Embed Size (px)
Citation preview

Überschrift
Speicherverwaltung
1
Prof. Dr. Margarita Esponda
Freie Universität Berlin2011/2012

M. Esponda-Argüero
Speicherverwaltung
Hauptziele:
❖ einen effizienten Zugriff auf den physikalischen Arbeitsspeicher eines Rechners zu ermöglichen.
❖ den Adress-Raum des Betriebssystems und der verschiedenen Prozesse gegen illegale Speicherzugriffe zu schützen.
❖ eine Schnittstelle für gemeinsame Verwendung von Speichern zu Verfügung zu stellen.
Speicher ist die zweite wichtigste Ressource, die das Betriebssystem verwalten muss.
2

M. Esponda-Argüero
Überschrift
3
❖ Speicherhierarchie (Motivation)❖ Speicherverwaltung-Mechanismen❖ Hardware-Unterstützung❖ Virtuelle Speicher
Inhalt

M. Esponda-Argüero
Motivation für Speicherhierarchie
Moderne Prozessoren können durch ihren
hohen Parallelisierungsgrad Instruktionen mit
ständig steigender Geschwindigkeit
verarbeiten.
Dies erfordert schnellere Speicherzugriffe, die
nur durch komplexe Speicherhierarchien
gewährleistet werden können.
4
Engpass!

M. Esponda-Argüero
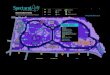
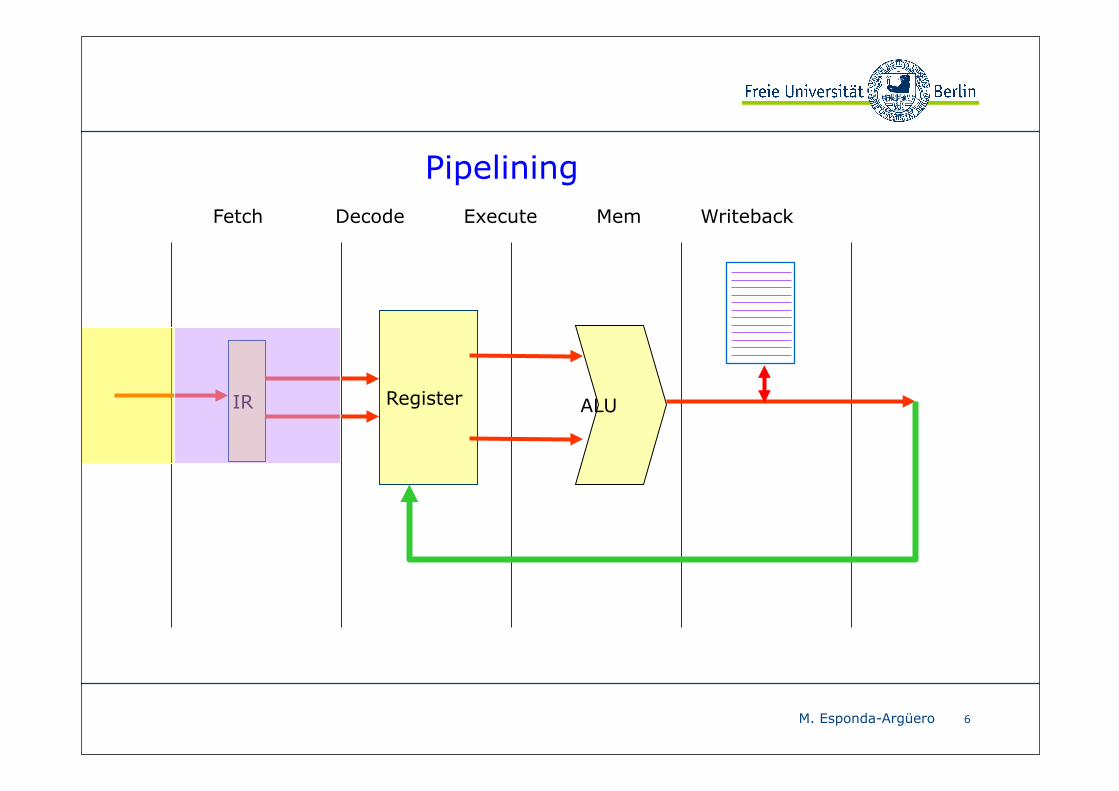
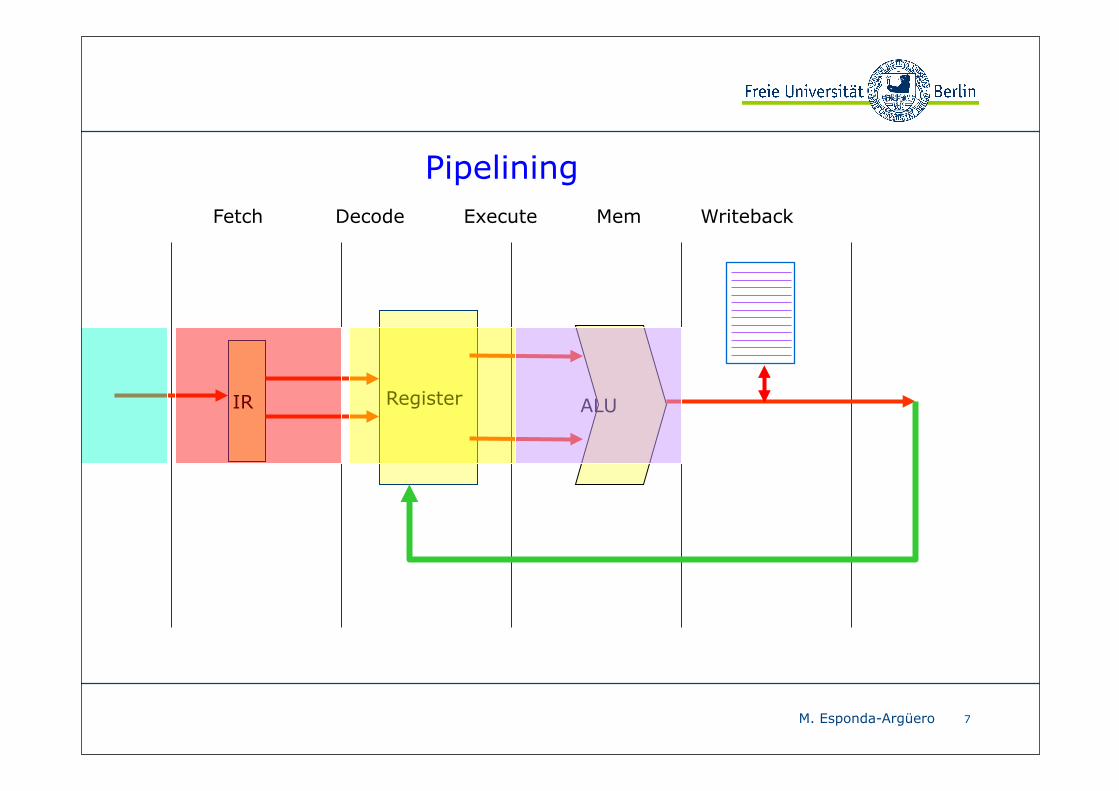
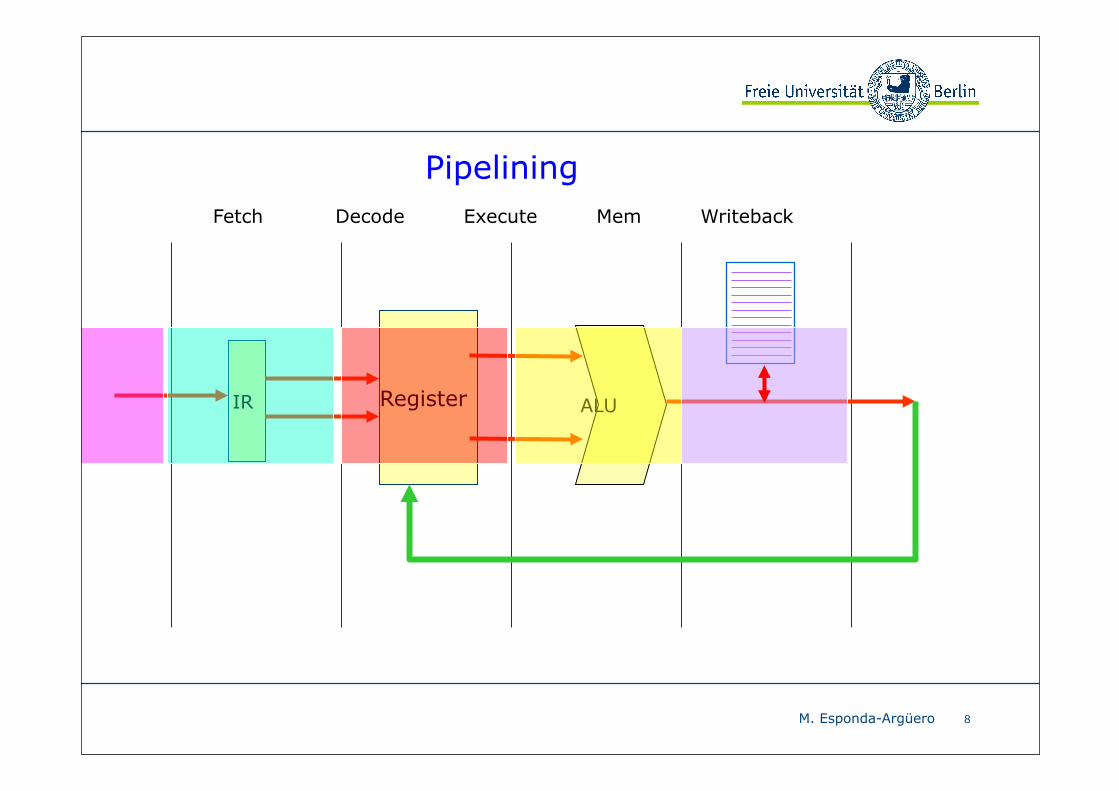
Pipelining
Beispiel: Pipeline mit 5 Stufen
❖ Befehl holen fetch
❖ Befehl dekodieren decode
❖ Befehl ausführen execute
❖ Auf Speicher zugreifen mem
❖ Ergebnis in Register zurück schreiben writeback
Pipelining ist eine der wichtigsten Parallelisierungstechniken moderner Prozessoren.
Die Ausführung eines Befehls wird in Stufen aufgeteilt und verschiedene Stufen von verschiedenen Befehlen parallel ausgeführt.
Eine Pipeline besteht typischerweise aus 4 bis 15 Stufen.
5
M. Esponda-Argüero
Register
Fetch Decode Execute Mem Writeback
IR ALU
Pipelining
6
M. Esponda-Argüero
Register
Fetch Decode Execute Mem Writeback
IR ALU
Pipelining
7
M. Esponda-Argüero
Register
Fetch Decode Execute Mem Writeback
IR ALU
8
Pipelining
M. Esponda-Argüero
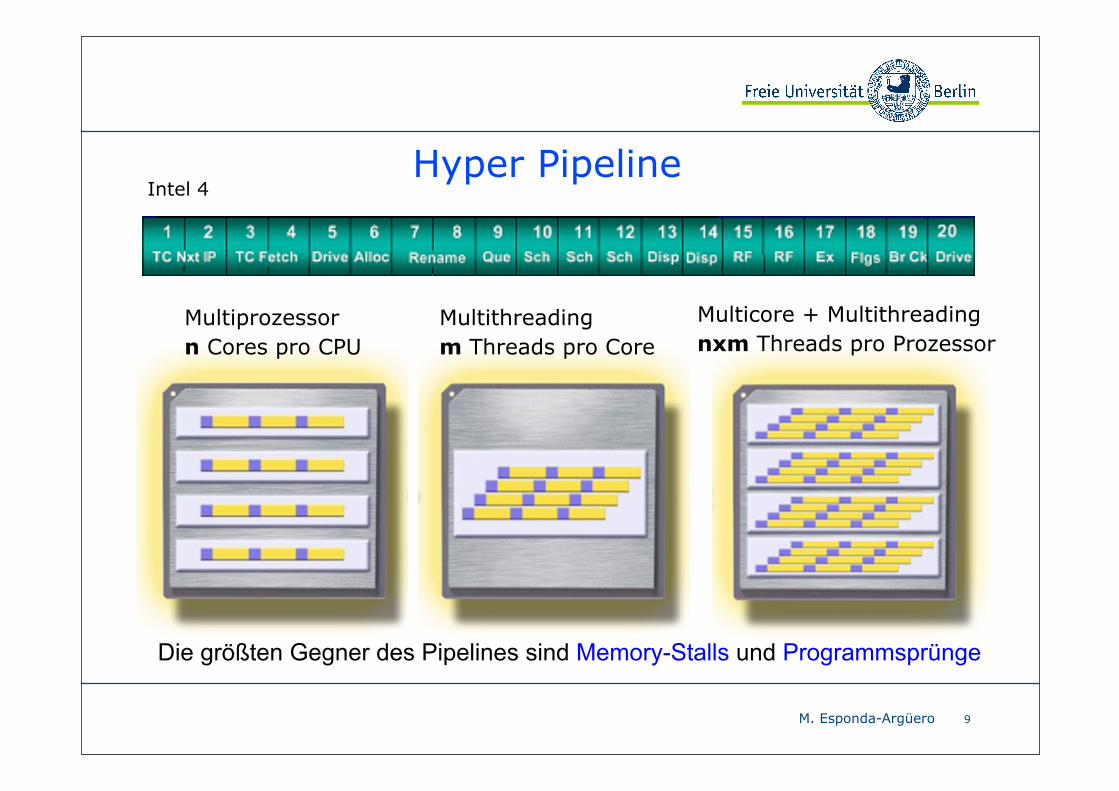
Hyper PipelineIntel 4
Multiprozessorn Cores pro CPU
Multithreadingm Threads pro Core
Multicore + Multithreadingnxm Threads pro Prozessor
Die größten Gegner des Pipelines sind Memory-Stalls und Programmsprünge
9
M. Esponda-Argüero
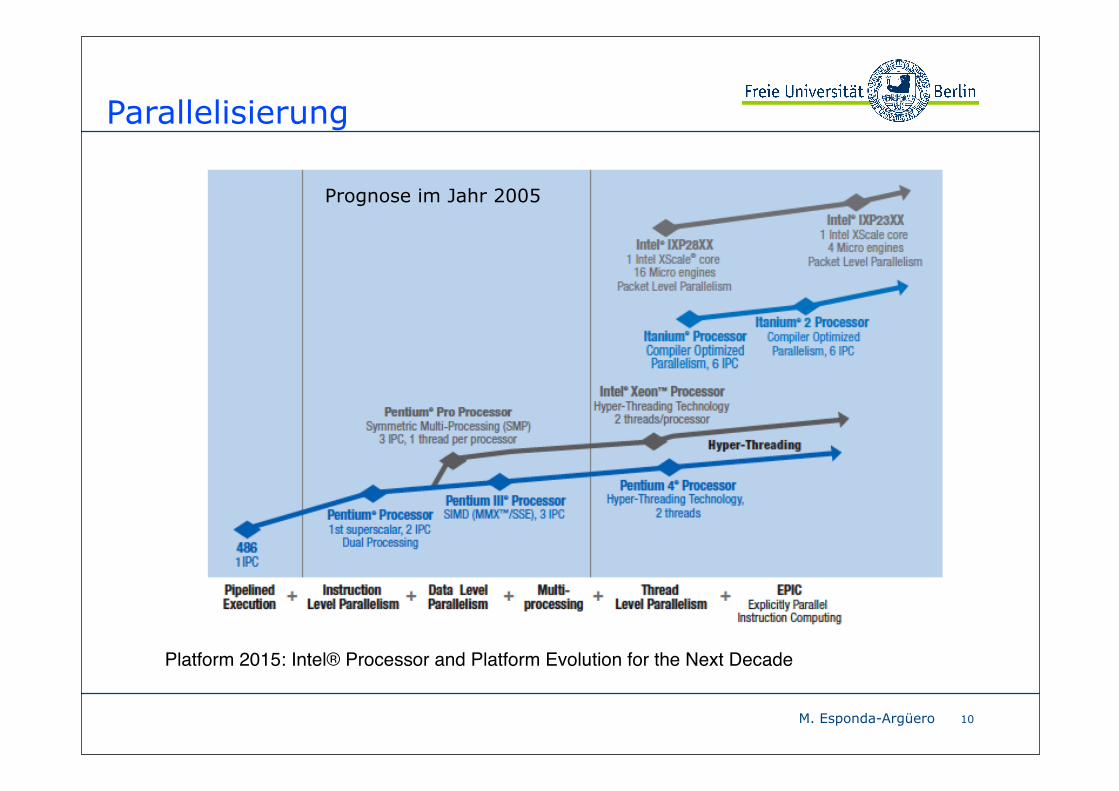
Parallelisierung
10
Platform 2015: Intel® Processor and Platform Evolution for the Next Decade
Prognose im Jahr 2005

M. Esponda-Argüero
Motivation für eine Speicherhierarchie
- Befehle und Daten sollen innerhalb eines Taktzyklus gelesen werden können.
- Der Prozessor hat nur zum Register oder zum internen Hauptspeicher direkten Zugriff.
- Da Speicherzugriffe länger als ein Taktzyklus dauern, wird meistens ein oder mehrere schnellere Speicher (Cache) zwischen der CPU und dem Hauptspeicher verwendet.
11

M. Esponda-Argüero
Motivation für Speicherhierarchie
12
Gut strukturierte Programme haben die Eigenschaft der Lokalität in zwei verschiedenen Formen:
❖ Zeitliche-Lokalität. Die Wahrscheinlichkeit, dass die zuletzt verwendeten Speicheradressen in naher Zukunft wieder verwendet werden, ist relativ groß.
❖ Räumliche-Lokalität. Die Wahrscheinlichkeit, dass nach einem Speicherzugriff als nächstes auf eine benachbarte Speicheradresse zugegriffen wird, ist relativ groß.
…sum = 0:for (i=0; i<array_size; i++) sum += array[i];return sum;...
Beispiel:
M. Esponda-Argüero
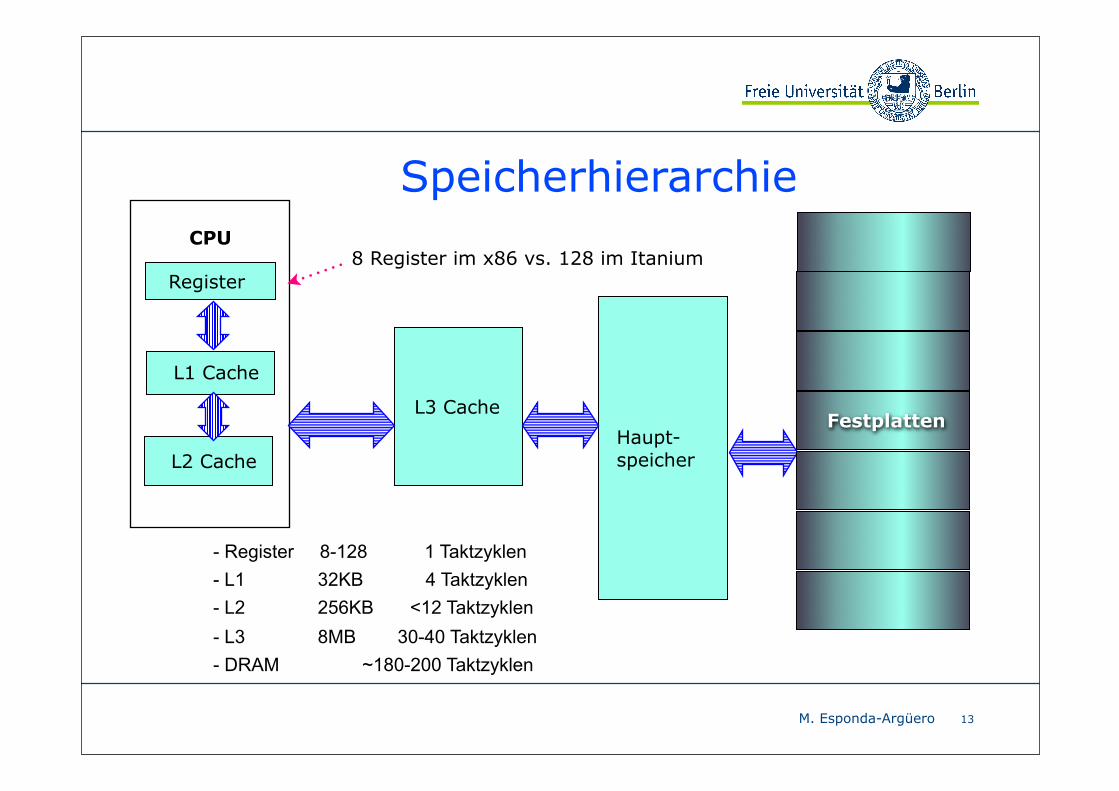
Speicherhierarchie
Register
L3 Cache
Haupt-speicher
CPU
L1 Cache
13
Festplatten
Festplatten
L2 Cache
8 Register im x86 vs. 128 im Itanium
- Register 8-128 1 Taktzyklen- L1 32KB 4 Taktzyklen- L2 256KB <12 Taktzyklen- L3 8MB 30-40 Taktzyklen- DRAM ~180-200 Taktzyklen
M. Esponda-Argüero
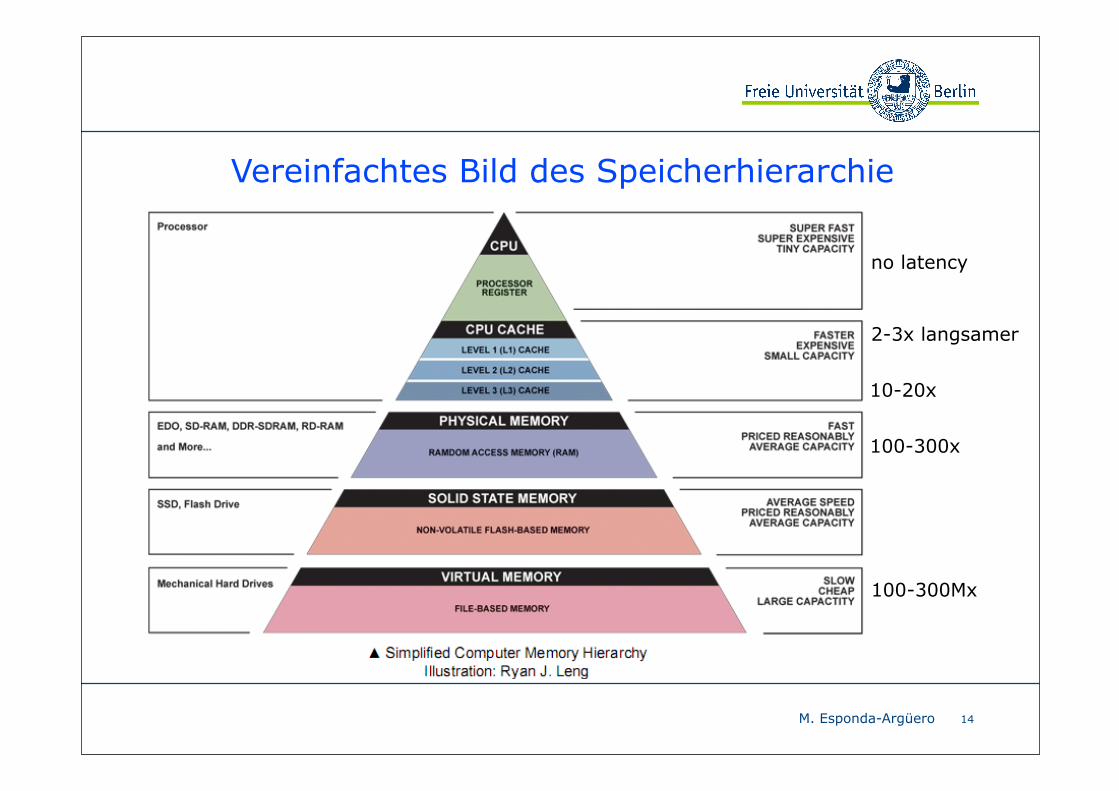
Vereinfachtes Bild des Speicherhierarchie
14
2-3x langsamer
10-20x
100-300x
100-300Mx
no latency
M. Esponda-Argüero
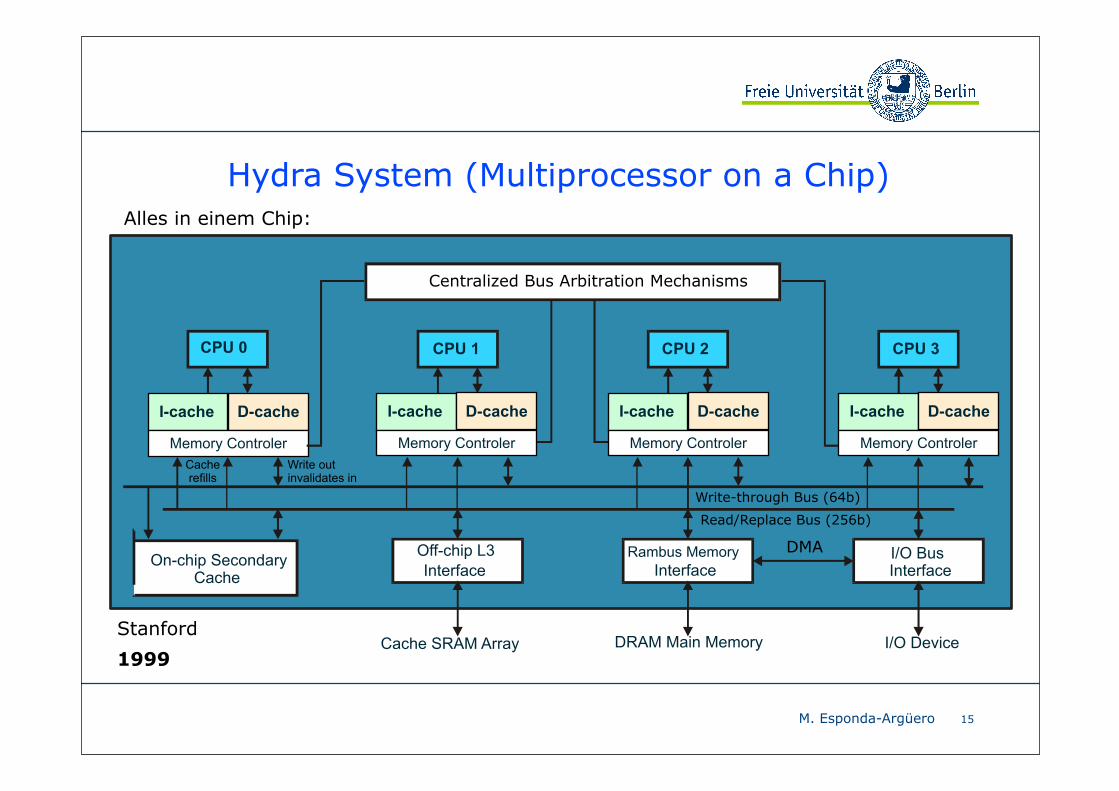
Hydra System (Multiprocessor on a Chip)
15
CPU 0
Centralized Bus Arbitration Mechanisms
Cache SRAM Array DRAM Main Memory I/O Device
I-cache D-cache
Memory Controler
Rambus MemoryInterface
Off-chip L3Interface
I/O BusInterface
DMA
CPU 1 CPU 2 CPU 3
On-chip Secondary Cache
Alles in einem Chip:
I-cache D-cache
Memory Controler
I-cache D-cache
Memory Controler
I-cache D-cache
Memory Controler
Write-through Bus (64b)
Read/Replace Bus (256b)
Cache refills
Write out invalidates in
Stanford
1999

M. Esponda-Argüero
SpeicherverwaltungsmechanismenDirekte Speicherverwaltung
- nur bei eingebetteten Systemen, die einen Prozess ausführen
- sehr einfache direkte VerwaltungSegmentierung
Segmentierung + Seiten-Adressierung
Virtuelle Speicherverwaltung
- früher weit verbreitet (MS-DOS)
- bei modernen Systemen
- fast in jedem modernen Betriebssystem
16
M. Esponda-Argüero
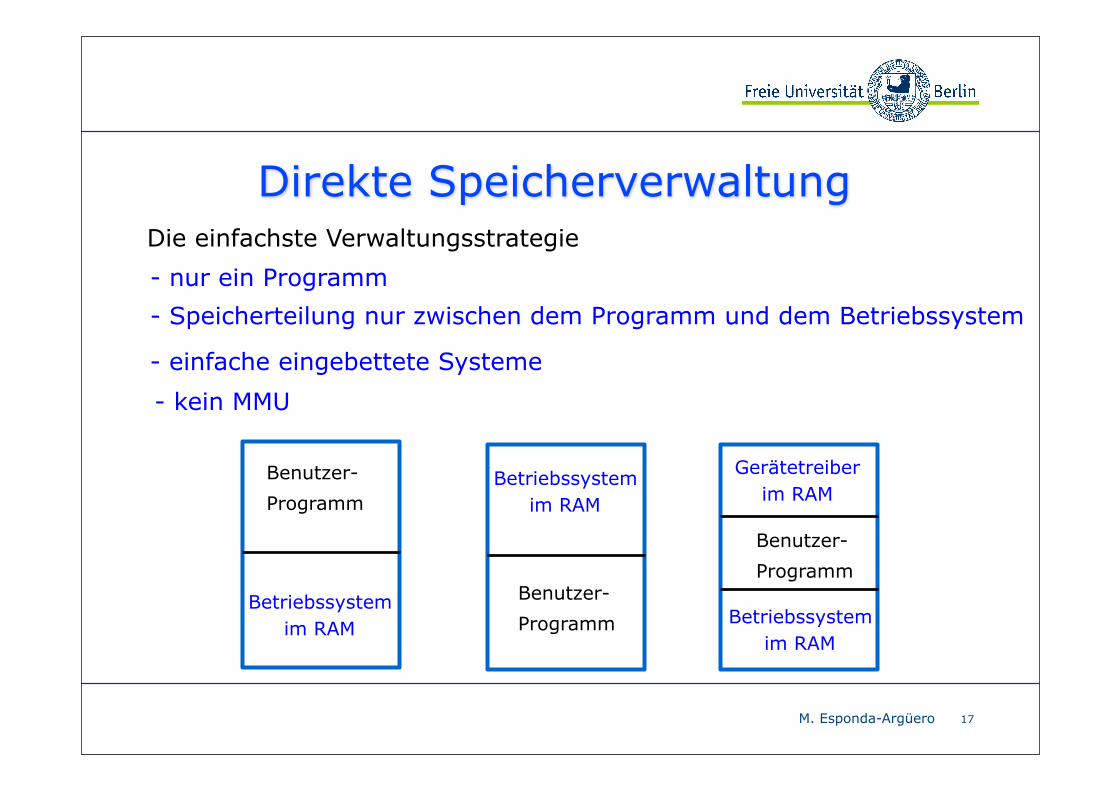
Direkte SpeicherverwaltungDie einfachste Verwaltungsstrategie
- nur ein Programm
- Speicherteilung nur zwischen dem Programm und dem Betriebssystem
- einfache eingebettete Systeme
17
Betriebssystem im RAM
Benutzer-
Programm
Benutzer-
Programm
Betriebssystem im RAM
Benutzer-
Programm
Betriebssystem im RAM
Gerätetreiber im RAM
- kein MMU

M. Esponda-Argüero
Speicherverwaltung für Multiprogrammierung
Durch Multiprogrammierung entstehen zwei wichtige Probleme:
- Relokation
- Speicherschutz
Alle Programme zusammen verwenden meistens viel mehr Speicher als der physikalische Speicher, der tatsächlich zur Verfügung steht.
Der Speicher-Adressraum der Prozesse muss geschützt werden.
Prozesse, die gerade nicht ausgeführt werden, werden vom Speicher ausgelagert und später wieder geladen.
Adressbindung
Swapping
18

M. Esponda-Argüero
Speicherverwaltung für Multiprogrammierung
Zwei spezielle Hardwareregister werden verwendet:
Das Basis-Register hat die kleinste Speicheradresse, die ein Prozess benutzen darf.
Das Grenz-Register hat die Größe des Adressraums eines Prozesses.
Es muss gesichert werden, dass jeder Prozess einen eigenen Adressbereich hat.
Das Betriebssystem hat Zugriff zu jedem Prozess-Adressraum.
Die Benutzerprozesse haben keinen Zugriff zum Adressraum anderer Prozesse und auch nicht zum Adressraum des Betriebssystems.
Speicherschutz
19
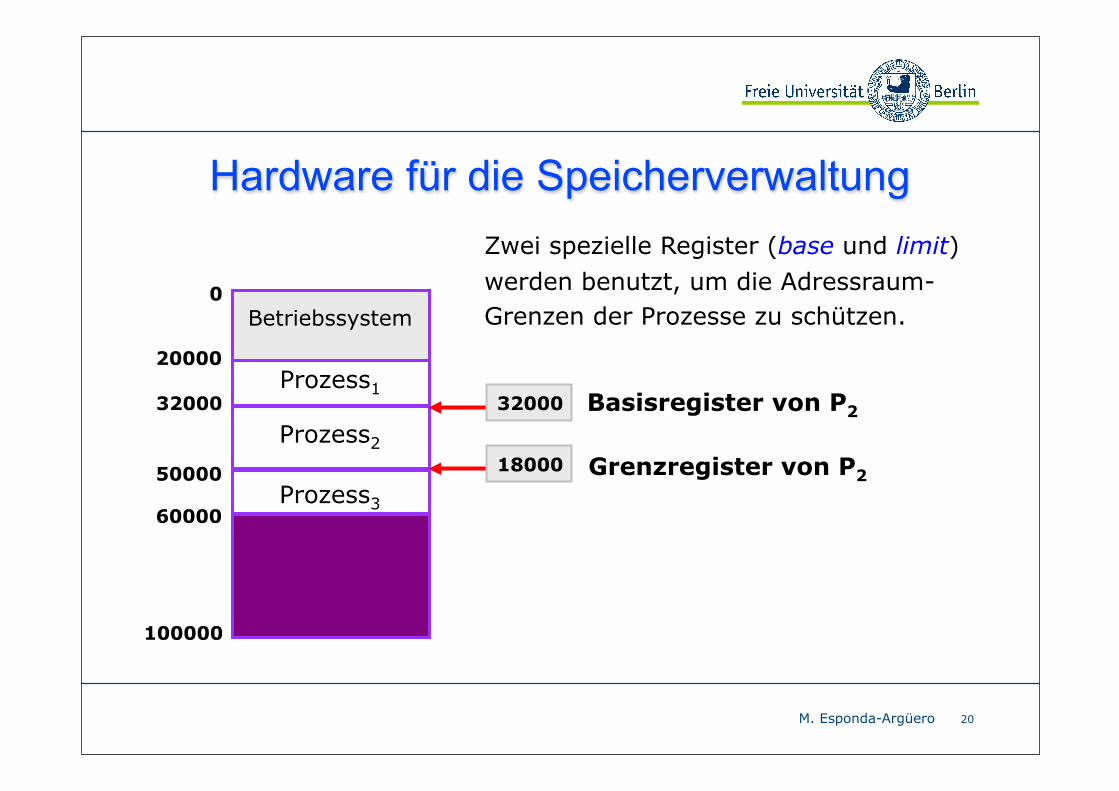
M. Esponda-Argüero 20
Hardware für die SpeicherverwaltungZwei spezielle Register (base und limit) werden benutzt, um die Adressraum-Grenzen der Prozesse zu schützen.Betriebssystem
Prozess1
Prozess2
Prozess3
20000
0
32000
50000
60000
100000
32000 Basisregister von P2
18000 Grenzregister von P2

M. Esponda-Argüero
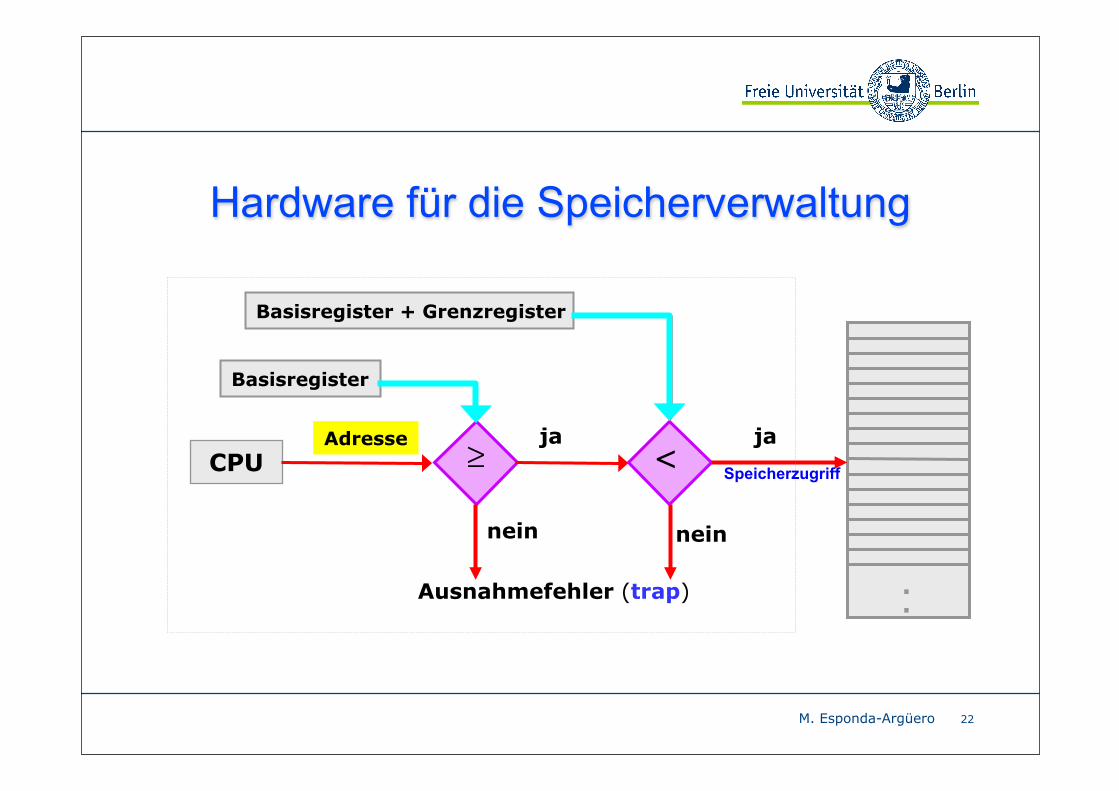
Einfache Hardware-Unterstützung
Die CPU vergleicht jede Adresse, die im Benutzermodus generiert
wird mit dem Basisregister und das Basisregister + Grenzregister der jeweiligen Prozesse.
Der Versuch eines Prozesses, auf den Adressraum des
Betriebssystems oder in den Adressraum eines anderen Prozesses zuzugreifen, löst einen Trap (Ausnahmefehler) aus, der
entsprechend behandelt wird.
21
Der Basisregister und der Grenzregister müssen bei Kontext-Wechsel gespeichert und zurückgesetzt werden.
M. Esponda-Argüero 22
Hardware für die Speicherverwaltung
CPU ≥ <
.
.
ja ja
neinnein
Ausnahmefehler (trap)
Basisregister
Basisregister + Grenzregister
Adresse
Speicherzugriff

M. Esponda-Argüero 23
Die CPU arbeitet mit logischen oder virtuellen Adressen.
Die MMU arbeitet direkt mit den physikalischen Adressen.
Logische vs. Physikalische Adressen
Das Konzept einer logischen Speicheradresse, die eine Bindung zu
einer getrennten physikalischen Adresse hat, spielt eine zentrale
Rolle in der Speicherverwaltung.
Vereinfacht linking, sharing und allocation!!!
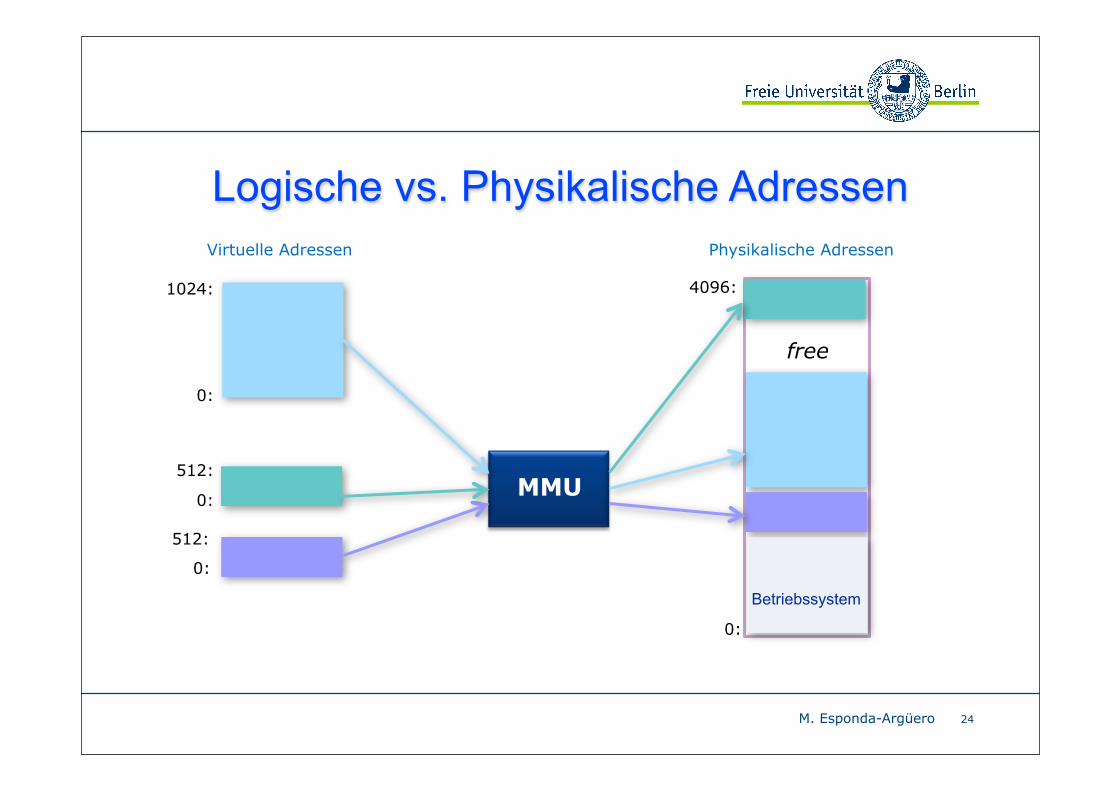
M. Esponda-Argüero
Logische vs. Physikalische Adressen
24
Virtuelle Adressen
1024:
0:
512:
0:
4096:
0:
Betriebssystem
MMU
free
Physikalische Adressen
512:
0:
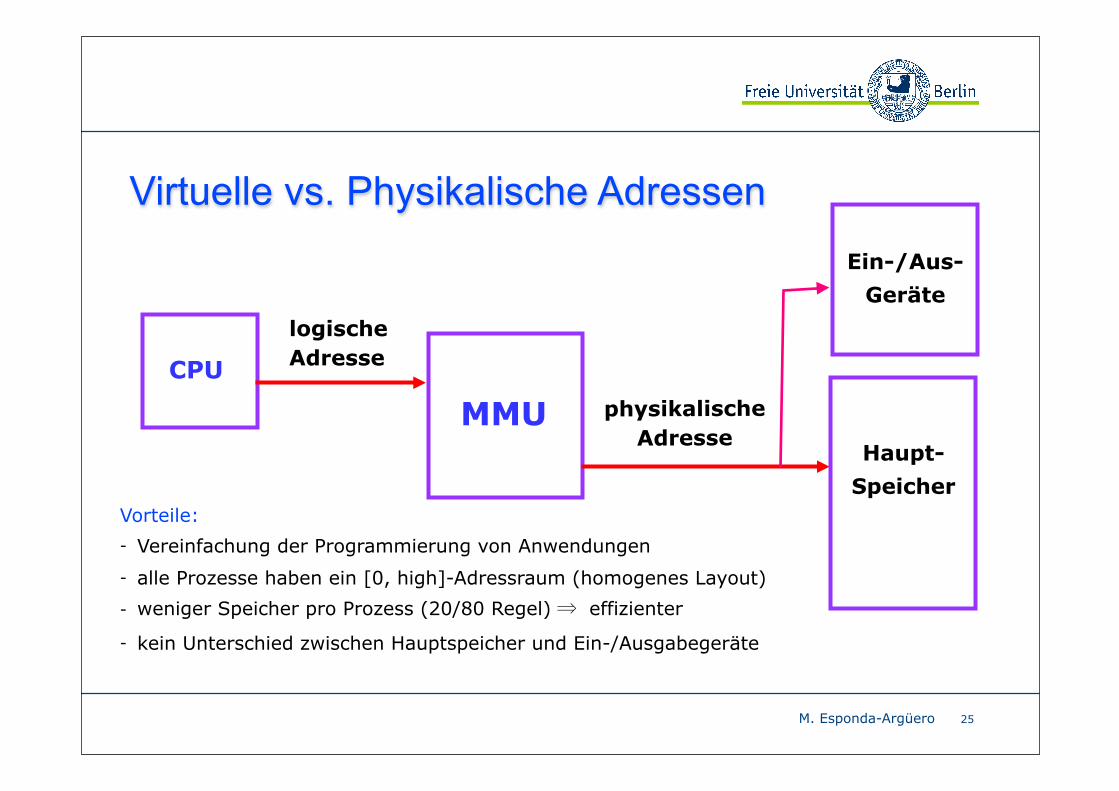
M. Esponda-Argüero 25
Virtuelle vs. Physikalische Adressen
CPU
MMU
logische Adresse
physikalische Adresse
Haupt-
Speicher
Ein-/Aus-
Geräte
Vorteile:
- Vereinfachung der Programmierung von Anwendungen
- alle Prozesse haben ein [0, high]-Adressraum (homogenes Layout)
- weniger Speicher pro Prozess (20/80 Regel) ⇒ effizienter
- kein Unterschied zwischen Hauptspeicher und Ein-/Ausgabegeräte

M. Esponda-Argüero
Memory Management Unit (MMU)
26
Die MMU war ursprünglich als externe Komponente des
Mikroprozessors gebaut.
Moderne Mikroprozessoren haben sogar mehrere MMUs
innerhalb des Prozessor-Chip.
Das Benutzerprogramm arbeitet nur mit logischen Adressen. Er sieht nie die physikalische Adresse, welche die MMU sieht.
Die Relocation- und Limit-Register sind Teil des Prozesskontextes und werden von dem Dispatcher als solches geladen.

M. Esponda-Argüero
SwappingNormalerweise werden Prozesse in eine schnelle Festplatte
kopiert und in den gleichen Adressraum im Hauptspeicher
zurückkopiert.
Wenn die Adressbindung während der Assembler- und Ladezeit
gemacht worden ist, kann dieser Prozess nicht in einen anderen
Adressraum zurückgeladen werden.
Wenn eine Ausführungszeit-Bindung benutzt wird, kann ein
Prozess in einen anderen Adressraum zurückgeladen werden.
27
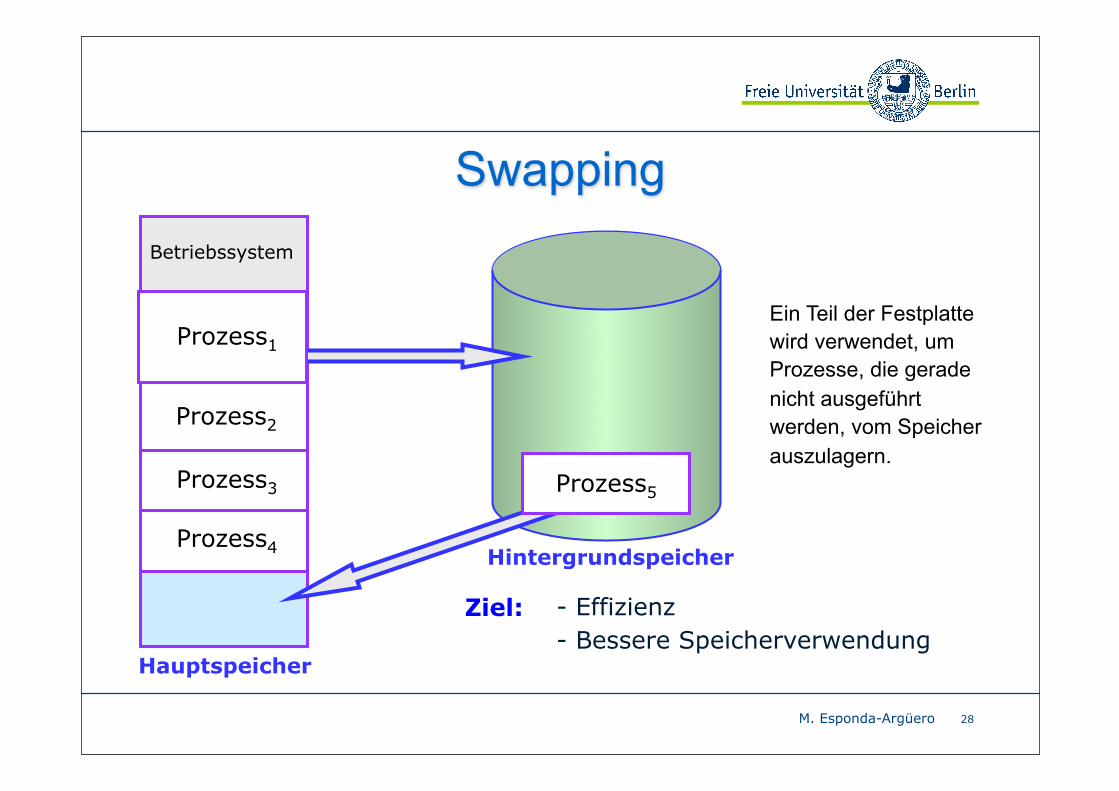
M. Esponda-Argüero
Swapping
28
Betriebssystem
Prozess2
Prozess3
Hauptspeicher
Prozess4 Hintergrundspeicher
Ein Teil der Festplatte wird verwendet, um Prozesse, die gerade nicht ausgeführt werden, vom Speicher auszulagern.
Prozess1
Prozess5
Ziel: - Effizienz- Bessere Speicherverwendung

M. Esponda-Argüero
Swapping-Strategie
29
Ein Prozess kann nur ausgelagert (swap out) werden, wenn es sicher ist, dass er sich im idle-Zustand befindet.
Möglichst viele ausführungsbereite Prozesse sollen im Hauptspeicher sein.
Prozesse, die auf I/O-Operationen warten, dürfen nur bedingt ausgelagert werden, z.B. wenn es ausgelagerte Prozesse gibt, die ausführungsbereit sind und die Prozesse, die ausgelagert werden sollen, auf keine I/O-Speicheroperationen warten.
Weitere Kriterien für die Ein- oder Auslagerung sind: - Prioritäten
- Speichergröße der Prozesse
- Fairness. Die Prozesse sollen rotierend ein- und ausgelagert werden.

M. Esponda-Argüero
Swapping
30
Swapping war die erste einfache Technologie, die im Betriebssysteme
verwendet worden ist, um das Problem des Speicherüberlaufs zu
lösen.
Einige moderne Betriebssysteme schalten das Swapping-System erst
dann ein, wenn der Speicherverbrauch sehr stark wird. Sonst wird
das Problem des Speicherüberlaufs mit Paging-Technologie gelöst.
Die meisten Betriebssysteme kombinieren Swapping mit Paging.
Was passiert wenn Hauptspeicher und Swapping-Speicher voll sind?
Linux OOM-Killer

M. Esponda-Argüero
Verwaltung freier Speicherlücken
31
Die meisten Prozesse verändern während ihrer Laufzeit ihre
Größe.
Wenn Prozesse ein- und wieder ausgelagert werden, oder
neuer Speicherplatz Prozessen dynamisch zugeteilt wird, muss
das Betriebssystem die freien Speicherbereiche verwalten.
Zwei Verwaltungstechniken
Bitmaps
Verkettete Listen

M. Esponda-Argüero
Speicherverwaltung mit Bitmaps
32
Der Hauptspeicher wird in Allokationseinheiten unterteilt.
Jede Einheit entspricht einem Bit in der Bitmap.
Je kleiner die Allokationseinheiten sind, desto größer
wird die Bitmap.
0 = frei1 = belegt
Große Allokationseinheit bedeutet
Speicherverschwendung an den Rändern von Prozessen.
Auch als interne Fragmentierung bekannt.
P2 P4P1
. . .
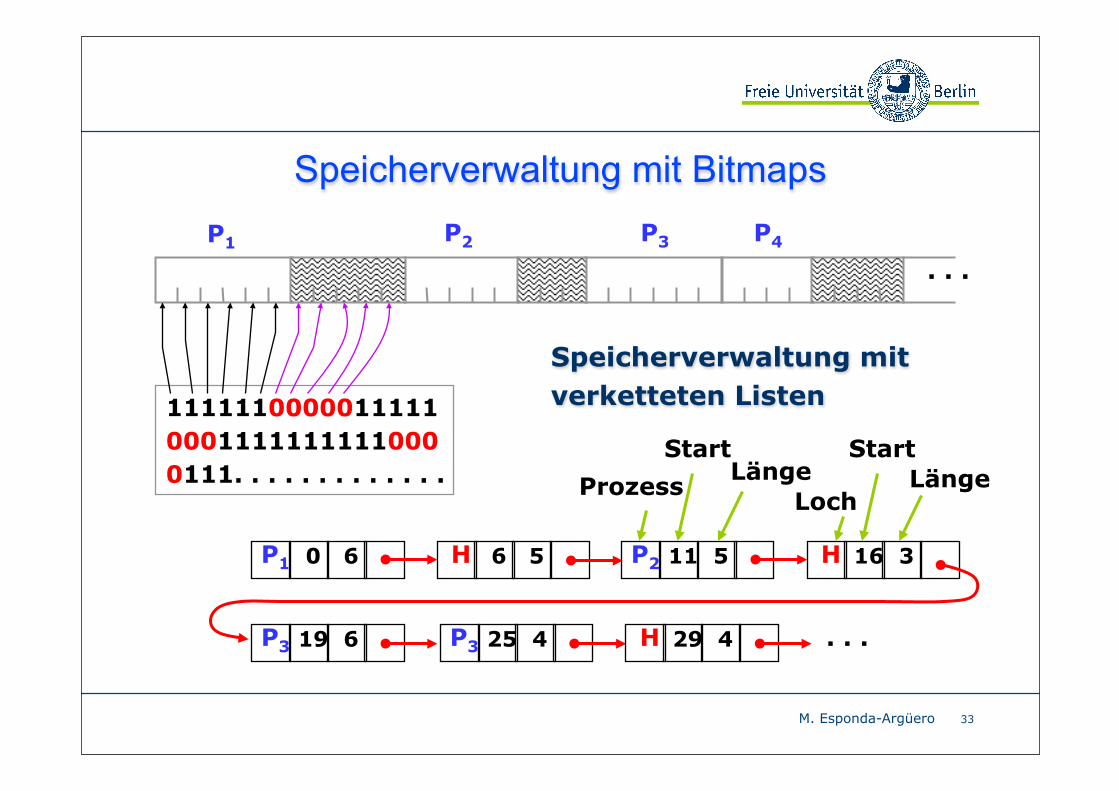
M. Esponda-Argüero
Speicherverwaltung mit Bitmaps
33
. . .
P1 P2 P4P3
111111000001111100011111111110000111. . . . . . . . . . . . .
P1 0 6 H 6 5 P2 11 5 H 16 3
P3 19 6 P3 25 4 H 29 4 . . .
Prozess
StartLänge
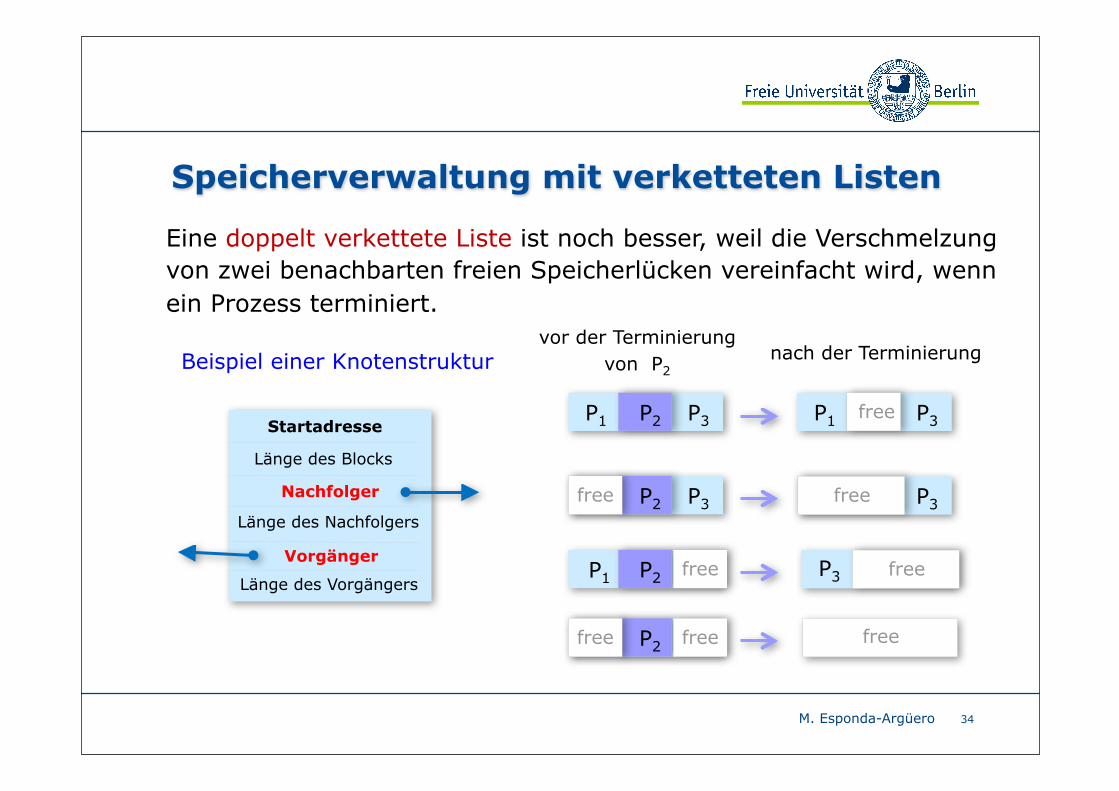
Speicherverwaltung mit verketteten Listen
Loch
StartLänge
M. Esponda-Argüero
Speicherverwaltung mit verketteten Listen
34
Eine doppelt verkettete Liste ist noch besser, weil die Verschmelzung von zwei benachbarten freien Speicherlücken vereinfacht wird, wenn ein Prozess terminiert.
Beispiel einer Knotenstruktur
P3P2 P3free free
P1 P2 free P3 free
P2free freefree
Länge des Blocks
Startadresse
Länge des Vorgängers
Länge des Nachfolgers
Vorgänger
Nachfolger
P3P1 P2 P3P1 free
nach der Terminierungvor der Terminierung
von P2
M. Esponda-Argüero
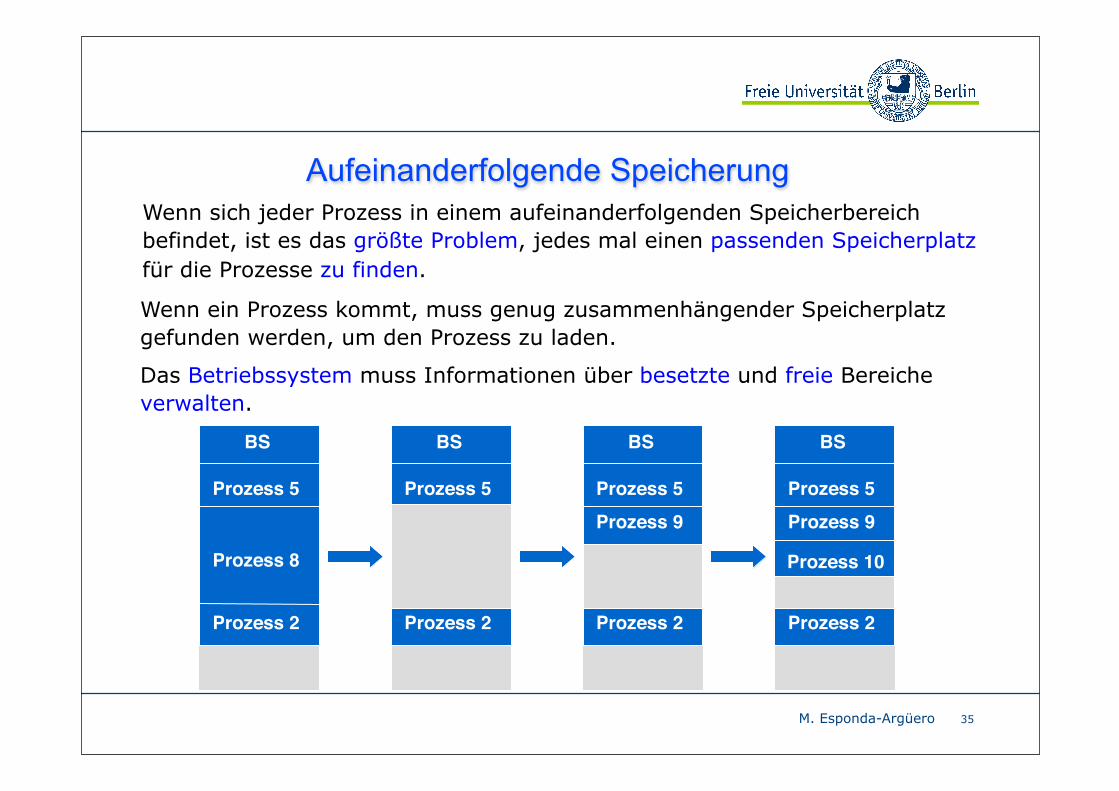
Aufeinanderfolgende Speicherung
35
Wenn sich jeder Prozess in einem aufeinanderfolgenden Speicherbereich befindet, ist es das größte Problem, jedes mal einen passenden Speicherplatz für die Prozesse zu finden.
Wenn ein Prozess kommt, muss genug zusammenhängender Speicherplatz gefunden werden, um den Prozess zu laden.
Das Betriebssystem muss Informationen über besetzte und freie Bereiche verwalten.
BS
Prozess 5
Prozess 8
Prozess 2
BS
Prozess 5
Prozess 2
BS
Prozess 5
Prozess 2
Prozess 9
BS
Prozess 5Prozess 9
Prozess 2
Prozess 10

M. Esponda-Argüero
Dynamisches Allokationsproblem
36
Wie kann ein Speicherbereich mit Größe n in einer Menge von freien Speicherbereichen am Besten gewählt werden?
First-Fit
Best-Fit
Worst-Fit
Sucht den ersten freien Bereich, der groß genug ist.
- schnelle Lösung
Sucht den kleinsten freien Bereich, der aber groß genug ist.
Sucht den größten freien Bereich.
- erzeugt den größten Restbereich.
Simulationen haben gezeigt, dass First-Fit und Best-Fit besser als Worst-Fit sind.
M. Esponda-Argüero
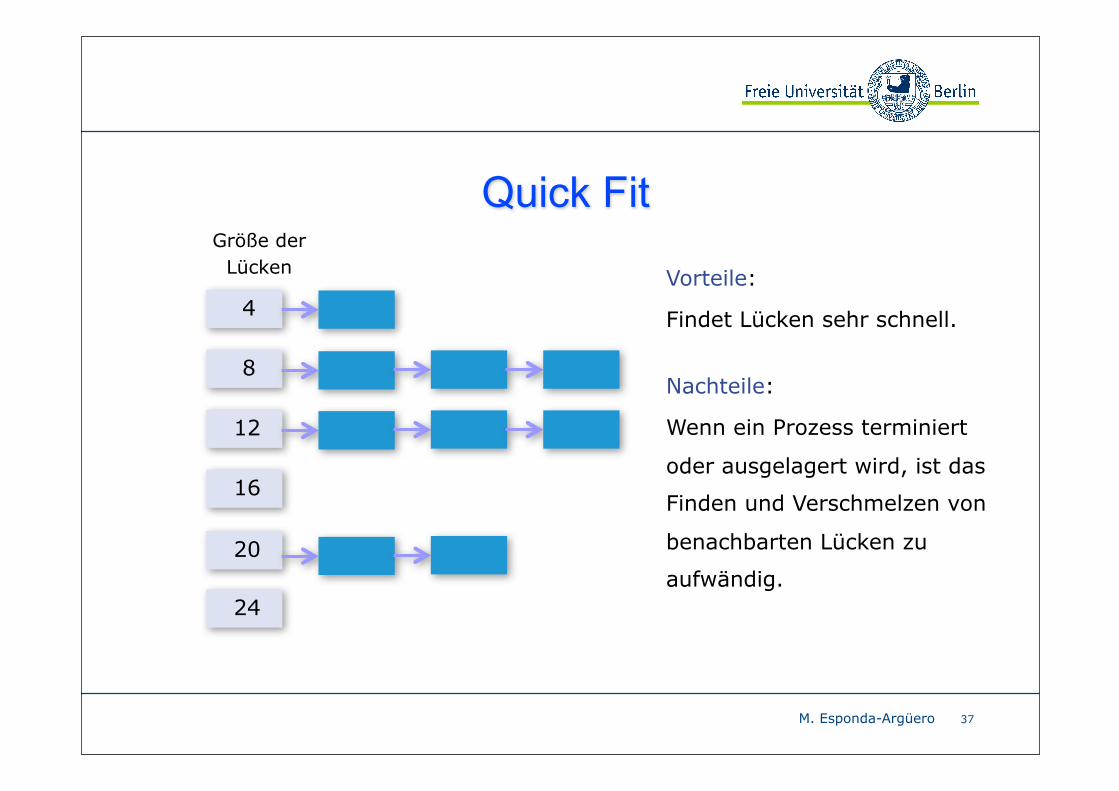
Quick Fit
37
Größe der Lücken
4
8
12
16
20
24
Vorteile:
Findet Lücken sehr schnell.
Nachteile:
Wenn ein Prozess terminiert
oder ausgelagert wird, ist das
Finden und Verschmelzen von
benachbarten Lücken zu
aufwändig.

M. Esponda-Argüero
Externe Fragmentierung
38
Nachdem die Prozesse öfter geladen und wieder entladen worden sind, zersplittert sich der freie Speicherbereich in immer mehr kleinere Stückchen.
Es kann passieren, dass es genug Speicher für einen Prozess gibt, aber nicht benutzt werden kann, weil die speicherfreien Räume nicht zusammenhängend sind.
Simulationen zeigten, dass etwa 1/3 des gesamten Speichers durch das Fragmentierungsproblem unbrauchbar wird.
Lösungen: - Speicherkomprimierung - sehr zeitaufwändig - nur wenn Laufzeit-Bindung.
- Probleme während Ein-/Ausgabe-OperationenProzesse können verteilt gespeichert werden, wo gerade Lücken vorhanden sind.
Paging und Segmentierung
M. Esponda-Argüero
Paging
39
Paging erlaubt Prozessen oder Programmen in Teilen zu laden und löst das Problem des Findens nach passender freier Speichergröße für einen Prozess.
Der physikalische Speicher wird in Frames geteilt.
Der logische Speicher wird in Pages geteilt, die genau so groß sind wie die Frames.
Um ein Programm mit n Pages zu laden, müssen n freie Frames im Speicher gefunden werden.
Eine Tabelle mit der Zuordnung zwischen Frames und Pages muss gesetzt werden.
Interne Fragmentierung kann entstehen.
M. Esponda-Argüero
Paging
40
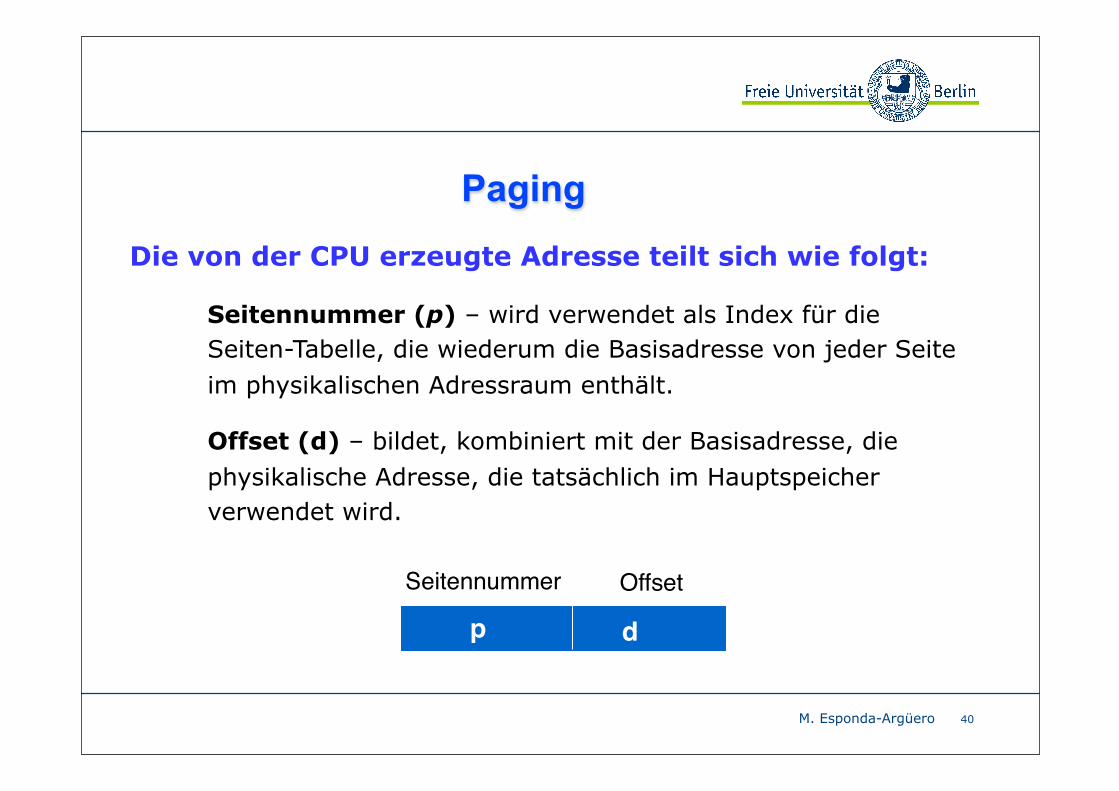
Die von der CPU erzeugte Adresse teilt sich wie folgt:
• Seitennummer (p) – wird verwendet als Index für die Seiten-Tabelle, die wiederum die Basisadresse von jeder Seite im physikalischen Adressraum enthält.
• Offset (d) – bildet, kombiniert mit der Basisadresse, die physikalische Adresse, die tatsächlich im Hauptspeicher verwendet wird.
Seitennummer Offset
p d
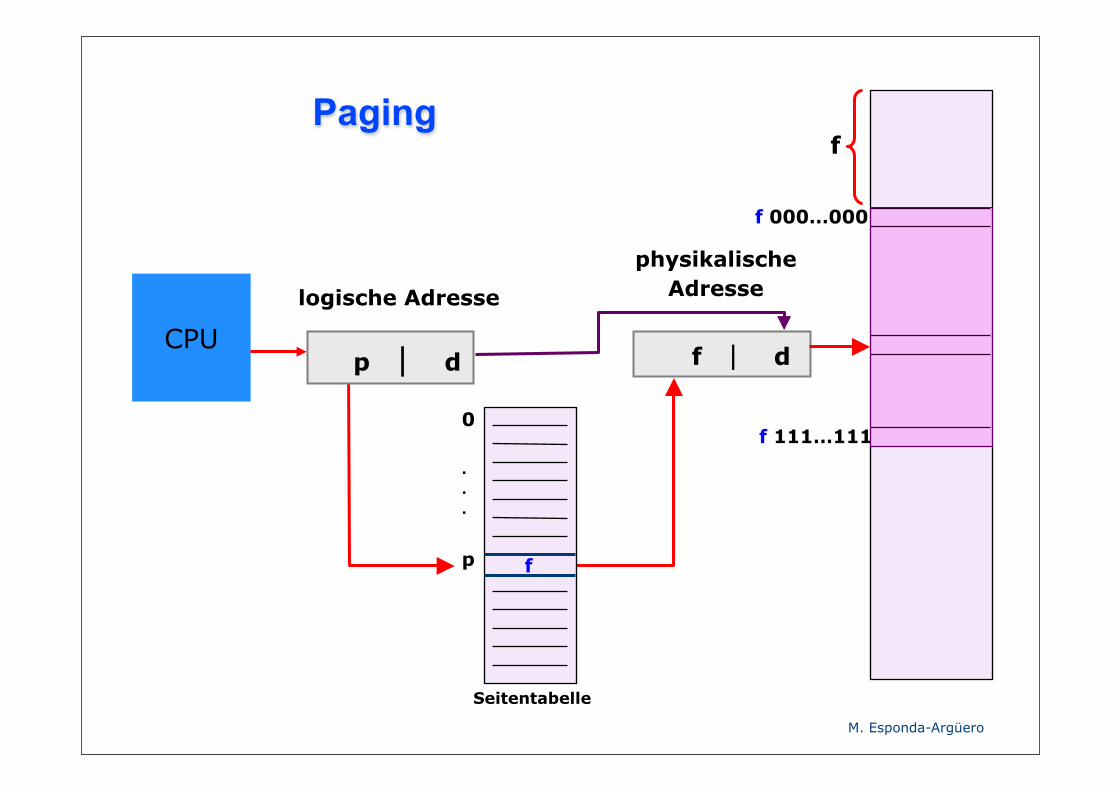
Paging
CPU p | d
logische Adresse
f | d
physikalische Adresse
f
0
.
.
.
p
f 000…000
f 111…111
f
Seitentabelle
M. Esponda-Argüero
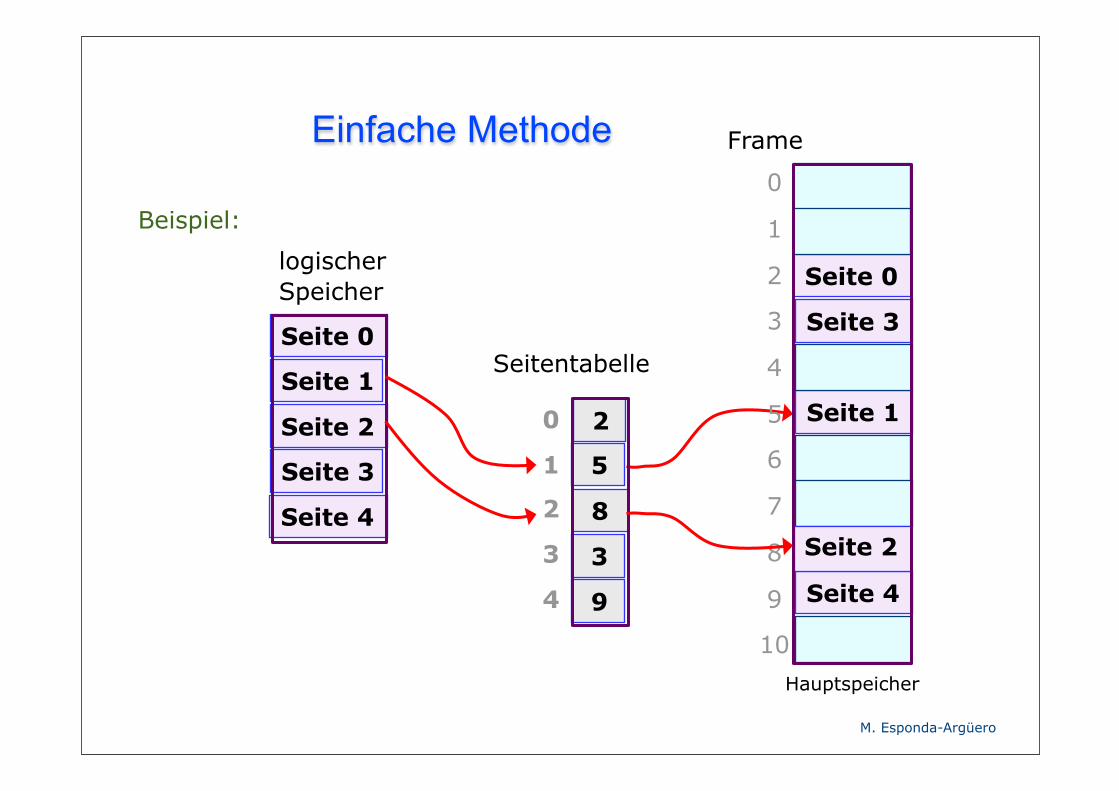
Einfache Methode
0
1
2
3
4
logischerSpeicher
Seitentabelle
Beispiel:
Seite 0
Seite 1
Seite 2
Seite 3
Seite 4
2
5
8
3
9
Seite 0
Seite 3
Seite 1
Seite 4
0
1
2
3
4
5
6
7
8
9
10
Seite 2
Frame
Hauptspeicher
M. Esponda-Argüero
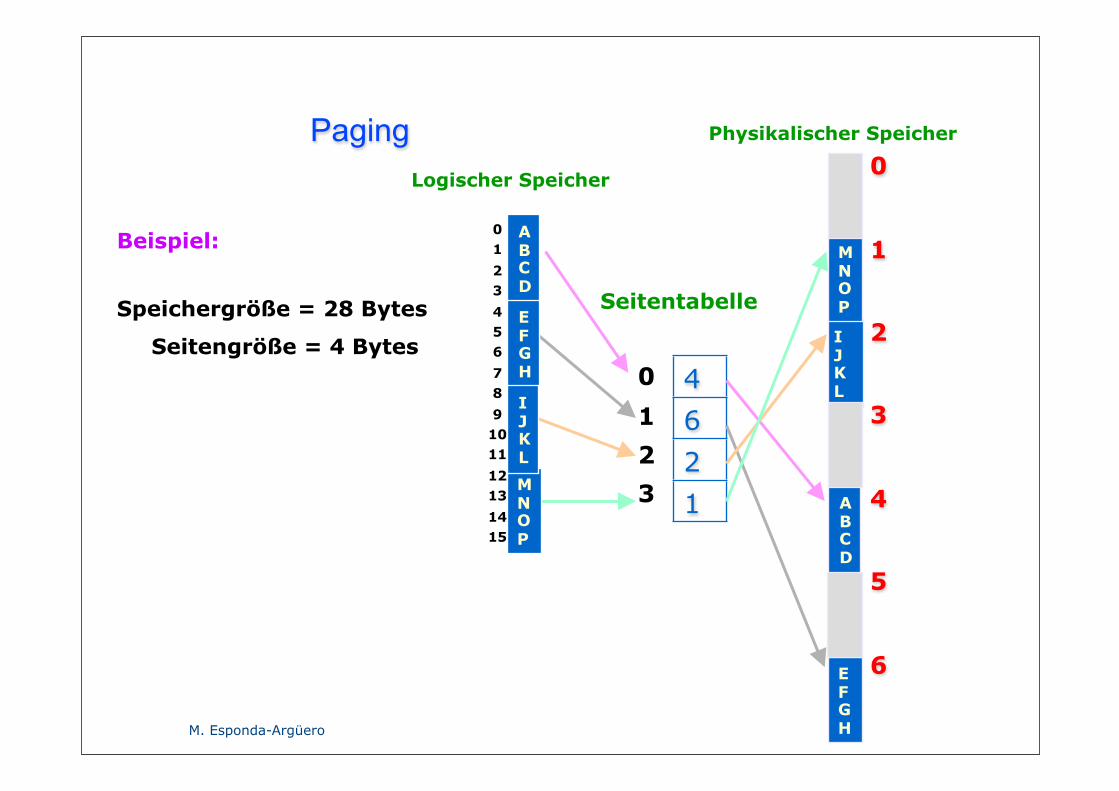
Paging
Beispiel:
Speichergröße = 28 Bytes
Seitengröße = 4 Bytes
0
1
2
3
4
5
6
Logischer Speicher
Seitentabelle
0
1
2
3
4
6
2
1
Physikalischer Speicher
ABCD
IJKL
MNOP
EFGH
ABCD
EFGH
MNOP
01
23
456
78
91011
1213
1415
IJKL
M. Esponda-Argüero
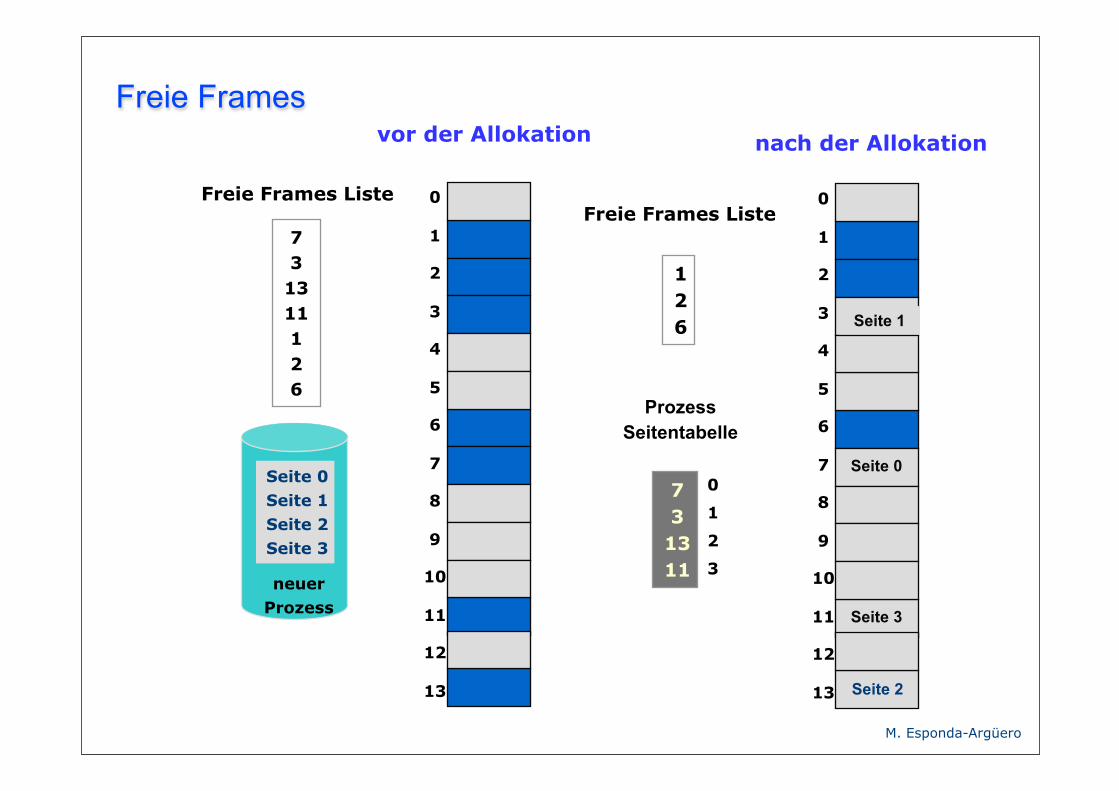
Freie Framesvor der Allokation
Freie Frames Liste
73
1311126
neuer Prozess
Seite 0Seite 1Seite 2Seite 3
73
1311
Freie Frames Liste
126
0
1
2
3
4
5
6
7
8
9
10
11
12
13
Prozess Seitentabelle
0
1
2
3
nach der Allokation
0
1
2
3
4
5
6
7
8
9
10
11
12
13
Seite 1
Seite 0
Seite 2
Seite 3
M. Esponda-Argüero

M. Esponda-Argüero
Implementierung der Page-Tabellen
45
1. Mit Registern innerhalb der CPU
- nur für sehr kleine Tabellen
2. Die Seitentabelle ist im Hauptspeicher
- die Zugriffszeit verdoppelt sich
3. Spezielle Hardware (TLB) Translation-Look-Aside-Buffer
- schnelle assoziative Cache-Speicher
- die TLB beinhaltet nur eine kleine Anzahl von Seiten (pages)
- bei jedem Kontextwechsel muss die TLB gelöscht und wieder geladen werden
- 2 spezielle Register (PTBR + PTLR)
Page-Table-Base-Register Page-Table-Length-Register

M. Esponda-Argüero
Hardwareunterstützung
46
Assoziative Cache-Speicher mit paralleler Suche
Seitennummer Frame-Nummer
Jede logische Adresse ist ein Tupel (p, d).
Wenn p im assoziativen Register von TLB (Seitennummer) steht, wird die entsprechende Frame-Nummer abgelesen und mit d die physikalische Adresse berechnet.
Sonst wird die Seitennummer im Hauptspeicher gesucht und dort die Frame-Nummer gelesen.
TLB
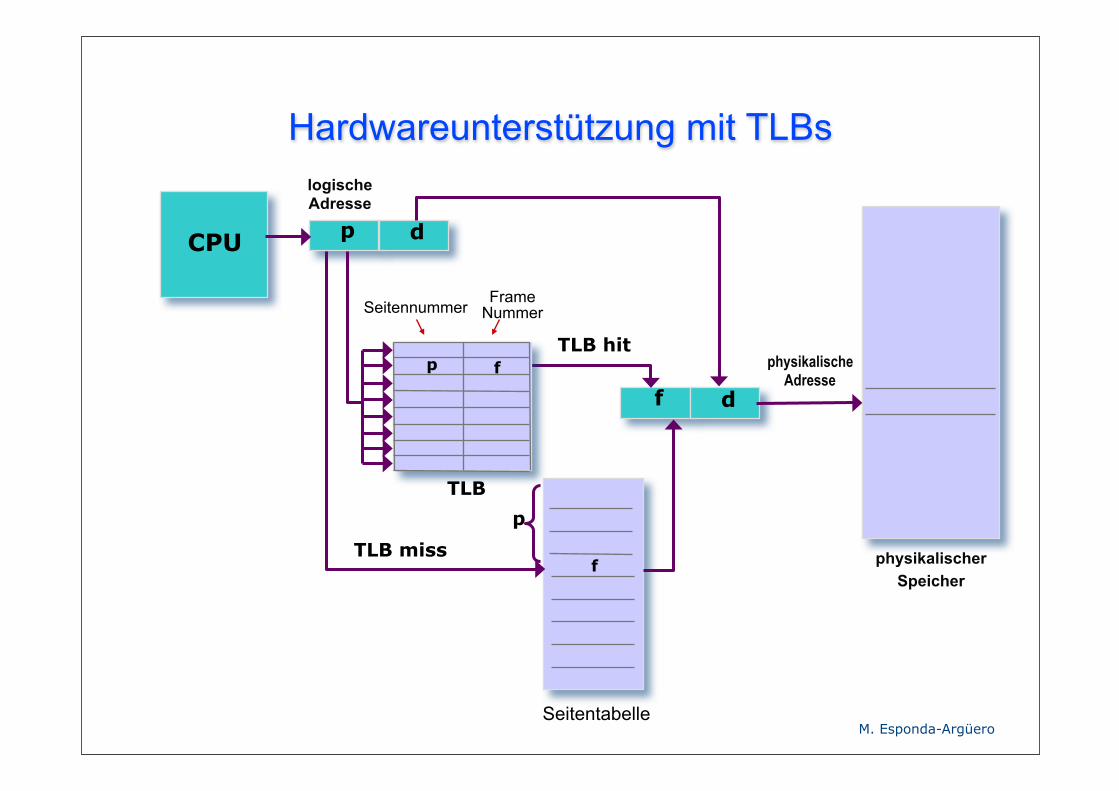
physikalischer Speicher
Hardwareunterstützung mit TLBs
CPU p d
logische Adresse
Seitentabelle
f d
physikalische Adresse
TLB hit
TLB
FrameNummerSeitennummer
TLB miss
p
fp
f
M. Esponda-Argüero

M. Esponda-Argüero
Zugriffszeit mit TLBs
48
Beispiel:
TLB - Zugriffszeit = 10 ns
Speicherzugriffszeit = 80 ns
Treffrate = 80%
Effektive Zugriffszeit = 0,8 ( 80 + 10 ) + 0,2 ( 160 + 10 )
= 106 ns
Treffrate = 95%
Effektive Zugriffszeit = 0,95 ( 80 + 10 ) + 0,05 ( 160 + 10 )
= 94 ns
… weiter am Freitag!