Embed Size (px)
Citation preview

Waldbestandeskartierung und Baumtypenerkennung im Sihlwald Masterarbeit von Simon Egger RSL Remote Sensing Laboratories Geographisches Institut der Universität Zürich Winterthurerstrasse 190 8057 Zürich Leitung: Prof. Dr. K. Itten Betreuung: Dr. T. Kellenberger Dipl. Geogr. R. Schmidt Zürich 2008


Zusammenfassung
I
Zusammenfassung
Das Ziel dieser Masterarbeit ist das Erstellen einer Waldbestandeskartierung und Baumty-penerkennung im Untersuchungsgebiet Sihlwald. Dafür steht eine Kombination von Laser-scanner- und Multispektralscanner-Daten zur Verfügung. Die Klassifikation der Datensät-ze wird mittels des in der Software Definiens Developer implementierten objektorientier-ten Klassifikationsansatzes durchgeführt. Die Arbeit baut auf den Erkenntnissen der Dip-lomarbeit von Christine Füllemann von 2007 auf. Das Untersuchungsgebiet Sihlwald bildet mit einer Grösse von rund 10 Quadratkilometern. den grössten zusammenhängenden Laubmischwald im schweizerischen Mittelland. Er liegt etwa 10 Kilometer südlich der Stadt Zürich im Sihltal zwischen Langnau am Albis und Sihlbrugg. Das Gebiet wird durch die Albiskette und den Zimmerberg eingerahmt. Der Sihlwald wurde jahrhundertelang intensiv genutzt, heute wird kein Holz mehr geschlagen, und er befindet sich auf der Rückwandlung zum Naturwald. Die Befliegungen für die Datengrundlagen wurden am 10. und 17. August mit dem LI-DAR-System Falcon II durchgeführt. Dieses System ermöglicht gleichzeitige Aufnahmen mit einem Laserscanner und einem multispektralen Zeilenscanner. Aus den Laserscanner-daten wurde mittels der Differenz des Oberflächenmodells und des Höhenmodells die Ve-getationshöhe gewonnen. Der Zeilenscanner besitzt vier Spektralkanäle (Rot, Blau, Grün und Nahinfrarot). Die Klassifikation wird mit Hilfe des objektorientierten Klassifikationsansatzes durchge-führt. In Definiens werden die Einzelpixel mittels einer ‚multiresolution’ Segmentation zu homogenen Objekten zusammengefasst. Dies geschieht in unterschiedlichen Grössenord-nungen, sodass ein Hierarchisches Objekt-Netzwerk entsteht. Die Trennung der Klassen wird anschliessend mit Anwendung von ‚Fuzzy Membership Functions’ durchgeführt. In die Klassifikation fliesst die berechnete Vegetationshöhe aus den LIDAR-Daten, die vier Spektralkanäle des Zeilenscanners sowie zusätzlich berechnete Vegetationsindizes. Die Waldfläche kann in Laub- und Nadelbäume aufgeteilt werden, eine weitere differen-zierung der Baumarten gelingt jedoch nicht. Damit kann das Hauptziel der Arbeit nicht erreicht werden. Eine Verifikation des klassierten Walbestandes wird anhand der VECTOR25-Waldfläche und der kantonalen Waldfläche 1:5'000 durchgeführt. Die Differenzierung von Laub- und Nadelbäumen wird mit der Waldbestandesaufnahme 2001 und der Klassifikation von Fül-lemann verglichen. Die Wald/Nichtwald Klassifikation weist eine sehr gute Genauigkeit auf. Die Güte der Laub-/Nadelbaum Klassifikation wird mittels eines Polygon-zu-Polygon Vergleiches mit der Waldbestandesaufnahme 2001 ermittelt. Dieses Resultat ist vergleich-bar mit demjenigen von Füllemann. Das Unterscheiden von verschiedenen Baumarten, das Kernanliegen dieser Arbeit, gelingt aus unterschiedlichen Gründen nicht. Es wird der Schluss gezogen, dass der von Definien-se Developer benutzte Segmentierungs-Algorithmus für die Bildung von Einzelbaumob-jekten Einzelbaumabtrennung nur bedingt geeignet ist.


Inhalt
III
Inhalt
TABELLENVERZEICHNIS........................................................................................... VI
ABBILDUNGSVERZEICHNIS.....................................................................................VII
GLOSSAR UND ABKÜRZUNGEN ............................................................................... IX
1 EINFÜHRUNG ............................................................................................................1 1.1 EINLEITUNG............................................................................................................1 1.2 ZIELSETZUNG..........................................................................................................1 1.3 GLIEDERUNG ..........................................................................................................2
2 GRUNDLAGEN...........................................................................................................3 2.1 DAS UNTERSUCHUNGSGEBIET ................................................................................3
2.1.1 Lage und Landschaft......................................................................................3 2.1.2 Nutzung des Sihlwaldes von früher bis heute ................................................4
2.2 DATENGRUNDLAGE ................................................................................................4 2.2.1 Falcon II ........................................................................................................4
2.2.1.1 Laserscanner-Datensatz ............................................................................5 2.2.1.2 Multispektraler orthorektifizierter Datensatz ............................................8
2.2.2 Bodenreferenzen zur Verifikation der Klassifikation.....................................9 2.2.2.1 Waldbestandesaufnahme 2001 ..................................................................9 2.2.2.2 Waldareal im Kanton Zürich 1:5’000 .....................................................10 2.2.2.3 VECTOR25-Waldfläche...........................................................................10 2.2.2.4 Versuchsfläche Birriboden ......................................................................11
2.3 WALDDEFINITIONEN .............................................................................................12 2.3.1 Walddefinition des Bundesamtes für Landestopographie Swisstopo ..........12 2.3.2 Walddefinition nach dem Schweizerischen Landesforstinventar LFI..........12 2.3.3 Walddefinition nach der Arealstatistik ........................................................13 2.3.4 Erfassung des Waldes durch den Sensor .....................................................14
3 KLASSIFIKATIONSMETHODE ...........................................................................15 3.1 OBJEKTORIENTIERTE KLASSIFIKATION .................................................................15 3.2 GRUNDLAGE DER SOFTWARE DEFINIENS DEVELOPER ..........................................15
3.2.1 Objekterzeugung durch ‚multiresolution’ Segmentation.............................15 3.2.2 Hierarchisches Objekt-Netzwerk .................................................................16 3.2.3 Labelling in Definiens Developer ................................................................17
3.2.3.1 Klassifikation mit ‚Fuzzy Membership Functions’ ..................................17

Inhalt
IV
4 ERSTELLUNG DER KLASSIFIKATION.............................................................19 4.1 ZUSÄTZLICH BERECHNETE LAYER BZW. DATENSÄTZE .........................................19
4.1.1 Normalized Difference Vegetation Index (NDVI)........................................19 4.1.2 Soil Adjusted Vegetation Index (SAVI) ........................................................19
4.2 AUFTEILEN DES DATENSATZES IN KACHELN ........................................................20 4.3 SEGMENTIERUNG ..................................................................................................21
4.3.1 Kanalgewichtung, Scale Parameter und Homogenitätskriterien ................21 4.3.2 Reproduktion von Segmenten - Randproblematik .......................................22
4.4 KLASSIFIKATIONEN...............................................................................................23 4.4.1 Klassifikation des Waldes ............................................................................23
4.4.1.1 Ausscheidung von Häusern und grobe Klassifikation .............................23 4.4.1.2 Spezifische Klassifikation der Waldrandsegmente ..................................24
4.4.2 Klassifikation verschiedener Baumarten .....................................................26 4.4.2.1 Unterscheidung von Laub- und Nadelbäumen ........................................26 4.4.2.2 Unterscheidung von weiteren Baumarten................................................26
4.4.3 Klassifikationsergebnisse.............................................................................28
5 VERIFIKATION DER KLASSIFIKATIONSRESULTATE ...............................29 5.1 DEFINITION DER GENAUIGKEITSMASSE ................................................................29
5.1.1.1 Overall Accuracy .....................................................................................30 5.1.1.2 Producer’s Accuracy ...............................................................................30 5.1.1.3 User’s Accuracy.......................................................................................30 5.1.1.4 Kappa Koeffizient ....................................................................................30
5.2 WALD/NICHTWALD-KLASSIFIKATION ..................................................................31 5.2.1 Nachbearbeitung der Wald/Nichtwald-Klassifikation.................................32 5.2.2 Spezielle Betrachtung der Waldränder........................................................33 5.2.3 Resultate ohne Nachbearbeitung .................................................................33 5.2.4 Resultate mit Nachbearbeitung (SIEVE) .....................................................34 5.2.5 Resultate mit einem Waldrand-Buffer von 20 Meter ...................................35
5.3 LAUBWALD/NADELWALD-KLASSIFIKATION.........................................................35 5.3.1 Perimeter .....................................................................................................35 5.3.2 Aufbereitung der Verifizierungsdaten..........................................................35 5.3.3 Resultate der Waldbestandesaufnahme 2001 ..............................................36
6 DISKUSSION.............................................................................................................38 6.1 BEURTEILUNG DER VERIFIKATIONSERGEBNISSE...................................................38
6.1.1 VECTOR25-Daten und kantonale Waldfläche 1:5’000...............................38 6.1.2 Waldbestandesaufnahme 2001 ....................................................................39 6.1.3 Klassifikation von Füllemann 2007 .............................................................43
6.1.3.1 Vergleich der Waldflächen ......................................................................43 6.1.3.2 Vergleich der Laub-/Nadelbaumklassifikationen ....................................45
6.2 SCHWIERIGKEITEN UND LÖSUNGSANSÄTZE ..........................................................48 6.2.1 Illuminationsunterschiede............................................................................48
6.2.1.1 Problematik..............................................................................................48 6.2.1.2 Mögliche Lösungsansätze ........................................................................49
6.2.2 Segmentierung .............................................................................................50 6.2.2.1 Problematik..............................................................................................50 6.2.2.2 Verbesserungsmöglichkeiten ...................................................................51
6.2.3 Softwareeinschränkungen............................................................................52

Inhalt
V
7 SCHLUSSFOLGERUNGEN....................................................................................53 7.1 FAZIT ....................................................................................................................53 7.2 AUSBLICK .............................................................................................................53
8 LITERATURVERZEICHNIS..................................................................................54

Tabellenverzeichnis
VI
Tabellenverzeichnis Tabelle 1 Angaben zu den Befliegungen im April 2004 und August 2006 ....................................................... 5 Tabelle 2 Technische Angaben zum Laserscanner Falcon II (TopoSys GmbH, 2008c) ................................... 8 Tabelle 3 Technische Angaben zum Zeilensacanner (TopoSys, 2008c)............................................................ 9 Tabelle 4 Grad der Übereinstimmung aufgrund von Kappa-Werten nach Landis und Koch (1977)............... 31 Tabelle 5 Attribute der VECTOR-25-Primärflächen, welche zur Bodenreferenz zählen ................................ 31 Tabelle 6 Resultat der unbearbeiteten Wald/Nichtwald-Klassifikation mittels den VECTOR25-Daten......... 33 Tabelle 7 Resultat der unbearbeiteten Wald/Nichtwald-Klassifikation mittels der Waldfläche 1:5’000......... 34 Tabelle 8 Resultat der mit SIEVE bearbeiteten Wald/Nichtwald-Klassifikation mittels den VECTOR25-
Daten...................................................................................................................................... 34 Tabelle 9 Resultat der mit SIEVE bearbeiteten Wald/Nichtwald-Klassifikation mittels der Waldfläche
1:5’000................................................................................................................................... 34 Tabelle 10 Resultat der Wald/Nichtwald-Klassifikation im Waldrand-Buffer von 20 m mittels den
VECTOR25-Daten................................................................................................................. 35 Tabelle 11 Resultat der Wald/Nichtwald-Klassifikation im Waldrand-Buffer von 20 m mittels der
Waldfläche 1:5’000................................................................................................................ 35 Tabelle 12 Resultat der Verifikation mittels der Waldbestandesaufnahme 2001 ............................................ 36 Tabelle 13 Resultate von Christine Füllemann 2007 ....................................................................................... 36

Abbildungsverzeichnis
VII
Abbildungsverzeichnis Abbildung 1 Übersicht des Untersuchunggebietes in Echtfarbendarstellung (August 2006) ............................ 3 Abbildung 2 Aufnahmestreifen der beiden Überflüge vom 10. & 17. August 2006 ......................................... 5 Abbildung 3 Scanmuster und Messpunkte des Falcon II Laserscanners (Toposys, 2008a)............................... 6 Abbildung 4 Reflexionsweise der ausgesendeten Laserstrahlen mit first und last echo (Toposys, 2008b) ....... 6 Abbildung 5 Oberflächenmodell (DOM); Ausschnitt aus dem Untersuchungsgebiet ....................................... 7 Abbildung 6 Höhenmodell (DHM); Ausschnitt aus dem Untersuchungsgebiet ................................................ 7 Abbildung 7 Differenz vom Oberflächenmodell und dem Höhenmodell (DOM – DHM); Vegetationshöhe;
Ausschnitt aus dem Untersuchungsgebiet............................................................................... 7 Abbildung 8 Multispektraler orthorektifizierter Datensatz; Ausschnitt aus dem Untersuchungsgebiet, eine
Echtfarbendarstellung (RGB) (links) und eine Falschfarbendarstellung (rechts) .................... 8 Abbildung 9 Polygone der Waldbestandesaufnahme 2001; Falschfarbendarstellung hinterlegt ....................... 9 Abbildung 10 Kantonale Waldfläche des Kantons Zürich 1:5’000 ................................................................. 10 Abbildung 11 VECTOR25-Waldfläche von Swisstopo................................................................................... 11 Abbildung 12 Versuchsfläche Birriboden der WSL, Birmensdorf .................................................................. 11 Abbildung 13 Definition des Waldes der WSL Birmensdorf mit der Abhängigkeit der Flächengrösse vom
Deckungsgrad (WSL, 2008) .................................................................................................. 13 Abbildung 14 Übersicht der verwendeten ‚multiresolution’ Segmentierung in Definiens Developer
(Definiens, 2007b: 22), verändert .......................................................................................... 16 Abbildung 15 Hierarchisches Netzwerk klassierter Objekte in unterschiedlichen Segmentierungslevel
(Definiens, 2007a: 27) ........................................................................................................... 17 Abbildung 16 Beispiel einer ‚Fuzzy Membership Function’ aus Definiens Developer.................................. 18 Abbildung 17 Raster für das Ausschneiden der Kacheln über dem Untersuchungsgebiet Sihlwald ............... 20 Abbildung 18 Ausschnitte der drei erstellten Objektlevel mit den Scale Parametern 5, 25 und 50................. 22 Abbildung 19 Segmente im Überlappungsbereich von benachbarten Kacheln (rot und schwarz) im Level 50
............................................................................................................................................... 22 Abbildung 20 Segmente vom Level 50: links Lärchengruppe; rechts eine Überbauung in Langnau am Albis
............................................................................................................................................... 23 Abbildung 21 Klassierte Waldrandsegmente in Level 50................................................................................ 24 Abbildung 22 Ausschnitte aus den Klassifikationsresultaten;: Level 50, Level 5 und Level 25 (von oben nach
unten) ..................................................................................................................................... 25 Abbildung 23 Laubbäume der Oberschicht in der Versuchsfläche Birriboden ............................................... 27 Abbildung 24 Nadelbäume der Oberschicht in der Versuchsfläche Birriboden .............................................. 27 Abbildung 25 Beispiel einer Fehlermatrix mit Fehler 1. und 2. Art (Kellenberger, 1996: 197; abgeändert) .. 29

Abbildungsverzeichnis
VIII
Abbildung 26 Beispiel des Fusions-Algorithmus SIEVE mit einem Grenzwert von 5 Pixel .......................... 32 Abbildung 27 Waldrandbuffer (rosa) von 20 Meter Breite, über RGB (links) und über die bearbeitete
Waldklassifikation (rechts) gelegt ......................................................................................... 33 Abbildung 28 Waldrandausschnitt als Falschfarbendarstellung; links die Bodenreferenz VECTOR25, rechts
zusätzlich in dunkelgrün die Klassifikation ........................................................................... 39 Abbildung 29 Klassifikation des Untersuchungsgebietes (links); Differenzbilder (Bodenreferenz –
Klassifikation): Laubbaumdifferenz (mitte) und Nadelbaumdifferenz (rechts)..................... 40 Abbildung 30 Ausschnitt aus dem Bereich 1 & 3 der Klassifikation (links); Nadelbaumdifferenz (mitte) und
Falschfarbendarstellung (rechts) ............................................................................................ 41 Abbildung 31 Ausschnitt aus dem Bereich 2 der Klassifikation (links); Nadelbaumdifferenz (mitte) und
Falschfarbendarstellung (rechts) ............................................................................................ 41 Abbildung 32 Ausschnitt aus dem Bereich 4 der Klassifikation (links); Laubbaumdifferenz (mitte) und
Falschfarbendarstellung (rechts) ............................................................................................ 42 Abbildung 33 Ausschnitt von Langnau am Albis; Falschfarbendarstellung (links) und Veränderung der
Waldfläche zur Klassifikation von Füllemann (2007) (rechts) .............................................. 44 Abbildung 34 Waldrandausschnitt; Falschfarbendarstellung`06 (oben links), Differenz der Waldfläche zur
Klassifikation von Füllemann (2007) (oben rechts) und Falschfarbendarstellung des Datensatzes vom April 2004.................................................................................................. 44
Abbildung 35 Ausschnitt eines steilen Abhanges in Adliswil; Falschfarbendarstellung (links) und
Veränderung von der Klassifikation von Füllemann (2007) zur Laub-/Nadelbaumklassifikation (rechts) ......................................................................................... 45
Abbildung 36 Westlich orientierter Talhang als Falschfarbendarstellung (links) und die Veränderung der
Klassifikation von Füllemann (2007) zur Laub-/Nadelbaumklassifikation (rechts) .............. 46 Abbildung 37 Waldausschnitt unterhalb des Aussichtturms Hochwacht; Falschfarbendarstellung (oben links)
Veränderung der Klassifikation von Füllemann (2007) zur Laub-/Nadelbaumklassifikation (oben rechts) und die Nadelbaumdifferenz zur Waldbestandesaufnahme 2001 (unten links)47
Abbildung 38 Vergleich der Kronendächer von Laub- und Nadelbäumen (links) und Waldfläche im Schatten
(rechts); beides Falschfarbendarstellungen ............................................................................ 49 Abbildung 39 Nicht optimal gebildeten Segmenten aufgrund unterschiedlicher Beleuchtung der Baumkrone;
Falschfarbendarstellung ......................................................................................................... 50 Abbildung 40 Nicht optimal gebildeten Segmenten aufgrund der Höhenunterschiede innerhalb der
Baumkronen; Falschfarbendarstellung................................................................................... 51

Glossar und Abkürzungen
IX
Glossar und Abkürzungen CHM Canopy Hight Model DHM Digitales Höhenmodell DOM Digitales Oberflächenmodell NDVI Normalized Vegetation Index NIR Nahes Infrarot; Wellenlängenbereich zwischen RGB Rot-Grün-Blau; Echtfarbendarstellung RSL ‚Remote Sensing Laboratories’; Abteilung für Fernerkundung am Geo-
graphischen Institut der Universität Zürich SAVI Soil Adjusted Vegetation Index UTC ‚universal time coordinated’; koordinierte Weltzeit, die gleichmässig wie
die Atomzeit verläuft; früher auch als GMT (Greenwich Mean Time) be-zeichnet und z.T. heute noch unter diesem Namen in Gebrauch
WSL Eidgenössische Forschungsanstalt für Wald, Schnee und Landschaft, Birmensdorf

Einführung
1
1 Einführung
1.1 Einleitung
Das Untersuchungsgebiet Sihlwald liegt 10 bis 15 km südlich der Stadt Zürich. Es handelt sich dabei um den grössten zusammenhängenden Laubmischwald des schweizerischen Mittellandes. In weniger als einer halben Stunde erreicht man diese nicht mehr bewirt-schaftete Waldwildnis. Im Jahre 1994 wurde die Stiftung Naturlandschaft Sihlwald mit dem Ziel gegründet, die charakteristische Landschaft des Gebietes auf eine Weise zu fördern, dass die natürlichen und naturnahen Waldökosysteme inklusive ihrer Tier- und Pflanzenwelt erhalten bleiben. Dabei sollen die Umweltkräfte unbehindert wirken können. Parallel dazu sollen Erholung und Naturerlebnisse sowie Forschung möglich sein. Zurzeit besteht das Bestreben, den Sihlwald und den Tierpark Langenberg einem vom Bund neu kreierten Label ‚Naturerlebnispark’ zuzuführen, das einem nationalen Schutz-standard entsprechen würde. Auf diese Weise wird das Gebiet zusätzlich als Naherho-lungsgebiet für die Stadt Zürich an Bedeutung gewinnen. (Stadt Zürich, 2007) Kurz nach der Stiftungsgründung wurde im Frühling 1994 das Informationssystem Sihl-wald ins Leben gerufen. Das Informationssystem soll den Informations- und Datenaus-tausch in der interdisziplinären Forschung im Sihlwald erleichtern. (Sihlwald Data Center, 2008) Die Entwicklung einer Waldlandschaft mit ihrer natürlichen und nicht antropogen beein-flussten Abläufe wissenschaftlich zu beobachten ist von grossem Interesse. Die über den Sihlwald gewonnen Erkenntnisse über die Veränderungen der Waldstrukturen wie Alters-struktur oder Baumartenzusammensetzung könnten auf andere Waldgebiete übertragen werden und als Forschungsgrundlage dienen. Mit Hilfe von konventionellen Methoden sind Dokumentationen der ablaufenden Prozesse und Strukturveränderungen nicht oder nur mit unverhältnismässig hohem Aufwand mög-lich. Der Einsatz von Fernerkundungsdaten bietet eine zeitsparendende und kostengünsti-ge Möglichkeit, diese Veränderungen zu verfolgen. Um diese erfassen zu können, sind jedoch Sensoren nötig, die über eine hohe räumliche und spektrale Auflösung verfügen, die charakteristische Waldstrukturen wie die Kronenoberfläche oder die verschiedenen Baumarten wiedergeben können. (Heurich, 2006: 17-18)
1.2 Zielsetzung
Das Ziel dieser Masterarbeit ist die Klassierung des Waldbestandes mit Hilfe einer Kombi-nation von Laserscanner- und Multispektralscanner Daten im Untersuchungsgebietes Sihl-wald. Dabei soll neben der Bestandesaufnahme der bestockten Fläche eine Unterscheidung von Laubbäumen und Nadelbäumen vollzogen werden. Das Hauptziel der Arbeit besteht schliesslich in der Unterscheidung einzelner Baumarten. Insbesondere die Laubbäume sol-len differenziert betrachtet werden. Der methodische Schwerpunkt der Arbeit liegt in der objektorientierten Klassifikation mit Hilfe der Software Definiens. Die Arbeit baut auf den Erkenntnissen der Diplomarbeit von Christine Füllemann von 2007 auf. Die erzielten Resultate sollen mit mit den Bodenreferenzdaten und der Klassifikation von Füllemann verglichen und bewertet werden.

Einführung
2
1.3 Gliederung
Entsprechend dem Arbeitsablauf ist die vorliegende Arbeit wie folgt gegliedert: Nach dem Einführungskapitel 1 werden in Kapitel 2 die Grundlagen dieser Masterarbeit vermittelt. Das Untersuchungsgebiet Sihlwald wird kurz beschrieben und auf die verwen-deten Datengrundlagen ausführlich beschrieben. Dazu gehören die Laserscanner- und mul-tispektralen Zeilenscanner-Daten sowie die zur Verifikation der Klassifikation verwende-ten Datensätze. Anschliessend wird der Begriff Wald genauer betrachtet, indem kurz auf unterschiedliche, in der Schweiz gebräuchliche, Walddefinitionen eingegangen wird. Im Kapitel 3 wird in die verwendete Klassifikationsmethode eingeführt und mittels der Funktionsweise der verwendeten Software Definiens Devoloper vertieft erklärt. Die Anwendung der Klassifikationsmethode und Vorgehensweise bei der Erstellung der Klassifikation wird in Kapitel 4 näher gebracht. Dabei werden die einzelnen Schritte je-weils erläutert, das Berechnen von weiteren Datensätzen, das Aufteilen des Datensatzes in Kacheln, die Segmentierung und der eigentliche Klassifikationsprozess beschrieben. In Kapitel 5 folgt die Verifikation der Klassifikation mittels der in Kapitel 2 beschriebenen Bodenreferenzen. Es werden verschiedene Genauigkeitswerte berechnet, welche Auf-schluss über die Qualität der Klassifikation geben. Eine Beurteilung der Verifikationsergebnisse und Diskussion der aufgetretenen Schwierig-keiten sowie über mögliche Lösungsansätze wird im Kapitel 6 durchgeführt. Schliesslich wird ein Fazit gezogen und ein kurzer Blick auf künftige Anwendungen ge-worfen.

Grundlagen
3
2 Grundlagen
2.1 Das Untersuchungsgebiet
2.1.1 Lage und Landschaft
Der Sihlwald liegt rund 10 Kilometer südlich der Stadt Zürich im Bezirk Horgen und um-fasst ein Gebiet mit einer Fläche von 1013 Hektaren. Die Waldflächen erstrecken sich fast über die gesamten Flanken des Sihltals von Langnau am Albis der Sihl entlang bis nach Sihlbrugg. Das Untersuchungsgebiet wird durch die Albiskette im Südwesten und dem Zimmerberg im Nordosten begrenzt. Der grösste Höhenunterschied besteht zwischen der tiefsten Stelle an der Sihl, 470 m ü M. und dem höchsten Punkt auf der Albiskette, welcher sich auf 915m ü M befindet. Im Talgrund verläuft die stark befahrene Sihltalstrass der Sihl entlang.
Abbildung 1 Übersicht des Untersuchunggebietes in Echtfarbendarstellung (August 2006)

Grundlagen
4
2.1.2 Nutzung des Sihlwaldes von früher bis heute
In der Geschichte wurde der Sihlwald jahrhundertlang als Rohstoffquelle genutzt. Im Mit-telalter wurde ein intensiver Holzschlag in Form von Saumschlägen (Kahlschlagprinzip) betrieben. So nahm während dieser Zeit die Waldfläche im ganzen Kanton kontinuierlich ab und durch die Übernutzung bildete sich mancherorts Niederwald. Veränderungen in der Artenzusammensetzung waren über die Jahrhunderte kaum spürbar. Die Zürcher Obrigkeit erkannte allerdings schon im 12./13. Jahrhundert, dass es eine nach-haltige Nutzung der Waldressourcen benötigt, um langfristig die Holzgewinnung zu er-möglichen. Im 14. Jahrhundert ging der Sihlwald vom Zürcher Kloster Fraumünster in den Besitz der Stadt Zürich über. Die stärkste Beeinflussung der Waldzusammensetzung erfolgte ab der ersten Hälfte des 19. Jahrhunderts, als der Kahlschlag zunehmend aufgegeben und begonnen wurde, in kon-struktiver Weise in die Entwicklung des Waldes einzugreifen. Durch Aufforstungen und Jungwuchspflege verschoben sich die Waldarten vermehrt in Richtung Nadelhölzer. Das natürliche Holzartenverhältnis des Sihlwaldes wurde auf diese Weise durch die klassische Forstwirtschaft dieser Zeit stark umgestaltet. Im 20. Jahrhundert nahm das Abbauvolumen stetig ab, was auf die nachlassende Bedeutung von Holz als Rohstoff zurückzuführen ist. (Hübner, 2005: S. 2-8) Mitte der 80er-Jahre keimte die Idee auf, das gesamte Gebiet in eine ursprüngliche Natur-landschaft zurückzuführen. Die Natur sollte sich gemäss ihren Gesetzen frei entfalten kön-nen, der Wald und angrenzendes Gebiet aber trotzdem als Naherholungsgebiet erhalten bleiben. Mit der Gründung der Stiftung Naturlandschaft Sihlwald wurde der forstwirt-schaftlichen Nutzung ein Ende gesetzt. Seit 1999 werden keine Bäume mehr geschlagen, Totholz liegengelassen und der Wald wird ganz der Natur überlassen. (Grün Stadt Zürich, 2008)
2.2 Datengrundlage
2.2.1 Falcon II
Die verwendeten Bild- und Höhendaten wurden alle mit dem LIDAR-System Falcon II aufgenommen. Der Sensor wurde von der deutschen Firma TopoSys GmbH für die drei-dimensionale Erfassung der Erdoberfläche entwickelt. Die Messmethode für das Generie-ren von digitalen Höhenmodellen basiert auf der aktiven Distanzmessung mit einem opto-elektronischen LIDAR-System (Light Detection And Ranging). Gleichzeitig ist ein opti-scher Zeilenscanner integriert, welcher digitale Aufnahmen in vier Kanälen aufzeichnet: Rot (R), Grün (G), Blau (B) und Nahinfrarot (NIR) (TopoSys GmbH, 2007). Die erste Befliegung des Untersuchungsgebietes erfolgte am 10. August 2006. Die Auf-nahmen wurden bei bedecktem Himmel unterhalb der Wolkendecke vorgenommen. Da-durch kann die Schatten-/Sonnenseiteproblematik vermindert und damit der Aufwand für die spätere Klassifikation reduziert werden. Um das gesamte Gebiet abdecken zu können, war jedoch 7 Tage später ein zweiter Flug nötig (Abbildung 2), da die Wetterbedinungen nicht stabil blieben. Daher wurde eine Woche später die restliche Fläche aufgenommen. Die vier Bildkanäle und das Digitale Oberflächenmodell (DOM) stammen von diesen bei-den Überflügen. Das Digitale Höhenmodell (DHM) wurde aus einem Überflug mit dem-selben Sensor von 2004 verwendet.

Grundlagen
5
2.2.1.1 Laserscanner-Datensatz Beim Laserscanning wird die Messung einer dreidimensionalen Punktkoordinate mit Hilfe eines aktiven Systems durchgeführt. Dafür kann entweder gepulstes oder kontinuierlich ausgesendetes Laserlicht verwendet werden. Es wird darüber die Postition eines Mess-punktes (Abbildung 3) in Bezug auf das Sensorsystem bestimmt, welches in einem Flug-zeug oder Helikopter installiert ist. Die äussere Orientierung, d.h. die Position und die La-ge des Sensors im Raum, errechnet sich aus einem GPS-System und einem inertialen Na-vigationssystem, sodass letztlich Koordinaten bezüglich eines Referenzsystems berechnet werden können.
Tabelle 1 Angaben zu den Befliegungen im April 2004 und August 2006
Datum 10. August 2006 17. August 2006 20. April 2004
Zeit 8:30 bis 9:50 UTC 6:25 bis 9:00 14:49 bis 17:35 UTC
Flughöhe ca. 1200 m über Grund ca. 1250 m über Grund
Referenzdaten 5 Gebäudepolygone und 144 Höhenreferenzpunkte 5 Gebäudepolygone und 53 Höhenreferenzpunkte
Bezugssystem Landeskoordinatensystem der Schweiz (LV95/CH1903+)
Streifenbreite 195 m
Anzahl Streifen 34
Anzahl Kacheln 20 Einzelszenen
Kachelgrösse 2000 m x 2000 m
Abbildung 2 Aufnahmestreifen der beiden Überflüge vom 10. & 17. August 2006

Grundlagen
6
Gepulste Lasersysteme können den ‚first pulse’ und ‚last pulse’ aufnehmen (auch ‚first’ und ‚last echo’). Der ‚first pulse’ bezeichnet den ersten Laserimpuls, der vom Boden bzw. für diese Arbeit besonders relevant, von der Baumkrone (Abbildung 4) reflektiert wird. Der ‚last pulse’ ist demzufolge der letzte vom Scanner empfangene Impuls, der von der Bodenoberfläche reflektiert wird.
Aus diesen Impulsen lässt sich ein digitales Oberflächenmodell (DOM) und ein digitales Höhenmodell (DHM) erstellen. Das DOM gibt die Bodenoberfläche inklusiv der Oberflä-che, der sich auf dem Boden befindlichen Objekte wieder. Im Untersuchungsgebiet ent-spricht das DOM in grossen Teilen den Baumkronen, es sind jedoch auch Häuser darin enthalten. Das DHM bildet hingegen die Bodenoberfläche ohne jegliche Objekte ab, es beschreibt den Geländeverlauf. Aus diesen beiden Modellen lässt sich die Differenz berechnen, sie entspricht der Vegeta-tionshöhe (Abbildung 7). Dieser Parameter ist für diese Arbeit von grosser Wichtigkeit, denn er wird zur Unterscheidung von Wald und Nichtwald verwendet.
Abbildung 3 Scanmuster und Messpunkte des Falcon II Laserscanners (Toposys, 2008a)
Abbildung 4 Reflexionsweise der ausgesendeten Laserstrahlen mit first und last echo (Toposys, 2008b)

Grundlagen
7
Abbildung 5 Oberflächenmodell (DOM); Ausschnitt aus dem Untersuchungsgebiet
Abbildung 6 Höhenmodell (DHM); Ausschnitt aus dem Untersuchungsgebiet
Abbildung 7 Differenz vom Oberflächenmodell und dem Höhenmodell (DOM – DHM); Vegetationshöhe; Ausschnitt aus dem Untersuchungsgebiet

Grundlagen
8
2.2.1.2 Multispektraler orthorektifizierter Datensatz Während den Befliegungen im August 2006 wurden zu den Laserscanner-Daten simultan mit einem Zeilenscanner multispektrale Bilddaten erfasst. Der Datensatz umfasst vier Spektralkanäle, welche einen Wellenlängenbereich von 450 nm bis 890 nm abdecken.
Es erfolgt streifenweise eine Entzerrung sowie eine Georeferenzierung der Bilddaten mit Hilfe des aus den Laserscanner gewonnen Oberflächenmodelles. Die Bildstreifen werden zum Schluss mosaikiert. Es entsteht ein vierkanaliger Bildverband mit einer Rasterbreite von 0.5 Meter.
Tabelle 2 Technische Angaben zum Laserscanner Falcon II (TopoSys GmbH, 2008c)
Rastergrösse 1.00 m
Höhenauflösung 0.01 m
Höhengenauigkeit < +- 0.15 m
Lagegenauigkeit < +- 0.50 m
Reichweite 1600 m
Öffnungswinkel 14.3°
Abtastrate 653 Hz
Laserimpulsfrequenz 83 000 Hz
Laserwellenlänge 1560 nm
Datenaufnahme Intensität, First & Last Echo
Abbildung 8 Multispektraler orthorektifizierter Datensatz; Ausschnitt aus dem Untersuchungsgebiet, eine Echtfarben-darstellung (RGB) (links) und eine Falschfarbendarstellung (rechts)

Grundlagen
9
2.2.2 Bodenreferenzen zur Verifikation der Klassifikation
2.2.2.1 Waldbestandesaufnahme 2001 Der Kanton Zürich liess 2001 eine Waldbestandesaufnahme für das gesamte Untersu-chungsgebiet Sihlwald durchführen. Es erfolgte eine manuelle Digitalisierung der Waldflä-che mit Hilfe eines Orthophotoplanes im Massstab 1: 5000. Die Aufnahme besteht aus 1025 Polygonen mit detaillierten Angaben zu der Baumartenzusammensetzung in den drei Waldschichten. Der aus der Luftbildinterpretation gewonnene Datensatz beinhaltet für die-se Arbeit relevante Parameter wie den Deckungsgrad der Bäume (DG), den Anteil der Hauptbaumart am Deckungsgrad (DBDG) und die Anteile von diversen Baumarten am Deckungsgrad (PRx).
Tabelle 3 Technische Angaben zum Zeilensacanner (TopoSys, 2008c)
Blau (B) 450 – 490 nm
Grün (G) 500 – 580 nm
Rot (R) 580 – 660 nm Spektralkanäle
Nahinfrarot (NIR) 770 – 890 nm
Pixel pro Kanal 682
Rastergrösse 0.5 m
Lagegenauigkeit < +- 0.5 m
Auflösung quer zur Flugrichtung 0.5 mrad
Öffnungswinkel 21.6° (+- 10.8°)
Blende 1:1.4
Abbildung 9 Polygone der Waldbestandesaufnahme 2001; Falschfarbendarstellung hinterlegt
Grundlagen
10
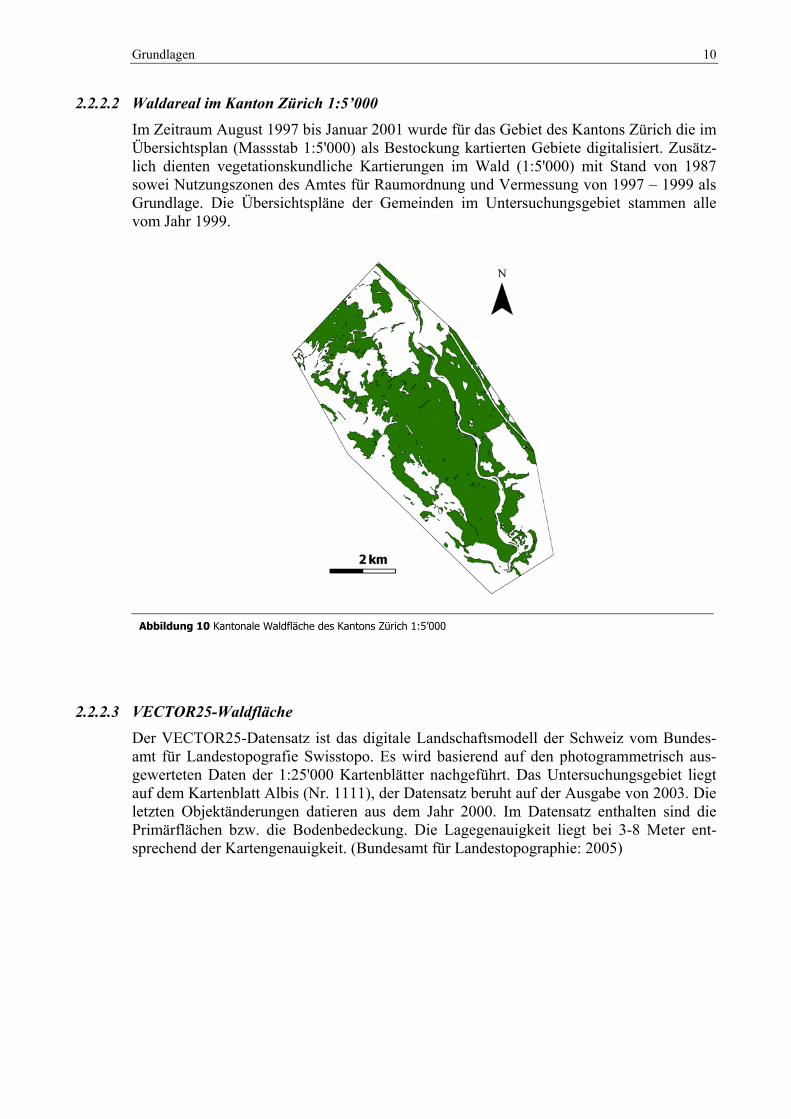
2.2.2.2 Waldareal im Kanton Zürich 1:5’000 Im Zeitraum August 1997 bis Januar 2001 wurde für das Gebiet des Kantons Zürich die im Übersichtsplan (Massstab 1:5'000) als Bestockung kartierten Gebiete digitalisiert. Zusätz-lich dienten vegetationskundliche Kartierungen im Wald (1:5'000) mit Stand von 1987 sowei Nutzungszonen des Amtes für Raumordnung und Vermessung von 1997 – 1999 als Grundlage. Die Übersichtspläne der Gemeinden im Untersuchungsgebiet stammen alle vom Jahr 1999.
2.2.2.3 VECTOR25-Waldfläche Der VECTOR25-Datensatz ist das digitale Landschaftsmodell der Schweiz vom Bundes-amt für Landestopografie Swisstopo. Es wird basierend auf den photogrammetrisch aus-gewerteten Daten der 1:25'000 Kartenblätter nachgeführt. Das Untersuchungsgebiet liegt auf dem Kartenblatt Albis (Nr. 1111), der Datensatz beruht auf der Ausgabe von 2003. Die letzten Objektänderungen datieren aus dem Jahr 2000. Im Datensatz enthalten sind die Primärflächen bzw. die Bodenbedeckung. Die Lagegenauigkeit liegt bei 3-8 Meter ent-sprechend der Kartengenauigkeit. (Bundesamt für Landestopographie: 2005)
Abbildung 10 Kantonale Waldfläche des Kantons Zürich 1:5’000

Grundlagen
11
2.2.2.4 Versuchsfläche Birriboden Im Herbst 2000 legte die Eidgenössische Forschungsanstalt für Wald, Schnee und Land-schaft Birmensdorf (WSL) im Sihlwald auf dem Birriboden eine 10 Hektar grosse Ver-suchsfläche an. In den 50 m x 50 m grossen Teilflächen wurde von allen 3236 lebenden und toten Bäumen die genauen Koordinaten, Höhe, Brustdurchmesser sowie Parameter zu deren Stammqualität aufgenommen. (WSL, 2001: 5-6)
Abbildung 11 VECTOR25-Waldfläche von Swisstopo
Abbildung 12 Versuchsfläche Birriboden der WSL, Birmensdorf

Grundlagen
12
2.3 Walddefinitionen
Da das Ziel dieser Arbeit die thematische Kartierung von Waldflächen bzw. die Differen-zierung von verschiedenen Baumarten ist, muss zuerst die genaue Definition von ‚Wald’ festgelegt werden. Generell lässt sich sagen, dass keine einheitliche und allgemeingültige Definition für Wald existiert. Nicht nur unter den Nachbarländern differieren die Merkmale zur Bestimmung der Waldfläche, sondern auch innerhalb der Schweiz benutzen diverse Institutionen eigene Regelwerke. Dazu gehören unter anderen das Bundesamt für Landestopographie Swissto-po, die Eidgenössische Forschungsanstalt für Wald, Schnee und Landschaft in Birmensdorf (Schweizerisches Landforstinventar LFI), das Bundesamt für Statistik (Arealstatistik). Die verwendeten Datengrundlagen zur Verifizierung der Klassifikationen stammen von diesen unterschiedlichen Stellen (Kap. 2.2.2). Aus diesem Grund drängt es sich auf, die jeweils verwendeten Walddefinitionen zu beschreiben.
2.3.1 Walddefinition des Bundesamtes für Landestopographie Swisstopo
Bei der Landestopographie spricht man nach Definition von Wald, wenn der Deckungs-grad der Bäume die 50%-Marke überschreitet: „Als Wald wird jede mit mehr als 3 m hohen Bäumen bepflanzte Fläche ausgeschieden, die von den Baumkronen zu mehr als der Hälfte beschirmt wird […]. Weder das Alter des Waldes noch der jeweilige Grad der Nutzung spielen bei der Festlegung der Waldumrisse eine Rolle. Somit sind Jungwälder und Wiederaufforstungen auf der Karte genau gleich gekennzeichnet wie der Hochwald.“ Diese Definition bestimmt die grün eingefärbte Fläche in der Landeskarte. Weniger ge-schlossene Baumbestände wie Gebüsch- und Buschwälder oder Einzelbäume werden hin-gegen mit Punkt und Kreissignaturen ausgewiesen (Bundesamt für Landestopographie, 1993).
2.3.2 Walddefinition nach dem Schweizerischen Landesforstinventar LFI
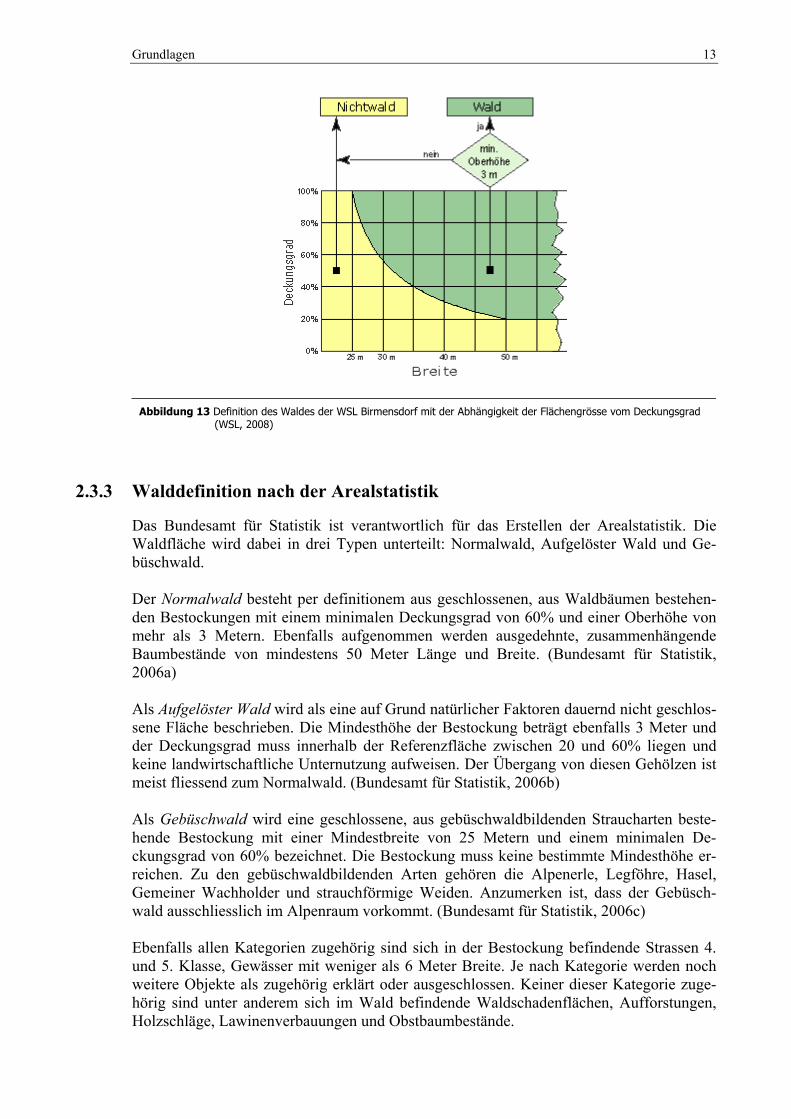
Das Schweizerische Landesforstinventar wird von der WSL durchgeführt. Die Definition des Waldes beinhaltet ebenfalls das Merkmal der minimalen Oberhöhe von 3 Metern. Da-von ausgenommen sind Aufforstungen, Verjüngungen, Schlag-, Sturm- und Schadenflä-chen, Gebüschwald aus Legföhren und Alpenerlen. Der Deckungsgrad der Bestockung steht in Kombination mit der Mindestbreite und daher mit der Mindestfläche. Sinkt der Deckungsgrad, wird gegenläufig die Mindestbreite grösser. Die Mindestbreite (25 – 50 m) ist abhängig vom Deckungsgrad (100 – 20%). (Keller, 2005: 393)
Grundlagen
13
Abbildung 13 Definition des Waldes der WSL Birmensdorf mit der Abhängigkeit der Flächengrösse vom Deckungsgrad
(WSL, 2008)
2.3.3 Walddefinition nach der Arealstatistik
Das Bundesamt für Statistik ist verantwortlich für das Erstellen der Arealstatistik. Die Waldfläche wird dabei in drei Typen unterteilt: Normalwald, Aufgelöster Wald und Ge-büschwald. Der Normalwald besteht per definitionem aus geschlossenen, aus Waldbäumen bestehen-den Bestockungen mit einem minimalen Deckungsgrad von 60% und einer Oberhöhe von mehr als 3 Metern. Ebenfalls aufgenommen werden ausgedehnte, zusammenhängende Baumbestände von mindestens 50 Meter Länge und Breite. (Bundesamt für Statistik, 2006a) Als Aufgelöster Wald wird als eine auf Grund natürlicher Faktoren dauernd nicht geschlos-sene Fläche beschrieben. Die Mindesthöhe der Bestockung beträgt ebenfalls 3 Meter und der Deckungsgrad muss innerhalb der Referenzfläche zwischen 20 und 60% liegen und keine landwirtschaftliche Unternutzung aufweisen. Der Übergang von diesen Gehölzen ist meist fliessend zum Normalwald. (Bundesamt für Statistik, 2006b) Als Gebüschwald wird eine geschlossene, aus gebüschwaldbildenden Straucharten beste-hende Bestockung mit einer Mindestbreite von 25 Metern und einem minimalen De-ckungsgrad von 60% bezeichnet. Die Bestockung muss keine bestimmte Mindesthöhe er-reichen. Zu den gebüschwaldbildenden Arten gehören die Alpenerle, Legföhre, Hasel, Gemeiner Wachholder und strauchförmige Weiden. Anzumerken ist, dass der Gebüsch-wald ausschliesslich im Alpenraum vorkommt. (Bundesamt für Statistik, 2006c) Ebenfalls allen Kategorien zugehörig sind sich in der Bestockung befindende Strassen 4. und 5. Klasse, Gewässer mit weniger als 6 Meter Breite. Je nach Kategorie werden noch weitere Objekte als zugehörig erklärt oder ausgeschlossen. Keiner dieser Kategorie zuge-hörig sind unter anderem sich im Wald befindende Waldschadenflächen, Aufforstungen, Holzschläge, Lawinenverbauungen und Obstbaumbestände.

Grundlagen
14
2.3.4 Erfassung des Waldes durch den Sensor
Die von den Sensoren des Satelliten empfangene und vom Wald reflektierte Strahlung bzw. Energie ist abhängig von seinen verschiedenen objektbedingten Eigenschaften. Dar-unter versteht man unter anderem die Artenzusammensetzung, die Phänologie, das Alter, Dichte des Kronendaches, Bodenfarbe und –feuchte etc. Für die Walderkennung sind in der optischen Fernerkundung die räumliche und die spektrale Auflösung von Bedeutung. (Kellenberger, 1996: 71-75) Durch die hohe räumliche und spektrale Auflösung des Datensatzes detektiert der Sensor Elemente, welche z.B. aufgrund von Generalisierungen nicht in den Bodenreferenzen ent-halten sind. Je nach Definition des Waldes kann es deshalb zu unterschiedlichen Abwei-chungen zwischen der Klassifikation und der Bodenreferenz kommen. Dies muss bei der Verifikation beachtet werden. Ein gemeinsamer Nenner der beschriebenen Walddefinitionen bildet die Mindesthöhe der Bestockung. Sie wird bei allen auf 3 Meter gesetzt. Dieser Wert wird ebenfalls in der Klas-sifikation als Grenzkriterium verwendet.

Klassifikationsmethode
15
3 Klassifikationsmethode
3.1 Objektorientierte Klassifikation
Die grundlegende Prozesseinheit der objektorientierten Bildanalyse sind Segmente, so ge-nannte Bildobjekte, und nicht einzelne Pixel. Vorteile der objektorientierten Analyse im Gegensatz zur pixelbasierten sind aussagekräftige Objekt-Statistiken, Texturberechnun-gen, eine Vergrösserung des unkorrelierten Merkmalraumes mit dem Gebrauch von Form-faktoren sowie topologische Parameter. Dazu kommt die nahe Verwandtschaft zwischen den Objekten in der Realität und den Bildobjekten. Diese Beziehung verbessert den Wert der Schlussklassifikation und kann von pixelorientierten Ansätzen nicht erreicht werden. (Eckert, 2006: 59) Da in dieser Arbeit die Klassifikationen mit der Software Definiens Developer (Weiter-entwicklungen von eCognition) vorgenommen wurden, wird der objektorientierte Klassifi-kationsansatz anhand des Ansatzes der verwendeten Software kurz erläutert.
3.2 Grundlage der Software Definiens Developer
Die erste allgemeine objektorientierte Bildanalyse-Software auf dem Markt war eCogniti-on. Dieses Softwareprodukt wurde von Definiens produziert. Obwohl eCognition eine spe-zifische Kombination von Prozessen beisteuert, gibt es einige charakteristische Aspekte des zugrunde liegenden objektorientierten Ansatzes, welche unabhängig von einer be-stimmten Methode sind. (Benz, 2004: 240)
3.2.1 Objekterzeugung durch ‚multiresolution’ Segmentation
Objekte werden durch die Segmentierung erzeugt, indem das Bild in homogene Regionen aufgeteilt wird. Für diese Bildsegmentierung existieren sehr viele unterschiedliche Metho-den und sie stellt ein lang anhaltendes Forschungsgebiet in der Bildanalyse dar. In Definiens Developer wird eine ‚multiresolution’ Segmentierung angewendet. Hierbei handelt es sich um eine Bootom-up-Methode, die mit Einzelpixel-Objekten startet. In klei-nen Schritten werden die Objekte vereinigt und gewinnen an Fläche. Das Kriterium für die Vereinigung bildet die Heterogenität innerhalb des Objektes bzw. zu den Nachbarobjekten. Innerhalb der Objekte soll dabei die Heterogenität möglichst klein gehalten werden. Das Wachstum der Segmente stoppt, wenn der Grenzwert, welcher durch den Scale Parameter definiert ist, überschritten wird. (Eckert, 2006: 61-62) Je höher der Scale Parameter gewählt wird, desto höher ist die Heterogenität innerhalb der Objekte und diese wachsen konsequenterweise an.

Klassifikationsmethode
16
Abbildung 14 Übersicht der verwendeten ‚multiresolution’ Segmentierung in Definiens Developer (Definiens, 2007b:
22), verändert
Die Homogenität wird aus vier Kriterien berechnet: Color, Shape, Compactness und Smoothness. Für die meisten Fälle ist das Color-Kriterium am bedeutendsten für das Bil-den von sinnvollen Objekten. Die Form-Homogenität kann in einem gewissen Grad die Qualität der Objektbildung verbessern, zum Beispiel in stark strukturierten Daten. (De-finiens Reference Book, 2007: 22) Starken Einfluss auf die Objektbildung spielen zudem die verwendeten Daten. Die ver-schiedenen Eingangskanäle können unterschiedlich gewichtet werden, um optimale Objek-te generieren zu können.
3.2.2 Hierarchisches Objekt-Netzwerk
Alle generierten Segmente sind in einem stark hierarchischen Netzwerk verbunden. Jeder neue Segmentierungslevel befindet sich zwischen einem tieferen (höhere räumliche Auflö-sung) und einem höheren Level (tiefere räumliche Auflösung). Dabei bildet die Ebene der Pixel immer den tiefsten und die Ebene des gesamten Bildes den höchsten Level. Um eine eindeutige Hierarchie bezüglich der räumlichen Ausdehnung der Objekte garantieren zu können, folgt die Segmentierung einigen Regeln:
• Objektgrenzen müssen den Grenzen des Objektes des nächst unteren Levels folgen. • Die Segmentierung ist durch die Grenzen des Objektes im nächst höheren Level
begrenzt. • Strukturen in verschiedenen Level können gleichzeitig dargestellt werden und da-
her in Relation zueinander klassiert werden. • Verschiedene Hierarchielevels können basierend auf unterschiedlichen Daten seg-
mentiert werden. • Eine Korrektur der Objektform basierend auf Sub-Objekten ist möglich. (Benz,
2004: 248)
Composition of the Homogeneity criterion
Color
Shape
Compactness
Smoothness
Color + Shape = 1 Compactness + Smoothness = Shape

Klassifikationsmethode
17
3.2.3 Labelling in Definiens Developer
Die Klassifikation ist der verknüpfende Prozess zwischen Klassen in einer Klassenhierar-chie (‚Class Hierarchy’ in Definiens) mit den Bildobjekten in einer Szene. Der Benutzer erstellt aufgrund seines Wissens und der gemachten Erfahrung eine solche Klassenhierar-chie, nach welcher die Klassifikation anschliessend ablaufen soll. Für die Klassifikation der einzelnen Segmente existieren in Definiens zwei Typen von ‚nearest neighbour’ Algorithmen: ‚nearest neighbour’ (NN) und ‚standard nearest neigh-bour’ (Std. NN). Die Bezeichnung nearest neighbour kann etwas irreführen, da die Klassen den Segmenten nach dem Minimum-Distanz-Prinzip zugeordnet werden, wie dies ein Mi-nimum-Distanz-Algorithmus typischerweise durchführt. Zusätzlich lassen sich in Definiens Developer mit ‚Membership Functions’ basierend auf der Fuzzy-Logik Theorie Klassen definieren. Im anschliessenden Kapitel wird daher aus-führlicher auf diese Methode eingegangen.
3.2.3.1 Klassifikation mit ‚Fuzzy Membership Functions’ Fuzzy-Klassifikation ist eine sehr leistungsfähige Klassifikationsmethode. Mit ihr können Ungenauigkeiten im Sensorsystem, Parametervariationen infolge begrenzter Sensorkalib-rierung, semantisch vage Klassenbeschreibung und Klassenvermischung aufgrund be-grenzter Auflösung berücksichtigt werden. (Benz, 2004: 251) Eine Fuzzy-Klassifikation besteht aus einem n-dimensionalen Tupel mit Zugehörigkeits-graden, welche die Abgrenzung zu den Klassen beschreibt. Die grundlegende Idee hinter der Theorie ist, die zwei boolschen Werte ‚wahr’ und ‚falsch’ durch kontinuierliche Werte zwischen 0 und 1 zu ersetzen. Das Umgehen von scharfen, willkürlich gesetzten Grenz-werten erlaubt es, sich der wirklichen Welt in ihrer Komplexität bedeutend besser anzunä-hern. (Eckert, 2006: 64) Die Unschärfe der Aussage eines Fuzzy-Systems bedeutet dabei nicht ein Mangel an In-formation, sondern die graduierte Bewertung des Wahrheitsgehaltes (Stolz, 1998: 83-84).
Abbildung 15 Hierarchisches Netzwerk klassierter Objekte in unterschiedlichen Segmentierungslevel (Definiens, 2007a:
27)

Klassifikationsmethode
18
Abbildung 16 Beispiel einer ‚Fuzzy Membership Function’ aus Definiens Developer

Erstellung der Klassifikation
19
4 Erstellung der Klassifikation
In diesem Kapitel wird das Vorgehen bei den verschiedenen Klassifikationen in Definiens Developer aufgezeigt.
4.1 Zusätzlich berechnete Layer bzw. Datensätze
Für die Segmentierung und anschliessende Klassierung wurden zu den Laserscannerdaten und Zeilenscanneraufnahmen zusätzlich noch zwei Vegetationsindizes verwendet. Die Berechnung derselben wird in den folgenden Unterkapiteln kurz ausgeführt.
4.1.1 Normalized Difference Vegetation Index (NDVI)
Der ‚Normalized Difference Vegetation Index’ ist einer der am häufigsten verwendeten Vegetationsindizes, wenn es um die Abschätzung von biophysikalischen Parametern geht. Der Index macht sich zu nutze, dass vitale Vegetation im sichtbaren Spektralbereich (VIS 0.4 – 0.7 μm) verhältnismässig wenig und im anschliessenden Nahinfrarot-Bereich (NIR 0.7 – 1.1 μm) ausserordentlich viel Strahlung reflektiert. „Ausserdem werden durch diese Art der Ratiobildung Unterschiede in den Beleuchtungsverhältnissen und Einflüsse der Geländeneigung weitgehend kompensiert.“ (Albertz, 2001: 219) Die Reflexion im NIR korreliert stark mit der Vitalität der Vegetation. Je grösser die Vitalität bzw. die photosyn-thetische Aktivität, desto grösser sind die Reflexionswerte.
RotNIRRotNIRNDVI
+−
= [1]
Der theoretische Wertebereich erstreckt sich aufgrund der Normierung von -1 bis +1. Meistens bewegen sich die Werte zwischen 0 und 1, negative Werte tauchen bei starker Absorption des NIR bei klaren, dunklen Wasseroberflächen auf (Beusch, 2005: 16). Der NDVI wird zu den einfachen Indizes gezählt. Er liefert jedoch sehr gute Resultate be-züglich der Vegetationserkennung und kann sogar komplizierter aufgebaute Indizes über-treffen (Fischer, 1999: 98-99). Für die vorliegende Arbeit wurde der NDVI nach der anschliessenden Formel berechnet, um ausschliesslich positive Werte zu erhalten und nur einen 8-bit-Kanal verwenden zu müssen. Der neue Wertebereich erstreckt sich deshalb von 0 bis 200.
1001 ⋅⎟⎠⎞
⎜⎝⎛ +
+−
=RotNIRRotNIRNDVI [2]
4.1.2 Soil Adjusted Vegetation Index (SAVI)
Der Soil Adjusted Vegetation Index wurde entwickelt, um Einflüsse des Bodens auf das Vegetationsspektrum zu minimieren. Der SAVI ist im Gegensatz zum NDVI eigentlich ein speziell für aride und semiaride Räume geeigneter Index, da er die Interaktion zwischen Boden- und Vegetationsreflexion berücksichtigt.

Erstellung der Klassifikation
20
)1( LLRotNIR
RotNIRSAVI +⋅++
−= [3]
L ist dabei eine Konstante, welche empirisch ermittelt wird, um die Empfindlichkeit des Vegetationsindex auf den Einfluss der Bodenreflexion zu vermindern. Je niedriger der Leaf Area Index (LAI), desto höher muss der Korrekturfaktor gewählt werden. Der Wertebe-reich von SAVI liegt identisch demjenigen vom NDVI zwischen -1 und 1. (Huete, 1988: 299) Für diese Arbeit wird der Index in Geomatica gerechnet, welche keine Einstellungen der Parameter und nicht direkt ersichtlich ist mit welchem Wert für L gerechnet wurde. Obwohl dieser Vegetationsindex eigentlich in ariden oder semiariden Gebiet eingesetzt wird und zusätzlich der verwendete Parameter L nicht bekannt ist, wird er für die Klassifi-kation verwendet. Die Ähnlichkeit zum NDVI ist gross, doch erwies sich der SAVI bei Grenzfällen in Probeklassifikationen als gute Unterstützung zum NDVI.
4.2 Aufteilen des Datensatzes in Kacheln
Füllemann (2007) hat bereits festgestellt, dass die Software eCognition mit grossen Da-tenmengen überlastet ist und den Segmentierungsvorgang abbricht. Die Weiterentwicklung ‚Definiens Developer’ weist weiterhin nur eine 32-bit Applikation auf, worauf nur 2 GB Speicherplatz bereitgestellt werden können. Für das Entwickeln einer geeigneten ‚Class Hierarchy’ und Übertragen derselben auf den gesamten Datensatz müssen Kacheln in geeigneter Grösse erstellt werden. Im Vergleich zu Füllemann liegen in dieser Arbeit die Spektralkanäle in 16-bit Rastern vor, was die maxi-male Kachelgrösse noch einmal senkt. Nach mehreren Testläufen wird die angestrebte ma-ximale Kachelgrösse auf 3'000 x 3’000 Pixel festgelegt. Aufgrund derAbweichung der Segmentierung in den Randbereichen (siehe Kap.4.3.2) wurden die Grundkacheln etwas kleiner festgelegt: 2666 x 2881 Pixel, wobei Kacheln am Rande kleiner ausfielen oder ver-grössert wurden, um das Entstehen von kleinen Restkacheln zu vermeiden.
Abbildung 17 Raster für das Ausschneiden der Kacheln über dem Untersuchungsgebiet Sihlwald

Erstellung der Klassifikation
21
4.3 Segmentierung
4.3.1 Kanalgewichtung, Scale Parameter und Homogenitätskriterien
Bei der objektorientierten Klassifikation stellt die Segmentierung den Grundstein für alle weiteren Schritte dar. Das Hauptziel der Segmentierung in der vorliegenden Arbeit liegt im Bilden von Objekten, welche möglichst genau den Baumkronen entsprechen. Je besser dies gelingt, desto geringer ist der Aufwand beim Erstellen der Klassifikation und desto höher die Genauigkeit derselben. Als Ausgangslage für die Segmentierung des Datensatzes werden die Parameter von Fül-lemann (2007) herangezogen. Sie klassierte das identische Untersuchungsgebiet ebenfalls mit Datensätzen vom LIDAR-System Falcon II mit dem Ziel, Baumarten unterscheiden zu können. Es gelang ihr, neben der Unterscheidung von Laub- und Nadelwald, auch die Lär-che zu klassieren. Aufgrund dieser guten Resultate werden die von ihr gewählten Parame-ter zuerst verwendet und dann mittels des ‚Try-and-Error’ Prinzips versucht, eine dem Zweck nützlichere Segmentierung zu erreichen. Für die Gewichtung der Kanäle wird hier-bei keine Einstellung gefunden, die bedeutend bessere Resultate ergibt. Deshalb werden diese Werte übernommen. Der Nahinfrarot Kanal spielt dabei mit der starken 20-fachen Gewichtung die bedeutendste Rolle, denn nach Löffler (In: Füllemann (2007): 27) ist die Reflexion von Pflanzen in diesem Wellenlängenbereich besonders differenziert. Ebenfalls stark gewichtet wird der grüne Kanal (7-fach) und die Vegetationshöhe (10-fach), welche unter anderem eine Unterscheidung von Wald und Nichtwald stark erleichtert. Der Blau- und Rotkanal werden nur einfach gewichtet und erhalten somit eine untergeordnete Rolle. Beim Bestimmen der Homogenitätskriterien (Abbildung 14) kann die Gewichtung der Form (Shape) von 0 – 1 festgelegt werden. Komplementär dazu ergibt sich die Gewichtung für die spektrale oder thematische Information (Color). Die Form setzt sich wiederum aus der Kompaktheit (Compactness) und der Glätte (Smoothness) zusammen, welche sich ebenfalls auf den Wert 1 ergänzen. Die spektrale Information ist bedeutend wichtiger als die Information über die Form der Objekte, deshalb wird sie 4-fach stärker gewichtet (Color: 0.8, Shape: 0.2). Die Kompakt-heit und Glätte werden mit jeweils 0.5 gleich stark gewichtet. Dies ist demnach der einzige Faktor, welcher im Vergleich zu Füllemanns Segmentierung abgeändert wurde. Um ein geeignetes Objektlevel bzw. –ebene zu erhalten, wird abermals das ‚Try-and-Error’ Prinzip angewandt. Es werden insgesamt drei unterschiedliche Objektlevels mit den Scale Parametern 5, 25 und 50 generiert. Dabei wird aufsteigend zuerst mit dem Objektle-vel mit geringster räumlicher Auflösung begonnen, jenes mit dem niedrigsten Scale Para-meter. So entstehen drei Objektlevel mit sehr unterschiedlichen Segmenten (Level 5, Level 25 und Level 50). In Level 50 sollen die Segmente primär den Gebäuden entsprechen. Die Objekte in Level 25 sollten möglichst genau einzelne Baumkronen umfassen und Level 5 sollte kleine Bildobjekte bereitstellen, um Grenzentscheidungen räumlich besser angehen zu können.

Erstellung der Klassifikation
22
4.3.2 Reproduktion von Segmenten - Randproblematik
Mit der Herausgabe von eCognition Version 3.0 wurde der Segmentierungs-Algorithmus mit der Berücksichtigung von reproduzierbaren Objektgrenzen verbessert. Dies ist von grosser Bedeutung wenn, wie in diesem Fall, grosse Datensätze zerschnitten und aufgrund von Software- oder Hardware-Beschränkungen (Kap. 4.2) in kleineren Teilprojekten bear-beitet werden müssen. Die klassierten Kacheln müssen anschliessend wieder zusammenge-fügt werden, daher sollte die Segmentierung identisch sein. Unglücklicherweise ist dies in den Randregionen nicht der Fall. Die Segmentierung wird erst ab einer gewissen Distanz vom Rand stabil, was wiederum von der Objektgrösse bzw. vom Scale Parameter abhängig ist. Je kleiner die Segmente, desto kürzer ist die Distanz bis die Objektgrenzen wieder de-ckungsgleich sind. Um dieses Phänomen zu umgehen, werden die Kacheln mit einem Überlappungsbereich von 200 Pixeln Breite zu jeder benachbarten Kachel zugeschnitten. Für den Level 50, der Objektlevel mit den grössten Segmenten, ist dieser Streifen ausreichend. In Abbildung 19 ist ersichtlich, dass an den Kachelgrenzen keine Abweichungen entstehen. Die Objektgren-zen stimmen nur im äusseren Teil des Überlappungbereiches nicht überein.
Abbildung 18 Ausschnitte der drei erstellten Objektlevel mit den Scale Parametern 5, 25 und 50
Überlappungsbereich
Abbildung 19 Segmente im Überlappungsbereich von benachbarten Kacheln (rot und schwarz) im Level 50

Erstellung der Klassifikation
23
4.4 Klassifikationen
Nach dem Generieren der Segmentierung erfolgt als nächster Schritt das Erstellen einer Klassenhierarchie für die Klassifikation. In den folgenden Unterkapiteln soll erläutert wer-den, in welchen Objektlevels und mit welchen Parametern die Klassen getrennt werden konnten. Ursprünglich war geplant, die Klassifikationsparameter an einem einzigen, etwas grösseren Ausschnitt zu bestimmen. Dies ist jedoch aus den beschriebenen Einschränkungen durch die Software Definiens (Kap. 4.2) nicht möglich. Das Definieren der verschiedenen Parameter erfolgt demzufolge in den in Kapitel 4.2 er-stellten Kacheln. Dabei werden die Kacheln auf eine Weise gewählt, dass möglichst alle Illuminationsverhältnisse und möglichst die ganze Vielfalt der Waldlandschaft abgedeckt wird.
4.4.1 Klassifikation des Waldes
Das erste Ziel stellt die Unterscheidung von Wald und Nichtwald dar. Der Nichtwald ist für den weiteren Verlauf der Klassifikation nicht interessant und soll ausgeschieden wer-den. Es ist das Ziel, die Wald-Klassifikation mit einer einzelnen Class Hierarchy durchführen zu können. Sie soll auf dem gesamten Untersuchungsgebiet einsetzbar sein und deshalb eine hohe Stabilität aufweisen.
4.4.1.1 Ausscheidung von Häusern und grobe Klassifikation Als erster Schritt wird im Level 50 (beinhaltet die grössten Elemente) eine erste ‚grobe’ Klassierung durchgeführt. Die Unterscheidung von Wald und Nichtwald lässt sich sehr gut mit den LIDAR-Daten (Vegetationshöhe) durchführen. Alle Felder, Wiesen, Strassen, Ge-wässer etc. verfügen über Höhenwerte um 0 Meter und werden daher ohne Probleme aus-geschieden. Der Grenzwert wird (nach Definition aus Kap. 2.3) bei 3 Metern festgelegt. Höhere Werte treten jedoch vor allem in den Siedlungen auf. Primär handelt es sich dabei um Häuser, es sind jedoch auch Brücken oder Starkstromleitung darin enthalten. Die spekt-ralen Eigenschaften dieser Objekte unterscheiden sich stark von den Waldbäumen. Nur Lärchen und Totholz besitzen ganz ähnliche Werte. Mit den relativ grossen Objekten in diesem Level kann diese Problematik teilweise umgangen werden.
Abbildung 20 Segmente vom Level 50: links Lärchengruppe; rechts eine Überbauung in Langnau am Albis

Erstellung der Klassifikation
24
Während die Häuser grösstenteils ein einzelnes Segment bilden, fallen bei den Lärchen oder toten Bäumen meistens mehrere Bäume in einem Objekt zusammen (Abbildung 19). Die Bereiche zwischen den Bäumen beeinflussen die Statistik des Objektes in den meisten Fällen stark genug, sodass sie mit dem NDVI von den Häusern unterschieden werden kön-nen. Nicht bei allen Segmenten ist dies möglich, sie werden mit Hilfe einer Nachbar-schaftsbedingung klassiert. Ist das Objekt mehr als zur Hälfte von bereits klassiertem Wald umgeben, wird es ebenfalls der Waldklasse zugefügt.
4.4.1.2 Spezifische Klassifikation der Waldrandsegmente Die Objektgrösse für die exakte Bestimmung des Waldrandes ist etwas ungenau, weshalb dieser Bereich noch etwas differenzierter betrachtet werden soll. Dieser Schritt wird im Level 5 durchgeführt, jedoch sollen nur jene Segmente untersucht werden, die sich in der Nähe des Waldrandes befinden. Um diese Objekte ansprechen zu können, wird eine Kopie von Level 50 (Level 50b) erstellt. Es werden zwei Waldrand-Klassen erstellt. Die eine Klasse soll die Segmente enthalten, welche in Level 50 als Wald klassiert sind und gleich-zeitig an mindestens ein als Nichtwald klassiertes Segment angrenzen. Die zweite Klasse soll den ‚gespiegelten’ Fall klassieren: als Nichtwald klassierte Objekte mit Nachbarschaft zu Objekten, die in Level 50 als Wald klassiert wurden.
In Level 5 werden nun die kleinen Segmente, welche sich innerhalb der Waldrandsegmen-te von Level 50 bzw. 50b befinden klassiert. Es geht hierbei nur noch um die Unterschei-dung zwischen Wald und Nichtwald. Die Vegetationshöhe trennt erneut den grössten Teil der Objekte klar auf. Tendenziell wird aber zu viel Wald klassiert und deshalb werden der NDVI und der NIR-Kanal zusätzlich hinzugezogen. Alle Objekte, welche nicht in den Waldrandbereich fallen, übernehmen die Klassenzuwei-sung aus der Klassifikation in Level 50.
Abbildung 21 Klassierte Waldrandsegmente in Level 50

Erstellung der Klassifikation
25
Abbildung 22 Ausschnitte aus den Klassifikationsresultaten;: Level 50, Level 5 und Level 25 (von oben nach unten)

Erstellung der Klassifikation
26
4.4.2 Klassifikation verschiedener Baumarten
In einem nächsten Schritt werden die als Wald klassierten Segmente aus Level 5 in den mittleren Objektlevel (Level 25) übertragen. Als Bedingung wird ‚Existence of sub object’ benutzt. Die Waldfläche wird dadurch vor allem an den Waldrändern etwas vergrössert.
4.4.2.1 Unterscheidung von Laub- und Nadelbäumen Als erstes werden in einer einzelnen Kachel die Laubbäume von den Nadelbäumen ge-trennt. Dies ist mit wenigen Einschränkungen gut möglich. Schwierigkeiten entstehen erst bei der Übertragung der Class Hierarchy auf andere Kacheln. Die Illuminationsunterschie-de sind zum Teil so gross, dass viele Anpassungen an den bestehenden Klassen durchge-führt sowie diverse neue Klassen erstellt werden müssen. Insgesamt wird die Klassifikation in ca. 10 Kacheln verteilt über das ganze Untersuchungsgebiet übertragen. Ziel bleibt es, dabei immer möglichst wenige Klassen zu verwenden, um bei einer späteren Wiederver-wendung für einen anderen Datensatz nur wenige Änderungen der Parameter vornehmen zu müssen. Dies ist jedoch nur schwer zu erreichen. Die Klassen werden jeweils auf die spezifischen Beleuchtungsverhältnisse, Bestandesalter (Grösse) angepasst. Ebenfalls werden für die unterschiedlichen Befliegungszeitpunkte Klassen erstellt. Da die Segmente oft nicht die gesamte Baumkrone umfassen, werden spe-zielle ‚Kronenrandklassen’ generiert. Auf diese Weise werden insgesamt 12 Laubwald-klassen und 9 Nadelwaldklassen erstellt. In steilen Westhängen sind die Verhältnisse sehr dunkel und die Reflexionswerte erlauben in manchen Bereichen keine sichere Klassenzuweisung. Diese Segmente werden als un-klassierbare Schatten abgetrennt. Die Abtrennung von Laub- und Nadelbäumen erfolgt primär mit den Mittelwerten des Nahinfrarot-Kanals, dem NDVI und ebenfalls mit dem SAVI. Der Blau-Kanal wird im Vergleich zu Füllemann nie gebraucht, was auf die unterschiedlichen Aufnahmezeitpunkte der Daten zurückzuführen ist. Der Grün- und der Rot-Kanal besitzen beide einen zu gros-sen Grenzbereich, in welchem sich Laub- und Nadelbäume überschneiden, sodass sie nicht für die Hauptabgrenzung benutzt werden und nur vereinzelt eingesetzt werden. Das gleiche trifft grundsätzlich auf den Blau-Kanal zu, nur in den Schattenbereichen ist er für Abtren-nungen zu gebrauchen.
4.4.2.2 Unterscheidung von weiteren Baumarten Das Hauptziel dieser Arbeit ist das Erkennen von Baumtypen, insbesondere das Unter-scheiden von Laubbaumarten. Da die Unterscheidung zwischen Laub- und Nadelbaumar-ten bereits relativ starke Anpassung der Parameter für jede Kachel verlangt, wird die weite-re Trennung von Baumarten im Perimeter der WSL Versuchsfläche Birriboden durchge-führt. Zuerst werden alle Bäume, welche nicht der Oberschicht angehören aus der Bodenreferenz entfernt. Für jeden Baum ist ein Koordinatenpaar angegeben, was erlaubt, den Datensatz als thematischen Layer in Definiens zu importieren und entsprechend darzustellen. Die Lagegenauigkeit der Bäume ist sehr gut, die Punkte lassen sich ohne grössere Schwierig-keiten den entsprechenden Baumkronen zuordnen. Die Resultate der einzelnen Klassifika-tionsversuche können jeweils sogleich mit dem thematischen Layer verglichen werden.

Erstellung der Klassifikation
27
Ein Nachteil der Bodenreferenz liegt in der Artenverteilung der aufgenommenen Bäume. Die vorherrschende Laubbaumart ist die Buche. Die restlichen Laubbäume (Esche, Ahorn und Ulme) sind nur in geringer Anzahl vertreten (Abbildung 23). Es wird versucht, die einzelnen Arten mit Hilfe des NDVIs und des NIR-Kanals zu trennen. Die Ulme ist zu stark untervertreten, sodass keine Abtrennung erfolgen kann. Bei Ahorn und Esche werden verschiedene Bäume als Sample genommen, doch liegen die entsprechenden Segmente nicht optimal über den Baumkronen. Die Unterscheidung von Laubbaumarten kann aufgrund der starken Dominanz der Buche und der ungenügenden Segmenten nicht erfolgreich durchgeführt werden.
Abbildung 23 Laubbäume der Oberschicht in der Versuchsfläche Birriboden
Abbildung 24 Nadelbäume der Oberschicht in der Versuchsfläche Birriboden
1
2

Erstellung der Klassifikation
28
Die Verteilung der Nadelbaumarten zeigt sich etwas ausgeglichener. Am häufigsten kommt die Fichte vor, an zweiter Stelle folgt die Tanne. Von der Lärche werden unter 10 Exemplare gezählt. Sie ist zusammen mit Totholz deutlich von den restlichen Bäumen ab-trennbar, die spektralen Eigenschaften gleichen denjenigen von Gebäuden und Stras-sen(Kap. 4.4.1.1). Aufgrund der geringen Anzahl in der Versuchsfläche wird keine Ab-trennung vorgenommen. Innerhalb der Versuchsfläche kommt die Eibe relativ häufig vor, doch reicht keines der Exemplare bis zur Oberschicht. Auch die Unterscheidung der Na-delbäume wird durch Probleme erschwert. Im Bereich 1 der Abbildung 24 befinden sich junge Fichten und Tannen in unmittelbarer Nachbarschaft. Die Bäume stehen jedoch so nahe zusammen, dass mehrere Bäume inklusive Zwischenbereiche in ein Segment fallen und sich die Bestände spektral nicht zu unterscheiden sind. Eine zweite Ansammlung von Tannen im Südwesten des Gebietes (Bereich 2) befindet sich auf einer Hangkante. Teil-weise stehen diese Bäume im Schatten und die Baumkronen von anderen Exemplaren sind so dicht von Laubbäumen umgeben, dass sie kaum lokalisiert werden können. Ungenaue Segmentierungen erschweren auch hier der Entnahme charakteristischer Spektralwerte. Aufgrund dieser Schwierigkeiten kann bei den Nadelbäumen ebenfalls keine weitere Un-terscheidung vorgenommen werden.
4.4.3 Klassifikationsergebnisse
Die Abtrennung des Nichtwaldes gelingt mit Hilfe der Vegetationshöhe sehr gut. Die Un-terscheidung von Laub- und Nadelwald gelingt ebenfalls mit gewissen Einschränkungen in beschatteten Gebieten. Die Differenzierung von weiteren Baumarten konnte nicht durchge-führt werden, die Klassifikationsversuche auf der Versuchsfläche ergaben keine brauchba-ren Resultate. Das Abtrennen von Lärchen und Totholz ist möglich, wurde jedoch in keiner Klassifikation umgesetzt

Verifikation der Klassifikationsresultate
29
5 Verifikation der Klassifikationsresultate Für die Verifikation der Waldklassifikationen werden drei verschiedene Datensätze ver-wendet. Dabei handelt es sich um die Waldbestandesaufnahme von 2001, die Versuchsflä-che Birriboden der WSL aus dem Jahre 2000 und die Waldklassifikation von Christine Füllemann von 2007. Die Vorgehensweise und Auswertung wird in den folgenden Kapi-teln erläutert. Die Auswertung erfolgt anhand einiger statistischer Masse, welche zu Be-ginn in Kap. 5.1 besprochen werden.
5.1 Definition der Genauigkeitsmasse
Die Ausführungen in diesem Kapitel beruhen weitgehend auf Kellenberger (1996: 196-201). Um die räumliche und inhaltliche Genauigkeit einer Klassifikation abschätzen zu können, wird ein Pixel-zu-Pixel-Vergleich mit den Referenzdaten durchgeführt. Eine Möglichkeit zur Darstellung der Ergebnisse besteht im Erstellen einer Fehlermatrix, in welcher die Verhältnisse der Falschklassierungen ersichtlich werden. Die richtig klassierten Pixel der Klassifikation befinden sich in der von rechts oben nach links unten verlaufenden Diagonale der Fehlermatrix (Abbildung 25). Bei dem Pixel in den restlichen Feldern handelt es sich um Klassierungsfehler, welche nach ‚Fehler 1. Art’ und ‚Fehler 2. Art’ unterschieden werden. - Fehler 1. Art (commission error): Alle irrtümlich einer anderen Klasse zugewiesenen
Elemente. - Fehler 2. Art (omission error): Alle von ihrer Klasse nicht erkannten Bildelemente.
Bodenreferenz
Klasse 1 2 …
1 richtig
klassierte Pixel
2 commission
error; Fehler 1. Art
Kla
ssif
ikat
ion
… omission
error; Fehler 2. Art
Abbildung 25 Beispiel einer Fehlermatrix mit Fehler 1. und 2. Art (Kellenberger, 1996: 197; abgeändert)

Verifikation der Klassifikationsresultate
30
5.1.1.1 Overall Accuracy Oft wird für die Beurteilung der Gesamtgenauigkeit das Mass der Gesamtgenauigkeit ver-wendet. Dabei wird die Summe aller richtig klassierten Pixel (Diagonale in der Fehlermat-rix) durch die Gesamtpixelanzahl dividiert.
100⋅=Pixelalle
PixelrklassierterichtigSummeAccuracyOverall [3]
Die Fehler 1. Art und 2. Art werden nicht berücksichtigt, und es kann zu zufälligen Über-einstimmungen kommen.
5.1.1.2 Producer’s Accuracy Der Hersteller der Karte ist daran interessiert, wie gut eine Objektklasse i klassiert werden kann bzw. wie genau sie der Bodenreferenz entspricht.
100)(
)(' ⋅=hGroundtrutimbKlassederPixelAnzahl
bKlassederPixelklassierterichtigAccuracysroducerP [4]
Fehler 1. Art werden nicht berücksichtigt.
5.1.1.3 User’s Accuracy
Der Kartenbenutzer möchte hingegen wissen, wie zuverlässig die Klassifikation ist und mit welcher Wahrscheinlichkeit ein als Klasse i ausgewiesenes Pixel auch in Wirklichkeit die-ser Klasse entspricht.
100)(
)(' ⋅=tionKlassifikaderinbKlassederPixelAnzahl
bKlassederPixelklassierterichtigAccuracysUser [5]
Fehler 2. Art werden nicht berücksichtigt.
5.1.1.4 Kappa Koeffizient
Für die Beurteilung von Klassifikationsresultaten hat sich der Kappa Koeffizient bewährt, da er die Zufallsübereinstimmung eliminiert und durch den maximalen Wert der Zufalls-übereinstimmung normalisiert.
ngreinstimmuZufallsübengreinstimmuZufallsübeuigkeitGesamtgenatKoeffizienKappa
−−
=1
[6]
Der Kappa Koeffizient besitzt sehr wünschenswerte Eigenschaften. Eine vollständige Übereinstimmung wird mit dem Wert 1 ausgedrückt. Den Wert 0 erhält er, wenn die beo-bachtete Übereinstimmung auch per Zufall entstanden sein könnte. Die Kappa-Statistik ist bewiesenermassen ein nützlichliches Mass für den direkten Ver-gleich von globalen Vegetationskarten. Kappa-Werte für einzelne Vegetationszonen bild-
Verifikation der Klassifikationsresultate
31
ten deutliche Unterschiede und Gemeinsamkeiten zwischen diesen Karten. (Monserud und Leemans, 1992: 290) Eine nützliche Einteilung zur Beurteilung von Kappa-Werten bieten Landis and Koch (1997) (In: Monserud und Leemans, 1992: 285) an.
5.2 Wald/Nichtwald-Klassifikation
Für die Beurteilung der Genauigkeit der Unterscheidung von Wald und Nichtwald werden Waldfläche der VECTOR25-Daten von Swisstopo (Kap. 2.2.2.3) und die kantonalen Waldflächen 1:5’000 herangezogen. Die verwendeten VECTOR25-Daten beinhalten die Primärflächen als Attribute von Poly-gonen. Die Attribute in Tabelle 5 wurden mit Ausnahme von ‚Wald offen’, welches im Untersuchungsgebiet auf kein Polygon zutrifft, zusammengefasst. Der Datensatz des Kantons Zürich musste nicht zusammengefasst werden, die Polygone besitzen beim Attribut ‚GRUEN05’ eine Wald/Nichtwald-Codierung.
Tabelle 4 Grad der Übereinstimmung aufgrund von Kappa-Werten nach Landis und Koch (1977)
Degree of agreement Range
No 0.00 - 0.05
Very Poor 0.05 – 0.20
Poor 0.20 – 0.40
Fair 0.40 – 0.55
Good 0.55 – 0.70
Very Good 0.70 – 0.85
Excellent 0.85 – 0.99
Perfect 0.99 – 1.00
Tabelle 5 Attribute der VECTOR-25-Primärflächen, welche zur Bodenreferenz zählen
Attribut Bezeichnung
Z_BaumS Baumschule
Z_ObstAn Obstanlage
Z_Wald Wald
Z_WaldOF Wald offen*
Z_SumWa Sumpf im Wald
* im Datensatz nicht vorhanden

Verifikation der Klassifikationsresultate
32
5.2.1 Nachbearbeitung der Wald/Nichtwald-Klassifikation
Wenn eine Verifikation mit einer Bodenreferenz durchgeführt wird, ist es wichtig, die Her-kunft und Entstehung derselben zu kennen. Unabhängig vom betriebenen Aufwand handelt es sich immer nur um eine Annäherung an die Wirklichkeit, die dementsprechend fehler-behaftet ist. Die Aktualität spielt hierbei ebenfalls eine wichtige Rolle. Bei einem Ver-gleich mit der Klassifikation kann sich diese Ungenauigkeit je nach Ausmass und Form auf die Genauigkeitswerte auswirken. Aus diesen Gründen wird der früher übliche Begriff des ‚ground truth’immer weniger gebraucht. Tilton (1992: 1401) meint, dass man mit dem Ausdruck ‚Bodenreferenz’ eine semantische Problematik vermeiden kann. Wenn als Bei-spiel die Bodenreferenz mit Daten anderer Herkunft verbessert werden möchten, wird die Aussage vermieden, es werde die Wahrheit bzw. Wirklichkeit (truth) verändert oder ver-bessert. Die VECTOR25-Daten und die Waldfläche 1:5'000 sind beides Datensätze, die ihren Ur-sprung in Karten haben. Diese werden bei der Erstellung aus Gründen der Lesbarkeit und Verständlichkeit generalisiert und eine wirklichkeitsgetreue und vollständige Wiedergabe ist nicht mehr nötig. So werden in den VECTOR25-Daten Einzelbäume und kleinere Baumgruppen nicht als Waldfläche aufgeführt. Sie werden entweder gar nicht aufgenom-men oder separat als Einzelsignaturen abgebildet. Diese einzelnen Bäume werden vom Sensor trotzdem detektiert und in der Klassifikation der Klasse Wald zugeschrieben. Um diese vom Sensor gegenüber der Bodenreferenz ‚zu viel’ klassierten Einzelpixel bzw. kleineren Pixelgruppen der Klasse Nichtwald zuzuordnen, wurde ein Algorithmus (SIEVE) der Software Geomatica verwendet. Das Argument für die Elimination bildet die Anzahl Pixel mit gleichem Wert, welche di-rekten Kontakt miteinander haben, d.h., wenn sie horizontal oder vertikal zueinander lie-gen, sie also mit einer Seite aneinander grenzen. Als Grenzwert wurden 50x50 Pixel fest-gelegt, was einer realen Fläche von 156.25 m2 entspricht. Die Mindestbreite von 25 m wur-de aufgrund der Definition des LFI (Kap. 2.3.2) festgelegt, da Swisstopo den Wald ohne Minimalfläche angibt (Kap. 2.3.1). Pixelgruppen mit geringerer Ausdehnung werden dem grössten Nachbarn (Nichtwald) angerechnet. Um zu verhindern, dass auch Nichtwaldpixel eliminiert werden, wurde der Wald von der Bedingung ausgeschlossen.
Durch den Einsatz des Algorithmus werden insgesamt 13’999'990 Waldpixel der Klasse Nichtwald zugeschrieben. Dies entspricht 1.5% der ursprünglichen Waldklasse.
Abbildung 26 Beispiel des Fusions-Algorithmus SIEVE mit einem Grenzwert von 5 Pixel
SIEVE
Grenzwert: 5 Pixel blockiert: Weiss

Verifikation der Klassifikationsresultate
33
5.2.2 Spezielle Betrachtung der Waldränder
Für die spezielle Betrachtung der Waldränder wird ein zusätzlicher Vergleich angestellt. Dazu wird ein beidseitiger Buffer von 10 Meter entlang der Waldränder der Klassifikation erstellt. Die restliche Fläche wird ausmaskiert und der Vergleich nur über den unmittelba-ren Waldrand gezogen. Der Buffer wird anhand der bearbeiteten Klassifikation erstellt und ebenfalls mit derselben verglichen. Die Vergleichsfläche verringert sich gegenüber des gesamten Untersuchungsgebietes auf diese Weise um mehr als 78%.
5.2.3 Resultate ohne Nachbearbeitung
Abbildung 27 Waldrandbuffer (rosa) von 20 Meter Breite, über RGB (links) und über die bearbeitete Waldklassifikation (rechts) gelegt
Tabelle 6 Resultat der unbearbeiteten Wald/Nichtwald-Klassifikation mittels den VECTOR25-Daten
Wald Nichtwald
Klassengrösse (Bodenreferenz) 84'467'155 76'366'625
User's Accuracy 89.0 % 95.2 %
Producer's Accuracy 96.0 % 86.9 %
Kappa Koeffizient 0.833
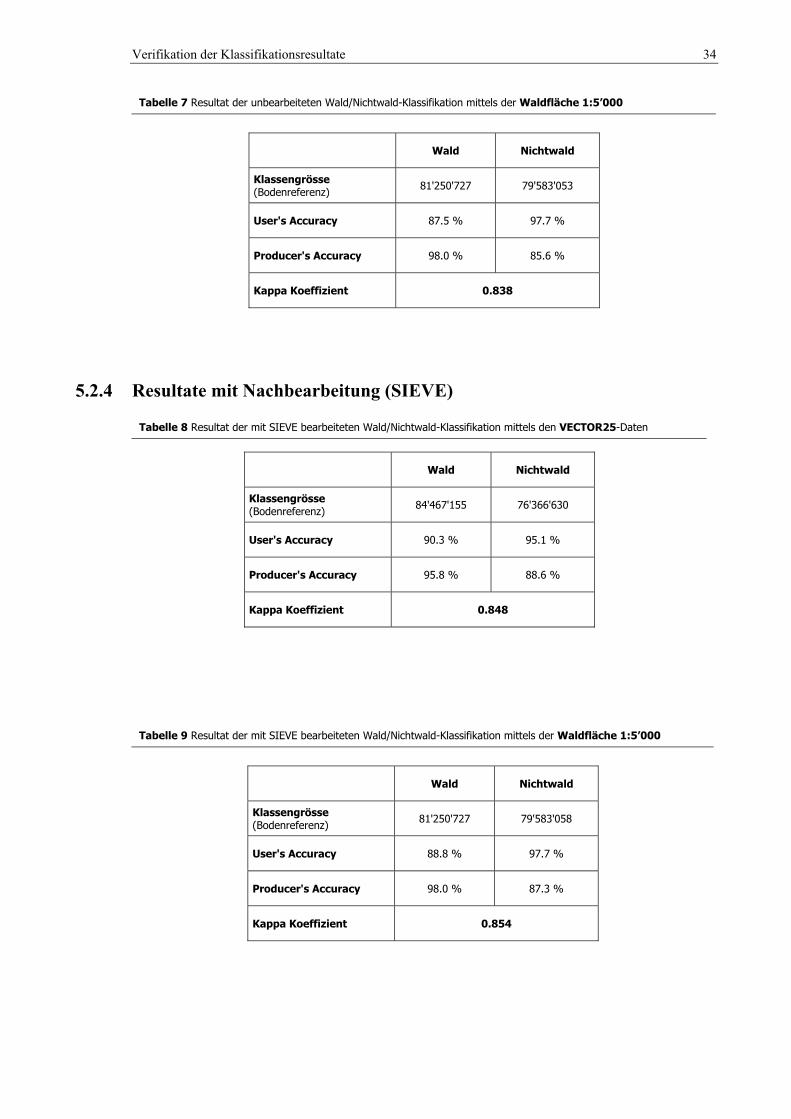
Verifikation der Klassifikationsresultate
34
5.2.4 Resultate mit Nachbearbeitung (SIEVE)
Tabelle 8 Resultat der mit SIEVE bearbeiteten Wald/Nichtwald-Klassifikation mittels den VECTOR25-Daten
Wald Nichtwald
Klassengrösse (Bodenreferenz) 84'467'155 76'366'630
User's Accuracy 90.3 % 95.1 %
Producer's Accuracy 95.8 % 88.6 %
Kappa Koeffizient 0.848
Tabelle 7 Resultat der unbearbeiteten Wald/Nichtwald-Klassifikation mittels der Waldfläche 1:5’000
Wald Nichtwald
Klassengrösse (Bodenreferenz) 81'250'727 79'583'053
User's Accuracy 87.5 % 97.7 %
Producer's Accuracy 98.0 % 85.6 %
Kappa Koeffizient 0.838
Tabelle 9 Resultat der mit SIEVE bearbeiteten Wald/Nichtwald-Klassifikation mittels der Waldfläche 1:5’000
Wald Nichtwald
Klassengrösse (Bodenreferenz) 81'250'727 79'583'058
User's Accuracy 88.8 % 97.7 %
Producer's Accuracy 98.0 % 87.3 %
Kappa Koeffizient 0.854
Verifikation der Klassifikationsresultate
35
5.2.5 Resultate mit einem Waldrand-Buffer von 20 Meter
5.3 Laubwald/Nadelwald-Klassifikation
5.3.1 Perimeter
Für die Verifikation der Klassifikation mit Differenzierung von Laub- und Nadelwald wird die Walbestandesaufnahme von 2001 herangezogen. Die Daten zur Waldzusammenset-zung umfassen jedoch lediglich die ‚vorläufige’ Parkfläche, weshalb die Klassifikation auf den Perimeter der Aufnahme reduziert wird.
5.3.2 Aufbereitung der Verifizierungsdaten
Da die Informationen über die Waldstruktur in der Waldbestandesaufnahme im Gegensatz zur Klassifikation nicht pixelweise, sondern in eigenen Polygonen zusammengefasst ist, müssen diese Daten zuerst aufbereitet werden. Das Vorgehen entspricht aus Gründen der Vergleichbarkeit demjenigen von Füllemann (2007: 40-42).
Tabelle 10 Resultat der Wald/Nichtwald-Klassifikation im Waldrand-Buffer von 20 m mittels den VECTOR25-Daten
Wald Nichtwald
Klassengrösse (Bodenreferenz) 11'543'727 24'730'564
User's Accuracy 53.0 % 87.3 %
Producer's Accuracy 79.0 % 67.3 %
Kappa Koeffizient 0.410
Tabelle 11 Resultat der Wald/Nichtwald-Klassifikation im Waldrand-Buffer von 20 m mittels der Waldfläche 1:5’000
Wald Nichtwald
Klassengrösse (Bodenreferenz) 9'643'782 26'630'509
User's Accuracy 47.4 % 92.1 %
Producer's Accuracy 84.4 % 66.0 %
Kappa Koeffizient 0.404
Verifikation der Klassifikationsresultate
36
5.3.3 Resultate der Waldbestandesaufnahme 2001
Die Polygone enthalten die Deckungsgrade der Bäume und den Anteil der einzelnen Arten an diesem Deckungsgrad. Daraus wird der absolute Deckungsgrad bzw. Flächenanteil ei-ner Art oder Artengruppe (Nadelbäume und Laubbäume) berechnet. Die Klasse Nichtwald wird in der Aufnahme nicht speziell aufgeführt, ergibt sich jedoch aus dem Komplementär zu den Deckungsgraden der Bäume. Der Flächenanteil wird mit den Klassen der Klassifi-kation verglichen, aus welcher die Werte mittels zonaler Statistik extrahiert werden. Die absolute Differenz einer Klasse (z.B. Laubbaum) in einem Polygon zur Bodenreferenz wird mit der Anzahl klassierten Pixel dieser Klasse (Laubbaum) in diesem Polygon multip-liziert. Auf diese Weise wird der Einfluss der Fehlklassierung nach Anzahl Pixel in einem Polygon gewichtet. Dies soll bewirken, dass Polygone mit wenigen Pixeln einer Klasse einen kleineren Einfluss auf die gesamte Berechnung ausüben als jene Polygone mit vielen Pixeln dieser Klasse. Für die Auswertung werden die Fehlpixel aller Klassen berechnet und ebenfalls gewichtet. Das Resultat ist der Prozentsatz der fehlklassierten Pixel im Untersuchungsgebiet. Er be-trägt 23.2%. Die Overall Accuracy, oder auch Gesamtgenauigkeit, ist das einfachste deskriptive Mass, welches als prozentualer Anteil korrekt klassierter Pixel definiert ist (Kap. 5.1.1.1). Aus der Overall Accuracy und den Fehlpixeln zusammen ergibt sich daher ein Wert von 100%.
Da Füllemann (2007) ebenfalls die Waldbestandesaufnahme von 2001 zur Verifikation benutzte und in dieser Arbeit auf dieselbe Weise vorgegangen wird, können die Resultate miteinander verglichen werden.
Tabelle 12 Resultat der Verifikation mittels der Waldbestandesaufnahme 2001
Klasse Laubbaum Nadelbaum Nichtwald Schatten Unklassiert
Fehlpixel 20 % 31 % 22 % 2 % 4 %
Klassierte Pixel 28'992’517 11'598’522 1'619’812 159’045 209’630
Fehlpixel über die ge-samte Klassifikation 23.2 %
Overall Accuracy 76.8 %
Tabelle 13 Resultate von Christine Füllemann 2007
Klasse Laubbaum Nadelbaum Nichtwald Lärche Unklassiert
Fehlpixel 15 % 35 % 22 % 3.5 % 0.4 %
Klassierte Pixel 24'572’875 15'752’070 1’888’686 352’976 1’285
Fehlpixel über die ge-samte Klassifikation 22.8 %
Overall Accuracy 77.2 %

Verifikation der Klassifikationsresultate
37
Der Vergleich ist erstaunlich, da der Anteil der Fehlpixel bzw. die Overall Accuracy sich nur um 0.4 Prozentpunkte voneinander unterscheiden und die Klassifikationsgenauigkeit als identisch betrachtet werden kann. Unterschiede lassen sich jedoch in der Unterschei-dung von Laub- und Nadelbäumen ausmachen. In dieser Klassifikation der vorliegenden Arbeit sind die Nadelbäume mit weniger Fehlpixel klassiert worden als bei Füllemann (2007), dagegen die Laubbäume mit mehr. Der Nichtwald wurde wieder mit gleicher Ge-nauigkeit klassiert.

Diskussion
38
6 Diskussion
6.1 Beurteilung der Verifikationsergebnisse
6.1.1 VECTOR25-Daten und kantonale Waldfläche 1:5’000
Die Genauigkeitswerte für die Verifikationen mit der VECTOR25- und der kantonalen 1:5'000 Waldfläche sind sich sehr ähnlich. Der Kappa Koeffizient liegt bei 0.83 und 0.84. Dieser Wert steht für ein sehr gutes Klassifikationsresultat (Kap. 5.1.1.4). Die Werte liegen ausserdem nur knapp unterhalb der Grenze zu einem ‚exzellenten’ Ergebnis (0.85). Werden die User’s und Producer’s Accuracys betrachtet, zeigt sich, dass die Producer’s Accuracy der Klasse Wald bei 97% sprich um 7% bzw. 9.5% höher liegt als die User’s Accuracy. Die Klasse Nichtwald zeigt hingegen genau das gegenteilige Bild. Die Produ-cer’s Accuracy liegt bei etwa 86% und hiermit gut 10% unter der User’s Accuracy. An-hand dieser Zahlen lässt sich ablesen, dass bis auf etwa 3% der gesamten Waldfläche rich-tig klassiert wurde. Dabei ist die Waldklasse gegenüber der beiden Bodenreferenzen mehr klassiert worden, weshalb die User’s Accuracy der Waldklasse leidet. Jeder klassierte Waldpixel entspricht dennoch zu fast 90% der Bodenreferenz. Wird das Klassifikationsresultat wie in Kapitel 5.2.1 nachbearbeitet, steigern sich die Kap-pa Koeffizienten zwar nur geringfügig, jedoch wird der Grenzwert 0.85, zumindest gegen-über einer Bodenreferenz, überschritten. Das Eliminieren von Waldklasspixeln wirkt sich direkt auf die User’s Accuracy der Wald-klasse und die Producer’s Accuracy des Nichtwaldes aus. Sie steigen um ca. 1-2%. Mit Hilfe eines Buffers von 20 Metern Breite entlang des Waldrandes der bearbeiteten Klassifikation wurde für beide Bodenreferenzen erneut eine Error-Matrix erstellt. Die Flä-che beträgt noch 23% des ganzen Untersuchungsgebietes. Die Werte sind bei dieser Veri-fikation im Vergleich sehr tief. Nur noch gut jeder zweite als Wald klassierte Pixel gehört auch in der Bodenreferenz zur Waldklasse. Es werden demnach fast 50% zu viele Pixel als Wald klassiert. Der Kappa Koeffizient fällt mit 0.41 nur noch sehr tief aus, und kann gera-de noch als ‚fair’ bezeichnet werden. Dieses Resultat veranlasste dazu, die Bodenreferenzen im Waldrandbereich genauer zu betrachten. In Abbildung 28 ist im linken Bild ein Waldrandabschnitt im Untersuchungs-gebiet zu sehen, darüber wurde die VECTOR25-Waldfläche gelagert. Es ist deutlich er-sichtlich, dass in diesem Bereich ein etwa 10 Meter breiter Streifen Wald in der Bodenrefe-renz fehlt. Im rechten Bild ist zusätzlich die Waldfläche der Klassifikation dargestellt. Der Wechsel von Wald zu Nichtwald (nicht eingefärbter Bereich) verläuft beinahe perfekt auf der von Auge wahrgenommenen Waldgrenze. Diese Charakteristik lässt sich in vielen Be-reichen des Untersuchungsgebietes feststellen.

Diskussion
39
Die Anzahl der fehlklassierten Pixel unterhalb des Waldrandbuffers beträgt bei beiden Bo-denreferenzen um 10.5 Millionen Pixel. Die Fehlpixelanzahl über das gesamte Untersu-chungsgebiet beträgt 11.7 und 12.2 Millionen. Demnach fallen 90% bzw. 87% der Fehlpi-xel in den Bereich der Waldränder! Werden die beschriebenen Ungenauigkeiten der Bodenreferenzen berücksichtigt, kann davon ausgegangen werden, dass der Kappa Koeffizient eindeutig höher einzuschätzen ist. Es kann deshalb von einer ‚exzellenten’ Klassifikation gesprochen werden.
6.1.2 Waldbestandesaufnahme 2001
Die Overall Accuracy der Klassifikation, verifiziert mit der Waldbestandesaufnahme 2001, beträgt 77%. Dies entspricht einem Fehlpixelanteil über den gesamten Perimeter von 23%. Dieser Anteil ist nicht bei allen Klassen gleich stark ausgeprägt. Die Klasse Nadelbaum wurde mit 31% Fehlpixeln deutlich schlechter klassiert als die Laubbäume mit 20% oder der Nichtwald mit 22% falsch klassiertern Pixeln. Werden die absoluten Flächen bezüglich der Referenz betrachtet, lässt sich feststellen, dass die Baumklassen zu gross sind und die Nichtwaldklasse deutlich zu klein. Es wurden etwa 18% zu viele Laubbäume und mehr als 100% zu viele Nadelbäume klassiert, die Fläche des klassierten Nichtwaldes beträgt nur 13% der Referenzklasse. Die Nadelbäume wurden in fast allen Polygonen zu viel klassiert, bei den Laubbäumen ist das Verhältnis ausgegli-chener, doch wurden insgesamt ebenfalls zu viele Objekte dieser Klasse zugewiesen. Die unklassierten und die als Schatten klassierten Objekte umfassen nur 0.8% der Fläche der Waldbestandesaufnahme und üben daher einen vernachlässigbaren Einfluss auf das Gesamtresultat aus. In Abbildung 29 werden die Bereiche, welche besonders von Fehlklassierungen betroffen sind, dargestellt. Sie zeigt die prozentuale Differenz zwischen der Bodenreferenz und der Klassifikation pro Polygon. Grüne Bereiche entsprechen Polygonen mit einer sehr gerin-gen Abweichung zur Bodenreferenz, gelb eingefärbte Polygone haben einen maximalen Fehler von 25%. Bereiche mit grossen Unterschieden sind orange und die Zonen mit den grössten Abweichungen rot eingefärbt. In der Mitte befindet sich die Laubbaumdifferenz, rechts die Nadelbaumdifferenz. Die Bereiche mit den grössten Differenzen sind markiert
Abbildung 28 Waldrandausschnitt als Falschfarbendarstellung; links die Bodenreferenz VECTOR25, rechts zusätzlich in dunkelgrün die Klassifikation
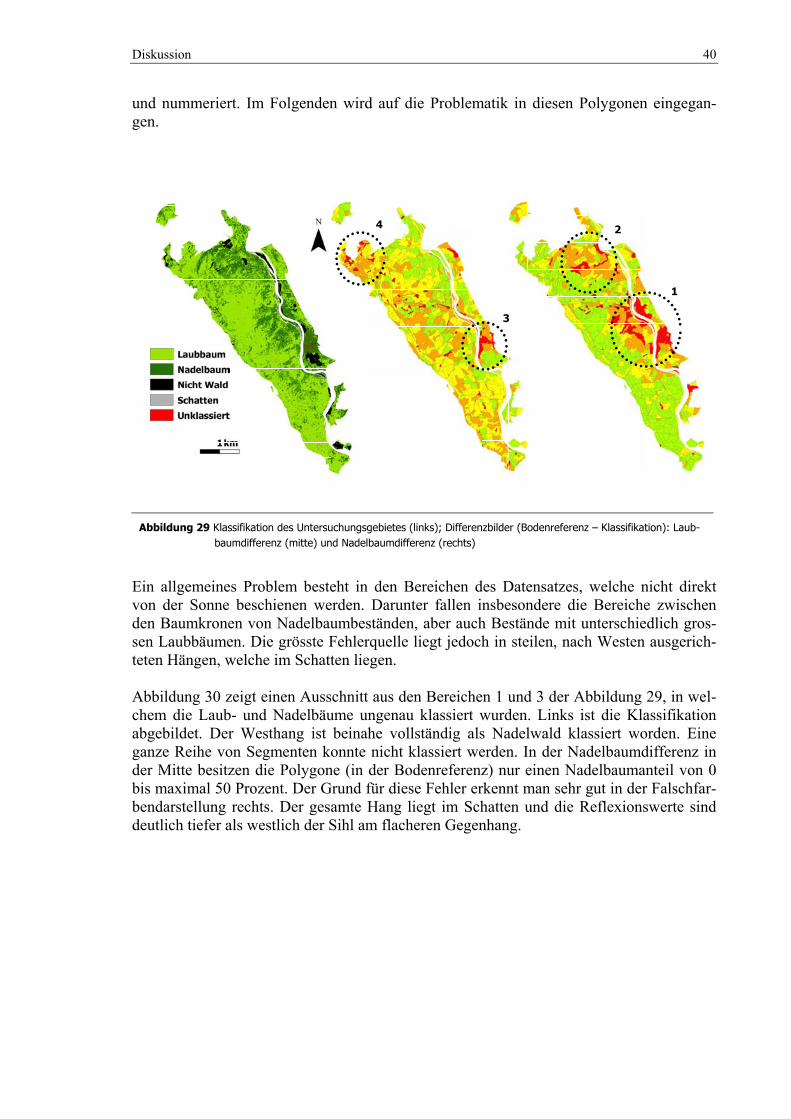
Diskussion
40
und nummeriert. Im Folgenden wird auf die Problematik in diesen Polygonen eingegan-gen.
Ein allgemeines Problem besteht in den Bereichen des Datensatzes, welche nicht direkt von der Sonne beschienen werden. Darunter fallen insbesondere die Bereiche zwischen den Baumkronen von Nadelbaumbeständen, aber auch Bestände mit unterschiedlich gros-sen Laubbäumen. Die grösste Fehlerquelle liegt jedoch in steilen, nach Westen ausgerich-teten Hängen, welche im Schatten liegen. Abbildung 30 zeigt einen Ausschnitt aus den Bereichen 1 und 3 der Abbildung 29, in wel-chem die Laub- und Nadelbäume ungenau klassiert wurden. Links ist die Klassifikation abgebildet. Der Westhang ist beinahe vollständig als Nadelwald klassiert worden. Eine ganze Reihe von Segmenten konnte nicht klassiert werden. In der Nadelbaumdifferenz in der Mitte besitzen die Polygone (in der Bodenreferenz) nur einen Nadelbaumanteil von 0 bis maximal 50 Prozent. Der Grund für diese Fehler erkennt man sehr gut in der Falschfar-bendarstellung rechts. Der gesamte Hang liegt im Schatten und die Reflexionswerte sind deutlich tiefer als westlich der Sihl am flacheren Gegenhang.
Abbildung 29 Klassifikation des Untersuchungsgebietes (links); Differenzbilder (Bodenreferenz – Klassifikation): Laub-baumdifferenz (mitte) und Nadelbaumdifferenz (rechts)
1
2 4
3

Diskussion
41
In Abbildung 31 wird ein Polygon dargestellt, in welchem die Nadelbäume in der Klassifi-kation zu 78% vertreten sind, in der Bodenreferenz jedoch nur einen Anteil von 21% der Fläche bedecken. Die Bäume bilden in diesem Ausschnitt keine ‚ebene’ Baumkronende-cke, es handelt sich um einen stark strukturierten Bestand mit jungen und alten Bäumen. Daraus resultieren vermehrt Schattenflächen, welche eine Unterscheidung erschweren und der Klasse der Nadelbäume zugeschrieben werden.
Abbildung 30 Ausschnitt aus dem Bereich 1 & 3 der Klassifikation (links); Nadelbaumdifferenz (mitte) und Falschfar-
bendarstellung (rechts)
Abbildung 31 Ausschnitt aus dem Bereich 2 der Klassifikation (links); Nadelbaumdifferenz (mitte) und Falschfarbendar-stellung (rechts)

Diskussion
42
Das nächste Beispiel in Abbildung 32 (Bereich 4 in Abbildung 29) zeigt nun eine Situati-on, in welcher zu wenig Nadelbäume und zuviel Laubbäume klassiert wurden. Von Auge ist rechts in der Falschfarbendarstellung klar ersichtlich, dass die Polygone den Grenzen der Monokulteren folgen. In der Klassifikation werden nur die Spitzen der Nadelbäume erkannt und die Zwischenbereiche den Laubbäumen zugeschrieben.
Der Vergleich mit der Waldbestandesaufnahme 2001 zeigt deutlich die Gebiete an, in wel-chen die Klassifikation fehlerbehaftet ist. Anhand der Bildbeispiele konnten die Charakte-ristiken dieser ‚Problemzonen’ dargestellt werden. Für eine Überarbeitung der Klassifika-tion wäre diese Lokalisierung der Schwierigkeiten sehr wertvoll. Es bedarf allerdings auch der Betrachtung der Entstehung und Genauigkeit dieser Bodenre-ferenz (Kap. 5.2.1, erster Abschnitt). Die Daten der Waldbestandesaufnahme wurden durch Beobachtungen vor Ort und Analyse von Luftbildern vorgenommen. Die Polygone besit-zen willkürliche Grenzen und folgen z.B. keinen natürlichen Änderungen in der Bestan-deszusammensetzung, was die Aussagekraft eines Vergleichs abschwächt. Der Deckungs-grad der Bäume beruht auf Schätzungen, welche in 10%-Schritten aufgenommen wurden. Schätzungen können personenbezogen sehr unterschiedlich ausfallen. Der Deckungsgrad der Bäume verfälscht die Genauigkeitswerte beim vorgenommenen Vergleich mit der Klassifikation. In Kapitel 6.1.1 wurde festgestellt, dass die Trennung von Wald und Nichtwald exzellent gelungen ist. Auf dem Gebiet der Waldbestandesaufnahme trennt die Klassifikation jedoch 7 Mal weniger Nichtwald ab als in der Bodenreferenz. Die-ser Flächenunterschied entspricht etwa 1.5 Mal der Nadelwaldklasse in der Referenz. Die kleinen Nichtwald-Flächen zwischen den einzelnen Bäumen werden in der Klassifikation nicht abgetrennt, da sie zu klein sind um ein eigenes Segment zu bilden. Es wäre nicht zweckmässig einzelne Pixel zwischen den Bäumen (in einer geschlossenen Waldfläche) als Nichtwald zu klassieren. Die Folge daraus ist, dass der Fehlpixelanteil aller Klassen zu hoch ausfällt. Eine Einschätzung der Ungenauigkeiten des Einflusses auf die Verifikations-resultate ist nur schwer möglich.
Abbildung 32 Ausschnitt aus dem Bereich 4 der Klassifikation (links); Laubbaumdifferenz (mitte) und Falschfarbendar-stellung (rechts)

Diskussion
43
6.1.3 Klassifikation von Füllemann 2007
Da die vorliegende Arbeit auf der Diplomarbeit von Füllemann (2007) aufbaut, ist es mehr als sinnvoll, die Klassifikationen zu vergleichen. Es wurde ebenfalls das Aufnahmesystem Falcon II verwendet mit den Laserscanner- und Zeilenscannerdaten mit der gleichen Auf-lösung. Der grösste Unterschied zu Füllemanns Arbeit besteht im Zeitpunkt der Datenauf-nahme. Die Aufnahmen wurden im April 2004 durchgeführt und die Laubbäume trugen zu dieser Zeit noch keine Blätter. Trotzdem konnten Laub- und Nadelbäume und sogar die Lärche klassiert werden. Der Vergleich der beiden Klassifikatione beruht auf der Annahme, dass sich die Waldflä-che und Waldzusammesetzung in der Zeit zwischen den Aufnahmezeitpunkten (2.67 Jah-re) nicht verändert hat. Es wird die unbearbeitete Klassifikation als Vergleich genommen. Die Verifikation der beiden Klassifikationen wurde im Kapitel 5.3.3 bereits kurz gegen-übergestellt. Dabei wurde festgestellt, dass der Fehlpixelanteil über die gesamte Klassifika-tion beider Arbeiten 23% beträgt. Die Grösse und Genauigkeit der einzelnen Klassen un-terscheidet sich jedoch teilweise. In der vorliegenden Arbeit werden 18% mehr Laubbäume und einen Fehlpixelanteil von 20% gegenüber von 15% ausgewiesen. Dagegen ist die Na-delbaumklasse um 26% kleiner, der Fehlpixelanteil mit 31% um 4% geringer. Der Nicht-wald wurde mit gleicher Genauigkeit abgetrennt, auch wenn die Klasse bei Füllemann um 14% grösser ist. Des Weiteren unterschied Füllemann die Lärche im gesamten Untersu-chungsgebiet. In dieser Arbeit wird diese Unterscheidung nicht gemacht.
6.1.3.1 Vergleich der Waldflächen Die beiden Resultate haben folglich zwischen den Klassen einige Differenzen. Werden nur die Wald- und Nichtwaldflächen über das ganzes Untersuchungsgebiet verglichen, zeigt sich ein reltaiv stabiles Verhältnis zwischen den beiden Klassifikationen. Insgesamt klas-siert Füllemann 3% mehr Waldpixel. Beide Klassen vollzogen jedoch eine Änderung von etwas 7% ihrer Fläche. Der Einbezug eines Levels mit grösseren Objekten (Level 50) zur Klassifikation der Häu-ser macht sich bemerkbar, im Vergleich zu Füllemann wird weit weniger Waldfläche kar-tiert (gelbe Flächen in Abbildung 33).

Diskussion
44
Ebenfalls weniger Wald wird in gewissen Waldrandbereichen klassiert. Die Falschfarben-darstellung des Datensatzes von 2004 (Abbildung 34, unten links) macht die Unterschiede zum Datensatz von 2006 (oben links) klar deutlich. Der Waldrand lässt sich nur schwer von Auge festlegen. Im Differenzbild oben rechts ist ersichtlich, dass der Waldrand mit dem Datensatz aus dem Sommer 2006 eine glattere Linie bildet.
Abbildung 33 Ausschnitt von Langnau am Albis; Falschfarbendarstellung (links) und Veränderung der Waldfläche zur
Klassifikation von Füllemann (2007) (rechts)
Abbildung 34 Waldrandausschnitt; Falschfarbendarstellung`06 (oben links), Differenz der Waldfläche zur Klassifikation
von Füllemann (2007) (oben rechts) und Falschfarbendarstellung des Datensatzes vom April 2004

Diskussion
45
Eine Verschiebung von Nichtwald zu Wald (Abbildung 35, rot) tritt vor allem in einem steilen, nach Südwesten orientierten Abhang und entlang der Sihl auf. Für die Fehlklassie-rung von Füllemann ist der Untergrund verantwortlich. Im Abhang befinden sich Felsen sowie vegetationslose Erde und an der Sihl zum Teil das Flussbett unter den (Laub-) Bäu-men. Die spektrale Signatur dieser Flächen gleicht Strassen und Häusern, was zu Falsch-klassierungen führt.
Die identischen Genauigkeitswerte aus dem Vergleich mit der Waldbestandesaufnahme 2001 verleiten zur Annahme, dass in beiden Klassifikationen die Waldfläche mit ähnlicher Genauigkeit dargestellt wird. Die oben angeführten Beispiele zeigen jedoch auf, dass die Klassifikation von Füllemann im Vergleich zur erneut durchgeführten Klassifikation ge-wisse Schwächen aufweist. In Siedlungsgebieten kommt es in dieser Arbeit zu weit weniger Fehlkassifikationen, da die Gebäude im Vorfeld gut abgetrennt werden konnten. Im Waldrandbereich wird eine ruhigere Grenze gebildet, da dank den LIDAR-Daten eine Abgrenzung des Nichtwaldes sehr simpel und zuverlässig möglich ist. Ebenfalls ist dadurch die Klassifikation unabhän-gig vom Walduntergrund.
6.1.3.2 Vergleich der Laub-/Nadelbaumklassifikationen
Den Statistiken zufolge sind die Laub- und Nadelbaumklassen der beiden Klassifikationen unterschiedlich verteilt. Die Laubbaumklasse ist im Vergleich zu Füllemann um 17% grös-sere und die Nadelbaumklasse um 27% kleiner. Von Füllemanns Klassifikation wechseln ingesamt 17% der Laubbäume zu den Nadelbäumen und 55% der Nadelbäume zu den Laubbäumen. Die Klasse der Nadelbäume ist in der erstellten Klassifikation nicht nur stark verkleinert, sondern auch räumlich verschoben. Ein Beispiel dieser räumlichen Verschiebung ist in Abbildung 36 dargestellt. Es handelt sich um einen praktisch identischen Ausschnitt aus Abbildung 30. In diesem Abschnitt
Abbildung 35 Ausschnitt eines steilen Abhanges in Adliswil; Falschfarbendarstellung (links) und Veränderung von der
Klassifikation von Füllemann (2007) zur Laub-/Nadelbaumklassifikation (rechts)

Diskussion
46
sind die Laubbäume viel zu wenig klassiert worden. Im Vergleich dazu weist die Klassifi-kation von Füllemann wesentlich mehr Laubbäume (rot) auf.
Unterhalb des Aussichtsturms Hochwacht (Abbildung 37) ist die Situation wieder umge-kehrt. Füllemann klassiert hier im Vergleich zur Laub-/Nadelbaumklassifikation viel mehr Nadelbäume (blau).
Abbildung 36 Westlich orientierter Talhang als Falschfarbendarstellung (links) und die Veränderung der Klassifikation
von Füllemann (2007) zur Laub-/Nadelbaumklassifikation (rechts)

Diskussion
47
Die Übervertretung der Nadelbäume in Füllemanns Klassifikation könnten unter anderem darauf zurückzuführen sein, dass nicht nur die Nadelbäume der Oberschicht klassiert wur-den. Ohne die Blätter der Laubbäume sind auch die kleineren Nadelbäume sichtbar, welche normalerweise verdeckt werden. In der Klassifikation dieser Arbeit bereiten vor allem die unterschiedlichen Beleuchtungs-verhältnisse Schwierigkeiten und es scheint, dass diese in der Klassifikation von Fülle-mann weniger relevant sind bzw. die Resultate weniger stark beeinflussen. Die Unterschiede zwischen den beiden Klassifikationen sind trotz der praktisch identischen Genauigkeitswerte erstaunlich gross. Die Unterschiede detailliert zu analysieren ist ver-gleichsweise schwierig, da die Vergleiche zur Bodenreferenz nicht ohne Vorbehalte be-trachtet werden können. Die Differenz zwischen den Resultaten ist viel zu gross, um eine Aussage über mögliche Strukturveränderungen des Waldes machen zu können. Der zeitli-che Abstand zwischen den Aufnahmen ist mit 2.5 Jahren ohnehin zu kurz, um natürliche Veränderungen des Waldes detektieren zu können. Der Nachteil der Waldbestandesaufnahme 2001 als Bodenreferenz zu verwenden, liegt im Zusammenfassen der Daten in grössere Einheiten. Innerhalb der Polygone kann es zu Zu-fallsübereinstimmungen kommen, welche nicht erfasst werden können. Es fehlt die genaue räumliche Lokalisierung um aussagekräftige Analysen durchführen zu können. Die Versuchsfläche Birriboden stellt eine optimale Bodenreferenz dar. Jeder Baum ist mit einem Koordinatenpaar genau lokalisiert, inklusive der Angaben zur Schichtzugehörigkeit. Anhand eines solchen Datensatzes lassen sich die Fehlklassierungen genau charakterisie-
Abbildung 37 Waldausschnitt unterhalb des Aussichtturms Hochwacht; Falschfarbendarstellung (oben links) Verände-rung der Klassifikation von Füllemann (2007) zur Laub-/Nadelbaumklassifikation (oben rechts) und die Nadelbaumdifferenz zur Waldbestandesaufnahme 2001 (unten links)

Diskussion
48
ren. Voraussetzung dafür ist allerdings auch die Lagegenauigkeit der Baumkoordinaten. Ansonsten muss bei einer Verifikation mit Buffern gearbeitet werden, was den Informati-onsgehalt wiederum schmälert (Füllemann, 2007: 43). Der Nachteil dieser Art von Referenzdaten ist die mit sehr hohem Aufwand verbundene Aufnahme der Daten. Für das Erstellen einer möglichst nützlichen Verifikation ist diese Art eines Datensatzes eindeutig erste Wahl.
6.2 Schwierigkeiten und Lösungsansätze
Während des gesamten Arbeitsprozesses von der Segmentierung bis zur Klassifikation traten unterschiedliche Probleme auf. Diese Schwierigkeiten und mögliche Lösungsansätze werden in Kapitel 6.2 beschrieben.
6.2.1 Illuminationsunterschiede
6.2.1.1 Problematik
Aufgrund der Grösse des Datensatzes muss wie in Kapitel 4.4 das ganze Untersuchungs-gebiet in 29 einzelnen Kacheln klassiert werden. Die topographischen Verhältnisse im Un-tersuchungsgebiet führen zu einer grossen Variabilität der Illumination. Die nötigen An-passungen der Klassen bzw. der gesamten Class Hierarchy für die einzelnen Kacheln sind grösstenteils auf die unterschiedlichen Beleuchtungsverhältnisse zurückzuführen. In den meisten Fällen ist diese Problematik mit dem Erstellen spezifischer Klassen für die ent-sprechenden Illuminationsverhältnisse beizukommen. Der benötigte Aufwand darf aller-dings nicht unterschätzt werden. Im Speziellen steigt der Zeitbedarf je allgemeiner und robuster die Klassifikation zum Schluss sein sollte. Für eine Übertragung auf weitere Da-tensätze, z.B. für das Erstellen einer ‚Change Detection’, zahlt sich eine einfache Struktur aus, wenn nur wenige Parameter verändert werden müssen. In der vorliegenden Arbeit tritt jedoch das Problem auf, dass bestimmte Objekte in son-nenbeschienen Hängen dem spektralen Grundsignal der beschatteten Gebiete sehr ähnlich sind. Die Rede ist hierbei von den Nadelbäumen. Treten Nadelbaumbestände auf, bilden sie ein nicht annähernd so dichtes Kronendach wie dies bei den Laubbäumen der Fall ist (Abbildung 38, links). Deshalb sind Nadelbäume oft von einem dunklen Bereich umgeben, welcher im Schatten liegt. Diese Zwischenbereiche besitzen sehr ähnliche spektrale Eigen-schaften wie die meisten Schattenflächen (Abbildung 38, rechts). Sie sind deshalb in einer Klassifikation nur schwer voneinander zu trennen. Da die Bildobjekte in der Regel nicht nur die Nadelbaumkrone umfassen (siehe Kap. 6.2.2), überträgt sich die Problematik der spektralen Ähnlichkeit auf die Nadelbaumobjekte.
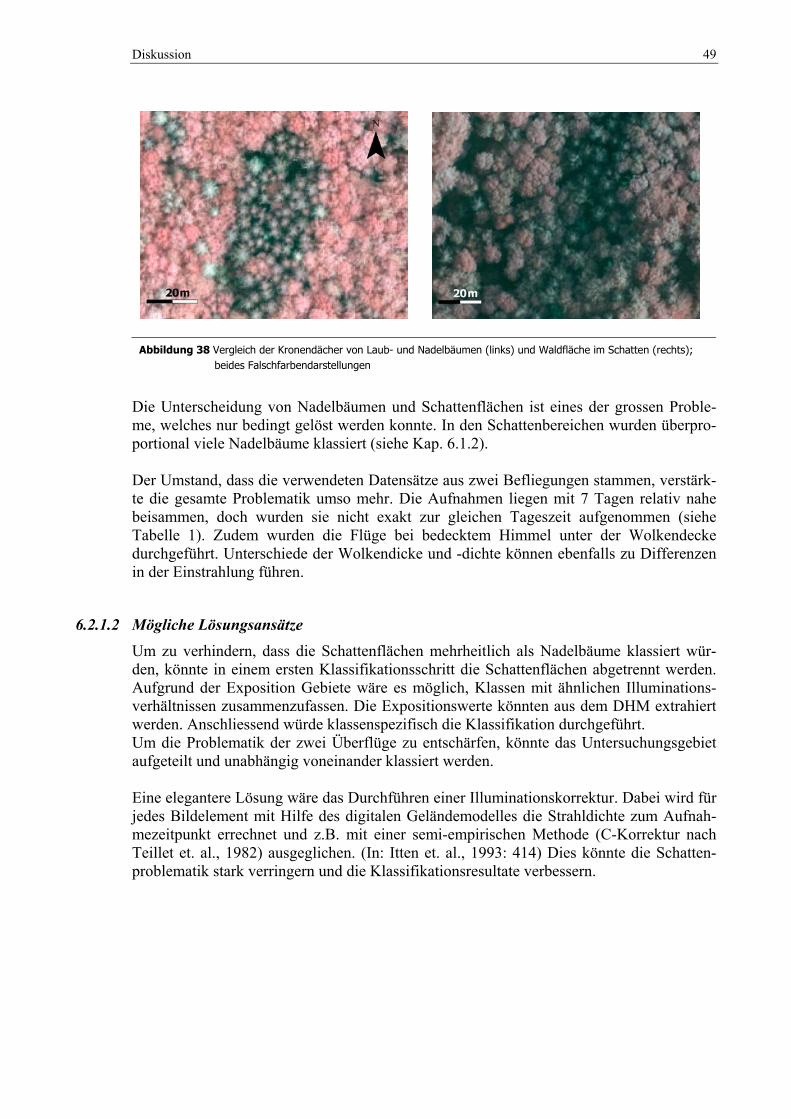
Diskussion
49
Die Unterscheidung von Nadelbäumen und Schattenflächen ist eines der grossen Proble-me, welches nur bedingt gelöst werden konnte. In den Schattenbereichen wurden überpro-portional viele Nadelbäume klassiert (siehe Kap. 6.1.2). Der Umstand, dass die verwendeten Datensätze aus zwei Befliegungen stammen, verstärk-te die gesamte Problematik umso mehr. Die Aufnahmen liegen mit 7 Tagen relativ nahe beisammen, doch wurden sie nicht exakt zur gleichen Tageszeit aufgenommen (siehe Tabelle 1). Zudem wurden die Flüge bei bedecktem Himmel unter der Wolkendecke durchgeführt. Unterschiede der Wolkendicke und -dichte können ebenfalls zu Differenzen in der Einstrahlung führen.
6.2.1.2 Mögliche Lösungsansätze Um zu verhindern, dass die Schattenflächen mehrheitlich als Nadelbäume klassiert wür-den, könnte in einem ersten Klassifikationsschritt die Schattenflächen abgetrennt werden. Aufgrund der Exposition Gebiete wäre es möglich, Klassen mit ähnlichen Illuminations-verhältnissen zusammenzufassen. Die Expositionswerte könnten aus dem DHM extrahiert werden. Anschliessend würde klassenspezifisch die Klassifikation durchgeführt. Um die Problematik der zwei Überflüge zu entschärfen, könnte das Untersuchungsgebiet aufgeteilt und unabhängig voneinander klassiert werden. Eine elegantere Lösung wäre das Durchführen einer Illuminationskorrektur. Dabei wird für jedes Bildelement mit Hilfe des digitalen Geländemodelles die Strahldichte zum Aufnah-mezeitpunkt errechnet und z.B. mit einer semi-empirischen Methode (C-Korrektur nach Teillet et. al., 1982) ausgeglichen. (In: Itten et. al., 1993: 414) Dies könnte die Schatten-problematik stark verringern und die Klassifikationsresultate verbessern.
Abbildung 38 Vergleich der Kronendächer von Laub- und Nadelbäumen (links) und Waldfläche im Schatten (rechts); beides Falschfarbendarstellungen

Diskussion
50
6.2.2 Segmentierung
6.2.2.1 Problematik In vorangehenden Kapiteln wurde bereits mehrfach darauf hingedeutet, dass die verwende-te Segmentierung nicht allen Ansprüchen genügen konnte. Das Hauptziel des Segemtie-rungs-Prozesses bestand im Generieren eines Objektlevels, in welchem die Segmente de-ckungsgleich mit den Baumkronen sind. Leider konnte dieses Ziel nicht wunschgemäss erreicht werden. Sehr oft kam es zu folgenden Segmentbildungen:
• In den Regionen zwischen den Bäumen entstehen längliche Mischsegmente. • Eine einzelne Baumkrone wird in zwei oder mehrere Objekte unterteilt, die Grenze
verläuft unter anderem bei Nadelbäumen direkt durch die Kronenmitte. • Mehrere Bäume gleicher Art befinden sich innerhalb eines Segmentes. • Mehrere Bäume unterschiedlicher Art befinden sich innerhalb eines Segmentes.
Die Ursachen für diese Segmentbildungen in Definiens sind sehr vielfältig. Die Grund-problematik liegt jedoch in der Eigenschaft des verwendeten Algorithmus, welcher Regio-nen auf Basis der Homogenität zusammenfasst (Heurich, 2006: 137). Für das Erstellen von Objekten einer allgemeinen Landschaftsklassifikation ist das Segmentierungsverfahren gerade für landwirtschaftlich genutzte Flächen sehr gut geeignet. Beim Erkennen von Ein-zelbäumen weist es jedoch Schwächen auf. Ein Baum bzw. eine Baumkrone lässt sich nur eingeschränkt als homogenes Objekt definieren. Sehr häufig sind die verschiedenen Baumteile unterschiedlicher Beleuchtung ausgesetzt. In der Folge werden die einzelnen Bereiche in separaten Segmenten zusammengefasst. In Abbildung 39 ist diese Teilung der Baumkrone sehr gut zu sehen. Die roten Segmente ent-sprechen der sonnenzugewandten Seite des Baumes. Der beschattete Teil wird nur selten sauber in einem Objekt zusammengefasst, es entstehen Mischsegmente mit benachbarten beschatteten Pixeln. Die Übergangsbereiche zu anderen Bäumen können zudem sehr un-scharf sein. Die Kronen von nahe zusammenstehenden Bäumen überlagern sich und bilden gemeinsam eine Baumkrone.
Abbildung 39 Nicht optimal gebildeten Segmenten aufgrund unterschiedlicher Beleuchtung der Baumkrone; Falschfar-bendarstellung

Diskussion
51
Eine Segmentierung bezüglich der Homogenität der Höhendaten ist ebenfalls keine opti-male Lösung, denn Bäume besitzen keine homogene Höhenverteilung in der Krone. Na-delbäume weisen vielmehr eine charakteristisch runde Kegelform auf mit einem Höhen-maximum im Zentrum und einer Abnahme der Höhe gegen den Kronenrand hin. Bei der Erstellung der Segmentierung wurde die Höheninformation besonders gewichtet, was wie in Abbildung 40 zur Aufteilung von Baumkronen in zwei Objekte führt. Der Mittelpunkt mit der Maximalhöhe wird abgetrennt und rund um die Baumspitze wird ein Ringsegment gebildet. Grundsätzlich sind Segmente dieser Art relativ gut zu klassieren. In den meisten Fällen tritt bei den Ringobjekten eine Mischsegmentproblematik auf. Auf Basis dieser Kegelform könnte jeoch eine vom Zentrum ausgehende Segmentierung mit dem lokalen Maximalwert als Startpunkt eine durchaus geeignete Möglichkeit zur Segmentierung von Einzelbäumen sein (siehe folgendes Kapitel) (Heurich, 2006: 137). Durch die beschriebenen Probleme konnten die im Level 25 gebildeten Objekte nicht für die Unterscheidung von (Laub-) Baumarten verwendet werden. Die Segmente beinhalteten entweder nur kleinere Bereiche der Baumkrone oder es wurden Mischsegmente gebildet.
Aus den aufgeführten Gründen wird der Schluss gezogen, dass eine Segmentierungsme-thode, welche ausschliesslich auf dem Vergleichen von Homogenitäten basiert, Objekte bildet, die für das Erstellen von Einzelbaumsegmenten nur bedingt geeignet ist.
6.2.2.2 Verbesserungsmöglichkeiten Die verwendete Segmentierungsmethode scheint für die Objektbildung einzelner Bäume nur begrenzt geeignet. Es sollen nun einige Verbesserungsmöglichkeiten erwähnt werden, welche das Resultat verbessern könnten. Alle drei verwendeten Objektlevels sind mit denselben Parametereinstellungen erzeugt worden. Für den mittleren Level (25), welcher den Baumkronen entsprechen sollte, wurde demnach ebenfalls die Vegetationshöhe stark gewichtet. Diese Gewichtung führt jedoch wie erwähnt (Abbildung 40) zu unerwünschten Objekten. Da es sich um eine Bottom-up-Segmentierung handelt, würde eine weniger starke Gewichtung keine grossen Veränderun-gen bringen, da die Objektgrenzen bereits vom Initiallevel (Level 5) vorgegeben werden. Deshalb müsste eine Waldmaske aus der Wald/Nichtwald-Segmentierung erstellt, die ver-
Abbildung 40 Nicht optimal gebildeten Segmenten aufgrund der Höhenunterschiede innerhalb der Baumkronen; Falschfarbendarstellung

Diskussion
52
wendeten Objektlevel gelöscht und anschliessend neu segmentiert werden. Dadurch könn-ten nur noch auf Basis der spektralen Information Objekte gebildet werden. Eine zusätzliche Erweiterung wäre eine vorgängige Klassifikation der unterschiedlichen Bestandestypen in einem ‚höheren’ Level, wie dies von Tiede et. al. (2006) durchgeführt wurde. Für die Unterscheidung wurde der Objektlevel mit einem Scale Parameter von 100 erstellt und mit NDVI zwischen eng oder dicht zusammenstehenden Laub- und Nadelbäu-men sowie gemischten Beständen unterschieden. Mittels der Vegetationshöhe wurden die Laub- und Nadelbäume noch weiter in Alt- und Jungbestände unterteilt. Tiede et. al. (2006) benutzten diese klassierten Waldtypen als Randbedingungen, um eine regionenspezifische 2-Levelhierarchie zu definieren. Dieser Ansatz bietet die Möglichkeit, Regionen zu pixelgrossen Objekten aufzuspalten, welche jedoch dem ‚höheren’ Objektle-vel (Waldtypen) zugehörig bleiben. Innerhalb dieser Regionen werden mittels des ‚region growing’ Segmentierungs-Algorithmus in Definiens Developer neue Objekte gebildet. Als ‚seed points’ werden die Baumspitzen (lokale Maxima) verwendet. Diese Methode scheint besser geeignet, da sie die Einzelbaumsegmente nicht direkt auf-grund von spektralen Eigenschaften definieren. Für jeden Bestandestyp muss jedoch ein eigener Grenzwert für das Wachstum festgelegt werden, was den Aufwand deutlich erhöht. Zudem ist es in heterogenen Wäldern besonders schwer, Gebiete mit Objekten mehr oder weniger der gleichen Grössenordnung zu segmentieren. (Tiede et. al., 2006))
6.2.3 Softwareeinschränkungen
Seit mindestens zwei Jahrzehnten ermöglicht die Rechenleistung von erschwinglichen Computern Bildverarbeitung und Bildsegmentierung, was diese Methoden für die Bildana-lyse in der Fernerkundung anwendbar macht. (Benz, 2004: 240) Doch was diese Arbeit betrifft, stellen die Einschränkungen der Software Definiens (Kap. 4.2) ein Grundproblem dar, welches über fast alle Arbeitsschritte hinweg präsent war. Ein grosser Vorteil von Fernerkundungsmethoden besteht unter anderem in der Möglich-keit, dass Analysen und Klassifikationen über grosse Gebiete und in kurzer Zeit durchge-führt werden können. Eine Aufteilung eines grossen Datensatzes stellt keine Schwierigkeit dar, doch aufgrund der Problematik der Reproduktion der Objektgrenzen an den Kachel-grenzen wird der zeitliche Aufwand zur Bearbeitung erhöht. Füllemann (2007: 57) schätzt den Aufwand für das Verschneiden und Mosaikieren der Kacheln für einen Sihlwald-Datensatz auf je einen Tag. Bei einer Gesamtdauer einer Veränderungsbeobachtung von 13 Tagen wird mehr als 1/7 der Zeit für das Datenmanagement gebraucht. Innerhalb eines Projektes wie z.B. einer ‚Change Detection’ spielt dies eher eine unterge-ortnete Rolle. In Zukunft wird die Datenmenge noch weiter zunehmen, weniger aufgrund besserer räumlicher, sondern der spektralen Auflösung (Hyperspektral-Sensoren). Die An-forderungen an die rechnerische Leistungsfähigkeit werden deshalb weiterhin steigen.

Schlussfolgerungen
53
7 Schlussfolgerungen
7.1 Fazit
Das Hauptziel der Arbeit, das Unterscheiden von Baumarten im Untersuchungsgebiet Sihlwald konnte nicht erreicht werden. Es wurde aufgezeigt, dass der von Definiens Developer benutzte Segmentierungs-Algorithmus für die Bildung von Einzelbaumobjekten Einzelbaumabtrennung grundsätz-lich nur bedingt geeignet ist. Bäume lassen sich nicht aufgrund von Homogenitätskriteren abgrenzen. Ein geigneter An-satz stellt die Erfassung der Baumkrone durch das Detektieren von lokalen Maxima und anschliessendem ‚region growing’ dar. Auf diese Weise werden unter anderem auch durch Beleuchtungsunterschiede verursachte Schwierigkeiten umgangen. Die durchgeführte Waldbestandesaufnahme im Untersuchungsgebiet schneidet in der Veri-fikation sehr gut ab. Damit konnte bestätigt werden, dass mit der Verwendung eines Laser-scanners und eines objektorientieren Klassifikationsansatzes die Waldflächen auf sehr ein-fache Weise mit hervorragenden Resultaten klassiert werden können Ebenfalls wurde nachgewiesen, dass eine erste ‚Vorklassierung’, in einem Objektlevel mit mit grösseren Segmenten, die Fehlkassierungen im Siedlungsgebieten deutlich verringern kann. Eine solche Vorklassierung könnte ebenfalls verwendet werden, um homogene Be-stände nach Alter und Art (Laub- oder Nadelbäume) zu klassieren. Bedingt durch Topografie und das Zusammensetzen des Datensatzes aus zwei Befliegun-gen kann es innerhalb eines grossen Gebietes zu starken Illuminationsunterschieden kom-men. Diese erschweren die Unterscheidung von Baumarten erheblich, weshalb die Korrek-tur dieser Beleuchtungsunterschiede bei einer geplanten Baumartenunterscheidung sehr empfohlen wird. Um die Genauigkeit einer Baumtypenklassierung überprüfen zu können ist eine Bodenre-ferenz auf der räumlichen Ebene des Einzelbaumes mit entsprechender Lagegenauigkeit nötig. Nur so kann dieser Methode die erforderliche Zuverlässigkeit, welche für den Ein-satz einer ‚change detection’ nötig ist, nachgewiesen werden.
7.2 Ausblick
Der Schlüssel zur Unterscheidung von verschiedenen Baumarten liegt in der Einzelbaum-erkennung. Das Ziel ist es Algorithmen mit möglichst hoher Erkennungsrate, insbesonder für Laubbäume zu entwicklen. Um diese Algorithmen auch in einem Monitoring oder all-gemein in der Forstwirtschaft anwenden zu können, sollten Untersuchungen zur Optimie-rung der Bodenrefernz durchgeführt werden. Es muss abgeklärt werden, wie umfassend eine Bodenreferenz sein muss, um die Kosten zu minimieren und gleichzeitig eine gesich-tere Zuverlässigkeit der Ergebnisse zu erhalten. Für die Forstwirtschaft eröffnet der Einsatz von Laserscanning neue Anwendungsfelder. Die Dynamik des Waldes kann flächendeckend erfasst werden und z.B. bewirtschaftete von nicht bewirtschafteten Wäldern verglichen werden.

Literaturverzeichnis
54
8 Literaturverzeichnis Albertz, J. (2001): Einführung in die Fernerkundung. Grundlagen der Interpretation von
Luft und Satellitenbildern. Wissenschaftliche Buchgesellschaft, Darmstadt.
Beusch, M. (2005): Ableitung der Waldbestandesstruktur von spektral und räumlich hoch-aufgelösten Fernerkundungsdaten, Diplomarbeit, Geographisches Institut der Uni-versität Zürich.
Benz, U. C., Hofmann, P., Willhauck, G., Lingenfelder, I., Heynen, M.(2004): Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready in-formation. In: ISPRS Journal of Photogrammetry & Remote Sensing, Vol. 58, 239-258.
Bundesamt für Landestopographie (1993): Topografica. Interne Richtlinien für die Karto-graphie, Wabern.
Bundesamt für Landestopografie Swisstopo (2005): VECTOR25, Die Geodaten der Schweiz des Bundesamtes für Landestopografie für den professionellen Einsatz.
http://www.swisstopo.admin.ch/internet/swisstopo/de/home/products/landscape/vector25.parsysrelated1.47641.downloadList.97827.DownloadFile.tmp/vector25flyerdefr.pdf Zugriff: 22.04.08
Bundesamt für Statistik BFS(2006a): Nomenklatur Arealstatistik, Normalwald. http://www.bfs.admin.ch/bfs/portal/de/index/infothek/nomenklaturen/blank/blank/noas04/03/03_11.parsys.0009.downloadList.00091.DownloadFile.tmp/as50d.pdf Zugriff: 23.04.08
Bundesamt für Statistik BFS(2006b): Nomenklatur Arealstatistik, Aufgelöster Wald. http://www.bfs.admin.ch/bfs/portal/de/index/infothek/nomenklaturen/blank/blank/noas04/03/03_15.parsys.0009.downloadList.00091.DownloadFile.tmp/as56d.pdf Zugriff: 23.04.08.
Bundesamt für Statistik BFS(2006c): Nomenklatur Arealstatistik, Gebüschwald. http://www.bfs.admin.ch/bfs/portal/de/index/infothek/nomenklaturen/blank/blank/noas04/03/03_21.parsys.0009.downloadList.00091.DownloadFile.tmp/as57d.pdf Zugriff: 23.04.08.
Definiens (2007a): User Guide Definiens Developer 7.
Definiens (2007b): Reference Book Definiens Developer 7.
Eckert, S. (2006): A Contribution to Sustainable Forest Management in Patagonia, Object-oriented Classification and Forest Parameter Extraction based on ASTER and Landsat ETM+ Data, Dissertation, Geographisches Institut der Universität Zürich.
Fischer, R. (1999): Untersuchung der Systematik von Vegetationsindizes aus Fernerkun-dungsdaten am Beispiel Zürich, Diplomarbeit, Geographisches Institut der Univer-sität Zürich.
Füllemann, Ch. (2007): Multisensorale Waldklassifikation im Sihlwald, Diplomarbeit, Geographische Institut der Universität Zürich.
Grün Stadt Zürich (2008): Trägerschaft http://www.stadt-zuerich.ch/internet/gsz/home/naturraeume/sihlwald/ueber_uns/ traegerschaft.html Zugriff: 16.4.08.

Literaturverzeichnis
55
Heurich, M. (2006): Evaluierung und Entwicklung von Methoden zur automatisierten Er-fassung von Waldstrukturen aus Daten flugzeuggetragener Fernerkundungssenso-ren, In: Forstliche Forschungsberichte München, Nr. 202; Bayerische Landesanstalt für Wald und Forstwirtschaft, Freising
Huete, A.R. (1988): A soil adjusted vegetation index (SAVI). In: Remote sensing of envi-ronment, Vol. 25, Nr. 2, S. 295-309.
Hübner, L. (2005): Sichtbare Strukturveränderungen im Sihlwald - Vom Wirtschaftswald zum Waldreservat, Diplomarbeit, Professur für Natur- und Landschaftsschutz an der ETH Zürich.
Itten, K. I.; Meyer, P.; Kellenberger T.; Sandmeier, St.; Sandmeier-Leu, R.; Leiss, I. und Ehrler, C., (1993): Versuche zur Verwendung von Satellitendaten für die Nachfüh-rung der Schweizerischen Arealstatistik. In: VPK Vermessung Photogrammetrie Kulturtechnik, Nr. 6, S. 410-413.
Kellenberger, T. (1996): Erfassung der Waldfläche in der Schweiz mit multispektralen Satellitenbilddaten. Grundlagen, Methodenentwicklung und Anwendungen, Disser-tation, Geographisches Institut der Universität Zürich.
Keller, M. (Hrsg.) (2005): Schweizerisches Landesforstinventar, Anleitung für die Feld-aufnahmen der Erhebung 2004-2007. Eidgenössische Forschungsanstalt WSL, Bir-mensdorf.
Monserud, A.; Leemans, R. (1991): Comparing global vegetation maps with the Kappa statistic. In: Ecological Modelling
Sihlwald Data Center (2008): About, Historic View. http://www.sihlwald.unizh.ch/about.shtml Zugriff: 12.04.08
Stadt Zürich (2007): Medienmitteilung 03.12.07, Auf dem Weg zum Naturpark Sihlwald. http://www.stadt-zuerich.ch/internet/mm/home/mm_07/12_07/071203b.html Zugriff: 16.04.08.
Stolz, R. (1998): Die Verwendung der Fuzzy Logic Theorie zur wissensbasierten Klassifi-kation von Fernerkundungsdaten. Ein methodischer Ansatz zur Verbesserung von Landnutzungsklassifikationen in mesoskaligen heterogenen Räumen, dargestellt am Einzugsgebiet der Ammer. Institut für Geographie der Universität München. Geo-Verlag, München.
Tiede, D.; Lang, S. und Hoffmann, Ch. (2006): Supervised and forest type-specific multi-scale segmentation for a one-level-representation of single trees. Proceedings of the 1th International Conference on Object-based Image Analysis (OBIA), 4.-5. Juli, Salzburg.
Tilton, J.C. (1992): Interactive explorations of hierarchical segmentations. Proceedings of the 12th Annual International Geoscience and Remote Sensing Symposium (I-GARSS), 26.-29. Mai, Housten, S. 1401-1402.
TopoSys (2007): Topographische Systemdaten. http:www.toposys.com Zugriff: 15.03.08.
TopoSys (2008a): Falcon II, Scan Pattern http://www.toposys.com/toposys-en/lidar-systems/falcon-fiber-scanner-and-scan-pattern.php?print=true Zugriff: 13.05.08.
TopoSys (2008b): Airborne Laserscanning http://www.toposys.com/toposys-de/lidar-systems/images/FirsLastEcho_500px.jpg Zugriff: 15.03.08.

Literaturverzeichnis
56
TopoSys (2008c): FALCON II, Specification http://www.toposys.com/toposys-en/lidar-systems/falcon-technical-data.php?print=true Zugriff: 13.05.08
WSL (Hrsg.) (2001): Informationsblatt Forschungsbereich Wald, Nr. 6, Birmensdorf. http://www.wsl.ch/publikationen/reihen/wald/006.pdf Zugriff: 22.4.08.
WSL (2008): So werden Daten erhoben. http://www.lfi.ch/lfi/methoden1.php Zugriff: 20.3.08.





























