Embed Size (px)
Citation preview

2 Verteilungen 51
Elementare Stochastik Rolf Biehler WS 2006/2007
2.12 Verteilungsvergleich am Beispiel einer stochastischen Simu-lation
Wir beschäftigen uns mit der folgenden Aufgabe Betrachten Sie die beiden folgenden Tests, bei denen der Prüfling entweder ja oder
nein ankreuzen kann: Test 1 besteht aus 10 Fragen. Test 2 besteht aus 20 Fragen. Beide Tests sind bestanden, wenn mindestens 60% der Fragen richtig beantwortet sind. Bei welchem der beiden Tests hat ein Prüfling größere Chancen zu bestehen, wenn er nur rät? Test 1
Test 2
In beiden gleich wahrscheinlich
Weiß ich nicht Diese Aufgabe gehört eigentlich in die Wahrscheinlichkeitsrechnung. Man kann sie aber mit Mitteln der beschreibenden Statistik lösen, in dem man sich zu der Situation experimentelle Daten erzeugt, die man mit statistischen Mitteln analysiert.
Eine intuitive richtige Antwort auf die Frage ist zunächst: Test 1 ist leichter durch Raten zu bestehen, denn je größer die Fragenanzahl desto näher liegt der Anteil richtig beantworteter Fragen beim theoretischen Wert von ½. Bei kleinen Stichprobenumfängen liegt man eher mal weit vom theoretischen Wert entfernt.
Wie kann man die Chance zu bestehen durch experimentelle Daten ermitteln? Man führt den Test etwa 1000mal durch, wobei das Raten durch den Wurf mit einer fairen Münze simuliert wird. Wir ermitteln dann, in wie viel Prozent der 1000 Fälle der Test bestanden wurde. Diese relative Häufigkeit des Bestehens nehmen wir dann als ein empirisches Maß für die Chance den Test zu bestehen.
Als Untersuchungs- oder Beobachtungseinheit dient uns also eine Testdurchführung. Als Merkmal betrachten wir die Anzahl richtig beantworteter Fragen und bezeichnen es mit X. Dieses Merkmal kann bei Test1 die Werte 0, 1, … 10 annehmen, d.h. { }1, 2, ,10XW = … . Wenn wir diesen Test n = 1000 mal wiederholen erhalten wir eine Kollektion aus 1000 Fäl-len, den 1000 Testwiederholungen, also 1000nΩ = = . Wir visualisieren und analysieren dann die Verteilung von X und ermitteln ( 6)Xh X ≥ . Bei Test2 bezeichnen wir die Anzahl richtig beantworteter Fragen mit Y , haben { }1, 2, , 20YW = … und interessieren uns für die rela-tive Häufigkeit ( 12)Yh Y ≥ .
Wir planen folgende schrittweise Realisierung in Fathom:
Schritt Aktivität Fathom
1 Durchführen eines einzelnen Tests mit 10(20) Fragen
Erzeugen einer Kollektion aus 10 Elementen mit einem Merkmal „FrageTest1(2)“ mit dem Kom-mando Zufallwahl(„richtig“;„falsch“)
2 Feststellen des Wertes von X (Y), der Anzahl der richtig be-antworteten Fragen
Definieren einer „Messgröße“ Anz_richtige_Fragen über die Formel Anzahl(Frage = „richtig“)
52
Elementare Stochastik Rolf Biehler WS 2006/2007
3 Wiederholung des Tests mit Wiederholungszahl 1000; Proto-kollierung der Werte der Merk-male X(Y)
„Messgrößen sammeln“; es entsteht die Kollekti-on Ω von 1000 Testdurchläufen mit dem einzigen Merkmal Anz_richtige_Fragen
4 Verteilungsvergleich und –analyse der Merkmale X und Y
Verteilungsvergleich in Fathom mit üblichen Mit-teln
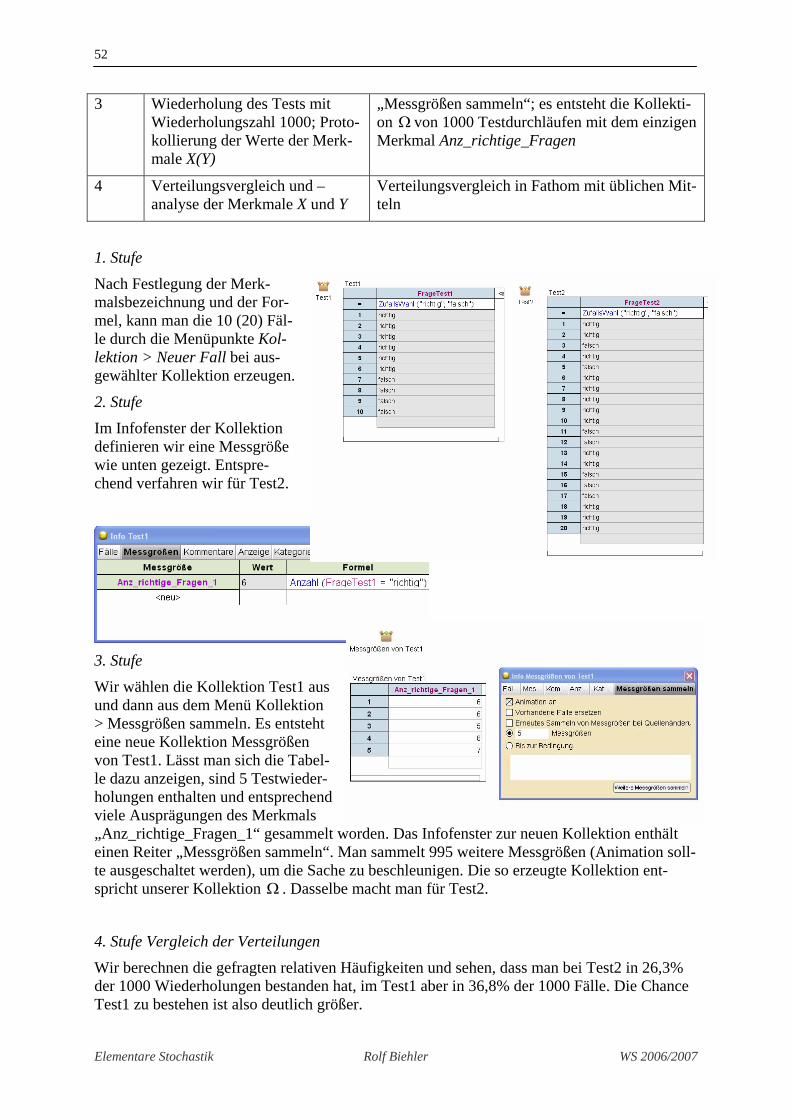
1. Stufe
Nach Festlegung der Merk-malsbezeichnung und der For-mel, kann man die 10 (20) Fäl-le durch die Menüpunkte Kol-lektion > Neuer Fall bei aus-gewählter Kollektion erzeugen.
2. Stufe
Im Infofenster der Kollektion definieren wir eine Messgröße wie unten gezeigt. Entspre-chend verfahren wir für Test2.
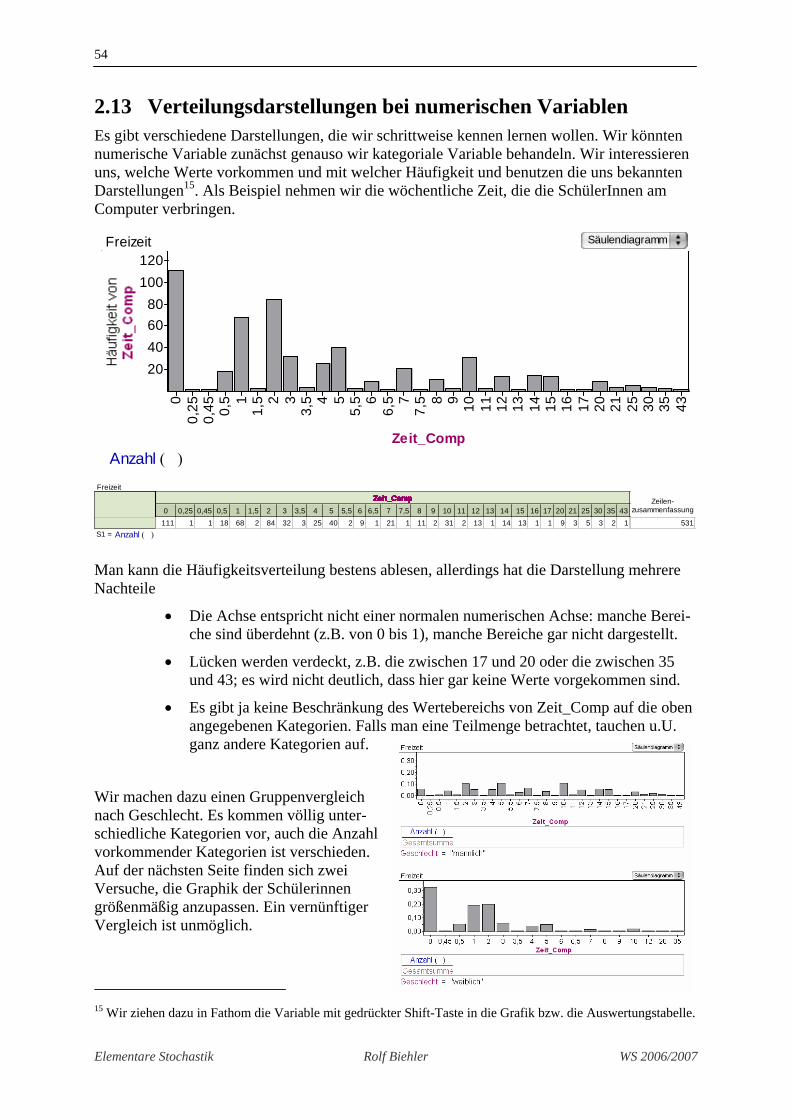
3. Stufe
Wir wählen die Kollektion Test1 aus und dann aus dem Menü Kollektion > Messgrößen sammeln. Es entsteht eine neue Kollektion Messgrößen von Test1. Lässt man sich die Tabel-le dazu anzeigen, sind 5 Testwieder-holungen enthalten und entsprechend viele Ausprägungen des Merkmals „Anz_richtige_Fragen_1“ gesammelt worden. Das Infofenster zur neuen Kollektion enthält einen Reiter „Messgrößen sammeln“. Man sammelt 995 weitere Messgrößen (Animation soll-te ausgeschaltet werden), um die Sache zu beschleunigen. Die so erzeugte Kollektion ent-spricht unserer Kollektion Ω . Dasselbe macht man für Test2.
4. Stufe Vergleich der Verteilungen
Wir berechnen die gefragten relativen Häufigkeiten und sehen, dass man bei Test2 in 26,3% der 1000 Wiederholungen bestanden hat, im Test1 aber in 36,8% der 1000 Fälle. Die Chance Test1 zu bestehen ist also deutlich größer.

2 Verteilungen 53
Elementare Stochastik Rolf Biehler WS 2006/2007
13
In den beiden Graphiken14 sind relative Häufigkeiten in Prozent dargestellt und der Bereich derjenigen Fälle (Testwiederholungen) hervorgehoben, bei denen man den Test besteht. Die Anpassung der x-Achsen erlaubt gleiche prozentuale Ergebnisse übereinander zu sehen (6 im Test1 entspricht 12 im Test2). Man kann erkennen, dass die relative Häufigkeit im unteren Diagramm größer ist (erkennbar als Anteil der roten Fläche zur Gesamtfläche).
Wir untersuchen dieselbe Situation noch mal mit einem Test mit 200 Fragen. Hier ist die Wahrscheinlichkeit, zufällig zu bestehen wieder deutlich geringer.
( )AnzahlGesamtsumme
100
0123456
Anz_richtige_Fragen_2
83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
Messgrößen von Test2 Säulendiagramm
Die letzte Graphik zeigt die Verteilung bei einer Testlänge von 200 Fragen, bei denen man bestanden hat, wenn mindestens 60% also 120 Fragen richtig beantwortet wurden. Es kom-men Werte zwischen 83 und 135 vor, in 10,4% der Fälle hat man per Zufall bestanden.
13 In einer älteren Version von Fathom hieß das Kommando Gesamtanzahl noch Gesamtsumme. 14 In der Voreinstellung zeigt Fathom nur die Ausprägungen an, die tatsächlich vorgekommen sind. Das wären bei Test2 hier die Ergebnisse 3, …16; bei Test1 die Ergebnisse 1, … 9. Will man dafür sorgen, dass alle mögli-chen Ergebnisse auch auf der Achse erscheinen, muss man sich eine entsprechende „Kategorienliste“ für diese beiden Merkmale definieren, die alle Werte { } { }0,1,...,10 bzw. 0,1,..., 20 enthalten.
Messgrößen von Test2
0,104
S1 = Anz_richtige_Fragen_2 120≥( )Anzahl
1000
54
Elementare Stochastik Rolf Biehler WS 2006/2007
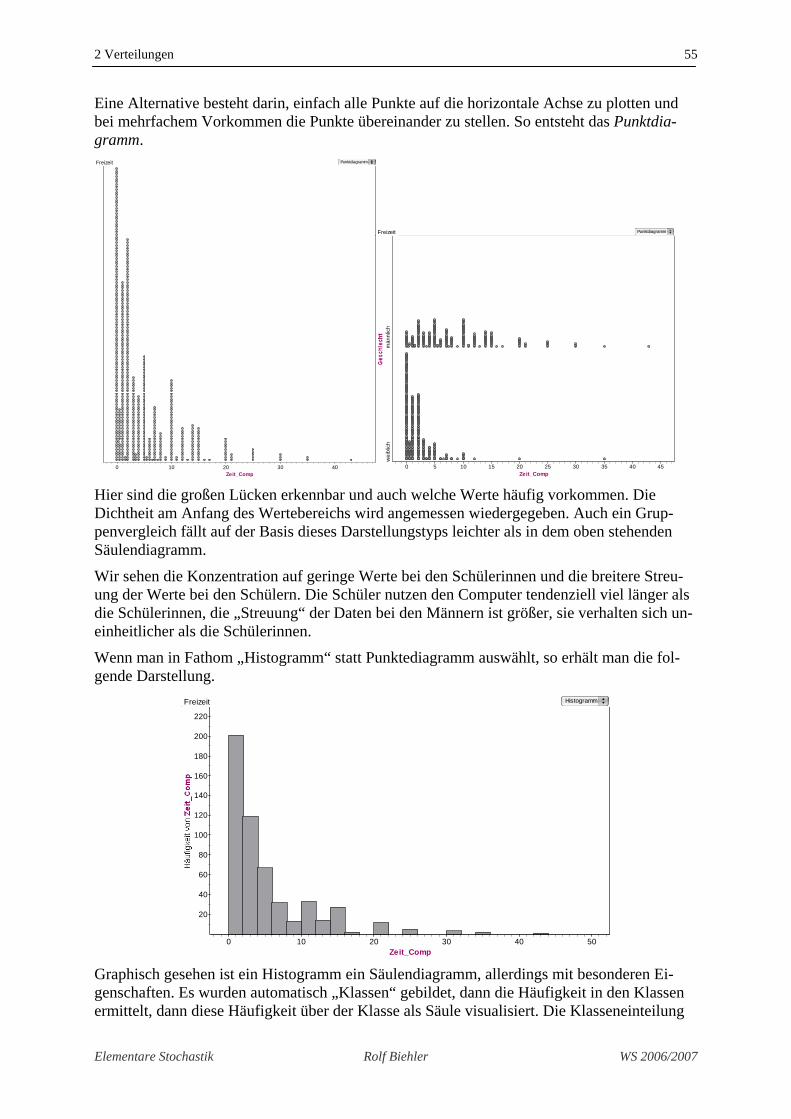
2.13 Verteilungsdarstellungen bei numerischen Variablen Es gibt verschiedene Darstellungen, die wir schrittweise kennen lernen wollen. Wir könnten numerische Variable zunächst genauso wir kategoriale Variable behandeln. Wir interessieren uns, welche Werte vorkommen und mit welcher Häufigkeit und benutzen die uns bekannten Darstellungen15. Als Beispiel nehmen wir die wöchentliche Zeit, die die SchülerInnen am Computer verbringen.
( )Anzahl
20406080
100120
Zeit_Comp
00,
250,
45 0,5 1
1,5 2 3
3,5 4 5
5,5 6
6,5 7
7,5 8 9 10 11 12 13 14 15 16 17 20 21 25 30 35 43
Freizeit Säulendiagramm
Freizeit
Zeilen-zusammenfassung
Zeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_CompZeit_Comp0,25 0,45 0,5 1 1,5 2 3 3,5 4 5 5,5 6 6,5 7 7,5 8 9 10 11 12 13 14 15 16 17 20 21 25 30 35 43
Zeit_Comp0
111 1 1 18 68 2 84 32 3 25 40 2 9 1 21 1 11 2 31 2 13 1 14 13 1 1 9 3 5 3 2 1 531S1 = ( )Anzahl
Man kann die Häufigkeitsverteilung bestens ablesen, allerdings hat die Darstellung mehrere Nachteile
• Die Achse entspricht nicht einer normalen numerischen Achse: manche Berei-che sind überdehnt (z.B. von 0 bis 1), manche Bereiche gar nicht dargestellt.
• Lücken werden verdeckt, z.B. die zwischen 17 und 20 oder die zwischen 35 und 43; es wird nicht deutlich, dass hier gar keine Werte vorgekommen sind.
• Es gibt ja keine Beschränkung des Wertebereichs von Zeit_Comp auf die oben angegebenen Kategorien. Falls man eine Teilmenge betrachtet, tauchen u.U. ganz andere Kategorien auf.
Wir machen dazu einen Gruppenvergleich nach Geschlecht. Es kommen völlig unter-schiedliche Kategorien vor, auch die Anzahl vorkommender Kategorien ist verschieden. Auf der nächsten Seite finden sich zwei Versuche, die Graphik der Schülerinnen größenmäßig anzupassen. Ein vernünftiger Vergleich ist unmöglich.
15 Wir ziehen dazu in Fathom die Variable mit gedrückter Shift-Taste in die Grafik bzw. die Auswertungstabelle.
2 Verteilungen 55
Elementare Stochastik Rolf Biehler WS 2006/2007
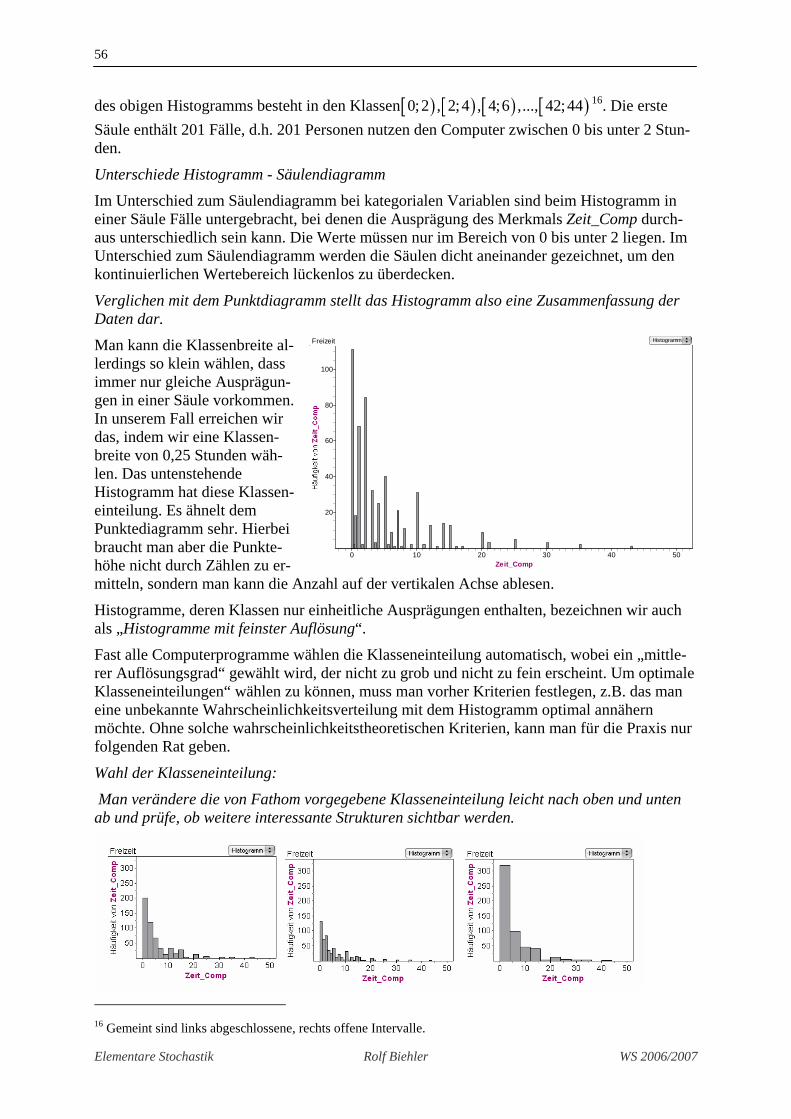
Eine Alternative besteht darin, einfach alle Punkte auf die horizontale Achse zu plotten und bei mehrfachem Vorkommen die Punkte übereinander zu stellen. So entsteht das Punktdia-gramm.
Zeit_Comp0 10 20 30 40
Freizeit Punktdiagramm
män
nlic
hw
eibl
ich
Zeit_Comp0 5 10 15 20 25 30 35 40 45
Freizeit Punktdiagramm
Hier sind die großen Lücken erkennbar und auch welche Werte häufig vorkommen. Die Dichtheit am Anfang des Wertebereichs wird angemessen wiedergegeben. Auch ein Grup-penvergleich fällt auf der Basis dieses Darstellungstyps leichter als in dem oben stehenden Säulendiagramm.
Wir sehen die Konzentration auf geringe Werte bei den Schülerinnen und die breitere Streu-ung der Werte bei den Schülern. Die Schüler nutzen den Computer tendenziell viel länger als die Schülerinnen, die „Streuung“ der Daten bei den Männern ist größer, sie verhalten sich un-einheitlicher als die Schülerinnen.
Wenn man in Fathom „Histogramm“ statt Punktediagramm auswählt, so erhält man die fol-gende Darstellung.
20
40
60
80
100
120
140
160
180
200
220
Zeit_Comp0 10 20 30 40 50
Freizeit Histogramm
Graphisch gesehen ist ein Histogramm ein Säulendiagramm, allerdings mit besonderen Ei-genschaften. Es wurden automatisch „Klassen“ gebildet, dann die Häufigkeit in den Klassen ermittelt, dann diese Häufigkeit über der Klasse als Säule visualisiert. Die Klasseneinteilung
56
Elementare Stochastik Rolf Biehler WS 2006/2007
des obigen Histogramms besteht in den Klassen[ ) [ ) [ ) [ )0;2 , 2;4 , 4;6 ,..., 42;44 16. Die erste Säule enthält 201 Fälle, d.h. 201 Personen nutzen den Computer zwischen 0 bis unter 2 Stun-den.
Unterschiede Histogramm - Säulendiagramm
Im Unterschied zum Säulendiagramm bei kategorialen Variablen sind beim Histogramm in einer Säule Fälle untergebracht, bei denen die Ausprägung des Merkmals Zeit_Comp durch-aus unterschiedlich sein kann. Die Werte müssen nur im Bereich von 0 bis unter 2 liegen. Im Unterschied zum Säulendiagramm werden die Säulen dicht aneinander gezeichnet, um den kontinuierlichen Wertebereich lückenlos zu überdecken.
Verglichen mit dem Punktdiagramm stellt das Histogramm also eine Zusammenfassung der Daten dar.
Man kann die Klassenbreite al-lerdings so klein wählen, dass immer nur gleiche Ausprägun-gen in einer Säule vorkommen. In unserem Fall erreichen wir das, indem wir eine Klassen-breite von 0,25 Stunden wäh-len. Das untenstehende Histogramm hat diese Klassen-einteilung. Es ähnelt dem Punktediagramm sehr. Hierbei braucht man aber die Punkte-höhe nicht durch Zählen zu er-mitteln, sondern man kann die Anzahl auf der vertikalen Achse ablesen.
Histogramme, deren Klassen nur einheitliche Ausprägungen enthalten, bezeichnen wir auch als „Histogramme mit feinster Auflösung“.
Fast alle Computerprogramme wählen die Klasseneinteilung automatisch, wobei ein „mittle-rer Auflösungsgrad“ gewählt wird, der nicht zu grob und nicht zu fein erscheint. Um optimale Klasseneinteilungen“ wählen zu können, muss man vorher Kriterien festlegen, z.B. das man eine unbekannte Wahrscheinlichkeitsverteilung mit dem Histogramm optimal annähern möchte. Ohne solche wahrscheinlichkeitstheoretischen Kriterien, kann man für die Praxis nur folgenden Rat geben.
Wahl der Klasseneinteilung:
Man verändere die von Fathom vorgegebene Klasseneinteilung leicht nach oben und unten ab und prüfe, ob weitere interessante Strukturen sichtbar werden.
16 Gemeint sind links abgeschlossene, rechts offene Intervalle.
20
40
60
80
100
Zeit_Comp0 10 20 30 40 50
Freizeit Histogramm

2 Verteilungen 57
Elementare Stochastik Rolf Biehler WS 2006/2007
In der obigen Graphik hat das erste Histogramm die Klasseneinteilung 2, das zweite 1, das dritte 4 Stunden. Die vertikale Achse wurde immer gleich skaliert. Als Hauptstruktur wird sichtbar, dass die Häufigkeiten tendenziell zu größeren Werten systematisch abnehmen.
Wir wollen nun genauer mathematisch verstehen, was hinter solchen Histogrammen steckt. Dazu einige Definitionen. In Definition 2.2 haben wir die Häufigkeiten für einzelne Werte aus der Wertemenge XW definiert. Im Histogramm betrachten wir Häufigkeiten in Intervallen. Dem entspricht die folgende Definition.
Definition 2.4: Häufigkeiten, dass Merkmale Werte in Teilmengen annehmen
Sei X eine numerische Variable und B ⊂ R . Dann heißt { }( ) : ( )XH B X Bω ω= ∈Ω ∈ die absolute Häufigkeit von Werten von X in B.
( )( ) : XX
X
H Bh B =Ω
heißt die relative Häufigkeit von Werten von X in B ohne fehlende
Werte
( )( ) : XX
H Bh B =Ω
heißt die relative Häufigkeit von Werten von X in B mit Berücksich-
tigung von fehlende Werten.
Oft betrachtet man Intervalle der Form ( ] ]( ), oder , oder ,b a b a b−∞ ⎡⎣ und interessiert sich für die Häufigkeit von X-Werten in diesen Intervallen.
Definition 2.5: Für ]( ,B a b= wird ( )XH B mit )( bH a X ≤< bezeichnet. Entsprechen-
des gilt für relative Häufigkeiten ,h h und für andere Intervalle. Beispielsweise ist )(( ) ( ) für , .X Xh B h X b B b= < = −∞
Für die relativen und absoluten Häufigkeiten gilt eine einfache Eigenschaft: Die Häufigkeit zweier vereinigter Mengen, die keine gemeinsamen Elemente haben, ermittelt man dadurch, dass man einfach die Häufigkeiten addiert.
Satz 2.3 (Additivitätssatz für Häufigkeiten):
X sei eine numerische statistische Variable.
(a) Es seien , ( ) mit XA B W A B⊂ = ∩ =∅R , dann gilt:
( ) ( ) ( ) und
( ) ( ) ( )
( ) ( ) ( )
X X X
X X X
X X X
H A B H A H Bh A B h A h B
h A B h A h B
∪ = +∪ = +
∪ = +
(b) Es seien 1 2, , ( )k XA A A W⊂ =… R paarweise disjunkte Mengen, dann gilt
1 2 1 2
1 2 1 2
1 2 1 2
( ) ( ) ( ) ( ) und( ) ( ) ( ) ( )
( ) ( ) ( ) ( )
X k X X X k
X k X X X k
X k X X X k
H A A A H A H A H Ah A A A h A h A h A
h A A A h A h A h A
∪ ∪ = + +∪ ∪ = + +
∪ ∪ = + +
… …… …
… …

58
Elementare Stochastik Rolf Biehler WS 2006/2007
Beweis: Anschaulich klar für absolute Häufigkeiten. Die Summe der Anzahlen zweier dis-junkter Mengen erhält man durch Abzählen der Vereinigungsmenge. Wir führen die Eigen-schaft von disjunkten Teilmengen von XW auf disjunkte Teilmengen von der Kollektion zu-rück.
{ }( ){ } { }( ){ }( ) { }( )
( ) ( )
( ) ( )
( ) ( ) nach Satz 1.1
( ) ( )
X X
X
X X
X X
H A B H X A B
H X A X B
H X A H X B
H A H B
ω ω
ω ω ω ω
ω ω ω ω
∪ = ∈Ω ∈ ∪
= ∈Ω ∈ ∪ ∈Ω ∈
= ∈Ω ∈ + ∈Ω ∈
+
Für die relativen Häufigkeiten folgt das entsprechend, formal:
( ) ( ) ( )( ) ( ) ( )X X XX X X
X X
H A B H A H Bh A B h A h B∪ +∪ = = = +
Ω Ω
Hinweis: Die Aussage von Satz 2.3 gilt auch entsprechend für kategoriale Variable X mit be-liebiger endlicher Wertemenge XW .
Satz 2.4 (Eigenschaften von Häufigkeiten): X sei eine numerische statistische Variab-le und , ( ) mit XA B W A B⊂ = ⊂R . Dann gilt
(a) ( ) ( ) und ( ) ( ), ( ) ( )X X X X X XH A H B h A h B h A h B≤ ≤ ≤
(b) ˆ ˆ( ) ( ) und ( ) ( ) 1X X X X X X X X XH W H W h W h W= = Ω = =
Beweis: Es ist anschaulich klar, dass Mengen B, die A umfassen auch mindestens die Häufig-keit wie die von B haben. Wählt man den Wertebereich XW oder die Menge der vorkommen-
den Werte ˆXW so haben wir hiermit die ganze Menge XΩ erfasst.
Auf dieser Basis können wir nun erklären, wie ein Histogramm definiert und erzeugt wird.
Definition 2.6 Klasseneinteilung (äquidistant und allgemein). Sei X eine numerische statistische Variable.
Wir wählen 1 2 3 1ka a a a +< < < <… so, dass 1 1min( ) und max( ) ka X X a +≤ < . Dann gilt
[ ) [ ) [ )1 2 2 3 1ˆ, , ,k k Xa a a a a a W+∪ ∪ ⊃… . Wir nennen dies eine (vollständige, disjunkte)
Klasseneinteilung des Wertebereichs von X.
1a nennen wir den Startpunkt, 1ka + den Endpunkt der Klasseneinteilung, k heißt Klas-senanzahl. Die Intervalle können i.A. eine unterschiedliche Breite aufweisen.
Die Klasseneinteilung heißt äquidistant, wenn die Intervallbreiten alle gleich sind. Die einheitliche Klassenbreite nennen wir 1: i iI a a+Δ = − und bezeichnen sie als die Klas-senbreite.
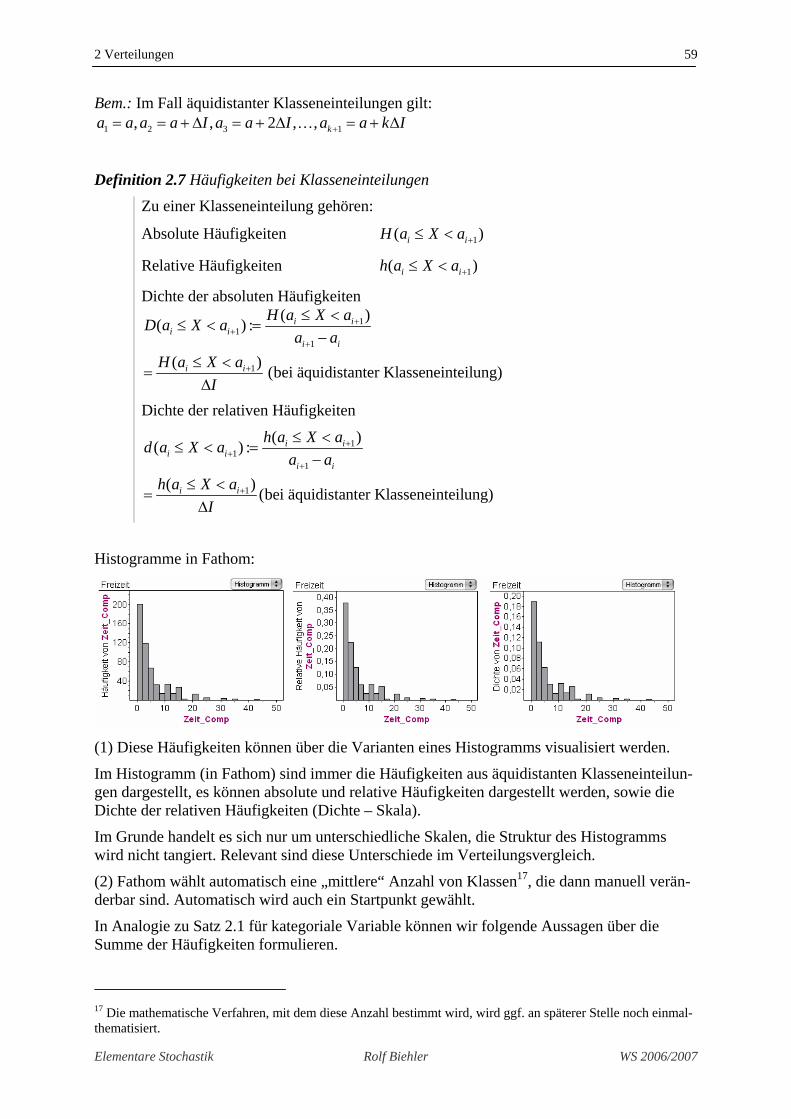
2 Verteilungen 59
Elementare Stochastik Rolf Biehler WS 2006/2007
Bem.: Im Fall äquidistanter Klasseneinteilungen gilt: 1 2 3 1, , 2 , , ka a a a I a a I a a k I+= = + Δ = + Δ = + Δ…
Definition 2.7 Häufigkeiten bei Klasseneinteilungen Zu einer Klasseneinteilung gehören:
Absolute Häufigkeiten 1( )i iH a X a +≤ <
Relative Häufigkeiten 1( )i ih a X a +≤ <
Dichte der absoluten Häufigkeiten
11
1
1
( )( ) :
( ) (bei äquidistanter Klasseneinteilung)
i ii i
i i
i i
H a X aD a X aa a
H a X aI
++
+
+
≤ <≤ < =
−
≤ <=
Δ
Dichte der relativen Häufigkeiten
11
1
1
( )( ) :
( ) (bei äquidistanter Klasseneinteilung)
i ii i
i i
i i
h a X ad a X aa a
h a X aI
++
+
+
≤ <≤ < =
−
≤ <=
Δ
Histogramme in Fathom:
(1) Diese Häufigkeiten können über die Varianten eines Histogramms visualisiert werden.
Im Histogramm (in Fathom) sind immer die Häufigkeiten aus äquidistanten Klasseneinteilun-gen dargestellt, es können absolute und relative Häufigkeiten dargestellt werden, sowie die Dichte der relativen Häufigkeiten (Dichte – Skala).
Im Grunde handelt es sich nur um unterschiedliche Skalen, die Struktur des Histogramms wird nicht tangiert. Relevant sind diese Unterschiede im Verteilungsvergleich.
(2) Fathom wählt automatisch eine „mittlere“ Anzahl von Klassen17, die dann manuell verän-derbar sind. Automatisch wird auch ein Startpunkt gewählt.
In Analogie zu Satz 2.1 für kategoriale Variable können wir folgende Aussagen über die Summe der Häufigkeiten formulieren.
17 Die mathematische Verfahren, mit dem diese Anzahl bestimmt wird, wird ggf. an späterer Stelle noch einmal-thematisiert.

60
Elementare Stochastik Rolf Biehler WS 2006/2007
Satz 2.5: X sei eine numerische statistische Variable, dann gilt:
(a) 11
( )k
i i X Xi
H a X a n+=
≤ < = Ω =∑
(b) 11
( ) 1k
i ii
h a X a +=
≤ < =∑
(c ) 11
1Bei äquidistanter Einteilung gilt zusätzlich: ( )k
i ii
d a X aI+
=
≤ < =Δ∑
Beweis: Die Aussagen sind anschaulich klar. (a) bedeutet, dass die Summe aller absoluten Häufigkeiten gleich der Anzahl aller Fälle ist, die Werte für X angegeben haben. Da die Inter-valle der Klasseneinteilung die vorkommenden Werte überdecken und sich auch nicht über-schneiden (paarweise disjunkt sind), folgt dies aus Satz 2.3 und 2.4, wenn man
[ )1,i i iA a a += setzt und bedenkt, dass die Vereinigung aller dieser Mengen ˆXW überdeckt. (b)
und (c) folgen aus (a), formal ist z.B.
11 1
1 1 1
( ) 1 1 1ˆ( ) ( ) ( ) 1k k k
i ii i i i X X
i i iX X X X
H a X ah a X a H a X a H W++ +
= = =
≤ <≤ < = = ≤ < = = Ω =
Ω Ω Ω Ω∑ ∑ ∑wobei die letzte Umformung aus (a) folgt.
Visualisierungsprinzipien im Histogramm 1
Histogramme werden konstruiert, indem man die Häufigkeiten bzw. Dichten durch Strecken (Höhe der Säulen) visualisiert. Wir haben dabei eine flächige Darstellung gewählt. Da alle In-tervalle gleich breit sind, sind auch die Flächen den Höhen proportional und damit auch den Häufigkeiten bzw. den Dichtewerten. Genauer gilt, dass sich errechnet Fläche Höhe Breite Häufigkeit I= ⋅ = ⋅Δ
Histogrammtyp H h d
Fläche18 zwischen 1 und i ia a + :
1( )i iFläche a X a +≤ <
1( )i iH a X a I+≤ < ⋅Δ 1( )i ih a X a I+≤ < ⋅Δ 1
1
( )( )i i
i i
d a X a Ih a X a
+
+
≤ < ⋅Δ= ≤ <
18 Gilt streng genommen nur bei gleichem Maßstab auf horizontaler und vertikaler Achse.
2 Verteilungen 61
Elementare Stochastik Rolf Biehler WS 2006/2007
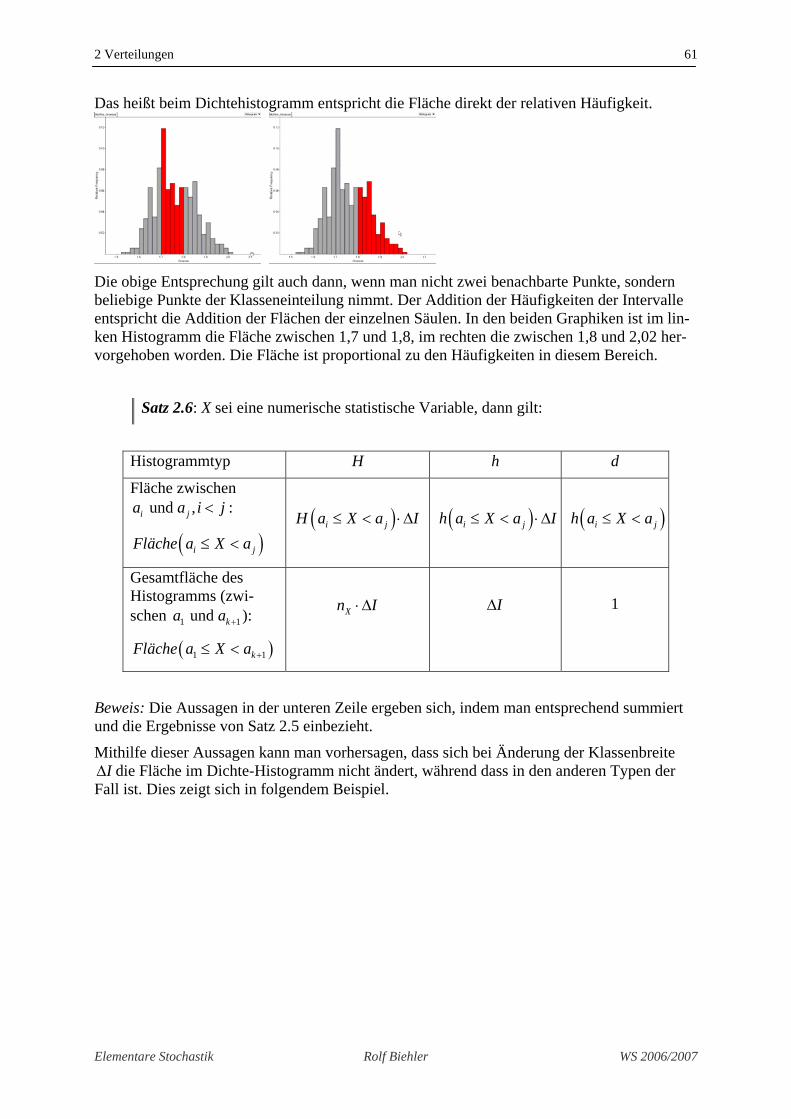
Das heißt beim Dichtehistogramm entspricht die Fläche direkt der relativen Häufigkeit.
Die obige Entsprechung gilt auch dann, wenn man nicht zwei benachbarte Punkte, sondern beliebige Punkte der Klasseneinteilung nimmt. Der Addition der Häufigkeiten der Intervalle entspricht die Addition der Flächen der einzelnen Säulen. In den beiden Graphiken ist im lin-ken Histogramm die Fläche zwischen 1,7 und 1,8, im rechten die zwischen 1,8 und 2,02 her-vorgehoben worden. Die Fläche ist proportional zu den Häufigkeiten in diesem Bereich.
Satz 2.6: X sei eine numerische statistische Variable, dann gilt:
Histogrammtyp H h d
Fläche zwischen und ,i ja a i j< :
( )i jFläche a X a≤ <
( )i jH a X a I≤ < ⋅Δ
( )i jh a X a I≤ < ⋅Δ
( )i jh a X a≤ <
Gesamtfläche des Histogramms (zwi-schen 1 1 und ka a + ):
( )1 1kFläche a X a +≤ <
Xn I⋅Δ
IΔ
1
Beweis: Die Aussagen in der unteren Zeile ergeben sich, indem man entsprechend summiert und die Ergebnisse von Satz 2.5 einbezieht.
Mithilfe dieser Aussagen kann man vorhersagen, dass sich bei Änderung der Klassenbreite IΔ die Fläche im Dichte-Histogramm nicht ändert, während dass in den anderen Typen der
Fall ist. Dies zeigt sich in folgendem Beispiel.
62
Elementare Stochastik Rolf Biehler WS 2006/2007
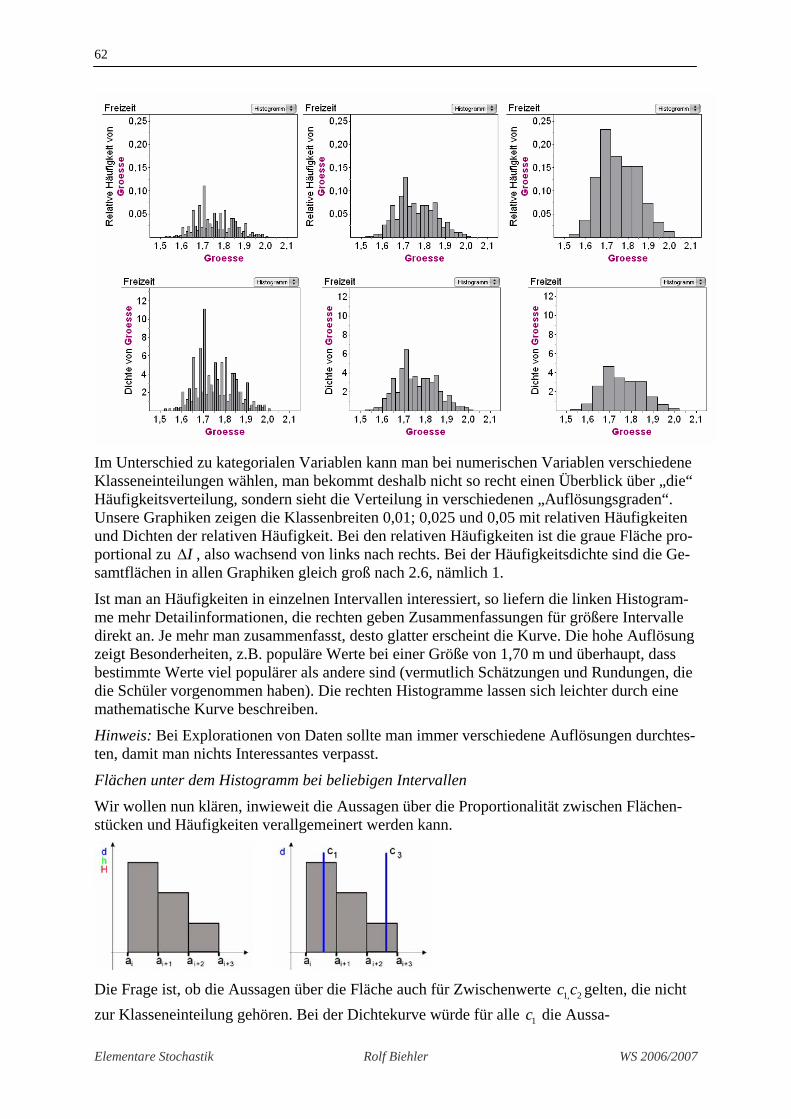
Im Unterschied zu kategorialen Variablen kann man bei numerischen Variablen verschiedene Klasseneinteilungen wählen, man bekommt deshalb nicht so recht einen Überblick über „die“ Häufigkeitsverteilung, sondern sieht die Verteilung in verschiedenen „Auflösungsgraden“. Unsere Graphiken zeigen die Klassenbreiten 0,01; 0,025 und 0,05 mit relativen Häufigkeiten und Dichten der relativen Häufigkeit. Bei den relativen Häufigkeiten ist die graue Fläche pro-portional zu IΔ , also wachsend von links nach rechts. Bei der Häufigkeitsdichte sind die Ge-samtflächen in allen Graphiken gleich groß nach 2.6, nämlich 1.
Ist man an Häufigkeiten in einzelnen Intervallen interessiert, so liefern die linken Histogram-me mehr Detailinformationen, die rechten geben Zusammenfassungen für größere Intervalle direkt an. Je mehr man zusammenfasst, desto glatter erscheint die Kurve. Die hohe Auflösung zeigt Besonderheiten, z.B. populäre Werte bei einer Größe von 1,70 m und überhaupt, dass bestimmte Werte viel populärer als andere sind (vermutlich Schätzungen und Rundungen, die die Schüler vorgenommen haben). Die rechten Histogramme lassen sich leichter durch eine mathematische Kurve beschreiben.
Hinweis: Bei Explorationen von Daten sollte man immer verschiedene Auflösungen durchtes-ten, damit man nichts Interessantes verpasst.
Flächen unter dem Histogramm bei beliebigen Intervallen Wir wollen nun klären, inwieweit die Aussagen über die Proportionalität zwischen Flächen-stücken und Häufigkeiten verallgemeinert werden kann.
Die Frage ist, ob die Aussagen über die Fläche auch für Zwischenwerte 1, 2c c gelten, die nicht zur Klasseneinteilung gehören. Bei der Dichtekurve würde für alle 1c die Aussa-
2 Verteilungen 63
Elementare Stochastik Rolf Biehler WS 2006/2007
ge ( ) ( )1 1 1 1i iFläche c X a h c X a+ +≤ < = ≤ < dann exakt gelten, wenn die Datenpunkte im Inter-
vall [ )1,i ia a + gleichmäßig verteilt wären. Das ist im Allgemeinen nicht der Fall, aber die obige Aussage gilt wenigstens oft näherungsweise. Diese geometrischen Eigenschaften sind für manche Analysen, die man mit Histogrammen macht, nützlich, man kann z.B. optisch ab-schätzen, in welchem Bereich die erste Hälfte (das erste Drittel) der Daten liegt.
Visualisierungsprinzipien im Histogramm 2: Umwandeln von numerischen Variablen in kate-goriale entsprechend einer äquidistanten Klasseneinteilung
Im Unterschied zum Säulendiagramm bei kategorialen Variablen werden die Säulen im Histogramm dicht an dicht gezeichnet. Die horizontale Achse wird als kontinuierlich interpre-tiert und die Lückenlosigkeit der Intervalle der Klasseneinteilung wird insofern gut zum Aus-druck gebracht. Man könnte die Klasseneinteilung aber auch so interpretieren, dass aus einer numerischen Variablen mit jeder Klasseneinteilung eine kategoriale Variable X_kat kon-struiert wird, vermöge der folgenden Zuordnung:
Werte von X
Kategorie
1 2a X a≤ < Klasse_1
2 3a X a≤ < Klasse_2
… …
1k ka X a +≤ < Klasse_k
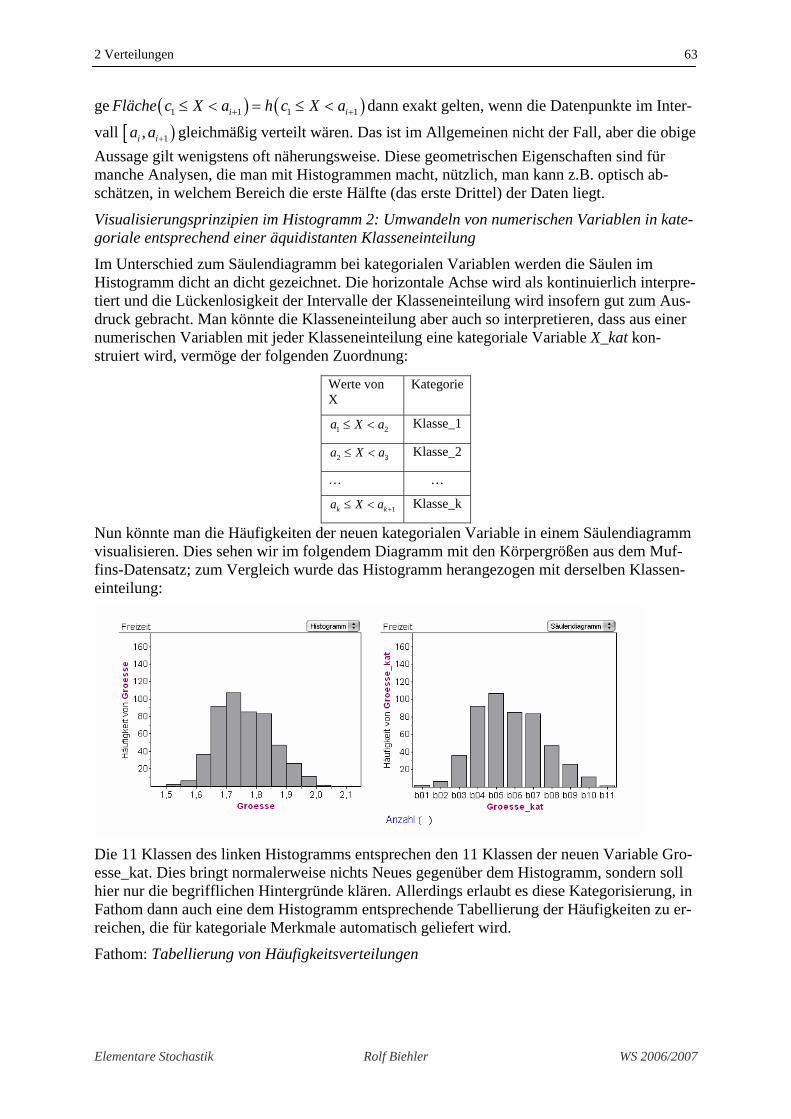
Nun könnte man die Häufigkeiten der neuen kategorialen Variable in einem Säulendiagramm visualisieren. Dies sehen wir im folgendem Diagramm mit den Körpergrößen aus dem Muf-fins-Datensatz; zum Vergleich wurde das Histogramm herangezogen mit derselben Klassen-einteilung:
Die 11 Klassen des linken Histogramms entsprechen den 11 Klassen der neuen Variable Gro-esse_kat. Dies bringt normalerweise nichts Neues gegenüber dem Histogramm, sondern soll hier nur die begrifflichen Hintergründe klären. Allerdings erlaubt es diese Kategorisierung, in Fathom dann auch eine dem Histogramm entsprechende Tabellierung der Häufigkeiten zu er-reichen, die für kategoriale Merkmale automatisch geliefert wird.
Fathom: Tabellierung von Häufigkeitsverteilungen

64
Elementare Stochastik Rolf Biehler WS 2006/2007
Freizeit
=e_ Schule Jahrgan... Geschle... Alter Groesse Groesse_kat
Groesse 0,05 1,5 2,1; ; ;( )klass
1234567
104 11 männlich 17 1,88 b08107 11 weiblich103 11 weiblich 17 1,7 b05
-g... 107 11 weiblich 17 1,7 b05102 11 weiblich 17 1,8 b07105 11 männlich 16 1,9 b09
M 102 11 ibli h 17 1 8 b07 Gegeben seien eine Intervallbreite sowie der Start- und Endpunkt einer Klasseneinteilung:
1 1, , kI a a +Δ dann definieren wir zu X eine neue Variable mit der Formel ( )1 1, , , kklass X I a a +Δ .
Hierbei werden beispielsweise die Zahlen aus )1 2,a a⎡⎣ der Kategorie b01 zugeordnet. Diese Variable stellen wir dann im Säulendiagramm oder einer Auswertungstabelle dar. Am Bei-spiel der Groesse sieht die Datentabelle und die Auswertungstabelle in Fathom dann wie oben aus. Freizeit
Zeilen-zusammenfassung
Groesse_katGroesse_katGroesse_katGroesse_katGroesse_katGroesse_katGroesse_katGroesse_katGroesse_katGroesse_katb02 b03 b04 b05 b06 b07 b08 b09 b10 b11
Groesse_katb01
200
60,01
0,2
360,07
1,4
920,19
3,8
1070,22
4,4
850,17
3,4
830,17
3,4
470,09
1,8
260,05
1
110,02
0,4
100
4961
20S1 = ( )Anzahl
S2 = ( )AnzahlGesamtsumme
2;( )runde
S3 = ( )Anzahl
Gesamtsumme2;( )runde
0,05 19 Man sieht dort auch jeweils die zugeordneten Klassen. Diese Umwandlung mit dem klass - Kommando die einzige Möglichkeit, eine Tabellierung der dem Histogramm entsprechenden Häufigkeiten im Rahmen einer Auswertungstabelle zu bekommen.
Wir sehen die absoluten (S1), die relativen Häufigkeiten (S2) und die relative Häufigkeits-dichte (S3). Die Summen der Zeilen stimmen mit dem überein, was Satz 2.4 aussagt, z.B. 1 1 20
0.05I= =
Δ.
Kumulative Häufigkeiten
Man kann sich von der relativen Willkür der Klasseneinteilung unabhängig machen, indem man sogenannte kumulative Häufigkeiten betrachtet, die wir auch schon bei kategorialen Merkmalen kennengelernt haben.
19 Man ersetze hier wieder Gesamtsumme durch Gesamtanzahl.

2 Verteilungen 65
Elementare Stochastik Rolf Biehler WS 2006/2007
Zellen aus Freizeit Tabelle
=
Zeit_HA Häufigkeit KumHäufigkeit Rel_Häufigkeit KumRelHäufigkeitHäufigkeit KumHäufigkeit( )VorgängerWert+ Häufigkeit
533100
Rel_Häufigkeit KumRelHäufigkeit( )VorgängerWert+
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
0 11 11 2,1 2,1
0,5 4 15 0,8 2,8
1 22 37 4,1 6,9
1,5 1 38 0,2 7,1
2 39 77 7,3 14,4
2,5 8 85 1,5 15,9
3 51 136 9,6 25,5
3,5 10 146 1,9 27,4
3,75 3 149 0,6 28,0
4 39 188 7,3 35,3
4,5 1 189 0,2 35,5
5 85 274 15,9 51,4
6 44 318 8,3 59,7
6,5 1 319 0,2 59,8
7 51 370 9,6 69,4
7,5 4 374 0,8 70,2
8 35 409 6,6 76,7
8,5 1 410 0,2 76,9
9 18 428 3,4 80,3
10 60 488 11,3 91,6
10,5 1 489 0,2 91,7
11 2 491 0,4 92,1
11,5 1 492 0,2 92,3
12 17 509 3,2 95,5
13 5 514 0,9 96,4
13,5 1 515 0,2 96,6
14 8 523 1,5 98,1
15 6 529 1,1 99,2
17 2 531 0,4 99,6
20 2 533 0,4 100,0
Die Tabelle enthält die Variable Zeit_HA (Wochenstunden für Hausaufgaben / muffins). Die erste Spalte zeigt alle vorkommenden Werte an20, die zweite die absolute Häufigkeit für diese Werte,. Die dritte Spalte summiert alle jeweils vorherigen absoluten Häufigkeiten auf, die vierte enthält die relative Häufigkeit in % (gerundet), die letzte Spalte führt die Kumulation in % durch. Beispielsweise ist ( ) ( )_ 19 428, _ 19 80,3%H Zeit HA h Zeit HA≤ = ≤ = . Aus einer solchen Tabelle kann man beliebige Intervallhäufigkeiten rekonstruieren, z.B. ist
( ) ( ) ( )( ) ( ) ( )
4 _ 19 _ 19 _ 4 428 38 390
4 _ 19 _ 19 _ 4 80,3% 7,1% 73, 2%
H Zeit HA H Zeit HA H Zeit HA
h Zeit HA h Zeit HA h Zeit HA
< ≤ = ≤ − ≤ = − =
< ≤ = ≤ − ≤ = − =
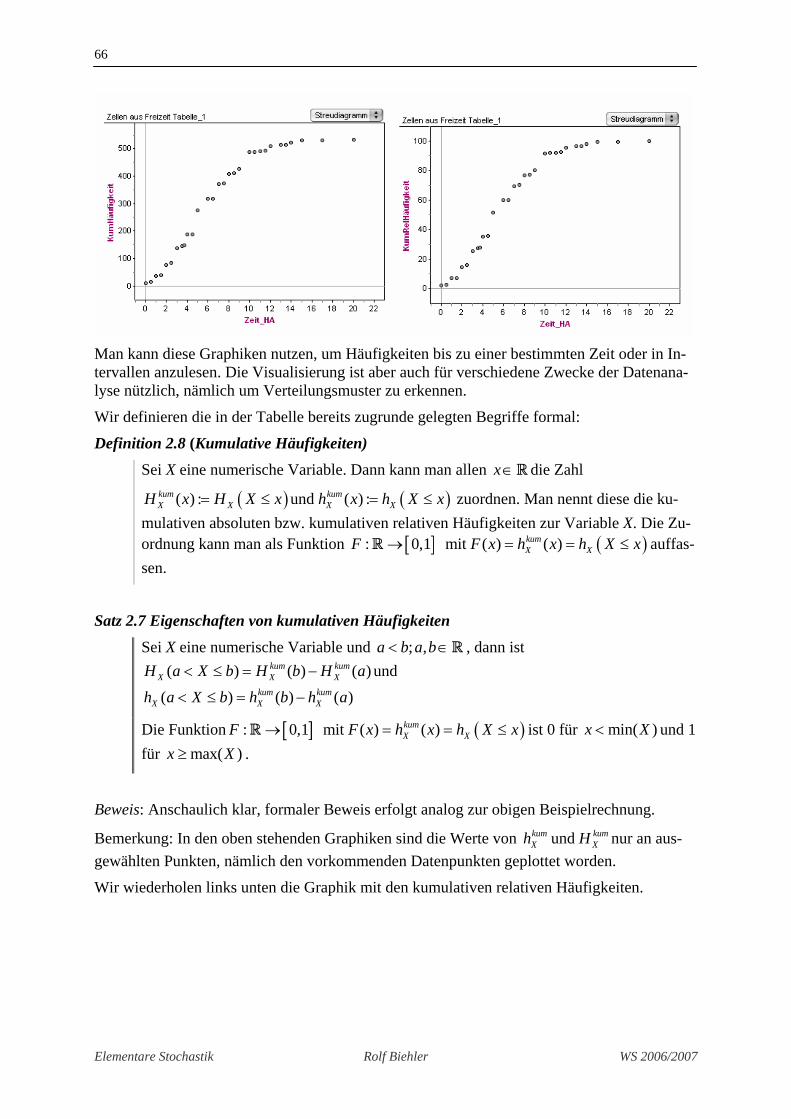
Für verschiedene Anwendungen ist auch die graphische Darstellung dieser kumulierten (an-gehäuften) Häufigkeiten informativ. Wir sehen in der nächsten Grphik einmal die relativen kumulierten Häufigkeiten in % und einmal die absoluten kumulierten Häufigkeiten. Die Gra-phiken sehen sich sehr ähnlich, weil die jeweiligen auf der y-Achse abgetragenen Werte zu-einander proportional sind.
20 Die ersten beiden Spalten entstehen automatisch in Fathom, wenn man die Variable Zeit_HA mit shift, also als kategoriale Variable in eine Auswertungstabelle zieht. Anschließend wählt man „Kollektion aus Zellwerten erstellen“ und erzeugt eine neue Kollektion, bei der man nach obigen Formeln die weiteren Spalten erstellen kann.
66
Elementare Stochastik Rolf Biehler WS 2006/2007
Man kann diese Graphiken nutzen, um Häufigkeiten bis zu einer bestimmten Zeit oder in In-tervallen anzulesen. Die Visualisierung ist aber auch für verschiedene Zwecke der Datenana-lyse nützlich, nämlich um Verteilungsmuster zu erkennen.
Wir definieren die in der Tabelle bereits zugrunde gelegten Begriffe formal:
Definition 2.8 (Kumulative Häufigkeiten)
Sei X eine numerische Variable. Dann kann man allen x∈R die Zahl
( ) ( )( ) : und ( ) :kum kumX X X XH x H X x h x h X x= ≤ = ≤ zuordnen. Man nennt diese die ku-
mulativen absoluten bzw. kumulativen relativen Häufigkeiten zur Variable X. Die Zu-ordnung kann man als Funktion [ ] ( ): 0,1 mit ( ) ( )kum
X XF F x h x h X x→ = = ≤R auffas-sen.
Satz 2.7 Eigenschaften von kumulativen Häufigkeiten
Sei X eine numerische Variable und ; ,a b a b< ∈R , dann ist ( ) ( ) ( ) und
( ) ( ) ( )
kum kumX X X
kum kumX X X
H a X b H b H a
h a X b h b h a
< ≤ = −
< ≤ = −
Die Funktion [ ] ( ): 0,1 mit ( ) ( )kumX XF F x h x h X x→ = = ≤R ist 0 für min( )x X< und 1
für max( )x X≥ .
Beweis: Anschaulich klar, formaler Beweis erfolgt analog zur obigen Beispielrechnung.
Bemerkung: In den oben stehenden Graphiken sind die Werte von und kum kumX Xh H nur an aus-
gewählten Punkten, nämlich den vorkommenden Datenpunkten geplottet worden.
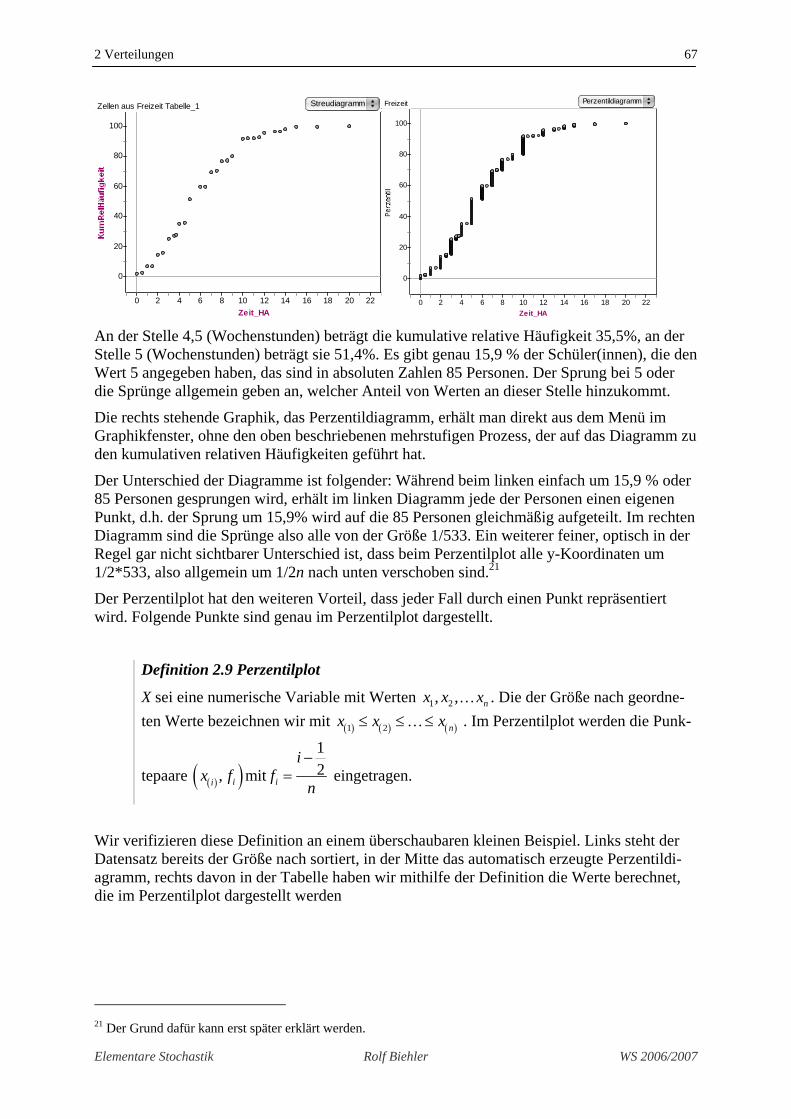
Wir wiederholen links unten die Graphik mit den kumulativen relativen Häufigkeiten.
2 Verteilungen 67
Elementare Stochastik Rolf Biehler WS 2006/2007
0
20
40
60
80
100
0 2 4 6 8 10 12 14 16 18 20 22Zeit_HA
Zellen aus Freizeit Tabelle_1 Streudiagramm
0
20
40
60
80
100
0 2 4 6 8 10 12 14 16 18 20 22Zeit_HA
Freizeit Perzentildiagramm
An der Stelle 4,5 (Wochenstunden) beträgt die kumulative relative Häufigkeit 35,5%, an der Stelle 5 (Wochenstunden) beträgt sie 51,4%. Es gibt genau 15,9 % der Schüler(innen), die den Wert 5 angegeben haben, das sind in absoluten Zahlen 85 Personen. Der Sprung bei 5 oder die Sprünge allgemein geben an, welcher Anteil von Werten an dieser Stelle hinzukommt.
Die rechts stehende Graphik, das Perzentildiagramm, erhält man direkt aus dem Menü im Graphikfenster, ohne den oben beschriebenen mehrstufigen Prozess, der auf das Diagramm zu den kumulativen relativen Häufigkeiten geführt hat.
Der Unterschied der Diagramme ist folgender: Während beim linken einfach um 15,9 % oder 85 Personen gesprungen wird, erhält im linken Diagramm jede der Personen einen eigenen Punkt, d.h. der Sprung um 15,9% wird auf die 85 Personen gleichmäßig aufgeteilt. Im rechten Diagramm sind die Sprünge also alle von der Größe 1/533. Ein weiterer feiner, optisch in der Regel gar nicht sichtbarer Unterschied ist, dass beim Perzentilplot alle y-Koordinaten um 1/2*533, also allgemein um 1/2n nach unten verschoben sind.21
Der Perzentilplot hat den weiteren Vorteil, dass jeder Fall durch einen Punkt repräsentiert wird. Folgende Punkte sind genau im Perzentilplot dargestellt.
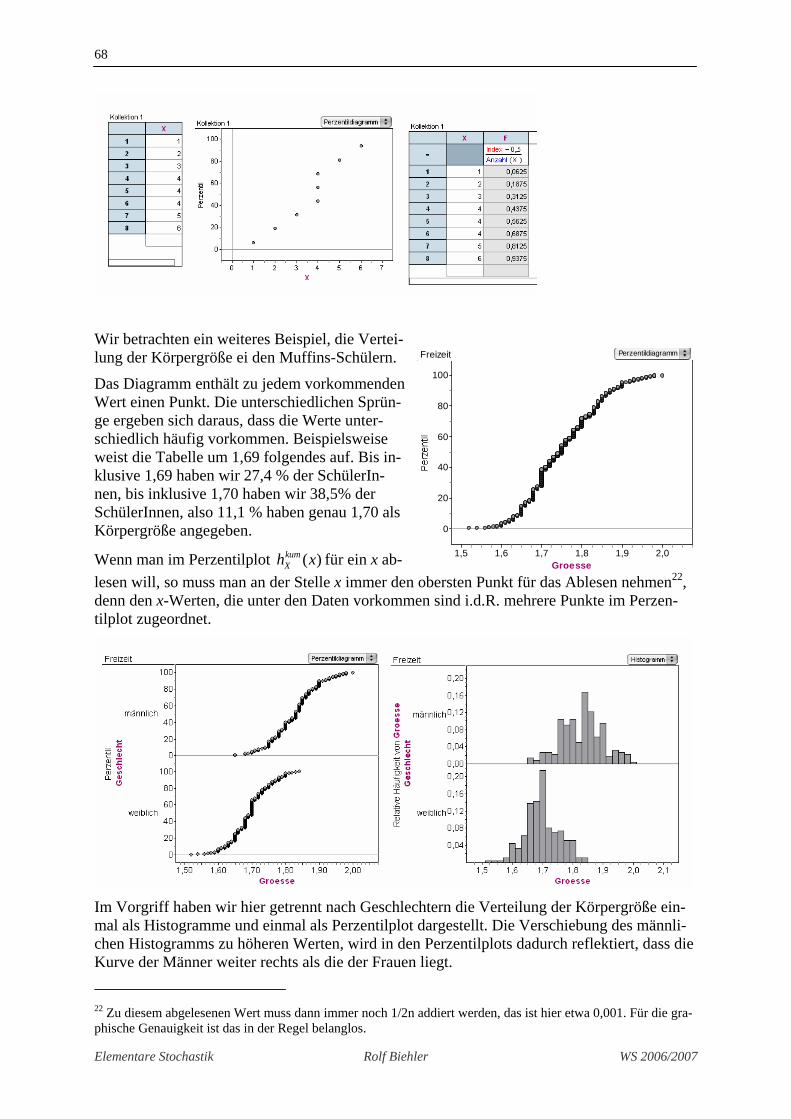
Definition 2.9 Perzentilplot
X sei eine numerische Variable mit Werten 1 2, , nx x x… . Die der Größe nach geordne-ten Werte bezeichnen wir mit ( ) ( ) ( )1 2 nx x x≤ ≤ ≤… . Im Perzentilplot werden die Punk-
tepaare ( )( )12, mit i ii
ix f f
n
−= eingetragen.
Wir verifizieren diese Definition an einem überschaubaren kleinen Beispiel. Links steht der Datensatz bereits der Größe nach sortiert, in der Mitte das automatisch erzeugte Perzentildi-agramm, rechts davon in der Tabelle haben wir mithilfe der Definition die Werte berechnet, die im Perzentilplot dargestellt werden
21 Der Grund dafür kann erst später erklärt werden.
68
Elementare Stochastik Rolf Biehler WS 2006/2007
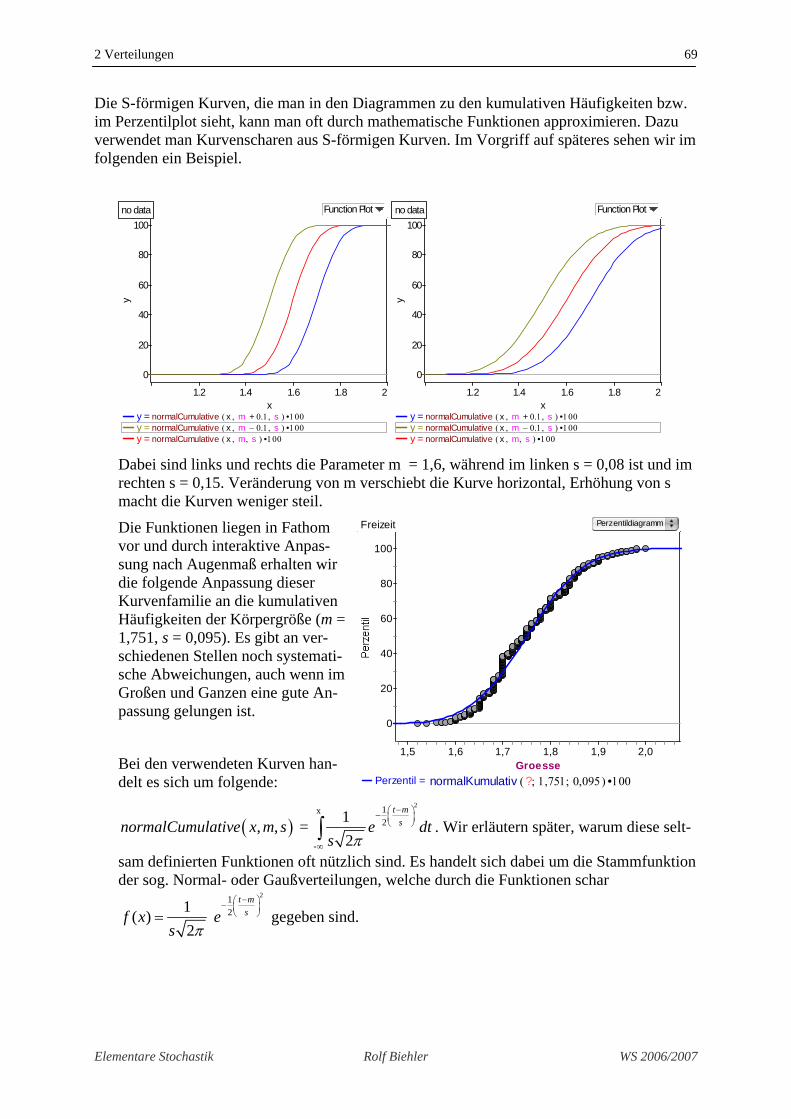
Wir betrachten ein weiteres Beispiel, die Vertei-lung der Körpergröße ei den Muffins-Schülern.
Das Diagramm enthält zu jedem vorkommenden Wert einen Punkt. Die unterschiedlichen Sprün-ge ergeben sich daraus, dass die Werte unter-schiedlich häufig vorkommen. Beispielsweise weist die Tabelle um 1,69 folgendes auf. Bis in-klusive 1,69 haben wir 27,4 % der SchülerIn-nen, bis inklusive 1,70 haben wir 38,5% der SchülerInnen, also 11,1 % haben genau 1,70 als Körpergröße angegeben.
Wenn man im Perzentilplot ( )kumXh x für ein x ab-
lesen will, so muss man an der Stelle x immer den obersten Punkt für das Ablesen nehmen22, denn den x-Werten, die unter den Daten vorkommen sind i.d.R. mehrere Punkte im Perzen-tilplot zugeordnet.
Im Vorgriff haben wir hier getrennt nach Geschlechtern die Verteilung der Körpergröße ein-mal als Histogramme und einmal als Perzentilplot dargestellt. Die Verschiebung des männli-chen Histogramms zu höheren Werten, wird in den Perzentilplots dadurch reflektiert, dass die Kurve der Männer weiter rechts als die der Frauen liegt. 22 Zu diesem abgelesenen Wert muss dann immer noch 1/2n addiert werden, das ist hier etwa 0,001. Für die gra-phische Genauigkeit ist das in der Regel belanglos.
0
20
40
60
80
100
Groesse1,5 1,6 1,7 1,8 1,9 2,0
Freizeit Perzentildiagramm
2 Verteilungen 69
Elementare Stochastik Rolf Biehler WS 2006/2007
Die S-förmigen Kurven, die man in den Diagrammen zu den kumulativen Häufigkeiten bzw. im Perzentilplot sieht, kann man oft durch mathematische Funktionen approximieren. Dazu verwendet man Kurvenscharen aus S-förmigen Kurven. Im Vorgriff auf späteres sehen wir im folgenden ein Beispiel.
0
20
40
60
80
100
y
1.2 1.4 1.6 1.8 2.x
y = x m s, ,( )normalCumulative 100•
y = x m 0.1+ s, ,( )normalCumulative 100•y = x m 0.1− s, ,( )normalCumulative 100•
no data Function Plot
0
20
40
60
80
100
y1.2 1.4 1.6 1.8 2.
x
y = x m s, ,( )normalCumulative 100•
y = x m 0.1+ s, ,( )normalCumulative 100•y = x m 0.1− s, ,( )normalCumulative 100•
no data Function Plot
Dabei sind links und rechts die Parameter m = 1,6, während im linken s = 0,08 ist und im rechten s = 0,15. Veränderung von m verschiebt die Kurve horizontal, Erhöhung von s macht die Kurven weniger steil.
Die Funktionen liegen in Fathom vor und durch interaktive Anpas-sung nach Augenmaß erhalten wir die folgende Anpassung dieser Kurvenfamilie an die kumulativen Häufigkeiten der Körpergröße (m = 1,751, s = 0,095). Es gibt an ver-schiedenen Stellen noch systemati-sche Abweichungen, auch wenn im Großen und Ganzen eine gute An-passung gelungen ist.
Bei den verwendeten Kurven han-delt es sich um folgende:
( )21x
2
-
1, , = 2
t msnormalCumulative x m s e dt
s π
−⎛ ⎞− ⎜ ⎟⎝ ⎠
∞∫ . Wir erläutern später, warum diese selt-
sam definierten Funktionen oft nützlich sind. Es handelt sich dabei um die Stammfunktion der sog. Normal- oder Gaußverteilungen, welche durch die Funktionen schar
2121( )
2
t msf x e
s π
−⎛ ⎞− ⎜ ⎟⎝ ⎠= gegeben sind.
Perzentil = ? 1,751 0,095; ;( )normalKumulativ 100•
0
20
40
60
80
100
Groesse1,5 1,6 1,7 1,8 1,9 2,0
Freizeit Perzentildiagramm
70
Elementare Stochastik Rolf Biehler WS 2006/2007
Rel
ativ
e Fr
eque
ncy
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.18
0.20
0.22
Gewicht40 50 60 70 80 90
Freizeit Histogram
Geschlecht "weiblich"=
Rel
ativ
e Fr
eque
ncy
Ges
chle
cht
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.80.9
maennlich
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.80.9
weiblich
Zeit_Comp0 5 10 15 20 25 30 35 40 45 50
Freizeit Histogram
<new filter>
3 Beschreiben von Verteilungen von numerischen Variab-len
Grundlegende Fragen zu der Verteilung einer statistischen Variablen sind z.B.:
• Wo ist die Verteilung lokalisiert?
• Wo liegt ihre Mitte, ihr Zentrum?
• Wie weit, wie stark ist sie ausgedehnt? Wie groß sind die Abweichungen der Daten vom Zentrum?
• Welche Form weist die Verteilung auf?
Verteilungsformen
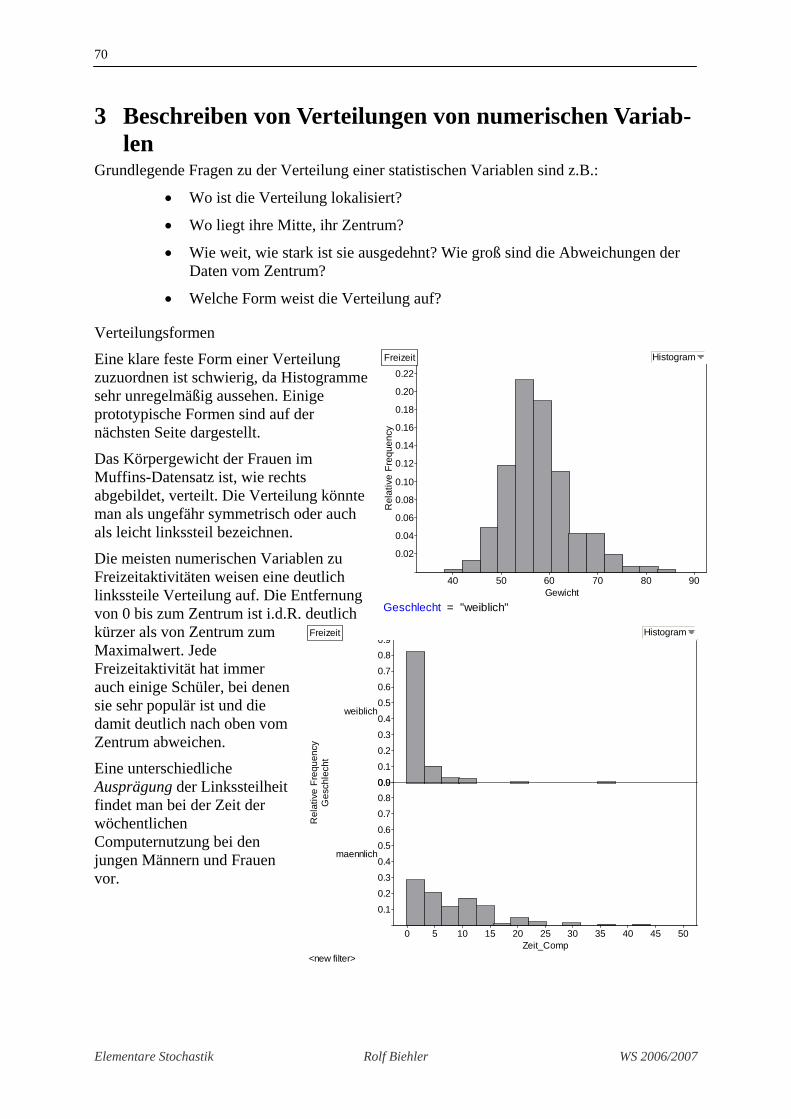
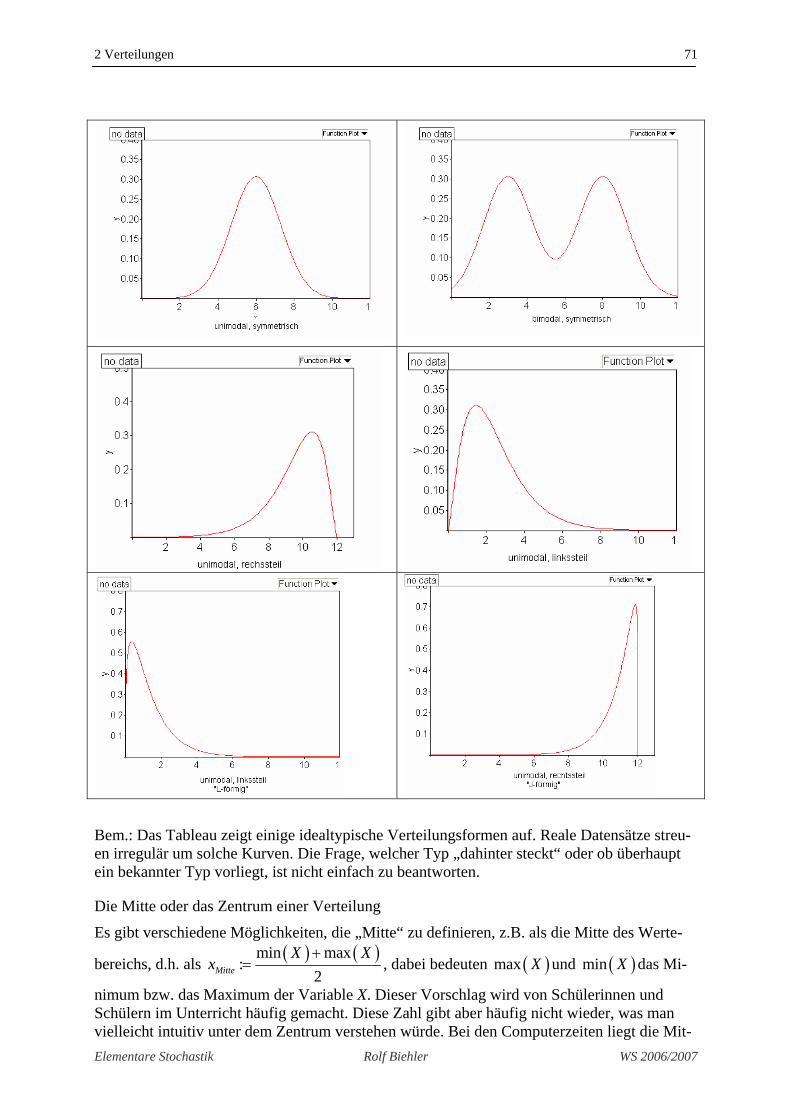
Eine klare feste Form einer Verteilung zuzuordnen ist schwierig, da Histogramme sehr unregelmäßig aussehen. Einige prototypische Formen sind auf der nächsten Seite dargestellt.
Das Körpergewicht der Frauen im Muffins-Datensatz ist, wie rechts abgebildet, verteilt. Die Verteilung könnte man als ungefähr symmetrisch oder auch als leicht linkssteil bezeichnen.
Die meisten numerischen Variablen zu Freizeitaktivitäten weisen eine deutlich linkssteile Verteilung auf. Die Entfernung von 0 bis zum Zentrum ist i.d.R. deutlich kürzer als von Zentrum zum Maximalwert. Jede Freizeitaktivität hat immer auch einige Schüler, bei denen sie sehr populär ist und die damit deutlich nach oben vom Zentrum abweichen.
Eine unterschiedliche Ausprägung der Linkssteilheit findet man bei der Zeit der wöchentlichen Computernutzung bei den jungen Männern und Frauen vor.
2 Verteilungen 71
Elementare Stochastik Rolf Biehler WS 2006/2007
Bem.: Das Tableau zeigt einige idealtypische Verteilungsformen auf. Reale Datensätze streu-en irregulär um solche Kurven. Die Frage, welcher Typ „dahinter steckt“ oder ob überhaupt ein bekannter Typ vorliegt, ist nicht einfach zu beantworten.
Die Mitte oder das Zentrum einer Verteilung
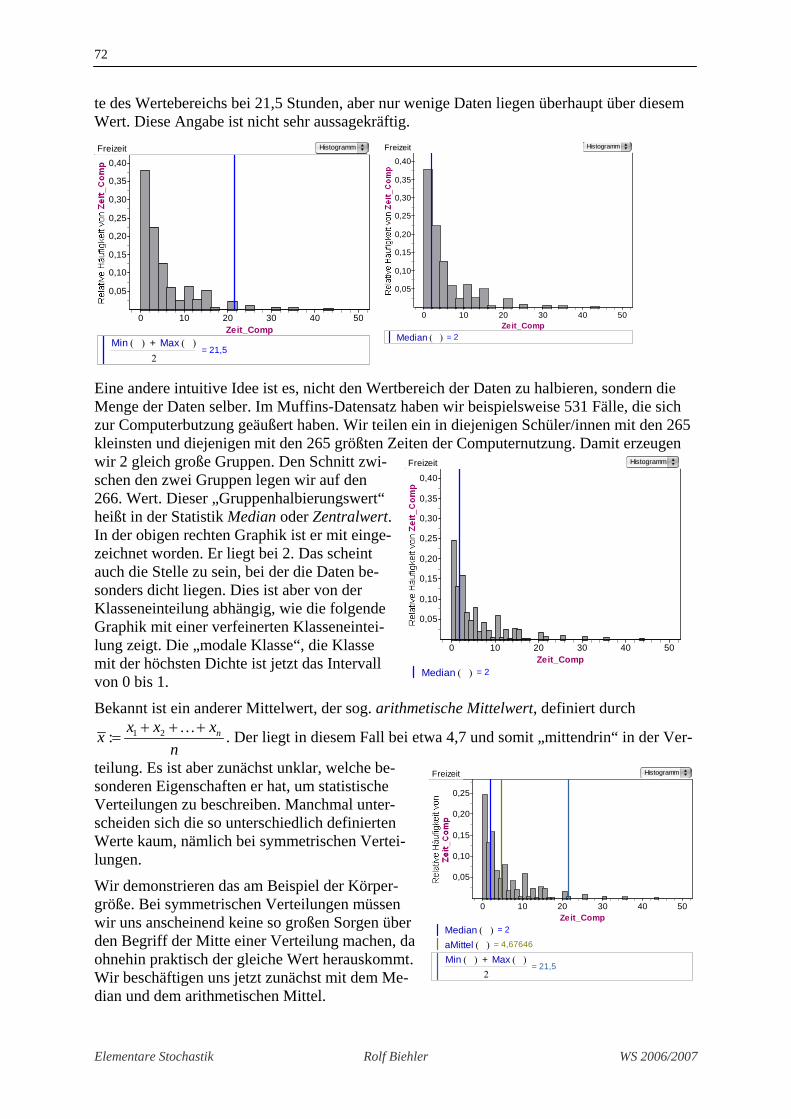
Es gibt verschiedene Möglichkeiten, die „Mitte“ zu definieren, z.B. als die Mitte des Werte-
bereichs, d.h. als ( ) ( )min max:
2Mitte
X Xx
+= , dabei bedeuten ( ) ( )max und minX X das Mi-
nimum bzw. das Maximum der Variable X. Dieser Vorschlag wird von Schülerinnen und Schülern im Unterricht häufig gemacht. Diese Zahl gibt aber häufig nicht wieder, was man vielleicht intuitiv unter dem Zentrum verstehen würde. Bei den Computerzeiten liegt die Mit-
72
Elementare Stochastik Rolf Biehler WS 2006/2007
te des Wertebereichs bei 21,5 Stunden, aber nur wenige Daten liegen überhaupt über diesem Wert. Diese Angabe ist nicht sehr aussagekräftig.
( )Median = 2
0,05
0,10
0,15
0,20
0,25
0,30
0,35
0,40
0 10 20 30 40 50Zeit_Comp
Freizeit Histogramm
Eine andere intuitive Idee ist es, nicht den Wertbereich der Daten zu halbieren, sondern die Menge der Daten selber. Im Muffins-Datensatz haben wir beispielsweise 531 Fälle, die sich zur Computerbutzung geäußert haben. Wir teilen ein in diejenigen Schüler/innen mit den 265 kleinsten und diejenigen mit den 265 größten Zeiten der Computernutzung. Damit erzeugen wir 2 gleich große Gruppen. Den Schnitt zwi-schen den zwei Gruppen legen wir auf den 266. Wert. Dieser „Gruppenhalbierungswert“ heißt in der Statistik Median oder Zentralwert. In der obigen rechten Graphik ist er mit einge-zeichnet worden. Er liegt bei 2. Das scheint auch die Stelle zu sein, bei der die Daten be-sonders dicht liegen. Dies ist aber von der Klasseneinteilung abhängig, wie die folgende Graphik mit einer verfeinerten Klasseneintei-lung zeigt. Die „modale Klasse“, die Klasse mit der höchsten Dichte ist jetzt das Intervall von 0 bis 1.
Bekannt ist ein anderer Mittelwert, der sog. arithmetische Mittelwert, definiert durch 1 2: nx x xx
n+ + +
=… . Der liegt in diesem Fall bei etwa 4,7 und somit „mittendrin“ in der Ver-
teilung. Es ist aber zunächst unklar, welche be-sonderen Eigenschaften er hat, um statistische Verteilungen zu beschreiben. Manchmal unter-scheiden sich die so unterschiedlich definierten Werte kaum, nämlich bei symmetrischen Vertei-lungen.
Wir demonstrieren das am Beispiel der Körper-größe. Bei symmetrischen Verteilungen müssen wir uns anscheinend keine so großen Sorgen über den Begriff der Mitte einer Verteilung machen, da ohnehin praktisch der gleiche Wert herauskommt. Wir beschäftigen uns jetzt zunächst mit dem Me-dian und dem arithmetischen Mittel.
( )Min ( )Max+2
= 21,5
0,05
0,10
0,15
0,20
0,25
0,30
0,35
0,40
Zeit_Comp0 10 20 30 40 50
Freizeit Histogramm
( )Median = 2
0,05
0,10
0,15
0,20
0,25
0,30
0,35
0,40
0 10 20 30 40 50Zeit_Comp
Freizeit Histogramm
( )Median = 2
( )aMittel = 4,67646
( )Min ( )Max+2
= 21,5
0,05
0,10
0,15
0,20
0,25
0 10 20 30 40 50Zeit_Comp
Freizeit Histogramm





























