Embed Size (px)
Citation preview

Historische Semantik und Semantic Web
Workshop der Heidelberger Akademie der Wissenschaften
und der Union der deutschen Akademien der Wissenschaften
AG „Elektronisches Publizieren“
14. bis 16. September 2015, Heidelberger Akademie der Wissenschaften
14. September 2015
11.00-13.00 Uhr Sitzung der AG „Elektronisches Publizieren“
13.00-13.30 Uhr
13.30-14.00 Uhr
Verteilung der Namensschilder und Tagungsmappen
Grußworte und Einführung
Bernd Schneidmüller (Heidelberg)
Sekretär der Philosophisch-Historischen Klasse
der Heidelberger Akademie der Wissenschaften
Sebastian Zwies (Mainz) In Vertretung des Generalsekretärs der Union der deutschen Akademien der
Wissenschaften
Kurt Gärtner (Mainz)
AG „Elektronisches Publizieren“
14.00-16.00 Uhr I. Sektion „Portale und Lexika“
Nicolas Apostolopoulos, Nadja Juhnke, Margit Wunsch Gaarmann (Berlin) 1914-1918-online. International Encyclopedia of the First World War
Isabelle Mandrin / Eckhart Arnold (München)
Virtuelles Europäisches Wörterbuch des Mittellateinischen auf der Basis semantischer Technologien Felix Lange (Berlin)
Inschriften im Bezugssystem des Raumes: Kollaborative Erstellung und Auswertung
multimodaler Ressourcensammlungen mit semantischen Technologien
Bryan Jurish (Berlin)

DiaCollo: Ein interaktives Werkzeug zur Extraktion und interaktiven Exploration
diachroner Kollokationen
16.00-16.30 Uhr Kaffeepause
16.30-18.30 Uhr I. Sektion (Fortsetzung)
Thomas Burch (Trier)
Wörterbuchvernetzungen
Katrin Einicke / Sascha Heße (Halle)
Ein Wörterbuchportal für das Sanskrit? – Arbeitsinstrument für künftige
Untersuchungen zur Historischen Semantik
Stefan Baums (München)
Bedeutungswandel und Übersetzung: Die historische Semantik buddhistischer Texte
und das Dictionary of Gāndhārī
Sabine Tittel (Heidelberg)
Semantische Integration von Wissen zum Europäischen Mittelalter: Ein Projekt der
europäischen Lexikographie
19.00-20.00 Uhr Abendvortrag
Bernhard Jussen / Alexander Mehler (Frankfurt/Main)
Computergestützte Historische Semantik. Das Projekt „CompHistSem“
20.00-22.00 Uhr Empfang der Heidelberger Akademie der Wissenschaften
15. September 2015
9.00-11.00 Uhr II. Sektion „Semantic Web und Korpora“
Stefan Dumont / Torsten Schrade (Berlin / Mainz) Digitale Briefeditionen im Semantic Web
Ingo Caesar / Andreas Wagner (Frankfurt/Main) Die Schule von Salamanca: ein elektronisches Publikationsprojekt und eine
semantische Herausforderung
Tilmann Walter (Würzburg)
Semantische Suchen in den „Frühneuzeitliche Ärztekorrespondenzen des
deutschsprachigen Raums (1500-1700)“
Michael Kempe (Hannover)
Die Leibniz-Connection: Personen- und Korrespondenz-Datenbank der Leibniz-Edition
11.00-11.30 Uhr Kaffeepause

11.30-13.00 Uhr II. Sektion (Fortsetzung) Vera Hildenbrandt / Jörg Ritter (Trier / Halle)
Erschließung und Erforschung thematischer Zusammenhänge in
heterogenen Briefkorpora
Jörg Wettlaufer (Göttingen)
Herausforderungen und Perspektiven bei der Erprobung von Semantic Web-
Technologien und LOD für Akademieprojekte
Antonie Magen / Markus Hellmann (München / Göttingen)
Semantic Web am Beispiel des Projekts „Gelehrte Journale und Zeitungen der
Aufklärung“
13.00-13.45 Uhr Mittagsimbiss
13.45-16.00 Uhr
III. Sektion „Historische Semantik und Erschließungsverfahren“
Julia Burkhardt (Heidelberg)
Die Welt des 13. Jahrhunderts erzählen. Das „Bienenbuch“ des Thomas von Cantimpré
– Edition und Auswertung
Laura Carrara / Andreas Dafferner / Christine Radtki (Heidelberg)
Die Chronik des Johannes Malalas und ihre historische Erschließung
Andreas Kuczera (Mainz)
Graphdatenbanken für Historiker mit Perspektiven für die Historische Semantik
François Charette / Stefan Müller (München / Würzburg)
Semantik und Lexikographie des ptolemäischen Kosmos: Ein mehrsprachiges digitales
Glossar der mittelalterlichen und frühneuzeitlichen Astronomie und Astrologie
16.00-16.30 Uhr Kaffeepause
16.30-18.30 Uhr III. Sektion (Fortsetzung)
Jonathan Groß / Ulrike Henny / Patrick Sahle (Düsseldorf / Würzburg / Köln)
„Semantisierungspotentiale“ in Akademievorhaben am Beispiel der „Kleinen und Fragmentarischen Historiker der Spätantike“ (KFHist) James M.S. Cowey (Heidelberg) Heidelberger Gesamtverzeichnis der griechischen Papyrusurkunden Ägyptens in
Papyri.info
Stylianos Chronopoulos (Freiburg)

Pollux‘ WordNet. Zur digitalen Edition eines griechischen Thesaurus des 2.
Jahrhunderts n. Chr.
Christian Orth (Freiburg)
Semantische Probleme in den Fragmenten der griechischen Komödie
ab 19.00 Uhr
Gemütliches Beisammensein im Café Villa Heidelberg, Hauptstr. 187, 69117 Heidelberg
16. September 2015
9.00-11.00 Uhr
IV. Sektion „Semantik und Wörterbuch“
Andreas Deutsch (Heidelberg)
Zur Symbiose zwischen ‚Zettelkasten‘ und ‚Datenbank‘ bei der Artikelerstellung im
Deutschen Rechtswörterbuch
Volker Harm (Göttingen)
Das retrodigitalisierte Deutsche Wörterbuch als Quelle für die historische Semantik
Christian Prager (Düsseldorf)
Textdatenbank und Wörterbuch des klassischen Maya
Ursula Welsch (München)
Semantische Wörterbuch-Strukturen. Ein Erfahrungsbericht am Beispiel des
Bayerischen Wörterbuchs
11.00-11.30 Uhr Kaffeepause
11.30-13.30 Uhr
V. Sektion „Semantische Aspekte digitaler Editionen“
Klaus Wachtel (Münster)
Editio Critica MaiorAperta: Zu einer offenen digitalen Edition des Neuen Testaments
Fabian Kaßner / André Kischel (Rostock)
Stand der Überlegungen für eine Digitale Edition der Uwe Johnsons-Werkausgabe
Oliver Immel (Oldenburg)
Digitale Karl Jaspers-Gesamtausgabe
Jörg Riecke (Heidelberg)
Digitale Edition der Werke Grimmelshausens
ca. 13.30 Uhr
Wolfgang Raible (Freiburg) Schlusswort

Historische Semantik und Semantik Web
Workshop der Heidelberger Akademie der Wissenschaften und
der Union der deutschen Akademien der Wissenschaften
AG „Elektronisches Publizieren“
14. bis 16. September 2015
Heidelberger Akademie der Wissenschaften
Abstracts, Referate und Präsentationen
Abkürzungen:
AG EP = Arbeitsgruppe „Elektronisches Publizieren“
der Union der deutschen Akademien der Wissenschaften
AdWG = Akademie der Wissenschaften zu Göttingen
AWH = Akademie der Wissenschaften in Hamburg
AdWL-Mainz = Akademie der Wissenschaften und der Literatur, Mainz
BAdW = Bayerische Akademie der Wissenschaften
BBAW = Berlin-Brandenburgische Akademie der Wissenschaften
BMBF = Bundesministerium für Bildung und Forschung
HAdW = Heidelberger Akademie der Wissenschaften
NRWAWK = Nordrhein-Westfälische Akademie der Wissenschaften und Künste
Die Abstracts sind z.T. ersetzt durch die vollständigen Referate.
Die Folien zu den Referaten und einige vollständige Referate sind am Ende des Abstracts
durch aktivierbare Verweise zugänglich gemacht.
Einen ausführlichen Tagungsbericht von Jörg Wettlaufer s. unter:
http://www.hsozkult.de/conferencereport/id/tagungsberichte-6238

I. Sektion „Portale und Lexika“
1914-1918-online. International Encyclopedia of the First World War
Nadja Juhnke und Margit Wunsch Gaarmann (FU Berlin, Friedrich-Meinecke-Institut)
Zum 100. Jahrestag des Kriegsbeginns 1914 ist an der Freien Universität Berlin ein
englischsprachiges, von namhaften Experten geschriebenes, virtuelles Nachschlagewerk über
den Ersten Weltkrieg entstanden, das seit Oktober 2014 online verfügbar ist. Das
internationale Verbundprojekt „1914-1918-Online. International Encyclopedia of the First
World War“ wird von Prof. Dr. Oliver Janz, Historiker am Friedrich-Meinecke-Institut und
Prof. Dr. Nicolas Apostolopoulos, Leiter des Centers für Digitale Systeme (CeDiS), geleitet.
Das gemeinsam mit der Bayerischen Staatsbibliothek durchgeführte Projekt bietet einen
globalgeschichtlich orientierten Überblick über den Ersten Weltkrieg und verstärkt die
Vernetzung internationaler Forschung. Zudem werden neue Navigationsverfahren für
elektronische Handbücher und Enzyklopädien erforscht und erprobt. Die Deutsche
Forschungsgemeinschaft (DFG) hat das Vorhaben mit rund einer Million Euro gefördert.
Das Zusammenwirken von über 1.000 Projektbeteiligten aus über 50 Ländern ermöglicht eine
umfassende Darstellung der „Urkatastrophe des 20. Jahrhunderts“ in einer globalen
Perspektive. Die weltweit kostenlos zugängliche Enzyklopädie spiegelt nicht nur die sich
zunehmend internationalisierende Forschung zum Ersten Weltkrieg wider, sondern treibt sie
auch durch Identifizierung von Lücken und Desiderata entscheidend voran. Die Qualität der
Artikel wird durch ein zweistufiges Peer Review Verfahren sichergestellt. Die Artikel werden
durch Bild-, Audio-, Video- und Kartenmaterial angereichert sowie durch externe Links mit
weiterführenden Online-Ressourcen verbunden.
Gleichzeitig steht die Entwicklung und Erprobung modellhafter Navigationsverfahren für
thematische Wissensräume im Fokus des Projektes. Diese erleichtern dem Nutzer die
Orientierung in komplexen, nichtlinearen Textkonvoluten wie elektronischen Handbüchern,
Enzyklopädien und Anthologien. Ein Semantic Media Wiki bildet die Grundlage als
Redaktions- und Publikationsumgebung mit diversen Erweiterungen und Schnittstellen zur
Veredelung und Anreicherung von Metadaten. „1914-1918-online“ bindet zudem durch
bibliothekarische Sacherschließung multilingualer Schlagworte einschlägige virtuelle
Fachbibliotheken und andere Informationssysteme ein. Das Nachschlagewerk setzt so auch
Maßstäbe im Bereich des elektronischen Publizierens in den Geisteswissenschaften.
Weitere Informationen unter:
http://www.1914-1918-online.net

Virtuelles Europäisches Wörterbuch des Mittellateinischen auf Basis semantischer
Technologien
Eckhart Arnold (BAdW, Leitung IT / Digital Humanities-Referat), Dr. Isabelle Mandrin
(BAdW, Mittellateinisches Wörterbuch), N.N (Institut de recherche et d’histoire des textes
(IRHT) Paris, Novum Glossarium Mediae Latinitatis)
Aus historischen Gründen gibt es in Europa eine größere Zahl mehr oder weniger
unabhängiger Wörterbuchprojekte des Mittellateinischen. Es wäre nur sinnvoll, diese Projekte
stärker zusammenzuführen. Mit Hilfe semantischer Technologien sollte es möglich sein, die
Ergebnisse dieser Wörterbuchprojekte im Internet so zu präsentieren, dass die Nutzer auf den
Gesamtbestand aller Wörterbuchprojekte zugreifen können, ohne in mehreren, und auf Grund
der langen Erarbeitungszeiten, jeweils noch lückenhaften Einzelwörterbüchern nachschlagen
zu müssen. Das französische Novum Glossarium Mediae Latinitatis (NGML) und das
deutsche Mittellateinische Wörterbuch (MLW) möchten durch ein geplantes gemeinsames
Wörterbuchportal einen Grundstein dafür legen. In diesem Zusammenhang sollen die
Wörterbuchdaten für das Semantic Web aufbereitet werden und auch mit den Quellentexten
verknüpft werden, soweit diese digital vorliegen. Die Realisierung dieses Vorhabens hängt
wegen des großen Arbeitsaufwandes davon ab, ob es gelingt, Mittel dafür einzuwerben.
Weitere Informationen unter:
http://www.mlw.badw.de/index.html
http://www.mlw.badw.de/dictionnaire/index.html
http://www.irht.cnrs.fr/en/recherche/sections/lexicographie-latine

Inschriften im Bezugssystem des Raumes: Kollaborative Erstellung und Auswertung
multimodaler Ressourcensammlungen mit semantischen Technologien
Felix Lange (Max-Planck-Institut für Wissenschaftsgeschichte, Berlin)
Im BMBF-geförderten Projekt “Inschriften im Bezugssystem des Raumes” (IBR, 2012-15)
erarbeiteten die AdW Mainz und die Mainzer Fachhochschule gemeinsam neue Wege, 3D-
Daten zum Quelleninventar raumbezogener geisteswissenschaftlicher Forschung
hinzuzufügen. Am Beispiel von Kircheninschriften aus dem späten Mittelalter und der Frühen
Neuzeit sollte IBR konkret aufzeigen, wie die Integration von objektiv erhobenen
Messinformationen zum räumlichen Inschriftenkontext epigraphischen Arbeiten zu einer
höheren empirischen Qualität und Nachprüfbarkeit verhelfen kann.
Die im Projekt entwickelte Webanwendung ‘GenericViewer’ ermöglicht es, geometrische
Objekte vermittelt über semantische Vokabulare mit digitalen Inschrifteneditionen und
nutzergenerierten Annotationen zu verknüpfen. Am Beispiel der Inschriften der
Liebfrauenkirche in Oberwesel und ihrer in den Deutsche Inschriften Online (DIO)
gesammelten Editionen haben wir untersucht, wie auf diese Weise physische Quellen und
Forschungsliteratur in ein integriertes Repositorium gebracht werden können.
In diesem Ansatz werden semantische Technologien dazu eingesetzt, einen
Forschungsgegenstand mit standardisierten Vokabularen zu beschreiben und als Datensatz zu
veröffentlichen. Mit Hilfe der Annotationsfunktion soll darüber hinaus aber auch die
Möglichkeit eröffnet werden, den wissenschaftlichen Diskurs über Objekte in einem
semantischen Datengraph nachvollziehbar abzubilden. Die im Projekt gemachten Erfahrungen
resümierend widmet sich der Vortrag organisatorischen, methodologischen und technischen
Fragen zur Erstellung und Auswertung solcher Graphen.
Weitere Informationen unter:
http://www.inschriften.net/
http://www.spatialhumanities.de/ibr/startseite.html
Das Abstract als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Lange_Abstract.pdf

DiaCollo: ein interaktives Werkzeug zur Extraktion und Exploration diachroner
Kollokationen
Bryan Jurish (BBAW, DWDS)
DiaCollo ist ein Softwarewerkzeug zur effizienten Extraktion, zum Vergleich und zur
interaktiven Visualisierung von Kollokationen aus einem diachronen Textkorpus. Im
Gegensatz zu konventionellen Kollokationswerkzeugen, eignet sich DiaCollo zur Extraktion
und Analyse diachroner Kollokationsdaten, d. h. Kollokatenpaaren, deren Assoziationsstärke
von dem Zeitpunkt ihres Auftretens abhängt. Durch das Aufspüren von Veränderungen in
den typischen Kollokaten eines Worts im zeitlichen Verlauf kann DiaCollo helfen, ein
klareres Bild diachroner Veränderungen im Wortgebrauch zu liefern, insbesondere solcher,
die auf Phänomene semantischer Prozesse zurückzuführen sind. Nicht nur in der
Sprachwissenschaft können DiaCollo-Profile verwendet werden, sondern auch z.B. für
Historiker oder Philosophen können Überblicke über die Diskursthemen erstellt werden, die
mit einem Abfrageterm typischerweise assoziiert sind, zusammen mit ihren Variationen über
bestimmte Zeiträume oder Korpusteilmengen. Sogenannte Vergleichs- bzw. “Diff”-Profile
dagegen heben die prominentesten Unterschiede zwischen zwei unabhängigen Zielabfragen
hervor. Neben traditionellen tabellarischen Anzeigeformaten bietet ein Webservice-Modul
diverse interaktive Online-Visualisierungen diachroner Profildaten für technisch nicht
besonders versierte Nutzer.
Weitere Informationen unter:
http://kaskade.dwds.de/dstar/dta/diacollo/

Wörterbuchvernetzungen
Thomas Burch (Kompetenzzentrum für elektronische Erschließungs- und
Publikationsverfahren in den Geisteswissenschaften, Universität Trier)
Wörterbücher und Nachschlagewerke sind auf vielfältige Art aufeinander bezogen und damit
in gewisser Weise implizit „vernetzt“. Digitale Nachschlagewerke, die zusätzlich durch
inhaltlich-strukturelles Markup in standardisierte und damit aufeinander abbildbare
Informationseinheiten gegliedert und durch Metadaten angereichert sind, bilden eine
hervorragende Ausgangsbasis, um diese impliziten Vernetzungen explizit zu machen. Im
Gegensatz zu einer bloßen, unverbundenen Bereitstellung einzelner Nachschlagewerke bieten
derartige Wörterbuchverbünde mit multidirektionalen Verlinkungen komplexe und gezielt
spezifizierbare Zugänge zum Material. Diese Verlinkungen gehen dabei über eine rein
ausdrucksseitige Verknüpfung hinaus, indem sie philologische und
informationswissenschaftliche Methoden verbinden.
Konzepte, die solche Strukturen abbilden, können am besten auf der Grundlage einer
repräsentativen Auswahl aus verschiedenen Kategorien von Nachschlagewerken bzw.
Wörterbuchtypen entwickelt werden, da diese Typen unterschiedliche und je spezifische
wissensorganisierende Strukturen aufweisen. Ausgehend von den der Trierer Arbeitsgruppe
zur Verfügung stehenden annotierten Wörterbücher werden in dem Beitrag Methoden und
Verfahren zu deren Vernetzung vorgestellt, die einerseits die vorhandenen Verweisstrukturen
ausnutzen und andererseits mit Hilfe von Berechnungsverfahren aus dem Bereich des
Informationretrieval versuchen, neue Verweise zu ermitteln.
Weitere Informationen unter:
http://woerterbuchnetz.de/
http://kompetenzzentrum.uni-trier.de/de/
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Burch_Woerterbuchnetz_Folien.pdf

Ein Wörterbuchportal für das Sanskrit –
Arbeitsinstrument für künftige Untersuchungen zur Historischen Semantik?
Sascha Heße und Katrin Einicke (Martin-Luther-Universität Halle-Wittenberg)
Dem Altindischen kommt als einziger Großcorpus-Sprache, welche vom 2. Jt. v. Chr. bis
heute kontinuierlich im Gebrauch blieb, eine zentrale Rolle u.a. auch bei der Erforschung der
Indogermanischen Sprachfamilie zu. Durch ein relativ konservatives Festhalten an (durch
Morpheme regelhaft erweiterbaren) Wortstämmen bilden sich semantische
Veränderungprozesse des Sanskrit weniger stark an der äußeren Lautgestalt des betreffenden
Lexems als vielmehr auf Ebenen von diachron und synchron außerordentlich breitgefächerten
Konnotationen ab. Vor dem Hintergrund einer nahezu viertausendjährigen Textproduktivität,
die sich über Literaturschichten aus Sozio-, Regio- und „Religio“-lekten zieht und die von
einer reichen Textsortenvielfalt unter terminologischer Ausdifferenzierung einheimischer
Wissenssysteme geprägt ist, lässt sich von einer hochgradigen Polysemie des Sanskrit
sprechen.
Dieser Erkenntnis wird in den Großwörterbüchern des Sanskrit (Petersburger Wörterbücher,
1879-1889 und Schmidt, 1928) im Aufbau der Artikel naturgemäß noch unzureichend
begegnet. Dort wurden alle Lemmata als mehr oder weniger in sich geschlossene Einheiten
wiedergegeben, und Stellenbelege aus unterschiedlichen Epochen und Themengebieten den
jeweils gemeinsamen Bedeutungsansätzen strukturell untergeordnet. Das verstellt bzw.
erschwert den Versuch, einen diachronen Überblick über die historische Entwicklung der
altindischen Semantik zu gewinnen.
Das derzeit in Halle und Marburg erstellte Kumulative Nachtragswörterbuch des Sanskrit
erfasst die seit 1928 verstreut und sehr heterogen publizierten Ergebnisse der Sanskrit-
Lexikographie in einer einheitlichen Struktur, um sie mit modernen benutzeroptimierten
Suchfunktionen abfragbar zu machen. In diesem Rahmen wurde daher die Anlage der
Aufnahmen von vornherein so verankert, dass bei allen bearbeiteten Glossaren durch die
verpflichtende Zuordnung von kategorisierenden Metadaten zum zugrundeliegenden
Wortschatz (Textgattung, Sachkategorie, ggf. Datierung und Lokalisierung) jedes Lemma
bzw. jeder Bedeutungsansatz sofort hinsichtlich dieser grundlegenden Fragestellungen
eingeordnet werden kann. Das bringt mit sich, dass die Ergebnisse einer Lemma-Recherche
automatisch nach Textgattung bzw. Sachkategorie gefiltert oder gegliedert werden können, so
dass der Ausgabeartikel die diachrone Entwicklung bzw. synchrone Breite der
Bedeutungsansätze auch optisch übersichtlich abbildet und diese Information mittels der
genau-en Zuordnung konkreter Stellenbelege noch vertieft. Umgekehrt kann durch die
einheitliche Strukturierung der Ergebnisse einer Volltextsuche z.B. die semantische
Entwicklung von Lexemen über den gesamten erfassten Zeitraum hinweg oder innerhalb einer
ausgewählten Textgattung aufgezeigt werden.
Der Vortrag soll auch als Impuls verstanden werden, die Potentiale ins Auge zu fassen, die
sich aus informationstechnologisch gestützten, gezielten Abfrageroutinen zur Semasiologie
einer Sprache mit der wohl längsten und ausdifferenziertesten Sprachgeschichte innerhalb der

Indogermania für erweiterte linguistische Fragestellungen ergeben könnten. Bei Einbezug
auch der o.g. Großwörterbücher in die für das Nachtragswörterbuch bereits entwickelten
Recherche-Strukturen lässt sich von einer vollständigen Verzeichnung des Wortschatzes
ausgehen. Dichte und Streuung der umfassend dargestellten lemmatischen Belege würden
eine belastbare Grundlage zur Behandlung unterschiedlichster Problemkreise im Rahmen der
historischen Semantik bieten.
Heße, Sascha, M.Sc., Kumulatives Nachtragswörterbuch des Sanskrit, MLU Halle-Wittenberg, Institut
für Informatik, Von-Seckendorff-Platz 1, 06120 Halle, Tel.: +49 (0)345 55 24793,
E-Mail: [email protected]
Einicke, Katrin, Dr., Kumulatives Nachtragswörterbuch des Sanskrit, MLU Halle-Wittenberg,
Seminar für Indologie, Emil-Abderhalden-Str. 9, 06099 Halle; Tel.: +49 (0)345 55 23656,
E-Mail: [email protected]
Weitere Informationen unter:
http://www.informatik.uni-halle.de/ti/forschung/ehumanities/sanskrit/

Bedeutungswandel und Übersetzung: Die historische Semantik buddhistischer Texte
und das Dictionary of Gāndhārī
Stefan Baums (BAdW, Buddhistische Handschriften aus Gandhāra)
Die mehrsprachige Recherche über ein heterogenes Korpus von Handschriften und
überlieferten Kanones stellt eine der Grundbedingungen der Arbeit an altbuddhistischen
Texten dar. Neben einer Reihe indischer Dialekte (besonders Pali, Gāndhārī und Sanskrit) hat
man auch mit umfangreichen Übersetzungsliteraturen ins Chinesische, Tibetische und
verschiedene zentralasiatische Sprachen zu tun, die oft im indischen Original verlorenes
Material bewahren und auf Schritt und Tritt berücksichtigt werden müssen. Dabei stellt man
Textzustände nebeneinander, die einen recht verschiedenen Status haben, nämlich am einen
Ende des Spektrums Handschriften, die Einzelschöpfungen darstellen und durchaus ohne
weiteren Einfluß geblieben sein können, und am anderen Ende kanonische Sammlungen, die
eine jahrhundertelange Redaktion im Rahmen buddhistischer Institutionen durchlaufen haben.
In der langen Textgeschichte des Buddhismus läßt sich Bedeutungswandel im Sinne eines den
einzelnen unbewußten linguistischen Prozesses beobachten, aber auch Vorgänge bewußter
Bedeutungspflege und Bedeutungsschöpfung, zum Teil unter Zuhilfenahme von Instrumenten
wie Kommentaren und Glossaren. Der Gültigkeitsbereich von Bedeutungen buddhistischer
Begriffe kann hierbei ganz verschieden gelagert sein: Bei Handschriften besteht die
Möglichkeit, daß ein bestimmtes Verständnis (oder auch Mißverständnis) nicht über den
Verfasser hinaus existierte; bei kanonischen Sammlungen darf ein breiter und nachhaltiger
Konsens in der Tradition vorausgesetzt werden. Ich möchte dieses Spannungsfeld hier vom
Blickwinkel neuentdeckter Handschriften in der mittelindischen Sprache Gāndhārī
beleuchten, die oft ein Bindeglied zwischen frühbuddhistischen Texten, wie wir sie in Pali‐
Form vorliegen haben, und späteren Entwicklungen in der buddhistischen Sanskrit‐Literatur
darstellen. Als Beispiele werde ich drei Begriffe heranziehen, von denen einer (viṣavida) eine
semantische Neuschöpfung darstellte, die im buddhistischen Sanskrit Allgemeingültigkeit
erlangte; einen anderen (die Gruppe der ayadana), in denen die Gāndhārī‐Tradition ein auch
im Pali nachweisbares Alternativ‐Verständnis widerspiegelt, das sich aber letztlich nicht
durchsetzen konnte; und einen dritten (moraśikha), den der Schreiber einer Handschrift in
seinem individuellen Ringen um Verständnis schuf, der aber keine weiteren Folgen hatte. Das
von mir selbst und Andrew Glass (Seattle) seit 2002 erstellte Dictionary of Gāndhārī
beschreibt die historische Semantik dieser und anderer Begriffe. Ich werde darstellen, wie wir
versuchen, ihrem mehr oder weniger breiten Geltungsbereich dabei Rechnung zu tragen, und
werde zeigen, welche technischen Möglichkeiten wir geschaffen haben, um solche
Bedeutungsentwicklungen über Sprachgrenzen hinweg aufzuspüren.
Weitere Informationen unter:
http://www.gandhara.indologie.uni-muenchen.de/index.html
http://gandhari.org/a_dictionary.php

Semantische Integration von Wissen zum Europäischen Mittelalter: Ein Projekt der
europäischen Lexikographie
(Lexicographic Semantic Integration in the European Middle Ages – LexEMA)
– Abstract -neu–
Sabine Tittel, Dictionnaire étymologique de l’ancien français – DEAF, Heidelberger
Akademie der Wissenschaften
Inhaltsverzeichnis
1 Einleitung ........................................................................................................................................... 14
2 Historische Lexikographie ................................................................................................................. 15
2.1 Herausforderung im europäischen Kontext ................................................................................ 15
2.2 Bestandsaufnahme ...................................................................................................................... 15
3 Das Projekt LexEMA ......................................................................................................................... 15
3.1 Konzept ....................................................................................................................................... 16
3.2 Arbeitsschritte ............................................................................................................................. 16
3.3 Welche Sprachen werden eingebunden? ..................................................................................... 17
4 Finanzierung ....................................................................................................................................... 17
5 Fazit .................................................................................................................................................... 17
1 Einleitung
Europa ist
„ein über 2000 Jahre gewachsenes Gebilde mit vielfältigen historischen, kulturellen und
philosophisch-theologischen Wurzeln [... mit Jahrhunderten,] die von einer weltweit einzigartigen
wechselseitigen Befruchtung in Politik, Wissenschaft, Kunst und Kultur geprägt gewesen sind. Das
Ergebnis dieser Entwicklung manifestiert sich in dem gemeinsamen kulturellen Erbe Europas.“ (zit.
aus http://www.akademienunion.de/-
fileadmin/redaktion/user_upload/Projektbeschreibung_BMBF_Projekt.pdf).
Die Sprache ist ein Träger und Vermittler unserer Kultur. Sie wurzelt in ihrer Vergangenheit.
Sie wächst, unterliegt Einflüssen der Umwelt, bringt Neues hervor während manches abstirbt.
Sie ist der Speicher unseres kulturellen Erbes und der Spiegel unserer soziokulturellen
Interaktion.
Das europäische Mittelalter ist eine Epoche, die geprägt war von dynamischem Wachstum in
allen Lebensbereichen: Es erlebte den Höhepunkt der Romanik und den Beginn der Gotik, das
Aufblühen der volksprachlichen Literatur, bedeutende Entwicklungen innerhalb der
Wissenschaften, die sich – basierend auf griechischem Wissen und arabischen Einflüssen –
über die Volksprachen vermittelten, die Entstehung der Universitäten, usw. Das Mittelalter
war der Startpunkt für das moderne Europa.

„Was fehlt, ist ein länderübergreifendes gemeinsames europäisches Forschungsprogramm für
langfristig angelegte Grundlagenforschung in den Geistes- und Sozialwissenschaften, das die
reziproken historischen Entwicklungen sowie die Frage einer europäischen Identität, eines
gemeinsamen kulturellen Erbes und eines europäischen Bewusstseins untersucht.“ (zit. aus ebd.).
Um diese europäische Identität zu verstehen, müssen wir verstehen, wie die Europäer dachten
und wie sie die Welt sahen. Und dies gelingt über die Sprache, die sie verwendeten.
2 Historische Lexikographie
Die historische Lexikographie erfasst und analysiert diese Sprache. Große Mengen an Wissen
über unsere mittelalterliche Kultur und Gesellschaft sind das Ergebnis jahrzehntelanger
lexikographischer Arbeit auf höchstem wissenschaftlichen Niveau.
Die vergangenen Jahre brachten die Digitalisierung vieler Wörterbücher und damit die
Erreichbarkeit des Wissens über ein zweites Medium – zusätzlich zum gedruckten Buch.
2.1 Herausforderung im europäischen Kontext
Allerdings ist das erarbeitete Wissen – im europäischen Kontext gesehen – fragmentiert
gespeichert und in seiner Gesamtheit schwer zugänglich: Es lagert in den Bänden großer
Wörterbücher, die schwer unter einen Nenner zu bekommen sind. Die Wörterbücher
untersuchen unterschiedliche Sprachen, verwenden unterschiedliche Metasprachen und
besitzen unterschiedliche Artikelstrukturen.
2.2 Bestandsaufnahme
Es gibt bereits Nutzeranwendungen, die verschiedene Projekte der Lexikographie unter einem
Dach vereinen wollen. Z.B. gibt es Plattformen, die das Französische durch mehrere
französische Wörterbücher hindurch untersuchen. Beispiele sind die Plattform des Centre
National de Ressources Textuelles et Lexicales – CNRTL1 und Lexilogos
2 für das
Französische, The free dictionary by Farlex3 für das Englische und das Wörterbuchnetz des
Trier Center for Digital Humanities4 für die verschiedenen Sprachstufen des Deutschen.
Die bestehenden Nutzeranwendungen sind jedoch problematisch, weil sie entweder a)
modernsprachlich oder b) einzelsprachlich sind, die mittelalterliche Welt war jedoch nicht
monolingual. Und, und das ist das wichtigste Merkmal, weil sie c) wortbasiert sind: Sie sind
auf das Suchen von Wörtern ausgerichtet. Dies erschwert den Zugang zu unserem Wissen
über unsere Kultur und ihre Geschichte.
3 Das Projekt LexEMA
Das Projekt Lexicographic Semantic Integration in the European Middle Ages – LexEMA hat
sich zur Aufgabe gesetzt, aus Europas großen historischen Wörterbüchern ein digitales
Netzwerk zu formen, um einen leichten Zugang zu den reichen Inhalten der einzelnen Werke
zu schaffen. Dieses Netzwerk wird interdisziplinär sein, intersprachlich und international. Die
1 S. <http://www.cnrtl.fr/definition/>.
2 S. <http://www.lexilogos.com>.
3 S. <http://www.thefreedictionary.com>.
4 S. <http://woerterbuchnetz.de>.

Hauptaufgabe ist dabei nicht eine informatische – für ein digitales Netzwerk verschiedener
Werke muss das Rad nicht neu erschaffen werden –, sondern eine inhaltliche.
3.1 Konzept
LexEMA will selbstverständlich, denn das ist eine Standardanforderung, einen wortbasierten
Zugang zum Inhalt der beteiligten Wörterbücher anbieten, mit Suffix- und Präfixsuche, Suche
nach Etyma, usw. (Zudem sollen Suchfunktionen zur Verfügung stehen, die außersprachliche
Informationen aufgreifen: ein textbasierter Zugang, ein autorbasierter Zugang, usw.)
Der in bereits bestehenden Wörterbuchportalen genutzte Verknüpfungspunkt der WÖRTER ist
aber nicht in der Lage, die Inhalte der historischen Wörterbücher über verschiedene Sprachen
oder Sprachstufen hinweg zu verknüpfen. Das Konzept LexEMAs will diesen Missstand
beheben, indem es die Wörterbücher über das verbindet, was ihnen allen gemein ist: alle
Wörterbücher historischer Sprachstufen geben die B e d e u t u n g e n der behandelten
Wörter an.
Die Bedeutungen sind in Definitionen gefasst, und in diesen manifestieren sich nun die
Unterschiede zwischen den einzelnen Wörterbüchern erneut: Manche Wörterbücher
definieren aristotelisch (Genus proximum et differentia specifica), manche geben
Translationsangebote, „Ein-Wort-Definitionen“. Und auch hier sind die Metasprachen
(annähernd) so zahlreich wie die Wörterbücher selbst.
LexEMA will dieses Problem lösen, indem es einen Zugang zum Wissen schafft, der von den
K o n z e p t e n der Sprache ausgeht. Basierend auf dem frühen Saussure‘schen binären
Zeichenbegriff (signifié = Bezeichnetes – signifiant = Bezeichnendes) will LexEMA nicht
primär den signifiant, das Bezeichnende, als Zugang auswerten (also etwa Hund – chien –
cane – canis – dog), sondern den signifié, das Bezeichnete (also das sprachlichen Konzept
‚Hund’).
Auf diesem Weg erschließt das Projekt unser in den Wörterbüchern gespeichertes Wissen
zwar auch semasiologisch, aber vor allem – und das ist das wegweisende Element –
onomasiologisch. So ist es in der Lage, über verschiedene Sprachen und Sprachstufen hinweg
Inhalte nutzbar zu machen.
3.2 Arbeitsschritte
Die folgenden Arbeitsschritte sind wesentlich: Es muss zunächst eine Ontologie/ein
Thesaurus erarbeitet, bzw. bestehende Ontologien/Thesauri geprüft und gegebenenfalls
adaptiert werden. Diese Ontologie/dieser Thesaurus muss die mittelalterliche Lebenswelt
abbilden. In Vorarbeiten wurden bereits der sog. Hallig-Wartburg5, der Art & Architexture
Thesaurus Online des Getty Research Institute6 und der Historical Thesaurus des Oxford
English Dictionary – HTOED7 geprüft, wobei letzterer spielversprechend ist.
5 R. Hallig - W. von Wartburg, Begriffssystem als Grundlage für die Lexikographie / Système raisonné des
concepts pour servir de base à la lexicographie, 2e éd., Berlin (Akademie-Verlag) 1963.
6 S. < http://www.getty.edu/research/tools/vocabularies/aat/>.
7 S. < http://www.oed.com/thesaurus>.

Die Entwicklung von intuitiven Benutzeroberflächen ist die Aufgabe der Informatik. Sie muss
die technische Infrastruktur sowohl für die Verknüpfung von Wörtern/Definitionen
verschiedenster Wörterbücher mit Konzepten bereitstellen. Zudem muss sie die Oberfläche
für den späteren europäischen Benutzer entwickeln (Suchmöglichkeiten, Darstellung der
Ergebnisse durch die verschiedenen Wörterbücher hindurch, Filterfunktionen, Timebar, usw.).
Der dritte Arbeitsschritt ist das (digitale) Verknüpfen von jeder Bedeutung jedes Wortes in
jedem teilnehmenden Wörterbuchprojekt mit dem semantischen Konzept (innerhalb der
Ontologie/des Thesaurus), das vom jeweiligen Wort reflektiert wird. Dieser Schritt scheint
einfach, aber hier liegt der Teufel sowohl im Detail als auch in der Masse, was ihn zum
zeitintensivsten und inhaltlich anspruchsvollsten Arbeitsschritt des Prozesses macht.
3.3 Welche Sprachen werden eingebunden?
Das Projekt will in in einem ersten Projektstatus die beiden Sprachen einbinden, die im
mittelalterlichen Europa die größte Verbreitung und Alltagsbedeutung besaßen: Dies sind a)
das Mittellateinische als die meistverwendete Sprache im europäischen Raum und b) das
Altfranzösische als die prestigeträchtigste Vernakularsprache. Sie wurde die im Raum des
heutigen Frankreichs, nördlichen Spaniens, in Italien und auf den britischen Inseln gesprochen
und übte Einfluss auf das Mittelhochdeutsche aus und darüber hinaus. Das Projekt schließt
zudem das Altitalienische ein, dessen Bedeutung im späten Mittelalter etwa mit der
europäischen Verbreitung der Werke Dantes, Pertrarcas und Boccaccios deutlich wird.
In späteren Stadien kann LexEMA für die mittelalterlichen Sprachstufen anderer europäischer
Sprachen geöffnet werden (Mittelenglisch, Altspanisch, etc.) sowie für jüngere Sprachstufen.
4 Finanzierung
Sieben Wörterbücher aus sechs Ländern und internationale Informatik haben unter der
inhaltlichen Federführung von David Trotter (Anglo-Norman Dictionary – AND,
Aberystwyth) und Sabine Tittel (DEAF, HAdW, Heidelberg) das Projekt während der COST
Action IS1005 „Medieval Europe: Medieval Cultures and Technological Resources“
(03/2011-03/2015) herausgearbeitet. Ein Finanzierungsantrag im EU-Förderprogramm
„Horizon2020 / FET-Open“ wurde 2014 abgelehnt. Finanzierung und Zukunft des Projektes
sind offen.
5 Fazit
„Ein zweites Ziel soll es sein, die an vielen europäischen Standorten bearbeiteten
Langfristvorhaben enger miteinander zu verzahnen sowie bestehende Standards, Tools und
Instrumente für die Bearbeitung solcher Vorhaben und deren Strategien für digitales Publizieren zu
harmonisieren sowie gegenüber der Politik, der Wissenschaft und der Öffentlichkeit zu
kommunizieren. Schließlich soll das Vorhaben die Basis legen für das Fernziel, ein gemeinsames
europäisches geistes- und sozialwissenschaftliches Förderprogramm zum kulturellen Erbe und zur
europäischen Identität zu initiieren.“ (zit. aus ebd.).
Wenn dieses Fernziel erreicht werden soll, dann muss sichergestellt sein, dass das Wissen, das
von den Langfristvorhaben erarbeitet wird, auch weiterhin erarbeitet wird. Schließlich ist es

eine Selbstverständlichkeit, dass erst erarbeitet werden muss, was international und
interdisziplinär digital weiter verarbeitet werden soll.
Für die Verarbeitung bietet sich das Konzept LexEMAs als eine Möglichkeit an, das von den
Wörterbüchern erarbeitete Wissen über Sprachen, Zeiten und Länder hinweg
zusammenzuführen, erreichbar und nutzbar zu machen.

ABENDVORTRAG
Computergestützte Historische Semantik: Das Projekt „CompHistSem“
Bernhard Jussen / Alexander Mehler (Universität Frankfurt)
Computational Historical Semantics = CompHistSem zielt auf die zeitbezogene
Modellierung von Wort- und Textbedeutungen ausgehend von Corpora mittelalterlicher
lateinischer Texte. Eine der Herausforderungen einer solchen computergestützten historischen
Semantik betrifft die möglichst genaue sprachliche Modellierung der Texte auf Wort- und
Satzebene. Zu diesem Zweck hat das Projekt eine größere Zahl von Ressourcen entwickelt,
welche ausgehend von einem eigens generierten Lexikon der Lateinischen Sprache eine Reihe
von Vorverarbeitungswerkzeugen für das Lemmatisieren ebenso wie für das Erkennen von
Wortarten und grammatischen Kategorien umfasst. Der Vortrag stellt diese Ressourcen und
deren Verwendung im Rahmen der Webseite www.CompHistSem.org vor und erörtert auf
dieser Grundlage neuartige Methoden für das elektronische Publizieren.
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Jussen_Mehler_HistSemantik.pdf

II. Sektion „Semantic Web und Korpora“
Digitale Briefeditionen im Semantic Web
Stefan Dumont (BBAW, TELOTA), Torsten Schrade (AdWL-Mainz, Digitale Akademie)
Zusammenfassung
Der Doppelvortrag möchte anhand zweier Webservices zeigen, wie Briefe durch
Technologien des Semantic Web erschlossen, vernetzt und analysiert werden können. Zum
einen wird mit correspSearch ein Webservice präsentiert, der Briefeditionen und -repositorien
zentral recherchierbar macht. Zum anderen wird mit XTriples ein Webservice vorgestellt, der
die implizit semantischen Informationen TEI-XML kodierter Briefeditionen in RDF
explizieren und dadurch neue Analysemöglichkeiten eröffnen kann. Beide Webservices
wurden im Rahmen einer gemeinsamen Entwicklerinitiative zwischen BBAW und AWLM
miteinander verschaltet. Neben der Vorstellung beider Dienste wird auch der Nutzen
Webservice-orientierter Architekturen für die digitale geisteswissenschaftliche
Forschungsarbeit in den Blick genommen.
correspSearch – Briefeditionen vernetzen
Briefe bilden eine äußerst wichtige Quellengattung für die geschichts- und
literaturwissenschaftliche Forschung: In ihnen werden die unterschiedlichsten Themen,
Ereignisse, Personen oder Publikationen aus der Lebenswelt der Korrespondenten erwähnt,
geschildert oder kommentiert. Die Heterogenität des Inhalts von Briefen hat zur Folge, dass
sie für eine Vielzahl von wissenschaftlichen Fragestellungen relevant sind. Gleichzeitig sind
Inhalte von Briefen schwer zu recherchieren, denn Briefeditionen werden natürlich nicht
thematisch, sondern stets nur im Hinblick auf eine besonders wichtige Persönlichkeit oder gar
einen Briefwechsel zwischen zwei Korrespondenten erstellt. Das heißt, editierte Brieftexte
bilden bisher stets nur Inseln, deren Vorhandensein, Lage und Beschaffenheit man kennen
muss, um sie ansteuern zu können.
Den Bedarf, Briefeditionen projekt- und institutionsübergeifend zu vernetzen, hat daher die
literatur- und geisteswissenschaftliche Forschung schon länger geäußert.8 Mit correspSearch
hat die TELOTA-Arbeitsgruppe an der BBAW letztes Jahr einen Webservice entwickelt, der
dieses Desiderat einlösen möchte. correspSearch aggregiert dezentral bereitgestellte
Korrespondenzmetadaten (Absender, Empfänger, Schreibort, Datum etc.) und stellt sie für die
Recherche zur Verfügung. Dadurch können Forscher zum einen nicht zentral edierte
Briefwechsel recherchieren und zum anderen untersuchen, wie Zeitgenossen politische oder
gesellschaftliche Ereignisse, Themen oder Publikationen kommentieren. Dabei beschränkt
sich der Webservice weder auf einen thematischen noch auf einen zeitlichen Schwerpunkt, so
dass die Daten auch für bisher noch nicht entwickelte Forschungsfragen genutzt werden
können.
Grundlage des Webservices sind digitale Briefverzeichnisse, die von gedruckten oder
digitalen Briefeditionen bzw. -repositorien bereitgestellt wurden. Um die dafür notwendige
Interoperabilität herzustellen, wurde in Zusammenarbeit mit der Correspondence Special
Interest Group9 der Text Encoding Initiative (TEI) das Correspondence Metadata Interchange
8 So z.B. Wolfgang Bunzel: Briefnetzwerke der Romantik. Theorie – Praxis – Edition. In: Anne Bohnenkamp
und Elke Richter (Hg.): Brief-Edition im digitalen Zeitalter (=Beihefte zu editio Bd. 34) Berlin/Boston 2013. S.
109-131, hier S. 117. 9 http://wiki.tei-c.org/index.php/SIG:Correspondence

Format entwickelt.10
Es basiert auf den TEI-Richtlinien und benutzt im Wesentlichen die im
Frühjahr dieses Jahres in den Richtlinien implementierte TEI-Erweiterung Correspondence
Description (correspDesc).11
Für das Austauschformat wird correspDesc allerdings in einer
stark reduzierten und restriktiven Weise benutzt. So werden u.a. zur projektübergreifenden
Identifizierung von Personen und Orten durchgehend IDs von gängigen Normdatensystemen
verwendet.12
Neben einer Website bietet correspSearch auch eine freie Schnittstelle13
, über die Anfragen
automatisiert gestellt und die Daten unter einer freien Lizenz14
bezogen werden können.
Dadurch können in Zukunft Forscher den Datenbestand auch mit Technologien abfragen, die
neuartig sind oder für die der Webservice selbst keine technische Basis bietet. So wird mit
einer ausreichenden Datenmenge und einer entsprechenden Software auch die Erforschung
von sozialen Netzwerken möglich sein. Darüber hinaus können sich digitale Briefeditionen
mit Hilfe der Schnittstelle automatisiert verknüpfen.
XTriples: Semantische Aussagen aus TEI-XML
Wie der Webservice correspSearch setzen zahlreiche Briefeditionen zur Modellierung ihrer
Forschungsdaten auf die TEI-Richtlinien und somit auf XML als primäre Datengrundlage.
XML als semistrukturiertes Datenformat eignet sich sehr gut zur Lösung editorisch-
philologischer Aufgabenstellungen und entspricht den Forderungen nach Interoperabilität und
Nachhaltigkeit.
XML-codierten Daten beinhalten in jeder Hinsicht semantische Informationen. Doch sind
diese Informationen nur implizit und nicht explizit in den Daten vorhanden. Im Gegenzug
gründen sich Semantic Web-Technologien auf dem Resource Description Framework (RDF)
des W3C15
zur Formulierung semantischer Aussagen (statements) in Form von Subjekt –
Prädikat – Objektbeziehungen (sogen. triples). Die Stärke von RDF liegt in der Verbindung
(interlinking), Zusammenführung (merging) und Analyse (inferencing) digitaler Ressourcen.
RDF ist modellierungstechnisch auf einer höheren Abstraktionsebene anzusiedeln als TEI-
kodierte XML-Daten. Somit existiert eine Lücke: Auf der einen Seite die zahlreichen
geisteswissenschaftlichen XML-Repositorien mit implizit semantischem Potential, auf der
anderen Seite die Technologien und Datenmodelle des Semantic Web, die neue Sichten und
Analysemethoden eröffnen könnten. Zwar existieren Sprachkonzepte, Methoden und Tools
zur Übersetzung zwischen XML und RDF, diese sind jedoch ausnahmslos komplex, teilweise
technisch veraltet, verfügen nur über prototypische Implementierungen oder sind hochgradig
spezialisiert auf den jeweiligen Datenbestand.16
Das Prinzip der Explizierung semantischer Aussagen aus XML-Ressourcen ist dabei nicht
sonderlich komplex: Wird der Uniform Resource Identifier (URI) einer XML-Ressource als
10
http://correspsearch.bbaw.de/index.xql?id=participate_cmi-format&l=de 11
http://www.tei-c.org/release/doc/tei-p5-doc/de/html/ref-correspDesc.html 12
Derzeit unterstützt der Webservice für Personen fünf Normdatensysteme, die er aufeinander abbildet. So z.B.
die Gemeinsame Normdatei (GND) der Deutschen Nationalbibliothek 13
http://correspsearch.bbaw.de/index.xql?id=api&l=de 14
Creative Commons License CC-BY 4.0, https://creativecommons.org/licenses/by/4.0 15
http://www.w3.org./RDF 16
Projekte wie bspw. SPQR (http://spqr.cerch.kcl.ac.uk/?page_id=3) oder das Textual Encoding Framework
(http://rdftef.sourceforge.net/) sind veraltet und technisch nicht generalisiert. Einen interessanten Ansatz bietet
die XSPARQL Language Specification des DERI (http://www.w3.org/Submission/xsparql-language-
specification/), die in Form einer W3C Member Submission niedergelegt ist. Hier fehlen jedoch praktische
Implementierungen. Die Benutzung von RDF a innerhalb von XML-Daten stellt eine weitere Möglichkeit dar,
doch verfolgen die wenigsten geisteswissenschaftlichen Fachdatenrepositorien eine so ausgerichtete Markup-
Strategie.
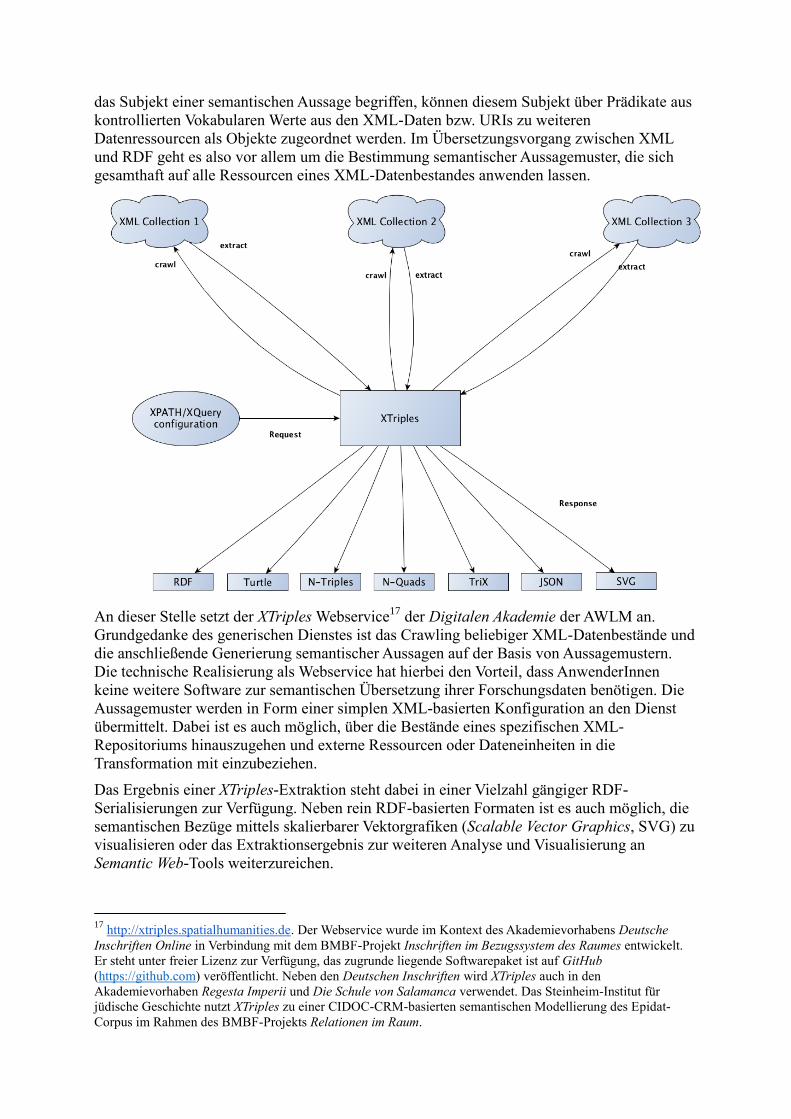
das Subjekt einer semantischen Aussage begriffen, können diesem Subjekt über Prädikate aus
kontrollierten Vokabularen Werte aus den XML-Daten bzw. URIs zu weiteren
Datenressourcen als Objekte zugeordnet werden. Im Übersetzungsvorgang zwischen XML
und RDF geht es also vor allem um die Bestimmung semantischer Aussagemuster, die sich
gesamthaft auf alle Ressourcen eines XML-Datenbestandes anwenden lassen.
An dieser Stelle setzt der XTriples Webservice17
der Digitalen Akademie der AWLM an.
Grundgedanke des generischen Dienstes ist das Crawling beliebiger XML-Datenbestände und
die anschließende Generierung semantischer Aussagen auf der Basis von Aussagemustern.
Die technische Realisierung als Webservice hat hierbei den Vorteil, dass AnwenderInnen
keine weitere Software zur semantischen Übersetzung ihrer Forschungsdaten benötigen. Die
Aussagemuster werden in Form einer simplen XML-basierten Konfiguration an den Dienst
übermittelt. Dabei ist es auch möglich, über die Bestände eines spezifischen XML-
Repositoriums hinauszugehen und externe Ressourcen oder Dateneinheiten in die
Transformation mit einzubeziehen.
Das Ergebnis einer XTriples-Extraktion steht dabei in einer Vielzahl gängiger RDF-
Serialisierungen zur Verfügung. Neben rein RDF-basierten Formaten ist es auch möglich, die
semantischen Bezüge mittels skalierbarer Vektorgrafiken (Scalable Vector Graphics, SVG) zu
visualisieren oder das Extraktionsergebnis zur weiteren Analyse und Visualisierung an
Semantic Web-Tools weiterzureichen.
17
http://xtriples.spatialhumanities.de. Der Webservice wurde im Kontext des Akademievorhabens Deutsche
Inschriften Online in Verbindung mit dem BMBF-Projekt Inschriften im Bezugssystem des Raumes entwickelt.
Er steht unter freier Lizenz zur Verfügung, das zugrunde liegende Softwarepaket ist auf GitHub
(https://github.com) veröffentlicht. Neben den Deutschen Inschriften wird XTriples auch in den
Akademievorhaben Regesta Imperii und Die Schule von Salamanca verwendet. Das Steinheim-Institut für
jüdische Geschichte nutzt XTriples zu einer CIDOC-CRM-basierten semantischen Modellierung des Epidat-
Corpus im Rahmen des BMBF-Projekts Relationen im Raum.

Um die Potentiale einer schnittstellenbasierten, dynamischen Verbindung von correspSearch
und XTriples in Form einer Webservice-Prozesskette auszuloten, haben TELOTA und Digitale
Akademie eine interakademische Zusammenarbeit auf Entwicklungsebene angestoßen. Das
Referat präsentiert erste Ergebnisse dieser Zusammenarbeit.
Weitere Informationen:
http://www.bbaw.de/telota/telota
http://www.digitale-akademie.de/
http://correspsearch.bbaw.de
http://xtriples.spatialhumanities.de/index.html

Die Schule von Salamanca: ein elektronisches Publikationsprojekt und eine semantische
Herausforderung
Andreas Wagner und Ingo Caesar (AMLM, Projekt „Die Schule von Salamanca“,
Universität Frankfurt)
Im Rahmen des Vorhabens „Die Schule von Salamanca. Eine digitale Quellensammlung und
ein Wörterbuch ihrer juristisch-politischen Sprache“ wird ein ideen- und geistesgeschichtlich
sehr einflussreicher Diskussionszusammenhang der frühneuzeitlichen Theologie, Jurisprudenz
und Philosophie durch eine digitale Edition und ein Wörterbuchvorhaben erschlossen. Nach
einem Überblick über die im ersten Projektabschnitt realisierten Arbeitspakete
(Digitalisierungsworkflow, Datenformat, Server-Infrastruktur und Web-Anwendung) wird ein
zentrales Forschungsproblem angeschnitten, für dessen Bearbeitung die Technologien des
Semantic Web eine entscheidende Hilfestellung sein können. Anders als seine
ideengeschichtliche Bedeutung ist nämlich sowohl das Wesen und die Bezeichnung jenes
Zusammenhangs (Ist es eine Schule? Was ist überhaupt eine Schule?) als auch seine interne
Differenzierung (nach Orten, nach Disziplinen u.ä.) alles andere als geklärt. Zur Bearbeitung
dieses Problems müssen zum Studium von Quellentexten, wie es in den betroffenen
Disziplinen gang und gäbe ist, auch vielgestaltige Kontext- und Netzwerk-Analysen
hinzutreten. So wird in der Präsentation gezeigt, wie das Projekt einerseits selbst Daten für
das Semantic Web anbietet und wie es sich andererseits von der Vernetzung mit anderen
Anbietern und dem Einsatz von Semantic Web-Technologien Antworten auf genuine
Forschungsfragen erhofft.
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Caesar_Salamanca.pdf

Semantische Suchen in den Frühneuzeitlichen Ärztebriefen des deutschsprachigen
Raums (1500-1700)
Tilmann Walter (BAdW; Institut für Geschichte der Medizin, Universität Würzburg)
Das Akademieprojekt Frühneuzeitliche Ärztekorrespondenzen, 1500-1700 der BAdW hat im
Februar 2009 seine Arbeit aufgenommen. Seine Aufgabe ist die Erschließung und nähere
Erforschung der Korrespondenzen deutschsprachiger akademischer Ärzte vor dem Jahr 1700.
Arbeitsziel ist weder ein Wörterbuch noch eine Edition, sondern eine möglichst vollständige
Katalogisierung der in Archiven, Bibliotheken und über Editionen überlieferten Ärztebriefe.
Gemeint sind mit „Briefen“ dabei klassische lateinische Gelehrtenkorrespondenzen ebenso
wie volkssprachige berufliche, private und amtliche Briefwechsel (Konsile, Diätanweisungen,
Bewerbungen, Petitionen, amtliche Berichte und Gutachten), in gewissem Umfang auch
Verträge, insbesondere Bestallungsverträge. In unsere Datenbank haben wir bisher über
27.000 solcher Briefe aus 289 Bibliotheken und Archiven in Deutschland und der
deutschsprachigen Schweiz sowie Österreich, Polen, Frankreich, Italien, den Niederlanden,
Dänemark, Tschechien, Russland, Großbritannien und den USA eingetragen. Die Ärztebriefe
werden in folgender Weise k a t a l o g i s i e r t :
Besitzende Institution Burgerbibliothek <Bern>
Signatur Cod. 496 (A) 251
Blatt 224r-225v
Literatur Verena Schneider-Hiltbrunner: Wilhelm Fabry von Hilden 1560-
1634. Verzeichnis der Werke und des Briefwechsels, Bern /
Stuttgart / Wien 1976, 82 (Katalogeintrag)
Person VON Belinus, Zacharias (fl.-1604-1607) [Verfasser/in] [gesichert]
Person AN Fabry, Wilhelm <1560-1634> [Adressat/in] [gesichert]
Entstehungszeit 25.02.1604
Absenderort Basileae (Basel) [gesichert]
Sprache Latein
Land Schweiz
Ausreifungsgrad Abschrift
Inhaltsangabe "Anfrage wegen Unterricht in Anatomie und Botanik bei
Fabricius." (Onlinekatalog der Burgerbibliothek Bern)
Außerdem werden Links zum Online-Katalog der besitzenden Institution und (soweit
verfügbar) zum Digitalisat des Manuskripts oder der Edition angeboten.
Da das Projekt von Anfang an als Online-Datenbank geplant wurde, können, anders als in
einem gedruckten Katalog, sämtliche Inhalte zu jedem beliebigen Zeitpunkt ergänzt und
verbessert werden. So werden für eine stetig wachsende Zahl der Briefe detaillierte
Inhaltsangaben (oder Regesten) erstellt und die Briefe durch ein stetig erweitertes
Schlagwortregister miteinander vernetzt. Unser Schlagwortthesaurus enthält derzeit über
4.300 Einträge mit 1.750 Synonymen; hier die ersten 30 Registereinträge:
Aal, Aalborg, Aarau, Abano Terme <Padua>, Abaton <Pflanze>, Abbildung <Botanik>,
Abbildung <Ethnographie>, Abbildung <Fötus>, Abbildung <Zoologie>, Abdecker,

Abendmahl, Abendmahlsstreit, Abführmittel, Abrechnung, Absage <Hofamt>, Abstinenz,
Abszess, Abtreibung, Abulfeda <Werke>, Aconitum pardalianche <Pflanze>, Adel, Aderlass,
Ägypten, Aegyptiacum <Pflanze>, Aelianus <Werke>, Ärztekritik, Ärzteveteran, Ärztin . . .
Natürlich sind sämtliche Inhaltsangaben auch durch eine Volltextsuche mit der Möglichkeit
der Trunkierung mit Sternchen durchsuchbar. Wir empfehlen den wissenschaftlich
interessierten Benutzern, uns überdies via E-Mail zu kontaktieren, um das Ergebnis ihrer
Anfragen zu optimieren. So haben wir bspw. auf bestimmte Anfragen hin unsere Schlagwörter
weiter ausdifferenziert, oder wir können uns entscheiden, Briefe von bestimmten Ärzten im
Hinblick auf ein kommendes Jubiläum hin bevorzugt zu erschließen u.s.w.
Ebenfalls der inhaltlichen Erschließung dient ein P e r s o n e n r e g i s t e r , zu dem die
biographischen Basisinformationen entweder aus den Briefen selbst, aus der GND oder aus
dem von uns gepflegten WIKI zu Ärztebiographien, Archiven oder Bibliotheken sowie zur
wissenschaftlichen Literatur entnommen sind;
Name Fabry, Wilhelm <1560-1634>
Andere Namen Fabricius Hildanus, Guilelmus; Fabry von Hilden, Wilhelm; Fabry
von der Schmitten, Wilhelm; Fabricius Hildanus, Wilhelm; Hildanus,
Wilhelm Fabricius; Fabri, Wilhelm; Fabricius, Guilelmus <Hildanus>;
Hildenius, Guilelmus; Fabricius, Guilhelmus; Fabricius, Guilielmus;
Hilden, Guilielmus; Hildanus, Guilhelmus F.
Geschlecht männlich
Lebensdaten 25.06.1560 - 14.02.1634
Land Deutschland
Angaben zur Person Sohn des Gerichtsschreibers Peter Andreas Fabry; 1576 Lehre bei
Johann Dümgens in Neuss, 1580 bei Cosmas Slotanus, Wundarzt
Herzog Wilhelms V. von Jülich-Kleve-Berg; Wanderjahre führen ihn
zu Johann Bartisch in Metz und Jean Griffonius in Genf; 1587 verh.
mit Marie Colinet; 1589 Praxis in Hilden, 1593 in Köln, seit 1594
häufiger Ortswechsel; 1602-1610 Stadtwundarzt in Peterlingen, seit
1615 in Bern
Geographischer Bezug Hilden [Geburtsort]
Sachbezug Wundarzt [Beruf/Funktion]
Fundstelle/Quelle M, B; LoC-NA; NDB 4, 738 f.
Von dieser Person 11 Dokumente im Katalog
Von dieser Person 590 Ärztebriefe
An diese Person 351 Ärztebriefe
Über diese Person 36 Ärztebriefe
Homepage des Vorhabens:
http://www.medizingeschichte.uni-wuerzburg.de/akademie/index.html
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Walther_Folien.pdf

Die Leibniz-Connection. Personen- und Korrespondenz-Datenbank der Leibniz-Edition
Michael Kempe (AdW-Goe, Leibniz-Forschungsstelle/Leibniz-Archiv, Hannover)
Der Beitrag zielt im Kern darauf, die neue Datenbank der Leibniz-Edition in all ihren
Aspekten vorzustellen und ihre Funktionen zu erläutern. Dabei gilt es auch danach zu fragen,
auf welche Weise die Datenbank weiterentwickelt und mit anderen ähnlichen Datenbanken
etwa zu gelehrten Korrespondenznetzwerken der europäischen frühen Neuzeit verknüpft
werden kann. Die SQL-Datenbank ist gewissermaßen noch klassisch als relationale
Datenbank aufgebaut. Es soll hier deshalb ebenso thematisiert und zur Diskussion gestellt
werden, inwieweit es möglich wäre, die Leibniz-Connection in Richtung Semantic Web
auszubauen.
Weitere Informationen unter:
https://leibniz.uni-goettingen.de/pages/index

Erschließung und Erforschung thematischer Zusammenhänge in heterogenen
Briefcorpora
Vera Hildenbrandt (Universität Trier) und Jörg Ritter (MLU Halle-Wittenberg)
Das vom BMBF geförderte Projekt „Vernetzte Korrespondenzen | Exilnetz33“ widmet sich
der Erforschung und Visualisierung sozialer, räumlicher, zeitlicher und thematischer Netze in
Briefkorpora. Im Zentrum stehen dabei die Briefe deutschsprachiger Kulturschaffender aus
der Zeit zwischen 1932 und 1950, die durch die Machtergreifung der Nationalsozialisten ins
Exil gezwungen wurden. Ziel des Projektes ist die Entwicklung eines modularen interaktiven
Portals zur Beantwortung von Fragen der Form: Wer hat wo wann mit wem worüber
geschrieben?
Dabei spielt das „worüber“, also die thematische Dimension eine herausragende Rolle. Im
kollaborativen Verbund der drei Projektpartner Deutsches Literaturarchiv Marbach,
Kompetenzzentrum für elektronische Erschließungs- und Publikationsverfahren in den
Geisteswissenschaften an der Universität Trier und Institut für Informatik der MLU Halle-
Wittenberg werden Methoden entwickelt, um Themen in Briefen effizient und so objektiv wie
möglich zu identifizieren, auszuzeichnen und deren Weg und Verbreitung im
Korrespondenznetzwerk zu untersuchen. Im Rahmen des Vortrages wollen wir den Aufbau
eines Exilthesaurus und eine semi-automatische, interaktive Verschlagwortung vorstellen,
welche zusammen die Grundlage für die Erschließung der thematischen Zusammenhänge im
Briefnetzwerk bilden. Der Aufbau des Exil-Thesaurus erfolgte über detailliertes verstehendes
und interpretierendes Lesen der Exilbriefe, die Identifikation der jeweils relevanten
Textstellen und das Übertragen des im Text Gemeinten in sinnvolle Schlagwörter. So entstand
ein umfassender Thesaurus des Exils, der später bei der Verschlagwortung erweitert bzw.
modifiziert werden wird. Die interaktive Verschlagwortung selbst basiert auf dem Ansatz,
dem Bearbeiter für alle Stichwörter aus den Briefen und den zugehörigen
Stellenkommentaren Vorschläge zu unterbreiten, welche Themen aus dem Thesaurus diesem
Stichwort zugeordnet werden könnten. Die Kandidaten für die Vorschläge berechnen sich
über textuelle Ähnlichkeit zu Themen im Thesaurus, über Synonyme und über Übersetzungen
bei fremdsprachigen Einschüben bzw. Briefen in englischer und französischer Sprache.
Zusätzlich werden alle durchgeführten Zuweisungen von Themen zu Stichwörtern gelernt und
ebenfalls als Kandidaten für Vorschläge genutzt.
Die Einbindung des resultierenden Exilthesaurus und der Verschlagwortung in das Briefnetz-
portal erlaubt nicht nur die thematische Erschließung des Korrespondenznetzwerkes, sondern
auch die Analyse und Visualisierung der sozialen, räumlichen und zeitlichen Ausbreitung von
Themen.
Weitere Informationen unter:
http://exilnetz33.de/de/

Herausforderungen und Perspektiven bei der Erprobung von Semantic Web-
Technologien und LOD für Akademieprojekte
Jörg Wettlaufer (AdW-Goe)
Semantische Technologien, also Standards und Formate, die semantische Informationen für
Maschinen lesbar und verstehbar machen, haben seit der Vision eines Semantic Web von Tim
Berners Lee vor 15 Jahren Einzug in den Kanon der Standards der Webprogrammierung und
der KI-Forschung gehalten. Welche Potentiale, Herausforderungen und Probleme sich damit
verbinden, soll an einführenden Beispielen und vor dem Hintergrund des von 2012-2015 im
Rahmen des Niedersächsischen Digital Humanities Forschungsverbundes von der Akademie
der Wissenschaften zu Göttingen durchgeführten Projekts „Semantic Blumenbach“ im
Rahmen des Verbundvorhabens „Digitale Bibliothek und virtuelles Museum“ dargestellt und
diskutiert werden.
Die digitale Darstellung von Texten und Museumsobjekten wird durch zwei unterschiedliche
wissenschaftliche Communities kuratiert: das TEI- Konsortium für Textauszeichnung und der
CIDOC Conceptual Reference Model Gruppe für Kulturgüter (Goerz und Scholz, 2009). Seit
etwa zehn Jahren beobachten wir Bemühungen, diese beiden Communities und die
Weiterentwicklung der von ihnen betreuten Standards miteinander in Kontakt zu bringen.
Christan-Emil Ore und Øyvind Eide veröffentlichten im Jahr 2006 einen ersten Vorschlag für
den Austausch von Informationen zwischen TEI und CIDOC (Eide und Ore, 2006). Seitdem
wurde die TEI Ontologien Special Interest Group (SIG) gegründet, aber bisher gibt es keinen
Konsens, wie man die Herausforderungen am besten meistern.
In dem Projekt „Semantic Blumenbach“ wurden semantische Informationen aus den Schriften
Johann Friedrich Blumenbachs (1752-1840) automatisiert erkannt (Named Entity
Recognition), in TEI P5 ausgezeichnet und ebenfalls automatisiert mit Objektbeschreibungen
einer Datenbank mit naturhistorischen Sammlungsobjekten verknüpft. Als Top Level
Ontologie wurde eine OWL-DL 1.0 Implementation von CIDOC CRM (Erlangen-CRM)
verwendet., als „semantisches Framework“ kam die wissenschaftliche
Kommunikationsumgebung (WissKI) in der Version 1.0 zum Einsatz, die das CMS Drupal
mit einem Triple-Store und der Ontologie Erlangen-CRM verknüpft und Pfade für die
semantische Modellierung bereitstellt. Weitere Experimente wurden mit der Einbindung von
dbpedia-Daten über SPARQL-Abfragen zur Anreicherung der zu den Entitäten verfügbaren
Informationen angestellt. Die Ergebnisse illustrieren die oben beschriebenen
Herausforderungen und bieten zugleich einen Einblick in Chancen und Fallstricke für eine
Verwendung von Semantic Web-Technologien (SWT), Linked Open Data (LOD) und
Semantic Mashups in Akademieprojekten.
Weitere Informationen unter:
http://www.tei-c.org/Activities/SIG/Ontologies/
http://www.cidoc-crm.org/official_release_cidoc.html
Eide und Ore 2006: http://www.cidoc-crm.org/workshops/heraklion_october_2006/ore.pdf
Goerz und Scholz 2009: http://www.cidoc-crm.org/workshops/heraklion_october_2006/ore.pdf
http://wiss-ki.eu/wisskiproject/; http://erlangen-crm.org/; http://www.blumenbach-online.de/
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Wettlaufer__Blumenbach.pdf

Semantic Web am Beispiel des Projekts „Gelehrte Journale und Zeitungen der
Aufklärung“
Antonie Magen (Abteilung für Handschriften und Alte Drucke, Bayerische Staatsbibliothek)
und Marcus Hellmann (AdW-Goe)
Bei unserem Projekt handelt es sich um eine Kooperation zwischen der Göttinger Akademie,
der Universitätsbibliothek Leipzig und der Bayerischen Staatsbibliothek München; es
erschließt gelehrte Zeitschriften der Aufklärung wissenschaftlich, veröffentlicht die
Erschließungen datenbankgestützt (vgl. hierzu die Suchmaschine http://www.gelehrte-
journale.de/startseite/ ) und stellt Digitalisate der erschlossenen Rezensionen zusammen mit
den Erschließungen zur Verfügung.
1. Inhaltliche und technische Einführung in das Projekt, aktueller Stand.
In den Korpus der Datenbank ist auch das Material zweier Vorgängerprojekte der Akademie
Göttingen "Index deutschsprachiger Zeitschriften 1750-1815" (IdZ 18) und „Systematischer
Index zu deutschsprachigen Rezensionszeitschriften des 18. Jahrhunderts" (IdRZ 18)
eingegangen; die Daten wurden zu diesem Zweck konvertiert. Der besondere Reiz des
Projektes, gerade im Hinblick auf das semantic web, liegt in der innovativen Kooperation von
Akademie und Bibliotheken. So erfolgt die Dateneingabe in der bibliothekarischen
Erfassungssoftware WinIBW, die von einigen Verbünden, beispielsweise dem GBV, aber auch
von der ZDB, verwendet wird. Die Datenhaltung erfolgt in der GBV-Datenbank PICA. Aus
dieser Datenbank wird täglich ein OAI-basierter Datenabzug erstellt, aus der sich die
Datenpräsentation auf der projekteigenen Website mit Suchfunktionen speist
(http://www.gelehrte-journale.de/startseite/).
2. Möglichkeiten einer zukünftigen Semantisierung
Indem wissenschaftliche Inhalte in bibliothekarischen Systemen dargestellt werden, sind sie
auch mit einer Vielzahl von bibliothekarischen Normdaten verknüpfungsfähig. Gegenwärtig
ist hier vor allem der Konnex mit VD18 zu nennen. Perspektivisch geplant sind u. a. eine
GND-Verknüpfung sowie die Bereitstellung der Volltexte der Digitalisate auf Solr-Index. Mit
diesem Vorgehen ist eine Datenstruktur garantiert, die Einfallmöglichkeiten für Linked Open
Data und mehrere Möglichkeiten für die Semantisierung der Daten bietet. Damit sind
vielfältige Möglichkeiten gegeben, zukünftig über LOD einerseits wissenschaftliche
Erschließungen in bibliothekarische Nachweissysteme zu integrieren, andererseits
bibliothekarische Datenbanken für die wissenschaftliche Nachnutzung zu optimieren.
Weitere Informationen unter:
Homepage des Projekts: http://www.gelehrte-journale.de/startseite/
Index deutschsprachiger Zeitschriften des 18. Jahrhunderts:
http://adw.sub.uni-goettingen.de/idrz/pages/Main.jsf

III. Sektion „Historische Semantik und Erschließungsverfahren“
Die Welt des 13. Jahrhunderts erzählen. Das „Bienenbuch“ des Thomas von Cantimpré
– Edition und Auswertung
Julia Burkhardt (HAdW, Projekt „Klöster im Hochmittelalter“)
Autor und Text
Im zweiten Drittel des 13. Jahrhunderts vollendete der Dominikaner Thomas von Cantimpré
mit dem Bonum universale de apibus sein Spätwerk, eine monumentale Exempelsammlung,
die als Handbuch für die Prediger seiner Zeit konzipiert war. Ausgehend von dem Beispiel
einer hierarchisch in den König und sein Volk gegliederten Bienengemeinschaft wurden darin
in kleinen Geschichten und Anekdoten vornehmlich aus dem Brabanter und flandrischen
Raum lebensnahe Probleme des menschlichen Alltags, zeitgenössische politische und
gesellschaftliche Themen und schließlich theologische Fragen thematisiert. Wie die
Überlieferungs- und Rezeptionsgeschichte des umfangreichen (ca. 300 Druckseiten starken)
Textes zeigt, wurde das „Bienenbuch“ in den Jahrhunderten nach seiner Entstehung immer
wieder tradiert, bearbeitet und weiterverwendet: So sind aus dem 13.-16. Jahrhundert rund
130 Handschriften vorrangig mit lateinischen, aber auch mit volkssprachlichen Textfassungen
bekannt; Drucke aus dem 15.-17. Jahrhundert bieten den Text in vollem Umfang sowie
teilweise auch Annotationen; schließlich enthalten etwa 100 Handschriften kurze Ausschnitte
und Exzerpte aus dem Werk („Streuüberlieferung“).
Editionsvorhaben
Trotz dieser beachtlichen Wirkungsgeschichte existieren bislang weder eine kritische Edition
noch eine umfassende historische Würdigung des gesamten Werkes. Das Editionsprojekt setzt
hier an und will mit der ersten kritischen Edition des lateinischen Textes und der Auswertung
des „Bienenbuchs“ in kulturhistorischer Perspektive einen Modellvorschlag, der auch für
Texte mit ähnlicher Überlieferungs- und Rezeptionsgeschichte anwendbar sein könnte,
entwickeln.
Ausgehend von den Fragen, wie sich ein derart umfassend überlieferter Text in einem
angemessen Rahmen edieren lässt und inwiefern seine Überlieferungsgeschichte in der
Edition zu berücksichtigen ist, sollen im Vortrag Überlegungen zur Verortung des Texts im
Kontext der politischen und religiösen Auseinandersetzungen des 13. Jahrhunderts
(Historizität/ Vermittelbarkeit), Methoden zu Abgleich und Auswahl von Handschriften sowie
das Konzept der Edition kurz vorgestellt werden.
Kontakt und weitere Informationen unter:
http://www.haw.uni-heidelberg.de/forschung/forschungsstellen/kloester.de.html

Die Chronik des Johannes Johannes Malalas und ihre historische Erschließung
Andreas Dafferner (HAdW, EDV-Abteilung), Claudia Carrara und Christine Radtki (HAW,
Projekt „Historisch-philologischer Kommentar zur Chronik des Johannes Malalas“,
Universität Tübingen)
Die Chronik des Johannes Malalas
Im 6. Jahrhundert n. Chr. verfasste Johannes Malalas eine ‚Weltchronik‘ – eine Darstellung
der Geschichte von Adam bis in seine eigene Zeit. Diese Chronik besitzt herausragende
Bedeutung für die spätere mittelalterliche Geschichtsschreibung: Nachfolgende byzantinische
Chronisten haben sich nicht nur an ihrem Aufbau orientiert, sondern auch vielfach Teile des
Textes übernommen und weiter ausgearbeitet, so dass Malalas‘ Werk letztlich einen
Grundpfeiler der byzantinischen Historiographie darstellt. Die Chronik behandelt nach
biblischer Geschichte, der römischen Königszeit und der Geschichte Alexanders des Großen
und seiner Nachfolger in zunehmender Ausführlichkeit die römische Kaiserzeit mit einem
Schwerpunkt auf den Jahrzehnten, die der Autor selbst erlebt hat, d.h. die Regierungszeiten
der Kaiser Anastasios (491–518), Justin I. (518–527) und Justinian (527–565). Gerade für das
6. Jahrhundert stellt dieses Geschichtswerk somit ein grundlegendes Quellendokument dar,
aber auch für die älteren Perioden bietet es wichtige Informationen.
Das Projekt der HAdW
Die ‚Weltchronik‘ des Johannes Malalas konnte von der Forschung bisher noch nicht
hinreichend erschlossen werden. Aufgabe der seit 2013 an der Eberhard Karls Universität
Tübingen eingerichteten Forschungsstelle ist es, diese Lücke zu schließen. Im Zentrum des
Vorhabens steht die Erarbeitung eines umfassenden philologisch-historischen Kommentars
zur Chronik. Mit diesem Kommentar soll ein Arbeitsinstrument vorgelegt werden, das den
Zugang zu diesem Werk erleichtert und eine konkretere wissenschaftliche
Auseinandersetzung mit ihm ermöglicht. Dazu ist es erforderlich, Sacherläuterungen zum
Text zu erarbeiten, die aus historischer, philologischer, kirchengeschichtlicher und
archäologischer Perspektive sprachliche und inhaltliche Aspekte gleichermaßen behandeln.
Die Datenbank
Als Grundlage für einen am Ende der Projektlaufzeit zu veröffentlichenden schriftlichen
Kommentar wird derzeit ein online-Kommentar erstellt, der dem interessierten Fachpublikum
eine passgenaue Hilfestellung zur Analyse gezielter Textpassagen oder schlicht zur Textsuche
bietet. In einer das komplette Textcorpus umfassenden Datenbank werden dabei alle historisch
wie philologisch relevanten Inhalte der Chronik aufgeschlüsselt und sind für Buch 18 bereits
in Teilen individuell abrufbar. Nach einigen Vorarbeiten und Testversionen liegt mittlerweile
eine Version 2.0 vor, die es dem Nutzer ermöglicht, einen zur Einzelstelle bzw. zum
Einzelwort aufklappbaren Kommentar, der in die Großkategorien „historisch“ und
„philologisch“ aufgeteilt ist, sowie eine kurze Inhaltsangabe zum jeweiligen Kapitel, ferner
die relevanten Stellen der Nebenüberlieferung und Hinweise auf einschlägige
Forschungsliteratur abzurufen.

Historische Semantik
Vor dem Hintergrund des Tagungsthemas der „Historischen Semantik“ sollen im Rahmen
dieses Vortrages nach einer generellen Vorstellung der Datenbank verschiedene Beispiele
gezeigt werden, die den Autor Malalas im Kontext seiner Zeit und seiner Tätigkeit im
unmittelbaren Umfeld spätantiker Administration verorten. Als Beispiel können die von
Malalas verwendeten Latinismen angesehen werden, die vor dem Hintergrund historischen
Sprachwandels Bedeutung gewinnen und nicht nur den Blick auf den Autor selbst, sondern
auch auf gesellschaftliche Entwicklungen seiner Zeit freigeben.
Weitere Informationen unter:
http://www.haw.uni-heidelberg.de/forschung/forschungsstellen/malalas/projekt.de.html

Graphdatenbanken für Historiker mit Perspektiven für die Historische Semantik
Andreas Kuczera (AdWL-Mainz, Regesta Imperii)
Die zunehmende Menge an Volltexten in den Geschichtswissenschaften bietet neue Chancen
für die Forschung, erfordert aber auch neue Methoden und Sichtweisen. Der Beitrag möchte
die Verwendung von Graphdatenbanken bei der Erschließung von Quellenmaterial vorstellen.
Momentan werden digitale Quellen meist in XML oder in SQL-Datenbanken abgelegt. XML
hat sich als Standard bewährt und findet in vielen Editionsprojekten als Datenformat
Verwendung, während Websites meist auf SQL-Datenbanken als Daten-Repositories
zurückgreifen. XML-Dateien sind meist noch verständlich lesbar, bei SQL-Datenbanken ist
die Lesbarkeit ohne Kenntnis der zu Grunde liegenden Datenstrukturen in der Regel nicht
mehr gegeben. Hier könnte die Verwendung von Graphdatenbanken ein neuer Ansatz für die
Speicherung von zu erschließendem Wissen sein.
In SQL-Datenbanken sind die Informationen in Tabellen abgelegt, die untereinander
verknüpft sind. Graphdatenbanken folgen hier einem völlig anderen Ansatz. In einem Graph
gibt es Knoten und Kanten. Vergleicht man die Knoten mit einem Eintrag in einer Tabelle
einer SQL-Datenbank, wäre eine Kante eine Verknüpfung zwischen zwei Tabelleneinträgen.
Im Unterschied zu SQL-Datenbanken können Knoten und Kanten jeweils Eigenschaften
haben.
Wie dies genau aussieht und wie man einen solchen Graphen anschließend auswerten kann,
wird im Vortrag ausführlich vorgestellt.
Weitere Informationen unter:
http://www.regesta-imperii.de

Semantik und Lexikographie des ptolemäischen Kosmos: Ein mehrsprachiges digitales
Glossar der mittelalterlichen und frühneuzeitlichen Astronomie und Astrologie
François Charette (BAdW, Projekt „Ptolemaeus Arabus et Latinus“, Universität Würzburg),
Stefan Müller (IT-Referat BAdW)
Im Rahmen des Projektes „Ptolemaeus Arabus et Latinus“ an der Bayerischen Akademie
werden sämtliche astronomischen und astrologischen Texte des Claudius Ptolemäus in
arabischen und lateinischen Quellen und deren Bearbeitungen erfasst. Aus diesen entsteht zur
Zeit ein umfangreiches digitales Glossar der mittelalterlichen und neuzeitlichen Sternkunde.
Im ersten Teil der Präsentation wird nach einer allgemeinen philologischen und
wissenschaftshistorischen Einleitung zum Projekt das Konzept des Glossars erklärt und
dessen technische Implementierung mittels einer Graphdatenbank erläutert. Die Vorzüge einer
solchen Datenbank für das Erforschen der behandelten Texte werden anhand einiger Beispiele
hervorgehoben. Im Anschluss daran wird gezeigt, wie das Glossar auf den Netzseiten
erscheinen und verwendet werden könnte, indem es zum einen für die Maschine lesbar in
RDFa eingebunden, zum anderen für den Menschen durch Verlinkungen, Einblendungen und
filterbare Auflistungen nutzbar gemacht wird.
Das Glossar und seine Darbietung im Netz sollen nicht so sehr selbst Forschungsergebnisse
darstellen als vielmehr Mittel für künftige Forschung sein: für die weitere inhaltliche
Erschließung der dargebotenen Texte, aber auch für sprachkundliche Untersuchungen, die
jenseits vom Forschungsschwerpunkt des Ptolemaeusprojektes liegen.
Weitere Informationen unter:
http://ptolemaeus.badw.de/pal/public/index

„Semantisierungspotentiale“ in Akademievorhaben am Beispiel der „Kleinen und
Fragmentarischen Historiker der Spätantike“ (KFHist).
Jonathan Groß, Ulrike Henny, Patrick Sahle (Cologne Center for eHumanities, Universität zu
Köln)
Die „Kleinen und Fragmentarischen Historiker der Spätantike“ (KFHist) sind ein
Editionsprojekt an der Universität Düsseldorf, das seit 2012 im Akademienprogramm der
Nordrhein-Westfälischen Akademie der Wissenschaften und Künste gefördert wird. Es ediert
ein Corpus von über 80 kürzeren bzw. nur in Fragmenten erhaltenen Historikern der
Spätantike (3.-6. Jh. n. Chr.) mit kritischem Apparat, deutscher Übersetzung und philologisch-
historischem Kommentar. Die Edition erscheint in einer Druckausgabe samt PDF für
Subskribenten; darüber hinaus werden Einleitungen und Originaltexte in Kooperation mit dem
Cologne Center for eHumanities (CCeH) im Open Access erscheinen.
Durch die digitale Publikation werden die Forschungsergebnisse aus KFHist einem potentiell
größeren Leserkreis und anderen Rezeptionsformen leichter zugänglich gemacht. Als Web-
Präsentation meint dies neben dem „Lesen“ der edierten Texte vor allem browsende und
suchende Zugänge. Auf der analytischen Ebene ist ein Fortschritt aber nur zu erreichen, wenn
die Daten selbst in Formaten zur Verfügung gestellt werden, die eine Nachnutzung durch
algorithmische Verfahren erlauben. Dies betrifft einerseits die Frage der Bereitstellung an
standardisierten Schnittstellen und andererseits die Form, in der das Wissen gegeben ist.
Ausdrucksweisen aus dem Bereich des Semantic Web erlauben es, Informationen so explizit
zu machen, dass sie für „semantische“ Formen der Informationsverarbeitung zugänglich
werden.
Auf der Ebene der Metadaten betrifft dies für die KFHist zunächst die edierten Autoren und
Werke. Sobald diese mit kanonischen Bezeichnern (URIs) identifiziert werden, wird eine
Anbindung an Wissen möglich, das außerhalb des Projektes liegt. Die KFHist werden über
solche Brückenköpfe Teil des „Giant Global Graph“.
Weitere Anknüpfungspunkte bilden die Metadaten zu den Überlieferungsträgern sowie zu
Voreditionen. Auch hier sind Personen, Werke sowie bibliografische Entitäten mit ihren
verschiedenen Eigenschaften (wie Entstehungsorten, Entstehungszeiten etc.) zu identifizieren.
Auf der Ebene der Texte selbst ist zunächst die kanonische Ansprechbarkeit von Texten,
Textfassungen und Textteilen zu regeln, für die persistente Adressen geschaffen werden
müssen. Darauf können dann in den Texten identifizierte „named entities“ wie Personen und
Orte, aber auch andere kontrollierte Begriffe, wie Schlagwörter, verweisen. Jenseits dieser
klassischen semantischen Einheiten gibt es z.B. mit den „Ereignissen“ weitere
Themenkomplexe, die ebenfalls semantisch expliziert werden könnten, bei denen die
Entwicklung praktischer Lösungen aber noch am Anfang steht. Nochmals anders stellt sich
die Situation für den Wortbestand der Texte selbst dar: die einzelnen Wörter können zwar
identifiziert und lemmatisiert und damit mit anderen Texten und Lexika verbunden werden,
eine Nutzung der semantischen Dimension selbst ist damit aber nur grundsätzlich vorbereitet.
Für die praktische Umsetzung der Semantisierung eines Forschungsprojektes wie die KFHist
sind zunächst die bestehenden Modelle wie SKOS auf ihre Einsetzbarkeit zu prüfen. Sodann
ist zu evaluieren, ob für die in Frage stehenden Entitäten bereits Normdaten von den zentralen

Einrichtungen (z.B. via GND) vergeben sind, ob sie von der jeweiligen Community (hier den
„Digital Classics“) entwickelt werden oder ob im Projekt Identifikatoren gebildet werden
müssen. In einem zweiten Schritt muss dann eine Strategie entwickelt werden, wie die
bestehenden Daten eigentlich mit möglichst geringem Aufwand bei möglichst hoher Qualität
semantisch angereichert bzw. übersetzt werden können. Danach stellt sich die Frage des
„exposure“: Linked Open Data wird im Idealfall an technischen Schnittstellen bereitgestellt,
um von anderen abgerufen zu werden, die darauf Suchanwendungen aufbauen, sie in
übergreifende Systeme einspeisen oder für analytische Zwecke nutzen.
Der Beitrag möchte am Beispiel der KFHist zeigen, welche Anknüpfungspunkte bereits
digital gewordene, „typische“ Akademievorhaben für Verfahren des Semantic Web bieten.
Damit ist die Vorbereitung von Verknüpfung mit anderen Informationsbeständen verbunden,
die zunächst zu einer besseren Auffindbarkeit und Benutzbarkeit von Forschungsergebnissen
führen können und dem Fernziel des Semantic Web entsprechend eines Tages das Ziehen von
Schlüssen (reasoning) erlauben. Bereits vorhandene Anschlussmöglichkeiten, die im Falle der
KFHist vor allem aus dem Bereich der Digital Classics kommen, sollen in diesem Beitrag den
Blick genommen und mögliche Umsetzungs- und Nutzungsszenarien am Beispielprojekt
aufgezeigt werden.
Weitere Informationen unter:
Homepage des Projekts: http://www.phil-fak.uni-duesseldorf.de/historiker-der-spaetantike/
Cologne Center for eHumanities: http://www.cceh.uni-koeln.de/node/520

Heidelberger Gesamtverzeichnis der griechischen Papyrusurkunden Ägyptens in
Papyri.info
James M. S. Cowey (HAdW, Papyrus-Editionen)
Die digitale Plattform papyri.info wird präsentiert und ihre Erfolge dargestellt. Das Vorhaben
"Papyrus-Editionen" der Heidelberger Akademie der Wissenschaften, das eine Laufzeit von
1989 bis 2002 hatte, etablierte die Datenbank „Heidelberger Gesamtverzeichnis der
griechischen Papyrusurkunden Ägyptens“ (HGV). Diese Datenbank bot und bietet noch
Metadaten für alle veröffentlichten Papyri und Ostraka. 1982 begann an der Duke University
(NC) ein ähnliches Projekt, die „Duke Database of Documentary Papyri“ (DDbDP). Diese bot
griechische und lateinische Texte mit begleitenden minimalen Metadaten aller
veröffentlichten Papyri und Ostraka. Diese zwei Projekte ergänzten sich und so entstand im
Laufe der Jahre eine Zusammenarbeit. Zu Beginn dieses Jahrhunderts haben beide Projekte
unter mangelnder Finanzierung gelitten. Diese missliche Lage trug zu der Entstehung von
papyri.info bei, einem Projekt, das unterschiedliche Materialien von verschiedenen
papyrologischen Datenbanken, darunter HGV und DDbDP, zusammenführte.
Die zusammengeführten Ressourcen unterliegen Versionskontrollen und der Überprüfung von
Fachleuten: Es werden Texte, Übersetzungen, Kommentare, wissenschaftliche Metadaten,
Daten aus Bestandskatalogen, Bibliographien und Digitalfaksimiles bearbeitet und
dargeboten. Anhand von papyri.info wird illustriert, wie sich die von der Heidelberger
Akademie der Wissenschaften begründeten Projekte weiterentwickeln und wie existierende
Datenbanken nachhaltig betreut und vor der Fossilisierung bewahrt werden können.
Weitere Informationen unter:
http://papyri.info/
http://www.rzuser.uni-heidelberg.de/~gv0/gvz.html

Pollux’ WordNet. Zur digitalen Edition eines griechischen Thesaurus des 2.
Jahrhunderts u. Z.
Stylianos Chronopoulos (Seminar für Klassische Philologie der Universität Freiburg)
Pollux’ Onomastikon ist ein griechischer Thesaurus, verfasst im 2. Jh. u. Z. In zehn Büchern
werden die Wortfelder von verschiedenen Begriffen aufgefasst. Pollux strukturiert
hierarchisch jedes Wortfeld (Mikrostruktur), bemüht sich aber nicht, die Begriffe in ein
logisches System einzuordnen (Makrostruktur). Das Onomastikon ist zugleich ein
attizistisches Lexikon: es beinhaltet Wörter, die zum größten Teil bei kanonischen Autoren
der klassischen Zeit zu finden sind, es führt, wenn notwendig, Belege und Zitate auf, und in
mehreren Fällen rät den Benutzer von der Verwendung mancher Wörter ab.
Das Onomastikon ist in mehreren Handschriften überliefert, die auf eine revidierte Edition des
9.–10. Jh. zurückgehen. Der Text variiert beträchtlich von Handschrift zu Handschrift. Die
aktuelle Druckedition stammt von Erich Bethe (Bd. 1: 1900; Bd. 2: 1931; Bd. 3, Indices:
1937), der einen “vollständigen” Text rekonstruiert, indem er die überlieferten Texten aller
Handschriften zusammenlegt.
Die im Rahmen des Projekts “Open Greek and Latin” (http://www.dh.uni-
leipzig.de/wo/projects/ opengreek-and-latin-project/) geplante digitale Edition des
Onomastikon beruht sich auf Bethes Druckedition, wird aber ein reichhaltigeres Modell für
den Text vorlegen, so dass die Edition in ihrer vollständigen Form die folgenden
Nutzungsbedürfnisse abdecken wird:
1. lineare Lektüre und Suche nach Wörterformen bzw. Lemmata;
2. Sichtbarkeit der verschiedenen Fassungen des Onomastikon, so wie sie über die
verschiedenen Handschriften überliefert worden sind
3. Überblick über der Mikrostruktur der Wortfeldern (Wie sind sie organisiert? Welche
Ontologien stellt Pollux her?) und Suche nach Strukturmustern;
4. Benutzung des Onomastikon als Thesaurus/Lexikon der altgriechischen Sprache;
5. Benutzung des Onomastikon als Quelle für antiken Autoren, Werktiteln und Zitaten;
6. Untersuchung der metalexikographische Anmerkungen;
7. Verknüpfung des Onomastikon mit der antiken lexikographischen/enzyklopädischen
Tradition Der Text und der kritische Apparat der Edition von Bethe wird digitalisiert
und in TEI XML (EpiDoc) ausgezeichnet. Zusätzlich zu Bethes Edition werden auch
die metalexikographischen Anmerkungen gekennzeichnet. Die Hinweise auf Autoren,
Werke und die Zitate sowie die Elemente der Mikrostruktur jedes Wortfeldes werden
durch stand-off markup in RDF ausgezeichnet. Eine Bearbeitung des im Onomastikon
aufgeführten Vokabulars durch Anwendung der Kategorien für Synsets-Beziehungen
zwischen Wörtern derselben Wortart (POS) sowie „cross-POS“ Beziehungen, die
WordNet (https://wordnet.princeton.edu) verwendet werden, wird das Onomastikon zu
einem digitalen Thesaurus machen. Drei hauptsächliche Darstellungsmodi sind für die
Edition vorgesehen:
1. Text mit Suchfunktionen, Hyperlinks zu anderen antiken Lexika und Möglichkeit
auszuwählen, welche Handschrift(en) sichtbar sein soll(en);
2. Darstellung der Struktur/Ontologie eines oder mehreren Wortfelder;
3. WordNet-ähnliche Darstellung und Suche.

Kontakt:
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Chronopoulos__Pollux_Folien.pdf

Semantische Probleme in den Fragmenten der griechischen Komödie
Christian Orth (HAdW, Projekt „Kommentierung der Fragmente der griechischen Komödie“,
Universität Freiburg)
Bei der Kommentierung der Fragmente der griechischen Komödie spielen Fragen der
historischen Semantik eine wichtige Rolle. Die Vielfalt sprachlicher Register und die
sprachliche Kreativität der Gattung haben zur Folge, dass eine große Zahl von Wörtern
überhaupt nur oder erstmals in der Komödie bezeugt ist. Zugleich liefert die Komödie
wichtige Anhaltspunkte für die Bedeutungsentwicklung von auch in anderen Gattungen
bezeugten Wörtern. Das Verständnis eines Worts in einer bestimmten Passage einer Komödie
ist oft erst unter Berücksichtigung des weiteren Kontexts der sprachlichen Entwicklung, aber
auch kultureller Umstände möglich. Durch die Untersuchung der Entwicklung von Wörtern in
ihrem historisch-kulturellen Kontext leisten die Kommentare somit auch einen Beitrag zur
griechischen Lexikographie.
In meinem Beitrag soll (1) an ausgewählten Beispielen gezeigt werden, wie in unserem
Projekt die Bedeutung und Bedeutungsentwicklung einzelner Wörter untersucht wird, und (2)
die Frage gestellt werden, wie die dabei gewonnenen Ergebnisse in einer digitalen Publikation
zugänglich gemacht werden können.
Weitere Informationen unter:
http://www.haw.uni-heidelberg.de/forschung/forschungsstellen/kofrgrkom.de.html

IV. Sektion „Semantik und Wörterbuch“
Zur Symbiose zwischen „Zettelkasten“ und „Datenbank“ bei der Artikelherstellung im
Deutschen Rechtswörterbuch
Andreas Deutsch (HAdW, Deutsches Rechtswörterbuch)
Die Ermittlung der Semantik historischer Rechtswörter stellt oft genug eine Herausforderung
dar. Bisweilen scheinen Wörter noch heute geläufig, hatten aber bei genauerer Betrachtung in
der Vergangenheit eine völlig andere Bedeutung. Oft genug wandelt sich die Semantik eines
Wortes im Laufe der Geschichte mehrfach. In der Forschungsstelle des Deutschen
Rechtswörterbuchs (DRW, vgl. http://www.deutsches-rechtswoerterbuch.de/ueber.htm) an der
Heidelberger Akademie der Wissenschaften wird die Bedeutung historischer Rechtstermini im
Kern auf zwei Wegen eruiert: zum einen auf der Basis von rund 2,5 Millionen „Belegzetteln“,
also handschriftlich gefertigten und in Archivkästen sortierten Wortnachweisen, die in der
Anfangszeit des Wörterbuchs erstellt wurden, indem die zum Corpus des Rechtswörterbuchs
gehörigen mehreren tausend Quellen systematisch nach aussagekräftigen Belegstellen eines
Wortes durchforstet wurden, zum anderen auf der Basis einer stetig wachsenden Datenbank
mit elektronischen Volltexten ausgewählter, zum Corpus gehöriger Quellen.
Auf den ersten Blick erscheint eine möglichst breite Beleglage der beste Weg, um ein klares
Bild über die Entwicklung eines Wortes zu gewinnen. Extensiv angelegte elektronische
Textarchive können eine Materialgrundlage liefern, die weit über das hinaus geht, was ein
„Zettelkasten“ mit Belegexzerpten bieten kann. Bei häufig vorkommenden Wörtern (etwa
„schon/schön“ oder „Schuld“) ergeben sich bei einer Datenbankrecherche allerdings schnell
mehrere tausend Treffer, die hinsichtlich ihrer semantischen Ausdifferenzierung nicht mehr
überblickt werden können.
Beispiel „sein“: Verb oder Possessivpronomen?
Im Zettelkasten findet sich eine überschaubare Anzahl ausgewählter Belege. Sie sind auf rechtlich Relevantes beschränkt und bereits dem richtigen Wort zugeordnet:
● zum Pronomen alle Schreibformen komplett 77 Belege
● zum Verb alle Schreibformen komplett 121 Belege
Nicht mehr überschaubar ist demgegenüber die überhohe Anzahl von Treffern im elektronischen Textarchiv:
● allein für die Schreibform „sein“ (z.B. als Infinitiv): 85.116 Belege
● allein für die Schreibform „seyn“ (z.B. als Infinitiv): 11.822 Belege
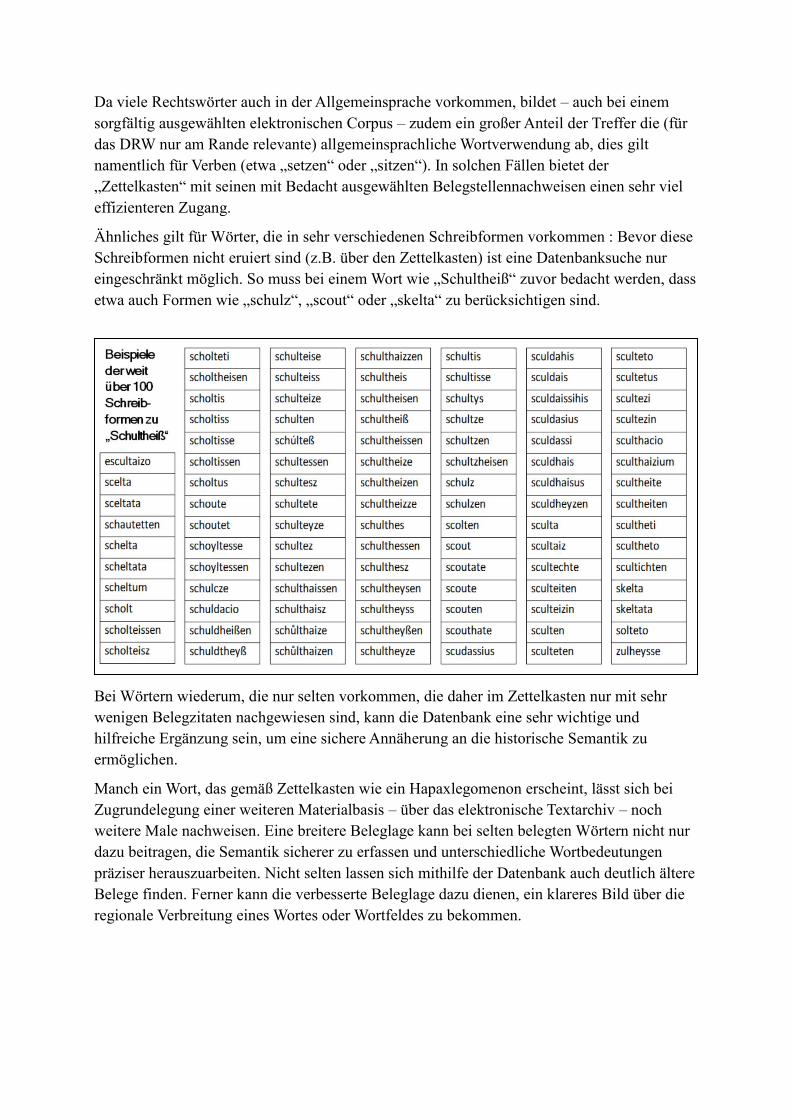
Da viele Rechtswörter auch in der Allgemeinsprache vorkommen, bildet – auch bei einem
sorgfältig ausgewählten elektronischen Corpus – zudem ein großer Anteil der Treffer die (für
das DRW nur am Rande relevante) allgemeinsprachliche Wortverwendung ab, dies gilt
namentlich für Verben (etwa „setzen“ oder „sitzen“). In solchen Fällen bietet der
„Zettelkasten“ mit seinen mit Bedacht ausgewählten Belegstellennachweisen einen sehr viel
effizienteren Zugang.
Ähnliches gilt für Wörter, die in sehr verschiedenen Schreibformen vorkommen : Bevor diese
Schreibformen nicht eruiert sind (z.B. über den Zettelkasten) ist eine Datenbanksuche nur
eingeschränkt möglich. So muss bei einem Wort wie „Schultheiß“ zuvor bedacht werden, dass
etwa auch Formen wie „schulz“, „scout“ oder „skelta“ zu berücksichtigen sind.
Bei Wörtern wiederum, die nur selten vorkommen, die daher im Zettelkasten nur mit sehr
wenigen Belegzitaten nachgewiesen sind, kann die Datenbank eine sehr wichtige und
hilfreiche Ergänzung sein, um eine sichere Annäherung an die historische Semantik zu
ermöglichen.
Manch ein Wort, das gemäß Zettelkasten wie ein Hapaxlegomenon erscheint, lässt sich bei
Zugrundelegung einer weiteren Materialbasis – über das elektronische Textarchiv – noch
weitere Male nachweisen. Eine breitere Beleglage kann bei selten belegten Wörtern nicht nur
dazu beitragen, die Semantik sicherer zu erfassen und unterschiedliche Wortbedeutungen
präziser herauszuarbeiten. Nicht selten lassen sich mithilfe der Datenbank auch deutlich ältere
Belege finden. Ferner kann die verbesserte Beleglage dazu dienen, ein klareres Bild über die
regionale Verbreitung eines Wortes oder Wortfeldes zu bekommen.

Für die Erforschung der historischen Rechtssprache gilt daher: Die besten Ergebnisse werden
durch eine sinnvolle Kombination von „Zettelkasten“ und „Datenbank“ erzielt.
Das Deutsche Rechtswörterbuch bildet als großes Belegwörterbuch in seinen Wortartikeln
nach Möglichkeit nicht nur die semantische Bandbreite eines Wortes (im jeweiligen
rechtlichen Kontext) ab. Soweit möglich bieten die Belegzitate auch einen (je nach Größe des
Artikels unterschiedlich ausführlichen) Überblick über jeweils vorkommenden
Schreibformen. So sind bei Wörtern wie „Schultheiß“ oder „setzen“ jeweils über hundert
verschiedene Schreibweisen nachgewiesen. Über die Online-Version des Wörterbuchs (für
alle frei unter: www.deutsches-rechtswoerterbuch.de) sind diese besonders leicht auffindbar.
Die Artikel sind zwar stets neuhochdeutsch lemmatisiert. Wer aber nicht weiß, zu welchem
neuhochdeutschen Wort sein gesuchtes Wort in historischer Schreibung gehört, kann einfach
das Wort in der historischen Schreibweise eingeben. Die Suche liefert dann nicht nur die
verfügbaren Artikel mit Lemma in genau dieser Schreibweise, sondern unter anderem auch
alle Artikel, in denen ein Beleg mit entsprechender Schreibform vorkommt. Mehr Tipps und
Tricks zum Onlinewörterbuch bieten die Benutzungshinweise (unter Hilfe in DRW-Online
oder direkt hier: http://drw-www.adw.uni-heidelberg.de/drw-cgi/zeige?dok=benutz.htm).
Mehr Informationen über das Deutsche Rechtswörterbuch (DRW) bietet die
Projekthomepage: http://www.deutsches-rechtswoerterbuch.de/ueber.htm
Beispiel „Sohnstochter“: Selten belegt
Der einzige im Zettelkasten nachgewiesene Beleg zu diesem Wort stammt aus einem Jahr nach der Zeitgrenze, die für die Erstellung von DRW-Wortartikeln bei Komposita vorgegeben ist; gäbe es nur diesen späten Beleg, müsste der Artikel daher wegfallen, obwohl das Wort in Wirklichkeit deutlich älter ist:
„vorbehalt zu gunsten der sohns-töchter, in ansehung ihres großvatters säßhaus, gewehr, kleider und kleinodien“
BernStR. VII 2, S. 889, 1762.
Ein zusätzlicher elektronischer Beleg aus dem Textarchiv (hier aus dem online
verfügbaren Projekt DRQEdit, www.drqedit.de) hilft als neuer Erstbeleg:
„der vasall kan die lehen von der verlassen sonstochter nit empfahen“
Zasius,Lehnr.(Lauterbeck), Bl. Mv., 1553.

Das retrodigitalisierte Deutsche Wörterbuch als Quelle für die historische Semantik
Volker Harm (Göttingen)
Das von Jacob Grimm und Wilhelm Grimm begründete und 1960 in einer ersten Bearbeitung
von 32 Bänden abgeschlossene Deutsche Wörterbuch (1DWB) ist ein Grundlagenwerk der
historischen Sprachforschung und insbesondere der historischen Semantik. Dies gilt auch für
die seit 1960 an der Berlin-Brandenburgischen Akademie der Wissenschaften sowie der
Akademie der Wissenschaften zu Göttingen erarbeitete Neubearbeitung, die die am stärksten
veralteten Bände der Erstbearbeitung ersetzt. Die Erstbearbeitung liegt seit Längerem digital
vor, die Digitalisierung der Neubearbeitung wird zur Zeit beantragt. Da die Beschreibung der
Bedeutungsgeschichte des Wortschatzes das erklärte Hauptziel des 2DWB (wie in großen
Teilen auch des 1DWB) ist, sollte auch für die digitale Version des
2DWB ein erhebliches
Auswertungspotential für historisch-semantische Fragestellungen zu erwarten sein. Im
Gegensatz zu formbezogenen Informationspositionen, die relativ leicht verbindbar und
erschließbar sind, stellt die artikelübergreifende Abfrage semantischer Informationen eine
erhebliche Herausforderung dar. Dies zeigt sich vor allem am der Scheitern von Versuchen,
einzelne Bedeutungspositionen wörterbuchintern bzw. -extern zu verlinken. Trotz der
angedeuteten Schwierigkeiten, die auf die stark „einzelwortbiographische“ Anlage des Werkes
zurückzuführen sind, bietet das digitale 2DWB ein beträchtliches Potential für die
Beantwortung von artikelübergreifender Fragen der historischen Semantik. Als Vorteil des 2DWB erweist sich dabei u.a. die ausgeprägte Binnendifferenzierung der Artikel, die relativ
konsistente Strukturierung der lexikographischen Angaben sowie die vergleichsweise
reichhaltigen Metadaten zu den Belegstellen. In dem Referat soll an ausgewählten Beispielen
gezeigt werden, wie über eine Korrelierung unterschiedlicher lexikographischer
Informationstypen – z. B. die Verknüpfung von Wortbildungsangaben mit
Gliederungsübersichten, von bibliographischen Informationen mit wortgeschichtlichen
Angaben – neue Einsichten in die historische Semantik gewonnen werden können.
Gleichzeitig soll geprüft werden, inwiefern die Nutzbarkeit des digitalen 2DWB durch
weitergehende semantische Annotierungen sowie die Einbeziehung des bisher noch nicht
digital vorliegenden Quellenmaterials erhöht werden kann.
Weitere Informationen unter:
http://www.uni-goettingen.de/de/118878.html
https://de.wikipedia.org/wiki/Deutsches_W%C3%B6rterbuch
http://dwb.uni-trier.de/de/
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Harm_DWB_als_Quelle_fuer_HistSem.pdf

Textdatenbank und Wörterbuch des klassischen Maya
Christian M. Prager (AWK-NRW, Projekt „Textdatenbank und Wörterbuch des Klassischen
Maya“, Universität Bonn)
Die an der Universität Bonn angesiedelte Arbeitsstelle „Textdatenbank und Wörterbuch des
Klassischen Maya“ der Nordrhein-Westfälischen Akademie der Wissenschaften und der
Künste erforscht Schrift und Sprache der Klassischen Mayakultur, deren Überreste in den
heutigen Staaten Mexiko, Guatemala, Belize und Honduras zu finden sind. Ziele des Projekts
sind die Erschließung des hieroglyphischen Ausgangsmaterials in einem digitalen Textkorpus
und die Erstellung eines Wörterbuchs des Klassischen Maya, das als Datenbank und in
gedruckter Form den gesamten Sprachschatz und dessen Verwendung in der Schrift abbildet.
Dies ist ein dringendes Desiderat, denn die Schrift und die zugrunde liegende Sprache sind
noch nicht vollständige entschlüsselt. Dabei werden Methoden und Werkzeuge aus dem
Bereich der Digital Humanities genutzt und weiterentwickelt, wie sie im Virtual Research
Environment von TextGrid zur Verfügung gestellt werden, um ein linguistisch annotiertes
Sprach- und Schriftkorpus mitsamt Metadaten zur Kultur- und Objektgeschichte und
Forschungsreferenzen zu erstellen und open access auf zwei Plattformen zur Verfügung zu
stellen.
In unserem Workshopbeitrag wollen wir nicht nur Einblicke in unsere Arbeit mit den
Hieroglyphentexten der Klassischen Maya geben, sondern auch die im Aufbau befindliche
virtuelle Forschungsumgebung für die epigraphische Arbeit vorstellen und die geplante
Publikation der Texte mitsamt ihrer Analysen in digitaler Form vorstellen. Abschließend
möchten wir auch rechtliche Fragen bei der Nutzung von urheberrechtlich geschützten
Werken in solchen virtuellen Plattformen ansprechen und unsere Strategien dazu vorstellen.
Weitere Informationen unter:
www.mayawoerterbuch.de
https://textgrid.de/

Semantische Wörterbuchstrukturen: Ein Erfahrungsbericht am Beispiel des
Bayerischen Wörterbuchs
Ursula Welsch (BAdW, IT: Digital Humanities)
Die semantische Erschließung von Quelleneditionen, digitalen Wörterbüchern und Katalogen
und Verzeichnissen beginnt mit der semantischen Auszeichnung der digitalen Bestände. Je
genauer und klarer die Bedeutung einer jeden Informationseinheit resp. Struktureinheit direkt
benannt wird, umso granularer und eindeutiger ist die so ausgezeichnete Datenbasis auf das
Generieren semantischer Verschlagwortung und die Umsetzung in Facettierungen bei der
Suche vorbereitet.
Gerade Wörterbücher mit ihrer potenziell hochkomplexen inhaltlichen Struktur bieten sich für
die semantische Strukturierung an. Zudem lässt sich auf diesem Weg die bisweilen recht
arbeitsaufwendige lexikografische Aufbereitung (z. B. Interpunktion, Abkürzung des
Lemmas, sonstige Abkürzungen) deutlich vereinfachen.
Der Vortrag beschreibt das Vorgehen bei der Strukturerstellung und berichtet von den
Erfahrungen bei der Retrodigitalisierung und bei der Neuerfassung weiterer Artikel beim
Bayerischen Wörterbuch. Dabei wird auch auf die Arbeitsumgebung eingegangen.
Weitere Informationen unter:
http://www.bwb.badw.de/
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Welsch_SemantWBstrukturen_Folien.pdf

V. Sektion „Semantische Aspekte digitaler Editionen“
Editio Critica Maior Aperta: Zu einer offenen digitalen Edition des Neuen Testaments
Klaus Wachtel (Institut für neutestamentliche Textforschung, Münster)
In dem Beitrag werden am Beispiel des New Testament Virtual Manuscripts Room (NTVMR)
das Konzept einer offenen digitalen Edition des Neuen Testaments und Ansätze zu ihrer
Realisierung dargestellt. Eine offene digitale Edition ist die ultimative Weiterentwicklung des
Publikationsformats, das im Kontext des Buchdrucks als kritische Edition bekannt ist. Anders
als ein Druckwerk beschränkt sich eine offene digitale Edition nicht auf einen fixierten
Basistext und eine Liste der Überlieferungsvarianten, die mit der Herstellung der
Druckvorlage geschlossen wird. Aus dem herkömmlichen kritischen Apparat wird ein Portal,
das den Weg zu den Quellen eröffnet. Rezipienten sind zugleich Mitherausgeber, denn sie
werden ermutigt, neue Materialien hinzuzufügen, vorhandene Dokumente zu annotieren und
zu verbessern, nach den eigenen Bedürfnissen neu anzuordnen und eigene Forschungsprojekte
an die offene Edition anzuschließen.
Weitere Informationen unter:
http://ntvmr.uni-muenster.de/
http://egora.uni-muenster.de/intf/aecm/aecm.shtml
Die Präsentation als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Wachtel_NT.pdf

Stand der Überlegungen für eine Digitale Edition der Uwe Johnson‐Werkausgabe
Fabian Kaßner, André Kischel (BBAW, Uwe Johnson-Werkausgabe; Universität Rostock)
Die Uwe Johnson‐Werkausgabe ist ein Vorhaben der Berlin‐Brandenburgischen Akademie der
Wissenschaften an der Universität Rostock. Erstmals wird mit Uwe Johnson ein Schriftsteller
des 20. Jahrhunderts in einem Akademienvorhaben ediert. Es handelt sich um eine auf
Vollständigkeit angelegte, historisch-kritische Edition in drei Abteilungen: Werke, Schriften
und Briefe. Die Ausgabe wird sowohl in gedruckter wie auch digitaler Form erscheinen.
Dabei bieten die 40 geplanten Bände der Buchedition philologisch gesicherte Texte,
angereichert um eine allgemeine Einführung in den jeweiligen Band, sinnstiftende
Kommentare, Korrekturen und Varianten in sprechender Auswahl sowie Erläuterungen zur
Entstehungs- und Überlieferungsgeschichte, exemplarisch dokumentiert an ausgewählte
Abbildungen, orientierende Register und Verzeichnisse schließen jeden Band ab.
Bindeglied zwischen Gedrucktem und Digitalem ist dabei eine seiten- und zeilenidentische
Darstellungsoption, die sich bei Bedarf um die vorhandenen Textvorstufen, Varianten und
weiterführende Erläuterungen ergänzen lässt. Wesentliche materielle Grundlage der Ausgabe
ist das Uwe Johnson-Archiv, das für die Werkausgabe in einem ersten Schritt vollständig
digitalisiert wird. Diese Digitalisate bilden, angereichert mit deskriptiven Metadaten, ein
zentrales Element der digitalen Edition.
Sämtliche Texte werden transkribiert und gemäß den TEI (P5)-Guidelines mit einem XML-
Markup versehen. Diese Auszeichnung dokumentiert einerseits die Textgenese und enthält
andererseits alle kommentierenden Bemerkungen der Herausgeber, sowie schließlich auch
Anknüpfungspunkte für Verbindungen über den einzelnen Text hinaus. Um eine doppelte
Datenhaltung zu vermeiden, wird das Markup so gestaltet, dass daraus – nach dem Prinzip: 1
Text = 1 Datei = X Darstellungen – sowohl die gedruckte wie auch die digitale Edition mittels
XSL-Transformation realisiert werden können. Die für den Druck vorgesehenen Annotationen
werden mit einem speziellen Set von Tags versehen, alle anderen Anmerkungen können so
von den Druckdaten unterschieden werden. Im Digitalen stehen dann die Druck- wie auch alle
weiteren, darüber hinausgehenden Informationen zur Verfügung. Je nach Interessenlage und
Fragestellung des Nutzers lassen sich diese Daten ein- oder ausblenden. Neben der
Vermeidung redundanter Datenhaltung spielen hier weitere Gründe hinein. Zum einen sollen
im Druck ›lesbare‹ Bücher entstehen, die ein Laien- wie auch ein Fachpublikum ansprechen.
Erreicht wird dies durch die Bereitstellung der gesicherten Textbasis sowie die sinnstiftende
Kommentarauswahl. Zum anderen erscheint – auch das eine Premiere für ein
Akademienvorhaben – die Buchedition in einem Publikumsverlag, dem Suhrkamp Verlag.
Dieser hält sämtliche Rechte an den Texten Uwe Johnsons und stellt sie für die Werkausgabe
zur Verfügung.
Bei einer Buchedition ist man an eine ›traditionelle‹ Gliederung eines Œuvres in Abteilungen
und Bände gebunden, allein schon zur Orientierung des Lesers wie auch zur Sortierung
unterschiedlicher Textsorten. Eine solche Ordnung ist aber stets von außen herangetragen und
wird häufig dem Schaffen eines Schriftstellerlebens nur bedingt gerecht. Besonders im Falle
Uwe Johnsons zeigen sich dabei Grenzen. Denn Johnsons Arbeitsweise greift über alle
philologischen Grenzziehungen hinweg: In Briefen werden Prosaversuche unternommen, in

seinen Reden und Schriften kommen Figuren seiner Romane zu Wort, öffentliche
Diskussionen werden Material für poetologische Erörterungen. Diesem Arbeiten wird die
digitale Edition gerecht, indem sie die strengen, von Buchdeckeln gezogenen Schranken
durchlässig werden lässt. So kann die historisch-kritische Kommentierung etwa die
Textgenese, unter Einbeziehung der Archiv-Digitalisate, in einem viel höheren Grad sichtbar
werden lassen, als das durch bloße kommentierende Erörterungen möglich ist. An diesem
Punkt kann dann auch eine semantische Auszeichnung ansetzen, und textinterne wie -externe
Beziehung funktional beschreiben. Das erlaubt schließlich, den von Johnson ausgelegten
Spuren über alle Textgrenzen hinweg zu folgen, etwa in Form graphischer Darstellungen von
Relationen, personellen wie thematischen Verbindungen oder auch historischen und
geographischen Gegebenheiten, seien sie nun im Text besprochen oder Begleitumstände
seiner Entstehung.
Weitere Informationen unter:
http://www.bbaw.de/forschung/johnson/projektdarstellung
http://www.germanistik.uni-rostock.de/forschung/uwe-johnson/werkausgabe/

Digitale Karl Jaspers-Gesamtausgabe
Oliver Immel (AdW-Goe, Jaspers-Edition; Universität Oldenburg)
Kontakt und weitere Informationen:
https://adw-goe.de/forschung/forschungsprojekte-akademienprogramm/jaspers-edition/
http://www.haw.uni-heidelberg.de/forschung/forschungsstellen/jaspers.de.html

Digitale Edition der Werke Grimmelshausens
Jörg Riecke (Germanistisches Seminar, Universität Heidelberg)
Vorgestellt wird die Heidelberger digitale Ausgabe der Schriften Grimmelshausens, die –
gefördert von der Thyssen-Stiftung – in Zusammenarbeit mit der Herzog August Bibliothek in
Wolfenbüttel erarbeitet wurde und kurz vor dem Abschluss steht. Die Bedeutung dieser
Ausgabe soll zunächst vor dem Hintergrund der Editionsgeschichte der Werke
Grimmelshausens erläutert werden, bevor in einem zweiten Teil Möglichkeiten der
semantischen und lexikographischen Erschließung der Ausgabe und deren Wert für die
Grimmelshausen-Philologie und die Sprachgeschichtsforschung insgesamt umrissen werden
können. Das Grimmelshausensche Textcorpus, das in der zweiten Hälfte des 17. Jahrhunderts
entstanden und daher nicht mehr Gegenstand des Sprachstadiums Frühneuhochdeutschen ist,
erweist sich als idealer Baustein für eine exemplarische Schließung der lexikographischen
Lücke zwischen dem Frühneuhochdeutschen Wörterbuch einerseits und – für die frühe
moderne Periode – z.B. des Goethe-Wörterbuchs andererseits. Eine mögliche Erweiterung der
für die digitale Edition verwendeten Erstausgaben um die späteren, stark veränderten
Nachdrucke würde zudem stärker als bisher die Dynamik des Sprachwandels im
17. Jahrhundert zum Ausdruck bringen.
Weitere Informationen unter:
http://www.gs.uni-heidelberg.de/personen/riecke_baer_grmhs.html
Referat als PDF:
http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/Praesentation
_Workshop_EP/Riecke_GrimmelshausenAkademie.pdf





























