Embed Size (px)
Citation preview

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
0
Klassifikation

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
1
Überblick• Grundkonzepte• Entscheidungsbäume• Evaluierung von Klassifikatoren• Lernen von Regeln • Klassifikation mittels Assoziationsregeln• Naïver Bayescher Klassifikator• Naïve Bayes für Text Klassifikation• Support Vektor Maschinen• Ensemble-Methoden: Bagging und Boosting• Zusammenfassung

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
2
Bayesche Klassifikation• Probabilistische Sicht: Überwachtes Lernen kann auf
elegante Weise probabilistisch formuliert werden. • Seien A1 bis Ak diskrete Attribute. Das Klassenattribut sei
C. • Gegeben sei ein Testbeispiel d mit den beobachteten
Attributwerten a1 bis ak.• Die Klassifikation besteht darin die folgende Aposteriori-
Wahrscheinlichkeit zu berechnen. Die Vorhersage ist die Klasse cj s.d.
maximal wird

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
3
Anwendung von Bayes’ Regel
Pr(C=cj) ist die Klasse Prior-Wahrscheinlichkeit: leicht aus den Trainingsdaten zu schätzen.
∑=
====
=====
==
=====
===
||
1||||11
||||11
||||11
||||11
||||11
)Pr()|,...,Pr(
)Pr()|,...,Pr(
),...,Pr()Pr()|,...,Pr(
),...,|Pr(
C
rrrAA
jjAA
AA
jjAA
AAj
cCcCaAaA
cCcCaAaAaAaA
cCcCaAaAaAaAcC

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
4
Berechnung der Wahrscheinlichkeiten
• Der Nenner ist irrelevant für Entscheidung , da er für jede Klasse gleich ist.
• Nur P(A1=a1,...,Ak=ak | C=ci) wird gebraucht, was umgeformt werden kann alsPr(A1=a1|A2=a2,...,Ak=ak, C=cj)* Pr(A2=a2,...,Ak=ak |C=cj)
• Der zweite Faktor kann rekursiv auf die gleiche Weise weiter zerlegt werden.
• Jetzt kommt noch eine Annahme.
A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
5
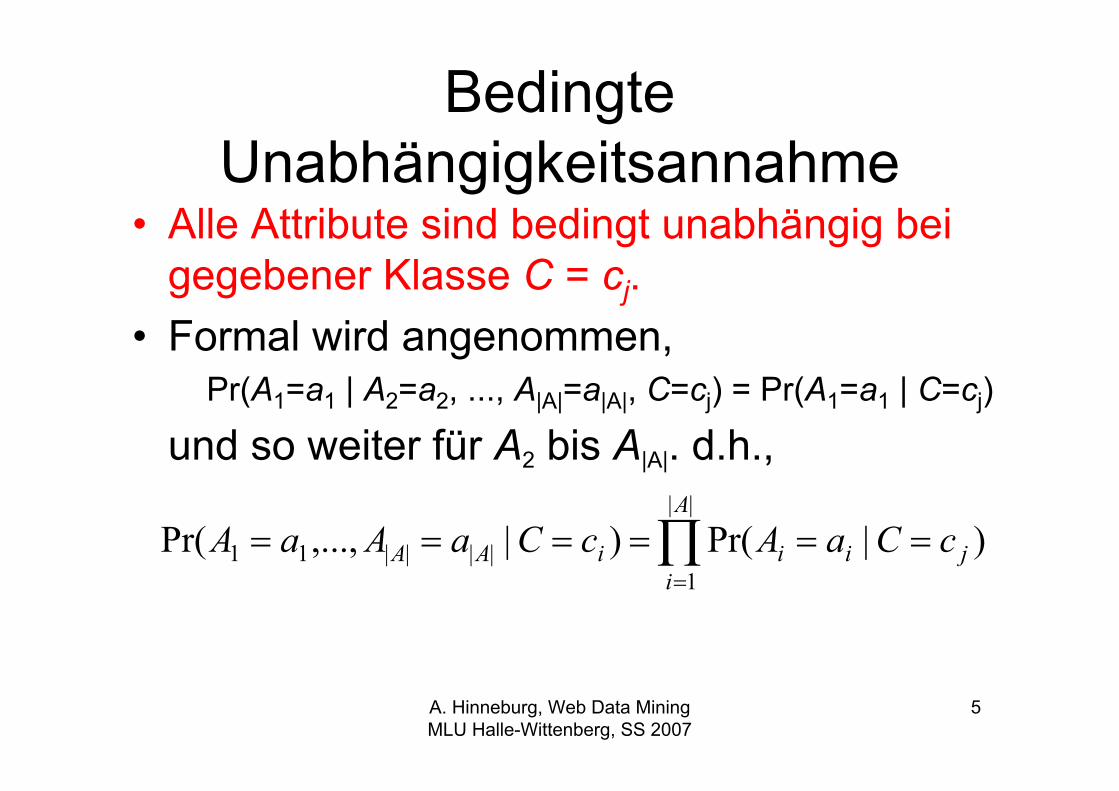
BedingteUnabhängigkeitsannahme
• Alle Attribute sind bedingt unabhängig beigegebener Klasse C = cj.
• Formal wird angenommen,Pr(A1=a1 | A2=a2, ..., A|A|=a|A|, C=cj) = Pr(A1=a1 | C=cj)
und so weiter für A2 bis A|A|. d.h.,
∏=
======||
1||||11 )|Pr()|,...,Pr(
A
ijiiiAA cCaAcCaAaA
A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
6
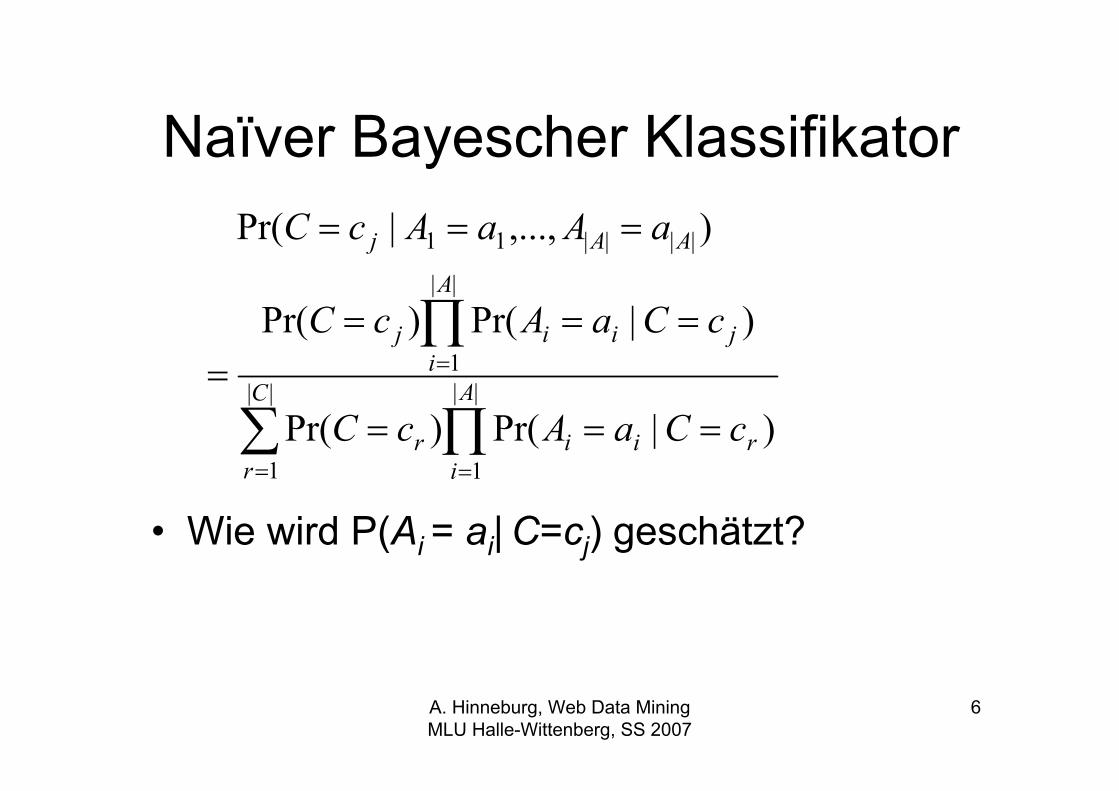
Naïver Bayescher Klassifikator
• Wie wird P(Ai = ai| C=cj) geschätzt?
∑ ∏
∏
= =
=
===
====
===
||
1
||
1
||
1
||||11
)|Pr()Pr(
)|Pr()Pr(
),...,|Pr(
C
r
A
iriir
A
ijiij
AAj
cCaAcC
cCaAcC
aAaAcC

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
7
Klassifikation einer Testinstanz• Wenn die wahrscheinlichsten Klasse
vorhergesagt wird, braucht nur der Zählerberechnet werden, da der Nenner für alleKlassen gleich ist.
• Für ein gegebenes Testbeispiel, wird dasfolgende berechnet
∏=
===||
1)|Pr()Pr(maxarg
A
ijiij
ccCaAcc
j
A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
8
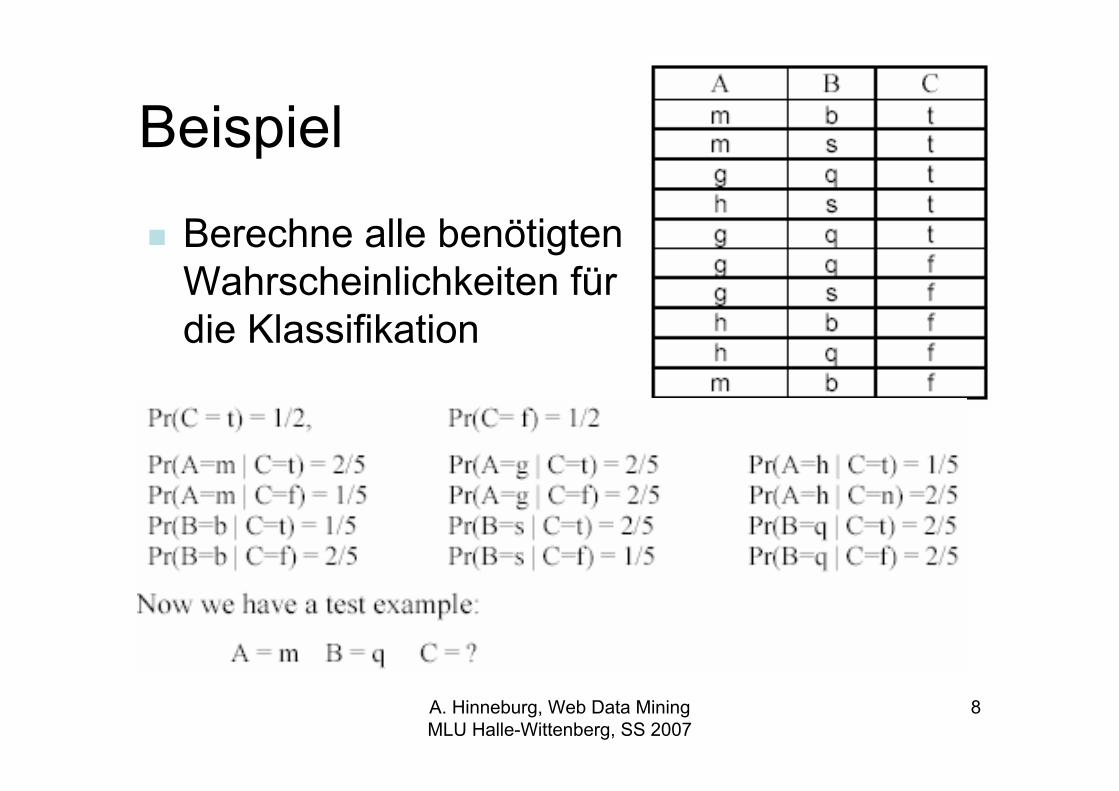
Beispiel
Berechne alle benötigtenWahrscheinlichkeiten fürdie Klassifikation

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
9
Beispiel, Fortsetzung
• Für C = t, ergibt sich
• Für Klasse C = f, ergibt sich
• C = t ist wahrscheinlicher. t ist deshalb die Vorhersage.
252
52
52
21)|Pr()Pr(
2
1=××==== ∏
=jjj tCaAtC
251
52
51
21)|Pr()Pr(
2
1
=××==== ∏=j
jj fCaAfC

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
10
Probleme• Numerische Attribute: Naïves Bayesches
Lernen nimmt an, dass alle Attribute kategorischsind. Numerische Attribute müssen diskretisiertwerden.
• Anzahl=Null: Ein bestimmter Attributwert tauchtunter Umständen nicht mit einer Klassegemeinsam auf. Abhilfe durch Glättung.
• Fehlende Werte: werden ignoriertij
ijjii nn
ncCaA
λλ
+
+=== )|Pr(

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
11
Diskussion zum naïvenBayesches Klassifikator
• Vorteile: – Leicht zu implementieren– Sehr effizient– Liefert gute Ergebnisse bei vielen Anwendungen
• Nachteile– Annahme: Klassen sind bedingt unabhängig,
deshalb geht Vorhersagegenauigkeit verloren, wenn diese Annahme stark verletzt wird. (z.B. beistark korrellierten Daten)

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
12
Überblick• Grundkonzepte• Entscheidungsbäume• Evaluierung von Klassifikatoren• Lernen von Regeln • Klassifikation mittels Assoziationsregeln• Naïver Bayescher Klassifikator• Naïve Bayes für Text Klassifikation• Support Vektor Maschinen• Ensemble-Methoden: Bagging und Boosting• Zusammenfassung

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
13
Text Klassifikation/Kategorisierung• Weil die Anzahl elektronischer Dokumente stark
steigt, wird automatische Dokumentklassifikationimmer wichtiger.
• Die bisher vorgestellten Techniken können zwarangewendet werden, sind aber nicht so effektivwie die nachfolgenden Methoden.
• Heute wird eine naïve Bayesche Methodediskutiert, die speziell für Texte zugeschnitten ist, und Text-spezifische Eigenschaften nutzt.
• Die Ideen sind ähnlich zu naïve Bayes.

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
14
Probabilistischer Rahmen• Generatives Modell: Jedes Dokument wird
durch eine parametrisierte Verteilungerzeugt, die von versteckten Parameternbeeinflußt ist.
• Das generative Modell macht zweiAnnahmen
– Die Daten (oder Textdokumente) werden von einem Mischmodell erzeugt,
– Zwischen den Komponenten derMischverteilund und den Dokumentklassengibt es eine eins-zu-eins Beziehung.

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
15
Mischmodell• A Mischmodell beschreibt die Daten
durch mehrere statistische Verteilungen. – Jede Verteilung korrespondiert zu einem
Daten-Cluster und die Parameter derVerteilung sind eine Beschreibung des Clusters.
– Jede Verteilung im Mischmodell wird auchMischkomponente genannt.
• Eine Verteilung/Komponente kann von beliebiger Art sein

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
16
Beispiel• Die Abbildung zeigt eine Wahrscheinlichkeits-
dichtefunktion einer 1-dimensionale Datenmenge(mit zwei Klassen) erzeugt durch– eine Mischung von zwei Gauss-Verteilungen, – eine pro Klasse, deren Parameter (beschrieben durch θi)
der Durchschnitt (µi) und die Standardabweichung (σi), d.h., θi = (µi, σi).
Klasse 1 Klasse 2

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
17
Mischmodell (Fortsetzung …)• Sei K die Anzahl der Mischkomponenten (oder
Verteilungen) in einem Mischmodell. • Die jte Verteilung hat die Parameter θj. • Sei Θ die Menge der Parameters alle
Komponenten, Θ = {ϕ1, ϕ2, …, ϕK, θ1, θ2, …, θK}, wobei ϕj das Mischgewicht (oder Prior Wahrscheinlichkeit) eine Mischekomponente jsei und θj die Parameter der Komponente j.
• Wie erzeugt das Modell die Dokumente?

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
18
Dokumenterzeugung• Wegen der eins-zu-eins Beziehung zwischen Klassen
und Mischkomponenten sind die Mischgewichte die Klassen-Prior-Wahrscheinlichkeiten, d.h., ϕj = Pr(cj|Θ).
• Das Mischmodell erzeugt ein Dokument di durch:– Auswahl der Mischkomponente (oder Klasse) bezüglich der
Klassen-Prior.-Wahrscheinlichkeiten (d.h., der Mischgewichte), ϕj = Pr(cj|Θ).
– Nachdem eine Komponente (cj) gewählt ist, wird ein Dokument dibezüglich der Parameter mit der Verteilung Pr(di|cj; Θ) erzeugt, oder genauer Pr(di|cj; θj).
) ;|Pr()Θ|Pr()|Pr(||
1
Θ=Θ ∑=
C
jjiji cdcd (23)

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
19
Modellierung von Textdokumenten• Der naïve Bayes-Klassifikator behandelt jedes
Dokument als “bag of words”. • Das erzeugende Modell macht weitere
Annahmen:– Wörter werden bei gegebener Klasse unabhängig von
einander erzeugt (wie beim naïven Bayes).– Die Wahrscheinlichkeit eines Wortes ist unabhänigi
von seiner Position im Dokument. Die Dokumentlängewird unabhängig von der Klasse gewählt.

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
20
Multinomiale Verteilung• Wegen der bisherigen Annahmen, kann eine
Dokument durch eine Multinomial-Verteilungerzeugt werden.
• D.h. jedes Dokument wird aus einer Multinomial-Verteilung von Worten gezogen, die Anzahl derVersuche entspricht der Dokumentlänge.
• Die Worte sind aus einem gegeben VokabularV = {w1, w2, …, w|V|}.

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
21
Verteilungsfunktion einerMultinomial-Verteilung
wobei Nti ist die Anzahl des Auftretens von Wort wt in Dokument di und
∏=
Θ=Θ
||
1 !);|Pr(|!||)Pr(|);|Pr(
V
t ti
tiNjtiiji
Ncwddcd
||||
1
i
V
t
it dN =∑=
.1);|Pr(||
1∑=
=ΘV
t
jt cw
(24)
(25)

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
22
Parameter-Schätzung• Parameter werden durch empirische Anzahlen
geschätzt.
• Um 0 Anzahlen für seltene Worte, die nicht in der Trainingsmenge aber in der Testmengeauftauchen, wird die Wahrscheinlichkeits-schätzung geglättet. Lidstone Glättung, 0 ≤ λ ≤ 1
.)|Pr(
)|Pr()ˆ;|Pr( ||
1
||
1
||
1
∑ ∑∑= =
==Θ V
s
D
i ijsi
D
i ijtijt
dcN
dcNcw
.)|Pr(||
)|Pr()ˆ;|Pr( ||
1
||
1
||
1
∑ ∑∑
= =
=
+
+=Θ V
s
D
i ijsi
D
i ijtijt
dcNV
dcNcw
λ
λ
(26)
(27)

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
23
Parameter-Schätzung (Fortsetzung…)
• Klassen-Prior-Wahrscheinlichkeiten, welche die Mischgewichte ϕj sind könnenleicht aus den Trainingsdaten geschätztwerden
||)|Pr(
)ˆ|Pr(||
1
Ddc
cD
iij
j∑ ==Θ (28)

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
24
Klassifikation• Gegeben eine Test-Dokument di, mit den Gleichungen
(23) (27) und (28)
∑ ∏∏
= =
=
ΘΘ
ΘΘ=
ΘΘΘ
=Θ
||
1
||
1 ,
||
1 ,
)ˆ;|Pr()ˆ|Pr(
)ˆ;|Pr()ˆ|Pr(
)ˆ|Pr()ˆ;|Pr()ˆ|Pr()ˆ;|Pr(
C
r
d
k rkd
d
k kd
i
ir
ij
ij
i
jijij
cwc
cwc
dcdcdc

A. Hinneburg, Web Data MiningMLU Halle-Wittenberg, SS 2007
25
Diskussion• Die meisten Annahmen beim naïven Bayes-
Klassifikator werden zu einem gewissen Grad in der Praxis verletzt.
• Trotzdessen, ergibt der naïve BayesKlassifikator brauchbare Modelle. – Die Hauptannahme ist die der Mischverteilung. Wenn
diese Annahme stark verletzt wird, kann die Klassifikationsgenauigkeit rapide sinken.
• Der naïve Bayes-Klassifikator ist sehr effizient.





























