Embed Size (px)
Citation preview

Informationssystem
Architekturen
Wirtschaftsinformatik
Rundbrief der GI-Fachgruppe 5.10
8. Jahrgang, Heft 1, August 2001

Dieser Rundbrief wird von der Fachgruppe 5.10 Informationssystem-Architekturen: Modellierung betrieblicher Informationssysteme (MobIS) der Gesellschaft für Informatik e.V. (GI) herausgegeben und erscheint im halbjährlichen Abstand. Gegenstand des Rundbriefes sind Forschungsergebnisse im Bereich betrieblicher Informationssystem-Architekturen und Praxisbeispiele von fortschrittlichen Anwendungen in Wirtschaft und Verwaltung.
Der Rundbrief dient den Mitgliedern und den Arbeitskreisen der Fachgruppe 5.10 zum Informations- und Erfahrungsaustausch. Über den Abdruck von eingereichten Beiträgen entscheiden die Leitungs-gremien der Fachgruppe und der Arbeitskreise. Die abgedruckten Beiträge geben stets die Meinung der jeweiligen Autoren wieder.
Alle Mitglieder der Fachgruppe 5.10 erhalten den Rundbrief. Es ist möglich, ohne gleichzeitige Mit-gliedschaft in der GI der Fachgruppe beizutreten. Anträge auf Aufnahme in die GI oder die Fachgruppe sind an die Geschäftsstelle der GI zu richten (Postanschrift: Gesellschaft für Informatik e.V., Wissenschaftszentrum, Ahrstr. 45, 53175 Bonn, Tel.: 0228/302-145). Aus Gründen der einfacheren Verwaltung werden Eintritte jeweils zu Beginn des Kalenderjahres wirksam.
Leitungsgremium der Fachgruppe 5.10 Informationssystem-Architekturen
Prof. Dr. Jörg Becker Institut für Wirtschaftsinformatik Westfälische Wilhelms-Universität Grevener Str. 94 48159 Münster Tel.: 0251/83-9751 e-mail: [email protected]
Dr, Martin Bertram Debis Systemhaus Dienstleistungen GmbH Fasanenweg 9 70771 Leinfelden-Echterdingen Tel.: 0711/972-3202 e-mail: [email protected]
Prof. Dr. Ulrich Frank Universität Koblenz-Landau Institut für Wirtschaftsinformatik Reihnau 1 56075 Koblenz Tel.: 0261/911-9482 e-mail: [email protected]
Klaus-Walter Müller (stellv. Sprecher) KPMG Consulting AG Financial Services / Insurance Elektrastraße 6 81925 München Tel.: 089/9282 - 4358 e-mail: [email protected]
Prof. Dr. Andreas Oberweis Johann Wolfgang Goethe-Universität Institut für Wirtschaftsinformatik II Postfach 11 19 32 60054 Frankfurt am Main Tel.: 069/798-28722 e-mail: [email protected]
Prof. Dr. Herrad Schmidt Universität-Gesamthochschule Siegen FB Wirtschaftswissenschaften 57068 Siegen Tel.: 0271/740-3261 e-mail: [email protected]
Prof. Dr. Elmar J. Sinz (Sprecher) Universität Bamberg Lehrstuhl für Wirtschaftsinformatik Feldkirchenstr. 21 96045 Bamberg Tel.: 0951/863-2512 e-mail: [email protected]
Dr. Michael Teufel, RWE Systems AG Bereich IT-Anwendungen Flamingoweg 1 44139 Dortmund Tel.: 0231/438-4210 e-mail: [email protected]

1
Inhalt
Editorial ................................................................................................................. 3
Aufruf zur Wahl des Leitungsgremiums ............................................................. 5
Einladung zur Mitgliederversammlung der GI-Fachgruppe 5.10 MobIS ........ 11
Tagungsankündigung VertIS 2001 .................................................................... 13
Call for Papers „Modellierung 2002“................................................................. 19
Beiträge des Arbeitskreises 5.10.4: Modellierung und Nutzung von Data Warehouse Systemen .......................... 21
Bericht des Arbeitskreises .............................................................................. 23
M. Böhnlein, A. Ulbrich-vom Ende (Universität Bamberg): Ein konzeptuelles Data Warehouse-Modell für die Erstellung multidimensionaler Datenstrukturen ............................................................... 25
Knobloch, B. (Universität Bamberg): Der Data-Mining-Ansatz zur Analyse betriebswirtschaftlicher Daten .............. 59

2

3
An die Mitglieder und Interessenten
der Fachgruppe 5.10 Informationssystem-Architekturen: Modellierung
betrieblicher Informationssysteme (MobIS)
Editorial
Sehr geehrte Damen und Herren,
die vorliegende Ausgabe des Rundbriefs enthält zwei Beiträge aus dem Arbeitskreis 5.10.4
Modellierung und Nutzung von Data-Warehouse-Systemen. Michael Böhnlein und Achim
Ulbrich-vom Ende berichten über ein konzeptuelles Data-Warehouse-Modell für die
Erstellung multidimensionaler Datenstrukturen. Bernd Knobloch gibt eine Einführung in den
Data-Mining-Ansatz zur Analyse betriebswirtschaftlicher Daten.
Die Amtszeit des Leitungsgremiums der Fachgruppe 5.10 ist abgelaufen. Sie finden in diesem
Rundbrief einen Wahlaufruf für die Briefwahl einer neuen Fachgruppenleitung und ich
ermuntere Sie hiermit, sich zahlreich an der Wahl zu beteiligen.
Schließlich möchte ich Sie herzlich einladen, an der Verbundtagung VertIS 2001 am 4. und 5.
Oktober 2001 in Bamberg teilzunehmen. Sie wird von den Fachgruppen 1.1.6 VKI, 2.5.2
EMISA und 5.10 MobIS sowie dem DFG-Schwerpunktprogramm 1083 gemeinsam
veranstaltet und ersetzt in diesem Jahr unsere klassische MobIS-Jahrestagung. Mit dem
Konzept der Verbundtagung wollen wir einen Beitrag zur Bündelung von Tagungsaktivitäten
leisten. Aktuelle Informationen finden Sie unter http://ceus.uni-bamberg.de/vertIS2001/. Ich
würde mich freuen, Sie in Bamberg begrüßen zu dürfen und verbleibe
mit herzlichen Grüßen
Ihr Elmar Sinz

4

5
Aufruf zur Wahl des Leitungsgremiums der GI-Fachgruppe 5.10
„Informationssystem-Architekturen: Modellierung betrieblicher Informationssysteme“ (MobIS)
Sehr geehrte Fachgruppenmitglieder,
das Leitungsgremium einer Fachgruppe wird für drei Jahre gewählt. Da die Amtszeit des
Leitungsgremiums abgelaufen ist, stehen Neuwahlen an.
Folgende Kandidaten stehen zur Wahl:
• Prof. Dr. J. Becker (UNI Münster) http://www-wi.uni-muenster.de/is/mitarbeiter/
• Dr. M. Bertram (Commerzbank AG, Frankfurt)
• Prof. Dr. M. Esser (Artificial Life und UNI St. Petersburg)
• Prof. Dr. W. Esswein (UNI Dresden) http://wiseweb.wiwi.tu-dresden.de/Team/weness.htm
• Prof. Dr. U. Frank (UNI Koblenz-Landau) http://www.uni-koblenz.de/~iwi/mitarbeiter/UlrichFrank.html
• K.-W. Müller (KPMG, München)
• Prof. Dr. A. Oberweis (UNI Frankfurt) http://www.wiwi.uni-frankfurt.de/~oberweis/
• Prof. Dr. M. Rebstock (FH Darmstadt) http://www.fbw.fh-darmstadt.de/rebstock
• Prof. Dr. E. J. Sinz (UNI Bamberg) http://www.seda.sowi.uni-bamberg.de/mitarbeiter/sinz.html
• Dr. M. Teufel (VEW Energie AG, Dortmund)
Nachfolgend finden Sie eine kurze Vorstellung der einzelnen Kandidaten. Alle Mitglieder der
Fachgruppe 5.10 sind wahlberechtigt. Auf dem Stimmzettel, der die Kandidatenliste enthält,
kann bei jedem Kandidaten entweder „Ja“ oder „Nein“ angekreuzt werden. Gewählt sind die
9 Kandidaten, die die größte positive Differenz aus „Ja“- und „Nein“-Stimmen erreichen.

6
Füllen Sie bitte Stimmzettel und Adresszettel aus. Auf dem Stimmzettel darf pro Zeile
höchstens ein Kreuz eingetragen werden. Eine Stimmenthaltung (kein Kreuz) ist zulässig. Ein
Stimmzettel ist nur dann gültig, wenn für jeden Kandidaten eine eindeutige Ja/Nein-
Entscheidung bzw. Stimmenthaltung erkennbar ist. Ihre Stimmabgabe kann nicht gewertet
werden, wenn Sie nicht Mitglied der FG 5.10 sind, keine gültige GI-Mitgliedsnummer
angegeben haben oder den Adresszettel nicht unterschrieben haben.
Stecken Sie bitte den ausgefüllten Stimmzettel in den kleineren weißen Umschlag. Legen Sie
diesen Umschlag zusammen mit dem ausgefüllten und unterschriebenen Adresszettel in den
größeren weißen Umschlag und senden sie diesen an den Wahlleiter (Adresse ist bereits
aufgedruckt):
Dr. Klaus Schmitz Bamberger Centrum für betriebliche Informationssysteme Universität Bamberg Feldkirchenstr. 21 96045 Bamberg
Der Endtermin für den Eingang des Wahlbriefs ist der 30.09.2001.
Eine Fachgruppe ist auf das Engagement ihrer Mitglieder angewiesen, daher bitte ich Sie, von
Ihrem Wahlrecht Gebrauch zu machen.
Ihr Elmar Sinz

7
Vorstellung der Kandidaten: Prof. Dr. J. Becker :
Lehrstuhl für Wirtschaftsinformatik und Informationsmanagement Institut für Wirtschaftsinformatik Westfälische Wilhelms-Universität Münster http://www-wi.uni-muenster.de/is/mitarbeiter/ - Jahrgang 1959; - Studium der Betriebswirtschaftslehre an der Universität des Saarlandes; - Studium der Betriebs- und Volkswirtschaftslehre an der University of Michigan, Ann Arbor, USA; - Wissenschaftlicher Mitarbeiter am Institut für Wirtschaftsinformatik (IWi) der Universität des
Saarlandes (Leitung: Prof. Dr. A.-W. Scheer); - Berater der IDS Gesellschaft für Integrierte Datenverarbeitungssysteme GmbH; - Seit 1990 Universitätsprofessor, Inhaber des Lehrstuhls für Wirtschaftsinformatik und
Informationsmanagement der Westfälischen Wilhelms-Universität Münster, Direktor des Instituts für Wirtschaftsinformatik (seit 1995 geschäftsführend), Hauptgesellschafter der Prof. Becker GmbH, einem Beratungsunternehmen in Fragen der Organisations- und Informationssystemgestaltung.
Forschungsschwerpunkte: Informationsmanagement, Informationsmodellierung, Datenmanagement, Logistik, Handelsinformationssysteme, Führungsinformationssysteme, Prozessmanagement, Workflow-managementsysteme.
Dr. M. Bertram: Commerzbank AG Zentraler Servicebereich TransAction Banking / Securities - Trading Services Mainzer Landstraße 293 D - 60326 Frankfurt Tel.: +49 – (0)69 - 136 - 43315 E-Mail1: [email protected] E-Mail2: [email protected] - Jahrgang 1955; verheiratet 1 Kind; - Studium und Promotion in Mathematik; - 1984-1990 Softwareentwicklung / Methoden und Verfahren; - 1991-2000 Unternehmensberatungen mit Schwerpunkt IT-Strategien / Methoden und Verfahren; - Seit 2000 Commerzbank AG im Großprojektmanagement.
Mein Leitsatz: "Nichts in so praktisch wie eine wohl fundierte Theorie" [stammt aber nicht von mir ;-)].
Prof. Dr. M. Esser: Artificial Life und Universität St. Petersburg Email: [email protected]
Prof. Dr. W. Esswein (UNI Dresden): Lehrstuhl für Wirtschaftsinformatik, insb. Systementwicklung Technische Universität Dresden http://wiseweb.wiwi.tu-dresden.de/Team/weness.htm - Studium der BWL in Augsburg; - Wissenschaftl. MA in Regensburg und Bamberg; - Praxiserfahrungen bei der Siemens AG sowie in zahlreichen Projekten; - Seit SS 1994 Inhaber des Lehrstuhls für Wirtschaftsinformatik, insb. Systementwicklung an der TU-
Dresden.
Forschungsschwerpunkt: Unternehmensspezifische Anpassung von Modellierungssprachen sowie die werkzeugtechnische Unterstützung von Business-Excellence-Projekten.

8
Prof. Dr. U. Frank: Institut für Wirtschaftsinformatik Universität Koblenz-Landau http://www.uni-koblenz.de/~iwi/mitarbeiter/UlrichFrank.html - Studium der Betriebswirtschaftslehre an der Universität Köln, Angewandte Informatik im Nebenfach; - Wissenschaftlicher Mitarbeiter an der Universität Mannheim bei Prof. Dr. Alfred Kieser; - Promotion zum Dr. rer. pol. an der Universität Mannheim (1986); - Habilitation an der Universität Marburg (1993); - Professor für Wirtschaftsinformatik an der Universität Koblenz (1995); - Gastprofessor an der Deakin-University in Melbourne (1998); - Ruf auf den Lehrstuhl für Wirtschaftsinformatik II an der Universität Augsburg (2000) – abgelehnt.
Forschungsschwerpunkte: multiperspektivische Unternehmensmodellierung, objektorientierte Modellierung und Software-Entwicklung, Konzepte und Systeme zur Unterstützung des Wissensmanagement, Modellierungskonzepte für E-Commerce Plattformen, Frameworks und Design Patterns im Rahmen betrieblicher Informationssysteme.
K.-W. Müller: KPMG Consulting AG Financial Services / Insurance Elektrastraße 6 81925 München Tel.: +49 – (0)89 - 9282 – 4358 E-Mail: [email protected]
Prof. Dr. A. Oberweis: Lehrstuhl für Entwicklung betrieblicher Informationssysteme Goethe-Universität, Frankfurt am Main http://www.wiwi.uni-frankfurt.de/~oberweis/ - Jahrgang 1962; - Studium des Fachs Wirtschaftsingenieurwesen an der Universität Karlsruhe (Diplom 1984); - wissenschaftl. Mitarbeiter an der Universität Karlsruhe, der Technischen Hochschule Darmstadt sowie
der Universität Mannheim; - Promotion 1990 in Mannheim; - wiss. Assistent an der Universität Karlsruhe und Habilitation (1995); - Seit 1995 Inhaber eines Lehrstuhls für Entwicklung betrieblicher Informationssysteme am Fachbereich
Wirtschaftswissenschaften der J.W. Goethe-Universität in Frankfurt/Main.
Haupt-Forschungsgebiete: Software Engineering Management, Geschäftsprozess- und Workflow-Management, Entwicklung verteilter betrieblicher Informationssysteme. Autor bzw. Herausgeber von 9 Büchern sowie ca. 100 Zeitschriftenartikeln und Tagungsbeiträgen. Gründungsgesellschafter der PROMATIS AG Karlsbad.

9
Prof. Dr. M. Rebstock: Fachhochschule Darmstadt http://www.fbw.fh-darmstadt.de/rebstock - Jahrgang 1962; - Studium der Betriebswirtschaftslehre an der Universität Mannheim und der University of Wales, UK; - Promotion zum Dr. rer. pol. am Lehrstuhl für ABWL und Organisation, Prof. Dr. Alfred Kieser,
Universität Mannheim; - 1988 bis 1995 Management- und IT-Consultant bei zwei führenden Management- and IT-
Beratungsunternehmen; - Seit 1995 Professor für Betriebswirtschaftslehre und betriebswirtschaftliche Informationsverarbeitung an
der Fachhochschule Darmstadt University of Applied Sciences.
Mitgliedschaften und Aktivitäten in verschiedenen Organisationen, u.a. der Gesellschaft für Informatik, der Association of Computing Machinery und der Schmalenbach-Gesellschaft.
Prof. Dr. E. J. Sinz: Lehrstuhl für Wirtschaftsinformatik, insb. Systementwicklung und Datenbankanwendung Otto-Friedrich-Universität Bamberg http://www.seda.sowi.uni-bamberg.de/mitarbeiter/sinz.html - Jahrgang 1951; - Diplom-Ingenieur (FH) für Maschinenbau (1972); - Diplom-Kaufmann (1977) - Promotion zum Dr. rer. pol. an der Universität Regensburg 1983; - Habilitation zum Dr. rer. pol. habil. für das Fach Wirtschaftsinformatik an der Universität Regensburg
(1987); - Seit 1988 Inhaber des Lehrstuhls für Wirtschaftsinformatik, insbesondere Systementwicklung und
Datenbankanwendung, der Universität Bamberg.
Vorsitzender der Wissenschaftlichen Kommission Wirtschaftsinformatik im Verband der Hochschullehrer für Betriebswirtschaft e.V. (1995 - 1997). Sprecher der Fachgruppe 5.10 Informationssystem-Architekturen der Gesellschaft für Informatik (seit 1993). Mitherausgeber der Zeitschrift WIRTSCHAFTSINFORMATIK (seit 1990).
Dr. M. Teufel: RWE Systems AG Bereich IT-Anwendungen Flamingoweg 1 44139 Dortmund Tel.: +49 – (0)231 - 438-4210 E-Mail: [email protected]

10

11
Einladung zur Mitgliederversammlung der GI-Fachgruppe 5.10 MobIS
Die Mitgliederversammlung findet im Rahmen der Verbundtagung VertIS 2001 in Bamberg
statt. Eingeladen sind alle Mitglieder und Interessenten der Fachgruppe 5.10 MobIS.
Ort: Universität Bamberg
Zeit: 4. Oktober 2001 18.00 Uhr , Raum n.v.
Tagesordnung: 1. Begrüßung
2. Bericht des Sprechers
3. Finanzen und Mitgliederzahlen
4. Geplante Aktivitäten der Fachgruppe
5. Verschiedenes
Elmar J. Sinz Sprecher der Fachgruppe 5.10 MobIS

12

13
Tagungsankündigung VertIS 2001
Fachgruppe 1.1.6 VKI: Verteilte Künstliche Intelligenz, Fachgruppe 2.5.2 EMISA: Entwicklungsmethoden für Informationssysteme und deren Anwendung, Fachgruppe 5.10 MobIS: Informationssystem-Architekturen: Modellierung betrieblicher Informationssysteme, DFG-Schwerpunktprogramm (1083) "Intelligente Softwareagenten und betriebswirtschaftliche Anwendungsszenarien"
Einladung und Programm
Verbundtagung
VertIS 2001
Verteilte Informationssysteme auf der Grundlage von
Objekten, Komponenten und Agenten
4. und 5. Oktober 2001 Universität Bamberg

14
Veranstalter Fachgruppe 1.1.6 VKI: Verteilte Künstliche Intelligenz, Fachgruppe 2.5.2 EMISA: Entwicklungsmethoden für Informationssysteme und deren Anwendung, Fachgruppe 5.10 MobIS: Informationssystem-Architekturen: Modellierung betrieblicher Informationssysteme, und das DFG-Schwerpunktprogramm (1083) "Intelligente Softwareagenten und betriebswirt-schaftliche Anwendungsszenarien" laden herzlich zur Verbundtagung „Verteilte Infor-mationssysteme auf der Basis von Objekten, Komponenten und Agenten“ ein. Ziele und Themen Die Tagung bietet ein breites Forum für die Präsen-tation und Diskussion aktueller Themen im Bereich der Modellierung, Entwicklung und Nutzung verteil-ter Informationssysteme im Dialog von Wissenschaft und Praxis. Inhaltlicher Schwerpunkt ist die Nutzung von objekt-, komponenten- und agenten-orientierten Methoden und Technologien, die als Grundlage für die verteilte Informationsverarbeitung insbesondere in offenen Umgebungen eingesetzt werden. Die von jeweils zwei Gutachtern beurteilten Beiträge befassen sich mit den Themenbereichen Modellierung von Agentensystemen, Entwurf von Software-komponenten, Anwendung von Agentensystemen, Verhalten und Steuerung von Agenten und Agententechnologien. Zusätzlich werden drei Workshops mit den Themen Datenbankanfragen und XML, Modellierung und Spezifikation von Fachkomponenten und Modellierung und Nutzung von Data-Warehouse-Systemen angeboten. Veranstaltungsort: Otto-Friedrich-Universität Bamberg Feldkirchenstr. 21 D-96045 Bamberg Alle Vorträge finden in Hörsälen des Standorts Feldkirchenstraße der Universität Bamberg statt. Anreisemöglichkeiten bestehen mit dem Auto (A3/B505, A70, A73) oder mit der Bahn. Der Standort Feldkirchenstraße ist vom Bahnhof mit den Buslinien 1 bzw. 14 (Richtung Gartenstadt, Haltestelle Kloster-Banz-Straße) oder mit der Buslinie 7 (Richtung Memmelsdorf, Haltestelle Feldkirchenstraße) erreichbar. Eine Wegbeschreibung sowie nähere Informatio-nen über ausgewählte Hotels finden sich im WWW oder können beim Tagungsbüro angefor-dert werden.
Programmkomitee: Vorsitzende des Programmkomitees Prof. Dr. S. Jablonski (UNI Erlangen-Nürnberg, FG 2.5.2), Prof. Dr. S. Kirn (TU Ilmenau, DFG-SPP 1083), Prof. Dr. E. J. Sinz (Tagungsleitung, UNI Bamberg, FG 5.10), Dr. G. Weiß (TU München, FG 1.1.6).
Weitere Mitglieder des Programmkomitees Prof. Dr. J. Becker (UNI Münster), Dr. M. Bertram (Commerzbank AG, Frankfurt), Prof. Dr. H.-D. Burkhard (Humboldt-UNI Berlin), Prof. Dr. J. Desel (KU Eichstätt), Prof. Dr. M. Esser (Artificial Life und UNI St. Petersburg), Dr. K. Fischer (DFKI Saarbrücken), Prof. Dr. U. Frank (UNI Koblenz-Landau), Prof. Dr. M. Grauer (UNI Siegen), M. Hannebauer (GMD FIRST, Berlin), Prof. Dr. O. Herzog (Lenze GmbH & Co KG, Hameln), Dr. M. Jeusfeld (UNI Tilburg), Dr. R. Kaschek (UBS AG, Zurich), Dr. R. Klischewski (UNI Hamburg), Dr. J. Küng (UNI Linz), Dr. G. Lindemann (Humboldt-UNI Berlin), Dr. J. Müller (Siemens AG, München), K.-W. Müller (KPMG, München), PD Dr. Thomas Myrach (UNI Bern), Prof. Dr. A. Oberweis (UNI Frankfurt), Dr. H. Paul (Wissenschaftszentrum NRW, Gelsenkirchen), Dr. P. Petta (Austrian Research Institute for Artificial Intelligence, Wien), T. Pohley (Vereins- und Westbank AG, Wismar), Dr. Th. Rose (FAW Ulm), Prof. Dr. G. Saake (UNI Magdeburg), Dr. R. Schütte (UNI Essen), Dr. K. Sundermeyer (DaimlerChrysler, Berlin), Dr. M. Teufel (VEW Energie AG, Dortmund), I. Timm (UNI Bremen), PD Dr. K. Turowski (UNI der Bundeswehr München), Prof. Dr. G. Vossen (UNI Münster), PD Dr. G. Wagner (UNI Eindhoven), Prof. Dr. M. Weske (Hasso-Plattner-Institut für Softwaresystemtechnik, Potsdam). Tagungsbüro: Dipl.-Wirtsch.Inf. Markus Plaha Otto-Friedrich-Universität Bamberg Lehrstuhl für Wirtschaftsinformatik, insb. Systementwicklung und Datenbankanwendung Feldkirchenstr. 21 D-96045 Bamberg Tel.: 0951/863-2771 Fax: 0951/93 70 412 e-mail: [email protected] Weitere Informationen: Aktuelle Informationen zur Tagung finden sich im WWW unter: http://ceus.uni-bamberg.de/vertIS2001

15
Donnerstag, 4. Oktober 2001
9:30 Begrüßung
E. J. Sinz (Universität Bamberg)
Modellierung von Agentensystemen 10:00 M. Köhler, D. Moldt, H. Rölke
(Universität Hamburg) Einheitliche Modellierung von Agenten und Agentensystemen mit Referenznetzen
10:45 W.-U.Raffel (Freie Universität Berlin), K. Taveter (VTT Information Technology), G. Wagner (Technische Universität Eindhoven) Agent-Oriented Modeling of Business Rules and Business Processes:The Case of Automatically Guided Transport Systems
11:30 H. Knublauch, T. Rose (Universität Ulm) Werkzeugunterstützte Prozessanalyse zur Identifikation von Anwendungsszenarien für Agenten
12:15 Mittagspause*
Entwurf von Softwarekomponenten 13:30 U. Frank, J. Jung
(Universität Koblenz) Prototypische Vorgehensweise für den Entwurf anwendungsnaher Komponenten
14:15 R. Holten, R. Knackstedt (Universität Münster), M. Böhnlein, A. Ulbrich-vom Ende (Universität Bamberg) Identifikation und Anwendung semantischer Modellbausteine für Managementsichten
15:00 Kaffeepause
Anwendung von Agentensystemen 15:30 L. Mönch
(Technische Universität Ilmenau) Analyse und Design für ein agenten-basiertes System zur Steuerung von Produktionsprozessen in der Halbleiter-industrie
16:15 J. Schumacher (Universität Bonn), M. Beetz (Technische Universität München) Ein agentenbasiertes Verfahren zur effizienten Beantwortung von Lieferterminanfragen in einer Supply Chain
17:00 Mitgliederversammlung der FG 2.5.2 EMISA
18:00 Mitgliederversammlung der FG 5.10 MobIS
Workshop I Donnerstag, 4. Oktober 13:30 – 15:00
Datenbankanfragen und XML Moderation: G. Vossen (Universität Münster) Der Workshop wird veranstaltet vom GI-Arbeitskreis "Web & Datenbanken" und umfasst die folgenden Vorträge: A. Theobald (Universität des Saarlandes), XXL: Ranked Retrieval auf XML-Daten mit Hilfe von Ontologien
G. Lausen, P. J. Marron (Universität Freiburg), Effiziente und flexible Anfragebearbeitung von XML-Dokumenten mittels XPATH
E. Rahm (Universität Leipzig), Benchmarking von XML-Datenbanksystemen

16
Freitag, 5. Oktober 2001
Verhalten und Steuerung von Agenten 9:30 D. Dörner (eingeladener Vortrag)
(Universität Bamberg) Autonomie und Motivation
10:15 Kaffeepause
10:45 I. J. Timm (Universität Bremen) Dynamisches Konfliktmanagement zur Verhaltenssteuerung kooperativer Agenten
11:30 R. Herrler, F. Puppe, F. Klügl (Universität Würzburg), S. Kirn, C. Heine (Technische Universität Ilmenau) Terminverhandlung unter Agenten – von der Beispielanalyse zum Protokoll
12:15 Mittagspause**
Agententechnologien 13:30 K. Nagi, J. Nimis, P. C. Lockemann
(Universität Karlsruhe) Transactional Support for Cooperation in Multiagent-based Information Systems
14:15 M. Berger, B. Bauer (Siemens AG München) LEAP – A scalable Agent Platform enabling next generation Distributed Information Systems
15:00 S. Albayrak, K. Bsufka (Technische Universität Berlin) Integration von Public Key Infrastruktur Funktionalitäten in Agenten-Toolkits
16:00 Schlusswort E. J. Sinz (Universität Bamberg)
Workshop II Freitag, 5. Oktober 9:30 – 12:15
Modellierung und Spezifikation von Fachkomponenten
Moderation: K. Turowski (Universität der Bundeswehr München) Der Workshop des GI-Arbeitskreises 5.10.3 „Komponentenorientierte betriebliche Anwendungssysteme“ umfasst ausgewählte Diskussionsbeiträge und Fallstudien aus Praxis und Wissenschaft zur Vereinheitlichung der Spezifikation von Fachkomponenten.
Workshop III Freitag, 5. Oktober 9:30 – 12:15
Modellierung und Nutzung von Data-Warehouse-Systemen
Moderation: E. J. Sinz, M. Böhnlein, M. Plaha, A. Ulbrich-vom Ende (Universität Bamberg) Der Workshop des GI-Arbeitskreises 5.10.4 „Nutzung und Modellierung von Data-Warehouse-Systemen“ umfasst ausgewählte Kurzreferate aus Praxis und Wissenschaft zu aktuellen Problemstellungen der Modellierung und Nutzung von Data-Warehouse-Systemen. * Sitzung des Leitungsgremiums
der Fachgruppe 2.5.2 EMISA am Donnerstag um 12:15 Uhr
** Sitzung des Leitungsgremiums
der Fachgruppe 5.10 MobIS am Freitag um 12:15 Uhr

17
Anmeldung: Die Anmeldung wird über das Anmeldeformular im WWW erbeten:
http://ceus.uni-bamberg.de/vertIS2001
Die Anmeldung kann außerdem unter Verwendung des Formulars in diesem Faltblatt erfolgen. In diesem Fall senden Sie bitte das ausgefüllte Formular per Fax oder auf dem Postweg an das Tagungsbüro. Bitte vermerken Sie Ihren Teilnahmewunsch an den gewünschten Workshops, damit wir entsprechend disponieren können.
Tagungsbeiträge:
Anmeldung bis zum 31.08.2001 danach
Nicht GI-Mitglied 200,- DM 250,- DM
Mitglied der GI 150,- DM 200,- DM
Student 50,- DM 70,- DM
Student (GI-Mitgl.) 30,- DM 50,- DM (Studenten gegen Vorlage einer Studentenbescheinigung)
Die Zahlung in DM kann per Verrechnungsscheck oder durch Banküberweisung auf folgendes Konto erfolgen:
Gesellschaft für Informatik e.V. Sonderkonto VertIS 2001 Dresdner Bank Bamberg
BLZ 760 800 40 Konto-Nr.: 03 642 239 01
Geben Sie bitte auf dem Überweisungsträger das Stichwort „VertIS 2001“ und Ihren Namen bzw. bei Sammelüberweisungen die Namen sämtlicher Teilnehmer an.
Stornierungen sind nur bis zum 16.09.2001 möglich. Die Rückzahlung erfolgt unter Abzug einer Bearbeitungsgebühr von DM 20,-.

18


20

21
Beiträge des Arbeitskreises 5.10.4: Modellierung und Nutzung von
Data-Warehouse-Systemen

22

23
Bericht des Arbeitskreises
Prof. E.J. Sinz, M. Böhnlein, A. Ulbrich-vom Ende
Lehrstuhl für Wirtschaftsinformatik, Universität Bamberg Feldkirchenstr. 21, D-96045 Bamberg
E-Mail: {elmar.sinz | michael.boehnlein | achim.ulbrich } @sowi.uni-bamberg.de Die Gründung des Arbeitskreises 5.10.4. wurde am 15.10.1998 im Rahmen der Vollversammlung der Fachgruppe 5.10 "Informationssystemarchitekturen: Modellierung betrieblicher Informationssysteme (MobIS)" beschlossen. Die erste offizielle Veranstaltung des Arbeitskreises fand im Rahmen der Tagung MobIS im Oktober 1999 statt.
Ziel des Arbeitskreises ist es, Probleme im Bereich der Modellierung, des Betriebs und der Nutzung von Data Warehouse-Systemen gleichermaßen aus praktischer und wissenschaftlicher Sicht zu diskutieren und zu bewerten. Dabei ist der inhaltliche Schwerpunkt des Arbeitskreises durchgängig im Bereich der Wirtschaftsinformatik angesiedelt. Zu dem Themenschwerpunkt Modellierung von Data Warehouse-Systemen zählt neben der konzeptuellen und logischen Modellierung die Entwicklung von Vorgehensmodellen zur Erstellung von Data Warehouses, sowie Aspekte der Verwaltung von Metadaten. Darüber hinaus befasst sich der Arbeitskreis insbesondere mit Techniken zur Ermittlung des Informationsbedarfs von Entscheidungsträgern und Führungskräften. Im Rahmen des Betriebs von Data Warehouse-Systemen hingegen werden beispielsweise mögliche Sicherheitsanforderungen und Qualitätsaspekte von Data Warehouse-Systemen diskutiert. Dabei wird durch die Berücksichtigung kommerzieller Data Warehouse-Lösungen ein enger Bezug zur industriellen Praxis garantiert. Für die Nutzung von Data Warehouse-Systemen spielen vor allem die Einsatzgebiete in der Praxis und deren betriebswirtschaftliche Nutzenpotentiale eine entscheidende Rolle. Aus diesem Grund beschäftigt sich der Arbeitskreis sowohl mit Synergieeffekten zwischen E-Commerce-/E-Business- und Data Warehouse-Systemen als auch mit der umfassenden Integration von Data Mining-Umgebungen in Data Warehouse-Lösungen. Unter diesem Teilaspekt wird auch Mitarbeitern industrieller Projekte Raum für die Diskussion von praxisrelevanter Problemstellungen und Lösungen eingeräumt.
Trotz seines kurzen Bestehens erfreut sich der Arbeiskreis eines starken Zuwachses und zählt mittlerweile 150 eingetragene Mitglieder. Hierbei ist besonderes die hohe Beteiligung von Vertretern aus der Praxis zu unterstreichen. Nach der ersten Veranstaltung auf der MobIS 1999 fanden bisher drei weitere themenspezifische Workshops statt. Der erste Workshop (Freiburg, März 2000) wurde in Zusammenarbeit mit dem Kompetenzzentrum Data Warehousing Strategie der Universität St. Gallen (Prof. Dr. Winter, Dr. Jung) mit dem Themenschwerpunkt "Fachkonzeptentwurf und Metadaten beim Data Warehousing" organisiert. Ein weiterer Workshop des Arbeitskreises auf der MobIS 2000 richtete den Fokus auf "Möglichkeiten und Grenzen gängiger ETL-Werkzeuge". Im April 2001 wurde eine Veranstaltung in Zusammenarbeit mit dem Arbeitskreis "Konzepte des Data Warehousing"

24
unter Koordination des Lehrstuhls von Prof. Chamoni (Universität Duisburg) mit dem Themenschwerpunkt "Knowledge Discovery in Databases" durchgeführt.
Weitere Informationen über den Arbeitskreis finden sich auf der Internetseite http://ceus.uni-bamberg.de/ak5104. Mitglieder steht neben Data Warehousespezifischen Inhalten und den Beiträge zu den bisherigen Veranstaltungen auch eine Mailingliste und ein Diskussionsforum zur Verfügung.
Wir möchten uns hiermit noch einmal ganz herzlich bei unseren Mitglieder für Ihre rege Beteiligung und konstruktive Arbeit in den letzten beiden Jahren bedanken.
Elmar J. Sinz, Michael Böhnlein, Achim Ulbrich-vom Ende

25
Ein konzeptuelles Data Warehouse-Modellfür die Erstellung
multidimensionaler Datenstrukturen
M. Böhnlein, A. Ulbrich-vom EndeLehrstuhl für Wirtschaftsinformatik, Universität Bamberg
Feldkirchenstr. 21, D-96045 BambergE-Mail: {achim.ulbrich | michael.boehnlein}@sowi.uni-bamberg.de
Abstract
Die Modellierung multidimensionaler Datenstrukturen im OLAP- und Data Warehouse-Umfeld findet zur Zeit noch überwiegend auf einer logischen bzw. physischen Entwurfsebene statt.Bekannte Vertreter logischer Modellierungsansätze, wie z.B. Star oder Snowflake Schema, wurdenfür das relationale Datenbankmodell geschaffen und erlauben keine rein konzeptuelle Betrachtungdes zugrunde liegenden Modellierungsproblems. Das in der vorliegenden Arbeit vorgestellte Seman-tische Data Warehouse-Modell (SDWM) adressiert diese Problemstellung. Anhand eines integrier-ten Meta-Modells werden Sichten und korrespondierende Modellierungsbausteine auf multidimen-sionaler Datenstrukturen aufgezeigt. Modellierungsbeispiele aus dem universitären Umfeld dienenzur Verdeutlichung des Modellierungsansatzes.
Keywords
Data Warehouse, OLAP, Kennzahlensystem, konzeptuelles Datenmodell, semantisches Datenmo-dell, Modellierungsansatz, multidimensionale Datenstrukturen, Würfelmetapher
1 Einführung
In der aktuellen Diskussion wird für unstrittig gehalten, daß die Verwendung der für On-LineTransactional Processing-Probleme zur Verfügung stehenden Datenmodelle gerade für dieErfordernisse von OLAP-Anwendungen im Umfeld betriebswirtschaftlicher Entscheidungssi-tuationen problematisch ist ([Sche99, S. 305][Bulo96, S. 33]).
Der Fokus der multidimensionalen Modellierung im OLAP- und Data Warehouse-Umfeld liegtzur Zeit auf Modellierungsansätzen, wie z.B. Star oder Snowflake Schema oder Varianten, diestärker dem logischen als dem konzeptuellen Entwurf zuzuordnen sind. Sie weisen i.d.R. einestarke Abhängigkeit von den Eigenschaften des relationalen Datenbankmodells auf. Zu fordernist hingegen ein stärker konzeptuell geprägtes Datenmodell, das eine explizite Unterscheidungvom zugrundeliegenden Datenbankmodell ermöglicht und als Diskussionsgrundlage zwischenFachabteilung und Entwickler dienen kann.
Das im folgenden vorgeschlagene semantische Datenmodell SDWM (Semantisches Data Ware-house-Modell) soll hierzu einen Beitrag leisten.

26
Nach einer kurzen Einführung in die Grundlagen multidimensionaler Datenstrukturen(Abschnitt 2) wird der Modellierungsansatz SDWM in die Entwurfsebenen der Softwareent-wicklung eingeordnet (Abschnitt 3). Anschließend werden in Abschnitt 4 wesentliche Grund-lagen der Modellbildung aufgezeigt. Abschnitt 5 beschäftigt sich mit der Modellierung mitSDWM. Zuerst erfolgt ein Überblick über spezifische Charakteristika des Modellierungsansat-zes, wobei vor allem die Sichtenbildung zur Komplexitätsbewältigung hervorgehoben wird.Darauf aufbauend werden sukzessive Sichten auf multidimensionale Datenstrukturen aufge-zeigt, die anhand von Projektionen auf das zugegrundeliegende Meta-Modell definiert werden.Mit Praxisbeispielen aus dem universitären Umfeld werden die Sichten veranschaulicht.Abschnitt 6 faßt die wesentlichen Aspekte der Arbeit zusammen und gibt einen Ausblick aufmögliche Weiterentwicklungen von SDWM.
2 Strukturteil multidimensionaler DatenstrukturenEntscheidungsunterstützungssysteme lassen sich durch ihr inhärentes VerarbeitungskonzeptOn-Line Analytical Processing (OLAP) klar von operativen Systemen (On-Line TransactionalProcessing, OLTP-Systemen) abgrenzen. Dabei soll das OLAP-Konzept Entscheidungs- undFührungskräften einen schnellen, analytischen Zugriff auf multidimensionale betrieblicheInformationen ermöglichen [PeCr95]. „Grundlage der OLAP-Ansätze ist eine mehrdimensio-nale Sichtweise auf die Daten, die der Sicht des Managers eher entspricht als ein relationalesModell, das den operativen Systemen meist zugrundeliegt.“ [Sche99, S. 282]
Die multidimensionalen Datenstrukturen von OLAP-Systemen sind durch Strukturbeschrei-bungen und generische Operationen näher charakterisierbar. Da mit SDWM der Fokus aus-schließlich auf der Entwicklung eines Datenmodells für multidimensionale Strukturen gelegtwerden soll, ist im folgenden nur der Strukturteil zu behandeln.1 Zur Verdeutlichung der Aus-führungen dienen dabei Modellierungsbeispiele aus dem universitären Umfeld([SiBU99][Sinz98][SKMW96]).
Die Erläuterung des Strukturteils erfolgt anhand der wesentlichen Beschreibungselemente,deren Beziehungen und Semantik. Als Grundidee multidimensionaler Datenstrukturen dient dieUnterscheidung in qualitative und quantitative Daten [Shos82, S. 208 ff.]. Quantitative Größen(Maßzahlen, Kennzahlen, measures, facts bzw. measured-facts) werden nach verschiedenenqualitativen Aspekten (Blickwinkeln, Dimensionen) aufgeschlüsselt. Um die in der Literaturvorhandene Begriffsvielfalt ([Pilot98][Kena95]) einzuschränken, werden im folgenden diequantitativen Daten als Kennzahlen und die qualitativen Aspekte als Dimensionen bezeichnet.Beispielsweise ist eine Auswertung der Kennzahl Anzahl der Studierenden nach den Dimensio-nen Zeit, Studienabschnitt und Studienausrichtung möglich (vgl. Abbildung 1). In einem mehr-dimensionalen Koordinatensystem, das durch die betrachteten Dimensionen festgelegt wird,entsteht an der Schnittstelle je eines Dimensionselements der verschiedenen die Datenstruktur
1. Weitergehende Informationen über den Operationsteil und den damit verbundenenNavigationsmöglichkeiten in multidimensionalen Datenstrukturen entnehmen Siebitte [BoUl00a].
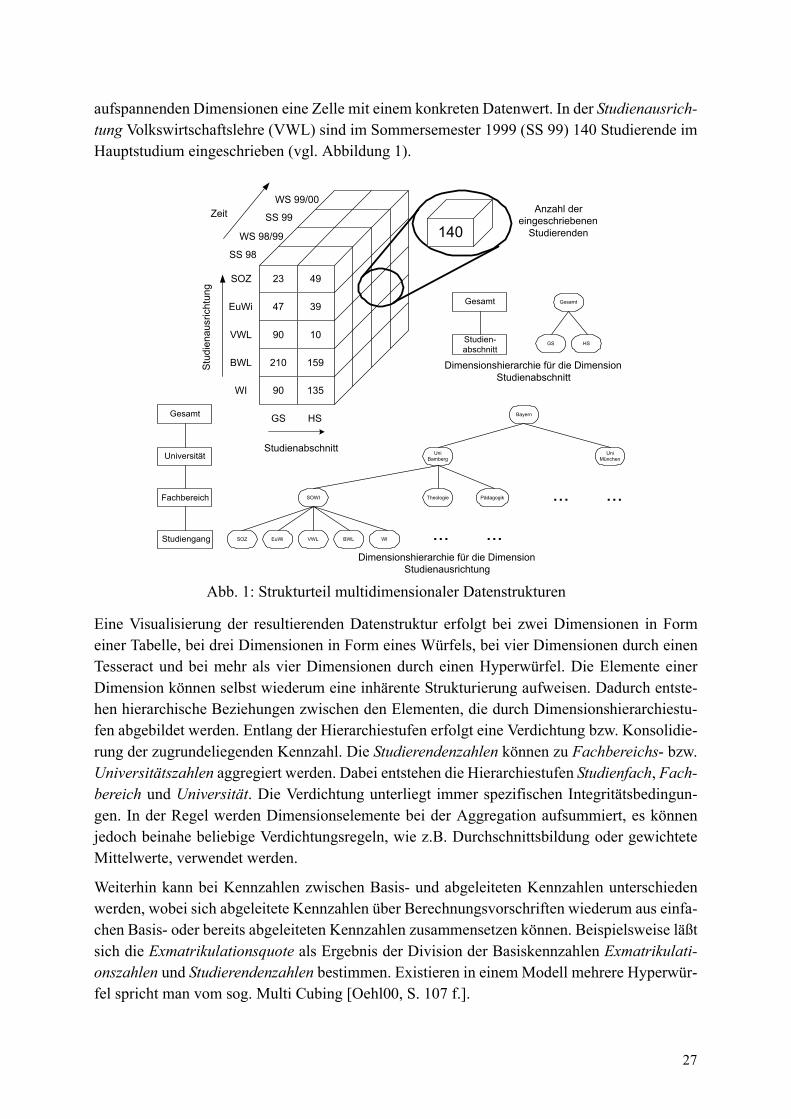
27
aufspannenden Dimensionen eine Zelle mit einem konkreten Datenwert. In der Studienausrich-tung Volkswirtschaftslehre (VWL) sind im Sommersemester 1999 (SS 99) 140 Studierende imHauptstudium eingeschrieben (vgl. Abbildung 1).
Eine Visualisierung der resultierenden Datenstruktur erfolgt bei zwei Dimensionen in Formeiner Tabelle, bei drei Dimensionen in Form eines Würfels, bei vier Dimensionen durch einenTesseract und bei mehr als vier Dimensionen durch einen Hyperwürfel. Die Elemente einerDimension können selbst wiederum eine inhärente Strukturierung aufweisen. Dadurch entste-hen hierarchische Beziehungen zwischen den Elementen, die durch Dimensionshierarchiestu-fen abgebildet werden. Entlang der Hierarchiestufen erfolgt eine Verdichtung bzw. Konsolidie-rung der zugrundeliegenden Kennzahl. Die Studierendenzahlen können zu Fachbereichs- bzw.Universitätszahlen aggregiert werden. Dabei entstehen die Hierarchiestufen Studienfach, Fach-bereich und Universität. Die Verdichtung unterliegt immer spezifischen Integritätsbedingun-gen. In der Regel werden Dimensionselemente bei der Aggregation aufsummiert, es könnenjedoch beinahe beliebige Verdichtungsregeln, wie z.B. Durchschnittsbildung oder gewichteteMittelwerte, verwendet werden.
Weiterhin kann bei Kennzahlen zwischen Basis- und abgeleiteten Kennzahlen unterschiedenwerden, wobei sich abgeleitete Kennzahlen über Berechnungsvorschriften wiederum aus einfa-chen Basis- oder bereits abgeleiteten Kennzahlen zusammensetzen können. Beispielsweise läßtsich die Exmatrikulationsquote als Ergebnis der Division der Basiskennzahlen Exmatrikulati-onszahlen und Studierendenzahlen bestimmen. Existieren in einem Modell mehrere Hyperwür-fel spricht man vom sog. Multi Cubing [Oehl00, S. 107 f.].
Abb. 1: Strukturteil multidimensionaler Datenstrukturen
SOZ EuWi VWL BWL WI
SOWI Theologie Pädagogik
UniBamberg
Bayern
UniMünchen
... ...
... ...
Studiengang
Fachbereich
Universität
Gesamt
HSGS
Gesamt
Studien-abschnitt
Gesamt
Dimensionshierarchie für die DimensionStudienabschnitt
Dimensionshierarchie für die DimensionStudienausrichtung
90 135
210 159
90 10
47 39
23 49
WI
BWL
VWL
EuWi
SOZ
SS 98
WS 98/99
SS 99
WS 99/00
GS HS
Stud
iena
usric
htun
gZeit
Studienabschnitt
140Anzahl der
eingeschriebenenStudierenden

28
Die hiermit eingeführten intuitiv verständlichen Begriffsdefinitionen werden bei der Beschrei-bung des konzeptuellen Modells SDWM präzisiert und, wenn nötig, verfeinert.
3 Einordnung von SDWM in die Entwurfsebenen der multidi-mensionalen Modellierung
Beim Datenbankentwurf klassischer operativer OLTP-Systeme hat sich die Unterscheidung indie Entwurfsebenen des konzeptuellen, logischen und physischen Entwurfs mit den korrespon-dierenden Entwurfsergebnissen konzeptuelles, logisches und physisches Schema durchgesetzt([MaDL87, S. 481 ff.][Voss99. S. 75 ff.]). Diese Trennung wird im folgenden auf den OLAP-Bereich übertragen.
Während der konzeptuelle Entwurf der fachlichen Modellierung zuzurechnen ist, beziehen sichlogischer und physischer Entwurf auf die softwaretechnische Modellierung. Folglich wird hierdie Unabhängigkeit vom zugrundeliegenden Datenbanksystem aufgegeben. Ein konkretesDatenbankmanagementsystem erlaubt nicht den Umgang mit beliebigen Informationsstruktu-ren, sondern ist auf ein spezifisches Datenbankmodell und damit auf einen bestimmten Grund-vorrat an Beschreibungsmitteln beschränkt. Die meisten im Moment diskutierten Modellie-rungsansätze im Data Warehouse-Umfeld sind der logischen Entwurfsebene zuzuordnen. Popu-läre Beschreibungsformen bei der Entwickung von Data Warehouse-Strukturen, wie z.B. dasStar Schema [McGu96], das Snowflake Schema und deren Varianten([Kimb96][Rade95][Info98][Poe96][AnMu97][EhHe98]) sind durch ihre enge Verbindungzum relationalen Datenbankmodell beispielsweise als Diskussionsgrundlage zwischen Ent-wickler und Fachabteilung schlecht geeignet.2
Die weiteren Ausführungen beschäftigen sich ausschließlich mit dem konzeptuellen Entwurfund dem damit korrespondierenden konzeptuellen Schema, das von den speziellen Eigenschaf-
Abb. 2: Entwurfsebenen der multidimensionalen Modellierung
Konzeptueller Entwurf
Logischer Entwurf
Physischer Entwurf
KonzeptuellesSchema
LogischesSchema
PhysischesSchema
Semantisches Data Warehouse-Modell (SDWM)nach Böhnlein, Ulbrich-vom Ende
Developed Star Schema von der SAP AG [SAP97][SAP98a]Dimensional Modelling nach Kimball [Kimb96]Fact/Constellation Schema nach Raden [Rade95][Rade96]Galaxy Schema [McGu96]Partial Snowflake [Info98]Simple Star, Multiple Star Schema nach [Poe96]Snowflake SchemaStar SchemaStarflake Schema nach Anahory und Murray [AnMu97]Uniformes Datenschema (Unimu) nach Ehrenberg und Heine [EhHe98]
SpeicherungsstrukturenZugriffsmechanismen und ZugriffspfadeDatenbanktuningDenormalisierungIndizierungFragmentierung
Fach
liche
Ebe
neSo
ftwar
etec
hnis
che
Eben
e

29
ten des einzusetzenen Zieldatenbanksystems unabhängig ist. Da klassische Modellierungsme-thoden für OLTP-Systeme für die Spezifikation multidimensionaler Datenstrukturen nur alsbedingt geeignet erscheinen ([Kimb96, S. 8-10][Bulo96, S. 252-253][Oehl00, S. 237]),beschäftigen sich neuere Forschungsaktivitäten mit Modellierungsvorschlägen, die ausschließ-lich auf die multidimensionale Modellierung ausgerichtet sind und keine Ursprünge in klassi-schen Datenmodellierungsmethoden besitzen ([BuFo98][GoMR98]). Mit SDWM wird ein neu-artiger Vorschlag eines semantischen Datenmodells für die Modellierung multidimenisonalerDatenstrukturen unterbreitet. Die spezifischen Eigenschaften und Charakteristiken, die diesenAnsatz besonders hervorheben, werden dabei in Abschnitt 5.1 und Abschnitt 5.2 herausgearbei-tet. Zunächst werden jedoch wesentliche Grundlagen der Modellbildung vorgestellt, die für dieweiteren Ausführungen eine zentrale Rolle einnehmen.
4 Grundlagen der ModellbildungIm folgenden wird aufbauend auf den klassischen Modellbegriff eine Definition für Modellie-rungsansätze vorgestellt, wobei insbesondere deren zentrale Bestandteile herausgearbeitet wer-den sollen. Diese Definition und ein damit korrespondierendes Meta-Meta-Modell dienen zurBeschreibung des Modellierungsansatzes SDWM in Abschnitt 5. Da SDWM zu den semanti-schen, datenorientierten Modellierungsansätzen zu zählen ist, erfolgt anschließend eine expli-zite Unterscheidung zwischen Datenmodell und Datenbankmodell.
Ein Modell (vgl. Abbildung 3) kann durch ein 3-Tupel mit den Bestandteilen Objektsystem S0,Modellsystem SM und Modellabbildung f beschrieben werden [FeSi98, S. 118], wobei dieSystemkomponenten des Objektsystems V0 durch die Modellabbildung auf Systemkomponen-ten des Modellsystems VM abgebildet werden.3 Bei der Datenmodellierung erfolgt die Spezifi-kation des zweckorientiert abgegrenzten, relevanten Ausschnitts der betrieblichen Realität(Objektsystem) in Form eines konzeptuellen, semantischen Datenschemas (Modellsystem).
„Voraussetzung für die Durchführung der Modellierungsaufgabe durch den Menschen ist eingeeigneter Beschreibungsrahmen, der die Sichtweise des Modellierers auf Objektsystem undModellsystem sowie das zur Spezifikation des Modellsystems verwendete Begriffssystem fest-legt.“ [FeSi98, S. 119] Ein Modellierungsansatz beschreibt einen derartigen Gestaltungs- bzw.Beschreibungsrahmen, der durch zwei wesentliche Bestandteile charaktierisierbar ist:
2. Im Star Schema sind die zwei zentralen Bausteine Tabellen (Fakt- bzw. Dimensionstabellen), die direktkorrespondierenden Datenbanktabellen entsprechen.
3. Umgangsprachlich wird häufig das Modell- bzw. Bildsystem ebenfalls als Modell bezeichnet.
Abb. 3: Modell
Objektsystem S Modellsystem S
Meta-Modell
f: V -> V MO
OM

30
• Eine Metapher ist die Beschreibung einer Sichtweise, die der Modellierer bei der Erfassungder Komponenten des Objektsystems zugrundelegt und anschließend auf die Spezifikationder Komponenten des Modellsystems überträgt.
• Mit Hilfe eines Meta-Modells wird ein mit der Metapher abgestimmtes Begriffssystem defi-niert. Dieses umfaßt die verfügbaren Arten von Modellbausteinen, die Arten von Beziehun-gen zwischen Modellbausteinen, die Regeln für die Verknüpfung von Modellbausteinendurch Beziehungen sowie die Bedeutung (Semantik) der Modellbausteine und Beziehungen.
Bei der Modellierung sind zwei Paare von Eigenschaften eines Modells von besonderer Bedeu-tung: Struktur- und Verhaltenstreue bzw. Konsistenz und Vollständigkeit.
Struktur- und Verhaltenstreue sind Eigenschaften der Modellabildung. Daher sollte ein Modell-system möglichst struktur- und verhaltenstreu in bezug auf das zugrundeliegende Objektsystemspezifiziert werden. Eine ansatzweise Überprüfung ist durch ein eng mit der Metapher abge-stimmtes Begriffssystem möglich, wobei sich dessen Semantik möglichst nahe am Objektsy-stem orientieren sollte.
Die Konsistenz und Vollständigkeit des Modellsystems läßt sich ausschließlich mit Hilfe deszugehörigen Meta-Modells überprüfen. Es wird festgestellt, ob das Modellsystem den Gesetz-mäßigkeiten des Meta-Modells genügt.
Um eine einheitliche Beschreibung der Meta-Modelle von SDWM in Abschnitt 5 zu gewährlei-sten, soll im folgenden ein Meta-Meta-Modell als Bezugsrahmen zur Spezifikation der Meta-Modelle von Modellierungsansätzen eingeführt werden (vgl. Abbildung 3). Die zur Darstellungder Meta-Modelle verwendeten Symbole sind in den Elementen des Meta-Meta-Modells ange-geben.
Das Meta-Meta-Modell besteht aus Meta-Objekttypen, die durch Meta-Beziehungen miteinan-der verbunden sind [Sinz96]. Dabei können Meta-Beziehungen durch die Angabe von Kardina-litäten in (min,max)-Notation präzisiert werden. Beispielsweise ist ein Metaobjekttyp mit min-destens einer Meta-Beziehung verknüpft, wobei jede Meta-Beziehung genau zwei Metaobjekt-typen verbindet. Bei den Meta-Beziehungen unterscheidet man zwischenGeneralisierungsbeziehungen (is_a), Assoziationsbeziehungen (connects), Attribut-Zuord-nungsbeziehungen (has) und Teil-/Ganzes-Beziehungen (is part of)4.
4. Bei der Teil-/Ganzes-Beziehung handelt es sich um eine Erweiterung des Meta-Meta-Modells nach Fer-stl/Sinz.
Abb. 4: Meta-Meta-Modell in Anlehnung an [FeSi98, S. 122]
Meta-Objekttyp
Meta-Beziehung
2,2 1,*
hasis_a connects
1,1
0,1 0,1 0,1
Kard. 1
Kard. 20,1
0,1
1,11,1
is_part_of
0,1

31
Das in Abschnitt 5 einzuführende Meta-Modell von SDWM ist eine Extension des beschriebe-nen Meta-Meta-Modells.
Datenorientierte Modellierungsansätze konzentrieren sich auf die Spezifikation der Struktur derDatenbasis und beziehen dabei vor allem die Datensicht eines Informationssystems ein. Wäh-rend ein konzeptuelles Datenmodell ein konkretes Meta-Modell zur Datenmodellierung[FeSi98, S. 133] beschreibt5, stellt ein Datenbankmodell ein Meta-Modell dar, in dem ein kon-zeptuelles Datenschema aus Sicht eines Datenbankverwaltungssystems beschrieben wird([FeSi98, S. 354][PeMa88, S. 155]).
5 Modellierung mit SDWM
Ziel von Abschnitt 5 ist es, in den neuartigen Modellierungsansatz Semantisches Data Ware-house-Modell (SDWM) einzuführen. Nach Abschnitt 4 wird dieser Modellierungsansatz alsGestaltungs- bzw. Beschreibungsrahmen durch eine Metapher und ein Meta-Modell umfassendbeschrieben.
Der multidimensionalen Modellierung liegt die Metapher eines mehrdimensionalen Würfelszugrunde [Oehl00, S. 52]. Entscheidungs- und Führungskräfte möchten quantitative Informa-tionen nach vielfältigen Blickwinkeln auswerten, was sich bildlich in Form eines mehrdimen-sionalen Würfels visualisieren läßt.
Das dem SDWM zugrundeliegende Meta-Modell wird in den folgenden Abschnitten vorgestellt,wobei als zentrales Strukturierungsmittel für SDWM eine Betrachtung differenzierter Sichtenauf multidimensionale Datenstrukturen herangezogen wird. Ausgehend von Teil-Meta-Model-len für die einzelnen Sichten wird sukzessive ein integriertes Meta-Modell für SDWM entwik-kelt. Syntax und Semantik der verwendeten Bausteine werden ausführlich anhand von zahlrei-chen Modellierungsbeispielen aufgezeigt.
Zunächst erfolgt jedoch eine kurze Beschreibung der spezifischen Charakterista von SDWM.Anschließend wird die Notwendigkeit der Unterscheidung verschiedener Sichten auf multidi-mensionale Datenstrukturen begründet.
5.1 Spezifische Charakteristika von SDWM
Im folgenden sollen die wesentlichen Konzepte, die bei der Entwicklung von SDWM einebedeutsame Rolle gespielt haben, kurz vorgestellt werden. SDWM stellt ein konzeptuellesDatenmodell für multidimensionale Datenstrukturen zur Verfügung, dessen zentraler Einsatz-bereich bei OLAP- bzw. Data Warehouse-Systemen liegt. Zu den Merkmalen von SDWM zäh-len vor allem:
5. „A data model defines the rules according to which data are structured.“ ist eine korrespondierende Defi-nition nach [TsLo82, S. 10].

32
• Die Begrifflichkeiten des konzeptuellen Modells sind an den Fachtermini der multidimen-sionalen Modellierung ausgerichtet, wie z.B. Dimensionen, Dimensionshierarchien undKennzahlen. Dadurch ist eine unmittelbare Übertragbarkeit auf multidimensionale Problem-stellungen gesichert.
• Eine explizite Sichtenbildung trägt zur Komplexitätsbewältigung bei. Es werden verschie-dene Sichten auf multidimensionale Strukturen unterstützt (vgl. detaillierter in Abschnitt5.2). Beispielsweise fordern auch Gabriel und Gluchowski in [GaGl97, S. 52 f.] eine sich-tenspezifische Modellierung multidimensionaler Datenstrukturen.
• Eine semiformale Darstellungsweise in Form von Diagrammen ermöglicht eine adäquateVisualisierung und damit eine leichte Erlernbarkeit des Modellierungsansatzes.
• Zusammenhänge zwischen Kennzahlen werden explizit dargestellt. Komplexe abgeleiteteKennzahlen sind aus Basis- oder bereits abgeleiteten Kennzahlen, gegebenenfalls mehrstu-fig, berechenbar. In ([BSHD98a][BSHD98b]) wird die Verwendung von komplex struktu-rierten Kennzahlen in einem konzeptuellen multidimenisonalen Modell ausdrücklich gefor-dert: „The contents of a cell of the multidimensional cube can also be structured in a complexway.“ [BSHD98b].
• Weiterhin erfolgt bei multidimensionalen Datenstrukturen eine explizite Trennung zwischenStruktur und Inhalt („separation of structure and content“ nach [BSHD98a] und[BSHD98b]). Dimensionselemente auf der Ausprägungsebene werden getrennt von derStrukturierung einer Dimension betrachtet. Dies führt beispielsweise zu einer extensionalenund einer intensionalen Betrachtung der Dimensionssicht.
• Für multidimensionale Datenmodelle ist Modellierungseindeutigkeit zu fordern [Ruf97, S.116 f.]. Eine größtmögliche Flexibilität bei der Modellierung darf nicht dazu führen, daß dergleiche Sachverhalt mit SDWM unterschiedlich dargestellt werden kann.
• Das konzeptuelle Modell soll als Diskussionsgrundlage für die Abstimmung mit der Fach-abteilung dienen. „Die frühzeitige Einbeziehung des Endanwenders in den Prozeß derModellierung multidimensionaler Datenstrukturen im Sinne einer Partizipation erscheintangebracht, kann jedoch nur gelingen, wenn eine Kommunikationsplattform gefunden wird,die allen Beteiligten gerecht wird“ [GaGl97, S. 32]. Daher muß das Modell gleichermassenleicht für den Anwender wie für den Entwickler zugänglich sein.
• Es erfolgt weiterhin eine explizite Trennung zwischen Dimensionen und Kennzahlen, washäufig durch die Unterscheidung von quantitativen und qualitativen Daten gefordert wird[Shos82, S. 208 ff.]. Dies wird in der Praxis teilweise durch Verwendung einer sog. Varia-blendimension umgangen. Die Gleichbehandlung bzw. Austauschbarkeit von Dimensionenund Kennzahlen im Datenbankmodell auf physischer bzw. logischer Ebene [AgGS97] darfsich aber nicht auf die konzeptuelle Ebene auswirken. Die Trennung von Kennzahlen undDimensionen ist eines der fundamentalen Konzepte der multidimensionalen Modellierung.

33
• SDWM unterscheidet strikt zwischen fachlichen und implementierungsspezifischen Aspek-ten. Das konzeptuelle Datenmodell ist unabhängig vom jeweiligen Zieldatenbankmodell aufder logischen Ebene [Sche99, S. 281]. Diese Forderung wird beispielsweise auch von([BSHD98a][BSHD98b]) erhoben: „implementation independent formalism: The formalmodel must be purely conceptual, thus not containing any details of the implementation.“
• Das entwickelte konzeptuelle Modell muß leicht in ein logisches Daten(bank-)modell trans-formierbar sein [Sche99, S. 281]. Es darf keine wesentliche Rolle spielen, ob es sich beimZieldatenbanksystem um ein relationales, objektrelationales, objektorientiertes oder ein mul-tidimensionales Datenbanksystem handelt. Dies ist durch sprachlich reichhaltige undadäquate Beschreibungsmittel auf konzeptueller Ebene sicherzustellen. Dabei sollte derLeitsatz „So einfach wie möglich, so komplex wie nötig“ oberste Maxime sein.
5.2 Sichtenbildung zur Komplexitätsbewältigung
Mit Hilfe von Sichten lassen sich Ausschnitte eines Modellsystems darstellen. Jede Sicht kanndabei als eine Projektion auf das zugrundeliegende Meta-Modell verstanden werden. Eine Sich-tenbildung erfolgt i.d.R. aus Gründen der Komplexitätsbewältigung [Sinz97a, S. 876].
Abb. 5: Sichten auf multidimensionale Datenstrukturen
34 12 17 45
23 4 87 21
65 34 73 91
312 54 49 72
64 23 89 25
WI
BWL
VW
LTH
EO
THEO
SOW
I
BA
LITU
RSt
udie
nfac
h
Fach
bere
ich
Uni
vers
ität
Dimensionssicht
Sicht auf eine Basiskennzahl
Anzahl der eingeschriebenenStudierenden
Anzahl der Exmatrikulationen [Semester] /Anzahl der Exmatrikulationen [Vorsemester]
Anzahl der exmatrikuliertenStudierenden
Exmatrikulationsquote:Anzahl der eingeschriebenen Studierenden /
Anzahl der exmatrikulierten Studierenden
Anzahl der eingeschriebenenStudierenden
Anzahl der Studierenden [Studienfach] /Anzahl der Studierenden [Fachbereich]
12 6 13 36
1 2 45 19
25 19 52 74
234 12 28 55
23 11 8 12
Anzahl der exmatrikuliertenStudierenden
Sicht auf das Kennzahlensystem
Datenstruktursicht
Integrierte Gesamtsicht

34
Auch bei der multidimensionalen Datenmodellierung bietet sich eine Unterscheidung von Sich-ten an. Jedes komplexere multidimensionale Schema umfaßt mehrere multidimensionaleDatenstrukturen (Hyperwürfel) und wird daher als Multi Cube Schema bezeichnet. Ein solchesSchema stellt eine integrierte Gesamtsicht auf das multidimensionale Schema dar und dientfolglich als Basis für eine Sichtenbildung (vgl. Abbildung 5). Die beiden fundamentalenBeschreibungsmittel für Hyperwürfel sind Dimensionen und Kennzahlen. Dimensionen weiseneine komplexe innere Strukturierung auf und können gleichzeitig Bestandteil mehrerer Hyper-würfel sein. Daher bietet sich die Spezifikation einer Dimensionssicht an, die einerseits dieStrukturierung der jeweiligen Dimension (intensionale Beschreibung), andererseits den Zusam-menhang zwischen Dimensionsausprägungen (extensionale Beschreibung) ermöglicht. Einemultidimensionale Datenstruktur entsteht aus der Kombination von Kennzahlen und der mitihnen in Beziehung stehenden Dimensionen. Unterscheidet man bei den Kennzahlen zwischenBasiskennzahlen und abgeleiteten Kennzahlen bieten sich die beiden Sichten Sicht auf eineBasiskennzahl und Sicht auf die multidimensionale Datenstruktur an. Während die Sicht aufeine Basiskennzahl die jeweilige Basiskennzahl und die zugehörigen Dimensionen beinhaltetenthält die Sicht auf eine multidimensionale Datenstruktur (Hyperwürfel) zusätzlich noch alleabgeleiteten Kennzahlen. Kennzahlen verschiedener Hyperwürfel können über Berechnungs-vorschriften gegebenenfalls mehrstufig miteinander verknüpft werden. Eine Sicht auf ein sichdaraus ergebendes Kennzahlensystem betrachtet den Zusammenhang zwischen Basis- undabgeleiteten Kennzahlen unabhängig von den zugrundeliegenden Hyperwürfeln. Bei SDWMwird folglich ausgehend von der integrierten Gesamtsicht die Dimensionssicht, die Sicht aufeine Basiskennzahl, die Sicht auf eine multidimensionale Datenstruktur und die Sicht auf einKennzahlensystem unterschieden.
Beispielsweise fordern auch Gabriel und Gluchowski in [GaGl97, S. 52 f.] eine sichtenspezifi-sche Modellierung multidimensionaler Datenstrukturen. Da die Sichten durch Projektion aufein integriertes Meta-Modell gebildet werden, bleibt der Zusammenhang zwischen den Sichtengewahrt [Sinz97a].
5.3 Dimensionssicht
Im folgenden wird ein Meta-Modell für die Dimensionssicht von SDWM vorgestellt. Daraufaufbauend wird die Modellierung von Dimensionen mit einfachen Hierarchien anhand einesBeispiels aufgezeigt. Der Unterabschnitt schließt mit einer Behandlung von zwei Sonderfällenbei der Modellierung von Dimensionsstrukturen, der Modellierung paralleler bzw. unbalancier-ter Hierarchien.
5.3.1 Meta-Modell für die Dimensionsicht
Ein wesentlicher Bestandteil jeder multidimensionalen Datenstruktur sind die qualitativenDaten, ihre Dimensionen. Dabei sind vor allem adäquate Darstellungsmittel zur Repräsentationder vielfältigen Strukturierungsmöglichkeiten innerhalb einer Dimension vorzusehen. Ausge-hend von einer ausführlichen Beschreibung des zugrundeliegenden Meta-Modells für die

35
Dimensionssicht als gültige Extension des in Abschnitt 4 vorgestellten Meta-Meta-Modellswerden anschließend Sonderfälle bei der Modellierung von Dimensionen vorgestellt.
Die intensionale Dimensionssicht enthält die Metaobjekte Dimension, Dimensionshierarchie-stufe, Aggregationsbeziehung und Dimensionsschnittstelle. Dabei sind die Symbole für dieVisualisierung der Metaobjekte bei den jeweiligen Elementen in Abbildung 6 dargestellt. JedeDimension besteht aus (is_part_of) Dimensionshierarchiestufen, Aggregationsbeziehungen undDimensionsschnittstellen.
Eine Dimension enthält mindestens zwei Dimensionshierarchiestufen und eine gerichteteAggregationsbeziehung, die die beiden Dimensionshierarchiestufen miteinander verbindet.Aggregationsbeziehungen dienen zur Visualisierung der Verdichtung von Datenwerten voneiner niedrigeren zu einer höheren Hierarchiestufe. Eine hierarchisch höher gelegene Stufe stehtüber eine Aggregationsbeziehung zu einer niedriger gelegenen Stufe in einer 1:N-Beziehung,die durch die Angabe von Kardinalitäten in (min,max)-Notation präzisiert werden kann. Umdifferenzierte und hierarchisch mehrstufige Dimensionsgebilde abzubilden, wird zwischenSub-Dimensionshierarchiestufen (Hierarchiestufen auf der Ebene 1 bis n-1) und einer Stufe derEbene n, der Gesamt-Dimensionshierarchiestufe, unterschieden, wobei eine sukzessive Ver-dichtung von Stufe 1 in Richtung Stufe n erfolgt. Es existiert in einer Dimension jeweils nureine Gesamt-Dimensionshierarchiestufe Gesamt, zu der gegebenenfalls mehrstufig die Daten-werte aller übrigen Hierarchiestufen aggregiert werden. Für die Sub-Dimensionshierarchiestu-fen gilt, daß jede Stufe (mit Ausnahme von Stufe 1) zumindest eine eingehende und eine aus-gehende Aggregationsbeziehung besitzen muß (Integritätsbedingung 1). Es ist möglich die
Abb. 6: Meta-Modell für die Dimensionssicht [Boeh01]
Sub-Dimensions-hierarchie-stufe (SDH)
Gesamt-Dimensions-hierarchie-stufe (GDH)
Dimension
SDH1 / SDH2
GDH / SDH
Stufe < n
Stufe = n
Dimensions-hierarchie-stufe
Aggregations-beziehung
Dimensions-Attribut
Stufe Kardinalität
Dimensions-schnittstelle
Rolle
2,*
1,1 1,1 1,1
1,*
1,*
1,1 1,1
0,1
0,1
0,1
0,1
1,*
1,*
1,1
1,1
1,1
2,2
0,1
1,1
1,11,1 1,*
0,*
1,1
0,1
0,11,1
Stufe = 1,...,nDH = Menge der Dimensionshierarchiestufen AB(a,b) Aggregationsbeziehung von a nach bDH' = {dh ∈ DH | dh.Stufe > 1 ∧ dh.Stufe < n} DS(c) c besitzt eine DimensionsschnittstelleDH'' = {dh ∈ DH | dh.Stufe = 1} r.Stufe Zugriffsoperator auf die Eigenschaft Stufe von r
wobei a,b,c,r ∈ DHIntegritätsbedingungen:
∀ x ∈ DH': ∃ v, n ∈ DH : AB(x, v) ∧ x.Stufe > v.Stufe ∧ AB(n, x) ∧ x.Stufe > n.Stufe∀ u ∈ DH'': ∃ DS(u)
gerichteteAggregationsbeziehungvon/nach
gerichteterAggregationsbeziehungvon/nach
SDH1.Stufe > SDH2.Stufe
Stufe < n
Stufe = n

36
Dimensionshierarchiestufe durch Angabe von Dimensionsattributen eingehender zu charakte-risieren.
Weiterhin gibt es in jeder Dimension zumindest eine Dimensionsschnittstelle, um sie mit Basis-kennzahlen in Beziehung setzen zu können (vgl. Abbildung 13 zur Zuordnung von Kennzah-len). Eine Dimension kann mehrere Dimensionsschnittstellen besitzen, die durch Rollennamenvoneinander unterschieden werden können, sie muß aber zumindest eine Schnittstelle auf derStufe 1 besitzen (Integritätsbedingung 2).
Im folgenden wird das Meta-Modell der Dimensionssicht durch konkrete Modellierungsbei-spiele weiter verdeutlicht. Ausgehend von einfachen Dimensionshierarchien wird zu Sonderfäl-len in der Dimensionsmodellierung (parallelen Hierarchien und unbalancierten Bäumen) über-geleitet.6
5.3.2 Dimensionen mit einfachen Hierarchien
Zur Verdeutlichung der verschiedenen Modellierungskonstrukte der Dimensionssicht werdenBeispiele aus dem universitären Umfeld herangezogen. Jede Dimension kann auf Typ- (inten-sionale Ebene) bzw. Instanzebene (extensionale Ebene) betrachtet werden. Dimensionen miteinfachen Hierarchien bestehen intensional aus einer linearen Folge von Dimensionshierarchie-stufen, die durch gerichtete Aggregationsbeziehungen miteinander verknüpft sind, wobei jedeDimension mindestens zwei Hierarchiestufen umfaßt (vgl. Abbildung 7). Beispielsweisekönnte die Dimension Studienausrichtung aus den Hierarchiestufen Studienfach, Fachbereich,Universität und Gesamt bestehen. Eine Verdichtung der Daten erfolgt von der niedrigsten Hier-archiestufe Studienfach (mit der Stufe 1) zu der höchsten Hierarchiestufe Gesamt (mit der Stufe4). Die höchste Hierarchiestufe zur Konsolidierung aller Datenwerte einer Dimension ist obli-gatorisch. Die Dimension Studienausrichtung besitzt weiterhin eine Dimensionsschnittstelleauf der Hierarchiestufe Studienfach, um in Verbindung mit Kennzahlen eine multidimensionaleDatenstruktur zu bilden.
6. Diese Sonderformen werden von Holthuis in [Holt97, S. 20 f.] auch als Strukturanomalien in Dimen-sionen bezeichnet.
Abb. 7: DimensionssichtDimensionsname
Dimensions-hierarchiestufe 1
Gesamt
Studienfach
Fachbereich
Universität
Gesamt
Legende:(Intensionale Dimensionssicht)
Dimension
Dimensionshierarchiestufe
Aggregationsbeziehung
Dimensionschnittstelle
Dimensions-hierarchiestufe n-1
Studienausrichtung

37
Dimensionshierarchiestufen können durch beschreibende Attribute (Dimensionsattribute)näher charakterisiert werden (vgl. Abbildung 8). Beispielsweise dient in Abbildung 8 Dekan alsbeschreibendes Attribut für die Fakultät und Rektor als beschreibendes Attribut für die Univer-sität. Eine Zuordnung derartiger Attribute zu einer Hierarchiestufe ist unbeschränkt möglich.
Außerdem ist es möglich, den Aggregationsgrad zwischen zwei benachbarten Hierarchiestufendurch eine Komplexitätsangabe in (min, max)-Notation zu präzisieren. Dabei bestimmen dieEckwerte die minimale und die maximale Anzahl von Dimensionselementen der Stufe n-1 mitder ein Element der Stufe n in Beziehung stehen kann. Ohne Angabe der Komplexität einerBeziehung wird im folgenden eine (1,*)-Beziehung unterstellt, wobei * als Platzhalter für einebeliebige Anzahl von Dimensionselementen steht. Im Beispiel aus Abbildung 8 hat ein Fach-bereich mindestens zwei und höchstens 15 Studienfächer. Außerdem besteht eine Universitätaus höchstens fünf Fachbereichen.
In Abbildung 8 ist der intensionalen Sicht der Dimension Studienausrichtung ein Ausschnitt ausder korrespondierenden Ausprägungsebene, ihre extensionale Sicht, gegenübergestellt. DieDimensionselemente der verschiedenen Hierarchiestufen bilden eine vollständig ausgeglicheneBaumstruktur.7 Ausgehend von den Blattknoten (Elemente der Hierarchiestufe Studienfachz.B. BWL, VWL und Philosophie) werden die Elemente mehrstufig bis zum Wurzelknoten, demElement Gesamt, verdichtet. Die resultierende Struktur korrespondiert weitgehend mit einemazyklischen Graphen in der Graphentheorie. Ausprägungen für die beschreibenden Attributesind den jeweiligen Dimensionselementen in runden Klammern zugeordnet.
7. Bei einem vollständig ausgeglichenen Baum sind alle Pfadlängen vom Wurzelknoten zu den Blattkno-ten gleich lang und variieren nicht.
Abb. 8: Intensionale vs. extensionale Dimensionssicht
Studienausrichtung
Uni Bamberg(Huber)
SOWI(Mayer)
PPP(Müller)
VWL PhilosophieBWL Pädagogik
Universität
Fachbereich
Studienfach
Uni München(Schulz)
Gesamt
...
...
Studienausrichtung
Studienfach
Fachbereich
Universität
Gesamt
Dekan
(1,5)
(2,15)
Rektor
Extensionale SichtIntensionale Sicht
Legende:(Intensionale Dimensionssicht)
Dimension
Dimensionshierarchiestufe
Aggregationsbeziehung
Dimensionsschnittstelle
Dimensionsattribut
Legende:(Extensionale Dimensionssicht)
Dimension
Dimensionselementmit dimensionalemAttributwert in Klammern
Beziehung zwischenDimensionselementen
Informatik(Meier)
Informatik ...

38
Als nächstes werden zwei Sonderfälle bei der Modellierung von Dimensionsstrukturen vorge-stellt.
5.3.3 Dimensionen mit parallelen Hierarchien (Sonderfall 1)
Innerhalb einer Dimension existieren häufig mehrere gleichrangige Möglichkeiten der Hierar-chisierung [McGu96].8 Lassen sich Dimensionselemente auf verschiedene Arten sinnvoll kon-solidieren, spricht man von parallelen Hierarchien. Eine Hierarchie wird dabei durch einelineare Folge von Hierarchiestufen von 1 bis n beschrieben. Ein typisches Beispiel für paralleleHierarchien liefert die Zeitdimension (vgl. Abbildung 9). Tage lassen sich zu Monaten bzw. zuWochen verdichten, es läßt sich aber keine eindeutige Zuordnung zwischen Wochen und Mona-ten angeben. Beispielsweise kann die 5. Kalenderwoche zum Teil im Januar und zum Teil imFebruar liegen. Deshalb enthält die Zeitdimension in Abbildung 9 zwei parallele Hierarchien.Einerseits kann von Tag, über Monat und Jahr zu Gesamt verdichtet werden, andererseits istebenso eine Konsolidierung von Tag, über (Kalender-)Woche und Jahr zu Gesamt möglich.Parallele Hierarchien dürfen neben der höchsten Hierarchiestufe (Gesamt) durchaus noch wei-tere Stufen gemeinsam haben. Sie müssen sich aber zumindest in einer Hierarchiestufe unter-scheiden. Zu fordern ist lediglich, daß alle Dimensionselemente der Blattknotenebene in jederHierarchie vollständig und unabhängig voneinander zum Wurzelelement Gesamt verdichtetwerden können. In Abbildung 9 ist der intensionalen Ebene wiederum die Ausprägungsebenegegenübergestellt.
8. McGuff spricht anstelle von parallelen Hierachien von „alternate hierarchies“.
Abb. 9: Sonderfall der parallelen Hierarchien
Intensionale Sicht
Zeit
Tag
Woche
Jahr
Gesamt
Monat
(52,52)(12,12)
(28,31) (7,7)
Extensionale Sicht
Zeit
Jahr
Monat und Woche
Tag
Gesamt
... ... ...
2000
Januar Dezember 1. Woche2000
5. Woche2000
1.1.2000 2.1.2000 ... 7.1.2000 ... 31.1.2000 1.2.2000 ...
...
4. Woche2000Februar
Legende:(Intensionale Dimensionssicht)
Dimension
Dimensionshierarchiestufe
Aggregationsbeziehung
Dimensionsschnittstelle
Dimensionsattribut
Legende:(Extensionale Dimensionssicht)
Dimension
Dimensionselementmit dimensionalemAttributwert in Klammern
Beziehung zwischenDimensionselementen

39
5.3.4 Dimensionen mit unbalancierten Hierarchien (Sonderfall 2)
Unbalancierte Hierarchien stellen einen weiteren Sonderfall der multidimensionalen Modellie-rung dar. Auf Ausprägungsebene liegt hier eine Baumstruktur vor, bei der sich die Pfadlängenvon der Wurzel zu den Blattknoten um mindestens Eins unterscheiden. Klassische Definitionenaus der Graphentheorie lassen sich jedoch nicht direkt auf unbalancierte Hierarchien übertra-gen. Beispielsweise definieren [OtWi93, S. 298] einen Baum als nicht höhenbalanciert, wenndie Länge der kürzesten Pfade zweier Blätter eines Baumes (atomare Elemente) zum Wurzel-knoten (höchste Verdichtungsstufe) um mehr als Eins differieren.9 Bei der intensionalenDimensionssicht sind unbalancierte Hierarchien durch zwei oder mehr Dimensionsschnittstel-len auf unterschiedlichen Hierarchiestufen erkennbar.
In Abbildung 10 wird die Dimension Studienausrichtung um die Hierarchiestufe Vertiefungerweitert. Studienfächer können, müssen aber keine weiteren Vertiefungsfächer enthalten.Während die Studienfächer BWL und VWL kein Vertiefungsfach besitzen, gibt es bei der katho-
9. Auch die häufig verwendete Definition eines nicht ausgeglichenen Baums ([Oehl00, S. 70][Holt98a, S.160 f.]) impliziert als Gegenteil einen ausgeglichenen Baum. Ein ausgeglichener Baum ist jedoch alsabgeschwächte Form einer vollständig ausgeglichenen Baumstruktur definiert, bei der sich die Pfadlän-gen um nicht mehr als Eins unterscheiden [Wirt99].
Abb. 10: Sonderfall der unbalancierten Hierarchien (Beispiel 1)
Extensionale SichtIntensionale Sicht
Studienausrichtung
Studienfach
Fachbereich
Universität
Gesamt
Vertiefung
Studienausrichtung
Uni Bamberg(Huber)
SOWI(Mayer)
Theologie(Karl)
VWL TheologieBWL Liturgie
Universität
Fachbereich
Studienfach
Uni München(Schulz)
Gesamt
...
...
Informatik(Meier)
Informatik ...Vertiefungsfach
Biblische T. Theo-retische T.
PraktischeT.
(0,3)
Legende:(Intensionale Dimensionssicht)
Dimension
Dimensionshierarchiestufe
Aggregationsbeziehung
Dimensionsschnittstelle
Dimensionsattribut
Legende:(Extensionale Dimensionssicht)
Dimension
Dimensionselementmit dimensionalemAttributwert in Klammern
Beziehung zwischenDimensionselementen
Dekan
Rektor

40
lischen Theologie die Vertiefungsfächer Biblische, Theoretische und Praktische Theologie. AufAusprägungsebene liegen variierende Pfadlängen von der Wurzel zum Blattknoten vor, die sichhier um Eins unterscheiden.
Sowohl die Hierarchiestufe Studienfach als auch die Stufe Vertiefung besitzen daher eine eigeneDimensionsschnittstelle. Zudem weist auch der untere Eckwert 0 bei der Kardinalitätsangabefür die Stufe Studienfach auf eine unbalancierte Hierarchie hin.
Ein weiteres Beispiel für eine unbalancierte Hierarchie liefert Abbildung 11. Bei der geogra-phischen Herkunft von Studierenden kann zwischen Inländern und Ausländern unterschiedenwerden. Während bei den Ausländern nur die Hierarchiestufen Land und Gesamt erfaßbar sind,lassen sich bei Inländern zusätzlich noch Kreis und Bundesland bestimmen. Auch diese Dimen-sion besitzt zwei Dimensionsschnittstellen (auf den Stufen 1 und 3), die durch Rollenbezeich-nungen (Inland bzw. Ausland) näher charakterisiert sind.
5.4 Sicht auf eine Basiskennzahl
Nach einer kurzen Vorstellung des Meta-Modells für die Sicht auf eine Basiskennzahl wird die-ses anhand eines Beispiels aus dem universitären Umfeld veranschaulicht.
Abb. 11: Sonderfall der unbalancierten Hierarchien (Beispiel 2)
Extensionale SichtIntensionale SichtGeographische Herkunft
Kreis
Bundesland
Land
Gesamt
Geographische Herkunft
Deutschland
Bayern Hessen
München FrankfurtBamberg Gießen
Land
Bundesland
Kreis
Österreich
Gesamt
...
...
...
(0,16)
Inland
Ausland
Schweiz
...
Legende:(Intensionale Dimensionssicht)
Dimension
Dimensionshierarchiestufe
AggregationsbeziehungDimensionsschnittstelle
Dimensionsattribut
Legende:(Extensionale Dimensionssicht)
Dimension
Dimensionselement
Beziehung zwischenDimensionselementen

41
5.4.1 Meta-Modell für die Sicht auf eine Basiskennzahl
Die Kombination von quantitativen Daten (Kennzahlen) mit qualitativen Daten (Dimensionen)ist ein zentrales Charakteristikum multidimensionaler Datenstrukturen. Nach Reichmann[Reic95, S. 16] sind Kennzahlen Wertgrößen, die quantitativ erfaßbare Sachverhalte in konzen-trierter Form erfassen. „Betriebswirtschaftliche Kennzahlen sind [...] Verhältniszahlen undabsolute Zahlen, die in konzentrierter Form über einen zahlenmäßig erfaßbaren betriebswirt-schaftlichen Tatbestand informieren.“ [Stae67, S. 62]. Die Auffassung, auch absolute Zahlenseien als Kennzahlen zu betrachten, hat sich heute weitgehend durchgesetzt (vgl. [Sieg92, S.23], [Bott93, S. 4], [Reic95, S. 21]). Für die Sicht auf eine Basiskennzahl werden nur Grund-kennzahlen, von Staehle als absolute Zahlen bezeichnet, herangezogen. Abgeleitete Kennzah-len, sog. Verhältniszahlen, sind in Abschnitt 5.5 Gegenstand der Betrachtung. Zentrale Bestand-teile des Meta-Modells für eine Basiskennzahl sind Dimensionen, Dimensionsschnittstellenund Basiskennzahlen. Die zugehörigen Symbole für die genannten Elemente sind inAbbildung 12 hinterlegt. Die Beziehung zwischen Dimensionen und Basiskennzahlen wirdüber die Dimensionsschnittstelle hergestellt. Jede Dimension besitzt mindestens eine Dimensi-onsschnittstelle und jede Basiskennzahl steht mit mindestens einer Dimensionsschnittstelle inBeziehung, während eine Dimensionsschnittstelle genau eine Dimension mit einer Basiskenn-zahl verbindet.
Dimensionsschnittstellen sind durch die Zuordnung von Constraints bzw. Aussagen über dieAdditivität von Dimensionen näher beschreibbar. Die Verdichtung der Datenwerte entlang derHierarchien einer Dimension kann additiv, semiadditiv oder nicht additiv sein ([Kurz99, S.132], [Kimb96]). Beispielsweise sind Bestandskennzahlen entlang der Zeitdimension grund-sätzlich semiadditiv, d.h. es können zwar Durchschnittsbildungen aber keine Summationen beider Aggregation erfolgen. Die Anzahl der eingeschriebenen Studierenden ist bezüglich derDimension Studienausrichtung jedoch uneingeschränkt additiv, da sie auf allen Konsolidie-rungsebenen der assoziierten Dimension durch eine einfache Additionsoperation berechnetwerden kann. Klassische Beispiele für nicht additive Kennzahlen sind Durchschnitte bzw. pro-zentuelle Werte, welche nicht mittels Additionsoperation summiert werden können.
Durch Constraints können außerdem sog. Dimensionslinien modelliert werden [Wiek99, S. 132f.]. Mit Hilfe von Dimensionslinien läßt sich die Granularität einer Basiskennzahl steuern,indem die für sie geltende niedrigste Hierarchiestufe einer Dimension festgelegt wird. Bei-spielsweise könnte für die Dimension Studienausrichtung (Abbildung 8) und die Kennzahl
Abb. 12: Meta-Modell für die Sicht auf eine Basiskennzahl [Boeh01]
Basis-kennzahl (BK)
Dimensions-schnittstelle (DS)
Dimension
Aggregier-barkeit
Dimensions-linie0,*
0,1
1,11,1
1,*
1,1
1,* 1,1

42
Anzahl der eingeschriebenen Studierenden mit der Dimensionslinie Fachbereich die Granula-rität der Kennzahl auf den jeweiligen Fachbereich festgelegt werden.10
5.4.2 Beispiel für die Sicht auf eine Basiskennzahl
In Abbildung 13 werden der Basiskennzahl Anzahl der eingeschriebenen Studierenden überDimensionsschnittstellen die drei Dimensionen Studienausrichtung, geographische Herkunftund Zeit zugeordnet. Eine derartige Darstellung erlaubt eine kompakte Visualisierung desZusammenhangs zwischen Basiskennzahlen und Dimensionen, wobei die jeweilige Innensichtder Dimensionen verborgen bleibt.
Die vorliegende Kennzahl ist zudem hinsichtlich der Zeitdimension nur eingeschränkt aggre-gierbar, da es sich um eine Bestandskennzahl mit der impliziten Aggregationsfunktion Summie-rung handelt. Die Semiaggregierbarkeit (S) der Kennzahl wird durch ein Beschriftung der Kantezwischen Dimension und Kennzahl angezeigt, bei der nur eine eingeschränkte Aggregierbarkeitmöglich ist. Folglich wird in Abbildung 13 die Kante zwischen Anzahl der eingeschriebenenStudierenden und der Zeitdimension durch die Angabe von S:Zeit präzisiert. Da die Kennzahlhinsichtlich aller Konsolidierungsebenen der übrigen assoziierten Dimensionen (Studienaus-richtung und geographische Herkunft) durch eine einfache Additionsoperation uneingeschränktberechnet werden kann, werden diese Kanten nicht weiter beschriftet.
Abbildung 14 hingegen erweitert die Darstellung von Abbildung 13 unter Zuhilfenahme der in-neren Strukturierung der beteiligten Dimensionen.
10. Verbindet man gedanklich die Ebenen der jeweils feinsten Granularität je Dimension miteinander, er-gibt sich die sog. maximale Dimensionslinie einer Kennzahl. Sie gibt an, bis zu welcher Detaillierungeine Kennzahl hinsichtlich aller ihrer Dimensionen für Analysen zur Verfügung steht.
Abb. 13: Sicht auf eine Basiskennzahl
Basiskennzahl
Dimension1
Dimension2
Dimensionn
Anzahl dereingeschriebenen
Studierenden
Studien-ausrichtung
Geo-graphische
HerkunftZeit
Legende:(Basiskennzahlensicht)
Dimension
Basiskennzahl
Dimensionsschnittstelle
S:Zeit

43
5.5 Sicht auf das Kennzahlensystem
Nach einer kurzen Vorstellung des Meta-Modells für die Sicht auf das Kennzahlensystem wirddieses anhand eines Praxisbeispiels verdeutlicht.
5.5.1 Meta-Modell für die Sicht auf das Kennzahlensystem
Im folgenden soll der Zusammenhang zwischen den Kennzahlen eines multidimensionalenSchemas betrachtet werden (vgl. Abbildung 15). Dabei wird die Verbindung der Kennzahlen zuDimensionen zunächst vernachlässigt, d.h. die untersuchten Kennzahlen können durchausBestandteil mehrerer Hyperwürfel sein. Isolierte Kennzahlen haben in der Regel geringe Aus-sagekraft, so daß man sich normalerweise auf eine Zusammenstellung in sogenannten Kennzah-lensystemen konzentriert. Diese umfassen zwei oder mehr betriebswirtschaftliche Kennzahlen,die in rechentechnischer Verknüpfung oder in einem Systematisierungszusammenhang zuein-ander stehen und die Informationen über einen oder mehrere betriebswirtschaftliche Tatbe-stände beinhalten [Meye94, S. 9]. Häufig wird lediglich gefordert, daß Kennzahlensysteme einhierarchisch aufgebautes Beziehungsgefüge ausgewählter Kennzahlen darstellen [Bram90, S.340]. Weiterhin wird bei einem Kennzahlensystem nicht zwangsläufig vorausgesetzt, daß alleKennzahlen zu einer einzigen Spitzenkennzahl verdichtbar sind. Dabei lassen sich Basis- undabgeleitete Kennzahlen unterscheiden. Den Hauptanteil abgeleiteter Kennzahlen stellen Ver-hältniszahlen dar, auch als relative Kennzahlen bezeichnet, die durch in Beziehung setzenzweier hierarchisch untergeordneten Kennzahlen entstehen. Es können drei verschiedene Typendifferenziert werden (vgl. [Stae67, S. 64-65]): Gliederungszahlen, Beziehungszahlen undIndexzahlen. Gliederungszahlen setzen eine Teilgröße zu einer Gesamtgröße ins Verhältnis.
Abb. 14: Erweiterte Sicht auf eine Basiskennzahl
Studienausrichtung
Studienfach
Fachbereich
Universität
Gesamt
Vertiefung
Geographische Herkunft
Kreis
Bundesland
Land
Gesamt
InlandAusland
Zeit
Semester
Gesamt
Anzahl der eingeschriebenenStudierenden
S:Zeit
Legende:(Basiskennzahlensicht)
Dimension
Dimensionshierarchiestufe
Aggregationsbeziehung
Dimensionsschnittstelle
Basiskennzahl

44
Dagegen stellen Beziehungszahlen gleichwertige inhaltliche aber ungleichartige statistischeMasse in einen logisch sinnvollen Zusammenhang. Indexzahlen weisen die Verhältnisse gleich-artiger aber zeitlich oder örtlich verschiedener Zahlen zu einer Basiszahl aus. Abgeleitete Kenn-zahlen werden durch Berechnungsvorschriften aus anderen Basis- bzw. abgeleiteten Kennzah-len ermittelt, wobei gegebenfalls eine mehrstufige Anordnung der verknüpften Kennzahlenmöglich ist. Der Zusammenhang zwischen den jeweils verbundenen Kennzahlen wird durcheine gerichtete Kennzahlenbeziehung visualisiert. Eine Kennzahlenbeziehung verbindet entwe-der genau eine Basis- mit einer abgeleiteten Kennzahl oder zwei abgeleitete Kennzahlen. Überdie im Meta-Modell hinterlegte Integritätsbedingung wird sichergestellt, daß abgeleitete Kenn-zahlen auf einer höheren Berechnungsstufe nicht isoliert im Kennzahlensystem stehen können(vgl. Abbildung 15). Aus Sicht der Graphentheorie bildet ein Kennzahlensystem einen endli-chen gerichteten Graphen, aber nicht zwangsläufig eine Baumstruktur.
Nicht alle der in einem Schema enthaltenen Basiskennzahlen müssen explizit Bestandteil einesKennzahlensystems sein. Vielmehr können sie, wenn keine sinnvolle technische oder systema-tische Verknüpfung möglich ist, durchaus auch isoliert neben in Kennzahlensystemen enthalte-nen Kennzahlen stehen.
Abb. 15: Meta-Modell für das Kennzahlensystem [Boeh01]
Kennzahl
Basis-kennzahl (BK)
AbgeleiteteKennzahl (AK)
Gliederungs-zahl
Beziehungs-zahl
Index-zahl
AK1 / AK2BK / AK
Kennzahlen-beziehung
Stufe
Berechnungs-vorschrift
1,1
1,1
1,11,*
0,1 0,10,1 0,1
1,1 1,1
0,* 0,*1,1 1,1 0,*1,1
0,1 0,1 0,1
0,1
gerichtete Kennzahlen-beziehung von/nach
AK1.Stufe < AK2.Stufe
gerichtete Kennzahlen-beziehung von/nach
Stufe = 1,...,nK = Menge der Kennzahlen KB(a,b) Kennzahlenbeziehung von a nach bK' = {k ∈ K | ak.Stufe > 0 ∧ ak.Stufe < n} r.Stufe Zugriffsoperator auf die Eigenschaft Stufe von r
wobei a,b,r ∈ KIntegritätsbedingungen:
∀ x ∈ K': ∃ y ∈ Κ : KB(y, x) ∧ y.Stufe < x.Stufe

45
5.5.2 Beispiel für die Sicht auf das Kennzahlensystem
Die geschilderten Zusammenhänge in der Sicht auf ein Kennzahlensystem sollen im folgendenanhand von zwei Beispielen verdeutlicht werden.
Das Kennzahlensystem in Abbildung 16 umfaßt zwei Berechnungsstufen. Auf der erstenBerechnungsstufe stehen die beiden Basiskennzahlen Anzahl der eingeschriebenen Studieren-den und Anzahl der exmatrikulierten Studierenden. Mit Hilfe dieser zwei Basiskennzahlen wer-den drei abgeleitete Kennzahlen auf Berechnungsstufe zwei gebildet. Jeder abgeleiteten Kenn-zahl ist die zugrundeliegende Berechnungsvorschrift in Abbildung 16 zugeordnet. Die Exma-trikulationsquote ist ein Beispiel für eine Beziehungszahl, da hier ungleichartige statistischeMassen (Anzahl der eingeschriebenen Studierenden und Anzahl der exmatrikulierten Studie-renden) in einen sinnvollen Gesamtzusammenhang gestellt werden. Hingegen handelt es sichbeim Studierendenanteil um eine Gliederungszahl, die eine Teilgröße (Anzahl der eingeschrie-benen Studierenden bezogen auf Studienfächer) zu einer Gesamtgröße (Anzahl der eingeschrie-benen Studierenden bezogen auf Fachbereiche) in Beziehung setzt. Dabei wurde die betrachteteKennzahl durch die Zuordnung von Hierarchiestufen der Dimension Studienausrichtung ineckigen Klammern (Studienfach, Fachbereich) eingeschränkt. Beim Exmatrikuliertenanteilliegt eine Indexzahl vor, da dabei gleichartige aber zeitliche verschiedene Zahlen in Beziehunggesetzt werden (Anzahl der exmatrikulierten Studierenden bezogen auf ein Semester und daszugehörige Vorsemester).
Ein klassisches betriebswirtschaftliches Kennzahlensystem ist das DuPont-Kennzahlensystemzur Berechnung des Return on Investment (ROI) ([Baum88, S. 125][Kuep95, S. 327][Horv94,S. 557]). Bereits im Jahre 1920 wurde dieses Kennzahlensystem zur Steuerung einer dezentra-len Geschäftsbereichsorganisation von einem amerikanischen Chemiekonzern eingesetzt[BeHa95, S. 67].
Abb. 16: Sicht auf das Kennzahlensystem
Anzahl der eingeschriebenenStudierenden
Anzahl der exmatrikuliertenStudierenden
ExmatrikulationsquoteAnzahl der exmatr. Studierenden / Anzahl der
eingeschr. Studierenden
Studierendenanteil [Studienfach | Fachbereich]
Anzahl der eingeschr. Studierenden [Studienfach] /Anzahl der eingeschr. Studierenden [Fachbereich]
Exmatrikuliertenanteil [Semester| Vorsemester]Anzahl der exmatr. Studierenden [Semester] / Anzahl der
eingeschr. Studierenden [Vorsemester]
Legende:(Sicht auf das Kennzahlensystem)
Basiskennzahl
Abgeleitete Kennzahl
Kennzahlenbeziehung
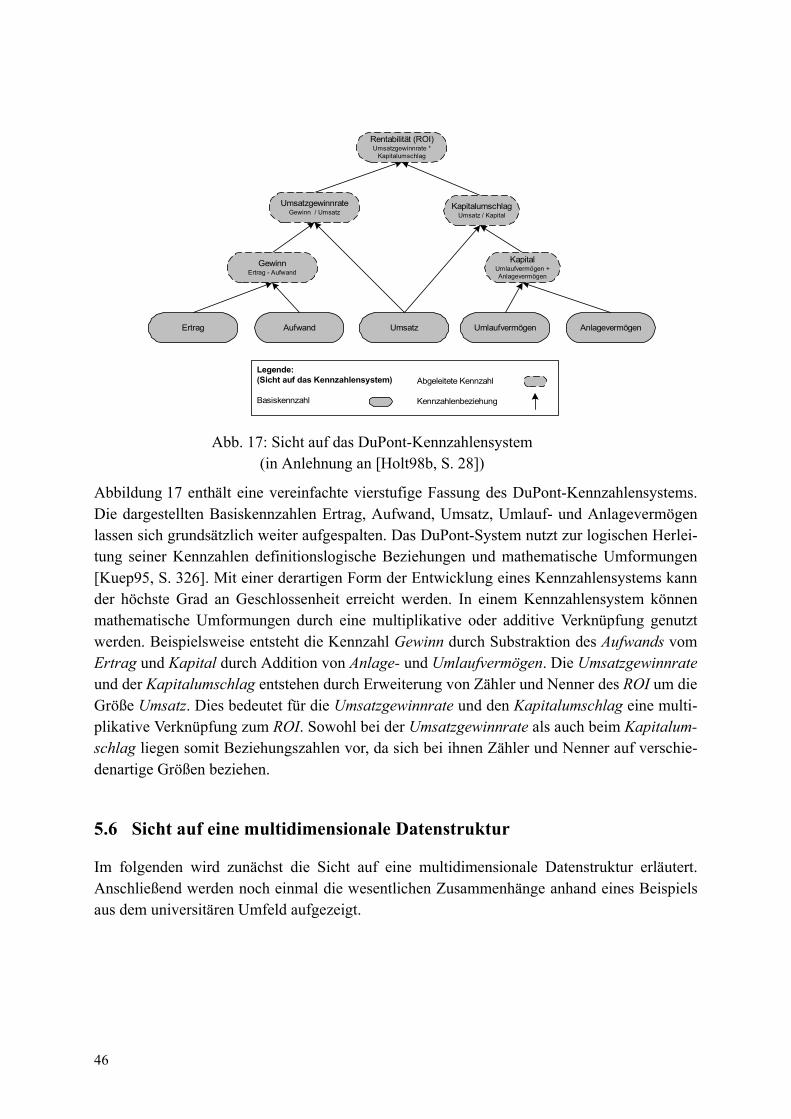
46
Abbildung 17 enthält eine vereinfachte vierstufige Fassung des DuPont-Kennzahlensystems.Die dargestellten Basiskennzahlen Ertrag, Aufwand, Umsatz, Umlauf- und Anlagevermögenlassen sich grundsätzlich weiter aufgespalten. Das DuPont-System nutzt zur logischen Herlei-tung seiner Kennzahlen definitionslogische Beziehungen und mathematische Umformungen[Kuep95, S. 326]. Mit einer derartigen Form der Entwicklung eines Kennzahlensystems kannder höchste Grad an Geschlossenheit erreicht werden. In einem Kennzahlensystem könnenmathematische Umformungen durch eine multiplikative oder additive Verknüpfung genutztwerden. Beispielsweise entsteht die Kennzahl Gewinn durch Substraktion des Aufwands vomErtrag und Kapital durch Addition von Anlage- und Umlaufvermögen. Die Umsatzgewinnrateund der Kapitalumschlag entstehen durch Erweiterung von Zähler und Nenner des ROI um dieGröße Umsatz. Dies bedeutet für die Umsatzgewinnrate und den Kapitalumschlag eine multi-plikative Verknüpfung zum ROI. Sowohl bei der Umsatzgewinnrate als auch beim Kapitalum-schlag liegen somit Beziehungszahlen vor, da sich bei ihnen Zähler und Nenner auf verschie-denartige Größen beziehen.
5.6 Sicht auf eine multidimensionale Datenstruktur
Im folgenden wird zunächst die Sicht auf eine multidimensionale Datenstruktur erläutert.Anschließend werden noch einmal die wesentlichen Zusammenhänge anhand eines Beispielsaus dem universitären Umfeld aufgezeigt.
Abb. 17: Sicht auf das DuPont-Kennzahlensystem (in Anlehnung an [Holt98b, S. 28])
Ertrag Aufwand Umsatz Umlaufvermögen Anlagevermögen
GewinnErtrag - Aufwand
KapitalUmlaufvermögen +Anlagevermögen
UmsatzgewinnrateGewinn / Umsatz
KapitalumschlagUmsatz / Kapital
Rentabilität (ROI)Umsatzgewinnrate *
Kapitalumschlag
Legende:(Sicht auf das Kennzahlensystem)
Basiskennzahl
Abgeleitete Kennzahl
Kennzahlenbeziehung

47
5.6.1 Meta-Modell für die Sicht auf eine multidimensionale Datenstruktur
Die Sicht auf eine multidimensionale Datenstruktur enthält alle Informationen über einenHyperwürfel des multidimensionalen Modells. Ein Hyperwürfel besteht aus der Kombinationvon Kennzahlen und zugehöriger Dimensionen. Die Sicht auf eine multidimensionale Daten-struktur entsteht aus der Integration der Sicht auf eine Basiskennzahl und aller direkt von dieserBasiskennzahl abgeleiteten Kennzahlen, wobei sich aber alle betrachteten Kennzahlen auf die-selben Dimensionen beziehen müssen. Für eine ausführliche Erläuterung des verwendetenMeta-Modells vgl. Abschnitt 5.4 (Sicht auf eine Basiskennzahl) und Abschnitt 5.5 (Sicht auf einKennzahlensystem).
5.6.2 Beispiel für die Sicht auf eine multidimensionale Datenstruktur
Abbildung 19 zeigt ein Anwendungsbeispiel für die Sicht auf eine multidimensionale Daten-struktur. Hierzu wird das Beispiel aus Abbildung 13 geeignet erweitert. Neben Basiskennzahlensind nun auch alle abgeleiteten Kennzahlen enthalten, die sich auf dieselbe Menge von Dimen-sionen beziehen. Zwischen den Kennzahlen Anzahl der eingeschriebenen Studierenden, Studie-rendenanteil[Studienfach|Fachbereich] und Studierendenanteil[Semester|Vorsemester] undden drei Dimensionen Studienausrichtung, Zeit und geographische Herkunft besteht eine engeBeziehung, da diese Dimensionen analyserelevante Auswertungsrichtungen für die genanntenKennzahlen darstellen. Bei der Kennzahl Studierendenanteil[Studienfach|Fachbereich] liegteine Gliederungszahl vor. Hingegen stellt der Studierendenanteil[Semester|Vorsemester] eineIndexzahl dar. Abbildung 19 zeigt eine kompakte Darstellung der Sicht auf eine multidimensio-nale Datenstruktur, bei der die interne Strukturierung nicht weiter betrachtet wird.
Abb. 18: Meta-Modell für die Datenstruktursicht [Boeh01]
Dimensions-schnittstelle (DS)
Aggregier-barkeit
Dimensions-linie0,*
0,1
1,11,1
1,* 1,1
Dimension
1,*
1,1
Kennzahl
Basis-kennzahl (BK)
AbgeleiteteKennzahl (AK)
Gliederungs-zahl
Beziehungs-zahl
Index-zahl
AK1 / AK2BK / AK
Kennzahlen-beziehung
Stufe
Berechnungs-vorschrift
1,1
1,1
1,11,*
0,1 0,10,1 0,1
1,1 1,1
0,* 0,*1,1 1,1 0,*1,1
0,1 0,1 0,1
0,1
gerichtete Kennzahlen-beziehung von/nach
AK1.Stufe < AK2.Stufe
gerichtete Kennzahlen-beziehung von/nach
Stufe = 1,...,nK = Menge der Kennzahlen KB(a,b) Kennzahlenbeziehung von a nach bK' = {k ∈ K | ak.Stufe > 0 ∧ ak.Stufe < n} r.Stufe Zugriffsoperator auf die Eigenschaft Stufe von r
wobei a,b,r ∈ KIntegritätsbedingungen:
∀ x ∈ K': ∃ y ∈ Κ : KB(y, x) ∧ y.Stufe < x.Stufe
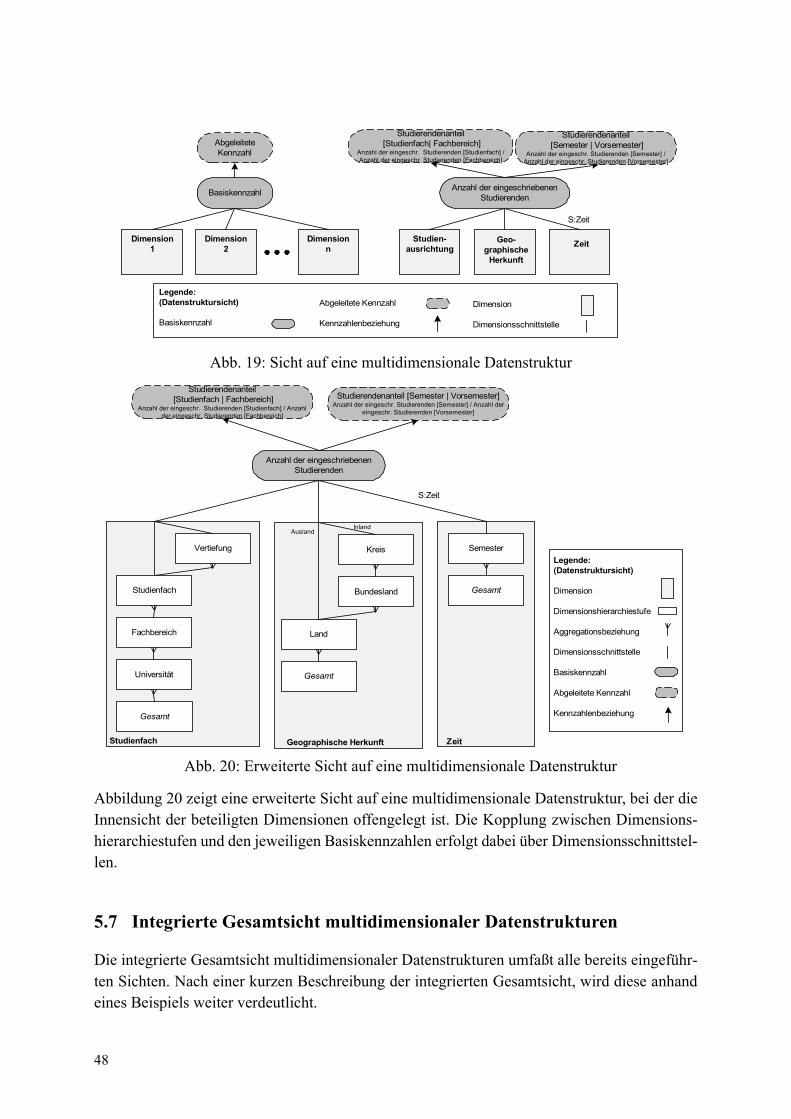
48
Abbildung 20 zeigt eine erweiterte Sicht auf eine multidimensionale Datenstruktur, bei der dieInnensicht der beteiligten Dimensionen offengelegt ist. Die Kopplung zwischen Dimensions-hierarchiestufen und den jeweiligen Basiskennzahlen erfolgt dabei über Dimensionsschnittstel-len.
5.7 Integrierte Gesamtsicht multidimensionaler Datenstrukturen
Die integrierte Gesamtsicht multidimensionaler Datenstrukturen umfaßt alle bereits eingeführ-ten Sichten. Nach einer kurzen Beschreibung der integrierten Gesamtsicht, wird diese anhandeines Beispiels weiter verdeutlicht.
Abb. 19: Sicht auf eine multidimensionale Datenstruktur
Basiskennzahl
Dimension1
Dimension2
Dimensionn
Anzahl der eingeschriebenenStudierenden
Studien-ausrichtung
Geo-graphische
Herkunft
Zeit
AbgeleiteteKennzahl
Studierendenanteil [Studienfach| Fachbereich]
Anzahl der eingeschr. Studierenden [Studienfach] /Anzahl der eingeschr. Studierenden [Fachbereich]
Studierendenanteil [Semester | Vorsemester]
Anzahl der eingeschr. Studierenden [Semester] /Anzahl der eingeschr. Studierenden [Vorsemester]
S:Zeit
Legende:(Datenstruktursicht)
Basiskennzahl
Abgeleitete Kennzahl
Kennzahlenbeziehung
Dimension
Dimensionsschnittstelle
Abb. 20: Erweiterte Sicht auf eine multidimensionale Datenstruktur
Studienfach
Studienfach
Fachbereich
Universität
Gesamt
Vertiefung
Geographische Herkunft
Kreis
Bundesland
Land
Gesamt
InlandAusland
Zeit
Semester
Gesamt
Anzahl der eingeschriebenenStudierenden
Studierendenanteil [Studienfach | Fachbereich]
Anzahl der eingeschr. Studierenden [Studienfach] / Anzahlder eingeschr. Studierenden [Fachbereich]
Studierendenanteil [Semester | Vorsemester]Anzahl der eingeschr. Studierenden [Semester] / Anzahl der
eingeschr. Studierenden [Vorsemester]
S:Zeit
Legende:(Datenstruktursicht)
Dimension
Dimensionshierarchiestufe
Aggregationsbeziehung
Dimensionsschnittstelle
Basiskennzahl
Abgeleitete Kennzahl
Kennzahlenbeziehung
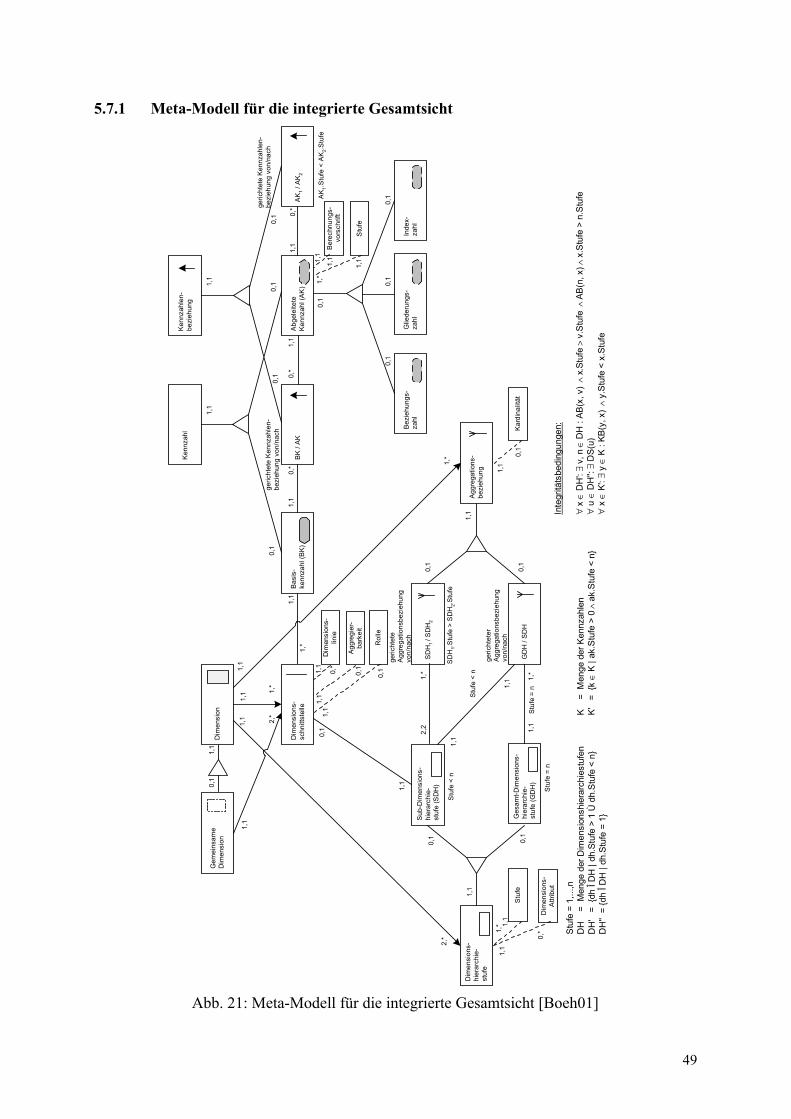
49
5.7.1 Meta-Modell für die integrierte Gesamtsicht
Abb. 21: Meta-Modell für die integrierte Gesamtsicht [Boeh01]
Gem
eins
ame
Dim
ensi
on
Aggr
egie
r-ba
rkei
t
Rol
le
0,*
0,1
1,1
1,1
1,1
0,1
1,*
1,1
2,*
1,1 Su
b-D
imen
sion
s-hi
erar
chie
-st
ufe
(SD
H)
Ges
amt-D
imen
sion
s-hi
erar
chie
-st
ufe
(GD
H)
Dim
ensi
on
SDH
1 / S
DH
2
GD
H /
SDH
Dim
ensi
ons-
hier
arch
ie-
stuf
e
Aggr
egat
ions
-be
zieh
ung
Dim
ensi
ons-
Attr
ibut
Stuf
eKa
rdin
alitä
t
Dim
ensi
ons-
schn
ittst
elle
Dim
ensi
ons-
linie
2,*
1,1
1,1
1,1
1,*
1,*
1,1
1,1
0,1
0,1
0,1 0,1
1,*
1,1
1,1
1,1
0,1
1,1
1,1
1,1
1,*
0,*
1,1
0,1
0,11,
1
Stuf
e <
n
Stuf
e =
n
1,*
2,2
Inte
gritä
tsbe
ding
unge
n:
∀ x
∈ D
H':
∃ v,
n ∈
D
H :
AB(x
, v)
∧ x.
Stuf
e >
v.St
ufe
∧
AB(n
, x) ∧
x.S
tufe
> n
.Stu
fe∀
u ∈
D
H'':
∃ D
S(u)
∀ x
∈ K
': ∃
y ∈
K :
KB(y
, x)
∧ y.
Stuf
e <
x.St
ufe
geric
htet
eAg
greg
atio
nsbe
zieh
ung
von/
nach
geric
htet
erAg
greg
atio
nsbe
zieh
ung
von/
nach
SDH
1.Stu
fe >
SD
H2.S
tufe
Stuf
e <
n
Stuf
e =
n
Kenn
zahl
Basi
s-ke
nnza
hl (B
K)Ab
gele
itete
Kenn
zahl
(AK
)
Glie
deru
ngs-
zahl
Bezi
ehun
gs-
zahl
Inde
x-za
hl
AK1 /
AK 2
BK /
AK
Kenn
zahl
en-
bezi
ehun
g
Stu
fe
Bere
chnu
ngs-
vors
chrif
t1,
1
1,11,
11,
*
0,1
0,1
0,1
0,1
1,1
1,1
0,*
0,*
1,1
1,1
0,*
1,1
0,1
0,1
0,1
0,1
geric
htet
e Ke
nnza
hlen
-be
zieh
ung
von/
nach
AK1.S
tufe
< A
K 2.Stu
fe
geric
htet
e Ke
nnza
hlen
-be
zieh
ung
von/
nach
K
= M
enge
der
Ken
nzah
len
K'
= {k
∈ K
| ak
.Stu
fe >
0 ∧
ak.
Stuf
e <
n}
Stuf
e =
1,...
,nD
H
= M
enge
der
Dim
ensi
onsh
iera
rchi
estu
fen
DH
' =
{dh
Î D
H |
dh.S
tufe
> 1
Ù d
h.St
ufe
< n}
DH
'' =
{dh
Î DH
| dh
.Stu
fe =
1}

50
Das Meta-Modell für die integrierte Gesamtsicht vereint alle Informationen über ein multidi-mensionales Datenmodell. Die in den Abschnitten 5.3 (Dimensionssicht), 5.4 (Sicht auf eineBasiskennzahl), 5.5 (Sicht auf ein Kennzahlensystem) und 5.6 (Sicht auf eine multidimensio-nale Datenstruktur) beschriebenen Teil-Meta-Modelle stellen Projektionen auf das integrierteMeta-Modell in Abbildung 21 dar. Die dabei vorgenommene Sichtenbildung erfolgte aus Grün-den der Komplexitätsbewältigung [Sinz97a, S. 876].
Mit Hilfe einer integrierten Gesamtsicht kann zusätzlich ein expliziter Zusammenhang zwi-schen den verschiedenen multidimensionalen Datenstrukturen (Hyperwürfeln) hergestellt wer-den. Hyperwürfel können immer dann zueinander in Beziehung gesetzt werden, wenn sie min-denstens eine Dimension gemeinsam haben.11 Während sich Dimensionen immer auf wenig-stens eine Basiskennzahl beziehen müssen, wird für deren Spezialfall einer gemeinsamenDimension eine Verbindung zu mindestens zwei Basiskennzahlen gefordert (vgl.Abbildung 21). Damit wird auch die Existenzberechtigung eines eigenständigen Hyperwürfelsdeutlich: Er muß sich zumindestens in einer Dimension von einem anderen Hyperwürfel unter-scheiden. Mögliche Auswertungsdimensionen abgeleiteter Kennzahlen können damit, gegebe-nenfalls mehrstufig, durch Vereinigung der Dimensionen vorgelagerter Kennzahlen ermitteltwerden.
Abbildung 22 zeigt noch einmal abstrakt den Zusammenhang zwischen den geschilderten Bau-steinen auf.
11. Da in Data Warehouse-Modellen fast zwangsläufig eine Historisierung der Datenwerte über eine Zeit-dimension vorgenommen wird, ist die oben genannte Voraussetzung für die Kombination von Hyper-würfel meist implizit erfüllt.
Abb. 22: Integrierte Gesamtsicht
Basiskennzahl 1
Dimension1
GemeinsameDimension
1
GemeinsameDimension
2
AbgeleiteteKennzahl 1
Basiskennzahl 2
AbgeleiteteKennzahl 3
GemeinsameDimension
n
Dimension2
AbgeleiteteKennzahl 2
Legende:(Integrierte Gesamtsicht)
Dimension
Gemeinsame Dimension(en)
Dimensionsschnittstelle
Basiskennzahl
Abgeleitete Kennzahl
Kennzahlenbeziehung

51
5.7.2 Beispiel für die integrierte Gesamtsicht multidimensionaler Datenstrukturen
Abbildung 23 zeigt den Zusammenhang zwischen zwei voneinander unabhängigen Hyperwür-feln auf. Der erste Hyperwürfel besitzt die drei Dimensionen Studienausrichtung, Zeit und geo-graphische Herkunft, sowie die Kennzahlen Anzahl der eingeschriebenen Studierenden undStudierendenanteil [Studienfach|Fachbereich]. Hingegen enthält der zweite Hyperwürfel dievier Dimensionen Studienausrichtung, Zeit, geographische Herkunft und Studienabschluß,sowie die Kennzahlen Anzahl der exmatrikulierten Studierenden und Exmatrikuliertenan-teil[Semester|Vorsemester]. Die beiden multidimensionalen Strukturen haben die drei Dimen-sionen Studienausrichtung, Zeit und geographische Herkunft gemeinsam, was in Abbildung 23explizit visualisiert ist. Das Beispiel enthält weiterhin die abgeleitete Kennzahl Exmatrikulati-onsquote, die durch eine Berechnungsformel aus den zwei Basiskennzahlen der beteiligtenHyperwürfel ermittelt wird. Diese Kennzahl kann bezüglich aller Dimensionen der beidenHyperwürfel ausgewertet werden. Für die übrigen Kennzahlen stellen lediglich die Dimensio-nen ihres jeweils zugeordneten Hyperwürfels geeignete Auswertungsmöglichkeiten zur Verfü-gung.
Während Abbildung 23 eine kompakte Darstellung der integrierten Gesamtsicht liefert, zeigtAbbildung 24 zusätzlich die Innensicht der beteiligten Dimensionen.
Eine Übersicht über alle im multidimensionalen Datemodell zur Visualisierung verwendetenModellbausteine und der zugehörigen Beziehungen werden noch einmal in Abbildung 25 imAnhang aufgezeigt.
Abb. 23: Integrierte Gesamtsicht (Beispiel)
Studien-ausrichtung Zeit
Geo-graphische
Herkunft
Anzahl der eingeschriebenenStudierenden
Anzahl der exmatrikuliertenStudierenden
ExmatrikulationsquoteAnzahl der exmatr. Studierenden / Anzahl der
eingeschr. Studierenden
Studierendenanteil [Studienfach | Fachbereich]
Anzahl der eingeschr. Studierenden [Studienfach] /Anzahl der eingeschr. Studierenden [Fachbereich]
Exmatrikuliertenanteil[Semester | Vorsemester]
Anzahl der exmatr. Studierenden [Semester] / Anzahlder eingeschr. Studierenden [Vorsemester]
Exmatriku-lationsgrund
S:ZeitS:Zeit
Legende:(Integrierte Gesamtsicht)
Dimension
Gemeinsame Dimension(en)
DimensionsschnittstelleBasiskennzahl
Abgeleitete Kennzahl
Kennzahlenbeziehung

52
6 Zusammenfassung und Ausblick
Herkömmliche logische Modellierungsansätze im OLAP- und Data Warehouse-Umfeld, wiez.B. Star und Snowflake Schema, wurden für das relationale Datenbankmodell geschaffen underlauben keine rein konzeptuelle Betrachtung des zugrunde liegenden Modellierungsproblems.Das vorgestellte Semantische Data Warehouse Modell (SDWM) adressiert diese Problemstel-lung und bietet einen konzeptuellen, semantischen Modellierungsansatz für die Erstellung mul-tidimensionaler Datenstrukturen. Anhand eines integrierten Meta-Modells wurden Sichten undkorrespondierende Modellierungsbausteine auf multdimensionale Datenstrukturen aufgezeigt.Modellierungsbeispiele aus dem universitären Umfeld dienten zur Veranschaulichung des vor-gestellten Modellierungsansatzes.
SDWM bietet eine Reihe von Vorteilen gegenüber herkömmlichen Modellierungsansätzen, dieeine adäquate Modellierung multidimensionaler Datenstukturen ermöglichen. Die Begrifflich-keiten des konzeptuellen Modells sind an den Fachtermini der multidimensionalen Modellie-rung ausgerichtet. Eine explizite Bildung von Sichten trägt zur Komplexitätsbewältigung bei.Weiterhin werden Zusammenhänge zwischen Kennzahlen explizit dargestellt. Außerdemerfolgt bei der Modellierung multidimensionaler Datenstrukturen eine explizite Trennung zwi-
Abb. 24: Integrierte Gesamtsicht (Beispiel in erweiterter Darstellung)
Geographische Herkunft
Kreis
Bundesland
Land
Gesamt
InlandAusland
Zeit
Semester
Gesamt
Anzahl der eingeschriebenenStudierenden
Studierendenanteil [Studienfach | Fachbereich]
Anzahl der eingeschr. Studierenden [Studienfach] /Anzahl der eingeschr. Studierenden [Fachbereich]
Exmatrikulations-grund
Exmatrikulations-grund
Gesamt
Anzahl der exmatrikuliertenStudierenden
ExmatrikulationsquoteAnzahl der exmatr. Studierenden / Anzahl der
eingeschr. Studierenden
Exmatrikuliertenanteil [Semester | Vorsemester]
Anzahl der exmatr. Studierenden [Semester] / Anzahlder eingeschr. Studierenden [Vorsemester]
Studienausrichtung
Studienfach
Fachbereich
Universität
Gesamt
Fächergruppe Dekan
Rektor
S:Zeit S:Zeit
Dimension
Gemeinsame Dimension(en)
Dimensionshierarchiestufe
Aggregationsbeziehung
Basiskennzahl
Abgeleitete Kennzahl
Kennzahlenbeziehung
Dimensionsschnittstelle
Legende: (Integrierte Gesamtsicht)
(0,16)

53
schen Struktur und Inhalt. Durch eine strikte Unterscheidung zwischen fachlichen und imple-mentierungsspezifischen Aspekten ist das erstellte konzeptuelle Datenmodell unabhängig vomjeweiligen Zieldatenbanksystem auf der logischen Ebene.
Die vorliegende Arbeit führte in die Grundkonzepte von SDWM anhand eines integriertenMeta-Modells ein. Die vorgestellten Konzepte sind um eine detaillierte Beschreibung einesVorgehensmodells bei der Entwicklung konzeptueller Datenschemata für multidimensionaleDatenstrukturen zu ergänzen ([BoUl99a][BoUl99b]). Hierbei spielt die Anwendung von heuri-stischen Modellierungswissen in Form von Mustern eine entscheidende Rolle. Durch die Ein-bettung in eine geschäftsprozeßorientierte Vorgehensweise wird eine an den Unternehmenszie-len ausgerichtete Entwicklung von multidimensionalen Datenschemata möglich [BoUl00b].Dabei sind auch Regeln für eine Transformation des erstellten konzeptuellen Modells in einelogische und physische Repräsentationsform zu berücksichtigen.
Weiterhin kann die Akzeptanz von SDWM durch die Entwicklung eines computergestütztenModellierungswerkzeugs verbessert werden, das eine explizite Prüfung von Konsistenz undVollständigkeit bei der Erstellung multidimensionaler Modelle ermöglicht.

54
7 LiteraturAgGS97 Agrawal, R.; Gupta, A.; Sarawagi, S.: Modeling Multidimensional Databases,
Research Report, IBM Almaden Research Center, 1997.
AnMu97 Anahory, S.; Murray, D.: Data Warehouse - Planung, Implementierung und Administration, Addison-Wesley, Bonn, 1997.
Baum88 Baumbusch, R.: Normativ-deskriptive Kennzahlen-Systeme im Management, Frankfurt, 1988.
BeHa95 Bea, F.X.; Haas, J.: Strategisches Management, Fischer, Stuttgart, 1995.
Boeh01 Böhnlein, M.: Konstruktion semantischer Data-Warehouse-Schemata, DUV, Wiesbaden, 2001.
BSHD98a Blaschka, M.; Sapia, C.; Höfling, G.; Dinter, B.: Finding Your Way through Mul-tidimensional Data Models, in: Proceedings of the 9th International Workshop on Database and Expert Systems Applications (DEXA'1998, Wien, Österreich, 24.-28. August), IEEE Computer Society Press, 1998, S. 198-203.
BSHD98b Blaschka, M.; Sapia, C.; Höfling, G.; Dinter, B.: An overview of multidimensio-nal data models for OLAP, Technical Report, http://www.forwiss.tu-muen-chen.de/~system42/publications/techreport.pdf.
Bott93 Botta, V.: Kennzahlensysteme als Führungsinstrumente: Planung, Steuerung und Kontrolle der Rentabilität im Unternehmen, 4. Auflage, Berlin, 1993.
BoUl99a Böhnlein, M.; Ulbrich-vom Ende, A.: Using the Conceptual Data Models of the Operational Information Systems for the Construction of Initial Data Warehouse Structures, Modellierung betrieblicher Informationssysteme (MobIS 1999, Bam-berg, 14.-15. Oktober), 1999, S. 66-82.
BoUl99b Böhnlein, M.; Ulbrich-vom Ende, A.: Deriving Initial Data Warehouse Structures from the Conceptual Data Models of the Unterlying Operational Information Systems, Proceedings of the ACM Second International Workshop on Data Ware-housing and OLAP (DOLAP 1999, Kansas City, 6. November), 1999, S. 15-21.
BoUl00a Böhnlein, M.; Ulbrich-vom Ende, A.: Grundlagen des Data Warehousing: Model-lierung und Architektur, Bamberger Beiträge zur Wirtschaftsinformatik Nr. 55,Bamberg, Februar 2000.
BoUl00b Böhnlein, M.; Ulbrich-vom Ende, A.: CEUS - Ein Data-Warehouse-System für die bayerischen Hochschulen - Architektur - Vorgehensweise - Modellierung, Workshop MSS-2000 "Modellierungsansätze zum Aufbau von Data Warehouse-Anwendungen", (MSS-2000, Bochum, 23.-24. März), 2000.
Bram90 Bramsemann, R.: Handbuch Controlling, Methoden und Technikenk, Hanser, München, 1990.

55
Bulo96 Bulos, D.: A New Dimension, in: Database Programming & Design, Vol. 9, No. 6, Juni 1996, S. 33-38.
BuFo98 Bulos, D.; Forsman, S.: Getting Started with ADAPT - OLAP Database Design, Symmetry Corporation, 1998.
EhHe98 Ehrenberg, D.; Heine, P.: Konzept zur Datenintegration für Management Support Systeme auf der Basis uniformer Datenstrukturen, in: Wirtschaftsinformatik, 6/1998, S. 503-512.
FeSi98 Ferstl, O.K.; Sinz, E.J.: Grundlagen der Wirtschaftsinformatik, 3. vollständig überarbeitete und erweiterte Auflage, Oldenbourg, München, 1998.
GaGl97 Gabriel, R.; Gluchowski, P.: Semantische Modellierungstechniken für multidi-mensionale Datenstrukturen, in: HMD - Praxis der Wirtschaftsinformatik, Heft 195, 34. Jahrg., Mai 1997, S. 18-37.
GoMR98 Golfarelli, M.; Maio, D.; Rizzi, S.: Conceptual Design of Data Warehouses form E/R Schemes, Proceedings of the Hawaii International Conference on System Sci-ences (HICS 1998, Kona, Hawai, 6.-9. Januar), 1998.
Holt97 Holthuis, J.: Modellierung multidimensionaler Daten - Modellierungsaspekte und Strukturkomponenten, Arbeitsbericht des Lehrstuhls für Informationsmanage-ment und Datenbanken, European Business School, Oestrich-Winkel, 1997.
Holt98a Holthuis, J.: Multidimensionale Datenstrukturen - Modellierung, Strukturkompo-nenten, Implementierungsaspekte, in: Muksch, H.; Behme, W. (Hrsg.): Das Data Warehouse-Konzept - Architektur - Datenmodelle - Anwendungen, 3. Auflage, Gabler, 1998, S. 143-193.
Holt98b Holthuis, J.: Der Aufbau von Data Warehouse-Systemen - Konzeption - Daten-modellierung - Vorgehen, DUV Verlag, Wiesbaden, 1998.
Horv94 Horvath, P.: Controlling, 5. Auflage, München, 1994.
Info98 Informix: Warehouse Manager's Guide - MetaCube ROLAP Option for Informix Dynamic Server, Informix, 1998.
Kena95 Kenan Technologies: An Introduction to Multidimensional Database Technology, White Paper, Kenan Technologies, 1995.
Kimb96 Kimball, R.: The Data Warehouse Toolkit - Practical Techniques for Buidling Dimensional Data Warehouses, Wiley & Sons, 1996.
Kuep95 Küpper, H.-U.: Controlling - Konzeption, Aufgaben und Instrumente, Schäffer-Poeschel, Stuttgart, 1995.
Kurz99 Kurz, A.: Data Warehousing - Enabling Technology, MITP, Bonn, 1999.
MaDL87 Mayr, H.C.; Dittrich, K.R.; Lockemann, P.C.: Datenbankentwurf, in (Hrsg: Lockemann, P.C.; Schmidt, J.W.): Datenbankhandbuch, Springer, Heidelberg, 1987, S. 481-557.

56
McGu96 McGuff, F.: Hitchhiker's Guide to Decision Support, http://members.aol.com/fmcguff/dwmodel/frtoc.htm.
Meye94 Meyer, C.: Betriebswirtschaftliche Kennzahlen und Kennzahlen-Systeme, 2. Auf-lage, Stuttgart, 1994.
Oehl00 Oehler, K.: OLAP - Grundlagen, Modellierung und betriebswirtschaftliche Lösungen, Hanser, München, 2000.
OtWi93 Ottmann, T.; Widmeyer, P.: Algorithmen und Datenstrukturen, 2. Auflage, Spek-trum, Heidelberg, 1993.
PeCr95 Pendse, N.; Creeth, R.: Synopsis of the OLAP Report, Business Intelligence, 1995, http://www.busintel.com.
PeMa88 Peckham, J.; Maryanski, F.: Semantic Data Models, ACM Computing Surveys, Vol. 20, No. 3, September 1988, S. 153-189.
Pilot98 Pilot Software: A Introduction to OLAP Multidimensional Terminology and Technology, White Paper, Pilot Software, http://www.pilotsw.com/olap/olap.htm.
Poe96 Poe, V.: Building a Data Warehouse for Decision Support, Prentic Hall, New Jer-sey, 1996.
Rade95 Raden, N.: Star Schema 101, http://members.aol.com/nraden/str.htm.
Rade96 Raden, N.: Modeling the Data Warehouse, http://members.aol.com/iw0196_1.htm.
Reic95 Reichmann, T.: Controlling mit Kennzahlen und Managementberichten: Grund-lagen einer systemgestützten Controlling-Konzeption, 4. Auflage, München, 1995.
Ruf97 Ruf, T.: Scientific & Statistical Databases - Datenbankeinsatz in der multidimen-sionalen Datenanalyse, Vieweg, Wiesbaden, 1997.
SAP97 SAP AG: Business Information Warehouse - Technology, White Paper, SAP AG, 1997.
SAP98a SAP AG: Data Modeling with BW - ASAP for BW Accelerator, Business Infor-mation Warehouse Online Support Center, 1998.
Sche99 Schelp, J.: Konzeptionelle Modellierung mehrdimensionaler Datenstrukturen, in: Chamoni, P.; Gluchowski, P. (Hrsg.): Analytische Informationssysteme - Data Warehouse, On-Line Analytical Processing, Data Mining, 2. Auflage, Springer, Berlin, 1999.
Shos82 Shoshani, A.: Statistical Databases: Characteristics, Problems and some Soluti-ons, in: Proceedings of the 8th International Conference on Very Large Data Bases (VLDB 1982, Mexico City, Mexico, 8.-10. Sept.), 1982, S. 208-222.

57
SiBU99 Sinz, E.J.; Böhnlein, M.; Ulbrich-vom Ende, A.:Konzeption eines Data Wareh-ouse-Systems für Hochschulen, Workshop "Unternehmen Hochschule" (Informa-tik '99, 29. Jahrestagung der Gesellschaft für Informatik, Paderborn, 5.-9. Okto-ber),1999, S. 111 - 124.
Sieg92 Siegwart, H.: Kennzahlen für die Unternehmensführung, 4. Auflage, Bern, 1992.
Sinz96 Sinz, E.J.: Ansätze zur fachlichen Modellierung betrieblicher Informationssy-steme - Entwicklung, aktueller Stand und Trends, in: Heilmann, H.; Heinrich, L.J.; Roithmayr, F. (Hrsg.): Information Engineering, Oldenbourg, München, 1996.
Sinz97a Sinz, E.J.: Architektur betrieblicher Informationssysteme, In: Rechenberg, P.; Pomberger, G. (Hrsg.): Handbuch der Informatik, Hanser-Verlag, München 1997, S. 875-887.
Sinz97b Sinz, E.J.: Architektur betrieblicher Informationssysteme, Bamberger Beiträge zur Wirtschaftsinformatik, Nr. 40, Bamberg, 1997.
Sinz98 Sinz, E.J.: Universitätsprozesse, In: Küpper, H.-U.; Sinz, E.J. (Hrsg.): Gestal-tungskonzepte für Hochschulen. Effizienz, Effektivität, Evolution, Schäffer-Poe-schel, Stuttgart, 1998, S. 13 - 57.
SKMW96 Sinz, E.J.; Krumbiegel, J.; Merten O.; Wagner, W.: Geschäftsprozeß- & Anwen-dungssystemarchitektur der WU Wien, Teilprojektdokumentation im Projekt WU IS 2000, Bamberg, Juli 1996.
Stae67 Staehle, W.H.: Kennzahlen und Kennzahlensysteme: Ein Beitrag zur modernen Organisationstheorie, München, 1967.
TsLo82 Tsichritzis, D.C.; Lochovski, F.H.: Data Models, Prentice-Hall, Englewood CLiffs, 1982.
Voss99 Vossen, G.: Datenbankmodelle, Datenbanksprachen und Datenbankmanagement-systeme, 3. Auflage, Oldenbourg, München, 1999.
Wiek99 Wieken, J.-H.: Der Weg zum Data Warehouse - Wettbewerbsvorteile durch struk-turierte Unternehmensinformationen, Addison-Wesley, München, 1999.
Wirt99 Wirth, N.: Algorithmen und Datenstrukturen, 5. Auflage, Teubner, Stuttgart, 1999.

58
8 Anhang
Abb. 25: Symbole der SDWM-Notation
Intensionale Dimensionssicht:
Dimension
Dimensionshierarchiestufe
Aggregationsbeziehung
Dimensionsschnittstelle
Dimensionsattribut
Extensionale Dimensionssicht:
Dimension
Dimensionselement
Beziehung zwischenDimensionselementen
Kennzahlen:
Basiskennzahl
Abgeleitete Kennzahl
Zuordnungsbeziehung
Kennzahlenbeziehung
Gemeinsame Dimension(en)

59
Bernd Knobloch
Der Data-Mining-Ansatz zur Analyse
betriebswirtschaftlicher Daten
Lehrstuhl für Wirtschaftsinformatik,
insb. Systementwicklung und Datenbankanwendung
Otto-Friedrich-Universität Bamberg

60

61
„We live in an expanding universe of data
in which there is too much data and too little information.“ [ADZA96, 2]
1 Einleitung Der Erfolg vieler Unternehmen hängt heute durch steigenden Wettbewerbsdruck in zunehmendem Maße davon ab, wie schnell und effektiv sie verfügbare Informationen in Entscheidungen und Handlungen umsetzen können. In diesem Zusammenhang werden Daten aus der operativen Geschäftsabwicklung nicht mehr nur als Nebenprodukt ange-sehen, sondern als strategische Ressource verstanden. Sie repräsentieren den aktuellen Zustand des Unternehmens und stellen Informationen dar die (gegebenenfalls durch Kombination mit Daten aus anderen Quellen) Aussagen über die vorliegende Unter-nehmenssituation und über zukünftige Entwicklungen und Chancen ermöglichen [SiLK95, 282; Bigu96, 4].
Die technischen Fähigkeiten zur Generierung und Speicherung von Daten sind in den vergangenen Jahren sprunghaft angestiegen. Durch die zunehmende Automatisierung von Geschäftsprozessen werden immer größere Datenbestände erzeugt, da eine Vielzahl alltäglicher Vorgänge wie Telefongespräche, Kreditkartentransaktionen oder Einkaufs-handlungen in Supermärkten automatisiert erfasst und verarbeitet werden [FrPM91, 1]. Fortschritte in der Speichertechnologie, billigere Speichermedien und leistungsfähige Datenbankverwaltungssysteme ermöglichen zudem die Aufbewahrung dieser Daten-mengen auch über längere Zeiträume hinweg [FaPS96, 1f.].
Das stetige Wachstum der Datenbestände macht allerdings den Zugriff auf die gewünschten Informationen immer schwieriger. ADRIAANS UND ZANTINGE vergleichen die Situation mit der berühmten Suche nach der Nadel im Heuhaufen, wobei dieser jedoch stetig weiter wächst [ADZA96, 5]. Aus der Erkenntnis, dass in den operativen Datenbeständen enthaltenes Wissen zur Erlangung von Wettbewerbsvorteilen beitragen kann, ist die Notwendigkeit erwachsen diese verborgenen Informationen aufzuspüren [FRPM91, 2]. Traditionelle Methoden der Datenanalyse wie Tabellenkalkulation und Ad-hoc-Datenbankanfragen sind für derartige Untersuchungsprobleme nicht geeignet. Vielmehr besteht Bedarf nach einer neuen Generation von Untersuchungskonzepten, die den Menschen bei der Suche nach nützlichem, neuem Wissen in großen Datenbeständen auf „intelligente“ Weise unterstützen [FAPS96, 2]. Im Mittelpunkt steht der Wunsch nach Ansätzen, die weitgehend autonom interessante Auffälligkeiten in großen Datenmengen entdecken [KÜPP99, 13f.]. Auch moderne On-Line-Analytical-Processing- (OLAP-)

62
Systeme sind nicht in der Lage den veränderten Analyseerfordernissen vollständig zu entsprechen [BIGU96, 4f.].
Der Data-Mining-Ansatz verspricht diese Aufgabe zu erfüllen. Er ermöglicht die automatische Extraktion und Filterung interessanter Informationen aus Datenbeständen. Dies geschieht durch selbständige Suche nach Auffälligkeiten und „Mustern“, die den Entscheidungsträgern normalerweise verborgen bleiben [ADZA96, 5; BIGU96, 5; KÜPP99, 34f.].
Der vorliegende Beitrag stellt eine umfassende Einführung in den Data-Mining-Ansatz einschließlich des Knowledge Discovery in Databases (KDD) dar. In Kapitel 2 wird ein kurzer Überblick über die in der Literatur geführte Diskussion über den Data-Mining-Begriff gegeben und aufgrund der teilweise sehr divergierenden Auffassungen eine problemorientierte Sichtweise vorgeschlagen. Hierzu werden in Kapitel 3 das Konzept der Untersuchungssituation vorgestellt und Probleme der Datenmustererkennung von anderen Problemstellungen abgegrenzt. Auf dieser Grundlage kann in Kapitel 4 eine Definition für Data Mining angegeben werden. Kapitel 5 zeigt auf, dass zur Lösung von Datenmuster-erkennungsaufgaben die bloße Anwendung von Data-Mining-Verfahren nicht ausreicht und stellt deren Einbettung in den KDD-Prozess dar. Kapitel 6 erörtert die Potenziale und Formen der Anbindung von Data Mining Tools an Data-Warehouse-Systeme. Eine abschließende Zusammenfassung des Beitrags mit Hinweisen auf weiteren Forschungs-bedarf findet sich in Kapitel 7.

63
2 Der Data-Mining-Begriff In der Vergangenheit wurden unterschiedliche Bezeichnungen für das Auffinden „nützlicher“ Muster in Datenbeständen gebraucht, wie z.B. Data Mining, Knowledge Discovery in Databases (KDD), Knowledge Extraction, Information Discovery, Information Harvesting, Data Archaeology, Data Pattern Processing, Siftware oder Data Dredging [FAPS96, 3; KÜPP99, 17]. In jüngerer Zeit werden vornehmlich die Begriffe Knowledge Discovery in Databases und Data Mining verwendet. Als deutsche Übersetzung schlagen BISSANTZ UND HAGEDORN den Begriff Datenmustererkennung vor [BIHA93].
In der Literatur ist eine Vielzahl unterschiedlicher Definitionen und Abgrenzungen des Data-Mining-Begriffes zu finden, von denen sich die meisten auf eine methodenorientierte Betrachtung beschränken. Während ein Teil der Autoren unter Data Mining nur eine begrenzte Menge von Verfahren der Datenanalyse versteht, die den Forschungsgebieten der Künstlichen Intelligenz, der Statistik und des Maschinellen Lernens entstammen, verwenden ihn andere als Oberbegriff für sämtliche Formen der rechnergestützten Datenanalyse [HAGE96, 22].
So beschränken z.B. HOLSHEIMER UND SIEBES ihre Definition des Data Mining auf eine Teilmenge von Algorithmen aus dem Bereich des Maschinellen Lernens (ML), nämlich auf einfache Formen des induktiven Lernens [HOSI94, 7]. Eine große Anzahl von Publikationen rechnet neben ML-Methoden auch Ansätze aus der Künstlichen Intelligenz wie Neuronale Netze sowie einen Reihe statistischer Modelle (z.B. Bayes-Verfahren zur Clusteranalyse) zu den Data-Mining-Verfahren.1 Andere Autoren hingegen wie z.B. MATTISON nehmen eine sehr allgemeine Sichtweise ein und beschreiben Data Mining Tools als Produkte, die dem Anwender (ohne die Notwendigkeit problemspezifischer Programmierung) innerhalb einer Data-Warehouse-Umgebung direkte Datenzugriffs- und -analysemöglichkeiten bieten. Darunter fallen Query Managers und Report Writers zur reinen Datenbereitstellung, Tabellenkalkulationsprogramme, multidimensionale Datenbanken, statistische Analyse-programme, „höhere“ Werkzeuge aus dem Bereich der Künstlichen Intelligenz sowie Visualisierungsprogramme [MATT96, 319-323]. Solche weit gefassten Definitionen werden in anderen Veröffentlichungen als unzulässige Aufweichung des Data-Mining-Begriffes kritisiert (vgl. z.B. [KÜPP99, 20; KRWZ98, 23; BISS96, 7]).
Nach Auffassung von KÜPPERS hat die große Anzahl unterschiedlicher Definitionen ihre Ursache in der Tatsache, dass die verwendeten Methoden an sich keinen neuen Ansatz darstellen, sondern in den jeweiligen Forschungsfeldern seit langem bekannt sind [KÜPP99, 19f.]. Es besteht offensichtlich eine gewisse Neigung der Autoren, die eigenen Ansätze im Umfeld des aktuellen Schlagwortes Data Mining zu positionieren. KRAHL ET AL. stellen fest, dass viele Software-Anbieter ihre Produkte aus Marketinggründen als Data-Mining-
1 Stellvertretend sei an dieser Stelle auf [BeLi97], [ChBu97] und [KrWZ98] verwiesen.

64
Werkzeuge bezeichnen, weisen allerdings auch auf große Fortschritte bei der Entwicklung neuer Verfahren und ihrer Umsetzung in einsatzfähige Produkte hin [KRWZ98, 12].
Die Tendenz, Data Mining aus einer methodenorientierten Perspektive zu definieren, ist jedoch nicht unkritisch. Sie führt nicht nur zu uneinheitlichen Abgrenzungen des Begriffes, sondern schränkt die potenziell für Data-Mining-Analysen geeigneten Verfahren unnötig auf Teilmengen ein [KÜPP99, 20], woraus wiederum eine Begrenzung der damit lösbaren Untersuchungsprobleme resultiert. Zudem kann in bestimmten Fällen gerade die Kombination unterschiedlicher Methoden ein eigenes Data-Mining-Verfahren darstellen. Diese Sichtweise wäre bei Zugrundelegung starrer methodenorientierter Definitionen jedoch nicht zulässig.
Aus diesem Grund wird im vorliegenden Beitrag ein problemorientierter Blickwinkel eingenommen. Bevor in Kapitel 4 eine entsprechende Data-Mining-Definition vorgestellt wird, sei im folgenden Abschnitt eine Einordnung des Data Mining in den Kontext betrieblicher Datenanalyseprobleme vorgenommen.

65
3 Einordnung von Data-Mining-Problemen Der Data-Mining-Ansatz ist, wie eben diskutiert, in den Bereich der Datenanalyse einzuordnen. Zur Abgrenzung der Datenmustererkennung von traditionellen Ansätzen erfolgt in Abschnitt 3.1 zunächst eine allgemeine Beschreibung betriebswirtschaftlicher Datenanalyseprobleme. Auf Basis dieser Darstellung kann in Abschnitt 3.2 eine Ein-ordnung von Data-Mining-Problemen vorgenommen werden.
3.1 Betriebswirtschaftliche Datenanalyseprobleme2
Zur Charakterisierung von Datenanalyseproblemen wird im Folgenden das von FERSTL vorgeschlagene Konzept der Untersuchungssituation eingeführt [FERS79, 43-53]. Demnach kann die Untersuchung eines Objektes als eine Folge von vier Aktivitäten beschrieben werden:
1. Spezifikation des Untersuchungsobjekts durch Beschreibung bekannter Eigenschaften des betrachteten Systems,
2. Festlegung eines Untersuchungsziels, welches meist als Frage nach unbekannten Eigen-schaften des Untersuchungsobjekts formuliert wird,
3. Ermittlung von für die Erreichung des Untersuchungsziels geeigneten Untersuchungs-verfahren, und schließlich
4. Durchführung der Untersuchung durch Anwendung von mindestens einem der Untersuchungsverfahren.
Ein Untersuchungsproblem ergibt sich aus der Kombination eines Untersuchungsobjektes mit einem diesbezüglich verfolgten Untersuchungsziel. Die Anwendung eines Unter-suchungsverfahrens auf ein Untersuchungsproblem begründet eine Untersuchungs-situation. Das Ergebnis der Anwendung eines Untersuchungsverfahrens bezüglich eines Untersuchungszieles liefert eine Problemlösung. Ein Untersuchungsobjekt kann dabei Gegenstand m verschiedener Untersuchungsziele sein, welche wiederum auf der Grundlage von n unterschiedlichen Untersuchungsobjekten verfolgt werden können. Hieraus folgt eine m:n-Beziehung zwischen Untersuchungszielen und -objekten. Dasselbe gilt für die Beziehung zwischen Untersuchungsproblemen und -verfahren (Abb. 1).
2 Zur Abgrenzung von Datenanalyseproblemen in anderen Bereichen wie z.B. der Wissenschaft wird hier die Bezeichnung „betriebswirtschaftliche Datenanalyseprobleme“ verwendet.

66
Untersuchungsziele
U'-Problem(b,B)
U'-Problem(b,A)
U'-Problem(a,A)
U'-Objekt b
Untersuchungsobjekte
U'-Ziel A
U'-Objekt a
U'-Ziel B
U'-Verfahren 1
U'-Verfahren 2
Untersuchungs-verfahren
U'-Situation(b,B,1)
U'-Situation(b,B,2)
Abb. 1: Untersuchungsprobleme und -situationen (vgl. [Fers79, 43])
Als Untersuchungsobjekte werden allgemein reale oder formale Systeme angenommen, die durch Beschreibung bekannter Eigenschaften zu spezifizieren und von ihrer Umwelt abzugrenzen sind. Untersuchungsziele richten sich auf unbekannte Struktur- und Ver-haltenseigenschaften der Untersuchungsobjekte. In Abhängigkeit dieser bekannten und unbekannten Systemeigenschaften sind folgende grundlegende Problemtypen zu unter-scheiden:
• Konstruktionsprobleme: Untersuchungsziel ist die Struktur eines zu konstruierenden Systems (Unter-suchungsobjekt), welches ein vorgegebenes Verhalten zeigen soll. Das Unter-suchungsobjekt kann durch Beschreibung seiner Umgebung abgegrenzt werden. (Beispiel: Konstruktion eines Computerprogramms, welches ein Rechnersystem zu einem gewünschten Verhalten veranlasst.)
• Analyseprobleme: Untersuchungsziel ist das Verhalten eines bezüglich seiner Struktur und Abgrenzung bekannten Systems (Untersuchungsobjekt). Das Verhalten realer Systeme bestimmt sich durch deren Interaktion mit ihrer Umwelt, jenes formaler Systeme durch formale Input-Output-Relationen. Analyseprobleme können durch Konkretisierung des Unter-suchungsziels hinsichtlich der Output- bzw. der Input-Menge weiter spezialisiert werden: � Input-Output-Analyseprobleme suchen zu einer gegebenen Eingabemenge die
korrespondierende Ausgabemenge. (Beispiel: Bestimmung des Funktionswertes y eines Polynoms f(x) bei vorgegebenem Eingabewert x.) � Output-Input-Analyseprobleme suchen nach der zu einer bekannten Ausgabemenge
gehörenden Eingabemenge. (Beispiel: Ermittlung des Input-Wertes x zu einem Funktionswert y einer Funktion f(x) durch Anwendung der inversen Funktion f -1(y).)

67
� Entscheidungsprobleme ermitteln aus einer Alternativenmenge eine Kombination von Input- und Output-Mengen, die in Abhängigkeit von Präferenz- und Toleranz-funktionen einer Zielrelation (Untersuchungsziel) genügt.
Auf einen weiteren Problemtyp, die Black-Box-Probleme, die vereinfacht ausgedrückt eine Folge abwechselnd auftretender Analyse- und Konstruktionsprobleme darstellen, soll an dieser Stelle nicht näher eingegangen werden.3
Die Untersuchungsobjekte betriebswirtschaftlicher Datenanalyseprobleme bilden all-gemein die im Unternehmen verfügbaren Datenbestände. Sie stellen den unmittelbaren Untersuchungsgegenstand der Datenanalyse dar, wenngleich sie in der Regel reale Systeme wie z.B. Märkte, Kunden, Produkte, Geschäftsprozesse, Transaktionen, etc. repräsentieren, die als mittelbare Untersuchungsobjekte angesehen werden können. Die Daten sind demnach als Modelle4 der realen Systeme zu interpretieren. Zunächst soll davon ausgegangen werden, dass die entsprechenden Modellabbildungen der realen Systeme auf die Daten durch die operativen Prozesse und Anwendungssysteme den allgemeinen Qualitätsanforderungen an die Modellbildung genügen.5 Da diese Prämisse in der betrieblichen Praxis jedoch keineswegs immer erfüllt ist, muss mitunter erheblicher Zusatzaufwand vor der eigentlichen Analyse in Kauf genommen werden, um negative Auswirkungen auf die Güte der Untersuchungsergebnisse zu vermeiden (vgl. Abschnitt 5.2.3).
Wie bereits in ihrer Bezeichnung deutlich wird, steht als Untersuchungsziel der Daten-analyse grundsätzlich die Ermittlung von Verhaltenseigenschaften der Untersuchungs-objekte im Vordergrund (Problemtyp Analyseproblem). Reine Konstruktionsprobleme treten im Zuge der Datenanalyse prinzipiell nicht auf.
3.2 Data-Mining-Probleme
Datenanalyseprobleme können differenziert werden nach dem Ausmaß, in dem Hypothesen des Anwenders eine Rolle spielen. Im folgenden Abschnitt werden „hypothesengetriebene“ und „hypothesenfreie“ Untersuchungsprobleme beschrieben und Data-Mining-Aufgaben als tendenziell hypothesenfrei charakterisiert. Anschließend wird aufgezeigt, wie die beiden Ansätze sich ergänzen und im Rahmen eines Datenanalysezyklus interagieren können. Die Einordnung von Datenmustererkennungsproblemen bildet die Basis für Kapitel 4, das dem Data Mining und geeigneten Lösungsverfahren gewidmet ist.
3 Vgl. hierzu [FERS79, 51-53]. 4 Vereinfacht ausgedrückt ist ein Modell ein System, welches ein anderes System zielorientiert abbildet [FESI01, 18]. 5 Zur Abbildung eines Ursprungssystem auf ein Modellsystem wird im Wesentlichen die Forderung nach Struktur- und Verhaltenstreue erhoben, die durch homomorphe Modellabbildungen bezüglich Struktur und Verhalten erfüllt werden kann [FESI01, 18f.].

68
3.2.1 Typen von Datenanalyseproblemen
Eine Hypothese ist ein Erklärungsvorschlag (Annahme), der auf seine Gültigkeit hin zu überprüfen ist. Diese Prüfung kann durch die Analyse von beobachteten oder explizit durch Experimente erzeugten Daten erfolgen [BELI97, 65].
Eine Fragestellung wie „Wie viel Prozent der Käufer von Produkt A kaufen auch Produkt B?“ basiert auf einer Hypothese, nämlich dass zwischen den Käufen von Artikel A und denen von Artikel B eine Beziehung besteht. Die Datenbasis kann also auf eine Annahme hin untersucht werden, wodurch der Suchraum bereits erheblich eingeschränkt ist [DHST97, 168]. Eine hypothesenfreie Fragestellung im selben Kontext könnte z.B. lauten „Welche Artikel werden gemeinsam gekauft?“6 In diesem Falle ist der Suchraum wesentlich komplexer, da keine Begrenzung vorgegeben ist.
Demnach sind zwei grundlegende Problemtypen der Datenanalyse zu unterscheiden: Einerseits existieren hypothesengetriebene Fragestellungen, deren Ziel es ist, bestehende Annahmen oder Theorien anhand verfügbarer Daten zu verifizieren oder falsifizieren. Sie werden auch als Top-Down-Probleme bezeichnet, da die Datenbestände ausgehend von einer Hypothese untersucht werden. Andererseits lassen sich eher hypothesenfreie Pro-bleme identifizieren, denen keine konkreten Annahmen zugrunde liegen. Sie sind durch eine Bottom-Up-Vorgehensweise gekennzeichnet, die von den vorliegenden Daten ausgeht und aus ihnen neue Erkenntnisse erzeugt [BELI97, 64]. Der erstgenannte Problemtyp stellt gewissermaßen die Frage „Welche Daten passen zu diesem Muster?“, während das Problem im zweiten Fall lautet „Welches Muster passt zu diesen Daten?“ [DHST97, 168].
3.2.2 Abgrenzung und Einordnung
Auf Grundlage der vorangegangenen Darstellung können Data-Mining-Probleme von anderen Fragestellungen der Datenanalyse abgegrenzt werden. Dazu wird die in Teilen der Literatur dominierende methodenorientierte Sichtweise zugunsten eines problem-orientierten Blickwinkels aufgegeben. Im Folgenden wird Data Mining als Aufgabe interpretiert, welche mittels verschiedener, zunächst nicht näher beschriebener Lösungs-verfahren durchgeführt werden kann.
Data Mining wird häufig als eine Menge bestimmter Datenanalysemethoden definiert. Welche konkreten Verfahren dieser Menge zuzurechnen sind, ist allerdings umstritten. Weitgehende Einigkeit herrscht jedoch bezüglich der allgemeinen Zielsetzung des Data Mining, nämlich der Entdeckung bislang unbekannter Informationen (Muster) in großen Datenmengen.7 Als Konsequenz ist zu fordern, Data Mining nicht auf der Ebene der Methoden, sondern vielmehr auf der Ebene der Anwendungen und damit der Unter-suchungsprobleme zu definieren. Dies legt die Differenzierung der Betrachtung in zwei 6 Die Annahme, dass überhaupt Kaufbeziehungen zwischen Artikeln bestehen, kann je nach Sichtweise ebenfalls als Hypothese aufgefasst werden. 7 Vgl. stellvertretend [BIGU96, 9].

69
Ebenen, die Anwendungs- und die Verfahrensebene nahe, auf die im Folgenden näher eingegangen wird.
Der zentrale Aspekt der Data-Mining-Zielsetzung ist die Entdeckung. Es handelt sich also nicht um hypothesengetriebene Problemstellungen, sondern um eine datengetriebene Aufdeckung unbekannter Muster und Beziehungen (Bottom-Up-Vorgehen) [BIGU96, 9]. Die Hypothesenfreiheit ist als Hauptmerkmal des Data Mining zu betrachten, und die Datenmustererkennung als Analyseziel zu identifizieren. Die Suche nach Auffälligkeiten soll durch die Annahmen und subjektiven Präferenzen des Anwenders möglichst un-beeinflusst bleiben. Es erfolgt keine vorherige Festlegung, welche Variablen einen Zusammenhang erklären. Die betreffenden Fragestellungen sind daher typischerweise von einer Art wie „Welche Artikel verkaufen sich besonders gut zusammen?“ oder „Welche Charakteristika kennzeichnen unsere Stammkunden?“ [KÜPP99, 51].
DatenmustererkennungDatengetriebene Analyse, "Bottom Up"
Datenanalyse
nichtnutzergeführt nutzergeführt
HypothesenverifikationHypothesengetriebene Analyse, "Top Down"
ANWENDUNGSEBENE
VERFAHRENSEBENE
unüberwachteVerfahren
überwachteVerfahren
nutzergeführt
Analyseziel
Untersuchungs-problem
Grad derNutzerinteraktion
Autonomie desAnsatzes
Methode Data-Mining-Verfahren "klassische" Verfahren
Data M
ining
Abb. 2: Problemorientierte Einordnung des Data Mining
Klassische Vertreter von Top-Down-Problemen finden sich z.B. in statistischen Anwen-dungen. Hier sind die Variablen, von denen angenommen wird dass sie ein Phänomen erklären können, vorzugeben und die daraus resultierende Hypothese anhand des Datenmaterials zu prüfen. So testet die Regressionsanalyse beispielsweise, ob eine Be-ziehung zwischen als abhängig und unabhängig eingeschätzten Größen existiert [KÜPP99, 52]. Das Ziel von Top-Down-Analysen ist demnach die Hypothesenverifikation.
Hypothesenfreie Probleme können anhand des Kriteriums der Nutzerinteraktion weiter spezialisiert werden. Diese Differenzierung ist jedoch für die Einordnung von Data-Mining-Problemen nicht von Bedeutung und nimmt zudem bereits auf die Methoden Bezug. Sie wird deshalb in Abschnitt 4.5.1 unter dem Autonomieaspekt als Unterscheidung in überwachte und unüberwachte Verfahren behandelt.
Anhand der diskutierten Differenzierung kann die in Abbildung 2 dargestellte problem-orientierte Einordnung von Data Mining und „klassischen“ Datenanalyseansätzen durch-

70
geführt werden. Eine Datenanalysemethode ist demnach als Data-Mining-Verfahren zu klassifizieren, wenn sie in der Lage ist hypothesenfreie, datengetriebene Analysen mit dem Ziel der Datenmustererkennung durchzuführen.
Die scharfe Trennung zwischen hypothesenfreien und hypothesengetriebenen Problemen, wie in Abbildung 2 gezeigt, ist als idealisierende Systematik zu verstehen. Es ist fest-zustellen, dass vollkommen hypothesenfreie Fragestellungen nicht existieren. Eine völlig freie Suche nach „irgendwelchen“ Auffälligkeiten in den Daten wird im Allgemeinen als unsinnig erachtet. Vielmehr muss vor Durchführung der Analyse festgelegt werden, aus welchem Anwendungsbereich die Resultate stammen sollen und welche Art von Er-gebnissen erwartet wird.8 Im Data-Mining-Kontext ist also von tendenziell hypothesen-freien oder besser von datengetriebenen Analyseproblemen zu sprechen [KRWZ98, 30].
3.2.3 Kopplung von Datenanalyseproblemen
Bottom-Up-Probleme können ohne vorzugebende Annahmen ausgeführt werden und liefern als Lösung eine Hypothesenmenge zurück [ADZA96, 19]. Top-Down-Probleme hingegen basieren auf Hypothesen, die zu überprüfen sind. Diese Erkenntnis legt eine Kopplung hypothesengetriebener mit datengetriebenen Analyseproblemen nahe [MART97, 129]. Dies kann durch zyklische Verkettung von Untersuchungssituationen geschehen, die jeweils abwechselnd Analyseprobleme des einen und des anderen Typs behandeln: In einem ersten Schritt werden die in den Datenbeständen enthaltenen Phänomene durch Lösung eines Bottom-Up-Problems mittels generierter Hypothesen erklärt. Diese werden anschließend Top-Down-Analysen unterzogen, um sie anhand der Daten zu verifizieren oder falsifizieren. Weitere Schritte können folgen, woraus ein mehrfaches Durchlaufen des Analysezyklus resultiert (Abb. 3) [BELI97, 64].
Die Darstellung ist angelehnt an einen von ADRIAANS UND ZANTINGE als Empirischer Zyklus beschriebenen Prozess, wie er in der wissenschaftlichen Forschung zu beobachten ist: Ausgehend von einer Menge von Beobachtungen wird versucht, Muster in diesen Daten zu entdecken, die in eine Hypothese zur Erklärung der beobachteten Phänomene eingehen. Auf Basis dieser Hypothese werden Vorhersagen gemacht, welche mittels neuer Beobachtungen verifiziert werden können. Stellen sich die Vorhersagen dabei als nicht korrekt heraus, ist die Hypothese falsifiziert, und der Prozess kann erneut durchlaufen werden, um durch Analyse der neuen Beobachtungen weitere Hypothesen zu generieren. Auf diese Weise lassen sich Theorien beliebig verfeinern. Dieses Schema ist auch auf betriebswirtschaftliche Situationen anwendbar [ADZA96, 14f.]. Abbildung 3 zeigt den zur Verwendung im Kontext der Datenanalyse modifizierten Zyklus.9
8 Vgl. hierzu KÜPPERS, der die Suche nach jeglichen auffälligen Mustern aufgrund der heute verfügbaren Methoden ohnehin als unmöglich ansieht [KÜPP99, 82]. 9 Der zweite Teil des Zyklus kann auch im Sinne der Phase Umsetzung der Untersuchungsergebnisse des betrieblichen Datenanalyseprozesses aus Abschnitt 5.3 verstanden werden, wenn beispielsweise Vorhersage-aufgaben mit Data-Mining-Verfahren gelöst werden sollen (vgl. Abschnitt 4.3.1).

71
Datengetriebene Analyse:Generieren von Hypothesen
Hypothesengetriebene Analyse:Verifikation / Falsifikation von Hypothesen
Data-Mining-Analyse
HerkömmlicheDatenanalyse
HypotheseDatenbasis
"Bottom-Up-Probleme"
"Top-Down-Probleme"
Abb. 3: Datenanalysezyklus (vgl. [ADZA96, 14])
Wie Datenanalyseprobleme kombinierbar sind, zeigt das exemplarische Szenario in Abbildung 4. Nach einmaligem Durchschreiten des Zyklus ergibt sich in der Regel eine Reihe neuer Erkenntnisse und weiterer Fragestellungen, die zu weiteren Analyseschritten führen können. Da hierbei meist andere Untersuchungsprobleme als in vorangegangenen Iterationen vorliegen, ist der Einsatz anderer Analyseverfahren erforderlich.
Jeder Ansatz, der zur Untersuchung der in betrieblichen Datenbeständen verfügbaren Informationen sowie zur Extraktion des „unter der Oberfläche“ vorhandenen Wissens geeignet ist, kann im Rahmen von Datenanalyseprozessen zum Einsatz kommen [ADZA96, 47]. Die isolierte Anwendung einzelner Analyseverfahren ist damit wenig erstrebenswert, da bei einer Kopplung jeweils mehrere verschiedene Untersuchungsprobleme zu lösen sind. Neben Data-Mining-Aufgaben treten stets auch klassische Top-Down-Analyse-probleme auf, woraus die Notwendigkeit nach Systemen resultiert, die ein breites Spektrum an Analysemethoden (Data-Mining-Verfahren, OLAP, SQL, Statistik, etc.) zur Verfügung stellen [ADZA96, 90].

72
KäufersegmentierungNeuronales Netz
"Bottom-Up-Probleme" "Top-Down-Probleme"
SegmentbeschreibungEntscheidungsbaum
Analyse einzelnerKäufersegmente
OLAP
VerbundanalyseAssoziationsalgorithmus
Analyse vonAktionsartikel
OLAP
Aufdecken vonKäufersegmenten
Beschreibung derermittelten
Käufersegmente
gezielte Untersuchungdes Verhaltens
einzelnerKäufersegmente
Untersuchung desVerbundkaufverhaltensbesonders auffälliger
Käufersegmente
nähere Untersuchungbesonders stark
verbundener Aktionsartikel
Abb. 4: Szenario von Untersuchungssituationen im Datenanalysezyklus am Beispiel der Warenkorbanalyse

73
4 Data Mining (Datenmustererkennung) Dieser Abschnitt beschreibt die Voraussetzungen für die Durchführung von Data Mining und präzisiert die bereits dargestellten Zielsetzungen dieser Aufgabenklasse durch eine umfassende Definition. Nach einer Systematisierung möglicher durch Data Mining zu entdeckender Musterarten und der Vorstellung exemplarischer Einsatzbereiche folgt ein allgemeiner Überblick über Datenmustererkennungsverfahren. Anschließend werden Hinweise zur problemorientierten Auswahl von Methoden für konkrete Untersuchungs-probleme diskutiert.
4.1 Voraussetzungen
ADRIAANS UND ZANTINGE schätzen, dass etwa 20% der in betrieblichen Datenbeständen enthaltenen und tatsächlich sehr bedeutsamen Informationen mit herkömmlichen Analyse-ansätzen nicht zugänglich sind [ADZA96, 128]. Für ihre Extraktion sind Data-Mining-Untersuchungen notwendig, um Muster und Regelmäßigkeiten datengetrieben entdecken zu können. Für deren Durchführung sollte jedoch eine Reihe von Voraussetzungen erfüllt sein. Speziell im Data-Mining-Kontext sind folgende Aspekte zu beachten [FRPM91, 18f.]:
• Es sollten ausreichend unbekannte Muster in den Datenbeständen vermutet werden, deren Extraktion mithilfe klassischer Methoden nicht möglich ist.
• Das verfügbare Datenmaterial sollte zuverlässig sein, d.h. nur wenige Qualitätsmängel aufweisen und in ausreichender Menge zur Verfügung stehen.10 Je größer die Analyse-datenmenge, desto höher ist grundsätzlich die Qualität und Signifikanz der Ergebnisse [KRWZ98, 40f.].
• Im Unternehmen sollte ausreichend Unterstützung für Data-Mining-Projekte vorhanden sein. Da datengetriebene Analysen häufig erst mittelfristig brauchbare Ergebnisse liefern, sollten auch Projekte längerer Dauer akzeptiert werden.
• Über die Anwendungsdomäne sollte ausreichendes Expertenwissen verfügbar sein, um die ermittelten Muster sinnvoll interpretieren zu können und nicht Gefahr zu laufen, falsche Schlüsse zu ziehen.
Weiterhin ist zu fordern, dass die personelle und technische Infrastruktur zur Durchführung der Datenmustererkennung vorhanden ist. Neben Fachkräften zur Ausführung der Analysen sind geeignete Systeme und Werkzeuge vorzuhalten, die idealerweise nicht nur Data-Mining-Methoden, sondern auch herkömmliche Untersuchungsverfahren umfassen (vgl. Abschnitt 3.2.3) [KRWZ98, 40f.].
10 BERRY UND LINOFF formulieren die Forderung nach großen Datenbeständen sehr plakativ: „This is a theme that distinguishes data mining from other forms of analysis: more is better! More records, larger samples, more fields, more variables.“ [BELI97, 62]

74
4.2 Definition
Die Begriffe Data Mining und Knowledge Discovery in Databases (KDD) werden häufig synonym verwendet (vgl. Kapitel 2). Im vorliegenden Beitrag wird sich an die in der Literatur häufig zitierte Auffassung von FAYYAD ET AL. angelehnt, die Data Mining als Phase des übergeordneten KDD-Prozesses verstehen [FAPS96, 9]. Data Mining und KDD haben demnach identische Ziele, der KDD-Prozess jedoch eine größere Reichweite.
Analyseziel ist, wie bereits eingeführt, die Entdeckung nützlicher, bislang unbekannter Informationen in großen Datenmengen. Der eigentliche Data-Mining-Schritt des Prozesses dient der Extraktion von Mustern und Beziehungen aus den Daten („Datenmuster-erkennung“). Um sicherzustellen, dass es sich dabei tatsächlich um nützliche Informationen handelt, sind jedoch weitere Schritte zur Bewertung und Interpretation der Ergebnisse notwendig11 [FAPS96, 9]. Der KDD-Prozess widmet sich diesen Aufgaben und kann demnach als erweitertes generisches Lösungsverfahren für Bottom-Up-Daten-analyseprobleme verstanden werden. Der weitere Aufbau dieses Beitrags trägt dem Rechnung, indem im Anschluss an die Definition von Data-Mining-Analyseproblemen zunächst die eigentliche Datenmustererkennungsphase und in Kapitel 5 die weiteren Schritte des KDD-Prozesses behandelt werden.
Neben dem Hauptziel des Data Mining, der Entdeckung von Informationen aus großen Datenbeständen, können Gütekriterien identifiziert werden, denen die zu extrahierenden Muster genügen sollen. Daraus resultiert die folgende Definition:12
Data Mining ist die nicht-triviale Entdeckung gültiger, neuer, potenziell nützlicher und verständlicher Muster in Datenbeständen.
Die im Einzelnen enthaltenen Anforderungen werden nun ausführlich dargestellt.
• Entdeckung von Mustern: Daten sind eine Menge von Fakten F (z.B. Geschäftsvorfälle in einer Datenbank). Ein Muster ist ein Ausdruck E in einer Sprache L, der Fakten in einer Teilmenge FE von F beschreibt. E ist ein Muster, wenn es in gewisser Weise einfacher ist als die Aufzählung aller Fakten in FE. Diese bewusst sehr allgemeine Definition eines Musters schließt jede Beziehung zwischen Datensätzen, Datenfeldern, Daten innerhalb eines Satzes oder bestimmte Regelmäßigkeiten (z.B. Wenn-Dann-Regeln) ein13 [BISS96, 6].
• Nicht-Trivialität: Dieser Aspekt nimmt Bezug auf die Datengetriebenheit der Analyse. Der Entdeckungsprozess ist nicht-trivial und erfordert daher ein gewisses
11 KRAHL ET AL. argumentieren, dass Data Mining anders als traditionelle Analysen, die explizite Informationen erzeugen, implizite Informationen generiert, die erst durch weitere Schritte zu explizieren sind [KRWZ98, 24]. 12 Vgl. zu diesem Abschnitt insbesondere [FAPS96, 6-9] und [FRPM91, 3-5]. 13 An dieser Stelle sei darauf hingewiesen, dass im Zuge von Data-Mining-Analysen keine absichtlich, z.B. durch das Datenbank-Design verursachten Beziehungen zu ermitteln sind [KRWZ98, 11f.].

75
Maß an Suchautonomie. Rein statistische Berechnungen werden in diesem Kontext als triviale Resultate betrachtet und sind damit grundsätzlich uninteressant.
• Gültigkeit: Die aufgedeckten Muster sollen den Inhalt der Datenbasis beschreiben. Da sie jedoch selten bezüglich der gesamten Datenmenge wahr sind, sind sie um ein Sicherheitsmaß zu ergänzen. Dies ist eine Funktion C(E,F). Die Kenntnis der Gültig-keit ist essenziell zur Bestimmung des Vertrauens, das der Nutzer in die Analyse-ergebnisse setzen kann.
• Neuartigkeit: Die Muster sind neu, d.h. sie waren bislang unbekannt. Die Neuartigkeit kann im Hinblick auf Änderungen in den Daten (durch den Vergleich von aktuellen mit historischen oder erwarteten Werten) beurteilt werden. Generell sei angenommen, dass die Neuartigkeit durch eine Funktion N(E,F) gemessen wird.
• Potenzielle Nützlichkeit: Die Muster sollten potenziell zur Erreichung von Zielen des Anwenders beitragen bzw. in nützliche Handlungen umgesetzt werden können. Ihr Nutzen kann durch eine Funktion U(E,F) quantifiziert werden und ist stets von der konkreten Problemstellung abhängig. Als Beispiel sei der erwartete Umsatzzuwachs genannt, der auf Grundlage einer aus den neuen Erkenntnissen abgeleiteten Handlung realisierbar ist.
• Verständlichkeit: Die Muster sind in einer für den Menschen verständlichen Form zu präsentieren, um ein besseres Verständnis der ausgesagten Informationen zu ermöglichen. Die Verständlichkeit ist schwer quantifizierbar und basiert auf rein syntaktischen oder semantischen Erwägungen. Formal sei die Verständlichkeit eine Funktion S(E,F). Anzustreben ist grundsätzlich die Repräsentation in einer Hoch-sprache, oder wenigstens in einer maschinenlesbaren Form zur Weiterverarbeitung durch andere Systeme. Beispiel:
WENN Alter < 25 UND Fahrschulausbildung = NeinDANN Selbstverschuldeter_Unfall = JaMIT Sicherheit = 0,2 bis 0,3.
Die Aspekte der Gültigkeit, Neuartigkeit, Nützlichkeit und Verständlichkeit können zu einem allgemeineren Konzept der Interessantheit kombiniert werden (vgl. Abschnitt 5.2.5). Die Funktion I(E,F,C,N,U,S) beschreibt die Güte der Ergebnisse als Interessantheitsmaß, das stets im Hinblick auf nutzerdefinierte Kriterien zu ermitteln ist.
Im Kontext des Knowledge Discovery in Databases, also der Wissensentdeckung, ist die Bedeutung des Wissensbegriffes zu klären. FAYYAD ET AL. verstehen hierunter jedes Muster E, welches einem nutzerspezifischen Interessantheitskriterium i genügt: I(E,F,C,N,U,S) > i. Sie beschränken ihre Definition jedoch explizit auf den KDD-Kontext. Sie kann dahingehend begründet werden, dass nur interessante Informationen zu einem

76
Erkenntnisgewinn und damit einer Wissenserweiterung des Informationsempfängers führen.14
4.3 Analyseziele des Data Mining
Nach der Definition der Datenmustererkennung stellt sich die Frage nach den Mustern bzw. Mustertypen, die damit entdeckt werden können. Im Anschluss an die logische Trennung der Data-Mining-Analyse von der Verwendung der Analyseergebnisse im nächsten Abschnitt folgt daher eine Erläuterung verschiedener Mustertypen, in deren Rahmen auch Anwendungsbeispiele genannt werden. Abschnitt 4.4 ergänzt diese Darstellung durch die exemplarische Beschreibung eines erfolgreich eingesetzten Systems.
4.3.1 Beschreibungs- und Vorhersageaufgaben
Auf höchster Ebene werden häufig zwei grundlegende Anwendungsziele der Datenanalyse unterschieden, nämlich die Beschreibung und die Vorhersage [BELI97, 96f.]. Beschreibungsaufgaben erklären die Datenbestände in einer für den Menschen ver-ständlichen Form. Bei der Vorhersage werden auf Grundlage des verfügbaren Daten-materials aus der Vergangenheit bestimmte Variable oder Kennzahlenwerte für die Zukunft prognostiziert.15 Im Kontext der Datenmustererkennung sind prinzipiell nur Beschreibungsaufgaben von Bedeutung [FAPS96, 12]. Im vorliegenden Beitrag werden Vorhersageaufgaben als eine Form der Verwendung von Data-Mining-Ergebnissen auf-gefasst (vgl. hierzu die Beschreibung betriebswirtschaftlicher Datenanalyseprozesse in Abschnitt 5.3). Mit anderen Worten liefert die Datenmustererkennung hypothetische Beschreibungen von Datenbeständen, die wahlweise in direkte Handlungsmaßnahmen umgesetzt, als Grundlage für Prognoseaufgaben herangezogen oder im Rahmen weiterer Analysen durch Verifizierungsschritte verfeinert werden können.
So wird beispielsweise bei Klassifizierungsaufgaben im Zuge des Data Mining eine Beschreibung in Form eines Modells (z.B. Entscheidungsbaum) erzeugt, welche sodann zur Vorhersage der Klassenzugehörigkeit neuer Objekte genutzt werden kann. Diese Zuordnung ist eine Prognose, da sie auf einer hypothetischen Beschreibung beruht. Ob sich z.B. ein in eine bestimmte Risikoklasse eingeordneter Kunde tatsächlich gemäß dieser Klassifikation verhält, kann erst durch Beobachtung seines Verhaltens festgestellt werden [BELI97, 53f.].16
14 Bzgl. einer ausführlichen allgemeinen Diskussion über den Wissensbegriff vgl. z.B. [OPPE95, 195-202]. 15 Vgl. hierzu auch die Kopplung von Datenanalyseproblemen in Abschnitt 3.2.3: Die Vorhersagen erfolgen auf der Grundlage von Hypothesen, die durch weitere Analysen zu verifizieren sind. 16 Damit entspricht die Trainingsphase beim überwachten Data Mining der eigentlichen Datenmuster-erkennung, während die Anwendungsphase als Nutzung des ermittelten Wissens anzusehen ist (vgl. Abschnitt 4.5.1).

77
4.3.2 Mustertypen
Durch Verfeinerung des Untersuchungsziels „Datenmustererkennung“ lässt sich die Art der zu entdeckenden Muster spezifizieren, woraus die folgenden Data-Mining-Aufgaben resultieren.17 Sie geben in konkreten Anwendungsfällen Hinweise zur Auswahl geeigneter Verfahren, da sie in der Regel bereits bestimmte Methodenklassen implizieren. Es ist zwischen vier grundlegenden Aufgaben zu unterscheiden, die durch die angegebenen Mustertypen beschrieben werden [IBM96, 6; CHS+97, 62]: � Generieren von Prognosemodellen:
Klassifizierungs- und Vorhersageregeln � Abweichungsanalyse:
Änderungen und Abweichungen � Aufdecken von Beziehungsmustern:
Verknüpfungen, Abhängigkeiten und Sequenzen � Datenbanksegmentierung:
Segmente
Die genannten Mustertypen werden nun charakterisiert.
4.3.2.1 Klassifizierungs- und Vorhersageregeln
Die Ableitung von Klassifizierungsregeln verfolgt das Ziel, aus einer Datenmenge Beschreibungen vorgegebener Klassen auf Grundlage von Eigenschaften der ihnen zugeordneten Objekte zu generieren. Mithilfe des so gewonnenen Wissens soll es möglich sein, nicht klassifizierte Objekte der korrekten Klasse zuzuordnen. Voraussetzung für die Durchführung solcher Analysen ist ein Datenbestand, der Informationen über die Klassenzugehörigkeit der Objekte enthält, sowie eine Menge vorgegebener Klassen. Ein typisches Anwendungsbeispiel aus dem Finanzsektor ist die Ermittlung von Regeln zur Einstufung von Kreditantragstellern in vorgegebene Risikoklassen. Eine ähnliche Aufgabe ist die Extraktion von Regeln zur Vorhersage des zukünftigen Verhaltens von Objekten oder zur Schätzung bestimmter Variablenwerte, wie z.B. zur Aktienkursprognose. Als Methoden eignen sich beispielsweise Neuronale Netze, Regelinduktionsverfahren und Entscheidungsbaumalgorithmen [BELI97, 52f.; CHS+97, 64f., 70ff.].
4.3.2.2 Veränderungen und Abweichungen
Die Entdeckung signifikanter Veränderungen bestimmter Kennzahlen gegenüber früheren Werten oder Abweichungen von Sollwerten ist Gegenstand der Abweichungsanalyse [FAPS96, 16]. Die Datenbasis ist daraufhin zu prüfen, ob die entdeckten Anomalien durch die Werte anderer Variabler bzw. durch kausale Zusammenhänge erklärbar sind [IBM96, 6]. Ein Anwendungsbeispiel ist die automatische Navigation in Controlling-Daten, bei der 17 Ein alternativer Vorschlag zur Einordnung der Analyseziele findet sich z.B. bei [KÜPP99, 82-84].

78
versucht wird Entwicklungen auf aggregierten Stufen (z.B. Kostensteigerung auf Unternehmensebene) durch sukzessive Aufrisse auf niedrigere Ebenen (z.B. Sparten oder Abteilungen) auf dortige Wertentwicklungen zurückzuführen und somit eine Erklärung der beobachteten Phänomene zu finden. Für diese Form der Analyse werden zumeist spezielle Heuristiken eingesetzt [HAGE96, 2].
4.3.2.3 Verknüpfungen
Treten mehrere Objekte gemeinsam in Transaktionen18 auf, so liegen Verknüpfungen zwischen diesen Objekten vor. Ist diese Form der Beziehung zwischen einer Menge von Objekten häufiger zu beobachten, entstehen Verknüpfungsmuster. Eine typische Anwendungsdomäne der Verknüpfungsanalyse ist die Telekommunikation, da z.B. jeder getätigte Anruf eines Teilnehmers diesen mit seinem Gesprächspartner logisch verknüpft [GOSE95, 136-139]. Durch die Betrachtung transitiver Beziehungen können Verknüpfungs-netzwerke aufgebaut werden, die z.B. in der Verbrechensbekämpfung zur Aufklärung krimineller Delikte Anwendung finden. Betriebswirtschaftliche Einsatzmöglichkeiten ergeben sich vor allem im Marketing- und Vertriebsbereich. So lassen sich beispielsweise auf Basis von in der Vergangenheit beobachteten Kundenpräferenzen individuelle Angebote in Form von bestimmten Produkt- oder Leistungskombinationen erstellen [BELI97, 121]. Zur methodischen Unterstützung dieser Aufgabe sind spezielle heuristische Ansätze und insbesondere Visualisierungstechniken, mit Einschränkung auch Clustering-Verfahren geeignet.
4.3.2.4 Abhängigkeiten
Anders als Verknüpfungen, die lediglich Aussagen über das gemeinsame Auftreten von Objekten machen, beschreiben Abhängigkeiten neben der strukturellen Beziehung auch deren Richtung, die angibt, welche Größen von anderen abhängen, sowie die Abhängig-keitsstärke durch ein quantitatives Maß [FAPS96, 15].
Eine weit verbreitete Form der Abhängigkeitsanalyse ist die Ermittlung von Assoziationsregeln. Hierbei werden Objektmengen gesucht, die regelmäßig gemeinsam in Transaktionen auftreten, und die zugehörigen Häufigkeiten berechnet. Aus den so gewonnenen Informationen können Regeln formuliert werden, welche die Abhängigkeiten der Objekte untereinander durch Angabe ihrer bedingten Häufigkeiten beschreiben. Anwendung findet die Assoziationsregelsuche vor allem im Kontext der Warenkorbanalyse zur Ermittlung von Verbundkaufeffekten. Typische Regeln lauten z.B.: „In 20% der Fälle, in denen Artikel A gekauft wird, wird auch Artikel B gekauft. Beide Artikel sind in 2% aller Warenkörbe enthalten.“ [MICH98, 187f.] Derartige Untersuchungen können mit speziell für diese Aufgabe entwickelten Algorithmen durchgeführt werden [AMS+96B; BOLL96].
18 Transaktionen sind in diesem Zusammenhang im Sinne von Vorfällen oder Ereignissen zu verstehen.

79
4.3.2.5 Sequenzen
Durch Untersuchung des Verhaltens bestimmter Objekte im Zeitverlauf können regel-mäßige Ereignisfolgen (Sequenzen) ermittelt werden. Voraussetzung für derartige Analysen ist die Verfügbarkeit von Daten über diese Ereignisse, also die Zuordenbarkeit der Objekte (z.B. Kaufhandlungen) zu einem Zeitpunkt. Zum Aufdecken von sequenziellen Mustern ist eine logische Klammerung der Ereignisse notwendig, um die Bildung von Zeitreihen zu ermöglichen [BELI97, 150]. So sind z.B. sämtliche Kreditkartentransaktionen eines Karteninhabers in einem bestimmten Zeitraum zusammenzufassen. Auf diese Weise können typische Nutzungssequenzen identifiziert werden [KRWZ98, 141]. Anwendungsbeispiele sind die Erkennung von Betrugsdelikten bei der Kreditkarten-nutzung (z.B. „In 40% der Fälle, in denen einer hohen Abbuchung im Abstand von zwei Stunden eine kleinere Abbuchung vorausging, lag Betrug vor.“) [KRWZ98, 80f.], die Untersuchung des Kaufverhaltens von Versandhandelskunden im Zeitablauf oder die Identifikation von Ursache-Wirkungszusammenhängen, wie beispielsweise die Effektivität der Verabreichung von Medikamenten bei bestimmten Krankheiten [BELI97, 151]. Sequenzen können mittels spezieller Algorithmen analysiert werden [AMS+96A].
4.3.2.6 Segmente
Segmente (Cluster) sind Klassen, die durch Gruppierung von Objekten gebildet werden. Diese Gruppierung wird aufgrund der Selbstähnlichkeit der Objekte durchgeführt und soll derart erfolgen, dass die entstehenden Segmente in sich möglichst ähnliche Elemente enthalten, untereinander aber möglichst verschieden sind [HÜTT97, 319f.]. Hierbei repräsentiert allein die Zuordnung von Objekten zu Segmenten die Beschreibung der Daten; ihre Bedeutung muss der Anwender durch Interpretation oder im Rahmen weiterer Untersuchungen identifizieren. Im Gegensatz zur Erzeugung von Klassifizierungsregeln benötigt das Clustering keine Trainings- und keine vorgegebene Klassenmenge, da die Segmente aus dem Datenmaterial ermittelt werden. Die Clusteranalyse ist häufig der erste Schritt einer Untersuchungsreihe, in deren Verlauf die entdeckten Gruppen mittels weiterer Verfahren näher analysiert werden (vgl. Abb. 4). Beispielanwendungen sind die Gruppierung von Krankheitssymptomen zur Identifikation von Krankheiten und die Ermittlung homogener Teilmengen des Kundenstammes zur gezielten Ausrichtung von Marketingkampagnen [FAPS96, 14; BELI97, 55]. Als Verfahren eignen sich z.B. Neuronale Netze oder spezifische Segmentierungsalgorithmen (z.B. Demographisches Clustering der IBM [GRRU98]).
4.4 Eine Beispielanwendung des Data Mining
Im vorangegangenen Abschnitt sind bereits Beispiele für die Nutzung der mit Data Mining entdeckten Mustertypen erwähnt. Einen ausführlichen Überblick über weitere exem-plarische Anwendungen finden sich in der Literatur z.B. bei KÜPPERS [KÜPP99, 123-149], FAYYAD ET AL. [FRPM91, 17f.] sowie BERRY UND LINOFF [BELI97, 10-16]. Im Folgenden

80
sei beispielhaft ein System zur Abwendung von Kreditkartenmissbrauch vorgestellt, das aus einer beschreibenden und einer prognostizierenden Komponente besteht und die Potenziale des Data-Mining-Ansatzes verdeutlicht.
Die Gesellschaft für Zahlungssysteme (GZS) wickelt jährlich mehrere hundert Millionen Kreditkartentransaktionen ab. Da die frühzeitige Erkennung von Missbrauchsversuchen beim Einsatz der Kreditkarten große Einsparungspotenziale darstellt, wurde zur Lösung dieser Aufgabe ein Data-Mining-System implementiert, das ein Künstliches Neuronales Netz mit einem Entscheidungsbaumalgorithmus koppelt. Da in etwa 60% der Betrugs-delikte nichtgesperrte Karten verwendet werden, war ein Konzept zu entwickeln das in der Lage ist, Missbrauchsversuche bereits während des Autorisierungsvorgangs zu erkennen, den Zahlungsvorgang durch die zusätzliche Prüfung aber dennoch nicht nennenswert verlängert. Das Neuronale Netz ermittelt dazu auf Basis des persönlichen Nutzungsprofils des Karteninhabers und der Eigenschaften der Transaktion in kürzester Zeit einen Risikofaktor (Missbrauchswahrscheinlichkeit) für jede eingehende Transaktion. Bei hohem Risiko ist zur Autorisierung eine telefonische Bestätigung erforderlich, so dass geprüft werden kann, ob es sich beim Nutzer um den rechtmäßigen Karteneigentümer handelt. Zum regelmäßigen Training des Netzes werden Beschreibungen verwendet, die das Entscheidungsbaumsystem aus tatsächlichen Missbrauchsfällen ableitet (Data Mining). Hierdurch erlangt das System die Fähigkeit zur Erkennung auch neuer Missbrauchsmuster und ist damit „lernfähig“. Durch Einsatz dieses Systems, das sich bereits nach neun Monaten amortisiert hatte, war es der GZS möglich, das Verhältnis von Bruttomissbrauch zu Verrechnungsumsatz um die Hälfte zu senken [KÜPP99, 144].
4.5 Ansätze und Methoden
Der folgende Abschnitt gibt einen Überblick über Data-Mining-Verfahren. Da im Rahmen dieses Beitrags eine umfassende Darstellung der Vielzahl der für die Daten-mustererkennung geeigneten Methoden nicht möglich ist, erfolgt eine eher allgemeine Betrachtung. Dieser schließt sich ein Versuch zur Systematisierung der Methoden an, der auf von anderen Autoren vorgeschlagene Einordnungen zurückgreift.
4.5.1 Überwachte und unüberwachte Verfahren
HAGEDORN beschreibt Data-Mining-Verfahren als eine Menge „mehr oder weniger autonomer Analyseprogramme“ [HAGE96, 21]. Der Aspekt der Autonomie ist eine elementare Forderung an Datenmustererkennungsmethoden, da die Auswertung großer Datenmengen nach allgemeiner Auffassung nur dann durchführbar ist, wenn die Nutzer-interaktion so gering wie möglich ist [KÜPP99, 20].
Die Frage der Autonomie betrifft das Ausmaß, in dem der Anwender in den Untersuchungsvorgang eingreifen muss. Diese Eingriffe beziehen sich einerseits auf vorzugebende Hypothesen, andererseits auf die Lenkung des Analyseprozesses an sich. Der Problemkreis der Hypothesenfreiheit wurde bereits in Abschnitt 3.2 diskutiert, mit dem

81
Ergebnis, dass vollkommen hypothesenfreie Probleme nicht existieren. Bezüglich der Lenkung des Analyseprozesses ist eine sowohl von den gewünschten Mustertypen als auch von den Methoden abhängige Differenzierung möglich, die sich an eine im Kontext des induktiven Maschinellen Lernens gebräuchliche Unterscheidung anlehnt. Dort wird zwischen überwachten Verfahren (Lernen aus Beispielen) und unüberwachten Verfahren (Lernen durch Beobachtung) differenziert19 [KRWZ98, 60].
Data-Mining-Analysen können in die beiden Phasen Mustererkennung und Musterbeschreibung zerlegt werden. Während der Erkennung werden ähnliche Objekte zu Mustern oder Gruppen zusammengefasst, die anschließend durch eine intensionale Charakterisierung beschrieben werden [FRPM91, 15f.]. Bezüglich dieser Differenzierung sind unüberwachte Verfahren der Mustererkennungsphase zuzuordnen, überwachte Methoden hingegen widmen sich der Beschreibung bereits vorgegebener Muster. Hybridverfahren decken die Aufgaben beider Phasen ab. Es ist anzumerken, dass die Vorgabe von Mustern zur Beschreibung durch überwachte Methoden wiederum als eine Art Hypothese angesehen werden kann, woraus ein fließender Übergang zwischen Top-Down- und Bottom-Up-Analyseproblemen zu erkennen ist.
Die beiden Grundansätze, überwachte und unüberwachte Verfahren, werden nun genauer beschrieben.
4.5.1.1 Überwachte Verfahren
Die Gruppe der überwachten Verfahren beschränkt sich auf den Musterbeschreibungs-prozess, verlangt also nach vorgegebenen Mustern und zugehörigen Beispielen. Vor der Durchführung überwachter Analysen sind Zielattribute zu spezifizieren, deren Aus-prägungen durch andere in den Daten enthaltene Attributwerte erklärt werden sollen. So setzt die Ermittlung von Klassifizierungsregeln beispielsweise eine vorgegebene Menge von Kategorien voraus (Ausprägungen des Zielattributs „Klassenzugehörigkeit“), die im Rahmen der Untersuchung zu beschreiben sind. Die vorgegebenen Zielattributwerte stellen also die Muster dar, für die eine Erklärung gefunden werden soll [BELI97, 72].
Die Datenmustererkennung kann hier als Vorstufe von Vorhersageaufgaben angesehen werden, bei denen die Ausprägungen bestimmter Attribute neuer Datensätze auf der Grundlage historischer Daten zu prognostizieren sind. Um dieses Problem lösen zu können, muss zuvor Wissen zur Durchführung solcher Vorhersagen ermittelt werden. Diese Aufgabe ist im Forschungsbereich des Maschinellen Lernens als Trainingsphase von Berechnungsmodellen bekannt. Man spricht in diesem Zusammenhang von überwachtem
19 Im Data-Mining-Kontext kann der Begriff des Lernens als Erlernen (durch Erkennen und Beschreiben) neuer Erkenntnisse in Form von Regelmäßigkeiten oder Mustern aus den Datenbeständen interpretiert werden [HAGE96, 39].

82
Vorgehen, weil die Lernphase durch Vorgabe der historischen Daten gelenkt wird (Lernen aus Beispielen)20 [KRWZ98, 62].
Überwachtes Data Mining ist ein iterativer Vorgang, wobei nach jedem Schritt ein Fehlermaß berechnet wird, um die Güte der ermittelten Beschreibung zu bewerten. Wenn diese den Anforderungen genügt wird das Verfahren beendet, andernfalls ein neuer Schritt initiiert, bei dem die Zielabweichungen der vorangegangenen Iteration zur Anpassung des Beschreibungsmodells berücksichtigt werden (Rückkopplung) [KRWZ98, 62].
Die Klasse der überwachten Methoden ist prinzipiell zum Generieren von Prognose-modellen geeignet.
4.5.1.2 Unüberwachte Verfahren
Unüberwachte Verfahren ermitteln eigenständig Auffälligkeiten und bedürfen daher keiner Vorgabe von Mustern und demnach auch keiner Beispiele. Bei diesem Ansatz sind die Algorithmen ohne vorherige Spezifikation von Zielattributen anwendbar. Ziel ist es, interessante Beziehungen und Zusammenhänge in unstrukturierten Datenbeständen aufzu-decken. Die Ausprägungen und meist auch die Anzahl der Muster werden aufgrund der Eigenschaften und statistischen Verteilungen des zugrunde liegenden Datenmaterials während der Analyse bestimmt [BELI97, 80f.]. Die Datenbanksegmentierung und die Suche nach Beziehungsmustern werden im Allgemeinen mit unüberwachten Verfahren gelöst [KRWZ98, 78].
Unüberwachte Verfahren werden häufig vor der Durchführung überwachter Unter-suchungen eingesetzt, um die Schwächen des einen Ansatzes durch die Stärken des anderen bei der Erkennung bzw. Beschreibung von Auffälligkeiten zu kompensieren [KÜPP99, 99]. So wäre z.B. denkbar, zunächst eine unüberwachte Kundensegmentierung zur Ermittlung von Käufergruppen durchzuführen, welche anschließend einer überwachten Klassenbeschreibung (Erzeugung von Klassifizierungsregeln) unterzogen werden. Die resultierenden Hybridansätze sind demnach in der Lage, sowohl die Entdeckungs- als auch die Beschreibungsphase der Datenmustererkennung zu behandeln, wodurch es möglich wird, den erforderlichen Grad der Nutzerinteraktion weiter einzuschränken. Data-Mining-Werkzeuge sollten diese Art der Methodenkopplung unterstützen.
20 Überwachtes Data Mining verwendet gewissermaßen die Vergangenheit, um ein Modell der Zukunft zu erstellen [BELI97, 74f.].

83
4.5.2 Überblick über Data-Mining-Methoden
Im Rahmen dieses Beitrags kann nicht auf die Vielzahl der von verschiedenen Autoren als Data-Mining-Verfahren eingestuften Methoden detailliert eingegangen werden. Hierzu sei auf die umfangreiche Literatur verwiesen. Recht umfassende Darstellungen finden sich beispielsweise bei CHAMONI UND BUDDE [CHBU97] und KÜPPERS [KÜPP99].
NeuronaleNetze
MaschinellesLernen
StatistischeVerfahren
Visualisierungs-verfahren
HeuristischeAnsätze
Data-Mining-Verfahren
KonzeptionellesClustering
Entscheidungs-bäume
Entscheidungs-regeln
Bayes-Ansatz
HierarchischesClustering
PartitionierendesClustering
AutomatischeNavigation
CLUSMIN
Assoziations-algorithmus
Gruppen-vergleich
MultilayerPerceptrons
KohonenFeature Maps
...
Streudiagramme
Projektions-technik
Streudiagramm-Matrizen
Bildsymbole
......
... ...
Abb. 5: Systematisierung von Data-Mining-Verfahren
Die meisten zur Datenmustererkennung geeigneten Methoden beruhen auf Konzepten des Maschinellen Lernens, der Statistik und der Künstlichen Intelligenz, weshalb es nahe liegt eine entsprechende Systematisierung zu versuchen. Die in Abbildung 5 gezeigte Einordnung orientiert sich an den beiden genannten Quellen und erhebt, wie auch diese, keinen Anspruch auf Vollständigkeit. Weitere, häufig als ergänzende Ansätze bezeichnete Methoden sind aus Gründen der Übersichtlichkeit nicht enthalten.
4.5.3 Auswahl von Data-Mining-Methoden
Aus der bisherigen Darstellung ist ersichtlich, dass keine Methode gleichermaßen zur Lösung jeder Data-Mining-Aufgabe geeignet ist [BELI97, 51]. Zur Produktion einer bestimmten Art von Ergebnissen sind im Allgemeinen mehrere Verfahren geeignet; genauso sind einzelne Verfahren möglicherweise in der Lage, unterschiedliche Muster-typen zu erzeugen [KÜPP99, 82]. Die Auswahl des „richtigen“ Lösungsverfahrens erfordert eine exakte Spezifikation des Untersuchungsproblems sowie die profunde Kenntnis der Fähigkeiten und Grenzen der verfügbaren Ansätze. Die Dimensionen der an die Methoden erhobenen Anforderungen können in Abhängigkeit der konkreten Analyseziele stark variieren [DHST97, 12-14].

84
AnwenderorientierteKriterien
MethodenorientierteKriterien
DatenorientierteKriterien
Anforderungen anTransformation
Empfindlichkeit aufmangelnde Datenqualität
VerarbeitbareDatenmenge
Auswahl vonData-Mining-
Methoden
Charakterisierung vonUnsicherheit
Explizite und impliziteAnnahmen
Regularisierung(Über- / Unteranpassung)
Interessantheit derErgebnisse
Verständlichkeit vonErgebnis und Verfahren
Autonomiegrad derDurchführung
Abb. 6: Kriterien zur Auswahl von Data-Mining-Methoden (vgl. [KÜPP99, 87])
Zur Klärung der Frage, welche Verfahrensalternative die spezifizierten Anforderungen erfüllen kann, ist typischerweise ein iteratives Vorgehen notwendig. Für Data-Mining-Analysen existieren in der Regel keine geradlinigen Lösungswege; ein geeigneter Ansatz ist im Verlauf der Untersuchung zu ermitteln (vgl. Abschnitt 5.2.4). Zur Orientierung bei der Methodenauswahl kann der folgende von KÜPPERS vorgeschlagene Kriterienkatalog herangezogen werden (Abb. 6):21
Die Auswahl eines Lösungsansatzes sollte demnach sowohl nach methodenbezogenen als auch nach anwender- und datenorientierten Kriterien erfolgen. Aus Nutzersicht sollen Data-Mining-Analysen möglichst selbständig interessante und verständliche Ergebnisse liefern. Im Wesentlichen werden Ansätze mit Filtermechanismen gefordert, die nur als „interessant“ eingestufte Muster liefern, [SITU95, 275] da der Anwender andernfalls durch die Fülle irrelevanter Ergebnisse leicht den Überblick verliert. Darüber hinaus sollen die erzeugten Muster in verständlicher Form präsentiert werden. Auch die Erklärbarkeit der Methode ist in den meisten Fällen ein wesentlicher Aspekt, da die Nutzer gewöhnlich nur solche Ergebnisse akzeptieren, deren Ermittlung für sie nachvollziehbar ist. Schließlich sollte die Datenmustererkennung möglichst selbständig ablaufen und keiner ständigen Interaktion des Nutzers bedürfen. Es ist jedoch festzustellen, dass besonders autonome Verfahren im Allgemeinen einen eingeschränkten Anwendungsbereich besitzen, während weniger autonome Ansätze durch breitere Verwendbarkeit gekennzeichnet sind [BISS96, 8].
Hinsichtlich der Methoden selbst ist zu beachten, dass sie die den ermittelten Mustern anhaftende Unsicherheit durch entsprechende Signifikanzmaße quantifizieren und dass die ihnen zugrunde liegenden Annahmen und Voraussetzungen im konkreten Anwendungsfall erfüllt sind. So liefert beispielsweise die Anwendung eines linearen Modells auf Daten mit nicht-linearer Struktur keine brauchbaren Ergebnisse. Des Weiteren ist die Gefahr der 21 Vgl. zur weiteren Darstellung [KÜPP99, 87ff.].

85
Über- oder Unteranpassung (Overfitting, Underfitting) zu berücksichtigen (vgl. auch Abschnitt 5.2.4). Bei der Wissensermittlung muss die Ergebnismenge eine gewisse Komplexität besitzen, um die Daten korrekt repräsentieren zu können. Gleichzeitig muss diese Komplexität aber auch einer Beschränkung unterliegen, da der Extremfall der Abbildung jedes einzelnen Datensatzes zwar eine korrekte Repräsentation des Datenmaterials darstellt, jedoch nicht als Wissen bezeichnet werden kann, das auch zur Verwendung in anderen Problemsituationen geeignet ist.
Die Auswahl von Untersuchungsmethoden ist weiterhin von der Natur der verfügbaren Daten abhängig [BELI97, 5]. Diesbezüglich ist zu beachten, dass der Einsatz der meisten Verfahren bestimmter Darstellungsformen der Daten bedarf, die durch geeignete Transformationsmaßnahmen gegebenenfalls erst erzeugt werden müssen. Deshalb ist zu prüfen, welche Methode die Erreichung der Untersuchungsziele mit dem geringsten Transformationsaufwand erlaubt. Die Sensitivität eines Verfahrens gegenüber Daten-qualitätsmängeln ist schließlich ebenso in die Auswahlentscheidung einzubeziehen wie seine Effizienz bei der Anwendung auf die beabsichtigten Datenvolumina. Nicht alle Verfahren liefern in jedem Falle akzeptable Laufzeiten.
Derartige Entscheidungshilfen können selbstverständlich nur allgemeiner Natur sein. Eine knappe Gegenüberstellung ausgewählter Methoden aus eher pragmatischer Sicht findet sich z.B. bei KRAHL ET AL. [KRWZ98, 94f.].

86
5 Knowledge Discovery in Databases (KDD) Der folgende Abschnitt beschreibt die Notwendigkeit für einen dem Data Mining übergeordneten KDD-Prozess, der als Ergänzung der eigentlichen Lösungsverfahren der Datenmustererkennung anzusehen ist. Im weiteren Verlauf dieses Kapitels wird ein Überblick über die Teilschritte des Prozesses gegeben und anschließend auf diese detailliert eingegangen.
5.1 Motivation und Zielsetzung
Datengetriebene Analysen verfolgen das Ziel, verborgene Informationen in umfangreichen Datenbeständen zu entdecken. Hierzu werden Mechanismen eingesetzt, die in der Lage sind, Zusammenhänge in Form von Mustern aus den Daten zu extrahieren. In Abschnitt 4.5 wurden hierfür geeignete Ansätze diskutiert.
Diese Muster stellen jedoch noch kein Wissen dar. Erst durch ergänzende Bewertungs- und Interpretationsmaßnahmen kann entschieden werden, ob die ermittelten Informationen tatsächlich „interessant“ sind. Darüber hinaus sind auch Aspekte der Datenselektion, der Vorverarbeitung und der Datendarstellung zu beachten, um die Qualität des aufgefundenen Wissens sicherzustellen.22 FAYYAD ET AL. warnen vor der bloßen Anwendung von Data-Mining-Methoden ohne Berücksichtigung weiterer Aufgaben und stellen fest, dass ein solches Vorgehen zurecht als „Fischen“ oder „Baggern“ nach Daten kritisiert wird. Hierbei sind insbesondere negative Auswirkungen auf die Gültigkeit der Analyseergebnisse zu erwarten, die nicht gewährleistet bzw. nicht überprüft werden kann [FAPS96, 4].
Data-Mining-Probleme können also nicht allein durch Anwendung von Verfahren der Datenmustererkennung gelöst werden. Vielmehr sind weitere Aufgaben im Rahmen eines Wissensentdeckungsprozesses durchzuführen, der in Abhängigkeit des konkreten Unter-suchungsproblems zu gestalten ist. Der KDD-Prozess vereint diese Verarbeitungsschritte und kann deshalb als generisches Lösungsverfahren für Data-Mining-Aufgaben interpretiert werden. Die in Abschnitt 4.5 vorgestellten Methoden stellen allenfalls Teillösungsverfahren dar.
Darüber hinaus ist festzustellen, dass die im Zuge des KDD-Prozesses geforderten Maßnahmen nicht nur bei datengetriebenen Analyseproblemen Anwendung finden. Wie z.B. BERRY UND LINOFF zeigen, treten ähnliche Aufgaben auch im Kontext hypothesen-getriebener Untersuchungsprobleme auf: Nach dem Aufstellen zu überprüfender Hypothesen müssen Datenbestände ermittelt und beschafft werden, anhand derer die
22 „KDD Process is the process of using data mining methods (algorithms) to extract (identify) what is deemed knowledge according to the specifications of measures and thresholds, using the database F along with any required preprocessing, subsampling, and transformations in F.“ [FAPS96, 9]

87
Verifikation der getroffenen Annahmen erfolgen kann. Diese Daten sind anschließend für die Analyse vorzubereiten, bevor die eigentliche Untersuchung durchgeführt werden kann. Deren Ergebnisse sind zu bewerten und im Kontext der Fragestellung zu interpretieren [BELI97, 65-72].
Der KDD-Prozess bildet demnach einen allgemeinen Rahmen für die Analyse großer Datenbestände. Selbst zur Durchführung einfacher SQL-Datenbankabfragen oder von OLAP-Untersuchungen müssen die im folgenden Abschnitt näher spezifizierten Maßnahmen ergriffen werden. Durch Nutzung von Data Warehouses als Datenbasis treten die vor der Analyse auszuführenden Teilschritte für den Anwender jedoch kaum in Erscheinung, da sie im Zuge des Ladevorgangs größtenteils automatisiert im Hintergrund ablaufen.23 Zudem ist der Prozess bei traditionellen Analysen besser strukturiert als bei Data-Mining-Untersuchungen (vgl. Abschnitt 5.2). Die nachstehenden Ausführungen sind deshalb im Lichte von Data-Mining-Problemen zu sehen.
5.2 Phasen und Ablauf des KDD-Prozesses
Wie aus der vorangegangenen Diskussion ersichtlich ist, lassen sich auf höchster Ebene drei Phasen des Knowledge Discovery identifizieren: die Vorverarbeitung des Datenmaterials, die Durchführung der eigentlichen Analyse sowie die Interpretation der Analyseergebnisse.24 Durch weitere Zerlegung insbesondere der ersten Phase können weitere Teilaufgaben aufgedeckt werden, woraus je nach Genauigkeit der Betrachtung mehr oder weniger Teilschritte resultieren.
Nach Auswertung der Vielzahl der veröffentlichten Einteilungen und aus im Rahmen konkreter Data-Mining-Projekte gewonnenen Erfahrungen erscheint eine Dreiteilung der Vorverarbeitungsphase zweckmäßig, woraus sich die in Abbildung 7 dargestellte Strukturierung ergibt. Demnach werden die folgenden fünf Teilaufgaben unterschieden:25
� Selektion der Daten � Exploration der Daten � Manipulation der Daten � Analyse der Daten � Interpretation der Ergebnisse
23 Vgl. hierzu beispielsweise [BÖUL00, 18ff.]. 24 Vgl. hierzu auch [BIGU96, 10f.]. 25 Ein auf recht breiter Basis anerkannter Vorschlag zur detaillierten Systematisierung des KDD-Prozesses ist der sogenannte Cross-Industry Standard Process for Data Mining (CRISP-DM), der aus der Arbeit eines Industriekonsortiums hervorgegangen ist und mittlerweile in validierter Version vorliegt. Vgl. hierzu [CCK+00].

88
Knowledge Discoveryin Databases
Selektionder Daten
Explorationder Daten
Manipulationder Daten
Analyseder Daten
Interpretationder Ergebnisse
Abb. 7: Teilaufgaben im Rahmen des KDD-Prozesses
Bevor in den folgenden Abschnitten ausführlich auf die einzelnen Phasen eingegangen wird ist anzumerken, dass der KDD-Prozess nicht in jedem Falle geradlinig durchlaufen wird. Vielmehr ist in jeder Phase ein Rücksprung auf einen vorangegangenen Schritt möglich. Stellt sich z.B. im Rahmen der Analyse heraus, dass die Daten nicht den Anforderungen des Untersuchungsverfahrens genügen, ist zur Manipulationsphase zurückzuspringen, um weitere Transformationen vorzunehmen. Insbesondere das Ausmaß der Datenmängel kann in den seltensten Fällen auf Anhieb erkannt werden, sondern wird meist sukzessive bei Durchschreiten der Explorations- und Analysephase aufgedeckt [ADZA96, 37-39].
Jede Untersuchungssituation ist durch spezifische Eigenschaften und Anforderungen gekennzeichnet, jeder Datenbestand weist ihm eigene Mäkel und Schwachstellen auf. Daher können keine allgemeingültigen Vorgehensmodelle angegeben, sondern allenfalls Empfehlungen zur Strukturierung idealtypischer Untersuchungsvorgänge ausgesprochen werden [KRWZ98, 100]. Wie im konkreten Anwendungsfall vorzugehen ist, ergibt sich meist erst bei Durchführung der Untersuchung. Der KDD-Prozess ist ein komplexer und in besonderem Maße iterativer Vorgang [KRWZ98, 30], so dass auf die Darstellung einer Ablaufsicht verzichtet wird.26 Die in Abbildung 7 gezeigten Schritte sind damit als Teilaufgaben anzusehen, die gegebenenfalls mehrfach, jedoch nicht notwendigerweise in Form eines linearen Prozesses durchzuführen sind.
Die nun folgenden Abschnitte widmen sich ausführlich den einzelnen Teilaufgaben des Knowledge Discovery in Databases.
26 Vgl. hierzu das Prozessmodell von [CCK+00].

89
5.2.1 Selektion der Daten
Unter dem Oberbegriff Datenselektion soll neben der Identifikation geeigneter Daten-quellen, welche die Voraussetzung für weitere Aktionen bildet, die Bereitstellung des erforderlichen Datenmaterials durch Anwendung der Operatoren der Relationenalgebra27 betrachtet werden. Hierbei sind neben Verbundoperationen insbesondere die Auswahl von Datensätzen nach bestimmten Kriterien (Selektion), die Auswahl relevanter Datenfelder (Projektion) sowie die Bildung von Teilmengen des Datenbestandes (Selektion) von Interesse.28
Qualitativ hochwertiges Datenmaterial ist die Grundvoraussetzung für den Erfolg jeder Datenanalyse. Data Mining kann prinzipiell auf beliebigen Datenbeständen betrieben werden, ideale Datenquellen stellen jedoch Data Warehouses dar, deren Bestände in der Regel bereits bereinigt und konsolidiert sind (vgl. Abschnitt 6.1). Da nicht davon ausgegangen werden kann, dass immer ein Data Warehouse vorhanden ist und dass insbesondere alle notwendigen Daten darin enthalten sind, muss oft auf operative Datenbestände oder andere Quellen zurückgegriffen werden [BELI97, 74]. In solchen Fällen ist im Rahmen des Manipulationsschrittes eine Harmonisierung des meist sehr heterogenen Datenmaterials durchzuführen [ADZA96, 83]. Erstrecken sich die Untersuchungen über längere Zeiträume, so ist dafür Sorge zu tragen, dass die Datenbestände in dieser Zeit keinen Veränderungen unterliegen, um daraus resultierende Ergebnisverfälschungen zu vermeiden [KRWZ98, 31].
Die Selektion von Datensätzen erfolgt nach bestimmten Kriterien, die eine Fokussierung der Untersuchung auf als relevant erachtete Teilmengen widerspiegeln [ADZA96, 42]. Wird beispielsweise entschieden das Kundenverhalten in einer bestimmten Vertriebsregion zu analysieren, so werden nur diejenigen Datensätze aus den Quellbeständen extrahiert, welche dieser Bedingung genügen.
Die Auswahl relevanter Attribute gestaltet sich weitaus schwieriger. Oft ist im Voraus nicht bekannt, welche Einflussgrößen in welcher Weise auf die Analyseziele einwirken. Um die Potenziale des Data Mining auszuschöpfen wird deshalb häufig gefordert, grundsätzlich alle vorhandenen Attribute als relevant anzusehen und sie den Algorithmen zur Auswertung zur Verfügung zu stellen. In der Tat treten bei dieser Vorgehensweise bislang vernachlässigte Variable häufig als wichtige Einflussgrößen zutage [BELI97, 78]. Andererseits sind auch Sättigungseffekte zu beobachten, d.h. dass sich die Genauigkeit und Aussagekraft der Resultate durch Aufnahme immer neuer Attribute nicht beliebig steigern lässt [BIGU96, 49; KRWZ98, 44].
27 Vgl. hierzu beispielsweise [FESI01, 365]. 28 Das Hinzufügen zusätzlicher Daten aus anderen Quellen wird dem Manipulationsschritt (Abschnitt 5.2.3) zugerechnet. Die Auswahl von Zielattributen ist in die Analysephase (Abschnitt 5.2.4) einzuordnen, da sie als eine Form der Parametrisierung der Methode zu verstehen ist.

90
Die Aufteilung des Datenmaterials betrifft die Auswahl von Trainingsdaten für überwachte Verfahren (vgl. Abschnitt 5.2.4) und die Ziehung von Stichproben. Grundsätzlich ist mit Data Mining die Forderung nach möglichst großen Analysedatenmengen verbunden. Jedoch müssen nicht alle Schritte eines Datenanalyse-Prozesses auf den Gesamt-datenbeständen ausgeführt werden. Gerade initiale Iterationen zum Prüfen der Methoden und Parametrisierungen sowie die Explorationsphase sind auch auf der Grundlage kleinerer Datenmengen möglich. KRAHL ET AL. berichten von Projekten, bei denen die Ergebnisse der auf Stichproben durchgeführten Analysen prinzipiell mit den aus dem Gesamt-datenbestand gewonnenen Resultaten vergleichbar waren. Sie räumen jedoch ein, dass bestimmte Voraussetzungen der Stichprobentheorie (z.B. Spezifikation der maximalen Fehlerwahrscheinlichkeit und Genauigkeit) bei Data-Mining-Analysen in der Regel nicht erfüllt sind [KRWZ98, 153-155].
5.2.2 Exploration der Daten 29
Zweck der Exploration des Datenmaterials vor der eigentlichen Untersuchung ist das kennen Lernen der Analysedatenbestände. Auf diese Weise lassen sich Fehler und Mängel in den Daten frühzeitig aufdecken und Fehlinterpretationen der später gewonnenen Analyseergebnisse vermeiden.30
Die Kenntnis der Schwächen der Analysedaten ist elementar für die Qualität der Untersuchungsergebnisse. Die Anwender der Analysewerkzeuge müssen auf die Zuver-lässigkeit und Korrektheit der Daten vertrauen können. Fehlerhafte Daten verfälschen möglicherweise die Resultate, ohne dass der Analyst von diesen Mängeln Kenntnis erlangt, und fehlende Informationen verhindern eventuell die Berechnung wichtiger Kennzahlen. Die zunehmende Durchführung (teil-) automatisierter Datenanalysen hat eine erhöhte Anfälligkeit gegenüber Datenmängeln zur Folge, der durch geeignete Mechanismen zur Erkennung und Beseitigung solcher Schwächen zu begegnen ist [SILK95, 282].
Das Wissen über die Daten verbessert sich nur allmählich mit dem zunehmenden Voranschreiten des Prozesses [ADZA96, 50]. Werden im Rahmen des Analyseschrittes auffällige Muster oder unerklärliche statistische Häufigkeiten aufgedeckt, so können dies Indikatoren für bislang nicht erkannte Inkonsistenzen oder Datenfehler sein. Bevor mit der Analyse fortgefahren werden kann, sind diese Fehler durch Rücksprung zur Manipulationsphase (vgl. Abschnitt 5.2.3) zu beheben. Die Explorationsphase verfolgt das Ziel, die Anzahl dieser aufwendigen Iterationen durch vorgeschaltete Untersuchungen zu verringern. Da den meisten Unternehmen das Ausmaß der ihren Daten anhaftenden Mängel nicht bewusst ist, sollte ein gewisses Zeitbudget für die Exploration der Datenbestände reserviert werden [ADZA96, 84]. Dabei muss nicht nur die Syntax, sondern auch die
29 Unter Exploration werden im weiteren Verlauf solche Untersuchungen verstanden, die nicht unmittelbar zur Verfolgung der eigentlichen Analyseziele beitragen, sondern eher mittelbaren Einfluss auf die Untersuchungssituation nehmen. 30 Vgl. hierzu auch [BISS96, 10].

91
Semantik der Daten auf Korrektheit getestet werden, und Plausibilitätsprüfungen sollten elementarer Bestandteil dieser Aktivitäten sein.
Eingehende Analysen der Datenqualität liefern darüber hinaus Hinweise auf Schwach-stellen in den die Daten generierenden Systemen und können auf diese Weise zum Ausgangspunkt der Reorganisation und Neukonzeption betrieblicher Abläufe und Vor-gänge werden.
Abgesehen von Metadaten-Beschreibungen liegen über die Analysedatenbestände in der Regel keinerlei Informationen vor. Mithilfe von Datenbankwerkzeugen (z.B. SQL Tools) oder visuellen Explorationsmethoden31 ist es möglich, ein grundlegendes Verständnis dieser Daten zu erlangen. Bereits dadurch kann eventuell neues Wissen ermittelt werden. Viel wichtiger ist es jedoch an dieser Stelle, ein „Gefühl“ für das Datenmaterial zu bekommen. Die Exploration hat demnach weiterhin die Aufgabe, über die Strukturen des Datenbestandes Aufschluss zu geben, um die Interpretation der Analyseergebnisse, insbesondere die Bewertung ihrer Relevanz, Gültigkeit und Plausibilität, zu unterstützen sowie die Leistungsfähigkeit bzw. den Nutzen des Data Mining beurteilen zu können. Häufig reicht dazu schon die Ermittlung einfacher statistischer Verteilungsinformationen aus, aber auch tabellarische Auflistungen einzelner Kennzahlen nach mehreren Dimensionen können hilfreich sein [ADZA96, 47-50; BELI97, 67].
Ein umfassendes Grundverständnis des Datenmaterials ist auch im Zuge der Para-metrisierung von Data-Mining-Methoden wie beispielsweise bei der Auswahl von Ziel-attributen bei überwachten Ansätzen von Bedeutung. So sollte vermieden werden, Zielgrößen durch Variable erklären zu lassen, von denen die Zielgröße kausal abhängig ist. Derartige Modellierungsfehler führen zu trivialen und damit unbrauchbaren Mustern [KRWZ98, 159].
5.2.3 Manipulation der Daten
Die im Unternehmen verfügbaren Rohdatenbestände erweisen sich häufig in ihrer Ursprungsform nicht für Data-Mining-Analysen geeignet oder gar als fehlerhaft. Um sie den Qualitätsanforderungen anzupassen sind Prozeduren notwendig, die als Schritte der Datenvorverarbeitung oder der Manipulation bezeichnet werden.
Die Notwendigkeit für Manipulationen des Datenmaterials erwächst aus einer Reihe möglicher Probleme, die sich in die drei Klassen Verfügbarkeit, Inhalt und Qualität sowie Repräsentation systematisieren lassen. Über diese Problemkreise sei im Folgenden ein kurzer Überblick gegeben, um die zur Behebung der Mängel geeigneten Maßnahmen zuordnen zu können (Abb. 8).
31 Bzgl. eines Überblicks über Explorationsverfahren vgl. z.B. [DEGE99].

92
Anreicherung Bereinigung Konsolidierung Transformation
Verfügbarkeit Inhalt Repräsentation
Selektion
Dat
envo
lum
en
Dyn
amik
fehl
ende
Sät
ze
fehl
ende
Fel
der
fehl
ende
Wer
te
fehl
erha
fte W
erte
Red
unda
nzen
sem
antis
che
Inko
nsis
tenz
en
synt
aktis
che
Inko
nsis
tenz
en
Gra
nula
rität
Den
orm
alis
ieru
ng
Dar
stel
lung
sfor
m
Problemkreise der Datenqualität
Maßnahmen der Manipulation
Abb. 8: Mögliche Datenqualitätsprobleme und zugehörige Manipulationsmaßnahmen
Die Datenschemata operativer Systeme sind gewöhnlich nicht für analytische Zwecke konzipiert und besitzen deshalb häufig nicht ausreichenden Informationsgehalt. Man sieht sich gewissermaßen mit dem Paradoxon konfrontiert, dass trotz sehr großer Datenvolumina wichtige Informationen nicht vorhanden oder unterrepräsentiert sind. Der Aspekt der Datenverfügbarkeit bezieht sich insbesondere auf fehlende Datensätze und -felder, des Weiteren auf den Umfang der Datenbasis und deren Dynamik [BISS96, 8-10; KÜPP99, 114ff.]. Während die beiden letztgenannten Punkte in den Bereich der Datenselektion fallen, können nicht verfügbare Informationen unter Umständen aus anderen internen oder externen Quellen durch Anreicherung in die Analysedaten aufgenommen bzw. aus vorhandenen Attributen berechnet werden.
Mangelhafte Qualität der Inhalte der Daten kann zu invaliden Mustern beim Data Mining führen [ADZA96, 84]. Diesbezüglich treten häufig Probleme mit fehlenden Werten [BISS96, 9], unsicheren, ungenauen oder fehlerhaften Werten [FRPM91, 9f.], Redundanzen [ADZA96, 40] sowie semantischen Inkonsistenzen [BELI97, 69] auf. Nicht oder nicht korrekt gefüllte Datenfelder werden durch Bereinigungsprozeduren behandelt, während durch Redundanzen und andere Phänomene verursachte semantische Inkonsistenzen Gegenstand der Konsolidierung sind.
Rohdatenbestände entsprechen in den seltensten Fällen den zur Durchführung von Datenanalysen erforderlichen Formaten und Darstellungsformen. Werden die Daten aus mehreren Quellen extrahiert, sind syntaktische Inkonsistenzen zu erwarten. Weitere in diesem Kontext ebenfalls zu lösende Probleme sind die Umwandlung in eine geeignete Darstellungsform und Granularität sowie die Denormalisierung der Schemata [ADZA96, 44-46; BELI97, 67-69]. Mit Ausnahme der Sicherstellung der Konsistenz (Konsolidierung) werden sämtliche Datenrepräsentationsaspekte im Zuge der Transformation behandelt.

93
Aus der vorangegangenen Darstellung lassen sich vier Klassen von Manipulations-mechanismen ableiten, die nun genauer beschrieben werden. Sie behandeln die Aufgaben der Anreicherung, Bereinigung, Konsolidierung und Transformation.32 Anschließend erfolgt eine zusammenfassende Betrachtung des Ausmaßes und der Bedeutung der Daten-vorverarbeitung innerhalb des KDD-Prozesses.
5.2.3.1 Anreicherung
Eine Anreicherung der Analysedaten wird erforderlich, wenn diese nicht alle für eine erfolgreiche Durchführung der Untersuchung notwendigen Informationen enthalten. So ist das Fehlen einzelner Attribute oder ganzer Datensätze zu bestimmten Sachverhalten denkbar.33 Zur Behebung dieses Mangels ist grundsätzlich die Integration von in anderen Datenquellen des Unternehmens verfügbaren internen Daten, die Nutzung externer Informationen oder die Aufnahme zusätzlicher Attribute durch Berechnung der zuge-hörigen Werte denkbar. Durch Anreicherung von Daten aus anderen Quellen ergeben sich in der Regel weitere Schwierigkeiten hinsichtlich der Datenformate, der Wertebereiche und semantischer Inkonsistenzen, die durch Konsolidierungsprozeduren zu behandeln sind. Die Aufnahme externer Daten birgt jedoch zusätzliches Potenzial für die Analyse. So ist z.B. im Bereich des Marketing die Verfügbarkeit demographischer Informationen über bekannte Kunden von großem Interesse [ADZA96, 42].
Weniger problematisch gestaltet sich hingegen die Berechnung von Attributwerten. Von besonderer Bedeutung sind in diesem Zusammenhang betriebswirtschaftliche Kennzahlen [KEFI99, 90f.]. Für den Menschen triviales Erfahrungswissen oder implizit in den Daten enthaltene Informationen müssen für Data-Mining-Analysen explizit in den Daten repräsentiert sein, insbesondere wenn Beziehungen zwischen mehreren Attributen oder im Zeitablauf ermittelt werden sollen [BELI97, 75]. Als sehr hilfreich erweisen sich in diesem Kontext Verhältniszahlen, wie z.B.
Saldenaenderung := Aktueller_Saldo - Alter_SaldoBevoelkerungsdichte := Bevoelkerung / Flaeche
32 Vgl. hierzu auch die Forderung von GOLDBERG UND SENATOR nach KDD-Systemen mit wenigstens je einem Datenbereinigungs-, Konsolidierungs- und Attributberechnungsmodul [GOSE95, 141].
In der amerikanischen Literatur sind auch die Begriffe Data Migration, Data Scrubbing und Data Auditing gebräuchlich, die sich jedoch nur teilweise mit den hier beschriebenen Aufgaben Transformation, Bereinigung und Konsolidierung decken. Vgl. [CEMC95]. 33 Vgl. hierzu die Beispiele bei KÜPPERS [KÜPP99, 114] und FRAWLEY ET AL. [FRPM91, 10f.].

94
5.2.3.2 Bereinigung
Zur Vermeidung negativer Einflüsse auf die Analyseergebnisse sind Datenfehler durch geeignete Bereinigungsmaßnahmen zu beheben [KRWZ98, 42]. Als Datenfehler werden Attributsausprägungen verstanden, die bezüglich der durch sie beschriebenen realen Objekte nicht korrekt sind. Dazu zählen aufgrund nicht verfügbarer Werte nicht gefüllte Felder (NULL-Werte) [BISS96, 9], beliebige Werte, die aufgrund der Unkenntnis der tatsächlichen Werte als Platzhalter eingefügt werden (z.B. „01.01.1900“ als Geburtsdatum [ADZA96, 41]), sowie „verrauschte“ Werte, die unsicher oder ungenau sind.34
Welche Maßnahmen zur Fehlerbeseitigung zu ergreifen sind, ist in starkem Maße von der konkreten Situation und vom Analyseziel abhängig. Unvollständige Sätze oder solche, die durch Attributausprägungen mit besonders starker Abweichung vom erwarteten Wert-intervall auffallen (Ausreißer), haben besondere Beachtung verdient. In beiden Fällen ist das Eliminieren der Sätze aus der Datenbasis kritisch. In manchen Situationen können fehlende Informationen wertvolle Hinweise liefern. Möglicherweise bestehen kausale Zusammenhänge zwischen dem Fehlen von Informationen und bestimmten Sachverhalten, wie beispielsweise bei Untersuchungen zur Aufdeckung von Betrugsdelikten zu beobachten ist [ADZA96, 86]. Auch bei Ausreißern besteht die Chance, mit ihrer Hilfe Hinweise auf Missbrauch, fehlerhafte Geschäftsprozesse oder profitable Nischenmärkte zu erhalten. Anders als bei statistischen Analysen sollten derartige Datensätze nicht in jedem Falle aus dem Bestand entfernt werden [BELI97, 77f.].
Eine nachträgliche Ergänzung fehlender Werte kann ebenfalls riskant sein und sollte genau geprüft werden. Möglicherweise können sie von anderen verfügbaren Variablen abgeleitet werden. Auf Vorgabewerte wie „0“ oder „99999“ sollte verzichtet werden, da diese eine falsche Semantik unterstellen [BELI97, 71]. Fehlende Werte können aber auch per se sehr aufschlussreich sein, weshalb stets die explizite Kennzeichnung nicht gefüllter Datenfelder durch eine definierte NULL-Ausprägung in Betracht zu ziehen ist [FRPM91, 9]. Zur Minderung der Auswirkungen verrauschter Daten ist beispielsweise eine Glättung durch Mittelwertbildung denkbar [KRWZ98, 44f.].
Nach der Erkennung von Datenfehlern ist es in vielen Fällen möglich, automatisierte Bereinigungsprozeduren anzustoßen. In der Literatur wird auch von der erfolgreichen Anwendung von Data-Mining-Verfahren zur automatischen Suche nach Datenfehlern und deren Behebung berichtet [SILK95, 284]. Es ist jedoch unrealistisch anzunehmen, dass sämtliche Mängel auf Anhieb beseitigt werden können, weil viele Anomalien erst im Verlauf des KDD-Prozesses ans Tageslicht treten werden [ADZA96, 84]. Es zeigt sich wiederum, dass es sich hierbei um einen iterativen Prozess handelt.
34 Vgl. hierzu das Beispiel bei FRAWLEY ET AL. [FRPM91, 9f.].

95
5.2.3.3 Konsolidierung
Datenbanken enthalten oftmals multiple oder inkonsistente Repräsentationen einzelner Objekte. So tritt häufig der Fall ein, dass ein Kunde durch mehrere Datensätze mit verschiedenen Primärschlüsseln in den Stammdatenbeständen vertreten ist. Ein ähnliches Problem kann bei der Zusammenführung von Daten aus mehreren Quellen auftreten. Die Beseitigung derartiger Inkonsistenzen wird als Konsolidierung bezeichnet. Hierzu muss geklärt werden, welcher Datensatz welches reale Objekt repräsentiert. Sämtliche einem (realen) Kunden zugeordneten Eintragungen sind zu ermitteln und zu gruppieren. Anschließend müssen die ihn identifizierenden Informationen kombiniert und einem eindeutigen Schlüssel zugeordnet werden35 [GOSE95, 136f.].
Neben der Behandlung von durch Redundanzen verursachten Inkonsistenzen ist auch die Angleichung unterschiedlicher Datenformate (Datentypen) bei Nutzung mehrerer Datenquellen Gegenstand der Konsolidierung [KRWZ98, 42]. In diesem Kontext ist beispielsweise häufig zu beobachten, dass für ein inhaltlich gleiches Attribut verschiedene Datentypen auftreten [BELI97, 69], oder dass die Quellsysteme unterschiedliche Domänen oder Darstellungen für dieselbe Attributsausprägung verwenden, z.B. die Werte {0,1} und {m,w} für das Geschlecht. Weiterhin muss oft eine Vereinheitlichung verschiedener Attributsausprägungen mit derselben bzw. gleicher Werte mit unterschiedlicher Semantik (Synonyme bzw. Homonyme) durchgeführt werden. Semantische Abstimmungsprobleme resultieren nicht selten aus uneinheitlichen betriebswirtschaftlichen Begriffssystemen oder gesetzlichen Regelungen, wie z.B. aus unterschiedlichen Vorschriften zur Rechnungs-legung in verschiedenen Ländern [MUBE00, 11-13]. Diese Schwierigkeiten der An-gleichung abweichender Darstellungen und Werte werden häufig mithilfe sogenannter Umsetzungstabellen gelöst. Es ist aber durchaus denkbar, dass keine automatisierten Prozeduren zur Behebung von Konsolidierungsproblemen entwickelt werden können [KEFI99, 86-88].
5.2.3.4 Transformation
Im Rahmen der Transformation werden die Rohdaten in für die jeweiligen Data-Mining-Verfahren geeignete Darstellungsformen und Formate überführt [KRWZ98, 42]. Ziel der Transformation ist insbesondere die Gewährleistung invarianter Datendarstellungsformen (z.B. durch Übersetzung textueller Informationen in eindeutige Schlüssel oder Codes) sowie die Einschränkung von Wertebereichen zur Verringerung der Anzahl zu betrachtender Ausprägungen (Dimensionsreduktion) [FAPS96, 9-11].
Letzteres kann durch Verallgemeinerung von Attributwerten auf eine höhere Aggregationsstufe, z.B. durch Nutzung von Taxonomien [BIGU96, 50f.], oder durch Bildung von Wertintervallen geschehen, wodurch sich die Granularität der Daten ändert.
35 Eine ausführliche Darstellung und formale Beschreibung der Konsolidierung findet sich bei GOLDBERG UND SENATOR. Dort werden auch mögliche Ursachen für Inkonsistenzen diskutiert [GOSE95, 137f.].

96
Das tagesgenaue Geburtsdatum der Kunden erscheint für die Bildung von Kundensegmenten beispielsweise zu detailliert. In diesem Falle ist die Alters- oder Geburtsjahresinformation ausreichend. Unter Umständen kann auch eine weitere Verallgemeinerung auf Altersintervalle, z.B. in 10-Jahres-Schritten, hilfreich sein.36 Die Art der Datenrepräsentation nimmt möglicherweise erheblichen Einfluss auf die von den Algorithmen erzeugten Ergebnisse [ADZA96, 44]. Die Transformation numerischer Attributwerte, z.B. in Form einer Skalierung, Standardisierung oder Quantisierung,37 erweist sich daher häufig als nützlich, um die Bildung von Mustern aus den Daten zu vereinfachen [SAAR98]. Dies kann allein schon deshalb sinnvoll sein, weil nicht sicher ist, ob auf den feinen Detaillierungsebenen genügend Instanzen vorliegen, die zur Aufdeckung signifikanter Muster und Beziehungen ausreichen [BELI97, 68f.].
Für Data-Mining-Analysen stellen die im Rahmen der Normalisierung durchgeführten Zerlegungen von Relationstypen potenzielle Informationsverluste dar, da auf diese Weise Beziehungen zwischen Variablen und Objekten aufgelöst und eventuell interessante Zusammenhänge verschleiert werden. Zur Datenmustererkennung sind grundsätzlich solche Datenstrukturen zu wählen, die möglicherweise relevante Abhängigkeiten so gut wie möglich ausdrücken [ADZA96, 123f.].
In diesem Kontext stellt die Einebnung (Flattening) von Relationen eine bedeutende Transformation dar. Dabei wird ein Attribut der Kardinalität n (d.h. mit n kategorialen Ausprägungen) in n binäre Attribute umgewandelt. Z.B. kann die Information, dass ein Kunde einen bestimmten Artikel gekauft hat, bei n erworbenen Artikeln durch n getrennte Datensätze repräsentiert werden. Es ist jedoch (bei bekanntem und überschaubarem n) auch möglich, für jeden Kunden nur einen Datensatz anzulegen, der für jeden betreffenden Artikel ein binäres Attribut enthält, welches den Wert 1 annimmt, falls der betrachtete Kunde das entsprechende Produkt gekauft hat, andernfalls den Wert 0 [ADZA96, 46].
Manche Analyseverfahren verlangen darüber hinaus nach bestimmten Darstellungs-formen der Daten, wie z.B. einer Binärcodierung kategorialer Merkmalswerte. Die folgende Liste nennt einige exemplarische Transformationsfälle: � Verallgemeinerung von Adressinformationen auf Regionen oder Bezirke � Darstellung des Geburtsdatums durch Berechnung des Alters � Skalierung von Einkommenswerten durch Division mit dem Faktor 1000 � Transformation binärer kategorialer Merkmalswerte in die {1,0}-Form � Fortlaufende Nummerierung von Zeitintervallen (z.B. Monate von 1980 - 2000)
Die Form der Transformation ist stets im Hinblick auf die verfolgten Analyseziele zu wählen. Allgemein gilt, dass die Bildung einfacher Datenstrukturen für Data-Mining-Untersuchungen nicht unbedingt erstrebenswert ist. Vielmehr kann sich eine höhere
36 Es mag unter Umständen sogar sinnvoll sein, unterschiedliche Repräsentationen derselben Information in die Analysedaten redundant aufzunehmen, um für verschiedene Untersuchungsziele gewappnet zu sein. 37 Vgl. hierzu beispielsweise [RUNK00, 11ff.].

97
Komplexität der Datenstrukturen positiv auf die Ausschöpfung der Potenziale des Ansatzes auswirken, da hierdurch die Entdeckung von Mustern erleichtert wird [KÜPP99, 117].
5.2.3.5 Ausmaß und Bedeutung
Bereits die Anzahl denkbarer Datenmängel lässt erahnen, dass Exploration und Manipulation des Datenmaterials bei der Durchführung von Data-Mining-Analysen breiten Raum einnehmen. Nach Expertenschätzungen verzehren sie bis zu 80% der im Zuge von Datenmustererkennungsprojekten verbrauchten Ressourcen [BIGU96, 12]. Dieser Wert kann aufgrund eigener Erfahrungen des Verfassers bestätigt werden.
Die Literatur stuft die Vorverarbeitungsschritte einhellig als für den Erfolg des Data Mining entscheidend ein: „Vielleicht ist der wichtigste Aspekt die Bereitstellung eines sauberen und gut gepflegten Datenbestandes. Jedenfalls nimmt dies eine beträchtliche Zeit in Anspruch.“ [KRWZ98, 17] „Without the right data there is little gold to be mined; here again, we must apply the rule ‘garbage in, garbage out’.“ [ADZA96, 9]
5.2.4 Analyse der Daten
Liegen geeignete Datenbestände in befriedigender Qualität vor, können die Unter-suchungen durchgeführt werden. Dieser Schritt des KDD-Prozesses ist als eigentliches Data Mining zu bezeichnen, da hier mittels Anwendung der in Abschnitt 4.5 beschriebenen Ansätze Muster und Beziehungen in den Daten aufgedeckt werden.
Nach der Auswahl eines für die konkrete Problemstellung geeigneten Verfahrens muss dieses konfiguriert werden. Diese Parametrisierung bezieht sich auf die Vorgabe bestimmter methodenspezifischer Werte, wie z.B. die Festlegung minimaler relativer Häufigkeiten zur Realisierung eines Interessantheitsfilters, die Auswahl der bei der Musterbildung oder -beschreibung zu berücksichtigenden Attribute oder die Einstellung von Gewichtungsfaktoren für einzelne Eingabevariable, etc.
In den seltensten Fällen kann auf Anhieb eine zufriedenstellende Verfahrenskonfiguration gefunden werden. Häufig stellt sich bei der Durchführung der ersten Analysen heraus, dass das gewählte Berechnungsmodell bzw. der methodische Ansatz nicht zum gewünschten Ergebnis führt und eine andere Alternative gewählt werden muss [KRWZ98, 31]. Die Parametrisierung erweist sich als iterativer Prozess, für den KÜPPERS folgende Vorgehensweise vorschlägt [KÜPP99, 121]: Nach der Ermittlung einer geeigneten Methodenmenge, die vom verfolgten Analyseziel und den zu erzeugenden Mustertypen ausgeht, sind zwei Schritte auszuführen, von denen der erste als „Schleife“ über dem zweiten aufzufassen ist [FAPS96, 17]. Zunächst wird ein konkretes Verfahren ausgewählt (Modellsuche). Bevor damit erste Untersuchungen durchgeführt werden können, ist dieses zu konfigurieren. Zur Ermittlung der korrekten Parameter sind mehrere Testläufe mit unterschiedlichen Einstellungen erforderlich (Parametersuche). Führt diese Prozedur zu den gewünschten Resultaten, ist der Prozess beendet. Andernfalls wird zur Modellsuche

98
zurückgesprungen, eine andere Methode gewählt und die Parametersuche erneut durchlaufen.
Soll die Datenmustererkennung komplett über ihre beiden Phasen (Entdeckung und Beschreibung) ausgeführt werden und stehen keine geeigneten Hybridverfahren zur Verfügung, so können zwei diese Teilaufgaben getrennt behandelnde Methoden mit-einander gekoppelt werden (vgl. Abschnitt 4.5.1). Sehr anschaulich lässt sich dies am Beispiel eines Clustering- und eines Regelinduktionsverfahrens zeigen: Die Segmen-tierungsmethode ermittelt auffällige Objektgruppen, welche anschließend mithilfe von Entscheidungsregeln, die auf Eigenschaften der in den gebildeten Segmenten enthaltenen Objekte Bezug nehmen, erklärt werden (serielle Kopplung) [KÜPP99, 99f.; SAAR98].
Beim Einsatz überwachter Verfahren werden im Rahmen des Data Mining Beschreibungen erzeugt, die das (vergangene) Verhalten der durch die Datenbestände repräsentierten Objekte erklären und bei der späteren Anwendung auf neue Daten die Rolle von Vorhersagemodellen spielen. Die Verhaltensbeschreibungen beziehen sich hierbei grundsätzlich auf eine Variable (z.B. Risikoklasse, erwarteter Umsatz, etc.), die als Zielattribut spezifiziert wird und von anderen Variablen abhängig ist. Demnach ist die verfügbare Attributmenge in für die Beschreibung des Zielattributs relevante und irrelevante aufzuteilen.38
Die Nutzung überwachter Ansätze stellt besondere Anforderungen an die Durchführung der Datenmustererkennung. Um sicherzustellen, dass die erzeugten Modelle korrekte Vorhersagen liefern, ist dafür zu sorgen, dass zufällig in der Datenbasis enthaltene Phänomene nicht verallgemeinert werden. Man spricht in solchen Fällen von einer Überanpassung (Overfitting) des Modells an die Trainingsdaten, wenn dieses dazu neigt, deren Struktur als allgemeingültig anzunehmen.39 Zur Vermeidung dieses Problems sollte der Datenbestand in mindestens drei Teilmengen aufgeteilt werden. Eine erste Trainingsmenge wird zum Aufbau des initialen Modells herangezogen, das in weiteren Schritten mittels Testmengen verallgemeinert wird. Auf diese Weise lassen sich die während des Lernprozesses in die Mustermenge aufgenommenen Eigenheiten der Trainingsdaten eliminieren. Anhand einer Bewertungsmenge wird schließlich die Effektivität des Modells bei Anwendung auf neue Daten beurteilt. Um die Qualität des extrahierten Wissens im Sinne der Vorhersagegenauigkeit zu verbessern sind nach den einzelnen Testläufen jeweils Anpassungen der Parametrisierung notwendig. Ziel ist die Minimierung der Fehlerrate bei Anwendung auf unbekannte Daten (Abb. 9) [BELI97, 76-79].
38 Diese Klassifikation ist grundsätzlich hypothetischer Natur und bedarf möglicherweise einer iterativen Revision. 39 Trägt z.B. jeder profitable Kunde der Trainingsmenge zufällig den Namen Müller, so wird das Modell „vermuten“, dass auch jeder andere Kunde namens Müller als profitabel einzustufen ist [BELI97, 79].
99
optimaleTrainingsintensität
Fehl
erra
te
Trainingsintensität
unbekannte Daten
Trainingsdaten
Abb. 9: Abhängigkeit der Fehlerrate von der Trainingsintensität bei der Verwendung der Ergebnisse überwachter Data-Mining-Analysen (vgl.[BELI97, 80])
5.2.5 Interpretation der Ergebnisse
In Abschnitt 4.2 wurde Data Mining als Aufgabe definiert, deren Ziel die Entdeckung von Mustern und Beziehungen in großen Datenbeständen ist. Diese Muster sollen den Anforderungen der Gültigkeit, Neuartigkeit, Nützlichkeit und Verständlichkeit genügen, um neues Wissen zu repräsentieren und einer Interpretation zugänglich zu sein. Letztere ist Voraussetzung für die Umsetzung der gewonnenen Erkenntnisse im Rahmen konkreter Handlungsmaßnahmen.
Bei Weitem nicht alle der aufgedeckten Muster erfüllen jedoch diese Kriterien. Die Analyseverfahren fördern vielmehr eine Vielzahl von Regelmäßigkeiten zutage, die insignifikant, trivial, bereits bekannt sind, aus denen dem Unternehmen kein ökonomischer Nutzen erwachsen kann, oder die unverständlich und nicht nachvollziehbar sind. Aus diesem Grund wird vor der eigentlichen Interpretationsphase eine Bewertung der Untersuchungsergebnisse notwendig, die die Funktion eines Filters übernimmt und nur tatsächlich interessante Informationen übergibt [BIGU96, 14].
Der Interpretationsschritt umfasst demnach zwei Teilaufgaben, nämlich die Bewertung der Analyseresultate hinsichtlich ihrer Interessantheit sowie eine eingehende Interpretation zur Erlangung eines tiefen Verständnisses der enthaltenen Aussagen und der damit verbundenen Implikationen.
Resultate, die trivial oder auch mithilfe „traditioneller“ Analysetechniken wie Daten-bankanfragen oder Statistik ermittelbar sind, stellen keine interessanten Aussagen im Sinne

100
des Data Mining dar [BISS96, 10f.]. Im Folgenden werden die Ursachen mangelnder Interessantheit diskutiert.40
• Mangelnde Gültigkeit: Die Gültigkeit der Ergebnisse kann durch statistische Bedeutungslosigkeit und mangelnde Robustheit beeinträchtigt werden: � Mangelnde Signifikanz: Die Analyseresultate müssen statistisch signifikant sein um
gültiges Wissen darzustellen. Data-Mining-Ergebnisse die sich auf einzelne oder nur sehr wenige Objekte in der Datenbasis beziehen sind damit bedeutungslos. Aufgrund fehlender oder fehlerhafter Daten oder auch mangelnder Repräsentativität der Daten für die Anwendungsdomäne sind die erzeugten Muster häufig eher probabilistisch statt sicher. Aus diesem Grund ist es erforderlich die gelieferten Aussagen um Signifikanzmaße anzureichern, wie z.B. Häufigkeiten, Wahrscheinlichkeiten, Vertrauensintervalle, Belief-Maße oder Standardabweichungen. Zur Messung des „Sicherheitsgrades“ eignen sich prinzipiell statistische Verfahren [FRPM91, 14f.; ADZA96, 18f.; BISS96, 10f.]. � Mangelnde Robustheit: Operative Datenbanken, die ja der Dokumentation und
Verarbeitung von Geschäftsvorfällen dienen, verändern sich im Zeitablauf sehr schnell. Die bezüglich eines bestimmten Datenbankzustands entdeckten Zu-sammenhänge können hinsichtlich eines neuen Datenbankzustands ungültig oder inkonsistent sein. Dies wirft die Frage nach der Robustheit des entdeckten Wissens gegen dynamische Veränderungen des Datenbestandes auf [HSKN95, 156]. Auch bei Nicht-Volatilität der Datenbestände verlieren Analyseergebnisse mit der Zeit an Wert, weil sich das den Daten zugrunde liegende Verhalten der Kunden und Märkte (allgemein der realen Objekte) im Zeitablauf wandelt [BELI97, 34]. Zur Bewertung der Relevanz der gewonnenen Erkenntnisse sollte deren Robustheit zumindest annähernd abgeschätzt werden können.
• Mangelnde Neuartigkeit: Nach SHANNON kann der Informationsgehalt einer Aussage formal als Logarithmus der Wahrscheinlichkeit ihres Auftretens definiert werden: Informationsgehalt(A):=log(P(A)). Daraus folgt, dass unwahrscheinliche Aussagen einen hohen Informationsgehalt besitzen, während bereits bekannte Aussagen gar keine Information darstellen. Da der Informationsgehalt von Data-Mining-Analysen möglichst hoch sein soll, erweisen sich bereits bekannte, redundante oder triviale Ergebnisse somit als grundsätzlich uninteressant [ADZA96, 19, 116]: � Bekanntheit: Bereits bekannte Ergebnisse stellen prinzipiell keine nützlichen
Informationen dar. Sie sind allenfalls dazu geeignet, Annahmen zu bestätigen oder zu widerlegen [KRWZ98, 27]. Beispiele finden sich gerade bei Assoziationsanalysen zuhauf, wie etwa Verbünde zwischen Farbe und Pinsel, Holzkohle und Grillanzünder, etc. [BELI97, 127].
40 Vgl. hierzu auch die Diskussion bei GEBHARDT [GEBH94, 10-12].

101
� Redundanz: Beschreiben mehrere Muster denselben Sachverhalt auf unter-schiedlichen Betrachtungsebenen, so ist nur eine dieser Regeln interessant. Bei-spielsweise ist die Aussage „Im Vertreterbezirk Bamberg wurden Rekordumsätze erreicht“ redundant, wenn gleichzeitig auch das Ergebnis „In allen oberfränkischen Vertreterbezirken wurden Rekordumsätze erreicht“ vorliegt. Zur Eliminierung solcher Mehrfachresultate sind sogenannte Redundanzfilter verfügbar [BISS96, 11]. � Trivialität: Resultate, welche aus verschiedenen Gründen im betreffenden Kontext
als trivial empfunden werden, sind nicht interessant. Diese beschreiben z.B. Sachverhalte, die in der Natur der Dinge liegen („Bei Verkauf nach Übersee fallen überdurchschnittlich hohe Transportkosten an.“), die durch kausale Abhängigkeiten erklärt werden („Wenn ‘Konto geschlossen’, dann ‘Summe der Umsätze des Kontos=0’.“) oder die aktuelle Geschäftspolitik repräsentieren („In Außenbezirke wird nur bei Mindestbestellwert von DM 50,- geliefert.“) [BISS96, 11; BELI97, 34; KRWZ98, 26].41
• Mangelnde Nützlichkeit: Sind die gewonnenen Informationen zwar bezüglich aller anderen Kriterien als interessant einzustufen, können aber nicht in Handlungen umgesetzt werden, so sind sie dennoch irrelevant. Dies kann z.B. der Fall sein, wenn bestimmte externe Einflüsse vorliegen, auf die nicht eingewirkt werden kann. (Beispiel: „In Exportregion 0815 treten überdurchschnittliche Erlösschmälerungen wegen hoher Zölle auf.“ [BISS96, 11])
• Mangelnde Verständlichkeit: Die extrahierten Ergebnisse müssen genau formuliert und eingängig sein und dem Anwender in einer verständlichen Form, z.B. natürlichsprachig oder grafisch präsentiert werden [ADZA96, 18; BISS96, 10]. Die mangelnde Verständlichkeit kann somit mehrere Ursachen haben: � Mangelnde Nachvollziehbarkeit: Einerseits sind Aussagen denkbar, die allein ihres
Inhalts wegen nicht nachvollziehbar sind, in denen der Nutzer also keinen Sinn erkennen kann. (Beispiel: „Bei Neueröffnungen von Baumärkten sind Toiletten-dichtungen einer der am häufigsten verkauften Artikel.“ [BELI97, 127f.]) � Mangelnde Erklärbarkeit der Methode: Andererseits mag die Art des gewählten
Data-Mining-Verfahrens grundsätzlich eher unverständliches Wissen liefern. So ist es z.B. eine bekannte Schwäche Neuronaler Netze, das implizit in den Modellen enthaltene Wissen nicht explizieren zu können. Durch Anwendung derartiger Methoden erzeugte Ergebnisse müssen zum Zwecke ihrer Erklärung weiteren Analysen unterzogen werden [BIGU96, 12f.].
41 Unter bestimmten Voraussetzungen können auch triviale Muster interessant sein. So sollte eine Assoziationsregel wie „Wenn ‚Kasten Bier‘, dann ‚Pfandbetrag‘“ zu weiteren Untersuchungen Anlass geben, wenn z.B. die erwartete Konfidenz von 100% unterschritten wird: Wie kann es sein, dass nicht alle Verkäufe von Mehrweg-Getränken zu einer Buchung des zugehörigen Pfandbetrages führen?

102
� Mangelnde Präsentationsfähigkeit des Systems: Stellt das System keine oder nicht ausreichende Darstellungs- oder Visualisierungsfunktionalitäten zur Verfügung, so sind andere Werkzeuge zur Unterstützung des Interpretationsschrittes zu wählen. Für den Menschen sind natürlichsprachige Beschreibungen, formale Logiken (z.B. Wenn-Dann-Regeln, relationale Muster wie „X > Y“, etc.) und insbesondere grafische Darstellungen (z.B. Entscheidungsbäume, Semantische oder Kausale Netze, Diagramme, etc.) gut geeignet [FRPM91, 13f.].
Die Interessantheit von Analyseergebnissen ist eine Funktion der Gültigkeit, Neuartigkeit, Nützlichkeit und Verständlichkeit der Resultate (vgl. Abschnitt 4.2). Durch die Definition quantitativer Interessantheitsmaße ist es möglich, Interessantheitsfilter in Data-Mining-Systeme zu integrieren, um die dem Anwender präsentierte Ergebnismenge einzuschränken und damit einen Beitrag zur Unterstützung des Interpretationsschrittes zu leisten.42 Diese Mechanismen können an der Schnittstelle der Data-Mining-Verfahren zu den Präsentationsmodulen (Interessantheitsfilter) eingebaut oder direkt in die Daten-mustererkennungskomponente („Interestingness Engine“) integriert werden. Im zweiten Fall werden uninteressante Ergebnisse durch Fokussierungsmechanismen gar nicht erst erzeugt, während sie im ersten Fall nachträglich aus der Resultatemenge entfernt werden [SITU95, 275f.].
Die korrekte Interpretation von Data-Mining-Ergebnissen erfordert sowohl analytisch-methodische als auch profunde Domänenkenntnisse. Im Idealfall sollte ein Team von Experten aus unterschiedlichen Bereichen gebildet werden, um sicherzustellen, dass die Bewertung korrekt ist und die gewonnenen Informationen der bestmöglichen Nutzung zugeführt werden [BELI97, 72]. Die Interpretationsphase lässt sich durch gute Präsentationswerkzeuge sowie durch die Verfügbarkeit zusätzlicher Informationen über die Anwendungsdomäne unterstützen. Solches Hintergrundwissen ist einerseits durch die an der Bewertung beteiligten Domänenexperten repräsentiert [FRPM91, 12]. Darüber hinaus liefern die im Rahmen des Explorationsschrittes gewonnenen Einblicke in die Datenbasis wertvolle Hinweise, vor deren Hintergrund die Bedeutung mancher Analyseergebnisse klarer in Erscheinung treten wird.
In vielen Situationen kann es sinnvoll sein, die neuen Erkenntnisse vor ihrer Freigabe durch weitere Untersuchungen anhand der Datenbasis (Grundgesamtheit) zu prüfen [KRWZ98, 31]. Datengetriebene Analysen rufen in der Regel immer neue Fragestellungen hervor, bei deren Beantwortung die generierten Hypothesen verifiziert werden können. An dieser Stelle setzt die zyklische Kopplung von Untersuchungsproblemen an (vgl. Abschnitt 3.2.3). Die Prüfung der Ergebnisse initiiert einen neuen Schritt innerhalb des Zyklus, dem
42 Solche Interessantheitsmaße sind im Übrigen nicht objektiv, sondern in starkem Maße vom jeweiligen Anwender abhängig und damit subjektiv. Verschiedene Anwender können die Interessantheit derselben Ergebnisse völlig unterschiedlich bewerten. So mag z.B. ein erfahrener Experte nur noch an sehr speziellen Details interessiert sein, während ein Domänenfremder gegebenenfalls jedes Muster als interessant empfindet [KÜPP99, 88]. Objektive Interessantheitsmaße sind im Allgemeinen nicht verfügbar, da man nicht in der Lage ist die gesamte Komplexität der Einflussfaktoren zu erfassen. Vgl. hierzu [SITU95, 275f.].

103
folgende Kernidee zugrunde liegt: Die Ergebnisse einer Untersuchungssituation werden zu den Motivatoren für die nächste Analyse [BELI97, 92].
5.3 Betriebswirtschaftliche Datenanalyseprozesse
In Anlehnung an einen Vorschlag von BERRY UND LINOFF wird nun auf Grundlage des in Abschnitt 3.1 eingeführten Konzepts der Untersuchungssituation ein Handlungsschema vorgestellt, das die Einbettung von Datenanalyseprojekten in das betriebliche Umfeld beschreibt. Dieses Schema ist auf jedes betriebswirtschaftliche Datenanalyseproblem anwendbar und wird im Folgenden auch in diesem breiteren Kontext betrachtet.
Ausgangspunkt für die Entwicklung des Handlungsschemas war die Erkenntnis, dass reine Analysetätigkeiten keinen betriebswirtschaftlichen Nutzen generieren. BERRY UND
LINOFF fordern in einer einfachen Formel, dass Daten in Informationen, Informationen in Handlungen und Handlungen in Erträge umzusetzen sind, um den Aufwand für die Analysen zu rechtfertigen. Der zur Erfüllung dieser Forderung notwendige Prozess soll sich wie ein roter Faden durch die gesamte Organisation ziehen und elementarer Bestandteil der Management-Tätigkeit werden. Das Hauptaugenmerk ist dabei nicht allein auf die Untersuchungen gerichtet, sondern insbesondere auch auf die Handlungen, die auf Grundlage der gewonnenen Erkenntnisse ergriffen werden können („Actionable Information“) [BELI97, 18]. Nur operationalisierbare Analyseergebnisse, die ihren Niederschlag in konkreten Maßnahmen finden, werden als nützlich erachtet [ADZA96, 81].
Durchführungder Datenanalyse
Durchführungder Untersuchung
Spezifikation desUntersuchungsproblems
Umsetzungder Erkenntnisse
Evaluierung derUntersuchungssituation
Abb. 10: Handlungsschema betriebswirtschaftlicher Datenanalyseprozesse

104
Das Handlungsschema umfasst die folgenden vier Schritte (Abb. 10):43 � Spezifikation des Untersuchungsproblems � Durchführung der Untersuchung � Umsetzung der Untersuchungsergebnisse � Evaluierung der Untersuchungssituation
Das Schema wird ergebnisgetrieben durchlaufen, d.h. jede Phase ist von den Ergebnissen des vorherigen Schrittes abhängig. Die Phasen � und � betreffen größtenteils betriebswirtschaftliche Aspekte und stellen die Erfolgsfaktoren des Projektes dar. Die Anwender müssen erkennen, in welchen Situationen die Extraktion von Informationen aus verfügbaren operativen Daten zu besserem Wissen über Handlungsmöglichkeiten führt und diese anschließend durch Ergreifung entsprechender Maßnahmen nutzen [BELI97, 63].
Datenanalyseprojekte sind als zyklische, kontinuierliche Prozesse zu gestalten und liefern oft erst mittel- bis langfristig messbare Ergebnisse. Nur bei korrekter Spezifikation der Untersuchungssituationen (also Einsatz der richtigen Analysemethoden auf geeigneten Datenbeständen zur Verfolgung definierter Analyseziele) kann tatsächlich Wissen ermittelt und in Handlungen umgesetzt werden oder zur Verbesserung operativer Vorgänge beitragen. Datenanalyseprozesse lassen sich gemäß dem Regelkreisprinzip in Geschäfts-prozesse integrieren, um auf diese Weise aus vergangenen Erfahrungen, die in den Daten dokumentiert sind, Lehren für die Zukunft ziehen zu können (Abb. 11) [BELI97, 18, 30, 34f.; MART98, 24-26].
Ziele
Geschäftsprozess-Management
operative DatenMaßnahmenLenkungseingriffe,Gestaltungsvorgaben
Durchführung vonDatenanalysen
Geschäftsprozess
Dokumentation der Abwicklungvon Geschäftsvorfällen
�
�
��
Abb. 11: Geschäftsprozess-Management mithilfe der Datenanalyse
Die folgenden Abschnitte beschreiben die vier Phasen des Handlungsschemas.
43 Vgl. hierzu auch [BELI97, 22f.].

105
5.3.1 Spezifikation des Untersuchungsproblems
Ausgangspunkt für jede Analyseaktivität ist stets ein Untersuchungsziel in Form einer Fragestellung. In der Regel wird ein spezifischer Informationsbedarf im Hinblick auf eine konkrete Handlungsabsicht formuliert („Was will ich wissen, und welche Maßnahmen will ich auf Grundlage dieses Wissens ergreifen?“) [ADZA96, 81].
Alle Mitarbeiter eines Unternehmens sollten für die Identifikation möglicher Untersuchungsziele sensibilisiert werden, sofern sie durch bessere Informationsversorgung bei der Ausführung ihrer Aufgaben unterstützt werden können. Potenzielle Analyseziele können aus informationsintensiven Funktionen (wie z.B. der Marketingplanung), aus Beobachtungen des Managements (z.B. „Warum hinkt der Absatz in Region A weit hinter allen anderen Gebieten hinterher?“), durch Befragung von Mitarbeitern in Schlüssel-positionen abgeleitet oder auf beliebige andere Weise ermittelt werden [BELI97, 23-25].
Neben der Spezifikation der Untersuchungsziele gehört auch die Identifikation von Analysedatenbeständen zur Festlegung des Untersuchungsproblems. Die verfügbaren Daten sind hinsichtlich ihrer Eignung für die Verfolgung des Untersuchungsziels zu bewerten [ADZA96, 82f.]. Datenanalyseprojekte können auch durch verfügbares Daten-material angestoßen werden, das auf mögliche Untersuchungsziele verweist.
Vor dem Start eines Datenanalyseprojekts sollten weitere Aspekte Beachtung finden, die an dieser Stelle nur erwähnt werden sollen. So ist beispielsweise zu prüfen, ob die Analyse einmalig oder repetitiv durchgeführt werden soll, da im zweiten Fall eine organisatorische Einbettung in die regelmäßigen Abläufe des Unternehmens sinnvoll sein kann [KRWZ98, 32]. Weiterhin ist zu klären, ob nicht datenschutzrechtliche Rahmenbedingungen den verfolgten Untersuchungszielen entgegenstehen.44 Ebenso sind die technische Realisierbarkeit (z.B. hinsichtlich der Datenvorverarbeitung und der Rechnerinfrastruktur) und die erwartete Wirtschaftlichkeit des Vorhabens zu bewerten45 [KÜPP99, 103].
5.3.2 Durchführung der Untersuchung
Zur Durchführung der Datenanalyse ist ein geeignetes Untersuchungsverfahren zu wählen, welches das verfolgte Analyseziel auf Basis der verfügbaren Datenbestände am besten zu erreichen verspricht. Die Methodenauswahl ist in starkem Maße vom konkreten Untersuchungsproblem abhängig (vgl. Abschnitt 4.5.3). In welchen Fällen „traditionelle“ Ansätze wie Statistik, SQL oder OLAP bzw. Data-Mining-Methoden Verwendung finden können, wurde in Abschnitt 3.2 diskutiert. Es wird generell als Vorteil angesehen, ein möglichst breites Spektrum unterschiedlicher Untersuchungsverfahren zur Verfügung zu haben, wenngleich die Anwendung entsprechender Analysesysteme erhebliche Fach-kenntnisse erfordert und mit einigem Aufwand verbunden ist [BELI97, 84]. 44 Bzgl. datenschutzrechtlicher Bestimmungen vgl. z.B. [SCHW99] und die dort angegebene Literatur. 45 Bzgl. Überlegungen zu Wirtschaftlichkeitsbetrachtungen vgl. [KÜPP99, 117ff.] und die dort angegebene Literatur.

106
Die Analysetätigkeit kann in einzelnen Fachabteilungen oder an zentraler Stelle im Unternehmen durchgeführt werden. Treten häufig verschiedenartige Untersuchungs-probleme auf, so erscheint eine Zentralisierung der Analysefunktionen insbesondere wegen der Komplexität mancher Verfahren und des erforderlichen Know-hows durchaus sinnvoll. Auf diese Weise entstehen Synergieeffekte, die sich mit der Zeit auf die Behandlung bereichsübergreifender Fragestellungen sehr positiv auswirken können [KRWZ98, 36]. Andererseits ist bei wiederkehrendem Auftreten gleichartiger Untersuchungssituationen zu vermuten, dass deren Umsetzung durch Domänenexperten aufgrund besserer Fachkenntnisse vorteilhafter ist. Es ist in jedem Falle zu empfehlen, für jedes Datenanalyseprojekt eine individuelle Projektgruppe aus Analyse- und Fachspezialisten zu bilden, um die Vorteile beider Organisationsformen nutzen zu können.
5.3.3 Umsetzung der Untersuchungsergebnisse
Wegen des hohen Aufwandes für Datenanalysen wird im Verlauf der Untersuchungen mit Ergebnissen gerechnet, welche die hohen Anstrengungen und Kosten rechtfertigen. Insbesondere an die vergleichsweise komplexen Data-Mining-Projekte werden sehr hohe Ansprüche gestellt: „Man erwartet Ergebnisse, die zumindest das bisher Bekannte bestätigen (unteres Ende der Befriedigungsskala) oder bahnbrechende Erkenntnisse mit sich bringen.“ Diese Erwartungen können nicht immer erfüllt werden; häufig werden nur triviale, unspektakuläre oder gar unbrauchbare Lösungen geliefert [KRWZ98, 161].
Damit die Datenanalyse dem Unternehmen ökonomische Vorteile verschaffen kann, müssen die gewonnenen Erkenntnisse in konkrete Handlungskonsequenzen umgesetzt werden. Die Ableitung von hierfür geeigneten Maßnahmen erweist sich jedoch in der Regel als nicht-triviales Problem46 [BELI97, 27]. Grundsätzlich sind zwei Verwendungs-formen für Untersuchungsergebnisse denkbar. Neben der Durchführung (einmaliger) Aktionen wie z.B. Marketingkampagnen oder Massenbriefsendungen kann das neu erworbene Wissen in operative Vorgänge einfließen [KRWZ98, 31; BIGU96, 14]. Beispiele für die zweite Alternative sind die Nutzung ermittelter Klassifizierungsregeln zur Ein-ordnung neuer Kunden in Kundenklassen oder die Aufnahme des Wissens über die Zugehörigkeit von Kunden zu bestimmten Segmenten in die Stammdaten. Zur weiteren Umsetzung neuer Erkenntnisse trägt auch deren Bereitstellung für interessierte Nutzergruppen z.B. im Intranet oder das Ablegen der Informationen in einem Data Warehouse bei.
5.3.4 Evaluierung der Untersuchungssituation
Die Bewertung eines Analyseprojekts, bei der neben der Untersuchungssituation selbst auch die zur Umsetzung der gewonnenen Erkenntnisse ergriffenen Maßnahmen zu berücksichtigen sind, bildet die Grundlage einer kontinuierlichen Verbesserung der

107
Zielerreichung durch Lerneffekte. BERRY UND LINOFF bemängeln, dass der Ergebnis-evaluierung grundsätzlich zu wenig Bedeutung beigemessen wird und fordern, jedes Analyseprojekt durch Gegenüberstellung seiner Zielsetzung mit seinem tatsächlich realisierten Erfolg zu beurteilen. Erst dadurch können Verbesserungspotenziale für die nächste Analyse erkannt werden [BELI97, 28f.].
Die Bewertungsmaße sollten den betriebswirtschaftlichen Nutzen quantifizieren und sich auf konkrete Handlungsobjekte wie Kunden, Produkte oder Märkte beziehen, anstatt reine Kennzahlen wie Aufwand, Ertrag oder Rentabilität auszudrücken [BELI97, 30]. Zur Berechnung des Nutzens ist der durch eine ergriffene Maßnahme realisierte Ertrag dem Aufwand ihrer Umsetzung und dem der Datenanalyse gegenüberzustellen. Das Quanti-fizieren des Ertrags kann allerdings je nach Situation sehr schwierig sein (z.B. Schätzung des „Wertes“ eines neu gewonnenen Kunden) [BELI97, 109-111].
Nach einer betriebswirtschaftlichen Bewertung des Projekts sind die Elemente der Untersuchungssituation (Zielsetzung, Datenbasis und eingesetzte Verfahren) zu beurteilen. Bezüglich der Untersuchungsziele ist zu prüfen, ob sie mit den verfügbaren Methoden und Daten zufriedenstellend erreicht werden konnten, oder ob gegebenenfalls eine Ein-schränkung auf Teil- oder Unterziele bzw. eine Verallgemeinerung auf Oberziele sinnvoller wäre. Die Analysedaten sind hinsichtlich der in Abschnitt 5.2.3 beschriebenen Problemkreise Verfügbarkeit, Inhalt und Repräsentationsform, jeweils im Lichte der konkreten Untersuchungssituation, zu betrachten.
Bei der Methodenbeurteilung werden die Aspekte Genauigkeit der Ergebnisse, Genauigkeit der Beschreibung der Daten, Zuverlässigkeit und Verständlichkeit untersucht, die in Abhängigkeit vom konkreten Ansatz in verschiedenen Maßzahlen Ausdruck finden.47 Auch hier muss die Bewertung stets auf das zugehörige Untersuchungsproblem Bezug nehmen.
Der direkte Vergleich verschiedener Methoden oder Modelle gestaltet sich aufgrund ihrer im Allgemeinen sehr unterschiedlichen Eigenschaften meist schwierig [BELI97, 94]. Eine verfahrensübergreifende Evaluierung von Ergebnissen ist jedoch möglich. Hierzu wird empfohlen, jeweils das durch Einsatz einer Methode realisierte Ergebnis in Relation zum erwarteten Ergebnis zu setzen. Auf diese Weise wird die Verbesserung der Zielerreichung des Ansatzes gegenüber der Erwartung messbar. Solche Verbesserungsfaktoren können für alternative Verfahren ermittelt und verglichen werden. Als Beispiel diene eine geplante Massenbriefsendung, die mithilfe einer Data-Mining-Analyse unterstützt werden soll, indem aus dem Kundenstamm Empfänger mit einer möglichst hohen Antwort-wahrscheinlichkeit ausgewählt werden. Liefert die Untersuchung eine Kundengruppe mit einer tatsächlichen Rücklaufquote von 50% gegenüber einer (aufgrund der Verteilung in 46 Vgl. hierzu beispielsweise die Erfahrungen von STRÖHL UND MICHELS bei der Untersuchung der Retourenproblematik im Versandhandel [STMI98]. 47 Bzgl. detaillierterer Ausführungen zur Bewertung von Analyseansätzen, speziell im Data-Mining-Kontext, vgl. [BELI97, 97-107].

108
der Gesamtpopulation) erwarteten Antwortwahrscheinlichkeit von nur 5%, so beträgt der durch die Datenanalyse realisierbare Verbesserungsfaktor 50 : 5 = 10 [BELI97, 107].
Während der Evaluierungsphase erkannte Verbesserungsmöglichkeiten oder gewonnene Erkenntnisse können Hinweise auf neue Untersuchungsprobleme liefern und damit neue Projekte initiieren. In diesem Zusammenhang wird es als hilfreich erachtet, positive Erfahrungen aus einem Analyseprojekt im Unternehmen zu kommunizieren, damit andere Fachabteilungen auf die Potenziale von Datenanalysen aufmerksam werden oder Vorschläge machen können, wie Untersuchungssituationen modifiziert werden sollten [BELI97, 28].

109
6 Data Warehousing und Data Mining Der Data-Mining-Begriff wird häufig im Kontext des Data Warehousing verwendet, wodurch suggeriert wird, dass ein Data-Warehouse-System Voraussetzung für die Nutzung des Data-Mining-Ansatzes wäre. Dies ist keineswegs der Fall; die Datenmustererkennung kann prinzipiell auf beliebigen Datenbeständen betrieben werden [BIGU96, 11; KÜPP99, 44]. Dennoch ergibt sich durch Kombination der beiden Konzepte eine Reihe interessanter Potenziale. Der folgende Abschnitt motiviert die Anbindung von Data Mining Tools an Data-Warehouse-Systeme, und Abschnitt 6.2 beschreibt zwei grundlegende Realisierungs-formen.
6.1 Anbindung von Data Mining Tools an Data-Warehouse-Systeme
Die Verfügbarkeit von Verfahren der Datenmustererkennung ergänzt die Menge „klassischer“ Datenanalyse-Werkzeuge um die Möglichkeit der Durchführung daten-getriebener Untersuchungen und steigert damit die Nutzenpotenziale eines Data-Warehouse-Systems. Andererseits ergeben sich auch aus der Sicht des Data Mining Vorteile durch die Verwendung eines Data Warehouse als Datenquelle. Die folgende Aufstellung vermittelt einen Überblick über die durch eine Anbindung realisierbaren Nutzeffekte.
• Um die im Data Warehouse verfügbaren Daten in nutzbare Informationen zu transformieren und den Entscheidungsträgern zugänglich zu machen sind Daten-manipulations- und Analysesysteme erforderlich [DEVL97, 21]. Data-Mining-Systeme bilden eine Klasse solcher Werkzeuge, die nach Ansicht von CABENA ET AL. Die logische Fortsetzung der Bemühungen zur Steigerung des Nutzens der in Data Warehouses gesammelten großen Datenmengen darstellen. Mit zunehmenden Datenvolumina erwächst die Notwendigkeit nach datengetriebenen Mechanismen zur Extraktion und „Filterung“ interessanter Informationen als Ergänzung hypo-thesengetriebener Untersuchungsansätze [CHS+97, 20].
• Nutzen Data-Mining-Systeme Data Warehouses als Untersuchungsdatenquelle, werden die operativen Datenbanksysteme nicht durch ressourcenintensive Anfrageoperationen belastet. Operative Anwendungssysteme sind für die zeitnahe Verarbeitung wert- und mengenorientierter Daten aus Geschäftsvorfällen optimiert. Greifen Analysesysteme direkt auf sie zu, so sind Performanz und Antwortzeitverhalten der operativen Anwendungen gefährdet, da analytische Anfragen typischerweise sehr rechenintensiv sind [KRWZ98, 41, 53]. Umgekehrt können bei dieser Architektur auch keine vertretbaren Antwortzeiten der analytischen Systeme gewährleistet werden, da operative Datenbanksysteme nicht für Ad-hoc-Anfragen, wie sie für analytische Zwecke kennzeichnend sind, ausgelegt sind [KEFI99, 78].

110
• Aufgrund der Tatsache, dass der größte Anteil des Aufwandes für Data-Mining-Untersuchungen auf die Datenvorverarbeitung entfällt (vgl. Abschnitt 5.2.3.5), bietet die Verwendung eines Data Warehouse als Datenquelle für die Datenmustererkennung erhebliche Synergieeffekte. Die dort verfügbaren Daten haben einen Großteil der notwendigen Vorbereitungsschritte bereits an der Eingangsschnittstelle des Data Warehouse durchlaufen [SCBA99, 66]. Die Verfügbarkeit einer zuverlässigen, konsolidierten und bereinigten Datenbasis ist unabdingbare Voraussetzung für die Einführung des Knowledge Discovery in Databases als etablierten, jederzeit wiederholbaren Prozess und erweist sich aus Kostengesichtspunkten wesentlich günstiger als der direkte Zugriff auf isolierte (operative) Datenbestände, die erst aufwendigen Manipulationsmaßnahmen zu unterziehen sind [KRWZ98, 52].
• Wie erwähnt bedarf Data Mining nicht notwendig der Verfügbarkeit eines Data Warehouse, da die Güte der Analyseergebnisse nicht vom zugrunde liegenden Konzept der Datenversorgung, sondern ausschließlich von der Qualität der Analysedaten abhängig ist [KÜPP99, 44]. Durch die Bereitstellung bereits bereinigten und konsolidierten Datenmaterials bietet das Data-Warehouse-Konzept aber ideale Vor-aussetzungen für zuverlässige Untersuchungsresultate [KRWZ98, 54; ADZA96, 84].
• Data Warehouses stehen grundsätzlich allen Management-Funktionen als Grundlage ihrer Entscheidungsfindung zur Verfügung. Hieraus erwächst die Möglichkeit, die durch Data Mining gewonnenen Erkenntnisse in die betriebliche Organisation zu propagieren und für alle interessierten Entscheidungsträger bereitzustellen. Hierfür müssen die Analyseergebnisse in geeigneter Weise im Data Warehouse gespeichert werden [CHS+97, 21].
• Die direkte Anbindung eines Data Mining Tools an ein Data-Warehouse-System ermöglicht insbesondere die Realisierung des in Abschnitt 3.2.3 diskutierten Daten-analysezyklus. Die im Data Warehouse verfügbaren Datenbestände können von allen angekoppelten Analysewerkzeugen genutzt werden. Mittels Data Mining ermittelte Hypothesen lassen sich in einem weiteren Schritt sofort anhand derselben Datenbasis durch hypothesengetriebene OLAP-Untersuchungen verifizieren. Durch die Möglichkeit der beliebigen Verkettung von Untersuchungssituationen können die Potenziale des Datenanalysezyklus in großer Breite ausgeschöpft werden.
• Im Falle einer Anbindung haben Data-Mining-Prozesse auf sämtliche im Data Warehouse verfügbaren Datenbestände Zugriff. Hierzu gehören insbesondere auch aggregierte Daten und Hierarchiestrukturinformationen [KRWZ98, 53].

111
6.2 Alternative Formen der Anbindung
Data Mining Tools sind als Datenanalysesysteme prinzipiell in die Datenbereitstellungs-ebene des Data-Warehouse-Architekturmodells einzuordnen [BÖUL00, 17, 25f.]. Die Durchführung der Datenmustererkennung auf Datenbeständen des Data Warehouse kann hierbei auf zwei grundlegende Arten erfolgen, nämlich einerseits durch direkten Zugriff der Analysealgorithmen auf die Datenbank und andererseits durch Extraktion relevanter Daten und Zwischenspeichern dieser Extrakte [ADZA96, 29]. Im zweiten Fall operieren die Verfahren nicht physisch auf dem Data Warehouse, sondern auf eigens generierten Analysedateien.
Wenngleich auf dem Markt verfügbare Data-Mining-Werkzeuge den direkten Zugriff auf Datenbanken ermöglichen, so erscheint die zweite der beschriebenen Alternativen aus heutiger Sicht als zweckmäßiger. KRAHL ET AL. Empfehlen die Verwendung des indirekten Zugriffs nicht zuletzt aus Performanzgesichtspunkten. Weiterhin erfordert die im Zuge des Knowledge Discovery in Databases notwendige Datenmanipulation und die damit einher gehende Erstellung analysespezifischer Datenstrukturen sowie eine gegebenenfalls nötige Stichprobenziehung ohnehin eine Zwischenspeicherung, die in Form relationaler Datenbanktabellen nur mit Einschränkungen sinnvoll erscheint [KRWZ98, 43]. Andererseits ist bereits abzusehen, dass die Datenmustererkennung und das On-Line Analytical Processing zunehmend verschmelzen und „Data Mining Engines“ künftig Bestandteil eines Data-Warehouse-Systems sein werden.48 Hierbei darf jedoch keinesfalls die für die Durchführung von Datenanalysen erforderliche Flexibilität verloren gehen.
48 Vgl. hierzu den Hinweis bei [AMS+96A] sowie die Diskussion möglicher Alternativen bei [SATA98].

112
7 Ausblick Data Mining kann ohne Bezugnahme auf konkrete Untersuchungsverfahren als datengetriebene Form der Datenanalyse angesehen werden. Erst durch konsequente Nutzung dieses Ansatzes und Kombination mit hypothesengetriebenen Untersuchungs-ansätzen lassen sich die Potenziale, die sich durch die Analyse großer betriebs-wirtschaftlicher Datenbestände ergeben, richtig ausschöpfen. Datenanalysen führen nur durch organisatorische Einbettung in einen übergeordneten Prozess der Wissensentdeckung zu nutzbaren Ergebnissen, der durch erhebliche Komplexität gekennzeichnet ist und neben der eigentlichen Analyse eine Reihe weiterer Aufgaben umfasst.
Dieser Beitrag vermittelt einen umfassenden Überblick über den Data-Mining-Ansatz und behandelt zusätzlich die zur Lösung betriebswirtschaftlicher Probleme relevanten prozeduralen und organisatorischen Aspekte. Auf eine Vielzahl weiterer Probleme und Schwierigkeiten kann im Rahmen eines solchen Überblicks jedoch nur hingewiesen werden. Zudem ist eine Reihe bedeutender Problemfelder bislang nicht oder nur unzureichend behandelt worden, so dass erheblicher weiterer Forschungsbedarf besteht.
Beispiele hierfür sind � die Untersuchung der Auswirkungen mangelhafter Abläufe und nicht qualitäts-
gesicherter Vorgänge in der betrieblichen Praxis auf die Datenqualität und damit auch auf die Ergebnisse der Datenanalyse, � die systematische Ablage von Analyseergebnissen zur weiteren Nutzung, z.B. in
einem Data Warehouse, � die Frage der Effizienz von Datenanalyseprozessen im Allgemeinen und des Data
Mining im Speziellen, � die Unterstützung des Anwenders durch ergonomische Nutzerschnittstellen, sowie � die Konzeption und Entwicklung von Anwendungssystemen zur Datenanalyse in
abgegrenzten Domänen oder für Klassen spezifischer Untersuchungsprobleme.

113
Literatur ADZA96 Adriaans, P.; Zantinge, D.: Data Mining, Harlow 1996.
AMS+96A Agrawal, R.; Mehta, M.; Shafer, J.; Srikant, R.; Arning, A.; Bollinger, T.: The
Quest Data Mining System, http:/ www.almaden.ibm.com/cs/quest/papers/kdd96_quest.pdf, 1996 (15.02.1999).
AMS+96B Agrawal, R.; Mannila, H.; Srikant, R.; Toivonen, H.; Verkamo, A. I.: Fast Discovery of Association Rules, in: [FPSU96], S. 307-328.
BELI97 Berry, M. J. A.; Linoff, G.: Data Mining Techniques – For Marketing, Sales, and Customer Support, New York 1997.
BIGU96 Bigus, J. P.: Data Mining with Neural Networks – Solving Business Problems from Application Development to Decision Support, New York 1996.
BIHA93 Bissantz, N.; Hagedorn, J.: Data Mining (Datenmustererkennung), in: Wirtschaftsinformatik 35 (1993) 5, S. 481-487.
BISS96 Bissantz, N.: CLUSMIN – Ein Beitrag zur Analyse von Daten des Ergebniscontrollings mit Datenmustererkennung (Data Mining), Arbeitsberichte des Instituts für mathematische Maschinen und Datenverarbeitung 29 (1996) 7, Erlangen 1996.
BOLL96 Bollinger, T.: Assoziationsregeln – Analyse eines Data Mining Verfahrens, in: Informatik-Spektrum 19 (1996) 5, S. 257-261.
BÖUL00 Böhnlein, M.; Ulbrich-vom Ende, A.: Grundlagen des Data Warehousing – Modellierung und Architektur, Bamberger Beiträge zur Wirtschaftsinformatik 55, Bamberg 2000.
CCK+00 Chapman, P.; Clinton, J.; Kerber, R.; Khabaza, T.; Reinartz, T.; Shearer, C.; Wirth, R.: CRISP-DM 1.0 – Step-by-Step Data Mining Guide, http://www.crisp-dm.org/CRISPWP-0800.pdf, 2000 (28.10.2000).
CEMC95 Celko, J.; McDonald, J.: Don’t Warehouse Dirty Data, in: Datamation 41 (1995) 19, S. 42-53.
CHBU97 Chamoni, P.; Budde, C.: Methoden und Verfahren des Data Mining, Diskussionsbeiträge des Fachbereichs Wirtschaftswissenschaft der Gerhard-Mercator-Universität Gesamthochschule Duisburg 232, Duisburg 1997.
CHGL99 Chamoni, P.; Gluchowski, P. (Hrsg.): Analytische Informationssysteme – Data Warehouse, On-Line Analytical Processing, Data Mining, 2. Auflage, Berlin 1999.
CHS+97 Cabena, P.; Hadjinian, P.; Stadler, R.; Verhees, J.; Zanasi, A.: Discovering Data Mining – From Concept to Implementation, Upper Saddle River 1997.
DEGE99 Degen, M.: Statistische Methoden zur visuellen Exploration mehrdimensionaler Daten, in: [CHGL99], S. 393-414.

114
DEVL97 Devlin, B.: Data Warehouse – From Architecture to Implementation, Reading 1997.
DHST97 Dhar, V.; Stein, R.: Seven Methods for Transforming Corporate Data into Business Intelligence, Upper Saddle River 1997.
FAPS96 Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P.: From Data Mining to Knowledge Discovery: An Overview, in: [FPSU96], S. 1-34.
FAUT95 Fayyad, U.; Uthurusamy, R. (Hrsg.): Proceedings of The First International Conference on Knowledge Discovery & Data Mining (August 1995), Montréal 1995.
FERS79 Ferstl, O. K.: Konstruktion und Analyse von Simulationsmodellen, Beiträge zur Datenverarbeitung und Unternehmensforschung 22, Königstein/Ts. 1979.
FESI01 Ferstl, O. K.; Sinz, E. J.: Grundlagen der Wirtschaftsinformatik, Band 1, 4. Auflage, München 2001.
FPSU96 Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P.; Uthurusamy, R. (Hrsg.): Advances in Knowledge Discovery and Data Mining, Menlo Park 1996.
FRPM91 Frawley, W. J.; Piatetsky-Shapiro, G.; Matheus, C. J.: Knowledge Discovery in Databases: An Overview, in: Piatetsky-Shapiro, G.; Frawley, W. J. (Hrsg.): Knowledge Discovery in Databases, Menlo Park 1991, S. 1-27.
GEBH94 Gebhardt, F.: Interessantheit als Kriterium für die Bewertung von Ergebnissen, in: Informatik Forschung und Entwicklung 9 (1994) 1, S. 9-21.
GOSE95 Goldberg, H. G.; Senator, T. E.: Restructuring Databases for Knowledge Discovery by Consolidating and Link Formation, in: [FAUT95], S. 136-141.
GRRU98 Grabmeier, J.; Rudolph, A.: Techniques of Cluster Algorithms in Data Mining, Version 2.0, IBM Informationssysteme GmbH, o. O. 1998.
HAGE96 Hagedorn, J.: Die automatische Filterung von Controlling-Daten unter besonderer Berücksichtigung der Top-Down-Navigation (BETREX II), Arbeitsberichte des Instituts für mathematische Maschinen und Datenverarbeitung 29 (1996) 7, Erlangen 1996.
HOSI94 Holsheimer, M.; Siebes, A.: Data mining: the search for knowledge in databases, Centrum voor Wiskunde en Informatica (CIW) Amsterdam, Report CS-R9406 1994, ftp://ftp.cwi.nl/pub/CWIreports/AA/CS-R9406.ps.Z, 1994 (15.02.1999).
HSKN95 Hsu, C.-N.; Knoblock, C. A.: Estimating the Robustness of Discovered Knowledge, in: [FAUT95], S. 156-161.
HÜTT97 Hüttner, M.: Grundzüge der Marktforschung, 5. Auflage, München 1997.
IBM96 o. V. (IBM Corp.): IBM's Data Mining Technology, IBM Data Management Solutions White Paper, http://www.software.ibm.com/data/pubs/papers/datamine.pdf, 1996 (15.02.1999).

115
KEFI99 Kemper, H.-G.; Finger, R.: Datentransformation im Data Warehouse – Konzeptuelle Überlegungen zur Filterung, Harmonisierung, Verdichtung und Anreicherung operativer Datenbestände, in: [CHGL99], S. 77-94.
KRWZ98 Krahl, D.; Windheuser, U.; Zick, F.-K.: Data Mining – Einsatz in der Praxis, Bonn 1998.
KÜPP99 Küppers, B.: Data Mining in der Praxis – Ein Ansatz zur Nutzung der Potentiale von Data Mining im betrieblichen Umfeld, Frankfurt/M. 1999.
MART97 Martin, W.: Data Warehousing und Data Mining – Marktübersicht und Trends, in: Mucksch, H.; Behme, W. (Hrsg.): Das Data Warehouse-Konzept: Architektur – Datenmodelle – Anwendungen, 2. Auflage, Wiesbaden 1997, S. 119-133.
MART98 Martin, W.: Data Warehouse, Data Mining und OLAP: Von der Datenquelle zum Informationsverbraucher, in: Martin, W. (Hrsg.): Data Warehousing – Data Mining – OLAP, Bonn 1998, S. 19-37.
MATT96 Mattison, R.: Data Warehousing – Strategies, Technologies, and Techniques, New York 1996.
MICH98 Michels, E.: Data Mining-Analysen im Handel. Aufspüren und Nutzen von Informationen zu Cross Selling und Kundensegmentierung, in: Hummeltenberg, W. (Hrsg.): Information Management for Business and Competitive Intelligence and Excellence, Proceedings der Frühjahrstagung Wirtschaftsinformatik `98 (Braunschweig), Wiesbaden 1998, S. 185-190.
MUBE00 Mucksch, H.; Behme, W.: Das Data Warehouse-Konzept als Basis einer unternehmensweiten Informationslogistik, in: Mucksch, H.; Behme, W. (Hrsg.): Das Data Warehouse-Konzept: Architektur – Datenmodelle – Anwendungen, 4. Auflage, Wiesbaden 2000, S. 3-80.
OPPE95 Oppelt, R. U. G.: Computerunterstützung für das Management – Neue Möglichkeiten der computerbasierten Informationsunterstützung oberster Führungskräfte auf dem Weg von MIS zu EIS?, München 1995.
RUNK00 Runkler, T. A.: Information Mining – Methoden, Algorithmen und Anwendungen intelligenter Datenanalyse, Braunschweig, Wiesbaden 2000.
SAAR98 Saarenvirta, G.: Mining Customer Data – A step-by-step look at a powerful clustering and segmentation methodology, DB2 Magazine online, http://www.db2mag.com/98fsaar.html, 1998 (14.06.1999).
SATA98 Sarawagi, S.; Thomas, S.; Agrawal, R.: Integrating Association Rule Mining with Relational Database Systems: Alternatives and Implications, in: Proceedings of ACM SIGMOD International Conference on Management of Data (June 1998), Seattle 1998, S. 343-354.
SCBA99 Schinzer, H. D.; Bange, C.: Werkzeuge zum Aufbau analytischer Informationssysteme – Marktübersicht, in: [CHGL99], S. 45-74.
SCHW99 Schweizer, A.: Data Mining, Data Warehousing – Datenschutzrechtliche Orientierungshilfen für Privatunternehmen, Zürich 1999.

116
SILK95 Simoudis, E.; Livezey, B.; Kerber, R.: Using Recon for Data Cleaning, in: [FAUT95], S. 282-287.
SITU95 Silberschatz, A.; Tuzhilin, A.: On Subjective Measures of Interestingness in Knowledge Discovery, in: [FAUT95], S. 275-281.
STMI98 Ströhl, E.; Michels, E.: Retouren- und Kundenverhalten mit Data Mining analysieren – Baur Versand, Burgkunstadt, in: EuroHandelsinstitut e.V. (EHI) (Hrsg.): Enzyklopädie des Handels: Data Warehouse – Bestandsaufnahme und Perspektiven, Köln 1998, S. 34-37.

Arbeitskreise der Fachgruppe 5.10Arbeitskreis AK 5.10.2: Zeitorientierte betriebliche Informations-systeme (ZobIS) Prof. Dr. Gerhard Knolmayer Institut für Wirtschaftsinformatik Engehaldenstr. 8 CH 3012 Bern Tel.: 0041 31/631-3809 e-mail: [email protected]
Arbeitskreis AK 5.10.4: Modellierung und Nutzung von Data Warehouse-Systemen Prof. Dr. Elmar J. Sinz Universität Bamberg Feldkirchenstr. 21 96045 Bamberg Tel.: 0951/863-2512 e-mail: [email protected]
Arbeitskreis AK 5.10.3: Komponentenorientierte betriebliche Anwendungssysteme Dr. Klaus Turowski Otto-von-Guericke Universität Magdeburg Arbeitsgruppe Wirtschaftsinformatik Postfach 4120 39016 Magdeburg Tel.: 0391/6718386 e-mail: [email protected]
Hinweise für Autoren Veröffentlichungssprachen sind entweder Deutsch oder Englisch. Der Umfang sollte sechs A4-Seiten (einschließlich Bildern) nicht überschreiten. Die Seitenbegrenzungen sollen von oben 2,5 cm von rechts, links und unten 2 cm betragen. Von der Benutzung von Seitennummern, Kopf- und Fußzeilen ist abzusehen. Die Numerierung soll mit Bleistift auf der Rückseite erfolgen. Als Schriftart soll eine 12-Punkt Times-Roman benutzt werden. Dies gilt nicht für die Überschriften. Der Zeilenabstand beträgt 1,5 Zeilen. Der Text soll numerisch gegliedert sein. Das Instrumentarium der Mathematik soll soweit Verwendung finden, als es sich um formale Zusammenhänge handelt. Daneben ist jedoch eine verbale Kommentierung wichtiger Aussagen erwünscht. Bilder sollen numeriert und mit Unterschriften versehen sein.
Literaturhinweise werden im Text durch eine sechs- bis siebenstellige Kurzbezeichnung in eckigen Klammern gekennzeichnet und am Ende des Beitrags zusammengefaßt. Die Kurzbezeichnung setzt sich aus den Zunamen der Autoren und dem Erscheinungsjahr zusammen. Zur Unterscheidung mehrerer gleicher Kurzbezeichnungen kann ein Kleinbuchstabe angehängt werden. Beispiel:
[FeSi90] Ferstl, Otto K.; Sinz, Elmar J.: Ein Vorgehensmodell zur Objektmodellierung betrieblicher Informationssysteme im semantischen Objektmodell (SOM), In: Wirtschaftsinformatik, 33 (1991) 6, S. 477-491.
Jedem Beitrag sollen vorangestellt sein: - Titel (deutsch oder englisch), - Autorennamen mit vollen Vornamen und akademischen Graden, - Anschrift der Autoren zur Veröffentlichung (möglichst Firma/Institut), - Zusammenfassung (eine halbe Seite, deutsch oder englisch).





























