Embed Size (px)
Citation preview

Systemarchitekturen zurKonstruktion verteilter Systeme:
Kommunikationsarten, Architekturen und Paradigmen
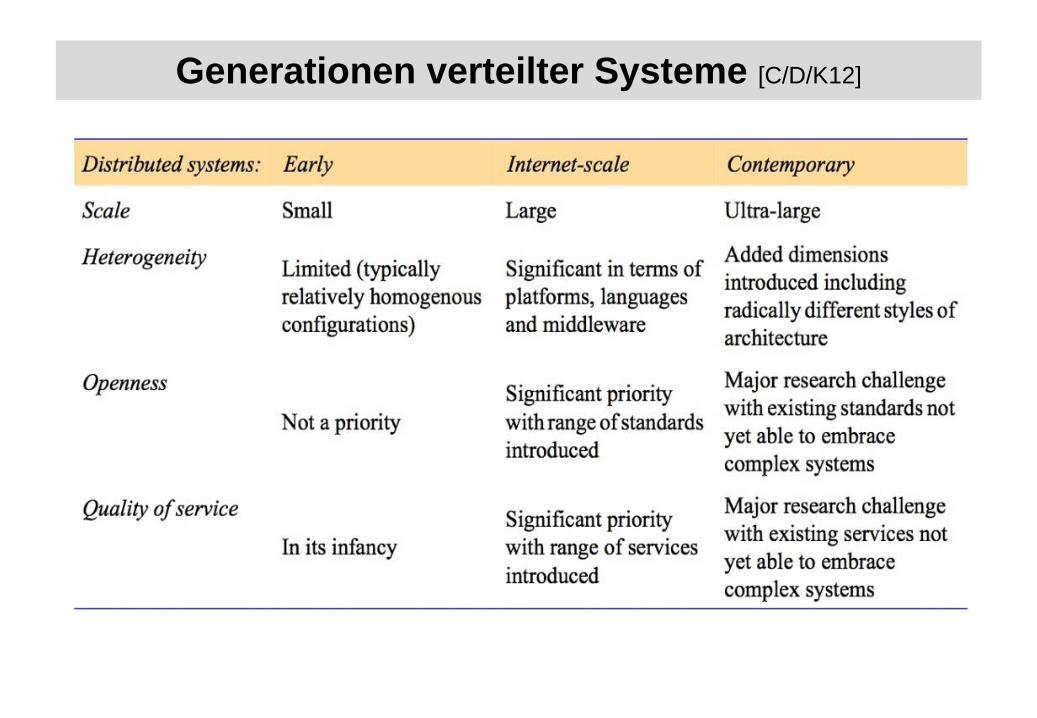
Generationen verteilter Systeme [C/D/K12]

GliederungKommunikationsformen
— nachrichtenbasiert— aufrufzentriert— datenzentriert— ereignisbasiert
Architekturen— Client/Server und Schichtenmodelle— Peer-to-Peer und Hybridmodelle— Umsetzung: Middleware und Selbstmanagement— Zum Vergleich: Betriebssystemarchitekturen
Konstruktionsparadigmen— objektorientiert— komponentenbasiert— dienstorientiert— agentenorientiert
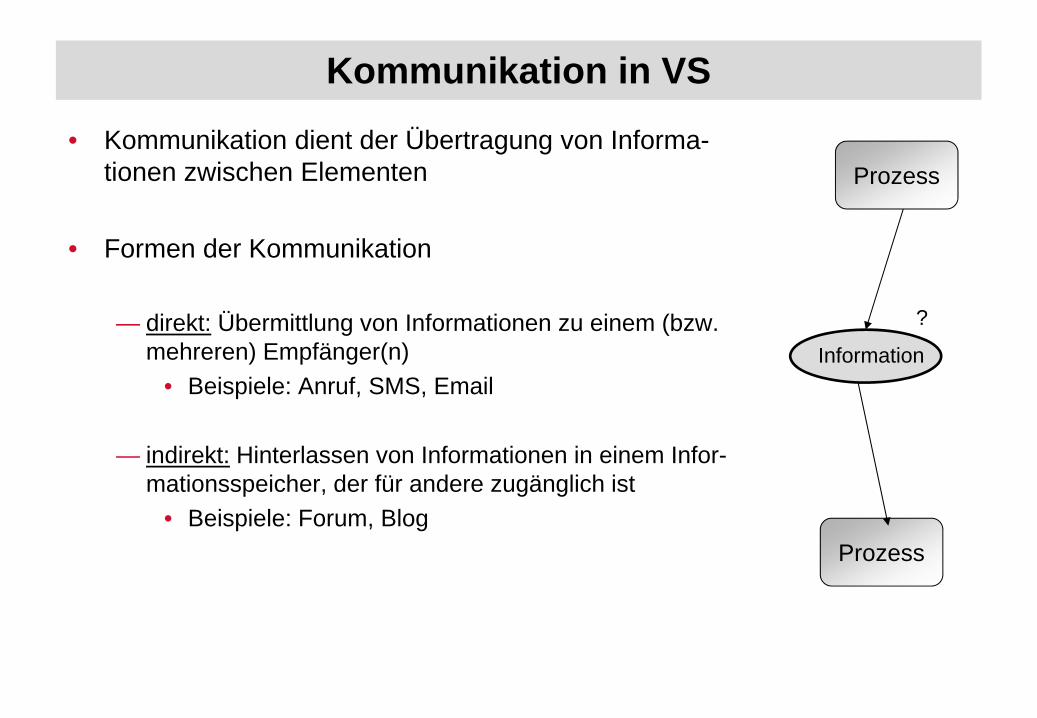
Kommunikation in VS
• Kommunikation dient der Übertragung von Informa-tionen zwischen Elementen
• Formen der Kommunikation
— direkt: Übermittlung von Informationen zu einem (bzw. mehreren) Empfänger(n)
• Beispiele: Anruf, SMS, Email
— indirekt: Hinterlassen von Informationen in einem Infor-mationsspeicher, der für andere zugänglich ist
• Beispiele: Forum, Blog
Information
Prozess
Prozess
?

Aufrufzentrierte Kommunikation
• stammt aus der objektbasierten Welt• Element A kennt Element B (bzw. dessen Adresse)• Element A kennt die Signatur der gewünschten Methode auf B• typischerweise erfolgt der Aufruf der Methode synchron, d.h. der aufru-
fende Kontrollfluss wartet auf das Ergebnis des Calls• Die Übergabesemanik von Parametern kann Call-by-Reference oder Call-
by-Value sein• Ist B nicht im Adressraum von A, so kann ein entfernter Methodenaufruf
durchgeführt werden (Remote Method Invocation – RMI)• Probleme im verteilten Fall: z.B. Netzwerkfehler, Parameterübergaben,
Kenntnis über Objekte und Schnittstellen, Heterogenität, enge Kopplung, Aufrufsemantiken und idempotente Operationen
AufrufA B
ErgebnisAufruf: ret = B.m1(args)

Nachrichtenbasierte Kommunikation
• Element A kennt Element B (bzw. dessen Adresse)• Nachricht ähnlich einem Brief, bestehend typischerweise aus einem Um-
schlag und dem eigentlichen Inhalt• Nachricht asynchron, da A nicht auf eine Antworten von B warten muss• kann auch zum Aufbau synchroner Kommunikation genutzt werden, denn
A kann selbst entscheiden, ob er auf eine Reaktion von B wartet• Nachrichten können Teil übergeordneter Protokolle sein, typisches
Beispiel: Request-Reply• Probleme in offenen Systemen z.B.: Wie verstehe ich die Nachricht und
deren Inhalt? Wie weiß A, dass B seine Nachricht erhalten hat?
• Beispiel: AgentensystemeNachricht
A BSenden: send(msg)
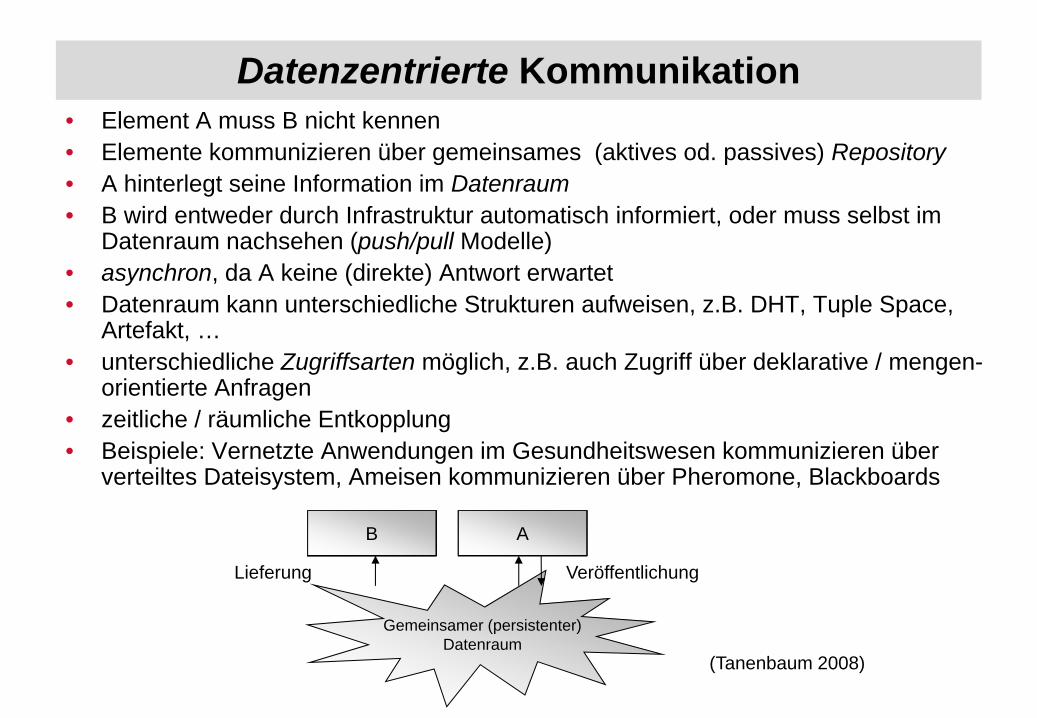
Datenzentrierte Kommunikation• Element A muss B nicht kennen• Elemente kommunizieren über gemeinsames (aktives od. passives) Repository• A hinterlegt seine Information im Datenraum• B wird entweder durch Infrastruktur automatisch informiert, oder muss selbst im
Datenraum nachsehen (push/pull Modelle)• asynchron, da A keine (direkte) Antwort erwartet• Datenraum kann unterschiedliche Strukturen aufweisen, z.B. DHT, Tuple Space,
Artefakt, …• unterschiedliche Zugriffsarten möglich, z.B. auch Zugriff über deklarative / mengen-
orientierte Anfragen• zeitliche / räumliche Entkopplung• Beispiele: Vernetzte Anwendungen im Gesundheitswesen kommunizieren über
verteiltes Dateisystem, Ameisen kommunizieren über Pheromone, Blackboards
Komponente Komponente
Lieferung
Komponente KomponenteKomponente KomponenteKomponenteKomponente KomponenteKomponente AB
(Tanenbaum 2008)
Gemeinsamer (persistenter)Datenraum
Veröffentlichung
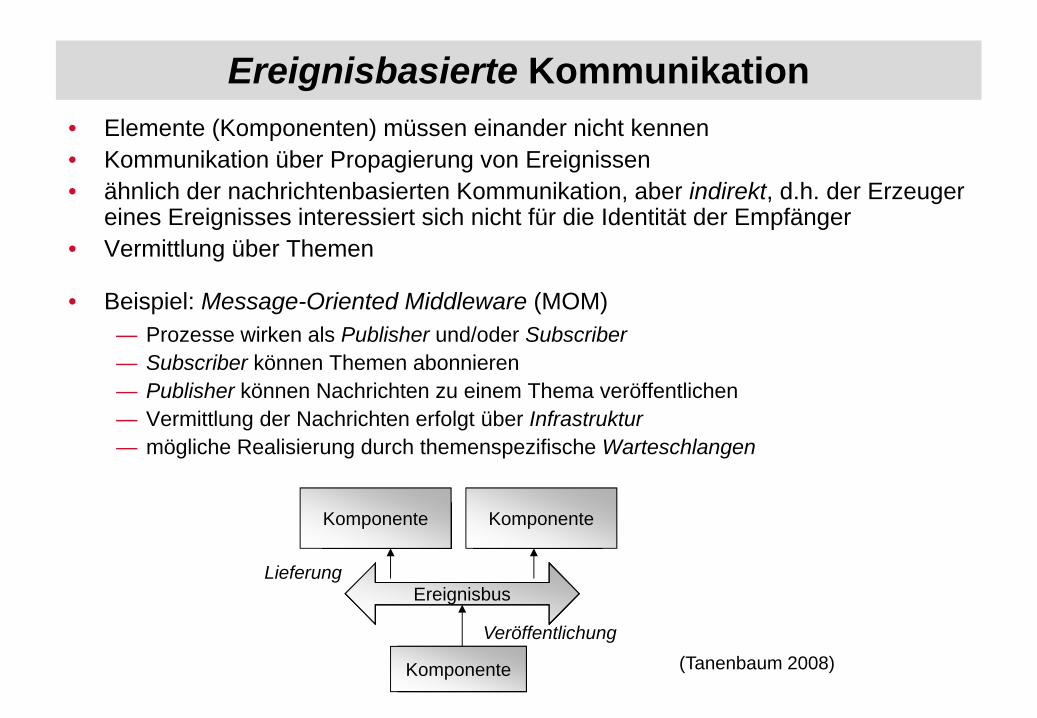
Ereignisbasierte Kommunikation• Elemente (Komponenten) müssen einander nicht kennen• Kommunikation über Propagierung von Ereignissen• ähnlich der nachrichtenbasierten Kommunikation, aber indirekt, d.h. der Erzeuger
eines Ereignisses interessiert sich nicht für die Identität der Empfänger• Vermittlung über Themen
• Beispiel: Message-Oriented Middleware (MOM)— Prozesse wirken als Publisher und/oder Subscriber— Subscriber können Themen abonnieren— Publisher können Nachrichten zu einem Thema veröffentlichen— Vermittlung der Nachrichten erfolgt über Infrastruktur— mögliche Realisierung durch themenspezifische Warteschlangen
Ereignisbus
Komponente
Komponente Komponente
Veröffentlichung
LieferungEreignisbus
Komponente Komponente
Ereignisbus
Komponente
Komponente
Komponente
Ereignisbus
Komponente
Ereignisbus
Komponente Komponente
Ereignisbus
Komponente
Komponente
Komponente
Ereignisbus
Komponente
(Tanenbaum 2008)
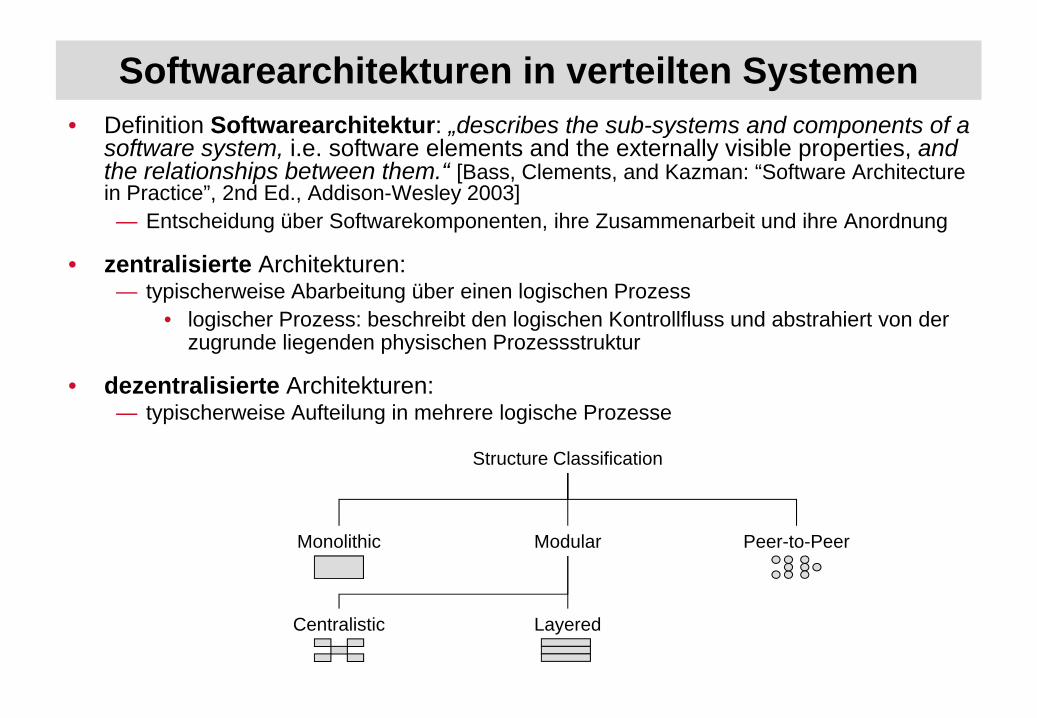
Softwarearchitekturen in verteilten Systemen• Definition Softwarearchitektur: „describes the sub-systems and components of a
software system, i.e. software elements and the externally visible properties, and the relationships between them.“ [Bass, Clements, and Kazman: “Software Architecture in Practice”, 2nd Ed., Addison-Wesley 2003]
— Entscheidung über Softwarekomponenten, ihre Zusammenarbeit und ihre Anordnung
• zentralisierte Architekturen:— typischerweise Abarbeitung über einen logischen Prozess
• logischer Prozess: beschreibt den logischen Kontrollfluss und abstrahiert von der zugrunde liegenden physischen Prozessstruktur
• dezentralisierte Architekturen:— typischerweise Aufteilung in mehrere logische Prozesse
Structure Classification
Monolithic Peer-to-Peer
Centralistic Layered
Modular

Client/Server-Architekturen
• Server: Dienstanbieter, d.h. Prozess, der einen bestimmten Dienst imple-mentiert (z.B. Datei, DB/IS)
• Client: Dienstnutzer, d.h. Prozess der Dienst von einem Server anfordert und auf Ergebnis wartet (request-reply)— Verschicken (request) und Empfangen einer Nachricht (reply) erfolgen als
Einheit — ermöglicht synchrone Kommunikation über asynchrone Infrastruktur— Umsetzung z.B. über unterschiedliche Warteschlangen für Request- und Reply-
Nachrichten
• vertikale Verteilung der Funktionen mithilfe von Schichten, typischerweise— Benutzungsschnittstelle— Verarbeitungsebene— Datenebene
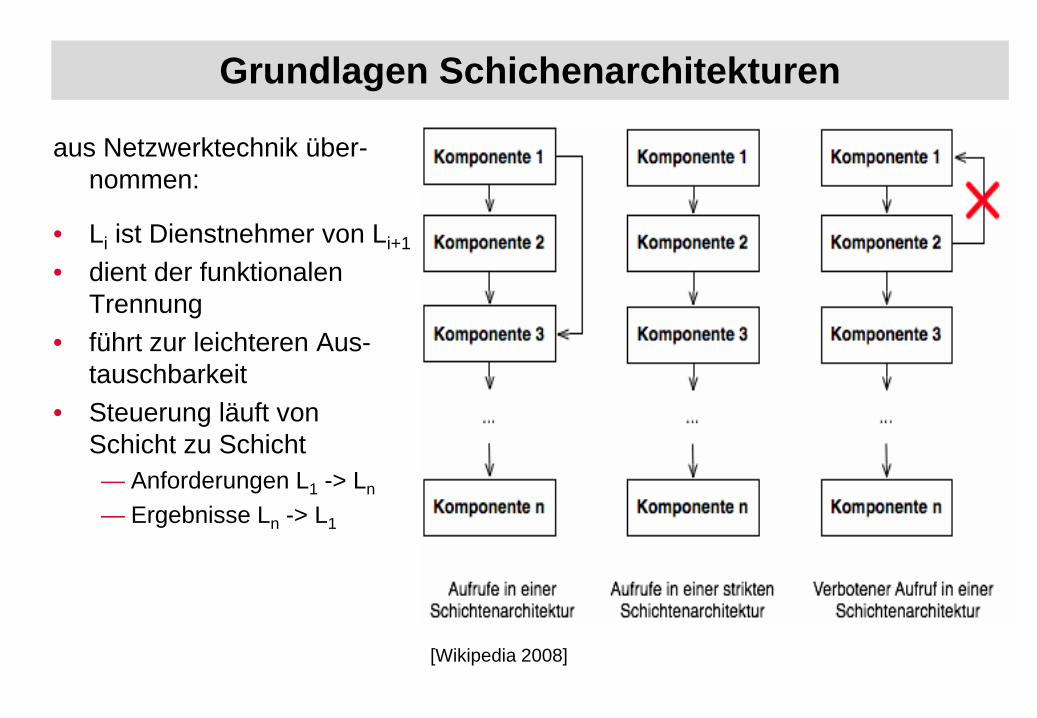
Grundlagen Schichenarchitekturen
aus Netzwerktechnik über-nommen:
• Li ist Dienstnehmer von Li+1
• dient der funktionalen Trennung
• führt zur leichteren Aus-tauschbarkeit
• Steuerung läuft von Schicht zu Schicht— Anforderungen L1 -> Ln
— Ergebnisse Ln -> L1
[Wikipedia 2008]
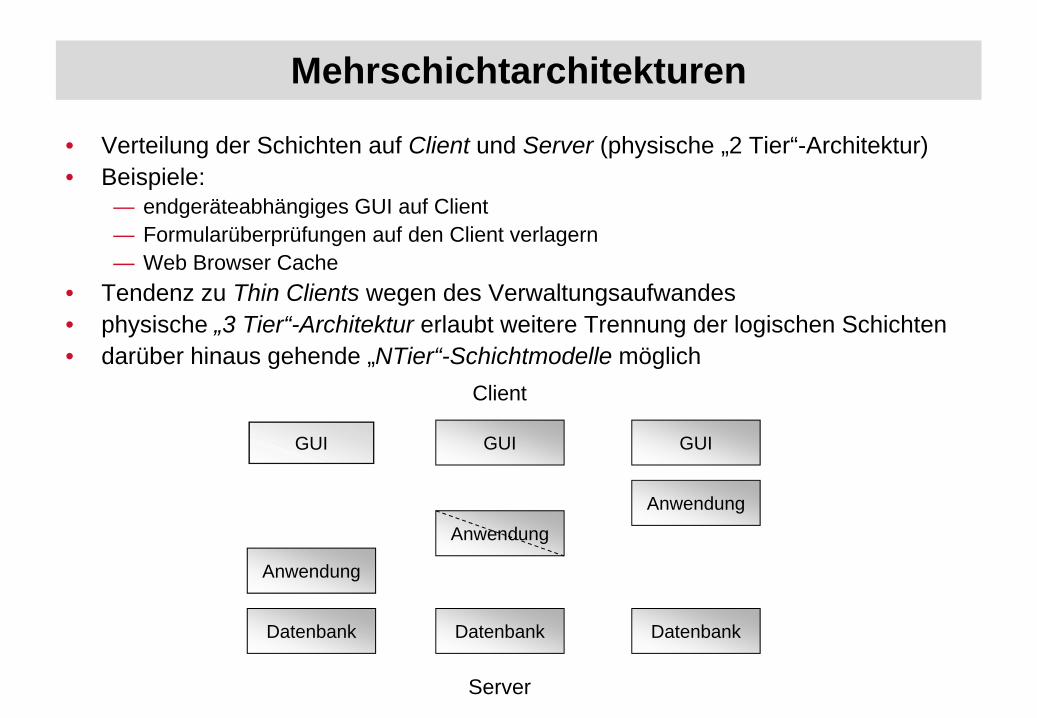
Mehrschichtarchitekturen
• Verteilung der Schichten auf Client und Server (physische „2 Tier“-Architektur)• Beispiele:
— endgeräteabhängiges GUI auf Client— Formularüberprüfungen auf den Client verlagern— Web Browser Cache
• Tendenz zu Thin Clients wegen des Verwaltungsaufwandes• physische „3 Tier“-Architektur erlaubt weitere Trennung der logischen Schichten• darüber hinaus gehende „NTier“-Schichtmodelle möglich
Datenbank
Anwendung
Anwendung
Datenbank
GUI GUI
Datenbank
GUI
Anwendung
Server
Client
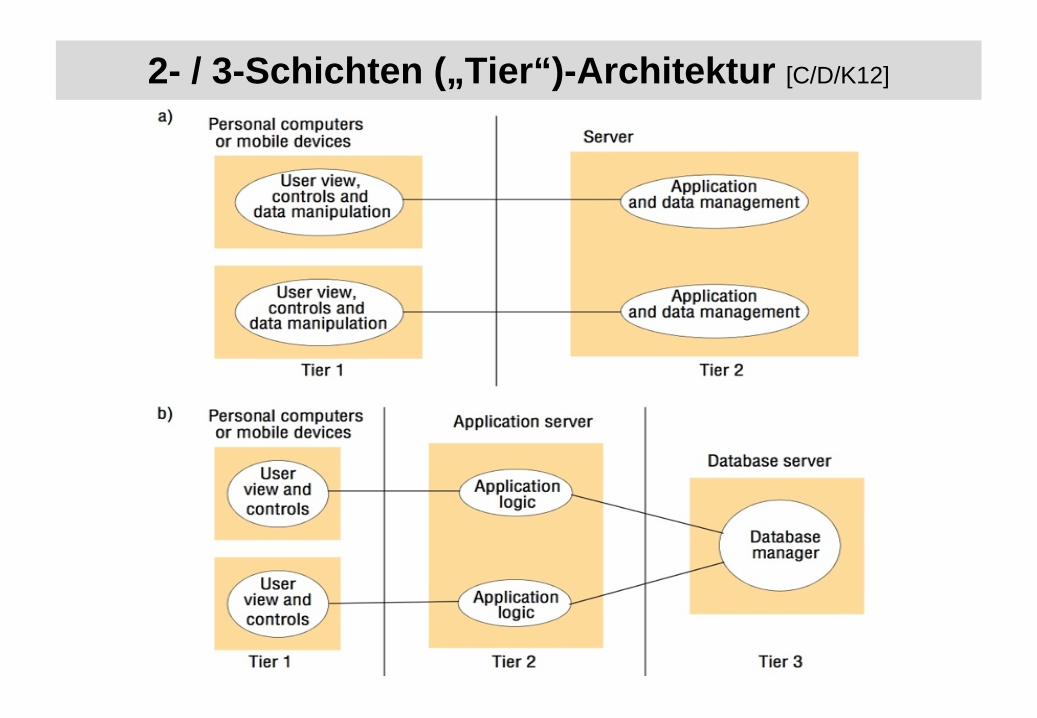
2- / 3-Schichten („Tier“)-Architektur [C/D/K12]
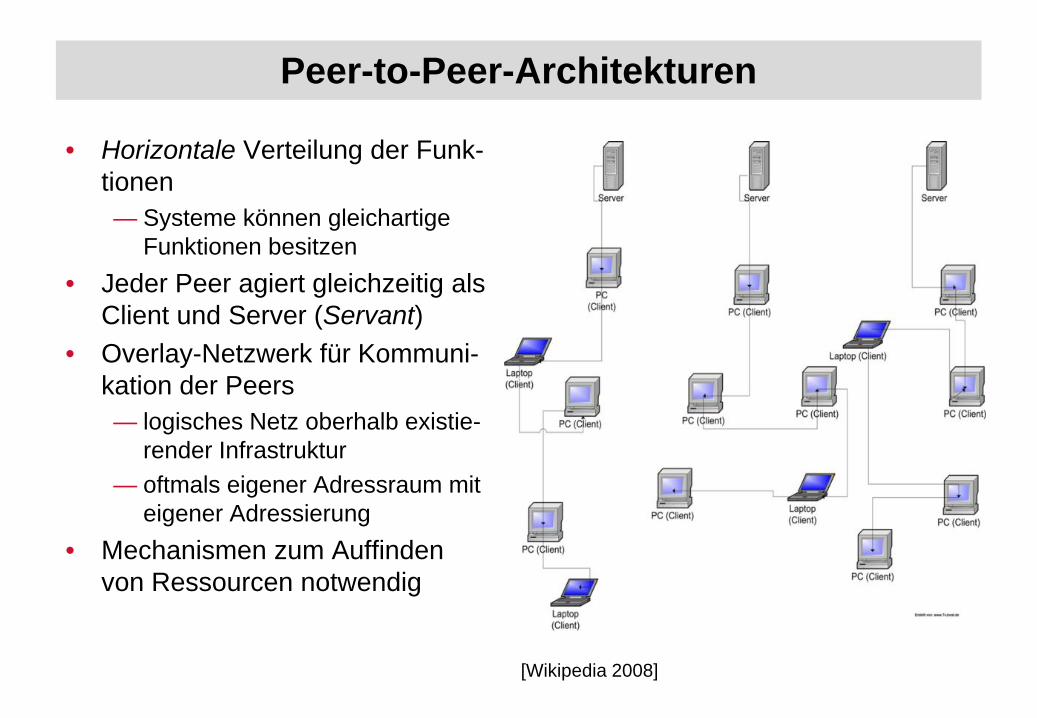
Peer-to-Peer-Architekturen
• Horizontale Verteilung der Funk-tionen— Systeme können gleichartige
Funktionen besitzen• Jeder Peer agiert gleichzeitig als
Client und Server (Servant)• Overlay-Netzwerk für Kommuni-
kation der Peers— logisches Netz oberhalb existie-
render Infrastruktur — oftmals eigener Adressraum mit
eigener Adressierung• Mechanismen zum Auffinden
von Ressourcen notwendig
[Wikipedia 2008]

Arten von Peer-to-Peer-Systemen
• strukturierte Peer-to-Peer-Architekturen— deterministische Generierung des Overlay-Netzwerks über z.B. DHT— Datenelementen werden systematisch bestimmte Konten zugeordnet — Bsp. CAN, räumliche Aufteilung der Teilnehmer und ihrer Verantwortlichkeiten
• unstrukturierte Peer-to-Peer-Architekturen— zufallsgesteuerte Generierung des Overlay-Netzwerks— jeder Knoten besitzt Liste von Nachbarn (partielle Sicht) – Austauschverfah-
ren für Listen— Datenelemente sind zufällig auf Knoten verteilt— Auffinden von Datenelementen über Flooding
• Hybridarchitekturen— Super-Peer-Systeme (centralized topology embedded in distributed system)— Edge-Server-Systeme (specific ‚edge servers‘ as safety guards to outside
world)

Umsetzung von Funktionalitäten verteilter Systeme
• Einzelne Middleware-Systeme folgen bestimmten Architekturstilen (zum Beispiel: CORBA ist objektbasiert)
• Damit fördern sie jedoch jeweils genau eine Art verteilter Anwendungen;unterschiedliche Lösungsmöglichkeiten:
— alle Funktionen integrieren
• Problem: aufgeblähte Software
— unterschiedliche Versionen
• Problem: aufwendig zu entwickeln und zu warten
— änderbare Middleware (am besten sich selbst anpassend)
• Problem: schwierig zu konstruieren, Ziele u.a.: Separation of Concerns, Reflektion, komponentenbasiertes Design

Selbstmanagement von Systemen
• Ziel: automatische Anpassung der Software— Anpassung des Ausführungsverhaltens— Anpassung der konstituierenden Softwarekomponenten
• Gründe:— Umgebung ändert sich— verteilte Anwendungen sind z.T. 24/7
• Eine Lösungsidee: Autonomic Computing— “Autonomic Computing is an initiative started by IBM in 2001. Its ultimate aim
is to develop computer systems capable of self-management, to overcome the rapidly growing complexity of computing systems management, and to reduce the barrier that that complexity poses to further growth.”
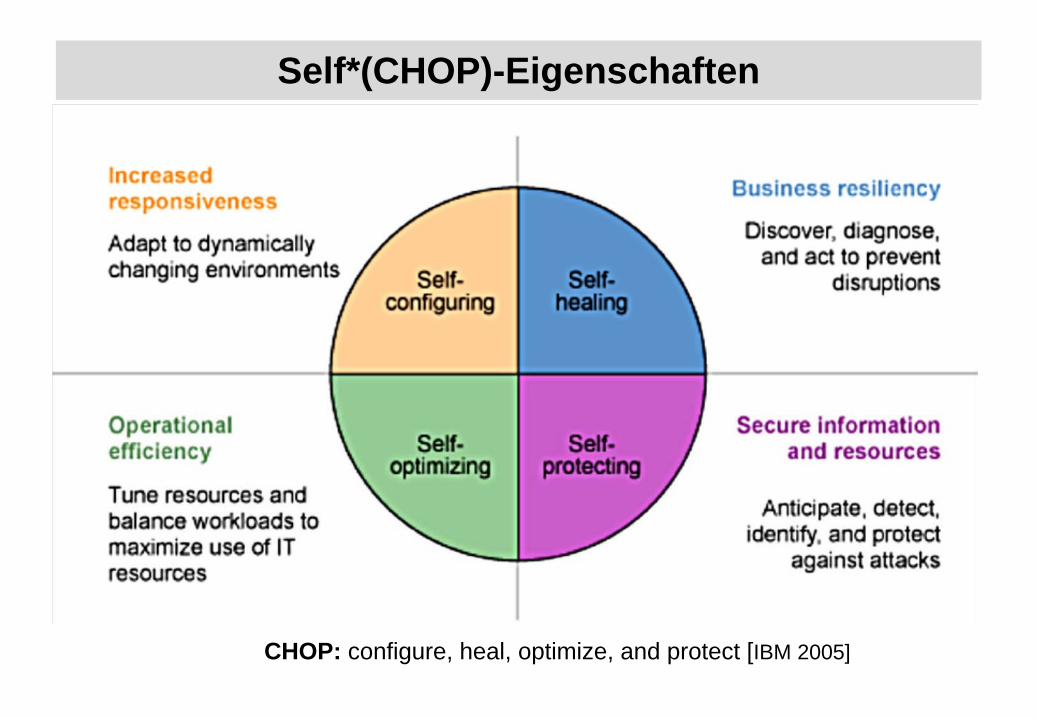
Self*(CHOP)-Eigenschaften
CHOP: configure, heal, optimize, and protect [IBM 2005]
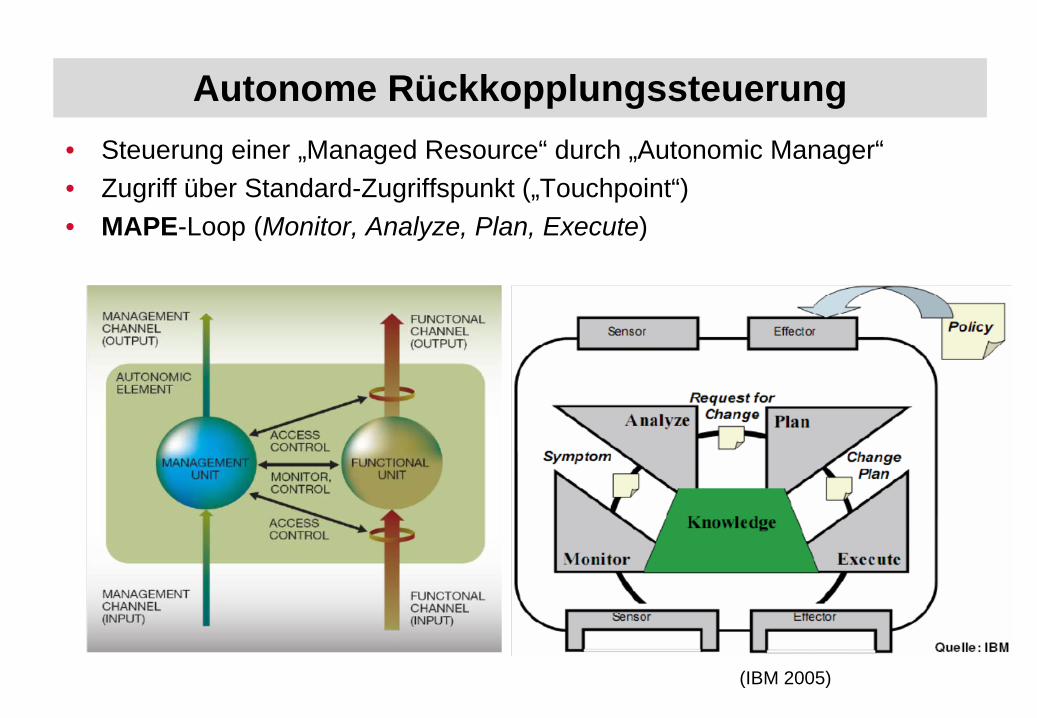
Autonome Rückkopplungssteuerung
(IBM 2005)
• Steuerung einer „Managed Resource“ durch „Autonomic Manager“• Zugriff über Standard-Zugriffspunkt („Touchpoint“)• MAPE-Loop (Monitor, Analyze, Plan, Execute)
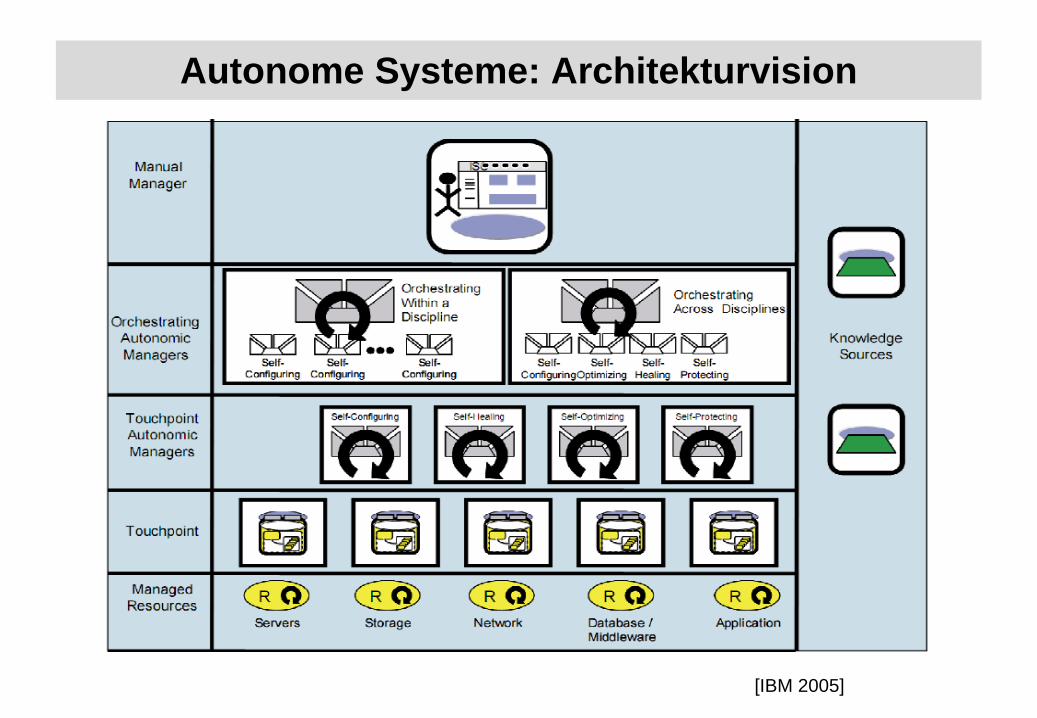
Autonome Systeme: Architekturvision
[IBM 2005]

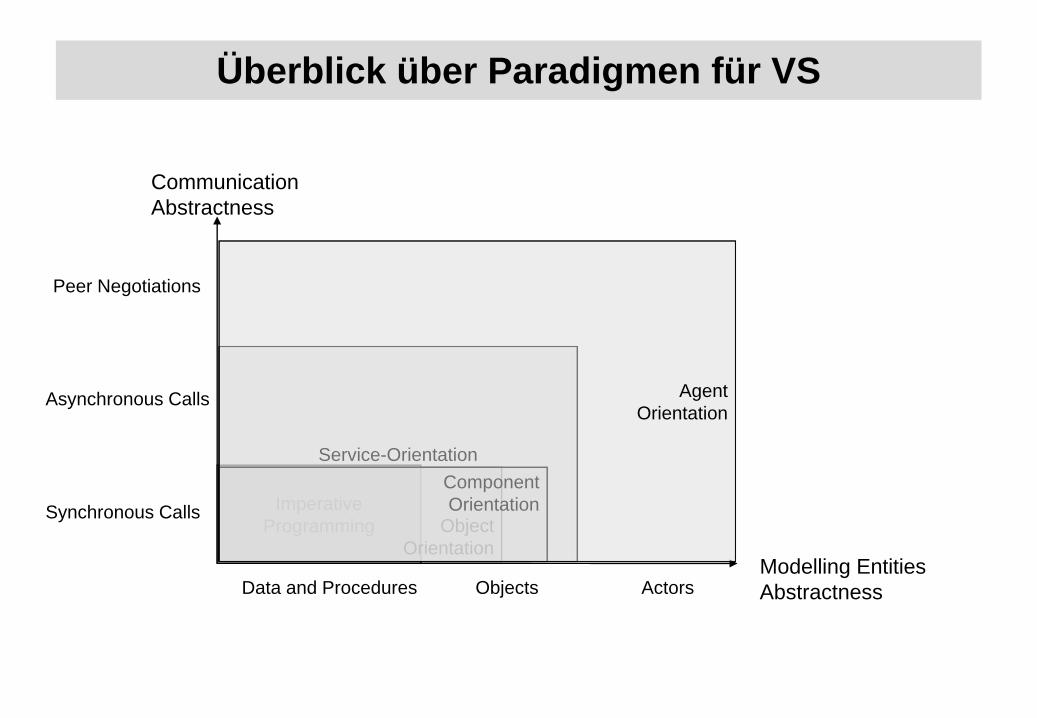
Paradigmen für die Konstruktion verteilter Systeme
Softwareparadigma• bestimmt die Konzepte für die Beschreibung und Realisierung von
Softwaresystemen• legt den Abstraktionsgrad für die Beschreibung fest („Weltmodell“)• fördert / behindert bestimmte Architekturen• entwickelt sich stetig weiter in Richtung abstrakterer Konzepte
• Historische Entwicklung Programmierparadigmen als Beispiel:von der imperativen zur objektorientierten Programmierung— imperativ: Computerprogramm als lineare Folge von Befehlen— objektorientiert: Kapselung von Daten und Methoden zu Klassen/Objekten
— konzeptionelle Vorbilder:• imperativ: von-Neumann-Rechner• objektorientiert: reale Welt bestehend aus (realen/virtuellen) Objekten
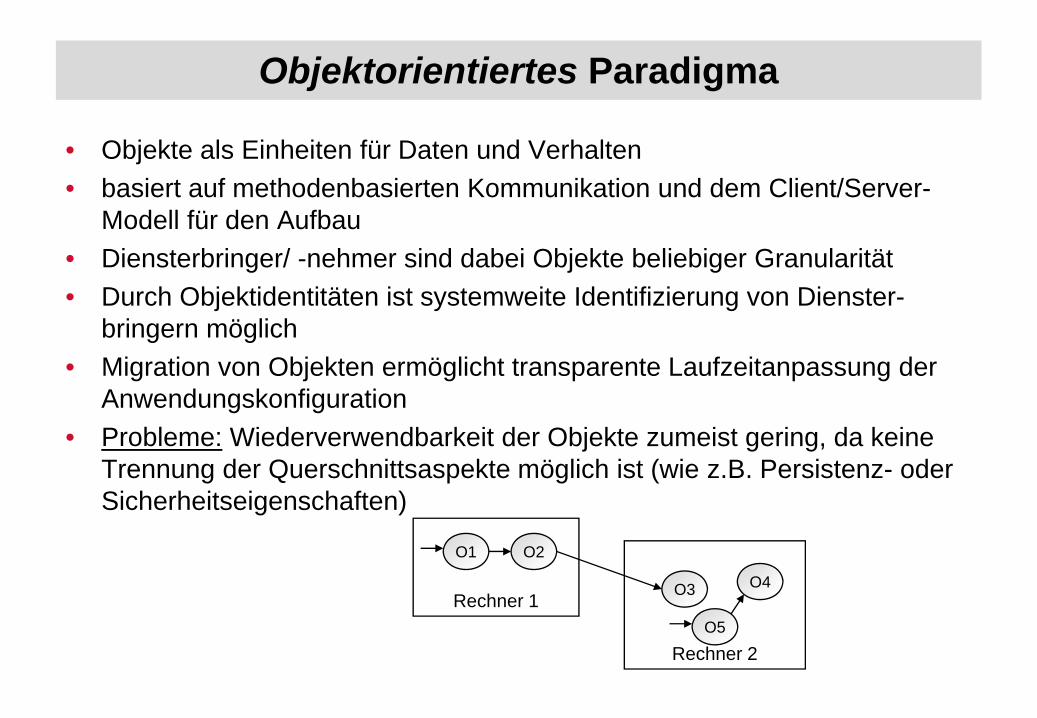
Objektorientiertes Paradigma
• Objekte als Einheiten für Daten und Verhalten• basiert auf methodenbasierten Kommunikation und dem Client/Server-
Modell für den Aufbau• Diensterbringer/ -nehmer sind dabei Objekte beliebiger Granularität• Durch Objektidentitäten ist systemweite Identifizierung von Dienster-
bringern möglich• Migration von Objekten ermöglicht transparente Laufzeitanpassung der
Anwendungskonfiguration• Probleme: Wiederverwendbarkeit der Objekte zumeist gering, da keine
Trennung der Querschnittsaspekte möglich ist (wie z.B. Persistenz- oder Sicherheitseigenschaften)
O1
Rechner 1
O2
O3
Rechner 2
O4
O5
Container 1
Container 1Rechner 1
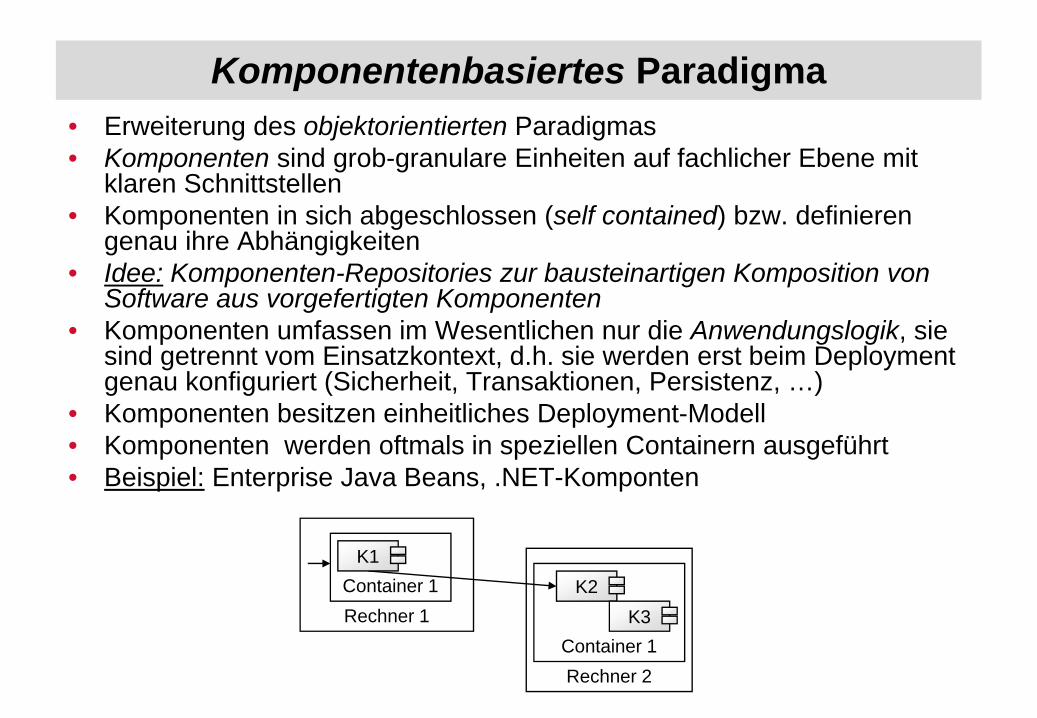
Komponentenbasiertes Paradigma• Erweiterung des objektorientierten Paradigmas• Komponenten sind grob-granulare Einheiten auf fachlicher Ebene mit
klaren Schnittstellen• Komponenten in sich abgeschlossen (self contained) bzw. definieren
genau ihre Abhängigkeiten• Idee: Komponenten-Repositories zur bausteinartigen Komposition von
Software aus vorgefertigten Komponenten• Komponenten umfassen im Wesentlichen nur die Anwendungslogik, sie
sind getrennt vom Einsatzkontext, d.h. sie werden erst beim Deployment genau konfiguriert (Sicherheit, Transaktionen, Persistenz, …)
• Komponenten besitzen einheitliches Deployment-Modell• Komponenten werden oftmals in speziellen Containern ausgeführt • Beispiel: Enterprise Java Beans, .NET-Komponten
Rechner 2
K1K2
K3
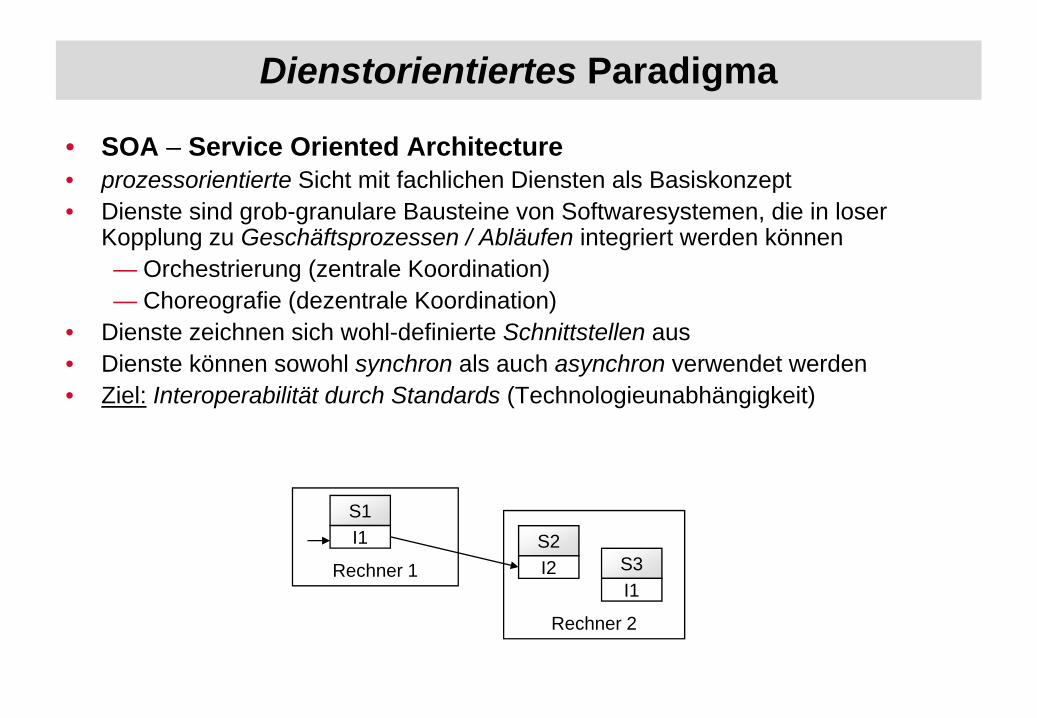
Dienstorientiertes Paradigma
• SOA – Service Oriented Architecture• prozessorientierte Sicht mit fachlichen Diensten als Basiskonzept• Dienste sind grob-granulare Bausteine von Softwaresystemen, die in loser
Kopplung zu Geschäftsprozessen / Abläufen integriert werden können— Orchestrierung (zentrale Koordination)— Choreografie (dezentrale Koordination)
• Dienste zeichnen sich wohl-definierte Schnittstellen aus• Dienste können sowohl synchron als auch asynchron verwendet werden• Ziel: Interoperabilität durch Standards (Technologieunabhängigkeit)
Rechner 1
Rechner 2
S2I2
S1I1
S3I1
Plattform 2
Plattform 1
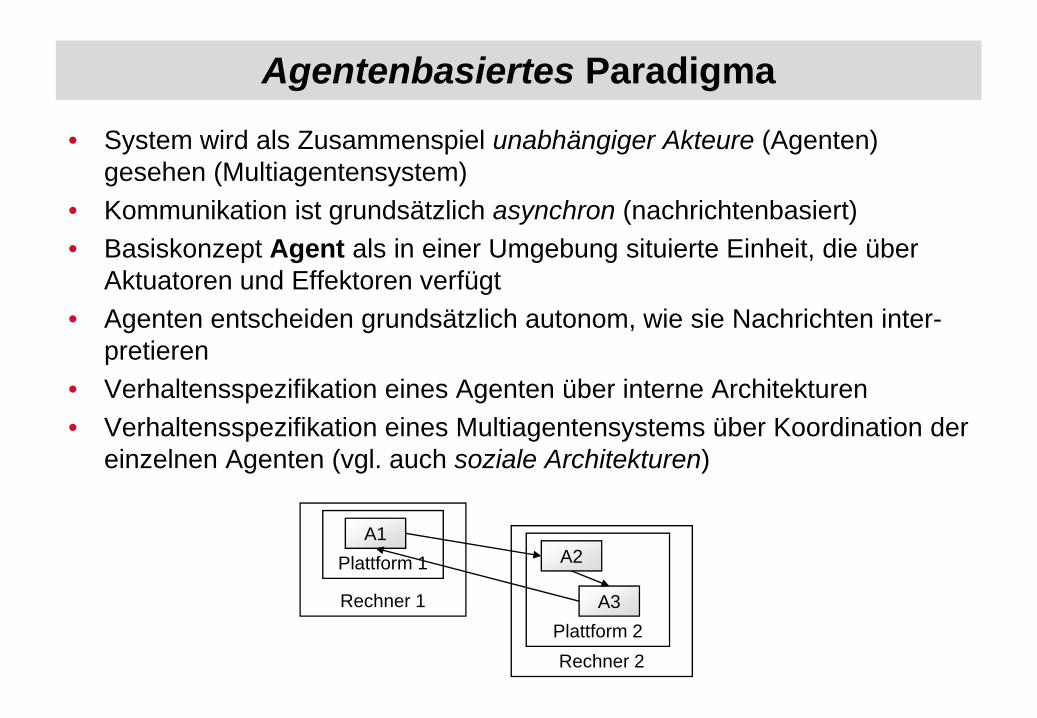
Agentenbasiertes Paradigma
• System wird als Zusammenspiel unabhängiger Akteure (Agenten) gesehen (Multiagentensystem)
• Kommunikation ist grundsätzlich asynchron (nachrichtenbasiert)• Basiskonzept Agent als in einer Umgebung situierte Einheit, die über
Aktuatoren und Effektoren verfügt• Agenten entscheiden grundsätzlich autonom, wie sie Nachrichten inter-
pretieren• Verhaltensspezifikation eines Agenten über interne Architekturen• Verhaltensspezifikation eines Multiagentensystems über Koordination der
einzelnen Agenten (vgl. auch soziale Architekturen)
Rechner 1
Rechner 2
A2A1
A3
Überblick über Paradigmen für VS
Modelling EntitiesAbstractness
CommunicationAbstractness
Synchronous Calls
Asynchronous Calls
Peer Negotiations
Data and Procedures Objects Actors
ImperativeProgramming Object
Orientation
Service-OrientationComponentOrientation
AgentOrientation

Zusammenfassung• Kommunikationsarten
— direkt vs. indirekt und die Realisierungskonzepte• Prozeduraufruf• Nachrichten• Ereignisse• gemeinsamer Datenraum
• Architekturen— von zentral bis vollständig dezentral – auch im Vergleich mit Betriebssystemen (-> GSS)
• Client/Server • netzwerkorientiert• Schichten • vollständig verteilt• Peer-to-Peer • Middleware-basiert
• Paradigmen für die Konstruktion verteilter Systeme— Versuchen, die Realität in Software abbildbar zu machen— VS sind charakterisiert durch die Art der Kommunikation und der Entitäten— Paradigmen bestimmen die Beschreibungsmöglichkeiten und damit das „Weltbild“





























