Embed Size (px)
Citation preview

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen
Überblick zu Kapitel 1 von „Einführung in die Informationstheorie”Dieses erste Kapitel beschreibt die Berechnung und die Bedeutung der Entropie, die entsprechendShannons Definition von Information ein Maß ist für die mittlere Unsicherheit über den Ausgang einesstatistischen Ereignisses oder die Unsicherheit bei der Messung einer stochastischen Größe. Etwassalopp ausgedrückt quantifiziert die Entropie einer Zufallsgröße deren „Zufälligkeit”.Im Einzelnen werden behandelt:
der Entscheidungsgehalt und die Entropie einer gedächtnislosen Nachrichtenquelle,die binäre Entropiefunktion und deren Anwendung auf nichtbinäre Quellen,die Entropieberechnung bei gedächtnisbehafteten Quellen und geeignete Näherungen,die Besonderheiten von Markovquellen hinsichtlich der Entropieberechnung,die Vorgehensweise bei Quellen mit großem Symbolumfang, zum Beispiel natürliche Texte,die Entropieabschätzungen nach Shannon und Küpfmüller.
Geeignete Literatur: [AM90] – [Bla87] – [CT06] – [Fan61] – [For72] – [Gal68] – [Har28] – [Joh92b] –[Kra13] – [Küp54] – [McE77] – [Meck09] – [PS02] – [Sha48] – [Sha51] – [WZ73]
Die grundlegende Theorie wird auf 28 Seiten dargelegt. Außerdem beinhaltet dieses erste Kapitel noch32 Grafiken, acht Aufgaben und vier Zusatzaufgaben mit insgesamt 66 Teilaufgaben, sowie dreiLernvideos und drei Interaktionsmodule.
Zusammenstellung der Lernvideos (LV) zu den Grundlagen:
• Klassische Definition der Wahrscheinlichkeit (Dauer 5:19)
• Bedeutung und Berechnung der Momente bei diskreten Zufallsgrößen (Dauer 6:32)
• Statistische Abhängigkeit und Unabhängigkeit (3 Teile – Dauer 4:17, 3:48, 3:48)
Zusammenstellung der Interaktionsmodule (IM) zu den Grundlagen und Kapitel 1:
• Entropien von Nachrichtenquellen (zu Kapitel 1.1)
• Ereigniswahrscheinlichkeiten einer Markovkette (zu Kapitel 1.2)
• Signale, AKF und LDS der Pseudoternärcodes (zu Kapitel 1.2)
Weitere Informationen zum Thema sowie grafikbasierte Simulationsprogramme und Aufgaben mitausführlichen Musterlösungen finden Sie im Versuch „Wertdiskrete Informationstheorie” des PraktikumsSimulation digitaler Übertragungssysteme, das von Prof. Günter Söder (Lehrstuhl fürNachrichtentechnik) für Studierende der Elektro– und Informationstechnik an der TU Münchenangeboten wird:
Herunterladen des Windows–Programms „WDIT” (Zip–Version)
Herunterladen der dazugehörigen Texte (PDF–Datei)
Lehrstuhl fuer Nachrichtentechnik (LNT) 1 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.1 Gedächtnislose Nachrichtenquellen
Modell und Voraussetzungen für Kapitel 1.1 (1)Wir betrachten eine wertdiskrete Nachrichtenquelle Q, die eine Folge áqνñ von Symbolen abgibt. Für die
Laufvariable gilt ν = 1, ... , N, wobei N „hinreichend groß” sein sollte. Jedes einzelne Quellensymbol qν
entstammt einem Symbolvorrat {qμ} mit μ = 1, ... , M, wobei M den Symbolumfang bezeichnet:
Die Grafik zeigt eine quaternäre Nachrichtenquelle (M = 4) mit dem Alphabet {A, B, C, D}. Rechts isteine beispielhafte Folge der Länge N = 100 angegeben.
Es gelten folgende Voraussetzungen:
Die quaternäre Nachrichtenquelle wird durch M = 4 Symbolwahrscheinlichkeiten pμ vollständig
beschrieben. Allgemein gilt:
Die Nachrichtenquelle sei gedächtnislos, das heißt, die einzelnen Folgenelemente seien statistischvoneinander unabhängig:
Da das Alphabet aus Symbolen (und nicht aus Zufallsgrößen) besteht, ist hier die Angabe vonErwartungswerten (linearer Mittelwert, quadratischer Mittelwert, Streuung, usw.) nicht möglich,aber auch aus informationstheoretischer Sicht nicht nötig.
Diese Eigenschaften werden auf der nächsten Seite mit einem Beispiel verdeutlicht.
Lehrstuhl fuer Nachrichtentechnik (LNT) 2 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.1 Gedächtnislose Nachrichtenquellen
Modell und Voraussetzungen für Kapitel 1.1 (2)
Beispiel: Für die Symbolwahrscheinlichkeiten einer Quaternärquelle gelte:
Bei einer unendlich langen Folge (N → ∞) wären die relativen Häufigkeiten hA, hB, hC und hD –
also die a–posteriori–Kenngrößen – identisch mit den a–priori–Wahrscheinlichkeiten pA, pB, pC und
pD. Bei kleinerem N kann es aber durchaus zu Abweichungen kommen, wie die folgende Tabelle
(Ergebnis einer Simulation) zeigt. Die Folge für N = 100 ist auf der letzten Seite angegeben.
Aufgrund der Mengenelemente A, B, C und D können keine Mittelwerte angegeben werden. Ersetztman die Symbole durch Zahlenwerte, zum Beispiel A ⇒ 1, B ⇒ 2, C ⇒ 3, D ⇒ 4, so ergeben sich
für den linearen Mittelwert:
für den quadratischen Mittelwert:
für die Standardabweichung (Streuung) nach dem „Satz von Steiner”:
Lehrstuhl fuer Nachrichtentechnik (LNT) 3 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.1 Gedächtnislose Nachrichtenquellen
Entscheidungsgehalt – NachrichtengehaltClaude E. Shannon definierte 1948 im Standardwerk der Informationstheorie [Sha48] denInformationsbegriff als „Abnahme der Ungewissheit über das Eintreten eines statistischen Ereignisses”.Machen wir hierzu ein gedankliches Experiment mit M möglichen Ergebnissen, die allegleichwahrscheinlich seien:
Unter dieser Annahme gilt:
Ist M = 1, so wird jeder einzelne Versuch das gleiche Ergebnis liefern und demzufolge bestehtkeine Unsicherheit hinsichtlich des Ausgangs. Wird uns das Versuchsergebnis mitgeteilt, so habenwir dadurch natürlich auch keinen Informationsgewinn.
Dagegen erfährt ein Beobachter bei einem Experiment mit M = 2, zum Beispiel dem „Münzwurf”mit der Ereignismenge {Z(ahl), W(app)} und den Wahrscheinlichkeiten pZ = pW = 0.5, durchaus
einen Informationsgewinn. Die Unsicherheit, ob Z oder W geworfen wurde, wird aufgelöst.
Beim Experiment „Würfeln” (M = 6) und noch mehr beim Roulette (M = 37) ist die gewonneneInformation für den Beobachter noch deutlich größer als beim „Münzwurf”, wenn er erfährt,welche Zahl gewürfelt bzw. welche Kugel gefallen ist.
Schließlich sollte noch berücksichtigt werden, dass das Experiment „Dreifacher Münzwurf” mitden M = 8 möglichen Ergebnissen ZZZ, ZZW, ZWZ, ZWW, WZZ, WZW, WWZ, WWW diedreifache Information liefert wie der einfache Münzwurf (M = 2).
Die nachfolgende Festlegung erfüllt alle hier verbal aufgeführten Anforderungen an ein quantitativesInformationsmaß bei gleichwahrscheinlichen Ereignissen, gekennzeichnet durch den Symbolumfang M.
Definition: Der Entscheidungsgehalt einer Nachrichtenquelle hängt nur vom Symbolumfang M abund ergibt sich zu
Gebräuchlich ist hierfür auch die Bezeichnung Nachrichtengehalt. Da H0 gleichzeitig den Maximalwert
der Entropie H angibt, wird in LNTwww teilweise auch Hmax als Kurzzeichen verwendet.
Anzumerken ist:
Der Logarithmus wird in unserem Tutorial unabhängig von der Basis mit „log” bezeichnet. Die vieroben aufgestellten Kriterien werden aufgrund folgender Eigenschaften erfüllt:
Meist verwenden wir den Logarithmus zur Basis 2 ⇒ Logarithmus dualis (ld), wobei dann diePseudoeinheit „bit” – genauer: „bit/Symbol” – hinzugefügt wird:
Weiter findet man in der Literatur auch Definitionen, basierend auf dem natürlichen Logarithmus
Lehrstuhl fuer Nachrichtentechnik (LNT) 4 / 32 Technische Universitaet Muenchen

(„ln”) oder dem Zehnerlogarithmus („lg”) entsprechend obigen Definitionen.
Lehrstuhl fuer Nachrichtentechnik (LNT) 5 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.1 Gedächtnislose Nachrichtenquellen
Informationsgehalt und EntropieWir verzichten nun auf die bisherige Voraussetzung, dass alle M möglichen Ergebnisse eines Versuchsgleichwahrscheinlich seien. Im Hinblick auf eine möglichst kompakte Schreibweise legen wir für dieseSeite lediglich fest:
Unter dieser Voraussetzung betrachten wir nun den Informationsgehalt der einzelnen Symbole, wobeiwir den Logarithmus dualis mit „ld”(manchmal auch mit „log2”) bezeichnen :
Man erkennt:
Wegen pμ ≤ 1 ist der Informationsgehalt nie negativ. Im Grenzfall pμ → 1 geht Iμ → 0.
Allerdings ist für Iμ = 0 → pμ = 1 → M = 1 auch der Entscheidungsgehalt H0 = 0.
Bei abfallenden Wahrscheinlichkeiten pμ nimmt der Informationsgehalt kontinuierlich zu:
Das heißt: Je weniger wahrscheinlich ein Ereignis ist, desto größer ist sein Informationsgehalt. DieserSachverhalt ist auch im täglichen Leben festzustellen:
„6 Richtige” im Lotto nimmt man sicher eher war als „3 Richtige” oder gar keinen Gewinn.
Ein Tsunami in Asien dominiert auch die Nachrichten in Deutschland über Wochen im Gegensatzzu den fast standardmäßigen Verspätungen der Deutschen Bahn.
Eine Niederlagenserie von Bayern München führt zu Riesen–Schlagzeilen im Gegensatz zu einerSiegesserie. Bei 1860 München ist genau das Gegenteil der Fall.
Der Informationsgehalt eines einzelnen Symbols (oder Ereignisses) ist allerdings nicht sehr interessant.Durch Scharmittelung über alle möglichen Symbole qμ bzw. durch Zeitmittelung über alle Folgenelemente
qν erhält man dagegen eine der zentralen Größen der Informationstheorie.
Definition: Die Entropie einer Quelle gibt den mittleren Informationsgehalt aller Symbole an:
Die überstreichende Linie kennzeichnet eine Zeitmittelung und E[...] eine Scharmittelung.
Die Entropie ist ein Maß für
die mittlere Unsicherheit über den Ausgang eines statistischen Ereignisses,die „Zufälligkeit” dieses Ereignisses,den mittleren Informationsgehalt einer Zufallsgröße.
Lehrstuhl fuer Nachrichtentechnik (LNT) 6 / 32 Technische Universitaet Muenchen
Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.1 Gedächtnislose Nachrichtenquellen
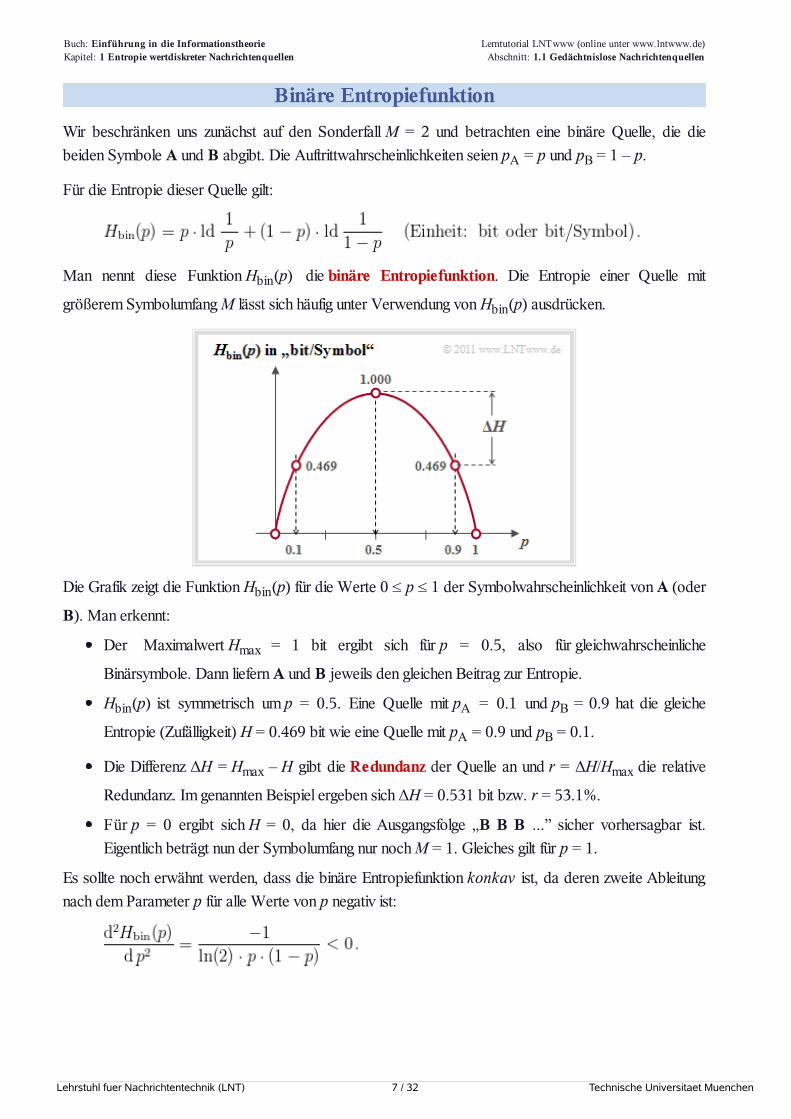
Binäre EntropiefunktionWir beschränken uns zunächst auf den Sonderfall M = 2 und betrachten eine binäre Quelle, die diebeiden Symbole A und B abgibt. Die Auftrittwahrscheinlichkeiten seien pA = p und pB = 1 – p.
Für die Entropie dieser Quelle gilt:
Man nennt diese Funktion Hbin(p) die binäre Entropiefunktion. Die Entropie einer Quelle mit
größerem Symbolumfang M lässt sich häufig unter Verwendung von Hbin(p) ausdrücken.
Die Grafik zeigt die Funktion Hbin(p) für die Werte 0 ≤ p ≤ 1 der Symbolwahrscheinlichkeit von A (oder
B). Man erkennt:
Der Maximalwert Hmax = 1 bit ergibt sich für p = 0.5, also für gleichwahrscheinliche
Binärsymbole. Dann liefern A und B jeweils den gleichen Beitrag zur Entropie.
Hbin(p) ist symmetrisch um p = 0.5. Eine Quelle mit pA = 0.1 und pB = 0.9 hat die gleiche
Entropie (Zufälligkeit) H = 0.469 bit wie eine Quelle mit pA = 0.9 und pB = 0.1.
Die Differenz ΔH = Hmax – H gibt die Redundanz der Quelle an und r = ΔH/Hmax die relative
Redundanz. Im genannten Beispiel ergeben sich ΔH = 0.531 bit bzw. r = 53.1%.
Für p = 0 ergibt sich H = 0, da hier die Ausgangsfolge „B B B ...” sicher vorhersagbar ist.Eigentlich beträgt nun der Symbolumfang nur noch M = 1. Gleiches gilt für p = 1.
Es sollte noch erwähnt werden, dass die binäre Entropiefunktion konkav ist, da deren zweite Ableitungnach dem Parameter p für alle Werte von p negativ ist:
Lehrstuhl fuer Nachrichtentechnik (LNT) 7 / 32 Technische Universitaet Muenchen
Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.1 Gedächtnislose Nachrichtenquellen
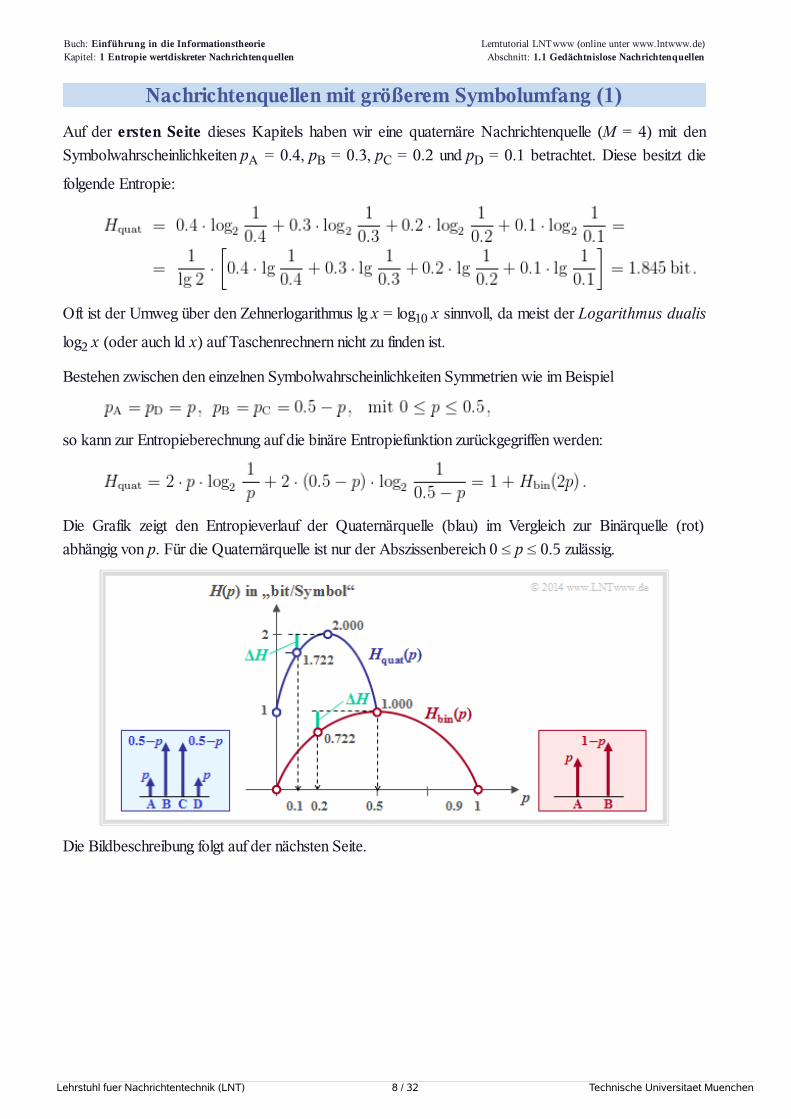
Nachrichtenquellen mit größerem Symbolumfang (1)Auf der ersten Seite dieses Kapitels haben wir eine quaternäre Nachrichtenquelle (M = 4) mit denSymbolwahrscheinlichkeiten pA = 0.4, pB = 0.3, pC = 0.2 und pD = 0.1 betrachtet. Diese besitzt die
folgende Entropie:
Oft ist der Umweg über den Zehnerlogarithmus lg x = log10 x sinnvoll, da meist der Logarithmus dualis
log2 x (oder auch ld x) auf Taschenrechnern nicht zu finden ist.
Bestehen zwischen den einzelnen Symbolwahrscheinlichkeiten Symmetrien wie im Beispiel
so kann zur Entropieberechnung auf die binäre Entropiefunktion zurückgegriffen werden:
Die Grafik zeigt den Entropieverlauf der Quaternärquelle (blau) im Vergleich zur Binärquelle (rot)abhängig von p. Für die Quaternärquelle ist nur der Abszissenbereich 0 ≤ p ≤ 0.5 zulässig.
Die Bildbeschreibung folgt auf der nächsten Seite.
Lehrstuhl fuer Nachrichtentechnik (LNT) 8 / 32 Technische Universitaet Muenchen
Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.1 Gedächtnislose Nachrichtenquellen
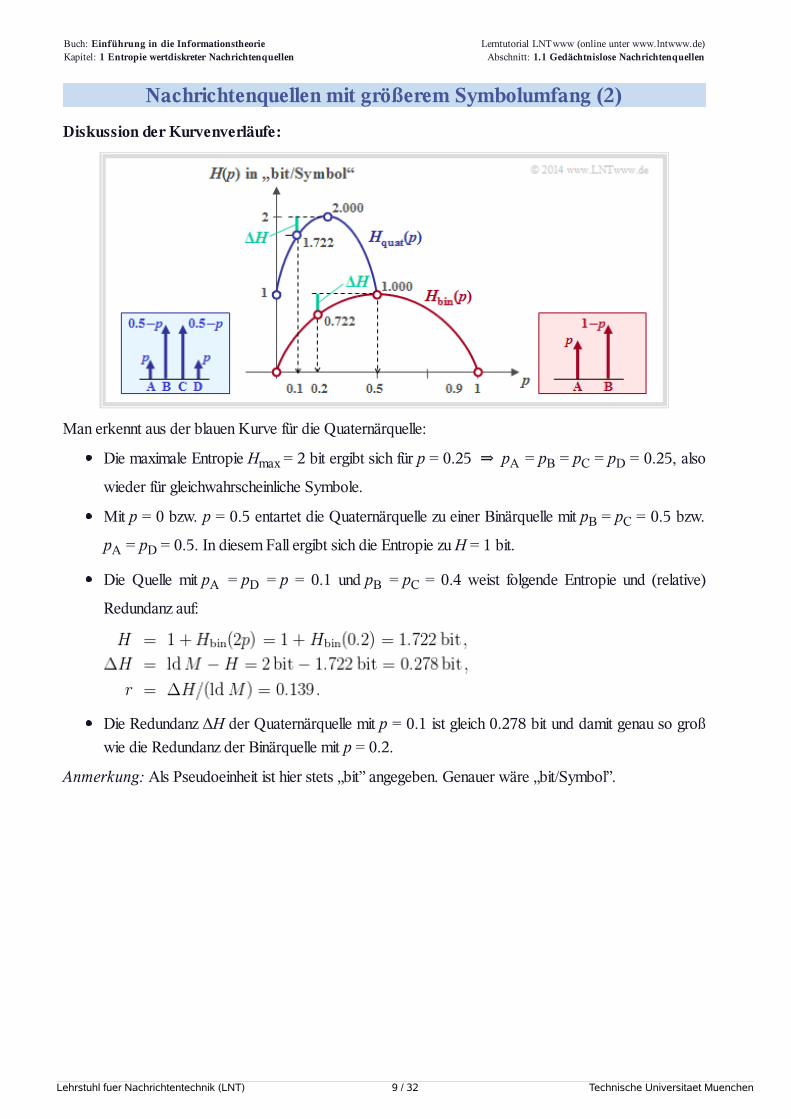
Nachrichtenquellen mit größerem Symbolumfang (2)Diskussion der Kurvenverläufe:
Man erkennt aus der blauen Kurve für die Quaternärquelle:
Die maximale Entropie Hmax = 2 bit ergibt sich für p = 0.25 ⇒ pA = pB = pC = pD = 0.25, also
wieder für gleichwahrscheinliche Symbole.
Mit p = 0 bzw. p = 0.5 entartet die Quaternärquelle zu einer Binärquelle mit pB = pC = 0.5 bzw.
pA = pD = 0.5. In diesem Fall ergibt sich die Entropie zu H = 1 bit.
Die Quelle mit pA = pD = p = 0.1 und pB = pC = 0.4 weist folgende Entropie und (relative)
Redundanz auf:
Die Redundanz ΔH der Quaternärquelle mit p = 0.1 ist gleich 0.278 bit und damit genau so großwie die Redundanz der Binärquelle mit p = 0.2.
Anmerkung: Als Pseudoeinheit ist hier stets „bit” angegeben. Genauer wäre „bit/Symbol”.
Lehrstuhl fuer Nachrichtentechnik (LNT) 9 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Ein einfaches einführendes BeispielZu Beginn des ersten Kapitels haben wir eine gedächtnislose Nachrichtenquelle mit dem Symbolvorrat{A, B, C, D} ⇒ M = 4 betrachtet. Eine beispielhafte Symbolfolge ist in der nachfolgenden Grafik alsQuelle Q1 nochmals dargestellt. Mit den Symbolwahrscheinlichkeiten pA = 0.4, pB = 0.3, pC = 0.2 und
pD = 0.1 ergibt sich die Entropie zu
Aufgrund der ungleichen Auftrittswahrscheinlichkeiten der Symbole ist die Entropie kleiner als derEntscheidungsgehalt H0 = log2 M = 2 bit/Symbol.
Die Quelle Q2 ist weitgehend identisch mit der Quelle Q1, außer, dass jedes einzelne Symbol nicht nureinmal, sondern zweimal nacheinander ausgegeben wird: A ⇒ AA, B ⇒ BB, usw.. Es ist offensichtlich,dass Q2 eine kleinere Entropie (Unsicherheit) aufweist als Q1. Aufgrund des einfachenWiederholungscodes ist nun H = 1.84/2 = 0.92 bit/Symbol nur halb so groß, obwohl sich an denAuftrittswahrscheinlichkeiten nichts geändert hat.
Dieses Beispiel zeigt:
Die Entropie einer gedächtnisbehafteten Quelle ist kleiner als die Entropie einer gedächtnislosenQuelle mit gleichen Symbolwahrscheinlichkeiten.
Es müssen nun auch die statistischen Bindungen innerhalb der Folge áqνñ berücksichtigt werden,
nämlich die Abhängigkeit des Symbols qν von den Vorgängersymbolen qν–1, qν–2, ...
Lehrstuhl fuer Nachrichtentechnik (LNT) 10 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Entropie hinsichtlich Zweiertupel (1)Wir betrachten weiterhin die Quellensymbolfolge áq1, q2, ... , qν–1, qν, qν+1, ...ñ, interessieren uns aber
nun für die Entropie zweier aufeinanderfolgender Quellensymbole. Alle Quellensymbole qν entstammen
einem Alphabet mit dem Symbolunfang M, so dass es für die Kombination (qν, qν+1) genau M2 mögliche
Symbolpaare mit folgenden Verbundwahrscheinlichkeiten gibt:
Daraus ist die Verbundentropie eines Zweier–Tupels berechenbar:
Der Index 2 symbolisiert, dass sich die so berechnete Entropie auf Zweiertupel bezieht. Um den mittlerenInformationsgehalt pro Symbol zu erhalten, muss H2' noch halbiert werden:
Um eine konsistente Nomenklatur zu erreichen, benennen wir nun die in Kapitel 1.1 definierte Entropiemit H1:
Der Index 1 soll darauf hinweisen, dass H1 ausschließlich die Symbolwahrscheinlichkeiten berücksichtigt
und nicht statistischen Bindungen zwischen Symbolen innerhalb der Folge. Mit dem EntscheidungsgehaltH0 = log2 M ergibt sich dann folgende Größenbeziehung:
Bei statistischer Unabhängigkeit der Folgenelemente ist H2 gleich H1.
Die bisherigen Gleichungen geben jeweils einen Scharmittelwert an. Die für die Berechnung von H1 und
H2 benötigten Wahrscheinlichkeiten lassen sich aber auch als Zeitmittelwerte aus einer sehr langen Folge
berechnen oder – etwas genauer ausgedrückt – durch die entsprechenden relativen Häufigkeitenannähern.
Auf den nächsten Seiten werden die Aussagen dieser Seite anhand von Beispielen verdeutlicht.
Lehrstuhl fuer Nachrichtentechnik (LNT) 11 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Entropie hinsichtlich Zweiertupel (2)
Beispiel 1: Wir betrachten die Folge áq1, ... , q50ñ entsprechend der folgernden Grafik:
Die Folgenlänge ist N = 50.Die Folgenelemente qν entstammen dem Alphabet {A, B, C} ⇒ Symbolumfang M = 3.
Durch Zeitmittelung über die 50 Symbole erhält man die Symbolwahrscheinlichkeiten pA ≈ 0.5,
pB ≈ 0.3 und pC ≈ 0.2, womit man die Entropienäherung erster Ordnung berechnen kann:
Aufgrund der nicht gleichwahrscheinlichen Symbole ist H1 < H0 = 1.585 bit/Symbol. Als Näherung für
die Wahrscheinlichkeiten von Zweiertupeln erhält man aus der obigen Folge:
Beachten Sie, dass aus den 50 Folgenelementen nur 49 Zweiertupel (AA, ... , CC) gebildet werdenkönnen, die in der obigen Grafik farblich unterschiedlich markiert sind.
Die daraus berechenbare Entropienäherung H2 sollte eigentlich gleich H1 sein, da die gegebene
Symbolfolge von einer gedächtnislosen Quelle stammt. Aufgrund der kurzen Folgenlänge N = 50 undder daraus resultierenden statistischen Ungenauigkeit ergibt sich ein etwas kleinerer Wert: H2 ≈ 1.39
bit/Symbol.
Auf der nächsten Seite folgen noch zwei weitere Beispiele.
Lehrstuhl fuer Nachrichtentechnik (LNT) 12 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Entropie hinsichtlich Zweiertupel (3)Verdeutlichen wir uns die Berechnung der Entropienäherungen H1 und H2 an weiteren Beispielen.
Beispiel 2: Wir betrachten eine gedächtnislose Binärquelle mit gleichwahrscheinlichen Symbolen,das heißt es gelte pA = pB = 1/2.
Die ersten zwanzig Folgeelemente lauten:
áqνñ = BBAAABAABBBBBAAAABAB ...
Aufgrund der gleichwahrscheinlichen Symbole und M = 2 gilt:
H1 = H0 = 1 bit/Symbol.
Die Verbundwahrscheinlichkeit pAB der Kombination AB ist gleich pA · pB = 1/4. Ebenso gilt
pAA = pBB = pBA = 1/4. Damit erhält man für die zweite Entropienäherung
Hinweis: Aus der oben angegebenen Folge ergeben sich aufgrund der kurzen Länge etwas andereVerbundwahrscheinlichkeiten, nämlich pAA = 6/19, pBB = 5/19 und pAB = pBA = 4/19.
Das nächste Beispiel liefert dagegen das Ergebnis H2 < H1.
Beispiel 3: Die zweite hier betrachtete Folge ergibt sich aus der oberen Folge durch Anwendung eineseinfachen Wiederholungscodes (wiederholte Symbole in Grau):
áqνñ = BBBBAAAAAABBAAAABBBB ...
Aufgrund der gleichwahrscheinlichen Symbole und M = 2 ergibt sich auch hier:
H1 = H0 = 1 bit/Symbol.
Wie in Aufgabe A1.3 gezeigt wird, gilt aber nun für die VerbundwahrscheinlichkeitenpAA = pBB = 3/8 und pAB = pBA = 1/8. Daraus folgt:
Wenn man sich die Aufgabenstellung genauer betrachtet, kommt man zu dem Schluss, dass hier dieEntropie H = 0.5 bit/Symbol sein müsste (jedes zweite Symbol liefert keine neue Information). Diezweite Entropienäherung H2 = 0.906 bit/Symbol ist aber deutlich größer als die Entropie H.
Dieses Beispiel legt den Schluss nahe, dass zur Entropiebestimmung die Näherung zweiter Ordnung nichtausreicht. Vielmehr muss man größere zusammenhängende Blöcke mit k > 2 Symbolen betrachten. Einensolchen Block bezeichnen wir im Folgenden als k–Tupel.
Lehrstuhl fuer Nachrichtentechnik (LNT) 13 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Verallgemeinerung auf k–Tupel und Grenzübergang (1)
Zur Abkürzung schreiben wir mit der Verbundwahrscheinlichkeit pi(k) eines k–Tupels allgemein:
Die Laufvariable i steht jeweils für eines der M k Tupel. Die Näherung H2 ergibt sich mit k = 2.
Definition: Die Entropie einer Nachrichtenquelle mit Gedächtnis ist der folgende Grenzwert:
Für die Entropienäherungen Hk gelten folgende Größenrelationen (H0: Entscheidungsgehalt):
Der Rechenaufwand wird bis auf wenige Sonderfälle (siehe nachfolgendes Beispiel) mit zunehmendem kimmer größer und hängt natürlich auch vom Symbolumfang M ab:
Zur Berechnung von H10 einer Binärquelle (M = 2) ist über 210 = 1024 Terme zu mitteln. Mit
jeder weiteren Erhöhung von k um 1 verdoppelt sich die Anzahl der Summenterme.
Bei einer Quaternärquelle (M = 4) muss zur H10–Bestimmung bereits über 410 = 1.048.576
Summenterme gemittelt werden.
Berücksichtigt man, dass jedes dieser 410 = 220 > 106 k–Tupel bei Simulation und Zeitmittelungetwa 100 mal (statistischer Richtwert) vorkommen sollte, um ausreichende Simulationsgenauigkeit
zu gewährleisten, so folgt daraus, dass die Folgenlänge größer als N = 108 sein sollte.
Beispiel: Wir betrachten eine alternierende Binärfolge ⇒ áqνñ = ABABABAB ... entsprechend
H0 = H1 = 1 bit/Symbol. In diesem Sonderfall muss zur Bestimmung der Hk–Näherung unabhängig
von k stets nur über zwei Verbundwahrscheinlichkeiten gemittelt werden:
k = 2: pAB = pBA = 1/2 ⇒ H2 = 1/2 bit/Symbol,
k = 3: pABA = pBAB = 1/2 ⇒ H3 = 1/3 bit/Symbol,
k = 4: pABAB = pBABA = 1/2 ⇒ H4 = 1/4 bit/Symbol.
Die Entropie dieser alternierenden Binärfolge ist demzufolge
Dieses Ergebnis war zu erwarten, da die betrachtete Folge nur minimale Information besitzt, die sichallerdings im Entropie–Endwert H nicht auswirkt, nämlich: „Tritt A zu den geraden oder ungeradenZeitpunkten auf?”
Man erkennt aber auch, dass Hk diesem Endwert H = 0 nur sehr langsam näher kommt: Die Näherung
H20 liefert immer noch 0.05 bit/Symbol.
Lehrstuhl fuer Nachrichtentechnik (LNT) 14 / 32 Technische Universitaet Muenchen

Lehrstuhl fuer Nachrichtentechnik (LNT) 15 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Verallgemeinerung auf k–Tupel und Grenzübergang (2)Die Ergebnisse der letzten Seiten sollen hier kurz zusammengefasst werden:
Allgemein gilt für die Entropie einer Nachrichtenquelle:
Eine redundanzfreie Quelle liegt vor, falls alle M Symbole gleichwahrscheinlich sind und es keinestatistischen Bindungen innerhalb der Folge gibt. Für diese gilt (r nennt man relative Redundanz):
Eine gedächtnislose Quelle kann durchaus redundant sein (r > 0). Diese Redundanz geht dannallerdings allein auf die Abweichung der Symbolwahrscheinlichkeiten von der Gleichverteilungzurück. Hier gelten folgende Relationen:
Die entsprechende Bedingung für eine gedächtnisbehaftete Quelle lautet:
Ist H2 < H1, dann gilt (nach Meinung des Autors) auch H3 < H2, H4 < H3, ... , also es ist das „≤”–
Zeichen in der allgemeinen Gleichung durch das „<”–Zeichen zu ersetzen. Sind die Symbolegleichwahrscheinlich, so gilt wieder H1 = H0, bei nicht gleichwahrscheinlichen Symbolen H1 < H0.
Lehrstuhl fuer Nachrichtentechnik (LNT) 16 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Die Entropie des AMI–CodesIm Buch „Digitalsignalübertragung” – Kapitel 2.4 wurde der AMI–Pseudoternärcode behandelt. Dieserwandelt die Binärfolge áqνñ mit qν ∈ {L, H} in die Ternärfolge ácνñ mit cν ∈ {M, N, P}. Die
Bezeichnungen der Quellensymbole stehen für „Low” und „High” und die der Codesymbole für „Minus”,„Null” und „Plus”. Die Codierregel des AMI–Codes (diese Kurzform steht für „Alternate MarkInversion”) lautet:
Jedes Binärsymbol qν = L wird durch das Codesymbol cν = N dargestellt.
Dagegen wird qν = H abwechselnd mit cν = P und cν = M codiert ⇒ Name „AMI”.
Durch die Codierung wird Redundanz hinzugefügt mit dem Ziel, dass die Codefolge keinen Gleichanteilbeinhaltet. Wir betrachten hier jedoch nicht die spektralen Eigenschaften des AMI–Codes, sonderninterpretieren diesen Code informationstheoretisch:
Aufgrund der Stufenzahl M = 3 ist der Entscheidungsgehalt der (ternären) Codefolge gleich H0 =
log2 3 ≈ 1.585 bit/Symbol. Die erste Entropienäherung liefert H1 = 1.5 bit/Symbol, wie
nachfolgende Rechnung zeigt:
Betrachten wir nun Zweiertupel. Beim AMI–Code kann „P” nicht auf „P” und „M” nicht auf „M”folgen. Die Wahrscheinlichkeit für „NN” ist gleich pL · pL = 1/4. Alle anderen (sechs) Zweiertupel
treten mit der Wahrscheinlichkeit 1/8 auf. Daraus folgt für die zweite Entropienäherung:
Für die weiteren Entropienäherungen und die tatsächliche Entropie H wird gelten:
Bei diesem Beispiel kennt man die tatsächliche Entropie H der Codesymbolfolge ácνñ. Da durch
den Coder keine neue Information hinzukommt, aber auch keine verloren geht, ergibt sich diegleiche Entropie wie für die redundanzfreie Binärfolge áqνñ:
Aufgabe A1.4 zeigt den bereits beträchtlichen Aufwand zur Berechnung der Entropienäherung H3;
zudem weicht H3 noch deutlich vom Endwert H = 1 bit/Symbol ab. Schneller kommt man zum Ergebnis,Lehrstuhl fuer Nachrichtentechnik (LNT) 17 / 32 Technische Universitaet Muenchen

wenn man den AMI–Code durch eine Markovkette beschreibt. Hierzu mehr auf der nächsten Seite.
Lehrstuhl fuer Nachrichtentechnik (LNT) 18 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Binärquellen mit Markoveigenschaften (1)Folgen mit statistischen Bindungen zwischen denFolgenelementen (Symbolen) werden oft durchMarkovprozesse modelliert, wobei wir uns hierauf Markovprozesse erster Ordnungbeschränken. Zunächst betrachten wir einenbinären Markovprozess (M = 2) mit denZuständen (Symbolen) A und B.
Oben sehen Sie das Übergangsdiagramm für einen binären Markovprozess erster Ordnung. Von denvier angegebenen Übertragungswahrscheinlichkeiten sind allerdings nur zwei frei wählbar, zum Beispiel
pA|B = Pr(A|B) ⇒ bedingte Wahrscheinlichkeit, dass A auf B folgt.
pB|A = Pr(B|A) ⇒ bedingte Wahrscheinlichkeit, dass B auf A folgt.
Für die beiden weiteren Übergangswahrscheinlichkeiten gilt dann
Aufgrund der vorausgesetzten Eigenschaften Stationarität und Ergodizität gilt für die Zustands– bzw.Symbolwahrscheinlichkeiten:
Diese Gleichungen erlauben erste informationstheoretische Aussagen über Markovprozesse:
Für pA|B = pB|A ergeben sich gleichwahrscheinliche Symbole ⇒ pA = pB = 0.5. Damit liefert die
erste Entropienäherung H1 = H0 = 1 bit/Symbol, und zwar unabhängig von den tatsächlichen
Werten der (bedingten) Übergangswahrscheinlichkeiten pA|B bzw. pB|A.
Die Quellenentropie H als der Grenzwert der Entropienäherung k–ter Ordnung Hk für k → ∞
hängt aber sehr wohl von den tatsächlichen Werten von pA|B und pB|A ab und nicht nur von ihrem
Quotienten. Dies zeigt das Beispiel auf der folgenden Seite.
Lehrstuhl fuer Nachrichtentechnik (LNT) 19 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Binärquellen mit Markoveigenschaften (2)Wir gehen von einer binären Markovquelle ersterOrdnung aus und setzen nun voraus:
Die 4 bedingten Wahrscheinlichkeiten seiensymmetrisch, das heißt, es gelte pA|B =
pB|A, pA|A = pB|B.
Für die beiden Symbolwahrscheinlichkeiten gilt somit: pA = pB = 0.5.
Beispiel: Wir betrachten hier drei solche binäre Markovquellen, die sich durch die Zahlenwerte dersymmetrischen Übergangswahrscheinlichkeiten pA|B = pB|A unterscheiden. Die beiden anderen
Übergangswahrscheinlichkeiten haben dann folgende Werte: pA|A = 1 – pB|A = pB|B.
Die mittlere Symbolfolge (mit pA|B = pB|A = 0.5) besitzt die Entropie H = 1 bit/Symbol. Das
heißt: In diesem Sonderfall gibt es keine statistischen Bindungen innerhalb der Folge.
Die linke (rote) Folge mit pA|B = pB|A = 0.2 weist weniger Wechsel zwischen A und B auf.
Aufgrund von statistischen Abhängigkeiten zwischen benachbarten Symbolen ist nunH ≈ 0.72 bit/Symbol kleiner.
Die rechte (grüne) Symbolfolge mit pA|B = pB|A = 0.8 hat die genau gleiche Entropie wie die
rote Folge. Hier erkennt man viele Bereiche mit sich stets abwechselnden Symbolen (...ABABAB ... ).
Zu diesem Beispiel ist noch anzumerken:
Hätte man nicht die Markoveigenschaften der roten und der grünen Folge ausgenutzt, so hätte mandas Ergebnis H ≈ 0.72 bit/Symbol erst nach langwierigen Berechnungen erhalten.
Auf den nächsten Seiten wird gezeigt, dass bei einer Quelle mit Markoveigenschaften dieserEndwert H allein aus den Entropienäherungen H1 und H2 ermittelt werden kann.
Ebenso lassen sich aus H1 und H2 alle Entropienäherungen Hk für k–Tupel in einfacher Weise
berechnen ⇒ H3, H4, H5, ... , H100, ...
Lehrstuhl fuer Nachrichtentechnik (LNT) 20 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Binärquellen mit Markoveigenschaften (3)Wir gehen weiterhin von der symmetrischenbinären Markovquelle erster Ordnung aus. Wieauf der vorherigen Seite verwenden wir folgendeNomenklatur:
Übergangswahrscheinlichkeiten pB|A, ...
ergodische Wahrscheinlichkeiten pA und pB,
Verbundwahrscheinlichkeiten, zum Beispiel pAB = pA · pB|A.
Wir berechnen nun die Entropie eines Zweiertupels (mit der Einheit „bit/Zweiertupel”):
Ersetzt man nun die Logarithmen der Produkte durch entsprechende Summen von Logarithmen, so erhältman das Ergebnis H2' = H1 + HM mit
Damit lautet die zweite Entropienäherung (mit der Einheit „bit/Symbol”):
Anzumerken ist:
Der erste Summand wurde nicht zufällig mit H1 abgekürzt, sondern ist tatsächlich gleich der ersten
Entropienäherung, allein abhängig von den Symbolwahrscheinlichkeiten.
Bei einem symmetrischen Markovprozess (pA|B = pB|A ⇒ pA = pB = 1/2) ergibt sich für diesen
ersten Summanden H1 = 1 bit/Symbol.
Der zweite Summand (HM) muss gemäß der zweiten der oberen Gleichungen berechnet werden.
Bei einem symmetrischen Markovprozess erhält man HM = Hbin(pA|B).
Auf der nächsten Seite wird dieses Ergebnis auf die k–te Entropienäherung erweitert.
Lehrstuhl fuer Nachrichtentechnik (LNT) 21 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Binärquellen mit Markoveigenschaften (4)Der Vorteil von Markovquellen gegenüber anderen Quellen ist, dass sich die Entropieberechnung für k–Tupel sehr einfach gestaltet. Für jede Markovquelle gilt:
Bildet man den Grenzübergang für k → ∞, so erhält man für die tatsächliche Quellenentropie:
Aus diesem einfachen Ergebnis folgen wichtige Erkenntnisse für die Entropieberechnung:
Bei Markovquellen genügt die Bestimmung der Entropienäherungen H1 und H2. Damit lautet die
Entropie einer Markovquelle:
Durch H1 und H2 liegen auch alle weiteren Entropienäherungen Hk fest:
Diese Näherungen haben allerdings keine große Bedeutung. Wichtig ist meist nur der GrenzwertH. Bei Quellen ohne Markoveigenschaften berechnet man die Näherungen Hk nur deshalb, um
den Grenzwert, also die tatsächliche Entropie, abschätzen zu können.
Alle auf dieser Seite angegebenen Gleichungen gelten auch für nichtbinäre Markovquellen (M > 2),wie auf der nächsten Seite gezeigt wird.
Hinweis: In der Aufgabe A1.5 werden die obigen Gleichungen auf den allgemeineren Fall einerunsymmetrischen Binärquelle angewendet.
Lehrstuhl fuer Nachrichtentechnik (LNT) 22 / 32 Technische Universitaet Muenchen
Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
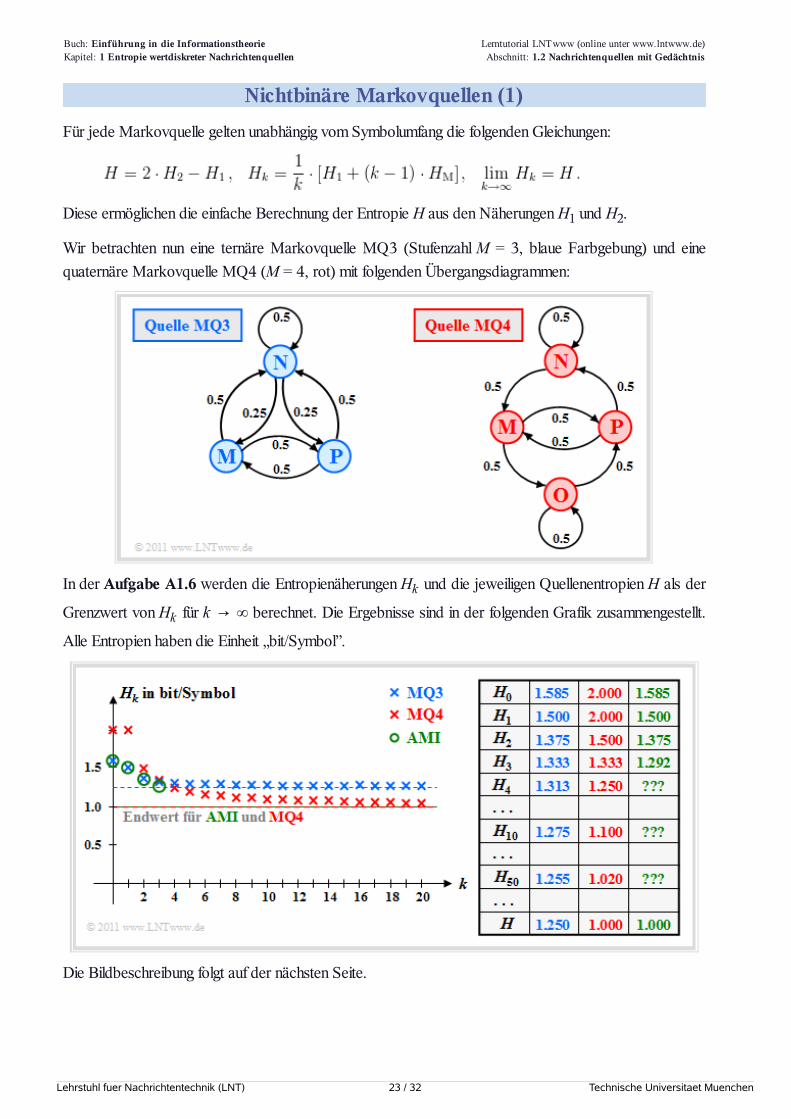
Nichtbinäre Markovquellen (1)Für jede Markovquelle gelten unabhängig vom Symbolumfang die folgenden Gleichungen:
Diese ermöglichen die einfache Berechnung der Entropie H aus den Näherungen H1 und H2.
Wir betrachten nun eine ternäre Markovquelle MQ3 (Stufenzahl M = 3, blaue Farbgebung) und einequaternäre Markovquelle MQ4 (M = 4, rot) mit folgenden Übergangsdiagrammen:
In der Aufgabe A1.6 werden die Entropienäherungen Hk und die jeweiligen Quellenentropien H als der
Grenzwert von Hk für k → ∞ berechnet. Die Ergebnisse sind in der folgenden Grafik zusammengestellt.
Alle Entropien haben die Einheit „bit/Symbol”.
Die Bildbeschreibung folgt auf der nächsten Seite.
Lehrstuhl fuer Nachrichtentechnik (LNT) 23 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.2 Nachrichtenquellen mit Gedächtnis
Nichtbinäre Markovquellen (2)Die Ergebnisse der letzten Seite – siehe unteren Grafik – lassen sich wie folgt interpretieren:
Bei der ternären Markovquelle MQ3 nehmen die Entropienäherungen von H1 = 1.500 über H2 =
1.375 bis zum Grenzwert H = 1.25 kontinuierlich ab. Wegen M = 3 beträgt derEntscheidungsgehalt H0 = 1.585 (alle Entropien in „bit/Symbol”) .
Für die quaternäre Markovquelle MQ4 (rote Markierungen) erhält man H0 = H1 = 2 (wegen den
vier gleichwahrscheinlichen Zuständen) und H2 = 1.5. Aus dem H1– und H2–Wert lassen sich
auch hier alle Entropienäherungen Hk und auch der Endwert H = 1 berechnen.
Die beiden Quellenmodelle MQ3 und MQ4 entstanden bei dem Versuch, den AMI–Codeinformationstheoretisch durch Markovquellen zu beschreiben. Die Symbole M, N und P stehenhierbei für „Minus”, „Null” und „Plus”.
Die Entropienäherungen H1, H2 und H3 des AMI–Codes (grüne Markierungen) wurden in
Aufgabe A1.4 berechnet. Auf die Berechnung von H4, H5, ... musste aus Aufwandsgründen
verzichtet werden. Bekannt ist aber der Endwert von Hk für k → ∞ ⇒ H = 1.
Man erkennt, dass das Markovmodell MQ3 für H0 = 1.585, H1 = 1.500 und H2 = 1.375 genau
die gleichen Werte liefert wie der AMI–Code. Dagegen unterscheiden sich H3 (1.333 gegenüber
1.292) und insbesondere der Endwert H (1.25 gegenüber 1).
Das Modell MQ4 (M = 4) unterscheidet sich vom AMI–Code (M = 3) hinsichtlich desEntscheidungsgehaltes H0 und auch bezüglich aller Entropienäherungen Hk . Trotzdem ist MQ4
das geeignete Modell für den AMI–Code, da der Endwert H = 1 übereinstimmt.
Das Modell MQ3 liefert deshalb zu große Entropiewerte, da hier die Folgen PNP und MNMmöglich sind, die beim AMI–Code nicht auftreten können. Bereits bei H3 macht sich der
Unterschied geringfügig bemerkbar, im Endwert H deutlich (1.25 gegenüber 1).
Beim Modell MQ4 wurde der Zustand „Null” aufgespalten in zwei Zustände N und O:
Hierbei gilt für den Zustand N: Das aktuelle Binärsymbol L wird mit dem Amplitudenwert „0”dargestellt, wie es der AMI–Regel entspricht. Das nächste auftretende H–Symbol wird als M(Minus) dargestellt, weil das letzte H–Symbol als P (Plus) codiert wurde.
Auch beim Zustand O wird das aktuelle Binärsymbol L mit dem Ternärwert „0” dargestellt. ImUnterschied zum Zustand N wird aber nun das nächste auftretende H–Symbol als P (Plus)dargestellt werden, da das letzte H–Symbol als M (Minus) codiert wurde.
Die von MQ4 ausgegebene Symbolfolge entspricht tatsächlich den Regeln des AMI–Codes und weistdie Entropie H = 1 bit/Symbol auf. Aufgrund des neuen Zustandes O ist nun allerdings H0 = 2 bit/Symbol
(gegenüber 1.585 bit/Symbol) deutlich zu groß und auch alle Hk–Näherungen sind größer als beim
AMI–Code. Erst für k → ∞ stimmen beide überein: H = 1 bit/Symbol.
Lehrstuhl fuer Nachrichtentechnik (LNT) 24 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.3 Natürliche wertdiskrete Nachrichtenquellen
Schwierigkeiten bei der EntropiebestimmungBisher haben wir uns ausschließlich mit künstlich erzeugten Symbolfolgen beschäftigt. Nun betrachten wirgeschriebene Texte. Ein solcher Text kann als eine natürliche wertdiskrete Nachrichtenquelle aufgefasstwerden, die natürlich auch informationstheoretisch analysiert werden kann, indem man ihre Entropieermittelt.
Natürliche Texte werden auch in heutiger Zeit (2011) noch oft mit dem 8 Bit–Zeichensatz nach ANSI(American National Standard Institute) dargestellt, obwohl es etliche „modernere” Codierungen gibt.
Die M = 28 = 256 ANSI–Zeichen sind dabei wie folgt belegt:
Nr. 0 bis 31: nicht druck– und darstellbare Steuerbefehle,Nr. 32 bis 127: identisch mit den Zeichen des 7 Bit–ASCII–Codes,Nr. 128 bis 159: weitere Steuerzeichen bzw. Alphanumerikzeichen für Windows,Nr. 160 bis 255: identisch mit Unicode–Charts.
Theoretisch könnte man auch hier die Entropie entsprechend der Vorgehensweise in Kapitel 1.2 als denGrenzübergang der Entropienäherung Hk für k → ∞ ermitteln. Praktisch ergeben sich aber nach dieser
Rezeptur unüberwindbare numerische Grenzen:
Bereits für die Entropienäherung H2 gibt es M2 = 2562 = 65536 mögliche Zweiertupel. Für die
Berechnung sind somit ebenso viele Speicherplätze (in Byte) erforderlich. Geht man davon aus,dass man für eine ausreichend sichere Statistik im Mittel 100 Entsprechungen pro Tupel benötigt,
so sollte die Länge der Quellensymbolfolge bereits N > 6.5 · 106 sein.
Die Anzahl der möglichen Dreiertupel ergibt sich zu M3 > 16 · 107 und damit ist die erforderliche
Quellensymbollänge N schon größer als 1.6 · 109. Dies entspricht bei 42 Zeilen pro Seite und 80Zeichen pro Zeile einem Buch mit etwa 500.000 Seiten.
Bei einem natürlichen Text reichen die statistischen Bindungen aber sehr viel weiter als zwei oderdrei Zeichen. Küpfmüller gibt für die deutsche Sprache einen Wert von 100 an [Küp54]. Zur
Ermittlung der 100. Entropienäherung benötigt man aber 2800 ≈ 10240 Häufigkeiten und für diegesicherte Statistik nochmals um den Faktor 100 mehr Zeichen.
Eine berechtigte Frage ist deshalb: Wie hat Karl Küpfmüller im Jahre 1954 die Entropie der deutschenSprache ermittelt, und vor ihm schon Claude E. Shannon die Entropie der englischen Sprache? Einessei vorweg verraten: Nicht mit dem oben beschriebenen Ansatz.
Lehrstuhl fuer Nachrichtentechnik (LNT) 25 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.3 Natürliche wertdiskrete Nachrichtenquellen
Entropieabschätzung nach Küpfmüller (1)Karl Küpfmüller hat die Entropie von deutschen Texten untersucht. Er geht bei seiner in [Küp54]veröffentlichten Abschätzung von folgenden Voraussetzungen aus:
ein Alphabet mit 26 Buchstaben (keine Umlaute und Satzzeichen),Nichtberücksichtigung des Leerzeichens,keine Unterscheidung zwischen Groß– und Kleinschreibung.
Der Entscheidungsgehalt ergibt sich somit zu H0 = log2(26) ≈ 4.7 bit/Buchstabe.
Seine Abschätzung basiert auf den folgenden Überlegungen:
1.) Die erste Entropienäherung ergibt sich aus den Buchstabenhäufigkeiten in deutschen Texten. Nacheiner Studie von 1939 ist „e” mit 16.7% am häufigsten, am seltensten ist „x” mit 0.02%.
2.) Hinsichtlich der Silbenhäufigkeit wertet Küpfmüller das von F.W. Kaeding herausgegebene„Häufigkeitswörterbuch der deutschen Sprache” aus. Er unterscheidet zwischen Stammsilben, Vorsilbenund Endsilben. Er kommt so auf den mittleren Informationsgehalt aller Silben:
Nach der Kaeding–Studie von 1898 bilden die 400 häufigsten Stammsilben (beginnend mit „de”)47% eines deutschen Textes und tragen zur Entropie mit HStamm ≈ 4.15 bit/Silbe bei.
Der Beitrag der 242 häufigsten Vorsilben – an erster Stelle „ge” mit 9% – wird von Küpfmüllermit HVor ≈ 0.82 bit/Silbe beziffert.
Der Beitrag der 118 meistgebrauchten Endsilben ist HEnd ≈ 1.62 bit/Silbe. Am häufigsten tritt „en”
am Ende eines Wortes mit 30% auf.
Der Rest von 14% verteilt sich auf bisher nicht erfasste Silben. Küpfmüller nimmt dazu an, dass esdavon 4.000 gibt und diese gleichverteilt sind. Er setzt dafür HRest ≈ 2 bit/Silbe an.
3.) Für die durchschnittliche Buchstabenzahl je Silbe ermittelte Küpfmüller den Wert 3.03. Darausschloss er auf die dritte Entropienäherung hinsichtlich der Buchstaben:
Die Beschreibung wird auf der nächsten Seite fortgesetzt.
Lehrstuhl fuer Nachrichtentechnik (LNT) 26 / 32 Technische Universitaet Muenchen
Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.3 Natürliche wertdiskrete Nachrichtenquellen
Entropieabschätzung nach Küpfmüller (2)Küpfmüllers Abschätzung der Entropienäherung H3 basierte vor allem auf den Silbenhäufigkeiten und
dem Mittelwert von 3.03 Buchstaben pro Silbe. Um eine weitere Entropienäherung Hk mit größerem k
zu erhalten, analysierte Küpfmüller zusätzlich die Wörter in deutschen Texten. Er kam zu folgendenErgebnissen:
4.) Die 322 häufigsten Wörter liefern einen Entropiebeitrag von 4.5 bit/Wort. Die Beiträge der restlichen40.000 Wörter wurden geschätzt, wobei angenommen wurde, dass die Häufigkeiten von seltenenWörtern reziprok zu ihrer Ordnungszahl sind. Mit diesen Voraussetzungen ergibt sich der mittlereInformationsgehalt eines Wortes zu ca. 11 bit.
5.) Die Auszählung ergab im Mittel 5.5 Buchstaben pro Wort. Analog zu Punkt (3) wurde so dieEntropienäherung für k = 5.5 angenähert:
Natürlich kann k gemäß Definition nur ganzzahlige Werte annehmen. Diese Gleichung ist deshalb so zuinterpretieren, dass sich für H5 ein etwas größerer und für H6 ein etwas kleinerer Wert ergeben wird.
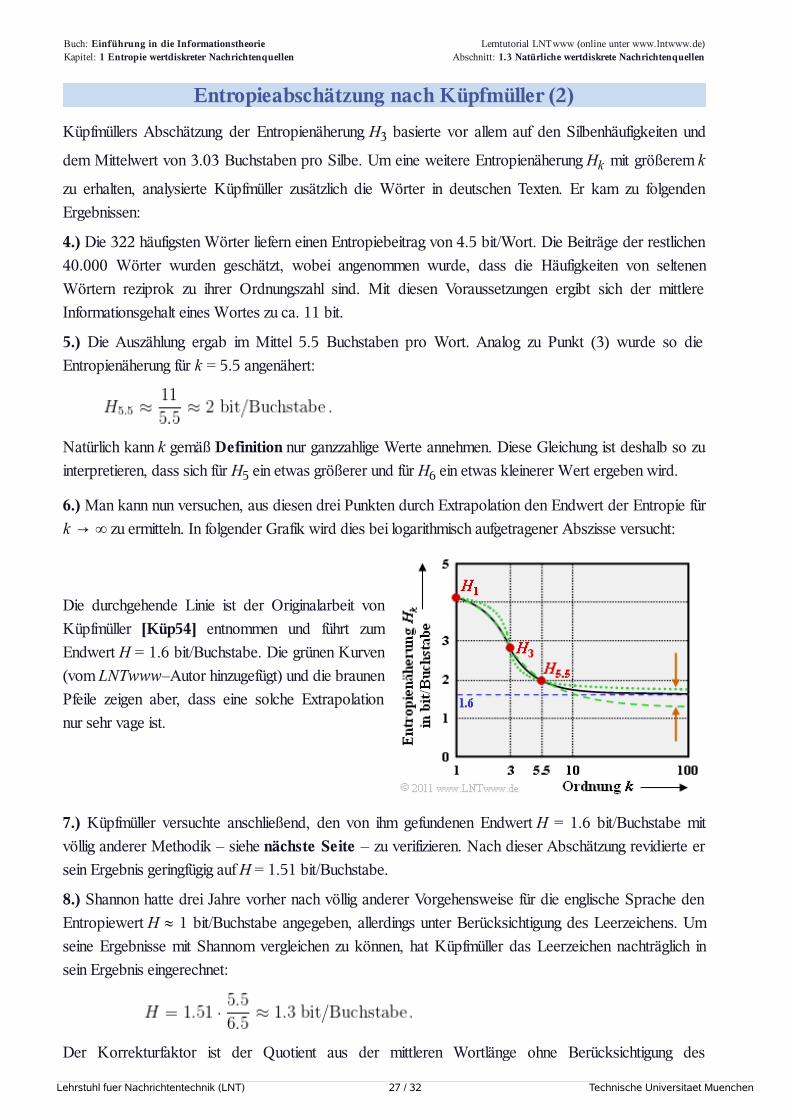
6.) Man kann nun versuchen, aus diesen drei Punkten durch Extrapolation den Endwert der Entropie fürk → ∞ zu ermitteln. In folgender Grafik wird dies bei logarithmisch aufgetragener Abszisse versucht:
Die durchgehende Linie ist der Originalarbeit vonKüpfmüller [Küp54] entnommen und führt zumEndwert H = 1.6 bit/Buchstabe. Die grünen Kurven(vom LNTwww–Autor hinzugefügt) und die braunenPfeile zeigen aber, dass eine solche Extrapolationnur sehr vage ist.
7.) Küpfmüller versuchte anschließend, den von ihm gefundenen Endwert H = 1.6 bit/Buchstabe mitvöllig anderer Methodik – siehe nächste Seite – zu verifizieren. Nach dieser Abschätzung revidierte ersein Ergebnis geringfügig auf H = 1.51 bit/Buchstabe.
8.) Shannon hatte drei Jahre vorher nach völlig anderer Vorgehensweise für die englische Sprache denEntropiewert H ≈ 1 bit/Buchstabe angegeben, allerdings unter Berücksichtigung des Leerzeichens. Umseine Ergebnisse mit Shannom vergleichen zu können, hat Küpfmüller das Leerzeichen nachträglich insein Ergebnis eingerechnet:
Der Korrekturfaktor ist der Quotient aus der mittleren Wortlänge ohne Berücksichtigung des
Lehrstuhl fuer Nachrichtentechnik (LNT) 27 / 32 Technische Universitaet Muenchen

Leerzeichens (5.5) und der mittleren Wortlänge mit Berücksichtigung des Leerzeichens (6.5).
Lehrstuhl fuer Nachrichtentechnik (LNT) 28 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.3 Natürliche wertdiskrete Nachrichtenquellen
Entropieabschätzung nach Küpfmüller (3)Der Vollständigkeit halber seien hier noch Küpfmüllers Überlegungen dargelegt, die ihn zum EndergebnisH = 1.51 bit/Buchstabe führten. Da es für die Statistik von Wortgruppen oder ganzen Sätzen keineUnterlagen gab, schätzte er den Entropiewert der deutschen Sprache wie folgt ab:
Ein beliebiger zusammenhängender deutscher Text wird hinter einem bestimmten Wort abgedeckt.Der vorhergehende Text wird gelesen, und der Leser soll versuchen, das folgende Wort aus demZusammenhang mit dem vorhergehenden Text zu ermitteln.
Bei sehr vielen solcher Versuche ergibt die prozentuale Zahl der Treffer ein Maß für die Bindungenzwischen Wörtern und Sätzen. Es zeigt sich, dass bei ein und derselben Textart (Romane,wissenschaftliche Schriften, usw.) ein und desselben Autors relativ schnell (etwa 100 bis 200Versuche) ein konstanter Endwert dieses Trefferverhältnisses erreicht wird.
Das Trefferverhältnis hängt aber ziemlich stark von der Art des Textes ab. Für verschiedene Texteergeben sich Werte zwischen 15% und 33%, mit dem Mittelwert bei 22%. Das heißt aber auch:Im Durchschnitt können 22% der Wörter in einem deutschen Text aus dem Zusammenhang herausermittelt werden.
Anders ausgedrückt: Die Zahl der Wörter eines langen Textes kann mit dem Faktor 0.78 reduziertwerden, ohne dass der Nachrichtengehalt des Textes eine signifikante Einbuße erfährt. Ausgehendvom Bezugswert H5.5 = 2 bit/Buchstabe (siehe Punkt (5), letzte Seite) für ein mittellanges Wort
ergibt sich somit die Entropie H ≈ 0.78 · 2 = 1.56 bit/Buchstabe.
Küpfmüller überprüfte diesen Wert mit einer vergleichbaren empirischen Untersuchung der Silbenund ermittelte den Reduktionsfaktor 0.54 hinsichtlich Silben. Als Endergebnis nennt Küpfmüller H= 0.54 · H3 ≈ 1.51 bit/Buchstabe, wobei H3 ≈ 2.8 bit/Buchstabe der Entropie einer Silbe mittlerer
Länge (≈ 3 Buchstaben, siehe Punkt (3), vorletzte Seite) entspricht.
Die vielleicht als zu kritisch empfundenen Bemerkungen auf dieser Seite sollen die Bedeutung vonKüpfmüllers Entropieabschätzung nicht herabsetzen, eben so wenig wie Shannon's Beiträge zur gleichenThematik. Sie sollen nur auf die großen Schwierigkeiten hinweisen, die bei dieser Aufgabenstellungauftreten. Dies ist vielleicht auch der Grund dafür, dass sich seit den 1950er Jahren niemand mehr mitdieser Problematik intensiv beschäftigt hat.
Lehrstuhl fuer Nachrichtentechnik (LNT) 29 / 32 Technische Universitaet Muenchen
Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.3 Natürliche wertdiskrete Nachrichtenquellen
Einige eigene Simulationsergebnisse (1)Die Angaben von Karl Küpfmüller hinsichtlich der Entropie der deutschen Sprache sollen nun mit einigenSimulationsergebnissen verglichen werden, die vom Autor G. Söder dieses Kapitels am Lehrstuhl fürNachrichtentechnik der Technischen Universität München gewonnen wurden. Die Resultate basieren auf
dem Programm WDIT (Wertdiskrete Informationstheorie) aus dem Praktikum [Söd01]; der Linkweist auf die Zip–Version des Programms,
einer ASCII–Version der deutschen Bibel mit fast N = 4.37 Millionen Schriftzeichen, die auf denSymbolumfang M = 33 reduziert wurde:
a, b, c, ... , x, y, z, ä, ö, ü, ß, LZ, ZI, IP.
Nicht unterschieden wurde bei unserer Analyse zwischen Groß– und Kleinbuchstaben. GegenüberKüpfmüllers Analyse wurden hier noch zusätzlich berücksichtigt:
die deutschen Umlaute „ä”, „ö”, „ü” und „ß”, die etwa 1.2% des Bibeltextes ausmachen,die Klasse IP (Interpunktion) mit ca. 3%,die Klasse ZI (Ziffer) mit ca. 1.3% in Folge der Vers–Nummerierung,das Leerzeichen (LZ) als das häufigste Zeichen (17.8%), noch vor dem „e” (12.8%).
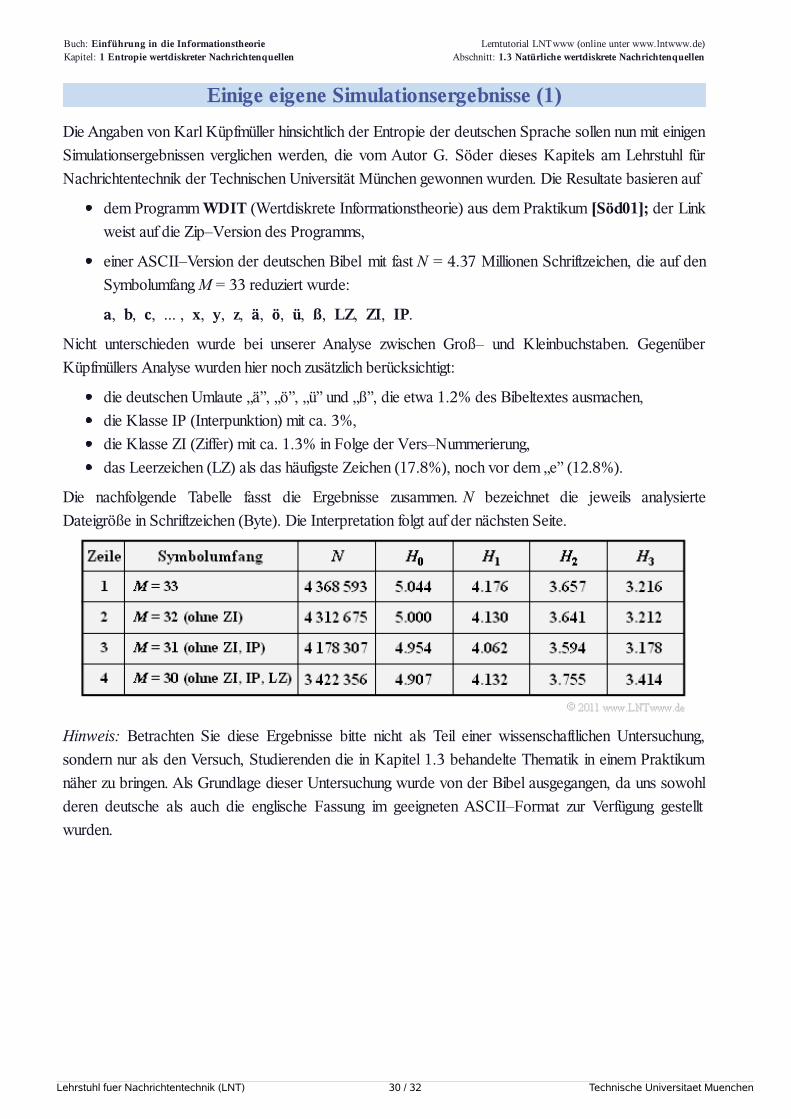
Die nachfolgende Tabelle fasst die Ergebnisse zusammen. N bezeichnet die jeweils analysierteDateigröße in Schriftzeichen (Byte). Die Interpretation folgt auf der nächsten Seite.
Hinweis: Betrachten Sie diese Ergebnisse bitte nicht als Teil einer wissenschaftlichen Untersuchung,sondern nur als den Versuch, Studierenden die in Kapitel 1.3 behandelte Thematik in einem Praktikumnäher zu bringen. Als Grundlage dieser Untersuchung wurde von der Bibel ausgegangen, da uns sowohlderen deutsche als auch die englische Fassung im geeigneten ASCII–Format zur Verfügung gestelltwurden.
Lehrstuhl fuer Nachrichtentechnik (LNT) 30 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.3 Natürliche wertdiskrete Nachrichtenquellen
Einige eigene Simulationsergebnisse (2)Die in der Tabelle angegebenen Entropien H0 (Entscheidungsgehalt), H1, H2 und H3 wurden jeweils aus
N Schriftzeichen ermittelt und sind jeweils in bit/Schriftzeichen angegeben. Die gesamte Datei „Bibel” (indeutscher Sprache) beinhaltet fast N = 4.37 Millionen Schriftzeichen, was bei 42 Zeilen pro Seite und 80Zeichen pro Zeile etwa einem Buch mit 1300 Seiten entsprechen würde. Der Symbolumfang ist M = 33.
Die Ergebnisse lassen sich wie folgt zusammenfassen:
In allen Zeilen nehmen die Entropienäherungen Hk mit wachsendem k monoton ab. Der Abfall
verläuft konvex, das heißt, es ist H1 – H2 > H2 – H3. Die Extrapolation des Endwertes (k → ∞)
ist aus den jeweils ermittelten drei Entropienäherungen nicht (oder nur sehr vage) möglich.
Verzichtet man auf die Auswertung der Ziffern (ZI, Zeile 2 ⇒ M = 32) und zusätzlich auf dieAuswertung der Interpunktionszeichen IP, Zeile 3 ⇒ M = 31), so nehmen die EntropienäherungenH1 (um 0.114), H2 (um 0.063) und H3 (um 0.038) ab. Auf den Endwert H als dem Grenzwert
von Hk für k → ∞ wirkt sich der Verzicht auf Ziffern (ZI) und Interpunktion (IP) voraussichtlich
kaum aus.
Lässt man bei der Auswertung noch das Leerzeichen (LZ, Zeile 4 → M = 30) außer Betracht,so ergibt sich nahezu die gleiche Konstellation wie von Küpfmüller ursprünglich betrachtet. Dereinzige Unterschied sind die eher seltenen deutschen Sonderzeichen „ä”, „ö”, „ü” und „ß”.
Der in der letzten Zeile angegebene H1–Wert 4.132 stimmt mit dem von Küpfmüller ermittelten
Wert H1 ≈ 4.1 sehr gut überein. Hinsichtlich der H3–Werte gibt es aber deutliche Unterschiede:
Unsere Analyse ergibt H3 ≈ 3.4 gegenüber Küpfmüllers 2.8 (alle Angaben in bit/Buchstabe).
Aus der Auftrittshäufigkeit des Leerzeichens (17.8%) ergibt sich hier eine mittlere Wortlänge von1/0.178 – 1 ≈ 4.6, ein kleinerer Wert als von Küpfmüller (5.5) angegeben. Die Diskrepanz lässtsich mit unserer Analysedatei „Bibel” erklären (viele Leerzeichen aufgrund der Vers–Nummern).
Interessant ist der Vergleich der Zeilen 3 und 4. Berücksichtigt man das Leerzeichen, so wird zwarH0 von log2(30) auf log2(31) vergrößert, aber man verringert dadurch H1 (um den Faktor 0.98),
H2 (um 0.96) und H3 (um 0.93). Küpfmüller hat diesen Faktor intuitiv mit 85% berücksichtigt.
Obwohl wir unsere eigenen Recherchen als nicht so bedeutend ansehen, so glauben wir doch, dass fürheutige Texte die von Shannon angegebenen 1.0 bit/Buchstabe für die englische Sprache und auchKüpfmüllers 1.3 bit/Buchstabe für Deutsch etwas zu niedrig sind, unter Anderem, weil
der Symbolumfang deutlich größer ist, als von Shannon und Küpfmüller bei ihren Analysenberücksichtigt – beispielsweise gilt für den ASCII–Zeichensatz M = 256,die vielfachen Formatierungsmöglichkeiten (Unterstreichungen, Fett- und Kursivschrift,Einrückungen, Farben) den Informationsgehalt eines Dokuments erhöhen.
Lehrstuhl fuer Nachrichtentechnik (LNT) 31 / 32 Technische Universitaet Muenchen

Buch: Einführung in die Informationstheorie Lerntutorial LNTwww (online unter www.lntwww.de)Kapitel: 1 Entropie wertdiskreter Nachrichtenquellen Abschnitt: 1.3 Natürliche wertdiskrete Nachrichtenquellen
Synthetisch erzeugte TexteIn der Grafik sind künstlich erzeugte deutsche und englische Texte angegeben, die [Küp54] entnommenwurden. Der zugrundeliegende Symbolumfang ist M = 27, das heißt, berücksichtigt sind alle Buchstaben(ohne Umlaute und „ß”) sowie das Leerzeichen.
Die Buchstabennäherung nullter Ordnung geht von gleichwahrscheinlichen Zeichen aus. Hierist kein Unterschied zwischen Deutsch (rot) und Englisch (blau) festzustellen.
Bei der ersten Buchstabennäherung werden bereits die unterschiedlichen Häufigkeitenberücksichtigt, bei den Näherungen höherer Ordnung auch die vorangegangenen Zeichen.
Bei einer Synthese 4. Ordnung ⇒ die Wahrscheinlichkeit für einen neuen Buchstaben hängt vonden drei zuletzt ausgewählten Zeichen ab – erkennt man bereits sinnhafte Worte.
Die Wortnäherung 1. Ordnung synthetisiert Sätze gemäß den Wortwahrscheinlichkeiten, dieNäherung 2. Ordnung berücksichtigt zusätzlich noch das vorherige Wort.
Weitere Information zur synthetischen Erzeugung von deutschen und englischen Texten finden Sie inAufgabe A1.8.
Lehrstuhl fuer Nachrichtentechnik (LNT) 32 / 32 Technische Universitaet Muenchen





























