
Singular Value Decomposition(SVD)Singularwertzerlegung
Katja Markert einige Folien von Julian Hitschler
Institut fur ComputerlinguistikUni Heidelberg
markertcluni-heidelbergde
June 11 2019
Bisher und heute
1 Hintergrund zu den mathematischen Begriffen und Methoden diefur Matrizenzerlegung notwendig ist
2 Jetzt der SVD-Hauptsatz (mit Konstruktion aber ohne Beweis)3 Die Intuition dahinter4 Reduced SVDrarr Dichte Embeddings5 Performanz von diesen dichten SVD-Embeddings in NLP
2
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
3
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
4
SVD
Eine reellwertige mtimesn - Matrix A lasst sich wie folgt faktorisieren
A = UΣV T
U ist eine orthonormale mtimesm - Matrix
Σ ist eine ldquodiagonalerdquo mtimesn - Matrix
V T ist die Transponierte einer orthonormalen ntimesn - Matrix
5
Singularwertzerlegung
A =
a11 a12 a1n
a21 a22 a2n
am1 am2 amn
=
u11 u12 u1mu21 u22 u2m
um1 um2 umm
σ11 0 0 00 σ22 0 0
0 0 0 σmn
v11 v12 v1nv21 v22 v2nv31 v32 v3n
vn1 vn2 vnn
T
Diagonale Eintrage in Σ werden als Singularwerte von A bezeichnet
Spalten in U werden als linke Singularvektoren von A bezeichnet
Spalten in V werden als rechte Singularvektoren von A bezeichnet
6
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Bisher und heute
1 Hintergrund zu den mathematischen Begriffen und Methoden diefur Matrizenzerlegung notwendig ist
2 Jetzt der SVD-Hauptsatz (mit Konstruktion aber ohne Beweis)3 Die Intuition dahinter4 Reduced SVDrarr Dichte Embeddings5 Performanz von diesen dichten SVD-Embeddings in NLP
2
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
3
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
4
SVD
Eine reellwertige mtimesn - Matrix A lasst sich wie folgt faktorisieren
A = UΣV T
U ist eine orthonormale mtimesm - Matrix
Σ ist eine ldquodiagonalerdquo mtimesn - Matrix
V T ist die Transponierte einer orthonormalen ntimesn - Matrix
5
Singularwertzerlegung
A =
a11 a12 a1n
a21 a22 a2n
am1 am2 amn
=
u11 u12 u1mu21 u22 u2m
um1 um2 umm
σ11 0 0 00 σ22 0 0
0 0 0 σmn
v11 v12 v1nv21 v22 v2nv31 v32 v3n
vn1 vn2 vnn
T
Diagonale Eintrage in Σ werden als Singularwerte von A bezeichnet
Spalten in U werden als linke Singularvektoren von A bezeichnet
Spalten in V werden als rechte Singularvektoren von A bezeichnet
6
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
3
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
4
SVD
Eine reellwertige mtimesn - Matrix A lasst sich wie folgt faktorisieren
A = UΣV T
U ist eine orthonormale mtimesm - Matrix
Σ ist eine ldquodiagonalerdquo mtimesn - Matrix
V T ist die Transponierte einer orthonormalen ntimesn - Matrix
5
Singularwertzerlegung
A =
a11 a12 a1n
a21 a22 a2n
am1 am2 amn
=
u11 u12 u1mu21 u22 u2m
um1 um2 umm
σ11 0 0 00 σ22 0 0
0 0 0 σmn
v11 v12 v1nv21 v22 v2nv31 v32 v3n
vn1 vn2 vnn
T
Diagonale Eintrage in Σ werden als Singularwerte von A bezeichnet
Spalten in U werden als linke Singularvektoren von A bezeichnet
Spalten in V werden als rechte Singularvektoren von A bezeichnet
6
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
4
SVD
Eine reellwertige mtimesn - Matrix A lasst sich wie folgt faktorisieren
A = UΣV T
U ist eine orthonormale mtimesm - Matrix
Σ ist eine ldquodiagonalerdquo mtimesn - Matrix
V T ist die Transponierte einer orthonormalen ntimesn - Matrix
5
Singularwertzerlegung
A =
a11 a12 a1n
a21 a22 a2n
am1 am2 amn
=
u11 u12 u1mu21 u22 u2m
um1 um2 umm
σ11 0 0 00 σ22 0 0
0 0 0 σmn
v11 v12 v1nv21 v22 v2nv31 v32 v3n
vn1 vn2 vnn
T
Diagonale Eintrage in Σ werden als Singularwerte von A bezeichnet
Spalten in U werden als linke Singularvektoren von A bezeichnet
Spalten in V werden als rechte Singularvektoren von A bezeichnet
6
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

SVD
Eine reellwertige mtimesn - Matrix A lasst sich wie folgt faktorisieren
A = UΣV T
U ist eine orthonormale mtimesm - Matrix
Σ ist eine ldquodiagonalerdquo mtimesn - Matrix
V T ist die Transponierte einer orthonormalen ntimesn - Matrix
5
Singularwertzerlegung
A =
a11 a12 a1n
a21 a22 a2n
am1 am2 amn
=
u11 u12 u1mu21 u22 u2m
um1 um2 umm
σ11 0 0 00 σ22 0 0
0 0 0 σmn
v11 v12 v1nv21 v22 v2nv31 v32 v3n
vn1 vn2 vnn
T
Diagonale Eintrage in Σ werden als Singularwerte von A bezeichnet
Spalten in U werden als linke Singularvektoren von A bezeichnet
Spalten in V werden als rechte Singularvektoren von A bezeichnet
6
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Singularwertzerlegung
A =
a11 a12 a1n
a21 a22 a2n
am1 am2 amn
=
u11 u12 u1mu21 u22 u2m
um1 um2 umm
σ11 0 0 00 σ22 0 0
0 0 0 σmn
v11 v12 v1nv21 v22 v2nv31 v32 v3n
vn1 vn2 vnn
T
Diagonale Eintrage in Σ werden als Singularwerte von A bezeichnet
Spalten in U werden als linke Singularvektoren von A bezeichnet
Spalten in V werden als rechte Singularvektoren von A bezeichnet
6
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Konstruktionsmethodologie I
1 Berechne die quadratische mtimesm Matrix A middotAT
2 Berechne die Eigenwerte σ2i und Eigenvektoren ui von A middotAT
3 Die Vektoren ui werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von U
4 Berechne die quadratische ntimesn Matrix AT middotA5 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotATip die positiven Eigenwerte sind gleich zu denen von A middotAT
6 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) undbilden die Spaltenvektoren von V
7 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolgedie Eintrage von Σ
8 Eventuell Korrektur der Vorzeichen von U bzw V
7
Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Beispiel (aus Kirk Bakers Tutorial)
Sei
A =
(3 1 1minus1 3 1
)
8
Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt 1 Berechne A middotAT
A middotAT =
(3 1 1minus1 3 1
)3 minus11 31 1
=
(11 11 11
)
9
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
Setze (11 11 11
)middot(
x1
x2
)= σ
(x1
x2
)Damit ergibt sich das Gleichungssystem
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
10
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Ergibt z B nach Umformungen (hier Zeilenabzug)
10x1minus10x2 = σx1minusσx2
und damit Eigenwert σ1 = 10Ergibt z B nach Umformungen (hier Zeilenaddition)
12x1 + 12x2 = σx1 + σx2
und damit Eigenwert σ2 = 12
11
Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt II Bestimme die Eigenwerte und Eigenvektoren vonA middotAT
1 11x1 + x2 = σx1
2 x1 + 11x2 = σx2
Zwei Eigenwerte σ1 = 10 und σ2 = 12 Damit ergibt sich fur dieEigenvektoren
1 11x1 + x2 = 10x1
2 x1 + 11x2 = 10x2 und damit3 x1 =minusx2
4 Wir wahlen x1 = 1 und damit x2 =minus1
sowie
1 11x1 + x2 = 12x1
2 x1 + 11x2 = 12x2 und damit3 x1 = x2
4 Wir wahlen x1 = 1 und damit x2 = 112
Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt III Bestimme U
Starte mit einer Matrix U die die bestimmten Eigenvektoren von A middotAT
geordnet nach der Groszlige der jeweiligen Eigenwerte enthalt
1 Fur Eigenwert σ1 = 10 hatten wir x1 = 1 und damit x2 =minus1gewahlt
2 Fur Eigenwert σ1 = 12 hatten wir x1 = 1 und damit x2 = 1 gewahlt3 Spaltenvektoren nach Eigenwertgroszlige geordnet
U =
(1 11 minus1
)
13
Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt III Bestimme U
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von U
U =
(1 11 minus1
)
1 Normalisiere ersten Spaltenvektor u(1) = u(1)
u(1) =
(1radic2
1radic2
)2 Berechne die Senkrechte u(2)minus〈u(1) u(2)〉 middotu(1)
3 Also
(1minus1
)minus〈
(1radic2
1radic2
)
(1minus1
)〉 middot
(1radic2
1radic2
)=
(1minus1
)4 Normalisiere die Senkrechte
(1minus1
)ergibt u(2) =
(1radic2minus1radic
2
)
14
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69
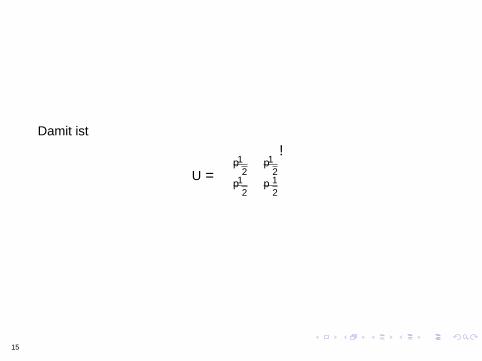
Schritt III Bestimme U
Damit ist
U =
(1radic2
1radic2
1radic2
minus1radic2
)
15
Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt IV Berechne AT middotA
AT middotA =
3 minus11 31 1
( 3 1 1minus1 3 1
)=
10 0 20 10 42 4 2
16
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Setze 10 0 20 10 42 4 2
middotx1
x2
x3
= σ
x1
x2
x3
Damit ergibt sich das Gleichungssystem
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
17
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
1 10x1 + 2x3 = σx1
2 10x2 + 4x3 = σx2
3 2x1 + 4x2 + 2x3 = σx3
Gleichung (ii) minus zweimal (i)
10x2 + 4x3minus20x1minus4x3 = σx2minus2σx2
und damit σ1 = 10
Mit ahnlichen Umformungen kann man σ2 = 12 sowie σ3 = 0berechnen
18
Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt V Bestimme die Eigenwerte und Eigenvektoren vonAT middotA
Drei Eigenwerte σ1 = 10 σ2 = 12 und σ3 = 0 Damit ergibt sich furdie Eigenvektoren
1 10x1 + 2x3 = 10x12 10x2 + 4x3 = 10x23 2x1 + 4x2 + 2x3 = 10x3 und damit4 x3 = 0 aus der ersten Gleichung und damit5 2x1 + 4x2 = 0 bzw x1 =minus2x26 Wir konnen die Lange des Eigenvektors wieder frei wahlen da
wir danach eh normalisieren Allerdings sind die Vorzeichen nichtmehr frei wahlbar da ja insgesamt bei U middotΣ middotV T wieder Aherauskommen muss Darauf macht das Tutorial nichtaufmerksamWir wahlen x1 = 2x2 =minus1 hatten aber auch(falschlicherweise)x1 =minus2x2 = 1 wahlen konnen
Ebenso bestimmen wir fur σ2 = 12 einen Eigenvektor (121) und furσ3 = 0 einen Eigenvektor (12minus5)19
Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt VI Bestimme V
Starte mit einer Matrix V die die bestimmten Eigenvektoren von AT middotAnach der Groszlige der jeweiligen Eigenwerte als Spaltenvektoren enthalt
1 Fur Eigenwert σ1 = 10 hatten wir (2minus10) gewahlt2 Fur Eigenwert σ2 = 12 hatten wir (121) bestimmt3 Fur Eigenwert σ3 = 0 hatten wir (12minus5) bestimmt4 Spaltenvektoren nach Eigenwertgroszlige geordnet
V =
1 2 12 minus1 21 0 minus5
20
Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt VI Bestimme V
Orthonormalisiere mit Gram-Schmidt die Spaltenvektoren von V
V =
1 2 12 minus1 21 0 minus5
1 Normalisiere ersten Spaltenvektor v (1) = v(1)
v(1) =
1radic6
2radic6
1radic6
2 Berechne die Senkrechte v (2)minus〈v (1) v (2)〉 middot v (1)
3 Also
2minus10
minus〈
1radic6
2radic6
1radic6
2minus10
〉 middot
1radic6
2radic6
1radic6
=
2minus10
4 Normalisiere die Senkrechte
2minus10
ergibt v (2) =
2radic5minus1radic
50
21
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69
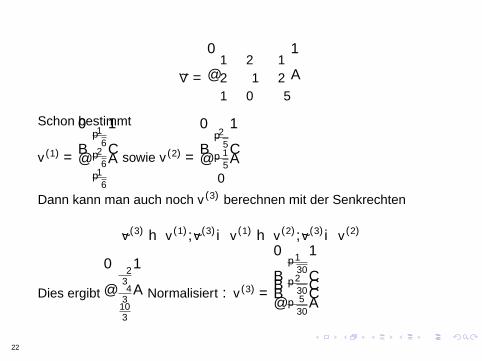
Schritt VI Bestimme V
V =
1 2 12 minus1 21 0 minus5
Schon bestimmt
v (1) =
1radic6
2radic6
1radic6
sowie v (2) =
2radic5minus1radic
50
Dann kann man auch noch v (3) berechnen mit der Senkrechten
v (3)minus〈v (1) v (3)〉 middot v (1)minus〈v (2) v (3)〉 middot v (2)
Dies ergibt
minus23minus43103
Normalisiert v (3) =
1radic302radic30minus5radic
30
22
Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt VI Bestimme V
Damit
V =
1radic6
2radic5
1radic30
2radic6
minus1radic5
2radic30
1radic6
0 minus5radic30
und damit
V T =
1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
23
Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt VII Bestimme Σ
Σ ist eine mtimesn (hier 2times3) ldquoDiagonalmatrixrdquo mit den Wurzeln derEigenwerte (von A middotAT bzw U bzw V auf der Diagonale) nach Groszligegeordnet
Σ =
(radic12 0 00
radic10 0
)
24
Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Alles Zusammen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
25
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69
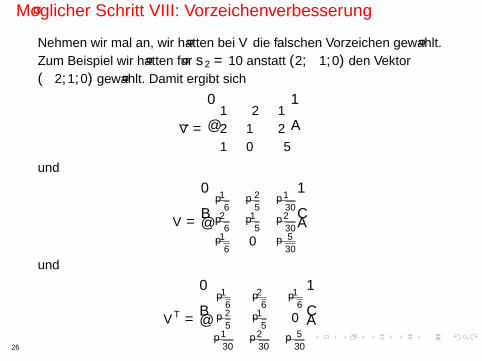
Moglicher Schritt VIII Vorzeichenverbesserung
Nehmen wir mal an wir hatten bei V die falschen Vorzeichen gewahltZum Beispiel wir hatten fur σ2 = 10 anstatt (2minus10) den Vektor(minus210) gewahlt Damit ergibt sich
V =
1 minus2 12 1 21 0 minus5
und
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
und
V T =
1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
26
Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Moglicher Schritt VIII Vorzeichenverbesserung
Leider ist nun
UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
=
(minus1 3 13 1 1
)
27
Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Moglicher Schritt VIII Vorzeichenverbesserung
Die unelegante Losung Gehe durch alle Zeilen von V T (Spalten vonV ) multizipliere sie systematisch mit minus1 bis es passt Durch dieMultiplikation mit minus1 bleiben die Vektoren immer noch normal undauch die Orthogonalitat andert sich nicht
Da eventuell auch mehrere Zeilen mit minus1 multipliziert werdenmussen ist dies leider exponentiell in der Zeilenanzahl von V T
(alle moglichen Kombinationen mussen probiert werden)
Es ist nicht gerade elegant
Man kann naturlich stattdessen auch durch die Spalten von Ugehen und diese anpassen
28
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Konstruktionsmethodologie II
1 Berechne die quadratische ntimesn Matrix AT middotA2 Berechne die Eigenwerte σ2
j und Eigenvektoren vj von AT middotA3 Die Vektoren vj werden orthonormalisiert (Gram-Schmidt) und
bilden die Spaltenvektoren von V4 Die Wurzeln der σ2-Werte werden in absteigender Reihenfolge
die Eintrage von Σ
5 Die Spaltenvektoren von U bis zum Rang r der AT middotA Matrix sindnun eindeutig bestimmt aus der Vorgabe A = UΣV T und werdendaraus berechnet
6 Wenn r lt m mussen noch mminus r Vektoren zur Orthonormalbasiserganzt werden
29
Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt I Bestimme V T und Σ wie bisher
Nach dem ublichen Verfahren sei also V T zum Beispiel1radic6
2radic6
1radic6
minus2radic5
1radic5
01radic30
2radic30
minus5radic30
bzw V
V =
1radic6
minus2radic5
1radic30
2radic6
1radic5
2radic30
1radic6
0 minus5radic30
Die Vorzeichen konnten auch anders seinWeiterhin ist
Σ =
(radic12 0 00
radic10 0
)
30
Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt II Bestimme U
Es muss gelten
A = UΣV T
und damit
AV = UΣV T V
Da V orthogonal ist V T V die Einheitsmatrix und damit
AV = UΣ
31
Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt II Bestimme U
Man bilde nun eine ntimesm Matrix Σprime die genau auf denentsprechenden Diagonaleintragen 1σi stehen hat Im Beispiel ist
Σprime =
1radic12
0
0 1radic10
0 0
Es gilt dass Σ middotΣprime die mtimesm Einheitsmatrix istUnd damit
AVΣprime = UΣΣprime = U
32
Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt II Bestimme U
Also giltU = AVΣprime
Damit gilt fur die Spalten von U wenn man sich dieMatrixmultiplikation genauer anschaut
u(j) =1σj
Av (j)
In unserem Beispiel
u(1) =1radic12
(3 1 1minus1 3 1
)1radic6
2radic6
1radic6
=
(1radic2
1radic2
)
33
Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Schritt II Bestimme U
Und ebenso
u(2) =1radic10
(3 1 1minus1 3 1
)minus2radic
51radic5
0
=
(minus1radic2
1radic2
)
Man sieht dass sich hier das veranderte Vorzeichen von v (2) imentgegengesetzten Vorzeichen von u(2) widerspiegelt Wir musstenauch nicht zweimal Eigenvektoren berechnen sondern U ist aus denvorherigen Berechnungen bestimmt
34
Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Beispiel mit einer Matrix mit niedrigerem Rang
Da wir durch 1σj
dividieren mussten geht dies nur fur Eigenwerteungleich Null Wenn aber die Matrizen niedrigere Range haben als mdann bekommen wir so nicht genugend U-Vektoren Was machen wirdann
Beispiel Sei eine Matrix von Rang 1 gegeben
A =
(1 01 0
)
35
Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Berechnung von V
AT A =
(1 10 0
)(1 01 0
)=
(2 00 0
)
36
Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Berechnung von V
(2 00 0
)hat die Eigenwerte 2 und 0 mit den jeweiligen Eigenvektoren (10)sowie (01)Daraus folgt
V =
(1 00 1
)Die ist schon eine Orthonormalmatrix also gilt V = V sowie daDiagonalmatrix V T = V
37
Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Bestimmung von Σ
Es gilt
Σ =
(radic2 0
0 0
)
38
Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Bestimmung von U
Der erste Spaltenvektor u(1) kann wie ublich bestimmt werden mit
u(1) =1radic2
Av (1) =1radic2
(1 01 0
)(10
)
=1radic2
(11
)=
(1radic2
1radic2
)
39
Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Bestimmung von U
Da wir keinen weiteren Eigenwert 6= 0 haben konnen wir leider sonicht weitermachen dh es geht nur bis zum Rang von A Es gilt aber(
1radic2
x21radic2
y2
)(radic2 0
0 0
)(1 00 1
)
=
(1 01 0
)= A
unabhangig von x2 und y2 Das heisst unser halb vollstandiges U istgenug fur eine Zerlegung
40
Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Bestimmung von U
1 Wir konnen also jedes x2 und y2 wahlen solange normiert undsenkrecht auf dem ersten Vektor stehend
2 Nach dem sogenannten Basiserganzungssatz geht dies immer3 In unserem Beispiel konnte man zum Beispiel (minus1radic
2 1radic
2) wahlen
4 Wie genau man diese weiteren Vektoren von U konstruiert ist furuns unerheblich da wir ja sowieso die letzten Spalten von U diezu den niedrigeren Eigenwerten gehoren ldquoabschneidenrdquowerden
41
SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

SVD Zwischenfazit
Wir haben eine Matrix in das Produkt einer OrthonormalmatrixDiagonalmatrix und Orthogonalmatrix zerlegt
Die Diagonalmatrix enthalt die Wurzeln von den Eigenwerten vonA middotAT nach Groszlige geordnet
Die erste Orthonormalmatrix enthalt die orthonormalisiertenEigenvektoren von A middotAT nach Eigenwertgrosse geordnet alsSpalten
Die zweite Orthonormalmatrix ist die Transponierte der Matrixdie die orthonormalisierten Eigenvektoren von AT middotA nachEigenwertgrosse geordnet als Spalten enthalt
42
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
43
Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Geometrische Interpretation bei quadratischen Matrizen
Bedeutung der SVD ist dass sich die Funktion in eine DrehungDrehspiegelung (V T )eine Verzerrung (Σ) und eine zweite DrehungDrehspiegelung (U) zerlegen lsst
Matrix
(1 10 1
)SVD Geometrische Interpretationa
aQuelle httpscommonswikimediaorgwikiFileSingular-Value-Decompositionsvg
44
Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Noch einige Bemerkungen
Die Eigenwerte und damit Σ sind eindeutig bestimmt
U und V sind nicht eindeutig bestimmt Es konnen Drehungenum 180 Grad oder Spiegelungen hinzukommen
Wir konnen in vielen Fallen einen Eigenvektor wahlen(Freiheitsgrade) mussen aber dann bei den Vorzeichen derzweiten Matrix aufpassen
45
Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Noch einige Bemerkungen
Wir haben implizit den Rang der Ursprungsmatrix A bestimmtDies kann man klar an U middotΣ sehen
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
radic10radic2
0radic
12radic2
minusradic
10radic2
0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(3 1 1minus1 3 1
)
46
Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Noch einige Bemerkungen
Deswegen wird manchmal die Singularwertzerlegung auch alsZerlegung in drei Matrizen Amtimesn = Umtimesr Σrtimesr V T
rtimesn wobei r der Rangder Matrix A ist beschrieben
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 00
radic10
)( 1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(radic12radic2
radic10radic2radic
12radic2
minusradic
10radic2
)(1radic6
2radic6
1radic6
2radic5
minus1radic5
0
)=
(3 1 1minus1 3 1
)47
Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Noch einige Bemerkungen
Bisher haben wir immer die Ausgangsmatrix einfach reproduziert(mit dem gleichen Rang) Man sieht den Rang besser und es gilt
Die ldquoZerrungrdquo durch die Matrix Σ ist bei den Dimensionen mit denhochsten Eigenwerten am groszligten Beispiel
(radic12 0 00
radic10 0
)x1
x2
x3
=
(radic12 middot x1radic10 middot x2
)Es macht also Sinn dass wir wenn wir eine Approximationunserer Ausgangsmatrix mit niedrigerem Rang wollen dann dieunwichtigen Dimensionen die durch niedrige Eigenwertegekennzeichnet sind weglassen
48
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
49
Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Reduced SVD Approximation niedrigeren Ranges
Approximation von mtimesn Matrix A mit Rang r durch mtimesn -Matrix Ak mit Rang k lt r
A = UΣV T asymp Ak = UΣk V T
Σk ist eine ldquodiagonalerdquo mtimesn - Matrix bei der nur auf den erstenk Stellen der Diagonalmatrix Werte 6= 0 stehen
U und V wie zuvor
50
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69
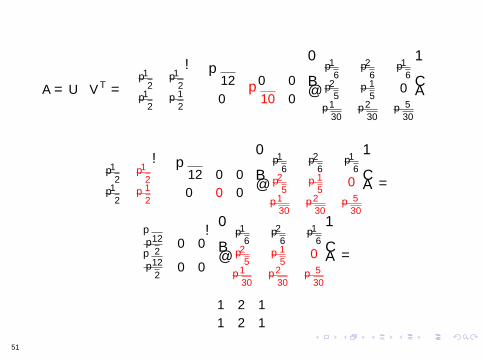
Beispiel
A = UΣV T =
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00
radic10 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
asymp
(1radic2
1radic2
1radic2
minus1radic2
)(radic12 0 00 0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(radic12radic2
0 0radic
12radic2
0 0
)1radic6
2radic6
1radic6
2radic5
minus1radic5
01radic30
2radic30
minus5radic30
=
(1 2 11 2 1
)51
Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Reduced SVD
Wir hatten auch nur die ersten k Spalten von U sowie die ersten kZeilen von V T behalten konnen
Aasymp
(1radic2
1radic2
)(radic12)( 1radic
62radic6
1radic6
)=
(radic12radic2radic
12radic2
)(1radic6
2radic6
1radic6
)=
(1 2 11 2 1
)
52
Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Als Bild
53
Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Als Algorithmus
Gegeben mtimesn Matrix A und gewunschter Rank k Wir produziereneine Rangminus k Approximation wie folgt
1 Wir berechnen eine SVD Zerlegung von A
Amtimesn = UmtimesmΣmtimesnV Tntimesn
2 Wir behalten nur die ersten k Spalten von U resultierend in Umtimesk
3 Wir behalten nur die Top k sprich die ersten k Diagonalwerte vonΣ resultierend in Σktimesk
4 Wir behalten nur die ersten k Reihen von V T resultierend in V Tktimesn
54
Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Reduced SVD
Diagonale Eintrage in Σk sind die k groszligten Eigenwerte vonA middotAT
Satz UΣk V T minimiert die Differenz der Frobenius-Normzwischen A und Ak unter der Bedingung rang(Ak ) = k
Das heisst Fur jede mtimesn Matrix A mit Rang r angestrebtemRang k lt r und jede mtimesn Matrix B mit Rang k gilt
Aminus Ak2 le AminusB2
wobei Ak die Rang-k Approximation ist die man aus der SVD vonA ableiten kann
55
Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Was hat man erreicht
Unkorrelierte Dimensionen (Orthonormalbasis) die nur nochverzerrt werden
Wir haben die Dimensionen mit der meisten Variation identifiziertund danach geordnet
ldquoUnwichtigerdquo Dimensionen werden weggelassenrarr Rauschenvermindert
Man braucht viel weniger Speicherplatz O(k(n + m)) anstattO(nm)
Die neuen ldquoverstecktenrdquo Dimensionen konnen zurAhnlichkeitsberechnung verwendet werden und funktionieren oftbesser
56
Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Wie wahlt man k
Meist empirisch Gesehen
1 In NLP oft die ersten 200 bis 300 Dimensionen2 In Recommender Systems Wahle k so dass die Summe der
ersten k Eigenwerte mindestens 10-mal der Summe alleranderen Eigenwerte
57
Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Ubersicht
1 SVD HauptsatzDer SVD-SatzKonstruktion am Beispiel Methodologie IKonstruktionsmethodologie II
2 Interpretation der SVD
3 Reduced SVD
4 Verwendung in NLP
58
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Dichte Embeddings
A ist Matrix von m WorternTermen und n Kontexten (PPMIfrequency )Reduced SVD resultiert in Ak mit
Umtimesk ist mtimes k - MatrixZeilen von Umtimesk reprasentieren TermeSpalten in Umtimesk latente Reprasentation der KontexteBenutze Umtimesk middotΣktimesk zur Berechnung von Termahnlichkeiten
Vorteile gegenuber der vollen Term-Kontext-MatrixDichte MatrixDimensionsreduktion effizientere VerarbeitungDe-Noising
59
Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Das Beispiel vom Anfang
Eine Wort-Dokument-Matrix M aus dem R5times3
d1 d2 d3ship 1 1 0boat 0 0 1
ocean 1 0 1motor 1 0 1wood 0 1 0
cossim(shipboat) = 0
cossim(shipocean) =12
cossim(boatocean) =1radic2
= 07
60
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69
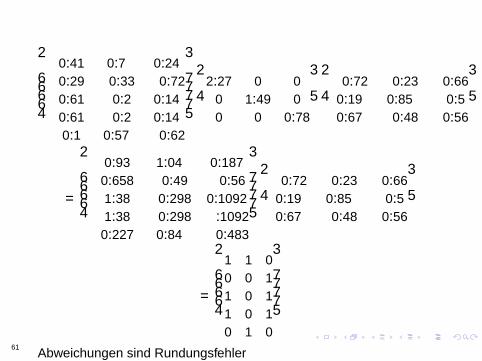
SVD Zerlegung war
minus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 078
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0187minus0658 minus049 minus056minus138 minus0298 01092minus138 minus0298 minus1092minus0227 084 minus0483
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
1 1 00 0 11 0 11 0 10 1 0
Abweichungen sind Rundungsfehler61
Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Niedrigdimensionale Approximation
Die kleinsten Eigenwerte sind die unwichtigsten Wir konnen dieseldquoweglassenrdquo = auf Null setzenrarr eine Matrix mit kleinerem Rang dieaber relativ ahnlich zur Ausgangsmatrix istminus041 07 024minus029 minus033 minus072minus061 minus02 014minus061 minus02 014minus01 057 minus062
227 0 0
0 149 00 0 0
minus072 minus023 minus066019 085 minus05067 minus048 minus056
=
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
minus072 minus023 minus066
019 085 minus05067 minus048 minus056
=
087 109 011038 minus027 068093 005 106093 005 106032 077 minus027
62
Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Die niedrigdimensionale Approximation
Wir interessieren uns fur die Matrix U2 = UΣ2 also die Matrix mit demniedrigerem Rang
minus093 104 0minus0658 minus049 0minus138 minus0298 0minus138 minus0298 0minus0227 084 0
Man kann diese nun als die Reprasentation unserer 5 Worter mit zweiversteckten Dimensionen auffassen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
63
Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Neue Ahnlichkeitsberechnungen
h1 h2ship minus093 104boat minus0658 minus049
ocean minus138 minus0298motor minus138 minus0298wood minus0227 084
cossim(shipboat) =(minus093) middot (minus0658) + 104 middot (minus049)radic
(0932 + 1042) middotradic
(06582 + 0492)= 009
cossim(shipocean) =(minus093) middot (minus138) + 104 middot (minus029)radic
(0932 + 1042) middotradic
(1382 + 0292)= 049
cossim(boatocean) = 09
64
Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Variationen
Benutze nur Umtimesk zur Ahnlichkeitsberechnung
Benutze Umtimesk middotΣpktimesk zur Ahnlichkeitsberechnungrarr Parameter p
sollte getuned werden Kann groszlige Unterschiede machen
Oft p = 0p = 05p = 1
65
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69
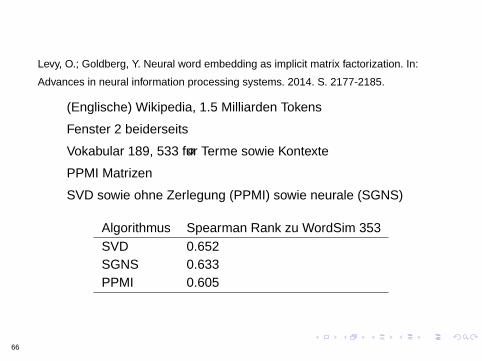
Performanz der Reduced-SVD-Embeddings
Levy O Goldberg Y Neural word embedding as implicit matrix factorization In
Advances in neural information processing systems 2014 S 2177-2185
(Englische) Wikipedia 15 Milliarden Tokens
Fenster 2 beiderseits
Vokabular 189 533 fur Terme sowie Kontexte
PPMI Matrizen
SVD sowie ohne Zerlegung (PPMI) sowie neurale (SGNS)
Algorithmus Spearman Rank zu WordSim 353SVD 0652SGNS 0633PPMI 0605
66
Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Latent Semantic Analysis und Word Embeddings
Levy2014
ldquoWe analyze skip-gram with negative-sampling (SGNS) [] and show that it isimplicitly factorizing a word-context matrix whose cells are the pointwise mutualinformation (PMI) of the respective word and context pairs shifted by a globalconstant When dense low-dimensional vectors are preferred exact factorizationwith SVD can achieve solutions that are at least as good as SGNSrsquoss solutions forword similarity tasks On analogy questions SGNS remains superior to SVD Weconjecture that this stems from the weighted nature of SGNSrsquos factorizationrdquo
67
Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Zusammenfassung
Reduced SVD resultiert in einer optimalen Approximation derOriginalmatrix mit niedrigerem Rang Optimal = optimal bzgl derFrobeniusnorm (bzw mean squared error)
Dadurch erhalten wir eine mathematisch fundierte dichtereMatrix die Rauschen (weniger wichtige Dimensionen) eliminiert
Wir konnen mittels Umtimesk Σktimesk weiterhin Wortahnlichkeitenberechnen
Es konnen Resultate erreicht werden die bei word similaritymindestens ebensogut sind wie mit neuralen word embeddings
Nachteile Kosten der SVD Berechnung fur mtimesn matrixO(n middotm2) (when m lt n)rarr Nicht gut fur sehr grosse Matrizen
Nachteile Geht nicht gut mit unbekannten Wortern um
Nachteile schlechter bei Wortanalogieaufgaben
68
Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69

Literatur
Guter erweiterter Hintergrundhttptheorystanfordedu˜tims15ll7pdf bishttptheorystanfordedu˜tims15ll9pdf
SVD Tutorial (ohne vollstandigen Hintergrund) Kirk Baker(2005) Singular Value Decomposition Tutorialhttpsdatajobscomdata-science-repoSVD-Tutorial-[Kirk-Baker]pdf Leider ist hier imKonstruktionsverfahren I die Vorzeichenproblematikfalschlicherweise nicht behandelt worden
Levy O Goldberg Y Neural word embedding as implicit matrixfactorization In Advances in neural information processingsystems 2014 S 2177-2185
Ubungsblatt II
69
Recommended







![0001B451 [Schreibgeschützt] [Kompatibilitätsmodus]2012.werkstaettentag.de/.../volkswagen_work2work.pdfWerksplan Wolfsburg 19. März 2012 Abteilung: K-SVD/1. 19. März 2012 Abteilung:](https://img.pdfslide.org/doc/110x75/60993e42b8f8345b80476bd3/0001b451-schreibgeschtzt-kompatibilittsmodus2012-werksplan-wolfsburg-19.jpg)









