

OWL Patterns for Modeling the Change over Time
Fig. 5. Pattern 4: Quality assignments temporally ordered.
The application of the pattern for the annotation of a singlecell with two distinct shapes at two different time points looks asfollows:
:oval a :Shape .:ellipse a :Shape .:t1 a :Time .:t2 a :Time .:my_cell
a :Cell ;:has_shape [
a :ShapeAssignment ;:has_value :oval;:at_time :t1] ;
:has_shape [a :ShapeAssignment ;:has_value :ellipse;:at_time :t2] .
Pattern 3 overcomes the limitations of patterns 1 and 2 reported atthe beginning of the current section. In pattern 3 time-indexed qua-lity value assignments are represented as instances only so even insituations with the high number of time-indexed value assignmentsthe number of classes in the ontology remains low.
On the other hand, the model introduces additional OWL clas-ses and OWL properties for representing time-indexed qualityascriptions, which, unfortunately reduces its lucidity.
In many situations not the time index of quality assignmentis relevant but only temporal order of quality assignments. Thismay also be true for some cell tracking experiments. In that situ-ation pattern 3 can be simplified and as presented on figure 5the property at time and the class Time can be replaced with pro-perty next assignement establishing a temporal order of qualityassignments.
3.4 Pattern 5: PresentialsTypically in cell tracking experiments at a single time point morethen one quality of a cell is observed, for instance, shape and loca-tion. In such a case, as presented on figure 4, the application ofpattern 3 results in a model with redundant at time time indexes.
That limitation can be fixed with pattern 5 based on the conceptof presentials introduced in GFO [Herre et al. (2006)]. In GFO apresential is an entity, being wholly present at a single time point.For instance, a cell observed at a single time point would be consi-dered as a presential cell. A presential may have multiple qualitiesassigned, all present at the same time point as the presential. A pre-sential is a snapshot of a time extended entity - a cell observed at asingle time point can be considered as a snapshot of a time extendedcell. The application of the presential pattern is presented on figure6.
Fig. 6. Pattern 5: Reified Presentials.
The annotation of an individual cell with the presential patternapplied would look as follows:
:oval a :Shape .:ellipse a :Shape .:location_1 a : Location .:location_2 a : Location .:t1 a :Time .:t2 a :Time .:my_cell
a :Cell ;:has_snapshot :my_presential_cell_1 ;:has_snapshot :my_presential_cell_1 .
:my_presential_cell_1a :PresentialCell ;has_shape :oval ;located_at :location_1 .
:my_presential_cell_2a :PresentialCell ;has_shape :ellipse ;located_at :location_2 .
The pattern, in contrast to pattern 4, reduces the number of timeindex links needed for representing multiple qualities. Additionally,it avoids the reification of quality assignments, which are not com-monly used. This, in turn, enables the reuse of quality assignmentlinks from external ontologies.
3.5 Pattern 6 and 7: Representing the Qualities ofEnduring Entities
In cell tracking experiments, basing on the sequences of observati-ons of presential cells and their qualities the qualities of the enduringcells are deduced. For instance, if a cell is observed to have ashape of oval over the sequence of observations taken at time pointst1,t2,..,tn then typically one can deduce that the cell has shape ovalin time interval (t1,tn). If, one is willing to store that informationexplicitly in his knowledge base then pattern 5 would not be suf-ficient and must be extended in a way that supports representingqualities of enduring entities.
For that purpose we propose to combine pattern 5 with pattern 2as it is presented on figure 7.
The application of the pattern for representing of two observati-ons of a cell’s shape at t1 and t2 is presented below. Not only twoobservations are modeled but likewise is, the deduced out of them,quality assignment in (t1, t2).
:oval a :Shape .:t1 a :TimePoint .:t2 a :TimePoint .
3Paper C

Patryk Burek 1,∗, Nico Scherf 2 and Heinrich Herre 15
Fig. 7. Pattern 6: Qualities of Presentials and Endurants
:t1_t2 a :TimeInterval .:my_cell
a :Cell ;:has_snapshot :my_presential_cell_1 ;:has_snapshot :my_presential_cell_2 .
:my_presential_cell_1a :PresentialCell ;has_shape :oval .
:my_presential_cell_2a :PresentialCell ;has_shape :oval .
:my_cella :Cell ;:has_shape [
a :ShapeAssignment ;:has_value :oval;:at_time :t1_t2] .
Here, multiple qualities observed at a single point are gluedinto a presential cell. That pattern, however, is not adopted forrepresenting the assignment of qualities to enduring cells.
The drawback of that approach is the increasing complication ofthe model as the number of qualities is growing. In order to limitthat number one could abstract the presential pattern to handle notonly presentials but also time extended parts of endurants. Ado-pting that approach to our domain of interest we reify not onlypresential cells but also the time extended temporal parts of cells(e.g. cell having a shape oval over interval (t1,t2)). As presented onfigure 8 we introduce an OWL class CellTemporalParticle denotingan entity having some qualities (e.g. shape and location) at sometemporal location (e.g. a time point or time interval).Cell temporalparticle covers both presentials and interval-indexed temporal partsof endurants. A particle can be decomposed into fine grained parti-cles with has temporal particle property. A cell (an endurant) itselfis considered as a particle as well.
The cell observed at two time points t1, t2, being oval over theinterval (t1,t2) can be defined with pattern 7 as follows:
:oval a :Shape .:t1 a :TimePoint .:t2 a :TimePoint .:t1_t2 a :TimeInterval .
Fig. 8. Pattern 7: Reified Temporal Particle
:my_cella :Cell ;:has_temporal_particle :
my_temporal_particle_1_2 .:my_temporal_particle_1_2
a :CellTemporalParticle ;:has_temporal_particle :
my_presential_cell_1 ;:has_temporal_particle :
my_presential_cell_2 ;: has_shape :oval ;:at_time :t1_t2 .
:my_presential_cell_1a :PresentialCell ;has_shape :oval .
:my_presential_cell_2a :PresentialCell ;has_shape :oval .
4 RELATED WORKThe topic of ontology design patterns is a well recognized andnumerous patterns have been already documented, see e.g. [Onto-logy Design Patterns (2014)]. However, according to our bestknowledge there is no literature presenting the overview of thepatterns for representing the change of quality values over time.Nevertheless, some of the patterns for representing n-ary relations,addressed by [Hayes et al. (2006)], can be utilized for that task- the patterns 3 and 4 presented in the current paper are inspiredrespectively by pattern 1 and 2 of Hayes and Welty.
The change of quality value over time is addressed by some of toplevel ontologies, e.g. in [Masolo et al. (2003)] are introduced axiomsfor time indexed quality assignments called there temporal quale.Unfortunately, the OWL serialization of DOLCE [Gangemi (2014)]does not contain constructs for representing change of qualities ofendurants over time.
The discussed problem seems to be so common that we expectthe choices, which brought us to the discussed patterns, being thecommon-day practice of many ontology engineers working on real-life ontologies. Therefore, we expect that the presented patterns canbe met in many ontologies, yet we have not found any literaturedocumenting their application and discussing their pros and cons.
4 Paper C

OWL Patterns for Modeling the Change over Time
5 CONCLUSIONS AND FUTURE RESEARCHThe current paper addresses the problem of modeling the change ofquality values over time. The paper lists several patterns and demon-strates their application to the domain of cell tracking experiments.
The patterns are dedicated for OWL yet the underlying conce-ptual choices are of more generic nature and can be applied to othertechnologies and formalisms as well.
We also expect that the patterns could be applied not only to thechange of quality values, but also to other types of changes, whichhappen over time.
The patterns have been investigated in context of developinga cell tracking ontology [Burek et al. (2010)]. Nevertheless, thepatterns are domain-independent and, since the change of qualityvalues is common for many biomedical domains, we believe thatthe application of patterns covers many different domains.
REFERENCESNico Scherf, Michael Kunze, Konstantin Thierbach, Thomas Zer-
jatke, Patryk Burek, Heinrich Herre, Ingmar Glauche, and IngoRoeder. Assisting the machine paradigms for humanmachineinteraction in single cell tracking. In Hans-Peter Meinzer, Tho-mas Martin Deserno, Heinz Handels, and Thomas Tolxdorff,editors, Bildverarbeitung fr die Medizin, Informatik Aktuell,pages 116121. Springer, 2013.
Gangemi A. The DOLCE and DnS ontologies. Available at:http://www.loa.istc.cnr.it/ontologies/DOLCE-Lite.owl. Cited at:2014.
Hayes, P., Welty, C. Defining N-ary Relations on the SemanticWeb. W3C Working Group Note 12 April 2006, Available at:
http://www.w3.org/TR/swbp-n-aryRelations/.Burek P, Herre H, Roeder I, Glauche I, Scherf N, Loeffler M.
Towards a Cellular Genealogy Ontology In: H. Herre, R. Hoe-hndorf, J. Kelso, S. Schulz (eds.): 2nd Workshop of the GI-Fachgruppe ”Ontologien in Biomedizin und Lebenswissenschaf-ten (OBML)”, 09-10. September 2010 in Mannheim, Germany.Universitt Leipzig (2010), ISBN: ISSN 1610-7233
W3C OWL Working Group. OWL 2 Web Ontology LanguageDocument Overview (Second Edition) W3C Recommendation11 December 2012. Available at: http://www.w3.org/TR/owl2-overview/
Beckett, D., Berners-Lee, T., Prud’hommeaux, E., Carothers, TurtleTerse RDF Triple Language W3C Working Draft 10 July 2012.Available at: http://www.w3.org/TR/2012/WD-turtle-20120710/
Herre, H., Heller, B., Burek, P., Hoehndorf, R., Loebe, F., Micha-lek, H. 2006. General Formal Ontology (GFO): A FoundationalOntology Integrating Objects and Processes. Part I: Basic Pri-nciples (Version 1.0). Onto-Med Report, Nr. 8. Research GroupOntologies in Medicine (Onto-Med), University of Leipzig.
Spear A.D. Ontology for the 21st Century. An IntroductionWith Recommendations (BFO Manual). 2006. Available at:www.ifomis.org/bfo/documents/manual.pdf
Masolo C, Borgo S, Gangemi A, Guarino N, Oltramari A, Schnei-der L: WonderWeb Deliverable D17. The WonderWeb Libraryof Foundational Ontologies Preliminary Report. Trento: ISTC-CNR; 2003.
Ontology Design Patterns . org Available at:http://www.ontologydesignpatterns.org/, cited at: 2014
5Paper C

1
Ontology for Molecular Structure
Henson Graves
Algos Associates, Fort Worth, Texas
ABSTRACT
A common modelling problem for engineering, molecular
biology, and human anatomy is how to represent the de-
scription of conceptualized structures as axioms so that the
valid interpretations are the intended ones. This correspond-
ence is needed to ensure that analysis and automated rea-
soning about the model yields correct results about the in-
terpretations. The problem, which has not been solved be-
fore, is solved for models which conform to a specific graph-
ical template. A Structure model is embedded as an axiom
set which extends an axiomatic ontology. The characteristic
pattern for a structure model is decidable and model devel-
opment tools can check conformity. A structure axiom set
generated by a structure model represents implicit assump-
tions used in the modeling domain, transparently to the
model developer. The valid interpretations are proven to be
the intended ones. Formulae within the theory of a Structure
axiom set are decidable and there is a finite canonical mini-
mal interpretation. Additional axioms can exclude additional
components so that all realizations are isomorphic.
Key words: Ontology, Molecular Structure, SysML, topos
theory.
1 INTRODUCTION
A model, as engineers use the term, is a description of
something that exists, or a specification for something to be
built. Models, in this sense, are routinely used in molecular
science [Vil 2007], as well as engineering [Gra 2011] to
describe molecules that have specific structure. Structural
models include a graphical representation of the structure.
The graphical structure represents constituent concepts and
roles which describe components and component connec-
tions that realize the concept. A model may describe a pat-
tern or template for molecules, as well as a specific struc-
ture. Informally, a realization is an interpretation of the
model as individuals which conform to the model descrip-
tion. In a given context there may be many individuals
which conform to the description of the model. A modeling
domain often uses implicit assumptions, for example that an
atom cannot be both a hydrogen atom and a carbon atom.
As a result models often underspecify their intended realiza-
* 2829 Cantey Street, Fort Worth, Texas 76109
tions without explicit assumptions for the informal implicit
ones.
Models are used to analyze and answer questions about
model realizations. For example, one might want to know if
a molecule satisfying a description contains a carbon ring.
Direct observation may not be possible. To use a graphical
model to analyze realizations generally requires adding as-
sumptions so that the realizations correspond to the intended
ones. Does the model describe the intended realizations suf-
ficiently and only the intended ones. The intended realiza-
tions have the graphical structure of the model. Automated
reasoning offers the potential to answer questions about
realizations from models, but only if this correspondence
holds. Without the correspondence automated reasoning
may yield incorrect results.
For models which use the graphical structure template the
problem of embedding a structural model into an axiom set
where the interpretations are the intended ones is solved. A
Structure model is embedded as axioms which extend axi-
oms for a first order topos theory [Lam 1988]. Metalogic
provides a template for implicit axioms used in a domain.
Structure models are embedded as terms rather than as pred-
icates as is common in many logic embeddings. The graph-
ical model syntax is used to generate a Structure axiom set,
transparently to the model developer. For a structure axiom
set the interpretations can be proven to be the intended ones.
2 STRUCTURE DIAGRAMS
Models may be represented informally such as the 2-Amino
acid model in Figure 1. The diagram is a template for the
Paper D

2
Fig. 1. An Amino Acid structural description
structure of amino acids. An amino acid has ten compo-
nents, nine atoms where N, H, C, O are abbreviations for
nitrogen, hydrogen, carbon, and oxygen atoms, and R is a
placeholder referred to as a “substitutient". The lines repre-
sent bonding relationships. A diagram such as the one for
amino acids has many implicit assumptions. For example,
the atoms and bonds are all assumed to be distinct. This
model is a template in the sense R can be substituted for by
other molecules with a specific configurations such as gly-
cine.
Formal computer modeling languages used for structural
modeling have the advantage that syntactic correctness can
be checked by model development tools. Figure 2 illustrates
a model for water in the modeling language SysML [Fri
2006], and a 3D simulation generated from this model. Not
all of the information used to generate the simulation is
shown. SysML has a graphical syntax. The SysML model,
unlike the amino acid model uses two diagrams. These dia-
grams distinguish concepts and roles in a structural realiza-
tion. The upper diagram, called a BDD, describes part roles.
The lower diagram, called an IBD describes connection
roles. In the case of water there are three part roles in the top
diagram and two bonding roles in the lower diagram.
Fig. 2. A Water Molecule Model and interpretation
The rectangles in the two diagrams, called blocks in SysML,
correspond to classes in some other modeling languages.
The lines are called associations in SysML. Associations
have a source and target block. The blocks in the BDD are
Water, Hydrogen, and Oxygen. The rectangles in the IBD
have prefixes, for example, hasHydrogenAtom1:Hydrogen.
The association covalentbond is disambiguated and replaced
by two associations covalentbond1 and covalentbond2.
covalentbond1 has as its source hasOxygenAtom:Oxygen
and target hasHydrogenAtom1:Hydrogen.
The model in Figure 2 comprising both diagrams is a di-
rected graph whose nodes are the blocks and whose arrows
are the associations. A Structure diagram is an abstraction of
the properties of these diagrams. The IBD consists of nodes
of the form q:X where q is a path composition of part asso-
ciations and X is a node in the BDD. The arrows in the IBD
connect these nodes. While the BDD is not a tree, it gener-
ates a tree whose nodes have the form q:X and each part
path in the BDD whose source is the root. While concrete
language conventions for structural diagrams may differ, the
concepts which make an abstraction possible are invariant.
The formal ontology language in which the model is em-
bedded represents blocks of the form p:X as subtypes of X.
For example, in water the types p1:Hydrogen and
p3:Hydrogen are each subtypes of the Hydrogen. Informal-
ly, this block constitutes of the hydrogen atoms which are
associated by the part association hasHydrogenAtom1 with
a water molecule. These blocks represent respectively the
oxygen atoms and hydrogen atoms which are components of
a water molecule. The intended realizations of the water
model are molecules which have three distinct atoms (from
the BDD) and for which the oxygen atom component is
bonded to both of the hydrogen atom components (from the
IBD). The bonding associations in the IBD make explicit
the bonds between the part atoms of a molecule.
By embedding a structure model into a formal ontology
language and adding axioms corresponding to informal as-
sumptions, one can prove that any realization of the water
model contains three distinct atoms. Some of these assump-
tions are that the blocks, Water, Hydrogen, and Oxygen are
disjoint, and that the part maps do not associate the same
hydrogen atom to a water molecule. Of course concepts
such as disjointness have to be expressed in the ontology
language.
The diagram in Figure 1 can also be represented as a struc-
ture model using the modeling conventions of Figure 2. Al-
ternatively the BDD can be reconstructed from the IBD by
adding a part path association p’ whose source is the root
and target X, corresponding to an expression of the form
p:X. For example, for hasHydrogenAtom1:Hydrogen one
adds the arrow hasHydrogenAtom1’ and the block Hydro-
gen.
3 AXIOMATIC ONTOLOGIES
While axiom sets have been used to directly represent scien-
tific theories, structure models have diagrammatic represen-
tation which is embedded as axiom sets within logic. Em-
bedding a model as an axiom set provides criteria for correct
reasoning that can be applied to models. The logic concept
of a valid interpretation can be used to make the concept of
a realization precise. The intended interpretations of a theo-
Paper D

Ontology for Molecular Structure
3
ry are said to constitute the ontological commitment of the
theory and its conceptualization [gua 1997]. In general it
may be difficult to know what the intended interpretations
are. However, for structure models the intended interpreta-
tions are the ones which have a specific graphic structure.
Fig. 3 An Axiom Set, its theory, and interpretations
The theory of an axiom set is the logical consequences of
the axioms in the formula language of the logic. An inter-
pretation specifies how the theory is to be corresponded to
the world. Reasoning in the theory is correct when conse-
quences of the axioms are true in all interpretations. The
concept of interpretation and characterizing the relationship
between logical consequence in a theory and truth in inter-
pretations has been employed in science and molecular the-
ory in particular [Hoe 2009].
When a model is represented as an axiom set, there may be
valid interpretations which do not have the correct graph
structure, depending on the nature of the logic and the way
the model is represented as axioms. The intended realiza-
tions are the ones which have, or contain this specific graph-
ical structure. A model for H2O should have the property
that the water molecules in any realization all have the same
structure of three atoms bounded appropriately. Construct-
ing an axiom set which rules out unintended interpretations
has proven difficult.
Figure 4 shows a diagram for a structure model for water
together with three possible realizations. Only (b) is the in-
tended one, in (a) the hydrogen atom is used twice, and in
(cb) an extra atom is connected to one of the hydrogen at-
oms. Since analysis of a description applies to all of its real-
izations, one needs the capability to rule out non-intended
realizations to apply automated reasoning.
Fig. 4 Three realizations of the water model
While formal logic provides criteria for correct reasoning it
doesn’t provide criteria for how models should be embed-
ded in logic or what logic they should be embedded in.
Models in formal languages, such as the SysML water mod-
el can be embedded into logic in different ways.
4 CRITERIA FOR ONTOLOGY EMBEDDING
A formal ontology for Structural models is one in which the
language constructions used in the models have a direct
physical interpretation. In science and engineering concep-
tual models generally have direct physical interpretations in
terms of recognition procedures. The direct physical inter-
pretation consists of recognizing individuals and associa-
tions, and other language constructions such as the recogni-
tion that an individual is an instance of a subblock.
The formal ontology, based on topos theory [Lam 1986], for
structural models embeds a structure diagram directly as a
graph in a first order logic. The symbols in the model are
symbols in the language of the ontology. The ontology lan-
guage is a direct generalization of directed graphs to include
the kinds of constructions needed to represent structure. In
the ontology language the blocks are called types and the
associations are called maps. Each map has a domain and a
range type. Two constructors, Domain and Range assign
the source and target types to a map. The notation f:X → Y
is an abbreviation for
Domain(f)= X, Range(f)= Y. (1)
The ontology language includes a composition constructor
for maps with the rule
f:Y → X, g:X → Z f.g :Y → Z (2)
Composition is written in left-to-right order, e.g., c1.c2, as
this notation corresponds to path composition in a graph.
Paper D

4
In the topos ontology language a map f:X → Y has an image
type construction, Image(f). This type is a subtype of Y. The
image construction is used to embed the SysML block con-
struction f:X. The SysML expression f:X maps to Image(f).
In the ontology language a map such as hasOxygen-
Atom:Oxygen:Water → Oxygen can be decomposed into a
map
hasOxygenAtom1:Water → Image(hasOxygenAtom) (3)
followed by an inclusion map of Image(hasOxygenAtom)
into Oxygen. By using a “dot” notation for paths in a di-
rected graph this can be represented as:
hasOxygenAtom1.covalentbond1 =
hasHydrogenAtom. (4)
The ontology language provides a specification for valid
interpretations which correspond to intended interpretations,
but without additional axioms representing implicit assump-
tions the unintended interpretations cannot be ruled out.
Additional axioms can be given directly for water model.
However, a template can be given for these axioms from
which the axioms can be generated from a structure dia-
gram.
5 METALOGIC AXIOM SET TEMPLATES
For water the intended interpretations are one or more mole-
cules with the structure in Figure 4, part (b). We have indi-
cated how Figure 2 is embedded into the ontology language
and indicated the need for additional axioms to constrain the
interpretations. Analysis of examples of structure models
and their axioms suggests that the axioms conform to a tem-
plate pattern, and that these axioms can be generated auto-
matically from a structure diagram.
The abstract Structure diagrams have the property that the
signature has two kinds of terms which we call maps and
types. The map symbols in the signature of a structure mod-
el split into two disjoint sets called PartMap and Connec-
tionMap. Meta types are constructed from the signature us-
ing Boolean set formation rules. PartType consists of the
type terms of the form p:X where p PartMap and X
Two part maps such as hasHydrogenAtom1 and hasHydro-
genAtom2 may have the same domain and range types.
However, if we replace the part maps with their image fac-
torization maps, or simply assume that the part maps are
onto their image, i.e., have the syntactic form p:Y → p:X
which disambiguates the range types. The types of the form
p:X are called part types. The resulting subgraph forms a
tree with a constant symbol as a root. The part paths are
acyclic in that no path of part maps starting from the root
loops back to any type so that the range type of a part map is
not one of the domain types of a part map in the path. As a
result the part paths are finite and any part path from the
root is unique.
The IBD template defines the connection structure. The
maps of the IBD are the connection maps. These maps are
defined only between part types. The domain and range of
all part maps are type symbols and the domain and range of
all connection maps are part types. To write this more for-
mally using sorted variables we have:
f ConnectionType ≡ f:MapSymbol,
Dom(f) PartType, Range(f) PartType (5)
Modeling language tools can enforce the abstract BDD and
IBD template and add the following axioms.
Structure Axioms. The following axioms are added to the
structure diagram embedding. The types that occur in Part-
Type are assumed to be disjoint. This means
p PartMap, q PartMap, p ≠ q,
domain(p) = domain(q) = X p:X q:X = Null. (6)
The notation A B is used as an abbreviation A B =
Null. Each p PartMap is also assumed to have an inverse
map p-1
which satisfies p. p-1
= p-1
.p which means that each
part map is an isomorphism, as are the connection maps.
This means each of these maps has an inverse map from
their image type to their domain type.
c ConnectionMap isomorphism(c) (7)
c ConnectionType, c:p:X → q:Y p.c = q
Maps in the theory of a Structure axiom set can be excluded
with the statement that no maps in the theory other than the
part and connection maps have as their ranges a part type
with
f Map, f PartMap Range(f) ≠ PartType. (8)
This excludes any map in the theory from being connected
to a part type.
Interpretations of Structure Axiom Sets. The valid inter-
pretations of a structure axiom set can be proved to corre-
spond to the intended ones. A canonical minimal realization
of a Structure axiom set with root, Start is constructed by
adding an individual m with m: One → Start to the theory
and using types of the form m.q:X, where q is a part path
from Start to X. The maps have the form m.q and maps of
the form, m.p.c where c is a connection map. The maps m.p
are distinct by the orthogonality axiom. By the connection
equations (7) a connection map c composed with a part map
Paper D

Ontology for Molecular Structure
5
equals a part map. Thus the connection maps applied to the
m.p do not add any new maps. Thus, for any m:One → Root
the paths and connections starting from m have the same
structure. Other models may be constructed by adding more
individuals whose range is the root. The Structure axioms
imply that realizations do not share any structure.
6 CONCLUSION
The problem of representing structure models as axiomatic
conceptualizations for which the valid interpretations are the
intended ones is solved by using the topos axiomatic ontol-
ogy together with the axiom template for structure axiom
sets. This modeling problem also occurs in manufactured
products, family relationships, and biomedical systems.
6.1 Comparisons of the ontology language
When axiomatic ontologies are used for automated theorem
proving some restricted version of first order logic is used to
ensure that an answer to a question can be arrived in a
bounded amount of time. That is the case for the topos axi-
omatic ontology. The topos ontology uses a first order lan-
guage with function symbols for term constructions. There
are two kinds of terms called types and maps. They corre-
spond to the nodes and arrows of the diagrams. The logic is
a first order rule system. A rule is a Horn rule. Both = and ≠
are used. However general negation is not used.
Fig. 5 Fragments of first order logic
Figure 5 illustrates two fragments of first order logic that
have been used as the target for embedding models. Both
fragments restrict the formulae so as to obtain computation-
ally tractability. The Description Logics do not have term
constructions, only individuals. The type theories have term
constructions represented by first order function symbols.
The representation of the structure diagram is as terms, ra-
ther than as predicates as is done in DL approaches. This
representation of classes and roles as terms rather than pred-
icates is also used in F-logic [Deb 2008] and HILOG [Che
1993] in that a higher order syntax is used with first order
semantics; classes are represented as terms rather than pred-
icates. The structure graph serves as a surface syntax for the
axiom set. The first order theory, generated by a collection
of term constructions and the signature of the model is a
generalization of the theory of a directed graph. The topos
system has some similarity to F-logic in that it is first order
and uses language constructions familiar from set theory.
The system here is different in that the language construc-
tions are given explicit axioms, which does not appear to be
the case for F-Logic.
Description Logic embeds nodes unary predicates, and em-
bed arrows as binary predicates. In DL axiom sets for mole-
cules almost always have unintended realizations [Baa
2003]. Consequently reasoning in DL often does not give
the results expected as the valid interpretations include non-
intended intended interpretations [Mot 2008]. DL axiom
sets are unable to constrain interpretations sufficiently to
only consist of the intended interpretations. Every DL axi-
om set has an interpretation with a tree structure. DL models
do not have the inability to exclude components, e.g.,
doesn’t contain a hydrogen molecule. Inability to describe
patterns, e.g., contains a carbon ring. This has led to several
generalizations of DL [Mag 2012] but problems still persist
with these generalizations. As noted in [Mot 2008] DLs
cannot be used to axiomatize a molecular structure such as
cyclobutane which always has a ring of carbon atoms. At
least one tree shaped structure will be consistent with the
axioms. This limitation of DLs to represent cycles has been
remedied (partially) by the extension of DLs with Descrip-
tion Graphs and rules (DGDL).
A logic formalism introduced in [Mag 2012] called Descrip-
tion Graph Logic Programs (DGLPs) has been suggested as
an approach to remedy deficiencies. A DGLP ontology (ax-
iom set) consists of function-free FOL Horn rules with ne-
gation-as-failure, together with a description graph which is
represented using first order function symbols. In addition a
transitive and irreflexive graph ordering is given to specify
which graph instances imply the existence of other graph
instances. DGLP does not contain an explicit representation
of the graph structures used in the descriptions and does not
permit classification of graph theoretic structures. DGLP
places the burden of modeling on identifying the functions
which represent the graph structure and on producing the
collection of graph orderings.
Embedding nodes and arrows as terms in logic avoids the
pitfalls of the DL embedding approach. This alternative
approach is used in rule systems such as HILOG [Che 1993]
and F-Logic [Deb 2008]. The embedding of the graphical
description is in contrast to the conventional approach
which embeds types and associations respectively as unary
and binary predicates. When types and associations are em-
bedded as predicates, then the predicates needed to express
Paper D

6
properties of a directed graph, such as it has a root, are
higher order. For example, DL, in which associations and
types are predicates, does not have the expressiveness nec-
essary to constrain the valid realizations to have a specific
graph structure.
6.2 Comparisons of the metamodel approach
The approach of directly embedding the graphical descrip-
tion of an application into a logical language where the
nodes and arrows of the diagrams are type and map terms
provides an integration of model development with logic.
The development of a model within a tool which uses the
Structure profile approach enables the model developer to
restrict attention to the development of a Structure diagram.
The profile axioms can be largely transparent to the user, as
the theory of the axiom set can be automatically generated
from the diagram.
A metamodel, in the sense used by the Object Management
Group (OMG) [Mil 2003] can be used to specify syntactic
constraints on a structure diagram. Both the diagrams in
Figures 1 and 2 are used to represent the molecular structure
of water. Analysis of models with graphical representations
for structure suggests that an abstraction of structural prop-
erties can be directly embedded into the logic in such a way
as to constrain interpretations to contain the specific graph-
ical structure. However, for a diagram such as that in Figure
1 additional axioms are required to ensure that the realiza-
tions to have the intended structure. These axioms capture
implicit assumptions of the molecular domain such as no
atom can be both a hydrogen and oxygen atom. These axi-
oms can be added to be transparent when users develop such
a diagram.
A metalogic is used to represent and analyze the language
syntax generated by a Structure diagram. The use of a meta-
logic to describe syntactic structure is a generalization of the
use of metamodels in computer science [Bez]. Both a met-
amodel and a metalogic are tools for describing the abstract
syntax of a model. However, a metalogic provides the abil-
ity to reason about syntactic structure. Structure diagrams
are built from constant symbols of the signature and term
constructions. For simplicity the metalogic uses set-
theoretic membership and the algebra of subsets. The meta-
logic enables a description of templates for specific syntac-
tic structures. For example, the component decomposition
tree in Figure 1 can be defined as a Structure diagram in
terms of sets defined in terms of the signature of the dia-
gram.
6.3 Domain Specific Modeling Languages
The formal ontology language and metalogic template is an
example of specifying a formal Domain Specific Modeling
Language (DSML). Templates can be developed within the
metalogic to enable the combination of diagrams to produce
more complex model descriptions. While in the H2O and
Cyclobutane the templates did not contain metavariables,
one can describe molecular structure templates which have
“place holders” for molecules which can be substituted for
the placeholders.
REFERENCES
[Ack 1962] Ackermann, W. (1962). Solvable cases of the decision
problem. North-Holland. [Baa 2003] Baader, F., Calvanese, D., McGuinness, D., Nardi, D.,
& Patel-Schneider, P. The Description Logic Handbook
(2003). Basic description logics, 43-95.
[Bez 2001] Bézivin, Jean, and Olivier Gerbé. "Towards a precise
definition of the OMG/MDA framework." Automated Software
Engineering, 2001.(ASE 2001). Proceedings. 16th Annual In-
ternational Conference on. IEEE, 2001.
[Che 1993] Chen, W., Kifer, M., & Warren, D. S. (1993). HiLog:
A foundation for higher-order logic programming. The Journal
of Logic Programming, 15(3), 187-230.
[Deb 2008] de Bruijn, J., & Heymans, S. (2008). On the relation-
ship between description logic-based and f-logic-based ontolo-
gies. Fundamenta Informaticae, 82(3), 213-236.
[Fri 2006] Friedenthal, Sanford, Alan Moore, and Rick Steiner.
"OMG Systems Modeling Language (OMG SysML™) Tutori-
al." INCOSE Intl. Symp. 2006.
[Gen ] Génova, Gonzalo What is a metamodel: the OMG’s meta-
modeling infrastructure
[Gra 2008] Graves, Henson. "Representing Product Designs Using
a Description Graph Extension to OWL 2." OWLED. 2008.
[Gra 2011] Graves, H., & Bijan, Y. (2011). Using formal methods
with SysML in aerospace design and engineering. Annals of
Mathematics and Artificial Intelligence, 63(1), 53-102.
[Gra 2011 b] Graves, Henson. “Structural Modeling in Biomedical
and Product Engineering.” INCOSE 201
[Gua 1998] Guarino, Nicola, ed. Formal ontology in information
systems: Proceedings of the first international conference
(FOIS'98), June 6-8, Trento, Italy. Vol. 46. IOS press, 1998.
[Hoe 2009] Hoehndorf, Robert, Janet Kelso, and Heinrich Herre.
"The ontology of biological sequences." BMC bioinformat-
ics 10.1 (2009): 377
[Lam 1988] Lambek, J., & Scott, P. J. (Eds.). (1988). Introduction
to higher-order categorical logic (Vol. 7). Cambridge Universi-
ty Press.
[Mag 2012] Magka, D., Motik, B., & Horrocks, I. (2012). Model-
ling structured domains using description graphs and logic pro-
gramming. In The Semantic Web: Research and Applica-
tions (pp. 330-344). Springer Berlin Heidelberg.
[Mil 2003] Miller, Joaquin, and Jishnu Mukerji. "MDA Guide
Version 1.0. 1." Object Management Group 234 (2003): 51.
[Mot 2008] Motik, B., Cuenca Grau, B., & Sattler, U. (2008,
April). Structured objects in OWL: Representation and reason-
ing. In Proceedings of the 17th international conference on
World Wide Web (pp. 555-564). ACM.
[Vil 2007] Villanueva-Rosales, N., & Dumontier, M. (2007, June).
Describing Chemical Functional Groups in OWL-DL for the
Classification of Chemical Compounds. In OWLED (Vol. 258).
Paper D

1
Butterflies and Embryos:
The Ontology of Temporally Qualified Continuants
Ludger Jansen 1 2*, Niels Grewe 2
1 Department of Philosophy, University of Münster
2 Institute of Philosophy, University of Rostock
ABSTRACT
Motivation:
Method
Result
1 INTRODUCTION
1.1 Temporal qualification: The OWL problem
An important feature of ontologies is the representation of
relations between classes. In the Web Ontology Language
(OWL) only binary object properties between individuals
are admitted (Motik et al. 2009); these are transformed to
class relations by means of universal quantification. This
leaves no room for a temporal qualification that would re-
quire at least a triadic relation following the general pattern
“Class1 subClassOf isRelatedTo some Class2 at time T”.
On the one hand, there is good reason to restrict the subclass
hierarchy to such cases that hold at all times because one
does not want to include accidental subclass relations any-
way. For example, “Material Object subClassOf has-
Location some Spatial Region” is true at any time as there
can never be a material object that has no location. On the
other hand, other relations like partOf or participatesIn do
call for a temporal qualification. More specifically, we have
to distinguish the following three cases (elucidated with
mereological examples):
* To whom correspondence should be addressed.
· Permanent specific relatedness: A bacterium has cell
membrane – it is the same membrane over the whole
time of its existence.
· Permanent generic relatedness: A multicellular organ-
ism at any time of its existence consists of cells – but
not always of the same cells.
· Temporary relatedness: A mature instance of the order
Lepidoptera has a pair of wings, but it did not have this
pair at every time of its existence.
If we consider assertions on class level, these three kinds of
temporary relatedness match to three typical non-equivalent
quantificational structures that can be expressed with the
universal and the existential quantifier (the first universal
quantifier being due to the semantics of class-level asser-
tions):
· Permanent specific relatedness:
For ALL x there is SOME y such that
at ALL times t: R(x, y, t)
· Permanent generic relatedness:
For ALL x at ALL times t
there is SOME y such that : R(x, y, t)
· Temporary relatedness:
For ALL x there is SOME y such that
at SOME time t: R(x, y, t)
Of these three, permanent specific relatedness is the strong-
est one. It implies permanent generic relatedness which, in
turn, implies temporary relatedness. Combinatorially, two
more cases are conceivable. These will, however, rarely be
important for the biomedical domain:
· Permanent universal relatedness:
For ALL x at ALL times t it holds
for ALL y that: R(x, y, t)
· Temporary simultaneous universal relatedness:
For ALL x at SOME time t it holds
for ALL y that: R(x, y, t)
· Temporary (possibly sequential) universal relatedness:
For ALL x and for ALL y it holds
at SOME time t that: R(x, y, t)
Paper E

L. Jansen
2
1.2 Use cases
Typical use cases for temporal qualifications are develop-
mental stages of an organism. E.g., the life of a normal in-
stance of the type Lepitoptera is the following: egg, caterpil-
lar, pupa, butterfly. Here we have a good example of an
instance of the same biological species passing through
these phases. Any instance in the butterfly stage will be dia-
chronically identical with some caterpillar instance some
time earlier. Another important use case is embryology and
developmental ontologies in general, for terms and distinc-
tions for different developmental phases abound: cygote,
embryo, fetus, morula, blastula, gastrula, embryo in the fifth
week after conception, conceptus in Carnegie stage 4.
1.3 Previous work
Phase sortals. The terms we mentioned as possible use-
cases are normally know under the name of “phase sortals”
in Philosophy (Wiggins 1980) or “phased sortals” in Ontol-
ogy Engineering (Guarino/Welty 2009). A phase sortal is
normally defined as “a count-noun such that a given object
may fall within its extension at one time but not at another”
(van Inwagen 2001, 136). Consequently, the OntoClean
method characterizes phased sortals as independent, anti-
rigid and supplying identity criteria (Guarino/Welty 2009,
215). In this paper, we explicitly do not deal with the terms
as such, but with the entities they refer to and we assume
that there are, in fact, entities that phased sortals refer to
rigidly, namely temporally qualified continuants.
The standard reading of OWL assertions. The semantic of
OWL assertions is to read relational statements as implicitly
universally quantified:
· “Heart_valve subClassOf part-of some Heart” is to be
understood as: “For all heart valve instances a there is a
heart instance b such that holds: a part of b.”
· “Uterus subClassOf part-of only (Female or not Or-
ganism)” is to be understood as: “For all uterus instanc-
es a holds: If there is a b of which a is a part, then b is
either female or not an organism.”
If we expand on this standard reading, we could extend the
universal quantification not only over the instances of the
first class mentioned in the assertion, but also over all times.
The above sample assertions would then read:
· “For all heart valve instances a at all times there is a
heart instance b such that holds: a part of b.”
· “For all uterus instances a holds at all times: If there is
a b of which a is a part, then b is either female or not an
organism.”
This, however, does only permit to express permanent ge-
neric relatedness, but not the other two varieties.
SNAP-SPAN. The original suggestion underlying the archi-
tecture of the Basic Formal Ontology (BFO;
http://www.ifomis.org/bfo) is to have various SNAP-
ontologies for various points in time (Grenon 2003; Smith
& Grenon 2004). It is, however, not possible to perform this
task in OWL: Once the various ontologies are connected
with a SPAN ontology and a common namespace is accept-
ed, this approach will lead to contradictions. For example,
one SNAP ontology concerning the phase of a butterfly’s
life in which the butterfly is still a caterpillar would assert
“Lepidoptera subClassOf not has-part some Wing”, while
one concerning its adult phase would assert “Lepidoptera
subClassOf has-part exactly 2 Wing”, leading to an incon-
sistency (something cannot have wings and no wings).
Introducing n-ary relations to OWL. There are some strate-
gies to incorporate n-ary relations into OWL (Aranguren et
al. 2009; Grewe 2010). These are, however, quite clumsy
and seriously impair the processing time of ontologies.
Hence, they really are workarounds rather than elegant sys-
tematic solutions. For example, one would turn the temporal
assertion that butterflies have wings during their adult phase
into a series of assertions connecting wings, the adult phase
and the butterfly through an intermediate class:
· ButterflyWingRelator subClassOf
(relatesSubject some Butterfly) and
(relatesObject some Wing) and
(relatesAtTime some AdultPhase)
· Butterfly subClassOf
subjectOf some ButterflyWingRelator
Here the hypothetical class “ButterflyWingRelator” serves
as the reification of the original ternary relation and con-
nects its elements.
Temporarily qualified relations. Another option would be to
introduce different relation terms for the relations to be dis-
tinguished, following the general scheme “R-at-some- time”
and “R-at-all-times” (e.g., Smith 2012). According to this
strategy we will have at least twice as many relations as one
thinks there are: has-part-at-some-time, has-part-at-all-
times, has-participant-at-some-time, has-participant-at-all-
times.
The main problem of this approach is that the relation
names are mere labels for OWL and OWL editors like Pro-
tégé – and that they are ‘invisible’ for the reasoning algo-
rithm. Their semantic content can only be hinted at by way
of the subrelation hierarchy that mirrors the implications
between the relations. Another drawback of this approach is
that it is quite complicated for potential users, as they have
to learn and use at least twice as many relations.
4D-Approach. The 4D view (also called ‘perdurantism’)
views objects as four-dimensional space-time ‘worms’ that
Paper E

Butterflies and Embryos: The Ontology of Temporally Qualified Continuants
3
can be split up into temporal ‘slices’ (cf. e.g. Welty & Fikes
2006). This would allow us to define as follows:
· x is (at least) a temporary part of y if y if and only if
there are time slices x* und y* of x and y, such that x*
is part of y*.
· x is a permanent part of y if and only if for all time
slices x* of x there exists a time slice y* of y such that
x* is part of y*.
This approach does allow a rigorous semantic accounting of
the various temporal varieties of relatedness. It is, however,
notoriously unclear how to distinguish interesting space-
time worms from spatio-temporal junk and it is not clear
how to account for time slices: Are they continuants or oc-
currents? In any case, this method does not square with the
3D approach of both our everyday handling of the world
and of biomedical science. We will, therefore, try to replace
worms and slices with temporally qualified continuants
(TQCs) and describe their place in a 3D ontology.
GFO Presentials. The GFO top-level ontology provides yet
another way to account for time-dependent relatedness,
which can at least be called “4D inspired”: Instead of con-
tinuants that are present as a whole at every point in time of
their existence, in GFO there are “presentials”, which are
present as a whole at exactly one point in time, thus being
analogous to instantaneous time slices. The diachronic iden-
tity that is a key characteristic of a continuant is then ob-
tained by postulating that for every individual continuant (in
non-GFO parlance) a certain universal (a “persistant”) exists
that is instantiated only by a temporally contiguous set of
presentials, one for every point in time (Herre et al. 2006).
In our eyes, this approach is not very attractive for two
reasons: it is at odds with the strong intuition that individual
continuants such as human beings exist and, second, it re-
quires multiple levels of universals to account for conven-
tional class level assertions. Regarding relations of different
temporal strength, GFO seems to have adopted an approach
where relations are reified as “relators”, which serve as con-
texts that aggregate the relata as “players” of certain “rela-
tional roles” (Loebe 2007). Additionally, GFO accounts for
different temporal modes of relatedness precisely by distin-
guishing between presentials and persistants.
2 TEMPORALLY QUALIFIED CONTINUANTS
2.1 What is a temporally qualified continuant?
In ordinary discourse as well as in formal ontology, we of-
ten assume that objects come along with their predefined
borders in space and time: When an animal dies, this is the
temporal end of an organism. When a caterpillar transforms
into a butterfly, this is not the end of an organism, but only
the transformation from one state of the organism to another
state of the very same organism. The word “butterfly”, that
is, does not apply to that organism at any stage of its exist-
ence, but only at some very special stage. The word “butter-
fly” is what is normally referred to as a phase sortal: It re-
fers to a thing in a certain phase of its existence. In a first
approximation it could be said that a temporally qualified
continuant is the referent of a phase sortal. Examples that fit
this descriptions are:
· young Socrates vs old Socrates
· a cell before an intervention vs that cell two days after
the intervention
· the juvenile body vs the adult body
· the liver of a child vs the liver of an adult
All these examples are temporal qualifications of independ-
ent continuants – of objects or object parts, in the parlance
of BFO. We could, however, easily apply the grammatical
device of temporal qualification to terms for dependent con-
tinuants, too:
· the colour of my skin after contact with the common
nettle
· the quantity of Lm11 proteins in the cell eight days af-
ter intervention
· the size of the cell eight days after intervention
· the muscle power after two months of training
· the ability to speak two hours after taking drugs
· the function of the sexual hormones in the aging body
· the role of garlic cloves around midnight.
This list of examples neatly displays a sundry of different
categories of dependent continuants from BFO.
2.2 Arguments for and against TQCs
To be sure, TQCs seem to be very strange entities, and there
are important arguments not to admit them into a serious
ontology We briefly sketch the relevant arguments here.
Arguments against TQCs. A strong argument against TQCs
can be derived from Occam’s Razor, i.e., the principle of
ontological sparsity. Natural language statements that are
seemingly about TQCs can be reformulated such that they
are statements about non-qualified continuants containing a
temporal modality acting on the whole sentence; e.g.: “Old
Socrates had grey hair” can be paraphrased as “When he
was young, Socrates had grey hair”. Also, old Socrates and
young Socrates seem to be the very same person, hence “old
Socrates” and “young Socrates” seem to be different labels
for the very same entity – and, hence, superfluous.
Arguments in favour of TQCs. On the other side, this onto-
logical commitment has to be compared with the ontological
commitments of alternative approaches, which come with
their own costs – spatiotemporal worms, temporal slices and
so on. We can also argue from the technical necessity of
Paper E

L. Jansen
4
having a technique to express temporary relatedness in
OWL ontologies in order to describe, e.g., the morphology
of an embryo in the course of its ontogenetic development.
It could also be argued that we do distinguish between con-
tinuants with different temporal qualifications in ordinary
parlance: To claim that young Socrates drank hemlock
would not only be odd, but false. This indicates, finally, that
young Socrates and old Socrates have incompatible proper-
ties and are, thus, not labels of the same entity at all.
2.3 TQCs as Continuants
The basic idea of our suggestion is to take serious the idea
that TQCs are continuants. This implies that they can have
spatial, but not temporal parts and that they are present ‘as a
whole’ at every time of their existence. When young Socra-
tes was on the Agora at noon, the whole young Socrates was
on the Agora at this time.
But how does this new class of TQCs relate to
BFO:Continuant, i.e., the class of continuants hitherto
acknowledged in BFO? Linguistically, TQCs seem to be
specially qualified continuants. This would hint at treating
TemporallyQualifiedContinuant as a subclass of Continuant.
The old BFO continuants could, however, also be seen as
continuants that are – implicitly – temporally qualified in a
very special way, namely with respect to their whole
lifespan or history. We would then treat BFO:Continuant as
a subclass of TemporallyQualifiedContinuant.
BFO 2 does already contain the means to talk about the
history of a material object, which is defined as the totality
of processes going on in the spatio-temporal region occu-
pied by the material object. This, in turn, allows us to define
the duration of an independent continuant as the temporal
projection of its history (using the object property
BFO2:projects_onto).
2.4 Bona fide and fiat boundaries in time
One strategy to make TQCs less offensive is to adopt the
distinction between bona fide boundaries and fiat bounda-
ries (Smith 1995, Smith & Varzi 2000; cf. Vogt 2012) to the
temporal boundaries of (the history of) material objects.
BFO is built around the assumption that some material enti-
ties are cut off from their environment by subject-
independent physical discontinuities. Other material objects
are only cut off from their environment by a cognitive act,
i.e., by human fiat: We can distinguish between the upper
femur and the lower femur without resorting to a saw.
The same idea can be applied to temporal boundaries:
When a vase breaks, this is a definitive temporal end of its
existence, as is the death of an organism. Similar thoughts
could be applied to the bona fide beginning of an organ-
ism’s existence (Smith & Broogard 2003). We can then
have the maximally temporally extended bona fide continu-
ants that can then be temporally shortened by way of fiat
boundaries. These boundaries can be crisp (“Socrates in the
first ten years of his life”) or vague (“young Socrates”); they
can refer to a time measure (“conceptus in the fourth week
of pregnancy”) or to other properties (“embryo in Carnegie
stage 5”).
If we expand on this contrast between TQCs and (tempo-
rally) bona fide continuants (BFCs), we can state that every
TQC is a TQC of some BFC. This gives rise to interesting
new relations:
· x hasMax y if and only if y is the BFC of which x is a
TQC.
The inverse relation is maxOf; both are transitive. hasMax
is functional and a fixpoint relation. These relations can
help us to define the equivalence class of all TQCs that are
TQCs of the same BFC:
· x and y belong to the same BFC if and only if x
hasMax ° maxOf y.
3 PUTTING TQCS TO WORK
3.1 Temporal Variants of Relatedness
We have now all we need to use TQCs to express the vari-
ous ways of temporal relatedness by means of the restricted
expressivity of OWL. In doing so, we assume that all relat-
edness on the instance level is grounded in some permanent
or instantaneous relatedness. X and Y being classes, we can
define:
· Temporary relatedness (class level): X is temporarily
R-related to Y if and only if for every instance x of X
there is a TQC x* with x* hasMax x and some TQC y*
with y* hasMax some Y such that: x* R y*.
· Permanent generic relatedness (class level): X is per-
manently generically R-related to Y if and only if
X subClassOf R some Y, i.e. if and only if for all
TQCs x* with x* hasMax some X there is a TQC y*
with y* hasMax some Y such that: x* R y*.
· Permanent specific relatedness (class level): X is per-
manently specifically R-related to Y if and only if
(1) X subclassOf R some Y and
(2) X-BFC subclassOf R exactly one Y-BFC.
In the latter specification, properly defining clause (2) re-
quires the introduction of a property chain (for example
“R ○ hasMax”). This construction is, however, not permis-
sible in OWL. We are, thus, not able to define permanent
specific relatedness due to the restrictions on the use of non-
simple object properties in OWL, though augmenting the
expressivity by using a rule language such as SWRL pro-
vides workarounds for this issue. (Batsakis & Petrakis
2012).
3.2 Transformations
Another interesting relation between TQCs that is of im-
portance for biomedical ontologies is transformation. In a
Paper E

Butterflies and Embryos: The Ontology of Temporally Qualified Continuants
5
biomedical ontology, something like the following could be
stated: Butterfly transformation_of some Caterpillar. The
Relation Ontology (RO, Smith et al. 2005) defines trans-
formation only on class level (making use of the BFC intui-
tion discussed in the previous section):
· Let C and C’ be types of independent continuants. Then
C is a transformation_of C’ if and only if, for all c and t,
if c is an instance of C at t, then there is a time t1 earlier
than t, at which c is an instance of C’, and there is no
time t2 such that c is at t2 both an instance of C and an
instance of C’.
However, due to the syntax of OWL (as opposed to OBO),
such a definition on class level is not sufficient and we are
in need of a definition of transformation on the level of in-
stances. We would want to say, e.g., that old Socrates is a
transformation of young Socrates. We can define this as
follows:
· x is a transformation of y if and only if (1) x and y are
TQCs, (2) x and y are TQCs of the same BFC, and (3)
the history of x projects on a later time than the history
of y.
4 CONCLUSION
We have introduced the new category of temporally quali-
fied continuants to enhance the expressivity of OWL. With
this new category of entities we are able to give strict defini-
tions of temporary and permanent generic relatedness. We
can also justify enriching OWL with rules. We are also able
to give a definition of transformation on instance level.
Of course, many problems remain. Not the least is the still
dubious ontological status of TQCs. Also, we have not dis-
cussed the question of whether TQCs need to have a contin-
uous history or whether it could make sense to admit also –
even more dubious – non-continuous TQCs (“sleeping Soc-
rates”, “contracted mitochondrium”).
We could also ask whether the inherence of a TQ-quality
in a TQ-substance implies the exact same identity of the
duration of these two TQCs or whether it would be suffi-
cient to assume a temporal overlap of the durations. These
two options come down to distinguishing a strong and a
weak version of predication, and weak predication could be
defined with the help of strong predication and TQCs.
ACKNOWLEDGEMENTS
The work presented here is part of a larger co-operative ef-
fort to enhance the temporal expressivity of OWL in the
course of the development of the OWL-version of BFO 2.
The present paper contents itself with the more philosophi-
cal aspects of the category of TQCs. We do, however, owe
much to discussions with members of this group and to dis-
cussions of a related paper on a workshop on time at the
Saar University in Saarbrücken. Many thanks are due to
Stefan Schulz for written comments on a previous version of
this paper, as well as to the reviewers for ODLS.
REFERENCES
Aranguren M et al. (2009), Nary Relationship. Ontology Design
Pattern Public Catalog, http://www.gong.manchester.ac.uk/
odp/html/Nary_Relationship.html.
Batsakis S, Petrakis E (2012), Imposing Restrictions over Tem-
poral Properties in OWL: A Rule-Based Approach. In: Bitakis
A, Giurca A, editors. Rules on the Web: Research and Applica-
tions. Proceedings of RuleML 2012. Berlin et al.: Springer. pp.
240–247.
Grenon, P (2003). BFO in a Nutshell: A Bi-categorical Axiomati-
zation of BFO and Comparison with DOLCE. IFOMIS Report,
Leipzig.
Grewe N (2010), A generic reification strategy for n-ary relations
in DL. In Herre H et al. (ed), 2nd Workshop of Ontologies in
Biomedicine and Life Sciences (OBML), Mannheim, 9.-10.9.
2010, pp. N1-N5.
Herre H et al. (2006) General Formal Ontology (GFO): A Founda-
tional Ontology Integrating Objects and Processes. Part
I:Basic Principles. Leipzig.
Loebe F (2007) Abstract vs. social roles — towards a general the-
oretical account of roles. Applied Ontology, 2, 127–158.
Motik B, Patel-Schneider P, Parsia B (2012), OWL 2 Web Ontolo-
gy Language Structural Specification and Functional-Style Syn-
tax. W3C Recommandation, http://www.w3.org/TR/2012/ REC-
owl2-syntax-20121211/.
Smith B (1995), On Drawing Lines on a Map. In: Frank AU, Kuhn
W, Mark DM, editors. Spatial Information Theory: Proceedings
in COSIT '95. Berlin/Heidelberg/Vienna/New York/London/
Tokyo: Springer. pp. 475–484.
Smith B et al. (2005), Relations in biomedical ontologies. Genome
Biology 6(5): R46.
Smith B et al. (2012), BFO 2, Graz release.
http://purl.obolibrary.org/obo/bfo/2012-07-20/Reference.
Smith B, Brogaard B (2003), Sixteen Days. Journal of Medicine
and Philosophy 28(1): 45-78.
Smith B, Grenon P (2004), The Cornucopia of Formal-Ontological
Relations. Dialectica 58(3): 279-296.
Smith B, Varzi AC (2000) Fiat and Bona Fide Boundaries. Philos-
ophy and Phenomenological Research 60(2): 401–420.
Vogt L, Grobe P, Quast B, Bartolomaeus T (2012), Fiat or Bona
Fide Boundary – A Matter of Granular Perspective. PLoS ONE
7(12): e48603. doi:10.1371/journal.pone.0048603.
Welty F, Fikes R (2006), A Reusable Ontology for Fluents in
OWL. In: Bennett B, Fellbaum C, editors. Proceedings of
FOIS-2006, IOS Press, Amsterdam, pp. 226–236.
Wiggins D (1980), Sameness and Substance, Harvard University
Press, Cambridge MA.
van Inwagen P (2001), Temporal parts and identity across time. In:
Ontology, Identity and Modality: Essays in Metaphysics, Cam-
bridge University Press, Cambridge, 122–143.
Paper E

Entities with Genetic Information – An Initial Perspectivefrom the Core Theme of Continuity and Change in BiologyFrank Loebe 1∗ and Vinay K. Chaudhri 21Department of Computer Science, University of Leipzig, Germany2SRI International, Menlo Park, California, USA
ABSTRACTGenetic information is transferred through biological processes
studied at different levels of granularity. Focusing on the continuityand change of genetic information and its phenotypic expression thusyields a cross-cutting theme in biology. The inspiring aim of this workis to integrate this theme into the knowledge base of an electronicbiology textbook. The paper describes first steps in this regard. Wepresent a definition of the theme to set its scope, sketch competencyquestions for future evaluation, and systematically identify a set ofinformation (bearing) units as key notions of the theme.
Due to the central role of genetic information in biomedical re-search, continuing the work towards the taxonomic classification ofthose key notions connects with their occurrence in biomedical on-tologies. Besides the taxonomy in the knowledge base, we brieflysurvey selected ontologies regarding the notions of gene, DNA, andDNA sequence. Beyond specific analyses, this leads us to con-clude with the need for novel solutions in dealing with multiple,but integrated perspectives on biological terms and for the efficientmanagement of detailed ontological distinctions.
1 INTRODUCTIONGenetic information is central in much of biomedical research andmeanwhile constitutes a large set of databases with a vast amount ofgenetic data. Supporting the annotation of genetic information hasled to the immense success of the Gene Ontology (GO) [1, 16], con-sequentially pioneering the overall field of biomedical ontologies.GO and many other bio-ontologies are applied by practicing biol-ogists and biomedical researchers. On the one hand, they alreadyserve certain needs of researchers, on the other hand new applica-tions and user requests promote the continued development of theontologies. They evolve not only in the light of new terms that needto be integrated, but further, for example, based on the alternativeanalysis of ontology terms and their relationships.
In the present work we aim at analyzing and representing continu-ity and change in genetic information, identified as a core biologytheme by the United States College Board [17]. We focus on pro-viding a scoping definition of the theme itself and propose a way toorganize its notions of major relevance. On that basis, we initiallystudy the relationship with representative biomedical ontologiesoverlapping this domain.
A large effort that aims at question answering and inference setsthe scene for our work. Its immediate application is the creation ofan electronic textbook for biology that supports question answeringand serves as a learning tool for students [5]. Substantial parts of thewidely used introductory college textbook Campbell Biology [13]have already been transformed into a knowledge base (KB) for an
∗to whom correspondence should be addressed
electronic version of Campbell Biology (abbreviated by KB-Bio, asa system). In order to answer questions from that KB, the biolog-ical content must be captured at a deeper level of detail, involvinga much higher amount of formally captured interrelationships thanis commonly found in biomedical ontologies. Our work covers aninitial stage in enriching its content to eventually include the coretheme of continuity and change.
There are eight core themes in Campbell Biology as they weredefined by the U.S. College Board for advanced placement courses[17]. Other core themes include structure and function [6], energytransfer and regulation [7], etc. Some of them have already beenrepresented in the KB. They all capture a coherent sub-domain ofbiological knowledge and have a specific thematic focus.
Representing a core theme starts with refining the brief definitionof the theme by the College Board for clarity about that focus. Aconceptualization of respective biological processes, entities, andtheir interrelations must then be devised and represented in the KB,and tested by demonstrating that the representation is feasible for thepurposes requested of the knowledge base. Our goal in these regardsis a set of ontology-based modeling patterns that serve as samplecases and guidelines for converting the overall biological knowledgeof the theme into extensions of the KB. The latter work is distributedover a larger team of domain experts trained in encoding knowledgeaccordingly. To a large extent this can proceed chapterwise, giventhe basis of the core theme representation.
In this paper, our aims are two-fold. In the first part, we detail ourmethods in designing a core theme representation for the knowledgebase in section 2 and then describe our initial results for the coretheme of continuity and change in section 3. This includes a scop-ing definition of the theme, an outline of competency questions forlater evaluation, and the identification of key entities together withsummarizing characterizations, including distinct views as availablefrom [13]. The second part of the paper, presented in section 4,focuses on the taxonomic placement of selected key entities in com-parison with existing ontologies in the biomedical domain. On thatbasis we discuss and conclude with general, interrelated researchtasks in ontological analysis and ontology representation and arguethat solutions to them would be of major impact, not only in thebiomedical domain, but with immediate applications therein.
2 METHODS2.1 Core Theme DesignIn the overall process of designing and checking basic core themerepresentations, i.e., targeting at a set of ontology-based modelingpatterns for a particular theme, we pursue these steps, cf. also [8]:
1. Synthesize a textual definition of the core theme;
2. Establish a set of informal competency questions;
1Paper F

F. Loebe and V. K. Chaudhri
3. Select/identify key concepts for the theme;
4. Propose/verify the position of the key concepts in the taxonomyof the KB;
5. Draft/determine/refine prototypical concept graphs for coretheme coverage; and
6. Conceive of possible reasoning patterns and simulate tests ofquestion answering.
In practice, the steps are not followed in a strict sequence and theirresults interact with each other, based on forms of dependence andvalidation occurring between the steps. While results on earlier stepsmay be improved by revisiting them based on later steps, thus goingthrough some iteration, we seek convergence of this overall process.
In the sections below we present the current status of our workfor the theme of continuity and change, focusing on steps 1-4. Ex-amples for step 5 and partially step 6 can be found in [8]. Giventhat continuity and change follows other core themes that have beencaptured in the KB, we actually start from that as a rich biologicalontology already. Hence, one concern in core theme design is thereuse of representations, where appropriate and practical. Next wesketch relevant aspects of the KB.
2.2 Component Library, KB Format and ContentThe foundational component of the KB is the Component Library(CLIB), an upper ontology which is linguistically motivated and de-signed to support the representation of knowledge for automatedreasoning [3]. CLIB adopts four simple top level distinctions: (1)entities (things that are); (2) events (things that happen); (3) rela-tions (associations between things); and (4) roles (ways in whichentities participate in events). In addition to these distinctions, CLIBprovides a vocabulary of actions and semantic relationships that hasproven to be easy to use by domain experts [10]. It is useful toencode the mereological structure of events and entities as well asways in which entities participate in different steps of an event.
The overall KB uses a representation based on first order logic.Most importantly, biologist encoders can edit existential rules [2]through a graphical user interface. Each graph captures a singlerule, i.e., a sentence quantified universally in one variable and ex-istentially in all others, cf. [7, 10]. All classes (unary predicates)are arranged in a taxonomy, a subsumption poly-hierarchy, the up-per levels of which are constituted by CLIB. Turning to biologicalcontent, for many notions central to continuity and change the KBalready contains representations from a structural and functionalpoint of view, cf. [6].
3 RESULTS3.1 Definition of Continuity and ChangeWe synthesized three perspectives into a scoping definition of thecore theme, see step 1 in section 2. The College Board syllabus [17]states: all species tend to maintain themselves from generation togeneration using the same genetic code. However, there are geneticmechanisms that lead to change over time, or evolution.
Campbell Biology [13, ch. 1, p. 8 ff.] starts the description ofthe theme as follows: The division of cells to form new cells isthe foundation for all reproduction and for the growth and repairof multicellular organisms. After referring to chromosomes as themain carriers of genetic material, the theme outline continues onthe structure and function of deoxyribonucleic acid (DNA) together
with its ability to store information, further highlighting the pro-cesses of replication and gene expression. It also establishes thelink between the genome of organisms and genomics, as the studyof genes and sets of genes within species, as well as cross-speciesgenome comparison.
The key aspects of continuity and change from the perspectiveof biology teachers that we have consulted with include the follow-ing: (1) it involves genetic information; (2) continuity is about themaintenance of the fidelity of the information from generation togeneration, cell to cell, organism to organism, or species to species;(3) change is about loss or altering of fidelity of the informationfrom generation to generation, cell to cell, organism to organism, orspecies to species; (4) it often involves a measurable or observableoutcome, and this outcome relates directly to continuity or changeof information.
This input evolved in later steps to our proposed theme definition:Continuity and change concerns genetic information and its phe-notypic expression, where the basic form of genetic information isgiven by nucleotide sequences. Continuity and change are consid-ered with respect to inheritance, more precisely regarding the flowof genetic information: (i) within events occurring in the transitionfrom generation to generation at different levels, namely of cells(or viruses), organisms, or populations; and (ii) in the evolution-ary development of species. Information flow requires informationunits (i.e., entities that carry information), which are complementedby observable effects of that information. We distinguish: (a) sub-cellular information units that are physical parts of cells (or viruses)(e.g., nucleic acid molecules (DNA, RNA), genes/alleles, and chro-mosomes); (b) aggregated information units that are derived fromthe sub-cellular units (e.g., genotype, genome, gene pool); and(c) traits/phenotypes of organisms, which are determined by ge-netic information. On this basis, continuity refers to maintainingthe sameness of genetic information as well as of information unitsthemselves, the latter supporting the former, and of phenotypes.Change refers to events generating differences in genetic informa-tion, in information units (if affecting carried information), or inresulting phenotypic characteristics.
3.2 Informal Competency QuestionsCompetency questions are intended for validating proposed repre-sentations for a core theme. We distinguish diagnostic questions thatare close to basic tasks and aim at testing representation adequacy,and educationally useful questions that are gathered by convening afocus group of teachers and students and serve as use cases in eval-uation studies after a substantial amount of the core theme contentin [13] will have been encoded in the KB.
Our suite of educationally useful questions on continuity andchange has approximately 100 different questions. We provide fourof them for illustration.
E1 What happens if crossing over occurs in the middle of a gene?E2 What would happen to the chromosomes in eukaryotes if
telomerase were lacking?E3 What is the difference between a translocation and an inver-
sion?E4 Because of their structure, DNA polymerases can add nu-
cleotides only to the 5 prime end of a primer of a growingDNA strand, never to the 3 prime end. True or False? Explain
2 Paper F

in terms of the antiparallel arrangement of the double helix theeffect on replication.
The diagnostic questions were abstracted from the educationallyuseful questions, thereby taking sets of diagnostic questions forother core themes into account. At present, these six schemes ofdiagnostic questions (with variables X and Y for events or entities)are available for checking modeling patterns:
D1 What remains the same/changes during X?D2 What causes the continuity/changes of X during Y ?D3 Describe continuity/changes during a process X .D4 What is an example of a process that maintains the continuity
of/changes X?D5 What does X contribute to continuity/change of Y ?D6 Which processes contribute to continuity/changes of X during
process Y ?
While reported in some more detail elsewhere [8], we notethat initial alternatives of representation patterns for continuity andchange have been designed and checked against instances of thesediagnostic questions. Sample processes under consideration includeDNA replication, meiosis, and natural selection.
3.3 Structural Levels in Biology and Information UnitsFor the identification of key notions (step 3 in section 2) we haveconducted a corpus analysis of Campbell Biology [13], gathering169 terms for potential further analysis. While this set of terms in-cludes entity as well as event types, we focus on entities (in the senseof CLIB) in the sequel.
Filtering key entity types from the set of terms is based on two as-pects. First, genetic information in an understanding as sequencesof nucleotide types is one central subject to continuity, comple-mented by phenotypic features as inheritable expression of geneticinformation. Secondly, we adopt the structural biological levels oforganization from [13], see Table 1, to organize what we abbreviateas information units, namely entities bearing genetic information (orphenotypes). For example, we consider ‘DNA strand’, understoodas a polynucleotide molecule, as an information unit because it com-prises a chain of nucleotide monomers, each of which instantiates aclass of nucleotides that is associated with the genetic code, such asadenine. Due to that connection nucleotide classes can be perceivedas types in the sense of the type-token distinction [18] and individ-ual polynucleotide molecules are considered as tokens of sequencesof (occurrences of) nucleotide types, cf. [18, sect. 8].
Table 2 displays the entities that we have identified, based on [13],as the main units bearing genetic information (or their phenotypicexpression) at different levels of organization. The third columncontains condensed characterizations of, partially multiple, readingsof the respective terms.
• molecules
• sub cellular entities
• cells
• tissues
• organs and organ systems
• organisms
• populations
• communities
• ecosystems
• the biosphere
Table 1. Structural levels of biological organization, derived from [13].Each term X stands for the respective “level of X”.
Table 2 as well as further analysis forms the basis for determin-ing or checking the position of the key notions in the taxonomy ofthe KB. This fourth step in our procedure in section 2 links withestablished biomedical ontologies as a major kind of related work.Moreover, while most of the notions can already be found in KB-Bio, cf. its column in Table 3, we see room for further analysis anddiscuss related general representation problems in the next section.
4 DISCUSSION4.1 Information Units in Biomedical OntologiesRegarding related work, we are not aware of any immediately sim-ilar approaches, neither of the overall project of establishing anelectronic textbook for biology, nor of the topic of / focus on con-tinuity and change as a whole. However, there is a wide range ofbiomedical ontologies that cover various notions identified duringcorpus analysis, among them the information units identified in Ta-ble 2. In order to establish relations to KB-Bio, we have started aninitial analysis of the coverage and representation of informationunits in biomedical ontologies.
Besides KB-Bio, Table 3 shows the taxonomic classification ofgene, DNA, and DNA sequence in the Sequence Ontology (SO)1
[9, 12], BioTop2 [4], General Formal Ontology for Biology (GFO-Bio)3, Ontology of Genes and Genomes (OGG)4, Gene RegulationOntology (GRO)5, National Cancer Institute Thesaurus (NCIt)6, andSNOMED-CT7, all retrieved via the NCBO BioPortal8. Those threeterms are selected for their central role, polysemous use in [13], andgood coverage in the selected ontologies.
Taking further terms into account, SO and NCIt apparently havevery elaborate sets of classes with labels that are relevant for con-tinuity and change. But clearly, one must pay attention to thebackground of each system to interpret its constituents correctly. Forexample, SO is rooted in genome annotation, such that special read-ings of the terms apply [12, p. 87], also visible in Table 3 in theupper-level classification in SO, cf. also [12, p. 88–89].
All shown ontologies have a term ‘DNA’, and all include ‘gene’,except for GFO-Bio (due to pending analysis). Across the on-tologies, the relationship between ‘gene’ and ‘DNA’ or ‘nucleicacid’ varies strongly, looking at whether subsumption is declaredor at which level ‘gene’ and ‘DNA’ have a common ancestor inthe taxonomy. Frequently, ‘material object’ is among the commonancestors.
We can neither provide an in-depth comparison of these existingsystems here, nor could we argue in detail for one or another solu-tion without taking the systems much more into account. However,
1 http://www.sequenceontology.org/ (Jan 29, 2014)2 http://www.imbi.uni-freiburg.de/ontology/biotop/(May 20, 2014)3 http://www.onto-med.de/ontologies/gfo-bio/ (Mar 02,2010)4 http://ogg.googlecode.com/ (May 22, 2014)5 http://www.ebi.ac.uk/Rebholz-srv/GRO/GRO.html (Oct11, 2010)6 http://ncit.nci.nih.gov/ (Jul 14, 2014)7 http://ihtsdo.org/ (Feb 21, 2014)8 http://bioportal.bioontology.org
3Paper F
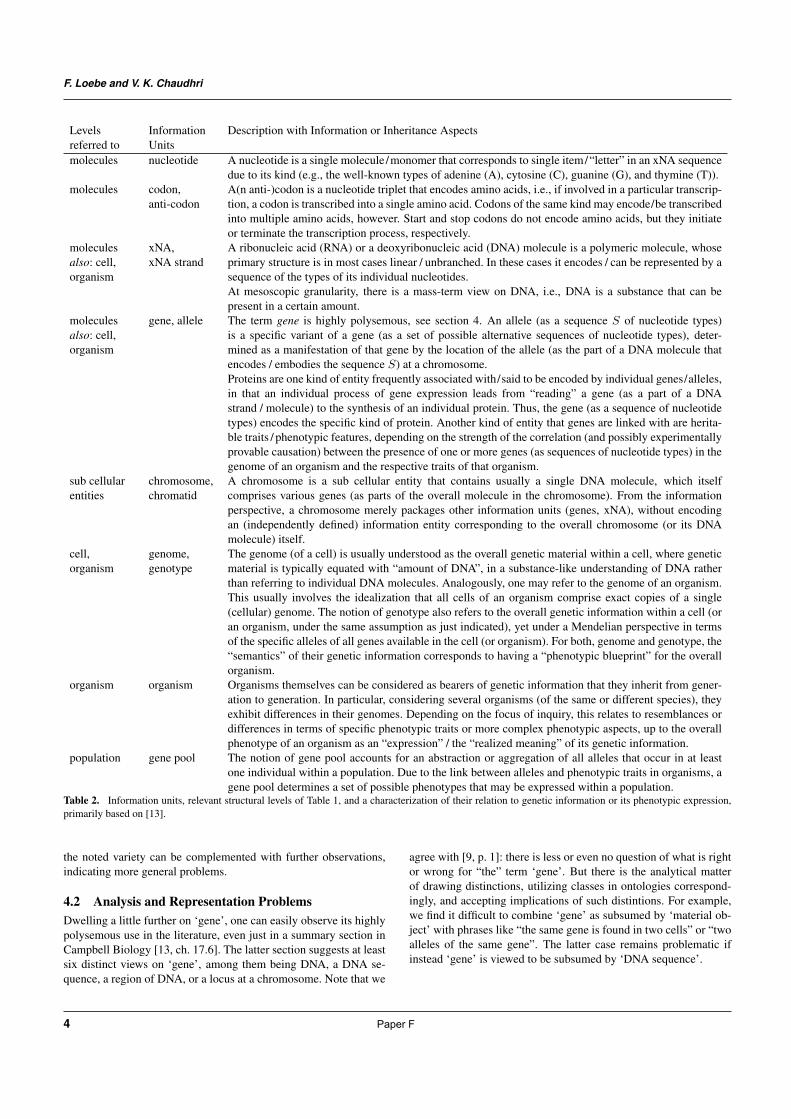
F. Loebe and V. K. Chaudhri
Levelsreferred to
InformationUnits
Description with Information or Inheritance Aspects
molecules nucleotide A nucleotide is a single molecule /monomer that corresponds to single item/“letter” in an xNA sequencedue to its kind (e.g., the well-known types of adenine (A), cytosine (C), guanine (G), and thymine (T)).
molecules codon,anti-codon
A(n anti-)codon is a nucleotide triplet that encodes amino acids, i.e., if involved in a particular transcrip-tion, a codon is transcribed into a single amino acid. Codons of the same kind may encode/be transcribedinto multiple amino acids, however. Start and stop codons do not encode amino acids, but they initiateor terminate the transcription process, respectively.
moleculesalso: cell,organism
xNA,xNA strand
A ribonucleic acid (RNA) or a deoxyribonucleic acid (DNA) molecule is a polymeric molecule, whoseprimary structure is in most cases linear / unbranched. In these cases it encodes / can be represented by asequence of the types of its individual nucleotides.At mesoscopic granularity, there is a mass-term view on DNA, i.e., DNA is a substance that can bepresent in a certain amount.
moleculesalso: cell,organism
gene, allele The term gene is highly polysemous, see section 4. An allele (as a sequence S of nucleotide types)is a specific variant of a gene (as a set of possible alternative sequences of nucleotide types), deter-mined as a manifestation of that gene by the location of the allele (as the part of a DNA molecule thatencodes / embodies the sequence S) at a chromosome.Proteins are one kind of entity frequently associated with/said to be encoded by individual genes/alleles,in that an individual process of gene expression leads from “reading” a gene (as a part of a DNAstrand / molecule) to the synthesis of an individual protein. Thus, the gene (as a sequence of nucleotidetypes) encodes the specific kind of protein. Another kind of entity that genes are linked with are herita-ble traits / phenotypic features, depending on the strength of the correlation (and possibly experimentallyprovable causation) between the presence of one or more genes (as sequences of nucleotide types) in thegenome of an organism and the respective traits of that organism.
sub cellularentities
chromosome,chromatid
A chromosome is a sub cellular entity that contains usually a single DNA molecule, which itselfcomprises various genes (as parts of the overall molecule in the chromosome). From the informationperspective, a chromosome merely packages other information units (genes, xNA), without encodingan (independently defined) information entity corresponding to the overall chromosome (or its DNAmolecule) itself.
cell,organism
genome,genotype
The genome (of a cell) is usually understood as the overall genetic material within a cell, where geneticmaterial is typically equated with “amount of DNA”, in a substance-like understanding of DNA ratherthan referring to individual DNA molecules. Analogously, one may refer to the genome of an organism.This usually involves the idealization that all cells of an organism comprise exact copies of a single(cellular) genome. The notion of genotype also refers to the overall genetic information within a cell (oran organism, under the same assumption as just indicated), yet under a Mendelian perspective in termsof the specific alleles of all genes available in the cell (or organism). For both, genome and genotype, the“semantics” of their genetic information corresponds to having a “phenotypic blueprint” for the overallorganism.
organism organism Organisms themselves can be considered as bearers of genetic information that they inherit from gener-ation to generation. In particular, considering several organisms (of the same or different species), theyexhibit differences in their genomes. Depending on the focus of inquiry, this relates to resemblances ordifferences in terms of specific phenotypic traits or more complex phenotypic aspects, up to the overallphenotype of an organism as an “expression” / the “realized meaning” of its genetic information.
population gene pool The notion of gene pool accounts for an abstraction or aggregation of all alleles that occur in at leastone individual within a population. Due to the link between alleles and phenotypic traits in organisms, agene pool determines a set of possible phenotypes that may be expressed within a population.
Table 2. Information units, relevant structural levels of Table 1, and a characterization of their relation to genetic information or its phenotypic expression,primarily based on [13].
the noted variety can be complemented with further observations,indicating more general problems.
4.2 Analysis and Representation ProblemsDwelling a little further on ‘gene’, one can easily observe its highlypolysemous use in the literature, even just in a summary section inCampbell Biology [13, ch. 17.6]. The latter section suggests at leastsix distinct views on ‘gene’, among them being DNA, a DNA se-quence, a region of DNA, or a locus at a chromosome. Note that we
agree with [9, p. 1]: there is less or even no question of what is rightor wrong for “the” term ‘gene’. But there is the analytical matterof drawing distinctions, utilizing classes in ontologies correspond-ingly, and accepting implications of such distintions. For example,we find it difficult to combine ‘gene’ as subsumed by ‘material ob-ject’ with phrases like “the same gene is found in two cells” or “twoalleles of the same gene”. The latter case remains problematic ifinstead ‘gene’ is viewed to be subsumed by ‘DNA sequence’.
4 Paper F

entity entityparticular individual category entity
concrete spatialentity
sequencefeature
sequenceattribute
presential continuant continuant
discretepresential
tangibleentity
independentcontinuant
substance
region material object materialobject
symbolstructure
physicalobject
materialentity
physicalcontinuant
substancecategorizedstructurally
biologicalregion
symbolsequence
drug, food,chemical orbiomedical
material
anatomicstructure,system, orsubstance
biologicalsubstance
chemicalentity
drug orchemical by
structure
micro-anatomicstructure
chemicalcategorizedstructurally
monomolecular entity molecule molecule2 molecularentity
macro-molecularstructure
polymerattribute
organic molecularentity
organicmolecule
informationbiopolymer
organicchemical
organiccompound
nucleicacid
nucleic acidstructure1
nucleicacid3
nucleicacid
nucleicacids5
nucleicacid
chain ofnucleotidemonomers
poly-nucleotidemolecule
nucleotidesequence
nucleotidesequence
DNA DNAchain
DNA DNAsequence
DNA DNA DNA DNAsequence
deoxyribonucleic
acid
DNAsequence4
DNAregion
gene gene gene gene gene gene6 geneSO BioTop GFO-Bio KB-Bio OGG GRO NCI Thesaurus SNOMED-CT
Table 3. Chart for the comparison of the categories gene, DNA, and DNA sequence by the taxonomic paths to the top-level categories in the biomedicalontologies identified in the bottom row. Within the (double-)columns for an ontology, a table cell above another represents generalization (except for ‘gene’ inNCI Thesaurus, see remark 6). For example, in BioTop, ‘DNA chain’ is generalized by ‘chain of nucleotide monomers’, which is generalized by ’nucleic acidstructure’. Starting from ‘gene’, ‘DNA’, and ‘DNA sequence’, categories of a comparable level of generality are aligned horizontally across the ontologies.For example, widely homogeneous levels can be found w.r.t. (i) gene, (ii) DNA / DNA sequence, (iii) nucleic acid, (iv) molecule, and (v) material object.Specific remarks: (ois stands for “omitted immediate supercategory”) 1 ois ‘nucleotide or nucleoside molecule or residue’; 2 ois ‘compound’; 3 omittedparallel path from ‘nucleic acid’ via ‘polymer’ to ‘chemical entity’; 4 omitted parallel path from ‘DNA sequence’ via ‘nucleic acid sequence’ to ‘nucleidacid’; 5 ois ‘nucleic acids, nucleosides, and nucleotides’; 6 ‘gene’ is a top-level category in NCI Thesaurus, whereas we saved the space of another column.
From an analytical point of view, we agree in general with [11]that a role-based account of ‘gene’ is adequate (which applies tovarious other notions, as well). Strong support for that is given by(especially same-strand) overlapping genes, which are observed ingenomes of various species including human [14], i.e., (with themolecular view on ‘gene’) parts of DNA that are read and translatedin different transcription processes. However, role-based analysisusually comes at the price of further discrimination. Distinctionsbecome additionally multiplied by different readings of other terms,cf. e.g. the four views on DNA discussed in [15, p. 112]. Accord-ingly, ‘gene’ may be related with double-stranded or single-strandedDNA. On the other hand, one may wish to be agnostic about thatdistinction unless explicitly required.
Problems of this kind have surely been noted earlier. Usually, atrade-off needs to be found between fine-grained distinctions andmaintaining comprehensibility and tractability. But large systemssuch as NCIt and SO that are applied in multiple contexts start toincorporate additional distinctions, cf. the SO:Molecules subset [12,
p. 87]. Similarly, we expect that answering a variety of questionsfrom KB-Bio will require further distinctions of the key entities incontinuity and change.
At the present stage, we see two major interrelated challengesregarding ontological analysis and representation in general (alsobeyond the biomedical domain). (1) There is the need to analyze“informal notions” from multiple perspectives, but in an integratedway. We expect this to lead to various, ontologically distinguishableand interrelated (types of) entities. (2) Given such analyses, new rep-resentational methods should be developed that hide the underlyingcomplexity and allow especially domain experts to work efficientlywith corresponding representations. In particular, the manual mul-tiplication and resulting curation of classes should be minimized.In our opinion, the above discussion in this section underlines theimportance of (1) and (2). We further suggest to integrate key no-tions of continuity and change as a “component” into biomedicalcore ontologies such as BioTop or GFO-Bio.
5Paper F

F. Loebe and V. K. Chaudhri
5 CONCLUSIONContinuity and change in genetic information is a rich topic area inbiology. This paper presents some of our preliminary results in de-signing representations for this core theme for KB-Bio, a knowledgebase for answering questions within an electronic biology textbook.We contribute a scoping definition for the theme and outline twotypes of competency questions for evaluating representations of thetheme. Moreover, key entity types in this area are systematicallyidentified and briefly characterized as information units, based onthe set of levels of biological organization in Campbell Biology [13].
Clearly, we have only scratched the surface of the topic, leav-ing much work for the future. Towards a more detailed analysisand a revised classification of the key entity types, a comparisonchart of gene, DNA, and DNA sequence in biomedical ontologiesis briefly discussed. This confirms our impressions from develop-ing first representations of events [8] that capturing continuity andchange would benefit from advancing ontology representation ingeneral, e.g. to support multiple, integrated views on biologicalterms, and to work efficiently with ontological distinctions drawnamong readings of polysemous terms.
ACKNOWLEDGEMENTThis work work has been funded by Vulcan Inc. and SRI Interna-tional. We thank Nikhil Dinesh, Sue Hinojoza, and William Webbfor numerous discussions that helped develop ideas in this paper.
REFERENCES[1]Michael Ashburner, Catherine A. Ball, Judith A. Blake, David
Botstein, Heather Butler, J. Michael Cherry, Allan P. Davis,Kara Dolinski, Selina S. Dwight, Janan T. Eppig, Midori A.Harris, David P. Hill, Laurie Issel-Tarver, Andrew Kasarskis,Suzanna Lewis, John C. Matese, Joel E. Richardson, MartinRingwald, Gerald M. Rubin, and Gavin Sherlock. Gene On-tology: tool for the unification of biology. Nature Genetics,25(1):25–29, May 2000.
[2]Jean-Francois Baget, Michel Leclere, Marie-Laure Mugnier,and Eric Salvat. On rules with existential variables: Walkingthe decidability line. Artificial Intelligence, 175(9):1620–1654,2011.
[3]Ken Barker, Bruce Porter, and Peter Clark. A library of genericconcepts for composing knowledge bases. In Yolanda Gil, MarkMusen, and Jude Shavlik, editors, Proceedings of the First In-ternational Conference on Knowledge Capture, K-CAP 2001,Victoria, British Columbia, Canada, Oct 22-23, pages 14–21,New York, 2001. ACM Press.
[4]Elena Beisswanger, Stefan Schulz, Holger Stenzhorn, and UdoHahn. BioTop: An upper domain ontology for the life sciences:A description of its current structure, contents and interfaces toOBO ontologies. Applied Ontology, 3(4):205–212, 2008.
[5]Vinay K. Chaudhri, Britte Cheng, Adam Overholtzer, JeremyRoschelle, Aaron Spaulding, Peter Clark, Mark Greaves, andDave Gunning. Inquire Biology: A textbook that answersquestions. AI Magazine, 34(3):55–72, 2013.
[6]Vinay K. Chaudhri, Nikhil Dinesh, and H. Craig Heller. Con-ceptual models of structure and function. In Proceedings of theSecond Annual Conference on Advances in Cognitive Systems,pages 255–271, 2013.
[7]Vinay K. Chaudhri, Nikhil Dinesh, and Stijn Heymans. Concep-tual models of energy transfer and regulation. In Oliver Kutzand Pawel Garbacz, editors, Proceedings of the 8th Interna-tional Conference on Formal Ontology in Information Systems,FOIS 2014, Rio de Janeiro, Brazil, Sep 22-25, page (in press),Amsterdam, 2014. IOS Press.
[8]Vinay K. Chaudhri and Frank Loebe. Modeling of continuityand change in biology. In Giancarlo Guizzardi, Oscar Pastor,Yair Wand, Sergio de Cesare, Frederik Gailly, Mark Lycett,and Chris Partridge, editors, Proceedings of the 2014 Work-shops on Ontologies and Conceptual Modeling, Onto.CoM, andOntology-Driven Information Systems Engineering, ODISE,Rio de Janeiro, Sep 22, 2014.
[9]Karen Eilbeck, Suzanna E. Lewis, Christopher J. Mungall,Mark Yandell, Lincoln Stein, Richard Durbin, and MichaelAshburner. The Sequence Ontology: a tool for the unificationof genome annotations. Genome Biology, 6(5):R44, 2005.
[10]David Gunning, Vinay K. Chaudhri, Peter E. Clark, Ken Barker,Shaw-Yi Chaw, Mark Greaves, Benjamin Grosof, Alice Le-ung, David D. McDonald, Sunil Mishra, John Pacheco, BrucePorter, Aaron Spaulding, Dan Tecuci, and Jing Tien. ProjectHalo update: Progress toward Digital Aristotle. AI Magazine,31(3):33–58, 2010.
[11]Hiroshi Masuya and Riichiro Mizoguchi. An ontology of gene.In Ronald Cornet and Robert Stevens, editors, Proceedingsof the 3rd International Conference on Biomedical Ontology,ICBO 2012, KR-MED Series, Graz, Austria, Jul 21-25, volume897 of CEUR Workshop Proceedings, Aachen, Germany, 2012.CEUR-WS.org.
[12]Christopher J. Mungall, Colin Batchelor, and Karen Eilbeck.Evolution of the Sequence Ontology terms and relationships.Journal of Biomedical Informatics, 44(1):87–93, 2011.
[13]Jane B. Reece, Lisa A. Urry, Michael L. Cain, Steven A.Wasserman, Peter V. Minorsky, and Robert B. Jackson. Camp-bell Biology. Benjamin Cummings imprint of Pearson, Boston,9. edition, 2011.
[14]Chaitanya R. Sanna, Wen-Hsiung Li, and Liqing Zhang. Over-lapping genes in the human and mouse genomes. BMCGenomics, 9:169.1–11, 2008.
[15]Stefan Schulz, Elena Beisswanger, Udo Hahn, JoachimWermter, Anand Kumar, and Holger Stenzhorn. From Geniato BioTop: Towards a top-level ontology for biology. In Bran-don Bennett and Christiane Fellbaum, editors, Formal Ontologyin Information Systems: Proceedings of the Fourth Interna-tional Conference (FOIS 2006), Baltimore, Maryland, USA,Nov 9-11, volume 150 of Frontiers in Artificial Intelligence andApplications, pages 103–114, Amsterdam, 2006. IOS Press.
[16]The Gene Ontology Consortium. The Gene Ontology project in2008. Nucleic Acids Research, 36:D440–D444, 2008.
[17]U.S. College Board. Biology: Course description. http://apcentral.collegeboard.com/apc/public/repository/ap-biology-course-description.pdf, 2010.
[18]Linda Wetzel. Types and tokens. In Edward N. Zalta, editor, TheStanford Encyclopedia of Philosophy. Stanford University, Cen-ter for the Study of Language and Information (CSLI), Stanford,California, spring 2011 edition, 2011.
6 Paper F

1
Ontology usage in Omics Standards Initiatives: Pros and Cons of
enriching XML data formats with controlled vocabulary terms
Daniel Schober1*, Michael Wilson2, Daniel Jacob3, Annick Moing3,Gerhard Mayer4, Mar-tin Eisenacher4, Reza M Salek5
, Steffen Neumann1
*1Leibniz Institute of Plant Biochemistry, Dept. of Stress and Developmental Biology, Weinberg 3, 06120 Halle,
Germany
2Department of Computing/Biological Sciences, University of Alberta, Edmonton, Canada
3INRA, Univ. Bordeaux, UMR1332 Fruit Biology and Pathology, Metabolome Facility of Bordeaux Functional Ge-
nomics Center, MetaboHUB, IBVM, Centre INRA Bordeaux, 71 av Edouard Bourlaux, F-33140 Villenave d’Ornon,
France
4Medizinisches Proteom Center (MPC), Ruhr-Universität Bochum, D-44801 Bochum, Germany
5European Molecular Biology Laboratory, European Bioinformatics Institute (EMBL-EBI), Wellcome Trust Genome
Campus, Hinxton, Cambridge, CB10 1SD, UK
EMAIL-ADDRESSES
Daniel Schober: [email protected]
Michael Wilson: [email protected]
Daniel Jacob: [email protected]
Annick Moing: [email protected]
Gerhard Mayer: [email protected]
Reza M Salek: [email protected]
Steffen Neumann: [email protected]
ABSTRACT
Motivation:
We here review a method of XML data enrichment with con-
trolled vocabularies (CV) in light of end-user compliance. We
outline the reasons that made major standard initiatives in
proteomics and metabolomics use this data enrichment
scheme on omics data in favor of more formal approaches,
e.g. description logics (DL) knowledge bases. We show that
in comparison to other knowledge representation formal-
isms, the list of prerequisite skills on the user-side and the
learning threshold is significantly lower, making the approach
feasible for bioinformaticians with average skill levels, i.e.
basic XML knowledge. Additionally our approach allows to
source out the ‘business logics’ from the terminology into
external rules. This enables the successive and encapsulat-
ed addition of semantics in a flexible way.
* To whom correspondence should be addressed.
We feel our approach contributes to increase the amount of
potential users, enabling them to participate in a peer-
produced standards development process.
1 INTRODUCTION
After the very successful introduction of the Gene Ontology
serving the genomics community with a convergent termi-
nology, recent years saw the successful launch of omics
standardisation initiatives such as the Proteomics Standards
Initiative (PSI) and the Metabolomics Standards Initiative
(MSI, Sansone 2007). Open data standards are needed in
these domains, as an ever growing mountain of data is pil-
ing up due to abundant usage of high throughput data gener-
ators, i.e. Mass Spectrometry (MS) and Nuclear Magnetic
Resonance spectroscopy (NMR).
The COSMOS (COordination of Standards in MetabOlom-
icS) EU consortium1 was tasked to foster the creation of an
1 http://www.cosmos-fp7.eu/
Paper G

D. Schober et al.
2
MSI-approved open exchange and storage standard2 for
metabolomics NMR data. It decided to leverage on a partic-
ular set-up proven already successful in the PSI community.
To improve compliance, PSI and MSI consciously refrain
from employing DL in their CV directly. Instead, they lev-
erage on a user-friendly and pragmatic method of solely
using the taxonomic backbones of ontologies in whatever
format available to augment values in simple XML files.
This allows shifting semantic constraints into the XML
Schema definition (XSD) and easy to read XML rules. Alt-
hough this set-up and methodology has already been de-
scribed (Mayer 2013), the reasons that led the OMICS
standardization bodies to prefer this set-up over a plethora
of alternative knowledge representation (KR) formats have
so far been largely implicit.
After briefly recapitulating the basic set-up, we elaborate on
the reasons for this pragmatic CV referencing approach by
highlighting the requirements with end-user compliance in
mind. We discuss the pros and cons of alternative KR for-
malisms such as Description Logics (DL) and Frames to
fulfill the same requirements.
2 MATERIAL AND METHODS
We discuss CV usage as occurring in the PSI and MSI XML
data standards in light of different knowledge representation
schools3, namely pragmatic life science users employing
GO style taxonomies, their arguments probably best sum-
marized in (Bada 2004) and academic formal logics ontolo-
gists creating DL-based axiomatised ontologies, their argu-
ments probably best summarized in (Schulz 2013). We
derive requirements from our use cases and compare key
features needed to fulfil these requirements for our
XML+CV approach with OWL-DL and Frames.
3 RESULTS
The COSMOS Standards workpackage developing the
nmrML data standard and nmrCV, had several overarching
goals guiding decision making. Based on the use cases and
derived requirements, we here list the distinct features of the
three compared KR approaches with respect to the defined
requirements (Tab 1).
3.1 CV Referencing from within XML data files
The nmrML XML format, inspired by the PSI mzML for-
mat (Mayer 2013), consists of an XML Schema Definition
(XSD) that is instantiated and accompanied by CV annota-
tions in a concrete XML data file. The XSD defines the
allowed XML elements, their attributes, cardinalities and
mandatoryness etc. The requirement and modality for a CV
2 http://nmrml.org 3 http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2447479/pdf/CFG-05-
623.pdf
term occurrence in an XML instance is specified in the XSD
by reference elements/types. The general approach can be
seen as adding outsourced semantics to XML4. At certain
locations specified in the XSD, the user is allowed to de-
scribe his data by <CVParam> tags, where attributes refer-
ence the standardized CV terms. The CV provides the ter-
minology to describe the data in detail and provide standard-
ized values for the XML tags. For example, the XSD de-
fines a ValueWithUnitType reference to hold a value and a
description of the unit the value is recorded in by means of a
Unit Ontology CV term. An example XML code specifying
the temperature of 30 °C of a given NMR sample XML
looks like this: <sampleAcquisitionTemperature unit-Name="degree Celsius" unitCvRef="UO" val-ue="30" unitAccession=" UO:0000027"/>
In areas where the terminology is likely to change faster
than the nmrML XSD can be updated and aligned, branch-
ing out from the XSD to CV usage can compensate for such
dynamics in a flexible way, as the CV can be maintained
externally and even in a decentralized and peer-produced5
manner. For example, new NMR probe types can be repre-
sented in an nmrML file by requesting and adding a new CV
term for the unchanged XML element, without the need for
any XSD revision, which in turn would require to also up-
date programs using nmrML. The XSD ‘branches out’ into
CV-usage where:
· Terms are unstable & dynamically evolving, or
need to be changed and updated often, such as
Hard- & software names/versions etc.
· Terms are lexically variant and need convergence
via synonym equivalence detection
· Terms describe contextual metadata, rather than
concrete NMR raw data, i.e. for cases where the
terminology is already extensively defined in exist-
ing ontologies or CVs, e.g. the unit ontology.
· Terms represent important search attributes for da-
ta querying; this will ease large scale database-
integration in an open linked data fashion.
· Terms should be accessible to rule-based or exter-
nal DL reasoning techniques for ontology audit,
validation and querying, e.g. to profit from sub-
sumption to generalize over query attributes and
increase result recall and precision.
3.2 Data Validation
The XSD+CV set-up allows for multiple data validation
levels to be established in an onion layered approach, con-
tributing to data consistency, completeness and overall qual-
ity assurance.
4 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.42.3250 5 http://en.wikipedia.org/wiki/Peer_production
Paper G
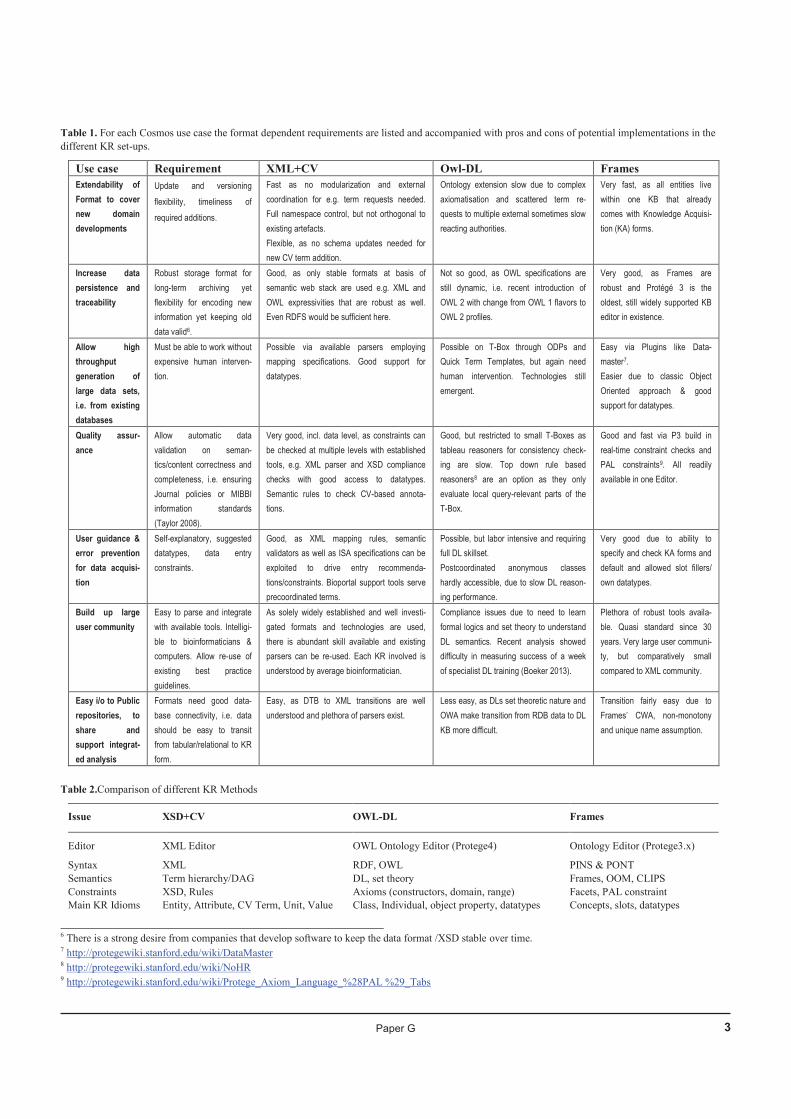
3
Table 1. For each Cosmos use case the format dependent requirements are listed and accompanied with pros and cons of potential implementations in the
different KR set-ups.
Use case Requirement XML+CV Owl-DL Frames
Extendability of
Format to cover
new domain
developments
Update and versioning
flexibility, timeliness of
required additions.
Fast as no modularization and external
coordination for e.g. term requests needed.
Full namespace control, but not orthogonal to
existing artefacts.
Flexible, as no schema updates needed for
new CV term addition.
Ontology extension slow due to complex
axiomatisation and scattered term re-
quests to multiple external sometimes slow
reacting authorities.
Very fast, as all entities live
within one KB that already
comes with Knowledge Acquisi-
tion (KA) forms.
Increase data
persistence and
traceability
Robust storage format for
long-term archiving yet
flexibility for encoding new
information yet keeping old
data valid6.
Good, as only stable formats at basis of
semantic web stack are used e.g. XML and
OWL expressivities that are robust as well.
Even RDFS would be sufficient here.
Not so good, as OWL specifications are
still dynamic, i.e. recent introduction of
OWL 2 with change from OWL 1 flavors to
OWL 2 profiles.
Very good, as Frames are
robust and Protégé 3 is the
oldest, still widely supported KB
editor in existence.
Allow high
throughput
generation of
large data sets,
i.e. from existing
databases
Must be able to work without
expensive human interven-
tion.
Possible via available parsers employing
mapping specifications. Good support for
datatypes.
Possible on T-Box through ODPs and
Quick Term Templates, but again need
human intervention. Technologies still
emergent.
Easy via Plugins like Data-
master7.
Easier due to classic Object
Oriented approach & good
support for datatypes.
Quality assur-
ance
Allow automatic data
validation on seman-
tics/content correctness and
completeness, i.e. ensuring
Journal policies or MIBBI
information standards
(Taylor 2008).
Very good, incl. data level, as constraints can
be checked at multiple levels with established
tools, e.g. XML parser and XSD compliance
checks with good access to datatypes.
Semantic rules to check CV-based annota-
tions.
Good, but restricted to small T-Boxes as
tableau reasoners for consistency check-
ing are slow. Top down rule based
reasoners8 are an option as they only
evaluate local query-relevant parts of the
T-Box.
Good and fast via P3 build in
real-time constraint checks and
PAL constraints9. All readily
available in one Editor.
User guidance &
error prevention
for data acquisi-
tion
Self-explanatory, suggested
datatypes, data entry
constraints.
Good, as XML mapping rules, semantic
validators as well as ISA specifications can be
exploited to drive entry recommenda-
tions/constraints. Bioportal support tools serve
precoordinated terms.
Possible, but labor intensive and requiring
full DL skillset.
Postcoordinated anonymous classes
hardly accessible, due to slow DL reason-
ing performance.
Very good due to ability to
specify and check KA forms and
default and allowed slot fillers/
own datatypes.
Build up large
user community
Easy to parse and integrate
with available tools. Intelligi-
ble to bioinformaticians &
computers. Allow re-use of
existing best practice
guidelines.
As solely widely established and well investi-
gated formats and technologies are used,
there is abundant skill available and existing
parsers can be re-used. Each KR involved is
understood by average bioinformatician.
Compliance issues due to need to learn
formal logics and set theory to understand
DL semantics. Recent analysis showed
difficulty in measuring success of a week
of specialist DL training (Boeker 2013).
Plethora of robust tools availa-
ble. Quasi standard since 30
years. Very large user communi-
ty, but comparatively small
compared to XML community.
Easy i/o to Public
repositories, to
share and
support integrat-
ed analysis
Formats need good data-
base connectivity, i.e. data
should be easy to transit
from tabular/relational to KR
form.
Easy, as DTB to XML transitions are well
understood and plethora of parsers exist.
Less easy, as DLs set theoretic nature and
OWA make transition from RDB data to DL
KB more difficult.
Transition fairly easy due to
Frames’ CWA, non-monotony
and unique name assumption.
Table 2.Comparison of different KR Methods
Issue XSD+CV OWL-DL Frames
Editor XML Editor OWL Ontology Editor (Protege4) Ontology Editor (Protege3.x)
Syntax XML RDF, OWL PINS & PONT
Semantics Term hierarchy/DAG DL, set theory Frames, OOM, CLIPS
Constraints XSD, Rules Axioms (constructors, domain, range) Facets, PAL constraint
Main KR Idioms Entity, Attribute, CV Term, Unit, Value Class, Individual, object property, datatypes Concepts, slots, datatypes
6 There is a strong desire from companies that develop software to keep the data format /XSD stable over time. 7 http://protegewiki.stanford.edu/wiki/DataMaster 8 http://protegewiki.stanford.edu/wiki/NoHR 9 http://protegewiki.stanford.edu/wiki/Protege_Axiom_Language_%28PAL %29_Tabs
Paper G

4
In OWL-DL it is difficult to set distinct stringency-levels on
data consistency checks. Although the expressivity regime
dictates the types of reasoning on the data, an OWL ontolo-
gy is either totally consistent or inconsistent10
.
Here, XML syntax and structural validity of XML instances,
e.g. XML element and attribute positions, order and cardi-
nality, can be validated by an XML parser against the XSD.
Additional mapping rule files are used to enforce semantic
validity by specifying which CV terms are allowed for an
element as well as their order and cardinality. A dedicated
semantic validator11
checks that the criteria outlined by the
mapping file are being met by a given XML instance. It
enforces simple IF-THEN rules not only making sure that
the terms are actually found in a specified CV, but also that
the correct terms are used in correct locations (XML Tags)
in the XML document and the required terms are present the
correct number of times. E.g. that there are two filler values
“Kelvin” or “Degree Celsius” allowed for the SampleTem-
perature-Element, and that these must come from the Unit
Ontologies’ “temperature unit” subtree. This allows greater
flexibility in the schema, but enforces order in how the CV
terms are used. This will require the discipline of using the
semantic validator exploiting validation rules for checking
an annotation prior to storage and submission.
The result is that new technologies or information can be
accommodated with adjustments to the controlled vocabu-
lary and validator, not to the schema which hence can stay
stable.
Validating the above XML data snippet with the following
validation rule (HTML version)
Identifier:sampleAcquisitionTemperature_must
Element:/nmrML/acquisition/acquisition1D/
acquisitionParameter-
Set/sampleAcquisitionTemperature@unitAccessi
on
Requirement level: MUST
Term: UO:0000012 ! kelvin
hence would result in a validation error, as the temperature
is specified in degree Celsius rather than Kelvin. The map-
ping file combined with the CV can also be used for intelli-
gent support in data acquisition, i.e. when creating an inter-
face that records NMR experiment information it can popu-
late a drop down menu or an autocomplete box with plausi-
ble entries.
3.3 Comparison of skills required by approaches
Table 2 summarizes the features leveraged on by the bio-
medical data curator applying the different KR approaches
for data annotation and storage. In amendment to Tab 1, it
also highlights some of the skill levels required on the end-
user side in comparison.
10 often violating whole branches, even though subsets might be correct. 11 http://nmrml.org/validator/
4 DISCUSSION
A large part of current discussions in the biomedical ontolo-
gy field is devoted to OWL and description logics (DL)
semantics. Beside its computational performance issues for
tableau reasoning in big data set-ups, DL semantics is rather
complex and requires users to get acquainted with its set
theoretic basis. These characteristics have hindered wide-
spread application of DL expressivity in high throughput
data exchange and annotation. Although strategies for sim-
plifying DL complexity were discussed in an earlier paper
(Schober 2010), DL expertise is still not as abundant as
needed for larger peer-produced formal ontology creation
and exploitation. Although through its recommendation by
the W3C, OWL became a major player even in the semantic
web domain, many people do not leverage on DL expressiv-
ity12
in OWL ontologies.
DL was never good at data-capture (Schulz 2010) and no
easy-to-use knowledge acquisition (KA) forms that con-
strain user entries to allowed datatypes are available, e.g.
like in Frames. Such tools13
are only now emerging.
Moreover, one can often find DL axiomatised class defini-
tions which put the burden of capturing many properties of
an individual or class which serve proper classification and
reasoning, but are trivial and uninteresting for the scientific
life science domain end user. We doubt that axioms that are
good for consistency checking and untangling, are neces-
sarily good for providing usable search attributes. We found
that information retrieval is in fact often not well supported
by DL axioms, e.g. in the following OBI example
Manufacturer SubclassOf MaterialEntity and
equivalentTo
('Homo sapiens' or organization)and
('has role' some 'manufacturer role')
the word-cloud that comes intuitively to the end users mind
when mentioning ‚manufacturer‘ is not well matched, e.g.
the axiomatisation misses out on important aspects like
product lists, contact details, location, etc. to be expected in
a data centric environment. Instead we are informed that a
manufacturer has a role manufacturer role, a statement
which will seem trivial, if not tautological, to the end user.
Such DL class definitions, exhibit dependencies to classes
for which real world owl:individuals are hard to imagine
e.g. what is the instance of a role ? Such individuals, entered
into a knowledge base solely for the sake of fulfilling design
patterns for DL reasoning will rather cause performance
problems than supporting terminological end user require-
ments.
12 A contributing factor might be that the OWL specification for DL was
less stable than XML and underwent transitions from OWL 1 flavors, over
OWL 2‘profiles’ to expressivity regimes. 13 http://www.isa-tools.org/tools.html
Paper G

Ontology usage in Omics Standards Initiatives: Pros and Cons of enriching XML data formats with controlled vocabulary terms
5
Another example of modeling against the users needs, not
meeting his requirements is
Decapitated organism equivalentTo
'material entity' and
(is_specified_output_of some decapitation)
, which misses out on the fact that the organism is now
consisting of two entities, cut along the head-neck joint, a
separated rump with extremities and a head. Also the fact
that it is now a dead organism with all its practical and ethi-
cal consequences, is missing in this reductionist definition.
In DL, such definitions rely on this information – although
being important – being drawn from sometimes distant
related entities in the ontology by the reasoner, e.g. the fact
that this definition applies to a living organism is entailed in
the decapitation process, whereas the definition itself sub-
classes material entity. Leveraging only on the local axioms
in the definition, it would not exclude a decapitated cigar or
teddy bear, as some of this essential information is factored
out elsewhere, i.e. here into superclasses of the decapitation
process. This makes the classes very dependent on the con-
textual model and DL reasoning and hence renders it less
usable when wanting to exploit the self-standing local class
definition, i.e. when annotating a database entry.
To reach domain coverage in an acceptable time in our CV
we simply pre-coordinate the terms according to appearance
in our use cases. In formal DL ontologies, modularization
policies demand that for each simple class addition of e.g.
“Library based computed concentration” its refactored se-
mantic Lego blocks are requesting in external artefacts, i.e.
Unit Ontology (concentration), Evidence Ontology (com-
puted), and maybe Information Artefact Ontology (Library).
So, orthogonality assurance, besides domain-borders being
difficult to determine, often requires time-costly requests for
term additions of unavailable terms in external artefacts, an
obstacle we avoid in our pragmatic CV setup.
Frames have a long and successful history in AI and with
good support of configurable data types and KA forms they
are ideally suited for data capture and drag and drop con-
ceptual annotation (Schober 2005). Its intuitive object-
oriented top down inheritance, e.g. of default slots with
values allows for many of the requirements outlined above
to be met in one monolithic and coherent format14
. Frames
and our rule based approach are also closer to the general
procedure of human knowledge generation, as due to its
non-monotonic reasoning ability, it allows a KB to be ex-
panded slowly by adding new knowledge with effect on the
truth value of already inferred statements. Such ability is
only now emerging in the OWL-DL field15
. The Protégé 3
14 It is interesting to note that this formalism is gaining attraction again, e.g.
see this conferences OntoStudyEdit submission by A. Uciteli and H. Herre 15 http://www.aifb.kit.edu/web/Epistemic_Reasoning_in_OWL_2_DL
editor is stable and besides data capture and editing, pro-
vides a plethora of plugins for processing, validation, query-
ing and visualization. However this virtue can also be seen
as burden, as although one single editing environment can
handle all needed KR tasks, the GUI becomes rather com-
plex. Non-programmers have difficulties to understand the
object oriented modeling principle and users need to learn
OKBC-CLIPS, a non-W3C supported KR language.
Compared to DL-based approaches, our approach relies on
simple taxonomic CVs, preferring intuitiveness over formal
rigidness and making no assumptions on any end user skill
other than XML and what an is-a hierarchy of terms is.
Our approach has the advantage of being an addition that
complements parallel DL approaches applied in the back-
ground i.e. for T-Box-reasoning-enabled ontology mainte-
nance tasks, rather than validation through A-Box reasoning
on data. In an additional reverse approach, lexical patterns
in term names can still be exploited to support DL axiomati-
sation of CVs. However, efforts to axiomatise the GO tax-
onomy were perceived as a very time consuming endeavor
(Wroe 2003). As DL tools become more mature and compu-
tational power increases, classification, consistency checks
via T-Box tableau reasoning can later still be done on such
axiomatised DL ontologies.
The approach to outsource completeness and consistency
checks into XML rules suits large data sets better, as rule
systems are faster than the slow DL tableau reasoning ap-
proaches. Besides performance, they are also better coping
with unfinished and incomplete/missing data as rules act
rather locally, whereas one distant missing axiom can render
a whole DL KB branch invalid.
On another line, the separation of CV term creation and
their formal semantic definition and validation can be seen
as outsourcing the ‘business logic’ from the data layer, ena-
bling more freedom on the end user side. Conflating the
validation layer with the terminology layer makes the over-
all artefact not only hard to grasp for end users, but it also
decreases shell-wise processing as all KR idioms are inher-
ently dependent on and interrelated with each other.
Our approach is also rather flexible with datatype specifica-
tions, i.e. allows capturing value-unit pairs.
We propose to let the pragmatic life-science users and aca-
demic formal logics ontologists do what they are best in,
and leverage on the best of both worlds, i.e. by connecting
them in a two-tiered hybrid approach along what was al-
ready proposed in Cornet (2005). This way, CVs in our
simple set-up can leverage from DL axiomatised top level
resources, even when our nmrML itself stays unaxio-
matised, e.g. we imported and subclassed an axiomatised
top level ontology (TLO). Running a DL reasoner on
nmrCV.owl, a class 'chemical compound formula‘ was
detected as inconsistent, because 'chemical compound for-
mula' was asserted as 'information object' AND 'chemical
compound attribute' (a subclass of 'quality'), but the TLO
Paper G

D. Schober et al.
6
declared 'quality' and 'information object' as disjoint16
. But
we ask again, would any such loss of distinction of being a
quality vs an information content entity really be a source of
erroneous scientific interpretation with impact on our use
case fulfilment? We feel these questions need a more thor-
ough investigation.
5 CONCLUSIONS
The omics communities need efficient processing tools and
results on available data today and cannot afford to wait
until mature DL ontologies are available in sufficient cover-
age and granularity. These just take too much time to build
and it is not clear that they capture what the end-users really
need17
. We have outlined justifications for a pragmatic ap-
proach for life science data standards, which shifts seman-
tics from ontologies to rules and exemplified them by indi-
cating how they contribute to end-user compliance. Our
simple taxonomies/CVs can be built by the life scientists
themselves in a peer production approach, ensuring fast
growth and sufficient timely domain coverage. The nmrML
standard is already sanctioned by the metabolomics stand-
ards initiative and is accepted by major opensource NMR
data processing tools. It will serve the MetaboLights reposi-
tory (Haug 2013), and other metabolomics data repositories,
with a stable storage format. Also tools and parsers are easy
to build as we exclusively leverage on established methods
and formats. Many aspects of Minimum Information on an
NMR experiment (MI NMR, Rubtsov 2007) can already be
captured and validated with our set-up. The outsourcing of
semantics into rule sets allows us to be flexible, e.g. having
settings to validate either the basic nmrML raw data level or
at a more comprehensive MI NMR compliance level, de-
pending on the needs of the user. Specifying such stringency
levels in a DL KB would be more difficult due to the inher-
ently non-local behavior of the reasoning algorithms.
Positive feedback by vendors at the Metabolomics 2014
conference and the offer to support nmrML parsers in the
ChenomX NMR suite hint for a good ‘buy in’ even from
commercial companies, which often look at OWL-DL for-
malisms with suspicion.
To conclude, the XML/XSD based CV usage is well suited
to meet the COSMOS requirements for an easy to under-
stand data standard and to capture our experimental data,
whereas OWL-DL better suited to formalize background
knowledge, and aid in ontology maintenance and audit.
16 https://github.com/nmrML/nmrML/issues/62 The erroneous assertion of
object attributes being a quality has now been removed and is now found
under information objects. 17 The Nobel laureate Manfred Eigen states that ‘a theory has only the
possibility of being right or wrong. A model has a third possibility; it may
be right but irrelevant.’
ACKNOWLEDGEMENTS
This work was financed via the EU FP7 project COSMOS
grant EC312941. GM is funded by the Deutsche Gesetzliche
Unfallversicherung (DGUV) project DGUV-Lunge (617.0
FP 339A. We thank Carol Goble and the Capulets from the
PSI ontology working groups for inspirations.
REFERENCES
Bada M, Stevens R, Goble CA, et al (2004) A short study on the
success of the Gene Ontology. J Web Semant 1: 235–240
Boeker M, Jansen L, Grewe N, Röhl J, Schober D, et al. (2013):
Effects of Guideline-Based Training on the Quality of Formal
Ontologies: A Randomized Controlled Trial. PLoS ONE 8 (5):
e61425.
Cornet R, Abu-Hanna A (2005): Description logic-based methods
for auditing frame-based medical terminological systems. Artif
Int in Med, 34(3): 201-217
Haug K, Salek, RM, Conesa P, et al. (2013) MetaboLights--an
open-access general-purpose repository for metabolomics stud-
ies and associated meta-data. Nucl acids res, 41(Database is-
sue), D781-786, doi:10.1093/nar/gks1004.
Mayer G, Jones AR, Binz PA et.al. (2013) Controlled vocabularies
and ontologies in proteomics: Overview, principles and prac-
tice. Biochim Biophys Acta. Feb 19. pii: S1570-9639(13)00080-
0. doi: 10.1016/j.bbapap.2013.02.017.
Rubtsov DV, Jenkins H, Ludwig C, Easton J, et al. (2007) Pro-
posed reporting requirements for the description of NMR-based
metabolomics experiments. Metabolomics, 3, 223-229.
Sansone SA, Fan L, Goodacre R et al. (2007) The metabolomics
standards initiative. Nat Biotechnol, 25, 846–848.
Schober D, Boeker M (2010) Ontology Simplification: new
buzzword or real need? 2nd Workshop of Ontologies in Bio-
medicine and Life Sciences (OBML), Mannheim, 9.-10.9.
2010). http://www.bioontology.org/node/628
Schober D, Leser U, Zenke M, Reich JG (2005) GandrKB--
ontological microarray annotation and visualization. Bioinfor-
matics 21(11): 2785-2786
Schulz S, Schober D, Daniel C, et al. (2010) Bridging the seman-
tics gap between terminologies, ontologies, and information
models. Stud Health Technol Inform; 160 (Pt 2): 1000-1004.
Schulz S; Balkanyi L; Cornet, R; Bodenreider, O (2013) From
Concept Representations to Ontologies: A Paradigm Shift in
Health Informatics? Healthc Inform Res.; 19(4):235-242
Taylor CF, Field D, Sansone SA, et al. (2008) Promoting coherent
minimum reporting guidelines for biological and biomedical
investigations: the MIBBI project, Nat Biotechnol.; 26(8):889-
96. doi: 10.1038/nbt.1411. , PMID:18688244
Wroe CJ, Stevens R, Goble CA, Ashburner M. (2003) A method-
ology to migrate the Gene Ontology to a description logic envi-
ronment using DAML+OIL. Pac Symp Biocomput 8: 624–635.
Paper G

Towards a teenager tailored ontology— Supporting inference about the obesity-related health status —
Aleksandra Sojic1∗, Walter Terkaj1, Giorgia Contini1, and Marco Sacco1
1Istituto Tecnologie Industriali e Automazione (ITIA) CNR, Milano, Italy
ABSTRACTIn this paper we outline the general framework of theontology that captures the obesity-related features ofteenagers. We present our particular choices regardingthe ontology-structure, which should be capable ofcapturing (1) multiple perspectives used to describean adolescent and (2) reasoning about the individualchanges during the time. In the same line, weaddress several issues related to the modelling ofnormative concepts related to obesity and depict how thepublic health concern impacts classification of teenagersaccording to their phenotypes. In particular, we presenta fragment of the ontology that supports inferenceabout individuals and a personalised assessment of theobesity-related health conditions.
1 INTRODUCTIONOverweight and obesity are estimated to result inthe deaths of about 320 000 people in westernEurope every year [15]. The prevalence rates ofobesity among children and adolescents motivatedthe public health organisations to engage in thepromotion of a healthy life style [15]. Nonetheless,the understanding of the causal links between obesityand numerous socio-behavioural aspects of life-styleis a complex task that involves multiple domains ofknowledge and the analysis of heterogenous kinds ofdata. This problem can be addressed by adoptingSemantic Web technologies, in particular ontologies,that are recognised as a convenient approach todeal with complex and heterogeneous informationacross various domains, enable knowledge generationvia reasoning and support data interoperability [22,10]. Several studies report on the use of ontologyand semantic technologies to target obesity (e.g.[21, 20]). Scala et. al [20] developed an e-Knowledge platform, based on an OWL1 ontologyand SWRL [9] rules, classifying individuals accordingto the obesity level and certain medical conditions(Sarcopenia, Hypertension, Dyslipidemia, Diabete,Insulin resistance, Metabolic syndrome). Arash et. al
∗Corresponding author: [email protected] http://www.w3.org/TR/owl2-overview/
[21] present the preliminary stage of the ontologydesigned to support a knowledge-based infrastructure,promoting healthy eating habits and lifestyles. While[20] focuses on adults and [21] on children, in thispaper we present the current state of the ontologythat captures formally obesity-related knowledge ina teenager tailored model. The main ontologicalstructure is formalised in OWL, specifying certaingeneric classes that are applicable to any human beingand represent explicitly the time-dependent changesin health condition (i.e. the issue that was notaddressed by [21, 20]). At a later stage, the ontologyshould be able to support the information flow andinteroperability between the technological tools andplatforms employed to monitor the changes of healthstatus, behaviour, and nutritional habits of teenagers.The initial step in the ontology development includesa multi-disciplinary analysis that considers a teenageras a dynamic agent who is constantly changing in theinteraction with his environment. The development ofthe teenager-centered ontology is initiated within theEuropean research project named PEGASO 2, whosemain goal is the enhancement of self-awareness andmotivation of adolescents towards a healthy lifestyle[6, 2, 3]. The project is driven by the public healthconcerns aiming at the decrease of the obesity-relatedrisks to health [6, 14]. The target population of theproject are the future adults whose behavioural habits atan early age can significantly impact their health statuson a life-long scale [2]. The project includes severalresearch initiatives and interventional strategies, mostof which go beyond the scope of this paper, e.g. thedevelopment of serious games [17, 6] that will promotean healthy life style, the design of a life companion[3], the use of wearable gadgets equipped with sensorsto monitor health status [3, 6], the design of mobileapplications such as a diary used to record dietaryhabits, etc. [3, 6].
The multidisciplinary studies of the interactionsbetween a teenager and his environment should providea comprehensive model, i.e. the so-called VirtualIndividual Model (VIM) [2] that will be used as a
2 http://pegasof4f.eu/
1Paper H

theoretical framework of the PEGASO project. Whilethe VIM captures obesity-related knowledge by thecommon representational means, e.g. natural language,tables and graphs (readable to competent humanexperts), the presented information is still implicit andit is not specified in a formal language. The VIMlacks a formal semantics that could disambiguate itsterminological and ontological assumptions, structuringthe concepts and relations in a comprehensive andmachine-readable form. After several interviews withthe domain-experts, the key targets of the ontology-model are specified to: (1) capture the health conditionof an Individual; (2) detect personal obesity-related riskfactors; (3) optimise the information structuring in orderto provide a personalised feedback that can motivatebehavioural changes towards a healthy lifestyle. In thefollowing section we first outline several theoreticaland practical aspects that will be relevant to describehow the preliminary ontology was designed and tojustify our decisions about the structural segments ofthe ontology. Then, we present the current state ofthe ontology that captures the physical domain andclassifies the health conditions based on assessment ofthe body constitution. Finally, we provide an exampleof reasoning over personal assessment of the obesecondition by combining OWL and the Semantic WebRule Language (SWRL) rules.
2 THE ONTOLOGY STRUCTUREThe framework of the ontology aims at integratingseveral fields of knowledge that are related to theproblem of obesity. In this section we identify the fieldsthat will be represented as the main ontology modules,each of which considers a particular aspect that isrelevant for the problem. Regarding the methodologicalstrategy of our approach, we keep in line with thetradition that considers ontology as an engineeringartifact that is useful to model some aspects of theworld. In other terms, we accept the position that in AIsystems, “what exists” is that which can be represented[5, p. 908–909]. The aim of this section is to explainand justify our representational choices in the contextof current scientific knowledge and goals of the work.
A cross-disciplinary approachWhile dealing with the problem of obesity it isimportant to consider several factors such as physicalinactivity, physiological dysfunction, unhealthy eatinghabits, social and psychological problems. In somecases, one of these aspects can be more decisive than theothers causing overweight or obesity, in other cases, thedisease is the result of a combination of many factors.In order to diagnose and modify the health status of an
individual it is necessary to take into account his/hercurrent condition through a comprehensive modelcapable of representing the human being as a whole.Such a model is an abstract representation that aims atintegrating the cross-disciplinary knowledge about anindividual, his/her characteristics and relationships ina broad context. It aims to comprehensively representall the components that influence the health status ofa teenager that is related to overweight and obesity.The model (i.e. VIM) focuses on three distinct levelsin order to characterise the states of an individual:(1) the physical-physiological level, (2) the nutritionallevel, and (3) the psychological level. All thesevarious perspectives constitute an integral approachto the understanding of an individual, providing thetheoretical framework to determine the individual’shealth status in a dynamic manner. The theoreticalmodel is considered as the initial ground that isused for the ontology development. The ontologymodel needs to specify further on a formal level thestructure, concepts, and the most relevant relationsthat hold between them. Designing such an ontologymodel that integrates all the relevant perspectives isa challenging task. First, it involves collaboration ofthe experts with different backgrounds (philosophers,biomedical experts, clinicians, psychologists, computerscientists, and engineers), positioning the ontology inan interdisciplinary environment that is dealing withthe terminological and conceptual problems in orderto merge numerous (domain-specific) perspectives (seee.g. [22]). Second, the ontology design involves thedecision on the ontology structure that will be crucialto its successful application. Currently, we considerthe most convenient modularisation strategy [1, 4] toorganise knowledge. At this point we have decided todivide the main ontology structure according to twocriteria: (a) the criterion of disciplinary perspectives[6, 2, 3](specifying modules 1-5) and (b) the criterionof an integrative view (specifying modules 6-7). Theresulting structure consists of the following modules:
1. Physical domain describing physical features of ateenager
2. Physical Activity and the related behaviour of ateenager.
3. Physiological domain
4. Psycho-social domain
5. Alimentary behaviour
6. Trends of change of an individual status that isformalised within (1-5). This module will be usedto model the decisions about the interventionalstrategies and a personalised feedback to teenagers
2Paper H

7. Commons module to support the interoperabilitybetween the modules (1-6)
The ontology is currently at an early stage ofdevelopment and has formalised only the segmentsrelevant for the first module. The module distinguishesthe relevant body features, linked to measurements andcertain classes of health conditions that will be usedto define the obesity-related status and potential riskfactors. In the following subsection we present thelinks between the measurements characterising bodyconstitution that are afterwords used to classify thecorresponding health conditions.
Capturing normative concepts: assessment ofobesity as a health conditionIn general terms, a description of a teenager via somestructural, functional, and behavioural characteristics isactually capturing aspects considered to be relevant todescribe the teenager-specific phenotype. A phenotypeis defined as a set of features of an organism thatemerges as a result of interactions of his geneticmaterial (specified as genotype) and the environment(see e.g.[11]). Herein, the genotype3 of a teenager isnot considered explicitly. We focus on the phenotypicfeatures describing the class to which a person belongsas determined by the description of his/her physical andbehavioural characteristics [11]. Thus, we consider thata person’s phenotype belongs to the class obese basedon his characteristics, description of which (despite ofindividual variations) fits to the description of an obesephenotype that is typical for every person of a certainage, gender, and with a specific body mass index.We define typical features of an obese phenotype interms of a conventional agreement at the current stageof knowledge. The reference system that we use tocharacterise the physical features of an obese phenotypeis provided by the World Health Organisation[14] and itincludes the age and gender specific ranges of values,e.g. body mass index of a teenager (see [16]). Thus, wetreat the description of body constitution as a specificcharacterisation of phenotype that is associated withhealth condition.
Figure 1 presents the hierarchy of the relevant healthconditions, specifying the physical constitution thatconsiders adiposity, body fat distribution, body mass,and central obesity. Each of the conditions is associatedwith a specific classification and linked to the referencevalues that characterise physical features relative togender and age [16]. These classifications are distinct
3 The class to which a person belongs as determined bythe description of his/her physical material made up of DNApassed to the organism by his parents.
as they are using diverse criteria to describe a conditionof body constitution.
Fig. 1. A fragment of the obesity-related classes used forthe assessment of a personal health condition that is directlydependent on gender and age at the time of assessment.
For instance, the criterion of body mass (provided asbody mass index [16]) in one of the classifications isused to distinguish people as belonging to one of thefollowing groups: obese, underweight, overweight ornormal weight [14]. According to the classification thatconsiders fat distribution, a person may be classifiedeither as android or as gynoid. In the following sectionwe provide an example of the personalised assessmentof the obese condition according to the measure of bodymass index, relative to gender and age at the time ofassessment.
A fragment of the ontologyAn ontology as an artefact is not intended to coverthe world in its entirety, but only chosen aspects ofthe world, on specific levels of abstraction, and forgiven purposes. Thus, we present here a ‘simplifiedview of the world that we wish to represent’[5] whilemodelling obesity-related knowledge in a declarativeformalism. We defined the scope of our universe ofdiscourse that is relevant for the goals of our formalmodel, i.e. (1) capturing the physical characteristics ofa person and then (2) evaluating the health conditionspecifically for a teenager. The former goal wasreached by developing an OWL ontology, whereas thelatter by defining SWRL rules. The class hierarchyof the OWL ontology consists of two key classes:Person and HealthCondition. These two classesare linked by a restriction involving the object propertyisInHealthCondition, so that a person can beassociated with one or more health conditions (seeFigure 2) while aiming at tracking the evolution of thehealth condition over time in a dynamic context. Theclassification of a generic health condition as belonging
3Paper H

Fig. 2. Depicting the general structure of the classes and relations used to support the reasoning over instances, e.g. the orangearrow (bold dashed) stands for an inferred relation that classifies TomCondition1 as an ObeseCondition.
Fig. 3. The example of the rules used to support reasoning about a personalised assessment of health condition, e.g. TomCondition1is ObeseCondition (inferred by the Pellet reasoner in Protégé.)
to one the HealthCondition subclasses (see Figure1) is performed by means of SWRL rules that makes useof (1) physical (structural) and functional (metabolic,etc.) features, (2) gender, and (3) age of a person.
The physical and functional features are directlyassociated with a health condition, e.g. the bodymass index is defined using the data propertyisCharacterizedByBodyMassIndex (see Figures2 and 3).
The gender is defined by instantiating a Person asbelonging to one of its subclasses, i.e. classes Male andFemale.
The exact age of a person when the health condition isevaluated is a crucial information because the referencevalues for the assessment are particularly varying inthe adolescence when body grows and changes [16].In order to capture this variability that can impacton the assessment, we associate Person with thebirth date and HealthCondition with the date ofassessment (year and month) by using the followingobject properties and restrictions:
Class: PersonSubClassOf: (1)
isInHealthCondition only HealthConditionisBornInYear only integer
4Paper H

isBornInMonth only integerClass: HealthCondition
SubClassOf: (2)isAssessedAtAge only decimalisAssessedOnDateYear only integerisAssessedOnDateMonth only integer
Having the data related to the date of birth andtime of assessment, we can apply a rule modelledin SWRL[9] in order to get an age value associatedwith a personal condition assessment (see Figure 3), sothat all the needed elaborations can be performed by areasoning tool without needing to interface with otherapplications.
We tested our ontology by instantiating the abovementioned classes and then running a reasoner (i.e.Pellet reasoner plug-in for Protégé4) to properly classifythe health conditions. The example in Figure 3 showsan instance of a boy, named Tom, who is assigned twoassessments of his health condition: TomCondition1(assessed in November 2014), and TomCondition2(assessed in November 2015). Since the reference valuefor the assessment of an obese condition changes withage (see the reference values in Figure 3), and in ourexample Tom’s body mass index stays unchanged, onlyTomCondition1 is inferred to be ObeseCondition.The same reasoning can be performed with the instancesof teenagers of different age and gender. We alsospecify the reference values relevant for assessmentof other obesity-related categories of health condition(e.g. provided as measure of waist circumference) bydefining a total of 74 SWRL rules. As a comparison, thework Scala et. al [20] contains approx. 40 rules.
The facts resulting from the reasoning can besaved into the ontology, thus actually enriching theknowledge. The ongoing work includes the extensionof the ontology module with the formal specification ofother relevant phenotypic features.
3 DISCUSSION AND FUTURE WORKWe presented the initial steps performed in the ontologydesign related to the PEGASO project. We depictedhow a public health concern such as obesity impacts thedecisions about the most relevant classes and relationsthat are used to represent phenotype of teenager andto integrate various perspectives and domain specificknowledge. Specifically, we presented the preliminaryresults of the ontology that (1) targets the populationof teenagers, (2) formally captures physical aspects ofphenotype, (3) classifies health conditions accordingto the physical constitution (obesity-related classes),
4 http://clarkparsia.com/pellet/protege/
(4) associates the condition of physical constitutionwith the personal assessment of the condition as ageand gender dependent, (5) supports reasoning overinstances, e.g. individual teenagers that may haveassigned diverse conditions at different time points (agedependent assessment).
We are currently working on the design of aninterlinked modular structure. Since our target is thephenotype of teenagers, in the future work we willconsider to link our ontology with relevant phenotypeontologies5. In addition, we aim at joining the efforts increating alignments [19, 7, 13] between our ontologyand the reference terminologies and ontologies 6, aswell as foundational ontologies7.
ACKNOWLEDGEMENTSThis work has been partially funded by the EU 7thFramework Programme under the grant agreementsNo: 610727, “Personalised Guidance Services forOptimising lifestyle in teenagers through awareness,motivation and engagement” (PEGASO). The project iscompliant with the European and National legislationsconcerning the user safety and privacy. We would liketo thank all the partners in the project, in particularClaudio Lafortuna, Giovanna Rizzo, and Sarah Tabozzi.We would especially like to thank Laura Cruz for hercontribution during the early stages of the project.
REFERENCES[1]Camila Bezerra, Frederico Freitas, Jérôme Euzenat,
Antoine Zimmermann, et al. Modonto: A tool formodularizing ontologies. In Proc. 3rd workshop onontologies and their applications (Wonto), 2008.
[2]Maurizio Caon, Stefano Carrino, Renata Guarnieri,Giuseppe Andreoni, Claudio L Lafortuna,O Abou Khaled, and Elena Mugellini. Apersuasive system for obesity prevention inteenagers: a concept. In Proceedings of the Second
5 http://bioportal.bioontology.org/ontologies/MPhttp://www.human-phenotype-ontology.org/6 http://ncit.nci.nih.gov/,http://www.ihtsdo.org/snomed-ct/,http://www.nlm.nih.gov/research/umls/,http://bioportal.bioontology.org/ontologies/HL7,http://www.who.int/classifications/icd/en/,http://bioportal.bioontology.org/ontologies/UO,http://obi-ontology.org/7 BFO http://www.ifomis.org/bfo/, GFO [8], http://www.onto-med.de/ontologies/gfo/, DOLCE [12], GALEN[18], the Foundational Model of Anatomy (FMA), http://sig.biostr.washington.edu/projects/fm/AboutFM.html
5Paper H

International Workshop on Behavior ChangeSupport Systems (BCSS2014), Padova, Italy, 2014.
[3]Stefano Carrino, Maurizio Caon, Omar AbouKhaled, Giuseppe Andreoni, and Elena Mugellini.Pegaso: Towards a life companion. In DigitalHuman Modeling. Applications in Health, Safety,Ergonomics and Risk Management, pages 325–331.Springer, 2014.
[4]Mathieu d’Aquin, Anne Schlicht, HeinerStuckenschmidt, and Marta Sabou. Ontologymodularization for knowledge selection:Experiments and evaluations. In Databaseand Expert Systems Applications, pages 874–883.Springer, 2007.
[5]T. R. Gruber. Toward Principles for theDesign of Ontologies Used for Knowledge Sharing.International Journal of Human-Computer Studies,43(4-5):907–928, 1995.
[6]Renata Guarneri and Giuseppe Andreoni. Activeprevention by motivating and engaging teenagersin adopting healthier lifestyles. In DigitalHuman Modeling. Applications in Health, Safety,Ergonomics and Risk Management, pages 351–360.Springer, 2014.
[7]M. Hartung, A. Groß, T. Kirsten, and E. Rahm.Effective Mapping Composition for BiomedicalOntologies. In Proc. of Semantic Interoperabilityin Medical Informatics (SIMI-12), Workshop atESWC-12, 2012.
[8]Heinrich Herre. General formal ontology (gfo) :A foundational ontology for conceptual modelling.In Roberto Poli and Leo Obrst, editors, Theoryand Applications of Ontology, volume 2. Springer,Berlin, 2010.
[9]Ian Horrocks, Peter F Patel-Schneider, HaroldBoley, Said Tabet, Benjamin Grosof, Mike Dean,et al. Swrl: A semantic web rule languagecombining owl and ruleml. W3C Membersubmission, 21:79, 2004.
[10]Botond Kádár, Walter Terkaj, and Marco Sacco.Semantic virtual factory supporting interoperablemodelling and evaluation of production systems.CIRP Annals-Manufacturing Technology,62(1):443–446, 2013.
[11]Richard Lewontin. The genotype/phenotypedistinction. In Edward N. Zalta, editor, The StanfordEncyclopedia of Philosophy. Summer 2011 edition,2011.
[12]C. Masolo, S. Borgo, A. Gangemi, N. Guarino,and A. Oltramari. WonderWeb Deliverable D18:Ontology Library. Technical report, ISTC-CNR,2003.
[13]Krystyna Milian, Zharko Aleksovski, RichardVdovjak, Annette ten Teije, and Frank vanHarmelen. Identifying disease-centric subdomainsin very large medical ontologies: A case-study onbreast cancer concepts in snomed ct. or: Finding2500 out of 300.000. In David Riaño, Annetteten Teije, Silvia Miksch, and Mor Peleg, editors,Knowledge Representation for Health-Care. Data,Processes and Guidelines, volume 5943 of LectureNotes in Computer Science, pages 50–63. SpringerBerlin / Heidelberg, 2010.
[14]World Health Organization. Obesity: Preventingand Managing the Global Epidemic. IIS microfichelibrary. World Health Organization, 2000.
[15]World Health Organization. European Food andNutrition Action Plan 2015?2020. WHO RegionalOffice for Europe, 2014.
[16]World Health Organization et al. Who childgrowth standards: methods and development:length/height-for-age, weight-for-age, weight-for-length, weight-for-height and body mass index-for-age. Geneva: WHO, 2006.
[17]Lucia Pannese, Dalia Morosini, Petros Lameras,Sylvester Arnab, Ian Dunwell, and Till Becker.Pegaso: A serious game to prevent obesity. InDigital Human Modeling. Applications in Health,Safety, Ergonomics and Risk Management, pages427–435. Springer, 2014.
[18]A.L. Rector and W.A. Nowlan. The galen project.Computer Methods and Programs in Biomedicine,45:75–78, 1993.
[19]Alan Rector. Modularisation of Domain OntologiesImplemented in Description Logics and relatedformalisms including OWL. In John Gennari, BrucePorter, and Yolanda Gil, editors, Proceedings ofthe Second International Conference on KnowledgeCapture (K-CAP’03), Sanibel Island, Florida, USA,Oct 23–25, pages 121–128, New York, 2003. ACMPress.
[20]Paolo L Scala, Davide Di Pasquale, DanieleTresoldi, Claudio L Lafortuna, Giovanna Rizzo,and Marco Padula. Ontology-supported clinicalprofiling for the evaluation of obesity and relatedcomorbidities. Studies in health technology andinformatics, 180:1025, 2012.
[21]Arash Shaban-Nejad, David L Buckeridge, andLaurette Dubé. Cope: childhood obesity prevention[knowledge] enterprise. In Artificial Intelligence inMedicine, pages 225–229. Springer, 2011.
[22]Aleksandra Sojic and Oliver Kutz. Openbiomedical pluralism: formalising knowledge aboutbreast cancer phenotypes. Journal of biomedicalsemantics, 3(2):1–31, 2012.
6Paper H

1
OntoStudyEdit: A new Approach for Ontology-Based Representa-
tion and Management of Metadata in Clinical and Epidemiological
Research
Alexandr Uciteli*, Heinrich Herre
Institute for Medical Informatics, Statistics and Epidemiology (IMISE), Leipzig University
ABSTRACT
The specification of metadata in clinical and epidemiological study
projects absorb significant expense. The validity and quality of the
collected data depend heavily on the precise and semantically
correct representation of their metadata.
In various research organizations, planning and coordinating the
studies, the required metadata are specified differently depending
on many conditions, e.g., on the used study management software.
The latter does not always meet the needs of a particular research
organization, e.g., with respect to the relevant metadata attributes
and structuring possibilities.
The objective of the research, set forth in this paper, is the devel-
opment of a new approach for ontology-based representation and
management of metadata. The basic features of this approach are
demonstrated by the software tool OntoStudyEdit (OSE). The OSE
can be easily adapted to different requirements, and it supports an
ontologically founded representation and efficient management of
metadata. The metadata specifications can by imported from vari-
ous sources; they can be edited with the OSE, and they can be
exported in/to several formats, which are used, e.g., by different
study management software.
1 INTRODUCTION
There is a large variety of particular clinical and epidemio-
logical research projects, which typically produce a large
amount of data. The data stem from questionnaires, inter-
views but also from specific findings and from laboratory
analyses. Before these data can be collected, the needed
metadata must be precisely specified. The specification of
the metadata in particular research organizations must con-
sider certain requirements, e.g., which item attributes are
relevant (e.g., name, label, range, data type, format, unit of
measure), how the items should be grouped (e.g., module,
item group), or which study management software or data
entry tools (hereinafter referred to as study software) are
used (e.g., OpenClinica1, ERT2).
In this paper we present and discuss a new approach for
ontology-based representation and management of metadata
* [email protected] 1 https://www.openclinica.com/ 2 https://www.ert.com/
in clinical and epidemiological research, which is demon-
strated by the software tool OntoStudyEdit (OSE). The OSE
can easily be adapted to the needs of a particular research
organization by the use of a suitable domain ontology. Fur-
thermore, it supports and provides an ontology-based con-
figuration of the import/export functions in the desired for-
mats without the necessity to change the source code. The
import/export functions need only to be implemented once
for a format type (e.g., xml, excel, sql, pdf), and can be
configured by an ontology-based definition of mappings
between a format type and the domain ontology. This ap-
proach has the advantage that the domain experts (e.g.,
biometrician, data manager) can specify the study metadata
according to the common usage in a particular research
organization by using the respective familiar terminology
and without dealing with technical issues. By the provision
of import from various sources and export to several formats
the differently specified metadata can be represented on the
same semantic basis; hence, the once specified metadata can
be reused in various research projects and utilized by differ-
ent study software (or other tools).
2 METHODS
2.1 Ontology-Based Representation of Metadata
Metadata are used to describe data, hence, they add more
precise meaning to data, the semantics of which remains
often underspecified. Since the metadata itself must be spec-
ified by some formal representation, the meaning of which
should be explained, we arrive at an infinite regress, which
must be brought to an end by some basic principle. In our
approach this infinite regress is blocked by using the top-
level ontology General Formal Ontology (GFO) (Herre,
2010) that provides the most basic layer for a semantic
foundation.
The OSE is a plug-in for Protégé-Frames3, which is con-
ceptually based on the notion of a frame. We decided to use
Protégé-Frames for our implementation because it supports
the generation of forms for input data. Frames are formal
representational structures, which are exhaustively classified
3 http://protege.stanford.edu/doc/tutorial/get_started/table_of_content.html
Paper I

A.Uciteli et al.
2
Fig. 1. Ontological architecture
into the following types: classes, slots, facets and individu-
als (Noy et al., 2000). Together with axioms they form the
building blocks for Protégé-Frames ontologies. Classes
represent concepts related to a domain. Slots represent prop-
erties or attributes of classes, whereas facets describe prop-
erties of slots. Slots may be attached to frames, and then
they describe properties of that frame. A slot, attached to a
frame, can have values, which might be constraint by facets.
A slot can be attached to a frame as a template slot or as an
own slot (Noy et al., 2000).
The concepts represented by Protégé classes are associat-
ed in GFO to categories, and the slots attached to a class
frame describe properties of that class. A category is defined
in GFO as an entity, independent of time and space that can
be instantiated. A category is represented by some symbolic
structure, which denotes a meaning, also called intension.
The notion of a class - as used, for example, in UML4,
OWL5, or Frames - captures relevant aspects of categories.
Subsequently, we use the term “class” in the sense of a
symbolic representation of a category and the term “slot” -
as a symbolic representation of a property or a relation. A
meta-class in Protégé-Frames corresponds in GFO to a cate-
gory the instances of which are themselves categories. In
Protégé-Frames each class is an instance of a Standard-
Meta-Class. In GFO there exists a meta-category, denoted
by Category(2), the instances of which are all categories of
first order. A category is of first order if all of its instances
are individuals. The meta-classes in Protégé correspond to
the second-order categories in GFO, which are extensional
subcategories of the category Category(2).
2.2 The Three Ontology Method
The OSE is designed and developed according to the three
ontology method (Hoehndorf et al., 2009). This method for
developing software is based on the interactions of three
different kinds of ontologies: a task ontology (TO), a do-
main ontology (DO) and a top-level ontology (TLO). The
TO is an ontology for the general problem that the software
is intended to solve. The DO provides the domain-specific
knowledge, whereas the TLO integrates the TO and the DO
and is used as the foundation of them. The TLO also pro-
vides means for integrating data from different domains. For
integrating the TO and the DO we use the TLO GFO be-
cause it is sufficiently expressive, in particular, it contains
an ontology of categories and admits categories of higher
order.
3 RESULTS
3.1 The Ontological Architecture of the OSE
4 http://www.omg.org/spec/UML/ 5 http://www.w3.org/TR/owl2-overview/
The ontological architecture of the OSE is represented by
systems of categories of several levels of abstraction and
relations between them (Fig. 1). The TO is an upper ontolo-
gy with respect to the considered DOs, hence, the DO cate-
gories are extensional subcategories of the TO categories.
The GFO is used as semantic foundation for both TO and
DO by classifying categories of TO and DO under particular
GFO categories (e.g., category, process, individual).
We use classes for the representation of categories and
slots for the representation of properties and relations in
Protégé-Frames ontologies.
3.1.1 Task and Domain Ontology of the OSE
In this section we consider the classes which represent cate-
gories of the TO and DO (Fig. 2).
The names of TO classes starts with the underline-sign.
The TO includes at the upmost level following classes:
_CONFIG, _ELEMENT, and
_REFERENCE_ONTOLOGY_ROOT. The reference on-
tologies are inserted below the node
_REFERENCE_ONTOLOGY_ROOT (see section 3.1.3).
The class _ELEMENT, its subclasses and instances are
visible for the user. The instances can be edited by the user
by means of graphical user interface (GUI). On the other
hand, the class _CONFIG, and its subclasses and instances
are hidden from the user; these classes and its instances are
used by the OSE in the background.
The subclasses of _ELEMENT are: _CONSTANT,
_OBJECT, _GROUP, _ANNOTATION, and _EXPORT.
The instances of _CONSTANT are used in expressions, the
class _OBJECT represents individual entities (e.g., items or
measurement units), whereas the class _GROUP stands for
lists, which might contain further elements (instances of
_ELEMENT). The instances of _ANNOTATION are anno-
tations of elements by concepts of the reference ontology (s.
3.1.3). The subclasses of _EXPORT represent export for-
mats provided for the export function.
The following subclasses of _CONFIG are introduced:
_FORMAT_MAPPING, _ANNOTATION_TYPE, the
former of which is described in more detail in section 3.1.2
and the later – in section 3.1.3. In particular, as instances of
Paper I

OntoStudyEdit: A new Approach for Ontology-Based Representation and Management of Metadata in Clinical and Epidemiological Research
3
_ANNOTATION_TYPE various annotation types can be
defined. The class _FORMAT_MAPPING and its sub-
classes are used to specify ontologically various import and
export formats.
The class _MATH and its subclasses are used by the ex-
pression editor, displayed in the working area E (see section
3.2). The class _MATH_EXPRESSION_RELATOR and its
subclasses describe various mathematical operations and
functions (for example: AND, >, +). These relators possess
arguments, being numbers (_NUMBER), constants
(_CONSTANT), particular study elements
(_STUDY_ELEMENT, e.g., Item), or further relators. With
these means the editor is able to build an expression in form
of tree. The TO includes a number of slots, the most im-
portant of which are the following: _contains and
_HIERARCHY_SUBCLASS. The _contains slot represents
the relation between instances (e.g., Page: B1 _contains
Module: Socio-demographic data), whereas the slot
_HIERARCHY_SUBCLASS describes the corresponding
basic relation between classes (example: Page has
_HIERARCHY_SUBCLASS Module). The relation
_HIERARCHY_SUBCLASS is formally defined as fol-
lows: Cat_1 _HIERARCHY_SUBCLASS Cat_2 := ( x y)
(x :: Cat_1 _contains(x,y) y :: Cat_2).
A further constituent of the ontological architecture is the
DO. This ontology is embedded into the TO, hence, these
classes are subclasses of TO classes. Classes like Study or
Module are placed below the class _GROUP, whereas Item
or Codelist are subclasses of _OBJECT. The slots of these
classes can freely be defined. The class Item, for example,
can possess following slots: name, description,
unit_of_measure, range, codelist or rules.
3.1.2 Ontological Specification of Mappings between Im-
port/Export Formats and Domain Ontology
In this section we outline the specification of mappings
between import/export formats and DO on the example of
an xml-based format, CDISC ODM6. For the mapping spec-
ification the subclasses of _FORMAT_MAPPING are used.
The tag structure of an xml-based format can be consid-
ered as a tree. As a first step the root tag (in our example,
<ODM>) must be specified as instance of _ROOT_TAG.
The other tags are defined as instances of _TAG. For each
tag its sub-tags and attributes must be specified in the in-
stance editor (Fig. 3). The tag <Study> contains, e.g., the
sub-tags <GlobalVariables>, <BasicDefinitions>, and
<MetaDataVersion> as well as the attribute “OID”. The tags
are mapped to the DO classes, whereas their texts and at-
tributes - to the DO slots. In our example, the tag <Study> is
mapped to the class Study and the attribute “OID” - to the
slot :NAME of the class Study.
3.1.3 Reference Ontology and Annotation
By using Protégé it is possible to include an ontology into
another one. We could include a reference ontology (e.g.,
ACGT Master Ontology7, phenotype or property ontologies,
LOINC8) and may use their categories for the annotation of
the instances of the DO of OSE (e.g., for concrete items like
the blood pressure item).
For this purpose, we introduced in TO the following clas-
ses:
• _ANNOTATION_TYPE (subclass of _CONFIG).
Within DO we may define various annotation types, be-
ing instances of _ANNOTATION_TYPE (e.g., anno-
tated_with, risk_factor_of, symptom_of).
6 CDISC Operational Data Model; http://www.cdisc.org/odm 7 http://www.ifomis.org/activities/acgt-master-ontology.html 8 http://loinc.org/
Fig. 2. Task and domain ontology
Fig. 3. ODM format mapping
Paper I

A.Uciteli et al.
4
• _ANNOTATION (subclass of _OBJECT). This class
has three slots: _annotated_elements, _annotation_type
und _annotating_concepts. Using OSE we may create
concrete annotations as instances of _ANNOTATION.
This is realized by selecting the elements to be annotat-
ed, taken from subclasses of _ELEMENT, by choosing
an annotation type from the instances of
_ANNOTATION_TYPE, and by selecting suitable
classes taken from the reference ontology.
• _REFERENCE_ONTOLOGY_ROOT. Below this
class reference ontologies can be inserted.
• _REFERENCE_ONTOLOGY_METACLASS (sub-
class of :STANDARD-CLASS). This is a meta-class,
containing all classes of the reference ontology as in-
stances. This class has an additional slot, denoted by
_annotations, which is defined as the inverse slot of
_annotating_concepts.
We may not only annotate single instances, but also sets
of instances. It is, e.g., not sufficient to annotate the item
ITEM:DYSPNEA_AT_REST as symptom of „Congestive
heart failure“, taken from the Human Phenotype Ontology9
(HPO). This item is associated with a codelist that includes
two possible values “YES” or “NO” (depending on whether
one have dyspnea or not). Only if “YES” is selected as an-
swer of the question whether “dyspnea at rest” holds, this
symptom is true. I.e., only the combination of the item
ITEM:DYSPNEA_AT_REST and the answer option “YES”
can be annotated (Fig. 4). If an item does not possess a
codelist, then also ranges can be annotated. An example is
the annotation of the item
ITEM:SYSTOLIC_BLOOD_PRESURE together with
Range [121;] (i.e., >= 121) with the concept „Elevated sys-
tolic blood pressure“ from HPO (Fig. 4).
By use of the inverse slot _annotations for classes of the
reference ontology we may realize the following valuable
feature: for a given concept all of its annotations can be
displayed. This functionality can be very important in
searching for items in certain domains during the planning
phase of a study. If we are planning, e.g., a study for heart
failure we may ask for all annotations of the class „Conges- 9 http://www.human-phenotype-ontology.org/
tive heart failure“ (and possibly of its subclasses). These
annotations will then be displayed. In this way one has a
quick access to items which can be used to query the symp-
toms or risk factors of the heart failure. (Fig. 5)
The annotation of different instances of the domain ontol-
ogy (even of different domain ontologies) by the same class
of the same reference ontology establishes a semantic con-
nection between these instances. Such annotations allow the
semantic search for items over the categories, which are
used in these annotations, but they also allow the compara-
bility of data which are acquired for various distinct studies.
3.2 Usage of the OSE
Subsequently we sketch the graphical user interface (GUI)
and the main functions of the OSE: specification, manage-
ment, import and export of metadata, searching and naviga-
tion.
The GUI is partitioned into five working regions A, B, C,
D and E (Fig. 6):
A: Study Elements. Within this region all study elements
(being subclasses of _ELEMENT) are represented and dis-
played. Besides of a class the number of its instances is
shown (put in brackets). Choosing a class shows in the
working field C (Instance Browser) its instances. A search-
ing field is available. For the export of the specified metada-
ta an export format must be selected (a subclass of
_EXPORT) and the button “exp” pressed. It is also possible
to export a metadata specification as an ontology that can be
used as Case Report Form (CRF) preview (Fig. 7).
B: Study Hierarchy. This hierarchy shows the structure of
a study. This hierarchy is formed by instances which are
connected by the contains-relation. The user may create new
elements in a group, may change the elements’ order, and
may remove elements from a group. By choosing an ele-
ment, a form for the acquisition of its slot values is shown in
the working area D (Instance Editor). A search field is
available.
Fig. 4. Annotation instance (examples)
Fig. 5. Concept annotations (example)
Paper I

OntoStudyEdit: A new Approach for Ontology-Based Representation and Management of Metadata in Clinical and Epidemiological Research
5
C: Instance Browser. The instance browser shows in-
stances of the class which is selected in the working area A.
By choosing an instance, a form for capturing its slot values
will be shown in the working area D (Instance Editor). In-
stances may be deleted. Furthermore it is possible to associ-
ate instances from this working area to groups from the
working area B by drag-and-drop. A search field is availa-
ble.
D: Instance Editor. The instance editor provides forms for
capturing the slot values of instances.
E: Expression Editor. This editor supports the editing of
formulas, being represented in form of trees. Various opera-
tors and numbers can be used, for example arithmetical,
logical operators, and other relations; furthermore, study
elements (for example items) and constants can be refer-
enced.
4 RELATED WORK
There are few systems that pursue similar purposes as OSE,
notably TIM (Trial Item Manager) (Löbe et al., 2009) and
ObTiMA (Ontology-based Managing of Clinical Trials)
(Stenzhorn et al., 2010), which are subsequently considered
in more detail.
ObTiMa is a system for ontology-based management of
clinical trials, which is composed of the two components:
“the Trial Builder for designing clinical trials and the Patient
Data Management System for handling patient data within a
trial.” Trial Builder allows the creation of CRF items, based
on the concepts of an ontology (ACGT Master Ontology).
The main difference between the ObTiMa’s Trial Builder
and the OSE consists in that the Trial Builder is based on
ODM and the possible item attributes (e.g., question, data
type, measurement unit) are fixed and cannot be changed or
extended, whereas in OSE item attributes are defined by
domain ontologies and can be flexibly handled. Hence, OSE
may take into account the needs of the diverse research
organizations, which usually differs with respect to the
practiced specification of metadata that typically use differ-
ent metadata types (e.g., items, codelists, modules), different
attributes, groupings, and hierarchical levels (e.g., study-
event-module-item). Furthermore, the flexible, ontology-
based development of mappings between the ontologies of
OSE and diverse import and export formats enables the
reuse of specified metadata in various research projects and
their utilization by different study software.
The TIM pursues aims, analogous to OSE, namely, to
support the specification of items in clinical trials. Similarly
as OSE, TIM is based on a semantic model consisting of a
fixed component (the meta-model and the core types of the
data model), and a flexible module (domain-specific types
of the data model). This structure supports the adaption to
user-specific needs. Though, there are differences between
TIM and OSE. In TIM the fixed component and the flexible
part are not clearly separated, whereas in OSE both compo-
nents (TO and DO) are explicitly divided and endowed with
an ontologically-based semantic basis. Consequently, OSE
exhibits a higher flexibility with respect to the change and
adaption of the domain-specific constituents. Furthermore,
OSE provides various additional functionalities, among
them, the ontologically-based creation of format mappings,
and the use of rule expressions. Finally, the usage of Protégé
supports the adaption of the input forms, and allows for an
extension of the software by additional plug-ins.
Fig. 6. GUI of the OSE
A
B
C
D
E
Paper I

A.Uciteli et al.
6
5 CONCLUSIONS AND FUTURE WORK
In this paper we presented and discussed a new approach for
ontology-based representation and management of metadata
in clinical and epidemiological research using the software
tool OntoStudyEdit (OSE). Advantages of this approach are:
1. the adaptability of the OSE to intended aims and given
needs by integrating suitable domain ontologies in a modu-
lar way; 2. the ontological specification of mappings be-
tween the import/export formats and the DO, such that no
changes of the source code are needed by the replacing of
the DO; 3. the specification of the study metadata in the
same manner and reuse of the specifications in different
research projects.
The OntoStudyEdit is a tab widget plug-in for Protégé-
Frames; this implies that all functionalities of Protégé can be
used. Of particular interest is the adaption of the input
forms. At present, we are working on the implementation of
further import/export functions, e.g., related to annotated
CRF in PDF format and to specifications for the import in
different study software.
Finally, we are planning the evaluation of the OSE based
on selected studies carried out in the Clinical Trial Centre
Leipzig10.
10 http://www.zks.uni-leipzig.de/
REFERENCES
Herre,H. (2010) General Formal Ontology (GFO): A Foundational
Ontology for Conceptual Modelling. In, Poli,R. et al. (eds),
Theory and Applications of Ontology: Computer Applications.
Springer, Netherlands, pp. 297–345.
Hoehndorf,R. et al. (2009) Developing Consistent and Modular
Software Models with Ontologies. In, Fujita,H. and Marik,V.
(eds), New Trends in Software Methodologies, Tools and Tech-
niques: Proceedings of the Eighth SoMeT_09, Frontiers in Arti-
ficial Intelligence and Applications. IOS Press, pp. 399–412.
Löbe,M. et al. (2009) A Knowledge-Based System for the Specifi-
cation of Variables in Clinical Trials. In, Fischer,S. et al. (eds),
Informatik 2009: Im Focus das Leben: GI 2009, Lübeck, 28.9.-
2.10.2009. Proceedings, Lecture Notes in Informatics. Köllen
Druck+Verlag, Bonn, pp. 1479–1486.
Noy,N.F. et al. (2000) The Knowledge Model of Protégé-2000:
Combining Interoperability and Flexibility. In, Dieng,R. and
Corby,O. (eds), Knowledge Engineering and Knowledge Man-
agement Methods, Models, and Tools: 12th International Con-
ference, EKAW 2000 Juan-les-Pins, France, October 2–6, 2000
Proceedings, Lecture Notes in Computer Science. Springer,
Berlin Heidelberg, pp. 17–32.
Stenzhorn,H. et al. (2010) The ObTiMA system - ontology-based
managing of clinical trials. Stud. Health Technol. Inform., 160,
1090–1094.
Fig. 7. CRF preview (example)
Paper I





























