Embed Size (px)
Citation preview

®
Kreuztabellenanalyse -Zusammenhangsmaße
14. Dezember 2007
Anja Hall,Bundesinstitut für Berufsbildung,
AB 2.2: „Qualifikation, berufliche Integration und Erwerbstätigkeit“
Lehrveranstaltung „Empirische Forschung und Politik beratung“der Universität Bonn, WS 2007/2008

®Anja Hall, AB 2.2
Empirische Forschung und PolitikberatungEinleitung
Bisher:
• Statistische Kennwerte und Mittelwertvergleiche
• Grundlegendes zu Kreuztabellen
Heute:
• Zusammenhangsmaße (Wiederholung Statistik)
• Zusammenhangsmaße (Beispiele mit SPSS)
Nächste Woche
• Kausalität, Scheinkorrelation
• Drittvariablenkontrolle

®Anja Hall, AB 2.2
Variablentypen und Skalenniveau
Variablentypen
Dichotome Variable: Merkmal, bei dem nur zwei Ausprägungen möglich sind z.B. Geschlecht. Wird eine Variable, die aus mehreren Ausprägungen besteht, zu zwei Kategorien zusammengefasst (z.B.: Einkommen unter 2000 Euro – Einkommen von 2000 oder mehr Euro), so spricht man von einer dichotomisierten Variablen.
Polytome Variable: Eine Variable mit mehr als zwei Ausprägungen.
Dummy-Variable: Eine D. ist eine binäre Variable mit den Ausprägungen 0 und 1
Skalenniveau
Bei einer Nominalskala bedeuten unterschiedliche Zahlen nichts anderes als unterschiedliche Merkmalsausprägungen.
Bei einer Ordinalskala drücken die Zahlen eine Rangfolge aus, aber sie sagen nichts über die Relationen der der Rangfolge zugrundeliegenden Eigenschaften.
Bei einer Intervallskala geben die Zahlen Informationen über die Abstände zwischen den gemessenen Ausprägungen, aber es gibt keinen »echten« Nullpunkt.
Bei einer Ratioskala ist außerdem ein sinnvoll interpretierbarer Nullpunkt vorhanden
®Anja Hall, AB 2.2
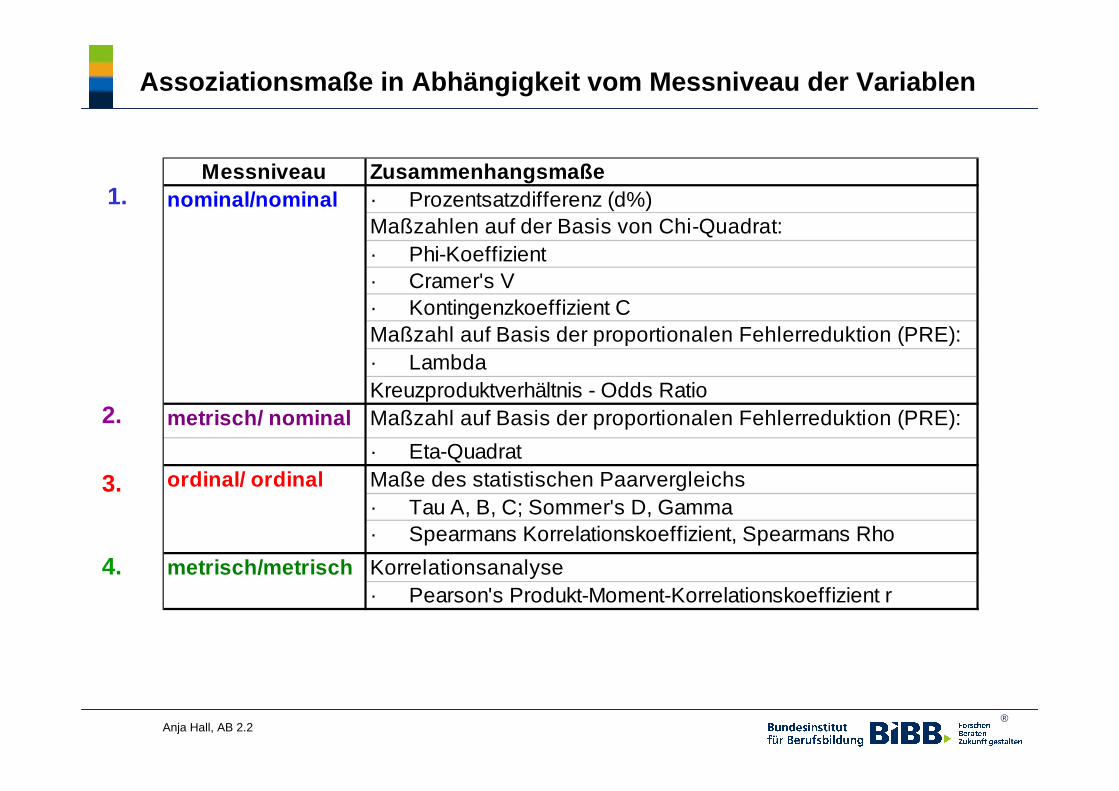
Assoziationsmaße in Abhängigkeit vom Messniveau der Variablen
Messniveau Zusammenhangsmaße· Prozentsatzdifferenz (d%)Maßzahlen auf der Basis von Chi-Quadrat:· Phi-Koeffizient· Cramer's V· Kontingenzkoeffizient CMaßzahl auf Basis der proportionalen Fehlerreduktion (PRE):· LambdaKreuzproduktverhältnis - Odds Ratio
metrisch/ nominal Maßzahl auf Basis der proportionalen Fehlerreduktion (PRE):
· Eta-QuadratMaße des statistischen Paarvergleichs· Tau A, B, C; Sommer's D, Gamma· Spearmans Korrelationskoeffizient, Spearmans Rho
Korrelationsanalyse· Pearson's Produkt-Moment-Korrelationskoeffizient r
nominal/nominal
ordinal/ ordinal
metrisch/metrisch
1.
2.
3.
4.

®Anja Hall, AB 2.2
1. Nominal/ Nominal
1a. Maßzahlen auf der Basis von Chi-Quadrat
1b. Maßzahl der proportionalen Fehlerreduktion (PRE )
1c. Kreuzproduktverhältnis - Odds Ratio

®Anja Hall, AB 2.2
1a. Chi-Quadrat-basierte Zusammenhangsmaße
Da von der Dimension der Tabelle abhängig ist, müssen die Werte für ein Zusammenhangsmaß normiert werden. Phi, Cramers-V und der Kontingenzkoeffizient K sind derartige Normierungen.
[ )χ 2 0∈ ∞,
Phi : Maßzahl für die Stärke des Zusammenhangs zwischen zwei nominalskalierten Variablen bei einer 2x2-Tabelle
Phi und Cramers V nehmen Werte zwischen 0 (kein Zusammenhang) und 1 (perfekter Zusammenhang) an. Die Richtung des Zusammenhangs wird aus der Tabelle ersichtlich.
Cramers V : Maßzahl für die Stärke des Zusammenhangs zwischen zwei nominalskalierten Variablen wenn (mindestens) eine der beiden Variablen mehr als zwei Ausprägungen hat
min[r,c] heißt: der kleinere der beiden Werte "Zahl der Zeilen" und "Zahl der Spalten"
Für 2x2-Tabellen sind Phi und Cramer´s V identisch, da immer min(r-1,c-1)=1

®Anja Hall, AB 2.2
1a. Chi-Quadrat-basierte Zusammenhangsmaße
Kontingenzkoeffizient: Maßzahl für die Stärke des Zusammenhangs zwischen zwei nominalskalierten Variablen wenn (mindestens) eine der beiden Variablen mehr als zwei Ausprägungen hat.
mit dem Wertebereich wobei M= min {k,m}KM
M∈ −
0
1,
Besteht keinerlei Zusammenhang zwischen den beiden Merkmalen, hat C den Betrag von 0. Problematisch ist, dass das Maximum von C von der Zahl der Ausprägungen der Variablen (also der Spalten und Zeilen der Tabelle) abhängt; C (max) ist i.d.R. kleiner als 1.
Der korrigierte Kontingenzkoeffizient ergibt sich durch: K KM
M* = −1 mit K*∈[0,1]
K=

®Anja Hall, AB 2.2
1b. Das Prinzip der proportionalen Fehlerreduktion: PRE - Maße
PREE E
E= −1 2
1PRE drückt aus, in welchem Ausmaß die (zusätzliche) Information über die X-Variable hilft, die Vorhersage der Variablen Y zu verbessern
1.Regel: Berechnung des Vorhersagefehlers E1:Wie gut" ist die Vorhersage der AV (=Y) ohne Berücksichtigung der Information über die UV (=X).
2.Regel: Berechnung des Vorhersagefehlers E2:Wie "gut" ist die Vorhersage der AV (=Y) mit Berücksichtigung der Information über die UV (=X).
Die Vorhersageregel hängt vom Messniveau der Variablen ab:Lambda (nominal/ nominal): Modalwert
Eta2 (nominal/ metrisch): Mittelwert
PRE-Maße sind Zusammenhangsmaße, die ausdrücken, wie gut durch die Kenntnis einer Variablen die Ausprägungen einer weiteren Variablen vorhergesagt werden kann. Die relative Verbesserung der Vorhersage (bzw. die Verringerung der Fehlerquote = Proportional Reduction of Error) wird im PRE-Maß ausgedrückt.
Für ein PRE-Maß benötigt man 2 Vorhersageregeln: Eine für den Fall, dass man keine Kenntnis über den Zusammenhang zwischen X (=UV) und Y (=AV) hat, und eine für den Fall, dass man über entsprechende Kenntnisse verfügt.

®Anja Hall, AB 2.2
Lambda (1)
( )λr
i j ijj
m
i
E E
E
n h h h
n h= − =
− − −
−
+ +=
+
∑1 2
1
1
max( ) [ max( )]
max( )
wobei, n = Gesamtzahl der Untersuchungseinheiten
max hi+ = Anzahl der Untersuchungseinheiten in der Modalkategorie der Zeilen-Randsummeh+j = Anzahl der Untersuchungseinheiten in der Randsumme der Spalten
max hij = Anzahl der Untersuchungseinheiten in der j-ten Spalte - Modalhäufigkeit
1. Regel für die Zuordnung ohne Benutzung der Information über die UVOrdne die Fälle jener Zeile der Tabelle zu, die insgesamt die höchste Besetzung aufweist.
2. Regel für die Zuordnung mit Benutzung der Information über die UVOrdne innerhalb jeder Spalte die Fälle jener Zelle zu, die die höchste Besetzung aufweist.

®Anja Hall, AB 2.2
Lambda (2)
Schuhgröße in Abhängigkeit vom Geschlecht
Frauen Männer ALLE Unter 39 60 30 90
39 und größer 40 70 110
N 100 100 200
Lambda wird jetzt folgendermaßen berechnet: Ohne Kenntnis des Geschlechts macht man die wenigsten Fehler, wenn man alle Fälle in die Kategorie "39 und größer" einstuft. Weiß man aber, welche Person männlich und welche weiblich ist, kann man die Vorhersage verbessern: Man stuft alle Frauen in der Größe "Unter 39" ein, alle Männer in der Größe "39 und größer". Damit macht man 60 + 70 = 130 richtige Vorhersagen, also nur noch 70 falsche Vorhersagen.
Der Wert von Lambda beträgt im Beispiel = (90-70)/90 = 20/90 = 0,22 oder 22%.
Wann nimmt Lambda den Wert 0 an und wann den Wert 1?
Lambda ist ein Maß für den Zusammenhang zwischen einer nominalen (unabhängigen) und einer nominalen (abhängigen) Variablen.

®Anja Hall, AB 2.2
Übung
1a: Chi-Quadrat-basierte Zusammenhangsmaße
1b: PRE-Maß Lambda
Übung:Erstellen Sie eine Kreuztabelle mit den Variablen Geschlecht undErwerbsbeteiligung (Ef504) . Bilden Sie hierzu eine Dummy-Variable „Erwerbstätig“ (Ja vs. Nein).
Beschränken Sie die Analyse auf Personen im Alter von 15-65 Jahren.
Berechnen Sie die Prozentsatzdifferenz zwischen Män ner und Frauen sowie ein geeignetes Zusammenhangs- und PRE-Maß. Interpretieren Sie die Ergebnisse.

®Anja Hall, AB 2.2
Richtungsmaße
,068 ,005 13,790 ,000
,000 ,000 .c .c
,117 ,008 13,790 ,000
,017 ,002 ,000d
,017 ,002 ,000d
Symmetrisch
et abhängig
ef32 abhängig
et abhängig
ef32 abhängig
Lambda
Goodman-und-Kruskal-Tau
Nominal- bzgl.Nominalmaß
Wert
Asymptotischer
Standardfehlera
Näherungsweises Tb
Näherungsweise
Signifikanz
Die Null-Hyphothese wird nicht angenommen.a.
Unter Annahme der Null-Hyphothese wird der asymptotische Standardfehler verwendet.b.
Kann nicht berechnet werden, weil der asymptotische Standardfehler gleich Null ist.c.
Basierend auf Chi-Quadrat-Näherungd.
Übung - Lösung
comp et=0.if ef504=1 et=1.
temp.sel if ef30 ge 15 and ef30 le 65.cro et by ef32 /cells=col /sta=phi lambda.
d%=70,5 - 58,1=12,4Der Anteil erwerbstätiger Männer ist um 12%-Punkte höher als der Anteil erwerbstätiger F.
Symmetrische Maße
-,130 ,000
,130 ,000
20015
Phi
Cramer-V
Nominal- bzgl.Nominalmaß
Anzahl der gültigen Fälle
Wert
Näherungsweise
Signifikanz
Die Null-Hyphothese wird nicht angenommen.a.
Unter Annahme der Null-Hyphothese wird der asymptotischeStandardfehler verwendet.
b.
Phi=0,13
Es besteht ein schwacher Zusammenhang zwischen Geschlecht und Erwerbstätigkeit
Lambda=0
Keine Vorhersageverbesserung mit Geschlecht
et Erwerbstätigkeit * ef32 Kreuztabelle
% von ef32
29,5% 41,9% 35,6%
70,5% 58,1% 64,4%
100,0% 100,0% 100,0%
,00 Nein
1,00 Ja
et Erwerbstätigkeit
Gesamt
1 Männer 2 Frauen
ef32
Gesamt

®Anja Hall, AB 2.2
1c. Kreuzproduktverhältnis - Odds, Odds Ratio
Die Odds und Odds Ratio sind eine Möglichkeit, Anteilswerte in Kreuztabellen auszudrücken und zu vergleichen. Man kann "Odds" mit "Chancen" und "Odds Ratio" mit "relative Chancen" übersetzen
Frauen Männer Kein Übergewicht 60 30
Übergewicht 40 70
Die "Chance", dass eine Frau kein Übergewicht hat, beträgt 60:40 oder 1,5. Die "Chance" von Männern, kein Übergewicht aufzuweisen, beträgt dagegen nur 30:70 oder 0,43.
Das Odds Ratio ist nun ein Maß für die Stärke des Unterschieds zwischen zwei Gruppen, hier Frauen und Männern. Das Odds Ratio setzt einfach die Odds der beiden Gruppen zueinander ins Verhältnis. Im Beispiel beträgt das Odds Ratio 1,5 : 0,43 = 3,5. D.h., die Chance von Frauen, nicht übergewichtig zu sein, ist 3,5 mal so groß wie bei Männern
Das Odds Ratio kann auch als Zusammenhangsmaß aufgefasst werden. Ein O.R. von 1 bedeutet, dass es keinen Unterschied in den Odds gibt, ist das O.R. >1, sind die Odds der ersten Gruppe größer, ist sie <1, sind sie kleiner als die der zweiten Gruppe.
Odds und Odds Ratios lassen sich immer nur in Bezug auf zwei Ausprägungen ausdrücken. In größeren als 2x2-Tabellen können dementsprechend mehrere Odds und Odds Ratiosberechnet werden.

®Anja Hall, AB 2.2
1c. Kreuzproduktverhältnis - Odds, Odds Ratio
Übung
Übung:
Berechnen Sie für die Kreuztabelle mit den Variable n Geschlecht und Erwerbsbeteiligung die Odds „ Erwerbstätig“ sowie das entsprechende Odds Ratio für Männer. Interpretieren Sie dies und vergleichen Sie es mit dem Zusammenhangs-und PRE-Maß.

®Anja Hall, AB 2.2
Übung - Lösung
et Erwerbstätigkeit * ef32 Kreuztabelle
Anzahl
2986 4145 7131
7148 5736 12884
10134 9881 20015
,00 Nein
1,00 Ja
et Erwerbstätigkeit
Gesamt
1 Männer 2 Frauen
ef32
Gesamt
Die "Chance", dass ein Mann erwerbstätig ist, beträgt 7148:2986 oder 2,4. Die "Chance" von Frauen erwerbstätig zu sein, beträgt dagegen 5736:4145 oder 1,4.
Das Odds Ratio beträgt 2,4 : 1,4 = 1,7.
D.h., die Chance von Männern erwerbstätig zu sein, ist 1,7 mal (also fast doppelt) so groß wie bei Frauen.
Vorsicht: Odds-Ratios sind keine Wahrscheinlichkeiten!
Odds-Ratios sind unabhängig von der Randverteilung und Grundlage binärer, multinomialer und ordinaler Regressionsmodelle sowie loglinearer Modelle

®Anja Hall, AB 2.2
2. Metrisch/ Nominal
Maßzahl der proportionalen Fehlerreduktion (PRE)

®Anja Hall, AB 2.2
Eta2
Eta² ist ein Maß für den Zusammenhang zwischen einer nominalen (unabhängigen) und einer metrischen (abhängigen) Variablen.
Eta² basiert auf der Zerlegung der Quadratsummen (QS). Die gesamte QS einer Variablen (QSges) kann in zwei Bestandteile zerlegt werden:
1. in die QS innerhalb der Gruppen, die durch die unabhängige Variable repräsentiert werden, also die Summe der quadrierten Abweichungen der Werte in den einzelnen Gruppen vom Gruppenmittelwert (QSin)
2. die QS zwischen diesen Gruppen, also die Summe der quadrierten Abweichungen der Gruppenmittelwerte vom Gesamtmittelwert (QSzw).
Es gilt: oder
Je größer QSzw relativ zu QSin, d.h., je mehr der Varianz der AV in den Gruppenunterschieden steckt bei kleiner Unterschiedlichkeit innerhalb der Gruppen, desto besser wird die Vorhersage auf der Grundlage der Gruppenmittelwerte im Vergleich zur Vorhersage des Gesamtmittelwerts.
Wann nimmt Eta² den Wert 0 an und wann den Wert 1?
η²
( . ..)²
( ..)²=
−
−
− −
==
−
==
∑∑
∑∑
yi y
yij y
j
ni
i
I
j
ni
i
I
11
11

®Anja Hall, AB 2.2
Eta2 – Beispiel aus der BIBB/BAuA-Erwerbstätigenbefragung 2 006
CROSSTABS/TABLES=f518 BY s1/FORMAT=NOTABLES/STATISTIC=ETA.
Richtungsmaße
,301
,477
f518 Höhe desmonatlichenBruttoverdienstesabhängig
s1 Geschlecht derZielperson abhängig
EtaNominal- bzgl.Intervallmaß
Wert
SUMMARIZE/TABLES=f518 BY s1/FORMAT=NOLIST TOTAL/MISSING=VARIABLE/CELLS=COUNT MEDIAN MEAN .
Zusammenfassung von Fällen
f518 Höhe des monatlichen Bruttoverdienstes
9560 2600,00 3035,09
7453 1500,00 1788,48
17013 2200,00 2488,95
s1 Geschlechtder Zielperson1 Männlich
2 Weiblich
Insgesamt
N Median Mittelwert
Zur Deskription
Höhe des monatlichen Bruttoeinkommens in Abhängigkeit vom Geschlecht.
-> Mir Kenntnis des Geschlechts kann 30% der Varianz des Einkommens erklärt werden

®Anja Hall, AB 2.2
3. Ordinal/ Ordinal
Tau-a
Tau-b
Tau-c
Sommers D
Gamma
Spearmans Rho

®Anja Hall, AB 2.2
Tau-a, Tau-b, Tau-c, Sommers D, Gamma (1)
Tau-a: nur sinnvoll, wenn es keine "Ties" oder "gebundenen Paare" gibt
Tau-b: wenn die Zahl der Ausprägungen der beiden Variablen gleich ist (sonst Tau-b < 1)
Tau-c : für nicht symmetrische Tabellen geeignet
Sommer’s D: liegt in der Größe zwischen den Tau-Koeffizienten und Gamma
Gamma : überschätzt den Zusammenhang (wird daher gern verwendet)
Die Logik der Koeffizienten beruht darauf, sämtliche Untersuchungseinheiten miteinander zu vergleichen:
Konkordantes Paar: Diejenige Person, die in der einen Variablen den kleineren Wert als die andere hat, hat auch in der anderen Variablen den kleineren Wert Nc= Zahl der konkordanten Paare
Diskordantes Paar: Diejenige Person, die in der einen Variablen den kleineren Wert als die andere hat, hat in der anderen Variablen den größeren Wert.Nd: Zahl der diskordanten Paare
„Ties“ (gebundene Paare): Solche Paare, die in einer Variablen den gleichen, aber in der anderen verschiedene Werte haben.Tx: Zahl der Ties in der Spaltenvariablen; Ty: Zahl der Ties in der Zeilenvariablen

®Anja Hall, AB 2.2
Tau-a, Tau-b, Tau-c, Sommers D, Gamma (2)
Übergewicht in Abhängigkeit vom Alter
Jung Alt ALLE
Kein Übergewicht 60 30 90
Übergewicht 40 70 110
N 100 100 200
Nc= 60 * 70 = 4.200 konkordante Paare
Nd= 30 * 40 = 1.200 diskordante Paare
Tx= 60 * 40 = 2.400 und 30 * 70 = 2.100 -> 4.500 Ties
Ty=60 * 30 = 1.800 und 40 * 70 = 2.800 -> 4.600 Ties
m = min (Zeilen, Spalten)
mit y als abhängiger Variablen
= ( 4200 - 1200 ) / ( 4200 + 1200 + 4600 ) = 0,30
= ( 4200 - 1200 ) / ( 4200 + 1200) = 0,36
= ( 4200 - 1200 )
( 4200 + 1200 + 4500 ) * ( 4200 + 1200 + 4600 )
= ( 4200 - 1200 ) / (0,5 *2002 *1/2) = 0,30
=0,30

®Anja Hall, AB 2.2
Spearmans Korrelationskoeffizient, Spearmans Rho
Von den ursprünglichen Werten der Variablen X und Y wird zu Rängen übergegangen, d.h. jedem x-Wert und jedem y-Wert wird als Rang die Platzzahl zugeordnet (werte werden nach der Größe sortiert). Aus den ursprünglichen Messpaaren (xi, yi) mit i = 1,...,n ergeben sich die neuen Rangdaten (rg (xi), rg (yi)) mit i = 1,...n.
Falls innerhalb der x-Werte oder innerhalb der y-Werte identische Werte auftreten ("Ties"), werden Durchschnittsränge berechnet, d.h. den identischen Messwerten wird als Rang dasarithmetische Mittel der Ränge zugewiesen
Differenzen di=rg (xi) - rg (yi)
rsp kann Werte von -1 bis +1 annehmen. Das bedeutet im Einzelnen:
rSP > 0: gleichsinniger monotoner Zusammenhang (Tendenz: wenn x groß wird, wird auch y groß bzw. wenn x klein wird, wird auch y klein);
rSP < 0: gegensinniger monotoner Zusammenhang (Tendenz: wenn x groß wird, wird y klein bzw. wenn x klein wird, wird y groß);
rSP ≈ 0: kein monotoner Zusammenhang

®Anja Hall, AB 2.2
Übung
Erstellen Sie eine Kreuztabelle mit den Variablen Alter und Einkommen. Kategorisieren Sie hierzu die Variable Alter (EF30) in die vier Altersgruppen 15-30 Jahre, 31-40 Jahre, 41-50 Jahre und 51 Jahre und mehr.
Kategorisieren Sie das Einkommen (EF372) in drei Kategorien: Kategorie 1-4 (bis unter 700), Kategorie 5-9 (700 bis unter 1700) und Kategorie 10-24 (1700 und mehr).Beschränken Sie die Analyse wieder auf Personen im Alter von 15-65 Jahren und berechnen Sie geeignete Zusammenhangsmaß e. Interpretieren Sie die Ergebnisse.

®Anja Hall, AB 2.2
4. Metrisch/ Metrisch
Produkt-Moment-Korrelations-Koeffizient r

®Anja Hall, AB 2.2
Produkt-Moment-Korrelations-Koeffizient r
Die P.-M.-K., auch als (Bravais-)Pearson'scher Korrelationskoeffizient r bezeichnet, ist ein Zusammenhangsmaß für metrische Variablen:
( )( )
( ) ( )r r
x x y y
x x y y
s
s sXY
i ii
n
ii
n
ii
n
XY
X Y
= =− −
− −==
= =
∑
∑ ∑
1
2
1
2
1
wobei sXY = die empirische Kovarianz zwischen X und Y sX = die Standardabweichung von X, sY = die Standardabweichung von Y und
r =1 perfekter positiver Zusammenhang
r=-1 perfekter negativer Zusammenhang)
r> positive Korrelation: Je höher X, desto höher Y
r<0 negative Korrelation: Je höher X, desto niedriger Y
r=0 keine Korrelation
Der Korrelationskoeffizient kann nur für metrische Daten angewandt werden. Ausnahme: Dichotome Variablen, die 0/1 kodiert sind. In diesem Fall entspricht der Korrelationskoeffizient der Chi²-basierten Maßzahl Phi.
®Anja Hall, AB 2.2
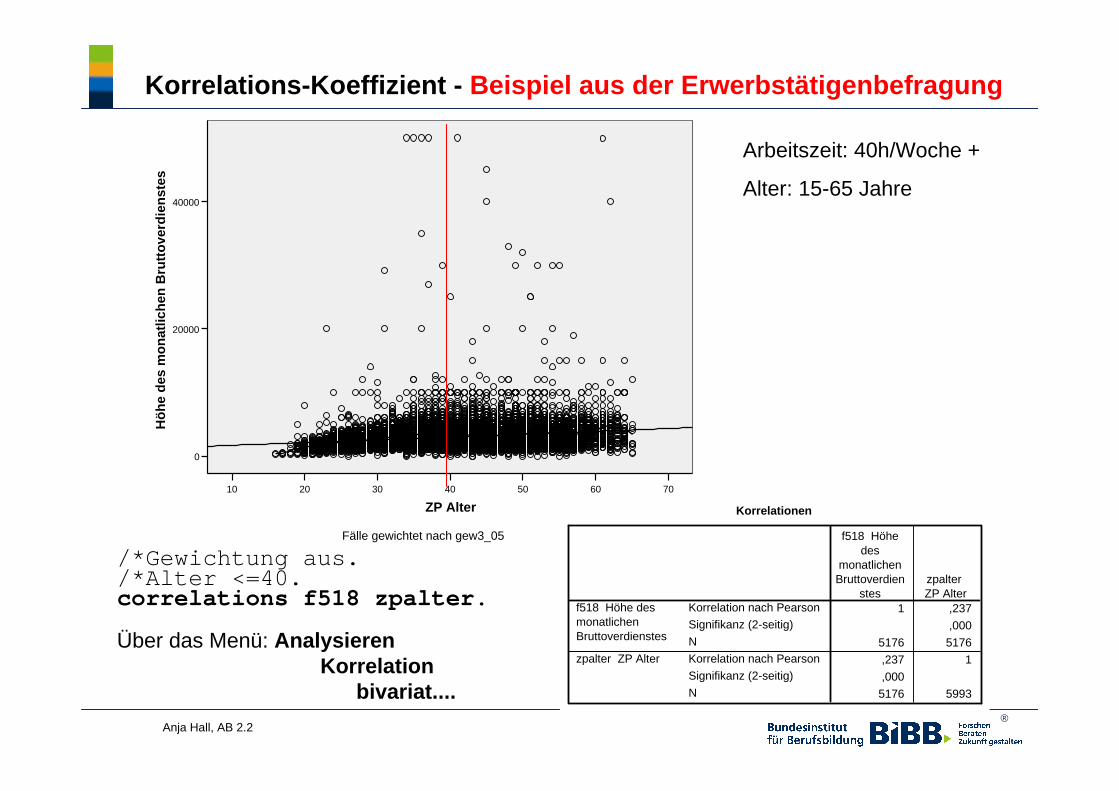
Korrelations-Koeffizient - Beispiel aus der Erwerbstätigenbefragung
70605040302010
ZP Alter
40000
20000
0
Höh
e de
s m
onat
liche
n B
rutto
verd
iens
tes
Fälle gewichtet nach gew3_05
Arbeitszeit: 40h/Woche +
Alter: 15-65 Jahre
/*Gewichtung aus./*Alter <=40.correlations f518 zpalter.
Korrelationen
1 ,237
,000
5176 5176
,237 1
,000
5176 5993
Korrelation nach Pearson
Signifikanz (2-seitig)
N
Korrelation nach Pearson
Signifikanz (2-seitig)
N
f518 Höhe desmonatlichenBruttoverdienstes
zpalter ZP Alter
f518 Höhedes
monatlichenBruttoverdien
steszpalter ZP Alter
Über das Menü: AnalysierenKorrelation
bivariat....

®Anja Hall, AB 2.2
Ausblick auf das nächste Mal:
Was bedeutet Kausalität?
Was ist eine Scheinkorrelation?
Unterscheiden sich Frauen und Männern im Berufserfo lg?
Wie ist Berufserfolg zu operationalisieren?
Nächste Woche











