Embed Size (px)
Citation preview

SAS
Statistical Analysis System
Eine erste anwendungsorientierte
Einfuhrung fur OkonometrikerDatum dieser Version: 5. Dezember 2002
Dipl.-Volksw. Marco CaliendoDipl.-Volksw. Dubravko RadicDipl.-Volksw. Stephan L. ThomsenLehrstuhl fur Statistik und Okonometrie
(Empirische Wirtschaftsforschung)
Johann Wolfgang Goethe-Universitat
Frankfurt/M.

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Inhaltsverzeichnis
1. Einfuhrung 4
2. Aufbau von SAS 6
1. Datenmanagement in SAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2. Einlesen und Formatieren von Daten . . . . . . . . . . . . . . . . . . . . . . . . . 7
3. Bearbeiten von Daten, Erzeugen und Transformieren von Variablen . . . . . . 9
4. Bedingte Ausfuhrung von Befehlen im DATA-Step . . . . . . . . . . . . . . . . . 11
5. Datenausgabe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3. Prozedur SQL 14
1. Abfragebefehl SELECT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2. Abfrage Operationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3. Statistische Funktionen in SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4. Where Bedingung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5. Zusammenfugen von Datensatzen . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4. Graphische Aufbereitung 20
5. Deskriptive Auswertungen 21
6. Lineare Regression 23
7. Prozedur PROBIT 25
1. SAS-Besonderheiten - Umkodieren der abhangigen Variable . . . . . . . . . . 27
2. Optionale Ausgestaltung des Schatzverfahrens . . . . . . . . . . . . . . . . . . 27
3. Das Output-Fenster bei der PROBIT-Prozedur . . . . . . . . . . . . . . . . . . . . 28
4. Beispiel: Schatzung der Kaufwahrscheinlichkeit fur ein Produkt . . . . . . . . . 29
8. Prozedur MODEL 30
1. Einfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2. Festlegung der Variablen und der Struktur des Modells . . . . . . . . . . . . . . 31
3. Schatzung des Modells (Fit) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4. Prognose und Simulation mit dem Modell (Solve) . . . . . . . . . . . . . . . . . . 34
2

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
9. Prozedur ARIMA 36
1. Einfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2. Analyse der Zeitreihe mit Identify . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3. Schatzung des Modells (Fit) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
10.Prozedur AUTOREG 39
1. Einfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2. Testen auf Autokorrelation mittels Generalized Durbin-Watson Teststatistiken . 41
3. Testen auf Heteroskedastie mittels Portmanteau Q-Teststatistiken . . . . . . . . 41
4. Schatzung des Modells mit autokorrelierten Residuen und GARCH-Effekt . . . 42
11.Prozedur TSCSREG 42
1. Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2. Schatzmethode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3. Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4. Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
12.Prozedur LIFETEST 49
1. Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2. Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3. Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
13.Prozedur PHREG 53
1. Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2. Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3. Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
14.Ubungsaufgaben 60
1. Quantitative Methoden der Volkswirtschaftslehre . . . . . . . . . . . . . . . . . 60
2. Grundlagen der Okonometrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3. Mikrookonometrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4. Finanzokonometrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
1. Einfuhrung
Bei SAS (Statistical Analysis System) handelt es sich um ein 1970 entwickeltes Statistik-
programm, mit dem nahezu alle in empirischen und okonometrischen Fragestellungen
anfallenden Probleme gelost werden konnen. Durch die Integration von SQL und der
Moglichkeit der Makroisierung von Programmablaufen, ist es daruber hinaus moglich,
das Programm individuellen Bedurfnissen anzupassen.
Erweiterungen des Basisprogramms, wie z.B. der”Enterprise Miner“, sorgen dafur, dass
auch unternehmensrelevante Fragestellungen (Marketing, Data Warehouse, Data Mining,
etc.) erledigt werden konnen. Dieses Skript dient als Kurzeinfuhrung in das Programm und
ist zugleich Grundlage fur die vorlesungsbegleitenden Ubungen in”Quantitative Metho-
den der Volkswirtschaftslehre“,”Grundlagen der Okonometrie“,
”Mikrookonometrie“ und
”Finanzokonometrie“. Das Skript ist modular aufgebaut und sollte chronologisch abgear-
beitet werden. Jeder Programmpunkt wird anhand von Datensatzen erlautert, die in Ka-
pitel 14. naher beschrieben sind und jedem Interessierten zur Verfugung gestellt werden.
Das Skript bezieht sich auf die Programmversion 8.2; leichte Abweichungen zu anderen
Versionen lassen sich nicht vermeiden. Als Literaturempfehlungen seien neben der ca.
2000 Seiten umfassenden SAS-Dokumentation folgenden Quellen genannt:
• Batz, Wolf-Dieter: Das SAS-Survival-Handbuch - Eine praxisorientierte Einfuhrung, Sprin-
ger-Verlag, 1995.
• Ortseifen, Carina: Der SAS Kurs - Eine leicht verstandliche Einfuhrung, Thomson Ver-
lag, Bonn u.a., 1997.
• Gottsche, Thomas: Einfuhrung in das SAS-System fur den PC, Gustav Fischer-Verlag,
Stuttgart, 1990.
• Falk, M., Becker, R., Marohn, F.: Angewandte Statistik mit SAS - Eine Einfuhrung, Sprin-
ger Verlag, Berlin u.a., 1995.
• Delwiche, Lora D., Susan, J. Slaughter: The little SAS Book - A primer, SAS Institute Inc.,
Cary, 1999.
Genau wie dieses Skript, konnen auch dieses Bucher nur sehr kleine Bereiche des SAS-
Programms darstellen. Fur eine ausfuhrliche Darstellung wird auf die SAS-Dokumentation
verwiesen. Daruber hinaus gibt es in SAS auch eine ausfuhrliche Hilfefunktion, die in An-
spruch genommen werden sollte.
SAS kann auf zwei Arten genutzt werden: Zum einen kann die SAS eigene Programmier-
sprache verwendet werden, um empirische Analysen durchzufuhren. Einfachere Statisti-
ken konnen aber auch mit Hilfe von SAS ASSIST erstellt werden, der eine einfache menuge-
steuerte Benutzeroberflache, ahnlich wie in SPSS, bereitstellt.
Der geneigte Leser mag sich fragen, warum wir uns dazu entschlossen haben, im folgen-
den die wichtigsten Elemente der SAS Programmiersprache darzustellen und nicht naher
auf den einfacher zu bedienenden SAS ASSIST eingehen. Wir sind davon uberzeugt, dass
die Notwendigkeit, bei empirischen Analysen eigene Programme schreiben zu mussen
eine Reihe von Vorteilen bietet.
4

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Sie tragt zum einen zu einer Klarung der Gedanken bei. Der Anwender wird gezwungen
die einzelnen Schritte bei seiner empirischen Analyse genau zu uberdenken, bevor er
sie implementiert. Ein weiterer Vorteil ist die Nachvollziehbarkeit: Sowohl der Nutzer selbst
als auch weitere Personen, die die Programmiersprache kennen, konnen nachvollziehen,
was mit den einzelnen Bestandteilen des Programms bezweckt wurde, um so die Ergeb-
nisse besser interpretieren zu konnen. Ein weiterer Grund, der fur die Erlernung der SAS
Programmiersprache spricht, ist die Tatsache, dass kompliziertere Analysen nicht mit mit
SAS ASSIST zu bewerkstelligen sind.
Zum besseren Verstandnis werden SAS-Befehlszeilen nachfolgend in courier dargestellt.
Erklarungen zur Syntax sind mit dem Icon gekennzeichnet. Zusatzlich werden alle Be-
fehlszeilen, die sich auf einen Beispieldatensatz beziehen und die ausgefuhrt werden sol-
len in einen Kasten gesetzt. Datensatze, auf die in diesem Skript eingegangen wird, eben-
so wie Beispielprogramme und weitere Unterlagen, sind auf unserer Homepage erhalt-
lich:http://www.wiwi.uni-frankfurt.de/Professoren/hujer/. Folgen Sie den Links, die auf die
einzelnen Vorlesungen bzw. Ubungen hinweisen.
Unser Dank gilt Paulo Rodrigues, der das Skript in LATEX umgesetzt hat.
5

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
2. Aufbau von SAS
Nach dem Starten von SAS erscheinen drei Fenster. Im OUTPUT-Fenster werden die Ergeb-
nisse der aufgerufenen Prozeduren angezeigt. Im LOG-Fenster zeigt SAS Informationen
uber die Abarbeitung der einzelnen Schritte des SAS-Programms (=SAS-Job) an. Neben
der Zeit, die ein Job benotigt hat, wird hier auch angezeigt, ob bei der Abarbeitung Fehler
(und wenn ja, welche) aufgetreten sind.
An dieser Stelle soll auf die”SAS-Farbenlehre“ eingegangen werden: Blau, so wird jeder
SAS Nutzer bald feststellen, ist dabei die angenehmste und beruhigendste Farbe, zeigt
sie doch an, dass das Programm ohne weitere Probleme abgearbeitet wurde. Mit grun
werden Warnungen angezeigt, die jedoch nicht so gravierend waren, als das sie zu einem
Abbruch des Programms gefuhrt hatten. Mit rot hingegen werden schwerwiegende Fehler
ausgegeben, die schließlich zu einem Abbruch des Programms gefuhrt haben.
In den PROGRAM-EDITOR (PGE) werden die Programmzeilen geschrieben und abgespei-
chert. Zum Abspeichern von Programmzeilen ist es wichtig, dass das PGE-Fenster aktiviert
ist, da sonst evtl. der Inhalt eines anderen Fenster abgespeichert wird und die Programm-
zeilen verloren sind. Will man eine Programmzeilen laufen lassen, markiert man die ent-
sprechenden Stellen und druckt F3 oder die RUN-Taste.
Alle Befehle in der SAS-Kommandosprache sind grundsatzlich mit einem Semikolon ab-
zuschließen. Will man die Befehlszeilen kommentieren (was sehr zu empfehlen ist), muss
man mit der Zeichenkombination /* beginnen und der Zeichenkombination */ enden.
Beispiel:
/* Dies ist ein Kommentar */
1. Datenmanagement in SAS
Daten werden von SAS, ahnlich wie in EXCEL, in Tabellen abgelegt. In den Zeilen stehen
die Beobachtungen (z.B. fur einzelne Jahre) wahrend die Spalten die Variablen (z.B. Brut-
tosozialprodukt, Konsum) angeben. In SAS werden diese Tabellen DATASETS oder synonym
TABLES genannt.
Beispiel:
sasdat.uebung1
/* Die Library sasdat enthalt einen SAS dataset mit dem Namen uebung1 */
Lasst man den Librarynamen weg, wird ein temporares, voreingestelltes Arbeitsverzeich-
nis (WORK) angesprochen. Datasets, die in diesem Verzeichnis gespeichert werden, sind
nach Beendigung der Sitzung verloren!
Die Zuweisung einer LIBRARY zu einem existierenden Pfad auf dem System erfolgt durch
die folgende Syntax:
6

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
LIBNAME sasdat "C:\SASKURS";
/* Die Library sasdat wird dem Verzeichnis C:\SASKURS zugewiesen */
Um zu uberprufen, ob die Zuweisung der Library erfolgreich war, wahlen Sie bitte aus dem
Icon-Menu den Punkt LIBRARIES. Hier sollte nun im linken Fenster die Library sasdat und
der spezifizierte Systempfad zu sehen sein.
2. Einlesen und Formatieren von Daten
Das Einlesen von Daten erfolgt mit einem DATA-step. Dieser DATA-step erzeugt einen neu-
en Datensatz an der definierten Stelle, gibt an, wie viele Variablen eingelesen werden
sollen, ob die Daten bearbeitet werden sollen und auch ob Daten behalten oder gestri-
chen werden sollen.
Der DATA-Step ist als eine”Schleife“ durch den einzulesenden Datensatz zu verstehen. Die
Input-Daten werden zeilenweise eingelesen. Ein RUN-Befehl schließt die Schleife ab. Die
Syntax sieht folgendermaßen aus:
DATA library.dataset;
In der Library sasdat wird ein SAS dataset erzeugt. Der Name kann frei gewahlt
werden, darf aber maximal 8 Zeichen lang sein.
INFILE "rohdatenfile";
INFILE bezeichnet die Datei, in der die Rohdaten im ASCII-Format gespeichert
sind. Der Ausdruck rohdatenfile muss die komplette Pfadangabe enthalten.
FORMAT var1 Formatangabe;
Die FORMAT-Anweisung weist den eingelesenen Variablen eine bestimmtes For-
mat zu. Numerische Variablen werden durch eine Variablen-Lange und die Nach-
kommastellen definiert. Die Zahl 100.334 wurde z. B. mit der Formatangabe 7.3
korrekt angezeigt werden. Der Dezimalpunkt ist bei der Lange mit einzurechnen.
Character (=Zeichen)-Variablen, werden durch das Dollar-Zeichen $ und eine
Langen-Angabe formatiert. Die Zeichenkette NAME kann mit der Formatanga-
be $4 korrekt formatiert ausgegeben werden.
Der FORMAT-Befehl muss dabei immer vor dem INPUT-Befehl stehen, damit die
Formate auch richtig zugeordnet werden.
INPUT var1 var2...;
7

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Mit INPUT werden die Variablen aufgelistet, die in der ASCII-Datei rohdatenfile
enthalten sind. Wichtig ist, dass die Reihenfolge der Variablennamen im INPUT-
Befehl der Reihenfolge der Variablen im rohdatenfile entspricht.
LABEL var1=’Beschreibung der Variable’;
Mit LABEL kann optional eine bis zu vierzig Zeichen lange Variablenbeschreibung
vergeben werden.
RUN;
Der RUN-Befehl schließt den DATA-Step ab.
Nachdem wir nun die Syntax fur das Einlesen und Formatieren von Daten kennen gelernt
haben, wenden wir dieses Wissen auf einen Beispieldatensatz an. Sie benotigen dazu den
ASCII-Datensatz uebung1.prn.
Ubungsaufgabe 1: Einlesen und Formatieren eines ASCII-Datensatzes
1. Erstellen Sie auf Ihrem Rechner ein SAS-Arbeitsverzeichnis, z.B. C:\SASKURS.
2. Kopieren Sie die Datei uebung1.prn in dieses Verzeichnis.
3. Vergeben Sie einen Library-Namen und weisen die Library dem Arbeitsverzeichnis
zu.
LIBNAME sasdat "C:\SASKURS";
4. Lesen Sie den Datensatz uebung1.prn ein, formatieren und benennen Sie die Varia-
blen.
DATA sasdat.uebung1;
INFILE "C:\SASKURS\uebung1.prn";
FORMAT JAHRE 4.0 ECP EIP K X XGNPDM YDH YL YNNI 8.3
LE LSE POP 7.4 LHT 5.0 PXGNP PECP 6.2
RL 5.3 TIME 3.0 UCUM YLA 6.3;
INPUT JAHRE ECP EIP K LE LHT LSE PECP POP PXGNP
RL TIME UCUM X XGNPDM YDH YL YLA YNNI;
LABEL JAHRE = ’Jahre’
ECP = ’Privater Verbrauch (Mrd. DM 1985)’
8

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
EIP = ’Anlageinv. a. Untern. (Mrd. DM 1985)’
K = ’Bruttoanlageverm. insg. (Mrd. DM 1985)’
LE = ’Beschaftige Arbeitnehmer insg. (Mio)’
LHT = ’Arbeitsvolumen insgesamt (Mio Std.)’
LSE = ’Selbstandige und Mithelfende (Mio)’
PECP = ’Impl. Preisindex. priv. Verb.(1985=100)’
POP = ’Wohnbevolkerung (Mio.)’
PXGNP = ’Impliziter Preisindex BSP (1985 = 100)’
RL = ’Langfristiger Zins’
TIME = ’Zeittrend’
UCUM = ’Kapazitatsauslastung insgesamt’
X = ’Bruttowertschopfung (Mrd. DM 1985)’
XGNPDM = ’Bruttosozialprodukt (Mrd. DM)’
YDH = ’Verfugb. Eink. der priv. HH. (Mrd. DM)’
YL = ’Eink. aus unselbst. Arbeit insg.(Mrd.DM)’
YLA = ’Durchsch. Eink. je Beschaftigter(Tsd.DM)’
YNNI = ’Nettosozialp. zu Faktork. (Mrd. DM)’;
RUN;
3. Bearbeiten von Daten, Erzeugen und Transformieren von Variablen
Wahrend wir im letzten Abschnitt einen ASCII-Datensatz in einen SAS-Datensatz umge-
wandelt haben, gehen wir nun davon aus, dass bereits ein SAS-Datensatz vorliegt, den
wir bearbeiten wollen. Dies ist z.B. dann der Fall, wenn wir Variablen aus dem Datensatz
entfernen oder neue Variablen generieren wollen. Zusatzlich zu dem DATA-Step lernen wir
nun den SET-Befehl kennen. Die Syntax sieht folgendermaßen aus:
DATA library.dataset;
Der SAS-dataset library.dataset soll erzeugt werden, bzw. ein bereits vorhandener
SAS-dataset mit diesem Namen soll editiert werden.
SET library.dataset
Falls schon ein SAS-dataset existiert, kann er mit dem Befehl SET direkt angespro-
chen werden. SET bezeichnet den SAS-dataset, aus dem die zu bearbeitenden
Daten entnommen werden sollen.
var1= ...;
9

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Fur die Generierung von Variablen ist eine Reihe von mathematischen/ statisti-
schen Funktionen vorhanden. Zu den validen Operatoren gehoren z.B.: +, - , / ,
LN(var1), EXP(var1), LAG(var1), . . . ; Die Funktion LAG erzeugt aus var1 eine um
eine Beobachtung verzogerte Variable.
DROP var1 var2 ...;
Mit dem Befehl DROP konnen einzelne Variablen aus dem Datensatz entfernt wer-
den.
KEEP var1 var2 ...;
Mit dem Befehl KEEP werden nur die angegebenen Variablen behalten.
Wir verwenden dieses Befehle nun, um aus dem bereits erstellten Datensatz uebung1 die
Kapitalintensitat zu berechnen und diese in einen neuen Datensatz mit dem Namen ue-
bung2 abzuspeichern.
Ubungsaufgabe 2: Berechnung des Indikators Kapitalintensitat in einem neuen Datensatz
1. Erstellen Sie einen neuen Datensatz mit dem Namen uebung2 Benutzen Sie als Da-
tengrundlage den Datensatz uebung1.
2. Berechnen und benennen Sie die Kapitalintensitat.
DATA sasdat.uebung2;
SET sasdat.uebung1;
ki = k/lht;
LABEL ki = ’Kapitalintensitat’;
RUN;
3. Streichen Sie aus dem neuen Datensatz uebung2 alle Variablen bis auf die Kapital-
intensitat.
DATA sasdat.uebung2;
SET sasdat.uebung2;
KEEP ki;
RUN;
10

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
4. Bedingte Ausfuhrung von Befehlen im DATA-Step
In einem DATA-Step lassen sich auch bedingte Transformation durchfuhren. Dies kann z.B.
sinnvoll sein, wenn man Beobachtungen mit bestimmten Eigenschaften selektieren will.
Die Syntax sieht folgendermaßen aus:
IF Bedingung THEN DO;
Befehl_1;
END;
Falls die Bedingung erfullt ist, wird ein bestimmter Befehl 1 ausgefuhrt. Der Befehl 1
wird mit END abgeschlossen.
ELSE DO;
Befehl_2;
END;
Falls die Bedingung nicht erfullt ist, wird stattdessen der Befehl 2 ausgefuhrt.
WHERE Bedingung;
Mit dem WHERE-Befehl konnen Beobachtungen mit bestimmten Eigenschaften se-
lektiert werden.
Die Bedingung kann sich z.B. auf einzelne Beobachtungen beziehen, die mit der System-
variablen N angesprochen werden konnen. N ist 1 fur die erste Beobachtung, 2 fur die
zweite, etc. Wir nutzen diese Syntax nun, um eine Dummy-Variable zu erzeugen und den
Datensatz anhand dieser Dummy-Variable zu splitten.
Ubungsaufgabe 3: Erzeugung einer Dummy-Variablen und Splitten des Datensatzes
1. Erzeugen Sie im SAS-dataset sasubd1 fur die ersten 10 Beobachtungen eine Dummy-
Variable, die den Wert Eins annimmt.
DATA sasdat.uebung1;
SET sasdat.uebung1;
IF _N_<=10 THEN DO;
dummy = 1;
END;
ELSE DO;
dummy = 0;
END;
LABEL dummy = ’Beobachtungen 1-10?’;
RUN;
11

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
2. Erzeugen Sie einen neuen Datensatz uebung3 in dem nur die ersten 10 Beobachtun-
gen enthalten sind.
DATA sasdat.uebung3;
SET sasdat.uebung1;
WHERE dummy=1;
RUN;
Spatestens nachdem man nun zum funften Mal den dataset sasdat.uebung1 angespro-
chen und niedergeschrieben hat, lernt man die Benutzung von Makrovariablen schatzen.
Mit Makrovariablen kann SAS effizienter genutzt werden. Makrovariablen werden mit die-
ser Anweisung erzeugt:
%LET makrovariable = Name der Makrovariablen;
&makrovariable;
Mit dem LET-Befehl wird eine Makrovariable erzeugt, die dann im Programmcode
mit &makrovariable angesprochen werden kann.
Um in unserer Analyse nicht standig den Datensatz sasdat.uebung1 mit Library-Name und
Dataset-Name ansprechen zu mussen, konnten wir die folgende Makrovariable erzeu-
gen:
Ubungsaufgabe 4: Erzeugung einer Makrovariablen
1. Erzeugen Sie fur sasdat.uebung1 eine Makrovariable mit dem Namen Data1. Erzeu-
gen Sie fur die ersten 5 Beobachtungen eine Dummy-Variable, die den Wert Zwei
annimmt.
\%LET Data1=sasdat.uebung1;
DATA &Data1;
SET &Data1;
IF _N_<=5 THEN DO;
dummy2 = 2;
END;
ELSE DO;
dummy2 = 0;
END;
LABEL dummy2 = ’Beobachtungen 1-5?’;
RUN;
12

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
5. Datenausgabe
Nachdem wir zu Beginn dieses Abschnitts aus einem ASCII-Datensatz einen SAS-Datensatz
erstellt haben, wollen wir nun einen SAS-Datensatz als ASCII-Datensatz zur Weiterverarbei-
tung bereitstellen.
Der Vorteil der ASCII-Schreibweise ist, dass sie von nahezu allen anderen Statistik-Pro-
grammen erkannt wird und verarbeitet werden kann. Der Nutzen dieses Befehls ist al-
lerdings in Zeiten von DBMS-Copy begrenzt. Die Ausgabe zur Weiterverarbeitung erfolgt
wiederum in einem DATA-step und ist analog zum Einlesen von ASCII-Daten. Die Syntax:
DATA _NULL_;
Es soll kein SAS-dataset erzeugt werden. Dies wird mit dem dataset-Namen NULL
erreicht.
FILE "rohdatenfile";
FILE bezeichnet die Datei, in der die Rohdaten im ASCII-Format gespeichert sind.
rohdatenfile muss die komplette Pfadangabe enthalten.
PUT var1 var2 ...;
Die Variablen var1 var2 . . . werden in den ASCII-Datensatz geschrieben.
Die Daten konnen dann etwa mit EXCEL wieder eingelesen werden. Wir uben dies mit dem
oben erzeugten dataset uebung3.
Ubungsaufgabe 5: Ausgabe eines Datensatzes im ASCII-Format
1. Schreiben Sie den oben erzeugten Datensatz, in dem nur die ersten 10 Beobachtun-
gen enthalten sind (uebung3), im ASCII-Format raus. Exportieren Sie die Variablen
ECP, EIP und KI.
DATA _NULL_;
SET sasdat.uebung3;
FILE "c:\SASKURS\test1.dat";
PUT ecp eip ki;
RUN;
13

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
3. Prozedur SQL
SQL - Structured Query Language - ist eine international genormte Datenbanksprache.
Sie dient sowohl der Erzeugung als auch der Abfrage von relationalen Datenbanken. In
nahezu jedem Datenverwaltungsprogramm ist eine solche SQL Umgebung implemen-
tiert. Obwohl international nach dem sog. ANSI Standard genormt, gibt es dennoch unter-
schiedliche Features und”Dialekte“ in unterschiedlichen Softwarepaketen. Im folgenden
soll gezeigt werden, wie mit der SQL Prozedur in SAS Datenbankabfragen vorgenommen
und verschiedene relationale Datensatze miteinander verknupft werden konnen.
1. Abfragebefehl SELECT
Mit Hilfe des SELECT Befehls konnen komplexe Abfragen vorgenommen werden. Im fol-
genden sollen nur die wichtigsten Bestandteile des SELECT Befehl innerhalb von SQL dar-
gestellt werden1:
PROC SQL;
Ruft die SQL Umgebung in SAS auf.
SELECT var1 var2 ...;
Enthalt die Liste der ausgewahlten Spalten.
FROM dataset;
Datensatz, auf den zugegriffen werden soll.
WHERE bedingung;
Bedingung, die erfullt sein muss fur die Abfrage.
QUIT;
Da die SQL eine sogenannte interaktive Prozedur ist, muss sie nicht mit RUN gest-
artet werden. Wenn im Code im Anschluss an die Prozedur keine weiteren Aufrufe
(Data-Steps oder andere Prozeduren folgen), muss der Nutzer sie durch den Be-
fehl QUIT beenden.
Im folgenden sollen mit Hilfe einiger Beispiele die Einsatzmoglichkeiten des SELECT Befehls
aufgezeigt werden.
1Fur eine umfassende Einfuhrung in SQL, vgl. Schicker, E. (1999), Datenbanken und SQL, Stuttgart u.a. Aus
diesem Buch ist auch der Beispieldatensatz entnommen
14

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
2. Abfrage Operationen
Die nachfolgenden Beispiele beziehen sich auf den folgenden Datensatz schick.bier:
Nr Sorte Hersteller Typ Anzahl
1 Hell Lammsbrau Trager 12
3 Roggen Thurn&Taxis Trager 10
4 Pils Lowenbrau Trager 22
8 Export Lowenbrau Fass 6
11 Weißbier Paulaner Trager 7
16 Hell Spaten Sixpack 5
20 Hell Spaten Trager 12
23 Hell EKU Fass 4
24 Starkbier Paulaner Trager 4
26 Dunkel Kneitlinger Trager 8
28 Marzen Hofbrau Trager 3
33 Weizen light Lamms Trager 6
36 Pils alkoholfrei Lowenbrau Sixpack 5
39 Weißbier Erdinger Trager 9
47 Pils Bischofshof Fass 3
Ubungsaufgabe 6: SQL Abfragen mit Hilfe des SELECT Befehls
1. Mit dem folgenden Befehl werden aus dem Datensatz schick.bier diejenigen Sorten
(sorte) und derjenige Hersteller (herstell) in dem Output Fenster ausgegeben, auf die
der Typ”Fass“ zutrifft:
PROC SQL;
SELECT sorte, herstell
FROM schick.bier
WHERE typ = "Fass";
QUIT;
Die in WHERE spezifizierten Bedingungen konnen dabei auch mit den logischen Operato-
ren AND, OR, NOT, IN, BETWEEN etc. verknupft werden.
Ubungsaufgabe 7: SQL Abfragen mit Hilfe des SELECT Befehls
15

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
1. In dem folgenden beiden Beispielen werden zunachst Hersteller und Anzahl ausge-
geben, bei denen die beiden Bedingungen”Pils“ und
”Trager“ zutreffen, wahrend
bei dem nachsten Beispiel Sorte, Hersteller und Anzahl ausgegeben werden, fur die
die Anzahl kleiner als vier ist:
PROC SQL;
SELECT herstell, anzahl
FROM schick.bier
WHERE sorte = "Pils" and typ = "Trager";
QUIT;
PROC SQL;
SELECT sorte, herstell, anzahl
FROM schick.bier
WHERE anzahl < 4;
QUIT;
2. Mit IN und BETWEEN werden diejenigen Sorten ausgegeben, bei denen die Anzahl
zwischen drei und vier betragt bzw. drei, vier, funf oder sechs:
PROC SQL;
SELECT * FROM schick.bier
WHERE anzahl between 3 and 4;
QUIT;
PROC SQL;
SELECT * FROM schick.bier
WHERE anzahl IN(3,4,5,6);
QUIT;
3. Daruberhinaus besteht auch die Moglichkeit, nach Stringeintragen in Zeilen zu su-
chen, die mit einem bestimmten vorgegebenen String ubereinstimmen. Mit dem
nachfolgenden Befehl z.B. werden fur alle Spalten (*) diejenigen Zeilen ausgege-
ben, fur die die Bedingung: name enthalt”heinz“ erfullt ist.
PROC SQL;
SELECT * FROM schick.bier
WHERE name CONTAINS "heinz";
QUIT;
Mit den bisherigen Befehlen wurde das Ergebnis der Abfrage lediglich in das Outputfenster
von SAS geschrieben. Mochte man die Ergebnisse in einem neuen Datensatz speichern,
um spater mit ihnen weiterarbeiten zu konnen, muss man die obigen Anweisungen noch
um den Befehl CREATE TABLE erganzen.
16

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Ubungsaufgabe 8: Erzeugen eines neuen Datensatzes in SQL
1. Mit dem nachfolgenden Befehl etwa wird das Ergebnis der select Abfrage in den
neuen Datensatz library.out geschrieben.
PROC SQL;
CREATE TABLE AS SELECT * FROM schick.bier;
WHERE name
CONTAINS "heinz";
QUIT;
3. Statistische Funktionen in SQL
Bei den Select Abfragen besteht die Moglichkeit, vordefinierte arithmetische und statisti-
sche Funktionen zu benutzen, um so neue Variablen zu definieren.
Ubungsaufgabe 9: Artithmetische Funktionen in SQL
1. Mit dem folgenden Befehl etwa wird auf die Datei schick.bier zugegriffen und die
folgenden Spalten ausgegeben: name und dosen, fur diejenigen Zeilen, fur die die
Bedingung Typ =”Sixpack“ erfullt ist. Aus der Spalte anzahl, in der die Anzahl an Six-
packs enthalten ist, entsteht durch die Multiplikation mit sechs die Anzahl an Dosen;
diese Variable wird unter dem Namen dosen abgespeichert:
PROC SQL;
SELECT herstell, 6*anzahl AS dosen
FROM schick.bier;
WHERE typ = "sixpack";
RUN;
In SQL sind daruberhinaus eine Reihe von statistischen Funktionen implementiert: Die Er-
mittlung des Durchschnittswertes uber alle Zeilen erfolgt mit AVG, die Anzahl an Zeilen mit
COUNT, der Maximal- bzw. Minimalwert mit MAX bzw. MIN und der Summenwert uber alle
Zeilen eines Datenfiles mit SUM.
Ubungsaufgabe 10: Statistische Funktionen in SQL
1. Mit dem folgenden Befehl etwa wird die durchschnittliche Anzahl an verschiedenen
Biersorten unter dem Namen avg, die maximale Anzahl unter max und die Anzahl
an verschiedenen Biersorten im Lager unter anzahl ausgegeben:
PROC SQL;
SELECT AVG(anzahl) AS avg, MAX(anzahl) AS max, COUNT(anzahl)
AS anzahl
FROM schick.bier;
QUIT;
17

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
4. Where Bedingung
Mit der WHERE Bedingung kann die Abfrage auf bestimmte Zeilen des Datensatzes be-
schrankt werden, die die where-Bedingung erfullen.
Ubungsaufgabe 11: Bedingte Abfragen mit dem WHERE Befehl in SQL
1. Mit dem folgenden Befehl wird aus der Datei schick.bier die niedrigste Anzahl ermit-
telt, die 5 uberschreitet:
PROC SQL;
SELECT MIN(anzahl);
FROM schick.bier;
WHERE anzahl > 5;
QUIT;
2. Nachfolgend eine Abfrage nach der maximalen Anzahl unter der Gruppe der hellen
Biere (man beachte, dass Stringvariablen, hier also hell, in Klammern gesetzt werden
mussen):
PROC SQL;
SELECT MAX(anzahl) FROM schick.bier;
WHERE sorte = "hell";
QUIT;
5. Zusammenfugen von Datensatzen
Im folgenden wollen wir zeigen, wie man mit SQL verschiedenen separate Datensatze zu
einem neuen Datensatz zusammenfugen kann. Die wichtigste Unterscheidung ist dabei
die zwischen einem sog. INNER und OUTER JOIN. Der Unterschied zwischen diesen beiden
Verknupfungen (joins) soll mit dem folgenden Beispiel verdeutlicht werden.
Gegeben seien zwei Datensatze. Der erste library.tab1 enthalte die beiden Variablen Id
und V1, der zweite library.tab2 die beiden Variablen Id und V2. Diese beiden Datensatze
sollen nun uber die in beiden Datensatzen enthaltene Variable Id verknupft werden. Bei
einem INNER JOIN werden nur diejenigen Individuen in den zu erzeugenden Datensatz
library.neu geschrieben, die sowohl in dem ersten als auch dem zweiten Datensatz ent-
halten sind. Der entsprechende SAS Befehl wurde wie folgt aussehen:
PROC SQL;
CREATE TABLE library.neu AS SELECT
a.Id, a.V1, b.V2
FROM library.tab1 a INNER JOIN library.tab2 b
ON a.id = b.id;
QUIT;
18

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Die neu zu erzeugende Datei enthalt aus der ersten Datei die beiden Variablen Id und V1
und aus dem zweiten Datensatz die Variable V2. Den auszuwahlenden Variablen in der
dritten Zeile werden dabei noch sog. Aliase, in unserem Beispiel die beiden Buchstaben a
und b, vorangestellt. In der vierten Zeile, in der spezifiziert wird, auf welche Datensatze zu-
gegriffen werden soll, muß dabei definiert werden, welche Datei zu welchem Alias gehort.
Das Ergebnis dieser Verknupfung wurde wie folgt aussehen:
ID V1
1 10
2 20
3 30
4 40
5 50
+
ID V2
1 100
2 200
5 500
6 600
=
ID V1 V2
1 10 100
2 20 200
5 50 500
Ein OUTER JOIN wird durch folgenden Befehl ausgefuhrt:
PROC SQL;
CREATE TABLE library.neu AS SELECT
a.id, a.v1, b.v2
FROM library.tab1 a FULL JOIN library.tab2 b
ON a.id = b.id;
QUIT;
Folgendes Ergebnis wird erzeugt:
ID V1
1 10
2 20
3 30
4 40
5 50
+
ID V2
1 100
2 200
5 500
6 600
=
ID V1 V2
1 10 100
2 20 200
3 30 –
4 40 –
5 50 500
6 – 600
19

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Man erkennt, dass die Ergebnisdatei nun alle Individuen enthalt, die in einer der beiden
Dateien auftauchen. Analog arbeitet der LEFT JOIN. Bei einem left join sind in der Ergebnis-
datei alle Individuen enthalten, die in der ersten Datei auftauchen und die entprechenden
Individuen der zweiten Datei.
4. Graphische Aufbereitung
Im folgenden soll mit der Prozedur GPLOT eine Moglichkeit der graphischen Aufbereitung
von Daten, insbesondere Zeitreihen gegeben werden. Die vereinfachte allgemeine Syn-
tax sieht dabei wie folgt aus:
SYMBOL1 V = dot I = spline h = 0.5
Fur jede Zeitreihe, die geplottet werden soll, konnen nach dem SYMBOL Statement
allgemeine Optionen festgelegt werden. SYMBOL1 legt z.B. fur die erste geplottete
Zeitreihe fest, dass die einzelnen Beobachtungen mit Punkten gekennzeichnet
werden sollen. Alternativ konnte hier auch STAR angegeben werden. I = spline
verbindet die einzelnen Punkte mit einer Spline-Funktion. Mit h kann die Dicke
der Linien und Punkte geregelt werden.
PROC GPLOT DATA = library.dataset;
Nach dem DATA Statement wird der Datensatz spezifiziert, der die Variablen
enthalt, die geplottet werden sollen.
PLOT var_y * var_x;
Nach dem PLOT Statement wird mit var y diejenige Variable spezifiziert, die auf
der Y-Achse und mit var x diejenige, die auf der X-Achse abgetragen werden
soll.
PLOT (var_y1 var_y2) * var_x / OVERLAY LEGEND;
Sollen zwei Variablen, z.B. var y1 und var y2, in einer Graphik gegenuber einer
dritten Variablen var x abgetragen werden, so muß zusatzlich noch die Option
OVERLAY spezifiziert werden. LEGEND fordert eine erklarende Legende der einzel-
nen Variablen an.
RUN; QUIT;
20

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Ubungsaufgabe 12: Graphische Aufbereitung
1. Plotten Sie aus dem Datensatz uebung1 die Entwicklung der Variablen ECP im Zeita-
blauf.
PROC GPLOT DATA=sasdat.uebung1;
PLOT ecp * jahre;
RUN; QUIT;
2. Bereiten Sie die zeitliche Entwicklung der Variablen ECP und XGNPDM in einer Gra-
phik auf, verbinden Sie die einzelnen Punkte miteinander und geben Sie auch eine
Legende an.
SYMBOL1 I = spline;
PROC GPLOT DATA=sasdat.uebung1;
PLOT (ecp xgnpdm) * jahre / OVERLAY LEGEND;
RUN; QUIT;
5. Deskriptive Auswertungen
Wir wenden uns nun einem wichtigen Bereich der statistischen Analyse, der Deskription
des vorliegenden Datenmaterials durch die Ermittlung von Kennwerten, zu. Deskriptive
Auswertungen werden in SAS mit Prozeduren (procedures) durchgefuhrt. Der PROC-step
beginnt mit der Anweisung PROC procedurename und endet mit dem RUN-Befehl.Die
Auswahl des geeigneten Verfahrens und die dieses Verfahren umsetzende SAS-Prozedur
hangt u.a. vom Mess- oder Skalenniveau der betrachteten Variablen ab. Bei kategoriel-
len (oder nominalen) Variablen (z.B. Geschlecht oder Wohnort), mochte man Haufigkei-
ten berechnen, wahrend bei stetigen, intervallskalierten Variablen eher der Mittelwert, der
Median und entsprechende Streuungsmaße gefragt sind. Aus der Fulle von Statistikproze-
duren, die das SAS-System bietet, konnen nur einige wenige Prozeduren vorgestellt wer-
den. Mit der Prozedur PROC MEANS oder PROC UNIVARIATE werden Kennwerte berech-
net, Konfidenzintervalle fur den Mittelwert bestimmt, Tests von Mittelwerten gegen einen
festen Wert und der Test auf Normalverteilung durchgefuhrt. Daruber hinaus konnen damit
grafische Darstellungen der empirischen Verteilungen einer Stichprobe erzeugt werden.
Die Prozedur PROC FREQ dient zur Tabulierung von Haufigkeiten und Kreuztabulierungen,
wahrend die Prozedur PROC CORR Zusammenhangsmaße zwischen Variablen berechnet.
Die Syntax:
21

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
PROC MEANS DATA=library.dataset NOPRINT;
CLASS var1;
VAR var1 var2...;
OUTPUT OUT=library.outputname;
In der ersten Zeile wir die MEANS-Prozedur aufgerufen und bestimmt, auf welchen
SAS-dataset sich die Auswertung bezieht. Verwendet man nur die DATA-Option
werden die Standardkennwerte aller numerischen Variablen im OUTPUT-Fenster
aufgelistet. Mit VAR kann man die Auswahl auf einige Variablen beschranken. Mit
der CLASS-Anweisung werden die Kennwerte getrennt fur die Auspragungen der
CLASS-Variablen berechnet. Werden die Kennwerte fur weitere Berechnungen
benotigt, kann man sie mit der Anweisung OUTPUT in einen neuen SAS-dataset
umleiten. Will man die Ergebnisse ausschließlich in einen dataset (und nicht in das
OUTPUT-Fenster) schreiben, erganzt man die erste Programmzeile um den Befehl
NOPRINT.
PROC MEANS DATA=library.dataset [Weitere Optionen];
[NMISS RANGE VAR CLM ALPHA=0.01 T PRT]
Einige weitere interessante Optionen, die dem DATA-Statement (ohne eckige
Klammern) folgen konnen, seien hier erwahnt: NMISS liefert die Anzahl der feh-
lenden Werte, Range informiert uber die Spannweite und VAR liefert die Vari-
anz. Um das 95%-Konfidenzintervall fur den Erwartungswert zu berechnen wird als
Schlusselwort CLM angegeben. Mit der ALPHA-Option lassen sich auch andere
Konfidenzintervalle berechnen. Mit der Option T wird die Teststatistik angefordert
und mit PRT der dazugehorige p-Wert.
PROC UNIVARIATE DATA=library.dataset;
VAR var1...;
Wahrend die MEANS-Prozedur Konfidenzintervalle und Hypothesentests berech-
net, die nur fur normalverteilte Variablen sinnvoll interpretiert werden konnen,
erhalt man mit der UNIVARIATE-Prozedur zusatzliche Kennwerte, die auch fur
nichtnormalverteilte und quantitative Variablen von Bedeutung sind (Median, Mo-
dalwert, Quartile, Quantile, etc...).
PROC FREQ DATA=library.dataset;
TABLES var1 var2 ...;
Mit der FREQ-Prozedur konnen die empirischen Haufigkeiten fur die mit TABLES
spezifizierten Variablen berechnet werden. Man erhalt die absoluten, relativen
und kumulierten Haufigkeiten.
PROC CORR DATA=library.datasetname [SPEARMAN];
VAR var1 var2 var3...;
22

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Mit der CORR-Prozedur konnen verschiedene Zusammenhangsmaße berech-
net und Korrelationen zwischen Variablen genauer untersucht werden. Stan-
dardmaßig (d.h. ohne weitere Angaben) wird der Pearsonsche’ Korrelationsko-
effizient berechnet. Daruber hinaus kann aber auch der Korrelationskoeffizient
nach Spearman mit der Option SPEARMAN (ohne Klammern) berechnet werden.
Ubungsaufgabe 13: Deskriptive Auswertungen
1. Berechnen Sie aus dem Datensatz uebung1 deskriptive Statistiken fur die Variablen
ECP, EIP und XGNPDM. Unterscheiden Sie dabei die ersten 10 Beobachtungen von
dem Rest der Beobachtungen. Schreiben Sie die Ergebnisse in einen neuen dataset
mit dem Namen descrip1.
PROC MEANS DATA=sasdat.uebung1;
CLASS dummy;
VAR ECP EIP XGNPDM;
OUTPUT OUT=sasdat.DESCRIP1;
RUN;
2. Untersuchen Sie den Zusammenhang zwischen den Variablen ECP (Privater Ver-
brauch) und YLA (Durchschn. Einkommen je Beschaftigtem).
PROC CORR DATA=sasdat.uebung 1;
VAR ECP YLA;
RUN;
6. Lineare Regression
Lineare Regressionen werden in SAS mit der Prozedur PROC REG durchgefuhrt. Die Syntax
hierzu sieht folgendermaßen aus:
PROC REG DATA= library.datasetname;
label:MODEL var1 = var2 var3 ....;
Es wird eine lineare Regression mit der abhangigen Variablen var1 und den exo-
genen Variablen var2,var3,.... durchgefuhrt. Das Modell kann optional mit einem
Namen versehen werden (label).
MODEL var1 = var2 var3... /NOINT DW;
23

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Standardmaßig wird eine Regressionskonstante berucksichtigt, die mit der Option
NOINT des MODEL-Befehls unterdruckt werden kann. Außerdem konnen zusatzli-
che Teststatistiken, wie z.B. die Durbin-Watson-Teststatistik d mit der Option DW,
ebenfalls im MODEL-Befehl angefordert werden.
TEST var2=0, var3=var4;
Mochte man bestimmte Hypothesen uber die Parameter simultan uberprufen, al-
so einen F -Test durchfuhren, so lasst sich dies mit dem Befehl TEST erreichen. Die
Hypothese, dass der Parameter von var2 (var3) nicht signifikant von 0 (dem Para-
meter von var4) verschieden ist, wird hier simultan mit einem F -Test gepruft.
RESTRICT var2=2*var3;
Man kann auch bestimmte Parameter mit dem Befehl RESTRICT von vorneherein
restringieren. Der Parameter von var2 wird auf das Zweifache des Parameters von
var3 restringiert.
OUTPUT OUT=library.dataset R=resid P=predic;
Mit dem Befehl OUTPUT kann man Schatzergebnisse fur die weitere Verarbeitung
herausschreiben. Mit dem Keyword OUT wird der neue SAS dataset bezeichnet, in
dem die Regressionsergebnisse abgespeichert werden sollen. Verfugbar sind z.B.
die geschatzten Residuen (R) und die Schatzwerte fur die abhangige Variable (P).
PLOT R.*OBS.;
Mit dem Befehl PLOT konnen außerdem Plots fur bestimmte Schatzergebnisse an-
gefordert werden. Z.B. erzeugt der obige Befehl zusatzlich zu den Schatzergebnis-
sen einen PLOT der geschatzten Residuen uber die Beobachtungen.
Um diese neue Prozedur kennen zu lernen, schatzen wir mit dem Datensatz uebung1 eine
keynesianische Konsumfunktion, bei der der private Verbrauch vom verfugbaren Real-
einkommen abhangt.
Ubungsaufgabe 14: Keynesianische Konsumfunktion
1. Berechnen Sie zunachst aus dem Datensatz uebung1 das verfugbare Realeinkom-
men.
24

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
DATA sasdat.uebung1;
SET sasdat.uebung1;
YDHR = (ydh/pecp)*100;
LABEL YDHR = ’reales verfugbares Einkommen’;
RUN;
2. Schatzen Sie nun die Konsumfunktion, benennen Sie das Modell und berechnen die
DW-Teststatistik. Schreiben Sie die Ergebnisse, inklusive der R- und P-Werte in einen
neuen Datensatz uebung4 und veranschaulichen Sie den Fit der Residuen graphisch.
PROC REG DATA = sasdat.uebung1;
Keynes:MODEL ecp = ydhr / DW;
OUTPUT OUT = sasdat.uebung4 R=Resid P=Predic;
PLOT R.*OBS.;
RUN;
7. Prozedur PROBIT
Fur die Schatzung von Logit- und Probit-Modellen stehen in SAS zwei Prozeduren zur Verfu-
gung. Mit Hilfe der PROBIT-Prozedur konnen dichotome Probit- und Logit-Modelle model-
liert und deren Parameter geschatzt werden, wahrend die LOGISTIC-Prozedur zusatzlich
polytome abhangige Variable berucksichtigt. Wir geben zunachst eine kurze Einfuhrung
in die wichtigsten Befehle der PROBIT-Prozedur, behandeln anschließend ein empirisches
Beispiel, bevor wir im nachsten Kapitel auf die LOGISTIC-Prozedur zu sprechen kommen.
PROC PROBIT DATA = library.datasetname;
CLASS variables;
Mit dem PROC PROBIT Befehl wird die Prozedur gestartet. Innerhalb dieses ersten
Schrittes erfolgt auch die Festlegung des Input-Datensatzes. Der CLASS-Befehl de-
finiert, welche Variable in dem anschließenden Modell die abhangige Variable
ist.
label:MODEL var1 = var2 var3... / Options;
Analog zur linearen Regression kann das Modell auch hier benannt werden. Der
Befehl MODEL initiiert das Modell, wobei var1 die endogene Variable ist und var2,
var3... die exogenen Variablen darstellen. Die abhangige Variable kann auch
als Quotient zweier anderer Variablen spezifiziert werden, z.B. kann eine Variable
Erfolg definiert werden als Erfolg = Treffer/Schusse. Es muss lediglich gewahrleistet
sein, dass der Quotient zwischen null und eins liegt, das also in diesem Fall Treffer
¡ Schusse fur jede Beobachtung gilt. Im Anschluss an den MODEL-Befehl konnen
optionale Einstellungen vorgenommen werden, die nachfolgend erklart werden.
25

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
D = Verteilung;
Nach dem Befehl d = kann eine Verteilungsannahme getroffen werden. Zur Aus-
wahl stehen die Normal- (normal), die logistische (logistic) und die Gompertzver-
teilung (gompertz), wobei die Normalverteilung voreingestellt ist.
C = Schwellenwert;
Dieser Befehl legt einen bestimmten Schwellenwert fest. Voreinstellung ist dabei
ein Schwellenwert von null, so dass z.B. in dem Fall einer dichotomen Variablen Y
diese einen Wert von 1 annimmt, wenn die latente Variable Y* einen Wert großer
null annimmt.
OPTC;
Mit diesem Befehl wird der Schwellenwert als unbekannt betrachtet und innerhalb
des Modells geschatzt.
INVERSECL HPROB=p;
Sollen fur die erste unabhangige Variable Konfidenzintervalle berechnet wer-
den, die fur ein gegebenes Signifikanzniveau zu einem bestimmten Wert fur die
abhangige Variable fuhren, muss der Befehl inversecl verwendet werden. Mit
dem Befehl hprob=p kann dabei ein bestimmtes Signifikanzniveau p vorgegeben
werden, das bei der Berechnung der Konfidenzintervalle verwendet wird. Vorein-
stellung ist dabei ein Signifikanzniveau von 10%.
LACKFIT;
Mit dem Befehl lackfit konnen Gutemaße berechnet und angezeigt werden. Es
werden ein Pearson Chi-Quadrat Test und ein Log-Likelihood-Ratio Test durch-
gefuhrt.
OUTPUT OUT = library.outfile;
Mit dem OUTPUT Befehl wird ein neuer Datensatz generiert, der alle Variablen des
Inputdatensatzes, die geschatzten Wahrscheinlichkeiten (prob), die geschatzten
x′b (xbeta) und die geschatzten Standardfehler (std) enthalt. Der Befehl out = li-
brary.outfile legt den Namen des Outputdatensatzes fest.
26

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
1. SAS-Besonderheiten - Umkodieren der abhangigen Variable
Eine (nicht zu erklarende) Besonderheit von SAS ist, dass im Falle einer abhangigen di-
chotomen Variable die Wahrscheinlichkeit p fur den kleineren und nicht fur den große-
ren Wert der Variablen modelliert wird. Wenn z.B. die Variable die beiden Auspragun-
gen 0 und 1 annehmen kann und ein Schwellenwert von c = 0 unterstellt wird, so gilt:
p = P (Yi = 0) = P (Y ′i ≤ 0) = P (u′
i ≤ x′iβ) = 1 − F (x′
iβ). SAS hingegen schatzt p wie folgt:
p = P (Yi = 0) = F (x′iβ), so dass man als Parametervektor nicht β erhalt, sondern −β. Wenn
man also einen Parameter βk mit negativem Vorzeichen erhalt, so heißt das nicht, dass
die exogene Variable xk c.p. die Wahrscheinlichkeit P (Yi = 1), sondern die Wahrschein-
lichkeit P (Yi = 0) verringert, also die Wahrscheinlichkeit P (Yi = 1) erhoht.
Um eine Aussage treffen zu konnen, ob eine bestimmte exogene Variable xk die Wahr-
scheinlichkeit P (Yi = 1) erhoht, muss das Vorzeichen des entsprechenden β umgekehrt
werden oder man kodiert die abhangige Variable vor Durchfuhrung der Schatzung um.
Handelt es sich um eine dichotome Variable, so muss aus der”0“ eine
”1“ und umgekehrt
aus der”1“ eine
”0“ werden.
Mit den folgenden Programmzeilen kann eine solche Umkodierung erfolgen. In dem Da-
tensatz inputfile, der die abhangige Variable endo enthalt, wird eine neue umkodierte
Variable endo 2 erzeugt:
DATA library.inputfile;
SET library.inputfile;
endo_2 = 1-endo;
RUN;
Nach einer solchen Umkodierung konnen die Parameterergebnisse in der gewohnten
Weise interpretiert werden.
2. Optionale Ausgestaltung des Schatzverfahrens
Bevor wir nun die PROBIT-Prozedur auf ein empirisches Beispiel anwenden wollen, lernen
wir noch einige Optionen kennen, die die Schatzverfahren in SAS betreffen.
CONVERGE = wert
MAXITER = wert
NOINT;
27

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Mit dem CONVERGE-Befehl kann ein Konvergenzkriterium angegeben werden.
Die Parameter werden iterativ mit dem Newton-Raphson Verfahren geschatzt. Die
Schatzung wird abgebrochen, wenn bei einem Parameter großer als 0,01 die re-
lative Veranderung zwischen zwei Schritten kleiner als der angegebene Wert ist
und bei einem Parameter kleiner als 0,01 die absolute Veranderung zwischen
zwei Schritten kleiner als der angegebene Wert ist. Voreinstellung ist ein Wert von
0,001. Mit dem Befehl MAXITER-Befehl kann die maximale Anzahl an Iteration an-
gegeben werden. Voreinstellung ist dabei eine Anzahl von 50. Mit NOINT wird ein
Modell ohne Konstante spezifiziert und geschatzt.
BY var2;
Es besteht zudem noch die Moglichkeit, den Datensatz in verschiedene Gruppen
einzuteilen und fur jede Gruppe eine separate Schatzung durchzufuhren. Dazu
wird nach dem Befehl BY diejenige Variable angegeben, die festlegt zu welcher
Gruppe der beobachtete Wert gehort. SAS erwartet dabei, dass der Datensatz
aufsteigend nach der Gruppenvariablen sortiert ist. Ist dies nicht der Fall, so muss
der Datensatz mit PROC SORT vor Durchfuhrung der Schatzung entsprechend sor-
tiert werden.
WEIGHT;
Mit dem WEIGHT-Befehl kann jede Beobachtung gewichtet werden. Gewichtet
wird sie dabei mit dem Wert der Variablen, die nach dem WEIGHT-Befehl ange-
geben wird. Der Beitrag jeder Beobachtung zur Likelihood wird dann mit dem
Gewichtungsfaktor multipliziert.
3. Das Output-Fenster bei der PROBIT-Prozedur
Bevor wir zu unserem Beispiel kommen ist es noch angebracht, das OUTPUT-Fenster der
PROBIT-Prozedur ein wenig zu kommentieren. Im Output-Fenster erhalten wir neben den
Parameterwerten und der Standardabweichung auch einen CHISQUARE-Wert, der das
Quadrat der ublichen t-Statistik ist. Die dahinterstehende Uberlegung ist, dass die t-Statistik
asymptotisch und unter der Nullhypothese, dass der Parameterwert gleich Null ist, stan-
dardnormalverteilt ist. Das Quadrat einer standardnormalverteilten Variable ist χ2-verteilt
mit einem Freiheitsgrad. Der p-Wert im Output-Fenster basiert auf dieser Annahme.
Als weitere Information erhalten wir den Wert der Log-Likelihhod-Funktion. Eine Warnung
ist an dieser Stelle angebracht. Bei allen nicht-linearen Schatzproblemen mussen Ent-
scheidungen uber Algorithmen, Konvergenzkriterien und die Berucksichtigung von Kova-
rianzmatrizen getroffen werden. Unterschiedliche Softwareprogramme losen diese Auf-
gabe in unterschiedlicher Weise, so dass es durchaus moglich ist, das zwei verschiedene
Programme zu unterschiedlichen Ergebnissen kommen.
Den Wert der Log-Likelihood konnen Sie verwenden um z.B. das R2 nach McFadden oder
Aldrich-Nelson zu berechnen.
28

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
4. Beispiel: Schatzung der Kaufwahrscheinlichkeit fur ein Produkt
Zur Verdeutlichung wenden wir uns nun einem empirischen Beispiel2. Der SAS-Datensatz
KAUF ROH enthalt 25 Beobachtungen von Individuen (INDIV), die ein bestimmtes Produkt
gekauft haben (BUY = 1) oder nicht (BUY = 0). Als zusatzliche Informationen sind in dem
Datensatz die Variablen Geschlecht (SEX) und Einkommen (INCOME) enthalten. Sie sollen
den Produktkauf in Abhangigkeit dieser beiden Variablen modellieren.
Ubungsaufgabe 15: Modellierung Kaufentscheidung (Dichotomes Logit-Modell)
1. Erzeugen Sie zunachst eine neue umkodierte abhangige Variable BUY 2.
DATA sasdat.kauf;
SET sasdat.kauf_roh;
BUY_2 = 1 - BUY;
RUN;
2. Schatzen Sie nun ein LOGIT-Modell (mit Konstante) fur die Kaufwahrscheinlichkeit
in Abhangigkeit der Variablen SEX und INCOME. Berechnen Sie auch Gutemaße.
Schreiben Sie die Ergebnisse, sowie die berechnete Kaufwahrscheinlichkeit, die Stan-
dardabweichung und den Wert fur in einen neuen Datensatz KAUF OUT.
PROC PROBIT DATA = sasdat.kauf;
CLASS BUY_2;
LOGIT:MODEL BUY_2 = SEX INCOME / d = logistic lackfit;
OUTPUT OUT = sasdat.kauf_out PROB = PROB STD = SA xbeta = xb;
run;
3. Vergleichen Sie die Kaufwahrscheinlichkeiten der Konsumenten 1 und 2.
Stimmen die Wahrscheinlichkeiten mit dem tatsachlichen Kaufverhalten uberein?
Wie wirkt sich eine Einkommenserhohung von 100,- DM auf das Kaufverhalten der
beiden betrachteten Konsumenten aus? (Hinweis: 0,00448041 ist der berechnete
Beta-Parameter aus 2.)
DATA sasdat.kauf_OUT;
SET sasdat.kauf_OUT;
pdf = (exp(xb)/(1+exp(xb))**2);
marg_100 = pdf*0.00448041*100;
LABEL marg_100 = ’marginaler Effekt von 100,-DM’;
RUN;
4. Berechnen Sie als Gutemaß das R2 nach McFadden und Aldrich-Neslon. (-6.0719 ist
der berechnete Wert der Log-Likelihood-Funktion aus 3).
2Aus:”Okonometrie“ von Eckey/Kosfeld/Dreger.
29

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
DATA sasdat.guete;
SET sasdat.kauf;
LL_0=14*log(14/25)+11*log(11/25);
KEEP LL_0;
RUN;
DATA sasdat.guete;
SET sasdat.guete;
R_2MF=1-(-6.0719/LL_0);
R_2AN=(2*(-6.0719/LL_0))/(2*(-6.0719/LL_0)+25);
RUN;
8. Prozedur MODEL
Mit Hilfe der SAS Prozedur MODEL konnen unbekannte Parameter von Mehrgleichungs-
modellen geschatzt werden. Mit den geschatzten Modellen konnen anschließend Simu-
lationen und Prognosen durchgefuhrt werden. Diese kurze Einfuhrung soll den Leser mit
den wichtigsten Befehlen und Eigenschaften dieser Prozedur bekannt machen.
1. Einfuhrung
PROC MODEL; OPTIONS;
RESET OPTIONS;
INCLUDE ...;
ENDOGENOUS variables; Festlegung der Variablen und
EXOGENOUS variables; der Struktur des Modells; Fest-
PARAMETERS ...; legung von allgemeinen Optionen
VAR variables;
FIT EQUATIONS;
INSTRUMENTS ...; Schatzung des Modells (Fit)
WEIGHT variables;
SOLVE variables; Prognose und Simulation (Solve)
BY variables;
ID variables; Kontrolle uber die beobachteten Werte
RANGE variables (=first) TO (=last);
30

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
OUTVARS variables; Festlegung der Variablen im Outputdatensatz
RUN;
In dieser Reihenfolge werden nun die wichtigsten Bestandteile der MODEL Prozedur an-
hand von Beispielen vorgestellt.
2. Festlegung der Variablen und der Struktur des Modells
In einem ersten Schritt werden die Variablen und Paramater, die in dem Modell auftau-
chen, sowie die Gleichungen, die diese miteinander verbinden, definiert.
Dabei kann man entweder explizit angeben, welche der in dem Modell auftauchenden
Variablen endogen (nach dem Befehl Endogenous, abgekurzt Endo) und welche exogen
(nach dem Befehl Exogenous, abgekurzt Exo) sind, oder man gibt, ohne eine Unterschei-
dung zu treffen, alle verwandten Variablen nach dem Befehl Var an und uberlaßt es SAS,
eine Unterscheidung zu treffen. SAS trifft diese Entscheidung gemaß der Rolle, die die Va-
riablen in den Subprozeduren Fit und Solve spielen.
Die getrennte Eingabe dient dabei vor allem der besseren Ubersichtlichkeit und weist SAS
zudem noch an, dass es bei spaterer Verwendung des Solve Befehls das System nach den
endogenen Variablen losen soll.
Nach der Parameters Anweisung (abgekurzt Parms) werden die Paramater des Glei-
chungssystems festgelegt. Hierbei besteht zudem noch die Moglichkeit, den Parametern
bestimmte Werte vorzugeben, indem man den entsprechenden Wert nach dem Para-
meter setzt (z.B. wird mit d1 1 der Parameter d1 auf 1 restringiert, insbesondere um die
Identifikation der Modelle zu gewahrleisten, sind solche Restriktion notwendig).
Im Anschluß werden die Strukturgleichungen des Modells festgelegt. Bei der Eingabe der
Gleichungen stehen zwei Wege zur Verfugung: Eingabe in normalisierter Form oder in
Standardform. Eingabe der Gleichungen in normalisierter Form meint dabei die Einga-
be der Gleichungen aufgelost nach jeweils einer endogenen Variablen: y = f(Y, X) + ε.
Eingabe in Standardform meint die Eingabe jeweils aufgelost nach der Storvariable: ε =g(Y, X). Bei dieser Eingabeart mussen zudem noch die Gleichungen bezeichnet werden
(siehe Beispiel weiter unten).
Als Beispiel sei folgendes Zweigleichungsmodell betrachtet:
(1) quantitydemand = quantity = d0 + d1price + d2income + ε1
(2) quantitysupply = quantity = s0 + s1price + s2unitcost + ε2
mit den beiden endogenen Variablen: quantitydemand = quantitysupply = quantity und price
und den exogenen Variablen: income und unitcost. Die Eingabe der Gleichungen erfolgt
31

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
im folgenden sowohl in normalisierter als auch in Standardform3. Den dazugehorigen Bei-
spieldatensatz lesen wir dabei in einem ersten Schritt mit der cards Anweisung unter dem
Namen dataset ein. Nach input werden dabei die Namen der einzulesenden Variablen
angegeben. Nach dem cards Statement folgen dann die einzulesenden Variablen, ge-
trennt mit einem Leerzeichen.
/* Einlesen des Datensatzes */
DATA library.dataset;
INPUT year income unitcost price quantity @@;
CARDS;
1976 2221.87 3.31220 0.17903 266.714
1977 2254.77 3.61647 0.06757 276.049
1978 2285.16 2.21601 0.82916 285.858
1979 2319.37 3.28257 0.33202 295.034
1980 2369.38 2.84494 0.63564 310.773
1981 2395.38 2.94154 0.62011 319.185
1982 2419.52 2.65301 0.80753 325.970
1983 2475.09 2.41686 1.01017 342.470
1984 2495.09 3.44096 0.52025 248.321
1985 2536.72 2.30601 1.15053 360.750
;
PROC MODEL;
/* Festlegen der Variablen */
VAR price quantity income unitcost;
/* Alternativ */
ENDO quantity price;
EXO income unitcost;
/* Festlegen der Parameter */
PARMS d0-d2 s0-s2;
/* Festlegen der Gleichungen */
/* Eingabe in Standardform */
EQ.demand = d0 + d1*price + d2*income - quantity;
/* Nachfragegleichung */
EQ.supply = s0 + s1*price + s2*unitcost - quantity;
/* Angebotsgleichung */
/* Alternativ */
3Die einzelnen Programmbestandteile der Model Procedure werden der besseren Ubersichtlichkeit halber
getrennt nacheinander aufgefuhrt. Um das Programm aber laufen lassen zu konnen, mussen die einzelnen
Bestandteile zusammen in einem Block eingegeben und dann gestartet werden.
32

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
/* Eingabe in normalisierter Form */
quantity = e0 + e1*income + e2*unitcost;
price = t0 + t1*income + t2*unitcost;
3. Schatzung des Modells (Fit)
In dem zweiten Schritt werden die Parameter des zuvor spezifizierten Modells geschatzt.
Dazu muss festgelegt werden, auf welchen Datensatz zugegriffen, welche Gleichungen
der zuvor spezifizierten mit welchem Schatzverfahren geschatzt und in welchen Daten-
satz die Schatzergebnisse der Parameter abgespeichert werden sollen. An Schatzme-
thoden stehen zur Verfugung: Ordinary least squares (OLS), seemingly unrelated least
squares (SUR), two stage least squares (2SLS) und three stage least squares (3SLS), wobei
alle Schatzverfahren sowohl lineare als auch nichtlineare Gleichungssysteme schatzen
konnen. Wenn auf 2SLS oder 3SLS zuruckgegriffen wird, konnen zudem mit dem Befehl
Instruments die Instrumentenvariablen explizit festgelegt werden.
In dem Beispiel sollen die beiden Gleichungen supply und demand bzw. die beiden
abhangigen Variablen quantity und price mit dem 2SLS Verfahren geschatzt werden. Da-
bei soll auf den zuvor erzeugten Datensatz library.dataset zugegriffen und der geschatzte
Parametersatz in die Datei library.output geschrieben werden. Wenn nicht explizit ange-
geben wird, welche Gleichungen geschatzt werden sollen, so schatzt SAS alle zuvor spe-
zifizierten Gleichungen.
/* Bei Eingabe in Standardform */
FIT supply demand / DATA=library.dataset OUTEST=library.output 2sls;
INSTRUMENTS income unitcost; /* Angabe optional */
RUN;
/* Bei Eingabe in normalisierter Form */
FIT quantity price / DATA=library.dataset OUTEST=library.output 2sls;
INSTRUMENTS income unitcost; /* Angabe optional */
RUN;
/* Alternativ bei beiden Eingaben */
FIT / DATA=library.dataset OUTEST=library.output 2sls;
33

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
4. Prognose und Simulation mit dem Modell (Solve)
Mit dem Unterbefehl Solve konnen Prognosen und Simulationen fur einen bestimmten In-
putdatensatz mit dem Modell durchgefuhrt werden. In dem Prognosemodus wird, sofern
vorhanden, der aktuelle Wert einer Variablen als Losungswert des Gleichungssystems ver-
wandt, wahrend in dem Simulationsmodus auf den entsprechenden vorhergesagten Wert
zuruckgegriffen wird.
In dem Prognosemodus (forecast) lost Proc Model also nur nach den aktuellen Variablen,
die in dem Inputdatensatz fehlen, wahrend in dem Simulationsmodus (simulate) auch
diejenigen Variablen gelost werden, die evtl. in dem Inputdatensatz vorhanden sind.
Zunachst muß also ein Datensatz angegeben werden, in dem die Inputvariablen enthal-
ten sind. Danach kann der Modus spezifiziert werden: Prognose- oder Simulationsmodus
(Voreinstellung ist der Simulationsmodus). Abschließend ist der Outputdatensatzes, in den
die vorhergesagten Werte geschrieben werden sollen, festzulegen.
In unserem Beispiel soll fur den nachfolgenden Datensatz, der bestimmte Werte fur die
exogenen Variablen enthalt eine Prognose fur die endogenen Variablen erstellt werden.
Zu diesem Zweck lesen wir mit cards zunachst den Inputdatensatz unter dem Namen
input 1 ein:
DATA library.input_1;
INPUT year income unitcost @@;
CARDS;
1986 2571.87 2.31220
1987 2609.12 2.45633
1988 2639.77 2.51647
1989 2667.77 1.65617
1990 2705.16 1.01601
;
Nun sollen Prognosen fur die endogenen Variablen price und quantity fur die entprechen-
den Jahre 1986-1990 erstellt werden. Die Ergebnisse sollen in den Datensatz output 1 ge-
schrieben werden:
34

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
SOLVE price quantity / DATA = library.input_1
OUT = library.output_1 FORECAST;
RUN;
Naturlich besteht auch die Moglichkeit, das Modell nach anderen als den endogenen
Variablen aufzulosen. Zu diesem Zweck lesen wir einen zweiten Datensatz input 2 ein, der
fiktive Werte fur die endogene Variable quantity und fiktive Werte fur die exogene Va-
riable income enthalt und lassen die prognostizierten Ergebnisse fur die beiden anderen
Variablen price und unitcost in den Datensatz output 2 schreiben:
DATA library.input_2;
INPUT year income quantity @@;
CARDS;
1986 2571.87 3794.4
1987 2603.24 3794.8
1988 2644.12 3795.2
1989 2678.13 3795.6
1990 2709.77 3796.0
;
SOLVE price unitcost / DATA=library.input_2 OUT=library.output_2
FORECAST;
RUN;
Es besteht auch die Moglichkeit, die endogenen Variablen fur den Beobachtungszeitraum
mit dem Modell zu simulieren. Als Inputdatensatz dient uns also der gleiche Inputdaten-
satz, den wir auch schon zur Schatzung des Modells verwandt haben. In unserem ersten
Beispiel ist das der Datensatz dataset. Die simulierten Ergebnisse fur die beiden endoge-
nen Variablen werden in den Datensatz output 3 geschrieben:
35

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
SOLVE price quantity / DATA=library.dataset
OUT=library.output_3 SIMULATE;
RUN;
9. Prozedur ARIMA
Mit Hilfe der ARIMA Prozedur konnen ARMA Modelle identifiziert, geschatzt und zu Pro-
gnosezwecken genutzt werden. Diese kurze Einfuhrung soll den Leser mit den wichtigsten
Befehlen und Eigenschaften dieser Prozedur bekannt machen.
1. Einfuhrung
PROC ARIMA DATA=library.dataset;
IDENTIFY
VAR = Zeitreihe aus dem Datensatz;
ESTIMATE
P = Ordnung AR-Teil
Q = Ordnung MA-Teil;
OUTEST = library.Datei fur Schatzergebnisse
METHOD = Schatzmethode;
FORECAST
ALPHA = Signifikanzniveau fur Konfidenzintervalle
ID = Variable, die Zeitstempel enthalt;
INTERVAL = Periodizitat der Prognose
LEAD = Anzahl an zu prognostizierenden Perioden
OUT = Datei, in die die Prognoseergebnisse geschrieben werden;
RUN;
QUIT;
36

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Bevor ein ARMA-Modell geschatzt werden kann, muss die Ordnung des Prozesses, d.h.
die maximale Laglange des AR- und MA-Teils, so festgelegt werden, daß er zu der mo-
dellierten Zeitreihe paßt. Die erfolgt in SAS mit Hilfe des Identify-Statements. Ist ein entspre-
chender ARMA-Prozeß festgelegt worden, kann er mit dem Estimate-Statement geschatzt
werden. Das geschatzte Modell kann anschließend mittels des Forecast-Statements zu
Prognosezwecken genutzt werden.
In dieser Reihenfolgen sollen nun die wichtigsten Bestandteile der ARIMA Prozedur vorge-
stellt werden, wobei auch auf den theoretischen Hintergrund eingegangen werden soll.
2. Analyse der Zeitreihe mit Identify
Bei der Identifikation einer Zeitreihe mussen eine Reihe von Schritten durchlaufen werden:
1. White Noise Test der Zeitreihe
2. Vergleich zwischen empirischen und theoretischen Autokorrelationen bzw. partielle
Autokorrelationen
3. Durchfuhren von Schatzungen fur verschiedene p und q
4. Bestimmen von Informationswerten fur die verschiedenen geschatzten Modelle
5. Uberprufen, ob die Parameter signifikant sind
6. White Noise Test der Residuen
Bei den Schritten eins und zwei wird man von SAS durch die Subprozedur Identify un-
terstutzt. Die entsprechende Befehlssequenz lautet dabei:
PROC ARIMA DATA=library.series;
IDENTIFY VAR = variable;
RUN;
Als Ergebnis erhalt man eine Reihe von statistischen Auswertungen fur die Variable va-
riable aus dem Datensatz library.series, die fur die Schritte eins und zwei genutzt werden
konnen.
In dem ersten Schritt, dem White Noise Test, muß uberpruft werden, ob die zu modellieren-
de Zeitreihe autokorreliert ist. Ist sie es nicht, so kann sie auch nicht mit ARIMA-Modellen
modelliert werden. SAS gibt zu diesem Zweck die Ergebnisse der Ljung-Box-Prufgroße her-
aus. Sind diese fur mindestens eine Laglange signifikant von null verschieden, so kann die
37

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Nullhypothese: Die Zeitreihe ist White Noise, abgelehnt und eine Modellierung mit ARMA
Modellen versucht werden.
Die Ljung-Box-Prufgroße ist dabei wie folgt definiert:
Q(K) =T
T + 2
k∑i=1
(T − i)−1r21
mit : T = Anzahl an Beobachtungen
r2i = Quadrierte Autocorrelation i-ter Ordnung
k = Anzahl der berucksichtigten Autocorrelationen
Sie ist asymptotisch χ2-verteilt mit k Freiheitsgraden. Wenn fur mindestens ein k die empi-
rische Prufgroße den kritischen Schwellenwert ubersteigt, wird die Nullhypothese, daß die
Zeitreihe einem White Noise Prozeß folgt, abgelehnt.
In einem zweiten Schritt, der Analyse der Autokorrelationen (ACF) und der partiellen Au-
tokorrelationen (PACF), werden die theoretischen mit den empirischen ACF und PACF ver-
glichen. Die ACF mißt die Korrelation zwischen zwei Zeitpunkten, d.h. sowohl den direkten
Zusammenhang zwischen diesen beiden Zeitpunkten als auch den indirekten. Die PACF
hingegen misst nur die direkte Abhangigkeit der Zeitreihe zu zwei Zeitpunkten.
Zur Identifikation des richtigen Prozesses konnen die folgenden heuristischen Regeln an-
gewandt werden4:
PROC ARIMA DATA=library.series;
IDENTIFY VAR=variable;
ESTIMATE Q=0 P=3 OUTEST=library.out METHOD=ML;
RUN;
QUIT;
Durch den obigen Code wird die zuvor analysierte Variable genutzt, um ein ARMA(3,0)
Modell zu schatzen (q bezeichnet die Lange des MA-, p die des AR-Teils). Die geschatzten
Ergebnisse (vorhergesagten Werte, vorhergesagte Residuen, etc.) werden in die Datei li-
brary.out geschrieben. Als Optimierungsverfahren wird die Maximum Likelihood Methode
verwandt.
Zusatzlich zu den geschatzten Parametern erhalt man sog. Informationswerte, deren Kennt-
nis von Nutzen sein kann zur Identifikation des richtigen Prozesses. Das Ziel besteht darin,
4Vgl. Hansmann, Karl-Werner (1983): Kurzlehrbuch Prognoseverfahren, Wiesbaden, S. 78.
38

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
ein Modell zu wahlen mit einem moglichst geringen Informationswert. SAS gibt zwei Infor-
mationswerte aus. Der Akaike Informationswert ist definiert als: AIC = −2 ln L + q + 2(p)wohingegen der Schwarz-Bayes Informationswert definiert ist als: −2 ln L + (p + q) ln T .
Die geschatzten Paramter sollten alle signifikant sein. Ahnlich wie bei der Probit Prozedur
ist hierbei jedoch eine Besonderheit von SAS zu beachten: SAS kehrt die Vorzeichen der
geschatzen Parameter um! Aus einem Plus wird ein Minus und umgekehrt.
Wahrend die modellierte Zeitreihe kein White Noise Prozeß sein darf, sollen die geschatz-
ten Residuen des ARMA-Modells jedoch, wie von der Theorie gefordert, White Noise sein!
SAS gibt hierzu die Ergebnisse eines White Noise Checks for Residuals aus. Im Gegensatz
zu dem zuvor besprochenen Ljung-Box-Test sollte nun die Nullhypothese: Die Zeitreihe ist
White Noise, beibehalten werden.
3. Schatzung des Modells (Fit)
Hat man ein ARMA Modell identifiziert und geschatzt, kann es genutzt werden, um die
Entwicklung der Zeitreihe mit Hilfe der Subprozedur Forecast zu prognostizieren.
PROC ARIMA DATA=library.series;
IDENTIFY VAR= variable;
ESTIMATE Q=0 P=3 OUTEST=library.out METHOD= ML;
FORECAST ALPHA=0.05 ID=date INTERVAL=month LEAD=24
OUT=library.out_p;
RUN;
QUIT;
Mit dem der zusatzlichen forecast Zeile in dem obigen Befehl wird eine Prognose fur die
nachsten 24 Monate vorgenommen. Fur die prognostizierte Zeitreihe werden zusatzlich
Konfidenzintervalle auf dem 5% Niveau ausgewiesen. Die Ergebnisse werden dabei in
der Datei library.out p gepeichert.
10. Prozedur AUTOREG
Wann immer davon ausgegangen werden muß, dass die Residuen nicht White Noise sind
und/oder die quadrierten Residuen einer untersuchten Zeitreihe nicht White Noise sind,
muss fur die Residuen und/oder die quadrierten Residuen ein autoregressives Modell un-
terstellt werden. Zu diesem Zweck kann die SAS Prozedur AUTOREG verwandt werden. Die-
se kurze Einfuhrung soll den Leser mit den wichtigsten Befehlen und Eigenschaften dieser
Prozedur bekannt machen.
39

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
1. Einfuhrung
Proc AUTOREG kann genutzt werden, um lineare multiple Regressionsmodelle zu schatzen,
unter zusatzlicher Berucksichtigung von:
• Autoregressiven Prozessen fur die Residuen
• ARCH bzw. GARCH Prozessen fur die Residuen
Die allgemeine Modellspezifikation lautet dabei wie folgt:
yt = x′tβ + vt
vt = εt − ϕ1vt−1 − . . .− ϕmvt−m
εt =√
htet
ht = ω +q∑
i=1
αiε2t−i +
p∑j=1
γjht−j
et ∼ i.i.d. N(0, 1)
Man erkennt, dass bei dieser allgemeinen Modellstruktur sowohl die Autokorreliertheit der
Residuen als auch der quadrierten Residuen berucksichtigt wird.
Die vereinfachte allgemeine Syntax der Prozedur AUTOREG, mit der diese Modellstruktur
implementiert werden kann, sieht wie folgt aus:
PROC AUTOREG DATA=library.dataset; /* Datensatz, auf den zugegriffen werden
soll */
MODEL y = var_1 ... / NLAG=2; /* Regressionsmodell und Anzahl an
berucksichtigten Lags des AR-Prozesses */
GARCH=(Q=q, P=p) MAXIT=100; /* Spezifikation des GARCH Prozesses und
maximale Anzahl an Iterationen */
OUTPUT OUT=library.dataset; /* Outputdatensatz */
RUN;
QUIT;
Die Vorgehensweise bei der Spezifikation dieser Art von Modellen ist ein interaktiver Pro-
zess, der die folgenden Schritte umfassen sollte:
40

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
1. Test, ob autokorrelierte und/oder heteroskedastische Residuen vorliegen
2. Spezifizieren des Modells fur die Residuen
3. Durchfuhren von Schatzungen fur verschiedene p und q
4. Schatzen des Modells
In dieser Reihenfolgen sollen nun die wichtigsten Bestandteile der AUTOREG Prozedur vor-
gestellt werden.
2. Testen auf Autokorrelation mittels Generalized Durbin-Watson Teststatistiken
Der Test auf Autokorrelation der Residuen erfolgt in SAS mittels folgender Befehlssequenz:
PROC AUTOREG DATA=library.dataset;
MODEL y = var_1 ... / DW=4 DWPROB;
RUN;
Mit data = library.dataset wird die zu analysierende Datei spezifiziert. Mit model y = var1 . . .
wird das eigentlich zu schatzende Modell spezifiziert. Mit DW = 4 wird die maximale
Laglange angeben, bis zu der generalized Durbin Watson Prugroßen berechnet werden
sollen. DWPROB weist SAS an, zusatzlich noch Signifikanzniveaus zu den Prufgroßen aus-
zugeben. Mit den generalized DW Prufgroßen kann nicht nur Autokorrelation erster, son-
dern auch hoherer Ordnung modelliert werden. Wenn zumindest eine DW Prufgroße signi-
fikant ungleich null ist, muß die Nullhypothese, dass die Zeitreihe nicht autokorreliert ist,
abgelehnt werden.
3. Testen auf Heteroskedastie mittels Portmanteau Q-Teststatistiken
Der Test auf Heteroskedastie der Residuen erfolgt in SAS mittels folgender Befehlssequenz:
PROC AUTOREG DATA=library.dataset;
MODEL y = var_1 ... / NLAG=2 ARCHTEST
DWPROB;
RUN;
41

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Bis auf die Option nlag = 2, mit der die maximale Laglange angeben wird, bis zu der
Q-Statistiken berechnet werden sollen, stimmen die ubrigen Befehle mit denen uberein,
die wir bereits oben kennengelernt haben. Naturlich konnen diese beiden Schritte auch
in einem Befehl ausgefuhrt werden. SAS gibt dann die Ergebnisse des sog. Portmanteau
Q-Test heraus. Wieder gilt, daß wenn zumindest eine Laglange diese Prufgroße signifikant
von null, verschieden ist, die Nullhypotheses abgelehnt werden muß, daß die Zeitreihe
nicht heteroskedastisch sei.
Wenn festgestellt wurde, dass die Residuen einem autokorrelierten Prozess folgen und zu-
dem noch GARCH Effekte vorhanden sind, kann ein passender Prozess fur die Residuen
entsprechend der bereits in dem vorhergehenden Kapitel besprochenen Kriterien spezifi-
ziert werden.
4. Schatzung des Modells mit autokorrelierten Residuen und GARCH-Effekt
Hat man ein Modell fur die Residuen mit der Hilfe der oben beschriebenen Tests spezifi-
zieren konnen, kann anschließend die Schatzung erfolgen:
PROC AUTOREG DATA=library.dataset;
MODEL y = var_1 ... / NLAG=2 GARCH=(Q=q,P=p) MAXIT = xxx;
OUTPUT OUT= library.out_dataset CEV=n P=m;
RUN;
Neu hinzugekommene Befehle sind dabei: NLAG = 2, mit dem spezifiziert wird, bis zu
welcher Laglange Autokorrelationen der Residuen zugelassen werden, GARCH = (Q =q, P = p), mit dem zusatzlich noch ein bestimmtes GARCH(p,q)-Modell fur die Residuen
modelliert wird, MAXIT = xxx, mit dem die maximale Anzahl an Iterationen festgelegt
werden kann und CEV = n bzw. P = m, womit die geschatzten Residuen bzw. geschatz-
ten Werte in der Outputdatei library.out dataset unter dem Namen n bzw. m gespeichert
werden konnen.
11. Prozedur TSCSREG
Die Prozedur TSCSREG (Time Series Cross Section Regression) dient zur Schatzung von
Panel-Modellen mit SAS. Zu beachten bei der Schatzung mit Panel-Daten ist das Vor-
liegen von unbeobachtbarer zeitlicher und individueller Heterogenitat; Nichtbeachtung
wurde zu verzerrten bzw. inkonsistenten Schatzern fuhren.
42

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Verschiedene Arten von Fehlerstrukturen sind deshalb in der Prozedur enthalten. Neben
Kovarianzmodellen (Fixed Effects-Modelle) konnen auch Fehlerkomponentenmodelle
(Random Effects-Modelle) geschatzt werden. Daruberhinaus konnen mit der Prozedur
auch Modelle mit autoregressiven Fehlerkomponenten geschatzt werden, auf die hier
allerdings nicht eingegangen wird.
Grundsatzlich konnen sowohl one-way als auch two-way error components-Modelle ge-
schatzt werden.
1. Syntax
PROC TSCSREG Optionen;
ID cross_section time_series;
Der Aufruf der Prozedur erfolgt uber den PROC TSCSREG Befehl. Verfugba-
re Optionen sind die Deklaration eines Input-Datensatzes uber DA-
TA=library.datasetname, oder das Erstellen eines Output-Datensatzes, der
neben den Schatzern auch Kovarianzstruktur (COVOUT) sowie Korrelationsmatrix
(CORROUT) und Testergebnisse enthalten kann. Der Output-Datensatz wird uber
den Befehl OUTEST=library.datasetname erzeugt.
Der ID Befehl dient zur Identifikation der Querschnitts- und Langsschnittsvariablen.
Fur die Schatzung ist es dabei wichtig, dass der Datensatz vorher nach diesen
Variablen sortiert wurde.
label:MODEL var1 = var2 var3 ... / Optionen;
Der MODEL Befehl definiert das zu schatzende Modell. In gewohnter Weise kann
das geschatzte Modell mit einem Label versehen werden. var1 ist die abhangige
Variable, var2, var3 ... sind die erklarenden Variablen. Der Unterschied zur klas-
sischen linearen Regression wird durch die Optionen erklart, die nachfolgend im
einzelnen erlautert werden sollen.
FIXONE;
Die FIXONE Option definiert, dass ein Fixed-Effects One-way error components
Modell geschatzt werden soll.
FIXTWO;
Die FIXTWO Option definiert, dass ein Fixed-Effects Two-way error components
Modell geschatzt werden soll.
RANONE;
43

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Die RANONE Option definiert, dass ein Random-Effects One-way error com-
ponents Modell geschatzt werden soll.
RANTWO;
Die RANTWO Option definiert, dass ein Random-Effects Two-way error com-
ponents Modell geschatzt werden soll.
Neben der Deklaration einer einzelnen Fehlerstruktur ist es auch moglich, mehre-
re Arten anzugeben. Die Prozedur schatzt dann sequentiell die einzelnen Modelle.
NOINT;
Die TSCSREG Prozedur schatzt grundsatzlich eine Konstante mit. Der Befehl NOINT
unterdruckt den Einbezug einer Konstanten in das Modell.
RUN;
Der RUN-Befehl startet die Prozedur.
2. Schatzmethode
Die Schatzung erfolgt in Abhangigkeit der unterstellten Fehlerstruktur. Wird ein Fixed Effects-
Ansatz verwendet, schatzt die Prozedur das Modell mit LSDV, d.h. OLS mit Dummy-Variablen
fur die spezifizierten Effekte.
Bei Unterstellung stochastischer Fehler fuhrt die Verwendung von OLS zu ineffizienten Schat-
zern. Das Programm verwendet hier Feasible GLS. Dies ist ein zweistufiges Verfahren, dass
auf der ersten Stufe die Varianz-Komponenten des Modells schatzt. Die geschatzte Varianz-
Kovarianz-Matrix ist dann Grundlage fur die GLS-Schatzung der zweiten Stufe.
3. Output
Das Output-Fenster der Prozedur TSCSREG enthalt standardmaßig folgende Angaben:
• Modellbeschreibung: Fehlerstruktur, Anzahl von Quer- und Langsschnitten
• Anpassungsgute
• (Varianz-Komponenten Schatzer: bei Random Effects-Modellen)
• Testergebnisse: F -Test bei Fixed Effects-Modellen, Hausman m-Test fur Random Effects-
Modelle
• Parameterschatzwerte mit t-Werten und plim
Optional kann daneben die Varianz-Kovarianz-Matrix ausgegeben werden, sofern die
COVB Option gewahlt wurde, sowie die Korrelations-Matrix, wenn die CORRB Option de-
klariert wurde.
44

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
4. Beispiel
Die Schatzung wollen wir am Beispiel5 der Schatzung einer Kostenfunktion verdeutlichen.
Wir verwenden hierzu Daten von Greene (1990)6. Die enthaltenen Variablen sind Produk-
tion von Strom in Millionen Kilowatt-Stunden sowie die daraus entstehenden Kosten (ag-
gregiert aus Arbeits- und Kapitalkosten) fur sechs Firmen zu vier Zeitpunkten.
Folgende Gleichung soll geschatzt werden:
lnCit = α + β lnYit + εit
Der Datensatz mit bereits logarithmierten Werten fur Kosten und Output enthalt die folgen-
den Variablen:
• FIRM (Querschnitts-Identifizierer),
• YEAR (Langsschnitts-Identifizierer),
• OUTPUT (Menge Strom) und
• COST.
5Das Beispiel stammt aus SAS INSTITUTE INC. (1999): SAS/ETS User’s Guide, Version 8, Cary NC., S. 1546 ff.6GREENE, W.H. (1990): Econometric Analysis, New York, MacMillan Publishing Company
45

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
1. Schritt: Einlesen und Sortieren des Datensatzes
DATA greene;
INPUT firm year output cost @@;
CARDS;
1 1955 5.36598 1.14867 1 1960 6.03787 1.45185
1 1965 6.37673 1.52257 1 1970 6.93245 1.76627
2 1955 6.54535 1.35041 2 1960 6.69827 1.71109
2 1965 7.40245 2.09519 2 1970 7.82644 2.39480
3 1955 8.07153 2.94628 3 1960 8.47679 3.25967
3 1965 8.66923 3.47952 3 1970 9.13508 3.71795
4 1955 8.64259 3.56187 4 1960 8.93748 3.93400
4 1965 9.23073 4.11161 4 1970 9.52530 4.35523
5 1955 8.69951 3.50116 5 1960 9.01457 3.68998
5 1965 9.04594 3.76410 5 1970 9.21074 4.05573
6 1955 9.37552 4.29114 6 1960 9.65188 4.59356
6 1965 10.21163 4.93361 6 1970 10.34039 5.25520
;
PROC SORT DATA=greene;
BY firm year;
RUN;
2. Schritt: Sortierung des Datensatzes:
PROC SORT DATA=greene;
BY FIRM YEAR;
RUN;
3. Schritt: Schatzung eines one-way Fixed Effects-Modells und eines one-way Random
Effects-Modells.
PROC TSCSREG DATA=greene;
ID FIRM YEAR;
MODEL cost=output / FIXONE RANONE;
RUN;
46
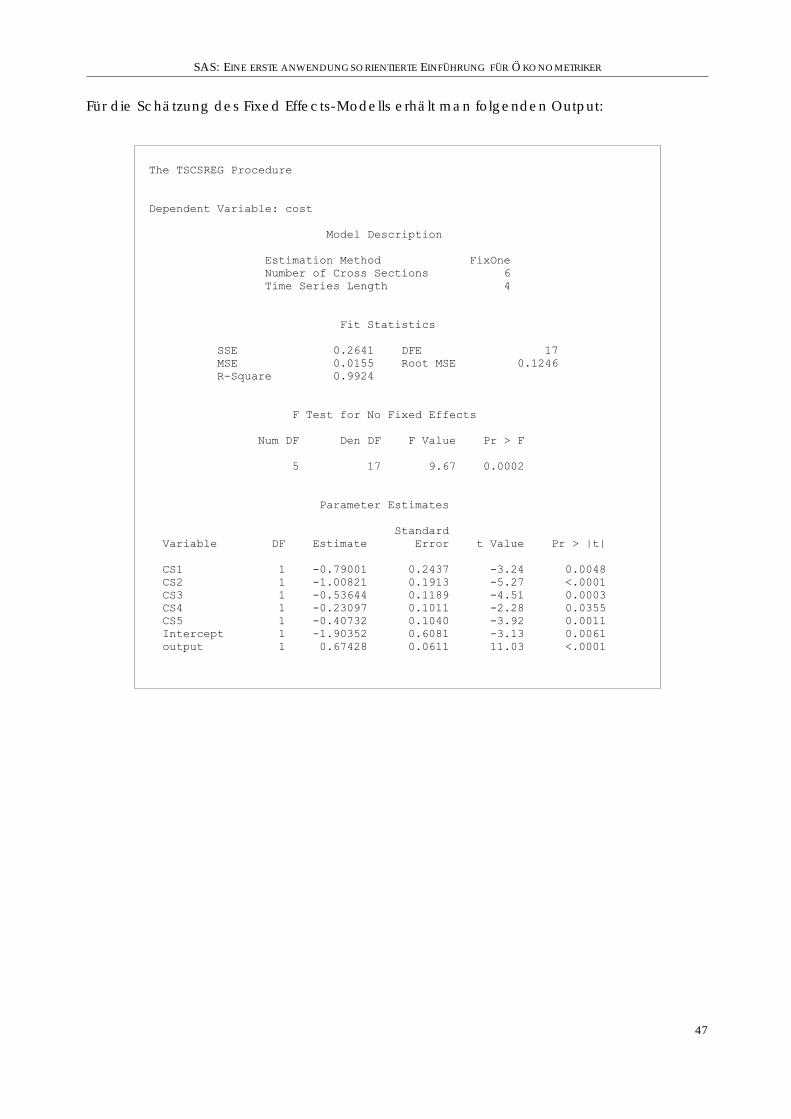
SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Fur die Schatzung des Fixed Effects-Modells erhalt man folgenden Output:
47

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Als Ergebnis der Random Effects-Schatzung erhalten wir:
48

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
12. Prozedur LIFETEST
Die Schatzung von Verweildauern mit Hilfe nichtparametrischer Methoden kann in SAS mit
Hilfe der Prozedur LIFETEST vollzogen werden. Im Gegensatz zu parametrischen Methoden
unterstellen nichtparametrische Schatzer keine funktionale Form fur Hazard-, Dichte- und
Uberlebensfunktion und vermeiden so Verzerrungen in den Schatzern durch eine zu große
Zahl von Restriktionen. Uberdies sind sie zur graphischen Darstellung vorhandener Daten
nutzlich oder fur Voranalysen zur Identifikation einer geeigneten parametrischen Spezifi-
kation.
Die Prozedur LIFETEST berechnet nichtparametrische Schatzer fur die Uberlebensfunktion
mittels Kaplan-Meier-Schatzer (Produkt-Limit-Schatzer) oder Sterbetafel-Methode. Dane-
ben werden Rangstatistiken berechnet, um Zusammenhange zwischen abhangiger Va-
riable und anderen Variablen zu erfassen.
Rechtszensierte Spells sind ein haufiges Problem von Verweildauerdaten. Berucksichtigt
man diese Falle nicht in der Analyse, kommt es zu Dauerverzerrungen, da ublicherweise
langere Episoden eher zensiert sind als kurzere. Eine valide Untersuchung muß also sowohl
nicht-zensierte als auch zensierte Spells umschließen.
1. Syntax
PROC LIFETEST Optionen;
Der Befehl PROC LIFETEST startet die Prozedur. Wichtige Optionen neben der De-
klaration des Input-Datensatzes uber DATA=library.datasetname fur die Analyse
sind folgende:
METHOD=PL; {oder} METHOD=LIFE;
Die Option METHOD legt die Schatzmethode fest. PL Definiert Schatzung mittels
Product-Limit bzw. Kaplan-Meier-Schatzers (alternativ KM). Fur ein Schatzung mit-
tels Sterbetafel-Methode muß LIFE (alternativ ACT (actual), LT) gewahlt werden.
OUTS=library.datasetname;
Der Befehl OUTS deklariert ein Output-Datensatz, der die Schatzer der Uberlebens-
funktion sowie die dazugegehorigen Konfidenzintervalle enthalt.
OUTT=library.datasetname;
Der Befehl OUTT deklariert ein Output-Datensatz, der die Testergebnisse der χ2-
Statistik, der Rangstatistiken sowie deren Varianz-Kovarianz-Matrix enthalt.
49

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
PLOTS=(wert);
Der Befehl PLOTS erstellt Plots der Uberlebensfunktion (S) oder zensierten Beob-
achtungen (C). Daneben konnen auch Plots der negativen logarithmierten Uber-
lebensfunktion (LS) sowie des Logarithmus’ der negativen logarithmierten Uberle-
bensfunktion (LLS) abgebildet werden, um eine unterliegende Exponential- oder
Weibullfunktion zu identifizieren.
Verwendet man die Sterbetafelmethode, konnen außerdem die Hazardrate (h)
sowie die Dichtefunktion (p) geplottet werden.
TIME var1*censor(wert);
Der Befehl TIME ist der wichtigste Befehl der Prozedur LIFETEST. var1 definiert die
Dauervariable, censor ist der Dummy fur zensierte bzw. unzensierte Spells. Zen-
sierte Spells werden durch”wert“ ausgedruckt.
STRATA var2 ...;
Der Befehl STRATA dient zur Einteilung der Daten in unterschiedliche Strata. Dies ist
sinnvoll, wenn man z.B. die Verweildauern von unterschiedlichen Gruppen (bspw.
Teilnehmer und Nichtteilnehmer an einem Experiment) oder unterschieden nach
bestimmten Kovariaten abbilden will. var2 ... sind hierbei Unterscheidungsvaria-
blen.
(Alternativ zum Befehl STRATA kann auch die BY-Option gewahlt werden; hierbei
ist allerdings zu beachten, daß der Datensatz zu erst nach den BY-Variablen ge-
ordnet sein muß. Jedoch werden hier die Plots einzeln zu jeder Auspragung der
BY-Variable erzeugt.)
RUN;
Der RUN-Befehl startet die Prozedur.
2. Output
Der Output der Prozedur LIFETEST enthalt als erstes eine Ubersicht uber die Verweildauern in
jedem Stratum mit Abgangszeitpunkt, Standardfehler und verbleibenden Beobachtungen
im Stratum. Zusatzlich werden weitere Verteilungsmerkmale, wie z.B. Quartile, Mittelwert
und Standardabweichung, ausgegeben.
Der zweite Teil des Outputs ist die Zusammenfassung zensierter und nicht-zensierter Beob-
achtungen, anteilig nach zugeordnetem Stratum und absolut fur die Grundgesamtheit.
Der dritte Teil (nur bei Definition einer Strata-Variable) gibt die Ergebnisse der Test fur Ho-
mogenitat zwischen abhangiger Variable und der (den) Kovariable(n) aus. Hierbei fuhrt
50

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
die Prozedur einen Log-Rank-Test sowie einen Wilcoxon-Rangsummen-Test durch. Neben
der Ausgabe der Rangreihen werden auch die dazugehorigen Kovarianz-Matrizen aus-
gegeben. Als letztes folgt die χ2-Statistik fur die Tests.
Ist die Option PLOTS gewahlt, werden außerdem die gewahlten Plots gegen die Zeit ab-
gebildet.
3. Beispiel
Mit Hilfe eines Kaplan-Meier-Schatzers wollen wir beispielhaft die Dauer einer Remission7
von 21 Leukamie-Patienten nach Behandlung mit einem Medikament (6-mercaptopurine
(6-MP)) sowie von 21 anderen, die mit einem Placebo behandelt wurden, messen. Der
Datensatz stammt von aus Lawless (1982)8 Der Datensatz mp 6 enthalt die Variablen DAYS,
CENSOR und TREATMENT.
• DAYS ist die Dauer der Remission
• CENSOR unterscheidet zensierte (1) und unzensierte (0) Spells
• TREATMENT beschreibt die Behandlung mit dem Medikament (1) oder mit dem Pla-
cebo (0).
1. Schritt: Einlesen des Datensatzes
DATA MP_6;
INPUT days censor treatment @@;
LABEL days="Dauer der Remission";
CARDS;
6 0 1 6 0 1 6 0 1
6 1 1 7 0 1 9 1 1
10 0 1 10 1 1 11 1 1
13 0 1 16 0 1 17 1 1
19 1 1 20 1 1 22 0 1
23 0 1 25 1 1 32 1 1
32 1 1 34 1 1 35 1 1
1 0 0 1 0 0 2 0 0
2 0 0 3 0 0 4 0 0
4 0 0 5 0 0 5 0 0
8 0 0 8 0 0 8 0 0
8 0 0 11 0 0 11 0 0
12 0 0 12 0 0 15 0 0
17 0 0 22 0 0 23 0 0
;
7Remission: Nachlassen von Krankheitserscheinungen, wird besonders bei Krebserkrankungen verwendet.8LAWLESS, J.F.(1982): Statistical Models and Methods for Lifetime Data, Wiley Series in Probability and Ma-
thematical Statistics, New York Chichester Brisbane Toronto Singapore
51
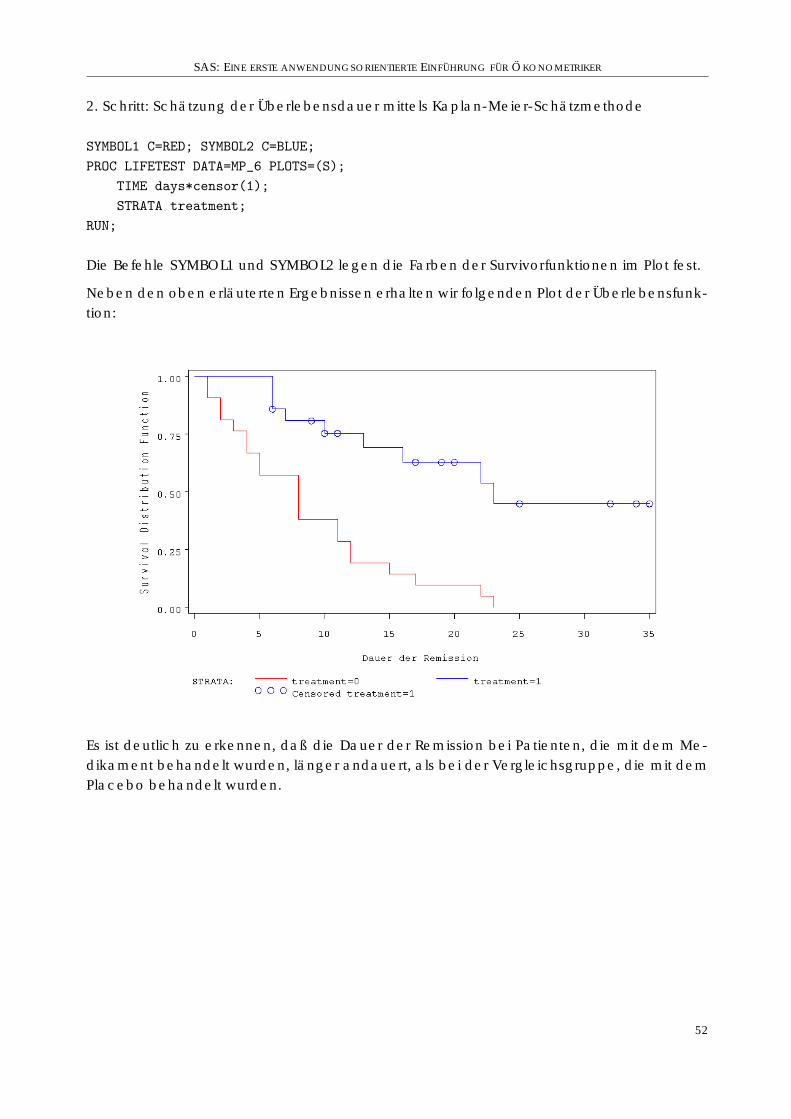
SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
2. Schritt: Schatzung der Uberlebensdauer mittels Kaplan-Meier-Schatzmethode
SYMBOL1 C=RED; SYMBOL2 C=BLUE;
PROC LIFETEST DATA=MP_6 PLOTS=(S);
TIME days*censor(1);
STRATA treatment;
RUN;
Die Befehle SYMBOL1 und SYMBOL2 legen die Farben der Survivorfunktionen im Plot fest.
Neben den oben erlauterten Ergebnissen erhalten wir folgenden Plot der Uberlebensfunk-
tion:
Es ist deutlich zu erkennen, daß die Dauer der Remission bei Patienten, die mit dem Me-
dikament behandelt wurden, langer andauert, als bei der Vergleichsgruppe, die mit dem
Placebo behandelt wurden.
52

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
13. Prozedur PHREG
Mit Hilfe der Prozedur PHREG (Proportional Hazards Regression) konnen Proportional Haz-
ards-Modelle geschatzt werden. Dieser semi-parametrische Ansatz wird verwendet, um
den Einfluss erklarender Kovariablen auf die Hazardrate zu untersuchen. Als Vorteil erweist
sich die Annahme, dass die Hazardraten verschiedener Individuen proportional zueinan-
der sind; daher ist eine parametrische Spezifikation der Hazardrate uberflussig.
Die hohere Flexibilitat auf der einen Seite fuhrt jedoch zu einer Beschrankung der An-
wendungsmoglichkeiten auf der anderen Seite. Um die Proportionalitat zu gewahrleisten,
durfen sich bestimmte erklarende Kovariablen in ihrem Verhaltnis uber die Zeit nicht un-
terscheiden. Jedoch kann dieses Problem durch Einfuhrung subpopulationsspezifischer
Basisubergangsraten uberwunden werden.
1. Syntax
PROC PHREG Optionen;
Der Befehl PROC PHREG startet die Prozedur. Wichtige Optionen neben der Dekla-
ration des Input-Datensatzes uber DATA=library.datasetname fur die Analyse sind
folgende:
SIMPLE;
Die Option SIMPLE gibt deskriptive Statistiken zu den erklarenden Variablen aus
(Mittelwert, Standardabweichung, Minimalwert und Maximalwert.
NOPRINT;
Die Option NOPRINT unterdruckt das Output-Fenster und steigert so die Rechen-
geschwindigkeit der Prozedur; sie ist sinnvoll, wenn man die Ergebnisse in ein ge-
sonderters Output-File ubergibt.
NOSUMMARY;
Die Option NOSUMMARY unterdruckt die Ausgabe der Ubersicht uber zensierte
und unzensierte Beobachtungen.
OUTEST=library.datasetname;
Erzeugt einen Output-Datensatz der die Regressionskoeffizienten enthalt. Wird au-
ßerdem die Option COVOUT deklariert, enthalt dieser Datensatz auch die Varianz-
Kovarianz-Matrix der Parameter.
53

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
BASELINE OUT=library.datasetname COVARIATES=library.datasetname;
Der Befehl BASELINE OUT=library.datasetname erzeugt einen Output-Datensatz,
der die Schatzer der Uberlebensfunktion fur alle erklarenden Variablen enthalt.
Der OUT-Befehl definiert den neuen Datensatz, der COVARIATES Datensatz (i.d.R.
der Input-Datensatz) muss die erklarenden Variablen enthalten.
MODEL var1*censor(wert)= var2 var3 ... / Optionen;
Der MODEL-Befehl ist das Kernstuck der Prozedur PHREG. Er definiert die abhangi-
ge Variable var1 sowie einen optionalen Zensur-Indikator censor (wert beschreibt
dabei den Index fur zensierte Beobachtungen). Uberdies mussen die erklaren-
den Kovariablen var2 var3 ... nach dem Gleichheitszeichen festgelegt werden.
Folgende Optionen zum MODEL-Befehl stehen zur Verfugung:
TIES=methode;
Die Option TIES=method spezifiziert die Behandlung von Ties (Beobachtungen
gleicher Lange) in der Schatzung. Standardmaßig wird die Likelihoodfunktion
uber den Ansatz von Breslow (1974)9approximiert (BRESLOW). Daruberhinaus ist
es moglich, das PH-Model durch ein diskretes logistisches Model fur diskrete
Zustande zu ersetzen (DISCRETE). Daneben stehen die Approximation von Efron
(1977) (EFRON) sowie ein exakter Ansatz (EXACT) zur Verfugung. Nahere Informa-
tion zu den Schatzern finden sich in Kalbfleisch et al. (1980)10.
SELECTION=method;
Ein wichtiger Anspruch an Verweildauermodelle stellt die Identifikation einflußrei-
cher Kovariablen auf die Hazardrate dar. Zu diesem Zweck kann man mittels der
Prozedur PHREG verschiedene Spezifikationen testen und schatzen. Die Auswahl
der Kovariablen bzw. Sets von Kovariablen kann uber die SELECTION=method Op-
tion erfolgen. Vier verschiedene Vorgehensweisen stehen zur Verfugung. Neben
der standardmaßigen Methode NONE, in der alle spezifizierten Kovariablen in das
Modell mit aufgenommen werden, kann man ausgehend vom Gesamtmodell
einzelne erklarende Variablen schrittweise eliminieren (BACKWARD), das Modell
schrittweise mit den aufgefuhrten Variablen aufbauen (STEPWISE), die Variablen
nacheinander in das Modell aufnehmen (FORWARD) sowie uber die χ2-Statistik
der einzelnen Variablen das beste Set von erklarenden Variablen identifizieren
(SCORE).
SEQUENTIAL;
Die Option SEQUENTIAL fuhrt zu einem aufnehmen der Variable in das Modell nach
der Reihenfolge, in der sie im MODEL-Befehl aufgefuhrt sind.
10BRESLOW, N. (1974):Covariance Analysis of Censored Survival Data, Biometrics, 30, S. 89-9910siehe hierzu KALBFLEISCH, J.D. und R.L. PRENTICE (1980).The Statistical Analysis of Failure Time Data, Wiley
& Sons, New York et al., S. 70 ff.
54

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
SLENTRY=wert;
Die Option SLENTRY=wert definiert das Signifikanzniveau zur Aufnahme einer Va-
riablen in das Modell.
SLSTAY=wert;
Die Option SLSTAY=wert definiert das Signifikanzniveau zur Eliminierung einer Va-
riablen aus dem Modell.
MAXITER=n;
Die Option MAXITER=n definiert die Obergrenze durchzufuhrender Iterationen.
Von vornherein ist dieser Wert auf 25 begrenzt, und kann bei Bedarf beliebig ver-
ringert oder vergroßert werden.
STRATA=variable;
Durch Einbindung von Strata konnen unrealistische Annahmen des PH-Modells
uberwunden werden. So ist es z.B. denkbar, dass sich die Verweildauer in be-
stimmten Intervallen oder fur bestimmte Subpopulationen unterscheidet, was ei-
ne Verletzung der Proportionalitatsannahme zur Folge hat. Mit dem Befehl STRA-
TA=variable konnen verschiedene Strata festgelegt werden, fur die das Verweil-
dauermodell geschatzt wird.
OUTPUT OUT=library.datasetname schatzer=name;
Der Befehl OUPUT OUT=library.datasetname erzeugt einen Output-Datensatz der
die Parameterschatzer (XBETA), Standardfehler der Schatzer (STDXBETA), Schatzer
der Uberlebensfunktion (SURVIVAL) sowie weitere Schatzwerte enthalt.
RUN;
Der RUN-Befehl startet die Prozedur.
2. Output
Folgende Informationen werden im Output-Fenster der Prozedur PHREG ausgegeben:
• Beschreibung des Input-Datensatzes, einschließlich Auffuhrung der abhangigen Va-
riablen, Zensur-Variablen, Methode zur Behandlung von Ties.
• Uberblick uber Anzahl zensierter und unzensierter Beobachtungen (außer bei Dekla-
ration von NOSUMMARY). Einfache Statistiken zu den erklarenden Variablen, sofern
SIMPLE deklariert wurde.
• Statistiken zur Gute des Modells
• Analyse der Maximum-Likelihood Schatzer mit Schatzwerten, Standardfehlern, χ2-
Statistiken sowie Hazardraten.
55

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
3. Beispiel
Die Schatzung mit der Prozedur PHREG wollen wir mit folgendem kleinen Beispiel verdeut-
lichen. Die Daten stammen aus Kalbfleisch et al. (1980)11. Es handelt sich dabei um die
Ergebnisse eines Experiments mit zwei Gruppen von Ratten, die mit dem krebserregenden
Stoff DMBA behandelt wurden sind. Zusatzlich wurden die Ratten radioaktiv bestrahlt. Eine
Gruppe der Ratten wurde in einer keimfreien Umgebung gehalten. Die zugrundeliegende
Fragestellung untersucht, welche Umgebung eine positivere Wirkung auf die Lebensdau-
er hat. Vier Beobachtungen im Datensatz sind rechtszensiert. Dies ist begrundet in einer
anderen Todesursache als dem Krebs.
1. Schritt: Einlesen der Daten. Der Datensatz enthalt die Variablen Dauer (Lebensdauer),
Gruppe (Gruppe 1: keimfreie Umgebung) sowie Zensur, dem Indikator fur zensierter Be-
obachtungen.
DATA RATTEN;
LABEL DAUER = ’Tage von Behandlung bis zum Tod’;
INPUT DAUER GRUPPE ZENSUR @@;
DATALINES;
143 1 0 164 1 0 188 1 0 188 1 0
190 1 0 192 1 0 206 1 0 209 1 0
213 1 0 216 1 0 220 1 0 227 1 0
230 1 0 234 1 0 246 1 0 265 1 0
304 1 0 216 0 0 244 0 0 142 1 1
156 1 1 163 1 1 198 1 1 205 1 1
232 1 1 232 1 1 233 1 1 233 1 1
233 1 1 233 1 1 239 1 1 240 1 1
261 1 1 280 1 1 280 1 1 296 1 1
296 1 1 323 1 1 204 0 1 344 0 1
;
2. Schritt: Schatzung des Modells. Dauer in Abhangigkeit von Gruppe.
PROC PHREG DATA=ratten;
MODEL dauer*zensur(0)=gruppe;
RUN;
Wir erhalten folgende Ergebnisse:
11siehe oben
56
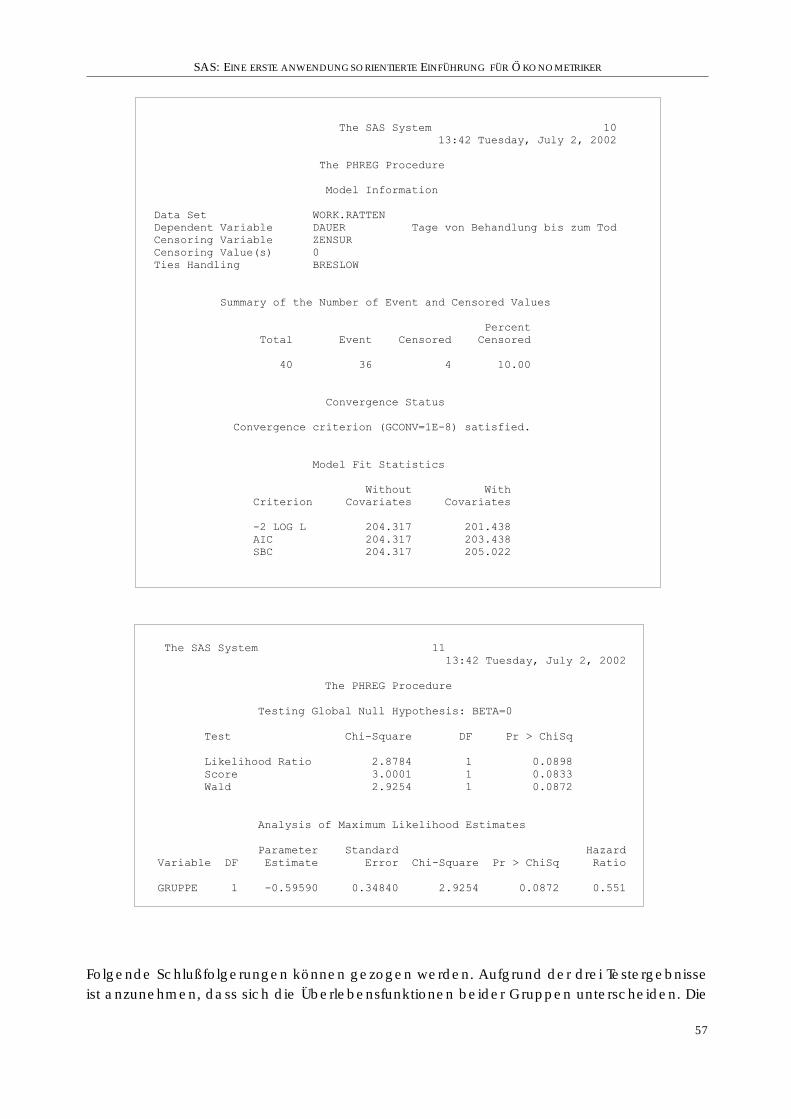
SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Folgende Schlußfolgerungen konnen gezogen werden. Aufgrund der drei Testergebnisse
ist anzunehmen, dass sich die Uberlebensfunktionen beider Gruppen unterscheiden. Die
57

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Hazardrate der Kovariablen Gruppe nimmt den Wert 0.551 an. Da die Variablen die Aus-
pragungen 0 und 1 hat, bedeutet dies, das die Hazardrate der Gruppe 1 niedriger ist als
die der Gruppe 0, d.h. Ratten in der Gruppe 1 (in der keimfreien Umgebung) haben eine
hohere Lebenserwartung als Ratten in der Gruppe 0.
Die Proportionalitats-Annahme ist nur gewahrleistet, wenn die Hazardrate nicht zeitabhan-
gig ist. In einem kurzen Test, wollen wir schauen, ob dies in unserem Beispiel gewahrleistet
ist.
Die Hazardraten in unserem Modell hatte die Form
λ(t) =
h0(t) wenn Gruppe = 0
h0(t)εβ1 wenn Gruppe = 1
Einfache Abweichungen von der Proportionalitatsannahme konnen mit folgender zeitab-
hangigen erklarenden Variablen untersucht werden x = x(t):
x(t) =
0 wenn Gruppe = 0
log(t)− 5.4 wenn Gruppe = 1
Wir verwenden den Logarithmus der Zeit um numerische Instabilitat zu vermeiden. Die
Konstante 5.4 ist der Durschnitt der logarithmierten Dauern. Die Hazardrate der beiden
Gruppen hat nunmehr folgende Form:
εβ1−5.4β2tβ2 ,
mit β2 als Parameter fur die zeitabhangige Variable x. Ist β2 > 0(β2 < 0) bedeutet dies, daß
sich die Hazardrate uber die Zeit erhoht (verringert).
3. Schritt: Ausrechnen der Konstante
DATA ratten;
SET ratten;
log_dauer=log(dauer);
RUN;
PROC MEANS DATA=ratten;
VAR log_dauer;
RUN;
Wir erhalten:
58

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
4. Schritt: Schatzung des Modells unter Einbezug der zeitabhangigen Variablen x:
PROC PHREG DATA=ratten;
MODEL DAUER*ZENSUR(0)=GRUPPE X;
X = GRUPPE * (log_dauer-5.4);
RUN;
Als Ergebnis erhalten wir
Da der Wert der Hazardrate der zeitabhangigen Variable den Wert null annimmt, konnen
wir davon ausgehen, daß in unserem Beispiel keine Anzeichen fur eine zeitabhangige
Hazardrate vorhanden sind.
59

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
14. Ubungsaufgaben
Zur Bearbeitung dieser Aufgabe benotigen Sie den ASCII-Datensatz uebung1.asc. Er steht
auf unserer Homepage http://www.wiwi.uni-frankfurt.de/Professoren/hujer/ zum Down-
load bereit.
1. Quantitative Methoden der Volkswirtschaftslehre
AUFGABE 1 (INDIKATOREN UND INDIZES):
a) Berechnen Sie aus den gegebenen Daten fur die Bundesrepublik Deutschland die
Zeitreihen fur folgende Kenngroßen:
- Kapitalintensitat
- Arbeitsproduktivitat
- Kapitalproduktivitat
- unbereinigte Lohnquote
- bereinigte Lohnquote
b) Bilden Sie wegen der besseren Vergleichbarkeit aus den berechneten Großen In-
dizes mit der Basis 1960 gleich 100. Stellen Sie die berechneten Indizes sowie die
Wachstumsraten der Indizes graphisch dar und interpretieren Sie die Verlaufe.
AUFGABE 2 (OLS):
a) Schatzen Sie mit Hilfe der Kleinst-Quadrate-Methode fur die Bundesrepublik Deutsch-
land die Parameter der folgende Cobb-Douglas-Produktionsfunktion:
Yt = C ·Kαt · eλ·t
mit:
Y : Output
K : Kapital
A : Arbeit
t : Zeittrend
C,α, β, λ : zu schatzende Parameter.
b) Interpretieren Sie die geschatzten Parameter und Teststatistiken.
Vorgehensweise:
- Logarithmische Transformation der Produktionsfunktion
60

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
- Auswahl und Generierung der benotigten Variablen
- Schatzung der logarithmierten Funktionsform mit Hilfe der Kleinst-Quadrate- Methode
- Interpretation der geschatzten Parameter und Teststatistiken
AUFGABE 3 (ARBEITSNACHFRAGE UND OLS):
a) Leiten Sie gemaß der neoklassischen Theorie die nachfolgende Arbeitsnachfrage-
funktion unter der Restriktion der in Aufgabe 2 spezifizierten Cobb-Douglas-Produk-
tionsfunktion her.
ln(Lt) = b0 + b1 · ln(Yt) + b2 · ln(w) + b3 · ln(r) + b4 · t
Um etwaige Rigiditaten auf dem Arbeitsmarkt berucksichtigen zu konnen, erweitern
Sie obige Arbeitsnachfragefunktion gemaß dem Modell der partiellen Anpassung
zu:
ln(Lt) = b0 + b1 · ln(Yt) + b2 · ln(w) + b3 · ln(r) + b4 · t + b5 · ln(Lt−1)
mit:
L: Beschaftigte Arbeitnehmer
Y : reales Bruttosozialprodukt
w: Reallohn
r: reale Kapitalkosten
t: Zeittrend
b0, b1, b2, b3, b4, b5: zu schatzende Parameter
b) Schatzen Sie die Parameter der beiden obigen Arbeitsnachfragefunktionen fur die
Bundesrepublik Deutschland mit Hilfe der Kleinst-Quadrate-Methode. Interpretieren
Sie die geschatzten Parameter und Teststatistiken.
Vorgehensweise:
• Theoretische Herleitung der Arbeitsnachfragefunktion gemaß der neoklassischen
Theorie, d.h. entweder nach dem Gewinnmaximierungsansatz oder nach dem Ko-
stenminimierungsansatz
• Formulierung eines Modells der partiellen Anpassung und Berucksichtigung des An-
passungsprozesses in der zu schatzenden Arbeitsnachfragefunktion
• Auswahl und Generierung der benotigten Variablen
• Schatzung der beiden Arbeitsnachfragefunktionen und Interpretation der geschatz-
ten Parameter und Teststatistiken
61

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
2. Grundlagen der Okonometrie
Die folgenden Ubungen beruhen großtenteils auf den Buchern:
• GRIFFITHS/ HILL/ JUDGE (1993): Learning and Practicing Econometrics, New York.
• HILL (1993): Learning SAS: A Computer Handbook for Econometrics. A Guide to Pro-
gramming for Learning and Practicing Econometrics and Introduction to the Theory
and Practice of Econometrics, New York [SAS-Begleitbuch zu GRIFFITHS/ HILL/ JUDGE
(1993)].
Zur Bearbeitung der Aufgabe benotigen Sie die ASCII-Datensatze airtrans.asc, kleingol.asc,
sugarcan.asc, weizen.asc und brd.asc. Die Datensatze stehen auf unserer Homepage
http://www.wiwi.uni-frankfurt.de/Professoren/hujer/ zum Download bereit.
AUFGABE 1 (OLS):
Der ASCII-Datensatz airtrans.asc enthalt Daten fur den Zeitraum 1948-1979 fur den Luft-
fracht-Sektor in den USA in der folgenden Reihenfolge: Jahr, Output (Y ), Kapitalkosten
(R), Kapital (K), Lohn (W ) und Arbeit (L), mit Ausnahme des Jahres jeweils in Form eines
Index. Es soll uberpruft werden, wie das Verhaltnis von Arbeit und Kapital vom relativen
Preis beider Faktoren und von der Hohe des Outputs abhangt. Dazu wird folgendes Modell
aufgestellt:
ln(
Lt
Kt
)= β1 + β2 ln
(Wt
Rt
)+ β3Yt + ut
a) Welches Vorzeichen erwarten Sie fur den Koeffizienten β2? Wie hangt das Vorzeichen
von β3 mit der Gestalt des Expansionspfades in einem Diagramm mit Kapital auf der
x- und Arbeit auf der y-Achse zusammen?
b) Fuhren Sie eine OLS-Schatzung des Modells durch. Lesen Sie dazu zunachst den
Datensatz airtrans.asc ein und fuhren die notwendigen Variablentransformationen
durch. Interpretieren Sie die Schatzergebnisse. Welcher Anteil der Varianz von ln(
LtKt
)wird durch das Modell erklart?
c) Testen Sie die gemeinsame Hypothese, daß β2 = 1 und β3 = 0. Was ist der theoreti-
sche Hintergrund fur diesen Test?
AUFGABE 2 (MULTIKOLLINEARITAT):
KLEIN/ GOLDBERGER(1955)12 verwenden das folgende Modell zur Schatzung des inlandi-
schen Konsums in der USA (c) in Abhangigkeit vom Lohneinkommen (w), Einkommen aus
12KLEIN/ GOLDBERGER (1955): An Econometric Model of the United States, 1929-1952, Amsterdam.
62

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
Landwirtschaft (a) und Einkommen, das weder Lohneinkommen noch Einkommen aus
Landwirtschaft ist, (p) fur den Zeitraum 1928-1950:
ct = β1 + β2wt + β3pt + β4at + ut
a) Klein/Goldberger schließen den Zeitraum von 1942-1944 aus der Schatzung aus.
Warum?
b) Erwarten Sie a priori Multikollinearitat in diesem Modell? Warum?
c) Uberprufen Sie Ihre Erwartung durch eine Korrelationsanalyse. Sie finden die Daten
in dem ASCII-Datensatz kleingol.asc (c, w, p, a).
d) Fuhren Sie eine OLS-Schatzung des Modells durch. Konnen Sie Multikollinearitat in
den Schatzergebnissen erkennen? Berechnen Sie sich auch die 95%-Konfidenzin-
tervalle fur die Parameterschatzwerte.
e) Welche Losungsmoglichkeiten zur Behebung von Multikollinearitat kennen Sie? Klein/
Goldberger verwenden folgende Parameter-Restriktionen zur Behebung, die auf fru-
heren empririschen Untersuchungen beruhen: β3 = 0, 75β2 und β4 = 0, 625β2 . Schatzen
Sie das Modell erneut unter Berucksichtigung dieser Restriktionen. Wie sehen die
Schatzergebnisse nun aus? Was ist das grundsatzliche Problem dieser Vorgehens-
weise? Uberprufen Sie mit einem F -Test, ob die Restriktionen vereinbar mit den Daten
sind.
AUFGABE 3 (AUTOKORRELATION):
In Bangladesch wird u.a. Zuckerrohr angebaut. Es soll ein Modell geschatzt werden, das
die Flache erklaren soll, auf der Zuckerrohr angebaut wird (Variable: area). Als erklaren-
de Variable dient der relative Preis des Zuckerrohrs gegenuber dem wichtigsten Alterna-
tivprodukt Jute. Der Preis des Zuckerrohrs ist p sugar, der von Jute p jute. In dem ASCII-
Datensatz sugarcan.asc finden sich die Variablen area, p sugar, p jute. Das zu schatzende
Modell lautet:
ln(area) = β1 + β2 ln(
p sugar
p jute
)+ ut
a) Fuhren Sie eine OLS-Schatzung des Modells durch. Hat der Schatzer fur β2 das er-
wartete Vorzeichen? Uberprufen Sie mit einem geeigneten Test, ob Autokorrelation
1.Ordnung vorliegt. Schauen Sie sich auch den Plot der Residuen uber die Beobach-
tungen an.
b) Modifizieren Sie Ihre Schatzung so, daß Ihnen die OLS-Residuen nach der Schatzung
erhalten bleiben und ermitteln Sie einen Schatzwert fur r in dem autoregressiven Pro-
zeß 1. Ordnung (AR(1)-Prozeß), der Autokorrelation 1. Ordnung zugrundeliegt (vgl.
GUJARATI, S.407 und 427). Ist das Ergebnis Ihrer Schatzung mit dem Ergebnis aus (a)
vereinbar?
(Hinweis: Achten Sie darauf, ob der AR(1)-Prozeß eine Konstante enthalt!)
63

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
c) GUJARATI (1995), S.427-428, schlagt mit der GLS-Methode eine Moglichkeit zur Behe-
bung der Autokorrelation vor. Transformieren Sie Ihre Daten entsprechend und fuhren
Sie die Schatzung aus (a) erneut durch. Wie sieht Ihre Teststatistik nun aus?
(Hinweise: Verwenden Sie zur Transformation den Schatzwert fur r aus (b); auch die
Regressionskonstante ist zu transformieren - generieren sie sich dazu eine neue Va-
riable, die sie statt der standardmaßigen Regressionskonstante in der Schatzung
berucksichtigen; beachten Sie auch, daß die die ersten Beobachtungen ( n = 1)
anders transformieren mussen.)
d) Warum ist ein Vergleich der Standardabweichungen aus (a) und (c) irrefuhrend?
AUFGABE 4 (HETEROSKEDASTIE):
ir betrachten die produzierte Menge an Weizen aggregiert uber alle Farmen in einem ein-
zelnen Anbaugebiet in Australien uber 26 Jahre. Man kann sicherlich sagen, dass diese
Menge zum einen vom (evtl. erwarteten) Weizenpreis, von der Technologie und vom Wet-
ter abhangt. Die Umsetzung in ein okonometrisches Modell stoßt auf das Problem, dass
es die”Wettervariable“ nicht geben kann, Wettereffekte werden deshalb Teil der Storva-
riable sein. Außerdem ist die verwendete Technologie schwer messbar. Wir verwenden
deshalb Zeit als eine Proxyvariable, die Anderungen in der Technologie reprasentieren
soll. Unser Modell sieht dann wie folgt aus (q = produzierte Menge Weizen; p = von der
Regierung garantierter Preis fur Weizen;t = 1, . . . , 26 als Trendvariable):
qt = β1 + β2pt + β3t + ut
Es ist außerdem bekannt, dass nach dem dreizehnten hier betrachteten Jahr neue Wei-
zenarten eingefuhrt wurden, die weniger anfallig auf das Wetter reagieren. Da Wetterein-
flusse in unsere Storgroße eingehen, wird die Annahme einer homoskedastischen Storva-
riablen nicht zu halten sein. Vielmehr werden nun folgende Annahmen uber die Storgroße
zugrundegelegt:
E[ut] = 0 t = 1, 2, . . . , 26
E[u2t ] = σ2
1 t = 1, 2, . . . , 13
E[u2t ] = σ2
2 t = 14, . . . , 26
Außerdem erwarten wir dem Hintergrund entsprechend, daß σ22 < σ2
1(warum?).
a) Lesen Sie den ASCII-Datensatz weizen.asc (q, p, t) ein und fuhren Sie separate OLS-
Schatzungen fur die beiden Teilzeitraume durch. Stimmen sie mit den Erwartungen
uberein?
b) Fuhren Sie aufgrund der Schatzergebnisse einen Goldfeld-Quandt-Test auf Heteros-
kedatie durch (s.GUJARATI(1995, S.374-377); aber besser: GREENE (1993, S.393-394)).
Verzichten Sie dabei aus Vereinfachungsgrunden darauf, vorher Beobachtungen
aus dem Sample zu entfernen. Dies hat nur einen Einfluß auf die Macht des Tests.
64

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
c) Fuhren Sie eine feasible GLS-Schatzung fur das gesamte Sample durch. Von einer
feasible GLS-Schatzung wird gesprochen, wenn man das von GUJARATI (1995, S.381-
382) diskutierte Verfahren anwendet und dabei statt der unbekannten wahren Vari-
anzen die geschatzen Varianzen verwendet. Interpretieren Sie die Schatzergenisse
im Vergleich zu denen aus (a).
(Hinweis: Erneut ist auch eine Transformation der Regressionskonstanten notwendig!)
AUFGABE 5 (PRODUKTIONSFUNKTION FUR DIE BUNDESREPUBLIK):
Schatzen Sie mit Hilfe von OLS die Parameter der folgenden Cobb-Douglas-Produktions-
funktion fur die Bundesrepublik Deutschland 1960 - 1991 und interpretieren Sie die Schatz-
ergebnisse:
Yt = δ ·Kαt ·Aβ
t · eλtt
mit: Y = Output; K = Kapital; A = Arbeit und t = Zeittrend Grundlage ist der Datensatz brd.asc
mit folgenden Variablen:
JAHR Jahr
ECP Privater Verbrauch (Mrd. DM 1985)
EIP Anlageinvestitionen aller Untern. (Mrd. DM 1985)
K Bruttoanlagevermogen insg. (Mrd. DM 1985)
LE Beschaftige Arbeitnehmer insg. (Mio)
LHT Arbeitsvolumen insgesamt (Mio Std.)
LSE Selbstandige und Mithelfende (Mio)
PECP Impl. Preisindex priv. Verb. (1985=100)
POP Wohnbevolkerung (Mio.)
PXGNP Impliziter Preisindex BSP (1985 = 100)
RL Langfristiger Zins TIME Zeittrend
UCUM Kapazitatsauslastung insgesamt
X Bruttowertschopfung (Mrd. DM 1985)
XGNPDM Bruttosozialprodukt (Mrd. DM)
YDH Verfugbares Einkommen der priv. HH. (Mrd. DM)
YL Eink. aus unselbst. Arbeit insg.(Mrd.DM)
YLA Durchsch. Einkommen je Beschaftigtem (Tsd.DM)
YNNI Nettosozialprodukt zu Faktorkosten (Mrd. DM).
65

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
3. Mikrookonometrie
Die folgenden Ubungen beruhen großtenteils auf den Buchern:
• GRIFFITHS/ HILL/ JUDGE(1993): Learning and Practicing Econometrics, New York.
• HILL(1993): Learning SAS: A Computer Handbook for Econometrics. A Guide to Pro-
gramming for Learning and Practicing Econometrics and Introduction to the Theory
and Practice of Econometrics, New York [SAS-Begleitbuch zu GRIFFITHS/ HILL/ JUD-
GE(1993)].
• GREENE (1997): Econometric Analysis, New York.
• ECKEY/ KOSFELD/ DREGER (1995): Okonometrie, Gabler-Verlag
Zur Bearbeitung der Aufgabe benotigen Sie die ASCII-Datensatze airtrans.asc, kleingol.asc,
sugarcan.asc, weizen.asc und brd.asc. Die Datensatze stehen auf unserer Homepage
http://www.wiwi.uni-frankfurt.de/Professoren/hujer/ zum Download bereit.
AUFGABE 1 (VERGLEICH ZWISCHEN LWM, LOGIT UND PROBIT):
SPECTOR UND MAZZEO (1980) untersuchten in einer Studie die Wirkung einer neuen Lehr-
methode in dem Fach Okonomie auf die Leistung von Schulern. Der SAS-Datensatz te-
ach enthalt 32 Beobachtungen von Schulern, die mit dieser neuen Lehrtechnik unter-
richtet wurden (PSI = 1). Die abhangige Variable GRADE zeigt an ob sich die Leistung
verbessert hat (GRADE=1) oder nicht (GRADE=0). Als weitere Variablen sind GPA, die
Durchschnittsno-tenpunktzahl, und TUCE, das Ergebnis eines Vortests der das okonomi-
sche Basiswissen uberpruft hat, enthalten.
a) Berechnen Sie die Erfolgswahrscheinlichkeit P(GRADE = 1) in Abhangigkeit der Va-
riablen GPA, PSI und TUCE. Schatzen Sie zunachst eine lineares Wahrscheinlichkeits-
modell, dann ein Probit-Modell und abschließend ein Logit-Modell.
b) Interpretieren Sie die Ergebnisse. Wie erklaren Sie sich die Unterschiede in den ver-
schiedenen Modellen?
c) Berechnen Sie Mc Faddens R2 fur das Logit- und das Probit-Modell.
d) Wie hoch ist die Erfolgswahrscheinlichkeit fur einen Schuler, mit den Auspragungen
(GPA: 2.4, TUCE: 27, PSI: 1) im Logit-Modell?
AUFGABE 2 (LOGIT UND PROBIT):
Der Datensatz vote enthalt die Ergebnisse der US-Prasidentschaftswahlen des Jahres 1976
fur 51 Staaten. Die Variablen DEMO und REP enthalten jeweils die auf die Demokrati-
sche und die Republikanische Partei entfallenen Stimmen (in Tausend). INCOME ist das
durchschnittliche Familieneinkommen aus dem Jahre 1975. Die Variable SCHOOL gibt die
66

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
durchschnittliche Anzahl von Schuljahren an, die von Personen uber 17 Jahren absol-
viert wurden. URBAN ist der Prozentanteil von Personen, die in einem”stadtischen Gebiet“
wohnen und REGION ist eine regionale Dummy-Variable, die die folgenden Auspragun-
gen annehmen kann: 1 = Northeast, 2 = Southeast, 3 = Midwest und Middle South, 4 = West
und Mountain States.
a) Generieren Sie eine Indexvariable, die den Wert 1 annimmt, wenn die Demokrati-
sche Partei in einem Staat gewonnen hat.
b) Schatzen Sie ein Logit- und ein Probit-Modell und verwenden Sie als erklarende Va-
riablen: INCOME, SCHOOL, URBAN und die Regionen. Interpretieren Sie die Ergebnis-
se.
67

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
4. Finanzokonometrie
Fur die folgenden Ubungen benotigen Sie Datensatze, die Sie von unsere Homepage
downloaden konnen: http://www.wiwi.uni-frankfurt.de/Professoren/hujer/. Die Datensatze
sind zumeist dem Buch von Mills (1996), The Econometric Modelling of Financial Time Se-
ries, Cambridge, entnommen.
AUFGABE 1 (IDENTIFIKATION VON ARIMA MODELLEN):
Modellieren Sie die Zeitreihe whatami, die Sie in der Datei whatami finden konnen. Dieser
Zeitreihe liegt ein simulierter stochastischer ARMA(p,q) Prozess zugrunde. Identifizieren Sie
die Ordnung der AR und MA-Teile.
AUFGABE 2 (SCHATZEN VON UND PROGNOSE MIT ARIMA MODELLEN):
Modellieren Sie die Zeitreihe der nominalen FTA-all-share monatlichen Returns (FTARET) als
ARIMA-Prozess.
a) Prufen Sie, zunachst nur graphisch und anhand der empirischen Autokorrelationen,
die Stationaritat von FTARET. Versuchen Sie zunachst, anhand der empirischen Auto-
korrelationsfunktion einen zugrundeliegenden ARIMA-Prozess zu identifizieren.
b) Schatzen Sie die Parameter der Modelle mit der Maximum-Likelihood-Methode. Scha-
tzen Sie die von Ihnen gewahlten AR(p) Prozesse mit Conditional Least Squares und
Maximum Likelihood. Vergleichen Sie die Schatzergebnisse.
c) Begrunden Sie die Wahl Ihres Modells anhand des Akaike- und Schwarz-Kriteriums,
der Signifikanz der Parameter-Schatzwerte und der Korrelationsstruktur der geschatz-
ten Residuen. Schreiben Sie das geschatzte Modell in verschiedenen Notationen ei-
nes ARMA-Modells.
d) Prognostizieren Sie FTARET 12 Perioden in die Zukunft. Diskutieren Sie die Progno-
segute des von Ihnen gewahlten Ansatzes. Stellen Sie die Prognose und die unteren
und oberen Grenzen des 95 % Konfidenzintervalles graphisch dar.
AUFGABE 3 (SCHATZEN VON GARCH MODELLEN):
Modellieren Sie die Zeitreihe der nominalen FTA-all-share monatlichen Returns (FTARET) als
GARCH-Prozess.
a) Spezifizieren Sie zunachst ein ARCH(1) und ein GARCH(1,1) Modell und schatzen Sie
die Parameter der Modelle mit der Maximum-Likelihood-Methode. Prufen Sie die
Stationaritat der von Ihnen geschatzten bedingten Varianzen.
b) Plotten Sie die sich ergebende Schatzung der bedingten Varianz der beiden Mo-
delle zusammen mit der Originalzeitreihe und diskutieren Sie die unterschiedlichen
Ergebnisse
68

SAS: EINE ERSTE ANWENDUNGSORIENTIERTE EINFUHRUNG FUR OKONOMETRIKER
c) Wahlen Sie nach Ihnen bekannten Modell-Selektionskriterien ein geeignetes GARCH
(p,q)-Modell zur Beschreibung von FTARET. Begrunden Sie Ihre Entscheidung
d) Schatzen Sie ein E-GARCH-Modell und prufen Sie die Hypothese asymmetrisch wir-
kender Schocks auf die Volatilitat von FRARET. Nehmen Sie das von Ihnen gewahlte
E-GARCH-Modell in Ihr Modellportfolio auf?
e) Prufen Sie auf G(ARCH) in Mean-Effekte. (Hoherer Return bei hoherer Volatilitat).
f) Schatzen Sie die Modelle nochmals unter der Annahme von t-verteilten Innovatio-
nen. Prufen Sie die Hypothese der Normalverteilung.
69
![References - Springer978-0-230-27275-0/1.pdf · References Alisch, M. and ] ... Comparative Statistical Analysis at National, ... A.C. and L.F. Katz (1991) 'The Company You Keep:](https://img.pdfslide.org/doc/110x75/5b2827027f8b9ab16e8b49b2/references-springer-978-0-230-27275-01pdf-references-alisch-m-and-.jpg)



























