Embed Size (px)
Citation preview

R-WORKSHOP II
Inferenzstatistik
Johannes Pfeffer
Dresden, 25.1.2011

01 Outline
Lösung der Übungsaufgabe
Selbstdefinierte Funktionen
Inferenzstatistikt-TestKruskal-Wallis Test
Übungsaufgabe
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 2 von 26

02 BartwuchsLösung der Übungsaufgabe aus Workshop I
Gerd Glatzel, der ein existenzielles Problem mit seinem Haarwuchs hat (denüppigsten Teil seiner Kopfbedeckung stellen die Augenbrauen dar), stößt bei derLektüre seiner Lieblingszeitschrift „Mann vorm Spiegel“ auf das folgende Inseratder Rapunzel AG:„Doppel-Haar, das erfolgreichste Haarwuchsmittel, das es je gab! 50% derAnwender hatten einen monatlichen Haarwuchs von 0,8 cm oder mehr - innerhalbeines Monats durchschnittlich 1,4 cm längeres Haar.“Die Lösung seines Problems erhoffend, greift Glatzel sofort zu. Einen Monat späterhat er auch noch die spärlichen Reste seiner „Kopfbedeckung“ verloren. Erbostsucht er die Rapunzel AG auf (die Blöße mit einem Hut bedeckend), um seinemÄrger Luft zu machen. Dort erhält er eine Tabelle mit Haarwuchsergebnissen vonTestpersonen des Mittels Doppel-Haar (Haarwuchs innerhalb eines Monats in cm;negative Werte stehen für Haarausfall).
2. Überprüfe die Herstellerangaben indem du den durchschnittlichen Haarwuchssowie den Median, die Varianz und die Standardabweichung desHaarwuchses berechnest.
3. Zeichne ein Boxplot des Haarwuchses.
4. Zeichne ein Histogramm des Haarwuchses.
5. Schätze mittels eines QQ-Plots ein, ob eine Normalverteilung vorliegt.

02 BartwuchsLösung der Übungsaufgabe aus Workshop I
2. Überprüfe die Herstellerangaben indem du den durchschnittlichen Haarwuchssowie den Median, die Varianz und die Standardabweichung desHaarwuchses berechnest.
> haar <-read.csv(file="haarwuchs.csv",head=TRUE ,sep=";")
> install.packages("pastecs")> library(pastecs)> stat.desc(haar)
Haarwuchs(...)min -4.2000000max 10.8000000range 15.0000000sum 56.0000000median 0.8000000 // <- "50% der Anwender ..."mean 1.4000000 // <- "Durchschnittlich ..."(...)var 10.1882051 // <- Varianzstd.dev 3.1918968 // <- Standardabweichungcoef.var 2.2799263

02 BartwuchsLösung der Übungsaufgabe aus Workshop I
3. Zeichne ein Boxplot des Haarwuchses.
> boxplot(haar)
●
05
10
Es wird sichtbar, dass ein extremer Ausreißer die Werbeaussage verzerrt.

02 BartwuchsLösung der Übungsaufgabe aus Workshop I
4. Zeichne ein Histogramm des Haarwuchses.
> hist(haar$Haarwuchs)Histogram of haar$Haarwuchs
haar$Haarwuchs
Fre
quen
cy
−5 0 5 10
02
46
8
Die Werte um den Nullpunkt weisen die höchste Häufigkeit auf. Der Ausreißer istdeutlich sichtbar. Negative Werte (Haarausfall) haben eine nicht zuvernachlässigende Häufigkeit.
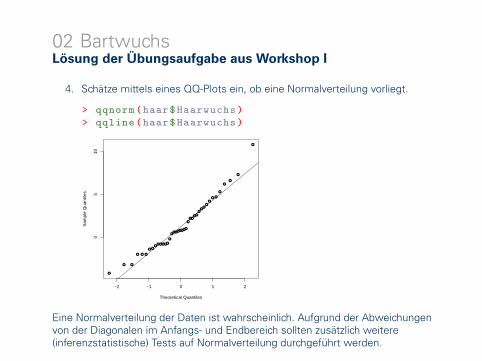
02 BartwuchsLösung der Übungsaufgabe aus Workshop I
4. Schätze mittels eines QQ-Plots ein, ob eine Normalverteilung vorliegt.
> qqnorm(haar$Haarwuchs)> qqline(haar$Haarwuchs)
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
−2 −1 0 1 2
05
10
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Eine Normalverteilung der Daten ist wahrscheinlich. Aufgrund der Abweichungenvon der Diagonalen im Anfangs- und Endbereich sollten zusätzlich weitere(inferenzstatistische) Tests auf Normalverteilung durchgeführt werden.

03 Selbstdefinierte FunktionenWeiterführende R-Syntax – Übung
Syntax
Funktionsname <- function(Argumente)\{R-Befehle \}
Die Funktion kann beliebig viele Befehle enthalten. Als letztes in jeder Funktion stehtimmer der Wert oder auch eine Liste von Werten, die ausgegeben werden soll.
Schreibe eine Funktion „sumnm“, die 1 bis n und 1 bis m aufaddiert
sumnm(n, m) =n∑
i=1+
m∑j=1
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 8 von 26

03 Selbstdefinierte Funktionenkleiner Hinweis
> sumnm <-function(n,m){+ x<-1:n+ ...
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 9 von 26

03 Selbstdefinierte FunktionenLösung
> sumnm <-function(n,m){+ x<-1:n+ y<-1:m+ z<-sum(x)+sum(y)+ z+ }> sumnm (5 ,10)[1] 70
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 10 von 26

04 InferenzstatistikAbgrenzung der schließenden Statistik
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 11 von 26

04 t-TestVoraussetzungen
• Merkmal mindestens intervallskaliert - Ausprägungen lassen sichquantitativ mittels Zahlen darstellen. Rangunterschiede und Abstandzwischen Werten können gemessen werden. Beispiele für intervallskalierteMerkmale sind Temperatur auf der Celsius-Skala, Jahreszahlen, Zeitpunkte.
• Stichproben müssen unabhängig sein - Ist z.B. nicht gegeben, wenn diegleichen Versuchspersonen direkt nacheinander zwei unterschiedliche GUIsbewerten.
• Annähernde Gaußverteilung der Daten lässt sich aus den Boxplots derDaten ablesen: Der Median sollte mittig in der Box liegen und die beidenWhisker etwa gleich lang sein. Aus der Gauß-Verteilung ergibt sich dieStetigkeit der Daten, z.B. Temperaturen in Kelvin oder Längen in Metern.
• Varianzhomogenität ist graphisch aus den Boxplots ersichtlich: Dieverschiedenen Boxen nebst Whiskern sollten gleich lang sein. Einstatistischer Test kann diese Evaluation ergänzen (F-Test, Levene-Test).
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 12 von 26

04 t-TestÜberprüfung der Voraussetzungen 1/2
> data2 .1 <- read.csv2(file.choose ()) # "ws2.1.csv"> data2 .1> summary(data2 .2)> boxplot(Aufgabenerf~GUI ,data2.1,xlab="GUI",ylab="
Aufgabenerfuellung",col="purple")> qqnorm(data2 .1$Aufgabenerf); qqline(data2 .1$Aufgabenerf)
• Intervallskalliert - OK
• Unabhängig - OK
• Annähernde Gaußverteilung– Der Median sollte mittig in der Box liegen und die beiden Whisker etwa
gleich lang sein. Die Punkte im QQ-Plot sollten ca. auf einer Linieliegen. - OK
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 13 von 26

04 t-TestÜberprüfung der Voraussetzungen 2/2
• Varianzhomogenität– Levene-Test
> library(car)> levene.test(data2 .1$Aufgabenerf , data2.1$GUI)
Wenn der p-Wert über a = 0.05 liegt, muss die Hypothese gleicher Varianzenbeibehalten werden.D.h.: alle Voraussetzungen sind erfüllt.
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 14 von 26

04 t-TestAnwendung
Die Nullhypothese für den t-Test lautet: „Die mittlere Aufgabenerfüllung ist fürbeide GUIs gleich.“ – H0: µ1 = µ2. Die Alternativhypothese lautet: „Die mittlereAufgabenerfüllung ist für beide GUIs ungleich.“ Das Risiko 1. Art wird mit a =0.05festgelegt.
> t.test(data2 .1$Aufgabenerf~data2 .1$GUI , alternative = "two.sided", paired = FALSE ,var.equal = TRUE , conf.level =0.95)
Hier ist es wichtig, die richtige Alternativhypothese und das gewünschte Risiko 1.Art zu wählen. Da es sich um zwei unabhängige Stichproben handelt, ist bei ’paired’der Wert ’FALSE’ zu wählen. Je nachdem, ob die Varianzen homogen sind odernicht, wird ’var.equal’ auf ’TRUE’ oder auf ’FALSE’ gesetzt. Die Tilde ’∼’ bedeutet,dass die Werte für „Aufgabenerfüllung“ nach dem Faktor „GUI“ gruppiert werden.Dies ist notwendig, weil jede Zeile des DataFrames einem eigenen Fall, hier alsojeweils einer anderen Versuchsperson entspricht.
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 15 von 26

04 t-TestInterpretation
Two Sample t-test
data: data2.1$Aufgabenerf by data2.1$GUIt = 2.1612, df = 27, p-value = 0.03971alternative hypothesis: true difference in means is not equal to 095 percent confidence interval:0.004327426 0.166720193
sample estimates:mean in group A mean in group B
0.7626667 0.6771429
Der p-Wert (0.03971) liegt unter dem gewählten Risiko 1. Art a = 0.05, daher mussdie Hypothese gleicher mittlerer Aufgabenerfüllung bei beiden GUIs verworfenwerden.TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 16 von 26

04 t-TestInterpretation
t = 2.1612, df = 27, p-value = 0.03971
Die Teststatistik t beträgt 2.1612. Dies ist die Testgröße, die normalerweise mit dem Tabellenwert verglichen
wird. Ist sie extremer, als der Tabellenwert des Quantils zum entsprechenden Freiheitsgrad (df), gilt der
Mittelwertvergleich als signifikant.
alternative hypothesis: true difference in means is not equal to 0
Die abstrakte Alternativhypothese.
95 percent confidence interval: 0.004327426 0.166720193
Angenommen, man würde den Versuch unendlich oft indentisch wiederholen, dann läge die wahre Differenz in
95% der Fälle im jeweiligen Konfidenzintervall. Praktische Anwendung: Wenn in einem Konfidenzintervall die
Null eingeschlossen ist, gilt das Testergebnis als nicht signifikant. Im Falle einer Signifikanz stellt der Abstand
von Null ein Maß für den Grad der Ablehnung der H0 dar.
sample estimates: mean in group A mean in group B 0.7626667 0.6771429
Die beiden Mittelwerte werden ausgegeben.

04 Daten aus Workshop IEigenschaften der Daten 1/2
> data2 .2 <- read.csv2(file.choose ()) # "ws2.2.csv"> data2 .2> summary(data2 .2)> boxplot(MW~GUI ,data2.2,xlab="GUI",ylab="
Aufgabenerfuellung",col="orange")> qqnorm(data2 .2$MW); qqline(data2 .2$MW)
• Intervallskalliert - OK• Unabhängig - OK• Mehr als 2 Gruppen• Annähernde Gaußverteilung
– Der Median sollte mittig in der Box liegen und die beiden Whisker etwagleich lang sein. Die Punkte im QQ-Plot sollten ca. auf einer Linieliegen. - NICHT OK für t-Test
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 18 von 26

04 Daten aus Workshop IEigenschaften der Daten 2/2
• Varianzhomogenität– Levene-Test
> levene.test(data2 .2$MW, data2.2$GUI)
Wenn der p-Wert über a = 0.05 liegt, muss die Hypothese gleicher Varianzenbeibehalten werden. - OK
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 19 von 26

04 Kruskal-Wallis TestVoraussetzungen
Was tun, wenn Voraussetzungen für t-Test o.ä. nicht erfüllt sind?Es muss auf ein nichtparametrisches Testverfahren ausgewichen werden. DieseTestverfahren haben großzügigere Voraussetzungen - aber in der Regel einegeringere Teststärke (d.h. größeren Beta-Fehler). Als Beta-Fehler oder Fehler 2. Artwird beim statistischen Testen der Fehler bezeichnet, den man begeht, wenn mandie Nullhypothese beibehält, obwohl die Alternativhypothese gilt.
Typische Voraussetzungen für nichtparametrische Tests:
• Varianzhomogenität - OK
• Mindestens ordinale Skalierung - OK
• Unabhängige Daten - OK
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 20 von 26

04 Kruskal-Wallis TestAnwendung
Die Nullhypothese (H0) lautet:„Die unterschiedlichen Benutzeroberflächen haben keinen Einfluss auf denMittelwert der Klassifizierungsgenauigkeit (MW)“. Die Nullhypothese wird mittels
des Kruskal-Wallis Tests überprüft. Dieser nichtparametrische Test eignet sich fürkleine Stichproben in Gruppen unterschiedlicher Größe, bei denen keineNormalverteilung nachgewiesen werden kann.
> kruskal.test(MW~GUI ,data2 .2)
Wenn der p-Wert über a = 0.05 liegt, kann H0 nicht verworfen werden. DieBenutzeroberfläche hat dann also keine nachweisbare Auswirkung auf denMittelwert der Klassifizierungsgenauigkeit.
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 21 von 26

05 ÜbungsaufgabeDateneingabe
20 Studenten wurden einem Stresstest unterzogen. Dabei wurden Paare gebildetdie sich in ihren bisherigen Prüfungsergebnissen möglichst ähnlich waren. EineGruppe wurde vor dem Test starkem Stress ausgesetzt die andere diente alsKontrollgruppe. Ihre Ergebnisse auf einer Skala von 0-15 Punkten (15 = bestesErgebnis), sehen Sie in folgender Tabelle (fiktive Daten).
Geben Sie die Daten mittels des folgenden Befehls in R ein.
> stress <-data.frame(); fix(stress)
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 22 von 26

05 ÜbungsaufgabeAuftrag
Führen Sie einen geeigneten t-Test durch.Hinweise:
• Formulieren Sie eine sinnvoll gerichtete unspezifische Hypothese
• Achtung - es geht um die Differenzen der Paare
• Überprüfen Sie die Voraussetzungen für den t-Test– Annähernde Gaußverteilung der Paardifferenzen, es wird Robustheit
des Tests gegenüber dem schief in der Box liegenden Medianangenommen
• Schlagen Sie in der R-Hilfe die notwendigen Parameter für den t-Test nach– Gepaarte Daten, da Studentenpaare gebildet wurden, die sich
möglichst ähnlich sein sollten.– Art der Alternativhypothese– ... ?
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 23 von 26

05 ÜbungsaufgabeLösung
=⇒ Gepaarter einseitiger t-Test (die eine Studentengruppe wurde einemStressprogramm ausgesetzt, was schlechtere Testergebnisse erwarten lässt).
H0: µStress >= µNormal - Die Stressbehandlung verschlechtert das Abschneiden derProbanden nicht.
H1: µStress < µNormal - Das Abschneiden der Probanden ist nach derStressbehandlung schlechter.
> unterschiede <-stress$Stress -stress$Normal> boxplot(unterschiede) # schief liegender Median> t.test(stress$Stress , stress$Normal , paired = TRUE ,
alternative = "less")# Achtung - Reihenfolge ist entscheidend , da einseitiger
Test
Der p-Wert (0.01568) ist kleiner als 0.05, deshalb ist das Ergebnis signifkant. DieStressbehandlung bewirkt ein verschlechtertes Abschneiden im Test.(Achtung: für die Übung wurden fiktive Daten verwendet)

05 ÜbungsaufgabeZusatzaufgabe
• Warum können Sie ihre Hypothese nicht direkt mit einem Kruskal-Wallis-Testüberpüfen?
• Wie müssen Sie sie dazu verändern?
• Führen Sie den Kruskal-Wallis Test durch.
TU Dresden, 25.1.2011 R-Workshop: Inferenzstatistik Folie 25 von 26




















![MT Q11 Strahlenschutz 24-11-2009.PPT [Schreibgeschützt] … Strahlenschutz 2009.pdf · 2011-09-30 · * Datenbasis: 75991 Exponierte, 5734 Krebsfälle, 260 mehr als in Kontrollgruppe](https://img.pdfslide.org/doc/110x75/5e9bae0e7757210f7a2fbd53/mt-q11-strahlenschutz-24-11-2009ppt-schreibgeschtzt-strahlenschutz-2009pdf.jpg)








