Embed Size (px)
Citation preview

Kapitel 6Relationale Entwurfstheorie
Funktionale AbhängigkeitenNormalformenNormalisierung durch Dekomposition

Ziele der relationalen EntwurfstheorieBewertung der Qualität eines Relationenschemas
RedundanzEinhaltung von Konsistenzbedingungen
Funktionale AbhängigkeitenNormalformen als GütekriteriumGgfls. Verbesserung eines Relationenschemas
Durch den SynthesealgorithmusDurch Dekomposition

Funktionale AbhängigkeitenSchema
R = {A, B, C, D}Ausprägung R
Seien R, Rgenau dann wenn r, s R mit r. = s. r. = s.
RA B C Da4 b2 c4 d3
a1 b1 c1 d1
a1 b1 c1 d2
a2 b2 c3 d2
a3 b2 c4 d3
{A} {B}
{C, D } {B}
Nicht: {B} {C}
Notationskonvention:
CD B
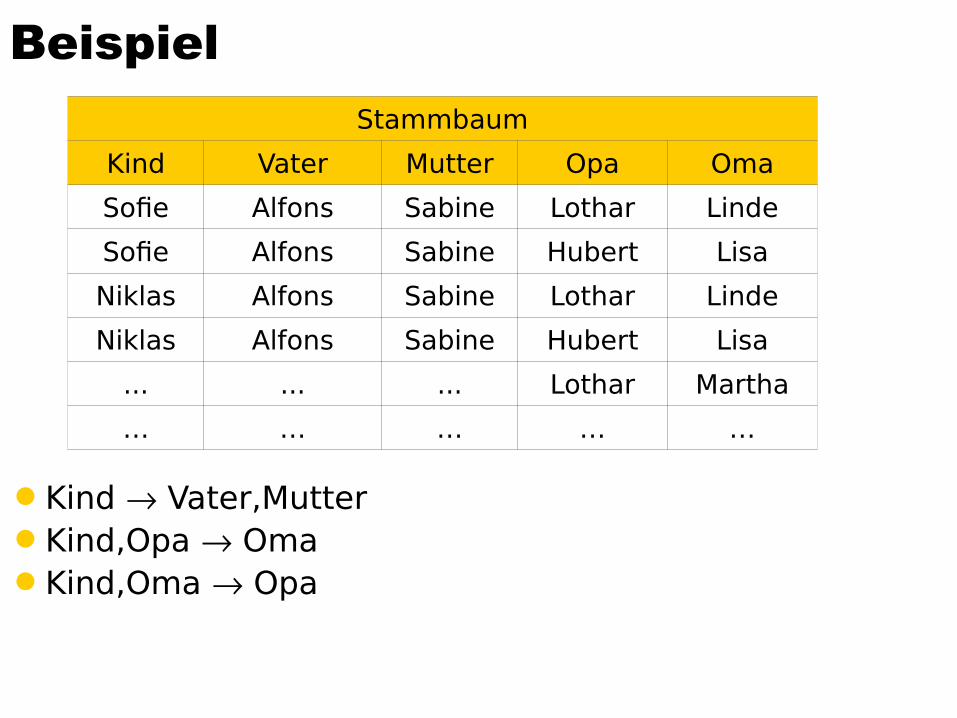
Beispiel
Kind Vater,MutterKind,Opa OmaKind,Oma Opa
Stammbaum
Kind Vater Mutter Opa Oma
Sofie Alfons Sabine Lothar Linde
Sofie Alfons Sabine Hubert Lisa
Niklas Alfons Sabine Lothar Linde
Niklas Alfons Sabine Hubert Lisa
... ... ... Lothar Martha
… … … … …

SchlüsselR ist ein Super-Schlüssel, falls folgendes gilt:
Rist voll funktional abhängig vongenau dann wenn gilt
und kann nicht mehr verkleinert werden, d.h.
A folgt, dass (nicht gilt, oder kürzerA (
Notation für volle funktionale Abhängigkeit: R ist ein Kandidaten-Schlüssel, falls folgendes gilt:
R Ist R Kandidaten-Schlüssel, so nennt man alle A
Schlüsselattribute. Nicht-Schlüsselattribute heißen alle Attribute, die in keinem Kandidaten-Schlüssel vorkommen.
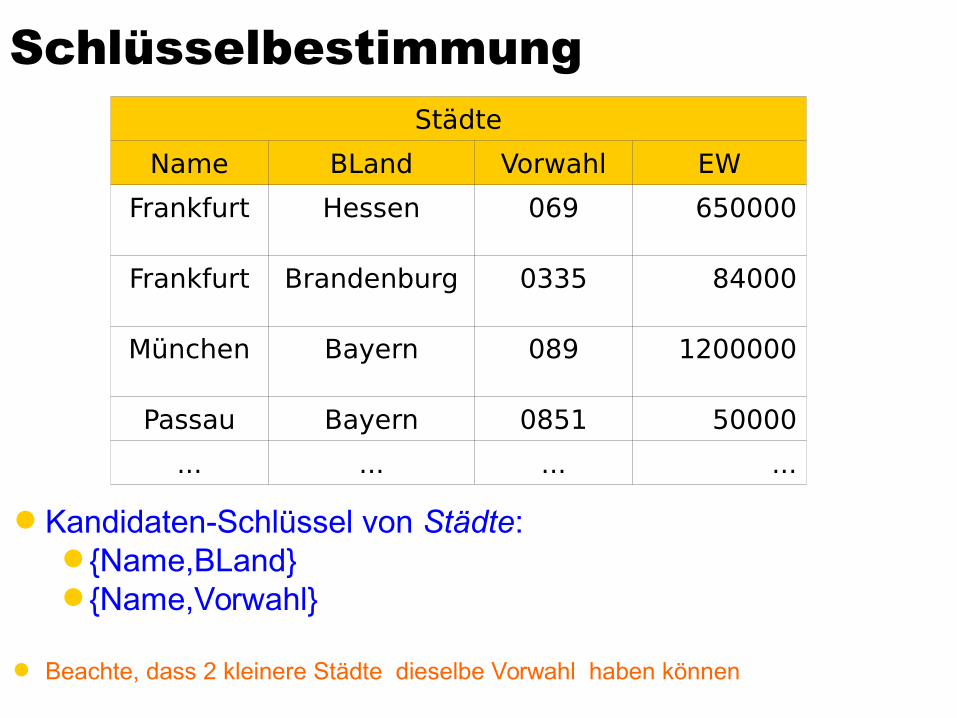
Schlüsselbestimmung
Kandidaten-Schlüssel von Städte:{Name,BLand}{Name,Vorwahl}
Beachte, dass 2 kleinere Städte dieselbe Vorwahl haben können
Städte
Name BLand Vorwahl EW
Frankfurt Hessen 069 650000
Frankfurt Brandenburg 0335 84000
München Bayern 089 1200000
Passau Bayern 0851 50000
... ... ... ...

Bestimmung funktionaler AbhängigkeitenProfessoren: {[PersNr, Name, Rang, Raum, Ort, Straße,
PLZ, Vorwahl, Bland, EW, Landesregierung]}– {PersNr} {PersNr, Name, Rang, Raum, Ort,
Straße, PLZ, Vorwahl, Bland, EW, Landesregierung}
– {Ort,BLand} {EW, Vorwahl}– {PLZ} {Bland, Ort, EW}– {Bland, Ort, Straße} {PLZ}– {Bland} {Landesregierung}– {Raum} {PersNr}
Zusätzliche Abhängigkeiten, die aus obigen abgeleitet werden können:
– {Raum} {PersNr, Name, Rang, Raum, Ort, Straße, PLZ, Vorwahl, Bland, EW, Landesregierung}
– {PLZ} {Landesregierung}
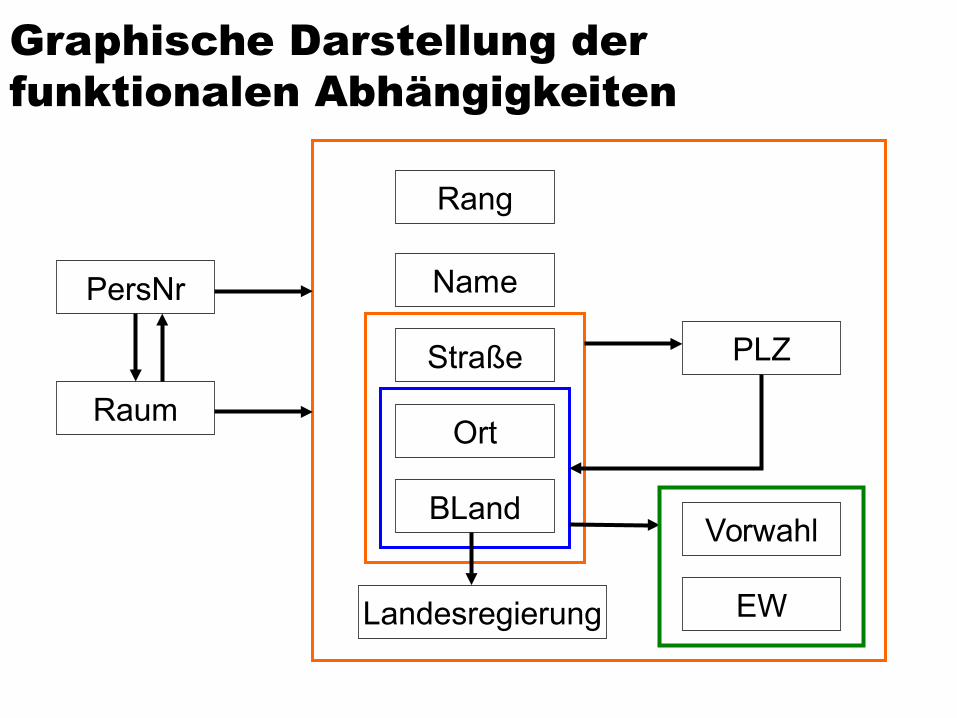
Graphische Darstellung der funktionalen Abhängigkeiten
Landesregierung
Rang
Name
Straße
Ort
BLand
PersNr
Raum
Vorwahl
PLZ
EW
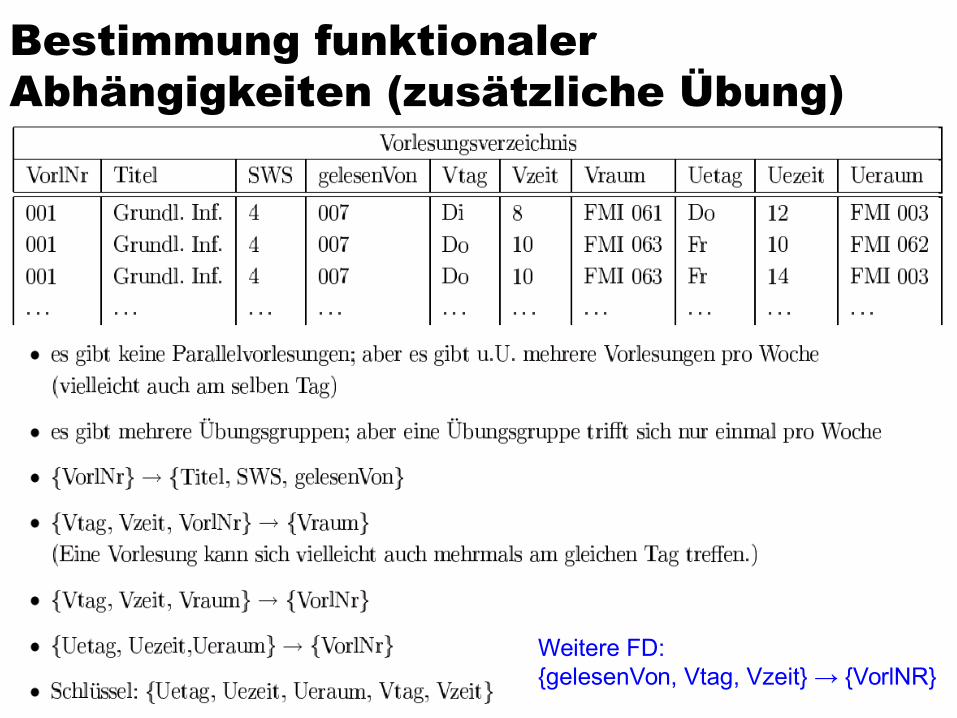
Bestimmung funktionaler Abhängigkeiten (zusätzliche Übung)
Weitere FD:{gelesenVon, Vtag, Vzeit} → {VorlNR}

Herleitung funktionaler Abhängigkeiten:Armstrong-Axiome Reflexivität
Falls eine Teilmenge von ist ( ) dann gilt immer . Insbesondere gilt immer .
VerstärkungFalls gilt, dann gilt auch Hierbei stehe z.B. für
Transitivität
Falls und gilt, dann gilt auch .
Diese drei Axiome sind vollständig und korrekt. Zusätzliche Axiome erleichtern die Herleitung:Vereinigungsregel:
Wenn und gelten, dann gilt auch Dekompositionsregel:
Wenn gilt, dann gelten auch und Pseudotransitivitätsregel:
Wenn und , dann gilt auch

10-11Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Beispiele zu InferenzregelnReflexivität: Name Semester → Name
Augmentation: Persnr →Raum => Persnr Ort → Raum Ort
Transitivität: Vorlnr → Persnr, Persnr → Raum => Vorlnr → Raum
Dekomposition: Matrnr → Name Semester => Matrnr → Name, Matrnr → Semester
Vereinigung: Matrnr → Name, Matrnr → Semester => Matrnr → Name Semester
Pseudotransitivität: EAN → Artikel, Artikel Menge → Preis => EAN Menge → Preis

Bestimmung der Hülle einer AttributmengeEingabe: eine Menge F von FDs und eine Menge von
Attributen Ausgabe: die vollständige Menge von Attributen +, für
die gilt +.
AttrHülle(F,)Erg := While (Änderungen an Erg) do
Foreach FD in F doIf Erg then Erg := Erg
Ausgabe + = Erg

Beispiel zur Hülle einer Attributmenge
{PLZ} {Bland, Ort}{Ort,BLand} {EW, Vorwahl}{Bland, Ort, Straße} {PLZ}{Bland} {Landesregierung}
● PLZ● PLZ Bland Ort● PLZ Bland Ort EW Vorwahl● PLZ Bland Ort EW Vorwahl Landesregierung

Kanonische Überdeckung(minimale Menge von FDs)
Fc heißt kanonische Überdeckung von F, wenn die folgenden drei Kriterien erfüllt sind:1. Fc F, d.h. Fc+ = F+2. In Fc existieren keine FDs , die überflüssige
Attribute enthalten. D.h. es muss folgendes gelten: A Fc - ((( Fc B Fc - (( Fc
3. Jede linke Seite einer funktionalen Abhängigkeit in Fc ist einzigartig. Dies kann durch sukzessive Anwendung der Vereinigungsregel auf FDs der Art und erzielt werden, so dass die beiden FDs durch ersetzt werden.

Berechnung der kanonischen ÜberdeckungErsetze alle X→{A1,A2,...,An} durch X→A1, X→A2, ..., X→An
Führe für jede FD F die Linksreduktion durch, also:
Überprüfe für alle A , ob A überflüssig ist, d.h., ob AttrHülle(F, - A) gilt. Falls dies der Fall ist, ersetze durch (- A).
Für jede FD F:– Wenn (F-{}) äquivalent zu F:
entferne aus FFasse mittels der Vereinigungsregel FDs der Form n zusammen, so dass ( ... n) verbleibt.

10-16Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
Algorithmus nach Elmasri / Navathe mit Zusatz!
AB→CDE
B→E
CD→F

10-17Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→CDE
B→E
CD→F
Jetzt: rechte Seite aufteilen

10-18Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
AB→E
B→E
CD→F
Nun: Linke Seiten vereinfachen

10-19Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
AB→E
B→E
CD→F
AB→C
AB→D
AB→E
B→E
CD→F

10-20Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
AB→E
B→E
CD→F
AB→C
AB→D
AB→E
B→E
CD→F

10-21Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
AB→E
B→E
CD→F
AB→C
AB→D
AB→E
B→E
CD→F

10-22Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
AB→E
B→E
CD→F
AB→C
AB→D
AB→E
B→E
CD→F

10-23Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
AB→E
B→E
CD→F
AB→C
AB→D
AB→E
B→E
CD→F

10-24Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
B→E
B→E
CD→F
AB→C
AB→D
B→E
B→E
CD→F

10-25Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
B→E
B→E
CD→F
AB→C
AB→D
B→E
B→E
CD→F

10-26Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
B→E
B→E
CD→F
Jetzt überflüssige Regeln streichen

10-27Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→C
AB→D
B→E
CD→F
Zum Schluss: Regeln mit gleichen linken Seiten zusammenfassen

10-28Copyright © 2004 Ramez Elmasri and Shamkant Navathe
Elmasri/Navathe, Fundamentals of Database Systems, Fourth Edition
Minimale Mengen von FDs (3)
AB→CD
B→E
CD→F
Fertig!
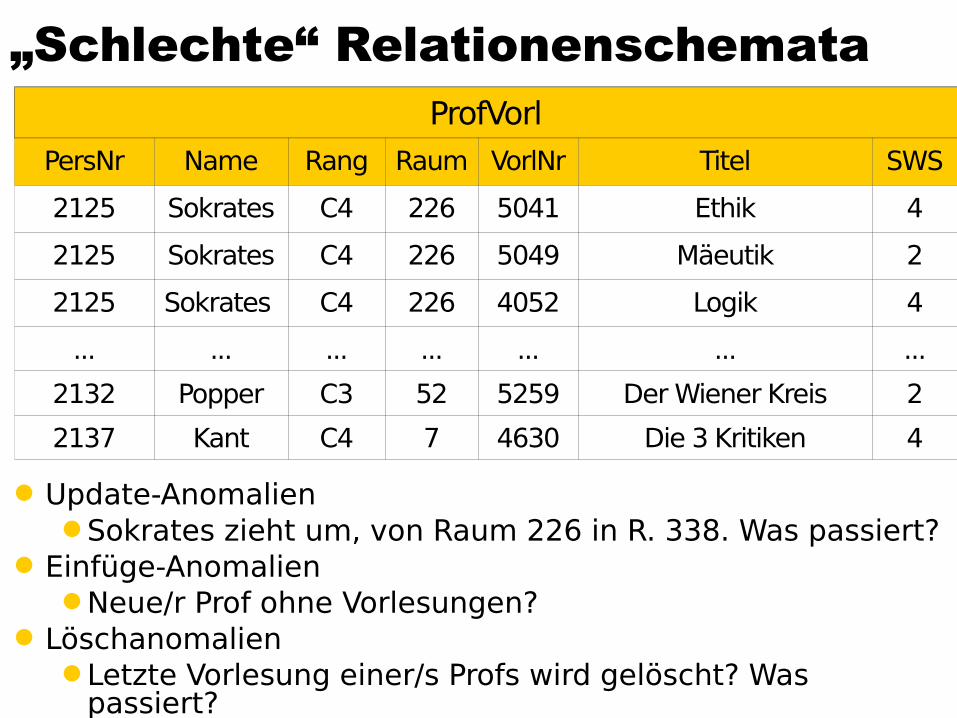
„Schlechte“ Relationenschemata
Update-AnomalienSokrates zieht um, von Raum 226 in R. 338. Was passiert?
Einfüge-AnomalienNeue/r Prof ohne Vorlesungen?
LöschanomalienLetzte Vorlesung einer/s Profs wird gelöscht? Was
passiert?
ProfVorlPersNr Name Rang Raum VorlNr Titel SWS
2125 Sokrates C4 226 5041 Ethik 4
2125 Sokrates C4 226 5049 Mäeutik 2
2125 Sokrates C4 226 4052 Logik 4
... ... ... ... ... ... ...
2132 Popper C3 52 5259 Der Wiener Kreis 2
2137 Kant C4 7 4630 Die 3 Kritiken 4

Zerlegung (Dekomposition) von Relationen Es gibt zwei Korrektheitskriterien für die Zerlegung von
Relationenschemata:
1. Verlustlosigkeit Die in der ursprünglichen Relationenausprägung R des
Schemas R enthaltenen Informationen müssen aus den Ausprägungen R1, ..., Rn der neuen Relationenschemata R1, .., Rn rekonstruierbar sein.
2.Abhängigkeitserhaltung●Die für R geltenden funktionalen Anhängigkeiten müssen auf
die Schemata R1, ..., Rn übertragbar sein.
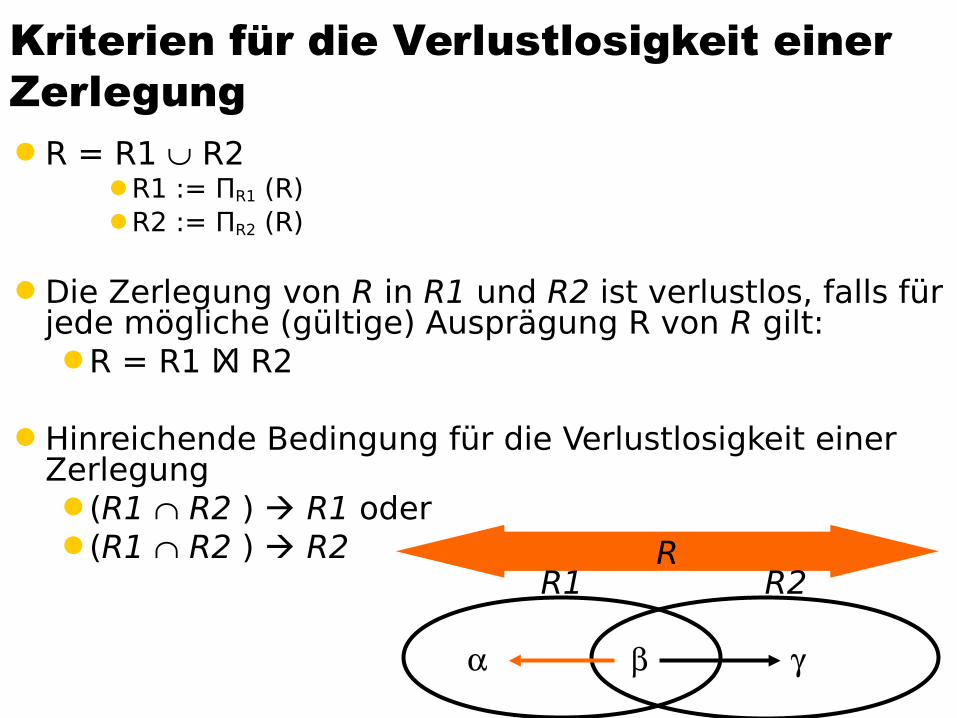
Kriterien für die Verlustlosigkeit einer ZerlegungR = R1 R2
R1 := ΠR1 (R)R2 := ΠR2 (R)
Die Zerlegung von R in R1 und R2 ist verlustlos, falls für jede mögliche (gültige) Ausprägung R von R gilt:R = R1 lXl R2
Hinreichende Bedingung für die Verlustlosigkeit einer Zerlegung(R1 R2 ) R1 oder(R1 R2 ) R2 R
R1
R2
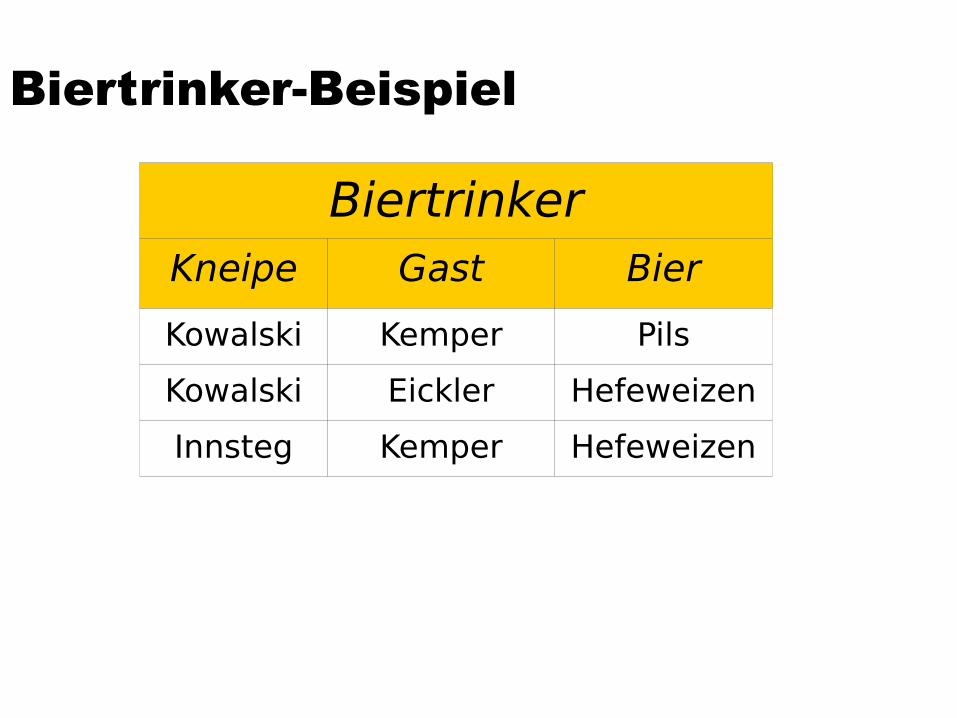
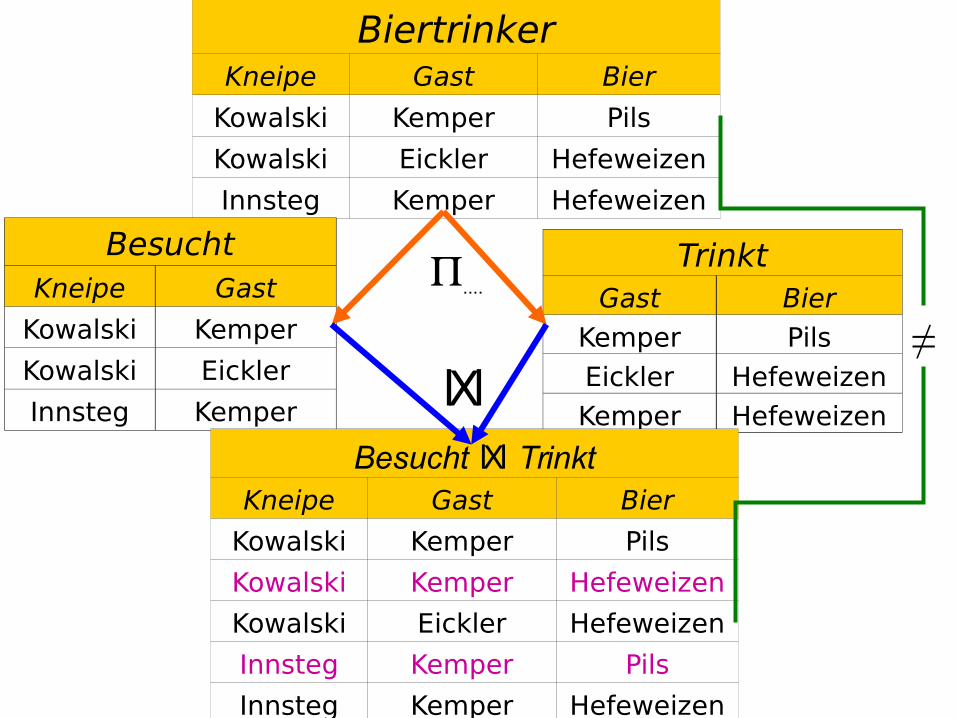
Biertrinker-Beispiel
BiertrinkerKneipe Gast Bier
Kowalski Kemper Pils
Kowalski Eickler Hefeweizen
Innsteg Kemper Hefeweizen
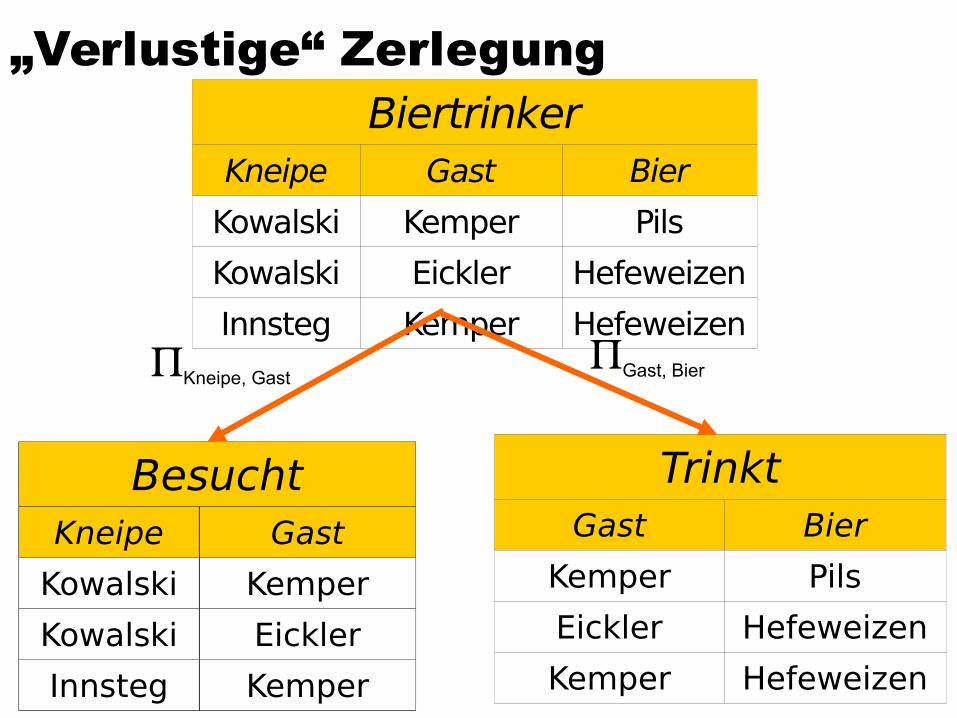
„Verlustige“ ZerlegungBiertrinker
Kneipe Gast Bier
Kowalski Kemper Pils
Kowalski Eickler Hefeweizen
Innsteg Kemper Hefeweizen
BesuchtKneipe Gast
Kowalski Kemper
Kowalski Eickler
Innsteg Kemper
TrinktGast Bier
Kemper Pils
Eickler Hefeweizen
Kemper Hefeweizen
Gast, BierKneipe, Gast
BiertrinkerKneipe Gast Bier
Kowalski Kemper Pils
Kowalski Eickler Hefeweizen
Innsteg Kemper Hefeweizen
BesuchtKneipe Gast
Kowalski Kemper
Kowalski Eickler
Innsteg Kemper
TrinktGast Bier
Kemper Pils
Eickler Hefeweizen
Kemper Hefeweizen
....
Besucht lXl TrinktKneipe Gast Bier
Kowalski Kemper Pils
Kowalski Kemper Hefeweizen
Kowalski Eickler Hefeweizen
Innsteg Kemper Pils
Innsteg Kemper Hefeweizen
lXl≠

Erläuterung des Biertrinker-BeispielsUnser Biertrinker-Beispiel war eine „verlustige“
Zerlegung und dementsprechend war die hinreichende Bedingung verletzt. Es gilt nämlich nur die eine nicht-triviale funktionale Abhängigkeit{Kneipe,Gast}{Bier}
Wohingegen keine der zwei möglichen, die Verlustlosigkeit garantierenden FDs gelten{Gast}{Bier}{Gast}{Kneipe}
Das liegt daran, dass die Leute (insbes. Kemper) in unterschiedlichen Kneipen unterschiedliches Bier trinken. In derselben Kneipe aber immer das gleiche Bier
(damit sich die KellnerInnen darauf einstellen können?)
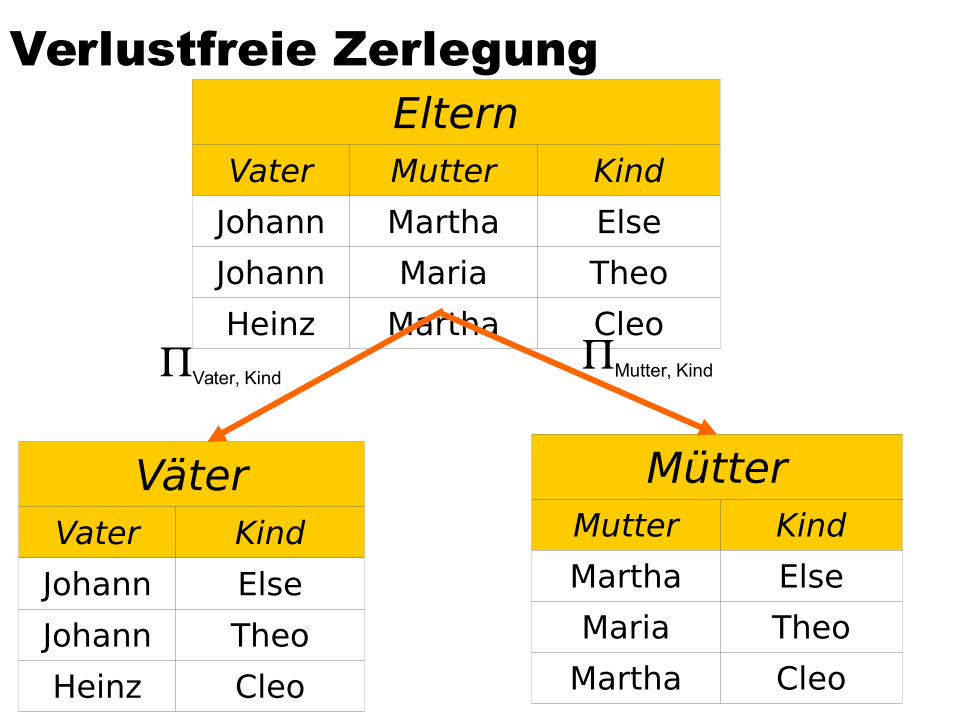
Verlustfreie ZerlegungEltern
Vater Mutter Kind
Johann Martha Else
Johann Maria Theo
Heinz Martha Cleo
VäterVater Kind
Johann Else
Johann Theo
Heinz Cleo
MütterMutter Kind
Martha Else
Maria Theo
Martha Cleo
Mutter, KindVater, Kind

Erläuterung der verlustfreien Zerlegung der Eltern-RelationEltern: {[Vater, Mutter, Kind]}Väter: {[Vater, Kind]}Mütter: {[Mutter, Kind]}
Verlustlosigkeit ist garantiertEs gilt nicht nur eine der hinreichenden FDs, sondern
gleich beide{Kind}{Mutter}{Kind}{Vater}
Also ist {Kind} natürlich auch der Schlüssel der Relation Eltern
Die Zerlegung von Eltern ist zwar verlustlos, aber auch ziemlich unnötig, da die Relation in sehr gutem Zustand (~Normalform) ist

AbhängigkeitsbewahrungR ist zerlegt in R1, ..., Rn FR = (FR1 ... FRn) bzw FR+ = (FR1 ... FRn)+Beispiel für Abhängigkeitsverlust
PLZverzeichnis: {[Straße, Ort, Bland, PLZ]}Annahmen
Orte werden durch ihren Namen (Ort) und das Bundesland (Bland) eindeutig identifiziert
Innerhalb einer Straße ändert sich die Postleitzahl nicht
Postleitzahlengebiete gehen nicht über Ortsgrenzen und Orte nicht über Bundeslandgrenzen hinweg
Daraus resultieren die FDs{PLZ} {Ort, BLand}{Straße, Ort, BLand} {PLZ}
Betrachte die ZerlegungStraßen: {[PLZ, Straße]}Orte: {[PLZ, Ort, BLand]}
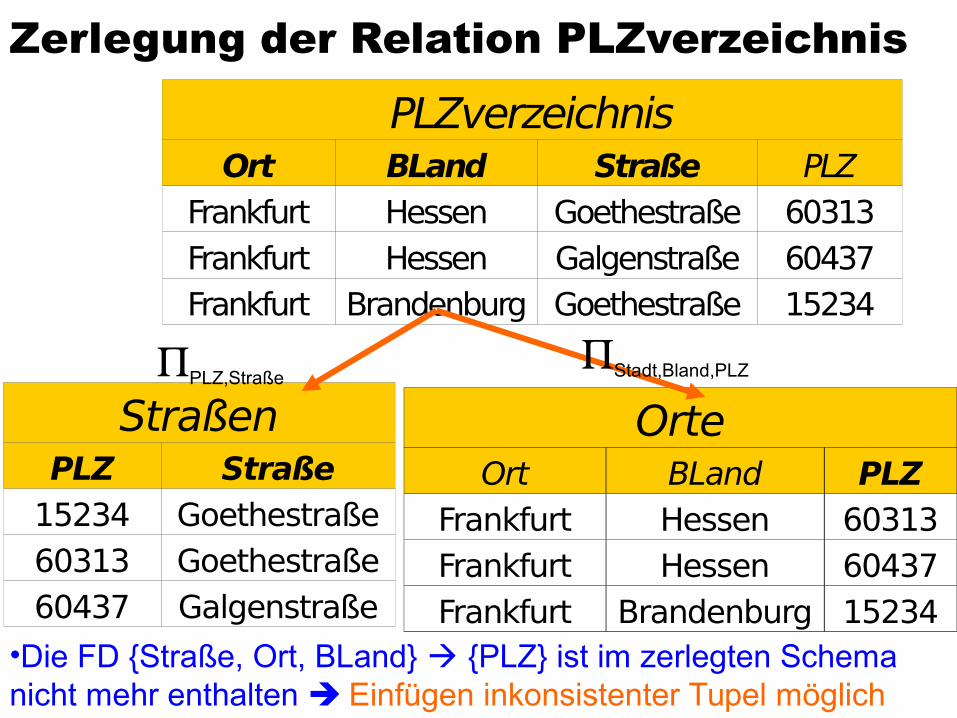
Zerlegung der Relation PLZverzeichnis
PLZverzeichnisOrt BLand Straße PLZ
Frankfurt Hessen Goethestraße 60313Frankfurt Hessen Galgenstraße 60437Frankfurt Brandenburg Goethestraße 15234
StraßenPLZ Straße
15234 Goethestraße60313 Goethestraße60437 Galgenstraße
OrteOrt BLand PLZ
Frankfurt Hessen 60313Frankfurt Hessen 60437Frankfurt Brandenburg 15234
Stadt,Bland,PLZPLZ,Straße
•Die FD {Straße, Ort, BLand} {PLZ} ist im zerlegten Schema nicht mehr enthalten Einfügen inkonsistenter Tupel möglich
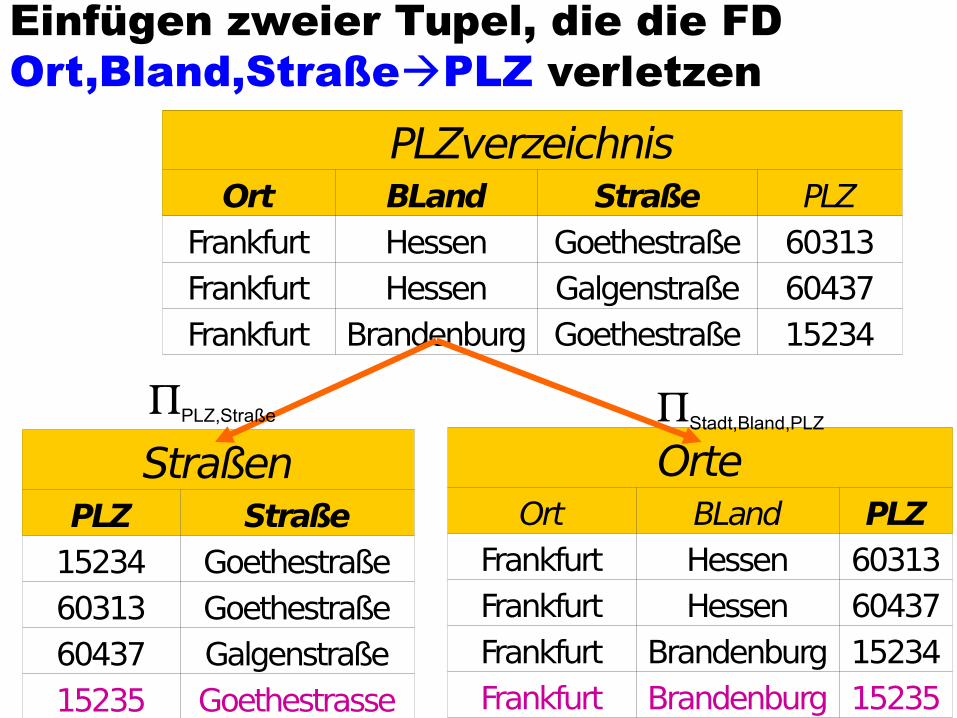
Einfügen zweier Tupel, die die FD Ort,Bland,StraßePLZ verletzen
PLZverzeichnisOrt BLand Straße PLZ
Frankfurt Hessen Goethestraße 60313Frankfurt Hessen Galgenstraße 60437Frankfurt Brandenburg Goethestraße 15234
StraßenPLZ Straße
15234 Goethestraße60313 Goethestraße60437 Galgenstraße15235 Goethestrasse
OrteOrt BLand PLZ
Frankfurt Hessen 60313Frankfurt Hessen 60437Frankfurt Brandenburg 15234Frankfurt Brandenburg 15235
Stadt,Bland,PLZPLZ,Straße
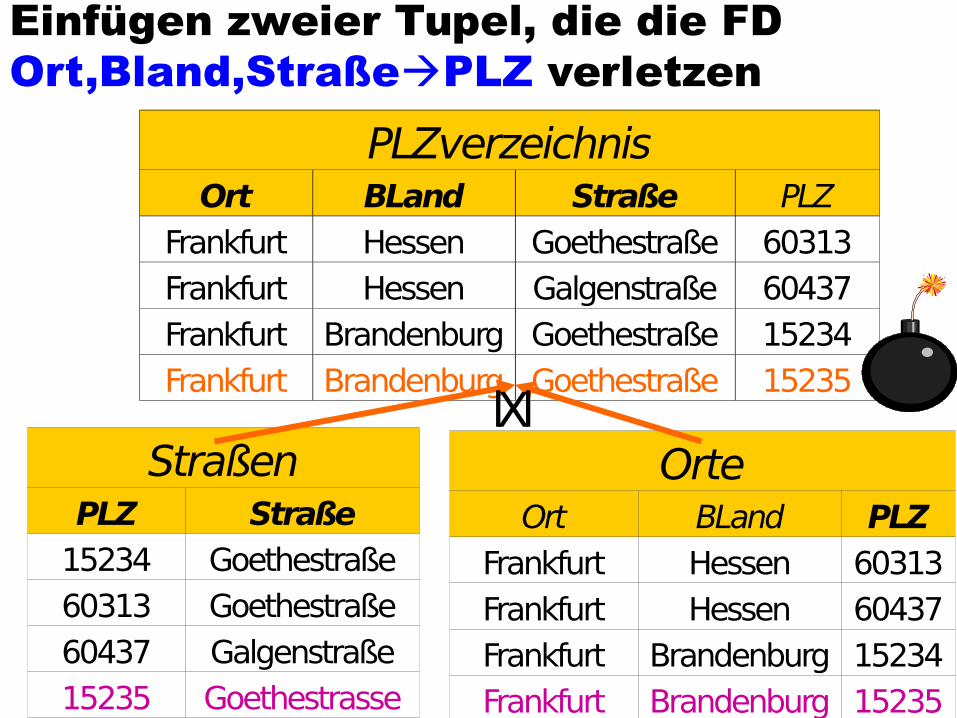
Einfügen zweier Tupel, die die FD Ort,Bland,StraßePLZ verletzen
PLZverzeichnisOrt BLand Straße PLZ
Frankfurt Hessen Goethestraße 60313Frankfurt Hessen Galgenstraße 60437Frankfurt Brandenburg Goethestraße 15234Frankfurt Brandenburg Goethestraße 15235
StraßenPLZ Straße
15234 Goethestraße60313 Goethestraße60437 Galgenstraße15235 Goethestrasse
OrteOrt BLand PLZ
Frankfurt Hessen 60313Frankfurt Hessen 60437Frankfurt Brandenburg 15234Frankfurt Brandenburg 15235
lXl
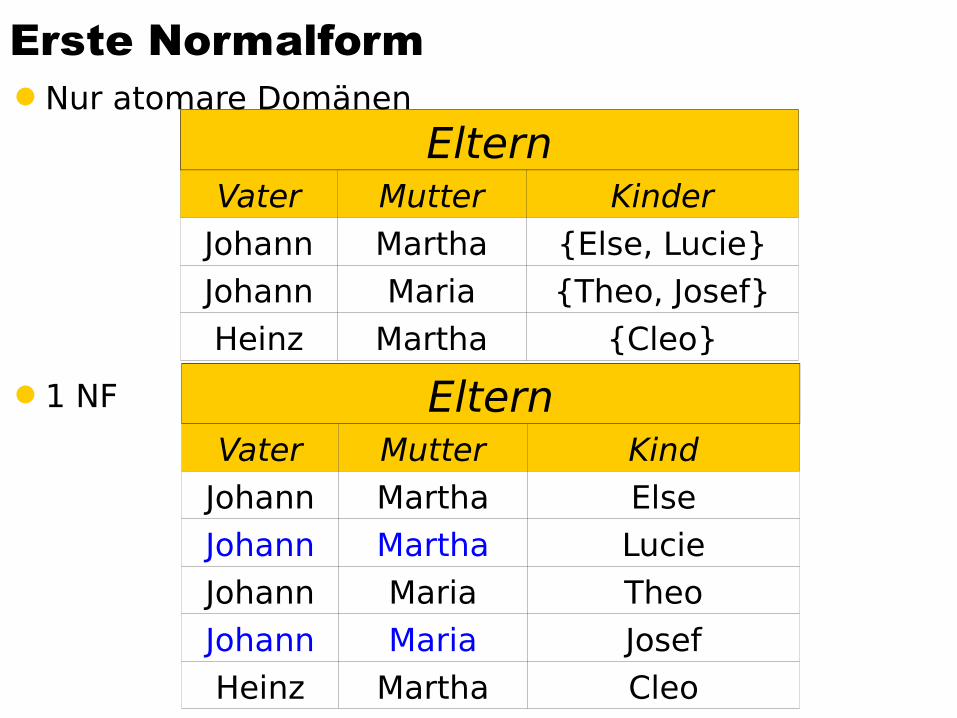
Erste NormalformNur atomare Domänen
1 NF
ElternVater Mutter Kinder
Johann Martha {Else, Lucie}
Johann Maria {Theo, Josef}
Heinz Martha {Cleo}
ElternVater Mutter Kind
Johann Martha Else
Johann Martha Lucie
Johann Maria Theo
Johann Maria Josef
Heinz Martha Cleo
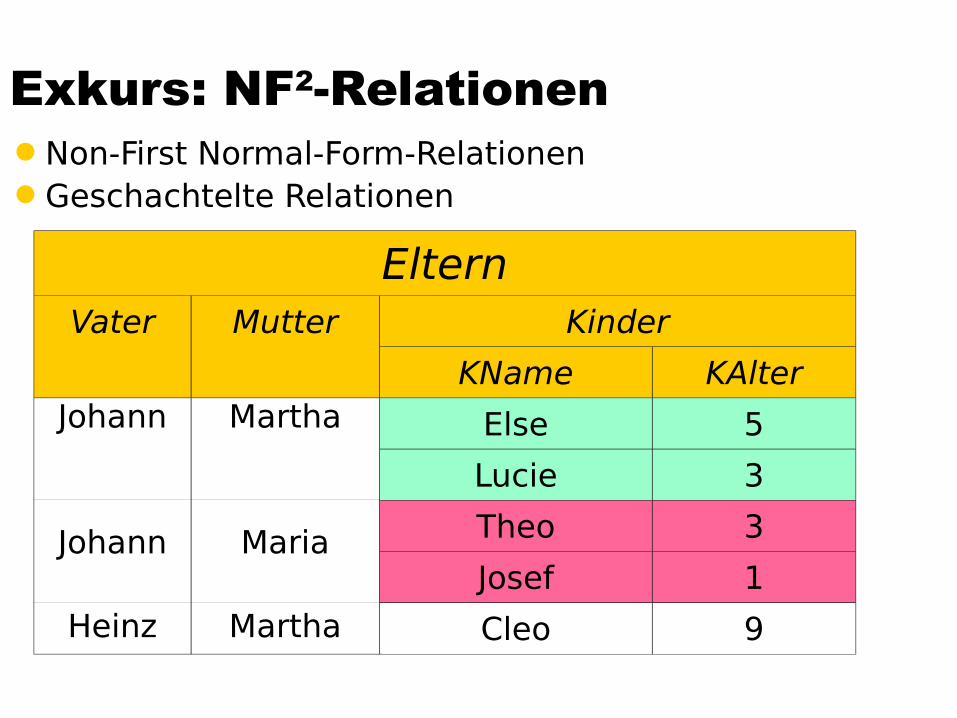
Exkurs: NF2-RelationenNon-First Normal-Form-RelationenGeschachtelte Relationen
ElternVater Mutter Kinder
KName KAlterJohann
Johann
Heinz
Martha
Maria
Martha
Else 5
Lucie 3
Theo 3
Josef 1
Cleo 9
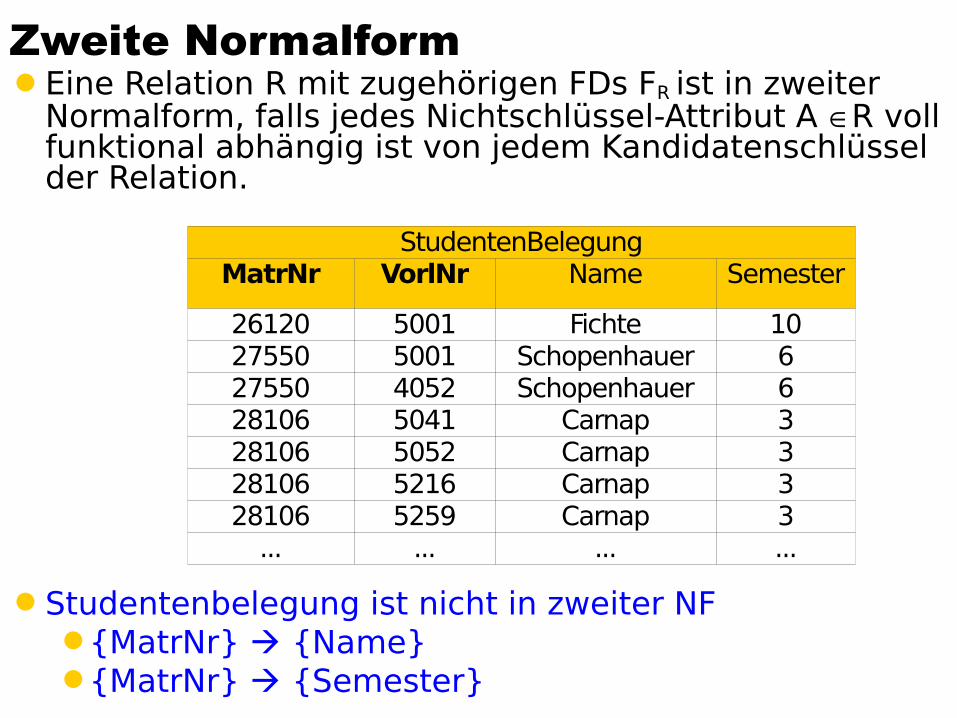
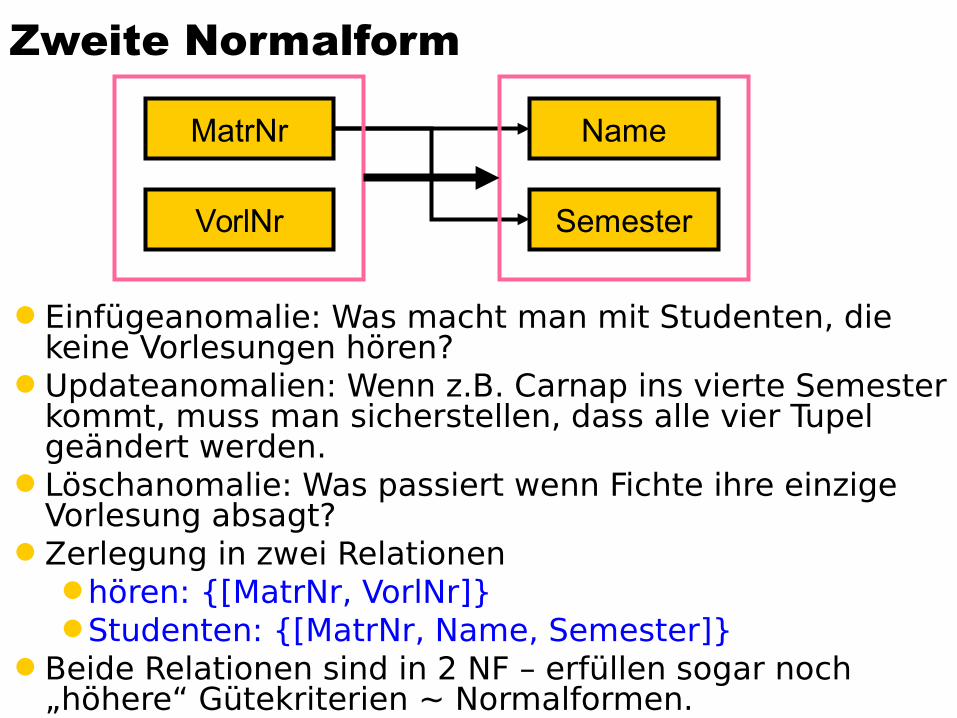
Zweite NormalformEine Relation R mit zugehörigen FDs FR ist in zweiter
Normalform, falls jedes Nichtschlüssel-Attribut A R voll funktional abhängig ist von jedem Kandidatenschlüssel der Relation.
Studentenbelegung ist nicht in zweiter NF {MatrNr} {Name}{MatrNr} {Semester}
StudentenBelegungMatrNr VorlNr Name Semester
26120 5001 Fichte 1027550 5001 Schopenhauer 627550 4052 Schopenhauer 628106 5041 Carnap 328106 5052 Carnap 328106 5216 Carnap 328106 5259 Carnap 3
... ... ... ...
Zweite Normalform
Einfügeanomalie: Was macht man mit Studenten, die keine Vorlesungen hören?
Updateanomalien: Wenn z.B. Carnap ins vierte Semester kommt, muss man sicherstellen, dass alle vier Tupel geändert werden.
Löschanomalie: Was passiert wenn Fichte ihre einzige Vorlesung absagt?
Zerlegung in zwei Relationenhören: {[MatrNr, VorlNr]}Studenten: {[MatrNr, Name, Semester]}
Beide Relationen sind in 2 NF – erfüllen sogar noch „höhere“ Gütekriterien ~ Normalformen.
MatrNr
VorlNr
Name
Semester

Dritte NormalformEin Relationenschema R ist in dritter Normalform, wenn
für jede für R geltende funktionale Abhängigkeit der Form mit B R und mindestens eine von drei Bedingungen gilt:
B , d.h., die FD ist trivial
Das Attribut B ist in einem Kandidatenschlüssel von R enthalten – also B ist prim
ist Superschlüssel von R
Alternative Formulierung: Für alle Nicht-Schlüsselattribute A gilt: für alle mit Aist Kandidatenschlüssel (A ist nicht transitiv abhängig von einem Kandidatenschlüssel).

Zerlegung mit dem SynthesealgorithmusWir geben jetzt einen sogenannten
Synthesealgorithmus an, mit dem zu einem gegebenen Relationenschema R mit funktionalen Abhängigkeiten F eine Zerlegung in R1, ..., Rn ermittelt wird, die alle drei folgenden Kriterien erfüllt.
R1, ..., Rn ist eine verlustlose Zerlegung von R.
Die Zerlegung R1, ..., Rn ist abhängigkeitserhaltend.
Alle R1, ..., Rn sind in dritter Normalform.

Synthesealgorithmus1. Bestimme die kanonische Überdeckung Fc zu F.
Wiederholung:a. einelementige rechte Seitenb. Linksreduktionc. Elimination redundanter funktionaler Abhängigkeitend. Zusammenfassung gleicher linker Seiten
2. Für jede funktionale Abhängigkeit Fc: Kreiere ein Relationenschema R := Ordne Rdie FDs F := {`` Fc | `` R} zu.
3. Falls eines der in Schritt 2. erzeugten Schemata einen Kandidatenschlüssel von R bzgl. Fc enthält, sind wir fertig. Sonst wähle einen Kandidatenschlüssel R aus und definiere folgendes Schema: R F
4. Eliminiere diejenigen Schemata Rdie in einem anderen Relationenschema R` enthalten sind, d.h., R R`
Anwendung des Synthesealgorithmus
Landesregierung
Rang
Name
Straße
Ort
BLand
PersNr
Raum
Vorwahl
PLZ
EW

10-51
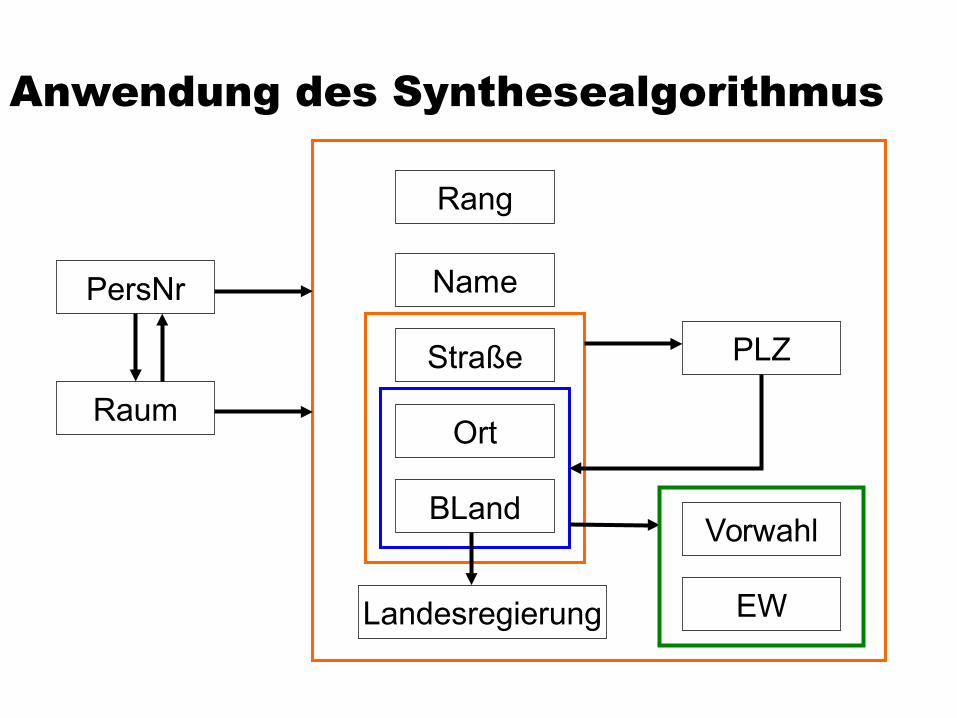
ProfessorenAdr: {[PersNr, Name, Rang, Raum, Ort, Straße, PLZ, Vorwahl, BLand, EW, Landesregierung]}
1. {PersNr} {Name, Rang, Raum, Ort, Straße, BLand}
2. {Raum} {PersNr}
3. {Straße, BLand, Ort} {PLZ}
4. {Ort,BLand} {EW, Vorwahl}
5. {BLand} {Landesregierung}
6. {PLZ} {BLand, Ort}
Professoren(PersNr, Name, Rang, Raum, Ort, Straße, Bland)
RP(Raum, PersNr)
PLZV(Straße, BLand, Ort, PLZ)
OrtsV(Ort, Bland, EW, Vorwahl)
Regierungen(BLand, Landesregierung)
PV(PLZ, Bland, Ort)

10-52
StudVorl(MatrNr,Name,Semester,VorlNr,Titel,SWS)
MatrNr → Name Semester
VorlNr → Titel SWSStudenten(MatrNr, Name, Semester)Vorlesungen(VorlNr ,Titel,SWS)Hört(MatrNr,VorlNr)

Boyce-Codd-NormalformDie Boyce-Codd-Normalform (BCNF) ist nochmals eine
Verschärfung der 3 NF. Ein Relationenschema R mit FDs F ist in BCNF, wenn
für jede für R geltende funktionale Abhängigkeit der Form F und mindestens eine von zwei Bedingungen gilt: , d.h., die Abhängigkeit ist trivial oder
ist Superschlüssel von R Alternative Formulierung: Alle Attribute A hängen vollständig nur
von Kandidatenschlüsseln ab: für alle mit Agilt: ist Kandidatenschlüssel
Man kann jede Relation verlustlos in BCNF-Relationen zerlegen
Manchmal lässt sich dabei die Abhängigkeitserhaltung aber nicht erzielen
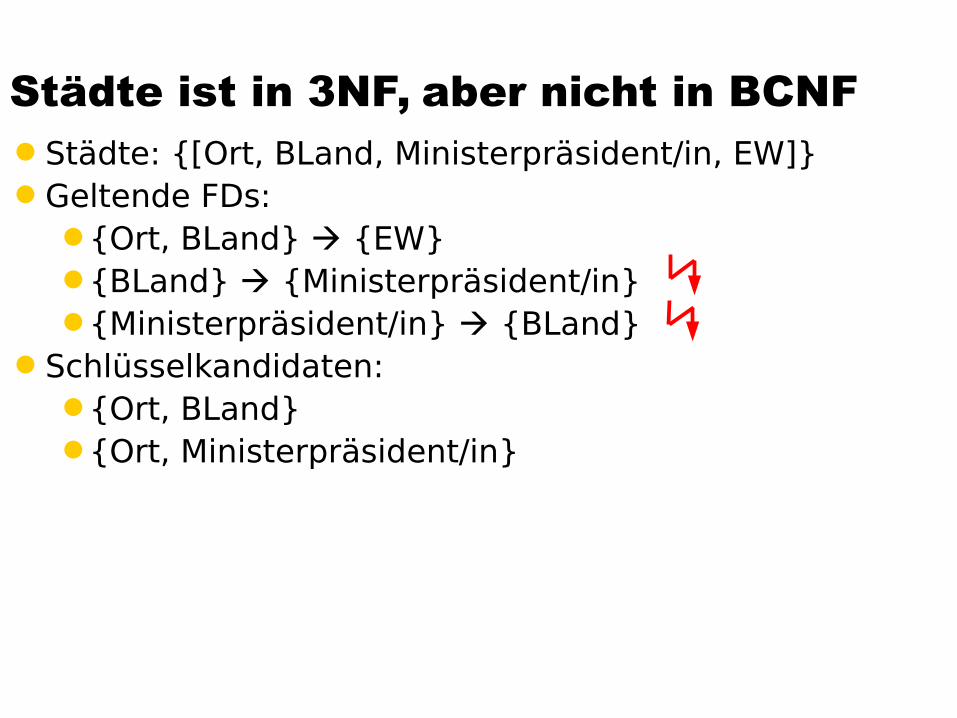
Städte ist in 3NF, aber nicht in BCNFStädte: {[Ort, BLand, Ministerpräsident/in, EW]}Geltende FDs:
{Ort, BLand} {EW}{BLand} {Ministerpräsident/in} {Ministerpräsident/in} {BLand}
Schlüsselkandidaten:{Ort, BLand}{Ort, Ministerpräsident/in}

DekompositionMan kann grundsätzlich jedes Relationenschema R mit
funktionalen Anhängigkeiten F so in R1, ..., Rn zerlegen, dass gilt:
R1, ..., Rn ist eine verlustlose Zerlegung von R.
Alle R1, ..., Rn sind in BCNF.
Es kann leider nicht immer erreicht werden, dass die Zerlegung R1, ..., Rn abhängigkeitserhaltend ist.

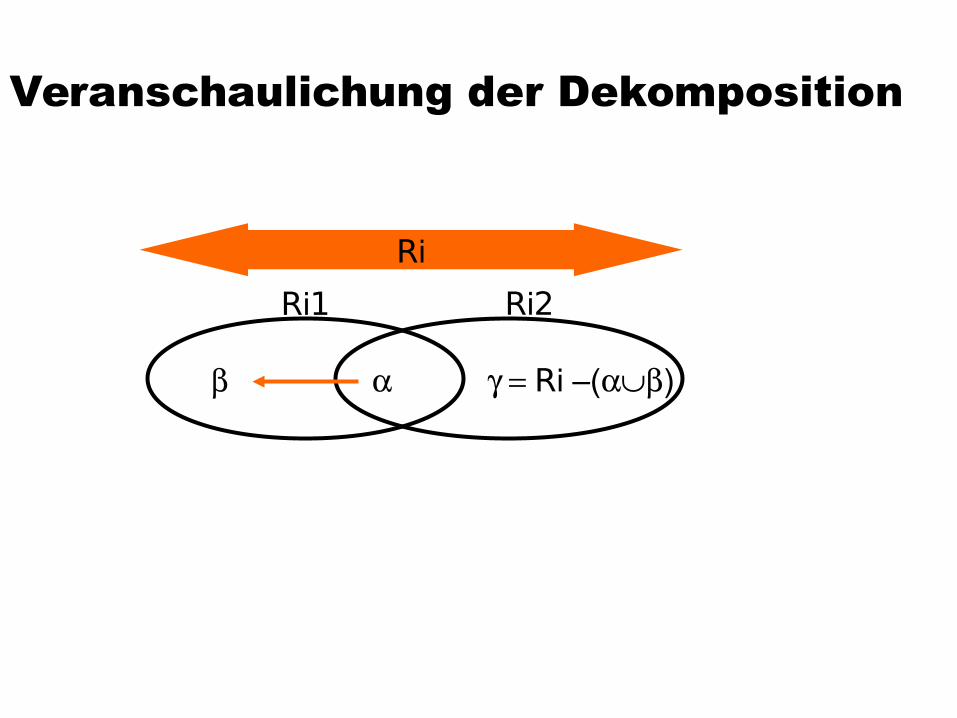
Dekompositions-AlgorithmusStarte mit Z = {R}Solange es noch ein Relationenschema Ri in Z gibt, das
nicht in BCNF ist, mache folgendes:Es gibt also eine für Ri geltende nicht-triviale
funktionale Abhängigkeit () mit = Ri)
Finde eine solche FDMan sollte sie so wählen, dass alle von funktional
abhängigen Attribute B (Ri - ) enthält, damit der Dekompositionsalgorithmus möglichst schnell terminiert.
Zerlege Ri in Ri1 := und Ri2 := Ri - Entferne Ri aus Z und füge Ri1 und Ri2 ein, also
Z := (Z – {Ri}) {Ri1} {Ri2}
Veranschaulichung der Dekomposition
Ri
Ri1
Ri2
Ri –()

Dekomposition der Relation Städte in BCNF-RelationenStädte: {[Ort, BLand, Ministerpräsident/in, EW]}Geltende FDs:
{BLand} {Ministerpräsident/in}{Ort, BLand} {EW}{Ministerpräsident/in} {BLand}
Ri1: Regierungen: {[BLand, Ministerpräsident/in]}
Ri2: Städte: {[Ort, BLand, EW]}
Zerlegung ist verlustlos und auch abhängigkeitserhaltend
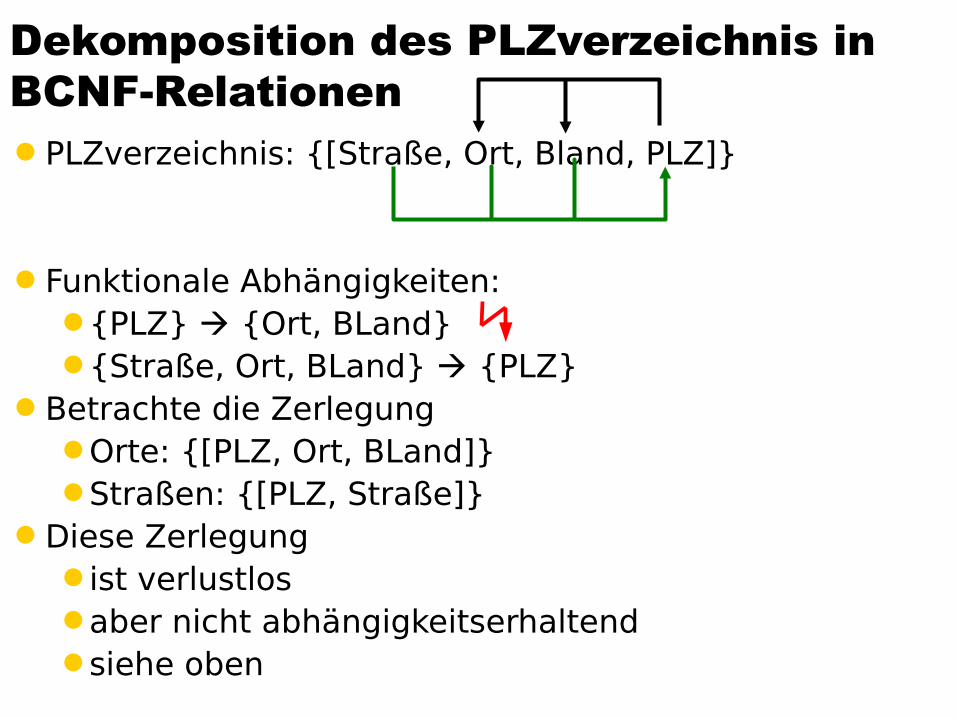
Dekomposition des PLZverzeichnis in BCNF-RelationenPLZverzeichnis: {[Straße, Ort, Bland, PLZ]}
Funktionale Abhängigkeiten:{PLZ} {Ort, BLand}{Straße, Ort, BLand} {PLZ}
Betrachte die ZerlegungOrte: {[PLZ, Ort, BLand]}Straßen: {[PLZ, Straße]}
Diese Zerlegung ist verlustlos aber nicht abhängigkeitserhaltendsiehe oben
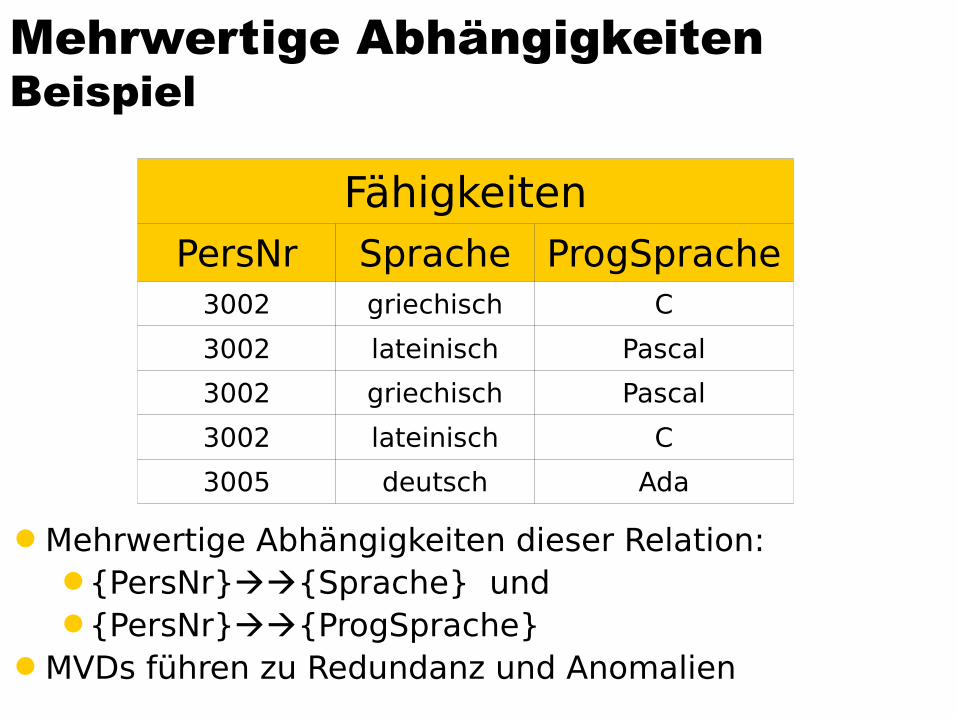
Mehrwertige AbhängigkeitenBeispiel
Mehrwertige Abhängigkeiten dieser Relation:{PersNr}{Sprache} und{PersNr}{ProgSprache}
MVDs führen zu Redundanz und Anomalien
FähigkeitenPersNr Sprache ProgSprache
3002 griechisch C
3002 lateinisch Pascal
3002 griechisch Pascal
3002 lateinisch C
3005 deutsch Ada
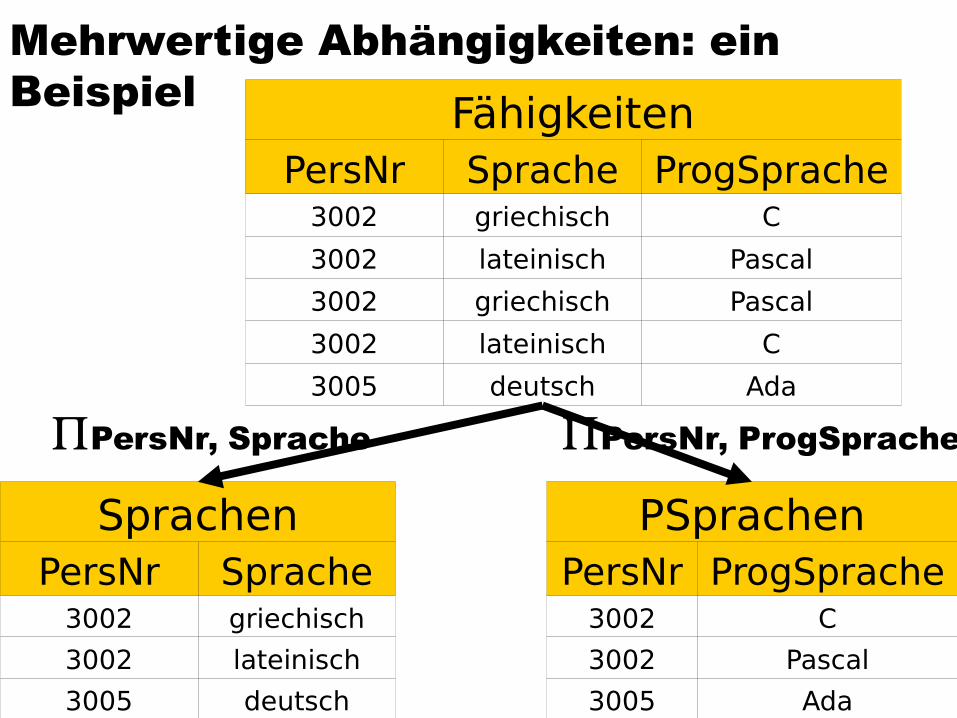
Mehrwertige Abhängigkeiten: ein Beispiel Fähigkeiten
PersNr Sprache ProgSprache3002 griechisch C
3002 lateinisch Pascal
3002 griechisch Pascal
3002 lateinisch C
3005 deutsch Ada
SprachenPersNr Sprache
3002 griechisch
3002 lateinisch
3005 deutsch
PSprachenPersNr ProgSprache
3002 C
3002 Pascal
3005 Ada
PersNr, Sprache PersNr, ProgSprache
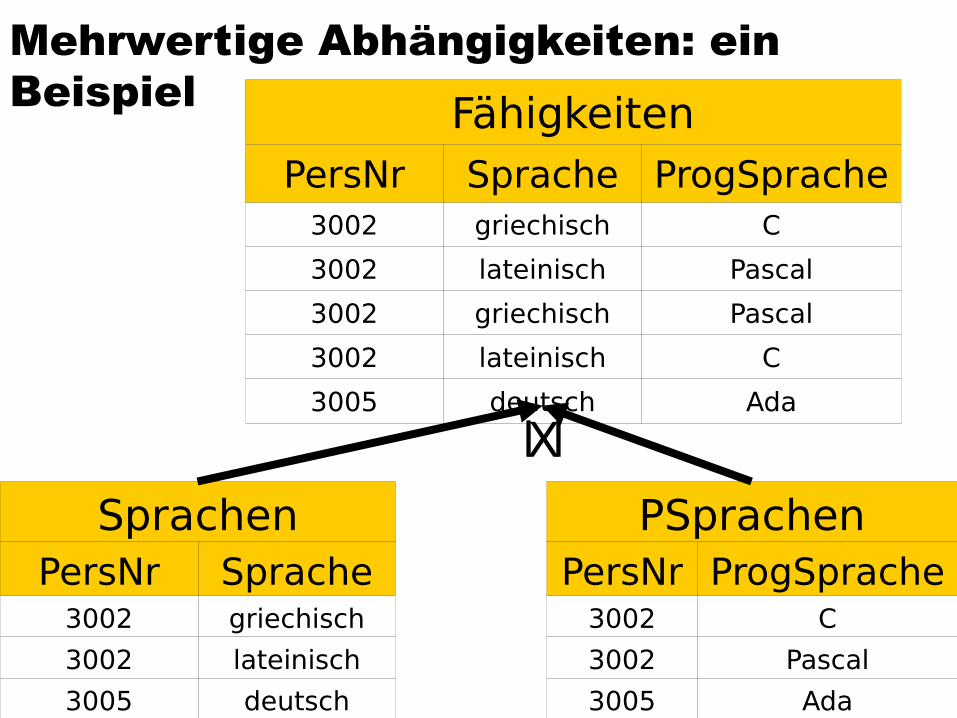
Mehrwertige Abhängigkeiten: ein Beispiel Fähigkeiten
PersNr Sprache ProgSprache3002 griechisch C
3002 lateinisch Pascal
3002 griechisch Pascal
3002 lateinisch C
3005 deutsch Ada
SprachenPersNr Sprache
3002 griechisch
3002 lateinisch
3005 deutsch
PSprachenPersNr ProgSprache
3002 C
3002 Pascal
3005 Ada
lXl
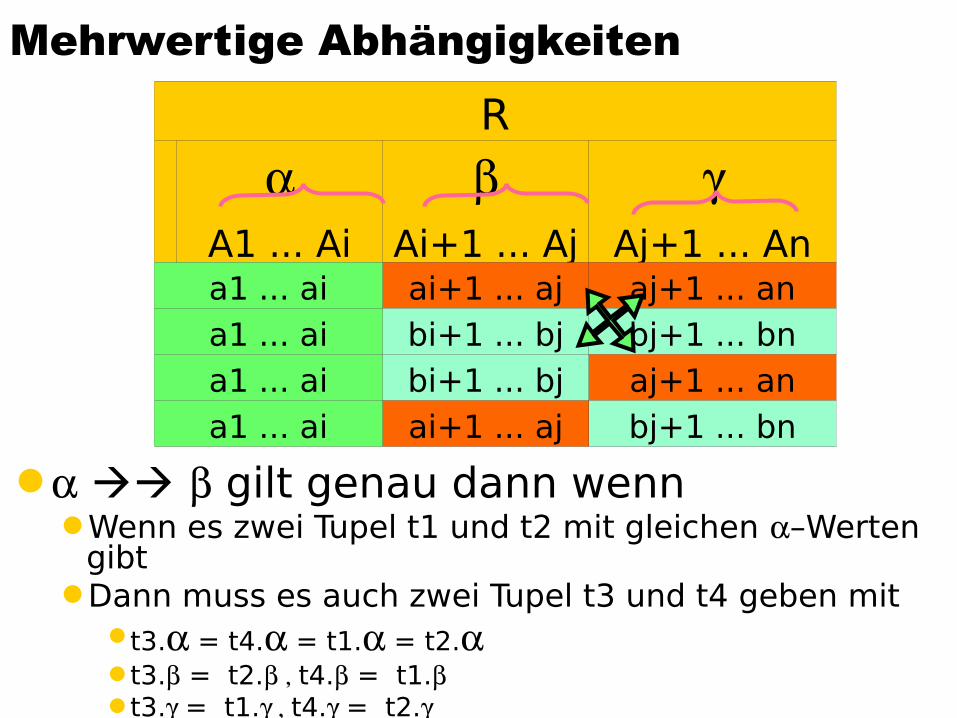
Mehrwertige Abhängigkeiten
gilt genau dann wenn Wenn es zwei Tupel t1 und t2 mit gleichen –Werten
gibtDann muss es auch zwei Tupel t3 und t4 geben mit
t3. = t4. = t1. = t2.t3. = t2.t4. = t1.t3. = t1.t4. = t2.
R
A1 ... Ai
Ai+1 ... Aj
Aj+1 ... An
a1 ... ai ai+1 ... aj aj+1 ... ana1 ... ai bi+1 ... bj bj+1 ... bna1 ... ai bi+1 ... bj aj+1 ... ana1 ... ai ai+1 ... aj bj+1 ... bn

MVDsTuple-generating dependencies
Man kann eine Relation MVD-konform machen, indem man zusätzliche Tupel einfügt
Bei FDs geht das nicht!!
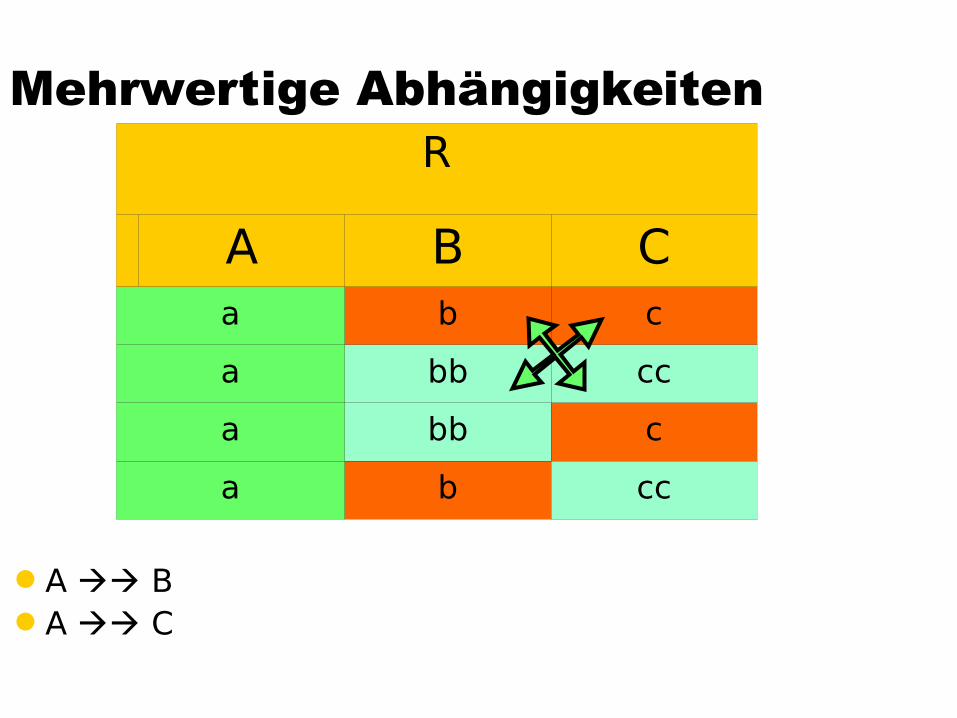
Mehrwertige Abhängigkeiten
A BA C
R
A B Ca b c
a bb cc
a bb c
a b cc

Verlustlose Zerlegung bei MVDs: hinreichende + notwendige BedingungR = R1 R2
R1 := ΠR1 (R)R2 := ΠR2 (R)
Die Zerlegung von R in R1 und R2 ist verlustlos, falls für jede mögliche (gültige) Ausprägung R von R gilt:R = R1 lXl R2
Die Zerlegung von R in R1 und R2 ist verlustlos genau dann wenn R = R1 R2 und mindestens eine von zwei MVDs gilt:(R1 R2) R1 oder(R1 R2) R2

Inferenzregeln für MVDs

Inferenzregeln für MVDs (Forts.)

Triviale MVDs …… sind solche, die von jeder
Relationenausprägung erfüllt werdenEine MVD ist trivial genau dann wenn
oder = R -

Vierte NormalformEine Relation R ist in 4 NF wenn für jede MVD
eine der folgenden Bedingungen gilt:Die MVD ist trivial oder ist Superschlüssel von R

Dekomposition in 4 NFStarte mit der Menge Z := {R}Solange es noch ein Relationenschema Ri in Z
gibt, das nicht in 4NF ist, mache folgendes:Es gibt also eine für Ri geltende nicht-triviale
MVD (), für die gilt:= Ri)
Finde eine solche MVDZerlege Ri in Ri1 := und Ri2 := Ri - Entferne Ri aus Z und füge Ri1 und Ri2 ein,
also Z := (Z – {Ri}) {Ri1} {Ri2}
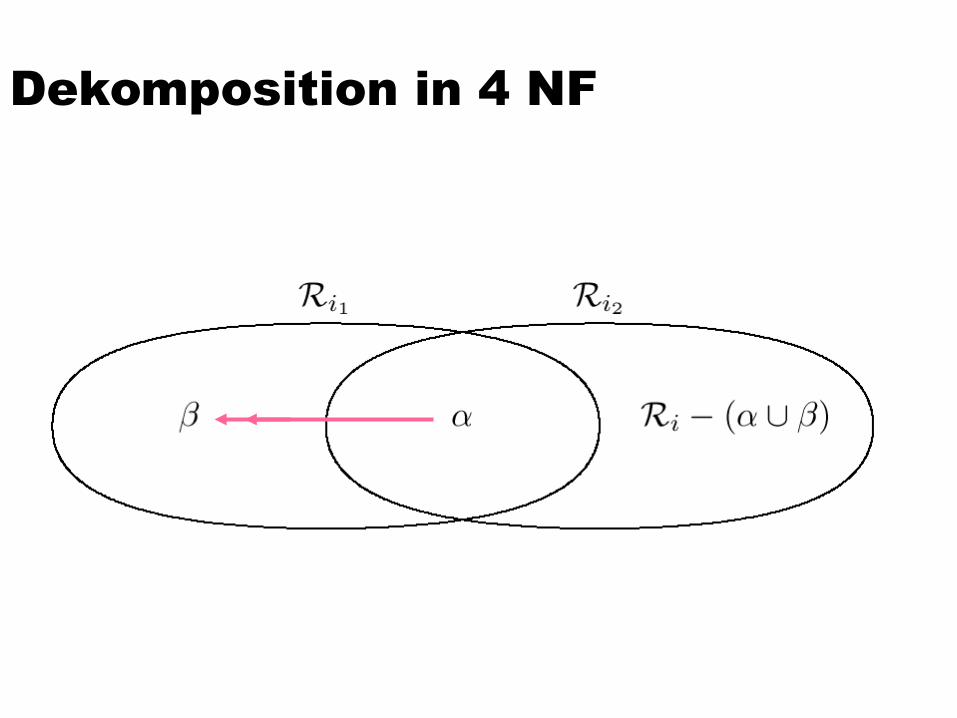
Dekomposition in 4 NF
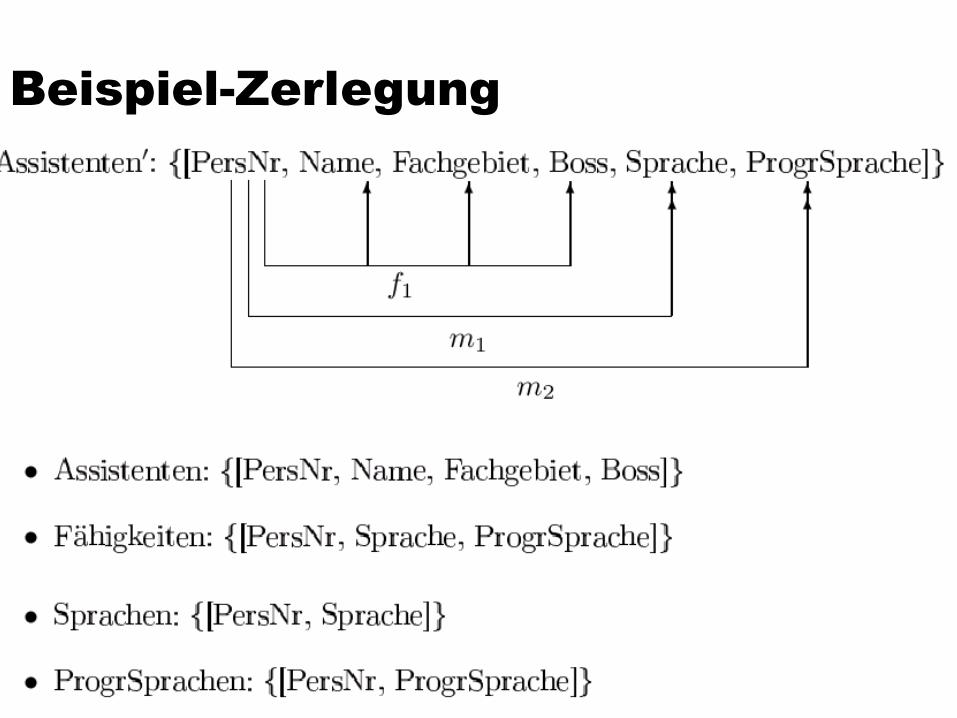
Beispiel-Zerlegung

74
10-74
Beispiel-Zerlegung (2)Assistenten'(PersNr, Name, Fachgebiet, Boss, Sprache, ProgSprache)
PersNr → Name Fachgebiet Boss
PersNr ->> Sprache
PersNr ->> ProgSprache
Assistenten(PersNr, Name, Fachgebiet, Boss)
ASP(PersNr, Sprache, ProgSprache)
Sprachen(PersNr, Sprache)
ProgSp(PersNr, ProgSprache)
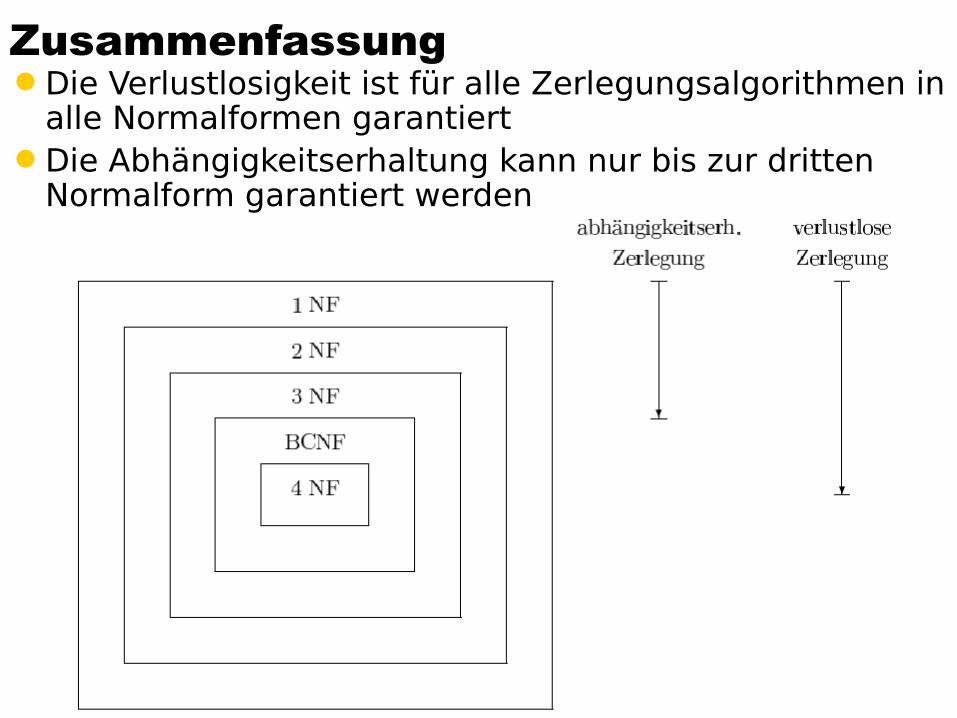
ZusammenfassungDie Verlustlosigkeit ist für alle Zerlegungsalgorithmen in
alle Normalformen garantiertDie Abhängigkeitserhaltung kann nur bis zur dritten
Normalform garantiert werden

Übung: FDs, MVDs, Normalisierung

77
10-77
Übung(2)Vorlesungen(VorlNr,Titel,SWS,gelesenVon,VTermin,VRaum,ÜTermin,ÜRaum)
VorlNr → Titel SWS gelesenVon
– Vorlesungen(VorlNr,Titel, SWS, gelesenVon)
– R1(VorlNr,VTermin,VRaum,ÜTermin,ÜRaum)
Vraum Vtermin → VorlNr
– R11(Vraum,Vtermin,VorlNr)
– R12(VTermin, Vraum, Ütermin, Üraum)
alternative Zerlegung von R1:
VorlNr ->>Vtermin VRaum
– R11'(VorlNr,Vtermin,VRaum)
– R12'(VorlNr,ÜTermin,ÜRaum)
4NF-2NF
4NF
4NF, nicht abh.-erhaltend
4NF
4NF, abh.-erhaltend

Weitere Übung: FamilieFamilie: {[Opa, Oma, Vater, Mutter, Kind]}
Annahme: [Theo, Martha, Herbert, Maria, Else] bedeutet
Theo und Martha sind Eltern von Herbert oderTheo und Martha sind Eltern von Maria
Abhängigkeiten:– K → V,M– K,Opa → Oma– K,Oma → Opa– V,M →→ K– V,M →→ Opa,Oma

Beispiel
Kind → Vater,MutterKind,Opa → OmaKind,Oma → Opa
Stammbaum
Kind Vater Mutter Opa Oma
Sofie Alfons Sabine Lothar Linde
Sofie Alfons Sabine Hubert Lisa
Niklas Alfons Sabine Lothar Linde
Niklas Alfons Sabine Hubert Lisa
Tobias Leo Bertha Hubert Martha
… … … … …

80
10-80
ZerlegungFamilie(Opa, Oma, Vater, Mutter, Kind)
Kind → Vater MutterEltern(Kind, Vater, Mutter)
– 4NF
– Großeltern(Kind, Opa, Oma)
– 4NF, abh.-erhaltend
alternative Zerlegung:– Vater Mutter ->> Kind
– Eltern(Kind, Vater, Mutter)
– 4NF
– EG(Vater, Mutter, Opa, Oma)
– 4NF, nicht abh.-erhaltend
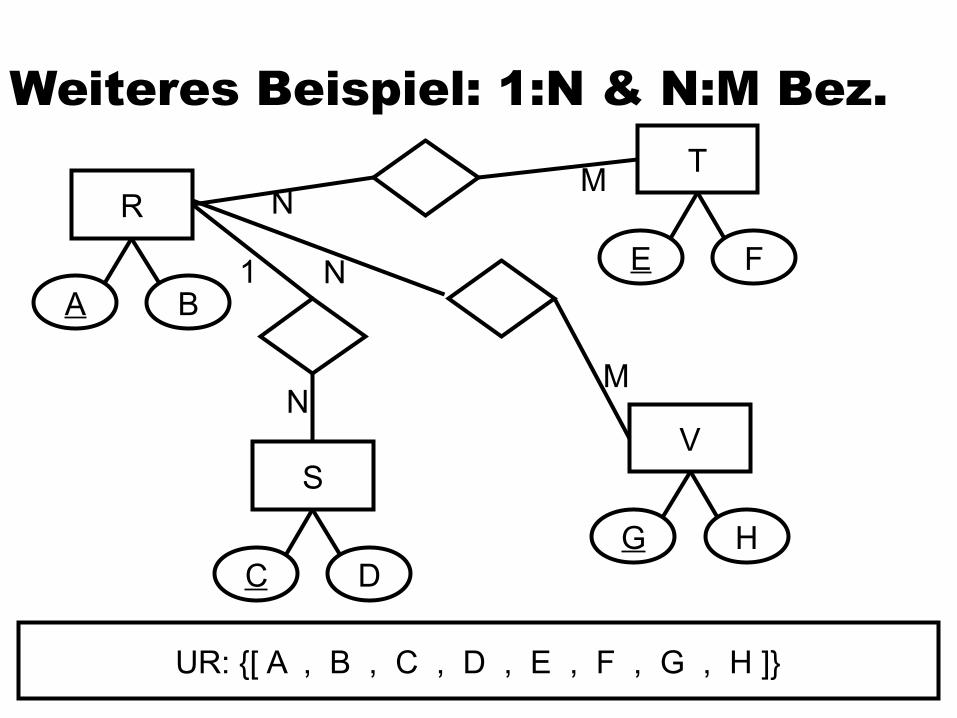
Weiteres Beispiel: 1:N & N:M Bez.
R
A B
S
C D
T
E F
V
G H
1
N
NM
N
M
UR: {[ A , B , C , D , E , F , G , H ]}

82
10-82
UR(A, B, C, D, E, F, G, H)
R(A,B)
UR'(A, C, D, E, F, G, H)
S(C,D)
UR''(A, C, E, F, G, H)
T(E,F)
UR'''(A, C, E, G, H)
V(G,H)
UR''''(A, C, E, G)
U(C,A)
UR'''''(C, E, G)
W(E,G)
X(C,E)
A → B
C → D
E → F
G → H
C → A
A->>C
A->>E
E->>A
A->>G
G->>A
E->>G
C->>G
C->>E





























