Embed Size (px)
Citation preview

Copyright 2015 FUJITSU LIMITED
FUJITSU Supercomputer PRIMEHPC FX100
0

Copyright 2015 FUJITSU LIMITED
Hardware and Software Overview
1

Copyright 2015 FUJITSU LIMITED
FUJITSU Supercomputers
Peak performance: 11.28 petaflops
K computer
PRIMEHPC FX10 Peak performance: up to 23.2 petaflops
PRIMEHPC FX100 Peak performance: over 100 petaflops
C RIKEN
Exascale
Fujitsu has been developing supercomputers nearly 40 years, and will continue its development to deliver the best application performance
2

PRIMEHPC FX100 Design Concept
Copyright 2015 FUJITSU LIMITED
Inherited the K computer features
Designed to be a massively parallel supercomputer system
Introducing new technologies for Exascale computing
High performance for a wide range of real applications
General purpose CPU architecture for application productivity 6D mesh/torus topology, hardware barrier synchronization, sector cache, etc.
HPC-ACE2 : Wide SIMD enhancements Assistant cores : Dedicated cores for non-calculation operation HMC : Leading-edge memory technology
3

SPARC64TM XIfx
Copyright 2015 FUJITSU LIMITED
Over 1 TF high performance processor
HPC-ACE2: ISA enhancements
Tofu2 interface
Tofu2 controller
L2 cache
L2 cache
HM
C interfa
ce H
MC
inte
rfac
e
PCI interface
core core
core core
core core
core core
core core
core core
core core
core core
core
core
core
core
core
core
core
core
core
core
core
core
core
core
core
core
Assistant core
Assistant core
Daemons, IOs, non-blocking MPI functions, etc. Offloading non-calculation operations
HMC support
32 compute cores 2 assistant cores:
Two 256-bit wide SIMD units per core Various SIMD instructions (stride load/store, indirect load/store, permutation, etc.)
480GB/s/node of theoretical memory throughput
4
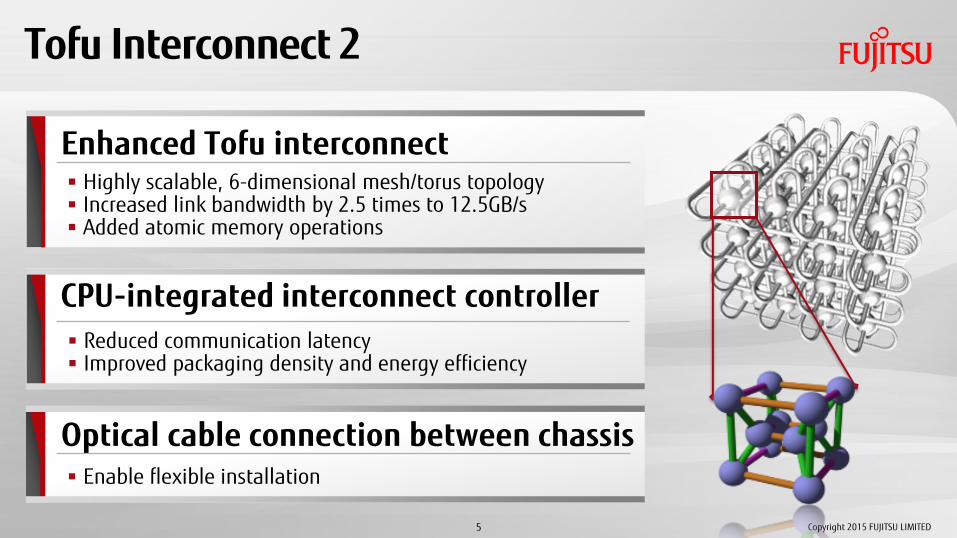
Tofu Interconnect 2
Copyright 2015 FUJITSU LIMITED
Enhanced Tofu interconnect
CPU-integrated interconnect controller
Optical cable connection between chassis
Highly scalable, 6-dimensional mesh/torus topology Increased link bandwidth by 2.5 times to 12.5GB/s Added atomic memory operations
Reduced communication latency Improved packaging density and energy efficiency
Enable flexible installation
5

Copyright 2015 FUJITSU LIMITED
Technical Computing Suite
Linux-based OS enhanced for FX100
Technical Computing Suite
Applications
PRIMEHPC FX100
Management software Programming Environment
High Performance File System FEFS
System management
Job management
Lustre-based distributed file system (enhanced for FX100)
MPI, OpenMP, COARRAY
Compilers(C,C++,Fortran) Mathematical libraries
Debugging and tuning tools
Enhanced software stack developed by Fujitsu
6
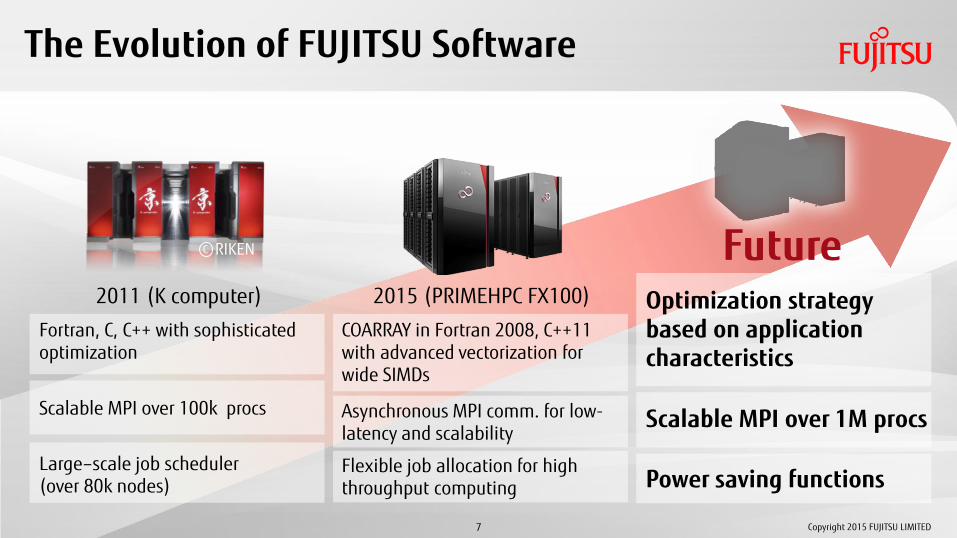
COARRAY in Fortran 2008, C++11 with advanced vectorization for wide SIMDs
C RIKEN
The Evolution of FUJITSU Software
Copyright 2015 FUJITSU LIMITED
2011 (K computer) 2015 (PRIMEHPC FX100)
Future
Fortran, C, C++ with sophisticated optimization
Scalable MPI over 100k procs
Large–scale job scheduler (over 80k nodes)
Asynchronous MPI comm. for low-latency and scalability
Flexible job allocation for high throughput computing
Optimization strategy based on application characteristics
Scalable MPI over 1M procs
Power saving functions
7

FX100 Performance and the Effect of the New Technologies
Copyright 2015 FUJITSU LIMITED 8
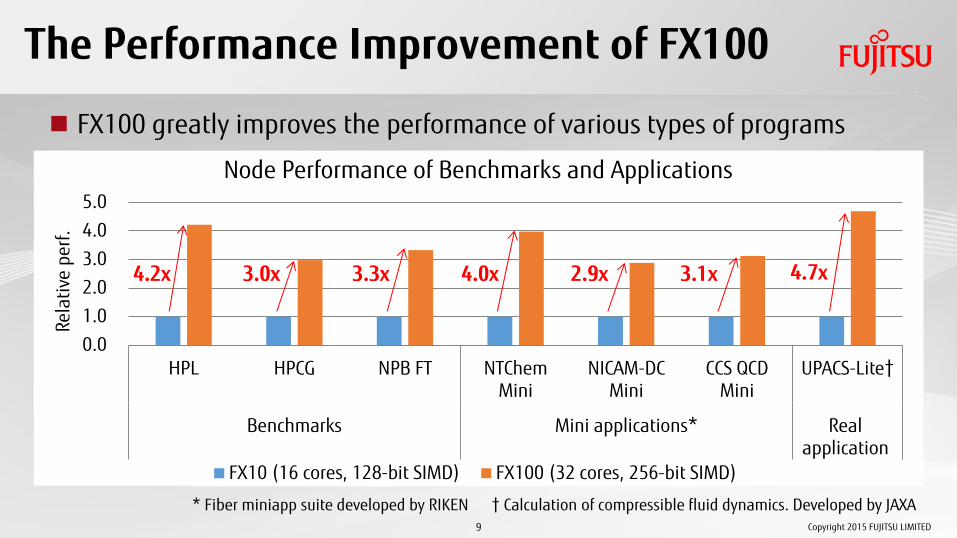
The Performance Improvement of FX100
Copyright 2015 FUJITSU LIMITED
FX100 greatly improves the performance of various types of programs
Node Performance of Benchmarks and Applications
* Fiber miniapp suite developed by RIKEN † Calculation of compressible fluid dynamics. Developed by JAXA
0.0
1.0
2.0
3.0
4.0
5.0
HPL HPCG NPB FT NTChemMini
NICAM-DCMini
CCS QCDMini
UPACS-Lite†
Benchmarks Mini applications* Realapplication
Rela
tive
per
f.
FX10 (16 cores, 128-bit SIMD) FX100 (32 cores, 256-bit SIMD)
3.1x 2.9x 3.3x 4.0x 3.0x 4.2x 4.7x
9
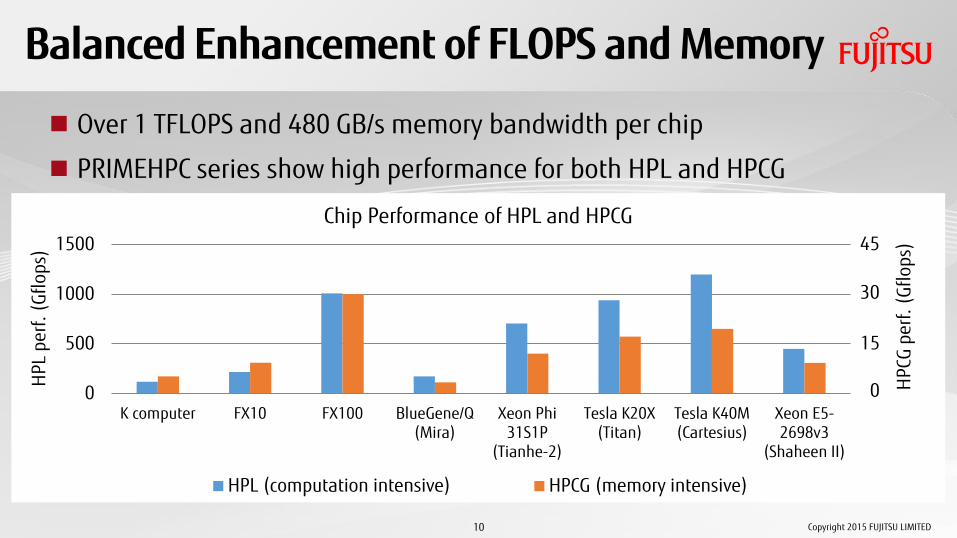
Balanced Enhancement of FLOPS and Memory
Copyright 2015 FUJITSU LIMITED
Over 1 TFLOPS and 480 GB/s memory bandwidth per chip
PRIMEHPC series show high performance for both HPL and HPCG
0
500
1000
1500
K computer FX10 FX100 BlueGene/Q(Mira)
Xeon Phi31S1P
(Tianhe-2)
Tesla K20X(Titan)
Tesla K40M(Cartesius)
Xeon E5-2698v3
(Shaheen II)
HPL
per
f. (
Gfl
ops)
Chip Performance of HPL and HPCG
HPL (computation intensive) HPCG (memory intensive)
45
30
0 HPC
G p
erf.
(G
flop
s)
15
10
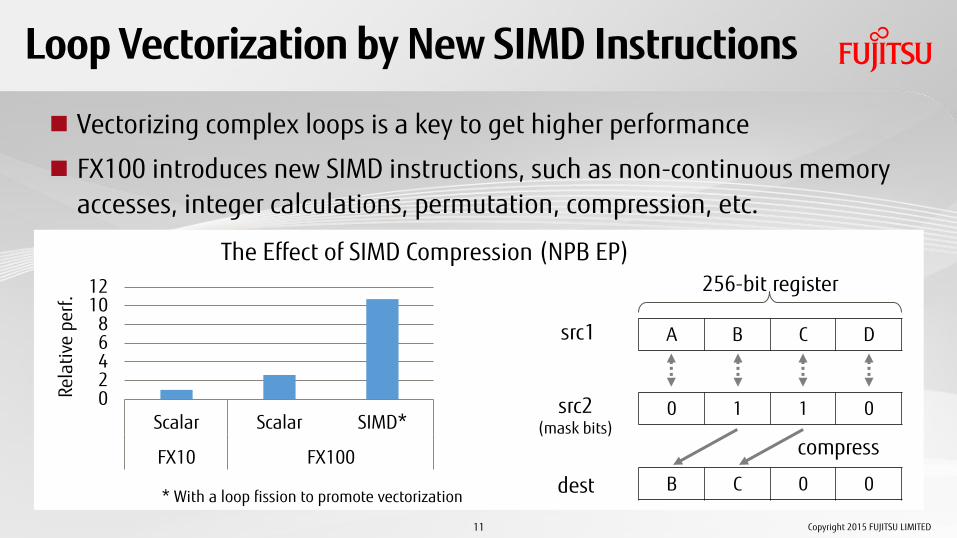
Loop Vectorization by New SIMD Instructions
Copyright 2015 FUJITSU LIMITED
Vectorizing complex loops is a key to get higher performance
FX100 introduces new SIMD instructions, such as non-continuous memory accesses, integer calculations, permutation, compression, etc.
02468
1012
Scalar Scalar SIMD*
FX10 FX100
Rela
tive
per
f.
* With a loop fission to promote vectorization
0 1 1 0
A B C D
B C 0 0
src1
src2 (mask bits)
dest
compress
The Effect of SIMD Compression (NPB EP) 256-bit register
11
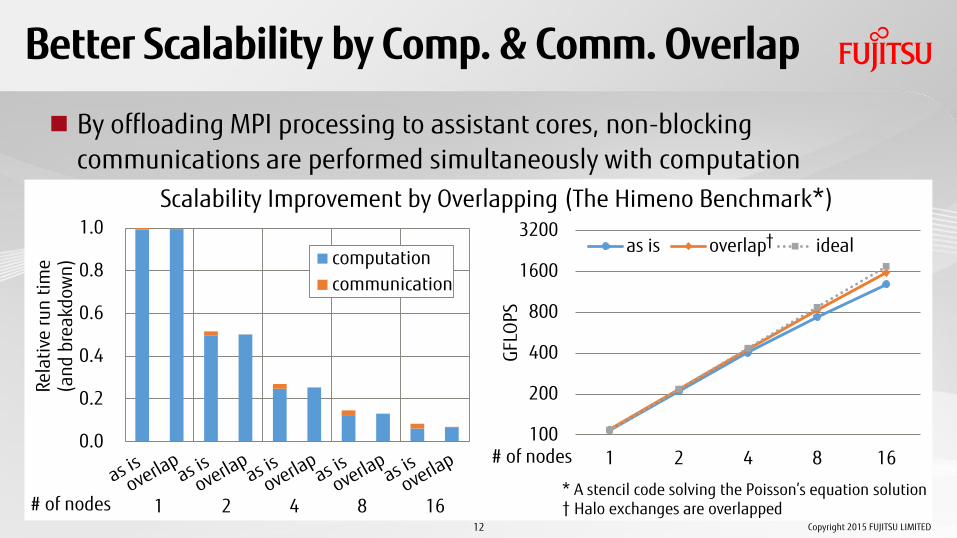
Better Scalability by Comp. & Comm. Overlap
Copyright 2015 FUJITSU LIMITED
By offloading MPI processing to assistant cores, non-blocking communications are performed simultaneously with computation
Scalability Improvement by Overlapping (The Himeno Benchmark*)
100
200
400
800
1600
3200
1 2 4 8 16
GFL
OPS
# of nodes
as is overlap ideal
# of nodes 1 2 4 8 16 * A stencil code solving the Poisson’s equation solution † Halo exchanges are overlapped
†
0.0
0.2
0.4
0.6
0.8
1.0
Rela
tive
run
tim
e (a
nd
bre
akdo
wn
) computation
communication
12
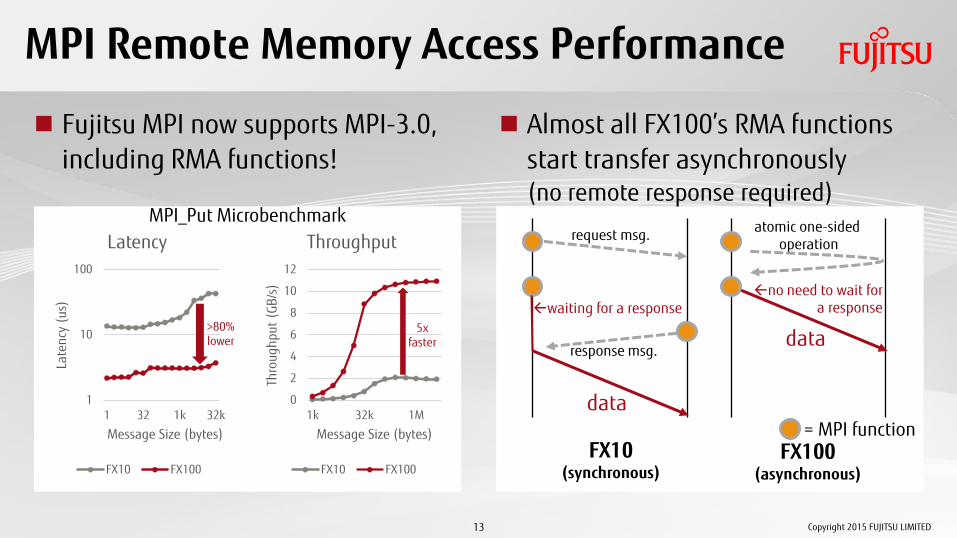
MPI Remote Memory Access Performance
Copyright 2015 FUJITSU LIMITED
Fujitsu MPI now supports MPI-3.0, including RMA functions!
Almost all FX100’s RMA functions start transfer asynchronously (no remote response required)
1
10
100
1 32 1k 32k
Late
ncy
(us
)
Message Size (bytes)
Latency
FX10 FX100
0
2
4
6
8
10
12
1k 32k 1M
Thro
ugh
put
(GB
/s)
Message Size (bytes)
Throughput
FX10 FX100
>80% lower
5x faster
MPI_Put Microbenchmark request msg.
data
FX10 (synchronous)
response msg.
atomic one-sided operation
FX100 (asynchronous)
data
= MPI function
waiting for a response no need to wait for
a response
13
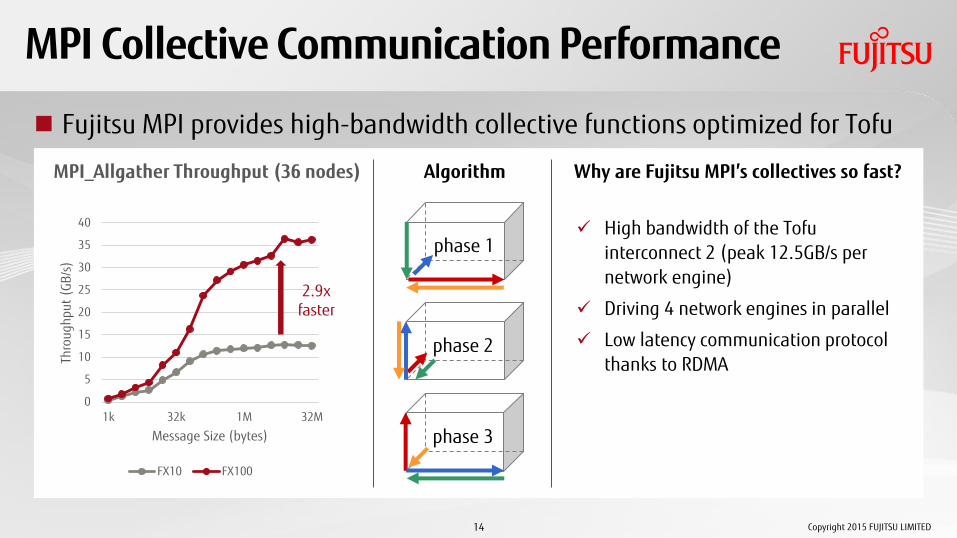
MPI Collective Communication Performance
Copyright 2015 FUJITSU LIMITED
Fujitsu MPI provides high-bandwidth collective functions optimized for Tofu
High bandwidth of the Tofu interconnect 2 (peak 12.5GB/s per network engine)
Driving 4 network engines in parallel
Low latency communication protocol thanks to RDMA
Why are Fujitsu MPI’s collectives so fast?
0
5
10
15
20
25
30
35
40
1k 32k 1M 32M
Thro
ugh
put
(GB
/s)
Message Size (bytes)
FX10 FX100
2.9x faster
Algorithm
phase 1
phase 2
phase 3
MPI_Allgather Throughput (36 nodes)
14

Copyright 2015 FUJITSU LIMITED
Summary
K computer PRIMEHPC FX10 PRIMEHPC FX100 C RIKEN
Exascale
FX100 achieves high performance of various applications by the new technologies and inherited features
This evolution is continuing to the next generations
15