Embed Size (px)
Citation preview



Digital Humanities im deutschsprachigen Raum (DHd)
DHd 2017Digitale Nachhaltigkeit
Konferenzabstracts
Universität Bern
13. bis 18. Februar 2017

Die Abstracts wurden von den Autorinnen und Autoren in einem Templateerstellt und mittels des von Marco Petris, Universität Hamburg, entwickeltenDHConvalidators in eine TEI konforme XML-Datei konvertiert.
Koordination der Publikation: Prof. Dr. Michael StolzKorrektur der Auszeichnung der Bibliographie undKonvertierung TEI nach PDF: Reto BaumgartnerTEI to PDF scripts: Karin Dalziel https://github.com/karindalziel/TEI-to-PDFBearbeitete Version von Aramís Concepción Durán https://github.com/aramiscd/dhd2016-boaKonferenz-Logo: Regina Wittwer (reGains | Atelier für Grafik und Illustration)Umschlaggestaltung: Simone Hiltscher
online verfügbar: http://www.dhd2017.ch

4. Tagung des Verbands Digital Humanities im deutschsprachigen Raum e.V.
Beachten Sie bitte die ergänzendenAbbildungen auf S. 304–306 am Ende des Bandes.

Plenarvorträge
Digitale Nachhaltigkeit: Mittel und/oder Zweck?Seele, Peter.............................................................................................................................. 11
Ein Bild sagt mehr als tausend Worte, aber sagen tausend Pixel mehr als einWort?
Süsstrunk, Sabine................................................................................................................... 12Wenn Forschen ein nicht reproduzierbarer Prozess ist – Nachhaltigkeit alsHerausforderung in der Archäologie
Fless, Friederike..................................................................................................................... 13
Workshops
Annotieren und Publizieren mit DARIAH-DE und TextGridKollatz, Thomas; Hegel, Philipp; Veentjer, Ubbo; Söring, Sibylle; Funk, Stefan E.... 15
CUTE: CRETA Unshared Task zu EntitätenreferenzenReiter, Nils; Blessing, Andre; Echelmeyer, Nora; Koch, Steffen; Kremer, Gerhard;Murr, Sandra; Overbeck, Maximilian; Pichler, Axel..................................................... 19
Daten sammeln, modellieren und durchsuchen mit DARIAH-DEGradl, Tobias; Aschauer, Anna; Dogunke, Swantje; Klaffki, Lisa; Schmunk,Stefan; Steyer, Timo.............................................................................................................. 22
Dokumente segmentieren und Handschriften erkennen: Arbeiten mit derPlattform Transkribus
Hodel, Tobias; Lang, Eva-Maria; Fiel, Stefan.................................................................. 28Einführung in das PANDORA Linked Open Data Framework.
Johnson, Christopher; Wettlaufer, Jörg............................................................................ 31HowTo build a your own »Digital Edition Web-App«
Kampkaspar, Dario; Andorfer, Peter; Baumgarten, Marcus; Steyer, Timo.............. 34Nachhaltiges Management von Bildmetadaten mit XMP, exiftool und Fotostation
Pohl, Oliver; Schrade, Torsten............................................................................................ 37open your data, open your code: Offene Lizenzierung fürgeisteswissenschaftliche Projekte
Hannesschläger, Vanessa; Losehand, Joachim; Kamocki, Paweł; Scholger,Walter; Witt, Andreas; Amini, Seyavash......................................................................... 40
Panels
Aktuelle Herausforderungen der Digitalen DramenanalyseWilland, Marcus; Trilcke, Peer; Schöch, Christof; Rißler-Pipka, Nanette; Reiter,Nils; Fischer, Frank............................................................................................................... 46
Citizen Science unter dem Blickwinkel nachhaltiger sozialer und technischerInfrastrukturen
Seltmann, Melanie; Wandl-Vogt, Eveline; Dorn, Amelie............................................... 49Das digitale Museum: ein nachhaltiger Partner der Digital Humanities?
Hohmann, Georg; Schmidt, Antje; Doppelbauer, Regina; Rehbein, Malte................ 52eValuation - Kriterien zur Evaluation digitaler Angebote undForschungsinfrastrukturen
Kurmann, Eliane; Baumann, Jan; Natale, Enrico........................................................... 56Hackathons als Zukunftslabor für die digitale Nachhaltigkeit
Noyer, Frédéric....................................................................................................................... 58

Nachhaltige Entwicklung digitaler Ressourcen und Werkzeuge für wenigerforschte historische Sprachen
Feige, Tillmann; González, Alicia; Prager, Christian; Vertan, Cristina; Werwick,Heiko......................................................................................................................................... 62
Virtuelle Forschungsplattformen im Vergleich: MONK, Textgrid, Transcribo undTranskribus
Piotrowski, Michael; Schomaker, Lambert; Horstmann, Wolfram; Burch,Thomas; Hodel, Tobias......................................................................................................... 66
Virtuelle Forschungsumgebung für objekt- und raumbezogene ForschungKuroczyński, Piotr; Stanicka-Brzezicka, Ksenia; Fichtl, Barbara; Köhler,Werner; Brahaj, Armand; Fichtner, Mark....................................................................... 69
Zugänglichkeit und dauerhafte Nutzbarkeit historischer Bildrepositorien fürForschung und Vermittlung
Niebling, Florian; Münster, Sander; Friedrichs, Kristina; Henze, Frank; Kröber,Cindy; Bruschke, Jonas......................................................................................................... 73
Vorträge
Ambige idiomatische Ausdrücke in kinderliterarischen Texten: Mehrwert einerDatenbankanalyse
Wagner, Wiltrud.................................................................................................................... 79Analyzing Features for the Detection of Happy Endings in German Novels
Jannidis, Fotis; Reger, Isabella; Zehe, Albin; Becker, Martin; Hettinger, Lena;Hotho, Andreas...................................................................................................................... 81
Anybody out there? Der Begriff der Masse im CrowdsourcingSchilz, Andrea......................................................................................................................... 86
Archival Cultural Heritage Online: Eine Virtuelle Forschungsumgebung imSpannungsfeld von Open Access, Nachhaltigkeit und Datenschutz
Lange, Felix; Wintergrün, Dirk; Wannenwetsch, Oliver; Schoepflin, Urs................. 89Aufbau eines historisch-literarischen Metaphernkorpus für das Deutsche
Pernes, Stefan; Keller, Lennart; Peterek, Christoph...................................................... 92Automatische Bild-Text-Analyse: Chancen für die Zeitschriftenforschung jenseitsvon reinen Textdaten
Rißler-Pipka, Nanette; Chandna, Swati; Tonne, Danah................................................ 94Autorschaftsattribution bei nicht-normalisiertem Mittelhochdeutsch. BessereErkennungsquoten durch ein Normalisierungswörterbuch
Dimpel, Friedrich Michael................................................................................................... 100Bild, Beschreibung, (Meta)Text Automatische inhaltliche Erschließung undAnnotation kunsthistorischer Daten
Dieckmann, Lisa; Hermes, Jürgen; Neuefeind, Claes..................................................... 103Das „Was-bisher-geschah“ von KOLIMO. Ein Update zum Korpus der literarischenModerne
Herrmann, J. Berenike; Lauer, Gerhard........................................................................... 107Datenmodellierung und -visualisierung mit Graphdatenbanken. Konzepte undErfahrungen anlässlich des Relaunches der Bilddatenbank REALonline
Matschinegg, Ingrid; Nicka, Isabella................................................................................ 111Datenvisualisierung als Aisthesis
Gius, Evelyn; Kleymann, Rabea; Meister, Jan Christoph; Petris, Marco................... 115„Der Helmut Kohl unter den Brotaufstrichen“. Zur Extraktion vossianischerAntonomasien aus großen Zeitungskorpora
Jäschke, Robert; Strötgen, Jannik; Krotova, Elena; Fischer, Frank............................ 120Die Impactomatrix – ein interaktiver Katalog für Impactfaktoren undErfolgskriterien für digitale Infrastrukuren in den Geisteswissenschaften
Thoden, Klaus; Wintergrün, Dirk; Stiller, Juliane; Gnadt, Timo; Meiners, Hanna.. 124

Digitale Modellierung literarischen RaumsBarth, Florian; Viehhauser, Gabriel.................................................................................. 128
Digitale Transformationen. Zum Einfluss der Digitalisierung auf diemusikwissenschaftliche Editionsarbeit
Meise, Bianca; Meister, Dorothee...................................................................................... 1323D-Metamodeling Christopher Polhem’s Laboratorium mechanicum 1696
Snickars, Pelle......................................................................................................................... 136Dokumentation, Werkzeugkasten, Pakete - Nachhaltigkeit von Daten undFunktionalität Digitaler Editionen
Czmiel, Alexander.................................................................................................................. 138Ein PoS-Tagger für „das“ Mittelhochdeutsche
Echelmeyer, Nora; Reiter, Nils; Schulz, Sarah................................................................ 141Entwicklung und Einrichtung einer digitalen Arbeitsumgebung für die JeremiasGotthelf-Edition. Ein Erfahrungsbericht
Zihlmann, Patricia; von Zimmermann, Christian.......................................................... 147Hermann Burgers Lokalbericht: Hybrid-Edition mit digitalem Schwerpunkt
Daengeli, Peter; Zumsteg, Simon....................................................................................... 151Kontextbasierte Zitationsanalyse soziologischer Klassiker im Verlauf von 100Jahren
Messerschmidt, Reinhard; Mathiak, Brigitte.................................................................. 155Langzeitinterpretierbarkeit auf Basis des CIDOC-CRM in inter- undtransdisziplinären Forschungsprojekten am Germanischen Nationalmuseum(GNM), Nürnberg
Große, Peggy; Wagner, Sarah............................................................................................. 158Nachhaltige Erschließung umfangreicher handschriftlicher Überlieferungen. EinFallbeispiel
Faßhauer, Vera....................................................................................................................... 162Nachhaltige Konzeptionsmethoden für Digital Humanities Projekte am Beispielder Goethe-PROPYLÄEN
Kasper, Dominik; Grüntgens, Max.................................................................................... 165Nachhaltige Softwareentwicklung in den Digital Humanities. Konzepte undMethoden.
Schrade, Torsten..................................................................................................................... 168Nachhaltigkeit als Prozess: Zur konzeptionellen Funktion digitaler Technologienin der Nachhaltigkeitssicherung für historische Fotos im Projekt efoto-Hamburg
Schumacher, Mareike........................................................................................................... 171Netzwerkdynamik, Plotanalyse – Zur Visualisierung und Berechnung der›progressiven Strukturierung‹ literarischer Texte
Trilcke, Peer; Fischer, Frank; Göbel, Mathias; Kampkaspar, Dario; Kittel,Christopher.............................................................................................................................. 175
Niklas Luhmanns Werk- und Lesekosmos - DH in der bibliographischenDimension
Goedel, Martina; Zimmer, Sebastian................................................................................ 180Perspektiven der Benutzeraktionsanalyse im Kontext der Evaluation vonForschungspraktiken in den Digital Humanities
Walkowski, Niels-Oliver....................................................................................................... 184Projekte und Aktivitäten im Kontext digitaler 3D-Rekonstruktion imdeutschsprachigen Raum
Münster, Sander; Kuroczyński, Piotr; Pfarr-Harfst, Mieke.......................................... 188„Quellen aus der Schweiz für die Welt: jederzeit, überall, für alle“ – NeueKooperationen der NB im digitalen Zeitalter
von Wartburg, Karin; Nepfer, Matthias........................................................................... 193

Semantische Suche in Ausgestorbenen Sprachen: Eine Fallstudie für dasHethitische
Daxenberger, Johannes; Görke, Susanne; Siahdohoni, Darjush; Gurevych, Iryna;Prechel, Doris.......................................................................................................................... 196
The Colorized Dead: Computerunterstützte Analysen der Farblichkeit von Filmenin den Digital Humanities am Beispiel von Zombiefilmen
Pause, Johannes; Walkowski, Niels-Oliver...................................................................... 200Von sammlungsspezifischen Visualisierungen zu nachnutzbaren Werkzeugen
Glinka, Katrin; Pietsch, Christopher; Dörk, Marian...................................................... 204Wiederholende Forschung in den digitalen Geisteswissenschaften
Schöch, Christof...................................................................................................................... 207Zur polykubistischen Informationsvisualisierung von Biographiedaten
Windhager, Florian; Mayr, Eva; Schreder, Günther; Wandl-Vogt, Eveline;Gruber, Christine.................................................................................................................... 212
Poster
AGATE – European Academies Internet Gateway: Konzept für eine digitaleInfrastruktur für die geistes- und sozialwissenschaftlichen Forschungsvorhabender europäischen Wissenschaftsakademien
Wuttke, Ulrike; Adrian, Dominik; Ott, Carolin............................................................... 217APIS – Eine Linked Open Data basierte Datamining-Webapplikation für dasAuswerten biographischer Daten
Schlögl, Matthias; Lejtovicz, Katalin................................................................................ 220Comparison of Methods for Automatic Relation Extraction in German Novels
Krug, Markus; Wick, Christoph; Jannidis, Fotis; Reger, Isabella; Weimer, Lukas;Madarasz, Nathalie; Puppe, Frank.................................................................................... 223
Die Odyssee zum richtigen Standard - Herausforderungen einer konsistentenDatenmigration von Ulysses: A Critical and Synoptic Edition (1984)
Schäuble, Joshua; Crowley, Ronan..................................................................................... 227Digitale Erschließung einer Sammlung von Volksliedern aus demdeutschsprachigen Raum
Burghardt, Manuel; Spanner, Sebastian; Schmidt, Thomas; Fuchs, Florian;Buchhop, Katia; Nickl, Miriam; Wolff, Christian........................................................... 228
Digitale Nachhaltigkeit bei Grundlagenforschung in Akademieprogramm: DasBeispiel „Johann Friedrich Blumenbach-online“
Wettlaufer, Jörg; Johnson, Christopher............................................................................ 234Digitale Nachhaltigkeit in den Geisteswissenschaften durch TOSCA: Nutzungeines standardbasierten Open-Source Ökosystems
Breitenbücher, Uwe; Barzen, Johanna; Falkenthal, Michael; Leymann, Frank....... 235Digitale Werkzeuge und Infrastrukturen zur Analyse und Beschreibung vonBewegungen in vormodernen Wissensbeständen
Hegel, Philipp; Tonne, Danah; Geukes, Albert; Krewet, Michael; Rapp, Andrea;Stotzka, Rainer; Uhlmann, Gyburg.................................................................................... 238
Einfaches Topic Modeling in Python - Eine Programmbibliothek fürPreprocessing, Modellierung und Analyse
Jannidis, Fotis; Pielström, Steffen; Schöch, Christof; Vitt, Thorsten........................... 240Entitäten als Topic Labels: Verbesserung der Interpretierbarkeit undEvaluierbarkeit von Themen durch Kombinieren von Entity Linking und TopicModeling
Lauscher, Anne; Nanni, Federico; Ponzetto, Simone Paolo......................................... 242Grotefend digital
Vogeler, Georg; Klugseder, Robert; Klug, Helmut W.; Steiner, Christian; Raunig,Elisabeth................................................................................................................................... 244

„IT for all“ – Das Projekt „Digitaler Campus Bayern – Digitale Datenanalyse in denGeisteswissenschaften“ als Beispiel für nachhaltige IT-Didaktik
Schulz, Julian.......................................................................................................................... 245Kollaborative Forschung über Linked Open Data Forschungsdatenbanken derUniversitätsgeschichte Implementierung des Heloise Common Research Model
Riechert, Thomas; Beretta, Francesco.............................................................................. 249Kompilation eines Diskursstruktur-annotierten deutschsprachigen Blogkorpus
Grumt Suárez, Holger; Karlova-Bourbonus, Natali; Lobin, Henning........................ 252Kriterienbasierte Evaluation und Dokumentation technischer Nachhaltigkeit vonForschungssoftware in einem Metadatenrepositorium
Druskat, Stephan................................................................................................................... 253Living Books about History
Baumann, Jan; Kurmann, Eliane; Natale, Enrico........................................................... 255Maßnahmen zur digitalen Nachhaltigkeit in Langzeitprojekten – Das BeispielCapitularia
Schulz, Daniela; Fischer, Franz; Geißler, Nils; Gödel, Martina................................... 257maus - eine WebApp zur einfachen Erstellung funktionaler Webdokumente
Dufner, Matthias; Kunz, Axel; Klammt, Anne................................................................. 259Nachhaltigkeit durch Zusammenschluss: Die DARIAH Data Re-Use Charter
Baillot, Anne; Busch, Anna; Puren, Marie; Mertens, Mike; Romary, Laurent.......... 260Nachhaltigkeitperspektiven von Graphdaten
Kuczera, Andreas................................................................................................................... 263PaLaFra – Entwicklung einer Annotationsumgebung für ein diachrones Korpusspätlateinischer und altfranzösischer Texte
Döhling, Lars; Burghardt, Manuel; Wolff, Christian..................................................... 264Paraphrasenerkennung im Projekt Digital Plato
Kath, Roxana; Keilholz, Franz; Klinker, Fabian; Pöckelmann, Marcus; Rücker,Michaela; Švitek, Mihael; Wöckener-Gade, Eva; Yu, Xiaozhou................................... 266
Raum und Zeit in Comics: Die Wirkung von Zwischenräumen aufAufmerksamkeit und empfundene Zeit beim Lesen graphischer Literatur
Hohenstein, Sven; Laubrock, Jochen................................................................................. 270relNet – Modellierung von Themen und Strukturen religiöser Online-Kommunikation
Elwert, Frederik; Tabti, Samira; Krech, Volkhard; Morik, Katharina; Pfahler,Lukas......................................................................................................................................... 271
„Soziale Datenkuratierung“: Nachhaltigkeit im Projekt Illuminierte Urkunden alsGesamtkunstwerk
Bürgermeister, Martina; Vogeler, Georg.......................................................................... 272TEASys (Tübingen Explanatory Annotations System): Die erklärende Annotationliterarischer Texte in den Digital Humanities
Zirker, Angelika; Bauer, Matthias..................................................................................... 274Tool zur Normalisierung und Historisierung
Eder, Elisabeth; Hadersbeck, Maximilian........................................................................ 276Twhistory mit autoChirp Social Media Tools für die Geschichtsvermittlung
Hermes, Jürgen; Hoffmann, Moritz; Eide, Øyvind; Geduldig, Alena; Schildkamp,Philip......................................................................................................................................... 277
UIMA als Plattform für die nachhaltige Software-Entwicklung in den DigitalHumanities
Hellrich, Johannes; Matthies, Franz; Hahn, Udo........................................................... 279Umfrage zu Forschungsdaten an der Philosophischen Fakultät der Universität zuKöln
Mathiak, Brigitte; Kronenwett, Simone............................................................................ 281

Visuelle Elemente grafischer Literatur: Aufmerksamkeitszuwendung undobjektive Beschreibung
Laubrock, Jochen; Richter, Eike; Hohenstein, Sven....................................................... 286... warum nicht gleich Wikidata?!
Schelbert, Georg..................................................................................................................... 287Webbasierte Morphemannotation Diachroner Korpora: Ein Weg zu mehrNachhaltigkeit?
Peukert, Hagen....................................................................................................................... 289Where the words are: a visual interactive exploration of plants names
Therón, Roberto; Dorn, Amelie; Seltmann, Melanie; Benito, Alejandro; Wandl-Vogt, Eveline; Gabriel Losada Gómez, Antonio.............................................................. 291
Zukünftiger Teil eines Fachinformationsdienstes: Eine Datenbank zurFachgeschichte der deutschsprachigen Musikwissenschaft zwischen ca. 1810 undca. 1990, projektiert am Max-Planck-Institut für empirische Ästhetik, Frankfurtam Main
van Dyck-Hemming, Annette.............................................................................................. 293Zwei grundlegende Fragen der digitalen Nachhaltigkeit: Wie können wir dieheterogenen Forschungsfragen und die Community bei der Verfügbarmachungvon Forschungsdaten miteinbeziehen?
Odebrecht, Carolin; Dreyer, Malte; Lüdeling, Anke; Krause, Thomas....................... 295

Plenarvorträge

Digital Humanities im deutschsprachigen Raum 2017
Digitale Nachhaltigkeit: Mittel und/oder Zweck?
Seele, [email protected]à della Svizzera italiana, Schweiz
Digitalisierung und Nachhaltigkeit stellen zwei der thematisch wichtigsten Themenkreise undTreiber sowohl des gesellschaftlichen Diskurses als auch der akademischen Forschung dar. Diesbetrifft nicht nur die sogenannten ‚harten‘ Wissenschaften, in denen naturwissenschaftlicheMessungen von Nachhaltigkeitsthemen wie Klimawandel, Kohlendioxid Emissionen oderBiodiversität Gegenstand der Forschung darstellen. Die beiden Themenkreise Digitalisierung undNachhaltigkeit haben in den letzten Jahren auch die Kultur- und Geisteswissenschaften erreicht.Der Plenarvortrag geht auf diese Neuerung als Form der Kombination von Digitalisierung undNachhaltigkeit in den Humanities und hier insbesondere in den Digital Humanities ein.
„Digitale Nachhaltigkeit“ als emergentes Thema und Konzept lässt sich dabei in zwei Haupttypenunterteilen, so der Vorschlag dieser Keynote:
1. Digitale Nachhaltigkeit als Mittel. Dies bedeutet, dass Digitalisierung als Mittel verstandenwird, nachhaltige Entwicklung zu fördern. Wie lassen sich also Big Data und Co dazu einsetzen,Nachhaltigkeit zu fördern?
2. Digitale Nachhaltigkeit als Zweck: Dies bedeutet, dass das Digitale an sich in einer Weise zugestalten wäre, die nachhaltig zu nennen wäre. In diesem Sinne wäre die Digitale Nachhaltigkeit derZweck.
Analog dazu liesse sich die Digitale Nachhaltigkeit als Topos der Digital Humanities skizzieren,wobei die Digital Humanities ebenso in der Unterscheidung nach Mittel und Zweck dargestellt werdenkönnen.
Beide Hauptpositionen werden im Vortrag dargelegt und anhand von Beispielen und erstenpositionsbestimmenden Forschungsbeiträgen diskutiert. Schliesslich verdient insbesondere dienormative Grundierung des Nachhaltigkeitsdiskurses in den Kultur- und Geisteswissenschaftenbesondere Beachtung, da Nachhaltigkeit als prädeliberatives Konzept bereits normativ positioniert istund dementsprechend wissenschaftlich zu reflektieren wäre.
11

Digital Humanities im deutschsprachigen Raum 2017
Ein Bild sagt mehr als tausend Worte, aber sagentausend Pixel mehr als ein Wort?
Süsstrunk, [email protected] Humanities Instituts (DHI) der École polytechnique fédérale de Lausanne, Schweiz
In diesem Vortrag werde ich das Wort „Digital“ in Digital Humanities genauer erläutern. Wasgenau ist eigentlich „digital“? Aus der Sicht der Informatik kann „digital“ Information sein, diein einem Format kodiert ist, das für eine Berechnung geeignet ist. Aber ist diese Kodierung fürdie Geisteswissenschaften überhaupt geeignet? Die ASCII-Kodierung eines Wortes hat sich alssinnvoll erwiesen und wird somit ausgenutzt. Aber wie ist es mit den Pixeln, die eine zwei- oderdreidimensionale Szene kodieren und entweder ein altes Manuskript, eine Kinderzeichnung, dieInterpretation der Klassik eines Kunsthistorikers oder ein berühmtes Jazzkonzert repräsentierenkönnten?
Anhand von Beispielen aus der Forschung des Digital Humanities Instituts (DHI) der ETH Lausanne(EPFL) werde ich die Kodierung visueller Informationen diskutieren, den Reichtum der bildlichenDarstellung für die Geisteswissenschaften erläutern, aber auch über die noch zu bewältigendenHerausforderungen diskutieren, bis wir die visuelle Information so nutzen können wie das Wort.
12

Digital Humanities im deutschsprachigen Raum 2017
Wenn Forschen ein nicht reproduzierbarer Prozessist – Nachhaltigkeit als Herausforderung in derArchäologie
Fless, [email protected] Archäologisches Institut, Deutschland
Ein Archäologe arbeitet sich bei einer Ausgrabung durch viele historische Schichten in dieTiefe. Dieser Prozess ist nicht umkehrbar, so dass der Dokumentation des Grabungsprozesses einebesondere Bedeutung zukommt. Wie aber sichert man solche Daten, die in vielfältigen Formatenheute digital erhoben werden, langfristig? Wie kann man diese Daten in einem geschlossenenDatenlebenszyklus für Nachnutzungen zur Verfügung stellen? In welcher Weise können wirmit der Vielfalt von Datenformaten umgehen? Diesen grundsätzlichen Fragen will der Vortragausgehend von einer konkreten Disziplin, der Archäologie, nachgehen und dabei auch dieaktuellen Entwicklungen im Bereich des Forschungsdatenmanagements aufzeigen. AktuelleVorschläge, wie sie der Rat für Informationsinfrastruktur in Deutschland für die Entwicklung einerNationalen Forschungsdateninfrastruktur publiziert hat, sollen dabei ebenso beleuchtet werdenwie die dahinter stehende Geschichte von Informationsinfrastrukturen, auf der diese Vorschlägeaufbauen. Um jenseits der grundlegenden Entwicklungen des Forschungsdatenmanagementsund der Informationsinfrastrukturen auch konkrete Beispiele und Lösungsansätze für dieFrage von Nachhaltigkeit zur Diskussion zu stellen, sollen die technischen Lösungen, die imRahmen der digitalen Angebote des Deutschen Archäologischen Instituts, aber auch des DFG-Projektes IANUS (Forschungsdatenzentrum für die Langzeitsicherung archäologischer undaltertumswissenschaftlicher Daten) vorgestellt werden.
13

Workshops

Digital Humanities im deutschsprachigen Raum 2017
Annotieren undPublizieren mit DARIAH-DE und TextGrid
Kollatz, [email protected] für deutsch-jüdischeGeschichte Essen, Deutschland
Hegel, [email protected] Universität Darmstadt, Deutschland
Veentjer, [email protected]ächsische Staat- undUniversitätsbibliothek Göttingen, Deutschland
Söring, [email protected]ächsische Staat- undUniversitätsbibliothek Göttingen, Deutschland
Funk, Stefan [email protected]ächsische Staat- undUniversitätsbibliothek Göttingen, Deutschland
Annotieren und Publizierenmit DARIAH-DE und TextGrid
Im Rahmen des halbtägigen Workshopswerden den Teilnehmerinnen und TeilnehmernWerkzeuge zum Publizieren und Annotieren vonForschungsdaten demonstriert, die im Rahmenvon Hands-On-Einheiten anhand eigener und /oder bereitgestellter Daten erprobt werdenkönnen.
Vorgestellt und angewendet werden dasTextGrid- und DARIAH-DE Repositorium, derDARIAH-DE Publikator und die DARIAH-DEAnnotation Sandbox. Zudem wird in die Arbeitmit dem Text-Bild-Link-Editor des TextGridLaboratoriums eingeführt und exemplarischgezeigt, diese Text-Bild Relationen mit Hilfedes Web-Publikationstools „SADE – ScalableArchitecture for Digital Editions“ in einedigitale Präsentation bzw. ein Web-Portal zuübernehmen.
Der Workshop richtet sich anGeisteswissenschaftlerinnen und –wissenschaftler aus text- und bildbasiertenDisziplinen aller Phasen des akademischenWerdegangs ebenso wie an Vertreterinnenund Vertreter von Institutionen – etwaBibliotheken, Forschungsverbünde oder Archive–, die im Rahmen ihrer Vorhaben digitaleForschungsinfrastruktur nutzen bzw. nutzenwollen, um ihre Forschungsdaten nachhaltigdigital zu publizieren und zu annotieren.
Der Workshop liefert durch Kurzvorträge undHands-On-Einheiten Einblicke in verschiedeneVerfahren, Anwendungen und Workflowsliefern, um Geisteswissenschaftlerinnen undGeisteswissenschaftlern die maschinenlesbareAnnotation von Text- und Bilddaten sowiedie Publikation solcher Forschungsdatenin einem Repositorium zu ermöglichen.Nach einer kursorischen Einführung in dieAngebote von TextGrid und DARIAH-DE liefertein Überblick über das Annotieren in dendigitalen Geisteswissenschaften verschiedeneAnwendungsszenarien, -anforderungen, -modelle und -technologien. Dabei werdenneben bereits bestehenden Angeboten wie demTextGrid Text-Bild-Link-Editor auch neuereEntwicklungen wie die Annotation Sandboxund das DARIAH-DE Repositorium und seinePublish GUI (Publikator) demonstriert und ininteraktiven Übungen durch die Teilnehmendenanhand eigener bzw. zur Verfügung gestellterDaten erprobt.
Der Workshop ist Teil zweier konzeptionelleigenständiger Einreichungen zu den Angebotender digitalen ForschungsinfrastrukturenTextGrid und DARIAH-DE. 1 . Der Besuchbeider Workshops ermöglicht einegrundlegende und umfassende Einführungin und Anwendung von Architektur,Tools, Diensten und Workflows zumAnnotieren, Sammeln, Modellieren,Recherchieren und Publizierengeisteswissenschaftlicher Forschungsdaten.
Annotationen in den digitalenGeisteswissenschaften
Digitales Annotieren ist zentrale Praxis beider Wissensgenerierung und variiert je nachspezifischer wissenschaftlicher Zielsetzungund Forschungsgegenstand. Verfahren desfachwissenschaftlichen digitalen Annotierensbilden heute eine der Kernanwendungen derDigital Humanities. Im Zentrum steht dabeiein weites Spektrum von Daten und / oder
15

Digital Humanities im deutschsprachigen Raum 2017
Objekten, z.B. Texte, Bilder und Musik (Töne,Noten). Digitale Annotationen unterscheidensich daher in Form, Funktion und Tragweite.Einführend werden die technischen Ebenenund theoretischen Dimensionen der digitalenAnnotation in den Geisteswissenschaftenexemplarisch erörtert. Die vermitteltenGrundlagen können danach im Workshoppraktisch angewandt werden.
Annotieren im Rahmen einerdigitalen Infrastruktur
Forschungsinfrastrukturen wie TextGrid undDARIAH-DE haben zum Ziel, methodologischeFähigkeiten auf diesem Gebiet zu vermitteln,entsprechende Verfahren zu evaluieren bzw.bereitzustellen und die nachhaltige Anwendungdieser Verfahren in den Fachwissenschaften zuermöglichen.
Die DARIAH-DE Annotation Sandbox (Beta)ermoglicht heute die Text- und Bildannotationder Bestände des TextGrid Repository. Darüberhinaus können beliebige Webseiten uberden DARIAH-DE Annotationsdienst annotiertwerden. Zudem lässt sich der DARIAH-DEAnnotationsdienst in eigene Webseiteneinbetten; hierzu wurden die digitalenWerkzeuge Annotator.js, Via und ein AnnotationManager über die DARIAH AAI (Authorizationand Authentification Service) verfügbargemacht.
Die DARIAH-DE Annotation Sandboxgestattet die direkte Verbindung der in denRepositorien publizierten Forschungsdaten mitihrer digitalen Annotation. Diese schließt sowohldie disziplinübergreifenden Nachnutzung alsauch die Datenanreicherung oder die Analyseein. Mittelfristig können Annotationen somitals Zwischenschritt des Forschungsprozesses,aber auch als genuines Forschungsergebnis- etwa im Sinne einer Mikropublikation -verstanden bzw. generiert, verfügbar gemachtund als solches nachgenutzt werden. ImRahmen einer digitalen Infrastruktur fließensie wie die Forschungsdaten, auf die sie Bezugnehmen, ebenfalls in die Archivierung ein, um weiterverarbeitet und nachgenutzt zu werden.
Bilder in TextGrid annotieren
Ein weiteres Anwendungsszenariodigitaler Annotation stellt die Annotation vonBildern bzw. Bilddaten dar. Eine Vielzahl vonWerkzeugen im TextGrid Laboratory erlaubt
das Arbeiten mit Texten und Bildern, aber auchbeispielsweise mit Noten und Digitalisaten.Eine dieser Komponenten, die auch für dieAnnotation von Bildbereichen dienen kann,ist der Text-Bild-Link-Editor. Er unterstütztden in TextGrid integrierten XML-Editor beider Alignierung von Text- und Bildelementen.Ziel ist die Erstellung einer Ausgabedatei,die die Textelemente und die topographischePosition von rechtwinkligen und polygonenBildbereichen in SVG miteinander verknüpft,wie dies zum Beispiel bei der Verbindung vonFaksimiles und Transkriptionen in kritischenEditionen der Fall ist. Auch können Bilder aufdiese Weise im Rahmen kunsthistorischerUntersuchungen annotiert werden.
Text-Bild-Relationenpublizieren
Die Software SADE der Berlin-Brandenburgischen Akademie derWissenschaften ist als „Skalierbare Architekturfür digitale Editionen“ in TextGrid eingebunden,um eigene Webportale für die Publikationgestalten zu können. Sie enthält ein Modul,mit dem die Verknüpfungen, die mit demText-Bild-Link-Editor erstellt wurden, in einWeb-Portal übernommen werden können.Dieses Modul basiert auf dem in DARIAH-DEintegrierten Werkzeug „Semantic TopologicalNotes” (SemToNotes). Es erlaubt unter anderem,Zeilen auf einem Digitalisat auszuwählen undTranskriptionen anzuzeigen.
Publizieren via Infrastruktur:Das DARIAH-DE Repositoriumund der DARIAH-DEPublikator
Das DARIAH-DE Repositorium bildet einezentrale Komponente der Infrastruktur,auf die mittels verschiedener Dienste undAnwendungen zugegriffen werden kann. DasRepositorium erlaubt es, Forschungsdaten zuspeichern, diese mit Metadaten zu versehenund die Forschungsdaten durch die GenerischeSuche aufzufinden. Die Daten werden imDARIAH-DE Storage sicher gespeichert. Darüberhinaus ermöglicht das Repositorium dienachhaltige und sichere Archivierung vonDatensammlungen bzw. Kollektionen.
16

Digital Humanities im deutschsprachigen Raum 2017
Abb.1: DARIAH-DE-Repositorium: ArchitekturDies ist komfortabel und intuitiv über ein
Web-Interface des DARIAH-DE Portals imBrowser möglich, dem DARIAH-DE Publikator.Daten im Repositorium sind in Kollektionenorganisiert, die zunächst vom Nutzer überden Publikator angelegt und mit Metadatenausgezeichnet werden. Einer Kollektion könnenbeliebig viele Dateien zugeordnet werden, dieebenfalls über den Publikator hochgeladenund mit Metadaten ausgezeichnet werden.Eine publizierte Kollektion sowie alle darinenthaltene Objekte können unmittelbar nachdem Publizieren per Persistent Identifier (PID)referenziert werden und sind damit öffentlichzugänglich und nachhaltig referenzier-und zitierbar. Im nächsten Schritt kanndie Kollektion in der Collection Registrynachgewiesen und veröffentlicht werden. Sobalddie Kollektion selbst ebenfalls in der CollectionRegistry publiziert wurde, sind die Daten auchmit der Generischen Suche recherchierbar.
Abb. 2: DARIAH-DE Publikator: Übersichtüber die Kollektionen
Abb. 3: DARIAH-DE Publikator: Kollektionbearbeiten
Anforderungen
Im Workshop werden exemplarischAnnotationen an einem Digitalisat in TextGridvorgenommen. Zu diesem Zweck ist eineigener Rechner mitzubringen, auf dem imIdealfall TextGrid bereits installiert ist – https://textgrid.de/download .
Eine Registrierung für TextGrid und DARIAHkann online beantragt werden unter
http://auth.dariah.eu/Bitte teilen Sie uns im Vorfeld des Workshops
(möglichst bis zum 5. Februar 2017) mit, obund welche eigenen Materialien Sie verwendenwollen.
17

Digital Humanities im deutschsprachigen Raum 2017
Für Rückfragen erreichen Sie uns [email protected]
Kontaktdaten
Mirjam Blümm, Niedersächsische Staats-und Universitätsbibliothek Göttingen, Abt.Forschung und Entwicklung, Papendiek 14,37073 Göttingen, [email protected]: VirtuelleForschungsumgebungen, DigitaleForschungsinfrastrukturen, Digitale Editionen
Stefan E. Funk, Niedersächsische Staats-und Universitätsbibliothek Göttingen, Abt.Forschung und Entwicklung, Papendiek 14,37073 Göttingen, [email protected]: Forschungsdatenmanagement, DigitaleLangzeitarchivierung, Repositoriums-Technologien.
Canan Hastik, Technische UniversitätDarmstadt, Dolivostraße 15, Institut für Sprach-und Literaturwissenschaft, 64293 Darmstadt, [email protected]: Digital Humanities,Semantisches Wissensmanagement, DigitaleKultur und Kunst
Philipp Hegel, Technische UniversitätDarmstadt, Institut für Sprach- undLiteraturwissenschaft, Dolivostraße 15, 64293Darmstadt, [email protected]: Digitale Editionen,virtuelle Forschungsumgebungen
Thomas Kollatz, Salomon Ludwig Steinheim-Institut für deusch-jüdische Geschichte,Essen, Edmund-Körner-Platz 2, 42157 Essen,[email protected]: Digitale Epigraphik,Jüdische Studien
Sibylle Söring, Niedersächsische Staats-und Universitätsbibliothek Göttingen, Abt.Forschung und Entwicklung, Papendiek 14,37073 Göttingen, [email protected]: VirtuelleForschungsumgebungen, DigitaleForschungsinfrastrukturen, Digitale Editionen
Ubbo Veentjer, Niedersächsische Staats-und Universitätsbibliothek Göttingen, Abt.Forschung und Entwicklung, Papendiek 14,37073 Göttingen, [email protected]: DigitaleForschungsinfrastrukturen, Text- und Bild-Annotation, Visualisierungstechnologien.
Zahl der möglichenTeilnehmerinnen undTeilnehmer.
Aufgrund des hohen Praxisanteils soll dieZahl der Teilnehmerinnen und Teilnehmer aufmöglichst 25 beschränkt bleiben.
Angaben zu einer etwabenötigten technischenAusstattung.
WLAN / Beamer / Stellwände /Verlängerungskabel
Fußnoten
1. Siehe auch Workshop "Daten sammeln,modellieren und durchsuchen mit DARIAH-DE“
Bibliographie
Becker, Rainer / Bender, Michael / Borek,Luise / Hastik, Canan / Kollatz, Thomas /Lordick, Harald / Mache, Beata / Rapp,Andrea / Reiche, Ruth / Walkowski, Niels-Oliver (2016): „Digitale Annotationen in dergeisteswissenschaftlichen Praxis“, in: Bibliothek– Forschung und Praxis 40 (2): 186–199 https://www.degruyter.com/view/j/bfup.2016.40.issue-2/bfp-2016-0042/bfp-2016-0042.xml?format=INT .
Bender, Michael / Borek, Luise /Kollatz, Thomas / Reiche, Ruth (2015):"Wissenschaftliche Annotationen: Formen –Funktionen – Anforderungen", in: DHd-Bloghttp://dhd-blog.org/?p=5388 .
Borek, Luise / Reiche, Ruth (2014):„Round Table ‚Annotation von digitalenMedien“ (Veranstaltungsbericht), in: DHd-Bloghttp://dhd-blog.org/?p=3831 .
Blümm, Mirjam / Funk, Stefan E. / Söring,Sibylle (2015): „Die Infrastruktur-Angebotevon DARIAH-DE und TextGrid“, in: Information.Wissenschaft & Praxis 66 (5–6): 304–312.
Neuroth, Heike / Rapp, Andrea /Söring, Sibylle (2015): TextGrid: Vonder Community für die Community – EineVirtuelle Forschungsumgebung für dieGeisteswissenschaften. Göttingen http://www.univerlag.uni-goettingen.de/handle/3/Neuroth_TextGrid .
18

Digital Humanities im deutschsprachigen Raum 2017
Schmunk, Stefan / Funk, Stefan (2015): „DasDARIAH-DE- und das TextGrid-Repositorium:Geistes- und kulturwissenschaftlicheForschungsdaten persistent und referenzierbarlangzeitspeichern“, in: Bibliothek Forschung undPraxis 40 (2): 213–221 10.1515/bfp-2016-0020
Söring, Sibylle (2016): „Technische undinfrastrukturelle Lösungen für digitaleEditionen: DARIAH-DE und TextGrid“, in:Bibliothek Forschung und Praxis 40 (2): 207–21210.1515/bfp-2016-0040 .
CUTE: CRETAUnshared Task zuEntitätenreferenzen
Reiter, [email protected]ät Stuttgart, Deutschland
Blessing, [email protected]ät Stuttgart, Deutschland
Echelmeyer, [email protected]ät Stuttgart, Deutschland
Koch, [email protected]ät Stuttgart, Deutschland
Kremer, [email protected]ät Stuttgart, Deutschland
Murr, [email protected]ät Stuttgart, Deutschland
Overbeck, [email protected]ät Stuttgart, Deutschland
Pichler, [email protected]ät Stuttgart, Deutschland
Einleitung
Der Workshop zum CRETA UnsharedTask (CUTE) verfolgt ein inhaltliches und einmethodisches Ziel. Das inhaltliche Ziel ist dieAnregung eines Diskurses über Entitäten,deren Annotation und Kategorisierung entlangvon geistes- und sozialwissenschaftlichenForschungsfragen sowie deren Potential alsdisziplinübergreifende Textanalyseaufgabe.Methodisch möchten wir ein Workshop-Format erproben, das unseres Erachtenseine produktive Schnittstelle zwischenGeistes-/SozialwissenschaftlerInnen undInformatikerInnen bildet. Das genaue Programmdes Workshops wird von den Teilnehmendendurch Beiträge gestaltet (durch Beiträge, sieheCall for Papers 1 ) und vor rechtzeitig vor demWorkshop auf der Webseite veröffentlicht 2 .
Entitätenreferenzen
Das Konzept der Entität und ihrer Referenzist ein bewusst weites, das anschlussfähig seinsoll für verschiedene Forschungsfragen aus denGeistes- und Sozialwissenschaften. Wir möchtendabei explizit verschiedene Perspektiven aufEntitäten berücksichtigen.
Entitäten in derLiteraturwissenschaft
Figuren in literarischen Textensind „mit ihrer sinnkonstitutiven undhandlungsprogressiven Funktion“ einzentraler Bestandteil der fiktiven Welt (Platz-Waury 1997). Von besonderem Interessedabei sind Figurenkonstellationen undInteraktionen, die Entwicklung von Figurensowie die Funktionalisierung von Figurenals Handlungsträger. Die Erkennung vonFigurenreferenzen ist grundlegend, um z.B.Figuren zu charakterisieren, ihre Relationenidentifizieren und Netzwerkanalysendurchführen zu können (vgl. Jannidis 2015,Trilcke 2013).
Neben der Figur rückt –- spätestens seit demspatial turn -– auch der Raum als relevanteEntität in den Fokus der Literaturwissenschaft.Der Handlungsraum in literarischen Textendient der Strukturierung der fiktiven Welt undist zumeist semantisiert (Lotman 1972). Zudemkann er in Wechselwirkung mit Aspekten derFigur („sujethafte Grenzüberschreitung“, Lotman
19

Digital Humanities im deutschsprachigen Raum 2017
1972) oder der Zeit stehen („Chronotopos“,Bachtin 1989).
Entitäten in derSozialwissenschaft
Politische Parteien, internationaleOrganisationen oder Institutionen sind seitjeher zentrale Analyseobjekte der empirischensozialwissenschaftlichen Forschung undwerden spätestens seit dem linguistic turn(Rorty 1967) in den Sozialwissenschaftenauch mittels inhalts- oder diskursanalytischerMethoden auf zunächst kleinen und zunehmendgrößeren Mengen von Textdokumenten(beispielsweise Parteiprogrammen, offizielleRegierungsdokumenten, Zeitungstexten)untersucht. Neben vielfältigen anderenAnalysen stehen dabei oftmals Fragen nachder Sichtbarkeit oder Bewertung bestimmterEntitäten, wie beispielsweise der EuropäischenUnion als supra-/internationaler Organisation(Kantner 2015) im Vordergrund.
Entitäten in der Philosophie
Im Unterschied zu den Literatur- undSozialwissenschaften spielen Entitäten alsUntersuchungsgegenstand in philosophischenTexten zunächst keine Rolle. Aufgrundihrer metareflexiven Ausrichtung fragtPhilosophie primär nicht nach individuellunterscheidbaren Objekten in der echtenoder einer fiktiven Welt, sondern beschäftigtsich mit transzendentalen Fragen nach denBedingungen und Möglichkeiten derartigerindividueller Objekte. Dabei arbeitet sie mitabstrakten Konzepten, die sich ebenfalls als --nicht-dingliche -- Objekte einer Welt auffassenlassen. Pragmatisch gesehen erfolgt die Referenzauf abstrakte Konzepte in Texten jedenfalls inähnlicher Weise wie die Referenz auf Figuren,Organisationen und Orten (s.u.).
FachübergreifendeAnnotationsschemata
Auch wenn die Interpretation von z.B. derErwähnung von Organisationen in politischenund des Auftretens von Figuren in literarischenTexten anderen Regeln folgt und mit anderenForschungsfragen zusammenhängt, gibt esGemeinsamkeiten auf linguistisch-struktureller
Ebene. Im Text realisiert werden Referenzenauf die o.g. Arten von Entitäten entwederals Eigennamen ( Angela Merkel/ ÄsthetischeTheorie), Pronomen ( sie/ sie) oder als appellativeNominalphrasen ( die Bundeskanzlerin/ dasSpätwerk Adornos). Wir haben daher eineinheitliches Vokabular und Annotationsschemaentwickelt und auf einem ausgewähltenheterogenen Korpus getestet. Dieses soll imRahmen des Workshops diskursiv erörtert undwenn möglich erweitert werden.
Abstrakt gesprochen verstehen wir unterEntitäten individuell unterscheidbare Objektein der echten oder einer fiktiven Welt. Wirunterscheiden sechs verschiedene Typenvon Entität: Personen, Orte, Ereignisse,Organisationen, kulturelle Artefakte undKonzepte. Die Bezeichnung als „Objekt“impliziert also nicht, dass es sich umphysikalische Objekte handelt. Die Einteilungin Typen ist von den oben skizziertenForschungsfragen und -feldern abgeleitet undist -- bei anderen Forschungsfragen oder -daten-- offen für Ergänzungen. Die Anwendbarkeitauf zusätzliche Texte und Textgattungen ist füruns (und für diesen Workshop) von besonderemInteresse.
Die Erstellung abstrakterAnnotationsrichtlinien und deren systematische,kontrollierte Anwendung (Annotation) aufkonkrete Texte verspricht im Wesentlichen zweiErgebnisse:
Das Erzeugen von parallelen Annotationenauf Basis von Richtlinien zwingt zu einemsehr genauen Lesen des Textes und sorgtfür eine intensive Auseinandersetzungmit den Annotationskategorien (und auchfür ein Hinterfragen derselben). Rechtschnell wird auf diese Weise deutlich,welche Annahmen bei der Anfertigungder Annotationsrichtlinien nicht von denDaten gedeckt waren. Auch Phänomene, dieinhaltlich berücksichtigt werden sollten,aber nicht in den Richtlinien enthaltensind, fallen den FachwissenschaftlerInnenschnell ins Auge. Dadurch, dass die eigenenAnnotationsentscheidungen ggf. diskutiertund verteidigt werden müssen, sorgenParallelannotationen für die Aufdeckung vonVagheiten in den Definitionen und damit füreine Klärung der Begriffe (vgl. Gius / Jacke2016).
Die Entwicklung von maßgeschneidertenTextanalysewerkzeugen für spezifischegeistes- und sozialwissenschaftlicheForschungsfragen stößt schnell an
20

Digital Humanities im deutschsprachigen Raum 2017
Ressourcengrenzen. Als Problem erweistsich oft, dass die Textanalyseaufgaben zuspeziell oder die Datenmengen zu kleinsind und damit ein Forschungsbeitrag inder Informatik oder Computerlinguistiknur schwer möglich ist (was typischerweisewiederum Auswirkungen auf denRessourceneinsatz hat). Eine Antwort aufdiese Herausforderung ist die Etablierungfachübergreifender Textanalyseaufgaben,etwa für bestimmte Annotationsebenen. Dieserlaubt die Entwicklung von allgemeineren,wiederverwendbaren Werkzeugen und --mit geeigneten Testdaten -- deren iterativeVerbesserung. Damit wird die Bearbeitunggeistes- und sozialwissenschaftlicherForschungsfragen letztlich nachhaltigerunterstützt als durch die Entwicklungspezieller, aber nach Projektende nichtweiterentwickelter Werkzeuge. EinKatalysator dafür können shared undunshared tasks sein (vgl. Kuhn / Reiter 2015).
Shared/Unshared Task
In diesem Sinne ist das zweite, methodischeZiel des Workshops zu verstehen: Wir möchteneinen Community-Task veranstalten, der eineshared und drei unshared-Tracks hat. Damitwird ein Workshop-Format auf die Probegestellt, das eine produktive Schnittstellezwischen Geistes-/SozialwissenschaftlerInnenund InformatikerInnen zu bilden verspricht(s.a. Belz / Kilgarriff 2006). Im Gegensatzzu shared tasks, bei denen die Performanzverschiedener Systeme, Ansätze oderMethoden direkt anhand einer klar definiertenund quantitativ evaluierten Aufgabeverglichen wird, sind unshared tasks offenfür verschiedenartige Beiträge, die aufeiner gemeinsamen Datengrundlage oderFragestellung basieren. Neben dem Call-- der bereits eine Sammlung möglicherFragestellungen nennt -- veröffentlichenwir daher ein heterogenes Korpus, das alsDatengrundlage dient. Im Rahmen von CUTEkönnen Forscherinnen und Forscher an denfolgenden Tracks teilnehmen:
Automatische Erkennung vonEntitätenreferenzen: Experimentezum automatischen Vorhersagen vonAnnotationen auf noch nicht annotiertenTexten, mit regelbasierten oder statistischenSystemen 3
Visualisieren von Entitätenreferenzen imText: Visualisierungsmöglichkeiten zur(interaktiven) Exploration der vorhandenenoder neuen Annotationen
Annotationsanalyse: Qualitativeoder quantitative Analyse dervorhandenen Annotationenoder der Annotationsrichtlinien;Annotationsexperimente zur Anwendbarkeitder Richtlinien auf neue Texte
Freestyle: Kreative Ideen, die keinen der obigenTasks adressieren
Beiträge zu Aufgabe 1 werden quantitativevaluiert und im Wettbewerb mit denEvaluationsergebnissen der anderen Beiträgeverglichen ( shared task, die technischen Detailsdazu werden auf der Webseite veröffentlicht).Beiträge für die Aufgaben 2 bis 4 werdenvom Programmkomitee qualitativ evaluiert (unshared task). Der Austausch während desWorkshops (in Form von Kurzvorträgen undDiskussion) wird insoweit eine Bandbreitean Zugängen abbilden, deren verbindendesElement die gemeinsame Datengrundlage seinwird. Da die Teilnehmerinnen und Teilnehmersich dann im Vorfeld intensiv mit den Datenaus verschiedenen Perspektiven beschäftigenwerden, erwarten wir für den Workshop eineerkenntnisreiche Diskussion.
Textgrundlage und Daten
Das von uns im Rahmen des Workshopsveröffentlichte Korpus umfasst vier Teilkorpora:
jeweils eine PolitikerInnenrede aus insgesamtvier Parlamentsdebatten des DeutschenBundestags (S. Leutheuser-Schnarrenbergeram 28.10.99, A. Merkel am 16.12.04, A. Ulricham 15.11.07 und A. Karl am 17.03.11)
Briefe aus Goethes Die Leiden des jungen Werther(1787) vom 4. Mai bis einschließlich 16. Juni
der Abschnitt Zur Theorie des Kunstwerks ausAdornos Ästhetische Theorie
die Bücher 3 bis 6 aus Wolframs von EschenbachParzival (mittelhochdeutsch)
Auch wenn jedes Teilkorpus seine eigenenBesonderheiten hat, wurden alle nacheinheitlichen Annotationsrichtlinien annotiert,die wir ebenfalls veröffentlichen und zurDiskussion stellen möchten.
21

Digital Humanities im deutschsprachigen Raum 2017
Ausrichter
Der Workshop wird ausgerichtet vomCentre for Reflected Text Analytics (CRETA)an der Universität Stuttgart. CRETA verbindetLiteraturwissenschaft, Linguistik, Philosophieund Sozialwissenschaft mit MaschinellerSprachverarbeitung und Visualisierung.Hauptaufgabe von CRETA ist die Entwicklungreflektierter Methoden zur Textanalyse,wobei wir Methoden als Gesamtpaket auskonzeptuellem Rahmen, Annahmen, technischerImplementierung und Interpretationsanleitungverstehen. Methoden sollen also keine"black box" sein, sondern auch für nicht-Technikerinnen und -Techniker so transparentsein, dass ihr reflektierter Einsatz im Hinblickauf geistes- und sozialwissenschaftlicheFragestellungen möglich wird.
Fußnoten
1. http://dhd-blog.org/?p=73332. http://www.creta.uni-stuttgart.de/index.php/de/cute/3. Von dem in der maschinellenSprachverarbeitung etablierten Task der namedentity recognition (NER) unterscheidet sich dievorliegende Aufgabe insofern, als dass unsereAnnotationen neben Eigennamen auch andereArten von Referenz enthalten. Werkzeuge(und tasks) zur NER sind darauf getrimmt,ausschließlich Eigennamen zu erkennen.
Bibliographie
Bachtin, Michail Michailowitsch / Kowalski,Edward / Wegner, Michael (1989): Formen derZeit im Roman. Untersuchungen zur historischenPoetik. Frankfurt am Main: Fischer.
Belz, Anja / Kilgarriff, Adam (2006): „Shared-task Evaluations in HLT: Lessons for NLG“, in:Proceedings of the Fourth International NaturalLanguage Generation Conference.
Gius, Evelyn / Jacke, Janina (2016):„Kollaboratives Annotieren literarischer Texte“,in: DHd 2016: Modellierung - Vernetzung -Visualisierung.
Jannidis, Fotis / Krug, Markus / Reger,Isabella / Toepfer, Martin / Weimer, Lukas /Puppe, Frank (2015): „Automatische Erkennungvon Figuren in deutschsprachigen Romanen“, in:DHd 2016: Von Daten zu Erkenntnissen.
Kantner, Cathleen (2015): War andIntervention in the Transnational Public Sphere:
Problem-solving and European identity-formation.New York: Routledge.
Kuhn, Jonas / Reiter, Nils (2015): „A Pleafor a Method-Driven Agenda in the DigitalHumanities“, in: DH2015: Global DigitalHumanities.
Lotman, Juri (1972): Die Struktur literarischerTexte. München: Fink.
Platz-Waury, Elke (1997): „Figur“, in:Weimar, Klaus (ed.): Reallexikon der deutschenLiteraturwissenschaft. Neubearbeitung desReallexikon der deutschen Literaturgeschichte.Berlin, New York: de Gruyter 587–589.
Rorty, Richard M. (1967): The Linguistic Turn.Chicago: University of Chicago Press.
Trilcke, Peer (2013): „Social NetworkAnalysis als Methode einer textempirischenLiteraturwissenschaft“, in: Ajouri, Philip /Mellmann, Katja / Rauen, Christoph (eds.):Empirie in der Literaturwissenschaft. Münster:Mentis 201–247.
Daten sammeln,modellieren unddurchsuchen mitDARIAH-DE
Gradl, [email protected]ät Bamberg
Aschauer, [email protected] für Europäische Geschichte (IEG)
Dogunke, [email protected] Stiftung Weimar
Klaffki, [email protected] August Bibliothek Wolfenbüttel
Schmunk, [email protected]ächsische Staats- undUniversitätsbibliothek Göttingen
22

Digital Humanities im deutschsprachigen Raum 2017
Steyer, [email protected] August Bibliothek Wolfenbüttel
Überblick
Die sammlungsübergreifende Rechercheund Nachnutzung geisteswissenschaftlicherForschungsdaten stehen im Blickpunkt aktuellerForschung in den Digital Humanities. Obwohldas Interesse an einer Zusammenführungdigitaler Forschungsdaten bereits kurz nachder Einführung erster digitaler Bibliothekenum die Jahrtausendwende entstand, bleibtdie Integration von Forschungsdatenüber Sammlungsgrenzen hinweg einaktuelles Forschungsthema. Bei einerforschungsorientierten Betrachtung vonSammlungen digitaler Daten (also z. B. digitaleTexte, Digitalisate, Normdaten, Metadaten)stellt sich die Frage nach den Anforderungenund Erfolgskriterien einer übergreifendenFöderation, Verarbeitung und Visualisierung vonForschungsdaten.
Entgegen der in der Praxis üblichenOrientierung an institutionellen Anforderungenstellen die in DARIAH-DE entwickelten Konzepteund Dienste zur Verzeichnung, Korrelationund Zusammenführung von Forschungsdatendie Bedürfnisse von WissenschaftlerInnenim Kontext ihrer Forschungsfragen in denMittelpunkt. Dies äußert sich beispielsweisedarin, dass DARIAH-DE keine strukturellenBedingungen an Forschungsdaten stellt.Stattdessen können Daten so publiziert,modelliert und integriert werden, dass einemöglichst gute Passung an den jeweiligengeisteswissenschaftlichen Kontext erreicht wird.
Dieser Workshop wird zunächst in Formkurzer Referate Hintergrundwissen zuden Konzepten und Diensten der DARIAH-DE Föderationsarchitektur 1 vermitteln.Wichtige Bereiche sind dabei nicht nur dieHandhabung der Daten selbst sowie Fragender Lizensierung von Forschungsdaten,sondern auch die Nachnutzbarkeit einmalerhobener oder gesammelter Daten für weitereForschungsfragen oder zur Nutzung durchandere WissenschaftlerInnen. Ein wesentlicherAnteil des Workshops wird dann insbesonderein der Hands-On-Anwendung der Komponentendurch die TeilnehmerInnen selbst bestehen.
Thematische Schwerpunkte
Die wesentlichen Themenschwerpunkte desWorkshops können wie folgt zusammengefasstwerden:
• Hintergründe und Best Practices zurLizensierung und Nachnutzbarkeit vonForschungsdaten
• Beschreibung und nachhaltigeReferenzierbarkeit von Sammlungen in derDARIAH-DE Collection Registry
• Modellierung von Daten in der DARIAH-DE Schema Registry zur Beschreibungdes Erstellungskontexts von Datensowie deren Transformation in einenforschungsorientierten Verwendungskontext
Anhand der generischen Suche vonDARIAH-DE werden die Auswirkungen derBenutzerinteraktion im Rahmen des Workshopssofort erkennbar, d. h. referenzierte Datenwerden anhand der entwickelten Datenmodelleverarbeitet und können gemeinsam durchsuchtund analysiert werden.
Der gesamte Workshop wird thematischbegleitet von der konkreten, historischenAnforderung (vgl. Szöllösi-Janze, Panter &Paulmann 2015), biographische Daten und Texteaus verschiedenen Datenquellen zu verarbeiten.Die schließlich integrierten biographischeProfile (vgl. Gradl & Henrich 2016b) könnenzur Unterstützung konkreter historischerForschung herangezogen werden. Das Beispielist so gewählt, dass den Teilnehmerinnen undTeilnehmern eine konzeptuelle Übertragungauf ihre eigenen Daten und Forschungsfragenerleichtert wird.
Zielpublikum
Der Workshop richtet sich gleichermaßen an:
• geisteswissenschaftlicheWissenschaftlerInnen in denunterschiedlichsten Phasen desakademischen Werdegangs
• VertreterInnen von Institutionen, dieDatensammlungen im Rahmen von DARIAH-DE auffindbar und zugreifbar machenmöchten,
• sowie auch VertreterInnen der Informatik,die ein Interesse an der Implementierungvon DARIAH-DE Komponenten bzw. den
23

Digital Humanities im deutschsprachigen Raum 2017
Datenaustausch auf Basis maschinellzugreifbarer Schnittstellen haben.
Wer bereits über digitale Daten verfügt, istherzlich eingeladen, diese für die Hands-On-Sessions mitzubringen, um an diesen konkretenBeispielen die DARIAH-DE-Tools zu erarbeiten.Für TeilnehmerInnen, die keine geeignetenDaten mitbringen können, werden Beispiele zurVerfügung gestellt. Bitte bringen Sie in jedem FallIhren eigenen Laptop mit!
Der Workshop ist Teil zweier konzeptionelleigenständiger Einreichungen zu den Angebotender digitalen ForschungsinfrastrukturenTextGrid und DARIAH-DE. Der erste Workshophat den Titel "Annotieren und Publizieren mitDARIAH-DE und TextGrid“. Der Besuch beiderWorkshops ermöglicht eine grundlegende undumfassende Einführung in und Anwendungvon Architektur, Tools, Diensten undWorkflows zum Annotieren, Sammeln,Modellieren, Recherchieren und Publizierengeisteswissenschaftlicher Forschungsdaten.
Inhalte und Ablauf desWorkshops
I - Impulsreferate “Sammeln”
• Lizensierung, Referenzierung undNachnutzbarkeit von Forschungsdaten ( LisaKlaffki)
• Transnationale Biographien als Beispieleiner historischen Motivation für dieforschungsorientierte Föderation vonDARIAH-DE ( Anna Aschauer)
II - Impulsreferat “Modellieren”
• Forschungsorienterte Modellierungund Korrelation von Daten in derFöderationsarchitektur von DARIAH-DE (Stefan Schmunk, Tobias Gradl)
III - Impulsreferat “Durchsuchen”
• Integriertes Suche über heterogeneDatenbestände – Anforderungen undLösungsansätze im Bereich des kulturellenErbes ( Timo Steyer, Swantje Dogunke)
IV - Hands-on Session “Sammeln, Modellieren& Durchsuchen”
• Anwendung der Föderationsarchitektur undgenerischen Suche von DARIAH-DE ( TobiasGradl)• Modellierung von Daten und
Vorbereitung einer Nachnutzung• Assoziation heterogener
wissenschaftlicher Sammlungen• Verfeinerung der benutzerdefinierten
Suchmöglichkeiten in der generischenSuche (Suchbild, Ranking etc.)
• Anpassung der generischen Suche undBereitstellung benutzerdefinierter Suchen
Komponenten des Workshops
Abbildung 1 zeigt die Zusammenhängezwischen den für die DARIAH-DE Infrastrukturzugänglichen Kollektionen, den Registriesund der generischen Suche. In der Übersichtdargestellte Komponenten und Verbindungenwerden im Rahmen des Workshops live durchdie TeilnehmerInnen beeinflusst, weshalbwir in diesem Abschnitt eine vorbereitendeEinführung anbieten möchten. Für weitereInformationen erlauben wir uns einen Verweisauf die weiterführenden Publikationen am Endedes Dokuments.
Abbildung 1: DARIAH-DEFöderationsarchitektur
“Sammeln”: CollectionRegistry
Die Collection Registry (vgl. Abbildung 2) istein zentrales Verzeichnis zur Registrierung undBeschreibung von Sammlungen von Ressourcen.Sammlungen können selbst direkt Ressourcenoder weitere untergeordnete Teilsammlungenbeinhalten und können sowohl physischeals auch digitale Objekte oder nur Datenaggregieren. Die Sammlungsbeschreibungen
24

Digital Humanities im deutschsprachigen Raum 2017
decken neben Verschlagwortung, zeitlichenund geografischen Dimensionen auchSammlungsformate und Informationen zurDatenpflege ab.
Abbildung 2: Bildschirmausschnitt„Sammlungen“ der DARIAH-DE CollectionRegistry
“Modellieren”: SchemaRegistry / Mapping Registry
In der Schema und Mapping Registrywerden Datenmodelle und Korrelationenzwischen diesen beschrieben. Die grundlegendeZielsetzung besteht in der Definition undnachnutzbaren Modellierung der Erstellungs-und Verwendungskontexte von Daten:
• Erstellungskontext: Ausgehendbeispielsweise von einem XML-Schema wirdein Datenmodell angelegt, verfeinert undum Hintergrundwissen z. B. zur Sammlung,Institution erweitert (vgl. Abbildung3). Hierdurch wird insbesondere eineNachnutzung von Daten außerhalb desoriginären Sammlungskontexts ermöglicht.
• Verwendungskontext: Durch die Definitioneines fallspezifischen Integrationsmodellskönnen Datenmodelle miteinander assoziiertwerden. Durch eine Formulierung vonTransformationsregeln werden Daten soumgewandelt und integriert, wie sie füreine weiterführende Untersuchung benötigtwerden (vgl. Abbildung 4).
Abbildung 3: Bildschirmausschnitt desSchema Editors
Abbildung 4: Bildschirmausschnitt desMapping Editors
“Durchsuchen”: GenerischeSuche
Mit der generischen Suche wird im Rahmenvon DARIAH-DE ein konkreter Anwendungsfallder Datenföderation umgesetzt. Hierbeiwerden Daten aus den in der CollectionRegistry verzeichneten Kollektionen nachden in der Schema Registry definiertenDatenmodellen verarbeitet und indexiert.Die Heterogenität der Ressourcen wird zumZeitpunkt konkreter Suchanfragen, basierendauf der zu durchsuchenden Menge vonKollektionen, mit Hilfe der Mapping Registryaufgelöst.
Über die Möglichkeit der einfachen Sucheüber die Daten verzeichneter Kollektionenhinaus, können auf Basis der Funktionalitätder generischen Suche weiterführende,fachspezifische Suchmaschinen implementiertwerden (s. Abbildung 5).
25

Digital Humanities im deutschsprachigen Raum 2017
Abbildung 5: FachwissenschaftlicheSpezialsuche im Rahmen der generischenSuche
“Durchsuchen”: HistorischerUse-Case Biographien
Der Use-case Biographien verbildlicht wieman eine historische Fragestellung anhanddigitaler Werkzeuge bearbeiten kann.
Prosopographische historische Forschungorientiert sich immer noch stark an nationalerGeschichtsschreibung: religiöse, berufliche,gesellschaftliche Gruppen werden oftinnerhalb der nationalen Grenzen, dieselbst ein Konstrukt der Moderne sind,untersucht. Das Zusammenführen der Daten ausunterschiedlichen biographischen Datenbankenkann helfen dieses Problem zu lösen undbiographische Recherchen über die nationalenGrenzen hinweg zu gestalten.
Zu diesem Zweck implementiert DARIAH-DE derzeit das CosmoTool (vgl. Gradl &Henrich 2016b), welches auf die Unterstützunghistorischer Forschung an biographischenDaten abzielt. Das Werkzeug kann dabei alslogische Konsequenz einer Spezialisierung dergenerischen Suche interpretiert werden:
• die Sammlung von Datenquellen erfolgt inder DARIAH-DE Collection Registry,
• die Modellierung der Daten, sowiederen Assoziation mit einem zentralen,biographischen Schema erfolgt in derDARIAH-DE Schema / Mapping Registry
• die Verarbeitung und Indexierung der Datenbasiert auf funktionalen Komponenten dergenerischen Suche
• Die Analyse und Visualisierung wurdeund wird dagegen spezifisch für den
Anwendungsfall entwickelt und bildet dentatsächlichen Kern des CosmoTools
Abbildung 6: Bildschirmausschnitt desCosmoTools
Zusammenfassung
Insgesamt werden den TeilnehmerInnenim Rahmen dieses Workshopsverschiedene Kenntnisse im Kontextder Sammlung, Modellierung und Suchegeisteswissenschaftlicher Forschungsdatenvermittelt. Durch die Anwendung derentsprechenden Komponenten von DARIAH-DE werden die in vorausgegangenen Referatenvorgestellten Ideen vertieft.
Die Begleitung des Workshops durchForschungsfragen und Daten im Kontextbiographischer Daten soll den TeilnehmerInnendie praktische Anwendung der Komponentendeutlich machen. Idealerweise wird dadurchdie Übertragbarkeit auf andere Datenund Fragen vermittelt, wodurch einenachhaltige Zugänglichkeit wissenschaftlicherForschungsdaten erreicht werden kann.
Kontaktdaten allerBeitragenden
Anna Aschauer, Leibniz-Institutfür Europäische Geschichte (IEG),Querschnittsbereich, Alte Universitätstraße 19,55116 [email protected]: Pietismusforschung,Geschichte Russlands, Migration der religiösenMinderheiten in der Frühen Neuzeit, DigitalHumanities.
Swantje Dogunke, ForschungsverbundMarbach Weimar Wolfenbüttel / Klassik Stiftung
26

Digital Humanities im deutschsprachigen Raum 2017
Weimar, Direktion Verwaltung, AbteilungInformationstechnik, Burgplatz 4, 99423 [email protected]: Dokumentation imMuseum, Museumsmanagement, digitalcuration, digitale Langzeitarchivierung, DigialHumanities
Tobias Gradl, Otto-Friedrich-UniversitätBamberg, Lehrstuhl für Medieninformatik, Ander Weberei 5, 96052 [email protected]: Forschungsdatenund Forschungsdatenmanagement, DigitalHumanities, Datenintegration, InformationRetrieval
Lisa Klaffki, Herzog August BibliothekWolfenbüttel, Abteilung 1, Lessingplatz 1, 38304Wolfenbü[email protected]: Archäologie dergermanischen Provinzen, Bestattungssitten derrömischen Kaiserzeit, Digital Humanities
Stefan Schmunk, Niedersächsische Staats-und Universitätsbibliothek Göttingen, Abt.Forschung und Entwicklung, Papendiek 14,37073 Göttingen,[email protected]: Forschungsdatenund Forschungsdatenmanagement,Digitale Geschichtswissenschaft, VirtuelleForschungsumgebungen, DigitaleForschungsinfrastrukturen
Timo Steyer, Forschungsverbund MarbachWeimar Wolfenbüttel / Herzog August BibliothekWolfenbüttel, Abteilung 1, Lessingplatz 1, 38304Wolfenbü[email protected]: Digitale Editionen,Datenmodellierung und Metadaten, DigitalHumanities
Zahl der möglichenTeilnehmerinnen undTeilnehmer
Die Zahl der möglichen Teilnehmer ist ausunserer Sicht nicht eingeschränkt. Einer sehrgroßen Zahl müsste ggf. durch mehrere Helfer inder Hands-On-Session entgegnet werden
Angaben zu einer etwabenötigten technischenAusstattung
Es wird keine zusätzliche Ausstattung nebender üblichen Präsentationstechnik benötigt. Vonden TeilnehmerInnen wird das Mitbringen eineseigenen Laptops für die aktive Teilnahme an derHands-On-Session erwartet.
Fußnoten
1. Repository, Collection Registry, Schema /Mapping Registry und Generische Suche vonDARIAH-DE (vgl. Gradl & Henrich 2016a,Schmunk & Funk 2016)
Bibliographie
Gradl, Tobias / Henrich,Andreas (2016a): „Die DARIAH-DEFöderationsarchitektur - Datenintegration imSpannungsfeld forschungsspezifischer unddomänenübergreifender Anforderungen“, in:Bibliothek - Forschung und Praxis 2016 40 (2):222–228 10.1515/bfp-2016-0027.
Gradl, Tobias / Henrich, Andreas (2016b):„Nutzung und Kombination von Daten ausstrukturierten und unstrukturierten Quellenzur Identifikation transnationaler Lebensläufe“,in: DHd 2016: Modellierung - Vernetzung -Visualisierung 129–132.
Gradl, Tobias / Lordick, Harald / Henrich,Andreas (2016): „Judaica recherchieren:Unterstützung bei der Realisierungforschungsspezifischer Suchlösungen durch diegenerische Suche“, in: DHd 2016: Modellierung -Vernetzung - Visualisierung 132–136.
Schmunk, Stefan / Funk Stefan (2016): „DasDARIAH-DE- und das TextGrid-Repositorium:Geistes- und kulturwissenschaftlicheForschungsdaten persistent und referenzierbarlangzeitspeichern“, in: Bibliothek - Forschungund Praxis 2016 40 (2): 213–221 10.1515/bfp-2016-0020.
Szöllösi-Janze, Margit / Panter, Sarah /Paulmann, Johannes (2015): „Mobility andBiography. Methodological Challenges andPerspectives“, in: Jahrbuch für EuropäischeGeschichte / European History Yearbook 16: 1–1410.1515/9783110415162-001.
27

Digital Humanities im deutschsprachigen Raum 2017
Dokumentesegmentieren undHandschriften erkennen:Arbeiten mit derPlattform Transkribus
Hodel, [email protected] des Kantons Zürich
Lang, [email protected] des Bistums Passau
Fiel, [email protected] Universität Wien, Faculty ofInformatics, Institute of Computer AidedAutomation, Computer Vision Lab
Die Aufbereitung und Erkennung vonhandschriftlichen Dokumenten ist sowohl fürMenschen als auch für Computeralgorithmeneine technische Herausforderung. DieBearbeitung von handschriftlichemMaterial wird bislang von spezialisiertenExperten durchgeführt, um technisch undqualitativ hochstehende Resultate aushistorischen Dokumenten zu erhalten. ZurErstellung hochwertiger Editionen ist dafürhilfswissenschaftliches Wissen (Paläographie,Editorik), historisches Hintergrundwissen undtechnisches Know-how gefragt.
Im Rahmen des Projekts READ (Recognitionand Enrichment of Archival Data) werdenunterschiedliche Aufgaben der Automatisierung(weiter-)entwickelt, um qualitativ guteErgebnisse mit optimalem Ressourceneinsatzzu erhalten. Ein speziell dafür entwickeltesTool ist die Software Transkribus, die die Arbeitvon Experten und maschineller Erkennleistungverkoppelt. Die Software ist frei verfügbarunter www.transkribus.eu. Im Workshop wirdTranskribus vorgestellt und kann durch dieTeilnehmenden mit eigenen oder zur Verfügunggestellten Dokumenten getestet werden.
Transkribus unterstützt alle Prozesse vomImport der Bilder über die Identifikation derTextblöcke und Zeilen, die zu einer detailliertenVerlinkung zwischen Text und Bild führtsowie die Transkription und Annotation der
Handschrift bis zum Export der gewonnen Datenin standardisierten Formaten.
Workflow in TranskribusUm Texte zu transkribieren oder zu edieren,
müssen digitale Bilder hochgeladen und danachmit Layouterkennungswerkzeugen bearbeitetwerden. Die Analyse des Layouts kannautomatisiert geschehen, wobei die manuelleKontrolle und falls nötig die Nachbearbeitung imMoment noch sinnvoll ist.
Texte aus in Transkribus aufbereitetenDokumenten können entweder mit bereitsbestehenden HTR-Modellen (Handwritten TextRecognition) erkannt oder händisch erstelltwerden und danach zum Training neuerModelle genutzt werden. Insbesondere für dieBearbeitung grosser Dokumentenkorpora, diein ähnlichen Handschriften verfasst wurden,lassen sich bereits heute Effizienzgewinne undVereinfachungen erzielen.
Aufbauend auf den Transkriptionen ist esmöglich eine Vielzahl von Auszeichnungenund Annotationen innerhalb des Textes, aberauch darüber hinaus für Einzeldokumenteund ganze Dokumentenbestände anzulegen.Neben der Anreicherung der Dokumente mitder Identifikation von Personen, Orten undSachwörtern ist somit auch die Möglichkeitder Herstellung von Bestandsbeschreibungenund der Hinterlegung von Transkriptions- undEditionsvorschriften gegeben.
AusgabeformateFür den Export stehen unterschiedliche
Formate und Ausgabeformen zur Verfügung. Soist es möglich XML-Dateien zu exportieren, dieden Vorgaben der TEI entsprechen. Ausgehenddavon können komplexe digitale Editionenerstellt werden, die jedoch im Unterschied zuherkömmlichen Editionen eine enge Verzahnungmit den verwendeten Bilddateien aufweisen.Dadurch werden Editionen ermöglicht, die dentranskribierten Text in der Zusammenschaumit der faksimilierten Vorlage sichtbar machen(analog zu state-of-the-art Editionen, wiebeispielsweise die Edition der Briefe AlfredEschers: https://www.briefedition.alfred-escher.ch/). Daneben sind auch Ausgaben alsDruckdaten (PDF) oder zur Weiterbearbeitungfür Textverarbeitungsprogramme (DOCX)implementiert. Schliesslich ist auch ein Exportim PAGE-Format (zur Anzeige in Viewernfür OCR gelesene Dokumente, Pletschacher,2010) sowie als METS (Metadata Encoding andTransmission) möglich.
Die Speicherung der Dokumente erfolgt inder Cloud (gehostet auf Servern der UniversitätInnsbruck). Die importierten Daten bleibenauch während der Bearbeitung unverändert
28

Digital Humanities im deutschsprachigen Raum 2017
im Dateisystem liegen und werden ergänztdurch METS und PAGE XML, letztere ineigenem Unterordner. Alle bearbeitetenDokumente und Daten bleiben somit in denunterschiedlichen Bearbeitungsstadien nichtnur lokal verfügbar, sondern können fürProjektmitarbeitende geteilt werden. Dankelaboriertem user-management ist die Zuteilungvon Rollen möglich. Die Erkennprozessewerden serverseitig durchgeführt, sodassdie Ressourcen auf den lokalen Rechnernnicht strapaziert werden. Transkribus ist mitJAVA und SWT programmiert und kann daherplattformunabhängig (Windows, Mac, Linux)genutzt werden.
ZielpublikumDie Plattform ist für unterschiedliche
Gruppen konzipiert. Einerseits fürGeisteswissenschaftlerInnen, dieselbst Transkriptionen und Editionenhistorischer Dokumente erstellen möchten.Andererseits richtet sich die Plattforman Archive, Bibliotheken und andereErinnerungsinstitutionen, die handschriftlicheDokumente in ihren Sammlungen aufbewahrenund ein Interesse an der Aufbereitung desMaterials haben. Angesprochen werden sollenauch Studierende der Geistes-, Archiv- undBibliothekswissenschaften mit einem Interessean der Transkription historischer Handschriften.
Das Ziel, eine robuste und technischhochstehende Automatisierung vonLayout und Handschrift, lässt sichnur durch die enge Zusammenarbeitzwischen Geisteswissenschaftlern undComputerspezialisten erreichen, diebezüglich Datenqualität und Herstellungvon Transkriptionen von unterschiedlichenVoraussetzungen und Ansprüchen ausgehen.Die Algorithmen werden daher nicht nurbis zu einem Status als proof-of-concepterarbeitet, sondern bis zur Praxistauglichkeitverfeinert und in grösseren Forschungs- undAufbewahrungsumgebungen getestet undverbessert. Die Computerwissenschaftlersind entsprechend ebenfalls ein wichtigesZielpublikum, wobei bei ihnen weniger dieNutzung der Plattform als das Beisteuernvon Software(teilen) anvisiert wird. Dieeingespeisten Dokumente und Daten bleibenprivat und vor dem Zugriff Dritter geschützt.Von Projektseite können vorgenommeneArbeitsschritte zwecks besserem Verständnisder ausgeführten Arbeiten und letztlich derVerbesserung der Produkte ausgewertet werden.
Layout- und TexterkennungDie zwei zentralen Automatisierungsprozesse
basieren auf Algorithmen, die in laufenden
Forschungsprojekten entwickelt und verbessertwerden. Die document image analysis(DIA) versucht Textblöcke zu identifizierenund von Dreck, Scanfehlern und anderenStörsignalen zu unterscheiden, wobei zwischenhandschriftlichen und gedruckten Textblöckendifferenziert wird (Zagoris 2012; Stamatopoulos2015).
In Transkribus werden auf derLayouterkennung aufbauend zwei handwrittentext recognition-Engines (HTR) angeboten, dieauf unterschiedlichen technischen Grundlagenbasieren: Erstens kann eine nach dem HiddenMarkov Model (HMM) operierende HTR derTechnischen Universität Valencia angewähltwerden (Toselli 2015, Puigcerver 2015). Zweitenskann ein Model basierend auf rekurrierendenneuronalen Netzwerken der Universität Rostockgenutzt werden (Leifert 2016).
Transkribus und das gesamteForschungsnetzwerk will die verfügbarentechnischen Möglichkeiten den Endnutzernnach möglichst gängigen Workflows aufbereiten,so dass dem schnellen Praxiseinsatz keineHindernisse im Weg stehen. Im Gegenzug wirddie Nutzung im grossen Umfang erhofft, dieden Subprojekten wichtige Trainingsdatenund Aufschlüsse bezüglich der Nutzung undden Problemen mit den Algorithmen sowiedem Graphical User Interface geben. Testszum Einsatz der Technik in Archiven undBibliotheken und unter unterschiedlichenBedingungen werden momentan getestet undevaluiert.
Als Businessmodel ist eine Überführung desForschungsprojekts in eine Kooperative geplant,die den Stakeholdern möglichst niederschwelligeund kostengünstige Angebote unterbreiten soll(Mühlberger, Preprint). Somit vereint das ProjektREAD die unterschiedlichsten Ansprüche anAutomatisierungs- und Erkennungsroutinen undorientiert sich dabei an gängigen Arbeitsformenim Kontext mit handschriftlichen Dokumenten(siehe auch die Projekthomepage: http://read.transkribus.eu).
Aus- und Seitenblicke im WorkshopZwei unterschiedliche Forschungsaspekte aus
READ werden im Rahmen des Workshops alsInputs demonstriert:
Einerseits der Umgang mit einer speziellenDokumentenform, Kirchenbüchern, in denenstark strukturierte Daten aus Pfarreiengesammelt wurden (Wurster, 2014 / 2015).Aufgrund der Strukturerkennung und der HTRwird es möglich, spezialisierte Suchroutinen zuproduzieren.
Andererseits können aufgrund der erhobenenDaten und durch c omputer vision Profile
29

Digital Humanities im deutschsprachigen Raum 2017
der Schreibenden erstellt werden, die dieIdentifikation der Personen als Schreibendeweiterer Dokumente naheliegend macht (Fiel,2012). Beide Anwendungen versprechen für dieGeisteswissenschaften neue Zugänge zu grossenDatenschätzen, die in den handschriftlichenBeständen gehoben werden können.
Programm/Ablauf des WorkshopsEinführung in Transkribus ( Tobias Hodel,
Zürich): 30‘Aufbau und Funktionieren des Programms,Demonstration des Gebrauchs anhand vonBeispielen. Aufzeigen der Möglichkeiten zumEinsatz der Automatisierungen.
Strukturierte Daten in Kirchenbüchern ( Eva-Maria Lang, Passau): 30‘Demonstration vom Umgang mitKirchenbüchern, einer spezifischen und starkstandardisierten Dokumentform, die mitTranskribus aufbereitet werden. Eine Suche inden Dokumenten wird über eigene Routinen undAbfragemöglichkeiten gewährleistet.
Selbstständiges Arbeiten der Teilnehmendenmit Transkribus: 90‘Die Möglichkeiten und Grenzen von Transkribussollen von den Teilnehmenden (wenn möglichmit eigenen Dokumenten) selbst ausgetestetwerden.
Schreiberidentifizierung ( Stefan Fiel, Wien):30‘Ein über Transkribus hinausgehender Teil desProjekts beschäftigt sich mit computer vision.Ziel ist die Identifizierung unterschiedlicherPersonen als Schreibende. Stefan Fiel berichtetüber den Stand der Forschung und wieTeilnehmende die Hände wichtiger Schreibenderzur Verfügung stellen können.
Diskussion über Vor- und Nachteile derSoftware: 45‘Inklusive Evaluation des Tools und derVeranstaltung. Feedbacks werden eingeholt, zurVerbesserung der Software (usability, Umfangund Leistung der Automatisierungen etc.).
Das Projekt READ und somit dieWeiterentwicklung von Transkribus werdenfinanziert durch einen Grant der EuropäischenUnion im Rahmen des Horizon 2020 Forschungs-und Innovationsprogramms (grant agreementNo 674943).
Kontaktdaten aller Beitragenden (inkl.Forschungsinteressen)
Tobias Hodel, Staatsarchiv des KantonsZürich, Winterthurerstrasse 170, CH-8057Zürich, Schweiz; [email protected] (DigitalHumanities; Handwritten Textrecognition;eArchiving; Information Retrieval).
Eva-Maria Lang, Archiv des BistumsPassau, Luragogasse 4, DE-94032 Passau,
[email protected] (AutomaticText Recognition, Digital Archives, ImageRecognition and Information Retrieval, SoftwareArchitecture).
Stefan Fiel, Technische Universität Wien,Faculty of InformaticsInstitute of Computer Aided Automation,Computer Vision Lab, Favoritenstr. 9/183-2,A-1040 Vienna, Austria; [email protected](Bilderverarbeitung und Dokumentenanalyse).
Zahl der möglichen Teilnehmerinnen undTeilnehmer
30-40 Personen (auch abhängig von derRaumgrösse)
Benötigte technische Ausstattung:Allgemein: Beamer, evtl. Whiteboard.Teilnehmende: Eigener Rechner (wennmöglich Installation von Transkribus; Hilfe zurInstallation von Transkribus wird 30 Minutenvor der Veranstaltung angeboten)
Anmeldungen und Rückfragen bitte [email protected]
Bibliographie
Fiel, Stefan / Sablatnig, Robert (2012):„Writer Retrieval and Writer Identification usingLocal Features“, in: 10th IAPR InternationalWorkshop on Document Analysis Systems http://www.ict.griffith.edu.au/das2012/attachments/FullPaperProceedings/4661a145.pdf .
Leifert, Gundram / Strauß, Tobias /Grüning, Tobias / Labahn, Roger (2016): Cellsin Multidimensional Recurrent Neural Networkshttps://arXiv.org/abs/1412.2620v02 .
Mühlberger, Günter / Colutto, Sebastian /Kahle, Philip (Preprint): Handwritten TextRecognition (HTR) of Historical Documentsas a Shared Task for Archivists, ComputerScientists and Humanities Scholars: The Model ofa Transcription & Recognition Platform (TRP).
Pletschacher, Stefan / Antonacopoulos,Apostolos (2010): „The PAGE (page analysis andground-truth elements) format framework“, in:Proc. ICPR 257–260.
Puigcerver, Joan / Toselli, AlejandroHéctor / Vidal, Enrique (2015): „Probabilisticinterpretation and improvements to the hmm-filler for handwritten keyword spotting“, in: 13thinternational conference on document analysisand recognition (ICDAR).
Stamatopoulos, Nikolaos / Gatos, Basilis(2015): „Goal-oriented performance evaluationmethodology for page segmentation techniques“,in: 13th international conference on documentanalysis and recognition (ICDAR) 281–285.
30

Digital Humanities im deutschsprachigen Raum 2017
Toselli, Alejandro Héctor / Vidal, Enrique(2015): „Handwritten text recognition results onthe Bentham collection with improved classicaln-gram-HMM methods“, in: Internationalworkshop on historical document imaging andprocessing (HIP).
Wurster, Herbert W. (2015): „Schritt fürSchritt ins Internet – Europas Matriken online“,in: insights: Archives and people in the digital age2: 16–17.
Wurster, Herbert W. (2014): „Matrikeln - Einkulturhistorischer Blick auf die Kirchenbücher“,in: Zeitschrift für bayerische Kirchengeschichte83: 87–93.
Zagoris, Konstantinos / Pratikakis, Ioannis /Antonacopoulos, Apostolos / Gatos, Basilis /Papamarkos, Nikos (2012): „Handwritten andMachine Printed Text Separation in DocumentImages Using the Bag of Visual Words Paradigm“,in: Frontiers in Handwriting Recognition (ICFHR),2012 International Conference 103–108 10.1109/ICFHR.2012.207.
Einführung in dasPANDORA Linked OpenData Framework.
Johnson, [email protected] der Wissenschaften zu Göttingen,Deutschland
Wettlaufer, Jö[email protected] der Wissenschaften zu Göttingen,Deutschland
Beschreibung des Workshops[Zeitrahmen 4h]
Der Workshop stellt eine Softwarearchitekturvor, die zurzeit im Rahmen des Projekts„Johann Friedrich Blumenbach – online“der Göttinger Akademie der Wissenschaftenim Zusammenhang mit der geplantendigitalen Edition der gedruckten Werkeund naturhistorischen Sammlungen J.F.Blumenbachs (1752-1840) entwickelt wird.Bei der Konzeption stehen Interoperabilität,Erweiterbarkeit und Nachnutzung alszentrale Entwicklungsziele im Vordergrund.Ausgangspunkt des PANDORA [ Presentation
(of) ANnotations (in a) Digital Object RepositoryArchitecture] Linked Open Data (LOD)Frameworks sind digitale Abbildungen vonTexten und Objekten, die in einem FedoraCommons Repository(1) gespeichert und überdas International Image InteroperabilityFramework (IIIF) visualisiert werden. DasFramework ist insbesondere für den Einsatz imMuseumskontext und im Bereich der digitalenPräsentation von Kulturgutüberlieferunggeeignet. Dabei können sowohl text- also auchobjektbasierte Fragestellungen untersucht bzw.Kulturgüter präsentiert und digital verfügbargemacht werden. Ein besonderer Vorteil istdabei die Bereitstellung der Daten als LOD unddie Möglichkeit der Einbindung der Ressourcenin andere Kontexte. In dem Workshop sollendie Einsatz- und Nachnutzungsmöglichkeitensowie die Nachhaltigkeit dieser Architekturvorgestellt, diskutiert und anhand vonBeispielanwendungen zusammen mit denTeilnehmerinnen und Teilnehmern erprobtwerden.
PANDORA ist zunächst einmal eine Sammlungvon Open Source Anwendungen, die überein gemeinsames „Manifest“ Dokument diePräsentation der Daten für den Anwenderorganisieren. Das „Manifest“ besteht auseinem JSON-LD(2) Dokument und wird auseinem digitalen Objektrepositorium überdie dynamische Verwendung von SPARQL-Abfragen(3) erzeugt. Es orientiert sich dabeian der Semantik und dem Konzept der „IIIFPresentation API“(4). Diese Schnittstelledefiniert, wie die Struktur und das Layouteines komplexen und bild-basierten Objekts ineinem Standardformat dargestellt werden kannund zielt darauf ab, die Interoperabilität undErweiterbarkeit von Präsentationen basierendauf dem Open Annotation Datenmodell(5) zuerleichtern. In diesem Modell ist oa:Annotationjede Ressource, die aus zwei Komponentenbesteht, einen „body“ und einen „target“:
[Abb. 1: Annotation Datenmodell]
31

Digital Humanities im deutschsprachigen Raum 2017
In der IIIF Presentation API ist das Ziel ein"canvas" (eine Leinwand), der eine Abstraktiondes Client-Arbeitsplatz oder Sichtbereichsdarstellt. Die Annotation (body) kann mit jedemverknüpften oder eingebetteten Objekt wieeinem Bild, einer Beschreibung oder einemsemantischen Tag verlinkt sein. Die assoziativeBeziehungen zwischen verschiedenenAnnotation-„bodies“ auf einem „canvas“ sindmit der Linked-Data Semantik im Manifestinstanziiert. Die Segmentierung ermöglichtdie Auswahl eines Bereichs eines Bildes odereines „canvas“ unter Verwendung rechteckigerBegrenzungsrahmen oder mit der „IIIF ImageAPI“(6), einem „stream“ von Bildausschnitten.Hotspot Verknüpfungen ermöglichen es dieAuswahl auf ein Anmerkungsobjekt zu lenken,um eine Zustandsänderung in einem anderenAnnotationsobjekt auszulösen.
Die Annotationen existieren im Fedora-Repository als LDP Container(7), der ineiner Hierarchie von Ressourcen eine HTTP-adressierbare Ressource ist. Wenn der LDPContainer in einem Triple-Store überführtwird, existiert er dort als RDF Ressource undals sog. „Named Graph“(8). Der IIIF ManifestService unterstützt die Serialisierung bzw.„Kanonikalisierung“(9) des JSON-LD Dokumentsin Form einer geordneten Liste, die im RessourceDescription Framework als „collection"bezeichnet wird. Die Darstellung einer Manifest-Sequenz eines „canvas“ als RDF Sammlungerfordert die Verwendung von leeren Knoten,sog. „blank nodes“, die wie folgt miteinanderverwoben sind:
<LDP_Manifest_Sequence_Container>sc:hasCanvases _:c11 .
_:c11 rdf:first <http://localhost:8080/fcrepo/rest/edition/base/canvas/c000> .
_:c11 rdf:rest _:c001._:c001 rdf:first <http://localhost:8080/fcrepo/
rest/edition/base/canvas/c001> ._:c001 rdf:rest …Im Fedora-Repository wird ein „blank
node“ mit einer bekannten Skolem IRI [nachRFC5785(10)] repräsentiert.
Durch die Verwendung des PANDORA IIIFManifest Services(11) wird die Konstruktionvon Präsentationen aus SPARQL Abfragenerlaubt, die eine sehr differenzierte Darstellungder Annotationen über JSON-LD ermöglichen.Der Entwurf einer LDP Container-Hierarchieund von Sammlungs-Definitionen im Einklangmit der Semantik der IIIF Presentation API"Annotation-Liste"(12) und "Layer"(13) fürdie Darstellung von Textsequenzen (Zeilen,Wortgruppen, Absätze, Seiten, Kapitel, etc.) istein integraler Bestandteil von PANDORA. Das
folgende Schaubild verdeutlicht die Architekturdes Frameworks und die Verknüpfung und dasZusammenspiel der einzelnen Komponenten:
[Abb. 2: PANDORA Architektur]Mit einer klaren Trennung der Domain- und
Client-Rollen bietet das PANDORA FrameworkFlexibilität und Erweiterbarkeit für allemöglichen Web-Client Präsentationsmethoden.Darüber hinaus unterstützt PANDORA Node.jsInstanzen, die durch socket.io und Redis Pub/Sub(14) Ereignisse verbunden sind und dadurchRedundanz und Durchsatz für dezentraleasynchrone Operationen bieten. Das Frameworkbesteht aus aktueller Open Source Softwarenach Industriestandards für Linked Data.Dazu gehören das Fedora-Repository, ApacheJena, Apache Camel, Apache Karaf, OpenVirtuoso und Solr. Es ist gekennzeichnetdurch Interoperabilität, Flexibilität undErweiterbarkeit und erlaubt, durch dieVerwendung von Standard-Software, ebenfallseine Nachnutzung der Forschungsdatenüber Linked Open Data Schnittstellen. DieseDaten können über den SPARQL-Endpointentweder lokal integriert oder extern zurNachnutzung angeboten werden. WeitereInformationen finden sich im GitHub Repository.(15) Eine ausführliche Dokumentation sowieeine Webseite mit Links zum Download derKomponenten befinden sich in Vorbereitung.
Eine zentrale Herausforderung für langfristigangelegte Forschungsprojekte, wie sie imAkademienprogramm der Bund-Länder-Kommission in Deutschland mit Laufzeitenzwischen 15 und 25 Jahren üblich sind, ist dieNachhaltigkeit von Systemarchitekturen ineiner ständig fortschreitenden Entwicklungvon Standardisierung und Versionierung.PANDORA begegnet dieser Herausforderung miteinem entkoppelten Aufbau auf der Grundlagevon relativ unabhängigen voneinander
32

Digital Humanities im deutschsprachigen Raum 2017
agierenden Systemkomponenten, die bei Bedarfeinfach ausgetauscht werden können, ohnedie Grundfunktionalität zu gefährden. Aufder Ebene der Viewer können verschiedeneEntwicklungen wie z.B. mirador(16) eingesetztwerden, ohne dass eine spezielle Anpassungnotwendig ist. PANDORA setzt in Hinblick aufdie langfristige Verfügbarkeit auf Standardsaus dem Bereich des Semantik Web, die sichinzwischen weltweit durchgesetzt haben unddamit sehr wahrscheinlich auch in Zukunfteine aktive Weiterentwicklung des Frameworkserlauben. Darüber hinaus ermöglichen dieseStandards eine effiziente Vernetzung mitanderen Ressourcen im Web.
In dem Workshop sollen die einzelnenKomponenten des PANDORA Frameworksvorgestellt und deren Installation undKonfiguration erklärt werden. In einerTestumgebung, die für die Teilnehmer aufeinem Server im Internet zur Verfügung stehenwird, können Beispieldatensätze gespeichertund die Funktionalität des Frameworkserprobt werden. Ebenfalls ist vorgesehen, dievorgestellte Architektur der Software intensivzu diskutieren und mit anderen Lösungen fürdigitale Repositorien/Präsentationsumgebungenzu vergleichen.
Für die gewinnbringende Teilnahmesind Grundkenntnisse in Semantik WebTechnologien sowie Kenntnisse der verwendetenStandards und/oder Open Source Softwarevon Vorteil. Der Workshop eignet sich für eineGruppe bis etwa 15 Personen. Die Teilnehmersollten einen eignen Rechner/Laptop mitVerbindung zum Internet zur Verfügunghaben, um im interaktiven Teil des Workshopsdie Funktionalitäten von PANDORA selberausprobieren zu können. Die lokale Installationvon zusätzlicher Software wird voraussichtlichnicht notwendig sein. Wichtige Informationenüber die PANDORA Architektur können auchschon vorab in einem Video angesehen werden.(17)
Organisatoren des Workshops:
Christopher Hanna Johnson, MA.Projekt “Johann Friedrich Blumenbach-
online” der ADW GöttingenGeiststraße 1037073 Gö[email protected] oder
[email protected]://github.com/blumenbachForschungsinteressen: Semantik
Web Technologien, Digitale Editionen,Softwareentwicklung, Cultural Heritage Studies
---------------------------------------------------------------Dr. Jörg WettlauferDigitisation Coordinator / ResearcherAkademie der Wissenschaften zu Göttingen
(ADWG)Göttingen Centre for Digital Humanities
(GCDH)Papendiek 1637073 GöttingenGermanyTel. +49 551 39 20477 | 39 [email protected] / skype: joewettForschungsinteressen: Digitale
Geschichtswissenschaft,
33

Digital Humanities im deutschsprachigen Raum 2017
Semantik Web Technologien, DigitaleEditionen
Linkliste
http://fedorarepository.org/https://www.w3.org/TR/json-ld/https://www.w3.org/TR/sparql11-query/http://iiif.io/api/presentation/2.1/http://www.openannotation.org/spec/core/
core.htmlhttp://iiif.io/api/image/2.1/https://www.w3.org/TR/ldp/#ldpchttps://www.w3.org/TR/rdf11-concepts/
#section-rdf-graphhttps://json-ld.github.io/normalization/spec/http://www.rfc-editor.org/rfc/rfc5785.txthttps://github.com/blumenbach/iiif-manifest-
servicehttp://iiif.io/api/presentation/2.1/#annotation-
listhttp://iiif.io/api/presentation/2.1/#layerhttp://redis.io/topics/pubsubhttps://github.com/blumenbach/http://github.com/IIIF/miradorFür ein einführendes Video zur PANDORA
Architektur siehe: https://youtu.be/TEqUkiO6tcA
HowTo build a your own»Digital Edition Web-App«
Kampkaspar, [email protected] August Bibliothek Wolfenbüttel,Deutschland
Andorfer, [email protected]Österreichische Akademie der Wissenschaften– Austrian Centre for Digital Humanities, Wien,Österreich
Baumgarten, [email protected] August Bibliothek Wolfenbüttel,Deutschland
Steyer, [email protected] August Bibliothek Wolfenbüttel,Deutschland
Motivation
Aufgrund zahlreicher Sommer-Schulen,Workshops, DH-Studiengänge und vielfältigeronline-Tutorials ist die Kodierung eines Textesin XML nach dem de-facto-Standard TEI einoft anzutreffender Projektbestandteil. Wasjedoch häufig fehlt sind einstiegsfreundlicheAnleitungen, Tutorials, HowTos zu dem sich andie Kodierung anschließenden Themenkomplexder Publikation einer digitalen Edition. Die Fragenach dem »Wohin?« der oftmals in langer undmühsamer Arbeit erstellten Editionen betrifftvor allem jene Forschende, welche nicht Teileines größer angelegten Projektes sind oder auchsonst über keine allzu starke Anbindung an einegut institutionalisierte Forschungsinfrastrukturverfügen. Zwar entwickeln zunehmendmehr Institutionen, vielfach in Verbindungmit konkreten Projekten, Kompetenzen,Workflows und (technische) Infrastrukturen zurVeröffentlichung Digitaler Editionen, aufgrundchronisch knapper Finanzierung können oftmalsaber nur wenige und in erster Linie nur eigene/interne Projekte hinreichend betreut werden.
Gleichzeitig kann in vielen DigitalenEditionsprojekten eine sehr starreArbeitsteilung zwischen so genanntenFachwissenschlafterInnen und TechnikerInnenbeobachtet werden. Obwohl es sicherlich nichtals Nachteil bewertet werden kann, wenn jederdas tut, wofür er ausgebildet wurde und was siebzw. er demzufolge auch gut kann, so besteht ineinem stark arbeitsteiligen Umfeld die Gefahrasymmetrischer Kompetenzverhältnisse unddaraus resultierender Abhängigkeiten. Seies durch unrealistische Wünsche seitens derFachwissenschaft, die aufgrund mangelndertechnischer Kenntnisse an die Technikherangetragen werden. Oder sei es dieVerzögerung des Arbeitsfortschritts aufgrundschleppender Implementierung basalerTechnologien oder von editorischer Seitedringend benötigter Funktionalitäten.
Der hier vorgeschlagene Workshop versucht,beide Problembereiche aufzugreifen, indemgemeinsam mit den Teilnehmern, welchevorzugsweise ihre eigenen XML/TEI Datenmitbringen, eine auf der XML-Datenbank eXistbasierte Web-Applikation zur Publikationeigener Editionen entwickelt wird.
34

Digital Humanities im deutschsprachigen Raum 2017
Die Applikation
Die Anforderungen für eine solcheApplikation stehen in engem Zusammenhangmit der im Kontext dieses Workshopsverwendeten Vorstellung über die Eigenschaftenund über potentielle Verwendungszwecke einerDigitalen Edition. Zur Erläuterung: Unter demBegriff »Digitale Edition« sollen ein kohärenterText oder mehrere kohärente Texte verstandenwerden, die mittels XML/TEI kodiert wurdenund worin in der Regel verschiedene Entitätenwie z.B. Personen, Orte, Werke oder ähnlicheserfasst, deren Form und Textgenese beschriebenund die um weiterführende Erläuterungen,Annotationen und Anmerkungen ergänztwurden. Eine solche Digitale Edition wirdvorwiegend im ›close reading‹ rezipiert mitdem Zweck, ein tieferes Verständnis über denText, dessen Inhalt sowie dessen Kontext undEntstehung zu erhalten. Abgesehen von einersolchen eher traditionellen Auseinandersetzungmit einer Digitalen Edition verfügt diese aberauch über den Mehrwert, systematisch und vorallem maschinell gelesen werden zu können.
Eine ›Digital Edition Web-App‹ sollteganz generell die kodierten Texte in einermöglichst benutzerfreundlichen Art und Weisepräsentieren und den »technischen Unterbau«dem Benutzer nicht aufbürden, wohl aber diecomputergestützte Weiterverarbeitung der Textejederzeit ermöglichen. Konkreter formuliertheißt das, dass eine solche Anwendung folgendeAnforderungen zu erfüllen hat.
Einstiegsseite
NutzerInnen sollen auf einer zentralenEinstiegsseite einen möglichst vollständigenÜberblick über den kompletten Umfang derEdition erhalten. Dies ist insbesondere dannvon großer Bedeutung, wenn die Edition ausmehreren Editionseinheiten besteht, wie zumBeispiel im Falle eines Briefwechsels.
In der im Zuge des Workshops zuentwickelnden Applikation wird das in Formeiner ListView gelöst, welche sämtliche XML/TEIDokumente bzw. ausgewählte Informationen ausdem teiHeader in einer von den NutzerInnensuch-, filter- und sortierbaren Ansichtpräsentiert. Von diesem Inhaltsverzeichnisgelangen die NutzerInnen dann über Verlinkungzu den einzelnen Dokumenten.
Responsive Design
Da Digitale Editionen im www verfügbarsind, muss davon ausgegangen werden, dassdiese generell in digitaler Form, sprich aufeinem PC, Notebook, Tablet, eventuell auchauf einem Smartphone gelesen werden.Insofern gilt es, den kodierten Text in einerleserfreundlichen Darstellung anzuzeigen, diedie verschiedenen Formate der Anzeigegeräteberücksichtigt (womit einige der Grundlagen dessog. ›responsive design‹ berücksichtigt werdenmüssen). Andererseits darf aber der Wunschvieler Nutzer, die Inhalte »klassisch« auf Papierzu nutzen, nicht vergessen werden.
Die digitale Darstellung im Weberöffnet indes auch die Möglichkeit fürdynamische, sprich von den Nutzer/innen freikonfigurierbare, Darstellungsweisen. Abhängigvom konkreten Mark-Up können, um nur einpaar Beispiele zu nennen, etwa Anmerkungenein- oder ausgeblendet, Abkürzungen aufgelöst,oder Korrekturschritte ausgeblendet werden.
In der ›Digital Edition Web-App‹ wird mittelsXSLT Transformation aus den XML Dateieneine HTML Dokument ›on the fly‹ generiert.Diese ›DetailView‹ verfügt, sofern aufgrund desMarkups des Ausgangsdokumentes möglich,über ein Navigationsmenü, welches eine rascheOrientierung im Text ermöglicht. Über einweiteres Menü können außerdem verschiedeneDarstellungsoptionen (de)aktiviert werden.
Suche
Die Möglichkeit, eine digitale Edition in ihrerGesamtheit im Volltext durchsuchen zu können,wird häufig als einer der größten Vorzüge einerdigitalen Edition beschrieben. Zusätzlich zueiner so genannten »einfachen Suche« wirddarüber hinaus auch gerne eine »erweiterteSuche« angeboten, welche eine spezifizierteSuche wie zum Beispiel nur in Anmerkungenoder über Metadaten ermöglicht.
Aufgrund der Integration der Volltext-Suchengine Lucene in die DatenbanksoftwareeXist-db ist die Realisierung sowohl einer»einfachen« wie auch einer »erweiterten«Suche im Rahmen der ›Digital Edition Web-App‹einfach zu bewerkstelligen, wobei die Spezifikader »erweiterten« Suche vom konkreten Markupder einzelnen Editionen abhängt.
Einige grundlegende Überlegungen zumErstellen einer Suche werden hierbei anhandkonkreter Beispiele mit den Teilnehmerndiskutiert und demonstriert werden.
35

Digital Humanities im deutschsprachigen Raum 2017
Register
Neben einer Volltextsuche bieten vieledigitale Editionen auch eine registerbasierteSuche an, mit deren Hilfe etwa gezielt Personenoder Orte in der Edition identifiziert werdenkönnen.
Je nach Art der Daten wird ein solchesRegister auf verschiedene Weisen demonstriertwerden.
PDF-Erzeugung
Als Nachteil einer digitalen Edition wird oftangesehen, dass ihr die Möglichkeit, einfacheAnmerkungen – ähnlich einem eigenenStudienexemplar – anzubringen, fehlt. Ausdiesem und anderen Gründen wird häufig dieHTML-Seite ausgedruckt.
Im Rahmen des Workshops werden hierzuzwei verschiedene Lösungswege kurz umrissen,ohne jedoch weiter ins Detail gehen zu können:Einerseits handelt es sich um ein für den Druckspezifisch erarbeitetes CSS-Stylesheet (»print-CSS«), andererseits die Generierung einer Dateifür das Satzprogramm LaTeX.
Schnittstellen
Da die Texte in einer (einigermaßen)standardisierten Art und Weise kodiert sind,können diese auch maschinell prozessiertwerden. Dafür ist es notwendig, dass nicht nureine HTML Darstellung der Daten veröffentlichtwird, sondern auch die eigentlichen XML/TEI-Daten.
Die ›Digital Edition Web-App‹ wird ihre Datenüber die in der eXist-db integrierte ›REST-StyleWeb API‹ veröffentlichen.
Ziel und Zielgruppe desWorkshops
Ziel des Workshops ist es, denTeilnehmerInnen einen ersten Einblick inweit verbreitete Workflows, Technologienund Terminologien sowie Konzepte zurUmsetzung der genannten Funktionalitätenzu vermitteln. Sie erhalten somit Grundlagenzur Weiterentwicklung oder auch Beurteilunganderer Plattformen und Tools.
Die von den TeilnehmerInnen im Zugedes Workshops erarbeitete Web-App wird
– auch aufgrund der Heterogenität der vonden TeilnehmerInnen gestellten Daten –keine produktionsreife Applikation sein, diealle Aspekte einer digitalen Edition umsetzt.Allerdings bildet die im Workshop teilweiseselbst geschriebene Software eine solide Basisfür weiteres Selbststudium, woraus sich späterfür die einzelnen Teilnehmer oder Institutioneneinfache, aber auf die spezifischen Bedürfnissezugeschnittene Plattformen entwickeln können.
Die TeilnehmerInnen des Workshops solltenüber Erfahrung in der Kodierung in XML/TEIverfügen und im besten Fall an einem konkretenProjekt arbeiten und über XML/TEI Dateienverfügen, auf deren Grundlage sie im Workshopihre eigene ›Digital Edition Web-App‹ entwickelnkönnen.
Ablauf und Teilnehmeranzahl
Die TeilnehmerInnen erhalten vorab einedetaillierte Anleitung zur Installation dernotwendige Software (eXist-db).
Im eigentlichen Workshop werden diejeweiligen Arbeitsschritte von einem derOrganisatoren live vorgeführt (dafür wirdein Beamer benötigt). Die konkreten Inhalteorientieren sich dabei an dem gleichnamigenBlog (Andorfer/Kampkaspar 2016), welchervon den Organisatoren im Rahmen der TEI-Konferenz 2016 offiziell präsentiert wurde.
Während des Workshops werden wir beiauftretenden Fragen und Problemen denTeilnehmenden helfend zur Seite stehen.Um eine möglichst gute Betreuung derTeilnehmerInnen gewährleisten zu können,sollte die Teilnehmerzahl 25 nicht überschreiten.
Organsiatoren
Peter Andorferhat im Zuge seiner Dissertation eine digitale
Edition erstellt und war im Editionsprojekt»Die Korrespondenz von Leo von Thun-Hohenstein« für die technische Umsetzung desProjektes (Entwicklung der Web-Applikation)verantwortlich. Gemeinsam mit DarioKampkaspar schreibt er außerdem für den Blog»HowTo build a digital edition web app«.
Dario Kampkasparerstellt im Rahmen seines
Dissertationsprojektes eine Edition einerfrühneuzeitlichen Handschrift. An der HAB ist erim Rahmen zweier Projekte (Andreas Bodensteinvon Karlstadt; Johannes Rist) intensiv mit Editionund Entwicklung beschäftigt. Gemeinsam mit
36

Digital Humanities im deutschsprachigen Raum 2017
Peter Andorfer schreibt er außerdem für denBlog »HowTo build a digital edition web app«.
Marcus Baumgartenist langjähriger Mitarbeiter an der HAB und
betreut unterschiedliche Editionsprojekte. ZurZeit arbeitet er in einem Kooperationsprojektmit dem historischen Seminar der UniversitätFreiburg (die »Tagebücher des Fürsten ChristianII. von Anhalt-Bernburg«) und gemeinsam mitdem Leibniz-Institut für europäische Geschichtein Mainz (»Digitale Edition europäischerReligionsfrieden zwischen 1500 - 1800«).
Gemeinsam mit Timo Steyer undStudierenden der TU Braunschweig betreibt erdas Weblog www.digital-ist-besser.net
Timo Steyerist aktuell in den Bereichen Metadaten und
Datenmodellierung im ForschungsverbundMarbach Weimar Wolfenbüttel am StandortWolfenbüttel tätig. In diesem Kontext beschäftigter sich mit Fragen und Methoden zu denThemen der Interoperabilität von digitalenEditionen und der Retrodigitalisierung vonbereits im Druck vorliegenden Editionen (z. B.»Controversia et Confessio« und »Die Briefe derFruchtbringenden Gesellschaft«).
Bibliographie
Andorfer, Peter / Kampkaspar, Dario(2016): How to build a Digital Edition Web-Apphttp://www.digital-archiv.at/howto-build-a-digital-edition-web-app/ .
NachhaltigesManagement vonBildmetadaten mit XMP,exiftool und Fotostation
Pohl, [email protected] Akademie derWissenschaften, Deutschland
Schrade, [email protected] der Wissenschaften und LiteraturMainz, Deutschland
Das Corpus VitrearumDeutschland als Use Case
Das interakademische Vorhaben zurmittelalterlichen und frühneuzeitlichenGlasmalereiforschung „Corpus Vitrearum MediiAevi“ (CVMA) in den Arbeitsstellen Potsdamund Freiburg steht derzeit der Herausforderunggegenüber, die im neu eingerichteten CVMA-Online-Bildarchiv 1 hinterlegten Bilddateiensamt Metadaten für die Langzeitarchivierungund -lesbarkeit vorzubereiten.
Das Hauptziel des CVMA ist es, alleGlasmalereien des Mittelalters fotografisch zuerfassen, zu dokumentieren und zu edieren, umnicht nur das kulturelle Erbe zu bewahren undins digitale Zeitalter zu überführen, sondernauch räumliche Distanzen zu überbrückenund die Glasmalereifotografien samt ihrerDokumentation der Öffentlichkeit zugänglich zumachen.
Für die zielgerichtete Dokumentation hatdas CVMA ein eigenes Metadatenschemaverfasst 2 , welches auf etablierte Schematawie Dublin Core (Weibel et al. 1998) und IPTC(IPTC 2014) aus der professionellen Fotografieaufbaut und diese mit einem speziell auf diewissenschaftlichen Bedarfe der Glasmalereiausgerichteten eigenen Namensraumerweitert. Dabei werden die Metadatenin das zugehörige Bild integriert, um sozusätzliche Abhängigkeiten von Datenbank- oderanderer Verwaltungssoftware zu vermeiden.Dadurch wird die plattformabhängige Nutzungund maschinelle Interpretierbarkeit desDatenbestands gefördert, was nötig ist, damitdie Daten auch in Zukunft von Mensch undMaschine nachgenutzt werden können (Libraryof Congress und National Science Foundation2003).
XMP
Zur Lösung der Herausforderungen imBereich Langzeitarchivierung orientiert sich dasCVMA an den bereits bestehenden Lösungen ausder digitalen Dokument-Langzeitarchivierungvon PDF-Dateien (Braun et al. 2010; ISO 2011),bei welcher sämtliche genutzte Abbildungen,Schriftarten und Metadaten mit in dasDokument eingebettet werden, sodass dieseDatei letztendlich alle Inhalte originalgetreuohne Zuhilfenahme dritter Anwendungenanzeigen kann.
37

Digital Humanities im deutschsprachigen Raum 2017
Der PDF-Standard (Adobe Systems 2006) nutztfür die Integration von Metadaten die eXtensibleMetadata Platform (XMP), mit welcher diezum Dokument zugehörigen Metadaten alsRDF/XML kodiert in das Dokument eingebettetwerden (Adobe Systems 2005; Bright 2006)ohne die digitale Interpretierbarkeit der zubeschreibenden Datei zu beeinflussen. Wird dieDatei von einem Programm geöffnet, welchesden XMP-Standard nicht unterstützt, wird dieseDatei dennoch angezeigt. Umgekehrt ist esmöglich, dieselbe Datei mit einem Texteditorzu öffnen, um die XMP Daten in Reintextformanzuzeigen.
Die Nutzung von XMP hat sich bereits aufmehreren Ebenen etabliert. Zu einem werdenbeim Abspeichern von DigitalfotografienEXIF- und IPTC-Daten von Digitalkamerasals XMP in die erzeugten Bilddateiengeschrieben (Tesic 2005) und können so durchBildverwaltungssoftware wie Adobe Bridge3 oder FotoWare Fotostation 4 gelesen undverwaltet werden. Des Weiteren wird XMP inder Digital Asset Management Community fürdie einfache Verwaltung von Dateibeständenbevorzugt genutzt (Regli 2009). Durch die Einheitvon Dokument und Metadaten verringertsich der Aufwand bei einem Datentransfersämtlicher Abhängigkeiten auf das Kopierendes Datenbestands (Binder 2006) und hältgleichzeitig die Möglichkeit offen, Datenbankenaus den vorliegenden XMP-Daten zu erstellenund auf die XMP-Daten aufbauende Tools zuimplementieren (Abdillah 2013). Der Kern vonXMP liegt inzwischen auch als ISO-Standardvor. 5 Das CVMA-Onlinebildarchiv dient hierfürals Beispiel, da sich die relationale Datenbankder Online-Plattform aus den XMP-Daten desverfügbaren Bildbestandes speist.
Ein weiterer Faktor für die internationaleVerbreitung des XMP-Standards ist seineErweiterbarkeit. Demnach ist es möglich,eigene Metadatenschemata als XMP anDateien anzuhängen. Zwar ist dieser Anhangals RDF/XML kodiert, allerdings besteht dieRestriktion kein RDFS und OWL nutzen zukönnen (Eriksson 2007). Das einzig gültigeSubjekt in den RDF-Tripeln in XMP ist die zubeschreibende Ressource, also die Datei selbst.Es ist also nicht möglich Ontologien wie imherkömmlichen Semantic-Web-Kontext zuverwenden. Für das CVMA-Bildarchiv genügtes jedoch, die beschreibenden Metadaten fürdie einzelnen Bildressourcen anzulegen und soden Funktionsumfang des XMP-Standards vollauszuschöpfen.
XMP Workflow beim CVMA
In Deutschland haben die zwei CVMA-Arbeitsstellen in Potsdam und Freiburgunterschiedliche Workflows implementiert,um XMP-Daten in die Bilddateieneinzupflegen. Beide benutzen zwar dasselbeMetadatenschema, allerdings unterscheiden sichdie Tools zur Eingabe der Metadaten und diedamit verbundenen Arbeitsabläufe.
Um sich für das Vorhaben der deutschenCVMA-Arbeitsstellen zu eignen, muss eineentsprechende Metadatenbearbeitungssoftwarefolgende Kriterien erfüllen: a) Die Softwaremuss fähig sein, XMP-Metadaten zu schreibenund auszulesen. b) Die Software muss dieAnzeige und Metadatenmanipulation vongängigen Bilddateiformaten wie TIFF undJPG unterstützen. c) Die Software muss dieMöglichkeit zur Konfiguration eines eigenenMetadatenschemas anbieten. d) Optional:Die Software bietet die Möglichkeit zurlokalen Recherche mit dem im c) angelegtenMetadatenschema.
Das Team in Freiburg nutzt dieFreeware exiftoolGUI 6 , welche einekonfigurierbare graphische Oberfläche fürdas Kommandozeilentool exiftool 7 bietet.exiftool selbst ist ein Programm zum Auslesenund zur Manipulation von Bildmetadaten undunterstützt das Lesen und Schreiben von XMP-Daten. Über eine Perl-Konfigurationsdateikann das anzuwendende Metadatenschemafür Datenmanipulationen via exiftool undsomit auch exiftoolGUI festgelegt werden. Dieinhärenten Vorteile von exiftool und exiftoolGUIsind deren Offenheit, Konfigurierbarkeitund Plattformunabhängigkeit. Die Nutzungvon exiftoolGUI für größere Bildbestände istjedoch eher unkomfortabel, da dieses Toolausschließlich zur Metadatenmanipulation undnicht als Bildverwaltungssoftware ausgelegt ist.
Die CVMA-Arbeitsstelle in Potsdam nutzthingegen die proprietäre Software FotoStationvon FotoWare (Version 8.0). Zwar liegt derQuellcode dieser Software nicht offen, jedochbesteht auch bei diesem Tool die Möglichkeitzur Konfiguration eigener Metadatenschemata.FotoStation bietet deutlich mehr Bedienkomfortim Vergleich zu exiftoolGUI und kann alsBildverwaltungssoftware genutzt werden,welche den lokalen Bildbestand samt Metadatenfür Recherchen indexiert und die Bilder aufeinem digitalen Lichttisch darstellt. Für dieKonfiguration des Metadatenschemas bietetFotoStation graphische Editoren, mit welchem
38

Digital Humanities im deutschsprachigen Raum 2017
nicht nur die zu verwendenden Namensräumeund Felder definiert werden können, sondernauch das Metadateneingabeinterface freigestaltet werden kann. Dabei ist es möglichkontrollierte Vokabulare zu anzulegenund die Nutzereingaben über reguläreAusdrücke validieren zu lassen. Weiterhinlässt sich die Gesamtkonfiguration vonFotostation leicht ex- und importieren,sodass sämtliche Informationen zumverwendeten Metadatenschema, Editorinterface,Vorschlagslisten, Bearbeitungsaktionen undRerchercheeinstiege leicht innerhalb des Teamsausgetauscht und aktualisiert werden können.
Ziele des Workshops
Die Teilnehmer an diesem Workshopsollen einen Einstieg in die nachhaltigeBildmetadatenverwaltung mit XMP erhalten. AlsÜbung wird mit den Teilnehmern gemeinsamzuerst ein Beispiel-Metadatenschema definiert.Anschließend werden die Teilnehmer in dieBenutzung von exiftoolGUI und FotoStationeingeführt, um daraufhin das zuvor definierteMetadatenschema für beide Tools umzusetzenund zu testen. Weiterhin wird das Abfragenvon XMP-Metadaten mit dem exiftool über dieKommandozeile geübt, um so das Potential vonXMP für die Erstellung von Tools, Services oderDatenbanken für Bildbestände aufzuzeigen.
Das CVMA-Deutschland erhofft sich,Interessierten und ähnlichen Projekten denEinstieg in die Erstellung und Manipulationvon XMP-Daten zu erleichtern und gleichzeitigweitere Lösungsansätze und Tools für denUmgang mit XMP-Daten kennenzulernen.
Für die Teilnahme an diesem Workshopwerden lediglich Grundkenntnisse inXML vorausgesetzt. Die Kenntnisse einerProgrammier- oder Skriptsprache sind zwarvon Vorteil, aber nicht erforderlich. DenTeilnehmern entstehen für die Nutzung vonSoftware während des Workshops keine Kosten,da exiftool und exiftool GUI kostenfrei sindund Fotostation für 14 Tage kostenfrei getestetwerden kann. Der Workshop ist für maximal 20Teilnehmer ausgelegt.
Forschungsinteressen
Oliver Pohl ist wissenschaftlicher Mitarbeiterbei TELOTA an der Berlin-BrandenburgischenAkademie der Wissenschaften und betreutdort das CVMA, das Langzeitvorhaben CorpusCoranicum sowie das Kooperationsprojekt
Paleocoran mit dem Collège de France. SeineForschungsinteressen sind Webtechnologienund Semantic Web Technologien für digitaleGeisteswissenschaften als auch maschinelleÜbersetzung.
Torsten Schrade ist Leiter der DigitalenAkademie der Mainzer Akademie derWissenschaften und der Literatur undbeschäftigt sich vorrangig mit demForschungsdatenmanagement und demEinsatz von Webtechnologien für diegeisteswissenschaftliche Grundlagenforschung.Daneben zählen Methoden undProgrammierparadigmen der agilenSoftwareentwicklung sowie die Technologien desSemantic Web zu seinen Forschungsinteressen.
Fußnoten
1. http://www.corpusvitrearum.de2. http://www.corpusvitrearum.de/cvma/1.1/(Stand: 25.08.2016)3. http://www.adobe.com/de/products/bridge.html4. http://www.fotoware.com/products/fotostation-client5. http://www.iso.org/iso/catalogue_detail?csnumber=574216. http://u88.n24.queensu.ca/~bogdan/ bzw.https://hvdwolf.github.io/pyExifToolGUI/7. http://www.sno.phy.queensu.ca/~phil/exiftool/
Bibliographie
Abdillah, Leon Andretti (2013): „PDFArticles Metadata Harvester“, in: arXiv PreprintarXiv:1301.6591. http://arxiv.org/abs/1301.6591[letzter Zugriff 25. August 2016].
Adobe Systems (2005): Extensible MetadataPlatform (XMP) Specification. Adobe Systemshttps://partners.adobe.com/public/developer/en/xmp/sdk/XMPspecification.pdf [letzter Zugriff 25.August 2016].
Adobe Systems (2006): PDF Reference, SixthEdition: Adobe Portable Document FormatVersion 1.7 http://wwwimages.adobe.com/content/dam/Adobe/en/devnet/pdf/pdfs/pdf_reference_1-7.pdf [letzter Zugriff 25. August2016].
Binder, Jennifer (2006): „Exchanging Assetsand Metadata across Platforms“, in: Journal ofDigital Asset Management 2 (5): 215–18 10.1057/palgrave.dam.3650045.
Braun, Kim / Buddenbohm, Stefan /Dobratz, Susanne / Herb, Ulrich / Müller,Uwe / Pampel, Heinz / Schmidt, Birgit
39

Digital Humanities im deutschsprachigen Raum 2017
(2010): DINI-Zertifikat Dokumenten-UndPublikationsservice 2010 https://pub.uni-bielefeld.de/publication/2491543 [letzter Zugriff25. August 2016].
Bright, Jason (2006): „First Steps: XMP“, in:Journal of Digital Asset Management 2 (3–4): 198–202 10.1057/palgrave.dam.3650025.
Eriksson, Henrik (2007): „The Semantic-Document Approach to Combining Documentsand Ontologies“, in: International Journal ofHuman-Computer Studies 65 (7): 624–639.
IPTC (2014): IPTC - NAA InformationInterchange Model Version 4.2. InternationalPress Telecommunicatoins Council http://www.iptc.org/std/IIM/4.2/specification/IIMV4.2.pdf [letzter Zugriff 25. August 2016].
ISO (2011): ISO 19005-1:2005 - DocumentManagement -- Electronic Document File Formatfor Long-Term Preservation -- Part 1: Use ofPDF 1.4 (PDF/A-1) http://www.iso.org/iso/home/store/catalogue_tc/catalogue_detail.htm?csnumber=38920 [letzter Zugriff 25. August2016].
Library of Congress / National ScienceFoundation (2003): It’s About Time: ResearchChallenges in Digital Archiving and Long-TermPreservation http://www.digitalpreservation.gov/documents/about_time2003.pdf [letzter Zugriff25. August 2016].
Regli, Theresa (2009): „The State of DigitalAsset Management: An Executive Summary ofCMS Watch’s Digital Asset Management Report“,in: Journal of Digital Asset Management 5 (1): 21–26.
Tesic, Jelena (2005): „Metadata Practices forConsumer Photos“, in: IEEE MultiMedia 12 (3):86–92.
Weibel, Stuart / Kunze, John / Lagoze, Carl /Wolf, Misha (1998): Dublin Core Metadata forResource Discovery http://www.rfc-editor.org/info/rfc2413 [letzter Zugriff 25. August 2016].
open your data, openyour code: OffeneLizenzierung fürgeisteswissenschaftlicheProjekte
Hannesschläger, [email protected] Austrian Centre for DigitalHumanities, Österreichische Akademie derWissenschaften, Österreich
Losehand, [email protected] commons Austria
Kamocki, Paweł[email protected] Mannheim, Deutschland
Scholger, [email protected] Zentrum fürInformationsmodellierung - Austrian Centre forDigital Humanities, Karl-Franzens-UniversitätGraz, Österreich
Witt, [email protected] Mannheim, Deutschland
Amini, [email protected] Austria
Einleitung
In Diskussionen über digitale Nachhaltigkeitsind rechtliche Fragen von zunehmenderBedeutung. Häufig entscheiden die rechtlichenRahmenbedingungen, ob, wie und wie langeDaten und Programme, die im Rahmenvon digitalen geisteswissenschaftlichenForschungsprojekten entwickelt werden,verfügbar sind. Gerade im digitalen Raum, dernationale Grenzen überschreitet, ergibt sich -auch aufgrund der territorialen Beschränkungdes jeweiligen Urheberrechts - die Notwendigkeit
40

Digital Humanities im deutschsprachigen Raum 2017
neuer rechtlicher Regelungen, die einerseitsdas Urheberrecht des Forschenden schützen,andererseits die Wiederverwendbarkeitihrer Arbeiten sicherstellen sollen. OffeneLizenzierungsmodelle bieten hier Lösungen,die internationale Forschung an lokal erzeugtenDaten und mit individuell entwickeltenSoftwares ermöglichen.
In den Geisteswissenschaften, in denen diePublikation von und die Arbeit mit “Rohdaten”im Rahmen der digitalen Wende substantiellan Bedeutung gewonnen haben, beginntdie Forschungscommunity zunehmend,sich diesem Thema im Kontext von OpenAccess-Diskussionen zu widmen. Obwohldas Bewusstsein für die Notwendigkeit derAuseinandersetzung mit diesen rechtlichenAspekten zunimmt, fehlt den Forschendenoft der Überblick über die unterschiedlichenMöglichkeiten der Lizenzierung ihrer Daten.Creative Commons-Lizenzen sind weltweit dasetablierteste Modell. Während sie in vielenFällen eine gute Lösung sind, kommen siehäufig auch nur deshalb zum Einsatz, weilden Forschenden Informationen über andereLizenzierungsmodelle fehlen. Auch wennCreative Commons-Lizenzen angemessensind, herrscht in vielen Fällen oft Unklarheitund Unsicherheit über die Wahl der konkretgeeigneten Lizenz. Noch komplexer ist dieLandschaft an verfügbaren Software-Lizenzen.
Dieser Workshop möchte zur Informationund Aufklärung der Community beitragen,indem zuerst ein allgemeiner Überblicküber die unterschiedlichen nationalenrechtlichen Rahmenbedingungen undüber verfügbare Daten- und Software-Lizenzen gegeben wird, bevor im zweitenTeil lizenzierte Beispielprojekte vorgestelltwerden. Eingegangen wird auch auf dieunterschiedlichen Materialtypen (z.B.Manuskript-, Photodigitalisate) und den umgangmit “verwaisten Werken”. Erwartet wird einPublikum, das sich einen Überblick über dieLizenz-Möglichkeiten, die sich für einzelneProjekte bieten, verschaffen und die passendeLizenz für das jeweils eigene Projekt findenmöchte. Dazu dient der dritte Abschnitt desWorkshops, der in der Art einer offenen Sitzunggestaltet ist, in der nach einer Einführungzu Lizenzierungstools Projekte aus demPublikum diskutiert werden. Die Beitragendensind Expert/innen für Lizenzierungs- undRechtsfragen und wünschen sich den Austauschmit Forschenden, die sich ebenfalls mit diesenThemen beschäftigen.
Daten-Lizenzen
Creative Commons (CC)
Creative Commons (CC) ist eine Non-Profit-Organisation, die eine Auswahl an Standard-Lizenzverträgen zur öffentlichen Nutzungvon Werken für juristische Laien entwickelthat. Der Ausgangspunkt dafür war, dass“[t]he idea of universal access to research,education, and culture is made possible by theInternet, but our legal and social systems don’talways allow that idea to be realized.” ( https://creativecommons.org/about/ ) CC-Lizenzensind standardisierte Lizenzen, die durch dieCreative-Commons-Stiftung entwickelt undausformuliert wurden und Rechteinhabendenzur freien Verwendung zur Verfügung stehen.Sie sind vorrangig für den Einsatz bei digitalenWerken und der Verbreitung im Internetgeschaffen worden, lizenzieren aber gleichzeitigauch die Verwendung im nicht-digitalenBereich (Druckwerke); sie umfassen alle(wesentlichen) urheberrechtlichen undleistungsschutzrechtlichen Aspekte.
CC-Lizenzen der Versionen 1.0 bis 3.0 wurdenvielfach mit nationalen Recht akkordiert (d.h.“portiert”) und so in spezifischen nationalenVarianten zur Verfügung gestellt. Ab Einführungder aktuellen Version 4.0 erfolgten keinespezifischen nationalen Adaptierungenmehr, um eine einheitliche, internationalgültige Lizenzierung und Rechtssicherheit zugewährleisten. In jedem Fall sind aber - wie beiallen Einzel- und Massenlizenzen - die jeweilsgeltenden nationalen urheberrechtlichen bzw.internationalen Regelungen vorrangig unddeshalb zu beachten.
Alle nach geltendem Recht urheberrechtlichschutzwürdigen Werke können durch dieRechteinhabenden zu jeder Zeit mit CreativeCommons (neu) lizenziert werden. Eine einmalerteilte CC-Lizenz kann grundsätzlich nichtwiderrufen und damit erteilte Nutzungsrechtekönnen grundsätzlich nicht eingeschränktwerden, jedoch kann die Lizenz in eineweniger einschränkende Lizenz umgewandeltwerden. Davon sollte jedoch nur in einzelnenAusnahmefällen Gebrauch gemacht werden.
CC-Lizenzen bestehen aus mehrerenModulen, wobei die Zusammensetzung nichtvon den Lizenzgebenden gewählt werden kann,sondern vorgegeben ist.
In den Digital Humanities hat es sichzum de-facto-Standard entwickelt, Projekte,Daten und Ergebnisse unter CC-Lizenzen zur
41

Digital Humanities im deutschsprachigen Raum 2017
Verfügung zu stellen, wobei die Unterschiedezwischen den verschiedenen Versionen,portierten und nicht portierten Fassungenund unterschiedlichen Lizenz-Inhalten oft zuUnklarheiten führen. In diesem Workshopwerden daher die Grundlagen des CC-Modellserklärt und zahlreiche weitergehende Aspekteerläutert.
Digital Peer Publishing (DiPP/DPPL)
Das Hochschulbibliothekszentrum desLandes Nordrhein-Westfalen (hbz) stellt zurErleichterung der Publikation von Open Access-Journals das System Digital Peer Publishing(DiPP) zur Verfügung, in dessen Rahmen auchdie Digital Peer Publishing Lizenzen (DPPL)entwickelt wurden. Aktuell ist die Version3.0. Die Grundlage dieser Lizenzen bildetdas deutsche Recht, was - anders als CC - iminternationalen Bereich häufiger zu Problemenführen kann. Um den Teilnehmenden einebreitere Perspektive zu ermöglichen, werden alseine mögliche Alternative zu Creative Commonsdie DPP-Lizenzen vorgestellt.
Software-Lizenzen
Es ist zu beachten, dass die obenbeschriebenen Datenlizenzen nicht zurLizenzierung von Software geeignet sind,da sie diverse Software-spezifische Aspektenicht berücksichtigen. Es müssen für diesenZweck daher spezifische Software-Lizenzenverwendet werden, die in einem weiteren Teildes Workshops vorgestellt werden.
Freie Lizenzen haben im Bereich derSoftware bereits eine längere Tradition, alsdies bei Daten und anderen Inhalten der Fallist: Die ersten öffentlichen Software-Lizenzengab es in den 1980er Jahren. Heute ist eineFülle an freien Softwarelizenzen in Gebrauch.Nach gegenwärtigen Standards gilt eineLizenz dann als Open Source, wenn sie denvon der Open Source Initiative entwickeltenKriterien entspricht ( https://opensource.org/osd-annotated ). Die Wichtigsten davon sind: DieMöglichkeiten des Zugangs, der Verbreitung undder Adaptierung von Quellcode.
Des Weiteren können Open Source Lizenzenin drei Kategorien eingeteilt werden:
• Freizügig ( permissive ): erlaubt breiteVerwendung der lizenzierten Software (z.B.BSD, MIT oder Apache Lizenzen)
• Starkes Copyleft: “virale” Lizenzen, dieden Benutzenden auferlegt, modifiziertenCode unter einer kompatiblen Copyleft-Lizenz zu veröffentlichen (GNU GPLs sind diewichtigsten Lizenzen dieser Gruppe)
• Schwaches Copyleft: Lizenzen, die dieBenutzenden verpflichten, modifizierteSoftware unter einer kompatiblen Copyleft-Lizenz zu veröffentlichen, aber dieVerbindung mit Bibliotheken erlauben, dieandere Lizenzen verwenden (z.B. GNU LGPL)
Aufgrund dieser breiten Auswahl anMöglichkeiten, von denen sich einige nurdurch Formalitäten unterscheiden, variiert dieLizenzierungspraxis zwischen Communities undProjekten stark. Das ist insofern problematisch,als dadurch in großen, verteilten Projekten oftkomplexe Kompatibilitätsprobleme entstehen.Es ist daher notwendig, gemeinsame “bestpractices” zu entwickeln, um die Bestrebungeninnerhalb der Digital Humanities Community zuharmonisieren.
Lizenzierungstools
Um den Teilnehmenden im praktischen Teildes Workshops nicht nur konkrete Beratungfür aktuelle Projekte anbieten zu können,sondern ihnen auch Unterstützung für dieEntscheidung von Lizenzierungsfragen imRahmen zukünftiger Projekte und Kontextezur Verfügung zu stellen, werden ausgewählteLizenzierungstools präsentiert und unmittelbarunter Anleitung der Beitragenden getestet. Zuden wesentlichsten Hilfsmitteln gehören:
• Europeana Available Rights Statement <http://pro.europeana.eu/share-your-data/rights-statement-guidelines >
• CLARIN License Category Calculator < https://www.clarin.eu/content/license-categories >
• Licentia License Tool < http://licentia.inria.fr/>
• ELRA License Wizard < http://wizard.elda.org/ >
• Public License Selector < https://ufal.github.io/public-license-selector/ >
Ablauf
10.00 Uhr: Einleitung
42

Digital Humanities im deutschsprachigen Raum 2017
10.15 Uhr: Vorstellung der Lizenzmodelle
• Lizenzen für geisteswissenschaftliche Inhalte(Joachim Losehand/Seyavash Amini)
• Free/Open Source Software Licensing (PawełKamocki)
• Diskussion
11.45 Uhr: Pause13.00 Uhr: Beispielprojekte
• Lizenzierungsmodelle in CLARIN (AndreasWitt)
• Das Geisteswissenschaftliche AssetManagement-System GAMS: Objekte,Digitalisate und Vervielfältigung (WalterScholger)
• Internationale Werke: Lizenzierung desAbstractbands der TEI-Konferenz 2016(Vanessa Hannesschläger)
• Diskussion
14.30 Uhr: Pause15.00 Uhr: hands-on: select your license
• Einführung: Lizenzierungstools (WalterScholger)
• Offene Diskussion & Beratungsrunde:Konkrete Beispiele aus dem Publikum
17.00 Uhr: Ende
Benötigte Infrastruktur,Teilnehmende
Erwartet wird ein großes Publikum, da derWorkshop konkrete Beratung für individuelleProjekte vorsieht. Um jedoch einen lebendigenAustausch garantieren zu können, möchten wirdie Zahl der Teilnehmenden auf 40 Personenbeschränken.
Teilnehmende werden gebeten, ihre eigenenLaptops mitzubringen.
Benötigt wird ein Raum für 40 Personenmit WLAN und einem Beamer; ein zusätzlicherComputer mit Bildschirm & installiertem Skype(für die Zuschaltung von Seyavash Amini) wärewünschenswert.
Eine Mittagspause von 11.45-13.00 Uhr undeine Kaffeepause von 14.30-15.00 Uhr ist geplant.Sollte für die Mittagspause keine Verpflegungverfügbar sein, werden die Teilnehmendengebeten, sich selbst zu versorgen. Kaffeeund Getränke in der Kaffeepause wärenwünschenswert.
Beitragende
Vanessa Hannesschläger <[email protected]>
studierte Germanistik in Wien. Sieist wissenschaftliche Mitarbeiterin desAustrian Centre for Digital Humanitiesder Österreichischen Akademie derWissenschaften (ACDH-ÖAW) und dort fürRechts- und Lizenzierungsfragen zuständig.Schon im Rahmen eines vorangegangenenForschungsprojekts am Literaturarchivder Österreichischen Nationalbibliothekbeschäftigte sie sich mit praktischen Fragendes Urheberrechts. Mitarbeit in CLARIN(CLARIN PLUS) und DARIAH (WG ThesaurusMaintenance). Zu ihren Forschungsinteressengehören digitales Edieren, Text- undDatenmodellierung, das Archiv im digitalenKontext, Vermittlungsstrategien in den DH sowiedigitale Infrastrukturen.
Joachim Losehand < [email protected]>ist Kulturhistoriker und studierte u.a.
Klassische Archäologie, Alte Geschichteund Altertumswissenschaften in Tübingen,München und Wien. Zwischen 2003 und2006 war er wissenschaftlicher Lektor undRedakteur, seit 2006 ist er Lehrbeauftragterund Lektor an Universitäten in Bremen,Oldenburg und Wien. 2009/10 war er Mitgliedder Lenkungsgruppe im Aktionsbündnis„Urheberrecht für Bildung und Wissenschaft“,seit 2013 ist er Projektkoordinator und Referentfür Urheberrecht u.a. im Verband Freier RadiosÖsterreich (VFRÖ) sowie Projektleiter ScienceCommons bei creative commons Austria.
Paweł Kamocki < [email protected]>
verfügt sowohl im Bereich des Rechts alsauch im Bereich der Sprachwissenschaftenüber breites Fachwissen; derzeit ist erwissenschaftlicher Mitarbeiter am Institut fürDeutsche Sprache in Mannheim und Lehr- undForschungsassistent an der Descartes Universitätin Paris und promoviert zu den rechtlichenFragestellungen der Open Science. Er ist Mitglieddes CLARIN Legal Issues Committee undarbeitete als rechtlicher Berater in zahlreichenanderen Projekten und Arbeitsgruppen (z.B.EUDAT, RDA, OpenMinTeD). Neben Urheberrechtund Datenschutz gilt sein Interesse auchden Sprachwissenschaften (insb. rechtlicheFachsprache).
Walter Scholger < [email protected]>
studierte Geschichte und AngewandteKulturwissenschaften in Graz und Maynooth
43

Digital Humanities im deutschsprachigen Raum 2017
und ist administrativer Leiter des Zentrums fürInformationsmodellierung - Austrian Centrefor Digital Humanities an der Universität Graz.In Projekten, internationalen Workshops unduniversitärer Lehre widmet er sich rechtlichenAspekten des digitalen Kulturerbes und Fragenoffener digitaler Publikationsformen.
Er ist Mitglied in facheinschlägigenArbeitsgruppen der Digital HumanitiesDachverbände und internationaler Projekte(ADHO, DHd, ICARUS, DARIAH) zu rechtlichenAspekten, digitalen Publikationen und Lehre imBereich der Digital Humanities.
Andreas Witt < [email protected]>leitet den Programmbereich
Forschungsinfrastrukturen am Institut fürDeutsche Sprache in Mannheim und istHonorarprofessor für Digital Humanitiesan der Universität Heidelberg. SeineForschungsinteressen konzentrierensich auf die Texttechnologie, die DigitalHumanities, die Informationsmodellierungund Auszeichnungssprachen. Bei CLARIN-D ister für die Arbeitsgruppe zu juristischen undethischen Fragen beim Umgang mit digitalenSprachressourcen verantwortlich.
Seyavash Amini < [email protected]>ist Rechtsberater der Universitätsbibliothek
Wien, Teamleiter des Clusters E - “Legal andEthical Issues” im Projekt e-InfrastructuresAustria, Berater der Geschäftsleitung einerGruppe von Medienunternehmen in Hannoversowie Lehrbeauftragter an den UniversitätenWien und Hannover. Er beschäftigt sich mitFragen des Informations-, Immaterialgüter-,Medien- und Datenschutzrechts. Im Rahmender jüngsten Novelle des österreichischenUrheberrechts hat der Gesetzgeber einenvon Seyavash Amini mitgestaltetenFormulierungsvorschlag aufgegriffen undumgesetzt. Er wird sich per Skype zumWorkshop zuschalten.
Bibliographie
Amini, Seyavash / Blechl, Guido / Losehand,Joachim (2015): FAQs zu Creative-Commons-Lizenzen unter besonderer Berücksichtigung derWissenschaft https://phaidra.univie.ac.at/view/o:408042 [letzter Zugriff 25. August 2016].
Creative Commons. https://creativecommons.org/ [letzter Zugriff 25. August2016].
DiPP - Digital Peer Publishing. http://www.dipp.nrw.de/ [letzter Zugriff 25. August2016].
Kamocki, Paweł / Ketzan, Erik (2014):Creative Commons and Language Resources:General Issues and What’s New in CC 4.0.CLARIN Legal Issues Committee: WhitePaper Series http://clarin-d.de/images/legal/CLIC_white_paper_1.pdf [letzter Zugriff 25.August 2016].
Kamocki, Paweł / Ketzan, Erik / Witt,Andreas (2016): „Lizenzauswahlwerkzeuge fürdie digitalen Geisteswissenschaften“, in: DHd2016: Modellierung - Vernetzung - Visualisierung336–337 http://dhd2016.de/boa.pdf [letzterZugriff 25. August 2016].
Klimpel, Paul (2013): Free knowledgethanks to creative commons licenses:Why a non-commercial clause oftenwon’t serve your needs. WikimediaDeutschland / iRights.info / CC DE. https://www.wikimedia.de/w/images.homepage/1/15/CC-NC_Leitfaden_2013_engl.pdf [letzter Zugriff 25.August 2016].
Klimpel, Paul / Weitzmann, John H. (2015):Forschen in der digitalen Welt. JuristischeHandreichung für die Geisteswissenschaften.DARIAH-DE Working papers 12 https://irights.info/wp-content/uploads/2015/08/Forschen-in-der-digitalen-Welt-Juristische-Handreichung-Geisteswissenschaften-dwp-2015-12.pdf .
44

Panels

Digital Humanities im deutschsprachigen Raum 2017
AktuelleHerausforderungender DigitalenDramenanalyse
Willand, [email protected]ät Stuttgart
Trilcke, [email protected]ät Potsdam
Schöch, [email protected]ät Würzburg
Rißler-Pipka, [email protected] Universität Eichstätt-Ingolstadt
Reiter, [email protected]ät Stuttgart
Fischer, [email protected] School of Economics, Moskau
Zielstellung und Konzeption
Das hier vorgeschlagene Panel greift mit derDigitalen Dramenanalyse einen sich derzeitdynamisch entwickelnden Bereich der digitalenLiteraturwissenschaften auf. Es setzt sich erstenszum Ziel, aktuelle Herausforderungen derDigitalen Dramenanalyse auf verschiedenenEbenen vorzustellen, wobei insbesonderedie Ebenen der dramatischen Gattung, derNetzwerkstrukturen und der dramatischenFiguren im Zentrum stehen werden. Zweitensmöchte das Panel mit dem Publikum möglicheLösungsansätze diskutieren, unter anderemdurch Bezug auf vielfältige, vorhandeneErfahrungen mit der Analyse narrativer Texte.In der Summe wird das Panel einerseits eineZwischenbilanz zum Stand der Forschunganbieten, andererseits auch im Sinne einerKonsolidierung des Forschungsfelds eine Agenda
für die weitere Entwicklung formulieren, beider es nicht zuletzt darum geht, Szenarieneiner integrativen, mithin diverse methodischeAnsätze synergetisch zusammenführendenForschung, zu diskutieren.
Dazu wird das Panel eine Art Laborsituationfingieren, in der die Erkenntnisziele,Möglichkeiten und Grenzen unterschiedlichermethodischer Zugänge zu dem titelgebendenForschungsbereich der digitalen Dramenanalysezu Tage treten sollen: Topic Modeling,(soziale) Netzwerkanalyse und Analyse derFigurenrede. Diese Gegenüberstellung soll esdem Publikum erlauben, Grundannahmen undPerspektivierungen der jeweiligen Ansätzedirekt zu identifizieren und in der Diskussionadressieren zu können. Welche Modellierungdes dramatischen Textes liegt der Methodezugrunde? Welche Aspekte eines dramatischenTextes werden durch die jeweilige Methodeeigentlich beobachtet, und welche nicht? Undwelche Art von Aussagen macht sie möglich?
In den digital literary studies wird zwarhäufig Methodenkritik geäußert, dies in derRegel aber nur mit Blick auf einzelne Methoden,auch wenn diese auf ganz unterschiedlicheForschungsgegenstände angewandt werdenkönnen. Dieses Vorgehen möchte das Panelinvertieren, indem nicht eine Methodeauf unterschiedliche Objekte, sondernunterschiedliche Methoden auf das gleicheObjekt angewandt werden: DigitalisierteDramen zwischen 1700 und 1900 aus demdeutsch- und französischsprachigen Raum.Erreicht werden soll durch dieses Vorgehen einesystematische Aufarbeitung der Möglichkeiteneiner methodisch reflektierten digitalenDramenanalyse, die zugleich theoretische undmethodologische Grundfragen der digitalenAnalyse literarischer Texte im Allgemeinenthematisiert.
In drei Kurzvorstellungen sollen diefolgenden Methoden von jeweils einerForschergruppe des Panels vorgestellt werden,wobei zur besseren Vergleichbarkeit der dreimethodisch unterschiedlich aufgestelltenArbeitsgruppen zeitlich und gattungsbezogenvergleichbare Textsammlungen analysiertwerden. Zwar werden diese Verfahrenjeweils anhand eines individuellen Teilkorpusvorgestellt, es ist jedoch zu berücksichtigen, dasssie alle auf der statistischen Analyse größererTextmengen basieren.
46

Digital Humanities im deutschsprachigen Raum 2017
Panelvorträge
Topic Modeling und Gattung(Christof Schöch, NanetteRißler-Pipka)
Der Einsatz von Topic Modeling (Blei2012) für die im weitesten Sinne inhaltlicheErschließung großer Sammlungen literarischerTexte zeigt zwei Dinge: Erstens sind dieerzielten Ergebnisse, insbesondere diejeweils dominanten Typen der Topics,textsortenabhängig (Schöch 2016). So sindnicht-fiktionale expositorische Texte (bspw.Pressemitteilungen) durch abstrakte thematischeTopics geprägt, fiktionale Erzähltexte (bspw.Romane) aber durch Topics, die sich aufnarrative und deskriptive Motive beziehen.Auch dramatische Texte zeichnen sich durch eineigenes Profil solcher Typen von Topics aus, indem diskursive und metadiskursive Topics einebesondere Rolle spielen. Dieser Umstand schärftauch den Blick auf die spezifische, textuelleFunktionsweise der jeweiligen Gattung undliterarischer Texte insgesamt.
Zweitens zeigt sich, dass sich einzelnedramatische Untergattungen wie Tragödie,Komödie oder Tragikomödie zwar in Bezugauf die jeweils dominanten Einzel topicsunterscheiden (und beispielsweise jeweilsein unterschiedlich strukturiertes Liebes-Topic haben können). Zugleich fördert TopicModeling aber keine scharfen Trennungslinienzu Tage, sondern zeigt auf, wie prototypischgedachte Untergattungen in der Praxis unscharfineinander übergehen können (Schöch, imErscheinen). Beide genannten Phänomene sindbekannt, aber sowohl in methodischer bzw.informatischer als auch in literaturtheoretischerPerspektive derzeit nicht ausreichend klarerfasst und damit auch nicht empirischüberprüfbar.
Netzwerkanalyse (FrankFischer, Peer Trilcke)
Die in den quantitativen Sozialwissenschaftenentwickelten Verfahren der Netzwerkforschungzielen auf eine formale Analyse sozialerStrukturen (Wasserman / Faust 1994).Angewandt auf literarische Texte ermöglichensie Strukturbeschreibungen, die aus einersignifikant anderen Perspektive erfolgen
als traditionelle literaturwissenschaftlicheVerfahren der semantikbasiertenStrukturanalyse (z.B. Titzmann 1977), insofernsie nicht die semantische Organisationliterarischer Texte, sondern die ästhetischeModellierung sozialer Formationen im Mediumder Literatur analysieren (Trilcke 2013). Obihres stark formalisierten Charakters operierennetzwerkanalytische Konzeptualisierungendabei zunächst mit epistemischen Objekten,die sich erheblich von den Objektender ›klassischen‹ Literaturwissenschaftunterscheiden. Gerade deshalb aberbilden solche Konzeptualisierungen einebenso attraktives wie kontroversesExperimentierfeld für computerbasierteZugänge zum Gegenstandsbereich ›Literatur‹,die nicht nur neue Antworten auf alte Fragenfinden, sondern dezidiert andere Fragenformulieren wollen. Diese Ausrichtung wirdnoch unterstützt durch die distant reading-Affinitität der literaturwissenschaftlichenNetzwerkanalyse: Zwar lässt sich die visuelleAuswertung in Form von statischen oderdynamischen Netzwerkgraphen noch imSinne des ›traditionellen‹ Paradigmas derEinzeltextanalyse verwenden (vgl. Moretti2011); insbesondere die Auswertung vonNetzwerkdaten mittels statistischer Methodenzielt jedoch auf die vergleichende Analysegrößerer Korpora, die im Bereich der digitalenDramenanalyse etwa mit historiographischem(Fischer et al. 2015) oder typologisierendem(Trilcke et al. 2016) Erkenntnisinteressebetrieben wird. Der hohe Abstraktionsgradinsbesondere der statistischen Ergebnisse vonliteraturwissenschaftlichen Netzwerkanalysensowie deren Korpusorientierung führenallerdings zu einer Spannung zu ›traditionellen‹Analyse- und Interpretationspraktiken derLiteraturwissenschaft, mit denen die Ergebnisseder Netzwerkanalyse auf den ersten Blickschwer zu vermitteln sind. Hier zeigen sichgleichermaßen die Gefahren (ein Transferder Ergebnisse zwischen digitalen Methodenund ›traditioneller‹ Literaturwissenschaftwird unmöglich) wie die Potenziale (die›andersartigen‹ Ergebnisse der digitalenMethoden führen zur produktiven Irritationender ›traditionellen‹ Literaturwissenschaft) derMethode, die in diesem Einzelvortrag anhandder Netzwerkanalyse von Dramen aus demdlina-Korpus 1 exemplarisch diskutiert werdensollen.
47

Digital Humanities im deutschsprachigen Raum 2017
Analyse der Figurenrede (NilsReiter, Marcus Willand)
Computerlinguistische Methoden wie NamedEntity Recognition und Koreferenzresolution(cf. Poesio et al. 2016) erlauben die Erkennungvon Figurenreferenzen in der Rede dramatischerFiguren. Die erkannten Referenzen wiederumkönnen genutzt werden, um den Stellenwerteiner Figur innerhalb des Gesamttextes zuidentifizieren. Neben der direkten Präsenz vonFiguren (im Sinne von: Figur spricht; siehe auchdas Problem der sog. Konfiguration, hierzuIlsemann 1995, 2008) lässt sich damit auchdie indirekte Präsenz (über eine Figur wirdgesprochen) messen.
Im Falle von Miss Sara Sampson und EmiliaGalotti (Lessing 1755, 1772) unterscheidensich die beiden titelgebenden Figuren – Saraund Emilia – hinsichtlich dieser Dimensionen:Während Sara den größten Redeanteil auf sichvereinigt, spricht Emilia weniger als halb soviel (relativiert für die Länge des Gesamttextes)2 . Im Gegensatz dazu wird über Emilia vielöfter gesprochen, so dass sie sozusagen passiveBühnenpräsenz zeigt. Anhand von Figuren wiedem König zeigt sich, dass auch passive Figurendie dramatische Handlung beeinflussen können.Dies gilt auch für Figuren und figurenähnlicheEntitäten, die nicht in den Dramatis Personaegenannt werden ( Gott, das Volk).
Unser Beitrag zum Panel diskutiertzum einen die Herausforderungen an diemaschinelle Sprachverarbeitung, wenn sie aufDramentexte angewendet wird (Blessing et al.2016). Zum anderen wollen wir untersuchen,inwiefern Autorinnen und Autoren sprachlicheEigenheiten der Figuren nutzen, um diesezu charakterisieren und z.B. als bestimmtenFigurentypus (zärtlicher Vater, Hanswurst usw.;cf. Sørensen 1984, Aust 1989, Kord 2009) zukennzeichnen.
Bilanzierung, Konsolidierung,Agenda
Die unterschiedlichen methodischen Zugängezu dramatischen Texten erlauben zwar einedirekte Gegenüberstellung und Diskussionder drei Forschungsansätze, ihrer Prämissen,aber auch der Relevanz ihrer Ergebnissefür literaturtheoretische oder -historischeFragestellungen. Die vorgestellten Verfahrensollen letztlich aber nicht als konkurrierend
oder unverbunden gedacht werden, sondernals Beiträge zu einem gemeinsamen Ziel: demdifferenzierteren literaturwissenschaftlichenVerständnis dramatischer Texte. Vor demHintergrund der das Panel leitenden Idee einerBilanzierung bisheriger und Konsolidierungaktueller Forschung auf dem Gebiet der DigitalenDramenanalyse könnten ausgehend von denEinzelbeiträgen daher folgende Fragen diskutiertwerden:
● Jede der drei Methoden verfolgtspezifische Fragen und birgt spezifischeHerausforderungen. In welchem Maße gibtes gemeinsame Forschungsziele, zu denenjede der Methoden einen Beitrag leistenkann? Können die verschiedenen Methodenbeispielsweise einen Beitrag zu einer empirischgesicherten Gattungsdifferenzierung oder für dieliteraturgeschichtliche Periodisierung leisten?
● Wie können Ergebnisse, die mitunterschiedlichen methodischem Vorgehengewonnen wurden, in Bezug zueinander gesetztwerden?
● Welche Ressourcen (insbesondereTextsammlungen) liegen vor und wie kann dieVerfügbarkeit geeigneter Ressourcen für dieDigitale Dramenanalyse zukünftig verbessertwerden? Wie können die teils unterschiedlicheAnforderungen der Methoden an die Formatevon Daten und Metadaten aufgefangen werden?
● Welche konzeptuellen und datenbezogenenStandards für dokumentbezogene Metadatenund strukturelle oder semantische,lokale Annotationen liegen vor, wiekann die Standardisierung (bspw. durchAnnotationsrichtlinien) weiter gefördertwerden?
● Welche Tools sind für die digitaleDramenanalyse derzeit verfügbar, wie könntedie Tool-Entwicklung zielgerichtet gefördertwerden? Welche generischen Tools könntenproduktiv eingesetzt werden, wie könnte derEinsatzbereich vorhandener Tools erweitert(Adaptierbarkeit, Übertragbarkeit) und so einebreitere Nutzerbasis geschaffen werden?
Indem das Panel die Vielfalt digitalerDramenanalysen vorführt und dieexplorative Kraft methodischer Innovationdurch die Digital Humanities für dieLiteraturwissenschaften betont, möchten wirdie fingierte "Laborsituation" im Sinne dertheoretischen und wissenschaftspolitischenImplikationen einer auf Überprüfbarkeit undWiederholbarkeit angelegten Wissenschaftverstanden wissen.
48

Digital Humanities im deutschsprachigen Raum 2017
Fußnoten
1. https://dlina.github.io/Introducing-DLINA-Corpus-15-07-Codename-Sydney/2. https://quadrama.github.io/blog/2016/10/07/ottokar-capulet
Bibliographie
Aust, Hugo (1989): Volksstück vomHanswurstspiel zum sozialen Drama derGegenwart. München: Beck.
Blei, David M. (2012): „Probabilistic TopicModels“, in: Communication of the ACM 55 (4):77–84 10.1145/2133806.2133826.
Blessing, Andre / Bockwinkel,Peggy / Reiter, Nils / Willand, Marcus(2016): „Dramenwerkbank: AutomatischeSprachverarbeitung zur Analyse vonFigurenrede“, in: DHd 2016: Modellierung -Vernetzung - Visualisierung 281–284 http://dhd2016.de/boa.pdf [letzter Zugriff 24. August2016].
Fischer, Frank / Göbel, Mathias /Kampkaspar, Dario / Trilcke, Peer(2015): „Digital Network Analysis ofDramatic Texts“, in: DH2015: Global DigitalHumanities http://dh2015.org/abstracts/xml/FISCHER_Frank_Digital_Network_Analysis_of_Dramati/FISCHER_Frank_Digital_Network_Analysis_of_Dramatic_Text.html [letzter Zugriff24. August 2016].
Ilsemann, Hartmut (1995): „ComputerizedDrama Analysis“, in: Literary and LinguisticComputing 10 (1): 11–21.
Ilsemann, Hartmut (2008): „More statisticalobservations on speech lengths in Shakespeare’splays“, in: Literary and Linguistic Computing 23(4): 397–407.
Kord, Susanne (2009): „Unmöglichkeiten.Vater-Tochter-Dramen im 18. und 19.Jahrhundert“, in: Martinec, Thomas / Nitschke,Claudia (eds.): Familie und Identität in derdeutschen Literatur. Frankfurt am Main: PeterLang 105–126.
Moretti, Franco (2011): „NetworkTheory, Plot Analysis“, in: Stanford LiteraryLab Pamphlets 2 http://litlab.stanford.edu/LiteraryLabPamphlet2.pdf [letzter Zugriff 24.August 2016].
Poesio, Massimo / Stuckardt, Roland /Versley, Yannick (2016): Anaphora Resolution:Algorithms, Resources, and Applications. Berlin /Heidelberg: Springer.
Schöch, Christof (2016): „What Are LiteraryTopics, Really?“, in: Digital Humanities Lunch.
Krakau, Institut für Polnische Sprache, 8. April2016 http://christofs.github.io/literary-topics/#/[letzter Zugriff 24. August 2016].
Schöch, Christof (im Erscheinen): „TopicModeling Genre: An Exploration of FrenchClassical and Enlightenment Drama“, in: DigitalHumanities Quarterly. (Preprint): https://zenodo.org/record/166356 [letzter Zugriff 15.November 2016].
Sørensen, Bengt Algot (1984): Herrschaft undZärtlichkeit der Patriarchalismus und das Dramaim 18. Jahrhundert. München: C.H. Beck.
Titzmann, Michael (1977): StrukturaleTextanalyse: Theorie und Praxis derInterpretation. München: W. Fink.
Trilcke, Peer / Fischer, Frank / Göbel,Mathias / Kampkaspar, Dario (2016): „TheatrePlays as ‚Small Worlds‘? Network Data on theHistory and Typology of German Drama, 1730–1930“, in: Digital Humanities 2016: ConferenceAbstracts http://dh2016.adho.org/abstracts/360[letzter Zugriff 24. August 2016].
Trilcke, Peer (2013): „Social NetworkAnalysis (SNA) als Methode einertextempirischen Literaturwissenschaft“,in: Ajouri, Philip / Mellmann, Katja /Rauen, Christoph (eds.): Empirie in derLiteraturwissenschaft. Münster: mentis 201–247.
Wasserman, Stanley / Faust, Katherine(1994): Social Network Analysis: Methods andApplications. New York: Cambridge UniversityPress.
Citizen Science unterdem Blickwinkelnachhaltiger sozialerund technischerInfrastrukturen
Seltmann, [email protected]Österreichische Akademie der Wissenschaften,Österreich
Wandl-Vogt, [email protected]Österreichische Akademie der Wissenschaften,Österreich
49

Digital Humanities im deutschsprachigen Raum 2017
Dorn, [email protected]Österreichische Akademie der Wissenschaften,Österreich
Unter Citizen Science wird eineForschungsform verstanden, in derWissenschaftler.Innen von Citizensin verschiedenen Bereichen desForschungsprozesses unterstützt werdenoder die gänzlich von Citizens durchgeführtwird. Die Verwendung von Citizen Sciencebringt für beide Seiten gewisse Vorteile:Wissenschaftler.Innen können auf neue Aspektein ihrem Forschungsschwerpunkt kommen,und Citizens können den Elfenbeinturm derWissenschaft durchbrechen und sich mit ihreneigenen Interessen in den Forschungsprozesseinbringen (vgl. Riesch & Potter, 2014). Zudemkommt es häufig zur Community-Bildunginnerhalb von Interessensgruppen, so darf dersoziale Aspekt nicht vernachlässigt werden.
Während Citizen Science ursprünglich oftmit Arbeitsweisen in naturwissenschaftlichenBereichen in Verbindung gebracht wurde, istdie Rolle von Citizen Science in den Humanitiesim Vergleich dazu noch weniger ausführlichbeleuchtet und scheint erst in den letztenJahren zunehmend an Aufmerksamkeit, zumBeispiel durch gezielte Förderprogramme oderInfrastrukturen, zu gewinnen. Aber ist demtatsächlich so? Dabei bietet die Hinzunahmeder Citizen Science in Forschungsprojekte eingroßes Potential in verschiedenen Bereichen:begonnen vom Finden interessanter undgesellschaftsrelevanter Fragestellungenüber die den meisten wohl zuerst in denSinn kommende Datensammlung bis hin zurDisseminierung können Citizens zentraleRollen, wie beispielsweise Partizipation bei derEntwicklung von Forschungsfragen, Co-Designdes Forschungsprozesses oder der Resultate,einnehmen. Welche Rolle spielt Citizen Sciencedemnach nun in den Humanities?
In dem vorgeschlagenen Panel greifenwir diese Thematik unter verschiedenenAnsatzpunkten auf. Es soll diskutiert werden,welche Rahmenbedingungen es für guteCitizen Science in (neuen) Humanities-Forschungsprojekten gibt und braucht. Zudemsoll angeregt werden, eine Gemeinschaft fürdie Vernetzung und explorative Forschung imRahmen der Digital Humanities aufzubauen undzu etablieren. In einem ersten Teil stellen diePanelisten ihre Standpunkte zum Thema CitizenScience in den Humanities dar. Diese vertretenunterschiedliche Plattformen, Fördergeber
und führende Akteure in den Citizen Science.Namentlich handelt es sich um:
Celine Loibl (Bundesministerium fürWissenschaft, Forschung und Wirtschaft(Österreich)): Programme Direktor SparklingScience
Das Förderprogramm des österreichischenBMWFW “Sparkling Science” fördert seit2007 Citizen Science Projekte. Es setzt bereitsim Schulalter an und bringt – einzigartigin Europa – Wissenschaftler.Innen undSchüler.Innen zusammen. Mit dieser Form vonCitizen Science zielt es im Besonderen daraufab, bei den Schüler.Innen Interesse an derForschung zu wecken und somit Forschungund Bildungspolitik zu verbinden. DesWeiteren können durch die Zusammenarbeitvon Wissenschaft und Schulen innovativewissenschaftliche Ansätze und Erkenntnissegeneriert werden. Es soll erläutert werden,warum derartige Förderprogramme zurVerfügung gestellt werden. Weiters soll derenSituation in einem deutschsprachigen Kontexterschlossen werden.
Mike Mertens (DARIAH): CEO, DARIAH PublicHumanities Grant
Nachdem auf den Istzustand der Verwendungvon Citizen Science in den Humanitieseingegangen wurde, soll das Augenmerk daraufgelegt werden, wie Infrastrukturen wie DARIAHCitizen Science sehen, und warum solcheOrganisationen die Hinzunahme von CitizenScience in den Humanities fördern. Warumhat Citizen Science in Förderprogrammen fürdie Humanities eine europäische Perspektive,und vor allem welche? Es soll erörtert werdenwarum dies wichtig ist und inwiefern sichdadurch etwas an unserer Forschung ändernkönnte.
Fermin Serrano Sanz (Socientize/Institute forBiocomputation and Physics of Complex Systems(BIFI), Univ. Zaragoza; Responsible Research andInnovation (RRI) liaison at ECSA): Citizen ScienceInfrastrukturen
Ein wichtiger Punkt, damit Citizen Scienceso eingesetzt werden kann, wie von allenBeteiligten (Fördergeber, Wissenschaftlerund Citizens) gewünscht, ist die Verwendungzuverlässiger und leicht verständlicherund nutzbarer Infrastrukturen. Es solleinen Überblick über Möglichkeiten vonetablierten Infrastrukturen geben, sowiederen Nutzen insbesondere für die Humanitiesaufgezeigt werden. Es wird erläutert inwiefernInfrastrukturen. u.A. auch aus technischerSicht, zur Verfügung stehen und inwiefern diesevon Citizen Science Projekten genutzt werden,beziehungsweise nutzbar sind. Als Beispiele
50

Digital Humanities im deutschsprachigen Raum 2017
können das Projekt Socientize, das WeißbuchCitizen Science, aber ebenso Themen wie “do-it-yourself” und “responsible science”, sowie diesoziale Infrastruktur ECSA und die COST Actionon Citizen Science herangezogen werden.
Roberto Barbera (Univ. of Catania/NationalInstitute for Nuclear Physics (INFN)): From OpenAccess and Open Data to Open Science
Schließlich soll der Blick geöffnet werden.Wie funktioniert Citizen Science in anderenDisziplinen und wie kann eine gute OpenAccess und Open Data Policy zu nachhaltigerund guter Open Science führen. Es sollerörtert werden inwiefern Open ScienceCommons (ein Ansatz zur gemeinsamenNutzung digitaler Dienste, wissenschaftlicherInstrumente, Daten, Wissen, etc. für leichtereund produktivere Zusammenarbeit) CitizenScience einbringen kann und inwiefern aktuelleForschungsinfrastrukturen Citizen Scienceunterstützen.
Eveline Wandl-Vogt (ÖsterreichischeAkademie der Wissenschaften): Koordinatorindes Lexicography Laboratory (lexlab) ACDH,Koordinatorin des Projekts exploreAT!
Sie berichtet von ihren Erfahrungen imBereich Open Innovation, Open Science undCitizen Science, sowie Open Innovation inScience Methoden und deren Bedeutung amBeispiel eines konkreten Projektes, exploreAT!.Weiters wird der Citizen Science Survey, der imRahmen des Projektes exploreAT! entstandenist, vorgestellt, um einen Status quo der CitizenScience in Humanities Projekten abschätzen unddarauf basierend Empfehlungen für (zukünftige)Projekte geben zu können.
Die Moderation des Panels wird durchgeführtvon Amelie Dorn ( Österreichische Akademieder Wissenschaften; ProjektmitarbeiterinexploreAT!).
Im zweiten Teil werden im Podiumwesentliche Fragen zu den Citizen Science inden (Digital) Humanities diskutiert. Begonnenwird mit der Metaebene, inwiefern Wissenetwas vergleichbares wie das Mode 2 im Sinneeiner Knowledge Society (vgl. Gibbons et al., 1994und Nowotny et al., 2003) ist, nämlich nicht einöffentliches Gut, sondern ein geistiges Eigentum,das wie andere Güter und Dienstleistungen ineiner Knowledge Society produziert, angehäuftund gehandelt wird. Ebenso soll gefragt werden,wie sich die Wissenschaft in ein solches Modelleinbetten kann.
Im zweiten Schritt soll erörtert werden,wie eine Förderung der Citizen Scienceaussieht oder aussehen kann. Daraufhin sollenpolitische und technische Infrastrukturenunter denen Citizen Science stattfinden kann
diskutiert werden. Von den politischen undtechnischen Infrastrukturen soll auf die sozialenInfrastrukturen übergegangen werden. Essoll beleuchtet werden, warum Fördertöpfevon Nöten sind und ob diese eher für Citizensoder Wissenschaftler.Innen gebraucht werden.Zudem soll die Frage aufgeworfen werden, ob esdamit weiters nur zu wissenschaftsgetriebenerCitizen Science kommen kann. Es stellt sich dieFrage, ob mit Fördertöpfen wirklich der Aufbauvon Netzwerken gefördert wird.
In einem weiteren Block werden Ein- undAusblicke von Fördergebern wie SparklingScience und Infrastrukturen wie DARIAHerörtert, warum Citizen Science in ist, warumCitizen Science verwendet werden sollte undwarum gerade zum jetzigen Zeitpunkt. Ebensosoll auf Strategiepapiere wie das White Paper(Serrano et al., 2016) auf europäischer Ebenesowie das Grünbuch (Bonn et al., 2016) aufdeutscher Ebene und deren konkreten Nutzeneingegangen werden. Im Hinblick auf diesePapiere soll gefragt werden, was zum einen diePolitik als ein gutes Projekt bezeichnet, zumanderen was der Wissenschaftler und inwiefernsich die beiden Ansichten voneinanderunterscheiden. Am Beispiel von Österreich sollverdeutlicht werden, inwiefern der Support fürWissenschaftler zu mehr Forschungsprojektengeführt hat.
Schließlich sollen Infrastrukturen undInterakteure miteinander verbunden werden.Was ist die konkrete Rolle der technischenInfrastrukturen? Können diese den Prozess derProjekte verbessern, beschleunigen und/oderfestigen? Wie können sie zu einer gediegenenProjektentwicklung beitragen? Und werdendie technischen Infrastrukturen nur von denWissenschaftler.Innen genutzt oder auchvon den Laien? Beziehungsweise werden sieüberhaupt genutzt?
Nachdem die Panelisten über dieseFragestellungen diskutiert haben, wird imdritten Teil das Publikum eingeschlossen.Zum einen gibt es vorbereitete Befragungenan das Publikum zu den zuvor diskutiertenInhalten, zum anderen kann das Publikumeigene aufgekommene Fragen an das Podiumstellen. Hierbei soll unter anderem auf dieEinschätzungen des Publikum zur Verwendungvon Citizen Science konkret in den Humanitieseingegangen werden. Die Annahmen desPublikums sollen mit den Ergebnissen aus demCitizen Science Survey verglichen werden undFragen des Publikums damit zu beantwortenversucht werden.
Des Weiteren soll erörtert werden, wie einpositives Bild von technischer und sozialer
51

Digital Humanities im deutschsprachigen Raum 2017
Entwicklung aussehen kann, durch welches füralle Seiten ermöglicht werden kann, bessereProjekte hervorzubringen. Es wird versucht,diese prinzipielle Frage durch eine interaktiveDirektbefragung zu entschlüsseln. Daraufhinwird das Podium gebeten, hierauf eine Antwortzu finden. Anschließend soll die Frage für dasPublikum geöffnet werden.
Abschließend lässt sich zusammenfassen,dass das vorgeschlagene Panel wichtige Themensowie einen vielfältigen, breiten Einblick in diesozialen und technischen Strukturen der CitizenScience anspricht und diskutiert. Die Ergebnisseder Diskussion zwischen Panel und Podium,zwischen Citizens und Wissenschaftlern, bietendie Möglichkeit für weitere Ansatzpunkteum einen gemeinsamen Weg für zukünftigeAusrichtungen zu schaffen. Ausserdem bietetdas vorgeschlagene Panel die MöglichkeitPersonen aus den verschiedensten Bereichendie mit Citizen Science in Berührung kommenim Dialog zusammenzubringen, was nichtnur eine günstige Chance für potentielleWeiterentwicklungen im Citizen ScienceBereich in den Humanities ist, sondern auchunabdingbar ist, um den direkten Austausch undKontakt auf lokaler und weiterer europäischerEbene zu stärken sowie zu avancieren.
Bibliographie
Bonn, Aletta / Richter, Anne / Vohland,Katrin / Pettibone, Lisa / Brandt, Miriam /Feldmann, Reinart / Goebel, Claudia / Grefe,Christiane / Hecker, Susanne / Hennen,Leonhard / Hofer, Heribert / Kiefer, Sarah /Klotz, Stefan / Kluttig, Thekla / Krause,Jens / Küsel, Kirsten / Liedtke, Christin /Mahla, A. / Neumeier, V. / Premke-Kraus,Matthias / Rillig, M. C. / Röller, Oliver /Schäffler, Livia / Schmalzbauer, Bettina /Schneidewind, Uwe / Schumann, Anke /Settele, Josef / Tochtermann, Klaus / Tockner,Klement / Vogel, Johannes / Volkmann,Wiebke / von Unger, Hella / Walter, D. /Weisskopf, Markus / Wirth, Christian / Witt,Thorsten / Wolst, Doris / Ziegler, David(2016): Grünbuch Citizen Science Strategie2020 für Deutschland. Leipzig: Helmholtz-Zentrum für Umweltforschung (UFZ) / DeutschesZentrum für integrative Biodiversitätsforschung(iDiv) Halle-Jena-Leipzig / Berlin: Museumfür Naturkunde Berlin / Leibniz-Institut fürEvolutions- und Biodiversitätsforschung(MfN) / Berlin-Brandenburgisches Institutfür Biodiversitätsforschung (BBIB). http://www.buergerschaffenwissen.de/sites/
default/files/assets/dokumente/gewiss-gruenbuch_citizen_science_strategie.pdf [letzterZugriff 01. Dezember 2016].
Gibbons, Michael / Limoges, Camille /Nowotny, Helga / Schwartzman, Simon / Scott,Peter / Trow, Martin (1994): The New Productionof Knowledge: The Dynamics of Science andResearch in Contemporary Societies. London:Sage.
Nowotny, Helga / Scott, Peter / Gibbons,Michael (2003): „Mode 2 revisited: The NewProduction of Knowledge“, in: Minerva 41: 179–194.
Riesch, Hauke / Potter, Clive (2014): „Citizenscience as seen by scientists: Methodological,epistemological and ethical dimensions“, in:Public Understanding of Science 23 (1): 107–120.
Serrano Sanz, Fermín / Holocher-Ertl, Teresa / Kieslinger, Barbara / SanzGarcía, Francisco / Silva, Cândida G. (2014):White Paper on Citizen Science for Europe.Socientize Consortium https://www.zsi.at/object/project/2340/attach/White_Paper-Final-Print.pdf[letzter Zugriff 01. Dezember 2016].
Das digitale Museum:ein nachhaltiger Partnerder Digital Humanities?
Hohmann, [email protected] Museum, München
Schmidt, [email protected] für Kunst und Gewerbe, Hamburg
Doppelbauer, [email protected], Wien
Rehbein, [email protected]ät Passau
Ausgangslage
In der digitalen Gesellschaft steht dasMuseum als Gedächtnisinstitution vorbesonderen Herausforderungen. Sammeln,Bewahren, Forschen und Vermitteln als die
52

Digital Humanities im deutschsprachigen Raum 2017
klassischen Aufgabenbereiche des Museumsmüssen von Grund auf hinterfragt und inHinblick auf digitale Möglichkeiten undAnforderungen angepasst, verändert underweitert werden.
Wie kaum ein anderes Fach steht die Disziplinder Digital Humanities als Repräsentantdafür, welche Anforderungen und Ansprüchevor allem von Seiten der Wissenschaft anmoderne Gedächtnisinstitutionen gestelltwerden. Waren und sind Museen seit jeherwichtige Partner und auch Horte der historischorientierten Geisteswissenschaften, müssen siesich nun an die Gegebenheiten der digitalenGeisteswissenschaften anpassen, um ihreBedeutung zu erhalten und vielleicht sogarauszubauen. Das Museum kann nicht mehrnur ein begehbarer Ort des kulturellenErbes sein, sondern muss auch als digitalerWissensspeicher seine Informationen zurVerfügung stellen (Clough 2013: 2). DieVerantwortung gegenüber den realen Objektenerweitert sich auf die Sphäre der digitalenInformation (Keene 1998: 23), die ebenso wiediese nach wissenschaftlichen Maßstäbengesammelt, bewahrt, erforscht und vermitteltwerden will, wobei das Museum gleichzeitigals Aggregationspunkt und Erzeuger fungiert.Dabei wird das Museum an seinen eigenenAnsprüchen gemessen, nämlich die Objekteseiner Betrachtung „für die Ewigkeit“ zubewahren und dauerhaft der Allgemeinheit zurVerfügung zu stellen (ICOM 2004). Wie kanndies in einer digitalen Umgebung nachhaltiggelingen?
Themenbereiche
Digitalisierung
Die Digitalisierung von Objekten hatinzwischen flächendeckenden Einzug in dieMuseen gehalten. Grundsätzlich geht es dabeium den Vorgang, von analogen Objekten digitaleAbbilder zu generieren, aber auch um dieÜberführung analoger Informationsträgernin digitale Formate. Hier sind eine Vielzahlvon grundlegenden Entscheidungen zutreffen. Dazu gehört die Definition des eigenenQualitätsanspruchs und dessen Abwägungmit den Anforderungen einer ökonomischenMassendigitalisierung. Durch die ständigeWeiterentwicklung im Bereich der digitalenErfassungstechniken stellt sich auch dieFrage, ob eine schlichte Digitalfotografie zurDigitalisierung überhaupt ausreichend ist. Soll
ein Digitalisat ein Original in der Ausstellungund für Forschungsfragen gar ersetzen, um dasOriginal besser zu schützen?
Erschließung
Ein Aspekt der Digitalisierung, der oftsubsumiert wird, ist die wissenschaftlicheErschließung von Objekten zur Erzeugungdigitaler Daten. Im Museum ist dies oft keineinfacher Vorgang der Übertragung vonanaloger in digitale Information, da dieInformation im Vorfeld gar nicht strukturiertvorhanden ist, sondern erst wissenschaftlicherarbeitet werden muss. Die Tiefe unddie Perspektive mit der digitalisiert underschlossen wird, bestimmen zu einem nichtgeringen Grad die Möglichkeiten der späterenwissenschaftlichen Bearbeitung. In der Praxis istdie Erschließung häufig eher von pragmatischenErwägungen geprägt als von konzeptuellemVorgehen (Koch 2015). Auch stellt sich dieFrage nach dem Umfang. Werden einzelneObjekte in der Tiefe erschlossen, oder wird – ineinem ersten Schritt - auf eine flächendeckendeFlacherschließung gesetzt, um die Quantität(mit Verlust der Qualität) zu steigern? Nichtzuletzt sind die Kenntnis und die Anwendungvon adäquaten Standards, Normdaten undTechniken für eine nachhaltige Erschließungunabdingbar.
Langzeitarchivierung und -verfügbarkeit
Die größte technologische Herausforderungstellt sich im Bereich der digitalenLangzeitarchivierung. Mit ihren digitalenAssets sollten Museen ebenso wie mitihren realen Objekten umgehen, d.h. siedauerhaft archivieren und die idealenLagerbedingungen einhalten. Aufgrund derschieren Menge an digitalen Daten kanndiese Aufgaben kaum mehr adäquat voneinzelnen Häusern alleine gestemmt werden.Auch die notwendige technische Expertisezur Einhaltung internationaler Standards zurLangzeitarchivierung übersteigt Fähigkeitenund Aufgaben eines Museums. Hier bieten sichKooperationen mit Dienstleistern an, die aberkoordiniert und nachhaltig finanziert werdenwollen.
53

Digital Humanities im deutschsprachigen Raum 2017
RechtlicheRahmenbedingungen
Spätestens bei der Veröffentlichung vonDaten stellt das Rechtemanagement eine großeHürde dar (Müller, Truckenbrodt 2013). WelcheDaten oder Digitalisate dürfen überhauptgezeigt werden? Wie ist die Rechteklärungzu organisieren und welche verschiedenenGesetze (Urheberrecht, Markenrecht,Vervielfältigungsrecht, Nutzungsrecht etc.)sind zu berücksichtigen? Die Prinzipien desOpen Access sind auch für viele Museenerstrebenswert, aber die weitgehend unklareRechtslage ist letztlich oft ein Hinderungsgrund,die Open Access Gedanken vollständigumzusetzen (Hamburger Note 2015).
Bereitstellung undVermittlung
Die digitalen Inhalte von Museen werdenüblicherweise über Online-Portale vermittelt.Um aber explizit eine wissenschaftlicheNutzung der Daten zu ermöglichen, sindzudem viele Rahmenbedingungen einzuhaltenund Schnittstellen anzubieten. Besondersdie digitalen Geisteswissenschaften stellenin dieser Hinsicht hohe Anforderungen, umautomatisierte Verfahren anwenden zu können.Die Daten sollten im Idealfall über technischeSchnittstellen verfügbar sein, die wiederselbst nach unterschiedlichen Vorgaben undModellen organisiert sein können. Zudem kannin diesem Bereich noch kaum auf etablierteSysteme zurückgegriffen werden, wodurchEigenentwicklungen notwendig werden.
Strukturwandel
Mit einer Hinwendung zum Digitalengeht auch eine Metamorphose der InstitutionMuseum einher, die Auswirkungen aufArbeitsabläufe, Aufgabenbereiche undZielsetzungen hat. Dies kann sogar so weitführen, das ganze Aufgabenbereiche wegfallenund und andernorts neue entstehen, etwa dieeines Museum Information Curators (Low, Doerr2010). Um den entsprechenden Nachwuchsheranzubilden, sind Museen zur aktivenMitgestaltung der Aus- und Weiterbildungaufgefordert. Diese tiefgreifenden strukturellenÄnderungen sollten von einem umfassendenChange Management begleitet werden, was aber
die Kapazitäten der meisten Häuser übersteigendürfte.
Perspektiven
Das Panel widmet sich den skizziertenThemenbereichen unter verschiedenenPerspektiven, wobei von der These ausgegangenwird, dass die Themen eng zusammenhängenund aufeinander aufbauen. Es kann daherweniger um eine Detaildiskussion einzelnerTechniken und Vorgehensweisen gehen, sondernum die Feststellung des State-of-the-Art in derdeutschsprachigen Museumsszene sowie um dieDiskussion der Zukunft von Museen in Hinblickauf ihr Potenzial als nachhaltiger Partner für diedigitale Gesellschaft und Forschung.
Impulsvorträge
Moderation: Mareike Schumacher(Universität Hamburg) & Etta Grotrian (JüdischesMuseum Berlin)
Georg Hohmann: Das digitaleMuseum
In einer umfassenden Maßnahme werdenam Deutschen Museum die Bestände ausObjektsammlungen, Archiv und Bibliothekerschlossen und digitalisiert, womit derWeg zu einem Digitalen Museum eingeleitetwird. Die Ergebnisse werden in einemgemeinsamen Online-Portal präsentiert, dasden Wissenskosmos des Deutschen Museumsowohl für wissenschaftliche als auch fürinteressierte Fachnutzer in aller Welt zugänglichmacht. Ein großes Potential hat die interneund externe Vernetzung der Daten, bei derdie Nutzung einheitlicher Standards undNormdaten eine zentrale Rolle spielt. DerBeitrag fokussiert die technischen Aspekte zurBereitstellung von musealen Forschungsdatenund thematisiert die Voraussetzungen undPerspektive zur Nutzung dieser Daten in dendigitalen Geisteswissenschaften.
Antje Schmidt: Offene Datenals nachhaltige Ressource
Die Herausforderungen liegen für dieMuseen heutzutage nicht nur in der digitalen
54

Digital Humanities im deutschsprachigen Raum 2017
Bereitstellung von Informationen z.B.über Sammlungsdatenbanken, sondernauch in der nachhaltigen Vermittlung undNachnutzbarmachung dieser. Das Managementder rechtlichen Bedingungen, unter denendiese Informationen bereitgestellt werdenkönnen und deren klare Vermittlung sinddafür unabdingbar. Mit der MKG SammlungOnline hat das Museum für Kunst und GewerbeHamburg als erstes Museum in Deutschlanddiejenigen digitalisierten Bestände, für diedies rechtlich möglich ist, zur freien Nutzungzur Verfügung gestellt und dies mit Hilfevon Creative Commons Lizenzen dargestellt.Jedes einzelne Digitalisat kann individuelllizensiert werden. In den meisten Online-Sammlungspräsentationen sind die rechtlichenMetadaten allerdings an den Datensatzgebunden. Dies führt zu Problemen, wennz.B. für ein Objekt mehrere Abbildungen mitunterschiedlichen Lizensierungen vorhandensind. Zudem sind diese rechtlichen Metadatennicht einheitlich mitgeführt, sobald es um dieWeitergabe an andere Portale geht.
In dem Vortrag soll erläutert werden, welcheBedingungen geschaffen werden müssen, umdas Potenzial digitaler Sammlungen zu entfalten,diese nachhaltig zu öffnen und nachnutzbar zumachen.
Regina Doppelbauer:Digitalisierung von 1400Klebebänden
Der überwiegende Teil der Druckgraphikender Albertina Wien ist in historischenGroßfoliobänden eingeklebt. Diese 1436Volumina spiegeln Wissen und Ästhetik des18. und frühen 19. Jahrhunderts wider. DieBlätter selbst erzählen die Entwicklung derDruckgraphik und enthalten ikonographischunser neuzeitliches Bildgedächtnis. EinForschungsprojekt der Albertina zielt aufdie dringend notwendige Autopsie undVeröffentlichung der Bände: Diese werdendigital erfasst, mit Metadaten versehenund so rasch wie möglich nicht nur derForschungscommunity online zur Verfügunggestellt.
Der Beitrag stellt den Ansatz vor, der Füllemit Augenmaß zu begegnen und gleichwohlStandards und Nachhaltigkeit zu gewährleisten:Da eine Bandseite bis zu zwanzig Objekteaufweist, ist eine Einzelobjekterfassung vongeschätzten 500.000 Werken nicht zu leisten. Es
wird daher ein generisches Erfassungsmodellentwickelt, das vom obligatorischen Scanjeder Seite bis hin zu einer detailliertenMetadatenerfassung der darauf montiertenObjekte mehrere Stufen der Erschließungermöglicht. Wird ein Band flach erschlossen,so werden alle technischen Vorkehrungengetroffen, um spätere Anreicherungen –hausintern oder durch crowd/niche-sourcing -vornehmen zu können.
Malte Rehbein: VirtuelleVerbundsysteme alsNachhaltigkeitsstrategiefür Museen und andereKulturerbe-Institutionen
Sowohl für die Bewahrung des KulturellenErbes als auch für dessen Präsentation bietet dieDigitalisierung neue Möglichkeiten; dass in derRegel erhebliche Ressourcen aufzuwenden sind,um diese Chancen des Digitalisierungstrendszu nutzen, ist vor allem für kleine und mittlereInstitutionen eine große Herausforderung.Zudem ist eine nachhaltige Ausgestaltung derdigitalen Innovationen ein Schlüssel für ihrenlangfristigen Nutzen.
Der Vortrag illustriert die Anforderungen anMuseen aus der Sicht der Digital Humanitiesam Beispiel des 2016 gestarteten Projekts„Virtuelle Verbund-Systeme und Informations-Technologien für die touristische Erschließungvon kulturellem Erbe (ViSIT)“, das in einemgrenzüberschreitenden regionalen Verbund vonStandorten und den dort ansässigen Kulturerbe-Institutionen mit Hilfe digitaler Kooperations-und Vermittlungsformen das Ziel verfolgt, dieVermittlung von Regionalgeschichte innovativ zugestalten.
Bibliographie
Clough, G. Wayne (2013): Best of both worlds:Museums, libraries, and archives in a digital age.Washington: Smithsonian Institution.
Keene, Suzanne (1998): Digital collections:Museums and the information age. Oxford:Butterworth-Heinemann.
ICOM (2004): ICOM Code of Ethics forMuseums http://icom.museum/the-vision/code-of-ethics/ [letzter Zugriff 24. August 2016].
Koch, Gertraud (2015): „Kultur digital.Tradieren und Produzieren unter neuen
55

Digital Humanities im deutschsprachigen Raum 2017
Vorzeichen“, in: Bolenz, Eckard / Franken, Lina /Hänel, Dagmar: Wenn das Erbe in die Wolkekommt: Digitalisierung und kulturelles Erbe.Essen: Klartext.
Müller, Carl Christian / Truckenbrodt,Michael (2013): Handbuch Urheberrecht imMuseum: Praxiswissen für Museen, Ausstellungen,Sammlungen und Archive. Bielefeld: transcript.
Hamburger Note (2015): Hamburger Notezur Digitalisierung des kulturellen Erbes http://hamburger-note.de/ [letzter Zugriff 24. August2016].
Low, Jyue Tyan / Doerr, Martin (2010):A Postcard is Not a Building: Why weNeed Museum Information Curators http://network.icom.museum/fileadmin/user_upload/minisites/cidoc/ConferencePapers/2010/low.pdf[letzter Zugriff 24. August 2016].
eValuation - Kriterienzur Evaluation digitalerAngebote undForschungsinfrastrukturen
Kurmann, [email protected], Schweiz
Baumann, [email protected], Schweiz
Natale, [email protected], Schweiz
eingereicht von: infoclio.ch – Fachportal fürdie Geschichtswissenschaften der Schweiz
Referierende: Gabi Schneider / AlexanderHasgall / Philipp Steinkrüger
Moderation: Eliane Kurmann (infoclio.ch) /Jan Baumann (infoclio.ch)
Mit der Etablierung der Digital Humanities anden Universitäten und Forschungseinrichtungenwerden, wenn auch noch zögerlich,neue Modelle zur Evaluation digitalerInfrastrukturprojekte und zur Rezensiondigitaler Inhalte und Angebote entwickelt underprobt. Die Evaluationsverfahren dienender Beurteilung der Projekte und Initiativenim Hinblick auf die weitere finanzielle
Förderung und die Leistungsanerkennungim akademischen Umfeld. Beim Rezensierengeht es zudem um die Sichtbarmachung undHervorhebung besonders gelungener Projekteund Angebote. Und schliesslich werden geplanteAngebote und Infrastrukturen an den bereitsetablierten Qualitätsmerkmalen ausgerichtet.
Verschiedene Institutionen undVereinigungen sind damit beschäftigt,Evaluationsverfahren auszuarbeiten,die über die Messung der traditionellenForschungsleistungen hinausgehen. Nebenden fachspezifischen wissenschaftlichenKriterien werden bei der Evaluation digitalerAngebote und Infrastrukturen beispielsweiseauch technische Aspekte, die Interoperabilität,Design und Anwenderfreundlichkeit sowie dasInteragieren von Inhalt und Präsentationsform,die Zugänglichkeit oder die Dauerhaftigkeit derInhalte berücksichtigt.
Erste Kriterienkataloge sind bereitsausgestaltet, die Instrumente undMethoden ihrer Anwendung stellen weitereHerausforderungen dar: Wie verändern sichdie Qualitätskriterien mit der fortlaufendentechnischen Entwicklung? Wie wird etwadie Reichweite der Resultate im WorldWide Web festgestellt und innerhalb derForschungsevaluation gewertet? Was bedeutetDauerhaftigkeit im digitalen Kontext? Diskutiertwird aber auch die grundsätzliche Frage, ob esangesichts der Vielfalt der digitalen Projekteüberhaupt möglich ist, standardisierte Verfahrenund einheitliche Richtlinien zu definieren. Undzielen die Neuerungen auf die Erweiterung dertraditionellen Evaluationsverfahren, sodassdiese auch auf digitale Projekte anwendbarwerden, oder verlangen die Digital Humanitieseigene Beurteilungsmodelle?
Für die Dhd2017-Tagung schlägt infoclio.chein Panel vor, in dem neue Evaluationsmodellevorgestellt werden. Expertinnen und Experten,die sich mit der Konzipierung und Anwendungneuer Verfahren und Kriterien beschäftigen,berichten von ihren Erfahrungen und stellengrundsätzliche Überlegungen zur Diskussion.Die digitale Nachhaltigkeit wird dabei inzweifacherweise thematisiert: Zum einen wirdsie als Qualitätsmerkmal in der Beurteilung vondigitalen Inhalten, Tools und Infrastrukturendiskutiert. Zum andern fördert die Evaluationgrundsätzlich die Qualität und damit dieNachhaltigkeit, da die professionelle Beurteilungeines Projekts seine Fortführung begünstigt.
Für die drei 1 nachfolgend beschriebenenBeiträge sind jeweils 10 bis 15 minütigePräsentationen vorgesehen, die zugleich
56

Digital Humanities im deutschsprachigen Raum 2017
die Grundlage für die anschliessendeDiskussion (45 Minuten) bilden. Die Beiträgebeschäftigen sich mit der Evaluation vondigitalen Forschungsinfrastrukturen, demUmgang mit Digital-Humanities-Projekten in derForschungsevaluation und mit der kritischenBesprechung von digitalen Editionen. Diskutiertwerden bereits erprobte und im Entstehenbegriffene Evaluationsverfahren, wobei dieErfahrungsberichte die Herausforderungenin der praktischen Anwendung deutlichmachen. Mit Blick auf das Tagungsthemafindet die digitale Nachhaltigkeit inallen Beiträgen besondere Beachtung.Einerseits soll thematisiert werden, welcheBedeutung der digitalen Nachhaltigkeitals Evaluationskriterium zukommt; zumandern sollen Erfahrungen aus der Praxisdes Evaluierens zur Konkretisierung derKonzepte der digitalen Nachhaltigkeit beitragen.Gefragt wird unter anderem, wie die digitaleNachhaltigkeit „gemessen“ wird, geht es dabeidoch nicht nur um technische Aspekte, sondernauch um die freie Zugänglichkeit sowie dieNutzungsrechte der digitalen Inhalte undInfrastrukturen.
BeiträgeGabi Schneider, stellvertretende Leiterin des
Programms „ Wissenschaftliche Information:Zugang, Verarbeitung und Speicherung “
Beitrag: Evaluation digitalerForschungsinfrastrukturen
Das Programm „WissenschaftlicheInformation: Zugang, Verarbeitung undSpeicherung“ von swissuniversitiesfördert den Aufbau eines nationalverfügbaren Grundangebots an digitalenInhalten sowie optimaler Werkzeuge(Tools und Infrastrukturen) für derenVerarbeitung. Projekte werden von denHochschulen eingereicht und im Rahmender Programmorganisation in Bezug auf dieMittelvergabe evaluiert. Die Qualität unddie Nachhaltigkeit von Projekten werden inverschiedenen Stadien gefördert. Zum einenwerden Kriterien wie technische Standards,Interoperabilität oder die Bezugnahme aufinternationale Referenzprojekte in denProgrammunterlagen (Strategiepapiere,Antragsformular und Wegleitung) explizitgenannt. Zum anderen werden die Projekteim Evaluationsverfahren auf diese Kriterienhin geprüft. Im Rahmen des Programmswurde seit 2013 ein erstes Portfolio vonDiensten aufgebaut. Im weiteren Verlauf sollenAnforderungskriterien für eine periodischeÜberprüfung dieser Dienste definiert werden.Da Grossprojekte mit „nationalem“ oder
internationalem Anspruch meistens vonverschiedenen Geldgebern unterstützt werden,gewinnen dabei der Austausch und dieVerständigung mit anderen Förderinstitutionenan Bedeutung. Der Beitrag zeigt Ansätze auf.
Alexander Hasgall, WissenschaftlichenKoordinator, SUK P3 „ Perfomances de larecherche en sciences humaines et sociales “
Beitrag: Evaluationsverfahren in den DigitalHumanities
Im Rahmen von Evaluationsverfahrenspielen digital präsentierte Inhalte oftmalskeine gesonderte Rolle. Jedoch weist dieForschung in den Digital Humanities u.a.im Hinblick auf Fragen von Zugänglichkeit,der Wahrnehmung und Verbreitung in derWissenschaftscommunity oder auch derNachhaltigkeit der Forschungsergebnissewichtige Besonderheiten auf, welche inherkömmlichen Evaluationsverfahren nichtimmer angemessen reflektiert werden.Im Rahmen des Panel-Beitrags soll auf dieAuswirkung von Evaluationsverfahren aufdie Forschung in den Digital Humanitieseingegangen und zugleich diskutiertwerden, inwieweit Nachhaltigkeit selbst einQualitätsmerkmal von Forschung bilden kann.
Philipp Steinkrüger, Gründungsmitglieddes Instituts für Dokumentologie und Editorikund Managing Editor der RezensionszeitschriftRIDE (Review Journal for digital editions andressources)
Beitrag: Digitale Nachhaltigkeit imKriterienkatalog
Die Zahl wissenschaftlicher Onlineangebote,darunter auch zahlreiche digitale Editionen,nimmt stetig zu. Eine kritische Reflektionund Evaluation solcher Angebote istjedoch noch sehr peripher, da sich dieetablierten Rezensionsorgane weiterhin aufPrintpublikationen konzentrieren. RIDE,die erste Rezensionszeitschrift explizit fürdigitale Editionen, bietet seit 2015 ein Forum,in dem digitale Editionen kritisch besprochenwerden. Der Komplexität solcher Editionen, diesich durch die vielfältigen Möglichkeiten desdigitalen Paradigmas und ihrer Umsetzungenergibt, versucht RIDE mit einem Kriterienkatalogzu begegnen, der Rezensenten in ihrenBesprechungen leiten soll.
Der Beitrag wird insbesondere auf dasThema „digitale Nachhaltigkeit“ eingehen.Erstens wird vorgestellt, was RIDE selbst zurdigitalen Nachhaltigkeit beiträgt. Der Katalogals Grundlage aller Besprechungen enthälteine Reihe von Kriterien, die zentral für dieMöglichkeit langfristiger Verfügbarkeit sind.Besprechungen in RIDE dokumentieren, ob
57

Digital Humanities im deutschsprachigen Raum 2017
und inwiefern aktuelle digitale Editionen dieseKriterien erfüllen und tragen dazu bei, dasszukünftige Editionsprojekte diese Kriterien vonAnfang an im Blick behalten. Zweitens wird fürjede Besprechung eine Vielzahl von Aspektenformalisiert abgefragt und gespeichert. Dieserlaubt einen Einblick in die Frage, ob undwie aktuelle Editionen dem Thema „digitaleNachhaltigkeit“ begegnen. Obwohl das Samplenoch zu klein ist, um eine allgemeingültigeAussage zu formulieren, gibt es doch Hinweisedarauf, dass das Thema digitale Nachhaltigkeitnoch mehr in den Fokus der Editorinnenund Editoren rücken muss, damit Editionenlangfristig verfügbar gehalten werden können.
Richtlinien und Kriterienkataloge zurEvaluierung digitaler Projekte und Ressourcen
18thConnect; NINES: Guidelines andPeer Review Criteria. Online: 18thConnect– Eighteenth-century Scholarship < http://
www.18thconnect.org/about/scholarship/peer-review/#new >American Historical Association (2015):
Guidelines for the Professional Evaluationof Digital Scholarship by Historians. Online:American Historical Association < https://www.historians.org/teaching-and-learning/digital-history-resources/evaluation-of-digital-scholarship-in-history/guidelines-for-the-professional-evaluation-of-digital-scholarship-by-historians >
Modern Language Association, Committeeon Information Technology: Guidelines forEvaluating Work in Digital Humanities andDigital Media. Online: Modern LanguageAssociation < https://www.mla.org/About-Us/Governance/Committees/Committee-Listings/Professional-Issues/Committee-on-Information-Technology/Guidelines-for-Evaluating-Work-in-Digital-Humanities-and-Digital-Media >
Modern Language Association, Committee onInformation Technology: Guidelines for Authorsof Digital Resources. Online: Modern LanguageAssociation < https://www.mla.org/About-Us/Governance/Committees/Committee-Listings/Professional-Issues/Committee-on-Information-Technology/Guidelines-for-Authors-of-Digital-Resources >
Sahle, Patrick (2014): Kriterienkatalog für dieBesprechung digitaler Editionen. Online: Institutfür Dokumentologie und Editorik < http://www.i-d-e.de/publikationen/weitereschriften/kriterien-version-1-1/ >
Fußnoten
1. Noch offen ist die Beteiligung desUsabilityLabs der HTW Chur, dem „SchweizerKompetenzzentrum für die Evaluation vonOnline-Angeboten“. Der Beitrag würde sichauf die Erfahrungen des UsabilityLabs in derEvaluation digitaler Präsentationsformenrichten.
Bibliographie
Akademien der Wissenschaften Schweiz(2014): „Open Access“: Für einen freien Zugangzu Forschungsergebnissen. Positionspapierder Schweizerischen Akademie derMedizinischen Wissenschaften. Swiss AcademiesCommunications 9 (1) http://www.samw.ch/dam/jcr:9d2d13bd-1757-401a-962e-0a8ec946fb27/positionspapier_samw_open_access.pdf .
Arts and Humanities Research Council(2006): Peer review and evaluation of digitalresources for the arts and humanities.Institute of Historical Research, School ofAdvanced Study, University of London http://www.history.ac.uk/sites/history.ac.uk/files/Peer_review_report2006.pdf .
European Strategy Forum on ResearchInfrastructures (2016): Strategy Report onResearch Infrastructures. ESFRI Roadmap2016 http://www.esfri.eu/sites/default/files/20160308_ROADMAP_single_page_LIGHT.pdf .
Open Scholar: Independent Peer ReviewManifesto http://www.openscholar.org.uk/independent-peer-review-manifesto/ .
Pfannenschmidt, Sarah L. / Clement, TanyaE. (2014): „Evaluating Digital Scholarship:Suggestions and Strategies for the Text EncodingInitiative“, in: Journal of the Text EncodingInitiative 7 http://jtei.revues.org/949 .
DORA: San Francisco Declaration on ResearchAssessment: Putting science into the assessment ofresearch http://www.ascb.org/dora/ .
Hackathons alsZukunftslabor für diedigitale Nachhaltigkeit
Noyer, Frédé[email protected] Opendata.ch, Schweiz
58

Digital Humanities im deutschsprachigen Raum 2017
Im vorgeschlagenen Panel gehen wir derFrage nach, welchen Mehrwert Hackathonsfür die nachhaltige Entwicklung der DigitalHumanities bieten. Das Panel nimmt Bezug aufdie Erfahrungen, die im Rahmen der beidenOpen Cultural Hackathons gemacht wurden,die 2015 und 2016 von der schweizerischenOpenGLAM Working Group, einer Arbeitsgruppedes Vereins opendata.ch, und lokalen Partnernorganisiert wurden.
Im Panel werden insbesondere drei Themenin Zusammenhang mit dem TagungsthemaDigitale Nachhaltigkeit angegangen. Das ersteThema betrifft die Rolle von Open Data imForschungsbereich der Digital Humanities.Es soll aufgezeigt werden, in welchem MasseOpen Data als nachhaltiger Faktor für dieDigital Humanities-Forschung betrachtetwerden kann, insbesondere in den BereichenQualitätssicherung und Wiederverwendung vondigitalen Daten.
Das zweite Thema betrifft dieInterdisziplinarität, die oft als essentiellerFaktor einer gelungenen und nachhaltigenAusbildung in den Digital Humanities betrachtetwird. Im Panel soll aufgezeigt werden, wiedas Format des Hackathons eine Gelegenheitfür die interdisziplinäre Auseinandersetzungzwischen verschiedenen Akteuren bietenkann, insbesondere zwischen Forschenden undGedächtnisinstitutionen.
Beim dritten Thema, das ebenfalls imZusammenhang mit der Entwicklung einerAusbildung in den Digital Humanities steht,bezieht sich auf die praktische Ausrichtung desHackathons. "Less Yak, more Hack" war eine derDevisen in den Anfängen der Digital Humanities.In welchem Masse kann ein experimentellerRahmen, konzentriert auf eine kurze Zeitspanne,wie ihn die Hackathons zur Verfügung stellen, zueiner nachhaltigen Forschungsumgebung für dieDigital Humanities beitragen?
Seit Jahren digitalisieren Bibliotheken,Archive und Museen ihre Bestände undmachen diese teilweise online verfügbar.Parallel dazu liegen vermehrt auch Metadatenund andere strukturierte Daten in digitalerForm vor. Das Potential dieser Daten undDigitalisate ist heute jedoch bei weitem nichtausgeschöpft. Hier setzt der Hackathonan, indem er Forschende, Vertreter vonMuseen, Archiven und Bibliotheken sowieSoftware-Entwicklerinnen, Wikipedianerinnenund Software-Designer zusammenbringt,damit diese in der Praxis gemeinsam dasPotenzial des digitalen Kulturerbes und dessenWeiterverwendung ergründen können.
Ergebnisse des Hackathons bildenüblicherweise Projektideen, Konzepte und erstePrototypen sowie der Knowhow-Austauschund neue Kooperationen zwischen denGedächtnisinstitutionen, den Forschenden undden anderen Teilnehmerinnen und Teilnehmern.Damit hat der Hackathon in erster Linie eineKatalysator-Funktion. Der Hackathon ist zudemeine Gelegenheit, Gedächtnisinstitutionenzu ermuntern, Kulturdaten zur freienWeiterverwendung bereitzustellen. EtlicheInstitutionen nutzen den Event, um eineminteressierten Publikum neu verfügbare Datenzur weiteren Nutzung vorzustellen.
Das Panel besteht aus vier Beiträgen. Er wirddie Prinzipien von Open Data vorstellen undaufzeigen, welche Rolle Hackathons aus Sichtder Organisierenden im Rahmen der DigitalHumanities in der Schweiz spielen können. Diedrei weiteren Beiträge wiederspiegeln die Sichtder drei verschiedenen Teilnehmergruppen: dieForschenden, die Gedächtnisinstitutionen sowiedie Software-Entwickler und Webdesignerinnen.Gemeinsam werden sie über die Grundidee desHackathons und deren konkrete Umsetzungdiskutieren. Der Fokus liegt dabei auf OpenData und damit der langfristigen Bereitstellungvon Daten, der Rolle von Open SourceSoftware, der Austausch mit verschiedenenStakeholdergruppen sowie der Vorgehensweiseim Vorfeld und während des Anlasses. Konkretwerden dabei die folgenden Fragen thematisiert:
• Welche Bedeutung hat die Open-Data-Politikfür die digitale Nachhaltigkeit?
• Inwiefern ist das Format des Hackathonsgeeignet für die langfristige Entwicklung desDigital Humanities-Umfelds?
• Welche Rolle haben Hackathons bezüglichder längerfristigen Innovation undEtablierung von Qualitätsstandards?
• Die Hackathonprojekte zwischenKurzlebigkeit und langfristigen Projekten undLösungen: Wo liegt der Beitrag zur digitalenNachhaltigkeit?
Frédéric Noyer ist Mitglied desOrganisationsteams des SchweizerKulturhackathons und wird im Rahmen desPanels die Perspektive von OpenGLAM und denOrganisierenden des Hackathons vertreten.
OpenGLAM ist eine Bewegung der OpenKnowledge Foundation, die sich an Gedächtnis-und Kulturinstitutionen richtet. Die Philosophievon Open(GLAM steht im Englischen für„Galleries, Libraries, Archives, Museums“) lässt
59

Digital Humanities im deutschsprachigen Raum 2017
sich anhand von fünf Prinzipien einfach auf denPunkt bringen 1 :
1. Digitale Informationen zuÜberlieferungsobjekten (Metadaten) werdenmittels einer geeigneten Lizenz ohneNutzungsbeschränkungen verfügbar gemacht[…].
2. Gemeinfreie Werke werden (insbesondereim Zusammenhang mit der Digitalisierung)keinen neuen Nutzungsbeschränkungenunterworfen.
3. Bei der Publikation von Daten wird explizitund unmissverständlich kommuniziert, welcheArt von Weiterverwendung erwünscht bzw.erlaubt ist […].
4. Bei der Publikation von Daten werdenoffene, maschinenlesbare Dateiformateverwendet.
5. Neue Möglichkeiten, Internet-NutzerInneneinzubeziehen, werden aktiv genutzt.
Damit wird für die Metadaten das Open-Data-Prinzip verankert. Bei den eigentlichen Inhaltenwird die Respektierung der Public Domaineingefordert, aber ansonsten viel Spielraumgelassen. Erwünscht ist allerdings, dassGedächtnisinstitutionen nicht nur gemeinfreieInhalte für die freie Weiterverwendung durchDritte bereitstellen, sondern auch alle übrigenInhalte aus ihren Beständen, sofern keineurheberrechtliche oder andere rechtlicheGründe dagegen sprechen. Damit wird nämlichdie Nutzung der Daten durch Verringerung derTransaktionskosten merklich erleichtert. Nebender Öffnung von Daten und Inhalten steht auchdas Schaffen neuer Partizipationsformen imVordergrund, die durch das Internet ermöglichtwerden. Damit lässt sich OpenGLAM als logischeFortschreibung der Entwicklung verstehen, diemit dem Aufkommen des Internets (Web 1.0 undWeb 2.0) und der zunehmenden Digitalisierungvon Überlieferungsobjekten angestossen wurde.
Frédéric Noyer wird den im Rahmendes Schweizer Kulturhackathons verfolgtenAnsatz vorstellen und mit Ergebnissen derTeilnehmerbefragungen der beiden erstenSchweizer Kulturhackathons aufwarten können.Diese umfassen Angaben zur Akzeptanz derOpenGLAM-Prinzipien und der Evaluierungihres Nutzens für die Forschung in den DigitalHumanities, zu den bisherigen Hackathon-Erfahrungen der Teilnehmenden, zu ihrer Rollewährend des Anlasses, zu ihren Aktivitätenwährend und nach dem Hackathon sowie zurZufriedenheit und zur Wahrnehmung derWirksamkeit des Hackathons in Bezug aufverschiedene Ziele, wie Knowhow-Austausch,Networking, das Generieren von neuen Ideen,
das Umsetzen von Projekten oder die Förderungvon Open Data unter Gedächtnisinstitutionen.
Projekt “Visual Exploration of Vesalius'Fabrica”Danilo Wanner, YAAY, Basel (unter Vorbehalt)
Danilo Wanner ist Designer und Mitgliedvon YAAY, eine Informationsdesign-Agenturaus Basel. Ihre Arbeit besteht darin, durchkreatives Design komplexe Informationenzu konsolidieren, umzustrukturieren und zuvereinfachen.
Das Team von YAAY schloss sich am OpenCultural Hackathon mit Radu Suciu zusammen,einem Spezialisten für frühneuzeitlichemedizinische Publikationen. Das Team befasstesich mit dem Digitalisat des medizinischenBuchs “De humani corporis fabrica” desniederländischen Anatomisten Adreas Vesualisaus dem 16. Jahrhundert. Suciu hatte das Buchim Rahmen seiner Dissertation untersucht. 2
Die Originalversion des Buchs liegtin der Universitätsbibliothek Basel, demVeranstaltungsort des zweiten Schweizer OpenCultural Hackathons. Das Buch wurde von derBibliothek digitalisiert und in einer PDF-Versiononline zur Verfügung gestellt. Im Gespräch mitSuciu wurde klar, dass es nicht möglich ist,aufgrund der PDF-Version den Wert und dieBedeutung des Buchs richtig einzuschätzen.Da das Buch unter strengen konservatorischenVorschriften gelagert werden muss, ist esnur schwer zugänglich. Inhaltlich ist dasBuch ausserdem nur mit grossem Fachwissenverständlich.
Das Ziel dieser Zusammenarbeit von Forscherund Designern war nun, die digitale Versiondes Buchs zu analysieren. Die Seiten desBuches wurden in verschiedene Kategorien –Illustrationen, Text und Kombination dieserbeiden – eingeteilt. Aufgrund dieser Analysewurden vier “Stories” erstellt und auf einemFarbbalken visualisiert. Basierend auf denMetadaten des Digitalisats wurde eine Infografikmit interessanten Fakten zum Buch erstellt.
Diese Art der Buchanalyse könnte auf alleBücher mit einem seltenen und/oder wertvollenInhalt angewendet werden, um Leserinnenund Lesern den Zugang zu vereinfachen.Die Analysemethode könnte ausserdem aufweitere Kunst- oder Wissenschaftsformen wieAusstellungen oder Bilder übertragen werden.
Das Ergebnis des Projekts ist ein Prototypeines Software-Programms, das an derKonferenz vorgestellt wird. Ausserdemwurden durch den Vergleich der Illustrationeninteressante Entdeckungen zur Untersuchung
60

Digital Humanities im deutschsprachigen Raum 2017
des Buchs gemacht. Die verschiedenen Resultatewerden im Referat präsentiert.
Dodis goes HackathonChristiane Sibille & Sacha Zala, Dodis, Bern
Die Diplomatischen Dokumente derSchweiz (DDS) sind ein Projekt zur Editionzentraler Dokumente zur Geschichte derschweizerischen Aussenbeziehungen. IhreDatenbank Dodis ermöglicht den freien Zugangzu einer grossen Anzahl von digitalisiertenDokumenten und liefert Informationenzu in- und ausländischen Personen undKörperschaften, die aussenpolitisch aktiv waren.
Für den ersten Swiss Cultural Hackathonstellten die DDS Daten zu den vorhandenenDokumenten zur Verfügung. Ein Schwerpunktlag hierbei auf geographischen Metadaten,die kurz vor dem Hackathon vollständiggeolokalisiert wurden. Seit 2015 stehen dieseDaten unter opendata.dodis.ch zur Verfügung.
Bei beiden Hackathons stiessen die zurVerfügung gestellten Daten auf grosses Interesse,wobei insbesondere die fertige Geolokalisationvon den Teilnehmenden sehr geschätzt wurde.
Dies hat gezeigt, dass qualitativ hochwertigaufbereitete Forschungsdaten nicht nur für dieScientific Community relevant sind, sondernauch für die Weiterverarbeitung durch eineinteressierte Öffentlichkeit attraktiv sind. DieHackathons haben DDS darin bestärkt, dasPrinzip der digitalen Offenheit, das auf den dreiSäulen Open Access, Open Source und Open Databasiert fortzusetzen und weiter auszubauen.
Aufbauend auf Erfahrungen, die währenddes Hackathons gemacht wurden, haben die DDSdaher auch ihr Engagement im Bereich LinkedOpen Data verstärkt.
Die Präsentation wird auf die Rolle desHackathons für die Langzeitstrategie in Bezugauf Innovation und Kommunikation einesForschungszentrums wie Dodis eingehen.Ausserdem wird kritisch auf die gemachtenErfahrungen im Rahmen der zwei Hackathonseingegangen.
VSJF-Flüchtlingsmigration zwischen1898-1975 in der SchweizMaria-Elisabeth Züger, Archiv fürZeitgeschichte, Zürich
Unsere Gruppe bestand aus 6 Mitgliedernaus unterschiedlichen Bereichen. Es kamenEntwickler mit Datenspezialisten sowieArchivaren und dem Datenlieferant zusammen.
Die Daten sind ein Auszug aus derVSJF-Datenbank, welche durch das Archivfür Zeitgeschichte an der ETH Zürich(Datenlieferant) verwaltet wird. Die Datenbankbeinhaltet Daten zu Flüchtlingen, welchebei dem Verband Schweizerischer Jüdischer
Fürsorgen (VSJF) verzeichnet sind. Sie istResultat eines langjährigen Projektes in welchemInhalte aus Akten des VSJF händisch übertragenwurden.
Auf Basis des VSJF-Datenauszugesentwickelten wir eine interaktive Visualisierungdes Migrationsflusses zur und durch die Schweizim Zeitraum von 1898-1975. Um den Fluss zuveranschaulichen nutzten wir eine Schnittstellezu Google Maps. Die Visualisierung wird ineiner HTML-Seite mittels JavaScript dargestellt.Auf einer Karte wird der Migrationsfluss vonüber 20,000 Flüchtlingen im zeitlichen Verlaufabgebildet.
Der Weg eines Flüchtlings beginnt beimGeburtsort und setzt fort mit dem Ort von demaus die Einreise in die Schweiz stattfand (sofernbekannt). Dann folgt eine Reihe an Aufenthaltenin der Schweiz. Schlussendlich verlässt derFlüchtling die Schweiz wieder von einem Ortin der Schweiz zu einem Bestimmungsortausserhalb des Landes.
Eine wichtige Aufgabe während desHackathons war es die Daten für dieVisualisierung vorzubereiten. Der Fluchtwegmusste aus den vorhandenen Daten extrahiertund für die Schnittstelle aufbereitet werden.Hierfür verwendeten wir Google Refine (jetztbekannt unter OpenRefine) und reguläreAusdrücke zur Textmustererkennung um dieDaten in mehreren Schritten automatisiertzu strukturieren. Lager und Aufenthaltsortewurden geocodiert und nach Typenkategorisiert. Die Kategorien sind auf der Kartemittels Farben dargestellt. Zudem wurdenrelevante historische Ereignisse recherchiertund als Hintergrundinformation in dieVisualisierung eingebettet.
Nach dem Hackathon erhielten wir positivesFeedback des Archivs für Zeitgeschichte undeine Diskussion über Nutzen und Möglichkeiteneiner derartigen Visualisierung fand statt.
Moderiert wird das Panel von Jan Baumann.Er ist Mitarbeiter von infoclio.ch und hatdie beiden ersten Ausgaben des SchweizerKulturhackathons mitorganisiert.
In der Diskussion wird es unter anderem umfolgende Fragen gehen:
• Welchen Nutzen haben Hackathons fürdie Forschung in den Digital Humanities?Welchen Nutzen bieten Hackathonsin methodologischer Hinsicht für dieForschung?
• Welche Bedeutung hat die Open-Data-Politik für die digitale Nachhaltigkeit? Kanndie langfristige Erhaltung von digitalen
61

Digital Humanities im deutschsprachigen Raum 2017
Daten durch die freie Zugänglichkeit bessergesichert werden, als wenn der Zugangbeschränkt bleibt?
• Wie gelingt die Integration derunterschiedlichen Stackholder(Programmierer, Vertreter der Daten-Lieferanten, Forschende, Wikipedianer,Designer) währende eines Hackathons?
• Wie steht es um die Nachhaltigkeit deram Hackathon entwickelten Projekte?Werden Projekte nach dem Hackathonweiterentwickelt? Gibt es Best Practices füreine nachhaltige Weiterentwicklung derProjekte?
Fußnoten
1. See http://openglam.org/principles/2. Radu Suciu, André du Laurens - Discoursdes maladies mélancoliques (1594), Paris,Klincksieck, 2012.
Bibliographie
Briscoe, Gerard / Mulligan, Catherine(2014): „Digital Innovation: The HackathonPhenomenon“, in: Working Papers ofThe Sustainable Society Network https://qmro.qmul.ac.uk/xmlui/handle/123456789/11418[letzter Zugriff 1. Dezember 2016].
Decker, Adrienne / Eiselt, Kurt / Voll,Kimberly (2015): „Understanding and Improvingthe Culture of Hackathons: Think Global HackLocal“, in: Presentations and other scholarship,30. September 2015. http://scholarworks.rit.edu/other/847 [letzter Zugriff 1. Dezember 2016].
Groen, Derek / Calderhead, Ben(2015): „Science hackathons for developinginterdisciplinary research and collaborations“,in: eLife 10.7554/eLife.09944.
Johnson, Peter / Robinson, Pamela (2014):„Civic Hackathons: Innovation, Procurement,or Civic Engagement?“, in: Review of PolicyResearch 31 (4): 349–357 10.1111/ropr.12074.
Komssi, Marko / Pichlis, Danielle /Raatikainen, Mikko / Kindström, Klas /Järvinen, Janne (2015): „What are Hackathonsfor?“, in: IEEE Software 32 (5): 60–67.
Melissa, Gregg (2015): „FCJ-186Hack for good: Speculative labour, appdevelopment and the burden of austerity“,in: The Fibreculture Journal 25 http://twentyfive.fibreculturejournal.org/fcj-186-hack-for-good-speculative-labour-app-development-and-the-burden-of-austerity [letzter Zugriff 01.Dezember 2016].
Prahalad, C.K. / Ramaswamy, Venkat (2004):„Co-creation experiences: The next practicein value creation“, in: Journal of InteractiveMarketing 18 (3): 5–14 10.1002/dir.20015.
Pui Ying To, Jacqueline (2016):Understanding the Potential of PublicEngagement: Hackathons and Jams.Master Thesis, OCAD University, Torontohttp://openresearch.ocadu.ca/666/1/To_Jacqueline_2016_SFIN_MRP_withRevisions.pdf[letzter Zugriff 1. Dezember 2016].
Nachhaltige Entwicklungdigitaler Ressourcen undWerkzeuge für wenigerforschte historischeSprachen
Feige, [email protected]ät Hamburg, Deutschland
González, [email protected]ät Hamburg, Deutschland
Prager, [email protected] Akademie der Wissenschaften und derKünste
Vertan, [email protected]ät Hamburg, Deutschland
Werwick, [email protected]ät Jena, Deutschland
Das Panel wird durch vier Kurzvorträge inProbleme der Nutzung digitaler Werkzeuge fürnicht-indoeuropäische Sprachen einführen.Die Vorträge basieren auf Erfahrungenaus langfristig angelegten Projekten undhaben jeweils individuelle Lösungen für diespezifischen Anforderungen gefunden, diehauptsächlich durch die Sprache formuliertwerden.
62

Digital Humanities im deutschsprachigen Raum 2017
Allen Projekten gemein sind Problemeder Nutzung von digitalen Werkzeugen, dieinsbesondere bei der Verwendung von Quellenhistorischer oder wenig erforschter Sprachenauftreten.
Aktuelle Content Management Systeme undAnnotationstools wurden selten im Hinblickauf Anforderungen aus Orchideenfächernentwickelt. Dies betrifft beispielsweise einigeSprachen mit nichtkonkatenativer Morphologieoder komplexen Schriftsysteme. Daher müssenfür erwähnte Sprachen entweder existierendeAnwendungen angepasst oder erschaffenwerden.
Bei der Adaption können während derModellierung wichtige Eigenschaften nichtberücksichtigt werden oder bleiben nurals Kommentar erhalten, was eine weiteremaschinelle Bearbeitung erschwert. Bezüglichder Datenkodierung ergibt sich das Problemder Ineffizienz. So wurden morphologischeTagsets primär für die indo-europäischeSprachfamilie entwickelt. Für eine tiefelinguistische Annotation müssen aber dieseStandards beispielweise für einige semitischeSprachen angepasst werden.
Nicht selten ist die Alternative dieEigenentwicklung projektbezogener Lösungen,die aber aufgrund der Anforderungen miteigenen Datenformaten arbeiten, und so nichtmehr den geltenden Standards folgen undden Austausch erschweren. Hinzu kommt derimmense Zeit- und Ressourcenaufwand bei derImplementierung.
Allerdings sind gerade im deutschsprachigenRaum viele langfristige Projekte auf digitaleTools angewiesen.
Durch eine Vernetzung solcher Projektekönnen gemeinsame Anforderungen an,und Begrenzungen von aktuellen Lösungenbesprochen und Initiativen zur Entwicklungdigitaler Tools und Ressourcen koordiniertwerden. Daher ist das Ziel dieses Panelseine erste Zusammenführung langfristigausgerichteter Projekte im deutschenSprachraum, die mit historischen nicht-indo-europäischen Sprachen im digitalen Kontextarbeiten. Dabei sollen die Probleme derNachhaltigkeit entwickelter Werkzeuge undRessourcen, sowie der bearbeiteten Datenbesprochen werden. Anschließend werdendie vielfältigen Herangehensweisen mit einemFokus auf drei große Punkte diskutiert:
• Nachhaltigkeit von Repositorien
• Welche Frameworks werden für welcheDatentypen benötigt?
• Wie können Informationen über unpräziseDaten gespeichert werden?
• Wie gehen verfügbare Systeme mitMultilingualität um?
• Nachhaltigkeit von(Annotations-)Werkzeugen
• Analyse historischer Daten impliziertdie Annotation von Textmaterialien inSprachen, die aus verschiedenen Gründen zuProblemen führen.
• Welche Annotationstools können genutztwerden? Mit welchen Limitierungen?
• Was bedeutet es, ein neues Tool zuentwerfen?
• Häufige Anforderungen durch strukturellkomplexe Sprachen: Multilevel-Annotation, Textkorrektur während derAnnotationsphase, Multilevel-Segmentierung
• Nachhaltigkeit des annotierten Materials(Standards)
• Während der Standard TEI-XML alsSchnittstellenformat sehr nützlich ist,ergeben sich dennoch Probleme wie:• für interne Verarbeitung kann dessen
Verwendung hinderlich sein. Dahermüssen projekt-spezifische Lösungenmit standardisiertem Export entwickeltwerden.
• Können diese Daten von Dritten in TEI-XML verarbeitet werden?
• Welche anderen Formate können genutztwerden (z.B. JSON)?
• Sind existierende Tagset-Formateausreichend spezifiziert, um auch nicht-europäische Sprachen taggen zu können?
Herausforderungen in derNutzung vorhandener Toolsfür arabische Daten
Alicia González, Tillmann FeigeUniversität HamburgERC- Projekt COBHUNI ( https://
www.cobhuni.uni-hamburg.de/ )Email: [email protected];
[email protected] beschreiben den Ansatz, einen Korpus
der neben modernem auch klassischesArabisch (siehe Romanov, 2016) enthält, mit
63

Digital Humanities im deutschsprachigen Raum 2017
computerlinguistischen und semantischenVerfahren analysierbar zu machen. Wirsetzen auf bereits vorhandene Software fürdie Hauptpunkte Annotation und Analyse.Dazu wurde ein Pflichtenheft erstellt, dass mitvorhandenen Tools abgeglichen wurde.
Da wir mit arabischen Daten arbeiten,ist eine große Herausforderung die Schrift.Es ist eine linksläufige verbundene Schrift,die durch Konsonanten und lange Vokalerepräsentiert wird. Kurze Vokale sind Diakritika,die optional gesetzt werden und gerade beiReferenzen auf religiöse Quellen im Textkorpusvorkommen. Dabei ist vollständige UTF-8Unterstützung und die saubere Darstellung derSchrift unabdingbar. Dies reduziert die Auswahlerheblich. Hinzu kommt, dass wir auf flexibleImport- und Exportmöglichkeiten angewiesensind. Ähnliche Probleme führen Peralta undVerkinderen auf (Peralta / Verkinderen 2016).Durch unsere Herangehensweise gibt es weitereEinschränkungen wie Mehrebenen-, Multitoken-aber auch Subtoken-Annotation.
Die Auswahl für die semantischeAnnotation fiel auf WebAnno, dass durchsein spezielles Datenmodell die erforderlicheDatenaufbereitung und Kontrolle gestattet.
Als Visualisierungstool haben wir ANNISausgewählt, dass ebenfalls Arabisch unterstützt,einen konfigurierbaren Converter mitbringtund Mehrebenenkorpora erlaubt, so dassauch hier die Hauptkriterien erfüllt wurden.Zusätzlich lassen sich potentielle Problemein der Darstellung durch eine anpassbareHTML-Visualisierung umgehen. DurchZusammenarbeit mit den Entwicklern beiderProgramme wurde die Unterstützung fürArabisch stetig ausgebaut.
Im Beitrag werden wir die einzelnen Punkteerläutern und darstellen, warum wir uns fürdie angeführten Programme und gegen eineEigenentwicklung entschieden haben, sowiewelche Implikationen diese Entscheidung für dieNachhaltigkeit des Projekts, der Daten und dergenutzten Tools hat.
Tiefe Mehrebenen-Annotationfür semitische Sprachen: derFall von Ge'ez
Cristina VertanUniversität HamburgERC-Projekt TraCES ( https://www.traces.uni-
hamburg.de/ )Email: [email protected]
Das südsemitische Gәʿәz ist die Sprachedes Königreichs Aksum in der heutigennordäthiopischen Provinz Tigray, von woaus die im 4. Jahrhundert beginnendeChristianisierung Äthiopiens ihren Anfangnahm. Die in der Folge entstehende reicheLiteratur ist in großem Umfang geprägt vonÜbersetzungen, was durch grammatischeInterferenzphänomene reflektiert wird. DasAltäthiopische hat aus einer südsemitischenSchrift ein eigenes Silbenalphabet entwickelt,das bis heute in mehreren modernen SprachenÄthiopiens und Eritreas Verwendung findet.Innerhalb der semitischen Sprachen fällt esdurch die verwendete Rechtsläufigkeit auf;außerdem werden die Vokale vollständiggeschrieben. Beides unterscheidet das Gәʿәzvon verwandten Sprachen wie Altsüdarabisch,Arabisch, Hebräisch und Syro-AramäischMit den genannten eng verwandtensemitischen Sprachen teilt das Altäthiopischedie nichtkonkatenative Morphologie.Durch das äthiopische Silbenalphabetsind Morphemgrenzen in der Schrift nichtdarstellbar, so dass beispielsweise eineinzelner Vokal als Bestandteil einer Silbe eineeigenständige Wortart darstellt und tokenisiertwerden muss.
Die Komplexität des Annotationstools wirdsehr vielfältige linguistische Anfragen unddetaillierte Analysen der Sprache ermöglichen,aber auch eine vollautomatische Annotationverhindern. Ein alle morphologischen Merkmaleabdeckendes Vektorraum-Modell (das fürmaschinelle Lernverfahren benutzt werdenmuss) wäre zu groß. Vorstellbar ist lediglicheine flache automatische Annotation (z. B.der Wortarten); jedoch wird auch für einesolche zunächst eine relativ große Mengean Trainingsdaten benötigt. Daher ist dieEntwicklung eines Werkzeugs für die manuelleAnnotation ein obligatorischer Schritt.
Die Besonderheit der entwickelten Lösung(Vertan/Ellwardt/Hummel 2016) sind:
• automatische Transkription• manuelle Korrektur der Transkription
während des Annotationsprozesses• semi-automatische Verfahren: automatische
Verläufe werden farbig markiert und sindautomatisch zur manuellen Korrekturhinterlegt
• Mehrebenenannotation: Linguistik, Edition,Textstruktur
• Anpassungen an unterschiedlicheSchriftsysteme und Transkriptionsregeln
64

Digital Humanities im deutschsprachigen Raum 2017
Nutzungs- undNachhaltigkeitsstategien imProjekt "Textdatenbank undWörterbuch des KlassischenMaya"
Christian M. PragerNRW Akademie der Wissenschaften und der
Künstehttp://mayawoerterbuch.de/Email:Die Mayaschrift ist das einzig lesbare
Schriftsystem der vorspanischen Amerikas. Dieüber 10.000 Texte sind in einer logographisch-syllabischen Hieroglyphenschrift verfasstund von den rund 800 Zeichen sind erst60% sicher entziffert. Die Texte enthaltentaggenaue Kalenderangaben, die es unsermöglichen die rund 2000jährige Sprach- undSchriftgeschichte genau zu dokumentieren.Das Projekt (Prager 2015) wird sämtlicheInschriften einschließlich Metadaten in einerDatenbank einzupflegen und darauf basierendein digitales Wörterbuch des Klassischen Mayazu kompilieren. Herausforderung dabei ist, dassdie Schrift noch nicht vollständig entziffert istund bei der Modellierung zu berücksichtigenist. Unser Projekt verfolgt den Ansatz, wonachdie Bedeutung von Wörtern ihre Verwendungist - Texte nehmen Bezug auf den Textträgerund den Verwendungskontext und nur dieexakte Dokumentation sogenannter nicht-textueller Informationen erlaubt es, textuelleund nicht-textuelle Informationsbereichezueinander in Beziehung zu setzen und bei derEntzifferung von Zeichen und Textstellen zuberücksichtigen. Zum Zweck der Nachhaltigkeitund Nachnutzung greift das Projekt bei derBeschreibung der Artefakte und der relevantenobjektgeschichtlichen Ereignisse auf CIDOCCRM zurück, das eine erweiterbare Ontologiefür Begriffe und Informationen im Bereich deskulturellen Erbes anbietet. Das entstandeneAnwendungsprofil wird durch Elemente ausweiteren Standards und Schemata angereichertund wird damit auch für vergleichbare Projektnachnutzbar. Die Schemata und erstelltenMetadaten werden in einer Linked (Open)Data-Struktur (LOD) abgebildet. Durch dieRepräsentation im XML-Format, sowie dieNutzung von HTTP-URIs wird eine einfacheAustauschbarkeit und Zitierbarkeit der Datenermöglicht. Durch diese Umsetzung könnenObjektmetadaten getrennt vom erfassten Text
gespeichert werden und durch die Verwendungder HTTP-URI verlinkt werden. Die Nachnutzungbereits bestehender und fachlich anerkannterTerme trägt darüberhinaus auch zu einer hohenInteroperabilität mit anderen Datenbeständenund Informationssystemen bei. Das ausgestalteteSchema hat eine ontologisch-vernetzte Struktur,die komplexe Beziehungen und Zusammenhängeabbildet.
Interdisziplinäre DigitaleZusammenarbeit für selteneSprachen und Kulturen
- Eine Fallstudie über jiddischeTexte aus der frühen Neuzeit -
Walther v. Hahn (Universität Hamburg),Berndt Strobach (Wolffenbüttel)
Email: [email protected]. de,[email protected]>
In den Geisteswissenschaften werdenhäufig die fachlichen Interpretationen und diesprachlichen Erklärungen von verschiedenenGruppen mit unterschiedlicher Kompetenzbearbeitet. Gute Beispiele sind Studien zu Textenaus semitischen Sprachen, wobei, speziell beihistorischen Dokumenten die historische odergeistes- und sozialgeschichtliche Würdigungvon Forschern verfasst werden muss, die desHebräischen, Arabischen, Aramäischen etc.nicht mächtig sind, die sprachwissenschaftlichenForscher dagegen bei der Interpretationgelegentlich weniger engagiert bleiben.Extremfälle wie Studien über das Sephardischein Spanien (Ladino, Djudezmo) machen etwasolide Kenntnisse zumindest des Spanischen,Hebräischen, Türkischen, Griechischen undItalienischen zur Voraussetzung für seriösehermeneutische Forschungsergebnisse.Wirberichten über Studien zu jiddischen Textenaus dem Wolffenbüttel des 18. Jahrhunderts,in denen die Rolle der "Hofjuden" und ihreskultur- und sozialgeschichtlichen Hintergrundesdiskutiert wird.
Die Herausforderung einer interdisziplinärenZusammenarbeit zwischen Historikern,Sprachwissenschaftlern und Informatikernbesteht darin,
1. die Lesbarkeit der Originalquellen für alleGruppenmitglieder sicher zu stellen (InvertierteTranskriptionen, Vokalisierung, Visualisierung),sowie
65

Digital Humanities im deutschsprachigen Raum 2017
2. in der Gruppe eine gemeinsameBehandlung von Vagheit, Unsicherheit undUnbekanntem zu definieren, so dass dieUnklarheiten in den einzelnen Forschungsstufenerhalten und im Endergebis sichtbar bleiben(Vagheits-Annotationen und vage Inferenzen).Heute werden derartige Unsicherheiten meistbereits in den Annotationen unterschlagen (vonHahn, 2016).
Bibliographie
Hahn, Walther von (2016): „Humanities meetComputer Science – Digital Humanities betweenExpectations and Reality“, zu erscheinen in: vonHahn, Walter / Papadima, Liviu / Vertan, Cristina(eds.): Humanities2020, New Trends in Educationand Research. Bukarest: University of BucharestPublishing House.
Peralta, José Haro / Verkinderen, Peter(2016): „‚Find for me!‘: Building a Context-BasedSearch Tool Using Python“, in: Muhanna, Elias(ed.): The Digital Humanities and Islamic &Middle East Studies. Berlin: Walter de GruyterGmbH 199–231.
Prager, Christian M. (2015): „DasTextdatenbank- und Wörterbuchprojektdes Klassischen Maya: Möglichkeiten undHerausforderungen digitaler Epigraphik“, in:Neuroth, Heike / Rapp, Andrea / Söring, Sibylle(eds.): TextGrid: Von der Community - für dieCommunity: Eine Virtuelle Forschungsumgebungfür die Geisteswissenschaften. Glückstadt:Werner Holsbusch 105–124 https://www.academia.edu/17957108/Das_Textdatenbank-_und_W%C3%B6rterbuchprojekt_des_Klassischen_Maya_M%C3%B6glichkeiten_und_Herausforderungen_digitaler_Epigraphik .
Romanov, Maxim (2016): Creating Frequency-Based Readers for Classical Arabic http://maximromanov.github.io/2016/05-30.html[letzter Zugriff 1. Dezember 2016].
Vertan, Cristina / Ellwardt, Andreas /Hummerl, Susanne (2016): „Ein Mehrebenen-Tagging-Modell für die Annotationaltäthiopischer Texte“, in: DHd 2016:Modellierung - Vernetzung - Visualisierung http://www.dhd2016.de/abstracts/vorträge-061.html .
VirtuelleForschungsplattformenim Vergleich: MONK,Textgrid, Transcribo undTranskribus
Piotrowski, [email protected]é de Lausanne
Schomaker, [email protected]ächsische Staats- undUniversitätsbibliothek Göttingen
Horstmann, [email protected]ät Trier
Burch, [email protected] des Kantons Zürich
Hodel, [email protected] für europäische GeschichteMainz
Eine zentrale Forderung zur Unterstützungdigitaler Editionen ist das Anbieten virtuellerUmgebungen (Interfaces, Software) zurProduktion, aber auch zum Managementdigitaler Daten (BMBF 2013). In den letztenJahren wurden aufgrund dieser durchFachwissenschaftlerInnen getragenen Nachfragemehrere Plattformen und Softwareangebote/Infrastrukturen geschaffen, die Prozesse derdigitalen Datenerstellung von der Aufnahme vonInformationen (Metadaten, Transkriptionen)über die Auswertung und Anreicherungbis zur Publikation unterstützen (DARIAH-DE (Hg.), 2015) und nachhaltig betriebenwerden sollen. Unterschiedliche Konzepteund angebotene Abläufe sowie integrierteHilfsmittel stehen für eine je eigene Profilierungder Plattformen. Merkmale der Angebote,insbesondere Leistungsfähigkeit, unterstützteProzesse und Ausrichtungen unterscheidensich zwangsläufig. Im Panel werden aus
66

Digital Humanities im deutschsprachigen Raum 2017
diesem Grund wichtige und häufig eingesetztePlattformen in ihrem Leistungsumfangverglichen und einander gegenübergestellt. ImSinne geisteswissenschaftlicher software studies(Andrews, 2016) müssen die Plattformen nichtnur aus pragmatischen Gründen gegeneinanderabgewogen werden sondern auch, um in denangebotenen Prozessen angelegte Praktikenauf ihre Logik und dadurch entstehendeFolgen zu untersuchen (Drucker, 2013).Anhand eines klar umrissenen Fragebogenspräsentieren Monk, Textgrid, Transcribound Transkribus Arbeitsabläufe, Servicesund Vernetzungsmöglichkeiten. Damit wirdInteressierten in einem Panel aus erster Handein Vergleich wichtiger, produktiv nutzbarerAngebote geliefert.
Das Panel wird moderiert von MichaelPiotrowski (IEG Mainz).
Folgende Frage- und Themenschwerpunktewerden schriftlich und in kurzen Präsentationendargeboten:
• Idealtypischer/Schematisierter Ablauf fürden Gebrauch der Plattform
• Zeitliche Anforderungen, um ein Projektaufzusetzen/ein Dokument zu verarbeiten; zuexportieren
• Herstellung von Transkriptionen• Bild-Text-Verknüpfung• Text-Markup• Ausgabemöglichkeiten (für Edition und/oder
Transkription)• Vernetzungsmöglichkeiten (Wörterbücher,
externe Ressourcen, Ontologien)• Datei-/Bildverwaltung• Projektverwaltung• Auswertungs-/Abfrageoptionen• Automatisierungen• Crowdsourcing/Optionen zum Einbezug von
Laien oder Externen• Nachhaltigkeit der Plattform/der enthaltenen
Daten• Updates bis 2018
Monk (presented by Lambert Schomaker,Rijksuniversiteit Groningen)
The Monk system is a trainable search enginefor handwritten material. For the humanities,it may serve as a method for getting keywordaccess to scanned pages at the earliest stagesafter a document digitisation. For patternrecognition research, it is an observatory forcomplicated visual material and its human-provided labels (e.g., word or character labels).The system act as an e-Science service that iscontinuously available.
An internal image and metadata format isused, which can be exported to, e.g., PAGE xml.Provisional transcriptions can be retrieved asflat text. Indices can be exported upon request.
The system makes a distinction betweenfour different forms of annotation: page (scan)descriptors, typically page titles, page regions ofinterest (tags for visual objects), transcription ofsegmented lines, and finally, word labeling. Thesystem could export in TEI, however, within theOCR community, there is a preference for layout-centric description languages, as opposed toeditorial descriptions. In practice, both TEI andPAGE are used, as well as other formalisms thatallow to provide metadata to polygonal imagesections.
In order to proceed data in Monk, scansare uploaded via sftp or mailed hard disks.The collection is then judged on the requiredpreprocessing steps (multicolumn, contrastenhancement, line segmentations), and‘ingested’. Within one or two days users canstart to label words. The system performs datamining on the collection and presents hit lists forwords which can be labeled further, and so on.Static indices and provisional transcriptions areupdated nightly.
At the moment 400 documents from differentperiods and handwriting styles are beingprocessed. The Monk system is one of the first24/7 machine learning systems. The systemdetects where compute resources should bedirected, on the basis of observed user activitiesand interests.
The Monk system is part of the large multi-petabyte Target platform of the university ofGroningen, in collaboration with astronomy,genomics and the IBM company.
TextGrid (präsentiert durch WolframHorstmann, Niedersächsische Staats- undUniversitätsbibliothek Göttingen)
HintergrundDie Entwicklung von TextGrid, einer
Virtuellen Forschungsumgebung für dieGeistes- und Kulturwissenschaften, wurdedurch die zunehmende Nachfrage ausden Fachwissenschaften nach digitalenWerkzeugen v.a. des philologischen Edierensund kollaborativen Arbeitens angestoßen. DasBundesministerium für Bildung und Forschung(BMBF) hat TextGrid als Verbundprojekt mitüber zehn institutionellen und universitärenPartnern zwischen 2006 und 2015 gefördert.
Die Software steht mittlerweile in einerstabilen Version 3.0 zum kostenfreien Downloadbereit. Software, Archiv und damit das gesamteAngebot werden in Zusammenarbeit mitAnwenderInnen, FachwissenschaftlerInnen
67

Digital Humanities im deutschsprachigen Raum 2017
und Fachgesellschaften und in Kooperation mitDARIAH-DE - Digital Research Infrastructure forthe Arts and Humanities weiter entwickelt unddauerhaft betrieben.
ZielpublikumFachwissenschaftlerInnen, die mit TextGrid
Forschungsprojekte wie z.B. digitale Editionenerarbeiten
EntwicklerInnen, die TextGrid-Toolsund Services für eigene Vorhaben anpassenoder externe Services und Tools in TextGridintegrieren
Forschungsprojekte und -institutionen, dieDaten in TextGrid archivieren und für Drittezugänglich und nutzbar machen (Repository)
Form des EinsatzesDie virtuelle Forschungsumgebung (VFU)
TextGrid unterstützt digital arbeitendeGeisteswissenschaftlerInnen im gesamtenForschungsprozess – insbesondere beimErstellen digitaler Editionen.
Sie besteht aus drei Kernbereichen:- Die Software TextGrid Laboratory stellt
den Einstiegspunkt in die VFU dar und bietetunterschiedliche Open-Source-Werkzeuge und-Services für den gesamten Forschungsprozesszur Verfügung, z. B. einen Text-Bild-Link Editorfür die Verknüpfung von Digitalisaten undTranskriptionen
- Im TextGrid Repository, einemLangzeitarchiv für geisteswissenschaftlicheForschungsdaten, können XML / TEI-kodierteTexte, Bilder und Datenbanken sichergespeichert, publiziert und durchsucht werden.
- Die beständig wachsendeTextGrid Community trifft sich beiregelmäßigen Nutzertreffen zu themen- bzw.anwendungsspezifischen Workshops, dienicht zuletzt auch den Austausch zwischendigitalen Forschungs- vorhaben aus denGeisteswissenschaften befördern.
Eine StärkeTextGrid unterstützt den gesamten
wissenschaftlichen Arbeitsprozess im Rahmender Erstellung digitaler Editionen vomIngest des Ausgangsmaterials (Text- und/oder Bilddatei- en / Faksimiles) über dieAnreicherung und Auszeichnung der Daten(Annotationen, Verknüpfungen) bis zurVeröffentlichung (Portal, Print) und nachhaltigenArchivierung (Repository) und wird stetigbasierend auf konkreten fachwissenschaftlichenAnforderungen weiterentwickelt.
Eine SchwächeTechnisch setzt TextGrid auf dem Eclipse-
Framework auf, aus heutiger Sicht, wärenwebbasierte Tools wünschenswerter. Zugleichverdeutlicht dies, dass Softwareentwicklungen
permanente Weiterentwicklung benötigen,um sich neuen technologischen aber auch sichwandelnden User-Requirements stellen zukönnen.
Transcribo (präsentiert durch Thomas Burch,Universität Trier)
Transcribo wird in enger Zusammenarbeitvon Philologen und Informatikern derKooperationspartner entwickelt. Diegrafische Nutzeroberfläche ist um das digitaleFaksimile, also in der Regel den gescanntenÜberlieferungsträger, zentriert. Beliebiggroße Einheiten (z.B. Wörter, Zeilen oderAbsätze) können mittels eines Rechteck- oderPolygonwerkzeugs markiert, transkribiert undannotiert werden. Dabei wird jede Bilddateidoppelt dargeboten: links liegt das Originalzur Ansicht, die rechte Version dient alsArbeitsunterlage, hier wird der transkribierteText topografisch exakt über das leichtausgegraute Faksimile gelegt. Wo die räumlicheAnordnung nicht der textuellen Wortreihenfolgeentspricht, können Wörter in der grafischenOberfläche zu Sequenzen zusammengefasstund so die semantischen Zusammenhänge imTranskript protokolliert werden. Ein zentralesMerkmal des Programms liegt außerdem inder Möglichkeit, in jeder erfassten Einheittextgenetische und editionsphilologischrelevante Phänomene zu kennzeichnen undmit Annotationen zu versehen. Dabei kommtein Kontextmenü mit einer projektspezifischenAuswahl zum Einsatz. Diese umfasst bisherunterschiedliche Varianten von Korrekturen(wie etwa Sofortkorrekturen, Spätkorrekturenmit ein-, zwei- oder mehrfacher Durchstreichungund Überschreibung), die Kennzeichnungvon Hervorhebungen sowie von unsicherenLesungen oder nicht identifizierten Graphen.Diese Auswahl ist jedoch beliebig erweiterbarund wird über den gesamten Projektverlaufhinweg an die Erfordernisse der Textgrundlageangepasst.
Transkribus (präsentiert durch Tobias Hodel,Staatsarchiv Zürich)
HintergrundTranskribus ist eine Plattform, die zur
automatisierten Erkennung und Annotierungvon Texten dient. Sie leistet einerseits eineVerlinkung zwischen Text und Bild (auf Block,Zeilen und Wortebene), produziert andererseitsstandardisierte Exportformate (XML nachTEI-Standard, PDF, aber auch METS für dieIntegration in Repositorien). Damit steht einevollausgerüstete Softwaresuite zur Verfügung,die von der Segmentierung über die Erkennung,Transkription und Edition bis zur Ausgabe alle
68

Digital Humanities im deutschsprachigen Raum 2017
Schritte in der Herstellung hochwertiger Datenunterstützt.
Die im Projekt READ weiterentwickelteSoftware vereint somit praxisnah dieBedürfnisse von GeisteswissenschaftlerInnenund Aufbewahrungsinstitutionen mit dentechnischen Möglichkeiten und Angeboten,die momentan im Bereich der Informatik undComputerlinguistik ermöglicht werden.
Die Software steht in einer stabilen Versionzum kostenfreien Download bereit. Das ProjektREAD wird unterstützt durch das Horizon 2020Forschungs- und Innovationsprogramm derEuropäischen Union.
ZielpublikumAufbewahrungsinstitutionen, die eigene
Bestände und Dokumente aufbereiten und zurVerfügung stellen wollen
Geisteswissenschaftlerinnen, die eigeneTranskriptionen und Editionen in Transkribuserstellen wollen oder mit darin aufbereitetenDaten arbeiten
Interessierte Laien, die sich anCrowdsourcing-Initiativen beteiligen wollen
ComputerwissenschaftlerInnen, die mitden gewonnenen Daten arbeiten und eigeneAlgorithmen entwickeln oder verbessern wollen
Form des EinsatzesAuf Transkribus werden Bilddateien
hochgeladen, mit Layoutverlinkungen undTranskriptionen sowie Annotationen versehen.Unterstützt werden die Vorgänge durchAutomatisierungsvorgänge im Bereich derLayouterkennung und der Transkription.Der Export der gewonnen Daten ist inunterschiedlichen Formaten möglich. Zusätzlichwerden Module zum Crowdsourcing undzukünftig für e-Learning und Analyse mitSmartphone bereitgestellt.
Eine StärkeTranskribus nutzt neueste
Automatisierungsprozesse (u.a. mit rekursivenneuronalen Netzen) somit werden bestmöglicheResultate in Aussicht gestellt.
Eine SchwächeTranskribus ist eine Expertensoftware und
benötigt entsprechende Einarbeitungszeit, umdie Dokumente effizient und zielgerichtet zubearbeiten.
Bibliographie
Andrews, Tara (2015): „Softwareand Scholarship – Editorial“, in:Interdisciplinary Science Reviews 40: 342–34810.1080/03080188.2016.1165456.
BMBF (Bundesministerium fürBildung und Forschung) (eds.) (2013):Forschungsinfrastrukturen für die Geistes- undSozialwissenschaften https://www.bmbf.de/pub/forschungsinfrastrukturen_geistes_und_sozialwissenschaften.pdf .
DARIAH-DE (ed.) (2015): Handbuch DigitalHumanities: Anwendungen, Forschungsdaten undProjekte http://handbuch.io/w/DH-Handbuch .
Drucker, Johanna (2013): „PerformativeMateriality and Theoretical Approaches toInterface“, in: DHQ: Digital Humanities Quarterly7 (1) http://digitalhumanities.org:8081/dhq/vol/7/1/000143/000143.html .
Schomaker, Lambert (2016): „Designconsiderations for a large-scale image-basedtext search engine in historical manuscriptcollections“, in: Information Technology 58 (2):80–88 10.1515/itit-2015-0049.
VirtuelleForschungsumgebungfür objekt- undraumbezogeneForschung
Kuroczyński, [email protected] für historischeOstmitteleuropaforschung – Institut der Leibniz-Gemeinschaft, Deutschland
Stanicka-Brzezicka, [email protected] für historischeOstmitteleuropaforschung – Institut der Leibniz-Gemeinschaft, Deutschland
Fichtl, [email protected] für historischeOstmitteleuropaforschung – Institut der Leibniz-Gemeinschaft, Deutschland
Köhler, [email protected] Dokumentationszentrum fürKunstgeschichte - Bildarchiv Foto Marburg,Deutschland
69

Digital Humanities im deutschsprachigen Raum 2017
Brahaj, [email protected] Karlsruhe - Leibniz-Institut fürInformationsinfrastruktur, Deutschland
Fichtner, [email protected] Nationalmuseum Nürnberg,Deutschland
Die Digitalisierung der Gesellschaft hatlängst alle Sparten unseres Lebens erfasst.Die computer-gestützte Forschung in denGeisteswissenschaften, allen voran dieComputerlinguistik, blickt bereits auf eineüber fünfzigjährige Tradition zurück. Mit deminformationstechnologischen Fortschritt derletzten drei Dekaden verfügt die zeitgenössischeWissenschaft über ein reichhaltiges, teilsunüberschaubares Arsenal an digitalenForschungswerkzeugen und Applikationen,Dokumentationsstandards, Datenformaten, etc.Gleichzeitig führen die neuen Informations-und Kommunikationstechnologien zu einem niezuvor beobachteten Wachstum von Daten undWissen (Abb. 1).
Abb. 1: Gesamtmenge an generierten Datenin den vergangenen Jahren (Quelle: http://edition.cnn.com/2014/11/04/tech/gallery/big-data-techonomics-graphs/ )
Diese Entwicklung stellt dieInformationsgesellschaft vor neueHerausforderungen. Eine in letzten Jahrenan Bedeutung gewinnende Vorgehensweisestellt die Strukturierung und Vernetzungder Forschungsdaten in einem mensch-und maschinenlesbaren Format. Einenentscheidenden Anteil an diesem Prozessnimmt die Idee von Semantic Web (Web 3.0)für sich in Anspruch (Berners-Lee / Hendler /Lassila, 2001). Mit der Öffnung der Datensilosund Verknüpfung der Daten geht die Ideeeiner semantischen Datenmodellierung undDisambiguierung der Forschungsdaten einher,die in ein weltweites Netzwerk miteinanderin Verbindung stehenden Information(Linked Data) mündet. Diesen Ansatz folgendversuchen zurzeit viele Disziplinen ihrefachspezifischen Fragestellungen mit Hilfe einersprachlich gefassten und formal geordnetenDarstellung einer Menge von Begrifflichkeiten(Entitäten) und der zwischen ihnenbestehenden Beziehungen zu repräsentieren(Referenz- und Applikationsontologien).Diese konzeptionellen mensch- undmaschinenlesbaren Wissensrepräsentationen
können infolge einer Implementierunginnerhalb einer Web Ontology Language (OWL)die generierten Forschungsdaten im RDF-Formatvon Linked Data vorhalten (Graphdatenbank).Für die Disambiguierung der digital vernetzenDatensätze stellt die Entwicklung undZurverfügungstellung von kontrolliertenVokabularen, Thesauri und Normdaten alsLinked Data sowie deren Anbindung an eigeneForschungsdaten einen weiteren bedeutendenEckpunkt der Datenaufbereitung.
Die Gewährleistung einer erfolgreichenStrukturierung und Bereitstellungvon Forschungsdaten innerhalb derGeisteswissenschaft im Sinne von Web 3.0hängt im Wesentlichen von der Verfügbarkeitund Akzeptanz sogenannter VirtuellerForschungsumgebungen und digitalerForschungsinfrastrukturen, die denWissenschaftlern einen leichten, intuitiven undMehrwert versprechenden Zugang zum eigenenForschungsthema im Kontext von Linked Dataanbieten.
Vor dem Hintergrund des diesjährigenDHd-Tagungsthemas der Nachhaltigkeitmöchten wir uns der CIDOC CRM referenziertenDatenmodellierung und den VirtuellenForschungsumgebungen sowie ihren Modulenund Features widmen. Das Panel nimmt sichvier laufende Forschungsprojekte auf demGebiet der objekt- und raumbezogenenForschung zum Anlass aus praktischerErfahrung multiperspektivisch zu berichten.Dabei wollen wir die E-CRM Entwickler ausDFG-geförderten WissKI I und II Projekt(2009-12, 2014-16) und die Anwender aus sichin unterschiedlichen Stadien befindendengeisteswissenschaftlichen Forschungsprojektenzur Sprache kommen lassen. Zum Ausdrucksoll u. a. die Herausforderung der nichtkonvergierenden Zielsetzung einzelnerForschungsprojekte kommen, derenForschungsdaten jedoch im Sinne vonLinked Data in der Praxis zusammengeführtwerden sollen. Darüber hinaus wollen wirdie Schwierigkeiten bei der Entwicklung voneinzelnen Features und Modulen unter derZielsetzung “einen gemeinsamen Weg zu gehen”offenlegen und mögliche Vorgehensweisenfür die Zukunft projizieren. Anschließendwollen die die Zukunftsfähigkeit von WissKI-basierten (OWL DL / Graphdatenbank)Forschungsumgebungen und anderen Ansätzen(MySQL/Relationale Datenbank) in derDiskussionsrunde besprechen.
Virtuelle Rekonstruktionen intransnationalen Forschungsumgebungen –Das Portal:
70

Digital Humanities im deutschsprachigen Raum 2017
Schlösser und Parkanlagen im ehemaligenOstpreußen (ViReBa), 2013-2016
Piotr Kuroczyński Das ViReBa-Projekt untersucht den gesamten
Prozess der 3D-Computer-Rekonstruktionverloren gegangener Kunst und Architektur.Die vorläufigen Ergebnisse basieren aufder digitalen 3D-Rekonstruktion zerstörterostpreußischer Barockschlösser (Schlodien,Friedrichstein) und bringen neue Erkenntnissefür die Quellenerschließung, Dokumentation,semantische Modellierung und Visualisierungvon 3D-Datensätzen innerhalb der WebGL-Technologie. Der Schwerpunkt liegt dabeiauf der Entwicklung eines menschen- undmaschinenlesbaren Datenmodels zur Annotationund Integration diverser Meta- und Paradateneinschließlich der semantischen Auszeichnungvon 2D und 3D-Datensätzen. Für kollaborative,interdisziplinäre und internationale Forschungbei und an der digitalen 3D-Rekonstruktionwird das CIDOC-CRM-basierte Framework vonWissKI als Virtuelle Forschungsumgebung (VFU)seit 2014 adaptiert. Der Impulsvortrag zeigtkritisch die Erfahrungen, Herausforderungenund Potenziale, bei der Einrichtung einer VFUfür die digitale hypothetische 3D-Rekonstruktion,die Dokumentation und Archivierung derForschungsdaten und ihrer Derivate (u. a. im“Virtuellen Museum”).
Forschungsinfrastruktur Kunstdenkmälerin Ostmitteleuropa (FoKO), 2014-2017
Ksenia Stanicka-BrzezickaDigitale Datenbanken sind in den letzten
Jahren in der Erschließung von Kunstobjektenaller Art zum Standard geworden. Dabeiändern sich die technischen Möglichkeitenschnell und die Anpassung der Praktiken undMethoden der Kunstgeschichte stellt erheblicheHerausforderungen. Trotzdem entstehenviele neue kunsthistorische Datenbanken, vorallem in Rahmen von kurzfristigen Projekten,deren Nachhaltigkeit nicht garantiert ist. „DieKunstgeschichte als Disziplin [hat] es bisherverpasst, neue methodische Grundlagen imSinne einer nachhaltigen digitalen Quellenkritikbereitzustellen“ – lautet das Urteil in derEinleitung vom Summer Institut “DigitalCollections” 2016 in Zürich/Lausanne (http://digital-collections.online/).
Das FoKO-Projekt, ein internationalesVerbundprojekt, das den Aufbaueiner interaktiven kunsthistorischenForschungsinfrastruktur zum Ziel hat, stelltjedoch die Frage der Nachhaltigkeit starkin den Fokus. Im Austausch mit weiterenWissKI-Projekten (ViReBa, CbDD) strebt esnach der Entwicklung eines Datenmodells, das
prototypenhaft für Foto- und Kunstdatenbankenverschiedene Entitäten, wie Kunstobjekteund Fotografien, zum einen einzeln, zumanderen Ihrer Eigenschaft der technischenVervielfältigung nach multipel erfassenund beschreiben kann. Den Schwerpunktdes Projektes stellt die Entwicklung einesDatenmodells, das insgesamt nutzbar undübertragbar sein kann.
Corpus der barocken Deckenmalerei inDeutschland (CbDD), 2015-2040
Werner KöhlerDas Akademie-Projekt ist Mitte 2015 gestartet
und hat die umfassende kunsthistorischeErforschung, Dokumentation und Präsentationder zwischen 1550 und 1800 entstandenenWerke der Wand- und Deckenmalerei auf demGebiet der Bundesrepublik Deutschland zurAufgabe, wobei bis zum Jahr 2040 mehr als 5.000bekannte Objekte dokumentiert werden.
Die lange Projektdauer ermöglicht dieprototypische Entwicklung einer virtuellenForschungsumgebung (VFU) für die Domäne derKunstgeschichte insgesamt. Die Sicherstellungder Nachhaltigkeit einer solchen Entwicklungstellt eine zentrale Aufgabe der IT-Planung unddes IT-Projektmanagements dar.
Aktuell wird das CIDOC-CRM-basierteVFU-Framework WissKI eingesetzt und vordem Hintergrund der ISO-Qualitätsmodellezum Software Engineering (ISO/IEC 9126,ISO/IEC 25000) hinsichtlich Funktionalität,Zuverlässigkeit, Benutzbarkeit, Effizienz,Änderbarkeit und Übertragbarkeit der Softwareevaluiert.
Im Panel sollen die Projekterfahrungen mitWissKI seit Oktober 2015 konkret dargestellt undmit den Erfahrungen aus den anderen WissKI-Projekten verglichen und diskutiert werden.Darüber hinaus sollen die Rahmenbedingungenfür die kontinuierliche Anpassung, Erweiterungund Weiterentwicklung eines grundlegendenVFU-Frameworks für die Digital Humanitiesund die Entwicklung und Verstetigung einernachhaltigen Infrastruktur thematisiert sowieWege zu deren Realisierung aufgezeigt werden.
Topographie in Raum und Zeit: Eindigitales Raum-Zeit-Modell für vernetzteForschung am Beispiel Nürnberg (TOPORAZ),2015-2018
Armand BrahajTOPORAZ focusses on the topography of
a quarter of historical Nuremberg, which isdisplayed at three to four time levels: the earlymodern period; (1870), 1939; and the present.The representation consists of geo-referenced2D maps and 3D models and a factual databasecovering buildings, furnishing, iconography,
71

Digital Humanities im deutschsprachigen Raum 2017
persons, and social networks. Maps and 3Dmodels serve as a structure for navigation andhelp visualizing results from database queries.The information is maintained in a relationaldatabase which implements a semantic datamodel heavily influenced by CIDOC CRM. Thisapproach enables researcher to query for factslike ‘Who inhabited a building at a given time?’,‘How did a building evolve through history?’ or‘Who donated this statue and where is it locatedtoday?’
TOPORAZ directly links 3D objects of theinteractive city model (e.g. streets, buildings,floors and rooms) to research literature andsource material (texts, images, sound) viahotspots. The Virtual Research Environment(VRE) presents those materials to users basedon their virtual location within the modeland the chosen time level. The VRE supportsinterdisciplinary research approaches andtransdisciplinary networking, brings togetherresearchers from art history, architecture, 3Dmodelling and computer science.
WissKI im Museum – Einsatzszenarien imGermanischen Nationalmuseum
Mark FichtnerDas Germanische Nationalmuseum (GNM)
vereint als größtes kulturgeschichtlichesMuseum des deutschen Sprachraums vielfältigeSammlungen und Archive, das Institutfür Kunsttechnologie und Konservierungsowie die größte öffentlich zugänglicheSpezialbibliothek für deutsche Kulturgeschichte.Die Forschungseinheiten führten aushistorischen Gründen und bedingt durchverschiedene Erschließungskonventionen zuspartenspezifischen, an die Anforderungenangepassten Datenbanksystemen. Darausresultieren nachhaltige Probleme, so sind dieDaten trotz ähnlicher Nutzerkreise und sichüberschneidender, ergänzender Inhalte nurschwer austauschbar, kaum verknüpfbar undnicht homogen durchsuchbar.
Zur Lösung dieses Problems wurde imDFG geförderten Projekt „WissenschaftlicheKommunikationsInfrastruktur“ (WissKI) eineSoftware entwickelt, die eine ideale Plattformfür Linked Open Data bietet. Auf Basis von ISO21127 (CIDOC CRM) als gemeinsame LinguaFranca bleibt die Interpretierbarkeit derInhalte gewährleistet, während das Systemdurch Domänenontologien an die jeweiligenFachbereiche angepasst werden kann.
Der Vortrag stellt WissKI, das seit 2013am GNM im stetigen Einsatz in nahezu allenForschungs- und Ausstellungsprojekten ist,aus der Sicht der Informatik vor. Das häufigsteder drei Nutzungsszenarien ist der Einsatz
als virtuelle Forschungsinfrastruktur, dieKernaufgabe für die das System auch konzipiertwurde. Weiterhin dient es als Softwareplattformfür virtuelle Ausstellungen und als einheitlichesAusstellungs- und Planungstool.
Anforderungen an nachhaltigeEntwicklung von Software fürForschungsinfrastrukturen
Barbara FichtlAufbauend auf den Erfahrungen der im Panel
vorgestellten Projekte stellt der abschließendeBeitrag die Frage nach der Nachhaltigkeit vonSoftware-Entwicklung im Bereich der DigitalHumanities. Welche Rahmenbedingungensind nötig, um Forschungsinfrastrukturenlangfristig zu betreiben? Was sollte bei derProjektentwicklung und -durchführunghinsichtlich der Nachhaltigkeit beachtetwerden? Wie müsste eine Projektförderungaussehen, die nachhaltige Software-Entwicklung und den langfristigen Betrieb vonForschungsinfrastrukturen unterstützt?
Bibliographie
Berners-Lee, Tim / Hendler, James / Lassila,Ora (2001): „The Semantic Web“, in: ScientificAmerican 34–43.
Caraffa, Constanza (2011): „‚Wenden!‘Fotografien in Archiven im Zeitalter ihrerDigitalisierbarkeit: ein ‚materialturn‘“, in:Rundbrief Fotografie 18, 3: 8–15.
Cellary, Wojciech / Walczak, Krzysztof(2012): Interactive 3D Multimedia Content:Models for Creation, Management, Search andPresentation. Heidelberg: Springer.
Bentkowska-Kafel, Anna / Denard, Hugh /Baker, Drew (2012): Paradata and Transparencyin Virtual Heritage. London: Ashgate.
Rat für Informationsinfrastrukturen(2016): Leistung aus Vielfalt: Empfehlungen zuStrukturen, Prozessen und Finanzierung desForschungsdatenmanagements in Deutschlandhttp://www.rfii.de/de/category/dokumente/[letzter Zugriff 25. August 2016].
Münster, Sander / Pfarr-Harfst, Mieke /Kuroczyński, Piotr / Ioannides, Marinos (2016):How to manage data and knowledge relatedto interpretative digital 3D reconstructions ofCultural Heritage?. Heidelberg: Springer LNCS.
Kuroczyński, Piotr / Bell, Peter /Dieckmann, Lisa (2016): Computing Art Reader:Einführung in die digitale Kunstgeschichte.Arthistoricum.net-ART-Books, Heidelberg (inEdition).
72

Digital Humanities im deutschsprachigen Raum 2017
Zugänglichkeitund dauerhafteNutzbarkeit historischerBildrepositorienfür Forschung undVermittlung
Niebling, [email protected] Universität Würzburg,Deutschland
Münster, [email protected] Universität Dresden, Deutschland
Friedrichs, [email protected] Universität Würzburg,Deutschland
Henze, [email protected] Technische UniversitätCottbus-Senftenberg, Deutschland
Kröber, [email protected] Universität Dresden, Deutschland
Bruschke, [email protected] Universität Würzburg,Deutschland
Digitalisate historischer Fotografienund deren Nutzbarkeit zurgeschichtswissenschaftlichen Forschungund quellenbasierten Vermittlung stellenebenso wie räumliche Modelle historischerObjekte Kernthemen der Digital Humanitiesdar. Angesichts des Umfangs derartigerRepositorien besteht eine wesentlicheHerausforderung darin, für die Beantwortunggeschichtswissenschaftlicher Fragestellungenrelevante und aussagekräftige Quellenzu finden, zu kontextualisieren sowie diedarin beschriebenen historischen Objekte
vorstellbar zu machen. Die Verbindung zwischendigitalen Bildrepositorien und Raumbezugverspricht durch eine Zusammenführungund nutzerzentrierte Präsentation vonInformationsbeständen ein umfassendesRepertoire technischer Unterstützungsoptionengeschichtswissenschaftlicher Forschungspraxis.Im Gegensatz zu bisherigen Zugängen zuBild- und Planrepositorien wird durchdie dreidimensional-räumliche Verortungvon Quellen, ebenso wie durch ihre Vor-Ort-Präsentation ein hohes Maß intuitiverZugänglichkeit und Kontextbezuges geschaffen.Im Panel diskutiert werden innovativeSoftwarewerkzeuge und damit verbundenemethodische Ansätze für die Verwendunghistorischer Bildrepositorien in der stadt-und architekturgeschichtlichen Forschung.Hierbei sollen ausgehend von aktuellen digitalenRekonstruktionsprojekten Forschungsmethodenvorgestellt, kategorisiert und hinsichtlichvorhandener Unterstützungsbedarfediskutiert werden. Davon ausgehend werdensoftwaretechnische Methoden aufgezeigt, welcheeinerseits den Zugang zu Bildrepositorienerleichtern und dadurch eine dauerhafteBenutzbarkeit sicherstellen sollen, sowieandererseits in Fotografien verborgenes Wissen,beispielsweise über den Betrachterstandpunktund den Zeitpunkt der Aufnahme zugänglichmachen.
Dr. Kristina Friedrichs: Methodenarchitekturgeschichtlicher Forschung
Die Kunstgeschichte kann auf einelange Tradition der wissenschaftlichenAuseinandersetzung mit Architekturzurückblicken. Im Zuge dessen haben sichverschiedene Methoden des Herangehensentwickelt, die sowohl tatsächlich erhalteneals auch nie gebaute oder später zerstörteBauwerke zum Zwecke der Chronologisierung,der historischen Kontextualisierung undBedeutungsentschlüsselung erschließen.
Neue technologische Möglichkeiten erlaubenes Architekturhistorikern einerseits, ihreUntersuchungen auf einen größeren Fundusan Quellen aufzubauen, die beispielsweisedurch digitale Bildarchive zur Verfügunggestellt werden. Andererseits ergeben sich neuemethodische Ansätze aus innovativen Software-Werkzeugen, die helfen, die Quellen zeitlichwie räumlich zu verorten, oder die Forschungdurch Visualisierungen bei der Erstellung vonDatierungen, stilkritischen Betrachtungen,der Zuweisung von Autorenschaften oderbauarchäologischen Untersuchungen zuunterstützen (Verstegen 2007).
73

Digital Humanities im deutschsprachigen Raum 2017
Gerade am Beispiel der Stadt Dresden mitihrer reichen und wechselhaften Geschichtelassen sich dank umfangreicher Bildrepositorienneue Untersuchungsfelder eröffnen. AmDresdner Zwinger wurden große Teileder Planungs- und Baugeschichte durchVisualisierungen nachvollzogen und darüberhinaus die fertigen Modelle in die Vermittlunginnerhalb eines musealen Kontextes überführt(Jahn/Welich 2009). Für die Kunstgeschichteergeben sich vor diesem Hintergrundmannigfaltige neue Arbeitsansätze, die sowohlhinsichtlich ihrer Methodik diskutiert werdenmüssen, als auch einer Unterstützung mithilfevon adäquaten Werkzeugen aus den technischenDisziplinen bedürfen.
Dr. Sander Münster: Eine Wissensbasis fürdie Digital Visual Humanities
Eine daran eng anknüpfende Frage istdie nach einer methodischen Validierungdigitaler Methoden sowie insbesondereder Verwendung von Bildrepositorien imKontext der Architekturgeschichte (c.f.Arbeitstagung digitale Kunstgeschichte2014). Dies umfasst zunächst einmal denBedarf, ein Spektrum digitaler Werkzeugesowie Verwendungskontexte im Kontext derKunstgeschichte zu systematisieren (Kohle 2013,Heusinger 1989). Vor diesem Hintergrund sollenim Rahmen dieses Vortrags Ergebnisse dreierWorkshops vorgestellt werden, welche 2016auf internationalen Konferenzen abgehaltenwurden und bei welchen unter Einbeziehungvon ca. 100 Experten mit den SchwerpunktenCultural Heritage und Digital Visual Humanitieswesentliche Methoden und Forschungsansätzesowie Podien erfasst und systematisiert wurden.
Darüber hinaus sollen im Vortragexemplarisch spezifische fachkulturellesowie wissenschaftlich-methodischeHerausforderungen des Einsatzesdigitaler Methoden sowie insbesonderevon Bildrepositorien im Kontextarchitekturgeschichtlicher Forschung beleuchtetwerden. Dazu gehören Aspekte wie dieTransparentmachung von Erkenntnisprozessen(Benkowska-Kafel et al. 2012) ebenso wieeine bildgestützte Diskurskultur (vgl.Münster, Friedrichs & Hegel in Vorb.) sowienicht zuletzt der Blick auf eine digitaleNachhaltigkeit. Im Ergebnis sollen somit nichtnur ein methodologischer State-Of-the-Artvorgestellt, sondern auch die Determinantenfür die Konzeption digitaler Werkzeuge undUnterstützungsoptionen skizziert werden
Cindy Kröber: Zielgruppen-orientierteErstellung von Werkzeugen für die Arbeit mitBildrepositorien
Der Erfolg von Bilddatenbanken hängtstark von der Usability der Anwendungsowie der Tauglichkeit als Forschungs- oderVermittlungstool ab. Bisherige Werkzeuge undFunktionalitäten entsprechender Anwendungenentsprechen häufig nicht den Bedarfen derarchitektur- und kunstgeschichtlichen Forschungund Vermittlung (Dudek et al. 2015).
Allgemeine Anforderungen der Nutzersind ein schnelles Verstehen der Datenund Informationen, effiziente Such- undFilterfunktionen und eine intuitiv bedienbareSoftwareoberfläche und Navigation (Barreauet al. 2014). Für Forschungsanliegen spielenwissenschaftliche Standards wie dieausführliche Dokumentation durch Metadateneine wichtige Rolle (Maina/Suleman 2015).Eine interessierte Öffentlichkeit erwartethingegen eine direkte und überschaubargestaltete Einführung in das Thema unddie entsprechenden Daten (Maina/Suleman2015) sowie weitere Informationsangebotenach Bedarf. Für die Forschung sindvisuelle Darstellungen von Hypothesen undZusammenhängen wichtig (López-Romero2014). Die erweiterte Bildanalyse von Fotos einesObjektes über die Zeit erlaubt die Detektionbaulicher Veränderungen.
Um zielgruppen-orientiertSoftwarewerkzeuge für die Arbeit mitBildrepositorien und insbesondereBilddatendanken zu entwickeln, müssen dieUnterstützungsmöglichkeiten identifiziert,konzipiert und überprüft werden. Die Nutzersind von Beginn an mit Hilfe qualitativerInterviews und umfassenden Untersuchungenzu Nutzerverhalten und Nutzerinteraktioninvolviert.
Jonas Bruschke: Werkzeugefür die Dokumentation digitalerRekonstruktionsprozesse
Digitale Rekonstruktionen könnenExperten und Laien ein Bild nicht mehr odernur in Teilen existenter Gegenstandändevermitteln. 3D-Modelle sind dabei nichtnur Gegenstand der Betrachtung, sondernauch Forschungsgegenstände. Neben denmateriellen Quellen die bei der Erstellung von3D-Modellen eingesetzt werden, wie Pläneund Fotografien, handelt es sich oft auchum immaterielle Quellen, beispielsweise dieEntscheidung von Experten. ResultierendeVisualisierungen haben letztendlich aber keinendirekten Bezug mehr zu den verwendetenQuellen. In aller Regel ist für eine externe,nicht an der Entstehung des Modells beteiligtePerson oft nur schwer nachvollziehbar, obeine Rekonstruktion auf verlässlichen Fakten
74

Digital Humanities im deutschsprachigen Raum 2017
beruht und inwieweit und welche Hypothesenbei der Erstellung eine Rolle spielten. Eineausführliche, lückenlose Dokumentation derRekonstruktion ist daher essentiell und solltemöglichst alle Aspekte und jegliches währendder Bearbeitung erlangte Wissen umfassen.Dies betrifft nebst der Protokollierung derEntscheidungen auch Schwierigkeiten währenddes Entstehungsprozesses.
Eine solch umfangreiche Dokumentationkommt in den Rekonstruktionsprojektenin der Regel nicht zustande (Pfarr 2010,Münster 2014). Zur Unterstützung desDokumentationsverhaltens müsseninterdisziplinären Projektteams, vorrangigbestehend aus Historikern und Modelleuren,geeignete Werkzeuge in die Hand gelegt werden.Die Abläufe und Problemstellungen solcherProjekte wurden bereits umfangreich untersucht(Münster 2014). Darauf aufbauend wurde einerster Prototyp entwickelt (Bruschke 2015),welcher zum einen als zentrales Elementwährend eines Projektes zum Einsatz kommensoll, indem es von der Koordination desProjektes über das Einpflegen und Haltender Daten bis hin zur direkten Arbeit undDiskussion am 3D-Modell viele Abläufeeines Rekonstruktionsprojektes unterstütztund gleichzeitig auch protokolliert. Diesesangesammelte Wissen kann außenstehendenPersonen in Form einer Rechercheplattformzugänglich gemacht werden und gegebenenfallsdurch sie verifiziert werden.
Dr. Frank Henze: PhotogrammetrischeMethoden zur Wissensgenerierung ausBildbeständen
Das Potenzial fotografischer undphotogrammetrischer Aufnahmen reicht vonder reinen Bilddokumentation im Bereichder Archäologie und Denkmalpflege, überdie Bildinterpretation, zum Beispiel fürSchadensdokumentationen, bis hin zurErstellung maßstäblicher Bildpläne undkomplexer 3D-Modelle für baugeschichtlich-archäologische Untersuchungen (z.B. Bührer etal. 2001, Hanke 2001).
Aus fotografischen Aufnahmen lassen sich,bei Vorliegen entsprechender Bildinhalte,geometrische Informationen über dieabgebildeten Objekte zum Zeitpunkt derAufnahme rekonstruieren. Die Grundlagenfür die geometrische Rekonstruktion aushistorischen Fotografien bilden die analytischenVerfahren der Photogrammetrie, d.h. dieGewinnung zwei- und dreidimensionalerObjektgeometrien aus den zweidimensionalenBildinformationen. Beispiele für diephotogrammetrische Auswertung historischer
Aufnahmen und Messbilder finden sich unteranderem in Wiedemann et al. 2000, Bräuer-Burchardt und Voss 2001, Henze et al. 2009 oderSiedler et al. 2011. Die klassischen Verfahrender analytischen Photogrammetrie werdendabei zunehmend ergänzt durch angepassteVerfahren der digitalen Bildverarbeitungund Bildanalyse. Der aufwändige Prozessder manuellen Bildauswertung kann damitweitgehend automatisiert werden, womit auchgroße Bildbestände für eine automatischeGewinnung geometrischer Informationenerschlossen werden können (Pomaska 2011).
Bisher werden automatisiertephotogrammetrische Verfahren in der Regeljedoch ausschließlich für die Auswertungaktueller, zumeist digitaler Aufnahmeneingesetzt. Angepasste Verfahren füreine (semi-) automatische Auswertunghistorischer Bildbestände fehlen bisher.Dabei muss u.a. auf die Besonderheitengescannter Analogaufnahmen mit zumeistunbekannter Kamerageometrie, fehlendenbzw. minimalen Objektinformationen und z.T.geringer radiometrischer und geometrischerAuflösung reagiert werden. Ziel ist es,anwendungsorientierte Werkzeuge für einephotogrammetrische Auswertung historischerFotografien zu entwickeln und diese in denProzess der geschichtswissenschaftlichenBildanalyse zu integrieren und damit einenräumlichen Bezug zur heutigen Situation zuschaffen.
Dr.-Ing. Florian Niebling: Augmented Realityin den Visual Humanities
Bei der Nutzung digitaler Bildrepositoriensind zwei wesentliche Vorgehensweisender Informationserschließung erkennbar:Einerseits ein selbstgesteuertes Durchsuchenvon Sammlungen historischer Fotografien,Zeichnungen und Pläne, andererseits eine orts-oder kontextbezogene Informationsvermittlungbeispielsweise im Zuge stadträumlicher odermusealer Präsentation (Münster et al. 2016).Die Vor-Ort-Darstellung von und Interaktionmit geschichtswissenschaftlichen Daten in derAugmented Reality hat hierbei in den letztenJahren an Bedeutung gewonnen und wurdevielfältig erprobt und untersucht (Livingston etal. 2008; Zöllner et al. 2010; Walczak 2011).
Augmented Reality beschreibt dabei dieAnreicherung der realen Welt durch virtuelleDaten, wobei es sich sowohl um 3D-Modelle,Texte, Bilder, Filme oder auch Audiodatenhandeln kann. Durch die Anreicherung derRealität oder Ersetzung von Teilen der Realitätkönnen Augmented Reality Methoden helfenden Unterschied zwischen verschiedenen
75

Digital Humanities im deutschsprachigen Raum 2017
Zuständen von Objekten darzustellen (Niebling,2008). Im geschichtswissenschaftlichenund stadthistorischen Kontext wird es demBetrachter ermöglicht, interaktiv visuelle undtextuelle Informationen zu dreidimensionalvermessenen Objekten in ihrem historischenräumlichen Bezugssystem zu erfassen.Ein Hauptaugenmerk liegt dabei auf derZugänglichkeit historischer Datenbestände.Wie können Interaktionsmöglichkeiten mitvirtuellen Gebäuden und mit ihnen verknüpftenInformationen gestaltet werden? Könnenaus dem Umgang mit Mobilgeräten bekannteInteraktionsmetaphern in der AugmentedReality weiterverwendet werden? WelcheVermittlungsmethoden können in AugmentedReality Anwendungen zum Einsatz kommen?
Bibliographie
Barreau Jean-Baptiste / Gaugne, Ronan /Bernard, Yann / Le Cloirec, Gaétan /Gouranton, Valérie (2014): „Virtual realitytools for the West Digital Conservatory ofArchaeological Heritage“, in: Proceedings of the2014 Virtual Reality International Conference 1–4.
Bentkowska-Kafel, Anna / Denard, Hugh /Baker, Drew (2012): Paradata and Transparencyin Virtual Heritage. Burlington: Ashgate.
Bräuer-Burchardt, Christian / Voss, Klaus(2001): „Facade Reconstruction of DestroyedBuildings Using Historical Photographs“, in:Albertz, Jörg (ed.): Proceedings of the XVIII.International CIPA Symposium 543–550.
Bruschke, Jonas (2015): DokuVis –Ein Dokumentationssystem für DigitaleRekonstruktionen. Masterarbeit, HTW Dresden.
Bührer, Thomas / Grün, Armin / Zhang,Li / Fraser, Clive / Rüther, Heinz (2001):„Photogrammetric Reconstruction and 3DVisualization of Bet Gorgis, a Rock-hewn Churchin Ethiopia“, in: Albertz, Jörg (ed.): Proceedings ofthe XVIII. International CIPA Symposium 338–344.
Dudek, Iwona / Blaise, Jean-Yves / De Luca,Livio / Bergerot, Laurent / Renaudin, Noémie(2015): „How was this done? An attempt atformalising and memorising a digital asset'smaking-of“, in: Digital Heritage 2: 343–346.
Gabbard, Joseph L. / Swan, J. Edward (2008):„Usability Engineering for Augmented Reality:Employing User-Based Studies to Inform Design“,in: IEEE Transactions on Visualization andComputer Graphics, 14 (3): 513–525.
Henze, Frank / Lehmann, Heike / Bruschke,Bettina (2009): „Nutzung historischer Pläne undBilder für die Stadtforschungen in Baalbek /
Libanon“, in: Photogrammetrie - Fernerkundung -Geoinformation 3/2009: 221–234.
Hertzig, Stefan / Friedrichs, Kristina (i.Vorb.): Das Japanische Palais in Dresden: VomPorzellanschloss Augusts des Starken zu einemMuseum des Bildungsbürgertums.
Heusinger, Lutz (1989): „Applications ofComputers in the History of Art“, in: Hamber,Anthony / Miles, Jean / Vaughan, William (eds.):Computers and the History of Art. London:Mansell Pub 1–22.
Internationale Arbeitstagung „DigitaleKunstgeschichte: Herausforderungen undPerspektiven“ (2014): Zürcher Erklärung zurdigitalen Kunstgeschichte.
Jahn, Peter Heinrich / Welich, Dirk (2009):„Zurück in die Zukunft: die Visualisierungplanungs- und baugeschichtlicher Aspekte desDresdner Zwingers“, in: Jahrbuch StaatlicheSchlösser, Burgen und Gärten Sachsen 16: 51–72.
Kohle, Hubertus (2013): DigitaleBildwissenschaft. Glückstadt.
Livingston, Mark A. / Bimber, Oliver /Saito, Hideo (2008): Proceedings of the 7thIEEE International Symposium on Mixed andAugmented Reality. Cambridge, UK. / Piscataway,N.J.: IEEE Xplore.
López-Romero, Elías (2014): „Out of the box:exploring the 3D modelling potential of ancientimage archives“, in: Virtual archaeology review 5(10): 107–116.
Maina, Job King’ori / Suleman, Hussein(2015): „Enhancing Digital Heritage ArchivesUsing Gamified Annotations“, in: DigitalLibraries: Providing Quality Information 9469.Seoul: 169-179.
Münster, Sander (2014): InterdisziplinäreKooperation bei der Erstellung virtuellergeschichtswissenschaftlicher 3D-Rekonstruktionen. Dissertation, TU Dresden.
Münster, Sander / Niebling, Florian(2016): „HistStadt4D - Multimodale Zugänge zuhistorischen Bildrepositorien zur Unterstützungstadt- und baugeschichtlicher Forschung undVermittlung“, in: DHd 2016: Modellierung -Vernetzung - Visualisierung 203-208.
Münster, Sander / Friedrichs, Kristina /Hegel, Wolfgang (eingereicht): „3DReconstruction techniques as a Cultural Shift inArt History?“, in: International Journal of DigitalArt History.
Niebling, Florian / Griesser, Rita T. /Woessner, Uwe (2008): „Using AugmentedReality and Interactive Simulations to RealizeHybrid Prototypes“, in: Advances in VisualComputing, 4th International Symposium ISVC2008. Proceedings I: 1008–1017.
76

Digital Humanities im deutschsprachigen Raum 2017
Pfarr, Mieke (2010): Dokumentationssystemfür Digitale Rekonstruktionen am Beispiel derGrabanlage Zhaoling, Provinz Saanxi, China.Dissertation, TU Darmstadt.
Pomaska, Günter (2011): „ZurDokumentation und 3D-Modellierung vonDenkmalen mit digitalen fotografischenVerfahren“, in: Heine, Katja / Rheidt, Klaus /Henze, Frank / Riedel, Alexandra (eds.): VonHandaufmaß bis High Tech III – 3D in derhistorischen Bauforschung. Mainz: Verlag Philippvon Zabern 79–84.
Siedler, Gunnar / Sacher, Gisbert / Vetter,Sebastian (2011): „PhotogrammetrischeAuswertung historischer Fotografien amPotsdamer Stadtschloss“, in: Heine, Katja /Rheidt, Klaus / Henze, Frank / Riedel, Alexandra(eds.): Von Handaufmaß bis High Tech III - 3D inder historischen Bauforschung. Mainz: VerlagPhilipp von Zabern 26–32.
Verstegen, Ute (2007): „Vom Mehrwertdigitaler Simulationen dreidimensionaler Bautenund Objekte in der architekturgeschichtlichenForschung und Lehre“, Vortrag am 16.3.2007, in:XXIX. Deutscher Kunsthistorikertag, Regensburg.
Walczak, Krzysztof / Cellary, Wojciech /Prinke, Andrzej (2011): „InteractivePresentation of Archaeological Objects UsingVirtual and Augmented Reality“, in: Jerem,Erszébet / Redő, Ferenc / Szeverényi, Vajk(eds.): On the Road to Reconstructing the Past.Proceedings of the 36th International Conferenceon Computer Applications and QuantitativeMethods in Archaeology (CAA). Budapest:Archaeolingua.
Wiedemann, Albert / Hemmleb, Matthias /Albertz, Jörg (2000): „Reconstruction ofhistorical buildings based on images fromthe Meydenbauer archives“, in: InternationalArchives of Photogrammetry and Remote SensingXXXIII (B5/2): 887–893.
Zöllner, Michael / Becker, Mario / Keil,Jens (2010): „Snapshot Augmented Reality- Augmented Photography“, in: Artusi,Alessandro / Joly-Parvex, Morwena / Lucet,Genevieve / Ribes, Alejandro / Pitzalis, Denis(eds.): 11th International Symposium on VirtualReality, Archaeology and Cultural Heritage (VAST2010). Paris: Eurographics Association.
77

Vorträge

Digital Humanities im deutschsprachigen Raum 2017
Ambige idiomatischeAusdrücke inkinderliterarischenTexten: Mehrwert einerDatenbankanalyse
Wagner, [email protected] Karls Universität Tübingen,Deutschland
In meinem Vortrag setze ich mich mitder Frage auseinander, welchen Beitrag dieDatenbank TInCAP („Tübingen InterdisciplinaryCorpus of Ambiguity Phenomena“), diebei der Tagung der Digital Humanities imdeutschsprachigen Raum 2016 in Leipzigvorgestellt wurde und die der Sammlung undAnnotation von Ambiguitätsbelegen dient,zur Erforschung des Phänomens „Ambiguität“leisten kann. Den Mehrwert, den TInCAP durchdie innovative interdisziplinäre Annotation unddie Zusammenführung von Belegen in einerdurchsuchbaren Datenbank liefert, werde icham Beispiel ambiger idiomatischer Ausdrücke inkinderliterarischen Texten illustrieren.
Die Datenbank TInCAP entsteht im Rahmendes interdisziplinären GraduiertenkollegsGRK 1808 Ambiguität – Produktion undRezeption ( www.ambiguitaet.uni-tuebingen.de ;Arbeitsgruppe TInCAP: Wiltrud Wagner, LisaEbert, Jutta Hartmann, Gesa Schole, SusanneWinkler) mit dem Zweck, Ambiguitätsbelegeaus allen beteiligten Disziplinen zu sammelnund zu annotieren. Hauptziele sind dabei dieinterdisziplinäre Auseinandersetzung mit demPhänomen Ambiguität durch die Erstellungeines gemeinsamen Annotationsschemassowie die nachhaltige Speicherung undZugänglichmachung der Datensammlungfür die nationale und internationaleForschungsgemeinschaft (in Kürze über dieHomepage des GRK 1808).
Auch wenn alle an diesem Projekt beteiligtenWissenschaftlerInnen das Interesse amPhänomen der Ambiguität verbindet, dashier als Doppel- oder Mehrdeutigkeit in ihrenverschiedensten Formen verstanden wird,so sind die zu annotierenden Belege dochsehr divers: Durch die Vielzahl der beteiligtenDisziplinen unterscheiden sich die Belegehinsichtlich Medium (aktuell: Schrift, Audio,
Bild, Video) und Sprache (aktuell: Deutsch,Englisch, Französisch, Hebräisch, Italienisch,Latein, Spanisch, Griechisch), aber auchUmfang. Im Bestreben, eine gemeinsameDatenbank aufzubauen, sahen wir unsdemnach zwei großen Herausforderungengegenüber gestellt: (1) Der Erarbeitung einerdisziplinenübergreifenden Terminologie,die einerseits präzise, andererseits abernicht an das Vokabular einer der Disziplinengebunden ist, und (2) der Entwicklung einesinterdisziplinären Annotationsschemas, das –trotz der notwendigen Komplexitätsreduktion– den Anforderungen der einzelnen Disziplinengenügt und für alle Beteiligten profitabel ist.
Das Ergebnis ist ein Annotationsschema, dasdie folgenden fünf Punkte fokussiert:
Communication level: Auf welcher Ebeneder Kommunikation wird die Ambiguitätannotiert? Für literarische Texte wird zumBeispiel zwischen der Ebene der fiktivenCharaktere, der Ebene des/der Erzähler(s)und der Ebene des Autors und Lesersunterschieden.
Strategic or non-strategic production and/orperception: Wird die Ambiguität strategischproduziert? Wird die Ambiguität strategischrezipiert?
Level of Trigger and Range: Zu annotierenist, auf welcher Ebene die Ambiguitätausgelöst wird und bis zu welcher Ebenesie relevant ist. Die Ebenen für Auslöserund Wirkung der Ambiguität bilden dabeiein Größenverhältnis ab, analog zummenschlichen Körper, bei dem sich größereElemente aus kleineren zusammensetzen(z.B. die Ebene Subelement, die u.a. Phoneme,Grapheme und Morpheme umfasst; dieEbene Element, die u.a. Worte umfasst; usw.).
Type of Paraphrase Relation: In welchemVerhältnis stehen die möglichen Lesartenzueinander? Sind sie voneinander abgeleitetoder völlig unabhängig voneinander?
Phenomenon: Welches Phänomen stehtmit der vorliegenden Ambiguitätim Zusammenhang? Hier kann undsoll disziplininternes Vokabular zurAnwendung kommen, um die Einbindungin den jeweiligen Forschungskontext zugewährleisten.
Zusätzlich ist die Verknüpfung vonAnnotationen möglich, zum Beispiel,wenn ein Beleg auf verschiedenenKommunikationsebenen (unterschiedlich)annotiert wird.
79

Digital Humanities im deutschsprachigen Raum 2017
Die Nachhaltigkeit der gesammelten Datenwird durch eine Kombination verschiedenerFaktoren gewährleistet: Das von uns entwickelteXML-Schema ist soweit möglich TEI-konform, eswurde für die inhaltliche Annotation der Datenum ein eigenes Schema erweitert. Der gesamteKorpus bzw. Subkorpora können im XML-Formatim- und exportiert werden. Diese XML-Dateienwerden in Kooperation mit Clarin-D Tübingenim Rahmen der universitären Infrastrukturlangfristig gespeichert, katalogisiert undmit PIDs zugänglich gemacht. Teilkorporakönnen dabei ebenso exportiert werden wiedas Gesamtkorpus. Bei Video-, Audio- undBilddateien halten wir uns an die üblichenStandards für nachhaltige Datenformate (nicht-proprietäre Formate, Formate mit gutemNachnutzungswert).
Nach der allgemeinen Vorstellung derDatenbank wende ich mich im zweiten Teil desVortrags der Frage zu, was die Datenbank imHinblick auf konkrete Fragestellungen leistet.Die von mir in die Datenbank eingebrachtenAmbiguitätsbelege entstammen zum größten Teilmeiner Dissertation, die einen interdisziplinärenBeitrag zur Ambiguitätsforschung leistet:Der linguistische Teil der Arbeit untersucht,wie idiomatischen Ausdrücken das Potentialzur Ambiguität inhärent sein kann. An derSchnittstelle zur Literaturwissenschaft zeigt dieArbeit, wann und wie idiomatische Ausdrückein Interaktion mit unterschiedlichen Kotextenihr Ambiguitätspotential entfalten. Am Beispielvon kinderliterarischen Texten wird schließlichdargestellt, wie die aus dieser Interaktionresultierende Bewusstmachung von Ambiguitätals sprachspielerisches Potential für literarischeTexte produktiv gemacht werden kann. (a)-(c)stellen typische Beispiele aus meinem Korpusdar, die jeweils annotierten Stellen sind fettmarkiert:
(a)
One day he went to King Big-Twytt, who waseating a bathtub of roast chicken, custardand chips, and said: 'King - I want a licence tocatch ye dragons.'
'What?' said King Twytt. 'But ye dragons aredangerous! They eat ye farm animals.'
'So do we,' said Sir Nobonk, 'and no one sayswe're dangerous.'
'Yea, very well,' said King Twytt, 'I will giveyou a licence, but be it on your own head.'
So Sir Nobonk strapped the licence to hishead.
Sir Nobonk had been in many wars. Usually[…]
(Spike Milligan: Sir Nobonk and the terrible,awful, dreadful, naughty, nasty Dragon, 1982)
(b)
Draw the drapes when the sun comes in.
read Amelia Bedelia. She looked up. The sunwas coming in. Amelia Bedelia looked at thelist again. "Draw the drapes? That's what itsays. I'm not much of a hand at drawing, butI'll try."
So Amelia Bedelia sat right down and shedrew those drapes.
(Peggy Parish: Amelia Bedelia,1963.)
(c)
Tom ging auf den frierenden König zu.„Ich bin gekommen, um mein Versprecheneinzulösen“, sagte er und warf dieSatteltasche auf den Tisch.
König Knöterich schaute ungläubig auf dieTasche. „Hast du mir etwa ein Paar warmeHandschuhe mitgebracht?“
„Nein, Herr König“, antwortete Tom. „Etwasviel Kostbareres. Ich habe für Euch dengoldenen Dings, äh, Kelch erobert.“
„Aahhh! Oohhh!“, hallte es durch den Saal.
„Ihr wollt wohl den König auf den Armnehmen“, sagte Friedrich von Edelstein.
„Ich fürchte, mit den vielen Umhängen undMützen ist mir der König zu schwer“, grinsteTom.
(Bernd Schreiber: Ritter Tollkühn und dergoldene Dings, 2010.)
Die Annotation meiner Beispiele mitTInCAP ermöglicht die Sichtbarmachung vonAspekten, die bei der reinen linguistischenoder literaturwissenschaftlichen Analysemöglicherweise verborgen bleiben.Besonderes Gewicht kommt dabei derMöglichkeit zu, Ambiguitäten auf mehrerenKommunikationsebenen zu annotieren und dieresultierenden Annotationen zu verknüpfen.Dies möchte ich anhand von Beispielen wie (a)-(c) illustrieren und mich dabei auf folgendePhänomene konzentrieren:
strategische vs. nicht-strategische Produktion/Rezeption: In den untersuchtenkinderliterarischen Texten erfolgt meistdie Produktion auf der innersten Ebene(Ebene der Figuren) nicht strategisch, auf der
80

Digital Humanities im deutschsprachigen Raum 2017
äußersten Ebene (Ebene des Autors) jedochstrategisch.
Typ der Ambiguitätsverwendung: Sehr häufigwird in den untersuchten kinderliterarischenTexten die Ambiguität auf der innerstenEbene nicht erkannt, auf der äußerstenEbene muss jedoch eine semantischeReanalyse erfolgen, wodurch die Ambiguitätsichtbar gemacht wird.
Erste Lesart (phrasal vs. kompositional): Dieerste (und damit oftmals einzige) Lesartauf der innersten Ebene ist sehr häufig diekompositionale. Auf der äußersten Ebeneist es jedoch die phrasale Lesart, die primärverarbeitet wird, woraus die Notwendigkeitder semantischen Reanalyse resultiert.
Diese Phänomene, die erst durchdie Annotation mit TInCAP und durchentsprechende Suchabfragen sichtbar werden,zeigen das Potential, das diese Datenbankinnerhalb eines Projekts entfaltet. In einemabschließenden Ausblick möchte ich darüberhinaus auf den interdisziplinären Nutzen derDatenbank verweisen, der im Rahmen des GRK1808 bereits zum Tragen kommt, insbesonderein der Vergleichbarkeit, die über Medien hinweggeschaffen wird.
Bibliographie
Hartmann, Jutta / Sauter, Corinna /Schole, Gesa / Wagner, Wiltrud /Gietz, Peter / Winkler, Susanne (2016):TInCAP – ein interdisziplinäres Korpus zuAmbiguitätsphänomenen. Posterpräsentation,in: DHd 2016: Modellierung - Vernetzung -Visualisierung.
Hartmann, Jutta / Ebert, Lisa / Schole,Gesa / Wagner, Wiltrud / Winkler,Susanne (eingereicht): „AnnotatingAmbiguity Across Disciplines: The TübingenInterdisciplinary Corpus of AmbiguityPhenomena“, in: Bauer, Matthias / Zirker,Angelika (eds.): Strategies of Ambiguity.
Hartmann, Jutta / Ebert, Lisa / Schole,Gesa / Wagner, Wiltrud / Winkler, Susanne (inVorbereitung): TInCAP User Manual.
Klein, Wolfgang / Winkler, Susanne(eds.) (2010): Ambiguität. Zeitschrift fürLiteraturwissenschaft und Linguistik 40 (158).Stuttgart: Metzler.
TEI Consortium (eds.): Guidelines forElectronic Text Encoding and Interchange.[6.4.2015]. http://www.tei-c.org/P5/ .
Wagner, Wiltrud (in Vorbereitung): Idiomsand Ambiguity in Context: Compositional andPhrasal Readings of Idiomatic Expressions.Dissertation. Tübingen.
Winkler, Susanne (eds.) (2015): Ambiguity:Language and Communication. Berlin: deGruyter.
Winter-Froemel, Esme / Zirker, Angelika(2010): „Ambiguität in der Sprecher-Hörer-Interaktion. Linguistische undliteraturwissenschaftliche Perspektiven“, in:Klein, Wolfgang / Winkler, Susanne (eds.):Ambiguität. Zeitschrift für Literaturwissenschaftund Linguistik 40 (158). Stuttgart: Metzler 76–97.
Winter-Froemel, Esme / Zirker, Angelika(2015): „Ambiguity in Speaker-Hearer-Interaction: A Parameter-Based Model ofAnalysis“, in: Winkler, Susanne (eds.): Ambiguity:Language and communication. Berlin: de Gruyter283–339.
Analyzing Features forthe Detection of HappyEndings in GermanNovels
Jannidis, [email protected]ät Würzburg, Deutschland
Reger, [email protected]ät Würzburg, Deutschland
Zehe, [email protected]ät Würzburg, Deutschland
Becker, [email protected]ät Würzburg, Deutschland
Hettinger, [email protected]ät Würzburg, Deutschland
Hotho, [email protected]ät Würzburg, Deutschland
81

Digital Humanities im deutschsprachigen Raum 2017
Einleitung
Note: An English version of this paper isavailable from https://arxiv.org/abs/1611.09028 .
Der Plot ist ein grundlegendesStrukturelement literarischer Texte.Dementsprechend wären Methoden zurcomputergestützten Repräsentation von Plotoder bestimmten Plot-Elementen ein großerGewinn für die quantitative Literaturanalyse.Dieses Paper betrachtet ein solches Plot-Element:das Ende; genauer gesagt untersuchen wirdie Frage, ob ein Werk ein Happy End hatoder nicht. Dazu setzen wir Sentimentanalyseein, wobei wir den Fokus auf die qualitativeBetrachtung bestimmter Features und derenPerformanz legen, um tiefere Einsicht in dieFunktionsweise der automatischen Klassifikationzu erhalten. Außerdem zeigen wir, wie diebeschriebene Vorgehensweise auf nachfolgendeForschungsfragen angewendet werden unddabei zu interessanten Ergebnissen hinsichtlichder Erscheinungszeit der Romane führen kann.
Verwandte Arbeiten
In einer der ersten Arbeiten beschäftigt sichMark Finlayson mit folkloristischen Erzählungenund entwickelt einen Algorithmus, derEreignisse erkennt und daraus übergeordneteKonzepte wie Niedertracht oder Belohnungabstrahiert (Finlayson 2012). Reiter et al.identifizieren Ereignisse sowie deren Teilnehmerund Reihenfolge und nutzen maschinelleLernverfahren, um strukturelle Ähnlichkeitenüber Erzählungen hinweg aufzudecken (Reiter2013, Reiter et al. 2014).
In letzter Zeit richtet sich einigeAufmerksamkeit auf die Sentimentanalyse,insbesondere seit Matthew Jockers emotionaleErregung als Indikator für Plotstrukturenvorgeschlagen hat (Jockers 2014). Er unterteiltRomane in Segmente und bildet darausemotionale Plot-Kurven (Jockers 2015).Obwohl die Idee, Sentimentanalyse in diesemZusammenhang einzusetzen, gut aufgenommenwurde, wurde Jockers für seine Verwendungder Fourier-Transformation zur Glättung derresultierenden Plot-Kurven kritisiert (Swafford2015, Schmidt 2015).
Micha Elsner (Elsner 2015) verwendet, nebenanderen Features, ebenfalls Sentimentkurven,um Repräsentationen des Plots romantischerWerke zu erstellen. Er verknüpft diese Kurvenmit bestimmten Figuren und untersucht auchdas gemeinsame Auftreten von Figuren. Die
Auswertung seines Ansatzes zeigt, dass er echteRomane mit beachtlichem Erfolg von künstlichumgestellten Versionen unterscheiden kann,was darauf hindeutet, dass seine Methodentatsächlich bestimmte Aspekte der Plotstrukturabbilden.
In vorhergehenden Arbeiten haben wirSentiment-Features verwendet, um HappyEnds, als ein wichtiges Plot-Element, indeutschsprachigen Romanen zu erkennen, wobeiwir einen F1-score von 73% erreichen konnten(Zehe et al. 2016).
Korpus und Ressourcen
Unser Datensatz besteht aus 212deutschsprachigen Romanen, die hauptsächlichaus dem 19. Jahrhundert stammen. 1 Zu jedemRoman wurde manuell annotiert, ob er einHappy End hat (50%) oder nicht (50%). Diedafür relevanten Informationen stammenaus den Zusammenfassungen des KindlerLiteratur Lexikon Online 2 und aus Wikipedia 3
. Sofern keine Zusammenfassung eines Romansverfügbar war, wurde das Ende von denAnnotatoren gelesen.
Unsere Sentimentanalyse erfordert eineRessource, die auflistet, welche Gefühle Lesertypischerweise mit bestimmten Worten oderPhrasen eines Textes assoziieren. DiesesPaper verwendet das NRC Sentiment Lexikon(Mohammad und Turney 2013), zu dem eineautomatisch übersetzte deutsche Versionverfügbar ist 4 . Eine besondere Eigenschaftdieses Lexikons ist, dass zu jedem Wort nebenje einem binären Wert (0 oder 1) für positiveund negative Konnotation (2 Features) auchseine Zugehörigkeit zu 8 Basisemotionen (Wut,Angst, Ekel, Überraschung, Freude, Vorfreude,Vertrauen und Trauer) festgehalten ist (vgl.Tabelle 1). Zusätzlich ermitteln wir die Polaritäteines Wortes, indem der negative vom positivenWert abgezogen wird (ein Wort mit einempositiven Wert von 0 und einem negativen Wertvon 1 erhält also die Polarität -1). Die Polaritätdient als ein zusammengefasster Emotionswert.Insgesamt betrachten wir also 11 Features.
Tabelle 1: Beispieleinträge aus dem NRCSentiment Lexikon
82

Digital Humanities im deutschsprachigen Raum 2017
Wort/Dimension
verabscheuenbewundernswertZufall
Positiv 0 1 0Negativ 1 0 0Polarität -1 1 0Wut 1 0 0Vorfreude 0 0 0Ekel 1 0 0Angst 1 0 0Freude 0 1 0Trauer 0 0 0Überraschung0 0 1Vertrauen 0 1 0
Experimente
Ziel dieses Papers ist es, Features, die zurErkennung von Happy Ends in Romanengenutzt wurden, genauer zu untersuchen, umEinsichten in die Relevanz bestimmter Featureszu erhalten. Dazu übernehmen wir die Featuresund Methoden, wie sie in Zehe et al. (2016)beschrieben sind. Die Parameter der linearenSVM sowie die Einteilung in 75 Segmente sindebenfalls aus diesem Paper übernommen.
Features. Da keine verlässlichenKapitelannotationen verfügbar waren,wurde jeder Roman in 75 gleichgroße Blöckeunterteilt, die wir als Segmente bezeichnen.Für jedes lemmatisierte Wort werden die obenbeschriebenen 11 Sentiment-Werte ermittelt.Anschließend wird für jedes Segment derentsprechende Durchschnitt berechnet, sodass11 Werte pro Segment vorliegen. Diese werdenals ein Feature-Set betrachtet.
Qualitative Feature-Analyse. Da unser Korpuszu gleichen Teilen aus Romanen mit undohne Happy End besteht, erreichen sowohldie Random Baseline, als auch die Mehrheits-Baseline eine Klassifikationsgenauigkeit von50%.
Aufgrund unserer Annahme, dass dierelevante Information zur Klassifikation vonHappy Ends am Ende eines Romans zu findenist, wurden zunächst die Sentiment-Werte desletzten Segments als einziges Feature-Set (fd, n)verwendet, was zu einer Genauigkeit von 67%führte.
Um unserer Intuition gerecht zu werden, dassnicht nur das letzte Segment an sich, sondernauch sein Verhältnis zum Rest des Romans fürdie Klassifikation von Bedeutung ist, wurdensogenannte Sektionen ( sections) eingeführt:das letzte Segment eines Romans bildet die final
section, während die übrigen Segmente zur mainsection gehören. Über die Sektionen wurdenwiederum Durchschnittswerte gebildet, indemder jeweilige Wert aller 11 Features über alleSegmente in der betreffenden Sektion gemitteltwurde. Um das Verhältnis zwischen diesenSektionen abzubilden, wurden die Differenzenzwischen den Sentiment-Werten der finalsection und den durchschnittlichen Sentiment-Werten aller Segmente in der main section alszusätzliche Features betrachtet. Dies hatte jedochkeine Auswirkungen auf die Ergebnisse.
Diese Beobachtung führte uns zu derAnnahme, dass unser Begriff des "Endes"nicht differenziert genug ist, da die Anzahl anSegmenten für jeden Roman und damit auch dieGrenzen des finalen Segments relativ willkürlichgewählt wurden. Daher wurde die Aufteilungin final section und main section im Folgendenvariiert, sodass die final section mehr als nur dasletzte Segment enthalten kann.
Abbildung 1: Klassifikationsgenauigkeit fürverschiedene Unterteilungen in main und finalsection. Die gestrichelte Linie gibt die Baselinean, die gepunktete Linie markiert die Aufteilung,bei der der maximale F1-score erreicht wird.
Abbildung 1 zeigt, dass dieKlassifikationsgenauigkeit steigt, wennmindestens 75% der Segmente in der mainsection sind und ein Maximum bei ca. 95%erreicht (bei 75 Segmenten insgesamt bedeutetdas 4 Segmente in der final section und 71Segmente in der main section). Mit dieserAufteilung verbessert sich der F1-Wert auf68%, wenn nur das Feature-Set der final section(fd, final) verwendet wird, und weiter auf 69%,wenn die Differenzen zu den durchschnittlichenSentiment-Werten der main section (fd, main - final)miteinbezogen werden.
Da sich die Ergebnisse durch dieEinbeziehung des Verhältnisses zwischen derfinal section und der main section verbessert
83
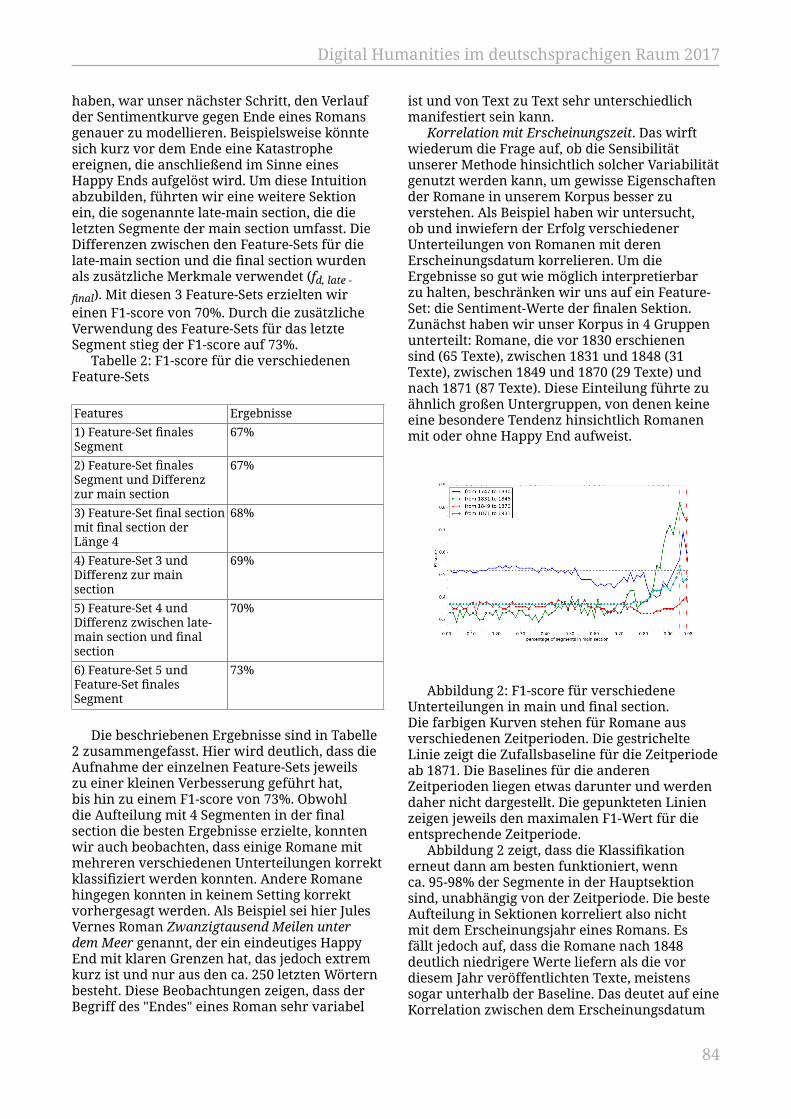
Digital Humanities im deutschsprachigen Raum 2017
haben, war unser nächster Schritt, den Verlaufder Sentimentkurve gegen Ende eines Romansgenauer zu modellieren. Beispielsweise könntesich kurz vor dem Ende eine Katastropheereignen, die anschließend im Sinne einesHappy Ends aufgelöst wird. Um diese Intuitionabzubilden, führten wir eine weitere Sektionein, die sogenannte late-main section, die dieletzten Segmente der main section umfasst. DieDifferenzen zwischen den Feature-Sets für dielate-main section und die final section wurdenals zusätzliche Merkmale verwendet (fd, late -
final). Mit diesen 3 Feature-Sets erzielten wireinen F1-score von 70%. Durch die zusätzlicheVerwendung des Feature-Sets für das letzteSegment stieg der F1-score auf 73%.
Tabelle 2: F1-score für die verschiedenenFeature-Sets
Features Ergebnisse1) Feature-Set finalesSegment
67%
2) Feature-Set finalesSegment und Differenzzur main section
67%
3) Feature-Set final sectionmit final section derLänge 4
68%
4) Feature-Set 3 undDifferenz zur mainsection
69%
5) Feature-Set 4 undDifferenz zwischen late-main section und finalsection
70%
6) Feature-Set 5 undFeature-Set finalesSegment
73%
Die beschriebenen Ergebnisse sind in Tabelle2 zusammengefasst. Hier wird deutlich, dass dieAufnahme der einzelnen Feature-Sets jeweilszu einer kleinen Verbesserung geführt hat,bis hin zu einem F1-score von 73%. Obwohldie Aufteilung mit 4 Segmenten in der finalsection die besten Ergebnisse erzielte, konntenwir auch beobachten, dass einige Romane mitmehreren verschiedenen Unterteilungen korrektklassifiziert werden konnten. Andere Romanehingegen konnten in keinem Setting korrektvorhergesagt werden. Als Beispiel sei hier JulesVernes Roman Zwanzigtausend Meilen unterdem Meer genannt, der ein eindeutiges HappyEnd mit klaren Grenzen hat, das jedoch extremkurz ist und nur aus den ca. 250 letzten Wörternbesteht. Diese Beobachtungen zeigen, dass derBegriff des "Endes" eines Roman sehr variabel
ist und von Text zu Text sehr unterschiedlichmanifestiert sein kann.
Korrelation mit Erscheinungszeit. Das wirftwiederum die Frage auf, ob die Sensibilitätunserer Methode hinsichtlich solcher Variabilitätgenutzt werden kann, um gewisse Eigenschaftender Romane in unserem Korpus besser zuverstehen. Als Beispiel haben wir untersucht,ob und inwiefern der Erfolg verschiedenerUnterteilungen von Romanen mit derenErscheinungsdatum korrelieren. Um dieErgebnisse so gut wie möglich interpretierbarzu halten, beschränken wir uns auf ein Feature-Set: die Sentiment-Werte der finalen Sektion.Zunächst haben wir unser Korpus in 4 Gruppenunterteilt: Romane, die vor 1830 erschienensind (65 Texte), zwischen 1831 und 1848 (31Texte), zwischen 1849 und 1870 (29 Texte) undnach 1871 (87 Texte). Diese Einteilung führte zuähnlich großen Untergruppen, von denen keineeine besondere Tendenz hinsichtlich Romanenmit oder ohne Happy End aufweist.
Abbildung 2: F1-score für verschiedeneUnterteilungen in main und final section.Die farbigen Kurven stehen für Romane ausverschiedenen Zeitperioden. Die gestrichelteLinie zeigt die Zufallsbaseline für die Zeitperiodeab 1871. Die Baselines für die anderenZeitperioden liegen etwas darunter und werdendaher nicht dargestellt. Die gepunkteten Linienzeigen jeweils den maximalen F1-Wert für dieentsprechende Zeitperiode.
Abbildung 2 zeigt, dass die Klassifikationerneut dann am besten funktioniert, wennca. 95-98% der Segmente in der Hauptsektionsind, unabhängig von der Zeitperiode. Die besteAufteilung in Sektionen korreliert also nichtmit dem Erscheinungsjahr eines Romans. Esfällt jedoch auf, dass die Romane nach 1848deutlich niedrigere Werte liefern als die vordiesem Jahr veröffentlichten Texte, meistenssogar unterhalb der Baseline. Das deutet auf eineKorrelation zwischen dem Erscheinungsdatum
84

Digital Humanities im deutschsprachigen Raum 2017
und der Klassifikationsgenauigkeit hin: Vor demRealismus erschienene Romane sind hinsichtlichdes Happy Ends leichter zu klassifizieren alsrealistische Romane. Eine mögliche Erklärungfür diese Beobachtung könnte die stärkerschematische Struktur der vor-realistischenRomane sein.
Wir sind uns bewusst, dass die Anzahlder Romane für die einzelnen Zeitperiodenrelativ klein ist, sodass diese Beobachtungenzunächst als exploratorische Einblickegesehen werden müssen. Nichtsdestotrotzzeigen diese vorläufigen Ergebnisse, dass dieautomatische Erkennung von Happy Ends, sogarmit nur einem recht einfachen Feature-Set,Zusammenhänge zu anderen Eigenschaftenvon Romanen aufdecken kann, die für dieLiteraturwissenschaft von großem Interessesind.
Fazit und zukünftige Arbeiten
Die automatische Erkennung von HappyEnds als wesentlichem Plot-Element vonRomanen ist ein nützlicher Schritt in Richtungeiner umfassenden computergestütztenRepräsentation des Plots literarischer Texte.Unsere Experimente zeigen, dass verschiedeneFeatures auf Basis von Sentimentanalyse eineErkennung von Happy Ends in Romanen mitunterschiedlicher, aber insgesamt soliderGenauigkeit ermöglichen. Obwohl unserAnsatz relativ einfach gehalten ist, kanner zu substantiellen Erkenntnissen für dieLiteraturwissenschaft führen.
In zukünftigen Arbeiten soll die Genauigkeitunserer Methode verbessert werden, indemdie hohe Variabilität des Endes in Romanendifferenzierter betrachtet wird. Außerdemkönnte der Ansatz eingesetzt werden,um bestimmte Eigenschaften weitererRomankorpora tiefergehend zu untersuchen.
Fußnoten
1. Quelle: https://textgrid.de/digitale-bibliothek2. www.kll-online.de3. https://de.wikipedia.org4. http://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm
Bibliography
Elsner, Micha (2015): „AbstractRepresentations of Plot Structure“, in: LinguisticIssues in Language Technology 12 (5).
Finlayson, Mark A. (2012): LearningNarrative Structure from Annotated Folktales.PhD thesis, Massachusetts Institute ofTechnology.
Jockers, Matthew L. (2014): Anovel method for detecting plot. http://www.matthewjockers.net/2014/06/05/a-novel-method-for-detecting-plot/ [letzter Zugriff 25.August 2016].
Jockers, Matthew L. (2015):The rest of the story. http://www.matthewjockers.net/2015/02/25/the-rest-of-the-story/ [letzter Zugriff 25. August 2016].
Mohammad, Saif / Turney, Peter (2013):„Crowdsourcing a Word-Emotion AssociationLexicon“, in: Computational Intelligence 29 (3):436–465.
Reiter, Nils (2013): Discovering StructuralSimilarities in Narrative Texts using EventAlignment Algorithms. PhD thesis, HeidelbergUniversity.
Reiter, Nils / Frank, Anette / Hellwig,Oliver (2014): „An NLP-based Cross-DocumentApproach to Narrative Structure Discovery“, in:Literary and Linguistic Computing 29 (4): 583–60510.1093/llc/fqu055.
Schmidt, Benjamin M. (2015): Commodiusvici of recirculation: the real problem withSyuzhet. http://benschmidt.org/2015/04/03/commodius-vici-of-recirculation-the-real-problem-with-syuzhet/ [letzter Zugriff 25. August2016].
Swafford, Annie (2015): “ „Problemswith the Syuzhet Package“. https://annieswafford.wordpress.com/2015/03/02/syuzhet/ [letzter Zugriff 25. August 2016].
Zehe, Albin / Becker, Martin / Hettinger,Lena / Hotho, Andreas / Reger, Isabella /Jannidis, Fotis (2016): „Prediction of HappyEndings in German Novels“, in: Proceedingsof the Workshop on Interactions between DataMining and Natural Language Processing 2016.
85

Digital Humanities im deutschsprachigen Raum 2017
Anybody out there? DerBegriff der Masse imCrowdsourcing
Schilz, [email protected]ät Passau, Deutschland
Thematik
Die „Masse“ als „Beschaffer“ definierterInformationen hat sich ihren Platz im Feld derDigital Humanities bzw. in der Schnittmenge vonDH und Institutionen für den Erhalt kulturellenErbes erobert. Aufgaben ganz verschiedenerSchwierigkeitsgrade werden an eine anonymeMenge interessierter Individuen delegiert,die so zu produktiven Beiträgern spezifischerProjekte werden. Oft zitierte Beispiele sind OldWeather und Transcribe Bentham (Dunn/Hedges2012), beides Transkriptions-Projekte; auf demGebiet von OCR-Korrektur und Annotation wirdauch mit Gamification gearbeitet (Digitalkoot,Metadata Games, ARTigo).
Das Thema Crowdsourcing zeigt sich inden DH freilich nicht nur empirisch; es liegenUntersuchungen zu Typologien und Modellensowie Fallstudien vor, und auch ethische Fragenwerden verhandelt. Der Diskurs tendiert dabeidazu, das im kommerziellen Crowdsourcingzentrale Argument des Ökonomischen als ehersekundär einzustufen. Vorrangig wird demcrowdbasierten Generieren wissenschaftlichverwertbarer Daten bzw. dem nachhaltigenAnreichern digitalisierter Quellen hinsichtlichdes weichen Faktors einer Sensibilisierung fürkulturelles Erbe hohes Potential zugesprochen.Dabei gibt es für das zielführende Einsetzendemokratisierten Wissens eine Blaupause, dienaturwissenschaftlich ausgerichtete CitizenScience. Die Plattform Zooniverse spielt hierbeieine namhafte Rolle, obgleich auch analogeVarianten nach wie vor ihre Berechtigung haben(bekannt sind die saisonalen ornithologischenZählungen).
Ausgehend von dieser Gesamtsituationentwickelt dieser Beitrag Fragenkomplexezu einer kulturwissenschaftlichenKontextualisierung des Crowdsourcings fürdie DH. Die Kernfrage ist dabei, inwiefern sichgeisteswissenschaftliche Konnotationen desMasse-Begriffs in Konzepten zum „Gebrauch“
der Crowd spiegeln und welche gesellschaftlicheRelevanz daraus erwächst.Angrenzend wird betrachtet, wie sichCrowdsourcing vor der Digitalität gestaltete undwelche „Crowd“ gemeint war. Außerdem:Wosind Chancen und Grenzen des Crowdsourcingszu detektieren, bezüglich Machbarkeit, Effizienz,Ethik, und welche Schlüsse ziehen die DHdaraus? Was lässt sich aus der Situation für denAnspruch an eine nachhaltige Datengenerierungableiten?
Begründung
Zwei Determinanten bestimmen dieThemenwahl. Erstens: Im Feld der DigitalHumanities ist Crowdsourcing ein Thema.Zweitens: Kernfaktor des Crowdsourcings ist dieRessource „Masse“.
Aktuelle Positionen in den DH begreifen, wieoben skizziert, Crowdsourcing nicht als bloßesProduktionsmittel. Mein Beitrag baut auf diesenUntersuchungen auf und ergänzt sie durch dieThese, dass für die DH zu einem adäquatenUmgang mit der Methode Crowdsourcing aucheine kritisch angebundene Diskussion desMasse-Begriffs unter dezidiert kultur- bzw.geisteswissenschaftlichen Gesichtspunktengehören sollte. Ich nähere mich dem PhänomenCrowdsourcing unter diesen Prämissen an, unterDeklaration einer notwendigen Subjektivität:Meine Argumentationslinie stellt eine vonvielen Optionen dar – andere mögen weiterehinzufügen.
Prolog: AnalogesCrowdsourcing
Das Delegieren definierter Aufgaben anpotentiell unbekannte Zuträger ist nichterst ein Phänomen des digitalen Zeitalters.Es gab in der Geschichte der Geistes- undKulturwissenschaften einige prominenteProjekte mit akkumulativem Charakter, dieBeiträger (aus einem vorher definierten Pool)über Aufrufe akquirierten und auf aktivepositive Reaktion entscheidend angewiesenwaren.Beispiele sind die Aufrufe vonGeorge PerkinsMarsh für das New English Dictionary 1859(Ridge), die erste groß angelegte volkskundlicheFragebogenaktion von Wilhelm Mannhardt1865 zu „alten agrarischen Gebräuche(n)und Erntesitten“ sowie das Kulturraum-
86

Digital Humanities im deutschsprachigen Raum 2017
Forschungsprojekt Atlas der deutschenVolkskunde (1930-1935).
Kritik der Masse
Die Masse umgibt eine semantische Aura,die ganz bestimmten Bildern entstammtund in diese mündet: Amorph, wesenhaft,unberechenbar, entindividualisiert, und indialektischer Weise lenkbar und unsteuerbar.Die Masse als Negativ zur Selbstbestimmtheitist, naheliegend, historisch unterfüttert, nachLinks wie nach Rechts. Das Zurückweisender Masse als Identifikationsmoment wird,auch dies liegt nahe, bestimmt durch eine vonräumlichen, zeitlichen und soziopolitischenRahmenbedingungen bedingte Enkulturation.In Anlehnung an Sartre ließe sich formulieren:„Die Masse, das sind die anderen.“ DieserAbwehrreflex weist eine kulturgeschichtlicheDimension auf, die im Folgenden in grobenZügen freigelegt wird.
Die gefährliche und diedumme Masse
Gustave Le Bon, früher und wirkmächtigerVertreter der Massenpsychologie, sah „dieMassen“ als kulturzerstörende Kraft, wobei derKulturbegriff, zeittypisch, mit dem Momentder „Rasse“ gekoppelt wird. In Le Bons Konzeptder Masse wird, wiederum zeittypisch, einDeutungsmuster manifest, das Eingang inskulturelle Gedächtnis finden wird: Masse/Tief vs.Kultur/Hoch.
Ein Misstrauen in die Masse und einedaraus resultierende Angst vor ihrernivellierenden Macht fand insbesonderein der Figur der Massenseele Ausdruck.Der so abstrahierten Masse werden quasimetaphysische Eigenschaften zugewiesen,woraus sich (unschwer) ein Negieren desIndividuums ableiten lässt. Exemplifiziertwird dies anhand einer kurzen Skizze zumÜberbevölkerungsdiskurs, der in den 1970erJahren global erneuert wurde und die historischgesetzte Verwerfung Arm/Reich um jene vonNorden/Süden erweitert hat.
Komplementär zur Gefährlichkeit istdie Dummheit, welche der Masse distinktivzugeschrieben wird. Dies hat in derGeisteswissenschaft früh ein Echo erzeugt, das indekonstruierende Reaktion geht. Bei Marx undEngels werden Ansätze erkennbar, den Masse-Begriff als elitäres Produkt herauszuarbeiten.
Zeitgenosse Charles Mackay formulierte mitder provokanten These vom „Wahnsinn derMassen“ eine Kritik sozialer Mechanismen. Guthundert Jahre später definiert Pierre BourdieuMuster der Distinktion in Abgrenzung zurMasse und präzisiert das Affirmative des Nicht-Massenmenschen.
Die unheimliche und diekonstruktive Masse
Zoomt man in der Analyse der Masse von derMakroebene zur Mikroebene heran, begegnetman dem „Massenmenschen“. BerechtigtesMisstrauen in ihn äußert beispielsweise WalterBenjamin. Überhaupt steht die FrankfurterSchule der Masse bzw. den für sie bestimmtenProdukten bekanntlich skeptisch gegenüber. Andiesem Punkt der Erzählung von der „modernenMasse“ stoßen wir aber auch auf eine paralleleLesart, mit der ein ästhetisches Fassen desMassenmenschen einhergeht, das auf dasWesen der Popkultur verweisen wird. Poesungreifbarer, geschichtsloser „Man in theCrowd“ scheint auf, sowie Baudelaires „Heimat“im Urbanen, in der die Singularisierung alsChance für ein Man-selbst-sein in der Mengebegriffen wird.
Benjamin deutet, Bezug nehmend aufBaudelaires Auffassung vom Flaneur in derMenge, diese Figur kritisch als Metapher fürdie Gefahr des Scheins, der vom Kollektivausgeht. Doch der Flaneur bietet auch dieMöglichkeit einer positiven Umdeutung vordem Hintergrund des Gemeinnützigkeit-Gedankens. Es geht dabei um das Gebiet derWissensallmende: um gemeinsames Gut derInformationsgesellschaft – digitales Gemeingut.Wikipedia übersetzt „Allmendefertigung durchGleichberechtigte“ für Commons-based PeerProduction (CBPP), ein von Yochai Benklergeprägter Begriff. Er führt uns zur Masse imdigitalen Raum bzw. zum Flanieren im WWW,dem Browsen. Mit welchen Konzepten begegnenwir potentiellen Partizipatoren unserer Crowd?
Konzepte
Wer die „Weisheit der Masse“ (JamesSurowiecki) nutzt, setzt auf Schwarmintelligenz:Kollektive Lösungen sind besser als individuelle,lautet das Credo. Unter welchen ökonomischen,methodischen und ethischen Implikationen einfür das eigene Ziel nützlicher Schwarm generiertwird, unterscheidet sich jedoch maßgeblich.
87

Digital Humanities im deutschsprachigen Raum 2017
Task und Methode
Das ökonomisch boomende Modell desMicrotaskings kommt dem am nächsten, wasJeff Howe, der den Begriff Crowdsourcingprägte, als „Future of Business“ (Howe)sieht. Materielle Basis sind diskrete, einfacheAufgaben, die, in Arbeitspakete gesplittet,effizienter durch Menschen - Crowdworker -als mit Maschinen gelöst werden. Prominent istAmazon's Mechanical Turk, doch auch in denDH wird mit kommerziell basiertem Crowdworkexperimentiert.
Microtasking findet sich jedoch auchin ganz anderer Weise in DH-Projektenwieder, die gemäß dem CBPP-Ansatz von derGrundannahme einer reflektiert agierendenMasse, konstituiert über selbstbestimmteIndividuen, getragen werden. Die Methode derFolksonomy ist hier zu nennen, auf die z. B. diegamifizierte Metadaten-Sammlung ARTigo setztsowie andere niederschwellige, spielerischeSettings, angeboten als Open Source über diePlattform Metadata-Games.
Methodisch angrenzend an das Microtaskingfindet sich das Macrotasking (Brandon Walsh).Bei diesem Crowdsourcing-Konzept stehtAkkumulation statt Aggregation im Vordergrund,neue komplexe Informationen werden generiert– flächig bekanntes Beispiel ist hier Wikipedia.Macrotasking ist skizzierbar als Microtaskingmit Spezialisierungsbedarf seitens der Crowd, imFeld der DH ein häufiges Desideratsprofil. Etwaauf dem Feld des Transkribierens: Exemplarischwird aufgezeigt, wie variantenreich Konzepte,Vorgehen und Bereiche sich darstellenkönnen, und was dies für Auswirkungenauf Projektspezifikationen hat. Aspekte sinddabei Formatierung, Annotation sowie dasstrukturierte Akkumulieren verteilter Daten(Kearney/Wallis).
Motiv und Modell
Für das ergebnisorientierte Akquiriereneiner Crowd bedarf es einerseits gezielterKommunikation im Vorfeld – der Aufruf ist einwesentliches Erfolgsmoment. Was motiviertandererseits dazu, Angebote anzunehmenund, nicht weniger relevant, sie mittel- bislängerfristig verlässlich teilnehmend zuverfolgen? Grundlegende Argumente sindBezahlung, Bindung, Teilen und Spielen (Oomen/Aroyo). Zudem müssen die Beschaffenheit derQuellen, Ergebnis-Desiderate und Konzepte fein
abgestimmt werden, um Projekte erfolgreich zurealisieren.
In den DH wurden differenzierte Typologienentwickelt, um insbesondere auch das Problemder Akquise methodologisch zu schärfen.Flankiert wird dies durch eine Palette an OpenSource-Werkzeugen, die niederschwelligeEinstiegsoptionen durch benutzerfreundlicheSchnittstellen und klare Strukturen schaffen.DH-geeignete Projektdeterminanten sind bereitserprobt worden, empirische Erfahrungenindizieren jedoch öfters ein asymmetrischesVerhältnis im Profil der liefernden Crowd: Essind nur wenige Beiträger, die den Hauptanteilan der Bearbeitung tragen.
Nachhaltigkeit
Ein Kernargument im DH-Diskurs für daszielführende Erzeugen und Binden einer Crowdist das Moment der Identifikation – ein Teilvon etwas Großem zu sein (Terras). Was sagtdies aus über die Masse und über jene, die sienutzen wollen? In Bezug auf angesprocheneKonnotationen der Masse wird kursorischdiskutiert, welche Crowd wir wollen: Diekontrollierbare und effiziente, die die Arbeiterledigt, oder die interessierte und empathische,die um Kulturerhalt besorgt ist. Ist beidesmöglich? An dieser Stelle wird bilanziert, woMöglichkeiten und Grenzen des Crowdsourcingsin den DH liegen und welche Konsequenzendaraus in puncto Nachhaltigkeit zu benennensind – nicht nur bezüglich Datengenerierung und-optimierung, sondern auch explizit hinsichtlichdes Faktors Mensch.
88

Digital Humanities im deutschsprachigen Raum 2017
Archival CulturalHeritage Online:Eine VirtuelleForschungsumgebungim Spannungsfeldvon Open Access,Nachhaltigkeit undDatenschutz
Lange, [email protected] für Wissenschaftsgeschichte,Berlin
Wintergrün, [email protected] für Wissenschaftsgeschichte,Berlin
Wannenwetsch, [email protected] für wissenschaftlicheDatenverarbeitung mbH, Göttingen
Schoepflin, [email protected] für wissenschaftlicheDatenverarbeitung mbH, Göttingen
Wie sich die langfristige wissenschaftlicheNutzbarkeit von großen digitalenDatenrepositorien sicherstellen lässt, ist einein den letzten Jahren in der DH-Communityund darüber hinaus intensiv diskutierte undnoch nicht abschließend geklärte Frage. 1 Inden Digitalen Geisteswissenschaften werdenin diesem Zusammenhang zur Zeit vorrangigProbleme der technischen Nachhaltigkeitund der Datenstandards diskutiert [Fornaro(2016)]. Im Hinblick auf Repositorien fürdie gegenwartsnah arbeitenden geistes-und sozialwissenschaftlichen Disziplinenwie die Zeitgeschichte sind aber auchkomplexe datenschutz- und urheberrechtlicheAnforderungen zu berücksichtigen. Eineim Archivwesen diskutierte Antwort aufdiese Herausforderung ist es, die rechtliche
Absicherung des Zugangs zu Digitalisaten in sog.„digitalen Lesesälen“ zu organisieren, die einenZugriff ausschließlich in den Räumlichkeiten desjeweiligen Archivs zulassen [Plassmann (2016),S. 219]. Dabei wird aber das Ziel der Open-Access-Bewegung, wissenschaftliche Quellenund Forschungsergebnisse einer möglichstgroßen Fachöffentlichkeit zugänglich zu machen,verfehlt. 2 In den Sozialwissenschaften hatdie Brisanz dieser Frage bereits zur Gründungvon Datenzentren geführt, die Fragen dertechnischen und der rechtlichen Datensicherheitin den Mittelpunkt stellen. 3 Der vorliegendeBeitrag stellt mit Archival Heritage Online –ArCHO eine digitale Forschungsinfrastrukturvor, die dazu dient, das Verlangen nach offenerwissenschaftlicher Nutzung mit den rechtlichenBedingungen für den nachhaltigen Zugang zuzeitgeschichtlichem Archivmaterial in Einklangzu bringen. 4
Der prototypische Anwendungsfallfür ArCHO ist das seit 2014 laufendeund auf zunächst fünf Jahre angelegteForschungsvorhaben „Geschichte derMax-Planck-Gesellschaft“ (GMPG). 5 Esuntersucht die Geschichte der MPG vonihrer Gründung im Jahre 1948 bis zum Jahr2002 und legt dabei den Schwerpunkt aufinstitutsubergreifende Fragestellungenzu Themenfeldern wie Periodisierungen,Innovationen, Internationalisierung, Forschungund Wirtschaft, Gender und Wissenschaftsowie Konkurrenz und Kooperation. DieseThemen lassen sich naturgemäß nicht alleindurch kleinere Fallstudien bearbeiten, sondernerfordern thematisch und chronologisch breitangelegte Querschnittsuntersuchungen mit einerentsprechend umfänglichen Quellengrundlage.Aus diesem Grund wird im Laufe des Projektesein großes digitales Textkorpus angelegt,dessen Schwerpunkt Digitalisate von mehrerenRegalkilometern an Verwaltungsschriftgutaus der Generalverwaltung der MPG undeinzelnen Instituten bilden. Desweiteren werdenthematisch spezialisierte Datenbestände wieeine Patent- und eine Personendatenbank sowieein digitales Korpus mit Veröffentlichungender MPG aufgebaut. Mit dafür entwickeltenoder angepassten Tools [Kruse et al. (2015)]lassen sich so beispielsweise Konjunkturenvon Forschungsthemen, unterschiedlicheprofessionelle Netzwerke zwischenWissenschaftlerInnen und wissenschaftlicheKarrierewege erforschen. Im Sinne derguten wissenschaftlichen Praxis 6 sollendie Arbeitsergebnisse, also sowohl die
89

Digital Humanities im deutschsprachigen Raum 2017
digitalisierten und annotierten Quellenals auch alle statistischen Auswertungen,mindestens zehn Jahre nach Projektendeabrufbar bleiben. ArCHO als digitales Findmittelund Analyseplattform ist daher mit einemFokus auf langfristiger Verfügbarkeit vonForschungsdaten konzipiert worden. Dabeiwurde eine Nachhaltigkeitsstrategie entwickelt,die der noch ungeklärten Aufgabenteilungzwischen Forschungseinrichtungen,Gedächtnisinstitutionen sowie Daten- undRechenzentren bei der Langzeitarchivierunggeisteswissenschaftlicher ForschungsdatenRechnung trägt. Denn diese Aufgabe kannangesichts der großen technischen Komplexitätund des Wartungsaufwandes für VirtuelleForschungsinfrastrukturen sowie der großenMenge an vorzuhaltenden Daten nicht alleinGedächtnisinstitutionen wie wissenschaftlichenArchiven überantwortet werden. Andererseitssind Rechen- und Datenzentren nur bedingtdazu in der Lage, neben dem Archivrechtauch komplexe spezifische Zugangsregelnfür einzelne Datenrepositorien umzusetzen.Daher ermöglicht es ArCHO mit einemverlässlichen Zugangsmanagement, dass dieForschungseinrichtung den Zugang selbstrechtssicher regeln kann.
Die in ArCHO implementierteZugangsverwaltung setzt auf eine starkeDifferenzierung von Nutzerrollen einerseitsund von Bestandteilen einzelner Datensätzeandererseits. Auf der Nutzerseite mussbeispielsweise im Anwendungsfall GMPGunterschieden werden zwischen derwissenschaftlichen Öffentlichkeit, Forscherninnerhalb des Forschungsvorhabensmit einem privilegierten Zugang zu denAktenbeständen und einem Projektkollegium,das besonders sensible Datenbestände nacheiner Einzelfallprüfung für die Forscher freigibt.Weitere Abstufungen von Zugangsrechtenkönnen sich aus spezifischen Aufgabenbereichenbei der Dateneingabe und -verwaltung ergeben[vgl. Neuroth et al. (2010), 16:14 ff.]. DieAufgabe der Zugangsregelung muss auchnach Projektende weiter von dazu befugtenPersonen ausgeübt werden können und istdaher eine wichtiger Nachhaltigkeitsaspekt.Denn beispielsweise ist bei datenschutzrechtlichsensiblen Dokumenten mit Personenbezug,deren Sichtung durch Forscher der Einwilligungder betroffenen Personen bedarf, je nachkonkreter rechtlicher Ausgestaltung dieseBewilligung an das Forschungsvorhabenund damit an dessen Laufzeit gebunden.Die Nutzungserlaubnis erlischt in diesenFällen nach Projektende und entsprechend
muss auch der digitale Zugang verwehrtwerden. Auf der anderen Seite werden mancheAkten erst nach Ende der Archivschutzfristvollständig nutzbar, was in einer nachhaltigenForschungsinfrastruktur ebenfalls berücksichtigtwerden sollte.
Auf der Datenseite ermöglicht ArCHOeine starke Differenzierung von einzelnenzu einem Dokument gehörenden Daten mitdem Ziel, unter Einhaltung der rechtlichenVorgaben möglichst viele Informationen fürdie Forschung zur Verfügung zu stellen. Sosind bei einer Personalakte mit sensiblenInhalten möglicherweise die Signatur, Laufzeitund Angaben zur inhaltlichen Klassifikationdurch das haltende Archiv nicht schutzwürdig,wohl aber der Volltext und der Titel. Eskann also je nach Bestand jedes Metadatumund jedes Derivat des Digitalisates (OCR-Erfassungen u.a.) eine andere Schutzwürdigkeithaben. Die Gesamtzahl dieser Regeln, diezwischen beliebigen Typen von (Meta-)Datenunterscheiden, und die Vielzahl von abgestuftenNutzerrechten führen zu einer Matrix ausNutzerrollen und Teildatensätzen, dereneinzelne Werte sich stets ändern können.Sie wird technisch realisiert durch einensogenannten Policy Decision Point (PDP).Dabei handelt es sich um ein außerhalb deseigentlichen Dokumentkorpus angesiedeltesund technisch eigenständiges Softwaremodul,das zwischen der Nutzer-Datenbank und demKorpus vermittelt.
Die Umsetzung eines solchen Rechtemodellsinnerhalb einer ansonsten marktüblichenWebanwendung leistet den oben geschildertenAnforderungen aber noch nicht Genüge. Dennein solches System wäre höchst verwundbargegenüber Hacking-Angriffen. So ist denkbar,dass durch Injection-Attacken sensible Teileder Datenbank, und im schlimmsten Fall sogardie Zugangsverwaltung, ausgelesen werden.7 Weiterhin stellt der Download größererMengen an Dateien im Projektalltag ein gewissesRisiko der ungewollten Weiterverbreitung darund ist angesichts der notwendigen hohenDokumentqualität auch recht zeitaufwändig.Eine sinnvolle Alternative ist daher eineViewer-Anwendung, welche Dokumentebereits serverseitig so gut aufbereitet, dassein kompletter Download vermieden werdenkann. Die Anforderungen solch vergleichsweisekomplexer Anwendungen an die Client-Software(i. A. Browser) können jedoch im Laufe derZeit zu Inkompatibilitäten führen und somitdie Nachhaltigkeit der gesamten Anwendunggefährden.
90

Digital Humanities im deutschsprachigen Raum 2017
Daher realisiert ArCHO auf der Ebene derMiddleware mit Containern und VirtualisierungArchitekturprinzipien, wie sie (aus zum Teilsehr verschiedenen Gründen) in der Diskussionum nachhaltige wissenschaftliche Softwarezur Zeit eine große Rolle spielen. 8 In derkonkreten Implementierung wird erreicht,dass der Bildschirm des Nutzers einen perRDP-Protokoll bereitgestellten VirtuellenDesktop zeigt, der jeweils Einzelansichtenvon Dokumentseiten wiedergibt. 9 Diesekönnen nicht ohne Weiteres heruntergeladenwerden. Auch ein programmatischer Zugriffauf die Datenbank ist nicht möglich, daherkönnen Angreifer keinen massenhaften Abzugsensibler Daten erreichen. Außerdem wird dieWebanwendung als solche technisch nachhaltiggemacht. Denn da sie sich in einem sehr starkabgeschlossenen System befindet, ist dietechnische Konfiguration des Client-Rechnerszumindest mittelfristig fast ohne Belang.
Die geschilderte Kombination vonVirtualisierung, Middleware-Containernund der feingranularen Zugangsverwaltungist eine pragmatische Antwort auf dasungelöste Problem des rechtssicherenZugangs zu schutzwürdigen digitalisiertenArchivalien. Sie bietet eine Alternativezur räumlichen Zugangsbeschränkung aufArchivlesesäle. ArCHO soll dazu beitragen,die nachhaltige Nutzbarkeit von Daten, diein Forschungsprojekten erhoben wurden,über Orts- und Disziplingrenzen hinweg zuermöglichen und damit eines der wesentlichenVersprechen der Digitalisierung in denGeisteswissenschaften einzulösen.
Fußnoten
1. Als Beispiel einer über dieGeisteswissenschaften hinausgehenden,internationalen Initiative sei die Arbeit derResearch Data Alliance genannt: https://rd-alliance.org/ [letzter Zugriff 20. August 2016].2. S. hierzu die „Berlin Declaration onOpen Access to Knowledge in the Sciencesand Humanities“, die auch vom MPI fürWissenschaftsgeschichte unterstützt wird:https://openaccess.mpg.de/Berlin-Declaration[letzter Zugriff 20. August 2016].3. Z. B. das „GESIS Secure Data Center“: http://www.gesis.org/en/services/data-analysis/data-archive-service/secure-data-center-sdc/ [letzterZugriff 26.11. 2016].4. ArCHO befindet sich zum Zeitpunkt derAbfassung im Stadium eines Prototypen und
wird in der Projektlaufzeit zu einem generischenService erweitert.5. http://gmpg.mpiwg-berlin.mpg.de [letzterZugriff 20. August 2016].6. Vgl. die Empfehlung 7 der Denkschrift„Sicherung guter wissenschaftlicher Praxis“der DFG: http://www.dfg.de/download/pdf/dfg_im_profil/reden_stellungnahmen/download/empfehlung_wiss_praxis_1310.pdf [letzterZugriff 20. August 2016].7. Dieses für die meisten historischenQuellenkorpora absurd klingende Szenario ist imBereich der Zeitgeschichte durchaus als denkbaranzunehmen.8. Beachte z. B. die thematische Ausrichtung desFORGE-2016-Workshops: https://www.gwiss.uni-hamburg.de/gwin/ueber-uns/forge2016.html[letzter Zugriff 20. August 2016].9. Die Desktop-Virtualisierung wird mitApache Guacamole realisiert: https://guacamole.incubator.apache.org [letzter Zugriff20. August 2016].
Bibliographie
Fornaro , Peter R. / Rosenthaler, Lukas(2016): „File Formats for Archiving: Stabilityand Persistence Issues“, in: DH2016: ConferenceAbstracts 507–508.
Kruse, Sebastian / Schmaltz, Florian /Stiller, Juliane / Wintergrun, Dirk (2015):„Herausforderung ‚Big Data’ in der historischenForschung“, in: DHd 2015: Von Daten zuErkenntnissen 171–174 https://dhd2015.uni-graz.at/de/nachlese/book-of-abstracts [letzterZugriff 20. August 2016].
Neuroth, Heike / Oßwald, Achim /Scheffel, Regine / Strathmann, Stefan / Huth,Karsten (2010): nestor-Handbuch: Eine kleineEnzyklopädie der digitalen Langzeitarchivierung.Göttingen: Niedersächsische Staats- undUniversitätsbibliothek Göttingen http://www.nestor.sub.uni-goettingen.de/handbuch/index.php [letzter Zugriff 20. August 2016].
Plassmann, Max (2016): „Archiv 3.0?Langfristige Perspektiven digitaler Nutzung“, in:Archivar. Zeitschrift für Archivwesen 3: 219–223http://www.archive.nrw.de/archivar/hefte/2016/Ausgabe_3/Archivar_3_2016.pdf [letzter Zugriff20. November 2016].
91

Digital Humanities im deutschsprachigen Raum 2017
Aufbau eineshistorisch-literarischenMetaphernkorpus fürdas Deutsche
Pernes, [email protected]ät Würzburg, Deutschland
Keller, [email protected]ät Würzburg, Deutschland
Peterek, [email protected]ät Würzburg, Deutschland
Überblick
Metaphorischer Sprachgebrauch umfasstkomplexe gedankliche Würfe genauso wiealltägliche Begrifflichkeiten. Die Metaphergilt als Untersuchungsgegenstand nichtnur in den Literaturwissenschaften,Sprachwissenschaften und der Anthropologie,sondern hat auch Relevanz für so disparateForschungsprogramme wie das der KünstlichenIntelligenz und der Kritischen Diskursanalyse.Darüber hinaus stellt die Erkennung undAuflösung von Metaphern ein wichtigesDesiderat in sprachtechnologischenAnwendungen dar, deren Gegenstand dieDisambiguierung von Wortbedeutungenumfasst. Korpusuntersuchungen zeigen, dassmetaphorischer Sprachgebrauch in gängigenTextsorten durchschnittlich in jedem dritten Satzzu finden ist (vgl. Steen et al. 2010; Shutova undTeufel 2010) – ein Beleg für die Ubiquität derMetapher, die in erster Linie darin begründetliegt, dass die idealtypische Karriere einesmetaphorischen Ausdrucks als kühne Betonungbeginnt und als konventionelle Form endet.Eine Sprachressource zum Metapherngebrauchkann also eine wichtige Ergänzung bei derautomatischen inhaltlichen Erschließung vonTextbeständen darstellen. Dabei stellt das hierentwickelte Korpus annotierter Sätze, dessenGrundlage eine Sammlung deutschsprachigenRomane aus dem 19. Jahrhunderts bildet, einenspezifischen Beitrag zur Erschließung vonhistorischen Textbeständen dar.
Die große Mehrheit der heute verfügbarenMetaphernkorpora basiert auf dem Prinzip,einige wenige Zielbegriffe sowie unterUmständen ausgewählte konzeptuelle Domänenzu definieren und alle passenden sprachlichenRealisierungen aus einem großen Textbestandzu extrahieren. Diese Herangehensweiselässt vermuten, dass die damit modelliertenEigenschaften sich nicht auf arbiträren Textin realen Anwendungsszenarien übertragenlassen, denn jedes vordefinierte lexikalischeoder konzeptuelle Inventar wird dabei zukurz greifen (vgl. Shutova 2015). Im Gegensatzdazu enthält das hier entwickelte Korpus keineEinschränkungen hinsichtlich der konzeptuellenDomänen oder der erfassten sprachlichenKonstruktionen, bis auf die Tatsache, dass es sichaus literarischen Prosatexten zusammensetzt. Essollte noch darauf hingewiesen werden, dass mitder Hamburg Metaphor Database eine weiteredeutschsprachige Ressource zur Metapherexistiert, diese jedoch nach wesentlich anderenGesichtspunkten erstellt wurde und lediglicheine kleine Zahl ausgewählter Beispielsätzeenthält.
Korpuserstellung
Grundlage für die Erstellung des Korpusbildet die Romansammlung der DigitalenBibliothek des Projektes TextGrid. Die Sammlungumfasst insgesamt 454 Werke vom frühen 16.bis zum frühen 20. Jahrhundert, wobei derBedarf nach orthographisch normalisiertemText die Datengrundlage auf 383 Romaneaus den Jahren 1830 bis 1940 eingeschränkthat. Zur Ziehung der zu annotierenden Sätzewird eine balancierte Sampling-Strategiehinsichtlich zeitlicher Streuung und Genderder AutorInnen eingesetzt. Es handelt sichdabei um eine Quotenstichprobe, die aus jedem10-Jahres-Abschnitt und zu gleichen Teilenmännlicher und weiblicher Autorinnen Sätzeauswählt. Darüber hinaus wird im Rahmendes Samplings eine automatische Vorauswahlgetroffen, sodass die Hälfte der Sätze Metaphernenthält. Möglich wird dies durch einenClassifier, der anhand von TF-IDF Scores – aufGrundlage einer lemmatisieren Version desgesamten Romankorpus – feststellen kannwie “ungewöhnlich” ein zu klassifizierenderSatz ist. Anhand eines empirisch festgestellten,von der Größe des TF-IDF Korpus abhängigen,Schwellenwerts ist es anschließend möglich,eine Vorauswahl zu treffen, die indirektMetaphorizität erfasst. Es handelt sich dabei umeine vereinfachte Form des von Schulder & Hovy
92

Digital Humanities im deutschsprachigen Raum 2017
(2014) entwickelten Klassifikationsansatzes.Ziel des hier entwickelten Korpus ist es, einenGesamtumfang von bis zu 2000 annotiertenSätzen zu erreichen. Als Grundlage dafürwurden insgesamt 3000 Sätze ausgewählt.
Annotation
Wir orientieren uns an der MetaphorIdentification Procedure (MIP) der PragglejazGroup (Pragglejaz Group 2007; Steen et al.2010) und sehen zunächst jedes Wort imText als potentielle Metapher. Gegenstandder Metaphernannotation ist es somit, jedesWort als metaphorisch beziehungsweise nichtmetaphorisch zu klassifizieren. Die Aufgabe istdabei auf metaphorische Äußerungen auf derWortebene beschränkt, das heißt Satzmetapherund Textmetapher sowie Phänomenegrammatischer Metapher sind ausgenommen.Aufgrund der Neigung des Deutschenzur Kompositabildung wird jedoch eineautomatische Kompositazerlegung durchgeführt.Da der Umfang der zu annotierenden Sätze eineHerausforderung für eine solche detallierteHerangehensweise wie das MIP darstellt, wirdeine automatische Vorselektion potentiellerMetaphernkandidaten durchgeführt.
Auf Grundlage von Part-of-Speech-Informationen und Dependency-Bäumen werden aus den Sätzen folgendeKonstruktionstypen als Kandidaten für einemetaphorische Verwendung extrahiert (zu denTypen vgl. Skirl und Schwarz-Friesel 2007):Substantivmetapher – dazu gehören Komposita,Kopulakonstruktionen ("X ist ein Y"), Simile ("Xist wie ein Y"), Genitivmetapher – sowie Verb-,Adjektiv-, Präpositions- und 'als'-Metapher. Wirfolgen mit diesem Ansatz der automatischenVorauswahl Gandy et al. (2013), die dadurchbei der Metaphernauszeichnung eineÜbereinstimmung der Annotatoren von Kappa =0.80 erreichen. Die extrahierten Konstruktionenwerden anschließend zusammen mit den Sätzenfür die Annotation in ein geeignetes Formatexportiert und in die AnnotationsumgebungWebAnno (Yimam et al. 2014) geladen.
Für den manuellen und bei weitemumfassendsten Teil der Arbeit wurde einAnnotationsleitfaden verfasst, der dieIdentifikationsstrategie MIP reproduziert,Hinweise zum Umgang mit lexikalisiertenmetaphorischen Ausdrücken und derAbgrenzung zur Metonymie enthält.Darüber hinaus ist dargestellt, welcheKonstruktionstypen vormarkiert werden undwelche Ausnahmen dabei zu erwarten sind
(Eigennamen und Hilfsverben sind von derMarkierung ausgenommen, vgl. Shutova undTeufel 2010). Schließlich wird festgelegt wiemit Ausnahmen und fehlerhaften Sätzen zuverfahren ist. Satzfragmente, starke dialektaleFormen sowie Sätze, die ohne Kontext nichtinterpretierbar sind, werden als Ausschussmarkiert, fehlerhafte Vormarkierungen werdengekennzeichnet und im Rahmen der Kurationder annotierten Sätze verbessert.
Ergebnis
Es kann von den folgenden vorläufigenErgebnissen der automatischen Vorauswahl undder manuellen Annotation berichtet werden:
Die automatische Extraktion der möglicherMetaphernkandidaten hat es ermöglicht, einkorpusgestütztes Bild darüber zu erlangenwie die Konstruktionen in einer relativoffenen Domäne – einem Romankorpus,das diverse Gattungen umfasst – verteiltsind. Des Weiteren ist ausgehend von derAnnotationspraxis festzustellen, dass dieerhobenen Konstruktionen – zumindestim Rahmen der hier zugrundeliegendenTexte – theoretisch alle Vorkommen vonmetaphorischen Äußerungen auf der Wortebeneabdecken. In der Praxis kommt es jedochaufgrund komplexer Hypotaxen und fehlenderautomatischer Koreferenz-Auflösung zufehlerhaften Vormarkierungen.
Die vorbereitende, automatischeKlassifikation der Sätze in Metapherbeziehungsweise Nicht-Metapher führt zueinem Anteil von 48% an Sätzen, die lebendigeMetaphern enthalten. Werden lexikalisiertemetaphorische Ausdrücke mit eingerechnet,steigt der Anteil der Sätze, die Metaphernenthalten, auf 61%. Ein erheblicher Vorteil,der sich aus der Klassifikation der Sätze ergibt,ist die Fülle des Materials, die sich dadurchgenerieren lässt. Ohne Vorauswahl liegt diedurchschnittliche Anzahl von metaphorischenAusdrücken pro Satz – je nach Textsorte –zwischen 0.12 und 0.54 (vgl. Shutova & Teufel2010), während mit dem hier vorgestelltenAnsatz ein Wert von 1.91 Metaphern pro Satzerreicht wird. Eine genaue Auswertung derPräzision des Classifiers steht noch aus, inBezug auf die Struktur der so ausgewähltenSätze kann jedoch festgestellt werden, dassdie Klassifizierung keine Auswirkung auf dieVerteilung der erhobenen Konstruktionstypenhat.
Für die Übereinstimmung zwischen zweiAnnotatoren beim Aufbau des hier vorgestellten
93

Digital Humanities im deutschsprachigen Raum 2017
Metaphernkorpus kann ein Wert von 0.87(Cohen’s Kappa) berichtet werden. Werdenlediglich die vormarkierten Konstruktionenals Grundlage der Berechnung herangezogen,schwankt Kappa je nach Einbezug lexikalisierterÄußerungen zwischen 0.77 bis 0.80.
Bibliographie
Gandy, Lisa / Allan, Nadji / Atallah,Mark / Frieder, Ophir / Howard, Newton /Kanareykin, Sergey / Koppel, Moshe / Last,Mark / Neuman, Yair / Argamon, Shlomo(2013): „Automatic identification of conceptualmetaphors with limited knowledge“, in:Proceedings of AAAI 2013.
Schulder, Marc / Hovy, Eduard (2014):„Metaphor detection through term relevance“,in: Proceedings of the Second Workshop onMetaphor in NLP.
Shutova, Ekaterina / Teufel, Simone (2010):„Metaphor corpus annotated for source - targetdomain mappings“, in: Proceedings of LREC 20103255–3261.
Shutova, Ekaterina (2015): „Design andEvaluation of Metaphor Processing Systems“, in:Computational Linguistics 41 (4): 579–623.
Skirl, Helge / Schwarz-Friesel, Monika(2007): Metapher. Universitätsverlag Winter.
Steen, Gerard J. / Dorst, Aletta G. /Herrmann, J. Berenike / Kaal, Anna A. /Krennmayr, Tina / Pasman, Trijntje (2010):A method for linguistic metaphor identification:From MIP to MIPVU. Amsterdam / Philadelphia:John Benjamins.
Yimam, Seid Muhie / Eckart de Castilho,Richard / Gurevych, Iryna / Biemann Chris(2014): „Automatic Annotation Suggestionsand Custom Annotation Layers in WebAnno“,in: Proceedings of ACL-2014, demo session,Baltimore, MD, USA.
Automatische Bild-Text-Analyse: Chancen für dieZeitschriftenforschungjenseits von reinenTextdaten
Rißler-Pipka, [email protected] Universität Eichstätt-Ingolstadt,Deutschland
Chandna, [email protected] Institute of Technology, Deutschland
Tonne, [email protected] Institute of Technology, Deutschland
Zeitschriften und multimodaleWahrnehmung
Gerade die Epoche der Moderne(1850-1945) geht mit einer Veränderung dermenschlichen Wahrnehmung einher, als mitden aufkommenden Avantgardebewegungen(sowie im Zuge der technischen, ökonomischenund sozialen Weiterentwicklung) weltweit dieAnzahl der Kulturzeitschriften explosionsartigsteigt. Nicht so sehr die vielzitierte technischeReproduzierbarkeit des Kunstwerks (Benjamin1935-39) zeugt von dieser Veränderung alsvielmehr die Fähigkeit zur multimodalenWahrnehmung, heraus gebildet durchdie dynamische Medienlandschaft zu derneben Photographie und Film vor allem dieZeitschriften gehören. Für Lateinamerikavergleicht Raquel Macciuci die Rezeption dermodernen Presse und Zeitschriften mit derNutzung digitaler Medien (Macciuci 2015: 209),während für den deutschsprachigen Raumgleich zwei Tagungen zu Zeitschriften derenMultimodalität auf der einen Seite („IllustrierteZeitschriften um 1900: Multimodalität undMetaisierung“, 2014) und die Funktionsweiseder visuellen Zeitschriftenkultur auf deranderen Seite („Deutsche illustrierte Magazine– Journalismus und visuelle Kultur in derWeimarer Republik“, 2013) beleuchten.
94

Digital Humanities im deutschsprachigen Raum 2017
Das Desiderat der Forschung wird in dieserBeziehung schon 2010 von Frank et al. genaubestimmt:
So wissen wir inzwischen relativ gut darüberBescheid, welche und wie viele einschlägigeZeitschriften es gab und gibt; weniger schon,wer darin worüber aus welcher Perspektiveund mit welcher Stoßrichtung geschriebenhat; kaum mehr zuletzt aber, welcheGestaltung die Zeitschriften prägte undwelcher Stellenwert dergleichen Publizistikzukam. (Frank et al.: 2010, 10)
Es geht auch hier in der Literatur- undKulturwissenschaft vor allem um Zahlen,Metadaten und eine Möglichkeit die „Gestaltung“der Zeitschriften quantitativ zu ermessen.Genau diese Felder sind prädestiniert für dieZusammenarbeit mit den DH.
Wenn wir für mehr als 200 Zeitschriftentitelsagen könnten, wie das quantitative Bild-Text-Verhältnis ist und Metadaten dazu vergleichenkönnten, wie z.B. die programmatischeAusrichtung des Titels, die Zielgruppe, dieAkteure, der Standort und Verbreitungsgrad,dann ließen sich die von Frank et al. gestelltenFragen beantworten. In einer verfeinertenAnalyse der Gestaltung kann überprüft werden,ob progressives, avantgardistisches Layout(gekennzeichnet durch viel Leerraum, reduzierteOrnamente, klare Schrifttypen) mit denentsprechend programmatisch eingeordnetenTiteln übereinstimmt.
Automatische Bild-Text-Erkennung: ein Versuch mitSWATI
Am konkreten Beispiel mit Daten aus demProjekt Revistas culturales 2.0 (UniversitätAugsburg) wurde vor dem Hintergrund diesesDesiderats der Versuch einer automatischenBild-Text-Erkennung anhand von zunächst 69Beispielseiten eines Heftes der argentinischenKulturzeitschrift „El Hogar“ (Dec. 1919)unternommen. Während im Projekt dieMetadaten der Zeitschriften bereits mit digitalenTools zur Netzwerkvisualisierung (Ehrlicher /Herzgsell 2016) oder zur Zeit/Ort-Visualisierungmit dem DARIAH-DE Geo-Browser (http://geobrowser.de.dariah.eu/storage/199501) fürÜberblicksdarstellungen analysiert wurden,fehlte nach wie vor die Möglichkeit einerquantitativen Bild-Text-Analyse, die Gestaltungder Zeitschriften entsprechend.
Der technische Ansatz zur Durchführungeiner solchen quantitativen Bild-Text-Analysebasiert auf den Entwicklungen des eCodicologyProjektes, in dem die Digitalisate des „VirtuellenSkriptoriums St. Matthias“ automatischausgewertet und die so erfassten Merkmalein den beschreibenden Metadaten abgelegtund anschließend visualisiert wurden. Auchaus informationstechnologischer Sicht stelltsich die Frage, ob die für mittelalterlicheHandschriften verwendeten Verfahren undAlgorithmen generisch einsatzbar sind undPotential für alternative Anwendungsfelder,hier am Beispiel spanischsprachiger Magazineuntersucht, besitzen. Die Exploration vonErweiterungsmöglichkeiten verspricht ebenfallszusätzlichen Erkenntnisgewinn für allebeteiligten Disziplinen.
Zur Extraktion der Merkmale wird der SWATIWorkflow (Software Workflow for the AutomaticTagging of Medieval Manuscript Images) genutzt(Chandna et al. 2015). Andere bestehendeMethoden zur Image Document Analysis führtennicht zum erwarteten Resultat, da sie nur aufspezielle und kleine Datensätze angewendetwerden können (vgl. DIVAServices-Spotlight).Hier wurde der SWATI-Workflow speziell an dieheterogene Layout-Struktur der Zeitschriftenangepasst.
Als Basis der Untersuchung wurden auf denDigitalisaten der spanischsprachigen Magazinedie Seitengröße sowie der Text- und Bildraumvermessen und jeweils die Fläche, Breite, Höhe,Koordinaten der linken oberen Ecke sowie derNeigungswinkel bestimmt.
Da auf einer Seite mehrere Text- und/oderBildbereiche wie beispielsweise Überschriften,Haupttext, Notizen, Initialen, Zeichnungenoder Glossen auftreten können, werden diegenannten Werte für jeden Bereich einzelnermittelt und gespeichert. Zusätzlich werdendie Werte auch als relative Angaben in Prozentunabhängig von der Einheit der Messungenaufgeführt, um die Übertragbarkeit beiunterschiedlichen Auflösungen der Digitalisatezu gewährleisten.
Im Bildbeispiel sind die Ergebnisse derjeweiligen automatischen Bild-Text-Erkennungzu erkennen: Originalbild (links) sowiesegmentierte Bild- (Mitte) bzw. Textbereiche(rechts). Zusätzlich wird zur Vermessung desSeitenbereiches jeweils eine Segmentierung derSeite durchgeführt (hier nicht dargestellt)
95

Digital Humanities im deutschsprachigen Raum 2017
Abbildung 1: Originalseite „El Hogar“
Abbildung 2: Bilderkennung
Abbildung 3: Texterkennung
Abbildung 4: Originalseite “El Hogar”
96

Digital Humanities im deutschsprachigen Raum 2017
Abbildung 5: Bilderkennung
Abbildung 6: Texterkennung
Wie man an diesen beiden Beispielseitender Zeitschrift „El Hogar“ (Dec. 1919) erkennt,
funktioniert die Bild- und Texterkennungsehr zuverlässig auch bei komplexeren Bild-Text-Gefügen, wie z.B. in Werbeanzeigen.Größere ins Bild integrierte Schriften,z.B. die Werbeüberschrift in Abb. 1 oder 4wird als Teil des Bildes erkannt. Das ist ausgestaltungsanalytischer Sicht auch nicht falsch,hat die Werbeüberschrift doch gleichzeitig Bild-und Textfunktion.
Ein anderes Problem ist die Zuordnungkleinerer Bild- oder Textflächen zu einer Einheit,z.B. gehört in Abb. 4-5 der Schriftblock amunteren rechten Bildrand zum Werbebildund gibt dem zentral stehenden Text eineRahmung. Als Messergebnis erscheinen aberzwei verschieden große, unabhängige Text- bzw.Bildbereiche.
Die eigentliche Analyse der gewonnenenMetadaten (Messdaten) ist dann für alleBeteiligten eine erneute Herausforderung, kannaber genau das oben beschriebene Problem derZuordnung semantisch zusammenhängenderText- und Bildbereiche lösen. Durch eineFiltereinstellung werden bei mehr als 10erkannten Text/Bildbereichen nur die 10 größtenausgewählt. Diese Selektion vermindert denEinfluss von Messartefakten und erleichtert diestatistische Auswertung der Daten sowie derenVisualisierung. Auch dieser Bereich wurde imZusammenhang des eCodicology Projekts bereitsfür das Korpus mittelalterlicher Handschriftenerprobt (Chandna et al. 2016) und konnte auf dasvorliegende Fallbeispiel übertragen werden.
Abbildung 7: Visualisierung der 69Beispielseiten, hier nur Textbereiche
97
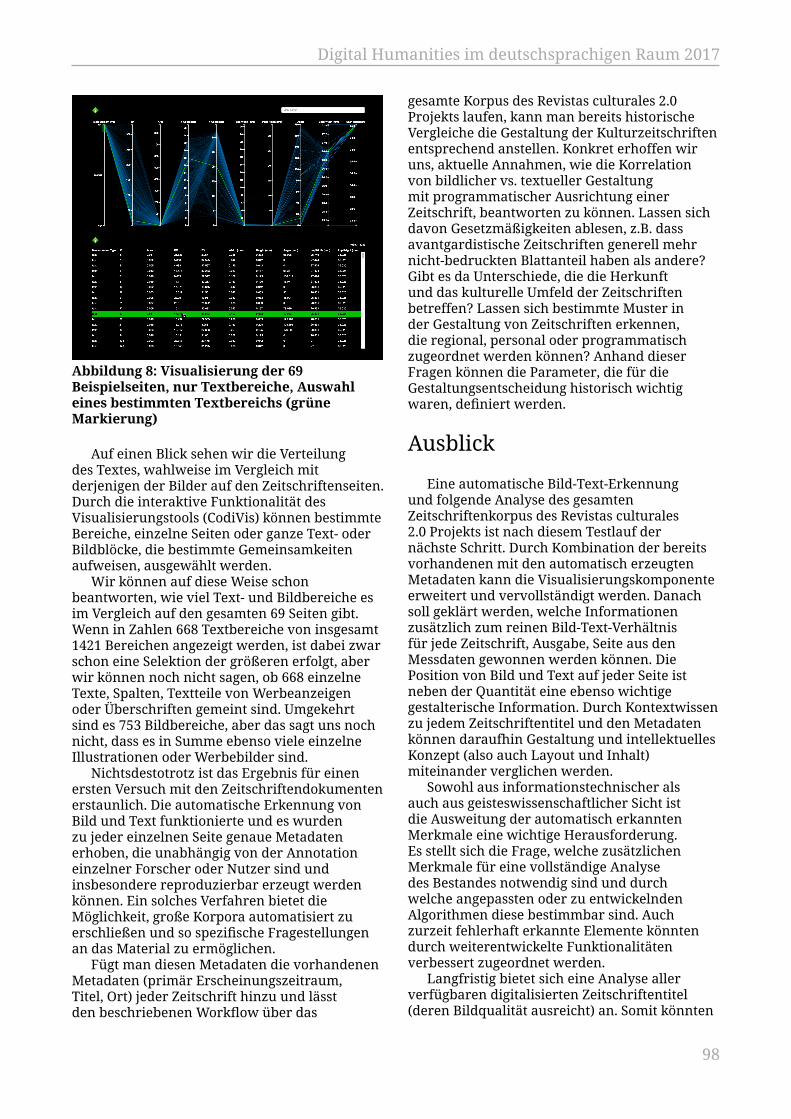
Digital Humanities im deutschsprachigen Raum 2017
Abbildung 8: Visualisierung der 69Beispielseiten, nur Textbereiche, Auswahleines bestimmten Textbereichs (grüneMarkierung)
Auf einen Blick sehen wir die Verteilungdes Textes, wahlweise im Vergleich mitderjenigen der Bilder auf den Zeitschriftenseiten.Durch die interaktive Funktionalität desVisualisierungstools (CodiVis) können bestimmteBereiche, einzelne Seiten oder ganze Text- oderBildblöcke, die bestimmte Gemeinsamkeitenaufweisen, ausgewählt werden.
Wir können auf diese Weise schonbeantworten, wie viel Text- und Bildbereiche esim Vergleich auf den gesamten 69 Seiten gibt.Wenn in Zahlen 668 Textbereiche von insgesamt1421 Bereichen angezeigt werden, ist dabei zwarschon eine Selektion der größeren erfolgt, aberwir können noch nicht sagen, ob 668 einzelneTexte, Spalten, Textteile von Werbeanzeigenoder Überschriften gemeint sind. Umgekehrtsind es 753 Bildbereiche, aber das sagt uns nochnicht, dass es in Summe ebenso viele einzelneIllustrationen oder Werbebilder sind.
Nichtsdestotrotz ist das Ergebnis für einenersten Versuch mit den Zeitschriftendokumentenerstaunlich. Die automatische Erkennung vonBild und Text funktionierte und es wurdenzu jeder einzelnen Seite genaue Metadatenerhoben, die unabhängig von der Annotationeinzelner Forscher oder Nutzer sind undinsbesondere reproduzierbar erzeugt werdenkönnen. Ein solches Verfahren bietet dieMöglichkeit, große Korpora automatisiert zuerschließen und so spezifische Fragestellungenan das Material zu ermöglichen.
Fügt man diesen Metadaten die vorhandenenMetadaten (primär Erscheinungszeitraum,Titel, Ort) jeder Zeitschrift hinzu und lässtden beschriebenen Workflow über das
gesamte Korpus des Revistas culturales 2.0Projekts laufen, kann man bereits historischeVergleiche die Gestaltung der Kulturzeitschriftenentsprechend anstellen. Konkret erhoffen wiruns, aktuelle Annahmen, wie die Korrelationvon bildlicher vs. textueller Gestaltungmit programmatischer Ausrichtung einerZeitschrift, beantworten zu können. Lassen sichdavon Gesetzmäßigkeiten ablesen, z.B. dassavantgardistische Zeitschriften generell mehrnicht-bedruckten Blattanteil haben als andere?Gibt es da Unterschiede, die die Herkunftund das kulturelle Umfeld der Zeitschriftenbetreffen? Lassen sich bestimmte Muster inder Gestaltung von Zeitschriften erkennen,die regional, personal oder programmatischzugeordnet werden können? Anhand dieserFragen können die Parameter, die für dieGestaltungsentscheidung historisch wichtigwaren, definiert werden.
Ausblick
Eine automatische Bild-Text-Erkennungund folgende Analyse des gesamtenZeitschriftenkorpus des Revistas culturales2.0 Projekts ist nach diesem Testlauf dernächste Schritt. Durch Kombination der bereitsvorhandenen mit den automatisch erzeugtenMetadaten kann die Visualisierungskomponenteerweitert und vervollständigt werden. Danachsoll geklärt werden, welche Informationenzusätzlich zum reinen Bild-Text-Verhältnisfür jede Zeitschrift, Ausgabe, Seite aus denMessdaten gewonnen werden können. DiePosition von Bild und Text auf jeder Seite istneben der Quantität eine ebenso wichtigegestalterische Information. Durch Kontextwissenzu jedem Zeitschriftentitel und den Metadatenkönnen daraufhin Gestaltung und intellektuellesKonzept (also auch Layout und Inhalt)miteinander verglichen werden.
Sowohl aus informationstechnischer alsauch aus geisteswissenschaftlicher Sicht istdie Ausweitung der automatisch erkanntenMerkmale eine wichtige Herausforderung.Es stellt sich die Frage, welche zusätzlichenMerkmale für eine vollständige Analysedes Bestandes notwendig sind und durchwelche angepassten oder zu entwickelndenAlgorithmen diese bestimmbar sind. Auchzurzeit fehlerhaft erkannte Elemente könntendurch weiterentwickelte Funktionalitätenverbessert zugeordnet werden.
Langfristig bietet sich eine Analyse allerverfügbaren digitalisierten Zeitschriftentitel(deren Bildqualität ausreicht) an. Somit könnten
98

Digital Humanities im deutschsprachigen Raum 2017
nicht nur transatlantisch spanischsprachigeKulturzeitschriften verglichen werden, sondernauch die internationale Szene modernistischerZeitschriften (vgl. Blue Mountain Project) oderdeutschsprachige illustrierte Magazine (vgl.Projekt: “illustrierte Magazine”).
Bibliographie
AsymEnc: http://asymenc.wp.hum.uu.nl[letzter Zugriff 20. November 2016].
Benjamin, Walter (1935-39): „DasKunstwerk im Zeitalter seiner technischenReproduzierbarkeit“ in: Tiedemann, Rolf (ed.):Walter Benjamin. Gesammelte Schriften 1 (2).Frankfurt am Main: Suhrkamp, 1980, 471–508.
DIVAServices-Spotlight: http://wuersch.pillo-srv.ch/#/ [letzter Zugriff 22. November 2016].
Chandna, Swati / Tonne, Danah / Stotzka,Rainer / Busch, Hannah / Vanscheidt, Philipp /Krause, Celia (2016): „An Effective VisualizationTechnique for Determining Co-Relations inHigh-Dimensional Medieval Manuscripts Data“,in: Visualization and Data Analysis 2016, SanFrancisco, California, USA, 14.–18. Februar,1–6 http://ist.publisher.ingentaconnect.com/contentone/ist/ei/2016/00002016/00000001/art00013
Chandna Swati / Tonne, Danah / Jejkal,Thomas / Stotzka, Rainer / Krause, Celia /Vanscheidt, Philipp / Busch, Hannah /Prabhune, Ajinkya (2015): „Softwareworkflow for the automatic tagging of medievalmanuscript images (SWATI)“, in: Ringger, EricK. / Lamiroy, Bart (eds.): Proceedings SPIE9492,Document Recognition and Retrieval XXII, 940201(8. Februar 2015), San Francisco.
Chinese Women's Magazines: http://kjc-sv013.kjc.uni-heidelberg.de/frauenzeitschriften/index.php [letzter Zugriff 20. November 2016].
Chinesische Unterhaltungspresse: http://projects.zo.uni-heidelberg.de/xiaobao/index.php?p=start [letzter Zugriff 20. November 2016].
Die Fackel, Austrian Academy Corpus:http://corpus1.aac.ac.at/fackel [letzter Zugriff 20.November 2016].
eCodicology Projekt: http://www.ecodicology.org [letzter Zugriff 20.November 2016].
Ehrlicher, Hanno / Herzgsell, Teresa (2016):„Zeitschriften Als Netzwerke Und Ihre DigitaleVisualisierung: Grundlegende MethodologischeÜberlegungen Und Erste Anwendungsbeispiele“,in: Revistas Culturales 2.0. http://www.revistas-culturales.de/de/buchseite/hanno-ehrlicher-teresa-herzgsell-zeitschriften-als-netzwerke-und-ihre-digitale [letzter Zugriff 20. November 2016].
ESPrit: http://www.espr-it.eu [letzter Zugriff20. November 2016].
Europeana Newspapers: http://www.europeana-newspapers.eu [letzter Zugriff20. November 2016].
illustrierte magazine: http://magazine.illustrierte-presse.de [letzter Zugriff20. November 2016].
Frank, Gustav / Podewski, Madleen /Scherer, Stefan (2010): „Kultur – Zeit – Schrift.Literatur- und Kulturzeitschriften als ‚kleineArchive‘“, in: Internationales Archiv fürSozialgeschichte der deutschen Literatur (IASL)34 (2): 1–45.
Macciuci, Raquel (2015): „T ecnica, soporte,ambitos de sociabilidad y mecanismos delegitimaci on: sobre la construcci on de espaciosde literatura en la prensa peri odica“, in:Schlünder, Susanne / Macciuci, Raquel (eds.):Literatura y técnica: derivas ficcionales ymateriales: Libros, escritores, textos, frente a lamáquina y la ciencia. Actas del VIII CongresoOrbis Tertius. La Plata: Ediciones del lado de acá205–231.
Revistas culturales 2.0: VirtuelleForschungsumgebung zur Erforschungspanischsprachiger Kulturzeitschriften derModerne (2014–2016): Universität Augsburg.2014-2016. http://www.revistas-culturales.de[letzter Zugriff 20. November 2016].
Rißler-Pipka, Nanette (2014): „SobreLos Problemas de Investigación ConRevistas Culturales Digitalizadas Del MundoHispanohablante“, in: Rißler-Pipka, Nanette /Ehrlicher, Hanno (eds.): Almacenes de un tiempoen fuga: Revistas culturales en la modernidadhispánica. Aachen: Shaker 59–80.
Virtuelles Skriptoriums St. Matthias:http://stmatthias.uni-trier.de [letzter Zugriff 20.November 2016].
WeChangEd: http://www.wechanged.ugent.be[letzter Zugriff 20. November 2016].
Yang, Tze-I / Torget, Andrew / Mihalcea,Rada (2011): „Topic Modeling on HistoricalNewspapers“, in: Workshop on LanguageTechnology for Cultural Heritage, SocialSciences, and Humanities LaTeCH, 24. Juni2011 Portland, Oregon, USA, Proceedings ofthe Workshop, Association for ComputationalLinguistics, Stroudsburg, USA, 96–104. https://www.aclweb.org/anthology/W/W11/W11-15.pdf[letzter Zugriff 20. November 2016].
ZEFYS: http://zefys.staatsbibliothek-berlin.de[letzter Zugriff 20. November 2016].
99

Digital Humanities im deutschsprachigen Raum 2017
Autorschaftsattributionbei nicht-normalisiertemMittelhochdeutsch.BessereErkennungsquotendurch einNormalisierungswörterbuch
Dimpel, Friedrich [email protected] Erlangen-Nürnberg, Deutschland
Einleitung: Delta imMittelalter und in derForschung
Im Bereich der Autorschaftsattributionsind in den letzten Jahren große Fortschritteerzielt worden; insbesondere der Delta-Test nach Burrows’ (2002) und Variantenzu Burrows’ Verfahren haben sich in vielenValidierungsstudien als sehr erfolgreicherwiesen (Hoover 2004, Eder / Rybicki 2011,Eder 2013a, Eder 2013b, Jannidis / Lauer 2014,Evert / Proisl / Jannidis / Pielström / Schöch / Vitt2015, Evert / Proisl / Jannidis / Pielström / Reger/Schöch / Vitt 2016). In mittelalterlichen Textenstellen sich jedoch besondere Probleme: Hierist die Schreibung weitgehend nicht normiert,das Wort ‚und‘ wird teilweise mit ‚u‘ oder ‚v‘,mit weichem ‚d‘ oder hartem ‚t‘ geschrieben; dieGenitiv-Form zum nhd. Wort ‚Gott‘ lautet ‚gotes‘oder ‚gotis‘ (Viehhauser 2015).
Im Rahmen eines Vortrags auf der DHd-Tagung 2016 in Leipzig konnte ich zeigen(Dimpel 2016), dass Delta bei normalisiertenmittelhochdeutschen Texten sehr gutfunktioniert, insbesondere dann, wenn Texteverwendet werden, die aus mindestens5.000 Wörtern bestehen, und wenn die Bag-of-Words-Technik (vgl. Eder 2013b) zumEinsatz kommt. Um die Erkennungsquotezu ermitteln, habe ich ein „Ratekorpus“und ein „Validierungskorpus“ gebildet. Inbeiden Sammlungen sind Texte mit bekannterAutorschaft enthalten. Zu jedem Autor, der imRatekorpus enthalten ist, ist jeweils ein Textdes gleichen Autors im Validierungskorpus
enthalten. Ermittelt wurde der Prozentsatz derrichtig erkannten Autoren. Bei einem Test mit 16Texten im Validierungskorpus und 15 Texten imRatekorpus wurde eine Erkennungsquote von97,1% ermittelt.
Erster Validierungstest nicht-normalisierte Texte
Zu nicht-normalisierten Texten habe ich2016 erste Zahlen ebenfalls mit positivemErgebnis vorlegen können, die allerdings nichtvalide sind, weil mir zu diesem Zeitpunktnur sehr wenige nicht-normalisierte Textedigital verfügbar waren: bei einer Textlängevon 5.000 Wörtern konnte ich gegen einValidierungskorpus mit 14 Texten nur 6 Textevon 5 Autoren prüfen. Nunmehr liegen weitereTexte vor, so dass für einen Validierungstest nunein Ratekorpus mit 15 Texten von 10 Autoren zurVerfügung steht. Im Validierungskorpus ist je einText dieser 10 Autoren enthalten, dazu kommenweitere 10 Texte, die Fehlattributionen auslösenkönnten.
Dass Delta bei nicht-normalisierten Textenschlechtere Erkennungsquoten liefert, istdeshalb zu erwarten, weil Delta auf derVerteilung von hochfrequenten Wörtern beruht.Wenn im Werk X überwiegend ‚unt‘ steht, wennsich im Werk Y des gleichen Autors jedoch derAbschreiber für die Graphie ‚vnnd‘ entschiedenhat, wird die Zuordnung des richtigen Autorsdadurch erschwert. Erwartungsgemäß liegt dieErkennungsquote mit ca. 80% (bei Bag-of-Wordsmit 5.000 Wörtern; 50 Iterationen zum Ausgleichvon Zufallsschwankungen bei der Bag-of-Words-Bildung; davon der Mittelwert für die Vektoren200, 400, 600 und 800) deutlich unter der Quotefür normalisierte Texte. Um eine Verbesserungder Erkennungsquote zu ermöglich, wurden nunAnsätze zur automatischen Teilnormalisierungerprobt.
Teilnormalisierung:Normalisierungswörterbuchund Vollformenwörterbuch
Ein erster Schritt dabei ist die Eliminierungder Sonderzeichen und der deutschen Umlaute– auch in dem soeben erwähnten Test war dieseBereinigung bereits implementiert. Eine weitereautomatische Teilnormalisierung ist deshalbökonomisch realisierbar, weil für den Delta-Testkeine vollständige Normalisierung nötig ist. Weil
100

Digital Humanities im deutschsprachigen Raum 2017
Delta auf den hochfrequenten Wörtern beruht,sollte bereits eine Normalisierung der häufigenWörter zu einer Verbesserung führen.
In einem nächsten Schritt wurde ein Skriptentwickelt, das aus einigen kürzeren nicht-normalisierten Texten die hochfrequentenWortformen heraussucht und den User bittet,die normalisierte Form zuzuordnen. EineVorschlagsliste aus einem normalisiertenLachmann-Korpus, die mittels Levenshtein-Distanz generiert wurde, hat meiner Hilfskraftdas Leben leichter gemacht. Zudem habeich zwei Datengeschenke bekommen: SonjaGlauch hat mir Daten aus dem Projekt„Lyrik des Mittelalters“ gegeben, das eineZuordnung von normalisierten zu nicht-normalisierten Wortformen herstellt. Mit denSkript-Daten und den Lyrik-Projekt-Daten lagein Normalisierungswörterbuch mit gut 1.100Zuordnungen vor, als mir Thomas Klein Datenaus dem Referenzkorpus Mittelhochdeutschüberlassen hat. Die vorbildliche Struktur desReferenzkorpus hat es möglich gemacht, weitereZuordnungen zu extrahieren und sie in dasNormalisierungswörterbuch einspeisen, dasnunmehr gut 120.000 Zuordnungen enthält.
Eine Sichtung desNormalisierungswörterbuchs hat jedoch gezeigt,dass teilweise auch solche diplomatischeWortformen wie ‚sluc‘ zu ‚sluoc‘ normalisiertwerden, die eigentlich auch selbst alsnormalisierte Form eines anderen Lemmasstehen könnten: ‚sluc‘ kann als starkesFemininum etwa nhd. „ein Schluck“ heißenund müsste dann nicht durch eine anderenormalisierte Form ersetzt werden. Mitunterwurde im Lyrikprojekt und im ReM unerwartetnormalisiert: So findet sich bspw. eineNormalisierung der Wortform ‚chunich‘ zu‚küninc‘, während im BMZ und im Lachmann-Parzival meist ‚künec‘ steht.
Um das Normalisierungswörterbuchzu überprüfen und vereinheitlichen zukönnen, wurde ein mittelhochdeutschesVollformenwörterbuch benötigt, das dieWortformen enthält, die zu normalisiertenLemmata durch Flexion gebildet werdenkönnen.
Aus der CD „MittelhochdeutscheWörterbücher im Verbund“ (Trier,Kompetenzzentrum für elektronischeErschließungs- und Publikationsverfahrenin den Geisteswissenschaften 2002) wurdenDaten extrahiert und mögliche Flexionsformenzu den Lemmata generiert. Wenn es aufVollständigkeit und Korrektheit ankommenwürde, wäre die Erstellung eines derartigenVollformenwörterbuchs eine große
Herausforderung. Doch geht es sowohl beidem Normalisierungswörterbuch als auchbei dem Vollformenwörterbuch hier nurdarum, eine prozentuale Verbesserung derDelta-Erkennungsquote zu erreichen. Fehlerbei seltenen Wortformen sind bei Deltameist zu vernachlässigen, wichtig ist eineVereinheitlichung der häufigen Wörter. MancheProbleme haben sich überwiegend erfreulichlösen lassen: Zu Ablaut und grammatischemWechsel sind Informationen BMZ hinterlegt.Schwache Verben mit sogenanntem Rückumlautgeneriert das Skript dann, wenn im SingularPräsens ein umgelauteter Vokal sowiePositionslänge oder Naturlänge vorliegen. In derverfügbaren Zeit wurde Vieles nicht vollständiggelöst – für Nomina mit Umlaut müssten imArtikel noch die Belegstellen examiniert werden,hier wird bislang nur der Artikelkopf des Lexerausgewertet. Funktionswörter sind überwiegendlistenbasiert ergänzt.
Eine Evaluierung hat gezeigt, dasseine vollständige Bereinigung desNormalisierungswörterbuchs um Formen wie‚sluc‘ zu einer minimalen Verschlechterung derErkennungsquote führt, so dass die Eliminierungvon diplomatischen Wortformen, die auchnormalisierte Wortformen sein könnten, beihoch- und mittelfrequenten Wortformen nichtangewendet wurde.
Delta-Verbesserung: Z-Wert-Begrenzung
Bei Delta berechnet man bspw. für 200Most-Frequent-Words für jedes dieser Worteeinzeln Z-Werte, in die die Abweichung derHäufigkeit eines Wortes in einem Text zurHäufigkeit dieses Wortes im Gesamtkorpus unterBerücksichtigung der Standardabweichungeingeht. Delta ist das arithmetische Mittelder positiven Z-Wert-Differenzen (Burrows2002). Evert / Proisl / Jannidis / Pielström /Reger/ Schöch / Vitt 2016 haben meinenVerdacht evaluiert, dass Delta wenigeraufgrund einzelner Extremwerte funktioniert(Ausreißerhypothese), sondern eher aufgrundeiner breiten autorspezifischen Verteilung der Z-Werte (Schlüsselprofilhypothese).
Fehlt eine Wortform in einem Text, kanndies mitunter mit erhöhten negativen Z-Werten einhergehen. Evert et alia habenbesonders hohe Z-Werte auf einen Maximalwertbegrenzt, so dass „Ausreißer“ nur abgemilderteingehen. Wenn der Erfolg von Delta den„Ausreißern“ zu verdanken wäre, hätte sich die
101
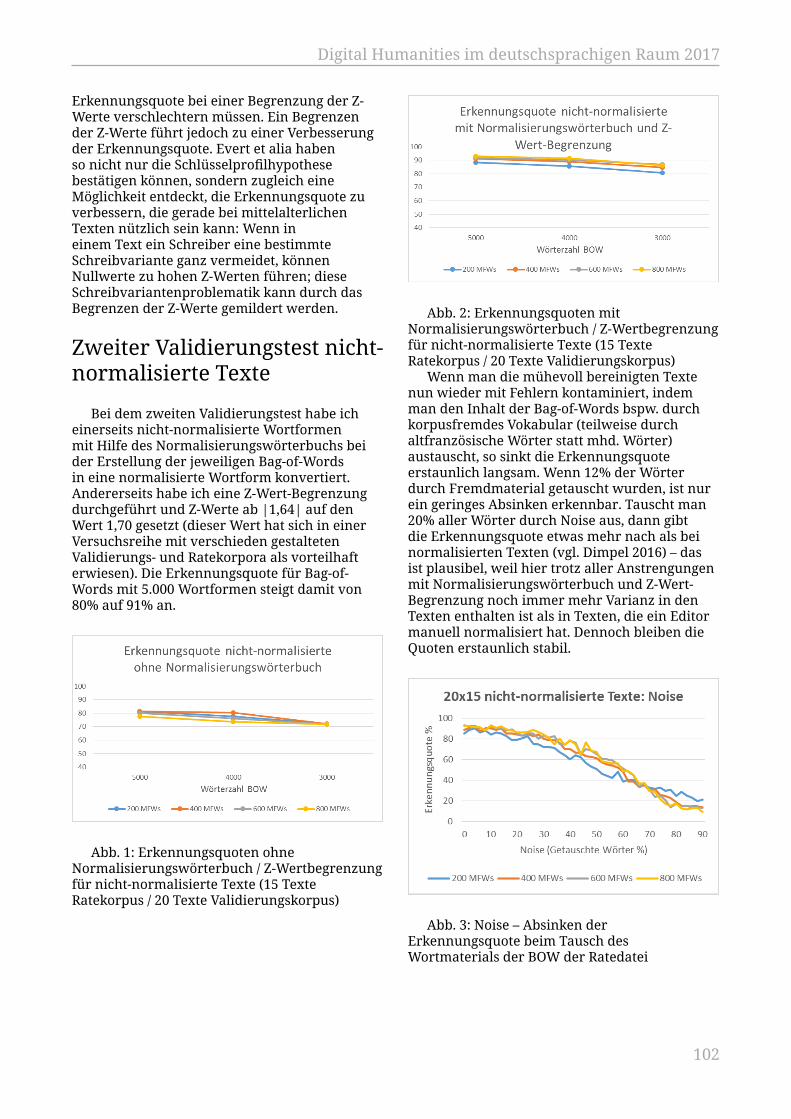
Digital Humanities im deutschsprachigen Raum 2017
Erkennungsquote bei einer Begrenzung der Z-Werte verschlechtern müssen. Ein Begrenzender Z-Werte führt jedoch zu einer Verbesserungder Erkennungsquote. Evert et alia habenso nicht nur die Schlüsselprofilhypothesebestätigen können, sondern zugleich eineMöglichkeit entdeckt, die Erkennungsquote zuverbessern, die gerade bei mittelalterlichenTexten nützlich sein kann: Wenn ineinem Text ein Schreiber eine bestimmteSchreibvariante ganz vermeidet, könnenNullwerte zu hohen Z-Werten führen; dieseSchreibvariantenproblematik kann durch dasBegrenzen der Z-Werte gemildert werden.
Zweiter Validierungstest nicht-normalisierte Texte
Bei dem zweiten Validierungstest habe icheinerseits nicht-normalisierte Wortformenmit Hilfe des Normalisierungswörterbuchs beider Erstellung der jeweiligen Bag-of-Wordsin eine normalisierte Wortform konvertiert.Andererseits habe ich eine Z-Wert-Begrenzungdurchgeführt und Z-Werte ab |1,64| auf denWert 1,70 gesetzt (dieser Wert hat sich in einerVersuchsreihe mit verschieden gestaltetenValidierungs- und Ratekorpora als vorteilhafterwiesen). Die Erkennungsquote für Bag-of-Words mit 5.000 Wortformen steigt damit von80% auf 91% an.
Abb. 1: Erkennungsquoten ohneNormalisierungswörterbuch / Z-Wertbegrenzungfür nicht-normalisierte Texte (15 TexteRatekorpus / 20 Texte Validierungskorpus)
Abb. 2: Erkennungsquoten mitNormalisierungswörterbuch / Z-Wertbegrenzungfür nicht-normalisierte Texte (15 TexteRatekorpus / 20 Texte Validierungskorpus)
Wenn man die mühevoll bereinigten Textenun wieder mit Fehlern kontaminiert, indemman den Inhalt der Bag-of-Words bspw. durchkorpusfremdes Vokabular (teilweise durchaltfranzösische Wörter statt mhd. Wörter)austauscht, so sinkt die Erkennungsquoteerstaunlich langsam. Wenn 12% der Wörterdurch Fremdmaterial getauscht wurden, ist nurein geringes Absinken erkennbar. Tauscht man20% aller Wörter durch Noise aus, dann gibtdie Erkennungsquote etwas mehr nach als beinormalisierten Texten (vgl. Dimpel 2016) – dasist plausibel, weil hier trotz aller Anstrengungenmit Normalisierungswörterbuch und Z-Wert-Begrenzung noch immer mehr Varianz in denTexten enthalten ist als in Texten, die ein Editormanuell normalisiert hat. Dennoch bleiben dieQuoten erstaunlich stabil.
Abb. 3: Noise – Absinken derErkennungsquote beim Tausch desWortmaterials der BOW der Ratedatei
102

Digital Humanities im deutschsprachigen Raum 2017
Abb. 4: Noise – Ausschnittvergrößerung 0-30% Noise
Bibliographie
Burrows, John (2002): „‚Delta‘: A Measureof Stylistic Difference and a Guide to LikelyAuthorship“, in: Literary and LinguisticComputing 17 (3): 267–87 10.1093/llc/17.3.267.
Dimpel, Friedrich Michael (2016): „Burrows’Delta im Mittelalter: Wilde Graphien undmetrische Analysedaten“, in: DHd 2016:Modellierung - Vernetzung - Visualisierung 65–70.
Eder, Maciej (2013a): „Mind Your Corpus:systematic errors in authorship attribution“, in:Literary and Linguistic Computing 28: 603–61410.1093/llc/fqt039.
Eder, Maciej (2013b): „Does size matter?Authorship attribution, small samples, bigproblem“, in: Literary and Linguistic ComputingAdvanced Access 29: 1–16 10.1093/llc/fqt066.
Eder, Maciej / Rybicki, Jan (2011): „DeeperDelta across genres and languages: do we reallyneed the most frequent words?“, in: Literary andLinguistic Computing 26 (3): 315–321 10.1093/llc/fqr031 .
Evert, Stefan / Proisl, Thomas / Jannidis,Fotis / Pielström, Steffen / Schöch, Christof /Vitt, Thorsten (2015): „Towards a betterunderstanding of Burrows’s Delta in literaryauthorship attribution“, in: Proceedings of theFourth Workshop on Computational Linguisticsfor Literature. Denver, CO: Association forComputational Linguistics, 79–88 10.5281/zenodo.18177 http://www.aclweb.org/anthology/W/W15/W15-0709.pdf [letzter Zugriff 20. August2015].
Evert, Stefan / Proisl, Thomas / Jannidis,Fotis / Pielström, Steffen / Reger, Isabella/Schöch, Christof / Vitt, Thorsten (2016):„Burrows Delta verstehen“, in: DHd 2016:Modellierung - Vernetzung - Visualisierung 61–65.
Hoover, David L. (2004): „Delta Prime?“, in:Literary and Linguistic Computing 19 (4): 477–49510.1093/llc/19.4.477 .
Jannidis, Fotis / Lauer, Gerhard (2014).„Burrows’s Delta and Its Use in German LiteraryHistory“, in: Erlin, Matt / Tatlock, Lynne (eds.):Distant Readings: Topologies of German Culturein the Long Nineteenth Century. New York: 29–54.
Jannidis, Fotis / Pielström, Steffen / Schöch,Christof / Vitt, Thorsten (2015): „ImprovingBurrows’ Delta - An Empirical Evaluation of TextDistance Measures“, in: DH2015: Global DigitalHumanities http://dh2015.org/abstracts/xml/JANNIDIS_Fotis_Improving_Burrows__Delta___An_empi/JANNIDIS_Fotis_Improving_Burrows__Delta___An_empirical_.html
Viehhauser, Gabriel (2015): „HistorischeStilometrie? Methodische Vorschläge für eineAnnäherung textanalytischer Zugänge an diemediävistische Textualitätsdebatte“, in: Baum,Constanze / Stäcker, Thomas (eds.): Grenzenund Möglichkeiten der Digital Humanities.Sonderband ZfdG 1.
Bild, Beschreibung,(Meta)Text Automatischeinhaltliche Erschließungund Annotationkunsthistorischer Daten
Dieckmann, [email protected]ät zu Köln, Deutschland
Hermes, Jü[email protected]ät zu Köln, Deutschland
Neuefeind, [email protected]ät zu Köln, Deutschland
Der Vortrag thematisiert die automatischeinhaltliche Erschließung und linguistischeAnnotation der digitalen Repräsentationen kunst- und kulturhistorischer Artefakteinnerhalb des prometheus Bildarchivs( http://prometheus-bildarchiv.de ), dasderzeit 89 Datenbanken aus Museen undForschungsinstitutionen mit insgesamtüber 1,5 Mio. Datensätzen zusammenführt
103

Digital Humanities im deutschsprachigen Raum 2017
(Dieckmann 2015). Das durch eine bereitsabgeschlossene Vorstudie initiierte Projektverfolgt zwei unterschiedliche, teilweiseaufeinander aufbauende Ansätze: Zumeinen die Annotation von Freitexten zurstrukturierten Erschließung kunsthistorischerDaten, zum anderen die Analyse der Identitätvon Datensätzen über die Berechnunggradueller Ähnlichkeiten von Objekten. BeideAnsätze dienen erstens einer Verbesserungdes Retrievals, zweitens einer nachhaltigenSicherung der Daten durch die Verknüpfungmit Normdaten; drittens sollen die zusätzlicherschlossenen Informationen längerfristig alsGrundlage für weiterführende (fachspezifische)Fragestellungen eingesetzt werden, etwa zurRekonstruktion von Künstlergruppen durchdie Erstellung von Personen-Netzwerken.Das Projekt wird an der Universität zuKöln in enger Zusammenarbeit zwischenFachwissenschaftlern der Kunstgeschichte undder Sprachlichen Informationsverarbeitung( http://www.spinfo.phil-fak.uni-koeln.de/ )durchgeführt, deren Schwerpunkte u.a. aufSystemen zur syntaktischen und semantischenAnalyse und Verarbeitung textueller Daten(Hermes 2012, Schwiebert 2012) sowie zurAnnotation nicht-standardisierter Daten(Neuefeind 2013) liegen.
Metadaten undReferenzobjekte
Die digitalen Repräsentationen der inprometheus zusammengeführten kunst- undkulturhistorischen Artefakte stellen insoferneine besondere Herausforderung für dieautomatisierte Erschließung inhaltlicherInformationen dar, als dass die Metadatenund Texte strukturell und inhaltlich sehrheterogen und in unterschiedlichen Kontextenvorliegen. Die Datensätze der einzelnenBilddatenbanken sind zwar stets in eineigenes Metadatenschema eingepasst, jedocherfolgt die Erschließung der Werke an denjeweiligen Institutionen nicht nach einereinheitlichen Methodik, was u.a. datenbank-oder sammlungsspezifische Gründe hat. Zumeinen liegt innerhalb der Klassifikationen derjeweiligen Datenbanken eine Vielzahl an Textenvor, die bislang nicht strukturiert erschlossensind, sondern derzeit nur über eine einfacheVolltextsuche miteinbezogen werden (eshandelt sich hierbei oftmals um unstrukturierteFreitextfelder, die z.B. Angaben über Standort(e),die Publikationsgeschichte oder ausführliche
Bildbeschreibungen enthalten können).Zum anderen wird selten ein bestimmterMetadatenstandard zugrunde gelegt oder aufFachvokabulare und Terminologieressourcenzurückgegriffen, was dazu führt, dass zumTeil stark variierende Schreibweisen u.a.bei Künstler- oder Ortsnamen existieren. Inder kunsthistorischen Forschung haben sichzudem selten einheitliche Bezeichnungenfür Werktitel durchgesetzt. So liegt bspw. dasWerk “Bonaparte überquert den großen SanktBernhard” von Jacques-Louis David (Malmaison,1801) in prometheus in mindestens siebenverschiedenen Titelbezeichnungen vor, diezumeist in Teilen, unter Umständen aber auchvollständig voneinander abweichen (etwa“Napoleon überquert die Alpen” gegenüber“Bonaparte auf dem großen Sankt Bernhard”).Eine Verknüpfung mit Normdaten wie derGemeinsamen Normdatei der DeutschenNationalbibliothek (GND, http://d-nb.info/gnd/1067141367 ) ist auf dieser Grundlagenicht möglich. Diese wäre aber nötig, umeine automatische Zusammenführung derEinzelabbildungen zu Objekten vornehmenund die Objekte eindeutig und damit nachhaltigidentifizieren zu können, was zugleich dieGrundlage für eine weitere Anreicherungmit GND-verknüpften Daten oder weiterenNormdaten (z.B. VIAF, http://viaf.org ; Wikidata,https://www.wikidata.org ) bilden würde.
Methodologie
Die Heterogenität der Daten wird inprometheus bereits teilweise in Anwendunglinguistischer Analyseverfahren bei derIndexierung ausgeglichen, wobei derSchwerpunkt hier v.a. auf der orthographischenund morphosyntaktischen Ebene liegt,etwa auf Grundlage sprachspezifischerWörterbücher (u.a. zur Grundformreduzierung,Phrasenerkennung, Synonymgenerierung,Kompositazerlegung) sowie durch Anreicherungmit synonymen Künstlernamen (siehe http://prometheus-bildarchiv.de/tools/pkn d).Diese Maßnahmen dienen in erster Liniedazu, das Retrieval zu optimieren und denRecall zu verbessern. In Bezug auf die obenaufgeworfenen Probleme der Normalisierungund Zuordnung von Einzeldarstellungen zuObjekten sind sie jedoch nur als ein erster Schrittanzusehen. Ziel ist vielmehr ein erweiterterThesaurus, in dem die tatsächlich auftretenden,zum Teil stark variierenden Schreibweisenvon Werktiteln und Künstlernamen auf dieverfügbaren Normdaten abgebildet werden.
104

Digital Humanities im deutschsprachigen Raum 2017
Da die Variation in den Schreibweisen keineeindeutige Zuordnung erlaubt, bedarf eshierbei zusätzlicher Kriterien. Im Zugedes Projekts wird hierfür ein semantischmotiviertes Verfahren erarbeitet, das diegesamten zu einem Objekt verfügbarenInformationen berücksichtigt: Neben denbereits erschlossenen Metainformationen (wieName, Titel, Datierung, Standort, etc.) sollenauch die in den bislang nur unstrukturiertvorliegenden Freitextfeldern (s.o.) enthaltenenInformationen genutzt werden können. Zudiesem Zweck werden die Texte zunächst mittelsInformationsextraktion aufbereitet (Annotationvon Orts- und Personennamen, Zeitausdrücken,etc). Auf Grundlage dieser neu gewonnenenInformationen werden zusätzliche, das Objektbeschreibende Merkmale erstellt und in Formvon Feature-Vektoren kodiert (Features sind z.B.„Personen“, „Orte“, „Material“, o.ä.; Werte sindjeweils die konkreten Nennungen, vgl. Abb. 1).
Abb. 1: Beispiel einer Freitextbeschreibung imprometheus-Bildarchiv, in der exemplarischmittels Informationsextraktion identifizierteElemente markiert wurden.
Aus den zusätzlichen Merkmalen kann nun,in Kombination mit den bereits vorhandenenMetainformationen, für jedes Objekt ein„semantisches Profil“ bzw. „Fingerprint“erstellt werden, anhand dessen sich dieÄhnlichkeit zwischen Objekten ermittelnlässt. Die Ähnlichkeit wird dabei zunächst inBezug auf die einzelnen Merkmale ermittelt(u.a. mittels Edit-Distance oder Soundex- bzw.Metaphone-Difference zwischen einzelnenFeldern, Abgleich zeitlicher Angaben, Distanzzwischen Feature-Vektoren zu „Personen“,„Orten“, „Material“, etc.), wobei der Einflusseinzelner Merkmale unterschiedlich gewichtetwerden kann. Daraus wird ein kombiniertesMaß der Übereinstimmung zwischen zwei
Datensätzen errechnet, das auch bei deutlichabweichenden Schreibweisen eine Aussagedarüber erlaubt, ob es sich um das gleiche Objekthandelt. Auf dieser Grundlage können identischeObjekte dann auf das jeweilige Referenzobjektder GND abgebildet werden.
In einem vorbereitenden Projekt fürdas laufende Vorhaben wurden zunächstdie bestehenden Metadaten der einzelnenDatenbanken des prometheus-Bildarchivsquantitativ ausgewertet, um einen Überblickdarüber zu erlangen, wie sich der Umfangder zu erschließenden Daten darstellt. Diemeisten der 89 Datenbanken verfügen über nochnicht erschlossene Freitextbeschreibungen derObjekte. Diese erstrecken sich zu einem nichtgeringen Teil über mittellange (25-75 Wörter)und lange (>75 Wörter) Texte, die im Zuge desProjekts aufbereitet werden sollen. Abb. 2zeigt die Verteilung dieser unterschiedlichenTextsorten in ausgewählten Datenbanken.Einige verfügen über keinerlei Freitext-Bildbeschreibungen, z.B. die Datenbank desZentralarchivs für Kunstgeschichte in München(zi_muc). Andere, etwa die Erlanger DatenbankZeichnungen der graphischen Sammlung(erlangen_z), weisen fast ausschließlich kurzeBeschreibungen auf, wieder andere enthaltendagegen auch eine Reihe mittellanger und langerTexte.
Abb. 2: Verteilung der Freitextlängen überverschiedene Datenbanken des prometheus-Bildarchivs
Zur Nutzung der in den Bildbeschreibungenund Ikonographien enthaltenen Informationenmüssen diese zunächst identifiziert undentsprechend ausgezeichnet werden. Dafürwurde zunächst ein Komponenten-Workflowkonzipiert und auf Basis des UIMA-Frameworks(Unstructured Information ManagementArchitecture, siehe https://uima.apache.org )implementiert. Im Zuge der Verarbeitungwerden die zu annotierenden Informationen
105

Digital Humanities im deutschsprachigen Raum 2017
in ausgewählten Feldern der Datensätzeidentifiziert (vgl. Abb. 3). Dabei kommenStandardmethoden der Informationsextraktion(z.B. Temporal Expression Detection, NamedEntity Recognition) genauso zum Einsatz wieinformationstheoretische Maße (etwa Log-Likelihood oder tf.idf), um domänenspezifischrelevante Terme zu bestimmen.
Abb. 3: Workflow zur Informationsextraktion inFreitexten im prometheus-Bildarchiv.
Die erste Projektphase diente vor allemder Evaluierung von Werkzeugen, etwa demStanford Named Entity Tagger (siehe http://nlp.stanford.edu/software/CRF-NER.shtml )zur Identifikation von (Orts-)Namen,oder HeidelTime (siehe http://dbs.ifi.uni-heidelberg.de/index.php?id=129 ) zur Annotationvon Zeitausdrücken, um den voraussichtlichenBedarf an Anpassungen der Werkzeuge fürdie kunsthistorische Domäne zu ermitteln.Abb. 4 zeigt das Ergebnis der StanfordNER-Komponente, die in einem Text der Datenbank“The Daumier Register” ( http://www.daumier-register.org/ ) Eigennamen auszeichnet:Künstlernamen (“Henry Monnier”), Werktitel(“Séraphita”), Werkstoffe (“China-Papier”), sowieOrtsnamen (“Sevilla”) werden mit verschiedenenTags (I-PERS, I-MISC, I-LOC) gekennzeichnet. Wiesich zeigt, werden jedoch nicht alle Eigennamenaufgefunden (etwa “Balzac, Honoré de”),was v.a. darauf zurückzuführen ist, dass hierzunächst nur das für das Deutsche verfügbarNER-Modell zum Einsatz kam. In der weiterenProjektlaufzeit muss die Erkennungsratedurch eine Erweiterung und Modifikation dervorhandenen Modelle verbessert werden, damitdie Daten möglichst präzise und vollständigauswerten werden können.
Abb. 4: Exemplarisches Ergebnis derAnwendung eines verfügbaren Standard-Modellszur Named Entity Recognition.
Zusammenfassung undAusblick
Das beschriebene Vorgehen wird derzeitexemplarisch an ausgewählten Datensätzenentwickelt, um anschließend auf dengesamten Bildpool des prometheus-Bildarchivsangewendet zu werden. Ein wesentlichesZiel des Projekts ist es, eine größtmöglicheAutomatisierung in der Thesauruserstellung zuerreichen. Das hierfür vorgesehene kombinierteÄhnlichkeitsmaß ist flexibel erweiterbar. Sokönnen zum einen zusätzliche Informationenaus externen Quellen herangezogen werden,etwa indem weitere, digital vorliegendekunsthistorische Texte (z.B. das Reallexikonzur Deutschen Kunstgeschichte, RDK, siehehttp://www.rdklabor.de ), Ausstellungs-und Auktionskataloge (z.B. Getty Art andArchitecture, siehe http://www.getty.edu/research/tools/vocabularies/aat/ , UB Heidelberghttp://artsales.uni-hd.de ) oder auch Wikipediaanalysiert und klassifiziert werden undmittels des erstellten Thesaurus mit denDatensätzen in prometheus verknüpft werden.Zum anderen soll das Ähnlichkeitsmaßauch durch komplementäre (z.B. optische)Verfahren des Bildvergleichs erweitertwerden. So wurde bspw. zusammen mit derComputer Vision Group Heidelberg bereitsein Projekt zur automatischen Bilderkennungangestoßen (siehe Bell/Dieckmann 2015).Durch die Kombination verschiedenerMethoden der Ähnlichkeitsberechnung zueinem gemeinsamen, multidimensionalenÄhnlichkeitsmaß ist der hier vorgeschlageneAnsatz in hohem Maße adaptierbar fürvergleichbare Anwendungen. Die im Projekt
106

Digital Humanities im deutschsprachigen Raum 2017
erarbeitete Vorgehensweise ist somit auf weitereMetadatenpools kulturhistorischer Inhalteübertragbar und dank der Automatisierungbeliebig skalierbar.
Bibliographie
Bell, Peter / Dieckmann, Lisa (2015): „DieKunst als Ganzes. Heterogene Bilddatensätzeals Herausforderung für die Kunstgeschichteund die Computer Vision“, in: DHd 2016:Modellierung - Vernetzung - Visualisierunghttp://dhd2016.de/boa.pdf#118 [letzter Zugriff23.11.2016].
Bell, Peter / Dieckmann, Lisa / Ommer,Björn / Takami, Masato (2015): Passion Search.Prototype of an unrestricted image search ofthe crucifixion. http://hci.iwr.uni-heidelberg.de/COMPVIS/projects/suchpassion/ [letzter Zugriff23.11.2016]
Dieckmann, Lisa (2015): „prometheus –das verteilte digitale Bildarchiv für Forschung& Lehre e. V.“, in: Euler, Ellen / Hagedorn-Saupe, Monika/ Maier, Gerald/ Schweibenz,Werner/ Sieglerschmidt, Jörn (eds.): HandbuchKulturportale. Online-Angebote aus Kultur undWissenschaft. Berlin / Boston: DeGruyter 223–229.
Hermes, Jürgen (2012): Textprozessierung:Design und Applikation. Dissertation, Universitätzu Köln. http://kups.ub.uni-koeln.de/id/eprint/4561 [letzter Zugriff 23. November 2016].
Neuefeind, Claes (2013): „The DigitalRomansh Chrestomathy. Towards an AnnotatedCorpus of Romansh“, in: Zampieri, Marcos /Diwersy, Sascha (eds.), Special Volume on Non-Standard Data Sources in Corpus-Based Research(ZSM Studien 5). Aachen: Shaker 41–58.
Schwiebert, Stephan (2012): Tesla - einvirtuelles Labor für experimentelle Computer-und Korpuslinguistik. Dissertation, Universität zuKöln. http://kups.ub.uni-koeln.de/id/eprint/4571[letzter Zugriff 23. November 2016].
Das „Was-bisher-geschah“ von KOLIMO.Ein Update zum Korpusder literarischenModerne
Herrmann, J. [email protected]ät Göttingen, Deutschland
Lauer, [email protected]ät Göttingen, Deutschland
Der vorgeschlagene Beitrag dokumentiertden Fortschritt beim Aufbau unseres digitalenKorpus der literarischen Moderne (KOLIMO), dasim Herbst 2016 in der Beta-Version veröffentlichtwerden soll (abrufbar unter https://kolimo.uni-goettingen.de/). Im Fokus des Beitrags stehendas Verfahren zur Aufbereitung der Texte(insb. Format und Metadaten in TEI) und daslinguistische Tagging (POS).
Als Teil des laufenden Projektes Q-LIMO(Quantitative Analyse der literarischenModerne) ist KOLIMO ein repräsentativesund computerlinguistisch solide aufbereitetesKorpus von narrativen fiktionalen Erzähltextender literarischen Epoche der Moderne. Umdurch stratifiziertes Sampling Repräsentativität(verstanden als „extent to which a sampleincludes the full range of variability in apopulation“; vgl. Biber 1994) zu ermöglichen,umfasst das Korpus ein möglichst breitesSpektrum der literarischen Moderne, verteiltüber kanonische und nichtkanonische Texte. Sowurden in das Korpus bislang ca. 596.000.000Wörter aus frei zugänglichen Repositorienimportiert (s. Abbildung 1).
Abbildung 1Gesamtanzahl Wörter aus den drei
Hauptressourcen (Zwischenstand August 2016)
107

Digital Humanities im deutschsprachigen Raum 2017
Die Datenbank umfasst so neben Textenaus TextGrid und Gutenberg-DE (s. Abbildung2) und dem DTA auch eine wachsende Zahlvon Retrodigitalisaten. Das Sampling ist nichtzuletzt dadurch beeinflusst, dass KOLIMO auchdas Kafka/Referenzkorpus (KAREK) beinhaltet,welches zum Ziel hat, Kafkas Texte und Texte,die Kafkas Schreibprozess beeinflusst habenkönnten, möglichst umfangreich abzubilden (vgl.Herrmann / Lauer 2016a,b).
Abbildung 2Screenshot KOLIMO-WebApp: Anzahl Wörter,
Autoren und Einträge aus TextGrid & Gutenberg-DE (ohne DTA und andere Quellen, Stand August2016)
Um philologischen Ansprüchen an deneditorischen Status literarischer Texteund die Abbildung von Epochen sowieGattungskonzepten zu genügen, war einehohe Genauigkeit und Konsistenz bei derinformatischen Vorverarbeitung Textmarkup(XML-TEI) inklusive der Metadaten (Autor,Entstehungszeitpunkt und Gattung) besonderswichtig. Gerade die Auszeichnung der genanntenMetadaten stellt eine Schnittstelle zwischen deninformatischen und philologischen Dimensionenunseres Projektes dar: so sind Metadaten (a) dieunabhängigen Variablen unserer stilistischenAnalyse und (b) variieren in den von unsimportierten Korpus-Ressourcen stark inqualitativer und quantitativer Hinsicht (Fehler,
missing entries, unterschiedliche Ontologien).Der vorgeschlagene Beitrag wird so erstenseinen kurzen Einblick in unsere Vorgehensweisegeben, wobei Kriterien der Nachhaltigkeitberücksichtigt werden:
• Strategien der Textextraktion nach Genre-Kriterien unter Nutzung bestehenderMetadatenschemata (ausgeschlossen wurdenz.B. alle Texte, deren Metadaten sie alsdramatisch und lyrisch ausflaggten, sowieTexte, die keine Absätze [without (tei:p)]enthielten);
• ein transparenter Workflow zurKorpusauszeichnung (internes eXistWebinterface);
• Anwendung eines standardisiertenText-Markups (u.a. Transformation derTextGrid und Gutenberg Header in das DTA-Basisformat TEI);
• Strategien der konsistenten Implementierungund Verbesserung von Metadatenschemata(Ineinandergreifen von händischen undskriptgestützen Workflows, wie Recherche zu[Erst-]Erscheinungsdaten bei missing entries,Zusammenführung der unterschiedlichenGattungschemata, Überprüfung und ggf.Zuweisung von GNDs für Autoren);
• die nachhaltige Veröffentlichung desKorpus auf einem eigenen Server mitstandardisierten Datenschnittstellen;
• Datenbankabbild (nonpublic) zurLangzeitarchivierung.
Zweitens wird der Beitrag unser Vorgehenbezüglich der linguistischen Anreicherungzusammenfassen: Unter der Annahme, dass Stilquantitativ beschreibbar ist (vgl. Herrmann /van Dalen-Oskam / Schöch 2015), und dassWortarten verlässliche Indikatoren für Registerund Genrevariation sind (vgl. z.B. Biber / Conrad2009), haben wir uns für die linguistischeAnnotation auf POS (STTS Tagset; vgl. Schiller /Teufel / Thielen 1995) entschieden. POS sind imVergleich mit anderen Variationsmarkern durcheine relativ akkurate automatische Annotationbesonders praktikabel. Das Webinterface liefertvariablen Zugriff auf die annotierten Daten, u.a.eine Volltextansicht (siehe Abbildung 3); geplantsind zur Veröffentlichung die Exportierbarkeitin .csv-Files und TCF-Format.
Abbildung 3Screenshot KOLIMO WebApp Textview POS-
Tagging
108

Digital Humanities im deutschsprachigen Raum 2017
Zwar liefern bereits trainierte Modellevon einigen Taggern (z.B. TreeTagger) einegute Genauigkeit für das gegenwärtigeStandarddeutsch, angewendet auf ältereSprachstufen oder vom Standarddeutschenabweichende Register wie „Literatur“ sinktdie Genauigkeit jedoch. Ein bereits auf POSannotiertes Korpus ist das Deutsche Textarchiv(DTA, Berlin-Brandenburgische Akademie derWissenschaften 2016), ein Referenzkorpusfür das Deutsche, das sowohl historischeSprachstufen als auch das Register „Literatur“enthält. Die POS-Annotation baut hier auffehlertoleranten linguistischen Analysehistorischer Texte auf und verwendet einTool zur Morphologisierung (Jurish 2012), istallerdings hinsichtlich ihrer Qualität noch nichtumfassend evaluiert worden. Ausgehend vondiesem Datensatz haben wir zwei Strategienverfolgt: (1) Ein epochensensitives POS-Tagging, das verschiedene Tagger auf demDatensatz des DTA, aber auf unterschiedlichenliterarischen Epochen trainiert (vgl. Paluch etal. in Vorbereitung); (2) eine Überprüfung derQualität der DTA-POS-Tags durch quantitativeund qualitative Verfahren.
In Strategie (1) machen wir uns zunutze,dass Annotationsgenauigkeit erhöht werdenkann, wenn Tagger auf verschiedene Register/Sprachstände trainiert und diese trainiertenModelle dann auf noch nicht trainierte Textedes gleichen Registers angewendet werden(vgl. Giesbrecht / Evert). Für KOLIMO habenwir u.a. den TreeTagger (vgl. Schmid 1994),Perceptron (vgl. Rosenblatt 1958) und MarMoT(vgl. Müller / Schmid / Schütze 2013) verwendet.Durch die Wahl unterschiedlicher Tagger sollgewährleistet werden, dass die Genauigkeitder POS-Annotation maximiert werden kann,indem nur derjenige Tagger mit den bestenErgebnissen pro Register verwendet wird.Die Auswahl der Tagger basierte einerseitsdarauf, dass sie unterschiedliche Prinzipienbenutzen: So funktioniert der TreeTaggernach dem Hidden Markov Model (HMM, vgl.
Baum / Petrie 1966), MarMot nach dem Prinzipder Conditional Random Fields (DRF, vgl.Hammersly / Clifford 1971) und Perceptronnach dem neuronaler Netzwerke. Der Grundfür die Wahl des TreeTaggers war zudemseine Prävalenz in der Forschungsliteratur, dienicht zuletzt durch gute Ergebnisse begründetscheint (vgl. Dipper 2012; Giesbrecht / Evert2009). In einem ersten Schritt (vgl. Paluchet al. in Vorbereitung) wurden hier bereitsgetaggte Texte aus dem DTA in fünf Epochengeordnet. Neben der Moderne umfassten diesezu Vergleichszwecken auch Barock, Aufklärung,Romantik, und Realismus. Für die Einteilung derEpochen in Zeitperioden sowie der Einteilungvon Autoren zu bestimmten Epochen wurdeneinschlägige Literaturgeschichten zu Rategezogen (u.a. Beutin 2001; Jørgensen / Bohnen /Øhrgaard 1990; Meid 2009; Schulz 2000;Sprengel 1998, 2004). Anschließend wurdendie Tagger auf jeweils eine Epoche trainiert,indem die Texte randomisiert in Trainings-und Evaluationstexte getrennt wurden undeine k-fold cross validation (vgl. Witten / Elbe2005) für jeden Tagger durchgeführt wurde.Die Ergebnisse (vgl. auch Paluch et al. inVorbereitung) weisen auf eine gute Genauigkeitinsbesondere von Perceptron hin, müssen aberunter dem Vorbehalt betrachtet werden, dass derStatus des DTA als Goldstandard für POS-Taggingnoch fraglich ist.
Hier setzen wir mit Strategie (2) an, mit derwir zunächst für alle POS-Tags Übereinstimmungund Abweichung (Matches und Missmatches)des Outputs des Tree-Taggers und MarMots mitdem DTA-Datensatz vergleichen. Aufbauend aufdiese quantitative Überprüfung der einzelnenTag-Zuweisung evaluieren wir zudem händischStichproben der Nichtübereinstimmungen in derAnnotation der einzelnen Tags.
Unsere quantitative Überprüfung ergibteine generelle Übereinstimmung mit dem DTA-Datensatz in POS-Tags für den TreeTaggerund den Marmot Tagger von jeweils 80%. Diegenerelle Übereinstimmung zwischen den Tagsdes TreeTaggers und denen des MarMot Taggershingegen liegt bei 0.78%.
Tabelle 1 zeigt Ergebnisse aus der Analyseder Übereinstimmungen (Matches) undAbweichungen (Missmatches) bei der POS-Tagzuweisung von TreeTagger (TT) und MarMot(MM) im Vergleich mit den Tags des DTA.Abgebildet sind hier solche Fälle pro POS-Tag,in denen TT und MM übereinstimmen, abervom DTA abweichen. Die Tabelle listet die elfPOS-Tags, die (von TT und MM gemeinsam)die proportional den höchsten Anteil derAbweichung vom DTA ausmachen.
109

Digital Humanities im deutschsprachigen Raum 2017
Tabelle 1 Abweichung zu POS-Tags des DTA(Übereinstimmung MM und TT)
POS-Tag* Häufigkeit Rel. HäufigkeitNE 1444048 0.12NN 1443795 0.12VVFIN 1326081 0.11ADJA 1309006 0.11ADJD 741903 0.06ADV 618465 0.05VAFIN 582791 0.05FM.la 404341 0.03PPOSAT 397465 0.03APPR 362774 0.03PDAT 255896 0.02
*STTS TagsetAufbauend auf diesen Daten wird im
nächsten Schritt die tatsächliche Qualitätder bereits vorhandenen DTA-Tags für denDatensatz der literarischen Texte evaluiert. Aufder Grundlage von randomisiertem Samplingverbessern wir die POS-Annotationen beitatsächlichen Fehlern händisch, um in der Folgeu.a. eigene Sprachmodelle für unser spezifischesKorpus narrativer Texte zu trainieren. Sosoll schließlich unter Nutzung vorhandenerRessourcen ein Silber- oder sogar Goldstandardfür das POS-Tagging historischer literarischerTexte des Deutschen erreicht werden.
KOLIMO wird in der Beta-Versionzur Tagung veröffentlicht (s. https://kolimo.uni-goettingen.de ) und so derForschungsgemeinschaft zur Verfügung gestellt.Es soll eine hypothesengetriebene, aber auchexplorative, quantitative Stilistik ermöglichen(vgl. Herrmann eingereicht); zum Zeitpunkt derTagung sind erste Ergebnisse zur stilistischenVariation der literarischen Moderne zu erwarten(vgl. schon Herrmann / Lauer / Mattner 2016).
Gleichzeitig planen wir eine detaillierteDokumentation der Arbeitsschritte zuveröffentlichen, die ähnlichen Projekten alsLeitfaden zur Verfügung zu stehen soll. UnserProjekt dokumentiert in seinem gegenwärtigenStatus Entscheidungen auf verschiedenenkonzeptionellen, analytischen und prozeduralenEbenen. Es zeigt, dass der Aufbau eines digitalenliterarischen Korpus, das den synchronenund diachronen quantitativen Vergleicheiner Schwerpunktepoche erlauben soll, beiWeitem keine triviale Aufgabe darstellt. Sowurde zum Beispiel deutlich, wie Hypothesenzur Konstitution von Epochen, Autorschaftund Gattungen die Korpuskompilation
steuern – und deshalb auf einer möglichstpräzisen Modellierung der zugrundeliegendentextwissenschaftlichen Theorien fußen sollten.Gleichzeitig sind Metadaten (u. a. Autor, Titel,Publikationsdatum, Publikationsort, Gattung)und linguistische Parameter (wie POS) geradedie Ansatzpunkte, an denen philologischeFragestellungen in präzise und praktikableKategorien umgewandelt werden können. Nichtzuletzt deshalb sollten literarische Daten inflexiblen Architekturen gespeichert werden, diezusätzliche Annotationsebenen zulassen – dennhermeneutische Erkenntnisprozesse stellen eineerwachsene Stärke der Geisteswissenschaftendar, die auch im digitalen Zeitalter einen explizitmodellierten Platz einnehmen muss.
Bibliographie
Baum, Leonard E. / Petrie, Ted (1966):„Statistical inference for probabilistic functionsof finite state markov chains“, in: The annals ofmathematical statistics 37 (6) :1554–1563.
Berlin-Brandenburgische Akademie derWissenschaften (2016): Deutsches Textarchiv.http://www.deutschestextarchiv.de/ [letzerZugriff 24. Mai 2016].
Beutin, Wolfgang (2001): DeutscheLiteraturgeschichte: von den Anfängen bis zurGegenwart. Stuttgart: Metzler.
Biber, Douglas / Conrad, Susan (2009):Register, Genre, and Style. Cambridge: CambridgeUniversity Press.
Dipper, Stefanie (2012): „Morphologicaland part-of-speech tagging of historicallanguage data: A comparison“, in: Workshopon Annotation of Corpora. http://www.coli.uni-saarland.de/conf/ACRH10/slides/dipper.pdf .
Gaede, Friedrich (1971): Humanismus,Barock, Aufklärung: Geschichte der deutschenLiteratur vom 16. bis zum 18. Jahrhundert. Bern:Francke Verlag.
Giesbrecht, Eugenie / Evert, Stefan (2009):„Is part-of-speech tagging a solved task? Anevaluation of pos taggers for the German webas corpus“, in: Proceedings of the fifth Web asCorpus Workshop 27–35.
Hammersley, John M. / Clifford, Peter(1971): Markov fields on finite graphs andlattices. http://www.statslab.cam.ac.uk/~grg/books/hammfest/hamm-cliff.pdf .
Herrmann, J. Berenike (eingereicht): „In testbed with Kafka. Introducing a mixed-methodapproach to digital stylistics“, in: Chambers,Sally / Jones, Catherine / Kestemont, Mike /Koolen, Marijn / Zundert, Joris van (Eds.). Special
110

Digital Humanities im deutschsprachigen Raum 2017
Issue DHBenelux 2015, Digital HumanitiesQuarterly.
Herrmann, J. Berenike / Lauer, Gerhard(2016a): „KAREK: Building and Annotating aKafka/Reference Corpus“, in: DH2016: ConferenceAbstracts.
Herrmann, J. Berenike / Lauer, Gerhard(2016b): „Aufbau und Annotation des Kafka/Referenzkorpus“, in: DHd 2016: Modellierung -Vernetzung - Visualisierung.
Herrmann, J. Berenike / Lauer, Gerhard /Mattner, Cosima (2016): Measuring Kafka'sDiaries. A Psychostylistic Approach InternationalSociety for the Empirical Study of Literature andMedia (IGEL), Chicago, USA.
Herrmann, J. Berenike / van Dalen-Oskam,Karina / Schöch, Christof (2015): „RevisitingStyle, a Key Concept in Literary Studies“, in:Journal of Literary Theory 9 (1): 25–52.
Jørgensen, Sven Aaage / Bohnen, Klaus /Øhrgaard, Per (1990): Aufklärung, Sturm undDrang, frühe Klassik: 1740 - 1789. (Boor, Helmutde / Newald, Richard, eds.). München: Beck.
Jurish, Bryan (2012): Finite-stateCanonicalization Techniques for HistoricalGerman. PhD, Universität Potsdam.
Manning, Christopher D. / Raghavan,Prabhakar / Schütze, Heinrich (2008):Introduction to information retrieval 1.Cambridge: Cambridge University Press.
Meid, Volker (2009): Die deutsche Literatur imZeitalter des Barock: vom Späthumanismus zurFrühaufklärung: 1570 - 1740. (Boor, Helmut de /R. Newald, Richard, eds.) ([Neuausg.].). München:Beck.
Müller, Thomas / Schmid, Helmut / Schütze,Hinrich (2013): „Efficient higher-order CRFs formorphological tagging“, in: Proceedings of the2013 Conference on Empirical Methods in NaturalLanguage Processing.
Nekula, Marek (2003): „Franz KafkasDeutsch“, in: Linguistik online 13 (1) https://bop.unibe.ch/linguistik- online/article/view/879/1533 .
Paluch, Markus / Rotari, Gabriela / Steding,David / Weß, Maximilian / Moritz, Maria (inVorbereitung): Non-static analysis of part-of-speech tagging of historical German texts.
Rosenblatt, Frank (1958): „The perceptron:a probabilistic model for information storageand organization in the brain“, in: PsychologicalReview 65 (6): 386.
Schiller, Anne / Teufel, Simone / Thielen,Christine (1995): „Guidelines für das Taggingdeutscher Textcorpora mit STTS“, in: Manuscript,Universities of Stuttgart and Tübingen.http://www.sfs.uni-tuebingen.de/resources/stts-1999.pdf .
Schmid, Helmut (1994): „Probabilistic part-of-speech tagging using decision trees“, in:Proceedings of the international conference onnew methods in language processing 12: 44–49.
Schulz, Gerhard (2000): Das Zeitalter derFranzösischen Revolution: 1789 - 1806. (Boor,Helmut de / Newald, Richard, eds.) (2., neubearb.Aufl.). München: Beck.
Sprengel, Peter (1998): Geschichte derdeutschsprachigen Literatur 1870 - 1900: von derReichsgründung bis zur Jahrhundertwende. (Boor,Helmut de / Newald, Richard, eds.). München:Beck.
Sprengel, Peter (2004): Geschichte derdeutschsprachigen Literatur 1900 - 1918: vonder Jahrhundertwende bis zum Ende des ErstenWeltkriegs. (Boor, Helmut de / Newald, Richard,eds.). München: Beck.
Witten, Ian H. / Elbe, Frank (2005): DataMining: Practical machine learning tools andtechniques. San Francisco: Morgan KaufmannPublishers.
Datenmodellierungund -visualisierung mitGraphdatenbanken.Konzepte undErfahrungen anlässlichdes Relaunchesder BilddatenbankREALonline
Matschinegg, [email protected]ät Salzburg, Österreich
Nicka, [email protected]ät Salzburg, Österreich
Mit der Thematik der digitalen Nachhaltigkeitsind Gedächtnisinstitutionen, die sich dieumfassende digitale Sicherung und Erschließungdes Kulturerbes zum Ziel setzen, gleichermaßenkonfrontiert wie Forschungsprojekte, bei denendigitale Daten generiert, computergestütztausgewertet und in Forschungsdatenbankenzugänglich gemacht werden. Dabei liegt
111

Digital Humanities im deutschsprachigen Raum 2017
das Hauptaugenmerk nicht nur auf derLangzeitsicherung und Archivierung;die größeren Herausforderungen stellensich vor allem bei den Aktualisierungender Datenmodelle, Analysemethodenund Präsentationsformen, um die neuenWerkzeuge der Digital Humanities bestmöglicheinsetzen zu können. Die Überlegungenim Vorfeld derartiger Relauncharbeitenbewegen sich erfahrungsgemäß zwischenvorsichtiger Adaptierung und radikalemUmbau der vorliegenden Datenarchitektur.Dass dabei alle vorhandenen Informationenverlustfrei übertragen werden sollen,versteht sich von selbst. Der folgende Beitragmöchte die Transformation von Daten einesLangzeitprojekts in eine neue Datenarchitekturfür eine Bilddatenbank vorstellen, bei der eineGraphdatenbank zum Einsatz kommt:
Am Institut für Realienkunde desMittelalters und der frühen Neuzeit (IMAREAL),einem interdisziplinär ausgerichtetenForschungsinstitut, das Teil der UniversitätSalzburg ist, wird die materielle Kultur desMittelalters und der frühen Neuzeit untersucht.Bildquellen bilden dabei neben Schriftquellenund überlieferten Objekten die Grundlagen derAnalysen. Mit dem Aufbau der BilddatenbankREALonline wurde am IMAREAL in den1970ern auf der Grundlage der von ManfredThaller speziell für die Anforderungen derhistorischen Grundwissenschaften entwickeltenDatenbanksysteme begonnen – zunächstDescriptor und in weiterer Folge Κλειώ(Thaller 1980 u. 1989). Der Datenbestand vonREALonline wurde seither und wird weiterhinkontinuierlich erweitert, damit dargestellteDinge und ihre Kontexte erforscht werdenkönnen. Die Datenbank ist seit 2002 unterhttp://tethys.imareal.sbg.ac.at/realonline onlineverfügbar (Matschinegg 2004). Anhand derDatenbank ist es möglich, die Bedeutung undFunktion der materiellen Kultur im Bilddiskurszu untersuchen: Welche Objekte waren zuwelchen Zeiten in welchen Gesellschaften undKontexten als visuelle „Requisiten“ gegenwärtigoder vor- und damit auch darstellbar? Wiewurden Dinge im Bild verhandelt und welcheRolle nehmen sie innerhalb von ins Bildüberführten Narrativen ein?
Um diese Fragen beantworten zu können,wurde am IMAREAL entschieden, nebenden Metadaten zum Werk bzw. Bildträgersystematisch alle im Bild dargestelltenElemente auszuzeichnen (Abb. 1). Im Gegensatzzu anderen Bilddatenbanken wird dasDargestellte nicht nur mit einigen wenigenSchlagwörtern erfasst. Diesem Umstand ist
es zu verdanken, dass die in REALonlineerhobenen Daten sowohl im Rahmen voninterdisziplinären Forschungen zur materiellenKultur ausgewertet werden können, als auchin unterschiedlichen geisteswissenschaftlichenUntersuchungskontexten und fürKulturerbedokumentationen eine wertvolleRessource darstellen.
Abb. 1: Erfassungsschema der Metadaten inREALonline
Im Modell für die Erfassung derdargestellten Entitäten im Bild werden folgendeInformationen erhoben: Für Subjekte werdenneben dem Subjektnamen die KategorienGeschlecht, Beruf bzw. Stand und Gestik erfasst.Bei Objekten werden der Objektname und dieInformationen zu Farbe, Material und Formerhoben. Weiters wird die Struktur dieserMetadaten zu den Bildinhalten festgehalten undkann damit im Rahmen von Analysen abfragbargemacht werden: Direkte Subjekt-Objekt- bzw.Objekt-Objekt-Relationen werden erfasst, um amKörper getragene bzw. von Figuren gehalteneObjekte zu dokumentieren oder einen Bezugzwischen einzelnen dargestellten Dingen (etwaein auf einem Tisch stehender Krug) in denDaten abbilden zu können. Darüber hinauskönnen sowohl Körperteile als auch Teile vonObjekten als Metadaten zum Dargestelltengespeichert werden (Jaritz 1993: 23-43).
Graphdatenbanken eignen sich u.a. besondersdafür, die vielfältigen Beziehungen zwischenPersonen oder Personen und Gegenständen bzw.Ereignissen sowie auch zwischen den Dingenuntereinander möglichst flexibel abzubilden undsind nun auch in der historischen Forschungim Kommen; als Software wird oft Neo4jeingesetzt (Raspe 2014, Kaufmann & Andrews2015, Kuczera 2015). Die verzweigte Strukturder erfassten Metadaten in REALonline isteiner der Hauptgründe, warum für die neueDatenarchitektur ein property-graph-Modellgewählt wurde. Ein weiterer Leitgedankewar, dass das Beziehungsnetz von Subjekten,Objekten und Handlungen in mittelalterlichen
112

Digital Humanities im deutschsprachigen Raum 2017
und frühneuzeitlichen Bildern anhand desModells eines verzweigten Graphen besserveranschaulicht werden kann als in einer langenListe mit Metadaten. Die Graphdatenbankbietet im Fall von REALonline sowohl beider Präsentation für die Nutzer_innen imFrontend, für die Abfrage und Darstellungder Abfrageergebnisse als auch für dieEingabe der Daten im Backend (siehe Abb. 2)eine Verbesserung der Usability gegenüberdem zuvor verwendeten hierarchischenDatenbankmodell.
Abb. 2: Screenshot des Graphen zumDargestellten im Bild (Backend)
In unserem Projekt hat sich die Kombinationvon Neo4j für die Modellierung und Abfrageder „beziehungsrelevanten“ Daten mit einerNoSQL-Mongo-Dokumentendatenbankangeboten (Abb. 3). Diese Lösung bauteinerseits auf dem in der Praxis bereitsbewährten softwareseitigen Ineinandergreifenbei der semantischen Transformation derInformationen auf und bietet gleichzeitig dieMöglichkeit zur Speicherung und Abfrage vonwerkgeschichtlich wie auch projektgeschichtlichrelevanten Informationen zu den einzelnenBilddokumenten, die im Verlauf diesesLangzeitprojektes erhoben wurden und laufenderweiterbar bleiben sollen.
Abb. 3: Datenarchitektur von REALonlineIm Vortrag möchten wir aber auch auf die
Herausforderungen hinweisen, denen wir unsim Zuge des Entwurfs der Datenarchitektur von
REALonline stellen mussten: So war etwa in derStruktur des hierarchischen Datenmodells dieInformation zur dargestellten Handlung aufderselben Ebene angesiedelt wie die EntitätenSubjekt und Objekt. Beim Datenexport aus derbis dato verwendeten Κλειώ -Datenbank unddem Import in Neo4j konnte – nachdem indiesem Fall keine automatisierten Zuweisungender Handlung zu Personen bzw. Objektenmöglich waren – dieser Umstand nur in dasneue Datenmodell mitübernommen werden. Mitder Entscheidung für eine Graphdatenbank istdennoch gewährleistet, dass in einem weiterenSchritt Informationen, wie jene zur dargestelltenHandlung, statt in Knoten in die Kanten desGraphen gelegt werden können und damit dieStruktur von RDF-Triples (Subjekt-Prädikat-Objekt) bekommen.
Aufgrund der zeitintensiven Datenerhebungwar ein wichtiger Aspekt des Relaunchs, dieDateneingabe so effizient wie möglich zugestalten. Der Beitrag wird die gefundeneLösung präsentieren. Langfristig gesehensollte versucht werden, den Zeitaufwandfür die Erhebung von Metadaten zu den aufhistorischen Bildern dargestellten Elementenzu minimieren. Daher möchten wir die inREALonline während mehr als 40 Jahrenerhobenen Informationen als Trainingsdatenin transdisziplinäre Projekte zwischen denGeisteswissenschaften und der Computer Vision– insbesondere zur (semi-)automatisiertenBilderkennung – einbringen, so dafürFördermittel eingeworben werden können.
Mit dem Relaunch von REALonline kanndie Menge der erhobenen Metadaten zumim Bild Dargestellten (aktuell sind innerhalbvon 23316 Datensätzen 1.165562 Begriffedazu erfasst) besser zugänglich gemachtwerden: Abfragen der Graphdatenbank undVisualisierungen (z.B. mit Software wie gephi–The Open Graph Viz Platform oder yEd grapheditor) dieser Ergebnisse können komplexeZusammenhänge innerhalb der Bilddetailsaufdecken oder Aufschlüsse zu Mustern sowie„Ausreißern“ in unterschiedlichen Samplesliefern, die nicht nur als Resultate statistischerAuswertungen verstanden werden sollen,sondern vor allem dazu dienen können, neueFragen in der (interdisziplinären) Forschunganzustoßen. Beispielsweise wurde in 154Datensätzen das Bildthema „GeißelungChristi“ erfasst. Bei der Erschließung dieserDatensätze wurden wiederum 516 Objekteverzeichnet, die von Figuren im Bild in derHand gehalten werden. Die Visualisierung(Abb. 4) beschränkt sich auf jene Objekte, dienur einmal vorkommen (gelb) und die ihnen
113

Digital Humanities im deutschsprachigen Raum 2017
übergeordneten Thesauruskategorien (grün,dunkelrot). Während die meisten Objekte demgängigen Narrativ „Geißelung“ zugeordnetwerden können, sind die Objekte Münzeund Geldbeutel nur über einen Konnex zummittelalterlichen Drama erklärbar (Nicka 2014,280–282): Die Darstellung einer Bezahlung derGeißler Christi, die nur auf einem Flügelaltarim niederösterreichischen Pöggstall im Bildfestgehalten wurde, kennen wir ansonsten nuraus Passionsspielen, wo jüdische Protagonistennegativ gekennzeichnet werden, indem sie denGerichtsknechten Geld geben, um besonders festmit den Ruten zuzuschlagen (siehe auch Abb. 2).
Abb. 4: Visualisierung der dargestelltenObjektbegriffe und Körperbezeichnungen ausden Bildbeschreibungen in ihrer Zuordnung zurjeweiligen Thesauruskategorie
Abschließend bleibt zu erwähnen, dass sichmit der Notwendigkeit, eine gut eingeführte,aber in ihren technischen Funktionalitätennicht mehr zeitgemäße Bilddatenbankzu modernisieren, auch die Chance zurbesseren Nutzung der umfangreichenDatenbestände verbinden lässt. Im Zugeder Relaunchvorarbeiten haben wir dieKonzepte und Lösungsansätze aufgegriffen,die gegenwärtig in den Digital Humanitiesdiskutiert und getestet werden. Wir habendie Umsetzung in enger Zusammenarbeit mitden Grazer Entwicklerfirmen complement.atund zedlacher.net realisiert. Der Beitrag gibteinen knappen Überblick über die wichtigstenEntscheidungsfindungsprozesse sowie dieSchwierigkeiten und Potentiale, die bei derÜberführung in die neue Datenarchitektur unddie gewählte Frontend-Lösung entstanden sind.Der Aspekt der Nachhaltigkeit hat dabei vonAnfang an eine große Rolle gespielt; sowohl beider Erhaltung aller vorhandenen Informationenals auch bei der nachhaltigen Nutzbarkeit der
erhobenen Daten. So ist die Zitierbarkeit derDaten über einen PID (persistent identifier) miteinem handle gewährleistet und die Metadatenwerden mit einer Creative Commons by-nc-sa 4.0-Lizenz zur Verfügung gestellt. Die neue Online-Version von REALonline wird gegenwärtiggetestet und optimiert und 2017 freigeschaltet.
Bibliographie
Jaritz, Gerhard (1993): Images: A Primerof Computer-Supported Research with ΚλειώIAS. Halbgraue Reihe zur historischenFachinformatik A 22. St. Katharinen: ScriptaMercaturae Verlag.
Kaufmann, Sascha / Andrews, TaraLee (2016): „Bearbeitung und Annotationhistorischer Texte mittels Graph-Datenbankenam Beispiel der Chronik des Matthias vonEdessa“, in: DHd 2016: Modellierung - Vernetzung- Visualisierung 176–178 http://dhd2016.de/boa.pdf [letzter Zugriff 20. August 2016].
Kuczera, Andreas (2015):„Graphdatenbanken für Historiker. Netzwerkein den Registern der Regesten KaiserFriedrichs III. mit neo4j und Gephi“, in:Mittelalter. Interdisziplinäre Forschung undRezeptionsgeschichte, 5. Mai 2015, http://mittelalter.hypotheses.org/5995 (ISSN 2197-6120)[letzter Zugriff 20. August 2016].
Matschinegg, Ingrid (2004): „REALonline– IMAREAL's Digital Image-Server“, in: [Enterthe Past]. The E-way into the Four Dimensionsof Cultural Heritage. CAA 2003 | ComputerApplications and Quantitative Methods inArchaeology | Proceedings of the 31st Conference,Vienna, Austria, April 2003 (BAR InternationalSeries 1227). Oxford: archaeopress, 214-216.
Nicka, Isabella (2014): „Interfaces.Berührungszonen von Transzendenz undImmanenz im spätmittelalterlichen Sakralraum“,in: Meyer, Marion / Klimburg-Salter, Deborah(eds.): Visualisierungen von Kult. Wien / Köln /Weimar: Böhlau, 260-293, Abb. auf 438-444.
Nicka, Isabella (im Erscheinen):„REALonline–Explore and Find Out. Wohin führtdas Digitale die Kunstgeschichte?“, Beitrag zumTagungsband der vom 6.-8. Nov. 2015 in Wienabgehaltenen Konferenz „Newest Art History“.Wohin geht die jüngste Kunstgeschichte?
Raspe, Martin (2014): Zuccaro. Ein modernes,konfigurierbares Informationssystem für dieGeisteswissenschaften. http://zuccaro.biblhertz.it/dokumentation/zuccaro [letzter Zugriff 20.August 2016].
Thaller, Manfred (1980): „Descriptor:Probleme der Entwicklung eines
114

Digital Humanities im deutschsprachigen Raum 2017
Programmsystems zur computerunterstütztenAuswertung mittelalterlicher Bildquellen“,in: Europäische Sachkultur des Mittelalters:Gedenkschrift aus Anlaß des 10jährigenBestehens des Instituts für mittelalterlicheRealienkunde Österreichs (Veröffentlichungendes Instituts für mittelalterliche RealienkundeÖsterreichs 4 / Sitzungsberichte der Akademieder Wissenschaften, Phil.-Hist. Klasse 374).Wien: Verlag der Österreichischen Akademie derWissenschaften, 167–194.
Thaller, Manfred (1989): Κλειώ. EinDatenbanksysten. Halbgraue Reihe zurhistorischen Fachinformatik B1. St. Katharinen:Scripta Mercaturae Verlag.
Datenvisualisierung alsAisthesis
Gius, [email protected]ät Hamburg, Deutschland
Kleymann, [email protected]ät Hamburg, Deutschland
Meister, Jan [email protected]ät Hamburg, Deutschland
Petris, [email protected]ät Hamburg, Deutschland
Visualisierung als Expansion
Jede/r DH-Praktiker/in weiß:Computergestützte Forschung in denGeisteswissenschaften beginnt mit derÜbersetzung relevanter Phänomene in digitaleDaten. Seltener thematisiert wird dagegen,dass die digitale Operationalisierung (Moretti2013) ein wichtiges Gegenstück am Endedes Forschungsprozesses hat: Die digitaleRepräsentation des Untersuchungsgegenstandeswie das generierte Daten-Output müssen ineine nicht-algorithmisierte Form gebrachtwerden, um überhaupt sinnvoll von Menschenverstanden und weiter bearbeitet werden zukönnen. Für diesen Prozess der Rückübersetzung
hat Goodings (2003) das Konzept der Expansioneingeführt. 1
Derartige Expansionsverfahren systematischzu beschreiben, ist in den Geisteswissenschaften2 schwierig, besitzen Primär- und Metadaten3 hier doch meist komplexe und teils sogarexponentiell expandierende Datenstrukturen.Mehr noch: Forschungsfragen, die dengeisteswissenschaftlichen Erkenntnisprozessmotivieren, sind typischerweisemultidimensional; sie reflektieren Zustände,aber zugleich auch historische Abläufe undBezüge; sie interagieren i.d.R. dynamischmit dem Erkenntnisinteresse. Das machtModellierungen wie Datenanalysen um einVielfaches aufwendiger – und dies nicht nur fürden Computer, der die primären Eingabedatenverarbeitet und neue sekundäre Daten generiert,sondern vor allem für die Forscher/innen,die beide Datentypen wieder miteinanderabgleichen und für ihren Erkenntnisprozessfruchtbar machen wollen.
Visualisierungen gelten heutedisziplinübergreifend als probates Mittel der“Expansion” schwer überschaubarer Primär-und Sekundärdaten in intuitiv erfassbarer Form(Goodings 2003:281). In der disziplinspezifischenPerspektive ist allerdings zugleich zu fordern,dass den methodologischen Besonderheitender Humanities Rechnung getragen wird.4 Drei spezifische Merkmale sind hier zuberücksichtigen:
Geisteswissenschaftliche Verstehensprozessesind grundsätzlich organisiert alsfortlaufende, dynamische Iteration vonempirisch-analytischen und theoretisch-modellierenden Operationen.
GeisteswissenschaftlicheInterpretationsverfahren sind in derRegel ebenfalls nicht als unilineare‘Auslegungen’ konzipiert, sondern wirkenauf die Ausgangsdaten zurück, indemsie diese anreichern, relativieren oderrekonfigurieren.
Geisteswissenschaftliche Verstehensprozessesind nicht nur in hohem Maßekontextsensitiv, sondern zudem reflexiv:Verstanden werden will nicht nur das jegegebene Untersuchungsobjekt, sondernverstanden werden sollen auch (und inDisziplinen wie der Literaturwissenschaftoder der Philosophie mitunter sogar primär)die Bedingungen und Möglichkeiten desVerstehensprozesses selbst.
115

Digital Humanities im deutschsprachigen Raum 2017
Datenvisualisierungen, die als visuelleExpansionsverfahren geisteswissenschaftlichfunktional sein sollen, müssen diese dreiProzessmerkmale in Form von methodischenwie technischen Spezifikationen abbilden.Sie müssen vor allen Dingen aber auch voneinem übergreifenden Visualisierungskonzeptangeleitet werden, das epistemologischausgerichtet ist und danach fragt, auf welcheArt von Erkenntnis die Geisteswissenschafteneigentlich zielen.
Trotz der großen Vielfalt anbestehenden Visualisierungstools undVisualisierungsmetaphern gibt es allerdingsbislang kein derartiges, theoretisch reflektiertesVisualisierungskonzept, das von einerTypologie der Forschungsfragen wie dermethodischen Logik geisteswissenschaftlicherForschungsprozesse her entworfen wäre.Digitale Visualisierungslösungen werdenvielmehr von den Geisteswissenschaftenunhinterfragt aus anderenVerwendungskontexten importiert (z. B.Kreisdiagramme, Verlaufskurven, ScatterPlots etc. aus der Statistik) oder bestenfalls alsein ‚irgendwie‘ erstaunlich funktionales Toolangenommen (z. B. Word Clouds). Das aber hatzur Folge, dass die Verstehensmöglichkeiten derGeisteswissenschaften von den je gewählten,vielfach aus evidenzzentriert verfahrendenDisziplinen übernommenen visuellenMetaphern determiniert werden. 5
Zur Entwicklung einervisuellen Grammatikfür hermeneutischeVerstehensprozesse
Grundlagen: Interaktivitätund methodische Passung
Gegenstand des Projekts “3DH– dreidimensionale dynamischeDatenvisualisierung und Exploration fur DigitalHumanities-Forschungen” ist die Entwicklungund prototypische Implementierung einessolchen Konzepts der geisteswissenschaftlichenDatenvisualisierung. 6 Mit der ‘drittenDimension’ ist dabei nicht primär die räumlichez-Achse gemeint, sondern grundsätzlicherdie einer konzeptionellen ‘Achse’, die denmethodologischen Erfordernissen derGeisteswissenschaften Rechnung trägt.
Grundlegendstes dieser Erfordernisseist, die bildhafte Veranschaulichungvon Daten konsequent bi-direktional zudenken. Die interaktive Exploration 7
geisteswissenschaftlicher Datenkomplexe istdeshalb methodische Leitidee für das im Projektentwickelte Visualisierungskonzept. Konkretheißt dies: Der Bildschirm muss vom bloßenRenderer zum Two Way Screen werden, der nichtnur Daten und Datenstrukturen als visuellesOutput darstellt, sondern umgekehrt auchderen interaktive Manipulation und Analyseermöglicht. Damit wird der hermeneutischenAnalyse- und Interpretationspraxis Rechnunggetragen, in der Verstehen ein “produktivesVerhalten” ist (Gadamer 1972:280).
Zweites Erfordernis ist, dass hermeneutischfunktionale Visualisierungen neben generischenAnforderungen auch die Besonderheitengeisteswissenschaftlicher Praxis in denEinzeldisziplinen berücksichtigen. Fürderen je spezifische Datentypen undModi der Datenaggregation sind nebengeeigneten visuellen Metaphern insbesonderedisziplinspezifische Verfahren der Daten-Manipulation und -Konfiguration zu bestimmen,die technisch als interaktive Manipulation vonVisualisierungen umgesetzt werden können, umdatenbasierte Forschungszugänge zu eröffnenund zu unterstützen.
Das skizzierte Spannungsverhältnis zwischenden allen Geisteswissenschaften gemeinsamenund den disziplinspezifischen Anforderungen aneine visuelles ‘Expansionskonzept’ hat Grinstein(2012) zur Formulierung einer ‘grand challenge’motiviert:. Er fordert ein Visualisierungssystem,das auf disziplinspezifische Anforderungenreagiert und die in Hinblick auf die jeweiligeForschungsfrage wie die verfügbaren Datenoptimale Visualisierungslösung automatischgenerieren kann. Diese Vision mag zwar inder Tat ‘grand’ und unter dem Gesichtspunktder Implementierbarkeit utopisch anmuten;als konzeptionelle Messlatte für das 3DHProjekt ist sie dennoch richtig. Denn nurVisualisierungslösungen, die den systematischenZusammenhang zwischen den methodischenAnforderungen eines Forschungsvorhabensund den objektspezifischen Eigenschaften derin diesem Kontext erhobenen und generiertenDaten konzeptionell reflektieren, habenzumindest eine theoretische Chance, die vonGrinstein verlangten ‘Passungen’ automatisch zuermitteln. 8
116

Digital Humanities im deutschsprachigen Raum 2017
Vorgehen und ersteErgebnisse
Das 3DH-Projekt erforscht denPhänomenbereich ‘Datenvisualisierung’ vordiesem Hintergrund unter drei systematischenAspekten, nämlich
(1) einer Typologie hermeneutischerRoutinen, Bedingungen und Zielsetzungendes begriffsorientierten (d.h. natürlich-bzw. fachsprachlich artikulierten)Interpretierens von Daten, die in ihrer für dengeisteswissenschaftlichen Verstehensprozesskennzeichnenden Ausprägung zu definierensind;
(2) einer Syntax grafischer Strategien, die –je nach Kontextbedingung und Prozessphase –die ‘bottom up’-definierten Grundlagen für einerkenntnisproduktives visuelles ‘mapping’ dervorgenannten hermeneutischen Operationenauf die jeweils behandelten Primär- undSekundärdatensets bereitstellen; und
(3) einer nach Designprinzipien geordnetenTaxonomie konkreter Visualisierungstypen,die als ‘top-down’-Determinanten undepistemologische Paradigmen aufgefasst werdenkönnen. Die Designprinzipien werden ihrerseitsnicht auf die Funktion der bloßen Steuerungvisueller Datenrepräsentation am Ende einesgeisteswissenschaftlichen Arbeitszyklusreduziert; sie sollen vielmehr als eigenständige,komplementäre Verfahren nicht-sprachlicher,bildgebundener Verstehensoperationenaufgefasst werden.
Die Bearbeitung der drei Aspekte soll nebender theoretischen Konzeptentwicklung auchzur Erarbeitung einer visuellen Grammatik fürgeisteswissenschaftliche Datenvisualisierungführen.
Im ersten Schritt haben wir eine Reiheexemplarischer Use Cases der DH-Forschung9 betrachtet. In Anlehnung an Unsworths‘scholarly primitives’ (Unsworth 2000)wurde untersucht, welche epistemologischenPrinzipien dabei für die Deutung und interaktiveBearbeitung von geisteswissenschaftlichenDaten wichtig waren. Diese Prinzipien könnentabellarisch als Gegensatzpaare dargestelltwerden:
Unreliability(inconsistency)
Reliability
Contradiction ConsentAmbiguity DefinitenessUncertainty PlausibilityIncompleteness (partialknowledge)
Comprehensiveness
Analogy IdentityProbability FactualitySalience Speculativeness
Tabelle 1: epistemologische GegensatzpaareJedes dieser Gegensatzpaare markiert
eine Dimension hermeneutischer Praxis,in der datenbasierte Erkenntnisprozesse inder Regel nicht auf normativ geregelte finiteAuslegungen von Bedeutung und Wert, sondernauf kontextsensitive, skalierte dynamischeZuschreibungen von Informationsgehalt undRelevanz abzielen.
Als epistemologische Matrix bildet dieseTabelle zugleich die Grundlage für dieEntwicklung einer ‘Grammar of Graphics’ inAnlehnung an Bertin (1983) und Wilkinson(2005). Wie von Satyanarayan et al. (2016)vorgeschlagen, müssen diese Ansätzeallerdings um den Aspekt der Interaktivitäterweitert werden. Graphische Merkmalesollen entsprechend durch sog. “Aktivatoren”visuell modalisierbar werden. 10 DerGrad an Unsicherheit einer spezifischenhermeneutischen Zuschreibung könntez.B. visuell ausgedrückt werden, indem amBildschirm nachträglich – also erst im Zuge dergeisteswissenschaftlichen Dateninterpretation– die Transparenz einer Grafik interaktivmanipuliert und zugleich als Datenwert in derzugrundeliegenden Datentabelle erfasst wird.
Die so erweiterte visuelle Grammatiksoll in eine Notation überführt werden, diemöglichst allgemein verständlich, generischund unabhängig von einer bestimmtenProgrammiersprache implementierbar seinmuss; aufgrund der großen Verbreitungvon XML in den Digital Humanities isteine zusätzliche XML-Notation geplant.Daneben sollen für eine Reihe exemplarischerhermeneutischer Verstehens- undInterpretationsprozesse die systematischenZusammenhängen zwischen Datenstrukturenund geeigneten Visualisierungsprinzipienerforscht und adäquate Vorschläge für eine(oder mehrere) Visualisierungen erarbeitetwerden.
Die Implementierung der entwickeltenVisualisierungen wird eine webbasierte
117

Digital Humanities im deutschsprachigen Raum 2017
Browser-Anwendung sein, die kollaborativesArbeiten ermöglicht und über ein WebService Interface mit anderen Systemenverbunden werden kann. Die Spezifikationder Visualisierungen mit Hilfe einer von einerGrafik-Engine unabhängigen Grammatik erlaubtprinzipiell beliebige Ausgabeformate. Aufgrundder Interaktivität und Webfähigkeit ist zunächstSVG als Format geplant.
Ausblick
Auch wenn die weiteren Schritte zurErarbeitung der visuellen Grammatikund der prototypischen Implementierunggeisteswissenschaftlich funktionalerVisualisierungsansätze vorgezeichnet scheinen:Die Frage nach der methodischen Adäquatheitdes Vorgehens bleibt für unser Vorhabenweiterhin virulent.
So stehen bei den epistemologischenGegensatzpaaren in Tabelle 1 bislanglogische Gegensätze des Typs A und non-A (z. B. Reliablity vs. Unreliability) undphänomenologische Gegensätze (z. B. Probabilityvs. Factuality) nebeneinander. Noch ist nichtgeklärt, ob es sich hier um Kategorienfehlerim analytischen Sinne handelt, oder obnicht gerade dieses Nebeneinanderstehenkategorial unterschiedlicher Konzeptedem hermeneutischen Prozess gerechtwird. Welche Konsequenzen hätte es zumBeispiel für ein geisteswissenschaftlichesVisualisierungskonzept, wenn sichstrikt logische, binäre Modellierungenhermeneutischer Prozesse sogar als prinzipiellungeeignet erweisen?
Unter diesem kritischen Vorbehalt erscheinenzum einen konkrete, etablierte visuelleVerfahren in einem neuen Licht. Kann zumBeispiel Shneidermans (1996) bekanntesOverview, Zoom, Details on Demand-Mantra fürdas geisteswissenschaftliche Arbeiten, das aufexemplarisches Sinnverstehen und nicht aufmöglichst solide fundierte empirische Übersichtausgerichtet ist, überhaupt Gültigkeit besitzen?
Erst das Nachdenken über die Erfordernisseeines geisteswissenschaftlichen Visualisierungskonzepts macht es zum anderen möglich, dieepistemologische Funktion von Visualisierungenjenseits der bloßen Repräsentation vonDatenpunkten auf einem Bildschirm zubegreifen. So gesehen steht die Praxisder Visualisierung als Expansion bzw.‘Rückübersetzung’ und als Vermittlung zwischenAbstraktion und Phänomenologie in derphilosophischen Tradition der Aisthesis - ein
Aspekt, auf den Wilkinson (2005:1) verweist,wenn er feststellt: “Aesthetics, in the originalGreek sense, offers principles for relatingsensory attributes (color, shape, sound, etc.) toabstractions.”
Fußnoten
1. vgl. Goodings (2003:281): „Having reducedsome aspect of the world to a form that can beprocessed according to rules, the output of thecomputation needs to be reintroduced into theworld of meaningful, human action. [...] Thisinvolves translating the output into a familiarnotational system and, in some cases, restoringmore basic sensory modes of apprehension,as in the case of data visualization or thephenomenology of a thought experiment. [...]Instead of looking for cognitive capacities of thesort required by an algorithmic view of scienceas rule-based reasoning about an inherentlydigitizable world, we should investigate thosecognitive capacities that enable practitionersfrom different cultures to exchange meaningsand methods.“2. Wir betrachten die Geisteswissenschaftennicht als Gegensatz zu den Naturwissenschaftenoder Informationswissenschaften, sonderngehen vielmehr von einem Kontinuum aus,das sich zwischen den Polen Subjektivität/Einmaligkeit/Besonderheit und Objektivität/Reproduzierbarkeit/Allgemeingültigkeitentfaltet. Die Wechselwirkung zwischenBeobachtenden und Beobachtetem spieltnicht nur in der geisteswissenschaftlichenHermeneutik oder den Sozialwissenschaften(z. B. in Kontext der Feldforschung),sondern auch in den eher als “objektiv”wahrgenommenen Naturwissenschafteneine Rolle, etwa in der Beobachtung vonHeisenberg, dass sich die Wellenfunktion in derQuantenmechanik durch unsere Beobachtungändert (Heisenberg 1959:37). Entsprechend sinddie Ausführungen in diesem Beitrag potenziellfür alle Wissenschaften bzw. Fragestellungenrelevant, in denen hermeneutische oder analogePrinzipien gelten.3. Als Daten verstehen wir alle multimedialenbzw. intermedialen Primärdaten sowie dasGesamtspektrum an Meta- und Sekundärdatenund Verweisen, die auf diese referieren.4. vgl. zu den speziellen Anforderungen fürVisualisierungen in den Geisteswissenschaftenz. B. Stone (2009) und Drucker (2011), sowieWindhager (2013) für einen Ansatz zurUmsetzung der Anforderungen.
118

Digital Humanities im deutschsprachigen Raum 2017
5. Auch generalisierende Beiträge zurVisualisierung – wie etwa Ward et al. (2010) –klammern die disziplinär-methodischen Fragenaus, die mit der Visualisierung verbundensind. In der Visualisierungscommunity setztsich allerdings langsam das Bewusstseinum die Spezifik geisteswissenschaftlicherDaten durch. So stellen etwa die Organisator/innen des Workshop on Visualization for theDigital Humanities im Kontext der IEEE VIS2016-Konferenz fest: „Despite the growingpopularity of digital methods for researchin the humanities, digital humanists areunderserved by academics in visualization,and under-represented in visualizationconferences”. Diesen Mangel machen sie indisziplinären Unterschieden fest, die durchdie interdisziplinäre Kommunikation über dieBedarfe der Geisteswissenschaften adressiertwerden sollen [vgl. http://vis4dh.com/ , gesehenam 18.08.2016].6. Das Projekt “3DH – dreidimensionaledynamische Datenvisualisierung undExploration fur Digital Humanities-Forschungen” wird in der ersten Projektphase(02/2016-01/2019) von der Behörde fürWissenschaft, Forschung und Gleichstellunggefördert. Für weitere Informationen vgl.www.threedh.net [gesehen am 18.08.2016].7. Vgl. Sinclair et al. (2013:2) zur Rolle voninteraktiven Visualisierungen: „Interactivevisualizations [...] aim to explore availableinformation, often as part of a process that isboth sequential and iterative. That is, some stepscome before others, but the researcher mayrevisit previous steps at a later stage and makedifferent choices, informed by the outcomesproduced in the interim.“8. Vgl. dazu auch Culy (2013), der Grinsteins‘grand challenge’ einschätzt als „worth takingas a point of departure for the visualization oflanguage and linguistic data.”9. Bei den Use Cases handelt es sich uminsgesamt fünf laufende oder abgeschlosseneDH-Forschungsprojekte der Projektmitglieder,die in der Gruppe intensiv im Hinblick aufdie tatsächliche und mögliche Rolle vonVisualisierungen im Forschungsprozessdiskutiert wurden.10. Diese graphischen Aktivatoren sind: tone(white to black/brightness), value (saturation),color (hue), transparency, texture, shape,orientation, position, size, resolution, blur,direction of motion, rate of movement,acceleration, rate of change, duration, form,surface, motion, sound (tone, volume, rhythm),voice, text.
Bibliographie
Bertin, Jacques (1983): Semiology of Graphics.University of Wisconsin Press.
Coles, Katharine (2016): Show Ambiguity.Workshop on Visualization for the DigitalHumanities at IEEE VIS 2016. http://vis4dh.com/papers/Show%20Ambiguity%20Collaboration%20Anxiety%20and%20the%20PLeasures%20of%20Unknowing.pdf [letzter Zugriff 3. November2016].
Culy, Chris (2013): „Tackling a grandchallenge in the visualization of language andlinguistic data“, in: DGfS 2013 Workshop onthe Visualization of Linguistic Patterns. http://ling.uni-konstanz.de/pages/home/hautli/LINGVIS/dgfs13_culy_abstract.pdf [letzter Zugriff 17.November 2016].
Drucker, Johanna (2011): „HumanitiesApproaches to Graphical Display“, in:DHQ: Digital Humanities Quarterly 5(1). http://digitalhumanities.org/dhq/vol/5/1/000091/000091.html [letzter Zugriff 17.November 2016].
Gadamer, Hans Georg (1972): Wahrheitund Methode. Grundzüge einer philosophischenHermeneutik 3. Aufl. Tübingen: Mohr.
Gooding, David (2003): „Varying theCognitive Span: Experimentation, Visualisation,and Computation“, in: Radder, Hans (ed.):The Philosophy of Scientific Experimentation.Pittsburgh, PA: University of Pittsburgh Press255–283.
Grinstein, Georges (2012): „New GrandChallenges in Information Visualization: NewTheories, New Devices, and New Capabilities“ in:Keynote address at iV2012.
Heisenberg, Werner (1959): Physik undPhilosophie. Stuttgart: Hirzel.
Moretti, Franco (2013): „Operationalizing“,in: New Left Review 84. https://newleftreview.org/II/84/franco-moretti-operationalizing [letzterZugriff 30. November 2016].
Satyanarayan, Arvind / Dominik Moritz /Kanit Wongsuphasawat / Jeffrey Heer (2017):„Vega-Lite: A Grammar of Interactive Graphics“,in: IEEE Transactions on Visualization andComputer Graphics 23 (1): 341–50 10.1109/TVCG.2016.2599030.
Shneiderman, Ben (1996): „The eyes have it:a task by data type taxonomy for informationvisualizations“, in: Proceedings of the IEEESymposium on Visual Languages. IEEE ComputerSociety Press, 336–43.
Sinclair, Stéfan / Ruecker, Stan /Radzikowska, Milena (2013): „InformationVisualization for Humanities Scholars“, in: Price,
119

Digital Humanities im deutschsprachigen Raum 2017
Kenneth M. / Siemens, Ray (eds.) Literary Studiesin the Digital Age: An Evolving Anthology. NewYork: Modern Language Associaton. https://dlsanthology.commons.mla.org/information-visualization-for-humanities-scholars/ [letzterZugriff 17. November 2016].
Stone, Mareen (2009): „InformationVisualization: Challenge for the Humanities“, in:Working together or apart: Promoting the nextgeneration of digital scholarship. Washington, DC:Council on Library and Information Resources43-56 https://www.clir.org/pubs/resources/promoting-digital-scholarship-ii-clir-neh/stone11_11.pdf [letzter Zugriff 17. November2016].
Unsworth, John (2000): „Scholarly Primitives:what methods do humanities researchers havein common, and how might our tools reflectthis?“, in: Symposium on Humanities Computing:formal methods, experimental practice. http://www.people.virginia.edu/~jmu2m/Kings.5-00/primitives.html [letzter Zugriff 17. November2016].
Ward, Matthew / Grinstein, Georges / Keim,Daniel (2010): Interactive data visualization:foundations, techniques, and applications. Natick,Mass.: Peters.
Windhager, Florian (2013): „On Polycubism.Outlining a Dynamic Information VisualizationFramework for the Humanities and SocialSciences“, in: Füllsack, Manfred (ed.): NetworkingNetworks: Origins, Applications, Experiments.Wien; Berlin: Turia + Kant 28–63.
„Der Helmut Kohl unterden Brotaufstrichen“.Zur ExtraktionvossianischerAntonomasien ausgroßen Zeitungskorpora
Jäschke, [email protected] of Sheffield
Strötgen, [email protected] für Informatik, Saarbrücken
Krotova, [email protected] School of Economics, Moskau
Fischer, [email protected] School of Economics, Moskau
Einführung undForschungslage
Wenn Peter Paul Rubens als »Tarantino desBarock« beschrieben wird (im Tagesspiegel,2014) oder Alice Schwarzer als der »ErichHonecker des Feminismus« (in Cicero,2014), dann handelt es sich um eineVossianische Antonomasie. Diese Trope istnach dem niederländischen Humanisten undRhetoriklehrer Vossius benannt (und wirdim Folgenden als ›Vossanto‹ abgekürzt, inAnlehnung an den Vorschlag von Fischer/Wälzholz 2014). Generell spricht man vonAntonomasie, wenn eine bestimmte Eigenschafteiner Person für diese selbst steht (z. B. »derLeimener« für Boris Becker). Beim Spezialfallder Vossanto wird einer Person über dieNennung einer anderen (bekannteren,populäreren, berüchtigteren) Person alsReferenzgröße eine bestimmte Eigenschaftzugeschrieben. Dabei sorgt ein »untypologisches,aktualisierendes Signal« (Lausberg 1960)für den Bedeutungstransfer (in den obengenannten Beispielen wären dies der Barockund der Feminismus). Anders ausgedrückt:Die Vossanto stellt über einen ›modifier‹ einenZusammenhang zwischen ›source‹ und ›target‹her (Bergien 2013). Entitäten können sowohl als›source‹ als auch als ›target‹ auftreten, wie ebd.am Beispiel Obama demonstriert: bis 2011 trater in Vossantos vor allem als ›target‹ auf, danachdiente er immer mehr als ›source‹. Die ›source‹-Referenz wird im Fachdiskurs im Anschluss anLakoff 1987 auch als ›paragon‹ bezeichnet (»aspecific example that comes close to embodyingthe qualities of the ideal«, ebd.).
Der Begriff »Vossianische Antonomasie«wird international kaum verwendet, stattdessenwird etwa zwischen »Antonomasia1« und»Antonomasia2« unterschieden: »metonymic«vs. »metaphorical antonomasia« (Holmqvist/Płuciennik 2010). Innerhalb diesesKlassifikationsschemas wäre unsere Vossantoein Spezialfall von »Antonomasia2«, nämlichwenn es um »comparisons with paragonsfrom other spheres of culture« geht: »Lyotard
120
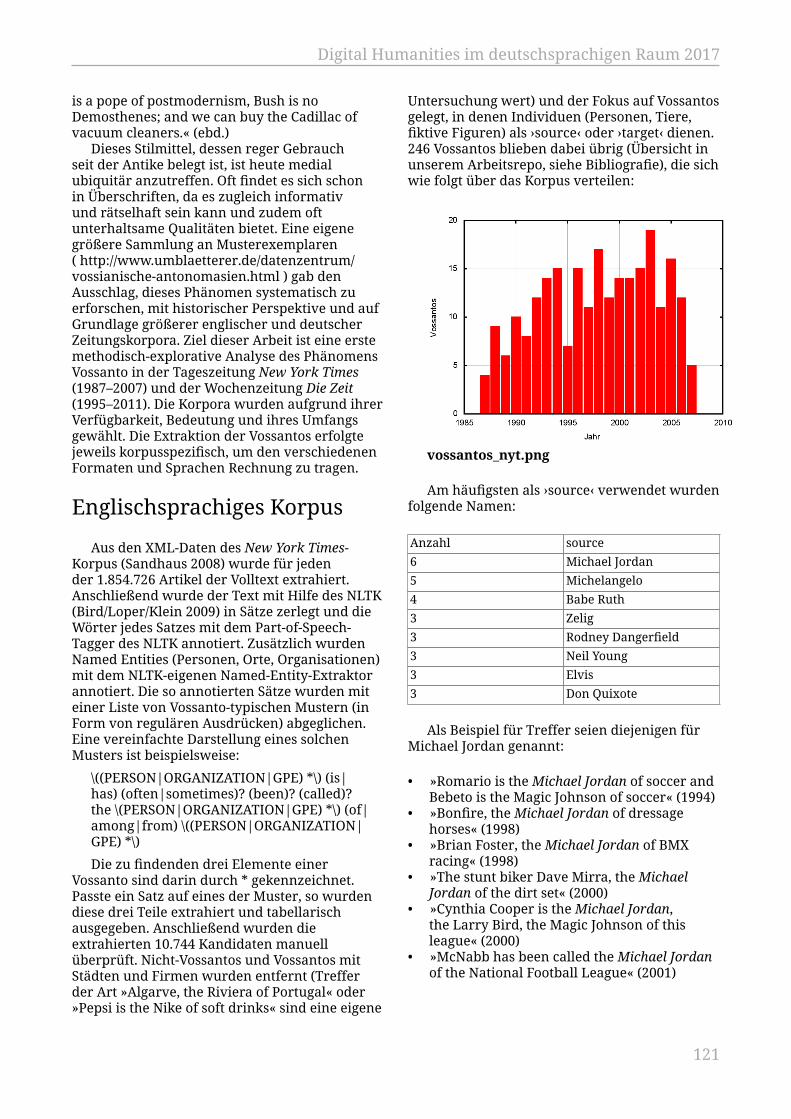
Digital Humanities im deutschsprachigen Raum 2017
is a pope of postmodernism, Bush is noDemosthenes; and we can buy the Cadillac ofvacuum cleaners.« (ebd.)
Dieses Stilmittel, dessen reger Gebrauchseit der Antike belegt ist, ist heute medialubiquitär anzutreffen. Oft findet es sich schonin Überschriften, da es zugleich informativund rätselhaft sein kann und zudem oftunterhaltsame Qualitäten bietet. Eine eigenegrößere Sammlung an Musterexemplaren( http://www.umblaetterer.de/datenzentrum/vossianische-antonomasien.html ) gab denAusschlag, dieses Phänomen systematisch zuerforschen, mit historischer Perspektive und aufGrundlage größerer englischer und deutscherZeitungskorpora. Ziel dieser Arbeit ist eine erstemethodisch-explorative Analyse des PhänomensVossanto in der Tageszeitung New York Times(1987–2007) und der Wochenzeitung Die Zeit(1995–2011). Die Korpora wurden aufgrund ihrerVerfügbarkeit, Bedeutung und ihres Umfangsgewählt. Die Extraktion der Vossantos erfolgtejeweils korpusspezifisch, um den verschiedenenFormaten und Sprachen Rechnung zu tragen.
Englischsprachiges Korpus
Aus den XML-Daten des New York Times-Korpus (Sandhaus 2008) wurde für jedender 1.854.726 Artikel der Volltext extrahiert.Anschließend wurde der Text mit Hilfe des NLTK(Bird/Loper/Klein 2009) in Sätze zerlegt und dieWörter jedes Satzes mit dem Part-of-Speech-Tagger des NLTK annotiert. Zusätzlich wurdenNamed Entities (Personen, Orte, Organisationen)mit dem NLTK-eigenen Named-Entity-Extraktorannotiert. Die so annotierten Sätze wurden miteiner Liste von Vossanto-typischen Mustern (inForm von regulären Ausdrücken) abgeglichen.Eine vereinfachte Darstellung eines solchenMusters ist beispielsweise:
\((PERSON|ORGANIZATION|GPE) *\) (is|has) (often|sometimes)? (been)? (called)?the \(PERSON|ORGANIZATION|GPE) *\) (of|among|from) \((PERSON|ORGANIZATION|GPE) *\)
Die zu findenden drei Elemente einerVossanto sind darin durch * gekennzeichnet.Passte ein Satz auf eines der Muster, so wurdendiese drei Teile extrahiert und tabellarischausgegeben. Anschließend wurden dieextrahierten 10.744 Kandidaten manuellüberprüft. Nicht-Vossantos und Vossantos mitStädten und Firmen wurden entfernt (Trefferder Art »Algarve, the Riviera of Portugal« oder»Pepsi is the Nike of soft drinks« sind eine eigene
Untersuchung wert) und der Fokus auf Vossantosgelegt, in denen Individuen (Personen, Tiere,fiktive Figuren) als ›source‹ oder ›target‹ dienen.246 Vossantos blieben dabei übrig (Übersicht inunserem Arbeitsrepo, siehe Bibliografie), die sichwie folgt über das Korpus verteilen:
vossantos_nyt.png
Am häufigsten als ›source‹ verwendet wurdenfolgende Namen:
Anzahl source6 Michael Jordan5 Michelangelo4 Babe Ruth3 Zelig3 Rodney Dangerfield3 Neil Young3 Elvis3 Don Quixote
Als Beispiel für Treffer seien diejenigen fürMichael Jordan genannt:
• »Romario is the Michael Jordan of soccer andBebeto is the Magic Johnson of soccer« (1994)
• »Bonfire, the Michael Jordan of dressagehorses« (1998)
• »Brian Foster, the Michael Jordan of BMXracing« (1998)
• »The stunt biker Dave Mirra, the MichaelJordan of the dirt set« (2000)
• »Cynthia Cooper is the Michael Jordan,the Larry Bird, the Magic Johnson of thisleague« (2000)
• »McNabb has been called the Michael Jordanof the National Football League« (2001)
121

Digital Humanities im deutschsprachigen Raum 2017
Trotz der zeitlichen Einschränkungdes Korpus lassen sich bereits einigevielversprechende Beobachtungen anstellen undThesen bilden: 1. Produktive Referenzgrößeneiner Vossanto sind sowohl reale als auchfiktionale Figuren (Bsp. für letztere aus derobigen Liste: Woody Allens »Zelig«, Cervantes’»Don Quixote«). 2. Öffentliche Personenoder bekannte fiktionale Charaktere habenbestimmte Eigenschaften, die sie für dieVerwendung als Referenzgröße einer Vossantoprädestinieren oder nicht (es bleibt etwa zuerforschen, warum gerade Michael Jordanund Michelangelo sich so gut eignen undnicht andere Sportler bzw. Künstler). 3. Esgibt historisch stabile Referenzgrößen, derenBekanntheit vorausgesetzt werden kann(z. B. Michelangelo), und es gibt ephemereReferenzgrößen, die ab irgendeinem Zeitpunktnicht mehr als Bezugspunkt taugen (für dasbenutzte zeitgenössische Korpus eher noch nichtrelevant).
Deutschsprachiges Korpus
Das deutsche Datenset besteht aus einerSammlung des Archivs der Wochenzeitung DieZeit und enthält die Artikel aus den Jahren 1995bis 2011. Insgesamt umfasst das Korpus 126.702Dokumente.
Zunächst wurden die Volltexte (inklusiveÜberschriften) aller Dokumente extrahiert.Diese wurden dann mit Hilfe des Part-of-Speech-Taggers und Named-Entity-Recognition-Toolsdes Stanford CoreNLP Package verarbeitet. Fürdie Analyse deutschsprachiger Texte enthältStanford CoreNLP speziell für das Deutschetrainierte Modelle (Faruqui und Pado 2010).Somit können alle Texte auf drei Ebenenuntersucht werden: auf der Wortebene, derPart-of-Speech-Ebene sowie der Named-Entity-Ebene. Mithilfe von regulären Ausdrücken,die auf den verschiedenen Ebenen angewandtwerden können, wurde dann nach Vossanto-Mustern gesucht. Im Gegensatz zur Verarbeitungdes englischsprachigen Korpus wurde jedochnoch nicht versucht, auch das ›target‹ einerVossanto zu extrahieren. Stattdessen wurdenMuster entworfen, die das ›source‹-Objektsowie das »aktualisierende Signal« matchen.Ausschlaggebend für diese Herangehensweisewaren die in einem Testdurchlauf beobachtetehohe Anzahl an Vossantos ohne unmittelbarenVerweis auf das ›target‹ sowie eine große Vielfaltan möglichen Formulierungen, die auf dieRelation zum ›target‹ hinweisen können. Mithilferelativ strikter Regeln konnte die Anzahl an
falschen Extraktionen im Rahmen gehaltenwerden. Ein vereinfachtes Beispiel für eineExtraktionsregel lautet etwa: »eine Art PERSON(der|des) (ADJECTIVE)? NOUN«.
Die Produktivität der beiden häufigstenReferenznamen des NYT-Korpus bestätigtsich im verwendeten deutschen Korpus, etwawenn vom »Michael Jordan der analytischenPhilosophie« die Rede ist ( Die Zeit 44/1999) odervom »bulgarischen Michelangelo« ( Die Zeit14/2001). Ansonsten scheint es sprachen- bzw.kulturspezifische Präferenzen zu geben. Diehäufigsten ›sources‹ sind:
Anzahl source9 Robin Hood6 Bill Gates4 Franz Beckenbauer3 Daniel Düsentrieb3 Heinz Rühmann3 James Dean3 Jesus Christus3 Norbert Blüm3 Willy Brandt
Ähnlich wie im NYT-Korpus ist erkennbar,wie stark typisierend mythische bzw. fiktiveFiguren sind (Robin Hood, Daniel Düsentrieb).Daneben zeigt sich, dass »Bill Gates«, der imNYT-Korpus nur zweimal als ›source‹ einerVossanto vorkommt, im Zeit-Korpus sechs Malals Referenz vertreten ist:
• »eine Art Bill Gates des Stolperns« (1998)• »Der Bill Gates von Aurich« (2001)• »der Bill Gates von Ostfriesland« (2001)• »der Bill Gates von Aurich« (2002)• »der britische Bill Gates« (2008)• »der Bill Gates von Estland« (2010)
Die wiederholte Verwendung des »Bill Gatesvon Aurich« zeigt, wie stark ein ›target‹ miteiner ›source‹ verwachsen kann. (Paradebeispielhierfür ist im Übrigen Vittorio Hösle, »der BorisBecker der Philosophie«, eine Bezeichnung,die es bis in den Wikipedia-Artikel zu Höslegeschafft hat.) Am Beispiel Bill Gates’ lässt sichwie zuvor am Beispiel Obama demonstrieren,dass ein Name sowohl als ›target‹ als auch als›source‹ vorkommen kann. Bevor Bill Gatesselbst als Referenz verwendet wird, wird er ineinem Artikel von 1995 noch durch eine anderePerson beschrieben: »Bill Gates ist der HenryFord des Computerzeitalters«.
122
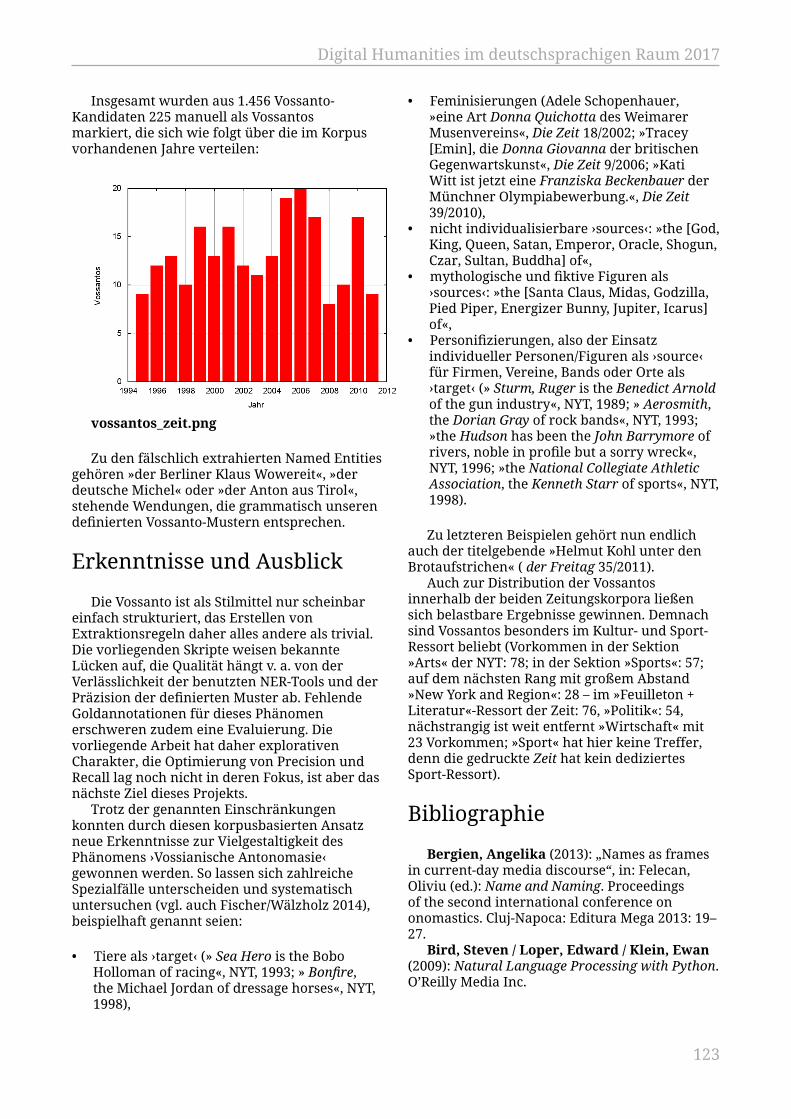
Digital Humanities im deutschsprachigen Raum 2017
Insgesamt wurden aus 1.456 Vossanto-Kandidaten 225 manuell als Vossantosmarkiert, die sich wie folgt über die im Korpusvorhandenen Jahre verteilen:
vossantos_zeit.png
Zu den fälschlich extrahierten Named Entitiesgehören »der Berliner Klaus Wowereit«, »derdeutsche Michel« oder »der Anton aus Tirol«,stehende Wendungen, die grammatisch unserendefinierten Vossanto-Mustern entsprechen.
Erkenntnisse und Ausblick
Die Vossanto ist als Stilmittel nur scheinbareinfach strukturiert, das Erstellen vonExtraktionsregeln daher alles andere als trivial.Die vorliegenden Skripte weisen bekannteLücken auf, die Qualität hängt v. a. von derVerlässlichkeit der benutzten NER-Tools und derPräzision der definierten Muster ab. FehlendeGoldannotationen für dieses Phänomenerschweren zudem eine Evaluierung. Dievorliegende Arbeit hat daher explorativenCharakter, die Optimierung von Precision undRecall lag noch nicht in deren Fokus, ist aber dasnächste Ziel dieses Projekts.
Trotz der genannten Einschränkungenkonnten durch diesen korpusbasierten Ansatzneue Erkenntnisse zur Vielgestaltigkeit desPhänomens ›Vossianische Antonomasie‹gewonnen werden. So lassen sich zahlreicheSpezialfälle unterscheiden und systematischuntersuchen (vgl. auch Fischer/Wälzholz 2014),beispielhaft genannt seien:
• Tiere als ›target‹ (» Sea Hero is the BoboHolloman of racing«, NYT, 1993; » Bonfire,the Michael Jordan of dressage horses«, NYT,1998),
• Feminisierungen (Adele Schopenhauer,»eine Art Donna Quichotta des WeimarerMusenvereins«, Die Zeit 18/2002; »Tracey[Emin], die Donna Giovanna der britischenGegenwartskunst«, Die Zeit 9/2006; »KatiWitt ist jetzt eine Franziska Beckenbauer derMünchner Olympiabewerbung.«, Die Zeit39/2010),
• nicht individualisierbare ›sources‹: »the [God,King, Queen, Satan, Emperor, Oracle, Shogun,Czar, Sultan, Buddha] of«,
• mythologische und fiktive Figuren als›sources‹: »the [Santa Claus, Midas, Godzilla,Pied Piper, Energizer Bunny, Jupiter, Icarus]of«,
• Personifizierungen, also der Einsatzindividueller Personen/Figuren als ›source‹für Firmen, Vereine, Bands oder Orte als›target‹ (» Sturm, Ruger is the Benedict Arnoldof the gun industry«, NYT, 1989; » Aerosmith,the Dorian Gray of rock bands«, NYT, 1993;»the Hudson has been the John Barrymore ofrivers, noble in profile but a sorry wreck«,NYT, 1996; »the National Collegiate AthleticAssociation, the Kenneth Starr of sports«, NYT,1998).
Zu letzteren Beispielen gehört nun endlichauch der titelgebende »Helmut Kohl unter denBrotaufstrichen« ( der Freitag 35/2011).
Auch zur Distribution der Vossantosinnerhalb der beiden Zeitungskorpora ließensich belastbare Ergebnisse gewinnen. Demnachsind Vossantos besonders im Kultur- und Sport-Ressort beliebt (Vorkommen in der Sektion»Arts« der NYT: 78; in der Sektion »Sports«: 57;auf dem nächsten Rang mit großem Abstand»New York and Region«: 28 – im »Feuilleton +Literatur«-Ressort der Zeit: 76, »Politik«: 54,nächstrangig ist weit entfernt »Wirtschaft« mit23 Vorkommen; »Sport« hat hier keine Treffer,denn die gedruckte Zeit hat kein dediziertesSport-Ressort).
Bibliographie
Bergien, Angelika (2013): „Names as framesin current-day media discourse“, in: Felecan,Oliviu (ed.): Name and Naming. Proceedingsof the second international conference ononomastics. Cluj-Napoca: Editura Mega 2013: 19–27.
Bird, Steven / Loper, Edward / Klein, Ewan(2009): Natural Language Processing with Python.O’Reilly Media Inc.
123

Digital Humanities im deutschsprachigen Raum 2017
Faruqui, Manaal / Pado, Sebastian (2010):„Training and Evaluating a German NamedEntity Recognizer with Semantic Generalization“,in: Proceedings of Konvens 2010.
Fischer, Frank / Wälzholz, Joseph (2014):„Jeder kann Napoleon sein: VossianischeAntonomasie: Eine Stilkunde“, in: FrankfurterAllgemeine Sonntagszeitung 51 (21. Dezember2014): 34 http://www.umblaetterer.de/wp-content/uploads/2014/12/vossanto_fas.png .
Holmqvist Kenneth / Płuciennik Jarosław(2010): „Princess antonomasia and thetruth: Two types of metonymic relations“,in: Burkhardt, Armin / Nerlich, Brigitte(eds.): Tropical Truth(s): The Epistemology ofMetaphor and Other Tropes. Berlin/New York: DeGruyter 373–381 10.1515/9783110230215.
Lakoff, George (1987): Women, Fire, andDangerous Things: What Categories Reveal aboutthe Mind. Chicago: The University of ChicagoPress.
Lausberg, Heinrich (1960): Handbuch derliterarischen Rhetorik. Eine Grundlegung derLiteraturwissenschaft 2. München: Hueber.
Sandhaus, Evan (2008): The New YorkTimes Annotated Corpus LDC2008T19. DVD.Philadelphia: Linguistic Data Consortium.
Arbeitsrepositorium: https://github.com/weltliteratur/vossanto
Folien zum Vortrag: https://lehkost.github.io/slides/2017-bern/
Die Impactomatrix –ein interaktiver Katalogfür Impactfaktorenund Erfolgskriterienfür digitaleInfrastrukuren in denGeisteswissenschaften
Thoden, [email protected] für Wissenschaftsgeschichte,Deutschland
Wintergrün, [email protected] für Wissenschaftsgeschichte,Deutschland
Stiller, [email protected]ät zu Berlin, Deutschland
Gnadt, [email protected]ächsische Staats- undUniversitätsbibliothek Göttingen, Deutschland
Meiners, [email protected]ächsische Staats- undUniversitätsbibliothek Göttingen, Deutschland
Einführung
Wissenschaftliche Großprojekte in denGeistes- und Kulturwissenschaften müssen sichdamit auseinandersetzen, welchen Mehrwertsie für die wissenschaftliche Communityschaffen, wie sie diesen sichtbar/messbarmachen und wie sie die in sie investiertenMittel nutzbringend verwenden. Ausgehenddavon war ein Forschungsziel in der erstenFörderphase von DARIAH-DE 1 , dezidiert für dieGeistes- und Kulturwissenschaften einsetzbareErfolgskriterien und Impactfaktoren für digitaleTools und Infrastrukturkomponenten zuerheben. Dabei sollten nicht allein quantitativeMerkmale wie Nutzungsstatistiken, sondernauch qualitative Merkmale wie beispielsweiseTransparenz oder Nachhaltigkeit, berücksichtigtwerden.
Die dabei zentralen Themen Erfolgsmessung,Impact und Evaluation sind bereits ineinigen Publikationen – auch im Bereichder Digital Humanities – behandelt worden,beschränken sich jedoch in der Regel aufNutzeranforderungen und -bedürfnisse fürbestimmte Dienste und zu entwickelndeTools (z.B. Brown u.a. 2006). Die Erfüllungdieser Anforderungen kann zwar als Erfolggewertet werden, greift aber für eineumfassende Bewertung zu kurz. Genauso bietenNutzerstudien einen Anhaltspunkt, wie Diensteund Tools genutzt und wo Verbesserungenangesetzt werden können. Beispielhaft soll hierdie Nutzerstudie zu den Korpusplattformen, diebei der DHd 2016 vorgestellt wurde, genanntwerden (Fandrych u.a. 2016).
Innerhalb des von der DFG gefördertenProjektes "Erfolgskriterien fur den Aufbauund nachhaltigen Betrieb von VirtuellenForschungsumgebungen (DFG-VRE)" 2 wurde
124

Digital Humanities im deutschsprachigen Raum 2017
ein generisches Set an Erfolgskriterien erstellt,welches an gegebene Projekte angepasst werdenkann (Buddenbohm u.a. 2014) und nicht nur dieNutzerperspektive berücksichtigt, sondern auchinterne Problematiken und Aspekte.
Zur tatsächlichen Messung vonVeränderungen wurde im Rahmen der erstenFörderphase von DARIAH-DE, sowie in derDARIAH-EU Working Group for impact factorsand success criteria 3 eine Übersicht entwickelt,die verschiedene Impact-Bereiche, dieseBereiche beeinflussende Faktoren sowieKriterien zusammenträgt: Die Impactomatrix4 . Ziel war neben der Bewertung derverschiedenen Kriterien und Faktoren unterBerücksichtigung verschiedener Stakeholder(WissenschaftlerInnen, BetreiberInnen,FörderInnen und EntwicklerInnen) auch einmodularer und erweiterbarer Aufbau.
Begriffe und Methodik
Den methodischen Untersuchungen gingeine extensive Literaturanalyse voraus, bei derImpact-Bereiche, und die diese beeinflussendenKennzahlen und Faktoren extrahiert wurden –insgesamt konnten Begriffe aus 11 einschlägigenQuellen gezogen werden, die in Gnadt u.a.(2015) näher beschrieben sind. Basierend aufdiesen Vorarbeiten wurden Erhebungen unterverschiedenen Stakeholdergruppen in Bezugauf digitale Tools und Infrastrukturdienstedurchgeführt.
Innerhalb der geistes- undkulturwissenschaftlichen Community wurdenzwei groß angelegte Online-Umfragen mitjeweils unterschiedlichen Zielgruppenvorgenommen: erstens 24 erfahrene, digital undin einem internationalen Kontext arbeitendeFachwissenschaftlerInnen (Gnadt, Stiller& Höckendorff 2015) und zweitens 103FachwissenschaftlerInnen, die hauptsächlichnicht digital arbeiten (Stiller u.a. 2015, Bulatovicu.a. 2016). Bei diesen Umfragen ging es vorallem um eine Einschätzung des Ist-Zustandesim Umgang mit digitalen Werkzeugen in derForschung und der Nutzung von virtuellenForschungsinfrastrukturen. Eine weitereBefragung zu Impactfaktoren und -kriterienfand unter den TeilnehmerInnen eines DINI-Workshops 5 sowie den DiensteanbieterInnenund DiensteentwicklerInnen in DARIAH-DE statt. Hierbei konnten die insgesamt 44TeilnehmerInnen ihre Einschätzung derWichtigkeit verschiedener Eigenschafteneines Tools abgeben, wie z.B. "Bedienbarkeit",
"Funktionsumfang", "Dokumentation","Einbeziehung von NutzerInnen", "curricularerEinsatz" und "Zahl an Referenzierungen".Zusätzlich wurden von einer Studentin imRahmen ihrer Masterarbeit am Institut fürBibliotheks- und Informationswissenschaftder Humboldt-Universität zu Berlin sechsInterviews mit VertreterInnen verschiedenerFachdisziplinen durchgeführt (Rose 2015). Inden Interviews widmete sich die Autorin vorallem Fragen zur Einschätzung des Erfolgsvon virtuellen Forschungsumgebungen undden eingesetzten Tools und Software in denjeweiligen Fachdisziplinen.
Auf Grundlage dieser Erhebungen undStudien wurde ein Katalog erarbeitet, derImpact-Bereiche, Faktoren und Kriterienzusammenfasst (Gnadt u.a. 2015). DieseEinteilung erfolgte auf der Basis der folgendenaus der Literatur abgeleiteten Definitionen vonImpact, Erfolg, Kriterium und Faktor:
• Impact bezeichnet die Form, den Gradoder die Diversität einer Änderung einesVerhaltens oder Einstellung einer Gruppe
• Erfolg bezeichnet eine positive Resonanz aufeine Maßnahme oder ein Produkt, welche inihrem Ausmaß messbar ist
• Faktoren beschreiben Eigenschaften oderMittel zur Veränderung eines Zustands
• Kriterien beschreiben konkrete Merkmalezur Unterscheidung zwischen Zuständen
Abbildung 1 zeigt das Zusammenspielvon Impact-Bereichen, Faktoren, mit denendiese Bereiche beeinflusst und Kriterien,mit denen die Veränderungen gemessenwerden können. Als Faktoren wurden aufder Basis der hergeleiteten DefinitionenEigenschaften, Mittel und Maßnahmenvon Tools bzw. Forschungsinfrastrukturenklassifiziert, als Kriterien hingegen messbareGrößen wie Kennzahlen, Indikatoren undUmfrageauswertungen. Der Erfolg von Tools undForschungsinfrastrukturen wurde – ebenfallsauf der Basis der Literaturauswertungen – alsÜbereinstimmung von Nutzeranforderungen miterreichtem Impact definiert.
125

Digital Humanities im deutschsprachigen Raum 2017
Abbildung : Zusammenspiel von Impact,Erfolg, Faktoren und Kriterien.
Die Impactomatrix
Aus den unterschiedlichen Erhebungenund der Literatur wurden Begrifflichkeiten fürdie Bereiche Impact, Kriterien und Faktorengesammelt, ggf. übersetzt, zusammengefasstund in eine oder mehrere der drei Kategorieneingeordnet. Insgesamt wurden 101 relevanteBegriffe extrahiert, von denen 21 als Impact-Bereiche identifiziert wurden. 67 Begriffewurden als Faktoren eingestuft und 25 alsKriterien. 6 Bei einigen Begriffen gab esMehrfachzuordnungen, da eine eindeutigeTrennung nach Faktoren und Kriterien nichtimmer möglich war.
Die Begriffe wurden außerdem ins Englischeübertragen, mit dem Ziel, den Katalog einemgrößtmöglichen Publikum zugänglich zumachen. Auch die weitere Entwicklung derImpactomatrix wird auf Englisch erfolgen.Um diese gesammelten Daten nun für dieEntwicklung, Anpassung und das Angebotvon digitalen Diensten nutzen zu können,haben wir eine Übersicht in Form derImpactomatrix entwickelt und auf GitHubzur Verfügung gestellt. 7 Ausgehend von den21 Impact-Bereichen können somit leicht dieFaktoren ermittelt werden, die diese Bereichebeeinflussen. Zur positiven Veränderungvon Impact in einem bestimmten Bereichsollten also diese Mittel eingesetzt bzw. dieseEigenschaften verbessert werden. Es könnenauch geeignete Kriterien bestimmt werden, mitdenen Veränderungen im gegebenen Impact-Bereich gemessen werden können.
Die 21 Impact-Bereiche bzw. -Formen sind:
• Außenwirkung(External Impact)
• Bildung (Education)• Datensicherheit/
Datenschutz (DataSecurity/ Safety)
• Dissemination(Dissemination)
• Effektivität(Effectivity)
• Effizienz (Efficiency)• Förderperspektiven
(Funding Perspective)• Innovation
(Innovation)• Integration
(Integration)• Kohärenz (Coherence)
• Kollaboration(Collaboration)
• Kommunikation(Communication)
• Kompetenzvermittlung(Transfer of Expertise)
• Nachhaltigkeit(Sustainability)
• Nutzung (Usage)• Publikationen
(Publications)• Relevanz (Relevance)• Reputation
(Reputation)• Transparenz
(Transparency)• Wettbewerbsfähigkeit
(Competitiveness)• Wissenstransfer
(Transfer ofKnowledge)
Die Impactomatrix kann dazu verwendetwerden, das Problembewusstsein für die Belangeund Notwendigkeiten aller beteiligten Gruppenzu reflektieren und im Endeffekt erfolgreichereAngebote innerhalb einer Infrastruktur zuschaffen.
Zum Beispiel kann die Steigerung desImpacts in den Bereichen Effizienz undEffektivität erzielt werden, indem unter anderemMaßnahmen wie eine leichte Bedienbarkeit,die Einbettung in wissenschaftliche Workflowsund die Bereitstellung von Hilfestellungenfür die Nutzer umgesetzt werden. Ob dieseMaßnahmen dann erfolgreich sind, umEffizienz und Effektivität zu steigern, kann inder Folge anhand verschiedener Indikatorennachgewiesen werden. Solche Indikatoren sindbeispielsweise die Intensität und der Umfang derNutzung sowie das Ansehen und die Akzeptanzin der Community. Abbildung 2 zeigt einenScreenshot der Impactomatrix für den BereichNachhaltigkeit (Sustainability).
Abbildung : Screenshot der Impactomatrix.
126

Digital Humanities im deutschsprachigen Raum 2017
Ausblick undZusammenfassung
Die Impactomatrix bietet verschiedenenStakeholdern einen Zugang zur Problematikder Erfolgsmessung von digitalen Tools undDiensten. Die Verzahnung der Impact-Bereichemit ihren sie beeinflussenden Faktoren undKriterien bietet eine einzigartige Möglichkeit,den Mehrwert von Entwicklungen in denDigital Humanities zu hinterfragen. AlsAnwendungsbeispiel kann das Schreiben vonAnträgen dienen, wenn es darum geht, aufden erhofften Impact des beantragten Projektseinzugehen sowie Maßnahmen zu bestimmenund festzulegen, die diesen Impact noch steigernkönnen.
Hervorzuheben ist auch, dass in derImpactomatrix nicht nur die üblichenquantitativen Messzahlen in einer Listezusammengetragen, sondern auch einenBeitrag zur qualitativen Bewertung vondigitalen Diensten in den Geistes- undKulturwissenschaften geleistet wurde:Ausgehend von dem Beispiel in Abbildung2 ist ein Kriterium für die Nachhaltigkeitvon Infrastrukturen die Unterstützung vonoffenen Datenformaten. Hier stellt sich dieFrage, ob diese Kennzahl qualitativ (das meistgenutzte offene Datenformat wird unterstützt)oder quantitativ (viele verschiedene offeneDatenformate werden genutzt) gemessenwerden sollte.
Die Impactomatrix wird ständigweiterentwickelt, und so wollen wirsukzessive eine engere Verzahnung derFaktoren mit den Kriterien (oder auchKennzahlen) erzielen. Außerdem arbeitenwir an einer Ausdifferenzierung derPriorität verschiedener Impact-Bereiche fürunterschiedliche Stakeholdergruppen. Da dieseWeiterentwicklungen vornehmlich auf Feedbackaus der Fachcommunity beruhen, laden wirmit diesem Beitrag auch dazu ein, den Katalogkennenzulernen, kritisch zu hinterfragen undImpulse für die Weiterentwicklung zu geben.
Fußnoten
1. https://de.dariah.eu/2. https://www.sub.uni-goettingen.de/projekte-forschung/projektdetails/projekt/dfg-vre-1/3. http://www.dariah.eu/activities/working-groups.html
4. Der Bewertungskatalog der zur Entwicklungder Impactomatrix geführt hat, wird im DARIAH-DE Report 1.3.3 (Gnadt u.a. 2015) ausführlichbeschrieben.5. https://dini.de/veranstaltungen/workshops/digitales-arbeiten-in-den-geisteswissenschaften-ermoeglichen6. Das Ergebnis dieser Kategorisierung ist inGnadt u.a. 2015 (Tabelle C.1 im Anhang C) zusehen.7. Quelltext auf https://github.com/DARIAH-DE/Impactomatrix , interaktive Version auf https://dariah-de.github.io/Impactomatrix/ .
Bibliographie
Buddenbohm, Stefan / Enke, Harry /Hofmann, Matthias / Klar, Jochen / Neuroth,Heike / Schwiegelshohn, Uwe (2014):Erfolgskriterien für den Aufbau und nachhaltigenBetrieb Virtueller Forschungsumgebungen.DARIAH-DE Working Papers 7 http://nbn-resolving.de/urn:nbn:de:gbv:7-dariah-2014-5-4[letzter Zugriff 29. November 2016].
Brown, Stephen / Ross, Robb / Gerrard,David / Greengrass, Mark / Bryson, Jared(2006): RePAH: A User Requirements Analysis forPortals in the Arts and Humanities. De MontfortUniversity Leicester and The University ofSheffield http://repah.dmu.ac.uk/report/pdfs/RePAHReport-Complete.pdf [letzter Zugriff 29.November 2016].
Bulatovic, Natasa / Gnadt, Timo /Romanello, Matteo / Schmitt, Viola /Stiller, Juliane / Thoden, Klaus (2016):Usability von DH-Tools und Services (R1.2.3).Göttingen: DARIAH-DE https://wiki.de.dariah.eu/download/attachments/14651583/AP1.2.3_Usability_von_DH-Tools_und-Services_final.pdf [letzter Zugriff 29. November2016].
Fandrych, Christian / Frick, Elena /Hedeland, Hanna / Iliash, Anna / Jettka,Daniel / Meißner, Cordula / Schmidt, Thomas /Wallner, Franziska / Weigert, Kathrin(2016): „Wer bist du, Nutzer?“, in: DHd 2016:Modellierung - Vernetzung - Visualisierung122–126 http://www.dhd2016.de/abstracts/vorträge-053.html [letzter Zugriff 29. November2016].
Gnadt, Timo / Stiller, Juliane /Hockendorff, Mareike (2014): Umfrage zuErfolgskriterien (R1.3.1). Göttingen: DARIAH-DE https://wiki.de.dariah.eu/download/attachments/14651583/R%201.3.1%20-%20Erhebung%20einer%20Nutzerbefragung
127

Digital Humanities im deutschsprachigen Raum 2017
%20zu%20Nutzererwartungen%20und%20-kriterien.pdf [letzter Zugriff 29. November 2016].
Gnadt, Timo / Stiller, Juliane / Thoden,Klaus / Schmitt, Viola (2015): FinaleVersion. Erfolgskriterien (R1.3.3). Göttingen:DARIAH-DE https://wiki.de.dariah.eu/download/attachments/14651583/R133_Erfolgskriterien_Konsortium.pdf [letzterZugriff 29. November 2016].
Rose, Corinna (2015): Chancen undGrenzen der Abbildung fachspezifischerForschungsprozesse durch einevirtuelle Forschungsumgebung in denGeisteswissenschaften. Masterarbeit, Humboldt-Universität zu Berlin.
Stiller, Juliane / Thoden, Klaus / Leganovic,Oona / Heise, Christian / Höckendorff,Mareike / Gnadt, Timo (2015): (R 1.2.1/M 7.6).Göttingen: DARIAH-DE https://wiki.de.dariah.eu/download/attachments/26150061/Report1.2.1-final.pdf [letzter Zugriff 29. November 2016].
Stiller, Juliane / Gnadt, Timo / Romanello,Matteo / Thoden, Klaus (2016): „Anforderungenermitteln, Lösungen evaluieren und Erfolgemessen – Begleitforschung in DARIAH-DE“, in:Bibliothek Forschung und Praxis 40 (2): 250–258.DOI:10.1515/bfp-2016-0025.
Digitale Modellierungliterarischen Raums
Barth, [email protected]ät Stuttgart, Deutschland
Viehhauser, [email protected]ät Stuttgart, Deutschland
ProblemstellungIm Anschluss an den 1990 durch den
Humangeographen Edward Soja ausgerufenen‚Spatial Turn’ (Soja 1990) haben sich zahlreichekulturwissenschaftliche Forschungsarbeitenmit einer Beschreibung des Raums beschäftigt.In der Literaturwissenschaft fanden dabeiu.a. kartografische Darstellungen großeResonanz: Franco Moretti etwa untersuchtein seinem „Atlas of the European Novel“ Orteder literarischen Produktion und Rezeption(Moretti 1998), Barbara Piattis Studie „DieGeographie der Literatur“ richtete den Fokusauf die Illustration einer konkreten literarischthematisierten Gegend (die Zentralschweiz,
vgl. Piatti 2008). Besondere Aufmerksamkeitwurde literarischen Karten auch im Kontext derDigital Humanities zu Teil, in denen geografischeInformationssysteme (GIS) zum Einsatz kommen(typische Workflows beschreiben Gregory et. al.2015)
Den meisten dieser Ansätze ist dabei gemein,dass sie für ihre Datengrundlage in ersterLinie auf konkrete Nennungen von Ortsnamen(Toponymen) rekurrieren und weitereOrtsmarker weniger stark berücksichtigen.An der Konstitution literarischer Räume sindjedoch in der Regel auch komplexere Faktorenbeteiligt, zu deren Beschreibung bereits erstenarratologische Ansätze vorliegen (etwa vonKathrin Dennerlein [2009 und 2011] oder GabrielZoran [1984], vgl. auch die Überlegungen beiPiatti [2008]), die jedoch im Kontext der DigitalHumanities bislang noch zu wenig Beachtunggefunden haben.
In unserem Beitrag möchten wir dieseAnsätze aufgreifen, um das Instrumentarium derdigitalen Textanalyse hinsichtlich der Kategoriedes Raums zu schärfen und zu erweitern. Dazuscheinen uns insbesondere zwei Aspekte vonBedeutung: Zum einem die Unterscheidungvon Raummarkierungen hinsichtlich ihrerHandlungsrelevanz (I), zum anderen dieAusweitung der Analyse auf räumliche Begriffe,die über bloße Namensnennungen hinausgehen(II). Für beide Problemfelder präsentieren wirerste Verfahren zur automatischen Auswertungund geben Ausblicke auf die Möglichkeiten einervergleichenden Analyse.
I. Differenzierung von Räumen nachHandlungsrelevanz
Im Anschluss an Dennerleins Narratologiedes Raumes hat sich insbesondere der Terminusder räumlichen Gegebenheit als Grundeinheit zurBezeichnung von Ort und Raum durchgesetzt.Sind räumliche Gegebenheiten der Schauplatzeines konkreten Ereignisses, werden sie alsEreignisregionen spezifiziert. Diese haben alsdie zentralen handlungsrelevanten Räumebesondere Bedeutung gegenüber erwähntenräumlichen Gegebenheiten, die bei nicht-situationsbezogener Thematisierung von Raumentstehen. In ähnlicher Weise unterscheidenPiatti (2008) sowie Piatti et. al. (2011) zwischenSchauplatz und projizierten Orten.
Am Beispiel von Jules Vernes „Reise um dieErde in 80 Tagen“ lässt sich die Wichtigkeitdieser Unterscheidung aufzeigen: So bietet z.B.Kapitel 14 eine Zugfahrt durch das Gangestal mitAufenthalten in Allahabad und Benares sowieder Ankunft in Calcutta. Genannt werden imText jedoch auch weitere Städte Indiens unddas nächste Ziel Hongkong; eine Vielzahl der
128

Digital Humanities im deutschsprachigen Raum 2017
extrahierten Ortsnamen bezieht sich somit nichtauf den Handlungsort des Kapitels.
Erst die kategoriale Trennung derRaummarkierungen in Ereignisregionen underwähnte räumlichen Gegebenheiten ermöglichtdie valide Rekonstruktion einer Reiseroute,die dann in einer GIS-Darstellung visualisiertwerden kann (Abbildung 1).
Eine automatische Unterscheidungdieser Kategorien muss daher das Fernzielcomputerunterstützter Raumuntersuchungensein. Ansätze zu einer solchen Differenzierungsuchen wir in der Anwendung voncomputerlinguistischen Methoden derRelationsextraktion, bei denen sich ausstrukturellen Auffälligkeiten Regeln zurKlassifikation von Ereignisregionen underwähnten räumlichen Gegebenheiten ableitenlassen. Hierzu zwei Beispiele:
1. Das 14. Kapitel der „Reise um die Erdein 80 Tagen“ beginnt mit dem in Abbildung 2dargestellten Satz:
Vor allem der Hauptsatz mit dem Pfad [Figur– SUBJ – Bewegungsverb - OBJ – Raumnomen]zwischen "Phileas Fogg" und "Gangesthal"kennzeichnet letzteres als Ereignisregion.Dabei stellt insbesondere die Verbkategorie einIndiz für die Klassifikationsentscheidung dar:Statische Verben ("stehen", "sitzen") oder Verbender Bewegung ("gehen", "fahren") zeugen inspezifischen Satzstrukturen häufig von einerEreignishaftigkeit im Gegensatz zu Verben derKognition ("denken").
Zur Einteilung der Verben nutzen wir dasvon der Universität Tübingen entwickeltelexikalisch-semantische Netz GermaNet(Hamp/Feldweg 1997, Henrich/Hinrichs 2010),in dem eine Systematisierung vorliegt, dieauf den Verbkategorien von Levin und demValenzwörterbuch von Schumacher basiert(Levin 1993, Schumacher 1986).
2. Findet ein erzähltes Ereignis innerhalbeiner Bewegung im Raum statt, könnenmehrere Räume zu einem Bewegungsbereichzusammengefasst werden. Diese können beiStrukturen wie der folgenden leicht maschinellerkannt werden:
"Ich fuhr [...] von Königstadt, wo unserHauptbüro war, nach Gründerheim, wo wir eineNebenstelle hatten. Dort holte ich dringendeKorrespondenz, Gelder und schwebendeFälle." (Böll, Heinrich: Über die Brücke)
Im zweiten Satz findet sich zudem eineReferenz auf das Antezedens "Gründerheim".Eigentlich werden derartige deiktischeAdverbialausdrücke ("hier", "da" und "dort") beider Koreferenz-Resolution nicht berücksichtigt.Deshalb planen wir eine Erweiterung derTrainingssets bestehender Koreferenz-Systemehinsichtlich dieser Termini.
Die hier an zwei Beispielfällen dargestelltenRegeln zur Unterscheidung narratologischerRaumeinheiten sollen in Zukunft kontinuierlicherweitert und zunächst so gestaltet werden, dasssie eine hohe Präzision erzielen. Anschließendkönnen sie als Features für spätere maschinelleLernverfahren verwendet werden.
II. Anreicherung der RaumbeschreibungNetzwerkvisualisierung von RaumnomenEine kartografische Darstellung, wie sie
in Abbildung 1 ersichtlich ist, bleibt aufrealweltliche Ortsnamen beschränkt und lässtwesentliche Aspekte der Raumdarstellung außerAcht. Einen ersten Ansatz, die Vielfältigkeitder tatsächlichen Handlungsräume undihrer Zusammenhänge abzubilden, bietetdas Netzwerk in Abbildung 3. Hier werdenfür das angesprochene Kapitel 14 neben denToponymen auch unspezifische Raumnomenals Knoten berücksichtigt und Verbindungenimmer dann etabliert, wenn zwei Raumbegriffegemeinsam in einem Satz auftreten.
Insbesondere landschaftliche (grün)und architektonische Raumnomen (grau)stellen relevante Klassen von Raummarkerndar, die neben den konkreten Ortsnamenzentrale Komponenten der literarischenRaumbeschreibung bilden. Als räumlicheGegebenheiten kommen aber auch beweglicheObjekte, in denen sich Figuren aufhalten
129

Digital Humanities im deutschsprachigen Raum 2017
können, in Frage, wie die in der Grafik blaumarkierten Fahrzeuge.
Abbildung 3: NetzwerkLexikon und Taxonomien für RaumbegriffeZur lexikalischen Erfassung von
realweltlichen Toponymen greifen wir aufdie Named-Entitiy-Recognition von Weblicht(2012) zurück, deren Ergebnisse wir mitdem Rückgriff auf die frei zugänglichenDatenbanken GeoNames (www.geonames.org)und OpenStreetMap (www.openstreetmap.org,Datendownload über www.geofabrik.de) zuverfeinern trachten. Aufgrund des Problemsder möglichen Ambiguität von Ortsnamen(Leidner / Liebermann 2011, Gregory / Hardie2011) ist jedoch eine manuelle Nachbearbeitungnötig. Listen von unspezifischen Raumnomen(„Berg“, „Bach“, etc.) erstellen wir (ebenfallssemi-automatisch) auf der Basis von GermaNet.
Innerhalb dieses Lexikons planen wir zudemeine Einordung der Raumbegriffe in spezifischeTaxonomien:
i) Vertikale Raum-Ort-HierarchieNarratologisch wird unter dem Begriff
Raum ein umfassendes Gebiet in der erzähltenWelt verstanden, welches ein Innen undAußen besitzt und wiederum lokalisierbare,
punktuelle Orte beinhaltet (Dennerlein 2009).Diese Zuordnung erfolgt jedoch meist relationalzur Erzählsituation: In Alfred Döblins RomanBerlin Alexanderplatz bildet die Stadt den Raummit einzelnen Plätzen und Straßen als Orten.Unter einer geringfügigen Erweiterung desErzählspektrums wäre Berlin aber potentiell nurein Ort unter vielen im übergeordneten RaumDeutschland.
Statt einer festen Zuschreibung nähern wiruns dem Verhältnis von Ort und Raum übereine vertikale Taxonomie von räumlichenGegebenheiten an, die von der Planetenebenebis zu jenen Objekten reicht, in denen sichunter Annahme faktualer Gesetzmäßigkeitenkeine Figur mehr aufhalten kann. Im Sinnedes principles of minimum departure (Ryan1980) kann dabei so lange von einer nachrealweltlichen Gesetzen eingerichtetenErzählwelt ausgegangen werden, bis derenbewusste Aufhebung innerhalb fiktionaler Textein spezifischen Fällen eine gezielte Anpassungder Taxonomie erfordert (z.B. bei AladinsFlaschengeist in der Wunderlampe).
Abbildung 4 zeigt basierend auf denkapitelweise extrahierten Ereignisregionen in„Reise um die Erde in 80 Tagen“ die oberstentaxonomischen Stufen: 1. Kontinent, 2. Land,3. Stadt bzw. landschaftliche Region (inklusiveTransportmittel, markiert in blau).
Während in den ersten beiden Ebenen diesesBeispiels ausschließlich Toponyme vorkommen,beinhaltet zumindest die dritte Stufe in derNominalphrase „Latenenwald bei Allahabad“ einunspezifisches Raumnomen. Weitere allgemeineBegriffe wären vor allem auf einer hier nichtdargestellten vierten Ebene zu finden (z.B.„Sumpf“, „Bach“, „Weizenfeld“ innerhalb derLandschaft „Behar“, vgl. Abb. 3).
Zur automatischen Erstellung einer solchenHierarchie bieten sich bei Toponymen die inGeoNames vorhandenen Metadaten an, indenen bei jedem Stadt-Eintrag Informationenzu Land und Kontinent vorhanden sind.Bei unspezifischen Raumnomen eignet sichhingegen die hierarchische Struktur von
130
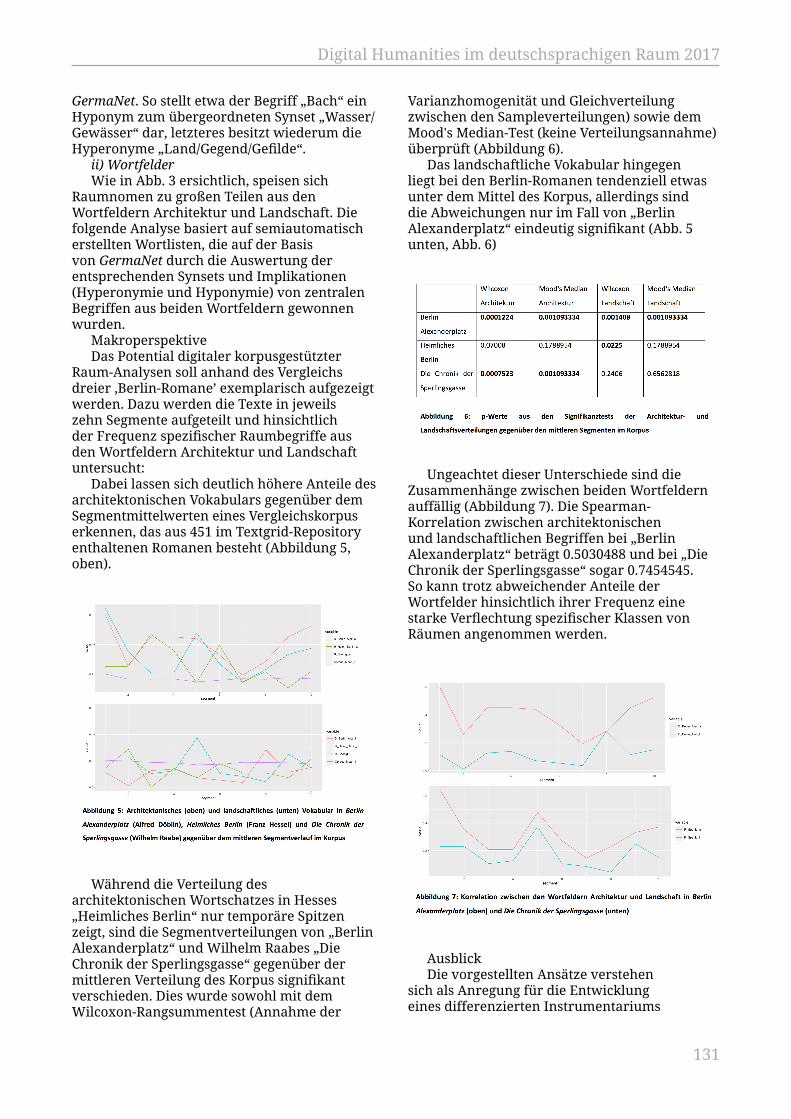
Digital Humanities im deutschsprachigen Raum 2017
GermaNet. So stellt etwa der Begriff „Bach“ einHyponym zum übergeordneten Synset „Wasser/Gewässer“ dar, letzteres besitzt wiederum dieHyperonyme „Land/Gegend/Gefilde“.
ii) WortfelderWie in Abb. 3 ersichtlich, speisen sich
Raumnomen zu großen Teilen aus denWortfeldern Architektur und Landschaft. Diefolgende Analyse basiert auf semiautomatischerstellten Wortlisten, die auf der Basisvon GermaNet durch die Auswertung derentsprechenden Synsets und Implikationen(Hyperonymie und Hyponymie) von zentralenBegriffen aus beiden Wortfeldern gewonnenwurden.
MakroperspektiveDas Potential digitaler korpusgestützter
Raum-Analysen soll anhand des Vergleichsdreier ‚Berlin-Romane’ exemplarisch aufgezeigtwerden. Dazu werden die Texte in jeweilszehn Segmente aufgeteilt und hinsichtlichder Frequenz spezifischer Raumbegriffe ausden Wortfeldern Architektur und Landschaftuntersucht:
Dabei lassen sich deutlich höhere Anteile desarchitektonischen Vokabulars gegenüber demSegmentmittelwerten eines Vergleichskorpuserkennen, das aus 451 im Textgrid-Repositoryenthaltenen Romanen besteht (Abbildung 5,oben).
Während die Verteilung desarchitektonischen Wortschatzes in Hesses„Heimliches Berlin“ nur temporäre Spitzenzeigt, sind die Segmentverteilungen von „BerlinAlexanderplatz“ und Wilhelm Raabes „DieChronik der Sperlingsgasse“ gegenüber dermittleren Verteilung des Korpus signifikantverschieden. Dies wurde sowohl mit demWilcoxon-Rangsummentest (Annahme der
Varianzhomogenität und Gleichverteilungzwischen den Sampleverteilungen) sowie demMood's Median-Test (keine Verteilungsannahme)überprüft (Abbildung 6).
Das landschaftliche Vokabular hingegenliegt bei den Berlin-Romanen tendenziell etwasunter dem Mittel des Korpus, allerdings sinddie Abweichungen nur im Fall von „BerlinAlexanderplatz“ eindeutig signifikant (Abb. 5unten, Abb. 6)
Ungeachtet dieser Unterschiede sind dieZusammenhänge zwischen beiden Wortfeldernauffällig (Abbildung 7). Die Spearman-Korrelation zwischen architektonischenund landschaftlichen Begriffen bei „BerlinAlexanderplatz“ beträgt 0.5030488 und bei „DieChronik der Sperlingsgasse“ sogar 0.7454545.So kann trotz abweichender Anteile derWortfelder hinsichtlich ihrer Frequenz einestarke Verflechtung spezifischer Klassen vonRäumen angenommen werden.
AusblickDie vorgestellten Ansätze verstehen
sich als Anregung für die Entwicklungeines differenzierten Instrumentariums
131

Digital Humanities im deutschsprachigen Raum 2017
der digitalen Raumanalyse, das in Zukunftweiter ausgebaut werden soll und dieGrundlage für die Behandlung weiterführenderliteraturwissenschaftlicher Fragestellungenbildet, die etwa Aspekte der Semantisierungvon Räumen (Lotman 1972), des raumzeitlichenEntwurfs von Erzählwelten (Bachtin 1989)und der Bedeutung von Raumkonstellationenfür die Gattungspoetik beinhalten (vgl.zusammenfassend Nünning 2009).
Bibliographie
Bachtin, Michail Michailowitsch (1989):Formen der Zeit im Roman. Untersuchungen zurhistorischen Poetik. Ed. von Kowalski, Edward /Wegner, Michael. Frankfurt am Main: Fischer.
Bastian Mathieu / Heymann Sebastian /Jacomy Mathieu (2009): „Gephi. An opensource software for exploring and manipulatingnetworks“, in: International AAAI Conference onWeblogs and Social Media.
Dennerlein, Katrin (2009): Narratologie desRaumes. Berlin: de Gruyter.
Dennerlein, Katrin (2011): „Raum“, in:Matías Martínez (ed.): Handbuch Erzählliteratur:Theorie, Analyse, Geschichte. Stuttgart / Weimar:Metzler 158–165.
Gregory, Ian / Hardie, Andrew (2011):„Visual GISting: bringing together corpuslinguistics and Geographical InformationSystems“, in; LLC 26: 297–314.
Gregory, Ian / Cooper, David / Hardie,Andrew / Rayson, Paul (2015): „Spatializingand Analyzing Digital Texts. Corpora, GIS, andPlaces“, in: David Bodenhamer / John Corrigan /Trevor Harris: Deep Maps and Spatial Narratives.Bloomington: Indiana University Press 150–178.
Hamp, Birgit / Feldweg, Helmut (1997):„GermaNet - a Lexical-Semantic Net forGerman“, in: Proceedings of the ACL workshopAutomatic Information Extraction and Building ofLexical Semantic Resources for NLP Applications.Madrid.
Henrich, Verena / Hinrichs Erhard (2010):„GernEdiT - The GermaNet Editing Tool“, in:Proceedings of LREC 2010 2228–2235.
Leidner, Jochen / Lieberman, Michael(2011): „Detecting Geographical References inthe Form of Place Names and Associated SpatialNatural Language“, in: SIGSPATIAL Special 3: 5–11.
Levin, Beth (1993): English Verb Classes andAlternations. University of Chicago Press.
Lotman, Juri (1972): Die Struktur literarischerTexte. München: Fink.
Moretti, Franco (1998): Atlas of the Europeannovel. 1800-1900. London / New York: Verso.
Nünning, Ansgar (2009): „Formen undFunktionen literarischer Raumdarstellung:Grundlagen, Ansätze, narratologische Kategorienund neue Perspektiven“, in: Wolfgang Hallet /Birgit Neumann (eds.): Raum und Bewegung inder Literatur: Die Literaturwissenschaften undder Spatial Turn. Bielefeld: Transcript 33–52.
Piatti, Barbara (2008): Die Geographieder Literatur. Schauplätze, Handlungsräume,Raumphantasien. Göttingen: Wallstein.
Piatti, Barbara / Reuschel, Anne-Kathrin /Hurni, Lorenz (2011): „A Literary Atlas ofEurope – Analysing the Geography of Fictionwith an Interactive Mapping and VisualisationSystem“, in: Proceedings of the 25th InternationalCartographic Conference. Paris.
Ryan, Marie Laure (1980): „Fiction, Non-Factuals, and Minimal Departure“, in: Poetics 8:403–422.
Schumacher, Helmut (1986): Verben inFeldern: Valenzwörterbuch zur Syntax undSemantik deutscher Verben. Berlin / New York: deGruyter Verlag,
Soja, Edward (1990): PostmodernGeographies: The Reassertion of Space in CriticalSocial Theory. London / New York: Verso.
WebLicht (2012): CLARIN-D/SfS-Uni.Tübingen 2012. WebLicht: Web-Based LinguisticChaining Tool. https://weblicht.sfs.uni-tuebingen.de/ [letzter Zugriff 1. Dezember 2016]
Zoran, Gabriel (1984): „Towards a theory ofspace in narrative“, in: Poetics Today 5: 309–335.
DigitaleTransformationen.Zum Einfluss derDigitalisierung auf diemusikwissenschaftlicheEditionsarbeit
Meise, [email protected]ät Paderborn, Deutschland
Meister, [email protected]ät Paderborn, Deutschland
132

Digital Humanities im deutschsprachigen Raum 2017
Zusammenfassung: Digitale Datenstellen den zentralen Forschungsfokusder Digital Humanities dar. Fragen derModellierung, Repräsentations-, Analyse-und Annotationsmöglichkeiten sind dabeiwichtige Forschungsdimensionen, ebensowie etwa die Weiterverarbeitung undNachnutzbarkeit. Die digitalen Daten sowie diebeschrieben Prozeduren werden jedoch auchvon EditorInnen bearbeitet und wirken sich aufderen wissenschaftliche Arbeit aus. In diesemBeitrag wird aus qualitativ empirischer Sichtdie Perspektive der EditorInnen als besondereNutzer- und Produzentengruppen im Prozess derDigitalisierung von Musikeditionen vorgestellt.Dabei gilt es weder WissenschaftlerInnen nochDaten singulär zu betrachten, sondern imAkt der Bearbeitung, Analyse, Repräsentationund Annotation eine besondere Perspektivein der Auseinandersetzung von Medien,Materialien und Subjekten zu erschließenund zu reflektieren. In diesem Sinne werdenin diesem Abstract zuerst theoretischeVerortungen für die Relevanz des Nutzersdiskutiert. Darauf aufbauend werden diemethodischen Grundlagen der Interviewstudievorgestellt, um anschließend einen Ausblickauf die Ergebnisse zu geben, der im Vortragvertieft wird. Dabei stehen die Veränderungendes wissenschaftlichen Arbeitsprozessesvon analog zu digital im Vordergrund.Darauf aufbauend stehen die Chancen undHerausforderungen dieses Paradigmenwechselsim Zentrum des Interesses, die sicherlichnicht nur für die Arbeitskontexte der digitalenMusikeditionen zutreffen. Abschließend werdenKristallisationspunkte und Konsequenzenzukünftiger Fragestellungen hinsichtlichder Digitalisierung von Musikeditionen,Veränderungen von Arbeitsstrukturen sowie derBildungs- und Wissensarbeit resultierend ausdiesen Ergebnissen thematisiert.
EinleitungDigitale Musikeditionen bieten potentiell
vielerlei Optionen für EditorInnen,WissenschaftlerInnen und geneigteRezipientInnen (vgl. etwa Veit 2010).So beschleunigt und ordnet etwa dieVerfügbarkeit digitaler Quellen den editorischenProzess, die Ansichten des Digitalenermöglichen größtmögliche Transparenz undNachvollzieharkeit. Umbestritten sind alsodie Errungenschaften, die mit den digitalenMusikeditionen einhergehen eine Bereicherungder wissenschaftlichen Arbeit (vgl. ebd.). Vieleswas im Kontext der Digital Humanities diskutiertwird, bezieht sich auf die digitale Repräsentationoder aber Transformation der kulturellen
Artefakte, deren weitergehenden Analyse bzw.Prozessierbarkeit sowie deren Nachnutzbarkeit.Diese Ebenen werden aus dem Fokus auf dieDaten heraus diskutiert. Was hingegen wenigerbetrachtet wird ist die Forschung im Digitalenals Wissensgenerierungsprozess: Was bedeutetes, sich digitale Techniken anzueignen, digitalQuellen zu bearbeiten, zu repräsentieren,zu analysieren? Die Auseinandersetzung mitdiesen Praktiken der Aneignung ermöglicht esein tieferes Verständnis für die Optionen derdigitalen Daten und deren wissenschaftlicheRelevanz im Arbeitsprozess zu eröffnen.Ebenso lassen sich die zuvor skizziertenForschungsthemen von Repräsentation,Transformation, Nachnutzbarkeit etc. ebensoaus der Sicht der Subjekte erschließen.
Theoretische RahmungNeben Fragen der Daten werden somit
zunehmend die Arbeitsprozesse interessant, diedurch die Digitalisierung der wissenschaftlichenArbeit beeinflusst werden. An dieser Stellebietet sich die seltene Gelegenheit dieVeränderungsprozesse dieses medialenParadigmenwechsel und dessen Einfluss aufForschung und Wissenschaft zu beobachtenund zu begleiten. Damit gilt es die NutzerInnenin den Blick zu nehmen (vgl. auch Stone 1982,Edwards 2012, Warwick 2012; Brockman2001) und vom forensic zum formal layer(vgl. Kirschenbaum 2008) zu wechseln. Aberauch Kirschenbaums formal layer bringtnicht ganz zum Ausdruck, was Drucker(2013) mit der performativen Ebene vonMaterialität als Nutzungsakt beschreibt:Handeln, der Umgang von NutzerInnen mitkulturellen, auch immateriellen Artefakten,prägen die Wahrnehmung, Beurteilung unddie kulturelle Bedeutung dieser Artefakte.Um die Bedeutung von Medien, konkretervon musikeditorischen Ergebnissen unterdigitalen Bedingungen, erschließen zukönnen, ist es notwendig, die vielschichtigenAuseinandersetzungsprozesse der Nutzer mitder Software bzw. der Auszeichnungssprachenund Metadaten zu erforschen. Damit verbundenist die sogenannte radikale Kontextualisierungin den Cultural Studies, bei der davonausgegangen wird, dass »Objekt und Subjekt,Medientechnologie und Kontext« (vgl.Winter 2010): sich stetig beeinflussen undmiteinander verwoben sind. Erst in derAnalyse dieser komplexen Verbindungenkann letztlich das Phänomen konturiert underforscht werden. Medientechnologien undihre Nutzer gehen demnach in zahlreichenAuseinandersetzungsprozessen eine Allianzein, die in dieser Perspektive eine besondere
133

Digital Humanities im deutschsprachigen Raum 2017
Qualität hervorbringt. Einen Schritt weitergeht Rainer Winter, indem er mit Rekurs aufHeidegger darauf hinweist, dass Medien nichtnur technische Artefakte sind, sondern geradein ihrer Einbettung in soziale und kulturelleProzesse, Optionen und Zugänge zur Weltumgestalten (vgl. ebd.). In dieser Hinsicht gilt esweitergehend Wissensgenerierungsprozesse inden Blick zu nehmen. In diesem Beitrag stehendie EditorInnen als besondere Nutzergruppe imZentrum des Interesses. Diese arbeiten an derSchnittstelle vom computer und cultural layer(Manovich 2001). Sie arbeiten mit Metadatenund Auszeichnungssprachen und müssen somitdie Logiken des Prozessierens des Computersverstehen, gleichzeitig arbeiten sie mit denTransformationen an der Oberfläche, lassen sichTeile oder Überblick bestimmte Werkaspekteanzeigen, um editorische Entscheidungen zutreffen und bilden damit einen ganz versiertenNutzer- und Produzententypus ab.
MethodeIm Projekt wurde auf die Prinzipien der
qualitativen, empirischen Sozialforschungzurückgegriffen, um diesen Prozessmöglichst offen und gegenstandsangemessenerforschen zu können (vgl. etwa Flick etal. 2000). Qualitative Sozialforschung birgtzunächst den Vorteil in einem unbekanntenForschungsfeld einsetzbar zu sein. Ergänzendzur quantitativen Forschung wird somit imProjekt ein hypothesengenerierendes undexploratives Verfahren verfolgt. Um die Sicht derEditorInnen in der Annäherung zu erschließen,können die Befragten durch unterschiedlicheMethoden beforscht werden (Beobachtung,unterschiedliche Arten von Interviews, Einzel-bzw. Gruppeninterviews etc. vgl. ebd.). DieAuswahl der Erhebungsmethode erfolgtdem Forschungsphänomen entsprechendangemessen. Erhebt also die quantitativeForschung Daten zu vielen Nutzern, umÜberblicke zu generieren und Themenfelderzu identifizieren ist die qualitative Forschungmit diesen Erhebungsmethoden dazu inder Lage in die Tiefe zu gehen und bspw.Bedeutungskontexte, implizites Wissen undunbewusste Routinen zu eruieren. Hierbeiwerden nicht nur Stichworte, sondernKontextinformationen aus der Sicht derSubjekte aus den Daten herauszuarbeiten(vgl. Flick 2002). Die Erforschung implizitenWissens, von Arbeitsroutinen, Expertisenund Gewissheiten lässt sich dabei kaum übereinzelne direkte Fragen realisieren. Um solchenPhänomenen auszuspüren ist zunächst derGesamtkontext wichtig. In diesem Sinne nutztdie qualitative Forschung verschiedene Formen
von Befragungstechniken, um unterschiedlicheArten von Narrationen zu erhalten, die imAnschluss verschriftlicht und analysiert werdenkönnen. Im Auswertungsprozess wird dannüber Interpretationen der Gesamtkontexterarbeitet und erschlossen. Dies geschieht indemeinzelne Wissensbestände mit anderen Aussagenverbunden werden, die im GesamtkontextEinblicke in das Zusammenwirken expliziterund impliziter Wissensbestände erlauben. AlsErhebungsform für diese qualitative Studiewurde das teilstandardisierte, narrativeInterview gewählt, das zwar einem Leitfadenfolgt, in der Interviewsituation allerdingsgrößtmögliche Spielräume hinsichtlich derFrageformulierungen, Nachfragestrategien undder Reihenfolge der Fragen zulässt (vgl. Keuneke2000) und der Narration der EditorInnen vielRaum gestattet. Der Leitfaden fokussiertebesonders Regelstrukturen der Handlungs- undNutzungsweisen, indem die Befragten nachbestimmten Nutzungssituationen und den damitverbundenen Bedeutungen und Relevanzenbefragt wurden. Diese Nutzungssituationenund Bedeutungen wurden allen interviewtenPersonen gleichermaßen vorgegeben. Die vonden Befragten formulierten Antworten konntenanschließend aufeinander bezogen werden.Zur Auswahl der Interviewpartner/innenwurden im Sinne des Theoretical Sampling (vgl.Przyborski/ Wohlrab-Sahr 2009) Expertinnenund Experten, die mit Edirom arbeiten befragt.Die Software Edirom erlaubt es Faksimiles,Digitalisate und digitale Daten von Notentextenoder anderen Quellen einzuarbeiten, zuspeichern, zu organisieren, zu kollationieren, zuannotieren und zu analysieren. Dabei handeltes sich nicht um eine Forschungsoberfläche,die Voraussetzungslos für die EditorInnen ist,sondern hier sind Auseinandersetzungen undErfahrungen mit XML, TEI und MEI erforderlich.Entscheidend war, dass sowohl weiblicheals männliche Nutzer/innen befragt wurden.Insgesamt wurden acht Interviews mit sechsEditorinnen und zwei Editoren geführt. Diesedauerten zwischen 90 Min. und 180 Min.Die erhobenen qualitativen Daten wurdendurch eine Variante des Kodierens 1 nachStrauss und Corbin, wie es Przyborski undWohlrab-Sahr vorschlagen, ausgewertet (vgl.ebd.). Die Auswertung wurde zunächst nichtmittels Auswertungsprogrammen strukturiert,sondern durch Textverarbeitungsprogramme. Sokonnten die sich herausbildenden Phänomeneeiner exemplarischen, interdisziplinärenSichtung unterzogen werden. In der Syntheseder exemplarischen Auswertung konnte das
134

Digital Humanities im deutschsprachigen Raum 2017
selektive Kodieren vorangetrieben werden,woraus eine Phänomen- und Kategorienlisteresultierte. Diese liefert einerseits konkreteHinweise für Optimierungen der Software,aber auch Kontextinformationen zu denArbeitsbedingungen, Routinen und Erfahrungender EditorInnen. Darüber hinaus lieferndie Interviews sehr gute Einblicke in dieÄnderungsprozesse der Wissensarbeit, desWissensmanagements als auch des erarbeitetenWissens als solches.
Ausblick auf die ErgebnisseWie die empirischen Daten belegen, ist
der Wechsel der Arbeit und der beforschtenGegenstände von analog zu digital nichtnur eine technische Änderung, vielmehrgehen damit auch editorische, rechtliche,organisatorische, soziale und nicht zuletztauch bildungswissenschaftliche Prozesseeinher, die betrachtet, reflektiert undweiterentwickelt werden müssen. Sie veränderndie wissenschaftliche Arbeitsorganisation,die editorische Tätigkeit und nicht zuletzt dieSicht auf Editionen und die damit verbundenenErkenntnissen selbst. EditorInnen recherchierenbei ihrer analogen Forschungsroutinenzunächst Quellen, analysieren diese undwählen Haupt- und Nebenquellen aus, umdie weitere Editionsarbeit zu gestalten. ImAnschluss daran wurden diese Quellen stetigmiteinander verglichen. Dazu musste sehr vielQuellenmaterial physisch verwaltet werden,um die einzelnen Änderungen in der jeweiligenQuelle mit anderen vergleichen und analysierenzu können. Die Arbeit an den digitalen Editionenist indes ein Konglomerat aus analogen unddigitalen Techniken. Zuerst werden die Quellenebenso recherchiert, analysiert und ausgewertetund ausgewählt. Die ausgewählten Quellenwerden von den Hilfskräften im Anschlussdigitalisiert, vertaktet und die Konkordanzenfestgelegt. Es findet also eine Arbeitsteilung statt,da die Vertaktung delegiert wird. Die Interviewsbelegen die hohen Vorteile und Freiheitsgradeder digitalen Editionen, den Rezipientensolcher Editionen kann nun erstmals dasgesamte Quellenmaterial zur Verfügunggestellt werden. Diese können nun editorischeEntscheidungen transparent nachvollziehenund eine eigene Meinung dazu entwickeln.Damit einhergehend sind aber auch einzunehmendes Maß an Komplexitätssteigerungund wachsenden Aufgaben zu verzeichnen.Bei Printeditionen steht die editorischeTätigkeit im Fokus. Der Wechsel zu digitalenEditionen bedeutet für die Editoren einenweiteren Komplexitätsschub: Nicht nur diemusikwissenschaftliche Expertise ist gefragt,
sondern auch Kenntnisse verschiedensterAuszeichnungssprachen, wie XML, TEI und MEI.Durch die Arbeitsteilung muss darüber hinausden Hilfskräften Wissen für die Vertaktungvermittelt, diese angeleitet und kontrolliertwerden. Zudem nutzen die EditorInnennotwendigerweise mehr Programme. Umnur einige zu nennen sind dies: Sibelius,Score, Finale, QuarkX, Indesign, OxygenXML,Lillypond, Word, Filemaker, oder aber Verovio.Wie die aufgeführten Notensatzprogrammeverdeutlichen, sind EditorInnen nun teilweiseauch mit Aufgaben beschäftigt, die vorhervon Verlagen erledigt wurden. Durch dieseTätigkeit kann auch das Rechtemanagementvon Originalquellen zu einem weiterenAufgabengebiet werden. Die Ergebnisseabstrahierend betrachtet sind im neuenMedium neue Forschungsfragen entstandenund bilden sich täglich neu aus: Wo sind dieAnfangs- und Endpunkte von Editionen, welcheNachnutzbarkeit kann gewährleistet werden,wie kann die Praxis von dem Wissen profitierenund dieses einsehen, wo ist Wissen gesicherterschlossen? Zudem gibt es kaum verbindlicheStandards im digitalen Editionsprozess,was nun, bei steigender Editionszahl undentsprechender Annotationsmenge immeroffensichtlicher und wichtiger wird. Einsystematischer Wissensaufbau informatischerGrundkenntnisse wird ebenso implizit evident,um die Potenziale der digitalen Repräsentations-und Verarbeitungsoptionen besser erschließenzu können.
Fußnoten
1. Das Kodieren bezeichnet im Gegensatzzu Semantiken aus der Informatik imKontext der qualitativen Forschung eineAuswertungstechnik.
Bibliographie
Brockman, William S. / Neumann, Laura /Palmer, Carole L. / Tidline, Tonyia J. (2001):Scholarly Work in the Humanities and theEvolving Information Environment. portal:Libraries and the Academy (Vol. 3). DigitalLibrary Federation. 10.1353/pla.2003.0012 .
Drucker, Johanna (2013): „PerformativeMateriality and Theoretical Approaches toInterface“, in: DHQ: Digital Humanities Quartely7 (1). http://www.Digitalhumanities.org/dhq/vol/7/1/000143/000143.html .
135

Digital Humanities im deutschsprachigen Raum 2017
Edwards, Charlie (2012): „The DigitalHumanities and Its Users“, in: Gold, MatthewK. (ed.): Debates in the Humanities. http://dhdebates.gc.cuny.edu/debates/text/31 [letzterZugriff 3. September 2015].
Flick, Uwe / Kardorff, Ernst von / SteinkeInes (eds.). (2000): Qualitative Forschung: EinHandbuch. Reinbeck: Rowohlt.
Flick, Uwe (2002): QualitativeSozialforschung: Eine Einführung. 6. überarb. underweiterte Aufl. Hamburg: Rowohlt.
Giesecke, Michael (1991): Der Buchdruck inder frühen Neuzeit: eine historische Fallstudieüber die Durchsetzung neuer Informations- undKommunikationstechnologien. Frankfurt a. M.:Suhrkamp.
Keuneke, Susanne (2005): „QualitativesInterview“, in: Mikos, Lothar / Wegener,Claudia (eds.): Qualitative Medienforschung: EinHandbuch. Konstanz: UVK 254–267.
Kirschenbaum, Matthew (2008):Mechanisms: New Media and the ForensicImagination. Cambridge: MIT University Press.
Manovich, Lev (2001): Language of NewMedia. Cambridge: MIT Press.
Polanyi, Michael (1985): Implizites Wissen.Frankfurt: Suhrkamp.
Przyborski, A. / Wohlrab-Sahr, M. (2009):Qualitative Sozialforschung. Ein Arbeitsbuch.München, Oldenbourg.
Stone, Sue (1982): „Humanities Scholars:Information Needs and Uses“, in: Journalof Documentation 38 (4): 292–313. http://www.emeraldinsight.com/journals.htm?articleid=1649976 .
Veit, Joachim (2010): „Es bleibt nichts, wiees war – Wechselwirkungen zwischen digitalenund ,analogen‘ Editionen“, in: editio 24: 37–5210.1515/9783110223163.0.37.
Warwick, Claire (2012): „Studying usersin digital humanities“, in; Warwick, Claire /Terras, Melissa / Nyhan, Julianne (eds.), DigitalHumanities in Practice. London: Facet Publishing1–21.
Winter, Rainer (2010):„Handlungsmächtigkeit und technologischeLebensformen: Cultural Studies, digitaleMedien und die Demokratisierung derLebensverhältnisse“, in: Pietraß, Manuela /Funiok, Rüdiger (eds.) Mensch und Medien.Philosophische und sozialwissenschaftlichePerspektiven. Wiesbaden: VS 139–157.
3D-MetamodelingChristopher Polhem’sLaboratoriummechanicum 1696
Snickars, [email protected] university, Schweden
In a letter from autumn 1696 to the RoyalSwedish Bergs Collegium, the scientist andpre-industrial inventor, Christopher Polhem(1661-1751)—sometimes described as “theFather of Swedish Technology” (Lindroth 1951;Johnson 1963, Lindgren 2011)—argued thatthe Swedish king really ought to establish aLaboratorium mechanicum, all in order to fosterfuture engineers. Importantly, this mechanicallaboratory should have included educationalwood models of contemporary equipment,machines and building structures, as well aswater gates, hoistings and locks. FollowingPolhem, mechanics was simply the foundationof all knowledge: ”mechaniken är en grundoch fundament til heela philosophien”. A fewyears later, a mechanical laboratory was indeedfounded by Polhem, established near the Falucopper mine. Essentially his Laboratoriummechanicum became a pioneering facility(albeit small) for the pre-industrial training ofSwedish engineers, as well as a laboratory fortesting and exhibiting Polhem’s own woodenmodels and designs. By the mid 1700, Polhem’sLaboratorium mechanicum had transformedinto the so called, Royal Model Chamber, aSwedish institution (funded by the king) forinformation and dissemination of technologyand architecture set up in central Stockholm. Itwas admired, for example, by Johann Beckmannon his trip through Sweden in the mid 1760s.Later, during the 19th century, the pedagogicalmodels belonging to the Royal Model Chamberwere frequently used by engineering studentsat the KTH Royal Institute of Technology (inStockholm). Apparently, this was especiallythe case with Polhem’s so called mechanicalalphabet. Initially, it consisted of 80 woodenmodels of basic machine elements like thelever, the wheel and the screw. Since a writernaturally had to know the alphabet in orderto create words and sentences, Polhem arguedthat a contemporary mechanicus had to grasphis mechanical alphabet to be able to construct
136

Digital Humanities im deutschsprachigen Raum 2017
and understand machines. Evidently, Polhem’smodels are interesting as physical traces of thematerial foundations of scientific knowledge(Ludwig, Weber & Zausig, 2014). Around 1930,however, part of the Royal Model Chamber andPolhem’s mechanical alphabet collection wastransferred to the Swedish National Museum ofScience and Technology. Ever since it has served—and been frequently exhibited—as a kindof meta-museological artifact, since Polhem’sdesigns proved to be pedagogical museologicalobjects avant la lettre.
One of the objectives of the London Charteron computer-based visualisation of heritagepromotes “intellectual and technical rigour indigital heritage visualisation” (London Charter2009)—yet, in what way should one todaydigitise Polhem’s Laboratorium mechanicum?What is the exact relation between “technicalrigour” and virtual heritage in a softwareculture permeated by constant updates?Within the interdisciplinary Swedish researchproject, “Digital Models. Techno-historicalcollections, digital humanities & narratives ofindustrialisation” (funded by the Royal SwedishAcademy of Letters, History and Antiquities)parts of Polhem’s collection has been 3D scannedand 3D reconstructed by different software.The project set up is part of the trend wereheritage institutions are today exploring how3D technologies can broaden access to, and theunderstanding of their collections (Urban 2016;Ioannides 2014). Then again, is a 3D scan of amodel (in our case) for example more rigourthan a simulation?
In general, the research project “DigitalModels” (that I am heading) explores thepotential of digital technologies to reframeSwedish industrialisation and its storiesabout society, people and environments. Theproject uses three different cultural heritageperspectives to examine the specificity ofdigitisation and its potential to bridge research,institutional heritage and interest from thegeneral public. Departing from the digitisationof three selected categories of material in theSwedish National Museum of Science andTechnology collections, these mirror the threephases of industrialisation: (A.) parts of thebusiness leader and industry historian, CarlSahlin’s extensive collection. (B.), all editions ofthe museum yearbook, Daedalus (1931-2014),and (C.) all of Polhem’s preserved woodenmodels. These materials and phases correspondto three methodological approaches: traditionaldigitisation (A.), mass digitisation (B.) and criticaldigitisation (C.). Digitisation methods are hencecorrelated with different industrial-historical
periods, resulting in three sets of digital tools,applications and/or game prototypes focused onvarious narratives of Swedish industrialisation.
In my presentation—done in English, butwhere questions can be posed in Germansince I am a fluent speaker—I want to presentthe ways in which we have worked with 3Dmodeling (parts of) Christopher Polhem’smechanical alphabet. Our 3D-metamodelinghas been conceived as both a scholarly and as amuseological practice. On the one hand we havetried to increase the historical understandingand knowledge about (and around) Polhem’smodels via visualisation, virtualisation andsimulation, and on the other to experimentwith novel ways to use the model’s inherentpedagogical quality, and especially so within amuseological context at the Swedish NationalMuseum of Science and Technology. We havefor example 3D scanned some of Polhem’smodels using a simple iPad iSense 3D scanner—and where we have also 3D printed some ofour resulting imagistic models (with movingparts). Some of these digitisation activities havebeen performed within the actual museumspace as a pedagogical activity, stressing theways in which Polhem’s old models still have adidactic quality to them. In addition, we havedesigned a few simple virtual reality models(of the models). Furthermore, in co-operationwith Visualiseringscenter C (at LinköpingUniversity) we have also CT-scanned someof Polhem’s models—i.e where images aretaken from different angles to produce a cross-sectional and tomographic 3D image, a kindof virtual slice, allowing one to see inside themodels without breaking them. Digital geometryprocessing has, in short, been used to generatea three-dimensional image of the inside of themodels and their different parts. We have alsoco-operated with the professional animatorRolf Lindberg; on YouTube he has uploaded anumber of videos of Polhem’s models (Lindberg2016). Lindberg, however, did not 3D scanPolhem’s mechanical models—he computer-animated them in Cinema4D.
Hence, from a museological perspective,digitising Polhem’s mechanical alphabet hasproduced a number of really different results.The London Charter on computer-basedvisualisation of heritage defines principlesfor the use of computer-based visualisationmethods “in relation to intellectual integrity,reliability, documentation, sustainability andaccess” (London Charter 2009). Indeed, thecharter recognises that the range of availablecomputer-based visualisation methods isconstantly increasing. Still, the linkage and
137

Digital Humanities im deutschsprachigen Raum 2017
genealogy between copy and original sometimesbecomes weak. For animator Lindberg, ratherthan 3D scanning Polhem’s heritage items, it wasway easier—and more pedagogical and visuallyenticing to simulate them—that is, buildingand constructing brand new virtual objects. Theprecious and highly esteemed original modelscollected at the museum—Polhem’s mechanicalalphabet—then becomes a model (rather thanvice versa). Still, in the case of Polhem’s models,the theme of (digital) reconstruction also hasa profound historical dimension, since hesincerely believed (as a pre-industrial inventor)that physical models were always superior todrawings and abstract representations. Thequestion is if he would have considered 3Dreconstructions in a similar manner.
Bibliographie
Ioannides, Marinos et. al. (eds.) (2014):Digital Heritage: Progress in Cultural Heritage.Cham: Springer.
Johnson, William A. (1963): ChristopherPolhem, The Father of Swedish Technology.Hartford: Trinity College Press.
Lindberg, Rolf (2016): https://www.youtube.com/channel/UC0UKj1XHuArjk-EZOrQRafQ .
Lindgren, Mikael H. (2011): ChristopherPolhems testamente. Stockholm:Innovationshistoria förlag.
Ludwig, David / Weber, Cornelia / Zausig,Oliver (eds.) (2014): Das Materielle Model.Paderborn: Fink.
Lindroth, Sten (1951): Christopher Polhemoch Stora Kopparberget. Uppsala: Almqvist &Wiksell.
London Charter (2009): http://www.londoncharter.org/fileadmin/templates/main/docs/london_charter_2_1_en.pdf .
Urban, Richard (2016): CollectionsCubed: Into the third dimension. http://mw2016.museumsandtheweb.com/paper/collections-cubed-into-the-third- dimension/ .
Dokumentation,Werkzeugkasten, Pakete- Nachhaltigkeit vonDaten und FunktionalitätDigitaler Editionen
Czmiel, [email protected] Akademie derWissenschaften, Deutschland
Die Rolle digitaler Ressourcen in denGeisteswissenschaften und die zunehmendeBedeutung von Algorithmen werden nochimmer unterschätzt. In den letzten Jahrenbzw. Jahrzenten wurden zahlreiche Software-Werkzeuge, virtuelle Forschungsumgebungenund interaktive Publikationen, wieDatenbanken oder Digitale Editionen, fürdie geisteswissenschaftliche Forschungentwickelt. Diese werden innerhalb derForschungscommunity mit zunehmenderTendenz akzeptiert und inzwischen breiteingesetzt. Jedoch stehen wir heute vorder Herausforderung diese verschiedenenRessourcen, die zu einem großen Teil aufunterschiedlichen technischen Grundlagenbasieren, weiter zu pflegen und verfügbar zuhalten. Transparenz und Reproduzierbarkeit vonForschungsergebnissen, die mit einer digitalenRessource oder Software erstellt wurden leidendarunter, dass diese Software oft nach wenigenJahren nicht mehr gepflegt wird und damit nichtmehr lauffähig ist.
Der Vortrag beleuchtet die hier skizzierteProblematik am Beispiel Digitaler Editionen. Eswerden drei Punkte vorgeschlagen, wie durcheinen Bottom-Up-Ansatz die Nachhaltigkeitdigitaler Ressourcen gefördert werden kann. DerFokus liegt dabei auf den Erfahrungen, die imLaufe der letzten 10 Jahre mit der Entwicklungvon XML-basierten Digitalen Editionen und demEinsatz ausgewählter Software-Werkzeuge, wieder nativen XML-Datenbank eXistdb ( http://exist-db.org ), gewonnen wurden.
Bei digitalen Ressourcen handelt es sich umdynamische Objekte. Das bedeutet einerseits,dass die Inhalte jederzeit korrigiert, erweitertoder verändert werden können. Andererseitsmuss die technologische Basis fortlaufendaktuell, sicher und verfügbar gehalten werden.Diese beiden Prozesse sind Teilaufgaben eines
138

Digital Humanities im deutschsprachigen Raum 2017
größeren Aufgabenbereichs, der unter demBegriff „ data curation“ zusammengefasstwerden kann.
Eine Digitale Edition ist mehr als nur ihreForschungsdaten. Letztere, in vielen Fällen XML-Dokumente, werden oft erst durch eine adäquateDarstellung, durch Visualisierungen, wie Text-Bild-Verlinkungen, verschiedene Ansichtenauf den Text, Netzwerke oder Timelines oderauch Verknüpfungen mit anderen externenRessourcen „zum Leben erweckt“. DiesesLeben in Form programmierter Funktionalitätist ein genuiner Forschungsbereich derDigital Humanities. Allerdings führt dieFunktionalitätsschicht (siehe Abbildung 1) einerDigitalen Edition auch dazu, dass data curationeine sehr komplexe Aufgabe werden kann,da hier die Flexibilität der Implementierungerheblich höher ist als auf der Ebene derDatenschicht.
Abbildung 1: Schichtenmodell Digitale Edition
Digitale Editionen sind Software-Werkzeugefür die Analyse von Forschungsdaten. Damitsind sie ein Teil des Forschungsprozesses,der erhalten werden muss, um dieReproduzierbarkeit der Forschungsergebnisse zugewährleisten.
Eine digitale geisteswissenschaftlicheRessource durchläuft üblicher Weise einentypischen Lebenszyklus. Dieser beginntmit der Analyse der analogen Quellen, gehtüber die Datenmodellierung, die Auswahlbzw. Anpassung oder Neuentwicklung vonBearbeitungswerkzeugen sowie der digitalenPublikation der Forschungsergebnisse bishin zu Fragen der Langzeitverfügbarkeit undLangzeitarchivierung. Bei jedem dieser Schrittesind verschiedenen Kompetenzen involviert.Das bedeutet, der Aufbau einer Digitalen Editionist immer Teamwork. Dieses Team setzt sich inden meisten Fällen aus Personen zusammen,die einerseits das inhaltliche Fachwissenmitbringen und andererseits aus Personen mit
einer Vielzahl unterschiedlicher technischerKompetenzen:
Analyse der Quellen (Geisteswissenschaftler)Anforderungsanalyse der digitalen
Ressource, Requirement Engineering (alleProjekbeteiligten)
Entwurf des Daten- / Dokumentenmodells,Auswahl von Standards(Geisteswissenschaftler,Datenbankspezialisten, Markupspezialisten,Metadatenspezialisten)
Auswahl, Anpassung bzw. Entwicklung von Tools(Programmierer, Geisteswissenschaftler)
Aufsetzen und Betreuen der Server(Systemadministratoren)
Konzept, Design und Umsetzung der Web-Publikation (Webdesigner, Webentwickler,Geisteswissenschaftler)
Vorbereitung für Langzeitverfügbarkeit / -archivierung (Metadatenspezialisten,Dokumentationsspezialisten)
Betreuung und Wartung nach Projektende („data curators“)
An jeder Stelle in diesem Lebenszyklus einerdigitalen Ressource werden Entscheidungengetroffen, die Auswirkungen auf dennachfolgenden Schritt haben. So bilden dieeigentliche Analyse der Inhalte, die z.B. ineiner Digitalen Edition publiziert werdensollen, und die Anforderungsanalyse dasFundament, auf dem alles aufbaut, vom Daten-oder Dokumentenmodell, bis hin zur Publikationund der data curation.
Aus methodischer Sicht, mit besonderemAugenmerk auf das zugrundeliegende Text-bzw. Dokumentenmodell, wurden DigitaleEditionen bereits ausführlich beschrieben (siehePierazzo 2015 und Sahle 2013). Eine Analyseaus technischer Sicht steht noch aus. Um dieEntwicklung, Betreuung und NachhaltigkeitDigitaler Editionen zu gewährleisten bedarf eseines technologischen Publikationskonzepts, dasaus möglichst standardisierten Komponentenbesteht.
Bisher existieren sehr erfolgreicheStandardisierungen auf dem Gebiet derMetadaten und der Textauszeichnungen, z.B. mitden Richtlinien der Text Encoding Initiative (TEI),aber wenig bis gar nichts bei der technischenUmsetzung und der Dokumentation. Dieswürde helfen anschlussfähigere, stabilere undnachhaltigere digitale Ressourcen aufzubauenund damit auch die Arbeit eines Datenkurators,der sich um die Pflege dieser Ressourcen nachProjektende kümmert, deutlich vereinfachen.
139

Digital Humanities im deutschsprachigen Raum 2017
Für eine aussichtsreiche Nachhaltigkeit kanndie Lösung nicht allumfassend sein, sondern nurfür klar definierte Anwendungsfälle gelten. Indem hier vorgestellten Fall ist dies eine XML-basierte Digitale Edition, die mit Technologienaus der X-Familie (XSLT, XQuery, XML-Schema,eXistdb) entwickelt wird. Das Grundprinzipist jedoch auf andere Anwendungsszenarienübertragbar:
Eine ausführliche DokumentationEin klar definierter WerkzeugkastenDie Paketierung aller Projektressourcen
DokumentationEine nachhaltige digitale
Forschungsressource bzw. –software istlangfristig verfügbar, gut dokumentiert,lizenziert und versioniert, um dieReproduzierbarkeit der Forschungsprozessezu garantieren. Die wichtigste Komponente isteine ausführliche, formalisierte Dokumentation,die mindestens die folgenden Informationenenthalten sollte:
• Den Namen des Projekts und aller beteiligtenInstitutionen und Personen.
• Den Projektstatus: geplant, in Arbeit,veröffentlicht, beendet.
• Die eingesetzten Technologien und Standardsinklusive Versionsangabe.
• Lizenzangaben zu Forschungsdaten,Quellcode, und anderen Komponenten, wieSchriftarten, Audio- oder Videodokumenten.
• Informationen darüber, wo der Quellcodeund die Forschungsdaten zu finden sind.
• Informationen über die bereitgestelltenAPIs und andere Schnittstellen, um dieForschungsdaten in verschiedenen Formatenabzurufen (XML, HTML, PDF, JSON usw.) undin anderen Kontexten weiterzuverarbeiten.
• Details über die Forschungsmethode und denHintergrund des Projekts. (Mehr dazu sieheFaniel 2015)
• Zitations- und Referenzierungsanweisungenfür die persistente Adressierung aktuellerund älterer Versionen der Forschungsdaten,Metadaten und Software.
• Eine standardisierte Historie derProjektentwicklung.
Selbstverständlich kann diese Liste nur einerster Vorschlag sein. Sie enthält keinesfallsalle möglichen Informationen, die zu einerDigitalen Edition angegeben werden können. DieDokumentation sollte maschinenlesbar (um z.B.als XML oder JSON weiter verarbeitet werden zu
können) und über eine standardisierte Adressebzw. einen klar definierten Zugriffspunkt (z.B.http://home.of.project/api/projectdescription)abrufbar sein. Dadurch wäre es möglich eineDigitale Edition bei einem zentralen Verzeichnisanzumelden, in dem alle Informationen undUpdates über Digitale Editionen, die demselbenPublikationsmodell folgen, gesammelt werden.Ein solches Verzeichnis existiert noch nicht.
Definierter WerkzeugkastenWie oben beschrieben kann Nachhaltigkeit
nur in einem definierten Rahmen hergestelltwerden, indem man klare Anwendungsfällebeschreibt. Selbst in diesen sind dieMöglichkeiten der Umsetzung nahezuunbegrenzt. Daher ist es wichtig, genau zudefinieren, welche Technologien, Standards undSoftware-Werkzeuge zum Einsatzkommen undwelche Abhängigkeiten bestehen. Es ist ratsamdie Zahl der eingesetzten Tools überschaubarzu halten und sich auf etablierte und gutdokumentierte Technologien zu konzentrieren.
PaketierungAlle zusammengehörenden Komponenten
einer Digitalen Ressource (Daten, Metadaten,Quellcode, Binärdatein, Dokumentation)müssen immer zusammen abrufbar sein. DiesePakete tragen deutlich zu einer nachhaltigerenEntwicklung bei. Es ist immer klar, wo sichalle relevanten Informationen und Datenbefinden. Zudem könnte ein Paket einerzentralen Kurationsstelle, z.B. einem DigitalHuamnities Data Center, übergeben werden, diesich um die Betreuung der digitalen Ressourcenabgeschlossener Projekte kümmert. DieseAnlaufstelle existiert ebenfalls noch nicht.
Für den hier vorgestellten Anwendungsfallbietet das von eXistdb verwendete EXPath-Format ( http://expath.org/ ) einen gutenAusgangspunkt für die Paketierung. DiesesFormat beschreibt ein Packaging-System ( http://expath.org/modules/pkg/ ), das es erlaubtXML-basierte Dokumente zusammen mitAbfrage- und Transformationsskripten sowieverschiedenen anderen Ressourcen auf einestandardisierte Art und Weise zu paketieren,das dieses Paket von allen Softwaresystemen,die diesem Standard folgen verstandenund ausgewertet werden kann. Damit kanndieses Packagesystem ähnlich fungieren, wieein App-Store für Smartphones. Auch derAnpassungsaufwand für Software, die währendder Projektlaufzeit eingesetzt wird, würde sichso verringern.
Andere Anwendungsszenarienlassen sich nicht auf Softwareebenepaketieren. In diesen Fällen kann man aufAnwendungsvirtualisierung zurückgreifen,
140

Digital Humanities im deutschsprachigen Raum 2017
wie sie zum Beispiel mittels Docker ( https://www.docker.com/ ) möglich ist.
Um eine solche Standardisierung aufder technischen Ebene durchzuführenbenötigt es eine aktive Digital-Humanities-Enwicklercommunity. Die Rolle des DH-Entwicklers ist im allgemeinen Diskursnoch deutlich unterrepräsentiert. Umwirklich erfolgreich Softwaretools fürdie geisteswissenschaftliche Forschungprogrammieren zu können, benötigt einEntwickler mehr als nur ein grundlegendesVerständnis der typischen Problematiken inden einzelnen Fachdisziplinen. Umgekehrterlauben Programmierkenntnisse einwesentlich besseres Verständnis über dieFunktionsweise der Software und damit bessereEinsatzmöglichkeiten sowie das Potential zueigenen Verbesserungen. Um hier Fortschritte zuerzielen, müssen sich die DH-Entwickler besserorganisieren. Die DH-Entwicklercommunitywäre der Kreis an Personen, die die Einführungund Anwendung von Standards, wie demEXPath-System diskutieren und tragen.Mittelfristig wäre das Ziel für jeden Schritt imLebenszyklus einer digitalen Ressource einenoder mehrere Vorschläge einer standardisiertenHerangehensweise in Form eines best-practice-Leitfadens zu haben, der sich alstechnical reader zur Erstellung digitalergeisteswissenschaftlicher Ressourcen eignetund Vorschläge zu Schnittstellen, Standards,Lizenzen, Dokumentation, Zitationshinweiseusw. anbietet.
Ein Ansatzpunkt dafür bietet die Arbeitdes 2010 gegründeten Software SustainabilityInstitute ( https://www.software.ac.uk/ ), Hong2010 sowie Hettrick 2016, die verschiedeneAnsätze zur Forschungs-Software-Nachhaltigkeituntersucht haben.
Bibliographie
Faniel, Ixchel (2015): Data Management andCuration in 21st Century Archives, 21. September2015, http://hangingtogether.org/?p=5375 .
Hettrick, Simon (2016): Research SoftwareSustainability. Report on a Knowledge ExchangeWorkshop.
Hong, N. Chue et al. (2010): SoftwarePreservation Benefits Framework. SoftwareSustainability Institute Technical Report.
Pierazzo, Elena (2015): Digital ScholarlyEditing, Theories, Models and Methods. Ashgate.
Sahle, Patrick (2013): DigitaleEditionsformen, Zum Umgang mit derÜberlieferung unter den Bedingungen des
Medienwandels. 3 Bände. Norderstedt: Books onDemand.
Ein PoS-Tagger für „das“Mittelhochdeutsche
Echelmeyer, [email protected]ät Stuttgart, Deutschland
Reiter, [email protected]ät Stuttgart, Deutschland
Schulz, [email protected]ät Stuttgart, Deutschland
Einleitung
Ein grundlegender Schritt für eine Vielzahlvon Aufgaben aus dem Bereich des NaturalLanguage Processing (NLP) ist das Part of Speech(PoS)-Tagging. Ein PoS-Tagger annotiert imKontext eines Satzes jedes Wort mit seinerWortart aus einer Menge an festgelegtenWortarten (Tagset).
Ein Großteil der dazu vorhandenen Arbeitenkonzentriert sich auf das Englische, auch fürdas Neuhochdeutsche sind vergleichbar vieleDaten verfügbar. Historische Sprachstufenstellen hingegen eine Herausforderung für NLP-Aufgaben wie PoS-Tagging dar, da sie keineStandardsprache kennen, sondern nur alsVielfalt dialektaler Varietäten existieren, undihre Verschriftlichung nicht nach einheitlichenRegeln erfolgt. Dies schlägt sich in einer hohenVarianz nieder, was die Annotation einerausreichenden Menge an Referenzdatenerschwert.
Mit diesem Beitrag möchten wir einenPoS-Tagger für das Mittelhochdeutschevorstellen, der auf einem thematisch breitenund diachronen Korpus trainiert wurde. AlsTagset verwenden wir ein Inventar aus 17universellen Wortart-Kategorien ( UniversalDependency-Tagset, Nivre et al. 2016). Mit denannotierten Daten entwickeln wir ein Modellfür den TreeTagger (Schmid 1995), das freizugänglich ist.
Dabei vergleichen wir drei verschiedeneMöglichkeiten, den PoS-Tagger zu trainieren.Zunächst verwenden wir ein kleines, manuell
141

Digital Humanities im deutschsprachigen Raum 2017
annotiertes Trainingsset, vergleichen dessenErgebnisse dann mit einem kleinen, automatischdisambiguierten Trainingsset und schließlich mitden maximal verfügbaren Daten.
Mit dem Tagger möchten wir nicht nureine „Marktlücke“ schließen (denn bishergibt es keinen frei verwendbaren PoS-Taggerfür das Mittelhochdeutsche), sondern aucheine größtmögliche Anwendbarkeit aufmittelhochdeutsche Texte verschiedenerGattungen, Jahrhunderte und regionalerVarietäten erreichen und weiteren Arbeiten mitmittelhochdeutschen Texten den Weg ebnen.
Forschungsstand
Tagset
Als PoS-Tagset hat sich für Neuhochdeutschdas Stuttgart-Tübingen-Tagset (STTS) etabliert(Schiller et al. 1999). Um auf die Besonderheitenhistorischer Sprachstufen besser eingehenzu können, entwickelten Dipper et al. (2013)ein hieran angelehntes Historisches Tagset(HiTS), das aus 12 Wortklassen besteht, die sichihrerseits in 84 Wortarten gliedern.
Mit dem Ziel eines universellen Tagsets,welches konsistente Annotation vereinfacht undsprachübergreifendes Lernen für automatischeSyntaxannotationen ermöglicht, wurde imRahmen des Universal Dependency-Projekts (UD)ein Tagset aus 17 Tags erstellt. Dieses kann beiBedarf um sprachspezifische Tags erweitertwerden.
Tagging
Die besten verfügbaren PoS-Tagger erreichenauf englischsprachigen Zeitungstexten über97% Accuracy (cf. Spoustová et al. 2009).Für deutschsprachige Zeitungstexte werdenum die 95% erzielt, für Web-Texte 90–93%(Giesbrecht / Evert 2009). PoS-Tagging für dasMittelhochdeutsche ist weit weniger erforscht.Schulz / Kuhn (2016) beschreiben Ansätzezum PoS-Tagging eines spezifischen Textes.Barteld et al. (2015) trainieren einen PoS-Tagger für Mittelniederdeutsch. Dipper (2011)berichtet eine Accuracy von ca. 92% für zweispezifische Modelle für die Dialekte Ober- undMitteldeutsch, trainiert auf normalisiertenLemmata und mit dem STTS-Tagset. Allegenannten Modelle sind auf eine bestimmteVarietät des Mittelhochdeutschen beschränkt,
zudem ist keines dieser Modelle (soweit unsbekannt) öffentlich verfügbar.
Korpora
Die wohl umfangreichsten Projekte zumMittelhochdeutschen sind das Wörterbuchnetz1 , ein online zugänglicher Verbund ausNachschlagewerken, das linguistisch motivierteReferenzkorpus Mittelhochdeutsch 2 (ReM,Dipper 2015) sowie die MittelhochdeutscheBegriffsdatenbank 3 (s.u.).
Die annotierten Textkorpora (cf. Dipper2015: 521–526) können z.T. über das SuchtoolANNIS (Zeldes et al. 2009) abgefragt werden,wobei Suchanfragen auf den Ebenen Wortform,Lemma und Morphologie möglich sind.
MittelhochdeutscheBegriffsdatenbank (MHDBDB)
Durch eine Kooperation mit dem Projekt„Mittelhochdeutschen Begriffsdatenbank“konnten wir für die Entwicklung unseresPoS-Taggers auf eine reiche Datensammlungzurückgreifen, bestehend aus 658 Texten mitinsgesamt knapp 10 Millionen Tokens. DieTexte umfassen eine Zeitspanne von etwa vierJahrhunderten (1100–1500), verschiedenedialektale Ausprägungen sowie nahezu alleGattungen (von großepischen Genres wieArtusroman, Heldenepik und Antikenromanüber Kleinepik hin zu Lyrik sowie diversennicht-literarischen Texten wie Kochbüchern,Alchemistischen Schriften und Flugblättern).
142

Digital Humanities im deutschsprachigen Raum 2017
Kürzel Name BeispielNOM Nomen acker, zîtNAM Name Uolrîch, Wiene,
RhînADJ Adjektiv grôz, schoeneADV Adverb schone,
schnelleclîcheART Artikel der, eineDET Determinante ditze, mîn, iemanPOS Possessivpronomenmîn, dîn, unserPRO Pronomen ich, ez, wirPRP Präposition ûf, zuo, underNEG Negation nie, âne, nihtNUM Numeral ein, zwô,
zweinzegestCNJ Konjunktion als, und, abrGRA Gradationspartikelsêre, vilIPA Interrogativpartikelswer, swar, wieVRB Verb liuhten, varnVEX Hilfsverb haben, sîn,
werdenVEM Modalverb müezen, sulnINJ Interjektion ahî, owêCPA Komparativpartikelals, wieDIG Zahl (Digit) IX, XVII, III
Tabelle 1: Grammatische Kategorien derMHDBDB
Die Daten der MHDBDB enthalten – nebenTokenisierung und Lemmatisierung – bereitsgrammatische Auszeichnungen (Tabelle 1).Diese sind allerdings nicht disambiguiert, dasie den Kontext eines Wortes unberücksichtigtlassen (Typ-level-Annotationen, z.B. NOM|ADJ|ADV für guot). Darüber hinaus kodierensie die morphologische Zusammensetzungvon Wörtern (z.B. NOM|NEG für unheil), sodass es zu häufigen Mehrfachauszeichnungenkommt (z.B. unvuoge NOM|ADJ|ADV|NEG).Hinzu kommt, dass das Tagset nicht allemöglichen Verwendungsformen der Wörterabdeckt: So kann z.B. daz nicht nur Artikeloder subordinierende Konjunktion sein(Satz 1), sondern auch als Relativ- (2) oderDemonstrativpronomen (3) fungieren:
(1) Daz edel kint hât mir verjehen, daz ez introume sî geschehen.(2) Wie staete ist ein dünnez eis daz ougestheizesunnen hât?(3) Daz sage ich iu vür ungelogen.
Trainings- und Testdaten
Obige Beobachtungen zeigen exemplarisch,dass die grammatischen Auszeichnungender MHDBDB einer Überarbeitung bedürfen,um für die Entwicklung eines PoS-Taggersnutzbar zu sein. Dazu annotieren wir einTeilkorpus, das für den mittelhochdeutschenWortart-Tagger als Trainings- und Testdateidient und für eine automatische Re-Annotationder restlichen MHDBDB-Daten herangezogenwird. Um Anschlussuntersuchungensowie sprachübergreifende Betrachtungenzu ermöglichen, greifen wir für unsereAnnotationen auf die universellen Kategorienaus dem UD-Tagset zurück (Tabelle 2).
143
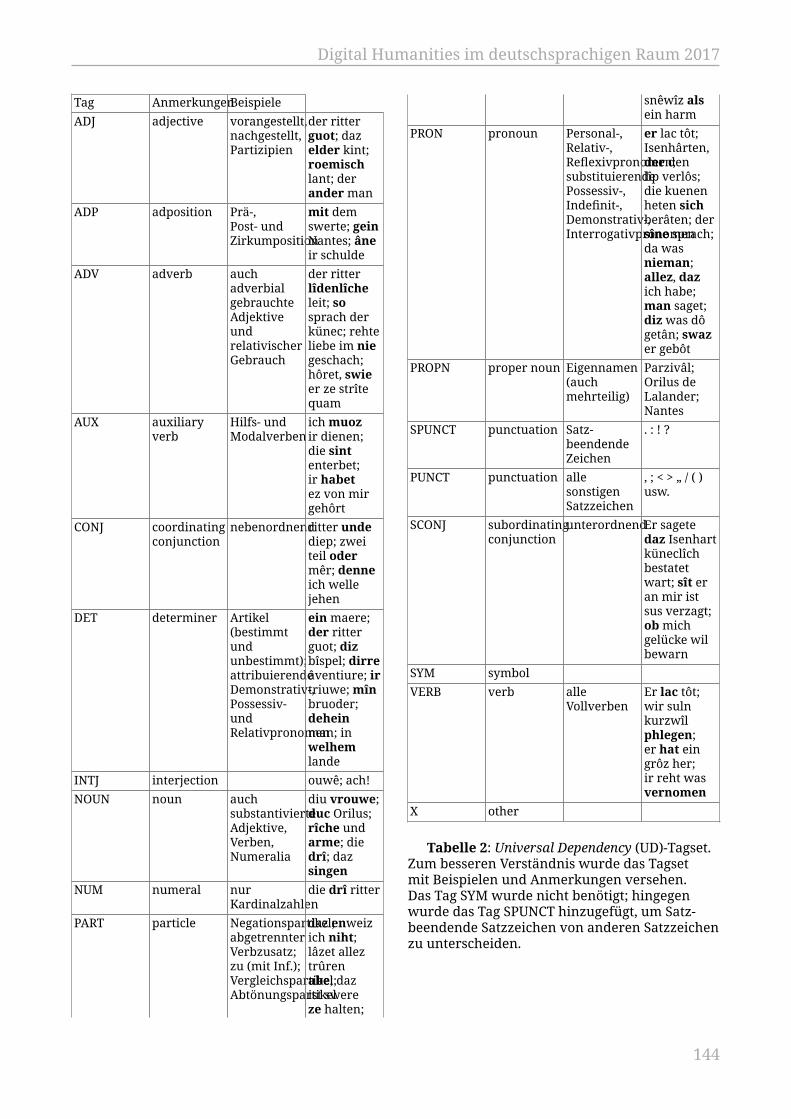
Digital Humanities im deutschsprachigen Raum 2017
Tag AnmerkungenBeispieleADJ adjective vorangestellt,
nachgestellt,Partizipien
der ritterguot; dazelder kint;roemischlant; derander man
ADP adposition Prä-,Post- undZirkumposition
mit demswerte; geinNantes; âneir schulde
ADV adverb auchadverbialgebrauchteAdjektiveundrelativischerGebrauch
der ritterlîdenlîcheleit; sosprach derkünec; rehteliebe im niegeschach;hôret, swieer ze strîtequam
AUX auxiliaryverb
Hilfs- undModalverben
ich muozir dienen;die sintenterbet;ir habetez von mirgehôrt
CONJ coordinatingconjunction
nebenordnendritter undediep; zweiteil odermêr; denneich wellejehen
DET determiner Artikel(bestimmtundunbestimmt);attribuierendeDemonstrativ-,Possessiv-undRelativpronomen
ein maere;der ritterguot; dizbîspel; dirreâventiure; irtriuwe; mînbruoder;deheinman; inwelhemlande
INTJ interjection ouwê; ach!NOUN noun auch
substantivierteAdjektive,Verben,Numeralia
diu vrouwe;duc Orilus;rîche undarme; diedrî; dazsingen
NUM numeral nurKardinalzahlen
die drî ritter
PART particle Negationspartikel;abgetrennterVerbzusatz;zu (mit Inf.);Vergleichspartikel;Abtönungspartikel
daz enweizich niht;lâzet alleztrûrenabe; dazist swereze halten;
snêwîz alsein harm
PRON pronoun Personal-,Relativ-,Reflexivpronomen;substituierendePossessiv-,Indefinit-,Demonstrativ-,Interrogativpronomen
er lac tôt;Isenhârten,der denlîp verlôs;die kuenenheten sichberâten; dersîne sprach;da wasnieman;allez, dazich habe;man saget;diz was dôgetân; swazer gebôt
PROPN proper noun Eigennamen(auchmehrteilig)
Parzivâl;Orilus deLalander;Nantes
SPUNCT punctuation Satz-beendendeZeichen
. : ! ?
PUNCT punctuation allesonstigenSatzzeichen
, ; < > „ / ( )usw.
SCONJ subordinatingconjunction
unterordnendEr sagetedaz Isenhartküneclîchbestatetwart; sît eran mir istsus verzagt;ob michgelücke wilbewarn
SYM symbolVERB verb alle
VollverbenEr lac tôt;wir sulnkurzwîlphlegen;er hat eingrôz her;ir reht wasvernomen
X other
Tabelle 2: Universal Dependency (UD)-Tagset.Zum besseren Verständnis wurde das Tagsetmit Beispielen und Anmerkungen versehen.Das Tag SYM wurde nicht benötigt; hingegenwurde das Tag SPUNCT hinzugefügt, um Satz-beendende Satzzeichen von anderen Satzzeichenzu unterscheiden.
144

Digital Humanities im deutschsprachigen Raum 2017
Manuelle PoS-Annotationen
Das manuell annotierte Teilkorpus bestehtaus 20.000 Tokens. Ein Teil der Daten (1.500Tokens) wurde doppelt annotiert, um das Inter-Annotator-Agreement zu bestimmen (Cohen‘skappa: 0.88; Cohen 1960). Um der Heterogenitätder Sprache gerecht zu werden, enthält dasTeilkorpus zufällig ausgewählte Abschnitte ausverschiedenen Textsorten des Gesamtkorpus.
Durch die Annotation aller Wörter imKontext eines Satzes wurden Ambiguitätenaufgehoben. Zur Bestimmung der Wortart kannder Substitutionstest herangezogen werden,bei dem ein Wort durch ein Wort der gleichenKategorie ersetzt wird. So wird schoene in dazschoene wîp durch ein anderes Adjektiv (z.B.daz minnicliche wîp), in die schoene saz bî imehingegen durch ein Nomen ersetzt (z.B. dievrouwe saz bî ime).
Als Schwierigkeiten bei der Annotationstellten sich u.a. die Trennschärfe von DETund ADJ heraus (insb. für Wörter wie „viele“/„alle“) oder die Annotation von noch nichtlexikalisierten bzw. grammatikalisierten Formen(z.B. das mittelhochdeutsche sît daz, bei dem dieBestandteile ADP und PRON noch identifizierbarsind, wohingegen neuhochdeutsch „seitdem“eine SCONJ ist).
Ein weiterer Sonderfall desMittelhochdeutschen besteht in der (weitgehendunsystematischen) Verwendung klitischerFormen, z.B. der Verschmelzung vonNegationspartikel und Verb ( enmac), derKontraktion mehrerer Pronomen ( siz = sie+ez), von Pronomen und Adposition ( zem= ze+im) o.Ä. In solchen Fällen werden allemiteinander verschmolzenen Wörter annotiert,wobei ein + die Verschmelzung der Wörteranzeigt ( zem ADP+PRON). Das UD-Tagsetmuss für das Mittelhochdeutsche also um„kombinierte Tags“ (in unseren Daten findensich 23 verschiedene Kombinationen) erweitertwerden.
AutomatischeDisambiguierung desGesamtkorpus
Das annotierte Teilkorpus dient nebenseiner direkten Verwendung als Trainings- undTestkorpus (Modell 1) auch der automatischenDisambiguierung des Gesamtkorpus. Hierfürverwenden wir einen sequenziellen Tagger(Conditional Random Fields), der auf dem
manuell annotierten Subkorpus trainiert wurde.Dieser lernt anhand der Annotationen undwortbasierten Eigenschaften, die ambigenAnnotationen auf ihre disambiguiertenEntsprechungen (UD-Tagset) abzubilden. Dasich in den Daten auch nicht-ambige Wörterbefinden, lernt der Tagger an vielen Stellen1-zu-1-Abbildungen, die als Anker fungierenkönnen.
Die Disambiguierung des Gesamtkorpuserreicht eine Accuracy von 86,9%. Die auf dieseWeise disambiguierten Daten kommen für dieModelle 2 und 3 als Trainingsdaten zum Einsatz.
Experiment und Evaluation
Um die Schwierigkeit der Aufgabe unddie Tagging-Qualität einschätzen zu können,vergleichen wir drei verschiedene Modelle:
• Baseline: Anwendung des neuhochdeutschenTreeTagger-Modells auf den Testdaten.
• Modell 1: Der TreeTagger wird nurmit den manuell annotierten Datentrainiert, die Evaluation erfolgt als 5-facheKreuzvalidierung (Cross-Validation), sodass in jedem Durchgang 16k Tokens alsTrainingsdaten zur Verfügung stehen. Vorteil:Qualitativ hochwertige Trainingsdaten,Nachteil: Geringe Datenmenge.
• Modell 2: Der TreeTagger wird auf zufälligausgewählten Sätzen trainiert, die zusammenetwa 16k automatisch disambiguierte Tokensumfassen. Die Trainingsmenge ist damitgleich groß wie für Modell 1 und erlaubt,die Auswirkungen der nicht-perfektenDisambiguierung abzuschätzen.
• Modell 3: Der TreeTagger wird mit allenautomatisch disambiguierten Daten aus derMHDBDB trainiert (9,9M Tokens).
145

Digital Humanities im deutschsprachigen Raum 2017
Modell Precision Recall F-Score AccuracyBaseline 40,3 35,4 33,1 45,4Modell 1(kleinesTrainingsset,manuellannotiert)
86,0 80,3 82,2 87,0
Modell 2(kleinesTrainingsset,autom.disambiguiert)
84,8 68,8 72,3 84,7
Modell 3(großesTrainingsset,autom.disambiguiert)
91,2 79,6 82,9 90,9
Tabelle 3: Ergebnisse des PoS-Taggingsmit verschiedenen Modellen. 4 Alle Modellewurden auf den gleichen Daten evaluiert, fürModell 1 kam Cross-Validation zum Einsatz.Der Precision, Recall und F-Score ermöglicheneine tiefere Einsicht in die Performanz unterBerücksichtigung aller Wortartenklassen,während Accuracy die Gesamtperformanzsichtbar macht und als Vergleichswert zu State-of-the-Art-Ergebnissen dient.
Die Ergebnisse der unterschiedlichen Modellesind in Tabelle 3 zusammengefasst. Zunächstzeigt sich erwartungsgemäß, dass die Baselinekeine zufriedenstellenden Ergebnisse liefert.Modell 1 erreicht eine Accuracy von 87%, Modell2 gut 2 Prozentpunkte weniger. Angesichts derTatsache, dass die Trainingsdaten automatischdisambiguiert wurden, ist das nur ein geringerVerlust. Die Performanz steigt deutlich, wenndas große Datenset zum Training herangezogenwird (Modell 3). Gegenüber Modell 1 erreichenwir eine Verbesserung von ca. 3 ProzentpunktenAccuracy und damit insgesamt fast 91%. EineKombination der Modelle 1 und 3 erzielte keineVerbesserungen gegenüber Modell 3.
Eine Inspektion der von Modell 3produzierten Annotationen ergibt, dassein Großteil der Fehler (53%) auf diekombinierten Tags entfallen, die überwiegendals Pronomen oder Verben getaggt werden. Dienächsthäufigsten Fehlerklassen sind Numeraliaund Partikeln. Die meisten Inhaltswörter(Nomen, Verben) werden korrekt erkannt (>90%).
Fazit
Mit unserem Beitrag stellen wir einennahezu universellen PoS-Tagger für dasMittelhochdeutsche vor, der auf Daten trainiertwurde, die dialektal, zeitlich sowie genremäßigvariantenreich sind. Damit gehen wir davonaus, dass der Tagger auf ebensolchen DatenErgebnisse erzielt, die ihn für darauf aufbauendeForschungen einsetzbar machen.
Daneben haben wir gezeigt, dass derVorverarbeitungsschritt der Disambiguierungkeineswegs perfekt funktionieren muss, ummit den Daten weiterzuarbeiten. Die Accuracyvon ca. 87% für die Disambiguierung führtzwar bei gleicher Datenmenge zu einem Verlustan Tagging-Performanz, durch die größere,automatisch vorverarbeitete Datenmenge wirddieser aber mehr als aufgefangen.
Um die Nutzung unsererForschungsergebnisse nachhaltig zuermöglichen, stellen wir das Modell sowohlauf der TreeTagger-Webseite 5 als auch übereine Webanwendung 6 zur Verfügung. DesWeiteren ist das Modell als Ressource ins Clarin-D-Repositorium 7 aufgenommen, wodurchdie Metadaten sowie die Links zum Modellpermanent auffindbar bleiben.
Fußnoten
1. Online zugänglich unter http://woerterbuchnetz.de/ , letzter Zugriff 23.08.2016.2. Online zugänglich unter http://referenzkorpus-mhd.uni-bonn.de , letzter Zugriff 23.08.2016.3. Online zugänglich unter http://mhdbdb.sbg.ac.at/ (MHDBDB), letzter Zugriff23.08.2016.4. Für die Evaluation wurden die kombiniertenTags zu einer Klasse zusammengefasst.5. http://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/ .6. www.ims.uni-stuttgart.de/forschung/ressourcen/werkzeuge/PoS_Tag_MHG.html .7. Die Ressource kann im IMS-Repositorygefunden werden: http://clarin04.ims.uni-stuttgart.de/fedora/objects/clarind-ims:92/datastreams/CMDI/content .
Bibliographie
Barteld, Fabian / Schröder, Ingrid /Zinsmeister, Heike (2015): „Unsupervisedregularization of historical texts for POS
146

Digital Humanities im deutschsprachigen Raum 2017
tagging“, in: Proceedings of the 4th Workshop onCorpus-based Research in the Humanities (CRH)3–12 www.slm.uni-hamburg.de/germanistik/personen/zinsmeister/downloads/barteld-etai-2015.pdf [letzter Zugriff 23. August 2016].
Cohen, Jacob (1960): „A coefficient ofagreement for nominal scales“, in: Educationaland Psychological Measurement 20: 37–46.
Dipper, Stefanie (2015): „AnnotierteKorpora für die Historische Syntaxforschung.Anwendungsbeispiele anhand desReferenzkorpus Mittelhochdeutsch“, in:Zeitschrift für Germanistische Linguistik 43: 516–563.
Dipper, Stefanie (2011): „Morphological andPart-of-Speech Tagging of Historical LanguageData: A Comparison“, in: Journal for LanguageTechnology and Computational Linguistics 26:25–37 (= Proceedings of the TLT-Workshopon Annotation of Corpora for Research in theHumanities 2012) www.jlcl.org/2011_Heft2/2.pdf[letzter Zugriff 23. August 2016].
Dipper, Stefanie / Donhauser, Karin /Klein, Thomas / Linde, Sonja / Müller,Stefan / Wegera, Klaus-Peter (2013): „HiTS:ein Tagset für historische Sprachstufen desDeutschen“, in: Journal for Language Technologyand Computational Linguistics 28: 85–137www.jlcl.org/2013_Heft1/5Dipper.pdf [letzterZugriff 23. August 2016].
Giesbrecht, Eugenie / Evert, Stefan (2009):„Is Part-of-speech tagging a Solved Task? AnEvaluation of POS Taggers for the German Webas Corpus“, in: Proceedings of the 5th Web asCorpus Workshop (WAC5) www.stefan-evert.de/PUB/GiesbrechtEvert2009_Tagging.pdf [letzterZugriff 23. August 2016].
Mittelhochdeutsche Begriffsdatenbank(MHDBDB). Universität Salzburg. Koordination:Margarete Springeth. Technische Leitung:Nikolaus Morocutti/Daniel Schlager. 1992–2016http://mhdbdb.sbg.ac.at/ [letzter Zugriff 23.August 2016].
Nivre, Joakim / de Marneffe, Marie-Catherine / Ginter, Filip / Goldberg, Yoav /Hajič, Jan / Manning, Christopher D. / McDonald, Ryan / Petrov, Slav / Pyysalo, Sampo /Silveira, Natalia / Tsarfaty, Reut / Zeman,Daniel (2016): „Universal Dependenciesv1: A Multilingual Treebank Collection“, in:Proceedings of the Tenth International Conferenceon Language Resources and Evaluation (LREC2016) 1659–1666 www.petrovi.de/data/lrec16.pdf[letzter Zugriff 23. August 2016].
Schiller, Anne / Teufel, Simone / Stöckert,Christine / Thielen, Christine (1999):„Guidelines für das Tagging deutscherTextcorpora mit STTS (Kleines und großes
Tagset)“. Universität Stuttgart / Tübingenwww.sfs.uni-tuebingen.de/resources/stts-1999.pdf [letzter Zugriff 23. August 2016].
Schmid, Helmut (1995): „Improvementsin Part-of-Speech Tagging with an Applicationto German“, in: Proceedings of the ACLSIGDAT-Workshop 47–50 http://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/data/tree-tagger2.pdf [letzter Zugriff 23. August 2016].
Schulz, Sarah / Kuhn, Jonas (2016):„Learning from Within? Comparing PoS TaggingApproaches for Historical Text“, in: Proceedingsof LREC 2010 4316–4322 www.lrec-conf.org/proceedings/lrec2016/pdf/1237_Paper.pdf [letzterZugriff 23. August 2016].
Entwicklungund Einrichtungeiner digitalenArbeitsumgebungfür die JeremiasGotthelf-Edition. EinErfahrungsbericht
Zihlmann, [email protected]ät Bern, Forschungsstelle JeremiasGotthelf, Schweiz
von Zimmermann, [email protected]ät Bern, Forschungsstelle JeremiasGotthelf, Schweiz
Ausgangslage
Die Historisch-kritische Gesamtausgabe derWerke und Briefe von Jeremias Gotthelf ( HKG),begründet von Prof. Dr. Barbara Mahlmann-Bauer und PD Dr. Christian von Zimmermann imJahr 2003, ist auf 67 Text- und Kommentarbändeangelegt und damit eines der grösserenEditionsvorhaben im deutschsprachigen Raum. 1
Nach der Publikation der ersten Bände (2012)wurden die Arbeitsprozesse evaluiert, um dieEdition adäquat auf digitale Arbeitsverfahrenund Publikationsformen ausrichten zu können.Texte und Kommentare sollten nun TEI-konform
147

Digital Humanities im deutschsprachigen Raum 2017
erfasst werden, zumal sich inzwischen dieerweiterten TEI-Guidelines als internationalereditionsphilologischer Standard durchsetzenkonnten. Die Umstellung sollte aber umfassendersämtliche editorischen Arbeiten von derTranskription und textgenetischen Analyseüber die Dokument- und Datenverwaltung,die Registeranbindung oder Kontrollroutinenbis hin zur Publikation in Print und Webberücksichtigen. Ein wichtiges Anliegenwar es, aus einem Datensatz mehrereAusgabenformate erzeugen zu können (d.h.:unterschiedliche Printformate und digitalePräsentationsformen). Schliesslich sollten die‘endgültigen’ Daten, die bisher allein in derhistorisch-kritischen Buchedition gedrucktvorlagen, in einem einheitlichen Datenformatin der Forschungsstelle zentral verfügbar,gesichert und anderweitig verwertbar sein.(Zuvor lagerten die durch Fahnenkorrekturenaktualisierten und in unterschiedlichenSatzprogrammen codierten Satzdaten beimehreren beauftragten Satzbüros.)
Diese unterschiedlichen Aspekte machendas Umstellungsprojekt aussergewöhnlichkomplex; einige der Etappenziele sind bereitserreicht worden. Unser Beitrag handelt vonden Erfahrungen der vergangenen vierJahre und gibt Aufschluss über Chancenund Schwierigkeiten des Umstiegs eineseditorischen Grossprojekts auf ein exaktes,weitestgehend inhaltsorientiertes Markup undauf computerphilologische Arbeitsweisen. Vonbesonderem Interesse ist für uns die Vermittlungzwischen übergreifenden editorischen unddigitalen Standards einerseits und individuellenProjektbedürfnissen andererseits. In unseremVortrag möchten wir zudem den Einflussinstitutioneller Rahmenbedingungen (DaSCH/DDZ, SAGW, SNF, metagrid 2 ) aufdie Durchführung computerphilologischerReformen thematisieren.
Kooperation mit der BBAWund Pagina
Der Weg zu einer Arbeitslösung für dieEdition erfolgt nicht durch eine eigeneProgrammentwicklung, deren Kosten auch beieinem nationalen Zusammenschluss mehrererProjekte so nicht tragbar wären. Mittlerweilehaben sich unterschiedliche modulare Lösungenetabliert (etwa auch textgrid etc.). Nach längererPrüfung entschied sich die Projektgruppe dazu,die Arbeitsumgebung Ediarum der BBAW fürdas eigene Projekt weiterzuentwickeln, zumal
Ediarum bereits für die Schleiermacher-Editionals digitale Arbeitsumgebung angewendet undauch für andere Projekte angepasst worden war.Ediarum basiert auf einer eXist-Datenbank, nutztden Oxygen Author und umfasst Module für denSatzprozess sowie die digitale Datenpräsentation(Dumont/Fechner 2012; Arbeitsgruppe Telotao.J.).
Inzwischen sind erste Module unsererArbeitsumgebung, die Schemata fürHandschriften und Drucktexte nebstentsprechenden Anpassungen im OxygenAuthor abgeschlossen. Für die Satzvorbereitungbesteht eine Kooperation mit der Firma Pagina,welche das Satzmodul mit Tustep für dieDruckvorstufe programmiert und in erstenVersionen für Drucktexte und Manuskriptebereits erfolgreich zur Verfügung gestellt hat(drucknaher Satzpreview für den Editionstextund Apparat).
Schema und Ausgabeformate
Die Entwicklung (insbesondere desHandschriftenschemas) war vor allem deshalbanspruchsvoll, da die Codierung nicht nur dieEinrichtung der historisch-kritischen Ausgabenach der bisherigen Gestalt sicherstellen musste,sondern auch davon abweichende gedruckteund digitale Präsentationsformen ermöglichensollte. Dabei sollten etwa an die Stelle derApparate der Drucktexte in der Webeditionmedienspezifische Annotationsformen tretenkönnen.
Die kritische Edition stellt einen Editionstextbereit und verzeichnet sämtliche textgenetischenProzesse in der Handschrift, Emendationenbei Drucktexten und allfällige Variantenzwischen Drucktexten und Handschriften amSeitenende in unterschiedlichen Apparaten(textgenetischer Apparat, Emendationsapparat,Variantenapparat, Textstufenapparat; häufigKombinationen).
Um die Apparate der kritischen Editionin der Printausgabe zu erzeugen, hätte einFreitextelement wie <note> völlig ausgereicht.Doch hätte eine solche Lösung, welche dieanalytischen Stärken der Codierung für dieeditionsphilologische Arbeit nicht nutzt, denAufwand für einen Umstieg auf XML/TEI nichtgerechtfertigt. Gerade die Möglichkeit zurpräzisen Erfassung textgenetischer Prozesseeinerseits und andererseits der Anspruch, einenDatensatz für unterschiedliche Ausgabeformatezu nutzen, legte den Umstieg nahe.
148

Digital Humanities im deutschsprachigen Raum 2017
Digitale Präsentation undKorrespondenzedition
Die digitale Präsentation soll im Wesentlichenim Rahmen der Edition von GotthelfsKorrespondenzen entwickelt werden (Zihlmann-Märki 2017). Dabei sind drei Ansichten fürunterschiedliche Nutzungsszenarien vorgesehen.Neben der historisch-kritischen Ansicht,welche die Tustep-Routine einbindet, und einerdiplomatischen Ansicht stellt eine Inhaltsansichtden finalen Text samt ausgezeichneten Entitätenund Stellenkommentaren bereit. Die Codierungwird die Vorschläge der TEI Special InterestGroup Correspondence berücksichtigen, unddie Verwendung standardisierter Daten istVoraussetzung für eine Integration in externeSuchumgebungen wie CorrespSearch. 3 Ebensokönnen Informationen aus anderen digitalenRessourcen dank dem Einsatz von Normdateienund dem BEACON-Format in der digitalenUmgebung angezeigt werden (Stadler 2012;Stadler 2014).
Vorzüge und Schwierigkeitender Reform
Überblickt man die bisherige Reform, habensich folgende Vorteile für die Arbeitsprozesseergeben:
• Durch neue Arbeitsabläufe der Texterfassung(angepasste Scann- und OCR-Verfahren beiDrucktexten) konnte eine nicht unerheblicheZeitersparnis erzielt werden.
• Unterschiedliche Previewansichten desEditionstextes erlauben die Hervorhebungspezifischer Besonderheiten, die füreinzelne Korrekturschritte notwendig sind(etwa Hervorhebung des Zeilenfalles oderHervorhebung von Stellen, die differenziertercodiert sind, als dies für die Druckedition imApparat ausgegeben wird etc.).
• Die Dokumentation derCodierungsrichtlinien ermöglichte es,unterschiedliche Aspekte zu verknüpfen:1) editorische Prinzipien konntenverbessert und verbindlicher gestaltetwerden, 2) Probleme im Übergang vonTranskription und Apparatgestaltungentfallen durch die Verbindung beiderProzesse, 3) die Verbindung vonCodeerläuterung, Transkriptionsbeispielund Präsentationsbeispiel hat der Satzfirma
die Programmierung der Satzroutinenerleichtert.
• Die Satzfirma Pagina investiert vor allemin die Konzeption von Satzroutinen undkommt dann nur noch für den Feinsatzder Buchausgabe zum Einsatz. DankRoundtripping können die Satzinformationen(Seiten- und Zeilenzahlen) in die originalenXML-Daten zurückgespielt werden; so verfügtdie Forschungsstelle über aktuelle Daten,die alle Informationen zur Druckausgabeenthalten und leicht auch für anderePräsentationsformen oder – in weiterenReformetappen – für digitale Querverweiseund Kommentarverankerungen genutztwerden können.
Zugleich erwies sich der Reformprozessals überaus anspruchsvoll sowie als zeit- undkostenintensiv.
Als Illusion erweist sich die Vorstellung, essei möglich, eine Codierung unabhängigvon späteren Ausgabeformaten zuentwickeln. Editionen, welche die Datentatsächlich für mehrere Formate bereithalten wollen und nicht nur auf einespezifische Ausgabe zielen, stehen hiervor bedeutenden Problemen, da sie dieDateninterpretation durch Webapplikationenebenso berücksichtigen müssen wie dieEigenheiten von Satzroutinen oder denWunsch nach einer mediumsspezifischenApparatgestaltung. Dies gilt umso mehrfür Projekte, welche die Umstellung imlaufenden Arbeitsprozess bei bereitsetablierten Editionsrichtlinien durchführen.
Innerhalb der modularen Arbeitsumgebungkonnte aufgrund der projektspezifischenBedürfnisse letztlich kein einzigesModul unverändert übernommenwerden. Da die Module jeweilsspezifischen Projektinteressen der an derModulentwicklung beteiligten Projektpartnerfolgen (müssen), sind sie – auch nachErfahrung von Telota – in keinem Fallohne Anpassung nutzbar. Andere Module(Druckvorstufe) konnten dagegen problemlosausgetauscht werden, und dies wäre wohleine Grundanforderung überhaupt anmodulare Editionsumgebungen.
Die graphische Oberfläche in Ediarum könnenwir für unsere Edition nicht nutzen,weil in ihr komplexe Textphänomeneund sich überlagernde Korrekturennicht übersichtlich darstellbar sind.Allerdings hat sich auch gezeigt, dass
149

Digital Humanities im deutschsprachigen Raum 2017
die Arbeit in der Code-Ansicht für diemeisten Mitarbeitenden unproblematischist. Für einzelne Arbeitsschritte wie dieLemmatisierung wäre die Arbeit in dergraphischen Oberfläche möglich.
Allein von der Kostenseite aus betrachtet,lohnt sich bei begonnenen Buchausgabendie Umstellung auf eine differenzierteCodierungspraxis nur bei einem bedeutendenProjektvolumen. Erst dann stehen dieEntwicklungs- und Anpassungskosten einerdigitalen Arbeitsweise in einem Verhältnis zurEinsparung von Satzkosten. Das gilt auch dann,wenn auf eine Buchedition gänzlich verzichtetwird.
Standardisierung undheterogene Editionslandschaft
Freilich wäre es zwecks Ressourcenschonungwünschenswert, dass andere Projektevon Schemata, von Satzroutinen, vonder Arbeitsumgebung und der digitalenPräsentation profitieren könnten, die inunserem oder einem anderen Projektentwickelt wurden. Tatsächlich sehen wir eingewisses Potential im Erfahrungsaustausch.Dass eigentliche Übernahmen vonProjektstrukturen hingegen schwierig sind,liegt weniger an den Codierungsstandardsals an heterogenen Editionstypen und -prinzipien. Verbindliche Prinzipien derTextwiedergabe und Apparatierung könntendie Digitalisierungsprozesse wie auch dielangfristige Sicherung vereinfachen ( einProzedere, ein Umwandlungsschema für alleDaten) und möglicherweise kostensenkendwirken. Die Diversität von Editionen entspringtaber nicht zufälligen Entwicklungen, sondernist tief in heterogenen Forschungstraditionenverankert, und die Entscheidung für einenEditionstyp geht in der Regel mit einerintensiven Auseinandersetzung mit demEditionsgegenstand einher. So rechtfertigt dieBerner Parzival-Edition ihr Projekt nicht zuletztdurch Annahmen über den mittelalterlichenTextbegriff (Stolz 2002), und die Berner Gotthelf-Edition hebt auf den politisch-publizistischenwie diskursiven Charakter der Texte ab, der nurdurch eine umfassende Kommentierung adäquatdargestellt werden kann (von Zimmermann2014).
Auch die TEI trägt der Diversität prinzipiellRechnung, stellt sie doch einen Pool möglicherCodes zur Verfügung, aus denen die
Einzelprojekte ihre eigenen Schemata erarbeitenmüssen. Ein über das Bekenntnis zu TEI/XML(oder einer anderen Auszeichnungssprache)hinausgehender, projektübergreifenderStandard, der die textphilologische Kernarbeit(Transkription und Apparatierung) betrifft,kann deshalb vermutlich eher nicht entwickeltwerden.
Fußnoten
1. Allgemeine Projektinformationen: http://www.gotthelf.unibe.ch2. http://www.metagrid.ch3. http://correspsearch.net/index.xql
Bibliographie
Dumont, Stefan / Fechner, Martin(2012): Digitale Arbeitsumgebung für dasEditionsvorhaben „Schleiermacher in Berlin1808–1834“. http://digiversity.net/2012/digitale-arbeitsumgebung-fur-das-editionsvorhaben-schleiermacher-in-berlin-1808-1834 [letzterZugriff 25. August 2016].
[ Arbeitsgruppe Telota]: Ediarum – DigitaleArbeitsumgebung für Editionsvorhaben. http://www.bbaw.de/telota/software/ediarum [letzterZugriff 25. August 2016].
Schweizerische Akademie der Geistes- undSozialwissenschaften (2015): Final report forthe pilot project „Data and Service Center for theHumanities“ (DaSCH). Swiss Academies Reports10 (1).
Stadler, Peter (2012): „Normdateien in derEdition“, in: editio 26: 174–183.
Stadler, Peter (2014): „Interoperabilitätvon digitalen Briefeditionen“, in: Delf vonWolzogen, Hanna / Falk, Rainer (Hg.): FontanesBriefe editiert. Internationale wissenschaftlicheTagung des Theodor-Fontane-Archivs Potsdam,18. bis 20. September 2013 (= Fontaneana 12).Würzburg: Königshausen & Neumann 278–287.
Stolz, Michael (2002): „Wolframs ‚Parzival‘als unfester Text. Möglichkeiten einerüberlieferungsgeschichtlichen Edition imSpannungsfeld traditioneller Textkritik undelektronischer Darstellung“, in: Haubrichs,Wolfgang / Lutz, Eckart C. / Ridder, Klaus(Hg.): Wolfram von Eschenbach – Bilanzen undPerspektiven.Eichstätter Colloquium 2000 (=Wolfram-Studien 17). Berlin: Schmidt 294–321.
Zihlmann-Märki, Patricia (2017):„Kommentierung in gedruckten und digitalenBriefausgaben“, in: Lukas, Wolfgang / Richter,Elke (Hg.): Kommentieren und Erläutern im
150

Digital Humanities im deutschsprachigen Raum 2017
digitalen Kontext (= Beihefte zu editio) [erscheint2017].
von Zimmermann, Christian (2014):„Geschichte, Ziele und Perspektiven derHistorisch-kritischen Gesamtausgabe derWerke und Briefe von Jeremias Gotthelf(HKG)“, in: Marianne Derron / Christian vonZimmermann (Hg.): Jeremias Gotthelf. NeueStudien. Hildesheim / Zürich / New York: Olms13–37.
Hermann BurgersLokalbericht: Hybrid-Edition mit digitalemSchwerpunkt
Daengeli, [email protected] Center for eHumanities
Zumsteg, [email protected] Literaturarchiv
Einleitung
Dreht sich ein Roman vorab um das Roman-Schreiben, den Zustand der zeitgenössischenLiteratur und die Kritik an ihr, dann ist esvielleicht gar nicht so abwegig, dass seincleverster Witz in seiner eigenen Nicht-Veröffentlichung steckt. Der schweizerischeSchriftsteller Hermann Burger griff auf denletzten Seiten seines Romans Lokalbericht(1970) zu genau dieser selbstreflexiven undauto-dekonstruktiven Volte, als er den Mentordes jungen Protagonisten und angehendenSchriftstellers urteilen lässt, so könne man heutenicht mehr schreiben, das Manuskript solleliegen bleiben, “ein Jahr, zwei Jahre, zehn Jahrelang” – und Burger sich offenbar selbst an denRatschlag hält und den Roman tatsächlich zeitseines Lebens nicht veröffentlicht.
Ausschlaggebend für die Nicht-Veröffentlichung war freilich nicht diese Pointe,sondern ein biographischer Umstand (vgl. dazuden Kommentar in Zumsteg 2016a: 257-304 bzw.http://www.lokalbericht.ch/kommentar). Ausheutiger Warte erscheint die Veröffentlichungjedoch zweifellos geboten. Der Lokalberichtnimmt in Burgers Lebenswerk und Werkleben
eine Scharnierfunktion ein, indem sich Burgerin diesem ‘Rohdiamanten’ erstmals ungestüman jene unverwechselbare Poetik herantastet,die ab seinem Roman Schilten: Schulberichtzuhanden der Inspektorenkonferenz von 1976zu seinem Markenzeichen wird. Die langwährende Beschäftigung Burgers mit demRomantext und seinen Vorstufen – schreibend,vorlesend, auszugsweise publizierend – legtdarüber hinaus Zeugnis ab für die Bedeutung,die er dem Text beimaß. Burgers Bonmot“Literatur ist, wenn man trotzdem druckt”,muss also zur Rechtfertigung dieser postumenVeröffentlichung gar nicht erst bemüht werden.
Der Lokalbericht als Hybrid-Edition
Die erstmalige Herausgabe des Romansaus dem Nachlass im SchweizerischenLiteraturarchiv, Bern (SLA), erforderte eineandere editorische Handhabe als die vorzwei Jahren erschienene Leseausgabe vonBurgers Werken in acht Bänden (Zumsteg2014), die sich auf den Wiederabdruck seinerbereits zuvor publizierten Texte beschränkte.Eine Hybrid-Edition, bestehend aus einerumfassenden digitalen Edition und einemschlichten Lesebändchen als deren Spin-off(Zumsteg 2016a, 2016b), wird dem Archivfundbesser gerecht, zumal sich die Entstehung desRomans dadurch auszeichnet, dass einzelneTextbausteine eine lange Vorgeschichte haben.Die Änderungen und Unterschiede werden dabeiviel weniger auf den einzelnen Typoskript-Seiten manifest als zwischen den Textstufen,sie werden erst im Vergleich der betreffendenDokumente erkennbar. Die Möglichkeiteneiner digitalen Edition, die nicht durch dasFormat der Buchseite und die lineare Folgebestimmt und begrenzt sind, boten sich für dieseSituation besonders an. Das digitale Formatgab überdies Gelegenheit, die vielfältigenallographen Materialien aus dem Nachlass undaus anderer Provenienz miteinzubeziehen, diefür die Kontextualisierung und das Verständnisder Autographen sowie für Burgers mosaikartigeArbeitsweise erhellend sind. Das Projekt botalso eine gute Ausgangslage, den vielgerühmtenMehrwert einer digitalen Edition gegenüberden hergebrachten Publikationsformenzu realisieren. Die digitale Edition (beta)ist seit dem 22. Oktober 2016 unter http://www.lokalbericht.ch verfügbar.
151

Digital Humanities im deutschsprachigen Raum 2017
Grundlage: hochqualitativeDigitalisate, dokument-orientierte TEI-Encodings
Neben den 179 beschriebenenTyposkriptseiten des Romans wurden vonden knapp 900 weiteren Textträgern, die imRahmen der digitalen Edition präsentiertwerden, hochauflösende Digitalisate im TIFF-Format und/oder mit OCR hinterlegte PDF-Dateien angefertigt. Aufgrund der fotografischhervorragenden Qualität und der ohnehinguten Leserlichkeit der (zumeist nur punktuellkorrigierten) Typoskripte und handschriftlichenDokumente nehmen diese Digitalisate den Rangder primären digitalen Repräsentation ein.
Die Digitalisate aller Dokumente, dieBestandteil des eigentlichen dossier génétiquesind, wurden durch dokument-orientierte, aufder Basis von OCR-Daten erstellte, TEI-Encodings(sourceDoc) ergänzt. Diese Encodings bilden dieGrundlage der diplomatischen Transkription,d.h. der Umschrift aller Texte inklusivemikrogenetischer Varianz. Die minutiöseAufzeichnung dieser Phänomene erwies sichals sehr zeitaufwändig. Retrospektiv wäre zuerwägen, die Tiefe des Encodings im Sinne desVermeidens eines “Over-taggings” (Bernhart/Hahn 2014, Hanrahan 2015) zu reduzieren,zumal die derart codierten Phänomeneaus der Perspektive der naheliegendenForschungsfragen nur einen begrenztenMehrwert gegenüber dem durchsuchbarenVolltext und den Digitalisaten schaffen.
Durch Extraktion der Text-Nodes inklusiveder regularisierten Varianten und basierend aufMilestone-Elementen (Absätze, Seitenumbrüche)ließen sich ab dem dokument-orientierten TEI-Encoding sowohl der für die Druckausgabeverwendete Lesetext als auch text-orientierteTEI-Encodings gewinnen, welche die Grundlagefür die Lesefassung der digitalen Edition bilden(Umschrift aller Texte ohne Berücksichtigungmikrogenetischer Varianz).
Die TEI-Encodings, die unter denBedingungen der CC BY 2.0-Lizenz nachnutzbarsind, enthalten selbstredend auch die Metadatendes jeweiligen Typoskript-Konvoluts oderBriefes.
Präsentation undFunktionalität
Als digitale Edition mit ausgeprägtertextgenetischer Komponente lehnt sichder Aufbau der Lokalbericht-Edition anvergleichbare aktuelle Projekte wie dietextgenetische Edition Wofgang Koeppens Jugend(Krüger, Mengaldo, Schumacher 2016) und diehistorisch-kritische Edition von Goethes Faustan (Bohnenkamp, Henke, Jannidis 2016). Dieangebotenen Interaktionsmechanismen lassensich mit der Edition Ch. G. Heynes' Vorlesungenüber die Archäologie vergleichen (Graepler o.J.). Die Benutzerin oder der Benutzer der Editionhat in jeder Dokumentansicht die Möglichkeit,zwischen den vier PräsentationsformenDigitalisat, Transkription, Lesefassung undMetadaten hin und her zu wechseln. Dabei gibtes drei Ansichtsmodi, die für unterschiedlicheLese- bzw. Benutzungspraktiken stehen:
In der Grundansicht wird eine Oberflächeeines Textträgers dargestellt. Schaltflächenerlauben das Navigieren innerhalb des Texts,offerieren aber auch Verknüpfungen zutextgenetisch verwandten Seiten andererKonvolute. Die verlinkten Ziele werdenstandardmäßig an Stelle des aktuellenDokumentes geladen. Die Grundansicht eignetsich daher besonders für eine (zumeist) lineareLektüre. Sie lässt sich im Gegensatz zu denbeiden Doppelansichten auch auf kleinenAnzeigegeräten verwenden.
Die Parallelansicht dient dazu, die gleicheTextstelle in zwei Ansichten zu vergleichen.Sie erlaubt z.B. die Gegenüberstellung vonDigitalisat und Transkription. Vor- undZurückblättern wirkt sich dabei jeweils auf beideAnsichten aus. Auch in der Parallelansicht lassensich Seiten anderer Konvolute laden, die einentextgenetischen Bezug zur aktuell dargestelltenSeite haben.
Die flexibelste Benutzungsmöglichkeitbietet schließlich die Synopsis. Sie ähnelt beimersten Aufruf der Parallelansicht, lässt imUnterschied zu ihr aber den Vergleich zwischentextgenetisch verwandten Textträgern Seite anSeite zu. In dieser Ansicht wird typischerweisezweimal die gleiche Präsentationsformgewählt, etwa Faksimile gegen Faksimileoder diplomatische Transkription gegendiplomatische Transkription.
152

Digital Humanities im deutschsprachigen Raum 2017
Digitale Edition Lokalbericht: SynoptischeDarstellung
Alle drei Ansichtsmodi binden unter derTextansicht auch eine visuelle Navigationin der Form eines skizzenbasierten Graphsein, der eine Vogelperspektive auf dasgesamte Materialkorpus bietet. Indem inBenutzerinteraktion die textgenetischenBezüge als Verbindungslinien (Links) zwischenden als Kreissymbolen (Nodes) dargestelltenEinzelblättern ein- und ausgeblendet werdenkönnen, lässt sich die Textentwicklung aufder Makroebene anschaulich verfolgen.Die einzelnen Verbindungslinien dienendabei zugleich als Links, über die sich diebeiden ausgewählten Blätter wiederum in dersynoptischen Ansicht laden lassen (Dängeli,Theisen, Wieland, Zumsteg 2016).
Editoriale Expertise zur Textgenesewird zusätzlich durch einen erläuterndenÜberblickskommentar und Stellenkommentarezum Romantext sowie durch Verweise aufeditionsinterne und -externe Ressourcenbefördert.
Durch die Auszeichnung von Personen(421), Orten (378) und Werken (191), die imRoman bzw. im Korpus vorkommen oder einen
wichtigen Bezug dazu haben, ist das Korpusüberdies auch semantisch erschlossen. Diese woimmer möglich auf Normdatensätze (VIAF, GND,GeoNames) referierenden Einheiten sind überRegister zugänglich, sie lassen sich aber auch inder Transkription und im Lesetext hervorheben.
Die Volltextsuche mit flexibel kombinierbarenFiltern (z.B. nach Textkategorie) bietet demBenutzer einen weiteren Einstiegspunkt in dievielfältigen und spannenden Materialien derdigitalen Edition.
Aspekte digitalerNachhaltigkeit
Weil von Anfang an die Perspektive bestand,die digitale Edition nach der Entwicklungam Cologne Center for eHumanities andas Schweizerische Literaturarchiv bzw.die Schweizerische Nationalbibliothek zuübergeben –, galt ab Projektbeginn die Prämisse,eine bewusst einfache und leichtgewichtigetechnische Lösung anzustreben, die nureinen geringen Anteil an serverseitigerProgammierung erfordert und die sich mittel-und langfristig leicht warten lässt. DieseKriterien legten es nahe, aus den TEI-Encodingsstatisches HTML zu erzeugen, das nur punktuelldurch dynamisch erzeugten Code ergänztwerden muss (z.B. freie Volltextsuche). Dasseine solche datenbanklose Lösung durchauszeitgemäß sein kann, zeigen die zahlreichenGeneratoren für statische Webseiten, diein jüngerer Zeit entwickelt wurden und diemitunter große Akzeptanz fanden. 1
Für die digitale Lokalbericht-Edition fiel dieWahl mit Apache Cocoon 2 auf eine vom Ansatzher in gewissem Grad vergleichbare, jedochbesser zu den vorliegenden XML-Daten passendeund insbesondere auch sehr ausgereifteAnwendung. Dabei profitierten wir von dersoliden Grundlage des im Produktiveinsatzbewährten Werkzeugs Kiln (vormals xMod)von Monteiro Viera und Norrish (2012), dasCocoon mit SOLR und Sesame bündelt und dankguter Dokumentation schnell einsatzbereitist. 3 Ergänzt um eigene Pipeline-Definitionenund XSL-Transformationen ließ sich aufder Grundlage von Kiln eine monolithischeWebanwendung erstellen, die abgesehen vomBildserver alle Funktionalitäten umschließtund die mit einem einzigen Befehl auf einemStandardwebserver lauffähig ist. Im Bedarfsfalllässt sich die Seite auch als komplett statischesHTML abspeichern, wodurch ein wesentlicher
153

Digital Humanities im deutschsprachigen Raum 2017
Schritt zur langfristigen Konservierung undVerfügbarmachung erfüllt sein sollte.
Um die Hürde der Applikations-Präservierungauch hinsichtlich der permanentenReferenzierung tief zu halten, verweisen diePermalinks lediglich auf – irgendwie geartete– digitale Repräsentationen real existierenderDokumente. Bestimmte Ansichten oderFunktionalitätszustände sind damit explizitnicht permanent referenzierbar, was dieVerantwortung der übernehmenden Institutionreduziert und ihr mehr Flexibilität für künftigekonzeptuelle oder technische Veränderungenzubilligt. Im Bedarfsfall sind die Benutzergehalten, bestimmte Ansichten selbständig zupersistieren, beispielsweise durch Übergabe derURL an die Wayback Machine. 4
Ein weiterer Mosaikstein zur Sicherung derNachhaltigkeit betrifft die (derzeit laufende)Aufnahme der Ressource durch das Data Centerfor the Humanities (DCH) 5 der Universitätzu Köln, in deren Rahmen neben der Klärungtechnischer und rechtlicher Fragen auchdie periodische Prüfung der Ressource nachfestgelegten Kriterien geregelt wird. Mögedies gewährleisten, dass der zu Lebzeitenunpubliziert gebliebene Lokalbericht nachseiner Erstveröffentlichung nicht abermals insarchivalische Dunkel versinkt.
Fußnoten
1. Die ihrerseits mit DocPad erstellte Listeunter https://staticsitegenerators.net führt perNovember 2016 445 derartige Tools auf. ZurBeliebtheit vgl. auch https://www.staticgen.com.Die Vorteile dieses Ansatzes liegen aufder Inputseite vorab in den einfachenQuellformaten, die zumeist zur Verwendungkommen (z.B. Markdown, Textile, YAML),auf der Outputseite in der durch die direkteHTML-Auslieferung bedingten hervorragendenPerformanz (Biilmann Christensen 2015,Kraetke/Imsiek 2016, Rinaldi 2015).2. Vgl. https://cocoon.apache.org/2.1/.3. Vgl. zu Kiln auch Turska 2014.4. Die Umsetzung einer technischenAdressierbarkeit granulärer Dateneinheiten warnicht Bestandteil des Projekts, sie könnte aufder Bestehenden Grundlage aber nachgerüstetwerden.5. Vgl. http://dch.phil-fak.uni-koeln.de.
Bibliographie
Bernhart, Toni / Hahn, Carolin (2014):„Datenmodellierung in digitalen Briefeditionenund ihre interpretatorische Leistung. Ontologien,Textgenetik und Visualisierungsstrategien.Workshop im Jacob-und-Wilhelm-Grimm-Zentrum der Humboldt-Universität zu Berlin,15./16. Mai 2014“, in: editio 28: 225-229.
Biilmann Christensen, Mathias (2015): „WhyStatic Website Generators Are The Next BigThing“, in: Smashing Magazine 2. November 2015https://www.smashingmagazine.com/2015/11/modern-static-website-generators-next-big-thing/[letzter Zugriff 24. August 2016].
Bohnenkamp, Anne / Henke, Silke /Jannidis, Fotis (2016): Historisch-kritischeFaustedition. Unter Mitarbeit von Gerrit Brüning,Katrin Henzel, Christoph Leijser, GregorMiddell, Dietmar Pravida, Thorsten Vitt undMoritz Wissenbach. Beta-Version 2. http://beta.faustedition.net [letzter Zugriff 28. Oktober2016].
Daengeli, Peter / Theisen, Christian /Wieland, Magnus / Zumsteg, Simon (2016):„Visualizing the Gradual Production of a Text“,in: DH2016: Conference Abstracts 767–769.
Graepler, Daniel (o. J.): Christian GottlobHeyne – Vorlesungen über die Archäologie. http://heyne-digital.de [letzter Zugriff 20. November2016].
Hanrahan, Elise (2015): „‚Over-tagging‘ withXML in Digital Scholarly Editions“, in: DHd 2015:Von Daten zu Erkenntnissen 193–196.
Kraetke, Martin / Imsieke, Gerrit (2016):„XSLT as a powerful static website generator.Hogrefe's Clinical Handbook of PsychotropicDrugs“, in: Proceedings of XML In, Web Out:International Symposium on sub rosa XML.Balisage Series on Markup Technologies 18 http://www.balisage.net/Proceedings/vol18/html/Kraetke02/BalisageVol18-Kraetke02.html [letzterZugriff 24. August 2016].
Krüger, Katharina / Mengaldo, Elisabetta /Schumacher, Eckhard (2016): WolfgangKoeppen. Jugend. http://www.koeppen-jugend.de/[letzter Zugriff 24. August 2016].
Monteiro Viera, Jose Miguel / Norrish,Jamie (2012): Kiln. https://github.com/kcl-ddh/kiln [letzter Zugriff 24. August 2016].
Rinaldi, Brian (2015): Static Site Generators.Modern Tools for Static Website Development.Sebastopol: O’Reilly.
Turska, Magdalena (2014): „What preventspeople from firing their own Kiln?“, in: NestingInstinct. Build in progress http://blogs.it.ox.ac.uk/mturska/2014/07/30/what-prevents-people-from-
154

Digital Humanities im deutschsprachigen Raum 2017
firing-their-own-kiln [letzter Zugriff 24. August2016].
Zumsteg, Simon (2014): Hermann Burger:Werke in acht Bänden. Zürich: Nagel und Kimche.
Zumsteg, Simon (2016a): Hermann Burger– Lokalbericht: Roman. Herausgegeben aus demNachlass. Zürich: Voldemeer.
Zumsteg, Simon / Dängeli, Peter / Wieland,Magnus / Wirtz, Irmgard (2016b): HermannBurger – Lokalbericht: Digitale Edition. http://www.lokalbericht.ch [Beta-Version vom 22.Oktober 2016].
KontextbasierteZitationsanalysesoziologischer Klassikerim Verlauf von 100Jahren
Messerschmidt, [email protected]ät zu Köln, Deutschland
Mathiak, [email protected]ät zu Köln, Deutschland
Bibliometrische Zitationsanalyse istin den Naturwissenschaften allgemeinüblich geworden, in den Geistes-und Sozialwissenschaften jedoch mitProblemen hinsichtlich der Datenbasis undunterschiedlicher Zitationsweisen konfrontiert.So betonen Sula und Miller (2013), dassverschiedene Referenzkontexte nicht ignoriertwerden dürfen, da intellektuelle Dispute zumgeisteswissenschaftlichen Kern gehören. Für dreiKlassiker der Soziologie haben wir daher dieZitationen in ihrem Zitationskontext, sowie imzeitlichen Verlauf analysiert und verschiedenegängige Hypothesen zu Trends in diesem Bereichstatistisch überprüft.
Datenbasis und MethodeDas zentrale Textkorpus besteht
aus digitalisierten Tagungsbänden(„Verhandlungen“) der Deutschen Gesellschaftfür Soziologie (DGS) von 1910 bis 2010 undumfasst 6869 Dokumente, sowohl direktkonvertiert aus dem Ausgangsmaterial, als auchOCR-behandelte Scans. Beide Dokumenttypenwurden zunächst nach diktionär- und n-gram
basierter Vorbereitung (Saad und Mathiak2013) in reinen Text konvertiert. Wie in denGeisteswissenschaften üblich, sind zwar vielewichtige Akteure im Korpus präsent, aberderen Hauptwerke üblicherweise Monografien,für die zusätzliche Quellkorpora konstruiertwurden. Ausgewählt wurden mit Karl Marx, MaxWeber und Theodor W. Adorno drei Klassiker,deren gesammelte bzw. ausgewählte Schriftendigital in hoher Qualität vorliegen und fürdie Soziologie selbst eine entscheidende Rollespielen. Weber ist dabei mit Abstand der amhäufigsten zitierte und gilt als Ahnherr derdeutschen Soziologie. Marx wurde (gemeinsammit Friedrich Engels) stark und insbesondereauch kontrovers diskutiert. Dem Werk Adornoskommt in der Soziologie und Sozialphilosophieder 1960er Jahre eine herausragende Stellungzu. Aufgrund des selektiven Charakters des DGS-Korpus bezüglich jeweiliger Tagungsthemenwurde zur Ergänzung ein Korpus aus seit 1949digital verfügbaren Fachzeitschriften 1 erstelltund annotiert.
Der Fokus des Projekts lag auf der Analysevon Text-ReUse sowie Sentiments in Zitationenund Paraphrasen. Vorhandene Ontologienwie CiTO 2 erwiesen sich aufgrund vielerfür unsere Zwecke irrelevanter Kategorienals zu komplex und zeitaufwändig. AusEffizienzgründen und auch um Erkenntnissein Bezug auf Sentimentpolarität (Boland et al.2013) nutzen zu können, haben wir uns primärauf drei Ausprägungen letzterer konzentriert:positiv, negativ und neutral. Weitere imRahmen von Sentimentanalysen üblicheDifferenzierungen hinsichtlich z.B. graduellerAbstufung und Subjektivität (Pang und Lee 2008)wurden bewusst ausgeblendet. Nach erstenAnnotationsversuchen wurde allerdings klar,dass zusätzliche Kategorien für Ambivalenz undNegationsstrukturen notwendig sind. Insgesamt3382 Codes 3 wurden dabei interpretativ undkontextbezogen von soziologischen Experten inMaxQDA 4 auf Basis des zuvor beschriebenenCodeschemas annotiert. Im Verlauf diesesProzesses wurden spezifische Charakteristikades Korpus deutlich, die bei der Analyse zuberücksichtigen waren:
Erstens zeigten sich im Datensatz strukturelleBrüche hinsichtlich der Dokumentanzahl jeTagung. Während diese von 1910 bis 1979 bereitszwischen 9 und 94 variiert, existieren ab 1980abgesehen von einer Ausnahme zwischen 240und 675 Dokumente. Dadurch sind absoluteZahlen von Autorennamen nicht vergleichbar(Abb. 1).
155
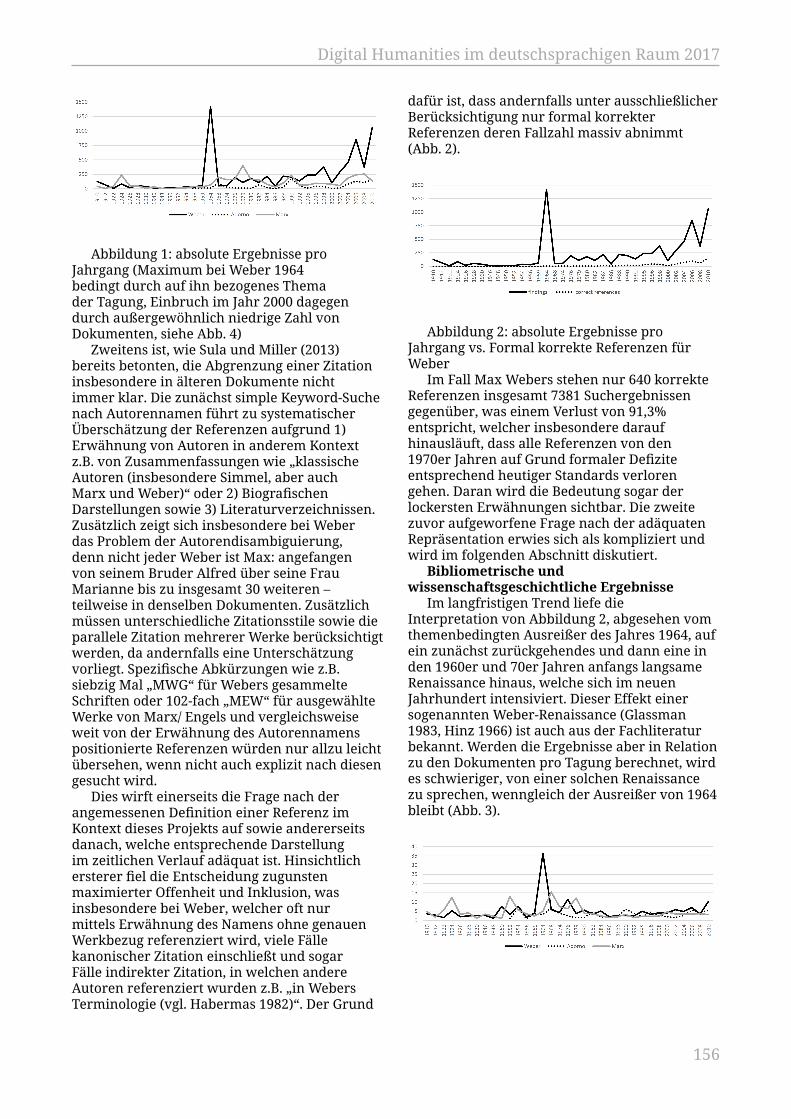
Digital Humanities im deutschsprachigen Raum 2017
Abbildung 1: absolute Ergebnisse proJahrgang (Maximum bei Weber 1964bedingt durch auf ihn bezogenes Themader Tagung, Einbruch im Jahr 2000 dagegendurch außergewöhnlich niedrige Zahl vonDokumenten, siehe Abb. 4)
Zweitens ist, wie Sula und Miller (2013)bereits betonten, die Abgrenzung einer Zitationinsbesondere in älteren Dokumente nichtimmer klar. Die zunächst simple Keyword-Suchenach Autorennamen führt zu systematischerÜberschätzung der Referenzen aufgrund 1)Erwähnung von Autoren in anderem Kontextz.B. von Zusammenfassungen wie „klassischeAutoren (insbesondere Simmel, aber auchMarx und Weber)“ oder 2) BiografischenDarstellungen sowie 3) Literaturverzeichnissen.Zusätzlich zeigt sich insbesondere bei Weberdas Problem der Autorendisambiguierung,denn nicht jeder Weber ist Max: angefangenvon seinem Bruder Alfred über seine FrauMarianne bis zu insgesamt 30 weiteren –teilweise in denselben Dokumenten. Zusätzlichmüssen unterschiedliche Zitationsstile sowie dieparallele Zitation mehrerer Werke berücksichtigtwerden, da andernfalls eine Unterschätzungvorliegt. Spezifische Abkürzungen wie z.B.siebzig Mal „MWG“ für Webers gesammelteSchriften oder 102-fach „MEW“ für ausgewählteWerke von Marx/ Engels und vergleichsweiseweit von der Erwähnung des Autorennamenspositionierte Referenzen würden nur allzu leichtübersehen, wenn nicht auch explizit nach diesengesucht wird.
Dies wirft einerseits die Frage nach derangemessenen Definition einer Referenz imKontext dieses Projekts auf sowie andererseitsdanach, welche entsprechende Darstellungim zeitlichen Verlauf adäquat ist. Hinsichtlichersterer fiel die Entscheidung zugunstenmaximierter Offenheit und Inklusion, wasinsbesondere bei Weber, welcher oft nurmittels Erwähnung des Namens ohne genauenWerkbezug referenziert wird, viele Fällekanonischer Zitation einschließt und sogarFälle indirekter Zitation, in welchen andereAutoren referenziert wurden z.B. „in WebersTerminologie (vgl. Habermas 1982)“. Der Grund
dafür ist, dass andernfalls unter ausschließlicherBerücksichtigung nur formal korrekterReferenzen deren Fallzahl massiv abnimmt(Abb. 2).
Abbildung 2: absolute Ergebnisse proJahrgang vs. Formal korrekte Referenzen fürWeber
Im Fall Max Webers stehen nur 640 korrekteReferenzen insgesamt 7381 Suchergebnissengegenüber, was einem Verlust von 91,3%entspricht, welcher insbesondere daraufhinausläuft, dass alle Referenzen von den1970er Jahren auf Grund formaler Defiziteentsprechend heutiger Standards verlorengehen. Daran wird die Bedeutung sogar derlockersten Erwähnungen sichtbar. Die zweitezuvor aufgeworfene Frage nach der adäquatenRepräsentation erwies sich als kompliziert undwird im folgenden Abschnitt diskutiert.
Bibliometrische undwissenschaftsgeschichtliche Ergebnisse
Im langfristigen Trend liefe dieInterpretation von Abbildung 2, abgesehen vomthemenbedingten Ausreißer des Jahres 1964, aufein zunächst zurückgehendes und dann eine inden 1960er und 70er Jahren anfangs langsameRenaissance hinaus, welche sich im neuenJahrhundert intensiviert. Dieser Effekt einersogenannten Weber-Renaissance (Glassman1983, Hinz 1966) ist auch aus der Fachliteraturbekannt. Werden die Ergebnisse aber in Relationzu den Dokumenten pro Tagung berechnet, wirdes schwieriger, von einer solchen Renaissancezu sprechen, wenngleich der Ausreißer von 1964bleibt (Abb. 3).
156
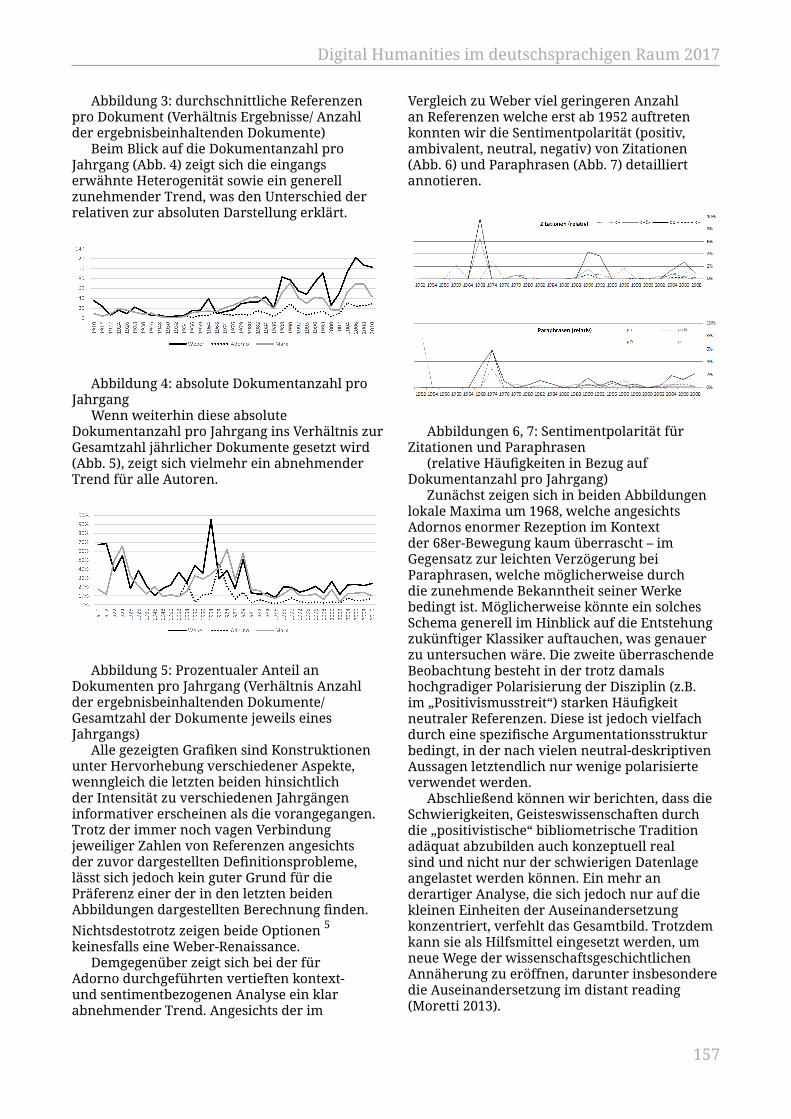
Digital Humanities im deutschsprachigen Raum 2017
Abbildung 3: durchschnittliche Referenzenpro Dokument (Verhältnis Ergebnisse/ Anzahlder ergebnisbeinhaltenden Dokumente)
Beim Blick auf die Dokumentanzahl proJahrgang (Abb. 4) zeigt sich die eingangserwähnte Heterogenität sowie ein generellzunehmender Trend, was den Unterschied derrelativen zur absoluten Darstellung erklärt.
Abbildung 4: absolute Dokumentanzahl proJahrgang
Wenn weiterhin diese absoluteDokumentanzahl pro Jahrgang ins Verhältnis zurGesamtzahl jährlicher Dokumente gesetzt wird(Abb. 5), zeigt sich vielmehr ein abnehmenderTrend für alle Autoren.
Abbildung 5: Prozentualer Anteil anDokumenten pro Jahrgang (Verhältnis Anzahlder ergebnisbeinhaltenden Dokumente/Gesamtzahl der Dokumente jeweils einesJahrgangs)
Alle gezeigten Grafiken sind Konstruktionenunter Hervorhebung verschiedener Aspekte,wenngleich die letzten beiden hinsichtlichder Intensität zu verschiedenen Jahrgängeninformativer erscheinen als die vorangegangen.Trotz der immer noch vagen Verbindungjeweiliger Zahlen von Referenzen angesichtsder zuvor dargestellten Definitionsprobleme,lässt sich jedoch kein guter Grund für diePräferenz einer der in den letzten beidenAbbildungen dargestellten Berechnung finden.Nichtsdestotrotz zeigen beide Optionen 5
keinesfalls eine Weber-Renaissance.Demgegenüber zeigt sich bei der für
Adorno durchgeführten vertieften kontext-und sentimentbezogenen Analyse ein klarabnehmender Trend. Angesichts der im
Vergleich zu Weber viel geringeren Anzahlan Referenzen welche erst ab 1952 auftretenkonnten wir die Sentimentpolarität (positiv,ambivalent, neutral, negativ) von Zitationen(Abb. 6) und Paraphrasen (Abb. 7) detailliertannotieren.
Abbildungen 6, 7: Sentimentpolarität fürZitationen und Paraphrasen
(relative Häufigkeiten in Bezug aufDokumentanzahl pro Jahrgang)
Zunächst zeigen sich in beiden Abbildungenlokale Maxima um 1968, welche angesichtsAdornos enormer Rezeption im Kontextder 68er-Bewegung kaum überrascht – imGegensatz zur leichten Verzögerung beiParaphrasen, welche möglicherweise durchdie zunehmende Bekanntheit seiner Werkebedingt ist. Möglicherweise könnte ein solchesSchema generell im Hinblick auf die Entstehungzukünftiger Klassiker auftauchen, was genauerzu untersuchen wäre. Die zweite überraschendeBeobachtung besteht in der trotz damalshochgradiger Polarisierung der Disziplin (z.B.im „Positivismusstreit“) starken Häufigkeitneutraler Referenzen. Diese ist jedoch vielfachdurch eine spezifische Argumentationsstrukturbedingt, in der nach vielen neutral-deskriptivenAussagen letztendlich nur wenige polarisierteverwendet werden.
Abschließend können wir berichten, dass dieSchwierigkeiten, Geisteswissenschaften durchdie „positivistische“ bibliometrische Traditionadäquat abzubilden auch konzeptuell realsind und nicht nur der schwierigen Datenlageangelastet werden können. Ein mehr anderartiger Analyse, die sich jedoch nur auf diekleinen Einheiten der Auseinandersetzungkonzentriert, verfehlt das Gesamtbild. Trotzdemkann sie als Hilfsmittel eingesetzt werden, umneue Wege der wissenschaftsgeschichtlichenAnnäherung zu eröffnen, darunter insbesonderedie Auseinandersetzung im distant reading(Moretti 2013).
157

Digital Humanities im deutschsprachigen Raum 2017
Fußnoten
1. Soziale Welt, Kölner Zeitschrift für Soziologieund Sozialpsychologie, Deutsche Zeitschrift fürPhilosophie2. http://purl.org/spar/cito/3. http://cceh.uni-koeln.de/share/annotation_soc_classics.zip4. http://www.maxqda.de/5. Die in der Bibliometrie übliche auf Textlängebasierende Berechnung erwies sich angesichtsdiesbezüglicher Heterogenität des DGS-Korpusals nicht anwendbar.
Bibliographie
Adorno, Theodor W. (2004): „Theodor W.Adorno, Gesammelte Schriften“, in: DigitaleBibliothek 97.
Boland, Katarina/ Wira-Alam, Andias/Messerschmidt, Reinhard (2013): „Creatingan annotated corpus for sentiment analysisof German product reviews“, in: GESIS-Technical Reports 2013/05 http://www.gesis.org/fileadmin/upload/forschung/publikationen/gesis_reihen/gesis_methodenberichte/2013/TechnicalReport_2013-05.pdf [letzter Zugriff 19.August 2016].
Glassman, Ronald (1983): „The Weberrenaissance“, in: Current Perspectives in SocialTheory 4: 239–271.
Hinz, Horst (1966): „Max-Weber-Renaissance?“, in: Vierteljahreshefte zurWirtschaftsforschung 4: 454–479.
Marx, Karl / Engels, Friedrich (2004):„Marx, Engels, ausgewählte Werke“, in: DigitaleBibliothek 11.
Moretti, Franco (2013): Distant Reading.London: Verso.
Pang, Bo / Lee, Lillian (2008): „4.1.2Subjectivity Detection and OpinionIdentification“, in: Opinion Mining and SentimentAnalysis . Now Publishers Inc.
Sula, Chris Alen / Miller, Matt (2013):„Citation studies in the humanities“, in: DH2013:Conference Abstracts http://dh2013.unl.edu/abstracts/ab-353.html [letzter Zugriff 19. August2016].
Saad, Farag / Mathiak, Brigitte (2013):„Revised mutual information approach forgerman text sentiment classification“, in:WWW '13 Companion. Proceedings of the22nd international conference on World WideWeb 579–586. http://dl.acm.org/citation.cfm?id=2487788.2487997 [letzter Zugriff 19. August2016].
Weber, Max (2004): „Max Weber, gesammelteWerke“, in: Digitale Bibliothek 58.
Langzeitinterpretierbarkeitauf Basis des CIDOC-CRM in inter- undtransdisziplinärenForschungsprojektenam GermanischenNationalmuseum (GNM),Nürnberg
Große, [email protected] Nationalmuseum, Deutschland
Wagner, [email protected] Nationalmuseum, Deutschland;für MUSICES¹
Im musealen Bereich spielt die Frage, wieman langfristig interpretierbare Daten erzeugtund bereitstellt, eine immer größere Rolle,insbesondere wenn, wie am GermanischenNationalmuseum (GNM), drittmittelgeförderteinter- und transdisziplinäre Forschungsprojektegroße Datenmengen zu den Objektbeständenerheben. Welche Lösungsansätze für dennachhaltigen Umgang mit Forschungsdatendas GNM verfolgt, soll anhand zweierForschungsprojekte dargestellt werden.
1. Anforderungen und Ziele destransdisziplinären Forschungsprojektes zuFriedensrepräsentationen in der Vormoderne
Das von der Leibniz-Gemeinschaftseit Juli 2015 geförderte internationaleKooperationsprojekt „Repräsentationen desFriedens im vormodernen Europa“ erforschtFriedensbilder im Zeitraum vom 16. bis18. Jahrhundert. Friedensvereinbarungenmussten über den reinen Vertragstext hinauserklärt, begründet und vermittelt werden. Dasübernahmen Friedensrepräsentationen, die einmultimediales Phänomen der Frühen Neuzeitwaren. Folglich nimmt das Forschungsprojektvisuelle Darstellungen, sprachliche Bilder sowiemusikalische Ausprägungsformen in den Blick.
158

Digital Humanities im deutschsprachigen Raum 2017
Dieser breite Ansatz erfordert die Kooperationunterschiedlicher geisteswissenschaftlicherFachrichtungen mit ihren jeweiligenAnalysekompetenzen und Perspektiven sowieInstitutionen mit geeigneten Beständen. 2
Um abstrakte Konzepte wie Frieden,Gerechtigkeit oder Wohlstand darzustellen,verwendeten Künstler, Dichter oderKomponisten einen Kanon von Motiven, dieeuropaweit genutzt und verstanden wurden.Dieses „Vokabular“ des Friedens soll beispielhafterschlossen und über die Gattungs- undGenregrenzen hinweg analysiert werden.Zudem wurden gemeinsame Fragestellungenzu transmedialen Rezeptionsvorgängen,Veränderungen der Motivik im Zusammenhangmit unterschiedlichen Friedensschlüssen, zuFunktion und Wahrnehmung von visuellen,sprachlichen und musikalischen Konzeptenentwickelt. Am Anfang steht daher dietransdisziplinäre Erfassung und Nutzung derheterogenen Bestände.
Ein entsprechendes Dokumentationssystemmuss demzufolge für alle beteiligtenWissenschaftlerInnen unabhängig vonder Art und Darstellungsform der Quellengewährleisten, dass sie schnell und effizient dierelevanten Informationen eingeben und abrufenkönnen. Die erfassten Informationen beziehensich auf objektbezogene Daten, aber auchauf deren Inhalte und Form, wie Ikonografie,Textgattung oder Instrumentierung. Außerdemsoll der inhaltliche Zusammenhang zwischenObjekten und Friedensereignissen dokumentiertwerden. Daher muss die Datenbank in derLage sein, auch Zusammenhänge strukturiertabbilden zu können. Die Ergebnisse sollen ineinem virtuellen Themenportal am Ende desProjektes veröffentlicht werden. Die Einbindungvon digitalen Bild-, Text- und Musikquellen istdaher wünschenswert, ebenso die Möglichkeitmit einem Thesaurus arbeiten und bereitsvorhandene Normdaten einbinden zu können.
2. Anforderungen und Ziele desinterdisziplinären Forschungsprojektes MUSICES
Das Projekt „MUSICES“ (MUSIkinstrumenten-Computertomographie-Examinierungs-Standard) hat es sich zur Aufgabe gemachteinen Standard zu entwickeln, der dieBedingungen für eine wissenschaftliche undpraxisnahe Abbildung von Musikinstrumentendurch 3D-Computertomographie beschreibt.Das zerstörungsfreie, bildgebendeVerfahren der Computertomographie istein wichtiges Instrument geworden, umInformationen über den Aufbau und dieKonstruktion von Musikinstrumenten
zu gewinnen und so Aussagen überHerstellungsweise, Erhaltungszustandund klangliche Eigenschaften zu liefern.In Kooperation von WissenschaftlerInnenund RestauratorInnen des GermanischenNationalmuseums und des Fraunhofer InstitutsEZRT (Entwicklungszentrum Röntgentechnik)in Fürth werden gemeinsam die technischenParameter, effiziente und objektschonendePraxisabläufe sowie die Möglichkeiten undGrenzen dieser Technik intensiv erarbeitet.
Die Entwicklung des Standards bestehtaus verschiedenen Aspekten: Zunächstbedarf es eines Schemas, das den komplettenAblauf der Untersuchung des Instrumentsdokumentiert, von der Auswahl eines Objektsund die Fragestellung an dieses bis überden Transport, die eigentliche Messung undderen Parameter sowie die daraus erzeugten3D-Röntgenbilder. Im Laufe des Projektswerden über 100 verschiedene Instrumenteerforscht, die in ihrer Auswahl eine möglichstgroße Vielfalt an Eigenschaften abbildensollen, um die Anwendbarkeit des Standardsauch auf andere Objekte übertragen zukönnen. Unterschiedliche Materialien und diegeometrischen Formen der Musikinstrumentespielen bei den einzustellenden Parameternder 3D-CT eine entscheidende Rolle, um diegewünschten Resultate zu erzielen. Für dieObjekte werden deshalb ihren Eigenschaftenentsprechend Kategorien definiert. Auf dieseWeise können Richtwerte entwickelt werden,beispielsweise für die Strahlungsdosis, dievom Material und dessen Stärke abhängigsind. Die Relation zwischen Objektkategorieund Messeinstellungen in Abhängigkeitvon der Forschungsfrage muss durch dasDokumentationsschema abgebildet werden.Letzteres muss zudem aufgrund der stetigenOptimierung des Untersuchungsprozesseswährend des Projektverlaufs flexibel gestaltetsein.
Als Teil des Standards soll dasDokumentationsschema in bestehendeStandards integriert werden und alsMetadatenmodell für künftige Projektedienen, die sich mit der 3D-CT von Objektenbeschäftigen. Alle gewonnenen Daten sollen zumProjektende in das Objektdokumentationssystemdes Germanischen Nationalmuseums integriert,darüber hinaus aber auch an internationalePortale geliefert und öffentlich zugänglichgemacht werden.
3. CIDOC CRM und WissKI als Werkzeuge derDokumentation und Langzeitinterpretierbarkeit
Die semantische Erschließung, die einenachhaltige Interpretierbarkeit von heterogenen
159

Digital Humanities im deutschsprachigen Raum 2017
Forschungsdaten zunächst innerhalb einerInstitution gewährleistet, erfolgt auf Grundlageeiner Ontologie, die es ermöglicht Wissen formalzu definieren, zu kategorisieren, zu beschreibenund auszutauschen. Forschungsprojekte amGNM verwenden das ISO-zertifizierte ConceptualReference Model (CIDOC CRM, ISO 21127,Doerr / Lampe / Krause 2011). 3 Da das CRMnicht maschinell lesbar ist, wurde dies imsog. „Erlangen-CRM“ 4 auf Basis von OWL 5
nachgeholt (Görz 2011).Damit die Projektdaten in einem
gemeinsamen Kontext unter Verwendungeiner gemeinsamen „Sprache“ dokumentiertwerden können, werden Anwendungs-bzw. Domänenontologie, basierend auf demCIDOC CRM, für jedes Projekt entwickelt.Der Austausch von Daten und derenLangzeitinterpretierbarkeit wird durchdie gemeinsame Basis des CIDOC CRMgewährleistet, während alle Spezifika derjeweiligen Projekte möglichst fachspezielldurch die Domänenontologie abgedeckt sind(Hohmann / Fichtner 2015, 117-118). Diesgeschieht unter dem Vorbehalt, dass innerhalbeiner Institution die Klassen und Eigenschaftengleich gehandhabt werden.
Um das angesprochene kollaborativeund transdisziplinäre Arbeiten zuermöglichen, benötigt man eine virtuelleForschungsumgebung. Ausgewählt wurdeWissKI 6 , dessen Fokus auf dem interaktivenund vernetzten Arbeiten basierend aufsemantischer Tiefenerschließung mit Hilfe desErlangen-CRM liegt. Die Erfassung kann text-und formularbasiert erfolgen. Die Oberflächendes Systems können den jeweiligen Bedürfnissender Projekte angepasst werden, wobei dieForm der Wissensrepräsentation und dieWiederverwendung der Daten gattungs-und disziplinübergreifend ermöglicht wird.Darüber hinaus können digitale Bild-, Text- undAudiodateien angezeigt und verwaltet werden.Zudem unterstützt WissKI die Erstellung lokalerVokabulare und die Nutzung bestehenderNormdaten.
3.1 Anwendungsbeispiel Projekt„Friedensrepräsentationen“
Das zentrale Anliegen des Projektes zurAnalyse der Friedensrepräsentationen istein transdisziplinärer und vergleichenderForschungsansatz basierend auf einerkooperativen Erschließung und Nutzungheterogener Quellenbestände. Angaben zu denObjekten und ihren Inhalten müssen ebensowie historische Daten zu Friedensereignissenerfasst werden. Diese unterschiedlichen
Informationen sollen semantisch vernetztsein, um eine langfristige und nachhaltigeInterpretierbarkeit sicher zu stellen. EineHerausforderung ist es, spezifische Datenund Anforderungen unterschiedlicherFachdisziplinen zu vereinheitlichen undSchnittpunkte zu bilden. Das CIDOC CRM erlaubtdurch die Definition geeigneter übergeordneterAbstraktionen und Relationen ein Erkennenund Kommunizieren gleicher Konzepteund dadurch eine disziplinunabhängigesemantische Vernetzung der Informationen.Durch die semantische Modellierung inForm von sog. Pfaden ist eine nachhaltigeInterpretierbarkeit der Zusammenhänge vonunterschiedlichen Informationen möglich,die für die inhaltliche Erschließung derQuellenbestände von Bedeutung ist. Die Pfadewiederum sind netzwerkartig miteinanderverbunden. So kann z. B. nachvollzogen werden,in welchem Verhältnis eine Person zu einemFriedensereignis oder zu einem Objekt steht,beides kann für die Forschungsfragen nachFunktion des jeweiligen Quelleninhaltes vonInteresse sein.
Für die Veröffentlichung der Ergebnissein einem virtuellen Themenportal könnenzur besseren Strukturierung und auch umAbhängigkeiten darzustellen, Informationenhierarchisch in Beziehung gesetzt werden, wieFriedensschlüsse und auf ihnen basierendeAnlässe oder Allegorien zu übergeordnetenBildtopoi. Auf allen hierarchischen Stufenbleiben die entsprechenden Eigenschaften undRelationen der entsprechenden Klassen erhaltenund können demzufolge immer mit abgebildetund abgefragt werden.
Die unterschiedlichen Informationenwerden in spezifisch modellierten Maskenerfasst, in deren Feldern Normdaten undVokabulare hinterlegt sind. Durch verschiedenesystemimmanente Eigenschaften könnenWissenschaftler sehr schnell in einerObjektmaske zugehörige Dokumente undObjekte angezeigt bekommen. Für den Benutzerdient dies bei ca. 2000 angestrebten Einträgender Übersichtlichkeit, so dass auch auf dieserEbene die Vernetzung sichtbar sein wird.
3.2 Anwendungsbeispiel Projekt „MUSICES“WissKI dient dem Projekt als Datenbank für
die zu untersuchenden Musikinstrumente undals Kommunikationsplattform. Darüber hinausist das System in der Lage, den komplettenUntersuchungsablauf sowie die Messergebnisseund die erzeugten 3D-Daten jedes einzelnenObjekts, zusammengefasst das im Standardenthaltene Dokumentationsschema und dasNetzwerk der Metadaten, abzubilden. Die zu
160

Digital Humanities im deutschsprachigen Raum 2017
erfassenden Metadaten beinhalten nicht nur dieobjektbezogenen des kulturwissenschaftlichenBereichs, sondern auch die vom FraunhoferInstitut zu dokumentierenden Messparameter,wie die Röntgenspannung, die applizierteStrahlungsdosis, aber auch Informationenzu den CT-Anlagen. Für die Erfassung derProjektdaten in einem gemeinsamen Kontextwurde eine Anwendungsontologie, basierendauf dem CIDOC CRM entwickelt, die ebenfallsTeil des im Projekt zu entwickelnden Standardsist. Durch eine klare Definition der Metadaten,die sich auch in der Modellierung derPfadstrukturen niederschlägt, entsteht eineDatenstruktur, die eine weitere Nutzbarkeitund Interpretierbarkeit der Projektergebnissegewährleistet.
Durch die Verwendung des CIDOC CRMkönnen die Metadaten in das museumsinterneObjektdokumentationssystem und darüberhinaus in internationale Portale integriertwerden. Im Rahmen des EU-Projekts MIMO 7
konnte mit MIMO-LIDO ein Metadatenmodellfür Musikinstrumente entwickelt werden, dasdie Grunddatenerfassung und die Zuordnungzu Sammlungskontexten standardisiert. DasMetadatenmodell für die 3D-CT-Aufnahmendes MUSICES-Projekts wird in MIMO-LIDOintegriert, steht darüber hinaus aber auchals eigenständige Domänenontologie zurVerfügung. Für den Bereich der Erforschungvon Musikinstrumenten und ihrer künftigenErfassung, insbesondere im Hinblick auf 3D-CT-Maßnahmen, wird das MUSICES-ProjektWegbereiter für einen Standard sein, der aufverschiedenen bestehenden Standards deskulturellen Bereichs aufbaut und diese für einenspezifischen Anwendungsfall ergänzt. Durchdie Publikation mit WissKI und internationalenPortalen kann garantiert werden, dass dieProjektdaten verfügbar und zitierbar sind.
In beiden Forschungsprojekten, obgleichihrer unterschiedlichen Disziplinen undObjektgattungen, kann durch Anwendung desCIDOC CRM eine nachhaltige Interpretierbarkeitund Austauschbarkeit der in den Projektenerhobenen Daten am GNM gewährleistetwerden. In Verbindung mit WissKI sind alleanwendungsspezifischen Anforderungenabgedeckt. Durch seine Systemarchitekturist WissKI flexibel genug, auch auf sichwährend der Projektlaufzeit neu ergebendeForschungsfragen zu reagieren.
Fußnoten
1. MUSICES: Sebastian Kirsch1, Frank Bär1,Theobald Fuchs2, Christian Kretzer2, MarkusRaquet1, Gabriele Scholz2, Rebecca Wagner2,Meike Wolters-Rosbach1; 1 GermanischesNationalmuseum, Nürnberg; 2 Fraunhofer-Entwicklungszentrum Röntgentechnik EZRT,Fürth2. Das Leibniz-Institut für EuropäischeGeschichte, Mainz, untersuchtFriedenspredigten, die Herzog August Bibliothek,Wolfenbüttel, Dichtungen und Festschriften,das Germanische Nationalmuseum Objekteaus den graphischen und numismatischenSammlungen, das Deutsche Historische Institut,Rom, Kantaten, Oratorien und Festmusikenvor allem in Bezug auf Italien und dasTadeusz Manteuffel Institut für Geschichteder Polnischen Akademie der Wissenschaften,Warschau, die Friedensrepräsentationen in denöstlichen Gebieten Europas.3. Diese Ontologie wurde vom InternationalCommittee for Documentation (CIDOC) als Teildes International Council of Museums (ICOM)erstellt (URL: http://www.cidoc-crm.org/ ), wobeidas Germanische Nationalmuseum federführendbeteiligt war.4. URL: http://erlangen-crm.org / (25.08.2016).5. OWL= Web Ontology Language, vgl. URL:https://www.w3.org/TR/owl2-overview/(25.08.2016).6. WissKI = Wissenschaftliche Kommunikations-Infrastruktur, URL: http://wiss-ki.eu /) basierendauf dem Open-Source Content ManagementSystem Drupal (URL: http://drupal.org /), undwurde in Zusammenarbeit zwischen demGermanischen Nationalmuseum, Nürnberg, demZoologischen Forschungsmuseum AlexanderKoenig, Bonn und der Friedrich-Alexander-Universität Erlangen-Nürnberg entwickelt.7. Musical Instrument Museums Online (URL:www.mimo-international.com .). Währendder Projektlaufzeit 2009 bis 2011 wurdenrund 50.000 Musikinstrumente in öffentlichenSammlungen digitalisiert und über MIMO-DBzugänglich gemacht (URL: http://www.mimo-db.eu/ (25.8.2016).
Bibliographie
Doerr, Martin / Lampe, Karl-Heinz / Krause,Siegfried (2011): Definition des CIDOC ConceptualReference Model Version 5.0.1. autor. durchdie CIDOC CRM Special Interest Group (SIG)
161

Digital Humanities im deutschsprachigen Raum 2017
(= Beiträge zur Museologie 1). Berlin: ICOMDeutschland.
Görz, Günther (2011): „WissKI: SemantischeAnnotation, Wissensverarbeitung undWissenschaftskommunikation in einer virtuellenForschungsumgebung“, in: Kunstgeschichte.Open Peer Reviewed Journal urn:nbn:de:bvb:355-kuge-167-7 [letzter Zugriff 22. November 2016].
Hohmann, Georg / Fichtner, Mark (2015):„Chancen und Herausforderungen in derpraktischen Anwendung von Ontologien fürdas Kulturerbe“, in: Robertson – von Trotta,Caroline Y. / Schneider, Ralf Y. (eds.): DigitalesKulturerbe. Bewahrung und Zugänglichkeit inder wissenschaftlichen Praxis. (= KulturelleÜberlieferung – digital 2). Karlsruhe: KITScientific Publishing 115-128.
Stein, Regine / Gottschewski, Jürgen /Heuchert, Regina / Ermert, Axel / Hagedorn-Saupe, Monika / Hansen, Hans-Jürgen / Saro,Carlos / Scheffel, Regine / Schulte-Dornberg,Gisela (2005): Das CIDOC Conceptual ReferenceModel. Eine Hilfe für den Datenaustausch? (=Mitteilungen und berichte aus dem Institutfür Museumskunde 31). Berlin: Institut fürMuseumskunde.
NachhaltigeErschließungumfangreicherhandschriftlicherÜberlieferungen. EinFallbeispiel
Faßhauer, [email protected]ät Frankfurt am Main,Deutschland
Angesichts stetig wachsender Kapazitätenzur Speicherung großer Datenmengen nutzenBibliotheken und Archive zunehmend dieMöglichkeit, ihre Sammlungen zu digitalisierenund die Faksimiles online bereitzustellen.Rein konservatorischen Erwägungen folgend,belassen sie es dabei häufig bei der Erfassungder Metadaten und verzichten auf dieweiterreichende inhaltliche Erschließung desMaterials. So bleibt es oftmals allein dem Nutzerüberlassen, sich einen Zugang zu den Inhaltender Sammlungen zu verschaffen.
Sofern es sich dabei um Druckwerkehandelt, ist dieses Vorgehen durchaushinreichend, zumal die Fähigkeit zur Lektürevon Antiqua- und Frakturdrucken zumindestim deutschsprachigen Raum allgemeinvorausgesetzt werden kann. Da mit Hilfe derOCR-Technologie inzwischen selbst bei derautomatischen Erkennung der Frakturschriftsehr gute Ergebnisse erzielt werden können,werden digitalisierte Druckwerke auch jenseitsder genauen inhaltlichen Erfassung nutzbar,indem sie durch distant reading und statistischeZugänge erschlossen werden können.
Anders verhält es sich bei historischenHandschriften: Da heutzutage nur sehr wenigePersonen über hinreichende paläographischeKenntnisse verfügen, stellen digitaleReproduktionen handgeschriebener Dokumentefür den größten Teil des Publikums nicht vielmehr als bloße Abbildungen historischerArtefakte dar, die in ihrer Materialität zwareine ganz bestimmte Oberflächenstrukturaufweisen, aber die darin transportierten Inhaltenur wenigen erfahrenen Lesern preisgeben.Zusätzlich erschwert wird die Lektüre imFall von Tagebuchaufzeichnungen oderNotizbüchern, die nur selten auch für fremdeAugen bestimmt waren.
Die Gewährleistung eines unbeschränktenund langfristigen Zugangs zu digitalisiertenhistorischen Handschriftenarchiven istalso nicht per se gleichbedeutend mit einerunbegrenzten Zugänglichkeit, Nutzbarkeitund Weiterverwertbarkeit ihrer Inhalte. Einewichtige Aufgabe der Digital Humanities beider nachhaltigen Pflege des kulturellen Erbesist deshalb eine über die bloß konservierendeAblichtung hinausgehende Erschließungder in diesen Textbeständen enthaltenenInformationen. Die Fragestellung ist also:Wie lassen sich diese Daten erfassen und fürclose- wie auch für distant reading-Prozesseaufbereiten? Lässt sich ein Zugang schaffen,ohne den gesamten Bestand manuell zubearbeiten? Und inwieweit kann die klassischepaläographische Hand- und Kopfarbeit durchautomatisierte Prozesse ersetzt werden? DerBeitrag stellt diese Problemlage zunächst amFallbeispiel der Senckenberg-Tagebücherexemplarisch dar und zeigt anschließendeine Lösungsstrategie auf, bei der manuelleund digitale Methoden kombiniert zumEinsatz kommen und bereits vorhandene, freizugängliche Software verwendet wird.
Der Frankfurter Arzt Johann ChristianSenckenberg (1707–1772) hinterließhandschriftliche Aufzeichnungen im Umfangvon 53 Quartbänden mit je etwa 700 Seiten.
162

Digital Humanities im deutschsprachigen Raum 2017
Während die späteren Bände einesteils inausführlichen ärztlichen Fallstudien undanderenteils in kritischen Bemerkungen überdie sittlichen Missstände der Reichsstadtbestehen, befassen sich die mit Observationesin me ipso factae übertitelten ersten dreizehnJahrgänge hauptsächlich mit dem Schreiberselbst. Da Senckenberg dem radikalenPietismus nahestand und sich ganz aus demkirchlichen Gemeindeleben zurückgezogenhatte, erfüllten die frühen Tagebücherhauptsächlich die Funktion eines religiösenGewissensspiegels. Darüber hinaus notierteer über Jahrzehnte hinweg täglich seinenSpeiseplan, sein Bewegungspensum und seineStoffwechselaktivität ebenso detailliert wie diejeweilige Wetterlage, die Umgebungstemperaturund den Luftdruck, die er mit den wechselndenZustände seines Gemüts und mit äußerenUmwelteinflüssen in Beziehung setzte. DerZweck dieser akribischen Beobachtungenwar seine diätetische und moralischeSelbstoptimierung, welche sowohl eineuntadelige Lebensführung im Diesseits als auchseine Erlösung im Jenseits gewährleisten sollte.Zugleich dienten sie der Erfassung und Deutungvon Korrelationen zwischen Vorgängen in Leib,Seele, Natur und Kosmos.
Diese Aufzeichnungen stellen sich nichtnur dem heutigen Publikum als Big Data dar,sondern wurden bereits von ihrem Autor alsriesiger Datenpool konzipiert: Zeitweise brachteer täglich bis zu 5000 Wörter in deutscher undlateinischer Sprache zu Papier, so dass er inmanchen der insgesamt 43 Jahrgänge ca. 2600Seiten sehr eng mit jeweils etwa 900 Wörternbeschrieb. Zugleich pietistisches Selbstzeugnisund wissenschaftliche Aufzeichnungsform,ist dieser schriftlich fixierte und weltweiteinzigartige Erfahrungsschatz eine Fundgrubefür die Erforschung der frühneuzeitlichenReligions- und Wissenschaftsgeschichte. Darüberhinaus wirft er neue historische Schlaglichterauf die aktuell diskutierten Möglichkeiten undGrenzen der Nutzung großer Datensammlungenund ihr Verhältnis zur Theorie (vgl. Anderson2008; boyd et al. 2012, Rosenberg 2014).
Mit Förderung durch die Dr.Senckenbergische Stiftung wurden die insgesamtca. 40.000 Quartseiten in hochaufgelöster Formdigitalisiert und von der UniversitätsbibliothekFrankfurt unter Open Access-Bedingungenonline zur Verfügung gestellt (UB Frankfurt2013–2016). Am Frankfurter Institut fürDeutsche Literatur und ihre Didaktik entstehtderzeit eine TEI/XML-basierte Online-Editionder Aufzeichnungen, welche gleichfalls vonder durch den Autor selbst begründeten
Stiftung finanziert wird. In Anbetrachtihres riesigen Umfangs und der schwerentzifferbaren Handschrift Senckenbergs isteine zeitnah fertigstellbare Volltextedition desGesamtbestandes schwerlich möglich und wäreaufgrund der bei dieser Aufzeichnungspraxisnaturgemäß häufig auftretenden inhaltlichenRedundanzen auch nicht sinnvoll. Aus diesemGrund wurde im Vorfeld eine repräsentativeBandauswahl getroffen, welche nach denMaßgaben der historischen Signifikanz, derthematischen Vielfalt und der größtmöglichenVermeidung von Redundanzen erfolgte. Dieinhaltliche Komplexität und die auf schnelleErfassung großer Datenmengen ausgerichteteSchreibroutine des Autors machen zudem eineTranskriptionsweise erforderlich, die weit überdie diplomatisch-zeichengetreue Textwiedergabehinausgeht: Abgesehen von der Tatsache, dasses sich um einen halb frühneuhochdeutschenund halb lateinischen Text handelt und derSchreiber oftmals mehrfach in einem Satzzwischen beiden Sprachen hin- und herwechselt,sind viele der Sätze so komplex, dass derLeser zum Verständnis auf alle verfügbarengrammatischen Merkmale angewiesen ist. Vorallem die morphologischen Merkmale sindaber im Deutschen wie auch im Lateinischenhauptsächlich in eben jenen Wortendungenenthalten, welche häufig durch Abkürzungentfallen. Ein ähnliches Problem besteht auchhinsichtlich der Symbole, die größtenteils demalchemistischen Kontext entstammen: Siekönnen ein ganzes Wort oder auch nur einenTeil davon ersetzen, bis zu vier verschiedeneWortbedeutungen und noch viel mehrgrammatische Formen repräsentieren und invöllig verschiedenen semantischen Umgebungenerscheinen. Um dem Leser einen hinreichendenZugang zum Sprachgebrauch des Autors zubieten und ein Textverständnis überhaupterst zu ermöglichen, müssen Abkürzungenund Symbole ihrem kontextspezifischenZusammenhang entsprechend aufgelöst undsowohl semantisch als auch grammatikalisch inden Text eingepasst werden.
Auf den ersten Blick scheinen digitaleMethoden hier kaum weiterzuhelfen: Zuwenig deutlich ist die Schrift, zu komplexdie Inhalte, zu spezifisch das Vokabularund zu mehrdeutig die einzelnen Zeichen.Hinzu kommt noch, dass sich sowohlSenckenbergs Handschrift als auch die Inhalteseiner Aufzeichnungen im Verlauf von vierJahrzehnten stark veränderten und mithinganz neue graphische Muster hervorbrachten.Wenngleich die Transkription der Texte nurhändisch erfolgen kann, wird dadurch doch
163

Digital Humanities im deutschsprachigen Raum 2017
ihre Maschinenlesbarkeit überhaupt erstgewährleistet und damit die grundlegendeVoraussetzung für automatisierte Prozessesowie die Anwendung, Weiterentwicklung undSchulung der sie ermöglichenden Technologiengeschaffen. So erfordert das Training des ToolsTranskribus (Universität Innsbruck o.J.) zunächsteinmal eine ausreichende Menge an manuellerzeugten und präzisen Texttranskriptionen unddie anschließende händische Überarbeitung desOutputs (vgl. Transkribus Wiki o.J.). Aufgrundder wachsenden Nachlässigkeit der Handschriftund der inhaltlichen Heterogenität der dreiUnterbestände muss der Lernprozess für jedenTeilbestand separat erfolgen. Nach Abschlussdieses Lernprozesses ist jedoch zumindest einehalbautomatische Texterfassung möglich. Dererkannte Text kann anschließend elektronischdurchsucht und wissenschaftlich ausgewertetwerden.
Ein ähnliches Verhältnis zwischen manuellenund automatisierten Prozessen bestehthinsichtlich der inhaltlichen Erschließung derTexte. Da sie von einem einzigen Schreiber mitumfassender grammatischer Bildung stammen,liegt nur eine geringe orthographische Varianzbei der Schreibung ein- und desselben Wortesvor. Anders als in heterogenen Korpora, dieTexte mehrerer Schreiber mit unterschiedlichemBildungshintergrund und sprachgeografischerHerkunft versammeln, ist deshalb eine vorherigehändische Normierung der Grafie nichtnotwendig (vgl. demgegenüber Faßhauer etal. 2013, Faßhauer et al. 2014). Mit Hilfe dervorliegenden Transkriptionen kann deshalbein effizientes Training des Tools TreeTagger(Schmid 1994-) für das Frühneuhochdeutscheund Neulateinische vorgenommen werden.Die halbautomatisch generierten Lemmataund Part-of-Speech-Tags, welche sowohl fürdie manuellen Transkriptionen als auchfür die automatisch erfassten Texte erstelltwurden, werden anschließend in den Partitur-Editor der Software EXMARaLDA (Hedelandet al. o.J.) eingespielt. Mit dem zugehörigenAnalysetool EXAKT werden per RegEx-Sucheauf der Lemmaspur zunächst alle Nominaherausgefiltert und in einem manuellenProzess Schlagwörter ausgewählt (ähnlichauch Biehl et al. 2015). Aus der Untermengeder großgeschriebenen Substantive, die sichmittels der automatischen Sortierfunktion derTrefferliste leicht ermitteln lassen, werden allePersonen- und Ortsnamen entnommen. Anhanddieser Recherchezugänge kann nun das gesamteKorpus systematisch recherchiert werden. Dievon EXAKT angebotenen Anfragen über RegExund Levenshtein-Distanzen ermöglichen dabei
eine schreibweisentolerante Begriffsermittlung,wodurch mancher HTR-Lesefehler überwundenwerden kann.
Bibliographie
Anderson, Chris (2008): „The End ofTheory: The Data Deluge Makes the ScientificMethod Obsolete“, in: Wired Magazine http://www.wired.com/2008/06/pb-theory/
Biehl, Theresia / Lorenz, Anne / Osierenski,Dirk (2015): „Exilnetz33. Ein Forschungsportalals Such- und Visualisierungsinstrument“,in: Baum, Constanze / Stäcker, Thomas(eds.): Grenzen und Möglichkeiten der DigitalHumanities (= Sonderband der Zeitschrift fürdigitale Geisteswissenschaften, 1).
Boyd, Danah / Crawford, Kate (2012):„Critical Questions for Big Data“, in: Information,Communication & Society 15 (5): 662–67910.1080/1369118X.2012.678878.
Fasshauer, Vera / Lühr, Rosemarie /Prutscher, Daniela /Seidel, Henry (2013):Dokumentation der Annotationsrichtlinienfür das Korpus FrühneuzeitlicheFürstinnenkorrespondenzen im mitteldeutschenRaum. dwee.eu/Rosemarie_Luehr/userfiles/downloads/Projekte/Dokumentation.pdf.
Fasshauer, Vera / Lühr, Rosemarie /Prutscher, Daniela /Seidel, Henry (2014):Fürstinnenkorrespondenz (version 1.1),Universität Jena, DFG. LAUDATIO Repository.http://www.indogermanistik.uni-jena.de/Web/Projekte/Fuerstinnenkorr.htm .
Hedeland, Hanna / Lehmberg, Timm /Schmidt, Thomas / Wörner, Kai (o.J.):EXMARaLDA. Werkzeuge für mündliche Korporahttp://www.exmaralda.org/ [letzter Zugriff 21.März 2016].
Rosenberg, Daniel (2014): „Daten vorFakten“, in: Reichert, Ramón (ed.): Big Data:Analysen zum digitalen Wandel von Wissen,Macht und Ökonomie. Bielefeld: transcript Verlag133–156.
Schmid, Helmut (1994-): TreeTagger. Apart-of-speech tagger for many languages.http://www.cis.unimuenchen.de/~schmid/tools/TreeTagger/ [letzter Zugriff 20. August 2016].
Transkribus Wiki (o.J.): Transkribus-Benutzeranleitung. https://transkribus.eu/wikiDe/index.php/Hauptseite [letzter Zugriff 20. August2016].
UB Frankfurt =UniversitätsbibliothekFrankfurt am Main (2013-2016): NachlassJohann Christian Senckenberg. http://sammlungen.ub.uni-frankfurt.de/senckenberg/nav/index/all [letzter Zugriff 20. August 2016].
164

Digital Humanities im deutschsprachigen Raum 2017
Universität Innsbruck (o.J.): Transkribus.https://transkribus.eu/Transkribus/ [letzterZugriff 20. August 2016].
NachhaltigeKonzeptionsmethodenfür Digital HumanitiesProjekte am Beispiel derGoethe-PROPYLÄEN
Kasper, [email protected] der Wissenschaften und der Literatur,Deutschland
Grüntgens, [email protected] der Wissenschaften und der Literatur,Deutschland
Vor dem Hintergrund desAkademievorhabens PROPYLÄEN.Forschungsplattform zu Goethes Biographicawerden zwei aktuelle Konzeptionsmethodenaus dem Bereich des Software-Engineeringvorgestellt, die sich unserer Erfahrung nachals geeignete Grundlage für nachhaltigeKonzeptionsprozesse in Digital HumanitiesProjekten erwiesen haben: Domain DrivenDesign sowie Behaviour Driven Development.Zunächst erfolgt ein Überblick über Aspektedigitaler Nachhaltigkeit bei der Beantragunggeisteswissenschaftlicher Langzeitvorhaben imAkademienprogramm.
Die PROPYLÄEN sindein 2015 imAkademienprogramm gestartetesForschungsvorhaben der Klassik StiftungWeimar, der Sächsischen Akademie derWissenschaften zu Leipzig und der Akademieder Wissenschaften und der LiteraturMainz ( http://www.goethe-biographica.de ).Geplant ist bei einer Gesamtlaufzeit von 25Jahren Fortführung und Abschluss von vier(Print-)Publikationsreihen: Die Editionen derBriefe von sowie an Goethe, seine Tagebücherund die Zeugnisse seiner Begegnungen undGespräche. Die gleichzeitig entstehendeForschungsplattform wird sukzessive alleBiographica in einer technisch und inhaltlichoffenen Infrastruktur bereitstellen sowie
Recherchezugänge und Visualisierungen auf denDatenbestand anbieten.
Eine Voraussetzung für die Aufnahme einesNeuvorhabens in das Akademienprogramm istein ausgearbeitetes Digitalisierungskonzept,zu dem unter anderem eine Strategie zurLangzeitarchivierung und Langzeitverfügbarkeitder Forschungsergebnisse gehört (Vgl. Herrmann2016: 9). Häufig konzentriert sich dieses aufeine enge Definition von Forschungsdaten, dieunter diesem Begriff lediglich edierten Textversteht. Im Falle einer Forschungsplattformwie der PROPYLÄEN sind nicht nur die in derDatenschicht – Faksimiles, Editionstext, kurzdie Gesamtheit der digitalen Forschungsdaten –befindlichen Komponenten für eine nachhaltigeund langfristige Bereitstellung vorzusehen (zuArchivierungsschicht und Präsentationsschichtvgl. Pempe 2012: 141). Daneben sollte auchdie Auswahl geeigneter Technologien ein Teilder Antragsstrategie sein. Unter Technologiesei alles vom Datenformat über ein Content-Management-System bis zur virtuellenForschungsumgebung verstanden. Angesichtsdes Verhältnisses zwischen langfristigerProjektförderung – die Akademienvorhabenwerden 12 bis 25 Jahre gefördert – und dertechnischen Entwicklung ist die Vorstellungder einmaligen Einrichtung einer digitalenArbeitsumgebung und Publikationsplattform amAnfang der Projektlaufzeit, welche daraufhin für25 Jahre verwendet würde, nur mit begleitenderWartung und Weiterentwicklung denkbar. Wirddas gewählte Datenformat in 30 Jahren nochmaschinenlesbar sein? Absolute Sicherheit gibtes in diesem Fall nicht, aber allgemein gilt dieVerwendung von (semistrukturierten) Rein-Textformaten – wie XML nach TEI – gegenüberproprietären Formaten als nachhaltiger.
Der Mehrwert der elektronischen Fassungentsteht aber vornehmlich durch neueVerbindungs-, Gruppier-, Sortier-, Filter- undSuchmöglichkeiten, die auf dynamischenVerarbeitungsmechanismen, also auf derGeschäftslogik der Anwendung, basieren.Diese nicht-statischen Elemente, die sichinsbesondere in der Präsentationsschicht einergeisteswissenschaftlichen Webanwendungkonkretisieren, müssen in ihrer Funktionalitätgenauso nachvollziehbar und reproduzierbarüber das Projektende hinaus zur Verfügungstehen.
Komplexer als die Datenschicht ist demnachdie dauerhafte Erhaltung der Applikationslogikund Präsentationsschicht: Wie kann diewebbasierte Verarbeitung von Anfragen unddie Wiedergabe von Ergebnissen auch 10Jahre nach Projektende noch funktionsfähig
165

Digital Humanities im deutschsprachigen Raum 2017
gehalten werden? Eine aktuell diskutierteStrategie ist die virtuelle Kapselung sämtlicherSoftwarekomponenten einer Applikation, diekünftig ein Emulieren aller Komponentenauf aktuellen Betriebssystemen ermöglicht(siehe dazu bspw. http://recomputation.org/ ).Vorhaben wie die PROPYLÄEN müssen dieserHerausforderung während der Projektlaufzeitbegegnen, indem sie eine hohe Flexibilitätsowie stete Aktualisierung und Anpassungder Technologien ihrer Infrastruktur in derGrundplanung vorsehen. Um diesen Prozessauf eine transparente Grundlage zu stellen, giltes bei der informationstechnischen Gestaltungdes Forschungsvorhabens eine möglichstgegenstandsnahe Abstraktion zu wählen und dieAnforderungen an die Software auf formalisierteWeise zu dokumentieren. Folgende Annahmenund Schlüsse gehen dieser Überlegung voran:
• Es wird während der Projektlaufzeit internwie extern neue Erkenntnisse zu GoethesZeit und Wirken geben, die unseren Blickauf den Forschungsgegenstand verändern.Dennoch ist es möglich, übergreifendeWissensobjekte zu identifizieren und in Formvon informatischen Entitäten abzubilden.
• Technologieunabhängige,anwendungsorientierteund allgemeinverständlicheFunktionsbeschreibungen derForschungsplattform sind formulierbar.Neue Erkenntnisse im Bereich der Goethe-Forschung wie im Bereich der usabilitywerden diese Anforderungen innerhalbder Projektlaufzeit höchstwahrscheinlichverändern.
In der Konzeptionsphase einer nachhaltigendigitalen Grundlage für den Daten-,Präsentations- und Applikationsteil derForschungsplattform PROPYLÄEN sind daherzwei Fragen leitend, deren Beantwortung unsnicht nur für Langzeitvorhaben mit Digital-Humanities-Anteil zentral erscheint (vgl.zu Prozessphasen und zur Konzeption hierund folgend: Schrade 2016: Step 14–21, zurKonzeption Step 17):
• Wie lassen sich Biographica Goethes fürtechnische und geisteswissenschaftlicheAnforderungen nachhaltig modellieren beigleichzeitiger Bewahrung der Flexibilitätin der Anwendungsarchitektur für dieIntegration gegebenenfalls noch nichtbekannter digitaler Ressourcen?
• Wie lassen sich die funktionalenAnforderungen an eine digitaleRechercheumgebung aus der Fachcommunitynachhaltig formulieren und dokumentieren?
Zur Beantwortung können zweiKonzeptionsmethoden aus dem Bereich desSoftware-Engineering fruchtbar gemachtwerden: Domain Driven Design (DDD) (sieheEvans 2003, Vernon 2013) und BehaviorDriven Development (BDD) (siehe North 2016). Beiden ist gemein, dass sie unabhängig vonDatenformaten, Programmiersprachen oderPräsentationstechnologien operieren.
DDD nimmt an, dass einem Konzeptions-bzw. Entwicklungsprozess dann die größtenErfolgschancen und daraus resultierend diebeste Nachhaltigkeit zukommen, wenn dievirtuellen Komponenten des informatischenModells ausgehend von ihren realenEntsprechungen gebildet werden. Damitkommt der fachwissenschaftlichen Logik,die sich aus dem Wissen von Domänen-Experten (im Anwendungsfall Goethe-Philologen) und deren Niederlegung inpublizierten Editionsbänden ableitet, einezentrale Rolle für die Modellierung zu. DieAusmodellierung der Wissensdomäne entstehtiterativ in einem konstanten kommunikativenProzess aller Projektbeteiligten. DDD löstdie gängige und nicht optimale Praxis einerausschließlichen Bedarfsformulierungdurch Geisteswissenschaftler und einerdarauffolgenden Umsetzung durchInformatiker zugunsten eines gemeinsamenModellierungsprozesses unter Verwendungeiner für alle Beteiligten verständlichen (ubiquitären) Sprache auf. Dieser im Rahmeneines Projektes von allen Beteiligten zuentwickelnden Sprache liegen eine Reihevon Komponenten für ein Modell derWissensdomäne ( domain model) zugrunde,das in seiner Gesamtheit alle Eigenschaften,Beziehungen und „Geschäftsprozessen“ derzukünftigen Anwendung abbilden kann. Diewichtigsten Komponenten für die Fachdomäne„PROPYLÄEN“ sind:
• Objekte mit eigener Identität ( entities):Briefe, Faksimiles, Personen, Orte, Werke
• Objekte, die sich über die Gesamtheit ihrerEigenschaften definieren ( value objects):Geokoordinaten (Länge-Breite), Datierungen(Anfangs-Enddatum), Korrespondenzvorgang(Sender-Empfänger) etc.
166

Digital Humanities im deutschsprachigen Raum 2017
• Die Beziehungen dieser Objekteuntereinander ( associations): Person →erwähnt in: Brief
• Zusammenfassungen von entities, valueobjects und associations zu Aggregaten ( aggregates); der Zugriff auf einzelneKomponenten eines Aggregates darfausschließlich über die Entität an derAggregat-Wurzel ( aggregate root)erfolgen. Aggregate gewährleisen logischeKonsistenz und funktionale Integrität einerAnwendungs- bzw. Wissensdomäne: Brief(Brieftext, Kommentar, Faksimile, Datierung,im Brief erwähnte Orte und Personen)
• Dienste zwischen Objekten derWissensdomäne ( services): Sortiere nachDatum etc.
Die Fachdomäne kann grafisch dargestelltwerden. Abbildung 1 dient der Illustrationdes DDD-Konzepts am Beispiel eines Teils derPROPYLÄEN-Domäne.
Abbildung 1: Wissensdomäne GoethePROPYLÄEN
Dan Norths Idee des BDD ist, Anforderungenan die geplante Applikation in Form vonuser stories und verhaltensorientiertenTestszenarien im Vorfeld der Realisierungunter Zuhilfenahme einer ubiquitären Sprachezu beschreiben. Durch die Verwendungvon Schlüsselwörtern in formalisierterNotation lässt sich eine einheitliche undleicht verständliche Dokumentation erstellen.Aufgrund starker Nutzerorientierungwird BDD im Qualitätsmanagement vonSoftwareanwendungen zu den Akzeptanztestsgerechnet (neben Unit-Tests, Funktionstests,Performance-Tests oder manuellen Tests).
Abbildung 2 zeigt ein BDD-Testszenario in denGoethe-PROPYLÄEN, das auf Gherkin-Notationbasiert (Siehe https://github.com/cucumber/cucumber/wiki/Gherkin , Stand 26.08.2016). Die
Schlüsselwörter Funktionalität, Beschreibung und Details enthalten übergeordneteInformationen, während im Bereich derSzenarios mit Hilfe der Operatoren Szenario bzw. Gege ben, Wenn, Dann, Und einzelneAnforderungen formuliert werden. DieAusführungen können dabei allgemein gehaltenwerden und lassen sich im späteren Verlaufauffächern.
Abbildung 2: BDD-Testszenario in Gherkin-Notation
Ein Vorteil ist, dass Szenarios durch denEinsatz einer verständlichen, formalisiertenSprache nicht nur gemeinsam zwischenGeisteswissenschaftlern und Informatikernwährend des Entwicklungsprozessformuliert werden, sondern dass beisyntaktisch korrekter Formulierungdiese als Grundlage für automatisierteTestverfahren der Präsentationsschicht einerWebanwendung herangezogen werden können(bspw. mit dem BDD Testing-Frameworkbehat; siehe http://docs.behat.org (Stand26.08.2016)). BDD ermöglicht somit eine zeit-ökonomische Überprüfung aller Bereiche undFunktionalitäten der Präsentationsschichtbei gleichzeitiger Dokumentation derFunktionalitäten in Reintext und natürlicherSprache. Änderungen in der technischenInfrastruktur einer Plattform (Softwarewechselder Datenbankschicht, Einführung neuerProgrammroutinen) können mit deutlichgesteigerter Verlässlichkeit im Hinblick aufeine gleichbleibende, dauerhafte Funktion derWebanwendung durchgeführt werden.
167

Digital Humanities im deutschsprachigen Raum 2017
Die gemeinsame Modellierung einerWissensdomäne mittels DDD und BDDführt notwendigerweise zu intensiverAuseinandersetzung mit allen geistes- wieinformationstechnischen Aspekten desProjektes. Dadurch wird projektintern einekommunikative Ebene entstehen, die einegemeinsame und unmißverständliche Spracheverwendet und perspektivisch eine verbesserteTiefenschärfe in Bezug auf funktionale Aspekteder zu realisierenden Forschungsanwendungermöglicht.
DDD und BDD helfen alsKonzeptionsmethoden, alle gemeinsamgetroffenen Entscheidungen über diegesamte Projektlaufzeit transparentund nachvollziehbar zu dokumentieren.Da es sich gleichzeitig im Bezug auf dieBDD-Akzeptanztests um „ausführbaresWissen“ handelt, wird eine dauerhafteund gleichbleibende Funktionalität derPräsentationsschicht geisteswissenschaftlicherWebanwendungen gewährleistet. Dies trägterheblich zu gesteigerter Nachhaltigkeit digitalerKomponenten eines geisteswissenschaftlichenForschungsprojektes bei.
Bibliographie
Evans, Eric (2003): Domain-Driven Design.Tackling Complexity in the Heart of Software.Boston et al.
Herrmann, Dieter (2016): „E-Humanties imAkademienprogramm“, in: Union der DeutschenAkademien der Wissenschaften (Hrsg.): DieWissenschaftsakademien – Wissensspeicherfür die Zukunft. Forschungsprojekte imAkademienprogramm. Berlin / Mainz 9–11.
North, Dan (2016): Introducing BDD. https://dannorth.net/introducing-bdd/ [letzter Zugriff26. August 2016].
Pempe, Wolfgang (2012):„Geisteswissenschaften“, in: Neuroth, Heike et al.(eds.): Langzeitarchivierung von Forschungsdaten– Eine Bestandsaufnahme. Göttingen 137–159.
Schrade, Torsten (2016): Nachhaltige Online-Applikationen in den Geisteswissenschaften –Modellierung und Implementierung. Vortragvom 11. April 2016, Hochschule Mainz, http://metacontext.github.io/nachhaltige-online-apps/[letzter Zugriff 26. August 2016].
Vernon, Vaugh (2013): Implementing Domain-Driven Design. Boston et al.
NachhaltigeSoftwareentwicklung inden Digital Humanities.Konzepte undMethoden.
Schrade, [email protected] der Wissenschaften und der LiteraturMainz, Deutschland
Ausgehend von den umfangreichenInfrastrukturinitiativen der vergangenenJahre existieren inzwischen vielfältige digitaleRessourcen, Werkzeuge und Dienste, die voneiner lebhaften digitalen Forschungskulturin den Geisteswissenschaften zeugen.Arbeitsgruppen wie beispielsweise NESTORoder auch die DINI-Initiative haben essich zur Aufgabe gemacht, Empfehlungenund best practices für den gesamtenLebenszyklus digitaler geisteswissenschaftlicherForschungsprojekte (Datenerfassung,Datenverwaltung, Datenpublikation,Datenarchivierung) zu entwickeln. Mit dem vonDARIAH und TextGrid initiierten Memorandumzur nachhaltigen Bereitstellung digitalerForschungsinfrastrukturen für die Geistes- undKulturwissenschaften in Deutschland ist dasThema ‚Digitale Nachhaltigkeit‘ ganz besondersin den Fokus gerückt (s. http://dhd-blog.org/?p=6559 ).
Während das Bewußtsein für einenachhaltige Erschließung kultureller Objektedurch den Einsatz entsprechender Datenformateund -standards inzwischen als hoch eingeschätztwerden kann, gelingt eine nachhaltigeIntegration von Softwarewerkzeugenin die konkrete Forschungswirklichkeitgeisteswissenschaftlicher Projekte noch nichtimmer. Die Gründe hierfür sind divers undreichen von einer immer noch existierenden,mangelnden Akzeptanz bzw. Berührungsangstder Geisteswissenschaftler_innen hinsichtlichinformationstechnischer Verfahren bis hin zueiner nicht an den Projektzielen ausgerichtetenImplementierung der benötigten Softwareseitens der technischen Partner eines Projektes.
Ein bisher wenig berücksichtigter aberganz zentraler Grund ist jedoch, dass dieEbene der Softwareentwicklung in denNachhaltigkeitsdiskussionen der Digital
168

Digital Humanities im deutschsprachigen Raum 2017
Humanities bisher kaum eine Rolle spielt.Erst seit diesem Jahr liegt ein erster Berichtzu generellen Voraussetzungen für dieNachhaltigkeit von Forschungssoftware vor(Hettrick 2016). Dieser kommt zu folgendemSchluss: „many researchers know how to code,but few understand the wider set of skills thatare needed to develop reliable, reproducibleand reusable software. […] software engineeringshould be incorporated […] at the very start ofa research career.“ (Hettrick 2016, S. 14). Nebenden sicherlich notwendigen Überlegungenzur Nachhaltigkeit geisteswissenschaftlicherForschungsdaten sollte künftig mehr daraufgeachtet werden, neben der reflexivenEbene auch das konkrete entwicklerischeHandwerkszeug in Digital HumanitiesStudiengänge einzubeziehen. Insbesonderemüssen entwicklerische Leistungen alsgleichrangige akademische Tätigkeit anerkanntwerden (vgl. Hettrick, S. 13). Neben die Theoriesollte ein akademisch anerkanntes DigitalHumanities “Craftsmanship” treten. 1
Die Gründe für eine nicht nachhaltigeEntwicklung geisteswissenschaftlicher Softwaresind relativ einfach zu identifizieren undkeineswegs spezifisch für das akademischeEntwicklungsumfeld. Sie spielen genauso inder freien Wirtschaft oder der Open SourceSzene eine Rolle. Zu den Hauptgründen einermangelnden Software-Nachhaltigkeit könnenbeispielsweise gehören:
• Eine ausgelaufene Projektfinanzierung,wodurch der Weiterbetrieb der Softwarenicht mehr gewährleistet ist,
• Entwickler_innen, die dem Projekt nichtmehr zu Verfügung stehen, aber vor ihremWeggang die ausschließlichen Wissensträgerwaren,
• eine veraltete und nicht mehr wartbareInfrastruktur,
• veralteter oder unverständlicherProgrammcode, der von neu einsteigendenEntwickler_innen weitergeführt werdenmuss,
• Sicherheitslücken, die vermeidbar gewesenwären, jetzt aber einen Weiterbetrieb derSoftware verhindern,
• (schwerwiegende) Bugs in der Software, dieerst im Produktivbetrieb auffallen, da vorherkeine Softwaretests durchgeführt wurden,
• ein fehlendes Monitoring dergeisteswissenschaftlichenForschungsanwendung, wodurch Störfällenicht oder erst spät auffallen.
Blickt man vor diesem Hintergrund in diefreie Wirtschaft und Softwareindustrie undfragt nach aktuellen Projektmanagement-Methoden bzw. Herangehensweisen zurSteigerung der Qualität und Nachhaltigkeit einerSoftware, lässt sich sehr schnell feststellen, dassinsbesondere die unter dem Stichwort „AgileSoftwareentwicklung“ gefassten methodischenAnsätze sich sehr gut eignen, um den genanntenHerausforderungen entgegenzutreten (vgl.Ayelt 2014). Obwohl agile Entwicklungsansätzehäufig unterschiedliche Teilaspekte einesEntwicklungs-Workflows adressieren (bspw. dieKonzeptionsebene, die Entwicklungsebene, dieEbene des Testings oder des Deployments einerSoftware), legen alle doch den Schwerpunktauf eine kontinuierliche Kommunikation allerProjektbeteiligten untereinander (von denStakeholdern über die Entwickler_innen bis zuden Testnutzer_innen und Endnutzer_innen).Agile Softwareentwicklung sieht häufig in einerfür alle nachvollziehbaren Kommunikation denentscheidenden Schlüssel für ein erfolgreichesund nachhaltiges Softwareprodukt.
Hiermit befinden wir uns aberwiederum sehr nahe an den DigitalHumanities. Schon lange wird für DigitaleGeisteswissenschaftler_innen einekommunikative Schlüsselstellung reklamiert.Als Mediatoren mit Fachwissen aus zweiWelten sollen sie eine für alle Parteiengemeinsame, verständliche Sprache entwickelnund so die unterschiedlichen geistes- undinformationswissenschaftlichen Konzepte einesForschungsprojektes miteinander in Einklangbringen.
Das Team der Digitalen Akademie derMainzer Akademie der Wissenschaften und derLiteratur integriert bereits seit 2009 Konzepteaus dem Bereich der agilen Softwareentwicklungin die tägliche Forschungs-, Entwicklungs- undProjektarbeit. Hierbei werden auf verschiedenenEbenen Konzepte angewendet, die sichüber die Zeit als besonders geeignet fürgeisteswissenschaftliche Anwendungskontexteherausgestellt haben. Sowohl zur Steigerungder Softwarequalität, insbesondere aberauch zur Steigerung der Nachhaltigkeit derForschungsapplikationen wurde mit derZeit eine an den Prinzipien der „ContinuousDelivery“ ausgerichtete Prozesskette aufgebaut(zum Begriff vgl. Wolff 2015).
Die nachfolgende Grafik gibt einen Überblicküber die einzelnen Ebenen dieser Prozesskette.
169

Digital Humanities im deutschsprachigen Raum 2017
Auf Ebene der Konzeption undProgrammierung kommen zweiHerangehensweisen zum Einsatz: dassogennannte Domain-Driven Design (DDD)und das Behaviour-Driven Development(BDD). Domain-Driven Design ist dabeizum einen eine Herangehensweise an dieModellierung komplexer Software, zum anderenein bestimmtes Denkkonzept zur Steigerungder Produktivität von Softwareprojekten imUmfeld komplexer fachlicher Zusammenhänge.Das Hauptaugenmerk fällt dabei auf dieEinführung einer ubiquitären (allgemeinverständlichen) Sprache, welche in allenBereichen der Softwareerstellung vonden Konzeptionsgesprächen mit denFachwissenschaftler_innen bis hin zurCode-Ebene verwendet werden sollte.Domain-Driven Design ist unabhängig vonProgrammiersprachen, Tools und Frameworks(vgl. Evans 2013, S. 13). DDD eignet sichausgezeichnet für eine nachhaltige undoffene Modellierung geisteswissenschaftlicherAnwendungskontexte, da iterativgearbeitet wird. Zu Beginn der Domänen-Modellierung ist in geisteswissenschaftlichenForschungsprojekten die eigentlicheDatengrundlage und der Funktionsumfang derzu erstellenden Software häufig nicht vollständigklar. Beides entsteht sukzessive in derBeschäftigung mit dem Forschungsgegenstand.Somit können während der eigentlichenEntwicklung häufig neue Gegenständeauftauchen, noch nicht bedachte Eigenschaftenhinzukommen oder sich auch Teile derApplikationslogik grundlegend ändern. Durchregelmäßige Iterationen nach dem DDD-Prinzipkann die Software kontinuierlich mit der sichstetig wandelnden Projektrealität verändern.
Die Codebasis bleibt dabei im Einklang mit derKonzeptions- bzw. Modellierungsebene.
Behaviour-Driven Development wiederumgeht davon aus, dass sich die Funktionalitäteiner Anwendungsdomäne (und somit dieGeschäftslogik eines Domänen-Modells)durch formalisierte Szenarien in einerallgemeinverständlichen Sprache beschreibenlässt. BDD ist ein „outside-in“-Ansatz,der von außen (also mit dem Blick derGeisteswissenschaftlerinnen) auf eineSoftware blickt und deren Funktionalität inausführbaren Tests dokumentiert. Ursprünglichim Umfeld des Test Driven Developmententstanden, achtet auch BDD darauf, dassdie Nutzungszenarien einer Software vorder eigentlichen Programmierung derSoftware erstellt werden. Dadurch dass dieTests in natürlicher Sprache nach einemfesten Dreischritt-Prinzip (Angenommen…,Wenn…, Dann…) formuliert werden, kanndie oftmals komplexe und wenig nachhaltigePräsentationsschicht und Funktionslogik einerSoftware in direkter Zusammenarbeit mitden Fachwissenschaftler_innen gemeinsambeschrieben und nachhaltig dokumentiertwerden. In der Umsetzung hat dies für dieEntwickler_innen den Vorteil, dass exakt nursoviel Code geschrieben werden muss, bis diejeweiligen Tests erfolgreich ablaufen und dieSoftware exakt wie geplant funktioniert.
Als dritte wichtige Säule in einemnachhaltigen Entwicklungsprozess istdie Virtualisierung und Automation derInfrastruktur nach ‚DevOps‘-Prinzipien(eine Zusammenfügung der beiden BegriffeDevelopment und Operations) zu nennen.‚DevOps‘ betrachtet ‚Infrastruktur als Code‘ undsetzt entsprechende Werkzeuge ein, um einevollständige Kapselung der Softwareschichtund gleichzeitige Reproduzierbarkeit derGesamtapplikation einschließlich ihrerInfrastruktur zu erreichen. Der große Vorteildieser Verfahrensweise liegt in der automatischenstehenden Dokumention hochgradigspezialisierter Anwendungsumgebungen.Gleichzeitiger sind die „Baupläne“ dieserAnwendungsumgebungen in einemVersionskontrollsystem versionierbar.
Alle bisher genannten Konzepte strebeneine Versionierbarkeit ihrer Outputs an,was die Nachvollziehbarkeit und somit dieNachhaltigkeit auf der Software-Ebene deutlichsteigert. Auf diese Weise hergestellte Softwarelegt nicht nur offen, wie sie funktioniert,sondern wie sie hergestellt wurde und das aufallen Ebenen, von der Konzeption über dieProgrammierung und das Testing bis hin zum
170

Digital Humanities im deutschsprachigen Raum 2017
Deployment. Insofern kommt dem ‚Commit‘,also dem wiederholten Einspielungsvorgangder jeweiligen Entwicklungsstände dieRolle des zentralen Dreh- und Angelpunkteseiner nachhaltigen Softwareentwicklung zu.Zusammenfassend lässt sich im Abgleich zu denoben genannten Punkten festhalten, dass beieiner nachhaltigen Softwareentwicklung
• insbesondere die beständige Kommunikationaller Projektbeteiligten untereinander einenzentralen Faktor darstellt,
• ein gemeinsames Vokabular festgelegtwerden und dies auf allen Ebenenkonsequent angewendet werden muss(Konzeption, Datenschema, Code, Tests etc.).
• auf forschungsgetriebene, agileEntwicklungsmethoden gesetzt werden sollte,
• ein nachvollziehbarer Entwicklungsprozessdurch Versionskontrolle gewährleistetwerden muss,
• die Infrastruktur nach DevOps-Prinzipienvirtualisiert und automatisiert werden sollte,
• Softwaretests vor jedem Live-Deploymentdurchzuführen sind,
• die Applikation im Produktivbetriebkontinuierlich überwacht werden muss.
Innerhalb des Vortrags werden diedargelegten Konzepte und Methoden anhandvon Projektbeispielen genauer illustriert undzur Diskussion gestellt. Der Beitrag verstehtsich somit als ein Erfahrungsbericht aus dermehrjährigen Arbeit im Kontext der DigitalHumanities Projekte der Digitalen Akademieder Mainzer Akademie sowie des MainzerZentrums für Digitalität in den Geistes undKulturwissenschaften (mainzed).
Fußnoten
1. In Anlehnung an den Begriff des softwarecraftsmanship.
Bibliographie
Komus, Ayelt (2014): Status Quo Agile 2014.Hochschule Koblenz. https://www.hs-koblenz.de/rmc/fachbereiche/wirtschaft/forschung-projekte-weiterbildung/forschungsprojekte/status-quo-agile/ [letzter Zugriff 26. August 2016].
Evans, Eric (2003): Domain-Driven Design:Tackling Complexity in the Heart of Software.Boston: Addison Wesley.
Hettrick, Simon (2016): Research SoftwareSustainability: Report on a KnowledgeExchange Workshop. Edinburgh: The SoftwareSustainability Institute.
Wolff, Eberhard (2015): ContinuousDelivery: Der pragmatische Einstieg. Heidelberg:dpunkt.verlag.
Vernon, Vaughn (2013): ImplementingDomain Driven Design. Boston: Addison Wesley.
Nachhaltigkeitals Prozess: ZurkonzeptionellenFunktion digitalerTechnologien in derNachhaltigkeitssicherungfür historische Fotos imProjekt efoto-Hamburg
Schumacher, [email protected]ät Hamburg, Deutschland
Abstract
efoto-Hamburg wird seit 2013 von derUniversität Hamburg wissenschaftlich geleitetund von der Kulturbehörde der Stadt gefördert.Ziel ist der Aufbau einer gemeinsamenBilddatenbank für private und behördlicheArchive und Museen Hamburgs. Zugleichwird eine mobile App entwickelt, die dieBilddaten für die Öffentlichkeit zugänglich,nutz- und erfahrbar macht. Als ein zentralesElement verknüpfen Narrative Abgebildetesmit der Lebenswirklichkeit der Nutzer.Das Erzählen als Basis anthropologischerÜberlieferung wird mit archivarischenArbeitsweisen und informationstechnologischenImplementierungen verknüpft, um historischesBildmaterial langfristig als Bestandteil einerlebendigen Stadtkultur zu erhalten. Unsereauf diesem Prinzip fußende interdisziplinärangelegte Nachhaltigkeitsstrategie möchte ichim hier vorgeschlagenen Vortrag erläuternund vor allen Dingen zur Diskussion stellen,welche Rolle digitale Technologien mit Blick aufNachhaltigkeit als konzeptionelles kulturelles
171

Digital Humanities im deutschsprachigen Raum 2017
Desiderat spielen können. Der Vortrag verknüpftdie Diskussion um digitale Nachhaltigkeit mitAnsätzen aus der Kultur- und Erzähltheorieund zeigt ein Anwendungsbeispiel kulturellerNachhaltigkeit, welches die Verbindung vonWissenschaft und Öffentlichkeit anstrebt.
Nachhaltigkeit kulturellerDaten: KonzeptionellesDesiderat und digitaleOptionen
Unser grundlegendes Verständnis vonNachhaltigkeit basiert auf einer frühenDefinition nachhaltiger Entwicklung ausdem Bericht der UN-Brundtland-Kommission“Our Common Future” (World Commissionon Environment and Development 1987).Darin heißt es:“Sustainable development isdevelopment that meets the needs of the presentwithout compromising the ability of futuregenerations to meet their own needs.” (Ebd.: 41)
Nachhaltigkeit stellt sich hier vorrangigals Prozess der Vermittlung zwischen denBedürfnissen der heutigen Gesellschaft unddenen zukünftiger Generationen dar. Auchin Bezug auf das kulturelle Erbe wird diesesSpannungsfeld, das auch als Enkelgerechtigkeit(Die Bundesregierung 2015: 23) bezeichnet wird,als bedeutsam eingestuft (Willer 2013: 141).
In der frühen Definition der Nachhaltigkeitliegt der Schwerpunkt auf ökologischenGesichtspunkten. Anschließend wurde dasKonzept allerdings bereits um kulturelleDimensionen erweitert. Für die efoto-Nachhaltigkeitsstrategie sind zwei Ansätzekonzeptionell von besonderer Bedeutung:
Kulturelle Nachhaltigkeit: Kultur 1 wird nebenWirtschaft, Ökologie und Gesellschaft alsTriebfeder für Nachhaltigkeit verstanden.Dabei geht es um die Frage, inwiefernKultur behilflich sein kann, eine nachhaltigeEntwicklung voran zu treiben. Nach diesemVerständnis kann Nachhaltigkeit nurgelingen, wenn diese in der Kultur einessozialen Systems verankert ist. (Brocchi 2007)
Nachhaltigkeit der Kultur: Hier geht eshauptsächlich um die Frage, wie kulturelleArtefakte langfristig erhalten und lebendiggehalten werden können. Dabei spielen inunserem Kontext Strategien eine besondereRolle, die das Nachhaltigkeitsdesiderat durchgezielte Nutzung digitaler Technologien zu
beantworten suchen. Es eröffnen sich dabeiunterschiedliche Problemfelder wie z.B.
Zugänglichkeit: Hier sind zwei Teilbereichevon überragender Bedeutung. Einerseitsmuss Zugang auf technischer Ebenegeschaffen werden und erhalten bleiben.Objekte, die nicht ursprünglich digital sind,müssen digitalisiert und in Datenbankenund Portale überführt werden. In diesemRahmen wird auch überlegt, wie digitaleLangzeitarchivierung in Hard- und Softwaream besten zu leisten ist (Giebel 2013).Der zweite umfassend problematisierteBereich ist der rechtliche Rahmen, derden öffentlichen Zugang meist erschwert(Steinhauer 2013). Die Vielfalt derObjektarten des kulturellen Erbes bedingt,dass häufig Rechte unterschiedlicher Artgreifen.
Kuration: Grundsätzlich bietet die digitaleArchivierung die Möglichkeit, Daten ingroßen Mengen zu erfassen. In Anbetrachtder Masse der digitalen Artefakte stelltsich allerdings die Frage, was würdigist, für das kulturelle Erbe bewahrt zuwerden. Die bisher vorherrschendemanuelle Sichtung durch Archivare undKuratoren wird angesichts der schierenDatenmengen zunehmend unmöglich.Automatische digitale Kuration wurde alsLösung zwar formuliert (Zorich 2016: 14),birgt aber die Gefahr des menschlichenKompetenzverlustes an den Computer bzw.an Algorithmen. Gleichzeitig scheint einegrößere Scheu vor der digitalen Löschungals vor dem ‘Wegschmeißen’ von Artefaktenzu bestehen, die als nicht archivwürdigklassifiziert werden. Das Löschen digitalerDaten wird oft als endgültig beschrieben,während ein weggeworfenes Objekt immernoch entweder physisch überdauern oder alsprivate Kopie zu einem späteren Zeitpunktwieder gefunden werden kann (Beinert;Straube 2013: 28f).
Authentizität: Dieser Punkt bezieht sichhauptsächlich auf ursprünglich digitaleArtefakte, wie Zeugnisse des digitalenWandels selbst (z. B. Webseiten). Aufgrundder Verankerung in Hard- und Software, dieoft schnell obsolet wird, sind die sogenannten“born digital” Artefakte oftmals schonfrühzeitig nicht mehr auf die gleiche Weiseaufrufbar wie zu der Zeit, als sie entwickeltwurden (Crueger 2013). Aber auch in Bezug
172

Digital Humanities im deutschsprachigen Raum 2017
auf grafische Darstellungen von Digitalisatenstellt sich die Frage, inwiefern technischlangfristig gewährleistet werden kann, dasskulturelle Artefakte zumindest ähnlichbetrachtet werden können wie ihre analogenPendants (Fröhlich 2013).
Eine Nachhaltigkeitsstrategiefür efoto-Hamburg
In den Partnerinstitutionen 2 von efoto-Hamburg liegen insgesamt mehrere MillionenBilddaten in analoger und digitaler Form vor,die unterschiedlich gut zugänglich sind. Ineinem ersten Schritt wird der Import einerTeilmenge von rund 100.000 Datensätzenaus fünf Partnerinstitutionen angestrebt, diein der mobilen App auf einer interaktivenKarte zugänglich gemacht werden. Darüberhinaus ist es eines der Projektziele, nach undnach möglichst viele der digital vorliegendenBilder so bereitzustellen, dass sie in diedigitale Nachhaltigkeit überführt werdenkönnen. Die Nachhaltigkeitsstrategie von efoto-Hamburg umfasst zwei einander ergänzendeVorgehensweisen.
Strategische Dimension:Diskursives Kulturkonzeptund narrative Struktur
Kulturelle Nachhaltigkeit muss nachunserem Verständnis als Entwicklungsprozessaufgefasst werden, der kulturelle Artefaktenicht nur im Sinne des kulturellen Erbes anFolgegenerationen übergibt, sondern vonBeginn an eine Art gelebte Enkelgerechtigkeitunterstützt. Erst Kultur als tatsächlicheReflexionspraxis macht die kulturellen Artefakteauch diskursiv funktional; sie etabliert somiteine Diskursstruktur, innerhalb derer prinzipielljeder als Zeitzeuge agieren und seine Eindrückefesthalten und teilen kann. In diesem Kontextkönnen kulturelle Artefakte zugleich Anlass wieGegenstand diskursiver und reflexiver Prozessewerden.
Diese strategische Prämisse von efoto-Hamburg ruht auf zwei konzeptionellenGrundpfeilern. Der erste ist ein an Luhmannangelehntes Kulturverständnis: Kultur wird alsein Prozess verstanden, der sich auf drei Ebenenabspielt; der Objektebene, der Reflektion ersterund der Reflektion zweiter Ordnung. Erst wennalle drei Ebenen miteinander verknüpft sind,
ist die Voraussetzung dafür gegeben, dass einArtefakt nachhaltig im Kulturprozess verankertsein kann. (Luhmann 2011: 140 und Luhmann1999: 99) Eine Verknüpfung der drei Ebenenkönnte z.B. wie folgt aussehen:
Die zweite Säule ist die narrative Naturdieses Kulturprozesses. Grundannahmeist hier, dass auch in der digitalisiertenGesellschaft Überlieferung nur durch narrativeKommunikation gewährleistet werden kann.Identitäten von Individuen und Gruppenwerden durch Minimalnarrative, sogenannteSmall Stories (Bamberg; Georgakopoulou 2008und Georgakopoulou 2007), ausgeformt. DieMotivation des oben abgebildeten Nutzers Aist demnach identitätsbildender Natur. Er odersie verknüpft das, was im kulturellen Artefaktdargestellt ist, mit einem Ereignis oder einemTeilaspekt aus der eigenen Lebensgeschichteoder seiner Persönlichkeit, um diese innerhalbder efoto-Community zu stärken und/oderauf ähnliche Persönlichkeiten und/oderLebensgeschichten zu treffen. Nutzer B undC sind ähnlich motiviert, auch wenn ihreKommunikation nicht durch das Objekt, sonderndurch die Reflexion über dasselbe ausgelöstwird. Indem alle drei Beispielnutzer überSmall Stories die historischen Bilddaten mitihrer Lebenswirklichkeit verknüpfen, haltensie diese lebendig. Artefakte, die so in einemaktuellen Kulturprozess verankert werden,sind für efoto besonders bewahrenswert. DieseBewertung erfolgt also dynamisch in einemsozio-kulturellen System. Damit ergibt sich nundie Frage, welche spezifische Rolle digitalenTechnologien in diesem Zusammenhangzukommt.
Die Rolle digitalerTechnologien im Kontext derNachhaltigkeitsstrategie
Im Vordergrund von eFoto-Hamburg stehtweder ein archivarisches Interesse noch eineKulturvermittlung als Überzeugungsarbeit:nicht das möglichst nachhaltige ‘Aufbewahren’historischer Bilder im digitalen Format und auchnicht das Erzeugen kultureller Akzeptanz fürdiese Bilder ist die raison d’etre des Projekts,sondern das Einbinden der Bilder in aktuellereflexive Prozesse.
Die manuelle Einzelprüfung durch Kuratoren,die in den Partnerinstitutionen von efoto-Hamburg bereits stattgefunden hat, bevor dieBilddaten auf die digitale Plattform gelangen,
173

Digital Humanities im deutschsprachigen Raum 2017
versteht sich daher als Vorstufe, die dieInteraktion der Community mit und überdie digitalisierten Artefakte vorbereitet undunterstützt. Jeder Nutzer gilt unabhängigvon Faktoren wie z.B. seinem Alter alsZeitzeuge und wird als solcher in den weiterenKurationsprozess einbezogen. Auf diese Weisenehmen Nutzer generationenübergreifendan der Entwicklung dieses Teilbestandes deskulturellen Erbes teil - und an eben dieser Stellebieten digitale Technologien nun die Möglichkeit,die Nachhaltigkeit kultureller Artefakte nichtnur im Sinne eines statischen (archivarischen)‘Vorhaltens’ digitaler Repräsentationen zusichern, sondern vielmehr auch im Sinne eines‘Lebendighaltens’ durch den aktiven Gebrauchund die Einbettung in gelebte kulturelleDiskursprozesse zu befördern.
Im Projekt efoto wird zu diesem Zweck einSystem aus konkreten technischen Featuresentwickelt, welches Nutzern unterschiedlicheMöglichkeiten eröffnet, die im digitalen Formatvorliegenden Bilder in aktive Gebrauchsprozesseeinzubinden und so kulturelle Nachhaltigkeitqua kultureller Nutzung zu sichern. Die mobileefoto-App umfasst Features wie Stadtrundgänge,Zeitzeugen-Interviews, ein Kommentar-System, einen Bildrechte-Wegweiser, eineinteraktive Karte oder das “historischeSelfie”. Anhand dieser Beispielfeatureswird im vorgeschlagenen Vortrag erläutertwerden, welche konzeptionellen Ideen in dieEntwicklung eingeflossen sind und wie diese dieNachhaltigkeitsstrategie umsetzen.
Relevanz undAnschlussfähigkeit
Der vorgeschlagene Beitrag verstehtsich als Anwendungsbeispiel einerinterdisziplinär ausgerichteten kulturellenNachhaltigkeitsstrategie. Ansätze aus derErzähltheorie, der Kulturwissenschaft undden Museumswissenschaften werden miteinem ökologisch-politischen Verständnis vonNachhaltigkeit verbunden. Damit versuchtefoto-Hamburg zu erproben, was bishersowohl im wissenschaftlichen als auch imgesellschaftlichen Diskurs lediglich theoretischreflektiert und teilweise auch proklamiertworden ist: eine kulturell angetriebeneNachhaltigkeit kulturellen Datenmaterials,deren Kernidee die Einbindung von Artefaktenin (digital unterstützte) Gebrauchs- undReflexionsprozesse und nicht deren bloßes
langfristiges ‘Bewahren’ in möglichst stabilenmedialen Formaten ist.
efoto-Hamburg ist dabei nicht nurinterdisziplinär ausgerichtet, sondernbezieht auch Bürger und Besucher derStadt auf allen oben skizzierten Ebenen desKulturprozesses ein. Damit verbindet dasProjekt Wissenschaft und Öffentlichkeit inmöglichst durchlässiger Weise. Für die digitalenGeisteswissenschaften stellt das Projekt nichtnur ein Anwendungsbeispiel dar, sonderneine lebendige Plattform, die für zahlreicheAnschlussuntersuchungen offen ist.
Fußnoten
1. Kultur wird hier - abweichend vom imFolgenden erläuterten Kulturverständnisinnerhalb des Projektes efoto-Hamburg - sehrumfassend als Wechselspiel der Einwirkung desMenschen auf seine Umwelt und der Einwirkungder Umwelt auf den Menschen verstanden.2. Dazu gehören das Hamburger Staatsarchiv,das Landesamt für Geoinformationund Vermessung, die HamburgerGeschichtswerkstätten, das Museum derArbeit, das Museum für Kunst und Gewerbe,das Polizeimuseum und die HamburgerFeuerwehrhistoriker.
Bibliographie
Bamberg, Michael / Georgakopoulou,Alexandra (2008): „Small stories as a newperspective in narrative and identity analysis“,in: De Fina, Anna / Georgakopoulou, Alexandra(eds.): Narrative Analysis in the Shift from TextstoPractices. Special Issue of Text & Talk 28: 377–396.
Beinert, Tobias / Straube, Armin (2013):„Aktuelle Herausforderungen der digitalenLangzeitarchivierung“, in: Klimpel, Paul / Keiper,Jürgen (eds.): Was bleibt? Nachhaltigkeit derKultur in der digitalen Welt. Berlin: iRights MediaVerlag 27–46.
Brocchi, Davide (2007): „Die kulturelleDimension der Nachhaltigkeit“, in: MagazinCultura21 http://davidebrocchi.eu/wp-content/uploads/2013/08/2007_dimension_nachhaltigkeit.pdf[letzter Zugriff 25. August 2016].
Bundesregierung (2015): Meilensteineder Nachhaltigkeitspolitik. Weiterentwicklungder nationalen Nachhaltigkeitsstrategiehttp://www.bundesregierung.de/Content/DE/_Anlagen/2015/02/2015-02-03-meilensteine-der-nachhaltigkeitspolitik.pdf?
174

Digital Humanities im deutschsprachigen Raum 2017
__blob=publicationFile [letzter Zugriff 17. August2016].
Crueger, Jens 2013): „Die Dark Ages desInternet“, in: Klimpel, Paul / Keiper, Jürgen (eds.):Was bleibt? Nachhaltigkeit der Kultur in derdigitalen Welt. Berlin: iRights Media Verlag 191–198.
Fröhlich, Jan (2013): „Farbraumund Bildzustand im Kontext derLangzeitarchivierung“, in: Klimpel, Paul / Keiper,Jürgen (eds.): Was bleibt? Nachhaltigkeit derKultur in der digitalen Welt. Berlin: iRights MediaVerlag 119–125.
Georgakopoulou, Alexandra (2007): „SmallStories, Interaction and Identities“, in: Studiesin Narrative 8. Amsterdam / Philadelphia: JohnBenjamins.
Giebel, Ralph (2013): „Speichertechnologieund Nachhaltigkeit“, in: Klimpel, Paul / Keiper,Jürgen (eds.): Was bleibt? Nachhaltigkeit derKultur in der digitalen Welt. Berlin: iRights MediaVerlag 95–108.
Luhmann, Niklas (1999): Die Kunst derGesellschaft. Frankfurt am Main: Suhrkamp.
Luhmann, Niklas (2011): Einführung in dieSystemtheorie. Heidelberg: Carl Auer.
Steinhauer, Eric (2013): „Wissen ohneZukunft? Der Rechtsrahmen der digitalenLangzeitarchivierung von Netzpublikationen“,in: Klimpel, Paul / Keiper, Jürgen (eds.): Wasbleibt? Nachhaltigkeit der Kultur in der digitalenWelt. Berlin: iRights Media Verlag 61–80.
Willer, Stefan (2013): „Kulturelles Erbe undNachhaltigkeit“, in: Klimpel, Paul / Keiper, Jürgen(eds.): Was bleibt? Nachhaltigkeit der Kultur inder digitalen Welt. Berlin: iRights Media Verlag139–152.
World Commission on Environment andDevelopment (1987): Our Common Future. http://www.un-documents.net/our-common-future.pdf[letzter Zugriff 17. August 2016].
Zorich, Diane (2015): Report of the Summitin Digital Curation in Art Museums http://advanced.jhu.edu/wp-content/uploads/2016/04/digitalCuration_summitReport10_2015.pdf [letzerZugriff 24. August 2016].
Netzwerkdynamik,Plotanalyse – ZurVisualisierungund Berechnungder ›progressivenStrukturierung‹literarischer Texte
Trilcke, [email protected]ät Potsdam, Deutschland
Fischer, [email protected] School of Economics, Moskau, Russland
Göbel, [email protected] und Universitätsbibliothek Göttingen,Deutschland
Kampkaspar, [email protected] Wolfenbüttel,Deutschland
Kittel, [email protected]ät Graz, Österreich
Forschungsstand
Die Anwendung von Methoden derNetzwerkanalyse auf literarische Texte hat sichin den letzten Jahren zu einem eigenständigenForschungsfeld der Digital Literary Studiesentwickelt. Im Vordergrund stehen dabei häufigcomputerlinguistische Fragen, insbesonderesolche nach der automatisierten Extraktionvon Netzwerkdaten (z.B. qua named entityrecognition, co-reference resolution) und derenEvaluation (u. a. Elson et al. 2010; Park et al.2013; Agrarwal et al. 2013; Rochat 2014; Fischeret al. 2015; Waumans et al. 2015; Jannidis et al.2016).
Darüber hinaus wird ausgelotet,inwiefern sich mittels visueller und/oder
175

Digital Humanities im deutschsprachigen Raum 2017
statistischer Auswertung der Netzwerkdatengenuin literaturwissenschaftlicheErkenntnisse gewinnen bzw. neue Wege derliteraturwissenschaftlichen Analyse entwickelnlassen: Neben Ansätzen zur quantitativenBeschreibung und Hierarchisierung desFigurenpersonals (Jannidis et al. 2016)werden hier, im Rahmen korpusbasierterAnalysen, Optionen der literaturhistorischenPeriodisierung auf Basis von quantitativenStrukturdaten diskutiert (Trilcke et al. 2015)sowie Typen der ästhetischen Modellierungsozialer Formationen in und durch literarischeTexte differenziert (Stiller et al. 2003; Stiller &Hudson 2005; Trilcke et al. 2016).
Forschungsdesiderat:Plotanalyse
Nahezu keine Rolle spielte bisher jedochein durchaus hehres Erkenntnisversprechen,das – bereits in der prä-automatisiertenZeit formuliert (de Nooy 2006) – auch denFluchtpunkt des einschlägigen ›Pamphlets‹von Franco Moretti steht: dass nämlich dieNetzwerkanalyse als ein Instrumentarium derquantitativen »plot analysis« (Moretti 2011)fungieren könne.
Tatsächlich lässt sich diesesErkenntnisversprechen mit den derzeitverfolgten Ansätzen im Bereich derliteraturwissenschaftlichen Netzwerkanalysekaum aufgreifen, geschweige denn einlösen (soauch Prado et al. 2016). Denn die sequentielleDimension literarischer Texte, mithinihre Temporalität, bleibt hier in der Regelausgeblendet: Erfasst, visualisiert und analysiertwerden statische Netzwerke. Plot ist jedochwesentlich ein Konzept, das die Temporalitätnarrativer (wie auch dramatischer) 1 Textetheoretisch fassen soll: »the repeated attemptsto redefine parameters of plot reflect boththe centrality and the complexity of thetemporal dimension of narrative« (Dannenberg2005: 435). Plot lässt sich begreifen alsKonzept zur Beschreibung der »progressivestructuration« (Kukkonen 2013, §4) literarischerTexte.
Versuche, die Netzwerkanalyse inRichtung einer quantitativen Plotanalyseweiterzuentwickeln, stehen also zunächstvor der Aufgabe, bei ihrer Modellierung desUntersuchungsgegenstandes die Zeitdimensionzu berücksichtigen. Der Text ist entsprechendnicht lediglich als ein statisches Netzwerk zumodellieren, sondern als eine sich über die Zeit
verändernde Folge von Netzwerkzuständen.Erst anhand dieser Netzwerkdynamikenlassen sich die Erkenntnispotenziale, dienetzwerkanalytische Zugänge für diequantitative Plotanalyse bergen, überhauptdiskutieren.
Forschungsvorhaben
Der projektierte Vortrag wird – in Anschlussan Prado et al. 2016 – aus theoretischer undmethodischer Perspektive sowie anhandexemplarischer Fallstudien eine Erweiterungder bisherigen, auf die Analyse statischerStrukturen fokussierten Forschung zuliterarischen Netwerken um die Analyseprogressiver Strukturierungen vorschlagen.Übergreifendes Ziel ist es, zu prüfen, ob (undmit welchen Einschränkung) sich auf diesemWege ein Beitrag zur Operationalisierungdes literaturwissenschaftlichen Plot-Konzepts erarbeiten lässt. Dabei soll es nichtdarum gehen, das semantische reiche undvielseitige Plot-Konzept der ›traditionellen‹Literaturwissenschaft durch ein quantitativesund insofern notgedrungen reduktionistischesKonzept zu ersetzen. Vielmehr soll zunächstder wesentlich bescheidenere Nachweiserbracht werden, dass sich bestimmte Aspektedessen, was gemeinhin im Rahmen desPlot-Konzepts diskutiert wird, durchausmittels der computerbasierten Analysevon Netzwerkdynamik beobachten lassen,etwa ereignishafte Konfliktverläufe (soschon Moretti 2011), Formen der sozialenIntegration und Desintegration von Figurenoder basale Techniken der Handlungsführung,z.B. die Komposition von Haupt- undNebenhandlung(en).
Entsprechend der zweigleisigenAuswertungsroutinen, die aufnetzwerkanalytische Daten angewendetwerden, wird der Vortrag zwei Szenarien dernetzwerkbasierten Analyse der progressivenStrukturierung literarischer Texte diskutieren:zum einen (3.1) sind Möglichkeiten undErkenntnispotenziale der Visualisierungdynamischer Netzwerke, zum anderen (3.2)Möglichkeiten und Erkenntnispotenziale derBerechnung netzwerkanalytischer Maße fürdynamische Netzwerke auszuloten.
176
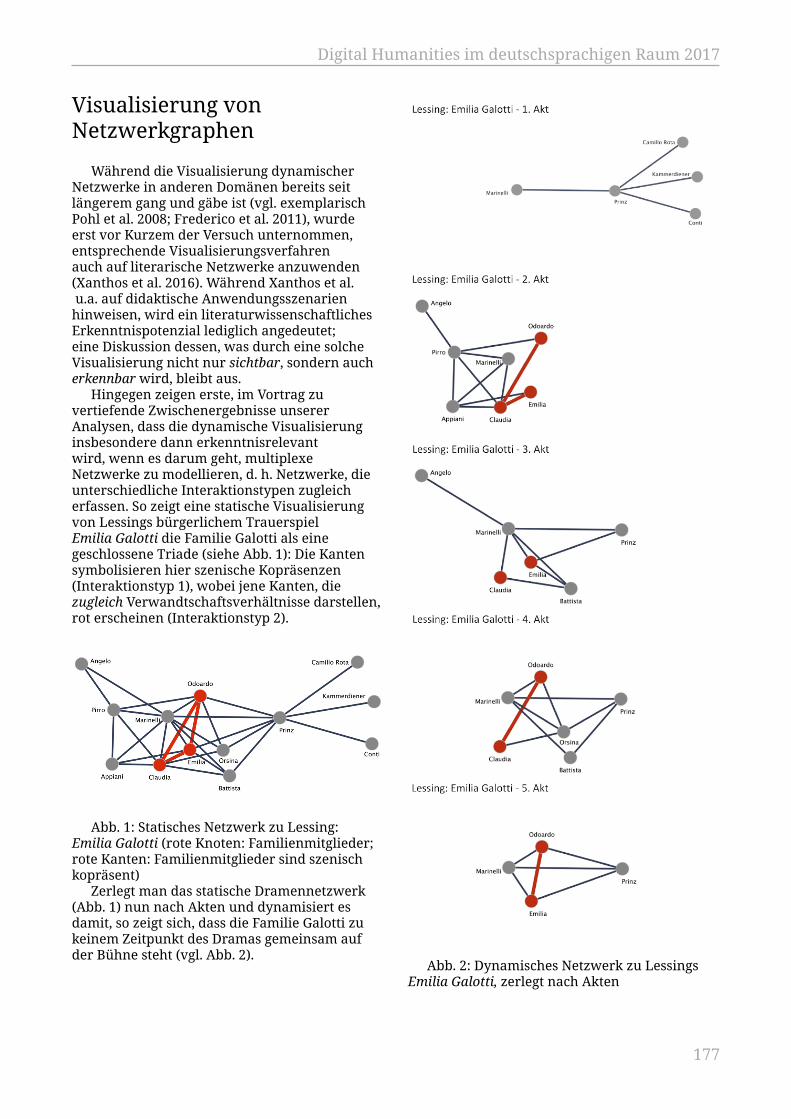
Digital Humanities im deutschsprachigen Raum 2017
Visualisierung vonNetzwerkgraphen
Während die Visualisierung dynamischerNetzwerke in anderen Domänen bereits seitlängerem gang und gäbe ist (vgl. exemplarischPohl et al. 2008; Frederico et al. 2011), wurdeerst vor Kurzem der Versuch unternommen,entsprechende Visualisierungsverfahrenauch auf literarische Netzwerke anzuwenden(Xanthos et al. 2016). Während Xanthos et al. u.a. auf didaktische Anwendungsszenarienhinweisen, wird ein literaturwissenschaftlichesErkenntnispotenzial lediglich angedeutet;eine Diskussion dessen, was durch eine solcheVisualisierung nicht nur sichtbar, sondern aucherkennbar wird, bleibt aus.
Hingegen zeigen erste, im Vortrag zuvertiefende Zwischenergebnisse unsererAnalysen, dass die dynamische Visualisierunginsbesondere dann erkenntnisrelevantwird, wenn es darum geht, multiplexeNetzwerke zu modellieren, d. h. Netzwerke, dieunterschiedliche Interaktionstypen zugleicherfassen. So zeigt eine statische Visualisierungvon Lessings bürgerlichem TrauerspielEmilia Galotti die Familie Galotti als einegeschlossene Triade (siehe Abb. 1): Die Kantensymbolisieren hier szenische Kopräsenzen(Interaktionstyp 1), wobei jene Kanten, diezugleich Verwandtschaftsverhältnisse darstellen,rot erscheinen (Interaktionstyp 2).
Abb. 1: Statisches Netzwerk zu Lessing:Emilia Galotti (rote Knoten: Familienmitglieder;rote Kanten: Familienmitglieder sind szenischkopräsent)
Zerlegt man das statische Dramennetzwerk(Abb. 1) nun nach Akten und dynamisiert esdamit, so zeigt sich, dass die Familie Galotti zukeinem Zeitpunkt des Dramas gemeinsam aufder Bühne steht (vgl. Abb. 2).
Abb. 2: Dynamisches Netzwerk zu LessingsEmilia Galotti, zerlegt nach Akten
177

Digital Humanities im deutschsprachigen Raum 2017
Anschaulich und erkennbar wird aufdiese Weise eine Position der traditionellenForschung, nach der Lessing in EmiliaGalotti nicht nur die äußere Bedrohung der›bürgerlichen‹ Kleinfamilie, sondern auchderen innere Problematik inszeniert hat(siehe z. B. Alt 1994: 268). Die Analyse derdynamischen Strukturierung zeigt hier diesoziale Desintegration der familäre Triade,die als formal beschreibbarer Teilaspekt deszentralen dramatischen Konflikts verstandenwerden kann.
Dass dynamische Visualisierungen in diesemSinne aus literaturwissenschaftlicher Sichtv.a. für die Analyse multiplexer Netzwerkeproduktiv gemacht werden können, werdenwir im Vortrag anhand weiterer Beispiele ausdem dlina-Korpus (philologisch kuratierteNetzwerkdaten zu 465 deutschsprachigeDramen aus der Zeit 1730–1930, siehe https://dlina.github.io/Introducing-DLINA-Corpus-15-07-Codename-Sydney/ ) zeigen. Darüber hinauswerden wir zum Zweck eines intergenerischenVergleichs exemplarisch dynamischeVisualisierung von Romannetzwerkendiskutieren. Zu reflektieren sind hierinsbesondere Fragen der Sequenzierung:Während Dramen mit ihrer Einteilung in Akteund Szenen eine naheliegende Segmentierungvorgeben, liefert die romantypische Einteilungin Kapitel keine vergleichbar überzeugendenErgebnisse.
Berechnungnetzwerkanalytische Maße
Mehr noch als die Visualisierung statischerNetzwerke stellt diejenige dynamischer imGrunde keine Option eines korpusbasiertendistant reading dar. Sie ermöglicht zwar dieanschauliche Modellierung einzelner Netzwerke,kann aber nur begrenzt Erkenntnisseüber eine große Anzahl von Netzwerkenliefern: Methoden, mit denen sich die aufalgorithmischen Layouts basierendenNetzwerkgraphen kontrolliert miteinandervergleichen lassen, fehlen weitgehend;zudem kostet die Rezeption von dynamischenVisualisierungen – etwa der von Xanthos etal. 2016 präsentierten Prototypen – schlichtZeit, wir haben es hier also eher mit fastreading, denn mit distant reading zu tun. DieBerechnung netzwerkanalytischer Maße undderen statistische Weiterverarbeitung bietethingegen Möglichkeiten, aus einer dezidiertendistant reading-Perspektive sowohl allgemeine
Charakteristika der Netzwerke eines Korpus zubeschreiben als auch, vergleichend, spezifischeformale Typen von Netzwerken innerhalb desKorpus zu identifizieren (entsprechend unsererÜberlegungen zum Small World-Phänomen instatischen Netzwerken, siehe Trilcke et al. 2016).
Von Carley (2003: 135–136) wurden dabeimehrere rudimentäre globale Maße (i. e.size, density, homogeneity in the distributionof ties, rate of changes in nodes, rate ofchanges in ties) für die Analyse dynamischerNetzwerke vorgeschlagen. Darüber hinaushaben Prado et al. 2016 für die Anwendungvon akteursorientierten Maßen, v.a.Zentralitätsindices, bei der Rekonstruktion vonPlot -Verläufen plädiert. Im Vortrag werden wireinzelne dieser Maße – u. a. size pro Akte undSzenen; density pro Akte und Szene; die change-rates; sowie einfache Zentralitätsmaße – fürdas dlina-Korpus berechnen; die dafür nötigenDaten liegen bereits, philologisch kuratiert,in den dlina-Zwischenformat-Dateien vor(zum Zwischenformat: https://dlina.github.io/Introducing-Our-Zwischenformat/ – die Datensind offen, siehe unser Github-Repositorium:https://github.com/dlina ); eine entsprechendeErweiterung des in Python geschriebenenAuswertungstools dramavis (Kittel / Fischer2016) wird derzeit entwickelt. Die erhobenenDaten werden wir schließlich mit Rekursauf ausgewählte literaturwissenschaftlicheKonzepte für die Beschreibung spezifischerPlot-Phänomene diskutieren, insbesondere inHinblick auf Expositionstypen (Pfister 1977:124–136), auf die ›klassische‹ Aktstruktur derTragödie sowie auf das Kompositionsprinzip vonHaupt- und Nebenhandlung (Pfister 1977: 286–289).
Resümee
Der Vortrag liefert einen Beitrag zurMethodenentwicklung und -reflektion imBereich der Digital Literary Studies. Aufliteraturtheoretisch-methodologischerEbene diskutiert er Möglichkeiten einernetzwerkanalytischen Operationalisierungdes literaturwissenschaftlichen Plot -Konzepts,wobei der literarische Text zu diesem Zwecknicht, wie bisher die Regel, als statische Struktur,sondern als ›progressive Strukturierung‹modelliert wird. Als empirische Grundlage derMethodendiskussion fungieren Analysen vonDramen und Romanen, in denen exemplarischdie Potenziale und die Grenzen des Ansatzesverdeutlich werden.
178

Digital Humanities im deutschsprachigen Raum 2017
Fußnoten
1. Unter systematischen Gesichtspunkten könnendie Unterschiede zwischen narrativen unddramatischen Texten in Hinblick auf das Plot-Konzept zunächst vernachlässigt werden (vgl.Korthals 2003); entsprechend wurden sowohl›epische‹ als auch ›dramatische‹ Texte bis ins 19.Jahrhundert hinein verschiedentlich unter demOberbegriff ›pragmatische Gattung‹ vereint.
Bibliographie
Agarwal, Apoorv / Corvalan, Augusto /Jensen, Jacob / Rambow, Owen (2012): „SocialNetwork Analysis of Alice in Wonderland“, in:Proceedings of the Workshop on ComputationalLinguistics for Literature. Montréal 88–96 http://www.aclweb.org/anthology/W12-2513 [letzterZugriff 25. August 2016].
Alt, Peter-André (1994): Die Tragödie derAufklärung. Eine Einführung. Tübingen / Basel:Francke.
Carley, Kathleen M. (2003): „DynamicNetwork Analysis“, in: Breiger, Ronald / Carley,Kathleen M. / Pattison, Philipp (eds.): DynamicSocial Network Modeling and Analysis. WorkshopSummary and Papers. Washington D.C.: 133–145http://www.nap.edu/read/10735/chapter/9 .
Dannenberg, Hilary (2005): „Plot“, in:Herman, David / Jahn, Manfred / Ryan, Marie-Laure (eds.): The Routledge Encyclopedia ofNarrative Theory. London: Routledge 435–439.
Fischer, Frank / Göbel, Mathias /Kampkaspar, Dario / Trilcke, Peer(2015): „Digital Network Analysis ofDramatic Texts“, in: DH2015: Global DigitalHumanities http://dh2015.org/abstracts/xml/FISCHER_Frank_Digital_Network_Analysis_of_Dramati/FISCHER_Frank_Digital_Network_Analysis_of_Dramatic_Text.html [letzter Zugriff25. August 2016].
de Nooy, Wouter (2006): „Stories, Scripts,Roles, and Networks“, in: Structure andDynamics 1.2 http://escholarship.org/uc/item/8508h946#page-1 [letzter Zugriff 25. August2016].
Elson, David K. / Dames, Nicholas /McKeown, Kathleen R. (2010): „ExtractingSocial Networks from Literary Fiction“,in: Proceedings of ACL-2010. Uppsala: 138–147 http://dl.acm.org/ft_gateway.cfm?id=1858696&type=pdf&CFID=659731302&CFTOKEN=83466756 [letzter Zugriff 25. August2016].
Federico, Paolo / Aigner, Wolfgang /Miksch, Silvia / Windhager, Florian / Zenk,Lukas (2011): „A Visual Analytics Approach toDynamic Social Networks“, in: Proceedings ofthe 11th International Conference on KnowledgeManagement and Knowledge Technologies (i-KNOW). Graz http://publik.tuwien.ac.at/files/PubDat_198995.pdf [letzter Zugriff 25. August2016].
Jannidis, Fotis / Reger, Isabella / Krug,Markus / Weimer, Lukas / Macharowsky,Luisa / Puppe, Frank (2016): „Comparisonof Methods for the Identification of MainCharacters in German Novels“, in: DH2016:Conference Abstracts 578–582 http://dh2016.adho.org/abstracts/297 [letzter Zugriff 25.August 2016].
Kittel, Christopher / Fischer, Frank (2016):dramavis (v0.2.1). GitHub https://github.com/lehkost/dramavis [letzter Zugriff 25. August2016].
Korthals, Holger (2003): Zwischen Dramaund Erzählung. Ein Beitrag zur Theoriegeschehensdarstellender Literatur. Berlin: ErichSchmidt
Kukkonen, Karin (2013): „Plot“, in: Hühn,Peter et al. (eds.): The Living Handbook ofNarratology. Hamburg http://www.lhn.uni-hamburg.de/article/plot [letzter Zugriff 25.August 2016].
Moretti, Franco (2011): Network Theory, PlotAnalysis (= Stanford Literary Lab Pamphlets,No. 2). 1.5.2011. http://litlab.stanford.edu/LiteraryLabPamphlet2.pdf [letzter Zugriff 25.August 2016].
Park, Gyeong-Mi / Kim, Sung-Hwan / Cho,Hwan-Gue (2013): „Structural Analysis onSocial Network Constructed from Characters inLiterature Texts“, in: Journal of Computers 8.9:2442–2447 http://ojs.academypublisher.com/index.php/jcp/article/view/jcp080924422447/7672[letzter Zugriff 25. August 2016].
Pfister, Manfred (1977): Das Drama. Theorieund Analyse. München: Fink.
Pohl, Mathias / Reitz, Florian / Birke,Peter (2008): „As Time Goes by. IntegratedVisualization and Analysis of DynamicNetworks“, in: AVI 2008 – Proceedingsof the Working Conference on AdvancedVisual Interfaces. Neapel 372–375 http://doi.acm.org/10.1145/1385569.1385636 [letzterZugriff 25. August 2016].
Prado, Sandra D. / Dahmen, Silvio R. /Bazzan, Ana L.C. / Carron, Padraig Mac /Kenna, Ralph (2016): „Temporal NetworkAnalysis of Literary Texts“, 24.2.2016 https://arxiv.org/pdf/1602.07275 [letzter Zugriff 25.August 2016].
179

Digital Humanities im deutschsprachigen Raum 2017
Rochat, Yannick (2014): Character Networksand Centrality. Thèse de Doctorat. Lausannehttps://infoscience.epfl.ch/record/203889/files/yrochat_thesis_infoscience.pdf [letzter Zugriff 25.August 2016].
Stiller, Jaames / Nettle, Daniel / Dunbar,Robin I. M. (2003): „The Small World ofShakespeare's Plays“, in: Human Nature 14: 397–408 https://www.staff.ncl.ac.uk/daniel.nettle/shakespeare.pdf [letzter Zugriff 25. August 2016].
Stiller, James / Hudson, Mathew (2005):„Weak Links and Scene Cliques Within the SmallWorld of Shakespeare“, in: Journal of Culturaland Evolutionary Psychology 3: 57–73.
Trilcke, Peer / Fischer, Frank / Göbel,Mathias / Kampkaspar, Dario (2015): „200 Yearsof Literary Network Data“ [Blogposts], https://dlina.github.io/200-Years-of-Literary-Network-Data/ [letzter Zugriff 25. August 2016].
Trilcke, Peer / Fischer, Frank / Göbel,Mathias / Kampkaspar, Dario / Kittel,Christopher (2016): „Theatre Plays as ›SmallWorlds‹? Network Data on the History andTypology of German Drama, 1730-1930“, in:DH2016: Conference Abstracts 417–419 http://dh2016.adho.org/abstracts/407 [letzter Zugriff 25.August 2016].
Waumans, Michaël C. / Nicodème,Thibaut / Bersini, Hugues (2015): „TopologyAnalysis of Social Networks Extracted fromLiterature“, in: Plos One 3. Juni 2015 10.1371/journal.pone.0126470.
Xanthos, Aris / Pante, Isaac / Rochat,Yannick / Grandjean, Martin (2016):„Visualising the Dynamics of CharacterNetworks“, in: DH2016: Conference Abstracts417–419 http://dh2016.adho.org/abstracts/407[letzter Zugriff 25. August 2016].
Niklas Luhmanns Werk-und Lesekosmos - DH inder bibliographischenDimension
Goedel, [email protected] Center for eHumanities, Universität zuKöln, Deutschland
Zimmer, [email protected] Center for eHumanities, Universität zuKöln, Deutschland
Der hier vorgestellte Workflow fürdie Digitalisierung und Integrationbibliographischer Informationen ist Teil desForschungsprojektes Niklas Luhmann - Theorieals Passion. Wissenschaftliche Erschließung undEdition des Nachlasses . Das Langzeitvorhaben(2015-2030) an der Fakultät für Soziologieder Universität Bielefeld in Kooperationmit dem Cologne Center for eHumanities(CCeH) wird im Akademienprogramm durchdie Nordrhein-Westfälische Akademie derWissenschaft und der Künste gefördert. WeitereKooperationspartner sind das Archiv und dieBibliothek der Universität Bielefeld. 1
Ziel des Gesamtprojektes ist die Sicherung,Digitalisierung, Erschließung, werkgenetischeErforschung und teilweise Edition deswissenschaftlichen Nachlasses Niklas Luhmanns.Zu diesem Zweck werden die bewahrenswertenTeile des Nachlasses (Manuskripte, Zettelkasten,Korrespondenz, Bibliothek etc.) zunächstarchivarisch gesichert und in den Teilen, diewissenschaftlich erschlossen werden sollen,digitalisiert, sowie für die weitere Bearbeitungbereitgestellt. Die daran anschließendeEdition will den Luhmannschen Nachlassals geistesgeschichtliches Dokument derwissenschaftlichen Forschung sowie derinteressierten Öffentlichkeit zugänglich machen.Sie bildet dadurch zugleich die Grundlage fürdie Entwicklung einer kritisch gesicherteninfrastrukturellen Wissensressource, aufwelche die interdisziplinäre und internationaleForschung zur und mit der Theorie Luhmannszukünftig zurückgreifen kann.
Bibliographische Informationen stellen einbesonders wichtiges verbindendes Elementzwischen den zu erschließenden und ggf. zuedierenden Materialien aus dem NachlassNiklas Luhmanns dar. Ihre Modellierung,Zusammenführung und Visualisierungverspricht einen vollständigen Überblick überGrundlagen, Rezeption und Verbreitung desLuhmannschen Werks aber auch detaillierteEinblicke in seine Arbeitsweise.
Quellen und Forschungsfragen
In Hinblick auf den Werkkosmos NiklasLuhmanns wurde am Institut für Soziologie inBielefeld eine Bibliographie aller Publikationen
180

Digital Humanities im deutschsprachigen Raum 2017
erstellt, die in digitaler Form finalisiert werdensoll. Enthalten sind Monographien, Aufsätze,Rezensionen, Festschriften. Gelistet werdenaußerdem alle bearbeiteten Neu-Auflagenund Übersetzungen. Die insgesamt etwa 1.900Datensätze sind stark miteinander vernetzt:Sowohl auf der Ebene von Monographienals auch bei Artikeln wird jeweils aufNachdrucke, Übersetzungen und weitereAuflagen hingewiesen. Die Aufbereitung dieserInformationen soll anschaulich machen, inwelchen Medien Luhmann hauptsächlichpubliziert hat und wie sich seine Schriften durchÜbersetzungen und Nachdrucke internationalverbreitet haben.
Schematische Darstellung zur Vernetzungder Datensätze
Den Lesekosmos Niklas Luhmannsdarstellbar und damit erforschbar zu machen,ist ein zweites zentrales Anliegen. Die folgendenQuellen bibliographischer Information liegendazu vor:
• die zitierte Literatur in den Zettelkästen• eigenständige bibliographische Abteilungen
je Zettelkasten (ca. 17.800 Einträge)• die zitierte Literatur in seinen eigenen
publizierten Werken• die Literaturhinweise in seinen
unpublizierten Manuskripten• die private Arbeitsbibliothek (ca. 4.000)
Nach Aufarbeitung dieser Materialien könnenwichtige werkhistorische Fragestellungenuntersucht werden: Welche und wie vielLiteratur (aus welchen wissenschaftlichenDisziplinen) hat Luhmann im Laufe seinerForschung rezipiert bzw. verarbeitet?Gibt es bestimmte Werke / Autoren, die erwiederkehrend konsultiert bzw. zitiert hat? Gibtes bevorzugte Zeitschriften?
Der Zettelkasten ist der zentrale Startpunktfür die Reise in den bibliographischen Kosmos.Er enthält durchgehend auf den NotizzettelnHinweise auf benutzte Literatur und ab derMitte der 70er Jahre auch eine eigenständigeBibliographie-Abteilung (insgesamt etwa 17.800Einträge).
Eine Auswertung der Zitatnachweise in dengedruckten Bänden Luhmanns soll dann die
Verbindung von Zettelkasten und Publikationenerleichtern. Wieviel der im Zettelkastennachgewiesenen Lektürearbeit ist tatsächlichin die Publikationen eingegangen? Und gibt esStellen in den Publikationen, die scheinbar keineWurzeln im Zettelkasten haben?
In den unveröffentlichten Manuskriptenfinden sich neben bereits standardisiertenLiteraturnachweisen häufig auchhandschriftliche Nennungen von Notizzetteln,die den Kreis über den Zettelkasten wiederschließen.
Datenmodell
Zu unseren Zielen gehört die Vernetzungder Datensätze zu visualisieren, um soden Werk- bzw. Lesekosmos erfahrbar zumachen. In Anlehnung an das FRBR-Modell2 verstehen wir die hier zu modellierendenbibliografischen Datensätze als Manifestationeneines Werks (Wiesenmüller 2008: 350 ). ImFall der Publikationen Niklas Luhmanns selbst,sind bereits Bezugsinformationen zu anderenManifestationen (z.B. im Sinne von "ist Teilvon") und Expressions (z.B. im Sinne von "istÜbersetzung von") enthalten. Perspektivischwerden hier noch übergeordnete Datensätzezu Werken und deren Expressions entstehen,mit denen die Fachwissenschaftler das Materialweiter strukturieren und die Werkgenesegenauer beschreiben können. 3 Vor allem imFall der unterschiedlichen ManuskriptfassungenLuhmanns wird die Bestimmung übergreifenderWerke eine explizit fachwissenschaftlicheAufgabe sein.
Die Basiskodierung erfolgt zunächstohne weiterführende ontologischenDifferenzierungen und Deutungen invoneinander getrennten Datensätzen aufgleicher Ebene . Die TEI bietet hier mit<biblStruct> ein geeignetes standardisiertesDatenmodell um Manifestationen zubeschreiben, aber auch bereits etablierteWege wie Personen, Körperschaften, Werktitelund später auch Sachschlagwörter mitNormdatensätzen 4 verbunden werden können.5 Beziehungen zu anderen Datensätzenwerden über <relatedItems> angereichert.Alle Erwähnungen und Verweise auf dasbibliograhierte Item werden über <idno>-Elemente aufgenommen . Selbst weiterführendeinhaltliche Informationen aus denunterschiedlichen Nachlasszusammenhängenkönnen über <note> mitgeführt werden.
181

Digital Humanities im deutschsprachigen Raum 2017
Die Offenheit einer TEI-Auszeichnungermöglicht uns, im Gegensatz zu anderenbestehenden bibliografischen Formaten, diemeist für Bibliothekszusammenhänge zugespitztwurden , alle vorliegenden Informationen imDatensatz selbst mitzuführen und schwellenlosprojektintern für die restlichen in TEI kodiertenMaterialien nutzbar vorzuhalten . 6
Umsetzung im DetailDie Guidelines empfehlen für strukturierte
bibliographische Informationen <biblStruct>-Items in Listen (<listBibl>). 7 Wir weichenin diesem Punkt ab und erzeugen fürjede Manifestation einen eigenständigenbibliographischen Datensatz in Form eines<biblStruct>-Single-Files. Jeder Datensatz enthältnur ein <monogr> bzw. ein <analytic> undein <monogr>. Die Dateien erhalten eineneindeutigen Dateinamen (Name des Autors +Erscheinungsjahr + ggf. Erweiterung) und eineentsprechende xml:id. Jedes Vorkommen, etwaim Zettelkasten oder in einem Manuskript,wird in einem <idno>-Element dokumentiert.Hinweise auf Reprints, Übersetzungen undweiterführende Informationen werdenin Form von <relatedItems> ergänzt. Dadie Dateinamen und xml:ids auf Basis desbibliographierten Werks sprechend benanntwurden, ist eine direkte Verlinkung derDatensätze untereinander problemlos möglich.
Die Aufspaltung in <biblStruct>-Single-Files lässt sich nun auch für die Vorhaltungvon unselbstständigen Titeln nutzen. DieTitelinformation für einen Aufsatz wirdin <analytic> erfasst, die Information zumSammelband in einem anschließenden<monogr>-Element. Um die Wiederholung dieserInformation für jeden Aufsatz des Sammelbandszu umgehen, wird ein eigenes <biblStruct>-Single-File für den Sammelband erzeugt.Über einen XInclude 8 -basierten Weg wirddas <monogr>-Element des Sammelbands indie Datei des Artikels eingebunden. Damit istdie TEI-Datei des Artikels auch während derBearbeitung vollständig (zusätzlich zu <analytic>wird das externe <monogr> des Sammelbandseingebunden). 9
Gliederungsansicht eines <biblStruct>-Elements, Typ Sammelband
”
Gliederungsansicht eines <biblStruct>-Elements, Typ “Artikel in Sammelband
Arbeitsumgebung
Als Arbeitsumgebung zur Bearbeitungund Neuerfassung von bibliographischenInformationen kommt ein speziell für diesesProjekt entwickeltes oXygen-Framework10 zum Einsatz. Ein solches Frameworkist eine Erweiterung für den oXygen XML-Editor, welches spezifische Vorgaben für diegrafische Darstellung und Funktionsweise eines
182

Digital Humanities im deutschsprachigen Raum 2017
Eingabeformulars für das hier entwickelteDatenmodell in oXygen macht. Außerdemwerden darin benutzerdefinierte Schaltflächenangelegt, die auf den Workflow des Bearbeitersausgerichtet sind. Damit ist es für Laien ohneVorkenntnisse in XML oder TEI auf einfacheWeise möglich, bibliographische Informationenauf Grundlage des verwendeten Datenmodellszu erstellen, zu bearbeiten und auszuzeichnen.Das Framework-Verzeichnis wird auf denRechnern der Bearbeiter zur Verfügung gestellt,von oXygen als solches erkannt und ist damitvom Bearbeiter verwendbar.
oXygen-Framework (Author-Mode)
Veröffentlichung
Nachdem die Daten in die Datenbankimportiert wurden, werden sie automatisiertim Projektportal veröffentlicht. Dies geschiehtmit einem modular aufgebauten Web-Präsentationssystem, bestehend aus etabliertenOpen-Source-Softwarelösungen wie eXist XMLDatabase 11 , NodeJS 12 , ReactJS 13 , sowiedem Design-Framework Material Design Lite14 . Die Datenbank verknüpft automatisch dieverschiedenen Datensätze und gibt sie aus,sodass der Benutzer des Portals sofort sehenkann, in welchem Verhältnis ein Werk zuverwandten Werken steht. Eine Visualisierungmittels eines Netzwerk-Graphs soll dieseVerknüpfungen zusätzlich veranschaulichen.
Die hier dargestellten Workflowssetzen ausschließlich auf Open-Source-Softwarelösungen, sowie offene Standards
wie TEI. Die Weitergabe des Frameworksmit allen Templates, der ODD, des Schemasund einer Dokumentation wird angestrebt.Die generische Architektur ist nachhaltigund nachnutzbar von anderen Projekten mitähnlichen Anforderungen.
Das Luhmann-Projekt eignet sich aufgrundder Heterogenität des bibliographischenMaterials sehr gut als Ausgangspunkt zurEntwicklung eines allgemeinen Modells, dasvom konkreten Projekt abstrahiert werden kannund soll. Im CCeH wird der Workflow schonvon weiteren Projekten eingesetzt und auf seineTauglichkeit geprüft.
Die für die Publikationen Luhmanns, ihreReprints und Veröffentlichungen vergebenenNamen und IDs werden, neben den luhmann-basierten Zettelkennungen, als autoritativeIdentifikatoren für das Werk Luhmannsnachnutzbar sein.
Fußnoten
1. Website des Niklas Luhmann-Archivs http://www.uni-bielefeld.de/soz/luhmann-archiv/[letzter Zugriff 30 . November 2016]2. “Functional Requirements for BibliographicRecords” (FRBR) : http://www.ifla.org/publications/functional-requirements-for-bibliographic-records [letzter Zugriff 30 .November 2016]3. Ein ähnliche Ansatz findet Anwendung imProjekt "Wome n Writer s in Review", vgl http://wwp.neu.edu/review/about/terms [letzter Zugriff30 . November 2016]4. Gemeinsame Normdatei der DeutschenNationalbibliothek (GND), http://www.dnb.de/DE/Standardisierung/GND/gnd_node.html [letzterZugriff 30 . November 2016]5. Nach dem FRBR-Modell betrifft das dieEntitäten der Gruppe 2 und 3 (Tillet 2010: 3)6. Bei späteren Exporten in anderebibliographische Formate, wie etwa BibTeX,können Hauptfelder gemappt werden,wohingegen Zusatzinformationen - je nachinhaltlicher Zielsetzung des Ausgabeformat s -schlicht nicht exportiert werden.7. Vgl. TEI-Guidelines, Abschnitt 3.11:Bibliographic Citations and References ( http://www.tei-c.org/release/doc/tei-p5-doc/en/html/CO.html#COBI [letzter Zugriff 30 . November2016]8. Vgl. W3C Empfehlung: https://www.w3.org/TR/xinclude/ und TEI Guidelines http://www.tei-c.org/release/doc/tei-p5-doc/en/html/SG.html#SG-mult [letzter Zugriff 25. August 2016]
183

Digital Humanities im deutschsprachigen Raum 2017
9. Für die Weitergabe der Daten nach außenwirddas XInclude wieder aufgelöst und für dieVerlinkung ergänzte IDs werden gelöscht, sodass die Ausgabe von standardkonformen undvollständigen <biblStruct>-Files sichergestellt ist.10. Vgl. oXygen Visual (WYSIWYG) XML Editors:https://www.oxygenxml.com/xml_author/WYSIWYG_Editors.html [letzter Zugriff 25.August 2016]11. Vgl. http://exist-db.org/exist/apps/homepage/index.html [letzter Zugriff 25. August 2016]12. Vgl. https://nodejs.org/en/ [letzter Zugriff 25.August 2016]13. Vgl. https://facebook.github.io/react/ [letzterZugriff 25. August 2016]14. Vgl. https://getmdl.io/ [letzter Zugriff 25.August 2016]
Bibliographie
Deutsche Nationalbibliothek (Hg.) (2009):Funktionale Anforderungen an bibliografischeDatensätze. Abschlussbericht der IFLA StudyGroup on the Functional Requirementsfor Bibliographic Records. Geänderte undkorrigierte Fassung, Februar 2009 (Leipzig/Frankfurt am Main/Berlin, 2009), http://www.ifla.org/files/assets/cataloguing/frbr/frbr_2009_de.pdf . [letzter Zugriff 30. November2016].
Tillett, Barbara (2003): „What is FRBR?“.Library of Congress Cataloging DistributionService, 2004 , in: Technicalities 25 (5) https://web.archive.org/web/20091229040757/http://www.loc.gov/cds/downloads/FRBR.PDF [letzterZugriff 30. November 2016].
Wiesenmüller, Heidrun / Horny, Silke(2015): Basiswissen RDA: Eine Einführung fürdeutschsprachige Anwender. De Gruyter Saur.
Wiesenmüller, Heidrun (2008): „Zehn Jahre‚Functional Requirements for BibliographicRecords“: Vision, Theorie und praktischeAnwendung“, in: Bibliothek, Forschung undPraxis 32 (3).
Niklas-Luhmann-Archiv: Webseite http://www.uni-bielefeld.de/soz/luhmann-archiv/[letzter Zugriff 30. November 2016].
TEI: Bibliographic Citations and References inden TEI-Guidelines http://www.tei-c.org/release/doc/tei-p5-doc/en/html/CO.html#COBI [letzterZugriff 30. November 2016].
IFLA: Functional Requirements forBibliographic Records (FRBR) http://www.ifla.org/publications/functional-requirements-for-bibliographic-records [letzter Zugriff 30.November 2016].
Perspektiven derBenutzeraktionsanalyseim Kontext derEvaluation vonForschungspraktiken inden Digital Humanities
Walkowski, [email protected] Akademie derWissenschaften, Deutschland
Ansätze zur Evaluation vonForschungsaktivität in denDigital Humanities
Die Dokumentation digitalerForschungsprozesse ist seit langem ein vieldiskutiertes Thema und wird im Allgemeinenmit dem Begriff Provenienz verbunden. Ziel derErhebung von Provenienz Daten in digitalerForschung ist es meist den Herstellungsprozessvon Ergebnissen aufzuzeichnen um diesedadurch wissenschaftlich nachvollziehbar undreproduzierbar zu machen.
Seit ca. 2-3 Jahren entsteht in den DigitalHumanities eine besondere Variante diesesThemas. Konkret geht es dabei um dasModellieren und Dokumentieren vonForschungsprozessen zur Identifikation digitalergeisteswissenschaftlicher Forschungspraktiken,bzw. -methoden. Zu diesem Zweck wurdenmit dem Scholarly Domain Model (SDM)(Gradmann et al. 2015) und der NeDiMAHMethod Ontology (NeMO) (Constantopoulos,Dallas, und Bernadou 2016) zwei Modellegeschaffen, die sowohl Konzepte für dieBeschreibung von Forschungsprozessen alsauch für deren Auswertung in Hinblick aufmethodische Fragestellungen bieten.
Der Hintergrund für diese Aktivitätenist zumeist das Bedürfnis vonInfrastrukturprojekten, im Falle der genanntenModelle Europeana und Dariah, Anforderungenvon NutzernInnen zu identifizieren und denqualitativen Gebrauch der bereitgestelltenDienste zu evaluieren. Darüber hinaus könnensie aber auch als ein digitales Angebot zurBearbeitung von Fragen der Science Studies
184

Digital Humanities im deutschsprachigen Raum 2017
verstanden werden. Im Kontext der DigitalHumanities geht diese Perspektive mit demWunsch nach der Herausbildung einesmethodischen Selbstbewusstseins einher(Constantopoulos, Dallas, und Bernadou 2016).
Versucht man die beiden genannten Ansätzedanach zu unterscheiden wie sie sich demForschungsprozess nähern, so fällt zunächst einUnterschied auf. Während in den beispielhaftenAnwendungen von NeMO (“DCU OnTo -NeDiMAH Ontology Navigation” 2016) dieBeschreibung rückblickend erfolgt, wird sie beiSDM vorausschauend vollzogen. SDM nimmthier Bezug auf das Konzept des 'modeling for'von Clifford Geertz.
Dieser Unterschied zwingt dazu, die zuvorgewählte Begrifflichkeit noch etwas weiterzu differenzieren. In der Forschungsliteraturwerden drei verschiedene Begriff fürmöglichen Varianten der Dokumentation vonForschungsaktivitäten verwendet (Hunter 2006).Diese sind:
WorkflowProvenienzLineage
Die Begriffe können auch als präskriptive,inskribierende, bzw. deskriptive Verfahrenbezeichnet werden. Sie unterscheiden sich durchden Zeitpunkt von dem aus die Darstellungeines Forschungsprozesses erfolgt. SDMund NeMO realisieren somit die Workflowund die Lineage Perspektive. Was fehlt isteine wirkliche Provenienz Perspektive imKontext der methodischen Evaluation vonForschungsprozessen in den Digital Humanities.Provenienzdaten sind Daten die während einerAktivität aufgezeichnet werden, indem zumBeispiel bestimmte Aktionen als Trigger fürdas Abspeichern von Informationen über dieseAktionen dienen.
Der Vorteil einer solchen Vorgehensweisegegenüber den anderen Ansätzen bei derMethodenevaluation ist zweierlei. DieGranularität mit der ein Forschungsprozessbeschrieben werden kann ist höher als inSDM und NeMO. Der Anteil inhaltlicherVorentscheidungen bei der Erfassung derDaten ist geringer. In der Beispielanwendungdes SDM soll die Erweiterung der Praxis desAnnotierens evaluiert werden. Gleichzeitignimmt die Entscheidung was wann mit demim SDM Vokabular bereitgestellten Begriff'Annotieren' beschrieben wird das Ergebnisder Evaluation schon ein Stück weit vorweg.In einem Provenienz Ansatz reicht es aus zu
definieren was aussagekräftige Ereignisse fürdie Dokumentation des Forschungsprozessessind. Die Interpretation einer Ereigniskette kannspäter erfolgen.
Der Vortrag stellt eine beispielhafteRealisierung für ein inskribierendes Verfahrenzur Evaluation von Forschungspraxis in denDigital Humanities im zuvor beschriebenenSinn vor. Die Arbeiten sind Bestandteil derdritten Förderphase des DARIAH-DE Projekts.Der Ausgangspunkt für die Entwicklungdes genannten Verfahrens bildet derWissensspeicher (“Digitaler Wissensspeicher”2016) der Berlin-Brandenburgischen Akademieder Wissenschaften.
Der Wissensspeicher ist einInfrastrukturprojekt, dass eine inhaltliche undtechnisch Interaktion mit den heterogenendigitalen Ressourcen an der BBAW ermöglicht.Ziel des Wissensspeichers ist es diese Interaktionnicht mit der Objekt-, sondern der hinterden Objekten stehenden Inhaltsebene zuermöglichen. Die Interaktionen können daherals wissensverarbeitende Prozesse verstandenwerden, die es bei entsprechender Evaluationerlauben Strategien der Wissensgenerierung zuidentifizierbar.
Verfahren der Benutzer-Interaktionsanalyse imKontext der Dokumentationvon Forschungspraxis
Da die Aufzeichnung der Provenienz Datendie Beschreibung von wissensverarbeitendenProzessen an Hand von bedeutungsvollenHandlungen zum Ziel hat und nicht einenTransformationsprozesses von Daten, ist dieDokumentation dieser Praxis schwierigerals zum Beispiel bei Hunter und anderenImplementierungen von Provenienz Modellen.Allerdings gibt es einen Forschungsbereichder sich tatsächlich mit einer ähnlichenFragestellung beschäftigt. Dieser Bereich istdie Benutzer-Aktions-Analyse, beziehungsweiseUser-Activity-Analysis. User-Activity-Analysiszeichnet die Mensch-Computer Interaktion mitdem Ziel auf, diese vor dem Hintergrund einerspezifischen Fragestellung zu analysieren. In denmeisten Fällen findet User-Activity-Analysis imBrowser statt, dies ist jedoch nicht zwingend.
Die zwei Bereiche in denen User-Activity-Analysis hauptsächlich durchgeführt wirdsind e-commerce und online-social-networks.Im Kontext des ersten Bereichs werden
185

Digital Humanities im deutschsprachigen Raum 2017
solche Analysen zum Beispiel für den Betriebvon Empfehlungssystemen druchgeführt(Plumbaum, Stelter, und Korth 2009). Bei Online-Social Networks steht häufig die Identifikationvon Verhaltensmustern von Menschen insozialen Interaktionen im Vordergrund (Dang etal. 2016)
Im Kontext akademischer Diensteund Umgebungen ist die User-Activity-Analysis noch nicht so weit verbreitet. EineAusnahme bilden spezielle Suchmaschinenfür Forschungsliteratur. Beiträge, die demhier vorgestellten Szenario noch am nächstenkommen sind die von Vozniuk et al. (2016) undSuire et al. (2016), die User-Activity-Analysis imKontext von e-learning und im cultural heritageBereich verorten.
Zwei Aufgabenstellungen sind zunächsteinmal konzeptuell von einander zu trennen.Zum einen stellt sich die Frage was, überhauptals Ausgangspunkt zur Erhebung von Daten ineiner spezifischen Mensch-Computer Interaktiondienen kann. Dieser Bereich kann auch alsUser-Activity-Tracking bezeichnet werden.Der andere Bereich umfasst die Frage mittelswelchen Verfahren den Ereignissen und aufderen Grundlage gewonnenen Daten Bedeutungzugeschrieben werde kann.
Viele unterschiedliche Strategien derErhebung von Nutzeraktivitätsdaten sind seitder Entstehung des Web vorgeschlagen worden(Calzarossa, Massari, und Tessera 2016). Dieam weitesten verbreitetste ist die sogenannteClick-Stream-Analyse bei der die Server-Logdateien, bzw. HTTP-Requests ausgewertetwerden, die das Klicken auf Links durch denBenutzer erzeugen. Dieser am einfachsten zurealisierende Ansatz ist aus verschiedenenGründen problematisch. So enthalten Server-Logdateien keine Informationen übersogenannte 'leise Interaktionen' (Benevenutoet al. 2009), also Klicks, die nicht mit einemRequest einhergehen und Interaktionenwie zum Beispiel Mausbewegungen, die garkeinen Klick beinhalten. Darüber hinausenthalten die erzeugten Daten keinerleiAngaben über den Inhaltskontext in dem dieInteraktion stattgefunden hat. Aus diesemGrund wurden Verfahren entwickelt, dieauf der Basis von Browser Plug-ins odermittels JavaScript (Dhawan und Ganapathy2009) eine detailliertere Dokumentationvon Benutzerinteraktion ermöglichen. Einweiterer Ansatz versucht mittels Parsing- undMiningverfahren Interaktionsspuren oderInhalte im Kontext von Interaktionen in dieAnalyse mit einzubeziehen (Vozniuk et al. 2016).
Wesentlich komplexer als die Frage danachwelche User-Activity-Daten wie erhobenwerden können ist die Frage wie ihnen undden Ereignissen die sie erzeugen Bedeutungbeigemessen werden kann. Hier existierenebenfalls eine Reihe unterschiedlicher Ansätzen.Grundsätzlich lassen sich 5 verschiedeneAnsätze unterscheiden. Dazu gehören solche, diedie Bedeutung von Ereignissen
• im Vorfeld festlegen,• vor dem Hintergrund von
Durchschnittswerten aus den Daten, die fürein bestimmtes Ereignis erhoben wurdenermitteln
• durch differentielle Verfahren wie zumBeispiel Clusteranalysen ermitteln (Wang etal. 2016)
• unter Einbeziehung des Zustandes derEreignisumgebung zum Ereigniszeitpunktwie dem Inhalt der Website bestimmen.
• zu erfassen zu suchen in dem Ereignissemit externen Quellen wie zum BeispielNutzerprofildaten gestellt werden.
Das einzig sinnvolle Verfahren im Kontext deszuvor beschriebenen Ziels ist eine Kombinationmehrerer Ansätze sowohl auf der Ebene desTracking als auch der Analyse. Ausgewertetwerden soll wie zuvor umschrieben dieInteraktion mit Wissen, also einem Gegenstand,der sich nicht mit einer Trägergröße alleinwie z.B. der Website in Übereinstimmungbringen lässt und der per Definition kontextuellkonstituiert ist. Wie eine solche Kombinationaussehen kann, hängt natürlich von dertechnischen aber auch sozialen Umgebung abinnerhalb der evaluiert wird.
Eine Architekturzu Evaluation vonForschungsaktivität imWissensspeicher
Konkret operiert der Use-CaseWissensspeicher im Bereich des Trackings miteiner Kombination aus:
• in das User-Interface hart kodiertenexpliziten Feedback-Möglichkeiten,
• ins User-Interface integrierte JavaScriptsnippets, die bei Interaktionen getriggertwerden und diese dokumentieren,
186

Digital Humanities im deutschsprachigen Raum 2017
• sowie Server-Log Dateien.
Ereignisse werden spezifiziert im Hinblickauf Ereignisgruppen (User Interface, Browser,Request und andere). User Interface Ereignissewerden weiterhin dahingehend kategorisiertauf welchem Seitentyp (Such Interface,Ressourcen Interface und andere) undwelchem Layoutbereich sie angesiedeltsind. Schließlich werden für jedes Ereignisvariable Eigenschaften bestimmt, die bei derAufzeichnung dokumentiert werden müssen.
Die Bedeutungsgebung soll ebenfallsdurch einen mehrstufigen auf einanderaufbauenden Prozess stattfinden. Das Konzeptsieht vor, Ereignisse in einem Task-Model(Yadav et al. 2015) einzuordnen, welchesantizipierte Interaktionsprozesse innerhalbdes Wissensspeicher formalisiert. Parallel dazuwird eine erste Auswertung von User-Activity-Daten wiederkehrende Ereignissequenzenidentifizieren, die mit dem Task-Modelverglichen werden. Dabei auftauchendeFragestellungen lassen sich dann in einemletzten Schritt mittels des Thinking-AloudVerfahrens (Kuusela und Paul 2000) aus demBereich des Usability Testing bearbeiten. Hierbeiarbeitet der Benutzer mit dem entsprechendenAngebot auf dem Computer und beschreibt waser tut, während er es tut.
Der Vortrag wird die vorangegangeneArgumentation für den gewählten Ansatznachzeichnen. Er wird darüber hinausdie ausgewählten Konzepte für dieGenerierung von User-Activity-Daten und ihrerBedeutungszuschreibung im Kontext einermethodischen Evaluation von Forschungspraxisim Use-Case diskutieren. Zu guter Letzt wirdein Ausblick auf ein Modell gegeben werden,dass eine gegenseitige Bereicherung zwischenAnsätzen wie SDM und NeMO und demvorgestellten aufzeigt.
Bibliographie
Benevenuto, Fabrício / Rodrigues, Tiago /Cha, Meeyoung / u. a. (2009): „Characterizinguser behavior in online social networks“, in:Proceedings of the 9th ACM SIGCOMM conferenceon Internet measurement conference. ACM 49–62.
Calzarossa, Maria Carla / Massari,Luisa / Tessera, Daniele (2016): „WorkloadCharacterization: A Survey Revisited“, in: ACMComput. Surv. 48 (3), 48:1–48:43 10.1145/2856127.
Constantopoulos, Panos / Dallas, Costis /Bernadou, Agiatis (2016): „Digital Methods in
the Humanities: Understanding and Describingtheir Use across the Disciplines“, in: Schreibman,Susan / Siemens, Ray / Unsworth, John (edt.): ANew Companion to Digital Humanities. 1. Aufl.Chichester, West Sussex, UK: John Wiley & Sons.
Dang, Anh / Moh’d, Abidalrahman / Milios,Evangelos / u. a. (2016): „What is in a Rumour:Combined Visual Analysis of Rumour Flowand User Activity“, in: Proceedings of the 33rdComputer Graphics International. ACM 17–20.
Dhawan, Mohan / Ganapathy, Vinod (2009):„Analyzing information flow in JavaScript-basedbrowser extensions“, in: Computer SecurityApplications Conference, 2009. ACSAC’09. Annual.IEEE 382–391.
Gradmann, Stefan / Hennicke, Steffen /Tschumpel, Gerold / u. a. (2015): „BeyondInfrastructure! Modelling the Scholarly Domain“.
Hunter, Jane (2006): „Scientific models:a user-oriented approach to the integrationof scientific data and digital libraries“, in:VALA2006 1–16.
Kuusela, Hannu / Paul, Pallab (2000): „AComparison of Concurrent and RetrospectiveVerbal Protocol Analysis“, in: The AmericanJournal of Psychology 113 (3): 387–40410.2307/1423365.
o. A. (o. J.): DCU OnTo - NeDIMAH OntologyNavigation. http://nemo.dcu.gr/ [Letzter Zugriff26. August 2016].
o. A. (o. J.): Digitaler Wissensspeicher. http://wissensspeicher.bbaw.de/ [Letzter Zugriff 26.August 2016].
Plumbaum, Till / Stelter, Tino / Korth,Alexander (2009): „Semantic Web Usage Mining:Using Semantics to Understand User Intentions“,in: Houben, Geert-Jan / McCalla, Gord / Pianesi,Fabio / u. a. (edt.): User Modeling, Adaptation, andPersonalization. Berlin / Heidelberg: Springer(Lecture Notes in Computer Science) 391–396.
Suire, Cyrille / Jean-Caurant, Axel /Courboulay, Vincent / u. a. (2016): „User ActivityCharacterization in a Cultural Heritage DigitalLibrary System“, in: Proceedings of the 16th ACM/IEEE-CS on Joint Conference on Digital Libraries.ACM 257–258.
Vozniuk, Andrii / Rodríguez-Triana, MaríaJesús / Holzer, Adrian / u. a. (2016): „CombiningContent Analytics and Activity Tracking toIdentify User Interests and Enable KnowledgeDiscovery“, in: Proceedings of the 6th Workshopon Personalization Approaches in LearningEnvironments (PALE 2016). 24th conference onUser Modeling, Adaptation, and Personalization(UMAP 2016), CEUR workshop proceedings.
Wang, Gang / Zhang, Xinyi / Tang, Shiliang /u. a. (2016): „Unsupervised ClickstreamClustering For User Behavior Analysis“, in:
187

Digital Humanities im deutschsprachigen Raum 2017
SIGCHI Conference on Human Factors inComputing Systems.
Yadav, Piyush / Kalyani, Kejul / Mahamuni,Ravi (2015): „User Intention Mining: A Non-intrusive Approach to Track User Activities forWeb Application“, in: Tan, Ying / Shi, Yuhui /Buarque, Fernando / u. a. (edt.): Advances inSwarm and Computational Intelligence. SpringerInternational Publishing (Lecture Notes inComputer Science) 147–154.
Projekte und Aktivitätenim Kontext digitaler3D-Rekonstruktion imdeutschsprachigenRaum
Münster, [email protected] / TU Dresden, Deutschland
Kuroczyński, [email protected] Institut Marburg, Deutschland
Pfarr-Harfst, [email protected] Architektur, Digitales Gestalten / TUDarmstadt, Deutschland
Einleitung
Die Arbeitsgruppe „Digitale Rekonstruktion“ging aus der 1. Jahrestagung der DigitalHumanities im deutschsprachigen Raum(25.-28.03.2014, Universität Passau) hervor.Die Arbeitsgruppe versammelt Kolleginnenund Kollegen, die sich dem Thema digitaleRekonstruktion aus dem Blickwinkelder Architektur, Archäologie, Bau- undKunstgeschichte sowie Computergraphikund Informatik verschrieben haben. DieArbeitsgruppe bietet eine Plattform für einenAustausch und eine feste Etablierung derdigitalen Rekonstruktion im Dienste einerErfassung, Erforschung und Vermittlungkultureller und geschichtlicher Inhalte innerhalbder Digital Humanities. Vorrangiges Zielder Arbeitsgruppe ist es, die Akteure imdeutschsprachigen Raum zusammenzubringen,
um sich den Fragen der Begriffsklärungund der Arbeitsmethodik sowie derDokumentation und Langzeitarchivierungvon digitalen Rekonstruktionsprojekten zuwidmen. Der Arbeitsgemeinschaft gehörenca. 50 Personen aus 29 Einrichtungen imdeutschsprachigen Raum sowie 4 assoziiertenMitgliedseinrichtungen im europäischen Rauman (Abb. 1).
Abb. 1. Example of research which includesthe use of digital methods: network analysis asan archival tool
Auf bisher drei Panels wurden beivergangenen DHd-Jahrestagungendurch die Arbeitsgemeinschaft„Allgemeine Standards, Methodik undDokumentation“ (Kuroczyński et al., 2014) und„aktuelle Herausforderungen“ (Kuroczyński etal., 2015) sowie Transformationsprozesse „vomdigitalen 3D-Datensatz zum wissenschaftlichenInformationsmodell“ (Kuroczyński et al.,2016) beleuchtet. Während damit vorallem Anforderungen und Perspektivendigitaler Rekonstruktion als Forschungs- undVermittlungsmethode aus generalisierenderPerspektive aufgezeigt wurden, sollen inkonsequenter Folge auf der DHd 2017 dievielfältigen aktuellen Aktivitäten und Projektevorgestellt werden, welche sich vor allem imdeutschsprachigen Raum mit digitaler 3D-Rekonstruktion in wissenschaftlichen Kontextenbeschäftigen. Diese Aufstellung soll dabei eineBandbreite aktueller Arbeitsschwerpunktesowohl aufzeigen als auch systematisieren.
188

Digital Humanities im deutschsprachigen Raum 2017
Datenbasis
Die Erstellung der Übersicht zu aktuellenVorhaben und Forschungsperspektiven stütztsich auf drei Zugänge:
1. Eine Aufstellung vonForschungsperspektiven und -vorhaben jenseitsdes spezifischen Objektes hat das derzeitin Vorbereitung befindliche Buchprojektder AG Digitale Rekonstruktion unter demArbeitstitel „Die Tugend der Modelle 2.0“ zumZiel. Im Zuge eines Call for Abstracts wurdendabei ca. 20 Beiträge eingereicht, welchenicht nur eine Vielzahl aktueller Projektebeschreiben, sondern auch einen Querschnittvon Forschungskontexten und einer analytischeAuseinandersetzung mit dem vielfältigenThemenkomplexen der Digitalen Rekonstruktionwiderspiegeln.
2. Bei einer Postersession zum Arbeitstreffender Arbeitsgemeinschaft im September 2016werden aktuelle Projekte der Mitglieder derAG vorgestellt. Diese werden ebenfalls in denhier vorgestellten Vortrag Eingang findenund die wissenschaftliche Vielschichtigkeitdieses Themengebietes in der aktuellenForschugnslandschaft verdeutlichen
3. Wie im folgenden Abschnitt dargestellt,beschäftigen sich zudem eine ganze Reihe vonForschungsvorhaben sowie Graduierungs-und Netzwerkaktivitäten mit einer Kartierung,Systematisierung und Kontextualisierung vonAktivitäten im Kontext digitaler Rekonstruktionund bieten damit gleichermaßen Übersichtüber Einzelvorhaben als auch Ansätze für eineSystematisierung von Vorhaben.
Was sind aktuell Forschungs-und Arbeitsschwerpunktedigitaler Rekonstruktion?
Ausgehend von den bereits getätigtenErhebungen lässt sich eine Reihe vonArbeitsschwerpunkten digitaler Rekonstruktionidentifizieren.
Anwendung digitalerRekonstruktion
Der noch immer wesentlichste Kontexteiner Anwendung digitaler Rekonstruktionist die Erstellung digitaler 3D-Modellekonkreter kulturhistorisch bedeutender
Objekte wie Siedlungsstrukturen,Einzelgebäude oder Bauwerksensembles sowieAusstattungsgegenstände ooder Kultobjekte.Dieses dreidimensionale digitale Abbild/ Modelldient vornehmlich zur Vermittlung, aberauch mehr und mehr zur objektbezogenenForschung. Eine systematische Kartierung vonVorhaben zur objektbezogenen Anwendungdigitaler Rekonstruktionen nimmt beispielsweisedas Wiki des Arbeitskreises digitalenKunstgeschichte vor, welches aktuell 3D-Modelleaus ca. 40 Orten auflistet (Arbeitskreis DigitaleKunstgeschichte). Eine thematisch gegliederteÜbersicht pflegt daneben Anna Bentkofska-Kafelfür das 3D Visualisation in the Arts network(Bentkowska-Kafel). Mit einer inzwischenreichlich 30-jährigen Geschichte und einerVielzahl von Einzelaktivitäten sowie Zäsurenstellt die digitale 3D-Rekonstruktion danebeninzwischen selbst Gegenstand historiografischerBetrachtungen dar. Beispielhaft dafür sei aufdas Dissertationsvorhaben von Heike Messemerverwiesen, welches sich aus kunsthistorischerPerspektive mit einer Erfassung vor allemkunsthistorisch relevanter 3D-Rekonstruktionenund deren Kontextualisierung (Messemer, 2016)beschäftigt.
Systematisierung undmethodische Validierung
Digitale Rekonstruktionen nutzen nichtnur Technologien aus der Informatik zurBearbeitung geisteswissenschaftlicherFragestellungen, sondern inkorporierendarüber hinaus eine Vielzahl unterschiedlicherdisziplinärer Perspektiven undVerwendungskontexte. Neben der Archäologiesowie verschiedenen Aufgaben des Umgangs mitKulturerbe als Schwerpunkte der EU-Förderungsind in der deutschen Forschungslandschaftspezifische Szenarien, beispielsweise ausSicht der Kunst- und Architekturgeschichte,Kulturwissenschaft, Bauforschung sowieMuseologie, relevant (Riedel et al., 2011,Burwitz et al., 2012). Vor diesem Hintergrundstehen eine Reihe von Vorhaben zur Erfassungund Systematisierung von Forschungs- undNutzungsansätzen digitaler Rekonstruktion(Münster and Niebling, 2016, Pfarr-Harfst,Forthcoming) sowie generell zu einerwissenschaftlich-methodischen Validierung (vgl.Münster et al., submitted paper).
189

Digital Humanities im deutschsprachigen Raum 2017
Modellierung
Im Mittelpunkt digitaler Rekonstruktionensteht die Erstellung eines 3D-Modells anhandder Interpretation historischer Quellen alsauch unter Einbeziehung unterschiedlicherWissensdomänen. Darüber hinaus findenverschiedenste Arten akquirierter Daten Eingangin derartige Projekte, beispielsweise in Formvon Laserscans oder photogrammetrischeRekonstruktionen noch existierenderObjektteile oder als Landschaftsmodelle. EineModellerstellung erfolgt dabei am Computermittels primär manuell zu bedienenderModellierungssoftwares. Vor dem Hintergrundeines damit verbundenen Aufwands beschäftigtsich eine Reihe von Projekten mit Ansätzenzur Vereinfachung dieser Prozesse durchVereinfachung von Modellierungswerkzeugen(Schinko et al., 2016, Snickars, 2016, Havemannet al., 2007) oder Abläufen (Ioannides, 2016).Andere dagegen versuchen den manuellenModellierungsprozess zu strukturieren,allgemeingültige Vorgehensweisenherauszufiltern und diese in digitale, aufOntologien basierende Handbücher als Beitragzur Qualitätssicherung zu transferieren (Pfarr-Harfst and Wefers, Forthcoming).
Wissensrepräsentation
Die Erfassung und Archivierung historischerQuellen unterschiedlicher Gattungen, digitalenForschungsartefakten und -ergebnissen sowiezugeordneten Meta-, Para- und Kontextdatensteht seit langem im Fokus einer Vielzahl voneuropäischen Vorhaben wie beispielsweiseEPOCH, 3D-COFORM, CARARE, 3D-ICONS.Darüber hinaus beschäftigen sich eine Reihevon Arbeiten mit grundlegenden Mechanismender Dokumentation und Klassifikationdigitaler Rekonstruktionen (Pfarr-Harfst, 2013,Huvila, 2014, Münster et al., Forthcoming).Darüber hinaus haben eine Vielzahl aktuellerProjekte wie beispielsweise IANUS, Monarch,DocuVis, OpenInfra oder DURAARK dieEntwicklung von Forschungsinfrastrukturenzum Ziel (Drewello et al., 2010, Bruschke andWacker, Forthcoming, Kuroczyński, 2012,Kuroczyński et al., Forthcoming, Beetz et al.,Forthcoming). Wenngleich sich diese Vorhabenhinsichtlich des jeweiligen Adressatenkreisesund Werkzeugspektrums unterscheiden,werden übergreifend Fragen wie nachBezüge zwischen Modell und (explizierbaren)Wissensgrundlagen wie beispielsweise Quellen,
der Transparentmachung einer Modelllogik(Hoppe, 2001, Günther, 2001), nach demModellierungsvorgehen sowie der Beschreibungder erstellten Modelle – beispielsweise mittelsübergreifender Referenzontologien undanwendungsspezifischer Applikationsontologien(Homann, 2011, Kuroczyński, 2014) –thematisiert.
Präsentation
Eine Präsentation von 3D-Rekonstruktionenerfolgt schlussendlich wiederum primär in Formvon Bildern des erstellten virtuellen 3D-Modells.Mit Blick auf die Qualität dieser Abbildungenergeben sich besondere Anforderungendabei hinsichtlich Interaktivität und derSimulationsqualität von Materialität undLichtstimmung, aber auch im Umgang mit einerheterogenen Belegbarkeit von Hypothesenund zum Umgang mit Alternativhypothesen.Forschungsprojekte beschäftigen sich sowohlmit Fragen der Ästhetik und visuellenEinbeziehung unterschiedlicher Grade vonHypothesenhaftigkeit (Heeb et al., 2016,Vogel, 2016, Lengyel and Toulouse, 2011b,Lengyel and Toulouse, 2011a), als auch mittechnologischen Fragen nach Interaktivität undcomputergrafischer Umsetzung (Fornaro, 2016).Hier schließt sich unmittelbar die Frage nach derAuthentizität solcher digitaler Rekonstruktionenan (Pfarr-Harfst, Forthcoming). Mit Blickauf eine Anknüpfbarkeit sind zudemeinfach zu bedienende Datenviewer zurDarstellung der 3D-Datensätze relevant, derenEntwicklung beispielsweise im Rahmen derbereits im vorherigen Abschnitt benanntenInfrastrukturvorhaben adressiert ist. Einvergleichsweise neues Präsentationsmediumstellen darüber hinaus 3D-Reproduktion dar(Grellert, Forthcoming), welche virtuelle Modellein eine Materialität überführen und sich alshybride Präsentationsformen mit den bisheretablierten kombinieren lassen. Wahrnehmung,Didaktik und Präsentation im musealen Kontextsind weitere aktuelle Forschungsthemen(Grellertand Pfarr-Harfst, 2014).
Kompetenzentwicklung
Gerade im geisteswissenschaftlichenUmfeld sind Affinität und Kompetenzhinsichtlich digitaler Forschungsmethodenbisher wenig ausgeprägt (Albrecht, 2013).Ähnlich wie für die Digital Humanitiesinsgesamt (Vorstand des Verbandes Digital
190

Digital Humanities im deutschsprachigen Raum 2017
Humanities im deutschsprachigen Raum,2014) stellt der methodenbezogene Wissens-und Kompetenzaufbau bei Forschern undPraxisanwendern wie bspw. Kuratorenhinsichtlich einer Herstellung, Bewertungund Nutzung digitaler Rekonstruktioneneine wesentliche Herausforderung dar.Entsprechend haben aktuell eine ganze Reihevon Projekten und Netzwerken beispielsweiseden Kompetenzerwerb zur Durchführungvon Digitalen Rekonstruktionen (Ioannides,2013, Kröber and Münster, 2016) oder zurNutzung von Digitalen Rekonstruktionen zurWissensvermittlung (bspw. Sprünker, 2013,Glaser et al., 2015) zum Ziel.
Vernetzungsaktivitäten
Aktuell umfasst eine Landschaft derdigitalen Rekonstruktion in Deutschland eineVielzahl von Akteuren unterschiedlicherHintergründe, welche bisher nur ungenügendvernetzt und organisiert sind. Daraus leitensich der Bedarf gemeinsamer Plattformenfür einen Austausch und eine Etablierungder digitalen Rekonstruktion im Kanonder Digital Humanities ebenso wie nachdisziplinübergreifenden koordinierendeStrukturen bzw. Institutionen einerwissenschaftlichen und anwendungspraktischenWeiterentwicklung ab. Ein diesbezüglich ersterSchritt war nicht zuletzt die 2014 erfolgteGründung der AG „Digitale Rekonstruktion“der DHd, welche auf europäischer Ebenewiederum in eine Reihe multinationaler undzumeist thematisch begrenzter Netzwerke,beispielsweise zu virtuellen Museen oder Farbeund Raum von Kulturgut (Boochs et al., 2014),eingebunden ist.
Bibliographie
H2020 Virtual Multimodal Museum[Online]. http://www.vi-mm.eu [letzter Zugriff 25.August 2016].
IANUS - ForschungsdatenzentrumArchäologie & Altertumswissenschaften[Online]. http://www.dainst.org/de/project/ianus-forschungsdatenzentrum-arch%C3%A4ologie-altertumswissenschaften?ft=all [letzter Zugriff25. August 2016].
OpenInfRA - Ein webbasiertesInformationssystem zur Dokumentationund Publikation archäologischerForschungsprojekte [Online]. http://www.tu-
cottbus.de/projekte/de/openinfra/ [letzter Zugriff25. August 2016].
Albrecht, Steffen (2013): „Scholars' Adoptionof E-Science Practices: (Preliminary) Resultsfrom a Qualitative Study of Network andOther Influencing Factors“, in: XXXIII. SunbeltSocial Networks Conference of the InternationalNetwork for Social Network Analysis (INSNA).
Arbeitskreis Digitale Kunstgeschichte:Liste digitaler Modelle historischerArchitektur [Online]. http://www.digitale-kunstgeschichte.de/wiki/Liste_digitaler_Modelle_historischer_Architektur[letzter Zugriff 25. August 2016].
Beetz, Jakob / Blümel, Ina / Dietze, Stefan /Fetahui, Besnik / Gadiraju, Ujwal / Hecher,Martin / Krijnen, Thomas / Lindlar, Michelle /Tamke, Martin / Wessel, Raoul / Yu, Ran(2016): „Enrichment and Preservation ofArchitectural Knowledge“, in: Münster, Sander /Pfarr-Harfst, Mieke / Kuroczyński, Piotr /Ioannides, Marinos (eds.): How to manage dataand knowledge related to interpretative digital3D reconstructions of Cultural Heritage? Cham:Springer.
Bentkowska-Kafel, Anna: 3DVisA Index of3D Projects [Online]. http://3dvisa.cch.kcl.ac.uk/projectlist.html [letzter Zugriff 25. August 2016].
Boochs, Frank / Bentkowska-Kafel, Anna /Degrigny, Christian / Karaszewski, Maciej /Karmacharya, Ashish / Kato, Zoltan / Picollo,Marcello / Sitnik, Robert / Trémeau, Alain /Tsiafaki, Despoina / Tamas, Levente (2014):„Colour and Space in Cultural Heritage: KeyQuestions in 3D Optical Documentation ofMaterial Culture for Conservation, Studyand Preservation“, in: Ioannides, Marinos /Magnenat-Thalmann, Nadia / Fink, Eleanor /Žarnić, Roko / Yen, Alex-Yianing / Quak, Ewald(eds.): Digital Heritage: Progress in CulturalHeritage: Documentation, Preservation, andProtection5th International Conference, EuroMed2014: Proceedings. Cham: Springer.
Bruschke, Jonas / Wacker, Markus(Forthcoming): „Simplifying the documentationof digital reconstruction processes: Introducingan interactive documentation system“, in:Münster, Sander / Pfarr-Harfst, Mieke /Kuroczyński, Piotr / Ioannides, Marinos (eds.):How to manage data and knowledge relatedto interpretative digital 3D reconstructions ofCultural Heritage? Cham: Springer LNCS.
Burwitz, Henning / Henze, Frank / Riedel,Alexandra (2012): „Alles 3D? – Über dieNutzung aktueller Aufnahmetechnik inder archäologischen Bauforschung“, in:Faulstich, Elisabeth Ida (ed.): Dokumentation undInnovation bei der Erfassung von Kulturgütern
191

Digital Humanities im deutschsprachigen Raum 2017
II, Schriften des Bundesverbands freiberuflicherKulturwissenschaftler 5, Online-Publikation derBfK-Fachtagung 2012. Würzburg.
Drewello, Rainer / Freitag, Burkhard /Schlieder, Christoph (2010): „Neues Werkzeugfür alte Gemäuer“, in: DFG Forschung Magazin 3:10–14.
Fornaro, P. (2016): „Farbmanagement im 3DRaum“, in: Der Modelle Tugend 2.0.
Glaser, Manuela / Lengyel, Dominik /Toulouse, Catherine / Schwan, Stephan (2015):„Designing computer based archaeological 3D-reconstructions: How camera zoom influencesattentaion“, in: Bares, William / Christie,Marc / Ronfard, Remi (eds.) Proceedings ofthe Eurographics Workshop on IntelligentCinematography and Editing EICED 2015. Goslar.
Grellert, Marc (2016): „Rapid Prototypingin the Context of Cultural Heritage andMuseum Displays. Buildings, Cities, Landscapes,Illuminated Models“, in: Münster, Sander /Pfarr-Harfst, Mieke / Kuroczyński, Piotr /Ioannides, Marinos (eds.): How to manage dataand knowledge related to interpretative digital3D reconstructions of Cultural Heritage? Cham:Springer LNCS.
Grellert, Marc / Pfarr-Harfst, Mieke(2014): „25 Years of Virtual Reconstructions.Project Report of Department Information andCommunication Technology in Architetctureat Technische Universität Darmstadt“, in: 18thInternational Conference on Cultural heritage andNew Technologies.
Günther, Hubertus (2001): „KritischeComputer-Visualisierung in derkunsthistorischen Lehre“, in: Frings, Marcus(ed.) Der Modelle Tugend: CAD und die neuenRäume der Kunstgeschichte. Weimar.
Havemann, Sven / Settgast, Volker /Lancelle, Marcel / Fellner, Dieter W. (2007): 3D-Powerpoint - Towards a Design Tool for DigitalExhibitions of Cultural Artifacts. Brighton, UK:Eurographics Association.
Heeb, N./ Christen, J./ Rohrer, J. / Lochau,S. (2016): „Strategien zur Vermittlung vonFakt, Hypothese und Fiktion in der digitalenArchitektur-Rekonstruktion“, in: Der ModelleTugend 2.0.
Hohmann, Georg (2011): „Die Anwendungvon Ontologien zur Wissensrepräsentation und-kommunikation im Bereich des kulturellenErbes“, in: Schomburg, Silke / Leggewie, Claus /Lobin, Henning / Puschmann, Cornelius (eds.):Digitale Wissenschaft - Stand und Entwickungdigital vernetzter Forschung in Deutschland. Köln:HBZ.
Hoppe, Stephan (2001): „Die Fußnotendes Modells“, in: Frings, Marcus (ed.) Der
Modelle Tugend. CAD und die neuen Räume derKunstgeschichte. Weimar.
Huvila, Isto (2014): Perspectives toArchaeological Information in the Digital Society.Uppsala, Institutionen för ABM och författarna.
Ioannides, Marinos (2013): „Initial TrainingNetwork for Digital Cultural Heritage: Projectingour Past to the Future“, in: Der Modelle Tugend2.0.
Ioannides, Marinos (2016): „MonumentDocumentation Engineering“, in: Der ModelleTugend 2.0.
Kröber, Cindy / Münster, Sander (2016):„Educational App Creation for the Cathedral inFreiberg“, in: Spector, J. Michael / Ifenthaler,Dirk / Sampson, Demetrios G. / Isaias, Pedro(eds.): Competencies, Challenges, and Changes inTeaching, Learning and Educational Leadership inthe Digital Age. Springer.
Kuroczyński, Piotr (2012): „3D-Computer-Rekonstruktion der Baugeschichte Breslaus:Ein Erfahrungsbericht“, in: Polnische Akademieder Wissenschaften (ed.): Jahrbuch desWissenschaftlichen Zentrums der PolnischenAkademie der Wissenschaften in Wien 3. Wien.
Kuroczyński, Piotr (2014): „DigitalReconstruction and Virtual ResearchEnvironments – A question of documentationstandards. Access and Understanding –Networking in the Digital Era“, in: Proceedings ofthe annual conference of CIDOC.
Kuroczyński, Piotr / Grellert, Marc / Hauck,O. / Münster, Sander / Pfarr-Harfst, Mieke /Scholz, Martin (2015): „Digitale Rekonstruktionund aktuelle Herausforderungen (Panel)“, in:DHd 2015: Von Daten zu Erkenntnissen.
Kuroczyński, Piotr / Hauck, Oliver B. /Dworak, Daniel (Forthcoming): „3D models ontriple paths - New pathways for documentingand visualising virtual reconstructions“,in: Münster, Sander / Pfarr-Harfst, Mieke /Kuroczyński, Piotr / Ioannides, Marinos / Quack,E. (eds.) The 2nd International Workshop onICT for the Preservation and Transmission ofIntangible Cultural Heritage ‚How to exchangeCultural Heritage 3D objects and knowledge inDigital Libraries?‘. Cham: Springer.
Kuroczyński, Piotr / Pfarr-Harfst, Mieke /Münster, Sander / Hoppe, Stephan / Hauck,Oliver / Blümel, Ina (2016): „Der ModelleTugend 2.0 – Vom digitalen 3D-Datensatz zumwissenschaftlichen Informationsmodell“, in: DHd2016: Modellierung - Vernetzung - Visualisierung.
Kuroczyński, Piotr / Pfarr-Harfst,Mieke / Wacker, Markus / Münster, Sander /Henze, Frank (2014): „Pecha Kucha: VirtuelleRekonstruktion – Allgemeine Standards,Methodik und Dokumentation (Panel)“, in:
192

Digital Humanities im deutschsprachigen Raum 2017
DHd 2014: Digital Humanities – methodischerBrückenschlag oder feindliche Übernahme?.Passau.
Lengyel, Dominik / Toulouse, Catherine(2011): „Darstellung von unscharfem Wissenin der Rekonstruktion historischer Bauten“,in: Heine, Katja / Rheidt, Klaus / Henze, Frank /Riedel, Alexandra (eds.): Von Handaufmaßbis High Tech III. 3D in der historischenBauforschung . Darmstadt: Verlag Philipp vonZabern.
Lengyel, Dominik / Toulouse, Catherine(2011): „Ein Stadtmodell von Pergamon -Unschärfe als Methode fur Darstellung undRekonstruktion antiker Architektur“, in:Petersen, Lars / Hoff, Ralf von den (eds.):Skulpturen in Pergamon – Gymnasion, Heiligtum,Palast. Freiburg: Archäologische Sammlung derAlbert-Ludwigs-Universität Freiburg.
Messemer, Heike (2016): „The Beginnings ofDigital Visualization of Historical Architecturein the Academic Field“, in: Hoppe, Stephan /Breitling, Stefan (eds.): Virtual Palaces, PartII. Lost Palaces and their Afterlife: VirtualReconstruction between Science and the Media.
Münster, Sander / Friedrichs, K. / Hegel,Wolfgang (eingereicht): „3D Reconstructiontechniques as a Cultural Shift in Art History?“, in:International Journal of Digital Art History.
Münster, Sander / Hegel, Wolfgang /Kröber, Cindy (2016): „A classificationmodel for digital reconstruction in context ofhumanities research“, in: Münster, Sander /Pfarr-Harfst, Mieke / Kuroczyński, Piotr /Ioannides, Marinos (eds.): How to manage dataand knowledge related to interpretative digital3D reconstructions of Cultural Heritage? Cham:Springer LNCS.
Münster, Sander / Niebling, Florian (2016):„Building a wiki resource on visual knowledgerelated knowledge assets“, in: Spender, J.C. /Schiuma, Giovanni / Nönnig, Jörg Rainer (eds.):Proceedings of the 11th International Forumon Knowledge Asset Dynamics (IFKAD 2016).Dresden.
Pfarr-Harfst, Mieke (2013): Documentationsystem for digital reconstructions Reference to theMausoleum of the Tang-Dynastie at Zhaoling, inShaanxi Province, China (unveröffentlicht).
Pfarr-Harfst, Mieke (Forthcoming): „TypicalWorkflows, Documentation Approaches andPrinciples of 3D Digital Reconstruction ofCultural Heritage“, in: Münster, Sander / Pfarr-Harfst, Mieke / Kuroczyński, Piotr / Ioannides,Marinos (eds.): How to manage data andknowledge related to interpretative digital 3Dreconstructions of Cultural Heritage? Cham:Springer LNCS.
Pfarr-Harfst, Mieke / Wefers, Stefanie(2016): „Digital 3D reconstructed models –Structuring visualisation project workflows“, in:Ioannides, Marinos (ed.): Proceedings of the 6thInternational Conference, EuroMed 2016. Cham:Springer.
Riedel, Alexandra / Henze, Frank / Marbs,Andreas (2011): „Paradigmenwechsel in derhistorischen Bauforschung? Ansätze für eineeffektive Nutzung von 3D-Informationen“, in:Heine, Katja / Rheidt, Klaus / Henze, Frank /Riedel, Alexandra (eds.): Von Handaufmaßbis High Tech III - 3D in der historischenBauforschung. Darmstadt: Philipp von Zabern.
Schinko, C. / Krispel, U. / Gregor, R. /Schreck, T. / Ullrich, T. (2016): „GenerativeModeling – the Combination of Knowledge andGeometry“, in: Der Modelle Tugend 2.0.
Snickars, Pelle (2016): „Metamodeling.3D-(re)designing Polhem’s Laboratoriummechanicum“, in: Der Modelle Tugend 2.0.
Sprünker, Janine (2013): „Making on-line cultural heritage visible for educationalproposes“, in: Digital Heritage InternationalCongress (DigitalHeritage) 405–408.
Vogel, G.-H. (2016): „Von derZweidimensionalität zur Dreidimensionalität:wissenschaftliche Rekonstruktion verlorenerArchitekturen als archäologische undkunsthistorische Wissensbilder vor demHintergrund ästhetischer Konzepte der Kunst-und Architekturgeschichte (Draft)“, in: DerModelle Tugend 2.0.
Vorstand Des Verbandes DigitalHumanities Im Deutschsprachigen Raum(2014): Digital Humanities 2020. Passau.
„Quellen aus derSchweiz für die Welt:jederzeit, überall,für alle“ – NeueKooperationen der NBim digitalen Zeitalter
von Wartburg, [email protected] Nationalbibliothek, Schweiz
193

Digital Humanities im deutschsprachigen Raum 2017
Nepfer, [email protected] Nationalbibliothek, Schweiz
Die Schweizerische Nationalbibliothek NBist eine Gedächtnisinstitution des Bundes.Gemeinsam mit anderen Bibliotheken, mit denArchiven und Museen trägt sie zur Erhaltung deskulturellen Erbes der Schweiz bei. Sie überliefertTexte, Bilder und Töne, die einen Bezug zurSchweiz haben, auf analogen und digitalenTrägern. Sie verfügt inzwischen über rundfünf Millionen Dokumente, die zum grösstenTeil seit der Gründung des Bundesstaates1848 entstanden sind. Zu der NB gehören dasSchweizerische Literaturarchiv SLA, das CentreDürrenmatt Neuchâtel CDN und die FonotecaNazionale FN.
In ihrer Strategie stellt sich die NB dendigitalen Herausforderungen und bekennt sichdazu, ihre Inhalte weltweit zugänglich machenzu wollen: „Quellen aus der Schweiz für dieWelt.“ Damit soll jeder und jedem Einzelnenermöglicht werden, diese Dokumente für dieeigenen Bedürfnisse zu nutzen. Im Fokus sinddabei Personen, für die die Sammlung derNB von Bedeutung ist: Studierende, Fachleuteund Forschende der Kulturwissenschaften,vor allem aber die Schweizer Bevölkerung.In strategischen Handlungsfeldern wirdfestgelegt, dass die Sammlung der NB leichtzu finden und einfach zu benutzen sein soll.Ausserdem wird der Anspruch formuliert, diePersonen, die an unseren Beständen forschenmit Dienstleistungen und Beratung wirkungsvollzu unterstützen. Im Fokus sind dabei dieLiteraturwissenschaft, die Schweizer Geschichteund die Auswertung von Bildbeständen.
Ausgangslage für die Formulierung dieserstrategischen Handlungsfelder war eineUmfeldanalyse, bei der zwei Herausforderungenund einen Trend identifiziert worden waren.
Eine erste Herausforderung besteht darin,dass jede Informationssuche im Internet miteiner Suchmaschine beginnt – nicht mit einemBibliothekskatalog, einer Archivdatenbankoder einem Portal von Gedächtnisinstitutionen.Dies entspricht der eigenen persönlichenErfahrung und es wird durch diverse Studien(Eine Zusammenstellung der Befunde beiSilipigni Connaway et al. 2010) bestätigt: Es istauch bekannt, dass die Online-EnzyklopädieWikipedia unter den ersten Treffern erscheint,sofern darin ein Artikel zum gesuchten Themavorhanden ist. Die relevanten Metadaten und/oder Inhalte von Gedächtnisinstitutionen
erscheinen – wenn überhaupt – viel weiter untenin der Liste der Suchresultate.
Eine andere Herausforderung sind die hohenErwartungen der Benutzenden: Diese wollennicht nur die Metadaten, also die Beschreibungvon Inhalten finden, sondern auf diese jederzeitund von überall her zugreifen können, um siesofort für die eigenen Zwecke verwenden zukönnen.
Der Open- Trend ist eine Chance: Der Rufnach Öffnung von Daten ist ein weltweiterTrend, die Rede ist von Open Access, OpenGovernment Data, Open Data, OpenGLAM,usw. Gedächtnisinstitutionen – oder ebendie mit dem Akronym GLAM gemeintenGalleries, Libraries, Archives and Museums –folgen bei der Erschliessung internationalenStandards und verwenden Normdaten. IhreMetadaten, vor allem die bibliografischenBeschreibungen der Bibliotheken, gelten alsqualitativ hoch stehend. Mit den fortwährendenDigitalisierungsbemühungen werden ausserdemlaufend attraktive Inhalte auf verschiedenenPlattformen online gestellt. Communities wie dieWikipedianer, Open Data- und Public Domain-Aktivistinnen, sowie Forschende der DigitalHumanities interessieren sich für diese Daten,sofern sich diese dank einer freien Lizenzproblemlos weiterverwenden lassen.
Die Umsetzung der Strategie hat zu neuenHandlungsfeldern und auch zu neuenKooperationen geführt, die in diesem Vortragvorgestellt werden sollen.
Neue Kooperationen und Aktivitäten sindbeispielsweise im Umfeld von OpenGLAM 1 zuverzeichnen.
• Die NB strebt an, die eigenen Daten gemässden von Open Knowledge Internationalverabschiedeten Prinzipien sichtbar und fürdiverse Nutzungen möglichst frei verfügbarzu machen. Ausserdem soll die Nachnutzungder offenen Daten aktiv gefördert werden.
• Die NB stellt den Forschenden resp. allenan ihrer Sammlung interessierten PersonenMetadaten, Normdaten, Digitalisate (Textund Bilder) und originär digitale Ressourcen(Webseiten, e-Medien) zur Verfügung. DieDaten werden nach Möglichkeit offen,ohne organisatorische, technische oderfinanzielle Hürden zur Verfügung gestellt.Zusätzlich zum eigenen Bibliothekssystemund der eigenen Archivdatenbank werdendafür gut sichtbare, stark frequentiertePlattformen wie die Mediendatenbank derOnline-Enzyklopädie Wikipedia, Wikimedia
194

Digital Humanities im deutschsprachigen Raum 2017
Commons oder das Portal für SchweizerBehördendaten opendata.swiss verwendet.
• Um die Nutzung der Daten zu fördern undmit interessierten Communities in Kontakt zutreten, beherbergte die NB 2015 den erstenKulturdaten-Hackathon in der Schweiz, andem auch Forschende der Digital Humanitiesteilnahmen. Der an diesem Hackathonentwickelte Prototyp Gugelmann-Galaxyzeigt exemplarisch, welche unerwarteten,innovativen Nutzungen „geschehen“können wenn Gedächtnisinstitutionengezielt Teile ihrer Sammlung aus denDatensilos befreien und der Öffentlichkeitzur Weiterverwendung überlassen.
• Grundlage für diese OpenGLAM-Aktivitäten waren einerseits die 2012verabschiedete Open-Data-Strategie derNB, andererseits die 2013 abgeschlosseneKooperationsvereinbarung mit WikimediaSchweiz. Nachdem die NB beschlossen hatte,ihre Metadaten und Inhalte „möglichst offen“zur Verfügung zu stellen, war der Weg frei,mit Wikimedia Schweiz eine langfristigeZusammenarbeit zu vereinbaren und alserste Massnahme temporär zwei Wikipediansin Residence (vgl. https://en.wikipedia.org/wiki/Wikipedian_in_residence#cite_note-Outreach-18 ) zu beherbergen.
Ein weiteres Handlungsfeld ist im Bereichder digitalen Erschliessung entstanden. Hierstehen laufendende Kooperationen mitAkteuren der Schweizer Geschichtswissenschaftim Fokus, deren Unterstützung, u.a. durchdie Weiterentwicklung der von der NBherausgegebene Bibliographie der SchweizerGeschichte BSG, ein strategisches Ziel darstellt.
• Ein wichtiges Projekt in diesem Bereichist Metagrid 2 bei welchem die NB seitBeginn des Projekts als Projektpartnerbeteiligt ist. Der Webservice Metagridermöglicht die Einrichtung, Verwaltung undAnalyse von Links zwischen identischenIdentitäten von verschiedenen Websites undDatenbanken. Seit Sommer 2016 sind derKatalog Helveticat und die BSG in Metagridintegriert und via Metagrid-Widget abrufbar.Zur Zeit beschränkt sich der Webserviceauf Personennamen. Die NB liefert demWebservice Namen von Autoren undPersönlichkeiten, welche mit einer GND-Nummer verknüpft sind. Auf diese Weisekönnen andere Projektpartner von Metagriddie eindeutige, in der Bibliothekswelt weit
verbreitete Identifikationsnummer direktübernehmen.
• In einem Pilotprojekt mit derRechtsquellenstiftung des SchweizerischenJuristenvereins werden seit 2015 von derRechtsquellenstiftung für deren Online-Editionen benötigte Literatur in derDatenbank der BSG erfasst, resp. die schonin der BSG vorhandenen Katalogisateangepasst. 3 Dank dieser Kooperationkönnen Doppelspurigkeiten bei derLiteraturerfassung vermieden, durch diegegenseitige Verlinkung die Visibilitätder verschiedenen Projekte erhöht unddie weiterführende Recherche für dieBenutzenden vereinfacht werden. Die BSGentwickelt sich dadurch von einem aufblosse bibliografische Nachweise orientiertenLiteraturverzeichnis hin zu einem„Literaturportal“ oder „Informationsraum“für Literatur zur Schweizer Geschichte(Wissen 2008: 223ff.). Datenbanken mithistorischem Content erhalten so dieMöglichkeit, Literaturnachweise zurSchweizer Geschichte in der BSG zu holen, zuverlinken und barrierefrei nachzunutzen.
Im Vortrag werden ausgewählte Resultatepräsentiert, die für Forschende der DigitalHumanities potentiell von Interesse seinkönnten, wie zum Beispiel die Inhalte der NBauf Wikimedia Commons , opendata.swiss oderdem Pilotportal Linked Data Service LINDAS, derPrototyp Gugelmann-Galaxy , Verwendungendes Webservices Metagrid und die VeranstaltungOpen Cultural Data Hackathon. Ausserdemwird die Nutzung resp. der Nutzen aus Sichtder NB thematisiert und ein vorläufiges Fazitgezogen. Am Schluss wird bezüglich denHandlungsfeldern und den Kooperationen einAusblick in die nähere und fernere Zukunftgewagt.
Fußnoten
1. OpenGLAM ist eine Initiative von OpenKnowledge International die eine Öffnungder Gedächtnisinstitutionen propagiert. DasSchweizer Chapter von Open KnowledgeInternational ist der Verein opendata.ch .2. Metagrid ist ein Projekt der SchweizerischenAkademie der Geisteswissenschaften SAGW,durchgeführt von den DiplomatischenDokumenten der Schweiz DDS mit derUnterstützung des Historischen Lexikons derSchweiz HLS. Vgl. www.metagrid.ch
195

Digital Humanities im deutschsprachigen Raum 2017
3. Im Rechtsquellenportal des StaatsarchivsZürich werden die in der Datenbank BSGbearbeiteten bibliografischen Aufnahmenim Literaturverzeichnis abgebildet ( http://www.rechtsquellen-online.zh.ch/startseite/literaturverzeichnis ). In der Personendatenbankder Rechtsquellenstiftung hingegen werden fürweiterführende Literatur direkt Links auf dieDatenbank BSG gesetzt (https://www.ssrq-sds-fds.ch/persons-db/?query=per001666&query-type=perid).
Bibliographie
Estermann, Beat (2015): „Diffusionof Open Data and Crowdsourcing amongHeritage Institutions. Based on data fromFinland, Poland, Switzerland, and TheNetherlands“, in: EGPA 2015 Conferencehttp://survey.openglam.ch/publications/EGPA2015_Estermann_Diffusion_of_Open_Data_and_Crowdsourcing_among_Heritage_Institutions_20150901.pdf[letzter Zugriff 26. August 2016].
Estermann, Beat (2013): Swiss HeritageInstitutions in the Internet Era: Results of a pilotsurvey on open data and crowdsourcing, 2013.http://espace.okfn.org/items/show/226 [letzterZugriff 26. August 2016].
Johnson, Larry / Adams Becker, Samantha /Estrada, Victoria / Freeman, Alex (2015):NMC Horizon Report: 2015 Library Edition.Austin, Texas: The New Media Consortiumhttp://www.nmc.org/publication/nmc-horizon-report-2015-library-edition/ [letzter Zugriff 26.August 2016].
Koller, Guido (2016): Geschichte digital.Historische Welten neu vermessen. Stuttgart: W.Kohlhammer.
„GLAM & Wikimedia“, in: arbido, Ausgabe3, 3. September 2015 http://www.arbido.ch/userdocs/arbidoprint/arbido_2015_3_low.pdf[letzter Zugriff 26. August 2016].
Open Knowledge Foundation (2013):OpenGLAM Principles. http://openglam.org/principles/ [letzter Zugriff 26. August 2016].
Sanderhoff, Merete (ed.) (2014): Sharingis caring. Openness and sharing in the culturalheritage sector. http://www.smk.dk/en/about-smk/smks-publications/sharing-is-caring/ [letzterZugriff 26. August 2016].
Pekel, Joris (2014): Democratising theRijksmuseum, Europeana Foundation http://espace.okfn.org/items/show/260 [letzter Zugriff26. August 2016].
Schweizerische Nationalbibliothek (2014):Strategie 2012 – 2019, Version 2014 http://www.nb.admin.ch/org/00779/index.html?
lang=de&download=NHzLpZeg7t,lnp6I0NTU042l2Z6ln1acy4Zn4Z2qZpnO2Yuq2Z6gpJCEdoR3fWym162epYbg2c_JjKbNoKSn6A--[letzter Zugriff 26. August 2016].
Silipigni Connaway, Lynn / Dickley, Timothy J.(2010): The Digital Information Seeker: Report ofthe Findings from Selected OCLC, RIN, and JISCUser Behaviour Projects http://www.jisc.ac.uk/media/documents/publications/reports/2010/digitalinformationseekerreport.pdf [letzterZugriff 26. August 2016].
Terrass, Melissa (2016): Opening Accessto Collections: the Making and Using of OpenDigitised Cultural Content. http://espace.okfn.org/items/show/259 [letzter Zugriff 26. August 2016].
The Europeana Public Domain Charter(2010): http://pro.europeana.eu/files/Europeana_Professional/Publications/Public%20Domain%20Charter%20-%20DE.pdf [letzterZugriff 26. August 2016].
Wissen, Dirk (2008): Zukunft derBibliographie – Bibliographie der Zukunft. EineExpertenbefragung mittels Delphi-Technik inArchiven und Bibliotheken in Deutschland,Österreich und der Schweiz. Berlin: Logos.
Semantische Suchein AusgestorbenenSprachen: Eine Fallstudiefür das Hethitische
Daxenberger, [email protected] Knowledge Processing Lab,Department of Computer Science, TechnischeUniversität Darmstadt
Görke, [email protected] Philologie, Institut fürAltertumswissenschaften, Johannes Gutenberg-Universität Mainz
Siahdohoni, [email protected] Knowledge Processing Lab,Department of Computer Science, TechnischeUniversität Darmstadt
196

Digital Humanities im deutschsprachigen Raum 2017
Gurevych, [email protected] Knowledge Processing Lab,Department of Computer Science, TechnischeUniversität Darmstadt
Prechel, [email protected] Philologie, Institut fürAltertumswissenschaften, Johannes Gutenberg-Universität Mainz
Einleitung
Mit dem Auftreten der Keilschrift am Endedes 4. Jt. v. Chr. bis zur Zeitenwende sindzahlreiche Sprachen des Vorderen Orientsaufgezeichnet, deren Kenntnis sich heute alleindem Erhalt der Schriftträger dankt: Eine nichtmehr überschaubare Anzahl von Tontafeln stelltdas wesentliche Medium zur Rekonstruktioneiner alle menschlichen Lebensbereicheumfassenden dreitausendjährigen Geschichteder heutigen Staaten Syrien, Libanon, Türkei,Irak und Iran dar. Zu den besser bezeugtenSprachen gehört neben dem semitischenAkkadischen das isolierte Sumerisch unddas indoeuropäische Hethitisch. Auchwenn sich inzwischen diverse Projekte mitder Digitalisierung des keilinschriftlichenKulturschatzes befassen, z.B. Cohen et al.(2004) und Tyndall (2012), ist der Zugangzu den kulturell, historisch und linguistischhochbedeutsamen Textcorpora, die zu großenTeilen noch unpubliziert in den Museen derWelt lagern, meist auf Fachwissenschaftlerbegrenzt. Um eine adäquate Verwendungder durch Grabungen stetig wachsendenAnzahl von Texten auch in fernerliegendenArbeitsbereichen zu ermöglichen, ist einumfassendes Angebot von Übersetzungen inmoderne Sprachen höchst wünschenswert.
Das hier skizzierte Projekt zielt insbesondereauf den Umstand, dass selbst die (wenigen)vorhandenen Übersetzungen aufgrund derDurchdringung mit autochtonen Terminies oft an Verständlichkeit vermissen lassen.Das Ziel unserer Pilotstudie ist eine digitaleAnnäherung an Keilschriftsprachen. Wirstellen eine erweiterte Suchfunktion vor,die es auch fachfremden Benutzern erlaubt,intelligente Suchanfragen in den hethitischenund akkadischen Textcorpora zu stellen. Dazuverwenden wir moderne Natural LanguageProcessing (NLP) Methodologie, die automatisiertlexikalisch-semantische Informationen in
mehrsprachigen Übersetzungen von aktuell gut500 Keilschriftdokumenten extrahiert. Durchden Einsatz vollautomatischer Methoden istdas Hinzufügen neuer Übersetzungen jederzeitmöglich – es gibt alleine für das Akkadische übereine halbe Million (noch) nicht digitalisierterQuelltexte. Das Ergebnis unserer Studie istin Form eines webbasierten Tools verfügbarund wurde in einer Benutzerstudie evaluiert.Die primären Anforderungen an das Tool 1
sind a) die Rückgabe von Suchergebnissen, dieneben exakten oder fast exakten Treffern auchsolche enthalten, die aufgrund semantischerÄhnlichkeit zustande kommen, sowie b) eineintuitive Bedienung durch Nutzer, die wedermit der Sprache noch mit sonstigen kulturellenGegebenheiten vertraut sind.
Vorarbeiten
Bereits seit Längerem wird an der digitalenMethodik zur Verarbeitung von Sprachendes Alten Orients geforscht. Dabei spielteinsbesondere die automatisierte morphologischeVerarbeitung eine Rolle, siehe bspw. Barthélemy(1998) und Kataja (1988). Neuere Arbeiten setzengrößtenteils auf statistische Verfahren anstellevon regelbasierten Ansätzen. Darunter fallenbspw. Liu et al. (2015) mit einer Studie zurLemmatisierung für Sumerisch sowie Homburgund Chiarcos (2016) zur Wort-Segmentierungim Akkadischen. Im Rahmen des ORACCProjekts werden Tools zur Annotation derMorphologie in Keilschriftsprachen entwickelt,überwiegend für Akkadisch und Sumerisch. 2
Zur semantischen Analyse von Keilschrifttextenexistieren hingegen kaum Arbeiten. LediglichJaworski (2008) entwickelte eine Ontologie fürsumerische ökonomische Aktivitäten, die miteiner semantischen Grammatik dargestelltwerden können. Einen Überblick über dielexikalisch-semantischen Analyseverfahren,die in dieser Arbeit zum Einsatz kommen,gibt bspw. Gurevych et al. (2016). Soweit unsbekannt ist, gab es bislang keine Studien, dieuntersuchen, inwiefern Keilschrifttexte bzw.deren Übersetzungen mittels semantischer-lexikalischer Verfahren für ein breiteresPublikum zugänglich gemacht werden können.
Methodik
Um semantische Suche in Keilschrifttextenzu ermöglichen, haben wir zunächst dietransliterierten und übersetzten Texte
197

Digital Humanities im deutschsprachigen Raum 2017
vorverarbeitet und für die Suche indexiert.Danach werden sie in einer Datenbank abgelegt,in der mittels einer webbasierten Oberflächegesucht werden kann.
Daten
Die Texte, die im Rahmen dieser Studieverarbeitet wurden, sind überwiegendhethitische, in Keilschrift verfasste Dokumente(Wilhelm 2008). Die Transliterationen undÜbersetzungen (auf Deutsch, Englisch, Italienischund Französisch) wurden an der JohannesGutenberg-Universität Mainz sowie vonPartnern an weiteren Forschungseinrichtungenim In- und Ausland erstellt. Die Originaltextestammen aus Anatolien (heutige Türkei) unddatieren in die zweite Hälfte des 2. Jt. v. Chr.Inhaltlich handelt es sich vornehmlich umreligiöse Texte wie bspw. Gebete oder Rituale.Die Dokumente sind auf Satz- oder Teilsatzebeneübersetzt und mit den Transliterationenabgeglichen, so dass einfach Bezüge zwischenden Übersetzungen und den Transliterationenhergestellt werden können. Für jedes Dokumentexistiert ein Einleitungstext, sowie jeweilseine (kommentierte) Übersetzung und eineTransliteration, siehe Abbildung 1. Die Texte sindunabhängig von dieser Arbeit online zugänglich.3
Abbildung 1: Eine manuell erstellteTransliteration (links) und normalisierteÜbersetzung (rechts). Quelle: http://www.hethport.uni-wuerzburg.de
NLP Pipeline zurVorverarbeitung der Texte
Die Übersetzungen und Transliterationenwerden direkt aus einem Textformat ineine Pipeline eingelesen, die die weiterelinguistische Vorverarbeitung übernimmt.Diese Pipeline erkennt die Struktur der
Eingabedokumente, bspw. Dokument-Titel, Sätze,Absätze oder Fußnoten. Außerdem werdendie zusammengehörigen Übersetzungen undTransliterationen auf (Teil-)Satzebene gekoppelt.Anschließend werden die mehrsprachigenÜbersetzungen mit Hilfe des NLP FrameworksDKPro Core ( Eckart de Castilho und Gurevych2014) analysiert. DKPro Core vereint dieVerwendung verschiedener NLP Werkzeugezur linguistischen Verarbeitung. So ist esmöglich, den Inhalt der Dokumente in vierSprachen zu segmentieren, zu lemmatisierenund nach Wortarten auszuzeichnen. 4 Imnächsten Schritt werden unter Zuhilfenahmedes Lesk Algorithmus (Lesk 1986) mehrdeutigeLemmata anhand ihres Kontexts disambiguiert.Dieser Schritt ist die Voraussetzung für dieanschließende Zuweisung von sogenanntensemantischen Labeln, die einzelne Lemmatamit abstrakteren Konzepten anreichert. Bspw.werden Verben, die eine Bewegung anzeigen,mit einem Label „Bewegung“ gekennzeichnet.Als Ergänzung zu diesen vollautomatischenVerfahren erlaubt es die Pipeline, manuellerstellte Listen für alternative Schreibweisenund Hyperonyme anzuwenden. 5 Darinenthalten sind bspw. geographische Einheitenoder Namen von hethitischen Königen oderGottheiten, die in den lexikalisch-semantischenRessourcen, die im Schritt zuvor eingesetztwerden, nicht oder nur teilweise enthaltensind. Bspw. werden verschiedene Namen desWettergottes (u.a. Taru, Teššup) als solchegelistet. Das Endresultat der Pipeline wird ineinem Zwischenformat gespeichert, so dasses anschließend in eine Datenbank importiertwerden kann.
Semantische Suchmaschine:Back- und Frontend
Eine MYSQL Datenbank nimmt dieDokumente inklusive der von der NLP Pipelinegenerierten zusätzlichen semantischenInformationen auf und legt diese in indexiertenTabellen ab. Suchanfragen über dasWebinterface werden in entsprechendeAbfragen auf die Tabellen übersetzt. DieAnordnung der Suchergebnisse wird über einePriorisierung der verschiedenen zusätzlichenInformationen geregelt. Wörtliche Trefferwerden entsprechend höher gerankt als solche,die durch Übereinstimmung mit semantischenLabeln oder alternativen Schreibweisenzustande kommen.
198

Digital Humanities im deutschsprachigen Raum 2017
Das Frontend der Suchmaschine bestehtaus dem Eingabefeld für einen oder mehrereSuchbegriffe. Die Suchergebnisse werden proDokument gebündelt und angeordnet nach derGüte der Übereinstimmung mit dem Suchbegriff.Abbildung 2 zeigt die Benutzeroberflächenach einer Suchanfrage. Ein Klick auf einSuchergebnis öffnet ein Fester, das denInhalt des gesamten Dokuments jeweils alsÜbersetzung und Transliteration zeigt.
Abbildung 2: Das Frontend mit Ergebnissenzu einer Suchanfrage.
Evaluation
Um zu überprüfen, ob die Suchmaschinedie eingangs gestellten Anforderungenerfüllt, haben wir eine anonyme Online-Benutzerstudie mit 23 Fragen unter 27Teilnehmern 6 durchgeführt. Die Mehrheit derTeilnehmer waren Studierende an deutschenUniversitäten. Etwa die Hälfte hatte einengeisteswissenschaftlichen Studienhintergrund,die andere Hälfte einen technischen. Inhaltlichbestand die Benutzerstudie aus einer kurzenEinleitung sowie drei Teilen mit Fragen. Dererste Teil beinhaltete einfache Fragen, diedas allgemeine Verständnis der Suchabfragenüberprüfen sollten (bspw. Suche nach einemBegriff in einem bestimmten Dokument). Derzweite Teil zielt explizit auf den semantischenTeil der Suchfunktion ab (bspw. Suche nach demNamen einer Gottheit). Im dritten Teil wurde dieallgemeine Bedienbarkeit und Nützlichkeit desTools erfragt.
Mit wenigen Ausnahmen wurdendie Aufgaben aus dem ersten Teil derBenutzerstudie von allen Teilnehmern korrektgelöst. Im zweiten Teil mussten diversehethitische Gottheiten, Könige oder Städtenamentlich benannt werden, diese Aufgabe
konnten sämtliche Teilnehmer korrekt lösen.Eine Frage, in der die (nicht vorhandene)Beziehung zwischen zwei Gottheiten anhand vonSuchergebnissen bestimmt werden sollte, wurdenur von etwa zwei Dritteln der Teilnehmerkorrekt gelöst. Tabelle 1 fasst die Abfragenund Ergebnisse aus dem dritten Teil derBenutzerstudie zusammen.
Kriterium Durchschnittswert (1-5)Sortierung der Ergebnissebasierend auf einerkonkreten Suchanfrage
4.15
Benutzerfreundlichkeitder Weboberfläche
4.19
Allgemeine Qualität derSuchergebnisse
4.26
Nützlichkeit fürFachfremde
4.3
Tabelle 1: Kriterien und Bewertungen(Auswahlmöglichkeiten zwischen 1 = sehrschlecht und 5 = sehr gut) des dritten Teils derBenutzerstudie.
Diskussion
In der Gesamtheit zeigen die Ergebnisseder Benutzerstudie, dass das Tool die eingangsgestellten Anforderungen erfüllt. Nebenden zu lösenden Aufgaben gab es auch dieMöglichkeit, per Freitextfeld Rückmeldung zugeben. Die so identifizierten Probleme sindzurückzuführen auf a) fehlende Erklärungenzur Formulierung von Suchanfragen, b)Fehlern in den manuell erstellten Listen mitalternativen Schreibweisen und Hyperonymen,und c) irreführender Hervorhebung vonWörtern bei Ergebnissen, die auf semantischeÜbereinstimmung zurückzuführen sind.
Zu den allgemeinen Herausforderungen beider Aufbereitung der Daten für die semantischeSuche zählt u.a. die Fragmenthaftigkeit diverserTexte. Da solche Phänomene zu Fehlern inder NLP Vorverarbeitung (bspw. bei derSegmentierung) führen, wurde eine Komponentein die Pipeline integriert, die Lücken soweitmöglich repariert. Der „Vocabulary Gap“zwischen den Termini in den lexikalisch-semantischen Ressourcen und dem in denÜbersetzungen tatsächlich verwendetenVokabular hat letztlich dazu geführt, dasszusätzlich manuell erstellte Wortlisten eingesetztwurden. Diese Listen müssen allerdings nureinmal erstellt werden und haben einenüberschaubaren Umfang.
199

Digital Humanities im deutschsprachigen Raum 2017
Neben der Behebung der oben genanntenProbleme ist als nächster Schritte u.a.vorgesehen, das Backend um eine Funktion zumeinfachen Upload neuer, transliterierter undübersetzter Texte in die Datenbank zu erweitern.Wir sind zuversichtlich, dass mit dieser Studieein erster Schritt hin zu einer einfacherenErschließung des Inhalts keilschriftlicherQuellen genommen ist.
Fußnoten
1. Zugänglich unter http://semsearch.ukp.informatik.tu-darmstadt.de.2. http://oracc.museum.upenn.edu3. http://www.hethiter.net4. Die gesamte Verarbeitungspipeline wurdehier veröffentlicht: https://github.com/UKPLab/DHd2017-semsearch-cuneiform5. Die Listen können hier eingesehen werden:https://github.com/UKPLab/DHd2017-semsearch-cuneiform6. Das Geschlecht wurde nicht erfasst, wirbeziehen uns jeweils auf alle Teilnehmerinnenund Teilnehmer.
Bibliographie
Barthélemy, François (1998): „Amorphological analyzer for akkadianverbal forms with a model of phonetictransformations“, in: Proceedings of theWorkshop on Computational Approaches toSemitic Languages 73–81.
Cohen, Jonathan / Duncan, Donald / Snyder,Dean / Cooper, Jerrold / Kumar, Subodh /Hahn, Daniel / Chen, Yuan / Purnomo,Budirijanto / Graettinger, John (2004): „iClay:Digitizing Cuneiform“, in: Proceedings of theInternational conference on Virtual Reality,Archaeology and Intelligent Cultural Heritage135–143.
Eckart de Castilho, Richard / Gurevych,Iryna (2014): „A broad-coverage collection ofportable NLP components for building shareableanalysis pipelines“, in: Proceedings of theWorkshop on Open Infrastructures and AnalysisFrameworks for HLT at COLING 1–11.
Gurevych, Iryna / Eckle-Kohler, Judith /Matuschek, Michael (2016): Linked Lexical-Semantic Knowledge Bases: Foundations andApplications. Morgan & Claypool Publishers.
Homburg, Timo / Chiarcos, Christian (2016):„Word Segmentation for Akkadian Cuneiform“,in: Proceedings of the International Conference onLanguage Resources and Evaluation.
Jaworski, Woyciech (2008): „ContentsModelling of Neo-Sumerian Ur III EconomicText Corpus“, in: Proceedings of the InternationalConference on Computational Linguistics 369–376.
Kataja, Laura / Koskenniemi, Kimmo (1988):„Finite-state description of semitic morphology:a case study of Ancient Akkadian“, in:Proceedings of the Conference on ComputationalLinguistics 313–315.
Lesk, Michael (1986): „Automatic sensedisambiguation using machine readabledictionaries: how to tell a pine cone froman ice cream cone“, in: Proceedings of theAnnual International Conference on SystemsDocumentation 24–26.
Liu, Yudong / Burkhart, Clinton / Hearne,James / Luo, Liang (2015): „Enhancing SumerianLemmatization by Unsupervised Named-EntityRecognition“, in: Proceedings of the Conference ofthe North American Chapter of the Association forComputational Linguistics 1446–1451.
Tyndall, Stephen (2012): „TowardAutomatically Assembling Hittite-languageCuneiform Tablet Fragments into Larger Texts“,in: Proceedings of ACL-2012 243–247.
Wilhelm, Gernot (2008): „Die Edition derKeilschrifttafeln aus Boğazköy und das Projekt‚Hethitische Forschungen‘ der Akademie derWissenschaften und der Literatur, Mainz“,in: Wilhelm, G. (ed.): Hattuša - Boğazköy: DasHethiterreich im Spannungsfeld des Alten Orients.Wiesbaden: Harrassowitz 73–86.
The Colorized Dead:ComputerunterstützteAnalysen derFarblichkeit vonFilmen in den DigitalHumanities am Beispielvon Zombiefilmen
Pause, [email protected] Universität Dresden, Deutschland
200

Digital Humanities im deutschsprachigen Raum 2017
Walkowski, [email protected] Akademie derWissenschaften, Deutschland / KU Leuven,Belgien
Ein Aspekt, der zunehmende Aufmerksamkeitin der jüngeren Geschichte algorithmischerund statistischer Filmanalyse gewinnt, ist dieAnalyse der Farbigkeit von Filmen. Ein frühesBeispiel ist die stark rezipierte Abschlussarbeitdes Grafikdesignstudenten Frederick Brodbeck(2011) (siehe Abbildung 1), der für eine Sequenzvon Frames aus verschiedenen Filmen diedominanten Farben analysiert, aneinanderreihtund so ein Farbprofil des Films erzeugt. Einenähnlichen Ansatz verfolgen Dillon Baker (2015)sowie Burghardt (2016). Die genannten Beispieleweisen sind jedoch trotz des interessantenEinblicks den sie bieten nicht unproblematisch.
Abbildung 1: Beispiele eines Farbclusteringsverschiedener Filme bei Brodbeck (2011)
Im Fall von Brodbeck und Burghard t wirdfür die Bestimmung der dominanten Farbenin einem Frame der Clustering-Algorithmus K-Means verwendet 1 . Dieser Algorithmus istdie gängigste Strategie zur Farbquantifizierungund findet sich auch in den einschlägigenComputer Vision Bibliotheken wie zum BeispielOpenCV 2 wieder . Die Problematik von K-Means im Kontext der filmwissenschaftlichenFarbanalyse ist vielfältig. Sie beginnt damit, dassdem Algorithmus vorgegeben werden muss,wie viele Farbcluster er erzeugen soll. Somitkann er bei der automatisierten Anwendungvon bis zu 180.000 Frames pro Film nicht demUmstand Rechnung tragen, dass es etwa farblichkomplexere und einfachere Frames gibt.
Tatsächlich gibt es ein überwachtesVerfahren in dem K-Means in einer Schleifemit unterschiedlicher Clusteranzahl auf denselben Frame angewendet wird und im Sinnedes sogenannten Silhouette Koeffizienten dasbester Ergebnis bestimmt wird. Allerdingsentspricht ein Clusteringergebnis bei dem dieClusterzentren bei weitestgehender Kompaktheitmöglichst weit voneinander entfernt sind
nicht unbedingt dem filmwissenschaftlichbrauchbarsten Ergebnis (siehe Abbildung 2).
Abbildung 2: Clusteranalyse eines Framesaus The Walking Dead mit 2 bis 9 Clustern.Die Anzahl von 2 Clustern erzeugt den bestenSilhouette Koeffizienten.
Intuitiv wichtige Farben eines Bildesgehen verloren. Dieses generelle Problem derAnwendung von K-Means lässt sich besonderseindrucksvoll an dem roten Mädchen ausSchindlers Liste aufzeigen (siehe Abbildung3). Ein Grund dafür ist die Tatsache, dass K-Means eine Tendenz zur Bildung gleichgroßerCluster aufweist. Folglich präferiert K-Means einauf Verteilung hin ausgerichtetes Konzept vonDominanz.
Ein weiteres Problem von K-Means istder Umstand, dass der Algorithmus bei jederAnwendung leicht variierende Ergebnisseerzeugt, wobei die Variation im häufigverwendeten Spektrum zwischen 3 und 5Clustern am größten ist. Dies kann dazuführen, dass bei einer Anwendung ein Farbtonvertreten ist, der in einem weiteren Durchlaufin anderen Clustern aufgeht. Ebenfallsbleibt in den bisherigen Projektkontextender Umstand unreflektiert, das K-Meansunterschiedlich clustered, je nachdemmit welchem Farbraummodell der Framerepräsentiert wird.
Abbildung 3: Farbclustering eines Ausschnittsaus Schindlers Liste
201

Digital Humanities im deutschsprachigen Raum 2017
Das Problem der Präferenz für einegleichmäßige Größe von Clustern sowie daszuletzt genannte zeigen die Notwendigkeitauf, die Idee einer dominanten Farbe imKontext der computerunterstützten Filmanalysestärker zu diskutieren. Dies ist bisher jedochnur unzureichend erfolgt. Ein Mitgrundhierfür ist der Umstand, dass die genanntenProjekte keine filmwissenschaftliche Deutungin Zusammenhang mit ihren Entwicklungenpubliziert haben. Dadurch bleibt völlig offen,welche Semantik die erzeugten Muster tragenund inwieweit sie die Interpretation von Filmenbeziehungsweise Filmkorpora inspirierenkönnen. Dieser eher theoretische Problematikläßt sich auch nicht durch ein Ausweichen aufandere Clustering-Algorithmen wie DBSCANoder Verfahren wie hierarchisches Clusteringentgehen.
Angesichts der genannten Probleme erscheintdie Entwicklung eines Ansatzes vonnöten,der einen technisch weniger anfechtbarenAusgangspunkt für eine computergestützteUntersuchung von Farben im Film liefertund zugleich Anschlüsse für möglicheInterpretationen der Werke bereitstellt.Ein in diesem Zusammenhang produktivesKonzept könnte das Modell der “SiebenFarbkontraste“ des Bauhaus-Künstlers undKunstpädagogen Johannes Itten darstellen(Itten 1961: 36-109), welches die Strukturenvon Farblichkeit innerhalb eines Bildes zusystematisieren erlaubt. Ausgehend von derGrundannahme, dass Farben ihre Wirkungimmer in Abhängigkeit von anderen im Blickfeldbefindlichen Farben entfalten, unterscheidetItten sieben grundlegende Kontrasttypen:
• den Farbe-an-sich-Kontrast, in demungetrübte und daher deutlichunterscheidbare Primär-, Sekundär- oderSpektralfarben aufeinander stoßen,
• den Hell-Dunkel-Kontrast,• den Kalt-Warm-Kontrast,• den Qualitätskontrast, der zwischen
gesättigten und trüben Farben entsteht,• den Quantitätskontrast, der sich aus der
Größe der gegenübergestellten Farbflächenergibt,
• den Komplementärkontrast sowie• den diesem entgegengesetzten
Simultankontrast, in dem gerade das Fehleneiner Komplementärfarbe zur subjektivenVerzerrung der dargestellten Farbflächenführt.
Jeder dieser Kontrasttypen ist nach Ittenmit spezifischen wirkungsästhetischenEinsatzmöglichkeiten verknüpft: So steuernsie etwa die Aufmerksamkeit der Zuschauer,ermöglichen Raumwirkungen, schaffenOrientierung oder Desorientierung, unterstützendie symbolische Semantik der Bilder oderlösen Assoziationen und Emotionen aus. Auchwenn sich die meisten dieser Effekte nichtgeneralisieren lassen, erscheint hier eineallgemeine rezeptionsästhetische Beschreibungdoch eher möglich als bei einer Interpretationvon Einzelfarben (etwa Rot als Signalfarbe, Blauals Symbol für Trauer oder Tod usw.), wie sie inder Filmanalyse bis heute Einsatz findet (etwabei Marschall 2009).
Eine computergestützte Bestimmungnicht nur des generellen Farbclusters einesFilmes, sondern der in ihm angelegtenwesentlichen Kontrasttypen kann einen erstenAnsatz für eine differenzierte Interpretationfilmischer Farbschemata liefern. So kann einFilm etwa durch einen über den gesamtenFilmverlauf hinweg stabilen Gegensatz vonwarmen und kalten Farben gekennzeichnetsein, auf der Ebene des Hell-Dunkel-Kontrastes aber eine deutlich progressiveDynamik aufweisen (zu progressiven undsynopitschen Farbschemata vgl. Wulff 1988)und in wenigen besonderen Szenen starkeKomplementärkontraste verwenden. Eine aufdiese Weise ausbuchstabierte Entschlüsselungder komplexer Farbaspekte eines Films ließesich dabei einerseits im Rahmen eines closereadings zurate ziehen, indem etwa diedynamischen Aspekte der Farbgestaltung aufdie Erzählstruktur des Werkes bezogen oder mitder Analyse inhaltlicher Leitmotive, bestimmterFiguren, dominanter Montageformen oderdes Mise en Scènes verbunden werden (zurgenerellen Problematik der Interpretation vgl.Flückiger 2011).
Andererseits ließe sich einecomputergestützte Kontrastanalyse für einensynchronen oder diachronen Vergleich mehrererEinzelwerke oder ganzer Werkgruppeneinsetzen: So ließe sich etwa überprüfen, ob sichder spezifische Stil eines Autorenfilmers auchin einem besonderen Farbprofil niederschlägt,ob sich nationale Kinematographien durchihre Farbigkeit unterscheiden lassen oder obsich für bestimmte Genres innerhalb konkreterZeitspannen ein charakteristischer Einsatzbesonderer Kontrastmomente nachweisen lässt.
Die Farbanalyse von Filmen in Form vonKontrasten bietet in der Umsetzung ebenfalls eine Reihe von Vorteilen gegenüber der zuvorbeschriebenen Verfahrensweise. Zunächst
202

Digital Humanities im deutschsprachigen Raum 2017
einmal erlauben einige Kontrastarten bereits dieUntersuchung von Merkmalen der Farbsprachedes Films vor der Identifikation zentralerFarben eines Frames und damit jenseits derAnwendung genannter Cluster-Algorithmen.Dies wird dadurch möglich, dass spezifischeRepräsentationen des Farbraums Farben inEigenschaften zerlegen, die direkt versuchenbestimmte Kontraste zu simulieren oder ausdenen sich Kontraste leichter ableiten lassen. Ameinsichtigsten ist dies im HSV-Farbmodel (Hue,Saturation, Value).
So is Value eine Form der Darstellung desHell-Dunkel-Kontrast, während Saturationden Qualitätskontrast beschreibt. Zu beachtenist hier jedoch auch, dass der Value Wertnicht vollständig identisch mit der Hell-Dunkel Empfindung eines durchschnittlichenFilmbetrachters ist. Eine Übersetzung in einensolch empfunden Hell-Dunkel Kontrast ist jedochmöglich.
Die Dynamik eines bestimmten Kontrastesin einem Film kann nun erzeugt werden,indem für jeden extrahierten Frame einHistogramm für den entsprechendenKontrasttyp generiert wird. Die Sequenz dieserWerte lässt es zu, Muster in der Gestaltungdieses Kontrastes innerhalb des Films odereines Filmkorpus zu identifizieren. Dabeibieten unterschiedliche Darstellungsweisender Histogrammergebnisse in Kombinationmit weiteren Phänomenen wie zum Beispielder Berechnung des mean absolute deviationweiteren Deutungsspielraum. Ein Beispiel füreine sequenzielle Aneinanderreihung vonHistogrammen eines Kontrasttyps als Scatterplotzeigt Abbildung 4.
Abbildung 4 : Scatterplot einer Histogramm-basierten Analyse des Hue Kontrasts in 28 DaysLater
Nicht alle Kontraste kommen ohne dieBestimmung eines als absolut verstandenenFarbwertes aus. Dies ist zum Beispiel beimSimultan- und Komplementärkontrast derFall. Der vorgestellte Ansatz ist auch nichtals Ersetzung von Clusteringverfahren zuverstehen. Beide Verfahren können auchkomplementär eingesetzt werden. So kanneine Analyse des Farbe-an-sich-Kontrastesder Schwierigkeit entgegenwirken, dass K-Means einer vorgegebenen Clusterzahl folgt,bzw. der Silhouette Koeffizient keine für die
Filminterpretation brauchbaren Ergebnisseproduziert. Konkret kann ein hoher Farben-an-sich-Kontrast zum Anlass für die Bestimmungeiner größeren Clusterzahl und umgekehrtgenutzt werden. Desweiteren erlaubt dasVerständnis von Farbigkeit als Kombinationvon Kontrasten das eingangs angesprochenePhänomen zu untersuchen und produktivanzuwenden, dass K-Means für Daten dieunterschiedlichen Farbraummodellen folgenunterschiedliche Ergebnisse liefert.
Der Hauptpunkt dieses Ansatzes ist es nicht‘objektiv richtigere’ Clusteringergebnisse zubekommen, sondern auf der Grundlage derErkenntnis das es kein ‘richtiges’ Clusteringvon Farben in Farbkompositionen gebenkann, hilfreiche und interpretierbareErgebnisse mit gleichen und komplementärenVerfahren zu produzieren. Der Kern von IttensHerangehensweise an Farbkompositionenist die Erkenntnis, dass ihre Analyse imwesentlichen ein wahrnehmungstheoretischesProblem ist. Entsprechend kann es erfolgreichersein, bei der Herausarbeitung bestimmterDimensionen von Farblichkeit zu beginnenanstatt die Varianz in diesen Dimensionendurch Clustering vor jeglicher Analyse zureduzieren. Die angedeuteten Verfahren zeigen,dass es technisch gesehen nicht schwierig seinmuss, diesem Umstand innerhalb einer DigitalHumanities Perspektive Rechnung zu tragen.Der Vortrag wird die aufgezeigten Probleme beider Farbanalyse von Filmen, den vorgestelltenalternativen Ansatz sowie die Brauchbarkeitdieses Ansatzes als unterstützendesRahmenwerk für die Filminterpretation an Handder drei Zombiefilme 28 Days Later , [REC] undWorld War Z vorstellen und illustrieren.
Fußnoten
1. Baker erzeugt lediglich ein Frame-Mittelwertund benötigt daher kein Clustering2. http://opencv.org
Bibliographie
Brodbeck, Frederic (2011): CINEMETRICS— film data visualization. http://cinemetrics.fredericbrodbeck.de/ [letzter Zugriff26. August 2017].
Burghardt, Manuel / Kao, Michael / Wolff,Christian (2016): „Beyond Shot Lengths –Using Language Data and Color Information asAdditional Parameters for Quantitative Movie
203

Digital Humanities im deutschsprachigen Raum 2017
Analysis“, in: DH2016: Conference Abstracts 753–755.
Dillon Baker (2015): „Spectrum“. DillonBaker. http://dillonbaker.com/spectrum/ [letzterZugriff 16. Mai 2016].
Flückiger, Barbara (2011): „Die Vermessungästhetischer Erscheinungen“, in: Hediger,Vinzenz / Stauff, Markus (eds.): Zeitschrift fürMedienwissenschaften 5: 44–60.
Itten, Johannes (1961): Kunst der Farbe.Ravensburg: Otto Maier Verlag.
Marschall, Susanne (2009): Farbe im Kino.Marbug: Schüren Verlag.
Wulff, Hans J. (1988): „Die signifikativenFunktionen der Farben im Film“, in: Kodikas/Code 11 (3–4): 363–376.
VonsammlungsspezifischenVisualisierungenzu nachnutzbarenWerkzeugen
Glinka, [email protected] Potsdam
Pietsch, [email protected] Potsdam
Dörk, [email protected] Potsdam
Einleitung
Die Entwicklung digitaler Werkzeuge lässtsich als wichtiger Teilbereich in den DigitalHumanities identifizieren (Davis und Kräutli2015; Schnapp et al. 2009). EntsprechendeForschung und Projektarbeit steht dabeikomplexen Herausforderungen gegenüber.Nicht nur die Frage nach verfügbarenDaten, methodologischer Fundierung undtechnologischer Umsetzbarkeit, sondernauch die Frage nach deren langfristigenVerfügbarmachung sind wiederkehrendeThemen in den Diskursen der letzten Jahre.Abgesehen von textbasierten Anwendungen
in Digital Humanities (Cheema et al. 2015)etablieren sich zunehmend Projekte undForschungsfragen im Bereich der Kunst- undBildwissenschaften als Digital Art History(Bentkowska-Kafel et al. 2005; Drucker 2013;Promey und Stewart 1997). Eine zentraleRolle für die Sicherstellung von Qualität undAnwendbarkeit der digitalen Werkzeuge,die sowohl für textbasierte Forschung alsauch im Bereich der Kunstgeschichte undBildwissenschaften entwickelt werden, istdie Einbindung von Forscher_innen derjeweiligen geisteswissenschaftlichen Disziplinenim Entwicklungsprozess (Drucker 2013).Gleichzeitig lässt sich die zentrale Bedeutungvon Interfacedesign, Nutzungsanleitungenund Benutzerfreundlichkeit als wichtigeFaktoren für die Etablierung von digitalenWerkzeugen im Forschungsprozess feststellen(Gibbs und Owens 2012). Doch selbst wenn dieseHerausforderungen bewältigt werden und eindigitales Werkzeug (erfolgreich) entwickeltwurde, stellt sich weiterhin die Frage, wiedie langfristige Nachnutzung im Sinne einerdigitalen Nachhaltigkeit sichergestellt werdenkann. Am Beispiel des Entstehungsprozesseseiner sammlungsspezifischen Visualisierungund deren Weiterentwicklung zu einemnachnutzbaren Werkzeug für diverseBildbestände werden einige zentrale Aspekte derbeeinflussenden Faktoren und Lösungsansätzevorgestellt. Unser Beitrag stellt sich somitder Frage, wie sichergestellt werden kann,dass digitale Tools auch über die Laufzeit vonFörderprojekten hinaus (und unabhängig vonspezifischen Use-cases) dauerhaft nutzbar undweiterentwickelbar sind.
Visualisierung derZeichnungen FriedrichWilhelms IV.
Im Rahmen des dreijährigen BMBFForschungsprojektes “Visualisierungkultureller Sammlungen (VIKUS)” wurde an derFachhochschule Potsdam (FHP) in Kooperationmit der Stiftung Preußische Schlösser undGärten (SPSG) ein webbasierter Prototyp[1]entwickelt, welcher historische Zeichnungenvon Friedrich Wilhelm IV. aus den Beständen derGraphischen Sammlung der SPSG visualisiertund in einem explorativen Interface verfügbarmacht (Glinka et al. 2016). Die Entwicklungder Visualisierungsumgebung zu FriedrichWilhelm IV., abgekürzt FW4, war zunächst
204

Digital Humanities im deutschsprachigen Raum 2017
spezifisch auf diesen Sammlungsbestandzugeschnitten und wurde kollaborativ ininterdisziplinären Workshops vorangetrieben.Während des Entwicklungsprozesses wurdenZwischenergebnisse, Wireframes, Mock-Ups und Vorüberlegungen auf öffentlichenWorkshops, im Rahmen von Vorträgen, aufKonferenzen und als Teil einer Ausstellungpräsentiert und diskutiert. Bereits zu diesemZeitpunkt zeichnete sich der Bedarf und dasInteresse anderer Sammlungsinstitutionen undForschungsgruppen an den Funktionen undDarstellungsmodi der Visualisierung ab. Trotzder ursprünglichen Entwicklungsfokussierungauf den FW4-Sammlungsbestand, stellten sichgrundlegende Funktionen und Strukturenals potenziell generalisierbar und auf andereBestände übertragbar heraus. Zentral hierbeiist die generische Struktur, entlang derer nichtnur die Sammlung von Friedrich WilhelmsZeichnungen organisiert ist, sondern welcheein zentrales Ordnungselement zahlreicherSammlungen darstellt: zeitliche Einordnungund Verschlagwortung. Somit entwickelte sichaus dem Ansatz einer sammlungsspezifischenVisualisierungsumgebung das Konzeptfür ein digitales Werkzeug. Diese nächsteEntwicklungsstufe erprobte zunächst dieÜbertragung auf vier weitere Beständein enger Kooperation mit den jeweiligenSammlungsinstitutionen und folgt dabei demAnspruch, die technologischen Lösungenund darstellerischen Optionen langfristigund nachhaltig für zahlreiche weitereAnwendungsfälle zugänglich zu machen.Die entwickelte Visualisierungsumgebungwird als VIKUS Viewer (kurz: »VV«) anderenSammlungsinstitutionen zur dauerhaftenNutzung zur Verfügung stehen.
Von FW4 zu »VV«
Die Grundstruktur derVisualisierungsumgebung zu den ZeichnungenFriedrich Wilhelms IV. beruht auf einerzeitlichen Anordnung und der Verknüpfungmit Stichworten. Im Browserfenster werdendie 1492 Zeichnungen auf einem dynamischenCanvas entsprechend ihres Entstehungsjahrs aufeiner Zeitleiste arrangiert. Die Darstellung ähneltdabei einem klassischen Balkendiagramm,wobei jedoch jeder Balken aus tatsächlichenDigitalisaten einzelner Zeichnungenzusammengesetzt ist. Hierdurch ist auf denersten Blick erkennbar, welches zeitlicheSpektrum die Sammlung abdeckt und welcheMenge an Objekten diesem Zeitraum zugeordnet
sind. Die Schlagworte wiederum sind am oberenRand angeordnet, alphabetisch sortiert undgeben über die Schriftgröße darüber Auskunft,wie häufig sie Objekten zugeordnet wordensind. Gleichzeitig fungieren die Schlagworteals Filter. Bei Auswahl eines oder mehrererSchlagworte werden die mit dem Begriffverknüpften Objekte oberhalb der Zeitleisteangezeigt, alle anderen unterhalb. Somit lassensich themenbezogene Häufungen oder dasAufkommen von thematischen Fokussierungenin ihrem zeitlichen Kontext ablesen. Dasgesamte Arrangement ist zugleich ein stufenloszoombares Interface. In jeder der beschriebenenAnordnungen kann also von der Übersicht(“distant viewing”) in einer kontinuierlichenBewegung in die hochauflösende Ansichtdes Digitalisats (“close viewing”) gezoomtwerden. In dieser Detailansicht werdenautomatisch in einem Textpanel die dem Objektzugeordneten Metadaten und beschreibendeTexte eingeblendet [2].
Für die Weiterentwicklung diesersammlungsspezifischen Visualisierung FW4 zumnachnutzbaren Werkzeug, dem VIKUS Viewer»VV«, ergeben sich schließlich eine Reihe anFragestellungen und Herausforderungen.
Um den »VV« für andere Sammlungennutzbar zu machen, muss dieser von derspezifischen Metadatenstruktur des FW4-Bestandes losgelöst werden. Trotz desAnspruchs, den VIKUS Viewer für eine Vielzahlan Beständen nutzbar zu machen, kannnicht jeder Sonderfall mit objektspezifischenHerausforderungen und Sammlungsgrößen inBetracht gezogen werden. Um die Potenzialeund Limitationen des »VV« zu erproben, wirddie Generalisierung daher zunächst auf Basisvon weiteren Beständen der SPSG und anderenProjektpartnern vorangetrieben. Hierbeiergeben sich als Minimalanforderungen andie vom »VV« abgedeckten Sammlungen eineListe an Eigenschaften. Dazu zählen primär diezeitliche Einordnung und die Verschlagwortungentlang eines kontrollierten Vokabulars.Zusätzlich sollte der Bestand in ausreichendguter Qualität digitalisiert sein (und als jpgvorliegen), um die Zoomfunktion (von derÜbersicht ins Detail) voll ausnutzen zu können.Die benötigten Sammlungsdaten müssen ineinem standardisierten CSV Format vorliegen,welches ein gängiges und einfach zu erstellendesDatenformat ist. Auch wenn dies bereits einerecht breite Nutzung erlaubt, werden darüberhinaus Lösungen für weitere Erweiterungen undAnsprüche entwickelt, welche in Kombinationdie langfristige und nachhaltige Nutzung und
205

Digital Humanities im deutschsprachigen Raum 2017
Verfügbarmachung des »VV« gewährleistensollen.
Skalierbarkeit: Während der Bestand zu FW4nur 1492 Zeichnungen umfasst, soll der »VV« fürSammlungen optimiert werden, die bis zu 7000Objekte umfassen. Weiterhin sollen Konzepte aufMachbarkeit überprüft werden, welche sogarDarstellungslösungen für größere Beständebieten. Hierzu zählen aggregierte Übersichten,in denen die eigentlichen Digitalisate erstnach einer Themeneinschränkung angezeigtwerden. Bei der Skalierbarkeit orientiertsich die Entwicklung des VV an den letztenbeiden Generationen von Laptops mittlererLeistungsstärke, um eine breite Einsatzfähigkeitzu sichern.
Alternative Ansichten und Gestaltung:zusätzliche Visualisierungsformenwie z.B. Anordnungen auf Basis vonMetadatenähnlichkeit erweitern zudem dieabbildbaren Facetten der verschiedenenSammlungen. Ebenso lassen sich im »VV«gestalterische Elemente wie Hintergrundfarbe,Textfarbe und -größe, Schriftart, Linkfarben etc.anpassen, so dass auf die visuellen Eigenschaftender dargestellten Sammlungen eingegangenwerden kann.
Gezielte Suche: Der Fokus bei FW4 lagauf der Visualisierung, die sich in diesemFall als Ergänzung zum bereits bestehendeneher klassischen digitalen Bestandskatalogversteht. Da im Bestandskatalog als primärerZugang u.a. eine Suchfunktion angeboten wird,wurde diese Funktion nicht als Teil der FW4Visualisierungsumgebung implementiert.Um den VIKUS Viewer von ergänzendenZugängen unabhängig zu machen, wird einegezielte Suchfunktion eingebunden. DieSuchanfragen werden in einer Rückkopplungauf die Darstellung und die Anordnung desBestandes Einfluss nehmen und somit visuellnachvollziehbar sein.
Mehrseitigkeit: Über die Darstellung vonzweidimensionalen und einseitigen Objekten(wie Zeichnungen oder Gemälde) hinaus, soll der»VV« sowohl dreidimensionale Objekte, welchebeispielsweise in mehransichtigen Abbildungendigitalisiert wurden, als auch mehrseitigeSchriften darstellen können. In der Detailansichtkönnen über verschiedene Darstellungsmodidie weiteren Abbildungen zum Objekt bzw. diezusätzlichen Seiten im Detail betrachtet werden.
Implementierung: Die FW4-Visualisierungbasiert auf einem komplexen Einsatz voninnovativen Webtechnologien, deren Kenntnisnicht als Voraussetzung für die Anwendungauf neue Bestände vorausgesetzt werdenkönnen. Somit wird für den VIKUS Viewer
ein zugänglicher Workflow entwickelt, der inKombination mit detaillierten Anleitungen dieImplementierung erleichtert und für wenigertechnisch versierte Nutzergruppen öffnet.Hierzu zählt eine ausführliche Dokumentationund Anleitung auf GitHub, wie der »VV«implementiert werden kann.
Langfristige Verfügbarmachung: Dieprototypische Umsetzung der FW4-Visualisierung ist bereits mit offenen undlanglebigen Web-Standards (HTML, CSS undJavaScript) erfolgt. Ebenso ist es das Ziel, dassBestände, die mittels »VV« in Zukunft verfügbargemacht werden, langfristig abrufbar undverlässlich archiviert werden können. DieKomponenten werden in der JavaScript libraryreact geschrieben, durch dieses modulbasierteProgrammieren und die Einhaltung vongängigen Standards wird die Erweiterbarkeitsichergestellt. Die hauptsächlich verwendetenJavaScript libraries wie d3.js, pixi.js, react, node,u.a. sind in der Open Source Community weitverbreitet. Auch wenn dies keine langfristigeNachnutzbarkeit garantiert, werden dielibraries jedoch von einer großen Communitykontinuierlich weiterentwickelt und bieten somiteine relativ hohe Verlässlichkeit in Bezug auflangfristige Funktionalität.
Open Source: Neben der Publikation desQuellcodes im offenen online-code-repositoryGitHub wird der VIKUS Viewer von einerausführlichen Dokumentation begleitet, welchedie Weiterentwicklung und Nutzung des Codesermöglicht und nachvollziehbar macht. Dieswird unterstützt durch aktives Community-Building wie z.B. Workshops und Einführungenin die Konfiguration und Nutzung des »VV«.
Diskussion
Dieser letzte Aspekt erweitert dievorangegangenen Überlegungen zu denFunktionalitäten des VIKUS Viewers aufallgemeinere Aspekte, welche im Zuge desEntwicklungsprozesses relevant wurden undweiterhin verhandelt werden. Selbst wenn einWerkzeug als Open Source Projekt entwickeltwird, hängt das langfristige Überleben voneiner aktiven Community und entsprechenderRessourcen ab. Die Vernetzung und der offeneAustausch innerhalb einer Forschungsgemeindesowie die enge Zusammenarbeit mitInstitutionen, die ebenso einen praktischenNutzen von einem solchen Werkzeug haben,erleichtert über die Bekanntheit eines Toolsdessen kontinuierliche Weiterentwicklungund Nutzung. Dies setzt das offene Teilen von
206

Digital Humanities im deutschsprachigen Raum 2017
(Zwischen-)Ergebnissen auch während desEntwicklungsprozesses voraus. Gleichzeitigist auf Seiten der Förderinstitutionen zubeachten, dass sie ebenso eine zentraleRolle in Bezug auf digitale Nachhaltigkeiteinnehmen. So kann beispielsweisedurch zielgerichtete Anschlussförderungvon vielversprechenden Ergebnissen,welche in der Forschungsgemeinschaftund bei Sammlungsinstitionen auf einegewisse “Nachfrage” stoßen, eine stabile,nachhaltige und zielgruppenorientierteImplementierung und Publikationen vonTools unterstützt und sichergestellt werden.Ebenso ist es erstrebenswert über dieEinbindung verschiedener institutioneller undwissenschaftlicher Akteure, welche Interessean der Weiterentwicklung und Anpassungvon digitalen Werkzeugen haben und somitzu längerfristigen Kooperationspartnernwerden, die Nachnutzung sicherzustellen.Somit soll der Weg dafür geebnet werden,dass das entwickelte digitale Angebot auchnach Ablauf der Projektförderung undsomit möglicherweise der Veränderungvon Team- und Mitarbeiterstrukturenaufrechterhalten werden kann. Bei derEntwicklung experimenteller DH-Tools habenwir bereits mehrfach gute Erfahrungenmit heterogenen und dynamischen Teamsgemacht, die sich neben wissenschaftlichenMitarbeiter_innen ebenso aus Studierendenund Freelancern zusammensetzen. Dabei stelltdie Finanzierung solcher freier Forscher_innennoch die Seltenheit dar und stößt regelmäßigan Grenzen, wenn es um die Akquise derentsprechenden Mittel geht. Der kürzlich vonder Open Knowledge Foundation Deutschlandund dem Bundesministerium für Bildung undForschung ausgeschriebene Prototype Fund[3]ist eine erfreuliche Ausnahme und zeigt in dierichtige Richtung.
[1] https://uclab.fh-potsdam.de/fw4/[2] Für eine detailliertere Beschreibung der
Funktionalität und des Interaktionsmodellssiehe Glinka, Katrin / Pietsch, Christopher /Dilba, Carsten / Dörk, Marian (2016): “Linkingstructure, texture and context in a visualizationof historical drawings by Frederick William IV(1795- 1861)”, in: International Journal of DigitalArt History, 2.
[3] https://prototypefund.de/
Bibliographie
Bentkowska-Kafel, Anna / Cashen, Trish /Gardiner, Hazel (eds.) (2005): „Digital art
history: a subject in transition“, in: Computersand the history of art series 1: 1. Intellect.
Boyd Davis, Stephen / Kräutli, Florian(2015): „The Idea and Image of HistoricalTime: Interactions between Design and DigitalHumanities“, in: Visible Language 49 (3): 101.
Cheema, Muhammad F. / Jänicke, Stefan /Franzini, Greta / Scheuermann, Gerik (2015):„On Close and Distant Reading in DigitalHumanities: A Survey and Future Challenges“,in: Eurographics Conference on Visualization(EuroVis) - STARs 83–103.
Drucker, Johanna (2013): „Is There a ‚Digital‘Art History?“, in: Visual Resources 29 (1–2): 5–13.
Gibbs, Fred / Owens, Trevor (2012):„Building better digital humanities tools:Toward broader audiences and user-centereddesigns“, in: DHQ: Digital Humanities Quarterly6, 2. http://www.digitalhumanities.org/dhq/vol/6/2/000136/000136.html [letzter Zugriff 1.Dezember 2016].
Glinka, Katrin / Pietsch, Christopher /Dilba, Carsten / Dörk, Marian (2016): „Linkingstructure, texture and context in a visualizationof historical drawings by Frederick William IV(1795- 1861)“, in: International Journal of DigitalArt History 2.
Promey, Sally M / Stewart, Miriam(1997): „Digital art history: A new field forcollaboration“, in: American Art 11 (2): 36–41.
Schnapp, Jeffrey / Presner, Todd /Lunenfeld, Peter et al. (2009): Thedigital humanities manifesto 2.0. http://manifesto.humanities.ucla.edu/2009/05/29/the-digital-humanities-manifesto-20/ [letzter Zugriff1. Dezember 2016].
WiederholendeForschung inden digitalenGeisteswissenschaften
Schöch, [email protected]ät Würzburg, Deutschland
Einleitung
Die Reproduzierbarkeit vonForschungsarbeiten ist in zahleichen Disziplinenein drängendes und vieldiskutiertes Problem.Laut einer Nature-Umfrage nehmen 52% der
207

Digital Humanities im deutschsprachigen Raum 2017
befragten ForscherInnen eine “significantreproducibility crisis” wahr (Baker 2016).Metastudien aus der Psychologie (Bohannon2015) oder den Wirtschaftswissenschaften(Camerer 2016) berichten von niedrigenReproduzierbarkeitsquoten. Forderungen nachreproduzierbarer Forschung werden nicht nurin der Informatik (Mesirov 2010, Peng 2010)formuliert. Insbesondere für die empirisch undggfs. quantitativ arbeitenden Teile der digitalenGeisteswissenschaften sind diese Debattenrelevant (Padilla und Higgins 2016).
Hier stehen allerdings nicht dieAnforderungen an wiederholbareForschung im Fokus, sondern umgekehrtdie Herausforderungen, vor denenwiederholende Forschung steht. Letztereist in den digitalen Geisteswissenschaftenin besonderem Maße aufschlussreich, stelltdoch der Paradigmenwechsel von dominanthermeneutischen zu dominant empirischenMethoden in den Geisteswissenschaftendie Kontinuität des wissenschaftlichenDiskurses auf eine Zerreißprobe. Die digitalenGeisteswissenschaft sind gefordert, dieeigene Anschlussfähigkeit an etablierteKonzepte, Fragestellungen und Erkenntniszielesicherzustellen. Studien, die vorhandeneArbeiten mit digitalen Mitteln wiederholen,platzieren diese Kontinuitätsfragegewissermaßen unter einem Mikroskop.Zudem treten im praktischen Nachvollzugeiner Originalstudie die (teils impliziten)Annahmen sowie die Stärken und Grenzenbeider Ansätze plastisch hervor. So versprechenWiederholungsstudien inhaltlichen ebenso wiemethodischen Erkenntnisgewinn (vgl. Rockwell2016).
Auf eine konzeptuellen und begrifflichenKlärung zum beschrieben Problemfeld derwiederholenden Forschung folgen im hierskizzierten Beitrag zwei unterschiedlicheliteraturwissenschaftliche Fallstudien, in denenvorhandene Forschungsbeiträge mit digitalenDaten und Methoden wiederholt worden sind.
Typen wiederholenderForschung
Für die vielfältigen Beziehungen zwischeneiner bereits vorliegenden Studie und einerdiese wiederholenden Studie sind in derForschungsliteratur zahlreiche Begriffevorgeschlagen worden, darunter insbesondereReplikation, Reproduktion und Reanalyse(Drummond 2009, Gomez und Juristo 2010).
Zur konzeptuellen Klärung werden hierdrei wesentlicheAspekte berücksichtigt:die Fragestellung, die Daten und dieAnalysemethode. Wiederholungsstudienunterscheiden sich, je nachdem ob Fragestellung,Daten und Methoden gegenüber derOriginalstudie identisch oder verändert sind(Abbildung 1).
Abbildung 1: Das konzeptuelle undbegriffliche Feld der wiederholendenForschung.
Der Begriff "Replikation" bezeichnet hierdie exakte Wiederholung einer Studie. Diegleiche Forschungsfrage wird mit gleicherDatengrundlage und gleichen Methoden erneutbearbeitet. Ziel ist es zu prüfen, ob die gleichenErgebnisse ermittelt werden können, was einHinweis auf die korrekte Durchführung derOriginalstudie ist.
Der Begriff "Reproduktion" bezeichnet einefreiere Wiederholung. Die gleiche Fragestellungwird mit den gleichen Analysemethoden,aber neu erhobenen oder erweiterten Datendurchgeführt. Ziel ist es zu prüfen, ob dieAnalysemethode auch mit veränderten Daten diegleichen Schlussfolgerungen erlaubt, d.h. ob dieErgebnisse generalisierbar sind.
Der Begriff "Reanalyse" bezeichnet ebenfallseine freiere Wiederholung. Hier wird die gleicheFragestellung mit den gleichen Daten, abereiner anderen (bspw. verbesserten oder neuimplementierten) Analysemethode bearbeitet.Wird die gleiche Fragestellung sowohl mitanderen Daten als auch mit anderen Methodenbearbeitet, kann man von “Nachfolgeforschung”sprechen.
Auch wenn eine veränderte Fragestellungim Fokus steht, kann ein Bezug zu einerfrüheren Studie bestehen. Die Bearbeitung einerveränderten Fragestellung mit den gleichenDaten und der gleichen Methode kann als“Reinterpretation” der Ergebnisse aus eineranderen Perspektive verstanden werden. Dererneute Einsatz von Daten oder Code aus einer
208

Digital Humanities im deutschsprachigen Raum 2017
früheren Studie für die Bearbeitung einerneuen Fragestellung ist eine “Nachnutzung”.Kein (hier wesentlicher) Bezug besteht, wennFragestellung, Daten und Code gegenüber einerfrüheren Studie verändert wurden.
Die folgenden beiden Fallstudien beziehensich auf sehr unterschiedliche Originalstudien,illustrieren die spezifischen Herausforderungen,die jeweils hiermit zusammenhängen undwerfen ein Schlaglicht auf das Verhältnis derdigitalen Geisteswissenschaften zu frühererForschung.
Erste Fallstudie: Richeaudeauzur Satzlänge bei GeorgesSimenon
Die erste Fallstudie bezieht sich auf dieWiederholung einer Studie von FrançoisRicheaudeau zur Satzlänge im umfangreichenWerk des belgischen Autors GeorgesSimenon. Die 1982 veröffentlichte Studie istquantitativ angelegt, wurde allerdings nichtcomputergestützt durchgeführt. ZentraleThese ist, dass Simenons Romanwerk sichdurch die Verwendung besonders kurzer Sätzeauszeichne. Dies wird als ein Faktor unteranderen interpretiert, der zum weltweiten Erfolgdes Autors beigetragen hat (Richeaudeau 1982).
Obwohl in diesem Fall die Textsammlungbekannt und das verwendete Verfahrenquantitativ ist, kann nur in Ansätzen eineReplikation der Studie (im oben definiertenSinne) vorgenommen werden. Beispielsweiseist nicht dokumentiert, wie Satz und Wort fürdie Messung der Satzlänge definiert sind. Diesmusste neu entschieden und implementiertwerden. Die erneute Messung der Satzlängenin den 25 von Richeaudeau untersuchtenTexten Simenons anhand einer einfachen,aber angemessen erscheinenden Definitionvon Satz und Wort ergibt um durchschnittlich15% niedrigere Werte (siehe Abbildung 2;Details in Schöch 2016). Das scheint zunächstRicheaudeaus These sogar noch zu stärken.
Abbildung 2: Von Richeaudeau (oben) und inder Wiederholungsstudie (unten) erhobeneSatzlängen unter Verwendung der gleichenTexte.
Allerdings wird deutlich, dass 25Werken nicht ausreichen, um Richeaudeausweiterführende Thesen einer EntwicklungSimenons’ Stils über die Zeit (hin zuzunehmend kürzeren Sätzen in denRomanen) sowie in Abhängigkeit der von ihmpraktizierten Gattungen (längere Sätze inden autobiographischen Schriften als in denRomanen) zu prüfen. Erst mit deutlich mehrWerken (hier 127 Texte) und mit Hilfe einesstatistischen Signifikanztests, kann die erstedieser Thesen geprüft und widerlegt werden,die zweite dieser Thesen dagegen klar bestätigtwerden (Abbildung 3).
209

Digital Humanities im deutschsprachigen Raum 2017
Abbildung 3: Satzlängen für 127Werke Simenons in drei Gattungen:autobiographische Werke (schwarz), Maigret-Romane (grau), psychologische Romane(weiß). Statistisch massiv signifikanterUnterschied zwischen Romanen undautobiographischen Werken.
Zudem verfügt Richeaudeau alsVergleichsmaßstab nur über Zahlen aus einerEinzelstudie zu Marcel Proust, im Vergleichzu dessen langen Sätzen Simenons Sätze kurzerscheinen müssen. Der Vergleich mit 195französischen Romanen, die wie SimenonsWerke zwischen 1930 und 1980 erschienensind, zeigt hingegen, dass es zwar einigewenige Romanciers gibt, die deutlich längereSätze verwenden als Simenon, dieser aberkeinesfalls ungewöhnlich kurze Sätze verwendet(Abbildung 4).
Abbildung 4: Satzlänge bei Georges Simenon(weiß) und in 195 zeitgenössischen Romanen(schwarz). Kein statistisch signifikanterUnterschied.
Abschließend kann festgehalten werden,dass hier weniger eine methodische Kluft
überwunden werden musste, als vielmehrmangelnde Dokumentation des eingesetztenVerfahrens eine Herausforderung darstellt.Anders in der folgenden Fallstudie.
Zweite Fallstudie: SpitzersStilanalyse des Werks JeanRacines
Die zweite Fallstudie bezieht sich aufdie Wiederholung einer bis heute vielbeachteten Stilanalyse, die der RomanistLeo Spitzer 1928 über den französischenDramatiker Jean Racine vorgelegt hat. Spitzerverfolgt die These, dass in Racines Tragödienein stilistischer "Dämpfungseffekt" (alsAutorenstil) aufgezeigt werden kann. Offenlässt Spitzer, inwiefern dieser Effekt zugleichparadigmatisch für die Klassik (als Epochenstil)ist. Spitzer unterscheidet rund 50 stilistischePhänomene, die zum “Nüchtern-Gedämpften,Verstandesmäßig-Kühlen, fast Formelhaften”in Racines Stils beitragen. Er beschreibtsie nuancenreich und illustriert sie mitzahlreichen Beispielen. Zur Veranschaulichungseien hier nur einige Definitionen Spitzerszitiert: “die Personifizierung von Abstrakta”,“konturverwischende Plurale” oder “dasentgrenzende où” (Spitzer 1928).
Für die Reproduktionsstudie stehen diegleichen Texte zur Verfügung, die auch Spitzerverwendet hat, allerdings in digitaler Formund anderen Textausgaben folgend. Spitzersstilistische Phänomene wurden in Formkomplexer Suchabfragen, die mit Hilfe der“Corpus Query Processing”-Sprache CQP ( http://cwb.sourceforge.net/files/CQP_Tutorial/ )formuliert wurden, im Textanalyse-Tool TXM( http://www.textometrie.fr ) nachmodelliert undquantifiziert (siehe Abbildung 5). Auch mit Hilfeaufwändiger Annotationen der Texte (morpho-syntaktische sowie semantische Annotation mitWordNet) gelang dies mit zufriedenstellenderGenauigkeit nur für 30 der rund 50 von Spitzeranalysierten stilistischen Phänomene.
210
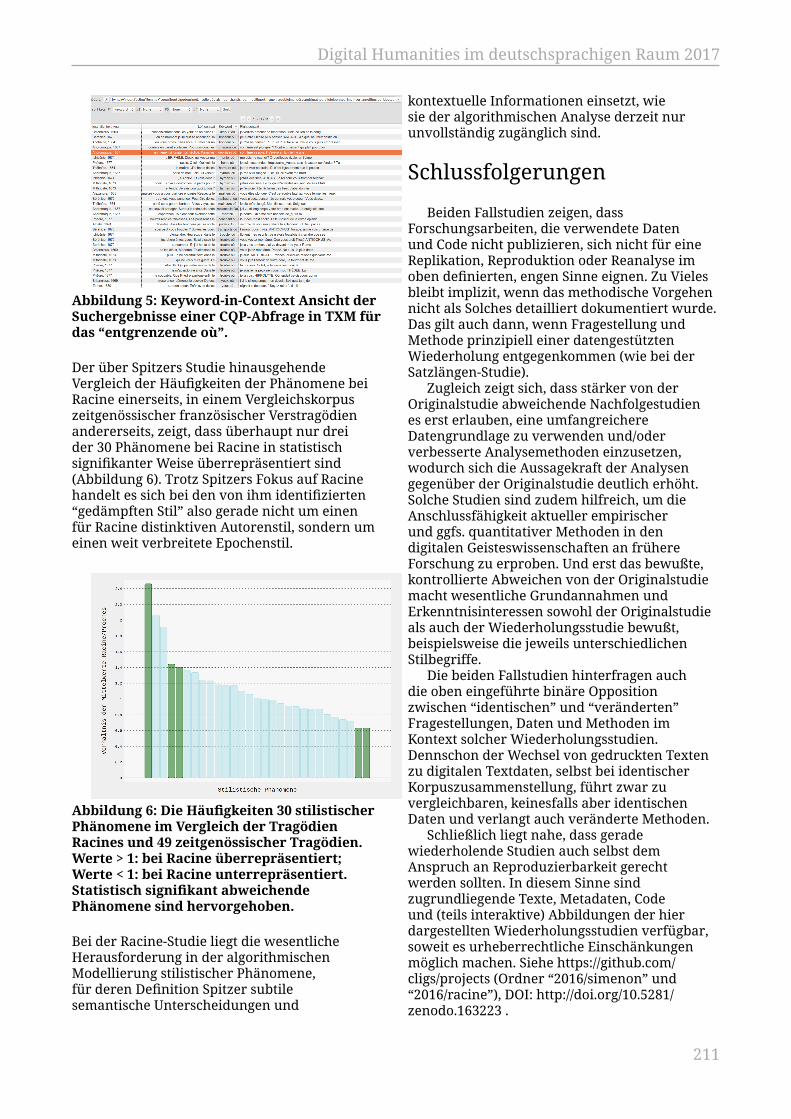
Digital Humanities im deutschsprachigen Raum 2017
Abbildung 5: Keyword-in-Context Ansicht derSuchergebnisse einer CQP-Abfrage in TXM fürdas “entgrenzende où”.
Der über Spitzers Studie hinausgehendeVergleich der Häufigkeiten der Phänomene beiRacine einerseits, in einem Vergleichskorpuszeitgenössischer französischer Verstragödienandererseits, zeigt, dass überhaupt nur dreider 30 Phänomene bei Racine in statistischsignifikanter Weise überrepräsentiert sind(Abbildung 6). Trotz Spitzers Fokus auf Racinehandelt es sich bei den von ihm identifizierten“gedämpften Stil” also gerade nicht um einenfür Racine distinktiven Autorenstil, sondern umeinen weit verbreitete Epochenstil.
Abbildung 6: Die Häufigkeiten 30 stilistischerPhänomene im Vergleich der TragödienRacines und 49 zeitgenössischer Tragödien.Werte > 1: bei Racine überrepräsentiert;Werte < 1: bei Racine unterrepräsentiert.Statistisch signifikant abweichendePhänomene sind hervorgehoben.
Bei der Racine-Studie liegt die wesentlicheHerausforderung in der algorithmischenModellierung stilistischer Phänomene,für deren Definition Spitzer subtilesemantische Unterscheidungen und
kontextuelle Informationen einsetzt, wiesie der algorithmischen Analyse derzeit nurunvollständig zugänglich sind.
Schlussfolgerungen
Beiden Fallstudien zeigen, dassForschungsarbeiten, die verwendete Datenund Code nicht publizieren, sich nicht für eineReplikation, Reproduktion oder Reanalyse imoben definierten, engen Sinne eignen. Zu Vielesbleibt implizit, wenn das methodische Vorgehennicht als Solches detailliert dokumentiert wurde.Das gilt auch dann, wenn Fragestellung undMethode prinzipiell einer datengestütztenWiederholung entgegenkommen (wie bei derSatzlängen-Studie).
Zugleich zeigt sich, dass stärker von derOriginalstudie abweichende Nachfolgestudienes erst erlauben, eine umfangreichereDatengrundlage zu verwenden und/oderverbesserte Analysemethoden einzusetzen,wodurch sich die Aussagekraft der Analysengegenüber der Originalstudie deutlich erhöht.Solche Studien sind zudem hilfreich, um dieAnschlussfähigkeit aktueller empirischerund ggfs. quantitativer Methoden in dendigitalen Geisteswissenschaften an frühereForschung zu erproben. Und erst das bewußte,kontrollierte Abweichen von der Originalstudiemacht wesentliche Grundannahmen undErkenntnisinteressen sowohl der Originalstudieals auch der Wiederholungsstudie bewußt,beispielsweise die jeweils unterschiedlichenStilbegriffe.
Die beiden Fallstudien hinterfragen auchdie oben eingeführte binäre Oppositionzwischen “identischen” und “veränderten”Fragestellungen, Daten und Methoden imKontext solcher Wiederholungsstudien.Dennschon der Wechsel von gedruckten Textenzu digitalen Textdaten, selbst bei identischerKorpuszusammenstellung, führt zwar zuvergleichbaren, keinesfalls aber identischenDaten und verlangt auch veränderte Methoden.
Schließlich liegt nahe, dass geradewiederholende Studien auch selbst demAnspruch an Reproduzierbarkeit gerechtwerden sollten. In diesem Sinne sindzugrundliegende Texte, Metadaten, Codeund (teils interaktive) Abbildungen der hierdargestellten Wiederholungsstudien verfügbar,soweit es urheberrechtliche Einschänkungenmöglich machen. Siehe https://github.com/cligs/projects (Ordner “2016/simenon” und“2016/racine”), DOI: http://doi.org/10.5281/zenodo.163223 .
211

Digital Humanities im deutschsprachigen Raum 2017
Förderhinweis
Die vorliegende Arbeit wurde im Rahmender Nachwuchsgruppe "Computergestützteliterarische Gattungsstilistik" (CLiGS) erstellt, dievom BMBF gefördert wird (FKZ 01UG1508).
Bibliographie
Baker, Monya (2016): „Is there areproducibility crisis?“, in: Nature 533: 452–454.
Bohannon, John (2015): „Many psychologypapers fail replication test“, in: Science Magazine349.6251: 910–911.
Camerer, Colin F. et al. (2016): „Evaluatingreplicability of laboratory experiments ineconomics“, in: Science Magazine 351.6280: 1433–1436.
Drummond, Chris (2009): „Replicability isnot Reproducibility: Nor is it Good Science“,in: Proceedings of the Evaluation Methods forMachine Learning Workshop at the 26th ICML.
Gomez, Omar S. / Juristo, Natalia / Vegas,Sira (2010): „Replication, Reproduction and Re-analysis: Three ways for verifying experimentalfindings“, in: RESER ’2010.
Padilla, Thomas / Higgins, Devin (2016):„Data Praxis in the Digital Humanities: Use,Production, Access“, in: DH2016: ConferenceAbstracts 644–646 http://dh2016.adho.org/abstracts/150 .
Peng, Roger D. (2011): „ReproducibleResearch in Computational Science“, in: ScienceMagazine 334: 1226–1227.
Richeaudeau, François (1982): „Simenon:une écriture pas si simple qu'on le penserait“, in:Communication et langages 53: 11–32 10.3406/colan.1982.1484.
Schöch, Christof (2016): „Does Short SellBetter? Belgian Author George Simenon’s useof sentence length“, in: The Dragonfly’s Gazehttps://dragonfly.hypotheses.org/922 / http://dragonfly.hypotheses.org/1005 .
Spitzer, Leo ([1928]): „Die klassischeDämpfung in Racines Stil“, in: Romanische Stil-und Literaturstudien I. Marburg: Elwert (1931)135–268.
Zur polykubistischenInformationsvisualisierungvon Biographiedaten
Windhager, [email protected]ät Krems, Österreich
Mayr, [email protected]ät Krems, Österreich
Schreder, Gü[email protected]ät Krems, Österreich
Wandl-Vogt, [email protected]Österreichische Akademie der Wissenschaften,Wien
Gruber, [email protected]Österreichische Akademie der Wissenschaften,Wien
Methoden der Informationsvisualisierungdienen der Unterstützung menschlicherKognition im Umgang mit abstrakten Datenund Themen (Scaife & Rogers, 1996). Dank dererfolgreichen Entwicklung entsprechenderVerfahren helfen interaktive visuelleRepräsentationen seit geraumer Zeit beider Analyse von multidimensionalenDaten in verschiedensten Disziplinen,inklusive zahlreicher geistes- undkulturwissenschaftlicher Forschungsfelder(cf. Sula, 2013; Jänicke, Franzini, Cheema &Scheuermann, 2015). Als Resultat ist mittlerweileein ganzes Spektrum von bildgebendenMethoden für die Exploration und Analyseder Daten von geisteswissenschaftlichenForscherInnen verfügbar. Dies gilt auch fürHistorikerInnen, die biographische Datensätzevon historischen Individuen exemplarischmit Hilfe von geographischen Karten,chronologischen Timelines, genealogischenBäumen, oder in relationalen Topologien undNetzwerken von Akteuren und Artefaktenveranschaulichen und visuell analysierenkönnen.
212

Digital Humanities im deutschsprachigen Raum 2017
Der Vortrag baut auf dieser Vielheit vonetablierten Methoden für die visuelle Analysebiographischer Daten auf – und präsentiertein neue Methode der visuellen Synthese undIntegration in einem konsistenten Rahmenwerk.Damit wird ein Vorschlag für die Gestaltungeines visuellen Interface unterbreitet, das diebessere kognitive Integration von mehrerenmöglichen Perspektiven auf komplexehistorische Datensätze ermöglicht.
Das Bezugsproblem stellt dabei die kognitiveHerausforderung dar, die auftritt, wenn multipleVisualisierungen (z.B. Karten, Treemaps oderNetzwerke – mit ihrer jeweiligen zeitlich-dynamischen Dimension) als Teilperspektivenauf denselben Datensatz zusammenkommen.Indem die resultierenden Bilder üblicherweisenur zeitlich gestaffelt (sequentiell) oderin räumlichem Nebeneinander (parallel,gelegentlich auch als „coordinated multipleviews“, Roberts, 2007) präsentiert werden,stellt die makrokognitive Synthese (Klein &Hofmann, 2008) dieser lokalen Teilperspektivenzu einem globalen bigger picture eine besondereHerausforderung dar, das die kognitivenSysteme von ForscherInnen nicht seltenüberlastet. KognitionswissenschaftlichenReflexionen zum Gebrauch visueller Interfaces(Hegarty, 2011; Liu, Nersessian, & Stasko,2008; Patterson et al., 2014) gehen davonaus, dass solche Synthesen qualitativ sehrunterschiedliche Ergebnisse zeitigen können– und dass ohne besonderen makrokognitivenAufwand nur das Zustandekommen vonunvollständigen und oftmals inkonsistenten„kognitiven Collagen“ (Tversky, 1993) zuerwarten ist.
Im Kontrast dazu präsentiert derVortrag ein polykubistisches Rahmenwerk(Windhager, 2013; Windhager et al., 2016),das eine Synthese von unterschiedlichenVisualisierungen schon auf der Ebene derexternen Repräsentation (i.e. des Displays)vornimmt, und somit die Konstruktion eineskonsistenten mentalen Modells als interneRepräsentation erleichtert. Als grundlegendeMethode der Visualisierung dienen hierbeisogenannte Raum-Zeit-Kuben (Space-TimeCubes), die zweidimensionale Visualisierungen(z.B. Karten) mit einer Zeitachse in der drittenDimension zusammenführen. Die geographischeBewegung von Individuen oder Objekten wirdin solchen Kuben als Raum-Zeit-Spur mit jeweilsspezifischer und charakteristischer Gestaltsichtbar: Während ruhende Objekte vertikaleTrajektorien in die Raumzeit zeichnen, werdenWanderungen und Ortsveränderungen alshorizontale Abweichungen sichtbar, die in der
Folge visuell analysiert werden können. Durchdie freie Skalierbarkeit solcher Kuben könnenräumliche Bewegungen (von lokalen bis zuglobalen Mustern) in allen zeitlichen Maßstäben(von Stunden bis zu Epochen) abgedeckt werden.
Dieses Verfahren, dass die beidenVisualisierungsmethoden von geographischenKarten und chronographischen Timelineszur Synthese bringt, kann in der Folgeauf andere Methoden wie Treemaps oderNetzwerkvisualisierungen übertragen werden(Federico, Aigner, Miksch, Windhager,& Zenk, 2011; Windhager, 2013). Damitwerden komplementäre Perspektiven aufdie Lebenswege von Individuen durchdie dreidimensionalen Topologien vongeografischer, sozialer oder kulturell-kategorialer Raumzeit zusammengeführt (Abb.1). Dieses Rahmenwerk von „coordinatedmultiple cubes“ dient durch seine generalisierteProjektionsmethode für zeit-orientierte Dateninsofern zugleich der visuellen Analyse, sowieder visuellen Synthese von üblicherweisegetrennten Einzelperspektiven. Die Kubenkönnen in der Folge mit verschiedenenMethoden der dynamischen Visualisierung imDetail exploriert werden (Bach et al., 2014),sowie durch die Nutzung weiterer visuellerKohärenztechniken (z.B. narrative Methoden,cf. Windhager, Schreder, Smuc, & Mayr 2015)verwoben werden. Darüber hinaus wird durchdie skizzierte Architektur die Trennung vonMethoden der “Scientific Visualization” undder “Information Visualization” (Rhyne, 2003)überbrückt, wodurch Vorteile und Synergien fürbeide Seiten zum Tragen kommen (Sedlmair etal., 2009).
Um die praktische Relevanz diesesRahmenwerks für die Exploration historischerDaten zu demonstrieren, präsentieren wir ersteErgebnisse der geo-temporalen Visualisierungvon biographischen Datensätzen aus dem APIS-Projekt (http://www.oeaw.ac.at/acdh/en/apis)mithilfe der Software GeoTime (Kapler & Wright,2005). In der Gegenüberstellung der Lebenswegevon Individuen verschiedener Berufsgruppen(z.B. von Abenteurern und Kunstschaffenden)kommen strukturelle Merkmale zum Vorschein,die der visuellen Analyse komplexer historischerDatensätze neue Möglichkeiten eröffnen.
213

Digital Humanities im deutschsprachigen Raum 2017
Abbildung 1: Rahmenwerk zurVisualisierung von Biographiedaten mitparalleler Perspektive auf geographische, sozialeund kategoriale Raumzeit.
Bibliographie
Bach, Benjamin / Dragicevic, Pierre /Archambault, Daniel / Hurter, Christophe /Carpendale, Sheelagh (2014): „A Review ofTemporal Data Visualizations Based on Space-Time Cube Operations“, in: EuroVis-STARs. TheEurographics Association 23–41.
Engelhardt, Yuri (2006): „Objects andspaces: The visual language of graphics“,in: International Conference on Theory andApplication of Diagrams. Berlin / Heidelberg:Springer 104–108.
Federico, Paolo / Aigner, Wolfgang /Miksch, Silvia / Windhager, Florian / Zenk,Lukas (2011): „A Visual Analytics Approach toDynamic Social Networks“, in: Proceedings ofthe 11th International Conference on KnowledgeManagement and Knowledge Technologies (i-KNOW), Special Track on Theory and Applicationsof Visual Analytics (TAVA). Graz: ACM 47:1–47:8.
Hegarty, Mary (2011): „The cognitive scienceof visual-spatial displays: Implications fordesign“ , in: Topics in Cognitive Science 3: 446–474.
Jänicke, Stefan / Franzini, Greta / Cheema,Muhammad Faisal / Scheuermann, Gerik(2015): „On Close and Distant Reading in DigitalHumanities: A Survey and Future Challenges“,in: EuroVis-STARs. The Eurographics Association.
Kapler, Thomas / Wright, William (2005):„GeoTime information visualization“, in:Information Visualization 4 (2), 136–146.
Klein, Gary / Hoffman, Robert R. (2008):„Macrocognition, mental models, and cognitivetask analysis methodology“, in: NaturalisticDecision Making and Macrocognition 57–80.
Liu, Zhicheng / Nersessian, Nancy J. /Stasko, John T. (2008): „Distributed cognitionas a theoretical framework for information
visualization“, in: IEEE Transactions onVisualization and Computer Graphics 14 (6) 1173–1180.
Patterson, Robert E. / Blaha, Leslie M. /Grinstein, Georges G. / Liggett, Kristen K. /Kaveney, David E. / Sheldon, Kathleen C. /Moore, Jason A. (2014): „A human cognitionframework for information visualization“, in:Computers & Graphics 42: 42–58.
Roberts, Jonathan C. (2007): „State of theart: Coordinated & multiple views in exploratoryvisualization“, in: Fifth International Conferenceon Coordinated and Multiple Views in ExploratoryVisualization (CMV’07) 61–71. IEEE.
Rhyne, Theresa-Marie (2003): „Does thedifference between information and scientificvisualization really matter?“, in: IEEE ComputerGraphics and Applications 23 (3): 6–8.
Scaife, Mike / Rogers, Yvonne (1996):„External cognition: how do graphicalrepresentations work?“, in: International Journalof Human-Computer Studies 45 (2): 185–213.
Sedlmair, Michael / Ruhland, Kerstin /Hennecke, Fabian / Butz, Andreas / Bioletti,Susan / O’Sullivan, Carol (2009): „Towardsthe big picture: Enriching 3d models withinformation visualisation and vice versa“, in:Smart Graphics. Springer 27–39.
Sula, Chris Alen (2013): „Quantifying Culture:Four Types of Value in Visualisation“, in: Bowen,Jonathan P. / Keene, Suzanne / Ng, Kia (eds.):Electronic Visualisation in Arts and Culture.Springer 25–37.
Swaab, Roderick I. / Postmes, Tom / Neijens,Peter / Kiers, Marius H. / Dumay, Adrie C.M. (2002): „Multiparty negotiation support:The role of visualization’s influence on thedevelopment of shared mental models“, in:Journal of Management Information Systems19 (1): 129–150.
Tversky, Barbara (1993): „Cognitive maps,cognitive collages, and spatial mental models“,in: Spatial Information Theory: A TheoreticalBasis for GIS. Berlin: Springer 14–24.
Windhager, Florian (2013): „On Polycubism.Outlining a Dynamic Information VisualizationFramework for the Humanities and SocialSciences“, in: Fuellsack, Manfred (ed.):Networking Networks: Origins, Applications,Experiments. Wien: Turia + Kant 26–63.
Windhager, Florian / Mayr, Eva / Schreder,Günther / Smuc, Michael / Federico, Paolo /Miksch, Silvia (2016): „Reframing CulturalHeritage Collections in a VisualizationFramework of Space-Time Cubes“, in:Proceedings of the 3rd International Workshop onComputational History (HistoInformatics 2016).CEUR 20–24.
214

Digital Humanities im deutschsprachigen Raum 2017
Windhager, Florian / Schreder, Günther /Smuc, Michael / Mayr, Eva (2015): „DrawingThings Together: Supporting InformationVisualizations' Coherence across MultipleViews“, in: Proceedings of the IEEE InformationVisualization Conference 2016 (PostersCompendium). IEEE Computer Society Press.
215
Poster

Digital Humanities im deutschsprachigen Raum 2017
AGATE – EuropeanAcademies InternetGateway: Konzeptfür eine digitaleInfrastruktur fürdie geistes- undsozialwissenschaftlichenForschungsvorhabender europäischenWissenschaftsakademien
Wuttke, [email protected] der deutschen Akademien derWissenschaften, Deutschland
Adrian, [email protected] der deutschen Akademien derWissenschaften, Deutschland
Ott, [email protected] der deutschen Akademien derWissenschaften, Deutschland
AGATE ist ein von der Union derdeutschen Akademien der Wissenschaften(Akademienunion) koordiniertesForschungsprojekt, das in engerZusammenarbeit mit ALLEA, demZusammenschluss von mehr als 50 europäischenAkademien der Wissenschaften, durchgeführtwird. Die Union der deutschen Akademiender Wissenschaften ist die Dachorganisationvon acht deutschen Wissenschaftsakademien.Ihre Hauptaufgabe ist die Koordination desAkademienprogramms, dem derzeit größtengeisteswissenschaftlichen Forschungsprogrammin Deutschland. Bei der Mehrheit dergeförderten Projekte handelt es sichum Langzeitvorhaben im Bereich dergeisteswissenschaftlichen, aber auch dersozialwissenschaftlichen Grundlagenforschung.
Gefördert vom Bundesministerium fürBildung und Forschung ist das Projektziel das
Ausloten des inhaltlichen, organisatorischenund technischen Rahmens für ein europäischesAkademienportal für die Geistes- undSozialwissenschaften (European AcademiesInternet Gateway, kurz AGATE). Im Rahmenvon AGATE sollen zum einen Informationenzu den umfangreichen geistes- undsozialwissenschaftlichen Forschungsaktivitätenan den europäischen Wissenschaftsakademiengebündelt zur Verfügung gestellt und diedigitalen Forschungsergebnisse und -datenbesser auffindbar und zugänglich gemachtwerden. Zum anderen sollen Informationen zunachhaltigen digitalen Forschungsmethodenund Publikationspraktiken bereitgestelltbzw. auf bereits bestehende Informations-und Serviceangebote verwiesen werden. Umdiese Ziele zu erreichen, sieht der momentaneStand der Planung für die Plattform zweigrundlegende Komponenten mit verschiedenenAusbaustufen vor: eine Projektedatenbank undein so genannter Service and Information Hub.
HintergrundDie Grundidee für AGATE beruht auf den
Erkenntnissen der SASSH-Umfrage ( Survey andAnalysis of Basic Social Science and HumanitiesResearch at the Science Academies and RelatedResearch Organisations of Europe, 2013-2015),in der erstmals über 600 Forschungsvorhabenan europäischen Wissenschaftsakademien undähnlichen Forschungsinstitutionen systematischzu verschiedenen Themengebieten befragtwurden (Leathem & Adrian 2015). Viele dereuropäischen Wissenschaftsakademien sindwichtige nationale Forschungszentren imBereich der Geistes- und Sozialwissenschaften(SSH). Die Umfrage zeigte, dass die geistes-und sozialwissenschaftliche Forschung anden europäischen Wissenschaftsakademienangesichts der zunehmenden Digitalisierungmit großen Herausforderungen konfrontiertist. Es zeigten sich bislang ungenutztePotentiale in den Bereichen Kooperationen undErfahrungsaustausch, digitale Infrastrukturensowie digitale Forschungsmethoden undPublikationspraktiken.
Aus der Studie ging zum einen hervor, dassKooperationen bzw. der Erfahrungsaustauschmit Forschungsvorhaben an anderen Akademienoftmals an mangelnden Informationen überpotentielle Partnervorhaben scheitern. Zumanderen zeigte sich ein Nachholbedarf bezüglichdes Wissensstandes über den Auftrag und dieAngebote bzw. Kooperationsmöglichkeiten mitden europäischen SSH-Infrastrukturen (wie zumBeispiel CLARIN, DARIAH und Europeana). DesWeiteren wurde festgestellt, dass die geistes-und sozialwissenschaftliche Forschung der
217

Digital Humanities im deutschsprachigen Raum 2017
Akademien im Internet und für die breitereÖffentlichkeit kaum sichtbar ist, wobei nebender stärkeren Nutzung des Internets alsKommunikationsweg über die Vorhaben undProjekte besonders eine stärkere Umsetzung vonPrinzipien wie Open Access und Open Data dieVerbreitung, Sichtbarkeit und Nachnutzung derdigitalen Forschungsergebnisse erhöhen würde.
Während des AGATE Kick-Off-Workshopsam 13. Juni 2016, bei dem unter anderemVertreter verschiedener europäischerWissenschaftsakademien Einblicke in dieHerausforderungen, verfügbaren Lösungenund Desiderata im Bereich der geistes- undsozialwissenschaftlichen Akademienvorhabendurch den Digital Turn gaben, wurdewiederholt die Sicherung der Nachhaltigkeitder digitalen Forschungsmethodenund Publikationsmethoden als großeHerausforderung betont.Mehr Informationenzum Programm des Workshops, einschließlicheines ausführlichen Berichts (Wuttke,Ott & Adrian, 2016), finden sich auf derAGATE-Projektseite. Durch die langeDauer der von Akademien durchgeführtenForschungsvorhaben und die entsprechendelangfristige Relevanz der Forschungsergebnissespielen gerade in diesem Bereich ein intensiver,möglichst interdisziplinärer Wissensaustausch,die verstärkte Abstimmung und Bündelung derAktivitäten und Ressourcen der Akademienuntereinander und die Zusammenarbeitmit starken Infrastrukturpartnern einewichtige Rolle. Generell würde hier einebessere Zusammenarbeit mit europäischenInfrastrukturanbietern und -initiativen wieCLARIN, DARIAH, Europeana und OpenAIRE,beziehungsweise die verstärkte Nutzung ihrerAngebote und das Aufzeigen von Bedarfen zueiner Situation mit Gewinn für alle Beteiligtenführen.
Entwicklung eines konzeptionellen Exposésfür AGATE
Aufbauend auf den Erkenntnissenaus der SASSH-Umfrage und dem erstenWorkshop sowie aus Expertengesprächen undNutzerinterviews zeichnen sich momentandrei Schwerpunktbereiche heraus, die durchdie Hauptkomponenten der im Rahmendes Posters vorgestellten paneuropäischendigitalen Infrastruktur für die geistes- undsozialwissenschaftliche Forschung (AGATE)adressiert werden sollten:
1) Sichtbarkeit und Konnektivität,2) Wiederverwendung digitaler
Projektergebnisse,3) Nachhaltige digitale Forschungs- und
Publikationspraktiken.
Die Ausarbeitung des konzeptionellenExposés für AGATE ist von dem Grundgedankengetragen, wo immer möglich, auf bestehendenAngeboten aufzubauen, diese breiter bekanntzu machen und den Bedürfnissen derWissenschaftlerinnen und Wissenschaftlerder Akademien anzupassen, um somit dieZusammenarbeit zwischen den Akademien undden relevanten Infrastrukturen zu stärken.
1) Sichtbarkeit und KonnektivitätTrotz ihrer großen Bedeutung für die
jeweilige nationale Wissenschaftslandschaftund ihrer langen Tradition, die sichinsbesondere in der Langfristigkeit ihrerForschungsvorhaben niederschlägt, sindInformationen über die an den europäischenAkademien durchgeführten geistes- undsozialwissenschaftlichen Forschungsprojektein vielen Fällen schwer online auffindbar.Um die Sichtbarkeit und Konnektivitätder geistes- und sozialwissenschaftlichenAkademienforschung zu verbessern, solleine Projektedatenbank aufgebaut werden.Diese Datenbank würde so entwickelt undeingerichtet werden, dass sie detaillierteInformationen über die Forschungsaktivitätender an Akademien angesiedelten Projekteund Vorhaben aufnehmen kann, wobeinicht nur klassische fachwissenschaftlicheKategorien (wie Forschungsgegenstand, Epoche,etc.), sondern auch digitale Methoden undFormate berücksichtigt würden, um denWissensaustausch in diesen Bereichen zubefördern.
Die Datenbank würde sowohl Fachleutenals auch der interessierten Öffentlichkeit alszentrale Informationsquelle auf europäischerEbene dienen. Gleichzeitig wäre sie für dieAkademien ein einfaches und verhältnismäßigniedrigschwelliges Angebot, um diegrundlegenden Informationen über einForschungsprojekt zu präsentieren, ohne eineeigene Projektwebseite aufbauen zu müssen.
Aus konzeptioneller und technischer Sichtstellt sich die Herausforderung, einen Katalogzu entwickeln, der es ermöglicht, Projektenach einer Reihe relevanter Bereiche undInformationen zu erfassen, durchsuchen undzu clustern, und gleichzeitig möglichst intuitivbedienbar ist. Zusätzlich soll ein Maximuman Konnektivität und Nachnutzung der Datengewährleistet werden. Aus organisatorischerSicht stellt sich die Frage, wie möglichst vieleProjekte dazu bewegt werden können, sichin der Datenbank zu registrieren, bzw. dienotwendigen Informationen zur Verfügung zustellen.
218

Digital Humanities im deutschsprachigen Raum 2017
2) Wiederverwendung digitalerProjektergebnisse
Um die Wiederverwendung digitalerProjektergebnisse durch bessere Auffindbarkeitzu steigern, soll die Datenbank von Beginn anso angelegt werden, dass in einem weiterenSchritt die verfügbaren digitalen Ressourcender Akademien und Projekte aufgezeigtwerden können. Unter den Begriff ‚digitaleRessource’ (siehe u.a. Sahle 2015: 44) werden imProjektkontext sowohl digitale Publikationenin ‚klassischen’ Formaten wie Artikel oderMonografien gefasst, als auch die in derAkademienforschung verbreiteten enhancedpublications (wie Datenbanken, digitaleEditionen und Wörterbücher), insbesondereWork in Progress, ebenso digitale ‚Quellen’wie Digitalisate oder Transkriptionen. Auchandere Formen wie Software-Code für DH-Tools sind denkbar. Der Anspruch an dieTiefe der Verknüpfung und Erschließungder digitalen Ressourcen beschränkt sichzunächst auf eine möglichst automatisierteSuche über Schnittstellen auf Metadatenebeneund die weitergehende Betrachtung bzw.Forschung mit den ermittelten Ressourcen inihrer originären Umgebung. Auch hier solldie Entwicklung in enger Abstimmung mitbestehenden infrastrukturellen Lösungen imeuropäischen Rahmen, wie etwa OpenAIRE,geschehen. AGATE würde somit den Wegebnen, um einen zentralen Sucheinstieg für dieheterogenen und verteilten digitalen geistes-und sozialwissenschaftlichen Ressourcen dereuropäischen Akademien zu entwickeln. DieVerknüpfung der heterogenen Ressourcen unddigitalen ‘Silos’ würde die AGATE-Datenbankzu einem wertvollen Rechercheinstrumentmachen und einem breiten Publikumeinen einfachen Zugang zu den digitalenForschungsergebnisse der Akademienermöglichen. Publikationen in Formaten, diefür die geistes- und sozialwissenschaftlicheForschung an den Akademien typisch sind, wieEditionen, Wörterbücher und Korpora, könntenbesonders hervorgehoben werden und würdendadurch erstmalig eine Plattform erhalten.
3) Nachhaltige digitale Forschungsmethodenund Publikationspraktiken
Um die generelle Stärkung derNachhaltigkeit der digitalen Forschung durchwissenschaftlichen Erfahrungsaustausch undKooperationen zwischen den Einzelakademienund darüber hinaus zu erreichen, insbesonderemit relevanten Infrastrukturpartnern und -initiativen auf nationaler, disziplinspezifischerund internationaler Ebene, ist ein so genannter
Service and Information Hub als weitereKomponente von AGATE angedacht.
AGATE würde eine enge transnationaleZusammenarbeit und Kooperationunterstützen, indem Informationen überrelevante Infrastrukturpartner, andereOrganisationen und Initiativen, ihreAngebote und Kooperationsmöglichkeitenentweder durch aktive Mitwirkung oder alsDatenlieferant bereitgestellt werden. AGATEwürde auch ein umfangreiches Angebot anInformationen zu Schulungen sowie Materialienbereitstellen, die sich auf digitale Forschungs-und Publikationspraktiken beziehen (z. B.Werkzeuge, Standards, Richtlinien und BestPractices). Um Dopplungen zu vermeiden,würden die konkreten Informationsmodule,die auf dem Portal angeboten werden, inenger Zusammenarbeit mit den relevanteneuropäischen Infrastrukturen im Bereich derGeistes- und Sozialwissenschaften abgestimmt.Der Fokus läge vor allem darauf, auf einschlägigeRessourcen und Aktivitäten von Dritten zuverweisen (z.B. DiRT Directory, DHd-Blog), nichteigene Materialien zu entwickeln.
In einem weiteren Schritt würdenredaktionell betreute Informationen zuSpezialthemen wie Open Access oderForschungsdatenmanagement im Service andInformation Hub einen Platz bekommen, wobeider Schwerpunkt auf der Bewusstseinsförderungund praktischen Handreichungen läge. DesWeiteren könnten in diesem Rahmen digitaleForschungswerkzeuge sowie weitere im Kontextder Akademien entwickelte digitale Lösungenpräsentiert werden (z.B. als „Tool des Monats“).Der Service and Information Hub würde fernerden Aufbau der Projektedatenbank flankieren,insbesondere wenn in diesem Rahmenkonkrete Unterstützung für die Integration vonProjektdaten und ggf. digitale Ressourcen in dieDatenbank angeboten werden würde.
Der Service and Information Hub würdeeinerseits ein Forum für Erfahrungsaustauschund Kooperationen unter den IT- und DigitalHumanities-Experten der europäischenWissenschaftsakademien über digitale Toolsund Methoden schaffen. Er würde aber auchandererseits eine Brücke zwischen dieserCommunity und den Fachwissenschaftlernschlagen und letztere stärker für Themen wieOpen Access und Forschungsdatenmanagementsensibilisieren und aktiv befähigen.
Auf dem Poster werden Details der geplantendigitalen Infrastruktur vorgestellt. Dabeizeichnet sich beim bisherigen Stand derArbeiten ab, dass bei der Konzeptionierungnicht nur innovative technische Lösungen
219

Digital Humanities im deutschsprachigen Raum 2017
ausschlaggebend sind. Ebenso wichtig sinddie Sicherstellung der organisatorischenNachhaltigkeit der geplanten Infrastruktur,die größtmögliche Einbindung der wichtigstenNutzergruppen schon in der Aufbauphase desPortals sowie rechtliche Fragen.
Das Projekt wird vom Bundesministeriumfür Bildung und Forschung (BMBF) unterdem Projekttitel „Aufbau eines europäischenAkademienportals“ (Laufzeit Oktober 2015-März2017, Förderkennzeichen 01UG1503) gefördert.
Bibliographie
Akademienunion: http://www.akademienunion.de/ [letzter Zugriff 30.November 2016].
AGATE-Projektseite: http://www.akademienunion.de/agate/ [letzter Zugriff30. November 2016].
ALLEA (ALL European Academies):www.allea.org [letzter Zugriff 30. November2016].
Leathem, Camilla / Adrian, Dominik (2015):Bestandsaufnahme und Analyse geistes- undsozialwissenschaftlicher Grundlagenforschungan den europäischen Wissenschaftsakademienund ähnlichen Forschungseinrichtungen. Unionder deutschen Akademien https://edoc.bbaw.de/files/1902/2015Projektpublikation_SASSH_deutsch_A1b.pdf [letzter Zugriff 30. November2016].
Sahle, Patrick (2015): „Forschungsdaten inden Geisteswissenschaften“, in: Bulletin SAGW4/2015: 43–45.
Wuttke, Ulrike / Ott, Carolin / Adrian,Dominik (2016): AGATE: Chances andChallenges of a European Academies InternetGateway: Kick-Off Workshop of the project“Elaboration of a Concept for a EuropeanAcademies Internet Gateway (AGATE).Workshop Report 1. Union of the GermanAcademies of Sciences and Humanities http://www.akademienunion.de/fileadmin/redaktion/user_upload/Publikationen/BMBF-Projekt/AGATE_Erster_Workshop_Bericht_23.08.2016.pdf[letzter Zugriff 30. November 2016].
APIS – Eine LinkedOpen Data basierteDatamining-Webapplikationfür das Auswertenbiographischer Daten
Schlögl, [email protected]Österreichische Akademie der Wissenschaften,Österreich
Lejtovicz, [email protected]Österreichische Akademie der Wissenschaften,Österreich
Einführung
Das ÖBL (Österreichisches BiographischesLexikon 1815-1950) ist ein umfassendes Werk,das derzeit rund 18,000 Biographien vonwichtigen historischen Persönlichkeiten aus derösterreichisch-ungarischen Monarchie und derErsten und Zweiten Republik Österreichs enthält.Während an dem Lexikon noch gearbeitet wird,erscheint es in gedruckter Form, und seit 2009 istes auch online verfügbar.APIS - Mapping historical networks: Buildingthe new Austrian Prosopographical |Biographical Information System - istein interdisziplinäres Digital HumanitiesProjekt, das WissenschaftlerInnen ausunterschiedlichen Themenbereichen (Biografien,Geschichte, Geographie, Sozialwissenschaften,Informationstechnologie) verbesserten Zugriff(Suchabfragen, API etc.) auf die ÖBL-Datenerlauben wird. Dadurch wird es möglich seininnovative, interdisziplinäre Forschung aufder Grundlage dieser einzigartigen Ressourcedurchzuführen. Als erstes Beispiel für einesolche angewandte wissenschaftliche Forschungund als wichtiger Test der Brauchbarkeit undEignung der entwickelten Lösung, wird bereitsim APIS Projekt eine soziodemografischeAnalyse, die die Formen und Muster derMigration von gesellschaftlichen Elitenuntersucht, umgesetzt.
220

Digital Humanities im deutschsprachigen Raum 2017
In unserer Präsentation konzentrieren wiruns auf die zugrunde liegende technischeLösung, vor allem auf die dynamischenAspekte - Workflow – und die Ergebnisse derverschiedenen angewandten Verfahren, um denaktuellen Stand der Umsetzung zu beschreiben.
Ansatz
ÖBL Daten stehen momentan in einemAd-hoc-XML-Format zur Verfügung. DieseXMLs enthalten einige Fakten (Geburts-und Todesdaten, Orte, Berufsangaben usw.)in strukturierter Form, der Großteil derInformation versteckt sich jedoch in demunstrukturierten Haupttext der Biographie.Das Hauptziel des Projektes ist Informationenautomatisch aus dem freien Text zu extrahieren,und sie in strukturierter Form zur Verfügungzu stellen. Um dieses Ziel zu erreichen, wird einzweifacher Hybrid-Ansatz verfolgt, der einerseitsautomatische und manuelle Textverarbeitungkombiniert und andererseits erlaubt dieerhobenen Daten in verschiedenen Formatenzu serialisieren. Letzteres beinhaltet nichtnur die Bereitstellung in verschiedenenFormaten (z.B. RDF/JSON), sondern auchdie Verwendung verschiedener Ontologien(z.B. CIDOC-CRM (Doerr 2003: 75-92), NDB(Historische Kommission bei der BayerischenAkademie der Wissenschaften 1953)). Dieextrahierten Entitäten sind mit mehrerensemantischen Referenz Ressourcen wiezum Beispiel GND (Pfeifer 2012: 80-91),GeoNames 1 oder DBpedia (Bizer 2009: 154-165)abgeglichen und mit URIs aus diesen versehen(Entity Linking). Dieser kombinierte Ansatzwurde gewählt, um die höchstmöglicheGenauigkeit der Annotationen zu gewährleisten,und den manuellen Aufwand so gering wiemöglich zu halten. Obwohl es bewährteTechniken und Methoden für die Verarbeitungnatürlicher Sprache gibt, wird manuelle Arbeit(Korrektur) der Forscher, die mit den jeweiligenWissenschaftsgebieten vertraut sind, nach wievor erforderlich sein.
Datenmodell
Das Datenmodell besteht aus fünf Entitäten(Personen, Institutionen, Orte, Werke undEreignisse) und einer Meta-Entität (Verweisauf den ursprünglichen Artikel). Es gibtBeziehungen zwischen allen Entitäten (z.B.Person - Institution, Person - Ereignis) und
Beziehungen sind auch zwischen den gleichenObjekttypen möglich (z.B. Person -> Vater_von-> Person). Die Beziehungen können auchtemporalisiert (Start- und Enddatum) undtypisiert werden (Typen können je nach Bedarfangegeben werden). Das erlaubt uns praktischalle möglichen Szenarien zu modellieren.Der ursprüngliche Plan war, die Daten nachbestehenden, gut definierten Ontologien zumodellieren. In der Evaluierungsphase wurdeuns aber klar, dass sehr viele verschiedeneOntologien existieren. Einige sind wie CIDOC-CRM Event basiert, andere verbinden Entitätendirekt. Wir haben uns deshalb entschlossenein eigenes (internes) Datenmodell zu erstellenund so den technischen Aufwand für dieVerarbeitung, Darstellung und Speicherung derDaten möglichst gering zu halten. Gleichzeitigwerden wir aber dieses interne Datenmodellmit Hilfe schon existierender Ontologien(NDB, CIDOC-CRM etc.) in verschiedenenFormen serialisieren und der Öffentlichkeitzur Verfügung stellen. Das stellt die möglichsteinfache, nachhaltige Nutzung unserer Datensicher.
Extraktion
Um strukturierte semantische Informationenaus den Biographien zu extrahieren, und diedadurch identifizierten Objekte zu Ressourcenwie GND, GeoNames zu verknüpfen verwendenwir automatische Tools. Die Ergebnisse werdenvon Experten verifiziert und ausgebessert umdie Qualität der Daten zu gewährleisten, undum unser System durch manuelle Korrekturzu verbessern. Während die NLP-Tools eineschnelle Verarbeitung ermöglichen sinddie Ergebnisse nicht zu 100% korrekt. Umdie Genauigkeit zu verbessern, setzen wirmehrere Systeme, Quellen und Analysen ein.Für die automatische Extraktion haben wirmehrere Tools getestet und bewertet, wie z.B.Stanford NER (Finkel 2005: 363-370), GATE(Cunningham 2011), OpenNLP 2 , Stanbol(Bachmann-Gmur 2013), basierend auf folgendeKriterien: 1) welche Sprachen unterstütztdas System 2) Möglichkeit der Anpassung, 3)Entity Linking Fähigkeiten, 4) Output Formatund 5) die Verfügbarkeit und Qualität der API.Apache Stanbol hat sich als das am bestengeeignete Werkzeug für unsere Zwecke gezeigt.Stanbol ermöglicht die Verknüpfung vonEntitäten wie Personen, Institutionen zuReferenzressourcen (Normdateien, Ontologien).Wir haben die Biographien mit GND und
221

Digital Humanities im deutschsprachigen Raum 2017
GeoNames abgeglichen, und planen weitereLOD 3 Ressourcen hinzuzufügen. Durch dieVerknüpfung von oben benannten Entitätenzu den semantischen Ressourcen können wirviele zusätzliche Informationen (z.B. AlternativeNamen, Titel von Werken usw.) zu unserenDaten hinzufügen, und so Inhalte mit fehlendenInformationen bereichern.
Anwendung
Um den manuellen Arbeitsaufwand(Korrektur der Daten etc.) zu minimieren habenwir eine effiziente und einfache Weboberflächegeschaffen, die es den ForscherInnen erlaubtmit den Daten zu interagieren. Im Sinneeiner nachhaltigen Nutzung und einfacherweiteren Betreuung des so entstandenen Toolshaben wir uns entschlossen auf erprobte Web-Technologien zu setzen (Django 4 /MySQL). DieWeb-Anwendung ist in Django, einem Python-basierten Web-Entwicklungs-Framework,implementiert. Django ist nicht nur einausgereiftes und verbreitetes Tool (Websiteswie Disqus, Pinterest und die Washington Timesnutzen es), sondern bietet auch die Möglichkeitdie volle Bandbreite der verschiedenen PythonBibliotheken nativ im Code zu verwenden (NLTK5 , scikit-learn 6 , NumPy 7 etc.) .Die Web-Anwendung stellt die Daten dereinzelnen Biographien strukturiert in dreiTeilen dar: primäre minimale Informationen,Haupttext mit markierten Anmerkungen und dieListen von Orten, Institutionen und Personen,die mit dem Biographierten in Zusammenhangstehen. Die Anwendung bietet auch Funktionenfür die Navigation: dropdown Listen sowieeinfache Volltextsuche.Eine weitere wichtige Funktion der Anwendungist die Möglichkeit, den Text manuell mitAnnotationen zu versehen. Dieses Featureerlaubt sowohl die Korrektur von automatischenAnnotationen, als auch das Hinzufügen vonneuen Annotationen. Die Kuratoren könnendie Entitäten mit der Maus auswählen oder imKontextmenü identifizieren.
Derzeit liegt der Schwerpunkt auf derDarstellung von Orten. Dementsprechendwird die Anwendung mit eingebettetenKarten ausgestattet, an denen identifiziertegeographische Orte visualisiert werden können.In der nächsten Phase des Projekts wird eineinteraktive Visualisierung entwickelt, um dasVerständnis der Daten und die Navigation imDatenbestand zu erleichtern.
Arbeitsablauf
Das System unterstützt zwei Workflows:im ersten Schritt schickt die Anwendung (dasExtrakt-Modul) die Biographien im Batch-Moduszu einem Extraktionsservice (lokale StanbolInstanz), welches die Abfragen an externeServices und/oder lokale Indizes weiterleitet unddie gematchten Entitäten in einer Liste in JSON-LD Format zurückgibt. Diese Entitäten werdenvon dem Extrakt-Modul analysiert und in derDatenbank abgespeichert. Danach werden siein der Web-Anwendung dargestellt und könnenvon den ForscherInnen überprüft und korrigiertwerden.Im zweiten Schritt wird der Workflow vomBenutzer gestartet: Der menschliche Annotatormarkiert einen String und identifiziert ihn alsOrt, die Anwendung schickt den ausgewähltenString zur Stanbol Instanz, die die verfügbarenRessourcen abfragt und mögliche Kandidatenzurückgibt. Diese Treffer werden dem/derForscherIn in Form eines Autocomplete Feldesangezeigt.
Schlussfolgerung
Während wir uns in unserem Abstraktauf die technische Umsetzung konzentrierthaben, ist es wichtig im Auge zu behalten,dass das System nur eine Voraussetzung istdie eigentliche Forschungsfragen beantwortenzu können. Alle im Projekt generierten Datensowie die entwickelte Forschungsumgebungwird der Öffentlichkeit zugänglich gemacht (eineerste Version der Forschungsumgebung wirdEnde September in unserem Github Accountzugänglich gemacht). Wie schon weiter obenangesprochen versuchen wir die Nachhaltigkeitunserer Lösung auf mehrfache Weise zuerreichen. Zum einen verwenden wir gutetablierte Web-Technologien und ermöglichensomit vielen Entwicklern weltweit unserenCode zu warten und/oder weiter zu entwickeln.Zum anderen verbinden wir unsere Daten mitder LOD-Cloud und serialisieren sie mit Hilfeverschiedener weit verbreiteter Ontologienin den gängigsten Formaten und stellen sosicher, dass andere Projekte unsere Daten mitäußerst kleinem Aufwand direkt in ihre Projekteeinbetten können.
Fußnoten
1. http://www.geonames.org/
222

Digital Humanities im deutschsprachigen Raum 2017
2. https://opennlp.apache.org/3. http://linkeddata.org/4. https://www.djangoproject.com/5. http://www.nltk.org/6. http://scikit-learn.org/stable/7. http://www.numpy.org/
Bibliographie
APIS: Mapping historical networks:Building the new Austrian Prosopographical |Biographical Information System (APIS) http://www.oeaw.ac.at/acdh/en/apis
Bachmann-Gmur, Reto (2013): InstantApache Stanbol (1st ed.). Packt Publishing. ISBN1783281235.
Bizer, Christian / Lehmann, Jens /Kobilarov, Georgi / Auer, Soren / Becker,Christian / Cyganiak, Richard / Hellmann,Sebastian (2009): „DBpedia - A crystallizationpoint for the Web of Data“, in: Journal of WebSemantics 7 (3): 154–165.
Cunningham, Hamish / Maynard, Diana /Bontcheva, Kalina (2011): Text Processingwith GATE (Version 6). University of SheffieldDepartment of Computer Science. ISBN0956599311.
Doerr, Martin (2003): „The CIDOC CRM– An Ontological Approach to SemanticInteroperability of Metadata“, in: AI Magazine 24(3): 75–92.
Finkel, Jenny Rose / Grenager, Trond /Manning, Christopher (2005): „IncorporatingNon-local Information into InformationExtraction Systems by Gibbs Sampling“, in:Proceedings of ACL-2005 363–370.
Historische Kommission bei derBayerischen Akademie der Wissenschaften(seit 1953): Neue deutsche Biographie, Berlin:Duncker & Humblot. ISBN 3-428-00181-8
ÖBL - Österreichisches BiographischesLexikon/Austrian BiographicalLexicon (1815-1950) Online-Editionund Österreischiches BiographischesLexikon ab 1815 (2. Überarbeitete Auflage- online). Verlag der ÖsterreichischenAkademie der Wissenschaften. Wien. http://www.biographien.ac.at/oebl [letzter Zugriff 26.August 2016]
Pfeifer, Barbara (2012): „Vom Projektzum Einsatz. Die gemeinsame Normdatei(GND)“, in: Brintzinger, Klaus-Rainer (ed.):Bibliotheken: Tore zur Welt des Wissens. 101.Deutscher Bibliothekartag in Hamburg 2012,Olms, Hildesheim u.a. 2013: 80–91.
Comparison of Methodsfor Automatic RelationExtraction in GermanNovels
Krug, [email protected]ät Würzburg, Deutschland
Wick, [email protected]ät Würzburg, Deutschland
Jannidis, [email protected]ät Würzburg, Deutschland
Reger, [email protected]ät Würzburg, Deutschland
Weimer, [email protected]ät Würzburg, Deutschland
Madarasz, [email protected]ät Würzburg, Deutschland
Puppe, [email protected]ät Würzburg, Deutschland
Einleitung
Die automatische Erkennung vonspezifischen Relationen ermöglicht Einsichtenüber die Beziehungen zwischen Entitäten.Solche Informationen können nicht nur alsKantenbezeichner in sozialen Netzwerkenfungieren, sondern auch als globale Constraintsfür das schwierige Problem der CoreferenceResolution eingesetzt werden. Darüberhinaus kann eine Relationserkennungzur Beantwortung diverser literarischerFragestellungen eingesetzt werden, z.B. obeine Romangattung sich mit bestimmtenRelationstypen befasst, oder ob die Arten
223

Digital Humanities im deutschsprachigen Raum 2017
der Relationen sich über die Jahrhunderteverändern. In dieser Arbeit stellen wir einLabel-Set für die Extraktion von binärenRelationen zwischen Personen-Entitäten vorund vergleichen Feature-basierte Ansätzedes maschinellen Lernens mit regelbasiertenAnsätzen zur automatischen Erkennung dieserRelationen. Da Trainingsmaterial zur Verfügungsteht, liegt der Fokus in dieser Arbeit auf demEinsatz überwachter Methoden, d.h. unsereregelbasierten Verfahren sind ebenfalls auf einerzuvor abgetrennten Menge entwickelt worden.Wir verwenden ein neues Korpus, das manuellmit mehr als 50 verschiedenen, hierarchischgegliederten Relationstypen annotiert wurde.
Related Work
Eine Übersicht über Arbeiten zurRelationserkennung findet sich in [Jung etal. 2012] sowie [Bach und Badaskar 2007].Sowohl für den überwachten, als auch denhalb-überwachten Fall wurden erfolgreicheMethoden entwickelt. Da dieses Paper sichhauptsächlich auf überwachte Algorithmenbezieht, geben wir nur einen knappen Überblicküber halb-überwachte Verfahren.
Algorithmen zur Relationsextraktion erhaltentypischerweise zwei (oder mehr) Referenzenzu Entitäten (sogenannte Instanzen) als Inputund sollen die Klasse, und das dazugehörigeLabel, vorhersagen, welche die Relationzwischen den Entitäten beschreibt. Die meistenExperimente wurden anhand englischer Texteund den Datensätzen der Automatic ContentExtraction (ACE) Workshops 2004 und 2006durchgeführt. Auf dem Datensatz von 2004wurden Experimente zur Unterscheidung von 5und 27 verschiedenen Klassen wie Arbeitsplatz-,körperliche, soziale, Mitgliedschafts- undDiskursrelationen (wobei manche Unterklassenvon anderen sein können) betrachtet. Hierfürgibt es zahlreiche Ansätze, die jedoch alleversuchen, eine diskriminative Beschreibungder Instanzen zu erhalten und diese davonausgehend zu klassifizieren:
• In der Feature-basierten Klassifikationwird eine Instanz (normalerweise zweiReferenzen zu Entitäten) durch einenFeature-Vektor mit manchmal mehr als einerMillion Dimensionen repräsentiert und mitMethoden wie Maximum Entropy Modellen[Kambhatla 2004] oder Support VectorMachines [Jiang und Zhai 2007] klassifiziert.Der letztere Ansatz konnte auf den ACE2004-
Daten einen F1-Score von 72,9% für dieErkennung von 7 verschiedenen Relationenerzielen. In unseren Experimentenverwenden wir für die Feature-basiertenMethoden ähnliche Features wie Kambhatla[Kambhatla 2004].
• Kernel-basierte Klassifikation wurdehäufig zur Relationsextraktion genutztund liefert konkurrenzfähige Ergebnisse[Zhou et al. 2007, Zhang et al. 2006, Zhaound Grishman 2005]. Während Feature-basierte Verfahren die Instanz direktrepräsentieren, funktionieren Kernel-basierte Methoden etwas anders. Aus einertechnischen Perspektive kann ein Kernelals eine Funktion betrachtet werden, diezwei Instanzen als Input erhält (also einPaar von Referenzen) und direkt einen Wertberechnet, der auf der "Ähnlichkeit" dieserInstanzen basiert, wobei einer höherer Werteine größere Ähnlichkeit anzeigt. Es wurdenzahlreiche Kernel für die Relationsextraktionvorgeschlagen; eine tiefgehende Analyse undErklärung findet sich in Jung et al. [Jung et al.2012].
• Die regelbasierte Klassifikationverwendet eine für den Menschenlesbare Repräsentation durch Regeln, dieentweder manuell erstellt oder gelerntwurden. Als Vorteile können die inhärenteErklärungsfähigkeit und die einfacheIntegration in Feature-basierte MachineLearning-Verfahren gesehen werden.
Im Folgenden vergleichen wir die genanntenMethoden anhand eines Label-Sets zurErkennung binärer Relationen zwischenFiguren in manuell annotierten Abschnitten vondeutschsprachigen Romanen.
Annotation, Datensatz undVorverarbeitung
Da Textstellen, an denen Relationen zwischenEntitäten explizit benannt werden, in Romanentypischerweise rar sind, ist es nicht sinnvoll,komplette Romane zu annotieren, da der Ertragan Daten zu gering wäre. Aus diesem Grundwurde zunächst eine kleine Teilmenge per Handannotiert und dann genutzt, um mit einemMaxEnt Classifier in einer Active Learning-Umgebung neue Sätze zum Labeln vorschlagenzu können. (Ein Überblick hierzu findet sich inFinn und Kushmerick [Finn und Kushmerick2003]). Diese Umgebung erhielt Sätze aus 312verschiedenen Romanen von Projekt Gutenberg
224

Digital Humanities im deutschsprachigen Raum 2017
und 215 Zusammenfassungen aus dem KindlerLiteratur Lexikon Online. Daraus entstandein Korpus mit 2412 Sätzen, die insgesamt1265 Relationen enthalten (was wiederumdie Knappheit an Daten illustriert). 33 Textewurden zufällig für die Testmenge ausgewählt,sodass es feste Test- und Trainingsdaten gibt(1988 respektive 424 Sätze mit 1070 respektive195 Relationen). Die verwendeten Label sindähnlich zu Massey et al. [Massey et al. 2015]. DieRelationen werden durch eine Ontologie mitmomentan 57 verschiedenen Relationstypenrepräsentiert, die hierarchisch geordnet sind(beispielsweise ist die Relation "Tochter" derRelation "Familie" untergeordnet). Abbildung 1zeigt die oberste Ebene des Label-Sets, mit dengleichen Kategorien wie in Massey et al. [Masseyet al. 2015] und einer zusätzlichen Relation"Liebe".
Abbildung 1: Die ersten beiden Ebenenunseres verwendeten Label-Sets mit den vierHaupttypen, die sich weiter in insgesamt 57Relationstypen untergliedern lassen.
Eine Relation wurde von einem Annotatorals ein benannter, gerichteter Bogen zwischenzwei Entitäten in einem Satz gelabelt, sofernsie explizit im Text beschrieben ist. Es wurdeimmer das spezifischste Label verwendet, da dieübergeordneten Relationstypen (vgl. Abbildung1) daraus abgeleitet werden können. Abbildung2 zeigt ein Beispiel einer Relation, wie sie inunserem Korpus annotiert ist.
Abbildung 2: Zwei gelabelte Instanzen vonRelationen in unserem Datensatz. Die erste zeigtdie Relation “hatTochter” und die zweite dieRelation “hatVerehrer”.
Um solche Relationen automatisch erkennenzu können, müssen die Texte eine große Zahlan Vorverarbeitungsschritten durchlaufen.Wir verwenden die Figurenerkennung vonJannidis et al. [Jannidis et al. 2015] und diegleiche Vorverarbeitung wie in [Krug et al. 2016].
Experimente
Wir verwenden einen regelbasierten Ansatzmit manuell erstellten Regeln und zwei Feature-
basierte Lernverfahren (Maximum Entropy,MaxEnt und Support Vector Machines, SVM).Der regelbasierte Ansatz nutzt sowohl dietextuelle Repräsentation, als auch den kürzestenPfad im Dependency-Baum und formuliert dieRegel auf Basis dieser Repräsentationen undder Repräsentationen aus dem reinen Text.Das folgende Beispiel zeigt Regeln, die zu denRelationen aus Abbildung 2 passen:
• Tochter des <Entität> => hatTochter(2,1)• Pfad: <Entität>->verliebt<->in<-<Entität> =>
hatVerehrer(2,1)
Die erste Regel basiert auf der angepasstenText-Repräsentation, während die zweiteRegel sich auf den kürzesten Dependency-Pfad zwischen "sich" und "sie" bezieht. DieZahlen in runden Klammern geben dieRichtung an (in beiden Fällen von Entität 2auf Entität 1). Die Regeln wurden manuell aufden zuvor gewählten Trainingsdaten erzeugt.Insgesamt wurden fast 500 solcher Regelnermittelt. Der Großteil der Relationen konntejedoch mit 3 Regeln (ab hier sogenannte Core-Regeln) abgedeckt werden, die Possessiv- undGenitivkonstruktionen abbilden.
Die Feature-basierten Ansätze wurden inzwei Szenarien evaluiert: a) nur mit bereitsbekannten Features aus Related Work und b)mit zusätzlichen Booleschen Features (eines proRegel), falls eine der 500 Regeln passt.
Tabelle 1 zeigt die Evaluationsergebnisse derverschiedenen Methoden für drei hierarchischeEbenen (alle Relationen, Relationen der oberstenEbene, alle 57 Relationstypen) und Tabelle 2die Ergebnisse für die vier Relationstypen derobersten Ebene. Während die Verwendungaller Regeln zu einem F1-Score von 71%für alle Relationen und 59% für die vierübergeordneten Relationstypen führt, erreichtder Feature-basierte Ansatz mit MaxEnt miteinem Booleschen Feature für jede Regel etwasbessere Ergebnisse (F1 von 73,6% und 61,2%).Ohne die Regel-Features liegt der Score derLernverfahren deutlich niedriger. Die SVMerreicht teilweise eine höhere Precision alsMaxEnt, aber im Allgemeinen einen signifikantgeringeren F1-Wert.
Tabelle 1: Ergebnisse der verschiedenenAnsätze für drei verschiedeneEvaluationsszenarien: binär (das reine Vorliegeneiner Relation), für die 4 Haupttypen und für alle57 Relationstypen insgesamt.
Tabelle 2: Ergebnisse für die verschiedenenAnsätze, aufgeschlüsselt nach den 4 Haupttypen.Familienrelationen erreichen sehr gute
225

Digital Humanities im deutschsprachigen Raum 2017
Ergebnisse mit einem F1-Wert von fast 80% undeiner Precision von bis zu 95%. Liebesrelationensind schwerer zu erkennen, liegen aber dennochbei 56,3% F1. Die anderen Relationstypen fallenin der Qualität ab, sind aber gleichzeitig wenigerrelevant.
Sehr auffällig ist das gute Ergebnis für diedrei Core-Regeln und dabei besonders diehervorragende Precision von 96,2% für Familien-Relationen. Eine genauere Betrachtung derFalse Positives (FP) in Tabelle 3 zeigt, dass dieseRelationen fast immer syntaktisch korrekterkannt wurden, aber semantisch irrelevantund daher nicht im Goldstandard annotiertsind (z.B. "mein Gott"). Hier zeigt sich eineSchwachstelle dieser Arbeit: teilweise unpräziseRichtlinien für die Annotation von Relationen.Das ist jedoch ein sehr schwieriges Problem,das eventuell umgangen werden kann, wenndie Relationserkennung kein Ziel in sich,sondern eine untergeordnete Aufgabe im Zugeder Erkennung der Hauptfiguren und derenBeziehungen in Romanen ist.
Tabelle 3: Auswertung der drei Core-Regelnauf unserem Datensatz
Regel Beispiel TP FP<Possessive>… <Entity>
seine liebeMutter[his lovedmother]
83 22
<Entity_Noun>...<GENITIV_Noun>Frau desKanzlers[wife of thechancellor]
21 7
<GENITIV_Noun><Entity_NN>
Peters Frau[Peter’swife]
19 5
Fazit und zukünftige Arbeiten
Dieses Paper hat gezeigt, dass automatischeRelationserkennung eine Herausforderungdarstellt. Einfache Regeln können jedoch bereitseinen wesentlichen Teil der Relationen mithoher Precision erkennen. Dennoch ist derBedarf an weiteren Verbesserungen durchfortschrittliche Methoden hier deutlich. Zudemist die Evaluation der Relationserkennungan sich schwierig und kann besser imKontext eines übergeordneten Ziels wie derautomatischen Erstellung eines Netzwerks derHauptfiguren eines Romans [Krug 2016] oderder Gattungsklassifikation [Hettinger et al. 2015]eingebracht werden.
Bibliography
Bach, Nguyen / Badaskar, Sameer (2007):„A review of relation extraction“, in: Literaturereview for Language and Statistics II.
Finn, Aidan / Kushmerick, Nicolas (2003):„Active learning selection strategies forinformation extraction“, in: Proceedings ofthe International Workshop on Adaptive TextExtraction and Mining (ATEM-03).
Hettinger, Lena / Becker, Martin / Reger,Isabella / Jannidis, Fotis / Hotho, Andreas(2015): „Genre classification on Germannovels“, in: Proceedings of the 12th InternationalWorkshop on Text-based Information Retrieval.
Jannidis, Fotis / Krug, Markus / Reger,Isabella / Toepfer, Martin / Weimer, Lukas /Puppe, Frank (2015): „Automatische Erkennungvon Figuren in deutschsprachigen Romanen“, in:DHd 2015: Von Daten zu Erkenntnissen.
Jiang, Jing / Zhai, ChengXiang (2007): „ASystematic Exploration of the Feature Space forRelation Extraction“, in: Proceedings of HumanLanguage Technologies: The Conference of theNorth American Chapter of the Association forComputational Linguistics (NAACL-HLT 2007).
Jung, Hanmin / Choi, Sung-Pil / Lee,Seungwoo / Song, Sa-Kwang (2012): „Survey onKernel-Based Relation Extraction“, in: Sakurai,Shigeaki (ed.): Theory and Applications forAdvanced Text Mining. InTech Open Science10.5772/51005.
Kambhatla, Nanda (2004): „Combininglexical, syntactic, and semantic features withmaximum entropy models for extractingrelations“, in: Proceedings of the ACL 2004 onInteractive poster and demonstration sessions.
Krug, Markus / Fotis, Jannidis / Reger,Isabella / Weimer, Lukas / Macharowsky,Luisa / Puppe, Frank (2016): „Attribuierungdirekter Reden in deutschen Romanen des18.-20. Jahrhunderts. Methoden zur Bestimmungdes Sprechers und des Angesprochenen“, in: DHd2016: Modellierung - Vernetzung - Visualisierung.
Krug, Markus / Fotis, Jannidis / Reger,Isabella / Weimer, Lukas / Macharowsky,Luisa / Puppe, Frank (2016): „Comparisonof Methods for the Identification of MainCharacters in German Novels“, in: DH2016:Converence Abstracts.
Massey, Philip / Xia, Patrick / Bamman,David / Smith, Noah A. (2015): „AnnotatingCharacter Relationships in Literary Texts“, in:arXiv, arXiv:1512.00728.
Zhao, Shubin / Grishman, Ralph(2005): „Extracting relations with integrated
226

Digital Humanities im deutschsprachigen Raum 2017
information using kernel methods“, in:Proceedings of ACL-2005.
Die Odyssee zumrichtigen Standard -Herausforderungeneiner konsistentenDatenmigration vonUlysses: A Critical andSynoptic Edition (1984)
Schäuble, [email protected]ät Passau, Deutschland;Reichsuniversität Groningen, Niederlande
Crowley, [email protected]ät Passau, Deutschland
Mit „Ulysses: A Critical and SynopticEdition“ erschien 1984 eine der erstenForschungseditionen, die auf Basisder systematischen Verwendung vonKollationierungssoftware digital erzeugtwurde. Das Münchner Team um HansWalter Gabler verwendete hierzu TUSTEPsowohl zur Validierung der Transkripteeinzelner Zeugen als auch zur Erschließungder zeugenübergreifenden Synopse. Für diegedruckte Edition wurden die halbautomatischerzeugten Kollationsergebnisse mit einem eigensentwickelten System komplexer Diakritikaausgezeichnet, die es dem geübten Leserermöglichen sollten, die Textentstehungüber stellenweise mehr als zwanzig inter-und intradokumentarische Textstufenhinweg in einer synoptisch integriertenTextfassung nachzuvollziehen. Während dieKonzeption und Umsetzung dieser Arbeitbis heute als bahnbrechend im Bereich derComputerphilologie zu bezeichnen ist, konntedas Potenzial der resultierenden Druckausgabefür die Joyce-Forschung nicht annäherndausgeschöpft werden. Zu komplex war dasMarkup, dem es gelingen sollte, zu verknüpfen,was zuvor getrennt war und zu hoch war derAufwand, sich in diese Systematik einzuarbeiten.
Im Digitalen hingegen führten die Datenjene Odyssee fort, die die Druckedition beendensollte. Auf der Suche nach einem Markup-Standard, der es vermag, die Inhalte derDruckedition digital zu repräsentieren, wurdendie TUSTEP Ergebnisse zunächst von TobiasRischer im Rahmen seiner Diplomarbeit (1997)in SGML/TEI transformiert und anschließendin mehreren Überarbeitungen über TEI P4bis hin zur aktuellen Version der TEI P5v3(2016) migriert. Dieser Beitrag vollziehtdie Evolution dieser “Legacy Data” nach,bis hin zu ihrer jüngsten Station - der nochandauernden Bemühung einer Migration nachTEI P5v3, welche im Rahmen des DFG- und NEH-geförderten Kooperationsprojektes “DiachronicMarkup and Presentation Practices for TextEditions in Digital Research Environments” amLehrstuhl für Digital Humanities der UniversitätPassau durchgeführt wird.
Erstmals seit der zweiten, überarbeitetenAusgabe der synoptisch-kritischen GablerEdition 1986 gelang es, aus den TEI-Daten die synoptische Visualisierung derDruckedition zu rekonstruieren und somit eineKonsistenzprüfung gegen die ursprünglichenDaten zu ermöglichen. Erst durch diesevisuelle Rückführung offenbarten sichmigrationsbedingte Fehler und Provisorien,welche zuvor, wenn überhaupt, nur in Fußnotenund privaten Aufzeichnungen vergangenerBeteiligter dokumentiert wurden. Nebendem allgemeinen Versuch, die vollzogenenÄnderungen aus den Aufzeichnungen undMigrationsergebnissen früherer Projektezu rekonstruieren, hat es sich das PassauerTeam zur Aufgabe gemacht, Strategien zurEntdeckung, Typisierung und Korrekturderartiger „Migrationsverluste“ zu entwickeln.Ein wesentlicher Bestandteil dieser Arbeit istdie Abschätzung der Leistungsfähigkeit undWirtschaftlichkeit von automatisierten Batch-Konvertierungen mittels XSLT und Python imVergleich zur manuellen Intervention undKorrektur der Kodierung.
Neben der Identifikation und Korrektur von„Migrationsfehlern“, steht die Rekonstruktionder textgenetischen Perspektive, durchwelche sich die Druckedition auszeichnete, imVordergrund. Während Gabler die textuelleEntwicklung, welche er mittels der Kollationchronologisch aufeinander folgender Textzeugenerschlossen hatte, im Druck synoptischdarstellen konnte, beinhalteten die TEIGuidelines bis zur Version P5v2 kein Modellzur Auszeichnung textgenetischer Prozesse. Esfehlte schlicht die Möglichkeit zur formalisiertenDokumentation einer stufenweisen,
227

Digital Humanities im deutschsprachigen Raum 2017
zeugenübergreifenden Chronologie derTextentwicklung. In der Druckeditionwurde jeder auktorialen Textänderunggenau eine Textstufe aus der heuristischerschlossenen Chronologie zugeordnet. Dieselineare Textentwicklung über intra- undinterdokumentarische Textstufen, in GablersTerminologie auch Overlay und Level genannt,musste im Digitalen in eine Auszeichnungüberführt werden, welche die Genese in denHintergrund rückt und zu jeder auktorialenModifikation anstelle einer Textstufe eine Listesämtlicher Zeugen verzeichnet, auf welcherdie spezifische Änderung Bestand hat. DieseArt der dokumentenorientierten Kodierungvon Textgenese entspricht zwar bis heute dergängigen Auszeichnungspraxis historisch-kritischer Editionsprojekte, repräsentierteaber zu keinem Zeitpunkt die textgenetischeIntension der 84er Ulysses Edition. Erst mitder Integration eines textgenetischen Modellsin die TEI Guidelines, kann die ursprünglicheIntension erstmals auch in TEI kodiert werden.Hierzu bedarf es einer weiteren Episode derDatenmigration auf der Odyssee zum richtigenStandard.
Bibliographie
Bruning, Gerrit / Henzel, Katrin / Pravida,Dietmar (2014): „Multiple Encoding in GeneticEditions: The Case of Faust“, in: Journal ofthe Text Encoding Initiative 4. Available from:jtei.revues.org.
Burnard, Lou / O’Brien O’Keeffe,Katherine / Unsworth, John (2006): ElectronicTextual Editing. New York: Modern LanguageAssociation of America.
Burnard, Lou / Jannidis, Fotis / Pierazzo,Elena / Midell, Gregor / Rehbein, Malte (2010):„An Encoding Model for Genetic Editions“, in:TEI: Text Encoding Initiative. Retrieved fromwww.tei-c.org/ Activities/Council/Working/tcw19.html/.
Joyce, James / Gabler, Hans Walter (eds.)(1984): Ulysses: A Critical and Synoptic Edition.New York: Garland.
Joyce, James (1922): Ulysses. Paris:Shakespeare and Company.
Fordham, Finn (2010): I do, I undo, I redo: TheTextual Genesis of Modernist Selves in Hopkins,Yeats, Conrad, Forster, Joyce, and Woolf. Oxford /New York: Oxford University Press.
Rischer, Tobias (1997): Eine TEI/SGML-Edition der textkritischen Ausgabe von JamesJoyces Ulysses. Diplomarbeit, LMU München.
TEI Consortium (eds.) (2016): TEI P5:Guidelines for Electronic Text Encoding andInterchange. P5v3. Available from: http://www.tei-c.org/Guidelines/P5/ .
Digitale Erschließungeiner Sammlung vonVolksliedern aus demdeutschsprachigenRaum
Burghardt, [email protected] Medieninformatik, UniversitätRegensburg, Deutschland
Spanner, [email protected] Medieninformatik, UniversitätRegensburg, Deutschland
Schmidt, [email protected] Medieninformatik, UniversitätRegensburg, Deutschland
Fuchs, [email protected] Medieninformatik, UniversitätRegensburg, Deutschland
Buchhop, [email protected] Medieninformatik, UniversitätRegensburg, Deutschland
Nickl, [email protected] Medieninformatik, UniversitätRegensburg, Deutschland
Wolff, [email protected] Medieninformatik, UniversitätRegensburg, Deutschland
228

Digital Humanities im deutschsprachigen Raum 2017
Projektkontext
Dieser Beitrag beschreibt ein laufendesProjekt 1 zur digitalen Erschließung einergroßen Sammlung von Volksliedern ausdem deutschsprachigen Raum, mit demZiel diese später über ein öffentlichesInformationssystem verfügbar zu machen.Mithilfe dieses Informationssystems sollneben der üblichen Exploration gescannterFaksimiles der Originalliedblätter zusätzlich einquantitativer Zugang zu den Daten ermöglichtwerden, der diese anhand unterschiedlicherParameter durchsuchbar und analysierbarmacht. Ziel des Projekts ist also nicht nur,einen in dieser Form einzigartigen Bestand anLiedblättern nachhaltig digital zu erschließenund zugänglich zu machen, sondern darüberhinaus computergestützt nach Auffälligkeitenin Form wiederkehrender Phrasen und Themenoder melodischen Universalien zu suchen, diefür verschiedene Regionen oder Zeitabschnittecharakteristisch sind.
Datenbasis
Die Datengrundlage des Projektsstellen umfangreichen Quellen zurVolksmusikforschung dar, die seit einigenJahren von der UniversitätsbibliothekRegensburg verwaltet werden. Die RegensburgerLiedblattsammlung umfasst etwa 140.000Blätter mündlich oder handschriftlichtradierter Volkslieder aus dem gesamtendeutschsprachigen Raum, und ist, wasAbdeckung und Umfang angeht, in dieser Formeinzigartig (Krüger, 2013). Die losen Einzelblätterenthalten einerseits handschriftliche,monophone Melodien und andererseitsLiedtexte, welche zumeist mit Schreibmaschineverfasst wurden (vgl. Abb. 1).
Abbildung 1: Ausschnitt aus dem Liedblatt Nr.A23: „Klana Mann wollt’ e grouß Fraa hou“.
Zu den Liedblättern existieren darüberhinaus Metadaten wie Titel, Text-Incipit,Sangesort und Jahr, die ursprünglich in einemumfangreichen Zettelkastensystem vorlagen,mittlerweile jedoch in eine Datenbank ( Augias)übertragen wurden. In Zusammenarbeitmit der Universitätsbibliothek Regensburgwerden zunächst Scans der Liedblättererstellt und mit den bereits vorhandenendigitalen Metadaten verknüpft. Daraufhinwerden die Scans inhaltlich erfasst und in einmaschinenlesbares Format gebracht, das erlaubt,die Daten computergestützt zu durchsuchenund zu analysieren. Dieser Beitrag beschreibtHerausforderungen und Lösungsansätze beider digitalen Erschließung der Liedblätterhinsichtlich ihrer Texte und Melodien.
Digitale Erschließung derLiedblätter
Für die Transkription der Texte und Melodienwurden Tools für die automatische Erfassungevaluiert. Neben automatischer Texterkennung(OCR, Optical Character Recognition), wurde auchdie automatische Notenerkennung (OMR, OpticalMusic Recognition) untersucht (vgl. Bainbridge &
229
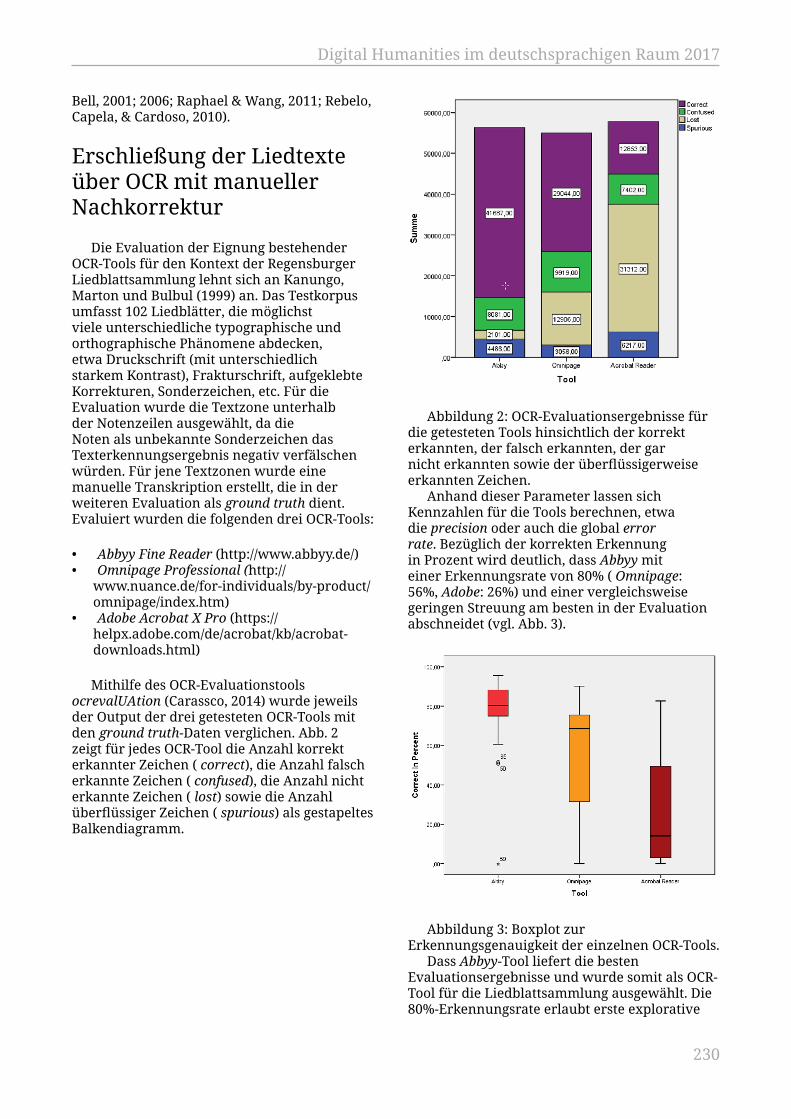
Digital Humanities im deutschsprachigen Raum 2017
Bell, 2001; 2006; Raphael & Wang, 2011; Rebelo,Capela, & Cardoso, 2010).
Erschließung der Liedtexteüber OCR mit manuellerNachkorrektur
Die Evaluation der Eignung bestehenderOCR-Tools für den Kontext der RegensburgerLiedblattsammlung lehnt sich an Kanungo,Marton und Bulbul (1999) an. Das Testkorpusumfasst 102 Liedblätter, die möglichstviele unterschiedliche typographische undorthographische Phänomene abdecken,etwa Druckschrift (mit unterschiedlichstarkem Kontrast), Frakturschrift, aufgeklebteKorrekturen, Sonderzeichen, etc. Für dieEvaluation wurde die Textzone unterhalbder Notenzeilen ausgewählt, da dieNoten als unbekannte Sonderzeichen dasTexterkennungsergebnis negativ verfälschenwürden. Für jene Textzonen wurde einemanuelle Transkription erstellt, die in derweiteren Evaluation als ground truth dient.Evaluiert wurden die folgenden drei OCR-Tools:
• Abbyy Fine Reader (http://www.abbyy.de/)• Omnipage Professional (http://
www.nuance.de/for-individuals/by-product/omnipage/index.htm)
• Adobe Acrobat X Pro (https://helpx.adobe.com/de/acrobat/kb/acrobat-downloads.html)
Mithilfe des OCR-EvaluationstoolsocrevalUAtion (Carassco, 2014) wurde jeweilsder Output der drei getesteten OCR-Tools mitden ground truth-Daten verglichen. Abb. 2zeigt für jedes OCR-Tool die Anzahl korrekterkannter Zeichen ( correct), die Anzahl falscherkannte Zeichen ( confused), die Anzahl nichterkannte Zeichen ( lost) sowie die Anzahlüberflüssiger Zeichen ( spurious) als gestapeltesBalkendiagramm.
Abbildung 2: OCR-Evaluationsergebnisse fürdie getesteten Tools hinsichtlich der korrekterkannten, der falsch erkannten, der garnicht erkannten sowie der überflüssigerweiseerkannten Zeichen.
Anhand dieser Parameter lassen sichKennzahlen für die Tools berechnen, etwadie precision oder auch die global errorrate. Bezüglich der korrekten Erkennungin Prozent wird deutlich, dass Abbyy miteiner Erkennungsrate von 80% ( Omnipage:56%, Adobe: 26%) und einer vergleichsweisegeringen Streuung am besten in der Evaluationabschneidet (vgl. Abb. 3).
Abbildung 3: Boxplot zurErkennungsgenauigkeit der einzelnen OCR-Tools.
Dass Abbyy-Tool liefert die bestenEvaluationsergebnisse und wurde somit als OCR-Tool für die Liedblattsammlung ausgewählt. Die80%-Erkennungsrate erlaubt erste explorative
230
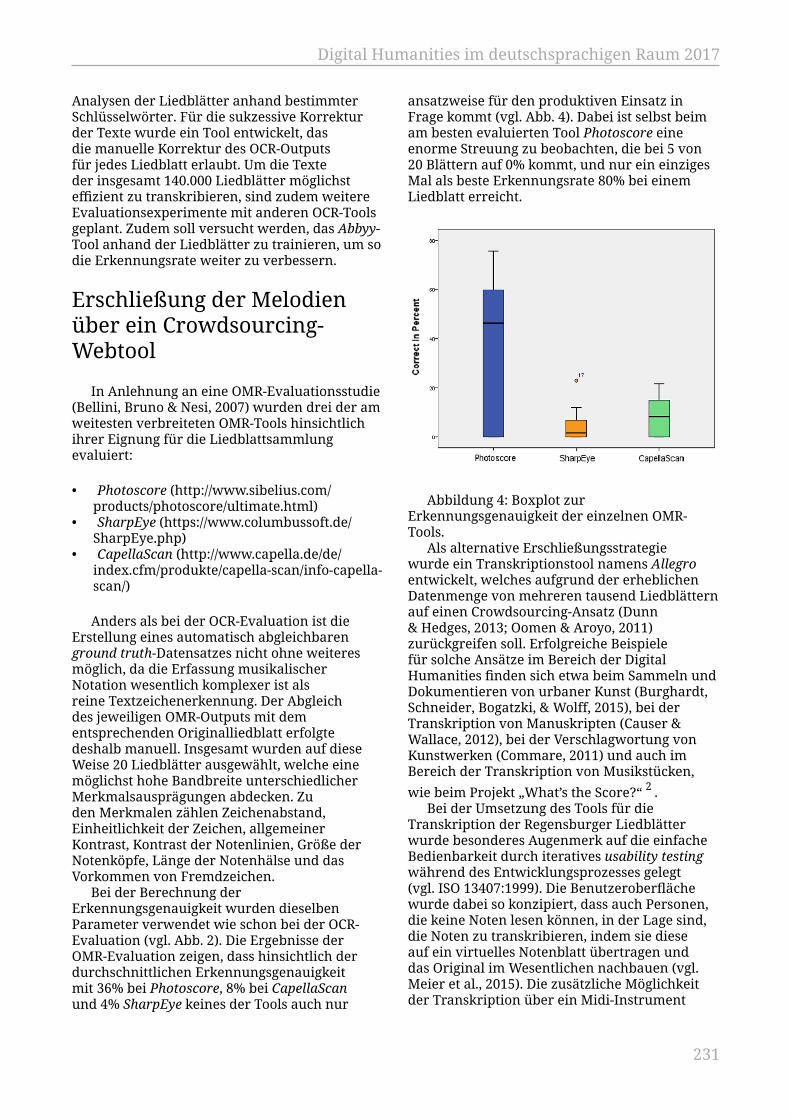
Digital Humanities im deutschsprachigen Raum 2017
Analysen der Liedblätter anhand bestimmterSchlüsselwörter. Für die sukzessive Korrekturder Texte wurde ein Tool entwickelt, dasdie manuelle Korrektur des OCR-Outputsfür jedes Liedblatt erlaubt. Um die Texteder insgesamt 140.000 Liedblätter möglichsteffizient zu transkribieren, sind zudem weitereEvaluationsexperimente mit anderen OCR-Toolsgeplant. Zudem soll versucht werden, das Abbyy-Tool anhand der Liedblätter zu trainieren, um sodie Erkennungsrate weiter zu verbessern.
Erschließung der Melodienüber ein Crowdsourcing-Webtool
In Anlehnung an eine OMR-Evaluationsstudie(Bellini, Bruno & Nesi, 2007) wurden drei der amweitesten verbreiteten OMR-Tools hinsichtlichihrer Eignung für die Liedblattsammlungevaluiert:
• Photoscore (http://www.sibelius.com/products/photoscore/ultimate.html)
• SharpEye (https://www.columbussoft.de/SharpEye.php)
• CapellaScan (http://www.capella.de/de/index.cfm/produkte/capella-scan/info-capella-scan/)
Anders als bei der OCR-Evaluation ist dieErstellung eines automatisch abgleichbarenground truth-Datensatzes nicht ohne weiteresmöglich, da die Erfassung musikalischerNotation wesentlich komplexer ist alsreine Textzeichenerkennung. Der Abgleichdes jeweiligen OMR-Outputs mit dementsprechenden Originalliedblatt erfolgtedeshalb manuell. Insgesamt wurden auf dieseWeise 20 Liedblätter ausgewählt, welche einemöglichst hohe Bandbreite unterschiedlicherMerkmalsausprägungen abdecken. Zuden Merkmalen zählen Zeichenabstand,Einheitlichkeit der Zeichen, allgemeinerKontrast, Kontrast der Notenlinien, Größe derNotenköpfe, Länge der Notenhälse und dasVorkommen von Fremdzeichen.
Bei der Berechnung derErkennungsgenauigkeit wurden dieselbenParameter verwendet wie schon bei der OCR-Evaluation (vgl. Abb. 2). Die Ergebnisse derOMR-Evaluation zeigen, dass hinsichtlich derdurchschnittlichen Erkennungsgenauigkeitmit 36% bei Photoscore, 8% bei CapellaScanund 4% SharpEye keines der Tools auch nur
ansatzweise für den produktiven Einsatz inFrage kommt (vgl. Abb. 4). Dabei ist selbst beimam besten evaluierten Tool Photoscore eineenorme Streuung zu beobachten, die bei 5 von20 Blättern auf 0% kommt, und nur ein einzigesMal als beste Erkennungsrate 80% bei einemLiedblatt erreicht.
Abbildung 4: Boxplot zurErkennungsgenauigkeit der einzelnen OMR-Tools.
Als alternative Erschließungsstrategiewurde ein Transkriptionstool namens Allegroentwickelt, welches aufgrund der erheblichenDatenmenge von mehreren tausend Liedblätternauf einen Crowdsourcing-Ansatz (Dunn& Hedges, 2013; Oomen & Aroyo, 2011)zurückgreifen soll. Erfolgreiche Beispielefür solche Ansätze im Bereich der DigitalHumanities finden sich etwa beim Sammeln undDokumentieren von urbaner Kunst (Burghardt,Schneider, Bogatzki, & Wolff, 2015), bei derTranskription von Manuskripten (Causer &Wallace, 2012), bei der Verschlagwortung vonKunstwerken (Commare, 2011) und auch imBereich der Transkription von Musikstücken,wie beim Projekt „What’s the Score?“ 2 .
Bei der Umsetzung des Tools für dieTranskription der Regensburger Liedblätterwurde besonderes Augenmerk auf die einfacheBedienbarkeit durch iteratives usability testingwährend des Entwicklungsprozesses gelegt(vgl. ISO 13407:1999). Die Benutzeroberflächewurde dabei so konzipiert, dass auch Personen,die keine Noten lesen können, in der Lage sind,die Noten zu transkribieren, indem sie dieseauf ein virtuelles Notenblatt übertragen unddas Original im Wesentlichen nachbauen (vgl.Meier et al., 2015). Die zusätzliche Möglichkeitder Transkription über ein Midi-Instrument
231

Digital Humanities im deutschsprachigen Raum 2017
soll später über einen speziell anzuwählendenExpertenmodus optional verfügbar gemachtwerden.
Als erster Schritt wird in Allegro zunächstdas Notenblatt manuell in einzelne Taktesegmentiert (Abb. 5):
Abbildung 5: Taktweise Segmentierung derLiedblätter mit dem Allegro.
Nach Angabe der Liedblattnummer sowie derAuswahl von Taktart und Tonart gelangt man inden eigentlichen Transkriptionsmodus, bei demTakt für Takt auf einer interaktiven Notenzeilemit Maus und Tastatur (Shortcuts) transkribiertwird (vgl. Abb. 6). Jeder einzelne Takt kannim Browser abgespielt werden, um so ggf. aufauditiver Ebene schnell Transkriptionsfehler zuerkennen.
Abbildung 6: Taktweise Transkription derLiedblätter mit dem Allegro-Tool.
Im Hintergrund werden die Eingabenauf das virtuelle Notenblatt schließlichin ein maschinenlesbares Format ( JSON)übersetzt, das mithilfe einer Converter-Toolbox in beliebige andere Formate wie etwaMusicXML transformiert werden kann. Dadie Transkription durch Laien eine erhöhteGefahr für Transkriptionsfehler mit sich bringt,wird jedes Liedblatt doppelt übersetzt (vgl. dasdouble keying-Konzept bei Texttranskriptionen).Liedblätter, bei denen die Transkriptionen nichtübereinstimmen, werden auf redaktionellerEbene final geprüft. Um den Anreiz zurBeteiligung an der Transkription zu erhöhen,ist es den Teilnehmern möglich die selbsttranskribierten Texte und Melodien in einerprivaten Sammlung zu speichern und bei Bedarfals PDF bzw. als MP3 herunterzuladen.
Das Transkriptionstool befindet sich aktuellin der offenen Beta-Testphase und findet gutenZuspruch bei den Anwendern:
• Allegro: http://allegro.sytes.net/
Zusammenfassung
Dieser Beitrag gibt einen Einblick in einlaufendes Projekt zur digitalen Erschließungeiner großen Sammlung von Liedblättern.Während OCR-Tools für die automatischeErfassung der Liedtexte annehmbare Ergebnissemit einer Erkennungsrate von bis zu 80% liefern,so liegt die Erkennungsgenauigkeit bestehenderOMR-Tools für die handschriftlichen Notensätzebei lediglich maximal 36%. Im Falle derNotenerkennung wurde von Grund auf einneues, intuitiv bedienbares Transkriptionstoolentwickelt, welches über einen Crowdsourcing-Ansatz die sukzessive Erschließung derNotensätze sicherstellen soll.
Ausblick
Aktuell liegt der Projektfokus auf derErschließung der Liedblätter. Parallel entstehenzudem erste Prototypen (vgl. Burghardt et al.,2016) für das angedachte Informationssystem,das die Analyse der Liedblätter anhand derverfügbaren Metadaten, der Liedtexte sowieanhand verschiedener melodischer Parameter(vgl. Mongeau & Sankoff, 1990; Orio & Rodá,2009; Typke, 2007) erlaubt. Im Rahmen desweiteren Projektverlaufs sollen anhand derdigital erschlossenen Liedblätter u.a. diefolgenden Fragestellungen untersucht werden:
• Welche sind die häufigsten Wörter inden Texten deutscher Volkslieder, undwelche Wörter treten besonders häufigzusammen auf (Kollokationen)? Lassen sichdaraus Rückschlüsse auf wiederkehrendeThemen ziehen, einerseits für das gesamteLiedblattkorpus, andererseits aus einerregionalen und diachronen Perspektive?
• Gibt es melodische Universalien, die typischfür deutsche Volkslieder sind, einerseits fürdas gesamte Liedblattkorpus, andererseitsaus einer regionalen und diachronenPerspektive?
• Lassen sich musikalisch-linguistischeKollokationen identifizieren, kommen alsobestimmte Melodien oder einzelne Rhythmen
232

Digital Humanities im deutschsprachigen Raum 2017
oder Intervalle besonders häufig in Textenmit auffälligen Schlüsselwörtern vor?
Fußnoten
1. Anmerkung: Erste Vorarbeiten zu denhier beschriebenen Vorhaben erfolgten imRahmen des DFG-Projekts „Erschließungvon Quellen der Volksmusikforschung,Zugänglichmachung durch Digitalisierungsowie virtuelle Wiederherstellung zerstreuterBestände“, vgl. http://rvp.ur.de.2. Projekt „What’s the Score?“ online: https://www.bodleian.ox.ac.uk/weston/our-work/projects/whats-the-score
Bibliographie
Bainbridge, David / Bell, Tim (2001): „Thechallenge of optical music recognition“, in:Computers and the Humanities 35: 95–121.
Bellini, Pierfranceso / Bruno, Ivan /Nesi, Paolo (2007): „Assessing Optical MusicRecognition Tools“, in: Computer Music Journal31 (1), 68–93.
Burghardt, Manuel / Lamm, Lukas /Lechler, David / Schneider, Matthias /Semmelmann, Tobias (2016): „Tool-basedIdentification of Melodic Patterns in MusicXMLDocuments“, in: Digital Humanities 2016:Conference Abstracts 440–442.
Burghardt, Manuel / Schneider, Patrick /Bogatzki, Christopher / Wolff, Christian(2015): „StreetartFinder – Eine Datenbank zurDokumentation von Kunst im urbanen Raum“,in: DHd 2015: Von Daten zu Erkenntnissen.
Carrasco, Rafael C. (2014): „An open-sourceOCR evaluation tool“, in: DATeCH 2014. NewYork: ACM Press.
Causer, Tim / Wallace, Valerie (2012):„Building A Volunteer Community: Results andFindings from Transcribe Bentham“, in: DHQ:Digital Humanities Quarterly 6 (2).
Commare, Laura (2011): „Social Tagging alsMethode zur Optimierung KunsthistorischerBilddatenbanken – Eine empirische Analysedes Artigo-Projekts“, in: Kunstgeschichte. OpenPeer Reviewed Journal urn:nbn:de:bvb:355-kuge-160-9.
Dunn, Stuart / Hedges, Mark (2013):„Crowd-sourcing as a Component of HumanitiesResearch Infrastructures“, in: InternationalJournal of Humanities and Arts Computing 7 (1-2):147–169.
Kanungo, Tapas / Marton, Gregory A. /Bulbul, Osama (1999): „Performance evaluation
of two Arabic OCR products“, in: The 27thAIPR workshop: Advances in computer-assistedrecognition 76–83.
Krüger, Gerd (2013): „Das ‚RegensburgerVolksmusik-Portal‘ der UniversitätsbibliothekRegensburg: Bestände – Problematiken –Perspektiven: Zwischenbericht aus einemErschließungsprojekt“, in: Mohrmann, Ruth-E.(ed.), Audioarchive – Tondokumente digitalisieren,erschließen und auswerten. Münster et al.:Waxmann Verlag 119–131.
Meier, Florian / Bazo, Alexander /Burghardt, Manuel / Wolff, Christian (2015):„A Crowdsourced Encoding Approach forHandwritten Sheet Music“, in: Music EncodingConference Proceedings 2013 and 2014 127–130.
Mongeau, Marcel / Sankoff, David (1990):„Comparison of Musical Sequences“, in:Computers and the Humanities 24: 161–175.
Oomen, Johan / Aroyo, Lora (2011):„Crowdsourcing in the Cultural HeritageDomain: Opportunities and Challenges“, in:C&T ’11 Proceedings of the 5th InternationalConference on Communities and Technologies138–149.
Orio, Nicola / Rodà, Antonio (2009): „AMeasure of Melodic Similarity Based on a GraphRepresentation of the Music Structure“, in:Proceedings of the 10th International Society forMusic Information Retrieval Conference (ISMIR2009) 543–548.
Raphael, Christopher / Wang, Jingya(2011): „New Approaches to Optical MusicRecognition“, in: 12th International Society forMusic Information Retrieval Conference (ISMIR)305–310.
Rebelo, Ana / Capela, G. / Cardoso, Jaime S.(2010): „Optical recognition of music symbols“,International Journal on Document Analysis andRecognition 13: 19–31.
Typke, Rainer (2007): Music Retrieval basedon Melodic Similarity. Ph.D Thesis, UtrechtUniversity.
233

Digital Humanities im deutschsprachigen Raum 2017
DigitaleNachhaltigkeit beiGrundlagenforschungin Akademieprogramm:Das Beispiel „JohannFriedrich Blumenbach-online“
Wettlaufer, Jö[email protected] der Wissenschaften zu Göttingen,Deutschland
Johnson, [email protected] der Wissenschaften zu Göttingen,Deutschland
Das Projekt „Johann-Friedrich Blumenbachonline“ ist ein Forschungsvorhaben derAkademie der Wissenschaften zu Göttingenmit einer Laufzeit von 15 Jahren bis2024. Es hat sich zum Ziel gesetzt, diegedruckten Veröffentlichungen sowie dieSammlungstätigkeit dieses Göttinger Gelehrtenund Begründers der physischen Anthropologie,die sich über einen längeren Zeitraum imletzten Viertel des 18. und im ersten Dritteldes 19. Jahrhunderts erstreckt, durch einedigitale Edition für die wissenschaftshistorischeForschung zu erschließen. Eine besondereHerausforderung für dieses ganz digitalkonzipierte Projekt ist dabei der Aufbau einernachhaltigen digitalen Infrastruktur über diegesamte Laufzeit des Projekts und darüberhinaus.
Nach einer Phase der Zusammenarbeit mitTextgrid, einer virtuellen Forschungsumgebungim Rahmen von dariah.de, wurde seit 2015 einneuer Ansatz für eine nachhaltige Präsentationder Ergebnisse präferiert, der auf LinkedOpen Data (LOD) basiert und sich neben dentranskribierten XML-Texten und den Metadatender erfassten Objekte auf die digitalisiertenAbbildungen von Texten und Objekten selberkonzentriert. Diese sollen in einer PANDORA[Presentation (of) ANnotations (in a) DigitalObject Repository Architecture] genanntenAnnotationsumgebung für die Forschung
erschlossen werden. Technologisch underkenntnistheoretisch schließt sich das Vorhabenden Standards an, die seit einigen Jahren vomInternational Image Interoperability Framework(IIIF) 1 vorangetrieben werden. Aufbauendauf die Schnittstellen dieses Frameworksbietet PANDORA über ein sog. „Manifest“ dieOrganisation der Präsentation von Bilddaten,die z.B. in einem Repository gespeichert werden.Dieses „Manifest“ besteht aus einem JSON-LD2 Dokument und wird dynamisch aus einemdigitalen Objektrepositorium mit Hilfe vonSPARQL-Abfragen 3 erzeugt. Es orientiert sichdabei an der Semantik und dem Konzept der„IIIF Presentation API“ 4 . Die Architektur desSystems ist in mehreren Schichten organisiert,die jeweils unterschiedliche Funktionenabdecken. Die unterste Ebene bildet derRepository-Layer, in dem mit Fedora Commonseine mächtige Speicherlösung zur Verfügungsteht, mit der die Bild- und Objektdaten sowiedie zugehörigen Annotationen verwaltet werdenkönnen. In den darauf aufbauenden Schichten(Service, API und Web Application Layer)werden die Daten für die Annotationen undPräsentation aufbereitet und schließlich imClient Layer in einem Viewer visualisiert.
Mit der Verwendung aktuellerstandardisierter APIs, die von namhaftenEinrichtungen der Kulturgutbewahrungeingesetzt und unterstützt werden, erhofftsich das Projekt eine besondere Nachhaltigkeitder Investitionen, die in den Aufbau desPortals und der Forschungsumgebung fließen.Durch eine Entkoppelung der Open-SourceKomponenten in PANDORA, die bei Bedarfeinfach ausgetauscht werden können, ohnedie Grundfunktionalität zu gefährden, solleine langfristige und ressourcenschonendeVerwendung der Forschungsumgebung
234

Digital Humanities im deutschsprachigen Raum 2017
gewährleistet werden. Für die Präsentationder Bilddaten können verschiedene Viewerwie z.B. mirador 5 eingesetzt werden, ohnedass eine spezielle Anpassung notwendig ist.Aufgrund der auf Semantic Web Technologienaufbauenden Architektur sowie der Möglichkeitder Bereitstellung der Daten als Linked OpenData über einen Triplestore (Jena Fuseki) isteine Nachnutzungsmöglichkeit der Daten durchandere Projekte gegeben, die ebenfalls zurNachhaltigkeit der PANDORA-Lösung beiträgt.
Langfristige Forschungsvorhaben imAkademienprogramm stehen vor besonderenHerausforderungen, da noch während derProjektlaufzeit technologische (Weiter-)Entwicklungen zu erwarten sind, die beiAntragstellung weder vorhergesehen nochvollständig antizipiert werden können. Dazukommt die Herausforderung, digitale Systemenicht nur für die Präsentation der Ergebnissesondern auch für den Arbeitsprozess bei derenErstellung vorzuhalten und kontinuierlichweiter zu entwickeln. Das Poster möchte,am Beispiel des Projekts „Johann-FriedrichBlumenbach online“, eine aktuelle undnachhaltige Lösung für diese Aufgabenstellungvorstellen und in der deutschen DigitalHumanities Community diskutieren.
Fußnoten
1. http://iiif.io/2. https://www.w3.org/TR/json-ld/3. https://www.w3.org/TR/sparql11-query/4. http://iiif.io/api/presentation/2.1/5. http://github.com/IIIF/mirador
Bibliographie
Kerzel, Martina / Reich, Mike / Weber,Heiko (2013): „Die Edition ‚Johann FriedrichBlumenbach – online‘ der Akademie derWissenschaften zu Göttingen“, in: Neuroth,Heike / Lossau, Norbert / Rapp, Andrea (eds.):Evolution der Informationsinfrastruktur:Kooperation zwischen Bibliothek undWissenschaft. Glückstadt: Verlag WernerHülsbusch 107–136.
Lauer, Gerhard (2014): „Johann FriedrichBlumenbach – online (Projektbericht für dasJahr 2013)“, in: Jahrbuch der Akademie derWissenschaften zu Göttingen: 2013. Boston /Berlin: De Gruyter 235–237.
Wettlaufer, Jörg / Johnson, Christopher /Scholz, Martin / Fichtner, Mark / Thotempudi,
Sree Ganesh (2015): „Semantic Blumenbach:Exploration of Text-Object Relationships withSemantic Web Technology in the History ofScience“, in: Terras, Melissa / Clivaz, Clare /Verhoeven, Deb / Kaplan, Frederic (eds.): DigitalScholarship in the Humanities (DSH), SpecialIssue „Digital Humanities 2014“ 30, Supplement1: i187–i198.
DigitaleNachhaltigkeit in denGeisteswissenschaftendurch TOSCA: Nutzungeines standardbasiertenOpen-SourceÖkosystems
Breitenbücher, [email protected] für Architektur vonAnwendungssystemen, Universität Stuttgart,Deutschland
Barzen, [email protected] für Architektur vonAnwendungssystemen, Universität Stuttgart,Deutschland
Falkenthal, [email protected] für Architektur vonAnwendungssystemen, Universität Stuttgart,Deutschland
Leymann, [email protected] für Architektur vonAnwendungssystemen, Universität Stuttgart,Deutschland
Einleitung
Die digitale Nachhaltigkeit von IT-Anwendungen in der Forschung spielt eineimmer größer werdende Rolle, da IT-gestützteForschungsergebnisse auch Jahre nach deren
235

Digital Humanities im deutschsprachigen Raum 2017
Publikation reproduzierbar sein müssen, umDritten das Nachvollziehen und Überprüfender Ergebnisse zu ermöglichen. Wenn dasForschungsresultat auf der automatisiertenAuswertung strukturiert dokumentierter Datenmittels Softwareprogrammen basiert, wird diestetige und zügige Weiterentwicklung von IT-Technologien jedoch zu einem immer größerenProblem: Werden Forschungsergebnissebeispielsweise mittels eines Windows 95-basierten Programms ermittelt, wird dessenAusführung mit jeder neuen Generation vonBetriebssystemen umständlicher, da sichSchnittstellen ändern und Annahmen nichtmehr erfüllt sind.
Während diese Probleme für einfacheSoftwareanwendungen mittels virtuellerMaschinen gelöst werden können, sindkomplexere Anwendungen mit diesem Ansatznicht ohne großen manuellen Aufwandreproduzierbar. Basiert ein Forschungsergebnisbeispielsweise auf einer umfangreichensoftwarebasierten Simulation, welcheunterschiedliche Dienste aufruft, die aufverschiedenen Betriebssystemen ausgeführtwerden müssen, erfordert das Aufsetzen derMaschinen und Softwarekomponenten sowiederen Konfiguration detaillierte Expertise und istmit großem Aufwand verbunden (Breitenbücheret al. 2013).
In diesem Beitrag zeigen wir auf, wie diestandardbasierte open-source TechnologieOpenTOSCA in den Digital Humanities eingesetztwerden kann, um die Reproduzierbarkeit IT-gestützter Forschungsergebnisse unabhängigvon Technologieentwicklungen zu ermöglichen.Insbesondere verdeutlichen wir, wie auchkomplexe Softwareanwendungen automatisiertbereitgestellt werden können, ohne detailliertetechnische Expertise aufweisen zu müssen.Dadurch wird die nachhaltige Entwicklung vonForschungssoftware ermöglicht, indem dieseauch Jahre später von Laien ausgeführt werdenkann.
Nutzung des OpenTOSCAÖkosystems zur Sicherung derdigitalen Nachhaltigkeit vonForschungsergebnissen
Das OpenTOSCA Ökosystem ist eineWerkzeugsammlung, welche die automatisierteBereitstellung und Verwaltung von IT-Anwendungen ermöglicht. Die Werkzeugebasieren auf der Topology and Orchestration
Specification for Cloud Applications (TOSCA)(OASIS 2013), einem OASIS Standard zurportablen Beschreibung von IT-Anwendungen.Der Standard definiert ein Metamodell zurModellierung von Anwendungsmodellen,die alle Komponenten einer Anwendung,beispielsweise Webserver und Datenbanken,sowie deren Beziehungen untereinanderbeschreiben. TOSCA ist anbieter- undtechnologieagnostisch, wodurch ein Vendor-Lock-in verhindert wird. Dadurch könnenbeliebige Komponententypen mittels TOSCAbeschrieben und in Anwendungsmodellenmiteinander kombiniert werden. Zurautomatisierten Bereitstellung der modelliertenAnwendungen definiert TOSCA die Konzepteder Deployment Artifacts (DA) und der Implementation Artifacts. DeploymentArtifacts stellen die Implementierungeiner Komponente dar. Beispielsweisekann die Java-Implementierung einesAnalysealgorithmus als Deployment Artifactan das zugehörige Komponentenelement desModells annotiert werden, siehe Abbildung 1.Managementoperationen, wie beispielsweise einInstallationsskript für einen Webserver, könnenmittels Implementation Artifacts modelliertwerden. Um Anwendungsmodelle inklusive allerArtefakte zu paketieren, definiert TOSCA dasselbstbeschreibende Archivformat Cloud ServiceArchive (CSAR).
Abbildung 1: Simplifiziert dargestelltesAnwendungsmodell
Zur automatisierten Bereitstellung TOSCA-basierter Anwendungen werden TOSCA-Laufzeitumgebungen eingesetzt, welchedie Anwendungsmodelle interpretierenund alle nötigen Bereitstellungsaktivitätenausführen, d.h. modellierte virtuelle Maschinen
236

Digital Humanities im deutschsprachigen Raum 2017
provisionieren, Webserver durch Ausführungvon Implementation Artifacts installieren,Komponentenimplementierungen in Form vonDeployment Artifacts ausliefern, etc. An derUniversität Stuttgart wurde die open-sourceLaufzeitumgebung OpenTOSCA (Binz et al.2013) sowie das TOSCA-ModellierungswerkzeugWinery (Kopp et al. 2013) entwickelt, um TOSCA-basierte Anwendungsmodelle auszuführenund zu erstellen. Das SelbstbedienungsportalVinothek (Breitenbücher et al. 2014)ermöglicht es Nutzern, mittels eines Klicks, dieBereitstellung einer Anwendung zu veranlassen.Abbildung 2 zeigt das Zusammenspiel derWerkzeuge.
Abbildung 2: Werkzeuge des OpenTOSCAÖkosystems
Dieses OpenTOSCA Ökosystem kann zurSicherung der digitalen Nachhaltigkeit vonForschungsergebnissen eingesetzt werden,indem Forschungssoftware in Form von CSARspaketiert wird. Durch die Möglichkeit, mitWinery alle erforderlichen Implementierungenin Form von Deployment und ImplementationArtifacts zu spezifizieren, sowie die Strukturder Anwendung inklusive aller Beziehungenzwischen Komponenten zu modellieren, könnenAnwendungen selbstbeschreibend als CSARarchiviert werden. Diese CSARs können auchJahre nach deren Entwicklung mittels derOpenTOSCA Laufzeitumgebung provisioniertwerden, da alle nötigen Softwareartefakte undModelle im CSAR enthalten sind und dadurchkeine Abhängigkeiten zu externen Dateienexistieren. Durch dieses Konzept könnenbeispielsweise „Snapshots“ mehrerer virtuellerMaschinen unterschiedlicher Betriebssystemein Form von Virtual Machine Images in dasCSAR gelegt und miteinander assoziiertwerden, oder auch spezifische Webserver-Implementierungen, die Jahre später in dergenutzten Form nur schwierig auffindbar sindbzw. von Laien nicht gemäß der erforderlichen
Konfiguration installiert werden können. DieOpenTOSCA Laufzeitumgebung unterstütztzudem gängige Bereitstellungstechnologienwie Ansible (Hochstein 2014) oder Docker(Mouat 2015), wodurch Artefakte dieserTechnologien ohne zusätzlichen Aufwand indas Anwendungsmodell eingebunden werdenkönnen. OpenTOSCA ermöglicht dadurchauch die effiziente Orchestrierung mehrererBereitstellungstechnologien.
Zur Reproduktion der Forschungsergebnissemuss die Software typischerweise mitauszuwertenden Forschungsdaten gestartetund parametrisiert werden. Häufig ist diesnicht trivial, beispielsweise wenn Data-Mining-Algorithmen auf Basis von Daten über Kostümein Filmen wiederkehrende Muster findensollen (Falkenthal et al. 2016). Das Konzept derCSARs ermöglicht auch diese Automatisierung,indem individuelle Provisionierungspläne füreine Anwendung modelliert werden können.Ein solcher Plan kann dann automatisiertvon OpenTOSCA ausgeführt werden, um dieAnwendung zu installieren und wie vorgesehenzu starten.
Bibliographie
Binz, Tobias / Breitenbücher, Uwe / Haupt,Florian / Kopp, Oliver / Leymann, Frank /Nowak, Alexander / Wagner, Sebastian (2013):„OpenTOSCA - A Runtime for TOSCA-basedCloud Applications“, in: Proceedings of the 11thInternational Conference on Service-OrientedComputing (ICSOC 2013). Springer.
Breitenbücher, Uwe / Binz, Tobias /Kopp, Oliver / Leymann, Frank / Wettinger,Johannes (2013): „Integrated Cloud ApplicationProvisioning: Interconnecting Service-Centricand Script-Centric Management Technologies“,in: On the Move to Meaningful Internet Systems:OTM 2013 Conferences (CoopIS 2013). Springer.
Breitenbücher, Uwe / Binz, Tobias / Kopp,Oliver / Leymann, Frank (2014): „Vinothek - ASelf-Service Portal for TOSCA“, in: Proceedings ofthe 6th Central-European Workshop on Servicesand their Composition (ZEUS 2014). CEUR-WS.org.
Falkenthal, Michael / Barzen, Johanna /Breitenbücher, Uwe / Brügmann, Sascha /Joos, Daniel / Leymann, Frank / Wurster,Michael (2016): „Pattern Research in the DigitalHumanities - How Data Mining TechniquesSupport the Identification of Costume Patterns“,in: Proceedings of the 10th Symposium andSummer School On Service-Oriented Computing(SummerSOC). Springer.
237

Digital Humanities im deutschsprachigen Raum 2017
Hochstein, Lorin (2014): Ansible: Up andRunning. O’Reilly Media.
Kopp, Oliver / Binz, Tobias / Breitenbücher,Uwe / Leymann, Frank (2013): „Winery– A Modeling Tool for TOSCA-based CloudApplications“, in: Proceedings of the 11thInternational Conference on Service-OrientedComputing (ICSOC 2013). Springer.
Mouat, Adrian (2015): Using Docker:Developing and Deploying Software withContainers. O’Reilly Media.
OASIS (2013): Topology and OrchestrationSpecification for Cloud Applications Version 1.0.
Digitale Werkzeugeund Infrastrukturenzur Analyse undBeschreibungvon Bewegungenin vormodernenWissensbeständen
Hegel, [email protected] Universität Darmstadt, Deutschland
Tonne, [email protected] Institut für Technologie, Deutschland
Geukes, [email protected] Universität Berlin, Deutschland
Krewet, [email protected] Universität Berlin, Deutschland
Rapp, [email protected] Universität Darmstadt, Deutschland
Stotzka, [email protected] Institut für Technologie, Deutschland
Uhlmann, [email protected] Universität Berlin, Deutschland
Einführung
Der Sonderforschungsbereich 980 „Epistemein Bewegung“ untersucht Prozesse desWissenswandels in europäischen und nicht-europäischen Kulturen vom 3. Jahrtausendvor Christus bis ca. 1750 nach Christus. Inden Analysen der insgesamt 22 Teilprojekteaus 20 Disziplinen wird gezeigt, wie geradedort, wo in den Selbstbeschreibungen dervormodernen Kulturen und aus der Perspektiveder Moderne Kontinuität und Stabilität imVordergrund stehen, vielfältige Formen desWandels und der Entwicklung beschriebenwerden können. Wissen wird dabei als Epistemegefasst. Dieser Begriff aus der griechischenAntike schließt Wissenschaft ebenso ein wienicht institutionalisierte Formen von Wissen.Er zeigt an, dass Wissen sich immer auf einenGegenstand bezieht und impliziert zudem,dass Wissen als Wissen von etwas immermit einem Geltungsanspruch versehen ist.Wissensbewegungen, die mit dem Terminus„Wissenstransfer“ als Neukontextualisierungvon Wissenselementen in neuen Kontextenbeschreibbar gemacht werden, finden immerin komplexen Austauschprozessen statt,in denen verschiedene Akteure, Medien,Praktiken, Diskurse und Institutionenmiteinander interagieren. Um diese komplexenmultidirektionalen und multidimensionalenProzesse erfassen und beschreiben zu können,werden digitale Werkzeuge entwickelt, diekomplementär zu qualitativen exemplarischenEinzelanalysen auf größere Mengen an Textenund Bildern angewendet werden können.
Bücher auf Reisen
In diesem Rahmen entwickelt dasInformationsinfrastrukturprojekt „Bücherauf Reisen“ Softwarewerkzeuge, durch dieräumliche und zeitliche Bewegungen vonHandschriften, Drucken oder anderen Text-und Bildträgern auch für größere Objektzahlenhinweg systematisch erforscht werden. DieErgebnisse werden als miteinander dynamischvernetzte Elemente visualisiert. Auch „innereReisen“, das heißt Bewegungen in Objektenwie das Hinzufügen von Randnotizen oderder Verweis auf andere Texte, sollen auf diese
238

Digital Humanities im deutschsprachigen Raum 2017
Weise digital aufbereitet und gespeichertwerden. Neben dem Schwerpunkt aufder Entwicklung informationstechnischunterstützter Verfahren zur Datenerschließungwird ein Forschungsdatenrepositoriumfür die digitalisierten Objekte mitsamt denneu ermittelten Metadaten zu Reisen undVeränderungsprozessen aufgebaut werden, dasnachhaltig nutzbar ist.
Zentrale Fragestellungen sind hierbei dieModellierung und Verwaltung der Relationender sehr heterogenen Datenbestände als„dynamische Metadaten“, eine verlässlicheSpeicherung aller Daten im Sinne einerLangzeitverfügbarkeit und eine sehr intuitiveund benutzerfreundliche Bedienung.Durch die Verwendung internationalanerkannter Standards und Schnittstellenwird die Interoperabilität mit anderenstandardisierten Infrastrukturen, zum BeispielDARIAH-DE, und die leichte Erweiterbarkeitgewährleistet. Alle entwickelten oderadaptierten Softwarekomponenten werden derÖffentlichkeit als open source zur Verfügunggestellt.
Zuerst werden anhand von Pilotprojektenmit Daten aus der Aristotelesüberlieferung,altägyptischen Pyramidentexten,frühneuzeitlichen Fremdsprachenlehrwerkenund einer Bibliothek des Osmanischen Reichesdas Forschungsdatenrepositorium und dieSoftwarewerkzeuge erprobt und schrittweiseverbessert, bis sie von allen Projektpartnertnverwendet werden können.
Handschriften in Bewegung
Im selben Rahmen werden im Gastprojekt„Handschriften in Bewegung“ digitaleVerfahren zur Analyse von Veränderungeninnerhalb von Handschriften im Sinne dergenannten „inneren Reisen“ entwickelt. MitAlgorithmen der Bildverarbeitung aus demProjekt „eCodicology“ können Merkmale desLayouts auf digitalisierten Buchseiten undHandschriften erkannt werden, die auch alsstrategische Momente zur Übermittlung vonWissen verstanden werden können. Auf derGrundlage dieser reproduzierbaren Messdatenwerden durch statistische Auswertungenneue Erkenntnisse über Veränderungen inEinzelhandschriften oder Entwicklungeneines gesamten Buchbestandes gewonnen.Die Ergebnisse können insbesondere genutztwerden, um De- und Rekontextualisierungenvon Wissensbeständen in Büchern aufzuzeigen.
Zu diesem Zweck werden verschiedene bereitsexistierende Softwarekomponenten eingesetzt:
Mit einem Bildverarbeitungsworkflow werdenSeiten, Text- und Bildflächen auf Digitalisatenvermessen.
Mit einer Annotationssoftware könnendie vermessenen Bildbereichegeisteswissenschaftlich eingeordnet und mitzusätzlichen Informationen angereichertwerden. So lässt sich die Wanderungeinzelner Wissensbestände in einem Korpusnachvollziehen.
Die Metadaten werden graphisch aufbereitet,um gattungsspezifische Differenzen undhistorische Veränderungen sichtbar zumachen.
Fazit und Überlegungen zurNachhaltigkeit
Die Forschungsfrage desSonderforschungsbereichs „Epistemein Bewegung“ mit seiner Vielfalt angeisteswissenschaftlichen Disziplinenund Methoden wird durch den Einsatzinformatischer Methoden und Fragestellungensubstantiell bereichert. Umgekehrt bedeutendie Multidisziplinarität und die Diversitätder Objekte ebenso eine Chance für dieWeiterentwicklung informatischer Werkzeugewie eine Herausforderung für die informatischeOperationalisierung von Fragestellungen.
Auf Grund von Erfahrungen in früherenProjektarbeiten wird ein besonderer Fokus aufNachhaltigkeit gelegt und diesem Bereich eineigenes Arbeitspaket gewidmet. Im Rahmeneiner engen Kooperation des SFB mit DARIAH-DE und dem Center für Digitale Systemeder Freien Universität Berlin stehen dernachhaltige Betrieb der erweiterten bzw. neugeschaffenen Forschungsdateninfrastruktursowie deren fachliche Anschlussfähigkeit bzw.Anwendbarkeit auch für andere Fachrichtungenim Vordergrund. Durch standardisierteSchnittstellen sowie Nachnutzung undErweiterung bestehender Werkzeuge werdenbereits in der Konzeption erste Ansätze verfolgt,zusätzlich sind aber auch die Integration inbestehende Infrastrukturen und Institutionenvor Ort sowie in institutionenübergreifendeInfrastrukturverbünde zentrale Fragestellungen.
239

Digital Humanities im deutschsprachigen Raum 2017
Bibliographie
Chandna, Swati / Tonne, Danah / Jeikal,Thomas / Stotzka, Rainer / Krause, Celia /Vanscheidt, Philipp / Busch, Hannah /Prabhune, Ajinkya (2015): „Softwareworkflow for the automatic tagging of medievalmanuscript images (SWATI)“, in: Ringger, EricK. / Lamiroy, Bart (eds.): Proceedings SPIE9492,Document Recognition and Retrieval XXII, 94020110.1117/12.2076124 .
Chandna, Swati / Tonne, Danah / Stotzka,Rainer / Busch, Hannah / Vanscheidt, Philipp /Krause, Celia (2016): „An effective visualizationtechnique for determining co-relations in high-dimensional medieval manuscripts data“,in: Proceedings of Visualization and DataAnalyses 2016 http://www.ingentaconnect.com/contentone/ist/ei/2016/00002016/00000001/art00013 .
Einfaches TopicModeling inPython - EineProgrammbibliothekfür Preprocessing,Modellierung undAnalyse
Jannidis, [email protected]ät Würzburg, Deutschland
Pielström, [email protected]ät Würzburg, Deutschland
Schöch, [email protected]ät Würzburg, Deutschland
Vitt, [email protected]ät Würzburg, Deutschland
Topic Modeling ist eine Methode zursemantischen Erschließung größerer
Textsammlungen, die in den letzten Jahrenzunehmend in den Fokus der Aufmerksamkeitdigital arbeitender Literaturwissenschaftlergerückt ist. Die Methode nutzt probabilistischeVerfahren um aus einer Textsammlungeine Reihe von Verteilungen über dieWahrscheinlichkeiten einzelner Wörter zuerzeugen. Diese werden dann als distinktesemantische Gruppen, sogenannte ‘Topics’,aufgefasst, also als Gruppen inhaltlichzusammenhängender Wörter, die in deneinzelnen Texten jeweils mehr oder wenigerstark präsent sind (Blei 2012, Steyvers undGriffiths 2006).
Ursprünglich entwickelt, um in größerenSammlungen kürzerer Fachartikel schnell jenezu identifizieren, die für bestimmte Themenrelevant sein könnten, kann diese Methodedarüber hinaus für eine Reihe von Problemim Bereich der digitalen Literaturwissenschaftinteressante neue Lösungsansätze bieten. Dazugehört die automatische Identifikation vonRomanen, die ähnliche Themen behandeln(wenngleich eine direkte Gleichsetzungprobabilistischer ‘Topics’ mit literarischen‘Themen’ durchaus problematisch ist),ebenso wie die Zuordnung zu bestimmtenGenres anhand inhaltlicher Aspekte, oderdie quantifizierende Betrachtung der zu-und abnehmenden Bedeutung einzelnerThemenfelder über den Verlauf eines einzelnenRomans (vgl. Blevins 2012, Jockers 2011, Rhody2012, Schöch in Vorbereitung).
Mit den Programmen ‘Mallet’ (vgl.McCallum 2002) und ‘Gensim’ (vgl. Rehurek2010) stehen zur Zeit zwei State-of-the-ArtImplementierungen von Topic Modeling-Algorithmen zur Verfügung. Um die Methodeproduktiv einzusetzen, sind aber neben derErzeugung des Modells weitere Arbeitsschrittenotwendig (Abb. 1). Im ‘Preprocessing’ gilt eszunächst, die Textsammlungen in eine Form zubringen, in der sie vom Modellierungsprogrammverarbeitet werden können. Darüber hinauswerden die Texte normalerweise durch dasHerausfiltern häufiger Funktionswörterauf die potentiell inhaltsrelevanten Wörterreduziert, was in der Regel den vorhergehendenEinsatz von NLP-Tools (Natural LanguageProcessing) erfordert. Sind die ‘Topics’ dannerst einmal errechnet worden, kann sich eineVisualisierung der Ergebnisse anschließen,oder ihre statistische Evaluierung anhandinterner oder externer Kriterien, ein Aspekt dembeim Einsatz von Topic Modeling-Verfahren imDH-Kontext bisher eher zu wenig Beachtunggeschenkt wurde.
240

Digital Humanities im deutschsprachigen Raum 2017
Ziel unseres Projektes ist es, den Einstiegin aktuelle Topic Modeling-Verfahren fürdigital arbeitende Literaturwissenschaftlerwesentlich zu vereinfachen, indem wirmöglichst viele der notwendigen Arbeitsschrittein einer einheitlichen, umfangreichen undgut dokumentierten Programmbibliothekfür die unter digital-quantitativ arbeitendenGeisteswissenschaftlern stark verbreiteteProgrammiersprache Python anbieten.Hierbei sollen Nutzerinnen und Nutzer beiallen Arbeitsschritten auf vorhandene, ineinem ausführlichen Tutorial dokumentierteFunktionen zurückgreifen und so weit wiemöglich wie mit einem Kommandozeilentoolarbeiten können, ohne selbst programmierenzu müssen. Die Anforderungen an dieProgrammierkenntnisse der Forschenden, diediese Verfahren einsetzen möchten, werdendamit minimiert und die Methode wird so einemgrößeren Nutzerkreis zugänglich gemacht.
Für das NLP-Preprocessing steht mitdem DARIAH-DKPro-Wrapper (DDW) einkomfortables Einheitswerkzeug zur Verfügung,das ein großes Spektrum an NLP-Aufgabenabdeckt und linguistische Annotationen in einemPython-Pandas-kompatiblen Ausgabeformaterzeugt. Ein Ziel unserer Bibliothek ist diedirekte Anbindung des DDW-Outputs anexistierende Implementierungen verschiedeneretablierter Varianten von Topic Modeling-Algorithmen.
Für die Untersuchung der resultierendenModelle möchten wir verschiedeneEvaluierungsverfahren anbieten, sowohl interneVerfahren wie z.B. das Perplexity-Maß, alsauch externe Vefahren, wie z.B. die Weglängezwischen zwei Begriffen in einem Wörterbuch.Hieran schließen sich verschiedene Optionen zurVisualisierung der Ergebnisse an.
Im Fokus der Entwicklung steht dieGestaltung schlüssig aufeinander aufbauenderProgrammbefehle, die einer einheitlichenSyntax folgen und deren Funktion sich schnellerschließen lässt. Sie sollen sich ohne längereEinarbeitung nutzen und zu einer Pipelinezusammenfügen lassen, die die spezifischenArbeitsschritte eines bestimmten TopicModeling-Projektes umsetzt. Hierbei könnenNutzerinnen und Nutzer auf detaillierteAnleitungen aus einem umfangreichen Tutorialzurückgreifen, in dem alle Funktionen, alleOutputs, und potentielle Kombinationendetailliert dokumentiert und anhand vonBeispielen erläutert werden.
Die Entwicklung der Programmbibliothekkann auf Erfahrungen mit einer vorhandenen,Python-basierten Implementierung eines
entsprechenden Workflows aufbauen, dieallerdings eher “proof of concept”-Character hat(Topic Modeling Workflow “tmw”, vgl. Schöch2015 und http://github.com/cligs/tmw ).
Abbildung 1: Workflow eines Topic Modeling-Projektes
Bibliographie
Blei, David M. (2012): „Probabilistic TopicModels“, in: Communication of the ACM 55 (4):77–84 10.1145/2133806.2133826.
Blevins, Cameron (2010): „Topic ModelingMartha Ballard’s Diary“, in: Historying . http://historying.org/2010/04/01/topic-modeling-martha-ballards-diary/ .
Jockers, Matthew L. (2013): Macroanalysis -Digital Methods and Literary History. Champaign,IL: University of Illinois Press.
McCallum, Andrew K. (2002): MALLET: AMachine Learning for Language Toolkit http://mallet.cs.umass.edu .
Rehurek, Radim / Sojka, Petr (2010):„Software framework for topic modelling withlarge corpora“, in: Proceedings of LREC 2010.
Rhody, Lisa M. (2012): „TopicModeling and Figurative Language“, in:Journal of Digital Humanities 2 (1) http://journalofdigitalhumanities.org/2-1/topic-modeling-and-figurative-language-by-lisa-m-rhody/ .
Richardson, Stephen D. / Braden-Harder,Lisa (1988): „The Experience of Developing aLarge-Scale Natural Language Text ProcessingSystem: CRITIQUE“, in: Proceedings of theSecond Conference on Applied Natural LanguageProcessing 195–202.
241

Digital Humanities im deutschsprachigen Raum 2017
Schöch, Christof (in Vorbereitung): „TopicModeling Genre: An Exploration of FrenchClassical and Enlightenment Drama“, in:DHQ: Digital Humanities Quarterly http://digitalhumanities.org/dhq . Preprint: https://zenodo.org/record/48356 .
Steyvers, Mark / Griffiths, Tom (2006):„Probabilistic Topic Models“, in: Landauer, T. /McNamara, D. / Dennis, S. / Kintsch, W.: LatentSemantic Analysis: A Road to Meaning. LaurenceErlbaum.
Entitäten als TopicLabels: Verbesserungder Interpretierbarkeitund Evaluierbarkeitvon Themen durchKombinieren von EntityLinking und TopicModeling
Lauscher, [email protected]ät Mannheim, Deutschland
Nanni, [email protected]ät Mannheim, Deutschland
Ponzetto, Simone [email protected]ät Mannheim, Deutschland
Im letzten Jahrzehnt haben Wissenschaftleraus dem Bereich der Geisteswissenschaftenzunehmend mit verschiedenen Text Mining-Techniken zur Exploration großer Textkorporaexperimentiert. Angefangen bei Kookkurrenz-basierten Verfahren (Buzydlowski, Whiteund Lin 2002) über automatische KeyphraseExtraktion (Hasan, Saidul und Ng 2014)ziehen sich die angewandten Techniken bishin zu Sequence Labeling Algorithmen, wiezum Beispiel im Falle von Named-EntityRecognition (Nadeau und Sekine 2007). Ausdiesen vielfältigen Techniken bedientensich die Forscher in den letzten Jahren vor
allem des Latenten Dirichlet Allokation(LDA) Topic Model Algorithmus (Blei, Ng undJordan 2003) (Meeks und Weingart 2012).Oftmals betonten Wissenschaftler dessenPotential für Serendipität (Alexander et al.2014) und für Analysen im Bereich des DistantReading (Leonard 2014; Graham, Milligan undWeingart 2016), also Studien, die über reineTextexploration hinausgehen.
In den letzten Jahren wurde LDA in denDigitalen Geisteswissenschaften intensivangewandt, obwohl bekannt ist, dass diedamit erzielten Ergebnisse schwierig zuinterpretieren (Chang et al. 2009; Newman etal. 2010) und dass die Möglichkeiten, derenQualität zu evaluieren, stark begrenzt sind(Wallach et al. 2009). Die direkte Konsequenzdaraus ist, dass Wissenschaftler im Bereichder Geisteswissenschaften momentan in einerSituation feststecken, in der sie Topic Modelsweiterhin anwenden, da sie Methoden dieserArt benötigen, aber auch gleichzeitig nur wenigneues geisteswissenschaftliches Wissen ableitenkönnen, weil die erzielten Ergebnisse bereitsintrinsisch begrenzt sind (Nanni, Kümper undPonzetto 2016). Diese Situation ist vor allemdarauf zurückzuführen, dass große Korporabestehend aus Primärquellen nun zum erstenMal digital verfügbar sind.
Von dieser Grundsituation ausgehend wollenwir dieses komplexe Problem bewältigen,indem wir zwei spezifische und integrierteLösungen zur Verfügung stellen. Als erstesbieten wir eine neue Methode zur Explorationvon Textkorpora, die Topics erzeugt, welcheleichter zu interpretieren sind als traditionelleLDA Topics. Dies erreichen wir durch dieKombination zweier Techniken, nämlich EntityLinking und Labeled LDA. Unsere Methodeidentifiziert in einer Ontologie eine Seriebeschreibender Labels für jedes Dokumentin einem Korpus. Daraufhin wird für jedesder identifizierten Labels ein Topic erzeugt.Durch die daraus resultierende direkteBeziehung zwischen Topic und Label wird dieInterpretation des Topics stark vereinfacht unddurch die Ontologie im Hintergrund wird dieAmbiguität der Labels vermindert. Da unsereTopics mit einer limitierten Anzahl an klarumrissenen Labels beschrieben werden, fördernsie die Interpretierbarkeit und die Anwendungder Ergebnisse als quantitativ grundierteArgumente in der geisteswissenschaftlichenForschung.
Da es äußerst wichtig ist, die Qualität derErgebnisse zu bestimmen, stellen wir zweitenseine dreischrittige Evaluationsplattform zurVerfügung, die die Ergebnisse unseres Ansatzes
242

Digital Humanities im deutschsprachigen Raum 2017
als Input verwendet und eine umfangreichequantitative Analyse ermöglicht. Dies gestattetden nutzenden Wissenschaftlern aus denDigitalen Geisteswissenschaften, einen Überblicküber die Ergebnisse der einzelnen Schritteder Pipeline zu erhalten und stellt Forschernim Natural Language Processing (NLP) eineSerie von Baselines zur Verfügung, die sie zurVerbesserung jedes Schrittes der vorgestelltenMethodik benutzen können.
Wir illustrieren das Potenzial dieses Ansatzesdurch dessen Anwendung zur Bestimmungder relevantesten Topics in drei verschiedenenDatensätzen. Der erste Datensatz bestehtaus der gesamten Transkription der Redenaus dem fünften Mandat des EuropäischenParlaments (1999-2004). Dieses Korpus (vanAggelen et al. 2016) wurde für Forschung imBereich der Computational Political Sciencebereits intensiv eingesetzt (Hoyland undGodbout 2008; Proksch und Slapin 2010; Høylandet al. 2014) und hat enormes Potential fürzukünftige politikgeschichtliche Forschungen.Das zweite Korpus ist der sogenannte Enron-Datensatz. Es handelt sich dabei um eine großeDatenbank mit über 600.000 E-Mails, die von 158Mitarbeiten der Enron Corporation erstellt unddie später durch die Federal Energy RegulatoryCommission während der Untersuchungennach dem Zusammenbruch des Unternehmensakquiriert wurden. In den letzten zehn Jahrenhat die NLP-Community diesen Datensatz unterAnwendung von netzwerk- und inhaltsbasiertenAnalysen intensiv untersucht. Unser Zielist es hierbei, die Qualität unseres Ansatzesanhand eines hochtechnischen und komplexenDatensatzes einer spezifischen Art (E-Mail), diein zukünftigen historischen Untersuchungenimmer wichtiger werden wird, zu beleuchten.In Verbindung damit wurde als drittes Korpusder Hillary Clinton E-Mail-Datensatz ausgewählt.Er repräsentiert eine Kombination der beidenvorherigen Datensätze, da es sich um kurzeKorrespondenzen via E-Mail handelt, die sichjedoch mehrheitlich auf politische Themenfokussieren.
Vor über einem Jahrzehnt hat Dan Cohen(2006) bereits vorhergesehen, dass künftigePolitikhistoriker in Anbetracht der Fülle anQuellen, die die öffentliche Verwaltung uns inden kommenden Jahrzehnten hinterlassen wird,auf ein Problem stoßen werden. Unsere Studiemöchte ein allererster experimenteller Ansatzzu sein, diese neuen Korpora von Primärquellenzu bewältigen und Historiker im digitalenZeitalter mit einer feinkörnigeren Lösung zurTextexploration als mittels traditionellen LDAsauszustatten.
Bibliographie
Alexander, Eric / Kohlmann, Joe / Valenza,Robin / Witmore, Michael / Gleicher, Michael(2014): „Serendip: Topic model-driven visualexploration of text corpora“, in: IEEE VAST 173–182.
Blei, David M / Ng, Andrew Y. / Jordan,Michael I. (2003): „Latent dirichlet allocation“,in: Journal of Machine Learning Research 3: 993–1022.
Buzydlowski, Jan W. / White, Howard D /Lin, Xia (2002): „Term co-occurrence analysisas an interface for digital libraries“, in: Visualinterfaces to digital libraries. Springer 133–144.
Chang, Jonathan / Gerrish, Sean / Wang,Chong / Boyd-Graber, Jordan L. / Blei, DavidM. (2009): „Reading tea leaves: How humansinterpret topic models“, in: NIPS 288–296.
Cohen, Dan (2006): When machines are theaudience.
Graham, Shawn / Milligan, Ian / ScottWeingart (2016): Exploring big historical data:The historian’s macroscope. Imperial CollegePress.
Hasan, Kazi Saidul / Ng, Vincent (2014):„Automatic keyphrase extraction: A survey ofthe state of the art“, in: Proceedings of ACL-20141262–1273.
Høyland, Bjørn / Godbout, Jean-Francois(2008): Lost in translation? Predicting party groupaffiliation from European parliament debates.Unveröff. Manuskript.
Høyland, Bjørn / Godbout, Jean-Francois /Lapponi, Emanuele / Velldal, Erik (2014):„Predicting party affiliations from Europeanparliament debates“, in: ACL 2014 Workshop onLanguage Technologies and Computational SocialScience 56–60.
Leonard, Peter (2014): „Mining large datasetsfor the humanities“ in: IFLA WLIC 16–22.
Meeks, Elijah / Weingart, Scott B. (2012):„The digital humanities contribution to topicmodeling“, in: Journal of Digital Humanities 2 (1):1–6.
Nadeau, David / Sekine, Satoshi (2007):„A survey of named entity recognition andclassification“, in Lingvisticae Investigationes 30(1): 3–26.
Nanni, Federico / Kümper, Hiram /Ponzetto, Simone Paolo (2016): „Semi-supervised textual analysis and historicalresearch helping each other: Some thoughtsand observations“ in: International Journal ofHumanities and Arts Computing 10 (1): 63–77.
Newman, David / Lau, Jey Han / Grieser,Karl / Baldwin, Timothy (2010): „Automatic
243

Digital Humanities im deutschsprachigen Raum 2017
evaluation of topic coherence“, in: HLT-NAACL100–108.
Proksch, Sven-Oliver / Slapin, Jonathan B.(2010): „Position taking in European parliamentspeeches“, in: British Journal of Political Science40 (3): 587–611.
van Aggelen, Astrid / Hollink, Laura /Kemman, Max / Kleppe, Martijn / Beunders,Henri (2016): „The debates of the Europeanparliament as linked open data“, in: SemanticWeb (Preprint) 1–10.
Wallach, Hanna M. / Murray, Iain /Salakhutdinov, Ruslan / Mimno, David (2009):„Evaluation methods for topic models“, in: ICML1105–1112.
Grotefend digital
Vogeler, [email protected]ät Graz, Österreich
Klugseder, [email protected]Österreichische Akademie der Wissenschaften
Klug, Helmut [email protected]ät Graz, Österreich
Steiner, [email protected]ät Graz, Österreich
Raunig, [email protected]ät Graz, Österreich
Die Entschlüsselung mittelalterlicherDatumsangaben setzt eine intensive Kenntnisdes christlichen Oster- und Heiligenkalendersvoraus. Historiker stützen sich bei derBerechnung von Zeitangaben in Handschriftenund Urkunden, die in der Regel auf derNennung von Kirchenfesten und deren Feier inbestimmten Regionen und Diözesen aufbauen,auf einschlägige Hilfsmittel, insbesondereden “Grotefend”. Zwischen 1891 und 1898veröffentlicht der Historiker und ArchivarHermann Grotefend (1845-1931) sein Werk Zeitrechnung des deutschen Mittelaltersund der Neuzeit in zwei Bänden, um damitsein veraltetes Handbuch der historischen
Chronologie zu ersetzen. Es ist gleichzeitig dieQuelle für das wiederholt aufgelegte auf dietägliche Praxis ausgerichtete Taschenbuch derZeitrechnung des deutschen Mittelalters und derNeuzeit . Grotefends Monumentalwerk ist 2004vom Archivar Horst Ruth retrodigitalisiert, fürdie Darstellung in HTML aufbereitet und – vorallem im Bereich des Heiligenverzeichnisses,das die Namen der Feste/Heiligen mitkalendarischen Daten und Ortsangabenverknüpft, – um eigene Forschungsergebnisseerweitert worden. Diese elektronische Ressourceist seit ihrer Entstehung ein beliebtes undeinschlägig bekanntes Hilfsmittel. Daraufbaut auch die semantische Modellierung desGrotefendschen Heiligenverzeichnisses auf: Diedigitale Ressource des Grotefend wird durchsemiautomatische Annotation (mithilfe vonregulären Ausdrücken und XSLT) am Zentrumfür Informationsmodellierung - Austrian Centrefor Digital Humanities (ZIM-ACDH) als SemanticWeb Resource (RDF) veröffentlicht.
Diese semantische Modellierung sollermöglichen, Festkalenderangaben ausunterschiedlichen Kontexten eindeutig zureferenzieren. Damit kann eine verteilteRessource aus den originalen Daten desGrotefend und RDF-Repräsentation vonhistorisch belegten Kalendarien entstehen, diefür kalenderbasierte Anwendungen nutzbarist. Als Beispielanwendungen dienen einedigitale Kalenderedition (Teil der digitalenEdition des Tegernseer Wirtschaftsbuchs amInstitut für Germanistik der Karl-Franzens-Universität Graz) und insbesondere das Projekt“Cantus Network - libri ordinarii of the Salzburgmetropolitan province” der ÖsterreichischenAkademie der Wissenschaften und des ZIM-ACDH. In letzterem werden mittelalterlicheLibri ordinarii, deren liturgische Kalenderbestimmten Regionen zugewiesen werdenkönnen, in XML modelliert und online publiziert.Durch den Abgleich mit dem Standardwerkzur historischen Datumsbestimmung könnendie Daten zu den einzelnen Heiligen, ihrenFesttagen im Jahreskreis und ihrem jeweiligenregionalen Geltungsbereich durch die jeweiligenHandschriften der Libri ordinarii historischverankert werden.
Ziel der Grotefend-Bearbeitung ist also, dendigitalen Datenbestand nicht mehr nur alsText sondern auch als Forschungsdatenbankonline zur Verfügung zustellen. Der Zugriffdarauf soll über manuelle Suchabfragenvon Heiligendaten ebenso wie über ein freiverfügbares Webservice als API möglich sein.Nach der semi-automatischen Modellierungdes Grotefend ist eine Implementierung der
244

Digital Humanities im deutschsprachigen Raum 2017
Ressource für den automatischen Vergleichvon regional unterschiedlichen Kalendernvorgesehen. Bei einer derartigen Anwendungwird es möglich sein, die Beziehungen zwischeneindeutig referenzierbaren Heiligennamen,deren Festen (bzw. den dazugehörigenKalenderdaten) und den davon betroffenenRegionen (Wirkungsbereiche, Diözesen, Orden)zu erkennen und grafisch darzustellen.
Das für die Konferenz geplante Posterlegt den Fokus auf die Modellierung desStandardwerks in RDF und die darausresultierenden Möglichkeiten für einekomplexe Suchoberfläche. Als Leitfragenstehen im Mittelpunkt: Wie weit könnenwenig strukturierte Textdaten möglichstautomatisiert modelliert werden? Wie undmit welchem Aufwand sind komplexe,technisch unstrukturierte Daten in einegraphenbasierte Struktur zu überführen? Wassind die Voraussetzungen für die automatisierteAnreicherung von mittelalterlichen Kalendern?
Dabei werden aktuelle Methoden derdigitalen Geisteswissenschaften angewandt:die Modellierung aller Daten in XML, dieautomatisierte Konvertierung der Kalenderdatenund des Grotefend in ein passendes RDF-Modell,die Zusammenführung dieser Datenquellenin einem Triplestore, die kontinuierlicheErweiterung der Datenbasis, die Abfrage derDaten mittels SPARQL.
Die damit geschaffene Ressource zurBestimmung historischer Datumsangaben wirdnach ihrer Fertigstellung der Öffentlichkeitfrei zur Verfügung gestellt und soll durch dieModellierung in RDF Anreize bieten, weitereKalendariendaten weltweit als Linked OpenData zur Verfügung zu stellen und somit zueinem großen gemeinsamen Datenbestandbeitragen. Einen Anfang macht das Projekt, indem es die Daten aus cantusdatabase.org, derStandardressouce zur Liturgieforschung, in RDFverwandelt und mit den Daten aus dem “großenGrotefend” verknüpft.
Bibliographie
Grotefend, Hermann (1970): Zeitrechnungdes deutschen Mittelalters und der Neuzeit. 2Bände. Neudruck: Aalen [Hannover 1891–1898].
Grotefend, Hermann (1891–1898):Zeitrechnung des deutschen Mittelalters und derNeuzeit. 2 Bände. 1891-1898. [Digitalisiert vonHorst Ruth 2004]. http://bilder.manuscripta-mediaevalia.de/gaeste//Grotefend/kopf.htm[letzter Zugriff 16. August 2016].
W3C (2004): Resource Description Framework(RDF). https://www.w3.org/RDF/ .
Ulrich, Theodor (1966): „Grotefend,Hermann“, in: Neue Deutsche Biographie 7.Berlin 165 f.
„IT for all“ – Das Projekt„Digitaler CampusBayern – DigitaleDatenanalyse in denGeisteswissenschaften“als Beispiel fürnachhaltige IT-Didaktik
Schulz, [email protected]ät München,Deutschland
Ausgangslage
Der Einfluss der unter Digital Humanities(DH) zusammengefassten digitalen Theorienund Methoden auf die geisteswissenschaftlichenDisziplinen wächst stetig. Digitale Projekteerleben in den Geisteswissenschaften einenrasanten Aufschwung (Koller 2016: 43).Damit einher geht der Bedarf an Absolventengeisteswissenschaftlicher Fächer, die bereitswährend ihres Studiums Kompetenzen imBereich der Digital Humanities erwerbenkonnten. Bereits 2013 forderten Vertreter/innen im „Manifest für die DH“ eine Etablierung„digitale[r] Trainingsprogramme in denGeisteswissenschaften“ (DH-Manifest:2013), angepasst an die unterschiedlichenBedürfnisse der Fachbereiche und diejeweiligen Karrierestufen. Auch der DHdmisst der Ausgestaltung der IT-Ausbildungvon Studierenden eine gesteigerte Bedeutungzu. Die Arbeitsgruppe zur Erarbeitung eines„Referenzcurriculums Digital Humanities“2 beschäftigt sich mit der Suche nach einerbestpraxis, von der Anwender und Institutionengleichermaßen profitieren (Sahle 2013; Thaller2015: 3).
Zahlreiche Universitätsstandorte haben aufdie neuen Anforderungen mit der Einrichtungunterschiedlich ausgestalteter DH-Studiengänge
245

Digital Humanities im deutschsprachigen Raum 2017
reagiert (Bartsch/Borek/Rapp 2016: 173; DHCourse Registry). Trotz dieser neugeschaffenenAngebote besteht ein zusätzlicher Bedarf aninformationstechnologischer Ausbildung in derBreite (Ehrlicher 2016: 625). Zunehmend wirdauch in „klassischen“ geisteswissenschaftlichenBerufsfeldern Sicherheit im Umgang mitSoftware und digitalen Technologienvorausgesetzt. Dieses Grundverständnis digitalerMethoden kann nicht mehr ausschließlich imSelbststudium angeeignet werden (Spiro 2013:332; Sahle 2016: 79).
Projektziele undRahmenbedingungen
Hier setzt das Projekt „Digitaler CampusBayern – Digitale Datenanalyse in denGeisteswissenschaften“ an, welches von derIT-Gruppe Geisteswissenschaften (ITG) derLudwig-Maximilians-Universität München (LMU)seit Beginn dieses Jahres durchgeführt wird.Grundgedanke ist eine IT-Grundausbildung(„ IT for all“), welche die Studierendenproblemorientiert in die Anwendungdigitaler Methoden einführt. Ausgehendvon fachwissenschaftlichen Fragestellungenwerden Lehrveranstaltungen mit IT-Inhalten in Kooperation mit verschiedenengeschichtswissenschaftlichen Disziplinenund der Kunstgeschichte konzipiert. Dabeisoll eine möglichst umfassend angelegteGrundlagenvermittlung in Erfassung,Modellierung, Analyse und anschließenderVisualisierung von Daten erfolgen (Lücke/Riepl2016: 77). Das Verständnis digitaler Methodensteht ebenso im Vordergrund wie eine fachlicheReflexion ihrer Potentiale (Rehbein 2016: 17).
Die Situation der DH an der LMU gestaltetesich bis Projektbeginn (Januar 2016 3 )ambivalent. In den vorgenannten Studiengängenwurden regelmäßig Überblicksveranstaltungenzur Einführung in die Informatik für Historikerbzw. Kunsthistoriker angeboten. Eine praktischeUmsetzung des theoretischen Wissens konnteim Rahmen dieser Veranstaltungen jedochnicht geleistet werden. Demgegenüberwerden durch die ITG, die auf langjährige undumfangreiche Erfahrungen im Bereich desdigitalen Projektmanagements 4 verweisenkann, optimale Voraussetzungen für eine fortanpraxisnahe IT-Ausbildung geschaffen.
Als Mitglied im Münchner Arbeitskreisfür digitale Geisteswissenschaften (dhmuc)5 kooperiert die IT-Gruppe zudem fach- und
institutionsübergreifend mit zahlreichenkulturellen Einrichtungen. An der Schnittstellezur universitären Lehre ist es möglich, die „ ITfor all“-Ausbildung geisteswissenschaftlicherStudierender auf die Anforderungen undWünsche der potentiellen Arbeitgeberseiteim (digitalen) Kultur-, Wissenschafts- undInformationssektor auszurichten.
Interaktive Lehr- undLernumgebung DHVLab
Für die praktische Umsetzung kommt eineinteraktive Lehr- und Lernumgebung, das DigitalHumanities Virtual Laboratory – kurz DHVLab– zum Einsatz 6 . Die im Entstehen begriffenePlattform umfasst mehrere Komponenten, die imFolgenden vorgestellt werden sollen:
Virtuelle Rechenumgebung
Die virtuelle Rechenumgebung ist das„Herzstück“ der Ausbildungsplattform. Aufdem virtuellen Desktop werden in Abstimmungmit dem/der Kursleiter/in Software und Toolsinstalliert. Dadurch wird die sukzessiveInstallation durch die Teilnehmer/innen obsolet,wodurch Probleme aufgrund unterschiedlicherBetriebssysteme und Versionierungenvermieden werden. Bei Anmeldung imDHVLab erhält jede/r Teilnehmer/in eineeigene SQL-Datenbank. Gleichzeitig werdenstrukturierteDatensammlungen vorgehalten.Diese sind für die Kursteilnehmer/innenzugänglich und für eigene oder im Kursbehandelte Fragestellungen verwendbar. ImLaufe der Lehrveranstaltung können neueForschungsfragen ausgearbeitet und eingrundsätzliches Verständnis für den sinnvollenEinsatz von Tools und Software 7 in denGeisteswissenschaften entwickelt werden.
Ausbildungsmaterialien
Im vergangenen Semester wurdedas System testweise in vorgenanntenEinführungsveranstaltungen eingesetzt. Diebei der Evaluation gesammelten Erfahrungenfließen unmittelbar in die Erstellung bzw.Erweiterung der Ausbildungsmaterialien.Anhand praxisnaher Manuale wird IT-Grundlagenwissen, in einzelne Lehreinheitengegliedert, anschaulich dargestellt und
246

Digital Humanities im deutschsprachigen Raum 2017
erklärt. Die Erstellung von Lehrvideosund Übungsaufgaben ist vorgesehen. Ausdiesem Portfolio können Dozentinnenund Dozenten Module entsprechend ihrerfachwissenschaftlichen Schwerpunktsetzungund der Voraussetzungen der Teilnehmer/innen auswählen. Die Seminarplanung und -durchführung erfolgt stets in enger Abstimmungmit den Projektmitarbeitern.
Publikationsumgebung
Für die Vor- und Nachbereitung der einzelnenSitzungen steht ein WordPress-Blog zurVerfügung. Dort können die Kursleiter/innenMaterialen einstellen, die Studierenden ihrenErkenntnisfortschritt und Analyseergebnissedokumentieren. Dabei erlernen sie gleichzeitigin praxi das wissenschaftliche Bloggen alsinnovative Form des Publizierens. Eineabschließende Publikation der studentischenSeminararbeiten ist auf dieser Plattformmöglich.
Datenrepositorium
In einem gesonderten Bereich derDatenbankumgebung werden die vonden Studierenden im Rahmen einerLehrveranstaltung erarbeiteten Datenbeständemodelliert und nachhaltig abgelegt.Langfristiges Ziel ist der Aufbau einesForschungsdatenrepositoriums. NachfolgendeKurse mit ähnlichen Seminarthemen könnenauf diese Datensammlungen zugreifen, fürdie eigene Forschungsarbeit verwenden unddadurch sukzessive erweitern. Unterstützungerfährt die ITG durch die Universitätsbibliothekder LMU als Kooperationspartnerinauf dem Gebiet der nachhaltigen undnachnutzbaren elektronischen Publikation vonForschungsdaten.
Entwicklung eigener Analyse-und Softwarekomponenten
Mit dem DHVLab Analytics Center wurdeeine Webanwendung entwickelt, die dazudient, konkrete geisteswissenschaftlicheFragestellungen mithilfe quantitativerstatistischer Methoden zu beantworten,sowie im Stile eines explorativen Werkzeugesneue Forschungsansätze zu eröffnen. Das Analytics Center kombiniert einführende
deskriptive Analysen mit komplexerenMethoden der multivariaten Statistik.Neben diesem Analysetool entsteht derzeiteine Editionsumgebung, die speziell aufdie Anforderungen von Studierenden undPromovierenden ausgerichtet wird. Diese wirderstmals im Sommersemester 2017 in einerÜbung zur Edition mittelalterlicher Urkundenzum Einsatz kommen. Die Entwicklung weitererInstrumente ist geplant.
Der Einsatz der Plattform inder Lehre
Nach der technischen Realisierung derPlattform und dem Aufbau grundlegenderAusbildungsmaterialien im erstenProjekthalbjahr kommt das System imWintersemester 2016/2017 erstmals ineigens konzipierten Lehrveranstaltungenzur Anwendung. In der Kunstgeschichtesoll das Analytics Center in einem Seminarzur Beschäftigung mit informatischenund mathematischen Verfahrensweisenanregen. Parallel dazu erfolgt eine Einführungin die Statistiksoftware RStudio. Eingeschichtswissenschaftliches Hauptseminarbeschreitet den Weg von der Originalquelle überdie strukturierte Aufnahme und Modellierungvon Forschungsdaten sowie die Einführung indie Arbeit mit relationalen Datenbanken hinzur Georeferenzierung. Die in den Seminarengewonnenen Erfahrungen und Erkenntnissefließen unmittelbar in die Verbesserung undAusweitung des bestehenden Lehrmaterials ein(u.a. Erstellung von Anwendungsszenarien).Neben den genannten Kursen wird die Plattformbereits in zahlreichen Lehrveranstaltungen alstechnische Grundlage verwendet 8 .
Konzeption einesfachspezifischen DH-Curriculums
Die sukzessive wachsende Plattform unddie aktuell angebotenen Kurse dienen alsGrundlage für eine Institutionalisierung der IT-Grundausbildung in Form eines fachspezifischenDH-Curriculums. Das Konzept für das geplantefreiwillige Zusatz-Zertifikat wird derzeit inder Projektgruppe erarbeitet und baut aufErfahrungen vergleichbarer Angebote imdeutschsprachigen Raum auf 9 . Angedacht
247

Digital Humanities im deutschsprachigen Raum 2017
ist eine Kombination aus Veranstaltungen,die explizit IT-Grundlagenwissen vermitteln,und praxisorientierten Kursen, in denen dieerlernten IT-Inhalte auf fachwissenschaftlicheGegenstände angewendet werden.Wichtig erscheint eine ausgewogeneVerschränkung von eLearning-Angeboten undPräsenzveranstaltungen, da insbesondereletzteren durch den intensiven Austausch derStudierenden mit DH-Spezialisten ein großerBeitrag zum Lernerfolg beigemessen wird 10 .
Grundlage einer nachhaltigenIT-Didaktik
Neben der Langzeitarchivierung derForschungsdaten wird auch die Nachhaltigkeitder informationstechnologischen Infrastruktur(Serveranlage mit redundant ausgelegtenFile-, Datenbank- und Web-Servern sowieausreichenden Storages) durch die IT-GruppeGeisteswissenschaften dauerhaft gewährleistet.Die Architektur des DHVLab ist flexibel undskalierbar gestaltet, sodass sie weiter ausgebautwerden kann (bei Bedarf ist ein Hosting derServer am Leibniz-Rechenzentrum in Garchingbei München möglich). Für eine nachhaltige IT-Didaktik spielt neben der langfristig gesichertentechnischen Infrastruktur insbesondere dieinhaltliche Kontinuität eine entscheidendeRolle. Die im Rahmen des Projektes erarbeitetenLehreinheiten werden dauerhaft zur Verfügunggestellt. Thematisch sind sie so zu gliedernund fachlich anzupassen, dass eine spezifischeAuswahl für eine Lehrveranstaltung und damiteine Integration in ein geisteswissenschaftlichesEinzelfach möglich ist. Die IT-Gruppe stellt auchnach Ende der Projektlaufzeit die unterstützendeBegleitung der Lehrveranstaltungen sicher.Der Vortrag möchte zur Diskussion anregen,inwiefern sich die Anpassung der Materialienan die sich rasch wandelnden Anforderungenim Bereich der Digital Humanities möglichsteffizient gestalten lässt. IT-Didaktik scheintnur dann einen Anspruch auf Nachhaltigkeitzu besitzen, wenn sie sich in einem stetenAnpassungsprozess befindet.
Ganz im Sinne des „Digitalen CampusBayern“ ist das Münchener Pilotprojekt aufeine Ausweitung auf andere Studienstandorteausgerichtet. Die Plattform wird beispielsweiseab 2017 in einem im Aufbau befindlichenKooperationsprogramm zur DH-Ausbildungder Universitäten Erlangen, München undRegensburg zum Einsatz kommen. Alle Moduledes DHVLab können kollaborativ von anderen
Hochschulen genutzt werden, um umfassendeSammlungen von Tutorials, Aufgaben,Softwarebeschreibungen, Anwendungsszenariensowie Sammlungen fachwissenschaftlicherObjekt- und Metadaten aufzubauen undgemeinsam zu pflegen.
Fußnoten
2. Vgl. http://www.dh-curricula.org/index.php?id=1 [letzter Zugriff: 30. November 2016].3. Die Projektlaufzeit beträgt zweiJahre. Das Vorhaben ist Teil einesFörderprogramms, welches das BayerischeWissenschaftsministerium aufgelegthat. Vgl. https://www.km.bayern.de/pressemitteilung/9340/.html [letzter Zugriff: 30.November 2016].4. Vgl. die Übersicht unter www.itg.lmu.de/projekte [letzter Zugriff: 30. November 2016].5. Vgl. http://dhmuc.hypotheses.org/uber [letzterZugriff: 30. November 2016].6. Für die Dokumentation der technischenInfrastruktur vgl. http://dhvlab.gwi.uni-muenchen.de/index.php/Category: Architektur[letzter Zugriff: 30. November 2016].7. Derzeit stehen in der virtuellen Umgebungu.a. folgende Software und Programme zurVerfügung: LibreOffice-Paket, OCRFeeder undOcrad (Texterkennung), Python (PyCharm),RStudio (Statistik), Gephi (Visualisierung),epcEdit (XML-Editor), AntConc und TreeTagger(Korpuslinguistik).8. Vgl. die Zusammenstellung auf derProjektseite: http://dhvlab.gwi.uni-muenchen.de/index.php/Das_DHVLab_im_Einsatz [letzterZugriff: 30. November 2016].9. Vgl. insbesondere die Angebote in Köln ( http://www.itzertifikat.uni-koeln.de/ ), Passau ( http://www.phil.uni-passau.de/zertifikat-dh/ ) undStuttgart („Das digitale Archiv“, http://www.uni-stuttgart.de/dda ), letztgenanntes als Vorläufereines DH-Masterstudienganges [letzter Zugriff:30. November 2016].10. Vor diesem Hintergrund erscheinengrundständige eLearning-Angebote wie„The Programming Historian“ ( http://programminghistorian.org/ ) für einenautodidaktischen Einstieg begrüßenswert.Die Initiatoren des DHVLab sind jedochder Auffassung, dass eine umfassendePräsenzausbildung nicht ersetzt werden kann.
248

Digital Humanities im deutschsprachigen Raum 2017
Bibliographie
Bartsch, Sabine / Borek, Luise / Rapp,Andrea (2016): „Aus der Mitte der Fächer, in dieMitte der Fächer: Studiengänge und Curricula –Digital Humanities in der universitären Lehre“,in: Bibliothek – Forschung und Praxis 40 (2): 172–178 10.1515/bfp-2016-0030.
DARIAH-EU: Digital Humanities Registry –Courses https://dh-registry.de.dariah.eu/ [letzterZugriff 30. November 2016].
DHI Paris (Teamaccount) (2013):„Wissenschaftlicher Nachwuchs in denDigital Humanities: Ein Manifest“, in: DigitalHumanities am DHIP, 23. August 2013 http://dhdhi.hypotheses.org/1995 [letzter Zugriff 30.November 2016].
Ehrlicher, Hanno (2016): „Fingerübungenin Digitalien. Erfahrungsbericht einesteilnehmenden Beobachters der DigitalHumanities aus Anlass eines Lehrexperiments“,in: Romanische Studien 4: 623–636 http://www.romanischestudien.de/index.php/rst/article/view/88 [letzter Zugriff 30. November2016].
Koller, Guido (2016): Geschichte digital:Historische Welten neu vermessen. Stuttgart:Kohlhammer.
Lücke, Stephan / Riepl, Christian (2016):„Auf dem Weg zu einem Curriculum in denDigital Humanities“, in: Akademie Aktuell57 (1): 74–77 http://badw.de/fileadmin/pub/akademieAktuell/2016/56/0116_17_Riepl_V04.pdf[letzter Zugriff 30. November 2016].
Rehbein, Malte (2016): Geschichtsforschungim digitalen Raum. Über die Notwendigkeitder Digital Humanities als historischeGrundwissenschaft. (Preprint) http://www.phil.uni-passau.de/fileadmin/dokumente/lehrstuehle/rehbein/Dokumente/GeschichtsforschungImDigitalenRaum_preprint.pdf[letzter Zugriff 30. November 2016].
Sahle, Patrick (2013): DH studieren! Auf demWeg zu einem Kern- und Referenzcurriculumder Digital Humanities (= DARIAH-DEWorking Papers 1). Göttingen: GOEDOC http://webdoc.sub.gwdg.de/pub/mon/dariah-de/dwp-2013-1.pdf [letzter Zugriff 30. November2016].
Sahle, Patrick (2016): „Digital Humanitiesals Beruf. Wie wird man ein „DigitalHumanist“, und was macht man danneigentlich?“, in: Akademie Aktuell 57(1): 78–83 http://badw.de/fileadmin/pub/akademieAktuell/2016/56/0116_18_Sahle_V04.pdf[letzter Zugriff 30. November 2016].
Spiro, Lisa (2012): „Openingup DigitalHumanities Education“, in: Hirsch, BrettD. (ed.): Digital Humanities Pedagogy:Practices, Principlesand Politics 331–363 http://www.openbookpublishers.com/product/161/[letzter Zugriff 30. November 2016].
Thaller, Manfred (2015): „Panel: DigitalHumanities als Beruf – Fortschritte auf dem Wegzu einem Curriculum“, in: Digital Humanitiesals Beruf: Fortschritte auf dem Weg zu einemCurriculum, vorgelegt auf der Jahrestagung2015 3–5 https://www.digitalhumanities.tu-darmstadt.de/fileadmin/dhdarmstadt/materials/Digital_Humanities_als_Beruf_-_Stand_2015.pdf[letzter Zugriff 30. November 2016].
Kollaborative Forschungüber Linked Open DataForschungsdatenbankenderUniversitätsgeschichteImplementierungdes Heloise CommonResearch Model
Riechert, [email protected] für Technik, Wirtschaft und Kultur(HTWK) Leipzig, Deutschland
Beretta, [email protected] de recherche historique Rhône-Alpes (LARHRA), Frankreich
Motivation
Die Beantwortung von Forschungsfragenüber bestehende Forschungsdatenquellen imLinked Open Data Web ist von besonders hoheRelevanz für nachhaltige Forschungsarbeitenin den Geisteswissenschaften und insbesonderein der Geschichtswissenschaft (vgl. MeroñoPeñuela et al. 2014: 1-27). Eine ständigwachsende Menge an Archivmaterialien,Literaturquellen, Forschungsergebnisse undForschungsdatenbanken ist online verfügbar.
249

Digital Humanities im deutschsprachigen Raum 2017
Durch Standardisierungsbestrebungen u.a. durch den Einsatz von RDF und OWL alsBeschreibungssprache von Daten ist es möglichdiese zu verknüpfen, und Inferenz-Algorithmenauf diesen Ressourcen anzuwenden. Einetypische Herangehensweise an die damiteinhergehenden Herausforderungen derDatenintegration ist die Verwendung vonStandard-Vokabularen, wie sie z. B. im E-Business erfolgreich praktiziert wird (vgl.Domingue et al. 2011). Im Bereich derGeisteswissenschaften haben sich zumBeispiel mit GND 1 und Europeana DataModel (EDM) 2 solche Vokabulare entwickelt.Darüber hinaus wird CIDOC-CRM 3 vonunterschiedlichen Projekten als Modell fürdie Veröffentlichung von Daten verwendet(vgl. Kurtz et al. 2009). Die Autoren sindin verschiedenen Forschungsprojekten inDeutschland und Frankreich im Bereich derInformatik und der Geschichtswissenschaftenaktiv und müssen konstatieren, dass der Weg derStandardisierung in der historischen Forschungschwieriger ist. Dies ist vor allem auf den hohenGrad der domänspezifischen Eigenheiten dervorliegenden Daten, und auf die besondere Rolleprojektbezogener Forschungsfragestellungenbei der Datenerstellung und Datenerhebungzurückzuführen (vgl. Beretta 2009).
Das im Jahr 2012 gegründete EuropäischeNetzwerk Héloïse 4 zur Vernetzung vononline verfügbaren Datenbanken im Bereichder Universitätsgeschichte 5 , sieht sichdieser Herausforderung gegenübergestellt.Inhalte regelmäßig stattfindender Workshopssind die Präsentation von verfügbarenForschungsdatenbanken und deren Verwendungbei auf diese heterogenen Datenbankenaufbauenden Forschungsfragestellungen.Parallel mit der Nutzung der Repositorienin zukünftigen Forschungskontexten erfolgteinekollaborative Daten-Kuration und sichertdaher die Langzeitlebigkeit von historischenForschungsdaten - nicht nur im Sinne vonDatensicherung, sondern auch von ständigerAnreicherung und Qualitätsverbesserung derDaten.
Heloise Common ResearchModel
Mit dem Heloise Common ResearchModel (HCRM) haben die beiden Autorendem Konsortium eine Methode präsentiert
(vgl. Beretta und Riechert 2016), welchesdurch die Forschungspartner gemeinsamverfeinert wird und in der Forschungsdomäneeingesetzt werden soll. Das HCRM ist alsSchichtenarchitektur konzipiert, bestehendaus drei Schichten: dem Repository-Layer, demApplication-Layer und dem Research-Interface-Layer. In einem parallelem Entwicklungsprozessentsteht neben der detaillierten Definition vonModulen (vgl. Abbildung 1, Beretta und Riechert2016) im HCRM eine Implementierung derMethodologie in Form der Héloïse-Plattform.
Abbildung 1: Heloise Common ResearchModell – Überblick über die Schichten undModule (links), Héloïse-Plattform (rechts)(vgl. Beretta und Riechert 2016)
Repository-Layer Die Datenbanken derPartnern des Héloïse-Netzwerkes, genausowie externe Informationsquellen, stellendie Basis zur Beantwortung übergeordneterForschungsfragen. Die Publikation der Datenals LOD erfolgt mit Hilfe etablierter Werkzeuge.So werden u. a. die Werkzeuge OntoWiki(Frischmuth et al. 2013) und D2RQ (Bizer undCyganiak 2006) zum Publizieren eingesetzt.Die Verlinkung erfolgt innerhalb etablierterAuthoring-Prozesse in den Forschungsprojekten.
Application-Layer: Die Applikations schichtunterstützt das Auffinden von Ressourcenund deren Verlinkung. Hierfür wird aufgenerische Werkzeuge und standardisierteVokabulare aufgebaut, damit einhergehend istder Zugang auf die Informationen auf dieseStandards beschränkt. Als erste Anwendungenim Forschungskonsortium wird gegenwärtigdie Implementierung einer Personen-Suche,basierend auf der BIO-Ontologie (Davis undGalbraith 2010), sowie die Darstellung relevantergeographischer Daten, über die Repositorien derPartner, entwickelt.
Research Interface Layer DieForschungsschicht des Modells bietet einenZugang auf die Forschungsdaten für neue
250

Digital Humanities im deutschsprachigen Raum 2017
wissenschaftliche Fragestellungen. Hierfürwird basierend auf einer Meta-Ontologie, wiesie das SyMoGIH Projekt (Beretta 2015, Beretta2016) für die Geschichtswissenschaft entwickelthat 6 , ein fachspezifisches Meta-Vokabularentwickelt. Dieses Vokabular verbindet einenkollaborativen, domänespezifischen Ansatzmit einer größtmöglichen Unabhängigkeitvon spezifischen, Projekt-bezogenenForschungsfragestellungen und ermöglicht denDatenaustausch im Héloïse-Netzwerk.
Héloïse-Plattform
Zentral für zukünftige Forschungsprojekte imHéloïse-Konsortium ist die Implementierung derMethodologie. Die heterogene Zusammensetzungdes Konsortium spricht gegen die Etablierungeiner zentralen Administration einersolchen Plattform. Vielmehr ist dieForschungskooperation auf der Ebene derHistoriker in einer vergleichbaren Art und Weisebei den assoziierten IT-Partnern zu finden. DieAutoren schlagen daher die Realisierung vonDiensten der Plattform durch Microservices vor.Microservice stellen unabhängige Dienste zurVerfügung und sind im Sinne der angestrebtenCloud-basierten Plattform virtualisierbar (vgl.Newman 2015).
Das Poster stellt die Resultate der iterativenImplementierung des HCRM im Héloïse-Forschungsnetzwerk detailliert vor. Es werdendie Ergebnisse der fachlichen Diskussion überzwei Heloise Workshops (Madrid, 2015 undPerugia, 2016) vorgestellt. Der komplette Katalog,der durchgängig im Kontext der Linked-Open-Data-Philosophie, als Open-Source verfügbarenMicroservices (Docker Container 7 ), wirdpräsentiert und deren Anwendung innerhalb derHeloise-Plattform online gezeigt 8 .
Fußnoten
1. GND Ontology http://d-nb.info/standards/elementset/gnd [25/08/2016]2. Europeana Data Model: http://pro.europeana.eu/page/edm-documentation[25/08/2016]3. CIDOC Conceptual Reference Model: http://www.cidoc-crm.org [25/08/2016]4. Héloïse - European Workshop on academicDatabase: http://heloisenetwork.eu/ [25/08/2016]5. Héloïse-Partner: http://heloisenetwork.eu/repositories [25/08/2016]
6. Ontologie und Instanzen des Vokabularssind auf der Webseite des Projektes onlinezugänglich: http://symogih.org [25/08/2016]7. Docker Virtualisierung: http://docker.com[25/08/2016]8. Héloïse-Network-Plattform: http://heloisenetwork.eu/platform [25/08/2016]
Bibliographie
Beretta, Francesco (2015): „Publishing andsharing historical data on the semantic web: theSyMoGIH project–symogih.org“, in: Workshop:Semantic Web Applications in the Humanities II.
Beretta, Francesco (2016): „L’interop erabilit edes donn ees historiques et la question dumod ele: l'ontologie du projet SyMoGIH“, in:Minel, Jean-Luc (ed.): Quels enjeux num eriquespour les m ediations scientifique et culturelle.Presses universitaires de Paris Ouest (imErscheinen).
Beretta, Francesco / Riechert, Thomas(2016): „Collaborative Research on AcademicHistory using Linked Open Data: A Proposalfor the Heloise Common Research Model“, in:CIAN-Revista de Historia de las Universidades,Norteamérica 19 (Juni).
Bizer, Christian / Cyganiak, Richard (2006):„D2r server-publishing relational databases onthe semantic web“, in: 5th International SemanticWeb Conference 294–309.
Davis, Ian / Galbraith, David (2010): BIO: Avocabulary for biographical information.
Domingue, John / Fensel, Dieter / Hendler,James A. (eds.) (2011): Handbook of semanticweb technologies. Berlin / Heidelberg: SpringerScience / Business Media.
Frischmuth, Philipp / Martin, Michael /Tramp, Sebastian / Riechert, Thomas / Auer,Sören (2014): „OntoWiki - An Authoring,Publication and Visualization Interface for theData Web“, in: Semantic Web Journal (IOS Press).
Kurtz, Donna / Parker, Greg / Shotton,David / Klyne, Graham / Schroff, Florian /Zisserman, Andrew / Wilks, Yorick (2009):„Claros-bringing classical art to a global public“,in: Fifth IEEE International Conference on e-Science 20–27.
Meroño-Peñuela, Albert / Ashkpour,Ashkan / van Erp, Marieke / Mandemakers,Kees / Breure, Leen (2014): „Semantictechnologies for historical research: A survey“,in: Semantic Web Journal (IOS Press).
Newman, Sam (2015): Building Microservices:Designing Fine-Grained Systems. O'Reilly Media.
251

Digital Humanities im deutschsprachigen Raum 2017
Kompilation einesDiskursstruktur-annotiertendeutschsprachigenBlogkorpus
Grumt Suárez, HolgerHolger.H.Grumt-Suarez@germanistik.uni-giessen.deJustus-Liebig-Universität Gießen, Deutschland
Karlova-Bourbonus, NataliNatali.Karlova-Bourbonus@germanistik.uni-giessen.deJustus-Liebig-Universität Gießen, Deutschland
Lobin, [email protected]ät Gießen, Deutschland
Das Poster „Interoperabilität bei derErstellung eines deutschsprachigen Blogkorpusfür die Repräsentation der Diskursstruktur“informiert über das Vorgehen sowie die erstenForschungszwischenergebnisse und die weiterenZiele der Kompilierung und Annotation einesdeutschsprachigen Blogkorpus. Gegenwärtig gibtes lediglich eine geringe Anzahl an öffentlichzugänglichen, umfangreichen Blogkorpora, wiezum Beispiel das englischsprachige BirminghamBlog Corpus der Birmingham Universität (vgl.WebCorp 2013) oder das bilinguale (deutsch-französische) Korpus d’apprentissage INFRAL(Interculturel Franco-Allemand en Ligne) (vgl.Abendroth-Timmer et al. 2014). Betrachtet manden großen Einfluss von Blogs für die Geschichteder Kommunikation im Internet, erscheint diegeringe Anzahl überraschend.
Bislang existiert kein Standard für dasRepräsentieren von sogenannten Computer-Mediated Communication-Daten (kurz CMC),allerdings arbeitet die Text Encoding InitiativeCMC Special Interest Group (TEI SIG) (vgl.Beißwenger 2016) seit 2013 an einem Schemafür die Repräsentation von CMC-Genres. EineStandardisierung, wie sie die Text EncodingInitiative für CMC anstrebt, ist ein wichtigerPunkt, wenn es um ‚Digitale Nachhaltigkeit‘ geht.Unser Forschungsvorhaben leistet hierfür einenBeitrag.
Das Hauptziel des Vorhabens umfasst diesemi-automatische Kompilation sowie dieRepräsentation der Blogdiskursstruktur. Dabeisollen die Relationen zwischen den textuellenund multimodalen Elementen (Blogbeiträge,Kommentare, Hyperlinks, Bilder und Töne)und den verschiedenen Textproduzenten(Blogger, Kommentatoren) abgebildet werden.Das annotierte Blogkorpus soll am Ende alseine nachhaltige Ressource verfügbar gemachtwerden. Hierfür stehen wir momentan inKontakt mit der Redaktion von Spektrum derWissenschaft Verlagsgesellschaft mbH, um dieForm der Bereitstellung zu klären.
Die Grundlage des Korpus bildet dasWissenschaftsblogportal SciLogs – Tagebücherder Wissenschaft (SciLogs 2016) und deckt denInhalt des Jahres 2015 vollständig ab. Die Datenwurden aus den vier SciLogs-Blogbereichen„WissensLogs“, „BrainLogs“, „KosmoLogs“und „ChronoLogs“ erhoben. Das Korpussoll mit drei Informationstypen annotiertwerden, die einerseits direkt, andererseitsindirekt in den Blogdaten vorhanden sindoder anhand von statistischen Analysen undcomputerlinguistischen Tools sichtbar gemachtwerden. Zum jetzigen Zeitpunkt beschränkensich die Annotationen des Korpus auf die direktauslesbaren Informationen des Blogs wiebeispielsweise der Titel des Blogbeitrags, derName des Bloggers und das Einstelldatum desBlogeintrags. Ferner wird darauf geachtet, dasssämtliche Informationen, die die Inhalte derScilogs-Website in Bezug auf die Bloginhalteliefern, ebenfalls annotiert werden. Wir sind derMeinung, dass auch auf den ersten Blick nichtfür die Diskursstruktur relevante Informationenausgezeichnet werden sollten. Im Fokus stehtder Ansatz, dass das Blogkorpus aus CMC-Datenspäter für die Erforschung unterschiedlicherlinguistischer Fragestellungen verwendetwerden kann.
Zusammenfassend soll das Poster nichtnur unser Vorhaben vorstellen, sondernauch einen Einblick in unser grundsätzlichesVorgehen bei der Erstellung eines CMC-Korpus geben. Der Fokus für die DHd 2017liegt unter anderem auf der Darstellungder Entscheidungsfindung innerhalb derAuszeichnungssprachen. Es soll erläutertwerden, warum wir uns beispielsweise für diedeskriptive Auszeichnungssprache TEI und nichtXML (Extensible Markup Language) entschiedenhaben. Des Weiteren möchten wir Einblicke indie semi-automatische TEI-Annotation gebenund unsere Erkenntnisse mit dem vorläufigen,von der TEI SIG bereitgestellten, TEI-Schemateilen. Letztlich wollen wir auch das bisherige
252

Digital Humanities im deutschsprachigen Raum 2017
Korpus selbst vorstellen, das aus ca. 3.000.000Tokens (ca. 1.200 Blogposts von 80 Bloggern und15.000 Kommentaren von 1500 Kommentatoren)besteht.
Bibliographie
Abendroth-Timmer, Dagmar / Bechtel,Mark / Chanier Thierry / Ciekanski, Maud(2014): Corpus d’apprentissage INFRAL(Interculturel Franco-Allemand en Ligne). Banquede corpus CoMeRe. Nancy: Ortolang.fr https://hdl.handle.net/11403/comere/cmr-infral [letzterZugriff 1. Juli 2016].
Beißwenger, Michael (2016): SIG:Computer-Mediated Communication http://wiki.tei-c.org/index.php/SIG:Computer-Mediated_Communication [letzter Zugriff 1. Juli2016].
SciLogs (2016): SciLogs: Tagebücher derWissenschaft. Spektrum der WissenschaftVerlagsgesellschaft mbH http://www.scilogs.de/impressum/ [letzter Zugriff 1. Juli 2016].
WebCorp (2013): Birmingham Blog Corpus.WebCorp: Linguist’s Search Engine. BirminghamCity University http://wse1.webcorp.org.uk/cgi-bin/BLOG/index.cgi [letzter Zugriff 1. Juli 2016].
KriterienbasierteEvaluation undDokumentationtechnischerNachhaltigkeit vonForschungssoftwarein einemMetadatenrepositorium
Druskat, [email protected]ät zu Berlin, Deutschland
Einleitung
Softwarenachhaltigkeit kann im Bezugauf verschiedene Aspekte definiert werden:Umwelt, Gesellschaft, Wirtschaft, Technik,Individuen (vgl. Becker et al. 2015). Von
besonderem Interesse für die Forschungist dabei die technische Nachhaltigkeit vonForschungssoftware, d.h., ob für die eigeneForschungsfrage verwendbare Softwareexistiert, ob diese eigenen Bedürfnissenanpassbar ist, inwiefern ihre Nachnutzbarkeit- und damit auch die Reproduzierbarkeit vonForschungsergebnissen - in Zukunft gesichertist, etc. Praktisch spielen dabei vor allemzwei Kriterien eine Rolle: die Sichtbarkeitnachnutzbarer Forschungssoftware und dienachvollziehbare Bewertung ihrer technischenNachhaltigkeit.
Parallel zur Dokumentation derNachhaltigkeit von Forschungsdaten inDatenmanagementplänen bieten sichSoftwaremanagementpläne zur Dokumentationder technischen Nachhaltigkeit neu erstellterForschungssoftware an und es ist anzunehmen,dass Förderer in Zukunft diesen Weg einschlagenwerden (vgl. Hettrick 2015). Zur Dokumentationvon Forschungssoftware bieten sich - ebenfallsparallel zu Forschungsdaten - Repositorien an,die mit Hilfe von Metadaten Forschungssoftwaresichtbar und für eine Verwendung bewertbarmachen.
State of the art
Solche Metadatenrepositorien existierenbereits, im geisteswissenschaftlichen Bereichbeispielsweise DiRT Directory und CLARINVirtual Language Observatory, für andereoder mehrere Disziplinen SciencePADund EGI Applications Database (vgl. auchre3data.org). Softwaremetadaten sind ebenfallszugänglich über Plattformen wie GitHub,Open Hub und Zenodo. Während dieseWerkzeuge für die Suche nach verwendbarerFoschungssoftware prinzipiell, wenn auchteilweise nur eingeschränkt, geeignet sind,dokumentiert keins von ihnen umfassendden Grad der technischen Nachhaltigkeit derpräsentierten Software ohne die Notwendigkeitmassiver Interpretation und Extrapolationseitens der Nutzerin.
Ein messendesMetadatenrepositorium fürForschungssoftware
Um sowohl die Sichtbarkeit als auch dieEinschätzbarkeit der technischen Nachhaltigkeitvon Forschungssoftware zu gewährleisten
253

Digital Humanities im deutschsprachigen Raum 2017
bietet sich daher die Konzeption einesTypus von Metadatenrepositorium an,der ausgehend von Druskat (2016) hierbeschrieben und weiterentwickelt wird.In einem solchen Repositorium werdenhinterlegte Metadaten unter Zuhilfenahmevon Nachhaltigkeitskriterien quantifiziert undauf dieser Grundlage Maße berechnet, dienachvollziehbar und reproduzierbar den Gradtechnischer Nachhaltigkeit abbilden können.Dabei muss ein Metadatenbegriff zu Grundegelegt werden, der weit genug ist, relevanteInformationen für die Bestimmung von sowohl(Nach-)Nutzbarkeit als auch technischerNachhaltigkeit erfassen zu können.
Voraussetzungen
Für die Umsetzung eines solchenRepositoriums müssen mindestens vierzentrale theoretische Probleme gelöst werden,nämlich 1. wie technische Nachhaltigkeitoperationalisierbar definiert werden kann, 2.wie Kriterien für technische Nachhaltigkeitdefiniert und gewichtet werden könnenund der Entwurf von 3. möglichst genauen,reproduzierbaren, manipulationssicherenund nachvollziehbaren Maßen sowie4. von Algorithmen zur Berechnungnachvollziehbarer und reproduzierbarer Maßefür technische Nachhaltigkeit auf Grundlage vonSoftwaremetadaten. Während 4. Gegenstandzukünftiger Forschungsvorhaben sein soll,können die Problemstellungen 1. bis 3. hier kurzdetailliert werden.
Technische Nachhaltigkeit vonForschungssoftware
Während im Zusammenhang mit Softwareder Begriff der Nachhaltigkeit strukturellund inhaltlich ambig diskutiert wird (vgl.Tate 2005; Penzenstadler 2013; Goble 2014;Gröger & Köhn 2015), geben Becker et al.(2015) eine kurze Definition von technischerNachhaltigkeit: "Technische [Nachhaltigkeit]bezieht sich auf die Langlebigkeit vonInformation, Systemen und Infrastrukturund deren angemessene Evolution unter sichändernden Umgebungsbedingungen" (Übers.d. Autors). Konkretisiert man die Aspekte'Langlebigkeit' und 'Evolution' auf Grundlagedes Nachhaltigkeitsmodells von Jörissen etal. (1999), lassen sich drei Ziele technischerNachhaltigkeit definieren: 1. Sicherung der
Existenz der Software, 2. Erhaltung desProduktivpotentials der Software, 3. Schaffungund Bewahrung der Weiterentwicklungs- undAdaptionsmöglichkeiten der Software.
Kriterien
Das zu entwickelnde Metadatenrepositoriummuss demnach Metadaten sammeln, die imHinblick auf diese drei Ziele quantifizierbar sind.Voraussetzung dafür sind Kriterienkataloge,die sich jeweils auf eines der Ziele beziehenund auf Basis derer die Kategorisierungund Quantifizierung der Metadaten erfolgt.Für das Erstellen der Kriterienkatalogebieten etwa Jackson, Crouch & Baxter (2011),CodeMeta (codemeta.github.io), oder OntoSoft(ontosoft.org) eine Arbeitsgrundlage, die jedochdurch dort fehlende Kriterienkategorien wiebeispielsweise 'personelle Mittel' erweitertwerden muss, etwa auf dem Wege desCrowdsourcing.
Interaktivität
Weiterhin liegt es nahe, Teile desRepositoriums interaktiv zu gestalten.Dies dient nicht nur der Bindung derCommunity an das Werkzeug, sondernerlaubt vor allem die Gewinnung zusätzlicherMetadaten - beispielsweise zu tatsächlicherund dokumentierter Nutzung einerForschungssoftware -, sowie die Evaluationbereits hinterlegter.
Maße für technischeNachhaltigkeit
Direkte Interaktion von Nutzern allerdingsgefährdet massiv die Objektivität undReproduzierbarkeit eines zu errechnendenMaßes für die technische Nachhaltigkeiteiner Forschungssoftware. Daher ist eineVerteilung der Bemessung über mehrereMaße geraten: Einfach zu quantifizierendeund objektive Metadaten (beispielweiseOffenheit des Quellcodes, interaktiv hinterlegteVerwendungsnachweise) tragen zu einemharten Maß bei, objektive aber wenigereinfach zu quantifizierende Metadaten(beispielsweise das verwendete Buildsystem)zu einem mittelharten Maß, weitere interaktiverhobene, subjektive und qualitative Metadaten(beispielsweise Nutzerfreundlichkeit) zu einem
254

Digital Humanities im deutschsprachigen Raum 2017
weichen Maß. Während die härteren Maße aufGrund ihrer Objektivität reproduzierbar undverhältnismäßig manipulationssicher sind,bietet das weiche Maß interpretationswürdigeAnhaltspunkte.
Ausblick
Das beschriebene Metadatenrepositoriumwäre ebenfalls ein geeignetesInstrument für die Dokumentationneu erstellter Forschungssoftware inSoftwaremanagementplänen.
Eine vollständige Entwicklungdes umrissenen Konzeptes und seineImplementierung ist im Rahmen der Dissertationdes Autors geplant.
Bibliographie
Becker, Christoph / Chitchyan, Ruzanna /Duboc, Leticia / Easterbrook, Steve /Penzenstadler, Birgit / Seyff, Norbert /Venters, Colin C. (2015): „Sustainability designand software: The Karlskrona Manifesto“, in:IEEE/ACM 37th IEEE International Conference onSoftware Engineering 467–476.
Druskat, Stephan (2016): „LightningTalk: A Proposal for the Measurementand Documentation of Research SoftwareSustainability in Interactive MetadataRepositories“, in: Proceedings of the FourthWorkshop on Sustainable Software for Science:Practice and Experiences (WSSSPE4) http://ceur-ws.org/Vol-1686/WSSSPE4_paper_20.pdf [letzterZugriff 1. Dezember 2016].
Goble, Carole (2014): „Better software, betterresearch“, in: IEEE Internet Computing 18: 4–8.
Gröger, Jens / Köhn, Marina (2015):„Nachhaltige Software. Dokumentationdes Fachgesprächs Nachhaltige Softwaream 28.11.2014“, in: Umweltbundesamt,Dokumentationen 07/2015 http://www.umweltbundesamt.de/en/publikationen/nachhaltige-software [letzter Zugriff 31. August2016].
Hettrick, Simon (2016): Research softwaresustainability: Report on a Knowledge Exchangeworkshop http://repository.jisc.ac.uk/6332/[letzter Zugriff 31. August 2016].
Jackson, Mike / Crouch, Steve / Baxter,Rob (2011): Software evaluation: criteria-basedassessment. Software Sustainability Institute.
Jörissen, Juliane / Kopfmüller, Jürgen /Brandl, Volker / Paetau, Michael (1999): Ein
integratives Konzept nachhaltiger Entwicklung.Karlsruhe: Forschungszentrum Karlsruhe.
Penzenstadler, Birgit (2013): „Towards adefinition of sustainability in and for softwareengineering“, in: Proceedings of the 28th AnnualACM Symposium on Applied Computing 1183–1185.
Tate, Kevin (2005): Sustainable SoftwareDevelopment: An Agile Perspective. Boston, MA:Addison-Wesley.
Living Books aboutHistory
Baumann, [email protected], Schweiz
Kurmann, [email protected], Schweiz
Natale, [email protected], Schweiz
infoclio.ch hat 2016 das digitale ProjektLiving Books about History lanciert. DieLiving Books sind eine neue Form digitalerAnthologien. Sie präsentieren kurze Essayszu aktuellen wissenschaftlichen Themen, dievon ausgewählten online und frei verfügbarenBeiträgen begleitet werden. Das Projekt erprobtein neues Format der wissenschaftlichenPublikation und will mit dem Wiederentdeckenund Neuverwenden wissenschaftlicher Texteund Quellen auf die Chancen von Open Accessaufmerksam machen.
255

Digital Humanities im deutschsprachigen Raum 2017
Auf einem Poster soll das Konzept desProjekts kurz erläutert und die sechs bereitsonline verfügbaren Living Books vorgestelltwerden. Dem Tagungsthema entsprechendwerden dabei auch jene Aspekte des Projektsbeschrieben, die die technische Nachhaltigkeitder Webseite und die konzeptionellen Ziele, dieauf eine langfristige Nutzung digital verfügbarerInhalte ausgerichtet sind, darlegen. Sie findenkurze Ausführungen zur Gestaltung des Postersim zweiten Teil dieser Bewerbung.
Die Living Books about History passenin mehrfacher Hinsicht ausgezeichnet zumTagungsthema „Digitale Nachhaltigkeit“:
• In konzeptueller Hinsicht verfolgt das Projektdie Idee, besonders lesenswerte oder zuUnrecht vergessen gegangene Texte ausder Masse der im Internet verfügbarenInformationen hervorzuheben. Mit demHervorheben sollen relevante Ressourcenund herausragende wissenschaftlicherBeiträge auch im digitalen Raum langfristigsichtbar und einfach zugänglich bleiben.
• Das digitale Projekt ist auch in technischerHinsicht auf Nachhaltigkeit bedacht: Zumeinen wird durch die Vergabe von DigitalObject Identifiers (DOI) für jedes LivingBook sichergestellt, dass die verlinktenWebseiten auch bei einer Veränderungder URL erreichbar bleiben; zum andernwird durch das Archivieren der Website imWebarchiv Schweiz durch die SchweizerischeNationalbibliothek garantiert, dass die LivingBooks dauerhaft zugänglich sind.
• Inhaltlich geht insbesondere das von TaraAndrews herausgegebene Living Book„Digital Humanities“ der Geschichte diesesFachs nach. Auch die anderen Living Booksbeschäftigen sich in formaler Hinsichtmit dem Digitalen, in dem u.a. vielseitige
Quellenformate wie Videos, Webseitenoder Bilder in die jeweiligen Anthologienintegriert werden.
• Mit der Sensibilisierung für die juristischenBestimmungen wird die Nutzung onlineverfügbarer Beiträge gefördert. DasProjekt verweist bei allen Beiträgenauf die bibliografischen Referenzender Erstveröffentlichung und dieNutzungsbedingungen.
Weitere Informationen zum Projektsowie zum Design, an das wir uns beider Ausgestaltung des Posters anlehnenwürden, finden Sie unter: http://www.livingbooksabouthistory.ch/de/
___________________________________In der Gestaltung des Posters sind folgende
Punkte vorgesehen:1. ) Kurze Einführung ins Projekt:
• Konzept und Ziele• Nachhaltigkeit der digitalen Infrastruktur• Open Access und Nutzungsrechte
2.) Präsentation der online und freizugänglichen Living Books:
• Tara Andrews - Digital Humanities: DieseAnthologie gibt eine Einführung in die DigitalHumanities. Im Fokus stehen die Geschichteund die Begriffe sowie Ratschläge zumEinstieg in die Digital Humanities.
• Almut Höfert – Wunder und Monster imMittelalter: Das Living Book beschäftigtsich mit Wundern und Mirakeln sowie dergesellschaftlichen Bedeutung, die ihnen imMittelalter zukam.
• Guido Koller & Sebastian Schüpbach –Geschichte der modernen Verwaltung:Quellen und Berichte aus demSchweizerischen Bundesarchiv gebenEinblick in die Entwicklung der Verwaltungim 19. und 20. Jahrhundert.
• Martin Lengwiler & Beat Stüdli – Geschichtedes Wohlfahrtstaats: Die Anthologie gibteinen Einblick in verschiedene Modelle desWohlfahrtstaats und beschäftigt sich mit derEntwicklung, die zur heutigen Vielfalt geführthat.
• Daniel Speich Chassé – „La situationcoloniale“: In diesem Living Book geht es umNord-Süd-Beziehungen im 20. Jahrhundert.Der Ausgangspunkt bildet ein Text von Georges Balandier aus dem Jahr1951.
256

Digital Humanities im deutschsprachigen Raum 2017
• Valérie Schafer – "Histoires de l'Internet etdu Web" (ab Herbst 2016): Anhand einerAuswahl von Quellen und Aufsätzen wirddie Geschichte des Internets und des Websnachgezeichnet.
3.) Hinweis darauf, dass die Reihe fortgesetztwird und wir Themenvorschläge für neue LivingBooks gerne entgegennehmen.
Maßnahmen zurdigitalen Nachhaltigkeitin Langzeitprojekten –Das Beispiel Capitularia
Schulz, [email protected] Universität Wuppertal; Universität zuKöln
Fischer, [email protected] Center for eHumanities
Geißler, [email protected] Center for eHumanities
Gödel, [email protected] Center for eHumanities
Bei der Planung und Durchführung vonlangfristigen (Editions-)Projekten stellen sichhinsichtlich der Nachhaltigkeit besondereHerausforderungen, da sich die technischenEntwicklungen der nächsten Jahre undJahrzehnte eben nur bedingt vorausahnenlassen. Gerade in der Anfangsphase müssen aberbereits zahlreiche, oftmals richtungsweisendeEntscheidungen getroffen werden, dieden zukünftigen Erfolg oder Misserfolg,potenziell auftretende Probleme undLösungsmöglichkeiten determinieren. Allerdingsscheint es auch überhaupt nur in Projekten mitlanger Laufzeit möglich, jenseits von reinenWillensbekundungen umfassende Strategien zurNachhaltigkeit zu entwickeln und entsprechendeMaßnahmen zu ergreifen. Damit leitet sichgleichzeitig die Pflicht ab, dies auch zu tun.
Am Beispiel des Projektes Capitularia,einem Langzeitprojekt (2014-2029), welchesmit einer Hybrid-Edition frühmittelalterlicherHerrschererlasse befasst ist, sollen dieverschiedenen Ebenen digitaler Nachhaltigkeit,damit verbundene Herausforderungen sowieerste Lösungsansätze präsentiert werden. Dervon uns vorgeschlagene und in Teilen bereitsumgesetzte Maßnahmenkatalog betrifft dieEbenen
• Datenmodellierung und Textauszeichnung,• Datenhaltung und Dokumentation,• Infrastrukturen (technisch und
institutionell),• Webseite und verwendete
(Web-)Technologien,• Präsentation, Zugänglichkeit und
Nachnutzbarkeit der Forschungsergebnisse.
Bei der Textauszeichnung sollte aufetablierte Standards zurückgegriffen werden,um die programm- und plattformunabhängigeWeiterverarbeitung der Daten langfristigzu gewährleisten. Bei Capitularia werdenTranskriptionen, Handschriftenbeschreibungen,Register und bibliographische Daten gemäß derim Projekt erarbeiteten Richtlinien in TEI-XMLcodiert und durch ein den projektspezifischenAnforderungen angepasstes, restriktivesSchema sowie den Einsatz von Schematron(ISO/IEC 19757-3) kontrolliert, um damit überdie gesamte Projektlaufzeit hinweg und auchbei wechselndem Personal die Konsistenz undEinheitlichkeit und damit die Qualität dererstellten Daten zu sichern. (Hedler u.a. 2011:11-12)
Dies bedingt von Beginn an eine umfassendeDokumentation, die nicht nur z.B. in Formeines Wikis vor allem für interne Zweckeverwendet wird, sondern auch möglichst vieleInformationen öffentlich zugänglich macht,so dass andere Projekte von den Erfahrungenprofitieren können. Die Entwicklung undRationalisierung von Arbeitsprozessen sowiederen genaue Darlegung gewährleisten dabeineuen Mitarbeitern einen möglichst einfachenEinstieg. Für die öffentliche Dokumentationbieten sich neben der eigenen Projektwebseitebeispielsweise Dienste wie GitHub an, auf denengleichzeitig eine transparente Datenhaltungmit Versionierung möglich ist, und aucheigene technische Entwicklungen einfach zurNachnutzung bereitgestellt werden können.Dies alles setzt natürlich die Verwendungentsprechender Open Access Lizenzen voraus.
257

Digital Humanities im deutschsprachigen Raum 2017
Die Sicherung der Langzeitverfügbarkeiteiner Ressource lässt sich generell nur durcheine entsprechende technische Infrastruktur(Daten-, Kompetenz-, Rechenzentren) inKombination mit institutioneller Anbindung(Universitäten, Forschungsbibliotheken,kulturbewahrende Institutionen) gewährleisten.(Wissenschaftsrat 2011) Zu unterscheiden istdabei zwischen der langfristigen Archivierungund Vorhaltung der Forschungsdaten und demmöglichst langen Erhalt der Webressourceinsgesamt, die ja ebenfalls mit allenFunktionalitäten über die Projektlaufzeit hinausverfügbar sein soll. (Oßwald u.a. 2012: 13-15)Die Voraussetzungen in Köln erscheinen ideal,da dem Projekt mit dem CCeH ein im Bereichder DH ausgewiesener technischer Partner zurVerfügung steht, der durch enge Kooperationmit weiteren universitären Einrichtungen wiedem Data Center for the Humanities und demKölner Rechenzentrum, ideale strukturelleVoraussetzungen für Aufbau und langfristigeErhaltung digitaler Ressourcen schaffen konnte.Zusätzlich nimmt das Capitularia-Projektauch am Webarchivierungsprogramm derBayerischen Staatsbibliothek teil.
Für die Webpräsentation wurden in engerZusammenarbeit mit dem technischen Partnergeeignete (open source) Technologienausgewählt, deren zukünftiger Erhalt sowiederen Weiterentwicklung von einer breitenCommunity getragen werden, und die sichin anderen Projekten bereits bewährt haben.Im Fall von Capitularia wird aktuell das PHP-basierte Content Management System WordPresszur Verwaltung der Webpräsenz verwendet.Dabei werden die Standardfeatures (Blog, Suche,Mehrsprachigkeit etc.) möglichst breit genutztund vereinzelt um weitere Eigenentwicklungenergänzt, die insbesondere den Bereich desXSLT-Pipelining betreffen. Diese im Kontextdes Projektes entwickelten Plugins sollen auchder Nachnutzung durch andere Projekte zurVerfügung stehen. WordPress erfüllt durch diefreie Zugänglichkeit des Quellcodes, der aktivenund heterogenen Entwickler-Gemeinschaft,des Ökosystems, welches sich um dieseSoftware etabliert hat, sowie der verwendetenLizenzmodells wichtige Voraussetzungendigitaler Nachhaltigkeit. (Stürmer 2015, S. 36-37)Die bewusst gewählten low-tech-Lösungengewährleisten weiterhin langfristig die leichteWartbarkeit des Systems sowie plattform- undauch personelle Unabhängigkeit. Bei Bedarfkönnte somit ohne größere Probleme auf einanderes Präsentationsframework umgezogenwerden.
Die Präsentation der Forschungsergebnissefindet auf mehreren Ebenen statt. Dieangefertigten Transkriptionen werdenzusammen mit weiteren Materialienprojektbegleitend auf der Webseiteveröffentlicht. Die Inhalte sind dort überPermalinks adressierbar und die zugrundeliegenden Daten ( XML) stehen zum Downloadbereit. Um die Nachnutzung der Daten weiterzu erleichtern, ist die Implementierung vonSchnittstellen (z.B. REST) vorgesehen. 1 Diekritische Edition erscheint in Druckfassung inder Leges-Reihe der Monumenta GermaniaeHistorica und wird somit auch langfristig überderen Online-Angebot (dMGH) verfügbar sein.Vorabversionen der kritischen Editionstextewerden aber bereits zeitnah in digitalaufbereiteter Form auf der Webpräsenz zurVerfügung gestellt.
Wenn auch finanzielle Ausstattungund Laufzeit von Projekten und damitauch deren Handlungsmöglichkeitenhinsichtlich Nachhaltigkeitsstrategien durchausunterschiedlich sind, so erscheinen doch dieBereiche, in denen Maßnahmen getroffenwerden können, allgemeingültig zu sein. Mitden hier vorgestellten Ansätzen soll ein aktiverund vor allem praxisorientierter Beitrag zurDiskussion um digitale Nachhaltigkeit geleistetwerden.
Fußnoten
1. Die freie Bereitstellung von im Rahmen vonDigitalen Editionen entstandenen (XML-)Datenlässt aktuell noch zu wünschen übrig. Nurdurch diese wird aber Nachnutzung und damitintegrative und innovative Forschung erstermöglicht. (Turska u.a. 2016: 1) TechnischeSchnittstellen können die Nachnutzungbefördern und stellen daher ein Kriterium eineraktuellen Ansprüchen genügenden digitalenEdition dar. (Sahle u.a. 2014).
Bibliographie
Hedler, Marko / Montero Pineda, Manuel /Kutscherauer, Nico (2011): Schematron.Effiziente Business Rules für XML-Dokumente.Heidelberg: dpunkt-Verlag.
Oßwald, Achim / Scheffel, Regine /Neuroth, Heike (2012): „Langzeitarchivierungvon Forschungsdaten. EinführendeÜberlegungen“, in: Neuroth, Heike /Strathmann, Stefan / Oßwald, Achim / Scheffel,
258

Digital Humanities im deutschsprachigen Raum 2017
Regine / Klump, Jens / Ludwig, Jens (eds.):Langzeitarchivierung von Forschungsdaten: EineBestandsaufnahme. Boizenburg: Verlag WernerHülsbusch 13–23 http://www.nestor.sub.uni-goettingen.de/bestandsaufnahme/nestor_lza_forschungsdaten_bestandsaufnahme.pdf[letzter Zugriff 9. November 2016].
Sahle, Patrick / Vogeler, Georg / IDE (eds.)(2014): Kriterien für die Besprechung digitalerEditionen. Version 1.1 Juni 2014 http://www.i-d-e.de/publikationen/weitereschriften/kriterien-version-1-1/ [letzter Zugriff 12. November 2016].
Stürmer, Matthias (2015): „Wann sindOpen Source Projekte digital nachhaltig?“, in:swissICT und Swiss Open Systems User Group(eds.): Open Source Studie: Schweiz 2015 36–37 http://www.swissict.ch/fileadmin/customer/Publikationen/OSS-Studie2015.pdf [letzter Zugriff9. November 2016].
Turska, Magdalena / Cummings, James /Rahtz, Sebastian (2016): „Challenging theMyth of Presentation in Digital Editions“, in:Journal of the Text Encoding Initiative 9 http://jtei.revues.org/1453 [letzter Zugriff 12. November2016].
Wissenschaftsrat (ed.) (2012); Empfehlungenzur Weiterentwicklung der wissenschaftlichenInformationsstrukturen in Deutschlandbis 2020. Drs. 2359-12. Berlin http://www.wissenschaftsrat.de/download/archiv/2359-12.pdf [letzter Zugriff 09. November2016].
maus - eine WebAppzur einfachenErstellung funktionalerWebdokumente
Dufner, [email protected] Mainz, Deutschland
Kunz, [email protected] Mainz, Deutschland
Klammt, [email protected] Zentrum für Digitalität in denGeistes- und Kulturwissenschaften (mainzed),Deutschland
Oft kommen Fachwissenschaftler(innen)in die Lage, Texte für zahlreiche verschiedenedigitale Formate (Blogs, Präsentationen, E-LeraningPlattformen) zu erzeugen. Sie stehendabei vor der Wahl, Texte immer wieder neueinzupassen oder sie in Dateiformaten zurVerfügung zu stellen, die strenggenommenzweckentfremdet werden. Powerpoint-Präsentationen sind als begleitendes Elementzu einer Vorlesung gedacht und nicht alsLernunterlagen, eine PDF-Datei soll imursprünglichen Sinne eine Druckvorstufe sein,dementsprechend sind sowohl Usability alsauch Lesbarkeit auf kleineren Bildschirmenmeistens mangelhaft. HTML5 Dateien kennendiese Probleme nicht. Sie sind gewissermaßendigitale Rohdaten, die ohne zusätzliche Softwarevon jedem modernen Browser interpretiertund dargestellt werden können. In HTMLzu schreiben ist jedoch unkomfortabel underfordert Kenntnisse. maus setzt genau andieser Stelle an und bietet eine leicht nutzbareEntwicklungsumgebung, die reichhaltigeHTML5-Dokumente exportieren kann. Dank derTrennung von Inhalt und Formatierung könnendabei alle mit maus erzeugten Dokumente inverschiedenen Kontexten wiederverwendetwerden. Daher wird maus vom MainzerZentrum für Digitalität in den Geistes- undKulturwissenschaften (mainzed) aktuellauch besonders mit Blick auf die Erzeugungnachhaltiger, offener digitaler Lehrmaterialien(OER) weiterentwickelt.
maus ist eine neu entwickelteWebanwendung. Sie besteht aus einemEditor, indem mit einfachem Markdown Textestrukturiert und semantisch angereichertwerden. Diese Texte werden in einem weiterenSchritt in HTML5 überführt und könnenautomatisiert mit CSS-Templates verknüpftwerden. Die vereinfachte AuszeichnungsspracheMarkdown fungiert somit als technische Brücke.Die Markdown-Syntax ist leicht zu erlernen undbelässt Inhalte in lesbarer Form – somit bleibendie Daten trotz Auszeichnungen übersichtlichund klar. Tatsächlich nutzt Markdown einfacheAuszeichnungselemente, um komplexeStrukturen im HTML zu generieren. Dieerstellten Dokumente können später alsHTML-Dateien exportiert werden. Der Editorunterstützt Syntax-Highlightning und eineVorschau des Dokuments. Er ist ansonstenbewusst einfach und schlank gehalten. mausunterscheidet sich damit auch von der Usabilityerheblich von den üblichen CMS-Systemen.Dennoch bietet auch maus eine Verwaltung vonNutzer(inne)n und Nutzergruppen. Weiterhinbesteht die Möglichkeit, private Dokumente zu
259

Digital Humanities im deutschsprachigen Raum 2017
erstellen oder Inhalte mit anderen Nutzern zuteilen. Ebenso ist das Zurücksetzen auf frühereVersionen eines Dokuments möglich.
Die Entwicklung ist aber noch einenSchritt weitergegangen, denn oftmalsreichen die durch Markdown unterstützenAuszeichnungselemente nicht aus. Hierzu zählenbeispielsweise das automatische Generierenvon Inhalts- und Quellenverzeichnissen,komplexen Bildunterschriften oder dynamischeBegriffserläuterungen. Um die hierfürnotwendigen komplexen HTML-Strukturenautomatisiert zu generieren, wurden neueAuszeichnungselemente eingeführt. Hierdurchkönnen die Markdown Dokumente u. a. mitsemantischen Elementen angereichert werden.Beispielsweise wird durch die Auszeichnung:{definition: mainzed} ein HTML-Elementerzeugt, das später im HTML-Dokumentbei eine Erklärung des Begriffes ‘mainzed’einblendet sobald sich der Cursor überdem Element befindet. Genauso kann mausaber auch Markdown-Dokumente ausgebenund hierbei die Erweiterungen entfallenlassen. Die Erweiterungen des Markdownsind also Optionen, die die Dokumente nichtkorrumpieren.
Die Stärke von maus liegt in der Möglichkeit,erstellte Bausteine je nach Anwendungszweckzu passgenauen Medien zusammensetzen zukönnen. Ihre Darstellung lässt sich mit Hilfeunterschiedlicher Templates (siehe Templates)ebenfalls ändern. Mit Hilfe von maus lassensich somit aus den selben digitalen Rohdatenproblemlos Lesedokumente, Präsentationen oderWebsites entwickeln. Die Arbeitsweise ist dabeigrundsätzlich auf Nachhaltigkeit angelegt, weilInhalt und Gestaltung getrennt bleiben. Es istsehr einfach möglich, einmal erstellte Inhaltezu einem späteren Zeitpunkt in anderer Formwiederzuverwenden.
Bei der Software Architektur handelt essich um einen MEAN Stack, einem Paket anfreier Open-Source-Software zur Entwicklungvon dynamischen Webanwendungen. Esbesteht aus MongoDB, Express, AngularJSund Node.js. Weiterhin wird CodeMirrorgenutzt, ein JavaScript basierender Texteditor,der die Hervorhebung von Markdown-Auszeichnungselementen unterstützt. Dieserwurde erweitert, um auch die neu erzeugtenElemente hervorzuheben. Der Markdownparser und compiler marked wird zumKonvertieren der Markdown- in HTML-Dokumente verwendet. maus selbst ist, wie seineeinzelnen Komponenten als Open-Source-Projektauf GitHub ( https://github.com/mainzed/maus )
freigegeben und kann somit frei genutzt undweiterentwickelt werden.
maus wird bereits in Projekten des mainzedeingesetzt, um beispielsweise Lehrmaterialienfür die Lernplattform OpenOLAT oderInhalte für den mainzed-Jahresbericht durchFachwissenschaftler(innen) erstellen zu lassen.
Im Fokus der Weiterentwicklung stehenderzeit die vereinfachte Erweiterbarkeit derAnwendung durch erfahrene Nutzer(innen).Diese sollen in der Lage sein, eigene Layoutsund Anreicherungselemente anzulegen, um diemomentan verfügbaren Vorlagen zu erweitern.Denkbar wären Layouts für wissenschaftlichePoster, Paper, Präsentationen und auchPrintmedien.
Nachhaltigkeit durchZusammenschluss: DieDARIAH Data Re-UseCharter
Baillot, [email protected] Marc Bloch, Deutschland
Busch, [email protected] Weimar MarbachWolfenbüttel
Puren, [email protected] Paris
Mertens, [email protected] Center for Digital Humanities
Romary, [email protected] Paris
Bedarf und Forschungsstand
Ausgangspunkt der Charter ist dieFeststellung, dass es bis dato keinen klarenRahmen gibt, der die wissenschaftlichenWeiternutzungsbedingungen von digitalen
260

Digital Humanities im deutschsprachigen Raum 2017
Daten regelt, die auf Beständen vonKulturerbeinstitutionen basieren. Einigeallgemeine Richtlinien wurden entwickelt,die allerdings nicht spezifisch die Interaktionzwischen digitalen Kulturerbedaten undForschung in den Blick nehmen, sondernbreiter angelegt sind. So etwa die Data Re-UseModels DANS oder die UNESCO Guidelinesfor the preservation of digital heritage(die wohlgemerkt nicht ausschliesslichKulturerbedaten in den Blick nehmen).Andere Initiativen haben die Evaluation derdigitalen Best-Practices in den Mittelpunktgestellt, so etwa der Data Seal of Approvaloder die Richtlinien zur Certification andAssessment of Digital Repositories des Centerfor Research Libraries. Im Bereich desForschungsökosystems selbst jedoch kann indiesem Sinne hauptsächlich auf den CERN Codeof Conduct hingewiesen werden, der zwarwenig konkrete Verpflichtungen definiert,dafür aber den Schwerpunkt auf eine Ethik derwissenschaftlichen Zusammenarbeit legt, dessenGeist ebenfalls in der hier dargestellten Chartervon wesentlicher Bedeutung ist.
Der Mangel eines klaren Rahmens fürdie Zusammenarbeit an und mit digitalenKulturerbedaten macht sich für alle beteiligtenAkteure im Alltag bemerkbar: Forscher undForscherinnen, die vor einem Scan stehen, ohnezu wissen, wie sie diesen weiterverwendenund zitieren dürfen; Kulturerbeeinrichtungen,die ihre Metadatensätze mit den entstehendenForschungsarbeiten verknüpfen möchten;Equipments, die Anfragen für die gleichenArtefakte immer wieder bekommen;Datenzentren, die der Schnittstelle zwischenKulturerbeeinrichtungen und Forschungfernbleiben bzw. von der Verwaltungder unterschiedlichen Rechte der vonihnen gehosteten Daten herausgefordertsind; Forschungseinrichtungen, denenStrukturen fehlen, um ihren Mitarbeitern undMitarbeiterinnen good-practice-Empfehlungenan die Hand zu geben. Der Mangel andefinitorischer Schärfe des betroffenenInformationsaustauschs steht im Gegensatzsowohl zu dem damit für alle Beteiligtenzusammenhängenden Bedarf als auch zu demoffensichtlichen Vorteil, den ein solcher fürdas ganze Ökosystem repräsentiert. Nachhaltigkann ein solcher Austausch nur dann werden,wenn neben den Datenproduzenten (Forscher/innen, Kulturerbeeinrichtungen, Equipments)auch Datenzentren daran beteiligt sind, wiees hier vorgesehen ist. Einige Einrichtungenübernehmen zwar mehrere dieser Funktionen,aber die Kommunikation zwischen den
entsprechenden Abteilungen ist auch dort nichtimmer optimal.
Nicht zuletzt für die Weiterentwicklungder Digital Humanities handelt es sich beidem hier geschilderten Zusammenhangum ein zentrales Anliegen, bilden dieseDaten ja die Grundlage für eine beachtlicheReihe geisteswissenschaflicher Forschungenetwa in den Bereichen der Archäologie, derKunstgeschichte, der Musikwissenschaft, aberauch u.a. der Literaturgeschichte und derEditionswissenschaft. Selbst vom Standpunktnicht-historischer Fächer ist es auf Dauervon Vorteil, wenn für digitale Daten allerArt hinsichtlich der Formate und StandardsRücksprache gehalten wird, wenn Equipmentsdie bereits durchgeführten Scanarbeitentransparent machen, wenn auf einen Blick klarwerden kann, zu welchen Kulturerbebeständenin welchen Datenzentren Arbeiten vorhandensind. Die DARIAH Data Re-Use Charter hatzum Ziel, die Transaktionen zwischen allden Akteuren, die an der wissenschaftlichenArbeit mit den digitalen Daten, die aufKulturerbedaten basieren, Interesse haben,einfacher, transparenter und nachhaltiger zumachen, sodass alle daraus einen Nutzen fürihre eigene Arbeit ziehen können.
Grundprinzipien
Die DARIAH Data Re-Use Charter isteine Interaktionsplattform für alle ander wissenschaftlichen Nutzung digitalerDaten von Kulturerbeeinrichtungeninteressierten Akteure. Die Charter stelltdiesen Textbausteine zur Verfügung, damitsie die Bedingungen ihrer Zusammenarbeitgemeinsam definieren können. Auf diesemWeg kann eine Kulturerbeinstitution dieNutzungsbedingungen ihres Gesamtbestands,aber auch von Sondersammlungenunterschiedlich beschreiben. Eine Universitätkann ihre Befürwortung der Open Access-Prinzipien deklarieren und ihren Mitarbeiter/innen empfehlen, ihre Kooperationenmit Kulturerbeeinrichtungen in diesemSinne zu konzipieren. Wie in diesen zweiBeispielen liefert die Charter ausformulierteBausteine für die Zusammensetzung einerKooperationsvereinbarung, an der ebenfallsInfrastruktureinrichtungen beteiligt sind, diemit der nachhaltigen Sicherung der Primär-bzw. Sekundärdaten betraut sind. Auf dieseArt und Weise werden Empfehlungen infolgenden Bereichen formuliert (wobei mehrere
261

Digital Humanities im deutschsprachigen Raum 2017
Formulierungen pro Bereich zur Verfügungstehen sowie jeweils ein freies Textfeld):
Zugang zu Metadaten, Texten, Bildern(beispielsweise im Fall einer zu edierendenHandschrift: Archivmetadaten, Transkriptionund Annotation, Scan, die dann auch explizitmiteinander verlinkt werden)
• Lizenzierung der Inhalte (mit Verweisauf weiterführende, informierendeDokumentation)
• Formate und Standards (ebenso)• Anreicherungen; Verknüpfung der
wissenschaftlichen Anreicherungen derKulturerbedaten mit den Metadaten
• Streuung sowohl der Kulturerbedaten alsauch der Anreicherungen
• Qualitätssicherung bei allen beteiligtenAkteuren
Darüber hinaus nennt jede Einrichtung den/die einschlägige(n) Ansprechspartner/in, damiteine Kommunikation erleichtert wird.
Neben den technischen Aspekten, bei denenmit Sicherheit Aufklärungsbedarf besteht, gehtes auch, wenn nicht vorrangig, darum, einedigitale Kooperationsethik zu fördern, die wie imCERN Code of Conduct auf dem Respekt vor demWerk anderer, der guten Zusammenarbeit, derFörderung von Kooperation und der Offenheitgegenüber der Öffentlichkeit beruht.
Umsetzung
Die Charter wird die Form einesWebinterfaces annehmen, auf dem sich dieAkteure in ihrer jeweiligen Funktion (Forscher/in, Kulturerbeinstitution, Datenzentrum,Equipment, Forschungseinrichtung) registrierenlassen können und von dort ausgehend unterden ihnen zur Verfügung stehenden Optionendiejenigen aussuchen können, zu denen siesich bekennen möchten. Im Vortrag wird nacheiner Einführung zum Grundgedanken derCharter spezieller auf den Teil des Interfaceseingegangen, das dem Forscher/der Forscheringewidmet ist.
Als registrierter Forscher/registrierteForscherin soll man sich in drei Bereichenpositionieren, die jeweils entweder imöffentlichen Profil oder im privatenBereich (nur für die eigens ausgewähltenKooperationspartner - Kulturerbeinstitution,Datenzentrum, Equipment - zugänglich)erscheinen.
Der erste Bereich betrifft den Zugang zu denDaten. Dort verpflichtet sich der Forscher dazu,den Anforderungen der Kulturerbeinstitutionenzu folgen, was die Verwendung (insbes.Zitierweise) der digitalen Kulturerbedatenangeht. Hier kann der Forscher ebenfalls dieBestände anklicken, für die er sich interessiertund diese Information auch publik machen odernur den betroffenen Institutionen zugänglichmachen.
Der zweite Bereich betrifft die Streuungder vom Forscher auf der Grundlage derKultuererbedaten produzierten Sekundärdatenoder angereicherten Metadaten. An dieser Stellekann der Forscher die Lizenzen nennen, dieer bevorzugt (weiterführende Dokumentationzu diesem Thema wird anklickbar gemacht).Eine Identifikation mittels einer ORCID-Nummer , die Referenzierung einer Id-HAL oderVergleichbares können ebenfalls an dieser Stelleangegeben werden.
Im dritten Bereich geht es um den Umgangmit den anderen Charter-Partnern: Best-Practices wie die systematische Nennung derKooperationspartner oder die explizite Nennungder Art und Weise, wie man selbst zitiert werdenmöchte, werden dort deklariert.
Diese drei Bereiche, die die Nutzung vonPrimärdaten, die Produktion- und Streuungvon Sekundärdaten und die allgemeineKooperationsethik bedingen und definieren,machen die Grundlage des Forscherprofilsaus. Von dort ausgehend kann er dann dieEinrichtungen, Bestände und Dienstleistungenrecherchieren, mit denen er zusammenarbeitenmöchte.
Die Charter hat somit eine doppelteDimension: die einer Information- undSelbstpositionierungsplattform und die einessozialen Netzwerkes, wobei auf die Balancezwischen Transparenz und Respekt derPrivatsphäre stets geachtet wird ;
Perspektiven
Die DARIAH Data Re-Use Charter wirdzwischen Herbst 2016 und Frühjahr 2017soweit entwickelt sein, dass ein Soft Launchim Frühjahr 2017 stattfinden kann. DasKernteam arbeitet sowohl an der Entwicklungder Webseite als auch an der Einholungvon Feedback interessierter Akteure, umdieses in der Entwicklung des Interfaces imAllgemeinen und der relevanten Bausteineim Besonderen zu integrieren. Sie wurdebereits in ihren Ansätzen auf Konferenzendargestellt und wird im Herbst in ähnlichen
262

Digital Humanities im deutschsprachigen Raum 2017
Kontexten vorgestellt, damit weiteres Feedbackeingeholt werden kann. Darüber hinaus findetim November 2016 in Berlin eine dedizierteArbeitssitzung statt sowie eine Woche spätereine entsprechende in Paris und im Januareine in Rom - womöglich können über denWinter ebenfalls in anderen EU-Ländernentsprechende Sitzungen stattfinden. Bis zurDHd wird das Interface als das Ergebnis dieserbreitgefächerten Konsultation demonstrierbarsein und kurz vor dem Launch stehen. Dasbereits signalisierte Interesse zahlreicherEinrichtungen und Forscher/innen lässtvermuten, dass die Vernetzungsfunktion derPlattform rasch Konturen gewinnen wird.
Ausgerechnet dieser Aspekt gilt es mitBlick auf Nachhaltigkeit zu unterstreichen:Wenn Equipments systematischer zitiertwerden, wenn Datenzentren expliziter an derSchnittstelle zwischen Kulturerbeinstitutionenund Forschung arbeiten können, wenn Forscher/innen ohne akademische Anbindung - und esgibt immer mehr prekäre Wissenschaftler/innen, die nichtsdestotrotz forschend tätig sind- einen Kooperationsraum finden können, dannist für das gesamte Forschungsökosystem vielgewonnen und ein entscheidender Beitragzur Nachhaltigkeit von digitalen Primär- undSekundärkulturerbedaten geleistet.
Nachhaltigkeitperspektivenvon Graphdaten
Kuczera, [email protected] Imperii, Universität Gießen, Akademieder Wissenschaften Mainz, Deutschland
Beispiele GraphbasierterErschließung der DatenbankNomen et Gens
Die Datenbank Nomen et Gens ist aus einemDFG-Projekt hervorgegangen und verzeichnetQuellen und die in Ihnen belegten Personenfür die vier Jahrhunderte vor der Zeit Karlsdes Großen. Das Abfragefrontend der Mysql-Datenbank ist im Internet unter www.nomen-et-gens.de zu erreichen.
Ein Teil der Datenbank wurde im Vorfeldeines DFG-Antrages in eine Graphdatenbank
konvertiert um neue Auswertungsmöglichkeitenzu testen, die im Rahmen dieses Postersdargestellt werden sollen.
Frage an die Datenbank:Zeige mir die Quelle „Annales Petaviani“
und alle Personen, die in dieser Quelle belegtsind und alle Quellen, in denen diese Personenwiederum gemeinsam belegt sind.
Abbildung 1: Visualisierung derGraphdatenbankabfrage.
Bewertung des Abfrageergebnisses:
Der interessanteste Information derVisualisierung ist die traversale Abfragezu Personen in einer Quelle, die wiederumin einer Quelle gemeinsam vorkommen.Die Abfrage „Zeige mir alle Personen ineiner Quelle" funktioniert ja auch mit einerrelationalen Datenbank. Aber es gibt keineMöglichkeit, auf die Weise auch noch gleichzu sehen, in welcher Quelle eine Personaußerdem noch steht. Insofern fügt dieGraphdatenbank hier eine "Dimension"hinzu.
Verwandtschaftliche Beziehungen zwischenPersonen stehen beim jeweiligenPersoneneintrag und sind damit immer nurbis zum nächsten Glied zu sehen.
Für Frühmittelalterhistoriker besondersinteressant sind gemeinsam urkundlichbelegte Personen. Eine solche Abfrage istüber die relationale Datenbank nur schwerumfassend durchzuführen.
Die Visualisierung aus der Graphdatenbankveranschaulicht die Überlieferungssituationvon einzelnen Personen. Der umkringelteRadbod ist, anders als z.B. Bonifatius zu
263

Digital Humanities im deutschsprachigen Raum 2017
dem es sehr viele Belege gibt, nur schwerhistorisch fassbar.
Bibliographie
Kuczera, Andreas (2016c): „Digital Editionsbeyond XML – Graph-based Digital Editions“,in: Proceedings of the 3rd HistoInformaticsWorkshop on Computational History(HistoInformatics 2016) 37–46 http://ceur-ws.org/Vol-1632/paper_5.pdf .
Kuczera, Andreas (2016b):„Graphbasierte digitale Editionen“, in:Mittelalter: Interdisziplinäre Forschungund Rezeptionsgeschichte 19. April 2016mittelalter.hypotheses.org/7994
Kuczera, Andreas (2016a): „Endcodingand Presenting Historical BiographicalData with Graph Data Bases“, in: CO:OP. TheCreative Archives' and Users' Network https://coop.hypotheses.org/297 .
Kuczera, Andreas (2015):„Graphdatenbanken für Historiker. Netzwerkein den Registern der Regesten KaiserFriedrichs III. mit neo4j und Gephi“, in:Mittelalter: Interdisziplinäre Forschungund Rezeptionsgeschichte 5. Mai 2015mittelalter.hypotheses.org/5995
Kuczera, Andreas (2014b): „Big DataHistory“, in: Mittelalter: InterdisziplinäreForschung und Rezeptionsgeschichte 10. Oktober2014 mittelalter.hypotheses.org/3962
Kuczera, Andreas (2014a):„Digitale Perspektiven mediävistischerQuellenrecherche“, in: Mittelalter:Interdisziplinäre Forschung undRezeptionsgeschichte 18. April 2014mittelalter.hypotheses.org/3492
PaLaFra –Entwicklung einerAnnotationsumgebungfür ein diachronesKorpus spätlateinischerund altfranzösischerTexte
Döhling, [email protected]ät Regensburg, Deutschland
Burghardt, [email protected]ät Regensburg, Deutschland
Wolff, [email protected]ät Regensburg, Deutschland
Ziel von PaLaFra 1 („Le passage du latin aufrançais“) ist der Aufbau eines digitalen Korpusspätlateinischer und altfranzösischer Texte, dasdurch die Kombination von Lemmatisierung,syntaktischer und morphologischerAnnotation sowie diskurspragmatischen undtexttypologischen Deskriptoren komplexeAbfragestrategien ermöglicht und so einequalitativ neuartige Nutzung der Texte bei derRekonstruktion des lateinisch-romanischenSprachwandels erreichen soll. Daran arbeitetein deutsch-französisches Team der UniversitätRegensburg, der Universität Tübingen, derÉcole Normale Supérieure in Lyon und derUniversität Lille, das seit Sommer 2015 vonder Deutschen Forschungsgemeinschaft(DFG) und der Agence Nationale de Recherche(ANR) gefördert wird. Das Projektteam istinterdisziplinär ausgerichtet und bestehtaus romanischen Sprachwissenschaftlern,Computerlinguisten und Medieninformatikern.Während für den Bereich des Altfranzösischenauf das bestehende Base de Francais M edi eval-Korpus 2 zurückgegriffen werden kann, soist die Erstellung eines — was die Annotationangeht — kompatiblen Korpus spätlateinischerTexte ein wichtiges Teilziel des PaLaFra-Projekts.
264

Digital Humanities im deutschsprachigen Raum 2017
In diesem Posterbeitrag berichten wir überHerausforderungen und Lösungsansätze beider Erstellung einer Annotationsumgebung undeines diachronen Tagsets, das gleichermaßenin der Lage ist, die Idiosynkrasien der beidenSprachstufen adäquat abzubilden, aber auchdie diachronen Elemente im Sprachwandeleinheitlich zu markieren.
Bereits für das spätlateinische Teilkorpuszeigt sich, dass es an einem standardisiertenTagset fehlt. Mindestens drei Varianten wurdenin der Vergangenheit für die Annotation(spät-)lateinischer Texte entwickelt: CoLaMer(Selig et al. 2015), CompHistSem (Eger etal. 2015) und LASLA (Denooz 1978). Dieseunterscheiden sich sowohl in den zugrundeliegenden linguistischen Konzepten als auch inihrer Granularität. Demzufolge existiert auchkein einfaches Mapping zwischen ihnen. Fürdie Entwicklung eines sprachübergreifendenTagsets in PaLaFra kommt erschwerend hinzu,dass die beiden Zielsprachen — Spätlatein undAltfranzösisch — trotz ihrer Verwandtschaftklare strukturellen Unterschiede aufweisen.
Zumindest für die Ebene der Wortarten(PoS, Part-of-Speech) liefert beispielsweisedas Projekt Universal Dependencies 3 wichtigeAnhaltspunkte für ein sprachübergreifendesTagset. Dieses Projekt hat sich die Entwicklungsprachübergreifend-kompatibler Baumbankenals Ziel gesetzt hat, die auf universellenWortartkategorien basieren. Trotzdem bedingtdie Entwicklung eines übergreifenden Tagsetsoft den manuellen Vergleich von Annotationen,z.B. durch visuelle Gegenüberstellungannotierter Parallelkorpora. Unsere Rechercheergab, dass es an einem adäquaten Werkzeugfür diese Aufgabe mangelt. Einerseits gibt esunzählige Annotationswerkzeuge, welcheauf die Darstellung nur eines Textes samtAnnotationen fokussieren (Burghardt 2014,Neves and Leser 2014). Auf der anderen Seitegibt es Alignierwerkzeuge, die auf die paralleleDarstellung von Texten spezialisiert sind, aberdabei Annotation meist ignorieren, z.B. LFAligner 4 , Moses 5 oder ParaVoz 6 . Um dieseLücke zu schließen, haben wir auf der Basisvon InterText 7 — einem im Webbrowser zubedienenden Alignierwerkzeug (Vondricka2014) — ein Vergleichswerkzeug für annotierteParallelkorpora entwickelt. Unsere Erweiterungunterstützt sowohl die Hervorhebungzueinander kompatibler (PoS-)Tags als auch dieflexible Darstellung von Lemmata und morpho-syntaktischen Annotationen ( Abbildung 1).Die dafür nötigen Informationen werden beim
Import aus den TEI-XML-Daten extrahiert undmit Hilfe von JavaScript dynamisch visualisiert.
Abbildung : Das Bildschirmfoto zeigt diemodifizierte InterText-Ansicht, erkennbaroben an der zusätzlichen Schalterleiste. Linksist die lateinische „Vita Benedicti“ (Vogüeund Antin 1979) zu sehen, annotiert mitdem LASLA Tagset (Denooz 1978), rechtsdas französische Gegenstück „Vie de saintBenoit“ (Foerster 1876), annotiert mit demCattex Tagset (Guillot et al. 2010). Aktuell istsowohl die Hervorhebung kompatibler PoS-Tags („Toogle color“) als auch die Anzeige dervollständigen PoS-Annotation („Toogle POS(full)“) aktiviert.
Neben der eigentlichen Datenaufbereitung istauch die Optimierung des Annotationsworkflowsmit geeigneten Werkzeugen im Sinneverbesserter User Experience ein wesentlichesProjektziel ( tool science, Wolff 2015).
Die Entwicklung des spätlateinisch-altfranzösischen Tagsets wird im Projekt — auchmit Hilfe unseres modifizierten InterText-Tools— vorangetrieben. In unserem Posterbeitragerläutern wir das Vorgehen und präsentierenerste Ergebnisse.
Fußnoten
1. http://www.palafra.org/2. http://bfm.ens-lyon.fr/3. http://universaldependencies.org/4. http://sourceforge.net/projects/aligner/5. http://www.statmt.org/moses/6. https://bitbucket.org/rvwfels/paravoz27. http://wanthalf.saga.cz/intertext
Bibliographie
Burghardt, Manuel (2014): „Engineeringannotation usability - Toward usabilitypatterns for linguistic annotation tools“. Diss.Phil., Universität Regensburg, Institut fürInformation und Medien, Sprache und Kultur,urn:nbn:de:bvb:355-epub-307682.
Denooz, Joseph (1978): „L’ordinateur etle latin, techniques et methods“, in: Revue de
265

Digital Humanities im deutschsprachigen Raum 2017
l’Organisation Internationale pour l’Etude desLangues Anciennes par Ordinateur 4.
Eger, Steffen / vor der Brück, Tim / Mehler,Alexander (2015): „Lexicon-assisted taggingand lemmatization in latin: A comparison of sixtaggers and two lemmatization methods“, in:LaTeCH 2015 105.
Guillot, Céline / Prévost, Sophie /Lavrentiev, Alexei (2010): Manuel de référencedu jeu cattex09. technical manual, UMR ICAR,CNRS/ENS-LSH. http://bfm.ens-lyon.fr/IMG/pdf/Cattex2009_manuel_2.0.pdf
Neves, Mariana / Leser, Ulf (2014): „Asurvey on annotation tools for the biomedicalliterature“, in: Briefings in bioinformatics 15 (2):327–340.
Selig, Maria / Eufe, Rembert / Linzmeier,Laura (2015): CoLaMer (corpus du latinmérovingien). (im Erscheinen).
Vondricka, Pavel (2014): „Aligning paralleltexts with intertext“, in: Proceedings of LREC2014.
Vogüé, Adalbert de / Antin, Paul (1979):GREGOIRE LE GRAND, Dialogues II. CambridgeUniversity Press.
Von Foerster, Wendelin (1876): Li DialogeGregoire lo Pape. Altfranzösische Uebersetzungdes XII. Jahrhunderts der Dialogen des PapstesGregor, mit dem lateinischen Original, einemAnhang: Sermo de Sapientia und Moralium inIob Fragmenta, einer grammatischen Einleitung,erklärenden Anmerkungen und einem Glossar,première partie: Textes. Paris: Champion.
Wolff, Christian (2015): „The case forteaching ‚tool science‘. Taking softwareengineering and software engineering educationbeyond the confinements of traditional softwaredevelopment contexts“, in: Global EngineeringEducation Conference (EDUCON), 2015 IEEE 932–938 10.1109/EDUCON.2015.7096085
Paraphrasenerkennungim Projekt Digital Plato
Kath, [email protected]ät Leipzig
Keilholz, [email protected] Universität Dresden
Klinker, [email protected] Universität Dresden
Pöckelmann, Marcusmarcus.poeckelmann@informatik.uni-halle.deMartin-Luther-Universität Halle-Wittenberg
Rücker, [email protected]ät Leipzig
Švitek, [email protected] Universität Dresden
Wöckener-Gade, [email protected]ät Leipzig
Yu, [email protected] Universität Dresden
Einleitung
Platons Werke wurden seit ihrer Entstehungbis in die heutige Zeit vielfach rezipiert unddirekt zitiert, seine enorme Wirkungsmacht istkaum zu unterschätzen, wie A.N. Whiteheads(1929, 63) berühmter Ausspruch verdeutlicht:“ The safest general characterization of theEuropean philosophical tradition is that itconsists of a series of footnotes to Plato “. Mitdem von der VolkswagenStiftung gefördertenProjekt Digital Plato: Tradition and Receptionunter Leitung von Prof. Dr. Paul Molitor, Dr.Jörg Ritter, Prof. Dr. Joachim Scharloth, Prof.Dr. Charlotte Schubert und Prof. Dr. Kurt Sierwird seit April 2016 das Vorhaben verfolgt,diese Rezeption und Nachwirkung Platons beiden griechischen Autoren bis zur Spätantikesystematisch zu untersuchen und zwar überdas möglichst umfassende Auffinden vonParaphrasen. Der vorliegende Beitrag beschreibtdie damit einhergehende grundlegendeProblematik am Beispiel und skizziert einenderzeit in Entwicklung befindlichen Ansatz zuderen Lösung.
266

Digital Humanities im deutschsprachigen Raum 2017
Die Textgrundlage
Die Werke Platons haben die Zeitweitestgehend überdauert und sind frei digitalverfügbar 1 . In den Handschriften sind 43Werke überliefert, mit Ausnahme der Apologieund der 13 Briefe alle in Dialogform verfasst.Heute werden die Dialoge in neun Gruppenzu je vier Schriften gruppiert (sogenannteTetralogienordnung). Damit sind wir in derexzeptionellen Lage, alle Werke Platonsuntersuchen zu können, die in der Antikebekannt waren, auch wenn einige davon ihmfälschlicherweise zugeschrieben wurden oderdie Autorenfrage umstritten ist. Diejenigensieben Werke, die die sogenannte AppendixPlatonica formen und schon in der Antike fürnicht platonisch gehalten wurden, liegen vorerstnicht im Projektfokus (Erler 2006, 27-36).
Die Tetralogien haben einen Umfang vonknapp 75.000 Zeilen. Dem gegenüber stehtdas wesentlich umfangreiche Gesamtwerkder antiken griechischen Autoren, das mitdem Thesaurus Linguae Graecae (TLG) indigitaler Form vorliegt und über neun MillionenTextzeilen umfasst.
ProblemaufrissParaphrasenerkennung
Um die Rezeption und Nachwirkung vonPlatons Werk in der antiken griechischenLiteratur untersuchen zu können, sollenÜbereinstimmungen zwischen seinen Textenund denen späterer Autoren im TLG gefundenwerden. Dies geht bei weitem über dasIdentifizieren wörtlicher Zitate hinaus, da es dasmöglichst zuverlässige Auffinden paraphrasiertwiedergegebener Textstellen umfasst. DerParaphrasenbegriff selbst wird im Rahmendes Projekts derzeit mit dem Arbeitskonzeptder ‚Relation’ bestimmt: Wie solche Relationenzwischen dem platonischen Werkkorpusund der übrigen griechischen Literatur derAntike aussehen und welche Aspekte damiterfasst werden können, soll folgendes Beispielveranschaulichen:
Pl. symp. 206 d 1-2ἀνάρμοστον δ᾽ ἐστὶ τὸ αἰσχρὸν παντὶ τῷ θείῳ,
τὸ δὲ καλὸν ἁρμόττον.Unvereinbar aber ist das Hässliche mit allem
Göttlichen, aber das Schöne ist vereinbar.Plot. enn. III 5, 1, 19-20τὸ μὲν γὰρ αἰσχρὸν ἐναντίον καὶ τῇ φύσει καὶ
τῷ θεῷ.
Denn das Hässliche ist sowohl der Natur alsauch dem Gott entgegengesetzt.
Beim Paraphrasieren einer Textstelle kannes zu verschiedenen Phänomenen kommen.Neben fast wortwörtlicher Übernahme einerTextstelle (ggf. mit Auslassungen) können in denTextfluss eingewobene Zitate mit umgestelltemSatzbau auftreten. Das Beispiel geht darüberhinaus: Die wörtliche Übereinstimmungbeschränkt sich auf einen geläufigen Ausdruck(„das Hässliche“). Zudem wird der Inhalteinerseits nur teilweise wiedergegeben (dieVereinbarkeit vom „Schönen“ und „Göttlichen“fehlt), andererseits um Neues erweitert(das „Hässliche“ ist nun auch der „Natur“entgegengesetzt). Mit dem Synonym „istentgegengesetzt“ statt „ist unvereinbar“ tritteine lexikalische Varianz in Erscheinung.Zudem wurde das substantivierte Adjektiv „demGöttlichen“ samt seines attributiven Zusatzes„allem“ durch das Nomen „dem Gott“ ersetzt.
Ferner sind bspw. die Verwendung vonAntonymen oder Metaphern denkbar, diedie Erkennung einer Rezeption zusätzlicherschweren.
Vorarbeiten
Da sich die aufzufindenden paraphrasiertenTextstellen nicht auf einen beliebigen Autor,sondern auf Platon beziehen, ergeben sicheinige Vorteile für die Suche. Der überschaubareUmfang der Texte ermöglicht die manuelle bzw.teil-automatisierte Extraktion von Informationenaus den Werken Platons. Dazu gehören Listenmit den vorkommenden Substantiven, Verben,Eigennamen oder Stoppwörtern. Aber auchdie Auflistung der zentralen Konzepte derplatonischen Philosophie 2 ist für die spätereParaphrasenerkennung hilfreich. Zudem liegenverschiedene Übersetzungen in elektronischerForm vor, die in das Projekt einfließen 3 .
Einen großen Gewinn stellt auch dieVorarbeit des an der Universität Leipzigdurchgeführten Projektes eAQUA 4 dar, welchesein Werkzeug zur Zitationsanalyse entwickelthat und damit die vorkommenden Zitate imKorpus bereitstellt.
Für die Bewertung und Extraktionvon Paraphrasen aus einem Textkorpusgibt es bereits verschiedene Ansätze, wieAndroutsopoulos und Malakasiotis (2010) ineinem Übersichtsartikel zusammengetragenhaben. Diese basieren häufig auf einerKontextanalyse und der Annahme, dassWorte in einem ähnlichen Kontext auch eine
267

Digital Humanities im deutschsprachigen Raum 2017
ähnliche Bedeutung haben. So können fürjedes Textsegment einer festen Länge (n-Gramme, meist mit n ≤ 5) die Kontexte allerVorkommen betrachtet und als ein Vektorrepräsentiert werden. Ähnlichkeitsmaßeauf Vektoren erlauben nun den Vergleichzweier Textsegmente. Für das Auffinden vonParaphrasen müssen auf diesem Weg alleTextsegmente miteinander verglichen werden.Allerdings sind die so extrahierten Paraphrasenbzw. -fragmente sehr kurz, im Gegensatz zuden teils umfangreichen Rezeptionen, die imRahmen des Projekts gefunden werden sollen.Zielführender sind Vorgehen, die zunächstAnker, d.h. eine Gemeinsamkeit zwischenzwei Textstellen, suchen und in einem zweitenSchritt die Fundstellen ausweiten. SolcheAnker können bspw. einzelne Wörter, die obenbeschriebenen n-Gramme sowie syntaktischeoder semantische Repräsentationen einerTextstelle sein. Naheliegend ist, die Fundstellenim zweiten Schritt auf den umliegendenSatz auszuweiten. Stattdessen kann auch dieSinneinheit über semantische Informationenrekonstruiert werden, wie ein erfolgreichauf englischsprachige Korpora angewandtesVerfahren von Regneri, Wang und Pinkal (2014)aufzeigt.
Viele der bestehenden Verfahren zumExtrahieren von Paraphrasen erlangen ihreEffektivität mittels umfangreicher Annotationender zu Grunde liegenden Texte, welche durchParser mit einem gewissen Wirkungsgradautomatisch bestimmt werden können. DieserWirkungsgrad ist wiederum stark von zu Grundeliegenden Trainingskorpora und damit derSprache der betrachteten Texte abhängig. Soist die Entwicklung für moderne Sprachen sehrweit vorangeschritten. Die Anwendung aufAltgriechisch ist hingegen deutlich seltenerund auf weniger umfangreiche Korporabeschränkt (Mambrini und Passarotti 2012).Einer der ersten Vertreter ist das regelbasierteAnalysewerkzeug Morpheus, das unter anderemLemmata bestimmen kann (Crane 1991). In eineraktuellen Studie von Celano, Crane und Majidi(2016) wurden fünf aktuelle POS-Tagger mitHilfe der Ancient Greek Dependency Treebank(Bamman und Crane 2011) trainiert und aufihre Wirksamkeit getestet, wobei der Mate-Tagger 5 mit einer Genauigkeit von 88% ambesten abschnitt. Das entsprechende Modellwurde dem Projekt zur Verfügung gestellt. Auchwenn die Parser sich stets weiterentwickeln,bleiben insbesondere die lange Zeitspanneund die vielfältigen Genres in dem von unsbetrachteten Korpus problematisch, sodass die
Parser und damit auch die darauf aufbauendenVerfahren zur Paraphrasenerkennung qualitativschlechtere Ergebnisse produzieren als fürmoderne Sprachen (Dik und Whaling 2008).
Umsetzung im Projekt
Das verbreitete Vorgehen zur Extraktionvon Paraphrasen über die Suche von Ankernwird für dieses Projekt durch die in Abschnitt 4beschriebenen Vorarbeiten und die Entwicklungeiner interaktiven Arbeitsumgebung für Sucheund Auswertung von Paraphrasen praktikabel.Zwei Anwendungsszenarien sind dabei zuunterscheiden: die Suche ausgehend von einemTextstück und das Auffinden möglichst allerRezeptionen Platons im Korpus. Der Fokus deraktuellen Arbeiten liegt zunächst in der erstenAufgabe, ist ihre Bewältigung doch Grundlagefür die zweite. Im Folgenden wird ein ersterAnsatz beschrieben, der derzeit umgesetzt wird.
Ausgehend von einem Textstück, wieeinem Satz von Platon, werden geeigneteAnker für die Suche gewählt. Statt dabeialle Wörter zu berücksichtigen, kann dieAuswahl auf Basis der angefertigten Listen aufbestimmte Wortarten oder auf die Begriffe derplatonischen Philosophie beschränkt werden.Diese erste Vorfilterung reduziert die Anzahlder Suchwörter auf möglichst aussichtsreicheKandidaten, um die anschließende Auswertunghandhabbar zu halten. Dennoch ist einegewisse Unschärfe, d.h. die Erweiterung einesSuchwortes zu einer Menge verwandter Worte,sinnvoll, um eine ganze Reihe von möglichenRezeptionen abzudecken. Das Suchwort wirddazu durch die Verknüpfung von Wortrelationenerweitert, bspw. um seine Synonyme sowieverschiedene Übersetzungen samt derenSynonyme, die wiederum ins Altgriechischezurückübersetzt werden (siehe Abbildung 1).
268

Digital Humanities im deutschsprachigen Raum 2017
Abb. 1: Durch die Verknüpfung vonLemmatisierung, Synonymen undÜbersetzungen kann das Suchwort θείῳ ('demGöttlichen') um θεῷ ('der Gott') erweitert und soein drittes Ankerpaar für das Beispiel gefundenwerden.
Diese Erweiterung von Wortrelationenwird erfolgreich für die Verschlagwortungvon Themen in Briefkorpora (Hildenbrandtet al. 2015) und in ähnlicher Form zumAufbau eines WordNet für Altgriechisch(Bizzoni et al. 2014) genutzt. Ergänzt umzusätzliche Relationen, wie bspw. Hyperonym-respektive Hyponymbeziehungen, wird dieSuche robuster gegenüber verschiedenenFormen der Paraphrasierung. Dabei gilt: Je mehrmöglichst kurze Verbindungen zwischen zweiWörtern liegen, desto größer ist die Aussagekraftdieses Paares. Wahrscheinliche Kandidaten fürRezeptionen sind dann Textstellen, in denen sehrviele aussagekräftige Anker nahe beieinanderwiedergefunden werden.
Durch die Unschärfe des Verfahrens sindauch viele Kandidaten zu erwarten, die keineParaphrasen sind und nicht als Rezeptiondes platonischen Werkes angesehen werdenkönnen. Die Ergebnisse sollen daher durcheine Arbeitsumgebung zunächst automatischbewertet und sortiert werden. Ausgehend voneinzelnen Treffern und einer transparentenVisualisierung, wie das System zur Entscheidunggelangte, soll eine interaktive Exploration derTexte die effiziente Recherche ermöglichen. Dasbeinhaltet das Wichten bzw. Entfernen einzelnerRelationen sowie das manuelle Einordnen dergefunden Textstellen. So können Fallbeispieleund Phänomene näher untersucht, aberauch neue entdeckt werden. Die qualifizierteBewertung auf der Basis der Fachexpertise vonAltertumswissenschaftlern hilft wiederum,die Sammlung bereits bekannter Rezeptionenzu erweitern und die zu Grunde liegendenAlgorithmen zu verbessern.
Die aus eAQUA bekannten Zitate sindfür den Beginn des Projekts eine wichtigeUnterstützung. Sie erlauben einen erstenEinblick in den Umfang der Rezeption Platons.Über die Verteilung lassen sich besonders häufigzitierte Passagen ermitteln, was möglicherweiseauch Rückschlüsse auf die Fundstellen vonParaphrasen zulässt. Eine naheliegende, aberzu prüfende Hypothese ist, dass häufig zitierteStellen auch anderweitig übernommen wurden.Das könnte zum zeitnahen Auffinden bisherunentdeckter Paraphrasen führen bzw. eineaufwendige Untersuchung an diesen Stellenrechtfertigen, um an besonders interessanteFallbeispiele zu gelangen.
Fußnoten
1. Siehe bspw. Perseus Digital Library http://www.perseus.tufts.edu/hopper/collection?collection=Perseus%3Acorpus%3Aperseus%2Cauthor%2CPlato2. Eine entsprechende Liste findet sich bei Gigonund Zimmermann (1974, 301ff.)3. Siehe bspw. Schleiermacher (Deutsch) oder Ü.Fowler (Englisch)4. Siehe http://www.eaqua.net/5. Siehe https://code.google.com/archive/p/mate-tools/
Bibliographie
Androutsopoulos, Ion / Malakasiotis,Prodromos (2010): „A Survey of Paraphrasingand Textual Entailment Methods“, in: Journal ofArtificial Intelligence Research 38: 135–187.
Bamman, David / Crane, Gregory (2011):„Ancient Greek and Latin dependencytreebanks“, in: Language Technology for CulturalHeritage 79–98 DOI:10.1007/978-3-642-20227-8_5.
Bizzoni, Yuri / Boschetti, Federico / Diakoff,Harry / Del Gratta, Riccardo / Monachini,Monica / Crane, Gregory (2014): „The Making ofAncient Greek WordNet“, in: Proceedings of LREC2010.
Celano, Giuseppe G. A. / Crane, Gregory /Majidi, Saeed (2016): „Part of Speech Tagging forAncient Greek“, in: Open Linguistics 2 (1), ISSN(Online) 2300–9969 10.1515/opli-2016-0020.
Crane, Gregory (1991): „Generating andParsing Classical Greek“, in: Literary andLinguistic Computing 6 (4): 243–245 10.1093/llc/6.4.243
Dik, Helma / Whaling, Richard (2008):„Bootstrapping Classical Greek Morphology“, in:DH2016: Book of Abstracts 105–106.
Erler, Michael (2006): Platon. München:C.H.Beck.
Gigon, Olof / Zimmermann, Laila (1974):Platon. Begriffslexikon. Zürich: Artemis Verlag.
Hildenbrandt, Vera / Kamzelak, Roland S. /Molitor, Paul / Ritter, Jörg (2015): „im Zentrumeines Netzes [...] geistiger Fäden - Erschließungund Erforschung thematischer Zusammenhängein heterogenen Briefkorpora“, in: Datenbank-Spektrum : Zeitschrift für Datenbanktechnologie:15 (2015, 1): 49–55.
Mambrini, Francesco / Passarotti, Marco(2012): „Will a parser overtake Achilles? Firstexperiments on parsing the Acient GreekDependency Treebank“, in: 11th International
269

Digital Humanities im deutschsprachigen Raum 2017
Workshop on Treebanks and Linguistic Theories,Lisbon, Portugal.
Regneri, Michaela / Wang, Rui / Pinkal,Manfred (2014): „Aligning predicate-argumentstructures for paraphrase fragment extraction“,in: Proceedings of the Ninth InternationalConference on Language Resources andEvaluation, Reykjavik, Iceland.
Whitehead, Alfred North (1929): Process andReality: An Essay in Cosmology. New York.
Raum und Zeit inComics: Die Wirkungvon Zwischenräumenauf Aufmerksamkeitund empfundene Zeitbeim Lesen graphischerLiteratur
Hohenstein, [email protected]ät Potsdam, Deutschland
Laubrock, [email protected]ät Potsdam, Deutschland
Aufgrund der Kombination von Text undBild stellen graphische Literatur und Comicskomplexe Medien dar. Diese Hybridität stelltan die Aufmerksamkeit beim Lesen andereAnforderungen als bei rein textbasiertenRomanen, da Informationen unterschiedlichenTyps erfasst und verarbeitet werden müssen.Wegen ihrer Konfiguration als eine Folge vonPanels werden Comics auch als sequenzielleKunst bezeichnet. Nach McCloud (1993) spieltder Raum zwischen den Panels, der als „gutter“bezeichnet wird, eine Rolle für die Verbindungder einzelnen Panels. Obwohl dieser Raumselbst leer ist, so vergeht doch nach McCloudZeit zwischen zwei Panels. Diesem Postulathinsichtlich der Empfindung, die durch den„gutter“ ausgelöst wird, haben wir uns imRahmen einer empirischen Studie gewidmet.
Die Wirkung zusätzlichen, leerenRaums zwischen Panels für die subjektiveWahrnehmung von Zeit beim Lesengraphischer Literatur haben wir mit
kognitionspychologischen Experimentenuntersucht. Dieses Vorgehen erlaubt es überdie reine Beschreibung des Materials hinausden subjektiven Eindruck der Leserin bzw.des Lesers zu erfassen. Für diese Experimentestellten wir eine Sammlung von einzelnen Panelsaus verschiedenen Comic-Reihen zusammen,beispielsweise „Astérix“ und „Donald Duck“.Die Auswahl der Panels erfolgte nach demKriterium, dass sie sich horizontal teilenlassen. Bei dieser Teilung wurde ein Panel perBildbearbeitungssoftware in mehrere kleinereUnterpanels geteilt. ZusammenhängendeTextabschnitte blieben dabei ungeteilt.
Im ersten Experiment wurde das Materialin zwei Bedingungen dargeboten. In derKontrollbedingung wurden die Panels jeweilsohne Teilung in ihrer ursprünglichen Formauf einem Bildschirm präsentiert. In derzweiten Bedingung wurden die Subpanelshintereinander auf dem Bildschirm gezeigt.Jeder Durchgang endete damit, dass dieProbanden gefragt wurde, wieviel Zeit währendder Geschichte, die in dem Panel erzählt wird,vergangen ist. Die Antworten der Probandenspiegeln somit deren subjektive Einschätzungder Dauer wider. Obwohl in beiden Bedingungenletztlich dieselben Panels gezeigt wurden, gabes bedeutsame Unterschiede in den Antworten.Die Teilung der Panels führte zu längerensubjektiven Dauern als die Kontrollbedingung.Dieses Ergebnis verdeutlicht den Einfluss derKonfiguration visueller Information auf dieWahrnehmung der Leserin bzw. des Lesers.
Um eine detailliertere Analyse derAufmerksamkeit der Probanden vornehmenzu können, haben wir im zweiten Experimentzusätzlich Blickbewegungen erhoben. Für dieKontrolle der Auswirkungen der Panel-Teilungauf die wahrgenommene Dauer haben wirzudem das Material in einer Weise präsentiert,die ähnlicher zu tatsächlichen Comics ist.Die Subpanels wurden nebeneinander mitzusätzlichem, leerem Zwischenraum angeordnet,so dass das Aussehen einer kurzen Comic-Geschichte mit mehreren Panels gleicht. In derKontrollbedingung wurden die Panels erneutungeteilt dargeboten. Erneut wurden die Dauernlänger eingeschätzt, wenn die Panels geteilt aufdem Bildschirm erschienen.
Die Auswertung der Blickbewegungenergab ein differenziertes Bild derAufmerksamkeitsverteilung beim Betrachtender Panels. Die Blickbewegungsmusterunterschieden sich in Hinblick auf dieexperimentelle Bedingung. Waren die Panelsgeteilt, so machten die Versuchspersonen mehrFixationen. Die höhere Anzahl an Fixationen ist
270

Digital Humanities im deutschsprachigen Raum 2017
somit eine mögliche Ursache für die subjektivlängere verstrichene Zeit. Außerdem zeigtesich eine leichte relative Tendenz zur Fixationnahe dem Zentrum eines jeden Subpanels, diebei geteilten Panels stärker ausgeprägt war.Diese und andere Befunde sprechen dafür, dassdie Teilung von Panels die Aufmerksamkeitbeim Lesen und Betrachten sowie die Wirkunggraphischer Literatur beeinflussen kann.
Bibliographie
McCloud, Scott (1993): Understanding comics:the invisible art. Northampton, MA: Tundra.
relNet – Modellierungvon Themen undStrukturen religiöserOnline-Kommunikation
Elwert, [email protected] Bochum, Deutschland
Tabti, [email protected] Bochum, Deutschland
Krech, [email protected] Bochum, Deutschland
Morik, [email protected] Universität Dortmund
Pfahler, [email protected] Universität Dortmund
Von der Weiterentwicklung quantitativerTextanalysemethoden in der Informatikprofitieren nicht nur die Geisteswissenschaften,auch für die qualitative Sozialforschungergeben sich neue Impulse. Die Verwandtschaftqualitativer Forschungsmethoden in denSozialwissenschaften und hermeneutischerAnalyseansätze in den Geisteswissenschaftenermöglicht hier einen engen Austausch.
Gleichzeitig stellt die Anwendung quantitativerTextanalysen zunehmend die ehemalsstrikte Trennung zwischen qualitativenund quantitativen Ansätzen in derSozialforschung in Frage. Mit dem Aufkommenwebbasierter Kommunikationsmedienkönnen Sozialwissenschaftler_innen undInformatiker_innen zudem auf einenstetig wachsenden Datenbestand sozialerInteraktionen zugreifen, was zur Entstehungder computational social sciences als eigenemForschungsfeld geführt hat (Lazer et al.2009:721–23). Die Netzwerkanalyse hat sichhier zu einem der zentralen Methodenansätzeentwickelt.
Die Religionswissenschaft ist ein dankbaresExperimentierfeld für diese Art der disziplinen-und schulenübergreifenden Forschungsansätze.Sie vereint in sich sowohl geistes- als auchsozialwissenschaftliche Traditionen und istin besonderer Weise am Zusammenspiel vonGeistesgeschichte und sozialen Struktureninteressiert, wie dies bereits Max Weber mitseiner Unterscheidung von Ideen und Interessen(Weber 1989 [1920]: 101) herausgearbeitet hat.Daraus ergeben sich nach wie vor relevanteFragen: Wie prägen religiöse Vorstellungen dassoziale Zusammenleben? Wie wirken sich aberauch soziale und politische Strukturen auf dieEntwicklung und Weitergabe religiöser Ideenaus?
Das Projekt „relNet – Modellierungvon Themen und Strukturen religiöserOnline-Kommunikation“ nimmt vordiesem Hintergrund ein spezielles Segmentgegenwärtiger Religiosität in den Blick: Neo-konservative christliche und islamischeBewegungen (etwa Evangelikale oderAnhänger der Salafiyya) haben in denletzten Jahren mit eigenen Online-ForenKommunikationsplattformen geschaffen,in denen sie jeweils eigene Auslegungen inTheologie und Fragen der Lebensführungdiskutieren (Becker 2009: 84; Neumaier 2016).
Bei allen Unterschieden zeichnen sich dieseBewegungen durch zwei Merkmale aus: a) eineUniversalisierung von Religion im Sinne einerAblösung „reiner“ Religion von Kultur undPolitik, und b) eine religiöse Durchdringungaller Lebensbereiche, die sich insbesonderedurch eine umfassende Regulierung derLebensführung ausdrückt (O. Roy 2010: 25). DieAnalyse dieser Online-Communities erlaubtes, Rückschlüsse über die Entwicklung undVerbreitung bestimmter Vorstellungen, aberauch über die Genese sozialer Strukturen undneuer Autoritäten zu ziehen.
271

Digital Humanities im deutschsprachigen Raum 2017
Das Projekt ist eine Kooperation zwischenReligionswissenschaftler_innen der Ruhr-Universität Bochum und Informatiker_innender TU Dortmund. Die interdisziplinäreZusammenarbeit erlaubt es dabei insbesondere,Methoden in enger Passung auf das spezifischeMaterial und die Fragestellungen zu adaptierenund zu entwickeln. In methodischer Hinsichtist dabei die Unterscheidung von Strukturenund Inhalten leitend. Die Anwendung bereitsetablierter Verfahren ermöglicht eine Analysevon Themen und ihrer zeitlichen Entwicklungeinerseits (etwa über topic models wie LDA(Blei, Ng, and Jordan 2003)) sowie der sozialenKommunikationsstrukturen in den Forenandererseits (etwa über social network analysis).Darüber hinaus werden im Rahmen des Projektsaber besonders solche Ansätze weiter erforscht,die beide Dimensionen in einem gemeinsamenModell abbilden können. Dies bietet etwadie Möglichkeit, Gruppen in Netzwerken zuidentifizieren, die sich nicht nur aufgrundihrer Interaktionsstruktur, sondern auch durchgemeinsame Themen auszeichnen (Natarajan,N., Sen, P., & Chaoji, V. 2013: 2174–2177).
Das Besondere dieses Ansatzesbesteht darin, dass die vergleichsweiseumfangreichen Datenbestände zureligiöser Onlinekommunikation nicht nurstichprobenartig, sondern in ihrer Gänze derAnalyse zugänglich gemacht werden können
Die zeitliche Tiefendimension der Datenerlaubt zudem Analysen, welche die Themennicht nur isoliert betrachten, sondern auchDiskursstränge in ihrer zeitlichen Abfolge undVerschränkung zu analysieren (Shahaf, Guestrin,and Horvitz 2012:1122–30).
Im Rahmen des Projekts werden dafürausgewählte Online-Foren gecrawlt und inein einheitliches Datenformat überführt. Fürdie eigentliche Analyse werden sie dann indie Software RapidMiner importiert, in derdann Verarbeitungs- und Analyseprozessemodelliert werden können. Neu entwickelteMethoden werden als Module für RapidMinerzur Verfügung gestellt. Dadurch lassensich die Verarbeitungsschritte transparentdokumentieren und reproduzieren.
Das Poster stellt das Projekt sowie ersteZwischenergebnisse vor. Das Projekt wird vomMercator Research Center Ruhr gefördert.
Bibliographie
Becker, Carmen (2009): „Gaining Knowledge:Salafi Activism in German and Dutch OnlineForums“, in: Masaryk University Journal
of Law and Technology 3 (1): 79–98 https://journals.muni.cz/mujlt/article/view/2526 [letzterZugriff 15. November 2016].
Blei, David M. / Ng, Andrew Y. / Jordan,Michael I. (2003): „Latent Dirichlet Allocation“,in: Journal of Machine Learning Research3: 993–1022 http://dl.acm.org/citation.cfm?id=944919.944937 [letzter Zugriff 15. November2016].
Lazer, David / Pentland, Alex / Adamic,Lada / Aral, Sinan / Barabási, Albert-László /Brewer, Devon / Christakis, Nicholas etal. (2009): „Computational Social Science“,in: Science 323 (5915): 721–23 10.1126/science.1167742 .
Natarajan, Nagarajan / Sen, Prithviraj /Chaoji, Vineet (2013): „Community Detectionin Content-Sharing Social Networks“, in: InProceedings of the 2013 IEEE/ACM InternationalConference on Advances in Social NetworksAnalysis and Mining 496–500: 2174–2177.
Neumaier, Anna (2016): Religion@home?Religionsbezogene Online-Plattformen Und IhreNutzung: Eine Untersuchung Zu Neuen FormenGegenwärtiger Religiosität. Religion in DerGesellschaft 39. Ergon Verlag.
Roy, Olivier (2010): Heilige Einfalt: Über DiePolitischen Gefahren Entwurzelter Religionen.München: Siedler.
Shahaf, Dafna, Carlos Guestrin, andEric Horvitz (2012): „Metro Maps of Science“,in: Proceedings of the 18th ACM SIGKDDInternational Conference on Knowledge Discoveryand Data Mining. KDD ’12. New York, NY, USA:ACM 1122–1130 10.1145/2339530.2339706 .
Weber, Max (1989 [1920]): „DieWirtschaftsethik Der Weltreligionen:Vergleichende Religionssoziologische Versuche:Einleitung“, in: Max Weber Gesamtausgabe 19.Tübingen: Mohr Siebeck 83–127.
„SozialeDatenkuratierung“:Nachhaltigkeit imProjekt IlluminierteUrkunden alsGesamtkunstwerk
Bürgermeister, [email protected], Universität Graz, Österreich
272

Digital Humanities im deutschsprachigen Raum 2017
Vogeler, [email protected], Universität Graz, Österreich
Das vom österreichischen WissenschaftsfondsFWF geförderte Projekt hat sich zum Zielgesetzt, die illuminierten Urkunden desMittelalters zu sammeln, auf der Plattformmonasterium.net zur Verfügung zu stellen undumfassend zu untersuchen. Die ExpertInnenaus den Bereichen der Diplomatik (ZajicAndreas, Gneiß Markus), der Kunstgeschichte(Roland Martin, Bartz Gabriele) und denDigitalen Geisteswissenschaften (Vogeler Georg,Bürgermeister Martina) arbeiten bewusstinterdisziplinär zusammen und achten dabei vorallem auch auf Nachhaltigkeit. Das Poster wirdzeigen, wie bei Materialerfassung, Erschließungund wissenschaftlicher Auswertung zukünftigeNutzerszenarien bedacht werden – alsodie soziale Dimension von Nachhaltigkeitkonsequent berücksichtigt wird. Es reichtnicht, die Daten von Festplatte zu Festplattezu kopieren (Langzeitarchivierung), sondernsie müssen auch nutzbar bleiben. Die imProjekt eingesetzten Mittel dafür sind 1.Datenkuratierung über eine etablierteOnline-Plattform mit projektübergreifendeminstitutionellem Interesse, 2. Datenmanagementdurch die Verwendung von gut dokumentiertenund öffentlichen Datenstandards und 3.kontrollierte Vokabularien für die inhaltlicheErschließung.
Datenkuratierung
Schon in der Planungsphase des Projekteswar klar, dass alle Projektdaten im weltweitgrößten Onlineangebot von Urkundenmonasterium.net verarbeitet werdensollen. Damit wird ein sozialer Aspekt vonNachhaltigkeit berücksichtigt: Monasteriumist ein seit 2002 existierendes Großprojekt zurZurverfügungstellung und (kollaborativen)Erschließung von Beschreibungen undFaksimiles von Urkunden des Mittelaltersund der Frühen Neuzeit. Das Portal wirdüberwiegend von Archiven gespeist, es sindaber auch retrodigitalisierte Urkundenbücherund von ForscherInnen erstellte Sammlungenenthalten. Hinter dem virtuellen ArchivMonasterium steht ICARUS, ein Konsortium vonArchiven und wissenschaftlichen Institutionen,das sein Wissen und seine Erfahrungenständig austauscht und erweitert. Die großeDatenmenge, die Etabliertheit des Angebots
in der Fachcommunity und der institutionelleHintergrund haben Monasterium aus einemkleinen DH-Projekt zu einem nachhaltigen Hostnicht nur für unser Projekt gemacht: 1. Dieprojektübergreifende Infrastruktur erlaubt, dassdie projektspezifischen Forschungsdaten überdie Projektdauer hinaus zur Verfügung stehen.2. Durch die Integration der Forschungsdatenin Monasterium bekommt jeder Datensatzauch einen persistenten Identifikator. D.h.alle Datensätze sind eindeutig adressierbarund zitierbar. 3. Das Interesse am Erhalt desAngebots ist groß, sodass selbst unter widrigenfinanziellen Bedingungen aktiv nach Lösungenfür den Erhalt der auf monasterium.netverfügbaren Daten gesucht werden wird.
Datenmanagement
Die im Projekt Illuminierte Urkundenentstehenden Forschungsdaten werdenals strukturierte Datensätze in einer XML-Datenbank verwaltet und archiviert. Dieeinzelnen Urkunden-Datensätze werden nachdem Standard der CEI annotiert, die sich alsTEI-P4-Dialekt in andere Datenstrukturenintegriert und öffentlich dokumentiert ist. Inder Datenbank ist ein für monasterium.netspezialisiertes Schema (XSD 1.1) im Einsatz,das einerseits die Verwendung der zulässigenBeschreibungselemente dokumentiert undandererseits die Konsistenz und Validitätder zu importierenden Daten prüft. Schonin der Projektplanungsphase haben dieProjektbeteiligten über Mittel und Möglichkeitender Datenmodellierung gemeinsam diskutiert.Da der CEI-Standard zur wissenschaftlichenBearbeitung von Urkunden initiiert wurde,brauchte die Überführung der aus demProjekt Illuminierte Urkunden stammendenForschungsdaten aus dem Bereich derDiplomatik keine Anpassungen an dasDatenmodell. Um aber die Beschreibungsdatenzu Dekor und Buchschmuck aufnehmenzu können, musste das Datenmodell umdie Möglichkeit einer kunsthistorischenBeschreibung erweitert werden. Dafürkonnten Strukturen aus der TEI direktübernommen werden. Die Daten werdenalso sozial nachhaltig, indem sie öffentlichdokumentierte und in der Fachcommunitygeläufige Datenbeschreibungsstandardsverwenden, Standards, die jede und jedernachlesen kann.
273

Digital Humanities im deutschsprachigen Raum 2017
Kontrollierte Vokabularien
Im Projekt Illuminierte Urkunden istdie Vergleichbarkeit von Datensätzen fürdie Weiternutzung ein wichtiger Faktor.Kulturelle Kontexte und Fragen derMehrsprachigkeit spielen seit Projektstarteine Schlüsselrolle, da von Beginn an mitForschungspartnern aus West-, Süd- undSüdosteuropa zusammengearbeitet wird.
Bisher werden noch keine vollständigenBeschreibungen in mehreren Sprachen aufmonasterium.net angeboten, aber im Rahmendes Projekts wurde die Möglichkeit entwickelt,Metadaten in mehrsprachigen kontrolliertenVokabularien zu erfassen. Sie werden imW3C SKOS als RDF/XML ausgedrückt. Bisherwurden ein viersprachiges kontrolliertesVokabular zur Klassifikation des Dekors vonUrkunden (vgl. Roland 2014) und ein Glossarerstellt. Diese Neuerung steigert die Qualitäteinerseits des Information Retrieval und führtzu einer umfassenden Kontextualisierungdes Forschungsgegenstandes. Damit sind alsoauch die Inhalte der Daten für eine breitereCommunity besser nachvollziehbar, ein Konzept,das wir vorläufig als „Langzeitverständlichkeit“bezeichnen möchten.
Zusammenfassung
Die kurze Laufzeit jedes Drittmittelprojektes– und damit auch des Projektes IlluminierteUrkunden macht Nachhaltigkeit als sozialesPhänomen zu einer zentralen Frage: DieForschungsdaten sollen einer sekundärenNutzung zur Verfügung gestellt werden undzu neuen Forschungsfragen führen. Deshalbwerden im Projekt Illuminierte Urkunden drei„soziale“ Nachhaltigkeitsstrategien angewandt.Integration in eine in der Forschercommunityund bei Institutionen etablierte Plattform(monasterium.net), Verwendung vonverbreiteten und facheinschlägigenMetadatenstandards und Erschließung vonInhalten mit kontrollierten Vokabularien.
Bibliographie
CEI, Charter Encoding Initiative: http://www.cei.lmu.de [letzter Zugriff 23. August 2016].
Heinz, Karl (2010): „Monasterium.net.Auf dem Weg zu einem europäischenUrkundeportal“, in: Kölzer, Theo (ed.):Regionale Urkundenbücher. Die Vorträge der
12. Tagung der Commission Internationale deDiplomatique, St. Pölten 2010 (Mitteilungen ausdem Niederösterreichischen Landesarchiv 14)139–145.
ICARUS, International Centre for ArchivalResearch: http://icar-us.eu/ [letzter Zugriff 23.August 2016].
Krah, Adelheid (2009): „Monasterium.net- das virtuelle Urkundenarchiv Europas:Möglichkeiten der Bereitstellung undErschließung von Urkundenbeständen“, in: AZ91: 221–246.
Roland, Martin (2013): „IlluminierteUrkunden im digitalen Zeitalter – Maßregelnund Chancen“, in: Ambrosio, Antonella /Barret, Sébastien / Vogeler, Georg (eds.): Digitaldiplomatics. The computer as a tool for thediplomatist?, Archiv für Diplomatik, Beiheft 14.Köln / Weimar /Wien 245–269.
Roland, Martin / Zajic, Andreas (2013):„Illuminierte Urkunden des Mittelalters inMitteleuropa“, in: Archiv für Diplomatik 58:237-428.
SKOS, Simple Knowledge OrganizationSystem: https://www.w3.org/2004/02/skos/[letzter Zugriff 23. August 2016].
TEASys (TübingenExplanatory AnnotationsSystem): Die erklärendeAnnotation literarischerTexte in den DigitalHumanities
Zirker, [email protected] Karls Universität Tübingen,Deutschland
Bauer, [email protected] Karls Universität Tübingen,Deutschland
Das Poster präsentiert das Lehr- undForschungsprojekt TEASys (TübingenExplanatory Annotations System) zurerklärenden Annotation literarischer Textin den Digital Humanities. Die erklärendeAnnotation wird dabei als Anreicherung bislang
274

Digital Humanities im deutschsprachigen Raum 2017
vor allem literarischer Texte um Informationenverstanden, die zum Textverständnis beitragenbzw. es überhaupt ermöglichen, d.h. sie dienenetwa der Überwindung von historischer Distanz(vgl. Hanna 1991). Eine Anwendung des Systemsauf andere (nicht-literarische) Texte wird derzeitvorbereitet.
TEASys arbeitet mit verschiedenenKategorien der erklärenden Annotation sowieihrer Präsentation auf mehreren Ebenen,die sich etwa bezüglich ihrer Komplexitätunterscheiden und aufeinander aufbauen(vgl. Bauer & Zirker 2015). Die Kategoriender erklärenden Annotation sind Sprache,Form, Intratextualität, Intertextualität,Kontext und Interpretation. Die Interpretationergibt sich dabei aus den Informationen, dieaus den anderen Kategorien zum besserenVerständnis an den Text herangetragen werden.Weitere Kategorien, die auf einer Meta-Ebeneangesiedelt sind, beinhalten philologischeInformationen (z.B. zu Varianten) sowieFragen oder Anmerkungen (z.B. zu Items, zudenen bislang keine Informationen gefundenwerden konnten sowie zur bislang bereitsstattgefundenen Recherche zu einzelnen Items).Letztere Kategorie ist vor allem auch im Hinblickauf Fragen der Nachhaltigkeit essentiell. DieEbenen der Annotation bauen aufeinanderauf, d.h. die erste von insgesamt drei Ebenenbietet Informationen an, die das Textverstehengrundsätzlich ermöglichen, und die weiterenEbenen nennen weitere, meist komplexere undausführliche Informationen.
TEASys geht auf ein Peerlearning-Projektzurück, das in Tübingen seit 2011 besteht undvon Studierenden der englischen Literaturund weiteren geisteswissenschaftlichenFächern getragen und von den Leitern desForschungsprojekts (Prof. Dr. Matthias Bauer& PD Dr. Angelika Zirker) wissenschaftlichunterstützt wird. Es gibt derzeit vierPeerlearning-Gruppen, die sich mit Textenverschiedener Gattungen und Epochenbeschäftigen und diese kollaborativ annotieren(zur Kollaboration in den DH s. z.B. McCarty2012; Meister 2012; Stroud 2006). DasForschungsprojekt widmet sich vor allem derTheoriebildung zur erklärenden Annotationenund der darauf aufbauenden Entwicklungeines best-practice-Modells, das wiederum aufdie Theorie rückwirken soll (s. dazu Bauer &Zirker 2015). Die DH-Komponente liegt vorallem in der entsprechenden Aufbereitung undVisualisierung der erklärenden Annotationen fürdas digitale Medium sowie der darin möglichenDynamik (s. Eggert 2009): Annotationensind, entgegen ihrer Darstellung im Buch,
ständig revidier- und erweiterbar und somiteiner möglichst großen Rezipientengruppeoffen, die umgekehrt für eine beständigeQualitätskontrolle sorgt. Ferner ermöglichtdie digitale Repräsentation das Filtern vonInformationen: je nach Bedarf können z.B.lediglich Annotationen zur Intertextualitätangezeigt werden.
Das Poster stellt sowohl den Aufbau vonTEASys als best-practice-Modell vor wieauch seine theoretischen Grundlagen undBeispielannotationen aus dem Peerlearning-Projekt, die von Studierenden erstelltwurden. Es macht deutlich, wie grundlegendehermeneutische Fragestellungen in das digitaleMedium übernommen und dort abgebildetwerden können (vgl. Drucker 2012) – und wieumgekehrt wiederum die digitale Präsentationaufgrund der theoretischen Überlegungenverbessert werden kann.
Bibliographie
Bauer, Matthias / Zirker, Angelika (2015):„Whipping Boys Explained: Literary Annotationand Digital Humanities“, in: Siemens, Ray /Price, Kenneth M: Literary Studies in theDigital Age: An Evolving Anthology. http://dlsanthology.commons.mla.org/under-review-matthias-bauer-and-angelika-zirker-whipping-boys-explained-literary-annotation-and-digital-humanities/ .
Drucker, Johanna (2012): „HumanisticTheory and Digital Scholarship“, in Gold,Matthew K. (ed.): Debates in the DigitalHumanities. Minneapolis: University ofMinnesota Press 85–95.
Eggert, Paul (2009): „The Book, the E-textand the ‚Work-site‘“, in: Deegan, Marilyn /Sutherland, Kathryn (eds.): Text Editing, Printand the Digital World. Ashgate 63–82.
Hanna, Ralph III (1991): „Annotation asSocial Practice“, in: Barney, Stephan A. (ed.):Annotation and Its Texts. New York: OUP 178–184.
McCarty, Willard (2012): „CollaborativeResearch in the Digital Humanities“, in: Deegan,Marilyn / McCarthy, Willard (eds.): CollaborativeResearch in the Digital Humanities. Farnham:Ashgate 1–10.
Meister, Jan-Christoph (2012): „CrowdSourcing ‚True Meaning‘: A CollaborativeApproach to Textual Interpretation“, in: Deegan,Marilyn / McCarthy, Willard (eds.): CollaborativeResearch in the Digital Humanities. Farnham:Ashgate 105–122.
275

Digital Humanities im deutschsprachigen Raum 2017
Stroud, Matthew D. (2006): „The ClosestReading: Creating Annotated Online Editions“,in: Bass, Laura R. / Greer, Margaret R. (eds.):Approaches to Teaching Early Modern SpanishDrama. New York: The MLA of America 214–219.
Tool zur Normalisierungund Historisierung
Eder, [email protected] Maximilians Universität München,Deutschland
Hadersbeck, [email protected] Maximilians Universität München,Deutschland
Das in diesem Poster vorgestellte, unter‹http://goethefind.cis.uni-muenchen.de/?translator› verfügbare Translationstoolüberführt historisches Deutsch aus einemungefähren Zeitraum von 1750 bis 1850 ingegenwartssprachliches Deutsch und umgekehrtmodernen deutschen Text in seine historischeVersion.
Für eine Normalisierung oderModernisierung von historischen Wörternwurden in den letzten Jahren unterschiedlicheHerangehensweisen präsentiert. Nebeneiner Modernisierung über Lexikon-Lookup,Transkriptionsregeln, Levenshtein-Distanzoder phonologische Ähnlichkeit fanden auchMethoden der statistischen maschinellenÜbersetzung Anwendung (Scherrer / Erjavec2015: 2f.). Um orthographischen Differenzenbei einer Translation einzelner Wörteraus eng verwandten Sprachen gerecht zuwerden, werden dabei im Gegensatz zurstandardmäßigen phrasenbasierten statistischenmaschinellen Übersetzung die Phrasen nicht ausWörtern, sondern aus Buchstabensequenzengebildet und anstelle der Wörter der Ausgangs-und der Zielsprache die Buchstaben derWortpaare aligniert [Pettersson et al., 2014].Buchstabenbasierte statistische maschinelleÜbersetzung zur Normalisierung historischerWörter wurde vielfach mit dem Tool ‹Moses›1 (Koehn et al. 2007) durchgeführt, wiebeispielsweise bei (Pettersson et al. 2014),(Nakov / Tiedemann 2012) oder (Scherrer /Erjavec 2015). Neben einem Gebrauch zur
Normalisierung wird dieses hier auch für dieumgekehrte Überführungsrichtung eingesetzt.
In einem weiteren Ansatz zurModernisierung und Historisierung bedientsich das Translationstool zudem neuronalermaschineller Übersetzung. Das dabei häufigverwendete Encoder-Decoder-Modell übertragenFaruqui, Tsvetkov, Neubig und Dyer (2016)auf die buchstabenbasierte Generierung vonWortflexion. Aufgrund der ähnlichen Grundlagekommt deren Tool ‹Morph-Trans› 2 , das sich ausLSTMs, einer speziellen Form von rekurrentenneuronalen Netzen, zusammensetzt, zumEinsatz. Nach Wissen der Autoren ist diesder erste Versuch, ein neuronales Encoder-Decoder-Modell für eine Historisierung undNormalisierung deutscher Texte zu gebrauchen.
Als Trainings- und Entwicklungsdatensätzefür die beiden Methoden dienten Wörter von200 literarischen Texten aus einem Zeitraumvon 1749 bis 1850. Diese Wörter wurdenmithilfe des ‹Cascaded Analysis Broker› 3 vomDeutschen Textarchiv normalisiert, um imAnschluss daran auf die derzeit gültige ‹s›-Schreibung aktualisiert zu werden. Aus denhistorischen und den modernen Schreibweisender Wörter wurden das Grundkorpus sowie einLookup-Lexikon gebildet. Im Translationstoolwerden die beiden Ansätze zusätzlichauch in Kombination mit diesem Lexikoneingesetzt. Zu Vergleichszwecken sind diesevier unterschiedlichen Ausgaben des Weiterenum ein auf einfachen Überführungsregelnund regulären Ausdrücken basierendesVerfahren ergänzt. Die unterschiedlichenHerangehensweisen können online anhandeigener Beispiele gegenübergestellt werden.
Tests auf exemplarischen Datensätzenzeigten, dass buchstabenbasierte statistischemaschinelle Übersetzung nicht nur für eineModernisierung, sondern im Deutschen ebensofür eine Historisierung dienlich ist und auchdas neuronale Encoder-Decoder-Modell imHinblick auf beide Überführungsrichtungennutzbringend eingesetzt werden kann,wobei das Normalisieren im Vergleich zumHistorisieren, wie zu erwarten war, durchwegbessere Resultate erzielte, was wohl unteranderem der Fülle an orthographischenVarianten in historischen Texten geschuldet ist.
Im geisteswissenschaftlichen Kontext isteine Modernisierung historischer Wörteroftmals für eine erfolgreiche Anwendungsprachtechnologischer Werkzeuge, wiezum Beispiel Part-of-Speech-Tagger, aufälteren Texten von Nöten, während eineHistorisierung beispielsweise bei der Suche
276

Digital Humanities im deutschsprachigen Raum 2017
auf historischem Text zu einer erheblichenErleichterung beitragen könnte, indemder moderne Suchterm historisiert wird,da von Anwendern und Anwenderinnennicht erwartet werden kann, dass sie umdie alten Schreibweisen der Wörter wissen.Eine Verwendung von buchstabenbasierterstatistischer maschineller Übersetzung undbuchstabenbasierten neuronalen Encoder-Decoder-Modellen zur Normalisierung undHistorisierung bezüglich solcher Aufgaben undähnlichen Problemstellungen im Bereich derGeisteswissenschaften ist vorstellbar.
Fußnoten
1. Online verfügbar unter: http://www.statmt.org/moses/2. Online verfügbar unter: https://github.com/mfaruqui/morph-trans3. Online verfügbar unter: http://www.deutschestextarchiv.de/demo/cab/
Bibliographie
Faruqui, Manaal / Tsvetkov, Yulia / Neubig,Graham / Dyer, Chris (2016): „MorphologicalInflection Generation Using Character Sequenceto Sequence Learning“, in: Proceedings of NAACLhttp://arxiv.org/pdf/1512.06110.pdf [letzterZugriff 1. August 2016].
Koehn, Philipp / Hoang, Hieu / Birch,Alexandra / Callison-Burch, Chris / Federico,Marcello / Bertoldi, Nicola / Cowan, Brooke /Shen, Wade / Moran, Christine / Zens,Richard / Dyer, Chris / Bojar, Ondrej /Constantin, Alexandra / Herbst, Evan (2007):„Moses: Open Source Toolkit for StatisticalMachine Translation“, in: Annual Meeting of theAssociation for Computational Linguistics (ACL),demonstration session, Prague, Czech Republic.
Nakov, Preslav / Tiedemann, Jörg (2012):„Combining Word Level and Character-LevelModels for Machine Translation Between CloselyRelated Languages“, in: Proceedings of ACL-2012
Pettersson, Eva / Megyesi, Beáta / Nivre,Joakim (2014): „A Multilingual Evaluation ofThree Spelling Normalisation Methods forHistorical Text“, in: Proceedings of the 8thWorkshop on Language Technology for CulturalHeritage, Social Sciences, and Humanities(LaTeCH) @ EACL 2014 32–41.
Scherrer, Yves / Erjavec, Tomaž (2015):„Modernising historical Slovene words“,in: Natural Language Engineering http://
archiveouverte.unige.ch/unige:82305 [letzterZugriff 1. August 2016]
Twhistory mitautoChirp SocialMedia Tools für dieGeschichtsvermittlung
Hermes, Jü[email protected]ät zu Köln, Deutschland
Hoffmann, [email protected] Historiker
Eide, Ø[email protected]ät zu Köln, Deutschland
Geduldig, [email protected]ät zu Köln, Deutschland
Schildkamp, [email protected]ät zu Köln, Deutschland
Public History (vgl. einführend Zündorf 2010)ist im deutschsprachigen Raum ein noch jungesFeld, die erste Professur wurde erst Ende 2012in Heidelberg eingerichtet. Die Disziplin istzurückzuführen auf die doppelte Erkenntnis,dass die Mehrheit der Fachstudierendennicht in der Geschichtswissenschaft wirdarbeiten können (und dementsprechendzielgerichtet in Vermittlungskompetenzenaller Art geschult werden muss) und dassdie meisten HistorikerInnen sich zwar übermangelnde Aufmerksamkeit für ihr Fach nichtbeklagen können, demgegenüber aber kaumwissenschaftlich valide Werkzeuge für denUmgang mit der Öffentlichkeit entwickeltwurden.
Paradoxerweise scheint die Public Historytrotz ihres modernen Selbstanspruchsden Fehler der herkömmlichenGeschichtswissenschaft zu wiederholen:Die Digitalisierung ihrer Arbeit bleibt weithinter den technischen Möglichkeiten
277

Digital Humanities im deutschsprachigen Raum 2017
zurück und beschränkt sich größtenteilsauf die Erleichterungen einer erweitertenSchreibmaschine. Doch Öffentlichkeiten, diesie schon ihrem Namen nach im Blick hat,migrieren zusehends in den digitalen Raumder sozialen Netzwerke und sollten genau dortangesprochen werden.
Eine Möglichkeit, die digitaleTeilöffentlichkeit zu erreichen, bietet dassoziale Netzwerk Twitter. Seit ungefähr sechsJahren werden dort historische Ereignisse in jemaximal 140 Zeichen zeitgenau nacherzählt, wasunter den Bezeichnungen „Re-Entweetment“oder auch “Twhistory” bekannt geworden ist.Dieses Potential des Medium wurde bislangfast ausschließlich von Laien genutzt, so überdie Accounts @TitanicRealTime und das MDR-Projekt @9Nov89live , das über einen Tag einefiktive Geschichte des Mauerfalls zeichnete. Injüngerer Zeit wird es aber zunehmend auch voneiner geringen Zahl von (Public) Historians aktivangeboten, beispielsweise für @NRWHistoryund das Zweitweltkriegsprojekt @DigitalPast , zudem parallel das Sachbuch “Als der Krieg nachHause kam” (Hoffmann 2015) veröffentlichtwurde. Wahrscheinlich besser als jede andereMedienform bietet Twhistory die Möglichkeit derErzählung in Echtzeit als nicht-textlichem Inhalt,über den Geschichte lebendig gemacht undvorhandenes historisches Interesse (re-)aktiviertwerden kann.
Insbesondere die Zeichenbegrenzung istfür das Re-Entweetment Chance und Risikozugleich: die Einstiegsschwelle ist im Vergleichzu herkömmlichen Darreichungsformen(Buch, Museum) äußerst gering, zugleichbesteht die Gefahr der Simplifizierung sowieder Falschdarstellung von Geschichte alsAneinanderkettung von Einzelereignissen.Trotz der mittlerweile international steigendenProjektzahl hat sich noch keine Best Practiceergeben, um diesen Risiken zu begegnen.Dadurch ist auch die Zahl der digitalen Toolsfür diesen Bereich noch sehr klein, die Listeder Desiderate an die Digital Humanities aberlang und äußerst divers. Beispielsweise sind fürdie Planung, die Sammlung, die Gesamtschauund die Quellenreferenzierung von InhaltenDatenbanken oder zumindest tabellarischeAufstellungen notwendig, für die noch keineMöglichkeit bestand, die aggregierten Inhalteauch automatisch mit der Twitter-Plattform zuverknüpfen.
Dies hat sich mit der Bereitstellung derSoftware autoChirp geändert, die an der KölnerInformationsverarbeitung entwickelt wurde,um die Umsetzung entsprechender Twhistory-Projekte zu unterstützen. Zum einen vereinfacht
autoChirp die Arbeit für die ErstellerInnenvon Twitter-Timelines historischer Ereignisse,indem es eine Schnittstelle zum automatischenUpload von tabellarischen Sammlungenunterschiedlichen Formats anbietet. Dabeikönnen neben dem gewünschten Datum, dergenauen Uhrzeit und den Tweet-Text auch Bilderund Geolocations für den Tweet angegebenwerden (vgl. Abb. 1). Auch können ganzeGruppen von Tweets per Mausklick auf eineneue Referenzzeit geschedulet werden.
Abb. 1: Sceenshot des autoChirp-Web-Clients,mit dem eine Reihe von Tweets automatischaus einer Tabelle geschedulet wurde. Das Web-Application-Frontend interagiert mit einerredundant angelegten Datenbank, um dieSicherung der in den verschiedenen Projektengenerierten Tweets auch jenseits der Twitter-Plattform nachhaltig zu gewährleisten.
Die autoChirp-App wird zur Zeit mindestensvon den Twitter-Projekten @DigitalPast( http://digitalpast.de/ ), @NRWHistory ( http://nrwhistory.de/ )und @goals_from_pastgenutzt und dabei unter anderem auchin der Lehre eingesetzt. Dabei stehen dieEntwicklerInnen im engen Austausch mitden AnwenderInnen, um das Potential fürWeiterentwicklungen abzuwägen. Aktuell wirddie Integration von autoChirp in das Tiwoli-Projekt (vgl.Fischer & Strötgen 2015) realisiert,was zeigt, dass nicht nur historische, sondernauch literaturwissenschaftliche Vorhaben voneiner Unterstützung im Zugang zur Twitter-Plattform profitieren können.Für einen niederschwelligen Einstiegläuft eine Instanz von autoChirp als Web-Application zur freien Nutzung unter https://autochirp.spinfo.uni-koeln.de/ . Dort finden sichauch ausführliche Tutorials zur Benutzung. FürWeiterentwicklungen steht der dokumentierteCode im Github-Verzeichnis https://github.com/spinfo/autoChirp zur Verfügung.
278

Digital Humanities im deutschsprachigen Raum 2017
Bibliographie
Fischer, Frank / Strötgen, Jannik (2015):„Wann findet die deutsche Literatur statt?Zur Untersuchung von Zeitausdrücken ingroßen Korpora“, in: DHd 2015: Von Daten zuErkenntnissen.
Hoffmann, Moritz (2015): Als der Krieg nachHause kam. Berlin: Ullstein.
Strötgen, Jannik / Gertz, Michael (2012):„Temporal Tagging on Different Domains:Challenges, Strategies, and Gold Standards“, inProceedings of LREC 2012 3746–3753.
Zündorf, Irmgard (2010): „Zeitgeschichteund Public History, Version: 1.0“, in:Docupedia-Zeitgeschichte, 11.2.2010 http://docupedia.de/docupedia/index.php?title=Public_History&oldid=68731 [letzter Zugriff24. August 2016].
UIMA als Plattformfür die nachhaltigeSoftware-Entwicklung inden Digital Humanities
Hellrich, [email protected] „Modell Romantik“, Friedrich-Schiller-Universität Jena, Jena, Deutschland
Matthies, [email protected] University Language & InformationEngineering (JULIE) Lab, Friedrich-Schiller-Universität Jena, Jena, Deutschland
Hahn, [email protected] University Language & InformationEngineering (JULIE) Lab, Friedrich-Schiller-Universität Jena, Jena, Deutschland
Texte und ihre automatische Analyse stehenim Zentrum vieler Untersuchungen in denDigital Humanities, etwa zur Erforschungsprachlicher und kultureller Wandlungsprozesse(siehe etwa Michel u.a. (2011)) oder imBereich der Stilometrie (siehe etwa Jannidis(2014)). Die automatische Analyse vonTexten beinhaltet typischerweise eine Reihezunehmend komplexer werdender Schritte,
angefangen bei der Segmentierung vonSätzen und Wörtern (Leerzeichen sind keinhinreichendes Kriterium, vgl. „New York“)über die syntaktische und semantischeAnalyse bis hin zu diskursstrukturellen undpragmatischen Analysen. Die für diese einzelnenSchritte nötigen sprachtechnologischenKomponenten sind oft, zumindest innerhalbeiner Anwendungsdomäne, wiederverwendbar.Folglich gibt es mittlerweile eine Fülle vonSoftware-Repositorien, die entsprechendecomputerlinguistische Komponenten sammeln,und Frameworks, die ihre Integration insogenannte Pipelines, also funktionsbezogenesequenzielle Kombinationen von einzelnenKomponenten, erleichtern. Die dadurchermöglichte Wiederverwendung vonKomponenten ist im Sinne nachhaltigerForschung, da diese so nicht mehrfachentwickelt werden müssen und der Software-Austausch zwischen Gruppen unterstützt wird.
Uima (Unstructured Information ManagementArchitecture) 1 ist ein solches Framework,das sowohl im akademischen Kontext (inDeutschland u.a. DKPro 2 (de Castilho &Gurevych, 2014) und JCoRe 3 (Hahn u.a., 2016))als auch in industriellen Anwendungen (etwa beiIBMs Jeopardy Champion Watson (Ferrucci u.a.,2010)) breite Verwendung findet (einen Vergleichunterschiedlicher Frameworks stellen Bank undSchierle (2012) an). Uima ist open source unterder Apache-Lizenz verfügbar und unterstütztmehrere Programmiersprachen, wobei Java inder Praxis eine dominierende Rolle zukommt.
Wir nutzen mit JCoRe seit fast einemJahrzehnt Uima für computerlinguistischeProblemstellungen in verschiedenenDomänen bzw. Sprachen und stellen diedabei entwickelten Komponenten öffentlichzur Verfügung. Aktuell arbeiten wir daran,unser ursprünglich für bio-medizinischeFragestellungen und englischsprachige Fachtexteentwickeltes Repositorium auf den DH-Bereich, primär für das Deutsche, zu erweitern.JCoRe stellt nicht nur sprachtechnologischeKomponenten zur Verfügung, sondern auchdie dafür nötigen Modelle für verschiedeneDomänen — denn vor allem die Erstellung dieserModelle ist ein enorm zeit- und rechenintensiverProzess, der zudem ein hohes Maß ancomputerlinguistischer Expertise verlangt. Umdie Einstiegshürden für die Benutzung solcherRessourcen zu senken, bieten wir Anleitungenund Beispiele zur deklarativen Erstellung vonTextanalyse-Pipelines mit Uima und habenzudem eine interaktive Anwendung entwickelt(Hahn u.a., 2016).
279

Digital Humanities im deutschsprachigen Raum 2017
Eine Vielzahl von existierendenSprachanalyse-Komponenten und Repositorienkann über Uima eingebunden werden,darunter auch einige, die nicht originär fürdas Framework entwickelt wurden, wie etwadas über DKPro verfügbare Stanford CoreNLP4 (Manning u.a., 2014) oder OpenNLP 5 .Während Uima für den produktiven Einsatzentwickelt wurde, steht beim alternativenNatural Language Toolkit (NLTK) 6 der Einsatzin der Lehre im Zentrum (Bird u.a., 2009).Uima ist eher mit dem General Architecturefor Text Engineering (GATE) Framework(Cunningham u.a., 2011) vergleichbar, das aberein „geschlossenes“ NLP-System repräsentiert,das exklusiv von den Entwicklern von Gateverwaltet wird. Generell sind integrierteFrameworks vorteilhaft gegenüber Pipelines auseinzelnen Werkzeugen, die mittels Textdateien/-strömen kommunizieren, da nicht bei jedemSchritt zwischen verschiedenen Formatenkonvertiert werden muss. Insbesondere werdendie bei selbstständigen Werkzeugen verbreitetenin-line-Annotationen (wie etwa „das_ArtikelHaus_Nomen“) vermieden, die sich oft alsunübersichtlich und fehleranfällig erweisen.
Uima und die anderen bisher genanntenFrameworks sind primär für den Einsatzauf lokaler Rechner-Infrastruktur gedachtund somit nur bedingt mit Systemen wieWebLicht 7 (Hinrichs u.a., 2010) vergleichbar,die als Webservice verschiedene dezentralverteilte Komponenten zusammenführen.Dadurch wird zwar der Einstieg in die Nutzungsprachtechnologischer Systeme erleichtert,jedoch sind derartige Systeme nicht für dieVerarbeitung großer Datenmengen geeignetund es entsteht eine eher intransparenteAbhängigkeit von fremder Infrastruktur. Uimaist somit kein Konkurrent für WebLicht, sondernermöglicht es vielmehr, Komponenten zuentwickeln, die bei Bedarf auch (durch in DKProenthaltene Konverter) in WebLicht eingebundenwerden können.
Im Kern ist Uima für die sequentielleAnreicherung mit Metadaten ausgelegt. Diemöglichen Annotationen werden frei über einobjektorientiertes Typensystem definiert (sieheetwa Hahn u.a., 2007). In Uima wird zwischenKomponenten unterschieden, die Annotationenvornehmen (Analysis Engines), und solchen,die Texte in das interne CAS (Common AnalysisSystem) Format konvertieren (CollectionReader); letztere können dabei auch bereits imUrsprungstext kodierte Metadaten verarbeiten.Die ersten Komponenten, die im Rahmen derErweiterung JCoRes um DH-Komponenten
entstanden und öffentlich zugänglich gemachtwurden, sind ein solcher Collection Reader, derdie neuerdings vom Deutschen Textarchiv 8 (Geyken, 2013) zur Verfügung gestellten Dateienmit TCF- 9 und Dublin Core-Annotationen 10
verarbeiten kann, sowie eine entsprechendeErweiterung unseres Typensystems. In derunmittelbaren Zukunft geplante Erweiterungenbetreffen Analysis Engines für Text- bzw.Wortsegmentierung und Wortartenerkennung(POS-Tagging) in historischen (literarischen)Texten.
Wir möchten durch unseren Beitraginsbesondere diejenigen, die primärcomputerlinguistische Anwendungen fürFragestellungen der Digital Humanitiesrealisieren wollen (und damit meist keinecomputerlinguistischen Entwicklungsinteressenverfolgen), anregen, sich aus dem breitenFundus existierender Komponenten zubedienen und diese durch den Einsatz desUima-Frameworks zu verbinden. Die dadurchimplizit eingeführte Modularität erleichtertzudem die Durchführung von Funktionstests,die Anpassung an neue Domänen und darüberhinaus den Austausch mit anderen Forschenden— allesamt Anforderungen an eine nachhaltigeSoftware-Infrastruktur.
Fußnoten
1. https://uima.apache.org2. https:// DKPro .github.io3. http://julielab.github.io4. http://stanfordnlp.github.io/Core NLP5. https://open NLP .apache.org6. http://www.nltk.org7. https://weblicht.sfs.uni-tuebingen.de8. http://www.deutschestextarchiv.de/download9. http://weblicht.sfs.uni-tuebingen.de/weblichtwiki/index.php/The_TCF_Format10. http://dublincore.org
Bibliographie
Bank, Mathias / Schierle, Martin (2012): „Asurvey of text mining architectures and the Uimastandard“, in: Proceedings of LREC 2012 3479–3486.
Bird, Steven / Klein, Ewan / Loper, Edward(2009): Natural Language Processing with Python:Analyzing Text with the Natural LanguageToolkit. Sebastopol, CA: O'Reilly.
de Castilho, Eckart R. / Gurevych, Iryna(2014): „A broad-coverage collection of portable
280

Digital Humanities im deutschsprachigen Raum 2017
NLP components for building shareable analysispipelines“, in: OIAF4HLT 2014 – Proceedingsof the Workshop on Open Infrastructures andAnalysis Frameworks for HLT @ COLING 2014 1–11.
Cunningham, Hamish / Maynard, Diana /Bontcheva, Kalina (2011): Text Processing withGATE. Murphys, CA: Gateway Press.
Ferrucci, David A. / Brown, Eric / Chu-Carroll, Jennifer / Fan, James / Gondek, DavidC. / Kalyanpur, Aditya A. / Lally, Adam /Murdock, J. William / Nyberg 3rd, Eric H. /Prager, John M. / Schlaefer, Nico / Welty,Christopher A. (2010): „Building Watson:An overview of the DeepQA project“, in: AIMagazine 31 (3): 59–79.
Geyken, Alexander (2013): „Wege zu einemhistorischen Referenzkorpus des Deutschen: dasProjekt Deutsches Textarchiv“, in: Perspektiveneiner corpusbasierten historischen Linguistik undPhilologie 221–234.
Hahn, Udo / Buyko, Ekaterina / Tomanek,Katrin / Piao, Scott / McNaught, John /Tsuruoka, Yoshimasa / Ananiadou, Sophia(2007): „An annotation type system for adata-driven NLP pipeline“, in: LAW 2007– Proceedings of the Linguistic AnnotationWorkshop @ ACL 2007 33–40.
Hahn, Udo / Matthies, Franz / Faessler,Erik / Hellrich, Johannes (2016): „Uima-basedJCoRe 2.0 goes GitHub and Maven Central: State-of-the-art software resource engineering anddistribution of NLP pipelines“, in: LREC 2016 –Proceedings of the 10th International Conferenceon Language Resources and Evaluation 2502–2509.
Hinrichs, Erhard W. / Hinrichs, Marie /Zastrow, Thomas (2010): „WebLicht: Web-basedLRT services for German“, in: Proceedings ofACL-2010: System Demonstrations 25–29.
Jannidis, Fotis (2014): „Der Autor ganznah: Autorstil in Stilistik und Stilometrie“, in:Schaffrick, Matthias / Willand, Marcus (eds.):Theorien und Praktiken der Autorschaft. Berlin:de Gruyter 169–195.
Manning, Christopher D. / Surdeanu,Mihai / Bauer, John / Finkel, Jenny Rose /Bethard, Steven J. / McClosky, David (2014):"The Stanford CoreNLP Natural LanguageProcessing Toolkit", in: Proceedings of ACL-2014:System Demonstrations 55–60.
Michel, Jean-Baptiste / Shen, Yuan K. /Aiden, Aviva P. / Veres, Adrian / Gray, MatthewK. / The Google Books Team / Pickett, JosephP. / Hoiberg, Dale / Clancy, Dan / Norvig, Peter /Orwant, Jon / Pinker, Steven / Nowak, MartinA. / Aiden, Erez L. (2011): „Quantitative analysis
of culture using millions of digitized books“, in:Science 331 (6014): 176–182.
Umfrage zuForschungsdaten an derPhilosophischen Fakultätder Universität zu Köln
Mathiak, [email protected]ät zu Köln, Deutschland
Kronenwett, [email protected]ät zu Köln, Deutschland
Executive Summary
Um den aktuellen Bedarf an derPhilosophischen Fakultät der Universität zuKöln im Umgang mit Forschungsdaten möglichstgenau identifizieren zu können, wurde vom DataCenter for the Humanities (DCH) in Kooperationmit dem Dekanat der Philosophischen Fakultätsowie der Universitäts- und Stadtbibliothek(USB) Köln 2016 eine Online-Umfrage unterdem akademischen Personal der Fakultätdurchgeführt. Ziel der Erhebung ist es, sowohldie aktuellen Bestände zu charakterisieren,als auch Informationen zum Bedarf in denBereichen Forschungsdatenmanagement (FDM)und Beratung zu erhalten. Im Vortrag werdendie Ergebnisse der Umfrage präsentiert unddiskutiert sowie mögliche Schlussfolgerungenerörtert.
Aktualität und Relevanz
Eines der wichtigsten neuen Handlungsfelderder Forschung, welche im Zuge derDigitalisierung von Information entstanden ist,betrifft das Management von Forschungsdaten.Die Hochschulen müssen sich darauf einstellen,ihren Wissenschaftlern und Forscherndie notwendigen Infrastrukturen undServices zur Verfügung zu stellen. Auf dieseDringlichkeit verwies auch jüngst der Ratfür Informationsinfrastrukturen in seinenEmpfehlungen Leistung aus Vielfalt (Rat 2016).Denn noch immer gehen laut Schätzungen der
281

Digital Humanities im deutschsprachigen Raum 2017
DFG bis zu 90% der digital produzierten Datenund Ergebnisse nach kurzer Zeit verloren bzw."verschwinden in der Schublade" (Kramer 2014)und stehen somit keiner weiteren Verwendungund Nachnutzung zur Verfügung (Winkler-Nees 2011). Auch deshalb verabschiedetedie Hochschulrektorenkonferenz (HRK)gleich zwei Grundsatzpapiere, in denendas Management von Forschungsdaten alszentrale strategische Herausforderung fürdie Hochschulleitungen angesehen wird(Hochschulschulrektorenkonferenz 2014und 2015). Um einerseits die vielfältigenAktivitäten und Akteure zu koordinieren undandererseits die Anschlussfähigkeit möglichstaller Hochschulen in den Scientific Communitiesauf nationaler und internationaler Ebenezu gewährleisten, erarbeitete die HRK einen6-Punkte-Leitfaden, die sich aus ihrer Sichtbeim Auf- oder Ausbau des institutionellenFDM ergeben und berücksichtigt werdensollen (Hochschulrektorenkonferenz 2015:6-15). Im Rahmen dieses Maßnahmenkatalogswird explizit empfohlen, zu Beginn eineStandortbestimmung an der jeweiligenHochschule vorzunehmen, "z.B. mittelsgeeigneter interner Erhebungen zumVerhalten der Wissenschaftlerinnen undWissenschaftler, aber auch zu derenBedarfen." (Hochschulrektorenkonferenz 2015:9)
Methodischer Ansatz
Der gewählte methodische Ansatz derUmfrage-basierten Studie orientiert sich anden sechs Leitlinien von (Müller et al. 2014)sowie an den einschlägigen Aufsätzen desHandbuchs Methoden der Bibliotheks- undInformationswissenschaft von Umlauf et al(Seadle 2013: 41-63; Fühles-Ubach 2013: 114-127;Fühles-Ubach 2013: 96-113; Fühles-Ubach,Umlauf 2013: 80-95).
Definition der Forschungsziele
Der Anlass für diese Studie ist die HRK-Empfehlung zur Durchführung einer Umfragezu Forschungsdaten an Hochschulen alsGrundlage für eine institutionelle FDM-Strategieentwicklung. Denn im Gegensatzzu einigen anderen deutschen Hochschulenfehlt für die drittgrößte Universität inDeutschland sowohl eine entsprechendeErhebung als auch weiterführend eineuniversitätsweite FDM-Policy. Der Fokus
liegt allerdings nicht auf einer quantitativenTotalerhebung zu Forschungsdaten an derKölner Volluniversität. Da professionelles FDMfachbereichsspezifisch erfolgen sollte (Sahleet al. 2013), richtet sich der Blick gezielt aufdie Forschungsdaten an der PhilosophischenFakultät der Universität zu Köln, einerder größten geisteswissenschaftlichenFakultäten Europas (UzK 2016). In diesemKontext werden die Ergebnisse derUmfrage helfen, zur konzeptionellenWeiterentwicklung und Optimierung desDCH-Beratungs- und Serviceangebots, einzentrales Dienstleistungsangebot der Fakultät,beizutragen.
Bestimmung der Zielgruppe
Die Teilnehmergruppe ist beschränkt aufdas akademische Personal der PhilosophischenFakultät der Universität zu Köln. Die Umfragezielte dabei besonders auf Wissenschaftlerund Forscher, die direkt für datengestützteForschungsprojekte verantwortlich sind.
Spezifizierung desFragebogendesigns
Für die inhaltliche, konzeptionelleund methodische Gestaltung der Umfragewurden die bisher verfügbaren Erhebungenzu Forschungsdaten an nationalen undinternationalen wissenschaftlichen Institutionenund fachspezifischen Forschungseinrichtungenanalysiert (forschungsdaten.org 2016; Burger etal. 2013) und auf die besonderen Gegebenheitenan der Philosophischen Fakultät zugeschnitten(Andorfer 2015; Stäcker 2015; CCeH 2016,DCH 2016a). Es wurden auch die Ergebnissemehrerer Experteninterviews des DCH mitWissenschaftlern der Philosophischen Fakultätberücksichtigt, die im Vorfeld der Erhebungim Rahmen von FDM-Beratungen durchdas DCH geführt wurden. Der Fragebogenwurde insgesamt in fünf Teilbereicheuntergliedert: 1) Forschungsdaten 2) Nutzungvon Datenarchiven 3) Unterstützung beimUmgang mit Forschungsdaten 4) Fachbereichund Position 5) Interesse.
Überprüfung und Pretests
Eine Word-Version des Fragebogens wurdezunächst an alle Kooperationspartner des
282

Digital Humanities im deutschsprachigen Raum 2017
Projektes verschickt. Nach Einarbeitungaller Rückmeldungen wurde der Fragebogenonline programmiert und der Testlink anWissenschaftler aller acht Fächergruppender Fakultät sowie an externe Experten mitsoziologischem Hintergrund für Pretestsversendet. In mehreren Iterationen wurde derFragebogen immer weiter adaptiert. Dies betrafu.a. die Reihenfolge der einzelnen Frageblöckeund die Auswahl der verwendeten Definitionensowie die Präzision der Fragestellungen. AlleSchritte erfolgten in enger Absprache mit demDatenschutzbeauftragten der Universität zuKöln.
Umsetzung und Einführung
Der Fragebogen wurde mit Hilfe des Online-Befragungstools von (Kronenwett&Adolphs 2016)erstellt und war vom 30.05.2016 bis 12.06.2016aktiv. Die Auswertung der Ergebnisse erfolgtemit R.
Weiterführende Informationen zurOnline-Umfrage sowie zu dem umfassendenErgebnisbericht können auf der DCH-Webseitezur Umfrage eingesehen werden: http://dch.phil-fak.uni-koeln.de/umfrage-2016.html (DCH2016b).
Deskriptive Datenanalyse:Ergebnisauswahl
Der Fragebogen wurde von 191 Personenbegonnen und von 136 Teilnehmern vollständigbeantwortet. 71.20% der Teilnehmer, dieden Fragebogen begonnen haben, haben dieBefragung auch beendet, d.h. sie haben alleFragen vollständig beantwortet und sich biszur Abschlussseite durchgeklickt. Die folgendeAuswahl der Datenauswertung berücksichtigtnur diese Teilnehmer (n=136). Unser Ziel bei derErstellung des Fragebogens war folgende Fragenzu beantworten:
• Welche Forschungsdaten gibt es?• Welchen Bedarf gibt es bezüglich
Forschungsdaten?• Welche Unterstützung wünschen sich die
Mitglieder der Fakultät von uns?
Zur ersten Frage war uns Nachhaltigkeitund Volumen wichtig. Zur Nachhaltigkeitkonnten wir feststellen, dass die Mehrzahl derBefragten die Daten auf ihren lokalen Rechnernspeichert: 70% auf dienstlichen Rechnern, 70%
auf privaten Rechnern, Mehrfachantwortenwaren möglich (vgl. Abb. 1). Nur 14% speichernihre Daten in einem Datenarchiv, eine Zahl, diesich auch in anderen Fragen reflektiert wird,etwa wie viele sich vorstellen können ihre Datenin einem Datenarchiv abzulegen.
Abb. 1: Speicherort der Forschungsdaten(n=136)
Dies ist für die Nachhaltigkeit fatal, danur in einem Datenarchiv ein strukturierterZugriff und insbesondere auch Auffindbarkeitgewährleistet sind. Cloud-Lösungen, dieauch weit verbreitet sind (35% Nutzungvon kommerziellen Anbietern und 14%von wissenschaftlichen Anbietern), stellenzwar sicher, dass der Nutzer immerfort undvon überall auf die Daten zugreifen kannund diese auch teilen kann. Aber für dieNachvollziehbarkeit von Forschungsergebnissenund die langfristige Sicherung sind diesedenkbar ungeeignet.
Wir gehen davon aus, dass dies daranliegt, dass die Forscher ihre Handlungsweisenicht bezüglich Nachhaltigkeit undNachvollziehbarkeit reflektieren. DieSelbsteinschätzung zu den eigenen Kenntnissenim Bereich FDM (vgl. Abb. 2) zeigt, dass dieKenntnisse größtenteils als durchschnittlich odernoch geringer (71%) eingeschätzt werden.
Abb. 2: Selbsteinschätzung der Kenntnisse imForschungsdatenmanagement (n=136)
Es kann aber auch ein Faktor sein, dassselbst bei hohen Kenntnissen schlicht dieMöglichkeiten fehlen, die Daten zu publizieren,
283
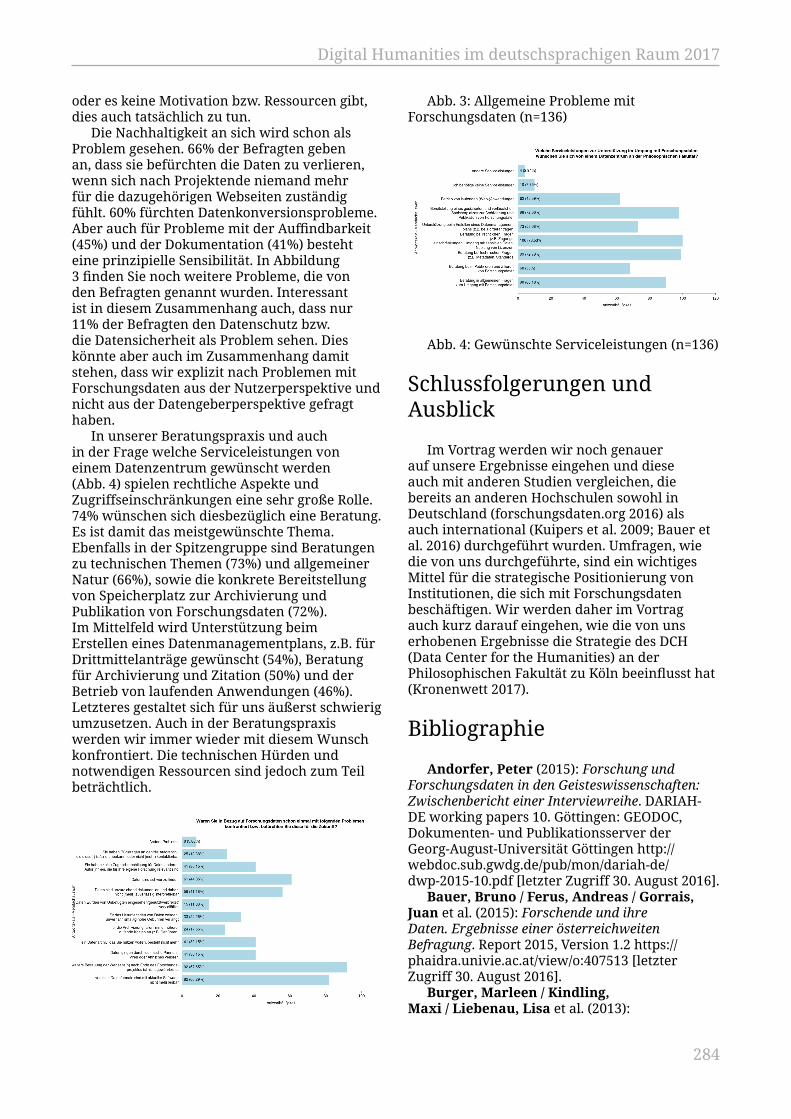
Digital Humanities im deutschsprachigen Raum 2017
oder es keine Motivation bzw. Ressourcen gibt,dies auch tatsächlich zu tun.
Die Nachhaltigkeit an sich wird schon alsProblem gesehen. 66% der Befragten gebenan, dass sie befürchten die Daten zu verlieren,wenn sich nach Projektende niemand mehrfür die dazugehörigen Webseiten zuständigfühlt. 60% fürchten Datenkonversionsprobleme.Aber auch für Probleme mit der Auffindbarkeit(45%) und der Dokumentation (41%) bestehteine prinzipielle Sensibilität. In Abbildung3 finden Sie noch weitere Probleme, die vonden Befragten genannt wurden. Interessantist in diesem Zusammenhang auch, dass nur11% der Befragten den Datenschutz bzw.die Datensicherheit als Problem sehen. Dieskönnte aber auch im Zusammenhang damitstehen, dass wir explizit nach Problemen mitForschungsdaten aus der Nutzerperspektive undnicht aus der Datengeberperspektive gefragthaben.
In unserer Beratungspraxis und auchin der Frage welche Serviceleistungen voneinem Datenzentrum gewünscht werden(Abb. 4) spielen rechtliche Aspekte undZugriffseinschränkungen eine sehr große Rolle.74% wünschen sich diesbezüglich eine Beratung.Es ist damit das meistgewünschte Thema.Ebenfalls in der Spitzengruppe sind Beratungenzu technischen Themen (73%) und allgemeinerNatur (66%), sowie die konkrete Bereitstellungvon Speicherplatz zur Archivierung undPublikation von Forschungsdaten (72%).Im Mittelfeld wird Unterstützung beimErstellen eines Datenmanagementplans, z.B. fürDrittmittelanträge gewünscht (54%), Beratungfür Archivierung und Zitation (50%) und derBetrieb von laufenden Anwendungen (46%).Letzteres gestaltet sich für uns äußerst schwierigumzusetzen. Auch in der Beratungspraxiswerden wir immer wieder mit diesem Wunschkonfrontiert. Die technischen Hürden undnotwendigen Ressourcen sind jedoch zum Teilbeträchtlich.
Abb. 3: Allgemeine Probleme mitForschungsdaten (n=136)
Abb. 4: Gewünschte Serviceleistungen (n=136)
Schlussfolgerungen undAusblick
Im Vortrag werden wir noch genauerauf unsere Ergebnisse eingehen und dieseauch mit anderen Studien vergleichen, diebereits an anderen Hochschulen sowohl inDeutschland (forschungsdaten.org 2016) alsauch international (Kuipers et al. 2009; Bauer etal. 2016) durchgeführt wurden. Umfragen, wiedie von uns durchgeführte, sind ein wichtigesMittel für die strategische Positionierung vonInstitutionen, die sich mit Forschungsdatenbeschäftigen. Wir werden daher im Vortragauch kurz darauf eingehen, wie die von unserhobenen Ergebnisse die Strategie des DCH(Data Center for the Humanities) an derPhilosophischen Fakultät zu Köln beeinflusst hat(Kronenwett 2017).
Bibliographie
Andorfer, Peter (2015): Forschung undForschungsdaten in den Geisteswissenschaften:Zwischenbericht einer Interviewreihe. DARIAH-DE working papers 10. Göttingen: GEODOC,Dokumenten- und Publikationsserver derGeorg-August-Universität Göttingen http://webdoc.sub.gwdg.de/pub/mon/dariah-de/dwp-2015-10.pdf [letzter Zugriff 30. August 2016].
Bauer, Bruno / Ferus, Andreas / Gorrais,Juan et al. (2015): Forschende und ihreDaten. Ergebnisse einer österreichweitenBefragung. Report 2015, Version 1.2 https://phaidra.univie.ac.at/view/o:407513 [letzterZugriff 30. August 2016].
Burger, Marleen / Kindling,Maxi / Liebenau, Lisa et al. (2013):
284

Digital Humanities im deutschsprachigen Raum 2017
Forschungsdatenmanagement an Hochschulen.Internationaler Überblick und Aspekte einesKonzepts für die Humboldt-Universität zuBerlin. Version 1.1 vom 3. März 2013 http://edoc.hu-berlin.de/oa/reports/reZ8xHXx2cLyc/PDF/28q8QGlHKwrRw.pdf [letzter Zugriff 30.August 2016].
Cologne Center for eHumanities (eds.)(2016): Digital Humanities. Strukturen - Lehre -Forschung. Universität zu Köln http://cceh.uni-koeln.de/broschure-digital-humanties-2016/[letzter Zugriff 30. November 2016].
Data Center for the Humanities (2016a):Homepage, http://dch.phil-fak.uni-koeln.de/[letzter Zugriff 12. August 2016].
Data Center for the Humanities(2016b): Homepage, Unterseite "UmfrageForschungsdaten 2016", http://dch.phil-fak.uni-koeln.de/umfrage-2016.html [letzter Zugriff 12.August 2016].
Drees, Bastian (2016): „Zukunft derInformationsinfrastrukturen: Das deutscheBibliothekswesen im digitalen Zeitalter“,in: Perspektive Bibliothek 5.1: 25–48urn:nbn:de:bsz:16-pb-313858 .
DV-ISA (2016): Umgang mit digitalen Daten inder Wissenschaft: Forschungsdatenmanagementin NRW. Eine erste Bestandsaufnahme, 14. April2016, Version 0.7 [Final] https://www.dh-nrw.de/fileadmin/dh-nrw/PDF/Veroeffentlichungen/DV-ISA-Bestandsaufnahme_FDM.pdf [letzter Zugriff10. August 2016].
Fühles-Ubach, Simone (2013a): „QuantitativeBefragungen“, in: Umlauf, Konrad / Fühles-Ubach, Simone / Seadle, Michael (eds.):Handbuch Methoden der Bibliotheks- undInformationswissenschaft. Bibliotheks-,Benutzerforschung, Informationsanalyse. Berlin:De Gruyter 96–113.
Fühles-Ubach, Simone (2013b): „Online-Befragungen“, in: Umlauf, Konrad / Fühles-Ubach, Simone / Seadle, Michael (eds.):Handbuch Methoden der Bibliotheks- undInformationswissenschaft. Bibliotheks-,Benutzerforschung, Informationsanalyse. Berlin:De Gruyter 114–127.
Fühles-Ubach, Simone / Umlauf, Konrad(2013): „Quantitative Methoden“, in: Umlauf,Konrad / Fühles-Ubach, Simone / Seadle, Michael(eds.): Handbuch Methoden der Bibliotheks-und Informationswissenschaft. Bibliotheks-,Benutzerforschung, Informationsanalyse. Berlin:De Gruyter 80–95.
forschungsdaten.org (2016):Homepage, Unterseite "Umfragenzum Umgang mit Forschungsdaten anwissenschaftlichen Institutionen", http://www.forschungsdaten.org/index.php/
Umfragen_zum_Umgang_mit_Forschungsdaten_an_wissenschaftlichen_Institutionen [letzterZugriff 29. August 2016].
Hochschulrektorenkonferenz(2014): Management von Forschungsdatenals strategische Aufgabe derHochschulleitungen. Empfehlung der16. HRK-Mitgliederversammlung am 13.Mai 2014 in Frankfurt am Main, https://www.hrk.de/uploads/tx_szconvention/HRK_Empfehlung_Forschungsdaten_13052014_01.pdf[letzter Zugriff 29. August 2016].
Hochschulrektorenkonferenz (2015):Wie Hochschulleitungen die Entwicklungdes Forschungsdatenmanagementssteuern können. Orientierungspfade,Handlungsoptionen, Szenarien. Empfehlungder 19. Mitgliederversammlung der HRKam 10. November 2015 in Kiel, https://www.hrk.de/uploads/tx_szconvention/Empfehlung_Forschungsdatenmanagement__final_Stand_11.11.2015.pdf [letzter Zugriff 29.August 2016].
Kramer, Bernd (2014): „Datenflut an Unis:Forscher müssen teilen lernen“, in: SpiegelOnline, 26. Februar 2014, http://www.spiegel.de/unispiegel/jobundberuf/umgang-mit-daten-der-glaeserne-forscher-a-954958.html [letzter Zugriff01. August 2016].
Kronenwett, Simone (2017):Forschungsdaten an der Philosophischen Fakultätder Universität zu Köln (= Kölner Arbeitspapierezur Bibliotheks- und Informationswissenschaft78). Technische Hochschule Köln.
Kronenwett&Adolphs (2016): Homepage,http://www.kronenwett-adolphs.com/de [letzterZugriff 12. August 2016].
Müller, Hendrik / Sedley, Aaron / Ferrall-Nunge, Elizabeth (2014): „Survey researchin HCI“, in: Olson, Judith S. / Kellogg, WendyA. (eds.): Ways of Knowing in HCI. New York:Springer 229–266.
Philosophische Fakultät (2016): Homepage,Unterseite "Fächergruppen", http://phil-fak.uni-koeln.de/9785.html [letzter Zugriff 12. August2016].
Rat für Informationsinfrastrukturen(2016): Leistung aus Vielfalt. Empfehlungen zuStrukturen, Prozessen und Finanzierung desForschungsdatenmanagements in Deutschland.Göttingen, http://www.rfii.de/?wpdmdl=1998[letzter Zugriff 30. August 2016].
Sahle, Patrick / Kronenwett, Simone(2013): „Jenseits der Daten: Überlegungen zuDatenzentren für die Geisteswissenschaftenam Beispiel des Kölner ‚Data Center for theHumanities‘“, in: LIBREAS. Library Ideas 23: 76–96 urn:nbn:de:kobv:11-100212726.
285

Digital Humanities im deutschsprachigen Raum 2017
Schöpfel, Joachim / Prost, Hélène (2016):„Research data management in social sciencesand humanities: A survey at the University ofLille (France)“, in: LIBREAS. Library Ideas 29: 98–112 urn:nbn:de:kobv:11-100238193.
Seadle, Michael (2013): „Entwicklung vonForschungsdesigns“, in: Umlauf, Konrad /Fühles-Ubach, Simone / Seadle, Michael(eds.): Handbuch Methoden der Bibliotheks-und Informationswissenschaft: Bibliotheks-,Benutzerforschung, Informationsanalyse. Berlin:De Gruyter 41–63.
Stäcker, Thomas (2015): „Nocheinmal: Was sind geisteswissenschaftlicheForschungsdaten?“, in: DHdBlog, 06.12.2015,http://dhd-blog.org/?p=5995 [letzter Zugriff 30.Juli 2016].
Universität zu Köln (2016): Homepage,Unterseite "Philosophische Fakultät", http://phil-fak.uni-koeln.de/studieninteressierte.html?&L=0[letzter Zugriff 30. Juli 2016].
Winkler-Nees, Stefan (2011): „Vorwort“,in: Büttner, Stephan / Hobohm, Hans-Christoph / Müller, Lars (eds.): HandbuchForschungsdatenmanagement. Bad Honnef: Bock+Herchen Verlag 5–6.
Visuelle Elementegrafischer Literatur:Aufmerksamkeitszuwendungund objektiveBeschreibung
Laubrock, [email protected]ät Potsdam, Deutschland
Richter, [email protected]ät Potsdam, Deutschland
Hohenstein, [email protected]ät Potsdam, Deutschland
Graphische Romane vereinen als hybrideGattung Aspekte von Literatur und bildenderKunst (McCloud, 1993). Wie interagieren Bildund Text beim Lesen graphischer Literatur undermöglichen das Verstehen des Gesamtwerkes?
Worauf fokussiert die Aufmerksamkeit desLesers? Als Methode zur Beantwortungdieser Fragen ist die Blickbewegungsmessungbesonders geeignet. Blickbewegungen habensich in einer Vielzahl an Studien als valides,nichtreaktives Maß für die Verarbeitung unddas Verstehen von Text und Bild erwiesen,in dem sich zudem auch unbewussteVerarbeitungsprozesse niederschlagen (Findlay& Gilchrist, 2003; Wade & Tatler, 2005).
In früheren Arbeiten (Laubrock, Hohenstein& Thoß, 2016; Dunst, Hartel, HohensteinLaubrock, 2016) haben wir mit Eyetracking-Analysen gezeigt, dass beim Lesen grafischerLiteratur der größte Teil der Aufmerksamkeitdem Text in Sprechblasen und Beschriftungen(Captions) zugewandt wird und nur einrelativ kleiner Teil den originär visuellenGestaltungselementen alloziert wird. Wirdder visuelle Inhalt gar nicht beachtet,oder kann er möglicherweise bereits imperipheren Sehen während der Fixationenauf dem Text verarbeitet werden? Wir hattenbereits berichtet, dass Comics-Expertenden Bildanteil stärker beachten und daraufverstehensrelevante Information extrahieren.In einer neuen Serie von Studien untersuchenwir mittels blickkontingenter Präsentation,ob (a) den Bildanteilen mehr Aufmerksamkeitzugewandt wird, wenn die Vorschau verhindertwird, indem das Bild erst eingeblendet wird,wenn der Blick sich auf ein Panel bewegt und (b)die Aufmerksamkeit andere grafische Elementeauswählt, wenn zwar der visuelle Teil der Panelssichtbar ist, der Text aber erst nach Fokussierungeines Panels eingeblendet wird.
Das visuelle Material wurde auf zweierleiWeise annotiert. Einerseits annotiertenMenschen Personen und einzelne Objekteinnerhalb der Panels. Andererseits versuchenwir eine objektiven Beschreibung des visuellenMaterials mithilfe von Deskriptoren aus demmaschinellen Sehen (Computer Vision), z.B.mittels Farbhistogrammen, lokalem Fourier-Spektrum oder SIFT-Deskriptoren (Lowe,1999). Der Vorteil dieser Beschreibung istneben der Objektivität die skriptgesteuerteAnwendbarkeit auf große Datenmengen, etwadigitalisierte Korpora grafischer Literatur.Vergleichbare Arbeiten aus der Schnittstelle vonKunstgeschichte und Informatik ermöglichenbeispielsweise eine automatisierte Klassifikationvon Kunstrichtungen (Saleh & Elgammal, 2015)und zeigen das Potenzial eines solchen Ansatzesals Stilometrie visueller Merkmale.
Für die Zuordnung der Blickbewegungsdatenauf das Stimulusmaterial nutzen wir die imProjekt entwickelte Graphic Novel Markup
286

Digital Humanities im deutschsprachigen Raum 2017
Language (GNML), eine Erweiterung derComic Book Markup Language (CBML; Walsh,2012). Das Material wurde mit unseremEditor annotiert, für Weiterverarbeitung undstatistische Analyse der Daten nutzten wirein in Entwicklung befindliches R-Paket. Dieobjektive Beschreibung des visuellen Materialsmit Deskriptoren aus dem maschinellen Sehenwurde unter Nutzung von OpenCV (Bradski,2000) und VLFEAT (Vedaldi & Fulkerson, 2008)teils in Python und teils in Matlab implementiert,da für R für diesen Anwendungsbereich keinehinreichend entwickelte Funktionsbibliothekexistiert.
Bibliographie
Bradski, Gary (2000): „The OpenCV library“,in: Dr. Dobb’s Journal of Software Tools 25 (11):120–125.
Dunst, Alexander / Hartel, Rita /Hohenstein, Sven / Laubrock, Jochen (2016):„Corpus Analyses of Multimodal Narrative:The Example of Graphic Novels“, in: DH2016:Conference Abstracts 178–180.
Findlay, John M. / Gilchrist, Ian D. (2003):Active Vision. The Psychology of Looking andSeeing. Oxford: Oxford University Press.
Laubrock, Jochen / Hohenstein, Sven /Thoß, Aalexander (2016): „Moving aroundthe city of glass“, in: DHd 2016: Modellierung -Vernetzung - Visualisierung 186.
Lowe, David G. (1999): „Object recognitionfrom local scale-invariant features“, in:Proceedings of the International Conference onComputer Vision (ICCV'99) 1150–1157.
McCloud, Scott (1993): Understanding comics:the invisible art. Northampton, MA: Tundra.
Saleh, Babak / Elgammal, Ahmed M. (2015):„Large-scale classification of fine-art paintings:Learning the right metric on the right feature“,in: CoRR abs/1505.00855, 1–21 http://arxiv.org/pdf/1505.00855v1.pdf .
Vedaldi, Andrea / Fulkerson, Brian (2008):VLFeat: An open and portable library of computervision algorithms. [Computer Software: http://www.vlfeat.org/ ]
Wade, Nicholas J. / Tatler, Benjamin W.(2005): The Moving Tablet of the Eye: Origins ofmodern eye movement research. Oxford: OxfordUniversity Press.
Walsh, John (2012): „Comic Book MarkupLanguage: An Introduction and Rationale“, in:DHQ: Digital Humanities Quarterly 6 (1).
... warum nicht gleichWikidata?!
Schelbert, [email protected]ät zu Berlin, Deutschland
Das digitale Bildformat verleiht analogenBildsammlungen eine zweite Existenz.Insbesondere aber schafft die Verbindungdes digitalen Formats mit dem Internet einenweitgehend raumunabhängigen universellenBilderpool, der die kaum fassbare Menge derProduktion überhaupt erst sichtbar werden lässt.
Die Mediathek des Instituts für Kunst- undBildgeschichte der HU besitzt eine umfangreicheSammlung historischer Fotografien undDiapositive, die bislang weitgehendunerschlossen ist. Diese wissenschaftlicheLehrsammlung eines traditionsreichenkunsthistorischen Universitätsinstituts,bestehend aus zwischen ca. 1890 und 1970hergestellten Glasdias im Format 8,5 x 10cm istauch hinsichtlich ihres Umfangs von etwa 60.000Stück herausragend.
Einerseits spiegelt die SammlungInteressensschwerpunkte großer, an derBerliner Universität lehrender Fachgelehrterwie Heinrich Wölfflin, Adolph Goldschmidt,Wilhelm Pinder und Richard Hamann wider,andererseits repräsentiert sie den gesamten,an der Universität über Jahrzehnte hinweggeformten Kanon der Kunstgeschichte, derinzwischen auch zu allgemeinem Bildungsgutgeworden ist.
Damit ist diese Sammlung ein typischesBeispiel eines kunsthistorischen Bildbestandes,der sich dadurch auszeichnet, dass er vor allemRepräsentationen von Werken beinhaltet, dieals solche bereits vielfach identifiziert underschlossen sind. Aus diesem Grund bestehtdie Aufgabe zunächst darin, die Bilddateimit bereits vorhandenen Wissensbeständenzu verbinden. Auch die vielen jüngerenAnsätze zum Umgang mit digitalen Bildern -Automatische Bilderkennung, Folksonomy-Tagging, Festlegung von Metadatenstandardseinschließlich der Verwendung vonVokabularen und Klassifikationen, Aufbau vonNormdatenrepositorien oder die Verwendungvon Georeferenzen - haben gezeigt, dass dieseAnsätze jeweils allein kaum befriedigendeErgebnisse liefern. Vielmehr kann derkomplexen Gesamtheit des Bildes wohl nurdie Verbindung mehrerer Methoden gerecht
287

Digital Humanities im deutschsprachigen Raum 2017
werden. Zugleich wird auch deutlich, dassweiterhin die Verbindung der Bilddateienmit (nach wie vor in Textform codierten)Inhaltskonzepten eine zentrale Aufgabe bleibenwird.
Der Beitrag wird sich auf die Fragekonzentrieren, wie diese Inhaltskonzepte inmöglichst pragmatischer Weise bereitgestelltwerden können. Hier stellen sich Fragen derStandardisierung beziehungsweise des Einsatzesvon sogenannten Normdaten.
Im Bereich der sogenannten Normdatengibt es für Kunstwerke – im Unterschied etwazu Personen – kaum ein flächendeckendesAngebot. Es ist auch kaum anzunehmen,dass die hierfür zuständigen Institutionen –in Deutschland etwa die DNB – dem Bedarfwerden ausreichend nachkommen können.Artefakte sind gegenüber Personennormdatenaufgrund ihrer Vielgestaltigkeit grundsätzlichschwerer zu handhaben und, je nach Definition,was alles als verzeichniswürdiges Kunstwerkzu verstehen ist, unter Umständen weitausumfangreicher in der Anzahl. Auch dort wosich einschlägige Institutionen der Aufgabeangenommen haben, bleibt das entweder aufdie nationale Dimenion beschränkt (etwa mitden Datenbanken Merimee oder Joconde inFrankreich, oder dem RKD in den Niederlanden),oder droht unweigertlich unausgewogen undfragmentarisch zu bleiben (CONA – The CulturalObjects Name Authority des Getty ResearchInstitute). Das Deutsche Dokumentatonszentrumfür Kunstgeschichte, Foto Marburg, hat zwarvielfach die Bedeutung von Werknormdatenunterstrichen, jedoch bislang keinenVorschlag für deren Bereitstellung gemacht.Nach heutigem Ermessen kann wohl auchnicht davon ausgegangen werden, dass esmöglich oder sinnvoll ist, ein vollständigesReferenzrepositorium aller Bau- undKunstwerke anzustreben.
Wenn man von dieser Annahme ausgeht,dann ist es aber geradezu notwendig, dassjederzeit kurzfristig Datensätze für jeweilsbenötigte Kunstwerke erzeugt werden können.Hierfür bietet sich ein Datenrepositoriuman, das von der Wikipedia-Community seit2012 parallel zur Wikipedia aufgebaut wird.Dabei ist für die folgenden Überlegungengrundlegend, dass Wikipedia-Artikel zwar inder Regel einem Wikidata-Datensatz zugeordnetsind, dass Wikidata-Datensätze jedoch auchohne Wikipedia-Artikel existieren könnenund somit auch nicht den von der Wikipediageforderten Relevanzkriterien entsprechenmüssen. Auch die – im Forschungskontext oftproblematischen .- Aspekte der inhaltlichen
Aktualität und Gültigkeit der Wikipedia-Artikelspielt keine Roll. Wikidata beschränkt sich aufdie Speicherung von atomaren Statements, diein beliebiger Zahl, in beliebiger Reihenfolgeund mit der Möglichkeit der Neudefinitionvon Aussageparametern im Prinzip von jederPerson erstellt werden können. Dabei steht –ebenso wie in unserem Anwendungsszenario –bei Wikidata der Gedanke der Identifizierungim Vordergrund, indem möglichst vielebereits bestehende „Identifiers“ andererReferenzrepositorien eingegeben werden. DieTatsache der Vielzahl solcher Repositorien (dieim Bibliotheksbereich mit der VIAF-Initiativezusammengefasst werden) relativiert den imDeutschen üblichen Begriff der Normdatenebenso wie den im Englischen üblichen desAuthority File. Beide Begriffe gehen von dernormativen Rolle einer Nationalbibliothekbei der Ansetzung von Personennamen undSchlagwortsystematiken aus. Im Fall vonKunstwerken ist ein normativer Ansatz, der überdie bloße Bezeichnung hinausgeht (und etwaZuschreibung, Datierung, Stilzugeörigkeit etc.festlegen wollte), eher schädlich als nützlich.Vielmehr geht es um die Identifizierung derWerke und deren Verfügbarmachung fürweitere Bildrepositorien und dergleichen.Diese Funktion erfüllt Wikidata, wobei diezusätzlichen inhaltlichen Statements je nachUmständen durchaus verwendet werdenkönnen.
Wikidata kann also als eine Art Meta-Referenzrepositorium fungieren, das zudemSkalierbarkeit im kollektiven Zugriff,Internationalität und Vielsprachigkeit, sowienicht zuletzt Nachhaltigkeit durch eine großeCommunity bietet. Zu berücksichtigen sindfreilich auch die offenen Fragen, etwa danach,welche Probleme in der Benutzbarkeit der Datensich aufgrund der unsystematischen Strukturund der grundsätzlich nicht festgelegtenEntwicklungsoptionen ergeben können.
Als Beispiel wird hierzu ein laufendesDigitalisierungsprojekt für die genanntehistorische Glasdiasammlung an der Humboldt-Universität als Poster vorgestellt, an dem diegenannten Aspekte dargestellt werden können.
Bibliographie
Kohle, Hubertus (2013): DigitaleBildwissenschaft. Glückstadt.
Krause, Celia / Reiche, Ruth (2015):Ein Bild sagt mehr als tausend Pixel?Digitale Forschungsansätze in den Bild- undObjektwissenschaften. Glückstadt.
288

Digital Humanities im deutschsprachigen Raum 2017
Patton, Glenn E. (2010): FunktionaleAnforderungen an Normdaten: Einkonzeptionelles Modell (IFLA Working Groupon Functional Requirements and Numbering ofAuthority Records - FRANAR). München.
Woitas, Kathi (2013): Bibliografische Daten,Normdaten und Metadaten im Semantic Web– Konzepte der Bibliografischen Kontrolleim Wandel. Berliner Handreichungen zurBibliotheks- und Informationswissenschaft 338.Berlin urn:nbn:de:kobv:11-100209272.
WebbasierteMorphemannotationDiachroner Korpora:Ein Weg zu mehrNachhaltigkeit?
Peukert, [email protected]ät Hamburg, Deutschland
Die Annreicherung historischer Texte mitderivationsmorphologischen Informationen istaus der Sichtweise automatisierter Verfahreneine doppelte Herausforderung. Im Gegensatzdazu zeigt die automatische Erkennung vonFlexionen bereits gute Ergebnisse (Dipper 2011,Bollmann et al 2014a,b). Die Herausforderungenlassen sich auf zwei wesentliche Unterschiedezurückführen. Erstens ist die Identifikationeines Derivationsmorphems aufgrund dervielzähligen Wortbildungsmechanismen unddaraus folgender Überlappungsprobleme beinicht agglutinierenden Sprachen algorithmischnicht exakt zu bestimmen (vgl. Givón 1971,Dryer et al 2011, Lehmann 1973) und derzeit nurdurch Abgleich mit einem a priori vorhandenenLexikon überhaupt in Annäherung möglich.Zweitens ändert sich sowohl Form als auchBedeutung eines Morphems über die Zeithinweg, sodass sich daraus eine weitereArt der Überschneidung von Form sowieInhalt (Bedeutung) einzelner Morphemeergeben kann (vgl. Berg 1998, Faiß 1992,Kastovsky 2009). Vorausgesetzt man lässt eineKomplexitätsreduktion durch die Einführungvon Zeitintervallen zu und vernachlässigt sodie relativ langen Zeiträume, in denen sichMorpheme in einer Übergangsphase hin zuneuer Form und Inhalt befinden, folgt darausimmer noch, dass entsprechende Lexika für
jede festgelegte Zeitperiode vorhanden seinmüssen, um größere Textkorpora automatischbearbeiten zu können. Je feinerkörnigerdie Zeitintervalle gewählt werden, destogrößer wird die Anzahl an benötigten Lexika(proportional zur Anzahl der Zeitperioden).Feine Unterteilungen in den Zeitintervallen sindoft notwendig, um in der Folge die beobachtetenSprachwandelmechanismen genauer undursächlich erklären zu können.
Die Lösung dieses Problems liegt demnach inder effizienten Erstellung einer entsprechendenRessource, welche neben dem Lemmamit der Ausweisung der morphologischenBestandteile auch die Zeit erfasst. Neben denmorphologischen Informationen (Wurzel,Position und Anzahl von Präfixen und Suffixen)werden auch die Wortklasse und das Korpuserfasst. Bei Composita gehören zudem Kopf undsemantische Kategorien (dvandva, bahuvrihi,appositional) zum Annotationsschema.Effizienzgewinne können dabei einerseitsdurch eine möglichst geschickte Aufteilungvon standardisierbaren Routineaufgaben,welche Automaten abarbeiten können, undkomplexeren Entscheidungsaufgaben, die einBearbeiter manuell treffen muss, erzielt werden.Andererseits kann dem Bearbeiter bei derEntscheidungsfindung mit der Bereitstellung vonwichtigen Informationen und Komfortabilitätbei der Bedienung und Präsentation geholfenwerden.
Ein Use Case eines solchenWortanalysewerkzeugs konnte mit demMorphilo-Toolset als Stand- A lone-Anwendungausprogrammiert werden. Diese Softwareberücksichtigt beim Abgleich großerTextkorpora mit dem Lexikon die Zeitspanne.Sind für das angegebene Zeitintervall Einträgevorhanden, werden diese automatischzugewiesen. Die übrigen (unbekannten) Typendes Textes werden als neue Lemmata angelegt.Falls ein Lemma in der Vorgängerperiodebereits existiert, wird der aktuelle Eintragmit den Informationen der Vorgängerperiodebelegt und zur Bearbeitung präsentiert.Andernfalls (d.h. der Eintrag ist auch in keinerVorgängerperiode registriert) wird das Tokenmit einer generischen Zerlegung automatisiertin seine morphemischen Bestandteile aufgeteilt.Der Nutzer bestätigt eine dieser Zerlegungenoder nimmt über entsprechende MenüsÄnderungen vor. Erst jetzt werden dieseInformationen persistent abgelegt (vgl. Peukert2012).
Im so etablierten Workflow hat sich zunächstgezeigt, dass die Bearbeitung von englischenTexten aus dem 17. Jahrhundert (PPCMBE,
289

Digital Humanities im deutschsprachigen Raum 2017
Kroch et al 2010) schnell und effizient zubewerkstelligen ist, wenn eine kritische Massean Einträgen bereits vorhanden ist, da das TTRmit zunehmender Textgröße gegen Null strebt,d.h. immer nur wenige unbekannte Wörter injedem neuen Text vorzufinden sind (Baayen1996). Dieser Effekt trat bei der Bearbeitungvon frühen mittelenglischen Texten aus dem 12.Jahrhundert (PPCME2, Kroch and Taylor 2000),nicht auf. Es zeigte sich, dass die fehlendenSchreibstandards von historischen Texten dienotwendige Lemmatisierung scheitern ließenund somit auch ein Abgleich mit dem Lexikonnicht gelingen konnte (vgl. Peukert 2014).
Berücksichtigt man diese beiden Erfahrungen– schnelle Annotation bei kritscher Massean Einträgen und langsame Annoation beifehlenden Standards – bei der Entwicklungvon Lösungsstrategien, trifft man unweigerlichauf den Nachhaltigkeitsgedanken beimRessourcenaufbau, der vorgibt, dass diekostenintensiven Annotationsaufgabenmöglichst nicht mehrfach erledigt, abernachgenutzt werden sollen. Dies impliziert einegemeinschaftlich-synergetische Bearbeitungder Annotationszuweisung, da man die spätereNutzung der Resource mit eigener (sehrgeringer) Annotationsarbeit “bezahlen” kann.Auf diese Weise können annotierte Datenunterschiedlicher Zeiträume gesammelt werden.In der Fortführung dieser Idee ist die Architektureiner webbasierten Komponente entstanden(Abb. 1), bei der ein Multi-User-Design dieAnnotationsarbeit an unterschiedlichen Korporaverteilt und Zuweisungen aus verschiedenenLexika aber der passenden Zeitperiode undSprache erlaubt. Um dem Problem der fraglichenQualität der Annotationen entgegenzuwirken, istes möglich, die Lexika, die man zur Bearbeitungbenötigt, auszuwählen. Möchte man seineigenes Korpus mit derivationsmorphologischenInformationen anreichern lassen, fliesst diejeweils eigens geleistete Annotationsarbeit inden Gesamtdatenbestand ein. Inwiefern diegesammelten Annotationsdaten mit weiterenVerfahren hinsichtlich ihrer Qualität getestet,bewertet und weiter bearbeitet werden können,wird Gegenstand einer weitergehendenDiskussion sein.
Abb. 1: Architekturentwurf zur Integration desAnnotationswerkzeugs in eine webbasierteAnwendung im Mehrnutzerbetrieb
Für die Lösung der noch nicht endgültigfertiggestellten Komponente (in Abb. 1mit “Quality Control” bezeichnet) werdenstatistische Verfahren in Anlehnung an dasmaschinelle Lernen vorgestellt, die sich an zweiunterschiedlichen Strategien ausrichten. Erstenssteht die häufigkeitsbedingte Analyse gleicheroder ähnlicher Einträge der verschiedenenDatenbestände der Nutzer (User_1, …, User_n)im Vordergrund. Diese Daten werden genutzt,um Ausreißer und falsche Annotationen mittelsautomatisierter statischer Signifikanztests zuidentifizieren. Dieser Ansatz wird mit einernutzerorientierten Strategie kontrastiert. Diesezweite Strategie bezieht die Verhaltensdatender Nutzer ein, d.h. wie oft werden welcheDatenbestände anderer Nutzer für dieanstehende Annotation ausgewählt. Auchhier basiert der Ausschluss von vermeindlichfehlerhaften Daten mittels eines vorherfestgelegten Signifikanzniveaus. Die mit einerdieser Strategie bereinigten Datenbeständekönnten danach in den Hauptdatenbestand(Morphilo_DB in Abb. 1) überführt werden.
Bibliographie
Baayen, Harald (1996): „The effects oflexical specialization on the growth curve of thevocabulary“, in: Computational Linguistics 22:455–480.
Berg, Thomas (2009): Structure in language: Adynamic perspective. New York: Routledge.
Bollmann, Marcel / Petran, Florian /Dipper, Stefanie / Krasselt, Julia (2014a):„CorA: A web-based annotation tool for historicaland other non-standard language data“, in:
290

Digital Humanities im deutschsprachigen Raum 2017
Proceedings of the 8th Workshop on LanguageTechnology for Cultural Heritage, Social Sciences,and Humanities (LaTeCH) 86–90.
Bollmann, Marcel / Petran, Florian /Dipper, Stefanie (2014b): „Applying Rule-BasedNormalization to Different Types of HistoricalTexts — An Evaluation“, in: Zygmunt Vetulaniand Joseph Mariani (eds.): Human LanguageTechnology Challenges for Computer Scienceand Linguistics. 5th Language and TechnologyConference, LTC 2011. Revised Selected Papers.Lecture Notes in Computer Science 8387.Springer 166–177.
Dipper, Stefanie (2011): „Morphological andPart-of-Speech Tagging of Historical LanguageData: A Comparison“, in: Journal for LanguageTechnology and Computational Linguistics.Special Issue 26 (2): 25–37.
Dryer, Matthew S. / Haspelmath, Martin(eds.). (2011): The world atlas of languagestructures Online. München: Max Planck DigitalLibrary.
Faiß, Klaus (1992): English historicalmorphology and word-formation: Loss versusenrichment. Trier: Wissenschaftlicher Verlag.
Givón, Talmy (1971): „Historical syntax andsynchronic morphology: An archaeologist’s fieldtrip“, in: Chicago Linguistic Society 7: 394–415.
Kastovsky, Dieter (2009): „Diachronicperspectives“, in: Lieber, Rochelle / Štekauer,Pavol (eds.): The Oxford handbook ofcompounding. Oxford: Oxford University Press321–340.
Kroch, Anthony / Santorini, Beatrice /Diertani, Ariel (2010): The Penn-Helsinki ParsedCorpus of Modern British English (PPCMBE).Department of Linguistics, University ofPennsylvania: CD-ROM, first edition http://www.ling.upenn.edu/hist-corpora/ .
Kroch, Anthony / Taylor, Ann (2000): ThePenn-Helsinki Parsed Corpus of Middle English(PPCME). Department of Linguistics, Universityof Pennsylvania: CD-ROM, first edition http://www.ling.upenn.edu/hist-corpora/ .
Lehmann, Winfred P. (1973): „A structuralprinciple of language and its implications“, in:Language 49 (1): 47–66.
Peukert, Hagen (2014): „The MorphiloToolset: Handling the Diversity of EnglishHistorical Texts“, in: Ammermann, Anne / Brock,Alexander / Pflaeging, Jana / Schildhauer, Peter(eds.): Facets of Linguistics: Proceedings of the14th Norddeutsches Linguistisches Kolloquium2013. Frankfurt: Peter Lang 161–172.
Peukert, Hagen (2012): „From Semi-Automatic to Automatic Affix Extraction inMiddle English Corpora: Building a SustainableDatabase for Analyzing Derivational Morphology
over Time“, in: Jancsary, Jeremy (ed.): EmpiricalMethods in Natural Language Processing, Wien,Scientific series of the ÖGAI 413–23.
Where the words are:a visual interactiveexploration of plantsnames
Therón, [email protected] de Salamanca, Spanien
Dorn, [email protected]Österreichische Akademie der Wissenschaften,Österreich
Seltmann, [email protected]Österreichische Akademie der Wissenschaften,Österreich
Benito, [email protected] de Salamanca, Spanien
Wandl-Vogt, [email protected]Österreichische Akademie der Wissenschaften,Österreich
Gabriel Losada Gómez, [email protected] de Salamanca, Spanien
Wo die Wörter sind: eine visuell-interaktive Erforschung von Pflanzennamen
In den Digital Humanities werdenhäufig Visualisierungsmethoden eingesetzt,um bestimmte Trends, Beziehungenoder Inhalte innerhalb oder zwischenverschiedenen Datensätzen hervorzuheben.Oft werden gut etablierte und weitverbreitete Arten graphischer Darstellungvon Daten herangezogen, wie Verbert(2015) gezeigt hat. Der Einsatz innovativerVisualisierungsmethoden für dieDatenerforschung und den Datenzugriff istjedoch bei Humanities-Projekten, die sich mit
291

Digital Humanities im deutschsprachigen Raum 2017
nicht-numerischen Daten beschäftigen, nochrelativ selten. In diesem Beitrag stellen wir einVisualisierungstool vor, das im Rahmen des DH-Projekts exploreAT! – exploring Austria’s culturethrough the language glass entwickelt wird, underläutern dessen Anwendung am Beispiel derPflanzennamen-Sammlung für das Wörterbuchder bairischen Dialekte in Österreich.
exploreAT! (vgl. Wandl-Vogt et al, 2015)bietet unterschiedliche Einblicke in dievielfältige Beschaffenheit der deutschenSprache in Österreich, durch explorativesErforschen mittels einer Synthese von digitalenInfrastrukturen, Lexikographie, visuellerAnalyse und Citizen Science. Das Projektbasiert auf einer Sammlung von Daten zuden bairischen Dialekten in Österreich ausdem frühen 20. Jahrhundert aus der Regionder ehemaligen österreichisch-ungarischenMonarchie. Die Datenerhebung erfolgteursprünglich mittels Fragebögen, die eineVielzahl von Themen aus dem Alltag abdecken.Die gesammelten Daten bestehen aus rund200.000 Stichwörtern in geschätzten 4Millionen Datensätzen. Teile davon wurdenals fünfbändiges Wörterbuch mit etwa 50.000Stichwörtern (WBÖ), und Teile als Datenbank(DBÖ) ausgegeben. Innerhalb des Projekts gibt esvier spezifische, aber miteinander verbundeneArbeitsbereiche: kulturelle Lexikographie,semantisch-technologieorientierteForschungsinfrastrukturen, visuelle Analyseund Bürgerwissenschaften. Des Weiterenwerden use-cases für spezifische Themen wiePflanzennamen, Farben oder Lebensmittelnentwickelt. TEI / XML Schnittstellen werdeneingesetzt, um die Organisation von Metadaten,Konzepten und linguistischen Daten zuverbessern. Darüber hinaus ist vorgesehen,weitere Zugangspunkte zur Arbeit mitLOD zu schaffen, ontologische Ressourcenzu nutzen und damit die Visualisierungvon konzeptionellen und semantischenInformationen zu gewährleisten.
Mit Hilfe des vorgestellten visuellenAnalysetools werden weitere Einblicke in diekomplexe Struktur dieser Dialektdaten gegeben,wobei ein intuitiver und leicht zugänglicherAnsatz vorgesehen ist. In diesem Beitrag nehmenwir Pflanzennamen als exemplarischen Fallfür die visuelle Exploration, Analyse undDarstellung von Datenstrukturen.
Der Prototyp dieses Tools basiert aufeiner Treemap-Visualisierungsmethode (vgl.Shneiderman, 1992), da diese eine kompakte Artund Weise für die Übertragung von Hierarchienermöglicht. Der Zweck des Tools bestehtdarin, ein Mittel zur interaktiven Erforschung
der verfügbaren Daten bereitzustellen,so dass der Benutzer Verständnis dafürgewinnt, wie das Wissen, das sich auf einbestimmtes Wort (oder eine Zeichenkette)bezieht, in der Datenbank "gespeichert"ist, wobei die jeweiligen Lemmata mit derBenutzerabfrage zusammenhängen. Abgesehenvon der Darstellung des resultierenden Sets vonLemmata, bauen wir eine Hierarchie je nachKontext der Lemmata (in diesem Fall sind wirdaran interessiert, die Lemmata in Bezug aufverschiedene Pflanzenarten zu gruppieren).Deshalb verwenden wir die beiden wichtigstenvisuellen Merkmale von Treemaps: a) dasTreemap-Layout (basierend auf einem Satzvon verschachtelten Rechtecken, wobei jedesRechteck einen Zweig der Hierarchie darstellt,der dann mit kleineren Rechtecken, welcheUnterzweige darstellen, gekachelt wird) und b)die Fläche jedes Rechtecks (die proportional zurGröße der Daten ist).
Da in diesem Prototyp Pflanzennamen vongrößter Bedeutung sind, aber dem Benutzer, dereventuell mit den wissenschaftlichen Namen derPflanzen nicht vertraut ist, wichtige Informationverborgen bleiben könnte, entschieden wir unsfür eine visuelle Art den Kontext (Pflanzen) derLemmata, die in Zusammenhang mit der Abfragestehen, zu vermitteln: wir verwenden den Flickr-Webdienst, um Fotos abzurufen, die mit demwissenschaftlichen Namen der Pflanze versehensind (siehe Abbildung 1).
Abbildung 1: Beispiel für eine visuelleDarstellung von Pflanzennamen mitverschachtelten Rechtecken.
Als Ergebnis unseres visuellen Ansatzes kannder Benutzer die Verteilung der Lemmata inAbhängigkeit von den Pflanzen, auf die sie sichbezieht, verstehen (jedes Rechteck enthält dasabgerufene Foto einer bestimmten Pflanze miteinem Bereich entsprechender Größe, die davonabhängt, wie viele Lemmata in Zusammenhangdamit stehen). Der Benutzer kann dann auf dasRechteck seiner Wahl klicken, um tiefer zu gehen
292

Digital Humanities im deutschsprachigen Raum 2017
und alle relevanten Informationen für die mitdieser Pflanze zusammenhängenden Lemmatazu erhalten (siehe Abbildung 2).
Abbildung 2: Beispiel für die Exploration vonPflanzennamen-Lemmata in einem bestimmtenRechteck, in diesem Fall Vaccinium myrtillus;Heidelbeere, Schwarzbeere, Blaubeere (sieheAbbildung 1).
Schließlich öffnen sich künftige Arbeitsfelderdank der Tatsache, dass dieser visuelle Ansatzauch noch gültig ist, wenn wir die Lemmatanach anderen Kriterien (d.h. nach einermehrstufigen Hierarchie) gruppieren. ZumBeispiel könnte man zuerst die Lemmata nachPflanze gruppieren; dann könnte man füreine bestimmte Pflanze die dazugehörigenLemmata nach Zeit gruppieren, die wiederumnach Regionen gruppiert werden. Mit diesenverschiedenen Arten der Gruppierung könnendiverse andere Daten mit einer ähnlichenstrukturellen Beschaffenheit in derselben Weisevisualisiert und analysiert werden. Dies würdeunser Tool vielseitig und auch offen für andereDaten, nicht nur Pflanzennamen, machen.
Bibliographie
Verbert, Karen (2015): „On the Use ofVisualization for the Digital Humanities“ in:DH2015: Global Digital Humanities.
Wandl-Vogt, Eveline / Kieslinger,Barbara / O’Connor, Alexander / Theron,Roberto (2015): „exploreAT! Perspektiveneiner Transformation am Beispiel eineslexikographischen Jahrhundertprojekts“, in: DHd2015: Von Daten zu Erkenntnissen.
Shneiderman, Ben (1992): „Tree visualizationwith tree-maps: 2-d space-filling approach“, in:ACM Transaction on Graphics (TOG) 11 (1): 92-99.
Zukünftiger Teil einesFachinformationsdienstes:Eine Datenbank zurFachgeschichte derdeutschsprachigenMusikwissenschaftzwischen ca. 1810 undca. 1990, projektiert amMax-Planck-Institut fürempirische Ästhetik,Frankfurt am Main
van Dyck-Hemming, [email protected] Planck-Institut für empirische Ästhetik,Deutschland
Die Musikwissenschaft unter dem Namen‚Musikwissenschaft‘ ist eine relativ jungeDisziplin an den Universitäten: erst abden zwanziger Jahren des 19. Jh. wurdenihr Lehrstühle zugestanden und nicht vorden 1880er Jahren Institute gegründet. Sieerlebte einen großen Aufschwung nach derJahrhundertwende und ließ sich in weiten Teileninstrumentalisieren im Nationalsozialismus.Wie andere Disziplinen hat auch dieMusikwissenschaft lange gebraucht, um sichdie Selbstverständlichkeit fachgeschichtlicherSelbstreflexion zuzugestehen (Gerhard 2000).Seit den 1990er Jahren jedoch wachsenForschungsinteresse und -output sehr deutlichan.
Davon inspiriert wurde 2014 am neugegründeten Max-Planck-Institut für empirischeÄsthetik in Frankfurt am Main ein Projektkonzipiert und etabliert, das zum Einen diePflege eines aktuellen Forschungsnetzwerkeszum Thema ‚Fachgeschichte in derMusikwissenschaft‘, zweitens die Förderung vonEinzelstudien und drittens die Bereitstellung vonQuellen und Forschungsergebnissen vorsieht.Als vierter Teil des Projektes ist geplant, mitder in der Musikwissenschaft relativ neuerarbeiteten Basis fachhistorischer Daten undvor dem Hintergrund der neueren und älteren
293

Digital Humanities im deutschsprachigen Raum 2017
soziologischen Netzwerkforschung die Datenvon fachgeschichtlich in Erscheinung getretenenPersonen und Institutionen (Universitäten,Akademien, Vereine, Verlage etc.) zu sammelnund miteinander sowie zu Art und Mengeder mit diesen Daten zusammenhängendenVeröffentlichungen in Beziehung setzen (vanDyck-Hemming/ Wald-Fuhrmann 2016).
Das Projekt dient der unumkehrbarenVerankerung historiographischer Reflexion inder Musikwissenschaft und so der Erweiterungund Verwissenschaftlichung musikologischerZugänge. Im Sinne von Ludwik Fleck (1935)und Thomas Kuhn (1967), die vom notwendigenZusammenhang zwischen dem Inhalteiner Wissenschaft und ihren historischenErkenntnisprozessen ausgingen, soll diemusikhistoriographische Datenbank keinLeistungsindex und keine Ahnentafel derMusikwissenschaft werden, sondern eine valideund nachprüfbare Datenbasis zusammenstellen,die präzise Darstellungen von Prozessen,Netzwerken und Verteilungen ermöglicht.
Mittels der sich Standards und Normdatenzunutze machenden, relationalen Datenbankwerden Thesen generiert werden könnenunter anderem in Bezug auf Fragen nach derExistenz und Art von Personennetzwerken inder Musikwissenschaft, nach Kontinuitätenoder Veränderungen musikwissenschaftlicherForschungspräferenzen, nach Abhängigkeitenzwischen zeitgeschichtlichen Veränderungenund der Institutionalisierung einer neuartigenWissensdisziplin. Die Ergebnisse sollenanschaulich visualisiert und dazu auch in Zeitund (historischen) Raum dimensioniert werden.Besonderer Wert wird gelegt auf technischniedrigschwellige Benutzeroberflächender schließlich öffentlich zugänglichenDatenbank bei gleichzeitig hohem Anspruchan Transparenz und Überprüfbarkeit vonQuellen und Verfahren. Teil des Konzeptsist auch, dass die weitere Befüllungdurch Fachwissenschaftlerinnen undFachwissenschaftler unter redaktionellerModeration erfolgen kann.
Als natürliche Partner dieses Projektes habensich Bibliotheken erwiesen: Durch mit derinstitutseigenen Bibliothek und den Verfahrender Deutschen Nationalbibliothek abgestimmteWorkflows wird sichergestellt, dass die mitfachgeschichtlichem Filter gewählten Personenund Institutionen Bestandteile der GemeinsamenNormdatei sind; gegebenenfalls werden alsErgebnis unserer Recherchen GND-Datensätzekorrigiert, ergänzt oder erstellt.
Über die GND hinausgehende Informationenwie Relationen und Beziehungsbeschreibungen
etc. nimmt unsere Datenbank außerdemauf. Alle Datensätze werden auf dieQuellen rückführbar sein; bislang in Formbibliographischer Nachweise.
Forschungspräferenzen sollenhauptsächlich über die Auswertung derSchlagworte und Klassifikationen vonmusikwissenschaftlichen Publikationenerfasst werden. Diese Bibliotheksdaten stelltuns die Musikabteilung der BayerischenStaatsbibliothek (BSB) zur Verfügung. Mit ihrwerden das Datenmodell sowie technischeVoraussetzungen und Entscheidungenabgestimmt und hinsichtlich der Realisierungauf allen Ebenen kooperiert: Die BSB führteseit Jahrzehnten den SammelschwerpunktMusikwissenschaft, besitzt umfassendeund intersubjektiv abgesicherte Kompetenzin der Formal- und Inhaltserschließungvon Publikationsdatensätzen und hat indiesem Rahmen auch bereits Vorarbeitenzu einer Ontologie der Musikwissenschaftgeleistet, an die wir uns anschließen wollen.Für die Fachöffentlichkeit stellt die BSBseit einigen Jahren das Webportal und dieInfrastruktur ‚FachinformationsdienstMusik‘ ( https://www.vifamusik.de ) zurVerfügung. In diesem Rahmen soll auchdie Datenbank zur Fachgeschichte derMusikwissenschaft implementiert und insgesamtoder in Teilen von der BSB gehostet werden.Ähnlich dem Suchportal BSB opac plus –eine Eigenentwicklung der BSB ( https://opacplus.bsb-muenchen.de/ ) – könnte diefachgeschichtliche Datenbank funktionieren– mit erweiterten Funktionen und sinnvollenVisualisierungsmöglichkeiten. Und wie imFall eines Bibliothekssuchportals wird diePerspektive auf weitere Anwendungenaußerhalb der Musikwissenschaft berücksichtigt.
Das Projekt am MPIEA ist mit einer WissMA-Stelle für 10 Jahre sowie Hilfskraft-Stellenausgestattet; geleitet wird es aber von derunbefristet eingesetzten Direktorin derAbteilung Musik. Nachhaltige öffentlicheVerfügbarkeit des in 10 Jahren zu erarbeitendenDatenbestandes verspricht darüber hinaus dasEinpflegen von Teilen der DB in die GemeinsameNormdatei, die präventive Kooperation mit derBayerischen Staatsbibliothek als mindestensebenso langfristig ausgerichteter und innachhaltiger Datenpflege erfahrene Institutionund die Implementierung des Webzugangsim Rahmen eines Fachinformationsdienstes.Über die Fertigstellung hinausreichendeDatenaktualität und beständige Erweiterungdes Datenbestandes erwarten wir uns von der
294

Digital Humanities im deutschsprachigen Raum 2017
Bereitstellung eines Zugangs für registrierteMusikwissenschaft Treibende.
Projektleitung: Dr. Melanie Wald-Fuhrmann(Direktorin Abteilung Musik),Projektkoordination: Dr. Annette van Dyck-Hemming (wiss. MA)
Bibliographie
Gerhard, Anselm (ed.) (2000):Musikwissenschaft – eine verspätete Disziplin.Stuttgart.
van Dyck-Hemming, Annette / Wald-Fuhrmann Melanie (2016): „Vom Datum zumhistorischen Zusammenhang. Möglichkeiten undGrenzen einer fachgeschichtlichen Datenbank“,in: Bolz, Sebastian / Kelber, Moritz / Knoth, Ina /Langenbruch, Anna (eds.): Wissenskulturen derMusikwissenschaft. Generationen – Netzwerke –Denkstrukturen. Bielefeld: transcript 261-278.
Fleck, Ludwik (2015): Entstehung undEntwicklung einer wissenschaftlichen Tatsache:Einführung in die Lehre vom Denkstil undDenkkollektiv. Frankfurt am Main 10. Auflage[Basel 1935].
Kuhn, Thomas S. (2014): Die Strukturwissenschaftlicher Revolutionen. Frankfurt amMain 24. Auflage.
Zwei grundlegendeFragen der digitalenNachhaltigkeit:Wie können wirdie heterogenenForschungsfragen unddie Community bei derVerfügbarmachungvon Forschungsdatenmiteinbeziehen?
Odebrecht, [email protected]ät zu Berlin, Deutschland
Dreyer, [email protected]ät zu Berlin, Deutschland
Lüdeling, [email protected]ät zu Berlin, Deutschland
Krause, [email protected]ät zu Berlin, Deutschland
Zielstellung
Digitale Nachhaltigkeit verstehen wir alseine komplexe Anforderung, die aus besondersvielen Blickwinkeln betrachtet werden kannund sollte. Wir stellen mit dem LAUDATIO-Projekt 1 eine Möglichkeit vor, digitaleNachhaltigkeit herzustellen, in dem wir einenunabhängigen und freien Zugriff auf historischeKorpora zum Zweck der Wiederverwendungfür Forschungszwecke, die über diejenigenhinausgehen, für die die Daten ursprünglichgesammelt wurden, ermöglichen. Eine sodefinierte digitale Nachhaltigkeit realisierenwir, in dem wir eine Vielzahl an verschiedenen,teils sehr unterschiedlichen historischenKorpusdaten inklusive einer umfangreichenaber einheitlichen Dokumentation, die ihreErschließbarkeit in Bezug auf konkreteNutzungsszenarien gewährleistet, bereitstellen.Aus dieser Arbeit zeigt sich, dass eineinterdisziplinäre und insbesondere lokaleinstitutionelle Zusammenarbeit mit denKorpuserstellern notwendig ist, die einenengen kommunikativen Austausch von Zielenund Anforderungen diesbezüglich sowie eineIdentifikation von möglichen Kooperationenerst ermöglicht. Digitale Nachhaltigkeit definiertsich dementsprechend aus der jeweiligenPerspektive der Daten, der Dokumentation undder Institutionen ein wenig anders. Diese dreiPerspektiven und deren Zusammenspiel inBezug auf die digitale Nachhaltigkeit wollen wiranhand von historischen Korpora (vgl. Claridge2008; Kytö 2011; Gippert und Gehrke 2015)diskutieren und an einem Best-Practice-Beispieleiner interdisziplinären Zusammenarbeitder Philosophischen Fakultät und demRechenzentrum der Humboldt-Universität zuBerlin (HU) erklären.
295

Digital Humanities im deutschsprachigen Raum 2017
Heterogenität vonForschungsdaten
Die vielfältige Datenlandschaft in denGeisteswissenschaften stellt eine großeHerausforderung in Bezug auf die digitaleNachhaltigkeit dar, da es unterschiedlicheDatenmodelle und -formate und verschiedeneAufbereitungs- und Analyseverfahren gibt, diealle aus immer neuen Nutzungsszenarien undihren Forschungsfragen, resultieren. In diesemSinne verstehen wir die Arbeit mit Korpora alseine innovative, fortlaufende, wissenschaftlicheArbeit, die sich nicht ausschließlich aufexistierende Standards stützen kann (auch wennsolche Standards natürlich immer beachtetwerden müssen). Es werden daher zusätzlichandere, neue Forschungsdatenmodelle und -formate sowie Ressourcentypen entwickeltund auf die unterschiedlichsten Weisen weiter-und wiedergenutzt. Beispielsweise werden inden Projekten, die LAUDATIO unterstützt, eineVielzahl an allein XML-basierten Formaten (nachz.B. Dipper 2005; Schmidt und Wörner 2009;Romary et al. 2015; TEI Consortium 2015) sowieCSV-basierte Formate (nach z.B. Nivre, Hall undNilsson 2004; Krause und Zeldes 2016) für dieErstellung von historischen Korpora genutzt.Daneben finden auch und graphbasiertenLösungen (nach z.B. Ide und Suderman 2014)sowie proprietäre Formate, wie bei Ágel undHennig (2007) 2 , und immer häufiger JSON-basierte Formate wie bei Vertan et al. (2016)Anwendung. Zusätzlich dazu können Korpora inmehreren Formaten vorliegen, vor allem wennKorpora in einer Mehrebenenarchitektur (vgl.Romary und Ide 2004; Lüdeling 2012) entworfenund verschiedene Formate für unterschiedlicheAbschnitte des Forschungsdatenzyklus (vgl.Rümpel 2011) genutzt werden.
Der innovative Charakter derKorpuserstellung zeigt sich neben denverwendeten Formaten auch in denAnnotationsrichtlinien: Einige Formate wieTIGER-XML (Romary et al. 2015) und tcf (Heidet al. 2010) legen die Anzahl und die Bedeutungder Annotationen inklusive ihrer Tagsets fest,andere wie TEI-XML (TEI Consortium 2015)lassen Spielraum in der Serialisierung undin der Anwendung, in dem es beispielsweisemehrere valide Möglichkeiten gibt, Autoren ineinem Dokument auszuweisen. 3 Wieder andereFormate wie EXMARaLDA-XML (Schmid undWörner 2009) oder PAULA-XML (Dipper 2005)geben keinerlei solcher Beschränkungen vor.
Insbesondere bei solchen Formaten mitgrößtmöglichem Spielraum für Interpretationenin Form von Annotationen zeigt sich dieVielfältigkeit der korpusbasierten Forschung.Ein typisches Annotationsbeispiel fürhistorische Korpora sind Normalisierungen.Viele Korpora besitzen eigene Richtlinienfür die Normalisierung, vgl. zum Beispiel fürhistorisches Deutsch Jurish (2010), Bollmannet al. (2012); Odebrecht et al., (eingereicht).Auch für verschiedene Forschungsfragenwesentliche Kategorisierungen wie Wortartengibt es annähernd für jedes historischeKorpus eine eigene Lösung. So werdenbeispielsweise de-facto-Standards wie das STTS(Schiller et al. 1999) jeweils für ein Korpusangepasst, z.B. Dipper et al. (2013) 4 oderFürstinnenkorresondenzkorpus 5 .
Diese Beispiele zeigen, dass sich Korporadesselben Formats und ein Korpus, das inverschiedenen Formaten vorliegt, in Bezug aufihre Annotationen stark unterscheiden können.
Ausgehend von dieser Datenlage erscheintdie Nachvollziehbarkeit des Lebenszyklus derKorpora als ein weiterer wesentlicher Faktor fürdie digitale Nachhaltigkeit. Welche der bishergenutzten Formate und Annotationskonzeptesich langfristig durchsetzen, welche Formatewie technisch unterstützt und welche neuenLösungen entwickelt werden, hängt dannim Wesentlichen von der Entwicklung derkorpusbasierten Forschung ab. Daher setzenwir eine Archivierung und Dokumentation allerverwendeten Formate und Annotationen einesKorpus in LAUDATIO um.
Metadaten
Über einheitliche extensive Metadatendieser heterogenen Korpusdaten und derenLebenszyklus kann eine umfangreicheKorpusdokumentation sowie eine einheitlicheSuche und ein gezielter Zugriff übereine Plattform auf die Forschungsdatenerstellerunabhängig gewährleistet werden(Bird und Simons 2001; Broeder et al. 2010;Burnard 2013; Hedges et al. 2013; Odebrechtet al. 2015). Die relevanten Kriterien für dieDokumentation und die Suche leiten sichaus den Wiederverwendungsszenarien ab(Odebrecht 2014). Um eine überfachlicheSuche zu ermöglichen, wird in LAUDATIOeine technisch-abstrakte Modellierung derMetadaten eingesetzt, um die fachspezifischenKonzepte von Korpora überfachlich abzubilden(Odebrecht 2015). Neben den deskriptiven
296

Digital Humanities im deutschsprachigen Raum 2017
Metadaten sind für eine nachhaltigeVorhaltung von Forschungsdaten auchadministrative, strukturelle, technische undArchivierungsmetadaten relevant (vgl. Xieund Matusiak 2016; Solodovnik 2011; NISO2004), die für eine technische Infrastrukturberücksichtigt werden müssen, um dieNachvollziehbarkeit über längere Zeiträumeund wechselnde Anwendergruppen hinweggewährleisten zu können. So ermöglicht daseinheitliche Metadatenmodell eine extensiveund transparente Informationsarchitekturfür die unterschiedlichen Ressourcen, waswiederum ein Baustein für deren digitaleNachhaltigkeit darstellt.
Institutionelle(Zusammen-)Arbeit
Bedingt durch die unterschiedlichenSichtweisen und Anforderungen zur digitalenNachhaltigkeit aus den Fachdisziplinen unddurch die technische Infrastruktur sindLösungen nur im Team und in Zusammenarbeitunterschiedlicher Kompetenzen plan-und erstellbar. Im Beispiel ist für denerstellerunabhängigen Zugang zu historischenKorpora die enge Zusammenarbeit zwischenden FachwissenschaftlerInnen und LAUDATIOerforderlich. Der Computer- und Medienservice(CMS) und die Arbeitsgruppe Korpuslinguistikam Institut für deutsche Sprache und Linguistikder HU setzen mit dem LAUDATIO-Projekteinen Schwerpunkt auf eine enge institutionelleZusammenarbeit mit den verschiedenenArbeitsgruppen der philosophischen Fakultät,in dem es die Anforderungen für die digitaleNachhaltigkeit von Forschungsdaten der Fakultätmit den ForscherInnen erarbeitet und umsetztund in Bezug auf die Hochschule als Ganzes ineinen Entwicklungsrahmen einbettet (Dreyerund Vollmer 2016). Der Betrieb des LAUDATIO-Repositoriums wird nach Ende des Projektes,in dem Entwicklungen und Anpassungen amSystem vorgenommen werden, weiterhindurch das CMS sowie durch die ArbeitsgruppeKorpuslinguistik am Institut für deutscheSprache und Linguistik gewährleistet. Um dieheterogene Datenlandschaft zu verstehen,die umfassende Dokumentation zu erstellenund die neuen Entwicklungen aufzunehmen,erweist sich eine lokale Zusammenarbeit überdie Fakultäten hinweg als sehr vorteilhaft. Sobestehen enge Kooperationen unter anderemmit Projekten
• der Sprachgeschichte: DDD-AD 6 , HIPKON 7 ,DDB 8 , Fürstinnenkorrespondenzkorpus 9
• der Germanistik: Märchenkorpus 10 undRIDGES 11
• der Slawistik: “Korpuslinguistik unddiachrone Syntax: Subjektkasus, Finitheit undKongruenz in slavischen Sprachen” 12
die jeweils sehr unterschiedlicheArbeitsweisen und Zielrichtungen haben. Durchdiese Synergiebildung können Projekte ohnegesonderte Finanzierung oder Ressourcennach ihrem Projektende durch eine genaueKenntnis der Forschungsdatenlandschaft ineiner Institution identifiziert und unterstütztwerden. Die durch die Förderer (z.B.Deutsche Forschungsgemeinschaft 2015) oderUniversitäten (z.B. Humboldt-Universitätzu Berlin 2014) vorgegeben Richtlinien zurVeröffentlichung und Archivierung vonProjektergebnissen können so ebenfallsberücksichtigt werden.
Mit diesem Ansatz können gleichzeitig zweiZiele erreicht werden: Die Projekte müssensich keinen umfangreichen semantischenAnforderungen unterwerfen und können sichfrei ausdrücken. Gleichzeitig können sie ihrefachspezifischen Anforderungen direkt andie Arbeitsgruppe Korpuslinguistik bzw. anden CMS richten. Andersherum können dieKorpusprojekte in Umfragen zur gewünschtenAnforderungen und Softwarelösungendirekt befragt und in die Entwicklung miteinbezogen werden. 13 Auf diese Art findet einCommunity-Aufbau statt, der sich nicht nur übergemeinsame technische Plattformen definiert,sondern rein über die inhaltliche Gemeinsamkeitder Arbeit mit historischen Korpora und somitauch über disziplinäre Grenzen hinweg.
Einordnung undSchlussfolgerungen
Der hier vorgestellte Weg, digitaleNachhaltigkeit von Forschungsdaten zuermöglichen, stützt sich auf eine Spezialisierungauf einen bestimmten Typ von Forschungsdaten- historisches Korpus - und grenzt sich so vonAnsätzen wie Zenodo 14 und dem VirtualLanguage Observatory (Van Uytvanck 2012) ab,die keine deutliche Eingrenzung hinsichtlich derDaten und deren Nutzungsszenarien machen.
Weiterhin zielt unsere Strategie auf dieUnterstützung der Diversität der genutzten
297

Digital Humanities im deutschsprachigen Raum 2017
Formate und Konzepte, die sich von den TEIspezialisierten Ansätzen wie dem DeutschenTextarchiv (Geyken 2013) und Textgrid (Hedgeset al. 2013) unterscheiden.
Die Korpusersteller selbst nutzen LAUDATIOauch mehr und mehr, um ihre eigenen neuenVersionen der historischen Korpora unddamit ihren wissenschaftlichen Fortschritt zuveröffentlichen. Dass unser Ansatz, sich aufdie erstellerunabhängige Wiederverwendungvon Korpora als eine Strategie für digitaleNachhaltigkeit zu fokussieren, auch außerhalbder Institution funktioniert, zeigt Dumont (2016).
Um die unterschiedlichen Entwicklungenund Innovationen bei der Korpuserstellungzu identifizieren, kennenzulernen und zudokumentieren, ist eine enge, auf eine reinfachliche Ebene bezogene Zusammenarbeit mitder Community notwendig, die wir angefangenhaben, im Rahmen der Philosophischen Fakultätder HU aufzubauen.
Fußnoten
1. LAUDATIO steht für Long-term Access andUsage of Deeply Annotated Informa tion.www.laudatio-repository.org . Zugriff am16.08.2016.2. Ágel, Vilmos; Hennig, Mathilde; KAJUK(Version 1.1), Justus-Liebig-Universität Gießen.http://www.uni-giessen.de/kajuk/index.htm.3. Wie es zum Beispiel mit den Element <author>möglich ist, vgl. http://www.tei-c.org/release/doc/tei-p5-doc/de/html/ref-author.html Zugriff am19.08.2016.4. Donhauser, Karin; Gippert, Jost;Lühr, Rosemarie; ddd-ad (Version 0.1),Humboldt-Universität zu Berlin. https://referenzkorpusaltdeutsch.wordpress.com/.http://hdl.handle.net/11022/0000-0000-7FC2-75. Lühr, Rosemarie; Faßhauer, Vera;Prutscher, Daniela; Seidel, Henry;Fuerstinnenkorrespondenz (Version1.1), Universität Jena, DFG. http://www.indogermanistik.uni-jena.de/Web/Projekte/Fuerstinnenkorr.htm.6. http://www.deutschdiachrondigital.de/ Zugriffam 16.08.2016.7. https://www.linguistik.hu-berlin.de/de/institut/professuren/sprachgeschichte/forschung/sfb632-informationsstruktur Zugriff am 16.08.2016.8. http://korpling.german.hu-berlin.de/ddb-doku/index.htm Zugriff am 16.08.2016.9. http://dwee.eu/Rosemarie_Luehr/?Projekte___DFG-Projekte___Fruehneuzeitliche_Fuerstinnen
korrespondenz_im_mitteldeutschen_RaumZugriff am 16.08.2016.10. Die Erstellung des Korpus erfolgte imRahmen von universitärer Lehre http://www.textbewegung.de/lehre.html Zugriff am16.08.2016.11. https://www.linguistik.hu-berlin.de/de/institut/professuren/korpuslinguistik/forschung/ridges-projekt/ Zugriff am 16.08.2016.12. https://www.slawistik.hu-berlin.de/de/member/meyerrol/subjekte/corpora Zugriff am16.08.2016.13. Zusätzlich helfen uns auch Evaluationenmit Kooperationspartner durch Dritte, dieangebotenen Lösungen zu verbessern (z.B. Stilleret al. 2016).14. http://zenodo.org Zugriff am 19.08.2016.
Bibliographie
Ágel, Vilmos / Hennig, Mathilde (eds.)(2007): Zugänge zur Grammatik der gesprochenenSprache. Germanistische Linguistik 269.Tübingen: Niemeyer.
Bird, Steven / Simons, Gary (2001):„The OLAC Metadata Set and ControlledVocabularies“, in: Proceedings of the 39th AnnualMeeting of the Association for ComputationalLinguistics 7–18 arXiv:cs/0105030v1.
Bollmann, Marcel / Dipper, Stefanie /Krasselt, Julia / Petran, Florian (2012): „Manualand semi-automatic normalization of historicalspelling - case studies from Early New HighGerman“, in: Proceedings of KONVENS 2012342–350 http://www.oegai.at/konvens2012/proceedings/51_bollmann12w/ [letzter Zugriff 22August 2016].
Broeder, Daan / Kemps-Snijders, Marc /Van Uytvanck, Dieter / Windhouwer, Menzo /Withers, Peter / Wittenburg, Peter / Zinn,Claus (2010): „A data category registry- andcomponent-based metadata framework“, in:Proceedings of LREC 2010 43–47.
Burnard, Lou (2013): „The Evolution of theText Encoding Initiative: From Research Projectto Research Infrastructure“, in: Journal of theText Encoding Initiative 5: 1–13 10.4000/jtei.811.
Claridge, Claudia (2008): „HistoricalCorpora“, in: Lüdeling, Anke / Kytö, Merja (eds):Corpus Linguistics. An International Handbook 1.Berlin: De Gruyter 242–259.
Dipper, Stefanie (2005): „XML-based Stand-off Representation and Exploitation of Multi-Level Linguistic Annotation“, in: Proceedings ofBerliner XML Tage 39–50.
Dipper, Stefanie / Donhauser, Karin /Klein, Thomas / Linde, Sonja / Müller, Stefan /
298

Digital Humanities im deutschsprachigen Raum 2017
Wegera, Klaus-Peter (2013): „HiTS. Ein Tagsetfür historische Sprachstufen des Deutschen“, in:Zinsmeister, Heike / Heid, Ulrich / Beck, Kathrin(eds.): Das Stuttgart-Tübingen Wortarten-Tagset:Stand und Perspektiven. Journal for LanguageTechnology and Computational Linguistics 28(1)85–137.
Deutsche Forschungsgemeinschaft (2015):Leitlinien zum Umgang mit Forschungsdaten.Bonn: DFG. http://www.dfg.de/download/pdf/foerderung/antragstellung/forschungsdaten/richtlinien_forschungsdaten.pdf [letzter Zugriff22. August 2016].
Dreyer, Malte / Vollmer, Andreas (2016):„An Integral Approach to Support ResearchData Management at the Humboldt-Universitätzu Berlin“, in: Proceedings of the EuropeanUniversity Information Systems organisation 320–327.
Dumont, Stefan (2016):„Fürstinnenkorrespondenzen. Experiment einerNachnutzung“, in: Entwicklung und Nutzunginterdisziplinärer Repositorien für historischetextbasierte Korpora. DHd 2016 Workshop http://www.laudatio-repository.org/laudatio/workshop-dhd2016/ [letzter Zugriff 22. August 2016].
Gippert, Jost / Gehrke, Ralf (eds.) (2015):Historical Corpora. Korpuslinguistik undinterdisziplinäre Perspektiven auf Sprache 5.Tübingen: Narr.
Geyken, Alexander (2013): „Wege zu einemhistorischen Referenzkorpus des Deutschen. dasProjekt Deutsches Textarchiv“, in: Hafemann,Ingelore (ed.): Perspektiven einer corpusbasiertenhistorischen Linguistik und Philologie.Internationale Tagung des Akademienvorhabens"Altägyptisches Wörterbuch“ an der BBAW.Thesaurus Linguae Aegyptiae, 4: 221–234.
Hedges, Mark / Neuroth, Heike / Smith,Kathleen M. / Blanke, Thomas / Romary,Laurent / Küster, Marc / Illingworth, Malcom(2013): „TextGrid, TEXTvre, and DARIAH.Sustainability of Infrastructure for TextualScholarship“, in: Journal of the Text EncodingInitiative 5: 1–13.
Heid, Ulrich / Schmid, Helmut / Eckart,Kerstin / Hinrichs, Erhard W. (2010): „ACorpus Representation Format for LinguisticWeb Services. The D-SPIN Text Corpus Formatand its Relationship with ISO Standards“,in: Proceedings of the Seventh InternationalConference on Language Resources andEvaluation 494–499.
Humboldt-Universität zu Berlin (2014):Grundsätze zum Umgang mit Forschungsdatenan der Humboldt-Universität zu Berlin. UnterMitarbeit von Elena Simukovic https://www.cms.hu-berlin.de/de/ueberblick/projekte/
dataman/hu-fdt-policy/view [letzter Zugriff 6.Juni 2016].
Ide, Nancy / Sudermann, Keith (2014): „TheLinguistic Annotation Framework. a standardfor annotation interchange and merging“, in:Language Resources and Evaluation 48 (3): 395–418.
Jurish, Bryan (2010): „More thanWords: Using Token Context to ImproveCanonicalization of Historical German“,in: Journal for Language Technology andComputational Linguistics 25 (1): 23–40.
Krause, Thomas / Zeldes, Amir (2016):„ANNIS3. A new architecture for generic corpusquery and visualization“, in: Digital Scholarshipin the Humanities 31 (1): 118–139 10.1093/llc/fqu057.
Kytö, Merja (2011): „Corpora andhistorical linguistics“, in: Revista Brasileirade Linguistica Aplicada 11: 417–457 10.1590/S1984-63982011000200007.
Lüdeling, Anke (2012): „A corpus-linguisticsperspective on language documentation,data, and the challenge of small corpora“, in:Seifart, Frank / Haig, Geoffrey / Himmelmann,Nikolaus P. / Jung, Dagmar / Margetts Anna /Trilsbeek, Paul (eds.): Potentials of LanguageDocumentation. Methods, Analyses, andUtilization 4. Language Documentation &Conservation Special Publication 3. Hawaii:University of Hawai‘i Press 32–38.
NISO (2004): Understanding Metadatada.Bethesda: NISO Press http://www.niso.org/publications/press/UnderstandingMetadata.pdf[letzter Zugriff 13. Februar 2015].
Nivre, Joakim / Hall, Johan / Nilsson, Jens(2004): „Memory-Based Dependency Parsing“,in: Proceedings of the Eighth Conference onComputational Natural Language Learning 49–56.
Odebrecht, Carolin / Belz, Malte /Zeldes, Amir / Lüdeling, Anke / Krause,Thomas (eingereicht): RIDGES Herbology -Designing a Diachronic Multi-Layer Corpus.Vorversion https://www.linguistik.hu-berlin.de/de/institut/professuren/korpuslinguistik/forschung/ridges-projekt/download-files/pubs/odebrechtetaleingereicht_ridgesherbology.pdf/at_download/file [letzter Zugriff 22. August 2016].
Odebrecht, Carolin (2014): „ModelingLinguistic Research Data for a Repositoryfor Historical Corpora“, in: DH2016: Book ofAbstracts 284–285.
Odebrecht, Carolin (2015): „InterdisziplinäreNutzung von Forschungsdaten mithilfeeiner technisch-abstrakten Modellierung“,in: DHd 2015: Von Daten zu Erkenntnissenhttps://dh2014.files.wordpress.com/2014/07/
299

Digital Humanities im deutschsprachigen Raum 2017
dh2014_abstracts_proceedings_07-11.pdf [letzterZugriff 22. August 2016].
Odebrecht, Carolin / Krause, Thomas /Lüdeling, Anke (2015): „Austausch vonhistorischen Texten verschiedener Sprachenüber das LAUDATIO-Repository“, in: DGfS-CLPoster Session. 37. Jahrestagung der DeutschenGesellschaft für Sprachwissenschaft http://asvdoku.informatik.uni-leipzig.de/dgfs2015cl-ps/index.html [letzter Zugriff 22. August 2016].
Romary, Laurent / Ide, Nancy (2004):„International standard for a linguisticannotation framework“, in: Natural LanguageEngineering 10 (3-4): 211–225.
Romary, Laurent / Zeldes, Amir / Zipser,Florian (2015): „<tiger2/>: serialising the ISOSynAF syntactic object model“, in: LanguageResources and Evaluation 49 (1): 1–18.
Rümpel, Stefanie (2011): „Der Lebenszyklusvon Forschungsdaten“, in: Büttner, Stephan /Hobohm, Hans-Christoph / Müller, Lars (eds.):Handbuch Forschungsdatenmanagement. BadHonnef: Bock + Herchen 25–34.
Schmidt, Thomas / Wörner, Kai (2009):„EXMARaLDA. Creating, analysing and sharingspoken language corpora for pragmaticresearch”, in: Pragmatics 19 (4): 565–582.
Schiller, Anne / Teufel, Simone / Stöckert,Christine / Thielen, Christine (1999):„Guidelines für das Tagging deutscherTextkorpora mit STTS“, in: Universität Tübingen(ed.): Seminar für Sprachwissenschaft.Technischer Report. http://www.sfs.uni-tuebingen.de/resources/stts-1999.pdf [letzterZugriff 22. August 2016].
Solodovnik, Iryna (2011): „Metadata issues inDigital Libraries. key concepts and perspectives“,in: Italian Journal of Library, Archives andInformation Science 2 (2): 4663-1–4663-27.10.4403/jlis.it-4663.
Stiller, Juliane / Thoden, Klaus / Zielke,Dennis (2016): „Usability in den DigitalHumanities am Beispiel des LAUDATIO-Repositoriums“, in: DHd 2016: Modellierung -Vernetzung - Visualisierung 244–247.
TEI Consortium (2015): TEI P5: Guidelines forElectronic Text Encoding and Interchange (2.9.1).http://www.tei-c.org/Guidelines/P5/ [letzterZugriff 15. November 2015].
Van Uytvanck, Dieter / Stehouwer,Herman / Lempen, Lari (2012): ”Semanticmetadata mapping in practice: the VirtualLanguage Observatory“, in: Proceedings of LREC2012 1029–1033.
Vertan, Cristina / Ellwardt, Andreas /Hummerl, Susanne (2016): „Ein Mehrebenen-Tagging-Modell für die Annotationaltäthiopischer Texte“, in: DHd 2016:
Modellierung - Vernetzung - Visualisierung 258–261.
Xie, Iris / Matusiak, Krystyna (2016):Discover Digital Libraries. Theory and Practice.Oxford: Elsevier.
300
Index der Autorinnenund AutorenAdrian Dominik ...................................................... 217Amini Seyavash .........................................................40Andorfer Peter ...........................................................34Aschauer Anna .......................................................... 22Baillot Anne ............................................................. 260Barth Florian ........................................................... 128Barzen Johanna .......................................................235Bauer Matthias ........................................................274Baumann Jan ......................................................56,255Baumgarten Marcus .................................................34Becker Martin ............................................................ 81Benito Alejandro .....................................................291Beretta Francesco ................................................... 249Blessing Andre ...........................................................19Brahaj Armand ..........................................................70Breitenbücher Uwe ................................................ 235Bürgermeister Martina ......................................... 272Bruschke Jonas .......................................................... 73Buchhop Katia ......................................................... 228Burch Thomas ............................................................66Burghardt Manuel .......................................... 228,264Busch Anna .............................................................. 260Chandna Swati ...........................................................94Crowley Ronan ........................................................227Czmiel Alexander ................................................... 138Daengeli Peter ......................................................... 151Daxenberger Johannes ..........................................196Döhling Lars ............................................................ 264Dieckmann Lisa ...................................................... 103Dimpel Friedrich Michael .................................... 100Dogunke Swantje ...................................................... 22Doppelbauer Regina .................................................52Dorn Amelie ....................................................... 50,291Dreyer Malte ............................................................295Dörk Marian .............................................................204Druskat Stephan ..................................................... 253Dufner Matthias ......................................................259Echelmeyer Nora ...............................................19,141Eder Elisabeth ......................................................... 276Eide Øyvind ..............................................................277Elwert Frederik .......................................................271Faßhauer Vera .........................................................162Falkenthal Michael .................................................235Feige Tillmann ...........................................................62Fichtl Barbara ............................................................69Fichtner Mark ............................................................70Fiel Stefan ................................................................... 28Fischer Frank ..............................................46,120,175Fischer Franz ...........................................................257Fless Friederike ......................................................... 13Friedrichs Kristina ................................................... 73Fuchs Florian ...........................................................228
Funk Stefan E. ........................................................... 15Gabriel Losada Gómez Antonio ..........................291Göbel Mathias ..........................................................175Gödel Martina ..........................................................257Geduldig Alena ........................................................277Geißler Nils .............................................................. 257Geukes Albert .......................................................... 238Gius Evelyn .............................................................. 115Glinka Katrin ........................................................... 204Gnadt Timo ...............................................................124Goedel Martina ....................................................... 180González Alicia ..........................................................62Gradl Tobias ............................................................... 22Görke Susanne ........................................................ 196Grüntgens Max ........................................................165Große Peggy ............................................................. 158Gruber Christine .....................................................212Grumt Suárez Holger ............................................ 252Gurevych Iryna ....................................................... 197Hadersbeck Maximilian ........................................276Hahn Udo ..................................................................279Hannesschläger Vanessa .........................................40Hegel Philipp ...................................................... 15,238Hellrich Johannes ...................................................279Henze Frank ...............................................................73Hermes Jürgen .................................................103,277Herrmann J. Berenike ........................................... 107Hettinger Lena ...........................................................81Hodel Tobias ......................................................... 28,66Hoffmann Moritz ....................................................277Hohenstein Sven ............................................. 270,286Hohmann Georg ........................................................52Horstmann Wolfram ................................................66Hotho Andreas ...........................................................81Jannidis Fotis .............................................. 81,223,240Johnson Christopher ........................................ 31,234Jäschke Robert .........................................................120Kamocki Paweł ..........................................................40Kampkaspar Dario ............................................34,175Karlova-Bourbonus Natali ................................... 252Kasper Dominik ...................................................... 165Kath Roxana .............................................................266Keilholz Franz ......................................................... 266Keller Lennart ........................................................... 92Köhler Werner ...........................................................69Kittel Christopher ................................................... 175Klaffki Lisa ................................................................. 22Klammt Anne ...........................................................259Kleymann Rabea .....................................................115Klinker Fabian .........................................................266Klug Helmut W. .......................................................244Klugseder Robert .................................................... 244Koch Steffen ............................................................... 19Kollatz Thomas ..........................................................15Krause Thomas ........................................................295Kröber Cindy ..............................................................73Krech Volkhard ....................................................... 271Kremer Gerhard ........................................................19
Krewet Michael ....................................................... 238Kronenwett Simone ............................................... 281Krotova Elena ..........................................................120Krug Markus ............................................................ 223Kuczera Andreas .....................................................263Kunz Axel ................................................................. 259Kurmann Eliane ................................................ 56,255Kuroczyński Piotr ..............................................69,188Lang Eva-Maria ......................................................... 28Lange Felix ................................................................. 89Laubrock Jochen ............................................. 270,286Lauer Gerhard .........................................................107Lauscher Anne ........................................................ 242Lüdeling Anke ......................................................... 295Lejtovicz Katalin ..................................................... 220Leymann Frank .......................................................235Lobin Henning ........................................................ 252Losehand Joachim .................................................... 40Madarasz Nathalie ................................................. 223Mathiak Brigitte .............................................. 155,281Matschinegg Ingrid ................................................ 111Matthies Franz ........................................................ 279Mayr Eva ...................................................................212Meiners Hanna ........................................................124Meise Bianca ............................................................132Meister Dorothee .................................................... 132Meister Jan Christoph ............................................115Mertens Mike ...........................................................260Messerschmidt Reinhard ......................................155Münster Sander ................................................. 73,188Morik Katharina ..................................................... 271Murr Sandra ...............................................................19Nanni Federico ........................................................242Natale Enrico ......................................................56,255Nepfer Matthias ...................................................... 194Neuefeind Claes ...................................................... 103Nicka Isabella .......................................................... 111Nickl Miriam ............................................................228Niebling Florian ........................................................ 73Noyer Frédéric ...........................................................58Odebrecht Carolin .................................................. 295Ott Carolin ................................................................ 217Overbeck Maximilian .............................................. 19Pause Johannes ....................................................... 200Pöckelmann Marcus .............................................. 266Pernes Stefan ............................................................. 92Peterek Christoph ..................................................... 92Petris Marco .............................................................115Peukert Hagen .........................................................289Pfahler Lukas ...........................................................271Pfarr-Harfst Mieke ................................................. 188Pichler Axel ................................................................ 19Pielström Steffen .................................................... 240Pietsch Christopher ................................................204Piotrowski Michael ...................................................66Pohl Oliver ..................................................................37Ponzetto Simone Paolo ..........................................242Prager Christian ........................................................ 62
Prechel Doris ........................................................... 197Puppe Frank .............................................................223Puren Marie ............................................................. 260Rapp Andrea ............................................................ 238Raunig Elisabeth ..................................................... 244Rücker Michaela ..................................................... 266Reger Isabella .....................................................81,223Rehbein Malte ............................................................52Reiter Nils ...................................................... 19,46,141Richter Eike ..............................................................286Riechert Thomas .....................................................249Rißler-Pipka Nanette .......................................... 46,94Romary Laurent ......................................................260Schöch Christof .......................................... 46,207,240Schelbert Georg .......................................................287Schildkamp Philip .................................................. 277Schilz Andrea .............................................................86Schlögl Matthias ......................................................220Schmidt Antje ............................................................ 52Schmidt Thomas ..................................................... 228Schmunk Stefan ........................................................ 22Schoepflin Urs ........................................................... 89Scholger Walter .........................................................40Schomaker Lambert .................................................66Schrade Torsten .................................................37,168Schreder Günther ...................................................212Schäuble Joshua ......................................................227Schulz Daniela .........................................................257Schulz Julian ............................................................ 245Schulz Sarah ............................................................ 141Schumacher Mareike .............................................171Seele Peter .................................................................. 11Seltmann Melanie ............................................. 49,291Siahdohoni Darjush ............................................... 196Snickars Pelle ...........................................................136Spanner Sebastian ..................................................228Söring Sibylle ............................................................. 15Süsstrunk Sabine ...................................................... 12Stanicka-Brzezicka Ksenia ......................................69Steiner Christian .....................................................244Steyer Timo ...........................................................23,34Stiller Juliane ........................................................... 124Stotzka Rainer ......................................................... 238Strötgen Jannik ....................................................... 120Tabti Samira .............................................................271Therón Roberto .......................................................291Thoden Klaus ...........................................................124Tonne Danah ...................................................... 94,238Trilcke Peer .........................................................46,175Uhlmann Gyburg .................................................... 238Veentjer Ubbo ............................................................ 15Vertan Cristina ...........................................................62Viehhauser Gabriel ................................................ 128Vitt Thorsten ............................................................ 240Vogeler Georg ...................................................244,273Wagner Sarah ..........................................................158Wagner Wiltrud ........................................................ 79Walkowski Niels-Oliver ................................. 184,201
Wandl-Vogt Eveline ...................................49,212,291Wannenwetsch Oliver ............................................. 89Wöckener-Gade Eva ...............................................266Weimer Lukas ......................................................... 223Werwick Heiko .......................................................... 62Wettlaufer Jörg .................................................. 31,234Wick Christoph ........................................................223Willand Marcus .........................................................46Windhager Florian .................................................212Wintergrün Dirk ................................................89,124Witt Andreas ..............................................................40Wolff Christian ................................................ 228,264Wuttke Ulrike .......................................................... 217Yu Xiaozhou .............................................................266Zehe Albin ...................................................................81Zihlmann Patricia ...................................................147Zimmer Sebastian .................................................. 180Zirker Angelika ....................................................... 274Zumsteg Simon ........................................................151van Dyck-Hemming Annette ............................... 293Švitek Mihael ........................................................... 266von Wartburg Karin .............................................. 193von Zimmermann Christian ................................ 147

Digital Humanities im deutschsprachigen Raum 2017
304
Ergänzungen Aufgrund eines technischen Problems sind im Abstractband einige Bilder nicht übernommen worden. Die folgenden Seiten enthalten die fehlenden Abbildungen sortiert nach Beitrag.
Panel: Virtuelle Forschungsumgebung für objekt- und raumbezogene Forschung Kuroczyński, Piotr; Stanicka-Brzezicka, Ksenia; Fichtl, Barbara; Köhler, Werner; Brahaj, Armand; Fichtner, Mark
Abb. 1: Gesamtmenge an generierten Datenin den vergangenen Jahren (Quelle: http://edition.cnn.com/2014/11/04/tech/gallery/big-data- techonomics-graphs/)
Vortrag: Nachhaltigkeit als Prozess: Zur konzeptionellen Funktion digitaler Technologien in der Nachhaltigkeitssicherung für historische Fotos im Projekt efoto-Hamburg Schumacher, Mareike

Digital Humanities im deutschsprachigen Raum 2017
305
Eine Verknüpfung der drei Ebenen könnte z.B. wie folgt aussehen:
Poster: Comparison of Methods for Automatic Relation Extraction in German Novels
Krug, Markus; Wick, Christoph; Jannidis, Fotis; Reger, Isabella; Weimer, Lukas; Madarasz, Nathalie; Puppe, Frank
Tabelle 1: Ergebnisse der verschiedenen Ansätze für drei verschiedene Evaluationsszenarien: binär (das reine Vorliegen einer Relation), für die 4 Haupttypen und für alle 57 Relationstypen insgesamt.

Digital Humanities im deutschsprachigen Raum 2017
306
Tabelle 2: Ergebnisse für die verschiedenen Ansätze, aufgeschlüsselt nach den 4 Haupttypen. Familienrelationen erreichen sehr gute Ergebnisse mit einem F1-Wert von fast 80% und einer Precision von bis zu 95%. Liebesrelationen sind schwerer zu erkennen, liegen aber dennoch bei 56,3% F1. Die anderen Relationstypen fallen in der Qualität ab, sind aber gleichzeitig weniger relevant.
Poster: Digitale Erschließung einer Sammlung von Volksliedern aus dem deutschsprachigen Raum
Burghardt, Manuel; Spanner, Sebastian; Schmidt, Thomas; Fuchs, Florian; Buchhop, Katia; Nickl, Miriam; Wolff, Christian
Abbildung 5: Taktweise Segmentierung der Liedblätter mit dem Allegro.





























