Embed Size (px)
Citation preview

Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
Digitale Kuratierungstechnologien: Anwendungsfälle in
Digitalen Bibliotheken
Georg [email protected] GmbH, Berlin
Clemens [email protected]
Staatsbibliothek zu Berlin

Überblick• Was ist digitale Kuratierung? • BMBF-Projekt Digitale Kuratierungstechnologien• DFKI-Teilprojekt • Digitale Kuratierung in Bibliotheken• Ausblick und Schlussfolgerungen
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 2

Was ist digitale Kuratierung?
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
Information
Information
Information
Information
Information
Information
Information
Information
Information
Information
3

Was ist digitale Kuratierung?
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
Information
Information
Information
Information
Information
Information
Information
Information
Information? ?
??Information
4

Was ist digitale Kuratierung?
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
Information
Information
Information
Information
Information
Information
Information
Information
Information? Information
OutputInput SoftwareProzesse
?
??
5
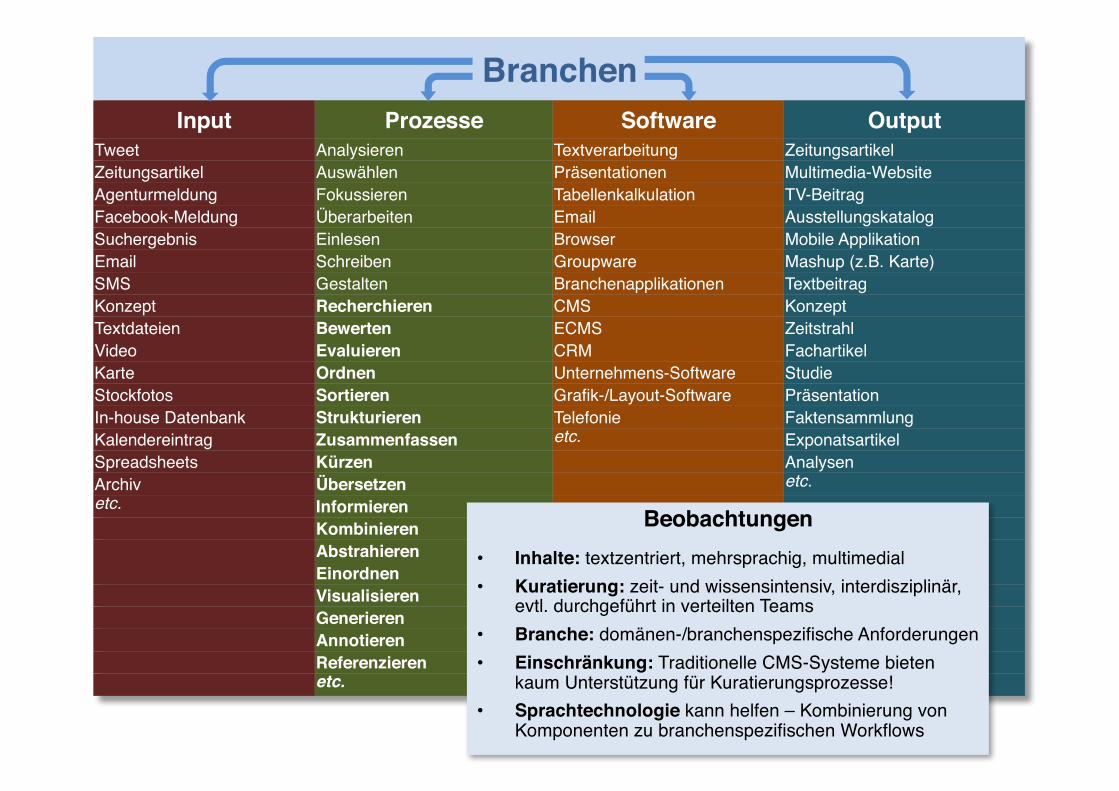
BranchenInput Prozesse Software Output
Tweet Analysieren Textverarbeitung ZeitungsartikelZeitungsartikel Auswählen Präsentationen Multimedia-WebsiteAgenturmeldung Fokussieren Tabellenkalkulation TV-BeitragFacebook-Meldung Überarbeiten Email AusstellungskatalogSuchergebnis Einlesen Browser Mobile Applikation Email Schreiben Groupware Mashup (z.B. Karte)SMS Gestalten Branchenapplikationen TextbeitragKonzept Recherchieren CMS KonzeptTextdateien Bewerten ECMS ZeitstrahlVideo Evaluieren CRM FachartikelKarte Ordnen Unternehmens-Software StudieStockfotos Sortieren Grafik-/Layout-Software PräsentationIn-house Datenbank Strukturieren Telefonie FaktensammlungKalendereintrag Zusammenfassen etc. ExponatsartikelSpreadsheets Kürzen AnalysenArchiv Übersetzen etc.etc. Informieren
KombinierenAbstrahierenEinordnenVisualisierenGenerierenAnnotierenReferenzierenetc.
Beobachtungen• Inhalte: textzentriert, mehrsprachig, multimedial• Kuratierung: zeit- und wissensintensiv, interdisziplinär,
evtl. durchgeführt in verteilten Teams• Branche: domänen-/branchenspezifische Anforderungen• Einschränkung: Traditionelle CMS-Systeme bieten
kaum Unterstützung für Kuratierungsprozesse!• Sprachtechnologie kann helfen – Kombinierung von
Komponenten zu branchenspezifischen Workflows

DKT Kick-off-Veranstaltung – 25. September 2015
Georg Rehm und Felix Sasaki. “Digital Curation Technologies.” In Proceedings of the 19th Annual Conference of the European Association for Machine Translation (EAMT 2016), Riga, Lettland, Mai 2016
Georg Rehm und Felix Sasaki. “Digitale Kuratierungstechnologien – Verfahren für die effiziente Verarbeitung, Erstellung und Verteilung qualitativ hochwertiger Medieninhalte.” In Proceedings der Frühjahrstagung der Gesellschaft für Sprachtechnologie und Computerlinguistik (GSCL 2015), S. 138-139, Duisburg, 2015
• Unterstützung und Optimierung digitaler Kuratierung durch Sprach- und Wissenstechnologien.
• Entwicklung innovativer Prototypen bei den KMU-Partnern.• Weiterentwicklung der DFKI-Technologien und Transfer mittels
Plattform für digitale Kuratierungstechnologien.
Sprach- und Wissenstechnologien
Kuratierungstechnologien
Branchentechnologien
Plat
tform
tech
nolo
gie
Branchenlösungen
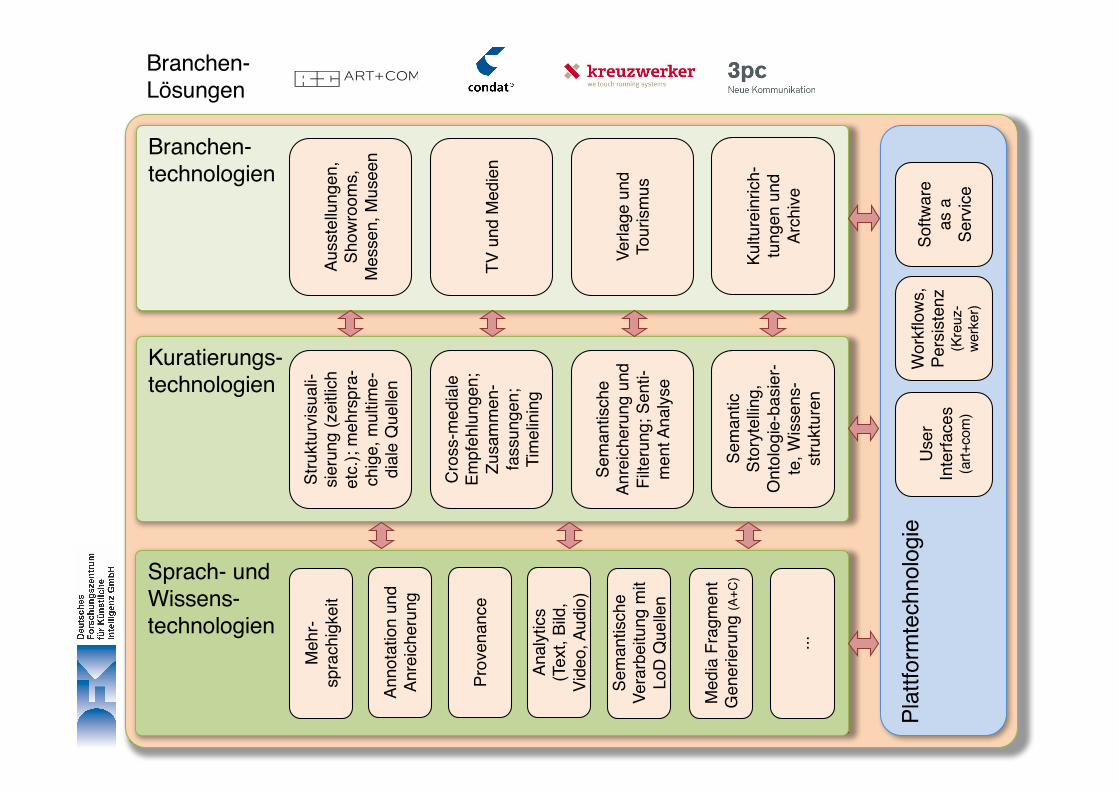
Sprach- und Wissens-technologien
Anno
tatio
n un
d An
reic
heru
ng
Prov
enan
ce
Anal
ytic
s(T
ext,
Bild
,Vi
deo,
Aud
io)
Sem
antis
che
Vera
rbei
tung
mit
LoD
Que
llen
Meh
r-sp
rach
igke
it
Med
ia F
ragm
ent
Gen
erie
rung
(A+C
)
Kuratierungs-technologien
Branchen-technologien
Plat
tform
tech
nolo
gie
Auss
tellu
ngen
, Sh
owro
oms,
M
esse
n, M
usee
n
TV u
nd M
edie
n
Verla
ge u
nd
Tour
ism
us
Kultu
rein
rich-
tung
enun
d Ar
chiv
e
Wor
kflo
ws,
Pe
rsis
tenz
(K
reuz
-we
rker
)
Use
r In
terfa
ces
(art+
com
)
Softw
are
asa
Serv
ice
Branchen-Lösungen
...
Stru
ktur
visu
ali-
sier
ung
(zei
tlich
et
c.);
meh
rspr
a-ch
ige,
mul
time-
dial
eQ
uelle
n
Cro
ss-m
edia
le
Empf
ehlu
ngen
; Zu
sam
men
-fa
ssun
gen;
Ti
mel
inin
g
Sem
antis
che
Anre
iche
rung
und
Fi
lteru
ng; S
enti-
men
tAna
lyse
Sem
antic
Stor
ytel
ling,
O
ntol
ogie
-bas
ier-
te, W
isse
ns-
stru
ktur
en

Visualisierung, UIs, Ausstellungskuratierung
Kuratierung für Medien-Redaktionen durch innovative Empfehlungen
Semantic Story Tellingfür Online-Redaktionen
Journalistische Kuratierungsworkflows für die digitalen Geschäftsmodelle klassischer Printmedien
Sprach- und Wissenstechnologien als Basis digitaler Kuratierungstechnologien
DKT besteht aus fünf Teilprojekten
Branche:Museen, Showrooms,Ausstellungen
Branche:TV, Radio, Web-TV, Medien
Branche:Öffentliche Archive
Branche:Journalismus
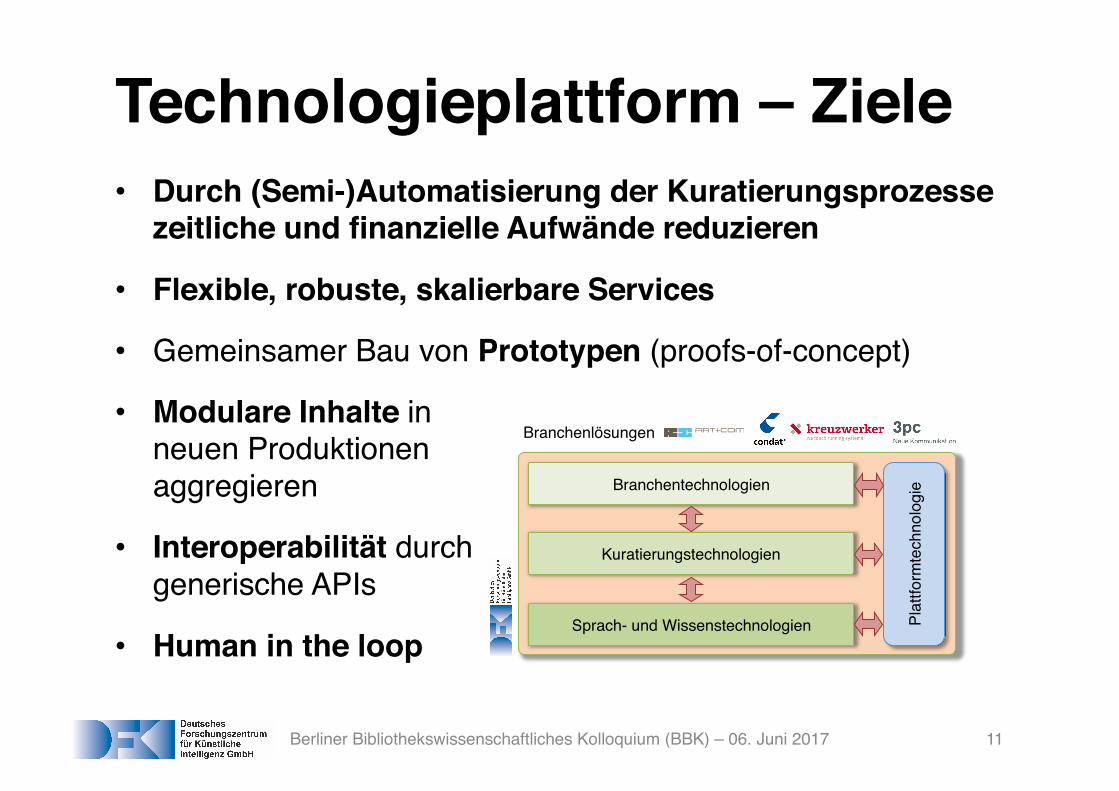
Technologieplattform – Ziele• Durch (Semi-)Automatisierung der Kuratierungsprozesse
zeitliche und finanzielle Aufwände reduzieren
• Flexible, robuste, skalierbare Services
• Gemeinsamer Bau von Prototypen (proofs-of-concept)
• Modulare Inhalte in neuen Produktionen aggregieren
• Interoperabilität durch generische APIs
• Human in the loop
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
Sprach- und Wissenstechnologien
Kuratierungstechnologien
Branchentechnologien
Plat
tform
tech
nolo
gie
Branchenlösungen
11

Die DFKI-Forschungsthemen• Semantische Analyse und Generierung, Mehrsprachigkeit• Integration von Nutzerfeedback in Kuratierungsservices• Domänenadaptierbarkeit: individuelles Training und
nutzerzentrische Anpassungsmöglichkeiten• Interoperabilität aller Services• Harmonisierung von Datenformaten• Hohe Qualität und Präzision• Kuratierungs-Dashboard
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
DFKI-Teilprojekt: Sprach- und Wissenstechnologien als Basis digitaler Kuratierungstechnologien
12
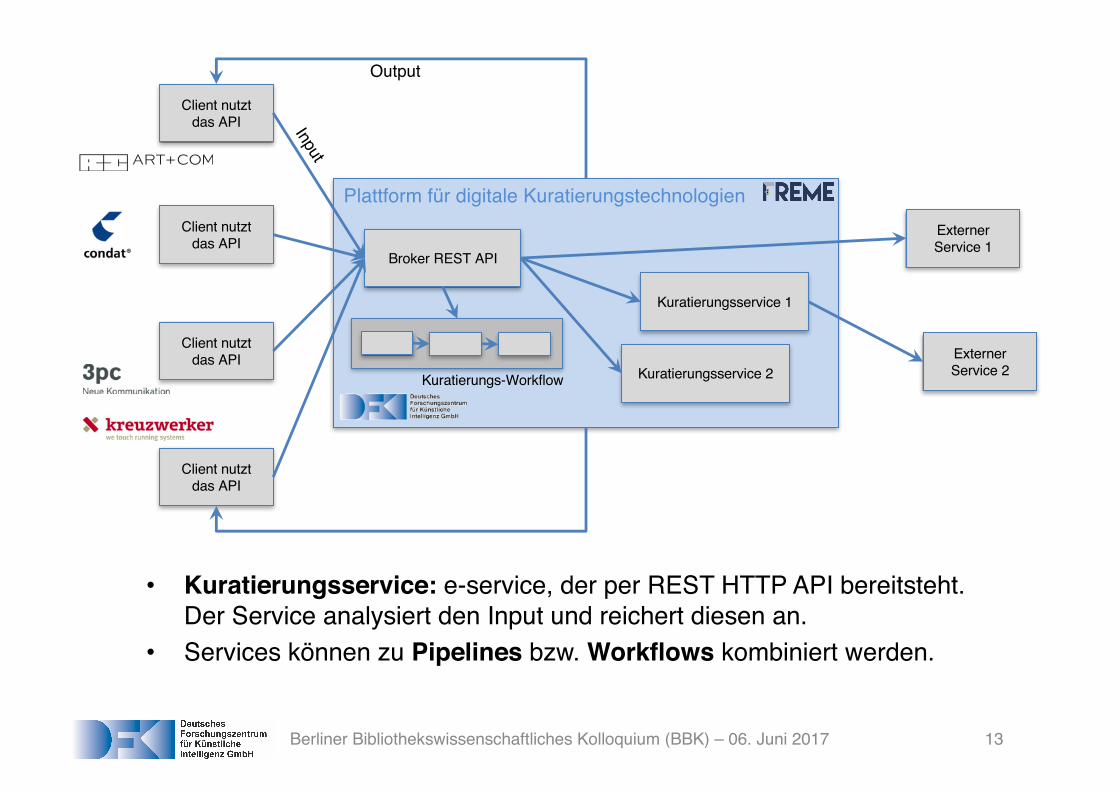
Plattform für digitale Kuratierungstechnologien
Broker REST API
Kuratierungsservice 1
Kuratierungsservice 2
Client nutztdas API
ExternerService 1
ExternerService 2
Client nutztdas API
Client nutztdas API
Client nutztdas API
Kuratierungs-Workflow
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
• Kuratierungsservice: e-service, der per REST HTTP API bereitsteht. Der Service analysiert den Input und reichert diesen an.
• Services können zu Pipelines bzw. Workflows kombiniert werden.
Output
13

Aktueller Stand• Plattform: Services und Service-Workflows• Implementierte Kuratierungsservices:
– Named Entity Recognition – e-entityrecognition e-service – Geolocation – e-entityrecognition, Visualisierung– Temporal Analyser – e-entityrecognition, Visualisierung– Classification – e-classification e-service– Clustering – e-clustering e-service– Textzusammenfassen– e-summarisation e-service– Maschinelle Übersetzung – e-translation e-service– Sentiment Analysis – work in progress– Event Extraction – work in progress– Semantic Storytelling – work in progress
• Kuratierungs-Dashboard: Erster Prototyp
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 14

NER, Linking, Geolokalisierung
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
...In the Viking colony of Iceland, an extraordinary vernacular literature blossomed in the 12th through 14th centuries......The ships were scuttled there in the 11th century, to block anavigation channel and thusprotect Roskilde, thenCopenhagen from seaborne assault......Viking Age inscriptions havealso been discovered on theManx runestones on theIsle of Man.…
Plain Text NIF-Anreicherung Visualisierunghttp://api.digitale-kuratierung.de/api/e-nlp/namedEntityRecognition?analysis=ner http://http://dev.digitale-kuratierung.de/admini/pages/geolocalization.php
• Modus 1: Modell-basiert (für Domänen, für die annotierte Trainingsdaten verfügbar sind)
• Modus 2: Wörterbuch-basiert (für Domänen, für die lediglich Namenslisten verfügbar sind)
• Basiert auf OpenNLP (mit NIF-Integration)
• Entity-Linking durch SPARQL-Querys auf DBPedia.• Für Lokationen werden GPS-Koordinaten bezogen. • Es werden Durchschnittsangaben berechnet auf
Dokumentebene (über alle Lokationen), um diese auf einer Karte visualisieren zu können.
Geolokalisierung als visuelles Zusammenfassen!
15
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
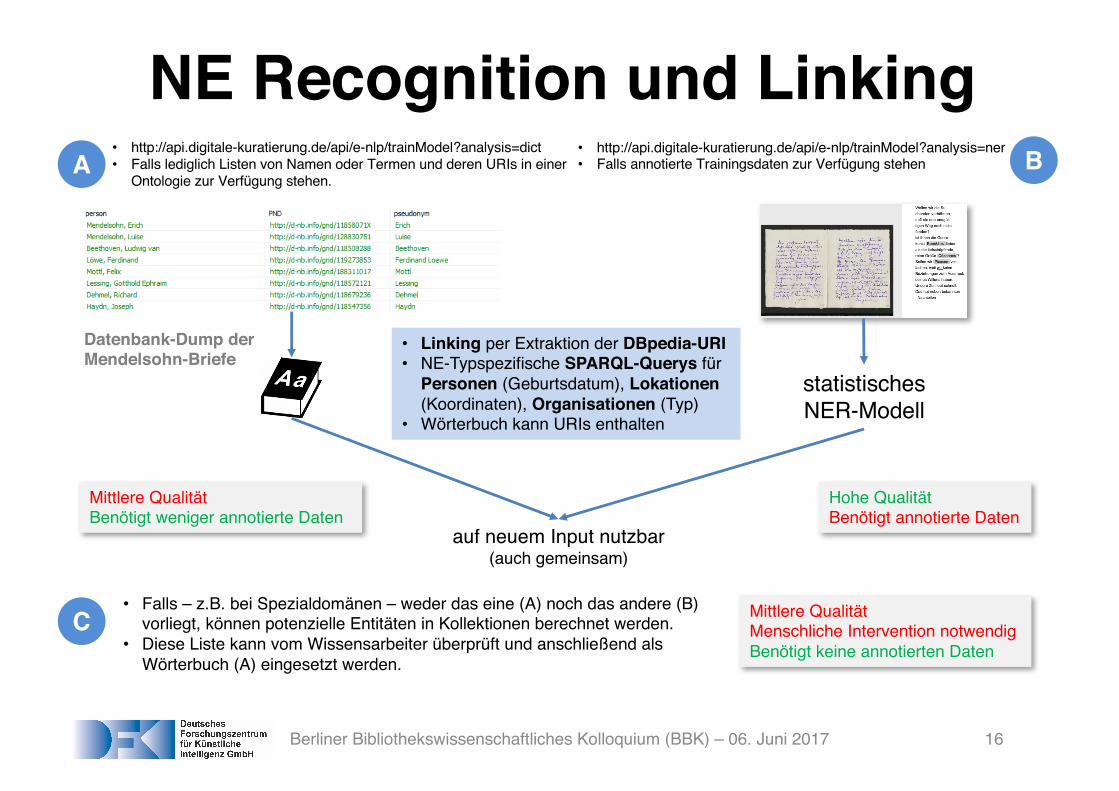
NE Recognition und Linking• http://api.digitale-kuratierung.de/api/e-nlp/trainModel?analysis=dict• Falls lediglich Listen von Namen oder Termen und deren URIs in einer
Ontologie zur Verfügung stehen.
• http://api.digitale-kuratierung.de/api/e-nlp/trainModel?analysis=ner• Falls annotierte Trainingsdaten zur Verfügung stehen
auf neuem Input nutzbar(auch gemeinsam)
statistischesNER-Modell
Datenbank-Dump der Mendelsohn-Briefe
Hohe QualitätBenötigt annotierte Daten
Mittlere QualitätBenötigt weniger annotierte Daten
• Falls – z.B. bei Spezialdomänen – weder das eine (A) noch das andere (B) vorliegt, können potenzielle Entitäten in Kollektionen berechnet werden.
• Diese Liste kann vom Wissensarbeiter überprüft und anschließend als Wörterbuch (A) eingesetzt werden.
Mittlere Qualität Menschliche Intervention notwendigBenötigt keine annotierten Daten
A B
C
• Linking per Extraktion der DBpedia-URI• NE-Typspezifische SPARQL-Querys für
Personen (Geburtsdatum), Lokationen (Koordinaten), Organisationen (Typ)
• Wörterbuch kann URIs enthalten
16
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
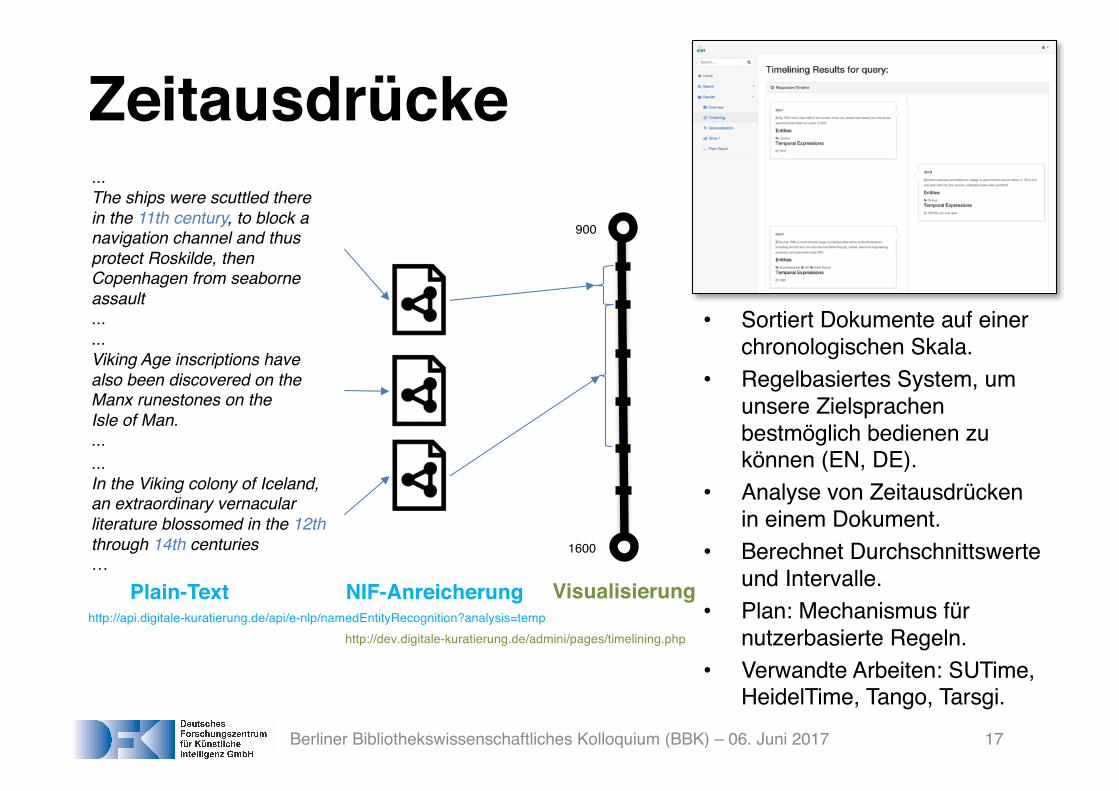
Zeitausdrücke...The ships were scuttled there in the 11th century, to block anavigation channel and thusprotect Roskilde, thenCopenhagen from seaborne assault......Viking Age inscriptions havealso been discovered on theManx runestones on theIsle of Man.......In the Viking colony of Iceland, an extraordinary vernacular literature blossomed in the 12ththrough 14th centuries…
900
1600
http://api.digitale-kuratierung.de/api/e-nlp/namedEntityRecognition?analysis=temphttp://dev.digitale-kuratierung.de/admini/pages/timelining.php
Plain-Text NIF-Anreicherung Visualisierung
• Sortiert Dokumente auf einer chronologischen Skala.
• Regelbasiertes System, um unsere Zielsprachen bestmöglich bedienen zu können (EN, DE).
• Analyse von Zeitausdrücken in einem Dokument.
• Berechnet Durchschnittswerte und Intervalle.
• Plan: Mechanismus für nutzerbasierte Regeln.
• Verwandte Arbeiten: SUTime, HeidelTime, Tango, Tarsgi.
17
Maschinelle Übersetzung
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
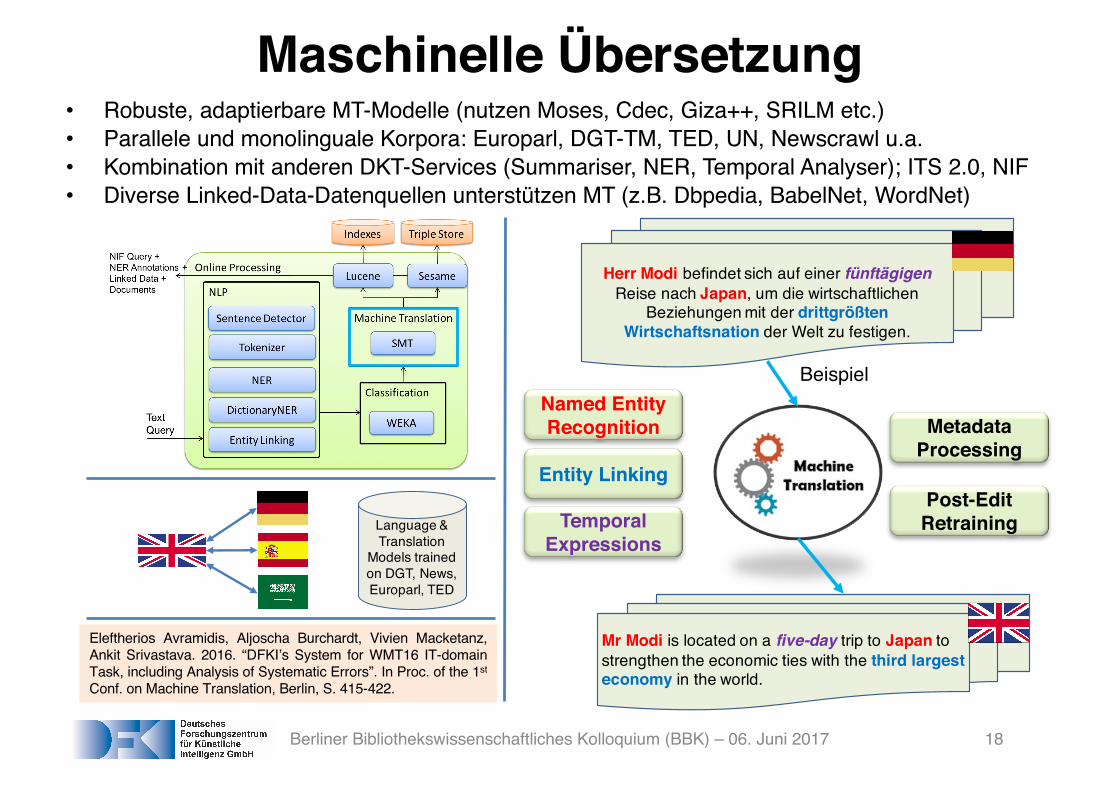
Workflow
Language & Translation
Models trained on DGT, News, Europarl, TED
Herr Modi befindet sich auf einer fünftägigenReise nach Japan, um die wirtschaftlichen
Beziehungen mit der drittgrößtenWirtschaftsnation der Welt zu festigen.
Mr Modi is located on a five-day trip to Japan to strengthen the economic ties with the third largest economy in the world.
Named Entity Recognition
Entity Linking
Temporal Expressions
Metadata Processing
Post-Edit Retraining
Beispiel
• Robuste, adaptierbare MT-Modelle (nutzen Moses, Cdec, Giza++, SRILM etc.)• Parallele und monolinguale Korpora: Europarl, DGT-TM, TED, UN, Newscrawl u.a.• Kombination mit anderen DKT-Services (Summariser, NER, Temporal Analyser); ITS 2.0, NIF• Diverse Linked-Data-Datenquellen unterstützen MT (z.B. Dbpedia, BabelNet, WordNet)
Eleftherios Avramidis, Aljoscha Burchardt, Vivien Macketanz,Ankit Srivastava. 2016. “DFKI’s System for WMT16 IT-domainTask, including Analysis of Systematic Errors”. In Proc. of the 1st
Conf. on Machine Translation, Berlin, S. 415-422.
Workflow
Language & Translation
Models trained on DGT, News, Europarl, TED
18

Textanalytik für bessere MT
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
Ankit Srivastava, Felix Sasaki, Peter Bourgonje, Julian Moreno-Schneider, Jan Nehring, undGeorg Rehm. 2016. “How to Configure Statistical Machine Translation with Linked Open DataResources”. In Proc. of Translating and Computer 38. London, November. Im Druck.
Quellsprache: Englisch1. A European Commission spokesman …2. MS Paint is a good option.
Zielsprache: Deutsch1. Ein Sprecher der European Commission …2. Frau Farbe ist eine gute wahl.
• Korrektur von Übersetzungsfehlern durch Textanalytik.• Unbekanntes Wort: “European Commission” sollte als „Europäische
Kommission“ übersetzt werden. Übersetzung kann aus Dbpedia bezogen werden.• Disambiguierung: “MS Paint” wird als Person und nicht als Produktname erkannt.
Lösung: Term wird als benannte Entität getaggt und bleibt unübersetzt.
19

Textzusammenfassen
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
Die Aktie der RWE AG fiel am Donnerstag um 0,21% auf 19,16 EUR und schwankte am Handelstag zwischen 19,08 und 19,32 EUR. Das Handelsvolumen der Aktie lag bei 1,79 Millionen Aktien und so unter dem 52-Wochen und 150-Tagesvolumen von 3,40 Millionen bzw. 3,96 Millionen Aktien. Im letzten Monat und den letzten 3 Monaten verlor die RWE-Aktie 3,79% bzw. 18,95% und in den letzten 3 Tagen 3,55%. Das PE und PB-Verhältnis der Unternehmensaktie liegt aktuell bei 11,44 bzw. 1,29, während die historischen PE und PB-Werte jeweils bei 11,77 bzw. 2,13 liegen.
Im letzten Monat und den letzten 3 Monaten verlor die RWE-Aktie 3,79% bzw. 18,95% und in den
letzten 3 Tagen 3,55%.
• Kuratierungsservice rankt Sätze – basierend auf div. Features – hinsichtlich ihrer Wichtigkeit.
• Modul ist in der Entwicklung.
• Beispiel: Artikel über den fallenden Aktienkurs von RWE (Daten stammen von Condat).
• Ausblick: Integration der Analyseergebnisse anderer DKT-Services in den Algorithmus.
20

Semantic Storytelling• Wichtige Funktionalität in allen KMU-Partner-Use Cases:
Automatisches Hyperlinking von Dokumentkollektionen• Input: Kohärente, in sich geschlossene Kollektion• Output: Angereicherte Kollektion, die als Hypertext zugreifbar
ist – für effizientes und intuitives Browsing• Semantic Storytelling – arbeitet auf diesem Hypertextgraph,
den wir auf der ursprünglichen Kollektion erzeugen• Ermöglicht multiple Rezeptionspfade durch die Kollektion• Semantic Storytelling ist die Identifizierung, das Ranking
und die Empfehlung sinnvoller Hypertextpfade• Es gibt noch zahlreiche Herausforderungen ...
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 21

Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
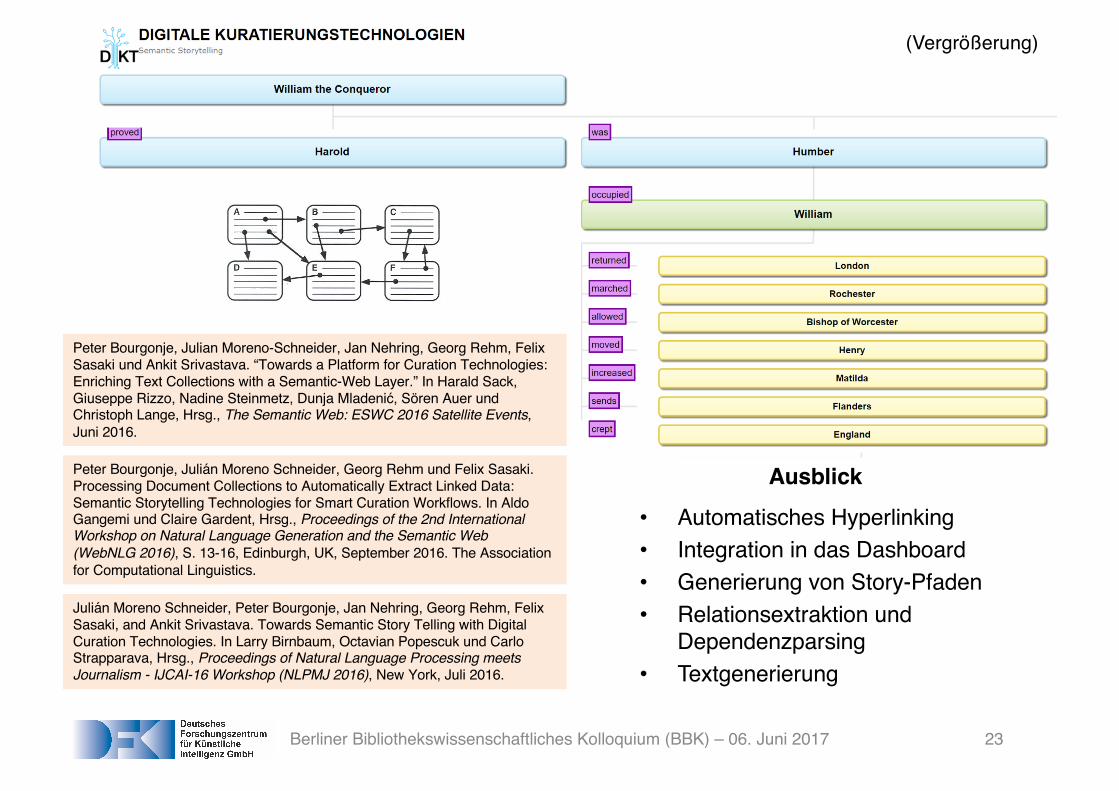
Semantic Storytelling• Aktueller, experimenteller Stand: GUI erlaubt dynamischen Überblick, welche
salienten, in einer Kollektion genannten Entitäten was und wo getan haben.• Nutzer sollen sich schnell einen Überblick über den Inhalt verschaffen können.
22
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
(Vergrößerung)
Julián Moreno Schneider, Peter Bourgonje, Jan Nehring, Georg Rehm, Felix Sasaki, and Ankit Srivastava. Towards Semantic Story Telling with Digital Curation Technologies. In Larry Birnbaum, Octavian Popescuk und Carlo Strapparava, Hrsg., Proceedings of Natural Language Processing meets Journalism - IJCAI-16 Workshop (NLPMJ 2016), New York, Juli 2016.
Peter Bourgonje, Julián Moreno Schneider, Georg Rehm und Felix Sasaki. Processing Document Collections to Automatically Extract Linked Data: Semantic Storytelling Technologies for Smart Curation Workflows. In Aldo Gangemi und Claire Gardent, Hrsg., Proceedings of the 2nd International Workshop on Natural Language Generation and the Semantic Web (WebNLG 2016), S. 13-16, Edinburgh, UK, September 2016. The Association for Computational Linguistics.
Peter Bourgonje, Julian Moreno-Schneider, Jan Nehring, Georg Rehm, Felix Sasaki und Ankit Srivastava. “Towards a Platform for Curation Technologies: Enriching Text Collections with a Semantic-Web Layer.” In Harald Sack, Giuseppe Rizzo, Nadine Steinmetz, Dunja Mladenić, Sören Auer und Christoph Lange, Hrsg., The Semantic Web: ESWC 2016 Satellite Events, Juni 2016.
Ausblick
• Automatisches Hyperlinking• Integration in das Dashboard• Generierung von Story-Pfaden• Relationsextraktion und
Dependenzparsing• Textgenerierung
23

Beispiel: Automatisches Glossar• Automatisches
Glossar (Personen, Orte, Organis.)
• Informieren über unbekannte Begriffe in einer Sammlung.
• Links verweisen auf die Vorkommen in Dokumenten.
• Bekannt aus Büchern und somit direkt verständlich.
Glossar der Mendelsohn-Briefe
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 24

Beispiel: Autoritative Dokumente• Über eine Entität
informieren, die in einer Kollektion auftaucht (1).
• Dokumentauswahl listet alle Entitäten auf (2).
• Klick listet Vorkommen in Kollektion auf, sortiert nach Frequenz (3).
• Hilft, diejenigen Doku-mente zu finden, die eine Entität häufig erwähnen und daher eine „Autorität“ bzgl. dieser Entität darstellen.
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017
1
2
3
Liste derjenigen Dokumente der Mendelsohn-Briefe,in denen „New York“ auftaucht (nach Häufigkeit sortiert)
25
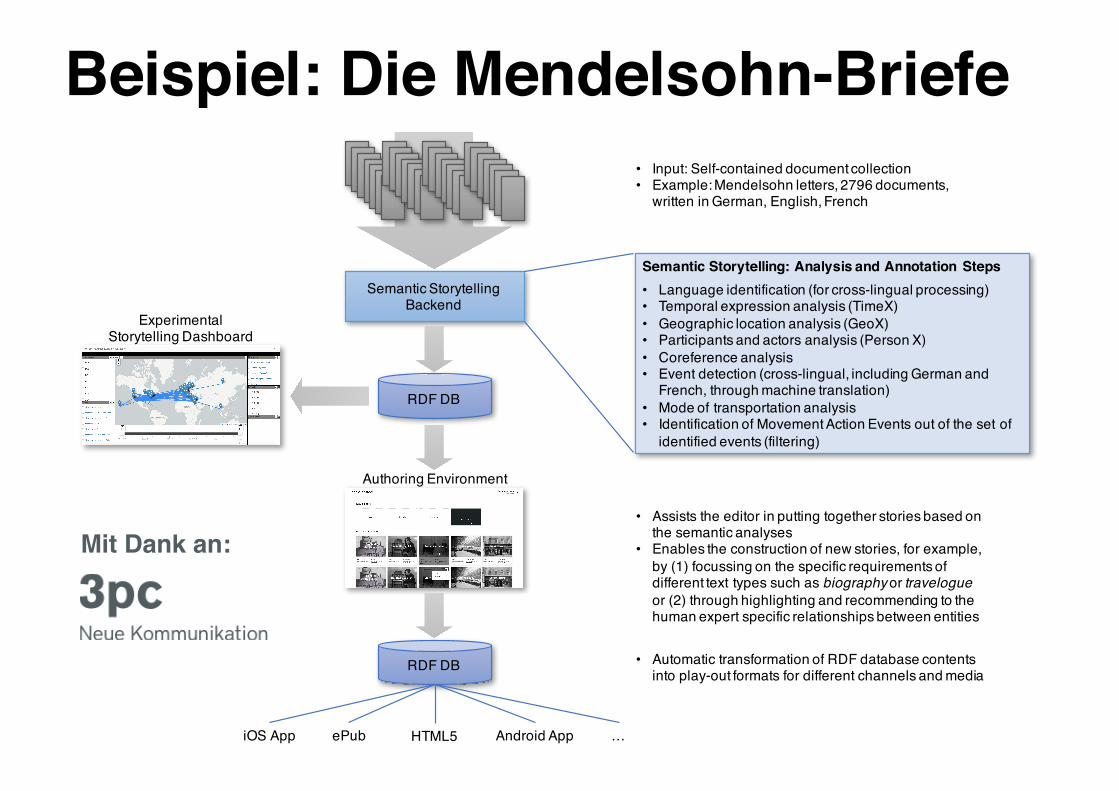
RDF DB
RDF DB
Semantic Storytelling Backend
Authoring Environment
iOS App Android AppHTML5ePub …
• Input: Self-contained document collection• Example: Mendelsohn letters, 2796 documents,
written in German, English, French
• Assists the editor in putting together stories based on the semantic analyses
• Enables the construction of new stories, for example, by (1) focussing on the specific requirements of different text types such as biography or travelogue or (2) through highlighting and recommending to the human expert specific relationships between entities
• Automatic transformation of RDF database contents into play-out formats for different channels and media
Semantic Storytelling: Analysis and Annotation Steps• Language identification (for cross-lingual processing)• Temporal expression analysis (TimeX)• Geographic location analysis (GeoX)• Participants and actors analysis (Person X)• Coreference analysis• Event detection (cross-lingual, including German and
French, through machine translation)• Mode of transportation analysis• Identification of Movement Action Events out of the set of
identified events (filtering)
ExperimentalStorytelling Dashboard
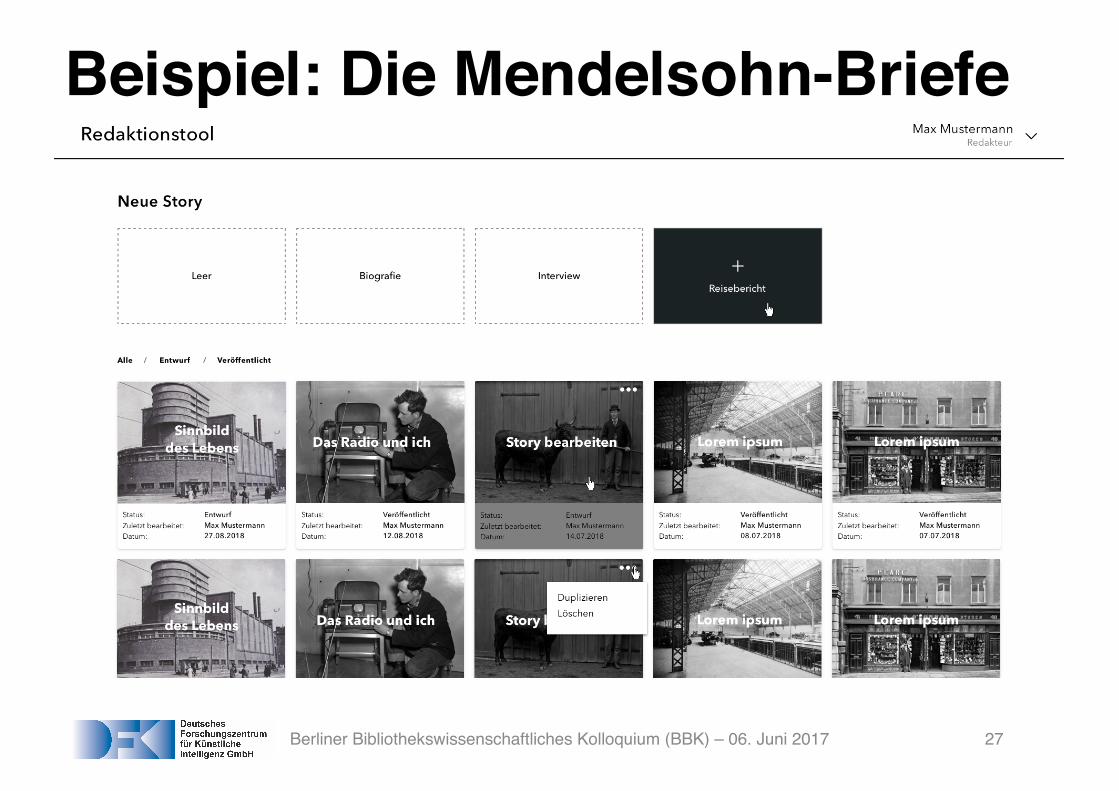
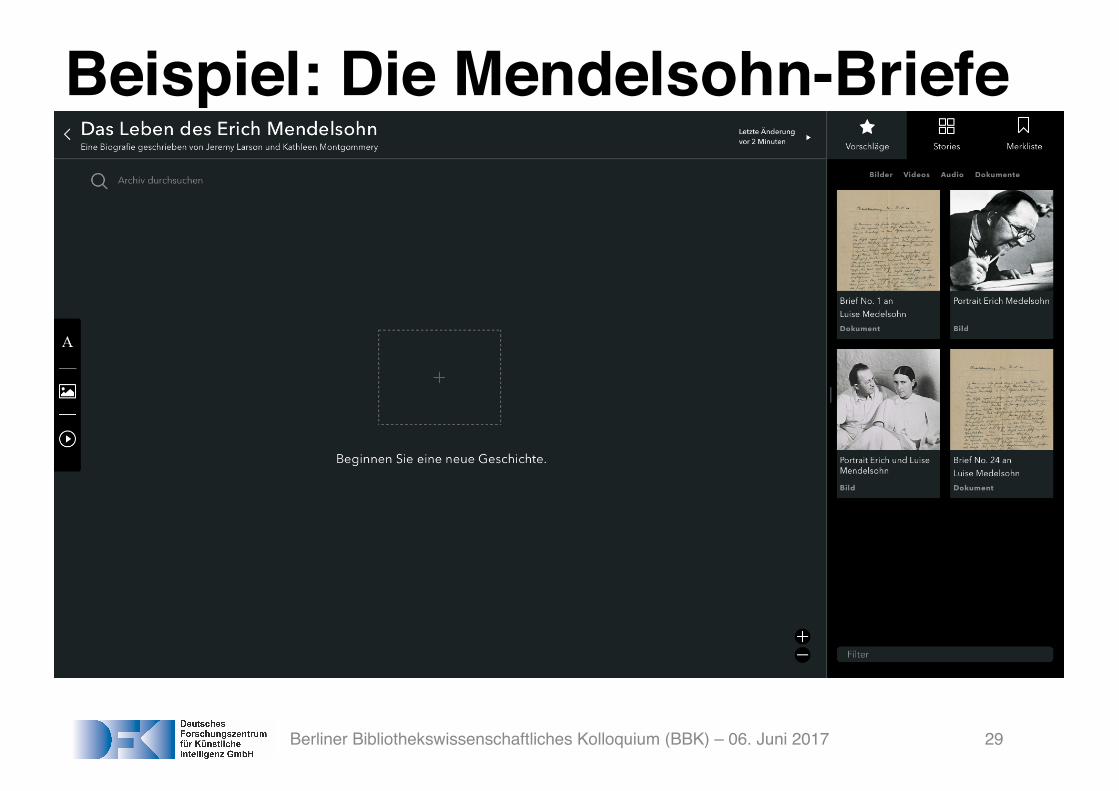
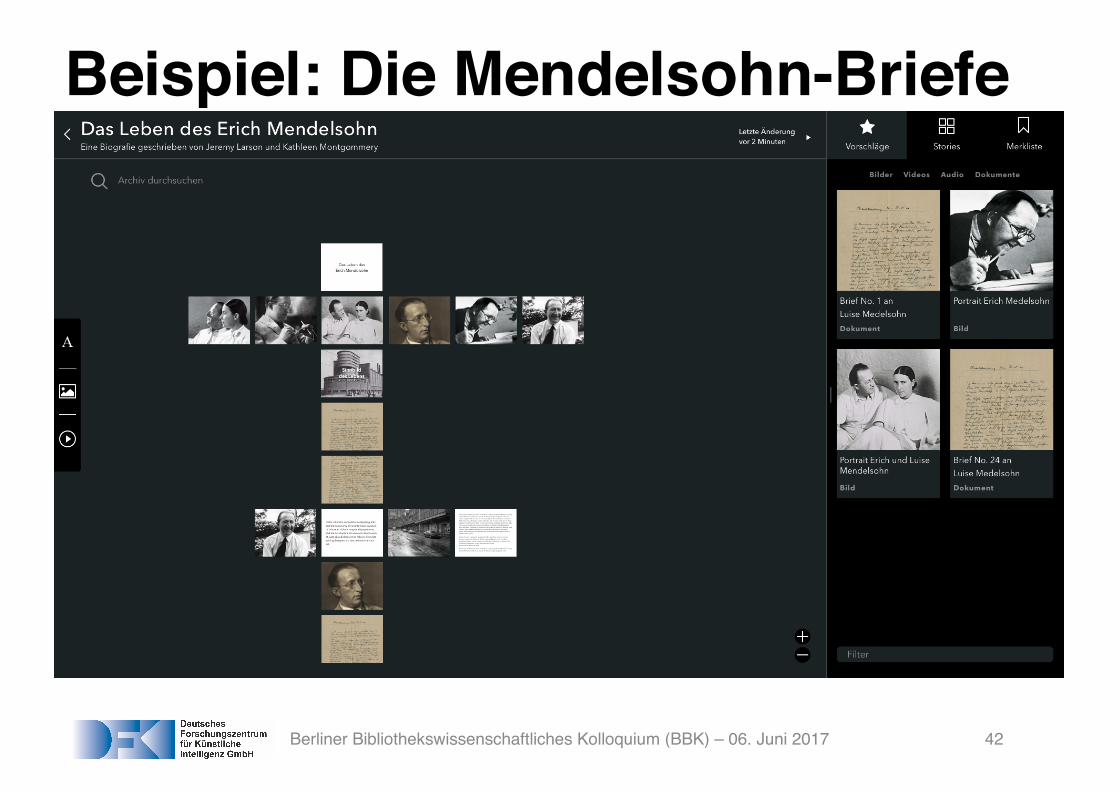
Beispiel: Die Mendelsohn-Briefe
Mit Dank an:
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 27
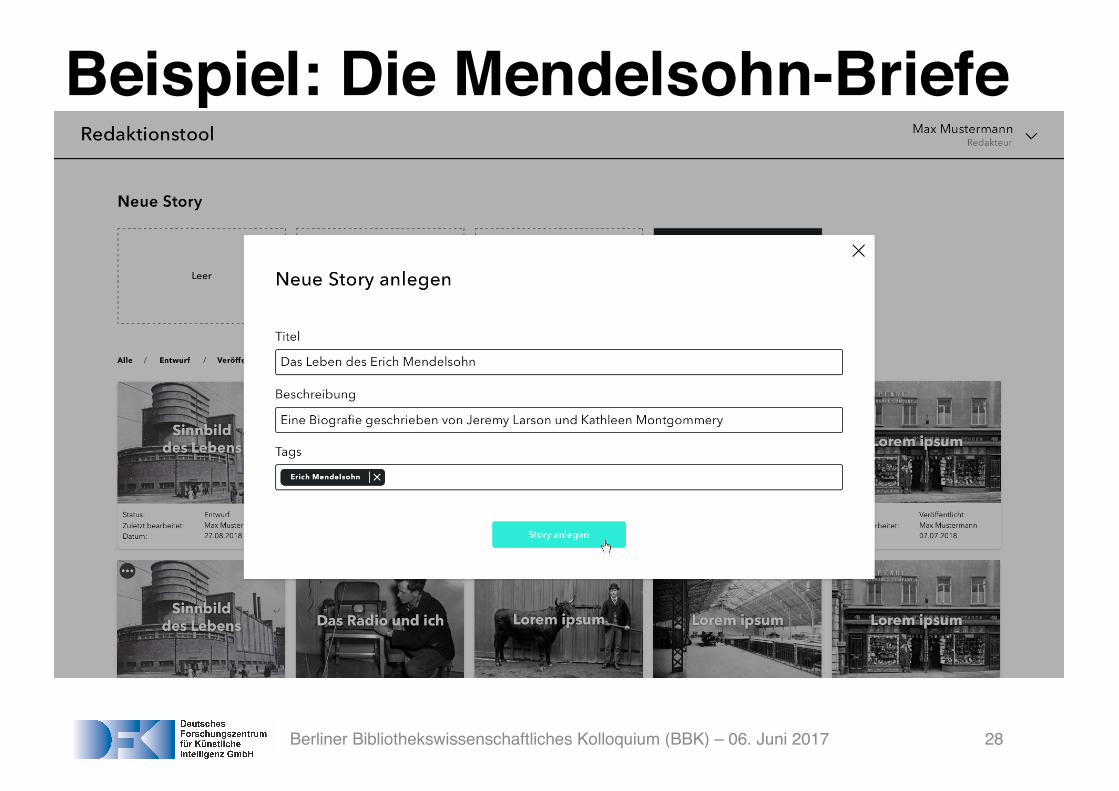
Beispiel: Die Mendelsohn-Briefe
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 28
Beispiel: Die Mendelsohn-Briefe
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 29
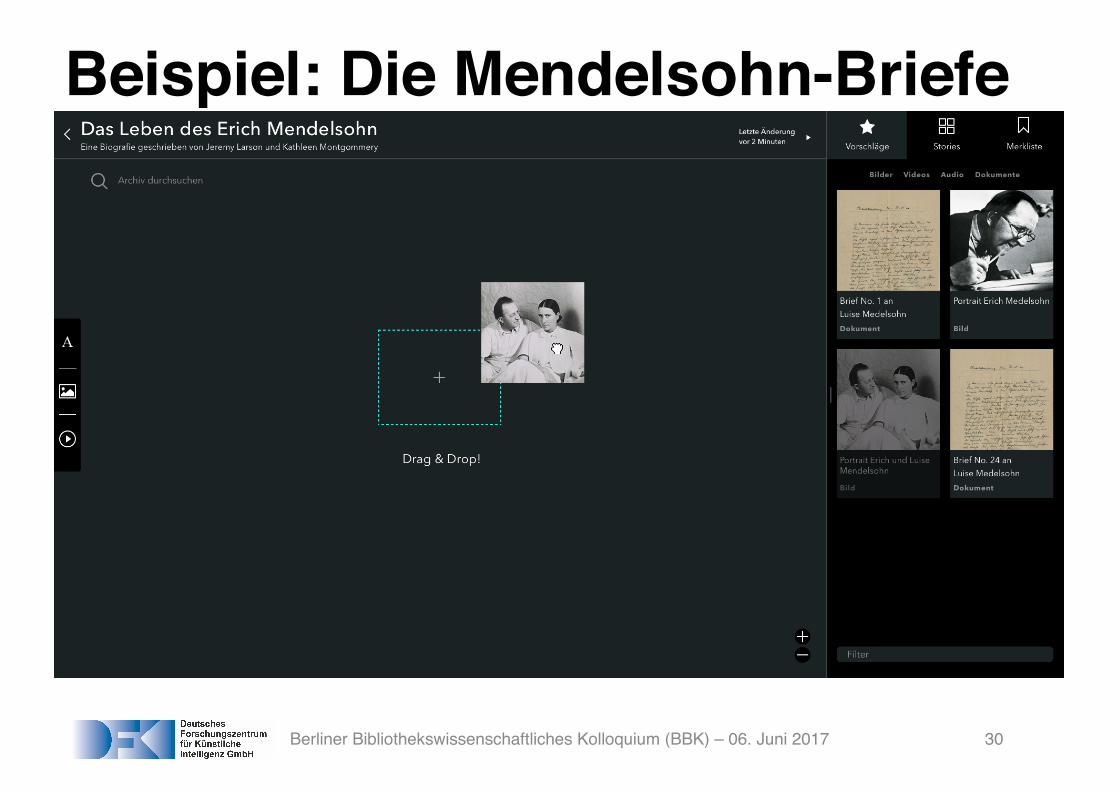
Beispiel: Die Mendelsohn-Briefe
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 30
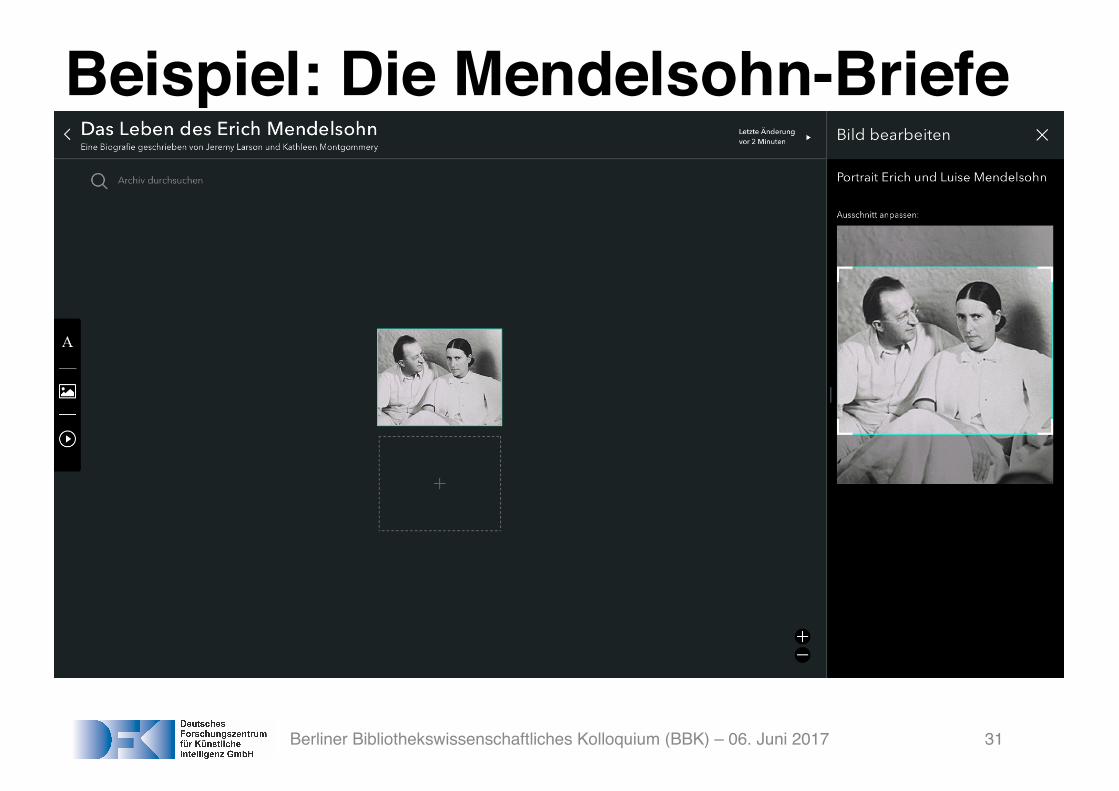
Beispiel: Die Mendelsohn-Briefe
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 31
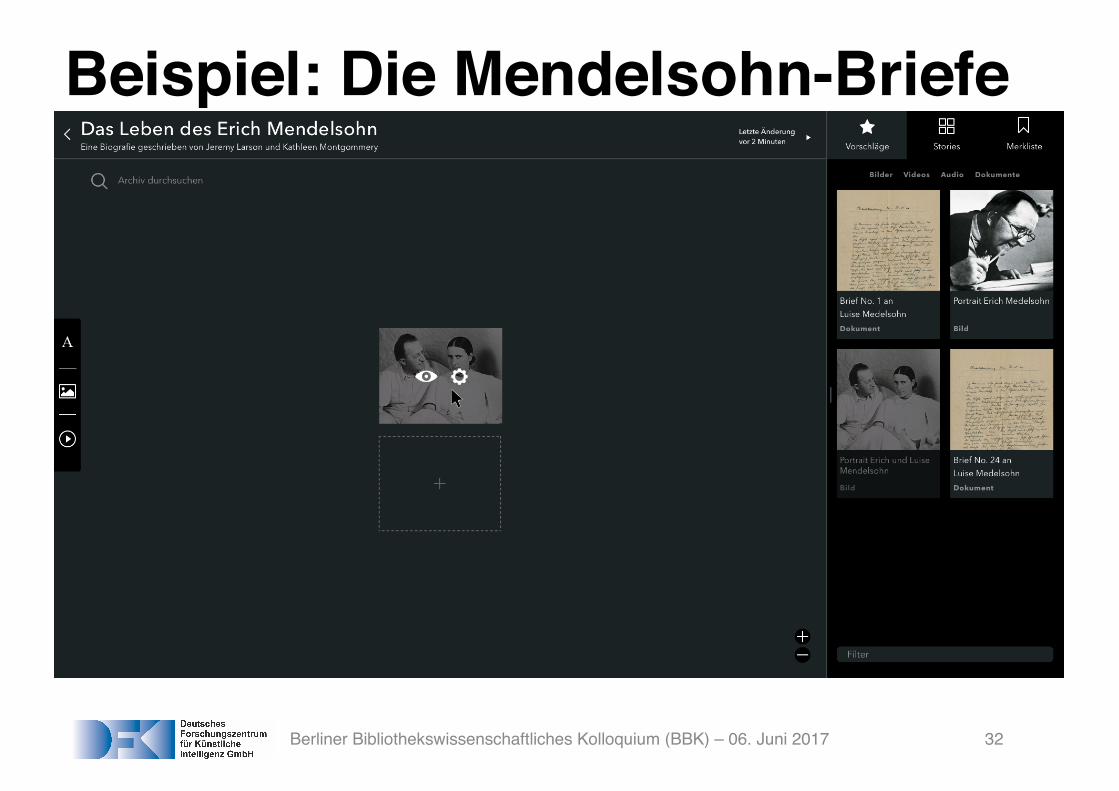
Beispiel: Die Mendelsohn-Briefe
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 32
Beispiel: Die Mendelsohn-Briefe
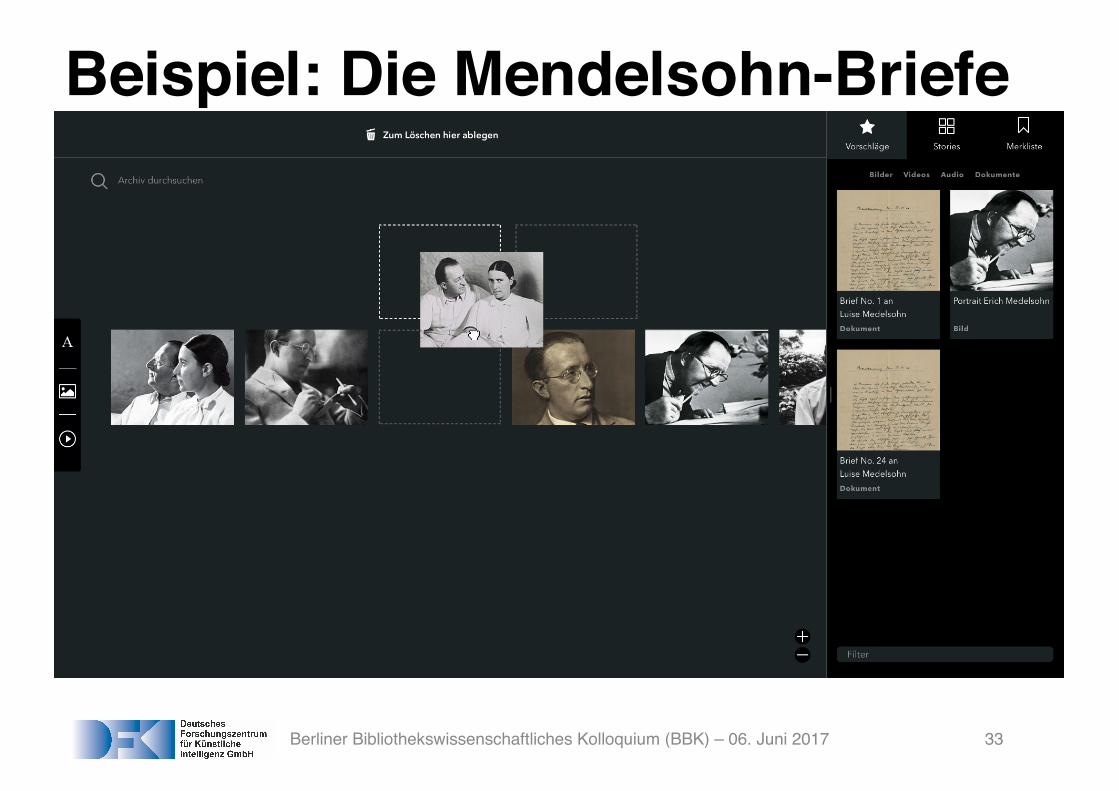
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 33
Beispiel: Die Mendelsohn-Briefe
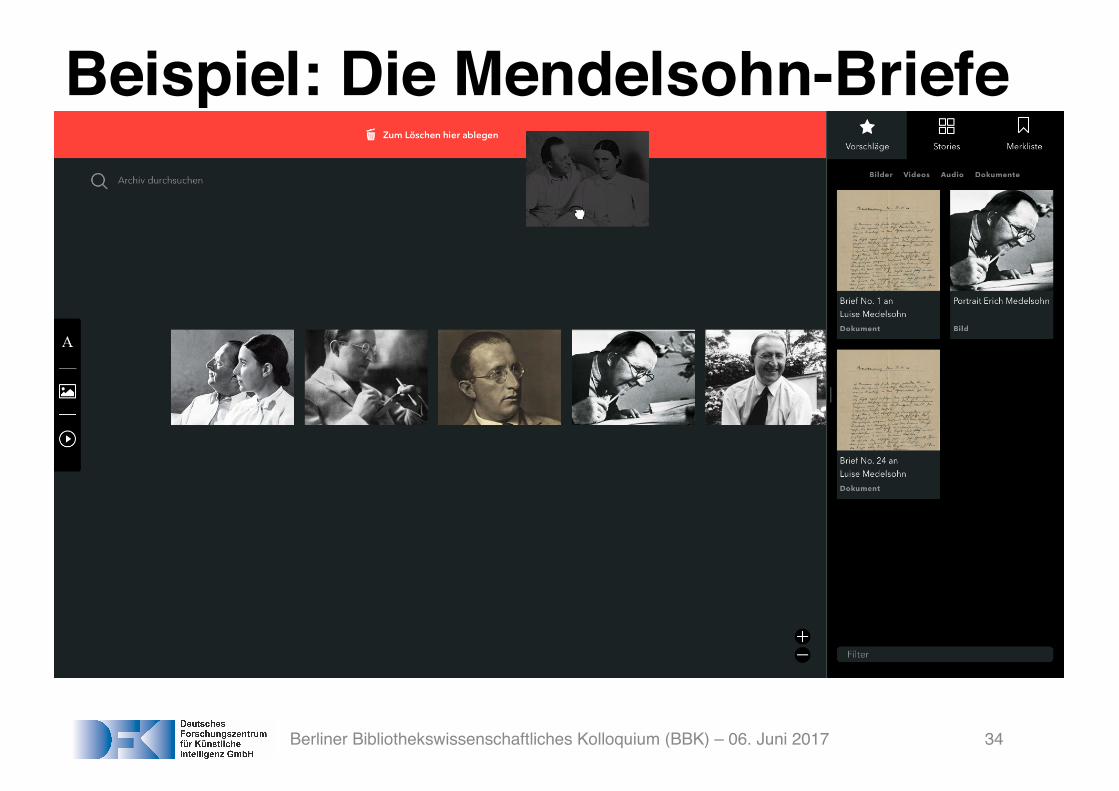
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 34
Beispiel: Die Mendelsohn-Briefe
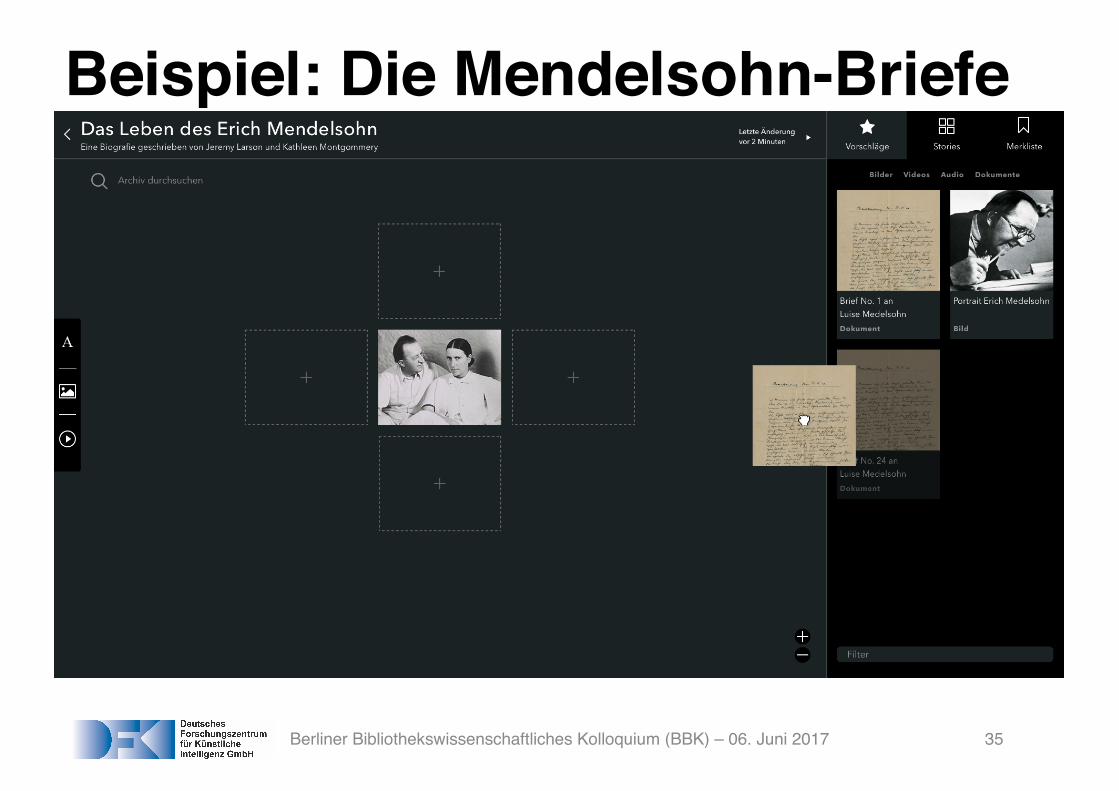
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 35
Beispiel: Die Mendelsohn-Briefe
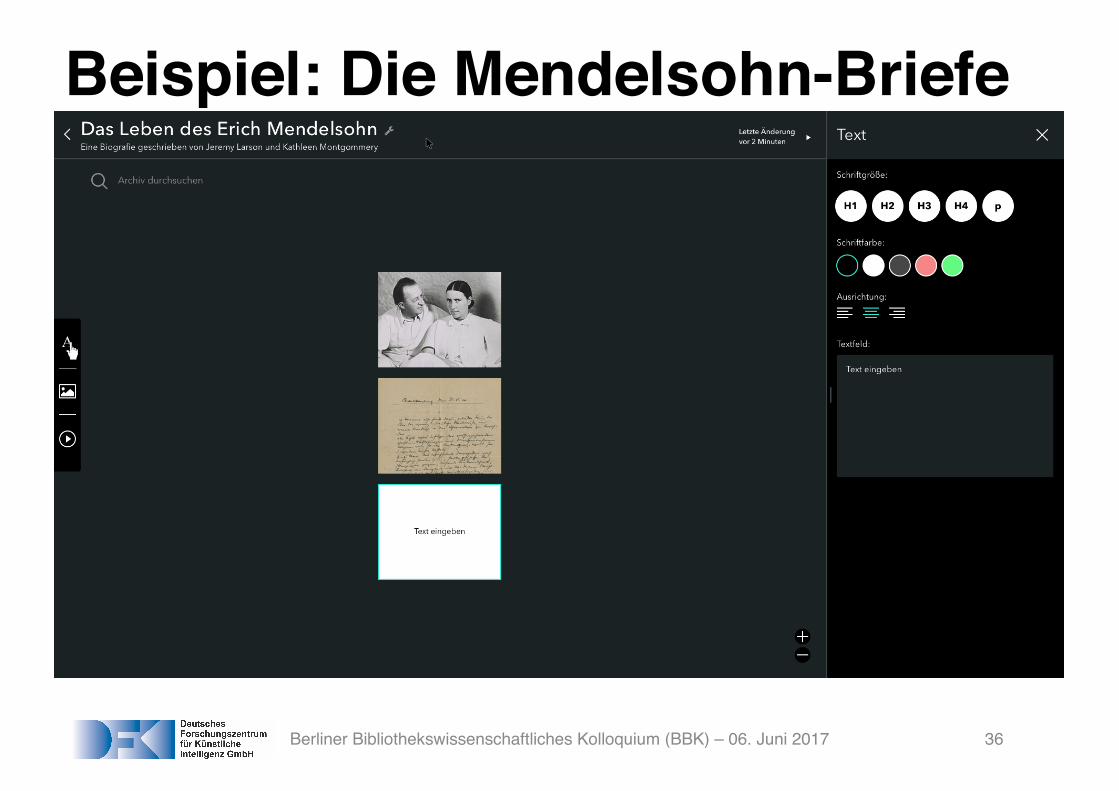
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 36
Beispiel: Die Mendelsohn-Briefe
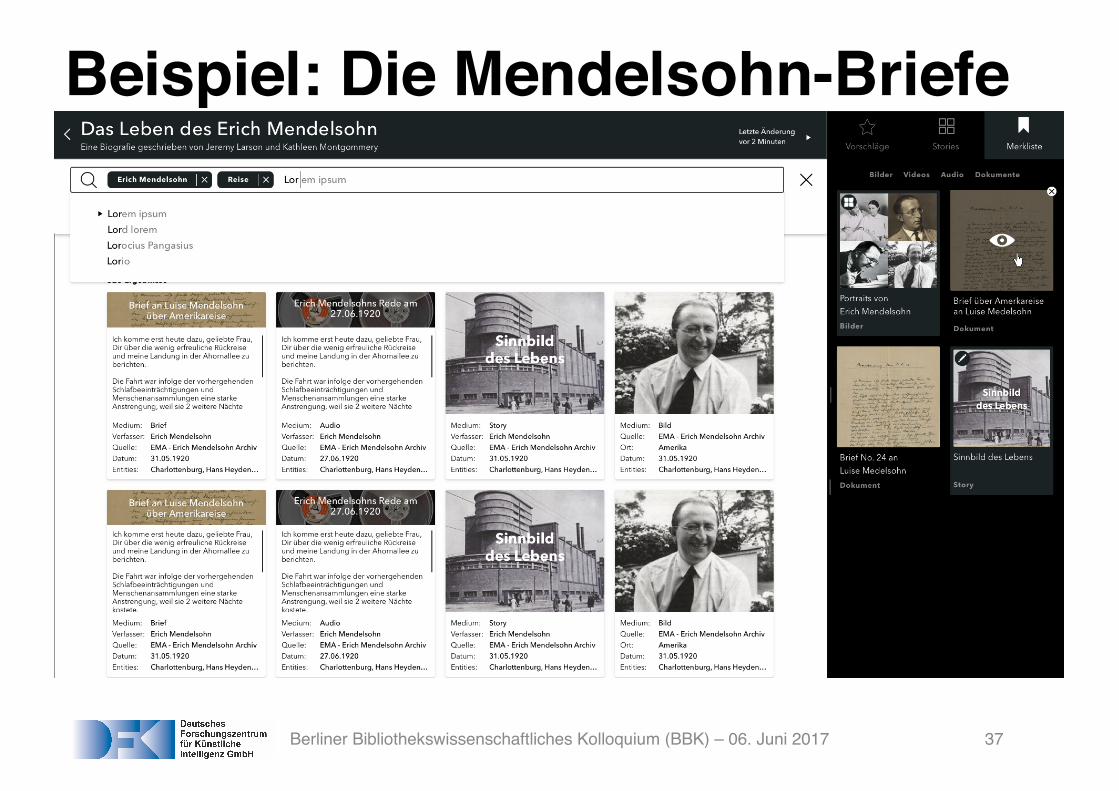
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 37
Beispiel: Die Mendelsohn-Briefe
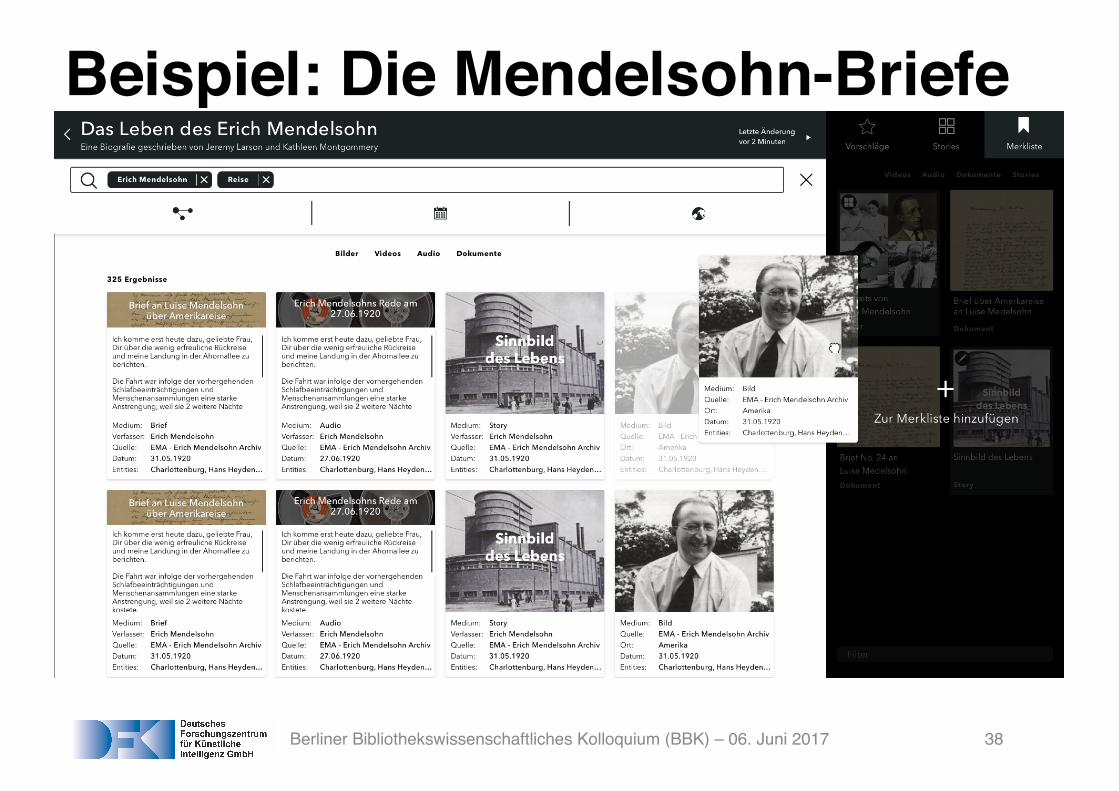
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 38
Beispiel: Die Mendelsohn-Briefe
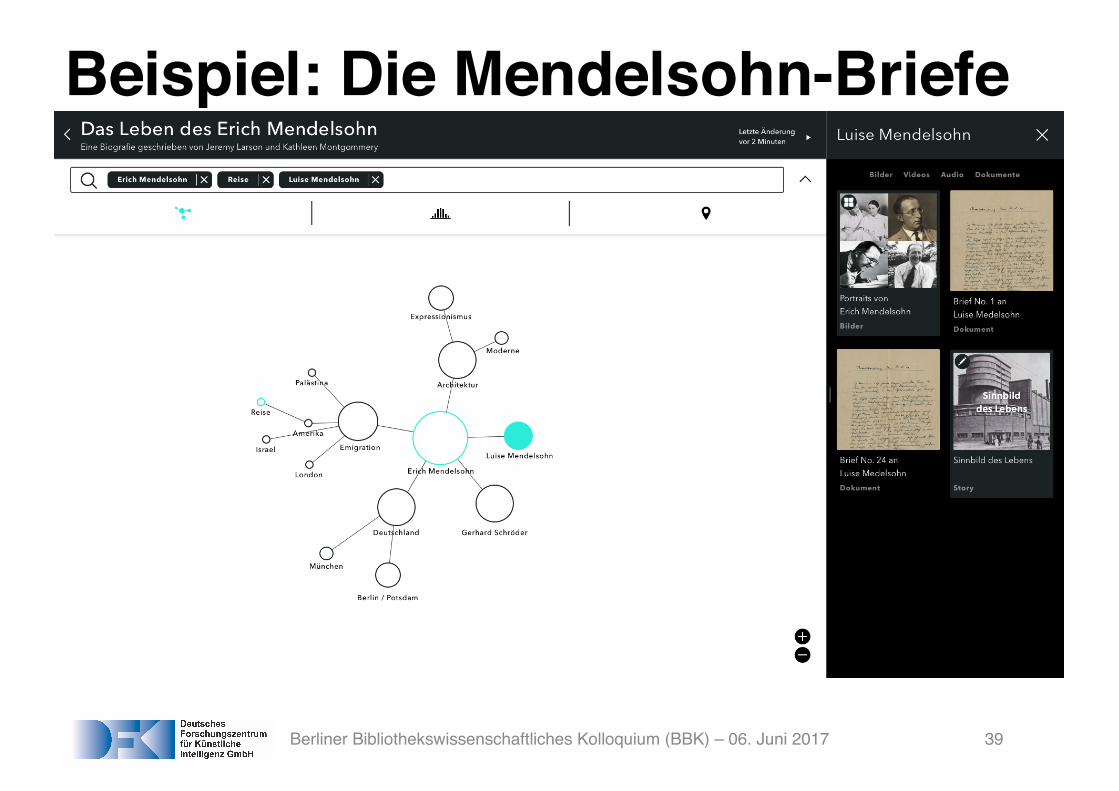
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 39
Beispiel: Die Mendelsohn-Briefe
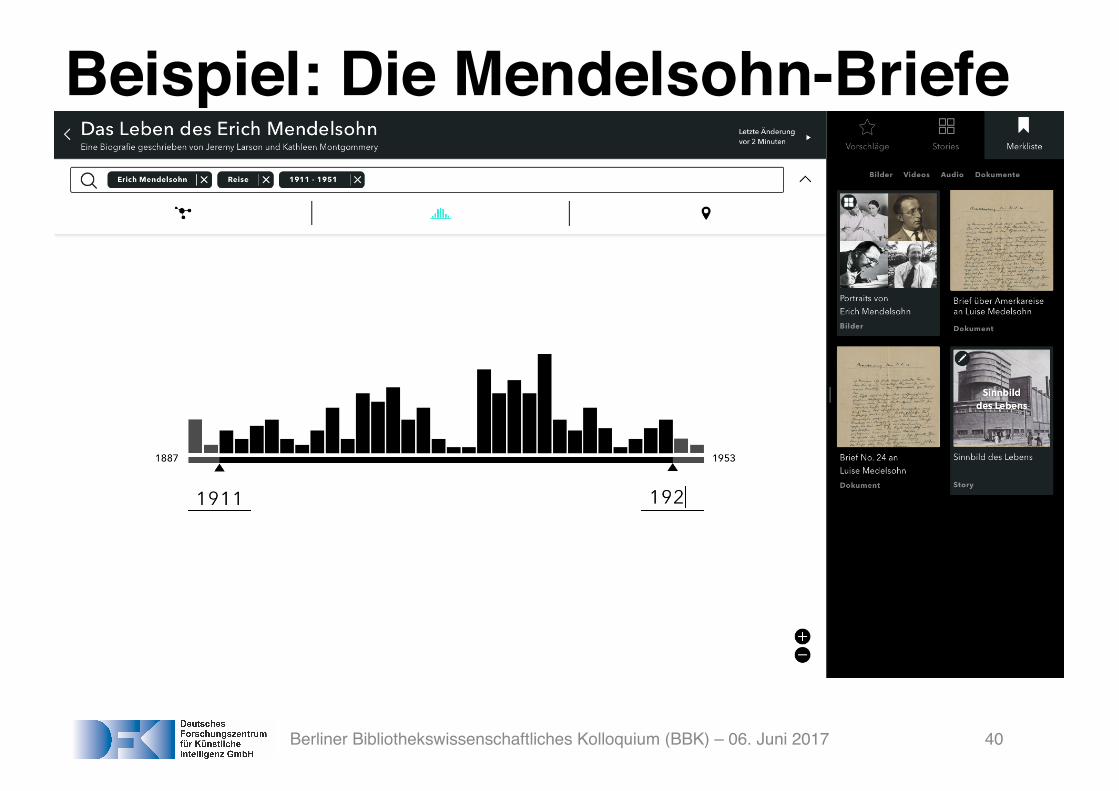
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 40
Beispiel: Die Mendelsohn-Briefe
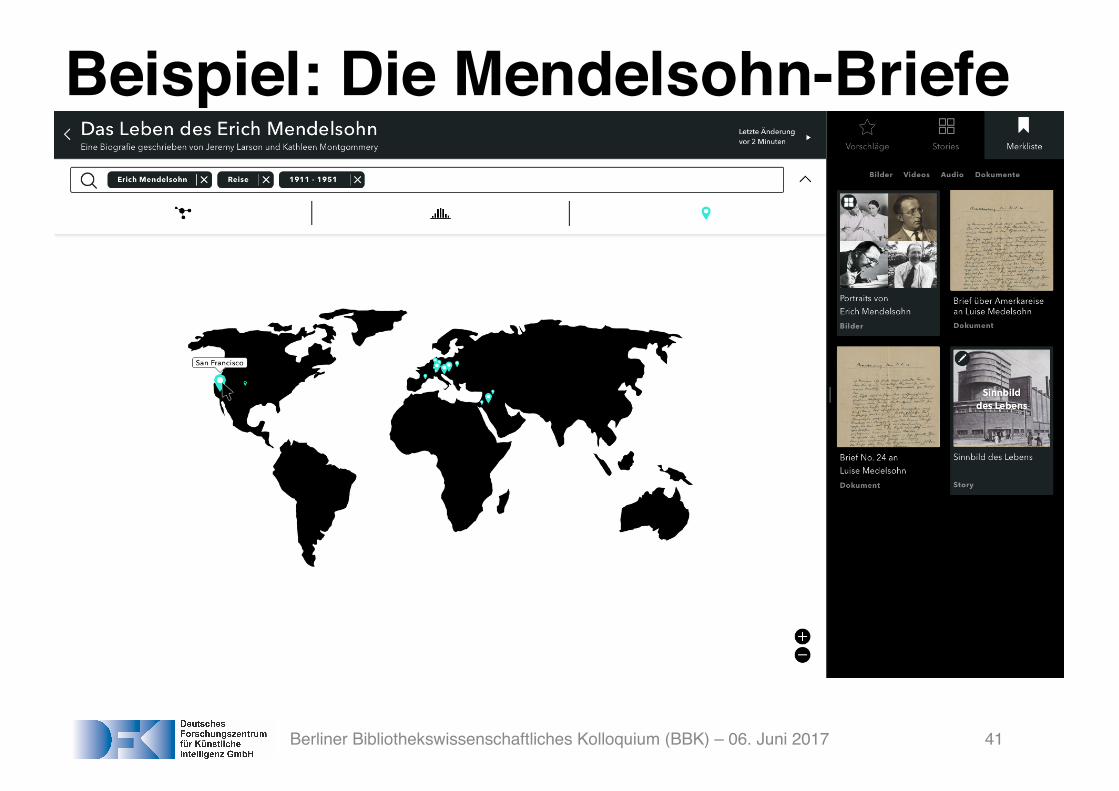
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 41
Beispiel: Die Mendelsohn-Briefe
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 42
Beispiel: Die Mendelsohn-Briefe

Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 43
Beispiel: Die Mendelsohn-Briefe
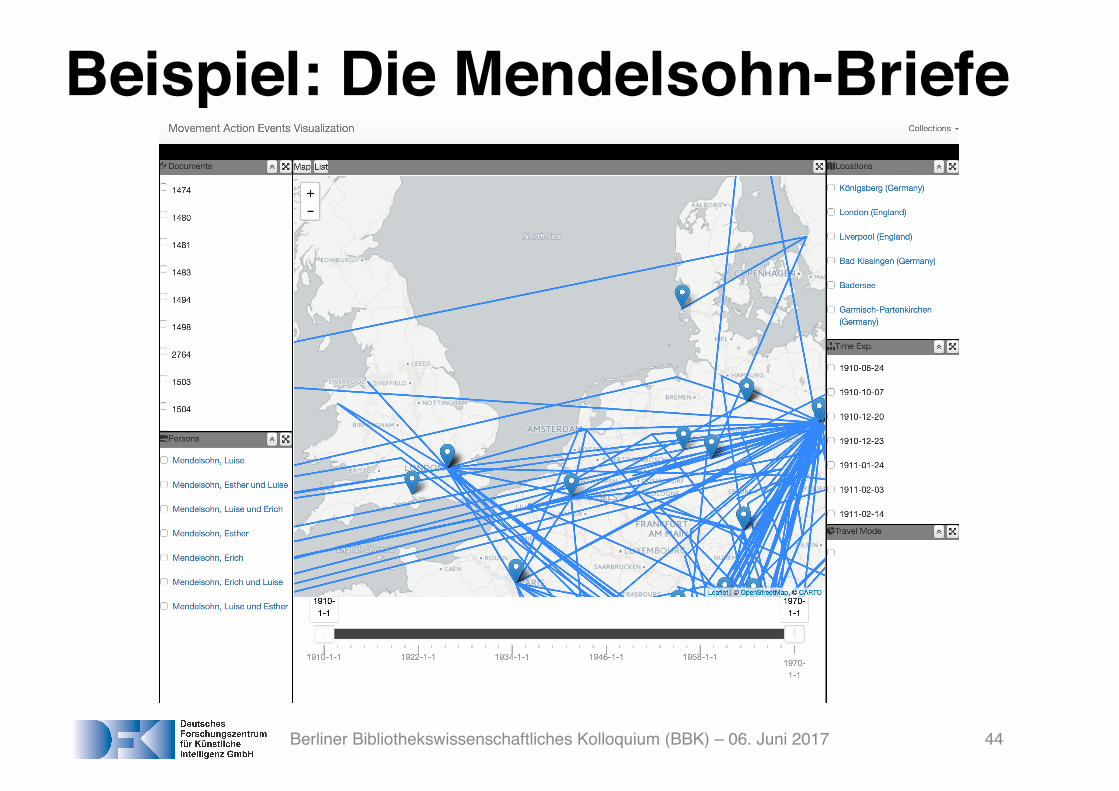
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 44
Beispiel: Die Mendelsohn-Briefe

Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 45

Digitale Kuratierung in Bibliotheken
Aktivitäten und Beispiele aus der Staatsbibliothek zu Berlin• Digitalisierung 2.0• Digitale Kuratierung• Beispiele
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 46

Digitalisierung 2.0• 2007: Aufbau eines eigenen Digitalisierungszentrum• 2013: 2-Schichten-System mit 24 Schichten• 2016: 20 Geräte (A2-A0, Scanroboter, Thermografie
Kamera, Grazer Buchtisch, etc.)• Aktuell ca. 13 Mio. Images,
Zuwachs ca. 1,7 Mio. Images pro Jahr
• Digitisation-on-Demand Service:http://staatsbibliothek-berlin.de/service/digitalisate-und-reproduktionen/
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 47

Daten, Daten, Daten• Digitalisierte Sammlungen: 14 Mio. Seiten,
pro Jahr um ca. 2,5 Mio. Seiten wachsend• ZEFYS: Ca. 3,5 Mio. Seiten Zeitungen, + 0,5 Mio./Jahr• Zeitschriftendatenbank (ZDB): 1,8 Mio. Titeldaten• Kalliope Katalog: 3,2 Mio. Datensätze zu Nachlässen
• Gemeinsame Normdatei (GND): 16 Mio. Daten• Deutsche Digitale Bibliothek (DDB): 20 Mio. Objekte• Europeana: 55 Mio. Objekte
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 48

Digitale Kuratierung• (automatische) Erschließung von Struktur und Inhalten
von Dokumenten über die rein beschreibende, bibliographische Erschließung hinaus
• Beispiele: – Europeana Newspapers:
Named Entity Recognition (Personen, Orte, etc.)– Europeana 1914-1918:
Linked Data (Relationen zwischen Entitäten, Schlagworten und Normdaten)
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 49

Europeana Newspapers• Europeana Newspapers
www.europeana-newspapers.eu
• 12 Mio. Seiten historische Zeitungen inkl. Volltexte (OCR)
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 50

Named Entity Recognition
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 51
https://github.com/EuropeanaNewspapers/ner-app

NER Kodierung• NER Kodierung in ALTO-XML (>= 2.1)
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 52
<String STYLEREFS="ID7" HEIGHT="132.0" WIDTH="570.0" HPOS="5937.0" VPOS="3279.0" CONTENT="Reynolds" WC="0.95238096" TAGREFS="Tag5"></String><String STYLEREFS="ID7" HEIGHT="102.0" WIDTH="540.0" HPOS="18438.0"VPOS="22008.0" CONTENT="Baltimore" WC="0.82539684" TAGREFS="Tag10"></String>…<Tags>
<NamedEntityTag ID="Tag5" TYPE="Person" LABEL="Reynolds"/><NamedEntityTag ID="Tag10" TYPE="Location" LABEL="Baltimore"/>
</Tags>

NER Korpus
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 53

NER Annotation• Evaluation von BRAT, WebAnno, INL Attestation
• INL Attestation wg.:– Optimiert für
schnelle Erfassung– Unterstützung für
ALTO-XML– Zusammenarbeit
und Support durchINT Leiden
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 54
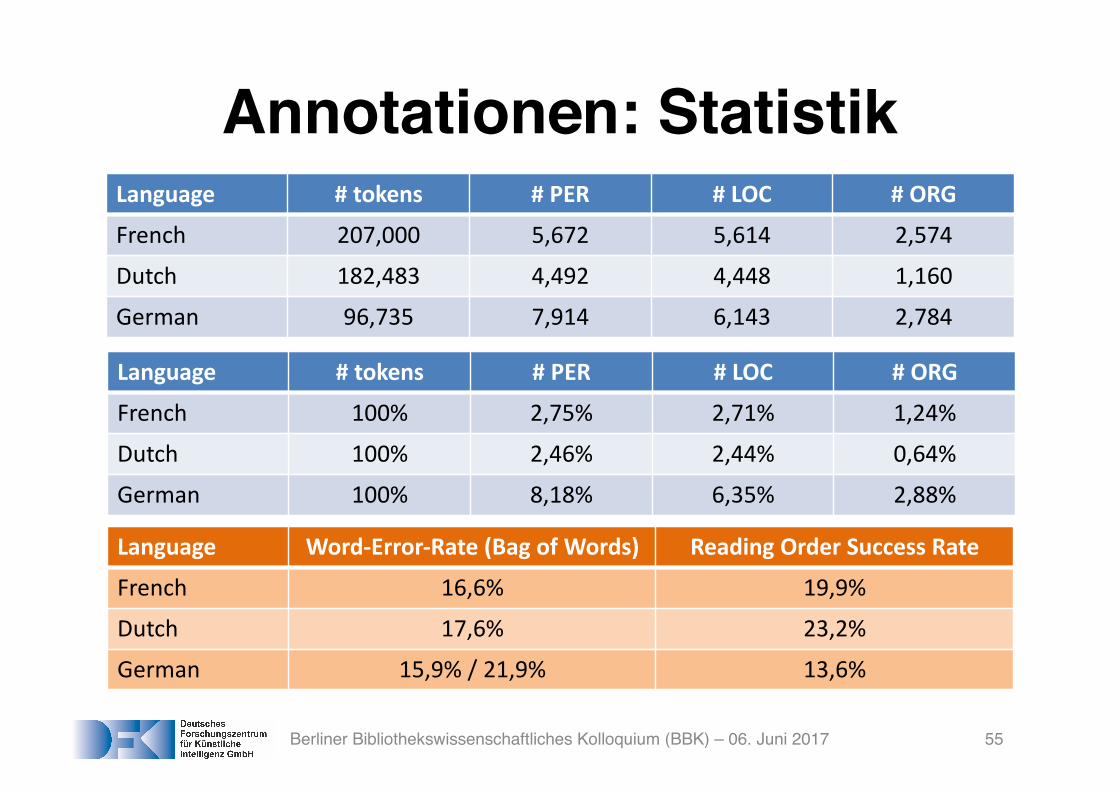
Annotationen: Statistik
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 55
Language # tokens # PER # LOC # ORG
French 207,000 5,672 5,614 2,574
Dutch 182,483 4,492 4,448 1,160
German 96,735 7,914 6,143 2,784
Language # tokens # PER # LOC # ORG
French 100% 2,75% 2,71% 1,24%
Dutch 100% 2,46% 2,44% 0,64%
German 100% 8,18% 6,35% 2,88%
Language Word-‐Error-‐Rate (Bag of Words) Reading Order Success Rate
French 16,6% 19,9%
Dutch 17,6% 23,2%
German 15,9% / 21,9% 13,6%
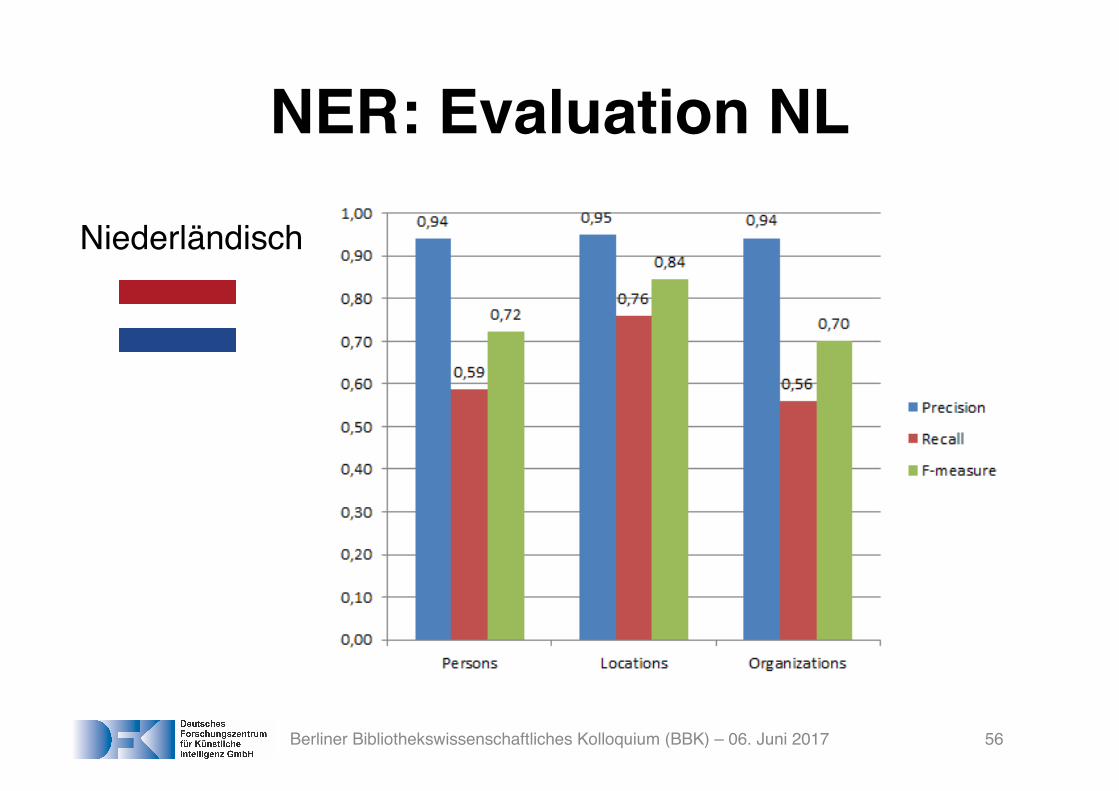
NER: Evaluation NL
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 56
Niederländisch
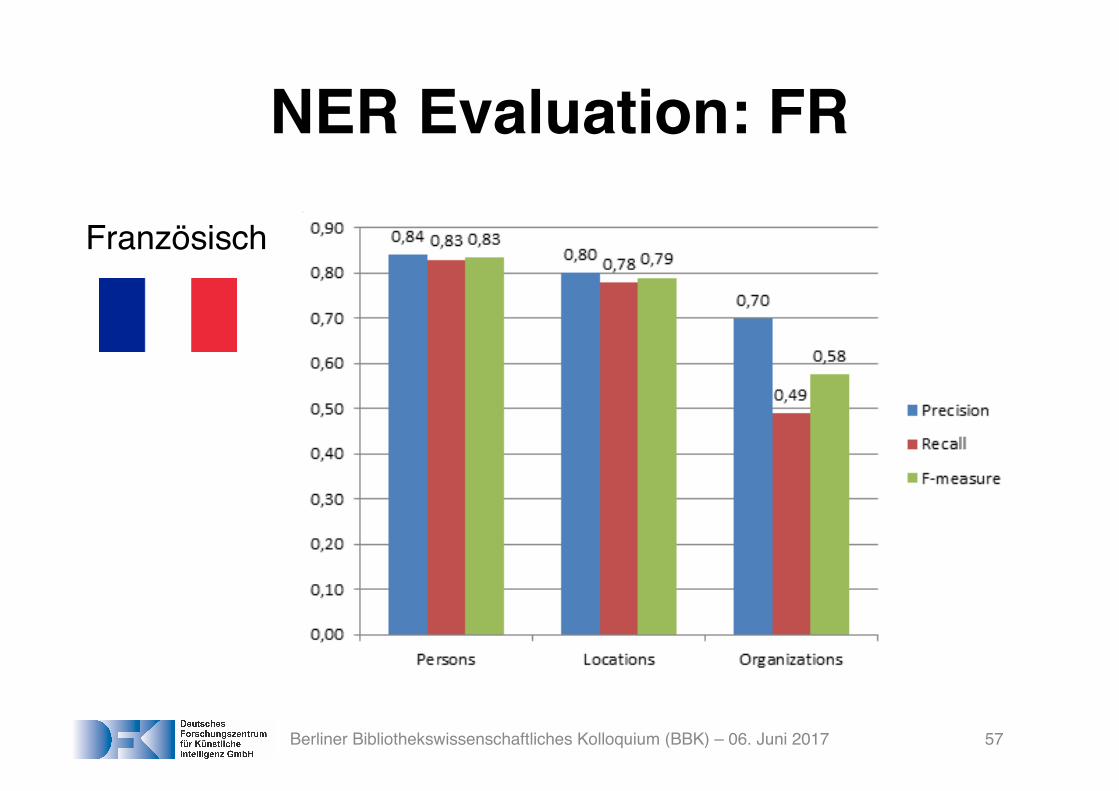
NER Evaluation: FR
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 57
Französisch
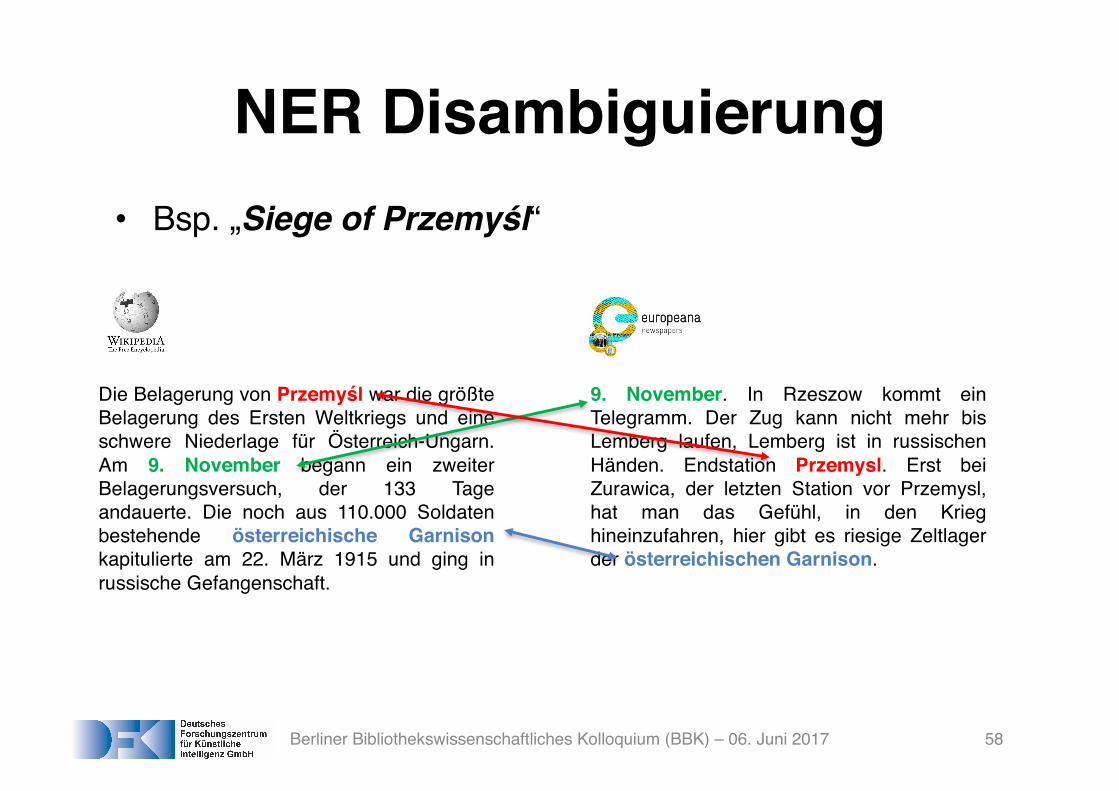
NER Disambiguierung• Bsp. „Siege of Przemyśl“
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 58
Die Belagerung von Przemyśl war die größteBelagerung des Ersten Weltkriegs und eineschwere Niederlage für Österreich-Ungarn.Am 9. November begann ein zweiterBelagerungsversuch, der 133 Tageandauerte. Die noch aus 110.000 Soldatenbestehende österreichische Garnisonkapitulierte am 22. März 1915 und ging inrussische Gefangenschaft.
9. November. In Rzeszow kommt einTelegramm. Der Zug kann nicht mehr bisLemberg laufen, Lemberg ist in russischenHänden. Endstation Przemysl. Erst beiZurawica, der letzten Station vor Przemysl,hat man das Gefühl, in den Krieghineinzufahren, hier gibt es riesige Zeltlagerder österreichischen Garnison.

Normdatenverlinkung
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 59
wikidata.org/wiki/Q698828
dbpedia.org/page/Q698828
lccn.loc.gov/sh95002132
Siege of Przemyśl

Europeana 1914-1918• Europeana 1914-1918
www.europeana1914-1918.eu
• 400,000 Dokumente aus Bibliotheken, Archiven, Museenwww.europeana-collections-1914-1918.eu
• 740h Film und 6100 Dokumente aus Filmarchivenhttp://project.efg1914.eu/
• Online Enzyklopädiewww.1914-1918-online.net
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 60
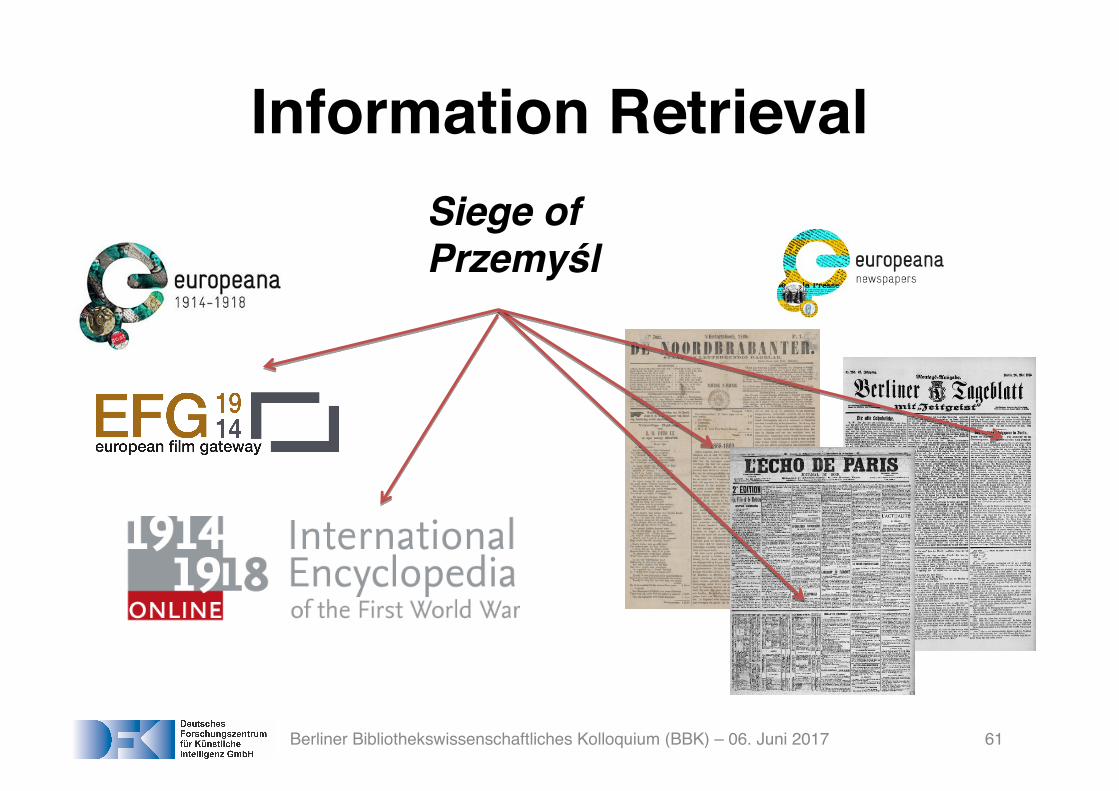
Information Retrieval
61
Siege of Przemyśl
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017

Systematik• Analyse des „Alten Realkatalog“ (ARK)
http://ark.staatsbibliothek-berlin.de/
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 62
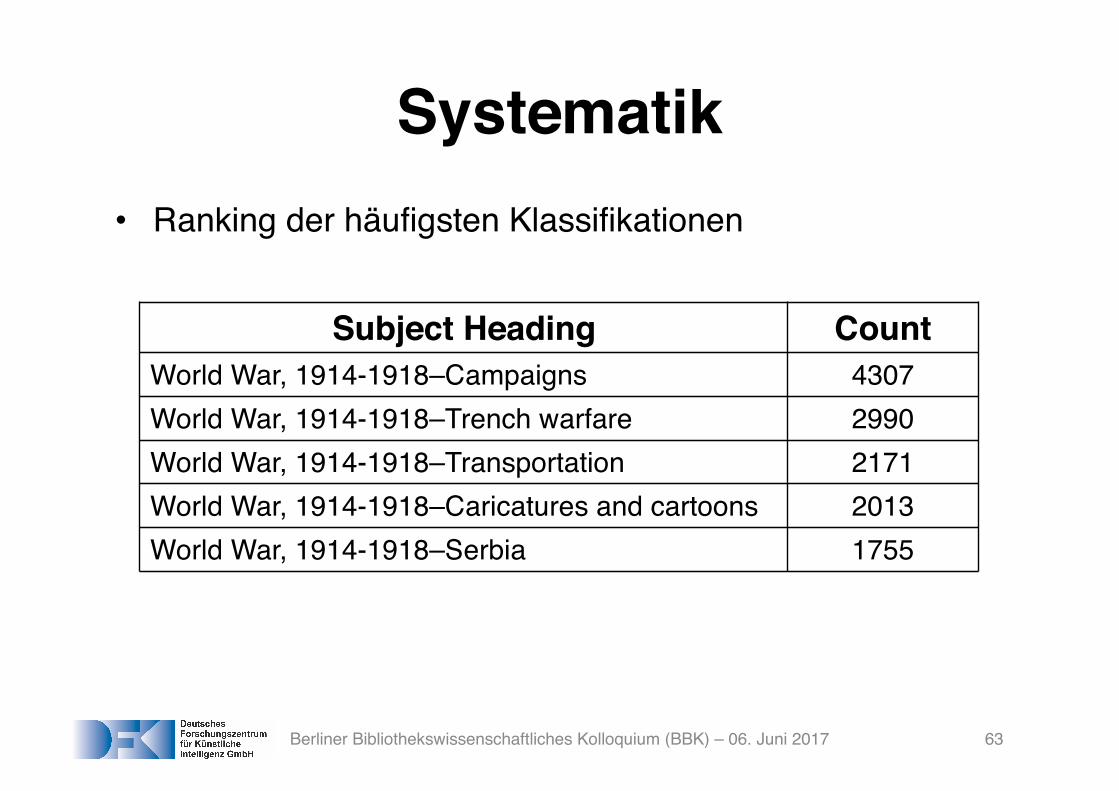
Systematik• Ranking der häufigsten Klassifikationen
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 63
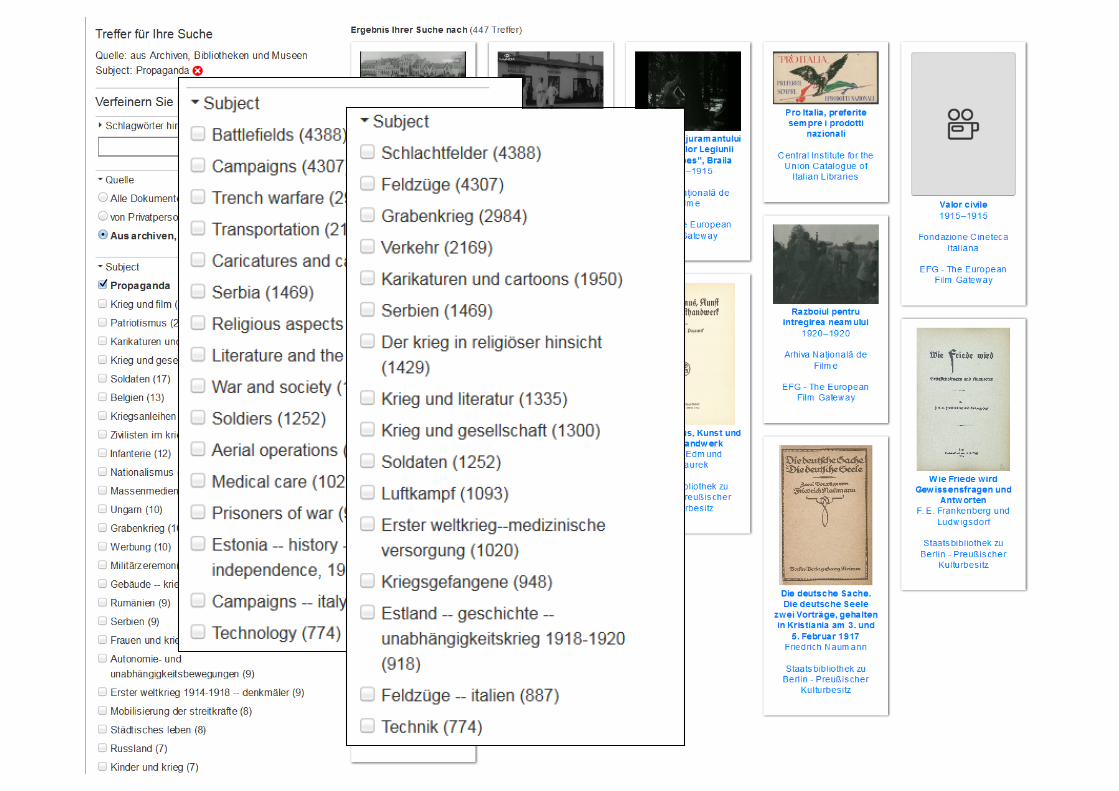
Subject Heading CountWorld War, 1914-1918–Campaigns 4307World War, 1914-1918–Trench warfare 2990World War, 1914-1918–Transportation 2171World War, 1914-1918–Caricatures and cartoons 2013World War, 1914-1918–Serbia 1755
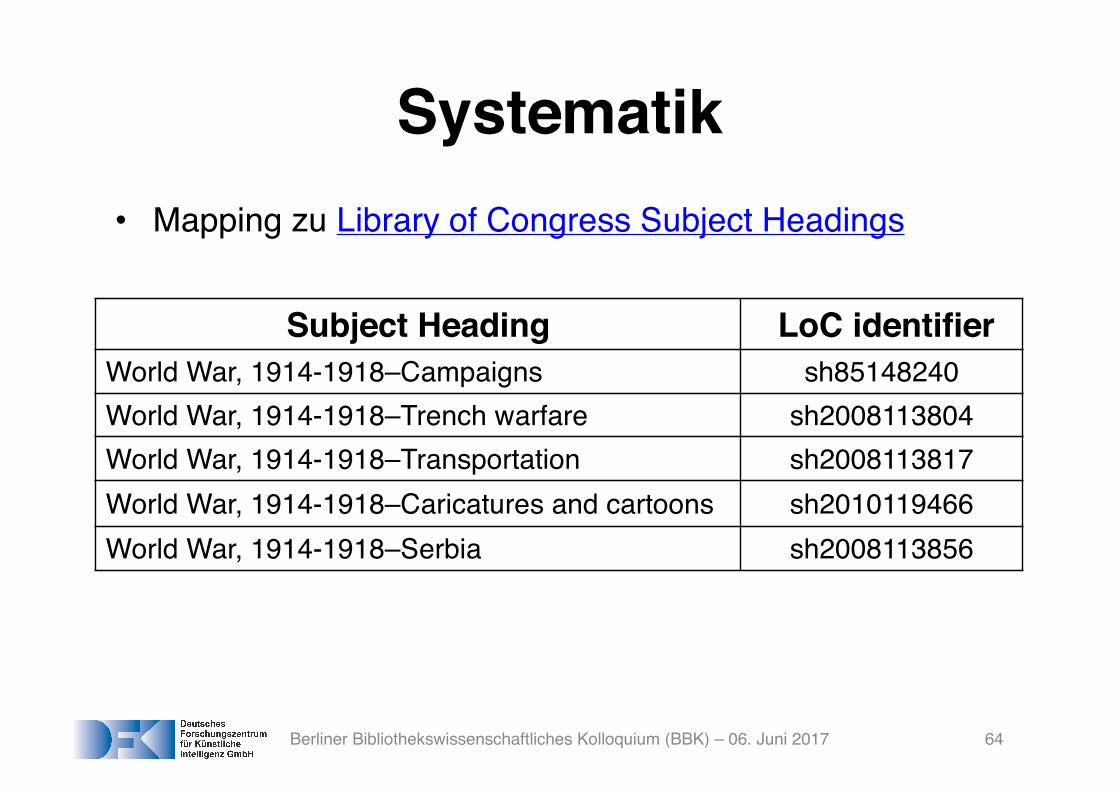
Systematik• Mapping zu Library of Congress Subject Headings
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 64
Subject Heading LoC identifierWorld War, 1914-1918–Campaigns sh85148240World War, 1914-1918–Trench warfare sh2008113804World War, 1914-1918–Transportation sh2008113817World War, 1914-1918–Caricatures and cartoons sh2010119466World War, 1914-1918–Serbia sh2008113856

Metadaten• Anreicherung der MODS-Metadaten mit LCSH IDs
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 65

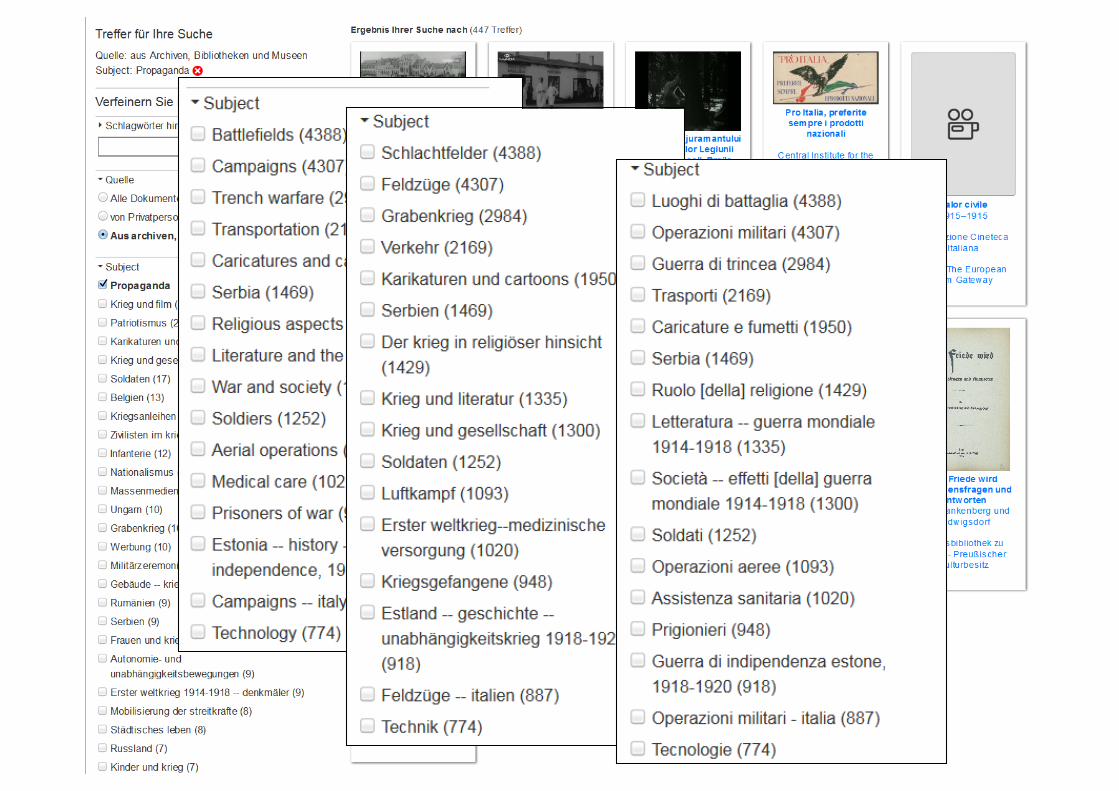
Übersetzungen• Übersetzungen aller Klassifikationen
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 66
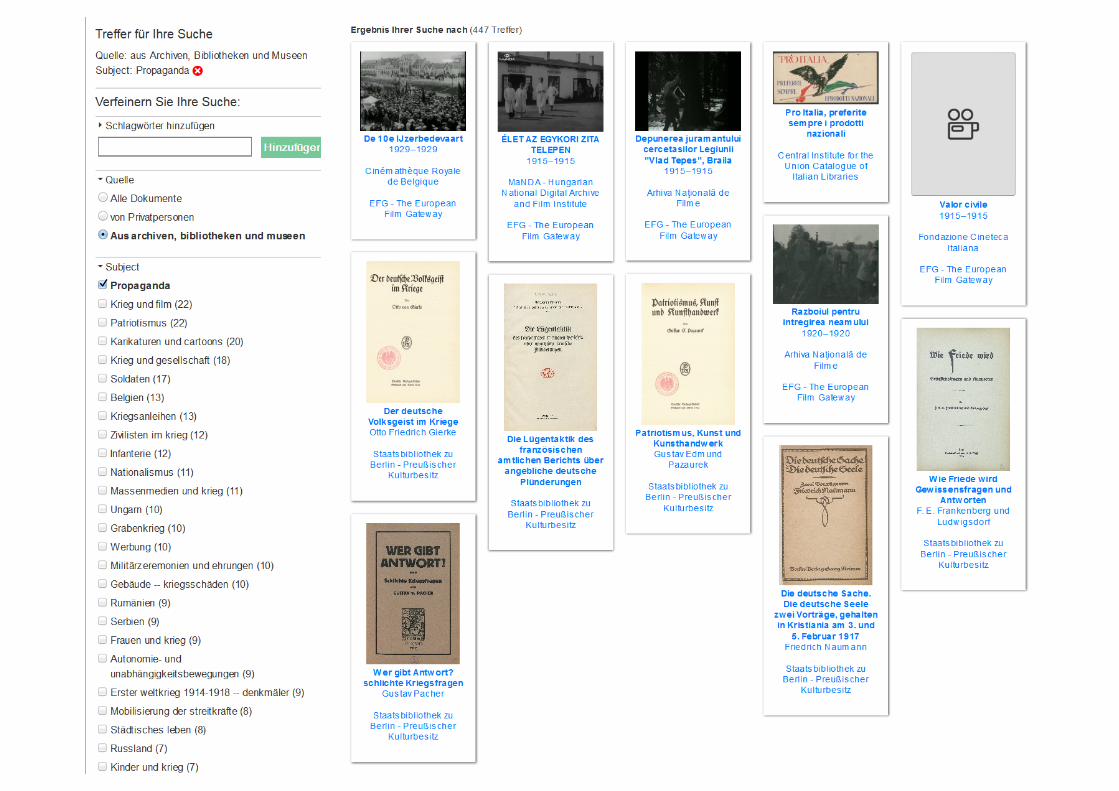
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 67
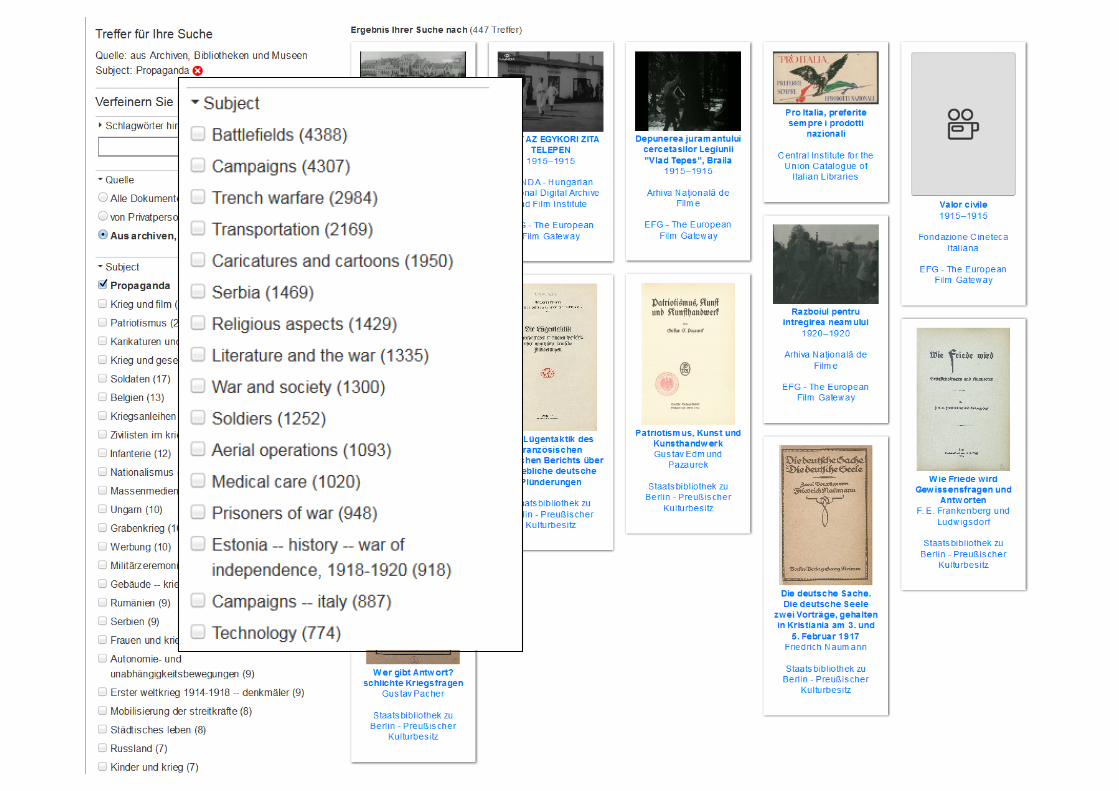
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 68
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 69
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 70

Europeana Transcribathon Campus• Wann?
22.-23. Juni 2017
• Wo?SBB Potsdamer Str. 33
• Was?Transkription & Verlinkung von Zeitungen und WW1-Dokumenten
• Mehr Infos?transcribathon.com/berlin2017
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 71
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 72

Schlussfolgerungen• Kuratierungstechnologien unterstützen Wissensarbeiter
beim Verarbeiten von digitalen Inhalten.• Enormes Potential für Folgeaktivitäten in zusätzlichen
Anwendungsszenarien – Projektantrag in Vorbereitung. • Kuratierungstechnologien werden benötigt, um die
Wissensspeicher der Bibliotheken in das Digitale zu übertragen und tief zu erschließen.
• Ziel: Bessere und einfachere Nutzbarkeit der Daten.• Bibliotheken können durch Bereitstellung frei nutzbarer,
hochqualitativer Daten die Weiterentwicklung von semantischen Erschließungsmethoden fördern sowie auch neue Geschäftsfelder entwickeln.
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 73

Vielen Dank!http://www.digitale-kuratierung.de
Berliner Bibliothekswissenschaftliches Kolloquium (BBK) – 06. Juni 2017 74





























