Embed Size (px)
Citation preview

Statistik B
Wahrscheinlichkeitsrechnung und induktiveStatistik
Prof. Dr. Alois KneipSommersemester 2010
Literatur:Fahrmeier, Künstler, Pigeot und Tutz (2004): Stati-stik, Springer VerlagFahrmeier, Künstler, Pigeot, Tutz, Caputo und Lang(2005): Arbeitsbuch Statistik, Springer Verlag
Statistik_II@finasto 0–1

Inhalt:
1) Wahrscheinlichkeitsrechnung
2) Diskrete Zufallsvariablen
3) Stetige Zufallsvariablen
4) Mehrdimensionale Zufallsvariablen
5) Stichproben und Schätzverfahren
6) Testen von Hypothesen
7) Spezielle Testprobleme
8) Lineare Einfachregression
Statistik_II@finasto 0–2

Einführung
Statistik I (Deskriptive Statistik)Analyse von konkreten Daten: Datenaufbereitung,Auswertung und Interpretation mit Hilfe von Maßzah-len (relative Häufigkeiten, Mittelwert, Median, usw.)
Statistik II (1. Teil: Wahrscheinlichkeitsrech-nung, Zufallszahlen)Entwicklung von stochastischen Modellen; Formalisie-rung eines Zufallsvorgangs; Fragestellung: Welche Re-sultate können eintreten und wie sind die zugehörigenWahrscheinlichkeiten?
Statistik II (2. Teil: Induktive Statistik)Vergleich konkreter Daten mit idealisierter Modellvor-stellung; Quantifzierung von Unsicherheit; Testen vonHypothesen.
Statistik_II@finasto 0–3

Fragestellungen der Wahrscheinlichkeits-rechnung
Historisches Beispiel:Analyse von „Glücksspiel“, Gewinnwahrscheinlichkeit
Frage des George Brossin Chevalier de Méré anBlaise Pascal:
Was ist wahrscheinlicher: Bei 4 Würfen mit einemWürfel (mindestens) einmal „6“ zu werfen oder bei 24Würfen mit 2 Würfeln mindestens eine „Doppelsechs“zu werfen?
Vermutung: Gleichwahrscheinlich.(Doppelsechs ist zwar 6-mal weniger häufig als „6“,aber dafür hat man 6-mal so viele Versuche.)
Feststellung des Chevalier de Méré (nach sehr vielenPartien am Spieltisch): Nicht gleichwahrscheinlich.
Systematische Analyse dieser Situation?
Beispiel:Wie groß ist die Wahrscheinlichkeit, im Lotto „6 Rich-tige“ zu tippen?
Statistik_II@finasto 0–4

Vorgehen der induktiven Statistik
Beispiel 1:Experiment: 100-maliges Werfen einer Münze
Statistik I: (Datenanalyse)⇒ Beobachtete absolute Häufigkeiten: 65 mal „Kopf“und 35 mal „Zahl“
Frage: Münze fair (d.h. Ergebnis nur Zufall) oder ma-nipuliert?
Statistik II:Modellannahme: „Münze ist fair“⇒ Chance für Kopf : Zahl stehen 50 : 50
Induktion: Falls die Modellannahme erfüllt ist, d.h.falls die „Hypothese“ einer fairen Münze richtig ist, soist die Wahrscheinlichkeit bei 100 Versuchen ≥ 65 malKopf zu beobachten nur 0, 003 (0,3%)
Schlussfolgerung: Die Hypothese einer fairen Münzeist abzulehnen, die Münze ist wohl manipuliert
Statistik_II@finasto 0–5

Beispiel: Meinungsforschung
Frage: Wieviel Prozent der Bevölkerung sind für odergegen eine bestimmte wirtschaftspolitische Entschei-dung der Bundesregierung?
Datenerhebung: Befragung von n = 1000 zufälligausgewählten Bürgerinnen und Bürgern (⇒ Zufalls-stichprobe).
Datenanalyse (Statistik I): Relative Häufigkeiten z.B.0, 513 = 51, 3% („dafür“) und 0, 487 = 48, 7% („dage-gen“)
Problem: Unsicherheit! Wie nahe liegt die aus derStichprobe berechnete relative Häufigkeit an dem wah-ren Prozentsatz in der Bevölkerung?
Induktive Statistik: Formalisierung des Problemsund Berechnung von „Konfidenzintervallen“ zur Quan-tifizierung der Unsicherheit:Mit einer sehr geringen Irrtumswahrscheinlichkeit liegtder wahre Prozentsatz in der Bevölkerung im Intervall
[0, 513± 0, 031] = [0, 482, 0, 544]
Statistik_II@finasto 0–6

6 Wahrscheinlichkeitsrechnung
6.1 Grundbegriffe
Ziel der Wahrscheinlichkeitsrechnung ist die Analyseeiner stochastischen Situation. Grundlage ist die Mo-dellierung von Zufallsvorgängen.
Zwei Fragen:
• Was kann alles passieren?
• Mit welcher Wahrscheinlichkeit passiert diesoder jenes?
Ein Zufallsvorgang führt zu einem von mehreren,sich gegenseitig ausschließenden Ergebnissen. Es istvor der Durchführung ungewiss, welches Ergebnistatsächlich eintreten wird.
Ein Zufallsexperiment ist ein Zufallsvorgang, derunter kontrollierbaren Bedingungen wiederholbarist.
Idee:Ein „Ergebnis“ ω ∈ S tritt ein, zufallsgesteuert.
Die (nichtleere) Menge S aller möglichen Ergebnisseheißt Ergebnisraum oder Ereignisraum.
Statistik_II@finasto 6–1

Beispiele:Lose ziehen (auf Kirmes)
S = Niete, Trostpreis, Teddy, Ferrari
Nächstes Spiel eines Fußballvereins
S = Gewinn, Niederlage, Unentschieden
Ein Münzwurf
S = Kopf,Zahl=+1,−1=0, 1
Würfel
S = 1, 2, 3, 4, 5, 6
Einarmiger Bandit
S = (z1, z2, z3)|zi ∈ Glocke, Krone, Apfel
2 Würfel (Monopoly, Backgammon, . . . )
S = (1, 1), (1, 2), (2, 2), (2, 3), . . . , (6, 6)
Statistik_II@finasto 6–2

Beispiele (Fortsetzung):
Ziehung der Lottozahlen(vereinfacht, ohne Zusatzzahl)
S = z1, . . . , z6|zi = zj 1 ≤ zi ≤ 49
n Münzwürfe
S = ω = (z1, . . . , zn)|zi ∈ K,Z
Anzahl Schadensmeldungen, die bei einer Versiche-rung in einem bestimmten Monat eingehen
S = 0, 1, 2, . . .
Anzahl Unfälle auf einer bestimmten Kreuzung
S = 0, 1, 2, . . .
Statistik_II@finasto 6–3

Beispiele (Fortsetzung):
Pfeilwurf auf Zielscheibe (mit Radius 20cm)
S = alle Punkte in einer Kreisscheibe mit Radius 20cm
=(x, y)|x2 + y2 ≤ 202 ⊂ R2
Drehen eines Glücksrads/Flaschendrehen
S = Winkel von 0 bis 360=[0, 360)
„Random-Taste“ auf Ihrem Taschenrechner
S = Zufallszahlen im Einheitsintervall=[0, 1]
Aktienkurs
S = Möglicher Tages-Verlauf der VW-Aktie morgen
= Alle „Pfade“ ausgehend von heutigem Schlusskurs
Statistik_II@finasto 6–4

Die letzten Beispiele zeigen:Oft ist das Eintreten jedes einzelnen Ergebnissessehr, sehr unwahrscheinlich (z.B.: einen festen Punktauf der Zielscheibe treffen).
⇒ Diskussion von Wahrscheinlichkeiten nicht auf derEbene der Ergebnisse, sondern auf der Ebene der Er-eignisse A ⊂ S.
Eine Teilmenge A des Ergebnisraums S heißt Er-eignis.Wir sagen: „A tritt ein“, wenn ein Ergebnis ω ∈ A
eintritt.
einzelnes Ergebnis ω ∈ S ⇔ Elementarereignis A =
ω
Beispiele:Ein Münzwurf:
A = „Kopf liegt oben“
= K ⊂ S = K,Z
1 Würfel:
A = „Eine 6 wird gewürfelt“ = 6 ⊂ 1, 2, 3, 4, 5, 6B = „Eine gerade Zahl wird gewürfelt“ = 2, 4, 6C = „Mehr als 4 wird gewürfelt“ = 5, 6
Statistik_II@finasto 6–5

Beispiele (Fortsetzung):2 Würfel:
A = „Pasch gewürfelt“
B = „Doppelsechs“
C = „Keine 4 dabei“
Einarmiger Bandit:
A = „Hauptgewinn“
= „Automat zeigt 3 Kronen“= (Krone,Krone,Krone)
Glücksrad / Flaschendrehen:
A = „Glücksrad bleibt in bestimmtem Sektor stehen“
= „Flasche zeigt auf bestimmte Person“
= Winkel ∈ [α, α]
Zielscheibe:
A = „Pfeil trifft ins Schwarze“
= (x, y)|x2 + y2 ≤ 1B = „Pfeil landet im äußeren Ring“
= (x, y)|182 < x2 + y2 ≤ 202
Statistik_II@finasto 6–6

Beispiele (Fortsetzung):Schadensmeldungen / Unfälle:
A = „kein Schaden“
= 0 ⊂ N
B = „höchstens 4 Schäden“
C = „Mehr als 100 Schäden“
Aktienkurs:
A = „Schlusskurs ist größer als Ausgangskurs“
B = „mehr als 3% zugelegt“
Statistik_II@finasto 6–7

6.2 Mengen und Ereignisse
x ∈ A: „x ist ein Element der Menge A“.
x ∈ A: „x ist kein Element der Menge A“. A ⊂ B: A ist Teilmenge von B; x ∈ A ⇒ x ∈ B.
Die Schnittmenge A ∩ B ist die Menge aller Ele-mente, die sowohl in A als auch in B sind;A ∩B = x : x ∈ A und x ∈ B
Die Vereinigungsmenge A∪B ist die Menge allerElemente, die in A oder B sind;A ∪B = x : x ∈ A oder x ∈ B.
Die Differenzmenge A\B ist die Menge aller Ele-mente, die in A aber nicht in B sind;A\B = x : x ∈ A und x ∈ B.
Für A ⊂ S ist die Komplementärmenge A von A
bzgl S die Menge aller Elemente von S, die nicht inA sind. (Andere Notation: Ac, A.)
Die Potenzmenge P(S) ist die Menge aller Teil-
mengen von S; P(S) = M |M ⊂ S.
Die Mächtigkeit (Kardinalität) von S ist die An-
zahl der Elemente in S; #S = #x : x ∈ S.
Statistik_II@finasto 6–8

Rechenregeln für Mengen
(Veranschaulichung im Venn-Diagramm)
• Kommutativgesetz:A ∩B = B ∩A
A ∪B = B ∪A
• Assoziativgesetz:(A ∩B) ∩ C = A ∩ (B ∩ C)
(A ∪B) ∪ C = A ∪ (B ∪ C)
• Distributivgesetz:(A ∪B) ∩ C = (A ∩ C) ∪ (B ∩ C)
(A ∩B) ∪ C = (A ∪ C) ∩ (B ∪ C)
• De Morgansche Regeln:(A ∪B) = A ∩ B
(A ∩B) = A ∪ B
• Aus A ⊂ B folgt B ⊂ A.
• Für die Differenzmenge A\B gilt:A\B = A ∩ B.
Statistik_II@finasto 6–9
Ein Ereignis ist jede beliebige Teilmenge des Er-eignisraumesBeispiel:Zufallsexperiment: einmaliges Werfen eines WurfelsEreignis A: \Werfen einer geraden Augenzahl") A= f2;4;6gSicheres Ereignis SEreignis, das als Ergebnis des Zufallsexperimentseintreten muUnmogliches Ereignis ;Ereignis, das im Ergebnis des Zufallsexperimentesauf keinen Fall eintreten kann
Statistik_II@finasto 6–10

KomplementarereignisMenge samtlicher Elementarereignisse des Ereig-nisraumes S, die nicht im betrachteten Ereignisenthalten sindA EreignisA Komplementarereignis zu AS = ;Beispiel:Zufallsexperiment: einmaliges Werfen eines WurfelsEreignis A: \Werfen einer geraden Augenzahl"A= f2;4;6gA= f1;3;5g
Statistik_II@finasto 6–11
Venn-Diagramm:
Statistik_II@finasto 6–12
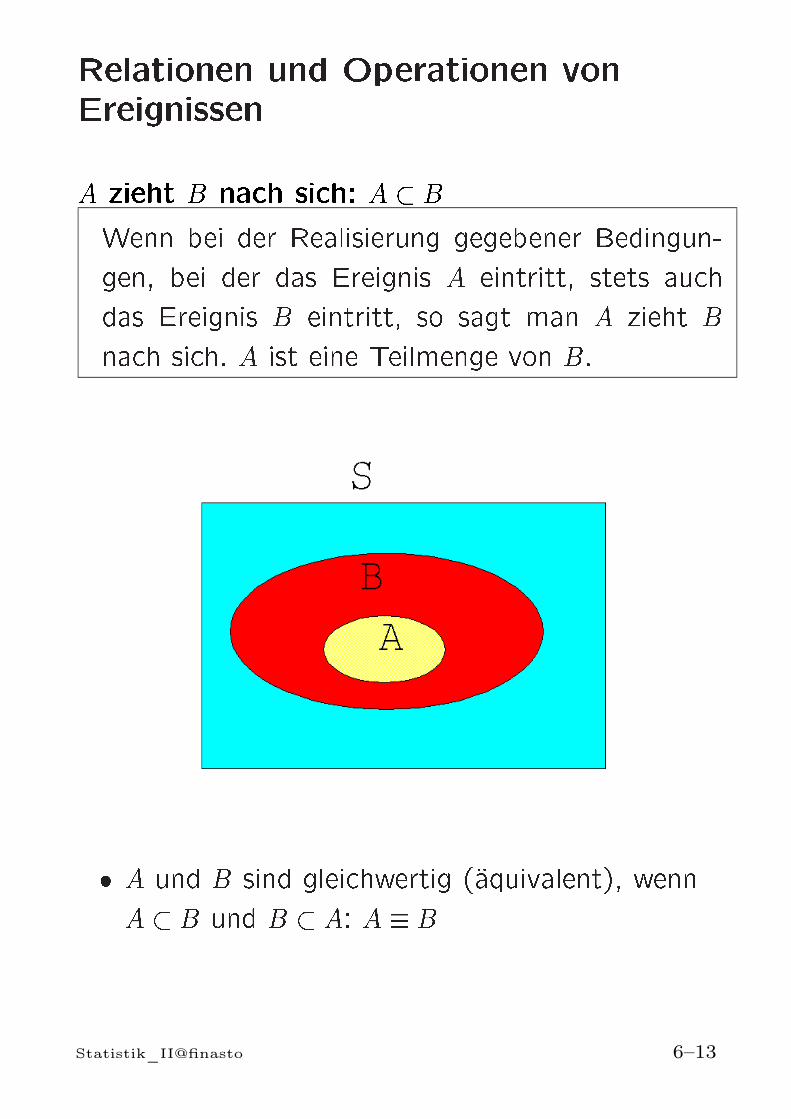
Relationen und Operationen vonEreignissenA zieht B nach sich: A BWenn bei der Realisierung gegebener Bedingun-gen, bei der das Ereignis A eintritt, stets auchdas Ereignis B eintritt, so sagt man A zieht Bnach sich. A ist eine Teilmenge von B.
A und B sind gleichwertig (aquivalent), wennA B und B A: A BStatistik_II@finasto 6–13
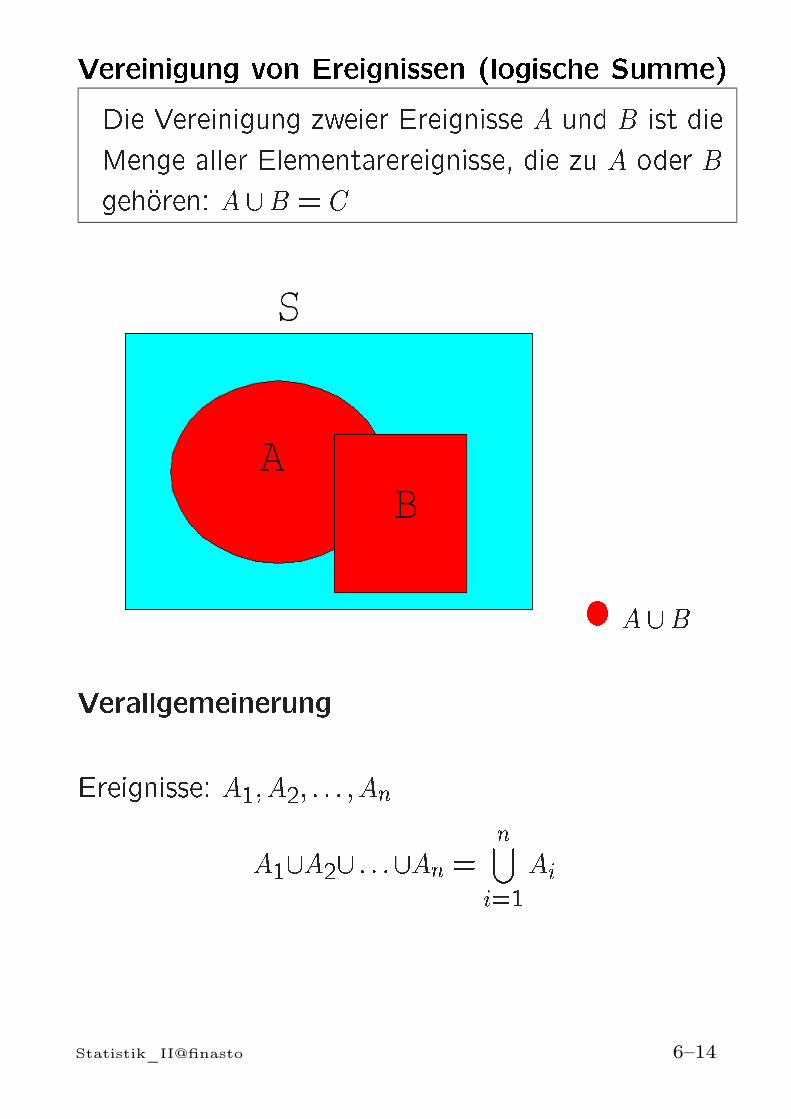
Vereinigung von Ereignissen (logische Summe)Die Vereinigung zweier Ereignisse A und B ist dieMenge aller Elementarereignisse, die zu A oder Bgehoren: A [B = C
A [BVerallgemeinerungEreignisse: A1; A2; : : : ; AnA1[A2[ : : :[An = n[i=1AiStatistik_II@finasto 6–14
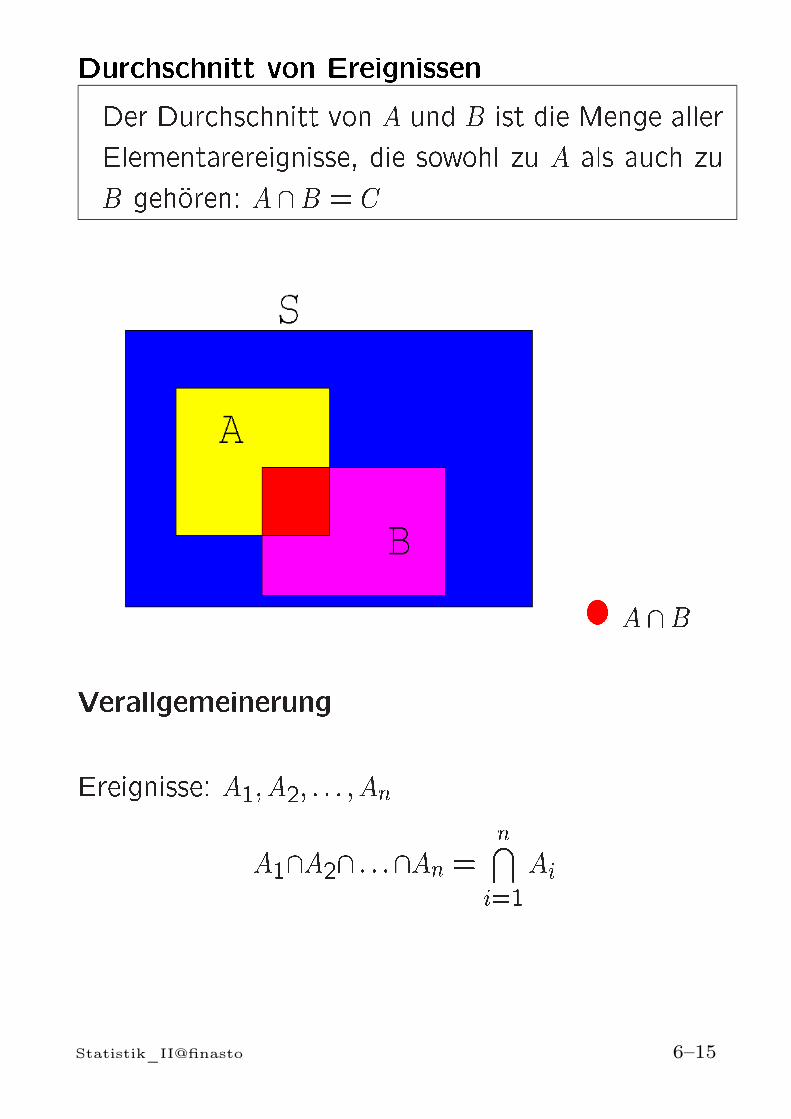
Durchschnitt von EreignissenDer Durchschnitt von A und B ist die Menge allerElementarereignisse, die sowohl zu A als auch zuB gehoren: A \B = C
A \BVerallgemeinerungEreignisse: A1; A2; : : : ; AnA1\A2\ : : :\An = n\i=1AiStatistik_II@finasto 6–15
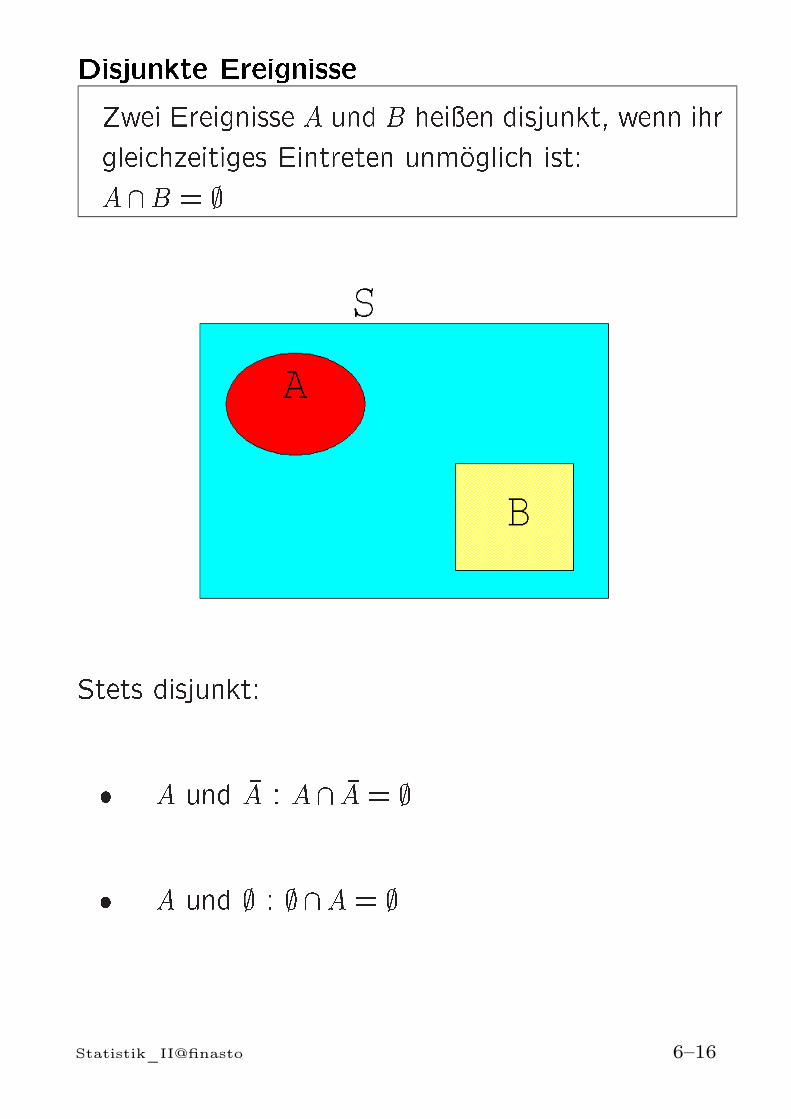
Disjunkte EreignisseZwei Ereignisse A und B heien disjunkt, wenn ihrgleichzeitiges Eintreten unmoglich ist:A \B = ;
Stets disjunkt: A und A : A \ A = ; A und ; : ; \A= ;
Statistik_II@finasto 6–16
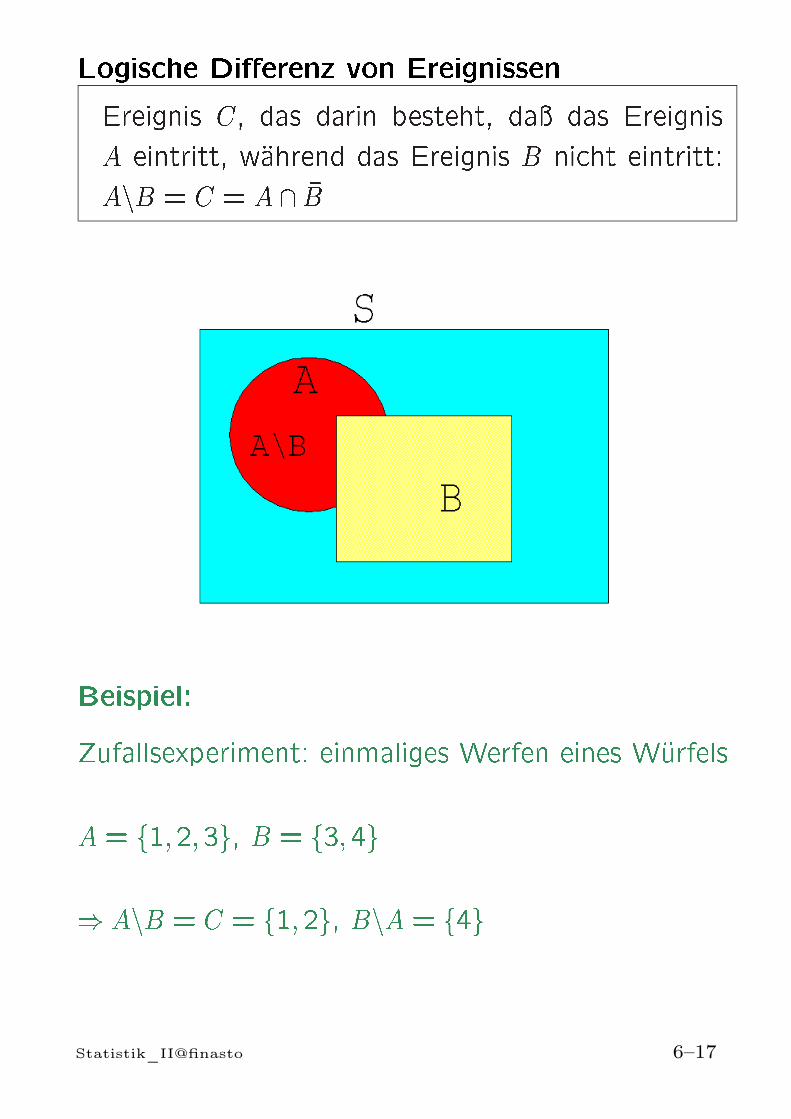
Logische Dierenz von EreignissenEreignis C, das darin besteht, da das EreignisA eintritt, wahrend das Ereignis B nicht eintritt:AnB = C = A \ B
Beispiel:Zufallsexperiment: einmaliges Werfen eines WurfelsA= f1;2;3g, B = f3;4g) AnB = C = f1;2g, BnA = f4gStatistik_II@finasto 6–17

Zerlegung des Ereignisraumes SEin System von Ereignissen A1; A2; : : : ; An heiteine Zerlegung von S, wenn die Relationen Ai 6= ;, (i = 1;2; : : : ; n) Ai \ Ak = ;, fur i 6= k, disjunkt A1 [A2 [ : : : [An = Sgelten und eines der Ereignisse bei einem Zufalls-experiment eintreten muBeispiel:Zufallsexperiment: Werfen eines WurfelsS = f1;2;3;4;5;6gA1 = f1g A2 = f3;4g A3 = f1;3;4gA4 = f5;6g A5 = f2;5g A6 = f6gZerlegung von S: A1; A2; A5; A6A1 \A2 = ; A1 \A5 = ; A1 \A6 = ;A2 \A5 = ; A2 \A6 = ; A5 \A6 = ;A1 [A2 [ A5 [A6 = SStatistik_II@finasto 6–18

Zerlegung des Ereignisraumes SEin System von Ereignissen A1; A2; : : : ; An heiteine Zerlegung von S, wenn die Relationen Ai 6= ;, (i = 1;2; : : : ; n) Ai \ Ak = ;, fur i 6= k, disjunkt A1 [A2 [ : : : [An = Sgelten und eines der Ereignisse bei einem Zufalls-experiment eintreten muBeispiel:Zufallsexperiment: Werfen eines WurfelsS = f1;2;3;4;5;6gA1 = f1g A2 = f3;4g A3 = f1;3;4gA4 = f5;6g A5 = f2;5g A6 = f6gZerlegung von S: A1; A2; A5; A6A1 \A2 = ; A1 \A5 = ; A1 \A6 = ;A2 \A5 = ; A2 \A6 = ; A5 \A6 = ;A1 [A2 [ A5 [A6 = SStatistik_II@finasto 6–19

ZusammenfassungBeschreibung des zugrunde-liegenden Sachverhaltes Bezeichnung (Sprech-weise) Darstellung A tritt sicher ein A ist sicheres Ereignis A = S A tritt sicher nicht ein A ist unmogliches Ereig-nis A = ; wenn A eintritt, tritt B ein A ist Teilmenge von B A B genau dann, wenn A eintritt,tritt B ein A und B sind aquivalen-te Ereignisse A B wenn A eintritt, tritt B nichtein A und B sind disjunkteEreignisse A \ B = ; genau dann, wenn A eintritt,tritt B nicht ein A und B sind komple-mentare Ereignisse B = A genau dann, wenn minde-stens ein Ai eintritt(genau dann, wenn A1 oderA2 oder : : : eintritt), tritt AeinA ist Vereinigung der Ai A =SiAi
genau dann, wenn alle Aieintreten(genau dann, wenn A1 undA2 und : : : eintreten), tritt AeinA ist Durchschnitt derAi A =TiAi
Statistik_II@finasto 6–20

6.3 Wahrscheinlichkeiten
Vor der Durchführung eines Zufallsvorgangs ist esungewiss, welches Ereignis eintritt. In der Wahr-scheinlichkeitsrechnung wird nun die Chance für dasEintreten eines bestimmten Ereignisses A ⊂ S durcheine Zahl, die „Wahrscheinlichkeit“ P [A], bewer-tet.
Problem: Wie kommt man zu Wahrscheinlichkeiten?
1) Klassischer Wahrscheinlichkeitsbegriff(Laplace-Wahrscheinlichkeiten)Bei „fairen“Würfeln, Glücksrädern, Münzen,Lotto-Ziehungsgeräten, etc., gilt
• S = ω1, . . . , ωN ist endlich
• Alle Ergebnisse sind gleichwahrscheinlich
⇒ Die Wahrscheinlichkeit von A ⊂ S ergibt sichdurch Abzählen:
P [A] =Anzahl der Elementarereignisse in A
Anzahl der Elementarereignisse in S
Beispiel: Würfel, A =”gerade Augenzahl
⇒ P [A] = 3/6 = 1/2
Statistik_II@finasto 6–21

2) Objektiver (statistischer) Wahrscheinlichkeits-begriffWahrscheinlichkeiten ergeben sich als Grenzwert derrelativen Häufigkeit eines Ereignisses A ⊂ S
• n-malige Wiederholung des interessierenden Zu-fallsexperiments ⇒ relative Häufigkeit fn(A)
• Feststellung: Für n → ∞ stabilisieren sich die re-lativen Häufigkeiten erfahrungsgemäß um einenfesten Wert. Dieser Wert entspricht der Wahr-scheinlichkeit P [A]
Beispiel: n = 100, 1000, 10000, . . . mal würfeln. Bei ei-nem fairen Würfel stabilisieren sich die relativen Häu-figkeiten von A =„gerade Augenzahl“ um P [A] = 1/2.
3) Subjektive WahrscheinlichkeitenSubjektive Wahrscheinlichkeiten geben persönliche Ein-schätzungen wider.Beispiele: Ihre Einschätzung der Chance, die KlausurStatistik II zu bestehen; Konjunkturprognose durcheinen Sachverständigen
Statistik_II@finasto 6–22
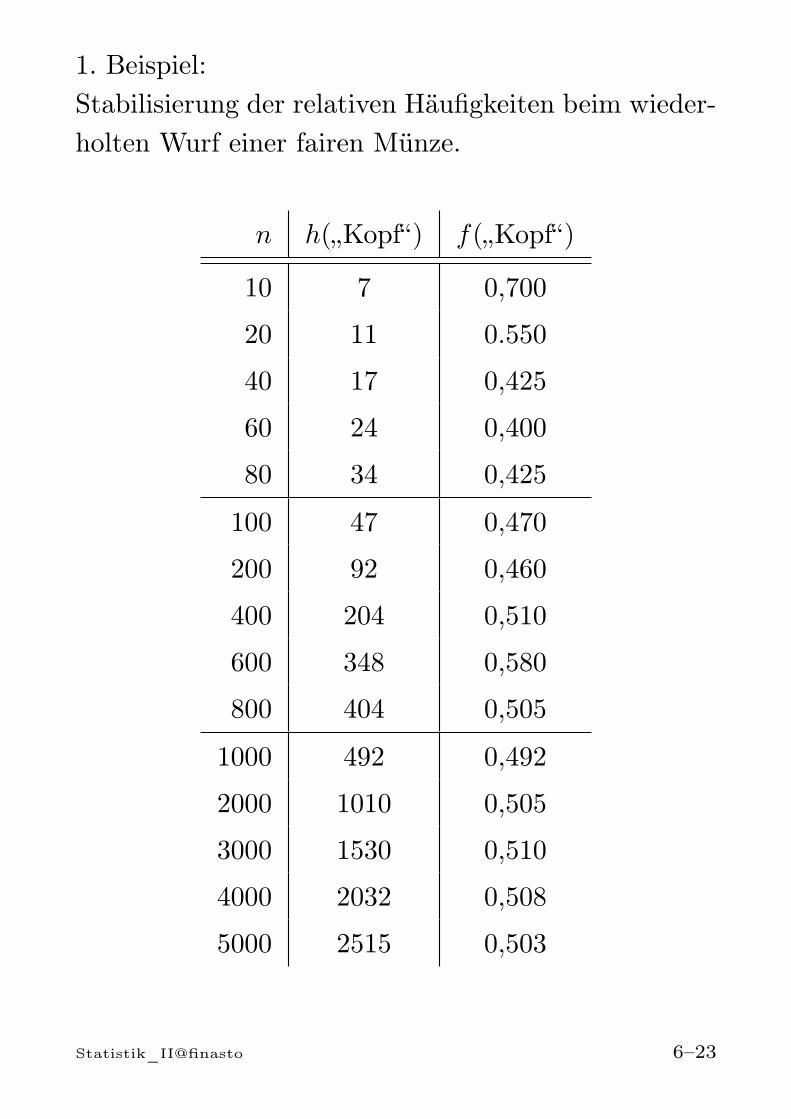
1. Beispiel:Stabilisierung der relativen Häufigkeiten beim wieder-holten Wurf einer fairen Münze.
n h(„Kopf“) f(„Kopf“)
10 7 0,700
20 11 0.550
40 17 0,425
60 24 0,400
80 34 0,425
100 47 0,470
200 92 0,460
400 204 0,510
600 348 0,580
800 404 0,505
1000 492 0,492
2000 1010 0,505
3000 1530 0,510
4000 2032 0,508
5000 2515 0,503
Statistik_II@finasto 6–23
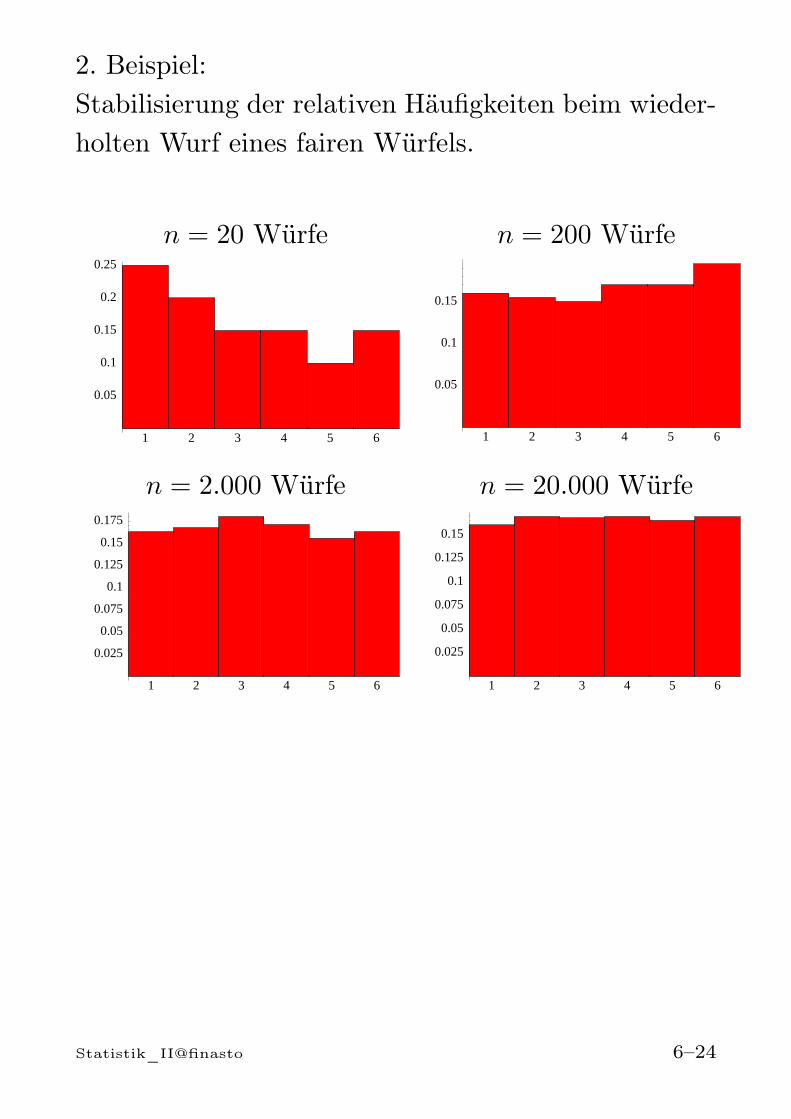
2. Beispiel:Stabilisierung der relativen Häufigkeiten beim wieder-holten Wurf eines fairen Würfels.
n = 20 Würfe n = 200 Würfe
1 2 3 4 5 6
0.05
0.1
0.15
0.2
0.25
1 2 3 4 5 6
0.05
0.1
0.15
n = 2.000 Würfe n = 20.000 Würfe
1 2 3 4 5 6
0.025
0.05
0.075
0.1
0.125
0.15
0.175
1 2 3 4 5 6
0.025
0.05
0.075
0.1
0.125
0.15
Statistik_II@finasto 6–24

3. Beispiel:
Man betrachte ein Land mit N = 82.000.000 Bürge-rinnen und Bürgern.
• 41.820.000 Frauen ⇒ Anteil = 51%
• 40.180.000 Männer ⇒ Anteil = 49%
• Zufallsexperiment: Ziehen eines zufällig ausgewähl-ten Individuums (⇒ 82.000.000 mögliche Elemen-tarereignisse
Frage: Wahrscheinlichkeit des Ereignisses A („Frau“)?
P [A] =41.820.000
82.000.000= 0.51
Wiederholtes Ziehen von n = 10, 100, 1000, ... Indi-viduen: Mit wachsendem n nähert sich fn(A) immerstärker der Wahrscheinlichkeit P [A] an.
Vollerhebung: fN (A) = P [A]
Statistik_II@finasto 6–25

6.4 Wahrscheinlichkeitsverteilungen
Ziel: Unabhängig von der Art des Wahrscheinlich-keitsbegriffs entwickeln wir einen Apparat, mit demwir die Ausgänge eines Zufallsvorgangs quantifizierenkönnen. Wir legen hier nur fest, welche EigenschaftenWahrscheinlichkeiten haben müssen und wie wir mitihnen rechnen dürfen.
Jede „sinnvolle“ Zuordnung von Wahrscheinlichkeitenfür Ereignisse A,B ⊂ S besitzt z.B. folgenden Eigen-schaften:0 ≤ P [A] ≤ 1
P [S] = 1
A ⊂ B ⇒ P [A] ≤ P [B]
P [A] = 1− P [A]
P [A ∪ B] = P [A] + P [B], falls A und B nicht gleich-zeitig eintreten können.
Die von Wahrscheinlichkeiten zu fordernden Eigen-schaften sind in den „Axiomen“ des russischen Ma-thematikers Kolmogoroff zusammengefasst.
Alle zum Umgang mit Wahrscheinlichkeiten wich-tigen Rechenregeln lassen sich aus diesen Axio-men ableiten.Statistik_II@finasto 6–26

Gegeben: Diskreter Ereignisraum S = ω1, ω2, . . .
Ein Wahrscheinlichkeitsmaß P ist eine Abbildung,die allen Ereignissen A eines Zufallsvorgangs eine ZahlP [A] zuordnet, und die folgenden Bedingungen (Ei-genschaften, Axiome) genügt:
Axiom 1:Die Wahrscheinlichkeit P [A] eines Ereignisses A isteine eindeutig bestimmte Zahl mit
0 ≤ P [A] ≤ 1 (Nichtnegativität)
Axiom 2:
P [S] = 1 (Normierung)
Axiom 3: (Additivität)Sind A1, A2, . . . , Ak, . . . paarweise disjunkt, danngilt Für disjunkte Ereignisse (A ∪B = ∅) gilt
P [A1∪A2∪. . .∪Ak . . .] = P [A1]+P [A2]+. . .+P [Ak]+. . .
(S,P[S], P ) heißt dann ein (diskreter) Wahrschein-lichkeitsraum und P heißt (diskrete) Wahrschein-lichkeitsverteilung.
Falls S endlich ist, S = (ω1, . . . , ωN ), sprechen wir voneinem endlichen Wahrscheinlichkeitsraum.
Statistik_II@finasto 6–27

S : „Was kann alles passieren?“genauer: „Welche Ereignisse sind modelliert?“
P : „Mit welcher Wahrscheinlichkeit treten die Ereig-nisse ein?“
Rechenregeln:
• P [S] = 1, P [∅] = 0
• P [A] ≤ P [B], falls A ⊂ B
• P [A] = 1− P [A] mit A = S\A
• P [A1∪A2∪. . .∪Ak] = P [A1]+P [A2]+. . .+P [Ak],falls A1, A2, . . . , Ak paarweise disjunkt
• P [A\B] = P [A]− P [A ∩B]
• Additionssatz:
P [A ∪B] = P [A] + P [B]− P [A ∩B]
Statistik_II@finasto 6–28

Beispiele:
1. Fairer Würfel:
• Elementarwahrscheinlichkeiten:
p1 = P [1] = 1
6= p2 = · · · = p6
• Wahrscheinlichkeit eine gerade Zahl zu würfeln:
P [„Gerade Zahl“ ] = P [2, 4, 6]
= p2 + p4 + p6 =1
6+
1
6+
1
6=
1
2
• Wahrscheinlichkeit eine ungerade Zahl zu würfeln:
P [„Ungerade Zahl“ ] = P [1, 3, 5]
= p1 + p3 + p5 =1
2= 1− P [„Gerade Zahl“ ]
• Wahrscheinlichkeit mehr als 4 zu würfeln:
P [„Mehr als 4“ ] = P [5, 6]
= p5 + p6 =1
6+
1
6=
1
3
Statistik_II@finasto 6–29

2. Gefälschter Würfel:
• Elementarwahrscheinlichkeiten:
p1 =1
12, p2 = p3 = p4 = p5 =
1
6, p6 =
1
4
• Wahrscheinlichkeit eine gerade Zahl zu würfeln:
P [„Gerade Zahl“ ] = P [2, 4, 6]
= p2 + p4 + p6 =1
6+
1
6+
1
4=
7
12
• Wahrscheinlichkeit eine ungerade Zahl zu würfeln:
P [„Ungerade Zahl“ ] = P [1, 3, 5]
= p1 + p3 + p5 =5
12= 1− P [„Gerade Zahl“ ]
• Wahrscheinlichkeit mehr als 4 zu würfeln:
P [„Mehr als 4“ ] = P [5, 6]
= p5 + p6 =1
6+
1
4=
5
12
Statistik_II@finasto 6–30

3. Warten auf die erste Zahl beim wiederholtenWurf einer fairen Münze:
• Elementarwahrscheinlichkeiten:P [„Zahl im 1. Versuch“ ] = 1
2 =: p1
P [„Zahl erst im 2. Versuch“ ] = 14 =: p2
P [„Zahl erst im 3. Versuch“ ] = 12 · 1
2 · 12 = 1
8 =: p3
P [„Zahl erst im kten Versuch“ ] =(12
)k=: pk
Probe:∞∑k=1
pk =∞∑k=1
(1
2
)k
= 1 (Geometr. Reihe)
• Wahrscheinlichkeit für eine gerade Anzahl von Ver-suchen:P [„Gerade Anzahl Versuche“ ]
= p2 + p4 + p6 + · · · =∞∑k=1
(1
2
)2k
=1
4
1
1− 14
=1
3
• Wahrscheinlichkeit für eine ungerade Anzahl vonVersuchen:P [„Ungerade Anzahl Versuche“ ]
= 1− 1
3=
2
3= p1 + p3 + p5 + · · ·
Statistik_II@finasto 6–31

Allgemeine Wahrscheinlichkeitsräume
Wenn der Grundraum nicht diskret ist, können dieWahrscheinlichkeiten von Ereignissen nicht mehr durchSummieren von Elementarwahrscheinlichkeiten berech-net werden.
Betrachtet man z.B. den Pfeilwurf auf eine Zielschei-be, so ist die Trefferwahrscheinlichkeit für jeden festgewählten, einzelnen Punkt der Scheibe gleich 0. Da-mit kann die Wahrscheinlichkeit für „einen Treffer insSchwarze“ nicht als Summe der Elementarwahrschein-lichkeiten aller Punkte „im Schwarzen“ erhalten wer-den.
Anmerkung: Bei nicht diskreten Räumen ist weiterhin zubeachten, dass es aus mathematischen Gründen nicht mög-lich ist, allen denkbaren Mengen A ⊂ S Wahrscheinlich-keiten zuzuweisen und gleichzeitig zu verlangen, dass dieRechenregeln für Wahrscheinlichkeiten weiter gelten. AlsAusweg betrachtet man eine Kollektion von Mengen, dieabgeschlossen ist unter mengentheoretischen Operationen(„σ-Algebra“). Nur noch den in der Kollektion enthaltenenEreignissen wird eine Wahrscheinlichkeit zugeordnet. Allein der Praxis relevanten Mengen wie z.B. Intervalle, Qua-drate, Rechtecke, Kreise, Kreissektoren, Kreisringe, usw.,sind i. Allg. in einer solchen Kollektion enthalten.
Statistik_II@finasto 6–32

6.5 Laplace-Modell
Annahmen im Laplace-Modell:• S endlich, S = ω1, . . . , ωN
• Alle Elementarereignisse gleichwahrscheinlich
⇒ Elementarwahrscheinlichkeiten:
pk = P [ωk] =1
N=
1
#Sfür alle k = 1, . . . , N
⇒ Berechnung der Wahrscheinlichkeit von A:
P [A] =∑ωk∈A
pk = #ωk|ωk ∈ A · 1
N
=#ωk|ωk ∈ A
#S
=Anzahl der für A günstigen Fälle
Anzahl aller Fälle
Beispiele: Fairer Würfel, faire Münze.
2 faire Würfel: P [„Pasch“ ] = 636 = 1
6
Kompliziertere Modelle (z.B. Wahrscheinlichkeit fuer3,4,5,6 Richtige beim Lotto)⇒ geschicktes Abzählen: Kombinatorik.
Statistik_II@finasto 6–33

6.6 Zufallsstichproben und Kombina-torik
Gegeben: Grundgesamtheit bestehend aus N Elemen-ten e1, . . . , eN
Beispiele: Urne bestehend aus 49 Kugeln (Lotto-zahlen), Gesamtheit aller Studenten in Bonn,...
Wir betrachten nun Stichproben, die durch zufälli-ge Ziehung von n Elementen der Grundgesamtheitentstehen
Beispiele: Ziehung der Lottozahlen, Erstellung einerZufallsstichprobe von Bonner Sudenten zu statisti-schen Zwecken
In vielen Fällen interessiert man sich dabei für dieWahrscheinlichkeit eine bestimmte Stichprobe zuziehen. Diese hängt ab von der Gesamtzahl dermöglichen Stichproben in Abhängigkeit von der Artund Weise des Ziehungsvorgangs. und erfordert dieAnwendung von kombinatorischen Überlegun-gen.
Statistik_II@finasto 6–34

Modell mit Zurücklegen
Grundgesamtheit aus N Elementen; n voneinanderunabhängige Ziehungen jeweils eines zufälligen Ele-ments ( nach jeder Ziehung wird das gezogene Ele-ment wieder in die Grundgesamtheit zurückgelegt).
Anzahl der möglichen Stichproben: Nn
Grundgesamtheit aus N = 3 Elementen a, b, cStichproben des Umfangs n = 2: a, a, a, b, a, c,b, a, b, b, b, c, c, a, c, b, c, c
Jede dieser Stichproben wird mit der gleichen Wahr-scheinlichkeit (1/9) gezogen
Stichproben, die durch unabhängiges Ziehen mit Zu-rücklegen aus einer Grundgesamtheit entstehen, hei-ßen einfache Zufallsstichproben.
Statistik_II@finasto 6–35

Die Antwort auf die Frage des Chevalier de Méré:
Was ist wahrscheinlicher: Aus 4 Würfen mindestenseine „6“ oder aus 24 Würfen mindestens eine „Dop-pelsechs“ zu erhalten?
Fall 1: Mindestens eine 6 aus 4 Würfen
• Gesamtzahl aller möglichen Stichproben (= Er-gebnisse der 4 Würfe): 64
• Gesamtzahl aller möglichen Stichproben (= Er-gebnisse der 4 Würfe), die keine 6 enthalten: 54
⇒ P [„mindestens eine 6 aus 4 Würfen“ ]
= 1− P [„keine 6 aus 4 Würfen“ ]
= 1− 54
64≈ 0, 5177
Analog: P [„mindestens eine Doppelsechs aus 24 Würfen“ ]
= 1− P [„keine Doppelsechs aus 24 Würfen“ ]
= 1− 3524
3624≈ 0, 4914
(An der kleinen Differenz der Wahrscheinlichkeitensieht man, dass der Chevalier de Meré ein äußerst eif-riger Spieler gewesen sein muss, um den Unterschiedam Spieltisch wahrzunehmen.)Statistik_II@finasto 6–36

Modell ohne Zurücklegen
Grundgesamtheit aus N Elementen; n aufeinan-derfolgende Ziehungen jeweils eines zufälligen Ele-ments. Nach jeder Ziehung wird das gezogene Ele-ment nicht wieder in die Grundgesamtheit zurück-gelegt).
Grundgesamtheit aus N = 3 Elementen a, b, c6 Stichproben des Umfangs n = 2 bei Ziehen ohneZurücklegen: a, b, a, c, b, a, b, c, c, a, c, b
Jede dieser Stichproben ist gleichwahrscheinlich (1/6).
Anmerkung: Beim Modell ohne Zurücklegen sinddie einzelnen Ziehungen nicht unabhängig vonein-ander; das Resultat einer Ziehung beeinflusst diemöglichen Ergebnisse jeder weiteren Ziehung
Statistik_II@finasto 6–37

Modell ohne ZurücklegenAnzahl der möglichen Stichproben vom Umfang n:
N · (N − 1) · (N − n+ 1) =N !
(N − n)!
FakultätDie Fakultät einer natürlichen Zahl k ist definiertdurch
k! = k · (k − 1) · (k − 2) · . . . · 2 · 1
Es gilt1! = 1, 0! = 1
Beispiele:2! = 2
3! = 6
4! = 24
10! = 3628800
20! = 2432902008176640000
Statistik_II@finasto 6–38

Permutationen
Grundgesamtheit aus N Elementen; durch N -maliges zufälliges Ziehen ohne Zurücklegen werdennacheinander alle Elemente der Grundgesamtheitgezogen.Die resultierenden Stichproben (Permutationen) un-terscheiden sich nur in der Reihenfolge der Ele-mente.
Anwendungsbeispiel: Auslosung der Startreihenfol-ge bei einem Sportereignis mit N teilnehmendenSportlern.
N = 3 Elementen a, b, c 6 mögliche Permutationen:a, b, c, a, c, b, b, a, c, b, c, a, c, a, b, c, b, a
Jede Permutation ist gleichwahrscheinlich (1/6)
Anzahl möglicher Permutationen bei N Objekten:
N !
Statistik_II@finasto 6–39

Modell ohne Zurücklegen und ohne Berück-sichtigung der Reihenfolge
Grundgesamtheit aus N Elementen; durch zufälli-ges Ziehen ohne Zurücklegen werden nacheinandern Elemente gezogen.Keine Berücksichtigung der Reihenfolge; zwei Stich-proben sind äquivalent, wenn sie die gleichen Ele-mente entahlten.
Anzahl der möglichen Stichproben vom Umfang n
(jeweils gleichwahrscheinlich):(N
n
)
BinomialkoeffizientDer Binomialkoeffizient
(Nn
)ist definiert als(
N
n
)=
N !
(N − n)! · n!
Es gilt (N
0
)= 1,
(N
1
)= N,
(N
N
)= 1,(
N
n
)= 0 falls N < n
Statistik_II@finasto 6–40

Anwendungsbeispiel: Ziehung der Lottozahlen.
Bei der Ziehung der Lottozahlen handelt es sich umein Beispiel für ein Modell ohne Zurücklegen undohne Berücksichtigung der Reihenfolge. Die Stich-probe
4, 7, 11, 13, 26, 28
wird nicht unterschieden von der Ziehung
11, 26, 13, 28, 4, 7
Es gibt also(49
6
)=
49!
(43)! · 6!= 13983816
Möglichkeiten 6 Lottozahlen aus 49 Kugeln zu ziehen
⇒ Wahrscheinlichkeit, dass eine bestimmte (getippte)Kombination die richtige ist:
P [”6 Richtige”] =1
13983816= 0, 000000072
Statistik_II@finasto 6–41

Wahrscheinlichkeit für 3, 4, 5, 6 Richtige?
Modell ohne Zurücklegen, Reihenfolge irrelevant
⇒ alle Ziehungen gleichwahrscheinlich
⇒ Laplace-Modell
P [„6 Richtige“] =1(496
) =1
13.983.816≈ 0, 000000072
P [„3 Richtige“] =#„3 Richtige und 3 Falsche“
#Alle möglichen Tipps
=
(63
)(49−66−3
)(496
) = ...
P [„k Richtige“] =#„k Richtige und 6− k Falsche“
#Alle möglichen Tipps
=
(6k
)(49−66−k
)(496
)
Statistik_II@finasto 6–42

Anmerkungen:
In der Sprache der Kombinatorik werden Zusam-menstellungen (Ziehungen) von n Elementen, diesich unter Berücksichtigung der Reihenfolge erge-ben, als Variationen bezeichnet
Zusammenstellungen (Ziehungen) von n Elemen-ten, die ohne Berücksichtigung der Reihenfolge er-geben, werden Kombinationen genannt
Anzahl Stichproben beim Modell mit Zurücklegenund ohne Berücksichtigung der Reihenfolge (Kom-bination mit Wiederholung):(
N + n− 1
n
)Vorsicht: Stichproben nicht gleichwahrscheinlich
Statistik_II@finasto 6–43

6.7 Bedingte Wahrscheinlichkeiten undUnabhängigkeit
Bei manchen Problemen der Wahrscheinlichkeitsrech-nung betrachtet man das Eintreten von Ereignissen inAbhängigkeit von bestimmten anderen Ereignissen.
Beispiel: Ein Unternehmen stellt 2000 Teile auf zweiMaschinen her.
• 1400 Teile werden auf Maschine 1 hergestellt.Davon sind 1162 Teile fehlerfrei.
• 600 Teile werden auf Maschine 2 produziert.Hiervon sind 378 Teile fehlerfrei.
A =Teil ist fehlerfrei
B =Teil auf Maschine 1 hergestellt
C =Teil auf Maschine 2 hergestellt
Statistik_II@finasto 6–44

fehlerfrei = A mit Fehlern = A
Maschine 1 = B 1162 238 1400
Maschien 2 = C 378 222 600
1540 460 2000
P [A] =1540
2000= 0, 77
P [B] =1400
2000= 0, 7
P [A ∩B] =1162
2000= 0, 581
Wie hoch ist die Wahrscheinlichkeit, dass ein zufälligentnommenes fehlerfreies Teil auf Maschine 1 herge-stellt wurde?
P [B|A] = P [A ∩B]
P [A]=
0, 581
0, 77= 0.7545
Statistik_II@finasto 6–45

Bedingte Wahrscheinlichkeit
Wollen definieren: Wahrscheinlichkeit von A, ange-nommen B tritt ein. (B ist „neuer“ Grundraum)
Bezeichnung: P [A|B]
Definition: [bedingte Wahrscheinlichkeit]Man betrachte Ereignisse A,B ⊂ S mit P [B] > 0.Die bedingte Wahrscheinlichkeit von A gege-ben B wird definiert durch
P [A|B] :=P [A ∩B]
P [B]
P [·|B] als Funktion der Ereignisse A heisst bedingteWahrscheinlichkeitsverteilung bzgl B.
Bedingte Wahrscheinlichkeiten sind wiederum Wahr-scheinlichkeiten im Sinne der Axiome von Kolmogoroff(alle Rechenregeln für „normale“ Wahrscheinlichkeitensind erfüllt).
Statistik_II@finasto 6–46

Unabhängigkeit
Definition: [Unabhängige Ereignisse]Ein Ereignis A ist dann von einem Ereignis B sto-chastisch unabhängig, wenn das Eintreten des Er-eignisses A von dem Eintreten oder Nichteintretendes Ereignisses B nicht abhängt.
P [A|B] = P [A] P [B|A] = P [B]
P [A ∩B] = P [A]P [B]
Bemerkung: unabhängig ist nicht gleichbedeutendmit disjunkt
Beispiel:Zwei Ereignisse: A und B mit P [A] > 0, P [B] > 0
P [A ∩B] = ∅ ⇒ P [A ∩B] = 0
aber: P [A ∩B] = 0 = P [A]P [B]
Statistik_II@finasto 6–47

Beispiel 1:
Zweimaliges Werfen eines Würfels
A = „Im ersten Wurf eine 6“B = „Im zweiten Wurf eine 6“
P [B|A] = P [B] =1
6, A und B sind unabhängig
Beispiel 2: Augenfarbe und Intelligenz
A = „Hohe Intelligenz“, B = „Blaue Augen“
Vierfeldertafel der Wahrscheinlichkeiten in einer Po-pulation:
IQ\Augen B (blau) B (nicht blau) Summe
A P [A ∩B] = 0.1 P [A ∩ B] = 0.4 P [A] = 0.5
A P [A ∩B] = 0.1 P [A ∩ B] = 0.4 P [A] = 0.5
Summe P [B] = 0.2 P [B] = 0.8 P [S] = 1
P [A ∩B] = P [A] · P [B] = 0.1,P [A ∩ B] = P [A)] · P [B] = 0.4
⇒ A und B sind unabhängig,
Statistik_II@finasto 6–48

Verallgemeinerung auf mehr als zwei Er-eignisse
Multiplikationssatz:Für Ereignisse A1, . . . , An
P [A1 ∩ . . . ∩An] = P [A1)] · P [A2|A1]
· P [A3|A1 ∩A2] · · ·
· P [An|A1 ∩ . . . ∩An−1]
Unabhängigkeit:Die Ereignisse A1, . . . , An heißen stochastisch unab-hängig, wenn für jede Auswahl Ai1 , . . . , Aim mitm ≤ n gilt
P [Ai1 ∩ . . . ∩Aim ] = P [Ai1 ] · P [Ai2 ] · · ·P [Aim ]
Statistik_II@finasto 6–49

6.8 Totale Wahrscheinlichkeit und dasTheorem von Bayes
Beispiel: [Weinkeller]
• Qualitätswein, Kabinett, Spätlese: 5:3:2
• Weißweinanteil: 1/5, 1/3 bzw. 1/4
Wahrscheinlichkeit für Weinsorten
A1 = Qualitätswein P [A1] = 0, 5
A2 = Kabinett P [A2] = 0, 3
A3 = Spätlese P [A3] = 0, 2
⇒ vollständige Zerlegung von S
A1 ∪A2 ∪A3 = S
A1 ∩A2 = ∅, A1 ∩A3 = ∅, A2 ∩A3 = ∅,
Frage: Wie hoch ist die Wahrscheinlichkeit für EreignisB, eine ausgewählte Flasche ist „Weißwein“?
P [B|A1] =1
5
P [B|A2] =1
3
P [B|A3] =1
4
Statistik_II@finasto 6–50

A
A B
AA
Qualitätswein
KabinettA SpätleseA
1
1
2
23
3
BB
Vorgehen: A1.A2, A3 bilden eine vollständige Zerle-gung des Grundraums S
⇒ B = (B ∩A1) ∪ (B ∩A2) ∪ (B ∩A3)
P [B] =P [(B ∩A1) ∪ (B ∩A2) ∪ (B ∩A3)]
=P [(B ∩A1)] + P [(B ∩A2)] + P [(B ∩A3)]
=P [B|A1]P [A1] + P [B|A2]P [A2]
+ P [B|A3]P [A3]
=1
5· 12+
1
3· 3
10+
1
4· 2
10
=1
4
Statistik_II@finasto 6–51

Totale Wahrscheinlichkeit
Satz von der totalen Wahrscheinlichkeit:Seien A1, . . . , Ak Ereignisse, die eine Zerlegungvon S bilden, d.h. es gilt: Ai ∩ Aj = ∅, i = j, undA1 ∪A2 ∪ · · · ∪Ak = S.Dann folgt für ein Ereignis B ⊂ S:
P [B] = P [A1 ∩B] + P [A2 ∩B] + . . .+ P [Ak ∩B]
=k∑
i=1
P [Ai ∩B]
=
k∑i=1
P [B|Ai] · P [Ai].
Statistik_II@finasto 6–52

Beispiel: [Weinkeller (Fortsetzung)]
Weitere mögliche Fragestellung:Wie groß ist die Wahrscheinlichkeit P [A1|B] dafür,daß eine zufällig ausgewählte Weißweinflasche Quali-tätswein ist?
Grundlage: Wir kennen die Wahrscheinlichkeiten
P [B|Ai] und P [Ai] i = 1, . . . , 3
Aus der Definition der bedingten Wahrscheinlichkeitfolgt:
P [A1 ∩B] = P [A1|B]P [B] = P [B|A1]P [A1]
⇒
P [A1|B] =P [B|A1]P [A1]
P [B]
=P [B|A1]P [A1]∑3i=1 P [B|Ai]P [Ai]
=15 · 1
214
=2
5
Statistik_II@finasto 6–53

Satz von Bayes
[Thomas Bayes, englischer Pastor, Mathematiker, (1702-1761)]
Seien die Vorraussetzungen des Satzes von der totalenWahrscheinlichkeit erfüllt. Dann kann auch nach derWahrscheinlichkeit von Ai gefragt werden unter derBedingung, dass B eingetreten ist (Wahrscheinlichkeita posteriori).
Satz von Bayes:
Seien A1, . . . , Ak Ereignisse, die eine Zerlegung vonS bilden Sei B Ereignis, derart daß P [B] > 0. Danngilt:
P [Aj |B] =P [Aj ]P [B|Aj ]∑ki=1 P [Ai]P [B|Ai]
=P [Aj ]P [B|Aj ]
P [B]
Wir nennen die Wahrscheinlichkeiten
• P [Ai] a-priori Wahrscheinlichkeiten
• P [Ai|B] a-posteriori Wahrscheinlichkeiten
Statistik_II@finasto 6–54
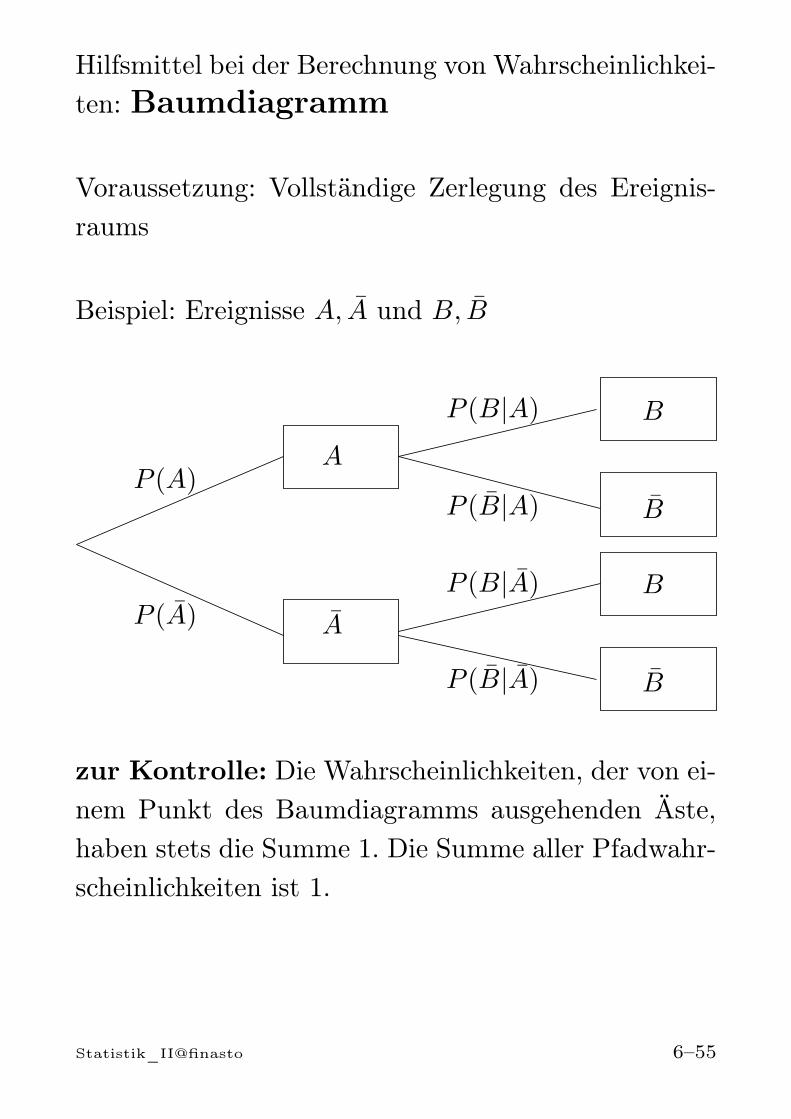
Hilfsmittel bei der Berechnung von Wahrscheinlichkei-ten: Baumdiagramm
Voraussetzung: Vollständige Zerlegung des Ereignis-raums
Beispiel: Ereignisse A, A und B, B
P (A)
P (A)A
A
P (B|A)
P (B|A)
P (B|A)
P (B|A)
B
B
B
B
zur Kontrolle: Die Wahrscheinlichkeiten, der von ei-nem Punkt des Baumdiagramms ausgehenden Äste,haben stets die Summe 1. Die Summe aller Pfadwahr-scheinlichkeiten ist 1.
Statistik_II@finasto 6–55

Pfadregeln:
1) Wird ein Ergebnis durch einen einzelnen Pfad be-schrieben, so ist die Wahrscheinlichkeit dieses Er-gebnisses (= Pfadwahrscheinlichkeit) gleich demProdukt aller Wahrscheinlichkeiten längs des zu-gehörigen Pfades.
2) Setzt sich ein Ereignis aus mehreren Pfaden zu-sammen, so werden die entsprechenden Pfadwahr-scheinlichkeiten addiert.
Statistik_II@finasto 6–56

2 Diskrete Zufallsvariablen
Beispiel:
Zufallsexperiment: dreimaliges Werfen einer idealenMünze (Kopf (K) und Zahl (Z))
EreignisraumΩ = KKK,KKZ,KZK,ZKK,KZZ,ZKZ,ZZK,ZZZAlle Elementarereignisse sind gleichwahrscheinlich
Zufallsvariable: X = Anzahl „Z“
Werte von X:
X = 0 falls das Elementarereignis KKK eintritt
X = 1 falls eines der Elementarereignisse KKZ,
KZK oder ZKK eintritt
X = 2 falls eines der Elementarereignisse KZZ,
ZKZ oder ZZK eintritt
X = 3 falls das Elementarereignis ZZZ eintritt
Statistik_II@finasto 2–1

ZufallsvariableEine numerische Variable oder ein Merkmal X, des-sen Werte oder Ausprägungen die Ergebnisse einesZufallsvorgangs sind, heißt Zufallsvariable X. DieZahl x ∈ R, die X bei einer Durchführung desZufallsvorgangs annimmt, heißt Realisierung oderWert von X.
Formal ist eine Zufallsvariable eine Abbildung, diejedem möglichen Elementarereignis ω ∈ Ω einen Zah-lenwert X(ω) zuweist:
ω 7→ X(ω)
Wie in der deskriptiven Statistik ist das Skalenniveaueines Merkmals entscheidend für das weitere Vorge-hen. Von besonderer Bedeutung ist die Unterschei-dung zwischen diskreten und stetigen Zufallsvaria-blen.
Statistik_II@finasto 2–2

Beispiele:
1) Ω = Menge aller Bürgerinnen und Bürger von Bonn
Zufallsexperiment: Zufälliges Ziehen aus Ω
Diskrete Zufallsvariable: In Abhängigkeit vom Geschlechtnimmt X die Werte 0 und 1 an
X =
0 falls weiblich
1 falls männlich
Stetige Zufallsvariable: Jedem Bürger wird seine Kör-pergröße zugewiesen, X = Körpergröße.
2) Würfelspiel: X = Anzahl der benötigten Versuchebis zum ersten Mal eine „6“ auftritt
X diskrete Zufallsvariable, jede natürliche Zahl istmögliche Ausprägung
Von statistischem Interesse: Wahrscheinlichkeiten, z.BP [X = 1], P [X ≤ 3], P [X ≥ 4], etc.
Anmerkung: Im Fall 1) entsprechen Wahrscheinlich-keiten den relativen Häufigkeiten in der Grundge-samtheit.
Statistik_II@finasto 2–3

2.1 Wahrscheinlichkeitsverteilungen
Eine Zufallsvariable heißt diskret, falls sie nurendlich oder abzählbar unendlich viele Wertex1, x2, . . . , xk, . . . annehmen kann. Die Wahr-scheinlichkeitsverteilung von X ist durch dieWahrscheinlichkeiten
P [X = xi] = pi, i = 1, 2, . . . , k, . . .
gegeben.
Beispiel: Dreimaliges Werfen einer idealen Münze
Elementar- Wahrschein- Anzahl Wahrscheinlich-
ereignis lichkeit der Z keiten von X
ωj P [ωj] xi P [X = xi] = pi
ω1 - KKK P [ω1] = 0, 125 x1 = 0 p1 = 0, 125
ω2 - KKZ P [ω2] = 0, 125 x2 = 1 p2 = 0, 375
ω3 - KZK P [ω3] = 0, 125
ω4 - ZKK P [ω4] = 0, 125
ω5 - KZZ P [ω5] = 0, 125 x3 = 2 p3 = 0, 375
ω6 - ZKZ P [ω6] = 0, 125
ω7 - ZZK P [ω7] = 0, 125
ω8 - ZZZ P [ω8] = 0, 125 x4 = 3 p4 = 0, 125
Statistik_II@finasto 2–4
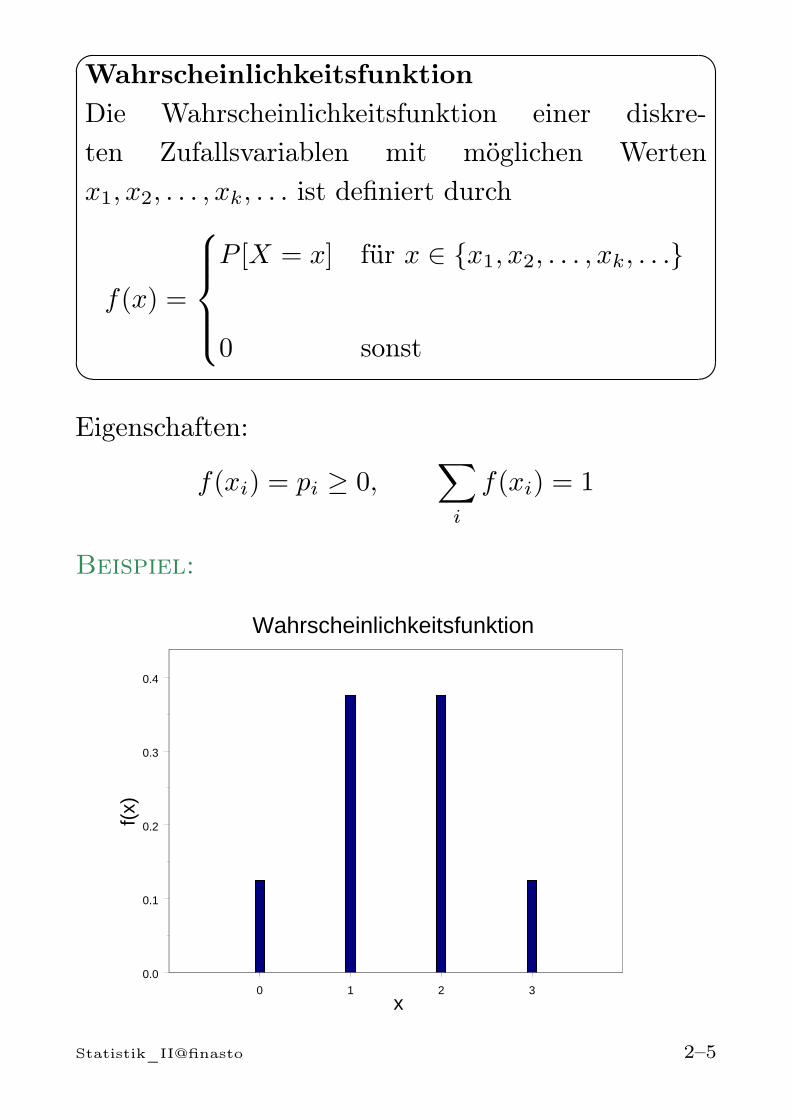
WahrscheinlichkeitsfunktionDie Wahrscheinlichkeitsfunktion einer diskre-ten Zufallsvariablen mit möglichen Wertenx1, x2, . . . , xk, . . . ist definiert durch
f(x) =
P [X = x] für x ∈ x1, x2, . . . , xk, . . .
0 sonst
Eigenschaften:
f(xi) = pi ≥ 0,∑i
f(xi) = 1
Beispiel:
0 1 2 3x
0.0
0.1
0.2
0.3
0.4
f(x)
Wahrscheinlichkeitsfunktion
Statistik_II@finasto 2–5
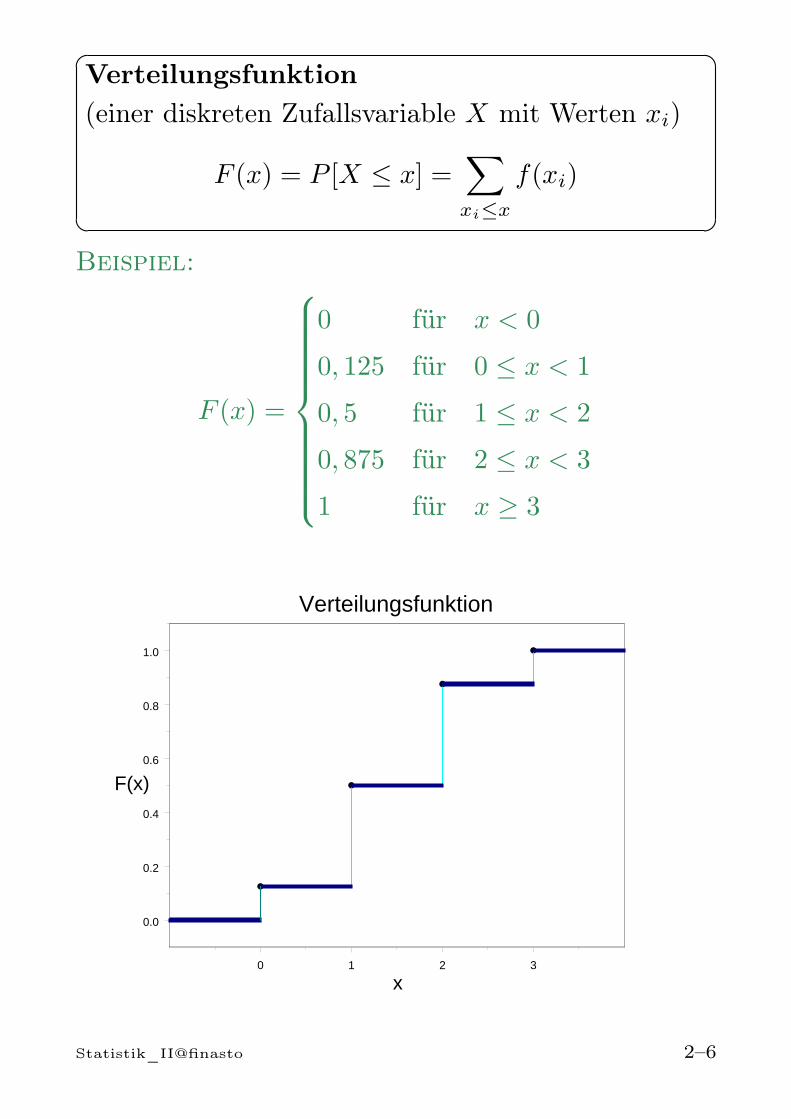
Verteilungsfunktion(einer diskreten Zufallsvariable X mit Werten xi)
F (x) = P [X ≤ x] =∑xi≤x
f(xi)
Beispiel:
F (x) =
0 für x < 0
0, 125 für 0 ≤ x < 1
0, 5 für 1 ≤ x < 2
0, 875 für 2 ≤ x < 3
1 für x ≥ 3
0 1 2 3
0.0
0.2
0.4
0.6
0.8
1.0
x
F(x)
Verteilungsfunktion
Statistik_II@finasto 2–6

Berechnung von Wahrscheinlichkeiten für be-liebige Ereignisse A ⊂ Ω:
P [X ∈ A] =∑
i:xi∈A
P [X = xi] =∑
i:xi∈A
pi
Spezialfälle:
P [X ≤ b] =∑
i:xi≤b
pi = F (b)
P [X ≥ a] =∑
i:xi≥a
pi
P [X > a] =∑
i:xi>a
pi = 1− F (a)
P [X ∈]a, b]] =∑
i:a<xi≤b
pi = F (b)− F (a)
Beispiel: Dreimaliges Werfen einer idealen Münze
P [X ≤ 2] = p1 + p2 + p3 = 0, 875
P [0 < X ≤ 1] = P [X = 1] = p2 = 0, 375
P [0 ≤ X ≤ 1] = p1 + p2 = 0, 5
P [2 ≤ X ≤ 3] = p3 + p4 = 0, 5
Statistik_II@finasto 2–7

2.2 Unabhängigkeit von Zufallsvariablen
Idee: Zwei Zufallsvariablen X und Y sind unabhängig,falls sie sich gegenseitig nicht beeinflussen.
Zwei diskrete Zufallsvariablen X und Y heißen un-abhängig, wenn für alle möglichen Werte x, y
P [X = x, Y = y] = P [X = x] · P [Y = y]
Verallgemeinerung:
X1, . . . , Xn heißen unabhängig, falls
P [X1 = x1, . . . , Xn = xn] = P [X1 = x1] · · ·P [Xn = xn]
Anmerkung: Seien X1, . . . , Xn Zufallsvariablen, diejeweils die einzelnen Versuche bei n-maliger unabhän-giger Wiederholung eines Zufallsexperiments beschrei-ben. Dann gilt
• Alle Xi haben die gleiche Verteilung
• X1, . . . , Xn sind voneinander unabhängig
Statistik_II@finasto 2–8

2.3 Erwartungswert und Varianz
Der Erwartungswert E(X) einer diskreten Zufalls-variable X ist definiert durch
E(X) = x1p1 + . . .+ xkpk + . . . =∑i≥1
xipi
bzw.
E(X) = x1f(x1) + . . .+ xkf(xk) + . . . =∑i≥1
xif(xi)
Statt E(X) schreibt man auch µX oder einfach µ,wenn klar ist, welche Zufallsvariable gemeint ist.
µ = E(X) wird häufig auch als „Mittelwert“ derZufallsvariable X bezeichnet.
Subjektive Interpretation von µX :
pi ist ein „Gewicht“, das dem Wert xi zukommt, daman diesen mit Wahrscheinlichkeit P [X = xi] = pi
erwartet. Für X „erwartet“ man dann die Summe dergewichteten Werte xipi.
Statistik_II@finasto 2–9

Analogie( Statistik I): Empirischer Mittelwert einesdiskreten Merkmals X mit k möglichen Ausprägun-gen: n Beobachtungen mit relativen Häufigkeitenf1,n, . . . , fk,n
x =k∑
i=1
xifi,n
Man beachte jedoch:E(X) charakterisiert eine Zufallsvariablex beschreibt den Schwerpunkt von Daten
„Asymptotischer“ Zusammenhang zwischen x
und E(X): Gesetz der großen Zahlen
Das der Zufallsvariable X zugrundeliegende Zufallsex-periment werde n mal unabhängig voneinander durch-geführt.
xn - Mittelwert der resultierenden Beobachtungen
Gesetz der großen Zahlen: Falls n groß ist, liegtxn mit hoher Wahrscheinlichkeit nahe bei E(X); jegrößer n, umso geringer der zu erwartende Unter-schied
⇒ Häufigkeitsinterpretation von µX .
Statistik_II@finasto 2–10

Beispiele: (Erwartete Wettgewinne)
1) Werfen einer Münze; Wetteinsatz: 1 DM Gewinnbei Zahl, 1 DM Verlust bei Kopf
Zufallsvariable: X =
1 falls „Z“
−1 falls „K“
E(X) =1
2· (−1) +
1
2· 1 = 0
Bei häufigem Werfen der Münze ist der „mittlere“ Ge-winn 0, Gewinne und Verluste gleichen sich aus
2) Dreimaliges Werfen einer Münze; Wetteinsatz: 10DM Gewinn bei „ZZZ“, jeweils 1 DM Verlust bei an-deren Ergebnissen
Zufallsvariable:
X =
10 falls „ZZZ“
−1 sonst
E(X) = 0, 125 · 10 + 0, 875 · (−1) = 0, 375
Bei häufiger Wiederholung des Zufallsexperiments istder „mittlere“ Gewinn 0,375 DM.
Statistik_II@finasto 2–11

Transformationen
Transformationsregel für ErwartungswerteSei g(x) eine reelle Funktion. Dann gilt für Y = g(X)
E(Y ) = E(g(X)) =∑i≥1
g(xi)pi =∑i≥1
g(xi)f(xi)
Beispiel: g(x) = x2, X diskret mit k möglichen Aus-prägungen
E(g(X)) = E(X2) = x21p1 + . . .+ x2
kpk
Lineare Transformationen• Für Y = aX + b gilt:
E(Y ) = aE(X) + b
• Für zwei Zufallsvariablen X1 und X2 und Kon-stanten a1, a2 gilt:
E(a1X1 + a2X2) = a1E(X1) + a2E(X2)
Statistik_II@finasto 2–12

2.4 Varianz und Standardabweichung
Die Varianz Var(X) einer diskreten ZufallsvariableX ist definiert durch
Var(X) = (x1 − µ)2p1 + . . .+ (xk − µ)2pk + . . .
=∑i≥1
(xi − µ)2f(xi)
und die Standardabweichung ist
σX =√Var(X)
Statt Var(X) schreibt man auch σ2X oder einfach σ2,
wenn klar ist, welche Zufallsvariable gemeint ist.
• Varianz als erwartete quadratische Abweichung
Var(X) = E(X − µ)2
• Rechentechnisch günstige Formel
Var(X) = E(X2)− µ2
Statistik_II@finasto 2–13

Lineare TransformationFür Y = aX + b ist
Var(Y ) = a2 Var(X) und σY = |a|σX
Unabhängige Zufallsvariablen: Sind X und Y
unabhängig, so gilt
E(X · Y ) = E(X) · E(Y )
Var(X + Y ) = Var(X) + Var(Y )
Beispiel: Werfen eines idealen Würfels; Gewinn vonX = 1 DM bei „1“ , . . . , X = 6 DM bei „6“
Erwartungswert:
µ = E(X) =
6∑i=1
1
6· i = 3, 5
Varianz:
σ2 = E(X2)− µ2 =6∑
i=1
1
6· i2 − (3, 5)2 = 2, 917
Statistik_II@finasto 2–14

2.5 Weitere Charakeristika von Vertei-lungen
Die Definition von Modus, Median, etc. erfolgt ana-log zu den entsprechenden Definitionen in Statistik I,indem man relative Häufigkeiten durch Wahrschein-lichkeiten ersetzt.
Modus: xmod ist ein Wert für den die Wahrschein-lichkeitsfunktion f(x) = P [X = x] maximal wird.
Quantile: Ein Wert xp mit 0 < p < 1 für den
P [X ≤ xp] = F (xp) ≥ p
undP [X ≥ xp] ≥ 1− p
gilt, heißt p−Quantil der diskreten Zufallsvaribale X.
Für p = 0, 5 heißt xmed = x0,5 Median
Bei symmetrischen Verteilungen gilt:xmod = xmed = µX
Statistik_II@finasto 2–15

2.6 Wichtige diskrete Verteilungsmo-delle
2.6.1 Die diskrete Gleichverteilung
Eine diskrete Zufallsvariable mit möglichen Aus-prägungen x1, . . . , xk heißt gleichverteilt aufx1, . . . , xk, wenn für alle i = 1, . . . , k
P [X = xi] =1
k
gilt
Anwendung: Werfen eines idealen Würfels
Die Zufallsvariable
X = „Augenzahl“
ist gleichverteilt auf 1, 2, . . . , 6
p1 = P [X = 1] = . . . = p6 = P [X = 6] =1
6
Statistik_II@finasto 2–16

Übersicht: Diskrete Gleichverteilung
• Wahrscheinlichkeitsfunktion
f(x) =
1k für x = x1, x2, . . . , xk
0 sonst
• Erwartungswert
E(X) = µ =1
k
k∑i=1
xi
• Varianz
Var(X) = σ2 =1
k
k∑i=1
(xi − µ)2
• Verteilungsfunktion
F (x) =
0 für x < x1
ik für xi ≤ x < xi+1, 1 ≤ i < k
1 für xk ≤ x
Statistik_II@finasto 2–17
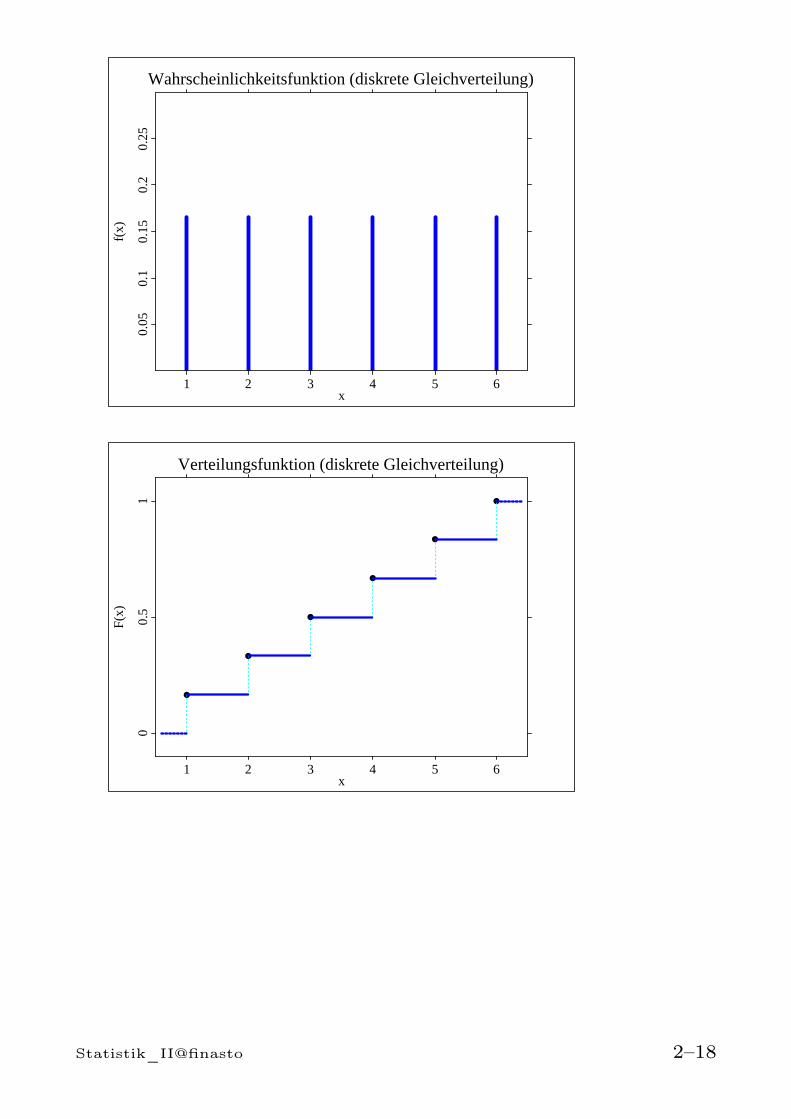
Wahrscheinlichkeitsfunktion (diskrete Gleichverteilung)
1 2 3 4 5 6x
0.05
0.1
0.15
0.2
0.25
f(x)
Verteilungsfunktion (diskrete Gleichverteilung)
1 2 3 4 5 6x
00.
51
F(x)
Statistik_II@finasto 2–18

Bernoulli Variablen
Oft interessiert man sich bei einem Zufallsvorgangnur dafür, ob ein bestimmtes Ereignis A eintritt odernicht. Man spricht dann von einem Bernoulli Vor-gang oder Bernoulli-Experiment. Die Zufallsvariable
X =
1 falls A eintritt
0 falls A nicht eintritt
heißt binäre Variable oder Bernoulli- Variable
Beispiele:A = „weiblich“ (X = 1), A = „männlich“ (X=0)A = „arbeitslos“ (X = 1), A = „nicht arbeitslos“(X=0)
X folgt einer Bernoulli-Verteilung mit Parameterp = P [A], kurz
X ∼ Bernoulli(p)
Es gilt dann:
P [X = 1] = p, P [X = 0] = 1− p
E(X) = p, Var(X) = p(1− p)
Statistik_II@finasto 2–19

2.6.2 Die geometrische Verteilung
Ein Bernoulli-Experiment werde solange wiederholt,bis zum ersten Mal das interessierende Ereignis A
eintritt. Man betrachte
X = Anzahl der Versuche bis
zum ersten Mal „A“ eintritt
Beispiel:
Würfelspiel: Man würfelt solange, bis zum ersten Maleine „6“ geworfen wird.
X = Anzahl der Würfe bis zum ersten Mal „6“ eintritt
⇒ X ist geometrisch verteilt mit Parameter p:
X ∼ G(p)
Herleitung:
Mögliche Werte von X: 1, 2, 3, . . . (alle nat. Zahlen!)
X nimmt einen Wert x an, falls zunächst x−1 mal dasKomplementärereignis A und dann im x−ten VersuchA eintritt. Die Unabhängigkeit der Ereignisse führtauf
P [X = x] = P (A ∩ . . . ∩ A︸ ︷︷ ︸x− 1 mal
∩A) = (1− p)x−1 · p
Statistik_II@finasto 2–20

Übersicht: Geometrische Verteilung
• Wahrscheinlichkeitsfunktion
fG(x) =
(1− p)x−1p für x = 1, 2, 3, . . .
0 sonst
• Erwartungswert
E(X) =1
p
• Varianz
Var(X) =1− p
p2
• Verteilungsfunktion
FG(x) =
[x]∑k=1
(1− p)k−1p für x ≥ 1
0 sonst
[x] - größte ganze Zahl mit [x] ≤ x
Statistik_II@finasto 2–21

Beispiel: Würfelspiel
X = Anzahl der Würfe bis zum ersten Mal „6“ eintritt
Da p = P [„6“ ] = 16 , gilt
X ∼ G(1
6)
E(X) =1
p= 6
Im „Mittel“ braucht man also 6 Versuche, um zumersten Mal eine „6“ zu würfeln.
P [X ≤ 2] = p+ (1− p)p =11
36= 0, 3056
Geometrische Reihe:∑lk=0 α
k = 1−αl+1
1−α für 0 ≤ α < 1
⇒ P [X ≤ 6] = p5∑
k=0
(1− p)k = p1− (1− p)6
p
= 1−(5
6
)6
= 0, 6651
P [X > 10] = 1− P [X ≤ 10]
= 1−
[1−
(5
6
)10]= 0, 1615
Statistik_II@finasto 2–22

2.6.3 Die Binomialverteilung
n unabhängige Wiederholungen eines Bernoulli-Experiments mit gleicher Erfolgswahrscheinlichkeitp. Man betrachte
X = Anzahl der Versuche, bei denen „A“ eintritt
Beispiele:Würfelspiel mit einem fairen Würfel: Mit Wahr-scheinlichkeit p = 1/6 wird eine „6“ geworfen
X = Anzahl der „6“ bei n = 20 Würfen
Meinungsumfrage zu einer bestimmten politischen Ent-scheidung; p = Anteil der Befürworter in der Popula-tion.Einfache Zufallsstichprobe vom Umfang n:
X = Anzahl Befürworter in der Stichprobe
⇒ X ist binomialverteilt mit den Parametern p
und n:X ∼ B(n, p)
Anmerkung: Bernoulli(p) = B(1, p)
Statistik_II@finasto 2–23

Herleitung der Binomialverteilung
Mögliche Werte von X: 0, 1, 2, . . . , n− 1, n
X nimmt einen Wert x an, falls z.B. das Ereignis „zu-nächst x mal A, danach n− x mal A“ eintritt. Unab-hängigkeit impliziert
P [A ∩ . . . ∩A︸ ︷︷ ︸x mal
∩ A ∩ . . . ∩ A︸ ︷︷ ︸n− x mal
] = px(1− p)n−x
Anzahl möglicher Ziehungen, bei denen jeweils x malA und n− x mal A auftritt:
n!
x!(n− x)!=
(n
x
)Alle diese Fälle sind gleichwahrscheinlich
⇒ P [X = x] =
(n
x
)px(1− p)n−x
Statistik_II@finasto 2–24

Herleitung von Erwartungswert und Varianz:
X läßt sich als Summe von unabhängigen Bernoulli-verteilten Zufallsvariablen schreiben:
X =n∑
i=1
Xi
mit
Xi =
1 falls beim i-ten Versuch „A“ eintritt
0 falls beim i-ten Versuch „A“ eintritt
X1, . . . , Xn sind unabhängig, und
E(Xi) = p, Var(Xi) = p(1− p) i = 1, . . . , n
Damit ergibt sich
E(X) = E(X1) + . . .+ E(Xn) = np
Var(X) = Var(X1) + . . .+Var(Xn) = np(1− p)
Statistik_II@finasto 2–25

Übersicht: Binomialverteilung
• Wahrscheinlichkeitsfunktion
fB(x) =
(nx
)px(1− p)n−x für x = 0, 1, 2, . . . , n
0 sonst
• Erwartungswert
E(X) = np
• VarianzVar(X) = np(1− p)
• Verteilungsfunktion
FB(x) =
[x]∑k=0
(nk
)pk(1− p)n−k für x ≥ 0
0 sonst
Statistik_II@finasto 2–26
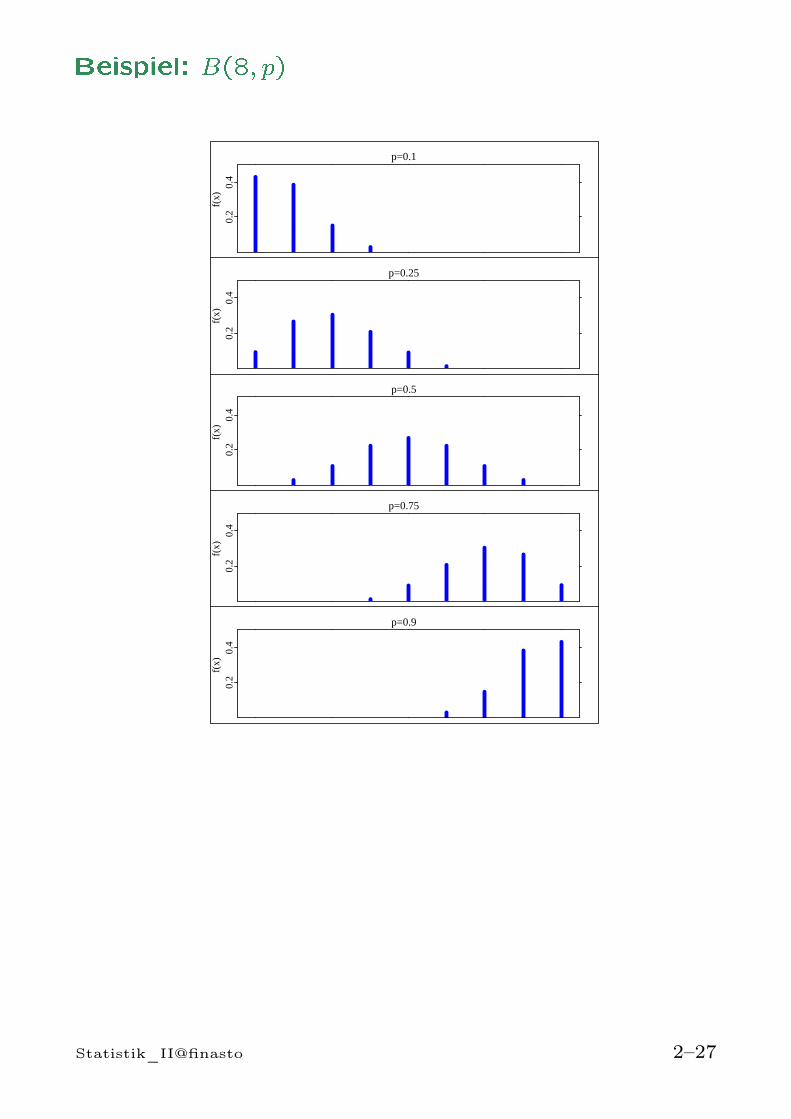
Beispiel: B(8; p)p=0.1
0.2
0.4
f(x)
p=0.25
0.2
0.4
f(x)
p=0.5
0.2
0.4
f(x)
p=0.75
0.2
0.4
f(x)
p=0.9
0.2
0.4
f(x)
Statistik_II@finasto 2–27

Beispiel: Schießen auf eine Zielscheibe
Mittelmäßiger Schütze:
p = P [„Treffer in Schwarze“ ] = 0, 3
X = Anzahl der „Treffer ins Schwarze“ bei n = 5
Schüssen
⇒ X ∼ B(5; 0, 3)
Wahrscheinlichkeit von 2 Treffern
P [X = 2] = fB(2) =
(5
2
)· 0, 32 · 0, 73 = 0, 3087
Wahrscheinlichkeits- und Verteilungsfunktion:
p = 0, 3, n = 5
x fB(x) FB(x)
0 0,1681 0,1681
1 0,3601 0,5282
2 0,3087 0,8369
3 0,1323 0,9692
4 0,0284 0,9976
5 0,0024 1,0000
Statistik_II@finasto 2–28

2.6.4 Die hypergeometrische Verteilung
Aus einer endlichen Grundgesamtheit von N Einhei-ten, von denen M eine interessierende Eigenschaft„A“ besitzen, wird n mal rein zufällig, aber ohne Zu-rücklegen gezogen. Man betrachteX = Anzahl der gezogenen Objekte mit der
Eigenschaft „A“
Beispiele:
Lotterie: Behälter mit N = 50 Losen, M = 10 Gewin-nen und N −M = 40 Nieten
X = Anzahl der „Gewinne“ beim Kauf von n = 25 Losen
Wohngemeinschaft mit N = 5 Personen, M = 2 Frau-en und N − M = 3 Männern. Zufällige Ziehung vonn = 2 unterschiedlichen Personen.
X = Anzahl der Frauen unter den 2 gezogenen Personen
⇒ X folgt einer hypergeometrischen Verteilungmit den Parametern n, M und N :
X ∼ H(n,M,N)
Anmerkung: H(1,M,N) = Bernoulli(p) = B(1, p)
für p = M/N
Statistik_II@finasto 2–29

Übersicht: Hypergeometrische Verteilung
Wir setzen voraus, dass N > n
• Wahrscheinlichkeitsfunktion
fH(x) =
(Mx )(
N−Mn−x )
(Nn)für x = 0, 1, 2, . . . , n
0 sonst
Achtung: Man setzt hier(k1
k2
)= 0, falls k2 > k1.
• Erwartungswert
E(X) = nM
N
• Varianz
Var(X) = nM
N(1− M
N)N − n
N − 1
• Verteilungsfunktion
FH(x) =
[x]∑k=0
(Mx )(N−Mn−k )
(Nn)für x ≥ 0
0 sonst
Statistik_II@finasto 2–30
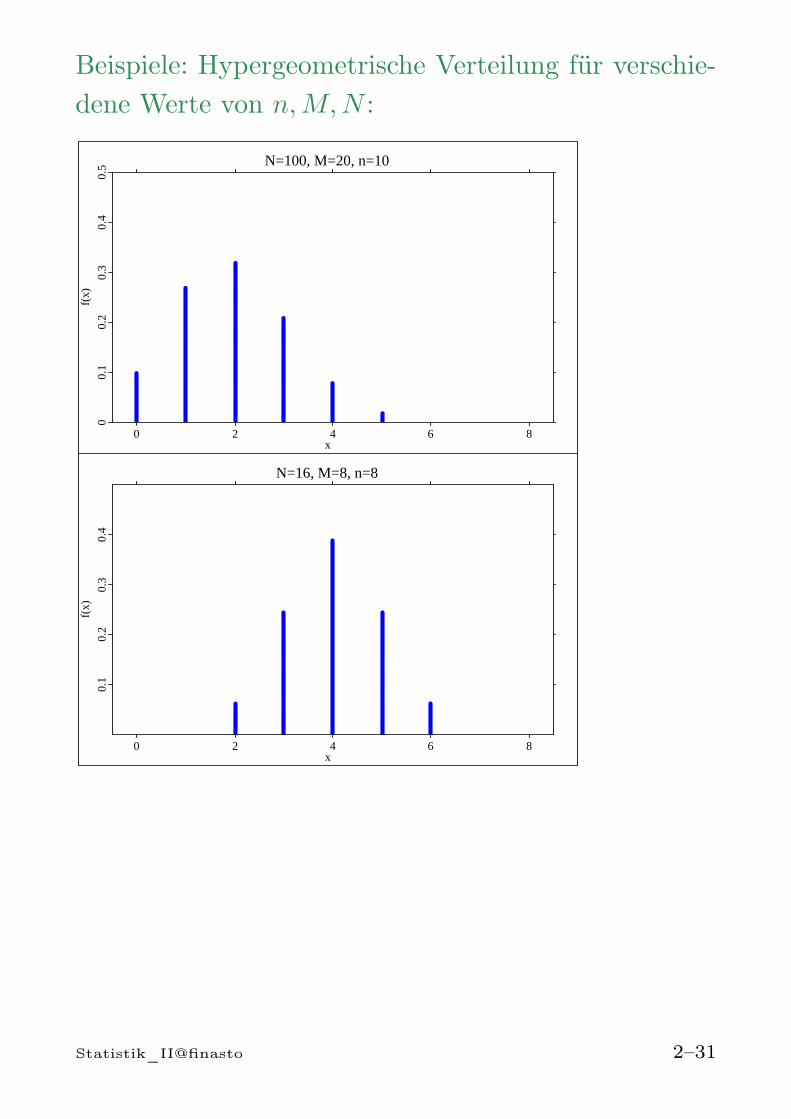
Beispiele: Hypergeometrische Verteilung für verschie-dene Werte von n,M,N :
N=100, M=20, n=10
0 2 4 6 8x
00.
10.
20.
30.
40.
5
f(x)
N=16, M=8, n=8
0 2 4 6 8x
0.1
0.2
0.3
0.4
f(x)
Statistik_II@finasto 2–31

Zusammenhang mit der Binomialverteilung
Ebenso wie eine binomialverteilte lässt sich auch ei-ne hypergeometrische verteilte Zufallsvariable X alsSumme von Bernoulli-verteilten Variablen schreiben:
X =
n∑i=1
Xi
mit
Xi =
1 falls bei der i-ten Ziehung „A“ eintritt
0 falls bei der i-ten Ziehung „A“ eintritt
Da ohne Zurücklegen gezogen wird, sind hier die Zu-fallsvariablen X1, . . . , Xn voneinander abhängig.
Beim Vergleich von XH ∼ H(n,M,N) und XB ∼B(n, p) mit p = M/N ergibt sich:
E(XH) = np = E(XB)
Var(XH) = np(1− p)N − n
N − 1< Var(XB) = np(1− p)
Für kleine Werte n/N ist der „Korrekturfaktor“ N−nN−1
praktisch gleich 1.
Approximation: Sind N und M groß gegenüber n,so gilt approximativ
P (XH = x) ≈ P (XB = x) für x = 0, 1, . . . , nStatistik_II@finasto 2–32

Beispiel: LotterieloseBehälter mit N Losen, M Gewinnen und N −M Nie-ten
X = Anzahl der „Gewinne“ beim Kauf von n = 2
Losen aus dem Behälter
⇒ X ∼ H(2,M,N)
N = 6,M = 2 ⇒ p = M/N = 1/3
H(2, 2, 6) B(2, 1/3)
x fH(x) fB(x)
0 615
= 0.4 49= 0.444
1 815
≈ 0.533 49≈ 0.444
2 115
≈ 0.067 19≈ 0.112
N = 60,M = 20 ⇒ p = M/N = 1/3
H(2, 20, 60) B(2, 1/3)
x fH(x) fB(x)
0 0.441 49= 0.444
1 0.452 49≈ 0.444
2 0.107 19≈ 0.112
⇒ H(2, 20, 60) ≈ B(2, 1/3)
Statistik_II@finasto 2–33

2.6.5 Die Poisson-Verteilung
Die Poisson-Verteilung dient zur Modellierung vonZählvorgängen in kontinuierlicher Zeit. Man be-trachtet
X = Anzahl des Auftretens eines Ereignisses
„A“ in einem festen Zeitintervall [0, 1]
Beispiele:
X = Anzahl der Insolvenzen in einem Jahr
X = Anzahl der Unfälle auf einem vorgegebenen Ab-schnitt der A61 innerhalb eines Monats
X = Anzahl der Anrufe bei der Hotline eines Unter-nehmens innerhalb eines Tages
Zur Modellierung solcher Zählvariablen X wird häufigvon einer „Poisson-Verteilung“ ausgegangen. Diejeweilige Struktur der Verteilung berechnet sich dannin Abhängigkeit von einem Parameter λ > 0, der demim Mittel zu erwartenden Wert von X entspricht. Manschreibt
X ∼ Po(λ)
Statistik_II@finasto 2–34

Übersicht: Poisson-Verteilung
• Wahrscheinlichkeitsfunktion
fPo(x) =
λx
x! e−λ für x = 0, 1, 2, . . .
0 sonst
• Erwartungswert
E(X) = λ
• VarianzVar(X) = λ
• Verteilungsfunktion
FPo(x) =
[x]∑k=0
λk
k! e−λ für x ≥ 0
0 sonst
Statistik_II@finasto 2–35
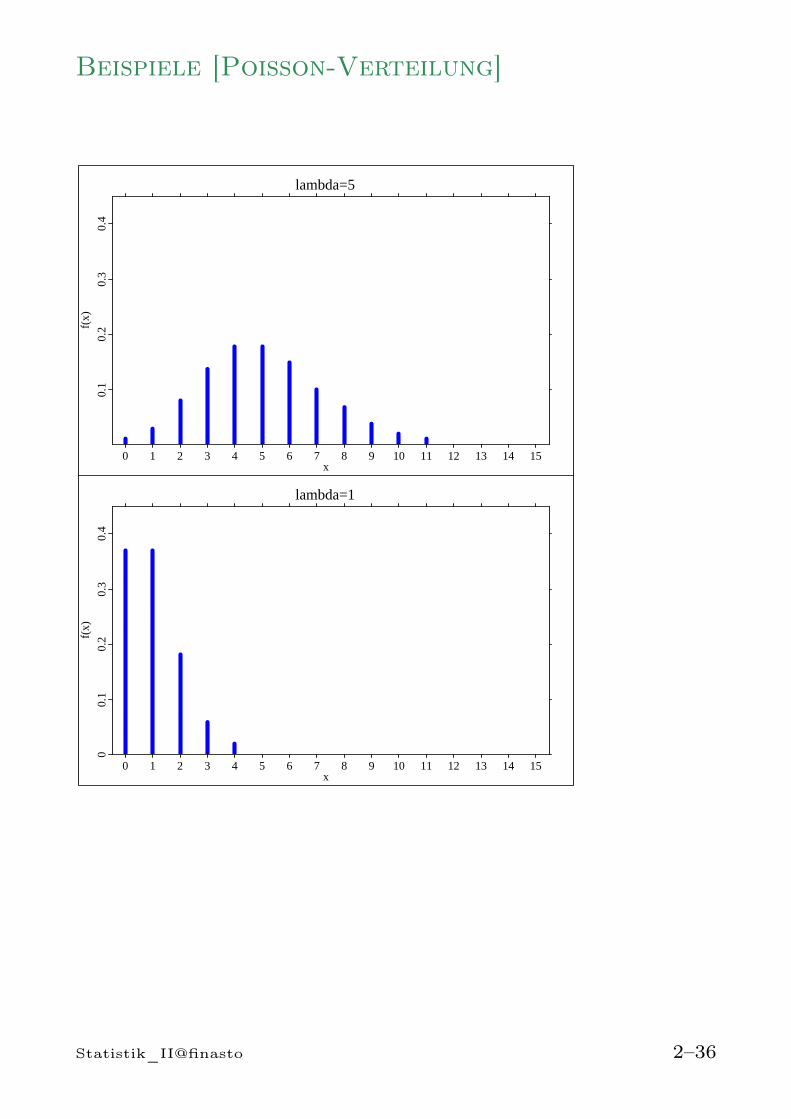
Beispiele [Poisson-Verteilung]
lambda=5
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15x
0.1
0.2
0.3
0.4
f(x)
lambda=1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15x
00.
10.
20.
30.
4
f(x)
Statistik_II@finasto 2–36

Poisson-Verteilung für Intervalle variabler Län-ge (Poisson-Prozess)
Sei
X = Anzahl des Auftretens eines Ereignisses
„A“ im Zeitintervall [0, 1]
und für einen Zeitpunkt t > 0 sei
Xt = Anzahl des Auftretens des Ereignisses
„A“ in dem Zeitintervall [0, t]
Falls X ∼ Po(λ), so ist Xt Poisson-verteilt mit Pa-rameter λ · t:
Xt ∼ Po(λt)
Hieraus folgt
• P [Xt = x] = (λt)x
x! e−λt für x = 0, 1, 2, . . .
• E(Xt) = λt, Var(Xt) = λt
Statistik_II@finasto 2–37

Anmerkung: Die Modellierung von Zählvorgän-gen durch die Poisson-Verteilung beruht auf eini-gen Annahmen, deren Gültigkeit - zumindest nähe-rungsweise - kritisch geprüft werden muss. Sei
X = Anzahl des Auftretens eines Ereignisses
„A“ im Zeitintervall [0, t]
X ist Poisson-verteilt, falls
• Die Wahrscheinlichkeit, dass zwei Ereignisse ge-nau gleichzeitig auftreten, ist Null.
• Die Wahrscheinlichkeit des Eintretens von „A“ in-nerhalb eines sehr kleinen Teilintervalls von [0, t]
ist proportional zur Länge des Intervalls und hängtnicht von dessen Lage auf der Zeitachse ab.
• Die Anzahlen von Ereignissen in zwei disjunktenTeilintervallen sind voneinander unabhängig.
Statistik_II@finasto 2–38

Beispiel:Es treten durchschnittlich zwei Defekte pro Monat aneiner Maschine auf
1) Wie groß ist die Wahrscheinlichkeit, dass in einemMonat kein Defekt auftritt?
X = Anzahl der Defekte in einem Monat
E(X) = λ = 2, X ∼ Po(2)
P [X = 0] = fPo(0) =20
0!e−2 = 0, 135
2) Wie groß ist die Wahrscheinlichkeit, dass in zweiMonaten kein Defekt auftritt?
X2 = Anzahl der Defekte in zwei Monaten
t = 2, X2 ∼ Po(λ · 2) = Po(4)
P [X2 = 0] =40
0!e−4 = e−4 = 0, 018
Statistik_II@finasto 2–39

3) Wie groß ist die Wahrscheinlichkeit, dass in t Mo-naten kein Defekt auftritt?
Xt = Anzahl der Defekte in t Monaten
E(Xt) = λt = 2t, X ∼ Po(2t)
P [Xt = 0] =(2t)0
0!e−2t = e−2t
4) Wie groß ist die Wahrscheinlichkeit, dass die War-tezeit bis zum nächsten Defekt mehr als zwei Monatebeträgt?
Y = Wartezeit bis zum nächsten Defekt
P [Y > 2] = P [X2 = 0] = e−4 = 0, 018
5) Wie groß ist die Wahrscheinlichkeit, dass die War-tezeit bis zum nächsten Defekt weniger als 1/2 Monatbeträgt?
P [Y < 0, 5] = 1− P [Y ≥ 0, 5] = 1− P [X0,5 = 0]
= 1− e−1 = 0, 632
Statistik_II@finasto 2–40

Approximation der Binomialverteilung durcheine Poisson-Verteilung
Sei X ∼ B(n, p). Für großes n bei gleichzeitig kleiner„Erfolgswahrscheinlichkeit“ p gilt
P [X = x] =
(n
x
)px(1− p)n−x ≈ (np)x
x!e−np,
d.h. X ist approximativ Poisson-verteilt mit Para-meter λ = np
Faustregel: Approximation sinnvoll, falls n groß undnp < 5
Beispiel: Lottospiel
Erfolgswahrscheinlichkeit: p = 1/13.983.816
X = Anzahl „6 Richtige“ bei n = 10.000.000 Lotto-spielern, np = 0, 715
⇒ Approximativ
X ∼ Po(0, 715)
Statistik_II@finasto 2–41

3 Stetige Zufallsvariablen
Eine Zufallsvariable heißt stetig, falls zu je zweiWerten a < b auch jeder Zwischenwert im Intervall[a, b] möglich ist
Beispiele:
X = „Alter“, X = „Körpergröße“, X = „Temperatur“,X = „Intelligenzquotient“
In der Praxis kommen häufig Variablen vor, die alsquasistetig aufzufassen sind. Quasistetig bedeutet,dass eine Zufallsvariable extrem viele Ausprägungenbesitzt und die Wahrscheinlichkeit eines einzelnen mög-lichen Wertes vernachlässigbar klein ist. Solche Merk-male werden in der Statistik wie stetige Zufallsvaria-blen behandelt.
Beispiele:
X = „Einkommen“, X = „Vermögen“, X = „Umsatzeiner Firma“,
Statistik_II@finasto 3–1

3.1 Wahrscheinlichkeitsverteilungen
Modellierung von stetigen Zufallsvariablen:
• P [X = x] = 0 für einen einzelnen möglichenWert x
• Ansatz: Man betrachtet Intervalle und zugehöri-ge Wahrscheinlichkeiten
P [X ∈ [a, b]]
Wahrscheinlichkeiten stetiger Zufallsvaria-blenFür stetige Zufallsvariablen X gilt
P [a ≤ X ≤ b] = P [a < X ≤ b] = P [a ≤ X < b]
= P [a < X < b]
undP [X = x] = 0 für jedes x ∈ R
Statistik_II@finasto 3–2

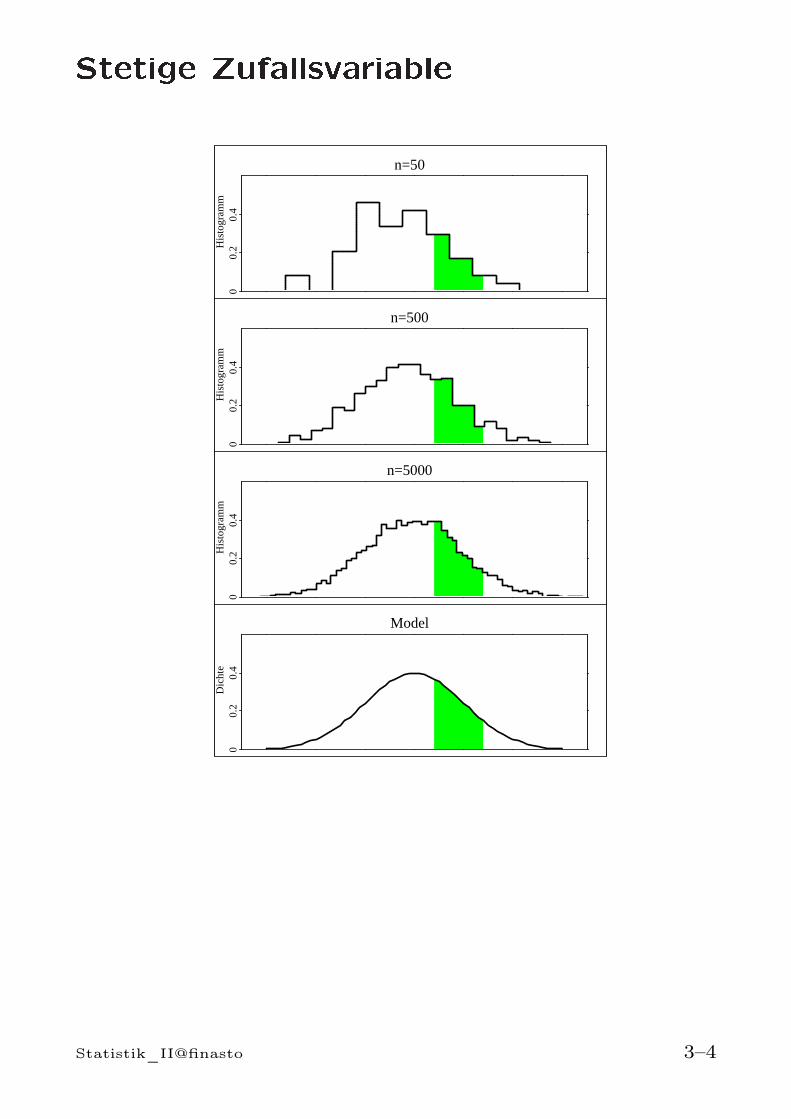
Die Verteilung einer stetigen Zufallsvariablen lässt sichdurch die zugehörige Dichtefunktion charakterisie-ren. Wahrscheinlichkeiten ergeben sich als Flächen un-ter der Dichtefunktion.
Analogie (Statistik I): Histogramm eines steti-gen Merkmals
• Gruppierung anhand von Klassen benachbarterIntervalle [c0, c1), [c1, c2), . . . , [ck−1, ck) der gleichenKlassenbreite δ
• Berechnung der relativen Häufigkeit fj für jedeKlasse [cj−1, cj)
• Histogrammwerte innerhalb jeder Klasse: fj/δ
• Fläche des Histogramms über [cj−1, cj) = fj
Verhalten für großes n:
• fj nahe an P [cj−1 ≤ X < cj ]
• Falls n → ∞ und gleichzeitig δ → 0, so konver-giert das Histogramm gegen eine Funktionf(x) ≥ 0 (=Dichtefunktion)
P [a ≤ X ≤ b] = Fläche von f(x) über [a, b]
=
∫ b
a
f(x)dx
Statistik_II@finasto 3–3
Stetige Zufallsvariablen=50
00.
20.
4H
isto
gram
m
n=500
00.
20.
4H
isto
gram
m
n=5000
00.
20.
4H
isto
gram
m
Model
00.
20.
4D
icht
e
Statistik_II@finasto 3–4

Flächen und Integrale:
Für eine positive Funktion f(x) ≥ 0 gilt∫ b
a
f(x)dx = Fläche von f(x) über [a, b]
Man betrachte eine allgemeine Funktion g(x) mitpositiven und negativen Werten.
• positiver Teil von g(x):
g+(x) = max0, g(x)
• negativer Teil von g(x):
g−(x) = min0, g(x)
⇒∫ b
a
g(x)dx = Fläche von g+(x) über [a, b]
− Fläche von g−(x) über [a, b]
Statistik_II@finasto 3–5

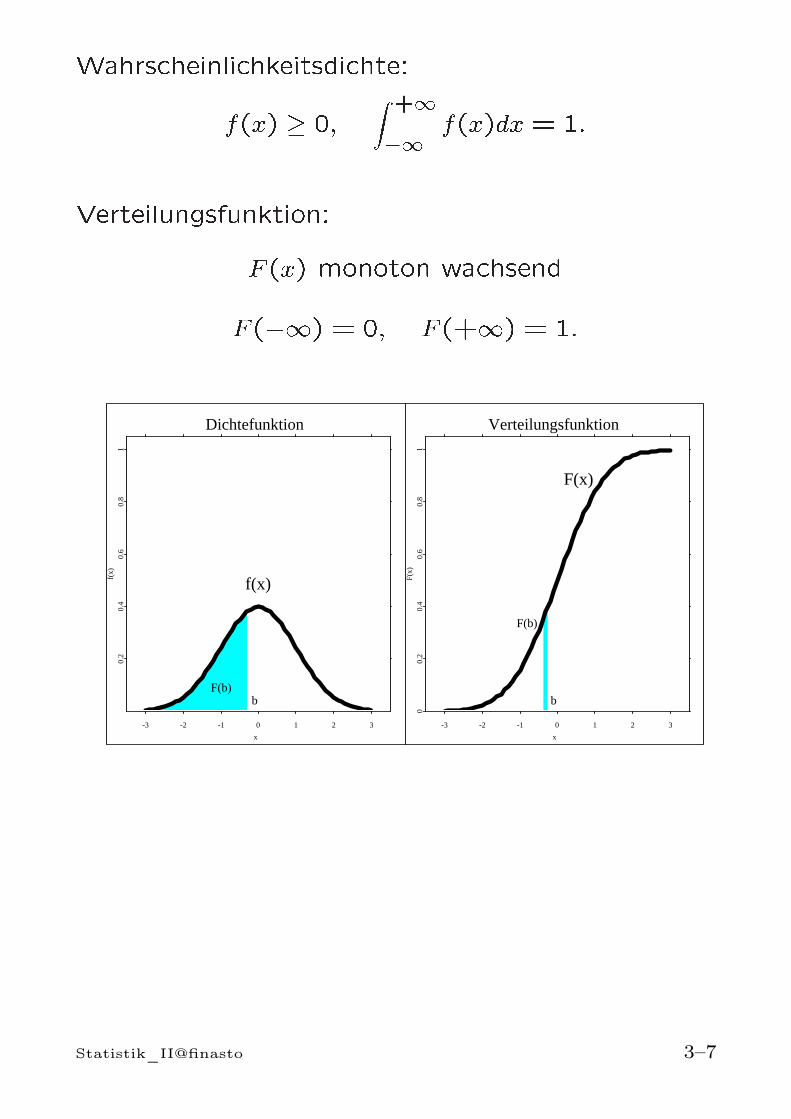
Stetige Zufallsvariablen und DichtenX stetige Zufallsvariable: Es existiert eine Funktionf(x), so dass für jedes Intervall [a, b]
P [a ≤ X ≤ b] =
∫ b
a
f(x)dx
f heißt (Wahrscheinlichkeits-) Dichte von X
Eigenschaften von Dichten:
• Positivität: f(x) ≥ 0
• Normierung: Die Gesamtfläche zwischenx-Achse und f(x) ist gleich 1,
P [−∞ < X < ∞] =
∫ ∞
−∞f(x)dx = 1
Verteilungsfunktion einer stetigen Zufallsva-riablen
F (x) = P [X ≤ x] =
∫ x
−∞f(t)dt
Statistik_II@finasto 3–6
Wahrscheinlichkeitsdichte:f(x) 0; Z +11 f(x)dx = 1:Verteilungsfunktion:F(x) monoton wachsendF(1) = 0; F(+1) = 1:
Dichtefunktion
-3 -2 -1 0 1 2 3
x
0.2
0.4
0.6
0.8
1f(
x)
f(x)
bF(b)
Verteilungsfunktion
-3 -2 -1 0 1 2 3
x
00.
20.
40.
60.
81
F(x)
F(x)
b
F(b)
Statistik_II@finasto 3–7

Die Verteilungsfunktion ist ein zentrales Werkzeug zurBerechnung von Wahrscheinlichkeiten. Die Verteilungs-funktion einer stetigen Zufallsvariable besitzt folgendeEigenschaften:
• F (x) ist eine stetige, monoton wachsende Funkti-on, 0 ≤ F (x) ≤ 1.
• F (a) = P [X < a]
• P [X ≥ a] = P [X > a] = 1− F (a)
• P [a ≤ X ≤ b] = P [a < X < b] = F (b)− F (a)
Interpretation von Dichten:
• f(x) groß für alle Werte in einem Intervall [a, b]:Es besteht eine relativ hohe Wahrscheinlichkeit,dass X einen Wert in [a, b] annimmt
• f(x) sehr klein für alle Werte in einem Intervall[c, d]: Es besteht eine sehr geringe Wahrscheinlich-keit, dass X einen Wert in [c, d] annimmt
Statistik_II@finasto 3–8
Klassifikation von Verteilungen
-3 -2 -1 0 1 2 30.0
0.1
0.2
0.3
0.4
symmetrisch, unimodal
0 1 2 3 40.0
0.2
0.4
0.6
linkssteil
-4 -3 -2 -10.0
0.2
0.4
0.6
rechtssteil
-3 -2 -1 0 1 2 30.0
0.2
0.4
0.6
0.8
1.0
bimodal
-2.5 -2.0 -1.5 -1.0 -0.5 0.0 0.5 1.0 1.5 2.0 2.5 3.00
1
2
3
4
multimodal
Statistik_II@finasto 3–9

Spezialfall: Stetige Gleichverteilung
Stetige GleichverteilungEine stetige Zufallsvariable mit Ausprägungen in ei-nem Intervall [a, b] heißt gleichverteilt, falls für je-des Teilintervall [c, d] ⊂ [a, b] gilt
P [c ≤ X ≤ d] =d− c
b− a
Man schreibt: X ∼ U(a, b)
Wahrscheinlichkeitsdichte
fU (x) =
1b−a für a ≤ x ≤ b
0 sonst
Verteilungsfunktion
FU (x) =
0 für x < a
x−ab−a für a ≤ x ≤ b
1 für x > b
Statistik_II@finasto 3–10
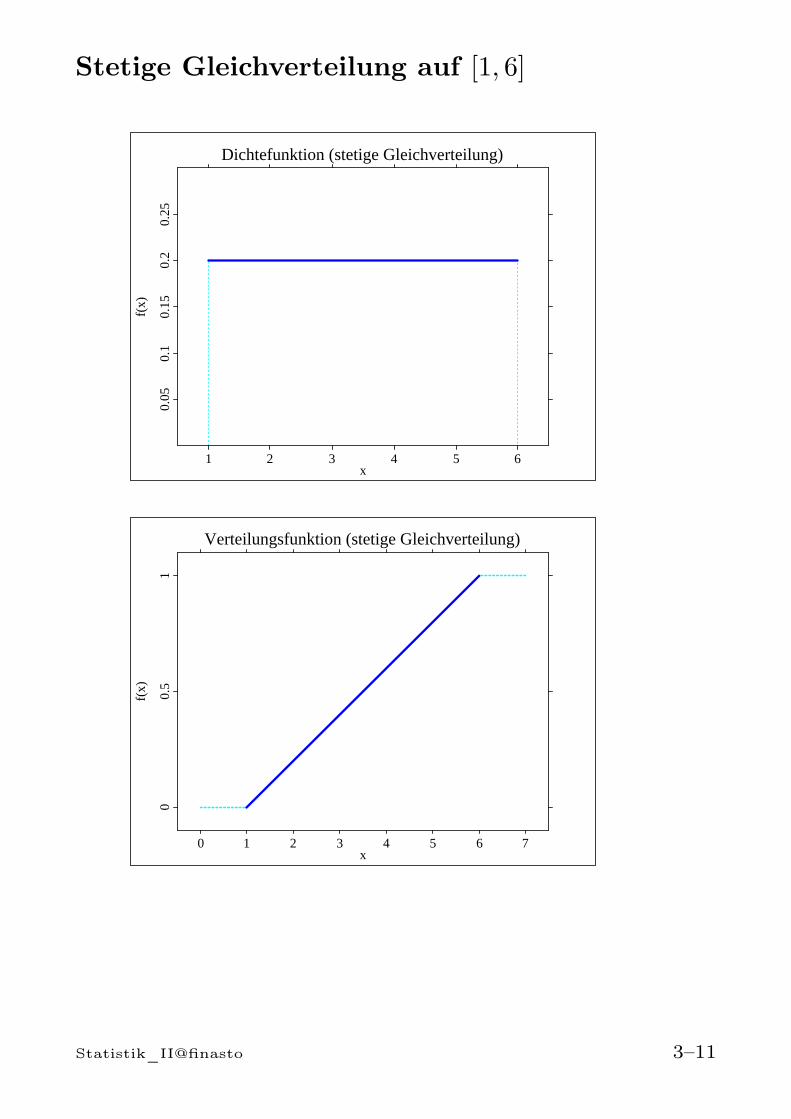
Stetige Gleichverteilung auf [1, 6]
Dichtefunktion (stetige Gleichverteilung)
1 2 3 4 5 6x
0.05
0.1
0.15
0.2
0.25
f(x)
Verteilungsfunktion (stetige Gleichverteilung)
0 1 2 3 4 5 6 7x
00.
51
f(x)
Statistik_II@finasto 3–11

Beispiel: Wartezeit auf eine Straßenbahn
• Ideale Welt: An einer bestimmten Haltestelle hältjeweils genau alle 20 Minuten eine Straßenbahn
• Eine Person kommt ohne Kenntnis des Fahrplanszu einer zufälligen Zeit an die Haltestelle
X = „Wartezeit (in Minuten) auf die nächste Stra-ßenbahn“
⇒ X ∼ U(0, 20)
P [0 ≤ X ≤ 20] = 1
P [X ≤ 10] =10
20= 0, 5
P [X ≥ 10] = 1− 10
20= 0, 5
P [5 ≤ X ≤ 10] =10
20− 5
20= 0, 25
Statistik_II@finasto 3–12

3.2 Verteilungsparameter
Erwartungswert
Diskrete Zufallsvariable:
µ = E(X) =∑i≥1
xif(xi)
Stetige Zufallsvariable:
µ = E(X) =
∫ ∞
−∞x · f(x)dx
Rechenregeln:
• Y = aX + b, a, b beliebig
E(Y ) = E(aX + b) = aE(X) + b
• Für zwei Zufallsvariablen X und Y
E(X + Y ) = E(X) + E(Y )
Beispiel: X ∼ U(a, b) → E(X) = a+b2
Statistik_II@finasto 3–13
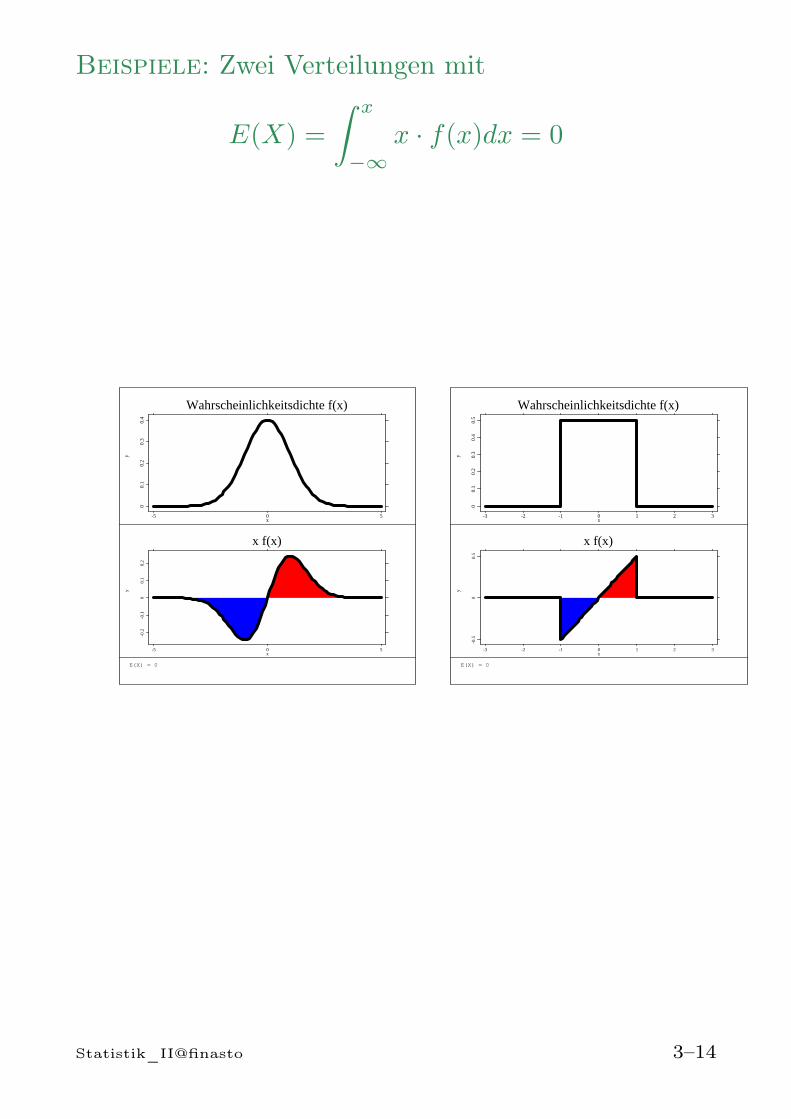
Beispiele: Zwei Verteilungen mit
E(X) =
∫ x
−∞x · f(x)dx = 0
Wahrscheinlichkeitsdichte f(x)
-5 0 5x
00.
10.
20.
30.
4
y
x f(x)
-5 0 5x
-0.2
-0.1
00.
10.
2
y
E(X) = 0
Wahrscheinlichkeitsdichte f(x)
-3 -2 -1 0 1 2 3x
00.
10.
20.
30.
40.
5
y
x f(x)
-3 -2 -1 0 1 2 3x
-0.5
00.
5
y
E(X) = 0
Statistik_II@finasto 3–14
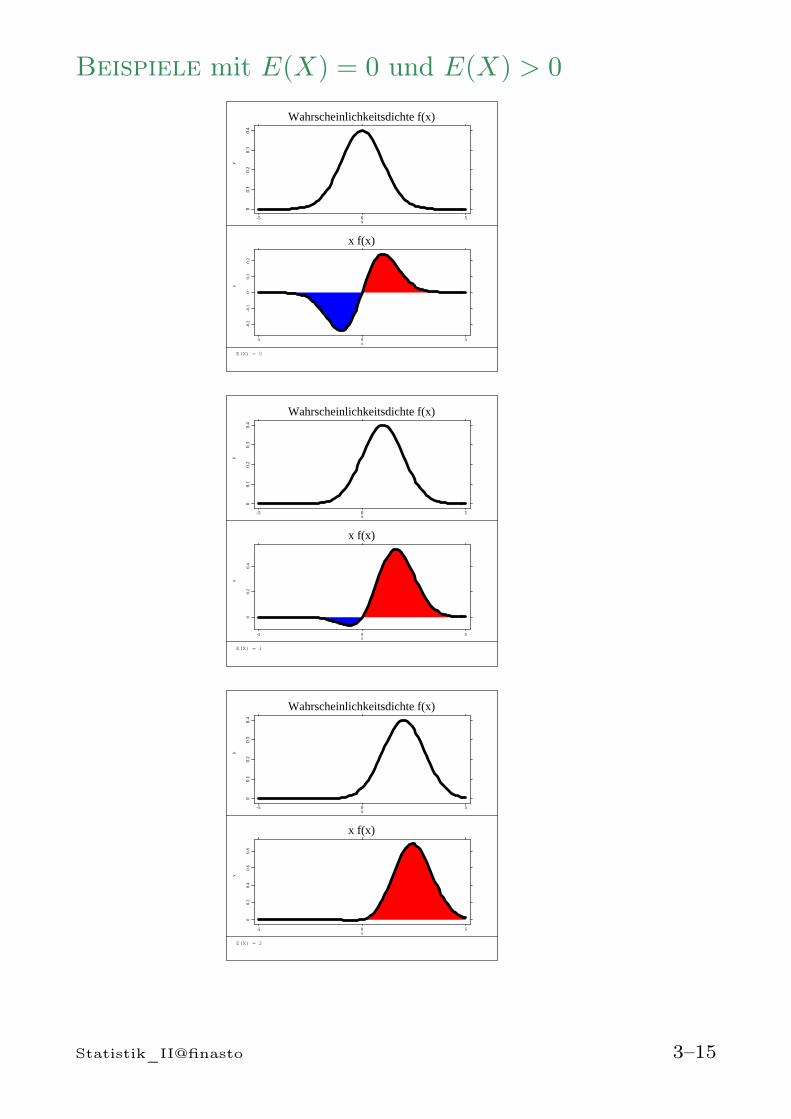
Beispiele mit E(X) = 0 und E(X) > 0
Wahrscheinlichkeitsdichte f(x)
-5 0 5x
00.
10.
20.
30.
4
y
x f(x)
-5 0 5x
-0.2
-0.1
00.
10.
2
y
E(X) = 0
Wahrscheinlichkeitsdichte f(x)
-5 0 5x
00.
10.
20.
30.
4
y
x f(x)
-5 0 5x
00.
20.
4
y
E(X) = 1
Wahrscheinlichkeitsdichte f(x)
-5 0 5x
00.
10.
20.
30.
4
y
x f(x)
-5 0 5x
00.
20.
40.
60.
8
y
E(X) = 2
Statistik_II@finasto 3–15

Varianz
Diskrete Zufallsvariable:
σ2 = Var(X) =∑i≥1
(xi − µ)2f(xi)
Stetige Zufallsvariable:
σ2 = Var(X) =
∫ ∞
−∞(x− µ)2 · f(x)dx
σ =√Var(X) heißt Standardabweichung
Rechenregeln:
• Var(X) = E(X − µ)2 = E(X2)− µ2
• Y = aX + b, a, b beliebig
Var(Y ) = Var(aX + b) = a2 ·Var(X)
• Für unabhängige Zufallsvariablen X und Y
Var(X + Y ) = Var(X) + Var(Y )
Beispiel: X ∼ U(a, b) ⇒ Var(X) = (b−a)2
12
Statistik_II@finasto 3–16

• Der Erwartungswert µ = E(X) ist ein Lagepara-meter, der Aufschluss über das Zentrum der Ver-teilung gibt.
• Die Standardabweichung ist ein Maß für dieDispersion
Ungleichung von Tschebyscheff:
P [|X − µ| > kσ] ≤ 1
k2für alle k > 0
⇒ P [µ− kσ ≤ X ≤ µ+ kσ] ≥ 1− 1
k2
[µ− kσ, µ+ kσ] heißt zentrales Schwankungsin-tervall
k P [µ− kσ ≤ X ≤ µ+ kσ]
2 ≥ 1− 14 = 0, 75
3 ≥ 1− 19 ≈ 0, 89
4 ≥ 1− 116 = 0, 9375
Achtung: Die Ungleichung gibt nur eine untere Schran-ke für die Wahrscheinlichkeit. Genauere Berechnungenauf der Basis spezieller Verteilungsmodelle.
Statistik_II@finasto 3–17
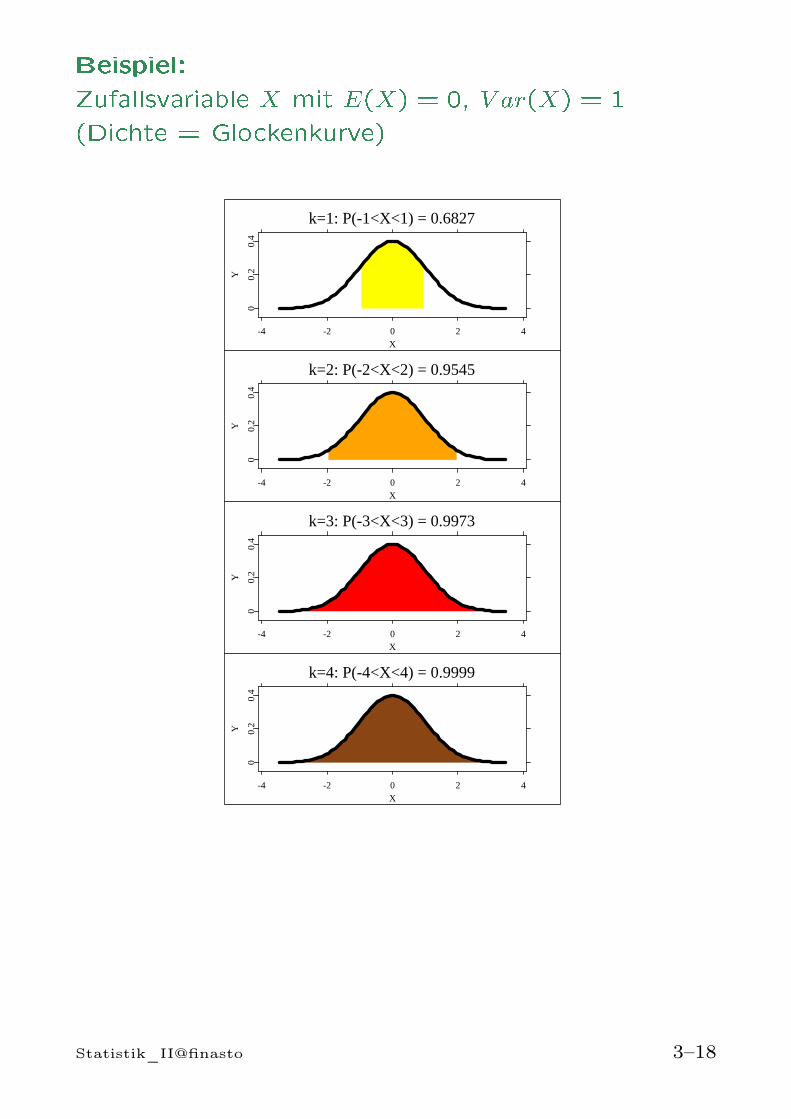
Beispiel:Zufallsvariable X mit E(X) = 0, V ar(X) = 1(Dichte = Glockenkurve)k=1: P(-1<X<1) = 0.6827
-4 -2 0 2 4X
00.
20.
4
Y
k=2: P(-2<X<2) = 0.9545
-4 -2 0 2 4X
00.
20.
4
Y
k=3: P(-3<X<3) = 0.9973
-4 -2 0 2 4X
00.
20.
4
Y
k=4: P(-4<X<4) = 0.9999
-4 -2 0 2 4X
00.
20.
4
Y
Statistik_II@finasto 3–18
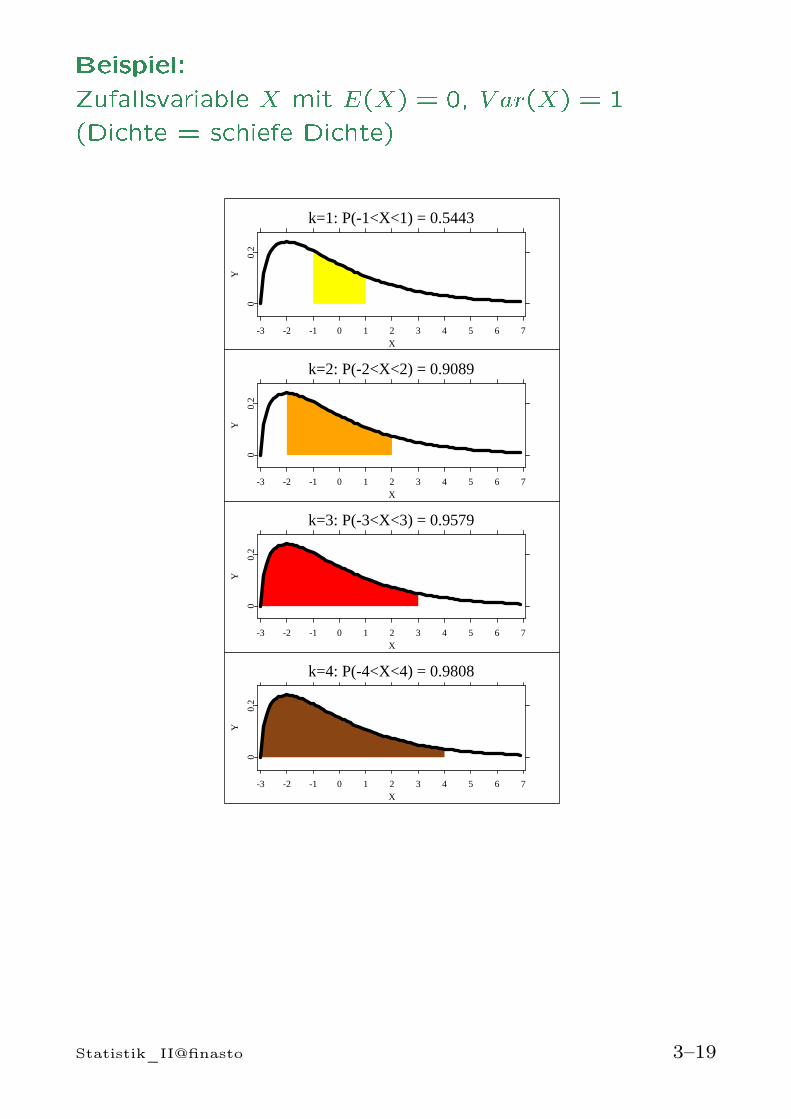
Beispiel:Zufallsvariable X mit E(X) = 0, V ar(X) = 1(Dichte = schiefe Dichte)k=1: P(-1<X<1) = 0.5443
-3 -2 -1 0 1 2 3 4 5 6 7X
00.
2
Y
k=2: P(-2<X<2) = 0.9089
-3 -2 -1 0 1 2 3 4 5 6 7X
00.
2
Y
k=3: P(-3<X<3) = 0.9579
-3 -2 -1 0 1 2 3 4 5 6 7X
00.
2
Y
k=4: P(-4<X<4) = 0.9808
-3 -2 -1 0 1 2 3 4 5 6 7X
00.
2
Y
Statistik_II@finasto 3–19

Weitere Verteilungsparameter einer stetigen Zu-fallsvariable X
Modus: xmod ist ein Wert, für den die Dichtefunktionf(x) maximal wird.
Median: xmed ist der Wert, für den gilt:
F (xmed) = P [X ≤ xmed] = P [X ≥ xmed] = 1−F (xmed) =1
2
Quantile: Für 0 < p < 1 ist das p-Quantil xp derWert, für den
F (xp) = P [X ≤ xp] = p
und1− F (xp) = P [X ≥ xp] = 1− p
gilt.
Median und Quantile sind eindeutig bestimmt, wenndie Verteilungsfunktion F streng monoton ist.
Statistik_II@finasto 3–20
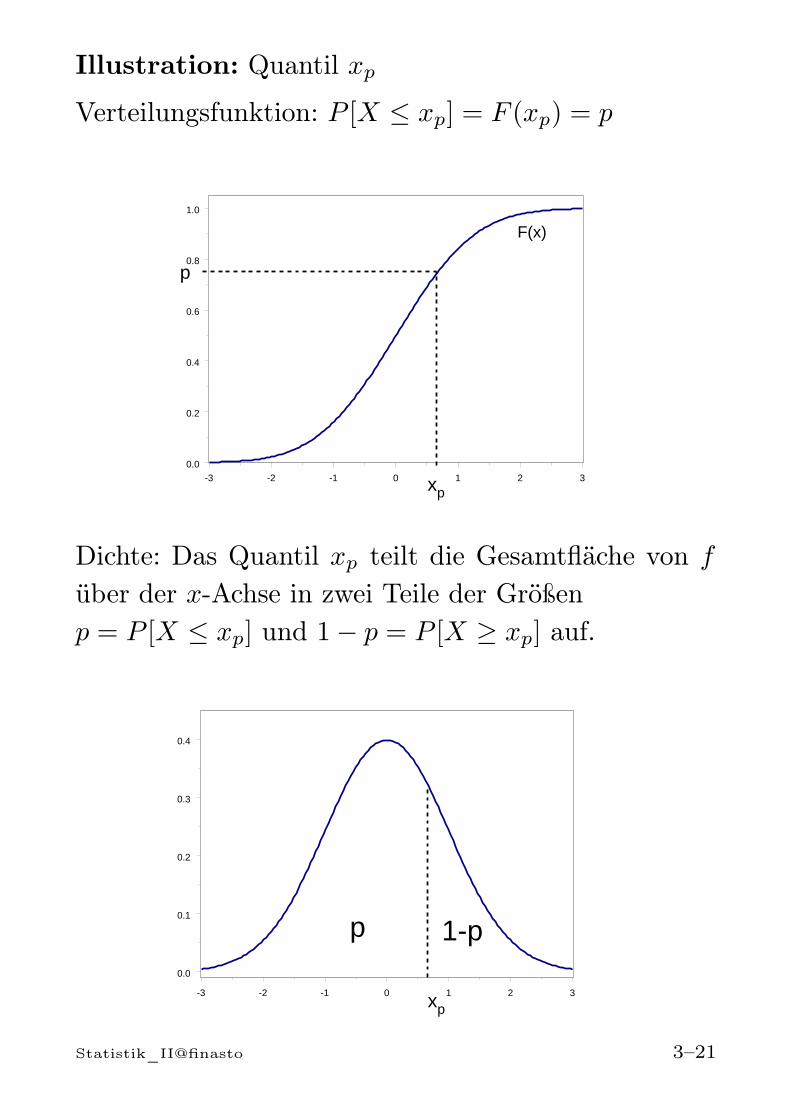
Illustration: Quantil xp
Verteilungsfunktion: P [X ≤ xp] = F (xp) = p
-3 -2 -1 0 1 2 3xp
0.0
0.2
0.4
0.6
0.8
1.0
p
F(x)
Dichte: Das Quantil xp teilt die Gesamtfläche von f
über der x-Achse in zwei Teile der Größenp = P [X ≤ xp] und 1− p = P [X ≥ xp] auf.
-3 -2 -1 0 1 2 3xp
0.0
0.1
0.2
0.3
0.4
1-pp
Statistik_II@finasto 3–21
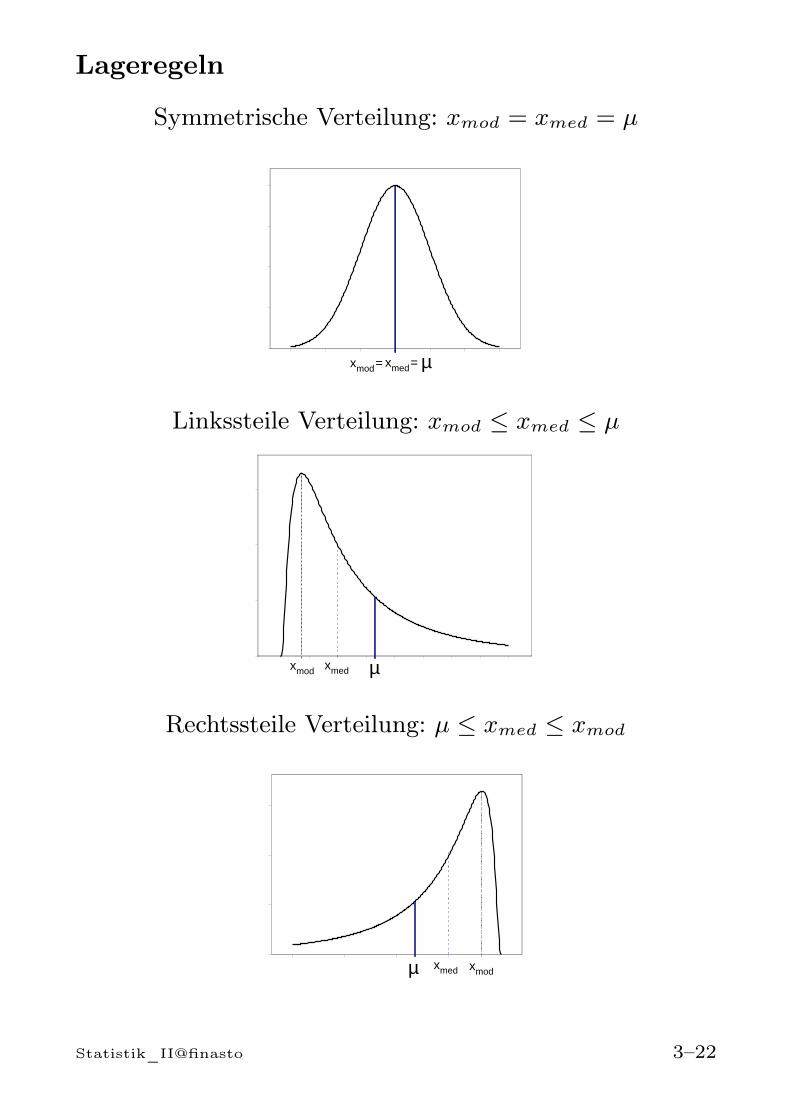
Lageregeln
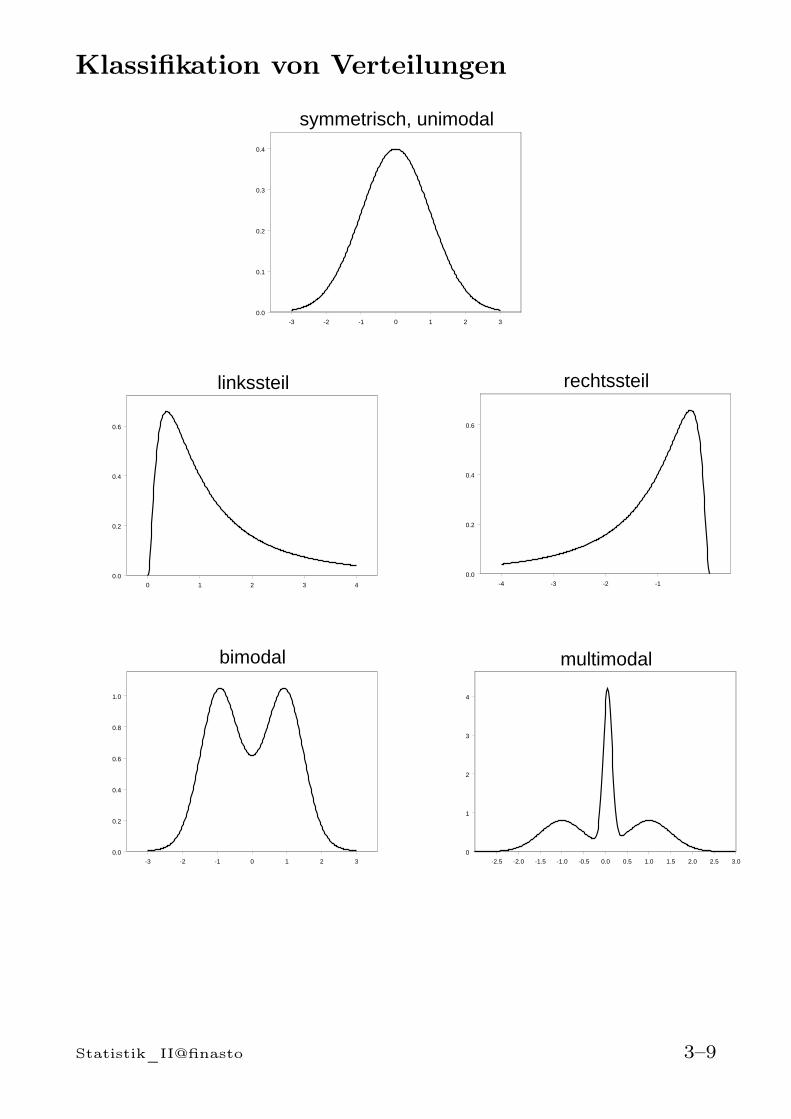
Symmetrische Verteilung: xmod = xmed = µ
xmod= xmed= µ
Linkssteile Verteilung: xmod ≤ xmed ≤ µ
xmod xmed µ
Rechtssteile Verteilung: µ ≤ xmed ≤ xmod
xmodxmedµ
Statistik_II@finasto 3–22
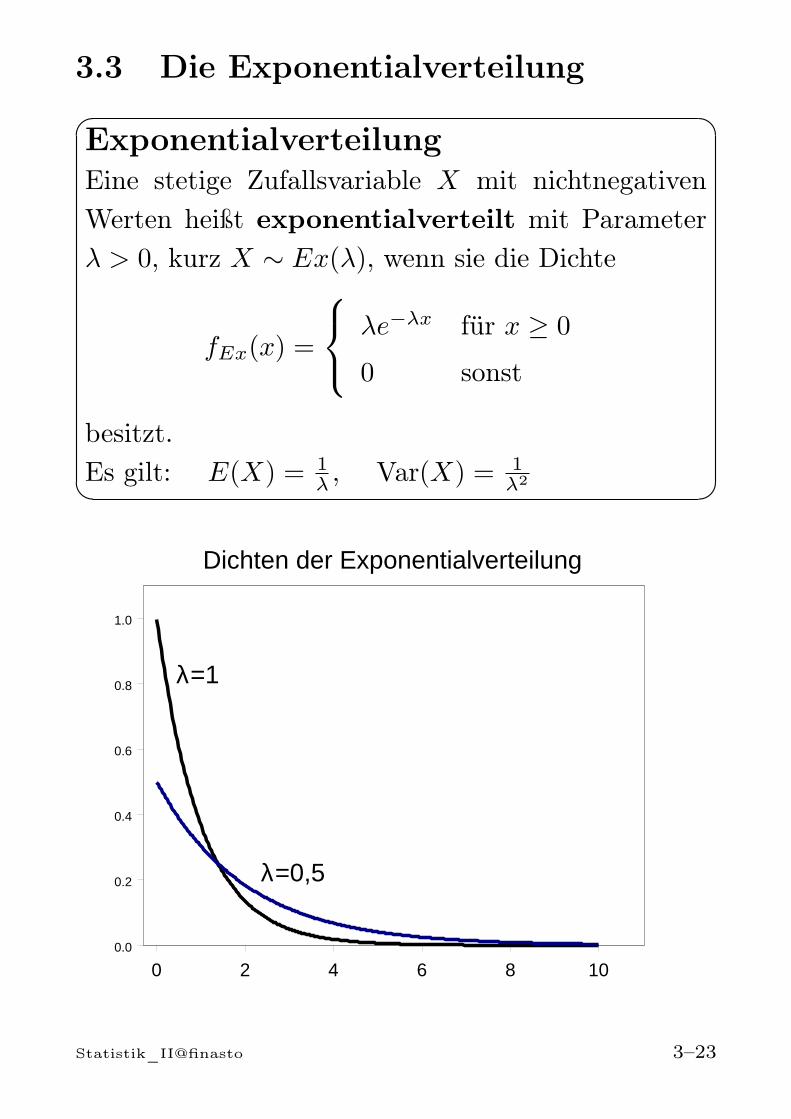
3.3 Die Exponentialverteilung
ExponentialverteilungEine stetige Zufallsvariable X mit nichtnegativenWerten heißt exponentialverteilt mit Parameterλ > 0, kurz X ∼ Ex(λ), wenn sie die Dichte
fEx(x) =
λe−λx für x ≥ 0
0 sonst
besitzt.Es gilt: E(X) = 1
λ , Var(X) = 1λ2
0 2 4 6 8 100.0
0.2
0.4
0.6
0.8
1.0
λ=1
λ=0,5
Dichten der Exponentialverteilung
Statistik_II@finasto 3–23

Verteilungsfunktion
FEx(x) =
1− e−λx für x ≥ 0
0 für x < 0
Zusammenhang mit der Poisson-Verteilung:
Y = Anzahl des Auftretens eines Ereignisses
„A“ in einem festen Zeitintervall [0, 1]
Yt = Anzahl des Auftretens des Ereignisses
„A“ in dem Zeitintervall [0, t]
Y ∼ Po(λ) ⇒ Yt ∼ Po(λt)
Für
X = Wartezeit bis zum ersten Auftreten
des Ereignisses „A“
gilt dannX ∼ Ex(λ),
denn
P [X ≤ t] = 1− P [Yt = 0] = 1− e−λt
Statistik_II@finasto 3–24

3.4 Die Normalverteilung(Gauß-Verteilung)
NormalverteilungEine Zufallsvariable X heißt normalverteilt mitParametern µ ∈ R und σ2 > 0, kurz X ∼ N(µ, σ2),wenn sie die Dichte
f(x) =1√2πσ
exp
(− (x− µ)2
2σ2
)für x ∈ R
besitzt.Es gilt: E(X) = µ, Var(X) = σ2
• Die Normalverteilung wird auch als Gauß-Verteilungund die Dichte als Gauß-Kurve bezeichnet
• Die Normalverteilung spielt eine zentrale Rollein der induktiven Statistik. Bei sehr vielen Zu-fallsphänomenen wird angenommen, dass sie zu-mindest approximativ normalverteilt sind.
• Normalverteilungen sind unimodal und symme-trisch un ihren Mittelwert µ
Statistik_II@finasto 3–25
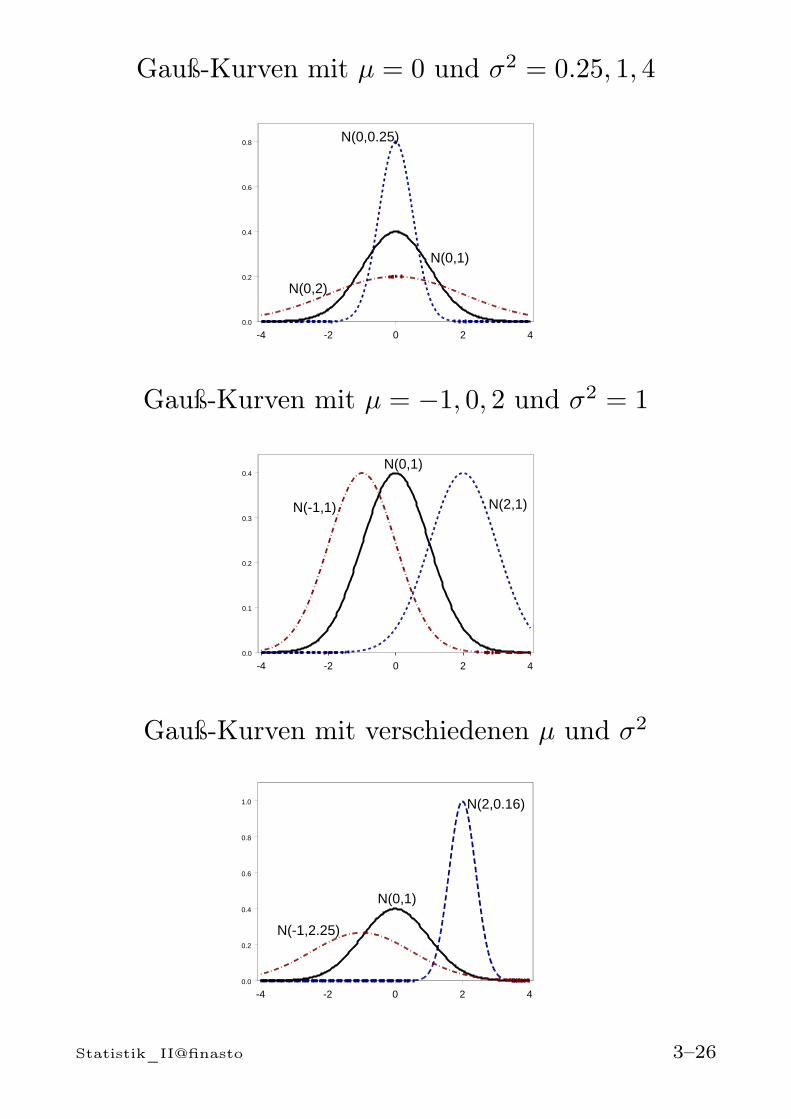
Gauß-Kurven mit µ = 0 und σ2 = 0.25, 1, 4
-4 -2 0 2 40.0
0.2
0.4
0.6
0.8 N(0,0.25)
N(0,1)
N(0,2)
Gauß-Kurven mit µ = −1, 0, 2 und σ2 = 1
-4 -2 0 2 40.0
0.1
0.2
0.3
0.4N(0,1)
N(-1,1) N(2,1)
Gauß-Kurven mit verschiedenen µ und σ2
-4 -2 0 2 40.0
0.2
0.4
0.6
0.8
1.0 N(2,0.16)
N(0,1)
N(-1,2.25)
Statistik_II@finasto 3–26

Spezialfall mit µ = 0, σ2 = 1:Standardnormalverteilung N(0, 1)
Dichte der Standardnormalverteilung N(0, 1):
ϕ(x) =1√2π
exp
(−x2
2
)für x ∈ R
Verteilungsfunktion:
Φ(x) =
∫ x
−∞ϕ(t)dt =
∫ x
−∞
1√2π
exp
(− t2
2
)dt
• Die Standardnormalverteilung ist symmetrisch zumNullpunkt,
Φ(−x) = 1− Φ(x)
• Die Werte von Φ(z) sind tabelliert.
Statistik_II@finasto 3–27
Die Quantile der Standardnormalverteilung
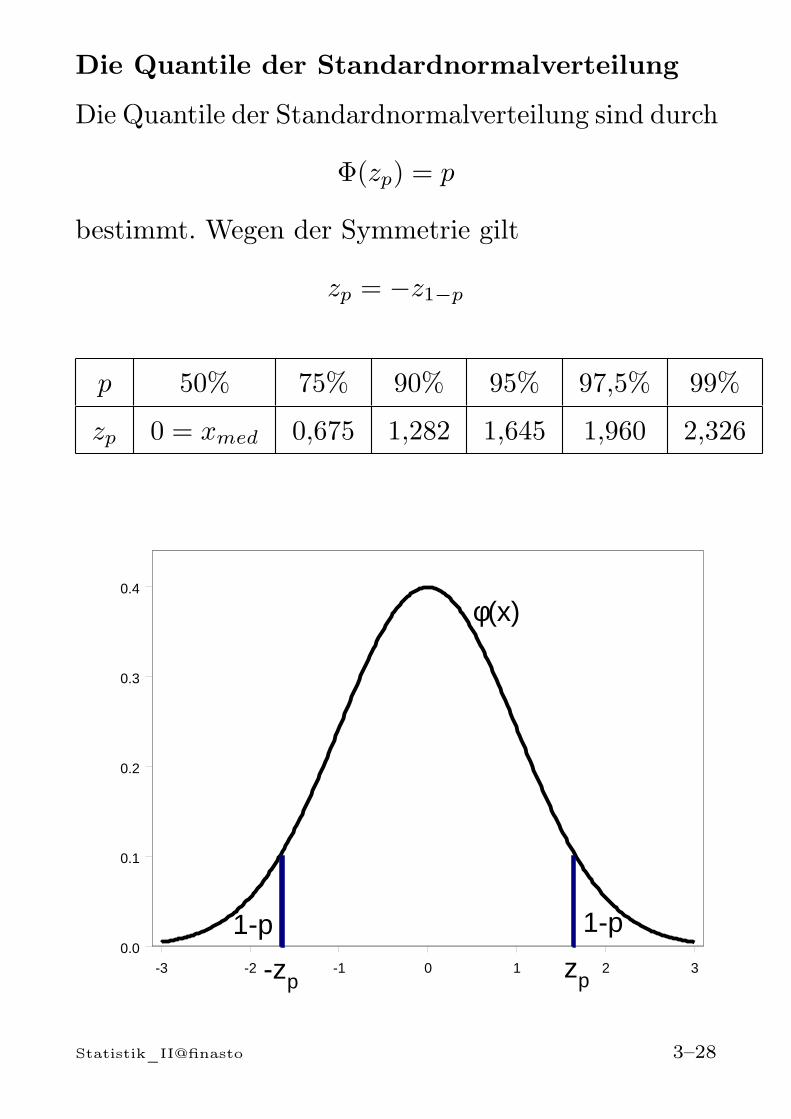
Die Quantile der Standardnormalverteilung sind durch
Φ(zp) = p
bestimmt. Wegen der Symmetrie gilt
zp = −z1−p
p 50% 75% 90% 95% 97,5% 99%
zp 0 = xmed 0,675 1,282 1,645 1,960 2,326
-3 -2 -1 0 1 2 30.0
0.1
0.2
0.3
0.4
φ(x)
zp-zp
1-p1-p
Statistik_II@finasto 3–28

Rückführung einer allgemeinen N(µ, σ2)-Verteilung aufdie Standardnormalverteilung:
Standardisierung:Ist X ∼ N(µ, σ2), so ist die standardisierte Zufalls-variable
Z =X − µ
σ
standardnormalverteilt, d.h. Z ∼ N(0, 1)
Für die Verteilungsfunktion F von X gilt:
F (x) = Φ
(x− µ
σ
)= Φ(z) mit z =
x− µ
σ
Quantile: Für 0 < p < 1 berechnet sich das p-Quantil xp der N(µ, σ)-Verteilung durch
zp =xp − µ
σbzw xp = µ+ σzp
⇒ P [a ≤ X ≤ b] = F (b)− F (a)
= Φ
(b− µ
σ
)− Φ
(a− µ
σ
)
Statistik_II@finasto 3–29

Beispiel: Füllmenge von Bier
In einer Abfüllanlage werden Flaschen mit nominal50 cl Bier gefüllt. Die Anlage arbeitet jedoch nichtvollständig exakt. Im Mittel werden tatsächlich 50 cleingefüllt, die Standardabweichung beträgt jedoch 1,2cl.
Modell:
X = „Füllmenge“ ∼ N(50, 1.44)
P [X ≤ 52] = F (52) = P
(Z ≤ 52− 50
1, 2
)= P [Z ≤ 1, 67] = Φ(1, 67) = 0, 953
P [X ≥ 49] = 1− F (49)
= 1− Φ
(49− 50
1, 2
)= 1− Φ(−0, 833)
= 1− (1− Φ(0, 833)) = 0, 797
Statistik_II@finasto 3–30
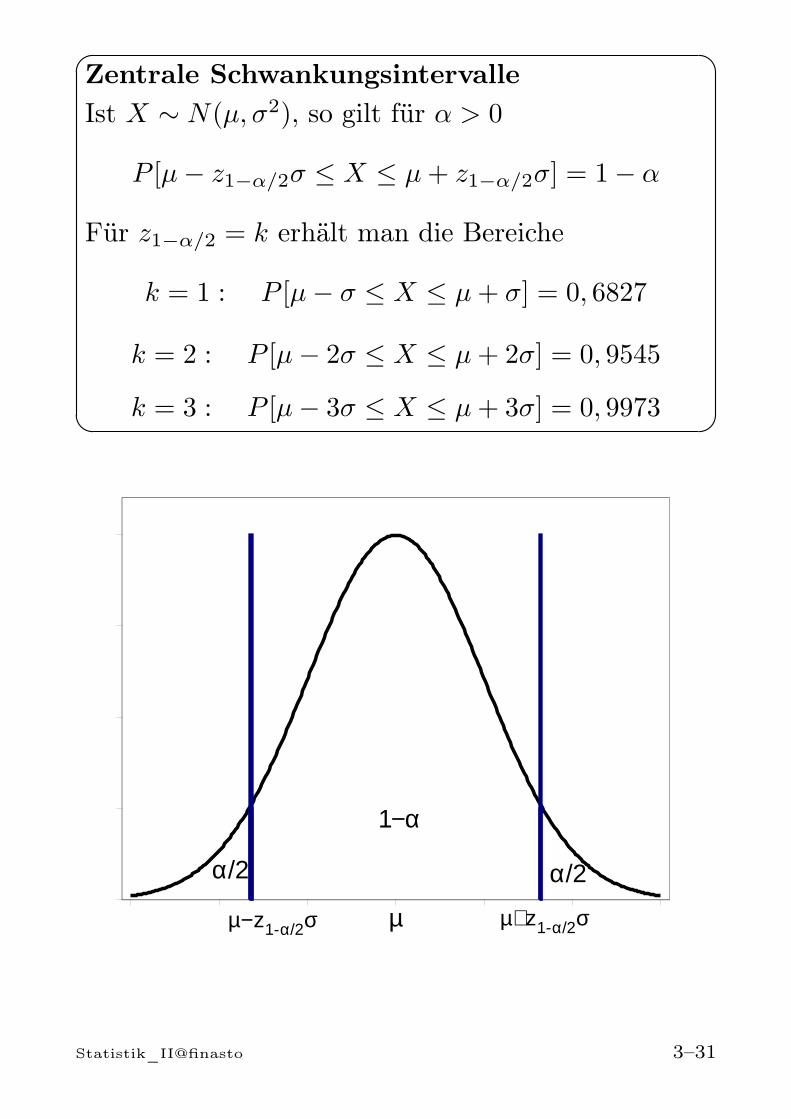
Zentrale SchwankungsintervalleIst X ∼ N(µ, σ2), so gilt für α > 0
P [µ− z1−α/2σ ≤ X ≤ µ+ z1−α/2σ] = 1− α
Für z1−α/2 = k erhält man die Bereiche
k = 1 : P [µ− σ ≤ X ≤ µ+ σ] = 0, 6827
k = 2 : P [µ− 2σ ≤ X ≤ µ+ 2σ] = 0, 9545
k = 3 : P [µ− 3σ ≤ X ≤ µ+ 3σ] = 0, 9973
µ−z1-α/2σ
1−α
µ
α/2 α/2
µ+z1-α/2σ
Statistik_II@finasto 3–31
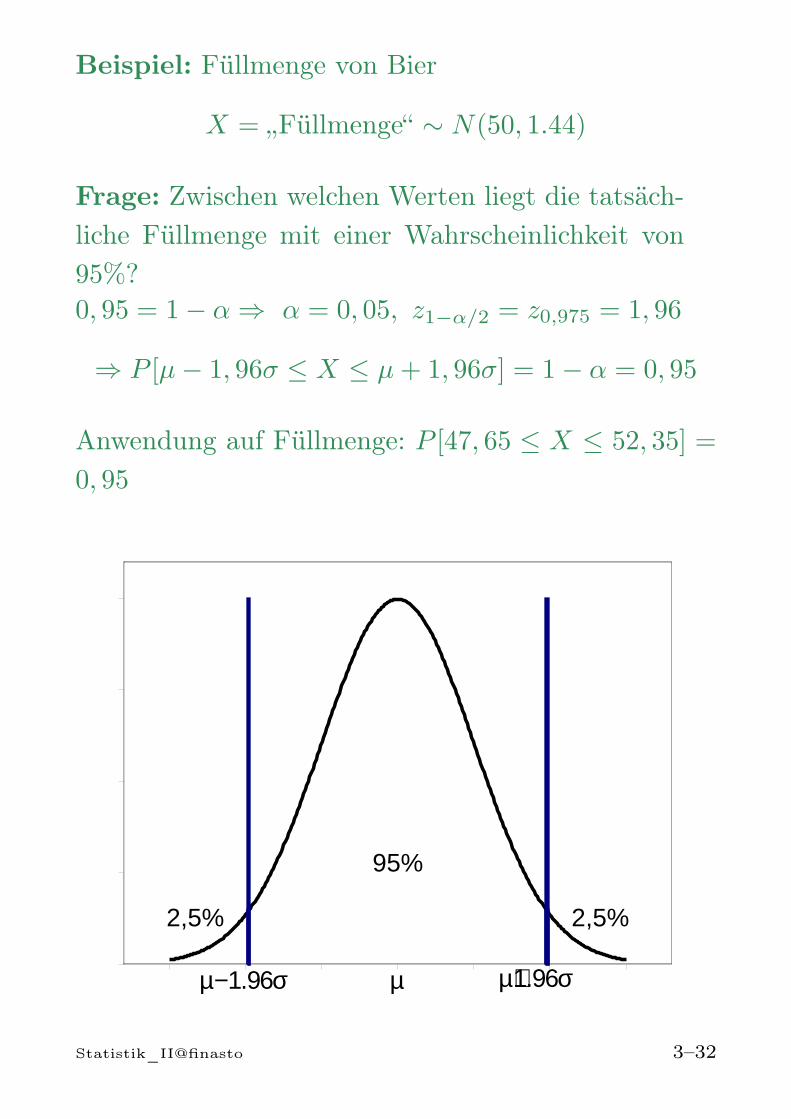
Beispiel: Füllmenge von Bier
X = „Füllmenge“ ∼ N(50, 1.44)
Frage: Zwischen welchen Werten liegt die tatsäch-liche Füllmenge mit einer Wahrscheinlichkeit von95%?0, 95 = 1− α ⇒ α = 0, 05, z1−α/2 = z0,975 = 1, 96
⇒ P [µ− 1, 96σ ≤ X ≤ µ+ 1, 96σ] = 1− α = 0, 95
Anwendung auf Füllmenge: P [47, 65 ≤ X ≤ 52, 35] =
0, 95
µ µ+1.96σµ−1.96σ
95%
2,5%2,5%
Statistik_II@finasto 3–32

Eigenschaften der Normalverteilung:
Lineare TransformationFür X ∼ N(µ, σ2) ist die linear transformierte Va-riable Y = aX + b wieder normalverteilt mit
Y ∼ N(aµ+ b, a2σ2)
AdditionSind X ∼ N(µX , σ2
X) und Y ∼ N(µY , σ2Y ) normal-
verteilt und unabhängig, so gilt
X + Y ∼ N(µX + µY , σ2X + σ2
Y )
Verallgemeinerung: Sind Xi ∼ N(µi, σ2i ) unab-
hängig, so ist jede Linearkombination Y = a1X1 +
. . .+ anXn normalverteilt mit
Y ∼ N(a1µ1 + . . .+ anµn, a21σ
21 + . . .+ a2nσ
2n)
Statistik_II@finasto 3–33

Der zentrale Grenzwertsatz
Zufallsvariable X (diskret oder stetig)Beispiele: X =”Geschlecht einer zufällig ausgewähltenPerson” (0/1 falls weiblich/männlich); X =”Einkommeneiner zufällig ausgewählten Person”,
Einfache Zufallsstichprobe des Umfangs n (bzw. n-malige unabhängige Wiederholung des Zufallsexperi-ments):
• Folge X1, . . . , Xn von Zufallsvariablen, die jeweilseine einzelne Ziehung (Wiederholung) beschreiben
• Alle Xi haben die gleiche Verteilung wie X undX1, . . . , Xn sind voneinander unabhängig,
µ = E(X) = E(Xi), σ2 = Var(X) = Var(Xi)
X1, . . . , Xn - unabhängig und identisch verteilte Zu-fallsvariablen (mit Mittelwert µ und Varianz σ2)
Statistik_II@finasto 3–34

Man betrachte nun den Mittelwert:
• X = 1n
n∑i=1
Xi (Zufallsvariable!!)
• x = 1n
n∑i=1
xi tatsächlich beobachteter (realisierter)
numerischer Wert (z.B. x = 0, 0456)
Zentraler GrenwertsatzSeien X1, . . . , Xn unabhängig und identisch verteilteZufallsvariablen mit Mittelwert µ und Varianz σ2.Dann gilt
P
(X − µ
σ/√n
≤ z
)→ Φ(z) für n → ∞
Mit anderen Worten: Für großes n gilt approximativ
X ∼ N
(µ,
σ2
n
)
Folgerung für Summen von Zufallsvariablen:n groß, so gilt approximativ
n∑i=1
Xi ∼ N(nµ, nσ2)
Anmerkung: Die asymptotische Normalität von X giltunabhängig von der Struktur der Verteilung der Xi (dieseVerteilung ist natürlich für alle Stichprobenumfänge n diegleiche (z:B. Exponentialverteilung, Bernoulli, etc.)Statistik_II@finasto 3–35

Beispiel:
N = 7 Kugeln: 10, 11, 11, 12, 12, 12, 16
X: „Zahl auf einer zufällig gezogenen Kugel“
x 10 11 12 16
f(x) 1/7 2/7 3/7 1/7
µ = E(X) = 12, σ2 = Var(X) = 22/7 = 3.143
Einfache Zufallsstichprobe (n = 2): Unabhängigund identisch verteilte Zufallsvariablen X1 und X2
X1: „Zahl auf der 1. gezogenen Kugel“X2: „Zahl auf der 2. gezogenen Kugel“
Mögliche Realisationen:
2.Kugel
1.Kugel 10 11 11 12 12 12 16
10 (10;10) 10;11 10;11 10;12 10;12 10;12 10;16
11 11;10 (11;11) 11;11 11;12 11;12 11;12 11;16
11 11;10 11;11 (11;11) 11;12 11;12 11;12 11;16
12 12;10 12;11 12;11 (12;12) 12;12 12;12 12;16
12 12;10 12;11 12;11 12;12 (12;12) 12;12 12;16
12 12;10 12;11 12;11 12;12 12;12 (12;12) 12;16
16 16;10 16;11 16;11 16;12 16;12 16;12 (16;16)
Statistik_II@finasto 3–36

Mögliche Stichprobenmittelwerte x
2. Kugel
1. Kugel 10 11 11 12 12 12 16
10 (10) 10,5 10,5 11 11 11 13
11 10,5 (11) 11 11,5 11,5 11,5 13,5
11 10,5 11 (11) 11,5 11,5 11,5 13,5
12 11 11,5 11,5 (12) 12 12 14
12 11 11,5 11,5 12 (12) 12 14
12 11 11,5 11,5 12 12 (12) 14
16 13 13,5 13,5 14 14 14 (16)
Wahrscheinlichkeitsverteilung von X
x 10 10.5 11 11.5 12 13 13,5 14 16
f(x) 149
449
1049
1249
949
249
449
649
149
E(X) = 12 = µ, Var(X) = 22/14 = σ2/2
Für wachsendes n gibt es immer mehr mögliche Wertevon X ⇒ Übergang zu einer quasistetigen Verteilung,die sich für genügend großes n durch eine Normalver-teilung approximieren lässt
X ∼ N
(12,
22/7
n
)Statistik_II@finasto 3–37
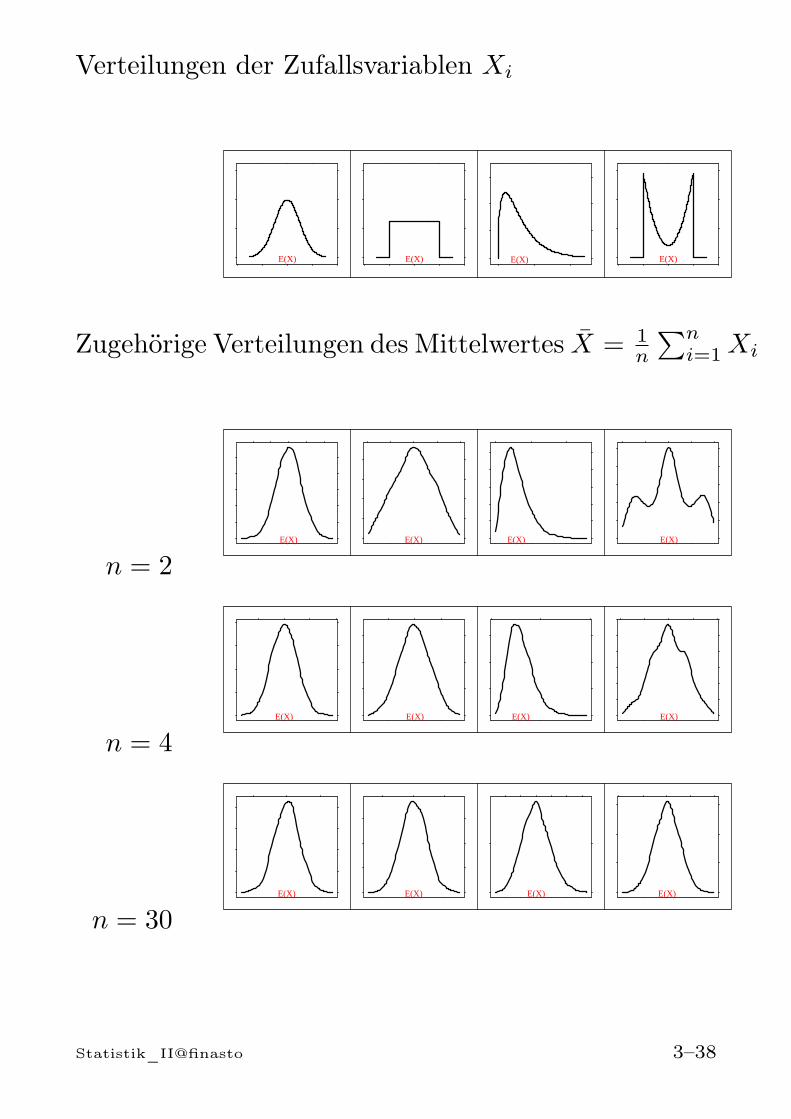
Verteilungen der Zufallsvariablen Xi
E(X) E(X) E(X) E(X)
Zugehörige Verteilungen des Mittelwertes X = 1n
∑ni=1 Xi
n = 2E(X) E(X) E(X) E(X)
n = 4E(X) E(X) E(X) E(X)
n = 30E(X) E(X) E(X) E(X)
Statistik_II@finasto 3–38
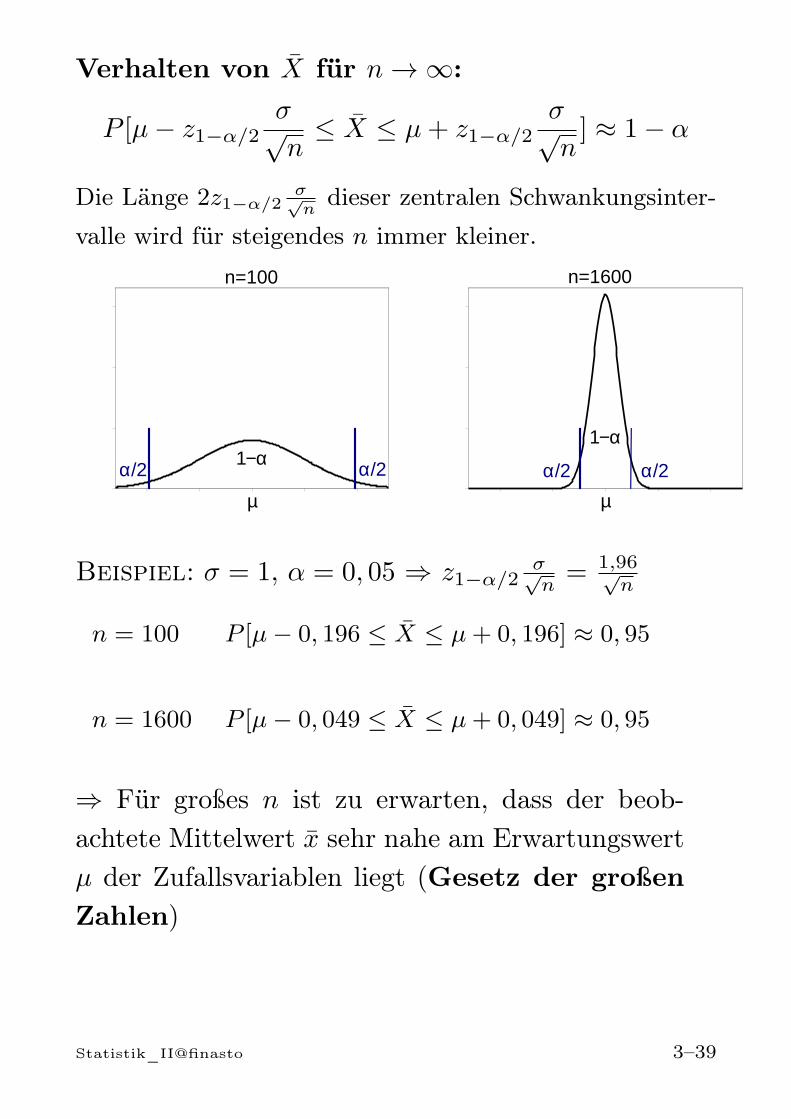
Verhalten von X für n → ∞:
P [µ− z1−α/2σ√n≤ X ≤ µ+ z1−α/2
σ√n] ≈ 1− α
Die Länge 2z1−α/2σ√n
dieser zentralen Schwankungsinter-valle wird für steigendes n immer kleiner.
µ
α/2
n=100
1−αα/2
µα/2
n=1600
1−α
α/2
Beispiel: σ = 1, α = 0, 05 ⇒ z1−α/2σ√n= 1,96√
n
n = 100 P [µ− 0, 196 ≤ X ≤ µ+ 0, 196] ≈ 0, 95
n = 1600 P [µ− 0, 049 ≤ X ≤ µ+ 0, 049] ≈ 0, 95
⇒ Für großes n ist zu erwarten, dass der beob-achtete Mittelwert x sehr nahe am Erwartungswertµ der Zufallsvariablen liegt (Gesetz der großenZahlen)
Statistik_II@finasto 3–39

Anwendung des zentralen Grenzwertsatzes: Appro-ximation der Binomialverteilung
Zentraler GrenzwertsatzSei X ∼ B(n, p). Für großes n gilt approximativ
Z =X − np√np(1− p)
∼ N(0, 1)
bzw.X ∼ N(np, np(1− p))
Faustregeln: np ≥ 5, n(1− p) ≥ 5
Anwendung (mit Stetigkeitskorrektur):
P [X < x] ≈ Φ
(x− 0, 5− np√
np(1− p)
)
P [X ≤ x] ≈ Φ
(x+ 0, 5− np√
np(1− p)
)
⇒ P [x1 ≤ X ≤ x2]
≈ Φ
(x2 + 0, 5− np√
np(1− p)
)− Φ
(x1 − 0, 5− np√
np(1− p)
)
Statistik_II@finasto 3–40

3.5 Spezielle Verteilungsmodelle
χ2-VerteilungSeien X1, . . . , Xn unabhängige und identischN(0, 1)-verteilte Zufallsvariablen. Dann heißt dieVerteilung von
χ2 = X21 + · · ·+X2
n
Chi-Quadrat-Verteilung mit n Freiheitsgraden,kurz χ2 ∼ χ2(n).
Es gilt: E(χ2) = n, Var(χ2) = 2n
0 5 10 15 200.0
0.1
0.2
0.3
0.4
0.5
n=2
n=5
n=10
Dichten der χ2-Verteilung
Statistik_II@finasto 3–41

• Die Dichten der χ2-Verteilung sind linkssteil, nä-hern sich jedoch für große n der Gauß-Kurve an(zentraler Grenzwertsatz)
• n > 30: χ2(n) ≈ N(n, 2n)
• Wichtige Quantile der χ2(n)-Verteilung sind ta-belliert. Für n > 30 benutzt man eine Normalver-teilungsapproximation
χ2p;n =
1
2(zp +
√2n− 1)2
Anwendungsbereich: Verfahren der inferentiellenStatistik (Anpassungstests, Tests im Zusammenhangmit Varianzen); spezielle Lebensdauermodelle
Statistik_II@finasto 3–42
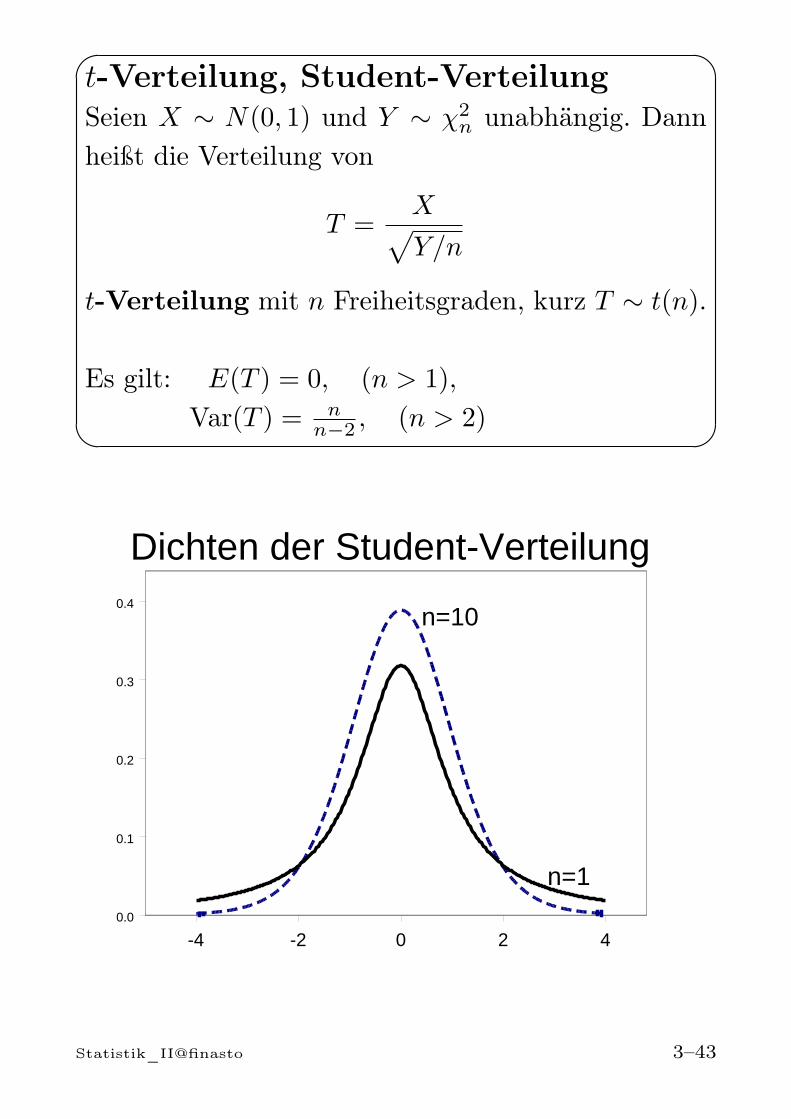
t-Verteilung, Student-VerteilungSeien X ∼ N(0, 1) und Y ∼ χ2
n unabhängig. Dannheißt die Verteilung von
T =X√Y/n
t-Verteilung mit n Freiheitsgraden, kurz T ∼ t(n).
Es gilt: E(T ) = 0, (n > 1),Var(T ) = n
n−2 , (n > 2)
-4 -2 0 2 40.0
0.1
0.2
0.3
0.4
n=1
n=10
Dichten der Student-Verteilung
Statistik_II@finasto 3–43

• Die Dichten der t-Verteilung sind symmetrisch um0. Im Vergleich zu ϕ besitzen sie für kleine n grö-ßere Enden, d.h. die Flächen unter den Dichtekur-ven für kleine und große Werte x sind größer.
• n groß (n > 30): t(n) ≈ N(0, 1)
• Wichtige Quantile der t(n)-Verteilung sind tabel-liert. Für n > 30 benutzt man eine Normalvertei-lungsapproximation
tp;n ≈ zp
Anwendungsbereich: Verfahren der inferentiellen Stati-stik (Tests im Zusammenhang mit Mittelwerten); robusteStatistik (Modellierung von Daten mit einem hohen Anteilextremer Werte)
Statistik_II@finasto 3–44
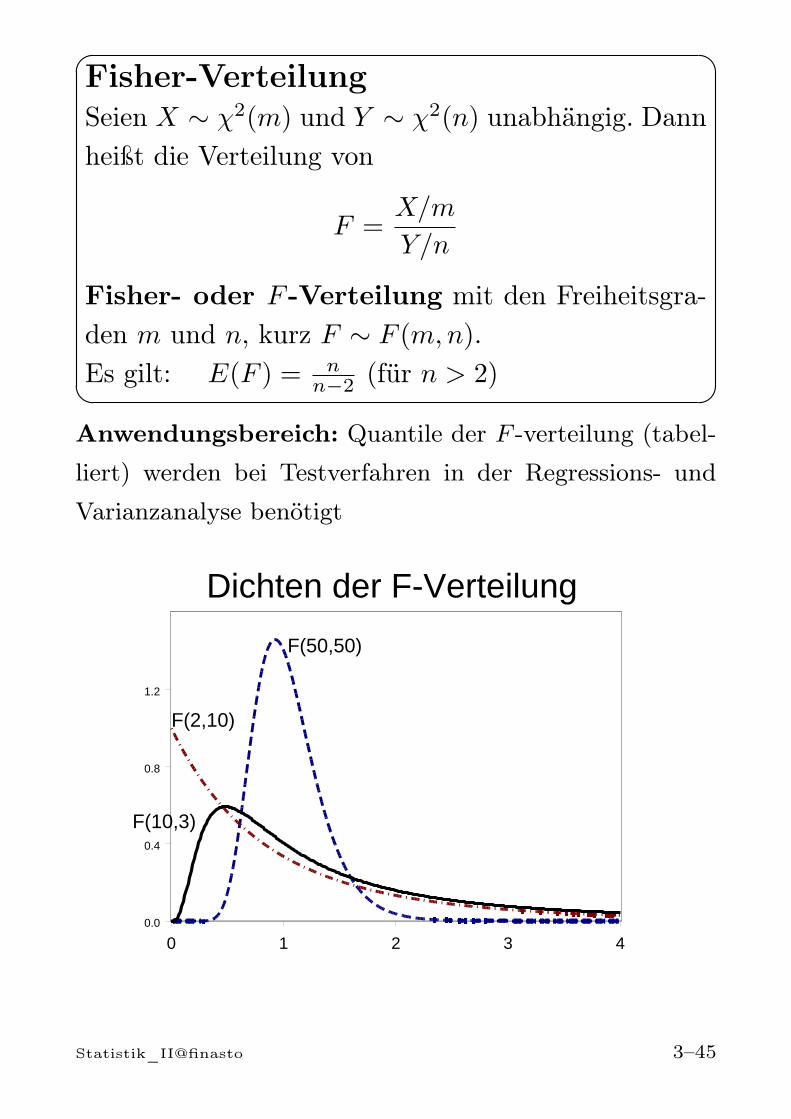
Fisher-VerteilungSeien X ∼ χ2(m) und Y ∼ χ2(n) unabhängig. Dannheißt die Verteilung von
F =X/m
Y/n
Fisher- oder F -Verteilung mit den Freiheitsgra-den m und n, kurz F ∼ F (m,n).Es gilt: E(F ) = n
n−2 (für n > 2)
Anwendungsbereich: Quantile der F -verteilung (tabel-liert) werden bei Testverfahren in der Regressions- undVarianzanalyse benötigt
0 1 2 3 40.0
0.4
0.8
1.2
F(50,50)
F(2,10)
F(10,3)
Dichten der F-Verteilung
Statistik_II@finasto 3–45