Embed Size (px)
Citation preview

Grundlagen der Informationsverarbeitung: Befehlsverarbeitung in einem Prozessor Prof. Dr.-Ing. habil. Ulrike Lucke
Maximaler Raum für Titelbild (wenn kleiner dann linksbündig an Rand angesetzt)
1 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen © 2016
Instruktionsformate in 07
Durchgeführt von Prof. Dr. rer. nat. habil. Mario Schölzel
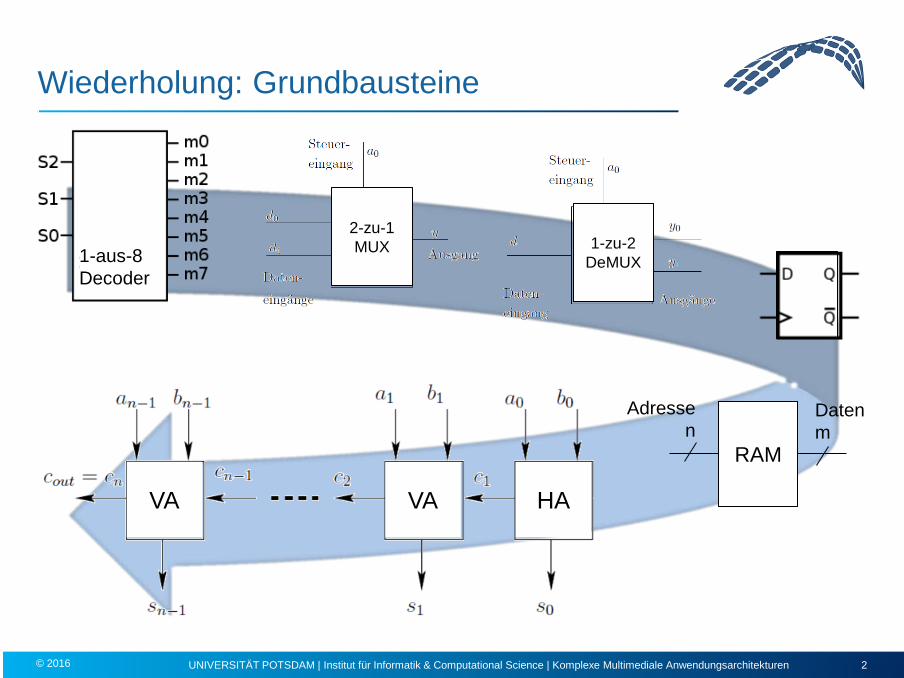
Wiederholung: Grundbausteine
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 2 © 2016
1-aus-8 Decoder
RAM
Adresse n
Daten m
2-zu-1 MUX 1-zu-2
DeMUX
HA VA VA
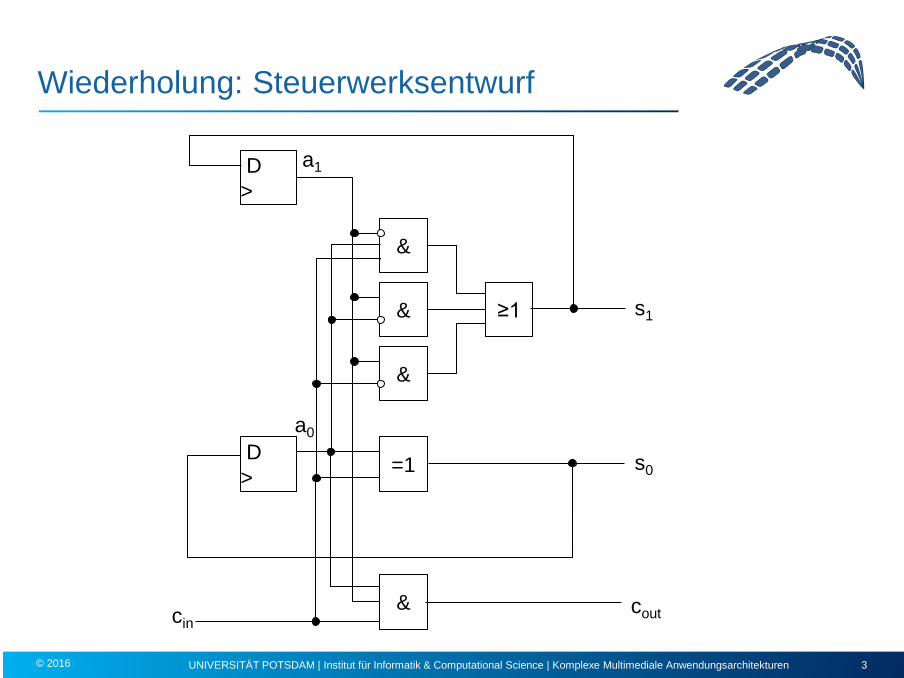
Wiederholung: Steuerwerksentwurf
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 3 © 2016
&
=1
&
&
&
≥1
D >
D >
s1
s0
cout cin
a1
a0

Inhalt der Vorlesung
• Binäre Modellierung • Codierung von Zahlen und Zeichen • Boolesche Funktionen • Schaltnetze • Schaltungsentwurf • Schaltwerke • Minimierungsverfahren • Grundbausteine der Computertechnik • Befehlsverarbeitung in einem Prozessor • Assembler-Ebene • Steuerwerke • Rechenwerke • Parallelität auf Instruktionsebene • Speicherhierarchie • Virtuelle Speicherverwaltung • Leistungsbewertung
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 4 © 2016
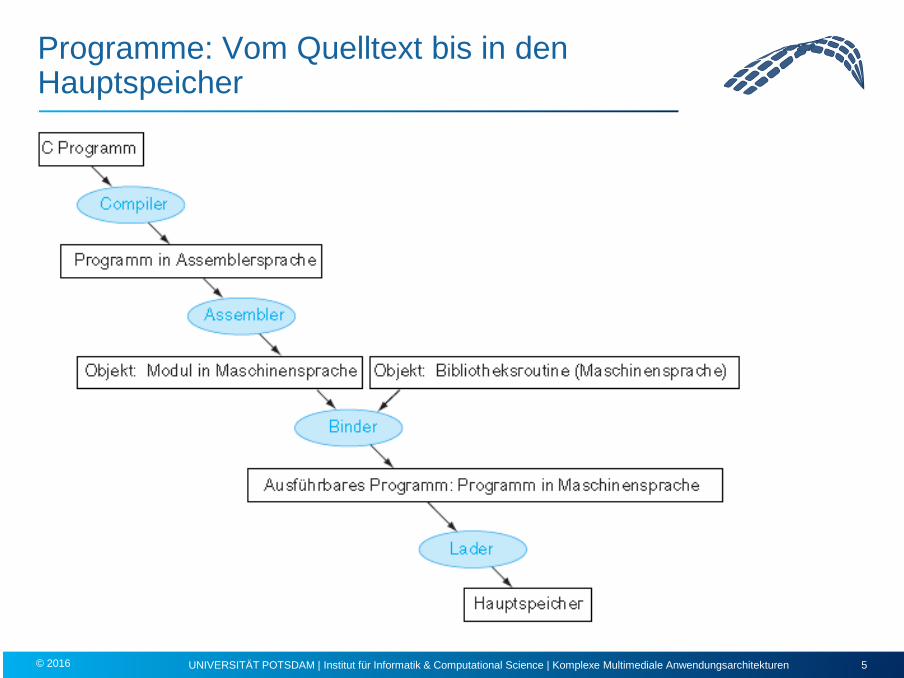
Programme: Vom Quelltext bis in den Hauptspeicher
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 5 © 2016
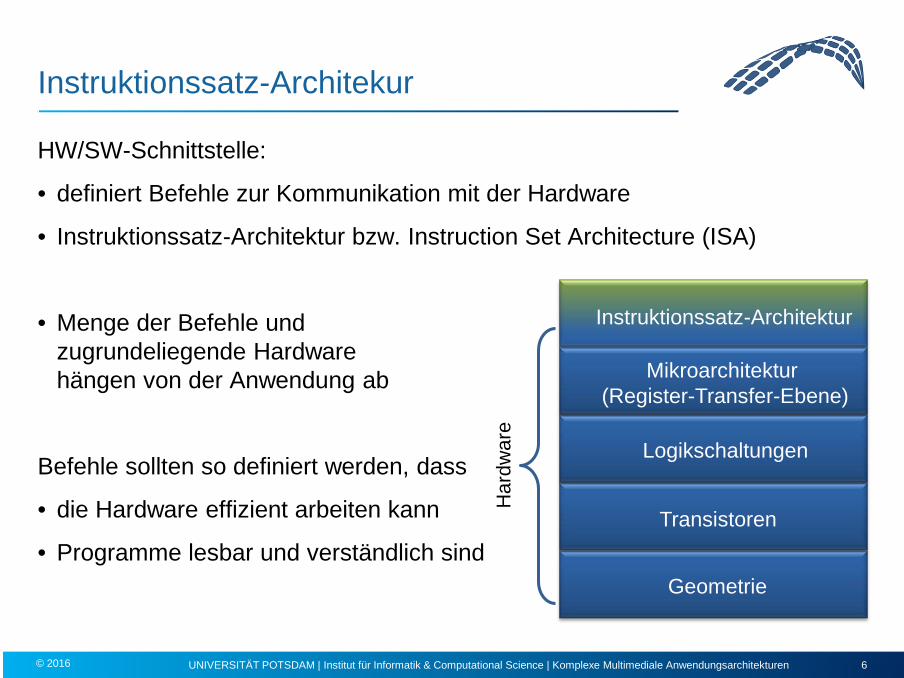
Instruktionssatz-Architekur
HW/SW-Schnittstelle:
• definiert Befehle zur Kommunikation mit der Hardware
• Instruktionssatz-Architektur bzw. Instruction Set Architecture (ISA)
• Menge der Befehle und zugrundeliegende Hardware hängen von der Anwendung ab
Befehle sollten so definiert werden, dass
• die Hardware effizient arbeiten kann
• Programme lesbar und verständlich sind
Geometrie
Transistoren
Logikschaltungen
Mikroarchitektur (Register-Transfer-Ebene)
Instruktionssatz-Architektur
Har
dwar
e
© 2016 6 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen

Grundstruktur eines von-Neumann-Computers
• Computer besteht aus Prozessor + Speicher + Ein-/Ausgabe
• Speicher besteht aus Worten fester Länge und enthält Daten und Instruktionen
– von-Neumann-Architektur: Daten und Instruktionen werden kodiert im selben Speicher abgelegt
• Prozessor besteht aus Rechenwerk und Steuerwerk – Rechen- und Steuerwerk = Central Processing Unit (CPU)
– Im Program Counter (PC, Befehlszähler) steht die Speicheradresse der nächsten auszuführenden Instruktion
– Weitere (Instruktions-)Register im Steuerwerk, da Operationen mit Registern viel schneller ausführbar sind als mit Operanden, die sich im Speicher befinden
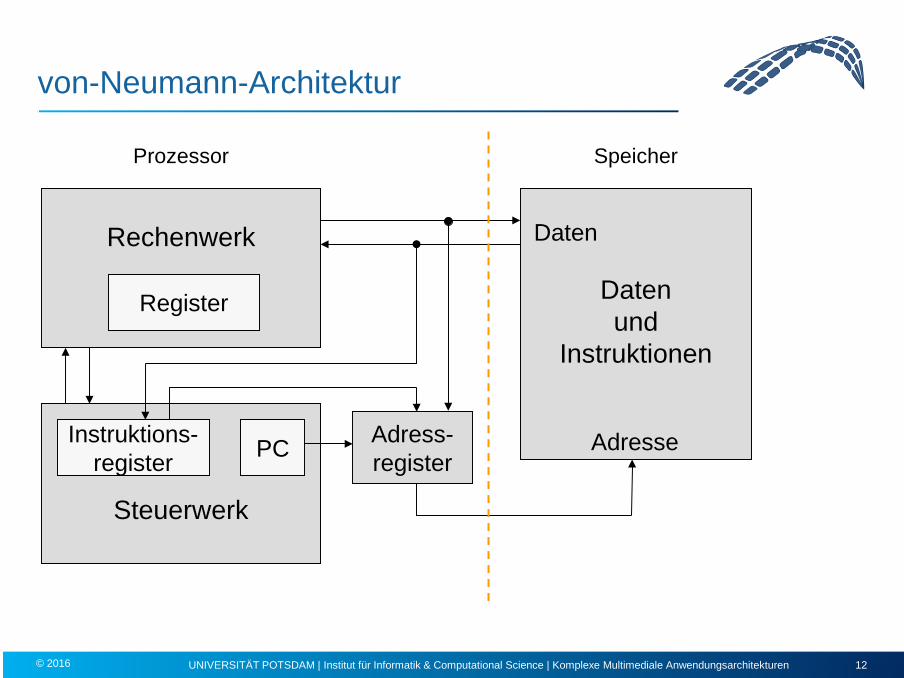
von-Neumann-Architektur
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 12 © 2016
Rechenwerk
Steuerwerk
Prozessor
Daten und
Instruktionen
Adress- register
Speicher
Instruktions- register PC
Daten
Adresse
Register
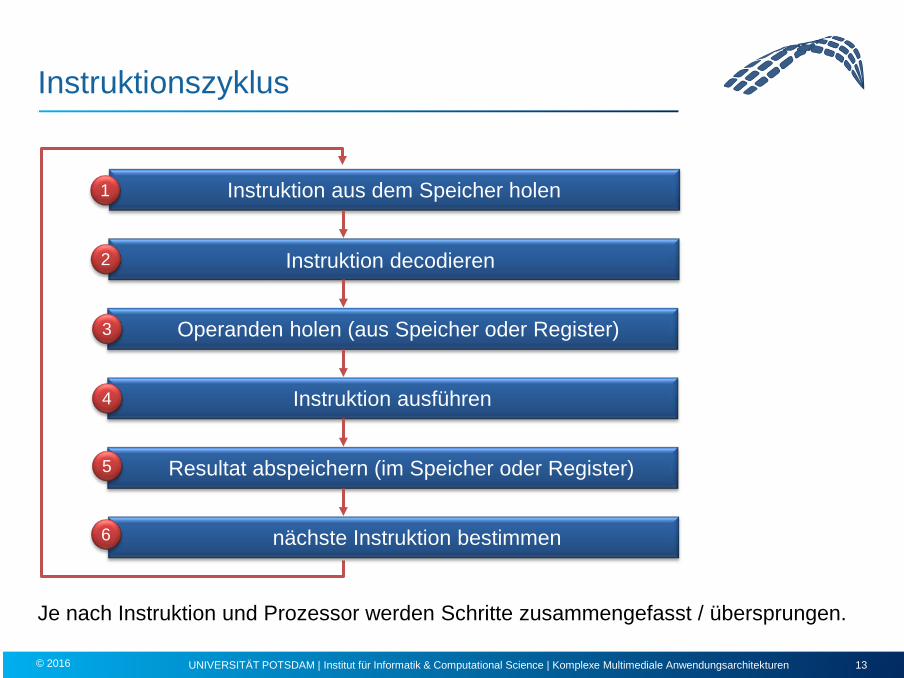
Instruktionszyklus
Je nach Instruktion und Prozessor werden Schritte zusammengefasst / übersprungen.
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 13 © 2016
Instruktion aus dem Speicher holen 1
Instruktion decodieren 2
Operanden holen (aus Speicher oder Register) 3
Instruktion ausführen 4
Resultat abspeichern (im Speicher oder Register) 5
nächste Instruktion bestimmen 6
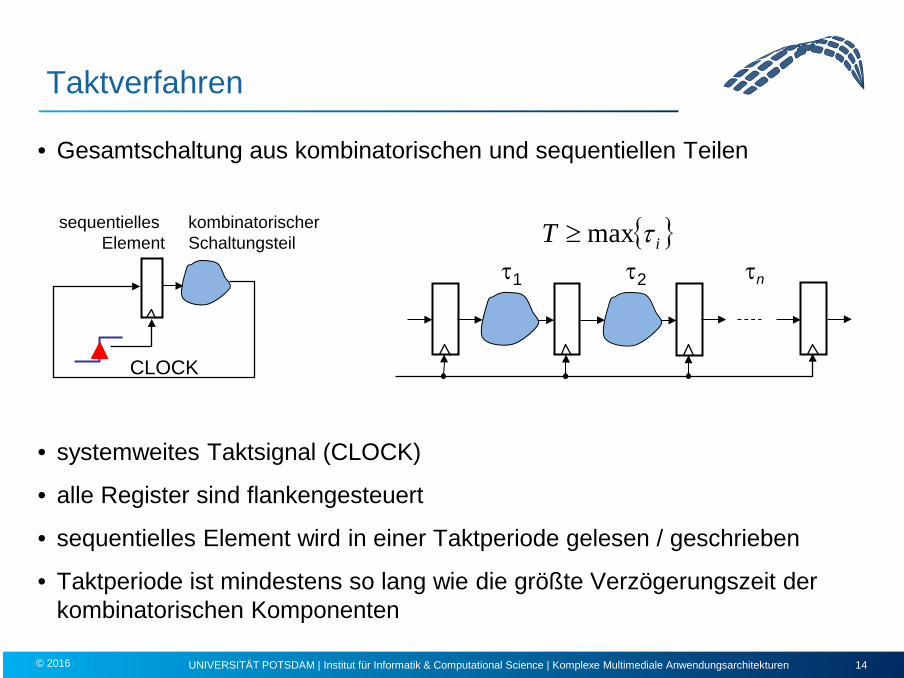
Taktverfahren
• Gesamtschaltung aus kombinatorischen und sequentiellen Teilen
• systemweites Taktsignal (CLOCK)
• alle Register sind flankengesteuert
• sequentielles Element wird in einer Taktperiode gelesen / geschrieben
• Taktperiode ist mindestens so lang wie die größte Verzögerungszeit der kombinatorischen Komponenten
τ1 τ2 τn
{ }iT τmax≥
CLOCK
kombinatorischer Schaltungsteil
sequentielles Element
© 2016 14 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen
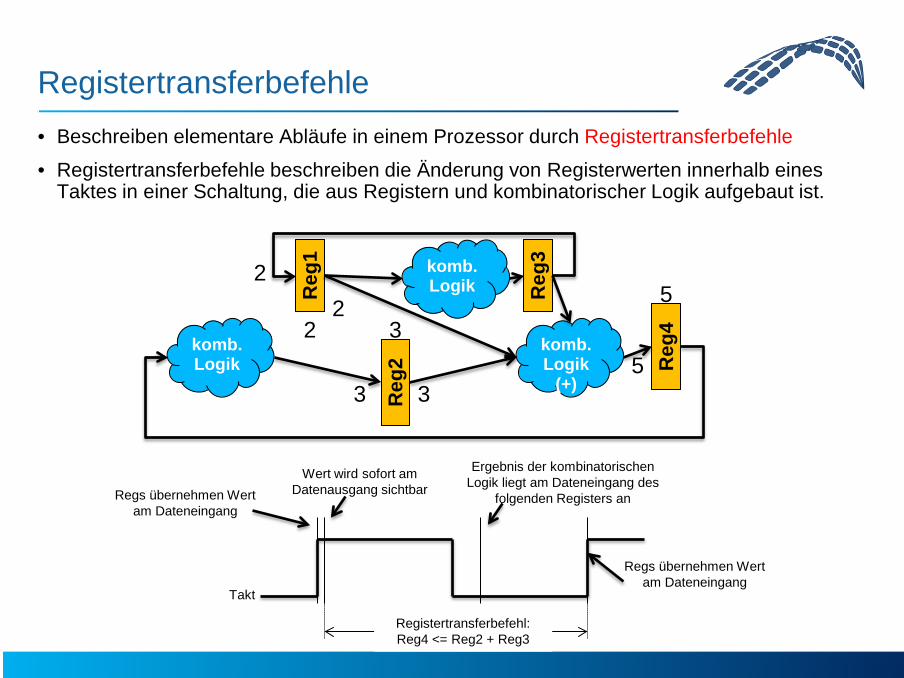
Registertransferbefehle • Beschreiben elementare Abläufe in einem Prozessor durch Registertransferbefehle
• Registertransferbefehle beschreiben die Änderung von Registerwerten innerhalb eines Taktes in einer Schaltung, die aus Registern und kombinatorischer Logik aufgebaut ist.
Reg
3
Reg
1
Reg
2 Reg
4
komb. Logik
komb. Logik
(+)
komb. Logik
Regs übernehmen Wert am Dateneingang
2
3
2 3
Wert wird sofort am Datenausgang sichtbar
3
2
Ergebnis der kombinatorischen Logik liegt am Dateneingang des
folgenden Registers an
5
Regs übernehmen Wert am Dateneingang
5
Takt
Registertransferbefehl: Reg4 <= Reg2 + Reg3

Allgemeine Form von Registertransferbefehlen
• Variante 1 eines RT-Befehls: lhs <= rhs, wobei – lhs bezeichnet ein Register – rhs ist ein Ausdruck, aufgebaut aus Operanden und Operationen – Operationen müssen durch kombinatorische Blöcke ausführbar sein – Operanden sind Register oder Eingangssignale
• Variante 2 eines RT-Befehls: if cond then stmt1 else stmt2, wobei: – stmt1 und stmt2 sind Registertransferbefehle der Variante 1 oder 2 – cond ist ein Ausdruck, aufgebaut aus Operanden und Operationen, der einen
Booleschen Wert ergibt
• Variante 3: nop – Alle load-Signale der Register sind 0
• Wächter: – Registertransferbefehl stmt kann mit Wächter cond versehen werden und wird nur
ausgeführt, wenn der Ausdruck des Wächters wahr ergibt: – Schreibweise: cond: stmt
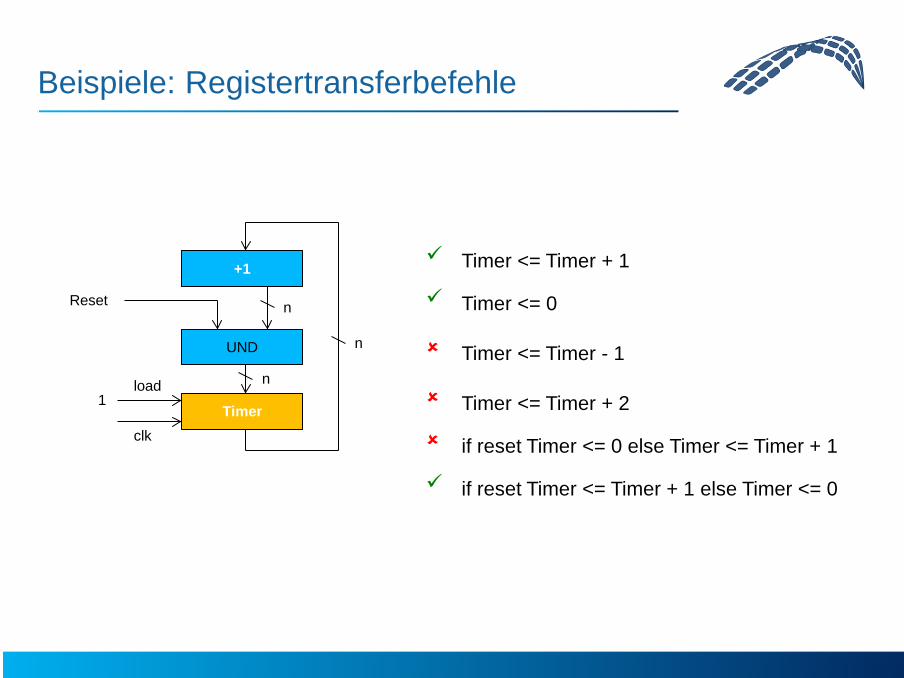
Beispiele: Registertransferbefehle
Timer
+1
UND
Reset
1
load
clk
n
n
n
Timer <= Timer + 1
Timer <= 0
Timer <= Timer - 1
Timer <= Timer + 2
if reset Timer <= 0 else Timer <= Timer + 1
if reset Timer <= Timer + 1 else Timer <= 0
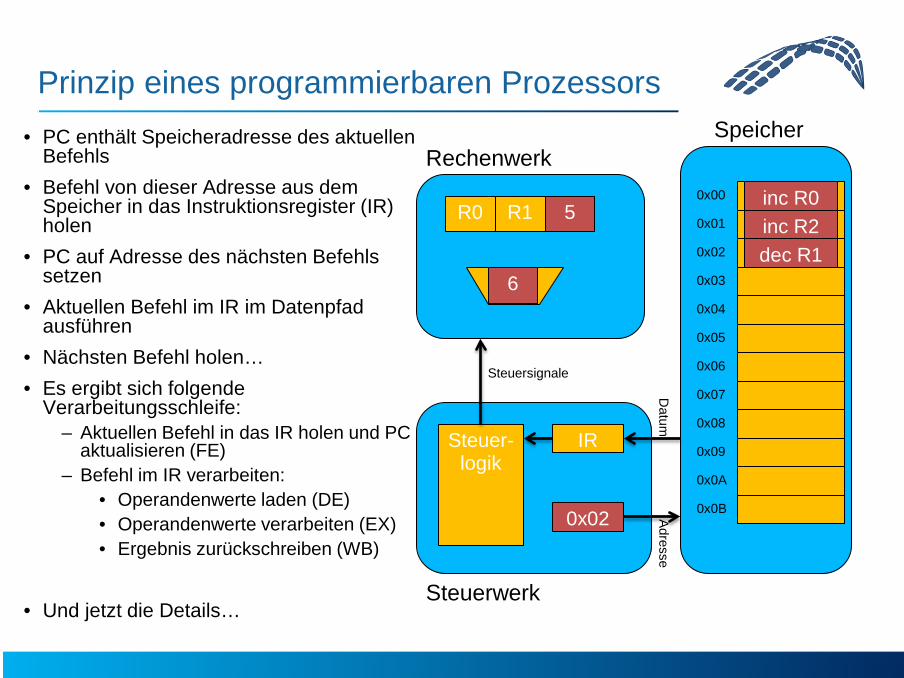
Prinzip eines programmierbaren Prozessors • PC enthält Speicheradresse des aktuellen
Befehls • Befehl von dieser Adresse aus dem
Speicher in das Instruktionsregister (IR) holen
• PC auf Adresse des nächsten Befehls setzen
• Aktuellen Befehl im IR im Datenpfad ausführen
• Nächsten Befehl holen… • Es ergibt sich folgende
Verarbeitungsschleife: – Aktuellen Befehl in das IR holen und PC
aktualisieren (FE) – Befehl im IR verarbeiten:
• Operandenwerte laden (DE) • Operandenwerte verarbeiten (EX) • Ergebnis zurückschreiben (WB)
• Und jetzt die Details…
Steuerwerk
Rechenwerk
IR
PC
R0 0x00
0x01
0x02
0x03
0x04
0x05
0x06
0x07
0x08
0x09
0x0A
0x0B
Speicher
Steuer- logik
ALU dec R1
inc R0 inc R2
0x01 0x02
R1 R2 5 inc R2
6
Steuersignale
Adresse D
atum
dec R1
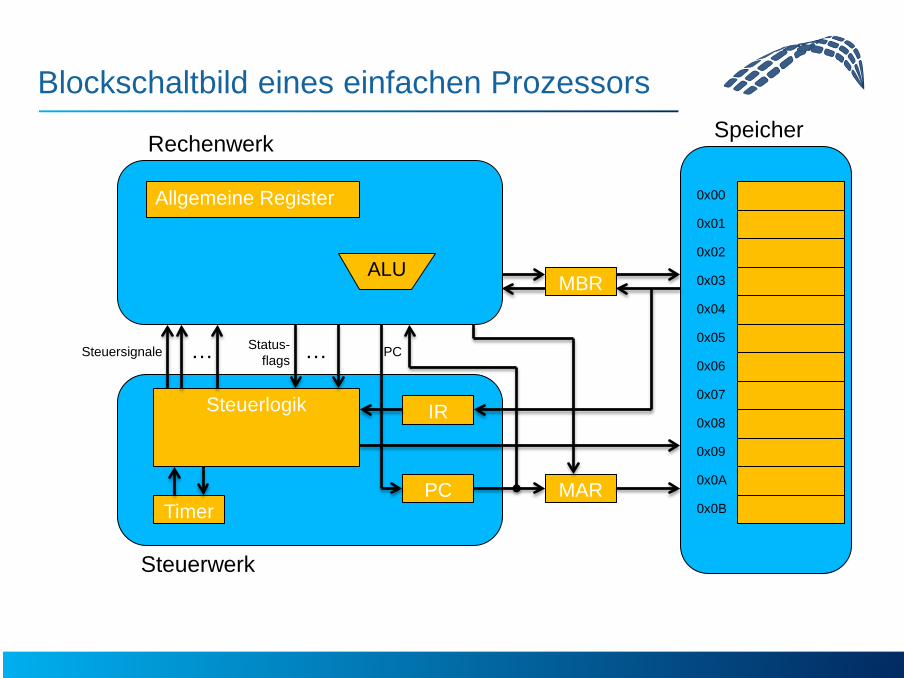
Blockschaltbild eines einfachen Prozessors
Steuerwerk
Rechenwerk
MAR
MBR
IR
Timer PC
Allgemeine Register 0x00
0x01
0x02
0x03
0x04
0x05
0x06
0x07
0x08
0x09
0x0A
0x0B
Speicher
Steuerlogik
… …
ALU
Steuersignale PC Status- flags
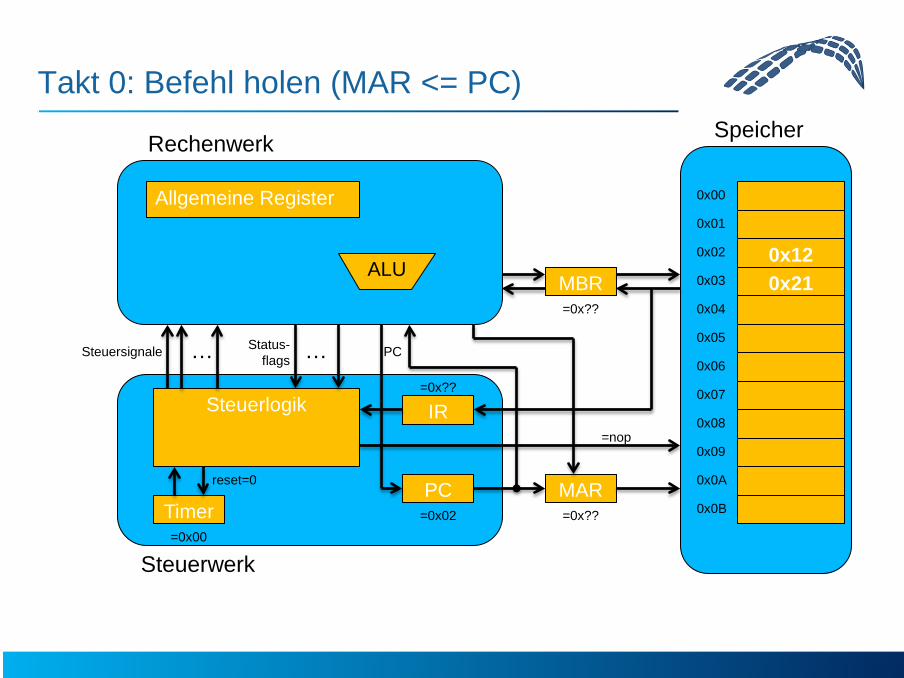
Takt 0: Befehl holen (MAR <= PC)
Steuerwerk
Rechenwerk
MAR
MBR
IR
Timer PC
Allgemeine Register
0x12
0x00
0x01
0x02
0x03
0x04
0x05
0x06
0x07
0x08
0x09
0x0A
0x0B
Speicher
Steuerlogik
… …
ALU
Steuersignale PC Status- flags
=0x02
=0x??
=0x??
=0x??
=0x00
=nop
0x21
reset=0
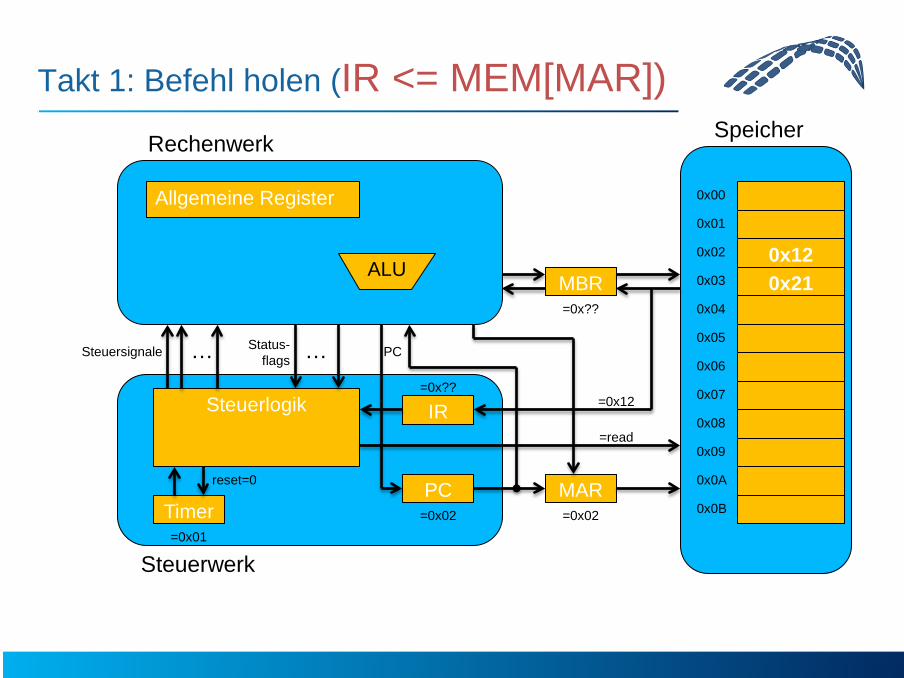
Takt 1: Befehl holen (IR <= MEM[MAR])
Steuerwerk
Rechenwerk
MAR
MBR
IR
Timer PC
Allgemeine Register 0x00
0x01
0x02
0x03
0x04
0x05
0x06
0x07
0x08
0x09
0x0A
0x0B
Speicher
Steuerlogik
… …
ALU
Steuersignale PC Status- flags
=0x02 =0x02
=0x??
=0x01
=0x??
=read
0x12 0x21
=0x12
reset=0
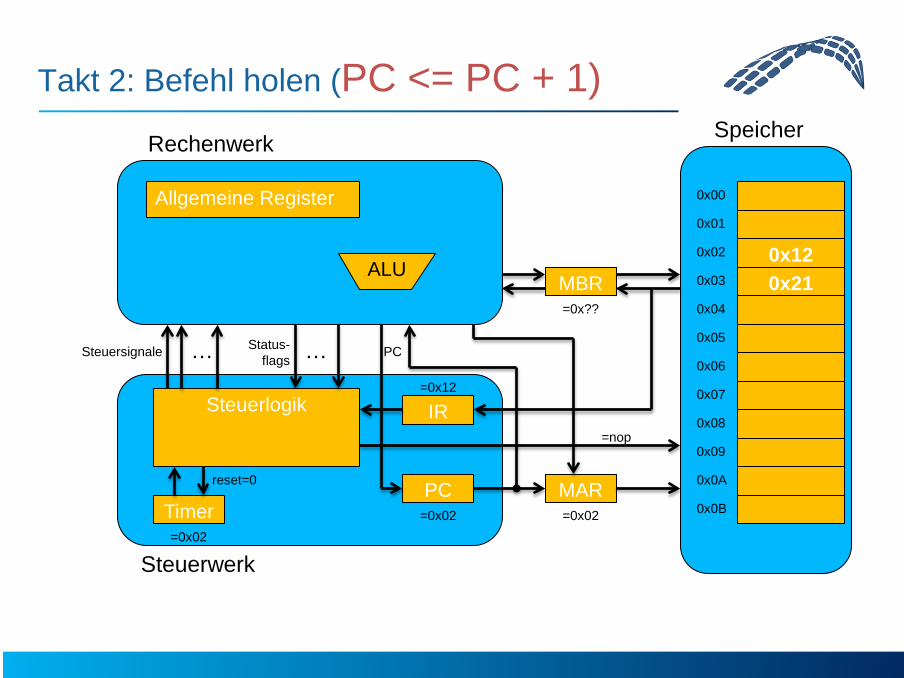
Takt 2: Befehl holen (PC <= PC + 1)
Steuerwerk
Rechenwerk
MAR
MBR
IR
Timer PC
Allgemeine Register 0x00
0x01
0x02
0x03
0x04
0x05
0x06
0x07
0x08
0x09
0x0A
0x0B
Speicher
Steuerlogik
… …
ALU
Steuersignale PC Status- flags
=0x02 =0x02
=0x??
=0x02
=0x12
=nop
0x12 0x21
reset=0
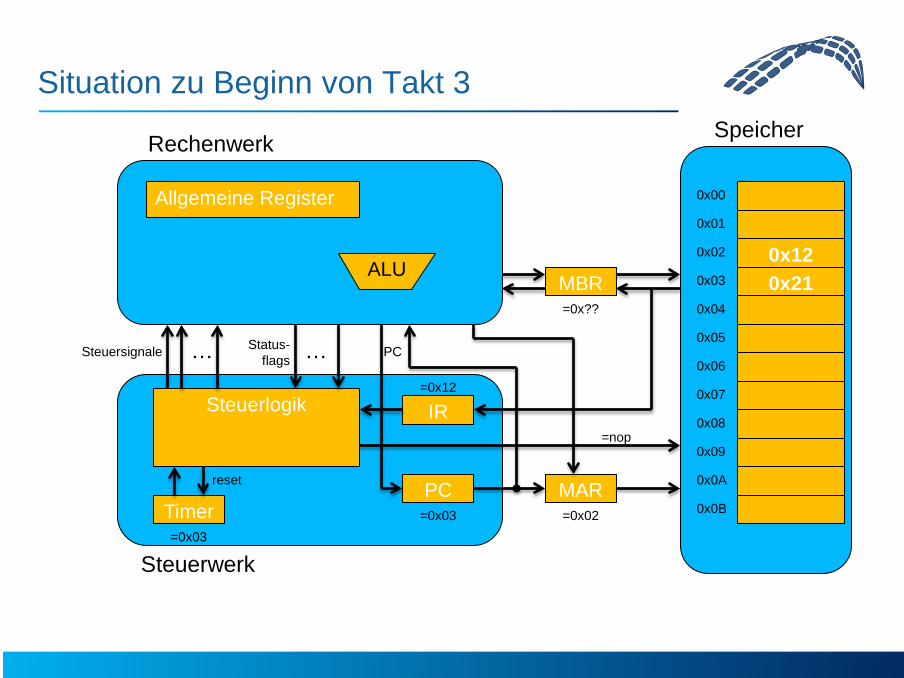
Situation zu Beginn von Takt 3
Steuerwerk
Rechenwerk
MAR
MBR
IR
Timer PC
Allgemeine Register 0x00
0x01
0x02
0x03
0x04
0x05
0x06
0x07
0x08
0x09
0x0A
0x0B
Speicher
Steuerlogik
… …
ALU
Steuersignale PC Status- flags
=0x03 =0x02
=0x??
=0x03
=0x12
=nop
0x12 0x21
reset
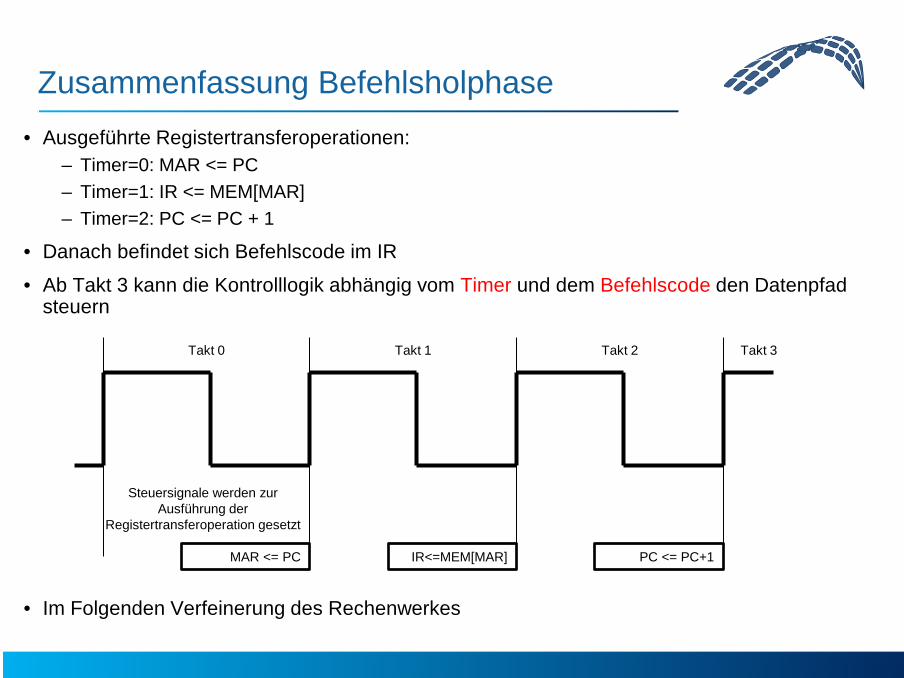
Zusammenfassung Befehlsholphase • Ausgeführte Registertransferoperationen:
– Timer=0: MAR <= PC – Timer=1: IR <= MEM[MAR] – Timer=2: PC <= PC + 1
• Danach befindet sich Befehlscode im IR
• Ab Takt 3 kann die Kontrolllogik abhängig vom Timer und dem Befehlscode den Datenpfad steuern
• Im Folgenden Verfeinerung des Rechenwerkes
Takt 0
Steuersignale werden zur Ausführung der
Registertransferoperation gesetzt
MAR <= PC IR<=MEM[MAR] PC <= PC+1
Takt 1 Takt 2 Takt 3
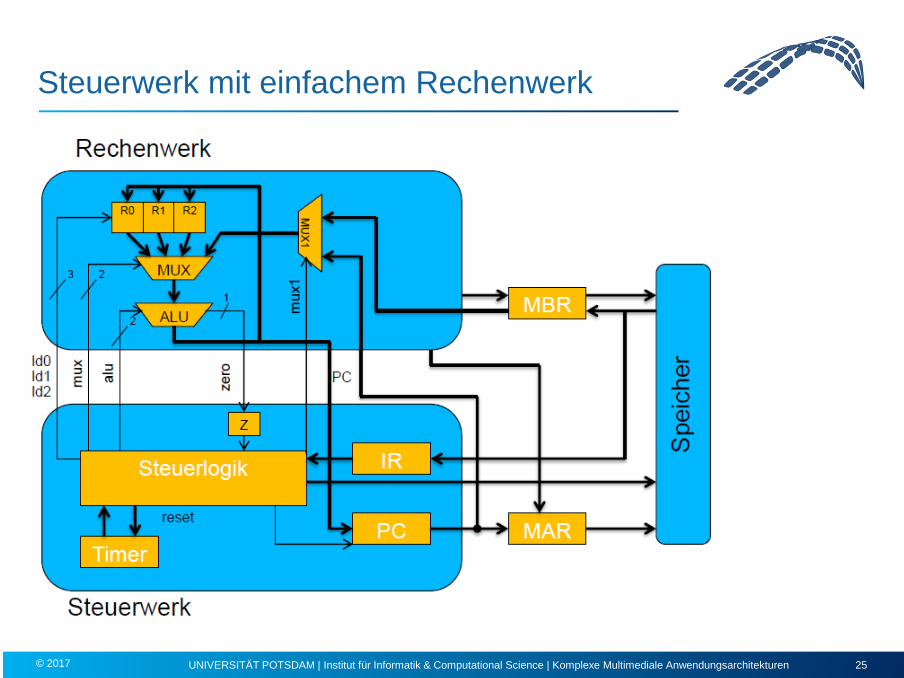
Steuerwerk mit einfachem Rechenwerk
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 25 © 2017
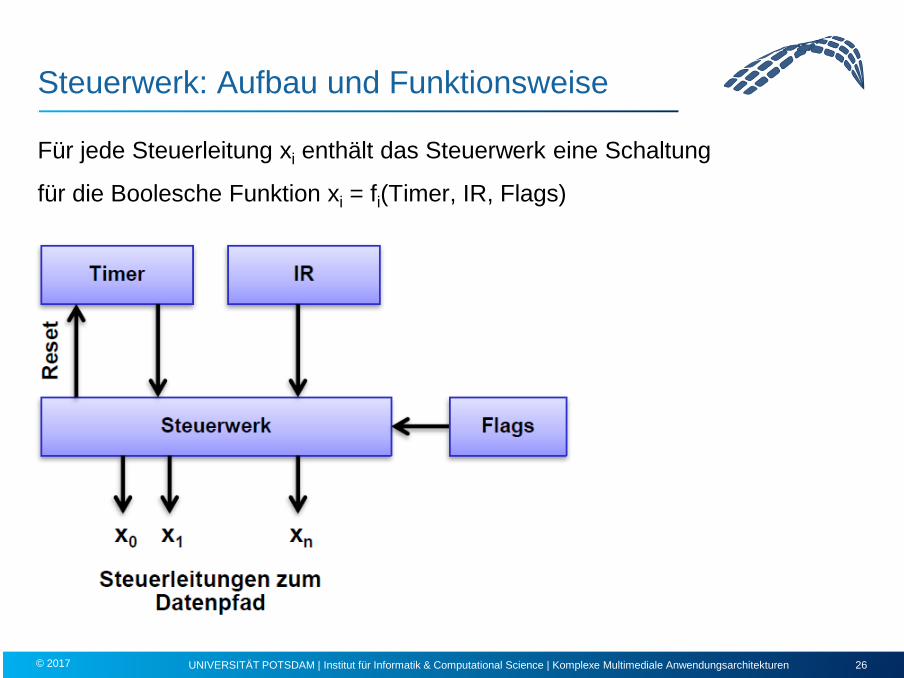
Steuerwerk: Aufbau und Funktionsweise
Für jede Steuerleitung xi enthält das Steuerwerk eine Schaltung
für die Boolesche Funktion xi = fi(Timer, IR, Flags)
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 26 © 2017
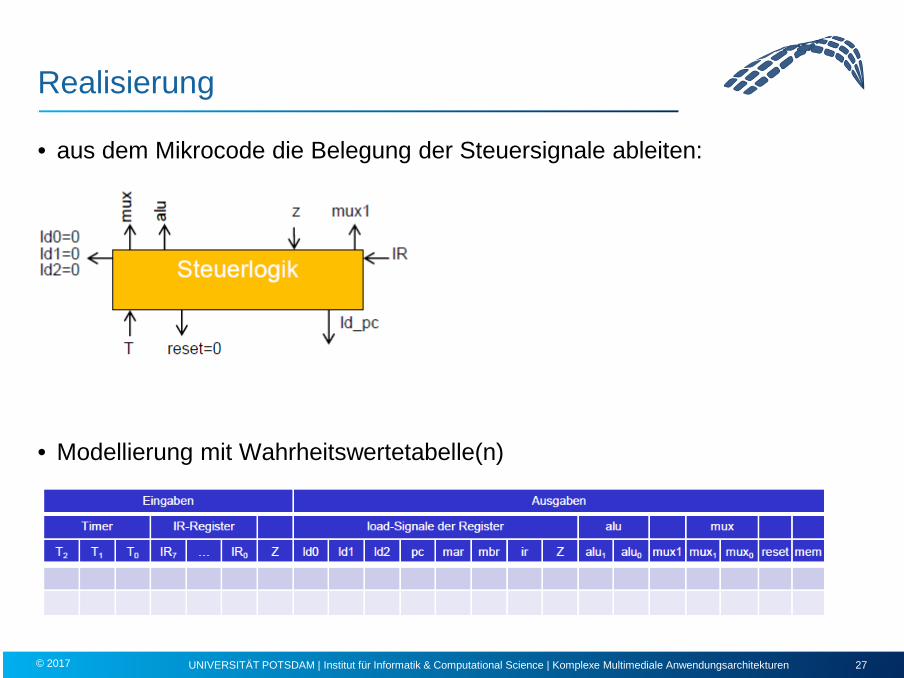
Realisierung
• aus dem Mikrocode die Belegung der Steuersignale ableiten:
• Modellierung mit Wahrheitswertetabelle(n)
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 27 © 2017
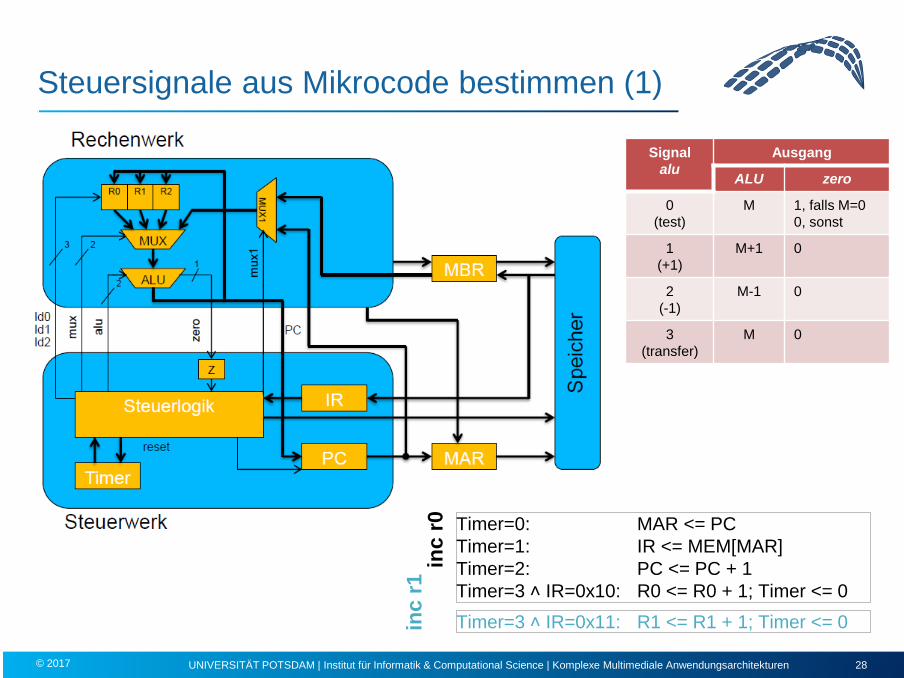
Steuersignale aus Mikrocode bestimmen (1)
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 28 © 2017
Timer=0: MAR <= PC Timer=1: IR <= MEM[MAR] Timer=2: PC <= PC + 1 Timer=3 ˄ IR=0x10: R0 <= R0 + 1; Timer <= 0
inc
r0
inc
r1
Timer=3 ˄ IR=0x11: R1 <= R1 + 1; Timer <= 0
Signal alu
Ausgang
ALU zero
0 (test)
M 1, falls M=0 0, sonst
1 (+1)
M+1 0
2 (-1)
M-1 0
3 (transfer)
M 0
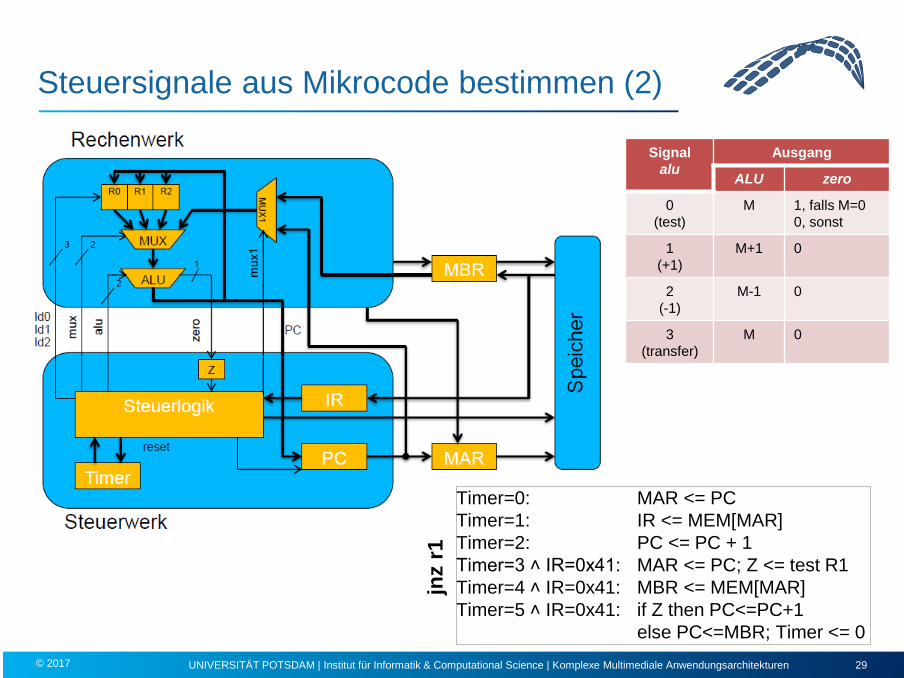
Steuersignale aus Mikrocode bestimmen (2)
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 29 © 2017
Timer=0: MAR <= PC Timer=1: IR <= MEM[MAR] Timer=2: PC <= PC + 1 Timer=3 ˄ IR=0x41: MAR <= PC; Z <= test R1 Timer=4 ˄ IR=0x41: MBR <= MEM[MAR] Timer=5 ˄ IR=0x41: if Z then PC<=PC+1 else PC<=MBR; Timer <= 0
jnz
r1
Signal alu
Ausgang
ALU zero
0 (test)
M 1, falls M=0 0, sonst
1 (+1)
M+1 0
2 (-1)
M-1 0
3 (transfer)
M 0
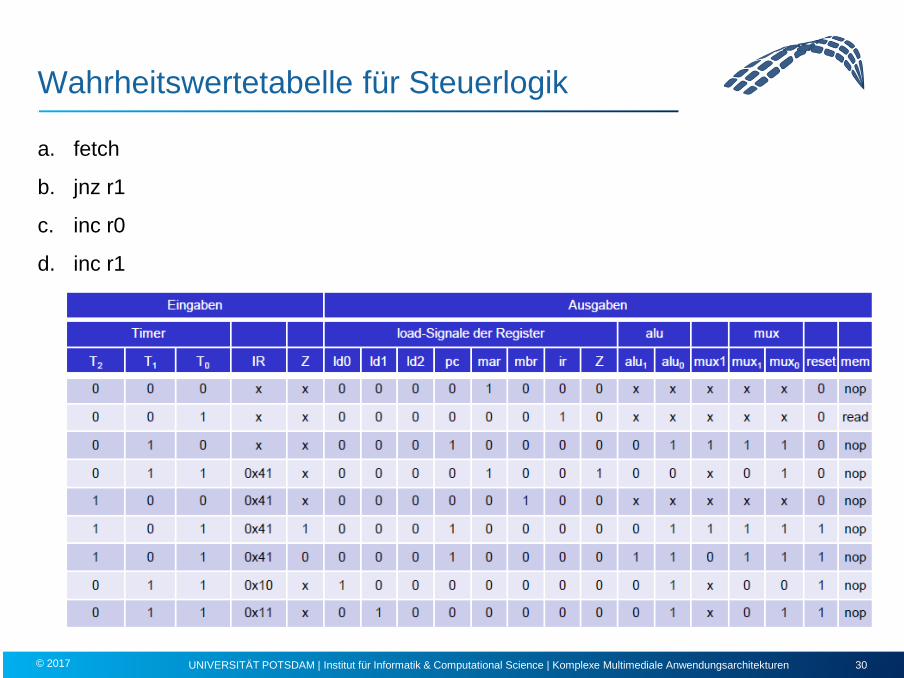
Wahrheitswertetabelle für Steuerlogik
a. fetch
b. jnz r1
c. inc r0
d. inc r1
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 30 © 2017
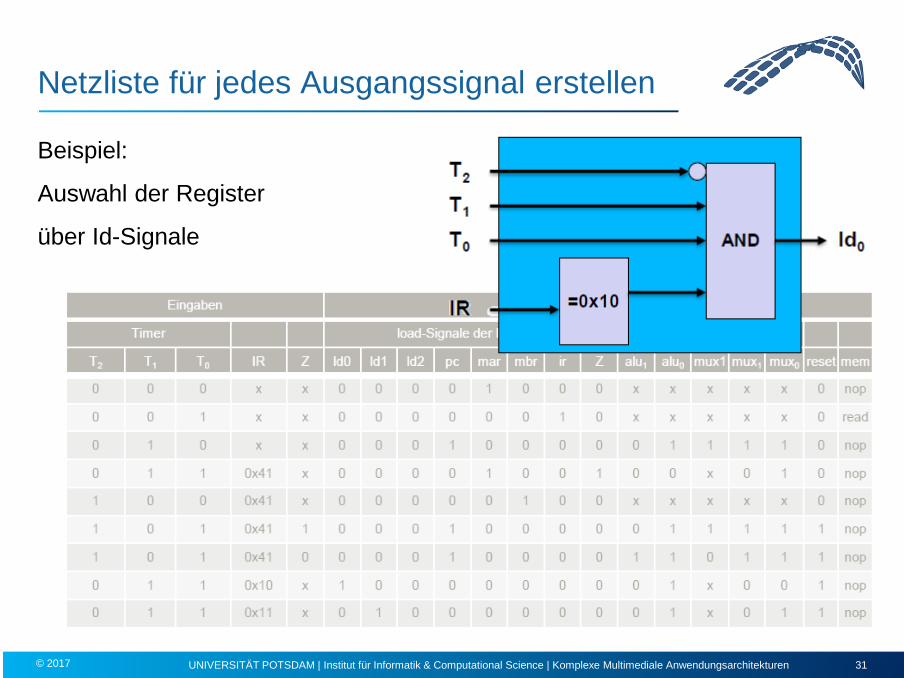
Netzliste für jedes Ausgangssignal erstellen
Beispiel:
Auswahl der Register
über Id-Signale
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 31 © 2017

Beispielarchitektur
Hennessy, Patterson:
“Computer Organization and Design: The Hardware Software Interface”
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 32 © 2016

Konzeption einer Prozessor-Architektur
• Elemente des Datenpfades / vereinfachter Instruktionssatz: – Laden der Instruktion, Inkrementieren des Program Counter – Datentransferinstruktionen: load, store – Arithmetik- und Logikinstruktionen: add, sub, and, or – Verzweigungsinstruktionen: compare & branch on zero (cbz), branch
Entwurf des Datenpfades – benötigte Komponenten – Steuer- und Statussignale
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 33 © 2016

Laden der Instruktion, Inkrementieren des Program Counter
• Pro Instruktionszyklus wird eine Instruktion aus dem Speicher geladen.
• Im Program Counter steht die Adresse dieser Instruktion.
• 32-Bit-Rechner: Mit Ausnahme von Sprungbefehlen ist die nächste Instruktion an der “folgenden” Adresse zu finden, d.h. PC ← PC + 4 .
• benötigte Komponenten: – Instruktionsspeicher:
Eingang: Adresse (32-Bit); Ausgang: Instruktion (32-Bit); keine Steuersignale – Program Counter:
Bei steigender Taktflanke wird ein neuer Wert in den PC geladen. – Addierer:
PC um 4 erhöhen
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 34 © 2016
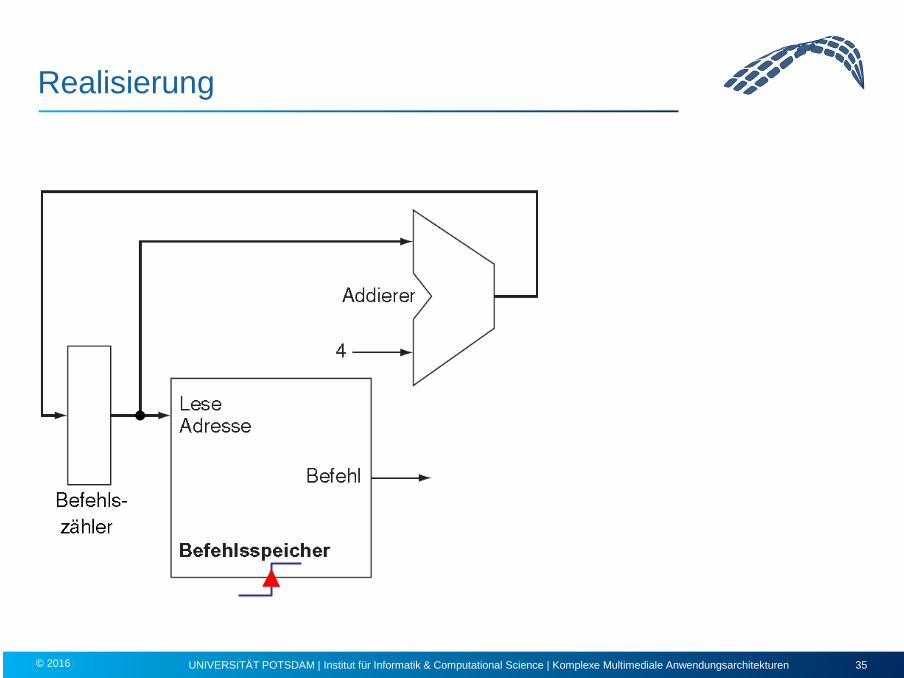
Realisierung
© 2016 35 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen

Tipp
Welche Konstante müsste bei einem 64-Bit-Rechner in den Addierer
geführt werden, um die Adresse des nächsten Befehls zu berechnen?
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 36 © 2016

Datentransferinstruktionen
Schreiben von Register in Speicher
oder
Lesen von Speicher in Register
Komponenten:
• Datenspeicher
• Registerfile
• Vorzeichenerweiterung
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 37 © 2016

Datenspeicher
• Eingänge: – Adresse (32-Bit) – zu schreibende Daten (32-Bit) – MemWrite: getaktetes “Write-Enable”-Signal, leitet Schreibvorgang ein – MemRead: signalisiert einen Lesezugriff auf den Datenspeicher
• Ausgang: 32-Bit Datenausgang
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 38 © 2016
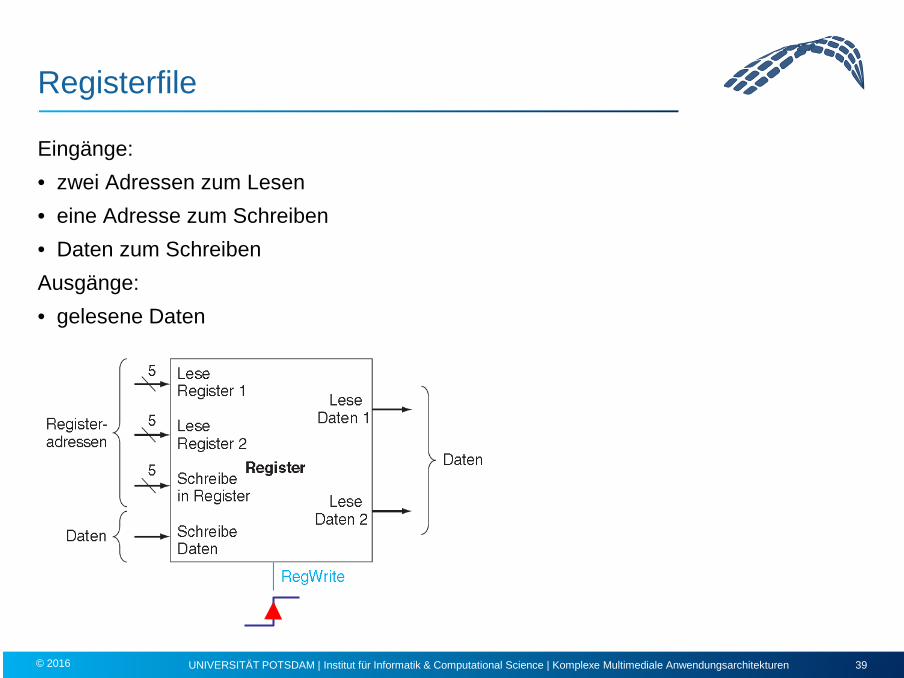
Registerfile
Eingänge: • zwei Adressen zum Lesen • eine Adresse zum Schreiben • Daten zum Schreiben Ausgänge: • gelesene Daten
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 39 © 2016
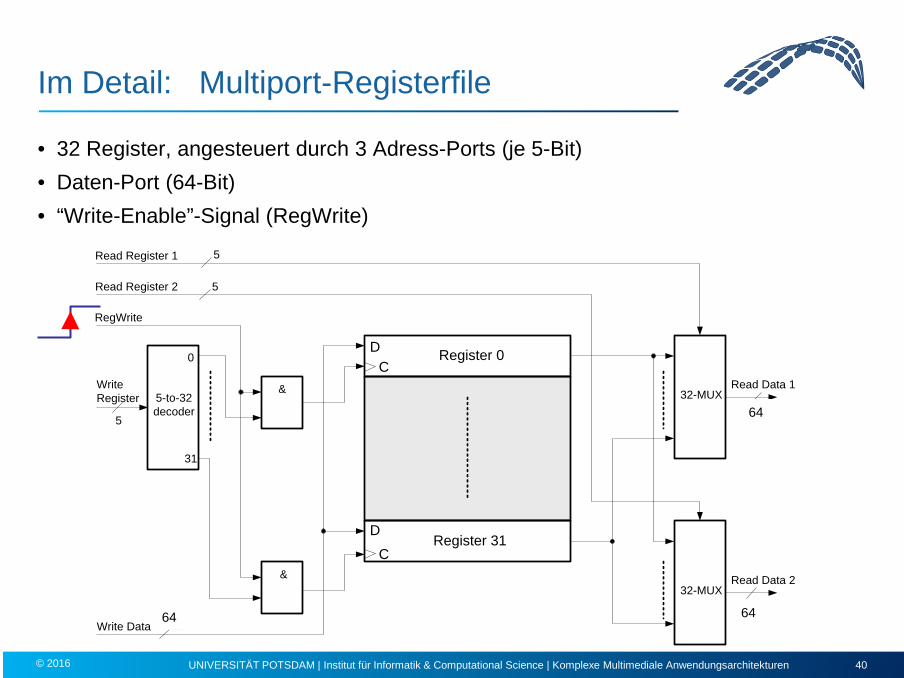
Im Detail: Multiport-Registerfile
• 32 Register, angesteuert durch 3 Adress-Ports (je 5-Bit) • Daten-Port (64-Bit) • “Write-Enable”-Signal (RegWrite)
a&
C
&
D
D
C
Register 0
Register 31
RegWrite
Write Data
WriteRegister
0
31
5
5-to-32decoder
32-MUX
32-MUXRead Data 2
Read Data 1
Read Register 1
Read Register 2
32
5
5
32
32
© 2016 40 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen
64
64 64

Vorzeichenerweiterung
• Eingang: Operand im 2er-Komplement (32-Bit)
• Ausgang: Operand im 2er-Komplement (64-Bit)
• 32
Kopieren von Bit 31 in alle höherwertigen Bits
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 41 © 2016
32 64
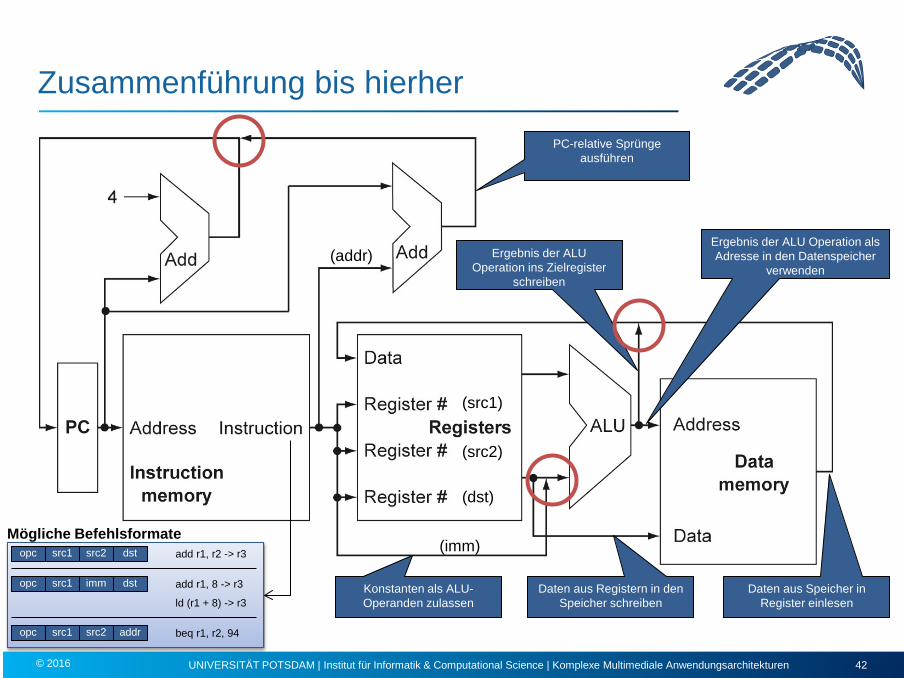
Zusammenführung bis hierher
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 42 © 2016
PC-relative Sprünge ausführen
Ergebnis der ALU Operation ins Zielregister
schreiben
Ergebnis der ALU Operation als Adresse in den Datenspeicher
verwenden
Konstanten als ALU-Operanden zulassen
Daten aus Registern in den Speicher schreiben
Daten aus Speicher in Register einlesen
opc src1 src2 dst add r1, r2 -> r3
opc src1 imm dst add r1, 8 -> r3
opc addr beq r1, r2, 94 src1
ld (r1 + 8) -> r3
Mögliche Befehlsformate
src2
(src1)
(src2)
(dst)
(imm)
(addr)
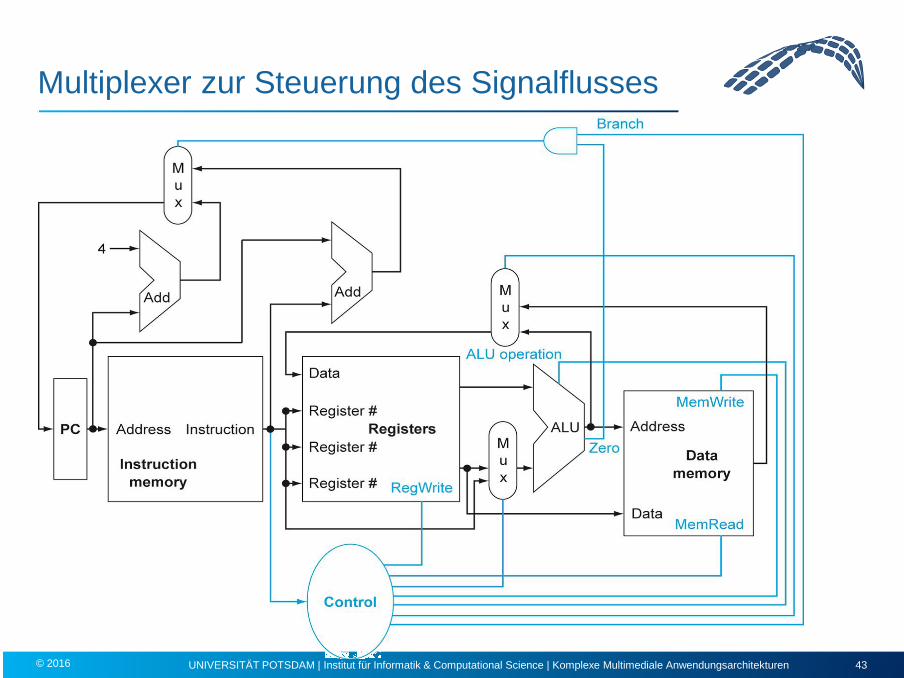
Multiplexer zur Steuerung des Signalflusses
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 43 © 2016

Weitere Registerarchitekturen
• Universalregisterarchitektur: Operanden in Registerblock
• Scratch-Pad-Memory: Operanden in Speicherblock
• Akkumulatorarchitektur: Akkumulatorregister ist Operand
• Spezialregisterarchitektur: Spezialregister für unterschiedliche Operationen
• Stack-Architektur: Operanden im Stapelspeicher
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 44 © 2017
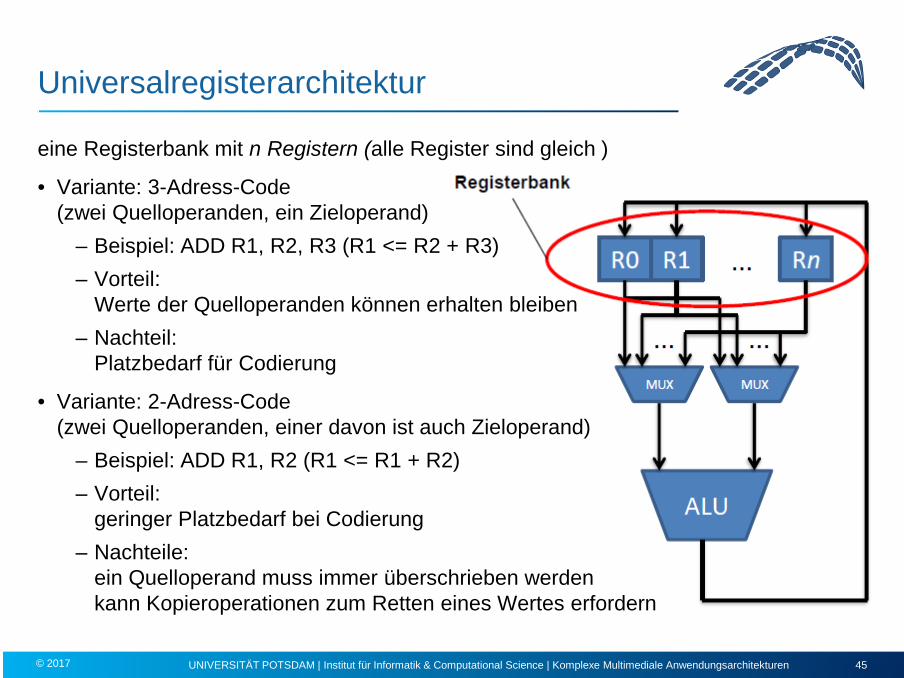
Universalregisterarchitektur
eine Registerbank mit n Registern (alle Register sind gleich )
• Variante: 3-Adress-Code (zwei Quelloperanden, ein Zieloperand)
– Beispiel: ADD R1, R2, R3 (R1 <= R2 + R3) – Vorteil:
Werte der Quelloperanden können erhalten bleiben – Nachteil:
Platzbedarf für Codierung
• Variante: 2-Adress-Code (zwei Quelloperanden, einer davon ist auch Zieloperand)
– Beispiel: ADD R1, R2 (R1 <= R1 + R2) – Vorteil:
geringer Platzbedarf bei Codierung – Nachteile:
ein Quelloperand muss immer überschrieben werden kann Kopieroperationen zum Retten eines Wertes erfordern
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 45 © 2017
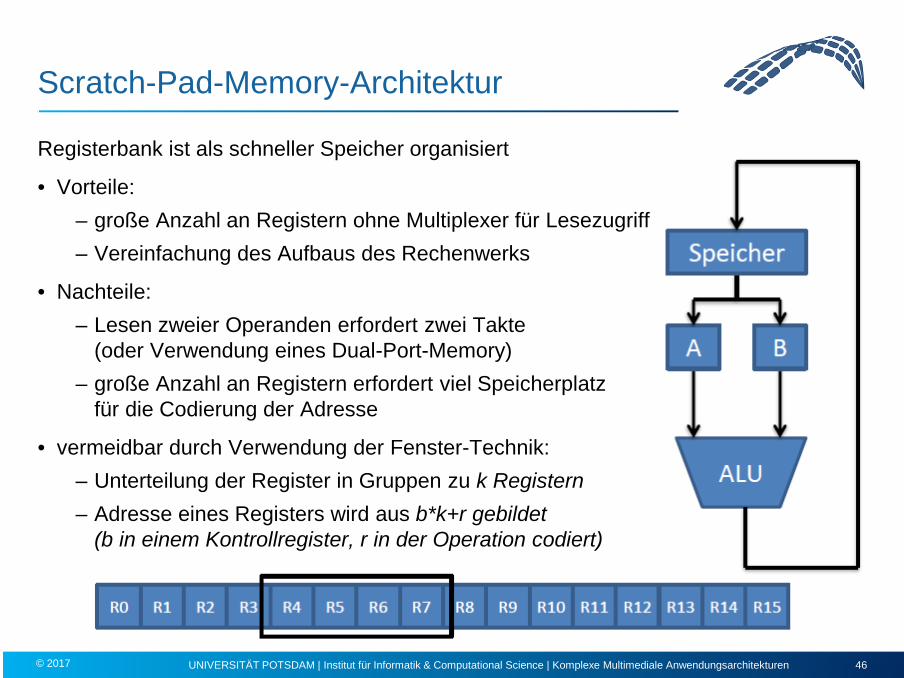
Scratch-Pad-Memory-Architektur
Registerbank ist als schneller Speicher organisiert
• Vorteile: – große Anzahl an Registern ohne Multiplexer für Lesezugriff – Vereinfachung des Aufbaus des Rechenwerks
• Nachteile: – Lesen zweier Operanden erfordert zwei Takte
(oder Verwendung eines Dual-Port-Memory) – große Anzahl an Registern erfordert viel Speicherplatz
für die Codierung der Adresse
• vermeidbar durch Verwendung der Fenster-Technik: – Unterteilung der Register in Gruppen zu k Registern – Adresse eines Registers wird aus b*k+r gebildet
(b in einem Kontrollregister, r in der Operation codiert)
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 46 © 2017
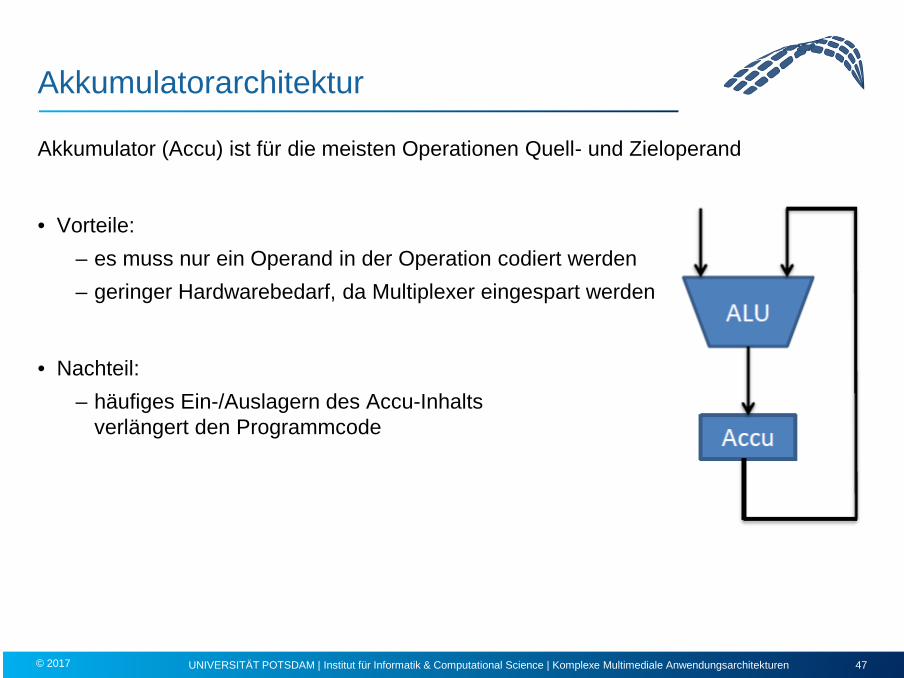
Akkumulatorarchitektur
Akkumulator (Accu) ist für die meisten Operationen Quell- und Zieloperand
• Vorteile: – es muss nur ein Operand in der Operation codiert werden – geringer Hardwarebedarf, da Multiplexer eingespart werden
• Nachteil: – häufiges Ein-/Auslagern des Accu-Inhalts
verlängert den Programmcode
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 47 © 2017
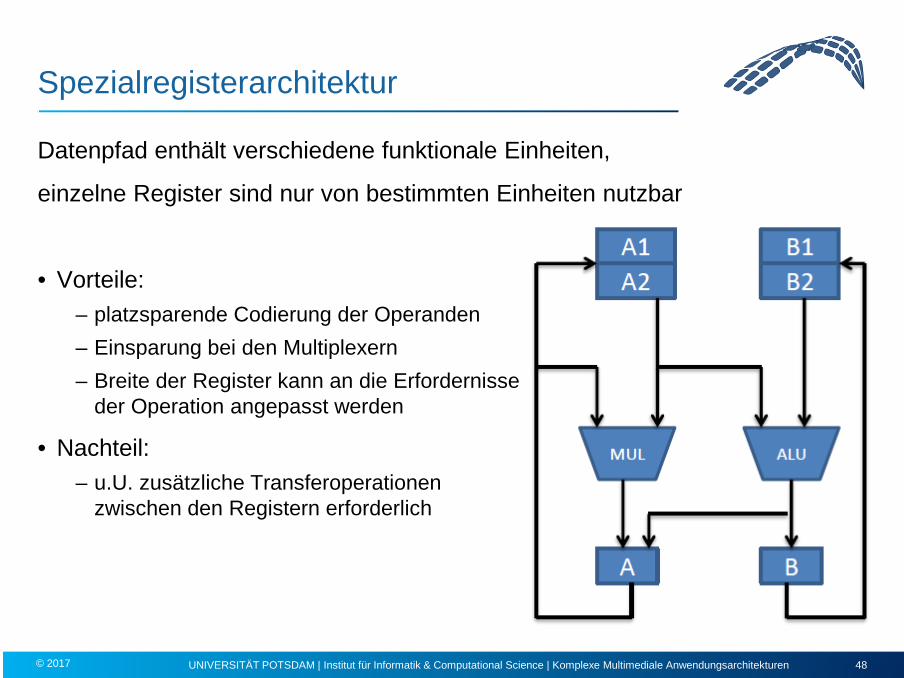
Spezialregisterarchitektur
Datenpfad enthält verschiedene funktionale Einheiten,
einzelne Register sind nur von bestimmten Einheiten nutzbar
• Vorteile: – platzsparende Codierung der Operanden – Einsparung bei den Multiplexern – Breite der Register kann an die Erfordernisse
der Operation angepasst werden
• Nachteil: – u.U. zusätzliche Transferoperationen
zwischen den Registern erforderlich
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 48 © 2017
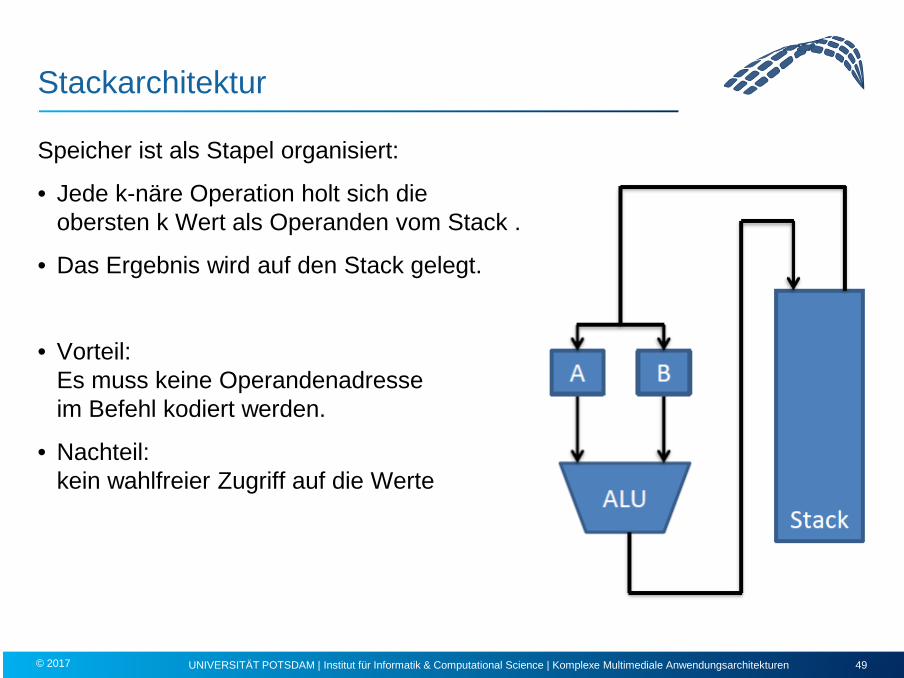
Stackarchitektur
Speicher ist als Stapel organisiert:
• Jede k-näre Operation holt sich die obersten k Wert als Operanden vom Stack .
• Das Ergebnis wird auf den Stack gelegt.
• Vorteil: Es muss keine Operandenadresse im Befehl kodiert werden.
• Nachteil: kein wahlfreier Zugriff auf die Werte
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 49 © 2017

Tipp
Welche Registerarchitektur finden Sie am besten? Warum?
Welche ist eher günstig für den (Assembler-)Programmierer,
welche für die Hardware-Realisierung?
Gibt es Vorteile bei bestimmten Applikationen?
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 50 © 2017

Arithmetik- und Logikinstruktionen
lesen 2 Register
führen die entsprechende Berechnung aus
schreiben in ein drittes Register
Y = f(A, B)
benötigte Komponenten:
• Registerfile
• Arithmetic-Logic-Unit (ALU)
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 51 © 2016
A
B
Y ALU
f
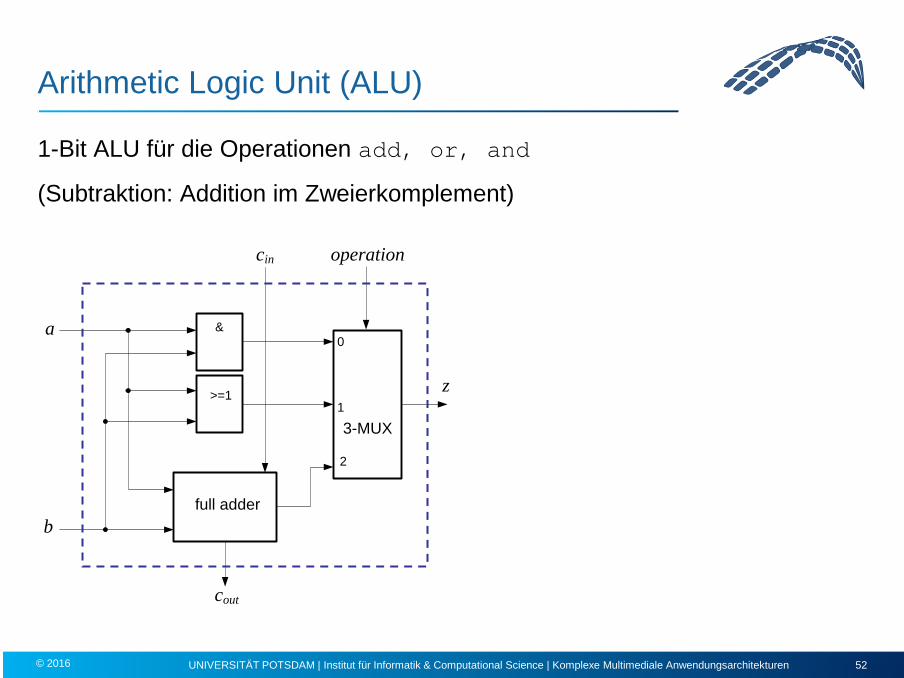
Arithmetic Logic Unit (ALU)
1-Bit ALU für die Operationen add, or, and
(Subtraktion: Addition im Zweierkomplement)
a &
>=1
b
cin
cout
0
1
2
z
operation
3-MUX
full adder
© 2016 52 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen
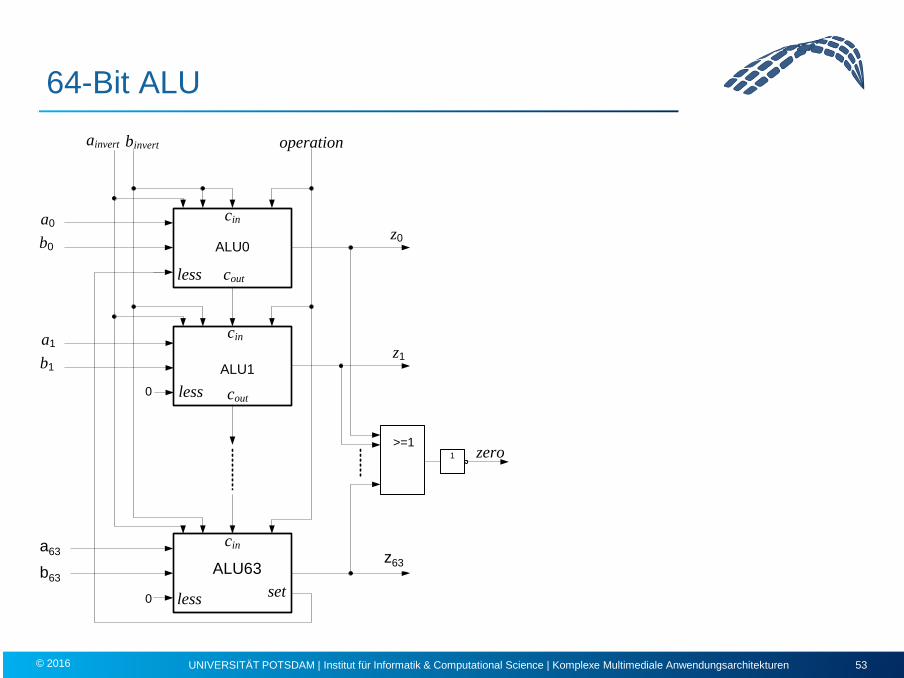
a0
b0
a1
b1
a31
b31
0
0
z31
z1
z0
>=1
less
cin
set
less
cin
cout
less
cin
cout
ainvert bnegate operation
1 zero
ALU0
ALU1
ALU31
64-Bit ALU
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 53 © 2016
invert
a63
b63
z63 ALU63
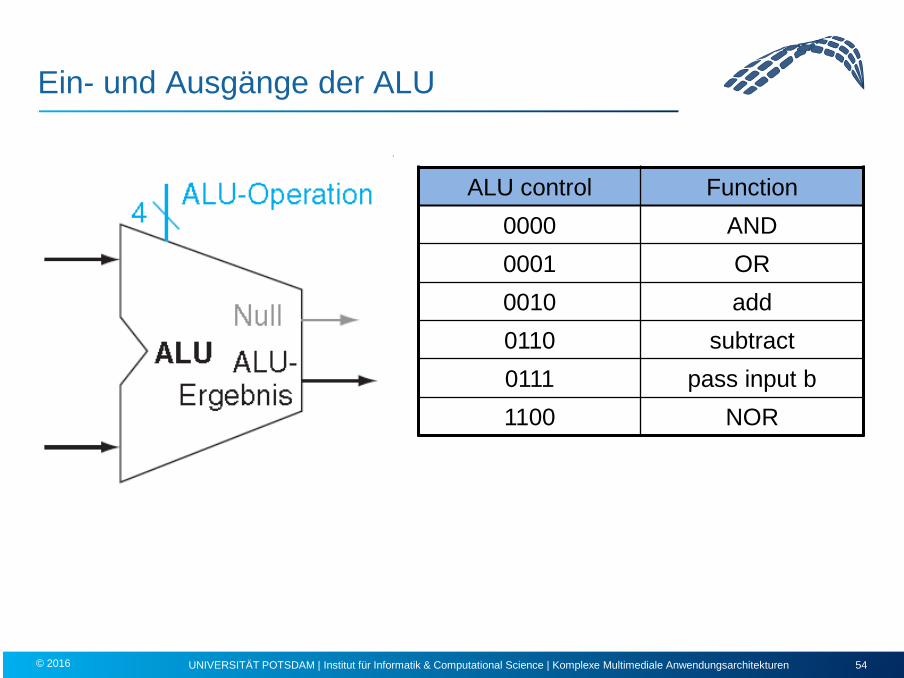
Ein- und Ausgänge der ALU
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 54 © 2016
ALU control Function 0000 AND 0001 OR 0010 add 0110 subtract 0111 pass input b 1100 NOR
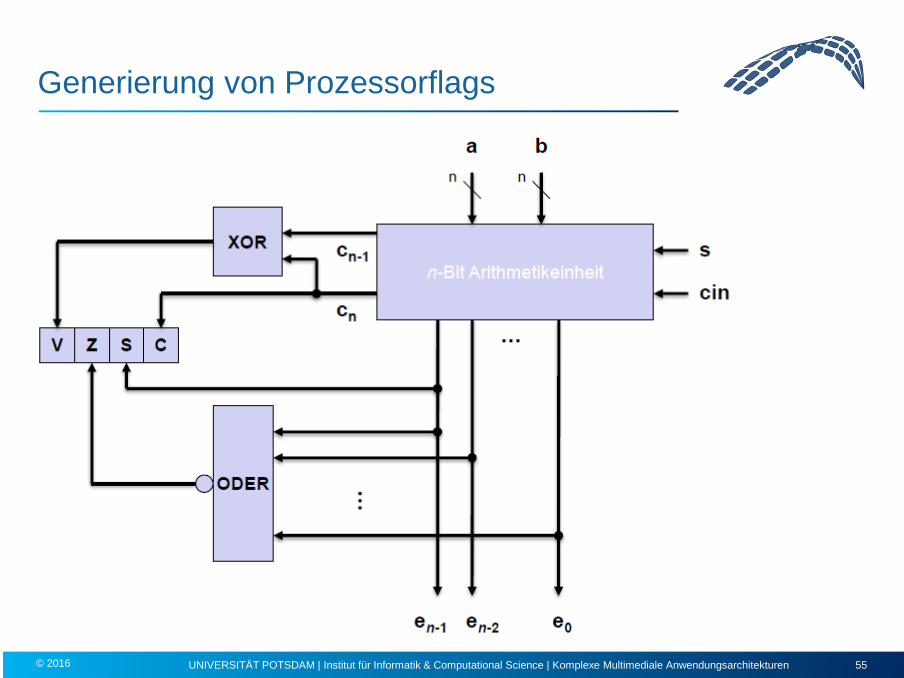
Generierung von Prozessorflags
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 55 © 2016

Rechenwerk: Prozessorflags
• Carry (C): – zeigt falsches Ergebnis bei Addition/Subtraktion vorzeichenloser Zahlen an – entspricht Ausgang cn der Arithmetikeinheit, d.h. Carry = 1 gdw.
bei einer n-Bit-Arithmetikeinheit ein Über-/Unterlauf in das Bit n+1 auftritt
• Zero (Z): – Zero = 1 gdw. Ergebnis einer ALU-Operation 0 ist
• Negative (N): – Negative = 0 gdw. MSB im Ergebnis der ALU 0 ist
• Overflow (V): – zeigt falsches Ergebnis bei Addition/Subtraktion vorzeichenbehafteter Zahlen an – Overflow =1 gdw. das Ergebnis ein falsches Vorzeichen aufweist
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 56 © 2016

Tipp
Welche Arithmetik-/Logik-Operationen fehlen Ihnen hier noch?
Schätzen Sie ab, wie viel komplexer dadurch die interne Realisierung wird
und wie viele Steuersignale hinzu kommen müssen.
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 57 © 2016
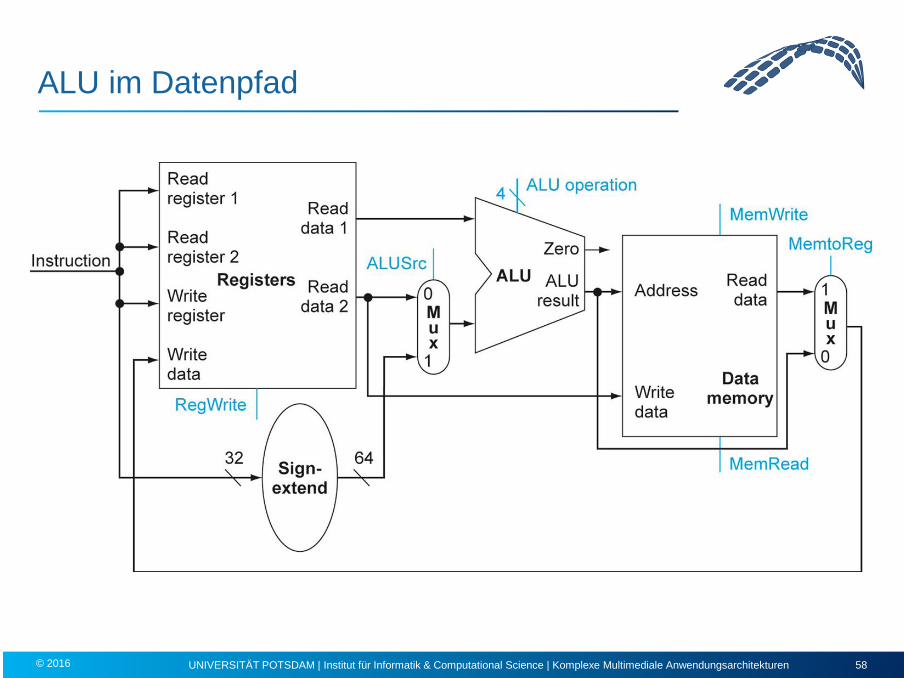
ALU im Datenpfad
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 58 © 2016

Verzweigungsinstruktionen
1. Feststellen, ob ein Sprung ausgeführt wird oder nicht
2. Berechnen der Zieladresse bestehend aus Basis und Offset – MIPS definiert als Basis für bedingte Sprünge die Adresse der Instruktion NACH
der Verzweigungsinstruktion (PC+4), d.h. der 16-Bit Offset muss zu PC+4 hinzuaddiert werden!
– Offset-Feld muss um 2 Bit nach links verschoben werden (Wortadresse)
Komponenten:
• Registerfile
• ALU
• Vorzeichenerweiterung
• Shifter
• Addierer
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 59 © 2016
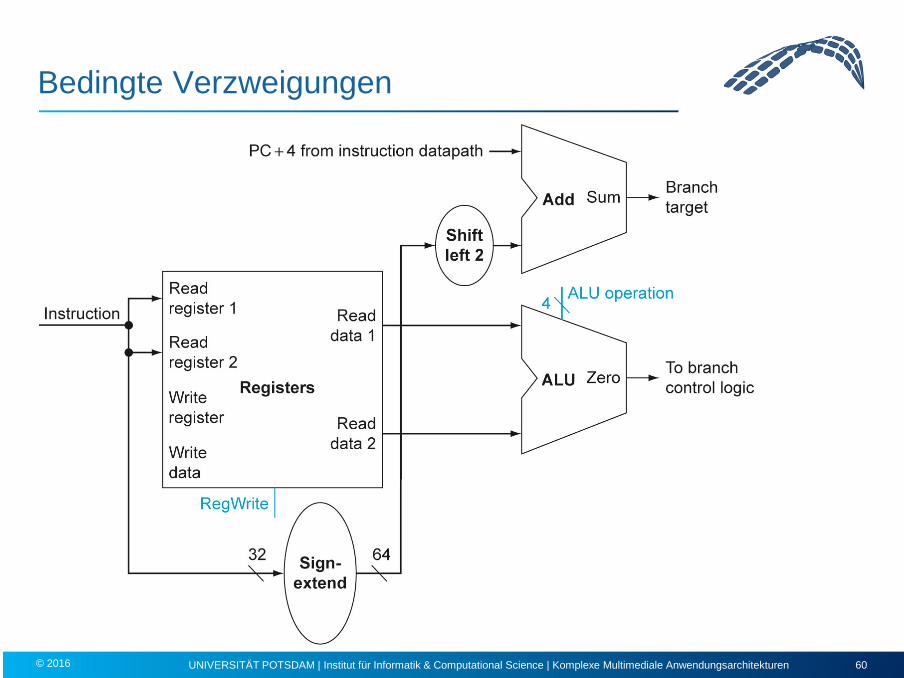
Bedingte Verzweigungen
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 60 © 2016
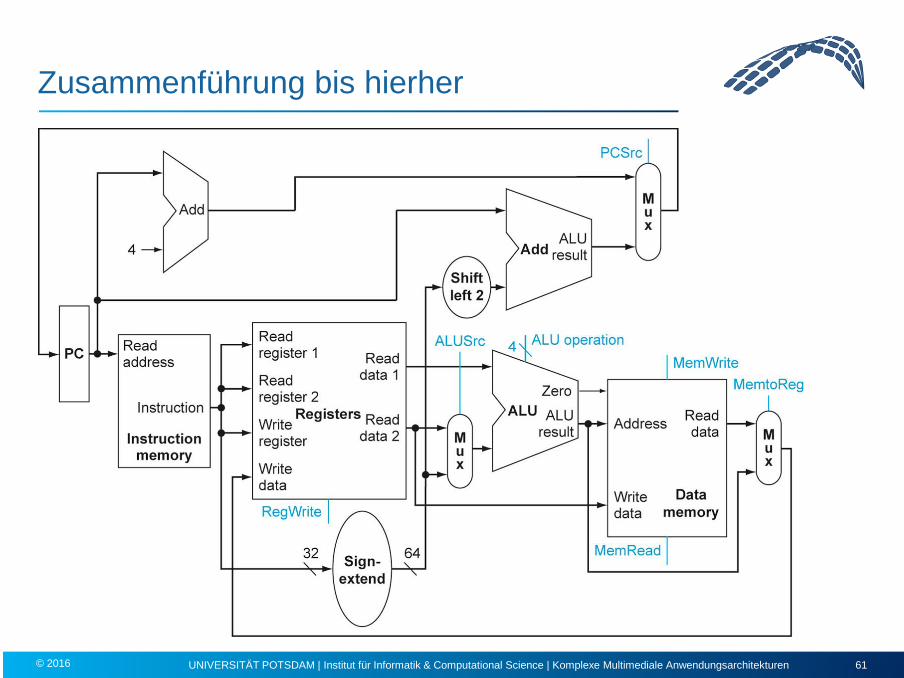
Zusammenführung bis hierher
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 61 © 2016
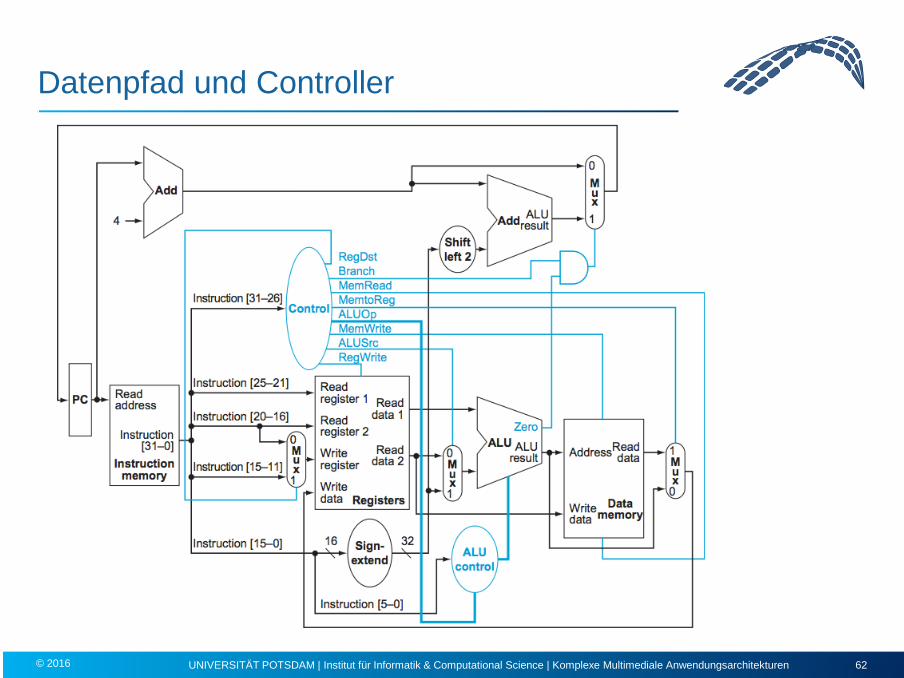
Datenpfad und Controller
© 2016 62 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen

Tipp
Welchen Vorteil könnte es bringen, die Arbeitsweise der Komponenten
zentral durch einen Controller regeln zu lassen?
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 63 © 2016

Einzyklenimplementierung
• Prinzip: – Jede Instruktion wird in einem Taktzyklus komplett ausgeführt. – Jede Komponente das Datenpfades kann während eines Instruktionszyklus
maximal einmal verwendet werden. getrennte Speicher für Instruktionen und Daten
• Vorteil: – einfache Realisierung, insbesondere des Controllers
• Nachteile: – Instruktionen benötigen unterschiedliche Datenpfadelemente.
• zumindest teilweise redundante Komponenten • unterschiedliche kombinatorische Gesamtverzögerungen
– Taktperiode T = Maximum aller Verzögerungen • Ausführung einer Instruktion in einem langen Takt
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 64 © 2016

Mehrzyklenimplementierung
• Prinzip: – Die Instruktionsabarbeitung wird in mehrere Schritte aufgeteilt. – Jeder Schritt benötigt einen Taktzyklus. – Je nach Instruktion sind verschieden viele Schritte notwendig.
• Vorteile: – Taktperiode kürzer als bei Einzyklenimplementierung → höhere Performance – Datenpfadelemente mehrmals in einem Instruktionszyklus verwendbar → Reduktion der Hardware
• Nachteile: – Register zur Signalspeicherung zwischen den Taktschritten nötig – komplexerer Controller
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 65 © 2016
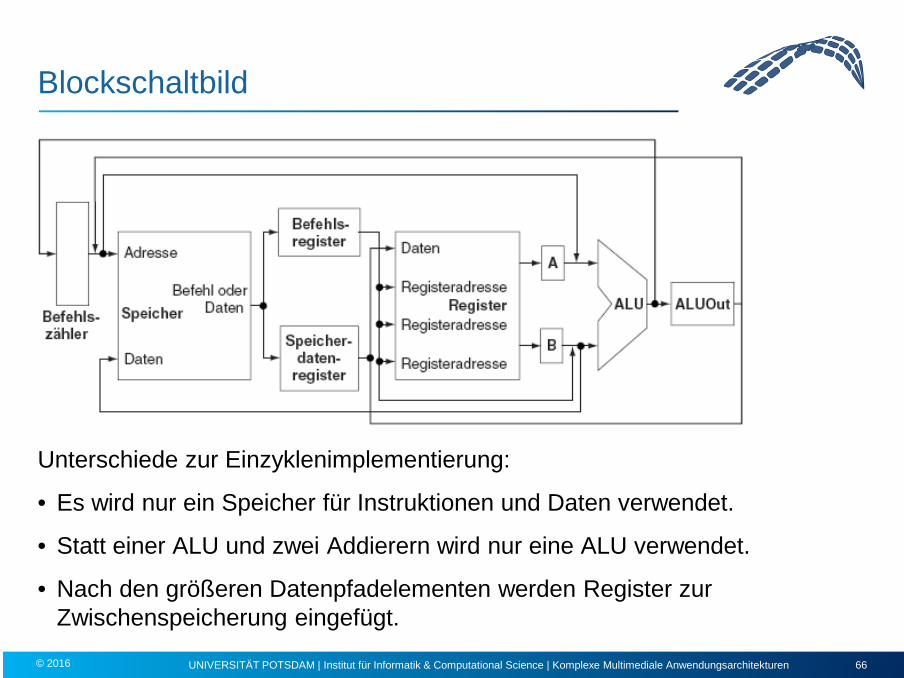
Blockschaltbild
Unterschiede zur Einzyklenimplementierung:
• Es wird nur ein Speicher für Instruktionen und Daten verwendet.
• Statt einer ALU und zwei Addierern wird nur eine ALU verwendet.
• Nach den größeren Datenpfadelementen werden Register zur Zwischenspeicherung eingefügt.
© 2016 66 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen

Wiederholung: Instruktionszyklus
Instruction Fetch 1
Instruction Decode, Register Fetch 2
Execution, Memory Address Computation, Branch Completion 3
Memory Access, R-type Instruction Completion 4
Memory Read Completion (Write Back) 5
IF
ID
EX
MEM
WB
© 2016 67 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen
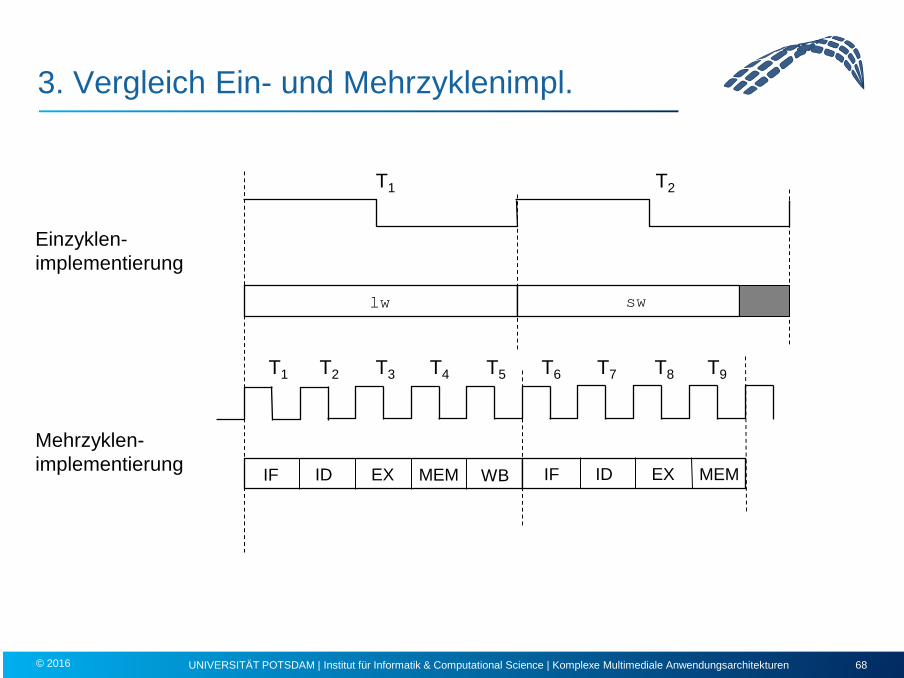
3. Vergleich Ein- und Mehrzyklenimpl.
T1 T2 T3 T4 T5 T6 T7 T8 T9
Mehrzyklen- implementierung IF ID EX MEM WB IF ID EX MEM
lw sw
T1 T2
Einzyklen- implementierung
© 2016 68 UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen

Tipp
Welche Hardware-Einheiten werden in den einzelnen Phasen benötigt?
UNIVERSITÄT POTSDAM | Institut für Informatik & Computational Science | Komplexe Multimediale Anwendungsarchitekturen 69 © 2016