Embed Size (px)
Citation preview

J.W. Goethe Universitat Frankfurt am Main
Fachbereich WirtschaftswissenschaftenVolkswirtschaftslehre, insbesondere Mikrookonomie
Prof. Dr. Matthias Blonski
Mathematik I
Vorlesungsbegleitendes Skriptum
Update: 1. Februar 2004

Inhaltsverzeichnis
1 Mengenlehre 11.1 Grundbegriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Mengenoperationen . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Rechenregeln fur Mengenoperationen . . . . . . . . . . . . . . . . 31.4 Tupel und kartesische Produkte . . . . . . . . . . . . . . . . . . . 4
2 Logik 62.1 Aussagen und Aussageformen . . . . . . . . . . . . . . . . . . . . 62.2 Verknupfungen von Aussagen . . . . . . . . . . . . . . . . . . . . 72.3 Quantifizierung von Aussageformen . . . . . . . . . . . . . . . . . 82.4 Definitionen, Lemmata, Satze, Theoreme und Beweise . . . . . . . 9
3 Zahlen und Arithmetik 133.1 Zahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.2 Potenzen und Wurzeln . . . . . . . . . . . . . . . . . . . . . . . . 153.3 Logarithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4 Gleichungen und Ungleichungen 184.1 Eindimensionale Gleichungen und Ungleichungen . . . . . . . . . 184.2 Mehrdimensionale Gleichungs- und Ungleichungssysteme . . . . . 224.3 Lineare Gleichungssysteme . . . . . . . . . . . . . . . . . . . . . . 234.4 Zweidimensionale Ungleichungssysteme . . . . . . . . . . . . . . . 24
5 Folgen und Grenzwerte 265.1 Folgen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265.2 Konvergenz und Grenzwert . . . . . . . . . . . . . . . . . . . . . . 285.3 Grenzwerte im Unendlichen . . . . . . . . . . . . . . . . . . . . . 325.4 Reihen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345.5 Mehrdimensionale Folgen . . . . . . . . . . . . . . . . . . . . . . . 40
6 Funktionen einer Variablen 436.1 Grundbegriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 436.2 Graphische Darstellung . . . . . . . . . . . . . . . . . . . . . . . . 44
2

Inhaltsverzeichnis
6.3 Eigenschaften von Funktionen . . . . . . . . . . . . . . . . . . . . 446.4 Grenzwerte und Stetigkeit . . . . . . . . . . . . . . . . . . . . . . 466.5 Typen von Funktionen . . . . . . . . . . . . . . . . . . . . . . . . 48
7 Ableitung von Funktionen einer Variablen 507.1 Das Konzept der Ableitung . . . . . . . . . . . . . . . . . . . . . 507.2 Ableitungen ausgewahlter Funktionen . . . . . . . . . . . . . . . . 527.3 Ableitungsregeln . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
8 Teilmengen des Rn 548.1 Grundbegriffe der Mengen-Topologie . . . . . . . . . . . . . . . . 548.2 Konvexe Mengen . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
9 Funktionen von Rm nach Rn 609.1 Grundbegriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 609.2 Verknupfungen von Funktionen . . . . . . . . . . . . . . . . . . . 619.3 Graphische Darstellung von Funktionen . . . . . . . . . . . . . . . 639.4 Umkehrfunktionen . . . . . . . . . . . . . . . . . . . . . . . . . . 719.5 Grenzwerte von Funktionen und Stetigkeit . . . . . . . . . . . . . 749.6 Monotonie und Homogenitat . . . . . . . . . . . . . . . . . . . . . 769.7 Konkavitat und Quasikonkavitat . . . . . . . . . . . . . . . . . . . 799.8 Ausgewahlte Typen von Funktionen . . . . . . . . . . . . . . . . . 84
10 Differentialrechnung 8710.1 Partielle Ableitungen . . . . . . . . . . . . . . . . . . . . . . . . . 8710.2 Richtungsableitung, Kettenregel, Satz von Euler . . . . . . . . . . 8810.3 Gradient, totales Differential . . . . . . . . . . . . . . . . . . . . . 9110.4 Hohere Ableitungen . . . . . . . . . . . . . . . . . . . . . . . . . . 9510.5 Eigenschaften von Funktionen und ihre Ableitungen . . . . . . . . 9710.6 Elastizitaten und deren okonomische Interpretation . . . . . . . . 10010.7 Der Satz uber implizite Funktionen . . . . . . . . . . . . . . . . . 103
11 Optimierung von Funktionen einer Veranderlichen 10611.1 Lokale und globale Extrema . . . . . . . . . . . . . . . . . . . . . 10611.2 Optimierung mit Nebenbedingungen . . . . . . . . . . . . . . . . 10811.3 Lagrangefunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
12 Optimierungstheorie 11512.1 Optimierung ohne Nebenbedingungen . . . . . . . . . . . . . . . . 11512.2 Geometrische Losung von Optimierungsproblemen . . . . . . . . . 11712.3 Haufige Irrtumer . . . . . . . . . . . . . . . . . . . . . . . . . . . 11812.4 Lagrangefunktion, Kuhn-Tucker Bedingungen und Beschrankungs-
qualifikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12012.5 Nebenbedingungen in Form von Gleichungen . . . . . . . . . . . . 124
3

1 Mengenlehre
Dieses Kapitel behandelt Grundlagen der Mengenlehre, die in gewisser Weiseam Anfang der Mathematik steht und eine Sprache bereitstellt, die zur weiterenFormulierung der Mathematik sehr hilfreich ist.
1.1 Grundbegriffe
Eine Menge ist eine Zusammenfassung wohlunterschiedener Objekte, wobei vonjedem Objekt eindeutig feststehen muß, ob es zur Menge gehort oder nicht.Gehort ein Objekt zu einer Menge, so bezeichnet man es auch als Element dieserMenge. Ist ein Objekt e Element einer Menge M , so schreibt man dafur e ∈ M(sprich: e Element M); ist e hingegen nicht Element von M , so schreibt mandafur e /∈ M (sprich: e nicht Element M).
Ublicherweise wird eine Menge auf eine von zwei Arten beschrieben: Die erstebesteht darin, alle ihre Elemente in geschweifte Klammern eingefaßt und durchKommata getrennt vollstandig aufzuzahlen. Beispielsweise beschreibt der Aus-druck a, e, i, o, u die Menge aller Vokale des lateinischen Alphabets. In un-zweideutigen Fallen, insbesondere Bei unendlichen Mengen und bei unzweideu-tigen Fallen ist auch die Verwendung von Ellipsen (. . .) moglich. So wird jedera, b, c, d, e, . . . , z unzweideutig als die Menge aller kleinen Buchstaben des la-teinischen Alphabets und 2, 4, 6, 8, 10, . . . als die Menge aller positiven undgeraden Zahlen erkennen.
Die zweite typische Art der Beschreibung ist die, eine allen Elementen einer Mengeund nur diesen anhaftende und somit fur Elemente dieser Menge charakteristischeEigenschaft anzugeben, z.B. x | x ist Vokal des lateinischen Alphabets .Eine spezielle Menge ist die sogenannte leere Menge und wird mit ∅ oder bezeichnet.
Ein weiterer wichtiger Begriff der Mengenlehre ist die Machtigkeit einer Menge.Sie ist fur Mengen mit endlich vielen Elementen die Anzahl deren Elemente. DieMachtigkeit von Mengen mit unendlich vielen Elementen wird mit dem Symbol ∞(sprich: unendlich) bezeichnet.1 Ublicherweise wird die Machtigkeit einer MengeM als |M | geschrieben.
1Bei unendlichen Mengen wird außerdem zwischen abzahlbar und uberabzahlbar unendlichenMengen unterschieden, was an dieser Stelle nicht weiter vertieft werden soll.
1

1 Mengenlehre
Beispiel 1.1:(i) Fur M := 2, 3, 4 ist |M | = 3.(ii) | 1, 2, 1, 3 | = 3.(iii) | 1, 2, 3, . . .| = ∞.
Gilt fur zwei Mengen A und B, daß jedes Element von A auch Element von Bist, so ist A Teilmenge von B. Man schreibt A ⊆ B. Existiert daruberhinaus einElement von B, welches nicht Element von A ist, so heißt A echte Teilmenge vonB, und man schreibt A ⊂ B. Gilt fur zwei Mengen A und B sowohl A ⊆ B alsauch B ⊆ A, haben also beide Mengen die gleichen Elemente, so heißen dieseMengen gleich, und man schreibt A = B.2 Falls zwei Mengen A und B ungleichsind bzw. A nicht Teilmenge bzw. nicht echte Teilmenge von B ist, wird durchdie Ausdrucke A = B, A ⊆ B bzw. A ⊂ B beschrieben.
Beispiel 1.2: Seien M := 2, 3, 4, N := 2, 4, P := 4, 3, 2 und Q := 2.Dann gilt:(i) N ⊆ M ⊆ P(ii) N ⊂ M und M ⊂ P(iii) M = P(iv) Q ⊂ M
In einigen Beispielen wurde bereits deutlich, daß Mengen wiederum Mengen alsElemente enthalten konnen. Die Menge aller moglichen Teilmengen einer MengeM ist oft von Interesse. Sie heißt Potenzmenge von M und wird durch das Symbol℘(M) bezeichnet.
Beispiel 1.3:(i) Fur M := 1, 2, 3 ist ℘(M) = ∅, 1, 2, 3, 1, 2, 1, 3, 2, 3, 1, 2, 3.(ii) Gegeben sei die Menge der Vokale V := a, e, i, o, u. Es gilt ℘(V ) = W |Wist eine Menge, deren Elemente Vokale sind .(iii) Die Potenzmenge der leeren Menge ist nicht leer ℘(∅) = ∅.
1.2 Mengenoperationen
Fur Mengen sind verschiedene Operationen definiert, die jeweils zwei Mengen zueiner Ergebnismenge verknupfen. Der Durchschnitt A∩B zweier Mengen A undB ist die Menge aller Elemente, die sowohl Element von A als auch Element
2Man beachte, daß auch die beiden Mengen a, b und a, b, b aufgrund der Forderung, daßalle Elemente wohlunterschieden sein mussen, gleich sind.
2

1 Mengenlehre
von B sind und Vereinigung A ∪ B zweier Mengen A und B ist die Menge derElemente, die entweder Element von A oder Element von B oder Element von Aund B sind. Ist der Durchschnitt zweier Mengen A und B leer, ist also A ∩ B =∅, so heißen diese beiden Mengen disjunkt. Die Differenz A \ B ist die Mengealler Elemente, die zwar Element von A, aber nicht Element von B sind. Manbeachte, daß die Bildung der Differenz zweier Mengen im Unterschied zur Bildungdes Durchschnitts oder der Vereinigung nicht kommutativ oder vertauschbar ist,d.h. es gilt im Allgemeinen nicht A \ B = B \ A. Dagegen gilt immer sowohlA ∪ B = B ∪ A als auch A ∩ B = B ∩ A. Fur zwei Mengen A und Ω mit A ⊆ Ωist das Komplement von A bezuglich Ω definiert als Ω \ A; man schreibt dafurublicherweise CΩA. Oft ist bei der Bildung eines Komplements aus dem jeweiligenKontext klar, bezuglich welcher Grundmenge Ω das Komplement gebildet wird.Verkurzend wird fur das Komplement einer Menge A dann nur CA oder auch Ageschrieben.
Beispiel 1.4:(i) Seien M := 1, 2, 3 und N := 3, 4. Dann gilt: M∩N = 3 und M∪N =1, 2, 3, 4(ii) Sei Ω := Kreuz, Pik, Herz, Karo und A := Kreuz, Pik. Dann ist CA =CΩA = Herz, Karo.(iii) Seien N := 1, 2, 3, . . ., G := 2, 4, 6, . . . und U := 1, 3, . . ., dann istCNG = U und CNCNG = G.
Mengenoperationen und Beziehungen zwischen Mengen werden haufig in soge-nannten Venn-Diagrammen veranschaulicht. In derartigen Diagrammen werdenMengen als geeignete Flachen in der Ebene dargestellt. In Abbildung 1.1 sindbeispielhaft die Bildung von Durchschnitt (a), Vereinigung (b), Differenz (c) undKomplement fur zwei nicht disjunkte Mengen A und B und eine Grundmenge Ωin Venn-Diagrammen wiedergegeben.
1.3 Rechenregeln fur Mengenoperationen
Fur beliebige Mengen A, B, C und Ω mit A, B, C ⊆ Ω gelten die folgendenRechenregeln:
Zunachst gelten fur Vereinigung und Durchschnitt sowohl das Kommutativ- alsauch das Assoziativgesetz, d.h. es gilt
A ∪ B = B ∪ A und A ∩ B = B ∩ A,A ∪ (B ∪ C) = (A ∪ B) ∪ C und A ∩ (B ∩ C) = (A ∩ B) ∩ C.
Es gelten die beiden Distributivgesetze
A ∪ (B ∩ C) = (A ∪ B) ∩ (A ∪ C),A ∩ (B ∪ C) = (A ∩ B) ∪ (A ∩ C).
3

1 Mengenlehre
(a)
ΩΩ
AA BB
AA ∩∩ BB
(b)
ΩΩ
AA BB
AA ∪∪ BB
(c)
ΩΩ
AA BB
AA \ BB
(d)
ΩΩ
AA
CCΩ
AA
Abbildung 1.1: Venn-Diagramme
Schließlich gelten noch folgende Regeln fur die Bildung von Komplementen:
A ∪ CA = Ω und A ∩ CA = ∅,C(A ∪ B) = CA ∩ CB und C(A ∩ B) = CA ∪ CB,
C∅ = Ω und CΩ = ∅,CCA = A.
1.4 Tupel und kartesische Produkte
Mengen sind nicht geordnete Zusammenfassungen von Objekten. Die Mengena, b und b, a sind also gleich. Ist dagegen auch die Reihenfolge zweier Objektevon Bedeutung, kann dieses durch das Konzept des Tupels erfasst werden. Sollenbeispielsweise die beiden Objekte a und b in der Weise geordnet zusammengefasstwerden, daß b vor a kommt, so werden sie in dem Tupel (b, a) zusammengefasst.Dabei ist b die erste Komponente dieses Tupels und a die zweite. Ein Tupel mitzwei Komponenten heißt auch Zwei-Tupel. Eine offensichtliche Verallgemeinerungdes Zwei-Tupels ist eine geordnete Zusammenfasung nicht nur von zwei, sondernvon beliebig vielen Objekten. Endliche derartige Zusammenfassungen heißen n-Tupel. Dabei gibt n ∈ 1, 2, 3, . . . die Anzahl der Komponenten des Tupels an.Mengen von n-Tupeln gleicher Art konnen uber die Bildung n-facher kartesischerProdukte definiert werden. Aufgrund der ordnungsgebenden Eigenschaft des Tu-pels gilt (b, a) = (a, b) fur a = b; zwei Tupel sind also nur dann gleich, wenn
4

1 Mengenlehre
sie jeweils in allen Komponenten ubereinstimmen. Das kartesische Produkt oderKreuz-Produkt A × B zweier Mengen A und B ist die Menge aller Tupel (a, b)von Elementen a ∈ A und b ∈ B.
Beispiel 1.5:(i) Die beiden Tupel (Karo, 7) und (Kreuz, Bube) kann man verwenden, umdie beiden entsprechenden Spielkarten zu reprasentieren. Die Menge aller Spiel-karten eines Skat-Blattes ist dann B = (f, w)|f ∈ Kreuz, Pik, Herz, Karo und w ∈ 7, 8, 9, 10, Bube, Dame, Konig, Ass . Fur jede Hand H zu Beginneines Skatspiels gilt H ⊂ B und |H| = 10.(ii) Sei A := 1, 2 und B := a, b. Dann ist A×B = (1, a), (1, b), (2, a), (2, b).(iii) Die Menge aller Felder eines Schachbretts ist A, B, . . . , H× 1, 2, . . . , 8.(iv) Seien A := u, v, w und B := x, y, z. (u, v, z) ist ein 3-Tupel und Ele-ment von A × A × B. (u, w, w, v, v, u) ist ein 6-Tupel und Element von A × A ×A × A × A × A = A6 (sprich: A hoch 6).
5

2 Logik
Ein anderer Grundpfeiler der Mathematik neben der Mengenlehre ist die Logik,welche sich mit Aussagen, Verknupfungen von Aussagen und deren Wahrheitsge-halt befaßt.
2.1 Aussagen und Aussageformen
In der Umgangssprache existieren verschiedene Arten von Satzen, beispielsweiseFragen, Meinungen, Befehls- und Aussagesatze. Eine Aussage A ist ein Satz,der entweder wahr oder falsch ist. Zu jeder Aussage A existiert eine gegenteiligeAussage, die Negation von A und wird mit den Symbolen ¬A oder A bezeichnetund ist genau dann wahr, wenn A falsch ist und umgekehrt.
Beispiel 2.1:(i) Aussagen sind die Satze: ’Der Mond kreist um die Erde’ oder ’Frankfurtliegt an der Wolga’. Keine Aussagen sind die Satze: ’Schroder ist doof’ oder’Kuss mich’ oder ’Verstehst Du das’.(ii) Von den Aussagen (i) ’Der Mond kreist um die Erde’ (ii)’Frankfurt liegt ander Wolga’ (iii) ’Verdi komponierte mindestens ein Streichquartett’ (iv) ’Neun isteine gerade Zahl’ sind (i) und (iii) wahr und (ii) und (iv) falsch.(iii) Die Negation der Aussage ’Frankfurt liegt an der Wolga’ ist ’Frankfurt liegtnicht an der Wolga’. Sei A := ’Der Mond kreist um die Erde’. Dann ist ¬A =’Der Mond kreist nicht um die Erde’. Offenbar ist A wahr und ¬A falsch.
Satze, die Variablen enthalten und erst dann zu Aussagen werden, wenn man denVariablen einen bestimmten Wert zuordnet, heißen Aussageformen. Sie werdenublicherweise mit einem großen lateinischen Buchtstaben fur die Aussageformselbst, gefolgt von einem oder mehreren in Klammern gesetzten kleinen lateini-schen Buchstaben fur die Variablen bezeichnet. Die Menge aller Objekte, die ineine Aussageform eingesetzt werden durfen, heißt Grundmenge der Aussageform;die Menge derjenigen Elemente der Grundmenge, fur die die Aussageform wahrist, heißt Losungsmenge der Aussageform.
Beispiel 2.2:(i) Sei A(x) := ’x komponierte neun Symphonien’ und die dazugehorige Grund-
6

2 Logik
menge Beethoven, Mahler, Haydn. Dann steht A(Mahler) fur die Aussage ’Mah-ler komponierte neun Symphonien’.(ii) Sei G(x) := ’x > 2’ und die zu G(x) gehorige Grundmenge 1, 2, 3, 4, 5.Dann ist 3, 4, 5 die Losungsmenge von G(x).
2.2 Verknupfungen von Aussagen
Aussagen und Aussageformen konnen mit Hilfe sogenannter Boolscher Operatorenzu neuen, zusammengesetzen Aussagen bzw. Aussageformen verknupft werden1.Einer dieser Operatoren ist die sogenannte Konjunktion oder Und-Verknupfung.Die Konjunktion zweier Aussagen A und B ist genau dann wahr, wenn sowohlA als auch B wahr sind. Formal wird die Konjunktion zweier Aussagen A undB durch den Ausdruck A ∧ B (sprich: A und B) beschrieben. Dagegen ist dieDisjunktion A ∨ B (sprich: A oder B) zweier Aussagen A und B dann und nurdann wahr, wenn A, B oder A und B wahr sind. Sie wird daher auch als Oder-Verknupfung bezeichnet. Es gilt
¬(A ∧ B) = ¬A ∨ ¬B,
¬(A ∨ B) = ¬A ∧ ¬B.
Beispiel 2.3: Seien die Aussagen A und B wahr und die Aussage C falsch.(i) Dann ist A∧B wahr und B ∧C falsch. Ferner ist A∨B wahr, B ∨C wahrund C ∨ C falsch.(ii) Die Negation der Aussage ’Claudia ist schon und klug’ ist die Aussage’Claudia ist nicht schon oder nicht klug’.(iii) Die Negation der Aussage ’Claudia ist schon oder klug’ ist die Aussage’Claudia ist weder schon noch klug’.
Ein weiterer Boolscher Operator ist die Implikation oder Folgerung. Sie wirdfur zwei Aussagen A und B durch den Ausdruck A ⇒ B (sprich: aus A folgtB) beschrieben und ist nur dann falsch, wenn A wahr und B falsch ist. In allenanderen Fallen ist sie wahr. Die Implikation A ⇒ B ist also identisch zur Aussage¬A∨B. A heißt auch hinreichende Bedingung fur B, da bei gultiger ImplikationA ⇒ B die Aussage B wahr sein muß, wenn A wahr ist, und B notwendigeBedingung fur A, da A nur dann wahr sein kann, wenn B wahr ist. Die AquivalenzA ⇔ B zweier Aussagen A und B ist genau dann wahr, wenn entweder A undB beide wahr oder beide falsch sind. Sie ist aquivalent (!) zum Ausdruck (A ⇒
1benannt nach George Boole (1815-1864), britischer Mathematiker
7

2 Logik
A B A ∧ B A ∨ B A ⇒ B A ⇔ Bw w w w w ww f f w f ff w f w w ff f f f w w
Tabelle 2.1: Wahrheitstafeln fur Konjunktion, Disjunktion, Implikation undAquivalenz
B) ∧ (B ⇒ A). Wir benutzen haufig die Sprechweise ’dann und nur dann’ oder’genau dann’ fur die Aquivalenz.
Man kann den Wahrheitsgehalt zusammengesetzer Aussagen in Abhangigkeitvom Wahrheitsgehalt der zugehorigen Einzelaussagen ubersichtlich in sogenann-ten Wahrheitstafeln darstellen. In diesen werden als Tabelle alle Kombinationenvon Wahrheitsgehalten der in die zusammengesetzte Aussage einfließenden ein-zelnen Aussagen dem sich ergebenden Wahrheitsgehalt der zusammengesetztenAussage gegenubergestellt. In Tabelle 2.1 sind Wahrheitstafeln fur die in diesemAbschnitt vorgestellten Verknupfungen zusammengestellt.
Beispiel 2.4: Die Wahrheitstafel zur Aussage A ∨ (B ∧ ¬C) ist:
A B C A ∨ (B ∧ ¬C)w w w ww w f ww f w ww f f wf w w ff w f wf f w ff f f f
2.3 Quantifizierung von Aussageformen
In Abschnitt 2.1 wurde gezeigt, wie Aussageformen zu Aussagen werden, indemman ein Element ihrer jeweiligen Grundmenge in sie einsetzt. Eine andere Art,Aussagen aus Aussageformen zu machen ist, diese zu quantifizieren. Sei im wei-teren A(x) eine Aussageform mit der Grundmenge G und der LosungsmengeL ⊆ G. Dann steht ∃x. A(x) (sprich: es existiert ein x mit A(x)) fur die Aussage,daß mindestens ein x ∈ G existiert, fur welches A(x) wahr ist. Das Symbol ∃heißt Existenzquantor. Ferner bedeutet ∀x. A(x) (sprich: fur alle x gilt A(x)), daß
8

2 Logik
A(x) fur alle x ∈ G wahr ist. Das Symbol ∀ heißt entsprechend Allquantor. Manbeachte, daß ∃x. A(x) genau dann wahr ist, wenn L = ∅ gilt, und daß ∀x. A(x)genau dann wahr ist, wenn L = G gilt. Daraus folgt, daß ∃x. A(x) wahr ist, falls∀x. A(x) wahr ist. In der Schreibweise der Logik ist das ∀x. A(x) ⇒ ∃x. A(x).Bezuglich der Negation quantifizierter Aussageformen gelten die Regeln:
¬∀x. A(x) ⇔ ∃x.¬A(x)¬∃x. A(x) ⇔ ∀x.¬A(x)
Beispiel 2.5:(i) Sei A(x) := ’x > 3’ eine Aussageform mit der Grundmenge G := 1, 2, 3, 4.Dann ist ∃x. A(x) eine wahre Aussage, da 4 > 3 wahr ist, und ∀x. A(x) eine falscheAussage, da beispielsweise 1 > 3 falsch ist.(ii) Die Verneinung der Aussage ’Alle Menschen sind sterblich’ ist ’Es gibt einenMenschen, der nicht sterblich ist’. Die Negation der Aussage ’Es gibt einen Stu-denten, der alles versteht’ ist ’Fur jeden Studenten gibt es etwas, das er nichtversteht’.
2.4 Definitionen, Lemmata, Satze, Theoreme undBeweise
Die Mathematik ist ein logisch aufgebautes Gedankengbaude. Ihre Sprache ver-wendet Begriffe und Strukturen, die zunachst definiert werden mussen. Wir ha-ben bis hier schon viele Begriffe definiert, zuletzt z.B. den Allquantor ∀. Kur-ze, einfache Definitionen werden in mathematischen Texten oft durch einfacheHervorhebungen im Text markiert. Langere und komplexere Definitionen werdenmeistens als solche hervorgehoben und fallen dadurch noch mehr auf. Mit Begrif-fen und Strukturen werden Aussagen gemacht. Unsere zuletzt gemachte Aussagemit zuvor definierten Begriffen war z.B. ¬∃x. A(x) ⇔ ∀x.¬A(x). Mathematikersortieren ihre Aussagen gerne nach ihrer Wichtigkeit. Dabei werden kleine, un-tergeordnete, oder Hilfsaussagen Lemma genannt, die meisten Aussagen nenntman Satz oder auf englisch proposition was gelegentlich falschlich als Vorschlagubersetzt wird.
Die wichtigsten Resultate in der Mathematik werden Theoreme genannt. Diesezu beweisen kann manchmal sehr schwierig und aufwendig sein. Großes Aufse-hen in der mathematischen Fachwelt erregte z.B. der Beweis des letzten Schrittesvon Fermat’s beruhmtem ’letzten Theorem’, aufgestellt vom franzosischen Ma-thematiker Pierre de Fermat um das Jahr 1630 als Randnotiz in einem zah-lentheoretischen Aufsatz mit dem Vermerk, daß ihm ein einfacher Beweis dafur
9

2 Logik
bekannt sei. Fermats letztes Theorem sagt aus, daß fur n = 3, 4, 5, . . . keineganzzahligen Losungen ungleich 0 der Gleichung xn + yn = zn existieren. Derbritische Mathematiker Andrew Wiles versetzte am 23. Juni 1993 die Fach-welt in große Aufregung, als er per email verbreitete, diese beruhmte Vermutungendgultig bewiesen zu haben2. In der Tat war dies nur der letzte Schritt in eineruber 350-jahrigen Suche nach einem Beweis, an dem sich viele der bedeutenstenMathematiker unserer und auch fruherer Zeiten beteiligten und die maßgeblichdie moderne Geschichte der Mathematik mit gepragt hat. Auf dem Weg zumendgultigen Beweis wurden zahlreiche neue Gebiete der Mathematik entwickelt,von denen viele Mathematiker heute glauben, daß sie fur sich genommen vielwichtiger sind, als Fermats ursprungliche Behauptung selbst.
Wirtschaftswissenschaftler im Gegensatz zu Mathematikern interessieren sich we-niger fur Beweise, also die internen Strukturen logischer Gedankengebaude, son-dern mehr fur die Anwendungen mathematischer Aussagen auf die reale Welt.Um dieses Ziel schneller erreichen zu konnen, werden auch in diesem Skriptumdie meisten Beweise weggelassen. So sahen wir noch keinen Beweis bis hier. AuchWirtschaftswissenschaftler sollten sich jedoch bewußt sein, daß das Weglassenund Ignorieren von mathematischen Beweisen verschiedene Gefahren in sich birgt.Zum Beispiel geht es auch dem Wirtschaftswissenschaftler oft um strukturellesVerstandnis, wenn okonomische Phanomene mit Hilfe von Modellen beschriebenund erklart werden. Daher liegt ein Teil des Verstandnisses des okonomischenPhanomens in der verwendeten Struktur des mathematischen Modells. Der ande-re (okonomische) Teil des Verstandnisses druckt sich oft in der Wahl geeigneterModell-Bestandteile und Annahmen aus. Beide Verstandnisarten bedingen sichoft gegenseitig. Es ist kein Zufall, daß viele der beruhmten Okonomen unserer Zeitgleichzeitig hervorragende Mathematiker sind oder sogar von der Mathematik zurOkonomie gekommen sind. Umgekehrt ist es schwierig, als angehender Okonoman die Front aktueller Forschung in Okonomie zu gelangen, ohne sich großzugigin der Welt der etablierten mathematischen Resultate zu bedienen. Es ist eineKunst, sich fur die relevanten mathematischen Strukturen zu interessieren unddie weniger relevanten okonomisch als ’black boxes’ zu benutzen auf dem Weg zueinem besseren okonomischen Verstandnis.
Da wir im Folgenden gelegentlich exemplarisch Beweise vorfuhren, sei hier kurzauf einige der wichtigsten Beweis-Techniken des Mathematikers eingegangen.
Als direkten Beweis bezeichnet man eine Kette von Implikationen, an deren An-fang die hineingesteckten Annahmen und an deren Ende die zu beweisende Be-hauptung steht.
Beispiel 2.6: Seien a, b ∈ 0, 1, 2, . . ., dann ist das geometrische Mittel√
a · bstets kleiner oder gleich dem arithmetischen Mittel a+b
2.
2Der Beweis wurde schließlich publiziert als Andrew Wiles, Modular elliptic curves andFermat’s Last Theorem, Ann. Math. 141 (1995), 443-551
10

2 Logik
Beweis:√
a · b ≤ a+b2
⇔ 4ab ≤ (a + b)2 ⇔ 0 ≤ (a − b)2, was stets wahr ist. Dafur a, b ∈ 0, 1, 2, . . . die Implikationen in beiden Richtungen gelten, gelten sieinsbesondere alle ruckwarts, also ist die am Anfang stehende Aussage wahr.
Der indirekte Beweis beruht auf der logischen Aquivalenz ¬(A∧B) = ¬A∨¬B, diein Kap. 2.2 eingefuhrt wurde. Die Quantifizierung dieser logischen Aquivalenz ist¬∀x. A(x) ⇔ ∃x.¬A(x). Statt eines Beispiels hier, wird auf das folgende Kapitelverwiesen, wo wir indirekt oder durch Widerspruch beweisen werden, daß
√2 eine
irrationale Zahl ist.
Falls die zu beweisende Behauptung fur alle naturlichen Zahlen n ∈ N zu zei-gen ist, so kann sie mit Hilfe vollstandiger Induktion bewiesen werden. DieseBeweismethode wird dem franzosischen Mathematiker Blaise Pascal (1623-1662), einem Zeitgenossen von P. de Fermat, zugeschrieben. Die Aussage wirdzunachst fur eine Zahl n0 ∈ N gezeigt. Die Zahl n0 ist oft 0 oder 1. Man nenntsie den Induktionsanfang. Aus der Induktionsvoraussetzung, also der Annahme,die Behauptung gelte fur n ∈ N, folgert man dann die Induktionsbehauptung,also die selbe Behauptung fur n + 1 ∈ N. In dieser Folgerung, also diesem Teildes Beweises, liegt meistens die eigentliche Beweisidee, daher nennen wir ihn denInduktionsbeweis.
Beispiel 2.7: (Gauss’sche Summenformel3) Es gilt ∀n ∈ N:
1 + 2 + · · · + n =n(n + 1)
2.(i) Induktionsanfang: 1 = 1·2
2.
(ii) Induktionsvoraussetzung: Es gelte fur n = k:
1 + 2 + · · ·+ k =k(k + 1)
2.(iii) Induktionsbehauptung: Dann gilt fur n = k + 1:
1 + 2 + · · ·+ k + (k + 1) =(k + 1)(k + 2)
2.(iv) Induktionsbeweis:
1 + 2 + · · · + k + (k + 1) =k(k + 1)
2+ (k + 1)
3benannt nach dem deutschen Mathematiker Carl Friedrich Gauss (1777-1855), vom demdie Legende sagt, daß er eine von seinem Lehrer gestellte Aufgabe, die Zahlen 1 bis 100aufzuaddieren im Handumdrehen losen konnte zu großen Verbluffung seines Lehrers undseiner Mitschuler. Gauss verwendete angeblich eine andere Idee. Statt die Zahlen sukzessivezu addieren rechnete er 1 + · · · + 100 = (1 + 100) + (2 + 99) + · · · + (50 + 51) = 50 · 101.
11

2 Logik
=k2 + k + 2k + 2
2
=(k + 1)(k + 2)
2.
12

3 Zahlen und Arithmetik
In diesem Kapitel werden Zahlen und einzelne Elemente aus dem Bereich derArithmetik rekapituliert. Insbesondere werden die reellen Zahlen eingefuhrt undeinige Rechenregeln wie Potenzrechnung und Logarithmieren wiederholt.
3.1 Zahlen
Grundlegend fur die Mathematik sind die Zahlen. Die Zahlen 1, 2, 3, . . ., die sichintuitiv aus dem Zahlen (z.B. der Finger) ergeben, heißen naturliche Zahlen oderpositive ganze Zahlen und werden mit dem Symbol N bezeichnet. Dazu gehoren of-fenbar die geraden Zahlen 2, 4, 6, . . . und die ungeraden Zahlen 1, 3, 5, . . .. Naturli-che Zahlen sind bezuglich der Addition und der Multiplikation abgeschlossen. Dasheißt, daß die Summe und das Produkt zweier naturlicher Zahlen wieder naturli-che Zahlen sind.
Positive und negative ganze Zahlen zusammen mit der 0, also . . . ,−2,−1, 0, 1, 2, . . .heißen ganze Zahlen und werden mit Z bezeichnet. Die ganzen Zahlen sind zusatz-lich bezuglich der Subtraktion abgeschlossen.
Bruche sind Zahlen wie 27, die sich als Quotient a
bzweier ganzer Zahlen a und
b mit b = 0 darstellen lassen. Sie heißen rationale Zahlen und werden als Q be-zeichnet. Verschiedene Bruche konnen die gleiche rationale Zahl darstellen, zumBeispiel ist 2
4= 1
2. Eine besondere Rolle spielen daher die gekurzten Bruche, deren
Zahler und Nenner teilerfremd sind und der Nenner stets positiv ist. Wir konnendaher jede rationale Zahl durch viele Bruche aber nur mit genau einem gekurztenBruch darstellen. Die rationalen Zahlen sind bezuglich aller vier Grundrechenar-ten +,−, ·, : abgeschlossen.
Die ganzen und auch die rationalen Zahlen lassen sich auf der Zahlengeradendarstellen. Angenommen, wir wurden alle rationalen Zahlen, also zuerst die 0,dann alle (positiven und negativen) Vielfachen von 1, dann alle (positiven undnegativen) Vielfachen von 1
2, dann alle (positiven und negativen) Vielfachen von
13, usw. auf der Zahlengeraden markieren. Es ist verfuhrerisch, zu denken, dann
gabe es keine Locher mehr auf der Zahlengeraden. Schon die Griechen der Antikebemerkten jedoch, daß dies nicht der Fall ist. Spatestens Euklid sah, daß keineganzen Zahlen p und q existieren, so daß (p
q)2 = 2 ist. Also ist
√2 keine rationale
13

3 Zahlen und Arithmetik
Zahl. Um dies zu zeigen, verwenden wir einen indirekten Beweis. Statt also zuzeigen ”p
qist gekurzter Bruch aus ganzen Zahlen” ⇒ ”(p
q)2 = 2” zeigen wir
”(pq)2 = 2” ⇒ ”p
qist nicht gekurzter Bruch aus ganzen Zahlen”. Dabei verwenden
wir also die logische Aquivalenz
(A ⇒ B) ⇔ (¬A ∨ B) ⇔ (B ∨ ¬A) ⇔ (¬B ⇒ ¬A).
Nehmen wir also umgekehrt an, es gabe einen gekurzten Bruch pq
=√
2. Also ist
auch p2
q2 ein gekurzter Bruch (warum?). Wegen p2
q2 = 2 ist also p2 = 2q2. Da q und
daher q2 ganze Zahlen sind, ist 2q2 und daher auch p2 eine gerade Zahl, denn warep ungerade so ware auch p2 ungerade. Also ist p2 sogar durch 4 teilbar. Wegenp2 = 2q2 muss dann aber auch q gerade sein. Dies widerspricht aber unsererAnnahme, daß p
qgekurzt ist. Da also (p
q)2 = 2 zu einem Widerspruch fuhrt, ist√
2 keine rationale Zahl.
Eine fur uns ubliche Art, Zahlen zu schreiben, ist die so genannte Dezimalschreib-weise. Jede naturliche Zahl kann mit Hilfe der zehn Symbole 0, 1, 2, . . . , 9 ge-schrieben werden. Die Anordnung der Ziffern als Zahl entspricht der Summe vonVielfachen der Potenzen von 10. Zum Beispiel bedeutet
2003 = 2 · 103 + 0 · 102 + 0 · 101 + 3 · 100.
Zusammen mit den Symbolen +,− konnen alle ganzen Zahlen im Dezimalsystemgeschrieben werden. Mit Hilfe von Kommastellen und negativen Potenzen von10 konnen wir auch rationale Zahlen, die keine ganzen Zahlen sind, in Dezimal-schreibweise darstellen, zum Beispiel
3.14 = 3 · 100 + 1 · 10−1 + 4 · 10−2.
Jeder Zahl, die auf diese Weise mit endlich vielen Ziffern in Dezimalschreibweisegeschrieben werden kann, ist eine rationale Zahl zugeordnet. Umgekehrt kannnicht jede rationale Zahl mit endlich vielen Ziffern in Dezimalschreibweise dar-gestellt werden. Zum Beispiel ist 1
3= 0.3 = 0.33 . . ., wobei der obere Balken die
zu wiederholenden Ziffern beschreibt oder die Punkte dafur stehen, daß die Ziffer3 unendlich oft wiederholt wird. Die Dezimalschreibweise jeder rationalen Zahlist jedoch periodisch, d.h. ab einer gewissen Stelle der Dezimalschreibweise wie-derholen sich die Ziffern unendlich oft in der gleichen Reihenfolge. Zum Beispielist
1
7= 0.142857 = 0.142857142857 . . . .
Eine intuitive Erweiterung der rationalen Zahlen ist offenbar die Menge allerZahlen in (unendlicher) Dezimalschreibweise, also auch die nichtperiodischen. Wir
14

3 Zahlen und Arithmetik
nennen alle solchen Zahlen, die nicht schon rationale Zahlen sind, irrational. Dazugehoren zum Beispiel
1, 01001000100001 . . . ,√
2,−√
11, π, e.
Rationale und irrationale Zahlen zusammen, also alle Zahlen in Dezimalschreib-weise, heißen reelle Zahlen und werden mit R bezeichnet. Dies ist die fur Oko-nomen wichtigste und am haufigsten verwendete Zahlenmenge und wird daherspater weiter vertieft. Reelle Zahlen sind wie die rationalen Zahlen abgeschlos-sen bezuglich der vier Grundrechenarten, aber daruber hinaus auch bezuglichder Bildung von Grenzwerten, die in Kap.??? eingehender behandelt werden. Diereellen Zahlen sind dagegen nicht abgeschlossen bezuglich der Bildung von Wur-zelausdrucken. Zum Beispiel ist
√−1 keine reelle Zahl. Der Abschluss der reellenZahlen bezuglich Wurzelaudrucken heißt komplexe Zahlen und wird mit C be-zeichnet. Die komplexen Zahlen sind fur die Mathematik und auch fur die Physikgrundlegend. Da jedoch komplexe Zahlen selten in den Wirtschaftswissenschaftenvorkommen, werden wir uns hier nicht weiter damit befassen.
Offensichtlich gilt N ⊂ Z ⊂ Q ⊂ R ⊂ C. Die komplexen Zahlen sind also derallgemeinste der funf hier aufgefuhrten Zahlenbegriffe.
3.2 Potenzen und Wurzeln
Das n-fache Produkt
a · a · . . . · a︸ ︷︷ ︸n mal
einer Zahl a ∈ R mit sich selbst wird als die n-te Potenz dieser Zahl bezeichnet.Dabei heißt a auch Basis oder Grundzahl und n Exponent oder Hochzahl derPotenz. Man schreibt dafur an.
Der Potenzbegriff wird uber die Definition a−n := 1an mit n ∈ N auf ganzzahlige
Exponenten kleiner Null erweitert und mit der Festsetzung a0 := 1 fur a = 0schließlich auf alle ganzzahligen Exponenten ausgedehnt.1 Fur das Rechnen mitPotenzen gilt fur alle n, m ∈ Z:
anam = an+m ; a, b ∈ Ran
am = an−m ; a, b ∈ R, a = 0anbn = (ab)n ; a, b ∈ R
an
bn =(
ab
)n; a, b ∈ R, b = 0
(an)m = anm ; a, b ∈ R
1Der Ausdruck 00 ist nicht definiert.
15

3 Zahlen und Arithmetik
Beispiel 3.1:(i) 32 · 33 = 35 = 3 · 3 · 3 · 3 · 3 = 243.(ii) 52
54 = 5−2 = 152 = 1
5·5 = 125
.(iii) 42 · 62 = (4 · 6)2 = 242 = 576.(iv) (22)
3= 26 = 64.
Fur die Potenz an = b mit b ≥ 0 und n ∈ N heißt a auch n-te Wurzel aus b undman schreibt a =
n√
b fur n = 2 und einfach nur a =√
b fur n = 2. Dabei wird bauch als Radikant bezeichnet. Das Wurzelziehen ist also die inverse Operation derPotenzierung. Wurzelausdrucke konnen auch als Potenzen mit nicht ganzzahligenExponenten geschrieben werden, indem
a1/n := n√
a.
festgesetzt wird. Dies ist offenbar konsistent zu den oben angefuhrten Potenz-Rechenregeln, denn
n√
an = (an)1/n = an/n = a.
Also gelten entsprechende Rechenregeln fur das Wurzelziehen, so daß fur dasRechnen mit Wurzeln mit a, b ≥ 0 und n, m ∈ N folgt:
n√
an√
b =n√
abn√an√
b= n√
ab
n√
am = ( n√
a)m
m√
n√
a = nm√
a
Beispiel 3.2:(i)
√16 = 161/2 = 4.
(ii) 4√
x12y8 = (x12y8)1/4
= (x12)1/4
(y8)1/4
= x12/4y8/4 = x3y2.
(iii) m√
x n√
y =(xy1/n
)1/m= x1/my1/mn.
3.3 Logarithmen
Mit dem Wurzelziehen wurde im vorhergehenden Abschnitt die zur Potenzierunginverse Operation bezuglich der Basis oder Grundzahl gebildet. Die inverse Ope-ration zur Potenzierung bezuglich des Exponenten oder der Hochzahl ist das sogenannte Logarithmieren.
Fur die Potenz ay = x mit a > 0 und a = 1 heißt y auch Logarithmus von x zurBasis a. Man schreibt dafur y = loga x. Der Logarithmus einer Zahl x zur Basis
16

3 Zahlen und Arithmetik
a ist also diejenige Zahl y, mit der a potenziert werden muß, um x zu erhalten.Besondere Basen sind in diesem Zusammenhang 10 und die Eulersche Zahl e ≈2, 718281828, die in vielen verschiedenen Zusammenhangen, insbesondere z.B.fur Wachstumsprozesse bedeutsam ist. Der Logarithmus zur Basis 10 wird haufignur mit log x, der Logarithmus zur Basis e mit lnx (fur ’logarithmus naturalis’)bezeichnet.
Beispiel 3.3:(i) log 100 = 2.(ii) log2 64 = 6.(iii) ln 1 = 0.
Fur das Rechnen mit Logarithmen gelten folgende Regeln. Fur a, b > 0, a, b = 1und x, y > 0 gilt:
logb x = loga xloga b
loga(xy) = loga x + loga yloga(x/y) = loga x − loga yloga(x
y) = y loga x
Beispiel 3.4:(i) log(100 · 10002) = log 100+ log(10002) = log 100+2 log 1000 = 2+2 · 3 = 8.
(ii) 27log x + 3
7log y − 5
7log z = 1
7(log(x2) + log(y3) − log(z5)) = 1
7log(
x2y3
z5
).
Man beachte, daß der Logarithmus nur fur Zahlen großer als Null gebildet werdenkann; fur alle Zahlen kleiner oder gleich Null ist er nicht definiert.
17

4 Gleichungen und Ungleichungen
In diesem Kapitel werden Techniken zur Bestimmung der Losungsmengen vonGleichungen und Ungleichungen rekapituliert.
4.1 Eindimensionale Gleichungen undUngleichungen
Eine Gleichung oder Ungleichung ohne Variablen ist eine Aussage, z.B. ist 1 = 1wahr und 0 > 1 falsch. Gleichungen oder Ungleichungen, bzw. mehrdimensionaleSysteme von Gleichungen und Ungleichungen mit Variablen heißen Bestimmungs-gleichungen bzw. ungleichungenund sind Aussageformen. Der einzige Unterschiedzwischen Bestimmungsgleichungen und -ungleichungen besteht darin, daß beiletzteren an der Stelle des Gleichheitszeichens eine der Relationen >,≥,≤, <, =steht.
Fur Gleichungen und Ungleichungen existieren Umformungen, die es ermogli-chen, eine Aussageform in eine andere Aussageform mit derselben Losungsmengezu uberfuhren, und die somit sehr nutzlich dafur sind, die Losungsmenge einerUngleichung zu bestimmen, indem mit ihrer Hilfe die Aussageform nach der Un-bekannten aufgelost wird. Die wichtigsten dieser Umformungen sind nachfolgendfur a, b, c ∈ R zusammengestellt:
a < (≤) b ⇒ b > (≥) aa < (≤) b ⇒ a + c < (≤) b + c
a < (≤) b ∧ c > 0 ⇒ ca < (≤) cba < (≤) b ∧ c < 0 ⇒ ca > (≥) cb
Man beachte, daß die Multiplikation einer Ungleichung mit einem Faktor c ∈ R,dessen Vorzeichen nicht bekannt ist, eine Fallunterscheidung fur c > 0 und c < 0erforderlich macht.
Sei U eine Ungleichung der Form a = b mit a und b als beliebige Ausdrucke,die eine unbekannte Variable enthalten. Eine Moglichkeit, deren LosungsmengeLU zu bestimmen, ist, zunnachst die Losungsmenge LG der Gleichung a = b zuberechnen. Es gilt dann LU = CRLG.
18

4 Gleichungen und Ungleichungen
Beispiel 4.1:(i) Die Losungsmenge der Ungleichung 2x ≥ 8 mit x als Unbekannter ist dieMenge aller reellen Zahlen, die großer oder gleich 4 sind, also das Intervall [4,∞).(ii) Die Losungsmenge der Ungleichung x+1 < 0 mit x als Unbekannter ist dieMenge aller reellen Zahlen, die kleiner als -1 sind, also das Intervall (−∞,−1).(iii) Die Losungsmenge der Ungleichung 3x− 5 ≥ 6x− (2x + 3) mit x als Unbe-kannter ist, wie die Kette
3x − 5 ≥ 6x − (2x + 3) |Auflosen der Klammer3x − 5 ≥ 6x − 2x − 3 |Zusammenfassen der x-Glieder3x − 5 ≥ 4x − 3 |+33x − 2 ≥ 4x | −3x
−2 ≥ x |Ungleichung aufgelost
von Umformungen erbringt, das Intervall (−∞,−2].(iv) Um die Losungsmenge der Ungleichung 5
x≤ 1 mit x als Unbekannter, an
welche zusatzlich die Forderung x = 0 erhoben wird, zu bestimmen, wird zunachstder Fall x > 0 betrachtet. Die Multiplikation der Ungleichung mit x fuhrt dannauf die Ungleichung 5 ≤ x. Also ist die Losungsmenge der urpsrunglichen Un-gleichung fur x > 0 das Intervall L1 = [5,∞). Fur den Fall x < 0 fuhrt dieMultiplikation der Ungleichung mit x hingegen auf die Ungleichung 5 ≥ x. DieLosungsmenge der urpsrunglichen Ungleichung ist folglich fur x < 0 das IntervallL2 = (−∞, 0), und die gesamte Losungsmenge ist L = L1 ∪ L2.
Es existieren Arten von Ungleichungen, welche mit dem bisher behandelten In-strumentarium allein nicht gelost werden konnen. Eine Ungleichung der Form
|a| < b, |a| ≤ b, |a| > b |a| ≥ b oder |a| = b
mit a und b als beliebige Ausdrucke, die eine unbekannte Variable enthalten, heißtUngleichung mit Absolutbetrag. Ist die Losungsmenge einer solchen Ungleichungzu bestimmen, sind die nachfolgenden Aquivalenzen sehr hilfreich:
1. |a| < b ⇔ a < b ∧ −a < b2. |a| ≤ b ⇔ a ≤ b ∧ −a ≤ b3. |a| > b ⇔ a > b ∨ −a > b4. |a| ≥ b ⇔ a ≥ b ∨ −a ≥ b5. |a| = b ⇔ a = b ∧ −a = b
Um die Losungsmenge L einer Ungleichung mit Absolutbetrag zu bestimmen,kann man gemaß dieser Aquivalenzen die Losungsmengen L1 und L2 zweierdazu aquivalenter Ungleichungen ohne Absolutbetrag bestimmen. Im Falle der∧−Verknupfung, also in den Fallen 1, 2 und 5 bildet man dann L = L1 ∩L2 undfur die ∨−Verknupfung, also in den Fallen 3 und 4, entsprechend L = L1 ∪ L2.
19

4 Gleichungen und Ungleichungen
Beispiel 4.2:(i) Die Ungleichung x ≤ |5 − x| ist (nach 4.) aquivalent zu
x ≤ 5 − x︸ ︷︷ ︸U1:=
∨ x ≤ −(5 − x)︸ ︷︷ ︸U2:=
.
Die Losungsmenge der Ungleichung U1 ist, wie die Kette
x ≤ 5 − x |+x2x ≤ 5 | : 2x ≤ 5/2 |Ungleichung aufgelost
von Aquivalenzumformungen erbringt, L1 = (−∞, 5/2]. Die Losungsmenge derUngleichung U2 ist, wie die Kette
x ≤ −(5 − x) |Klammer auflosenx ≤ −5 + x | −x0 ≤ −5 |Falsche Aussage
von Aquivalenzumformungen erbringt, L2 = ∅. Die Losungsmenge der ursprung-lichen Ungleichung ist also L = L1 ∪ L2 = (−∞, 5/2].(ii) Die Ungleichung |6 − x| < 8 ist (nach 1.) aquivalent zu
6 − x < 8︸ ︷︷ ︸U1:=
∧−(6 − x) < 8︸ ︷︷ ︸U2:=
.
Die Losungsmenge der Ungleichung U1 ist das offene Intervall L1 = (−2,∞),die Losungsmenge der Ungleichung U2 das offene Intervall L2 = (−∞, 14). DieLosungsmenge der Ungleichung |6 − x| < 8 ist also L = L1 ∩ L2 = (−2, 14).
Eine Ungleichung der Formx2 + px + q B 0,
wobei B fur eine der Relationen =, >,≥,≤, < oder = steht, heißt quadratischeGleichung oder Ungleichung.
Eine quadratische Gleichung hat entweder keine, eine oder zwei Losungen in R,welche sich mit Hilfe der sogenannten pq-Formel
x1,2 = −p
2±√(p
2
)2
− q
berechnen lassen. Diese Formel besagt, daß die oben angegebene quadratische
Gleichung fur(
p2
)2 − q > 0 zwei Losungen hat, namlich
x1 = −p
2+
√(p
2
)2
− q und x2 = −p
2−√(p
2
)2
− q,
20

4 Gleichungen und Ungleichungen
Fall (a): Fall (b): Fall (c):B 2 Losungen 1 Losung keine
xu, xo xu,o Losung
> (−∞, xu) ∪ (xo,∞) R \ xu,o R
≥ (−∞, xu] ∪ [xo,∞) R R
≤ [xu, xo] xu,o ∅< (xu, xo) ∅ ∅= R \ xu, xo R \ xu,o R
Tabelle 4.1: Losungsmengen quadratischer Ungleichungen
fur(
p2
)2 − q = 0 eine Losung, namlich
x1 = x2 = −p
2
und fur(
p2
)2 − q < 0 keine Losung, da die Wurzel einer negativen Zahl in R nichtdefiniert ist.1
Beispiel 4.3:(i) Die Gleichung x2 + 2x − 15 = 0 hat nach der pq-Formel x1,2 = −1 ±√
1 + 15 = −1 ± 4 die Losungsmenge 3,−5.(ii) Die Gleichung x2 +4x+10 = 0 hat nach der pq-Formel x1,2 = −2±√
4 − 10keine Losung, da
√−6 nicht definiert ist.
Um eine quadratische Ungleichung zu losen, sind zunachst etwa alle Losungender von der quadratischen Ungleichung abgeleiteten Gleichung
x2 + px + q = 0
zu bestimmen. Die Losungsmenge der quadratischen Ungleichung ergibt sich nunin Abhangigkeit von den Losungen der quadratischen Gleichung und der RelationB gemaß Tabelle 4.1.
Die in Tabelle 4.1 zusammengestellten Ergebnisse werden in Abbildung 5.2 ver-anschaulicht, in welcher fur die drei Falle (a), (b) und (c) jeweils eine durch eineentsprechende quadratische Gleichung beschriebene Parabel dargestellt ist.
Beispiel 4.4:(i) Die zur quadratischen Ungleichung x2 − x − 2 ≤ 0 gehorende Gleichungx2 − x− 2 = 0 hat nach der pq-Formel die beiden Losungen xu = −1 und xo = 2mit xu < xo. Dann ist die Losungsmenge der betrachteten quadratischen Unglei-chung das geschlossene Interval [−1, 2].
1Tatsachlich ist die Wurzel einer negativen reellen Zahl eine komplexe Zahl in C.
21

4 Gleichungen und Ungleichungen
(a)
xx
(c)
xx
(b)
xxxxuu
xxoo
xxu,o
Abbildung 4.1: Die drei Falle beim Losen quadratischer Ungleichungen
(ii) Die zur quadratischen Ungleichung x2 − 11x + 24 > 0 gehorende Gleichungx2 − 11x + 24 = 0 hat nach der pq-Formel die beiden Losungen xu = 3 undxo = 8. Dann ist (−∞, 3) ∪ (8,∞) die Losungsmenge der betrachteten quadrati-schen Ungleichung.(iii) Die quadratische Ungleichung x2 +1 ≤ 0 hat, wie man leicht erkennt, keineLosung. Ihre Losungsmenge ist daher ∅.
4.2 Mehrdimensionale Gleichungs- undUngleichungssysteme
Auch Bestimmungsgleichungen- oder ungleichungen mit n = 2, 3, . . . Unbekann-ten sind Aussageformen, deren Losungsmenge eine Menge von n-Tupeln oder n-Vektoren aus Elementen der Grundmenge ist. Ein Gleichungs- bzw. Ungleichungs-system besteht aus mehreren Bestimmungsgleichungen und -ungleichungen, diedieselben Variablen enthalten. Offenbar konnen auch Systeme auftreten, die so-wohl Gleichungen als auch Ungleichungen enthalten. Die Menge der n-Tupel vonZahlen, die gleichzeitig jede dieser Gleichungen und Ungleichungen erfullen, heißtauch Losungsmenge L des Gleichungs- bzw. Ungleichungssystems. Diese konnenwir fur ein System von Gleichungen oder Ungleichungen A1(x), . . . , Ak(x) mitx ∈ Rn bestimmen, indem wir zunachst deren jeweilige Losungsmenge Li miti = 1, . . . , k ermitteln. Es ist dann
L = L1 ∩ L2 ∩ . . . ∩ Lk.
Beispiel 4.5:(i) Die Bestimmungsgleichung 4x1 + 2x2 = 6 mit Variablen x1 und x2 hat die
22

4 Gleichungen und Ungleichungen
Losungsmenge (x1, x2)|x1 ∈ R ∧ x2 = 3 − 2x1.(ii) Die Losungsmenge der Bestimmungsungleichung x1x2 > 0 mit Variablenx1 und x2 besteht aus den 2-Tupeln (x1, x2), fur die gilt, daß x1 und x2 beideungleich Null sind und das gleiche Vorzeichen haben.(iii) Die beiden Gleichungen x1 + x2 = 0 und x1 − x2 = 0 bilden gemein-sam ein Gleichungssystem. Die Losungsmenge der ersten Gleichung ist L1 =(x1, x2)|x1 ∈ R ∧ x2 = −x1, die Losungsmenge der zweiten Gleichung istL2 = (x1, x2)|x1 ∈ R ∧ x2 = x1. Folglich ist die Losungsmenge des Gleichungs-systems L = L1 ∩ L2 = (0, 0).
4.3 Lineare Gleichungssysteme
Gleichungssysteme, deren Einzelgleichungen alle in jeder Unbekannten linear sind,heißen lineare Gleichungssyteme. Sie kommen in den Wirtschaftswissenschaftenhaufig vor und sind wegen der Linearitat leicht losbar. Ein lineares Gleichungs-system hat entweder keine, genau eine oder unendlich viele Losungen.
Beispiel 4.6:(i) Um die Losungsmenge des Gleichungssystems
2x + 3y = 14︸ ︷︷ ︸G1:=
und 4x − y = 0︸ ︷︷ ︸G2:=
mit den Variablen x und y zu bestimmen, kann man zunachst G2 nach y auflosenund erhalt dann y = 4x. Ersetzt man nun in G1 die Variable y durch 4x, ergibtsich 2x + 3(4x) = 14. Die Losung dieser Gleichung ist x = 1. Mit y = 4x folgty = 4. Die Losungsmenge des betrachteten Gleichungssystems ist also (1, 4).(ii) Um die Losungsmenge des Gleichungssystems
x + 2y = 3︸ ︷︷ ︸G1:=
und 2x + 4y − 4 = 0︸ ︷︷ ︸G2:=
zu bestimmen, kann man zunachst G1 nach x auflosen und erhalt dann x = 3−2y.Ersetzt man nun in G2 x durch 3−2y, folgt die Gleichung 2(3−2y)+4y−4 = 0,die wegen 2 = 0 keine Losung hat. Die Losungsmenge dieses Gleichungssystemsist also leer.
Ein effizienteres Verfahren zur Bestimmung der Losungsmenge linearer Glei-chungssysteme, der sogenannte Gauss-Algorithmus, wird in der Vorlesung Ma-thematik II (Lineare Algebra) behandelt.
23

4 Gleichungen und Ungleichungen
11 22 33 44 55 xx11
−2 −1 00
xx22
44
33
22
11
−1
xx22 ≤ 2 + xx
11
xx22 ≥≥ 1 − ½ xx
11
xx11 < 33
Abbildung 4.2: Losungsmenge zu Beispiel 4.7 (i)
4.4 Zweidimensionale Ungleichungssysteme
Im Fall mit zwei Variablen ist oft eine graphische Analyse in der euklidischenEbene hilfreich. Es ist ublich, den Rand von Flachen fur die Relationen ≤ und ≥mit durchgezogenen und fur < und > mit gestrichelten Linien darzustellen.
Beispiel 4.7:(i) Um die Losungsmenge des Ungleichungssystems
U1: x2 ≤ 2 + x1
U2: x2 ≥ 1 − 1/2x1
U3: x1 < 3
mit den Variablen x1 und x2 graphisch zu bestimmen, zeichnen wir zunachst diezu jeder Ungleichung gehorende Gerade in die euklidische Ebene ein (Abbildung4.2). Die Losungsmenge zu den jeweiligen Ungleichungen U1, U2 oder U3 ent-spricht jeweils der Halbebene rechts unterhalb, rechts oberhalb bzw. links dieserGeraden. Also ist die Losungsmenge des Ungleichungssystems ist das grau mar-kierte Dreieck ohne den rechten gestrichelten Rand (Abbildung 4.2).(ii) Die Losungsmenge des Ungleichungssystems
U1: x21 + x2
2 ≤ 1U2: x2 ≥−x1
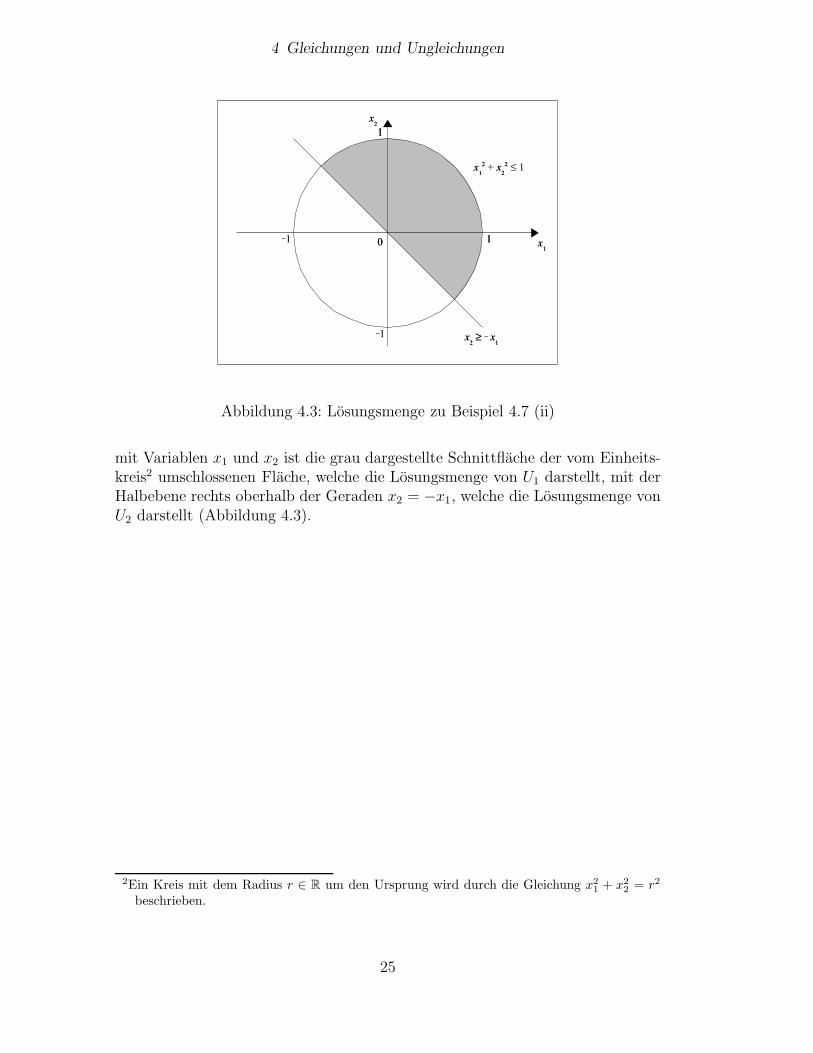
24
4 Gleichungen und Ungleichungen
xx11
−1
xx22
xx11
22 + xx22
22 ≤ 1
xx22 ≥≥ − xx
11
00
11
−1 11
Abbildung 4.3: Losungsmenge zu Beispiel 4.7 (ii)
mit Variablen x1 und x2 ist die grau dargestellte Schnittflache der vom Einheits-kreis2 umschlossenen Flache, welche die Losungsmenge von U1 darstellt, mit derHalbebene rechts oberhalb der Geraden x2 = −x1, welche die Losungsmenge vonU2 darstellt (Abbildung 4.3).
2Ein Kreis mit dem Radius r ∈ R um den Ursprung wird durch die Gleichung x21 + x2
2 = r2
beschrieben.
25

5 Folgen und Grenzwerte
In diesem Kapitel werden Folgen und der fur die Analysis grundlegende Begriffdes Grenzwerts behandelt.
5.1 Folgen
Definition 5.1 (Folge) Eine geordnete (unendliche) Liste von Zahlen
(a1, a2, . . . , an, . . .)
heißt Folge (engl.: sequence) und wird mit (an)n∈Nbezeichnet. Dabei heißt n der
Index und die an heißen Glieder der Folge. Falls klar ist, daß n ∈ N der Index istwird meistens die verkurzte Schreibweise (an) oder einfach an verwendet.
Der erste Folgenindex ist oft auch 0 oder jede andere beliebige naturliche Zahlstatt 1, also bedeutet oft auch (an) = (a0, a1, . . . , an, . . .). Wir legen uns dies-bezuglich nicht fest und verwenden verschiedene Notationen je nach Zusammen-hang. Folgen konnen auf verschiedene Arten dargestellt werden. Falls fur eineFolge an ein Folgenglied an durch eine Funktionsgleichung nur in n angegebenist, heißt dies geschlossene Darstellung. Bei einer rekursiven Darstellung einerFolge wird der Wert der ersten Folgenglieder a1, . . . , ak angegeben und alle wei-teren Folgenglieder n = k + 1, k + 2, . . . durch fruhere Folgenglieder ausgedruckt.Besonders einfach ist der Fall, bei dem fur alle n ∈ N der Zusammenhang zwi-schen zwei aufeinander folgenden Folgengliedern an und an+1 uber eine Funkti-onsgleichung beschrieben ist. Wenn klar ist, was mit damit gemeint ist, kann eineFolge auch durch Angabe einiger Folgenglieder und . . . beschrieben werden. Dierekursive Darstellung einer Folge ist oft unmittelbar aus der zu analysierendenFragestellung heraus gegeben, wahrend die geschlossene Darstellung einfacher zuanalysieren ist. Daher ist es offenbar hilfreich, die rekursive Darstellung der be-trachteten Folge in eine geschlossene Darstellung zu uberfuhren. Dieses gelingtoftmals, indem man die ersten Folgenglieder notiert und darin eine strukturelleGesetzmaßigkeit identifiziert, aus der sich eine geschlossene Darstellung der Fol-ge ergibt. Der Beweis, daß die so gefundene geschlossene Darstellung tatsachlichdie selbe Folge beschreibt wie die rekursive Darstellung, ist damit noch nichterbracht, jedoch haufig mit Hilfe eines Induktionsbeweises leicht zu fuhren.
26

5 Folgen und Grenzwerte
Beispiel 5.1:(i) Eine rekursive Darstellung der Folge an = (0, 0, 0, . . .) ist a1 = 0, an+1 = an.Die geschlossene Darstellung dieser Folge ist an = 0.(ii) Die rekursive Darstellung der Folge an = (1, 3, 5, . . .) ist a1 = 1, an+1 =an + 2. Die zugehorige geschlossene Darstellung ist an = 2n − 1.(iii) Bei der Folge (nt)t∈N
steht n nicht fur den Index der Folge sondern alsSymbol fur die Folgenglieder. Fur eine eindeutige Bedeutung ware in diesem Falldie weniger genaue Notation (nt) nicht ausreichend. Die ersten funf Glieder dieserFolge sind n, 2n, 3n, 4n und 5n.(iv) Die Folge an = (1, 2, 3, 5, 8, 13, 21, . . .) besitzt die rekursive Darstellung a0 =1, a1 = 2, an+2 = an + an+1.(v) Sei (Kt) eine Kapitalanlage mit Startkapital K1 = K, die mit einem Zinssatzi pro Periode verzinst wird. Die Folge (Kt)t∈N
beschreibt die Wertentwicklung derKapitalanlage im Zeitablauf. Falls keine Ein- oder Auszahlungen stattfinden, giltzwischen Kt in Periode t ∈ N und Kt+1 in der Folgeperiode t + 1 die rekursiveBeziehung
Kt+1 = Kt(1 + i).
Aus den ersten vier Gliedern dieser Folge,
K1 = K,K2 = K(1 + i),K3 = K(1 + i)2 undK4 = K(1 + i)3
ist leicht erkennbar, daß die geschlossene Darstellung dieser Folge gegeben istdurch
Kt = K(1 + i)t−1.
Existiert fur eine Folge an ein reelle Zahl c ∈ R, so daß fur alle n ∈ N dieBeziehung
an+1 − an = c
gilt, so heißt sie arithmetische Folge. Falls dagegen fur eine Folge an ein Konstantec ∈ R existiert, so daß fur alle n ∈ N die Beziehung
an+1
an= c
gilt, so heißt sie geometrische Folge. Die geschlossenen Darstellungen der arith-metischen Folge und der geometrischen Folge (gn) sind an ist an = c(n − 1) + dund gn = dcn−1 mit c, d ∈ R. Im vorhergehenden Beispiel sind (i),(ii) und (iii)arithmetische Folgen, (v) ist geometrische Folge und (iv) keines von beiden.
27

5 Folgen und Grenzwerte
Eine Folge an heißt monoton steigend bzw. streng monoton steigend, (engl.: strict-ly increasing), wenn fur alle n ∈ N gilt an+1 ≥ an (bzw.> fur ’streng’). Entspre-chend wird fallende Monotonie definiert. Monoton ist eine Folge also genau dann,wenn die Veranderung zwischen zwei aufeinander folgenden Gliedern immer dasgleiche Vorzeichen hat bzw. in die gleiche Richtung geht. Die Folge an heißt nachunten bzw. nach oben beschrankt (engl.: bounded from below, above), wenn eineKonstante c ∈ R existiert, so daß fur alle n ∈ N gilt an ≥ c (bzw. ≤). Sie heißtbeschrankt (engl.: bounded), wenn ein c ∈ R existiert, so daß fur alle n ∈ N
die Beziehung |an| ≤ c gilt. Die Konstante c wird untere, obere bzw. einfach nurSchranke (engl.: lower bound, upper bound, bound) genannt. Eine Folge an heißtalternierend (engl.: alternating), wenn fur alle n ∈ N gilt:
an · an+1 < 0,
also das Vorzeichen zwischen zwei aufeinander folgenden Folgengliedern alter-niert, d.h. sich jeweils abwechselt.
Beispiel 5.2:(i) Die Folge
(n + 1
n
)ist streng monoton steigend.
(ii) Die Folge (max4 − n, 0), deren erste funf Glieder 3, 2, 1, 0 und 0 sind, istmonoton aber nicht streng monoton fallend.1
(iii) Die Folge ((−1)n) ist alternierend und daher weder monoton steigend nochmonoton fallend.(iv) Fur die Folge an mit an = 3 + 7n existiert mit c = 3 wegen an ≥ c furalle n ∈ N offensichtlich eine untere Schranke. Die Folge ist somit nach untenbeschrankt.(v) Die Folge
(1n
)ist wegen 0 ≤ 1
n≤ 1 fur alle n ∈ N beschrankt.
(vi) Die Folge ((−2)n) ist alternierend und weder nach unten noch nach obenbeschrankt, da ihre Glieder beliebig groß und beliebig klein werden.
5.2 Konvergenz und Grenzwert
Von besonderem Interesse im Zusammenhang mit Folgen an ist ihr Verhalten fursehr große n. Insbesondere gilt unser Interesse dem Fall, daß eine Zahl existiert,der sich die Folgenglieder beliebig gut annahern wie die Folge
(1n
)der Zahl 0. Die
Begriffe Konvergenz und Grenzwert prazisieren dieses Verhalten.
1Dabei nimmt maxx, y fur x ≥ y den Wert x und fur x < y den Wert y an. Es ist alsobeispielsweise max3, 4 = 4.
28

5 Folgen und Grenzwerte
Definition 5.2 (Konvergenz und Grenzwert) Eine Folge (an)n∈Nheißt kon-
vergent (engl.: convergent) genau dann, wenn es ein a ∈ R gibt, so daß fur alleε > 0 ein n(ε) > 0 mit
|an − a| ≤ ε
fur alle n ≥ n(ε) existiert. Man schreibt dann
limn→∞
an = a oder an −→ a
und sagt, an konvergiere gegen den Grenzwert (engl.: limit) a.
Zeichnet man ein Intervall mit Radius ε um a, so mussen alle Folgenglieder außerden ersten n(ε) − 1 in diesem Intervall liegen, gleichgultig wie klein der Radiusε um a gewahlt wurde. Mit anderen Worten, eine Folge an konvergiert genaudann gegen a, wenn der Abstand zwischen den Folgengliedern und a ab einembestimmten n(ε) jedes noch so kleine vorgegebene ε > 0 nicht uberschreitet.
Beispiel 5.3:(i) Es gilt 1
n→ 0, da fur jedes vorgegebene ε > 0 die gesuchte Grenze durch
n(ε) = 1ε
gegeben ist, denn fur alle n ≥ n(ε) gilt∣∣∣∣ 1n − 0
∣∣∣∣ = 1
n≤ 1
1ε
= ε
.(ii) Die konstante Folge (c) mit c ∈ R konvergiert offenbar gegen c.(iii) Die Folgen ((−1)n) und (2n) konvergieren nicht.
Satz 5.1 Jede Folge besitzt hochstens einen Grenzwert.
Beweis. Indirekt: Angenommen, eine Folge an habe mehr als einen Grenzwertalso Grenzwerte a und a′ mit a = a′. Sei
ε =1
4|a′ − a|
(vgl. Abbildung 5.1). Dann existiert wegen an −→ a ein n(ε) mit |an − a| ≤ε fur alle n ≥ n(ε). Außerdem existiert wegen an −→ a′ auch ein n′(ε) mit|an − a′| ≤ ε fur alle n ≥ n′(ε). Sei nun m = maxn(ε), n′(ε). Dann ist offenbar|am−a|+|am−a′| < 2ε. Die sogenannte Dreiecksungleichung sagt aus, daß fur allex, y ∈ R gilt |x+y| ≤ |x|+|y|. Daher ist |am−a|+|am−a′| = |am−a|+|a′−am| ≥|am − a + a′ − am| = |a′ − a|, so daß insgesamt folgt:
|a′ − a| ≤ 2ε
29

5 Folgen und Grenzwerte
aa a’
22εε 22εε
||a’ − aa| = 4εε
Abbildung 5.1: Veranschaulichung des Beweises von Satz 5.1
Dieses widerspricht aber ε = 14|a′ − a|. Satz 5.1 ist damit bewiesen.
Wahrend mit dem letzten Satz gezeigt wurde, daß eine Folge hochstens einenGrenzwert besitzt, werden in den folgenden beiden Satzen ohne Beweis notwen-dige bzw. notwendige und hinreichende Bedingungen genannt, unter denen eineFolge konvergiert und also uberhaupt einen Grenzwert hat.
Satz 5.2 Fur jede Folge an gilt:
an konvergiert ⇒ an ist beschrankt.
Satz 5.3 Fur jede monoton steigende Folge an gilt:
an konvergiert ⇔ an ist nach oben beschrankt.
Fur jede monoton fallende Folge bn gilt:
bn konvergiert ⇔ bn ist nach unten beschrankt.
Beispiel 5.4:(i) Die Folge an mit an = 1+n
n2en + 1 = 1n2en + 1
nen + 1 fallt offenbar monoton. Sieist wegen an ≥ 1 nach unten beschrankt und daher wegen Satz 5.3 konvergent.(ii) Die Folge (n) steigt monoton und ist nicht nach oben beschrankt. Nach Satz5.3 konvergiert sie also nicht.
Bei einer konvergenten Folge richtet sich das Interesse naturgemaß meistens aufihren Grenzwert. Besonders fur komplizierte Folgen kann es aber sehr aufwendigsein, ihre Konvergenz allein unter Verwendung von Definition 5.2 zu untersuchen.Der folgende Satz macht Aussagen uber die Konvergenz und den Grenzwert vonFolgen, die mittels der vier Grundrechenarten aus anderen konvergenten Folgenzusammengesetzt sind.
30

5 Folgen und Grenzwerte
Satz 5.4 Seien an und bn zwei Folgen mit an −→ a und bn −→ b. Dann gilt
i) an + bn −→ a + b,
ii) an − bn −→ a − b,
iii) an · bn −→ a · b und
iv) an
bn−→ a
b, fur b = 0.
Nachfolgend ist nur der Beweis der Teilaussage i) von Satz 5.4 angegeben. DieBeweise der anderen Teilaussagen entsprechen diesem.
Beweis. Betrachte ein vorgegebenes ε > 0. Wegen an −→ a existiert ein na(ε)mit
|an − a| <ε
2
fur alle n ≥ na(ε). Analog existiert wegen bn −→ b ein nb(ε) mit
|bn − b| <ε
2
fur alle n ≥ nb(ε). Sei n(ε) = max na(ε), nb(ε). Dann gilt fur alle n ≥ n(ε)
|(an + bn) − (a + b)|= |(an − a) + (bn − b)|≤ |(an − a)| + |(bn − b)| (Dreiecksungleichung)< ε
2+ ε
2
= ε.
Die Konvergenz von (an + bn) gegen a + b ist damit bewiesen.
Beispiel 5.5:(i) Die Folge an mit an = 2n3−n2+1
3n3+nkonvergiert gemaß Satz 5.4 gegen 2
3, wie
sich aus der Darstellung der Folgenglieder in der Form
an =
→2︷︸︸︷2 −
→0︷︸︸︷1
n+
→0︷︸︸︷1
n3
3︸︷︷︸→3
+1
n2︸︷︷︸→0
und den angegebenen Grenzwerten der konvergenten Einzelfolgen (2),(
1n
),(
1n3
),(3)
und(
1n2
)ergibt.
31

5 Folgen und Grenzwerte
(ii) Die Folge an mit an = 6n2−2n5 konvergiert gemaß Satz 5.4 gegen 0, wie aus
der Darstellung der Folgenglieder in der Form
an =
→0︷︸︸︷6
n3−
→0︷︸︸︷2
n5
1︸︷︷︸→1
zu sehen ist.
Alternativ zur Dezimalschreibweise lassen sich reelle Zahlen mit Hilfe von Fol-gen und Konvergenz definieren indem man verschiedene konvergente Folgen vonrationalen Zahlen miteinander identifiziert und einer reellen Zahl zuordnet, fallsihre Differenz gegen 0 konvergiert.2 Mit anderen Worten, zwei konvergente Fol-gen an und bn heißen aquivalent, falls an− bn −→ 0. Alle zueinander aquivalentenkonvergenten Folgen bilden eine Aquivalenzklasse. Die Menge aller konvergentenFolgen rationaler Zahlen zerfallt also in – d.h. ist disjunkte Vereinigung von –Aquivalenzklassen von konvergenten Folgen, wobei jeweils zwei Reprasentantender gleichen Aquivalenzklasse gegen den gleichen Grenzwert streben. Die reellenZahlen sind also die Menge der Aquivalenzklassen konvergenter Folgen rationalerZahlen. Die im Kapitel Zahlen eingefuhrte Dezimalschreibweise mit Zehnerpo-tenzen ist jeweils ein Reprasentant einer solchen Aquivalenzklasse, also nur einevon vielen Moglichkeiten, reelle Zahlen mit Hilfe von rationalen Zahlen zu appro-ximieren. Satz 5.4 zeigt, daß die Rechenregeln der rationalen Zahlen sich auf diereellen Zahlen ubertragen.
5.3 Grenzwerte im Unendlichen
Folgen, die jede beliebig große Grenze m ab einem gewissen n(m) ∈ N nichtmehr unterschreiten oder aber jede beliebig kleine Grenze m ab einem gewissenn(m) ∈ N nicht mehr uberschreiten streben offenbar gegen ∞ bzw. −∞. Dadieses keine reellen Zahlen sind, nennen wir sie uneigentliche Grenzwerte.
Definition 5.3 (Uneigentlicher Grenzwert) Eine Folge an hat den uneigent-lichen Grenzwert ∞, wenn fur jedes m ∈ R ein n(m) mit
an ≥ m
fur alle n ≥ n(m) existiert. Man schreibt limn→∞ an = ∞ oder an −→ ∞.
2Um reelle Zahlen zu definieren, darf deren Definition nicht schon reelle Zahlen verwenden.Unsere bisherige Definition von Konvergenz beruht aber auf einem reellen Grenzwert. Indiesem Zusammenhang verwendet man daher eine alternative Definition von Konvergenz,die sogenannte Cauchy-Konvergenz, bei der eine Folge an konvergiert falls fur jedes ε > 0ein n(ε) existiert, so daß fur alle Folgenglieder an, am mit n, m ≥ n(ε) gilt |an − am| ≤ ε.
32

5 Folgen und Grenzwerte
Der uneigentliche Grenzwert −∞ wird entsprechend definiert.
Beispiel 5.6:(i) Die Folge (n) hat den uneigentlichen Grenzwert ∞.(ii) Die Folge 0, 2, 0, 4, 0, 6, 0, . . ., konvergiert nicht, auch nicht gegen einen un-eigentlichen Grenzwert.
Der folgende Satz zeigt, daß mit gewissen Einschrankungen die Rechenregeln derreellen Zahlen auf die uneigentlichen Zahlen ∞ bzw. −∞ erweiterbar sind.
Satz 5.5 Seien an und bn Folgen. Dann gilt:
i) an −→ ∞ ⇒ −an −→ −∞ii) an −→ ∞ ∧ bn nach unten beschrankt ⇒ an + bn −→ ∞iii) an −→ −∞ ∧ bn nach oben beschrankt ⇒ an + bn −→ −∞iv) an −→ ∞ (−∞) ∧ bn mit unterer Schranke s > 0 ⇒ anbn −→ ∞ (−∞)
v) an −→ ∞ (−∞) ∧ bn mit oberer Schranke s < 0 ⇒ anbn −→ −∞ (∞)
vi) an −→ 0 ∧ ∀n ∈ N an > (<) 0 ⇒ 1an
−→ ∞ (−∞)
vii) (an −→ ∞ ∨ an −→ −∞) ∧ bn beschrankt ⇒ bn
an−→ 0
viii) an −→ ∞ ∧ bn beschrankt ∧ ∀n ∈ N bn > (<) 0 ⇒ an
bn−→ ∞ (−∞)
ix) an −→ −∞ ∧ bn beschrankt ∧ ∀n ∈ N bn > (<) 0 ⇒ an
bn−→ −∞ (∞)
Die Aussage an −→ ∞ ⇒ −an −→ −∞ kann man verkurzt schreiben als(−1)∞ = −∞.
Beispiel 5.7:(i) Die Folge (n(sin n + 2)) strebt gemaß Satz 5.5 iv) gegen ∞, da (n) gegen∞ strebt und (sin n + 2) etwa durch 1 > 0 nach unten beschrankt ist.
(ii) Die Folge(
(−1)n
n
)konvergiert gemaß Satz 5.5 vii) gegen 0.
Den Abschluß dieses Abschnitts bildet Satz 5.6, der das Konvergenzverhalteneiniger haufig auftretender Folgen bzw. Klassen von Folgen zusammenfaßt.
Satz 5.6 Es gilt:
33

5 Folgen und Grenzwerte
i) nr −→ 0 fur r < 0 und r ∈ Q
ii) nr −→ ∞ fur r > 0 und r ∈ Q
iii) nrqn −→ 0 fur r ∈ Q und |q| < 1
iv) nrqn −→ ∞ fur r ∈ Q und q > 1
v) n√
c −→ 1 mit c > 0
vi) n√
n −→ 1
vii)(1 + 1
n
)n −→ e (Eulersche Zahl)
5.4 Reihen
Eine spezielle Klasse von Folgen sind die sogenannten Reihen. Ihre Glieder werdendurch die Summen der Glieder einer anderen Folge gebildet.
Definition 5.4 (Reihe) Sei an eine Folge. Dann heißt die Folge (sk)k∈Nmit
sk =
k∑n=1
an
fur alle k ∈ N zur Folge an gehorige Reihe (engl.: series). Ihre Glieder sk =∑kn=1 an bezeichnet man auch als Partialsummen.
Naturlich gelten alle Begriffe und Satze aus den vorangegangenen Abschnittenauch fur Reihen. So heißt eine Reihe
∑∞n=1 an konvergent, wenn die Folge der Par-
tialsummen(∑k
n=1 an
)k∈N
konvergiert. Der Grenzwert dieser Folge und haufig
auch die Reihe selbst wird mit∑∞
n=1 an bezeichnet. Eine wichtige notwendigeBedingung fur die Konvergenz einer Reihe gibt der folgende Satz.
Satz 5.7 Konvergiert die Reihe∑∞
n=1 an, dann konvergiert die Folge an gegen 0.
Er ist insbesondere dafur geeignet, die Nicht-Konvergenz oder Divergenz einerReihe zu zeigen. Der Begriff Divergenz wird in der Literatur uneinheitlich benutzt,manchmal nur fur Konvergenz gegen ∞ oder −∞, manchmal aber allgemeiner furNicht-Konvergenz gegen eine reelle Zahl. Wir werden ihn ab hier nur in letzteremSinne benutzen, also als Synonym fur Nicht-Konvergenz gegen eine reelle Zahl.
34

5 Folgen und Grenzwerte
Beispiel 5.8:(i) Die Reihe
∑∞n=1(1 + 1
n) divergiert gemaß Satz 5.7.
(ii) Die Reihe∑∞
n=1(−1)n, deren erste vier Partialsummen −1, 0, −1 und 0sind, divergiert.(iii) Die Reihe
∑∞n=1
12n−1 konvergiert gegen 2, wie die Beobachtung deutlich
macht, daß fur alle k ∈ N mit der Addition von 12k−1 der Abstand zwischen der
k − 1-ten Partialsumme∑k−1
n=11
2n−1 und 2 halbiert wird.
Wie bereits erwahnt, sind alle Satze uber Folgen auch fur Reihen anwendbar,da Reihen spezielle Folgen sind. Der folgende Satz, der bei der Bestimmung desGrenzwerts von Reihen hilfreich ist, die linear aus anderen konvergenten Reihengebildet werden, folgt aus Satz 5.4.
Satz 5.8 Seien∑∞
n=1 an und∑∞
n=1 bn zwei konvergente Reihen und α, β ∈ R.Dann konvergiert auch die Reihe
∑∞n=1(αan + βbn) und es gilt:
∞∑n=1
(αan + βbn) = α∞∑
n=1
an + β∞∑
n=1
bn.
In den Wirtschaftswissenschaften treten haufig geometrische Reihen auf, welchedurch die Partialsummen der Glieder geometrischer Folgen definiert sind.
Definition 5.5 (Geometrische Reihe) Sei an eine geometrische Folge. Dannwird
∑∞n=1 an geometrische Reihe (engl.: geometric series) genannt.
Die geometrische Reihe kann stets in der Form∑∞
n=1 dcn−1 mit c, d ∈ R \ 0geschrieben werden. Ihr Konvergenzverhalten in Abhangigkeit von c und d be-schreibt der folgende Satz.
Satz 5.9 Die geometrische Reihe
∞∑n=1
dcn−1
mit c, d ∈ R \ 0 konvergiert fur |c| < 1 gegen
d
1 − c.
Fur |c| ≥ 1 konvergiert sie nicht gegen eine reelle Zahl.
35

5 Folgen und Grenzwerte
Beweis. Sei sk =∑k
n=1 dcn−1 die k-te Partialsumme der geometrischen Reihe∑∞n=1 dcn−1. Dann gilt fur alle k ∈ N
sk − csk =
k∑n=1
dcn−1 − c
k∑n=1
dcn−1
=k∑
n=1
dcn−1 −k+1∑n=2
dcn−1
= d − dck.
Folglich hat die Folge (sk)k∈Ndie geschlossene Darstellung
sk =d − dck
1 − c.
Aus dieser folgt, daß∑∞
n=1 dcn−1 fur |c| < 1 gegen d1−c
konvergiert und fur |c| ≥ 1divergiert.
Das nachfolgende Beispiel ist eine Anwendung von Satz 5.9 auf in der Praxishaufig auftretende Falle, in denen eine Umindizierung der zu untersuchendenReihe hilfreich ist.
Beispiel 5.9:
(i)∑∞
n=1 2(
12
)n−1konvergiert gegen 2
1− 12
= 4.
(ii)∑∞
n=1
(87
)n−1divergiert.
(iii)∑∞
n=0 4(
13
)n=∑∞
n=1 4(
13
)n−1konvergiert gegen 4
1− 13
= 6.
(iv)∑∞
n=2
(25
)n−1= 2
5
∑∞n=1
(25
)n−1konvergiert gegen 2
51
1− 25
= 23.
Als Anwendung geometrischer Reihen in den Wirtschaftswissenschaften betrach-ten wir sogenannte Multiplikatoreffekte in einem stilisierten Modell zu den Moglich-keiten der Konjunkturbelebung durch staatliche Ausgabenprogramme.
Beispiel 5.10: Betrachtet wird eine Volkswirtschaft, in der das aggregierte Kon-sumverhalten aller Haushalte in einer Periode t > 1 durch die Gleichung
Ct = c(1 − τ)Yt−1
mit Ct als Konsumausgaben in Periode t, mit c ∈ (0, 1) als Konsumquote, mitτ ∈ (0, 1) als Einkommenssteuersatz und Yt−1 als Gesamteinkommen vor Steuernaller Haushalte in Periode t − 1 beschrieben sei. Es werde also angenommen,die Haushalte wurden in jeder Periode einen Anteil c ihres in der Vorperiode
36

5 Folgen und Grenzwerte
erzielten Einkommens nach Steuern konsumieren und den Rest sparen. Dann sind∆Ct = Ct − Ct−1 die Veranderung der Konsumausgaben und ∆Yt = Yt − Yt−1
die Veranderung des Einkommens zwischen zwei aufeinander folgenden Perioden.Also gilt
∆Ct = c(1 − τ)∆Yt−1.
Zur Vereinfachung nehmen wir an, daß zusatzliches Einkommen der Haushaltenur durch zusatzlichen Konsum erzeugt wird, also keine anderen einkommens-wirksamen Effekte auftreten, etwa im Unternehmenssektor oder im Ausland.Dann ist ∆Yt = ∆Ct und es folgt insgesamt
∆Yt = c(1 − τ)∆Yt−1.
Angenommen, der Staat interveniere in diese Volkswirtschaft, indem er in Periode1 einmalig den Betrag G etwa fur Arbeitsbeschaffungsmaßnahmen einbringt, also∆Y1 = G. Dann beschreibt die Folge (∆Yt)t∈N
mit
∆Y1 =G∆Y2 = c(1 − τ)∆Y1 = c(1 − τ)G
∆Y3 = c(1 − τ)∆Y2 = (c(1 − τ))2 G...
∆Yt = c(1 − τ)∆Yt−1 = (c(1 − τ))t−1 G
die Einzeleffekte dieser Intervention in jeder Periode t und die Reihe
∞∑t=1
∆Yt =∞∑t=1
(c(1 − τ))t−1 G
ihren Gesamteffekt ∆Y . Da c ∈ (0, 1) und τ ∈ (0, 1) ist auch 0 < c(1 − τ) < 1.Also konvergiert die betrachtete Reihe gemaß Satz 5.9 gegen
∆Y = G1
1 − c(1 − τ).
Daraus koennte man den Schluss ziehen, daß die Einkommenswirkung einer sol-chen konjunkturbelebenden Maßnahme des Staates auf dem Wege der Ausgaben-politik aufgrund des sogenannten Multiplikatoreffekts die Kosten dieser Staats-intervention wegen
1
1 − c(1 − τ)> 1
ubersteigt. Außerdem folgt aus dieser Argumentation, daß die Wirkung einersolchen Maßnahme umso großer ausfallt, je großer die Konsumquote c und jekleiner der Einkommenssteuersatz τ ist.
37

5 Folgen und Grenzwerte
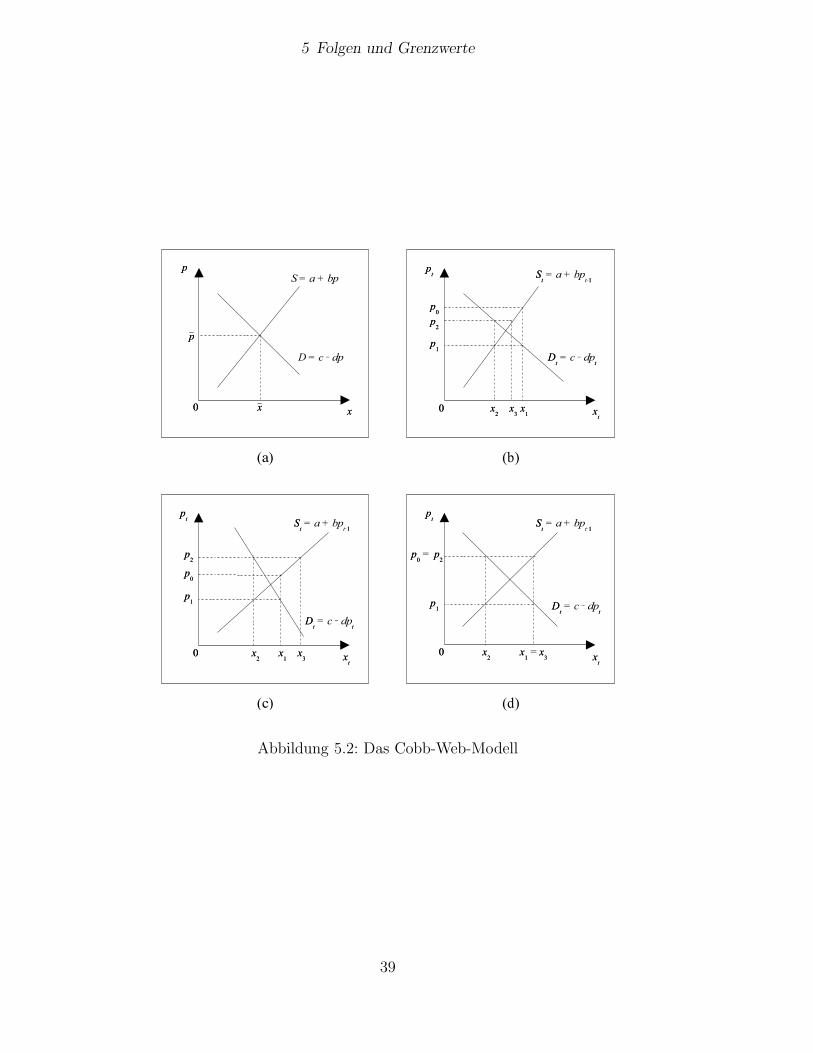
Im abschließende Beispiel studieren wir eine einfachen Variante eines Gedan-kenexperiments, des sogenannten Cobb-Web-Modells, welches dynamische An-passungsprozesse in Markten beschreibt, deren Angebot mit Zeitverzogerung aufPreisanderungen reagiert.
Beispiel 5.11: Betrachtet werde ein Markt, dessen Angebot S und Nachfrage Dlinear im Preis p seien, also
S = a + bp
mit a, b ∈ R und b > 0 und
D = c − dp
mit c, d ∈ R und d > 0. Sei dieser Markt zunachst ein sogenannter vollkomme-ner Markt, der unter anderem durch eine unendlich hohe Reaktionsgeschwindig-keit aller Marktteilnehmer bezuglich Anderungen von Marktparametern charak-terisiert ist. Unter diesen Voraussetzungen werden Angebot und Nachfrage uberPreisanpassungen ohne Zeitverzogerung ausgeglichen. Also bildet sich unmittel-bar ein Preis p, fur den die gehandelte Menge x gleich der angebotenen gleich dernachgefragten Menge ist, also
x = S = D
(vgl. Abbildung 5.2 (a)). Dann ist
p =c − a
b + dund x =
ad + bc
b + d.
Die so definierte Preis-Mengen-Kombination (p, x) wird als Marktgleichgewichtbezeichnet, da zu diesem Preis kein Marktteilnehmer einen Anreiz fur Verhal-tensanderungen hat.
Wir nehmen nun an, die Angebotsseite reagiere etwa wegen zeitlich ausgedehnterProduktionsprozesse mit Verzogerung auf Preisanderungen. Seien St, Dt und pt
Angebot, Nachfrage und Preis in Periode t ∈ N. Es sei
St = a + bpt−1 und Dt = c − dpt,
das Angebot richte sich also nach dem Marktpreis der Vorperiode, wahrend dieNachfrage wie zuvor vom gegenwartigen Preis abhange. Der Marktmechanismusbringe in jeder Periode t ∈ N Angebot und Nachfrage uber den Preis pt in Ein-klang, es gelte also also stets
xt = St = Dt.
Dann gilt fur die Preise zweier aufeinander folgender Perioden
pt =c − a
d− b
dpt−1 = α − βpt−1,
38
5 Folgen und Grenzwerte
(a) (b)
(c) (d)
pp
xx00
S = a + bp
D = c − dp
pp
xx
pptt
xxtt
00
SStt = a + bp
t−11
DDtt = c − dp
tt
pp00
xx11
pp11
xx22
pp22
xx33
pptt
00
SStt = a + bp
t−11
DDtt = c − dp
tt
pp00
xx11
pptt
00
SStt = a + bp
t−11
DDtt = c − dp
tt
pp00 = pp
22
xx11 = xx
33
pp11
xx22 xx
ttxx
ttxx
22xx
33
pp11
pp22
Abbildung 5.2: Das Cobb-Web-Modell
39

5 Folgen und Grenzwerte
wobei α = c−ad
und β = bd
sind. Sei p0 der Marktpreis in der Ausgangsperiodet = 0, dann gilt
p1 = α − βp0
p2 = α − βp1 =α − αβ + β2p0
p3 = α − βp2 =α − αβ + αβ2 − β3p0...
pt = α − βpt−1 =α∑t
i=1 (−β)i−1 + (−β)t p0.
Der Preispfad im Zeitablauf wird also durch die Folge
(pt)t∈N=
(α
t∑i=1
(−β)i−1 + (−β)t p0
)t∈N
beschrieben. Sie konvergiert gemaß Satz 5.9 fur β < 1 gegen c−ab+d
= p (vgl. Abbil-dung 5.2 (b)) und divergiert fur β ≥ 1 (vgl. Abbildungen 5.2 (c) und (d)). DieFolge
(xt)t∈N= (c − dpt)t∈N
,
die den zugehorigen Mengenpfad im Zeitablauf beschreibt, konvergiert bzw. di-vergiert unter der selben Bedingung.
Die betrachtete Variante des Cobb-Web-Gedankenexperimentes erlaubt also dieBeobachtung, daß ein Markt, in dem das Angebot mit zeitlicher Verzogerung aufden Preis reagiert, unter sonst gleichen Bedingungen sich langfristig genau dannauf dasselbe Gleichgewicht zu bewegt wie ein Markt mit unendlicher hoher Reak-tionsgeschwindigkeit aller Marktteilnehmer, wenn β = b
d< 1 ist. Das bedeutet,
daß die Steigung b der Angebotsfunktion dem Betrage nach kleiner als die Stei-gung d der Nachfragefunktion sein muß. Anderenfalls erwarten wir nicht, daß sichlangfristig ein gleichgewichtiger Zustand einstellt.
5.5 Mehrdimensionale Folgen
Im vorhergehenden Cobb-Web-Gedankenexperiment-Beispiel haben wir zwei Fol-gen, namlich den Preis- und den Mengenpfad gleichzeitig betrachtet. Die Folgext, pt kann daher als zweidimensionale Folge von Punkten oder Vektoren in R2
interpretiert werden. Eine naheliegende Verallgemeinerung von Definition 5.1 aufFolgen in Rk mit k ∈ N ist die folgende Definition.
Definition 5.6 (Mehrdimensionale Folge) Eine geordnete unendliche Listevon reellen k-Vektoren
(a1, a2, . . . , an, . . .)
heißt mehrdimensionale (engl.: multi-dimensional) Folge und wird mit (an)n∈N
bezeichnet. Die k-Vektoren an = (an1 , . . . , a
nk) ∈ Rk heißen Glieder der Folge.
40

5 Folgen und Grenzwerte
Eine mehrdimensionale Folge in Rk kann also als eine Zuordnung interpretiertwerden, die jedem n ∈ N einen Vektor aus Rk zuordnet. Wir schreiben denFolgenindex hier als Oberindex um den Unterindex fur die Indizierung der Kom-ponenten freizugeben.3
Beispiel 5.12:
(2n
n + 1n
)ist eine Folge in R2. Ihre ersten drei Glieder sind(
22
),
(4
2 + 12
)und
(6
3 + 13
).
Auch fur mehrdimensionale Folgen (an) ist ihr Verhalten fur große n von Interesse.Um die in Definition 5.2 eingefuhrten Begriffe der Konvergenz und des Grenzwertsauf Vektoren ubertragen zu konnen, brauchen wir zunachst ein Maß fur denAbstand zweier Vektoren x und y mit x, y ∈ Rk. Ein solches Maß fur den Abstandist die Euklidische Metrik.4 Sie ist fur alle k ∈ N und alle x, y ∈ Rk definiert als
||x − y|| =
√√√√ k∑i=1
(xi − yi)2
und somit wegen√
(x − y)2 = |x − y| fur alle x, y ∈ R eine Verallgemeinerung
des eindimensionalen Abstandes. Mit der Euklidischen Metrik lautet die Verall-gemeinerung von Definition 5.2 folgendermaßen.
Definition 5.7 (Konvergenz und Grenzwert) Eine Folge an in Rk mit k ∈N heißt konvergent, wenn ein a ∈ Rk existiert, so daß fur alle ε > 0 ein n(ε) ∈ N
existiert mit||an − a|| < ε
fur alle n ≥ n(ε). Man schreibt
limn→∞
an = a oder an −→ a.
Der Vektor a heißt Grenzwert.
Der nachfolgende, ohne Beweis angegebene Satz5 fuhrt die Konvergenz einermehrdimensionalen Folge bezuglich der Euklidischen Metrik auf die Konvergenzmehrerer eindimensionaler Folgen im Sinne der Definition 5.2 zuruck. Er laßtdaher die Verwendung aller bisher vorgestellten Satze fur die Untersuchung derKonvergenz auch fur mehrdimensionale Folgen zu.
3Es gibt verschiedene Moglichkeiten der Mehrfachindizierung.4Die Euklidische Metrik ist nur eines unter vielen Abstandsmaßen. Ein anderes ist die soge-
nannte Manhatten-Metrik, bei der die einfache Summe der Abstande in allen Komponentengebildet wird. Sie heißt Manhatten-Metrik, da man wie in Manhatten nicht diagonal geht,sondern nur entlang der Koordinatenachsen.
5Der an einem Beweis interessierte Leser sei auf Blume und Simon (1994, S. 262) verwiesen.
41

5 Folgen und Grenzwerte
Satz 5.10 Eine Folge (an) in Rk mit k ∈ N konvergiert genau dann gegen a ∈ Rk,wenn (an
i )n∈Ngegen ai ∈ R konvergiert fur alle i ∈ 1, . . . , k.
Beispiel 5.13:
(i) Die Folge
(2n1n
)divergiert gemaß Satz 5.10 wegen 2n −→ ∞.
(ii) Die Folge
( (1 + 1
n
)n(12
)n )konvergiert gemaß Satz 5.10 gegen
(e0
).
42

6 Funktionen einer Variablen
Die Wirtschaftswissenschaften sind voller Funktionen, z.B. Zielfunktionen, Nut-zenfunktionen, Reaktionsfunktionen, Angebots- und Nachfragefunktionen undvielen anderen. Da Funktionen grundlegend fur alles Weitere sind, studieren wirzunachst deren einfachste Art, Funktionen einer Variablen. Wirtschaftswissen-schaftler benutzen diese einfachsten Funktionen alltaglich. Zusatzlich ist derengrundliches Verstandnis eine hilfreiche Vorubung fur die ebenfalls alltaglichen,aber allgemeineren und also abstrakteren Funktionen mehrerer Variablen unddie daraus abgeleiteten Konzepte.
6.1 Grundbegriffe
Definition 6.1 (Funktion) Seien X und Y zwei beliebige nichtleere Mengen.Eine Funktion ist eine Vorschrift f , die jedem x ∈ X genau ein y ∈ Y zuordnet.Wir schreiben f : X → Y oder
xf−→ y
oder y = f(x). Die Menge Def(f) = x ∈ X|∃y ∈ Y, y = f(x) heißt De-finitionsbereich (engl.: domain), die Menge Wert(f) = f(X) = y ∈ Y |∃x ∈X, y = f(x) ⊆ Y Wertebereich (engl.: range). Die Variable x wird auch Argu-ment (engl.: argument) genannt und y Funktionswert (engl.: value). Falls X ⊆ R
und Y ⊆ R Teilmengen der reellen Zahlen sind, heißt f reellwertige Funktioneiner Variablen.
Die eine Variable und die Reellwertigkeit in der Definition beziehe sich also indiesem Kapitel sowohl auf den Definitionsbereich als auch auf den Wertebereich.Fur eine Funktion f : R → R heißen alle x ∈ R mit f(x) = 0 Nullstellen vonf und f(0) y-Achsenabschnitt oder einfach Achsenabschnitt. Warum kann eineFunktion keine bzw. mehr als eine Nullstelle haben aber niemals mehr als einenAchsenabschnitt?
Beispiel 6.1:(i) Die Funktion g : [−1, 1] → R mit g(x) = 5x + 1 hat den Definitionsbereich[−1, 1], den Wertebereich [−4, 6], die Nullstelle −1
5und den Achsenabschnitt 1.
43

6 Funktionen einer Variablen
Ihr Funktionswert vom Argument x = 12
ist g(12) = 7
2.
(ii) Es gibt keine Funktion, die jedem deutschen Staatsburger die Postleitzahlseines ersten Wohnsitzes zuordnet, da nicht jeder deutsche Staatsburger einenersten Wohnsitz hat.(iii) Eine Vorschrift, die jedem AOL-Nutzer eine Email-Adresse zuordnet, unterwelcher dieser Nutzer erreichbar ist, ist keine Funktion, da ein AOL-Nutzer meh-rere Email-Adressen besitzen kann.(iv) Sei f(x) = 4x2 − 1 mit Definitionsbereich R. Dann ist der Wertebereichgegeben durch [−1,∞). Die Nullstellen von f sind 1
2und −1
2und der Achsenab-
schnitt ist −1.(v) Sei h : R → R mit h(x) = 1
x, dann ist Def(h) = Wert(h) = R \ 0.
6.2 Graphische Darstellung
Funktionen mit R als Definitions- und Wertebereich kann man hervorragend inder Ebene, auf einem Papier oder an der Tafel darstellen. In einem Koordinaten-system wird meistens der Wert der unabhangigen Variablen horizontal entlangder x-Achse dieses Koordinatensystems und der Wert der abhangigen Variablenvertikal entlang der y-Achse aufgetragen.1 die Menge
Graph(f) = (x, y)|x ∈ D ∧ y = f(x)zur Funktion f : D → W heißt Graph von f .
Beispiel 6.2: Abbildung 6.1 zeigt die Graphen der Funktionen y = 12x + 1 und
y = (x − 1)2.
6.3 Eigenschaften von Funktionen
Eine Funktion f : R → R heißt monoton steigend, wenn fur alle x1, x2 ∈ R
mit x2 > x1 die Ungleichung f(x2) ≥ f(x1) gilt. Die Funktion monoton fal-lend, wenn fur alle x1, x2 ∈ R mit x2 > x1 die Ungleichung f(x2) ≤ f(x1) gilt.Ersetzt man in diesen beiden Ungleichungen die Relationen ≥ und ≤ durch >bzw. <, so erhalt man die Definitionen fur strenge Monotonie. Ferner heißt ei-ne Funktion f : R → R konvex, wenn fur alle x1, x2 ∈ R und alle a ∈ (0, 1)
1Die x-Achse wird oft auch als Abszisse und die y-Achse als Ordinate bezeichnet. In den Wirt-schaftswissenschaften wird aus historischen Grunden oftmals, insbesondere bei Angebots-und Nachfragefunktionen entgegen der mathematischen Konvention die unabhangige Va-riable auf der y-Achse und die abhangige Variable auf der x-Achse aufgetragen.
44
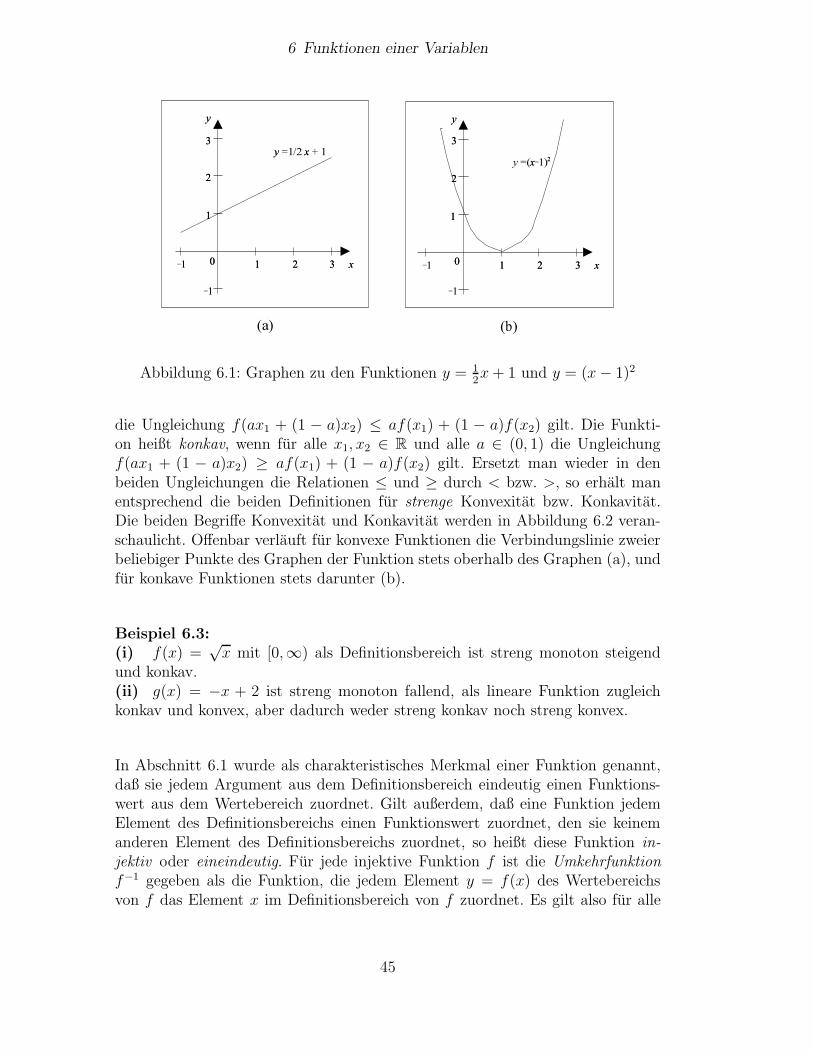
6 Funktionen einer Variablen
(a) (b)
11 22 33−1
−1
11
22
33
00 xx
yy
yy =1/2 xx + 1
11 22 33−1
−1
11
22
33
00 xx
yy
y =(xx−1)22
Abbildung 6.1: Graphen zu den Funktionen y = 12x + 1 und y = (x − 1)2
die Ungleichung f(ax1 + (1 − a)x2) ≤ af(x1) + (1 − a)f(x2) gilt. Die Funkti-on heißt konkav, wenn fur alle x1, x2 ∈ R und alle a ∈ (0, 1) die Ungleichungf(ax1 + (1 − a)x2) ≥ af(x1) + (1 − a)f(x2) gilt. Ersetzt man wieder in denbeiden Ungleichungen die Relationen ≤ und ≥ durch < bzw. >, so erhalt manentsprechend die beiden Definitionen fur strenge Konvexitat bzw. Konkavitat.Die beiden Begriffe Konvexitat und Konkavitat werden in Abbildung 6.2 veran-schaulicht. Offenbar verlauft fur konvexe Funktionen die Verbindungslinie zweierbeliebiger Punkte des Graphen der Funktion stets oberhalb des Graphen (a), undfur konkave Funktionen stets darunter (b).
Beispiel 6.3:(i) f(x) =
√x mit [0,∞) als Definitionsbereich ist streng monoton steigend
und konkav.(ii) g(x) = −x + 2 ist streng monoton fallend, als lineare Funktion zugleichkonkav und konvex, aber dadurch weder streng konkav noch streng konvex.
In Abschnitt 6.1 wurde als charakteristisches Merkmal einer Funktion genannt,daß sie jedem Argument aus dem Definitionsbereich eindeutig einen Funktions-wert aus dem Wertebereich zuordnet. Gilt außerdem, daß eine Funktion jedemElement des Definitionsbereichs einen Funktionswert zuordnet, den sie keinemanderen Element des Definitionsbereichs zuordnet, so heißt diese Funktion in-jektiv oder eineindeutig. Fur jede injektive Funktion f ist die Umkehrfunktionf−1 gegeben als die Funktion, die jedem Element y = f(x) des Wertebereichsvon f das Element x im Definitionsbereich von f zuordnet. Es gilt also fur alle
45
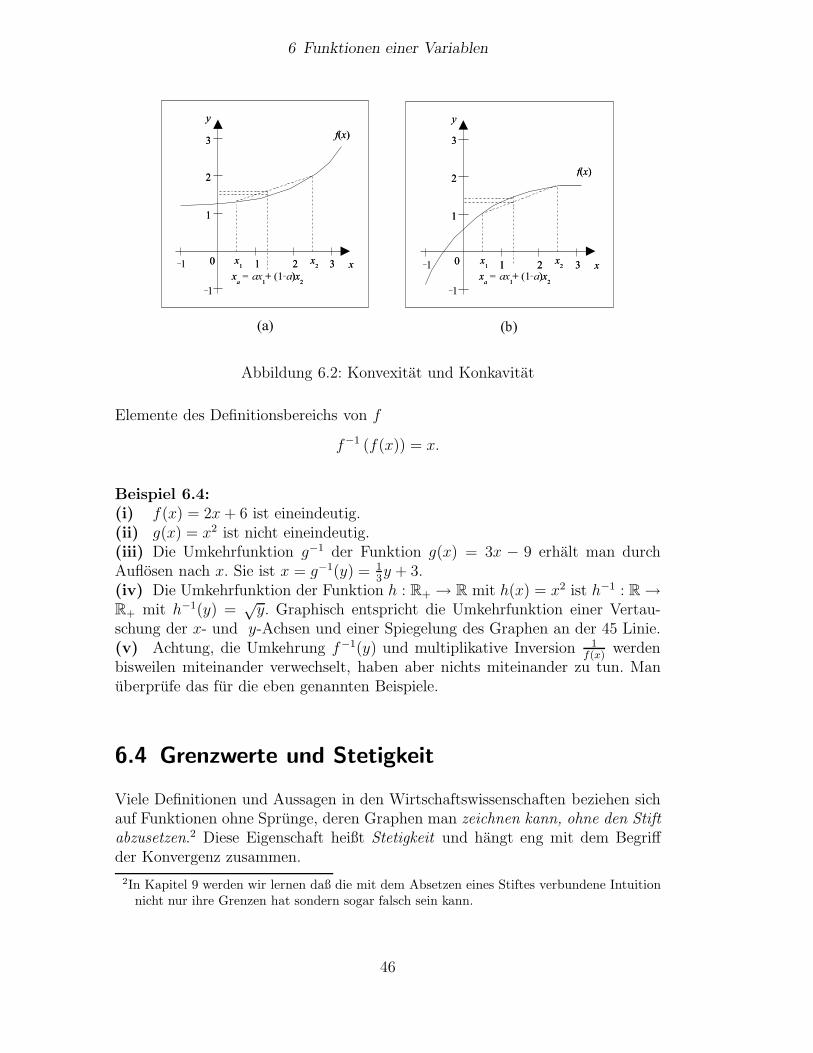
6 Funktionen einer Variablen
(a) (b)
11 22 33−1
−1
11
22
33
00 xx
yy
11 22 33−1
−1
11
22
33
00 xx
yy
ff((xx))
ff((xx))
xx11
xx22
xx11
xx22
xxaa = ax
11++ (1−a))xx
22xx
aa = ax
11++ (1−a))xx
22
Abbildung 6.2: Konvexitat und Konkavitat
Elemente des Definitionsbereichs von f
f−1 (f(x)) = x.
Beispiel 6.4:(i) f(x) = 2x + 6 ist eineindeutig.(ii) g(x) = x2 ist nicht eineindeutig.(iii) Die Umkehrfunktion g−1 der Funktion g(x) = 3x − 9 erhalt man durchAuflosen nach x. Sie ist x = g−1(y) = 1
3y + 3.
(iv) Die Umkehrfunktion der Funktion h : R+ → R mit h(x) = x2 ist h−1 : R →R+ mit h−1(y) =
√y. Graphisch entspricht die Umkehrfunktion einer Vertau-
schung der x- und y-Achsen und einer Spiegelung des Graphen an der 45 Linie.(v) Achtung, die Umkehrung f−1(y) und multiplikative Inversion 1
f(x)werden
bisweilen miteinander verwechselt, haben aber nichts miteinander zu tun. Manuberprufe das fur die eben genannten Beispiele.
6.4 Grenzwerte und Stetigkeit
Viele Definitionen und Aussagen in den Wirtschaftswissenschaften beziehen sichauf Funktionen ohne Sprunge, deren Graphen man zeichnen kann, ohne den Stiftabzusetzen.2 Diese Eigenschaft heißt Stetigkeit und hangt eng mit dem Begriffder Konvergenz zusammen.
2In Kapitel 9 werden wir lernen daß die mit dem Absetzen eines Stiftes verbundene Intuitionnicht nur ihre Grenzen hat sondern sogar falsch sein kann.
46

6 Funktionen einer Variablen
Definition 6.2 (Grenzwert einer Funktion) Der Grenzwert y einer Funkti-on f : R → R an der Stelle x existiert, falls fur jede Folge (xn)n∈N mit xn −→ xdie Folge
(f(xn))n∈N
stets gegen den selben Wert y konvergiert. Man schreibt in diesem Fall
limx→x
f(x) = y.
Definition 6.3 (Stetigkeit) Die Funktion f heißt stetig an der Stelle x, fallslimx→x f(x) existiert und
limx→x
f(x) = f(x).
Die Funktion f heißt stetig auf A ⊆ R, falls f stetig ist fur alle x ∈ A
Beispiel 6.5:(i) Die Funktion f(x) = 1/x mit dem Definitionsbereich R\0 ist nicht stetig,da man, um sie zu zeichnen, beim Uberqueren der y-Achse den Stift absetzenmuß. Um das gemaß unserer Definition formal zu erkennen, betrachte die Folgexn = (− 1
n)n mit limn→∞ xn = 0. Dann ist (f(xn)) = (−n)n, was nicht konvergiert.
(ii) Sei [x] fur alle x ∈ R die großte ganze Zahl n ∈ Z, fur die n ≤ x gilt.Der Graph der Funktion f(x) := [x] hat die Form einer Treppe (ohne vertikaleStriche). f ist also nicht stetig.
Man kann Definition 6.2 in der Art erweitern, daß fur (xn)n∈N und (f(xn))n∈Nauch
solche Folgen zugelassen werden, die gegen ∞ oder −∞ divergieren. Durch dieseErweiterung konnen zusatzliche Falle auftreten, die in der folgenden Ubersichtzusammengestellt sind.
xn −→ x xn −→ ∞ xn −→ −∞f(xn) −→ a lim
x→xf(x) = a lim
x→∞f(x) = a lim
x→−∞f(x) = a
f(xn) −→ ∞ limx→x
f(x) = ∞ limx→∞
f(x) = ∞ limx→−∞
f(x) = ∞f(xn) −→ −∞ lim
x→xf(x) = −∞ lim
x→∞f(x) = −∞ lim
x→−∞f(x) = −∞
Beispiel 6.6:(i) Sei f : R \ 0 → R mit f(x) = 1
x2 . Dann ist limx→0 f(x) = ∞, da zujeder Folge (xn) mit xn −→ 0 und xn = 0 die Folge (f(xn)) gegen ∞ divergiert.Außerdem ist limx→∞ f(x) = 0, da zu jeder Folge (xn) mit xn −→ ∞ und xn = 0die Folge (f(xn)) gegen 0 konvergiert.(ii) Sei f : R → R mit f(x) = −3x2 − x. Dann ist limx→∞ f(x) = −∞, da zujeder Folge (xn) mit xn −→ ∞ die Folge (f(xn)) gegen −∞ divergiert.
47

6 Funktionen einer Variablen
6.5 Typen von Funktionen
In diesem Abschnitt werden einige von Wirtschaftswissenschaftlern besondershaufig benutzte Funktionstypen vorgestellt.
Die Funktion
f(x) = a0 + a1x + · · · + anxn =n∑
i=0
aixi
mit n ∈ N und a0, a1, . . . , an ∈ R heißt Polynom vom Grad n, falls an = 0 ist.Die a0, a1, . . . , an nennt man Koeffizienten der Polynomfunktion. Es gilt, daß einPolynom n-ten Grades maximal n Nullstellen hat.
Beispiel 6.7: Lineare Funktionen sind Polynome vom Grad 1. Der Koeffizienta1 ist die Steigung und der Koeffizient a0 der Achsenabschnitt der zugehorigenGeraden.
Die Funktion f : R → R mitf(x) = xn,
wobei n ∈ Z ist, heißt Potenzfunktion. Ihr Definitionsbereich ist Def(f) = R
fur n ≥ 1, Def(f) = R \ 0 fur n ≤ −1, Def(f) = R+ fur n ∈ (0, 1) undDef(f) = R++ fur n ∈ (−1, 0). Der Graph einer Potenzfunktion ist fur n > 1eine Parabel, fur n = 1 eine Gerade, fur n ∈ (0, 1) eine gespiegelte Parabel (oderWurzelfunktion), fur n = 0 eine Gerade mit einer Unstetigkeitsstelle in x = 0und fur n < 0 eine Hyperbel. Die Funktion
f(x) = cap(x)
mit c ∈ R, a > 0 und p(x) ein Polynom heißt Exponentialfunktion. Sie kommtz.B. bei der Beschreibung von Wachstumsprozessen vor. Funktionen der Form
f(x) = loga x
heißen Logarithmusfunktionen zur Basis a. Schließlich sollen noch die zwei wich-tigsten trigonometrischen Funktionen genannt werden, der Sinus und der Cosi-nus. Abbildung 6.3 zeigt cosα (sprich: Cosinus alpha) als x-Koordinate und sin α(sprich: Sinus alpha) als y-Koordinate eines Punktes auf dem Einheitskreis, derauf einem vom Ursprung ausgehenden Strahl im Winkel α relativ zur x-Achseliegt.
Man beachte, daß die Argumente trigonometrischer Funktionen meistens nicht inGrad, sondern als Bogenmaß angegeben werden. In diesem Maß entsprechen 360Grad dem Umfang des Einheitskreises 2π. Andere Winkel werden entsprechendumgerechnet, d.h. ein Winkel von α Grad entspricht im Bogenmaß α
3602π.
48

6 Funktionen einer Variablen
xx
yy
11
−1
00 11−1
αα
1111
sin αα
cos αα
Abbildung 6.3: Sinus und Cosinus am Einheitskreis
49

7 Ableitung von Funktionen einerVariablen
In diesem Kapitel wird das Konzept der Ableitung von Funktionen behandelt. Esist zentraler Bestandteil der klassischen Optimierungstheorie, welche wiederuminsbesondere fur die positive und normative Modellierung menschlichen Verhal-tens in den Wirtschaftswissenschaften von großer Bedeutung ist.
7.1 Das Konzept der Ableitung
Der Koeffizient a einer linearen Funktion f(x) := ax + b mit a, b ∈ R ist dieSteigung der zugehorigen Geraden. Die Steigung gibt an, um wieviel Einheitender Funktionswert von f(x) steigt, wenn das Argument x um eine Einheit erhohtwird. Bei einer nicht-linearen Funktion g(x) hangt die Steigung von der Stellex ab, ist also nicht wie bei der Geraden konstant, sondern selbst eine von xabhangige Funktion, die Ableitung von g genannt wird.
Sei im folgenden f(x) eine stetige, reellwertige Funktion. Man kann auch beieiner nicht-linearen Funktion die durchschnittliche Steigung bzw. die Steigungder Sekante von f(x) zwischen zwei Punkten x0 und x0+∆x mit ∆x = 0 angebenmit
∆y
∆x=
f(x0 + ∆x) − f(x0)
∆x.
Dieser Ausdruck heißt Differenzenquotient und wird in Abbildung 7.1 veran-schaulicht. Dort gibt der Differenzenquotient die Steigung der Sekante zwischenden Punkten P und Q an. Die Ableitung ist die Steigung der Tangente t, die denGraphen von f(x) im Punkt P beruhrt, aber nicht schneidet.
Fur einen festen Ausgangspunkt x konvergiert also die Steigung der Sekantengegen die Steigung der Tangente an den Graphen von f im Punkte (x, f(x)),falls ∆x gegen 0 geht. Eine konvergente Folge von Sekantensteigungen gegen dieTangentensteigung ist genau die Idee der ersten Ableitung.
Definition 7.1 Die erste Ableitung der Funktion f : R → R an der Stelle x istdefiniert durch den Grenzwert
lim∆x→0
f(x + ∆x) − f(x)
∆x.
50
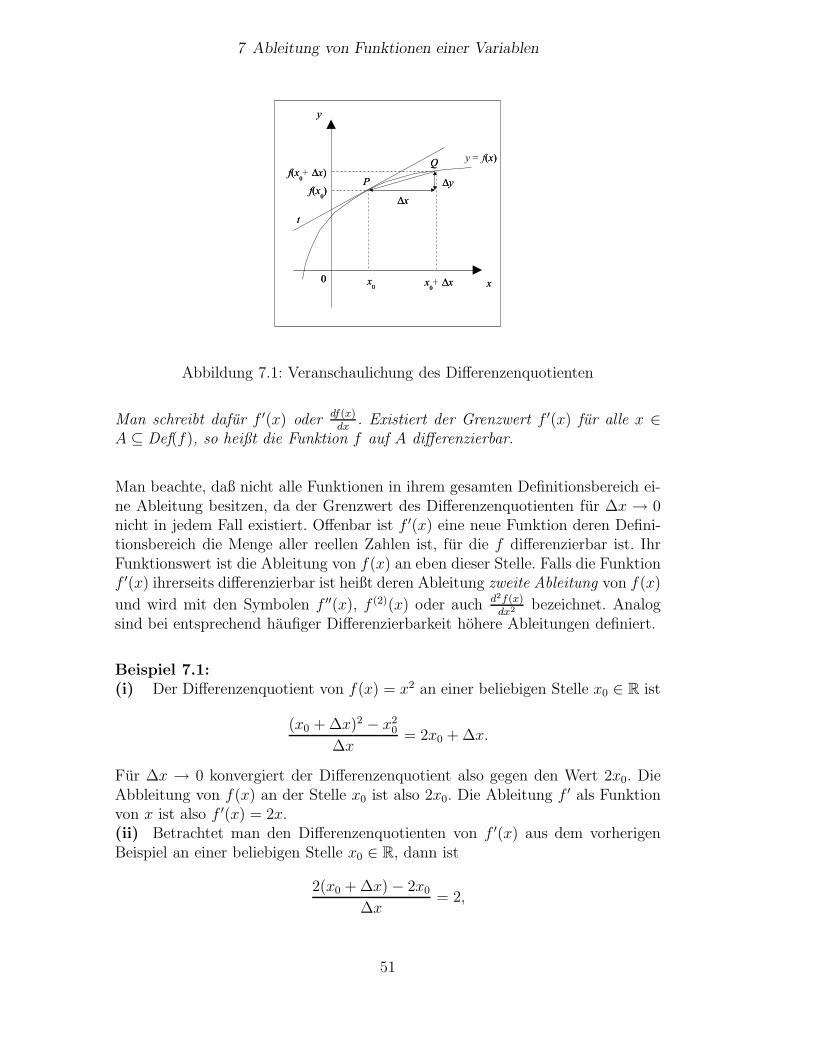
7 Ableitung von Funktionen einer Variablen
xx
yy
00
ff((xx00))
ff((xx00+ ∆∆xx))
xx00+ ∆∆xxxx
00
∆∆xx
∆∆yy
y = f((xx))
PP
tt
Abbildung 7.1: Veranschaulichung des Differenzenquotienten
Man schreibt dafur f ′(x) oder df(x)dx
. Existiert der Grenzwert f ′(x) fur alle x ∈A ⊆ Def(f), so heißt die Funktion f auf A differenzierbar.
Man beachte, daß nicht alle Funktionen in ihrem gesamten Definitionsbereich ei-ne Ableitung besitzen, da der Grenzwert des Differenzenquotienten fur ∆x → 0nicht in jedem Fall existiert. Offenbar ist f ′(x) eine neue Funktion deren Defini-tionsbereich die Menge aller reellen Zahlen ist, fur die f differenzierbar ist. IhrFunktionswert ist die Ableitung von f(x) an eben dieser Stelle. Falls die Funktionf ′(x) ihrerseits differenzierbar ist heißt deren Ableitung zweite Ableitung von f(x)
und wird mit den Symbolen f ′′(x), f (2)(x) oder auch d2f(x)dx2 bezeichnet. Analog
sind bei entsprechend haufiger Differenzierbarkeit hohere Ableitungen definiert.
Beispiel 7.1:(i) Der Differenzenquotient von f(x) = x2 an einer beliebigen Stelle x0 ∈ R ist
(x0 + ∆x)2 − x20
∆x= 2x0 + ∆x.
Fur ∆x → 0 konvergiert der Differenzenquotient also gegen den Wert 2x0. DieAbbleitung von f(x) an der Stelle x0 ist also 2x0. Die Ableitung f ′ als Funktionvon x ist also f ′(x) = 2x.(ii) Betrachtet man den Differenzenquotienten von f ′(x) aus dem vorherigenBeispiel an einer beliebigen Stelle x0 ∈ R, dann ist
2(x0 + ∆x) − 2x0
∆x= 2,
51

7 Ableitung von Funktionen einer Variablen
f(x) f ′(x)
xa (a ∈ R) axa−1
√x 1
2√
x1x
− 1x2
ex ex
ax (a > 0) ax ln alnx 1
x
loga x (a > 0) 1x lna
sin x cos xcos x − sin x
Tabelle 7.1: Ableitungen ausgewahlter Funktionen
also ist die zweite Ableitung von f(x) gegeben als f ′′(x) = 2.(iii) Sei g(x) = |x|. Der Differenzenquotient von g(x) an der Stelle x0 = 0 ist
|0 + ∆x| − |0|∆x
=|∆x|∆x
.
Fur beliebig kleine |∆x| > 0 hat dieser Differenzenquotient fur ∆x > 0 denWert 1 und fur ∆x < 0 den Wert −1. Es existiert also kein Grenzwert desDifferenzenquotienten fur ∆x → 0, und die Funktion g(x) ist an der Stelle 0nicht differenzierbar.
Der folgende Satz ohne Beweis zeigt, daß Differenzierbarkeit eine starkere Eigen-schaft als Stetigkeit ist, also Stetigkeit eine notwendige Bedingung fur Differen-zierbarkeit einer Funktion ist.
Satz 7.1 Jede auf A ⊆ R differenzierbare Funktion ist stetig auf A.
7.2 Ableitungen ausgewahlter Funktionen
Da die analytische Bestimmung der Ableitung uber ihre Definition, also demGrenzwert des Differenzenquotienten, oft muhselig ist, ist es sinnvoll, die Ablei-tungen der in den Wirtschaftswissenschaften haufig vorkommenden Funktionenzu kennen. In Tabelle 7.1 sind die Ableitungen ausgewahlter Funktionen zusam-mengestellt.
7.3 Ableitungsregeln
Um Funktionen abzuleiten, die aus anderen Funktionen, deren Ableitungen be-kannt sind, zusammengesetzt sind, sind die in diesem Abschnitt zusammenge-
52

7 Ableitung von Funktionen einer Variablen
stellten Ableitungsregeln sehr nutzlich. Seien nachfolgend f(x) und g(x) zweireellwertige und differenzierbare Funktionen. Nach der Summenregel ist
(f(x) + g(x))′ = f ′(x) + g′(x).
Die Produktregel besagt
(f(x) · g(x))′ = f ′(x) · g(x) + f(x) · g′(x).
Die Quotientenregel sagt(f(x)
g(x)
)′=
f ′(x) · g(x) − f(x) · g′(x)
(g(x))2
falls g(x) = 0. Gemaß der Kettenregel ist
(f(g(x)))′ = f ′(g(x)) · g′(x).
Es ist haufig notig, diese Ableitungsregeln kombiniert anzuwenden, um die Ab-leitung einer zusammengesetzten Funktion zu bestimmen.
Beispiel 7.2:(i) Die Faktorregel
(af(x))′ = af ′(x)
folgt offenbar aus der Produktregel.(ii) Die Ableitung von f(x) = 3 sinx ist nach der Faktorregel f ′(x) = 3 cosx.(iii) Die Ableitung von f(x) = 4x2 + 5x + lnx ist nach der Summen- und derFaktorregel f ′(x) = 8x + 5 + 1/x.(iv) Die Ableitung von f(x) = 4x sin x ist nach der Produkt- und der Faktorre-gel f ′(x) = 4 sin x + 4x cos x.(v) Die Ableitung von f(x) = x2
ex ist nach der Quotientenregel f ′(x) = 2xex−x2ex
e2x =2x−x2
ex .(vi) Die Ableitung von f(x) = 2 sin (x3) ist nach der Ketten- und der Faktorregelf ′(x) = 6x2 cos (x3).
53

8 Teilmengen des Rn
Die Menge der moglichen Handlungsalternativen eines Entscheidungsproblemswird Entscheidungsraum genannt. Die Entscheidungsraume vieler okonomischerEntscheidungsprobleme sind Teilmengen des Rn. In diesem Kapitel werden einigewichtige Eigenschaften solcher Teilmengen betrachtet, die fur die Losbarkeit unddie Bestimmung von Losungen von Entscheidungsproblemen von Bedeutung sind.
8.1 Grundbegriffe der Mengen-Topologie
Die Mengen-Topologie ist eine sehr allgemeine mathematische Methode, Mengenmit einer Struktur auszustatten, die es ermoglicht Nahe und Abstand qualitativzu charakterisieren. Der Rn besitzt viele verschiedene topologische Strukturen,von denen wir hier nur eine, die Standardtopologie, benotigen. Diese wird durchdie in Kapitel 5.5 eingefuhrte Euklidische Metrik aber auch durch andere Me-triken wie die Manhatten-Metrik oder Maximum-Metrik induziert. Die Grund-begriffe der Mengen-Topologie sind offene und abgeschlossene Mengen. Um dieStandardtopologie des Rn zu definieren, mussen offene und abgeschlossene Teil-mengen beschrieben werden. Ein moglicher Weg dazu, den wir hier beschreitenwollen, geht uber den Begriff der ε-Umgebung. Falls nicht anders hervorgehoben,sei in diesem Kapitel stets n ∈ N die Dimension des Rn.
Definition 8.1 (Epsilon-Umgebung) Sei x ∈ Rn und ε > 0. Die Menge
Bε(x) = y | y ∈ Rn, ||x− y|| < εheißt ε-Kugel oder ε-Umgebung (engl.: ε-ball, neighborhood) um x.
Die ε-Umgebung um x ∈ Rn ist also die Menge aller Punkte, die zu x einen striktgeringeren Abstand als ε bezuglich der Euklidischen Metrik haben. Sie ist alsoeine Kugel vom Radius ε um x ohne deren noch zu definierenden Rand. Diesendefinieren wir nun zusammen mit anderen topologischen Grundbegriffen.
Definition 8.2 (Innerer Punkt, Randpunkt, Rand) Der Punkt x ∈ M mitM ⊆ Rn heißt innerer Punkt (engl.: interior point) von M , wenn ε > 0 existiert,so daß
Bε(x) ⊆ M.
54

8 Teilmengen des Rn
(a) (b)
MM
xxεε
MM
xxεε
Abbildung 8.1: Ein innerer Punkt und ein Randpunkt
Umgekehrt heißt der Punkt y ∈ Rn Randpunkt (engl.: boundary point) der MengeM ⊆ Rn, falls fur alle ε > 0
Bε(x) ∩ M = ∅ und Bε(x) \ M = ∅.Die Menge aller Randpunkte heißt Rand und wird geschrieben als ∂M .
Ein Punkt ist also innerer Punkt einer Menge, wenn seine unmittelbare Nachbar-schaft nur aus Punkten dieser Menge besteht (vgl. Abbildung 8.1 (a)). Dagegenist ein Punkt Randpunkt einer Menge, wenn seine unmittelbare Nachbarschaftsowohl aus Punkten dieser Menge als auch deren Komplement besteht. Darausfolgt, daß ein Randpunkt einer Menge M nicht unbedingt zur Menge M gehorenmuß (vgl. Abbildung 8.1 (b)).
Beispiel 8.1:(i) B 1
2(3) =
(52, 7
2
).
(ii) Sei x = 0 ∈ R2. Dann ist B1(x) = y | y ∈ R2 ∧ y21 + y2
2 < 1.(iii) Der Punkt x = 1
2ist wegen B 1
4(x) ⊆ M innerer Punkt der Menge [0, 1).
Dagegen ist der Punkt x′ = 1 Randpunkt von [0, 1), da fur alle ε > 0 einerseitsx′ − ε ∈ M und andererseits x′ + ε /∈ M ist.(iv) Der Rand der Einheitskugel
K = (x, y) ∈ R2 | x2 + y2 ≤ 1ist ∂M = (x, y) ∈ R2 | x2 + y2 = 1. Die Menge der inneren Punkte von K istdie Menge M \ ∂M = (x, y) | x ∈ R ∧ y ∈ R ∧ x2 + y2 < 1.
55

8 Teilmengen des Rn
Auf den Begriffen des inneren und des Randpunkts bauen die der offenen undder abgeschlossenen Menge auf. Offene und abgeschlossene Mengen im Rn sindn-dimensionale Verallgemeinerungen von Vereinigungsmengen offener und abge-schlossener Intervalle in R.
Definition 8.3 (Offene und abgeschlossene Menge) A ⊆ Rn heißt offen (engl.: open),wenn alle x ∈ M innere Punkte von M sind. B ⊆ Rn heißt abgeschlossen(engl.: closed), wenn die Menge B ihren Rand ∂B enthalt, also ∂B ⊆ B. DieMenge
M := M ∪ ∂M
heißt Abschluß von M . Entsprechend heißt die Menge
M := M \ ∂M
Inneres von M .
Der Abschluß einer Menge ist stets abgeschlossen und das Innere ist stets of-fen. Komplemente abgeschlossener Mengen, beliebige Vereinigungen und endli-che Durchschnitte offener Mengen sind stets offen, wahrend Komplemente ab-geschlossener Mengen und beliebige Durchschnitte und endliche Vereinigungenabgeschlossener Mengen stets abgeschlossen sind. Falls die Menge A ⊆ Rn so-wohl offen als auch abgeschlossen ist, nennt man sie abgeschloffen (engl.: clopen).In der Standardtopologie gilt dies nur fur A = Rn oder A = ∅. Ein System vonoffenen und abgschlossenen Teilmengen, das diese Eigenschaften besitzt heißt to-pologischer Raum. Neben der Standardtopologie auf dem Rn gibt es viele andereTopologien.1 Da sich Okonomen meistens nur fur die Standardtopologie interes-sieren, verfolgen wir den sehr allgemeinen Begriff des topologischen Raumes hiernicht weiter.
Beispiel 8.2:(i) Die Einheitskugel K = (x, y) ∈ R2 | x2 + y2 ≤ 1 ist abgeschlossen.(ii) Die Menge (x, y) ∈ R2 | |x| + |y| < 1 ist offen (wie sieht sie aus?)(iii) Die Menge [0, 1) ist weder offen noch abgeschlossen, da sie mit 0 einen ihrerRandpunkte, wegen 1 /∈ [0, 1) aber nicht alle ihrer Randpunkte enthalt.(iv) Die Menge [0, 1]2 ∪ (x, y) ∈ R2 | x2 + y2 < 1 ist weder offen noch abge-schlossen (warum?).
Eine weitere wichtige Eigenschaft von Mengen ist die der Beschrankheit.
1Seien zum Beispiel nur der ganze Rn und ∅ abgeschloffen und alle anderen Teilmengen wederoffen noch abgeschlossen. Man uberzeuge sich davon, daß dann alle hier angefuhrten Eigen-schaften erfullt sind. Diese Topologie heißt auch grobste Topologie des Rn. Die sogenanntefeinste Topologie definiert alle Mengen als offen und abgeschlossen und erfullt ebenfalls alleEigenschaften.
56

8 Teilmengen des Rn
Definition 8.4 (Beschrankte Menge) Eine Menge M ⊆ Rn heißt beschrankt(engl.: bounded), wenn ein a ∈ R mit
||x|| ≤ a
fur alle x ∈ M existiert.
Eine Menge heißt also beschrankt, wenn sie in einer Kugel mit endlichem Radiusenthalten ist. Daß in unserer Definition die Kugel eine Ursprungskugel, also eineKugel um den Ursprung als Mittelpunkt, ist, spielt offenbar fur die Definitionkeine Rolle (warum?). In der Tat konnte man die Beschranktheit auch mit ei-nem Quader oder beliebigen anderen Formen definieren. Entscheidend fur einebeschrankte Menge ist, daß sie in keiner Richtung unendlich groß ist.
Beispiel 8.3:(i) Die Menge [0, a] mit a ≥ 0 ist wegen ||x|| = |x| ≤ a fur alle x ∈ R be-schrankt.(ii) Die Menge M = x | x ∈ R3 ∧ x1 +x2 +x3 ≥ 1 ist nicht beschrankt, da furalle h ≥ 1 der Punkt (h, h, h) Element von M ist, der Abstand ||(h, h, h)|| = h
√3
zwischen diesem Punkt und dem Ursprung allerdings mit steigendem h jedeSchranke uberschreitet.
Mit Hilfe der in diesem Abschnitt vorgestellten Begriffe konnen nun abschließendkompakte Mengen eingefuhrt werden. Diese spielen in der Optimierungstheorie,dem wichtigsten mathematischen Handwerkzeug des Okonomen eine zentrale Rol-le, da Kompaktheit der Auswahlmenge zusammen mit der Stetigkeit der Zielfunk-tion die Existenz einer Losung eines Optimierungsproblems garantiert. BezuglichKompaktheit gibt es eine gute und eine schlechte Nachricht. Die schlechte Nach-richt ist, daß Kompaktheit im Allgemeinen (in einem topologischen Raum) ab-strakt und kompliziert zu definieren ist. Die gute Nachricht ist, daß wir unsvorlaufig diese Muhe ersparen konnen, da im Spezialfall des Rn, auf den wir unshier konzentrieren, Kompaktheit sehr einfach ist.
Definition 8.5 (Kompakte Menge) Eine Teilmenge des Rn heißt genau dannkompakt (engl.: compact), wenn sie beschrankt und abgeschlossen ist.
Beispiel 8.4:(i) Die Menge [0, 1]× (2, 3) ist beschrankt, aber nicht abgeschlossen und dahernicht kompakt.(ii) Die Menge [0,∞)2 ist abgeschlossen, aber nicht beschrankt, also nicht kom-pakt.(iii) Die Menge ([0, 1] ∪ [2, 3]) × [1, 5] ist beschrankt und abgeschlossen, alsokompakt.
57

8 Teilmengen des Rn
8.2 Konvexe Mengen
Eine weitere bedeutsame Eigenschaft von Teilmengen des Rn im Zusammenhangmit wirtschaftswissenschaftlichen Fragestellungen ist die Konvexitat, da diese un-ter geeigneten Annahmen die Eindeutigkeit der Losung eines Optimirungspro-blems garantiert.
Definition 8.6 (Konvexe Menge) Die Menge M ∈ Rn heißt konvex (engl.: con-vex), wenn fur alle x, y ∈ M und alle λ ∈ [0, 1] gilt
λx + (1 − λ)y ∈ M.
Die gerade Verbindungsstrecke zwischen zwei Punkten x, y ∈ M muß also stetsganz in M liegen, damit M eine konvexe Menge ist (vgl. Abbildung 8.2 (a)).Falls diese Eigenschaft fur gewisse Punkte x, y ∈ M nicht gilt, so ist M nichtkonvex (vgl. Abbildung 8.2 (b)). Obwohl die Konvexitat einer Funktion mit derKonvexitat einer Menge verbunden ist , gibt es den umgekehrten Begriff derKonkavitat zwar fr Funktionen nicht im Zusammenhang mit Mengen.2
Beispiel 8.5:(i) Die Menge [0, 1] ist konvex, da fur alle x, y ∈ [0, 1] und alle λ ∈ [0, 1] dieUngleichnungen λx+(1−λ)y ≤ λ maxx, y+(1−λ) maxx, y = maxx, y ≤ 1und λx + (1 − λ)y ≥ 0 gelten.(ii) Die Menge M = x ∈ R2 | ||x|| ≥ 1 ∧ ||x|| ≤ 3 ist nicht konvex, dabeispielsweise die Konvexkombination 1
2x + 1
2x′ = (0, 0) /∈ M trotz x = (2, 0) ∈
M und y = (−2, 0) ∈ M ist.
Die Konvexitat einer Menge ergibt sich in den Wirtschaftswissenschaften oft ganznaturlich. Betrachtet man beispielsweise einen Haushalt, der sich mit seinem Bud-get entweder 20 Liter Bier oder 10 Liter Wein kaufen kann, so ist meistens sinnvollanzunehmen, daß er mit seinen Mitteln auch 20λ Liter Bier und 10(1 − λ) Li-ter Wein mit λ ∈ [0, 1] erwerben kann. Die Budgetmenge, also die Menge allerGuterbundel, die der Haushalt mit einem gegebenen Budget kaufen kann, istunter dieser Annahme konvex.
Satz 8.1 Der Durchschnitt A∩B zweier konvexer Mengen A und B ist konvex.
2Ein kleiner Vorgriff auf das folgende Kapitel mag dies illustrieren. Die untere Konturmengeeiner Funktion f : Rn → R ist die Menge aller Punkte x ∈ Rn deren Funktionswert f(x)einen bestimmten Wert nicht uberschreitet. Diese Menge ist stets konvex fur eine konvexeFunktion. Zum Beispiel ist die Einheitskugel die untere Konturmenge zum Wert 1 fur diekonvexe Funktion f(x1, x2) = x2
1 + x22. Die untere Konturmenge einer konkaven Funktion
ist nicht konvex, wird aber nicht konkav genannt. Das Komplement der Einheitskugel istein Beispiel fur eine solche Menge.
58

8 Teilmengen des Rn
(a) (b)
xx
xx
xx
xx
yyyy
yy
yy
Abbildung 8.2: Beispiele konvexer und nicht-konvexer Mengen
Beweis. Seien x, y ∈ A ∩ B, also x, y ∈ A und x, y ∈ B. Da A konvex ist,gilt λx + (1 − λ)y ∈ A fur alle λ ∈ [0, 1]. Da auch B konvex ist, gilt analogλx + (1 − λ)y ∈ B fur alle λ ∈ [0, 1]. Folglich ist λx + (1 − λ)y ∈ A ∩ B fur alleλ ∈ [0, 1].
59

9 Funktionen von Rm nach Rn
Die nachgefragte Menge an Weizenbier und Speiseeis am Sommeranfang im Jahr2004 kann vom Weizenbierpreis, vom Speiseeispreis vom Preis anderer Produkte(Doner, Wein, Wohnungsmiete, Benzin,...), vom Einkommen, vom Wetter an die-sem Tag (z.B. gemessen in Sonnenstunden oder Durchschnittstemperatur) undvielen anderen Variablen abhangen. Eine Zuordnung aller relevanter Variablenauf dieses 2-Tupel nachgefragter Mengen ist eine mehrdimensionale Funktion.Mehrdimensionale Funktionen sind Verallgemeinerungen von Funktionen einerVariablen. Viele darauf aufbauende Konzepte wie Ableitungen oder Konkavitatbauen daher auf der Intuition eindimensionaler Funktionen auf.
9.1 Grundbegriffe
Grundlage fur dieses Kapitel ist der bereits durch Definition 6.1 in Kapitel 6eingefuhrte allgemeine Begriff der Funktion. Gerade weil Funktionen so grund-legend fur die Mathematik sind, besitzen sie verschiedene Interpretationen. Sowird eine Funktion auch Abbildung genannt, ein Argument als Urbild oder alsunabhangige Variable und ein Funktionswert als Bild oder als abhangige Variable.Definitionsbereich und Wertebereich wie in Kapitel 6 eingefuhrt heißen in dieserTerminologie Urbildmenge und Bildmenge. Die Menge f(A) = y ∈ Y | ∃x ∈A mit y = f(x) bezeichnet man entsprechend als Bild einer Teilmenge A ⊆ Xund umgekehrt die Menge f−1(B) = x ∈ X | ∃y ∈ B mit y = f(x) als Urbildder Teilmenge B ⊆ Y .
In diesem Kapitel betrachten wir stets Funktionen f : X → Y mit X ⊆ Rn
und Y ⊆ Rm, wobei n, m ∈ N. Diese heißen reellwertige Funktionen. In einemsolchen Fall schreibt man fur den Funktionswert von f fur ein Argument x ∈ Xublicherweise f (x1, . . . , xn). Man beachte, daß dieser Funktionswert Element desRm ist. Daher schreibt man die m einzelnen Komponenten als
f (x1, . . . , xn) = (f1 (x1, . . . , xn) , . . . , fm (x1, . . . , xn)).
Nachfolgend betrachten wir oft Falle niedriger Dimensionen m = 1 oder n = 1,bei dem die Bilder oder Urbilder eindimensional sind.
Beispiel 9.1:(i) Sei X = a, b, c und Y = 1, 2. Dann ist f : X → Y mit f(a) = 1, f(b) =
60

9 Funktionen von Rm nach Rn
(a) (b)
xx
yy
ff
UU
ff((UU))
xx
yy
ff
ff−1((VV))
VV
Abbildung 9.1: Bild- und Urbildmenge
2 und f(c) = 1 eine Funktion mit Definitionsbereich a, b, c und Wertebereich1, 2.(ii) Der Funktionswert der reellwertigen Funktion g : R2 → R mit
g(x1, x2) = x31 + 2x2
2
fur das Argument (x1, x2) = (2, 3) ist g(2, 3) = 23 + 2 · 32 = 26.(iii) Sei f : R → R eine Funktion mit f(x) = 2x − 1. Dann ist f([2, 3]) = [3, 5]und f−1([5, 7]) = [3, 4].(iv) Sei g(x) = (2x,−x) eine Funktion R → R2. Dann ist
g(1, 2, 3) = (2,−1), (4,−2), (6,−3).
(v) Sei f : R → R eine Funktion mit f(x) = x2. Dann ist f([0, 1]) = [0, 1] undf−1([1, 4]) = [1, 2] ∪ [−2,−1].
9.2 Verknupfungen von Funktionen
Funktionen konnen mit Hilfe der auf den vier Grundrechenarten basierenden undauch anderen Verknupfungen zu komplexeren Funktionen zusammengesetzt wer-den. In diesem Abschnitt werden die wichtigsten Moglichkeiten zur Verknupfungvon Funktionen vorgestellt.
61

9 Funktionen von Rm nach Rn
Definition 9.1 (Addition, Subtraktion) Seien f : X → Rn und g : X → Rn
Funktionen, wobei X eine beliebige Menge sein kann. Dann bezeichnen f + gbzw. f − g Funktionen von X nach Rn definiert durch
(f + g)(x) = f(x) + g(x) bzw. (f − g)(x) = f(x) − g(x)
fur alle x ∈ X.
Fur die Addition oder Subtraktion ist also wichtig ein gemeinsamer Definitions-bereich und ein gemeinsamer Wertebereich mit einer additiven Struktur, die aufdem Rn in naturlicher Weise durch die komponentenweise Vektoraddition gegebenist. Analoges gilt fur die Differenz zweier Funktionen.
Definition 9.2 (Multiplikation, Division) Seien f : X → Rn und g : X →R Funktionen mit X als beliebiger Menge. Dann bezeichnen f · g bzw. f/g Funk-tionen von X in Rn definiert durch
(f · g)(x) = f(x) · g(x) bzw.
(f
g
)(x) = f(x) · 1
g(x)
fur alle x ∈ X. Dabei muß im Fall der Division fur alle x ∈ X die Bedingungg(x) = 0 erfullt sein.
Fur das Produkt oder den Quotienten zweier Funktionen benotigt man außer ei-nem gemeinsamen Definitionsbereich die Moglichkeit Funktionswerte miteinandermultiplizieren oder durcheinander dividieren zu konnen. Falls ein Funktionswertein Vektor reeller Zahlen und der andere eine (eindimensionale) reelle Zahl alsoein sogenannter Skalar ist, sind diese Rechenoperationen komponentenweise wie-der durch die entsprechenden Grundrechenarten auf den reellen Zahlen gegeben.Man beachte, daß die Multplikation eines Vektors aus Rn mit einem Skalar wiederein Vektor des Rn ist. Analoges gilt fur den Quotienten zweier Funktionen.
Beispiel 9.2:(i) Sei f : R2 → R eine Funktion mit f(x1, x2) = x1 + sin x2 und g : R2 → R
eine Funktion mit g(x1, x2) = 3x1 + 5x2. Dann ist f + g : R → R eine Funktionmit (f + g)(x) = x1 + sin x2 + 3x1 + 5x2 = 4x1 + 5x2 + sin x2.(ii) Seien f : R → R2 eine Funktion mit f(x) = (2x, 3) und g : R → R eineFunktion mit g(x) = x2 + 1. Wegen g(x) = 0 fur alle x ∈ R ist die Funktion f/gdefiniert. Fur sie ist (f/g)(x) = 1
x2+1(2x, 3).
(iii) Sei f : X → Rn eine Funktion mit X als beliebiger Menge und α ∈ R.Da der Skalar α offebar als konstante Funktion g(x) = α interpretiert werdenkann, ist die Multiplikation mit einem Skalar ein Beispiel fur das Produkt zweierFunktionen, also αf die Funktion von X nach Rn mit
(αf)(x) = αf(x)
62

9 Funktionen von Rm nach Rn
XX ZZ
YY
g oo ff
ff gg
Abbildung 9.2: Verkettung von Funktionen
fur alle x ∈ X.
Die wichtigste Verknupfung, die nicht auf den vier Grundrechenarten basiert, istdie nachfolgend definierte Verkettung oder Verknupfung.
Definition 9.3 (Verkettung) Seien f : X → Y und g : Y → Z Funktionenmit X, Y und Z als beliebigen Mengen. Dann heißt die Funktion g f : X → Zmit
(g f)(x) = g(f(x))
fur alle x ∈ X Verkettung (engl.: composition) von f und g.
Fur die Verkettung g f zweier Funktionen f und g muß der Wertebereich von fdem Definitionsbereich von g entsprechen. In diesem Fall ist die Verkettung derbeiden Funktionen eine andere Funktion, die jedes Element x des Definitionsbe-reichs von f in der Weise auf ein Element z des Wertebereichs von g abbildet,daß z = g(f(x)) gilt (vgl. Abbildung 9.2).
Beispiel 9.3:(i) Sei f : R → R eine Funktion mit f(x) = x2 und g : R → R eine Funktionmit g(x) = sin x. Dann ist g f : R → R eine Funktion mit (g f)(x) = sin (x2)und f g : R → R eine Funktion mit (f g)(x) = (sin x)2.(ii) Sei f : R → R2 eine Funktion mit f(x) = (x, 2x) und g : R2 → R eineFunktion mit g(x1, x2) = 2x1 + 5x2. Dann ist g f : R → R eine Funktion mit(g f)(x) = 2(x) + 5(2x) = 12x.
9.3 Graphische Darstellung von Funktionen
Wie bei Funktionen einer Variablen ist zur Untersuchung reellwertiger Funktioneneine graphische Analyse oft sehr hilfreich. Der Graph einer hoherdimensionalen
63

9 Funktionen von Rm nach Rn
Funktion kann in der Ebene (Tafel, Papier) nur durch geeignete Projektionendargestellt werden. In diesem Abschnitt werde verschiedene Moglichkeiten solcherProjektionen oder Schnitte eingefuhrt.
Definition 9.4 (Graph) Sei f : X → Y eine Funktion mit X ⊆ Rn, Y ⊆ Rm.Dann heißt die Menge
Graph(f) = Gf = (x, y) ∈ X × Y | y = f(x) ⊆ Rn+m
Graph (engl.: graph) von f .
Der Graph ist also die Menge aller Paare bestehend aus einem Element des De-finitionsbereichs von f und dessen Funktionswert im Wertebereich. Fur die Dar-stellung bedienen wir uns des Umstandes, daß sich Teilmengen von R in intuitiverWeise auf der Zahlengeraden und Teilmengen des R2 und R3, im Fall des R3 durchgeeignete perspektivische Projektion, in der Ebene darstellen lassen. Wir werdenab hier beide Schreibweisen Graph(f) und Gf verwenden.
Beispiel 9.4:(i) Zu f : R → R mit f(x) = x sin x ist
Gf = (x, y) ∈ R2 | y = x sin x.
Ein Ausschnitt von Gf ist in Abbildung 9.3 dargestellt.(ii) Zu f : R2 → R mit f(x, y) = sin x · sin y ist
Gf = (x, y, z) ∈ R3 | z = sin x · sin y.
Ein Ausschnitt von Gf ist, nach geeigneter Projektion auf die Ebene, in Abbil-dung 9.4 dargestellt.
Eine weitere Moglichkeit, einer reellwertigen Funktion eine Teilmenge des Rn zu-zuordnen, besteht in der Betrachtung sogenannter Isohohenlinien. Diese kommenin den Wirtschaftswissenschaften haufig als Isoquanten oder Indifferenzkurvenvor.
Definition 9.5 (Isohohenlinie) Sei f : X → Y eine Funktion mit X ⊆ Rn,Y ⊆ Rm und n, m ∈ N. Fur alle y ∈ Y wird die Menge
f−1(y)
auch als Isohohenlinie (engl.: level curve) zum Niveau y bezeichnet.
64
9 Funktionen von Rm nach Rn
2 4 6 8 10 12x
-10
-7.5
-5
-2.5
2.5
5
7.5
y
Abbildung 9.3: Teil des Graphen von f(x) = x sin x
65
9 Funktionen von Rm nach Rn
-2
0
2x
-2
0
2
y
-0.5
0
0.5z
-2
0
2x
Abbildung 9.4: Ausschnitt des Graphen von f(x, y) = sin x · sin y
66

9 Funktionen von Rm nach Rn
-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
Abbildung 9.5: Isohohenlinien von f(x, y) = sin x · sin y
Die Isohohenlinie zum Niveau y ∈ Y ist also ein Spezialfall des Urbildes ei-ner Menge bestehend aus dem einen Element y ∈ Y in der Bildmenge, also istf−1(y) ⊆ Rn.
Beispiel 9.5:(i) Die Isohohenlinie der Funktion f : R2 → R mit f(x, y) = x+2y zum Niveau4 ist f−1(4) = (x, y) ∈ R2 | x + 2y = 4 . Dies entpricht offenbar der Geradenin der x-y-Ebene mit der Gleichung y = 2 − 1
2x.
(ii) In Abbildung 9.5 sind einige Isohohenlinien der Funktion f : R2 → R mitf(x, y) = sin x · sin y zu verschiedenen Niveaus ausschnittsweise dargestellt.
Als letzte Moglichkeit der Darstellung reellwertiger Funktionen sollen noch diesogenannten projezierten Schnittlinien vorgestellt werden, die auf der im voran-gegangenen Abschnitt eingefuhrten Verkettung von Funktionen basieren.
Definition 9.6 (Projezierte Schnittlinie) Sei f : X → Y eine Funktion mitX ⊆ Rn, Y ⊆ Rm und g : Z → X eine Funktion mit Z ⊆ R. Dann heißt derGraph
Gfg
67
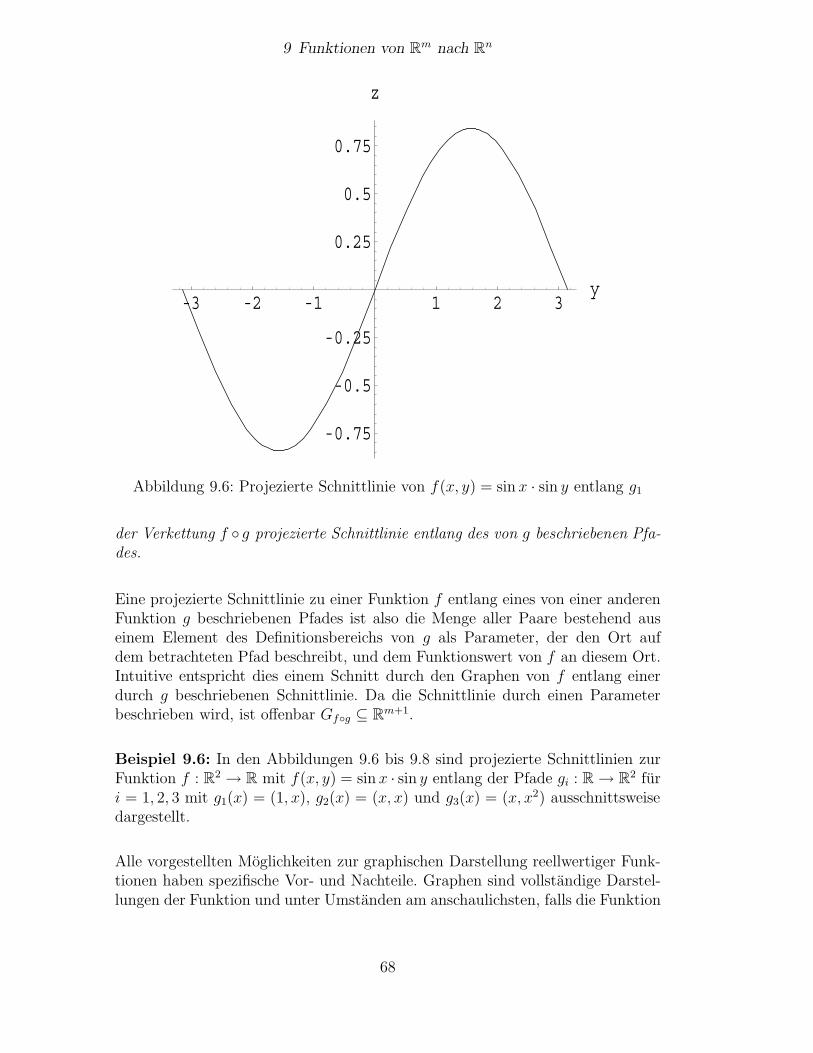
9 Funktionen von Rm nach Rn
-3 -2 -1 1 2 3y
-0.75
-0.5
-0.25
0.25
0.5
0.75
z
Abbildung 9.6: Projezierte Schnittlinie von f(x, y) = sin x · sin y entlang g1
der Verkettung f g projezierte Schnittlinie entlang des von g beschriebenen Pfa-des.
Eine projezierte Schnittlinie zu einer Funktion f entlang eines von einer anderenFunktion g beschriebenen Pfades ist also die Menge aller Paare bestehend auseinem Element des Definitionsbereichs von g als Parameter, der den Ort aufdem betrachteten Pfad beschreibt, und dem Funktionswert von f an diesem Ort.Intuitive entspricht dies einem Schnitt durch den Graphen von f entlang einerdurch g beschriebenen Schnittlinie. Da die Schnittlinie durch einen Parameterbeschrieben wird, ist offenbar Gfg ⊆ Rm+1.
Beispiel 9.6: In den Abbildungen 9.6 bis 9.8 sind projezierte Schnittlinien zurFunktion f : R2 → R mit f(x, y) = sin x · sin y entlang der Pfade gi : R → R2 furi = 1, 2, 3 mit g1(x) = (1, x), g2(x) = (x, x) und g3(x) = (x, x2) ausschnittsweisedargestellt.
Alle vorgestellten Moglichkeiten zur graphischen Darstellung reellwertiger Funk-tionen haben spezifische Vor- und Nachteile. Graphen sind vollstandige Darstel-lungen der Funktion und unter Umstanden am anschaulichsten, falls die Funktion
68
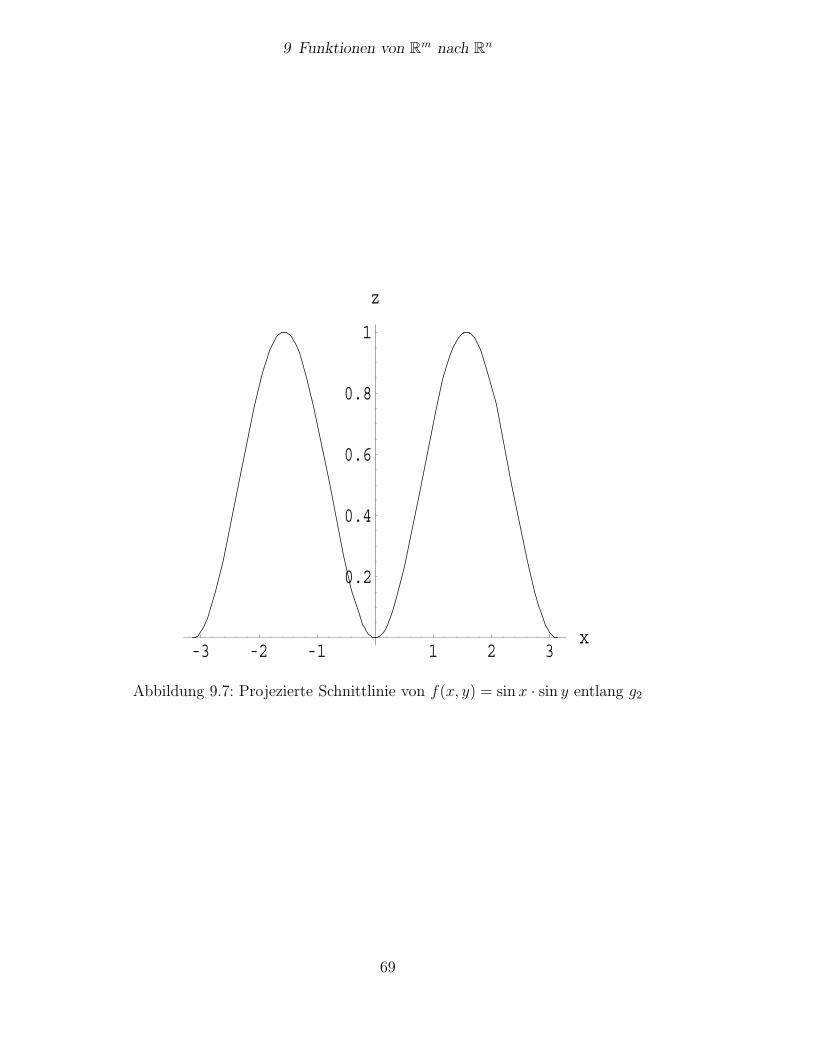
9 Funktionen von Rm nach Rn
-3 -2 -1 1 2 3x
0.2
0.4
0.6
0.8
1
z
Abbildung 9.7: Projezierte Schnittlinie von f(x, y) = sin x · sin y entlang g2
69
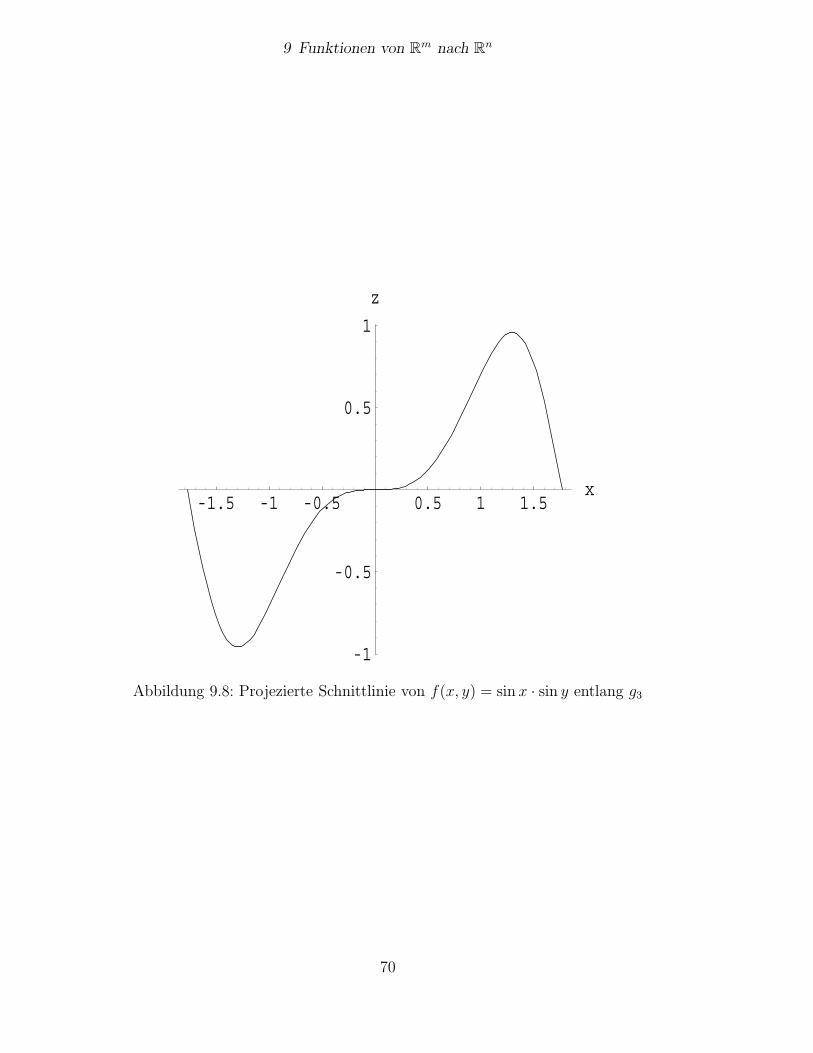
9 Funktionen von Rm nach Rn
-1.5 -1 -0.5 0.5 1 1.5x
-1
-0.5
0.5
1
z
Abbildung 9.8: Projezierte Schnittlinie von f(x, y) = sin x · sin y entlang g3
70

9 Funktionen von Rm nach Rn
niedrigdimensional, also n+m ≤ 3 ist. Isohohenlinien und projezierte Schnittlini-en lassen sich dagegen auch fur Funktionen mit n ≤ 3 bzw. m+1 ≤ 3 darstellen,sind dafur aber nur eine partielle Beschreibung der Funktion und daher oft we-niger anschaulich als Graphen.
9.4 Umkehrfunktionen
Funktionen sind gemaß Definition 6.1 dadurch charakterisiert, daß sie jedem Ele-ment ihres Definitionsbereichs genau ein Element ihres Wertebereichs zuordnen.Die Fragestellung, ob eine Funktion moglicherweise umgekehrt auch jedem Ele-ment ihres Wertebereichs genau ein Element ihres Definitionsbereichs zuordnet,fuhrt zum Begriff der Umkehrfunktion:
Definition 9.7 (Umkehrfunktion) Eine Funktion g : Y → X heißt Umkehr-funktion (engl.: inverse function) zu einer Funktion f : X → Y , wenn fur allex ∈ X gilt:
g(f(x)) = x.
Eine solche Funktion wird mit f−1 bezeichnet.
Eine Umkehrfunktion f−1 einer Funktion f : X → Y hat also den WertebereichY von f als Definitions- und den Definitionsbereich X von f als Wertebereichund ordnet jedem Funktionswert f(x) ∈ Y das zugehorige Argument x ∈ X zu.
Beispiel 9.7:(i) Zu der Funktion f : R → R mit y = f(x) = 2x+4 ist eine Umkehrfunktiongegeben durch f−1 : R → R mit x = f−1(y) = 1
2y − 2 die Umkehrfunktion, da
fur alle x ∈ R gilt:f−1(f(x))= f−1(2x + 4)
= 12(2x + 4) − 2
= x
(ii) Sei g : R → R+ mit g(x) = x2, dann sind sowohl g−11 (y) =
√y als auch
g−12 (y) = −√
y Umkehrfunktionen zur Funktion g und gehen beide von R+ nachR.
Wie das Beispiel zeigt, existiert allerdings nicht zu jeder Funktion eine eindeutigeUmkehrfunktion. So kann zu g : R → R mit g(x) = x2 keine Umkehrfunktion an-gegeben werden, da einigen Funktionswerten zwei Argumente zugeordnet werdenkonnen und anderen als Elementen des Wertebereichs von f grundsatzlich mogli-chen Funktionswerten kein Argument zugeordnet werden kann. Beispielsweise
71

9 Funktionen von Rm nach Rn
(a) (b)
XX
aa
bb
cc
dd
ee
YY
11
22
33
44
55
XX
aa
bb
cc
dd
ee
11
22
33
44
55
YY
ff ff
Abbildung 9.9: Injektivitat
existieren mit 1 und −1 zwei mogliche Argumente zum Funktionswert 1 und keinArgument zum Element −5 des Wertebereichs. Nachfolgend werden Funktions-eigenschaften vorgestellt, namlich Injektivitat, Surjektivitat und Bijektivitat, diezusammen die Existenz einer eindeutigen Umkehrfunktion garantieren.
Definition 9.8 (Injektivitat, Surjektivitat, Bijektivitat) Eine Funktion f :X → Y heißt injektiv (engl.: one-to-one), wenn fur alle x1, x2 ∈ X gilt
f(x1) = f(x2) ⇒ x1 = x2.
Eine Funktion f : X → Y heißt surjektiv (engl.: onto), wenn gilt
f(X) = Y.
Ist eine Funktion injektiv und surjektiv, so heißt sie bijektiv (engl.: bijective).
Eine Funktion ist also genau dann injektiv, wenn es moglich ist, vom Funktions-wert f(x) eindeutig auf das Argument x zu schließen. In Abbildung 9.9 wird dieserUmstand an (a) einer injektiven und (b) einer nicht-injektiven Funktion veran-schaulicht. Eine Funktion f ist surjektiv, wenn es moglich ist, zu jedem Elementy ihres Wertebereichs mindestens ein Element x des Definitionsbereichs anzuge-ben, welches von f auf y abgebildet wird. In Abbildung 9.10 wird dieser Umstandan (a) einer surjektiven und (b) einer nicht-surjektiven Funktion veranschaulicht.Offenbar ist unter diesen Abbildungen nur die durch 9.9(a) dargestellte Funktionbijektiv.
Beispiel 9.8:(i) f : R2 → R mit f(x, y) = 2(x − 1)y ist offenbar surjektiv, aber wegen
72

9 Funktionen von Rm nach Rn
(a) (b)
XX
aa
bb
cc
dd
ee
YY
11
22
33
44
XX
aa
bb
cc
dd
ee
11
22
33
44
YY
ff ff
Abbildung 9.10: Surjektivitat
f(1, 0) = f(2, 0) nicht injektiv.(ii) g1 : R → R mit g1(x) = x2 ist weder injektiv noch surjektiv. g2 : [0,∞) → R
mit g2(x) = x2 ist injektiv, aber nicht surjektiv und g3 : [0,∞) → [0,∞) mitg3(x) = x2 ist injektiv und surjektiv, also bijektiv.
Der nachfolgende Satz gibt eine notewendige und hinreichende Voraussetzung furdie Existenz einer Umkehrfunktion an.
Satz 9.1 Zu jeder bijektiven Funktion existiert eine eindeutige Umkehrfunktion.Umgekehrt ist eine Funktion mit eindeutiger Umkehrfunktion bijektiv.
Die Beweisidee ist, daß die Surjektivitat garantiert, jedem Element des Wertebe-reiches einer Funktion f durch die Umkehrfunktion f−1 mindestens ein Elementdes Definitionsbereichs von f zuzuordnen, wahrend Injektivitat sicherstellt, daßdurch die Umkehrfunktion jedem Element des Wertebereichs von f hochstens einElement des Definitionsbereichs von f zugeordnet wird.
Beispiel 9.9:(i) Die Funktion f : 1, 2, 3 → a, b, c mit f(1) = b, f(2) = a und f(3) = cist bijektiv. Ihre Umkehrfunktion ist f−1 : a, b, c → 1, 2, 3 mit f−1(a) = 2,f−1(b) = 1 und f−1(c) = 3.(ii) Die Funktion f : (−∞, 0] → [2,∞) mit f(x) = x2 +2 ist, wie an ihrem Gra-phen leicht erkennbar ist, bijektiv. Ihre Umkehrfunktion ist f−1(y) = −√
x − 2.
73

9 Funktionen von Rm nach Rn
Haufig ist es nutzlich und sinnvoll, auch zu injektiven aber nicht surjektivenFunktion f eine ’Umkehrfunktion’ anzugeben, indem man den Wertebereich von fauf die Bildmenge von f einschrankt und so eine bijektive Funktion f konstruiert,die auf dem Definitionsbereich identisch zur Funktion f ist und zu der nachSatz 9.1 eine Umkehrfunktion existiert. Der nachfolgende Satz prazisiert diesesVorgehen:
Satz 9.2 Jede injektive Funktion f : X → Y induziert genau eine bijektiveFunktion f : X → f(X) mit f(x) = f(x), zu der eine Umkehrfunktion f−1
existiert.
Beispiel 9.10: Die injektive Funktion f : R → R mit f(x) = ex induziert diebijektive Funktion f : R → (0,∞) mit f(x) = ex. Deren Umkehrfunktion istf−1 : (0,∞) → R mit f−1(y) = ln y.
9.5 Grenzwerte von Funktionen und Stetigkeit
In diesem Abschnitt werden die in den Definitionen 6.2 und 6.3 eingefuhrtenBegriffe Grenzwert und Stetigkeit auf hohere Dimensionen verallgemeinert. Dieentscheidende Vorarbeit ist bereits erledigt, da die diesen Konzepten zugrunde-liegenden Ideen und Intuitionen direkt auf hohere Dimensionen ubertragbar sind.Der Grenzwert einer Funktion ist wie zuvor durch die Konvergenz von zugehori-gen Folgen von Funktionswerten gegen einen Funktionswert beliebiger gegen denselben Wert konvergierender Folgen im Definitionsbereich der Funktion definiert.Fur die Existenz des Grenzwertes einer Funktion muß also die Konvergenz durchdie Funktion – in eindeutiger Weise – vom Urbild in das Bild ubertragen werden.
Definition 9.9 (Grenzwert einer Funktion) Sei f : X → Y eine Funktionmit X ⊆ Rn, Y ⊆ Rm. Der Grenzwert y der Funktion f an der Stelle x ∈ Xexistiert, falls fur jede Folge (xn)n∈N ∈ X mit xn −→ x die Folge
(f(xn))n∈N
stets gegen das selbe Element y ∈ Y konvergiert. Man schreibt wie im eindimen-sionalen Fall
limx→x
f(x) = y.
Definition 9.10 (Stetigkeit) Die Funktion f : X → Y heißt stetig an derStelle x ∈ X, falls limx→x f(x) existiert und
limx→x
f(x) = f(x).
Die Funktion f heißt stetig auf A ⊆ X, falls f stetig ist fur alle x ∈ A
74

9 Funktionen von Rm nach Rn
Fur die Definition des Grenzwertes einer Funktion wollen wir außerdem zulassen,daß einer Funktion f an einem Randpunkt x ∈ ∂X \X ihres Definitionsbereichs,der nicht Element dieses Definitionsbereichs ist, ein Grenzwert a zugeordnet wer-den kann, wenn unabhangig davon, entlang welchen durch eine Folge (xn)n∈N
beschriebenen Pfads man sich dem Randpunkt x anahert, die sich entlang diesesPfads ergebende Folge von Funktionswerten (f(xn))n∈N
immer gegen a konver-giert. Eine Funktion f : X → Y ist stetig an einer Stelle x ∈ X, wenn bei derKonvergenz gegen x entlang des durch eine solche konvergente Folge (xn) vor-gegebenen Pfads die Folge der Funktionswerte (f(xn)) gegen den Funktionswertf(x) konvergiert.
Da der Grenzwertbegriff fur Funktionen unmittelbar auf demjenigen fur Folgenaufbaut, gelten alle Aussagen des Satzes 5.4 entsprechend fur Grenzwerte vonFunktionen. In den nachfolgenden Beispielen wird davon verschiedentlich Ge-brauch gemacht.
Beispiel 9.11:(i) Sei f : (0, 1) → R mit f(x) = 2x. Dann ist limx→1 f(x) = 2, da zu jederFolge (xn) mit xn −→ 1 und xn ∈ (0, 1) die Folge (f(xn)) = (2xn) gegen 2konvergiert.(ii) Die Funktion f : R → R mit
f(x) =
1 fur x ≥ 00 fur x < 0
ist unstetig an der Stelle x = 0, da etwa zur Folge(− 1
n
)mit − 1
n−→ 0 die Folge(
f(− 1
n
))= (0) gegen 0 konvergiert, obgleich f(0) = 1 ist. Dieses Beispiel korre-
spondiert mit unserer in Kapitel 6 gegebenen Intuition des abzusetzenden Stiftesbei Unstetigkeiten. Das folgende Beispiel demonstriert dagegen die Unzulanglich-keit dieser Intuition.(iii) Sei f : (0,∞) → R mit f(x) = sin 1
x. Da zu der Folge
(1
2πn
)die Fol-
ge(f(
12πn
))= (sin 2πn) = (0) gegen 0 und zu der Folge
(1
2πn+ π2
)die Folge(
f(
12πn+ π
2
))=(sin(2πn + π
2
))) = (1) gegen 1 konvergiert, existiert limx→0 f(x)
nicht. Dieses Beispiel lehrt uns also, daß die in Kapitel 6 gegebene Intuition desabzusetzenden Stiftes bei Unstetigkeiten hier nicht hilfreich ist, da der durchdiese offenbar unstetige Funktion beschriebene Graph nicht in zwei unzusam-menhangende Teilmengen zerfallt, wie das Absetzen des Stiftes suggerieren mag.(iv) Die Funktion f : R → R mit f(x) = 3x + 5 ist stetig an jeder Stelle x, dafur alle Folgen (xn) mit xn −→ x gilt
|f(xn) − f(x)|= |3xn + 5 − 3x − 5|= 3|xn − x| −→ 3 · 0 = 0,
75

9 Funktionen von Rm nach Rn
also f(xn) −→ f(x).(v) Die Funktion f : R → R mit f(x) = x2 ist uberall stetig, da fur alle Folgen(xn) mit xn −→ x gilt
|f(xn) − f(x)|= |x2n − x2|
= |(xn − x)(xn + x)|= |xn − x| · |xn + x| −→ 0 · 2x = 0,
daher f(xn) −→ f(x).(vi) Die Funktion f : R2 → R mit f(x, y) = 2xy ist stetig an jeder Stelle(x, y) ∈ R2, da fur alle Folgen (xn, yn) mit (xn, yn) −→ (x, y) gilt
|f(xn, yn) − f(x, y)| = |2xnyn − 2xy| −→ 2(|xy − xy| = 0
und daher f(xn, yn) −→ f(x, y).(vii) Die Funktion f : R \ 0 → R mit f(x) = 1
xist stetig durch geeignete
Einschrankung des Definitionsbereiches.(viii)Die Funktion f : R → R mit
f(x) =
1 furx = 1
nmit n ∈ N
x sonst
ist unstetig an der Stelle x = 0, da etwa zur Folge(
1n
)mit 1
n−→ 0 die Folge(
f(
1n
))gegen 1 konvergiert, obgleich f(0) = 0 gilt.
9.6 Monotonie und Homogenitat
In den beiden folgenden Abschnitten werden Eigenschaften reellwertiger Funktio-nen von Rn nach R behandelt (also die Dimension der Bildmenge ist m = 1), diein den Wirtschaftswissenschaften von zentraler Bedeutung sind. Zunachst werdenwir Monotonie allgemein definieren.
Definition 9.11 (Monotonie) Eine Funktion f : X → Y mit X ⊆ Rn, Y ⊆ R
und f(x1, . . . , xn) = f(x) ∈ R heißt
i) monoton steigend (engl.: increasing) in der Komponente xi, wenn fur allex, x′ ∈ X mit x′
i > xi und x′j = xj fur alle j ∈ 1, . . . , n \ i gilt
f(x′) ≥ f(x).
ii) monoton fallend (engl.: decreasing) in der Komponente xi, wenn fur allex, x′ ∈ X mit x′
i > xi und x′j = xj fur alle j ∈ 1, . . . , n \ i gilt
f(x′) ≤ f(x).
76

9 Funktionen von Rm nach Rn
Ist f monoton steigend (fallend) in xi in allen Komponenten i = 1, . . . , n, soheißt f monoton steigend (fallend).
Ersetzt man in i) und ii) die Relationszeichen ≥ und ≤ durch > bzw. <, soerhalt man die entsprechenden Definitionen fur strenge Monotonie (engl.: strictmonotonicity).
Unsere aus Kapitel 6 aufgebaute Intuition gilt weiter, und zwar unabhangig furjede einzelne Komponente. Eine reellwertige Funktion ist also genau dann mo-noton steigend in einer Komponente ihres Arguments, falls der Funktionswertfur wachsende Werte dieser Komponente (schwach) mitwachst, wenn die anderenKomponenten konstant bleiben.
Beispiel 9.12:(i) Die Funktion f : R → R mit f(x) = −x3 ist streng monoton fallend in x.(ii) Die Funktion f : R2 → R mit f(x, y) = 2x−3y ist streng monoton steigendin x und steng monoton fallend in y (vgl. Abbildung 9.11).(iii) Die Funktion f : R2 → R mit f(x, y) = xy ist weder monoton steigend nochmonoton fallend in x, da etwa fur y = 1 die Funktionswerte mit steigendem xzu-, fur y = −1 jedoch abnehmen. Das Gleiche gilt aus Symmetriegrunden fur y.Dagegen ist die Funktion g : [0,∞)2 → R mit g(x, y) = xy aufgrund der Wahl desDefinitionsbereichs monoton steigend in x und in y und also insgesamt monotonsteigend.(iv) Die Funktion f : R2 → R mit f(x, y) = exy ist streng monoton steigend iny, da fur alle x ∈ R die Ungleichung ex > 0 erfullt ist.
Die Monotonie einer Funktion ergibt sich in den Wirtschaftswissenschaften oftganz naturlich. So ist es etwa sinnvoll anzunehmen, daß Produktionsfunktionen,welche die durch einen Produktionsprozeß vorgegebene Beziehung zwischen Out-putmenge und den Inputmengen eingesetzter Produktionsfaktoren, beispielsweiseKapital und Arbeit, beschreiben, monoton steigend sind, da eine Erhohung derInputmengen im relevanten Bereich eine Erhohung der Outputmenge bewirkt.
Eine weitere Eigenschaft von Funktionen ist die Homogenitat, eine Art abge-schwachte Form der Symmetrie, die in den Wirtschaftswissenschaften haufig ver-wendet wird, da sie je nach Zusammenhang leicht okonomisch interpretierbar istund den Rechenaufwand deutlich reduzieren kann.
Definition 9.12 (Homogenitat) Eine Funktion f : X → Y mit X ⊆ Rn, Y ⊆R und λx ∈ X fur alle x ∈ X und alle λ > 0 heißt homogen (engl.: homogeneous)vom Grad r ∈ R, wenn fur alle x ∈ X und alle λ > 0 gilt:
f(λx) = λrf(x)
77
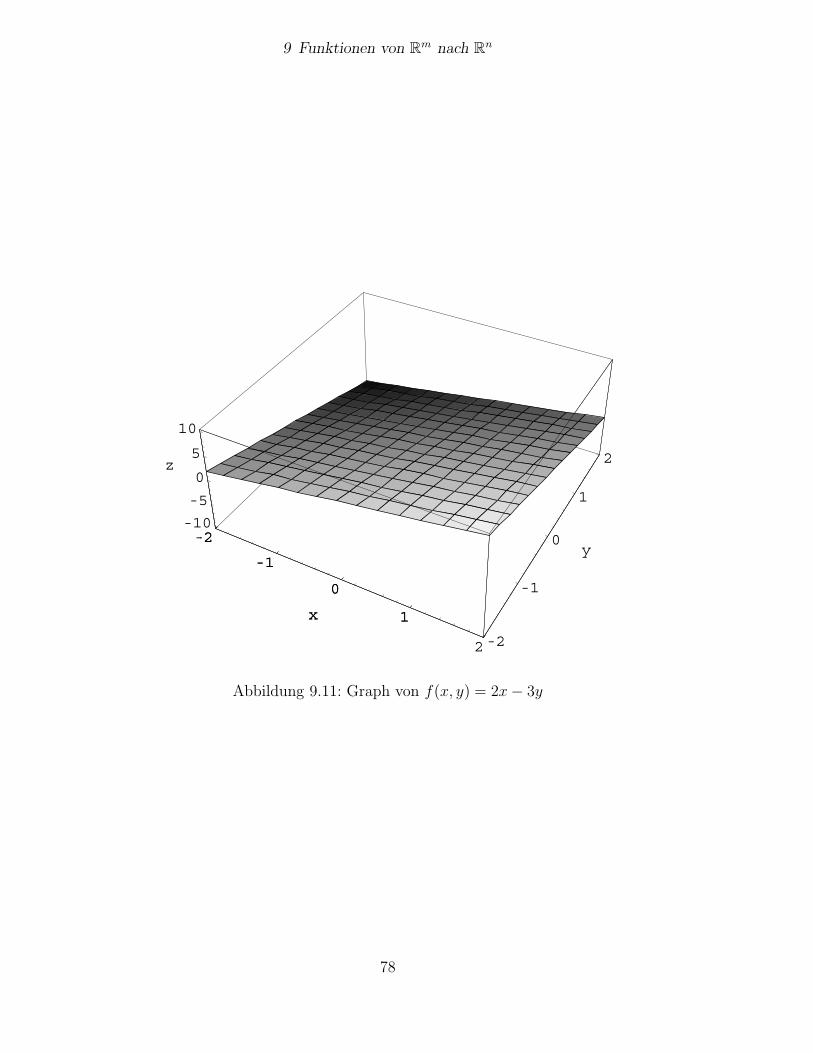
9 Funktionen von Rm nach Rn
-2
-1
0
1
2
x
-2
-1
0
1
2
y
-10
-5
0
5
10
z
-2
-1
0
1x
Abbildung 9.11: Graph von f(x, y) = 2x − 3y
78

9 Funktionen von Rm nach Rn
Eine Funktion ist also homogen vom Grad r, wenn eine Vervielfachung allerKomponenten ihres Arguments um einen Faktor λ > 0 eine Vervielfachung desFunktionswerts um den Faktor λr bewirkt.
Beispiel 9.13:(i) Die Funktion f : R2 → R mit f(x, y) = 2x2y3 ist homogen vom Grad 5, dafur alle λ > 0 und alle (x, y) ∈ R2 gilt:
f(λx, λy) =2(λx)2(λy)3
=λ5 · 2x2y3
=λ5f(x, y)
(ii) Die Funktion f : R2 → R mit f(x, y) = 5x2 − y2 ist homogen vom Grad 2,da fur alle λ > 0 und alle (x, y) ∈ R2 gilt:
f(λx, λy) =5(λx)2 − (λy)2
=λ2(5x2 − y2)=λ2f(x, y)
(iii) Die Funktion f : R2 → R mit f(x, y) = x2 + xy − y ist inhomogen,da beispielsweise eine Verdopplung aller Argumente an der Stelle (1, 1) wegenf(1, 1) = 1 und f(2, 2) = 6 eine Versechsfachung des Funktionswerts bewirkt,wahrend dieses bei einer Verdopplung aller Argumente an der Stelle (2, 2) wegenf(2, 2) = 6 und f(4, 4) = 28 nicht der Fall ist.(iv) Die Funktion f : Rn → R mit f(x) = minx1, . . . , xn und n ∈ N isthomogen vom Grad 1.
9.7 Konkavitat und Quasikonkavitat
Die folgenden Eigenschaften Konvexitat, Konkavitat und Quasikonkavitat cha-rakterisieren die Krummungseigenschaften von Funktionen. Wir werden dabeisehen, daß die Konzepte Konvexitat und Konkavitat genau wie bei eidimensiona-len Funktionen definiert werden. Das Konzept der Quasikonkavitat hat eine lan-ge Tradition, Verwirrung unter Anfangerstudenten der Wirtschaftswissenschaftenzu stiften. Die Quelle der Verwirrung ist der enge Zusammenhang quasikonkaverFunktionen mit konvexen Mengen, der im Folgenden erlautert werden soll. Wiedas Wort quasikonkav suggeriert, ist es aber eine Abschwachung der Konkavit2ateiner Funktion, d.h. jede konkave Funktion ist auch quasikonkav. Unglucklicher-weise ist genau dieser Begriff der Quasikonkavitat haufig der fur Wirtschafts-wissenschaften entscheidende, da er in vielen relevanten Zusammenhangen dieEindeutigkeit von Losungen garantiert.
79

9 Funktionen von Rm nach Rn
Definition 9.13 (Konvexitat und Konkavitat) Eine Funktion f : X → Ymit X ⊆ Rn als konvexer Menge, Y ⊆ R heißt
i) konvex (engl.: convex), wenn fur alle x, x′ ∈ X mit x = x′ und alle λ ∈ (0, 1)gilt
f(λx + (1 − λ)x′) ≤ λf(x) + (1 − λ)f(x′)
und
ii) konkav (engl.: concave), wenn fur alle x, x′ ∈ X mit x = x′ und alle λ ∈(0, 1) gilt
f(λx + (1 − λ)x′) ≥ λf(x) + (1 − λ)f(x′).
Ersetzt man in den beiden obigen Ungleichungen die Relationszeichen ≤ und ≥durch < bzw. >, so erhalt man die Definitionen strenger Konvexitat und Konka-vitat.
Eine Funktion ist also konvex, wenn die gerade Verbindungslinie zwischen zweibeliebigen Punkten auf dem Graphen der Funktion immer ausschließlich ober-halb des Graphen verlauft (vgl. Abbildung 9.12 (a)) und konkav, wenn dieseausschließlich unterhalb des Graphen verlauft (vgl. Abbildung 9.12 (b)).
Der analytische Nachweis mit Hilfe von Definition 9.13, daß eine Funktion konvexbzw. konkav ist, ist oft umstandlich oder nicht moglich. Da dies aber haufig mitHilfe von spater behandelten Ableitungseigenschaften gemacht wird und meistensnur die schwachere Eigenschaft Quasikonkavitat notig, ist verzichten wir an dieserStelle auf eine Diskussion an Beispielen und gehen gleich zu Quasikonkavitatweiter.
Definition 9.14 (Quasikonkavitat) Eine Funktion f : X → Y mit X ⊆ Rn
als konvexer Menge und Y ⊆ R heißt quasikonkav (engl.: quasiconcave), wennfur alle x, x′ ∈ X mit x = x′ und alle λ ∈ (0, 1) gilt
f(λx + (1 − λ)x′) ≥ min f(x), f(x′) .
Ersetzt man in dieser Ungleichung das Relationszeichen ≥ durch >, so erhaltman die Definition strenger Quasikonkavitat.
Eine Funktion f : X → Y ist also genau dann quasikonkav, wenn die Funktions-werte beliebiger Konvexkombinationen zweier Punkte den kleineren der beidenFunktionswerte an diesen Punkten nicht unterschreitet. Entsprechend kann manQuasikonvexitat definieren, die wir aber hier nicht weiter thematisiern, da sie inden Wirtschaftswissenschaften selten vorkommt. Der bereits erwahnte Umstand,daß Quasikonkavitat gegenuber Konkavitat eine schwachere Eigenschaft ist, wirdprazisiert durch Satz 9.3.
80

9 Funktionen von Rm nach Rn
(a)
yy xx xx00
yy
xx x’λλx+(1−λλ))x’
ff(λx+(1−λλ))x’))λλff((xx))++(1−λλ))ff((x’))
zz
(b)
yy xx xx00
yy
xx x’λλx+(1−λλ))x’
ff(λx+(1−λλ))x’))λλff((xx))++(1−λλ))ff((x’))
zz
00
00
Abbildung 9.12: Konvexitat und Konkavitat
81

9 Funktionen von Rm nach Rn
Satz 9.3 Jede konkave Funktion ist quasikonkav.
Beweis. Sei f : X → Y konkav mit X ⊆ Rn als konvexer Menge und Y ⊆ R.Dann gilt fur alle x, x′ ∈ X und alle λ ∈ (0, 1)
f(λx + (1 − λ)x′)≥λf(x) + (1 − λ)f(x′)≥λ min f(x), f(x′) + (1 − λ) min f(x), f(x′)= min f(x), f(x′)
Folglich ist f auch quasikonkav.
Eine aquivalente Charakterisierung von Quasikonkavitat gibt Satz 9.4. Er besagt,daß eine Funktion f : X → Y genau dann quasikonkav ist, wenn zu jedemNiveau a ∈ Y die sogenannte obere Konturmenge oder Bessermenge Ba, diealle x ∈ X mit f(x) ≥ a enthalt, konvex ist. Aus Satz 9.4 folgt insbesondere,daß die Konvexitat der oberen Konturmengen eine alternative Definition vonQuasikonkavitat darstellt. Dieser semantisch unguckliche Umstand ist haufigeQuelle von Irrtumern bei unbedarften Benutzern.
Satz 9.4 Eine Funktion f : X → Y mit X ⊆ Rn als konvexer Menge, Y ⊆ R
und n ∈ N ist genau dann quasikonkav, wenn fur alle a ∈ Y die Bessermenge(engl.: upper level set)
Ba = x | x ∈ X ∧ f(x) ≥ a
konvex ist (vgl. Abbildung 9.13).
Beweis. Da Satz 9.4 eine Aquivalenzaussage macht, mussen Implikationen inbeiden Richtungen gezeigt werden. Zeige also zunachst, daß aus der Quasikonka-vitat von f die Konvexitat von Ba fur alle a ∈ Y folgt. Seien x, x′ ∈ Ba fur einbeliebiges a ∈ Y . Dann ist f(x) ≥ a und f(′x) ≥ a. Da f nach Voraussetzungquasikonkav ist, gilt dann fur alle λ ∈ (0, 1) die Beziehung
f(λx + (1 − λ)x′) ≥ min f(x), f(x′) ≥ a.
Also ist λx + (1 − λ)x′ ∈ Ba und daher Ba konvex. Zeige nun umgekehrt, daßaus der Konvexitat von Ba fur alle a ∈ Y die Quasikonkavitat von f folgt. Seienx, x′ ∈ Ba mit a = min f(x), f(x′). Da Ba nach Voraussetzung konvex ist, giltfur alle λ ∈ (0, 1) die Beziehung
λx + (1 − λ)x′ ∈ Ba.
82
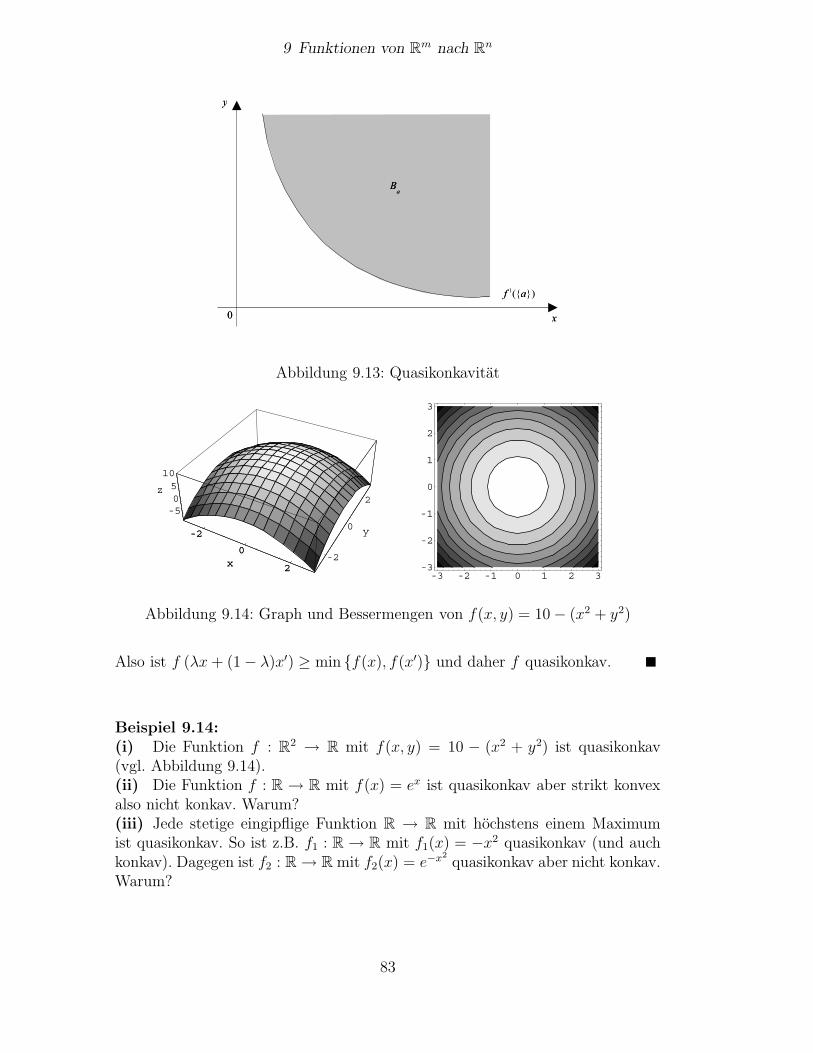
9 Funktionen von Rm nach Rn
xx00
yy
ff−1(aa)
BBaa
Abbildung 9.13: Quasikonkavitat
-2
0
2x-2
0
2
y
-505
10
z
-2
0
2x-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
Abbildung 9.14: Graph und Bessermengen von f(x, y) = 10 − (x2 + y2)
Also ist f (λx + (1 − λ)x′) ≥ min f(x), f(x′) und daher f quasikonkav.
Beispiel 9.14:(i) Die Funktion f : R2 → R mit f(x, y) = 10 − (x2 + y2) ist quasikonkav(vgl. Abbildung 9.14).(ii) Die Funktion f : R → R mit f(x) = ex ist quasikonkav aber strikt konvexalso nicht konkav. Warum?(iii) Jede stetige eingipflige Funktion R → R mit hochstens einem Maximumist quasikonkav. So ist z.B. f1 : R → R mit f1(x) = −x2 quasikonkav (und auchkonkav). Dagegen ist f2 : R → R mit f2(x) = e−x2
quasikonkav aber nicht konkav.Warum?
83

9 Funktionen von Rm nach Rn
Insbesondere Quasikonkavitat ist oft ganz naturlich eine Eigenschaft von Funk-tionen, die wirtschaftliche Phanomene beschreiben. So ist es beispielweise oftsinnvoll anzunehmen, daß Nutzenfunktionen, die den Zusammenhang zwischender ’Zufriedenheit’ eines Konsumenten und seinem Konsum beschreiben, quasi-konkav sind.
9.8 Ausgewahlte Typen von Funktionen
In diesem Abschnitt werden zum Abschluß dieses Kapitels einige Typen vonFunktionen vorgestellt, die bei der Beschreibung okonomischer Phanomene be-sonders haufig benutzt werden, da sie rechnerisch leicht zu handhaben sind. DenLesern wird als Ubung and Herz gelegt, die aufgezahlten Eigenschaften anhandder Definitionen dieses Kapitels zu verifizieren.
Definition 9.15 (Cobb-Douglas-Funktion) Eine Funktion f : [0,∞)n → R
mit
f(x) =n∏
i=1
xaii
mit festen ai > 0 fur alle i = 1, . . . , n heißt Cobb-Douglas-Funktion.
Cobb-Douglas-Funktionen sind monoton steigend in x1 bis xn, homogen vomGrad
∑ni=1 ai, quasikonkav und fur
∑ni=1 ai ≤ 1 zusatzlich konkav.
Definition 9.16 (Leontief- oder auch limitationale Funktion) Eine Funk-tion f : [0,∞)n → R mit
f(x) = min
x1
a1, . . . ,
xn
an
und mit festen ai > 0 fur alle i = 1, . . . , n heißt Leontief-Funktion.
Leontief-Funktionen sind monoton steigend in x1 bis xn, homogen vom Grade 1,quasikonkav und konkav.
Definition 9.17 (CES-Funktion) Eine Funktion f : [0,∞)n → R mit
f(x) =
(n∑
i=1
aixqi
) 1q
und mit festen ai > 0 fur alle i = 1, . . . , n, q ≤ 1 und q = 0 heißt CES-Funktion.
84
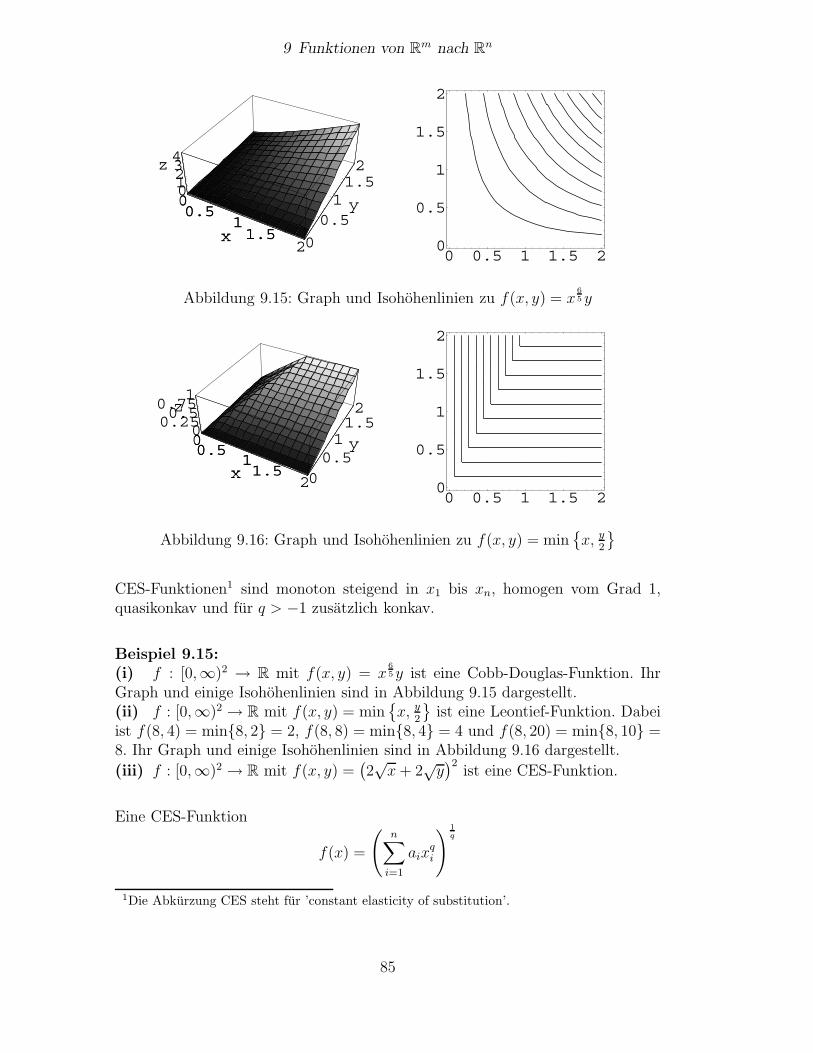
9 Funktionen von Rm nach Rn
00.5
11.5
2x 0
0.511.52
y01234z
00.5
11.5x
0 0.5 1 1.5 20
0.5
1
1.5
2
Abbildung 9.15: Graph und Isohohenlinien zu f(x, y) = x65 y
00.5
11.5
2x 0
0.511.52
y00.250.5
0.751
z
00.5
11.5x
0 0.5 1 1.5 20
0.5
1
1.5
2
Abbildung 9.16: Graph und Isohohenlinien zu f(x, y) = minx, y
2
CES-Funktionen1 sind monoton steigend in x1 bis xn, homogen vom Grad 1,quasikonkav und fur q > −1 zusatzlich konkav.
Beispiel 9.15:(i) f : [0,∞)2 → R mit f(x, y) = x
65 y ist eine Cobb-Douglas-Funktion. Ihr
Graph und einige Isohohenlinien sind in Abbildung 9.15 dargestellt.(ii) f : [0,∞)2 → R mit f(x, y) = min
x, y
2
ist eine Leontief-Funktion. Dabei
ist f(8, 4) = min8, 2 = 2, f(8, 8) = min8, 4 = 4 und f(8, 20) = min8, 10 =8. Ihr Graph und einige Isohohenlinien sind in Abbildung 9.16 dargestellt.
(iii) f : [0,∞)2 → R mit f(x, y) =(2√
x + 2√
y)2
ist eine CES-Funktion.
Eine CES-Funktion
f(x) =
(n∑
i=1
aixqi
) 1q
1Die Abkurzung CES steht fur ’constant elasticity of substitution’.
85

9 Funktionen von Rm nach Rn
approximiert fur q −→ −∞ eine Leontief-Funktion und fur q −→ 0 eine Cobb-Douglas-Funktion. Insofern konnen CES-Funktionen als die allgemeinsten derdrei hier vorgestellten Funktionstypen aufgefaßt werden.
86

10 Differentialrechnung
In diesem Kapitel wird das zentrale Instrument der Analysis auf Funktionenmehrerer Veranderlicher erweitert. Die Differentialrechnung (engl.: calculus) istauch das wichtigste Handwerkzeug der Wirtschaftswissenschaften.
10.1 Partielle Ableitungen
In diesem Abschnitt wird die Ableitung reellwertiger Funktionen mit mehrerenVeranderlichen behandelt. Eine Funktion mehrerer Veranderlicher kann wie wirbei den graphischen Darstellungen von Funktionen gelernt haben auf verschiedeneArt und Weise als Funktion einer Variablen interpretiert werden. Die einfachsteArt ist, alle Variablen außer einer konstant zu halten. Die Ableitung jeder die-ser so gebildeten Funktionen einer Variablen (deren Graphen die projeziertenSchnittlinien sind) heißen partielle Ableitungen.
Definition 10.1 (Partielle Differenzierbarkeit und Ableitung) Eine Funk-tion f : X → Y mit X ⊆ Rn, Y ⊆ R heißt fur i ∈ 1, . . . , n partiell differen-zierbar (engl.: partially differentiable) nach xi an der Stelle x ∈ X, wenn derGrenzwert
limxi→xi
f(x1, . . . , xi, . . . , xn) − f(x)
xi − xi= lim
∆xi→0
f(x1, . . . , xi + ∆xi, . . . , xn) − f(x)
∆xi
existiert. Dieser Grenzwert heißt dann erste partielle Ableitung (engl.: first-orderpartial derivative) von f nach xi an der Stelle x und wird geschrieben als
∂f
∂xi
(x) oder Dif(x) oder verkurzt fi(x).
Ist f an jeder Stelle x ∈ X partiell differenzierbar nach xi, so heißt f partielldifferenzierbar nach xi. Die Funktion, die jedem x ∈ X die partielle Ableitungvon f nach xi an der Stelle x zuordnet, heißt dann partielle Ableitung von f nachxi und wird bezeichnet mit
∂f
∂xi
oder Dif oder verkurzt als fi.
87

10 Differentialrechnung
Ist f partiell differenzierbar nach xi fur alle i ∈ 1, . . . , n, so heißt f partielldifferenzierbar. Sind außerdem alle partiellen Ableitungen von f stetig, so nenntman f C1-Funktion.
Beispiel 10.1:(i) Sei f(x1, x2) = a1x1 + a2x2 + b eine lineare Funktion von R2 nach R. Dannsind sind die partiellen Ableitungen konstant, also
∂f
∂x1
(x1, x2) = a1 und∂f
∂x2
(x1, x2) = a2.
(ii) Sei fy : R → R eine parametrisierte Funktionenschar mit fy(x) = 2x2y und
y ∈ R als Parameter. Dann ist fur alle x, y ∈ R die Ableitung dfy
dx(x) = 4xy.
Sei nun g : R2 → R eine Funktion mit g(x, y) = 2x2y. Dann ist ∂g∂x
(x, y) = 4xydie partielle Ableitung von g nach x an einer Stelle (x, y) ∈ R2, wie die folgendeGrenzwertbetrachtung erbringt:
lim∆x→0g(x+∆x,y)−g(x,y)
∆x= lim∆x→0
2(x+∆x)2y−2x2y∆x
= lim∆x→04xy∆x+2y(∆x)2
∆x
= 4xy
Graphisch kann man die partielle Ableitung ∂f∂xi
(x) einer Funktion f : X → Y mitX ⊆ Rn, Y ⊆ R darstellen als Steigung derjenigen Tangente an den Graphen vonf im Punkt (x, f(x)), die parallel zur (xi, f(x))-Ebene verlauft (vgl. Abbildung10.1).
10.2 Richtungsableitung, Kettenregel, Satz vonEuler
Mit Hilfe der partiellen Ableitungen definieren wir allgemeiner die Richtungs-ableitung, die die lokale Veranderung des Funktionswertes in einer beliebigenRichtung (also nicht unbedingt entlang einer der Koordinatenachsen) beschreibt.
Definition 10.2 (Richtungsableitung) Die Richtungsableitung der Funktionf : X → Y mit X ⊆ Rn, Y ⊆ R an der Stelle x in Richtung r ∈ Rn mit ‖r‖ = 1ist definiert durch
Df(x; r) = limh→0
f(x + hr) − f(x)
h.
88

10 Differentialrechnung
GGff
xx11
xx22
ff((xx11,,xx
22))
xx22
xx11
tt
Abbildung 10.1: Geometrische Interpretation der partiellen Ableitung
In dieser Definition wird die Richtung, in der die Funktion f abgeleitet wird, aufdie Lange 1 normiert, da in diesem Fall die Richtungsableitung in Richtung desi-ten Einheitsvektors ei = (0, . . . , 0, 1, 0, . . . , 0) (nur 1 bei der i-ten Koordinate,sonst 0) mit der jeweiligen partiellen Ableitung ubereinstimmt, also
Df(x; ei) =∂f(x)
∂xi
.
Es gilt die Rechenregel
Df(x; r) =
n∑i=1
∂f
∂xi(x) · ri.
Beispiel 10.2: Die Richtungsableitung der Funktion f(x1, x2) = 2x1x32 an der
Stelle x = (2, 1) in Richtung r =(
1√2, 1√
2
)ist
Df
((2, 1);
(1√2,
1√2
))= 2 · 1√
2+ 12
1√2.
Die Kettenregel fur Funktionen mehrerer Veranderlicher ist eine unmittelbareVerallgemeinerung der uns bekannten Kettenregel fur Funktionen einer Verander-licher. Da bei der Hintereinanderausfuhrung von Funktionen gleichzeitig alle Zwi-schenvariablen verandert werden konnen durch Veranderung einer Variablen in
89

10 Differentialrechnung
der Urbildmenge ergibt sich die Veranderung der zusammengesetzten Funktionwie bei der Richtungsableitung durch die Summe der Veranderungen der Zwi-schenvariablen.
Satz 10.1 (Kettenregel) Sei f : X1 × . . . × Xn → Y mit X1, . . . , Xn ⊆ R,Y ⊆ R eine partiell differenzierbare Funktion. Seien außerdem gi : T → Xi mitT ⊆ Rk und k ∈ N fur alle i ∈ 1, . . . , n partiell differenzierbare Funktionen.Dann ist die zusammengesetzte Funktion h : T → Y mit
h(t) = f (g1(t), . . . , gn(t))
differenzierbar fur alle j ∈ 1, . . . , k und es gilt
∂h
∂tj(t) =
n∑i=1
∂f
∂xi(g1(t), . . . , gn(t)) · ∂gi
∂tj(t).
Beispiel 10.3:(i) Seien insbesondere gi : T → Xi mit T ⊆ R differenzierbare Funktioneneiner Variablen. Dann ist die zusammengesetzte Funktion h : T → Y eine diffe-renzierbare Funktion einer Variablen mit
h(t) = f (g1(t), . . . , gn(t))
fur alle t ∈ T :dh
dt(t) =
n∑i=1
∂f
∂xi(g1(t), . . . , gn(t)) · dgi
dt(t).
(ii) Sei f : R2 → R mit f(x1, x2) = x21(x2 +1), g1 : R → R mit g1(t) = sin t und
g2 : R → R mit g2(t) = t2. Dann ist die Ableitung der Funktion h : R → R mit
h(t) = f (g1(t), g2(t))
gemaß des vorhergehenden Beispiels
dhdt
(t) = ∂f∂x1
(g1(t), g2(t)) · dg1
dt(t) + ∂f
∂x2(g1(t), g2(t)) · dg2
dt(t)
= 2(sin t)(t2 + 1) · cos t + (sin t)2 · 2t.
(iii) Sei f : R2 → R mit f(x1, x2) = x2 sin x1, g1 : R2 → R mit g1(t) = t1t2und g2 : R2 → R mit g2(t) = t2. Dann ist die partielle Ableitung der Funktionh : R2 → R mit
h(t) = f (g1(t), g2(t))
90

10 Differentialrechnung
nach t2 gemaß Satz 10.1
∂h∂t2
(t)= ∂f∂x1
(g1(t), g2(t)) · ∂g1
∂t2(t) + ∂f
∂x2(g1(t), g2(t)) · ∂g2
∂t2(t)
= t2(cos t1t2) · t1 + (sin t1t2) · 1.
Wir erinnern uns, daß Wirtschaftswissenschaftler gerne homogene Funktionen be-nutzen. Daher wird hier ein wichtiger Satz uber homogene Funktionen angefuhrt.Der Beweis und die weitere Vertiefung wird als Ubungsaufgabe behandelt.
Satz 10.2 (Satz von Euler) Sei f : [0,∞)n → R eine vom Grad r ∈ R homo-gene C1-Funktion. Dann gilt fur alle x ∈ [0,∞)n:
n∑i=1
∂f
∂xi(x)xi = rf(x).
10.3 Gradient, totales Differential
Die partiellen Ableitungen einer C1-Funktion werden haufig zu einem Vektor,dem sogenannten Gradient, zusammengefaßt:
Definition 10.3 (Gradient) Sei f : X → Y mit X ⊆ Rn, Y ⊆ R eine C1-Funktion. Dann heißt der Vektor
gradf(x) = ∇f(x) =
(∂f
∂x1(x), . . . ,
∂f
∂xn(x)
)
Gradient (engl.: gradient vector) von f an der Stelle x ∈ X.1
Beispiel 10.4: Sei f : R2 → R mit f(x, y) = 3x2y − x. Dann ist
∇f(x, y) =(6xy − 1, 3x2
).
Der Gradient ∇f(x) besitzt Eigenschaften, die ihn sehr anschaulich und leichtinterpretierbar machen:
• ∇f(x) zeigt an jeder Stelle x ∈ X in die Richtung des steilsten Anstiegsdes Funktionswerts.
1Das Symbol ∇ wird Nabla genannt.
91
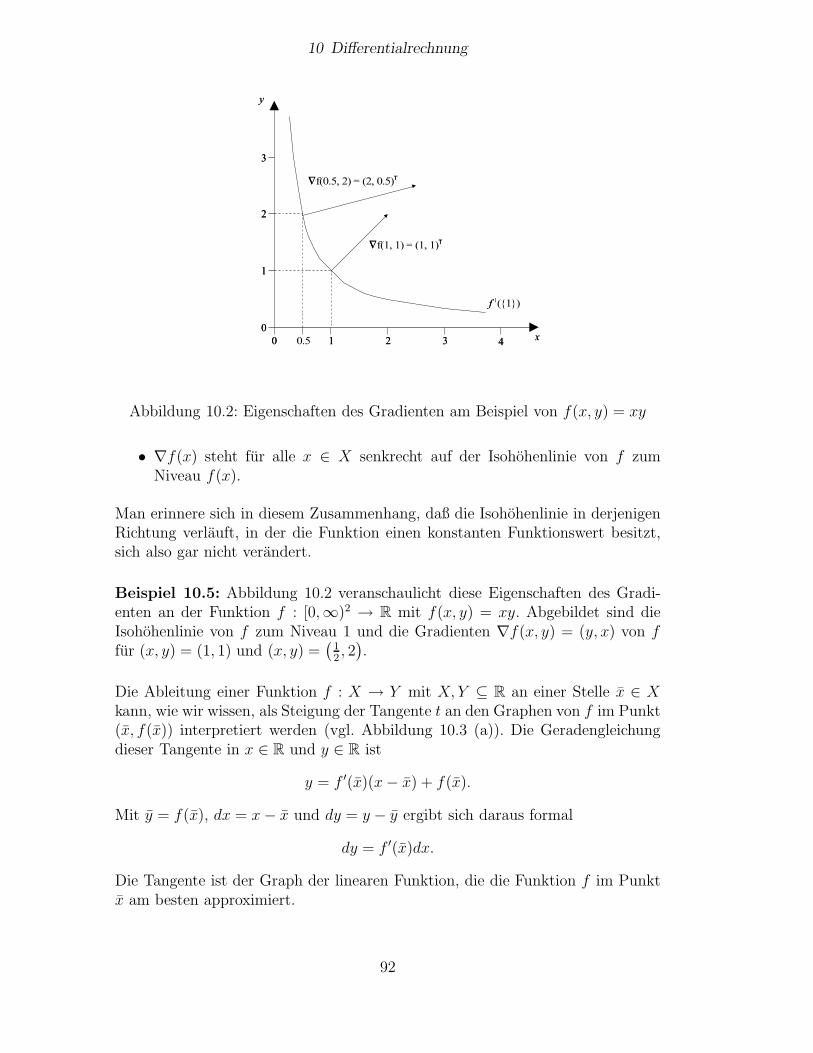
10 Differentialrechnung
xx
yy
00
11
22
33
00 11 22 33 44
ff−1(1)
∇∇f(1, 1) = (1, 1)TT
∇∇f(0.5, 2) = (2, 0.5)TT
0.5
Abbildung 10.2: Eigenschaften des Gradienten am Beispiel von f(x, y) = xy
• ∇f(x) steht fur alle x ∈ X senkrecht auf der Isohohenlinie von f zumNiveau f(x).
Man erinnere sich in diesem Zusammenhang, daß die Isohohenlinie in derjenigenRichtung verlauft, in der die Funktion einen konstanten Funktionswert besitzt,sich also gar nicht verandert.
Beispiel 10.5: Abbildung 10.2 veranschaulicht diese Eigenschaften des Gradi-enten an der Funktion f : [0,∞)2 → R mit f(x, y) = xy. Abgebildet sind dieIsohohenlinie von f zum Niveau 1 und die Gradienten ∇f(x, y) = (y, x) von ffur (x, y) = (1, 1) und (x, y) =
(12, 2).
Die Ableitung einer Funktion f : X → Y mit X, Y ⊆ R an einer Stelle x ∈ Xkann, wie wir wissen, als Steigung der Tangente t an den Graphen von f im Punkt(x, f(x)) interpretiert werden (vgl. Abbildung 10.3 (a)). Die Geradengleichungdieser Tangente in x ∈ R und y ∈ R ist
y = f ′(x)(x − x) + f(x).
Mit y = f(x), dx = x − x und dy = y − y ergibt sich daraus formal
dy = f ′(x)dx.
Die Tangente ist der Graph der linearen Funktion, die die Funktion f im Punktx am besten approximiert.
92
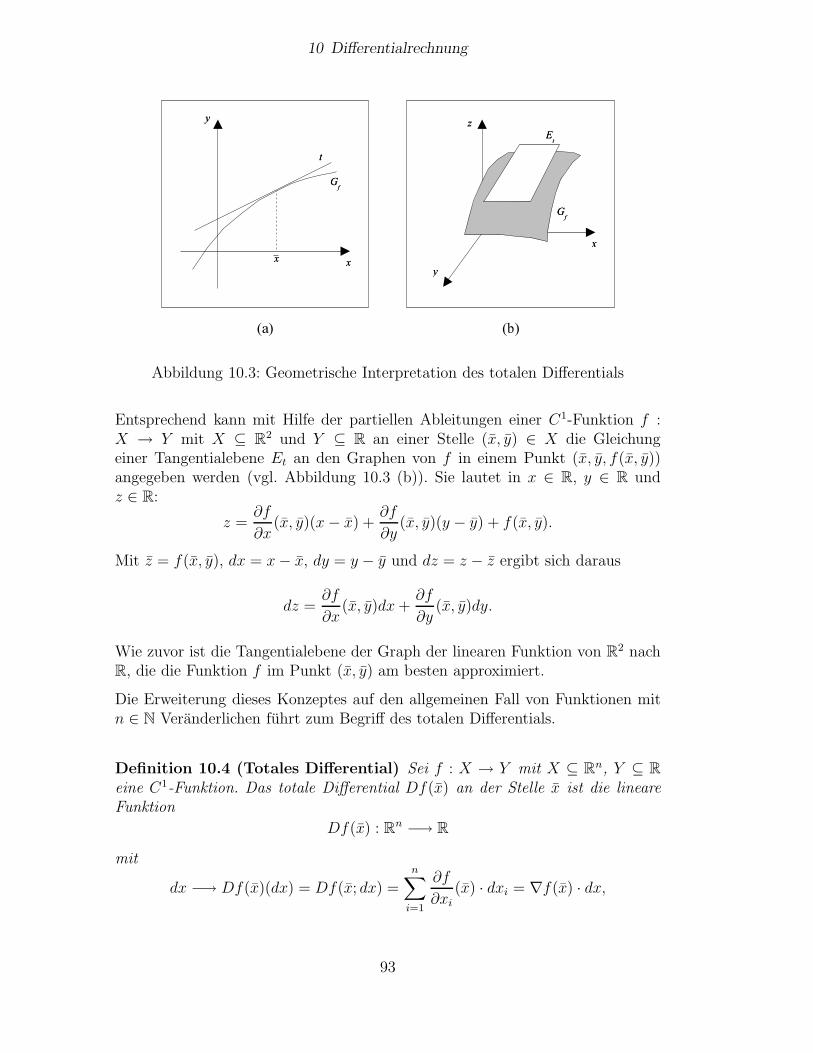
10 Differentialrechnung
(a) (b)
xx
yy
xx
tt
GGff
xxyy
zzEE
tt
GGff
Abbildung 10.3: Geometrische Interpretation des totalen Differentials
Entsprechend kann mit Hilfe der partiellen Ableitungen einer C1-Funktion f :X → Y mit X ⊆ R2 und Y ⊆ R an einer Stelle (x, y) ∈ X die Gleichungeiner Tangentialebene Et an den Graphen von f in einem Punkt (x, y, f(x, y))angegeben werden (vgl. Abbildung 10.3 (b)). Sie lautet in x ∈ R, y ∈ R undz ∈ R:
z =∂f
∂x(x, y)(x − x) +
∂f
∂y(x, y)(y − y) + f(x, y).
Mit z = f(x, y), dx = x − x, dy = y − y und dz = z − z ergibt sich daraus
dz =∂f
∂x(x, y)dx +
∂f
∂y(x, y)dy.
Wie zuvor ist die Tangentialebene der Graph der linearen Funktion von R2 nachR, die die Funktion f im Punkt (x, y) am besten approximiert.
Die Erweiterung dieses Konzeptes auf den allgemeinen Fall von Funktionen mitn ∈ N Veranderlichen fuhrt zum Begriff des totalen Differentials.
Definition 10.4 (Totales Differential) Sei f : X → Y mit X ⊆ Rn, Y ⊆ R
eine C1-Funktion. Das totale Differential Df(x) an der Stelle x ist die lineareFunktion
Df(x) : Rn −→ R
mit
dx −→ Df(x)(dx) = Df(x; dx) =n∑
i=1
∂f
∂xi
(x) · dxi = ∇f(x) · dx,
93

10 Differentialrechnung
wobei ∇f(x) ·dx fur das Vektorprodukt des Gradienten mit dx = (dx1, . . . , dxn) ∈Rn, einem beliebiger Vektor des Rn steht. Eine andere verkurzte Schreibweisedafur ist
df =n∑
i=1
∂f
∂xi
(x)dxi.
Die Schreibweise Df(x; dx) verdeutlicht, daß das totale Differential als verall-gemeinerte Richtungsableitung aufgefaßt werden kann. Im Gegensatz zur Rich-tungsableitung wird die Lange des Vektors dx aber nicht normiert, kann alsobeliebig sein. Der Graph des totalen Differentials ist, wie wir in den Dimensionenn = 1, 2 gesehen haben, der Tangentialraum oder die Tangetialhyperebene2 anden Graphen der Funktion f .
Beispiel 10.6: Sei f : R2 → R mit f(x, y) = x2 + y2. Dann ist das totaleDifferential von f an einer Stelle (x, y) ∈ R2
df = 2x · dx + 2y · dy
und fur (x, y) = (1, 1)
df = 2dx + 2dy.
Der Vergleich zwischen dem totalen Differential von f an der Stelle (x, y) = (1, 1)und der tatsachlichen Veranderung des Funktionswerts
∆f = ∆f((x, y), (dx, dy)) = f(x + dx, y + dy) − f(x, y)
bei einer Anderung der Komponenten des Arguments um dx und dy ausgehendvon (x, y) = (1, 1) fur verschiedene Werte von dx und dy ergibt die folgendeTabelle:
(dx, dy) ∆f df
(0.01, 0.01) 0.0402 0.04(0.1, 0.01) 0.2301 0.22(1, 1) 6 4(10, 10) 240 40
2Das ’hyper’ im Wort Tangentialhyperebene bezieht sich auf den Umstand daß deren Dimen-sion nicht unbedingt 2 sein muß wie das Wort ’Ebene’ suggerieren mag.
94

10 Differentialrechnung
10.4 Hohere Ableitungen
Wir verallgemeinern nun den Begriff der hoheren Ableitung auf Funktionen mitmehreren Veranderlichen.
Definition 10.5 (Ableitungen hoherer Ordnung) Ist fur i ∈ 1, . . . , n dieerste partielle Ableitung ∂f
∂xieiner nach xi partiell differenzierbaren Funktion f :
X → Y mit X ⊆ Rn, Y ⊆ R fur ein j ∈ 1, . . . , n partiell differenzierbarnach xj, dann heißt die erste partielle Ableitung von ∂f
∂xinach xj zweite partielle
Ableitung (engl.: second-order partial derivative) von f nach xi und xj. DieseAbleitung wird bezeichnet mit
∂2f
∂xj∂xi
oder verkurzt fji bzw. fur i = j mit∂2f
∂x2i
.
Die Fortschreibung dieser Definition fuhrt zur partiellen Ableitung k-ter Ordnungmit k ∈ N, die mit
∂kf
∂xik . . . ∂xi1
fur i1, . . . , ik ∈ 1, . . . , n bezeichnet wird.
Beispiel 10.7: Sei f : R2 → R mit f(x, y) = x2y + xy3. Die ersten partiellenAbleitungen sind
∂f
∂x(x, y) = 2xy + y3 und
∂f
∂y(x, y) = x2 + 3xy2.
Dann sind∂2f
∂x2(x, y) = 2y und
∂2f
∂y2(x, y) = 6xy
und∂2f
∂x∂y(x, y) = 2x + 3y2 und
∂2f
∂y∂x(x, y) = 2x + 3y2.
In diesem Beispiel fallt auf, daß die beiden gemischten Ableitungen ∂2f∂x∂y
und ∂2f∂y∂x
ubereinstimmen. Diese Aussage gilt allgemein fur zweimal stetig differenzierbareFunktionen, so genannte C2-Funktionen.
Definition 10.6 (C2-Funktion) Existieren zu einer Funktion f : X → Y mitX ⊆ Rn, Y ⊆ R alle zweiten partiellen Ableitungen und sind diese Ableitungenstetig, so heißt f C2-Funktion.
95

10 Differentialrechnung
Satz 10.3 Sei f : X → Y mit X ⊆ Rn, Y ⊆ R eine C2-Funktion. Dann gilt furalle i, j ∈ 1, . . . , n und fur alle x ∈ X
∂2f
∂xi∂xj
(x) =∂2f
∂xj∂xi
(x).
Alle zweiten partiellen Ableitungen einer C2-Funktion werden zur sogenanntenHesse-Matrix, deren Definition nachfolgend angegeben ist, zusammengefasst. Wiedie zweite Ableitung bei Funktionen von R nach R enthalt die Hesse-Matrix aneiner Stelle x Informationen uber die lokalen Krummungseigenschaften wie z.B.Konkavitat oder Konvexitat einer Funktion an dieser Stelle.
Definition 10.7 (Hesse-Matrix) Sei f : X → Y mit X ⊆ Rn, Y ⊆ R einezweimal partiell differenzierbare Funktion. Dann heißt die Matrix
D2f(x) =
∂2f∂x2
1(x) ∂2f
∂x2∂x1(x) · · · ∂2f
∂xn∂x1(x)
∂2f∂x1∂x2
(x) ∂2f∂x2
2(x) · · · ∂2f
∂xn∂x2(x)
......
. . ....
∂2f∂x1∂xn
(x) ∂2f∂x2∂xn
(x) · · · ∂2f∂x2
n(x)
Hesse-Matrix (engl.: Hessian) von f an der Stelle x ∈ X.
Offensichtlich ist die Hesse-Matrix einer C2-Funktion nach Satz 10.3 symme-trisch.3
Beispiel 10.8:(i) Sei f : R2 → R mit f(x, y) = 3x2y − 5y3. Dann ist
D2f(x, y) =
(∂2f∂x2 (x, y) ∂2f
∂y∂x(x, y)
∂2f∂x∂y
(x, y) ∂2f∂y2 (x, y)
)=
(6y 6x6x −30y
).
(ii) Sei f : R3 → R mit f(x, y, z) = x2yz − y3z2. Dann ist
D2f(x, y, z)=
∂2f∂x2 (x, y, z) ∂2f
∂y∂x(x, y, z) ∂2f
∂z∂x(x, y, z)
∂2f∂x∂y
(x, y, z) ∂2f∂y2 (x, y, z) ∂2f
∂z∂y(x, y, z)
∂2f∂x∂z
(x, y, z) ∂2f∂y∂z
(x, y, z) ∂2f∂z2 (x, y, z)
=
2yz 2xz 2xy
2xz −6yz2 x2 − 6y2z2xy x2 − 6y2z −2y3
.
3Eine Matrix A = (aij)n×n mit n ∈ N heißt symmetrisch, falls aij = aji fur alle i, j ∈1, . . . , n.
96

10 Differentialrechnung
10.5 Eigenschaften von Funktionen und ihreAbleitungen
In diesem Abschnitt werden Zusammenhange zwischen den in den Abschnitten9.6 und 9.7 vorgestellten Monotonie-, Konkavitats- und Quasikonkavitatseigen-schaften von Funktionen und ihren ersten und zweiten Ableitungen behandelt.Der nachfolgend angegebene Satz beschreibt den Zusammenhang zwischen denMonotonieeigenschaften einer Funktion und ihren ersten partiellen Ableitungen.
Satz 10.4 Sei f : X → Y mit X ⊆ Rn, Y ⊆ R und f : (x1, . . . , xn) −→ f(x)eine C1-Funktion. Dann gilt:
i) f steigt genau dann monoton in xi, wenn fur alle x ∈ X gilt:
∂f
∂xi
(x) ≥ 0.
ii) f steigt streng monoton in xi, wenn fur alle x ∈ X gilt:
∂f
∂xi(x) > 0.
Ersetzt man in i) und ii) die beiden Relationszeichen ≥ und > durch ≤ bzw. <,so erhalt man die entsprechenden Aussagen fur monoton fallende Funktionen.
Man beachte, daß der Satz fur strenge Monotonie nur eine hinreichende Bedin-gung nennt, wahrend er fur (schwache) Monotonie eine notwendige und hinrei-chende Bedingung angibt.
Beispiel 10.9:(i) Die Funktion f : R2 → R mit f(x, y) = 3x+5y3 steigt wegen ∂f
∂x(x, y) = 3 >
0 fur alle (x, y) ∈ R2 streng monoton in x. Außerdem steigt f wegen ∂f∂y
(x, y) =
15y2 ≥ 0 fur alle (x, y) ∈ R2 monoton in y. f steigt sogar streng monoton in y.Dies kann aber nicht aus Satz 10.4 geschlossen werden, da wegen ∂f
∂y(0, 0) = 0 die
hinreichende Bedingung nicht erfullt ist.(ii) Die Funktion f : [0,∞)n → R mit
f(x) =n∏
i=1
xaii
und a1, . . . , an > 0 ist fur alle i = 1, . . . n monoton steigend in xi wegen
∂f
∂xi(x) = aix
ai−1i ·
n∏j=1j =i
xaj
j ≥ 0.
97

10 Differentialrechnung
Wahrend die ersten Ableitungen einer Funktion Auskunft uber deren Monoto-nieeigenschaften geben, stehen die zweiten Ableitungen in engem Zusammen-hang mit den Konvexitats- und Konkavitatseigenschaften der Funktion. Allge-mein kann aus den Vorzeichen der Determinanten geeignet gewahlter Teilmatri-zen der Hesse-Matrix einer Funktion auf deren Krummung geschlossen werden.Wir beschranken uns im Rahmen diese Skriptums auf die entsprechenden Zu-sammenhange fur Funktionen mit einer oder zwei reellen Veranderlichen mit denSatzen 10.5 bis 10.7 ohne Beweise. 4
Satz 10.5 Sei f : X → Y eine C2-Funktion, wobei X ⊆ R eine offene undkonvexe Menge reeller Zahlen ist und Y ⊆ R . Dann gilt:
i) f ist genau dann konvex, wenn fur alle x ∈ X gilt:
d2f
dx2(x) ≥ 0
ii) f ist streng konvex, wenn fur alle x ∈ X gilt:
d2f
dx2(x) > 0
Ersetzt man in i) und ii) die beiden Relationszeichen ≥ und > durch ≤ bzw. <,so erhalt man zwei analoge Aussagen fur konkave Funktionen.
Satz 10.6 Sei f : X → Y eine C2-Funktion, wobei X ⊆ R2 offen und konvex istund Y ⊆ R . Dann gilt:
i) f ist genau dann konvex, wenn fur alle x ∈ X gilt:
∂2f∂x2
1(x)≥ 0
∂2f∂x2
2(x)≥ 0
det (D2f(x))≥ 0
ii) f ist streng konvex, wenn fur alle x ∈ X gilt:
∂2f∂x2
1(x) > 0
det (D2f(x))> 0
4Fur weiterfuhrende Aussagen zu diesem Thema sei der interessierte Leser auf Sydsæter etal. (1999, S. 79ff) verwiesen.
98

10 Differentialrechnung
Satz 10.7 Sei f : X → Y eine C2-Funktion, wobei X ⊆ R2 offen und konvex istund Y ⊆ R . Dann gilt:
i) f ist genau dann konkav, wenn fur alle x ∈ X gilt:
∂2f∂x2
1(x)≤ 0
∂2f∂x2
2(x)≤ 0
det (D2f(x))≥ 0
ii) f ist streng konkav, wenn fur alle x ∈ X gilt:
∂2f∂x2
1(x) < 0
det (D2f(x))> 0
Wiederum beachte man, daß diese Satze fur strenge Konvexitat und Konkavitatnur hinreichende Bedingungen angeben, wahrend sie fur (schwache) Konvexitatund Konkavitat notwendige und hinreichende Bedingungen angeben.
Beispiel 10.10:(i) Die Funktion f : R → R mit f(x) = x4 ist wegen d2f
dx2 (x) = 12x2 ≥ 0fur alle x ∈ R nach Satz 10.5 i) konvex. Ob f streng konvex ist, kann mit Satz10.5 hingegen nicht entschieden werden, da die hinreichende Bedingung wegend2fdx2 (0) = 0 nicht erfullt ist.
(ii) Die Funktion f : R2 → R mit f(x, y) = x2 + y2 + xy ist wegen ∂2f∂x2 (x, y) =
2 > 0 und
det(D2f(x, y)
)= det
(2 11 2
)= 3 > 0
fur alle (x, y) ∈ R2 nach Satz 10.6 ii) streng konvex.
(iii) Die Funktion f : R2 → R mit f(x, y) = −x− 3y2 ist wegen ∂2f∂x2 (x, y) = 0 ≤
0, ∂2f∂y2 (x, y) = −6 ≤ 0 und
det(D2f(x, y)
)= det
(0 00 −6
)= 0 ≥ 0
fur alle (x, y) ∈ R2 nach Satz 10.7 i) konkav. Ob f streng konkav ist, kann mitSatz 10.7 wegen det (D2f(x, y)) = 0 wieder nicht entschieden werden.
Der folgende Satz 10.8 gibt jeweils eine notwendige und eine hinreichende Bedin-gung fur die Quasikonkavitat einer Funktion mit zwei reellen Veranderlichen.
99

10 Differentialrechnung
Satz 10.8 Sei f : X → Y eine C2-Funktion, wobei X ⊆ R2 eine offene undkonvexe Menge reeller Zahlen ist und Y ⊆ R . Sei ferner
D(x) = 2∂f
∂x1
(x)∂f
∂x2
(x)∂2f
∂x1∂x2
(x) −(
∂f
∂x1
(x)
)2∂2f
∂x22
(x) −(
∂f
∂x2
(x)
)2∂2f
∂x21
(x)
Dann gilt:
i) Wenn f quasikonkav ist, gilt fur alle x ∈ X:
D(x)≥ 0
ii) f ist quasikonkav, wenn fur alle x ∈ X gilt:(∂f∂x1
(x))2
> 0
D(x) > 0
Beispiel 10.11: Die Funktion f : (0,∞)2 → R mit f(x, y) = x2y3 ist nach Satz10.8 ii) wegen (
∂f
∂x(x, y)
)2
=(2xy3
)2> 0
und
D(x, y)= 2 (2xy3 · 3x2y2 · 6xy2) − (2xy3)2 · 6x2y − (3x2y2)
2 · 2y3
=30x4y7
> 0
fur alle (x, y) ∈ (0,∞)2 quasikonkav.
10.6 Elastizitaten und deren okonomischeInterpretation
Der Begriff der Elastizitat, der seinen Ursrung den Wirtschaftswissenschaftenverdankt, baut unmittelbar auf den Begriff der Ableitung auf.
Definition 10.8 (Elastizitat) Sei f : X → Y mit X, Y ⊆ R eine differenzier-bare Funktion. Dann heißt fur ein x ∈ X mit f(x) = 0
ηf (x) =df
dx(x) · x
f(x)
Elastizitat von f an der Stelle x. Außerdem heißt f unelastisch an der Stelle xfalls |ηf(x)| < 1 elastisch falls |ηf (x)| > 1.
100

10 Differentialrechnung
Wahrend die Ableitung dfdx
(x) der Funktion f ein Maß fur die absolute Verande-rung des Funktionswerts von f im Verhaltnis zu einer infinitesimal kleinen abso-luten Veranderung des Argument an einer Stelle x ist, ist ihre Elastizitat ηf (x)ein Maß fur das Verhaltnis der relativen Veranderungen von Funktionswert undArgument. Die folgende Uberlegung verdeutlicht diese Interpretation der Elasti-zitat. Sei f : X → Y mit X, Y ⊆ R eine differenzierbare Funktion und x ∈ X.Dann gibt der Quotient
f(x+∆x)−f(x)f(x)
∆xx
das Verhaltnis der relativen Veranderung des Funktionswerts f(x+∆x)−f(x)f(x)
und
der relativen Veranderung des Arguments ∆xx
an der Stelle x bei einer absolutenVeranderung des Arguments um ∆x = 0 an. Fur ∆x −→ 0 konvergiert dieserQuotient wegen
f(x+∆x)−f(x)f(x)
∆xx
=f(x + ∆x) − f(x)
∆x· x
f(x)
wegen der Differenzierbarkeit von f gegen
df
dx(x) · x
f(x).
Elastizitaten unterscheiden sich von Ableitungen dadurch, daß sie keine Einheithaben. Sie machen also den Grad der der Abhangigkeit des Funktionswerts vomArgument fur unterschiedlichste Funktionalzusammenhange vergleichbar.
Beispiel 10.12: Sei die Nachfrage nach einem Gut A in einem Markt in Abhangig-keit vom Preis des Gutes pA ∈ R beschrieben durch die NachfragefunktionxA : R → R mit
xA(pA) = 30 · 106 − 30pA.
Dann ist die Preiselastizitat der Nachfrage an einer Stelle pA = 106
ηxA(pA) = −30 · pA
30 · 106 − 30pA.
Betragt der aktuelle Marktpreis fur Gut A pA = 105, dann ist die Preiselastizitatgegeben durch
ηxA(pA) = −1
9.
Sei außerdem die Nachfrage nach einem Gut B in diesem Markt in Abhangigkeitvom Preis des Gutes pB ∈ R beschrieben durch die Nachfragefunktion xB : R → R
mitxB(pB) = 30 · 106 − 106pB.
101

10 Differentialrechnung
Dann ist die Preiselastizitat der Nachfrage an einer Stelle pB = 30
ηxB(pB) = −106 · pB
30 · 106 − 106pB.
Betragt der aktuelle Marktpreis fur Gut B pB = 10−1, dann ist die Preiselastizitatgegeben durch
ηxB(pB) = − 1
299.
Wegen
|ηxA(pA)| =
1
9>
1
299= |ηxB
(pB)|ist es sinnvoll zu sagen, die Nachfrage nach Gut A sei preissensitiver als die nachGut B, auch wenn der Vergleich der Ableitungen∣∣∣∣dxA
dpA(pA)
∣∣∣∣ = 30 < 106 =
∣∣∣∣dxB
dpB(pB)
∣∣∣∣und damit des Verhaltnisses der absoluten Veranderungen umgekehrt ist.
Die Ubertragung von Definition 10.8 auf reellwertige Funktionen mit mehrerenVeranderlichen mit Hilfe partieller Ableitungen fuhrt zum Begriff der partiellenElastizitat, die entsprechend interpretiert wird.
Definition 10.9 (Partielle Elastizitat) Sei f : X → Y mit X ⊆ Rn, Y ⊆ R
eine in xi partiell differenzierbare Funktion. Dann heißt
ηf,xi(x) =
∂f
∂xi
(x) · xi
f(x)
fur ein x ∈ X mit f(x) = 0 partielle Elastizitat von f an der Stelle x bezuglichxi.
Beispiel 10.13: Sei die Nachfrage eines Haushaltes nach einem Gut gegebendurch die Funktion
x(p, Y, q1, . . . , qn),
wobei p ≥ 0 der Preis des Gutes sei, Y ≥ 0 das Haushaltseinkommen undq1, . . . , qn die Preise anderer fur den Haushalt relevanter Guter. ηx,p heißt Prei-selastizitat, ηx,Y Einkommenselastizitat und ηx,qi
fur i = 1, . . . , n Kreuzpreisela-stizitat der Nachfrage.
Ihre Anwendung finden diese Elastizitaten unter anderem bei der Charakterisie-rung okonomischer Phanomene, die im Zusammenhang mit dem Nachfragever-halten von Haushalten zu beobachten sind. Die nachfolgende Tabelle gibt hierzueine Ubersicht:
102

10 Differentialrechnung
Elastizitat Vorzeichen Phanomen
ηx,p < 0 normales GutPreiselastizitat
ηx,p > 0 Giffen-Gut, Veblen-Effektηx,Y < 0 inferiores Gut
Einkommenselastizitat ηx,Y ∈ [0, 1] normales Gutηx,Y > 1 superiores Gutηx,qi
< 0 KomplementaritatKreuzpreiselastizitat
ηx,qi> 0 Substitution
10.7 Der Satz uber implizite Funktionen
Der in diesem Abschnitt behandelte Satz uber implizite Funktionen ist nicht nurinnerhalb der Mathematik sehr bedeutsam. Er kommt auch innerhalb der Wirt-schaftswissenschaften oft vor, insbesondere im Zusammenhang mit komparati-ver Statik von Gleichgewichtsmodellen, also bei der Frage, wie eine gefundeneLosung zu einem Optimirungsproblem von den das Problem charakterisierendenParametern abhangt (in der Makrotheorie z.B. im so genannten IS-LM-Modell).5
Im Rahmen dieses Skriptums wird nur die einfachste zweidimensionale Variantebehandelt. Schon ganz am Anfang des typischen Curriculums des Wirtschafts-wissenschaftlers, namlich bei der Bestimmung der Steigung einer Isohohenlinie,tritt das folgende Problem auf.
Ein Zusammenhang zwischen zwei Großen x und y sei gegeben in der Form
F (x, y) = c
mit F : X −→ R, X ⊆ R2 und c ∈ R. Wir interessieren uns nun fur folgendeFragen.
1.) Definiert F (x, y) = c implizit eine Funktion φ : D −→ R mit geeignetgewahltem Definitionsbereich D ⊆ R, so daß fur alle x ∈ D
F (x, φ(x)) = c
gilt?
2.) Kann eine Aussage uber die Ableitung der impliziten Funktion φ getroffenwerden, falls sie existiert?
5Eine anwendungsbezogene Darstellung der allgemeineren Variante findet sich etwa bei Chiang(1984, S. 210ff) oder bei Sydsæter et al. (1999, S. 35).
103

10 Differentialrechnung
Beispiel 10.14:(i) Gegeben sei
F (x, y) = x2 − 5y = c = 10.
Auflosen dieser Gleichung nach y ergibt y = x2
5− 2. Dann gilt F (x, x2
5− 2) =
x2−5(x2
5−2) = 10, also existiert eine Funktion φ(x) = x2
5−2 mit der geforderten
Eigenschaft. Ihr Definitionsbereich ist D = R und ihre Ableitung dφ(x)dx
= 25x.
(ii) Gegeben seiF (x, y) = x2 + y2 = c = 1.
Auflosung dieser Gleichung nach y ergibt offenbar keine Funktion. Es gilt
y = ±√
1 − x2 mit x ∈ [−1, 1].
Das heißt, (i) nicht zu jedem x existiert ein y mit F (x, y) = x2 + y2 = 1 und (ii)zu einigen x existiert mehr als ein y mit F (x, y) = x2 + y2 = 1.
Wir stellen uns nun die Frage, ob man trotzdem sinnvolle Antworten auf die obengestellten Fragen geben kann. Dazu wollen wir eine lokale Betrachtung anstellen.Sei Bε(x, y) eine ε-Umgebung um den Punkt (x, y) mit F (x, y) = c. Wir stellenerneut die nun lokale Frage, ob Gleichung F (x, y) = c wenigstens innerhalb dieserε-Umgebung (fur hinreichend kleines ε > 0) eine Funktion mit der gefordertenEigenschaft eindeutig definiert.
Dazu betrachte in Beispiel 10.14 (ii) ε-Umgebungen um die Punkte A =(
1√2, 1√
2
)und B = (1, 0). In einer hinreichend kleinen ε-Umgebung um den Punkt A defi-niert die Gleichung x2 + y2 = 1 offenbar eine Funktion φ(x) mit der gefordertenEigenschaft. Sie lautet φ(x) =
√1 − x2. Um den Punkt B dagegen existiert auch
in einer beliebig kleinen ε-Umgebung keine eindeutige Funktion mit der geforder-ten Eigenschaft. Die Frage, unter welchen Bedingungen die Gleichung F (x, y) = cum einen Punkt (x, y) mit F (x, y) = c innerhalb einer hinreichend kleinen ε-Umgebung Bε(x, y) eine Funktion φ mit F (x, φ(x)) = c fur alle (x, y) ∈ Bε(x, y)definiert, beantwortet allgemein der nachfolgend angegebene Satz.
Satz 10.9 (Satz uber implizite Funktionen) Gegeben sei eine C1-FunktionF : X −→ R mit X ⊆ R2. Sei (x, y) innerer Punkt von X mit F (x, y) = c undc ∈ R. Dann definiert die Gleichung F (x, y) = c in einer hinreichend kleinen ε-Umgebung Bε(x, y) um (x, y) eine Funktion φ mit F (x, φ(x)) = c fur alle (x, y) ∈Bε(x, y), wenn gilt
∂F (x, y)
∂y= 0.
Die Ableitung von φ fur (x, y) ∈ Bε(x, y) lautet dann
φ′(x) =dφ(x)
dx= −
∂F (x,y)∂x
∂F (x,y)∂y
.
104

10 Differentialrechnung
Der Satz gibt also mit ∂F (x,y)∂y
= 0 eine Bedingung fur die Existenz einer Funktion
φ mit F (x, φ(x)) = c fur alle x nahe x. Ihre Ableitung ergibt sich direkt aus derKettenregel
dF (x,φ(x))dx
= ∂F (x,φ(x))∂x
· 1 + ∂F (x,φ(x))∂y
· dφ(x)dx
= 0
⇒ dφ(x)dx
=−∂F (x,φ(x))
∂x∂F (x,φ(x))
∂y
= −∂F (x,y)
∂x∂F (x,y)
∂y
.
Beispiel 10.15: Gegeben sei F (x, y) = y2 − x3 − x2 = 0. Daraus ergibt sichy2 = x3 +x2 = x2(x+1), also y = ±√x2(x + 1) = ±|x|√x + 1 mit x ≥ −1. EineFunktion φ wird offenbar nicht definiert um die beiden Punkte (0, 0) und (−1, 0).In der Tat sind diese auch die einzigen Punkte mit F (x, y) = 0 und
∂F (x, y)
∂y= 2y = 0.
105

11 Optimierung von Funktioneneiner Veranderlichen
In diesem Kapitel werden die bis hier behandelten Grundlagen der Analysis ge-nutzt, um Methoden aus der Optimierungstheorie fur eindimensionale Entschei-dungsmengen einzufuhren. Die zentrale Problemstellung der Optimierung bestehtdarin, den Wert einer Funktion durch die geeignete Wahl ihres Arguments zu ma-ximieren oder zu minimieren. Kann das Argument aus dem Definitionsbereich derFunktion beliebig gewahlt werden, so spricht man von unbeschrankter Optimie-rung oder auch der Optimierung ohne Nebenbedingungen; falls dagegen das Ar-gument zusatzliche Bedingungen erfullen muß, so spricht man von beschrankterOptimierung oder auch Optimierung unter Nebenbedingungen.
Insbesondere die beschrankte Optimierung steht in sehr enger Beziehung zu zen-tralen Fragestellungen der Wirtschaftswissenschaften, insbesondere im Zusam-menhang der bestmoglichen Verwendung knapper Ressourcen.
11.1 Lokale und globale Extrema
Wichtigstes Grundkonzept der Optimierungstheorie sind Extremwerte von Funk-tionen, also Maxima und Minima. Wir unterscheiden zwischen lokalen und glo-balen Extremwerten. Die Formulierung lokal bezieht sich auf die unmittelbareNachbarschaft (genugend kleine ε-Kugel) um den Extremwert, wahrend globalsich auf eine in Frage kommende oder betrachtete Zahlenmenge bezieht. Durchdie in der folgenden Definition vorgenommene Prazisierung kann ein lokales alsein relatives (relativ zur Nachbarschaft) Extremum aufgefaßt werden und einglobales als ein absolutes.
Definition 11.1 (Lokale und globale Extrema) Sei f : R −→ R. Das Ele-ment x ∈ A ⊆ Def(f) heißt lokales Maximum (Minimum) auf A genau dannwenn
∃ε > 0 : ∀x ∈ Bε = x ||x − x| ≤ ε ∩ A gilt: f(x) ≤ (≥)f (x) .
x ∈ A ⊆ Def(f) heißt dagegen globales Maximum (Minimum) auf A genau dannwenn
∀x ∈ A gilt: f(x) ≤ (≥)f (x) .
106

11 Optimierung von Funktionen einer Veranderlichen
insert picture here
Im Bild sind a und c lokale Maxima, b lokales Minimum und c globales Maximum,wahrend kein globales Minimum existiert.
Fur differenzierbare Funktionen stehen erste und zweite Ableitung in engem Zu-sammenhang mit der Extremwert
Satz 11.1 (Notwendige und hinreichende Bedingungen fur lokale Extremwerte)Sei f : R −→ R eine C2-Funktion mit Def(f) = R. Dann gilt:
1.) Falls x lokales Maximum ist, gilt
Df (x) = 0 und D2f (x) ≤ 0.
2.) Falls x lokales Minimum ist, gilt
Df (x) = 0 und D2f (x) ≥ 0.
3.) Falls
Df (x) = 0 und D2f (x) < 0
ist, dann ist x lokales Maximum.
4.) Falls
Df (x) = 0 und D2f (x) > 0
ist, dann ist x lokales Minimum.
Man beachte die feinen Unterschiede zwischen den notwendigen und hinreichen-den Bedingungen in den schwachen und starken Ungleichheitszeichen. Darausergibt sich ein einfaches Rezept fur den nach einem globalen Maximum suchen-den Protagonisten.
1.) Zunachst bestimme man diejenigen Punkte x mit der Eigenschaft, daß derenerste Ableitung gleich null ist, also Df (x) = 0.
2.) Unter diesen bestimme man diejenigen, fur die zusatzlich gilt D2f (x) <0. Nach Satz 11.1 ist sichergestellt, daß alle Punkte die beiden Kriteriengenugen lokale Maxima sind.
3.) Man bestimme deren Funktionswerte und wahle denjenigen (oder falls esmehr als einen gibt, diejenigen) mit dem hochsten Funktionswert aus.
107

11 Optimierung von Funktionen einer Veranderlichen
4.) Achtung jetzt sind wir noch nicht fertig, denn es kann noch passieren, daßdie Funktion f am Rand des Definitionsbereiches also fur x → ∞ oderx → −∞ nach ∞ strebt und daher kein globales Maximum existiert. LetzterSchritt ist also die Untersuchung des Randverhaltens.
Beispiel 11.1: Sei f(x) = −x4 + 2x2 + 4. Dann ist Df(x) = −4x3 + 4x undD2f(x) = −12x2 + 4. Erster Schritt: Erste Ableitung gleich null ergibt x1 =0, x2 = −1 und x3 = 1. Zweiter Schritt: Zweite Ableitung strikt negativ gilt furx2 und x3 aber nicht fur x1. Dritter Schritt: Da f(x2) = f(x3) ist, sind sowohlx2 als auch x3 mogliche Kandidaten fur globale Maxima. Vierter Schritt: Fur dasRandverhalten gilt
limx→∞
f(x) = limx→∞
x2(−x2 + 2) + 4 = −∞
und
limx→∞
f(x) = limx→−∞
x2(−x2 + 2) + 4 = −∞.
Eine Analyse der (strengen) Monotoniebereiche Mon++(f) = x | Df(x) > 0und Mon−−(f) = x | Df(x) < 0 ist eine alternative Methode zur Bestimmungder lokalen Extrema, die gleich die Analyse des Randverhaltens mit einschließt.
11.2 Optimierung mit Nebenbedingungen
Wir betrachten in den folgenden beiden Abschnitten stets Optimierungsproblemeder Form
maxx∈A
f(x),
wobei
A = [a,∞) oder A = (−∞, b] oder A = [a, b] mit a, b ∈ R.
Das heißt, der zulassige Bereich A, uber dem maximiert wird, ist ein abgeschlos-senes Intervall. In diesem Zusammenhang sei daran erinnert, daß z.B. [a,∞) eineabgeschlossene aber nicht kompakte da nicht beschrankte Teilmenge der reellenZahlen ist.
Beispiel 11.2:(i) insert picture(ii) insert picture
108

11 Optimierung von Funktionen einer Veranderlichen
Wir erkennen am zweiten Beispiel, daß im Gegensatz zur Optimierung ohne Ne-benbedingungen Df(x) = 0 keine notwendige Bedingung fur eine Losung desOptimierungsproblems maxx∈A f(x) ist. Offenbar braucht diese Bedingung ersterOrdnung genau dann nicht erfullt zu sein, wenn eine Losung x am Rand ∂A desIntervalls A liegt, also x = a oder x = b ist.
Satz 11.2 Sei f : A −→ R zweimal differenzierbar und konkav auf seinem Defi-nitionsbereich Def(f) = A, also D2f(x) ≤ 0 ∀x ∈ A. Dann gilt: Df(x) = 0 ⇒ xist globales Maximum auf A.
Df(x) = 0 ist also hinreichend dafur, daß x das Optimierungsproblem maxx∈A f(x)lost, falls f konkav auf A ist.
Beispiel 11.3: Sei f(x) = x3 −6x2 +7, A = [−5, 1], B = [−1, 3] und C = [3,∞].Dann ist Df(x) = 3x2 − 12x und D2f(x) = 6x− 12, also D2f(x) ≤ 0 fur x ∈ A.Aus Satz 11.2 folgt also, daß x = 0 das Maximierungsproblem
maxx∈A
f(x)
lost. Man beachte, daß Satz 11.2 keine notwendige Bedingung angibt, denn x = 0lost maxx∈B f(x), obwohl f nicht konkav auf B ist. Das Maximierungsproblemmaxx∈C f(x) besitzt keine Losung, wahrend auf das Minimierungsproblem
minx∈C
f(x)
wieder Satz 11.2 anwendbar ist durch die Umformung in das entsprechende Ma-ximierungsproblem maxx∈C −f(x). Da Df(4) = 0 und D2f(x) ≥ 0 fur x ∈ Clost x = 4 das Minimierungsproblem minx∈C f(x).
Beispiel 11.2 lehrt uns, daß es in der Optimierungstheorie genugt, Maximierungs-probleme zu studieren, da Minimierungsprobleme durch Umkehrung des Vor-zeichens der Zielfunktion stets in analoge Maximierungsprobleme umgewandeltwerden konnen.
11.3 Lagrangefunktion und Kuhn-TuckerBedingungen
Beispiel 11.2 zeigt, daß Satz 11.2 nicht befriedigt, denn selbst fur konkave Funktio-nen ist offenbar die Bedingung erster Ordnung Df(x) = 0 nicht notwendig fur dieLosung eines Problems vom Typ maxx∈A f(x). Die inzwischen 250 Jahre alte Idee
109

11 Optimierung von Funktionen einer Veranderlichen
des 18-jahrigen autodidaktischen Joseph-Louis Lagrange (1736-1813) war es,stattdessen eine andere Funktion einer hoheren Dimensionalitat zu definieren, de-ren Ableitung stets 0 ist fur die Losung des betrachteten Optimierungsproblems.1
insert picture
Sei fur den Moment A = (−∞, b]. Wir betrachten nun das Optimierungsproblemmaxx∈A f(x), das wir haufig auch schreiben als
maxx
f(x) u.d.N. b − x ≥ 0,
wobei u.d.N. die Abkurzung fur unter der Nebenbedingung ist.
Definition 11.2 Die Funktion
L(x, λ) = f(x) + λ(b − x)
heißt Lagrangefunktion zum Problem
maxx
f(x) u.d.N. b − x ≥ 0.
Die Variable λ heißt die zur Nebenbedingung b−x ≥ 0 gehorige Lagrangevariableoder Lagrangemultiplikator.
Die Lagrangevariable λ wird so bestimmt, daß fur eine Losung x des Optimie-rungsproblems stets ∂
∂xL(x, λ) = 0 gilt.
Definition 11.3 (Kuhn-Tucker Bedingungen) Die Bedingungen
(1) ∂∂x
L(x, λ) = 0(2) b − x ≥ 0(3) λ ≥ 0(4) λ(b − x) = 0
heißen Kuhn-Tucker Bedingungen (KT) zum Optimierungsproblem
maxx
f(x) u.d.N. b − x ≥ 0.
Falls x die Kuhn-Tucker Bedingungen erfullt, werden wir abkurzend sagen, xerfullt KT.
1Diese Methode des jungen italienischen Mathematikers wurde von seinem beruhmten Zeitge-nossen Leonard Euler als so bedeutsam eingestuft, daß Lagrange auf dessen Empfehlungkurz darauf als 19-jahriger zum Professor an der Universitat Turin ernannt wurde. Spatersoll Lagrange einmal geaußert haben ’Wenn ich reich gewesen ware, hatte ich mich wahr-scheinlich nicht der Mathematik gewidmet’.
110

11 Optimierung von Funktionen einer Veranderlichen
2 Falle: insert picture
Die Mathematiker Harold Kuhn und Albert Tucker haben ca. 200 Jahrespater die Idee von Lagrange verallgemeinert und notwendige und hinreichendeBedingungen fur die Losung von Optimierungsproblemen mit Nebenbedingungenin Form von Ungleichungen formuliert.2 Da rationales okonomisches Verhaltenmeistens auf genau diese Art von Problem reduzierbar ist, spielen diese Bedingun-gen ein zentrale Rolle fur Wirtschaftswissenschaftler. Bemerkenswerterweise sindvereinfachte und dadurch falsche Versionen dieser fur Wirtschaftswissenschaftlerso zentralen Theorie hartnackig bis heute Bestandteil des ublichen okonomischenCurriculums und der entsprechenden Literatur. In diesem Abschnitt werden die-se Bedingungen fur Funktionen einer Veranderlichen studiert. Da dies eine guteVorbereitung fur die allgemeine Formulierung darstellt, behandeln wir hier deneindimensionalen Fall aus didaktischen Grunden getrennt von der allgemeinerenmehrdimensionalen Formulierung.3
Satz 11.3 (Notwendige Bedingungen) Sei x∗ eine Losung des Optimierungs-problems
maxx
f(x) u.d.N. b − x ≥ 0.
Dann existiert ein λ∗, so daß (x∗, λ∗) die KT
(1) ∂∂x
L(x, λ) = 0(2) b − x ≥ 0(3) λ ≥ 0(4) λ(b − x) = 0
erfullt.
Die Umkehrung benotigt wie im Fall ohne Nebenbedingungen mehr Vorausset-zungen. Das folgende Bild zeigt, daß auch ein lokales Minimum die KT erfullenkann.
insert picture
2Man beachte, daß Nebenbedingungen in Form von Gleichungen stets durch die doppel-te Anzahl von Nebenbedingungen in Form von Ungleichungen ersetzbar ist. Z.B. giltg(x) = 0 ⇔ g(x) ≥ 0 ∧ g(x) ≤ 0. Da umgekehrt Ungleichungsnebenbedingungen nichtdurch Gleichungen reprasentierbar sind, ist die Formulierung auf Basis von Ungleichungenallgemeiner.
3Es ist haufig nicht schwierig, oder sogar einfacher, im eindimensionalen Fall Losungen zubestimmen, ohne auf KT zuruckzugreifen. Da der Rand des Optimierungsbereiches A nuraus hochstens zwei Elementen besteht, ist durch Bestimmung der lokalen Maxima in A undder Funktionswerte an den Randern ein direkter Vergleich sehr einfach.
111

11 Optimierung von Funktionen einer Veranderlichen
Satz 11.4 (Hinreichende Bedingungen) Sei f konkav auf A = (−∞, b] und(x∗, λ∗) erfulle die KT
(1) ∂∂x
L(x, λ) = 0(2) b − x ≥ 0(3) λ ≥ 0(4) λ(b − x) = 0.
Dann lost x∗ das Optimierungsproblem
maxx
f(x) u.d.N. b − x ≥ 0.
Statt der 4.) KT Bedingung λ(b − x∗) = 0 kann man auch schreiben L(x∗, λ∗) =f(x∗). Analoge Aussagen zu den Satzen 11.3 und 11.4 gelten offenbar fur A =[a,∞) oder A = [a, b]. Die Lagrangefunktion fur A = [a,∞) ist
L(x, λ) = f(x) + λ(x − a)
und die KT sind
(1) ∂∂x
L(x, λ) = 0(2) x − a ≥ 0(3) λ ≥ 0(4) λ(x − a) = 0.
Fur A = [a, b] ist die Lagrangefunktion
L(x, λ1, λ2) = f(x) + λ1(b − x) + λ2(x − a)
und es mussen zwei Ungleichungen erfullt sein. Die Zahl der KT erhoht sichentsprechend:
(1) ∂∂x
L(x, λ1, λ2) = 0(2) b − x ≥ 0 und x − a ≥ 0(3) λ1 ≥ 0 und λ2 ≥ 0(4) λ1(b − x) = 0 und λ2(x − a) = 0.
Beispiel 11.4: Betrachte das Optimierungsproblem
maxx
f(x) u.d.N. b − x ≥ 0
fur f(x) = 2 − x2.(i) Sei zunachst b = 1. Die Lagrangefunktion ist dann
L(x, λ) = 2 − x2 + λ(1 − x)
112

11 Optimierung von Funktionen einer Veranderlichen
und die KT sind
(1) ∂∂x
L(x, λ) = −2x − λ = 0(2) b − x = 1 − x ≥ 0(3) λ ≥ 0(4) λ(b − x) = λ(1 − x) = 0.
Da f konkav ist, lost wegen Satz 11.4 eine Losung x∗ der KT auch das Opti-mierungsproblem. Betrachte dazu zwei Falle: (i) λ > 0 ⇒ x = 1 fuhrt zu einemWiderspruch, denn es muß gelten −2 − 1 − λ = 0. Daher kann nur gelten (ii)λ = 0 ⇒ x = 0. Losung des Optimierungsproblems ist also x∗ = 0.(ii) Sei nun b = −1. Also
L(x, λ) = 2 − x2 + λ(−1 − x),
und die KT
(1) −2x − λ = 0(2) 1 − x ≥ 0(3) λ ≥ 0(4) λ(−1 − x) = 0.
Hier fuhrt (ii) λ = 0 zum Widerspruch denn dies impliziert x = 0 ⇒ −1 ≥0. Umgekehrt ist (i) λ > 0 ⇒ x = −1 ⇒ −2 · (−1) = λ = 2. Losung desOptimierungsproblems ist also x∗ = −1.(iii) Betrachte zuletzt b = 0. Also
L(x, λ) = 2 − x2 − λx,
und die KT sind
(1) −2x − λ = 0(2) −x ≥ 0(3) λ ≥ 0(4) λx = 0.
(i) λ > 0 ⇒ x = 0 ⇒ λ = 0 Widerspruch, also (ii) λ = 0 ⇒ x = 0. Losung desOptimierungsproblems ist also x∗ = 0.
Fur das Verstandnis allgemeiner mehrdimensionaler Optimierungstheorie ist eshilfreich, sich folgende Zusammenfassung zu globalen Maxima von Funktioneneiner Variablen einzupragen.
1.) Ohne Nebenbedingungen
x∗ lost maxx∈R
f(x)f ist konkav
Df(x∗) = 0.
113

11 Optimierung von Funktionen einer Veranderlichen
2.) Mit Nebenbedingungen
x∗ lost maxx∈A
f(x)f ist konkav
(x∗, λ∗) lost KT.
Offenbar ist 1.) in 2.) enthalten. Statt Konkavitat genugt auch Quasikonkavitatals schwachere Annahme fur die hinreichenden Bedingungen.
114

12 Optimierungstheorie
In diesem Kapitel wird die im vorherigen Kapitel eingefuhrte Methode verall-gemeinert auf Zielfunktionen mehrerer Veranderlicher. Sehr viele reale Entschei-dungsprobleme sind reduzierbar auf die Gestalt
maxx∈A
f(x),
wobei A die Menge der zulassigen Entscheidungsalternativen ist, und f eine dieWunsche oder die Praferenzen des Protagonisten reprasentierende Zielfunktion.In der mathematischen Entscheidungstheorie, die nicht Gegenstand der Vorle-sung und dieses Skriptums ist, wird genau analysiert, welche Auswahlentschei-dungen konsistent sind mit der Maximierung einer Zielfunktion. Grob vereinfachtlasst sich sagen, daß die Existenz einer Zielfunktion aus nur wenigen Konsistenz-annahmen hervorgeht, die haufig mit zielgerichteter rationaler Verhaltensweiseidentifiziert werden und das methodische Ruckgrad der modernen okonomischenAnalyse darstellt. Obwohl Experimentatoren und Verhaltensokonomen sich injungerer Zeit zunehmend fur Abweichungen von diesem Paradigma des homo oe-conomicus interessieren, wird die Standard-Entscheidungstheorie noch fur langeZeit die wichtigste Methode bleiben fur die Analyse okonomischer Phanomene.Diese Methode wird allein deshalb vermutlich nie aus dem Wergzeugkasten desOkonomen verschwinden, da sie fur normative Theorie, also Handlungsempfeh-lungen an Akteure, gebraucht wird, auch wenn wir mit deskriptiven Methodenhaufig beobachten, daß reale Menschen von rationalem Verhalten abweichen.
12.1 Optimierung ohne Nebenbedingungen
Lokale und globale Extremwerte fur Funktionen mehrerer Veranderlicher sind aufdie gleiche Art und Weise definiert wie im vorhergehenden Kapitel.
Definition 12.1 (Lokale und globale Extrema) Sei f : Rn −→ R. Das Ele-ment x ∈ A ⊆ Def(f) heißt lokales Maximum (Minimum) auf A genau dannwenn
∃ε > 0 : ∀x ∈ Bε = x ||x − x| ≤ ε ∩ A gilt: f(x) ≤ (≥)f (x) .
115

12 Optimierungstheorie
x ∈ A ⊆ Def(f) heißt dagegen globales Maximum (Minimum) auf A genau dannwenn
∀x ∈ A gilt: f(x) ≤ (≥)f (x) .
Optimierung ohne Nebenbedingungen, bedeute im Folgenden, daß die Menge derHandlungsalternativen A nicht eingeschrankt ist, also A = Rn. Wie zuvor stehenfur differenzierbare Funktionen erste und zweite Ableitung, also hier der Gradientund die Hesse-Matrix, in engem Zusammenhang mit der Extremwerteigenschaft.In einem lokalen (und daher auch globalen) Optimum x ∈ Rn ohne Nebenbe-dingungen muß die Ableitung der Funktion in allen Richtungen gleich 0 sein,also ∇f (x) = 0 (wobei hier mit 0 der Nullvektor im Rn gemeint ist), da sonstder Funktionswert bereits in Richtung des Gradienten erhoht werden konnte. Diefolgenden beiden Satze folgen ebenfalls dem Aufbau des vorhergehenden Kapitels.
Satz 12.1 (Notw. und hinr. Bedingungen fur lokale Extremwerte) Sei
f : Rn −→ R
eine C2-Funktion mit Def(f) = Rn. Dann gilt:
1.) Falls x lokales Maximum ist, gilt
∇f (x) = 0 und Hf (x) ist negativ semidefinit.
2.) Falls x lokales Minimum ist, gilt
∇f (x) = 0 und Hf (x) ist positiv semidefinit.
3.) Falls∇f (x) = 0 und Hf (x) negativ definit
ist, dann ist x lokales Maximum.
4.) Falls∇f (x) = 0 und Hf (x) positiv definit
ist, dann ist x lokales Minimum.
Satz 12.2 (Hinreichende Bedingung fur globalen Extremwert) Sei
f : Rn −→ R
zweimal differenzierbar und konkav. Dann gilt: ∇f(x) = 0 ⇔ x ist globales Ma-ximum.
116

12 Optimierungstheorie
Beispiel 12.1:(i) Sei f(x1, x2) = x2
1 + x22. Dann ist ∇f(x1, x2) = (2x1, 2x2) mit einziger Null-
stelle (x01, x
02) = (0, 0). Die Hesse-Matrix ist
Hf(x1, x2) =
(2 00 2
),
also ist f wegen Satz 10.6 streng konvex. Daher ist −f streng konkav und(x0
1, x02) = (0, 0) ist globales Minimum von f .
(ii) Sei f(x1, x2) = x21 − x2
2. Dann ist ∇f(x1, x2) = (2x1,−2x2) wieder miteinziger Nullstelle (x0
1, x02) = (0, 0). Die Hesse-Matrix ist
Hf(0, 0) = Hf(x1, x2) =
(2 00 −2
).
Da diese Hesse-Matrix indefinit ist, ist (0, 0) ein Sattelpunkt und es existiert keinglobales Maximum oder Minimum.(iii) Die Funktion f(x1, x2) = x3
1−3x22−6x1x2+4 hat den Gradienten ∇f(x1, x2) =
(3x21−6x2,−6x1−6x2) mit den Nullstellen (x0
1, x02) = (0, 0) und (x1
1, x12) = (−2, 2)
und die Hesse-Matrix
Hf(x1, x2) =
(6x1 6−6 −6
).
Also ist ∂2f∂x2
1(0, 0) = 0, ∂2f
∂x22(0, 0) = −6 und
det Hf(0, 0) = det
(0 6−6 −6
)= 36.
Wegen der Satze 10.6 und 10.7 ist Hf(0, 0) indefinit und daher (0, 0) kein lokaler
Extremwert. Weiter ist ∂2f∂x2
1(−2, 2) = −12, ∂2f
∂x22(−2, 2) = −6 und
det Hf(−2, 2) = det
( −12 6−6 −6
)= 108.
Wegen Satz 10.7 ist Hf(−2, 2) negativ definit und daher ist (−2, 2) lokales Ma-ximum (aber nicht globales, warum?).
12.2 Geometrische Losung vonOptimierungsproblemen
Seien f, g : R2 −→ R zwei Funktionen zweier Veranderlicher. Wir betrachten dasOptimierungsproblem
maxx
f(x) u.d.N. g(x) ≥ 0.
117

12 Optimierungstheorie
Das heißt, wir suchen ein globales Maximum von f auf der Menge
A =x ∈ R2|g(x) ≥ 0
.
Offenbar ist die Niveaulinie g−1(0) der Funktion g zum Niveau 0 die Begrenzungs-linie der Menge A. Um festzustellen, nach welcher Seite die Niveaulinie g−1(0)die Menge A begrenzt, betrachte den Gradienten ∇g(x). Fur ein x ∈ g−1(0) zeigt∇g(x) in die Menge A hinein.
insert picture here
Betrachte nun Niveaulinien f−1(y) von f , die durch die Menge A gehen, fur diealso f−1(y) ∩ A = ∅. Gesucht sind Niveaulinien mit moglichst hohem Niveau ydie gerade noch durch A gehen. ”Verschiebe” also Niveaulinie f−1(y) (verschiebendurch Veranderung von y) in Richtung von ∇f(x) fur x auf der Niveaulinie f−1(y)so weit wie moglich, so daß gerade noch ein nicht leerer Durchschnitt f−1(y) ∩A = ∅ bleibt. Der oder die verbleibenden Elemente dieser Durchschnittsmengef−1(y) ∩ A losen das betrachtete Optimierungsproblem
maxx
f(x) u.d.N. g(x) ≥ 0.
Entsprechend kann man verfahren, falls die Menge A der Entscheidungsalterna-tiven durch k > 1 Nebenbedingungen Xj = x ∈ R2|gj(x) ≥ 0 mit
A =
k⋂j=1
Xj
gegeben ist.
insert picture
Ein wichtiges Kriterium wird im Folgenden die Konvexitat der Menge A der Ent-scheidungsalternativen sein. In diesem Zusammenhang ist folgende hinreichendeBedingung hilfreich.
Satz 12.3 Seien gj : Rn −→ R konkave Funktionen fur j = 1, . . . , k. Sei ferner
A =⋂k
j=1 Xj mit Xj = x ∈ Rn|gj(x) ≥ 0. Dann ist A konvexe Menge.
Der Beweis folgt aus der Kombination der bereits bewiesenen Satze 8.1,9.4 und9.3.
12.3 Haufige Irrtumer
In diesem Abschnitt gehen wir einen ungewohnlichen didaktischen Weg. Wirnahern uns der allgemeinen Theorie durch eine Sequenz von gebrauchlichen Irrtumern,
118

12 Optimierungstheorie
denen nicht nur der unbefangene Optimierer sondern in unterschiedlichem Gradeauch eine nicht unerhebliche Zahl von Lehrbuchern unterliegen. Dazu kehren wirvorlaufig zum Fall n = 1 zuruck.
Betrachte eine differenzierbare Funktion f : R −→ R und das Optimierungspro-blem
maxx
f(x) u.d.N. g(x) ≥ 0.
Wir erinnern uns daß in den Abschnitten 11.2 und 11.3 die Nebenbedingung alslineare Funktion g(x) = b−x gegeben war. Diese Annahme wird nun aufgehoben.
Beispiel 12.2: Sei f(x) = −x und g(x) = (x − 1)3. Offenbar lost x = 1 dasOptimierungsproblem
maxx
f(x) u.d.N. g(x) ≥ 0.
Die erste der Kuhn-Tucker-Bedingungen lautet hier
∂
∂xL(x, λ) = −1 + λ3(x − 1)2 = 0.
Einsetzen von x = 1 zeigt, daß diese Bedingung offenbar nicht erfullt, also wedernotwendig noch hinreichend ist fur eine Losung.
Beispiel 12.3 lehrt uns, daß die bisherige Theorie im Falle nichtlinearer Neben-bedingungen bereits fur die Dimension n = 1 unvollstandig ist. Eine genauereBetrachtung ergibt, daß das Problem dieses Beispiels dadurch entsteht, daß furdie Losung x des Optimierungsproblems g′(x) = 0 und gleichzeitig f ′(x) = 0 ist.Falls dies der Fall ist, kann kein λ ∈ R existieren, so daß die erste der Kuhn-Tucker-Bedingungen ∂
∂xL(x, λ) = −f ′(x) + λg′(x) = 0 erfullt ist.
Ein moglicher Ausweg ware zu fordern, daß bei einer Randlosung, also im Fallg(x) = 0, zusatzlich gilt g′(x) = 0, damit KT notwendig ist. Die Verallgemeine-rung dieser zusatzlichen Forderung heißt, wie wir sehen werden, Beschrankungs-qualifikation.
Beispiel 12.3: Sei f(x) = x und g(x) = x2−1. Offenbar ist f linear, also konkav.Wir erkennen, daß x = −1 nicht das Optimierungsproblem
maxx
f(x) u.d.N. g(x) ≥ 0
lost, denn es gilt z.B. f(3) = 3 > −1 = f(−1). Jedoch erfullt (x, λ) = (−1, 12)
die KT (1) ∂∂x
L(−1, 12) = 1 − 1 = 0, (2) g(−1) = 1 − 1 ≥ 0, (3) 1
2≥ 0 und (4)
12g(−1) = 0.
119

12 Optimierungstheorie
Beispiel 12.3 lehrt uns, daß Konkavitat der Zielfunktion f und KT schon fur n = 1keine hinreichenden Bedingungen fur die Losung eines Optimierungsproblemssind, falls die Nebenbedingung nicht linear ist. Es ist nicht schwer zu erkennen,daß in diesem Fall die Ursache des Problems in der Nichtkonvexitat der Menge
A = x ∈ R|g(x) ≥ 0zu suchen ist, die im Beispiel 12.3 ein ”Loch” hat, d.h. nicht ein Intervall ist son-dern aus zwei (halboffenen) Intervallen besteht. Aus Satz 12.3, folgt, daß dieseSchwierigkeit entfallt, falls die Entscheidungsmenge durch konkave Funktionenbegrenzt wird. Wir werden sehen, daß diese zusatzliche Forderung zu hinreichen-den Bedingungen fuhrt. Insbesondere impliziert fur λ ≥ 0 die Konkavitat derZielfunktion und die Konkavitat der Nebenbedinung(en) die Konkavitat der La-grangefunktion L(x, λ).
12.4 Lagrangefunktion, Kuhn-Tucker Bedingungenund Beschrankungsqualifikation
Wir kommen zur allgemeinen Formulierung eines Optimierungsproblems mit mNebenbedingungen in Form von Ungleichungen. Zu jeder Nebenbedingung j =1 . . . , m gehort eine Lagrangevariable λj . Zur Unterscheidung von Zahlen undVektoren werden wir ab hier Vektoren stets mit unterstrichenen Variablen be-zeichnen, also z.B. bezeichne λ = (λ1, . . . , λm) den Vektor der m Lagrange-variablen. Betrachte m + 1 differenzierbare Funktionen f, gj : Rn −→ R mitx = (x1, . . . , xn) und das Optimierungsproblem
maxx
f(x) u.d.N. gj(x) ≥ 0 fur j = 1, . . . , m.
Definition 12.2 (Lagrange-Funktion und Kuhn-Tucker Bedingungen) DieFunktion
L(x, λ) = f(x) +
m∑j=1
λjgj(x)
heißt Lagrangefunktion zum Problem
maxx
f(x) u.d.N. gj(x) ≥ 0 fur j = 1, . . . , m.
Die Variablen λj heißen die zu den Nebenbedingungen gj(x) ≥ 0 gehorigen La-grangevariablen oder Lagrangemultiplikatoren. Die Bedingungen
(1) ∇f(x) +∑m
j=1 λj∇gj(x) = 0
(2) gj (x) ≥ 0 fur j = 1, . . . , m(3) λj ≥ 0 fur j = 1, . . . , m(4) λjgj (x) = 0 fur j = 1, . . . , m.
120

12 Optimierungstheorie
heißen Kuhn-Tucker Bedingungen (KT) zum Optimierungsproblem
maxx
f(x) u.d.N. gj(x) ≥ 0 fur j = 1, . . . , m.
Falls x∗ die Kuhn-Tucker Bedingungen erfullt, werden wir abkurzend sagen, x∗
erfullt KT.
Die im vorhergehenden Abschnitt bereits erwahnte Beschrankungsqualifikationverlangte fur eine Losung des Optimierungsproblems von der Nebenbedingung,daß deren Ableitung ungeich 0 ist, damit die KT fur die Losung erfullt sind. Ei-ne naheliegende Verallgemeinerung fur m Nebenbedingungen konnte lauten, daßdie Gradienten aller Nebenbedingungen ausgewertet an der Losung eines Opti-mierungsproblems ungleich 0 sind, damit KT notwendige Bedingungen fur dieLosung sind. Das folgende graphische Besipiel zeigt, daß eine Verallgemeinerungim eben beschriebenen Sinne nicht ausreicht.
Beispiel 12.4: insert picture here
Im Bild ist es offenbar nicht moglich, die Gleichung
∇f(x) = α1∇g1(x) + α2∇g2(x)
zu erfullen, da die Gradientenvektoren ∇g1(x) und ∇g2(x) auf einer Geraden lie-gen, die in einer anderen Richtung verlauft als der Gradientenvektor ∇f(x). Furα1 = −λ1 und α2 = −λ2 ist dies aber gerade die erste der KT. Zur Erfullung derKT bereitet offenbar die lineare Abhangigkeit der Gradientenvektoren der Neben-bedingungen in der Losung des Optimierungsproblems Schwierigkeiten. Darausergibt sich die korrekte Verallgemeinerung der Beschrankungsqualifikation.
Definition 12.3 (Beschrankungsqualifikation) Der Punkt x erfullt die Be-schrankungsqualifikation (BQ) genau dann, wenn die Gradientenvektoren ∇gj(x)linear unabhangig sind fur diejenigen j ∈ 1, . . . , m, fur die die zugehorigenNebenbedingungen bindend sind, also gj(x) = 0.
Beispiel 12.5:(i) Seien f(x) = x1 + x2, g1(x) = 4− 2x1 − x2 und g2(x) = 1− 1
2x1 − x2. Dann
erfullt x = (2, 0) die BQ, da ∇g1(x) = (−2,−1) = t(−12,−1) = t∇g2(x), also
∇g1(x) und ∇g2(x) linear unabhangige Vektoren sind.(ii) Seien nun f(x) = x1 + x2, g1(x) = 4 − 2x1 − x2, g2(x) = 1 − 1
2x1 − x2
und g3(x) = 3 − 12x1 − x2. Zwar sind nun ∇g2(x) und ∇g3(x) linear abhangig.
Trotzdem erfullt x = (2, 0) die BQ, da die dritte Nebenbedingung nicht bindend
121

12 Optimierungstheorie
ist, denn g3(2, 0) = 2 > 0 und fur die beiden anderen Nebenbedingungen ∇g1(x)und ∇g2(x) linear unabhangige Vektoren sind.
Wir kommen nun zu den entscheidenden Satzen, die mit Hilfe der Lagrangefunk-tion und der Kuhn-Tucker-Bedingungen notwendige und hinreichende Bedingun-gen zur Losung von Optimierungsproblemen mit Nebenbedingungen in Form vonUngleichungen formulieren.
Satz 12.4 (Notwendige Bedingungen) Seien f, gj fur j = 1, . . . , m an denrelevanten Stellen differenzierbare Funktionen von Rn nach R. Sei x eine Losungdes Optimierungsproblems
maxx
f(x) u.d.N. gj(x) ≥ 0 fur j = 1, . . . , m,
und x erfulle die Beschrankungsqualifikation, dann existieren Lagrangevariablenλ = (λ1, . . . , λm), so daß (x, λ) die Kuhn-Tucker-Bedingungen
(1) ∇f(x) +∑m
j=1 λj∇gj(x) = 0
(2) gj (x) ≥ 0 fur j = 1, . . . , m(3) λj ≥ 0 fur j = 1, . . . , m(4) λjgj (x) = 0 fur j = 1, . . . , m
erfullt.
Fur die hinreichende Bedingung sei nun gleich die allgemeinere Formuliereungbasierend auf Quasikonkavitat der Zielfunktion und ihrer Nebenbedingungen ge-nannt.
Satz 12.5 (Hinreichende Bedingungen) Seien f, gj fur j = 1, . . . , m quasi-konkave, an den relevanten Stellen differenzierbare Funktionen von Rn nach R.Ferner erfulle (x, λ) die Kuhn-Tucker-Bedingungen
(1) ∇f(x) +∑m
j=1 λj∇gj(x) = 0
(2) gj (x) ≥ 0 fur j = 1, . . . , m(3) λj ≥ 0 fur j = 1, . . . , m(4) λjgj (x) = 0 fur j = 1, . . . , m.
Dann ist x eine Losung des Optimierungsproblems
maxx
f(x) u.d.N. gj(x) ≥ 0 fur j = 1, . . . , m.
122

12 Optimierungstheorie
Beispiel 12.6:(i) Seien f(x) = −x2
1 − x22 und g(x) = 4 − x1 − x2. Die zugehorige Lagrange-
funktion ist
L(x, λ) = f(x) + λg(x) = −x21 − x2
2 + λ(4 − x1 − x2)
und die KT sind (1) ∇L(x) = (−2x1 − λ,−2x2 − λ) = 0, (2) 4− x1 − x2 ≥ 0, (3)λ ≥ 0 und (4) λ(4 − x1 − x2) = 0. Offenbar erfullt nur (x, λ) = (0, 0, 0) die KT,da λ > 0 zum Widerspruch zwischen der 1. und 2. Bedingung fuhrt. Da f und gkonkav sind, lost (x) = (0, 0) das Optimierungsproblem maxgj(x)≥0 f(x).(ii) Seien nun f(x) = −(x1 − 3)2 − (x2 − 3)2 und g(x) = 4 − x1 − x2 mitLagrangefunktion
L(x, λ) = f(x) + λg(x) = −(x1 − 3)2 − (x2 − 3)2 + λ(4 − x1 − x2).
Die KT sind (1) ∇L(x) = (−2(x1−3)−λ,−2(x2−3)−λ) = 0, (2) 4−x1−x2 ≥ 0,(3) λ ≥ 0 und (4) λ(4 − x1 − x2) = 0. Offenbar erfullt jetzt nur (x, λ) = (2, 2, 2)die KT, da hier λ = 0 zum Widerspruch zwischen der 1. und 2. Bedingungfuhrt. Da f und g konkav sind, lost also (x) = (2, 2) das Optimierungsproblemmaxgj(x)≥0 f(x).(iii) Betrachte f(x) = x1 und die beiden Nebenbedingungen g1(x) = 4−x1 −x2
und g2(x) = 2 − (x1 − 3)2 − (x2 − 3)2 mit Lagrangefunktion
L(x, λ) = x1 + λ1(4 − x1 − x2) + λ2(2 − (x1 − 3)2 − (x2 − 3)2).
Offenbar lost x = (2, 2) das Optimierungsproblem, denn dies ist der einzige Punktder beide Nebenbedingungen erfullt. Im Punkt x = (2, 2) ist die BQ nicht erfullt,da hier beide Nebenbedingungen g1(x) ≥ 0 und g2(x) ≥ 0 bindend sind und∇g1(2, 2) = (−1,−1) = −1
2∇g2(2, 2) = (2, 2) ist, also die beiden Gradientenvek-
toren ∇g1(2, 2) und ∇g2(2, 2) linear abhangig sind. Die erste KT-Bedingung
∇L(x) = (1 − λ1 − 2λ2(x1 − 3),−λ1 − 2λ2(x2 − 3)) = 0,
ist fur x = (2, 2) nicht erfullbar, da der Gradientenvektor ∇f = (1, 0) nichtim von den Vektoren ∇g1(2, 2) und ∇g2(2, 2) aufgespannten linearen Unterraumliegt.(iv) Gegeben sei f(x) = x2
1 + x22 und g(x) = 4 − x1 − x2 mit Lagrangefunktion
L(x, λ) = f(x) + λg(x) = x21 + x2
2 + λ(4 − x1 − x2).
Die KT sind (1) ∇L(x) = (2x1 − λ, 2x2 − λ) = 0, (2) 4 − x1 − x2 ≥ 0, (3) λ ≥ 0und (4) λ(4 − x1 − x2) = 0. Sie werden erfullt von den beiden Tupeln (x, λ) =(0, 0, 0) und (x, λ) = (2, 2, 4). Aus Beispiel (i) wissen wir, daß (x, λ) = (0, 0, 0)das zugehorige Minimierungsproblem lost. x = (2, 2) ist ebenfalls keine Losung,denn z.B. ist f(−3,−3) = 18 > f(2, 2). In diesem Beispiel ist die Zielfunktion f
123

12 Optimierungstheorie
nicht konkav. Daher sind die KT-Bedingungen nicht hinreichend fur eine Losungdes Optimierungsproblems maxx1+x2≤4 x2
1 + x22. Da sie aber notwendig sind und
die beiden Punkte x = (0, 0) und x = (2, 2) nicht als Losung in Frage kommen,existiert keine Losung zu maxx1+x2≤4 x2
1 + x22.
12.5 Nebenbedingungen in Form von Gleichungen
Betrachte in diesem Abschnitt eine differenzierbare Funktion f : Rn −→ R unddas Optimierungsproblem
maxx
f(x) u.d.N. g(x) = 0.
Dieses Optimierungsproblem ist offenbar aquivalent zu
maxx
f(x) u.d.N. g(x) ≥ 0 und − g(x) ≥ 0.
Die zugehorige Lagrangefunktion kann geschrieben werden als
L(x, λ1, λ2) = f(x) + (λ1 − λ2)g(x)
oder mit λ = λ1 − λ2 vereinfacht als
L(x, λ) = f(x) + λg(x).
Die KT-Bedingungen vereinfachen sich dann zu
(I) ∇f(x) + λ∇g(x) =(
∂∂x1
L(x, λ), ∂∂x2
L(x, λ))
= 0
(II) g(x) = ∂∂λ
L(x, λ) = 0.
Die ”alten” Bedingungen (3) λ1 ≥ 0 und λ2 ≥ 0 implizieren kein Vorzeichenfur λ = λ1 − λ2, wahrend (4) λg(x) = 0 bereits aus (2) folgt. Also sind dieBedingungen (3) und (4) redundant.
Die beiden folgenden Satze sind die Anwendungen der Satze 12.4 und 12.5 aufOptimierungsprobleme mit m Nebenbedingungen in Form von Gleichungen. Siefolgen unmittelbar mit Hilfe der vorgenommenen Notationskonvention.
Satz 12.6 (Notwendige Bedingungen) Seien f, gj : Rn −→ R fur j = 1, . . . , man den relevanten Stellen differenzierbare Funktionen. Seien ferner f eine quasi-konkave und gj lineare Funktionen. Falls x eine Losung des Optimierungsproblems
maxx
f(x) u.d.N. gj(x) = 0 fur j = 1, . . . , m,
124

12 Optimierungstheorie
ist und die Beschrankungsqualifikation erfullt, dann existieren Lagrangevariablenλ = (λ1, . . . , λm), so daß (x, λ) die vereinfachten Kuhn-Tucker-Bedingungen, abhier abgekurzt mit KT’
(I) ∇f(x) +∑m
j=1 λj∇gj(x) = 0
(II) gj (x) = 0 fur j = 1, . . . , m
erfullt.
Satz 12.7 (Hinreichende Bedingungen) Seien f, gj : Rn −→ R fur j =1, . . . , m an den relevanten Stellen differenzierbare Funktionen. Seien ferner feine quasikonkave und gj lineare Funktionen. Außerdem erfulle (x, λ) die verein-fachten Kuhn-Tucker-Bedingungen KT’
(I) ∇f(x) +∑m
j=1 λj∇gj(x) = 0
(II) gj (x) = 0 fur j = 1, . . . , m.
Dann ist x eine Losung des Optimierungsproblems
maxx
f(x) u.d.N. gj(x) = 0 fur j = 1, . . . , m.
Man beachte, daß diese Formulierung wegen der einfachen Form der KT’ zwareine Vereinfachung der allgemeineren Form KT mit Nebenbedingungen als Un-gleichungen darstellt aber gleichzeitig verschiedene Nachteile mit sich bringt.Zunachst sind die Handlungsalternativen in den meisten okonomischen Kontex-ten durch Ungleichungen in Form von Budget- oder Resourcenrestriktionen, alsoobere oder untere Schranken gegeben. Ferner enthalten die KT’ keine Informationzum Vorzeichen der Lagrangevariablen. Da außerdem die hinreichende Forderungder Quasikonkavitat aller Funktionen bei Nebenbedingungen in Form von Glei-chungen in die Forderung der Linearitat der Nebenbedingungen ubergeht, bleibennur wenige einfache Anwendungen ubrig, bei denen die KT’ (I) und (II) der Satze12.6 und 12.7 die maßgeblichen Kriterien zum Losen von Optimierungsproblemendarstellen.
Beispiel 12.7: Ein typisches solches Problem ist das Nutzenmaximierungspro-blem eines Haushaltes dessen Praferenzen erstens strikt monoton sind, der alsostets sein Budget voll ausschopft und dessen Budgetrestriktion daher als Glei-chung statt als Ungleichung angenommen werden kann. Wenn man zweitens an-nimmt, daß der Haushalt jedes Gut in strikt positiver Menge konsumieren mochte,also Indifferenzkurven nicht die Achsen schneiden, dann folgt, daß in vielen rele-vanten Fallen die Untergrenzen an die konsumierten Gutermengen nicht bindendsind und daher das betrachtete Nutzenmaximierungsproblem zum Nutzenmaxi-mierungsproblem mit Budgetgleichung als Nebenbedingung aquivalent ist. Dar-aus folgt, daß die Losung des Problems, also die Bestimmung der Nachfrage mit
125

12 Optimierungstheorie
Hilfe der beiden KT’ der Satze 12.6 und 12.7 das ursprungliche Problem nichtvereinfacht, denn zuvor muß sichergestellt sein, daß erstens die Budgetrestriktionbindend und zweitens keine andere Nebenbedingung bindend ist, was im Prinzipgenau der Analyse der KT-Bedingungen (3) und (4) entspricht, die – wie wir unserinnern – genau der Fallunterscheidung dient, ob Nebenbedingungen bindendsind oder nicht. Da dieser Stoff Gegenstand der Mikro-Veranstaltungen ist, seienhier nur wenige Beispiele genannt. Betrachte stets zweidimensionale Guterraumemit Guterbundel x = (x1, x2), Preisvektor p = (p1, p2), exogenem Einkommen Iund das Optimierungsproblem
maxx
u(x) u.d.N. I − p · x ≥ 0 und xi ≥ 0 fur j = 1, 2. (MAX)
Die zugehorige Lagrangefunktion ist
L(x, λ, α1, α2) = u(x) + λ(I − p1x1 − p2x2) + α1x1 + α2x2
und die ”normalen” KT sind
(1) ∇L(x) = ∇u(x) − λp + (α1, α2) = 0(2) I − p1x1 − p2x2 ≥ 0, x1 ≥ 0 und x2 ≥ 0(3) λ ≥ 0, α1 ≥ 0 und α2 ≥ 0(4) λ(I − p1x1 − p2x2) = 0, α1x1 = 0 und α2x2 = 0.
Wir sehen, daß unter diesen Bedingungen alle Nebenbedingungen linear sind.Dadurch sind gute Chancen gegeben, daß die vereinfachten KT’ gemaß der Satze12.6 und 12.7 zur Losung von (MAX) genugen. Sie lauten
(I) ∇u(x) − λp = 0
(II) p1x1 + p2x2 = I.
(i) Fur die konkave Cobb-Douglas-Nutzenfunktion u(x) = x121 x
122 , strikt positives
Einkommen und Preise I > 0, p1 > 0 und p2 > 0 gelten alle Voraussetzungen, umSatz 12.7 mit den vereinfachten KT’ anzuwenden, da die Nutzenfunktion striktmonoton ist, die Indifferenzkurven nicht die Achsen schneiden und alle Nebenbe-dingungen linear sind. Eine Losung der KT’ (I) und (II) lost also (MAX).(ii) Die Cobb-Douglas-Nutzenfunktion u(x) = x2
1x22 ist nicht konkav. Daher
konnen wir mit Hilfe von Satz 12.7 nicht schließen, das die vereinfachten KT’und zu einer Losung von (MAX) fuhren. In diesem Fall ist u(x) = x2
1x22 aber
quasikonkav, was als hinreichende Bedingung ausreicht.(iii) Die quasilineare Nutzenfunktion u(x) = x1 + ln x2 ist zwar strikt monotonund konkav, aber deren Indifferenzkurven schneiden die x1−Achse. Damit sinddie Voraussetzungen zur Anwendung der vereinfachten KT’ nicht erfullt. Die KT
126

12 Optimierungstheorie
konnen aber angewendet werden und fuhren zu stetigen aber nicht differenzier-baren Nachfragefunktionen.1
(iv) Die Nutzenfunktion u(x) = x21 + x2
2 ist nicht konkav und auch nicht quasi-konkav. Da die BQ fur p1 > 0, p2 > 0 auf dem ganzen R2
+ erfullt ist, muß eineLosung von (MAX) die KT (1) bis (4) erfullen. Es kann also Satz 12.4 angewendetwerden, hingegen nicht Satz 12.5. Die Lagrangefunktion ist
L(x, λ, α1, α2) = x21 + x2
2 + λ(I − p1x1 − p2x2) + α1x1 + α2x2
und die KT fur diese Nutzenfunktion lauten
(1) ∂∂x1
L(x) = 2x1 − λp1 + α1 = 0 und ∂∂x2
L(x) = 2x2 − λp2 + α2 = 0
(2) I − p1x1 − p2x2 ≥ 0, x1 ≥ 0 und x2 ≥ 0(3) λ ≥ 0, α1 ≥ 0 und α2 ≥ 0(4) λ(I − p1x1 − p2x2) = 0, α1x1 = 0 und α2x2 = 0.
Da u strikt monoton ist, gilt stets λ > 0 und p1x1 + p2x2 = I. Aus der Bedin-gung (4) ergeben sich also 3 mogliche Falle. Ecklosung (e1) mit α1 > 0 impliziertx1 = 0 und x2 = I
p2. Ecklosung (e2) mit α2 > 0 impliziert x2 = 0 und x1 = I
p1.
Tangentiallosung (t) mit α1 = α2 = 0 impliziert mit KT (1) Grenzrate der Substi-tution gleich Preisverhaltnis oder x1
x2= p1
p2. Unter diesen drei Fallen kommen nur
(e1) und (e2) als Losung von (MAX) in Frage2, da das durch (t) charakterisierteGuterbundel das Nutzenminimum aller Guterbundel auf der Budgetgeraden ist.Man beachte, daß die vereinfachten KT’ uns nur zum Nutzenminimum (t) auf derBudgetgeraden hinfuhren aber im Gegensatz zu KT nicht zur Losung des Nutzen-optimierungsproblems. Damit zeigt dieses letzte Beispiel insbesondere, daß KT’im Gegensatz zu KT keine notwendigen Bedingungen sind, falls die Zielfunkti-on nicht konkav ist, also zur Bestimmung einer Losung von (MAX) nicht helfenkonnen.
12.6 Existenz und Eindeutigkeit von Losungen
Wir haben Beispiele gesehen, bei denen keine Losung zu einem Optimierungspro-blem existiert. Der folgende Satz gibt hinreichende Bedingungen fur die Existenzvon Losungen zu Optimierungsproblemen.
Satz 12.8 (Satz von Weierstrass) Sei f : Rn −→ R stetig und die Auswahl-menge A ⊆ Def(f) ⊆ Rn nicht leer und kompakt. Dann existiert eine Losung zumOptimierungsproblem maxx∈A f(x).
1Die Berechnungen der Nachfragen sind Gegenstand der entsprechenden Mikro-Veranstaltungen.
2Beides sind lokale Maxima, das globale ergibt sich durch den Nutzenvergleich dieser beiden.
127

12 Optimierungstheorie
Beispiel 12.8: Als Fortsetzung des Beispiels 12.5 aus der Mikrookonomie be-trachte das Nutzenmaximierungsproblem MAX gegeben durch
maxx∈R2
u(x) u.d.N. p1x1 + p2x2 ≤ I, x1 ≥ 0, x2 ≥ 0
mit stetiger Nutzenfunktion u(x1, x2) auf dem 2-dimensionalen Guterraum Prei-sen p1, p2 und exogenem Einkommen I ≥ 0.(i) Betrachte zunachst den Fall strikt positiver Guterpreise p1, p2 > 0. Wirwollen zeigen, daß aus dem Satz von Weierstrass folgt, daß MAX eine Losungbesitzt. Dafur muß die Budgetmenge
A =x ∈ R2|p1x1 + p2x2 ≤ I, x1 ≥ 0, x2 ≥ 0
nicht leer und kompakt sein. A ist nicht leer, denn sie enthalt stets das Element(0, 0). Außerdem ist die Auswahlmenge beschrankt. Als obere Schranke wahle
z.B. a = max Ip1
, Ip2. Sei z.B. p1 ≤ p2. Dann gilt ||x|| =
√x2
1 + x22 ≤ a =
(Ip1
)2
fur alle x ∈ A, denn gabe es umgekehrt ein x ∈ A mit x21 + x2
2 > a2 =(
Ip1
)2
,
dann galte wegen 0 < p1 ≤ p2 auch
(p1x1 + p2x2)2 = (p1x1)
2 + 2p1x1p2x2 + (p2x2)2
≥ (p1x1)2 + (p2x2)
2
≥ (p1x1)2 + (p1x2)
2
≥ I2 also
p1x1 + p2x2 > I,
was x ∈ A widerspricht. Eine entsprechende Abschatzung gilt offenbar auch furp1 ≤ p2. Also ist A beschrankt. Die obere Schranke a = max I
p1, I
p2 ist tatsachlich
die kleinste obere Schranke der Budgetmenge, denn
max
∥∥∥∥(
I
p1, 0
)∥∥∥∥ ,
∥∥∥∥(
0,I
p2
)∥∥∥∥
= a.
Es bleibt zu prufen, ob A abgeschlossen ist. Da A seinen Rand ∂A enthalt, denndie A begrenzenden Ungleichungen sind alle schwach, ist A auch abgeschlossenund also kompakt. Gemaß des Satzes von Weierstrass existiert daher eine Losungvon MAX.(ii) Falls einer der Preise, z.B. p1 = 0 ist, ist die Budgetmenge
A =x ∈ R2|p1x1 + p2x2 ≤ I, x1 ≥ 0, x2 ≥ 0
nicht mehr beschrankt, also nicht kompakt. Dies erkennt man daran, daß fur dieeben definierte kleinste obere Schranke a gilt
limp1→0
a = limp1→0
max
I
p1,
I
p2
= ∞.
128

12 Optimierungstheorie
In der Tat besitzt MAX fur keine der in Beispiel 12.5 untersuchten Nutzenfunk-tionen eine Losung, da der Haushalt unersattlich bezuglich eines Gutes mit demPreis 0 ist.(iii) Sei nun die Auswahlmenge gegeben durch
A =x ∈ R2|p1x1 + p2x2 ≤ I, x1 > 0, x2 ≥ 0
,
d.h. vom Gut 1 darf nicht die Menge x1 = 0 konsumiert werden. Dann kannder Satz von Weierstrass nicht mehr angewendet werden, auch wenn die Preisep1, p2 > 0 strikt positiv sind und die Auswahlmenge daher beschrankt ist, dennfur I > 0 ist A nicht abgeschlossen und fur I = 0 ist A leer. Auch in diesem Falllassen sich einfach Nutzenfunktionen angeben, so daß MAX tatsachlich keineLosung besitzt, z.B. fur u(x) = x2 wurde der Haushalt gerne nur das Gut 2konsumieren. Da nicht die Menge 0 vom Gut 1 konsumiert werden kann, existiertzu jedem Guterbundel x ∈ A ein gegenuber diesem praferiertes.
Der Satz von Weierstrass zeigt uns, daß Stetigkeit eine wichtige Voraussetzungfur die Existenz von Losungen ist. Der folgende Satz zeigt entsprechend, daßKonvexitat bzw. strikte Quasikonkavitat eine wichtige Voraussetzung fur die Ein-deutigkeit von Losungen ist.
Satz 12.9 Sei A ⊆ Def(f) ⊆ Rn eine konvexe Auswahlmenge und f : Rn −→ R
strikt quasikonkav auf der Auswahlmenge A. Dann existiert nicht mehr als eineLosung zum Optimierungsproblem maxx∈A f(x).
Die Beweisidee ist, daß konvexe Kombinationen λx+(1−λ)x zweier verschiedenerLosungen x, x stets ebenfalls Losungen sein mussen wegen der Konvexitat derAuswahlmenge und der Quasikonkavitat. Wegen der strikten Quasikonkavitatgilt aber, daß strikte konvexe Kombinationen λx + (1 − λ)x fur 0 < λ < 1 sogarstrikt bevorzugt werden, was ein Widerspruch dazu ist, daß x, x Losungen sind.
Beispiel 12.9:(i) Sei A = 0, 1 und f(x) = x − x2. Dann ist f strikt konkav, also auchstrikt quasikonkav. Dennoch besitzt maxx∈A f(x) die beiden Losungen 0 und 1.Das liegt daran, daß A keine konvexe Menge ist. Wurde man die Auswahlmen-ge konvexifizieren, d.h. in diesem Fall zum Optimierungsproblem maxx∈[0,1] f(x)ubergehen, dann kommt Satz 12.9 zur Anwendung und es kann hochstens eineLosung existieren. In diesem Fall ware die eindeutige Losung x = 1
2.
(ii) Sei A = (0, 1) und f(x) = −x2, dann ist A konvex und f strikt quasikon-kav, also gilt Satz 12.9 und es existiert nicht mehr als eine Losung. In diesenBeispiel existiert keine Losung, da A nicht kompakt ist, also die Voraussetzungendes Satzes von Weierstrass nicht erfullt sind.
129

12 Optimierungstheorie
Satz 12.8 nennt Bedingungen, die mindestens eine Losung garantieren, wahrendSatz 12.9 Bedingungen nennt, die die Zahl der Losungen auf hochstens eine be-schrankt. Daraus folgt zusammen:
Satz 12.10 Sei A ⊆ Def(f) ⊆ Rn eine nicht-leere, kompakte und konvexe Aus-wahlmenge und f : Rn −→ R stetig und strikt quasikonkav auf der AuswahlmengeA. Dann existiert genau eine Losung zum Optimierungsproblem maxx∈A f(x).
Beispiel 12.10: Die Beispiele 12.7,(i) bis (iii) erfullen alle Voraussetzungen desSatzes 12.10 und garantieren daher eindeutige Losungen des Nutzenmaximie-rungsproblems. Daraus ergibt sich die Existenz einer Nachfragefunktion, die je-dem Tupel (p1, p2, I) ein eindeutiges am meisten praferiertes Guterbundel zuord-net. In Beispiel 12.5.(iv) dagegen ist die Nutzenfunktion nicht strikt quasikonkav.Die Nachfrage existiert wegen des Satzes von Weierstrass zwar, ist aber nicht mehreindeutig und daher keine Funktion3.
3Sie ist eine Korrespondenz, die nicht eindeutig zu sein braucht. Es ist nicht schwierig abernicht Gegenstand dieses Skriptums, die meisten zentralen Aussagen der Mikrotheorie vonFunktionen auf Korrespondenzen zu verallgemeinern.
130

Literaturverzeichnis
[1] K. Binmore (1983). Calculus. Cambridge, London, New York: CambridgeUniversity Press.
[2] L. Blume und C. Simon (1994). Mathematics for Economists. New York,London: W. W. Norton.
[3] I. Bronstein, K. Semendjajew und G. Musiol (1999). Taschen-buch der Mathematik. Erweiterte und uberarbeitete Auflage. Thun, Frank-furt/Main: Harri Deutsch.
[4] A. Chiang (1984). Fundamental Methods of Mathematical Economics. 3.Auflage. Auckland, London, Tokio: McGraw-Hill.
[5] A. Dixit (1990). Optimization in Economic Theory. 2. Auflage. New York,Oxford: Oxford University Press.
[6] A. Mas-Colell, M. Whinston und J. Green (1995). MicroeconomicTheory. New York, Oxford: Oxford University Press.
[7] D. Ohse (2002). Mathematik fur Wirtschaftswissenschaftler I - Analysis. 5.Auflage. Munchen: Vahlen.
[8] H. Rommelfanger (2001). Mathematik fur Wirtschaftswissenschaftler I5. Auflage. Heidelberg, Berlin: Spektrum: Akademischer Verlag.
[9] K. Sydsæter, und P. Hammond (2002).Essential Mathematics for Eco-nomic Analysis. 3. Auflage. Prentice Hall.
128







![Investition & Finanzierung [3ex] 2. Investitionsrechnung ...medien.cedis.fu-berlin.de/itunes/lehrveranstaltungen/0000/036/loeffl… · Vorlesung Sicherheit Grundbegriffe Dynamische](https://img.pdfslide.org/doc/110x75/605b31626d170b5608484132/investition-finanzierung-3ex-2-investitionsrechnung-vorlesung-sicherheit.jpg)





















