Embed Size (px)
Citation preview

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.

02

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
03
Einleitung 04
KI für Einsteiger – Licht im Buzzword-Dschungel 06
RegTech ist nicht gleich RegTech – KI im Kontext von Compliance-IT 08
Nicht ohne meine Daten 12
Nicht alles, was gefällt, ist auch erlaubt – Stichwort Regulatorenakzeptanz 14
Mehr als nur ein Spielzeug? Anwendungsszenarien im Aufgabenfeld des Chief Compliance Officer 17
Fazit 38
Vom Papiertiger zum lebenden Objekt: Verprobung von RegTech-basierten Lösungen im Deloitte RegTech Lab 40
Ansprechpartner: Deloitte Risk Advisory – Regulatory Risk 42

04
EinleitungArtificial Intelligence (AI) aka künstliche Intelligenz (KI) – ein inflationär genutztes Buzzword – ist nicht ganz neu, aber immer noch sagenumwoben, da kaum greifbar. KI ist keine Erfindung des 21. Jahrhunderts. Bereits in den 1950er-Jahren wurde dieses Themenfeld erstmals aufgegriffen und faszi-niert seitdem die Forschung. Insbesondere durch die immer schneller wachsenden Hardwarekapazitäten hat sich KI in den letzten Jahren rasant weiterentwickelt und die Schwelle zur Marktreife überschritten. Heute werden erste Ansätze von künstli-cher Intelligenz bereits im IT-Alltag einge-setzt – ohne dass wir es merken. Sei es in großen E-Commerce-Portalen („Kunden, die das gekauft haben, interessierten sich auch für …“) oder bei der Filterung von Spam. Doch darüber hinaus eröffnen IT-Lösungen auf Basis von künstlicher Intelligenz mannig-faltige Einsatzmöglichkeiten – insbesondere im Bereich Compliance und Regulatorik.
Der Einsatz von künstlicher Intelligenz bei Finanzdienstleistern birgt enormes Poten-tial. Mangelndes fachliches Wissen und unzureichende Praxiserfahrung schaffen jedoch hohe Unsicherheiten und Risiken bei der Auswahl und Umsetzung. Bis die vor-herrschende Skepsis gegenüber KI deutlich sinkt, auch aufseiten der Regulatoren, ist noch viel Überzeugungsarbeit von Unter-nehmen und Beratern zu leisten.
Aus Sicht der Aufsicht gibt es für Anwender als auch für Regulatoren selbst noch viel Handlungsbedarf. Regulierungslücken sind noch vorhanden und nicht ausreichend adressiert. Als zu lösende Herausforderung identifiziert die BaFin die Fähigkeit, Trans-parenz und Kontrolle über neu geschaffene Strukturen zu erhalten. Darüber hinaus müssen insbesondere bei der Nutzung von Algorithmen zur Finanzkriminalitätserken-nung Mindeststandards zum Nachweis von Effektivität in den verwendeten Verfahren als auch zur Erklärbarkeit und Nachvoll-ziehbarkeit definiert werden. Denkbar sind in diesem Zusammenhang eine Abnahme bzw. ein Genehmigungsverfahren der verwendeten Modelle und Verfahren durch die Aufsicht.
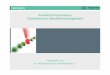
Wie bereits erwähnt, ist zur Schaffung von Vertrauen und Ablegung des Misstrauens gegenüber dem technischen Fortschritt noch viel Überzeugungsarbeit zu leisten. Das vorliegende Whitepaper liefert einen Überblick über die Grundlagen und innova-tive Einsatzszenarien künstlicher Intelligenz und soll damit einen Beitrag hierzu leisten (s. Abb. 1).
Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
05
• Hierfür werden in den ersten drei Abschnitten die wichtigsten Begriffe und Definitionen beschrieben, die im Zusammenhang mit dem Trendwort KI auftreten. Es wird zudem erläutert, was sich hinter dem Begriff „RegTech“ verbirgt und wo der tatsächliche Mehrwert zu bereits existierenden regulatorischen Technologien und Lösungen entsteht.
• Im vierten Abschnitt wird an einigen Bei-spielen die Rolle von hoher Datenqualität und der Datenkompetenz gegenüber KI erläutert bzw. warum ein Einsatz von KI nur dann erfolgreich sein kann, wenn „die richtigen“ Daten vorhanden sind.
• Fragestellungen in Bezug auf mögliche Stolpersteine durch den Regulator sind im fünften Abschnitt kurz beschrieben. Hier hat KI insbesondere durch ihren Blackbox-Charakter mit der Aufsicht zu kämpfen.
• Im eigentlichen Hauptteil dieses White-papers (Abschnitt sechs) werden zwölf exemplarische KI-basierte Anwendungs-szenarien zur praktischen Umsetzung von Compliance-Anforderungen dargestellt (für einen ersten Überblick s. Abb. 6 auf Seite 8). Dabei wird der Fokus auf aktuelle und zukünftige Herausforderungen sowie auf die Entwicklung von maßgeschneider-ten Compliance-Lösungen gelegt.
• Schließlich wird abrundend erläutert, wie durch Deloittes „RegTech+“- Ansatz im hauseigenen Labor mit Partnern und Kunden innovative Technologien und Lösungen evaluiert und erprobt werden.
3
KI – Nicht ohne
meine Daten
4
Nicht alles, was gefällt, ist erlaubt – Stichwort Regulatoren-
akzeptanz
2
RegTech ist nicht gleich RegTech –
künstliche Intelligenz imKontext von Compliance-IT
5
Und nun? Anwendungsszenarien
im Aufgabenfeld des Chief Compliance Officer
1
KI für Einsteiger – Licht im
Buzzword-Dschungel
6
Vom Papiertiger zum lebenden Objekt: Verprobung von RegTech-
basierten Lösungen im Deloitte RegTech Lab
Einleitung
7
Ansprechpartner:Deloitte Risk Advisory –
Regulatory Risk
Abb. 1 – Aufbau und Inhalt dieses Whitepapers

06
KI für Einsteiger – Licht im Buzzword-Dschungel
KI beschreibt vereinfacht dargestellt eine mathematische Technik, mit der ein (Soft-ware-)System selbstständig auf Basis von Daten unterschiedliche Muster und Regeln erkennt – d.h. eine Lösung für ein Problem ermittelt. Anders als bei klassischen Syste-men werden hier keine vorher festgelegten Regeln definiert, sondern das System erkennt selbstständig durch die Analyse der Daten diese Muster.
Maschinelles Lernen lässt sich unter den Oberbegriff KI subsumieren. KI-basierte Systeme generieren somit aus Erfahrungen (Output) Wissen (Regeln).
Deep Learning als Unterkategorie des maschinellen Lernens beschreibt eine Lernmethodik auf Basis von sogenannten künstlichen neuronalen Netzen. Grund-lage des Deep Learning sind statistische Datenanalysen und kein deterministischer Algorithmus. Statistische Datenanalyse finden dort ihren Einsatz, wo keine klar definierten Regeln existieren (s. Abb. 2), etwa in der Bildverarbeitung oder der Spracherkennung. Künstliche neuronale Netze übersetzen im Gehirn vorkom-mende biologische Abläufe in mathe-matische/IT-technische Strukturen. Ein neuronales Netz stellt ein Netzwerk aus vielen kleinen atomaren Einheiten (Neuro-nen) dar, welche untereinander verknüpft sind. Jede Einheit ist selbst lernfähig. Die Neuronen erfüllen hierbei einfache Aufga-ben – bilden aber im Netzwerk komplexe Aufgaben ab.
Natural Language Processing setzt primär auf DL-Methoden auf und versucht, menschliche Sprache in Informationen und Wissen zu transferieren – ohne starre, vordefinierte Regeln zu verwenden. Darüber hinaus findet KI Einsatz bei der Mustererkennung in Bildern. Auch hier findet ein vorangegangenes Trainieren der KI statt. NLP hingegen ist die Generierung von menschlicher Sprache durch KI.
Text Mining versucht ähnlich hierzu, unstrukturierte, textbasierte Daten mittels KI in Muster bzw. Beziehungen in den Mustern zu überführen. Text Mining bietet insbesondere im Umfeld der Digitalisie-rung und Auswertung von papiergebunde-nen Dokumenten (z.B. Legal Agreements) optimale Einsatzmöglichkeiten.
Kaum eine Publikation, kaum ein Artikel ohne ausufernde An-sammlung von Trendwörtern: Von KI über Deep Learning (DL), Text Mining, Natural Language Processing (NLP), neurale Netze, Machine Learning (ML) und Big Data werden die verschiedenen Teil- und Nachbardisziplinen als zukünftige Heilsbringer geprie-sen. Doch wie grenzen sich die einzelnen Themen voneinander ab? Oder ist es doch alles dasselbe?
Abb. 2 – KI vs. regelbasierte Systeme
Systeme lernen die Programmier-Regeln durch Iteration von neuen Daten
vs Programmierung von Regeln umgewünschtes Ergebnis zu erzielen
Input RulesOutput&
Input Rules Output&

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
07
Eine Visualisierung der Zusammenhänge im Umfeld von KI und Co. und der Schnitt-stellen zu Themen wie Analytics ist in Abbildung 3 zu sehen.
Wie man erkennen kann, sind die Grenzen hier fließend, was aber in Bezug auf prakti-sche Anwendungsfälle (s. Abschnitt 6) eher förderlich ist. Kombinationen aus verschiedenen Technologien resultieren in effizienzsteigernden Lösungen entlang der Compliance-Prozesse.
Abgrenzung Big Data, Advanced/Business Analytics und Predictive Analytics: Mit der zum Standardwerkzeug gereiften Massen-datenanalyse, der Business Intelligence (BI) und den weiterentwickelten Business Analytics (BA), wird versucht, die Frage nach den Ursachen, Zusammenhängen und Auswirkungen von z.B. gesetzlichen Änderungen oder geänderten Parametern zu beantworten. Sie eignet sich daher als Werkzeug zur Szenarienanalyse („Was wäre, wenn wir Parameter X im GRC-Werkzeug Y ändern?“). Anders als bei KI werden im Umfeld von Business Analytics die Modelle von Analysten (manuell) entworfen und simuliert. Predictive Analytics als einer der Grundpfeiler der BA fokussiert hierbei auf die Vorhersage von Auswirkungen in der Zukunft und insbesondere im Versiche-rungsumfeld unersetzlich, wo z.B. versucht wird, aus umfangreichen Vergleichsdaten die erwartete Lebensdauer eines Versi-cherten für eine Versicherungspolice zu bestimmen.
Abb. 3 – KI vs. regelbasierte Systeme
PredictiveAnalytics &BusinessAnalytics
KI/künstliche Intelligenz
BI
DeepLearning und
neuronaleNetze
MachineLearning und
KI
Bild-erkennung und
Muster-erkennung
Natural Language Processing
(NLP)
TextMining

08
Wenn es um Compliance und neue technologische Ansätze geht, fällt unwei-gerlich auch das Wort RegTech (Regulatory Technology). RegTech-Unternehmen (bzw. RegTechs) nutzen innovative Technologien, um beispielsweise die Flut neuer Regu-lierungen (Gesetze, Verordnungen etc.) effizient umzusetzen. Je nachdem, welchen Experten man konsultiert, wird dieser Reg-Tech als Subgruppe der FinTech (Financial Technology) einordnen oder als eigenstän-dige Kategorie benennen. Im Gegensatz zu RegTech fokussiert FinTech Lösungen für den (End-)Kunden bzw. neue Produkte für die Unternehmen im Finanzsektor mit B2C- sowie B2B-Fokus. RegTech legt ihren Anwendungsschwerpunkt, wie der Name es bereits erahnen lässt, auf regulatorische
und Compliance-Themenstellungen für die Unternehmen. Im Kontext dieses Whitepa-pers stellt RegTech IT-basierte Werkzeuge im Compliance-Regulatory-Umfeld dar.
Abbildung 4 zeigt aggregiert die verschie-denen Technologien, welche im Umfeld der RegTech verstärkt thematisiert und eingesetzt werden (kein Anspruch auf Voll-ständigkeit – das nächste Buzzword kommt bestimmt).
RegTech ist nicht gleich RegTech – KI im Kontext von Compliance-IT
Die Modernisierung der Compliance ist nicht länger optional. Mittelfristig werden regulatorische Anforderungen weiter steigen und verfügbare Budgets dafür weiter sinken. Der Compliance-Vorstand ist also gut beraten, bereits heute in die Compliance von morgen zu investieren.

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
09
Abb. 4 – Technologien im Umfeld von RegTech – KI als Schlüsselkomponente
BlockchainDezentrale Datenstrukturen, die Transakti-onen verfälschungssicher dokumentieren und hierdurch zur Entwicklung von neuartigen Handelsplattformen, Zahlungs-systemen und Austauschmechanismen von Informationen beitragen
Smart ContractsTechnologien, die (digitale) Verträge abbilden oder überprüfen als auch die Verhandlung und Abwicklung eines Vertrages technisch unterstützen
Cloud ComputingDynamische und bedarfsgerechte Bereit-stellung von IT-Infrastruktur, IT-Plattformen und Services über ein Netzwerk zum Austausch von Daten oder zur Verarbei-tung von Informationen
Künstliche Intelligenz (KI)Den menschlichen Denkprozessen nachempfundene „intelligente” Problemlö-sungsverfahren zur Bewältigung komplexer Herausforderungen
Application Interface (API)Eine für Software zugeschnittene und maschinenlesbare (standardisierte) Programmschnittstelle zum Austausch und zur Weiterverarbeitung von Daten und Inhalten.
Robotic Process Automation (RPA)Konfigurierbare Software-Roboter, die sich wiederholende und meist arbeitsinten-sive manuelle Vorgänge automatisiert ausführen
Predictive AnalyticsMethoden, um Datenbestände zu analysieren und anhand statistischer Verfahren Trends und Vorhersagen zu treffen
Machine LearningTechnologien, die aus strukturierten und unstrukturierten Datenmengen fachliche Modelle und Lösungsansätze ableiten und sich zudem selbst kontinuierlich verbes-sern können
Big DataTools, Werkzeuge und Programme zur schnellen und effizienten Auswertung komplexer, ggf. schwach strukturierter und heterogener Datenbestände

10
Ausufernde Regulatorik, kürzer werdende Zeitfenster für Meldefristen oder auch die wachsende Flut an Daten lassen sich mit-telfristig nicht mit klassischen Compliance- IT-Lösungen zufrieden stellend bewältigen und bedürfen innovativer Lösungen wie KI, Robotics Process Automation, Blockchain, Predictive Analytics und Co.
Zur Vereinfachung haben wir eine Unter-gliederung der RegTech-Lösungen unter anderem in RegTech+ vorgenommen. Es umfasst aus unserer Sicht diejenigen Compliance-Lösungen, welche auf Basis innovativer Technologieansätze einen essenziellen Mehrwert bieten (RegTech+ als kleine Teilmenge der Compliance-IT, wie in Abb. 5 visualisiert). Um die Compli-
ance-Abteilung der Unternehmen nicht nur punktuell und silohaft zu unterstützen, ist zumeist eine Kombination verschiedener RegTech+-Technologien sinnvoll. Der Daten- und KI-gestützte Roboter, welcher Vorauswertungen und die Ausfüllung von Masken und Formularen abarbeitet, sei hier nur beispielhaft genannt.
Auch ist die Betrachtung des Gesamtpro-zesses End-to-End und nicht nur einzelner Prozessschritte und Schwachstellen zielfüh-rend. Um die noch immer vorherrschenden Datensilos aufzubrechen und eine 360°-Sicht auf den Geschäftspartner zu haben, sollte in der Zielarchitektur ein breiter Blick auf die verschiedenen Compliance-Themen-felder geworfen werden.
Abb. 5 – RegTech+: Premiumsegment der Compliance-IT-Lösungen
RegTech+
ComplianceTechnology
Regulatorische Anforderungen
RegTech(ComTech)
RegTech+Intelligente IT-Lösungsansätze fürregulatorische Fragestellungen
• Data Mining und Analytics• Machine Learning• Robotic Process Automation• Predictive Analytics/• künstliche Intelligenz (KI)

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
11

12
Nicht ohne meine DatenEgal ob KI oder Business Analytics: Ohne eine umfangreiche und qualitativ hochwertige Datengrundlage kann es keine ver-lässlichen Ergebnisse geben, da diese essenziell ist, um Muster erlernen zu können.
Für das Erlernen von Mustern spielt das verwendete initiale „Trainingssample“ eine entscheidende Rolle. Damit das KI-basierte System Muster erlernen kann, müssen die zu analysierenden Zusammenhänge auch in ausreichender Quantität bereitgestellt werden. Sprich: Um z.B. Regeln im Financial- Crime-Umfeld wie Betrug, Bestechung und Geldwäsche (GW) erlernen zu können, müs-sen diese Muster auch im Datenbestand als „Betrüger“ bzw. „Geldwäscher“ dem Algorithmus genannt werden. Ähnlich der klassischen Stichproben-Methoden stellt die „Losgröße“ somit eine Voraussetzung für robuste KI-basierte Ergebnisse dar. Die Krux ist nun, dass ohne ausreichende Daten keine zielführende Mustererkennung stattfinden kann.
Hier ein klischeehaftes Beispiel: Der geld-waschende Vertreter des organisierten Verbrechens zeichnet sich mit durch ein Engagement im Gaststättengewerbe aus. Umfangreiche, nicht dem Geschäftszweck entsprechende Bartransaktionen ergänzen das Muster. Das Merkmal der „Auffälligkeit der Bareinzahlungen“ wird wiederum durch vergleichende Analysen mit anderen
typischen Speiserestaurants gleicher Art und Größe ermittelt. Ein KI-basiertes Moni-toring-Tool sollte somit den Imbissbesitzer mit umfangreichen Bareinzahlungen und nicht zu den Einnahmen passenden Immo-biliengeschäften für eine kritische Prüfung identifizieren. Ein erstes Anwendungsbei-spiel in diesem Zusammenhang ist somit die Erkennung von kriminellen bzw. betrügeri-schen Mustern (auch häufig als „Red Flags“ bezeichnet) im Bankenumfeld durch die Analyse von bestätigten1 GW-Verdachtsfäl-len (auch Suspicious Activity Reports; kurz SAR-Meldungen). Aber ohne ausreichende Datengrundlage gibt es keine zielführende Mustererkennung.
Obwohl Verfahren im Umfeld von Deep Learning mit unstrukturierten Daten umge-hen können, stellt die mangelnde Datenqua-lität ein Hindernis dar und muss beim Ein-satz bedacht werden. Um falsche Schlüsse zu vermeiden, müssen die Vertraulichkeit der Datenquelle, deren Aktualität und Rele-vanz vorab hinterfragt werden. Anders als bei BI-gestützten Methoden ist es bei KI im Vorfeld kaum möglich, fehlerhafte Daten zu entfernen, da die Merkmale eines fehlerhaf-
ten Datensatzes meist nicht bekannt sind. Enthält ein Datenpool beispielsweise keine Geldwäschefälle, kann das KI-basierende Monitoring-Tool dieses auch nicht erlernen. Auch würden fehlerhafte Daten in obigem Beispiel (z.B. falsche Berufsgruppenschlüs-sel für die Identifikation des Imbisses) zu falschen Mustern führen – es sei denn, diese fehlerhaften Daten werden erkannt.
Ein kleiner Trost: KI kann lernen, schlechte Daten selbst zu erkennen.
1 Anmerkung: Leider erhalten Kreditinstitute tatsächlich nur in den allerseltensten Fällen Rückmeldung über das Ergebnis der behördlichen Prüfung einer Verdachtsfallanzeige. Kontinuierliche Verbesserung wird mangels belastbaren Wissens erschwert.

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
13

14
Nicht alles, was gefällt, ist auch erlaubt – Stichwort RegulatorenakzeptanzRechtsprechung und Aufsichtsbehörden bemühen sich intensiv auf der Höhe der Zeit in Bezug auf die Entwick-lung von Geschäftsmodellen und technologischem Fortschritt zu sein.
Während insb. außereuropäische Aufsichten bereits Plattformen für ein RegTech- und Kryptowährung-Sandboxing geschaffen haben, ist die deutsche BaFin noch sehr zögerlich, was ihren Segen zu RegTech- Lösungen bzw. den dahinter liegenden KI-basierten Algorithmen anbelangt. Es existieren noch einige (überwindbare) Herausforderungen, die im Dialog mit den Aufsichtsbehörden zu lösen sind – die Aus-einandersetzung mit möglichen rechtlichen Hürden sollte aber bereits heute begonnen werden, um keine weitere Zeit zu verlieren.
Durch die Geschwindigkeit der techno-logischen Entwicklung besteht sonst die Gefahr, den Anschluss zu verlieren, vor allem auch im internationalen Vergleich. Es entwickelt sich geradezu ein Wettbewerb zur führenden Nation als Anbieter von KI- und Big-Data-Lösungen. Hier konkurrieren Länder wie die USA, UK oder China um eine vorherrschende Stellung. In Großbritannien steht beispielsweise die FCA (Financial Con-duct Authority) dem technischen Fortschritt positiver entgegen und sieht die Entwick-lung als Chance, eine Führungsposition in innovativen Technologien und als Anbieter von Finanzdienstleistungen einzunehmen. Die Regierung investierte hierzu 2018 einen Milliardenbetrag in die Forschung und Ent-wicklung von KI und errichtete das weltweit erste Zentrum für Datenethik.
Auch ermutigt die amerikanische Noten-bank FED (Federal Reserve) zur Entwicklung von innovativen Ansätzen und zur verant-wortungsvollen Umsetzung. Richtlinien und Leitfäden zur Nutzung von KI wurden veröffentlicht, welche eine klare Haltung und Anforderung an die genutzten Verfahren stellen. Beispielsweise werden Anforde-rungen an die unabhängige Überprüfung von verwendeten Modellen, notwendige Maßnahmen für unerklärliche oder intrans-parente Modelle sowie Vorgaben und Standards für den Einkauf von Know-how oder Dienstleistungen bei externen Techno-logieanbietern aufgeführt.
Die Implementierung eines einheitlichen Standards auf globaler Ebene ist nicht zu erwarten, da die Nutzungsansätze noch unterschiedlich bewertet und akzeptiert werden. Die Regierungen sind sich uneinig, welche Datenquellen für welche Zwecke genutzt werden dürfen und wie die zur Nut-zung erforderlichen Algorithmen reguliert und überwacht werden können. Ohne klare Definitionen, Zertifizierungen, Frameworks und einheitliche Auditing-Systeme stehen viele Vorbehalte im Raum.

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
15
Insbesondere im Bereich KI gibt es noch starke Vorbehalte. Die Nachvollziehbarkeit von Entscheidungen bzw. der Weg zur Findung von Mustern stellt eine der wesent-lichen Herausforderungen dar. Werden auf Basis von KI mittels RPA Entscheidungen umgesetzt, muss sichergestellt sein, dass sowohl für den Fachbereich als auch für die (interne) Revision und die Aufsicht dieser Prozess jederzeit nachvollziehbar ist.
Als Schnittstelle von der KI zur realen Welt ist der Mensch nicht zu ersetzen
Die Blackbox KI muss für den Revisor zur Whitebox transformiert werden, um die notwendige Nachvollziehbarkeit herzustel-len. In Zeiten immer komplexer werdender Algorithmen und Quellcodes ist dies eine nicht zu unterschätzende Aufgabe, da neben der Dokumentation auch das Testing der Entscheidungswege in den Vordergrund rückt.
Auch andere Bereiche stellen die Revision vor Herausforderungen. Ansätze für die Prüfung von RPA-basierten Systemen sind noch rar, und nicht jeder Revisor kennt die technologischen Besonderheiten der darunterliegenden RegTech. Somit ist auch eine Weiterentwicklung der Aufsicht und der Revisoren notwendig.
Denkt man über den klassischen Compli-ance-Bereich hinaus, tauchen andere recht-liche Unklarheiten auf. Arbeiten im Umfeld des Internets der Dinge verschiedene Sys-teme zusammen und werden hier system-seitig Entscheidungen getroffen, dann ist zu klären, wer im Falle eines Fehlers haftbar/schadensersatzpflichtig ist. Insbesondere bei der Automatisierung von Supply Chains in der Industrie oder der Digitalisierung von Beratungsprozessen im Finanzumfeld ist dieses Risiko nicht zu unterschätzen.
In Kombination mit einem selbstlernenden KI-Algorithmus und der heute anfallenden Datenflut in Zeiten von Big Data ist auch ein (stichprobenbasiertes) regelmäßiges Überprüfen kaum möglich, da sich zum Testzeitpunkt die Muster unter Umständen bereits verändert haben. Lediglich ein retrospektives Prüfen ist somit möglich. Es sei denn, der automatisierten, eigenständi-gen und kontinuierlichen Verbesserung wird ein Riegel vorgeschoben und Änderungen müssen – old fashioned – explizit von Men-schenhand freigegeben werden.
Zusammenfassend lässt sich sagen, dass hier noch viel Aufklärungsarbeit bei Regulatoren und Revisoren in Bezug auf KI beispielsweise von Bankenverbänden zu leisten ist, damit hier zeitnah Fortschritte erzielt und Chancen genutzt werden.

16

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
17
Mehr als nur ein Spielzeug? Anwendungsszenarien im Aufgabenfeld des Chief Compliance Officer
Die Motivation zur Evaluation und potenziel-len Implementierung von KI-basierten Reg-Tech-Lösungen in der Wirtschaft ist derzeit noch stark problemgetrieben. Ausgehend von existierenden, meist seit Langem schwelenden Effektivitäts- und Ressourcen-problemen tastet man sich allmählich an die neuen Technologien heran. Nur zaghaft wagen sich diejenigen Compliance Officers an das Thema heran, die nicht von z.B. ausufernden False Positives2 und den damit verbundenen Bergen an abzuarbeitenden Alerts und Fällen betroffen sind. Der Blick in die Zukunft zeigt jedoch zwingend: Mittelfristig werden regulatorische Anfor-derungen weiter steigen und verfügbare Budgets für Compliance weiter sinken. Der Compliance-Vorstand ist also gut beraten, bereits heute in die Compliance von morgen zu investieren.Vereinfacht lassen sich die Vorteile von KI und Co. in zwei Kategorien einordnen:
1. Kostensenkung durch Reduktion ineffizienter (meist manueller) Ent-scheidungsprozesse: Optimierung der Arbeitsabläufe in der Compliance durch Automatisierung von Abläufen (z.B. RPA-based) und der vorge-lagerten KI- und Predictive-Analytics- basierten Verbesserung von Detection- Modellen und ähnlichen sowie dadurch frei werdende Mitarbeiterkapazitäten für wertschöpfende Aktivitäten
2. Effizienzgewinnung durch Erhöhung der proaktiven Compliance- Wertschöpfung: Erhöhung der Aufdeckungsrate von Compliance-Risiken (z.B. Betrugsfälle) bzw. aktive Verhinderung von Verstößen gegen Gesetze und Verordnungen
Insbesondere im Financial-Crime-Themen-feld sind neuartige Finanzprodukte prädesti-niert für einen Missbrauch. Immer dort, wo in Fachabteilungen noch die Erfahrung und die Routine fehlen, können solche neuen Produkte für kriminelle Handlungen missbraucht werden. So kann es z.B. beim Handel von CO2-Zertifikaten aufgrund der fehlenden Erfahrung zu betrügerischen Handlungen kommen. Daher stellt das Thema Wissensmanagement einen ent-scheidenden Faktor dar, um Compliance in Unternehmen sicherzustellen. RegTech- Lösungen bieten hier eine Grundlage, um Compliance effizienter als bisher umzusetzen und um die Erfahrung durch KI schneller aufzubauen. Bevor über konkrete Anwendungsfälle gesprochen werden kann, sei vorweggenommen, dass KI in vielen Fällen ihr volles Wirkungspotenzial erst in Kombination mit weiteren innovativen Tech-nologien entfaltet. Das „Traumpaar“ auf der Bühne des Technologie-Tangos sind KI und Robotics. Hier liefern Deep Learning und Co. die Steuerungsregeln für nachgelagerte automatisierte Verarbeitungsprozesse.
Treten neue Fallkonstellationen auf, werden diese erkannt und in die Verarbeitung einbezogen (kontinuierliches Lernen und Verbessern). Bedingt durch die Datenab-hängigkeit von KI bilden auch Big-Data-/Business-Analytics-Kombinationen eine Grundlage, um nicht nur einzelne Prozess-schritte in der Compliance, sondern ganze Prozessabschnitte zu optimieren.
Abbildung 6 zeigt als Einstieg die exemp-larisch gewählten zwölf Lösungsansätze (Einsatzszenarien).
2 Von einem Detection-System generierter „Falscher Alarm“, der sich bei der notwendigen, zeitintensiven Prüfung auch als solche bestätigt.

18
Abb. 6 – Anwendungsszenarien im Aufgabenfeld des Chief Compliance Officer
Use Case Problemstellung Einsatzgebiet Technologie
1. Compliance (Detection) Model Tuning zur Reduktion von False Positives (Seite 20)
• Hohe False-Positive-Rate und umfangreiche, manuelle Nacharbeit
• Schlechte Kundensegmentierung
• Keine Trennung der wiederkehrenden gleichen oder ähnlichen Alerts
• AML/KYC
• Fraud
• Sanktionsüberwachung
• Kapitalmarkt-Compliance
2. Monitoring und Tracking regulatorischer Veränderungen (Seite 23)
• Vielzahl an Regulatoren und deren Anforderungen
• Barrieren durch den eigentlichen Inhalt
• Widersprüchliche Regularien
• Banken/Versicherungen
• Exportwirtschaft
• Energie
• Health Care/Pharma und Telekommunikation
3. Optimierung der Compliance-Datenqualität – Identifikation von Dateninkonsistenzen (Seite 24)
• Fehlerhafte und mangelhafte Compliance-relevante Daten
• Hohe Anzahl an False Positives
• AML/KYC
• Fraud
• Sanktionsüberwachung
• Kapitalmarkt-Compliance
4. Text-Mining-gestützte Dokumentenkonsolidierung und Metadaten-Extraktion (Seite 26)
• Fehlende Digitalisierung von Dokumenten
• Manuelle Bearbeitung wesentlicher Informationen
• Zeitaufwendige Konsolidierung von Dokumenten
• Vertragsmanagement/Trade Finance und Logistik
• AML/KYC
• Datenschutz
• Sanktionsüberwachung
5. Auswertung von öffentlich zugänglichen Informationen auf Relevanz (Seite 28)
• Beschränkung auf Standard-Recherchetools und Datenquellen
• Hoher manueller Aufwand bei regelmäßigen Überprüfungen
• Prüfung von Mitarbeitern vor der Einstellung
• AML/KYC
• Vertragsmanagement/Know your Businesspartner
• Reputationsmanagement
6. Predictive Analytics und KI im Umfeld der Risikosimulation (Seite 30)
• Verzögerung der Risikoanalysen und -simulationen
• Aufwendige Aufbereitung von Daten
• Risikomanagement
• Reputationsmanagement
7. Automatisierung im Umfeld des Compliance Testing mit intelligentem Design der Testfälle (Seite 30)
• Aufwändige Prüfung von Rechten • IT-Prüfung von Kontrollen
• Nachgelagerte Prüfung von toxischen Berechtigungen im SoD-Umfeld
8. Risk Sensing als Werkzeug zur frühzeitigen Erkennung von geografischen Risiken (Seite 31)
• Rasante Technologieentwicklung
• Globale politische Unsicherheit (z.B. Brexit)
• Geringe Verfügbarkeit von Informationen
• Corporate Strategy in Kombination mit Risikomanagement
• Financial Crime
• HR
• Kreditmanagement/Trade Finance
9. Automatisierte Erstellung von Reports und KPI-Dashboards durch NLP (Seite 32)
• Hohe Anzahl an Verdachtsfällen von Geldwäsche
• Hoher Aufwand zur Konsolidierung von Dokumenten
• Verspätete Geldwäschemeldungen
• Reporting und Risikosteuerung
• AML/KYC
• Alert-Bearbeitung
• Meldewesen an Aufsicht und Regulatoren
10 360°-Kundenblick sowie Ermittlung von Beziehungsgeflechten und Werteflüssen (Seite 34)
• Fehlende Verknüpfung zwischen Kunden-Entitäten und weiteren Beteiligten
• Unstrukturierte und komplexe Datenbestände
• Marketing/Vertrieb/Data Analytics
• AML/KYC
• Investigation/Trade Finance
• Fraud/Kartellrecht
11. Automatisierung im Umfeld Fraud-/ Bribery-Erkennung (Seite 35)
• Manuelle Prüfung von Belegen
• Hohe Anzahl der nicht erkannten Betrugshandlungen
• Online-Transaktionen
• eCommerce
• Versicherungsbetrug
12 Robotics- und KI- basierte Löschkonzepte (Datenschutz) (Seite 36)
• Verschärfte Anforderungen
• Dezentrale Datenverwaltung
• Datenschutz
• Schutz von Geheimnissen

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
19
Use Case Problemstellung Einsatzgebiet Technologie
1. Compliance (Detection) Model Tuning zur Reduktion von False Positives (Seite 20)
• Hohe False-Positive-Rate und umfangreiche, manuelle Nacharbeit
• Schlechte Kundensegmentierung
• Keine Trennung der wiederkehrenden gleichen oder ähnlichen Alerts
• AML/KYC
• Fraud
• Sanktionsüberwachung
• Kapitalmarkt-Compliance
2. Monitoring und Tracking regulatorischer Veränderungen (Seite 23)
• Vielzahl an Regulatoren und deren Anforderungen
• Barrieren durch den eigentlichen Inhalt
• Widersprüchliche Regularien
• Banken/Versicherungen
• Exportwirtschaft
• Energie
• Health Care/Pharma und Telekommunikation
3. Optimierung der Compliance-Datenqualität – Identifikation von Dateninkonsistenzen (Seite 24)
• Fehlerhafte und mangelhafte Compliance-relevante Daten
• Hohe Anzahl an False Positives
• AML/KYC
• Fraud
• Sanktionsüberwachung
• Kapitalmarkt-Compliance
4. Text-Mining-gestützte Dokumentenkonsolidierung und Metadaten-Extraktion (Seite 26)
• Fehlende Digitalisierung von Dokumenten
• Manuelle Bearbeitung wesentlicher Informationen
• Zeitaufwendige Konsolidierung von Dokumenten
• Vertragsmanagement/Trade Finance und Logistik
• AML/KYC
• Datenschutz
• Sanktionsüberwachung
5. Auswertung von öffentlich zugänglichen Informationen auf Relevanz (Seite 28)
• Beschränkung auf Standard-Recherchetools und Datenquellen
• Hoher manueller Aufwand bei regelmäßigen Überprüfungen
• Prüfung von Mitarbeitern vor der Einstellung
• AML/KYC
• Vertragsmanagement/Know your Businesspartner
• Reputationsmanagement
6. Predictive Analytics und KI im Umfeld der Risikosimulation (Seite 30)
• Verzögerung der Risikoanalysen und -simulationen
• Aufwendige Aufbereitung von Daten
• Risikomanagement
• Reputationsmanagement
7. Automatisierung im Umfeld des Compliance Testing mit intelligentem Design der Testfälle (Seite 30)
• Aufwändige Prüfung von Rechten • IT-Prüfung von Kontrollen
• Nachgelagerte Prüfung von toxischen Berechtigungen im SoD-Umfeld
8. Risk Sensing als Werkzeug zur frühzeitigen Erkennung von geografischen Risiken (Seite 31)
• Rasante Technologieentwicklung
• Globale politische Unsicherheit (z.B. Brexit)
• Geringe Verfügbarkeit von Informationen
• Corporate Strategy in Kombination mit Risikomanagement
• Financial Crime
• HR
• Kreditmanagement/Trade Finance
9. Automatisierte Erstellung von Reports und KPI-Dashboards durch NLP (Seite 32)
• Hohe Anzahl an Verdachtsfällen von Geldwäsche
• Hoher Aufwand zur Konsolidierung von Dokumenten
• Verspätete Geldwäschemeldungen
• Reporting und Risikosteuerung
• AML/KYC
• Alert-Bearbeitung
• Meldewesen an Aufsicht und Regulatoren
10 360°-Kundenblick sowie Ermittlung von Beziehungsgeflechten und Werteflüssen (Seite 34)
• Fehlende Verknüpfung zwischen Kunden-Entitäten und weiteren Beteiligten
• Unstrukturierte und komplexe Datenbestände
• Marketing/Vertrieb/Data Analytics
• AML/KYC
• Investigation/Trade Finance
• Fraud/Kartellrecht
11. Automatisierung im Umfeld Fraud-/ Bribery-Erkennung (Seite 35)
• Manuelle Prüfung von Belegen
• Hohe Anzahl der nicht erkannten Betrugshandlungen
• Online-Transaktionen
• eCommerce
• Versicherungsbetrug
12 Robotics- und KI- basierte Löschkonzepte (Datenschutz) (Seite 36)
• Verschärfte Anforderungen
• Dezentrale Datenverwaltung
• Datenschutz
• Schutz von Geheimnissen
Machine Learning Künstliche Intelligenz Big Data Predictive Analytics Robotic Process Automation Application Interface

20
Insbesondere im Financial-Crime-Umfeld sorgen ungenaue bzw. ungenügend konfigurierte Systeme für einen hohen Per-sonalaufwand. Die Finanzinstitute setzen hier heute noch primär auf eine manuelle Sortierung. Eine Vielzahl von internen Mitarbeitern und teuren externen Beratern prüft die Alerts der Monitoring-Systeme auf Relevanz.
1. Compliance (Detection) Model Tuning zur Reduktion von False Positives
Abb. 7 – Lösungsansatz KI und Detection Model Tuning
Big Data: Transaktionen, Prozessdaten, statische Daten, ...
Big Data + Trainings-proben (e.g. SARs, Kriminalitätstypologien)
Niedrig zutreffendePositivrate
Hohe Anzahl vonFehlalarmen
AlertsKundenscreening & -überwachung
Ist-Erkennungsmodell
KI-basiertes TuningSelbstlernend
Intransparenz beiunentdeckten Fällen
Aktualisiertes ErkennungsmodellOptimierte Parametrisierungfür Screening oderMonitoring-Tool
Im Einsatz: KI, Maschine Learning, Big Data und Predictive Analytics

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
21
Die Probleme hierbei sind vielschichtig:
a) Die Systeme generieren aufgrund ungenauer Kundensegmentierun-gen (oder sogar falscher Segmentie-rung) Alerts, die bei einer richtigen Eingruppierung des Kunden so nicht auftreten würden, da die Regeln für den Kunden bei einer richtigen Zuweisung im Normalfall nicht ausschlagen.
Hier können durch KI-getriebene Datenanalysen die Gruppierungen der Kunden entweder optimiert oder Falsch-segmentierungen erkannt werden.
b) Aufgrund schlechter Parametrisie-rung werden „falsche“ Alerts generiert (der klassische False Positive). Beispiels-weise können Schwellenwerte für das jeweilige Kundensegment zu niedrig angesetzt oder die Betrachtungsdauer im Falle von Profilbildungen zu kurz oder zu lang sein. Auch besteht hier das Risiko, dass aufgrund einer mangel-haften Parametrisierung die „richtigen“ Alerts gar nicht erst generiert werden.
Regressionsanalysen und eine KI-ge-stützte Kalibrierung der Systeme helfen an dieser Stelle, die richtige Konfigu-ration für die Systeme zu definieren. Hierbei werden die Regelwerke der eingesetzten Tools dazu verwendet, mittels Massendaten und unter Hinzu-fügung von bekannten (historischen) Alerts die optimale Balance zu finden.
c) Die nachgelagerten Workflow- Systeme (meist auch als Case-Manage-mentsysteme bezeichnet) sind nicht in der Lage, bereits von den Sachbe-arbeitern erkannte (und geprüfte) False Positives bzw. wiederkehrende glei-che oder ähnliche Alerts als solche herauszufiltern und zu unterdrücken. Der Bearbeiter muss somit zwangs-weise den gleichen Alert jedes Mal von Neuem prüfen, kommentieren und manuell schließen. Die Begründung kann hier auf Basis von NLP erfolgen – die Dokumentation RPA-basiert (siehe auch Use Case #9).
Hier kann z.B. ein kontinuierlich lernen-des System ad hoc wiederkehrende False Positives erlernen und unter-drücken. Auch RPA-basierte Systeme können zumindest dabei helfen, diese Alerts vorzus selektieren und in Bezug auf den Grund für das Schließen eine vordefinierte Kommentierung vorzu-nehmen. Zur Sicherstellung der Akzep-tanz mit dem Regulator sind manuelle (regelmäßige) Prüfungen unabdingbar. Auch die klügste KI kann vom unerfah-renen Bearbeiter falsch lernen.
Anwendbar sind solche Tuning-Ansätze im klassischen Transaction Monitoring im Zahlungsverkehr, beim Screening von Personen, Unternehmen und Transaktionen in Bezug auf Sanktionie-rung als auch im Umfeld der Fraud-De-tection sowohl im Finanz- als auch z.B. im Onlinehandel. Weitere Anwen-dungsfälle sind in allen Bereichen denkbar, bei denen hohe Volumina an Alerts generiert werden (z.B. die Überwachung von Handelsgeschäften im Umfeld Insidertrading).

22

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
23
War es in Zeiten ohne grenzüberschrei-tende Gesetzgebung und Regulierung noch relativ einfach, den Überblick über die zu berücksichtigenden Gesetze, Verordnun-gen und Co. zu behalten, sind spätestens seit der Globalisierung und dem Ausbau des weltweiten Handels die Aufwände massiv gestiegen, um Compliance, Risiken in den Griff zu bekommen bzw. den Durch-blick im Paragrafen-Dickicht zu behalten.
Die Herausforderungen liegen hier zum einen bei externen Faktoren:
• Vielzahl an Regulatoren und deren Anfor-derungen
• Barrieren durch den eigentlichen Inhalt (fremde Sprache)
• Widersprüchliche Regularien (z.B. Iran-Sanktionen der USA vs. Atomabkom-men mit den verbleibenden Vertragspart-ner EU, Russland & Co.)
Interne Faktoren, die das Monitoring der regulatorischen Anforderungen hemmen, existieren parallel:
• Unklare Governance bei global agieren-den Konzernen (zentrale vs. dezentrale Prüfung der Compliance-Risiken)
• Unterschiedliche Auslegung der Anwen-dungsrelevanz
• Mangelnde Übersicht über den Umset-zungsstatus in den einzelnen Bereichen/Gesellschaften
• Häufig fehlendes Fachwissen des Einzelnen über die Relevanz für andere Bereiche
• Unzureichende IT-technische Unter-stützung bei der Identifikation und Konsolidierung der regulatorischen Anforderungen (Medienbrüche)
Allein die Auswertung und Analyse eines neuen Gesetzestextes kann sehr zeit-auf-wendig sein. Dabei ist häufig nicht nur die Analyse zeitraubend, sondern auch die Identifikation von Änderungen will gekonnt sein. Ist der Gesetzestext in seine Einzelanforderungen „filetiert“, beginnt erst die eigentliche Arbeit: Die Prüfung auf Relevanz und Handlungsnotwendigkeit, Verortung in der Organisation, Monitoring der Umsetzung und Berichterstattung.
Bereits seit vielen Jahren gibt es Unter-nehmen, die als Dienstleistung die Identi-fikation und Analyse von Gesetzestexten anbieten. Hier entsteht aber zumeist bereits der erste Medienbruch. Aus der Datenquelle des externen Dienstleisters müssen die Informationen wiederum in interne GRC-Lösungen überführt werden. Sind dann die Anforderungen erst einmal im Haus, gilt es, diese in Bezug auf die Umsetzungszuständigkeit zu verorten. Ins-besondere bei global aktiven und dezentral arbeitenden Konzernen/Holdings wird der Zuweisungsprozess langwierig.
Weitere Einsatzmöglichkeiten im Umfeld des Monitorings von regulatorischen Ver-änderungen:
• Auswirkungsanalyse auf bestehende Richtlinien, Policies, und die schriftlich fixierte Ordnung bei Veränderungen (insbesondere via Text Mining)
• KI & Predictive Analytics zur Prognose der „Cost of Compliance“ beim Eintritt in neue Märkte oder bei der Einführung neuer Produkte. Datengestützte Lösun-gen können hier bei der Ermittlung der Kosten/Nutzen- Analyse unterstützen.
2. Monitoring und Tracking regulatorischer Veränderungen (Regulatory Monitoring)
Abb. 8 – Lösungsansatz KI und Regulatory Monitoring
Identifizierung neuer oder geänderter Vorschriften
Feststellung der Anwend-barkeit und Relevanz
Analyse der Auswirkungenauf interne Strukturen
Priorisierung &Implementierung
Überprüfung &Teststeuerung
#1 Automatisierte IdentifizierungAutomatisierter Prozess zum Abrufen und Organisieren von Änderungen am Regulator
#4 Konvertierung in DokumenteVerarbeitung natürlicher Sprache zur Umwandlung von Vorschriften in Dokumente (z.B. Richtlinien, Schulungen)
#3 Automatisierte AuswertungRoboterbasierte Prüfung von Kontrollen und Implementierung
#2 KI-basierte Bewertung & Auswirkungsanalyse Verwendung der RegTech-Lösungen, um die allgemeine Relevanz für Unternehmen oder Länder zu analysieren
Machine Learning Künstliche Intelligenz Robotic Process Automation

24
3. Optimierung der Compliance- Datenqualität – Identifikation von Dateninkonsistenzen Wie bereits mehrfach genannt, sind Daten sowohl ein essenzieller Input für KI-ge-stützte Lösungen als auch die Grundlage für die Compliance-Organisation für eine risikoorientierte Bewältigung der täglichen Arbeit.
Häufig sind die Datenbestände der Unter-nehmen historisch gewachsen und Daten-sätze dadurch unter Umständen veraltet. Durch kontinuierliche Weiterentwicklung der Systeme (und insbesondere der Einga-bemasken) oder veraltete Ausprägungen aus darunterliegenden Referenzlisten sind Datenfelder häufig mangelhaft belegt. Dies ist meist dann der Fall, wenn auf eine systematische Datenbereinigung nach einer Systemveränderung (aufgrund des zu erwartenden Aufwands für die Abteilun-gen) verzichtet wurde.
Ein Beispiel für fehlerhafte Daten ist die Kombination aus natürlicher Person (als Kunde) mit der Hinterlegung eines (ultima-tiv) wirtschaftlich Berechtigten für diesen Kunden. Zu hinterfragen ist nun: Ist die Zuordnung des wirtschaftlich Berechtigten falsch – sollte es eher ein Zeichnungs- oder Zugriffsbevollmächtigter sein – oder ist die Zuordnung des Kunden in die Gruppe der natürlichen Personen falsch (meist über die Rechtsform identifizierbar)?
Ein anderes Beispiel für fehlerhafte Com-pliance-relevante Daten sind Angaben zu nicht mehr existierenden Ländern, wie beispielsweise das ehemalige Jugoslawien, in Kundendatensätzen. Treten solche Informationen bei der automatisierten Kundenbewertung auf (z.B. Transaktions-überwachung), fehlt häufig ein aktueller Risikowert für das nicht mehr existierende Land.
Da (gute) Daten die Nahrung für viele Risikomodelle/Risikoratingverfahren sind, seien es Kreditrisiken oder Geldwäscheri-siken, beginnt hier nun das Dilemma. Sind Pflichtdaten unvollständig im System, kann entweder keine (automatisierte) Bewertung erfolgen oder Default-Werte müssen herangezogen werden, welche wiederum das Risiko verzerren. Sind Daten fehlerhaft, werden falsche Informationen für ein Rating herangezogen. Datenlücken können vor allem im Sanktionsumfeld die Erken-nungsrate empfindlich senken. Auch eine Auswirkung auf die Gefährdungsanalyse kann aus mangelhaften Daten resultieren.
KI bietet hier verschiedene Ansatzpunkte für die Evaluation und Optimierung der Datenqualität:
• Selbstlernende Datenqualitätskontrollen zur Aufdeckung von fehlerhaften Daten-kombinationen anstelle von starren, manuell zu ermittelnden regelbasierten Checks
• Automatisierung des Datenabgleichs bei Änderungen an Referenzlisten für Auswahlwerte (Ermittlung von nicht mehr gepflegten, aber noch genutzten Werteausprägungen wie Länder- oder Industrieschlüssel)
• Intelligente Ableitung von Default-Werten auf Basis des Kundenumfeldes (z.B. Ableitung von Länderzuordnungen aus Transaktionsdaten)
• Unterstützung bei Kunden- oder Lieferantenreviews durch Voranalysen zu veralteten oder möglicherweise inkonsis-tenten Daten
• Ermittlung von fehlerhaften Kunden-segmentierungen durch den Ab- und Vergleich der Merkmale anderer Kunden in der gleichen Gruppe und Abänderung der Zuordnung bei Bedarf (siehe auch Themenblock Model Tuning bzw. Abb. 7)
• Automatische Generierung von Daten-qualitätsberichten und Alerts

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
25
Abb. 9 – Lösungsansatz KI-basierte Optimierung der Kundensegmentierung
Upload vonDaten
Auswahl vonMerkmalen
Durchführungder Analyse
Segmentierungs-auswahl
Überprüfungvon Segmenten
ModelFine
Tuning
Die Daten werden zur Segmentie-
rungsanalyse auf die maschinelle Lernplattform hochgeladen
Merkmale, die von der maschinellen
Lernplattform berücksichtigt werden sollen,
werden ausgewählt
Topologische Daten-analyse (TDA) basierend
auf Machine Learning wird verwendet, um
eine Liste potenzieller Segmentierungen zu
erstellen
Die vom maschinel-len Lernsystem produzierten
Segmente werden überprüft und die beste Segmentie-rung ausgewählt
Zusammenarbeit mit dem Unternehmen zur Genehmigung und Überprüfung
einzelner Segmente. Ausgangssegmente
für das TM Fine
Vereinfacht lassen sich die Vorteile von KI und Co. in zwei Kategorien einordnen: 1. Kostensenkung durch Reduktion ineffizienter (meist manueller) Entscheidungsprozesse und 2. Effizienzgewinnung durch Erhöhung der proaktiven Compliance-Wertschöpfung.

26
4. Text-Mining-gestützte Dokumentenkonsolidierung und Metadaten-Extraktion Die Analyse papiergebundener Doku-mente, welche manuell nach wesentlichen Metainformationen geprüft werden müs-sen, um Compliance-relevante Informatio-nen für nachgelagerte Prozesse zu gewin-nen, ist sehr zeitaufwendig. Selbst wenn bereits Dokumente in digitaler Form vorlie-gen (als Textdokument oder als gescannte Grafik), ist die Auswertung bedingt durch die häufig vorliegende Flut an Dokumenten zeitaufwendig und fehleranfällig.
Die Konsolidierung von Dokumenten wie beispielsweise von Verträgen mit Lieferanten ist insbesondere im Umfeld dezentraler Strukturen ressourcenintensiv. Auch heterogene Strukturen der Verträge erleichtern das Kategorisieren und Ex tra-hieren von Informationen nicht. So hat z.B. bereits die EU-DSGVO gezeigt, wie sehr eine strukturierte Speicherung und Auswertung von Vertragsdokumenten mit Dritten Mitarbeiterkapazitäten bindet. Im Zuge der Einführung der EU-DSGVO muss-ten Verträge auf ihre Relevanz in Bezug auf die Datenerfassung und -verarbeitung geprüft und gegebenenfalls nachverhan-delt werden.
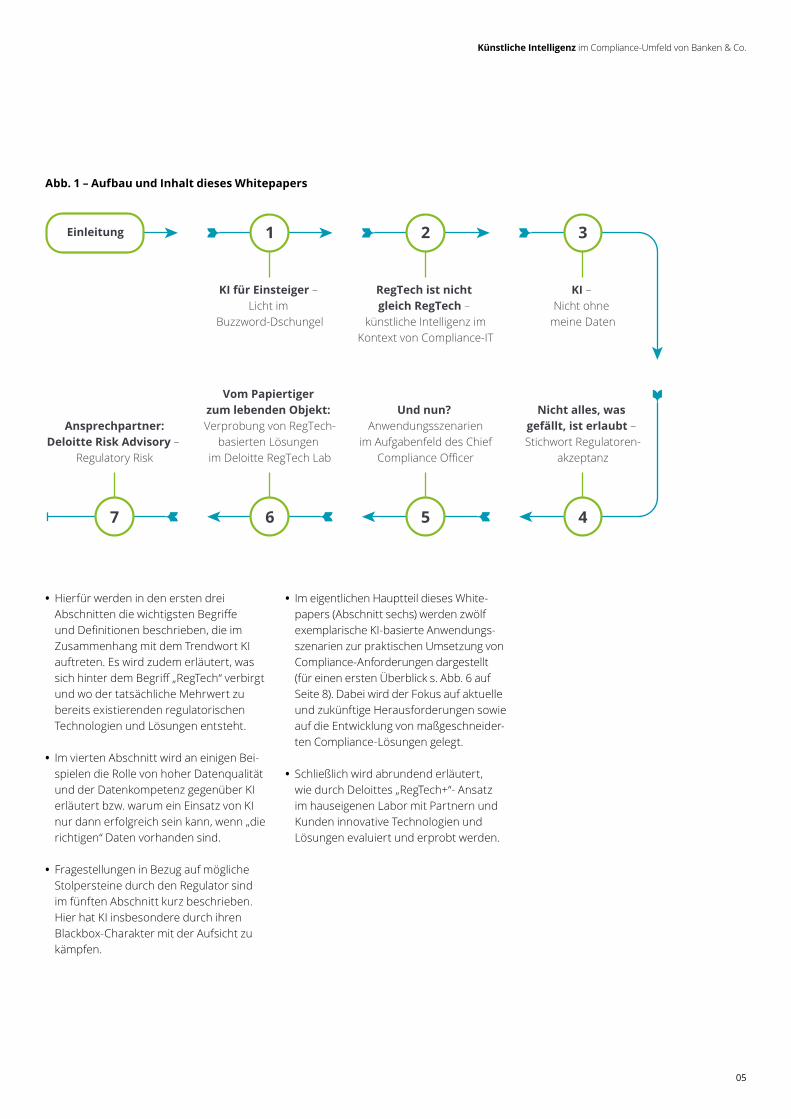
Auf Text Mining basierende Ansätze können dann einen Mehrwert generieren, wenn gleichartige Inhalte (z.B. Lieferan-tenverträge oder Kundenidentifikations-papiere) eingelesen, ausgewertet und weiterverarbeitet werden sollen. KI/Text Mining übernimmt an dieser Stelle die Aus-wertung der Dateninhalte (s.a. Abb. 10). KI transformiert in diesem Beispiel unstruktu-rierte Daten in strukturierte, auswertbare Informationen. Neben der Automatisierung im Vertragsmanagement finden sich Ansatzpunkte auch im Bereich Daten-schutz.
Was bei strukturiert vorliegenden Daten-beständen wie Stammdatensystemen verhältnismäßig einfach sein mag, ist in Zeiten von Dateiablagen und Sharepoints ohne ausreichende Governance eine Sisy-phusarbeit. Woher sollten der Fachbereich oder die IT Kenntnis darüber haben, was in welchem Dokument auf einer Dateiablage gespeichert ist?
Die Kombination aus RPA (für die automa-tisierte Prüfung von Verzeichnissen und Dokumenten auf Veränderung), Text Mining und KI erleichtert hier die Ermittlung von Dokumenten mit personenbezogenen Daten und deren nachgelagerte Kennzeich-nung bzw. die Speicherung der Metadaten in einem Datenschutzverzeichnis. Mittels Deep Learning wird die Erkennung von personenbezogenen Daten trainiert. Dar-über hinaus können Metadatenextraktion und Klassifizierung so weit gehen, dass personenbezogene Daten dahingehend unterschieden werden können, ob sie z.B. in die Kategorie der „besonderen“ perso-nenbezogenen Daten, wie Religion oder sexuelle Orientierung, fallen.
Weiteres Anwendungsgebiet ist die Extraktion von Basisinformationen aus Frachtdokumenten zur Sanktions- und Geldwäscheüberwachung im Trade-Finance- Umfeld bzw. zur Überwachung von Logistikabläufen. Häufig liegen Frachtdokumente wie Ladelisten, Frach-ter-Routen und Zolldokumente nur in (häufig suboptimaler) papiergebundener Form vor bzw. wurden diese ehemals papiergebundenen Dokumente überstürzt digitalisiert und weitergeleitet. Wie beim allseits beliebten Kinderspiel der Flüsterpost gehen hier (teilweise beabsichtigt) Qualität und somit auch die Möglichkeit zur Prüfung verloren. Darüber hinaus stellen Fremd-sprachen bzw. fremde Schriftzeichen eine weitere Herausforderung in der zeitnahen Prüfung dar.
Ähnlich dem Anwendungsfall des Vertrags managements können Text-Mining- gestützte Lösungen hier einen wesentlichen Vorteil generieren. Wesent-liche Informationen werden aus den bereitgestellten Dokumenten extrahiert und ausgewertet. Dem Prüfer in der Fachabteilung werden diese Basisinformati-onen zur weiteren Bearbeitung konsolidiert zur Verfügung gestellt – die ursprünglich verwendeten „Rohdokumente“ werden revisionssicher zentral aufbewahrt.
Abschließend sei noch auf die Möglichkeit zur Auswertung von Kundendokumen-ten bei der „Know Your Customer“-(KYC-) Prüfung verwiesen. Hier eignet sich Text Mining als Mittel zur automatisierten Aus-wertung von Identifikationsdokumenten und zur anschließenden Übertragung in die KYC- bzw. Stammdatensysteme im Zuge des Onboardings.
Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
27
Abb. 10 – Lösungsansatz Metadaten-Extraktion im Legal-Agreement-Umfeld
Dokumenten-ToolRevisions-Training
Automatisierte Metadata Extraktion
Vertrags-Datenbank
Manuelle Überprüfungfür optimale Präzision
Abgelehnte Vereinbarung
System Training basierend auf der „X“-Klausel“
Ausgewählte Vereinbarungen
validiert und hinterlegt für das Reporting
Machine Learning Künstliche Intelligenz Robotic Process Automation

28
5. Auswertung von öffentlich zugäng-lichen Informationen auf Relevanz (Negative News Screening)Aus der jüngeren Vergangenheit gibt es einige repräsentative Beispiele, die belegen, dass ein regelmäßiges Prüfen der öffentlich zugänglichen Quellen, wie Internet und Nachrichtenfeeds, finanzielle und Reputationsschäden verhindern kann. Ein Beispiel hier ist die Überweisung einer deutschen Bank an die Investmentbank Lehman, als bereits die Insolvenz dieser absehbar war.
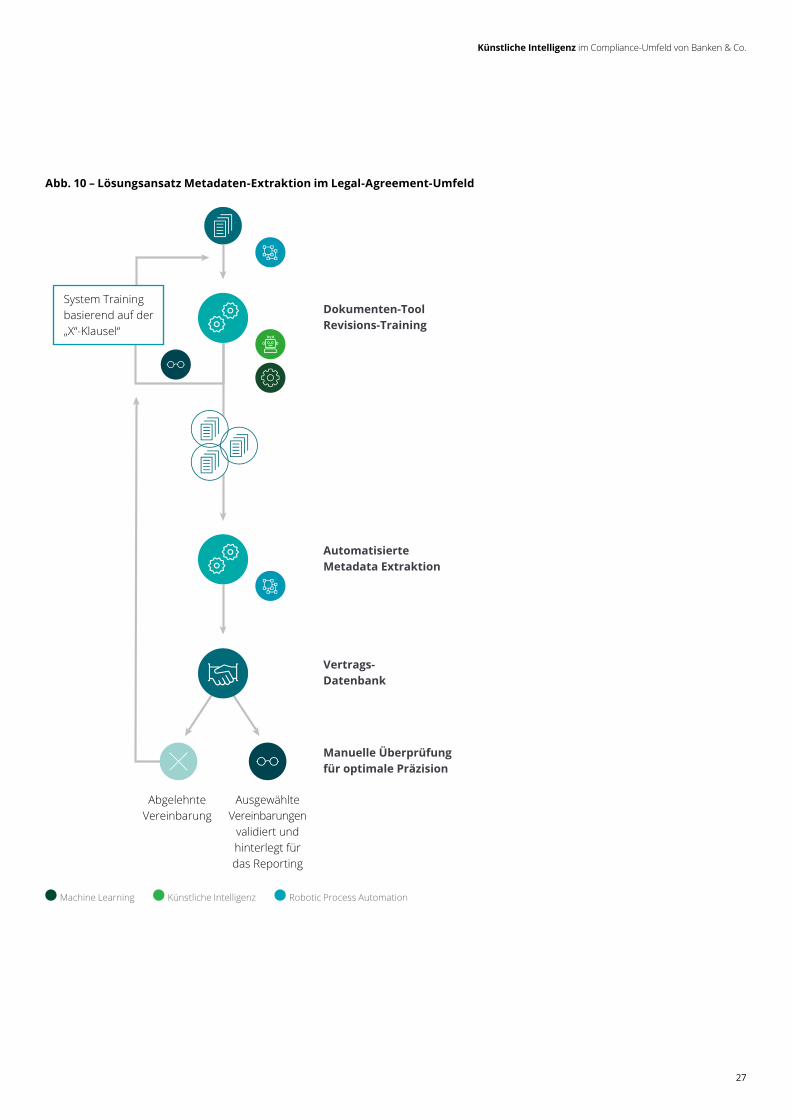
Aber wieso benötigt man hierfür KI, wenn es mittels Internet Explorer, Google und Co. auch funktioniert? In Zeiten von Fake- News-Vorwürfen, Propaganda-Trollen und aktiver Rufschädigung über soziale Medien wollen Informationen kritisch geprüft sein. Ein einzelner Eintrag im Google-Such ergebnis darf nicht überbewertet werden. Treten hingegen in verschiedenen Medien ähnliche Meldungen auf, sollte diese Information für die Risikobewertung des Geschäftspartners nicht außer Acht gelassen werden. Betrachtet man die Kundenseite, ist eine manuelle Abarbeitung via Suchportal aufgrund der Masse an zu prüfenden Kunden (insbesondere im Retail-Segment) nicht möglich. Auch ist die Sortierung der Suchergebnisse meist nicht nach tatsächlicher Relevanz organisiert, sondern durch verschiedene Faktoren beeinflusst.
Über neuartige Analyse- und Reporting-werkzeuge können automatisiert Prüfun-gen auf Reputationsrisiken vorgenommen werden. Hierbei werden verschiedenste Datenquellen (z.B. Web, Social Media, Dark-net, …) integriert und nach Relevanz für ein bestimmtes Compliance-Themenfeld geprüft und ausgewertet. Dem Complian-ce-Experten werden hierbei die manuelle Suche und Vorbewertung der Relevanz abgenommen. Große Kundenbestände können dadurch automatisiert geprüft und nur diejenigen Kunden im Detail analysiert werden, bei denen eine relevante Auffäl-ligkeit identifiziert wurde. Insbesondere im Bereich der Hochrisikokunden können solche KI-basierten Lösungen zu Kosten- und Zeitersparnissen führen.
Darüber hinaus bieten sich selbst lernende Lösungen für die fortlaufende Prüfung des eigenen Reputationsrisikos an. Der Kunde wird in die Lage versetzt, frühzeitig nega-tive Meldungen in den global verfügbaren Medien zu identifizieren und hierauf zu reagieren. Dies kann das eigene Unterneh-men, aber auch z.B. die Tochtergesellschaft oder eine Auslandsniederlassung betref-fen. Die RegTech-Lösung erlernt hierbei, welche Meldungen relevant sind (z.B. für
ein bestimmtes Compliance-Thema) bzw. ob die Quelle der Meldung vertrauens- bzw. glaubwürdig ist. Die Meldung eines einzelnen Bloggers ist ggf. noch als Fake zu betrachten, treten gleichartige Meldungen aber zeitnah durch vertrauenswürdige Quellen auf, kann es sich bereits um eine potenzielle Bedrohung handeln.
Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
29
Abb. 11 – Lösungsansatz Negative News Screening & Daten Evaluation aus Social Media & Co.
InhaltlicheÜberprüfungauf Relevanz
Monitoring/EDD
Daten-Aggregation für Downstream Prozesse und Berichterstattung
• AML• Betrug• Kreditrisiko • ...
Upload der Liste relevanter Personen
QA & DatenUpdate
Periodischer Negative News
Bericht
Aktualisierte Personen-
InformationDatenkonsolidierung
ÖffentlicheDatenbanken
Web
DarkWeb
Soziale Medien
Zeitungen
Aktualisierung derInformationen
Identifikation von Reputations-
Risiken
High RiskMedium RiskLow Risk
Globales RiskAssessment
Risikoklassifizierung & Berichterstattung
CRM/MasterDaten Systeme
Künstliche Intelligenz Big Data Robotic Process Automation Application Interface

30
6. Predictive Analytics und KI im Umfeld der Risikosimulation Eine effektive Wiederverwendung von Compliance-bezogenen Schadensdaten und historischen Risikoinformationen kann im Umfeld des Reputationsmanagements mithilfe von Big Data, Predictive Analytics und Deep Learning betrieben werden.
Noch immer werden Risikoanalysen und Risikosimulationen durch aufwendige Datenaufbereitungen verlangsamt. Auch sind Simulationen von den vorab definierten Risikoszenarien abhängig. Die Kombination aus KI und Predictive Ana-lytics kann hier z.B. helfen, aus historischen Schadensfalldaten (seien es Betrugsfälle, Schadensfälle aus Projekten oder auch IT-Incidents) betrügerische Handlungen abzuleiten. Weiter ist es möglich, hieraus zu simulieren, wie wahrscheinlich ähnliche Vorfälle in Zukunft sein werden bzw. wie hoch deren Schaden ausfallen kann. Der Mehrwert wird hier zum einen durch die Nutzung von unstrukturierten Daten generiert und zum anderen durch das Minimieren von aufwendigen Aufbereitun-gen, da KI-getrieben Daten aufbereitet und verknüpft werden können. Zum anderen werden für die eigentliche Simulation vorab durch Deep Learning neue Muster aus den Schadensdaten extrahiert und in die Simulation eingebettet.
7. Automatisierung im Umfeld des Compliance Testing mit intelligentem Design der TestfälleWer kennt es nicht: Die Prüfung eines Compliance-relevanten IT-Systems steht an und Testfälle zur Prüfung der Wirksamkeit von Kontrollen müssen erst erstellt und mit den „richtigen“ Eingabeparametern bestückt werden. Das eigentliche Testing ist dann (leider immer noch) meist manu-eller Natur. Testfall für Testfall werden ins System die Eingabeparameter ausgelesen und im System eingetippt, das Ergebnis protokolliert und mit dem erwarteten Ergebnis verglichen.
Die richtige Wahl der Testfallparameter ist bekanntlich eine Kunst für sich. Werden beliebige Werte selektiert, kann nur sehr aufwendig ermittelt werden, ob das System bei Grenzfällen richtig reagiert (beispiels-weise bei Freigabegrenzen). Text Mining und KI ermöglichen in solchen Szenarien das Ermitteln der relevanten Testfälle mit den richtigen Parametern zur Überprüfung der Grenzfälle. Input sind hier die Verfah-renskonzepte und Modelle des jeweiligen Systems, kombiniert mit einer RPA-ba-sierten Ermittlung der Prozessschritte im jeweiligen System. RPA ist dann wiederum involviert, wenn es um die Testfallausfüh-rung selbst geht.
Ähnliche Prüfungen können im Umfeld der Segregation of Duties (kurz SoD) vereinfacht werden. Die Herausforderung ist häufig, dass kein zentrales Rechte- Repository existiert bzw. IT-Systeme (und die darin verwendeten Rollen und Rechte) historisch gewachsen sind. Berechtigungen werden teilweise lokal verwaltet und die Prüfung auf toxische Kombinationen von Rechten ist ein aufwendiger Prozess, da die Beschreibung der Rechte meist in unterschiedlicher Granularität vorliegt (z.B. Einzelrechte vs. Rollen). KI-basierte Lösun-gen können hier erlernen, was das jeweilige Recht erlaubt auszuführen, und dann in einem nächsten Schritt die konsolidierten sowie standardisierten Rechte miteinander vergleichen. Es kann dann ermittelt wer-den, welcher Anwender toxische Kombina-tionen an Rechten aufweist.

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
31
8. Risk-Sensing als Werkzeug zur frühzeitigen Erkennung von geogra- fischen Risiken
Das Weltgeschehen kann sich in wenigen Minuten und Stunden rasant verändern – und hierdurch auch die Risikosituation eines Unternehmens. Den Überblick über die unzähligen Indikatoren und Meldun-gen aus den Medien und von Analysten im Auge zu behalten und hieraus auch Schlüsse für das eigene Unternehmen zu ziehen, fällt nicht immer leicht.
Aktuelle Informationen zur Bonität einzelner Länder können Auswirkungen auf Kredite haben. Die Einschätzung der Gefährdungslage in Krisenregionen wie-derum kann sogar Menschenleben retten. Ökonomische Prognosen zur Entwicklung von Regionen haben Auswirkungen auf die strategische Ausrichtung von Unterneh-men bei Expansionen und Exportüberle-gungen.
Global agierende Unternehmen oder auch öffentliche Einrichtungen, wie Ent-wicklungshilfe und Hilfsorganisationen, können auf Basis analysierter Massen-daten Entscheidungen treffen bzw. die Entscheidungsfindung beschleunigen und die Qualität der Entscheidung optimieren. Auch können Länderinformationen in Risi-komodelle für AML/KYC und Fraud integ-riert werden. Mithilfe solcher Darstellungen kann die Vielzahl an komplexen Informatio-nen kompakt aufbereitet und z.B. in einem Operation Center kontinuierlich überwacht werden.
KI kommt auch hier wieder in Kombination mit Big Data erst richtig zur Geltung. Über standardisierte Schnittstellen gelangen, wie in Abbildung 12 gezeigt, strukturierte Datensätze in den Datenpool zur späteren Analyse und Auswertung. Auch kann KI ein-gesetzt werden, um verschiedene Quellen wie unstrukturierte Newsfeeds und Webin-halte zu strukturieren. Die konsolidierten Daten werden dann mit historischen Daten verglichen und es werden Rückschlüsse sowohl auf die Ist-Situation als auch die zukünftige Entwicklung abgeleitet.
Abb. 12 – Lösungsansatz Visualisierung im Umfeld des KI-basierten Risk Sensing
VorbereitungSammelnvon Daten
• Risiko-Domäne• Strategische Ziele• Produkte & Services• Märkte & Geografien
• Daten-Quellen• Ontologin• Risiko-Themen
• Kognitives Berechnen• Advanced Analytics• Natural Language Processing • Konzept-Extraktion; Themenfindung
• Domänen-Erfahrung• Industrie-Kenntnisse• Professionelle Einschätzung
• Dashboards• Berichte• Visualisierung
• Verwaltetes strategisches und reputationelles Risiko• Gesteigerte operationelle Widerstandskraft• Flexible Strategien• Datenintegration in IT Systeme
Analyse Interpretation Integration &Reaktion
Künstliche Intelligenz Big Data Predictive Analytics Robotic Process Automation

32
9. Automatisierte Erstellung von Reports und KPI-Dashboards durch NLP Neben den üblichen Herausforderungen bei der Erstellung von Reports und der Befüllung von Templates (aufwendige Datenkonsolidierung, da keine standardi-sierte Datenbasis, Prüfung der Ergebnisse auf Konsistenz, Anpassung von Layout und Formatierung) stellt die manuelle Erarbei-tung von sinnvollen Texten zur Erläuterung von Sachverhalten eine wesentliche Herausforderung dar. Zwar können bereits heute regelbasierte Standardtexte verge-ben werden, aber diese sind zum einen „Standard“ und zum anderen gibt es nicht für alle Fälle eine Regel.
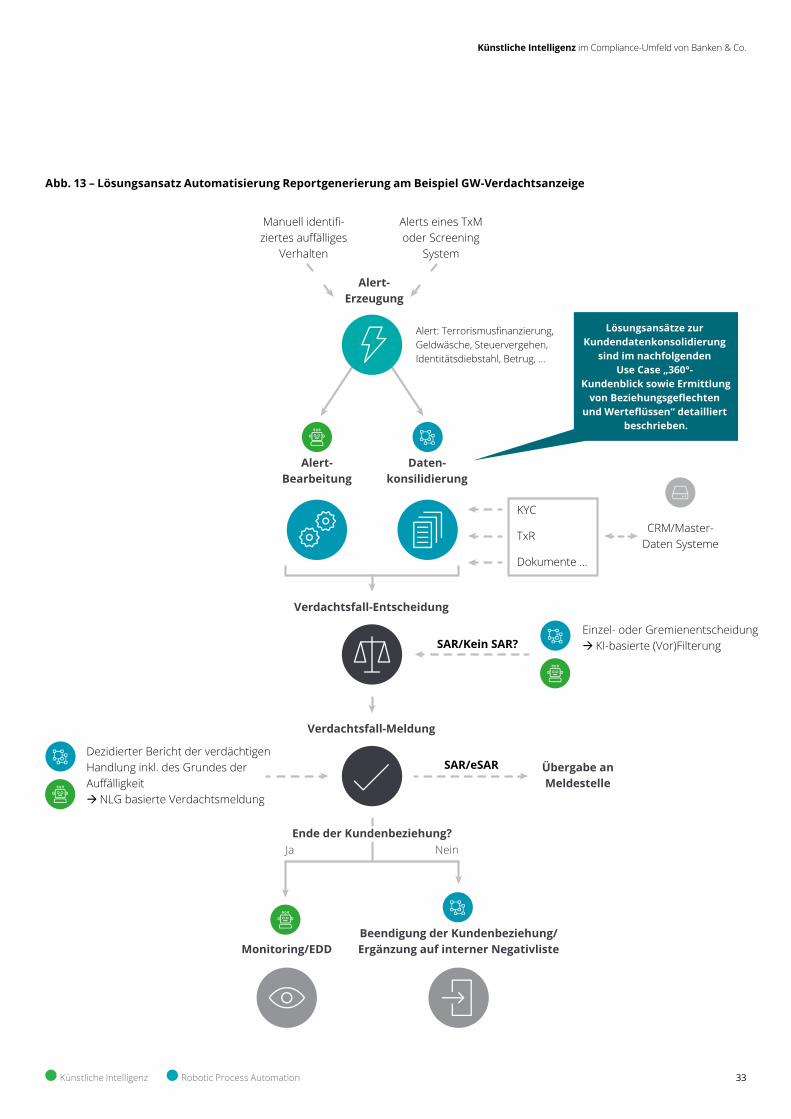
Insbesondere bei regulatorisch gefor-derten Meldungen wie der GW-Ver-dachtsfallbearbeitung stellen solche arbeitsintensiven Tätigkeiten einen Treiber für Personal- bzw. Beraterkosten dar. Die für einen Verdachtsfall relevanten Informa-tionen (z.B. Transaktionen, Belege, Konto-auszüge) müssen zuerst aus verschiedenen Systemen zusammengetragen und dann manuell in die vorgegebenen Formulare des Zolls übertragen werden – inklusive Begründungen und Erläuterungen.
Abbildung 13 erläutert den Weg von den Rohdaten hin zur Verdachtsfallanzeige und den nachgelagerten bankinternen Prozessen wie der Kündigung des Kontos oder der Durchführung der erweiterten Sorgfaltspflichten – falls das Konto nicht gekündigt werden kann.
Neben den vorgelagerten RPA- und KI-gestützten Prozessschritten wie Daten-konsolidierung zur Entscheidungsfindung bzw. -vorbereitung spielt NLP eine ent-scheidende Rolle, um sinnvolle und flüssige Begründungstexte und Co. zu generieren. In Kombination mit künstlicher Intelligenz wird erlernt, wie natürliche Sprache im Kontext der Verdachtsfallbegründung auszusehen hat.
Über die Verdachtsfallbearbeitung hinaus ist auch der Einsatz von NLP für vorgelagerte Entscheidungsprozesse (z.B. Betrugsprävention) interessant. KI-gestützte Lösungen können Systemmel-dungen (Alerts) der Überwachungssysteme vorselektieren und Begründungen für "unkritische" Fälle herausfiltern.
Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
33
Abb. 13 – Lösungsansatz Automatisierung Reportgenerierung am Beispiel GW-Verdachtsanzeige
Alert-Erzeugung
Alert-Bearbeitung
Verdachtsfall-Entscheidung
Verdachtsfall-Meldung
Übergabe anMeldestelle
Ende der Kundenbeziehung?Ja Nein
Daten-konsilidierung
CRM/Master-Daten Systeme
SAR/Kein SAR?
SAR/eSAR
Alerts eines TxM oder Screening
System
Manuell identifi-ziertes auffälliges
Verhalten
Alert: Terrorismusfinanzierung, Geldwäsche, Steuervergehen, Identitätsdiebstahl, Betrug, ...
Dokumente …
KYC
TxR
Beendigung der Kundenbeziehung/Ergänzung auf interner NegativlisteMonitoring/EDD
Einzel- oder Gremienentscheidungà KI-basierte (Vor)Filterung
Dezidierter Bericht der verdächtigen Handlung inkl. des Grundes der Auffälligkeità NLG basierte Verdachtsmeldung
Lösungsansätze zur Kundendatenkonsolidierung
sind im nachfolgenden Use Case „360°-
Kundenblick sowie Ermittlungvon Beziehungsgeflechten
und Werteflüssen“ detailliert beschrieben.
Künstliche Intelligenz Robotic Process Automation

34
10. 360°-Kundenblick sowie Ermitt-lung von Beziehungsgeflechten und WerteflüssenNicht nur im Vertrieb existiert der Wunsch nach einer vollständigen Informations-transparenz bezüglich der Kunden bzw. Vertragspartner, um hierdurch Verkaufspo-tenziale vollständig auszuschöpfen. Auch im Compliance-Umfeld ist die Transparenz zu Kunden und Geschäftspartnern unab-dingbar. Vor allem dann, wenn bereits ein höheres Risiko oder Auffälligkeiten in der Kundenhistorie existieren.
Die Verfügbarkeit der relevanten Daten in einem System ist leider auch in Zeiten von CRM-Systemen und Master Data Manage-ment noch nicht gegeben. Gründe hierfür sind nach wie vor historisch gewachsene IT-Strukturen oder auch M&A-Aktivitäten. Der gleiche Kunde ist in verschiedenen Systemen mit unterschiedlichen Kunden-identifikationsnummern (Identifiers/IDs) gepflegt. Und selbst wenn zumindest die internen Systeme eindeutige IDs verwen-den, ist die Koppelung mit externen Daten eine Herausforderung. Insbesondere dann, wenn Beziehungen und Werteströme mit (unstrukturierten) öffentlich verfügbaren Daten gekoppelt werden sollen, ist die Qua-lität der Ergebnisse häufig mangelhaft.
Typische Problemfelder durch verschie-dene Datenquellen sind:
• Erfassung der wirtschaftlich Berechtigten und weiterer wesentlicher Führungsper-sonen eines Unternehmens
• Fehlende Verknüpfung zwischen Kun-den-Entitäten und weiteren Beteiligten
• Aufdeckung von Unternehmensstruktu-ren bei Shell-Companies und Briefkasten-firmen
• Komplexe, unstrukturierte Datenbe-stände und Herausforderungen hieraus bei der Verknüpfung der Entitäten
• Rekonstruktion von Zahlungs- und Güterflüssen zwischen verschiedenen Beteiligten (Kunden und Nicht-Kunden)
• Komplexe, unstrukturierte Datenbe-stände und Herausforderungen hieraus bei der Verknüpfung der Entitäten
Hauptproblem ist zumeist die Verknüpfung von Kundennamen und ID mit weiteren beteiligten Dritten außerhalb der eigenen Datenhoheit. Ähnlich wie beim Name Screening ist die Fehlerrate bei der Ver-knüpfung hoch und eine manuelle Nachbe-arbeitung notwendig.
Durch neuartige Technologien wie KI/DL können die Qualität an diesem Pro-blempunkt verbessert und hierdurch
(weitestgehend) automatisiert Netzwerke und Verbindungen über verschiedene Datenbestände hinweg erstellt und visualisiert werden. Insbesondere im Inves-tigation-Bereich können solche Werkzeuge weiterhelfen, zeitnah und effektiv Auffällig-keiten zu identifizieren und die relevanten Informationen zu sichern. Die Wahrschein-lichkeit einer Aufdeckung von kriminellen Handlungen oder Non-Compliance ist dann wesentlich höher als im manuellen Fall. Entscheidender Vorteil von KI ist hierbei die Zusammenfassung von strukturierten und unstrukturierten Daten. Aus der Technikperspektive werden hier in einem ersten Schritt mittels API verschiedene Datenquellen zusammengezogen, um im nächsten Schritt Verbindungen identifizie-ren zu können. Eine Visualisierung o.Ä. ist dann der letzte Schritt.
Weitere Einsatzbereiche:
• Aufdeckung von Betrugsnetzwerken
• Identifikation von Steuerkarussellen
• Identifikation von Strohmännern/Post-kastenfirmen
• Aufdeckung von Korruption durch Analyse von Beziehungsnetzwerken und Zahlungsströmen
• Daten- und Dokumentenkonsolidierung für arbeits-, zivil- oder strafrechtliche Verfahren (z.B. Betrugsfälle)

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
35
11. Automatisierung im Umfeld Fraud-/Bribery-ErkennungDie Herausforderung bei der Prävention bzw. Aufklärung von Betrugsfällen ist es zum einen, die Masse an Daten auszuwerten, und zum anderen, die zeitintensive kontinuierliche Identifikation neuer Betrugsmodelle sicherzustellen, da kriminelle Organisationen und Personen den Aufsichtsbehörden und Banken meist einen Schritt voraus sind. Der dabei entste-hende Schaden für Unternehmen ist nicht zu unterschätzen.
Die manuelle Prüfung von eingereichten Belegen und Nachweisen ist dabei eine Ursache für unentdeckten Betrug im Ver-sicherungsumfeld. Nur mit viel Erfahrung können Auffälligkeiten identifiziert werden.Wie in Abbildung 14 skizziert, bilden wie-derum RPA und NLP die technologische Grundlage. Hierbei werden Auffälligkeiten nicht durch manuelle Sichtung und Ana-lyse, sondern durch KI identifiziert und für eine weitere Prüfung (manuell) konsolidiert.
Ähnliche Einsatzszenarien sind im Umfeld von Transaktionen und E-Commerce mög-lich. Betrügerische Transaktionen werden durch ihre Auffälligkeiten identifiziert. Diese erlernt der Algorithmus wiederum aus historischen Daten. Auffälligkeiten hierbei können z.B. zu niedrige Sofortkaufpreise oder auch verdächtige Beschreibungen z.B. in einer Auktion bzw. einer Onlineüberwei-sung sein.
Im Umfeld der Marktmanipulation können KI-basierte Lösungen eingesetzt werden, um nicht-konforme Verhaltensmuster von Mitarbeitern im Handel mit Aktien und Wertpapieren aufzudecken. Die jüngste Vergangenheit hat gezeigt, dass ein Twitter-Tweet eines CEO ausreicht, um z.B. eine Aktientalfahrt bei Tesla auszulösen. Solche gewollten oder auch ungewollten „Beeinflussungen“ des Marktes mögen noch erkennbar sein – die Herausfor-derung ist, die Manipulationen, die in kleinen, wohldosierten Mengen unterhalb des menschlichen Radars geschehen, zu
erkennen. Für eine ressourcenschonende und erfolgreiche Aufdeckung müssen wiederum Social Media und Kommunikati-onsdaten in die Analysen integriert werden, um Zusammenhänge zwischen Kursen und Kommunikation erkennen zu können. Ähnliche Lösungsmöglichkeiten sind auch in Bezug auf Insiderhandel möglich. Diese Anwendungsmöglichkeiten sind hierbei nicht nur auf Unternehmen beschränkt – auch die Aufsicht kann mit der Zeit gehen und Massendaten mit KI kombinieren, um proaktiv auf die Jagd nach Kriminellen zu gehen. Betrachtet man das Themenfeld Insiderhandel durch Familienmitglieder und Freunde/Bekannte, können Analy-sewerkzeuge, wie im vorangegangenen Anwendungsbeispiel beschrieben, helfen, um Verbindungen zwischen Geheimnisträ-gern und Bekannten zu identifizieren (z.B. via Analyse der Facebook-Freunde).
Abb. 14 – Lösungsansatz Optimierung der Betrugserkennung im Versicherungsumfeld
Erstattungs-Forderung
Ausreißer-Filterung
False Positives
Überprüfung derErstattungs-Forderung
Priorisierte ListeNatural
Language Processing
Boltzmann maschinelle, neuronale Netzwerk-
Algorithmen
Die Konsolidierung von verteilten Dokumenten und darin enthaltenen Information sowie Daten in Systemen und Datenbanken erfolgt durch RPA-gestützte Werkzeuge

36
12. Robotics- und KI-basierte Lösch-konzepte (Datenschutz)Ein Schreckgespenst der vergangenen Monate war und ist die EU-DSGVO mit ihren verschärften Anforderungen an das Management von personenbezogenen Daten. Neben dern Identifikation in Bestandsdaten stellt die Löschung von nicht mehr zulässigen Informationen, z.B. wenn das Vertragsverhältnis erloschen ist, eine Herausforderung dar. Dies ist primär bei Altdaten der Fall, deren Einstufung in Bezug auf eine Notwen-digkeit zum Speichern nicht strukturiert vorliegt. Insbesondere dort, wo die Datenverwaltung dezentral erfolgt (z.B. Dateilaufwerke und Onlinespeicher), werden personenbezogene Daten häufig „vergessen“. Auch scheinbar banale Fälle, wie Einladungslisten für einen betriebli-chen Gesundheitspräventionsworkshop (mit Adressen, Geburtsdaten und ggf. auch noch Informationen zu Allergien und Nahrungsunverträglichkeiten für das abschließende Buffet), können bereits einen Verstoß darstellen.
Mittels künstlicher Intelligenz können sowohl zentrale als auch dezentrale Datensätze identifiziert werden, für die eine Löschung erfolgen muss. Hier spielt KI mit Text Mining wiederum ihre Stärken aus. Aus unstrukturierten Daten, wie der oben genannten Geburtstagsliste, wird erkannt, dass es sich um personenbezo-gene Daten handelt und diese nicht mehr genutzt werden. Hierfür müssen dann wiederum verschiedene andere Quellen angebunden werden, aus denen sich Angaben zur Nutzung bzw. Rechtmäßig-keit der Datenspeicherung ableiten lassen lassen (z.B. Vertragsdaten, Zugriffsdaten).

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
37

38
Fazit • Immer dort, wo menschliche/manuelle Analysen für die Sicherstellung der Compliance notwendig sind (z.B. Muster-erkennung und Kundenreview), können KI-gestützte Lösungen Ressourcen schonen oder die Aufdeckungsrate von Compliance-Verstößen erhöhen. Auch wenn KI in vielen Fällen nicht die finale Entscheidung treffen sollte, können zumindest Voranalysen und Vorfilterun-gen bei der täglichen Arbeit unterstützen.
• KI stiftet den größten Wert in Kombina-tion mit anderen RegTech-Technologien. Seien es vorgelagerte Big-Data-Analysen, Cloud und API oder die nachgelagerte Abarbeitung mittels Robotics.
• „Compliance meets Marketing & Vertrieb“: KI kann über die Compliance- Fragestellungen hinaus zudem einen Wettbewerbsvorteil bei der weiteren Anreicherung mit Daten für Unterneh-men generieren, wobei datenschutz-rechtliche Schranken beachtet werden müssen. Denkbar sind KI-Auswertungen beim Beschwerdemanagement oder kundenspezifische Kreditangebote auf Basis von internen als auch externen Datenbeständen.
• Nicht zu unterschätzen ist dabei die Implementierung. Insbesondere bei neuartigen RegTech-Lösungen und den darunterliegenden Technologien wird meist in den Unternehmen noch Neuland betreten. Erfahrungen und Vergleichs-grundlagen sind noch rar – Fehlschläge häufig.

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
39

40
Vom Papiertiger zum lebenden Objekt: Verprobung von RegTech-basierten Lösungen im Deloitte RegTech Lab
Aus Erfahrung wissen wir, dass Innovation meist mit Skepsis gepaart ist. Viele Unter-nehmen scheuen Investitionen in wenig erprobte Technologien und neue Ansätze vor dem Hintergrund enger F&E-Budgets und fehlender Fachexperten.
Vor diesem Hintergrund hat Deloitte die RegTech Lab Initiative ins Leben gerufen. Als Plattform für die Verprobung von Reg-Tech+-Lösungen und die Weiterentwicklung von neuen Ansätzen dient das erste Ent-wicklungslabor dieser Art in Deutschland als zukünftiger Ursprungsort praxistaugli-cher Lösungen.
Zusammen mit externen Lösungspartnern erproben wir IT-Lösungen für aktuelle Com-pliance- und Regulatorik-Fragestellungen in unserer Sandbox-Umgebung. Ziele sind die Simulation aktueller und zukünftiger Herausforderungen unserer Kunden und die Entwicklung maßgeschneiderter Lösun-gen: von individuellen Softwarelösungen bis hin zu Managed RegTech (Risk & Compli-ance) Services.
Die im vorangegangenen Abschnitt skiz-zierten Anwendungsszenarien werden im Lab kundenspezifisch aufbereitet und deren Umsetzbarkeit objektiv bewertet, bevor kostenintensive Innovationen in der eigentlichen Kunden-Infrastruktur getätigt werden. Gemeinsam mit unseren Rechts-, IT- und Fachexperten wird das Problemfeld der Regulatorenakzeptanz stets im Auge behalten und in alle Überlegungen einbe-zogen.
Abb. 15 – Aufgabenschwerpunkt Deloitte RegTech Lab
Zentraler Anlaufpunkt für praxisnahe, funktionierende Lösungen
Bündelung von Technologie und Compliance-Fachexpertise
Showroom für Lösungen/Forum für die Diskussion zukünftiger Lösungen
Sandbox für Benchmarking und Innovationsmanagement im Kundenauftrag
Labor und Testumgebung für kundenspezifische Lösungen

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
41
Abb. 16 – Der RegTech-Lab-Ansatz: Compliance-Fachexpertise kombiniert mit innovativem Denken
Das Deloitte RegTech Lab bildet die Brücke zwischen Kundenbedürfnissen, möglichen Technologie-Lösungsoptionen sowie der für die erfolgreiche Implementierung not-wendigen Fachexpertise zu den jeweiligen Compliance-Anforderungen.
RegTech Sandboxing: Verknüpfung von regulatorischemVerständnis, Daten- und Technologie-Expertise in einemsicheren, innovativen Umfeld
Herausforderungen:Komplexe Governance, regulatorischer Druck, fragmentierte Prozesse, fehlende Fachexpertise
Gebündelte Deloitte-Kapazitäten: Regulatory Risk alsBaustein für den Markterfolg in Zusammenarbeit mitdiversen Geschäftsbereichen
Showroom für Lösungsdarstellung: Plattform für Initiativenund externe RegTech-Anbieter, um Kundenschwachstellenzu identifizieren
Deloitte als RegTech-partner: Deloitte Branding alsRegIntegrator und unangefochtener Marktführer bei RegTech-Innovation und -Integration
Grundlage für zukünftige Managed Services: Lab alsAppetizer, Katalysator und Inkubator für innovativeRegTech-bezogene Projekte
Uni
que
Selli
ng P
ropo
siti
on
Deu
tsch
land
s er
stes
RegT
ech
Lab
Deloitte Germany Innovation RegTech

42
Manfred Wandelt Regulatory SME & ClientsRegTech Client Relationship ManagementTel: +49 (0)151 5800 [email protected]
Das Deloitte RegTech Lab Team steht Ihnen bei Fragen zum Themenfeld KI und Com-pliance sowie RegTech-Lösungen zur Seite. Besuchen Sie uns im ersten RegTech Lab in Deutschland ab Q1 2019 im Herzen der FSI-Industrie (Frankfurt).
Unser Team aus erfahrenen Experten vereint das Fachwissen zu Compliance- und Regulatorik-Vorgaben mit technischem
Know-how und unterstützt Sie von der ersten Idee bis hin zur Implementierung.
Neben dem RegTech Lab wurden durch Deloitte weitere Innovationstreiber wie das Deloitte Blockchain Institute oder das KI-Studio etabliert, welche sich um die technologische Weiterentwicklung – unab-hängig von den fachlichen Einsatzgebieten wie Compliance – kümmern.
Sebastian Hainzl RegTech Integration ExperteRegTech Integration & ImplementationTel: +49 (0)151 5800 [email protected]
Peter Schadt PartnerHead of RegTech Lab Deloitte DeutschlandTel: +49 (0)151 5800 [email protected]
Über Ihre Anregungen und Rückmeldungen zu diesem Whitepaper an [email protected] würden wir uns sehr freuen.
Ansprechpartner: Deloitte Risk Advisory – Regulatory Risk

Künstliche Intelligenz im Compliance-Umfeld von Banken & Co.
43
Das Deloitte RegTech Lab bildet die Brücke zwischen Kundenbedürfnissen bzw. den aktuellen Compliance-Herausforderungen, möglichen Technologie-Lösungsoptionen sowie der für die erfolgreiche Implementierung notwendigen Fachexpertise zu den jeweiligen Compliance-Anforderungen.

44
Diese Veröffentlichung enthält ausschließlich allgemeine Informationen, die nicht geeignet sind, den besonderen Umständen des Einzelfalls gerecht zu werden, und ist nicht dazu bestimmt, Grundlage für wirtschaftliche oder sonstige Entscheidungen zu sein. Weder die Deloitte GmbH Wirtschaftsprüfungsgesellschaft noch Deloitte Touche Tohmatsu Limited, noch ihre Mitgliedsunternehmen oder deren verbundene Unternehmen (insgesamt das „Deloitte Netzwerk“) erbringen mittels dieser Veröffentlichung professionelle Beratungs- oder Dienstleistungen. Keines der Mitgliedsunternehmen des Deloitte Netzwerks ist verantwortlich für Verluste jedweder Art, die irgendjemand im Vertrauen auf diese Veröffentlichung erlitten hat.
Deloitte bezieht sich auf Deloitte Touche Tohmatsu Limited („DTTL“), eine „private company limited by guarantee“ (Gesellschaft mit beschränkter Haftung nach britischem Recht), ihr Netzwerk von Mitgliedsunternehmen und ihre verbundenen Unternehmen. DTTL und jedes ihrer Mitgliedsunternehmen sind rechtlich selbstständig und unabhängig. DTTL (auch „Deloitte Global“ genannt) erbringt selbst keine Leistungen gegenüber Mandanten. Eine detailliertere Beschreibung von DTTL und ihren Mitgliedsunternehmen finden Sie auf www.deloitte.com/de/UeberUns.
Deloitte erbringt Dienstleistungen in den Bereichen Wirtschaftsprüfung, Risk Advisory, Steuerberatung, Financial Advisory und Consulting für Unternehmen und Institutionen aus allen Wirtschaftszweigen; Rechtsberatung wird in Deutschland von Deloitte Legal erbracht. Mit einem weltweiten Netzwerk von Mitgliedsgesellschaften in mehr als 150 Ländern verbindet Deloitte herausragende Kompetenz mit erstklassigen Leistungen und unterstützt Kunden bei der Lösung ihrer komplexen unternehmerischen Herausforderungen. Making an impact that matters – für rund 286.000 Mitarbeiter von Deloitte ist dies gemeinsames Leitbild und individueller Anspruch zugleich.
Stand 01/2019