Embed Size (px)
Citation preview

Hans-Joachim Adam
z:\_skripte\betriebssysteme&netzwerke\adam skript\betriebssysteme adam 030121-1.doc
Jetzt lerne ich endlich ...
Betriebs-systeme
TGI 13
Informationstechnik

Inhalt
z:\_skripte\betriebssysteme&netzwerke\adam skript\betriebssysteme adam 030121-1.doc
Die Architektur eines Betriebssystems ...........................................................................................4
Dateisysteme......................................................................................................................................4 Speicher-Allokation .................................................................................................................4
Interne Verkettung .........................................................................................................4 Externe Verkettung ........................................................................................................4 Indexblock .....................................................................................................................4
MS-DOS ............................................................................................................................................5 DEBUG Befehle (Auszug) ............................................................................................5 Der Aufbau von Directory-Einträgen ............................................................................7
Erstellen von Verzeichnissen ...................................................................................................10 Dateien unter Windows oder DOS erstellen ............................................................................11 Defekte Sektoren......................................................................................................................12 Festplatten ................................................................................................................................12 Wiederholungsaufgaben...........................................................................................................13
NTFS..................................................................................................................................................14 Der Bootsektor bei NTFS ..............................................................................................15 Die MFT ........................................................................................................................15 Der Index-Record der MFT ...........................................................................................16 Der Record einer „gewöhnlichen“ Datei .......................................................................16 Record einer kleinen Datei.............................................................................................17 Record einer großen Datei .............................................................................................18 Record für ein kleines Verzeichnis ................................................................................19
Prozesse und Threads ......................................................................................................................21 Scheduling................................................................................................................................22
Prozesszustände .............................................................................................................23 First Come, First Served (FCFS) ...................................................................................23 Highest Priority First (non-preemptiv) (HPF-n) ............................................................24 Shortest Job First (SJF)..................................................................................................24 Round Robin Scheduling (RR) ......................................................................................24 Priority Scheduling (preemptiv): Highest Priority First (HPF-p) ..................................24 Dynamische Prioritäten..................................................................................................25
Deadlocks.................................................................................................................................27 Dinierende Philosophen.................................................................................................27 Trivialer Deadlock-Fall..................................................................................................28 Deadlock bei mehreren, voneinander abhängigen Prozessen ........................................28 Deadlock bei mehreren Prozessen und mehreren Ressourcen.......................................28 resource allocation graph ...............................................................................................29 Vermeidung von Deadlocks...........................................................................................29
Speicherverwaltung..........................................................................................................................30 Virtueller Speicher, Paging ......................................................................................................30
256 kByte reeller Speicher.............................................................................................30 1 MByte reeller Speicher ...............................................................................................31 Virtueller Speicher .........................................................................................................31 Seitenfehler, Page Fault .................................................................................................32 Seitenrahmen, Page Frames ...........................................................................................32
Vernetzte Systeme ............................................................................................................................35 Bedeutung der Vernetzung für Unternehmen ...............................................................35 Bedeutung der Vernetzung für Privatpersonen.............................................................35 Einteilung der Netzwerke ..............................................................................................35
Netzformen, -Topologien und -Komponenten ...............................................................................36 Netztopologien .........................................................................................................................36
Bussystem ......................................................................................................................36 Problem: Kollisionen .....................................................................................................36 Ringnetz (token -Ring) ..................................................................................................37 Sternnetz ........................................................................................................................37

Übertragungsmedien........................................................................................................................38 Aufbau einer Übertragungsleitung.................................................................................38
Koaxialkabel ............................................................................................................................38 Twisted Pair Leitung................................................................................................................39
Störung durch Induktion ................................................................................................39 Störung durch Influenz ..................................................................................................39
Lichtwellenleiter (LWL) ..........................................................................................................40
Ethernet.............................................................................................................................................41 CSMA/CD (Carrier Sense Multiple Access / Collision Detection) ...............................41 Erlaubte Verzögerungszeiten .........................................................................................43 Späte Kollisionen...........................................................................................................43
Aufbau eines Ethernet-Frames .................................................................................................43 Das Paketformat.............................................................................................................43 Rahmenformat nach Ethernet Version 2........................................................................43 Rahmenformat nach IEEE 802.3 ...................................................................................44
MAC-Adressen ........................................................................................................................44 Vom Koax-Bus zum Twisted-Pair-Stern .................................................................................45
Twisted-Pair...................................................................................................................45 Der Schritt zu 100 Mbit/s...............................................................................................45
Längenbegrenzung im Ethernet ...............................................................................................46
Fehlersicherung, Fehlererkennung.................................................................................................46 Redundanz................................................................................................................................46 Paritätsbit, Hammingdistanz ....................................................................................................47 Fehlerkorrektur.........................................................................................................................47
Blockparitätssicherung...................................................................................................47 Zyklische Redundanzprüfung (CRC).......................................................................................47
Zur Darstellung von Bitfolgen durch Polynome............................................................48 Rechenregeln .................................................................................................................48 Rechnen mit Polynomen ................................................................................................49 Addition / Subtraktion....................................................................................................49 Multiplikation / Division................................................................................................49 Algorithmus CRC ..........................................................................................................50 Beispiel: .........................................................................................................................50 Implementierung der Polynomdivision in Hardware.....................................................51 Erkennung von Fehlern..................................................................................................52 Einzelfehler....................................................................................................................52 Mehrfachfehler...............................................................................................................52 Eigenschaften einiger Generatorpolynome....................................................................53
Das ISO-OSI-7-Schichtenmodell.....................................................................................................53 Aufgaben der Schichten:................................................................................................53 Schichtenmodell und Paketaufbau.................................................................................54
Ein- und Auspacken von Paketen.............................................................................................54 Das OSI-Modell und TCP/IP im Vergleich .............................................................................54
Physical, Data Link (Layer 1 + 2) ...................................................................................................55 ARP - Adress Resolution Protocol ................................................................................55 Repeater (Hub)...............................................................................................................55 Bridge, Switch ...............................................................................................................55
Network (Layer 3) ............................................................................................................................56 IP-Adresse......................................................................................................................56 Router.............................................................................................................................57 Netzmaske......................................................................................................................58 Beispiel 1 .......................................................................................................................58 Beispiel 2 .......................................................................................................................58 Beispiel 3 .......................................................................................................................58 Beispiel 4 .......................................................................................................................59 Beispiel einer Routing-Tabelle ......................................................................................59
Planung eines Intranets (Subnetting)........................................................................................60

Beispiel 1 .......................................................................................................................60 Beispiel 2 .......................................................................................................................61
IP-Header .................................................................................................................................63
Application, Presentation, Session, Transport (Layer 4 - 7).........................................................64 Transport Layer........................................................................................................................64
Port, Socket....................................................................................................................64 TCP-Header ...................................................................................................................64 Segmentierung ...............................................................................................................65 Beispiel ..........................................................................................................................65
Gateway ...................................................................................................................................66
Verbindungsorientierte- und verbindungslose Kommunikation .................................................67 Verbindungsorientiert ....................................................................................................67 Verbindungslos ..............................................................................................................67
Betriebssystem anwenden................................................................................................................68 Wichtige MS-DOS-Kommandos .............................................................................................68 Einige Netzwerk-Befehle (unter TCP/IP) ................................................................................68 Skriptprogrammierung .............................................................................................................70
Client-Server-System .......................................................................................................................71 Organisation der Rechtevergabe ..............................................................................................71
Datensicherung .................................................................................................................................72 Sicherungsmedien ....................................................................................................................72 Sicherungsverfahren.................................................................................................................72
1. Vollsicherung (Normal) .............................................................................................72 2. Differentielles Backup (Differenz) ............................................................................72 3. Inkrementelles Backup (Hinzufügen, auch Zuwachssicherung)................................72 4. Kopieren: ...................................................................................................................72
Sicherungsstrategien ................................................................................................................72 a. Das Mischen von Voll- und Differenzsicherung........................................................72 b. Das Mischen von Voll- und Zuwachssicherung ........................................................73 c. Großväter–Väter– Söhne............................................................................................73
Erstellen eines Backup-Scripts.................................................................................................73

Inhalt
z:\_skripte\betriebssysteme&netzwerke\adam skript\betriebssysteme adam 030121-1.doc 4
Die Architektur eines Betriebssystems Aufgaben eines Betriebssystems (Operating System): Prozessorverwaltung, Speicherverwaltung, Dateiver-waltung, Geräteverwaltung, Auftragsverwaltung.
Aus Sicht des Betriebssystems fasst man: Prozessor Arbeitsspeicher Externspeicher Ein/Ausgabe-geräte unter dem Oberbegriff Betriebsmittel zusammen.
Dateisysteme*)
Speicher-Allokation
Interne Verkettung
Externe Verkettung
Indexblock
*) Literaturangaben (Wissensdatenbank): http://www.winhex.com/winhex/kb/index.html. FAT incl. Sourcecode: http://home.no.net/tkos/info/fat.html. Verzeichnisse (FH Berlin): http://www.tfh-berlin.de/~hornschu/ws01/bs_4.html#Verzeichnisorganisation. Ein gut lesbares Skript (FH Stralsund): http://www.bs.ti.fh-stralsund.de/vorlesung/skript2001_2.pdf . NTFS - Dokumentation: http://linux-ntfs.sourceforge.net/ntfs/index.html

MS-DOS Speicher-Allokation
5
1: Allokation
Erläutern Sie für jede der skizzierten Möglichkeiten die Arbeitsweise des Dateisystems.
Erweitern Sie die Darstellungen jeweils auf drei unabhängige Dateien.
Berücksichtigen Sie auch die Fälle, dass Dateien nachträglich gelöscht, verlängert oder verkürzt werden.
MS-DOS Alle heute gebräuchlichen Diskettentypen und Festplatten werden zweiseitig beschrieben und besitzen eine einheitliche Sektorgröße von 512 Bytes.
In der folgenden Tabelle sind die Daten der wichtigsten Diskettenfor-mate angegeben:
2: Diskette
Berechnen Sie in der Tabelle die Gesamtzahl der Sektoren.
mech. Grö-ße
Dichte Netto Kapazi-tät
Spuren pro Seite
Sektoren pro Spur
Gesamtzahl Sektoren
Spurdichte (TPI)
Bitdichte (BPI)
5¼ Zoll DD 360 kB 40 9 48 5876
5¼ Zoll HD 1.20 MB 80 15 96 8646
3½ Zoll DD 720 kB 80 9 135 8717
3½ Zoll HD 1.44 MB 80 18 135 17434
Mit den „Bordmitteln“ von Windows ist es möglich, den Inhalt von Disketten und Festplatten direkt sektorweise auszulesen. Das dazu nötige Programm heißt „de-bug.exe“. Das Lesen erfolgt in zwei Stufen: zuerst wird der Sektor in einen Arbeitsspeicherbereich kopiert, und danach kann dieser Bereich auf dem Bildschirm ausgege-ben werden
DEBUG Befehle (Auszug)
Mit Start - Ausführen - debug wird der Debugger gestartet. Der load-Befehl holt die Daten vom Medium in den Arbeitsspeicher.
l 0 0 0 20 load an Speicher 0 Medium Startsektor 0 Endsektor 20 Medium: 0 => LW A, 1 => LW B, 2 => LW C, etc.
Mit dem dump-Befehl kann anschließend der Speicherbereich betrachtet werden.
d 0 dump ab Speicher 0
Beachten Sie, dass vom Debugger alle Zahlenwerte als HEX-Werte interpretiert werden!
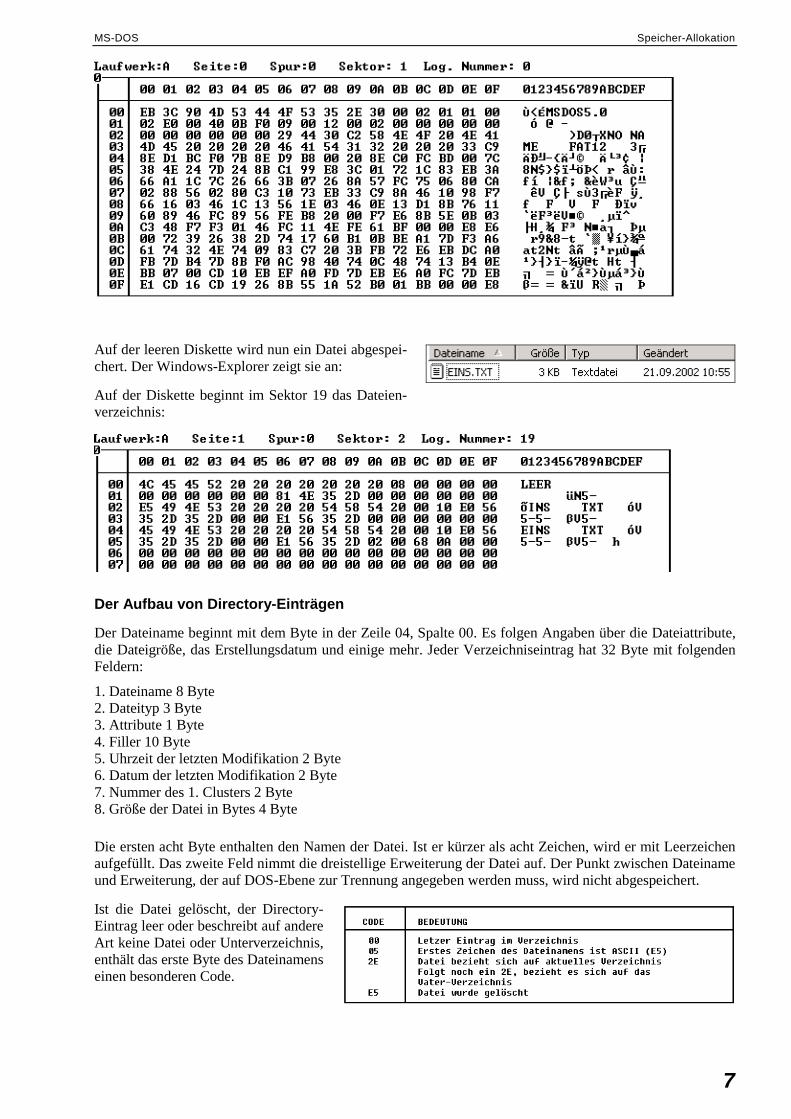
Sektor 1 Index-Loch
Schreib-/Lese-Kopf
Antrieb

MS-DOS Speicher-Allokation
6
Der Sektor 0 einer frisch formatierten Diskette:
Auf diese Weise können Sie alle weiteren Sektoren der Diskette auslesen, zum Beispiel auch den Sektor 1, in welchem die erste FAT (File Allocation Table) beginnt:
Weil die Diskette noch völlig leer ist, ist die FAT bis auf die ersten drei Bytes mit 00 gefüllt.
Der Bootsektor (Sektor 0) gibt Aufschluß über die Sektor- und Clustergröße, sowie über die Größen von FAT und Hauptverzeichnis.
Bootsektor: Länge: char ignored[3]; /* Boot strap short or near jump */ 3 Bytes char system_id[8]; /* Name - can be used to special case 8 Bytes partition manager volumes */ unsigned char BPS[2]; /* #bytes per logical sector */ 2 Bytes unsigned char SPC; /* #sectors per cluster */ 1 Byte unsigned short RES; /* #reserved sectors */ 2 Bytes unsigned char NFATS; /* #FATs */ 1 Byte unsigned char NDIRS[2]; /* #root directory entries */ 2 Bytes unsigned char NSECT[2]; /* #sectors total*/ 2 Bytes unsigned char MEDIA; /* media descriptor */ 1 Byte unsigned short SPF; /* #sectors/FAT */ 2 Byte unsigned short SPT; /* #sectors per track */ 2 Bytes unsigned short NSIDES; /* #heads */ 2 Bytes unsigned long NHID; /* #hidden sectors (unused) */ 4 Bytes unsigned long TSECT; /* #sectors (if sectors == 0) */ 4 Bytes Rest: Bootroutine
3: Format
Formatieren Sie eine Diskette. Betrachten Sie die Sektoren 0, 1, 10, 19 und 33. Versuchen Sie die Daten Bootsektors auszulesen und zu interpretieren.
Sektor 0 = Bootsektor Sektor 1 - 9 = 1. FAT (File Allocation Table) Sektor 10 - 18 = 2. FAT (Kopie der 1. FAT) Sektor 19 - 32 = Hauptverzeichnisbereich Sektor 33 - 2879 = Eigentlicher Datenbereich
Komfortableres Arbeiten ist mit dem Programm „LIESDISK.EXE“ des Autors möglich. Dieses Programm muss aus der DOS-Box von Windows („Eingabeaufforderung“) gestartet werden. Die DOS-Box kann mit Start - Ausführen - cmd gestartet werden.
MS-DOS Speicher-Allokation
7
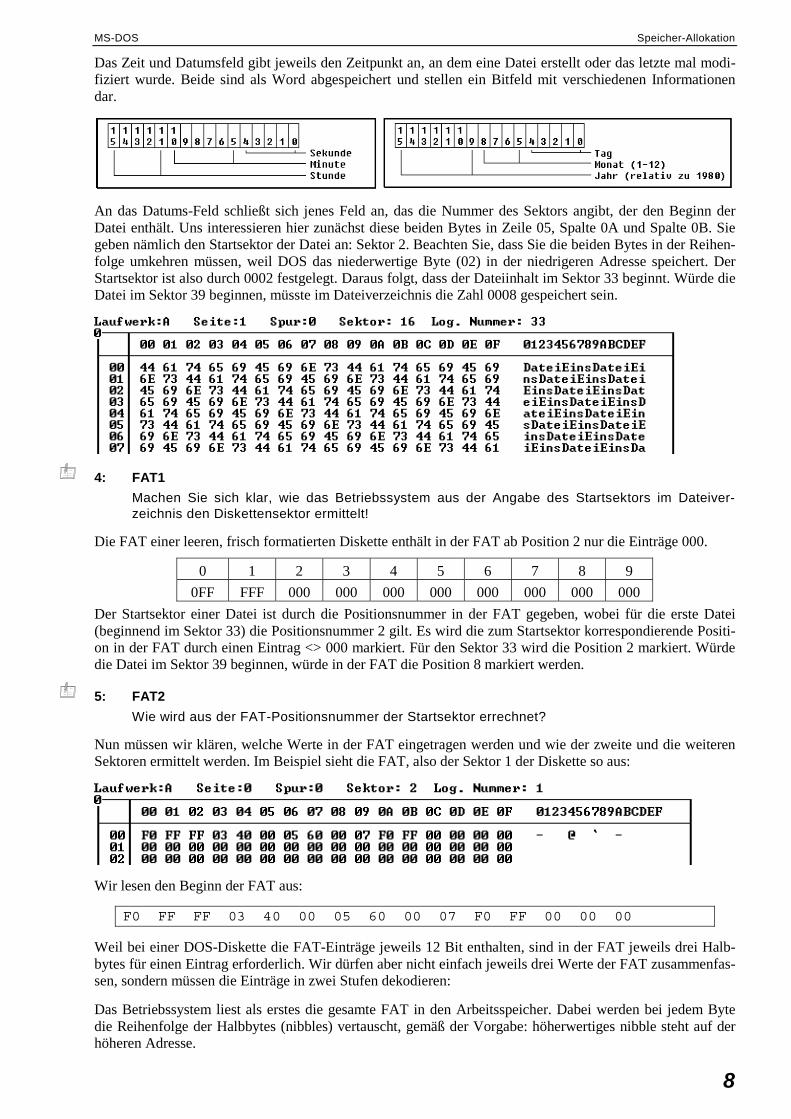
Auf der leeren Diskette wird nun ein Datei abgespei-chert. Der Windows-Explorer zeigt sie an:
Auf der Diskette beginnt im Sektor 19 das Dateien-verzeichnis:
Der Aufbau von Directory-Einträgen
Der Dateiname beginnt mit dem Byte in der Zeile 04, Spalte 00. Es folgen Angaben über die Dateiattribute, die Dateigröße, das Erstellungsdatum und einige mehr. Jeder Verzeichniseintrag hat 32 Byte mit folgenden Feldern:
1. Dateiname 8 Byte 2. Dateityp 3 Byte 3. Attribute 1 Byte 4. Filler 10 Byte 5. Uhrzeit der letzten Modifikation 2 Byte 6. Datum der letzten Modifikation 2 Byte 7. Nummer des 1. Clusters 2 Byte 8. Größe der Datei in Bytes 4 Byte
Die ersten acht Byte enthalten den Namen der Datei. Ist er kürzer als acht Zeichen, wird er mit Leerzeichen aufgefüllt. Das zweite Feld nimmt die dreistellige Erweiterung der Datei auf. Der Punkt zwischen Dateiname und Erweiterung, der auf DOS-Ebene zur Trennung angegeben werden muss, wird nicht abgespeichert.
Ist die Datei gelöscht, der Directory-Eintrag leer oder beschreibt auf andere Art keine Datei oder Unterverzeichnis, enthält das erste Byte des Dateinamens einen besonderen Code.
MS-DOS Speicher-Allokation
8
Das Zeit und Datumsfeld gibt jeweils den Zeitpunkt an, an dem eine Datei erstellt oder das letzte mal modi-fiziert wurde. Beide sind als Word abgespeichert und stellen ein Bitfeld mit verschiedenen Informationen dar.
An das Datums-Feld schließt sich jenes Feld an, das die Nummer des Sektors angibt, der den Beginn der Datei enthält. Uns interessieren hier zunächst diese beiden Bytes in Zeile 05, Spalte 0A und Spalte 0B. Sie geben nämlich den Startsektor der Datei an: Sektor 2. Beachten Sie, dass Sie die beiden Bytes in der Reihen-folge umkehren müssen, weil DOS das niederwertige Byte (02) in der niedrigeren Adresse speichert. Der Startsektor ist also durch 0002 festgelegt. Daraus folgt, dass der Dateiinhalt im Sektor 33 beginnt. Würde die Datei im Sektor 39 beginnen, müsste im Dateiverzeichnis die Zahl 0008 gespeichert sein.
4: FAT1
Machen Sie sich klar, wie das Betriebssystem aus der Angabe des Startsektors im Dateiver-zeichnis den Diskettensektor ermittelt!
Die FAT einer leeren, frisch formatierten Diskette enthält in der FAT ab Position 2 nur die Einträge 000.
0 1 2 3 4 5 6 7 8 9
0FF FFF 000 000 000 000 000 000 000 000
Der Startsektor einer Datei ist durch die Positionsnummer in der FAT gegeben, wobei für die erste Datei (beginnend im Sektor 33) die Positionsnummer 2 gilt. Es wird die zum Startsektor korrespondierende Positi-on in der FAT durch einen Eintrag <> 000 markiert. Für den Sektor 33 wird die Position 2 markiert. Würde die Datei im Sektor 39 beginnen, würde in der FAT die Position 8 markiert werden.
5: FAT2
Wie wird aus der FAT-Positionsnummer der Startsektor errechnet?
Nun müssen wir klären, welche Werte in der FAT eingetragen werden und wie der zweite und die weiteren Sektoren ermittelt werden. Im Beispiel sieht die FAT, also der Sektor 1 der Diskette so aus:
Wir lesen den Beginn der FAT aus:
F0 FF FF 03 40 00 05 60 00 07 F0 FF 00 00 00
Weil bei einer DOS-Diskette die FAT-Einträge jeweils 12 Bit enthalten, sind in der FAT jeweils drei Halb-bytes für einen Eintrag erforderlich. Wir dürfen aber nicht einfach jeweils drei Werte der FAT zusammenfas-sen, sondern müssen die Einträge in zwei Stufen dekodieren:
Das Betriebssystem liest als erstes die gesamte FAT in den Arbeitsspeicher. Dabei werden bei jedem Byte die Reihenfolge der Halbbytes (nibbles) vertauscht, gemäß der Vorgabe: höherwertiges nibble steht auf der höheren Adresse.

MS-DOS Speicher-Allokation
9
Die erste Zeile der FAT von oben sieht damit so aus:
0F FF FF 30 04 00 50 06 00 70 0F FF 00 00 00
Zu jedem FAT-Eintrag gehören drei nibbles. Wir fassen daher nun je drei nibbles zusammen und erhalten für die FAT-Einträge 0 bis 9 die Werte:
0 1 2 3 4 5 6 7 8 9
0FF FFF 300 400 500 600 700 FFF 000 000
Und nun folgt wieder die bekannte Regel: der höchste Wert hat die höchste Adresse. Für unsere gewohnte Leseweise (höchster Wert links) müssen wir also wieder die Reihenfolge vertauschen:
0 1 2 3 4 5 6 7 8 9
FF0 FFF 003 004 005 006 007 FFF 000 000
Nun endlich können wir die FAT auslesen: die Datei beginnt im Sektor 33, weil im Dateiverzeichnis auf den FAT-Eintrag Nummer 2 verwiesen wird. An dieser Stelle steht in der FAT der Wert 003, also ist der nächste von der Datei belegte Sektor der zweite Datensektor, Sektor 34.
6: FAT3
Erstellen Sie ein Rechenvorschrift zur Berechnung des Datensektors auf der Diskette aus dem FAT-Eintrag!
Gleichzeitig kann aus dem FAT-Eintrag Nummer 3 der wieder nachfolgende Sektor abgelesen werden. Der letzte Sektor der Datei ist in diesem Fall an der FAT-Position Nummer 7, also der Sektor (33 + 7 - 2) = 38, denn hier ist der Wert FFF eingetragen.
Dieser letzte Datensektor der Datei ist nicht mehr ganz gefüllt. Dieser Rest ist „verschwendet“ und kann auch durch eine andere Datei nicht mehr aufgefüllt werden. Im Mittel wird also je Datei ein halber Sektor (512 Bytes / 2 = 256 Bytes) verschenkt.
7: FAT4
Welche Sektoren der Diskette sind belegt, wenn die FAT folgende Eintragungen aufweist:
0 1 2 3 4 5 6 7 8 9
0FF FFF 003 FFF 005 009 000 FF 000 FFF
8: Datei EINS
Erstellen Sie mit Notepad eine Datei, die Sie auf der Diskette abspeichern. Kontrollieren Sie die Änderungen in den Sektoren 1, 19 und 33.
9: Datei Änderungen
Erstellen Sie weitere, auch größere Dateien. Vergrößern / verkleinern Sie nachträglich bereits gespeicherte Dateien. Löschen Sie Dateien. Beobachten Sie jedes Mal die Auswirkungen auf die FAT, das Dateiverzeichnis und den Datenbereich!
MS-DOS Erstellen von Verzeichnissen
10
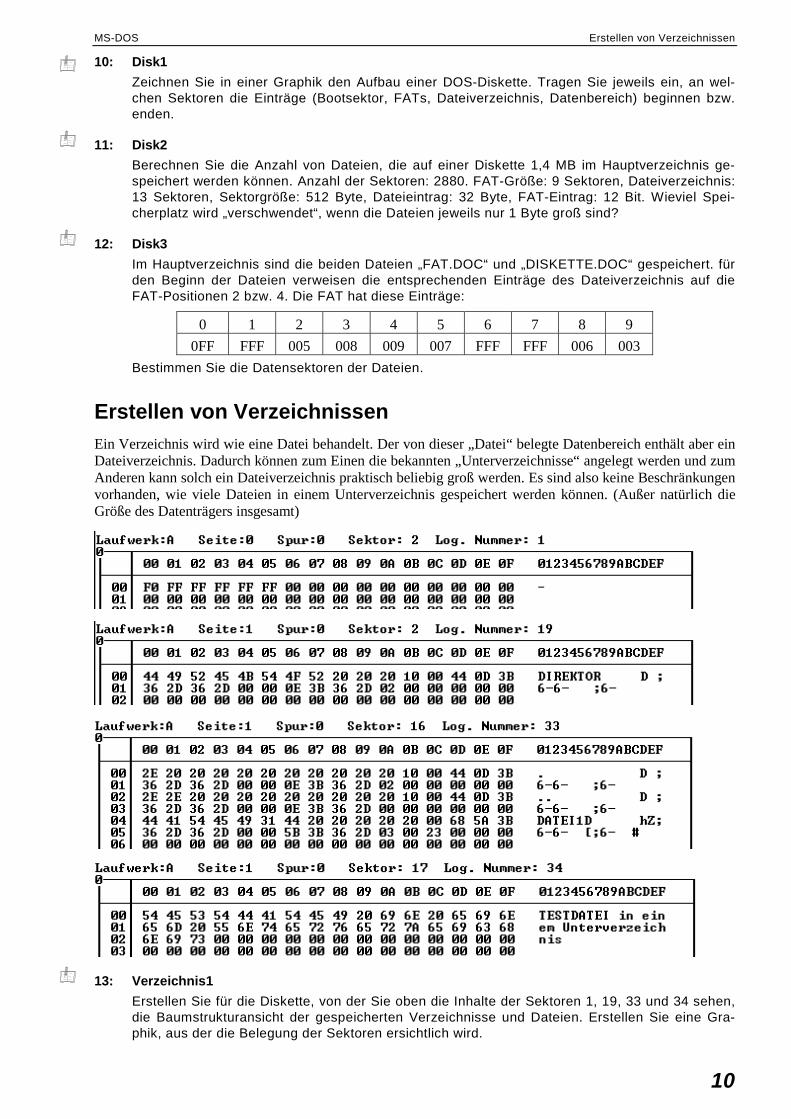
10: Disk1
Zeichnen Sie in einer Graphik den Aufbau einer DOS-Diskette. Tragen Sie jeweils ein, an wel-chen Sektoren die Einträge (Bootsektor, FATs, Dateiverzeichnis, Datenbereich) beginnen bzw. enden.
11: Disk2
Berechnen Sie die Anzahl von Dateien, die auf einer Diskette 1,4 MB im Hauptverzeichnis ge-speichert werden können. Anzahl der Sektoren: 2880. FAT-Größe: 9 Sektoren, Dateiverzeichnis: 13 Sektoren, Sektorgröße: 512 Byte, Dateieintrag: 32 Byte, FAT-Eintrag: 12 Bit. Wieviel Spei-cherplatz wird „verschwendet“, wenn die Dateien jeweils nur 1 Byte groß sind?
12: Disk3
Im Hauptverzeichnis sind die beiden Dateien „FAT.DOC“ und „DISKETTE.DOC“ gespeichert. für den Beginn der Dateien verweisen die entsprechenden Einträge des Dateiverzeichnis auf die FAT-Positionen 2 bzw. 4. Die FAT hat diese Einträge:
0 1 2 3 4 5 6 7 8 9
0FF FFF 005 008 009 007 FFF FFF 006 003
Bestimmen Sie die Datensektoren der Dateien.
Erstellen von Verzeichnissen Ein Verzeichnis wird wie eine Datei behandelt. Der von dieser „Datei“ belegte Datenbereich enthält aber ein Dateiverzeichnis. Dadurch können zum Einen die bekannten „Unterverzeichnisse“ angelegt werden und zum Anderen kann solch ein Dateiverzeichnis praktisch beliebig groß werden. Es sind also keine Beschränkungen vorhanden, wie viele Dateien in einem Unterverzeichnis gespeichert werden können. (Außer natürlich die Größe des Datenträgers insgesamt)
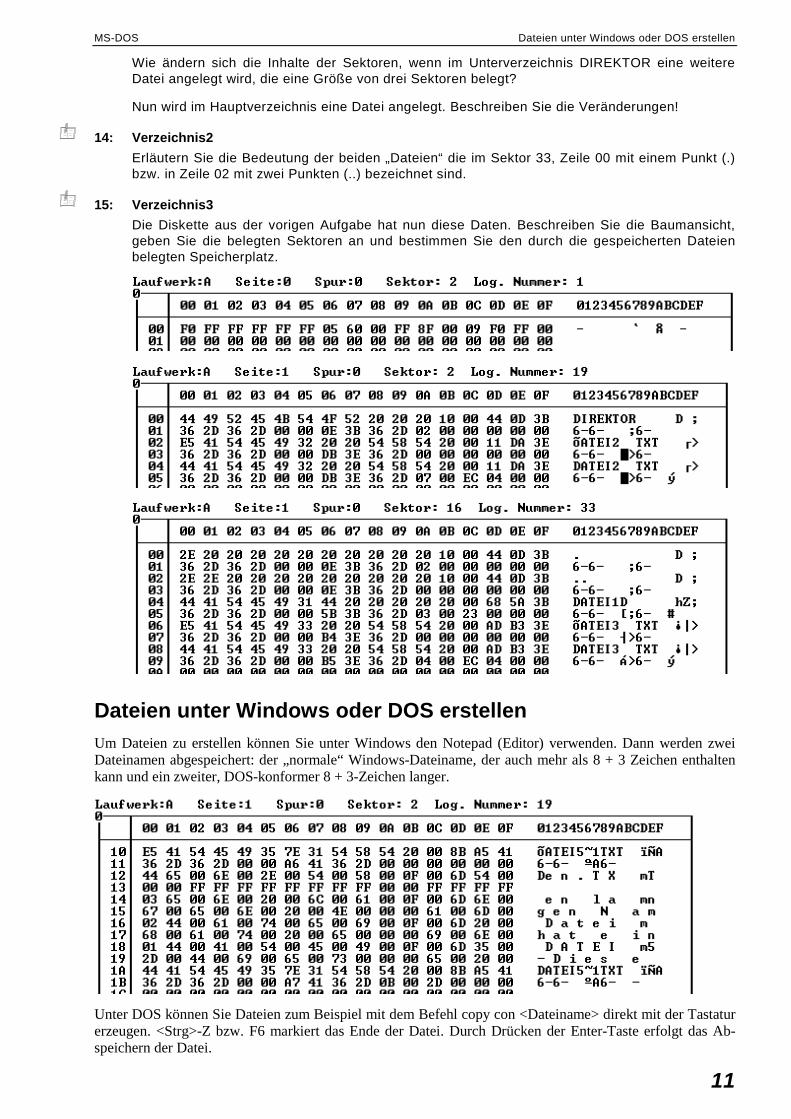
13: Verzeichnis1
Erstellen Sie für die Diskette, von der Sie oben die Inhalte der Sektoren 1, 19, 33 und 34 sehen, die Baumstrukturansicht der gespeicherten Verzeichnisse und Dateien. Erstellen Sie eine Gra-phik, aus der die Belegung der Sektoren ersichtlich wird.
MS-DOS Dateien unter Windows oder DOS erstellen
11
Wie ändern sich die Inhalte der Sektoren, wenn im Unterverzeichnis DIREKTOR eine weitere Datei angelegt wird, die eine Größe von drei Sektoren belegt?
Nun wird im Hauptverzeichnis eine Datei angelegt. Beschreiben Sie die Veränderungen!
14: Verzeichnis2
Erläutern Sie die Bedeutung der beiden „Dateien“ die im Sektor 33, Zeile 00 mit einem Punkt (.) bzw. in Zeile 02 mit zwei Punkten (..) bezeichnet sind.
15: Verzeichnis3
Die Diskette aus der vorigen Aufgabe hat nun diese Daten. Beschreiben Sie die Baumansicht, geben Sie die belegten Sektoren an und bestimmen Sie den durch die gespeicherten Dateien belegten Speicherplatz.
Dateien unter Windows oder DOS erstellen Um Dateien zu erstellen können Sie unter Windows den Notepad (Editor) verwenden. Dann werden zwei Dateinamen abgespeichert: der „normale“ Windows-Dateiname, der auch mehr als 8 + 3 Zeichen enthalten kann und ein zweiter, DOS-konformer 8 + 3-Zeichen langer.
Unter DOS können Sie Dateien zum Beispiel mit dem Befehl copy con <Dateiname> direkt mit der Tastatur erzeugen. <Strg>-Z bzw. F6 markiert das Ende der Datei. Durch Drücken der Enter-Taste erfolgt das Ab-speichern der Datei.

MS-DOS Defekte Sektoren
12
16: Dateiname
Unter welchem Namen sieht man die Datei mit dem langen Dateinamen unter DOS?
17: Dateiverzeichnis
Beschreiben Sie, warum in folgendem Dateiverzeichnis die Datei DATEI4 anders verzeichnet ist als die DATEI2.
18: Dateilesen
Erstellen Sie das Struktogramm für ein Programm, welches eine Datei von der Diskette liest und auf dem Bildschirm darstellt.
19: Dateispeichern
Erstellen Sie ein Ablaufdiagramm für den Vorgang: eine Datei wird gespeichert, danach wird sie nach Vergrößerung nochmals gespeichert.
Defekte Sektoren Defekte Sektoren werden in der FAT durch den Eintrag von FF7 gekennzeichnet.
20: Defekte
Wie viele Sektoren sind als defekt markiert? Wie häufig sind hintereinanderliegende Sektoren defekt?
Festplatten Festplatten können ebenfalls wie Disketten mittels FAT verwaltet werden. Man wendet allerdings nicht die FAT12 sondern eine FAT16 oder FAT32 an. Die Arbeitsweise ist aber jedes Mal gleich.
21: Festplatte1
Bestimmen Sie für eine FAT16 und FAT32 die maximale Größe der Festplatte. Wie viele 512-Byte-Sektoren muss die FAT umfassen?

MS-DOS Wiederholungsaufgaben
13
22: Festplatte2
Welche FAT ist erforderlich, wenn bei einer Sektorengröße von 512 Bytes 100 MB Daten gespei-chert werden sollen?
Wenn die Festplatte mehr Daten aufnehmen soll, kann man mehrere Sektoren zu einer organisatorischen Einheit (Cluster) zusammenfassen. Zum Beispiel können immer zwei Sektoren der Festplatte zusammenge-fasst sein. De Facto hat man dann eine „Sektorengröße“ von 1024 Bytes.
23: Festplatte3
Welche Probleme handelt man sich ein, wenn zur Verkleinerung der FAT mehrere Sektoren zu Clustern zusammengefasst werden?
24: Festplatte4
Entwerfen Sie eine Festplattenstruktur für eine 100 GB Festplatte!
25: Festplatte5
Wie groß sind bei einer FAT16 die Cluster bei einer Plattengröße von a) 512 MB, b) 1 GB, c) 2 GB?
Wiederholungsaufgaben
26: DOS1
Ein Betriebssystem reserviere auf einer Diskette für eine FAT12 3 Sektoren und für das Datei-verzeichnis 8 Sektoren zu je 512 Bytes. Der Bootbereich ist 1 Sektor groß. Wie viele Sektoren kann diese Diskette insgesamt umfassen? Wie viele Dateien können im Hauptverzeichnis erfasst werden? Kann der User auf dieser Diskette eine Datei mit 0,515 MB abspeichern? Wie viel Spei-cherplatz ist bei lauter 1-Byte-Dateien verschwendet?
27: DOS2
Die Kapazität einer Diskette sei ca. 360 KB. Wie groß muss die FAT12 sein?
28: DOS3
Das Dateiverzeichnis und die FAT enthalten folgende Daten:
Dateiname: BS.DOC LFB.DOC ... ... ...
“Cluster-Adresse”: 0002 0004
Cluster2 Cluster3 Cluster4 Cluster5 Cluster6 Cluster7 Cluster8 Cluster9 …. ….
0003 FFFF 0005 0009 0000 FFF7 0000 FFFF
FFFF: letztes Cluster der Datei 0000: leeres Cluster FFF7: defektes Cluster
Ein Eintrag ist 2 Byte lang (FAT16, Festplatte). Wie viele Cluster können angesprochen werden? Entwickeln Sie eine Formel zur Berechnung der Clustergröße bei gegebener Festplattengröße. Wie groß ist ein Cluster bei einer Plattengröße von:512 MB, 1 GB, 2GB?
Wie groß ist jeweils die Datei im Beispiel oben, die in Cluster 2 bzw. 4 beginnt bei einer Festplat-tengröße von 512 MB / 1 GB minimal / maximal?
29: Festplatte6
Wie groß sind die Dateien der Aufgabe Disk3 (Seite 10) minimal bzw. maximal, wenn die Spei-cherung auf einer a) Diskette, b) Festplatte mit 512 MB, c) Festplatte mit 1 GB erfolgt?

NTFS Wiederholungsaufgaben
14
NTFS Das MS-DOS-Dateisystem wie ich es in den vorigen Kapiteln beschrieben habe ist sehr unflexibel und hat für heute übliche größere Festplatten viel zu viele Einschränkungen. Zum Beispiel ist die maximale Datei-größe ca. 4 GB, weil die Größe einer Datei durch eine 4-Byte-Zahl angegeben werden muss. Das ist heute nicht mehr akzeptierbar: beispielsweise fallen für eine Video-Datei im DV-Format je Stunde etwa 13 GB Daten an. Das NTFS (New Technologie File System) ist wesentlich flexibler und hat zum Beispiel bezüglich der Dateigröße keine Einschränkung mehr*).
Das NTFS behandelt kleine und große Dateien unterschiedlich: Für jede Datei auf dem Datenträger wird in der Master File Table (MFT) ein ca. 1 kB oder größerer Bereich (record) angelegt. Wenn die Datei noch hier hineinpasst, werden hier sowohl die Metadaten für die Datei als auch der Dateiinhalt selbst abgelegt. Dateien die größer sind, werden in der MFT nach einem Index-Verfahren gespeichert.
So sieht eine frisch formatierte NTFS-Partition aus:
BOOT MFT frei Kopie von Metadaten
frei
In NTFS wird alles, auch die Metadaten, als “Datei” abgelegt. Zu diesen Dateien weist als Index die Master File Table (MFT). Lediglich der Bootsektor muss am Beginn des Datenträgers stehen. Im Bootsektor steht der Verweis auf den Speicherort der MFT. In der “Mitte” der Partition wird eine Kopie der ersten 4 Records der MFT abgespeichert, um bei einem Fehler in der MFT eine Reparaturmöglichkeit zu bieten. In der MFT wird auch ein Logfile gespeichert, in welchem Aktionen gespeichert werden, die auf dem Datenträger noch nicht vollständig durchgeführt wurden. Dadurch kann im Fall eines Systemabsturzes wieder ein konsistenter Zustand hergestellt werden.
Um zu verhindern, dass die MFT fragmentiert wird, reserviert das Betriebssystem zunächst 50% des freien Plattenplatzes. Erst wenn der verbliebene Rest mit Daten gefüllt ist, wird dieser Pufferbereich halbiert.
Hier einige Besonderheiten des NTFS: • Clustergröße: 512 bytes, 1k, 2k, 4k, 8k, 16k, 32k, 64k • Sehr flexibel: alle Systemdateien, außer dem Bootblock, sind frei verschiebbar • Alles, auch die Daten werden als Attribut bezeichnet • Die Attribute für eine bestimmte Datei können mehrere records, die nicht aufeinander folgen
müssen, in der MFT umspannen. • Dateinamen werden in Unicode gespeichert. • Transaktionen werden im Logfile zwischengespeichert: journalling file system • Datenkomprimierung möglich • LCNs und VCNs ermöglichen flexible Dateienspeicherung
*) Zum Studium des NTFS habe ich eine ZIP-Diskette verwendet. Wenn kein ZIP-Laufwerk zur Verfügung steht kann man auch eine (kleine) Partition auf der Festplatte für die Übungen erstellen. Ich rate davon ab, mit der (Haupt-)Partition C: Experimente durchzuführen ;-) Um die Daten von der ZIP-Diskette direkt auszulesen verwendete ich „WinHEX“ (http://www.sf-soft.de/index-d.html).

NTFS Wiederholungsaufgaben
15
Der Bootsektor bei NTFS
Wir beginnen zunächst mit der Betrachtung des Bootsektors des NTFS-Datenträgers. Wie auch bei DOS beginnt der Bootsektor im Sektor 0. Und auch wie bei DOS werden die Beschreibun-gen über den Datenträger und die Bootroutine hier untergebracht.
Im folgenden Speicherabbild habe ich drei Da-tenfelder umrahmt.
Das erste Feld (Offset C und B) bedeutet, dass jeder Sektor 02 00 = 512 Bytes groß ist.
Das nachfolgende Byte an der Offsetadresse D gibt an, wie viele Sektoren ein Cluster ergeben. Wir erkennen, dass hier ein Cluster genau 1 Sek-tor umfasst. Beachten Sie daher bei den folgen-den Beipielen, dass die Clustergröße 512 Bytes beträgt und damit (zufälligerweise) identisch mit der Sektorgröße ist.
Das nächste umrahmte Feld ab Adresse 30 gibt die Clusternummer (LCN = logical cluster num-ber) der Master File Table (MFT) an. Wie ge-wohnt, stellt der Editor die kleineren Adressen links dar: die Clusternummer der MFT ist also: 00 00 00 00 00 00 00 20 = 32.
An der Adresse 40 des Bootsektors steht die Größe eines Eintrags (record) der MFT. Hier sind es 02 Sekto-ren, also 1024 Bytes.
30: NTFS1
Geben Sie an, wie groß ein NTFS-Datenträger sein kann!
Die MFT
Im Beispiel beginnt die MFT (Master File Table) im Cluster 00 00 00 02HEX = 32, d.h. an der Speicherstelle LCN * Clustergröße = 32 * 512 = 16364 = 00 00 40 00HEX.
Offset Size Description
0000 3 Jump to the boot loader routine
0003 8 System Id: "NTFS " 000B 2 Bytes per sector 000D 1 Sectors per cluster 000E 7 Unused
0015 1 Media descriptor (a) 0016 2 Unused
0018 2 Sectors per track
001A 2 Number of heads 001C 8 Unused
0024 4 Always 80 00 80 00
0028 8 Number of sectors in the volume
0030 8 LCN of VCN 0 of the $MFT
0038 8 LCN of VCN 0 of the $MFTMirr 0040 4 Clusters per MFT Record (b) 0044 4 Clusters per Index Record
0048 8 Volume serial number ~ ~ ~
0200 Windows NT Loader
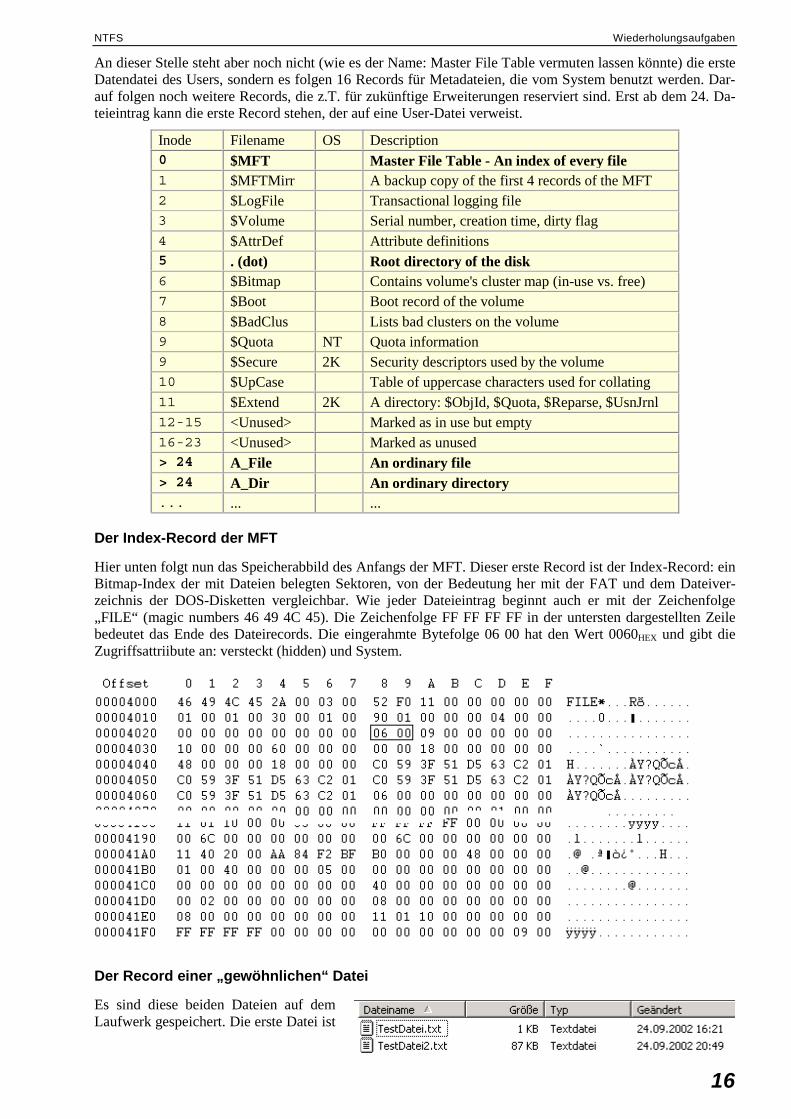
NTFS Wiederholungsaufgaben
16
An dieser Stelle steht aber noch nicht (wie es der Name: Master File Table vermuten lassen könnte) die erste Datendatei des Users, sondern es folgen 16 Records für Metadateien, die vom System benutzt werden. Dar-auf folgen noch weitere Records, die z.T. für zukünftige Erweiterungen reserviert sind. Erst ab dem 24. Da-teieintrag kann die erste Record stehen, der auf eine User-Datei verweist.
Inode Filename OS Description
0 $MFT Master File Table - An index of every file 1 $MFTMirr A backup copy of the first 4 records of the MFT
2 $LogFile Transactional logging file
3 $Volume Serial number, creation time, dirty flag
4 $AttrDef Attribute definitions 5 . (dot) Root directory of the disk
6 $Bitmap Contains volume's cluster map (in-use vs. free) 7 $Boot Boot record of the volume
8 $BadClus Lists bad clusters on the volume
9 $Quota NT Quota information
9 $Secure 2K Security descriptors used by the volume
10 $UpCase Table of uppercase characters used for collating
11 $Extend 2K A directory: $ObjId, $Quota, $Reparse, $UsnJrnl 12-15 <Unused> Marked as in use but empty
16-23 <Unused> Marked as unused
> 24 A_File An ordinary file > 24 A_Dir An ordinary directory
... ... ...
Der Index-Record der MFT
Hier unten folgt nun das Speicherabbild des Anfangs der MFT. Dieser erste Record ist der Index-Record: ein Bitmap-Index der mit Dateien belegten Sektoren, von der Bedeutung her mit der FAT und dem Dateiver-zeichnis der DOS-Disketten vergleichbar. Wie jeder Dateieintrag beginnt auch er mit der Zeichenfolge „FILE“ (magic numbers 46 49 4C 45). Die Zeichenfolge FF FF FF FF in der untersten dargestellten Zeile bedeutet das Ende des Dateirecords. Die eingerahmte Bytefolge 06 00 hat den Wert 0060HEX und gibt die Zugriffsattriibute an: versteckt (hidden) und System.
Der Record einer „gewöhnlichen“ Datei
Es sind diese beiden Dateien auf dem Laufwerk gespeichert. Die erste Datei ist
NTFS Wiederholungsaufgaben
17
daher frühestens im 24. Dateieintrag der MFT zu finden.
Record einer kleinen Datei
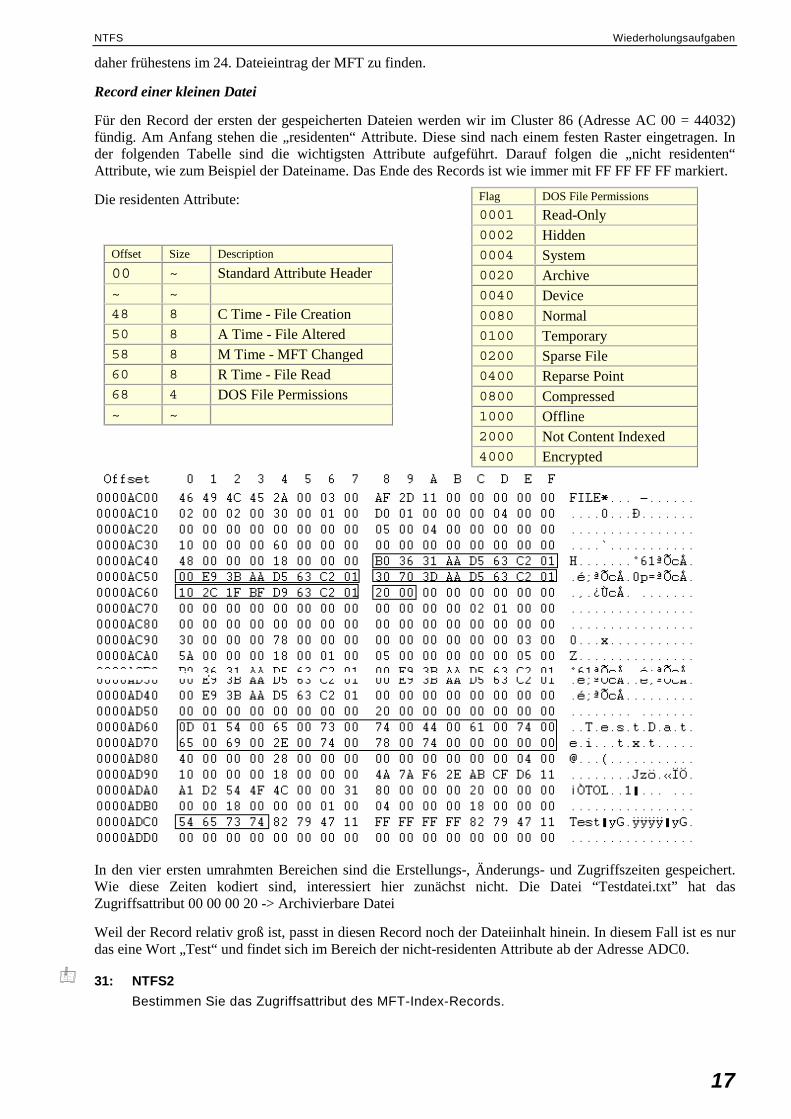
Für den Record der ersten der gespeicherten Dateien werden wir im Cluster 86 (Adresse AC 00 = 44032) fündig. Am Anfang stehen die „residenten“ Attribute. Diese sind nach einem festen Raster eingetragen. In der folgenden Tabelle sind die wichtigsten Attribute aufgeführt. Darauf folgen die „nicht residenten“ Attribute, wie zum Beispiel der Dateiname. Das Ende des Records ist wie immer mit FF FF FF FF markiert.
Die residenten Attribute:
Offset Size Description
00 ~ Standard Attribute Header ~ ~ 48 8 C Time - File Creation
50 8 A Time - File Altered
58 8 M Time - MFT Changed
60 8 R Time - File Read
68 4 DOS File Permissions ~ ~
Flag DOS File Permissions
0001 Read-Only
0002 Hidden
0004 System
0020 Archive
0040 Device
0080 Normal 0100 Temporary
0200 Sparse File 0400 Reparse Point 0800 Compressed
1000 Offline
2000 Not Content Indexed
4000 Encrypted
In den vier ersten umrahmten Bereichen sind die Erstellungs-, Änderungs- und Zugriffszeiten gespeichert. Wie diese Zeiten kodiert sind, interessiert hier zunächst nicht. Die Datei “Testdatei.txt” hat das Zugriffsattribut 00 00 00 20 -> Archivierbare Datei
Weil der Record relativ groß ist, passt in diesen Record noch der Dateiinhalt hinein. In diesem Fall ist es nur das eine Wort „Test“ und findet sich im Bereich der nicht-residenten Attribute ab der Adresse ADC0.
31: NTFS2
Bestimmen Sie das Zugriffsattribut des MFT-Index-Records.

NTFS Wiederholungsaufgaben
18
Record einer großen Datei
Zwei Cluster weiter (AC00 + 2*200 = B000) ist der Record für die zweite gespeicherte Datei. Diese ist grö-ßer und wird daher mittels Data-Runs (VCN und LCN) indiziert.
Vor Ende des Record ist die Tabelle der Datenläu-fe (Data Runs). Hier lautet sie: 22 AD 00 20 60 00. Das bedeutet: der erste Lauf (Run) wird durch zwei Byte für LCN und zwei Byte für die Länge beschrieben. Aus der Bytefol-ge 20 60 ergibt sich für die Adresse der ersten LCN 6020. Von dieser Adresse ab sind AD Cluster = 173 * 512 Bytes = 88576 Bytes = 87,5 kB durch diesen Datenlauf belegt. Diese Größe zeigt auch der Windows-Explorer an.
Diese Datei ist unfragmentiert, d.h. in einem Stück gespeichert: sie besteht aus einem einzigen Run. Das nächste Byte steht für den nächsten Datenlauf. Sein Header ist erwartungsgemäß 00, was anzeigt, dass es keinen weiteren Datenlauf gibt.
Wir müssen noch die Startadresse des LCN 6020 ermitteln: Jeder Cluster ist 512 = 200HEX Bytes groß: 6020 * 200 = C04000. An dieser Adresse beginnt der Dateninhalt.
Die Datei endet mit dem Cluster 6020 + AD = 60CD, welcher der Adresse 60CD * 200 = C19A00 ent-spricht. Der letzte Datencluster ist nicht vollständig gefüllt, daher sind die restlichen Bytes mit 00 aufgefüllt.

NTFS Wiederholungsaufgaben
19
Bei den folgenden Beispiele gehen Sie bitte von einer Clustergröße von 1 kB aus.
32: Run1
Data runs: 21 18 34 56 00
Bestimmen Sie LCN und die Anzahl der Datencluster.
Wenn die Datei fragmentiert ist, wird der Beginn des nächsten Clusters nicht absolut, sondern relativ zum Beginn des vorherigen Clusters angegeben. Bei “verschachtelten” (scrambled) Datenclustern muss auch “rückwärts” gesprungen werden. Die Bytes für den Offset repräsentieren daher ganze Zahlen: positive und negative Werte. E0 bedeutet -20 Cluster (also nach links).
33: Run2
a) Data runs: 31 38 73 25 34 32 14 01 E5 11 02 31 42 AA 00 03 00 (Lösung 1).
b) Data runs: 11 30 60 21 10 00 01 11 20 E0 00 (Lösung 2).
Bestimmen Sie die Anzahl der Runs, die LCN und die Anzahl der Datencluster sowie die Größe der Datei in Bytes
34: Run3
Wie lautet der MFT-Eintrag „Runtabelle“, wenn die Datei so fragmentiert ist:(Lösung)
Header Standard-informationen
Dateiname Zugriffsrechte Daten
VCN LCN Größe 0 877 6
6 2140 2 8 635 3
VCN 0 1 2 3 4 5 6 7 8 9 10 LCN 877 882 2140 2141 635 637
Record für ein kleines Verzeichnis
Die Metadaten eines Verzeichnis werden wie die einer Datei in einem Record der MFT abgelegt. Auch hier werden die Verweise auf die im Verzeichnis gespeicherten Dateien innerhalb des Record abgelegt, wenn das Verzeichnis „klein“ ist. Im Beispiel unten finden Sie die Dateienliste ab der Adresse B568.
Innerhalb des Verzeichnisrecord wird ein Index geführt, der die alphabetische Reihenfolge der Einträge er-gibt. Das dabei angewandte Verfahren ist ein B*-Baum. Darauf will ich hier nicht näher eingehen.
(Lösung 1) Fragmentiertes file, Größe 18E cluster, LCNs: 342573, 363758 und 393802.
(Lösung 2) Schlecht fragmentiertes file. Größe 80 cluster, LCNs: 60, 160 und 140. Dritter Datenblock zwischen dem ersten und dem zweiten.
(Lösung) 21 06 03 6D 21 02 04 EF 41 03 FF FF FA 1F 00

NTFS Wiederholungsaufgaben
20
Auf der ZIP-Disk wurde ein Verzeichnis „DIREKTOR“ und darin drei Dateien erzeugt. Nebenstehend sehen Sie die Struktur.
Der Record, der das Verzeichnis enthält ist im Cluster 90, also an der Adresse 90*512 = B400HEX. Die Bytes an den Speicherstellen B568, B5D0 und B638 enthalten die Clusternummer des zu der jeweiligen Datei gehörigen Records.
Hier ist der Anfang des Verzeichnisrecords:
Und hier das Ende mit dem Verzeichnisnamen und der Dateienliste. Die Liste ist klein genug und passt daher noch vollständig in das Record:
Der Record für die „Datei1D.txt“ findet sich an der 1E = 30. Position der MFT. Die Speicherstelle errechnet sich daher so: (Beginn der MFT) + Position*512*2, weil je MFT-Record zwei Sektoren belegt sind. Beginn der MFT ist gemäß Eintrag im Bootsektor der Cluster 32. Damit errechnet sich die Adresse zu 32*512 + 30*512*2 = 47104 = B800HEX.

Prozesse und Threads Wiederholungsaufgaben
21
35: NTFS-Verzeichnis1
Bestimmen Sie den Cluster des Records, seine Speicheradresse sowie die Speicheradresse für die Datei „Datei2D.txt“.
36: NTFS-Verzeichnis2
Die Datei „Datei3D.txt“ belegt folgenden Speicherbereich. Bestimmen Sie Cluster und Adresse des Dateirecords und die Runtabelle (Lösung).
Prozesse und Threads Bei vielen Programmierprojekten gibt es Aufgaben, die gleichzei-tig erfüllt werden müssen, oder bei denen dies zumindest günstig ist: Server müssen mehrere Anfragen gleichzeitig bearbeiten kön-nen; die numerische Verarbeitung von großen Datenmengen kann auf Mehrprozessor-Maschinen schneller geschehen, wenn alle Prozessoren unabhängig voneinander arbeiten; usw.. Jede der anstehenden Aufgaben wird von einem eigenen Prozess erledigt. Die Prozesse können miteinander kommunizieren und Daten aus-tauschen. Jeder Prozess hat einen eigenen Programmschritt-Zähler (PC program counter), ein eigenes Code-Segment und einen eige-nen Stack.
Lösung Dateirecord: Cluster 96, Adresse C000, Runtabelle: 31 12 77 93 01 00

Prozesse und Threads Scheduling
22
Durch Erzeugen weiterer Prozesse (Kindprozesse) entsteht ein Prozess-Strukturbaum.
Prozess A hat zwei Kindprozesse: B und C, Prozess B erzeugt die Kindprozesse D, E und F.
Zum Beispiel erzeugt der Prozess „Gärtnerei“ zwei Kindprozesse: Baumpflanzen und Rasen mähen. Baumpflanzen wiederum erzeugt Beet richten, Baum eingraben, gießen.
Prozess A Prozess B
Thread 3
Thread 1
Thread 2
Ein Prozess kann auch in mehrere Threads erzeugen
Threads könnte man als "leightweight processes" bezeichnen. Ein Thread ist ungefähr so wie ein Prozess, der sein Codesegment - also das eigentlich im Speicher liegende Programm - mit anderen Threads teilt, dieses aber unabhängig von den anderen durchläuft. Jeder Thread hat einen eigenen Programmzähler PC und seinen eigenen Stack und damit insbesondere seine eigenen lokalen Va-riablen. Es ist also so, als ob mehrere Prozesse im gleichen Pro-gramm laufen. Dadurch hat jeder Thread neben seinen eigenen lokalen Variablen auch Zugriff auf die für alle gültigen globalen, statischen Variablen. Auf diese Weise kön-nen die Threads miteinander kommunizieren.
Prozeß Thread Prozess = mit konkreten Daten ablaufendes Programm Instrument zum Ausführen eines Programms
Eigenständige Programmfragmente In einem Prozess können mehrere Threads ablaufen
Zugriff auf getrennte Adreßräume Zugriff auf dieselben Variablen möglich Multitasking: mehrere Programme/Prozesse laufen (quasi-)parallel ab
Multithreading: mehrere Threads laufen par-allel innerhalb eines Programms ab
Scheduling Im Idealfall steht für jeden Prozess bzw. Thread ein eigener Pro-zessor (Gärtner) zur Verfügung. Ein Prozessor kann nach Beendi-gung eines Prozesses durchaus weitere Prozesse bearbeiten.
Problematisch wird es, wenn zu wenig, etwa nur ein einziger Pro-zessor zur Verfügung steht. Die CPU-Zeit muss aufgeteilt werden. Wenn Prozesse „gleichzeitig“ laufen sollen, dann muss die Arbeit an einem Prozess immer wieder (zyklisch) unterbrochen werden, damit die anderen Prozesse auch Rechenzeit erhalten. Die Zutei-lung der jeweiligen Prozessorzeit-Anteile geschieht nach einem
Prozess B
Prozess F
Prozess D
Prozess E
Prozess C
Prozess A
A E
D
C
B CPU 1
CPU 3
CPU 2
Zeit

Prozesse und Threads Scheduling
23
komplizierten Verfahren und wird vom Scheduler*) verwaltet. Scheduling Algorithmen werden verwendet, um diese komplexen Planungsaufgaben zu lösen. Das Scheduling ist die Verteilung der Rechenzeit des Pro-zessors auf mehrere Prozesse, die gleichzeitig den Prozessor nutzen wollen. Die Aufgabe eines Schedulers ist es, nach einer vorgegebenen Strategie die Entscheidungen zu treffen, wann und wie lange welcher Prozess den Prozessor zur Verfügung hat.
Um verschiedene mögliche Lösungen miteinander vergleichen zu können, muss definiert werden, wodurch sich eine optimale Lösung auszeichnet. Dies geschieht durch die Definition einer Zielfunktion. Eine mögli-che Zielfunktion wäre zum Beispiel, dass ein Prozess in einer vorgegebenen Zeit bearbeitet ist oder dass die Auslastung der CPU optimiert ist.
Es gibt eine Reihe von möglichen Kriterien, nach denen die Scheduling-Strategie gewählt wird. Einige typi-sche Kriterien sind:
Fairneß: Jeder Prozeß erhält einen gerechten Anteil der Prozessorzeit.
Effizienz: Der Prozessor ist immer vollständig ausgelastet.
Antwortzeit: Die Antwortzeit für die interaktiv arbeitenden Benutzer wird minimiert.
Wartezeit: Die Wartezeit auf die Ausgaben von Stapelaufträgen (d.h. Rechenaufträgen, die ein-mal abgegeben werden, im Hintergrund laufen und deren Ergebnisse irgendwann abgeholt werden) wird minimiert.
Durchsatz: Die Anzahl der Aufträge, die in einem bestimmten Zeitintervall ausgeführt werden, wird maximiert.
Einige dieser Ziele widersprechen sich. Um zum Beispiel die Antwortzeit zu minimieren, sollten möglichst gar keine Stapelaufträge bearbeitet werden (oder nur nachts, wenn alle interaktiven Benutzer schlafen). Das erhöht natürlich die Wartezeit auf die Ausgaben der Stapelaufträge (auf mindestens eine Nacht). Ein anderes Beispiel: wenn jeder Prozess den gleichen Anteil an der Prozessorzeit bekommt (also auch die Prozesse, die den größten Teil ihrer Zeit blockiert sind, weil sie etwa auf Benutzereingaben warten), wird der Prozessor mit Sicherheit nicht optimal ausgelastet sein.
Es gibt daher keine optimale Scheduling-Strategie, die alle diese Kriterien gleichzeitig erfüllt. Je nachdem, welche dieser Kriterien höhere Priorität erhalten sollen, sind bestimmte Strategien geeigneter und andere ungeeigneter.
Prozesszustände
laufend, rechnend (running): benutzt gerade die CPU Der Prozess kann aus dem rechnendenden Zustand in den Zustand blockiert kommen, wenn er ein Betriebsmittel angefordert hat, dieses aber nicht bereit ist oder wenn er auf eine Eingabe durch den Nutzer wartet.
bereit (ready): lauffähig; temporär angehalten (durch den Sched-uler)
blockiert (blocked): wartet, bis ein bestimmtes Ereignis eintritt (z.B. eine Eingabe) Wenn das Ereignis eintritt, auf das der Prozess wartet, wird der Prozess in den Zustand bereit versetzt. Beachten Sie, dass der Prozess nicht „von sich aus“ direkt in den Zustand rechnend gelangen kann.
First Come, First Served (FCFS)
Die einfachste Strategie war in den früheren Batch-Systemen implementiert: ,,run to completion`` - ein Pro-zess verfügt über den Prozessor, bis er beendet ist, erst dann kann ein neuer Prozess gestartet werden.
*) wird ausgesprochen als: 'skediuler'
running
ready
1 2 3
4 blocked

Prozesse und Threads Scheduling
24
Highest Priority First (non-preemptiv) (HPF-n)
Bei diesem Verfahren wird nach Ende eines Prozesses aus den dann wartenden Prozessen der mit der höchs-ten Priorität ausgewählt und gestartet.
Shortest Job First (SJF)
Eine andere Art, Prioritäten zu setzen, ist Shortest Job First: Angenommen, eine Reihe von Prozessen kommt gleichzeitig in die Warteschlange und die Rechenzeiten, die diese Prozesse benötigen, können bereits vorher abgeschätzt werden. Dann wird die Gesamt-Wartezeit aller Prozesse minimiert, wenn man die kürzes-ten Prozesse zuerst rechnen lässt. Dies funktioniert allerdings nicht für Prozesse, die erst später zur Warte-schlange hinzukommen.
Round Robin Scheduling (RR)
Im Gegensatz zu den obigen Verfahren werden Strategien, die die zeitweilige Unterbrechung laufender Pro-zesse erlauben, als ,,preemptive scheduling`` bezeichnet. In diesem Fall muss sichergestellt werden, dass die Daten unterbrochener Prozesse nicht vom laufenden Prozess gestört werden können. Dazu dienen Schutzme-chanismen wie zum Beispiel Semaphore und Monitore.
Einer der einfachsten, fairsten und verbreitetsten Scheduling-Algorith-men ist Round Robin. Dabei werden alle rechenbereiten Prozesse in einer Warteschlange angeordnet. Jeweils der vorderste Prozess wird aus der Schlange genommen, bekommt ein festes Quantum Prozessorzeit und wird dann, falls er mehr Zeit benötigt, erneut hinten an die Warteschlange angestellt. Neu hinzukommende Prozesse werden ebenfalls an das Ende der Schlange gestellt. Das Zeitquan-tum ist immer gleich groß, typischerweise in Millisekunden-Größenordnungen.
Die Wahl eines geeigneten Quantums ist ein Kompromiss: Je kleiner das Quantum, desto grö-ßer wird der Zeitanteil, den das System mit der Umschaltung zwischen den Prozessen verbringt. Je größer das Quantum, desto länger werden die Antwortzeiten für interaktive Benutzer.
Priority Scheduling (preemptiv): Highest Priority First (HPF-p)
Mit Round Robin werden alle Prozesse gleich behandelt, es gibt aber auch die Möglichkeit, bestimmte Pro-zesse gegenüber anderen zu bevorzugen. Dazu wird jeder Prozess einer Prioritätsklasse zugeordnet (diese kann sich etwa aus dem Rang des Auftraggebers oder aus der Unterscheidung von System- und Anwen-dungsprozessen ergeben).
In erster Linie erfolgt die CPU-zuteilung mit dem Preemptive Priority (unterbrechendes) Verfahren. Dabei wird jedem Prozess eine Priorität zugeteilt. Sobald ein Prozess in den Zustand ,,ready`` kommt, wird geprüft, ob er eine höhere Priorität hat als der momentan laufen-de. Falls ja, wird der Kontext des Laufenden gesichert und der Prozess mit der höheren Priorität bekommt dann die CPU zugeteilt. Anschließend wird der unterbrochene Prozess an der Unterbrechungsstelle fortgesetzt. Entsprechend muss der Prozess mit einer niederen Priorität auf die CPU-Zuteilung durch das Betriebssystem warten bis der laufende Prozess abgelaufen ist. Zwischen
A F E
D
C
B
D
B
C
B
A E
D
C
B
D
B
C
B

Prozesse und Threads Scheduling
25
Prozessen gleicher Priorität kann dabei nach dem Round-Robin-Verfahren abgewechselt werden. Dies ergibt bei N Prioritätsklassen ein Modell mit N getrennten Warteschlangen.
Eine andere, fairere Möglichkeit ist, wie bei Round Robin alle Prozesse in eine Warteschlange zu stellen und die Prozesse mit höherer Priorität jeweils mehrere Quanten unmittelbar hintereinander rechnen zu lassen, ehe sie neu ans Ende der Schlange gestellt werden.
Dynamische Prioritäten
Die Einordnung der Prozesse in Prioritätsklassen muß nicht statisch sein. Das folgende Beispiel für dynami-sche Zuordnung von Prioritäten stammt von einem sehr frühen Betriebssystem, in dem die Prozeßumschal-tung noch verhältnismäßig lange dauerte und daher möglichst selten durchgeführt werden sollte:
Es gibt nur eine Warteschlange. Die Prioritätsklassen unterscheiden sich durch die Anzahl der Quanten, die die entsprechenden Prozesse unmittelbar hintereinander bekommen. Ein Prozess aus Klasse k bekommt je-weils 2k Quanten im Stück. Jeder neue Prozess und jeder Prozess, der zuletzt blockiert war, kommt in Priori-tätsklasse 0. Wenn ein Prozess aus Klasse k rechnet und seine 2k Quanten Rechenzeit voll ausnutzt (also nicht zwischendurch blockiert oder beendet wird), dann steigt er in Klasse k+1 auf. Auf diese Weise brau-chen rechenintensive Prozesse nicht oft unterbrochen zu werden, und trotzdem ist die Antwortzeit für inter-aktive Benutzer relativ klein. Ein Prozess, der zum Beispiel 1000 Quanten Rechenzeit benötigt, erhält nach-einander 1, 2, 4, 8, 16, 32, 64, 128, 256 und 512 Quanten, muss also nur neunmal unterbrochen werden.
37: Prozess Management
Im Diagramm sind die bekannten Thread / Prozess-Zustände aufgezeichnet. Ordnen Sie die Pfeile den aufgelisteten Beispielereignissen zu!
a. Timeslice (Zeitscheibe) abgelaufen b. Device I/O angefragt c. Prozess/Thread vom Scheduler ausgewählt d. Device I/O beendet
38: Scheduling1
a) Erklären Sie den Unterschied zwischen “non-preemptive” und “preemptive” Scheduling. Weshalb wird “preemptive scheduling” meist in Mehrbenutzersystemen angewandt?
b) Was ist der Unterschied zwischen einem Round-Robin und einem Prioritäten-Scheduler? In-wiefern hängen die zwei Methoden zusammen?
c) Beschreiben Sie eine eigene Scheduling-Methode, die zwar Round-Robin implementiert, es aber zusätzlich erlaubt, jedem Thread ein Gewicht zu zuordnen, welches beschreibt, wie groß seine Zeitscheibe relativ zu den anderen Threads ist! Wie ließe sich diese Methode ein-fach implementieren? Worin liegt der Unterschied zum bekannten Prioritäten- Scheduler?
39: Scheduling2
Gegeben seien folgende Programme (E-xecutables):
Die Notation soll folgendermaßen inter-pretiert werden (exemplarisch für E1): das Programm benötigt im ersten Schritt 4 Zeiteinheiten CPU-Rechenzeit, danach führt es eine E/A-Operation aus, die 9 Zeiteinheiten benötigt. Dann rechnet das Programm wieder 2 Zeiteinheiten unter Benutzung der CPU bis es schließlich terminiert.
Gehen Sie davon aus, dass der Rechner, auf dem die Programme ausgeführt werden beliebig viele E/A-Operationen parallel abarbeiten kann, jedoch lediglich über eine CPU verfügt.
Es werden nun folgende Prozesse gestartet: P1: Programm E1 zum Zeitpunkt t1=0, P2: Pro-gramm E2 zum Zeitpunkt t2=1, P3: Programm E3 zum Zeitpunkt t3=2.
Priorität Startzeit
E1: 4cpu, 9io, 2cpu 4 0
E2: 1cpu, 2io, 2cpu, 4io, 5cpu 1 1
E3: 4cpu, 6io, 1cpu 3 2

Prozesse und Threads Scheduling
26
a) Bestimmen Sie die Zeitpunkte, zu denen die einzelnen Prozesse frühestens beendet sind. („unbegrenzt“ viele CPUs vorhanden)
b) Bestimmen Sie die Zuteilung der CPU zu den Prozessen, nach der Strategie „Highest Priority First“. (Ein kleinerer Zahlenwert bedeutet dabei größere Priorität).
c) Wir verwenden „Round Robin“ als Scheduling Strategie. Nehmen Sie als „Zeitscheibe“ für diese Strategie eine Zeiteinheit (∆t=1). Berechnen Sie für jeden Zeitpunkt die Zuteilung der CPU. Zu welchen Zeitpunkten werden die Programme beendet? Vergleichen Sie die Zeit-punkte, zu denen die Prozesse zum ersten Mal die CPU zugeteilt bekommen mit Teil
Lösungsvorschlag:
Die folgende Abbildung zeigt die Zuteilung der CPU bei:
1. Vorhandensein von 3 CPUs (für die Angaben dieser Aufgabe werden auch 2 CPUs reichen, da die Prozesse die CPUs zeitlich versetzt benutzen)
2. Einer CPU und die Strategie „Highest Priority First“
3. Einer CPU und dem „Round-Robin“-Verfahren
40: Scheduling3
Die folgenden drei Jobs stehen zu den angegebenen Zeiten zur Ausführung an:
Berechnen Sie die Bearbeitungszeit eines jeden Jobs bei fol-genden Scheduling-Strategien: First-Come-First-Served (FCFS), Shortest-Job-First (SJF), Round-Robin (RR) mit Zeit Zeitquantum q = 2
Job-nummer
Ankunfts-zeit
Bearbeitungs-zeit
1 0.0 8 2 0.4 4 3 1.0 1

Prozesse und Threads Deadlocks
27
41: Scheduling4
Folgende Prozesse sollen betrachtet werden (die Zeiten seien in beliebigen Zeiteinheiten gegeben, die Priorität von 0 bis 2, wobei 0 die höchste Priorität bezeichne). Ein Prozess, der zum Zeitpunkt t eintritt, wird erst zum Zeit-punkt (t + 1) berücksichtigt. Wird ein Prozess vor seinem Terminieren zum Zeitpunkt t0 unterbrochen, so reiht er sich hinten in die Warteschlange mit Ankunftszeit t0 wie-der ein.
Geben Sie für die Strategien FCFS, SJF, Round Robin mit Quantum t = 3, Priority-Scheduling (non-preemptive) (HPF-n) und Priority-Scheduling (preemptive) (HPF-p) für die ersten 20 Zeiteinheiten an, wann welchem Prozess Rechenzeit zu-geteilt wird und wann die Prozesse ggf. terminieren.
Deadlocks
Dinierende Philosophen
Dijkstra 1965: Anhand des Synchronisationsproblems "the dining philosophers" können für Prozesse, die für den exklusiven Zugriff auf ein in beschränkter Menge vorhandenes Betriebsmittel (z.B. I/O Geräte) konkur-rieren, Lösungen erarbeitet werden.
"... five philosophers are seated around a table. Each philosopher has a plate of spaghetti. The spaghetti are so slippery that a philosopher needs two forks to eat it. Between each plate is a fork. The life of a philosopher consists of alternate periods of eating and thinking. (This is something of an abstraction, even for philo-sophers, but the other activities are irrelevant here.) When a philosopher gets hungry, she tries to acquire her left and right fork, one at a time, in either order. If successful in acquiring two forks, she eats for a while, then puts down the forks and continues to think. " The key question is: can you write a program for each philosopher that does what it is supposed to do and never gets stuck?
(It has been pointed out that the two-fork requirement is somewhat artificial; perhaps we should switch from Italian to Chinese food, substituting rice for spaghetti and chopsticks for forks.)
1. Problem der Verklemmung
Wir nehmen einmal an, alle Philosophen würden gleichzeitig Hunger bekom-men und nach dem rechts von ihnen liegenden Stäbchen greifen. Natürlich können sie mit einem Stäbchen nicht essen. Sie warten also auf das zweite. Dieses können sie aber nicht bekommen, weil es ihr Nachbar in der Hand hat, der ebenfalls wartet. Natürlich legt kein Philosoph sein Stäbchen aus der Hand, ohne gegessen zu haben. Der Effekt ist, dass gar nichts mehr geht. Eine Ver-klemmung ist eingetreten.
2. Organisation des gegenseitigen Ausschlusses in kritischen Abschnitten
Um die oben beschriebene Verklemmung zu vermeiden könnte abgesprochen werden, dass immer nur beide Stäbchen auf einmal aufgenommen werden dürfen. Der Philosoph muss also zuerst nachschauen, ob auch beide Stäbchen auf dem Tisch liegen und nur wenn das der Fall ist, darf er sie aufnehmen. Was aber passiert, wenn ein anderer Philosoph genau zu dem Zeitpunkt, wo der hungrige Philosoph festgestellt hat, daß beide Stäbchen da sind und das erste in die Hand nimmt, das andere Stäbchen wegnimmt? Der Zeitabschnitt vom Blick "Ist das erste Stäbchen da?" bis zum Aufnehmen des zweiten Stäbchens ist ein sogenannter kritischer Abschnitt, in dem verhindert werden muss, dass ein anderer Philosoph am Status Quo etwas ändert.
3. Aushungern eines Prozesses
Das kann man in unserem Beispiel fast wörtlich nehmen. Wenn ein Philosoph vergisst nach dem Essen das Stäbchen wieder auf den Tisch zu legen, oder während des Essens einen so interessanten Gedanken hat, dass er über das Denken das Essen vergisst und deshalb die Stäbchen in der Hand behält, können seine Nachbarn nicht essen. Denkbar wäre auch, dass sich der linke und der rechte Nachbar eines Philosophen absprechen, so dass immer eines der beiden Stäbchen unterwegs ist. Auch dann müsste unser armer Philosoph verhungern.
Prozess Ankunfts-
zeitpunkt Laufzeit Priorität
A 0 4 1 B 1 1 0 C 2 7 1 D 4 3 2 E 6 2 0 F 10 6 0 G 11 1 1

Prozesse und Threads Deadlocks
28
Übersetzt in die Welt der Prozeßsynchronisation bildet jeder Philosoph einen Prozeß, der nacheinander das linke bzw. das rechte Stäbchen aufnimmt. Angenommen alle Philosophen nehmen zunächst das linke Stäbchen auf. Dann kann keiner mehr sein rechtes Stäbchen aufnehmen. Wir haben einen Deadlock erreicht. Eine Idee dieses Problem zu lösen wäre, daß jeder Philosoph das linke Stäbchen wieder ablegt, wenn das rechte nicht mehr aufgenommen werden kann. Der Philosoph wartet dann eine bestimmte Zeit und versucht es erneut. Nun kann es passieren, daß alle Philosophen gleichzeitig starten. Dann ergibt sich ebenfalls keine Lösung, weil sie dann immer gleichzeitig Stäbchen aufnehmen und wieder hinlegen. Diesen Zustand nennt man Verhungern. Eine mögliche Lösung wäre die Wartezeit zufällig zu wählen. In der Regel wird das zur Lösung führen. Allerdings ist dies eine unsichere Lösung, die bei kritischen Steuerungen, wie Flugzeugen oder Atomkraftwerken sicher nicht angebracht ist. Eine sichere Lösung ist die Benutzung von Hilfsmitteln der Prozeßsynchronisation. Das ist möglich mit Semaphoren oder mit Monitoren.
Trivialer Deadlock-Fall
Ein einzelner Prozess ist verklemmt (in einer Deadlock Situation), wenn er auf eine Bedingung wartet, die nicht mehr wahr werden kann. Zum Beispiel schaltet der Prozess eine Regelung auf „Kühlen“ und wartet bis eine bestimmte Temperatur überschritten wird.
Deadlock bei mehreren, voneinander abhängigen Prozessen
Es kann zwischen den Prozessen untereinander eine Kopplung entstehen, wenn ein Prozess Zwischenergeb-nisse eines anderen benötigt oder wenn mehrere Prozesse die gleichen Betriebsmittel benötigen. Mehrere Prozesse sind untereinander verklemmt, wenn sie zyklisch aufeinander warten; d.h. die Wartebedingung des einen Prozesses kann nur von einem anderen, auch wartenden Prozess erfüllt werden.
Beispiel 1
In einer Gärtnerei kann der zweite Gärtner den Baum nur eingraben, wenn der Erste den Spaten freigibt, andererseits kann der erste Gärtner das Beet erst fertig richten, wenn der Baum eingegraben ist.
Beispiel 2
Der Dispatcher eines Windows-Programms verwaltet die eintretenden Ereignisse und startet die jeweils an-geforderten Ereignisbehandlungsprozeduren. Nur ein Prozess (und zwar der Hauptprozess) darf bzw. kann die Ereignisse verarbeiten. Wenn Ausgaben in ein Fenster erfolgen sollen, dann kann das immer nur ein Pro-zess erledigen, andere müssen warten, bis der aktive Prozess beendet ist. Dabei ist es sinnvoll, die Ausgabe in das Fenster ausschließlich im Hauptprogramm zu programmieren. Delphi bietet hier die Möglichkeit mit der Anweisung „Synchronize“ einen Prozess beim Dispatcher zu solch einem Zweck anzumelden. Der an-meldende Prozess arbeitet bis zur erfolgten Synchronisation nicht weiter, sondern verharrt in einer Endlos-schleife, bis der Dispatcher die Ausführung des Ereignisses meldet.
Nun kann es sein, dass gerade Ereignis 3 eingetreten ist und gleich-zeitig der Unterprozess „Synchronize“ aufgerufen hat um eine Aus-gabe im Fenster zu veranlassen. Der Hauptprozess kann das Syn-chronize-Ereignis nicht ausführen, weil er in diesem Beispiel auf die Rechenergebnisse des Unterprozesses wartet - hier also „bis in alle Ewigkeit“. Es bleibt anzumerken, dass dieser Fall möglicherweise in der Testphase nicht auftritt und sich damit einer Korrektur entzieht!
Man sieht, dass es trotz der Synchronisation von konkurrenten Prozessen zu Systemzuständen kommen kann, in denen sich mehrere Prozesse gegenseitig derart behindern, dass mindestens ein Prozess ohne äußeres Ein-greifen bis in alle Ewigkeit (meistens allerdings nur bis zum Ausschalten des Rechners) blockiert ist.
Deadlock bei mehreren Prozessen und mehreren Ressourcen
In den obigen Beispielen ist die Verklemmungssituation relativ leicht zu erkennen, wenn man die Arbeits-weise kennt. Beide Prozesse stehen in einer direkten Beziehung. Komplexer wird die Sache, wenn die Pro-zesse scheinbar unabhängig voneinander sind. Die Abhängigkeit kann aber entstehen, wenn mehrere Prozes-se die gleichen Ressourcen benötigen.

Prozesse und Threads Deadlocks
29
resource allocation graph
Um hier Überblick zu erhalten, kann man die Situation graphisch darstellen: Modellierung von Deadlocks: "resource allocation graph" (Holt, 1972). Es werden die Prozesse durch Kreise dargestellt, Ressourcen durch Quadrate. Dieses nennt man die Knoten. Die Beziehung der Knoten wird durch die “Kanten” dargstellt, das sind Pfeile, die von einem Ressourceknoten zu einem Prozessknoten zeigen, wenn der Prozess das Betriebs-mittel besitzt; bzw. von einem Prozessknoten zu einem Ressourceknoten, wenn der Prozess blockiert ist und auf die Ressource wartet.
Prozess besitzt die Ressource:
R P
Prozess wartet auf die Ressource:
R P
Beispiel: zwei Prozesse A, B wollen eine große Datei (von einem Bandlaufwerk) drucken:
(1) Prozess A fordert den Drucker an und bekommt diesen zugewiesen (2) Prozess B fordert Zugriff auf das Bandlaufwerk und bekommt dieses zugewiesen (3) A fordert das Bandlaufwerk an; Zugriff wird verweigert bis B dieses freigibt (4) B fordert den Drucker an; Zugriff wird verweigert, bis A diesen freigibt.
In einer Deadlock Situation enthält der resource allocation graph einen Zyklus: jeder Prozess wartet auf ein Ereignis, das nur von einem ande-ren Prozess dieser Menge kommen kann.In diesem (wie in den meis-ten) Fällen ist das Ereignis die Freigabe einer Ressource:
Definition: Eine Menge von Prozessen befindet sich im Deadlock gdw. jeder Prozess wartet auf ein Ereignis, das nur von einem anderen Prozess dieser Menge kommen kann.
Vier notwendige Bedingungen für das Entstehen eines Deadlocks (Coffman et al., 1971):
1. Bedingung des gegenseitigen Ausschlusses (mutual exclusion condition) Jede Ressource ist entweder genau einem Prozess zugewiesen oder erhältlich (Ein Prozess hat die exklusive Kontrolle über ein Betriebsmittel)
2. Besitz- und Wartebedingung (Hold and wait condition) Ein Prozess, der bereits eine Ressource besitzt, kann weitere Ressourcen anfordern (Während ein Prozess auf ein Betriebsmittel wartet, belegt er schon ein anderes exklusiv)
3. Bedingung der Nichtunterbrechung (No preemption condition) Ressourcen, die einem Prozess zugewiesen sind, können diesem nicht entzogen werden (Das Betriebsmittel bleibt bis zum Ende des Prozesse in dessen Gewalt)
4. Bedingung des zirkulären Wartens (Circular wait condition) Im resource allocation graph gibt es eine Kette von zwei oder mehr Prozessen, und jeder dieser Pro-zesse wartet auf eine Ressource, die der nächste Prozess in der Kette besitzt. (Es gibt mindestens zwei Prozesse, die die ersten drei Bedingungen erfüllen und auf Betriebsmittel warten, die vom jeweils anderen Prozess belegt sind)
Nur wenn alle diese Bedingungen erfüllt sind, liegt ein Deadlock vor.
Vermeidung von Deadlocks
Um Deadlocks gar nicht erst entstehen zu lassen, ist es nötig, dass alle Prozesse zu Beginn angeben, welche Betriebsmittel sie während ihrer Abarbeitung benutzen werden. Wird von einem Prozess ein Betriebsmittel angefordert, so wird berechnet, ob in Abhängigkeit von den anderen momentan benutzten Betriebsmitteln ein Deadlock prinzipiell möglich ist. Ist dies der Fall, so wird dem Prozess das Betriebsmittel verwehrt, und der Prozess muss warten. Die Nachteile dieser Methode sind, dass die Auslastung der Betriebsmittel klein ist und dass die Zeitspanne, in der das System mit der Systemverwaltung beschäftigt ist, zunimmt.
Drucker
A
Band
B

Speicherverwaltung Virtueller Speicher, Paging
30
Deadlocks kann man durch Regulieren des Zugangs zu den Betriebs-mitteln, durch Ändern der Prozessausführung oder geschicktere Auf-teilung der Prozesse vermeiden.
Diese Verklemmung lässt sich lösen, wenn man den Zugang zur Res-source „Kreuzung“ mit Ampeln reglementieren.
Eine weitere Möglichkeit ist, die Ressource selbst zu ändern: hier zu einem Kreisverkehr auszubauen.
Oder man kann die Regel (Rechtsfahrgebot) ändern: die Autos fahren links aneinander vorbei.
Praktischere Lösung: gelegentlich Deadlock erlauben. Dazu sind folgende Fragen zu klären:
• wie häufig ist ein Deadlock zu erwarten • wie häufig bricht das System aus anderen Gründen zusammen • welche Auswirkungen hat ein Deadlock
42: Deadlock1
Erläutern Sie, unter welchen Bedingungen ein Deadlock entstehen kann. Berücksichtigen Sie die Fälle: nur ein Prozess, zwei voneinander abhängige Prozesse und zwei voneinander unabhängi-ge Prozesse mit den jeweiligen Ressourcen.
43: Deadlock2
Zeichnen Sie den Ressource allocation graph für folgende Situation und begründen Sie, ob ein Deadlock vorliegt:
(1) Prozess A fordert den Drucker an und bekommt diesen zugewiesen (2) Prozess B fordert Zugriff auf den Scanner und bekommt diesen zugewiesen (3) Prozess C fordert Zugriff auf das Bandlaufwerk und bekommt dieses zugewiesen (4) A fordert das Bandlaufwerk an; Zugriff wird verweigert bis C dieses freigibt (5) C fordert den Scanner an; Zugriff wird verweigert, bis B diesen freigibt. (6) B fordert den Drucker an; Zugriff wird verweigert, bis A diesen freigibt.
Speicherverwaltung Problem: Arbeitsspeicher ist zu klein Idee: Arbeitsspeicher und Externspeicher logisch so vereinen, dass sie wie ein einziger Speicher wirken.
Virtueller Speicher, Paging Im Jahre 1961 wurde von Fotheringham ein Prinzip entwickelt, das bis heute eine große Bedeutung hat: Vir-tueller Speicher. Grundidee des virtuellen Speichers ist die, dass die zusammenhängende Größe des Pro-gramms, der Daten und des Stacks die Größe des tatsächlichen physikalischen Hauptspeichers überschreiten darf. Man spricht hier auch von dem virtuellen Adressraum, der mehr Adressen als der physikalische Adress-raum umfasst. Die Verwaltung des virtuellen Speichers übernimmt das Betriebssystem. Es hält die gerade aktiven Teile des Programms im Hauptspeicher und den Rest auf der Harddisk. Dadurch wird es möglich, dass auch ein 1MB-Programm auf einer 256kB-Hardware läuft, wobei dann zu jedem Zeitpunkt nur höchs-tens 256kB des Programms aktiv sein können.
256 kByte reeller Speicher
Das Programm fordert den Wert von Speicherplatz 1111 0000 1111 0000. Diese Adresse verweist auf einen Platz im untersten Bereich eines 256 kB-Speicherblocks.
Lies Adresse 1111 0000 1111 0000
11 1111 1111 1111 1111::::
11 0000 0000 0000 0000 10 1111 1111 1111 1111
:::: 10 0000 0000 0000 0000 01 1111 1111 1111 1111
:::: 01 0000 0000 0000 0000 00 1111 1111 1111 1111
:::: 00 0000 0000 0000 0000

Speicherverwaltung Virtueller Speicher, Paging
31
1 MByte reeller Speicher
Fordert das Programm höhere Adres-sen an, wie zum Beispiel die Adresse 1101 1111 0000 1111 0000, dann ist ein 1 MB-Speicherbereich erforderlich. Dieses Programm kann daher nur auf einem Rechner laufen, der mindestens 1 MB Arbeitsspeicher besitzt.
Virtueller Speicher
Man könnte nun auf den Ausweg kommen, die drei oberen 256-kB-Blöcke auf die Festplatte auszulagern, d.h. das Programm kann diese Adres-sen anfordern, erhält die Werte aber nicht direkt aus dem Arbeitsspeicher, sondern von der Festplatte. Dieses Verfahren würde funktionieren, aller-dings wäre damit die Arbeitsge-schwindigkeit stark herabgesetzt.
Wir können hier aber einen Kompro-miss finden. Bei den meisten Pro-grammen findet der Zugriff auf den Speicher nicht willkürlich im gesamten Adressraum statt, sondern es werden oft relativ nahe beieinanderliegende Speicherzellen gelesen. Es bringt daher eine dramatische Performance-Steigerung, wenn man den gerade be-nötigten 256-kB-Block (Page) von der Festplatte in den Arbeitsspeicher ko-piert. Alle weiteren Leseoperationen auf diesen Bereich laufen dann mit maximaler Geschwindigkeit. Man handelt sich allerdings Verwaltungs-aufwand ein, weil das Betriebssystem stets „wissen“ muss, welcher der virtuellen Speicherblöcke sich gerade im Arbeitsspeicher befindet. Diese Verwaltung wird mit Hilfe der Seitentabelle (Page Table, Memory Map) durchgeführt.
Die Memory-Mapping-Unit (MMU, Speicherverwaltungseinheit) des Betriebssystems hält die Belegung des virtuellen Speichers in der Memory-Map (Seitentabelle) fest. Der im reellen Speicher vorhandene Block hat das Präsentbit „1“.
Die MMU ist auch für die korrekte Umrechnung der virtuellen in die reelle Adresse verantwortlich. Im Beispiel (unten) erkennt die MMU den Zugriff auf die virtuelle Ad-resse 1101 1111 0000 1111 0000, stellt fest, dass dieser Bereich bereits im Arbeitsspei-cher ist, ersetzt die virtuelle 20-Bit-Adresse (1101 1111 0000 1111 0000) durch die reelle 18-Bit-Adresse (01 1111 0000 1111 0000) und führt den Speicherzugriff durch, d.h. liefert den unter dieser Adresse gespeicherten Wert an das Programm zurück. Die-ses merkt von der ganzen Manipulation nichts.
Lies Adresse 11 1111 0000 1111 0000
Lies Adresse 1111 0000 1111 0000
Lies Adresse1101 1111 0000 1111 0000
0011 1111 1111 1111 1111::::
0011 0000 0000 0000 00000010 1111 1111 1111 1111
::::0010 0000 0000 0000 00000001 1111 1111 1111 1111
::::0001 0000 0000 0000 00000000 1111 1111 1111 1111
::::0000 0000 0000 0000 0000
1111 1111 1111 1111 1111::::
1111 0000 0000 0000 00001110 1111 1111 1111 1111
::::1110 0000 0000 0000 00001101 1111 1111 1111 1111
::::1101 0000 0000 0000 00001100 1111 1111 1111 1111
::::1100 0000 0000 0000 00001011 1111 1111 1111 1111
::::1011 0000 0000 0000 00001010 1111 1111 1111 1111
::::1010 0000 0000 0000 00001001 1111 1111 1111 1111
::::1001 0000 0000 0000 00001000 1111 1111 1111 1111
::::1000 0000 0000 0000 00000111 1111 1111 1111 1111
::::0111 0000 0000 0000 00000110 1111 1111 1111 1111
::::0110 0000 0000 0000 00000101 1111 1111 1111 1111
::::0101 0000 0000 0000 00000100 1111 1111 1111 1111
::::0100 0000 0000 0000 0000
Lies Adresse 11 1111 0000 1111 0000
Lies Adresse 1111 0000 1111 0000
Lies Adresse1101 1111 0000 1111 0000
0011 1111 1111 1111 1111::::
0011 0000 0000 0000 00000010 1111 1111 1111 1111
::::0010 0000 0000 0000 00000001 1111 1111 1111 1111
::::0001 0000 0000 0000 00000000 1111 1111 1111 1111
::::0000 0000 0000 0000 0000
1111 1111 1111 1111 1111::::
1111 0000 0000 0000 00001110 1111 1111 1111 1111
::::1110 0000 0000 0000 00001101 1111 1111 1111 1111
::::1101 0000 0000 0000 00001100 1111 1111 1111 1111
::::1100 0000 0000 0000 00001011 1111 1111 1111 1111
::::1011 0000 0000 0000 00001010 1111 1111 1111 1111
::::1010 0000 0000 0000 00001001 1111 1111 1111 1111
::::1001 0000 0000 0000 00001000 1111 1111 1111 1111
::::1000 0000 0000 0000 00000111 1111 1111 1111 1111
::::0111 0000 0000 0000 00000110 1111 1111 1111 1111
::::0110 0000 0000 0000 00000101 1111 1111 1111 1111
::::0101 0000 0000 0000 00000100 1111 1111 1111 1111
::::0100 0000 0000 0000 0000
Memory Map Page Present
Bit
11 1
10 0
01 0
00 0

Speicherverwaltung Virtueller Speicher, Paging
32
Lies Adresse 11 1111 0000 1111 0000
Lies Adresse 1111 0000 1111 0000
Lies Adresse1101 1111 0000 1111 0000
0011 1111 1111 1111 1111::::
0011 0000 0000 0000 00000010 1111 1111 1111 1111
::::0010 0000 0000 0000 00000001 1111 1111 1111 1111
::::0001 0000 0000 0000 00000000 1111 1111 1111 1111
::::0000 0000 0000 0000 0000
1111 1111 1111 1111 1111::::
1111 0000 0000 0000 00001110 1111 1111 1111 1111
::::1110 0000 0000 0000 00001101 1111 1111 1111 1111
::::1101 0000 0000 0000 00001100 1111 1111 1111 1111
::::1100 0000 0000 0000 00001011 1111 1111 1111 1111
::::1011 0000 0000 0000 00001010 1111 1111 1111 1111
::::1010 0000 0000 0000 00001001 1111 1111 1111 1111
::::1001 0000 0000 0000 00001000 1111 1111 1111 1111
::::1000 0000 0000 0000 00000111 1111 1111 1111 1111
::::0111 0000 0000 0000 00000110 1111 1111 1111 1111
::::0110 0000 0000 0000 00000101 1111 1111 1111 1111
::::0101 0000 0000 0000 00000100 1111 1111 1111 1111
::::0100 0000 0000 0000 0000
11 1111 1111 1111 1111::::
11 0000 0000 0000 0000 10 1111 1111 1111 1111
:::: 10 0000 0000 0000 0000 01 1111 1111 1111 1111
:::: 01 0000 0000 0000 0000 00 1111 1111 1111 1111
:::: 00 0000 0000 0000 0000
0011 1111 1111 1111 1111::::
0011 0000 0000 0000 00000010 1111 1111 1111 1111
::::0010 0000 0000 0000 00000001 1111 1111 1111 1111
::::0001 0000 0000 0000 00000000 1111 1111 1111 1111
::::0000 0000 0000 0000 0000
1111 1111 1111 1111 1111::::
1111 0000 0000 0000 00001110 1111 1111 1111 1111
::::1110 0000 0000 0000 00001101 1111 1111 1111 1111
::::1101 0000 0000 0000 00001100 1111 1111 1111 1111
::::1100 0000 0000 0000 0000
1011 1111 1111 1111 1111::::
1011 0000 0000 0000 00001010 1111 1111 1111 1111
::::1010 0000 0000 0000 00001001 1111 1111 1111 1111
::::1001 0000 0000 0000 00001000 1111 1111 1111 1111
::::1000 0000 0000 0000 00000111 1111 1111 1111 1111
::::0111 0000 0000 0000 00000110 1111 1111 1111 1111
::::0110 0000 0000 0000 00000101 1111 1111 1111 1111
::::0101 0000 0000 0000 00000100 1111 1111 1111 1111
::::0100 0000 0000 0000 0000
MMU ersetzt die Adresse:1101 1111 0000 1111 0000durch die Adresse: 01 1111 0000 1111 0000
Seitenfehler, Page Fault
Wenn eine Adresse angefordert ist, die nicht im reellen Speicher präsent ist, tritt der Page Fault auf. Die MMU veranlasst das Betriebssystem die Bearbeitung des Programms anzuhalten, kopiert die angeforderte Page in den Arbeitsspeicher, korrigiert die MemoryMap und lässt den Lesebefehl erneut ausführen. Außer einer kurzen Verzögerung beim Zugriff merkt auch hier das Programm nichts von diesen Aktionen.
44: VirtuellerSpeicher1
Bestimmen Sie die Seitentabelle (Memory-Map) und die Rechenvorschrift zur Adressumrech-nung für 1 MB virtuellen und 64 kB reellen Speicherplatz.
45: PageFault
Zeichnen Sie einen Ablaufplan für den Zugriff auf den virtuellen Speicher für die Fälle:
a) Seite ist im Arbeitsspeicher
b) Seite ist nicht im Arbeitsspeicher.
Seitenrahmen, Page Frames
Meist wird der reelle Speicher nicht im Ganzen verwendet, sondern ist in z.B. vier Teilbereiche (Kacheln) geteilt. Diese vier Seitenrahmen (Kacheln, Page-Frames) können unabhängig voneinander Speicherseiten (Pages) aufnehmen. Die Seitentabelle (Page Table, Memory-Map) muss nun neben dem Präsentbit auch die Kachelnummer (Page-Frame) speichern.

Speicherverwaltung Virtueller Speicher, Paging
33
1111111011011100101110101001100001110110010101000011001000010000
Lies Adresse11011111000011110000
Lies Adresse00001111000011110000
1111 1111 1111 1111
0000 0000 0000 0000
Frame1111
1110
1101
1100
1011
1010
1001
1000
0111
0110
0101
0100
0011
0010
0001
0000
xxxx0100xxxxxxxx11xxxxxxxxxxxx10
0011000010000001
11
10
01
00
Der virtuelle Adressraum ist in Blöcke (Seiten, Pages) unterteilt. Die dazu korrespondierenden Einheiten im physikalischen Adressraum heißen Seiten (Pages). Die Speicherbereiche, die im Arbeitsspeicher die Pages aufnehmen können, heißen Seitenrahmen (Page-Frames). Für jede Seite, die sich im Hauptspeicher befindet, wird in der Seitentabelle (memory map) ein Present-Bit gesetzt, ansonsten ein Absent-Bit.
Die im Beispiel vier 64-kB-Blöcke brauchen nicht zusammenhängend zu sein. Dies ist deshalb vorteilhaft, weil dann das Programm in unterschiedlichen, nicht zusammen-hängenden Speicherbereichen arbeiten kann. Das kommt sehr häufig vor: ein Bereich speichert den Programmcode, ein zweiter die Daten und in einem dritten befindet sich der Stack.
46: VirtuellerSpeicher2
Ergänzen Sie die Graphik oben mit Verbindungslinien zwischen den kor-respondierenden Pages und den Page-Frames.
47: VirtuellerSpeicher3
Geben Sie graphisch die Speicherbelegung an, wenn die Memory Map die Daten im nebenstehenden Beispiel enthält.
48: VirtuellerSpeicher4
Bestimmen Sie die Memory-Map und die Adressumrechnung für 1 MB vir-tuellen Speicher und einen reellen Speicher, der in 8 Page-Frames je 32kB aufgeteilt ist.
Die höchsten Bit, aus denen die Seitennummer ermittelt wird, nennt man auch Selektor. Die Umrechnung dieses Selektors in die obersten Bit der reellen Adresse ist eine eindeutige Funkti-on und wird von der MMU erledigt.
Im Beispiel bilden die obersten vier Bit die Paging-Adressen (Selector). Diese Virtuelle Adresse hat 4 Bit für den Selektor, es können 16 Pages angesprochen werden. Der Offset ist 16 Bit: die Pagegröße beträgt 64 kB. Mit 2 Bit für die logische Framenummer können 4 Page-Frames verwaltet werden. Der Offset muss ebenfalls 16 Bit betragen.
Memory Map Page Page
Frame Pre-sent
1111 xx 0 1110 xx 0 1101 00 1 1100 xx 0 1011 xx 0 1010 xx 0 1001 10 1 1000 xx 0 0111 xx 0 0110 xx 0 0101 xx 0 0100 xx 0 0011 11 1 0010 xx 0 0001 xx 0 0000 01 1
Bit 19 ...... 16 15 ......... ......... 0
Logische Offset Pagenummer Selektor
Virtuelle Adresse
Pysikalische Adresse Bit 17 16 15 ......... ......... 0
Logische Offset Framenummer Selektor

Speicherverwaltung Virtueller Speicher, Paging
34
In der jeweils korrespondierenden Position der Memory-Map wird der entsprechende 2-Bit Adressteil ausge-lesen, die vier durch die zwei Bit ersetzt und der reelle Speicher ausgelesen. Die MMU ersetzt also die Fra-me-Nummer (Selektor-Bits) durch die Page-Frame-Nummer.
49: VirtuellerSpeicher5
Welche Aufgaben hat der Speichermanager?
50: VirtuellerSpeicher6
Für 1 MB virtuellen Speicher sollen 256 kB reeller Speicher mit einer Pagegröße von 4 kB einge-setzt werden. Bestimmen Sie die Anzahl der Pages.
51: VirtuellerSpeicher7
Bestimmen Sie die Blockgröße (Page), die Seitentabelle und die Seitenrahmen (Page-Frames) für die Aufgaben:
a) 16 MB virtueller, 4 MB realer Speicher, 4 Frame-Pages
b) 2 GB virtueller, 256 MB realer Speicher, 16 Frame-Pages
c) 2 GB virtueller, 8 MB realer Speicher, 16 Frame-Pages
52: VirtuellerSpeicher8
Gegeben sei ein reeller Speicher, der in 32 Frame-Pages zu je 8 kB geteilt ist. Wie groß ist der reelle Speicherbereich? Sie groß ist der virtuelle Speicher, wenn 6 Selector-Bits verwendet wer-den?
53: VirtuellerSpeicher9
Wieviele Frame-Pages sind erforderlich, wenn 2 GB virtueller Speicher auf 8 MB realen Speicher bei einer Frame-Page-Größe von 4 kB abgebildet werden? Wieviele Selektor-Bits und wie viele Pages ergeben sich? Machen Sie Angaben über die Seitentabelle!
54: VirtuellerSpeicher10
Sie haben 16-Bit-Adressen für die virtuelle Adressierung, wobei 4 Bit für den Offset genommen werden. Der physikalische Speicher ist mit 8 Bit adressierbar, wobei 4 Bit für den Offset genom-men werden. Die angeforderte virtuelle Adresse ist: 1000 0011 0000 1111. Die Memory-Map verweist für die Page 1000 0011 0000 auf den Page-Frame 0101. Gesucht: a) Größe der jeweili-gen Adressräume und der Pages. b) Physikalische Adresse mit Frame-Nummer und Offset.
55: VirtuellerSpeicher11
Eine virtuelle Adresse mit 32 Bit, 1 kB Pages und 24 Bit physikalische Adresse sind gegeben. Wie groß sind virtueller bzw. reeller Speicher?
Weitere Fragen wie zum Beispiel: Welcher Page-Frame wird bei einem Page-Fault ersetzt, oder wie werden die Speicherbereiche verwaltet wenn mehrere Prozesse gleichzeitig laufen (Multitasking) sind nicht mehr Gegenstand dieses Skripts.

Vernetzte Systeme Virtueller Speicher, Paging
35
Vernetzte Systeme
Bedeutung der Vernetzung für Unternehmen
Ressourcen gemeinsam nutzen • Drucker, Scanner, FAX • Programme, Datenbanken
Kosteneinsparung • Statt Großrechner: Client-Server Modell
Kommunikation • e-mail • Videokonferenz • Online-Diskussion
Skalierbarkeit • Systemleistung entsprechend der Arbeitslast
durch weitere Prozessoren, Clients, Server vergrößern
Work-Sharing • mehrere Personen bzw. Gruppen arbeiten an
verschiedenen Orten, auch „worldwide“
Bedeutung der Vernetzung für Privatpersonen
Zugriff auf entfernte Informationen • Online-Zeitungen und -Bücher
e-commerce • shopping • banking • Auktionen
Leasing statt kaufen • Programme, Anwendungen • Datenbanken, Bilder??
Kommunikation • e-mail • chat • Videokonferenzen • Newsgroups
Interaktive Unterhaltung • Video, Musik „on demand“ • interaktive Filme • Onlinespiele
Einteilung der Netzwerke
Reichweite • Local Area Network (LAN)
o wenige Kilometer innerhalb eines Gebäudes oder Komplexes • Metropolitan Area Network (MAN)
o Stadtnetz, mehrere Bürogebäude, Stadt • Wide Area Network (WAN)
o großer geographischer Bereich, Land, Kontinent
Übertragungstechnik • Broadcast Netz
o für kleine, geographisch enger zusammenliegende Netze o nur ein Übertragungskanal o Analogie: Ausrufen über eine Sprechanlage
• Punkt-zu-Punkt Netze o Verbindung von Maschinen paarweise o für größere, weit ausgedehnt Netze
Topologie • Stern • Ring • Bus

Netzformen, -Topologien und -Komponenten Netztopologien
36
Netzformen, -Topologien und -Komponenten Übertragungsgeschwindigkeit Geschwindigkeit -> pro Zeit z.B. Geschwindigkeit eines Autos: 100km/h kleinste Informationsmenge: 1 Bit (Ja/Nein, wahr/falsch, 1/ Übertragungsgeschwindigkeit = Information / Zeit -> Bit/s Beispiele: ISDN 64 kBit/s (k = 103 ) Ethernet 10 MBit/s (M = 106)
Netztopologien
Bussystem
Die Stationen sind wie Perlen an einer Kette angeordnet. Bei einer busförmigen Verkabelung wird ein zentrales Kabel verwendet, die einzelnen Stationen werden mit T-förmigen Steckern angebunden
Problem: Kollisionen
Vorteile Nachteile relativ einfacher Aufbau und In-betriebnahme
eine Unterbrechung der Leitung führt zum Ausfall des gesamten Netzes
geringe Verzögerungszeiten Unterbrechung der Leitung (bei großen Netzen) nur mit hohem Aufwand zu orten
Netz leicht erweiterbar der Zugang zum Netz muss so gesteuert werden, dass es durch et-waige Kollisionen zu möglichst geringen Zeitverzögerungen kommt
Alle sendenden Stationen müssen die Leitung abhören so lange sie senden. Ist eine Station mit Senden fertig, nimmt sie an, dass das Paket angekommen ist!
56: Ethernet1
Daten für das Ethernet:
Übertragungsgeschwindigkeit: R=10 MBit/s
kleinster Ethernet-Rahmen: l=72 Bytes
Zeitdauer dieses Pakets: t = l*8/R = 57,6 µs
Sendezeit für kleinsten Ethernet-Rahmen: tr = 72 Bytes* 8 Bit/Byte * 0,1 µs /Bit = 57,6 µs
Verkürzungsfaktor (Lichtgeschwindigkeit im Me-dium ist kleiner als im Vakuum):
k = 0,6
Lichtgeschwindigkeit c = 3*108 m/s
Laufzeit im Kabel bei L = 1 km tk = L/(k*c) = 5,5 µs
Das bedeutet, dass die Station bereits etwa 10 % der Daten auf das Kabel geschickt hat, bevor der Empfänger überhaupt erst etwas von der Übertragung bemerkt!

Netzformen, -Topologien und -Komponenten Netztopologien
37
Ringnetz (token -Ring)
Die Stationen sind im Ring angeordnet, jede Station hat dabei genau einen rechten und einen linken Nachbarn. Hier werden die Nachrichten von Station zu Station wei-ter gereicht. Damit hat die Übertragung in einem Ring eine Richtung.
Im Ring kreist ein Token. Nur die Station, die den Token „besitzt“ darf senden. Jede Station muss den Token nach einer festgelegten Zeit weitergeben
An der MAC-Adresse erkennt der Empfänger, ob der Rahmen für ihn ist oder nicht. Ist es „sein“ Rahmen, macht er sich eine Kopie des Paktes, hängt eine Markie-rung an das Ende und sendet diesen Rahmen weiter. Das kann als Empfangsbestätigung vom Sender ausgewertet werden. Der Absender nimmt den Rahmen wieder vom Ring..
Vorteile Nachteile sehr einfache Zugangsor-ganisation
Bei Ausfall einer Station ist der Ring unterbrochen, das Gesamtnetz ar-beitet nicht mehr
problemlose Erweiterung Auch bei geringen Lastsituationen tritt eine Wartezeit auf, weil jede Sta-tion an der Übertragung teilnimmt
geringer Kabelbedarf Fehler sind schnell zu orten alle Arbeitsrechner sind gleichrangig ( und damit leicht ersetzbar)
Sternnetz
Jede Station besitzt eine eigene Verbindung zu einer zentralen Verteilereinheit
Zentrale = z.B. Hub oder Switch. In diesem Fall ist innerhalb der Zentrale ein Bus vorhanden, sodass das Netz in Wirklichkeit ein Busnetz ist.
Vorteile Nachteile Gesamtnetz ist relativ ausfallsicher, bei Ausfall einzelner Übertra-gungsstrecken oder Staionen funk-tioniert der Rest immer noch
bei Ausfall der zentralen Verteilereinheit arbeitet das Netz nicht mehr
System ist leicht erweiterbar hoher Aufwand bei der Verkabelung (Arbeit und Material). Gefahr von Kollisionen ist gering Übertragungsvorgänge zwischen den einzelnen Stationen sind rela-
tiv aufwändig hohe Übertragungsbandbreiten und – geschwindigkeiten möglich

Übertragungsmedien Koaxialkabel
38
Übertragungsmedien
Aufbau einer Übertragungsleitung
Koaxialkabel Störungen werden daran gehindert, auf das Kabel zu kommen.
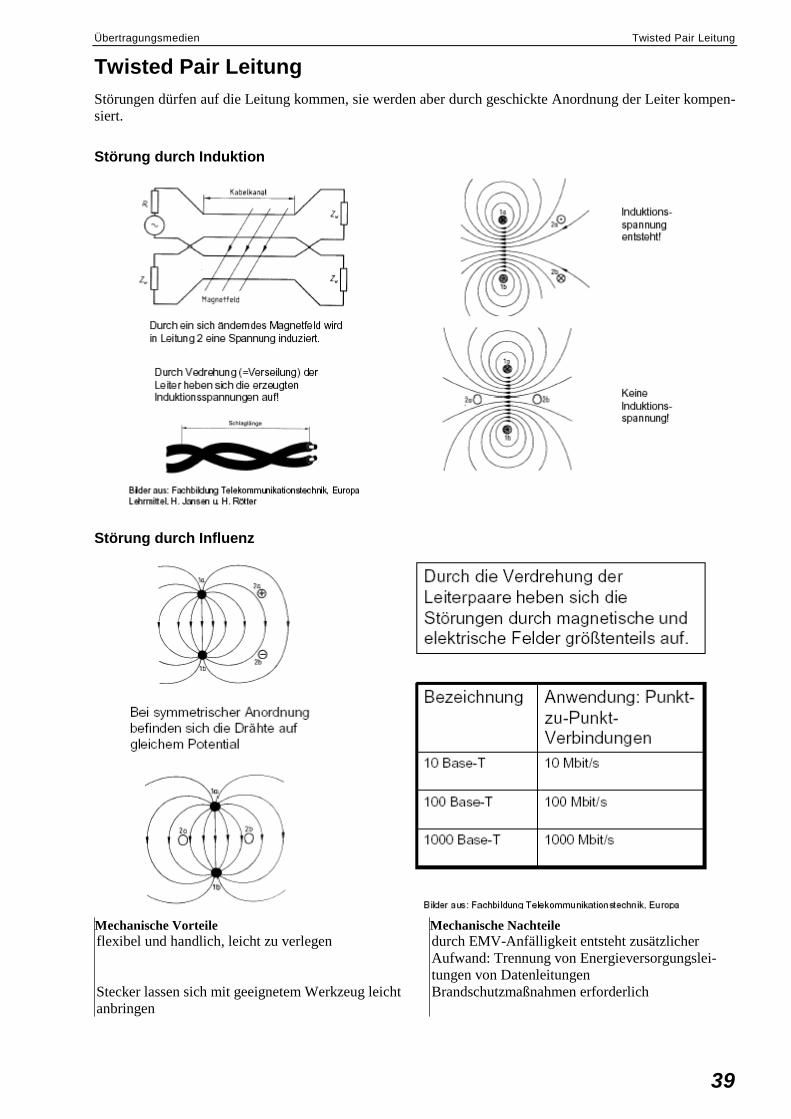
Übertragungsmedien Twisted Pair Leitung
39
Twisted Pair Leitung Störungen dürfen auf die Leitung kommen, sie werden aber durch geschickte Anordnung der Leiter kompen-siert.
Störung durch Induktion
Störung durch Influenz
Mechanische Vorteile Mechanische Nachteile flexibel und handlich, leicht zu verlegen durch EMV-Anfälligkeit entsteht zusätzlicher
Aufwand: Trennung von Energieversorgungslei-tungen von Datenleitungen
Stecker lassen sich mit geeignetem Werkzeug leicht anbringen
Brandschutzmaßnahmen erforderlich

Übertragungsmedien Lichtwellenleiter (LWL)
40
Übertragungstechnische Vorteile Übertragungstechnische Nachteile Prinzipiell sind verschiedene Übertragungsgeschwin-digkeiten möglich, durch Autosensing-Mechanismen kann die geeignete erkannt und gewählt werden.
Übertragungsbandbreite ist begrenzt
Beeinflussung durch elektromagnetische Störun-gen möglich Sehr hohe Übertragungsgeschwin-digkeiten (z.B. 10Gbit/s) sind mit Kupferkabeln nicht mehr zu realisieren.
Wirtschaftliche Vorteile Wirtschaftliche Nachteile Kabel und aktive Komponenten kostengünstig Daten-verkehr und Telefonverkehr können über eine Ver-kabelung geführt werden.
Investitionsschutz für zukünftige Technologien ist nicht gegeben, da aufgrund des physi-kalischen Aufbaus Grenzen bestehen Die Länge der Kabelsegmente ist begrenzt, daher sind zusätzliche aktive Komponenten nötig
57: TwistedPair
Wie kommt es zu Störungen und weshalb kompensieren sie sich? Erläutern Sie das mit Hilfe der Feldlinienbilder.
Lichtwellenleiter (LWL)
Trifft die Strahlung in einem Winkel, der kleiner ist als der Akzeptanzwinkel α auf den Kern auf, so wird das Licht im Kern weitergeleitet, weil am Mantel Totalreflexion auftritt.
Optischer Kern (Core), Träger des Lichtes aus dotiertem Siliziumdioxid, Durchmesser 8 µm bis 70 µm. Optischer Mantel (Cladding), aus hochrei-nem Quarzglas, der das Licht beugt, es auf den Kern begrenzt und einen Durchmesser von 125 µm besitzt.
Weitere Schichten, die nicht dem Transport des Lichtes dienen sondern einen mechanischen Schutz darstellen.
Mechanische Vorteile Mechanische Nachteile Kleine Kabeldurchmesser, platzsparend; geringes Gewicht. Das Anbringen von Steckverbindungen und
das Verbinden von Kabeln (Spleißen) ist aufwendig.
Geringere Gefährdung durch Kabelbrand Relativ große Biegeradien. LWL-Komponenten (besonders LEDs)
unterliegen einem Alterungsprozess. Zum Ausgleich muss eine zusätzliche Leistungs-reserve eingeplant werden.
Übertragungstechnische Vorteile Übertragungstechnische Nachteile Eine große Bandbreite ist möglich. Die Signaldämpfung ist gering, damit werden große Reich-weiten ohne zusätzlich verstärkende Elemente möglich.
Keine Beeinflussung durch elektromagnetische Felder.

Ethernet Lichtwellenleiter (LWL)
41
Dadurch niedrige Fehlerraten und hohe Netzverfügbarkeit erreichbar.
Es ist keine Signalübertragung von der Sendeleitung auf die Empfangleitung möglich.
Wirtschaftliche Vorteile Wirtschaftliche Nachteile Etagenverteiler sind nicht erforderlich, da die maximale Ver-legelänge 2 km beträgt.
Investitionsbedarf für aktive Komponenten ist hoch
Alle aktiven Komponenten befinden sich an zentraler Telefonverkabelung muss separat hergestellt werden
Stelle, das erleichtert das Netzmanagement. LWLs sind sehr zuverlässig, das führt zu niedrigen Betriebskosten durch Minimierung der Netzausfälle.
Aufwändige Bestimmung des Dämpfungs-budgets.
Hohe Investitionssicherheit, da die Glasfaserkabel theore-tische Übertragungsraten ermöglichen, die noch keine LAN-Technologie definiert.
Ethernet Bei den drahtgebundenen Netzwerken hat sich Ethernet als Standard etabliert. In den letzten 30 Jahren hat es sich bis zu einer Übertragungsrate von 10 Gbit/s gesteigert. Ende 1972 implementierte Dr. Robert Metcalfe mit seinen Kollegen am Xerox Palo Alto Research Center (PARC (www.parc.xerox.com) ein Netzwerk, um einige Xerox-Alto-Rechner zu vernetzen - einen zu dieser Zeit revolutionären Vorläufer der Personal Com-puter. Zunächst als Alto Aloha Network bezeichnet, setzte dieses Netzwerk bereits das CSMA/CD-Protokoll des späteren Ethernet ein. Die Übertragungsfrequenz lag jedoch zunächst nur bei 2,94 MHz, dem Systemtakt der Alto-Stations. Erst 1976 nannte Metcalfe das Netzwerk Ethernet.
CSMA/CD (Carrier Sense Multiple Access / Collision Detection)
Das Ethernet-Protokoll basiert auf den Komponenten Multiple Access, Carrier Sense und Collision Detecti-on: Multiple Access (MA): Alle Ethernet-Stationen greifen unabhängig voneinander auf das gemeinsame Übertragungsmedium (shared medium) zu. Carrier Sense (CS): Wenn eine Ethernet-Station senden will, so prüft sie zuerst, ob gerade eine andere Kommunikation läuft. Ist das Medium besetzt, so wartet die Station bis zum Ende der Übertragung und eine zusätzliche Zeitspanne von 9,6 µs. Ist das Medium frei, beginnt die Station sofort zu senden.

Ethernet Lichtwellenleiter (LWL)
42
Collision Detection (CD): Während des Sendens beobach-tet die sendende Station das Medium, um mögliche Kolli-sionen mit anderen Sendestationen zu erkennen. Wenn sie während des Sendevorgangs keine Störung erkennt, die auf eine Kollision mit einem anderen Paket zurückgeführt werden kann, gilt das Paket als erfolgreich versendet. Wenn die Sendestation eine Kollision erkennt:
• bricht sie die Übertragung ab und sendet ein „Jam-ming"-Signal (101010... - AAAAAAAA),
• wartet sie 9,6 µs plus einer zufällig bestimmten Zeit-spanne, die von der Anzahl der bisherigen Fehlversu-che für dieses Paket abhängt (Binary Backoff)
• und unternimmt dann einen erneuten Sendeversuch.
Dieses Verfahren funktioniert aber nur dann zuverlässig, wenn die sendende Station die Kollision entdecken kann, bevor die Übertragung des Pakets abgeschlossen ist. Dabei ist zu berücksichtigen, dass die Ausbreitung von Signalen auf Leitungen mit endlicher Geschwindigkeit geschieht.
Für einen erfolgreichen Einsatz des CSMA/CD-Protokolls muss die doppelte maximale Laufzeit zwischen zwei Stati-onen kürzer sein als die Übertragungsdauer der kürzesten zulässigen Pakete. Ausgehend von der Tatsache, dass die minimale Paketlänge eines Ethernet-Pakets 64 Byte (- 512 Bits) beträgt, muss also sichergestellt sein, dass die maxi-male Signallaufzeit (Round Trip Delay - RTD) 512 „Bit-zeiten" nicht übersteigt. Bei einer Datenrate von 10 Mbps dauert die Übertragung eines Bit 100 ns, so dass das RTD kleiner als 51,2 µs sein muss.
58: CSMA/CD
Wie ist es möglich, dass mehrere Rechner gleichzeitig über das selbe Kabel Daten übertragen?
Wie werden die Pakete „parallel“ übertragen?
Warum gibt es Kollisionen, wie geht man mit ihnen um?
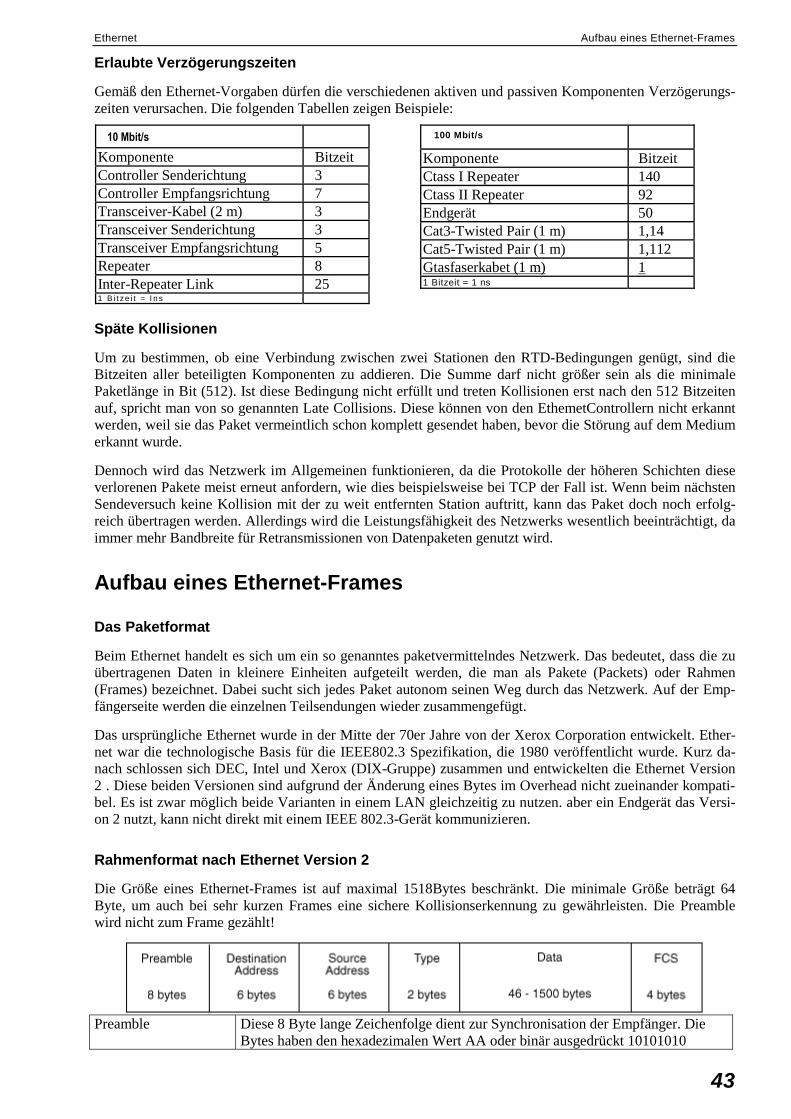
Ethernet Aufbau eines Ethernet-Frames
43
Erlaubte Verzögerungszeiten
Gemäß den Ethernet-Vorgaben dürfen die verschiedenen aktiven und passiven Komponenten Verzögerungs-zeiten verursachen. Die folgenden Tabellen zeigen Beispiele:
10 Mbit/s Komponente Bitzeit Controller Senderichtung 3 Controller Empfangsrichtung 7 Transceiver-Kabel (2 m) 3 Transceiver Senderichtung 3 Transceiver Empfangsrichtung 5 Repeater 8 Inter-Repeater Link 25 1 B i t z e i t = I n s
100 Mbit/s
Komponente Bitzeit Ctass I Repeater 140 Ctass II Repeater 92 Endgerät 50 Cat3-Twisted Pair (1 m) 1,14 Cat5-Twisted Pair (1 m) 1,112 Gtasfaserkabet (1 m) 1 1 Bitzeit = 1 ns
Späte Kollisionen
Um zu bestimmen, ob eine Verbindung zwischen zwei Stationen den RTD-Bedingungen genügt, sind die Bitzeiten aller beteiligten Komponenten zu addieren. Die Summe darf nicht größer sein als die minimale Paketlänge in Bit (512). Ist diese Bedingung nicht erfüllt und treten Kollisionen erst nach den 512 Bitzeiten auf, spricht man von so genannten Late Collisions. Diese können von den EthemetControllern nicht erkannt werden, weil sie das Paket vermeintlich schon komplett gesendet haben, bevor die Störung auf dem Medium erkannt wurde.
Dennoch wird das Netzwerk im Allgemeinen funktionieren, da die Protokolle der höheren Schichten diese verlorenen Pakete meist erneut anfordern, wie dies beispielsweise bei TCP der Fall ist. Wenn beim nächsten Sendeversuch keine Kollision mit der zu weit entfernten Station auftritt, kann das Paket doch noch erfolg-reich übertragen werden. Allerdings wird die Leistungsfähigkeit des Netzwerks wesentlich beeinträchtigt, da immer mehr Bandbreite für Retransmissionen von Datenpaketen genutzt wird.
Aufbau eines Ethernet-Frames
Das Paketformat
Beim Ethernet handelt es sich um ein so genanntes paketvermittelndes Netzwerk. Das bedeutet, dass die zu übertragenen Daten in kleinere Einheiten aufgeteilt werden, die man als Pakete (Packets) oder Rahmen (Frames) bezeichnet. Dabei sucht sich jedes Paket autonom seinen Weg durch das Netzwerk. Auf der Emp-fängerseite werden die einzelnen Teilsendungen wieder zusammengefügt.
Das ursprüngliche Ethernet wurde in der Mitte der 70er Jahre von der Xerox Corporation entwickelt. Ether-net war die technologische Basis für die IEEE802.3 Spezifikation, die 1980 veröffentlicht wurde. Kurz da-nach schlossen sich DEC, Intel und Xerox (DIX-Gruppe) zusammen und entwickelten die Ethernet Version 2 . Diese beiden Versionen sind aufgrund der Änderung eines Bytes im Overhead nicht zueinander kompati-bel. Es ist zwar möglich beide Varianten in einem LAN gleichzeitig zu nutzen. aber ein Endgerät das Versi-on 2 nutzt, kann nicht direkt mit einem IEEE 802.3-Gerät kommunizieren.
Rahmenformat nach Ethernet Version 2
Die Größe eines Ethernet-Frames ist auf maximal 1518Bytes beschränkt. Die minimale Größe beträgt 64 Byte, um auch bei sehr kurzen Frames eine sichere Kollisionserkennung zu gewährleisten. Die Preamble wird nicht zum Frame gezählt!
Preamble Diese 8 Byte lange Zeichenfolge dient zur Synchronisation der Empfänger. Die Bytes haben den hexadezimalen Wert AA oder binär ausgedrückt 10101010
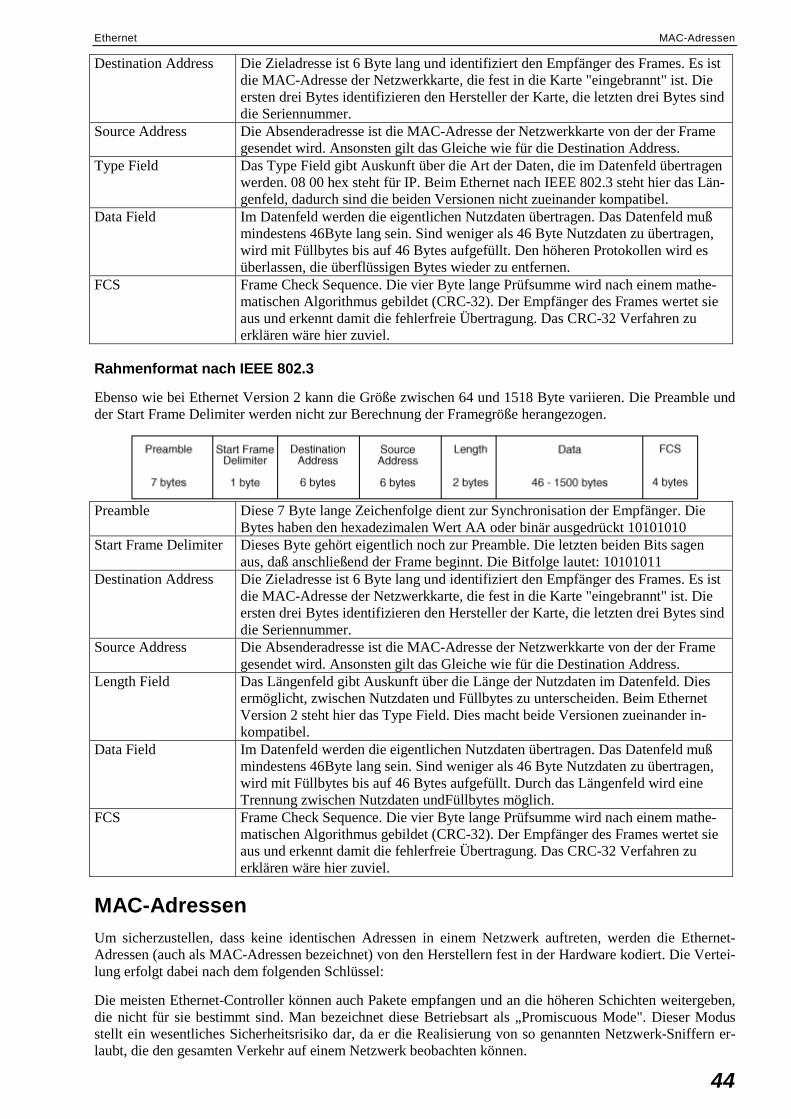
Ethernet MAC-Adressen
44
Destination Address Die Zieladresse ist 6 Byte lang und identifiziert den Empfänger des Frames. Es ist die MAC-Adresse der Netzwerkkarte, die fest in die Karte "eingebrannt" ist. Die ersten drei Bytes identifizieren den Hersteller der Karte, die letzten drei Bytes sind die Seriennummer.
Source Address Die Absenderadresse ist die MAC-Adresse der Netzwerkkarte von der der Frame gesendet wird. Ansonsten gilt das Gleiche wie für die Destination Address.
Type Field Das Type Field gibt Auskunft über die Art der Daten, die im Datenfeld übertragen werden. 08 00 hex steht für IP. Beim Ethernet nach IEEE 802.3 steht hier das Län-genfeld, dadurch sind die beiden Versionen nicht zueinander kompatibel.
Data Field Im Datenfeld werden die eigentlichen Nutzdaten übertragen. Das Datenfeld muß mindestens 46Byte lang sein. Sind weniger als 46 Byte Nutzdaten zu übertragen, wird mit Füllbytes bis auf 46 Bytes aufgefüllt. Den höheren Protokollen wird es überlassen, die überflüssigen Bytes wieder zu entfernen.
FCS Frame Check Sequence. Die vier Byte lange Prüfsumme wird nach einem mathe-matischen Algorithmus gebildet (CRC-32). Der Empfänger des Frames wertet sie aus und erkennt damit die fehlerfreie Übertragung. Das CRC-32 Verfahren zu erklären wäre hier zuviel.
Rahmenformat nach IEEE 802.3
Ebenso wie bei Ethernet Version 2 kann die Größe zwischen 64 und 1518 Byte variieren. Die Preamble und der Start Frame Delimiter werden nicht zur Berechnung der Framegröße herangezogen.
Preamble Diese 7 Byte lange Zeichenfolge dient zur Synchronisation der Empfänger. Die Bytes haben den hexadezimalen Wert AA oder binär ausgedrückt 10101010
Start Frame Delimiter Dieses Byte gehört eigentlich noch zur Preamble. Die letzten beiden Bits sagen aus, daß anschließend der Frame beginnt. Die Bitfolge lautet: 10101011
Destination Address Die Zieladresse ist 6 Byte lang und identifiziert den Empfänger des Frames. Es ist die MAC-Adresse der Netzwerkkarte, die fest in die Karte "eingebrannt" ist. Die ersten drei Bytes identifizieren den Hersteller der Karte, die letzten drei Bytes sind die Seriennummer.
Source Address Die Absenderadresse ist die MAC-Adresse der Netzwerkkarte von der der Frame gesendet wird. Ansonsten gilt das Gleiche wie für die Destination Address.
Length Field Das Längenfeld gibt Auskunft über die Länge der Nutzdaten im Datenfeld. Dies ermöglicht, zwischen Nutzdaten und Füllbytes zu unterscheiden. Beim Ethernet Version 2 steht hier das Type Field. Dies macht beide Versionen zueinander in-kompatibel.
Data Field Im Datenfeld werden die eigentlichen Nutzdaten übertragen. Das Datenfeld muß mindestens 46Byte lang sein. Sind weniger als 46 Byte Nutzdaten zu übertragen, wird mit Füllbytes bis auf 46 Bytes aufgefüllt. Durch das Längenfeld wird eine Trennung zwischen Nutzdaten undFüllbytes möglich.
FCS Frame Check Sequence. Die vier Byte lange Prüfsumme wird nach einem mathe-matischen Algorithmus gebildet (CRC-32). Der Empfänger des Frames wertet sie aus und erkennt damit die fehlerfreie Übertragung. Das CRC-32 Verfahren zu erklären wäre hier zuviel.
MAC-Adressen Um sicherzustellen, dass keine identischen Adressen in einem Netzwerk auftreten, werden die Ethernet-Adressen (auch als MAC-Adressen bezeichnet) von den Herstellern fest in der Hardware kodiert. Die Vertei-lung erfolgt dabei nach dem folgenden Schlüssel:
Die meisten Ethernet-Controller können auch Pakete empfangen und an die höheren Schichten weitergeben, die nicht für sie bestimmt sind. Man bezeichnet diese Betriebsart als „Promiscuous Mode". Dieser Modus stellt ein wesentliches Sicherheitsrisiko dar, da er die Realisierung von so genannten Netzwerk-Sniffern er-laubt, die den gesamten Verkehr auf einem Netzwerk beobachten können.

Ethernet Vom Koax-Bus zum Twisted-Pair-Stern
45
Vom Koax-Bus zum Twisted-Pair-Stern Ursprünglich sah die Ethernet-Spezifikation Koaxialkabel als Übertragungsmedium vor. Je nach Qualität der Kabel werden dabei Thick Coax (IOBase-5) und Thin Coax (1 OBase-2) unterschieden. Letzteres wird auf Grund der geringen Kosten auch als Cheapernet bezeichnet. Bei der Nutzung eines Koaxialkabels sind drei Punkte hervorzuheben:
• Es handelt sich auch in der Implementierung um einen physischen Bus, an den die Stationen ange-hängt werden. Hierzu dienen T-Stücke, die in das Kabel eingesetzt werden, oder so genannte Vampir-stecker.
• Für eine Kollisionserkennung muss die sendende Station den Zustand auf dem Kabel überprüfen. Stimmen die dort vorliegenden Pegel nicht mit den gesendeten Signalen überein, wird dies als Kollisi-on erkannt.
• In diesem Zusammenhang ist auch wichtig, dass die Kabelenden mit angepassten Widerständen abge-schlossen werden, um Reflexionen zu vermeiden, die unter Umständen als Kollisionen erkannt wür-den.
Koaxialkabel weisen jedoch eine Reihe von Nachteilen auf. So müssen etwa für den Einbau weiterer Statio-nen Kabel aufgetrennt werden, wodurch für eine gewisse Zeit keine Übertragung möglich ist. Deshalb wurde der Standard 1990 im Rahmen des 1OBase-T für den Einsatz von Twisted-Pair-Kabeln erweitert.
Twisted-Pair
Die Nutzung von Twisted-Pair-Kabeln stellt in einigen wichtigen Punkten eine Abkehr von den ursprüngli-chen Mechanismen dar:
• In den Koaxialkabeln werden Sendekanal (Transmit-Tx) und Empfangskanal (Receive - Rx) getrennt und jeweils auf einem Leitungspaar übertragen.
• Eine Kollision wird erkannt, wenn während des Sendens auf dem Tx-Leitungspaar Pakete auf dem Rx-Leitungspaar empfangen werden.
• Wenn zwei Teilnehmer unmittelbar miteinander kommunizieren wollen (Point-to-Point-Verbindung), dann muss der Sendekanal der einen Station mit dem Empfangskanal der anderen Station verbunden werden. Dies erfolgt mit einem so genannten gekreuzten Kabel (Crossover-Kabel).
• Wenn mehr als zwei Teilnehmer miteinander kommunizieren wollen, wird ein Hub als zentrale Station benötigt. Dieser gibt die Signale, die er auf dem Rx-Leitungspaar eines Ports empfangen hat, im ein-fachsten Fall an allen anderen Ports auf dem Tx-Leitungspaar wieder aus. Damit kann jede Station, die an diesen Hub angeschlossen ist, die Pakete auf seinem Rx-Kanal empfangen.
• Wichtig dabei ist jedoch, dass der Hub die Pakete nicht auf den Port der sendenden Station zurück-schickt. In diesem Fall würde die sendende Station Aktivität auf dem Empfangskanal detektieren, die dann als Kollision gedeutet würde.
• Allerdings erlaubt diese Trennung der Kanäle auch den Betrieb in einem Vollduplex-Modus, der 1997 in dem ergänzenden Standard 802.3x verabschiedet wurde. Dieser Modus basiert im Wesentlichen darauf, dass es erlaubt ist, sowohl auf dem Sende- als auch auf dem Empfangskanal zu übertragen und die Kollisionserkennung zu deaktivieren.
Der Schritt zu 100 Mbit/s
Mit dem Einsatz von immer leistungsfähigeren PCs stieg der Bedarf nach Bandbreite in den neunziger Jah-ren zusehends. Aus diesem Grund wurde 1995 der auch als Fast Ethernet bezeichnete Standard 100Base-T mit einer Datenrate von 100 Mbit/s verabschiedet. Folgende Aspekte verdienen hier besondere Beachtung:
• Das erlaubte Round Trip Delay ließen die Entwickler mit 512 Bitzeiten unverändert. Da aber wegen der höheren Datenrate eine Bitzeit nur noch 10 ns entspricht, ist dem Zeitbudget eine höhere Aufmerk-samkeit zu widmen. Während ein Signal bei 10 Mbit/s in einer Bitzeit (100 ns) auf dem Kabel etwa acht Meter zurücklegt, so schafft es bei 100 Mbit/s auf einem Cat-5-Kabel in einer Bitzeit (10 ns) we-

Fehlersicherung, Fehlererkennung Längenbegrenzung im Ethernet
46
niger als einen Meter. Ähnlich verschärfen sich auch die Anforderungen an die aktiven Komponenten (siehe „Erlaubte Verzögerungszeiten").
• Koaxialkabel kommen auf Grund ihrer unzureichenden elektrischen Eigenschaften nicht mehr zum Einsatz.
Längenbegrenzung im Ethernet Alle sendenden Stationen müssen die Leitung abhören so lange sie senden. Ist eine Station mit Senden fertig, nimmt sie an, dass das Paket angekommen ist! => Die maximale Ausdehnung eines Ethernet-Segment ist durch die Laufzeit des kleinstmöglichen Ethernet-Rahmens begrenzt.
Daten für das Ethernet:
Übertragungsgeschwindigkeit: 10 MBit/s
kleinster Ethernet-Rahmen: 72 Bytes
maximale Anzahl von Verstärkern: 4
Laufzeit pro Verstärker: 3,5 µs
Verkürzungsfaktor: k = 0,6
Sendezeit für ein Bit ts=1/10 000 000 s = 0,1 µs
Sendezeit für kleinsten Ethernet-Rahmen: tr = 72 Bytes* 8 Bit/Byte * 0,1 µs /Bit = 57,6 µs
Verzögerungszeit durch die Verstärker: tv = 2 * 4 * 3,5 µs = 28 µs
Laufzeit auf dem Kabel (hin und zurück): tk = 57,6 µs - 28 µs = 29,6 µs
Laufzeit auf dem Kabel (in eine Richtung): tl = 29,6 µs / 2 = 14,8 µs
max. Kabellänge: l = v0 * k * tl = 300 000 km/s * 0,6 * 14,8 µs = 2,66 km => Norm für 10 MBit/s: max. Länge 2,5 km; für 100 MBit/s: max. Länge 250 m Dies ist nur gültig sofern Kollisionen auftreten!!
59: Ethernet2
Ein Administrator vergrößert die minimale Paketlänge in seinem ganzen Netz auf 100 Byte.
Wie groß ist nun die maximale Netzausdehnung in seinem 10 MBit/s-Netz? (Restliche Werte entsprechen dem Standard) Es werden nur 2 Verstärker im Netz verwendet.
Wie groß ist nun die maximale Netzausdehnung in einem 10 MBit/s-Netz? (Restliche Werte ent-sprechen dem Standard) Erklären Sie die Folgen für ein Netz mit zu großer Ausdehnung!
Fehlersicherung, Fehlererkennung Um eine korrekte Übertragung der Daten zu Gewährleisten, ist die Fehlersicherung und Erkennung eine wichtige Komponente in der Vernetzung. Sie begegnet uns immer wieder auf allen Schichten im Schichten-modell. Der Begriff Redundanz spielt dabei die zentrale Rolle. Nur hiermit ist Fehlererkennung bzw. Korrek-tur möglich.
Redundanz Zum Übertragen der Zahl 127 sind drei Zeichen erforderlich. Man kann die Zahl aber auch in Worten als „EinhundertSiebenundZwanzig“ übertragen. Es sind nun mehr Zeichen zu übertragen, aber es ergeben sich Vorteile, wenn die Übertragung nicht „sicher“ ist und etwa einige Zeichen verwechselt oder auslässt.. Hier handelt es sich um Redundanz, zuviel an Information, wichtig für die Fehlererkennung und Korrektur.

Fehlersicherung, Fehlererkennung Paritätsbit, Hammingdistanz
47
Paritätsbit, Hammingdistanz Zur Fehlererkennung und -Korrektur wird eine Redundanz, z.B. 1 Bit je Byte verwendet.
Beispiel: Paritätsbit mit gerader Parität: Anzahl der „1“en gerade.
Ist beim Empfänger die Anzahl der „Einsen“ ungerade, dann ist es sicher, dass ein Fehler aufgetreten ist.
Wie viele Fehler werden in einem Wort erkannt?
An wie viel Stellen in einem gesicherten Wort unterscheiden sich 2 unterschiedliche Wörter? Im Beispiel oben sind das zwei Stellen, daher ist die Hammingdistanz h=2. h-1 Fehler sind sicher zu erkennen.
Fehlerkorrektur Ein „magisches Quadrat“ hat besondere Eigenschaf-ten. Daher können fehlende Felder leicht ergänzt werden: Fehlerkorrektur
6 1 8 0110 0001 1000
7 5 3 0111
2 9 4 0100
Ein normales magisches Quadrat der Ordnung n = 4 findet man in dem Kupferstich Melencolia I von Albrecht Dürer
16 3 2 13
5 10 11 8
9 6 7 12
4 15 14 1
Blockparitätssicherung
In diesem Beispiel ist vertikal eine gerade Parität und horizontal eine ungerade Parität vereinbart. Tritt ein Fehler auf, dass kann die Zeile (hier Zeile 3) und die Spalte (hier 3) erkannt und auch korri-giert werden. Ein Fehler wird mit diesem Verfahren sicher korri-giert, zwei Fehler sicher erkannt. Bei mehr Fehlern versagt dieses Verfahren.
Es ist nicht erforderlich, für die Zeilen und Spalten unterschiedliche Parität einzurichten.
Zyklische Redundanzprüfung (CRC) Das CRC-Prüfverfahren*) verallgemeinert die bisher vorgestellten Methoden der Paritätsprüfung; es hat all-gemein Anerkennung gefunden und wird heutzutage in vielen Bereichen für die Fehlererkennung bei der Übertragung von Daten verwendet. Allerdings stellt es hinsichtlich der Darstellung und der mathematischen Theorie etwas höhere Anforderungen, so dass es leider nicht überall dort eingesetzt wird, wo es sinnvoll wäre.
Das Verfahren wird als Zyklisches Redundanz-Prüf-Verfahren oder Polynomprüfverfahren bezeichnet (CRC = Cyclic Redundancy Check). Es erweitert die Paritätsprüfverfahren insofern, als es die Prüfung mehrerer Gruppen von Bits gestattet, soweit dieses für die Fehlererkennung sinnvoll ist.
*) Weitere Informationen können Sie hier erfahren: http://www.iti.fh-flensburg.de/lang/algorithmen/code/crc/crc.htm http://einstein.informatik.uni-oldenburg.de/rechnernetze/crc-verf.htm

Fehlersicherung, Fehlererkennung Zyklische Redundanzprüfung (CRC)
48
Das Prinzip dieses Verfahrens beruht darin, der Nachricht einen weiteren (Zahlen-)Wert (Redundanz) hinzu-addieren, sodass dieser übertragene Wert durch eine bestimmte Zahl (Generator) ganzzahlig teilbar ist. Über-tragungsfehler zerstören diese Teilbarkeit und werden dadurch erkannt.
Beispiel:
Datenwert: 3118, Generator: 15
Der Datenwert selbst ist nicht durch den Generator teilbar, es bleibt ein Rest: 3118 : 15 = 207 Rest 13
allgemein: Z : g = q + Rest oder Z = q ⋅ g + Rest
Es ist nun ein zusätzlicher Summand Rest* zu bestimmen, sodass gilt:
Z* = Z + Rest* und Z* : g = q* (ohne Rest) Rest* = g - Rest = 15 - 13 = 2
Nun muss Z und Rest* in einem Datenwort gemeinsam übertragen werden: 3118|2.
Um aus der übertragenen Nachricht die originale Nachricht Z leicht zu ermitteln, kann man vor der Addition von Rest* die Nachricht Z mit einem Faktor 10k (z.B. 102) multiplizieren. Dadurch wird durch Addition der Prüfsumme die originale Ziffernfolge nicht verändert und sie kann ganz einfach durch Weglassen der letzten beiden Stellen gewonnen werden:
Z* = Z ⋅ 10k + Rest* = 3118 ⋅ 100 + 2 = 311802
Zur Darstellung von Bitfolgen durch Polynome
Als erstes soll ein Verfahren vorgestellt werden, mit dem Nachrichtenblöcke etwas abstrakter dargestellt werden können. Statt wie bisher eine Bitfolge durch eine Folge von Nullen und Einsen zu schreiben, ver-wenden wir die Polynomschreibweise, d.h. die Bifolge: (ci)i=0..n-1 wird durch das Polynom in X:
V(X) = ci · Xi dargestellt, wobei die ci nur 0 oder 1 sind.
Zum Beispiel wird die Bitfolge mit 17 Bits
10001110011001001
als folgendes Polynom geschrieben:
X16 + X12 + X11 + X10 + X7 + X6 + X3 + 1
wobei üblicherweise X0 = 1 und X1 = X geschrieben wird. Es ist eigentlich beliebig, welches Bit der Bitfolge man der 1=X0 bzw. Xr zuordnet. Wir vereinbaren daher, daß das von rechts erste Bit stets der 1 zugeordnet werden soll, wodurch diese Schreibweise direkt in die Darstellung für die Polynomdivision übertragen wer-den kann.
Rechenregeln
Mathematisch handelt es sich bei dieser Schreibweise um den Ring der Polynome in X über dem Körper {0,1}; für die Ele-mente dieses Körpers gelten für Addition und Multiplikation die folgenden Rechenregeln:
Eine Potenz von X nennen wir auch einen Term. Dem Zeichenwert ck wird der Term ck·Xk zugeordnet. Bei
der Schreibung werden Terme mit dem Koeffizient '0' fortgelassen, während Terme mit dem Koeffizienten '1' addiert werden, wobei der Koeffizient nicht ausdrücklich geschrieben wird. Die Zeichenwerte '0' bzw. '1' des Codeworts werden also als Zahlenwerte null bzw. eins interpretiert.
Der Grad der Polynome wird durch die höchste Potenz definiert. Der Grad ist durch die längste Bitfolge be-schränkt und beträgt bei einer Codelänge von n Bits höchstens n-1, im obigen Beispiel offenbar 16.
Addition
⊕
0 1
0 0 1
1 1 0
Multiplikation
• 0 1
0 0 01 0 1

Fehlersicherung, Fehlererkennung Zyklische Redundanzprüfung (CRC)
49
Rechnen mit Polynomen
Addition / Subtraktion
Zur Einübung des Rechnens mit Polynomen sollen hier einige Rechenaufgaben vorgeführt werden. Als ers-tes Beispiel stellen wir die Polynom-Addition vor:
V(X) = X9 ⊕ X7 ⊕ X5 ⊕ X4 ⊕ X3 ⊕ 1 W(X) = X8 ⊕ X7 ⊕ X6 ⊕ X4 ⊕ X2 ⊕ X V(X) ⊕ W(X) = X9 ⊕ X8 ⊕ X6 ⊕ X5 ⊕ X3 ⊕ X2 ⊕ X ⊕ 1
Bei der Addition ist zu beachten, dass Xk ⊕ Xk = 0 ist, da nach den Rechenregeln für den Körper {0,1} gilt: 1 ⊕ 1 = 0. Aus diesem Grunde liefert die Subtraktion zweier Polynome jeweils das gleiche Ergebnis wie die Addition.
Die Addition zweier gleicher Polynome ergibt 0:
V(X) ⊕ V(X) = 0
Multiplikation / Division
Für Polynome kann sowohl eine Multiplikation als auch eine Division eingeführt werden. Es gelten die übli-chen distributiven, assoziativen und kommutativen Gesetze, so dass das Produkt zweier Polynome einfach ausmultipliziert werden kann. Es gilt für die beiden folgenden Polynome
V1(X) = X3 ⊕ X ⊕ 1 V2(X) = X3 ⊕ X V1(X) * V2(X) = X6 ⊕ X3 ⊕ X2 ⊕ 1
Die Division zweier Polynome wird im Prinzip als die umgekehrte Operation der Multiplikation defi-niert. Das Verfahren ist analog der üblichen manuellen Division, d.h. der Divisor wird vom dem Dividenden abgezogen und das restliche Polynom weiter dividiert, bis es kein Vielfaches des Divisors mehr gibt. Letzte-res wird als Rest der Division bezeichnet und wird uns im folgenden besonders interessieren. Insbesondere sind auch Verfahren zu entwickeln, den Rest möglichst effizient und automatisch bei der Übertragung von Nachrichtenblöcken zu ermitteln. Zunächst betrachten wir jedoch auch hier ein Beispiel. Es sollen die beiden folgenden Polynome dividiert werden
V1(X) = X3 ⊕ X ⊕ 1
V2(X) = X ⊕ 1 Man kann sich die Polynome so hinschreiben, als wären es ganze Zahlen; dazu wird der Divisor derart mit einem passenden Term Xk erweitert, daß der Grad von Divisor und Dividend übereinstimmen.
X3 ⊕ 0 ⊕ X ⊕ 1 / X ⊕ 1 = X2 ⊕ X Rest 1 X3 ⊕ X2 --------- X2 ⊕ X ⊕ 1 X2 ⊕ X --------------- 1 { = Rest}
Das Ergebnis wird üblicherweise in der folgenden Form als Produkt aufgeschrieben:
V1(X) = (X2 ⊕ X) * V2(X) ⊕ 1
Man beachte bei der obigen Division, dass zwei Polynome gleichen Grads stets voneinander subtrahiert wer-den können und dann ein Polynom geringeren Grads ergeben. Bei der Division mit ganzen Zahlen müssen gegebenenfalls Zahlenüberläufe berücksichtigt werden, was bei der Polynomdivision jedoch nicht der Fall ist. Diese Beobachtung vereinfacht die später noch zu beschreibende Implementation der Polynomdivision mittels Schieberegistern sehr.
Schreibt man statt der Polynomterme nur die Koeffizienten, also die Entsprechung als Binärzahlen 1011 für V1 und 11 für V2 so erhält man:

Fehlersicherung, Fehlererkennung Zyklische Redundanzprüfung (CRC)
50
1 0 1 1 / 1 1 = 1 1 0 Rest 1
1 1
----------
1 1 1
1 1
---------------
1 { = Rest}
Algorithmus CRC
Eingabe:
Nachricht der Länge n (entsprechend einem Polynom p vom Grad n-1), Generatorpolynom g vom Grad k < n
Ausgabe:
Codewort der Länge n (entsprechend einem Polynom h vom Grad n+k-1)
Methode:
1.Multipliziere p mit xk (k Nullen an die Nachricht anhängen):
f = p·xk.
2.Teile das Ergebnis f durch das Generatorpolynom g und bilde den Rest r:
f = q·g ⊕r mit grad(r) < grad(g) = k.
3.Addiere r zu f:
h = f ⊕r = q·g ⊕r ⊕r = q·g.
Das Ergebnis h entspricht dem gesuchten Codewort; h ist durch g teilbar.
Durch die Addition von r in Schritt 3 findet nur innerhalb der letzten k Stellen eine Veränderung statt, da grad(r) < k ist. Das Codewort besteht also aus der ursprünglichen Nachricht mit angehängten k Prüf-bits. Damit ist die Dekodierung eines Codewortes sehr einfach: Durch Weglassen der Prüfbits ergibt sich wieder die Nachricht.
Die Fehlererkennung wird durchgeführt, indem das dem empfangenen Wort entsprechende Polynom durch das Generatorpolynom geteilt wird. Ist der Rest ungleich Null, so ist ein Fehler aufgetreten.
Beispiel:
Gegeben sei das Generatorpolynom g = x5 ⊕x2 ⊕x ⊕1, entsprechend dem Wort 1 0 0 1 1 1, sowie die Nachricht 1 0 0 1 0 1 1 1 0 0 1 1 1 0 1.
1. Schritt:
Multipliziere das Polynom p, das der Nachricht entspricht, mit x5 (5 Nullen an die Nachricht anhän-gen) und erhält f
2. Schritt:
Teile das f durch das Generatorpolynom g und bilde den Rest r. Das Ergebnis q sieser Divisio ist im Folgenden uninteressant und braucht daher gar nicht aufgeschrieben zu werden.
1 0 0 1 0 1 1 1 0 0 1 1 1 0 1 0 0 0 0 0 1 0 0 1 1 1 0 0 0 0 1 0 1 1 0 0 1 0 0 1 1 1 0 0 1 0 1 1 1 1 1 0 0 1 1 1 0 0 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0 1 1 0 0 1 0 0 1 1 1 0 0 1 0 1 1 0 0 1 0 0 1 1 1 0 0 1 0 1 1 0

Fehlersicherung, Fehlererkennung Zyklische Redundanzprüfung (CRC)
51
Das Wort 10110 entspricht dem Rest r.
3. Schritt:
Addiere r zu f und erhalte h.
Das Ergebnis h entspricht dem gesuchten Codewort 10010111001110110110 bestehend aus der Nachricht 100101110011101 und den angehängten Prüfbits 10110.
Implementierung der Polynomdivision in Hardware
Der Kodierer bzw. Dekodierer muss offenbar eine Polynom-Division durchführen. Da heutige Hardware dann besonders günstig ist, wenn sie in großen Stückzahlen hergestellt wird, sollten Sender und Empfänger – so weit möglich – die gleiche Hardware verwenden. Außerdem sollte die Kodierung bzw. Dekodierung so schnell sein, dass sie die Übertragung nicht wesentlich behindert. Die heute übliche Realisierung geschieht durch ein Schieberegister (nach Peterson und Brown, 1961), welches auf der Sende- und Empfangsseite gleich aufgebaut ist. Es genügt daher den oben genannten Ansprüchen. Darüber hinaus ist natürlich stets auch eine Softwarelösung möglich.
Die Polynomdivision lässt sich, nach dem im obigen Beispiel verwendeten normalen Divisionsverfahren, überraschend einfach in Hardware realisieren.
Im Bild dargestellt ist ein Schieberegister, in das von rechts das zu dividierende Polynom h hineingeschoben wird. Wenn eine 1 in der vordersten Schieberegisterzelle erscheint, wird das Generatorpolynom (im Bild das Polynom 100111) mit dieser 1 multipliziert (Und-Gatter) und an der entsprechenden Position von dem zu dividierenden Polynom h subtrahiert (Xor-Gatter). Der verbleibende Rest zusammen mit der nächstfolgen-den Stelle von h wird anschließend um eine Position nach links geschoben. Wenn in der vordersten Schiebe-registerzelle eine 0 erscheint, wird das 0-fache des Generatorpolynoms subtrahiert, d.h. es geschieht nichts, außer dass der Schieberegisterinhalt geschoben wird.
Es ist leicht zu sehen, dass durch diese Hardware genau das o.a. Divisionsverfahren realisiert wird. Wenn das zu dividierende Polynom h zu Ende ist, d.h. keine Stellen mehr in das Schieberegister eingegeben werden, steht im Schieberegister der Divisionsrest.
Man sieht an dieser Beschreibung, dass die Berechnung der Prüfinformation so schnell wie die bitweise Ü-bertragung der Information durchgeführt werden kann, falls die Schieberegister so schnell schalten können wie Bits übertragen werden. Daher ist dieses eine geeignete Methode zur Fehlerüberprüfung bei der Daten-übertragung, weshalb diese Hardware fast überall eingesetzt wird.
Die Schaltung kann sowohl zur Codierung als auch zur Fehlererkennung verwendet werden. Zur Fehlerer-kennung wird durch eine Oder-Schaltung überprüft, ob der Divisionsrest gleich Null oder ungleich Null ist. Zur Codierung wird der Divisionsrest an die Nachricht angehängt. Vor Beginn einer Division muss das Schieberegister gelöscht werden.
Die Schaltung kann vereinfacht werden, wenn das Generatorpolynom festliegt. Dann können alle Und-Gatter mit einer 1 am Eingang durch eine einfache Drahtverbindung ersetzt werden. Alle Und-Gatter mit einer 0 am Eingang liefern am Ausgang konstant 0 und können daher wegfallen; die entsprechenden Xor-Gatter mit dieser 0 am Eingang können durch Drahtverbindungen ersetzt werden. Das vorderste Xor-Gatter kann eben-falls entfallen, da sein Ausgang nicht verwendet wird (er ist im übrigen immer 0). Es entsteht die vereinfach-te Schaltung, ein Linear Feed-Back Shift Register (LFSR), für das Generatorpolynom 1 0 0 1 1 1.

Fehlersicherung, Fehlererkennung Zyklische Redundanzprüfung (CRC)
52
Erkennung von Fehlern
Einzelfehler
Bei Auftreten eines Fehlers werden in dem gesendeten Wort ein oder mehrere Bits invertiert. Wird das Wort als Polynom aufgefasst, entspricht das Invertieren eines Bits der Addition eines Fehlerpolynoms, das eine 1 an dieser Position hat.
Beispiel:
Durch Addition des Fehlerpolynoms 1 0 1 0 0 werden zwei Bits verfälscht.
1 0 1 1 0 0 0 1 1 0 0 0 1 + 1 0 1 0 0 1 0 1 1 0 0 0 1 0 0 1 0 1
Das gesendete Polynom h ist durch das Generatorpolynom g teilbar. Somit ist das empfangene Polynom h' = h⊕e genau dann durch das Generatorpolynom teilbar, wenn das Fehlerpolynom e durch das Generator-polynom teilbar ist. Wenn also das Fehlerpolynom ungleich Null ist und durch das Generatorpolynom teilbar ist, wird der Fehler nicht erkannt. Umgekehrt wird der Fehler erkannt, wenn das Fehlerpolynom nicht durch das Generatorpolynom teilbar ist.
Satz:
Ist x⊕1 Teiler des Generatorpolynoms g, so wird jede ungerade Anzahl von Fehlern erkannt.
Beweis:
Eine ungerade Anzahl von Fehlern entspricht einem Fehlerpolynom e mit einer ungeraden Anzahl von Ein-sen. Polynome mit einer ungeraden Anzahl von Einsen sind nicht durch x⊕1 teilbar. Dies kann man sich leicht anhand des Divisionsverfahrens klarmachen. Damit ist e nicht durch x⊕1 teilbar, also erst recht nicht durch g, d.h. der Fehler wird erkannt.
Mehrfachfehler
Eine wichtige Eigenschaft des CRC-Verfahrens ist die Fähigkeit, Mehrfachfehler zu erkennen, bei denen die verfälschten Bits innerhalb eines begrenzten Bereiches auftreten.
Def.:
Ein Fehlerbündel der Länge b ist ein Fehler, bei dem die Position des ersten und des letzten falschen Bits den Abstand b-1 haben. Das einem Fehlerbündel der Länge b entsprechende Fehlerpolynom lässt sich schreiben als
e = xi · e1 mit grad(e1) = b-1
Beispiel:
Nachricht: h = 1 1 0 1 0 0 1 0 1 0 1 0
Fehlerbündel der Länge 5: e = 1 0 0 1 1 0 0 0
verfälschte Nachricht: h ⊕e = 1 1 0 1 1 0 1 1 0 0 1 0
Es ist e = x7 ⊕x4 ⊕ x3 = x3 · (x4 ⊕ x ⊕ 1) = x3 · e1
Satz:
Jedes Fehlerbündel der Länge b ≤ grad(g) wird erkannt.
Beweis:
Es liege ein Fehlerbündel der Länge b ≤ grad(g) vor.

Das ISO-OSI-7-Schichtenmodell Zyklische Redundanzprüfung (CRC)
53
Das entsprechende Fehlerpolynom sei e = xi · e1 mit grad(e1) = b-1
Angenommen, der Fehler werde nicht erkannt. Dann teilt das Generatorpolynom g das Fehlerpolynom e, d.h. es gilt
g | e ⇒ g | xi · e1 ⇒ g | e1,
da x nicht Teiler von g ⇒ grad(g) ≤ grad(e1) = b-1,
im Widerspruch dazu, dass b ≤ grad(g) ist.
Eigenschaften einiger Generatorpolynome
In der Praxis werden meist Polynome des Grads 16 oder 32 verwendet:
CRC-16 (Magnetband) X16⊕X15⊕X2⊕1 CRC-CCITT (Disketten) X16⊕X12⊕X5⊕1 CRC-32 (Ethernet) X32⊕X26⊕X23⊕X22⊕X16⊕X12⊕X11⊕X10⊕X8⊕X7⊕X5⊕X4⊕X2⊕X⊕1
Das erste Polynom CRC–16 wird häufig eingesetzt und ist daher sehr wichtig. Es hat im Wesentlichen die gleichen Eigenschaften wie das Generatorpolynom CRC–CCITT.
Während die ersten beiden Generator-Polynome, die jeweils eine gerade Anzahl von Termen besitzen, mit Sicherheit alle ungeraden Bitfehler erkennen, hat das dritte eine ungerade Anzahl von Termen und kann so-mit nicht alle ungeraden Bitfehler erkennen (beispielsweise die Bitfolge der Generatorpolynoms: 100000100110000010001110110110111).
Die Wahrscheinlichkeit, einen Fehler nicht zu entdecken, hängt auch von den verwendeten Daten ab, sowie von der Fehlercharakteristik des verwendeten Kanals. Empirische Untersuchungen für gute Fehlercodes be-nötigen normalerweise sehr große Stichproben. In einem Beispiel wurden bei 157.000 Blöcken der Länge 2048 Bits beim CRC-32 keine unentdeckten Fehler beobachtet. Eine Berechnung der Wahrscheinlichkeit für unentdeckte Fehler ergab, dass diese kleiner als 10-14 ist.
Das ISO-OSI-7-Schichtenmodell
Aufgaben der Schichten:
Anwendungsschicht: Anwendungen (z.B. Web-Server) Präsentationsschicht: Datendarstellung (z.B. bei unterschiedlichem Zeichensatz) Sitzungsschicht: aufbauen/managen/beenden von Sitzungen (sessions) zwischen Rechnern Transportschicht: Paketierung, Dienstekennung Netzwerkschicht: Adressierung weltweit, Wegefindung (Routing) weltweit Verbindungsschicht: Adressierung im Kleinen (physikalische Adresse), Medienzugriff

Das ISO-OSI-7-Schichtenmodell Ein- und Auspacken von Paketen
54
Bitübertragung: Physikalische Eigenschaften (Abmessungen der Stecker, elektrische Eigenschaften, Wie sieht das Signal für eine 1 bzw. 0 aus?)
Schichtenmodell und Paketaufbau
Hier wird wieder die Wichtigkeit des Schichtenmodell deutlich: Im Aufbau der Datenpakete ist die Schich-tung leicht nachzuvollziehen. Der Vergleich zwischen dem OSI-Modell und dem TCP/IP-Modell soll den Schülern den (theoretischen) Standard OSI und den (praktischen) Standard TCP/IP gegenüberstellen. An dieser Stelle sollte man noch weitere Protokoll-Stacks erwähnen (z.B. ISDN, Novell, ...), welche sich alle auf das OSI-Modell abbilden lassen.
Ein- und Auspacken von Paketen
In jeder Schicht wird ein Header vor die Daten geschrieben. Der Header der höheren Schicht und deren Hea-der bilden die Daten der darunterliegenden Schicht. In der Schicht 2 wird ein Link-Trailer angehängt. Er ist für die fehlerfreie Datenübertragung zuständig und ist meist eine CRC-Fehlererkennung. Nachteile des OSI-Modells: Das viele ein- und auspacken kostet Zeit und Ressourcen.
Das OSI-Modell und TCP/IP im Vergleich Layer Aufgabe Beim TCP/IP-Modell werden nur vier
Schichten unterschieden
7 Application
6 Presentation
5 Session
hier keine weiteren Erläuterung HTTP = Hypertext Transfer Protocol FTP = File Transfer Protocol
Verarbeitung
z.B. HTTP, FTP, ...
4 Transport TCP = Transmission Control Protocol UDP = User Datagram Protocol
Transport TCP, UDP
3 Network Wegewahl, Vermittlung IP = Internet Protocol ICMP = Internet Control Message Protocol
Internet IP, ICMP
2 Data Link
1 Physical
Zusammenfassung der Bits in Blöcke (Bytes, Frames), Flußsteuerung, Reihenfol-gesicherung, Fehlererkennung und Fehler-korrektur in Blöcken, mechanische Charak-teristika (z.B. Pin-Belegung, etc.), elektri-sche, elektromagnetische, akustische, opti-sche Charakteristika, Übertragungsart (z.B. analog/digital, synchron/asynchron, Modu-lation etc.)
Netzwerk
Ethernet, Token Ring

Physical, Data Link (Layer 1 + 2) Das OSI-Modell und TCP/IP im Vergleich
55
Physical, Data Link (Layer 1 + 2)
ARP - Adress Resolution Protocol
Jede Ethernet-Karte besitzt eine eindeutige Hardware-Adresse, auch als MAC-Adresse bezeichnet.
Jeder Host im Netz hat sich aber nun auch noch eine IP-Adresse zugeordnet und damit hat das Ethernet ein Problem: Mit der IP-Adresse 192.168.23.1 weiß es nichts anzufangen, mit der MAC-Adresse 08:00:00:04:72:98 allerdings schon. Ein Übersetzer muss her: Dass Adress Resoultion Protocol ARP über-setzt die IP-Adressen in Ethernet-Adressen. So gesehen gehört es eigentlich auch nicht vollständig in den Link Layer, sondern ist irgendwo zwischen Link und Network Layer einzuordnen.
Möchte nun eine Station die Hardware-Adresse des Hosts 192.168.20.11 heraus bekommen, schickt sie einen ARP-Request* ins Kabel: ``Wer hat hier IP 192.168.20.11?''. Der betreffende Host antwortet: ``Zu IP 192.168.20.11 gehört MAC-Adresse 08:00:a2:12:4d:aa''. Damit weiß der sendende Rechner, wohin er sein Ethernet-Paket zu schicken hat.
Das Ergebnis wird für eine festgelegte Zeit im ARP-Cache zwischengespeichert.
60: OSI
Auf welcher Schicht im OSI-Modell ist Ethernet angesiedelt?
Repeater (Hub)
Signalregenerierung => Physical Layer
Geräte, welche über einen Repeater verbunden sind, befinden sich logisch in einem Bus-Netz. Es treten immer noch Kollisionen auf => Collision Domain (Bereich von Kollisionen)
Multiport Repeater = Repeater mit mehreren Anschlüssen (Ports) (umgangssprachlich: Hub)
• Es kann immer nur ein Datenpaket nach dem anderen den Hub passieren
• Geschwindigkeit 10 oder 10/100 Mbps bei Dual Speed Hubs
• Hubs wissen nicht, an welchem Port welche Station angeschlossen ist, sie können es auch nicht ler-nen. Hubs müssen nicht konfiguriert werden.
• preisgünstiger als Switches
Bridge, Switch
Trennung von Netzen aufgrund von physikalischen Adressen => Data Link Layer
Eine Bridge/Switch trennt Collision Domains. MAC-Broadcasts (ff-ff-ff-ff-ff-ff) werden jedoch weitergeleitet => Broadcast Do-main.
Eine Bridge trennt zwei Ethernet-LANs physikalisch, Störungen wie z. B. Kollisionen und fehlerhafte Pakete gelangen nicht über die Bridge hinaus. Die Bridge ist protokolltransparent, d. h. sie überträgt alle auf dem Ethernet laufenden Protokolle. Die beiden beteiligten Netze erscheinen also für eine Station wie ein einziges Netz. Durch den Einsatz einer Bridge können die Längenbeschränkungen des Ethernets überwunden werden.
* Die Beschreibung dieser Vorgänge ist festgelegt in den RFC = Request For Comments = "Internet-Normen" Address Resolution Protocol (ARP, RFC 826)

Network (Layer 3) Das OSI-Modell und TCP/IP im Vergleich
56
Die Bridge arbeitet mit derselben Übertragungsrate, wie die beteiligten Netze. Die Anzahl der hintereinan-dergeschalteten Bridges ist auf 7 begrenzt (IEEE 802.1). Normalerweise wird man aber nicht mehr als vier Bridges hintereinanderschalten.
Der Switch ist wie die Bridge ein Gerät des OSI-Layers 2, d. h. er kann LANs mit verschiedenen physikali-schen Eigenschaften verbinden, z. B. Koax- und Twisted-Pair-Netzwerke. Allerdings müssen, ebenso wie bei der Bridge, alle Protokolle höherer Ebenen 3 bis 7 identisch sein!. Ein Switch ist somit protokolltransparent. Er wird oft auch als Multi-Port-Bridge bezeichnet, da dieser ähnliche Eigenschaften wie eine Bridge auf-weist. Jeder Port eines Switch bildet ein eigenes Netzsegment. Jedem dieser Segmente steht die gesamte Netzwerk-Bandbreite zu Verfügung. Dadurch erhöht ein Switch nicht nur - wie die Bridge - die Netzwerk-Performance im Gesamtnetz, sondern auch in jedem einzelnen Segment. Der Switch untersucht jedes durch-laufende Paket auf die MAC-Adresse des Zielsegmentes und kann es direkt dorthin weiterleiten. Der große Vorteil eines Switches liegt nun in der Fähigkeit seine Ports direkt miteinander verschalten zu können, d. h. dedizierte Verbindungen aufzubauen.
• Mehrere Datenpakete können den Switch gleichzeitig passieren
• Die Gesamtbandbreite (der Datendurchsatz) ist wesentlich höher als bei einem Hub
• Switches lernen nach und nach, welche Stationen mit welchen Ports verbunden sind, somit werden bei weiteren Datenübertragungen keine anderen Ports unnötig belastet, sondern nur der Port, an dem die Zielstation angeschlossen ist
• Geschwindigkeiten sind heute 10, 10/100 oder 1000 MBit/s (Gigabit Ethernet)
• Switches müssen nicht konfiguriert werden
Network (Layer 3) Die Aufgabe der Netzwerkschicht ist die Wegefindung (Routing). Hier sollte wieder auf das OSI-Schichtenmodell eingegangen werden. Exemplarisch wird dies mit Hilfe des Internet Protocols (IP) vermit-telt. Mit der Schicht 3 wird der Lokale Bereich (LAN) verlassen und eine Verbindung mit der ganzen Welt hergestellt.
Wichtig ist der Unterschied zwischen der physikalischen Adresse der Schicht 2 (MAC-Adresse) und der Adresse der Schicht 3. Die Adressen der Schicht 3 sind „geographisch“ strukturiert. Am Besten lässt sich dies mit einer Telefonnummer zeigen: +49 711 812345: Durch die weltweit genormte Länderkennung 49 wird der Telefonvermittlung angezeigt, dass der Kommunikationspartner sich in Deutschland befindet. Die weiteren Ziffern 711 spezifiziert dies genauer auf ein Telefon in Stuttgart.
Auch IP-Adressen sind in ähnlicher Weise strukturiert. Es gibt u.a. reservierte Adressbereiche für Amerika, Europa mit Afrika und dem Mittleren Osten und dem pazifischen Raum.
IP-Adresse
Eine IP-Adresse ist eine 32-Bit Dualzahl
z. B.: 192.168.57.1 => 1100 0000.1010 1000.0011 1001.0000 0001 1 Class-A-Netz Adressbereich 10.0.0.0 bis 10.255.255.255
16 Class-B-Netze Adressbereich 172.16.0.0 bis 172.31.255.255
256 Class-C-Netze Adressbereich 192.168.0.0 bis 192.168.255.255

Network (Layer 3) Das OSI-Modell und TCP/IP im Vergleich
57
Router
Trennung von Netzen aufgrund von logischen Adressen => Network Layer
Ein Router trennt Broadcast Domains und kann unterschiedliche Schicht 2 Protokolle verbinden (z.B. Ethernet mit Token-Ring).
Große Netzwerke wie das Internet bestehen aus vielen kleineren Teilnetzwerken. Die Verbindung der verschiedenen Netze wird durch spezielle Rechner hergestellt. Das sind, neben Bridges, Swit-ches und Gateways, im Internet vor allem Router. Diese haben die Aufgabe, Daten zwischen Rechnern in verschiedenen Netzen auf möglichst günstigen Wegen weiterzuleiten. Zum Beispiel wenn Rechner 1 im Netz B Daten an Rechner 2 im Netz C schicken möchte.
Router verbinden, im Gegensatz zu Bridges, in OSI-Schicht 3 auch Netze unterschiedli-cher Topologien. Sie sind Dreh- und Angel-punkt in strukturiert aufgebauten LAN- und WAN-Netzen.
Mit der Fähigkeit, unterschiedliche Netztypen sowie unterschiedliche Protokolle zu routen, ist eine optimale Verkehrslenkung und Netz-auslastung möglich. Routing wird erst dann erforderlich, wenn Kommunikation zwischen Stationen in unterschiedlichen Subnetzen erfolgen soll. Sie sind nicht protokolltranspa-rent, sondern müssen in der Lage sein, alle verwendeten Protokolle zu erkennen, da sie Informationsblöcke protokollspezifisch umsetzen.
Bevor ein Router ein Paket mit einer bestimmten IP-Adresse weiterleiten kann, muß er für diese Adresse zunächst den Weg durch das Netz zum Zielrechner bestimmen. Das geschieht mit Hilfe spezieller Protokolle wie ARP, RIP, OSPF, EGP/BGP. Er arbeitet also nicht wie die Bridge oder der Switch mit den Adressen der MAC-Ebene. Dieses hat den Vorteil, das ein Host nicht die MAC-Adresse des Empfängers wissen muß, um diesem eine Nachricht zu übermitteln. Die Adresse der Netzwerk-Protokollebene, z. B. IP genügt. Dieses Weiterleiten von Daten anhand einer Tabelle heißt Routen. In der Routingtabelle ist aber nicht der gesamte Weg zu einem Rechner mit einer bestimmten IP-Adresse gespeichert. Vielmehr kennt der einzelne Router nur die nächste Zwischenstation (engl. next hop) auf dem Weg zum Ziel. Das kann ein weiterer Router oder der Zielrechner sein.
Der Router besteht, wie ein Computer auch, aus CPU und Speicher. Dazu kommen mehrere Netz-werkadaptern, die eine Verbindung zu jenen Netzen herstellen, die mit dem Router verbundenen sind. Die Adapter sind meist über einen Systembus mit der CPU des Routers verbunden. Die CPU wiederum hält im Hauptspeicher des Rechners die Routingta-belle vor.

Network (Layer 3) Das OSI-Modell und TCP/IP im Vergleich
58
Router 1
Empfänger im Netzwerk Zustellung über 192.168.0.0 direkt 192.168.1.0 direkt 192.168.2.0 192.168.1.2 Router 2
Empfänger im Netzwerk Zustellung über 192.168.0.0 192.168.1.1
192.168.1.0 direkt 192.168.2.0 direkt
Aufgrund der IP-Empfängeradresse im IP-Header leitet jeder Router mit Hilfe seine Routing-Tabelle das Paket an den nächsten Router weiter. Das Paket „hüpft“ so von Router zu Router (hop by hop) bis es am Ziel angekommen ist.
Netzmaske
Mit Hilfe der Netzmaske erkennt der Rechner ob das Ziel im selben Netz liegt.
Die verschiedenen Netzmasken lassen sich in verschiedene Klassen unterteilen: Class-A-Netz haben die Netmask 255.0.0.0, Class-B-Netze die Netmask 255.255.0.0 und Class-C-Netze die Netmask 255.255.255.0. Netze mit anderen Netmasks bezeichnet man als Subnetze.
Beispiel 1
eigener Rechner: 192.168.57.1 Netzmaske: 255.255.240.0 = /20
Es wird mit ping 192.168.52.4 ein fremder Rechner angesprochen. Kann dieser Rechner erreicht werden?
eigene IP: 192.168.57.1 => 1100 0000.1010 1000.0011 1001.0000 0001 Netzmaske: 255.255.240.0 => 1111 1111.1111 1111.1111 0000.0000 0000 (UND) Netzadresse192.168.48.0 <= 1100 0000.1010 1000.0011 0000.0000 0000 fremde IP: 192.168.52.4 => 1100 0000.1010 1000.0011 0100.0000 0100 Netzmaske: 255.255.240.0 => 1111 1111.1111 1111.1111 0000.0000 0000 (UND) Netzadresse192.168.48.0 <= 1100 0000.1010 1000.0011 0000.0000 0000
=> die Netzadressen stimmen überein, d.h. der Rechner kann direkt über ARP erreicht werden!
Liegt das Ziel nicht im eigenen Netz, wird das Paket an den Default-Gateway geschickt.
Beispiel 2
Im ersten Beispiel verwenden wir als Netmask 255.255.0.0, d.h. die ersten 16 Bit der Adresse sind dem Netzteil vorbehalten, hier 141.89, die restlichen 16 Bit werden zur Adressierung des Hosts in diesem Netz verwendet, dazu bleiben 254*254, also gut 64.516 Möglichkeiten - praktisch können also über 64.000 Hosts in diesem Netz adressiert werden. Die Adresse 141.89.0.0 ist für das Netzwerk selbst reserviert, die Adresse 141.89.255.255 bezeichnet die sogenannte Broadcast-Adresse: Pakete an diese Adresse werden an alle Stati-onen im Netz verschickt.
Beispiel 3
Doch fahren wir mit unseren Beispielen fort. Unser Beispiel Nummer zwei beschreibt den Host 58.17.131.43 mit der Netmask 255.255.255.0. Hier sind also 24 Bit für den Netz- und 8 Bit für den Hostanteil reserviert. Theoretisch kann es in diesem Netz maximal 254 Hosts geben. Adresse für dieses Netzwerk ist 58.17.131.0, Broadcasts gehen an 58.17.131.0.
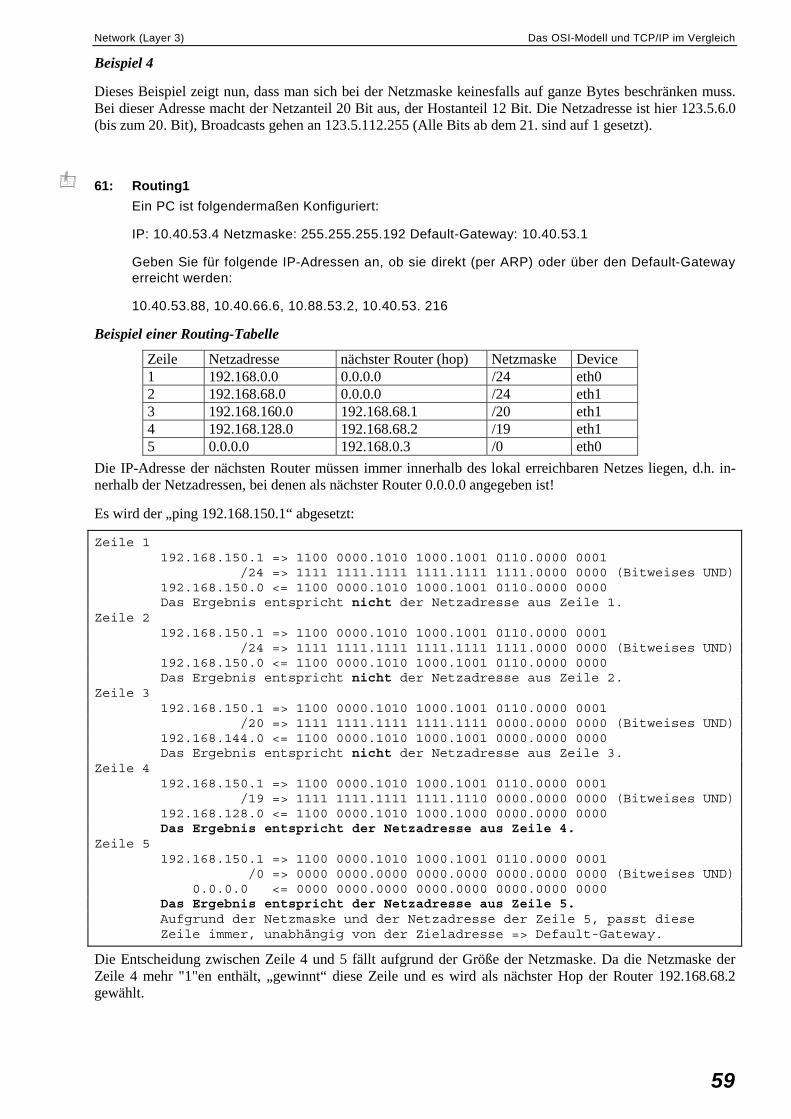
Network (Layer 3) Das OSI-Modell und TCP/IP im Vergleich
59
Beispiel 4
Dieses Beispiel zeigt nun, dass man sich bei der Netzmaske keinesfalls auf ganze Bytes beschränken muss. Bei dieser Adresse macht der Netzanteil 20 Bit aus, der Hostanteil 12 Bit. Die Netzadresse ist hier 123.5.6.0 (bis zum 20. Bit), Broadcasts gehen an 123.5.112.255 (Alle Bits ab dem 21. sind auf 1 gesetzt).
61: Routing1
Ein PC ist folgendermaßen Konfiguriert:
IP: 10.40.53.4 Netzmaske: 255.255.255.192 Default-Gateway: 10.40.53.1
Geben Sie für folgende IP-Adressen an, ob sie direkt (per ARP) oder über den Default-Gateway erreicht werden:
10.40.53.88, 10.40.66.6, 10.88.53.2, 10.40.53. 216
Beispiel einer Routing-Tabelle
Zeile Netzadresse nächster Router (hop) Netzmaske Device 1 192.168.0.0 0.0.0.0 /24 eth0 2 192.168.68.0 0.0.0.0 /24 eth1 3 192.168.160.0 192.168.68.1 /20 eth1 4 192.168.128.0 192.168.68.2 /19 eth1 5 0.0.0.0 192.168.0.3 /0 eth0
Die IP-Adresse der nächsten Router müssen immer innerhalb des lokal erreichbaren Netzes liegen, d.h. in-nerhalb der Netzadressen, bei denen als nächster Router 0.0.0.0 angegeben ist!
Es wird der „ping 192.168.150.1“ abgesetzt:
Zeile 1 192.168.150.1 => 1100 0000.1010 1000.1001 0110.0000 0001 /24 => 1111 1111.1111 1111.1111 1111.0000 0000 (Bitweises UND) 192.168.150.0 <= 1100 0000.1010 1000.1001 0110.0000 0000 Das Ergebnis entspricht nicht der Netzadresse aus Zeile 1. Zeile 2 192.168.150.1 => 1100 0000.1010 1000.1001 0110.0000 0001 /24 => 1111 1111.1111 1111.1111 1111.0000 0000 (Bitweises UND) 192.168.150.0 <= 1100 0000.1010 1000.1001 0110.0000 0000 Das Ergebnis entspricht nicht der Netzadresse aus Zeile 2. Zeile 3 192.168.150.1 => 1100 0000.1010 1000.1001 0110.0000 0001 /20 => 1111 1111.1111 1111.1111 0000.0000 0000 (Bitweises UND) 192.168.144.0 <= 1100 0000.1010 1000.1001 0000.0000 0000 Das Ergebnis entspricht nicht der Netzadresse aus Zeile 3. Zeile 4 192.168.150.1 => 1100 0000.1010 1000.1001 0110.0000 0001 /19 => 1111 1111.1111 1111.1110 0000.0000 0000 (Bitweises UND) 192.168.128.0 <= 1100 0000.1010 1000.1000 0000.0000 0000 Das Ergebnis entspricht der Netzadresse aus Zeile 4. Zeile 5 192.168.150.1 => 1100 0000.1010 1000.1001 0110.0000 0001 /0 => 0000 0000.0000 0000.0000 0000.0000 0000 (Bitweises UND) 0.0.0.0 <= 0000 0000.0000 0000.0000 0000.0000 0000 Das Ergebnis entspricht der Netzadresse aus Zeile 5. Aufgrund der Netzmaske und der Netzadresse der Zeile 5, passt diese Zeile immer, unabhängig von der Zieladresse => Default-Gateway.
Die Entscheidung zwischen Zeile 4 und 5 fällt aufgrund der Größe der Netzmaske. Da die Netzmaske der Zeile 4 mehr "1"en enthält, „gewinnt“ diese Zeile und es wird als nächster Hop der Router 192.168.68.2 gewählt.

Network (Layer 3) Planung eines Intranets (Subnetting)
60
62: Routing2
Ermitteln Sie für folgende IP-Adressen den nächsten Router:
192.168.68.7, 192.168.155.9, 192.168.175.20.
63: Routing3
IP 139.131.1.147 / 255.255.255.0
In welchem Netzwerk ist der Host? (139.131.1.0)
Wie lautet die Host-ID? (147)
Planung eines Intranets (Subnetting)
Beispiel 1
Max Subnetter ist Verwalter eines verteilten Netzwerkes. Es gibt vier Niederlassungen und es sollen bis zu 100 Rechner in jedem Teilnetz möglich sein. Unser Max braucht also 5 Teilnetze: eines für die Übertragung und je eines für jedes Teilnetz. Max könnte nun von der InterNIC (die Organisation, welche für die Vertei-lung der Nummern zuständig ist) 5 eindeutige Nummern einholen. Das wird ihm aber zu teuer. Deshalb lässt er sich eine (!) Nummer zuweisen und teilt diese in 5 Teilnetze auf. Wie hat er das gemacht? Hier eine kleine Schrittfolge:
Ermittlung, wie viel Stellen für die Darstellung von 100 (max. Anzahl der Rechner je Teilnetz, s.o.) notwen-dig sind. 100 dezimal = 1100100binär - folglich sind 7 Stellen nötig!
Wie viel Stellen sind für die Darstellung von 5 ( = Anzahl der Teilnetze ) nötig?
Antwort: 5 dezimal = 101binär - Also 3 Stellen!
Addieren der benötigten Stellen: 7 + 3 = 10
Das übersteigt die Breite eines Oktetts. Es ist also eine Adresse der Klasse B erforderlich!
Hintergrund dieser Überlegungen ist folgendes: Max leiht sich einen Teil von der Host-ID, den er für die Identifizierung der Teilnetze benötigt. Für unser Beispiel sind das drei Bits. Die Länge der Host-ID verrin-gert sich dadurch. Wenn aber je Teilnetz 100 Rechner vorgesehen sind, muss der Rest mindestens 7 Bit lang sein. Und das ist nur bei einem Klasse B-Netz der Fall.
Also beantragt Max fein säuberlich und mit x-fachem Durchschlag eine entsprechende Adresse. Er erhält z.B. die folgende Adresse: 148.120.0.0 (unterstrichen = Netz-ID), Netzmaske: 255.255.0.0
Die eben genannten 4 Schritte führen zu einer eigenen Subnet-Mask, welche sich von den Standard-Subnet-Masks in den besagten 3 Bits unterscheidet. Die Subnet-Mask für Maxens Netzwerk hat die folgende Gestalt (unterstrichen = Subnetz-Bits):
1111 1111.1111 1111.1110 0000.0000 0000binär - 255.255.224.0 dezimal
Max hat sich drei Bit von der Host-ID geliehen. Dadurch sind bis zu 6 Teilnetze möglich. Ich führe sie bes-ser noch einmal komplett auf:
1001 0100.1111 000.0000 0000.0000 0000binär - 148.120. 0.0 dezimal (ungültig da = 0) 1001 0100.1111 000.0010 0000.0000 0000binär - 148.120. 32.0 dezimal 1001 0100.1111 000.0100 0000.0000 0000binär - 148.120. 64.0 dezimal 1001 0100.1111 000.0110 0000.0000 0000binär - 148.120. 96.0 dezimal 1001 0100.1111 000.1000 0000.0000 0000binär - 148.120.128.0 dezimal 1001 0100.1111 000.1010 0000.0000 0000binär - 148.120.160.0 dezimal 1001 0100.1111 000.1100 0000.0000 0000binär - 148.120.192.0 dezimal 1001 0100.1111 000.1110 0000.0000 0000binär - 148.120.224.0 dezimal (ungültig da = 1)
Jetzt gilt es noch die Host-ID's und deren Bereiche zu bestimmen:

Network (Layer 3) Planung eines Intranets (Subnetting)
61
x.y. 32.1 - x.y. 63.254 - x.y.0010 0000.0000 0001 - x.y.0011 1111.1111 1110 x.y. 64.1 - x.y. 95.254 - x.y.0100 0000.0000 0001 - x.y.0101 1111.1111 1110 x.y. 96.1 - x.y.127.254 - x.y.0110 0000.0000 0001 - x.y.0111 1111.1111 1110 x.y.128.1 - x.y.159.254 - x.y.1000 0000.0000 0001 - x.y.1001 1111.1111 1110 x.y.160.1 - x.y.191.254 - x.y.1010 0000.0000 0001 - x.y.1011 1111.1111 1110 x.y.192.1 - x.y.223.254 - x.y.1100 0000.0000 0001 - x.y.1101 1111.1111 1110
Für Max ist jetzt alles klar. Er kann sich von den 6 Subnet-ID's seine 5 aussuchen und hat noch eines im Ärmel. Zu allem kommt noch hinzu, das unser Max nicht nur 100 sondern 8190 Rechner je Teilnetz adres-sieren kann. Wer es nicht glaubt wandelt einfach die Dualzahl 1 1111.1111 1110 in eine Dezimalzahl um!
Nun heißt es Ärmel hochkrempeln und jedem Rechner seine IP-Adresse zuweisen.
Beispiel 2
Uns wird der Adressbereich 192.169.80.0/23 zugewiesen. Wir sollen darin 6 Subnetze mit je maximal 50 Hosts aufbauen.
Die zugewiesene Netzmaske von 23 Bit erlaubt uns die Anzahl der möglichen IP-Adressen: 232-23= 512
Gesamtnetz: (192.168.80.0/23)
Netzadr.: 192.168. 80.0 = 1100 0000.1010 1000.0101 0000.0000 0000 Netzmaske: 255.255.254.0 = 1111 1111.1111 1111.1111 1110.0000 0000
Zur Dekodierung der Subnetze und Hosts verbleiben uns 32-23 = 9 Bit. Die Kodierung von 6 Subnetzen erfordert 3 Bit, da 23
= 8 etwas größer als 6. Die neue Netzmaske wird damit: 23+3 => /26. Gefordert sind 50 Hosts. Dafür sind 6 Bit erforderlich, da 26
= 64 etwas größer als 50 ist. Wir benötigen also für die geforderten Subnetze und Hosts: 3 Bit + 6 Bit = 9 Bit, und diese Anzahl haben wir zur Verfügung, also ist die Aufgabe lösbar.
192.168.80.0 = 1100 0000.1010 1000.0101 0000.0000 0000
Durch die zugewiesenen IP-Adressbereich sind 23 Bit fest. Die nächsten drei Bit bezeichnen die Subnetze und die letzten sechs Bit die Hosts. Im Bereich der 3 Bit der Subnetze werden die Dualzahlen 000 bis 111 eingesetzt und man erhält so die Subnetzadressen.
Subnetze:
Netzmaske: 255.255.255.192 = 1111 1111.1111 1111.1111 1111.1100 0000 Netz1: 192.168. 80.0 /26 = 1100 0000.1010 1000.0101 0000.0000 0000 Netz2: 192.168. 80.64 /26 = 1100 0000.1010 1000.0101 0000.0100 0000 Netz3: 192.168. 80.128/26 = 1100 0000.1010 1000.0101 0000.1000 0000 Netz4: 192.168. 80.192/26 = 1100 0000.1010 1000.0101 0000.1100 0000 Netz5: 192.168. 81.0 /26 = 1100 0000.1010 1000.0101 0001.0000 0000 Netz6: 192.168. 81.64 /26 = 1100 0000.1010 1000.0101 0001.0100 0000 Netz7: 192.168. 81.128/26 = 1100 0000.1010 1000.0101 0001.1100 0000 Netz8: 192.168. 81.192/26 = 1100 0000.1010 1000.0101 0001.1100 0000
Beispiel:
Host-Adressen für Subnetz 4 (192.168.80.192/26): 192.168.80.193 .. 192.168.80.254 (26 -2= 62 Host-Adressen). Die Adresse 192.168.80.255 ist als IP-Broadcast-Adresse reserviert (Host-Bereich alles auf 1).
64: Subnet 1
Planen Sie ein Intranet mit 2 Subnetzen und je maximal 150 Host-Rechnern. Später sollen evtl. weitere Subnetze hinzukommen. Ihr ISP (Internet Service Provider) stellt Ihnen folgenden Be-reich zur Verfügung: 11.10.160.0/22.
65: Subnet 2
Bilden Sie in 194.246.249.0 sechs Subnetze. Geben Sie die Subnetmask, alle Netzadressen und jeweils den ersten und den letzten Rechner an.

Network (Layer 3) Planung eines Intranets (Subnetting)
62
Lösung:
Für 6 Subnetze braucht man 3 Bit. Die Netmask lautet dann: 255.255.255.224 Die Netzadressen lauten: 194.246.249. 000 nicht erlaubt ! 001 = .32
010 = .64
011 = .96
100 = .128
101 = .160
110 = .192
111 nicht erlaubt ! De Bereich der Rechneradressen lautet jeweils: Netz 1. Rechner letzter Rechner
194.246.249.32 194.246.249.33 194.246.249.62
.64 .65 .94
.96 .97 .126
.128 .129 .158
.160 .161 .190
.192 .193 .222
66: Subnet 3
Die Netzwerkadresse lautet 199.120.197.144 Seine Netzmaske ist die 255.255.255.240. Wie vie-le IP-Adressen gibt es in diesem Netz? Wie viele COMPUTER können mit Adressen versehen werden? (Lösung)
67: Subnet 4
Geben Sie die binäre IP-Adresse 01101101.10000000.11111111.11111110 in Dezimalform an!
68: Subnet 5
Ihre IP-Adresse ist 165.247.200.100 und Ihr Internet-Netzwerk ist in 16 Subnetze unterteilt. Welche Subnet-Maske würden Sie benutzen, um die größtmögliche Anzahl Hosts in jedem Sub-netz unterzubringen? 255.255.224.0 255.255.240.0 255.255.248.0 255.255.252.0 255.255.254.0
69: Subnet 6
Ihre IP-Adresse ist 134.130.88.24 und Ihre Subnet-Maske ist 255.255.224.0. Welche Hosts be-finden sich in Ihrem lokalen Netzwerk? 134.130.95.9 134.130.96.18 134.130.67.53 134.130.72.132 134.130.66.66 134.130.98.24
(Lösung)
IP-Adressen in diesem Netz: 255.255.255.255 - 255.255.255.240 = 0.0.0.15. Also haben Sie 16 Adressen: von 199.120.197.144 bis 199.120.197.159
Anzahl Computer in diesem Netz: 14. Wir können keinem Computer die 199.120.197.144 geben, das ist die Netzwerk Adresse. Wir können keinem Computer die 199.120.197.159 geben, das ist die Broadcast Adresse.
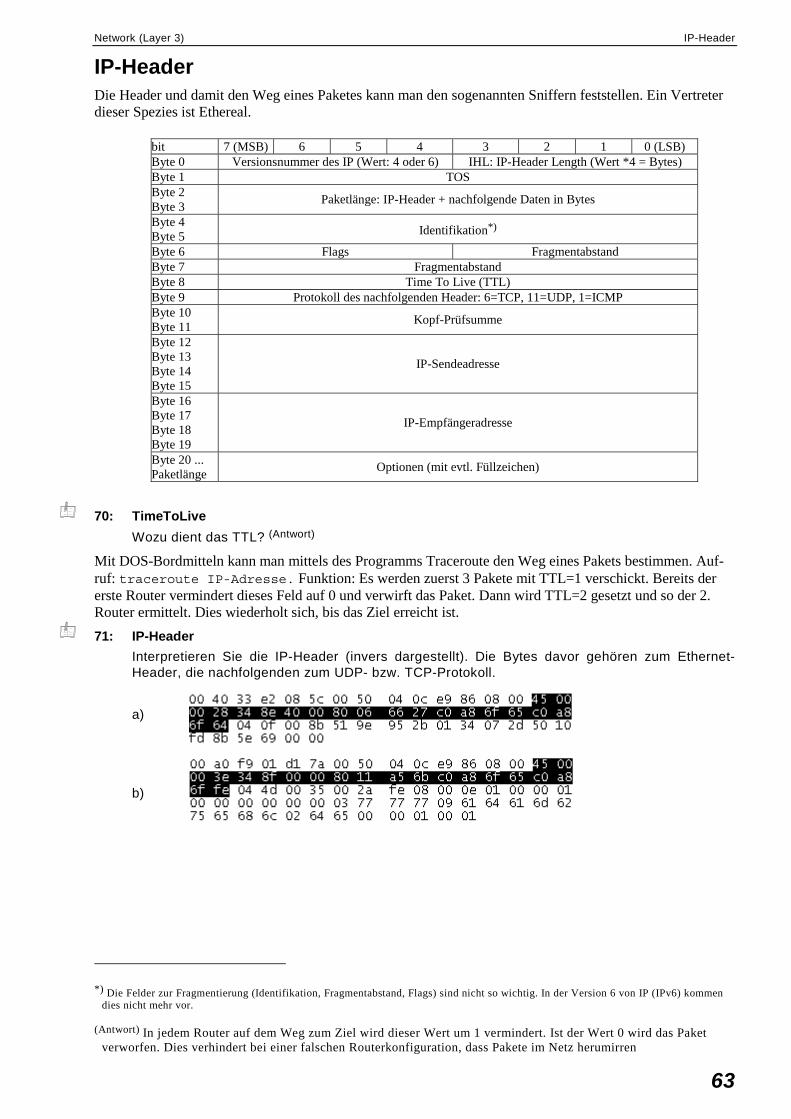
Network (Layer 3) IP-Header
63
IP-Header Die Header und damit den Weg eines Paketes kann man den sogenannten Sniffern feststellen. Ein Vertreter dieser Spezies ist Ethereal.
bit 7 (MSB) 6 5 4 3 2 1 0 (LSB) Byte 0 Versionsnummer des IP (Wert: 4 oder 6) IHL: IP-Header Length (Wert *4 = Bytes) Byte 1 TOS Byte 2 Byte 3
Paketlänge: IP-Header + nachfolgende Daten in Bytes
Byte 4 Byte 5 Identifikation*)
Byte 6 Flags Fragmentabstand Byte 7 Fragmentabstand Byte 8 Time To Live (TTL) Byte 9 Protokoll des nachfolgenden Header: 6=TCP, 11=UDP, 1=ICMP Byte 10 Byte 11
Kopf-Prüfsumme
Byte 12 Byte 13 Byte 14 Byte 15
IP-Sendeadresse
Byte 16 Byte 17 Byte 18 Byte 19
IP-Empfängeradresse
Byte 20 ... Paketlänge
Optionen (mit evtl. Füllzeichen)
70: TimeToLive
Wozu dient das TTL? (Antwort)
Mit DOS-Bordmitteln kann man mittels des Programms Traceroute den Weg eines Pakets bestimmen. Auf-ruf: traceroute IP-Adresse. Funktion: Es werden zuerst 3 Pakete mit TTL=1 verschickt. Bereits der erste Router vermindert dieses Feld auf 0 und verwirft das Paket. Dann wird TTL=2 gesetzt und so der 2. Router ermittelt. Dies wiederholt sich, bis das Ziel erreicht ist.
71: IP-Header
Interpretieren Sie die IP-Header (invers dargestellt). Die Bytes davor gehören zum Ethernet-Header, die nachfolgenden zum UDP- bzw. TCP-Protokoll.
a)
b)
*) Die Felder zur Fragmentierung (Identifikation, Fragmentabstand, Flags) sind nicht so wichtig. In der Version 6 von IP (IPv6) kommen dies nicht mehr vor.
(Antwort) In jedem Router auf dem Weg zum Ziel wird dieser Wert um 1 vermindert. Ist der Wert 0 wird das Paket verworfen. Dies verhindert bei einer falschen Routerkonfiguration, dass Pakete im Netz herumirren

Application, Presentation, Session, Transport (Layer 4 - 7) Transport Layer
64
Application, Presentation, Session, Transport (Layer 4 - 7)
Transport Layer Mit Hilfe der Netzwerkschicht wird jedes Endsystem weltweit eindeutig erreicht. Die Transportschicht ist zuständig für die Zuordnung der Dienste. Auf einem Endsystem können z.B. mehrere Dienste angeboten werden. In einem Rechner könnte dies heißen, dass darauf ein Web-Server, ein FTP-Server und ein Mail-Server installiert ist. Unter ISDN kann unter einer Telefonnummer ein Sprachdienst, ein Datendienst oder ein FAX-Dienst verlangt werden.
Port, Socket
Mit Hilfe des Ports (16 Bit-Zahl) im TCP-Header kann ein Rechner feststellen, welcher Dienst gewünscht wird. Viele Ports sind re-serviert, nicht reservierte Ports können „frei“ benutzt werden.
Beispiele:
Port 21 -> FTP Port 25 -> SMTP (Email versenden) Port 80 -> http Port 139 -> Net-BIOS
An die IP-Adresse wird nach einem Doppelpunkt die Portnummer angehängt. Das nennt man das Socket (z.B. 192.169.2.3:80). Aus der Kombination von Absender-Socket und Empfänger-Socket ergibt sich die weltweit eindeutige Verbindungskennung von Dienst zu Dienst. Im Beispiel muss der Client bei seiner An-frage an den Webserver die (Standard-)Portnummer (80 für den http-Dienst) verwenden. Er selbst vergibt eine (im Prinzip beliebige) Portnummer, zum Beispiel 1030. Damit richtet der Client ein Socket ein. Für ein zweites Browserfenster richtet der Client mittels einer anderen Portnummer ein zweites Socket ein. Auf-grund der Absenderport-Angabe des Browsers, wird die Web-Seite an das richtige Browserfenster geschickt. Der Absenderport wird also beim Verbindungsaufbau vom Client frei gewählt.
TCP-Header
Bit 7 (MSB) 6 5 4 3 2 1 0 (LSB) Byte 0 Byte 1
Source Port
Byte 2 Byte 3
Destination Port
Byte 4 Byte 5 Byte 6 Byte 7
Sequenznummer
Byte 8 Byte 9 Byte 10 Byte 11
Quittungsfeld (Piggyback, Acknowledgement Number)
Byte 12 Header-Länge reserviert Byte 13 reserviert URG ACK PSH RST SYN FIN Byte 14 Byte 15
Fenster Größe
Byte 16 Byte 17
Prüfsumme

Application, Presentation, Session, Transport (Layer 4 - 7) Transport Layer
65
Byte 18 Byte 19
Urgent Zeiger
Byte 20 ... Optionen (evtl. mit Füllzeichen)
Source Port: Bezeichnet die Anwendung, die dieses Datagramm verschickt hat. Destination Port: Bezeichnet die Anwendung, für die dieses Datagramm bestimmt ist. Sequenz-Nummer: Die Nummer des ersten Oktetts von Benutzerdaten in diesem Segment. Quittungsfeld: Wenn das ACK-Feld (Flaggen) gesetzt ist, die Nummer des Segments, welches der
Empfänger als nächstes erwartet. Flaggen: Kontrollbits für spezielle Funktionen
URG: Urgent Data (Urgent-Zeiger wird verwendet) ACK: Acknowledge (Quittungsnummer wird verwendet) PSH: Push, Daten sofort an Anwendungsprogramm weitergeben. RST: Reset, Verbindung sofort unterbrechen. SYN: Synchronize, Wunsch zum Verbindungsaufbau. FIN: Finish, Wunsch zum regulären Abbau der Verbindung.
Fenster Größe: Anzahl der Oktette, welches der Empfänger bereit ist zu Empfangen. Angefangen bei dem Oktett, welches im Quittungsfeld angegeben ist.
Prüfsumme: 1er Komplement der Prüfsumme. Die Prüfsumme wird jedoch aus Sicherheitsgründen nicht nur aus dem UDP-Header sondern auch aus Teilen des IP-Headers gebildet. Es er-gibt sich dabei ein Pseudo-Header der noch zusätzlich die IP-Sender und Empfängerad-resse und das Protokollfeld des IP-Headers beinhaltet.
Urgent-Zeiger: Dieser Offset wird auf den Wert von Sequenznummer aufaddiert und zeigt so den Ort der dringenden Daten an.
Optionen: Evtl. eine Sammlung von mehreren Optionen (mit Füllzeichen, um auf die 32-Bit Gren-ze zu kommen).
Segmentierung
Weiterhin ist der Transport-Layer für die Segmentierung zuständig. Größere Datenmengen werden in kleine-re Pakete unterteilt und beim Empfänger wieder zusammengesetzt.
Felder im TCP-Header die dies gewährleisten:
Sequenznummer: Gibt an, an welcher Position im Gesamtdatenstrom sich das erste Oktett dieses Segments befindet. Dies ist wichtig für die Einhaltung der Reihenfolge der einzelnen Segmente.
Quittungsfeld: Bei gesetztem ACK-Bit gibt der Empfänger dem Sender bekannt, welches Oktett im Ge-samtstrom als nächstes erwartet wird. Hierdurch erhält der Absender die Bestätigung, das alle Daten bis zu dieser Position korrekt empfangen wurden.
Beispiel
Stellen wir uns vor, wir möchten vom Rechner 10.0.1.1 eine FTP-Verbindung zu 10.0.1.2 aufbauen. Intern passiert dabei folgendes: Der FTP-Protokollstack baut ein Paket zusammen, das die Anfrage auf einen Ver-bindungsaufbau zu 10.0.1.2 beinhaltet. Dieses Paket wird nun in ein TCP-Paket verpackt und auch mit der Portnummer 21 (FTP) und einer Prüfsumme versehen. Von der TCP-Ebene wird das Paket weitergeleitet zum IP, das prüft, wo es denn das Paket hinzuschicken hat. Fühlt es sich dazu in der Lage, fragmentiert es dieses Paket gegebenenfalls in mehrere Bestandteile und gibt es dann an den Link Layer, also die Hardware, weiter. Anderenfalls wird eine ICMP-Nachricht abgesetzt, dass etwas nicht funktioniert. Handelt es sich im Link Layer um ein Ethernet, wird per ARP zuerst die Empfängeradresse in eine MAC-Adresse umgesetzt. Und dann kann das Paket, welches inzwischen viermal eingepackt wurde, endlich in das Kabel gehen.
Auf der Empfängerseite wiederholt sich dieses Spielchen in umgekehrter Richtung (wir erinnern uns an das OSI-Schichtenmodell?). Der Link Layer nimmt die Daten aus dem Kabel entgegen, das IP setzt sie gegebe-nenfalls wieder in der richtigen Reihenfolge zusammen und gibt sie an das TCP weiter, welches das Paket weiter entpackt und letztendlich erreicht das ursprüngliche FTP-Paket seinen Empfänger.
Für die Applikationsschicht, also in diesem Falle FTP, ist es völlig uninteressant, dass die beiden Rechner vorher eine TCP-Verbindung aufbauen oder dass das IP-Paket über mehrere Router geht, bevor es den Emp-

Application, Presentation, Session, Transport (Layer 4 - 7) Gateway
66
fänger erreicht. Die eine Schicht reicht ihre Daten in einer festgelegten Form an die andere durch und braucht von deren genauer Arbeitsweise exakt gar nichts zu wissen.
72: Port1
Wie erkennt ein Rechner, welcher Dienst (ftp, http, smtp, ...) von ihm verlangt wird?
73: Port2
Wie wird gewährleistet, dass bei 2 geöffneten Browserfenstern auf einem Rechner die neue Sei-te auf dem richtigen Browserfenster angezeigt wird?
74: Segment
Im Netz werden nur einzelne Pakete übertragen (max. 1500 Bytes). Wie ist es möglich, dass große Dateien (z.B. 2 MByte) sicher übertragen werden?
75: TCP-Header
Interpretieren Sie folgende TCP-Header. Geben Sie auch die Sockets komplett an indem Sie aus dem IP-Header, der dem TCP-Header vorangeht, die IP-Adressen ermitteln.
a)
b)
c)
Gateway Gateways können völlig unterschiedliche (heterogene) Netze und unterschiedliche Anwendungsprotokolle miteinander koppeln. Sie stellen einen gemeinsamen (virtuellen) Knoten dar, der zu beiden Netzen gehört und den netzübergreifenden Datenverkehr abwickelt. Gateways werden einerseits für die LAN-WAN-Kopplung (oder die LAN-WAN-LAN-Kopplung) andererseits für den Übergang zwi-schen unterschiedlichen Diensten verwendet (z. B. das Absetzen von Fax-Nachrichten aus einem LAN).
Ein Gateway ist ein aktiver Netzknoten, der von beiden Seiten aus adressiert werden kann. Er kann nicht auch mehr als zwei Netze miteinander koppeln. Gateways behandeln auf beiden Seiten unterschiedliche Pro-tokolle bis hinauf zur Schicht 7. Insbesondere ist das Routing über Netzgrenzen (korrekte Adressierung!) hinweg eine wichtige Aufgabe des Gateways. Man unterscheidet im wesentlichen zwei Typen:
Medienkonvertierende Gateways (Translatoren), die bei gleichem Übertragungsverfahren die Verbindung zwischen unterschiedlichen Protokollen der unteren beiden Ebenen (bei unterschiedlichem Transportmedi-um) herstellen - also dort, wo ein Router nicht mehr ausreichen würde.
Protokollkonvertierende Gateways, die unterschiedliche Protokolle der Ebenen 3 und 4 abwickeln und inein-ander überführen.
Der Gateway unterstützt hauptsächlich zwei wichtige Dienste: Die Übermittlung aufeinanderfolgender Nach-richten zwischen Quelle und Ziel als unabhängige Einheit und das Etablieren einer logischen Verbindung

Verbindungsorientierte- und verbindungslose Kommunikation Gateway
67
zwischen Quelle und Ziel. Um auf die unterschiedlichen Anforderungen der Flusskontrolle der zu verbin-denden Netze eingehen zu können, muss der Gateway gegebenenfalls Daten zwischenspeichern. Ist eines der beteiligten Netze leistungsfähiger als das andere, muss der Gateway dies erkennen und das "schnellere" Netz bremsen. Arbeiten beide Netze mit unterschiedlichen Paketgrößen, müssen Datenpakete "umgepackt" wer-den. Dies kann ganz einfach dadurch geschehen, dass zu große Pakete in kleinere Pakete aufgespalten und an Ziel gegebenenfalls wieder zusammengesetzt werden.
Verbindungsorientierte- und verbindungslose Kommunikation
Diese beiden unterschiedlichen Kommunikationsmöglichkeiten sind im Internet abhängig vom gewählten Protokoll auf der Schicht 4 (TCP, UDP). Auf allen anderen Schichten wird meist ein verbindungsloses Pro-tokoll verwendet.
In anderen Protokollstacks findet sich diese Unterscheidung aber auch auf anderen Schichten. Auch das E-thernet-Protokoll bietet die Möglichkeit einer Verbindungsorientierung. Dies wird aber praktisch nicht ver-wendet, da sie, wie alle verbindungsorientierten Protokolle, aufwendig ist.
Ist ein Protokoll im Protokoll-Stack verbindungsorientiert, dann ist die gesamte Kommunikation verbin-dungsorientiert. Deshalb gibt es bei den Internetprotokollen i.d.R. nur auf der Schicht 4 diese Auswahl.
Verbindungsorientiert - Entspricht dem Telefon - Eine feste Verbindung wird aufgebaut - Verbindung erhält eine Verbindungskennung - Datenpakete werden bestätigt - Reihenfolgeerhaltung, Fehlerkorrektur, Vermeidung
von Duplikaten
Verbindungslos - Entspricht dem Telegrammdienst - Wird als einmaliges Datenpaket verschickt - Keine Empfangsbestätigung - Empfangsbereitschaft wird vorausgesetzt
Vorteile: - Hohe Sicherheit - Fehlerkorrektur - Keine Duplikate
Vorteile: - Wenig Overhead - einfache Protokolle
Anwendung: - Dateiübertragung => TCP (Transmission Control Protocol)
Anwendung: - Streaming Video/Audio => UDP (User Datagram Protoc

Betriebssystem anwenden Wichtige MS-DOS-Kommandos
68
Betriebssystem anwenden
Wichtige MS-DOS-Kommandos CD CD Pfad oder change directory
CD .. (zur höheren Ebene) oder CD \ (Wurzelverzeichnis)
CLS clear screen (Bildschirm löschen) COPY COPY [Pfad]name.ext [Pfad][name.ext] kopieren.
Optionaler Parameter: /V verifizieren. Bsp.: COPY c:\ordner1\datei1.txt a:\datei2
DATE Datum tt.mm.jj DEL DEL [Pfad]name.ext Datei löschen (delete) DIR directory (Dateiverzeichnis) [.. höhere Ebene, /P seitenweise, /W kurz] ECHO ECHO [on off] (Text) Textausgabe auf Bildschirm ERASE ERASE [Pfad]name.ext Datei löschen (wie DEL) FIND z.B. DIR |FIND "EXE" (alle "..."-Dateien);
FIND [/V][/C][/N] "Zeichenfolge" [datei] FORMAT FORMAT A: Diskette formatieren (HD);
FORMAT A: /4 (5 1/4" auf 360 KB); FORMAT A: /S (DOS-Systemdiskette erzeugen)
MD make directory (neues Verzeichnis anlegen).
Bsp.: MD ebene2
PATH Suchpfade, PATH Pfad1;Pfad2;Pfad3 RD remove directory (Verzeichnis löschen; das Verzeichnis muß leer sein!) REN REN name1 name2 rename (neuer Name) SET Einstellungen anzeigen bzw. ändern (comspec, prompt, path) TIME Zeit hh:mm:ss TYPE listet eine ASCII-Textdatei (seitenweise mit |MORE) VER zeigt die MS-DOS-Versionsnummer VOL Laufwerksname wird angezeigt Ein-/Ausgabe-spezifikationen:
con (Terminal), prn od. lpt1 (Drucker), com1, com2,... (RS232)
Umlenkung der Ein- oder Ausgabe:
>prn Ausgabe auf den Drucker > datei Ausgabe auf eine Datei >> datei Ausgabe an eine Datei anhängen < datei Eingabe von einer Datei >nul Ausgabe unterdrücken
autoexec.bat (auf oberster Ebene!)
wird beim Programmstart ausgeführt
ECHO ECHO [ON OFF] (text) Textausgabe auf Bildschirm; < | > werden interpretiert (ggf. "<" benutzen)
FOR FOR %%variable IN (satz) DO befehl GOTO GOTO marke (Sprungbefehl)
:marke (die Sprungadresse [mit Doppelpunkt] muß als separate Zeile stehen) IF IF bedingung befehl
(bedingte Anweisung, z.B.: IF [NOT] EXIST [Pfad]name.ext ... [Datei existent?], IF %1==name ... [Übergabeparameter = name?], IF x%variable%==xParameter ... )
PAUSE wartet auf das Drücken einer Taste SET SET variable=parameter (setzt Parameter; Zuweisung) "Joker": Abkürzung (bei DIR, DEL, COPY)
? steht für ein Zeichen, * steht für mehrere Zeichen. (Vorsicht: DEL *.* löscht das gesamte Verzeichnis!)
Einige Netzwerk-Befehle (unter TCP/IP) Die wichtigsten Befehle, die neben den DOS-Befehlen in der Shell oder in einer Skript-Datei verwendet werden können sind folgende:
attrib Zeigt die Dateiattribute an oder ändert diese backup Legt eine Sicherungskopie von einer oder mehreren Dateien auf einem anderen Datenträger an cacls Zeigt die Zugriffskontrollisten (ACL, Access Control List) für Dateien an oder ändert sie
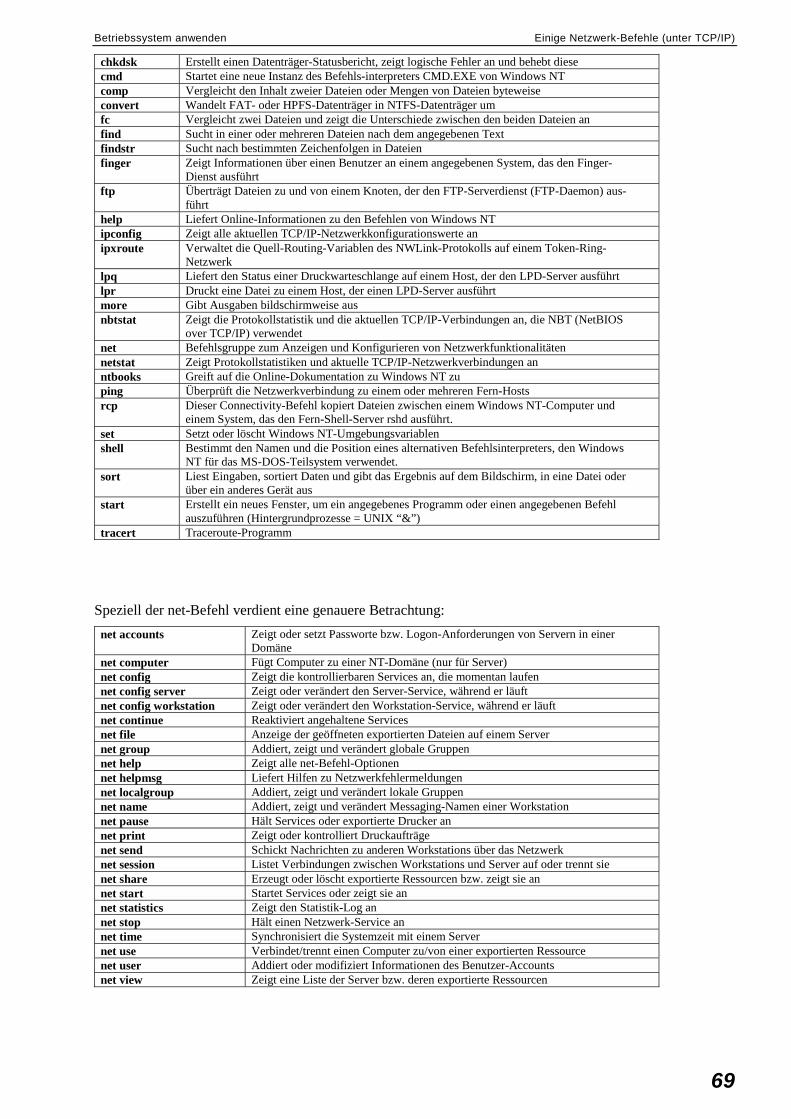
Betriebssystem anwenden Einige Netzwerk-Befehle (unter TCP/IP)
69
chkdsk Erstellt einen Datenträger-Statusbericht, zeigt logische Fehler an und behebt diese cmd Startet eine neue Instanz des Befehls-interpreters CMD.EXE von Windows NT comp Vergleicht den Inhalt zweier Dateien oder Mengen von Dateien byteweise convert Wandelt FAT- oder HPFS-Datenträger in NTFS-Datenträger um fc Vergleicht zwei Dateien und zeigt die Unterschiede zwischen den beiden Dateien an find Sucht in einer oder mehreren Dateien nach dem angegebenen Text findstr Sucht nach bestimmten Zeichenfolgen in Dateien finger Zeigt Informationen über einen Benutzer an einem angegebenen System, das den Finger-
Dienst ausführt ftp Überträgt Dateien zu und von einem Knoten, der den FTP-Serverdienst (FTP-Daemon) aus-
führt help Liefert Online-Informationen zu den Befehlen von Windows NT ipconfig Zeigt alle aktuellen TCP/IP-Netzwerkkonfigurationswerte an ipxroute Verwaltet die Quell-Routing-Variablen des NWLink-Protokolls auf einem Token-Ring-
Netzwerk lpq Liefert den Status einer Druckwarteschlange auf einem Host, der den LPD-Server ausführt lpr Druckt eine Datei zu einem Host, der einen LPD-Server ausführt more Gibt Ausgaben bildschirmweise aus nbtstat Zeigt die Protokollstatistik und die aktuellen TCP/IP-Verbindungen an, die NBT (NetBIOS
over TCP/IP) verwendet net Befehlsgruppe zum Anzeigen und Konfigurieren von Netzwerkfunktionalitäten netstat Zeigt Protokollstatistiken und aktuelle TCP/IP-Netzwerkverbindungen an ntbooks Greift auf die Online-Dokumentation zu Windows NT zu ping Überprüft die Netzwerkverbindung zu einem oder mehreren Fern-Hosts rcp Dieser Connectivity-Befehl kopiert Dateien zwischen einem Windows NT-Computer und
einem System, das den Fern-Shell-Server rshd ausführt. set Setzt oder löscht Windows NT-Umgebungsvariablen shell Bestimmt den Namen und die Position eines alternativen Befehlsinterpreters, den Windows
NT für das MS-DOS-Teilsystem verwendet. sort Liest Eingaben, sortiert Daten und gibt das Ergebnis auf dem Bildschirm, in eine Datei oder
über ein anderes Gerät aus start Erstellt ein neues Fenster, um ein angegebenes Programm oder einen angegebenen Befehl
auszuführen (Hintergrundprozesse = UNIX “&”) tracert Traceroute-Programm
Speziell der net-Befehl verdient eine genauere Betrachtung:
net accounts Zeigt oder setzt Passworte bzw. Logon-Anforderungen von Servern in einer Domäne
net computer Fügt Computer zu einer NT-Domäne (nur für Server) net config Zeigt die kontrollierbaren Services an, die momentan laufen net config server Zeigt oder verändert den Server-Service, während er läuft net config workstation Zeigt oder verändert den Workstation-Service, während er läuft net continue Reaktiviert angehaltene Services net file Anzeige der geöffneten exportierten Dateien auf einem Server net group Addiert, zeigt und verändert globale Gruppen net help Zeigt alle net-Befehl-Optionen net helpmsg Liefert Hilfen zu Netzwerkfehlermeldungen net localgroup Addiert, zeigt und verändert lokale Gruppen net name Addiert, zeigt und verändert Messaging-Namen einer Workstation net pause Hält Services oder exportierte Drucker an net print Zeigt oder kontrolliert Druckaufträge net send Schickt Nachrichten zu anderen Workstations über das Netzwerk net session Listet Verbindungen zwischen Workstations und Server auf oder trennt sie net share Erzeugt oder löscht exportierte Ressourcen bzw. zeigt sie an net start Startet Services oder zeigt sie an net statistics Zeigt den Statistik-Log an net stop Hält einen Netzwerk-Service an net time Synchronisiert die Systemzeit mit einem Server net use Verbindet/trennt einen Computer zu/von einer exportierten Ressource net user Addiert oder modifiziert Informationen des Benutzer-Accounts net view Zeigt eine Liste der Server bzw. deren exportierte Ressourcen

Betriebssystem anwenden Skriptprogrammierung
70
Skriptprogrammierung
76: Batch1
Interpretieren Sie das folgende Skript. Verwenden Sie die Tabellen für die DOS bzw. Netzwerk-befehle, sowie eine Einführung in die Batch-Programmierung, zum Beispiel: Batch für Einsteiger von Horst Schäffer.
@ECHO OFF if %OS%==Windows_NT goto NT :DOS cls echo Login Script für Abteilung EINKAUF echo DOS/Windows 95,98 goto END :NT cls echo Sie sind Mitglied der Domäne %userdomain% echo Ihr Benutzername lautet %username% echo Sie arbeiten an dem Rechner %computername% (NetBios-Name) if not exist u:\. net use u: \\server\%username% :END net use w: \\server\data\public net time \\server /set /yes pause if not exist %Systemroot%\system32\calc.exe goto COPY goto CALC :COPY copy W:\calc.exe %Systemroot%\System32 :CALC calc
77: Batch2
Schreiben Sie ein Batch-Skript, welches Verzeichnisse und Unterverzeichnisse anlegt, bestimm-te Dateien aus dem Systemverzeichnis in eines angelegten Unterverzeichnisse kopiert, ein ganz bestimmtes Verzeichnis aktiviert und den Debugger startet.
78: Batch3
Schreiben Sie ein Batch File: Es gibt die User Lehrer und Schueler. Bei der Anmeldung eines Users am Rechner erkennt ein vorgeschaltetes Skript mit Hilfe einer Datenbank aus dem Anmeldenamen ob es sich um einen Lehrer oder Schüler handelt und setzt die Variable %UserTyp% ent-sprechend auf L oder S. Ein Lehrer erhält Zugriff auf alle Schueler-Verzeichnisse. In jedem Verzeichnis gibt es für jeden User ein Unterver-zeichnis mit dem Usernamen. Dieses soll als Laufwerk H: (Homeverzeich-nis) für den jeweiligen User eingerichtet werden. Jeder erhält „Alle“ als Laufwerk T:. Bei Start auf dem Rechner L01 erhalten Schueler keine Ver-zeichnisse. Alle Vorgänge sollen auf dem Bildschirm protokolliert werden. Zum Schluss wird die Datei „HALLO.TXT“ aus dem Systemverzeichnis auf dem Bildschirm angezeigt.
79: Novell1
Erläutern Sie die Arbeitsweise des Anmeldeskripts:
MAP ROOT H: = GBSRV_1/USER:\farb2001\%LOGIN_NAME map ins S1:= GBSRV_1/SYS:public map T: = GBSRV_1/USER:farb2001\transfer map V: = GBSRV_1/USER:vorlagen WRITE login_name include z:\drucken.txt

Client-Server-System Organisation der Rechtevergabe
71
80: Novell2
Untersuchen Sie das folgende Skript (Beispiel für Auswahl einer Druckerwarteschlange in No-vell)
if OS="PC_31" then #capture l=1 Q=.raum_31l.drucker.gbs /NB /NFF /NT if OS="PC_31" then #capture l=2 Q=.raum_32c.drucker.gbs /NB /NFF /Nt if OS="PC_32" then #capture l=1 Q=.raum_32.drucker.gbs /NB /NFF /NT if OS="PC_32" then #capture l=2 Q=.raum_32c.drucker.gbs /NB /NFF /Nt if OS="BEC" then #capture l=2 Q=.raum_32c.drucker.gbs /NB /NFF /Nt if OS="BEC" then #capture l=3 Q=.raum_120.drucker.gbs /NB /NFF /Nt if OS="BEC" then #capture l=4 Q=.PQ_118_laser.RAUM_118.drucker.gbs /NB /NFF /NT if OS="220" then #capture l=3 Q=.PQ_220_laser.RAUM_220.drucker.gbs /NB /NFF /NT if OS="220" then #capture l=2 Q=.PQ_220_color.RAUM_220.drucker.gbs /NB /NFF /NT if OS="218" then #capture l=3 Q=.PQ_218_laser.RAUM_218.drucker.gbs /NB /NFF /NT if OS="218" then #capture l=2 Q=.PQ_218_color.RAUM_218.drucker.gbs /NB /NFF /NT
Client-Server-System
Organisation der Rechtevergabe Bei der Vergabe von Rechten in einem Netzwerk ist es ähnlich wie bei politischen Systemen. Je mehr Rechte bei dem Einzelnen sind, desto mehr Verantwortung muss er tragen, um das Ganze nicht zu gefährden.
Sicherheitseinstellungen: Vollzugriff, Ändern, Ausführen, Schreiben, Lesen
Zentral individuell
Einstellung gilt im ganzen Netzwerk Netzwerkbetreuer hat Überblick Änderung wird nur an einer Stelle vorgenommen Zeitersparnis
Jeder Benutzer erhält seine Einstellungen Differenzierung nach Aufgaben möglich Ressourceneinsparung (Nur notwendige Tools werden eingerichtet.)
vordefinierteGruppen:
DomänenbenutzerAdministratorenHauptbenutzer
selbstdefinierteGruppen:
Lehrer
Schüler
selbstdefinierteBenutzer:
...
...
...
...
...
...
Die Gruppen besitzen Rechte. Es gibt vordefinierte Gruppen: Domänenbenutzer, Administratoren und Hauptbenutzer. Durch Vererbung erhalten die neuen, selbstdefinierten Gruppen die Rechte der vordefinierten Gruppen. Die übernommenen Rechte können in den selbstdefinierten Untergruppen umkonfiguriert werden. Benutzer werden zu einer oder mehreren (Unter-)Gruppen zugeordnet. Dadurch werden den Benutzern durch Mitgliedschaft die Gruppenrechte vererbt. Ist ein Benutzer Mitglied von mehrere Gruppen, so setzen sich immer die „weicheren“, d.h. die am stärksten eingeschränkten Rechte durch.

Datensicherung Sicherungsmedien
72
Datensicherung
Sicherungsmedien Haltbarkeit von Bändern:
_ DAT-Bänder: 25 bis 100 Durchläufe, _ DLT-Bänder: 10 000 und mehr Durchläufe
Lagerung der Bänder: _ Aufrecht stehend in der Originalverpackung, dunkler Aufbewahrungsort, _ Zimmer-temperatur, nicht in der Nähe von starken Magnetfeldern, räumlich vom Server getrennt
Zeitbedarf für das Backup: hhGByte
GByte
eSchreibrat
DatenmengeBackupzeit 7
6,0
1,4 ≈==
Sicherungsverfahren
1. Vollsicherung (Normal)
Alle Daten werden - unabhängig vom Archivbit - auf dem Backup-Medium gesichert. Nach der Durchfüh-rung der Sicherung wird das Archivbit zurückgesetzt. Die Daten werden dadurch als gesichert gekennzeich-net.
Wiederherstellung: Die letzte Vollsicherung wird benötigt
2. Differentielles Backup (Differenz)
Gespeichert werden die Daten, die seit der letzten Gespeichert werden die Daten, die seit der letzten Vollsi-cherung erstellt oder verändert wurden. Nach der Durchführung der Sicherung bleibt das Archivbit gesetzt. Die Daten werden bei der nächsten Sicherung wieder gespeichert.
Wiederherstellung: Die letzte Vollsicherung und das letzte differentielle Backup werden benötigt
3. Inkrementelles Backup (Hinzufügen, auch Zuwachssicherung)
Die Daten, die seit dem letzten Backup erstellt oder geändert wurden, werden gesichert. Das Archivbit der gesicherten Daten wird zurückgesetzt.
Wiederherstellung: Die letzte Vollsicherung und alle Zuwachssicherungen werden benötigt
4. Kopieren:
Alle ausgewählten Dateien werden kopiert. Die Dateien werden aber im Gegensatz zur Vollsicherung nicht als gesichert gekennzeichnet; d.h. das Archivbit wird nicht zurückgesetzt. Diese Sicherungsart bietet sich an, wenn zusätzlich zum regulären Sicherungszyklus eine zusätzliche Kopie hergestellt werden soll (z.B. ein monatliches Archivband).
Sicherungsstrategien
a. Das Mischen von Voll- und Differenzsicherung
Fr. | Mo. | Di. | Mi. | Do. | ... Voll | Differenz| Differenz | Differenz | Differenz | ...
Vorteile des Verfahrens: Nur an Freitagen fällt ein großes zu sicherndes Datenvolumen an. Bei der Wieder-herstellung werden nur 2 Bänder benötigt.
Nachteile: Das Sicherungsvolumen nimmt am Ende der Woche zu. Dateien, die nur einmal geändert wurden, werden trotzdem mehrmals kopiert.

Datensicherung Erstellen eines Backup-Scripts
73
b. Das Mischen von Voll- und Zuwachssicherung
Fr. | Mo. | Di. | Mi. | Do. | ... Voll | Zuwachs | Zuwachs | Zuwachs | Zuwachs | ...
Vorteile des Verfahrens: Nur an Freitagen fällt ein großes zu sicherndes Datenvolumen an. Das Sicherungs-volumen bleibt an den restlichen Wochentagen klein
Nachteile: Bei der Wiederherstellung müssen mehrere Bänder (maximal 5) verwendet werden, was nur mit einem deutlich größeren Arbeits- und Zeitaufwand gegenüber der Differenzsicherung möglich ist.
c. Großväter–Väter– Söhne
1. Söhne:
Am Abend der Wochentage Mo, Di, Mi und Do wird jeweils ein differentielles Backup durchgeführt. Die Beschriftung der Bänder lautet: Montag, Dienstag, Mittwoch, Donnerstag. Diese Bänder sind die 4 “Söhne“.
2. Väter:
Am 1. 2. und 3. Freitag eines Monats wird jeweils ein Vollbackup durchgeführt. Beschriftung: 1. Woche, 2. Woche, 3. Woche Diese Bänder sind die 3 “Väter“.
3. Großväter:
Immer am letzten Freitag eines Monats wird ein Vollbackup durchgeführt. Beschriftung: Januar, Februar,... Dezember. Diese Bänder sind die 12 “Großväter“. Mit insgesamt 19 Bändern lässt sich über den Zeitraum eines Jahres folgende Wiederherstellungsgenauigkeit erreichen:
o Aktuelle Woche: tagesgenau
o Letzter Monat: Stand der jeweiligen Freitage
o Letztes Jahr: Stand des letzten Freitags im Monat
Erstellen eines Backup-Scripts Mit Hilfe eines NT-Servers sollen Backups von einem Datenverzeichnis gemacht werden. Am NTServer muss hierzu ein Bandlaufwerk angeschlossen sein. Um das Band möglichst wenig zu belasten, wird auf dem NT-Server eine Puffer-Platte installiert, die etwas größer ist, als das potentiell größte zu sichernde Verzeich-nis. Das bedeutet, dass der freie Plattenplatz auf dem NT-Server größer ist als jede zu sichernde Partition auf einer Client-Maschine. Der Grund für die Puffer-Platte besteht in der Problematik von langsamen Netzver-bindungen bei gleichzeitig schnellem Schreiben auf das Band.
Kommen die Daten zu langsam beim Bandlaufwerk an, so fährt es regelmäßig den Schreibkopf in eine War-testellung und zurück. Diese Aktion altert das Band künstlich und verursacht häufige Fehler. Aus diesem Grund sollte das Schreiben auf Band von einer lokalen Platte erfolgen. Das Sichern der Daten geschieht da-her in zwei Stufen: Kopieren der Daten auf die Puffer-Platte und schreiben der gepufferten Daten auf das Band.
Der NT-Server soll sich immer mit der Client-Maschine verbinden können, ohne dass die Sicherheit der Client-Maschine beeinträchtigt ist. Hierzu werden alle zu sichernden Verzeichnisbäume versteckt exportiert. Dies geschieht mit dem Dateimanager und den Menüpunkten <Datenträger> und <Freigeben als>. Durch Beenden des Freigabenamens mit einem "$"-Zeichen, wird dieser Name versteckt exportiert, d.h. er ist in keiner Browserliste sichtbar, sehr wohl aber ansprechbar.
Funktionsweise des Skripts:
1. Lösche Logdateien von möglichen vorhergehenden Backup-Aktionen auf dem Server
2. Verbinde den NT-Server zu einem Client-PC. Die Kennung des resultierenden Netzlaufwerkes soll "S:" sein. Das zu verbindende Clientlaufwerk mit den Daten sei "XXX$" (Versteckter Name).
3. Kopiere alle Daten von "S:" zum lokalen Verzeichnis X:\BACKUP\PC132?\XXX$ und schreibe ei-ne Logdatei namens BKPLOG.TXT darüber.

Datensicherung Erstellen eines Backup-Scripts
74
4. Gebe Netzlaufwerk "S:" wieder frei.
5. Starte das Windows-Programm NTBACKUP und sichere die kopierten Daten damit auf Band. Schreibe die Logdatei BANDLOG.TXT darüber.
6. Lösche die Daten auf X:\BACKUP\PC132?\XXX$ rekursiv.
Das Backup-Skript
1 echo Schreibe Daten von R132PC? auf die X-Platte von Server1 2 echo Loesche alte Logdateien 3 del x:\BACKUP\R132PC?\BKPLOG.TXT 4 del x:\BACKUP\R132PC?\BANDLOG.TXT 5 echo Stelle Verbindung Server-Client unter Laufwerk S: her 6 net use s: \\R132PC?\XXX$ 7 echo Kopiere alle Daten nach Laufwerk X: 8 xcopy s:*.* X:\BACKUP\R132PC?\XXX$ /S /E /H /C >
X:\BACKUP\R132PC?\BKPLOG.TXT 9 echo Kopieren beendet, Laufwerk S: freigeben 10 net use s: /d 11 echo Schreibe die gesicherten Daten auf Band 12 NTBACKUP BACKUP X:\BACKUP\R132PC?\XXX$ /a /D "PC132?" /HC:ON /T NORMAL
/L "X:\BACKUP\R132PC?\BANDLOG.TXT" 13 echo Loesche die Daten auf X: 14 del /s /q X:\BACKUP\R132PC?\XXX$\*.* 15 echo Sicherung fuer R132PC? erfolgreich beendet





























