Embed Size (px)
Citation preview

Einführung in dieZeitreihenanalyse
mit RStudio- Ein kleines Handbuch im Master Finance -
SeminararbeitFakultät für Mathematik - Professur Finanzmathematik
vorgelegt von: Salima AbdallaBetreuer: Dr. Dana Uhlig
Geburtsdatum: 09.06.1988 in SchweinfurtE-Mail: [email protected]: Reichenhainerstraße 77Matrikelnummer: 419651Studiengang: Master FinanceAbgabetermin: 23. Dezember 2017

Inhaltsverzeichnis1 Überblick 1
2 Analyseüberblick 22.1 Gegenstand der Analyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22.2 Analysemodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.3 Ablauf der Analyse - Überblick . . . . . . . . . . . . . . . . . . . . . . . . . 4
3 Die Zeitreihe und RStudio 73.1 Installation von RStudio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Datenimport in RStudio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.3 Plot der Zeitreihe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.4 Zerlegung der Zeitreihe mit decompose und stl . . . . . . . . . . . . . . . . . 143.5 (schwache) Stationarität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4 Die Trendbestimmung 204.1 Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204.2 Spline-Technik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.3 Trendumkehrpotentiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5 Periodizitäten 255.1 Korrelogramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255.2 Periodogramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265.3 Saisonbereinigung mithilfe von Filtern . . . . . . . . . . . . . . . . . . . . . 27
6 Ausblick 30
7 Anhang 31
II

Abbildungsverzeichnis3.1 CRAN Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.2 R Sources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.3 Daten als Textdatei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Tabellenverzeichnis2.1 stochastischer Prozess vs. Zeitreihe asdifsdfsagddffafl . . . . . . . . . . . . . 3
III

1 ÜberblickNicht nur in der Statistik werden heutzutage Daten verarbeitet, auch andere Disziplinen ge-brauchen verschiedene Auswertungsprogramme für ihre Berechnungen. Neben den offensicht-lichen, wie den klassischen Naturwissenschaften, gibt es auch viele Geisteswissenschaften, dieSoftware anwenden. So auch die Wirtschaftswissenschaften. Häufig haben diese Studierendenaber gewisse Lücken in ihrer Ausbildung, so dass sie eine Hemmschwelle entwickeln mit Pro-grammen zu arbeiten. Um diese Hemmschwelle zu überbrücken und einen leichten Einstiegin die Datenauswertung zu erhalten wurde dieses Handbuch geschrieben.Diese Arbeit soll vor allem den Master Finance Studenten zur Einarbeitung in die Zeitrei-henanalyse mit RStudio dienen. Dies dient zur vereinfachten Einarbeitung in R, einem sta-tistischen open-source Datenverarbeitungsprogramm. Am besten wird dieses Handbuch alsErgänzung zur Vorlesung „Einführung in die Zeitreihenanalyse“und den dazugehörigen Bü-chern genutzt, nachdem bereits der theoretische Inhalt der jeweiligen Kapitel behandeltwurde. Die Leser werden hier dazu angeregt, die Inhalte dieser Arbeit selbst nachzupro-grammieren und auf weitere Beispiele anzuwenden. Damit sollte es den Studenten am Endemöglich sein, eine geeignete Modellierung der Betrachtungen aufzustellen und diese zu ana-lysieren sowie im Anschluss eventuell bereits selbstständige Prognosen durchzuführen.Die Arbeit ist so aufgeteilt, dass zuerst Grundlagen zur Zeitreihenanalyse und die erstenSchritte in RStudio behandelt werden, um dann nach und nach auf die einzelnen Aspekteder Zeitreihenanalyse einzugehen. So wird von der Gesamtbetrachtung der Zeitreihe auf denTrend gelenkt, um dann die enthaltenen Periodizitäten zu untersuchen. Die verschiedenenstochastischen Prozessklassen und weiterführende Anwendungen kann sich der Leser nachdiesen ersten Ideen selbst aneignen. Dabei orientiert sich der Aufbau grundlegend an einemBuch und einem passenden Vorlesungsskript:
• „Zeitreihenanalyse“ von Prof. Dr. Rainer Schlittgen und Prof. Dr. Bernd H. J. Streit-berg [1] sowie
• am Vorlesungsskript „Einführung in die Zeitreihenanalyse“ von Prof. Dr. BerndHofmann aus dem Sommersemester 2012 [2].
Natürlich werden auch andere Quellen herangezogen und auf nützliche Links und ähnlichesverwiesen, was alles zur besseren Einarbeitung in die Problemstellung mit RStudio dienensoll. Besonders empfehlen kann man an dieser Stelle die zahlreichen Youtube-Tutorials1 sowiedas anwendungsorientierte Buch „Angewandte Zeitreihenanalyse mit R“ von Prof. Dr.Rainer Schlittgen.
1beispielsweise mittels einer Suche nach „time series analysis with R(Studio)“.
1

2 AnalyseüberblickDer vorliegende Abschnitt soll zu Beginn der Arbeit einen roten Faden für die Analyse aufzei-gen und dem Leser bereits vorab einen Gesamtüberblick über die Inhalte geben. Er dient alseine sehr kurze theoretische Einführung in die Hintergründe. Hier wird ganz knapp der Ge-genstand der Analyse, das zugrundeliegende Modell und ein grober Ablaufplan der Analysevorgestellt. Dieser Ablauf wird im zweiten Teil dann mehr unterteilt und einzeln betrachtet.So soll dem Leser veranschaulicht werden, warum eine Analyse in der Regel immer ähnlichaufgebaut ist und warum es häufig nicht ausreicht, schon bei den simpelsten Auswertungendie Analyse abzuschließen.Generell ist die Zeitreihenanalyse ein Bestandteil der Stochastik. Somit werden ab hier zu-mindest Grundkenntnisse in diesem Bereich vorausgesetzt, um nicht alle Einzelheiten auffüh-ren zu müssen. Für eine weitere Vertiefung empfiehlt sich „Wahrscheinlichkeitstheorie“ vonAchim Klenke oder auch „Stochastik“ von Hans Otto Georgii, aber auch viele weitere Stan-dardwerke. Zusätzlich gibt es auch verschiedene Onlinekurse zum Einarbeiten, beispielsweiseKurse von R-Stutorials [3] oder die Ergebnisse einer Suche nach „R“ oder „R Tutorials“ aufYoutube.
2.1 Gegenstand der AnalyseDer zentrale Gegenstand der weiteren Analyse ist die Zeitreihe, die im Folgenden definiertwerden soll. Sie ist eine Teilbetrachtung eines stochastischen Prozesses. Um eine genaueDifferenzierung zu verstehen, kann man hier beispielsweise die Definition nach Schlittgenheranziehen:
Definition„Stochastischer Prozess:Ein stochastischer Prozess ist eine Folge Yt von Zufallsvariablen. Der Index t, t ∈ N,N0oder Z wird i.d.R. als Zeit aufgefasst.
Zeitreihe:Eine Zeitreihe ist eine Folge y1, ..., yN von Realisationen eines Ausschnittes von Yt.Man nennt diese auch Zeitpfad oder Trajektorie des Prozesses.Oft wird (Yt) oder Y1, ..., YN selbst als Zeitreihe bezeichnet.“ [4, S. 4]
2

KAPITEL 2. ANALYSEÜBERBLICK
Stochastischer Prozess vs. ZeitreiheFür einen übersichtlichen Vergleich kann man sich noch folgenden Tabelle anschauen [1, S.91]:
ω\t t fest t variabel
ω festZahl
X ∈ R
Zeitreihe
Xt
ω variabelZufallsvariable bzw. -zahl
X(ω)
Stochastischer Prozess
(X(ω))t∈T
Tabelle 2.1: stochastischer Prozess vs. Zeitreihe asdifsdfsagddffafl
BeispieleDas Musterbeispiel eines stochastischen Prozesses ist die Braun’sche Bewegung. Sie bildetbeispielsweise die Bewegung eines Rußpartikels im Wasser ab. Ab einem bestimmten Start-punkt werden die Möglichkeiten des weiteren Verlaufs betrachtet, wobei man nicht genauweiß, wann sich der Partikel wo befindet und ob er bestimmte Punkte überhaupt durch-quert. Damit wird auch schon klar, warum dies ein Teilgebiet der Stochastik ist, denn zumModellieren benötigt man für diese Ungewissheit Wahrscheinlichkeiten.
Das dazugehörige Anwendungsbeispiel für eine Zeitreihe könnte dabei der exakte Pfad die-ses Partikels im Wasser sein. Hier kennt man also nicht nur den Startpunkt, sondern auchden Verlauf über eine bestimmte Zeit. Die betrachtete Trajektorie kann im Diskreten undim Stetigen betrachtet werden. Die diskrete Anwendung ist die in der Praxis am häufigstenbenutzte, weil die einzelnen Datenpunkte nicht zu engmaschig beieinander liegen müssenund der realen Datenerhebung mehr entsprechen. Bei der stetigen Betrachtung sollten diePunkte in minimal kleinen Intervallen untersucht werden, soweit es die Maßeinheit zulässt.Am Beispiel des Rußpartikels im Wasser kann man es interpretieren, dass ein in Zentimeterngemessener Pfad noch diskret ist und einer in kleinst-messbaren Abständen, bspw. Mikro-metern, als stetig angenommen werden kann.
2.2 AnalysemodellHier soll das addititve Komponentenmodell beschrieben werden, das häufig in den Einfüh-rungsbüchern, wie denen von Schlittgen oder Chatfield und anderen verwendet wird [5, 6, 7].
3

KAPITEL 2. ANALYSEÜBERBLICK
Dieses additive Modell wird ebenso bei den gängigen einfacheren Funktionen der Zeitreihen-analyse in R unterstellt.Zunächst ein kleiner Überblick über das Komponentenmodell, bei dem die Zeitreihe aufge-teilt wird. Die einzelnen Teilbereiche sind dann üblicherweise Trend, Konjunktur, Saison undRest.
Reihe = Trend + Konjunktur + Saison + Rest,
formal also:
xt = mt + kt + st + ut
mit mt + kt = gt als glatte Komponente und kt + st = zt als zyklische Komponente [1, S. 9].
Anmerkung:Ein (echt) multiplikatives Modell kann durch Logarithmieren in ein additives Modell trans-formiert werden; zur Einordnung der verschiedenen Modelle anhand der Plots der Zeitreihensollte in der Literatur nachgeschlagen werden [1, 4, S. 11, S. 22 f.].Die entsprechenden Funktionen in R und deren Handhabung kann man dem Booklet vonCoghlan entnehmen [4, 8, S. 23, S. 24 ff.].Anhand dieser einzelnen Komponenten wird auch in dieser Arbeit die ZeitreihenanalyseStück für Stück aufgebaut und entsprechend die Trendanaylse und -bereinigung, sowie dieSaisonbestimmung und -bereinigung durchgeführt. Bei ausreichender Güte der Anwendun-gen sollte man dann einen stationären stochastischen Prozess erhalten, den man für einePrognose heranziehen könnte.
2.3 Ablauf der Analyse - ÜberblickUm die eben genannten Teile nacheinander abzuarbeiten, sollte der Ablauf einer Zeitreihen-analyse mithilfe von RStudio möglichst in diesen Schritten erfolgen:
Schritt 1Plot der ZeitreiheSobald man die Daten einer Zeitreihe erhalten hat (und sie auch bereits in RStudio eingelesenhat), sollte man sich den Plot der Datenpunkte in zeitlicher Abfolge anschauen. So kann mansich einen ersten Überblick über die einzelnen Komponenten verschaffen und auch schonerste, zeitliche Zusammenhänge erkennen.
4

KAPITEL 2. ANALYSEÜBERBLICK
Schritt 2Periodizitäten überprüfenNach dem Plot der Zeitreihe selbst ist ein Korrelogramm empfehlenswert. Anhand dessenerkennt man, ob periodische Abhängigkeitsstrukturen vorliegen könnten [2]. Das Korrleo-gramm ist dabei ein Plot der Autokorrelationsfunktion einer Zeitreihe [1, S. 7]. An dieserStelle wird bereits auf die Ausreißerbeseitigung hingewiesen, die gegebenenfalls schon hiersinnvoll sein könnte [1, S. 8].Wenn die Abhängigkeiten weiter untersucht werden müssen, sollte man auch noch ein Pe-riodogramm anfertigen. In diesem kann man zwar nicht immer besonders gut erkennen, obzeitliche Abhängigkeiten vorliegen, dafür jedoch, an welcher Stelle und in welchem Umfangsie vorliegen. Also ist es ratsam diese Reihenfolge einzuhalten und zuerst abzuklären, obAbhängigkeiten vorliegen könnten, um im Anschluss die genaueren Spezifikationen zu be-trachten [2].
Schritt 3Auswerten und BereinigenIm Anschluss an die Periodizitätsbetrachtungen kann man sich an den ersten Teil der Arbeiteiner Zeitreihenanalyse machen: Man sollte nun die Trendbereinigung und im Anschluss dieSaisonbereinigung durchführen. Dazu kann man verschiedene Varianten anwenden, wie dieeinfachere Regression, Splines oder Auswertungen mittels Trendumkehrpotentiale. Auch beider Saisonbereinigung kann man über einfache Filter bis hin zur Lösung eines Inversen Pro-blems des Periodogramms viele Methoden anwenden, wobei hier nur auf ersteres eingegangenwird. Außerdem gibt es auch noch andere Ansätze, die zuerst die Saison bereinigen und erstdanach den Trend betrachten.1
Schritt 4Restkomponente betrachtenBleibt nach der Zeitreihenanalyse nur ein weißes Rauschen übrig, so kann man von einererfolgreichen Zuordnung des stochastischen Prozesses sprechen und auch einer aussagekräf-tigen Zeitreihenanalyse [4, S. 5]. Man hat dann sinnvoll die jeweiligen Komponenten bis aufden Rest seiner Zeitreihe zugeordnet und einen stationären Prozess zur weiteren Modellie-rung gewonnnen.Sollte allerdings das gewünschte Ergebnis noch nicht zu sehen sein, ist es zu empfehlen, dieZeitreihenanalyse nochmals mit verbesserten Instrumenten zu wiederholen. Hat man bei-spielsweise zuvor „nur“ eine Regression bei der Trendanalyse benutzt, könnte man jetzt zuden ausgefeilteren Splines übergehen. Dies wird auch beim Vergleich der ersten Zerlegungs-funktionen für Zeitreihen in RStudio im Kapitel 3.4 klar.
1vgl. beispielsweise die Funktion stl in R
5

KAPITEL 2. ANALYSEÜBERBLICK
Anmerkung: Damit klarer wird, was unter weißem Rauschen verstanden wird, existiertfolgende Definition [4, S. 4]:
Definition „Ein White-Noise-Prozess ist eine Folge von unabhängigen, identisch ver-teilten Zufallsvariablen. Derartige Prozesse werden [...] meist mit (εt) bezeichnet.White-Noise-Prozesse können beliebige (Rand-) Verteilungen haben. [Häufig wird]unterstellt, dass Erwartungswert und Varianz wohldefiniert sind. Außerdem werdensolche Prozesse meist bei null zentriert unterstellt.“
6

3 Die Zeitreihe und RStudioIn diesem Kapitel geht es um die ersten Erfahrungen mit RStudio und einer Zeitreihe. Eswird nicht vorausgesetzt, dass der Leser bereits mit R umgehen kann. Vielmehr soll der Lesermithilfe dieser Anleitung selbständig Zeitreihenanalysen durchführen können. Für eine weite-re Lektüre und tiefergehende Erklärungen wird nochmals auf die diversen Youtube-Channelssowie die entsprechenden Paper und Bücher zu R bzw. RStudio verwiesen [9, 10, 11, 12, 13]Wer sich vor der Anwendung auf die Zeitreihenanalyse erst ein wenig mit den allgemeinenBefehlen in RStudio auseinander setzten möchte, sei vor allem „RStutorials“empfohlen [14].Hier gibt es zahlreiche Übungsaufgaben auf verschiedenen Niveaus.Und wenn sich jemand mit den verschiedenen Veröffentlichungen zu den R-Packages aus-einander setzen möchte, um die Befehle besser zu verstehen, der sollte entweder in derklassischen R Dokumentation nachschauen oder die Contributions der Programmierer lesen[15, 16]:
Abbildung 3.1: CRAN Contributions
7

KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
3.1 Installation von RStudioDie Installation von RStudio erfolgt über das CRAN-Netzwerk. Die Installation des Basis-programms R ist Voraussetzung dafür, dass auch RStudio auf dem eigenen Rechner laufenkann. Man sollte sich außerdem bereits am Anfang einen CRAN-Mirror wählen, damit manauch aus der Console in RStudio heraus ohne Probleme Packages installieren kann und sienicht manuell einbinden muss.Für den genauen Ablauf der Installation empfiehlt es sich, entsprechende Videos im Internetzu Rate zu ziehen. Hier wird nicht noch genauer darauf eingegangen.
Abbildung 3.2: R Sources
Installation von Packages in RStudioAn dieser Stelle soll kurz beleuchtet werden, wie man Packages in RStudio installieren kannund welche ratsam für die Zeitreihenanalyse sind. Ganz allgemein kann man sich einen gutenÜberblick über die angebotenen Packages verschaffen, indem man die CRAN-Seiten studiert,insbesondere die Liste „CRAN Task View - Time Series Analysis [17].Die Packages installieren kann man mithilfe des folgenden Befehls:
install.packages("xts")install.packages("ggplot2", "forecast", dependencies = TRUE)install.packages("tseries", dependencies = TRUE)install.packages("stats", dependencies = TRUE)
8

KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
Bei R und RStudio muss man zwar nach jedem Schließen des Programms die Packages nichterneut installieren, dafür aber jedes Mal neu laden. Dies geschieht am Besten zu Anfangjeder neuen Sitzung mit:
library(xts)library(ggplot2)library(forecast)library(tseries, stats)
Diese Befehle kann man gerne auch immer direkt in der Konsole von R und RStudio einge-ben, für die weiteren Befehle wird aber immer empfohlen ein Skript zu schreiben, das mandann auch abspeichern kann.
Das Working Directory sollte auch passend beim Öffnen von R gewählt werden, so dass dieSkripte korrekt angezeigt werden und auch dort abgespeichert werden:
setwd("C:/Users/salim/Dropbox/R Anleitung")
3.2 Datenimport in RStudioBei dem Datenimport sei vorausgeschickt, dass der Befehl hierzu vom Datenformat abhängt.Der Befehl scan funktioniert bei fast allen Datenformaten, die annähernd eine Vektor- oderMatrix- Struktur aufweisen. Zur Anwendung dazu gibt es einige Youtube-Videos, Universi-tätsskripte und andere Tutorialseiten, so dass es hier nicht weiter ausgeführt wird [18, 19].Das in den Wirtschaftswissenschaften häufig benutzte Format .csv einer Excel-Datei sollteaber für einen unkomplizierten Import nach Möglichkeit entweder über die Benutzeroberflä-che von RStudio oder durch den Befehl „read.(.) “erfolgen. Der zweite Term der Funktionbeinhaltet dabei die Formate .table, .csv und .csv2 und noch einige mehr (vergleiche dieDokumentation des read-Befehls für weitere).Für diese Arbeit wurde ganz einfach selbst eine Zeitreihe zusammengestellt, indem auf dieWetterwerte für Deutschland in Wikipedia zugegriffen wurde [20]. Man kann sich die ge-wünschten Daten einfach kopieren und beispielsweise in ein Textdokument mithilfe des Tex-teditors speichern. Auf die zeitlich richtige Abfolge sollte man dabei achten oder, wenn manes schon kann, beim Übergeben an R ausbessern.In Figure 3.3 sieht man, wie die Daten in Form einer Textdatei abgespeichert sind. Die wich-tigen Punkte des nachfolgenden Befehls sind:
• Temperatur <- read.table entspricht der Zuweisung der Variablen Temperatur: Hierwird die eingelesene Datei in RStudio abgespeichert und kann im Environment aufge-rufen werden
9

KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
• ’C:/Users/salim/Dropbox/R Anleitung/TempD.txt’ ist der Pfad, in dem die Datei ab-gespeichert wurde; beachte: / (statt \)
• „header = TRUE“ gibt an, dass die erste Zeile der Datei für die Benennung der Spaltenherangezogen werden soll
• skip = 1 überspringt die erste Zeile der Datei, da sich in diesem Fall keine Daten,sondern lediglich eine Überschrift dort befindet
• sep = "\t" gibt die Trennzeichen als Tabulatoren an; es sind auch verschiedene andereTrennzeichen zwischen den einzelnen Einträgen der Tabelle einlesbar, siehe dafür dieDokumentation von read.table[21]
• fill = TRUE fügt für nicht ausgefüllte Felder bzw. nicht vorhandene Werte NA ein, sodass keine Fehlermeldung entsteht
• dec = "," übergibt den Befehl, das Dezimaltrennzeichen als , zu erkennen; auch hiergibt es weitere Varianten [21]
Temperatur <- read.table("C:/Users/salim/Dropbox/R Anleitung/TempD.txt",header = TRUE, skip = 1, sep = "\t", fill = TRUE, dec = ",")
Analog erfolgen auch die anderen read.(.) Befehle [21].Eine andere Möglichkeit, die Daten in RStudio einzuspeisen ist mithilfe der Benutzerober-fläche im Environment mit dem Feld Import Dataset. Da diese Methode sehr eingänglicheund anfängerfreundlich aufgebaut ist, sowie so gut wie selbst erklärend dadurch wird, wirdsie hier nicht weiter erläutert.Außerdem werden die folgenden anderen Befehle nicht mehr so ausführlich kommentiert, wiees hier gemacht wurde. Der Leser sollte mit Blick auf die Dokumentation jetzt in der Lagesein, die verschiedenen Befehle einer Funktion richtig anzuwenden.
Abbildung 3.3: Daten als Textdatei
10

KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
Anmerkung:An dieser Stelle ist es ratsam die Daten auch als Matrix mit abgespeichert zu lassen, weilman damit später vereinfacht eine Regressionsanalyse durchführen kann. Überprüfen kannman das, indem man im Environment von RStudio bei Values schaut und dann sieht, ob dasentsprechende Objekt vorliegt.
Um nun zu Überprüfen, ob die Matrix auch korrekt eingelesen wurde, empfiehlt es sich, dieMatrix mit folgendem Befehl aufzurufen:
Temperatur
Alternativ kann man einfach mit der Maus in das Objektfeld im R-Environment klicken, umsich die Daten anzeigen zu lassen. Allerdings ist der Umfang je nach Datensatz einfach zugroß, um ihn anzeigen zu lassen und manuell abzugleichen. So war es auch hier mit über1800 Dateneinträgen einfach zu viel Platz, der in Anspruch genommen worden wäre. Alsosollte man sich eine verkürzte Prüfmethoden überlegen, beispielsweise nur die Ausgabe derersten sechs Einträgen, bei uns eben der ersten sechs Jahre, aufzurufen:
Temperatur[1:6, 1:12]
## Jan Feb Maerz Apr Mai Jun Jul Aug Sept Okt Nov Dez## 1 -5.4 2.4 4.2 5.5 9.9 17.0 16.9 17.6 12.9 9.5 3.4 -0.5## 2 -1.8 0.0 5.4 9.2 14.0 14.6 16.2 15.8 13.6 9.9 2.7 0.4## 3 2.3 1.9 4.2 7.7 12.2 15.5 15.7 17.7 12.4 10.2 3.8 2.2## 4 -5.5 -1.2 4.0 5.5 9.9 14.8 15.3 14.0 12.3 7.0 2.1 -3.4## 5 -0.3 -3.9 -0.9 9.8 15.2 14.1 18.7 15.7 14.5 8.8 4.7 -0.1## 6 2.5 3.2 2.6 8.8 9.3 17.6 15.7 14.5 14.0 7.2 3.9 1.1
Einen kleinen Mangel hat dieses Methode natürlich: Man kann sich nicht sicher sein, ob dienicht angezeigten Daten korrekt sind. Sinnvoll gewählt wird das Intervall der Ausgabe so,dass man genug Werte zum Einschätzen sehen kann.
Damit man die Daten im weiteren Verlauf für die gängigen Basisbefehle in der Zeitreihenana-lyse benutzen kann, sollte man noch die zuvor eingelesene Matrix zu einem Vektor umbauen:
temp <- as.vector(t(Temperatur))
Jetzt kann man eine weitere verkürzte Prüfmethode anwenden, indem man nur prüft, obAnfang und Ende wirklich korrekt dargestellt werden. Das sollte die weitere Arbeit vereinfa-chen, indem man den Datenimport nur dann noch einmal detailliert überprüfen muss, wennentweder der erste Teil und/oder der letzte Teil der Daten nicht mit der gewünschten An-zeige übereinstimmen. In unserem Fall betrachten wir die ersten zwölf und die letzten zwölfWerte der Matrix:
11
KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
head(temp, n = 12)
## [1] -5.4 2.4 4.2 5.5 9.9 17.0 16.9 17.6 12.9 9.5 3.4 -0.5
tail(temp, n = 12)
## [1] -2.2 2.9 7.2 7.4 14.1 17.8 18.1 17.9 12.8 11.1 NA NA
Hier sieht man, dass die Temperaturwert für November und Oktober des letzten Jahres imDatensatz nicht vorhanden sind.
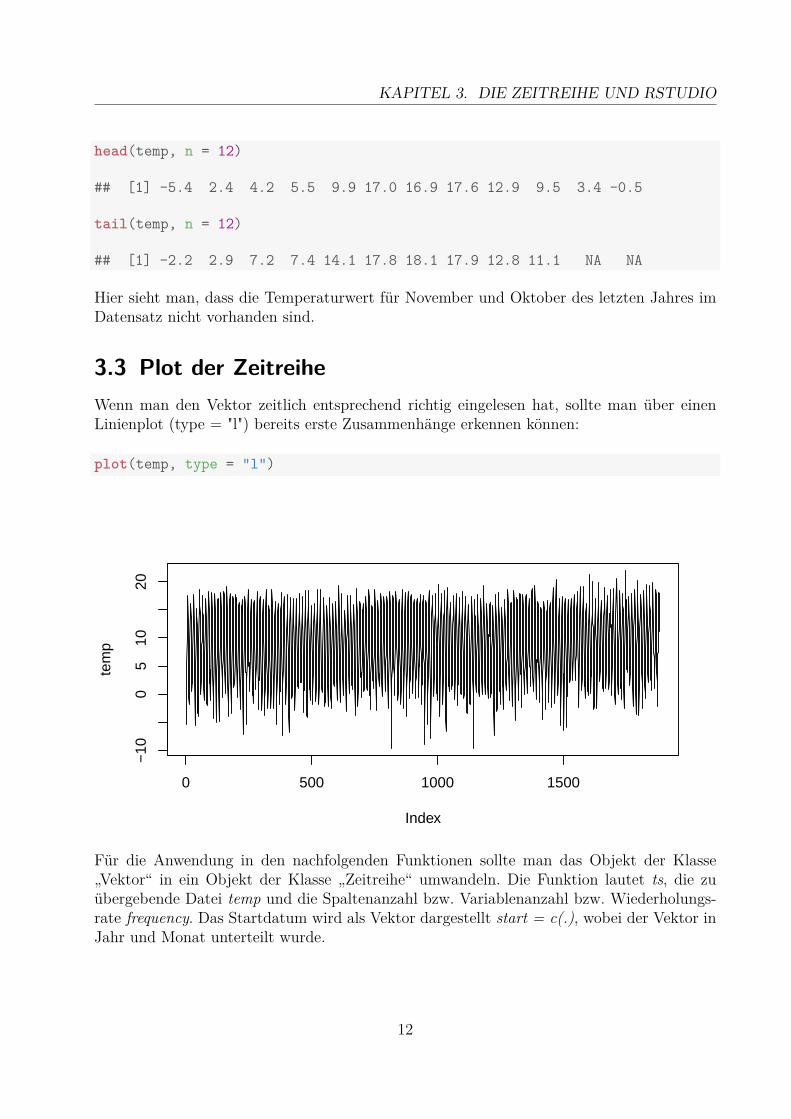
3.3 Plot der ZeitreiheWenn man den Vektor zeitlich entsprechend richtig eingelesen hat, sollte man über einenLinienplot (type = "l") bereits erste Zusammenhänge erkennen können:
plot(temp, type = "l")
0 500 1000 1500
−10
05
1020
Index
tem
p
Für die Anwendung in den nachfolgenden Funktionen sollte man das Objekt der Klasse„Vektor“ in ein Objekt der Klasse „Zeitreihe“ umwandeln. Die Funktion lautet ts, die zuübergebende Datei temp und die Spaltenanzahl bzw. Variablenanzahl bzw. Wiederholungs-rate frequency. Das Startdatum wird als Vektor dargestellt start = c(.), wobei der Vektor inJahr und Monat unterteilt wurde.
12
KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
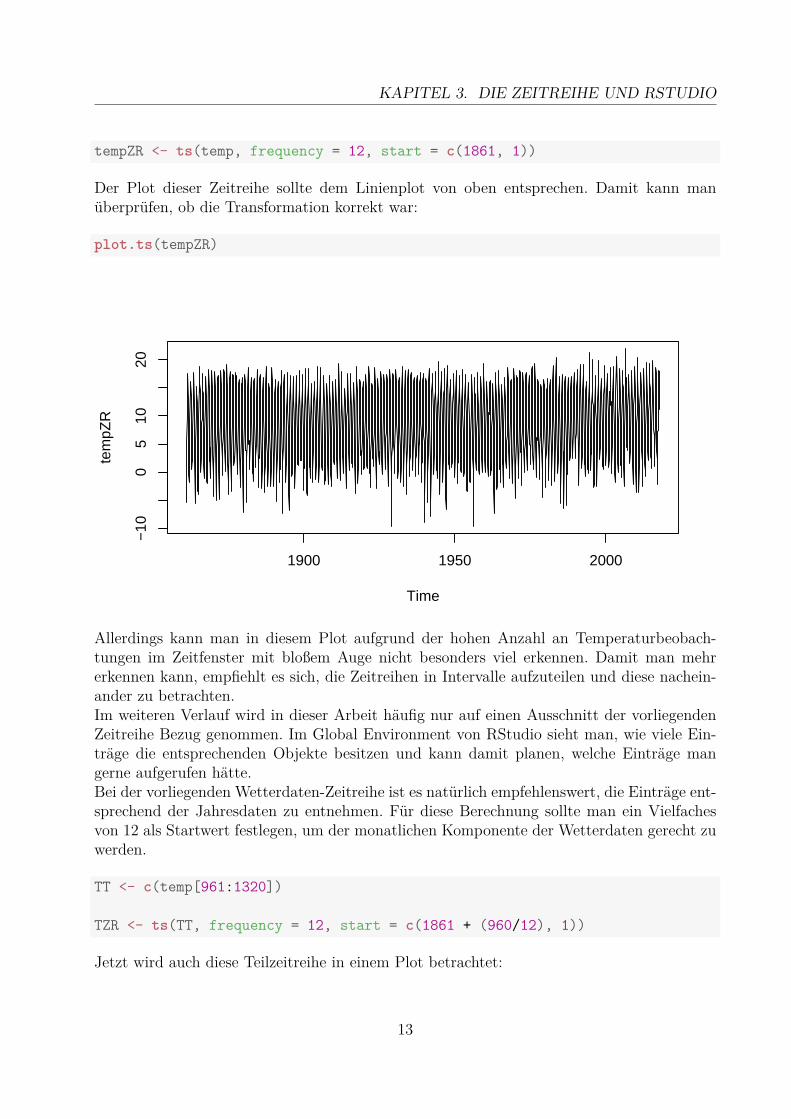
tempZR <- ts(temp, frequency = 12, start = c(1861, 1))
Der Plot dieser Zeitreihe sollte dem Linienplot von oben entsprechen. Damit kann manüberprüfen, ob die Transformation korrekt war:
plot.ts(tempZR)
Time
tem
pZR
1900 1950 2000
−10
05
1020
Allerdings kann man in diesem Plot aufgrund der hohen Anzahl an Temperaturbeobach-tungen im Zeitfenster mit bloßem Auge nicht besonders viel erkennen. Damit man mehrerkennen kann, empfiehlt es sich, die Zeitreihen in Intervalle aufzuteilen und diese nachein-ander zu betrachten.Im weiteren Verlauf wird in dieser Arbeit häufig nur auf einen Ausschnitt der vorliegendenZeitreihe Bezug genommen. Im Global Environment von RStudio sieht man, wie viele Ein-träge die entsprechenden Objekte besitzen und kann damit planen, welche Einträge mangerne aufgerufen hätte.Bei der vorliegenden Wetterdaten-Zeitreihe ist es natürlich empfehlenswert, die Einträge ent-sprechend der Jahresdaten zu entnehmen. Für diese Berechnung sollte man ein Vielfachesvon 12 als Startwert festlegen, um der monatlichen Komponente der Wetterdaten gerecht zuwerden.
TT <- c(temp[961:1320])
TZR <- ts(TT, frequency = 12, start = c(1861 + (960/12), 1))
Jetzt wird auch diese Teilzeitreihe in einem Plot betrachtet:
13
KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
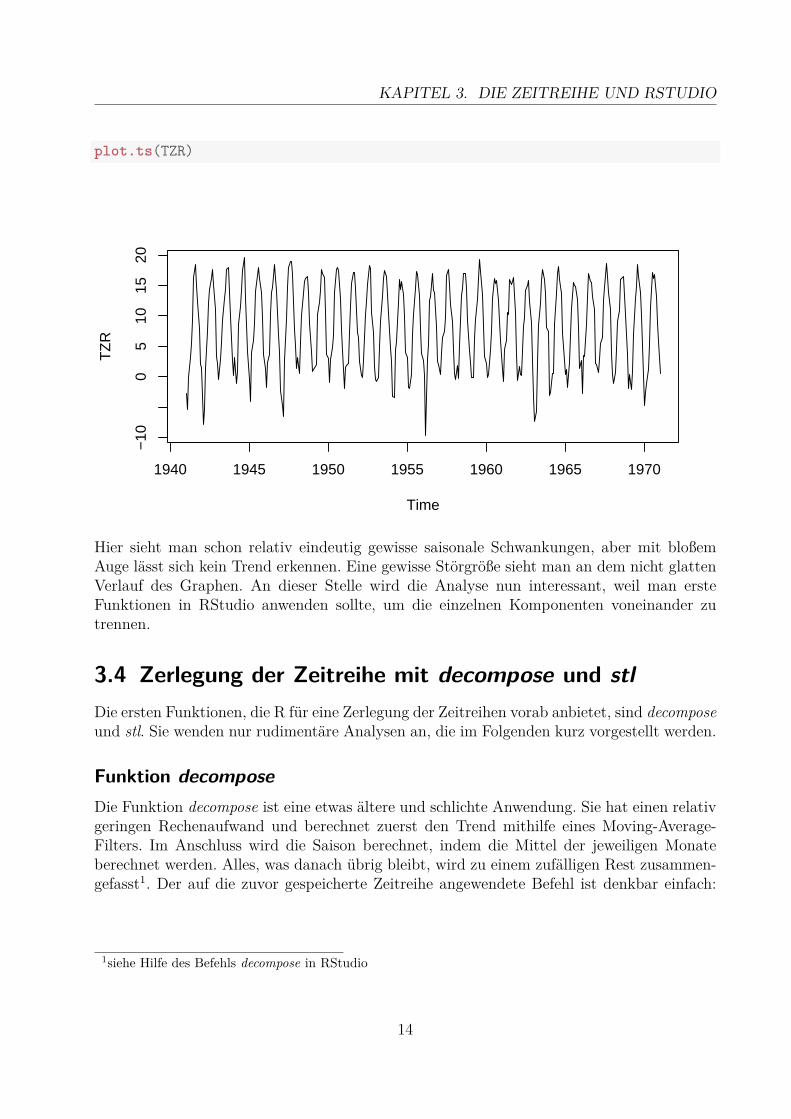
plot.ts(TZR)
Time
TZ
R
1940 1945 1950 1955 1960 1965 1970
−10
05
1015
20
Hier sieht man schon relativ eindeutig gewisse saisonale Schwankungen, aber mit bloßemAuge lässt sich kein Trend erkennen. Eine gewisse Störgröße sieht man an dem nicht glattenVerlauf des Graphen. An dieser Stelle wird die Analyse nun interessant, weil man ersteFunktionen in RStudio anwenden sollte, um die einzelnen Komponenten voneinander zutrennen.
3.4 Zerlegung der Zeitreihe mit decompose und stlDie ersten Funktionen, die R für eine Zerlegung der Zeitreihen vorab anbietet, sind decomposeund stl. Sie wenden nur rudimentäre Analysen an, die im Folgenden kurz vorgestellt werden.
Funktion decomposeDie Funktion decompose ist eine etwas ältere und schlichte Anwendung. Sie hat einen relativgeringen Rechenaufwand und berechnet zuerst den Trend mithilfe eines Moving-Average-Filters. Im Anschluss wird die Saison berechnet, indem die Mittel der jeweiligen Monateberechnet werden. Alles, was danach übrig bleibt, wird zu einem zufälligen Rest zusammen-gefasst1. Der auf die zuvor gespeicherte Zeitreihe angewendete Befehl ist denkbar einfach:
1siehe Hilfe des Befehls decompose in RStudio
14
KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
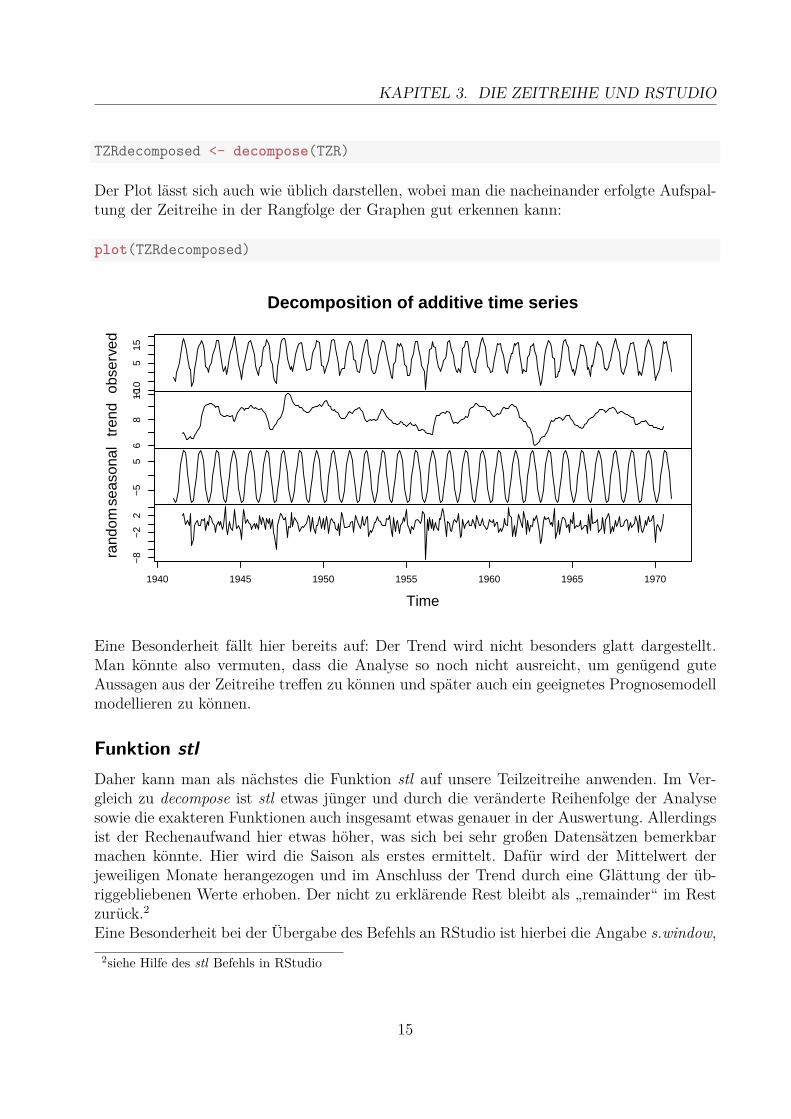
TZRdecomposed <- decompose(TZR)
Der Plot lässt sich auch wie üblich darstellen, wobei man die nacheinander erfolgte Aufspal-tung der Zeitreihe in der Rangfolge der Graphen gut erkennen kann:
plot(TZRdecomposed)
−10
515
obse
rved
68
10
tren
d
−5
5
seas
onal
−8
−2
2
1940 1945 1950 1955 1960 1965 1970
rand
om
Time
Decomposition of additive time series
Eine Besonderheit fällt hier bereits auf: Der Trend wird nicht besonders glatt dargestellt.Man könnte also vermuten, dass die Analyse so noch nicht ausreicht, um genügend guteAussagen aus der Zeitreihe treffen zu können und später auch ein geeignetes Prognosemodellmodellieren zu können.
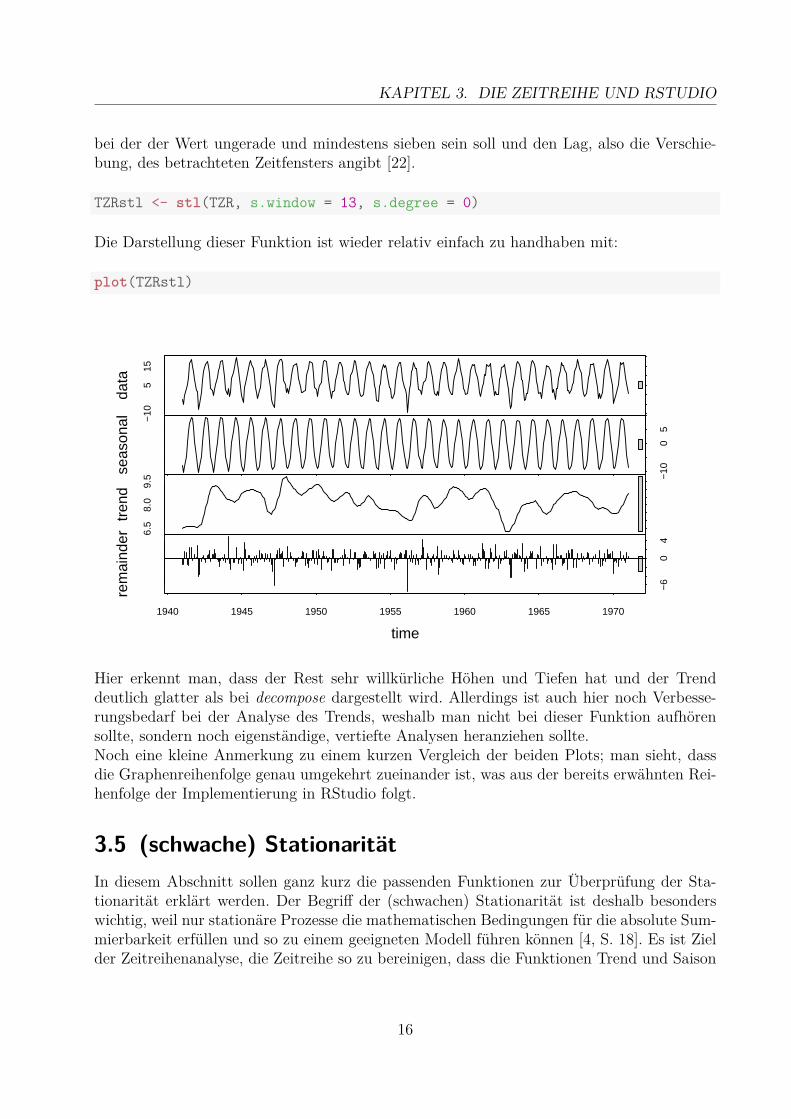
Funktion stlDaher kann man als nächstes die Funktion stl auf unsere Teilzeitreihe anwenden. Im Ver-gleich zu decompose ist stl etwas jünger und durch die veränderte Reihenfolge der Analysesowie die exakteren Funktionen auch insgesamt etwas genauer in der Auswertung. Allerdingsist der Rechenaufwand hier etwas höher, was sich bei sehr großen Datensätzen bemerkbarmachen könnte. Hier wird die Saison als erstes ermittelt. Dafür wird der Mittelwert derjeweiligen Monate herangezogen und im Anschluss der Trend durch eine Glättung der üb-riggebliebenen Werte erhoben. Der nicht zu erklärende Rest bleibt als „remainder“ im Restzurück.2Eine Besonderheit bei der Übergabe des Befehls an RStudio ist hierbei die Angabe s.window,
2siehe Hilfe des stl Befehls in RStudio
15
KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
bei der der Wert ungerade und mindestens sieben sein soll und den Lag, also die Verschie-bung, des betrachteten Zeitfensters angibt [22].
TZRstl <- stl(TZR, s.window = 13, s.degree = 0)
Die Darstellung dieser Funktion ist wieder relativ einfach zu handhaben mit:
plot(TZRstl)
−10
515
data
−10
05
seas
onal
6.5
8.0
9.5
tren
d
−6
04
1940 1945 1950 1955 1960 1965 1970
rem
aind
er
time
Hier erkennt man, dass der Rest sehr willkürliche Höhen und Tiefen hat und der Trenddeutlich glatter als bei decompose dargestellt wird. Allerdings ist auch hier noch Verbesse-rungsbedarf bei der Analyse des Trends, weshalb man nicht bei dieser Funktion aufhörensollte, sondern noch eigenständige, vertiefte Analysen heranziehen sollte.Noch eine kleine Anmerkung zu einem kurzen Vergleich der beiden Plots; man sieht, dassdie Graphenreihenfolge genau umgekehrt zueinander ist, was aus der bereits erwähnten Rei-henfolge der Implementierung in RStudio folgt.
3.5 (schwache) StationaritätIn diesem Abschnitt sollen ganz kurz die passenden Funktionen zur Überprüfung der Sta-tionarität erklärt werden. Der Begriff der (schwachen) Stationarität ist deshalb besonderswichtig, weil nur stationäre Prozesse die mathematischen Bedingungen für die absolute Sum-mierbarkeit erfüllen und so zu einem geeigneten Modell führen können [4, S. 18]. Es ist Zielder Zeitreihenanalyse, die Zeitreihe so zu bereinigen, dass die Funktionen Trend und Saison
16

KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
gut bestimmt sind und nur der Zufall übrig bleibt. Eine geeignete Art, diesen Zufall formaldarzustellen, ist mithilfe des Weißen Rauschens [4, S. 4 ff.].
Die Eigenschaften eines (schwach) stationären Prozesses sind [4, S. 13 ff.]:
i) konstanter Erwartungswert: E = µ, konstant
ii) konstante Varianz: σ2 = konstant
iii) zeitunabhängige, aber Lag-abhängige Autokovarianzfunktion:cov(Xt+τ , Xt) = γτ
Entweder kann man dafür selbst geeignete Funktionen schreiben [4, vgl. S. 15 ff.] oder ein-fach die vorgefertigten Funktionen in R anwenden. Eine dieser Funktionen ist beispielsweisestationary.test aus dem Package aTSA. Der Test basiert auf einem Hypothesentest undbei genügend kleinen p-Werten wird die Nullhypothese „Die vorliegende Zeitreihe ist statio-när.“ angenommen. Dies wird beim Ergebnisoutput in R darüber angezeigt, dass die p-Werte0,01 aufweisen. Die Implementierung und Auswertung erfolgt dann wie folgt [23]:
install.packages("aTSA", dependencies = TRUE)
library(aTSA)
stationary.test(temp)
## Augmented Dickey-Fuller Test## alternative: stationary#### Type 1: no drift no trend## lag ADF p.value## [1,] 0 -8.27 0.0100## [2,] 1 -14.22 0.0100## [3,] 2 -17.91 0.0100## [4,] 3 -14.45 0.0100## [5,] 4 -9.49 0.0100## [6,] 5 -6.03 0.0100## [7,] 6 -3.80 0.0100## [8,] 7 -2.52 0.0125## Type 2: with drift no trend## lag ADF p.value## [1,] 0 -13.8 0.01## [2,] 1 -26.0 0.01## [3,] 2 -42.4 0.01
17

KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
## [4,] 3 -49.2 0.01## [5,] 4 -46.5 0.01## [6,] 5 -39.6 0.01## [7,] 6 -30.6 0.01## [8,] 7 -23.2 0.01## Type 3: with drift and trend## lag ADF p.value## [1,] 0 -13.8 0.01## [2,] 1 -26.1 0.01## [3,] 2 -42.6 0.01## [4,] 3 -49.9 0.01## [5,] 4 -47.8 0.01## [6,] 5 -41.7 0.01## [7,] 6 -33.3 0.01## [8,] 7 -25.9 0.01## ----## Note: in fact, p.value = 0.01 means p.value <= 0.01
Eine alternative Anwendung ist den Augmented Dickey-Fuller Test direkt anzuwenden mitdem Befehl adf.test() [24].Bei der vorliegenden Zeitreihe kann man davon ausgehen, dass kein Trend vorliegt. Zumeinen sieht man das an dem Test Type 2, der auf einen Drift ohne Trend testet und einenp-Wert von 0,01 anzeigt, was bedeutet, dass der Testwert klein genug ist, um die Nullhypo-these (Drift und kein Trend) nicht zu verwerfen.Zum anderen sieht man das an dem Test Type 3, der auf einen Drift und einen Trend testetund einen ebenso geringen p-Wert aufweist und dieselbe Schlussfolgerung zulässt; und zu-sätzlich kaum unterschiedliche ADF-Werte aufweist im Vergleich zu Type 2.Der Test Type 1 allerdings ergibt, dass man die Nullhypothese (kein Drift, kein Trend) ver-werfen könnte, weil einer der p-Werte leicht unterschiedlich zum Konfidenzniveau ist.Allerdings kann man an dieser Stelle bereits Kritik an der Eignung dieses Tests aufwerfen,weil hier nur die Konstanz des Erwartungswerts geprüft wird, nicht aber die anderen beidenAspekte der Stationarität.
Ein alternativer Stationaritätstest ist im Package fractal implementiert: die Funktion statio-narity. Die Interpretation ist noch aufwendiger als die, des vorangegangenen Test [25].
install.packages("fractal", dependencies = TRUE)library(fractal)
statio <- stationarity(TZR, n.taper = 6, n.block = max(c(12,floor(logb(length(TZR), base = 12)))), significance = 0.05,center = TRUE, recenter = FALSE)
18

KAPITEL 3. DIE ZEITREIHE UND RSTUDIO
summary(statio)
Eine sehr leicht anwendbare Funktion hingegen ist is.stationary aus dem Package Laplaces-Demon. Der Test basiert auf einer Standard-Z-Statistik für Markovketten und evaluiert denMittelwert bezogen auf Lags der Zeitreihe [26]. Zwar ist auch hier wieder der Nachteil, dassman nur einen konstanten Mittelwert überprüfen kann, dafür ist die Auswertung denkbareinfach gestaltet. R gibt als Ergebnis eine Logik-Antwort aus, also entweder FALSE oderTRUE:
install.packages(LaplacesDemon)
library(LaplacesDemon)
#### Attaching package: ’LaplacesDemon’## The following object is masked from ’package:tseries’:#### read.matrix## The following object is masked from ’package:forecast’:#### is.constant
is.stationary(temp)
## [1] FALSE
Zusammenfassend kann man wohl sagen, dass die letzte Funktion für einen Vorabtest aufeinen konstanten Mittelwert in der Zeitreihe ausreicht, allerdings genügen die hier vorgestell-ten Tests alle nicht, um eine exakte Aussage über das Vorliegen von (schwacher) Stationaritätin der Zeitreihe zu treffen.
Dies trifft auch auf den letzten Test statcheck zu. Er kann zwar auch die Varianz betrachten,vernachlässigt aber die Autokovarianzfunktion. Für eine Anwendung und die entsprechen-de Auswertung wird nur auf [4, S. 16 ff.] verwiesen. Dort ist der Befehl auch bereits mitInterpretation ausführlich erklärt.
19

4 Die TrendbestimmungNachdem bisher eine erste grobe Analyse durchgeführt wurde und ein wenig auf die Statio-narität eingegangen wurde, beschäftigt sich dieser Teil der Arbeit mit dem Trend. Währendder Erwartungswert ein Wert (genauer: der Mittelwert) einer Zeitreihe ist, ist der Trendeine (nicht-) lineare Funktion. Sie beschreibt die Bewegung des (abschnittsweise-definierten)Mittels im Zeitablauf.Eigentlich sollte als zweiter Schritt zunächst das Korellogramm betrachtet werden, nach-dem der Plot der Zeitreihe angeschaut wurde. Um aber ein Hin- und Herspringen zwischenden verschiedenen Themengebieten zu vermeiden, wird hier erst in einem die Trendanalysebehandelt und im Anschluss die Periodizitäten als Gesamtes. So kommt auch die formaleEinführung der Autokovarianzfunktion erst im nächsten Kapitel.
4.1 RegressionEinen relativ kurzen Einblick erhält der Leser in die Regression. Zu diesem Thema gibt essehr viele Bücher und Paper, die diesen Bereich sehr gut abdecken, weshalb hier nicht tieferdarauf eingegangen wird.Im Allgemeinen kann man eine Regression linear oder multipel betrachten. Sie dient in jedemFall dazu, aus vorgegebenen Datenpunkten eine geeignete Funktion zu finden, die den Verlaufder Werte gut abbildet. Hier wird nur ganz kurz die lineare Regression betrachtet [4, S. 23]:
Das lineare Regressionsmodell beschreibt die Abhängigkeit der Zielvariablen Yt vonden fest vorgegebenen Werten der unabhängigen Variablen oder Regressoren Xi , i =1, ...,m mittels
Yt = β0 + β1x1t + ...+ βmxmt + εt
mit t = 1, ..., N .
Der passende Befehl für diese Herangehensweise ist in R lm aus dem Package stats. Beider Anwendung sollte man allerdings die Daten aus einer Matrix übergeben, so dass dieRegressoren direkt richtig zugeordnet werden können. Deshalb wird hier wieder die MatrixTemperatur vom Anfang benutzt und nicht die später extra angelegte Zeitreihe:
library(stats)
lm(Temperatur)
##
20

KAPITEL 4. DIE TRENDBESTIMMUNG
## Call:## lm(formula = Temperatur)#### Coefficients:## (Intercept) Feb Maerz Apr Mai## -3.26090 0.28189 0.13941 0.08224 0.21231## Jun Jul Aug Sept Okt## -0.26474 -0.06041 0.33167 -0.12589 -0.00672## Nov Dez## 0.07683 0.05107
Dabei dient der Januar als Startvariable x0, an dem die lineare Regression beginnt unddie anderen Werte bemessen werden. Die beschreibende Gleichung von oben würde mit denentsprechenden Koeffizienten (abgerundet) folgendermaßen aussehen:
Yt = −3, 26 + 0, 28x1t + 0, 13x2t + ...+ 0, 07x11t + 0, 05x12t
Mit dem nächsten Befehl kann man sich im Anschluss noch eine genauere Aufzählung dereinzelnen Ergebnisse geben lassen:
summary(lm(Temperatur))
Bei der linearen, polynomiellen Regression gehen die Regressoren potenziert in die Regres-sionsgleichung ein [1, S. 15 f.]:
Yt = β0 + β1x1t + β2x22t + ...+ βmx
m−1mt
Dafür kann man sich in R eines kleinen Tricks behelfen, indem man die Regressoren zunächstentsprechend ihrer Position in der Regressionsgleichung potenziert und sie potenziert einerVariablen zuweist, die dann in die Gleichung eingeht. Man könnte beispielsweise so vorgehen,wenn man den Januar durch den Februar beschrieben haben möchte [4, S. 25]:
Y <- Temperatur[,1]; x_1t <- Temperatur[,2]; x_2t <- Temperatur[,2]^2x_3t <- Temperatur[,2]^3; x_4t <- Temperatur[,2]^4
lm(Y ~ x_1t + x_2t + x_3t + x_4t)summary(lm(Y ~ x_1t + x_2t + x_3t + x_4t))1
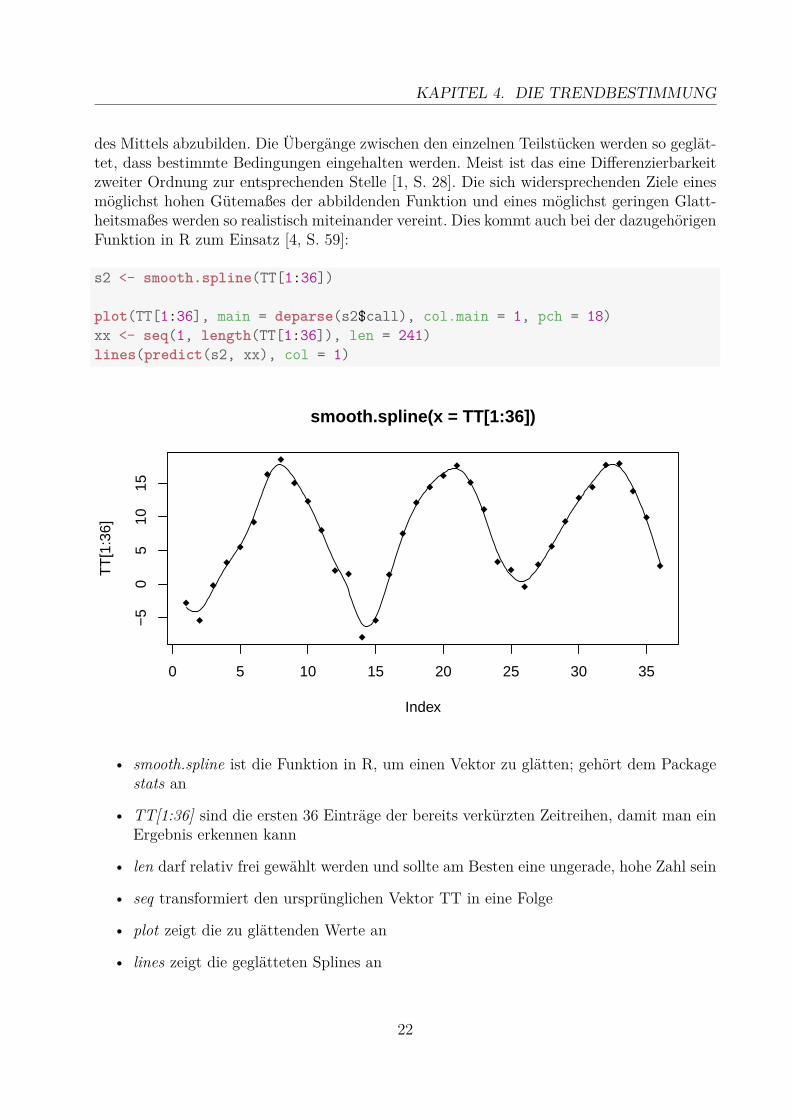
4.2 Spline-TechnikEine andere Möglichkeit, einen nicht linearen Trend zu modellieren, ist die Spline-Technik.Dabei werden relativ glatte Funktionen über Teile der Zeitreihe gelegt, um so die Bewegung
21
KAPITEL 4. DIE TRENDBESTIMMUNG
des Mittels abzubilden. Die Übergänge zwischen den einzelnen Teilstücken werden so geglät-tet, dass bestimmte Bedingungen eingehalten werden. Meist ist das eine Differenzierbarkeitzweiter Ordnung zur entsprechenden Stelle [1, S. 28]. Die sich widersprechenden Ziele einesmöglichst hohen Gütemaßes der abbildenden Funktion und eines möglichst geringen Glatt-heitsmaßes werden so realistisch miteinander vereint. Dies kommt auch bei der dazugehörigenFunktion in R zum Einsatz [4, S. 59]:
s2 <- smooth.spline(TT[1:36])
plot(TT[1:36], main = deparse(s2$call), col.main = 1, pch = 18)xx <- seq(1, length(TT[1:36]), len = 241)lines(predict(s2, xx), col = 1)
0 5 10 15 20 25 30 35
−5
05
1015
smooth.spline(x = TT[1:36])
Index
TT
[1:3
6]
• smooth.spline ist die Funktion in R, um einen Vektor zu glätten; gehört dem Packagestats an
• TT[1:36] sind die ersten 36 Einträge der bereits verkürzten Zeitreihen, damit man einErgebnis erkennen kann
• len darf relativ frei gewählt werden und sollte am Besten eine ungerade, hohe Zahl sein
• seq transformiert den ursprünglichen Vektor TT in eine Folge
• plot zeigt die zu glättenden Werte an
• lines zeigt die geglätteten Splines an
22

KAPITEL 4. DIE TRENDBESTIMMUNG
• main ist der Titel des Plots
• col.main ist die Farbe des Plots
• pch ist die Art der Punktdarstellung
• col ist die Farbe des Splinegraphen
An dem Graphen sieht man schön, dass nicht jeder Punkt bei der Berechnung der Trend-funktion voll eingebunden wurde. Dadurch entsteht eine schöne Glattheit für die Funktion,obwohl die Abbildung noch relativ realistisch ist.
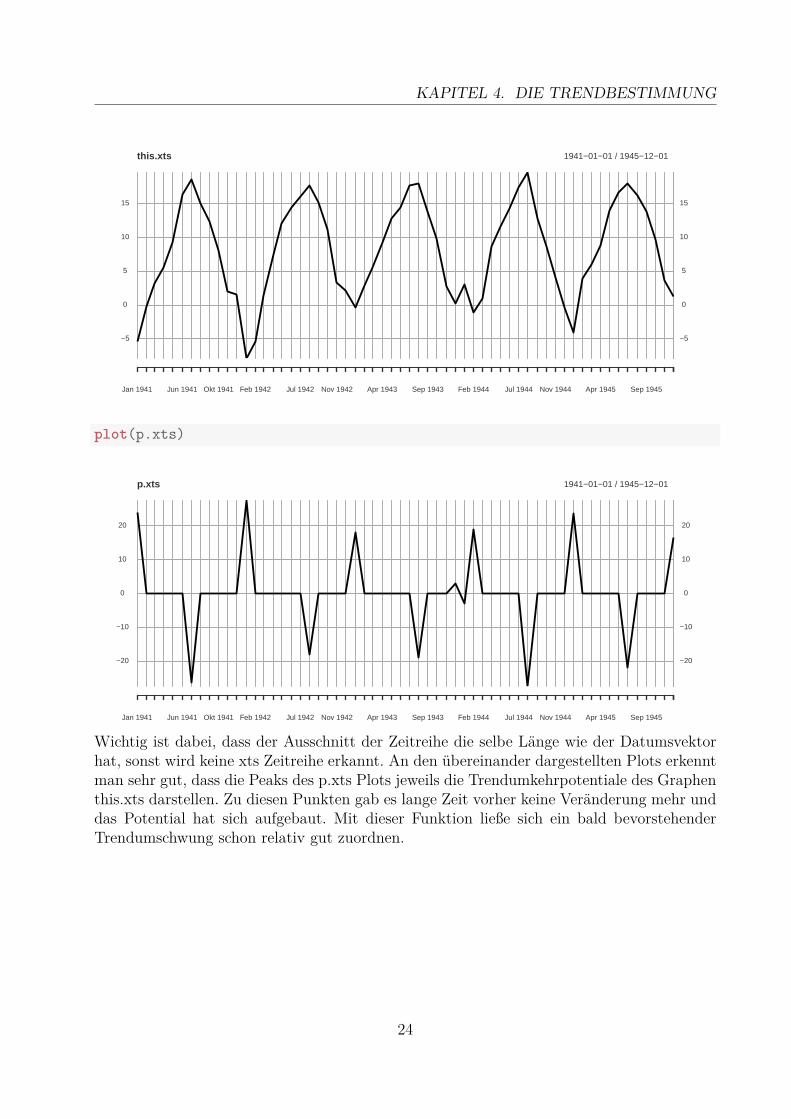
4.3 TrendumkehrpotentialeZu der Identifizierung von Trendumkehrpunkten gibt es zwar Literatur und Funktionen,jedoch sind diese für eine Zeitreihenanalyse nur bedingt geeignet. Deshalb wurde für dieseArbeit auf einen Algorithmus zurückgegriffen, der aus verschiedenen Quellen bezogen wurde.Der erste Kontakt damit war im Buch von Rainer Schlittgen [1, S. 32 f.], was im Zuge derVorlesung bei Prof. Bernd Hofmann nochmal mathematisch eindeutiger formuliert wurde undspäter durch Dr. Juri Merger in R implementiert wurde. Die Funktion dazu befindet sich imAnhang und beinhaltet im Wesentlichen, dass benachbarte Teilbereiche der Zeitreihe jeweilsmiteinander verglichen werden. Dazu werden zuerst die monotonen Stellen der Zeitreihe mit 0bewertet und fallen damit aus der Betrachtung. Anschließend werden die übrigen Zeitpunkteauf Basis der Differenz ihrer Werte so bewertet, dass zwischen Maxima und Minima einextrem hohes Potential einer nächstmöglichen Trendumkehr entsteht. Dabei betrachtet manvon Anfang an alle Punkte der Zeitreihe gleichzeitig und vergleicht nur benachbarte, möglicheTrendumkehrpotentiale in zeitlicher Relevanz.
x <- TT[1:60]t <- seq(as.Date("1941-01-01"), as.Date("1945-12-01"), by = "month")length(t)
## [1] 60
length(x)
## [1] 60
this.xts <- xts(x, t)p.xts <- trendUmkehrPotential(this.xts)plot(this.xts)
23
KAPITEL 4. DIE TRENDBESTIMMUNG
Jan 1941 Jun 1941 Okt 1941 Feb 1942 Jul 1942 Nov 1942 Apr 1943 Sep 1943 Feb 1944 Jul 1944 Nov 1944 Apr 1945 Sep 1945
this.xts 1941−01−01 / 1945−12−01
−5
0
5
10
15
−5
0
5
10
15
plot(p.xts)
Jan 1941 Jun 1941 Okt 1941 Feb 1942 Jul 1942 Nov 1942 Apr 1943 Sep 1943 Feb 1944 Jul 1944 Nov 1944 Apr 1945 Sep 1945
p.xts 1941−01−01 / 1945−12−01
−20
−10
0
10
20
−20
−10
0
10
20
Wichtig ist dabei, dass der Ausschnitt der Zeitreihe die selbe Länge wie der Datumsvektorhat, sonst wird keine xts Zeitreihe erkannt. An den übereinander dargestellten Plots erkenntman sehr gut, dass die Peaks des p.xts Plots jeweils die Trendumkehrpotentiale des Graphenthis.xts darstellen. Zu diesen Punkten gab es lange Zeit vorher keine Veränderung mehr unddas Potential hat sich aufgebaut. Mit dieser Funktion ließe sich ein bald bevorstehenderTrendumschwung schon relativ gut zuordnen.
24

5 PeriodizitätenDieser Abschnitt beschäftigt sich mit den periodischen Schwankungen einer Zeitreihe. Es solldarum gehen, ein Korellogramm, ein Periodogramm und zwei Arten von Filtern zur Zeitreihezu erstellen. Wie bereits zuvor erwähnt, wird auch hier noch einmal darauf verwiesen, dasses unter Umständen Sinn macht, nicht zuerst eine Trendanaylse und -bereinigung durchzu-führen, sondern als Erstes eine saisonelle Betrachtung. Das ist vor allem dann der Fall, wenndie saisonell Komponente so stark ausgeprägt ist, dass der Trend nicht mehr identifizierbarist. Deshalb sollte man auf jeden Fall für den Anfang mindestens eine der beiden zuvor vor-gestellten Zerlegungsfunktionen in R nutzen, um sich einen ersten Überblick über die Reihezu verschaffen.
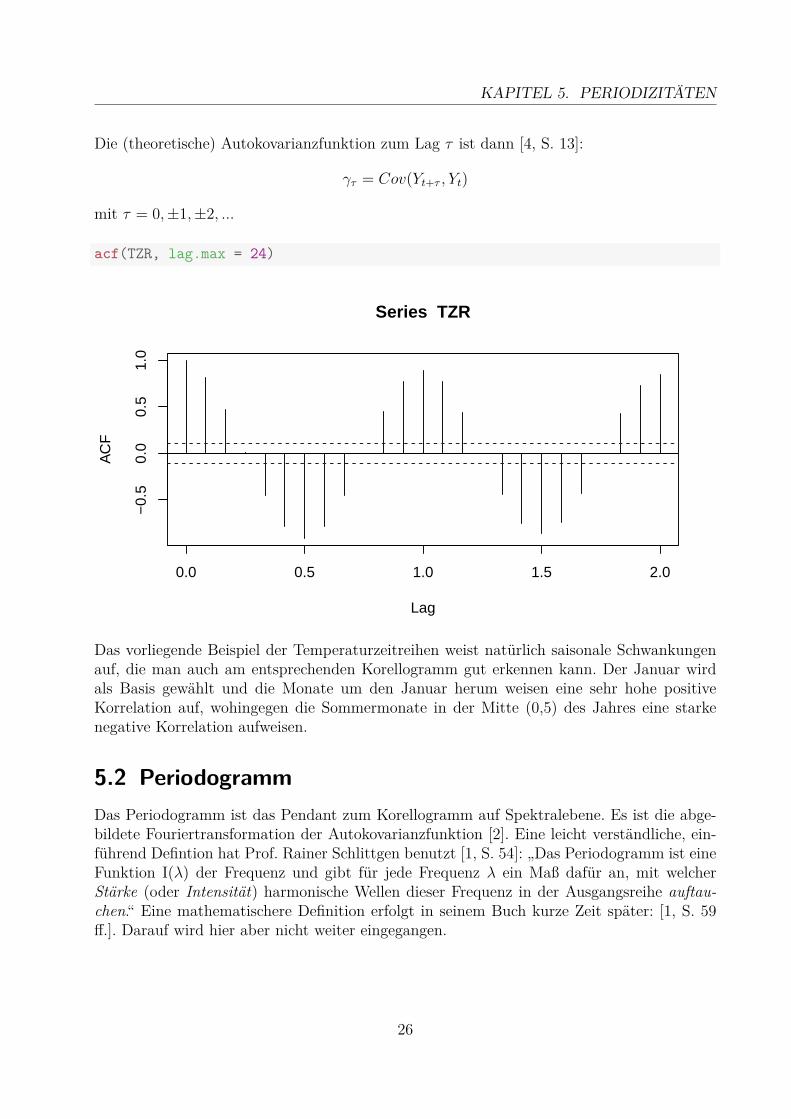
5.1 KorrelogrammEgal, ob bisher bereits der Trend bereinigt wurde oder die Zeitreihe noch relativ roh vorliegt,man sollte immer so früh wie möglich ein Korellogramm der Zeitreihe betrachten. An ihmerkennt man, ob periodische Abhängigkeiten vorliegen könnten [1, S. 12]. Das Korellogrammist dabei der Graph aus der Autokorrelationsfunktion, welche wiederrum auf der Autokova-rianzfunktion einer Zeitreihe basiert. Die Zusammenhänge lassen sich wie folgt darstellen:
Definition„empirische Autokovarianz- und AutokorrelationsfunktionDie i) empirische Autokovarianzfunktion (cτ ) einer Zeitreihe (Yt) sowie ihre ii) empi-rische Autokorrelationsfunktion, kurz ACF, (rτ ) sind definiert durch:
i)
cτ = 1/NN−τ∑t=1
(yt−τ − y)(yt − y),
ii)rτ = cτ
c0,
mit τ ≥ 0.Für τ < 0 wird cτ = c−τ und rτ = r−τ gesetzt.
Da sich die beide Funktionen cτ und rτ nur um einen Faktor unterscheiden, wird auch fürdie Autokovarianzfunktion das Kürzel ACF verwendet.“ [4, S. 11] Außerdem gibt es ausdemselben Grund nur einen Plot für beide Funktionen - das Korellogramm.
25
KAPITEL 5. PERIODIZITÄTEN
Die (theoretische) Autokovarianzfunktion zum Lag τ ist dann [4, S. 13]:
γτ = Cov(Yt+τ , Yt)
mit τ = 0,±1,±2, ...
acf(TZR, lag.max = 24)
0.0 0.5 1.0 1.5 2.0
−0.
50.
00.
51.
0
Lag
AC
F
Series TZR
Das vorliegende Beispiel der Temperaturzeitreihen weist natürlich saisonale Schwankungenauf, die man auch am entsprechenden Korellogramm gut erkennen kann. Der Januar wirdals Basis gewählt und die Monate um den Januar herum weisen eine sehr hohe positiveKorrelation auf, wohingegen die Sommermonate in der Mitte (0,5) des Jahres eine starkenegative Korrelation aufweisen.
5.2 PeriodogrammDas Periodogramm ist das Pendant zum Korellogramm auf Spektralebene. Es ist die abge-bildete Fouriertransformation der Autokovarianzfunktion [2]. Eine leicht verständliche, ein-führend Defintion hat Prof. Rainer Schlittgen benutzt [1, S. 54]: „Das Periodogramm ist eineFunktion I(λ) der Frequenz und gibt für jede Frequenz λ ein Maß dafür an, mit welcherStärke (oder Intensität) harmonische Wellen dieser Frequenz in der Ausgangsreihe auftau-chen.“ Eine mathematischere Definition erfolgt in seinem Buch kurze Zeit später: [1, S. 59ff.]. Darauf wird hier aber nicht weiter eingegangen.
26
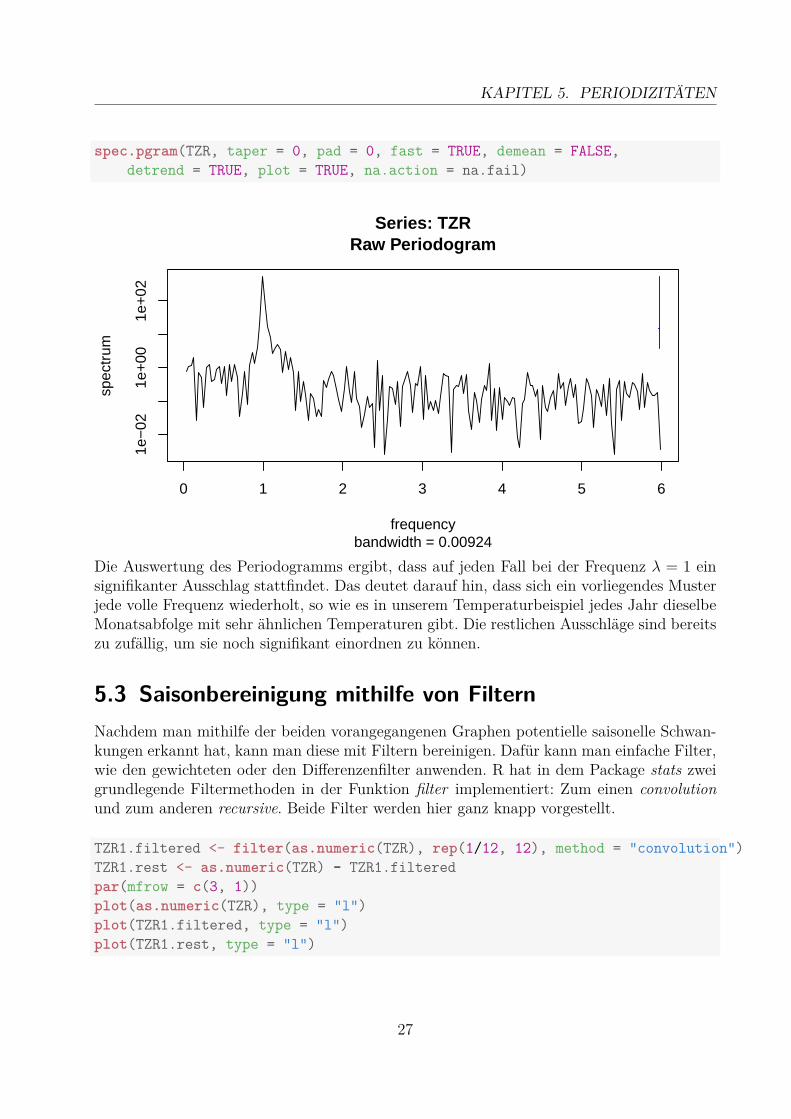
KAPITEL 5. PERIODIZITÄTEN
spec.pgram(TZR, taper = 0, pad = 0, fast = TRUE, demean = FALSE,detrend = TRUE, plot = TRUE, na.action = na.fail)
0 1 2 3 4 5 6
1e−
021e
+00
1e+
02
frequency
spec
trum
Series: TZRRaw Periodogram
bandwidth = 0.00924
Die Auswertung des Periodogramms ergibt, dass auf jeden Fall bei der Frequenz λ = 1 einsignifikanter Ausschlag stattfindet. Das deutet darauf hin, dass sich ein vorliegendes Musterjede volle Frequenz wiederholt, so wie es in unserem Temperaturbeispiel jedes Jahr dieselbeMonatsabfolge mit sehr ähnlichen Temperaturen gibt. Die restlichen Ausschläge sind bereitszu zufällig, um sie noch signifikant einordnen zu können.
5.3 Saisonbereinigung mithilfe von FilternNachdem man mithilfe der beiden vorangegangenen Graphen potentielle saisonelle Schwan-kungen erkannt hat, kann man diese mit Filtern bereinigen. Dafür kann man einfache Filter,wie den gewichteten oder den Differenzenfilter anwenden. R hat in dem Package stats zweigrundlegende Filtermethoden in der Funktion filter implementiert: Zum einen convolutionund zum anderen recursive. Beide Filter werden hier ganz knapp vorgestellt.
TZR1.filtered <- filter(as.numeric(TZR), rep(1/12, 12), method = "convolution")TZR1.rest <- as.numeric(TZR) - TZR1.filteredpar(mfrow = c(3, 1))plot(as.numeric(TZR), type = "l")plot(TZR1.filtered, type = "l")plot(TZR1.rest, type = "l")
27
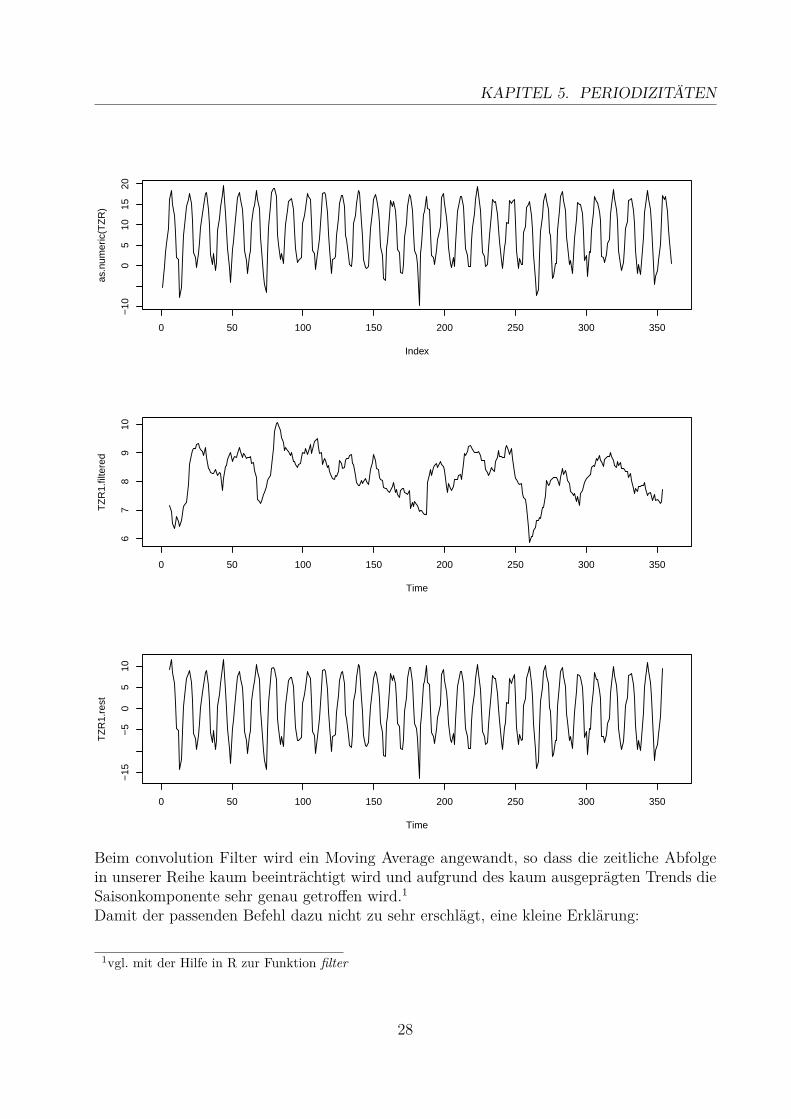
KAPITEL 5. PERIODIZITÄTEN
0 50 100 150 200 250 300 350
−10
05
1015
20
Index
as.n
umer
ic(T
ZR
)
Time
TZ
R1.
filte
red
0 50 100 150 200 250 300 350
67
89
10
Time
TZ
R1.
rest
0 50 100 150 200 250 300 350
−15
−5
05
10
Beim convolution Filter wird ein Moving Average angewandt, so dass die zeitliche Abfolgein unserer Reihe kaum beeinträchtigt wird und aufgrund des kaum ausgeprägten Trends dieSaisonkomponente sehr genau getroffen wird.1Damit der passenden Befehl dazu nicht zu sehr erschlägt, eine kleine Erklärung:
1vgl. mit der Hilfe in R zur Funktion filter
28

KAPITEL 5. PERIODIZITÄTEN
• die erste Zeile gibt den eigentlichen Filterbefehl an
• die zweite Zeile ordnet dem aus der Reihe rausgefilterten Werten eine Variable zumPlotten zu
• mit par und dem entsprechenden Befehl einer geeigneten Anzahl im Vektor werden imselben Plot drei Graphen gezeigt
• die drei Plot-Befehle zeigen die entsprechenden Variablen in Liniendiagrammen
Die Alternative dieses Befehls ist die recursive Methode. Hier wird ein Autoregressive Pro-zess zur Modellierung herangezogen. Dadurch eignet er sich eher zur Trendanalyse oder derBereinigung eines multiplikativen Modells und wird hier nicht weiter erwähnt. Der Befehl inR könnte wie folgt aussehen:
plot(filter(as.numeric(TZR), rep(1/12, 12), method = "recursive"),main = "recursive", ylab = "filtered")
# TZR1.filtered <- filter(as.numeric(TZR), rep(1/12, 12),# method = 'recursive') TZR1.rest <- as.numeric(TZR) -# TZR1.filtered par(mfrow = c(3, 1)) plot(as.numeric(TZR),# type = 'l') plot(TZR1.filtered, type = 'l') plot(TZR1.rest,# type = 'l')
Andere Filter findet man in R beispielsweise durch eine direkte Suche in der R Dokumenta-tion mit den entsprechenden Begriffen, wie „Kalman-Filter“, oder aber einer kombiniertenSuche, wie „filter+time series“.
29

6 AusblickBisher konnte nur in einige, wenige grundlegende Funktionen der Zeitreihenanalyse einge-führt werden. Um das Wissen des Lesers weiter aufzubauen, wäre es im Anschluss durch-aus interessant auch die verschiedenen Prozessklassen zu betrachten. So könnte man fürdie Zeitreihenanalyse die besonderen Eigenschaften der verschiedenen Mixtypen wie ARMAoder ARIMA nutzen. Man könnte den Unterschied zwischen dem einfachsten stochastischenProzess, dem bereits angesprochenen Weißen Rauschen, und einem weiteren sehr leicht zuhandhabenden Prozess, dem Moving Average Prozess, beleuchten. Letzterer taucht geradein den wirtschaftlich motivierten Arbeiten so häufig auf, dass ein Student dieses Fachs zu-mindest schon einmal davon gehört haben sollte. Ein weiterer interessanter Aspekt wäreein Vergleich der diskreten und stetigen Prozesse. Hier würde man vom klassischen Ran-dom Walk und der Braun’schen Bewegung zu Markovketten übergehen und wahrscheinlichganz neue Implementierungen in R kennenlernen. Natürlich gibt es in diesem Bereich nochunheimlich viel zu lernen und dieses Handbuch wollte lediglich eine handliche Einführungbieten und alle Leser dazu ermutigen, noch etwas tiefer in die Bücher zu blicken.
Was bei der Recherche zu dieser Arbeit extrem auffällig war, war die Redundanz der Befehleund Funktionen in R und dem CRAN-Netzwerk. Gerade beim Thema der Stationarität, dieformal mathematisch einen hohen Stellenwert für das weitere Herangehen an die stochasti-schen Prozesse einnimmt, gab es einen großen Bedarf an weiter ausgebauten Funktionen. Diemeisten Befehle prüften nur auf eine Mittelwert-Stationarität, jedoch nicht auf eine schwa-che Stationarität der Zeitreihen. Natürlich sollte man im Laufe der eigenen Analyse selbstherausfinden, ob die Zeitreihe schwach stationär ist. Die elaborierteren Funktionen würdenallerdings schon am Anfang der Betrachtung enorm unterstützen können. Vielleicht hat jetztja auch ein Leser Lust bekommen, selbst eine Funktion zum CRAN-Netzwerk beizusteuernund damit die Qualität der Zeitreihenanalyse und dadurch auch der Prognosen positiv zubeeinflussen.
30

7 AnhangAlgorithmus des Trendumkehrpotentials1
trendUmkehrPotential <- function(this.xts) {if (!any(class(this.xts) %in% "xts")) {
stop("Der Input muss von der Klasse xts sein!")}
# Sei x_t mit t in T0 eine Zeitreihe mit mindestens zwei# Werten. Die Trendumkehrpotentiale sind wie folgt bestimmt.x <- as.numeric(coredata(this.xts))T0 <- index(this.xts)p <- rep(NA, length(x))
# Schritt 1: Für all t < t_max mit x_tR - x_t = 0 wird p(t)# = 0 gesetzt und t als gelöscht betrachtet. Sei T1 die# Menge der nichtgelöschten Zeitpunkte. (tR, tL bezeichnet# den rechten bzw. linken Nachbarzeitpunkt von t)i <- which(diff(x) == 0)if (length(i) > 0) {
p[i] <- 0T1 <- T0[-i]
} else {T1 <- T0
}
# Schritt 2: Falls T1 einelementig dann p(t) = 0 und Abbruch# der Iterationif (length(T1) <= 1) {
p[which(T0 %in% T1)] <- 0return(p)
}# Für alle inneren Punkte t von T1 mit x_tL < x_t < x_tR# bzw. x_tL > x_t > x_tR setzt man p(t) = 0 und betrachte t
1geschrieben von Dr. Juri Merger, angelehnt an das Buch von Prof. Schlittgen [1, S. 32 f.] und das Skriptvon Prof. Hofmann [2], nicht veröffentlicht, mit ausdrücklicher Genehmigung genutzt, 2017
31

KAPITEL 7. ANHANG
# als gelöscht. Sei nun T2 die Menge der nicht gelöschten# Zeitpunkte.if (length(T1) >= 3) {
# T.innen <- T1[2:(length(T1) - 1)]x.T1 <- x[which(T0 %in% T1)]#xt.minus.xtL <- diff(x.T1[1:(length(x.T1) - 1)])xtR.minus.xt <- diff(x.T1[2:length(x.T1)])index.monoton <- which(xt.minus.xtL * xtR.minus.xt >
0) + 1if (length(index.monoton) > 0) {
p[which(T0 %in% T1[index.monoton])] <- 0T1 <- T1[-index.monoton]
}}T2 <- T1
# Schritt 3: Sei t' der kleinste Zeitpunkt, an dem der# minimale Abstand von je 2 aufeinanderfolgenden# Beobachtungen in T2 beginnt, d.h. t' = min{t: t in# T2\{t_max}: |x_tR - x_t| = min{|x_sR - xs|}, wobei s in# T2\{t_max} } (i) Falls t' und t'R beides innere Punkte# oder beides Randpunkte, so werden ihre Potentiale durch# p(t') = x_t'R - x_t' bzw. p(t'R) = x_t' - x_t'R bestimmt# und t' und t'R werden als gelöscht betrachtet. (ii) Für# t' = t_min und t'R < t_max wird p(t') = x_t'R - x_t'# gesetzt und t' gelöscht. Für t' > t_min und t'R = tmax# wird p(t'R) = x_t' - x_t'R gesetzt und t'R gelöscht. Sei# T3 die Menge der nichtgelöschten Zeitpunkte.for (i in 1:length(T2)) {
x.T2 <- x[which(T0 %in% T2)]differenz <- abs(diff(x.T2))index.minimum <- which(min(differenz) == differenz)t.strich <- T2[min(index.minimum)]t.strichR <- T2[min(index.minimum) + 1]
t.strich.innen <- t.strich %in% T2[2:(length(T2) - 1)]t.strichR.innen <- t.strichR %in% T2[2:(length(T2) -
1)]
# (i)if (t.strich.innen & t.strichR.innen | !t.strich.innen &
!t.strichR.innen) {
32

KAPITEL 7. ANHANG
p[which(T0 %in% t.strich)] <- x[which(T0 %in% t.strichR)] -x[which(T0 %in% t.strich)]
p[which(T0 %in% t.strichR)] <- x[which(T0 %in% t.strich)] -x[which(T0 %in% t.strichR)]
T3 <- T2[!T2 %in% c(t.strich, t.strichR)]# (ii)
} else if (!t.strich.innen) {p[which(T0 %in% t.strich)] <- x[which(T0 %in% t.strichR)] -
x[which(T0 %in% t.strich)]T3 <- T2[!T2 %in% t.strich]
} else if (!t.strichR.innen) {p[which(T0 %in% t.strichR)] <- x[which(T0 %in% t.strich)] -
x[which(T0 %in% t.strichR)]T3 <- T2[!T2 %in% t.strichR]
}
# Schritt 4: Setze T2 = T3 und wiederhole Schritt 3, falls T2# nicht leer ist.T2 <- T3if (!length(T2) > 0) {
break}
}
p.xts <- xts(p, T0)# par(mfrow = c(2, 1)) plot(this.xts) plot(p.xts)return(p.xts)
}
33

Eidesstattliche ErklärungHiermit versichere ich, Salima Abdalla, diese Arbeit eigenständig und mit keinen anderenQuellen, als den hier angegebenen, angefertigt zu haben. Außerdem wurde diese Arbeit beinoch keiner anderen Prüfungskommission zur Bewertung vorgelegt.
Chemnitz, den 23. Dezember 2017

Literaturverzeichnis[1] Schlittgen, R. ; Streitberg, B.H.J.: Zeitreihenanalyse. De Gruyter, 2001 (Lehr-
und Handbücher der Statistik). https://books.google.de/books?id=hy3pBQAAQBAJ.– ISBN 9783486710960
[2] Hofmann, Bernd: Vorlesungsskript „Einführung in die Zeitreihenanalyse“. 2012
[3] R-Stutorials. https://sites.google.com/site/tutorialrstudio/home
[4] Schlittgen, R.: Angewandte Zeitreihenanalyse mit R. De Gruyter Oldenbourg, 2015https://books.google.de/books?id=Ch9fCAAAQBAJ. – ISBN 9783110413991
[5] Chatfield, C.: Time-Series Forecasting. CRC Press, 2000 https://books.google.de/books?id=PFHMBQAAQBAJ. – ISBN 9781420036206
[6] Chatfield, C.: The Analysis of Time Series: An Introduction, Sixth Edition. CRCPress, 2016 (Chapman & Hall/CRC Texts in Statistical Science). https://books.google.de/books?id=qKzyAbdaDFAC. – ISBN 9780203491683
[7] Brockwell, P.J. ; Davis, R.A.: Introduction to Time Series and Forecasting. SpringerInternational Publishing, 2016 (Springer Texts in Statistics). https://books.google.de/books?id=P3fhDAAAQBAJ. – ISBN 9783319298542
[8] Welcome to a Little Book of R for Time Series! — Time Series 0.2 documentation.https://a-little-book-of-r-for-time-series.readthedocs.io/en/latest/
[9] R Documentation and manuals | R Documentation. https://www.rdocumentation.org/
[10] RDocumentation. https://www.rdocumentation.org/taskviews#TimeSeries
[11] CRAN Task View: Time Series Analysis. https://cran.r-project.org/web/views/TimeSeries.html
[12] Das beste package für Zeitreihenanalyse - Deutsches R-Forum. http://forum.r-statistik.de/viewtopic.php?t=320
[13] Quick-R: Time Series. https://www.statmethods.net/advstats/timeseries.html
[14] R-Stutorials. https://sites.google.com/site/tutorialrstudio/home
IV

Literaturverzeichnis
[15] R Documentation and manuals | R Documentation. https://www.rdocumentation.org/
[16] The Comprehensive R Archive Network. https://cran.r-project.org/
[17] CRAN Task View: Time Series Analysis. https://cran.r-project.org/web/views/TimeSeries.html
[18] R Tutorial on Reading and Importing Excel Files into R (article) - DataCamp. https://www.datacamp.com/community/tutorials/r-tutorial-read-excel-into-r
[19] This R Data Import Tutorial Is Everything You Need (article) - DataCamp. https://www.datacamp.com/community/tutorials/r-data-import-tutorial#txt
[20] Zeitreihe der Lufttemperatur in Deutschland – Wikipedia. https://de.wikipedia.org/wiki/Zeitreihe_der_Lufttemperatur_in_Deutschland
[21] read.table function | R Documentation. https://www.rdocumentation.org/packages/utils/versions/3.4.1/topics/read.table
[22] stl function | R Documentation. https://www.rdocumentation.org/packages/stats/versions/3.4.1/topics/stl
[23] How to check in R if time series is stationary? http://www.statosphere.com.au/check-time-series-stationary-r/
[24] Stationarity | R-bloggers. https://www.r-bloggers.com/stationarity/
[25] stationarity function | R Documentation. https://www.rdocumentation.org/packages/fractal/versions/2.0-4/topics/stationarity
[26] is.stationary function | R Documentation. https://www.rdocumentation.org/packages/LaplacesDemon/versions/16.1.0/topics/is.stationary
V








![Blockpraktikum [0.7ex] Zeitreihenanalyse mit R · Programmierung Schleifen und Abfragen whileSchleife WillmaneinenVorgangwiederholen,aberweißimVorweldnicht, wanndieSchleifeabbrechensoll,sohilfteinemdiewhileSchleife](https://img.pdfslide.org/doc/110x75/5ba0719a09d3f2fb538c9817/blockpraktikum-07ex-zeitreihenanalyse-mit-r-programmierung-schleifen-und.jpg)

![VO101 04 Zeitreihenanalyse.ppt [Kompatibilitätsmodus]¤sentationen/VO101... · 13.11.2010 1 Zeitreihenanalyse H.P. Nachtnebel Institut für Wasserwirtschaft, Hydrologie und konstruktiver](https://img.pdfslide.org/doc/110x75/5ba0719a09d3f2fb538c97d5/vo101-04-kompatibilitaetsmodus-sentationenvo101-13112010-1-zeitreihenanalyse.jpg)













![Blockpraktikum [0.7ex] Zeitreihenanalyse mit R · Hinweise zum Praktikum Gliederung 1 HinweisezumPraktikum 2 ProgrammstartundRUmgebung 3 Datenstrukturen Vektoren Datentabellen Matrizen](https://img.pdfslide.org/doc/110x75/5ba0719a09d3f2fb538c980f/blockpraktikum-07ex-zeitreihenanalyse-mit-r-hinweise-zum-praktikum-gliederung.jpg)




