Embed Size (px)
Citation preview

Forschungsstatistik IProf. Dr. G. Meinhardt
WS 2006/2007Fachbereich Sozialwissenschaften, Psychologisches Institut
Johannes Gutenberg Universität Mainz

I. Gliederung Vorlesung & Übung zur Vorlesung wöchentliche Hausaufgaben Tutorien (Übungen & Besprechung der HA) Zwischenklausur Abschlussklausur
II. Leistungskriterium Bestehen der Klausur
Organisatorische Hinweise
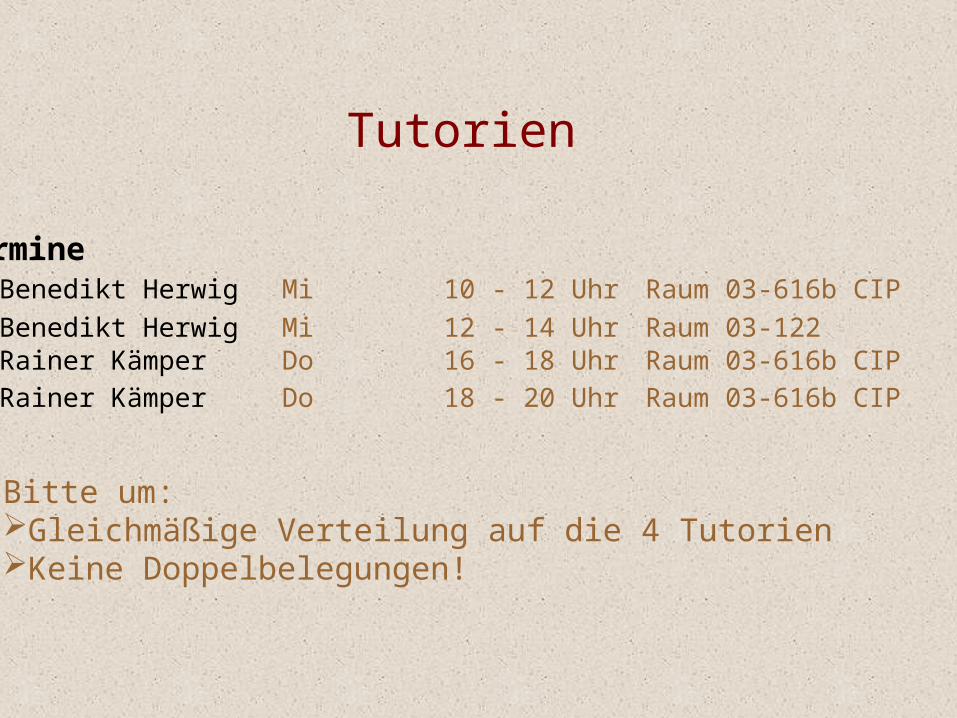
Tutorien
TermineBenedikt Herwig Mi 10 - 12 Uhr Raum 03-616b CIPBenedikt Herwig Mi 12 - 14 Uhr Raum 03-122 Rainer Kämper Do 16 - 18 Uhr Raum 03-616b CIPRainer Kämper Do 18 - 20 Uhr Raum 03-616b CIP
Bitte um:Gleichmäßige Verteilung auf die 4 TutorienKeine Doppelbelegungen!

Literatur (Arbeitsbücher)
Spiegel, M. R. (1990). Statistik.Hamburg: Schaum‘s Outlines
Lipschutz, S. L. (1992). WahrscheinlichkeitsrechnungHamburg: Schaum‘s Outlines(Als Kopie im Handapparat IB)

Literatur (Grundlagen)
Steland, A. (2004). MathematischeGrundlagen der empirischen Forschung.Heidelberg: Springer

Literatur (Basiswerke)
Bortz, J. (2004). Statistik fürSozialwissenschaftler (6. Aufl.).Berlin: Springer-Verlag
Fahrmeir, L., Künstler, R., Pigeot, I.& Tutz, G. (2002). Statistik - DerWeg zur Datenanalyse (4. Aufl.).Berlin: Springer.
Materialien, Hinweise & Scriptehttp://psymet03.sowi.uni-mainz.de/joomla/

Software (Illustration)
Simulation & Graphics BerechnungLösung von symbolischen und numerischen Problemen
www.wolfram.com
Studentenlizenzen!
Software (Illustration)
STATISTICA Version 6 – die Revolution im Bereich der Datenanalyse!
Statistische Analysen Inferenzstatistische Verfahren höhere & multivariate Verfahren
Verteilungen
Studentenlizenzen!
www.statsoft.de

Software (Arbeit)
DatenerfassungDatentransformationDeskriptive Auswertung Darstellung & VisualisierungKennwertberechnung
Einfache statistische Analysen
Einarbeitung und Mitarbeit gefordert!Nachvollziehen möglichst am eigenen Notebook!
Statistik verstehen durch Arbeit an Daten!

I. WS 2005 / 2006 Wahrscheinlichkeitslehre Deskriptive statistische Methoden Korrelations- und Regressionsrechnung,
multiple Regression, Faktorenanalyse
Inhalte
II. SS 2006 Prinzipien des statistischen Schliessens und Schätzens
(Inferenzstatistik) Inferenzstatistische Verfahren Versuchsplanung und Varianzanalyse

GegenstandDie Psychologie ist eine empirische Wissenschaft menschlichen Verhaltens und Erlebens.
Psychologie als Wissenschaft
Empirische Wissenschaft Auf Erfahrung beruhend, erfahrungswissenschaftlich Empirische Methoden:
Prinzip der systematischen Beobachtung und Manipulation Aussagen werden über die Regeln des logischen Schliessens
verküpft Prüfung von Hypothesen über Tatsachenbeobachtungen Verallgemeinerung durch „statistischen Induktionsschluss“

Wissenschaftliche Aussagen
Anforderungen Einfachheit
Eindeutigkeit / Verständlichkeit Logische Konsistenz
Prüfbarkeit durch Tatsachenbezug

Beispiel
„Wenn Menschen wirklich geliebt werden, haben sie keinerlei aggressive Antriebe mehr.“
Einfachheit Eindeutigkeit / Verständlichkeit Logische Konsistenz
Prüfbarkeit durch Tatsachenbezug

Beispiel
„Wenn man Menschen frustriert, verstärken sich ihreNeigungen aggressive Akte auszuführen.“
Einfachheit Eindeutigkeit / Verständlichkeit Logische Konsistenz
Prüfbarkeit durch Tatsachenbezug

Aussagen / Begriffe Psychologische Aussagen orientieren sich an den 4 Anforderungen für wissenschaftliche Aussagen. Die in psychologischen Aussagen enthaltenen Begriffe sind möglichst über Operationalisierung zu definieren: Durch eine Vorschrift, wie das Vorliegen des Begriffes über Beobachtung und Messung festgestellt werden kann Psychologische Begriffe sind möglichst als quantitative Begriffe zu fassen, die als Variablen beschrieben werden Nur für quantitative Variablen lassen sich Beziehungen in „Wenn-Dann“- Form (Hypothesen über Gesetzmässigkeiten) durch Beobachtung prüfen (Kovariationsprinzip).

Die Implikation
Schema:Antecedenz A
Konsequenz B
„Wenn Frustration, dann Aggression“Beispiele:
„Wenn es regnet, ist die Strasse nass “
„Wenn A, dann B“ : A B

Implikation in Mengendarstellung
„Wenn es regnet (A), ist die Strasse nass (B)“
„Wenn Herr K. der Mörder ist (A), war er am Tatort (B)“
BA
„Wenn A, dann B“ : A B

Implikation in Mengendarstellung„Wenn A, dann B“ : A B
BA
A B B A Die Umkehrung gilt nicht:
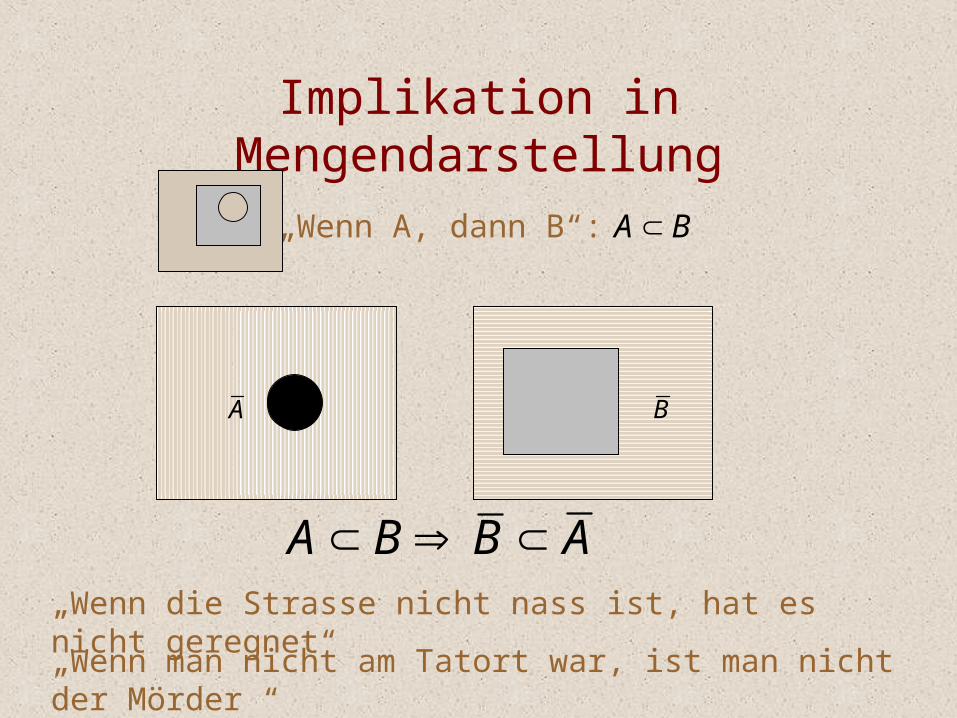
Implikation in Mengendarstellung
A B
A B B A
„Wenn A, dann B“: A B
„Wenn die Strasse nicht nass ist, hat es nicht geregnet“„Wenn man nicht am Tatort war, ist man nicht der Mörder “

Determinismus / Probabilismus
Probabilistisch „Wenn A, dann besteht eine Wahrscheinlichkeit P(B)“
„Es besteht eine Wahrscheinlichkeit P(B|A)“ (Lies: „B unter Bedingung A“)
alternativ:
Deterministisch „Wenn A, dann B“ („Wenn A, dann immer B“)

Probabilistische Zusammenhänge
• A B gilt nicht für alle a A, b B• Wirkung von Störvariablen• Nichtberücksichtigung komplexer Interaktionen• Unbestimmtheit von Anfangsbedingungen in
komplexen Situationen
In der Psychologie gilt eine Gesetzmäßigkeit als belegt, wenn die statistische Bedeutsamkeit des Zusammenhanges von UV und AV aufgezeigt wird

Statistische Einheiten (Merkmalsträger)Objekte, denen aufgrund ihrer Ausprägung in Eigenschaften Zahlen zugewiesen werden können(Personen, Gruppen, Organisationen, Systeme)
Statistik
Beobachtungen Informationen über Merkmalsträger in Form
von Zahlen Stammen aus technischen
Erhebungsmethoden (Befragung, systematische Beobachtung, Reaktions-Registrierung, elektrophysiologische und bildgebende Verfahren)

Variablen Merkmale, dessen Werte bei den statistischen
Einheiten beobachtet werden, heissen Variablen Eine Variable ist ein Merkmal, welches über
Merkmalsträger und Zeit variieren kann Variablen werden klassifiziert nach
(a) der Art der Daten, die sie beschreiben(b) der Quelle der Manipulation ihrer Werte

Variablen Eine diskrete Variable besitzt nur feste Werte,
die man über Ganzzahlen beschreiben kann (z.B. Geschlecht, Zugehörigkeit zu einer Partei, Augenzahl beim Würfelspiel)
Eine kontinuierliche (stetige) Variable Werte, die man über reelle Zahlen beschreibt(z.B. Alter, Reaktionszeit, Erregungsniveau)

Variablen Eine unabhängige Variable besitzt Werte, die ein
Versuchsleiter willkürlich hergestellt hat(z.B. Dosis eines verabreichten Medikamentes, Einteilung in Gruppen, die bestimmte Treatments bekommen)
Eine abhängige Variable besitzt Werte, die man über Beabachtung an den Merkmalsträgern gewinnt (z.B. Reaktionszeit, Fehlerquote, Erregungsniveau, etc.)Schema:
Unabhängige Variable UV
Abhängige Variable AV
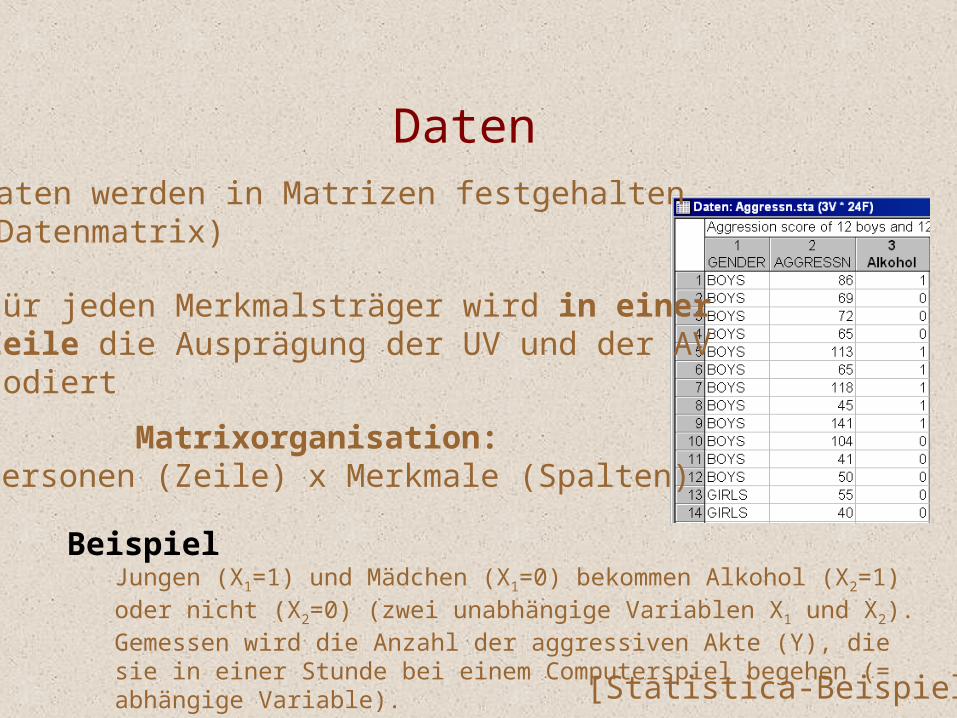
Daten Daten werden in Matrizen festgehalten(Datenmatrix)
Für jeden Merkmalsträger wird in einerZeile die Ausprägung der UV und der AVcodiert
Matrixorganisation:Personen (Zeile) x Merkmale (Spalten)
BeispielJungen (X1=1) und Mädchen (X1=0) bekommen Alkohol (X2=1) oder nicht (X2=0) (zwei unabhängige Variablen X1 und X2). Gemessen wird die Anzahl der aggressiven Akte (Y), die sie in einer Stunde bei einem Computerspiel begehen (= abhängige Variable).[Statistica-Beispiel]
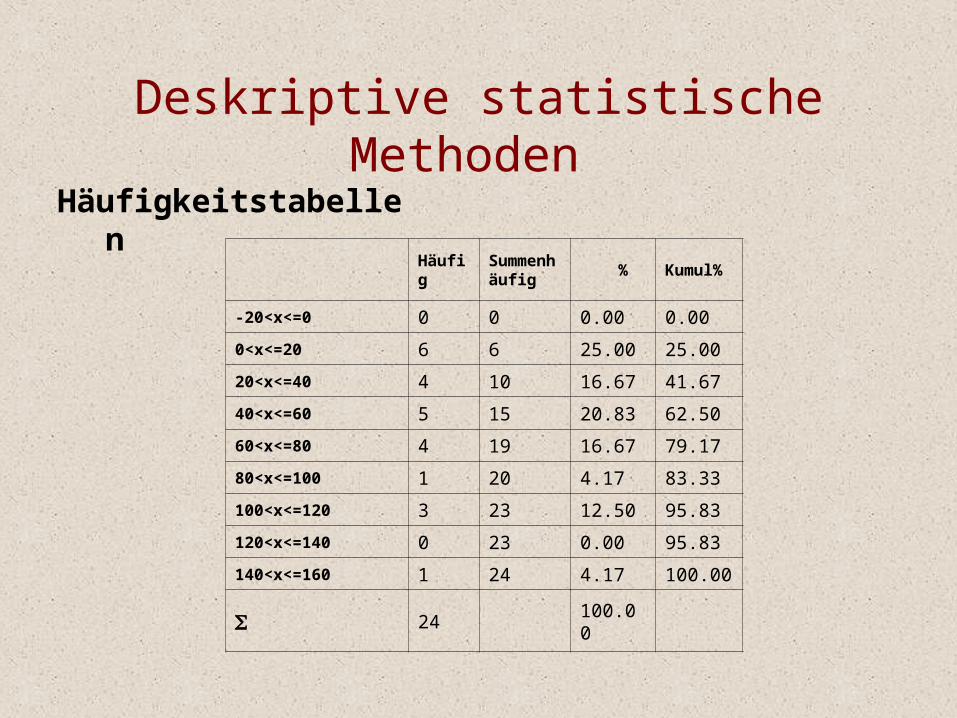
Häufigkeitstabellen
Deskriptive statistische Methoden
Häufig Summenhäufig % Kumul%
-20<x<=0 0 0 0.00 0.00
0<x<=20 6 6 25.00 25.00
20<x<=40 4 10 16.67 41.67
40<x<=60 5 15 20.83 62.50
60<x<=80 4 19 16.67 79.17
80<x<=100 1 20 4.17 83.33
100<x<=120 3 23 12.50 95.83
120<x<=140 0 23 0.00 95.83
140<x<=160 1 24 4.17 100.00
24 100.00
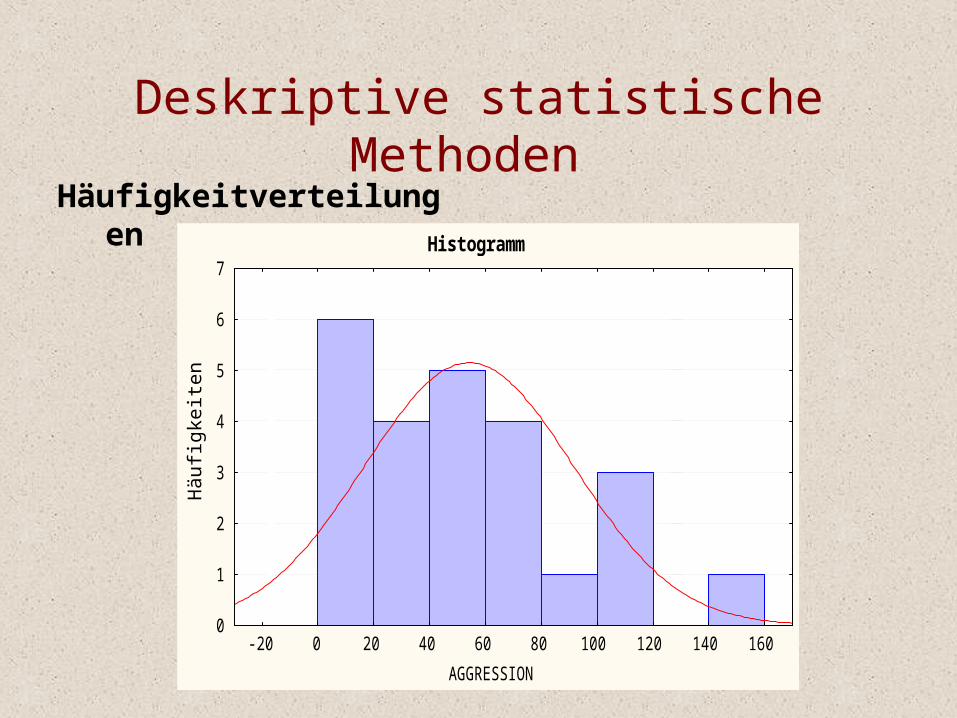
Häufigkeitverteilungen
Deskriptive statistische Methoden
Histogramm
-20 0 20 40 60 80 100 120 140 160AGGRESSION
0
1
2
3
4
5
6
7
Häu
figke
iten
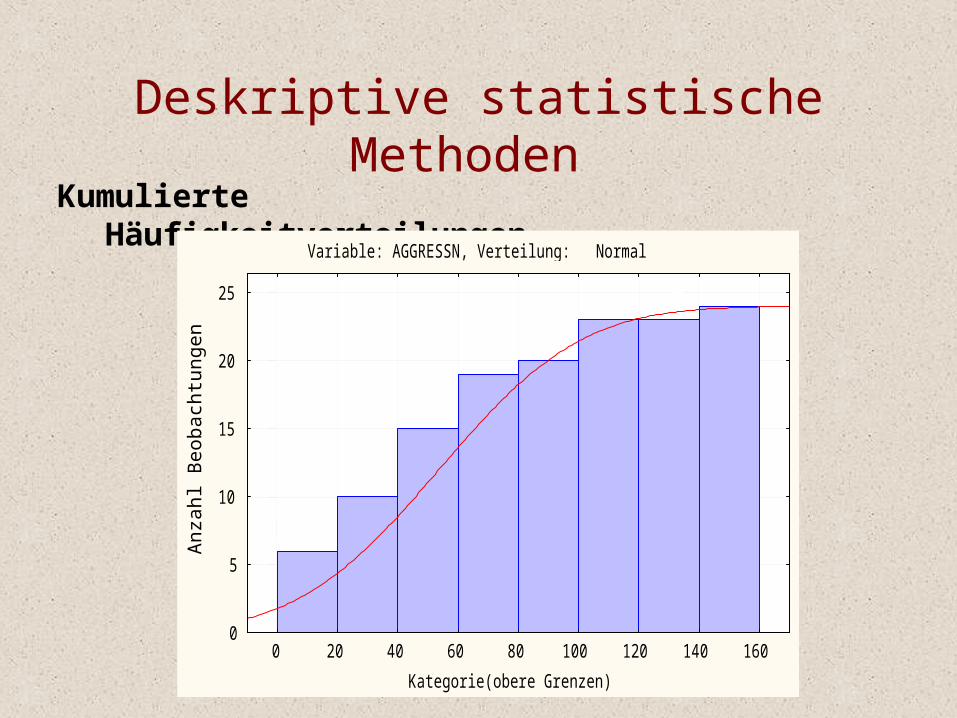
Kumulierte Häufigkeitverteilungen
Deskriptive statistische Methoden
Variable: AGGRESSN, Verteilung: Normal
0 20 40 60 80 100 120 140 160Kategorie(obere Grenzen)
0
5
10
15
20
25
Anz
ahl B
eoba
chtu
ngen

Statistische Kennwerte
Deskriptive statistische Methoden
Kennwerte fassen die Eigenschaften der Verteilung der gemessenen Zufallsvariablen zusammen Vergleiche von Kennwerten sind für statistische Entscheidungen wichtig Verteilungen von Kennwerten sind die Grundlage der schliessenden Statistik (Schätzung und Testung)
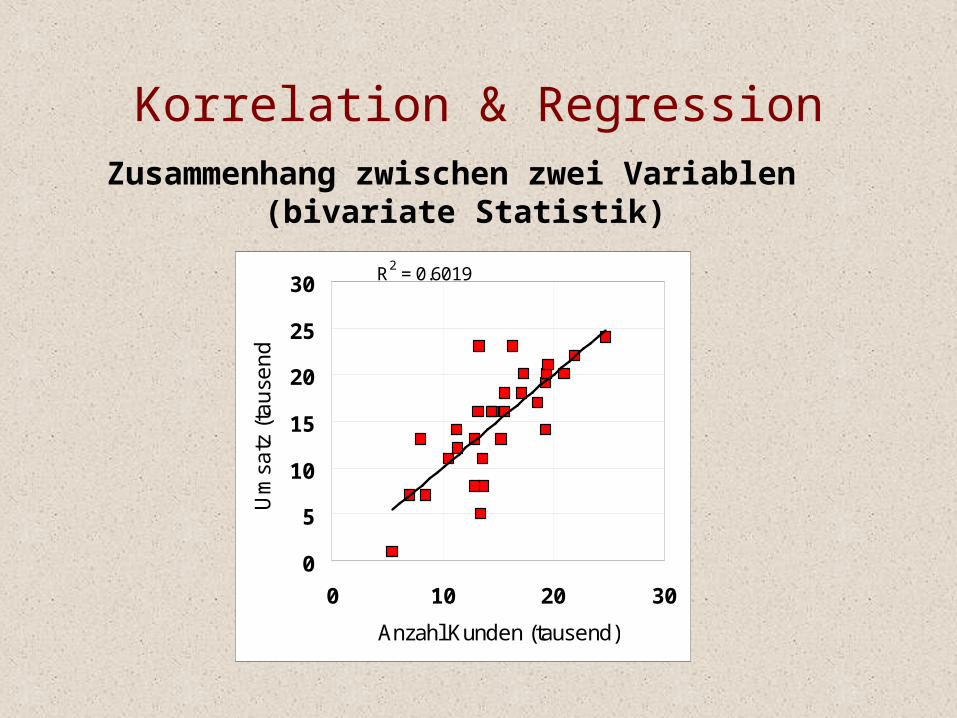
Zusammenhang zwischen zwei Variablen (bivariate Statistik)
Korrelation & Regression
R2 = 0.6019
0
5
10
15
20
25
30
0 10 20 30Anzahl Kunden (tausend)
Um
satz
(tau
send
)
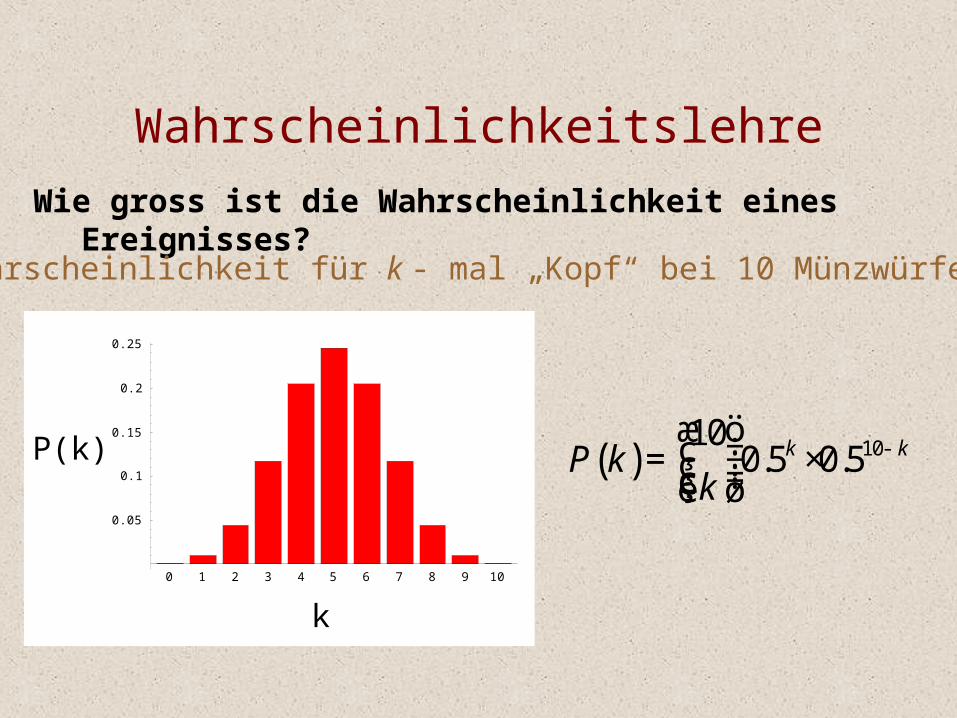
Wie gross ist die Wahrscheinlichkeit eines Ereignisses?
Wahrscheinlichkeitslehre
Wahrscheinlichkeit für k - mal „Kopf“ bei 10 Münzwürfen
0 1 2 3 4 5 6 7 8 9 10
0.05
0.1
0.15
0.2
0.25
k
P(k) ( ) 10100.5 0.5k kP k
k-æ ö÷ç= ×÷ç ÷ç ÷çè ø

Geburtstagsproblem
Wahrscheinlichkeitslehre
Wie viele Leute muss man auf eine Party einladen, damit die Wahrscheinlichkeit dafür, dass mindestens zwei Leute am selben Tag Geburtstag haben, gleich der Wahrscheinlichkeit ist, dass alle Gäste an verschiedenen Tagen Geburtstag haben?
50 8020 120
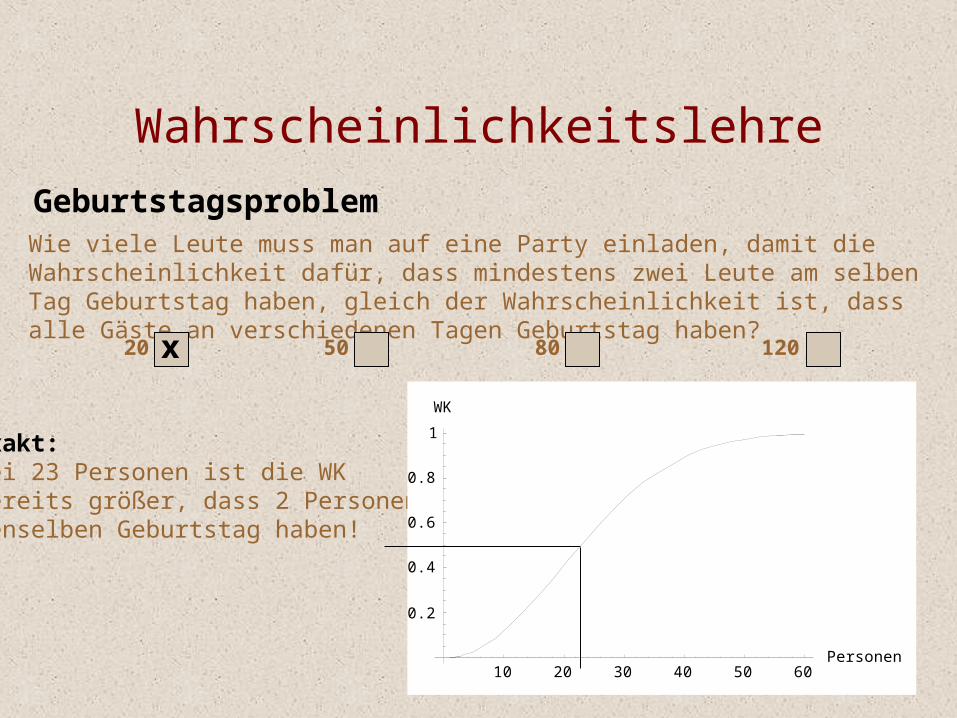
WahrscheinlichkeitslehreGeburtstagsproblemWie viele Leute muss man auf eine Party einladen, damit die Wahrscheinlichkeit dafür, dass mindestens zwei Leute am selben Tag Geburtstag haben, gleich der Wahrscheinlichkeit ist, dass alle Gäste an verschiedenen Tagen Geburtstag haben?50 80 12020 x
Exakt: Bei 23 Personen ist die WKbereits größer, dass 2 Personendenselben Geburtstag haben!
10 20 30 40 50 60Personen
0.2
0.4
0.6
0.8
1WK

Zusammenhänge von Stichprobe und GrundgesamtheitWas kann man mit Kennwerten, gewonnen aus Stichproben, über die Kennwerte der Population
aussagen?
Schliessende Statistik
SchätzenWie und wie genau kann man Kennwerte der Populationaus Stichproben schätzen?
TestenKann man etwas über die Gleichheit und Ungleichheit vonaus Stichproben geschätzen Kennwerten mit einer bestimmten statistischen Verläßlichkeit sagen?
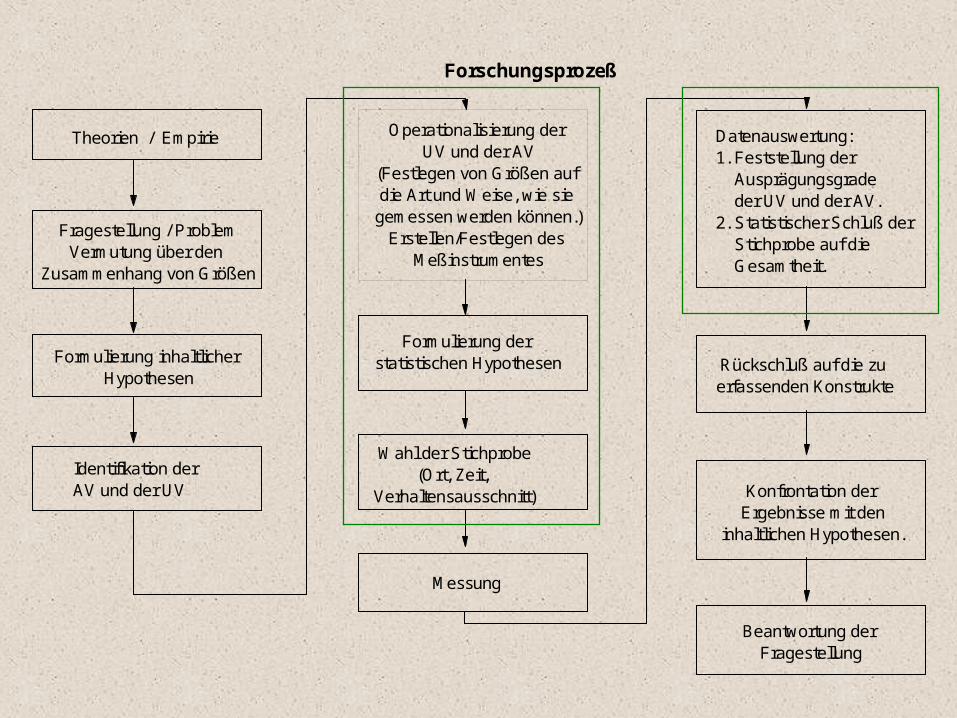
Forschungsprozeß
Theorien / Empirie
Fragestellung / ProblemVermutung über den
Zusammenhang von Größen
Formulierung inhaltlicher Hypothesen
Identifikation der AV und der UV
Operationalisierung der UV und der AV
(Festlegen von Größen auf die Art und Weise, wie sie gemessen werden können.)
Erstellen/Festlegen des Meßinstrumentes
Formulierung der statistischen Hypothesen
Wahl der Stichprobe(Ort, Zeit,
Verhaltensausschnitt)
Messung
Datenauswertung:1. Feststellung der Ausprägungsgrade der UV und der AV.2. Statistischer Schluß der Stichprobe auf die Gesamtheit.
Rückschluß auf die zu erfassenden Konstrukte
Konfrontation der Ergebnisse mit den
inhaltlichen Hypothesen.
Beantwortung der Fragestellung





























