Embed Size (px)
Citation preview

Begleitmaterial uber
Effiziente Algorithmen
Friedhelm Meyer auf der Heide

Kontakt
Friedhelm Meyer auf der HeideUniversitat PaderbornFakultat fur Elektrotechnik, Informatik und MathematikInstitut fur Informatik und Heinz Nixdorf InstitutFurstenallee 1133102 Paderborn
email: [email protected]
Stand:Wintersemester 2008/2009, 14. Oktober 2008

Inhaltsverzeichnis 3
Inhaltsverzeichnis
1 Algorithmische Geometrie 51.1 Orthogonal Range Searching . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.1.1 Der 1D-Fall . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.1.2 Der 2D-Fall . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.1.3 Schnellere Antwortzeiten im 2D-Fall . . . . . . . . . . . . . . . . . . 111.1.4 Orthogonal Range Searching in hohen Dimensionen . . . . . . . . . 121.1.5 Dynamisches Orthogonal Range Searching . . . . . . . . . . . . . . 12
1.2 Circular Range Searching . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.2.1 Spanner und weak Spanner . . . . . . . . . . . . . . . . . . . . . . 141.2.2 Sektorengraphen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2 Realisierung von Worterbuchern durchuniverselles und perfektes Hashing 192.1 Abstrakte Datentypen und Datenstrukturen . . . . . . . . . . . . . . . . . 192.2 Einfache Datenstrukturen fur Worterbucher . . . . . . . . . . . . . . . . . 202.3 Suchbaume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.4 Hashing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.4.1 Behandlung von Kollisionen: Hashing with Chaining . . . . . . . . 222.4.2 Universelles Hashing und Worst Case Expected Time Untersuchungen 222.4.3 Perfektes Hashing und worst case konstante Zeit fur Lookups . . . . 24
3 Flusse in Netzwerken 273.1 Das “Max-Flow Min-Cut Theorem’ (Satz von Ford und Fulkerson) . . . . . 283.2 Effiziente Algorithmen zur Berechnung maximaler Flusse . . . . . . . . . . 323.3 Berechnung von Sperrflussen: Ein O(n2)-Algorithmus . . . . . . . . . . . . 34
4 Graphalgorithmen: Das All-Pair-Shortest-Path Problem 384.1 Das All Pairs Shortest Paths Problem (APSP) . . . . . . . . . . . . . . . . 384.2 Der Floyd-Warshall Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . 38
4.2.1 Berechnung Transitiver Hullen . . . . . . . . . . . . . . . . . . . . . 40
5 Entwurfsmethoden fur Algorithmen 415.1 Dynamisches Programmieren . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.1.1 Problem 1: Matrizen-Kettenmultiplikation . . . . . . . . . . . . . . 415.1.2 Problem2: Optimale binare Suchbaume . . . . . . . . . . . . . . . . 42
5.2 Greedy-Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 455.2.1 Bruchteil-Rucksackproblem: optimal . . . . . . . . . . . . . . . . . 455.2.2 Rucksackproblem: sehr schlecht . . . . . . . . . . . . . . . . . . . . 465.2.3 Bin Packing: nicht optimal, aber gut . . . . . . . . . . . . . . . . . 465.2.4 Prefixcodes nach Huffman: optimal . . . . . . . . . . . . . . . . . . 485.2.5 Wann sind Greedy-Algorithmen optimal? . . . . . . . . . . . . . . . 51
14. Oktober 2008, Version 0.6

Inhaltsverzeichnis 4
6 Berechnung des Medians, k-Selektion 54
7 Randomisierte Algorithmen 567.1 Grundbegriffe zu probabilistischen Algorithmen . . . . . . . . . . . . . . . 58
7.1.1 Randomisierte Komplexitatsklassen . . . . . . . . . . . . . . . . . . 617.2 Einige grundlegende randomisierte Algorithmen . . . . . . . . . . . . . . . 62
7.2.1 Verifikation von Polynom-Identitaten und Anwendungen . . . . . . 627.2.2 Perfekte Matchings in Bipartite Graphen . . . . . . . . . . . . . . . 627.2.3 Perfekte Matchings in beliebigen Graphen . . . . . . . . . . . . . . 637.2.4 Effiziente Tests fur “p(x) = 0” . . . . . . . . . . . . . . . . . . . . . 647.2.5 Quicksort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
8 Ein randomisiertes Worterbuch: Skip-Listen 67
9 Berechnung minimaler Schnitte in Graphen 709.1 Ein sehr einfacher Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . 70
14. Oktober 2008, Version 0.6

5
1 Algorithmische Geometrie
Die Algorithmische Geometrie beschaftigt sich mit der Entwicklung effizienter und prak-tikabler Algorithmen zur Losung geometrischer Probleme und mit der Bestimmung deralgorithmischen Komplexitat solcher Probleme.Was sind geometrische Probleme?
Beispiel 1.1Bewegungsplanung:Ein Roboter ist in einem Raum an einem Punkt p positioniert. In diesem Raum sindHindernisse (Maschinen, Schranke, ...). Wie berechnet man zu einem Punkt q, ob es furden Roboter einen Weg von p nach q gibt? Wie findet man einen solchen Weg? Wie einenkurzesten Weg?
Geographische Datenbanken:Geographische Daten sind in einer Datenbank abgelegt, um Anfragen uber verschiedensteInformationen zu beantworten, z.B.: Was ist der kurzeste Weg von Paderborn nach Lingen?Was ist die maximale Entfernung von einem Ort im Ruhrgebiet zu einem Erholungsgebiet?
Geographische Datenverarbeitung:Gegeben ist eine (3-dimensionale) Szene (z.B. eine Stadt). Wie berechne ich zu einer Po-sition x und einer Richtung t das (2-dimensionale) Bild der Szene, das ich sehe, wenn ichvon x aus in Richtung t (mit Blickwinkel z.B. 45o) schaue?
Hierin sind viele Teilprobleme verborgen:
- Wie beschreibe ich die Szene im Rechner?
- Wie identifiziere ich meine Position in der Szene? (Point Location)
- Wie berechne ich verdeckte, also nicht sichtbare Teile der Szene? (Culling)
- Wie berechne ich alle Objekte der Szene, die nicht zu weit entfernt (also sichtbar)sind? (Circular Range Search)
- u.v.a.m.
Im Grundstudium haben einige von Ihnen eventuell schon einige Grundbegriffe der Algo-rithmischen Geometrie kennengelernt. Themen aus der algorithmischen Geometrie in dieserVorlesung sind Range Searching Probleme.
• Orthogonal Range SearchingVerwalte eine Punkt-Menge S ⊆ Rd so, daß zu einem gegebenen achsenparallelenQuader Q ⊆ Rd schnell Q ∩ S berechnet werden kann.
14. Oktober 2008, Version 0.6

6
• Circular Range SearchingVerwalte eine Punkt-Menge S ⊆ Rd so, daß zu einer gegebenen Kugel K ⊆ Rd schnellK ∩ S berechnet werden kann.
• Untere Schranken fur geometrische ProblemeDer Component Counting Lower Bound fur Berechnungsbaume.
Sie sollten sich an folgende Begriffe aus dem Grundstudium (lineare Algebra, Datenstruk-turen + Algorithmen) erinnern.
R: Menge der reellen Zahlen.
Rd: d-dimensionaler (Euklidischer) Raum; Rd := {(x1 . . . , xd), xi ∈ R, i = 1, . . . , d}
Fur (x1, . . . , xd) ∈ Rd schreiben wir kurz x.
Euklidischer Abstand: |x− y| = (d
Σi=1
(xi − yi)2)
12
Hyperebene: Fur a ∈ Rd, b ∈ R ist H(= Ha,b) = {x ∈ Rd, ax = b}.Halbraum: H+ = {x ∈ Rd, ax > b} (offen),H+ = {x ∈ Rd, ax ≥ b} (abgeschlossen)in R2 : Hyperebene = Geradein R3 : Hyperebene = Ebene
Achsenparalleler Quader: Fur a1, . . . , ad, b1, . . . , bd ∈ R, a1 ≤ b1, . . . , ad ≤ bd ist
Q =d
Πi=1
[ai, bi] ein achsenparalleler Quader
Kugel: z ∈ Rd, r ∈ R+ : K = {x ∈ Rd, |z − x| ≤ r}.
Rechenmodell: RAM (Random Access Machine)→ siehe Grundstudium. Wir gehen (ideali-siert) davon aus, das solche Maschinen arithmetische Operationen auf reellen Zahlen exaktin einem Schritt ausfuhren.
Range Searching (Bereichs-Suche)Ein Range Searching Problem ist durch eine Familie R von Bereichen (Ranges) R ⊆ Rd
definiert.
Aufgabe:Organisiere eine gegebene endliche Punktmenge S ⊆ Rd so, daß bei Eingabe R ∈ R dieMenge R ∩ S schnell berechnet werden kann.
Beispiel 1.2
• Orthogonal Range Searching: R ist Menge der (achsenparallelen) Quader in Rd.
• Circular Range Searching: R ist Menge der Kugeln in Rd.
14. Oktober 2008, Version 0.6
1.1 Orthogonal Range Searching 7
1.1 Orthogonal Range Searching
Anwendung: Einfache Datenbankanfragen: Es sind Personen mit ihrem Alter und Gehaltgespeichert (= Punkte in R2).Aufgabe: Zu a1, b1, a2, b2,∈ R, a1 ≤ a2, b1 ≤ b2 berechne alle Personen mit Alter zwischena1 und a2 und Gehalt zwischen b1 und b2 (R = [a1, a2]× [b1, b2]).
1.1.1 Der 1D-Fall
Aufgabe: Organisiere S = {p1, . . . , pn} ⊆ R so, daß fur gegebenes Intervall [a, b] schnell derSchnitt [a, b] ∩ S berechnet werden kann.
Algorithmus: Organisiere S in einem balancierten Suchbaum T , der p1, . . . , pn in denBlattern enthalt. In jedem inneren Knoten ist der Wert des rechtesten Blattes des un-ter ihm hangenden linken Teilbaums gespeichert.
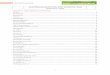
Beispiel 1.3 S = {3, 10, 19, 23, 30, 37, 49, 58, 62, 70, 80, 89, 100, 105}
3 10 19 23 30 37 58 62 70 80 100 105
3 19 30 49 58 70 89 100
10 37 62 89
23 80
49
Abbildung 1: Balancierter Suchbaum T fur die Menge S aus Bsp. 1.3
Lemma 1.4 T kann aus S in Zeit O(n log(n)) berechnet werden.
Beweis: Ubung (im wesentlichen Wiederholung von Techniken aus Info C bzw.“Einfuhrung in Datenstrukturen und Algorithmen”). 2
Wie berechnen wir nun fur ein Interval [a, b] die Menge S ∩ [a, b], d.h. wie soll Algorithmus1D-Range-Query (T [a, b]) arbeiten?
14. Oktober 2008, Version 0.6

1.1 Orthogonal Range Searching 8
Fur ein x ∈ R ist der Suchweg fur x in T derjenige Weg, der in der Wurzel startet und aneinem inneren Knoten y in den linken/rechten Teilbaum geht, falls x ≤ y/x > y gilt.
Wir berechnen zuerst die Suchwege Pa und Pb fur a und b in T . Fur a = 18, b = 80 sinddas im obigen Beispiel die Wege nach 19 und nach 80 .
Falls Pa in a’ , Pb in b’ endet, mussen alle Werte in den Blattern von a’ bis vor b’
ausgegeben werden, sowie zusatzlich der Wert von b’ , falls b′ = b gilt (wie in unserem
Beispiel der Fall). Die Blatter von a’ bis vor b’ berechnen wir wie folgt:
Zuerst berechnen wir den Split-Knoten von Pa und Pb, d.h. den (von oben gesehen) letztengemeinsamen Knoten von Pa und Pb. (Im Beispiel ist das die Wurzel. Achtung: Das mußnicht immer die Wurzel sein. Bei Anfrage [18, 37] z.B. ware es der Knoten 23.)
Fur jeden inneren Knoten x auf Pa (Pb) unterhalb des Split-Knotens, von dem aus Pa (Pb)uber den linken (rechten) Suchbaum verlauft, geben wir alle Blatter unter dem rechten(linken) Subbaum von Pa(Pb) aus. Im Beispiel liefert P18 die Subbaume mit Wurzeln 37,23 und das Blatt 19, P80 die mit Wurzeln 58 und 70.
Im folgenden beschreiben wir in einem Pseudo-Code zuerst den Algorithmus Find-Split(T, [a, b]), der in T den Split-Knoten von Pa und Pb findet, und dann den Algorithmus1D-Range-Query (T, [a, b]), der mit Hilfe von T zu [a, b] die Menge [a, b] ∩ S berechnet.Er benutzt dabei die (nicht naher beschriebene, simple) Prozedur Report-Subtree (r), diezu Knoten v von T die Werte der Blatter im Subbaum unter v ausgibt. right(r), left(u)bezeichnet fur innere Knoten r von T den rechten bzw. linken Nachfolger.
Find-Split (T, [a, b])Output: Der Splitknoten fur [a, b]v := root(T );while v ist kein Blatt and (a > xv or b ≤ xv) do
if b ≤ xv thenv := left(v);
elsev := right(v);
fiodreturn
1D-Range-Query (T, [a, b])Output: Alle Punkte von S in [a, b]
1. V Split := Find-Split (T, [a, b])i;
2. if V Split ist ein Blatt thengebe den Punkt in V Split zuruck,wenn er in [a, b] liegt.
14. Oktober 2008, Version 0.6

1.1 Orthogonal Range Searching 9
3. else
4. (* Folge dem Weg Pa und gebe die Punktein den rechten Teilbaumen zuruck *)v := left (V Split);while v ist kein Blatt do
if a < xv thenReport-Subtree (right (v)); v := left (v);
else v := right (v);fi
gebe den Wert von Blatt v zuruck, wenn er in [a, b] liegt.
5. (* Folge dem Weg Pb und gebe die Punktein den linken Teilbaumen zuruck*) ...
Analyse
Korrektheit:
- Es werden nur Elemente aus S ausgegeben.
- Es wird kein x < a ausgegeben, da dieses Blatt eines Subbaums ist, der unter einemlinken Sohn v eines Knotens auf Pa hangt, der nicht zu Pa gehort. Fur solche Knotenwird nie Report-Subtree (v) aufgerufen.
- Es wird kein x > b ausgegeben, ... (analog mit Pb)
- Sei x ∈ [a, b] ∩ S, Px der Suchweg nach x. Dieser Weg verlaßt entweder Pa unterhalbdes Split-Knotens nach rechts, oder Pb unterhalb des Split-Knotens nach links. Sei vder erste Knoten auf Px der nicht zu Pa bzw. Pb gehort. Dann wird im AlgorithmusReport-Subtree (v) aufgerufen. Hierbei wird (u.a.) x ausgegeben.
Laufzeit:Aufbau von T : Zeit O(n log(n)).(z.B.: Sortiere S zu p1 < . . . < pn.n = 1 : T = p1
n > 1 Berechne T1 fur p1, . . . , pn2, T2 fur pn/2+1, . . . , pn. T bekommt Wurzel pn/2 und lin-
ken/rechten Subbaum T1/T2.)
Zeit fur 1D-Range-Search (T, [a, b])
- ohne die Zeit fur die Report-Subtree-Aufrufe:O(log(n)), da nur die Wege Pa und Pb sowie die direkten Nachbarn der darauf lie-genden Knoten besucht werden.
14. Oktober 2008, Version 0.6

1.1 Orthogonal Range Searching 10
- Zeit fur Report-Subtree (v): O(Große des Subbaums unter v).= O (# Blatter des Subbaums unter v)= O (Outputgroße von Report-Subtree v)
- Zeit fur alle Report-Subtree-Anfragen= O (Gesamt-Output-Große) = O(|S ∩ [a, b]|).
Satz 1.5 Obiger Algorithmus benotigt zum Aufbau der Datenstruktur (d.h. des Baumes T )Zeit O(n log(n)) und Platz O(n); die Zeit pro 1D-Range-Query ist O(log(n) + k), wobei kdie Outputgroße ist.
1.1.2 Der 2D-Fall
Nun ist S = {p1, . . . , pn} ⊆ R2, pi = (xi, yi). Es werden Bereiche der Form [a1, b1]× [a2, b2]angefragt. Wir bauen zuerst einen 1D-Suchbaum T1 fur die Menge S1 = {x1, . . . , xn} derersten Koordinaten der Elemente von S auf.Wenn wir hierin 1D-Range-Query (T1, [a1, b1]) ausfuhren, erhalten wir als Ergebnis A1 =S ∩ ([a1, b1]×R). Um die Anfrage fur den Bereich [a1, b1]× [a2, b2] durchzufuhren, konntenwir nun analog einen Baum T2 aufbauen, der S2 = {y1, . . . , yn} verwaltet, um dort 1D-Range-Query (T2, [a2, b2]) auszufuhren. Wir wurden dann A2 = S ∩ (R× [a2, b2]) erhalten,und das gesuchte Ergebnis ist A1 ∩ A2. Die Laufzeit ist dann O(log(n) + |A1| + |A2|). Invielen Fallen ist das jedoch sehr langsam, da |A1| + |A2| sehr groß sein kann, obwohl diewirkliche Outputgroße, |A1∩A2|, sehr klein ist. Unser Ziel ist es, Laufzeit O(log(n)+k), k =Output-Große, zu erreichen. Unser erster Algorithmus wird Zeit O(log(n)2 + k) erreichen.Dazu konstruieren wir zuerst den oben beschriebenen 1D-Suchbaum T1 fur S1 ={x1, . . . , xn}, die ersten Koordinaten der Punkte in S. Betrachte nun einen Knoten v vonT1. Sei Sv ⊆ S die Menge der Punkte aus S, deren erste Koordinate an den Blattern desSubbaumes mit Wurzel v gespeichert sind. Wir bauen nun einen 1D-Suchbaum Tv fur dieMenge der zweiten Koordinaten der Knoten in Sv auf. Die Gesamt-Struktur, T1 und dieTv’s, bilden den 2D-Suchbaum T .Große von T :Jedes pi ∈ S wird auf jedem Level von T in genau einem Tv abgespeichert, also insgesamtlog(n) mal. Somit wird fur T Platz O(n log(n)) benotigt.Zeit zum Aufbau von T :T1 benotigt Zeit O(n log(n)). Jedes Tv benotigt Zeit O(|Sv| log(|Sv|). Allerdings setzt sichdiese Zeit zusammen aus: Sortieren von Sv (nach zweiter Koordinate (Zeit O(|Sv| log(|Sv|))plus Zeit zum Aufbau von Tv aus sortiertem Sv (Zeit O(|Sv|). Wenn wir einmal zu Beginnganz S nach zweiter Koordinate sortieren, konnen wir Tv in Zeit O(|Sv|) aufbauen.Da, wie oben gesagt, jedes pi ∈ S in log(n) vielen Mengen Sv liegt, ist Σ
v|Sv| = O(n log(n)),
d.h. wir konnen T in Zeit O(n log(n)) aufbauen.2D-Range-Query (T, [a1, b1] × [a2, b2]) arbeitet wie 1D-Range-Query (T1, [a1, b1]), mit fol-gender Modifikation: Jeder Aufruf Report-Subtree (v) wird ersetzt durch 1D-Range-Query(Tv, [a2, b2]).
14. Oktober 2008, Version 0.6

1.1 Orthogonal Range Searching 11
Korrektheit:Analog wie fur den 1D-Fall.
Laufzeit:O(log(n)), um Pa1 , Pb1 und den Split-Knoten zu finden. Zusatzlich wird fur l ≤ log(n)viele Knoten vi 1D-Range-Query (Tvi
, [a2, b2]) aufgerufen, Kosten O(log(|Svi| + kvi
)), mitkiv = |Svi
∩ [a2, b2]|.
Gesamtzeit= O(log(n) +l
Σi=1
log(|Svi|+ kvi
)
= O(log(n) + log(n)2 +l
Σi=1
kvi)
= O(log(n)2 + k), mit k = |S ∩ ([a1, b1]× [a2, b2])|
(Beachte: Hier wird benutzt, daß k =l
Σi=1
kvigilt. Dazu uberlege man sich, daß fur i 6= j
gilt: Svi∩ Svj
= ∅.)
Satz 1.6 Obiger Algorithmus benotigt zum Aufbau der Datenstruktur Zeit und PlatzO(n log(n)); die Zeit pro 2D-Range-Query betragt O(log(n)2 + k), wobei k die Output-Große ist.
1.1.3 Schnellere Antwortzeiten im 2D-Fall
In diesem Abschnitt geben wir eine Methode an, die es erlaubt, die Zeit fur eine Anfragevon O(log(n)2 + k) auf O(log(n) + k) zu reduzieren. Wir modifizieren dazu unsere Daten-struktur: Zuerst bauen wir wieder den Baum T1 auf, der ein 1D-Suchbaum bzgl. der erstenKoordinaten der Elemente aus S ist. Die Menge Sv ⊆ S, die zu einem Knoten v gehort,speichern wir allerdings nicht mehr als 1D-Suchbaum Tv (bzgl. der zweiten Koordinatender Punkte in Sv) ab, sondern in einem Array Av, sortiert bzgl. der zweiten Koordinaten.Wir werden nun zwischen Av und Av1 , Av2 (v1, v2 sind die Kinder von v) Pointer installie-ren, die folgendes ermoglichen:
Falls wir fur ein a ∈ R in Av den kleinsten Eintrag p ≥ a kennen, konnen wir die entspre-chenden Eintrage in Av1 und Av2 in konstanter Zeit berechnen.Das ist einfach: Wir legen von jedem Eintrag p in Av je einen Pointer in Av1 und Av2 zuder Position des kleinsten Eintrags p′ ≥ p. (p, p′ sind die zweiten Koordinaten der Punkte).(vgl. Abbildung 2)
Falls wir nun 2D-Range-Query ([a1, b1] × [a2, b2]) ausfuhren, berechnen wir wieder zuerstdie Wege Pa1 , Pb1 und den Split-Knoten v in T1. In Av berechnen wir die Position deskleinsten p′ ≥ a2(p
′ ist 2-te Koordinate des zugehorigen Punkts aus Sv) durch binareSuche, also in Zeit O(log(n)). Wir folgen nun bei dem weiteren Durchlauf des Weges Pa
auch immer den Pointern von p′ aus auf diesem Weg. Fur jeden Punkt v, fur den wir imletzten Algorithmus 1D-Range-Query (Tv, [a2, b2]) aufgerufen haben, konnen wir nun mit
14. Oktober 2008, Version 0.6

1.1 Orthogonal Range Searching 12
4 5 6 7 8
3 54 6 8... ... ... ...
... ...
Av1
Av
Av2
3
7
Abbildung 2:
Hilfe des Pointers direkt an die Position des kleinsten p′′ ≥ a2 in Av springen, und vondieser Position aus nachfolgenden die kv vielen Punkte mit 2-ter Koordinate ≤ b2 in ZeitO(kv) auslesen. Der log(n)-Aufwand taucht also nicht log(n), sondern nur einmal (bei derbinaren Suche in Av) auf! Also ergibt sich Suchzeit O(log(n) + k). Man kann sich einfachuberlegen, daß auch diese Datenstruktur mit Zeit und Platz O(n log(n)) aufgebaut werdenkann.
Satz 1.7 Obiger Algorithmus benotigt zum Aufbau der Datenstrukturen Zeit und PlatzO(n log(n)), die Zeit pro 2D-Range-Query ist O(log(n)+k), wobei k die Output-Große ist.
Die oben beschriebene Technik kann in allgemeiner Form fur viele Datenstrukturproblemeeingesetzt werden. Man nennt sie Fractional Cascading.
1.1.4 Orthogonal Range Searching in hohen Dimensionen
Die Algorithmen aus 1.2 und 1.3 konnen in naturlicher Weise auf hohere Dimensionenerweitert werden. In Rd ergibt sich Zeit und Platz O(n(log(n))d−1) fur den Aufbau derDatenstruktur, Zeit O(log(n)d + k) (bzw. O(log(n)d−1 + k) fur den Algorithmus aus 1.1.3)pro Anfrage.
1.1.5 Dynamisches Orthogonal Range Searching
Wir betrachten nun die dynamische Variante unserer Range Searching Verfahren: Ne-ben den Range-Queries sind nun auch Einfuge-und-Losche-Operationen erlaubt, die einenPunkt zu S hinzufugen bzw. aus S loschen.Im 1D-Fall ersetzen wir den (statischen) Suchbaum T hierfur durch einen dynamischenSuchbaum wie z.B. den aus dem Grundstudium bekannten rot-schwarz-Baum. Damitkonnen wir den gleichen Range-Query Algorithmus benutzen wie zuvor, haben aber zusatz-lich die Eigenschaft, dass Einfugen und Loschen in Zeit O(log(n)) durchgefuhrt werdenkann.
14. Oktober 2008, Version 0.6
1.2 Circular Range Searching 13
Man kann mit recht aufwendigen Uberlegungen die Version aus 1.1.3 dynamisieren. DiesesVerfahren stellen wir hier nicht genauer vor. Als Ergebnis halten wir jedoch fest:
Satz 1.8 Dynamisches Orthogonal Range Searching in 2D kann mit Speicherbe-darf O(n log n) durchgefuhrt werden, wobei Range-Queries Zeit O(log(n) + k) undEinfugen/Loschen Zeit O(log(n)) benotigen.
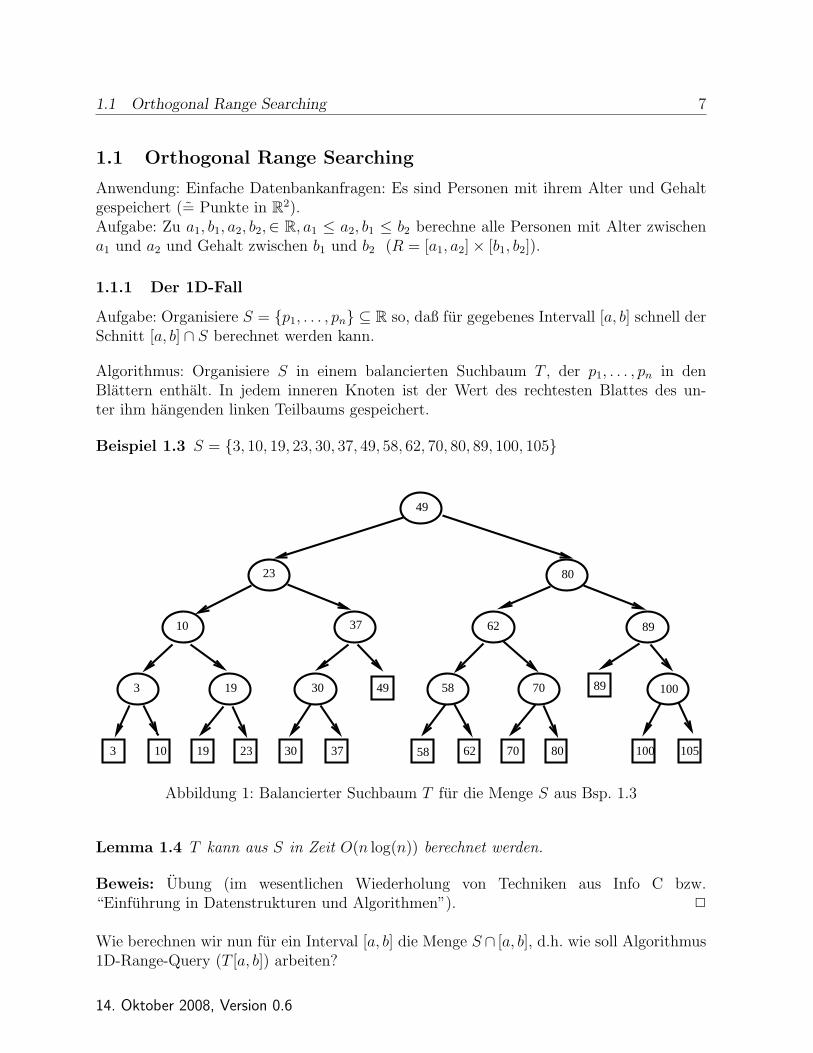
Zum Abschluß bemerken wir noch folgendes: Wir konnen in den oben genannten Algorith-men auch Intervallgrenzen auf −∞ oder ∞ setzen, d.h. z.B. Range Query (T, [−∞, b1] ×[−∞, b2]) durchfuhren. Einfache lineare Transformationen lassen es zudem zu, die Daten-strukturen so zu verallgemeinern, daß wir auch anstatt rechtwinkeliger, achsenparallelerKegel [−∞, b1]× [−∞, b2] auch beliebige “Verschiebungen” eines festen, beliebigen Kegelsabfragen konnen. Genauer:Betrachte einen festen Kegel K = {λ1z1 + λ2z2, λ1, λ2 ≥ 0} fur feste z1, z2 ∈ R2.Fur a ∈ R2 sei Ka := {x ∈ R2|x− a ∈ K}
1 2 3
1
2
K
z 1z 2
Abbildung 3:
Wenn wir jetzt Range Queries fur Ka fur beliebiges a durchfuhren wollen (aber festenKegel K!), konnen wir alle oben genannten Algorithmen benutzen, indem wir zu Beginneine lineare Transformation auf S anwenden (welche?) und die Kegel Ka in rechtwinkelige,achsenparallele Kegel [−∞, b1]× [−∞, b2] transformieren.Eine Technik, die ausnutzt, daß wir es nur mit Kegel anstatt mit Rechtecken zu tun ha-ben, erlaubt sogar die Reduktion des Speicherbedarfs auf O(n). Die dabei entstehendeDatenstruktur nennt sich Priority Search Tree.
1.2 Circular Range Searching
Anwendung: Computer Graphik, Walkthrough-Animation: Die Menge S = {p1, . . . , pn} ⊆R2 beschreibt z.B. Positionen von Hausern in der Ebene. Eine grundlegende Aufgabe be-
14. Oktober 2008, Version 0.6

1.2 Circular Range Searching 14
steht darin, zu einer Besucherposition ∈ R2 und einem Radius t alle Hauser im Abstandhochstens t zu q zu berechnen. Eine Circular Range Query wurde also mit Parametern q, taufgerufen, und muß S ∩K(q, t) berechnen, wobei K(q, t) den Kreis {x ∈ R2, |q − x| ≤ t}bezeichnet.Unser Ziel ist es, hierfur Datenstrukturen zu entwerfen, die in Zeit O(n log(n)) auf PlatzO(n) aufgebaut werden konnen, und Antwortzeiten O(log(n) + k) aufweisen, wobei k dieGroße der Ausgabe ist. Das wird uns nicht vollstandig gelingen, wir werden aber naheherankommen. Wir werden uns auf den Fall beschranken, dass unsere Queries immer vonder Form K(q, t) mit q ∈ S sind.
1.2.1 Spanner und weak Spanner
Sei S = {p1, . . . , pn} und f > 1. Ein (gerichteter oder ungerichteter) Graph G = (S, E)heißt f-Spanner, falls fur jedes Knotenpaar pi, pj gilt: In G existiert ein (ggf. gerichteter)Weg W von pi nach pj, mit ||W || ≤ f · |pi − pj. Dabei bezeichnet ||W || die Lange vonW , d.h. die Summe der (Euklidischen) Langen der Kanten auf W . f heißt Stretch-Faktor.G ist ein weak f -Spanner, falls fur jedes Knotenpaar pi, pj gilt: In G gibt es einen (ggf.gerichteten) Weg von pi nach pj, der nie K(pi, t) verlaßt, mit t = f · |pi − pj|.
Beobachtung: Jeder f -Spanner ist auch weak f -Spanner.
Satz 1.9 Sei G = (S, E) ein weak f -Spanner. Dann kann zu gegebenen p ∈ S, t > 0 dieMenge K(p, t) ∩ S in Zeit O(k ·D) berechnet werden. Dabei ist D der Grad bzw. Outgradvon G, und k = |K(p, f · t) ∩ S|.
Beweis: Wir starten in p eine Breitensuche, brechen die Suche aber immer dann ab, wennwir auf einen Knoten q mit |p − q| > f · t stoßen. Alle dabei gefundenen Knoten q, diezusatzlich |p− q| ≤ t erfullen, bilden die Ausgabe.
Korrektheit:Es werden nur Knoten q ∈ S mit |p−q| ≤ t ausgegeben. Andererseits: Sei q ∈ S, |p−q| ≤ t.Dann gibt es einen Weg von p nach q in G, der nie K(p, f · t) verlaßt. Da die Breitensuchealle Knoten in K(p, f · t) besucht, findet sie auch diesen Weg und somit q. Also wird qausgegeben.
Laufzeit:Die Breitensuche benotigt konstante Zeit pro Besuch eines Knotens. Sie besucht alle Knotenin K(p, f · t) (k Knoten) sowie alle deren Nachbarn (hochstens D · k viele). 2
Wir werden im nachsten Kapitel gerichtete Spanner und weak Spanner mit konstantemOutgrad konstruieren.
14. Oktober 2008, Version 0.6

1.2 Circular Range Searching 15
1.2.2 Sektorengraphen
Sei wieder S = {p1, . . . , pn} ⊆ R2, k ∈ N, k gerade.Wir definieren einen gerichteten Graphen mit Grad k auf S wie folgt:Betrachte Knoten pi. Zerlege den Raum um pi in k Kegel, die Sektoren, definiert durchk/2 viele Geraden g1, . . . , gk/2 durch pi. Dabei sind alle Winkel zwischen g1 und g2, g2
und g3, . . . , gk/2 und g1 gleich, namlich 2π/k. In jedem Sektor V bestimmen wir einenNachbarn von pi wie folgt: Wir definieren den Sektor-Abstand eines Punktes x ∈ V zu pi
als den Euklidischen Abstand von pi zur Projektion x′ von x auf die Mittelsenkrechte vonV .
x
Sektor V
pi
x’
Winkel = 26π
Abbildung 4: Bsp.: K = 6
Wie verbinden nun pi in jedem Sektor V mit einem pj ∈ V mit minimalem Sektor-Abstandzu pi.Wir erhalten damit einen gerichteten Graphen Gk(S) mit Outgrad k, also hochstens n · kKanten. Im folgenden nehmen wir an, daß S nicht degeneriert ist, d.h. dass kein Punkt ausS auf einer Sektorengrenze eines anderen Punktes aus S liegt.
Satz 1.10(i) Gk(S) kann in Zeit O(n log(n)) aus S konstruiert werden.(ii) Fur k ≥ 6 ist Gk(S) ein weak Spanner mit Stretch-Faktor
min{√
1 + 48 sin4 (γ
2),√
5 − 4 cos(γ)},mitγ =2π
k.
(iii) Fur k ≥ 8 ist Gk(S) ein Spanner mit Stretch-Faktor
1
1− 2 sin(γ2),mitγ =
2π
k.
14. Oktober 2008, Version 0.6

1.2 Circular Range Searching 16
Beispiel 1.11 Stretch-Faktoren fur weak Spanner:k = 6→ f = 2k = 8→ f ≈ 1.47k = 10→ f ≈ 1.33
Stretch-Faktoren fur Spanner:k = 8→ f ≈ 4.26k = 10→ f ≈ 2.62
Fur k →∞ gehen die Stretch-Faktoren fur Spanner und weak Spanner gegen 1.
Wir werden den Satz hier nicht vollstandig beweisen. Wir zeigen nur (i), sowie (ii) furk = 6.Beweis des Satzes:zu (i)Wir benutzen die Sweep-Line Technik. Zur Berechnung der Nachbarn im l-ten Sektor Vj
von pj gehen wir wie folgt vor: Zur einfacheren Veranschaulichung nehmen wir an, daßdie Mittelsenkrechte von Vj fur jeden Knoten parallel zur x-Achse verlauft, und Vj rechtsvon pj liegt. Wir sortieren S zuerst bzgl. der x-Koordinaten der pj. Nun benutzen wir zurBerechnung der Nachbarn eine Sweep-Line. Dieses ist eine Gerade M parallel zur y-Achse,die wir von links nach rechts uber die x-Achse schieben, d.h., die wir hintereinander durchp1, p2, . . . , pn verschieben.Dabei sei immer D ⊆ S so, daß D folgende Invariante erfullt. Falls die Sweep-Line bei pj
angekommen ist, enthalt D alle pj ∈ S, die links der Sweep-Line liegen und deren Nachbarnin Vj noch nicht gefunden wurden.Fur i = 1 ist D = ∅. Sei D fur Schritt i−1, d.h. fur die Situation, das die Sweep-line durchpi−1 lauft, berechnet. Wie entsteht das neue D fur die Sweep-line durch pi?
(i) Sei U die Menge aller pj ∈ D, fur die pj ∈ Vj gilt. Punkte pj ∈ U bekommen pi alsNachbarn in Vj, und werden aus D entfernt.(ii) pi wird zu D hinzugefugt.
Man uberlege sich, daß (i) korrekt ist, d.h. tatsachlich fur alle pj ∈ U der Punkt pi mitgeringsten Sektorenabstand in Vj hat. Damit ist dann auch die o.g. Invariante gewahrleistet.Seien Di, Ui die Mengen D, U nach der i-ten Iteration.Wie berechnen wir Ui? Wie aktualisieren wir Di−1 zu Dj? Dazu uberlegen wir uns folgendes.V ′
j entstehe aus Vj durch Spiegelung von Vj an der Senkrechten duch pj. Dann gilt: pj ∈ Vj
genau dann wenn pj ∈ V ′i .
Somit ist Uj = V ′j ∩Di−1, d.h. wir konnen Ui durch Range-Query (V ′
j ) bestimmen, die aufeiner Datenstruktur fur Di−1 arbeitet. Anschließend mussen wir jedes pj ∈ Ui aus Di−1
loschen, und dann pi einfugen. Das Ergebnis ist Di. Genau dieses kann ein Priority SearchTree (vgl. Ende Kapitel 1.1.5)!
14. Oktober 2008, Version 0.6

1.2 Circular Range Searching 17
Laufzeit:Jedes pi wird nur einmal, namlich in Dj eingefugt (wenn die Sweep-Line durch pj verlauft)und somit auch hochstens einmal aus einem Di geloscht. Jede dieser hochstens 2n Ope-rationen kostet Zeit O(log(n)). Die Laufzeit fur die Range-Query mit Ergebnis Ui istO(log(n) + |Ui|). Da aber pj aus D geloscht wird, sobald es einmal in einem Ui auftaucht,kann kein pj in mehr als einem Ui auftauchen. Somit sind alle Ui disjunkt.
Also ist die Gesamtlaufzeit aller Range-Queries
n
Σi=1
O(log(n) + |Ui|) = O(n log(n) +n
Σi=1|Ui|) = O(n log(n) + n) = O(n log n)
Wenn wir diesen Algorithmus fur alle k Sektoren durchfuhren, haben wir in Zeit O(n log(n))den Sektorengraphen konstruiert.
zu (ii) und (iii)Wir werden hier nicht (ii) und (iii) vollstandig beweisen, sondern nur folgende zwei Dingezeigen:Sei p, q ∈ S. Betrachte folgenden kanonischen p-q−Weg q1, q2, . . . in S : q1 = p. Fur i > 1ist qi der Nachbar von qi−1 in demjenigen Sektor von qi−1 in dem q liegt. Falls qi = q gilt,endet der Weg.
Lemma 1.12 (i) Fur k ≥ 6 ist der kanonische p-q−Weg endlich (und erreicht somit q).(ii) Fur k = 6 liegt dieser Weg in K(p, 2|p− q|).
Somit folgt aus dem Lemma, dass G6(S) ein weak Spanner mit Stretch Faktor 2 ist. Wirwerden die daruberhinaus gehenden Aussagen des Satzes hier nicht beweisen.Wir zeigen zuerst (ii). Sei |p− q| = t.
Behauptung 1.13 Jedes gleichseitige Dreieck, welches eine Ecke x in K(q, t) hat, undauf der x gegenuberliegenden Seite q enthalt, liegt vollstandig in K(q, t).
Beweis: Schulgeometrie.Wir zeigen nun, daß der kanonische p-q−Weg vollstandig in K(q, t) liegt. (Da p auf demRand von K(q, t) liegt, ist also K(q, t) ⊆ K(p, 2t), d.h. der kanonische p-q−Weg liegtvollstandig in K(p, 2t).)Wir zeigen obiges durch Induktion nach der Lange i des Weges.i = 1 : q1 = p liegt in K(q, t).i > 1 : qi−1 liegt nach Ind. Vor. in K(q, t). Sei V der Sektor von qi−1, in dem q liegt,D das Dreieck, welches entsteht, wenn wir V entlang der durch q verlaufenden, auf derMittelsenkrechten von V senkrecht stehenden Geraden abschneiden. D ist ein gleichseitigesDreieck, welches nach obiger Betrachtung in K(q, t) liegt. Da aber qi in D liegen muß, istsomit auch qi ∈ K(q, t).Damit verlauft der gesamte kanonische p-q−Weg in K(q, t) und somit auch in K(p, 2t).
14. Oktober 2008, Version 0.6

1.2 Circular Range Searching 18
zu (i) von Lemma 1.12.Wir gehen, wie zu Beginn gesagt, von “nicht-degenerierten” Fallen aus. In unserer Situationheißt das ja, dass kein Punkt auf S auf den Sektorengrenzen eines anderen Punktes liegt.Man kann sich deshalb einfach uberlegen, dass der (euklidische) Abstand |pi−q| der Punkteauf dem kanonischen p-q−Weg mit wachsendem i abnimmt, d.h.: |qi− q| < |qj − q| fur allei > j.Wurde dieser Weg nie q erreichen, so wurde, da S endlich ist, fur irgendwelche i > j qi = qj
gelten. Damit ware naturlich auch |qi − q| = |qj − q|, ein Widerspruch. 2
Wir konnen also eine Datenstruktur in Zeit O(n log(n)) aufbauen, die es erlaubt, RangeQueries fur Kugeln K(q, t) in Zeit O(|S∩K(q, f · t)|) zu beantworten, falls q ∈ S ist. Dabeiist f der Stretch-Faktor des weak Spanners (z.B. f = 2 bei 6 Sektoren).Wenn wir solche Anfragen auch fur K(q, t) mit q 6∈ S ermoglichen wollen, mussenwir erheblich mehr Aufwand treiben. Naheres hierzu findet sich in der Disserta-tion von Tamas Lukovszki. Weitere Informationen, auch uber die Nutzung solcherStrukturen in unserem Walkthrough System PaRSIWal (Paderborn Realtime Sy-stem for Interactive Walkthrough), finden sich im Netz unter http://www.uni-paderborn.de/fachbereich/AG/agmadh/WWW/DFG-SPP/#pub.
14. Oktober 2008, Version 0.6

19
2 Realisierung von Worterbuchern durch
universelles und perfektes Hashing
In diesem Kapitel werden wir kurz das Konzept der abstrakten Datentypen wiederho-len, und insbesondere die Datentypen “Worterbuch und statisches Worterbuch” genaueranschauen. Im Grundstudium sind dynamische Suchbaume wie z.B. rot-schwarz Baumeuntersucht worden. In dieser Vorlesung konzentrieren wir uns auf Hashing-Verfahren zurRealisierung von Worterbuchern.
2.1 Abstrakte Datentypen und Datenstrukturen
Ein abstrakter Datentyp (ADT) ist eine Menge von Objekten, zusammen mit auf den Ob-jekten definierten Operationen. Abstrakte Datentypen muß man selbst implementieren, inder Programmiersprache vorgegebene primitive Datentypen (z.B. Integer, mit Operationen,+, -, *, DIV, MOD, ...) und strukturierte Datentypen (Array, File, Record, ...) konnen dazubenutzt werden. Die Implementation eines abstrakten Datentyps heißt Datenstruktur.
Beispiel 2.1 Objekte: Mengen S von Elementen von gegebenem Grundtyp.
Operationen:Create S erzeuge eine leere Menge S
Insert (x, S) S := S ∪ {x}
Lookup (x, S) suche nach x in S (Antwort: ja/nein)
Delete (x, S) S := S \ {x}
Min (S) gebe Minimum von S aus
Max (S) gebe Maximum von S aus
Deletemin (S) S := S \ {min(S)}
Der ADT mit Operationen Insert, Deletemin, Min heißt Priority-Queue. Wir kennen eineImplementation: Heap−→ Der Heap ist eine Datenstruktur fur Priority Queues.
Zeit fur Insert: O(log(n))Zeit fur Min: O(1)Zeit fur Deletemin: O(log(n))
14. Oktober 2008, Version 0.6

2.2 Einfache Datenstrukturen fur Worterbucher 20
Der ADT mit Operationen Insert, Delete, Lookup heißt Worterbuch (Dictionary). FallsS vorgegeben ist, und in S nur Lookups durchgefuhrt werden, heißt der ADT statischesWorterbuch (denn S wird nie verandert, bleibt also statisch).
Beispiel 2.2 Folgen F von Elemente von gegebenem Grundtyp.
Operationen: z.B.:Find (F, p): gebe p-tes Element von F aus
Delete (F, p): ...
Insert (F, p, x): Fuge x in F an Position p ein
Operationen, die Folgen verknupfen:Concatenate (F1, F2): Hange F2 hinter F1.
Separate (F, p, F1): F = (a1, . . . , an)⇒ F := (a1, . . . , ap), F1 := (ap+1, . . . , an)
Copy (F1, F2): F2 := F1
Dieser ADT wird haufig Liste genannt. Eine Datenstruktur fur Listen ist die lineare Listemit den entsprechenden Operationen.
Bemerkung zu WorterbuchernIn Anwendungen sind die Objekte haufig Records (x, Info). Dabei ist x der Schlussel, unterdem die Info abgespeichert ist. Bei Suchen (Lookups) wird dann der Schlussel eingegeben,und als Antwort wird die zugehorige Info erwartet. Bei Insert wird Schlussel x und Infoeingegeben, und entweder neu eingefugt, oder, falls es schon (x, Info’) in S gibt, wirddieses durch (x, Info) uberschrieben. Bei Delete wird nur ein Schlussel eingegeben, derdann mitsamt seiner Info gestrichen wird.
Beispiel 2.3 (Name︸ ︷︷ ︸, Adresse, Telefonnummer)︸ ︷︷ ︸Schlussel Info
2.2 Einfache Datenstrukturen fur Worterbucher
statisch:a) S liegt in Array oder linearer Liste vor:Aufbauzeit: O(n)Suchzeit: O(n)
}schlecht
b) S liegt im sortierten Array vor:Aufbauzeit: O(n log(n)) (Sortieren)Suchzeit: O(log(n)) (Binare Suche)
14. Oktober 2008, Version 0.6

2.3 Suchbaume 21
dynamisch:a) wie a) oben (Lineare Liste)Einfugen/Streichen: O(n)
b) Einfugen/Streichen: O(n)
→ Ziel: Kombiniere Vorteil des sortierten Arrays (schnelle Suchzeit) mit Moglichkeiten, esschnell zu verandern.
2.3 Suchbaume
Im Grundstudium wurden Worterbucher durch dynamische Suchbaume realisiert. Dadurchergeben sich logarithmische Laufzeiten fur Lookup, Insert und Delete, etwa bei Rot-SchwarzBaume oder B-Baumen. Wir werden in dieser Vorlesung Verfahren untersuchen, die bessereLaufzeiten liefern. Sie konnen allerdings nicht zusatzliche Operationen wie “Berechne zu xdas nachstgroßere Objekt in S” unterstutzen.
2.4 Hashing
Einfache Idee fur Worterbuchimplementation, wenn S ⊆ U gilt, wobei U endlich ist:O.B.d.A. U = {0, . . . , p − 1}. Benutze Array A[0 : p − 1] mit A[i] ∈ {0, 1} undA[i] = 1↔ i ∈ S. Dann benotigen Insert, Delete, Lookup konstante Zeit!Aber: Sehr hoher Speicherplatzbedarf. Wir wollen den Speicherplatz reduzieren.Idee: Benutzte Funktion h : U → {0, . . . ,m − 1}, eine Hashfunktion, und ein ArrayT [0 : m− 1], das Hashtableau. Speichere x ∈ S in T [h(x)] ab.
Beispiel 2.4 m = 5, S = {3, 15, 22, 24} ⊆ {0, . . . , 99} = U, h(x) = x mod 5. T sieht wie
folgt aus T:0 1 2 3 415 22 3 24
Problem: Es kann Kollisionen geben, d.h. Paare x, y ∈ S mit h(x) = h(y) (aber x 6= y).Im Beispiel wurde etwa Einfugen von 27 (in T [2]) eine Kollision erzeugen, dort standendann 22 und 27.
Die Gute von Hashverfahren hangt ab von
- Wahrscheinlichkeit/Haufigkeit von Kollisionen.
- Große von m relativ zu n (Ideal: m = n oder m = cn, c kleine Kontstante)
- Zeit um h auszuwerten.
14. Oktober 2008, Version 0.6

2.4 Hashing 22
2.4.1 Behandlung von Kollisionen: Hashing with Chaining
Idee: Jedes T [i] ist lineare Liste, in der die Elemente {x ∈ S, h(x) = i} abgespeichert sind.Worst case Zeit fur Einfugen, Loschen, Suchen: Θ(n).Best case Zeit bei m ≥ n: 0(1) (namlich dann, wenn immer alle Listen Lange ≤ c, c konstanthaben.)
Durchschnittliche Laufzeit:Wir machen folgende Annahmen:
a) Hashfunktionen sind uniform, d.h. fur i ∈ {0, . . . ,m− 1} gilt |h−1(i)| ∈ {b pmc, b p
mc}.
(Auf jedes i ∈ {1, . . . ,m} werden gleichviele Schlussel abgebildet.)
b) Die Elemente aus S sind unabhangig, zufallig mit Wahrscheinlichkeit Prob (x wirdgewahlt) = 1
pausgewahlt. Dieses ist etwa von h(x) = x mod m erfullt. Diese Hash-
funktion kann außerdem in konstanter Zeit ausgewertet werden.
Wir nehmen nun an, daß wir n Operationen ausgefuhrt haben, zur Zeit eine Menge S vonl Elementen, l ≤ n, abgespeichert ist, und dann Insert (x), Delete (x) oder Lookup (x) furein zufalliges x ∈ U ausgefuhrt wird.
Dann ist fur jedes i ∈ {0, . . . ,m− 1} die Wahrscheinlichkeit fur (h(x) = i) = 1m
.
Sei nun Bi = h−1(i) ∩ S das i-te Bucket bi = |Bi| seine Große. Wir wissen:m
Σi=1
bi = l ≤ n.
Also hat bi durchschnittliche Große lm≤ n
m.
Falls h(x) = i ist, benotigt die Operation Insert (x), Delete (x), Lookup (x) hochstensbi + 1 Schritte.
Also: Durchschnittliche Zahl von Schritten fur diese Operation
≤m
Σi=1
Prob (h(x) = i) · (bi + 1) = 1m·
m
Σi=1
(bi + 1) = 1m
(m + l) ≤ 1 + nm
Satz 2.5 Sei m ≥ n. Um in einem Worterbuch, daß durch Hashing mit Chaining im-plementiert wird, auf einer Menge S, |S| ≤ n, eine Operation Insert (x), Delete (x) oderLookup (x) durchzufuhren, wird im worst case Zeit Θ(n), im best case Zeit O(1), im Durch-schnitt Zeit O(1 + n
m) = O(1) benotigt, und Speicherplatz O(m).
2.4.2 Universelles Hashing und Worst Case Expected Time Untersuchungen
Das Problem der durchschnittlichen Laufzeit: Inputs sind im allgemeinen nicht zufallig.Beim Quicksort haben Sie im Grundstudium Probabilistische Algorithmen kennengelernt,in denen der Ablauf der Rechnung nicht nur vom Input, sondern auch von Zufallsexpe-rimenten abhangt. Es wurden nur Algorithmen betrachtet, die immer, also unabhangigvon den Ergebnissen der Zufallsexperimente, korrekt sind. Die Laufzeit bei festem Input x
14. Oktober 2008, Version 0.6

2.4 Hashing 23
hangt allerdings von diesen Experimenten ab, wir messen sie deshalb als erwartete Zeit (≈durchschnittliche Zeit, Durchschnitt gebildet uber alle Laufzeiten bei Eingabe x, die sichdurch die verschiedenen Ergebnisse der Zufallsexperimente ergeben.) Der worst case uberdie erwarteten Zeiten, worst case genommen uber alle Inputs, der Lange n, ist dann T (n),die worst case expected time.
Im folgenden wird das Zufallsexperiment des Algorithmus darin bestehen, eine zufalligeFunktion h aus einer Menge H von Hashfunktionen auszuwahlen.
Definition 2.6 Eine Menge H ⊆ {h|h : U → {0, . . . ,m − 1}} ist c-universell, falls furalle x, y ∈ U, x 6= y, gilt: #{h|h ∈ H und h(x) = h(y)} ≤ c · |H|/m.
Satz 2.7 p = #U sei Primzahl. Dann ist H1(m) = {ha,b|a, b ∈ Uha,b(x) = ((ax +b) mod p mod m) c-universell, mit c = (b p
mc/ p
m)2(≈ 1).
Beweis:- #H1(m) = p2
- Sei x, y ∈ U, x 6= y. zz: #{(a, b) ∈ U |ha,b(x) = ha,b(y)} ≤ cp2/m(Dann folgt der Satz)Beweis: ha,b(x) = ha,b(y)⇔ ∃q ∈ {0, . . . ,m− 1} und r, s ∈ {0, . . . , bp/mc − 1} mit
ax + b = q + rm mod p
ay + b + q + sm mod p
Fur festes r, s, q gibt es genau eine Losung a, b fur obiges Gleichungssystem , da p Primzahlist, das Gleichungssystem also im Korper Zp gelost wird.
⇒ #{(a, b)|ha,b(x) = ha,b(y)} = #{(q, r, s)|q ∈ {0, . . . ,m− 1}, r, s ∈ {0, . . . , bp/mc − 1} =
m · b pmc2 = (b p
mc/ p
m)2︸ ︷︷ ︸
=c
p2
m2
Folgende Datenstruktur betrachte fur das Worterbuchproblem.
- Wahle zufallig ein h ∈ H, wobei H c-universell fur eine Konstante c ist, und jedesh ∈ H in konstanter Zeit erzeugt (i.e. aus konstant vielen Zufallszahlen in konstanterZeit berechnet) werden kann, und in konstanter Zeit ausgewertet werden kann. (Dieobige Klasse H1(m) ist z.B. ok).
- Fuhre mit diesem h Hashing with Chaining durch.
Satz 2.8 Sei m ≥ n. Um in einem Worterbuch, dass nach obigem Algorithmus imple-mentiert wird, auf einer Menge S, #S ≤ n, beliebige Operationen Insert (x), Delete (x),Lookup (x) durchzufuhren, wird worst case expected time O(1 + c · n/m) = 0(1) benotigt,und Speicherplatz 0(m).
14. Oktober 2008, Version 0.6

2.4 Hashing 24
Beweis:
Sei δh(x, y) =
{1 h(x) = h(y), x 6= y
0 sonst ,
δh(x, S) = Σy∈S
δh(x, y)(=# Elemente in S, die mit x kollidieren)
Es gilt:Erwartete Kosten fur Operation (x) = 1 + erwartete # Elemente in S, mit denen xkollidiert= 1
#HΣ
h∈H(1 + δh(x, S)) = (#H + Σ
h∈HΣ
y∈Sδh(x, y)) 1
#H
= (#H + Σy∈S
( Σh∈H
δh(x, y))) · 1#H
≤ (#H + Σy∈S
(c · #Hm
)) 1#H
≤ (#H · (1 + c · nm
)) · 1#H
= 1 + c nm
- Wir erhalten also auch konstante worst case expected
time pro Operation. 2
2.4.3 Perfektes Hashing und worst case konstante Zeit fur Lookups
Der Idealfall beim Hashing sieht so aus, dass die Hashfunktion auf S injektiv ist, denndann haben alle Listen Lange ≤ 1, und der Zugriff benotigt worst case konstante Zeit.
Definition 2.9 Sei S ⊆ U, #S = n, m ≥ n.h : U → {0, . . . ,m− 1} heißt perfekte Hashfunktion fur S falls h|S injektiv ist.
Wir suchen Methoden, um zu gegebener Menge S effizient eine perfekte Hashfunktion furS zu konstruieren, die wir in konstanter Zeit auswerten konnen, und die nur O(n) Platzbraucht.
Satz 2.10 Fur H1(m) (vgl. letztes Kapitel) gilt:Sei S ⊆ U beliebig, #S = n. Dann:
m−1
Σi=0
(bhi )
2 < n +4n2
m
gilt fur mindestens die Halfte der h ∈ H1(m). Dabei ist
Bhi := h−1(i) ∩ S, bh
i = #Bhi
Beweis: Σh∈H1
(m−1
Σi=0
(bhi )
2 − n)
= Σh∈H1
(m−1
Σi=0
(bhi )
2 −
=n︷ ︸︸ ︷m−1
Σi=0
bhi )
14. Oktober 2008, Version 0.6

2.4 Hashing 25
= Σh∈H1
m−1
Σi=0
(# geordneter Paare aus Bhi )
= Σh∈H1
m−1
Σi=0
(#{(x, y) ∈ S2, h(x) = h(y) = i, x 6= y})
= Σh∈H1
#{(x, y) ∈ S2, h(x) = h(y), x 6= y}
= Σ(x,y)∈S2,x 6=y
#{h|h ∈ H1, h(x) = h(y)}
≤ Σ(x,y)∈S2,x 6=y
c · p2
m(siehe Beweis zu Satz 2.7)
c·n2·p2
m< p2 · 2n2
m
Annahme:mehr als die Halfte der h ∈ H1 erfullt: Σ(bh
i )2 − n ≥ 4n2/m.
⇒ Σh∈H1
(Σ(Bhi )2 − n) ≥ p2
2· 4n2/m = p2 · 2n2
m
=⇒ Widerspruch zu obiger Rechnung.
Also: Fur mindestens die Halfte der h ∈ H1 gilt: Σ(bhi ) < 4n2
m+ n.
2
Korollar 2.11 Sei S ⊆ U gegeben, #S ≤ n.Ein probabilistischer Algorithmus kann in erwarteter Zeit O(n) eina) h ∈ H1(n) mit Σ(bh
i )2 ≤ 5n, bzw.
b) h ∈ H1(2n2), das perfekt fur S ist, finden.
Beweis: a) Wahle zufalliges h ∈ H1(n), teste ob Σ(bhi )
2 ≤ 5n ist (Zeit O(n)). Falls nicht,versuche noch einmal. Wegen Satz 2.10 mit m = n folgt, dass im Durchschnitt 2 Versuchereichen.b) Bei m = 2n2 hat man im Durchschnitt nach 2 Versuchen ein h gefunden mit Σ(bh
i )2 <
n + 2 (vgl. Satz 2.10 mit m = 2n2).Ein solches h ist jedoch immer injektiv auf S, denn ware ein bi ≥ 2, so ware Σ(bh
i )2 ≥
22 + n− 2 = n + 2. 2
Wir konnen nun eine probabilistische Konstruktion fur ein perfektes Hashschema fur Sangeben.
1. Konstruiere probabilistisch ein h ∈ H1(n) mit Σ(bhi )
2 ≤ 5n. Benutze ein Array
T1[0 : n− 1] und schreibe nach T1[i] die Werte 2(bhi )
2 und di =i−1
Σj=0
2(bhj )
2, d0 = 0.
2. Fur i = 0, . . . , n− 1 :Konstruiere probabilistisch hi = ((ax + b) mod p) mod (2(bh
j )2) ∈ H1(2(b
hj )
2), dasperfekt fur Bh
j ist. Schreibe auch a und b nach T1[i].
14. Oktober 2008, Version 0.6

2.4 Hashing 26
3. Lege Array T2[0 : 10n− 1] an, schreibe x ∈ S nach hh(x)(x) + dh(x).
Beachte:
1. Da Σ2(bhj )
2 ≤ 10n ist, ist T2 genugend groß.
2. Nach Konstruktion gibt es in T2 keine Kollisionen.
3. Um fur x ∈ U den Wert hh(x)(x) + dh(x) auszurechnen, genugt konstante Zeit, fallsh, hj, dj fur j = h(x), bekannt sind. h ist sowieso bekannt, dj steht in T1[j], ebensoeine Beschreibung von hj (durch a, b, 2(bh
j )2).
4. Also kann obiges perfektes Hashschema fur S in erwarteter Zeit O(n) aufgebautwerden.
Lookup (x): x ∈ S ⇔ T2[hh(x)(x) + dh(x)] = x.Nach obigem kann dieser Test in konstanter Zeit durchgefuhrt werden.
Satz 2.12 Obiges perfektes Hashschema fur S liefert ein statisches Worterbuch fur S,dass erwartete (worst case exp. time) Aufbauzeit O(n), Platzbedarf O(n) hat, und worstcase Zeit O(1) fur Lookups garantiert.
Bemerkung 2.13 Man kann mit Hilfe des obigen Schemas sogar ein dynamisches Worter-buch implementieren, mit worst case expected time O(1) fur Einfugen/Loschen, aber sogarworst case O(1) Zeit fur Lookups. Sehr aufwendige Techniken liefern sogar, dass bei li-nearem Speicherbedarf jede Operation - Einfugen, Loschen, Lookup - in konstanter Zeitmoglich ist, mit Wahrscheinlichkeit 1 − 1
nl . Dabei ist l eine beliebige Konstante, n dieaktuelle Große des Worterbuchs.
14. Oktober 2008, Version 0.6

27
3 Flusse in Netzwerken
Ein Transportnetzwerk N (kurz: Netzwerk) ist gegeben durch
• einen zusammenhangenden gerichteten Graphen G = (V, E)
• eine Kapazitatsfunktion c : E → R+
• Quelle s ∈ V und Senke t ∈ V .
N kann etwa ein Telefon- oder Rechnernetz beschreiben, die Kapazitaten beschreiben dieBandbreiten der einzelnen Verbindungen. Wir stellen uns nun die Aufgabe, soviel wiemoglich Bandbreite fur die Kommunikation von s nach t zu realisieren.
Ein Fluss in N ist eine Funktion f : E → R mit folgenden Eigenschaften.
(1) Kapazitatsrestriktion: ∀e ∈ E : 0 ≤ f(e) ≤ c(e).
(2) Erhaltungsgesetz (Kirchhoff-Regel): ∀v ∈ V, v 6= s, t : Σe∈in(v)
f(e) = Σe∈out(v)
f(e).
Dabei bezeichnet in(v) die Menge der in v hinein gerichteter Kanten, out(v) die Menge deraus v hinaus gerichteten Kanten.
Der Wert von f ist
val(f) := Σe∈out(s)
f(e)− Σe∈in(s)
f(e).
Typischerweise ist in(s) = ∅ (und out(t) = ∅), dann ist der Wert des Flusses gerade derGesamtfluss, der s verlasst.Ziel dieses Kapitels ist es, Algorithmen zu entwickeln, die zu gegebenem Netzwerk einenmaximalen Fluss, d.h. einen Fluss mit maximalem Wert berechnen. Den Wert eines solchenFlusses bezeichnen wir mit fmax. Dazu werden wir zuerst ein “Optimalitatskriterium”fur Flusse nachweisen, das uns gleichzeitig eine Basismethode zur Berechnung maximalerFlusse liefert.
Einige Eigenschaften von Flussen:
• Ist W ein gerichteter Weg von s nach t in N und 0 < r ≤ min{c(e), e ∈ W}, so istf : E → R+ mit [f(e) = r fur e ∈ W, f(e) = 0 sonst] ein Fluss in N .
• Seien f, f ′ Flusse in N , f + f ′ ≤ c. Dann ist f + f ′ ein Fluss in N .
14. Oktober 2008, Version 0.6

3.1 Das “Max-Flow Min-Cut Theorem’ (Satz von Ford und Fulkerson) 28
3.1 Das “Max-Flow Min-Cut Theorem’ (Satz von Ford und Ful-kerson)
Ein Schnitt in N ist eine disjunkte Zerlegung von V in S und T , mit s ∈ S, t ∈ T .
Die Kapazitat von (S, T ) ist die Summe der Kapazitaten der Kanten, die von S nach Tlaufen,
c(S, T ) := Σe∈E∩(S×T )
c(e)
Mit cmin bezeichnen wir den Wert eines minimalen Schnittes, d.h.
cmin := min{c(S, T ), (S, T ) Schnitt in N}
Satz 3.1 (Satz von Ford und Fulkerson, Max-Flow Min-Cut Theorem)Fur jedes Netzwerk gilt fmax = cmin, d.h., der Wert eines maximalen Flusses ist gleich demWert eines minimalen Schnittes.
Beweis:(a) zz: fmax ≤ cmin
Wir zeigen dazu:Sei f ein Fluss, (S, T ) ein Schnitt in N . Dann gilt val(f) ≤ c(S, T ).
Bew: f(S, T ) := Σe∈E∩(S×T )
f(e)− Σe∈E∩(T×S)
f(e)
bezeichne den Flusswert des Schnittes (S, T ).
Es gilt:
f(S, T )(i)
≤ Σe∈E∩(S×T )
f(e)(ii)
≤ c(S, T )
(i) gilt, da f(e) ≥ 0 also Σe∈E∩(T×S)
f(e) ≥ 0 ist.
(ii) gilt, da f(e) ≤ c(e) ist.
Wie groß ist f(S, T )?
Aus dem Erhaltungsgesetz folgt direkt, das alle f(S, T ) gleich sind, also auch z.B. gleich
f({s}, V \ {s}) = val(f).
(b) zz: fmax ≥ cmin
Fur diesen Beweis beschreiben wir im folgenden einen Algorithmus, der einen Fluss mitWert cmin berechnet. 2
14. Oktober 2008, Version 0.6

3.1 Das “Max-Flow Min-Cut Theorem’ (Satz von Ford und Fulkerson) 29
Der Basisalgorithmus von Ford und Fulkerson
Erste (falsche!) Idee:Erhohe einen bereits gefundenen Fluss f (zu Beginn: f ≡ 0) durch folgende Prozedur:Suche in N einen gerichteten Weg W von s nach t, auf dem keine Kante e saturiert ist,d.h. fur keine Kante e gilt f(e) = c(e). Erhohe den Fluss auf allen Kanten von w ummin{c(e)− f(e), e Kante auf W}.Falls kein solcher Weg existiert, gebe f aus.Folgendes Beispiel zeigt, dass dieser sehr intuitive Greedy-Algorithmus nicht optimal ist.
1
s t
1
1
1
1
1
1
a b
c d
Abbildung 5:
Falls wir zuerst den Weg s − a − d − t wahlen, erhalten wir einen Fluss mit Wert 1, denobiger Algorithmus nicht vergroßern kann. Der maximale Fluss hat aber offensichtlich denWert 2.
Eine gute Idee:Betrachte einen ungerichteten Weg von s nach t. Kanten auf W , die in Richtung von snach t gerichtet sind, heißen Vorwartskanten, die anderen Ruckwartskanten.Sei f ein Fluss in N . Die Restkapazitat r(e) (bzgl. f) einer Vorwartskante e auf W istc(e) − f(e), die einer Ruckwartskante f(e). Falls r = min{r(e), e Kante auf W} > 0 ist,heißt W vergroßernder Weg fur (N, f), r ist seine freie Kapazitat.
Lemma 3.2 W sei ein vergroßernder Weg fur Fluss f in N mit freier Kapazitat r. Fallswir f auf W um r vergroßern, d.h. falls wir fur jede Vorwartskante e von W f(e) um rvergroßern, fur jede Ruckwartskante f(e) um r verringern, erhalten wir einen Fluss f ′ mitval(f ′) = val(f) + r.
Beweis: Einfache Ubungen. 2
14. Oktober 2008, Version 0.6

3.1 Das “Max-Flow Min-Cut Theorem’ (Satz von Ford und Fulkerson) 30
Der Basisalgorithmus von Ford und Fulkerson
Eingabe: Netzwerk N .Starte mit dem leeren Fluss f ≡ 0.While Es gibt vergroßernden Weg W fur f in N Do
vergroßere f auf W umdie freie Kapazitat r von W
OdReturn f .
Folgendes Lemma schließt den Beweis des Max-Flow Min-Cut Theorems ab und zeigt dieOptimalitat des Basisalgorithmus, d.h. zeigt, dass der Basisalgorithmus einen maximalenFluss findet.
Lemma 3.3 Es gibt einen Schnitt (S, T ) in N , so dass fur den vom Basisalgorithmusberechneten Fluss f gilt: val(f) = c(S, T ).
Beweis: Wir stellen uns vor, wir suchen in N einen vergroßernden Weg durch Breiten-suche von s aus in der ungerichteten Version von N . Die Breitensuche hat zu Beginn dieKnotenmenge S = {s} besucht. Falls Knotenmenge S besucht ist, und ein Nachbar w einesv ∈ S untersucht wird, wird w zu s hinzugefugt, falls gilt: Entweder (v, w) ∈ E ((v, w) istKandidat fur eine Vorwartskante) und c(v, w) − f(v, w) > 0 oder (w, v) ∈ E ((v, w) istKandidat fur eine Ruckwartskante) und f(w, v) > 0.Falls dieser Algorithmus t erreicht, ist offensichtlich auch ein vergroßernder Weg gefunden.Falls er nicht t erreicht, wird er eine Menge S ⊆ V erreicht haben, mit s ∈ S, t 6∈ S. SeiT = V \ S. Die Arbeitsweise der oben skizzierten Breitensuche impliziert:
• f(v, w) = c(v, w) fur alle (v, w) ∈ E ∩ (S × T )
• f(v, w) = 0 fur alle (v, w) ∈ E ∩ (T × S)
Somit gilt
val(f) = f(S, T )
= Σ(v,w)∈E∩(S×T )
f(v, w)− Σ(v,w)∈E∩(T×S)
f(v, w)︸ ︷︷ ︸= 0
= Σ(v,w)∈E∩(S×T )
c(v, w) = c(S, T ).
2
14. Oktober 2008, Version 0.6

3.1 Das “Max-Flow Min-Cut Theorem’ (Satz von Ford und Fulkerson) 31
Zur worst-case Laufzeit des Basisalgorithmus:
• Zeit pro Flussvergroßerung (Breitensuche): O(|E|).
• # Flussvergroßerungen: Θ(val(f)) im schlimmsten Fall, auch wenn alle Kapazitatenganzzahlig sind. Begrundung:
val(f) reicht bei ganzzahligen Kapazitaten immer aus, da die freie Kapazitat eines ver-großernden Weges dann immer eine positive naturliche Zahl, also ≥ 1 ist. Folgendes Bei-spiel zeigt, dass val(f) Schritte notig sein konnen (falls man ungeschickte vergroßern-de Wege wahlt). Der Basisalgorithmus konnte als vergroßernde Wege immer abwechselnds − a − b − t und s − b − a − t wahlen, jeweils erhalt man nur freie Kapazitat 1,benotigt also 2 C Flussvergroßerungen.
C
s t1
C
C
C
a
b
Abbildung 6:
Da wir in der Eingabe die Kapazitaten binar kodieren, ist die Eingabegroße fur obigesNetzwerk O(log(C)). Somit hat der Basisalgorithmus exponentielle Laufzeit!
Einige Bemerkungen:
• Falls die Kapazitaten ganzzahlig sind, gibt es auch einen ganzzahligen maximalenFluss.
• Bei ganzzahligen Kapazitaten konnen auch (zusatzlich zu den ganzzahligen) nichtganzzahligen maximale Flusse existieren (Beispiel?).
• Jeder ganzzahlige Fluss kann als Summe von ganzzahligen, gerichteten Wegflussenbeschrieben werden. (Gerichteter Weg-Fluss: Fluss, der auf einem gerichteten Wegvon s nach t einen ganzzahligen Wert r hat, sonst uberall 0.) (Dieses entspricht jader Intuition von Transportnetzen!)
14. Oktober 2008, Version 0.6

3.2 Effiziente Algorithmen zur Berechnung maximaler Flusse 32
• Man kann das Flussproblem als ein lineares Programm beschreiben.Die Variablen dieses Programms sind {f(e), e ∈ E}. Die (linearen) Restriktionen(hier: Gleichungen und Ungleichungen) sind die Kapazitatsrestriktionen (eine proKante) und Erhaltungsgesetze (eines pro Knoten). Die zu maximierende Zielfunktion
ist val(f)(= Σe∈out(s)
f(e)− Σe∈in(s)
f(e))
• Das Max-Flow Min-Cut Theorem ist in diesem Sinne ein Spezialfall des Dualitats-satzes der linearen Optimierung.
• Diese spezielle Klasse von linearen Programmen haben eine sehr schone, fur linea-re Programme ungewohnliche Eigenschaft: Falls die Koeffizienten des Programms(d.h. hier: die Kapazitaten) ganzzahlig sind, gibt es auch eine ganzzahlige optimaleLosung, namlich den (wie oben gezeigt ganzzahligen) maximalen Fluss.)
3.2 Effiziente Algorithmen zur Berechnung maximaler Flusse
Wir haben uns im letzten Kapitel klar gemacht, dass der Algorithmus von Ford und Ful-kerson zwar korrekt arbeitet, aber im schlimmsten Fall auch bei ganzzahligen Kapazitatenpro Flussvergroßerung den Wert des Flusses nur um 1 erhoht, und so exponentielle (in derbinaren Eingabenlange) Laufzeit haben kann.Folgende einfache Modifikation (von Edmonds und Karp) liefert eine weit bessere Laufzeit:Wahle zur Flussvergroßerung jeweils einen kurzesten vergroßernden Weg. Ein solcher Wegkann mit Breitensuche ebenfalls in Zeit O(|E|) gefunden werden.
Satz 3.4 Der obige Algorithmus von Edmonds und Karp benotigt hochstens |E| · |V |/2viele Flussvergroßerungen, also Zeit O(|E|2 · |V |).
Wir werden nicht diesen Satz, sondern ein starkeres Resultat beweisen. Dabei ist die Grun-didee, pro Runde nicht nur entlang eines kurzesten vergroßernden Weges den Fluss zuerhohen, sondern alle kurzesten vergroßernden Wege auf einmal zu betrachten. Dazu be-rechnen wir zuerst zu einem Netzwerk N = (V, E) und einen Fluss f das Schichtennetz-werk LN fur f . (LN : Levelled Network)
Sei E1 = {(v, w), (v, w) ∈ E, f(v, w) < c(v, w)}E2 = {(w, v), (v, w) ∈ E, f(v, w) > 0}
(Die Kanten von E1(E2) konnen auf einem vergroßernden Weg als Vorwarts- (Ruckwarts-)Kanten genutzt werden.)
Wir definieren die Knotenwege V von LN als V = {v ∈ V, v ist durch Kanten aus E1 ∪E2
von s aus erreichbar}.
Fur i ≥ 0 istVi = {v ∈ V , der kurzeste Weg von s nach v uber Kanten aus E1 ∪ E2 hat Lange i}die i-te Schicht.
14. Oktober 2008, Version 0.6

3.2 Effiziente Algorithmen zur Berechnung maximaler Flusse 33
Wir definieren die Kantenmenge E von LN als E = (E1 ∪ E2) ∩⋃
i≥0(Vi × Vi+1), und die
Kapazitatsfunktion c : E → R+ alsc(e) = c(e)− f(e), falls e ∈ E1, undc(e) = f(e), falls e ∈ E2.
Das folgende Lemma fasst einige einfache Eigenschaften von LN zusammen.
Lemma 3.5 Sei LN das Schichtennetzwerk zu N, f .(i) LN kann in Zeit O(|E|) aus N, f berechnet werden.(ii) f sei ein Fluss in LN . Dann ist f ′ : E → R+ mit f ′(v, w) = f(v, w)+ f(v, w)− f(w, v)ein Fluss in N und val(f ′) = val(f) + val(f). (Falls (v, w) oder (w, v) /∈ E ist, definierenwir f(v, w) = 0 bzw. f(w, v) = 0.)(iii) f ist maximaler Fluss in N , genau dann wenn t /∈ V .
Beweis: zu (i): Breitensuche, einfache Ubung.zu (ii): Einfaches nachrechnen liefert, dass Kapazitatsrestriktionen und Erhaltungsgeset-ze fur f ′ gelten. Anschaulich: Jeder kurzeste vergroßernde Weg in N mit Restkapazitatr findet sich als gerichteter Weg in LN wieder: Seine Vorwartskanten sind in E1, seineRuckwartskanten sind in E2, seine Restkapazitat ist ebenfalls r.zu (iii): “⇐” Falls t /∈ V ist, gibt es in LN keinen vergroßernden Weg, also nach obigemauch keinen vergroßernden Weg in N . Somit ist f maximal.“⇒” Falls t ∈ V ist, gibt es in LN einen vergroßernden Weg (jeder Weg von s nach t inLN ist vergroßernd!). Der zugehorige Fluss in LN kann nach (ii) zur Vergroßerung von fgenutzt werden. 2
Wir konnen nun ein Schema zur Berechnung maximaler Flusse vorstellen. Dazu benotigenwir das Konzept eines Sperrflusses in LN .
Sperrfluss-AlgorithmusBegin
(1) f :≡ 0 (Wir starten mit dem leeren Fluss in N .)
(2) LN := Schichtennetzwerk fur (N, f)
(3) While t ∈ V
(4) Do berechne Sperrfluss f in LN
(5) f := f vergroßert gemaß f (vgl. Lemma 3.5 (ii))
(6) LN := Schichtennetzwerk fur (N, f)Od
14. Oktober 2008, Version 0.6

3.3 Berechnung von Sperrflussen: Ein O(n2)-Algorithmus 34
End
Schritt (2) bzw. (6) benotigt Zeit O(|E|) (Breitensuche). Nach Lemma 3.5 berechnet dieserAlgorithmus einen maximalen Fluss in N .
Fragen:(1) Wieviele Iterationen der While-Schleife sind notwendig?(2) Wie teuer ist Zeile 4 (Berechnung eines Sperrflusses?)
Zu Frage 1:Betrachte ein Schichtennetzwerk LN mit l Schichten und darin einen Sperrfluss f . Sei f ′ derFluss in N , der sich gemaß Lemma 3.5 (ii) aus f und f ergibt, LN ′ das Schichtennetzwerkfur (N, f ′). LN ′ habe l′ Schichten.
Behauptung 3.6 l′ > l.
Beweis: Die Kantenmenge E ′ von LN ′ kann sich von E, der Kantenmenge von LN , nurbei von f saturierten Kanten (v, w) unterscheiden, und zwar wie folgt:(v, w) ist nicht in E ′, allerdings ist (w, v) ∈ E ′, auch wenn (w, v) /∈ E ist.Betrachte nun einen gerichteten Weg W der Lange l′ von s nach t in LN ′. W enthalt furmindestens eine saturierte Kante (v, w) ∈ E die Kante (w, v), sonst ware W ja auch eingerichteter Weg von LN gewesen. Das ist jedoch nicht moglich, da alle solche Wege einesaturierte Kante enthalten, die aber in LN ′ fehlt.Man mache sich klar: Falls W fur s viele saturierte Kanten (v, w) ∈ E die Kante (w, v)enthalt, hat W die Lange l + s . Da nach obigem s ≥ 1 gilt, folgt l′ > l. 2
Somit wird in jeder Iteration der While-Schleife die Schichtenzahl von LN um mindestenseins vergroßert. Da diese Zahl zu Beginn ≥ 2, am Ende ≤ |V | ist, folgt:
Lemma 3.7 Der Sperrfluss-Algorithmus benotigt hochstens |V | − 2 Iteration der While-Schleife, also Zeit O(|V | · (|E|+ “Zeit zur Berechnung eines Sperrflusses”)).
3.3 Berechnung von Sperrflussen: Ein O(n2)-Algorithmus
Das “Maximum-Flow”-Problem ist nun auf die (n − 2)-fache Berechnung von Sperr-flussen in LN reduziert. Wir konnen daher N vergessen und zur einfachen NotationLN := (V, E, c, s, t) ubergehen. Mit einer Exploration von LN konnen wir durch Eli-mination nutzloser Knoten in Zeit O(|E|) erreichen, dass fur alle v ∈ V :
(∗) s∗−→
LNv
∗−→LN
t
d.h., v ist von s aus und t von v aus erreichbar. Die Berechnung eines Sperrflusses in LNbasiert auf dem Konzept des Potentials eines Knotens v, gegeben durch
14. Oktober 2008, Version 0.6

3.3 Berechnung von Sperrflussen: Ein O(n2)-Algorithmus 35
PO[v] := min
{Σ
e∈in(v)c(e)− f(e), Σ
e∈out(v)c(e)− f(e)
}bzw. PO[s] = Σ
e∈out(s)c(e)− f(e), PO[t] = Σ
e∈in(t)c(e)− f(e).
PO[v] gibt die maximale Flussvergroßerung durch Knoten v an. PO∗ := min{PO[v]|v ∈V } ist das minimale Potential der Knoten. Sei l die Schicht, in der PO∗ angenommen wirdund v ∈ Vl mit PO[v] = PO∗ der betreffende Knoten.
Idee: Erhohe mit den Prozeduren Forward und Backward den Fluss in LN um PO∗ Ein-heiten. Forward propagiert PO∗ Einheiten von v aus schichtenweise nach vorne bis zurletzten Schicht Vk = {t}. Analog propagiert Backward PO∗ Einheiten von v aus schich-tenweise nach hinten zur Schicht V0 = {s}. Da PO∗ minimal gewahlt war, erhalt keinKnoten mehr Einheiten als er propagieren kann. Nach erfolgter Propagation kann LN sovereinfacht werden, dass nach Loschen nutzloser Kanten und Knoten
i) alle saturierten Kanten aus LN entfernt sind,
ii) alle uberlebenden Knoten wieder (∗) erfullen,
iii) alle Kanten mit einem entfernten Knoten ebenfalls entfernt sind.
Beachte: Zumindest v mit allen inzidenten Kanten wird entfernt. Daher muß sich nachspatestens n Iterationen der geschilderten Idee ein Sperrfluss ergeben.
Wir geben nun die Umsetzung dieser Idee an.
Datenstrukturen: layer [x]: Index l mit x ∈ Vl (Schicht, die x enthalt)
S[x]: Uberfluss bei Knoten x (der noch vorwarts bzw.ruckwarts propagiert werden muß).
Sh : die Knoten mit Uberfluss in Schicht h, doppelt reprasen-tiert mit einer Liste und einem Bitvektor. (Mit dem Bit-vektor kann MEMBER in O(1) Schritten getestet undsomit Duplikate in der Liste vermieden werden).
DEL : Liste nutzloser Knoten.PO[x] : Potential des Knotens x.out(x) : Liste der von x ausgehenden Kanten.in(x) : Liste der in x eingehenden Kanten.
Das Hauptprogramm
begin % Berechnung eines Sperrflusses auf LN der Tiefe k %for each x ∈ V do compute PO[x]; S[x] := 0 od;
14. Oktober 2008, Version 0.6

3.3 Berechnung von Sperrflussen: Ein O(n2)-Algorithmus 36
for each h from 0 to k do Sh ← ∅ od;DEL := ∅;while LN is not emptydo v := argminx∈V PO[x];
PO∗ := PO[v];l := layer[v];S[v] := PO∗;Sl := {v};for h from l to k − 1do for each x ∈ Sh do Forward (x, S[x], h) od od;S[v] := PO∗;Sl := {v};for h from l step − 1 to 1do for each x ∈ Sh do Backward (x, S[x], h) od od;Simplify (DEL)
od
end
Die Prozedur Forward (x, S[x], h)
Vor: x ∈ Vh hat Uberfluss S.
Ziel: Propagation von S Flusseinheiten in Schicht h + 1; nebenbei Entfernen saturierterKanten sowie Aktualisierung aller Datenstrukturen und des aktuellen Flusses.
procedure Forward (x, S[x], h)beginwhile S > 0 % iterativer Abbau des Uberflusses bei Knoten x %do e = (x, y) := first edge from out (x);
δ := min{S, c(e)− f(e)};f(e) := f(e) + δ;if y 6∈ Sh+1 then add ytoSh+1 fi;S[y] := S[y] + δ;S := S − δ;if c(e) = f(e) then delete e from LN fi% Entfernen saturierter Kanten %
od;delete x from Sh;S[x] := 0;PO[x] := PO[x]− S;
14. Oktober 2008, Version 0.6

3.3 Berechnung von Sperrflussen: Ein O(n2)-Algorithmus 37
if (out(x) = ∅ and x 6= t)or(in(x) = ∅ and x 6= s)then add x to DEL
fi % Falls s oder t zu DEL gehoren, liegt ein Sperrfluss vor,der als Endresultat ausgegeben werden kann.Prozedur Simplify kann die Behandlung dieses Fallesubernehmen. %
end
Die Prozedur Backward ist spiegelsymmetrisch. Prozedur Simplify (DEL) ist in O(n + #entfernte Kanten) zu implementieren (s. Ubungen). Die Korrektheit des Algorithmus ergibtsich daraus, dass nur nutzlose Knoten und Kanten entfernt werden. Wenn LN leer ist, mussdemzufolge ein Sperrfluss vorliegen.
Zeitanalyse: Im Hauptprogramm finden maximal n Iterationen der while-Schleife statt.Der Aufwand pro Iteration ist O(n)+ “Gesamtaufwand fur maximal n Forward- bzw.Backwardaufrufe”. Bei Forward kann eine nachste Iteration der while-Schleife nur gestartetwerden, wenn die Kapazitat der zuletzt benutzten Kante erschopft, also auf Null gesetztist. In diesem Fall wird e entfernt. Der Aufwand fur einen Forward-Aufruf betragt somitO(1+# entfernte Kanten). Der Gesamtaufwand fur die maximal n Forward-Aufrufe betragtsomit O(n + # entfernte Kanten).
Satz 3.8 Ein Sperrfluss in LN kann in O(n2) Schritten berechnet werden.
Folgerung 3.9 Ein maximaler Fluss in N kann in O(n3) Schritten berechnet werden.
14. Oktober 2008, Version 0.6

38
4 Graphalgorithmen: Das All-Pair-Shortest-Path Pro-
blem
Wir setzen folgendes voraus, da es im Grundstudium vermittelt wurde:
• Darstellung von Graphen durch Adjazenzmatrizen, Inzidenzmatrizen und Adjazenz-listen.
• Tiefensuche (Depth First Search, DFS)
• Breitensuche (Breadth First Search, BFS)
• Algorithmen zur Berechnung von Minimalen Spannbaumen
• Algorithmus von Dijkstra zur Berechnung von kurzesten Wegen von einem Knotenaus (Single Source Shortest Paths, SSSP)
4.1 Das All Pairs Shortest Paths Problem (APSP)
Bei diesem Problem ist die Eingabe ein gerichteter, gewichteter Graph G = (V, E, w), w :E → R. Die Aufgabe besteht darin, fur jedes Paar (u, v) ∈ V 2 die Lange eines kurzestenWeges von u nach v zu berechnen.
1. MoglichkeitStarte einen SSSP-Algorithmus von jedem Knoten v ∈ V aus. Da dieser die kurzestenWege von v zu allen Knoten liefert, haben wir so das APSP-Problem gelost. Falls G keinenegativen Kreise enthalt (z.B. falls alle Gewichte nicht-negativ sind), konnen wir Dijkstra’sAlgorithmus anwenden und erreichen, je nach Implementierung der Priority Queue, ZeitO(|V |3), O(|V |·|E|·log(|V |) oder O(|V |2 log(|V |)+|V |·|E|). Falls negative Kantengewichteerlaubt sind, mussen wir |V | mal den Bellman-Ford Algorithmus starten, Zeit O(|V |2|E|),also Zeit O(|V |4) fur dichte Graphen. Geht es schneller?
4.2 Der Floyd-Warshall Algorithmus
Sei G = (V, E, w) ein gerichteter, gewichteter Graph. Wir definieren:
d(k)ij := Lange eines kurzesten Weges von i nach j, der ausser i und j nur Kanten aus{1, . . . , k} benutzt. (Dabei vereinbaren wir: Fur e 6∈ E ist w(e) :=∞). Die Resultate sind
dann die d(n)ij .
Wir erhalten folgende rekursive Definition der d(k)ij .
d(k)ij =
{w(i, j) k = 0
min{d
(k−1)i,j , d
(k−1)i,k + d
(k−1)k,j
}k ≥ 1
14. Oktober 2008, Version 0.6

4.2 Der Floyd-Warshall Algorithmus 39
Es ist einfach bei Eingabe von G als gewichtete Adjazenzmatrix aus obiger Rekursioneinen (iterativen) Algorithmus mit Laufzeit O(|V |3) zu machen. Ebenso kann man ihn somodifizieren, dass er auch die kurzesten Wege, nicht nur ihre Lange ausgibt.Dieser Algorithmus ist ein Beispiel fur dynamische Programmierung.
Eine andere Methode zur Berechnung von APSP:
Sei a(m)ij := Gewicht eines kurzesten Weges der Lange
hochstens m von i nach j.Dann gilt:
a(1)ij =
w(i, j) (i, j) ∈ E∞ (i, j) 6∈ E0 i = j
und fur m ≥ 2 :
a(m)ij = min
{a
(m−1)i,j , min
1≤k≤n
{a
(m−1)i,k + w(k, j)
}}= min
1≤k≤n
{a
(m−1)i,k + w(k, j)
}Wenn wir uns A(m) = (a
(m)ij ) als n×n-Matrix vorstellen, ist A(1) = (w(i, j)) (mit w(i, i) = 0,
und w(i, j) =∞ fur (i, j) 6∈ E).Fur m ≥ 2 konnen wir A(m) als A(m−1) · A(1) berechnen, wobei in diesen “Matrizenmulit-plikationen” die Multiplikation durch Addition und die Addition durch Minimumbildungersetzt ist.
Unser Ziel ist es A(n) = (A(1))n zu berechnen.Eine Matrizenmultiplikation kostet nach der “Schulmethode” Zeit O(n3). Wenn wir naivA(n) dadurch berechnen wurden, dass wir immer A(m) als A(m−1) ·A(1) berechnen, wurdenalso Zeit O(|n|4) notwendig. Das geht besser durch iteriertes Quadrieren:
Einfaches Beispiel: n = 2k.
Berechnung A(n)(A(1))(1) A← A(1)
(2) for l = 1 to k(3) A← A2
(4) return A
Am Ende ist A(2k) = A(n) berechnet, und nur k = log(n) Matrizenmultiplikationen aus-gefuhrt.
14. Oktober 2008, Version 0.6

4.2 Der Floyd-Warshall Algorithmus 40
Falls n keine Zweierpotenz ist, konnen wir einfach A(n′) mit n′ = 2dlog(n)e die kleinste Zwei-erpotenz großer oder gleich n anstatt A(n) selbst, berechnen. Somit erhalten wir LaufzeitO(n3 log(n)).
Haufig mochte man in anderen Zusammenhangen fur eine n × n Matrix A die Matrix Ar
berechnen, und nicht Ar′ mit r′ = 2dlog(r)e.
Das lasst sich ebenfalls mit einer Variante des iterierten Quadrierens erledigen:
Sei (bk, . . . , b0) die Binardarstellung von r.
IteriertesQuadrieren((bk, . . . , b0), A)(1) if b0 = 0 then Z ← I(2) else Z ← A(3) initialisiere Z mit Einheitsmatrix (I) oder mit A(4) for l = 1 to k(5) A← A2
(6) if bl =′ 1′ then Z ← Z · A
Am Ende ist Z = Ar, es werden k = dlog(r)eMatrizenmultiplikationen (jeweils Zeit O(n3))und hochstens k = log(r) Matrizenadditionen (jeweils Zeit O(n2)) benotigt. Somit ergibtsich fur die Laufzeit O(n3 log(r)).
4.2.1 Berechnung Transitiver Hullen
Die transitive Hulle eines gerichteten Graphen G = (V, E) ist der Graph G∗ = (V, E∗) mit[(i, j) ∈ E∗ ⇔ ∃ (gerichteten) Weg von i nach j in G]
Beide obigen Algorithmen konnen zur Berechnung der transitiven Hulle benutzt werden,falls wir Kantengewichte 1 fur Kanten aus E,∞ fur Kanten nicht aus E einsetzen. (i, j) ∈E∗ gilt dann genau wenn der kurzeste Weg von i nach j Lange <∞ hat.
14. Oktober 2008, Version 0.6

41
5 Entwurfsmethoden fur Algorithmen
Es gibt keinen “Meta-Algorithmus”, der zu einem Problem einen effizienten Algorithmusentwirft. Grundsatzlich gilt, dass man sich mit jedem Problem kreativ auseinandersetzenmuß, um gute Algorithmen zu finden. (Das macht Algorithmenentwicklung zwar schwierig,aber auch interessant.) Auf der anderen Seite haben sich Methoden herausgeschalt, diefur großere Klassen von Algorithmen interessant sind. Eine solche Methode kennen wirschon, namlich Divide & Conquer. Wir werden in diesem Kapitel zwei weitere Methodenkennenlernen, namlich Dynamische Programmierung und Greedy-Algorithmen.
5.1 Dynamisches Programmieren
Dynamische Programmierung ist eine Entwurfsmethode fur Algorithmen, die fur dieLosung eines Problems der Große n alle “fur diese Losung relevanten Teilprobleme” derGroßen 1, . . . , n−1 berechnet, und daraus die Gesamtlosung zusammensetzt. Das sieht aufden ersten Blick ahnlich wie Divide & Conquer aus, allerdings mußten wir dabei immerwissen, an welcher Stelle wir das Problem aufteilen.
5.1.1 Problem 1: Matrizen-Kettenmultiplikation
Hier sind die Matrizen M1, . . . ,Mn gegeben, wobei Mi eine pi−1×pi -Matrix ist, fur naturli-che Zahlen p0, . . . , pn. Somit ist M1 ·M2 · . . . ·Mn definiert. Die Kosten einer Multiplikationeiner p× q- mit einer q × r -Matrix sind nach der Schulmethode O(p · q · r), wir werden infolgenden Kosten p · q · r hierfur annehmen.
Da die Matrizenmultiplikation assoziativ (Achtung: aber nicht kommutativ) ist, gibt esmehrere Moglichkeiten M1 · . . . ·Mn zu berechnen.
Beispiel:Betrachte M1, M2, M3 als (50 × 10)-, (10 × 20)-, (20 × 5) -Matrizen. Wir konnen sie aufzwei Arten multiplizieren:
1. (M1 ·M2) ·M3
Kosten: 50 · 10 · 20 + 50 · 20 · 5 = 15000
2. M1 · (M2 ·M3)Kosten: 10 · 20 · 5 + 50 · 10 · 5 = 3500
Unser Ziel ist es, eine optimale Klammerung zu berechnen!Ein naiver Algorithmus probiert alle Klammerungen aus. Problem: Die Zahl k(n) der mogli-chen Klammerungen ist sehr groß:Es gibt (n − 1) Moglichkeiten fur die obersten Klammern. Eine feste solche Moglichkeitlaßt die Teilprobleme M1, . . . ,Mj bzw. Mj+1, . . . ,Mn zu klammern uber, also gilt:
14. Oktober 2008, Version 0.6

5.1 Dynamisches Programmieren 42
k(1) = 1
k(n) =n−1∑j=1
k(j) · k(n− j) fur n > 1
Die Losung dieser Rekursion liefern die sog. Catalan-Zahlen C(n) genauer (C(n) = k(n+1))Es gilt: C(n) =
(2nn
)· 1
n+1= Θ( 4n
n3/2 ). Somit ergibt sich exponentielle Laufzeit.
Wir wollen nun einen besseren Algorithmus finden, indem wir das Prinzip der dynamischenProgrammierung anwenden.
Seien m(i, j) die minimalen Kosten, um Mi , . . . , Mj zu multiplizieren. Unser Ziel ist es
nun, alle(
n2
)+ n = n(n+1)
2= Θ(n2) viele m(i, j) mit 1 ≤ i ≤ j ≤ n zu berechnen. (Beachte:
Unsere gesuchte Losung ist m(1, n).) Diese m(i, j) mochten wir dabei in einer Reihenfolgeberechnen, die es erlaubt, jedes m(i, j) mit geringem Aufwand aus dem vorher berechnetenm(i′, j′) zu erzeugen.
Dazu folgende Uberlegung:Sei die optimale außere Klammerung fur Mi, . . . ,Mj durch (Mi · . . . ·Mk) · (Mk+1 · . . . ·Mj)gegeben fur ein k ∈ {i + 1, . . . , j − 1}.
Mi · . . . ·Mk ist eine pi−1 × pk-Matrix,Mk+1 . . . , Mj ist eine pk × pj-Matrix,also kostet die letzte Multiplikation pi−1 · pk · pj.
Die Gesamtkosten sind dann:m(i, j) = m(i, k) + m(k + 1, j) + pi−1 · pk · pj.
Allerdings wissen wir zu Beginn nicht, welches k optimal ist. Wir konnen jedoch folgendeAussage machen:m(i, i) = 0 und fur j > i:
m(i, j) = mini≤k<j
{m(i, k) + m(k + 1, j) + pi−1 · pk · pj}
In welcher Reihenfolge rechnen wir die m(i, j) aus? Zuerst alle m(i, i), dann alle m(i, i+1),dann alle m(i, i + 2) usw. Fur die m(i, i) benotigen wir je Zeit O(1)(m(i, i) = 0), furm(i, i + l) benotigen wir Zeit O(l) = O(n). Also: Gesamtzeit = O(n) +
(n2
)·O(n) = O(n3).
5.1.2 Problem2: Optimale binare Suchbaume
Wir kennen binare Suchbaume aus dem Grundstudium. In diesem Kapitel gehen wir davonaus, dass zu den Schlusseln a1 < . . . < an Zugriffshaufigkeiten p1, . . . , pn gegeben sind. Ziel
14. Oktober 2008, Version 0.6

5.1 Dynamisches Programmieren 43
ist es, einen Suchbaum fur a1, . . . , an zu konstruieren, so dass die mittlere Suchzeitn∑
i=1
ti ·pi
minimiert wird. Dabei ist ti die Tiefe von ai im Suchbaum.
Wir stellen wieder fest, dass folgendes gilt:Falls ak die Wurzel im optimalen Suchbaum ist, konnen wir den optimalen Suchbaumdadurch konstruieren, dass wir als linken Ast unter ak einen optimalen Suchbaum fura1, . . . , ak−1 und als rechten Ast unter ak eine fur ak+1, . . . an hangen.
t(i, j) bezeichne die mittlere Suchzeit in einem optimalen Baum fur ai, . . . , aj, d.h. t(i, j) =j∑
l=i
pltl.
Dann gilt:
t(i, j) =
{pi i = jmini≤k<j {t(i, k − 1) + t(k + 1, j)}+ w(i, j) j − i > 0
mit w(i, j) =
j∑l=i
pl
(Beachte: Der Term w(i, j) entsteht folgendermassen: Zusatzlich zu min{. . .} entstehenfolgende Kosten: Fur ak: Kosten pk; fur jedes l ∈ {i, . . . , j} \ {k}: Kosten pl (wegen derersten Kante: ak → Wurzel des Suchbaums)).
Wiederum kann man obiges einfach berechnen, indem die t(i, j) in der Reihenfolge: Allet(i, i), dann alle t(i, i + 1), dann alle t(i, i + 2), usw. berechnet werden. Kosten: O(n3).
Kann man die mittlere Tiefe eines Suchbaums durch eine geschlossene Formel in pi, . . . , pn
ausdrucken?Ja, wir landen damit bei klassischen Ergebnissen der Informationstheorie. Wir betrachtendabei die folgende (nicht immer optimale) Konstruktion:
Sei q =m∑
l=1
pl.
Wahle die Wurzel ak so, dass gilt:
k−1∑l=1
pl ≤ q/2 ≤k∑
l=1
pl,
fahre rekursiv in den beiden Teilbaumen nach der gleichen Regel fort. Beachte: Es gilt auchn∑
l=k+1
pl ≤ q/2. Zur Analyse gehen wir davon aus, dass p1, . . . , pn eine Wahrscheinlichkeits-
verteilung ist, alson∑
l=1
pl = 1.
14. Oktober 2008, Version 0.6

5.1 Dynamisches Programmieren 44
Behauptung 5.1 Sei ak ein Element der Tiefe t im obigen Baum, der Teilbaum mit
Wurzel ak verwalte ai, . . . , aj. Dann gilt:j∑
l=i
pl ≤ 2−t.
Beweis: Induktion nach t :t = 0 : Nur die Wurzel ak hat Tiefe 0 und pk = 1 ≤ 20.Sei t > 0, ak habe Tiefe t, a′k sei Vorganger von ak und der Suchbaum mit Wurzel a′k
verwalte ai, . . . , aj. Nach Induktionsvoraussetzung istj∑
l=i
pl ≤ 2−(t−1). Der Subbaum mit
Wurzel ak verwaltet entweder ai, . . . , ak−1 oder ak+1, . . . , aj. Nach Konstruktion gilt aber:
k−1∑l=i
pl ≤1
2
j∑l=i
pl
Ind.V or.
≤ 1
2· 2−(t−1) = 2−t
und
j∑l=k+1
pl ≤1
2
j∑l=i
pl
Ind.V or.
≤ 1
2· 2−(t−1) = 2−t.
2
Aus der Behauptung folgt insbesondere:Sei tk die Tiefe von ak, dann ist pk ≤ 2−tk , also tk ≤ − log(pk), und somit folgt:
Mittlere Suchtiefe im optimalen Baum
≤ Mittlere Suchtiefe im obigen Baum
≤n∑
k=1
pktk ≤ −n∑
k=1
pk log(pk) = H(p1, . . . , pn)
die Entropie von p1, . . . , pn. Wir werden uns im nachsten Kapitel u.a. auch mit der Entropiebeschaftigen und u.a. zeigen, dass die obige Schranke bis auf einen Faktor 1/ log2(3) ∼ 0.631scharf ist.
Weitere Beispiele fur dynamische Programmierung:Der Cocke-Younger-Kasami-Algorithmus fur das Wortproblem kontextfreier Sprachen, wei-tere Optimierungsprobleme.
Mogliche Effizienzverbesserungen:In unseren beiden Beispielen haben wir die Aufgabe, zur Berechnung eines Wertes m(i, j)ein Minimum der Form
mini≤k≤j
{m(i, k) + m(k, j), . . . }
14. Oktober 2008, Version 0.6

5.2 Greedy-Algorithmen 45
odermini≤k≤j
{m(i, k) + m(k + 1, j)), . . . }
auszuwerten. Sei ki,j das optimale k. Fur unsere beiden Beispiele gilt: ki,j ≤ ki,j+1. (Ubung!)Dann gilt aber, dass wir bei der Berechnung von m(i, j + 1) nur min
ki,j≤k≤ki+1,j+1
berechnen
mussen, also entstehen fur m(i, j), m(i, j + 1), . . . ,m(i, n) insgesamt nur Kosten O(n),d.h. die Laufzeiten fur Matrizen-Kettenmultiplikation und optimale Suchbaume konnen aufO(n2) reduziert werden. Diese funktioniert aber nicht immer, z.B. nicht beim Algorithmusvon Cocke, Younger, Kasami.
5.2 Greedy-Algorithmen
Greedy heisst gierig, das beschreibt diesen Algorithmen-Typ recht gut. Er wird fur Opti-mierungsprobleme benutzt, bei denen aus einer Menge eine optimale Teilmenge gewahltwerden muß. Optimalitat kann dabei auf viele Arten definiert werden.Ein Greedy-Algorithmus wird diese Teilmenge Element fur Element aufbauen, und dabeiimmer “gierig” als nachstes dasjenige Element auswahlen, das den Nutzen bezuglich derZielfunktion am meisten erhoht. Ein Greedy-Algorithmus wird aber nie weiter vorausschau-en, oder getroffene Entscheidungen zurucknehmen. Wir fragen uns:
• Fur welche Probleme liefern Greedy-Algorithmen optimale Losungen?
• Fur welche beweisbar guten Losungen?
• Fur welche schlechten Losungen?
Wir starten mit drei einfachen Beispielen fur die drei oben genannten Falle.
5.2.1 Bruchteil-Rucksackproblem: optimal
Gegeben sind 2n + 1 positive Zahlen v1, . . . vn, g1, . . . , gn und G. Gesucht sind Zahlen
a1, . . . , an ∈ [0, 1], so dassn∑
i=1
aigi ≤ G undn∑
i=1
aivi maximal ist.
Beachte:Falls die ai ∈ {0, 1} sein mussen, ist obiges Problem eine Variante des NP-vollstandigenRucksackproblems.
Fur obiges Bruchteil-Rucksackproblem sortieren wir zuerst, so dass v1
g1≥ v2
g2≥ . . . ≥ vn
gn
gilt. vi
giist der relative Wert pro Gewichtseinheit, es scheint also sinnvoll zu sein, lieber vi
als vj in die Losung aufzunehmen, falls vi
gi>
vj
gjist. Der Greedy Algorithmus macht genau
das:Es nimmt zuerst Objekt 1, dann Objekt 2 usw. immer vollstandig, d.h. mit a1 = 1, a2 = 1,
14. Oktober 2008, Version 0.6

5.2 Greedy-Algorithmen 46
usw. auf, bis das nachste Objekt ak die Restriktionk∑
i=1
gi ≤ G verletzen wurde. Hiervon
nehmen wir nur den Bruchteil b ∈ (0, 1) auf, der dafur sorgt, dassk−1∑i=1
gi + bgk = G ist.
Behauptung 5.2 Obiger Greedy-Algorithmus liefert optimale Leistung.
Betrachte die lexikographisch erste optimale Losung a1, . . . , an. Warum existieren die? Fallsfur ein j > k gilt, dass aj > 0 ist, muß gelten: aj′ < 1 fur ein j′ < k oder ak < b. (Dennsonst ware die “≤ G”-Restriktion nicht erfullt.) Dann konnten wir aber aj fur ein genugendkleines ε > 0 um ε
gjverringern, und aj′ bzw. ak um ε
gj′bzw. ε
gkerhohen. Dadurch bleibt
das Grundgewicht der Losung gleich, also ≤ G. Diese Losung liefert wegen der Sortierungder vi
gikeinen schlechteren Zielfunktionswert, ist aber lexikographisch großer.
Die Laufzeit wird durch das Sortieren dominiert, ist also O(n log(n)).
5.2.2 Rucksackproblem: sehr schlecht
Wir benutzen den gleichen Algorithmus, erlauben aber nun nur ai ∈ {0, 1}. Damit ist dieLosung gegenuber der “Bruchteillosung” um b · gk kleiner. Wie schlimm kann das werden?
Betrachte das einfache Beispieln = 2, g1 = 1, g2 = G, v1 = 1, v2 = G− 1.
Dann istv1
g1= 1 > v2
g2= G−1
G.
Unser Algorithmus wurde also als Losung v1 = 1 liefern. Die optimale Losung ist aberoffensichtlich v2 = G− 1.(Naturlich konnen wir hier auch keine optimale Losung erwarten, da das RucksackproblemNP-vollstandig ist. Es gibt allerdings sehr viel bessere polynomielle Approximationsalgo-rithmen → Spezialvorlesung)
5.2.3 Bin Packing: nicht optimal, aber gut
Gegeben sind n Objekte mit Gewichten a1, . . . , an ∈ [0, 1]. Sie sollen auf moglichst wenigeBins (Kisten) verteilt werden, wobei jede Kiste hochstens Gewicht 1 aufnehmen kann.Bin Packing ist NP-schwer, also konnen wir keine schnellen optimalen Algorithmen erwar-ten.Wir konnen uns verschiedene Greedy-Algorithmen vorstellen. Wir haben Bins B1, B2, . . .zur Verfugung.
First Fit:Plaziere hintereinander a1, a2, . . . , an und zwar ai immer in das Bin Bj mit kleinstem j,in das ai noch hinein passt.
14. Oktober 2008, Version 0.6

5.2 Greedy-Algorithmen 47
Best Fit:ai wird jetzt in dem Bin platziert, in das es noch passt, das aber den geringsten Freiraumhat.
Satz 5.3 (i) Beide Algorithmen benotigen hochstens um einen Faktor 2 mehr Bins als einoptimaler Algorithmus.(ii) Es gibt Beispiele, in denen obige Algorithmen um einen Faktor 5/3 mehr Bins benotigenals ein optimaler Algorithmus.
Beweis zu (ii):Es sei n = 18m, a1 = . . . = a6m = 1
7+ ε, a6m+1 = . . . = a12m = 1
3+ ε und a12m+1 = . . . =
a18m = 12
+ ε, fur ε = 1126
.
Optimale Losung: Je ein Element der drei Typen fullen eine Kiste exakt; also Opt = 6m.Losung von FF : FF packt zuerst m Kisten jeweils mit 6 mal 1
7+ ε = 6
7+ 6ε. In diese
Kisten passen keine weiteren Objekte. Dann kommen 3m Kisten mit je 2 mal 13
+ ε. Dierestlichen 6m Objekte brauchen je eine neue Kiste. Also: FF liefert Losung 10m, ist alsoum Faktor 10
6= 5
3schlechter als Opt. Die obigen Beweise gelten analog fur Best Fit. 2
[Im obigen Beispiel hatten wir eine optimale Losung erhalten, wenn wir die Objekte zuerstmonton fallend sortiert hatten. Die so entstehenden Algorithmen First Fit Decreasing undBest Fit Decreasing sind naturlich auch nicht optimal (Bin Packing ist ja NP-vollstandig),aber man kann zeigen, dass der Gutefaktor 11
9ist.
(Bemerkung: (i) ist sogar mit dem Faktor 1.7 korrekt, allerdings ist der Beweis sehr langlich.(ii) gilt bereits mit Faktor 1.7-ε. (5/3 ≈ 1.667)).] 2
Beweis zu (i):Wir betrachten First Fit. Fur Eingabe a1, . . . , an sei OPT die optimale, FF die bei FirstFit erzielte Zahl von Bins. Es gilt:
1. Opt ≥n∑
i=1
ai
2. Falls bei First Fit alle Kisten mehr als halb voll sind, ist FF < 2 ·n∑
i=1
ai ≤ 2Opt.
3. Falls es eine Kiste mit Beladung ε ≤ 12
gibt, sind alle FF − 1 anderen Kisten mit
mindestens 1− ε beladen. Also ist OPT ≥n∑
i=1
ai ≥ (1− ε)(FF − 1) + ε, also FF ≤
(OPT − ε/(1− ε)) + 1 = (OPT + 1− 2ε)/(1− ε).
Da dieser Term mit ε monoton wachst, und ε ≤ 12
vorausgesetzt ist, nimmt er sein Maxi-mum fur ε = 1
2an. Also: FF ≤ 2 ·OPT . 2
14. Oktober 2008, Version 0.6

5.2 Greedy-Algorithmen 48
5.2.4 Prefixcodes nach Huffman: optimal
Σ = {a1, . . . an} sei ein Alphabet. Ein Prafixcode ist eine Abbildung c : Σ→ {0, 1}∗, so dasskein c(ai) Prafix (Anfangstuck) eines c(aj) fur j 6= i ist. [Beachte: Codeworte sind damitalle verschieden, sie durfen verschiedene Lange haben. Prafixcodes haben gegenuber “nor-malen” Codes den Vorteil, dass wir ein Wort d1d2 . . . dl ∈ Σ∗ einfach als c(d1)c(d2) . . . c(dl)codieren konnen, wir benotigen keine Trennsymbole und wissen trotzdem immer genau,wann die Codierung des nachsten Buchstabens beginnt.]Ein geschickt gewahlter Code sollte haufig benutzten Buchstaben (z.B. dem ‘e’ in einemdeutschen Text) kurze, und selten benutzten Buchstaben (z.B. ‘y’) langere Codeworte zu-ordnen.
Formal: Seien p1, . . . , pn Haufigkeiten fur das Auftreten von a1, . . . an. Ein Prafixcode furΣ heißt optimal bzgl. p1, . . . , pn, falls die mittlere Codewortlange
∑ni=1 pi(c(ai)) minimal
unter allen Prafixcodes fur (Σ, p1, . . . , pn) ist.
Beispiel 5.4 Σ = {a, b, c, d, e, f},
• p(a) = 0.45, p(b) = 0.13, p(c) = 0.12, p(d) = 0.16, p(e) = 0.09, p(f) = 0.05.
• Ein moglicher Prafixcode:c(a) = 0, c(b) = 101, c(c) = 100, c(d) = 111, c(l) = 1101, c(f) = 1100.
• Mittlere Codewortlange:0.45 · 1 + 0.13 · 3 + 0.12 · 3 + 0.16 · 3 + 0.09 · 4 + 0.05 · 4 = 2.24.
(Dieser Code ist tatsachlich optimal.)
Der Huffman AlgorithmusWir gehen davon aus, dass p1 ≤ p2 ≤ . . . pn gilt. Nun bauen wir den Baum bottom up (vonden Blattern startend) auf. Dazu werden wir zuerst die beiden Codeworte mit kleinsterHaufigkeit, als a1 und a2, zu einem Baum verschmelzen.a1 und a2 werden aus der Liste der Codeworter entfernt, und ein neues Element [a1, a2] insie eingefugt, und zwar gemaß ihres Gewichts p1 + p2. Im Beispiel wirderzeugt, f, e gestrichen und [f, e] mit Gewicht 0.14 in die Liste einsortiert. Mit der neuensortierten Liste von “Codewortern” fahren wir auf gleiche Weise fort:Wir verschmelzen die beiden kleinsten “Codeworter” wieder zu einem Baum. Im Beispielwurden wir b und c verschmelzen zub, c streichen, und [b, c] mit Gewicht 0.25 einsortieren. Somit haben wir nun folgende sor-tierte List vorliegen:
[e, f ], d, [b, c], a,0.14 0.16 0.25 0.45
Im nachsten Schritt wurde also [e, f ] und d verschmolzen, und es entsteht
14. Oktober 2008, Version 0.6
5.2 Greedy-Algorithmen 49
d
e
c b
a
10
1
1
1
1
0
0
0
0
f
Abbildung 7: Darstellung als Baum: Das Codewort von e ist am Weg zu e markiert: 1101
a 1 a 2
0 1
mit Gewicht 0.3, [e, f ] und d werden gestrichen, [[e, f ], d] wird mit Gewicht 0.3, also zwi-schen [b, c] und a einsortiert.Fur die Implementierung bietet sich zur Verwaltung der sortierten Liste offensichtlich einePriority Queue an (wir mussen n mal minimale Elemente entfernen, jeweils logn Zeit) und2n−1 mal Elemente einfugen (n mal, um a1, . . . , an einzufugen, n−1 mal, um neue Elemen-te einzufugen, jeweils O(log(n)) Zeit). Somit benotigt der Algorithmus Zeit O(n log(n)).
Korrektheit:Wir zeigen zuerst:
Behauptung 5.5 Es gibt einen optimalen Codebaum, so dass a1 und a2 Geschwister sind.
Beweis: Sei B ein optimaler Codebaum, ai und aj, i < j, zwei Geschwisterknoten auf demuntersten Level t von B. Was passiert mit der mittleren Codewertlange in B, falls wir a1
und aj vertauschen?a1 befinden sich auf Level t′ ≤ t. Die mittlere Codewortlange wird dann um folgenden Wertverandert:
0 1
f e
14. Oktober 2008, Version 0.6

5.2 Greedy-Algorithmen 50
0 1
b c
0 1
d
fe
0 1
(p1 · t− p1 · t′) + (pi · t′ − pi · t)
= (t′ − t)︸ ︷︷ ︸≤ 0
· (pi − p1)︸ ︷︷ ︸≥ 0
≤ 0,
d.h. der Baum wird nicht schlechter. Analoges folgt, wenn wir anschliessend a2 und aj
vertauschen. Somit folgt die Behauptung.2
Wir konnen nun zeigen:
Satz 5.6 Der Huffman Algorithmus berechnet einen optimalen Prafixcode.
Beweis: Induktion nach n.n = 1 : Das leere Wort wird berechnet und ist optimal.n > 1 :Sei wie oben p1 ≤ . . . ≤ pn. Nach Ind. Vor. berechnet die Huffman-Algorithmus einen opti-malen Codebaum B fur [a1, a2], a3, . . . , an, p1 +p2, p3, . . . , pn. Der Baum, den der Huffman-Algorithmus fur a1, . . . , an, p1, . . . , pn erzeugt, ist gerade der, den wir aus B erhalten, indemwir aus dem Blatt [a1, a2] einen inneren Knoten mit Kindern a1 und a2 machen. Sei m(B)bzw. m(B′) die mittlere Codewortlange fur B bzw. B′. Dann gilt:
m(B′) = m(B) + p1 + p2
Wir mussen zeigen, dass dieses optimal ist. Dazu sei B′′ ein optimaler Codebaum fura1, . . . , an, p1, . . . , pn. Wegen der Beh. durfen wir annehmen, dass in B′′ a1 und a2
Geschwister auf dem untersten Level sind. Ihr gemeinsamer Vorganger heißt a. Wirentfernen nun aus B′′ die Blatter a1 und a2 und erhalten einen Codebaum B fura, a3, . . . , an, p1 + p2, p3, . . . , pn. Da B hierfur optimal war, gilt:m(B) ≥ m(B). Ausserdem ist offensichtlich m(B′′) = m(B) + p1 + p2.Also folgt:
14. Oktober 2008, Version 0.6

5.2 Greedy-Algorithmen 51
m(B′) = m(B) + p1 + p2 ≤ m(B) + p1 + p2 = m(B′′).Da B′′ optimal ist, ist also m(B′) = m(B′′), also ist auch B′ optimal. 2
Beachte: Man kann zeigen (nicht sehr schwierig), dass H(p1, . . . , pn) ≤ m(B′) ≤H(p1, . . . , pn) + 1 gilt, falls p1, . . . , pn eine Wahrscheinlichkeitsverteilung, d.h. pi ≥ 0 und∑
pi = 1 ist.
Dabei ist H(p1, . . . , pn) = −n∑
i=1
pi log(pi)(=n∑
i=1
pi log( 1pi
)) die Entropie.
[Die Codewortlange fur ai ist ziemlich genau log( 1pi
). Genauer: Fur die Codewortlangen
t1, . . . , tn gilt:n∑
i=1
2−ti ≤ 1 (Kraft’sche Ungleichung). Dieses ist erfullt, falls ti ≥ blog( 1pi
)c
ist. Offensichtlich kann man einen Code mit Wortlangen dlog( 1pi
)e auch einfach angeben.]Die Aussagen
H(p1, . . . , pn) ≤ optimale mittlere Codewortlange ≤ H(p1, . . . , pn) + 1
ist Inhalt des beruhmten Resultats von Shannon, des Noiseless Coding Theorem.
5.2.5 Wann sind Greedy-Algorithmen optimal?
Sei E eine endliche Menge, U ein System von Teilmengen von E. (E, U) heißt Teilmen-gensystem, falls gilt:(i) ∅ ∈ U(ii) Fur jedes B ∈ U ist auch jede Teilmenge A von B in U . (Vererbungseigenschaft).
B ∈ U heißt maximal, falls keine echte Obermenge von B in U ist. Das zu (E, U) gehori-ge Optimierungsproblem besteht darin, zu gegebener Gewichtsfunktion w : E → R einemaximale Menge B zu bestimmen, deren Gesamtgewicht w(B) =
∑e∈B w(e) maximal ist
(unter den Gesamtgewichten der maximalen Mengen). (Analoges laßt sich fur Minimierungdefinieren.)
Wir konnen z.B. das 0-1-Rucksackproblem wie folgt darstellen:Seien g1, . . . , gn, G > 0 fest, E = {1, . . . , n}.B ⊆ E ist in U , genau dann wenn
∑i∈B
gi ≤ G gilt. Ziel ist es, bei Gewichten w1, . . . , wn ≥ 0
ein B ∈ U zu finden, welches∑
i∈B wi maximiert.
Da ∅ ∈ U ist, und fur B ⊆ U offensichtlich auch jede Teilmenge von B in U ist, gehortunser Optimierungsproblem zu einem Teilmengensystem.
Zu einem Teilmengensystem (E, U) und einer Gewichtsfunktion w arbeitet der kanonischeGreedy-Algorithmus folgendermaßen:
14. Oktober 2008, Version 0.6

5.2 Greedy-Algorithmen 52
KanonischGreedy((E, U))(1) sortiere E, so dass w(e1) ≥ . . . ≥ w(en) gilt(2) B ← ∅(3) for k = 1 to n(4) if B ∪ {ek} ∈ U then B := B ∪ {ek}(5) return Losung B
Der Algorithmus aus 5.2.2 (Rucksack) arbeitet z.B. genau so. Wir wissen, dass er nichtoptimal ist.
Wir konnen auch zum MST Problem (Minimaler Spannbaum) ein Teilmengensystemdefinieren:E ist die Kantenmenge des zusammenhangenden Graphen G = (V, E), V = {1, . . . , n},und U besteht aus allen Kantenmengen B ⊆ E, die keine Kreise enthalten.
(Beachte: maximale Mengen in U sind Spannbaume!)Somit berechnet man zu Gewichten w(e), e ∈ E, einen Spannbaum, indem man ein maxi-males T ∈ U berechnet, welche w(T ) maximiert. Wir haben also ein zu einem Teilmengen-systemen gehoriges Optimierungsproblem vorliegen.
Der kanonische Greedy-Algorithmus, angewandt auf dieses Problem ist ihnen bekannt:Kruskals Algorithmus. Er ist optimal!Konnen wir einem Teilmengensystem “ansehen”, ob seine Optimierungsprobleme durchden generischen Greedy-Algorithmus optimal gelost werden?
Definition 5.7 Ein Teilmengensystem (E, U) heißt Matroid, falls folgende “Austauschei-genschaft” gilt:Fur alle A, B ∈ U, |A| < |B| gibt es x ∈ B\A mit A ∪ {x} ∈ U .
Diese Eigenschaft gilt fur das zum MST gehorige Teilmengensystem; genau diese wurdefur den Beweis der Optimalitat des Krusal-Algorithmus nachgewiesen:Betrachte zwei kreisfreie Teilmengen A, B von E, |A| < |B|. Seien V1, . . . , Vk ⊆ V dieZusammenhangkomponenten von (V, A). (Beachte: Ein Baum auf n Knoten hat n − 1Kanten, ein kreisfreier Graph auf n Knoten also hochstens n− 1 Kanten.)
• Da |A| < |B| ≤ n− 1 ist, ist A kein Spannbaum, also k ≥ 2.
• Da B kreisfrei ist, kann B in jeder Menge Vi hochstens |Vi| − 1 Kanten haben.
• A hat in jedem Vi genau |Vi| − 1 Kanten.
Also gibt es in B hochstensk∑
i=1
(|Vi|−1) = |A| viele Kanten, die innerhalb eines Vi verlaufen.
Da |B| > |A| ist, gibt es in |B| also auch eine Kante e, die zwei verschiedene Vi verbindet.Diese kann aber in A keinen Kreis schließen, d.h. A ∪ {e} ∈ U .
14. Oktober 2008, Version 0.6

5.2 Greedy-Algorithmen 53
Dieses zeigt, das obiges System fur MST ein Matroid ist.
Das System fur das Rucksackproblem ist kein Matroid, denn man kann sich leicht uber-zeugen, dass alle maximalen Mengen in einem Matroid gleich groß sind. Dieses gilt offen-sichtlich nicht fur das Teilmengensystem des Rucksack-Problems.
Satz 5.8 Sei (E, U) ein Teilmengensystem. Der Kanonische Greedy-Algorithmus ist bzgl.jeder Gewichtsfunktion w : E → R optimal genau dann, wenn (E, U) ein Matroid ist.
Somit folgt aus obigen Uberlegungen direkt, dass Kruskals Algorithmus fur MST optimalist, aber der kanonische Greedy-Algorithmus fur Rucksack nicht optimal ist.
Beweis des Satzes:′′ ⇐ ′′ : Sei (E, U) ein Matroid, w : E → R eine Gewichtsfunktion, w(e1) ≥ . . . ≥w(en), T ′ = {ei1 , . . . , eik} eine optimale Losung.
Annahme:Die vom Greedy-Algorithmus gefundene Losung T = {ej1 , . . . , ejk
} ware nicht optimal,also w(T ) < w(T ′). Dann gilt w(ejl
) < w(eil) fur irgendein l. Betrachte das derartigeminimale l. Sei A = {ej1 , . . . ejl−1
}, B = {ei1 , . . . , eil}. Die Austauschseigenschaft impliziert,dass es eir ∈ B gibt mit A′ = A ∪ {ejr} ⊆ U . Wegen der Minimalitat von l gilt aberw(eir) ≥ w(eil) > w(ejl
). Somit hatte der Greedy-Algorithmus vor ejlbereits eir gewahlt.
Somit ergibt sich ein Widerspruch zur Annahme.
′′ ⇒ ′′ Annahme: Die Austauscheigenschaft gelte nicht, d.h. fur bestimmte A, B ⊆ U, |A| <|B| gelten fur alle e ∈ B, dass A ∪ {e} 6∈ U ist. Sei |B| = r.Betrachte folgende Gewichtsfunktion:
w(e) =
r + 1 e ∈ Ar e ∈ B\A0 sonst
Der Greedy-Algorithmus wird dann zuerst alle e ∈ A wahlen. Von den folgenden e ∈ B\Akann er dann keines wahlen, weil die A ∪ {e} fur e ∈ B nicht in A sind.Demzufolge hat die Greedy-Losung Gewicht (r + 1) · |A| ≤ (r + 1)(r − 1) = r2 − 1. Einemaximale Menge T , die B enthalt, ist aber besser: w(T ) ≥ w(B) = r2. Also ist der Greedy-Algorithmus nicht optimal, falls die Austauscheigenschaft nicht gilt.
2
14. Oktober 2008, Version 0.6

54
6 Berechnung des Medians, k-Selektion
Wir haben beim Quicksort die Bedeutung des Medians kennengelernt. Wenn wir ihn alsSplit-Element benutzen, erreichen wir die best case Laufzeit. Wir werden ihn nun effizientberechnen, und allgemeiner ein effizientes Verfahren fur die k-Selektion vorfuhren. (Daherdarf k auch von n abhangen, also etwa, wie beim Median,
⌈n2
⌉sein.)
Selektion(k ; a1, ..., an)(*berechnet k-t kleinstes Element von a1, ..., an *)
Falls n < 50 −→ MergeSort
sonst:
(1) Zerlege a1, ..., an in⌈
n5
⌉Gruppen der Große 5
(bzw. eventuell eine kleinere Gruppe)
(2) Berechne in jeder Gruppe den Median.
−→ Wir kennen die Gruppenmediane b1, ..., bdn5 e und fur jedes i
die Elemente der i-ten Gruppe, die kleiner bzw. großer als bi
sind.
(3) Selektion(⌈
n5
⌉/2 ; b1, ..., bdn
5 e) (Median der Mediane berechnen)
Ergebnis sei a.
(4) Bestimme den Rang r von a, und
D1 := {ai, ai < a}, D2 := {ai, ai > a}.(5) Falls k < r: Selektion(k, D1),
falls k > r: Selektion(k − r, D2).
Korrektheit: O.k.# Vergleiche:
Fur n < 50: n log(n) (vgl. MergeSort)n ≥ 50: Sei T (n) die maximale Zeit fur Inputs aus
{(k; a1, ..., an); k ∈ {1, ..., n}, ai ∈ IN}.
# Vergleiche fur:(1): 0(2):
⌈n5
⌉· 7 (7 Vergleiche reichen, um den Medi-
an von 5 Elementen zu berechnen →Ubung)
(3): T (⌈
n5
⌉)
(4): n− 1(5): max{T (|D1|), T (|D2|)}
Frage: Wie groß sind D1, D2?
14. Oktober 2008, Version 0.6

55
ahalle b ∈ E1
sind ≤ a
alle b ∈ E2sind ≥ a
ccccc
E1cccccE2
cccc
bi
?Gruppe i
ccccc
cccc
ccccc
ccccc���9
(l − 1) Gruppen-mediane ≤ a
��:
⌈n5
⌉− l Gruppen-
mediane > a
Die Menge E1 (siehe Bild) enthalt nur Elemente ≤ a (sie sind ≤ einem Gruppenmedianbi, dieser ist ≤ a), und |E1| ≥ 1
2
⌈n5
⌉· 3 (≈ 3
10n).
Analog: E2 enthalt nur Elemente ≥ a, und |E2| ≥ 12
⌈n5
⌉· 3 (≈ 3
10n).
Fur n ≥ 50 sind |E1|, |E2| ≥ 14n.
Also: 14n ≤ r ≤ 3
4n, i.e.
|D1| = r − 1 ≤ 3
4n
|D2| = n− r ≤ n− 1
4n ≤ 3
4n
→ Zeit fur (5) ≤ T (3
4n)
Insgesamt: T (n) ≤ T (n5) + T (3
4n) + 2.4 · n
Behauptung: T (n) ≤ 48nBeweis: Induktion nach n
n ≤ 50 : T (n) ≤ n log(n) ≤ 48n
n > 50 : T (n) ≤ T (n5) + T (3
4n) + 2.4n
Ind.Vor.≤
(48n · 1
5
)+(48n · 3
4
)+ 2.4n
≤ 9.6n + 36n + 2.4n
= 48n ≤ 48n.
Satz 6.1 k-Selektion kann fur beliebige (auch von n abhangige) Werte fur k mit 48n Ver-gleichen durchgefuhrt werden.
Korollar 6.2 Mit der Wahl des Medians als ausgewahltes Element erhalt Quicksort eineworst-case O(n log(n)) Laufzeit.
(Die Konstante ist allerdings sehr groß, diese Variante des Quicksort wird somit fur diePraxis sehr schlecht.)
14. Oktober 2008, Version 0.6

56
7 Randomisierte Algorithmen
Randomisierte (oder probabilistische) Algorithmen haben die Eigenschaft, dass es als Ope-ration erlaubt ist, eine zufallige Zahl aus {0, . . . ,m} zu erzeugen. (Random(m) liefert einesolche Zahl.) In der Praxis werden hierfur Pseudozufallszahlengeneratoren genutzt, die aufverschiedenste Art realisiert werden konnen, allerdings nicht im strengen Sinne “zufalligeZahlen” (was ist das uberhaupt?!?) erzeugen. Wir werden im folgenden dieses Problemignorieren, und davon ausgehen, dass Random(m) zufallig, gleichverteilt eine Zahl aus{0, . . . ,m − 1} auswahlt, und dass verschiedene Aufrufe von Random stochastisch un-abhangige Ergebnisse liefern.
Ein einfaches Spiel
Gegeben: n geschlossene Dosen, in k ≤ n von ihnen ist eine Praline.Ziel: Finde eine Praline, aber offne so wenige Dosen wie moglich.
Ein deterministischer Algorithmus wird irgendeine Reihenfolge der Dosen festlegen, undsie in dieser Reihenfolge offnen.Laufzeit:
Best Case: 1
Worst Case: n− k + 1
RandomisierterAlgorithmus()(1) repeat(2) I ← Random(n)(3) offne Dose I(4) until “gefunden”
Laufzeit:
Worst Case: ∞
Worst Case tritt mit Wahrscheinlichkeit 0 auf!
Erwartete Laufzeit:
Pr(genau l Fehlversuche) =
(n− k
n
)l
· kn
14. Oktober 2008, Version 0.6

57
E(#Fehlversuche) =∞∑l=0
Pr(genau l Fehlversuche) · l
=∞∑l=1
(n− k
n
)l
· kn· l
=k
n· n− k
n
∞∑l=1
(n− k
n
)l−1
· l
(∗)=
k
n· n− k
n·(
1− n− k
n
)−2
=n− k
n·(
k
n
)−1
=n− k
k
(*) gilt: Da fur |x| < 1 gilt:∞∑l=1
xl−1 · l = (1− x)−2
Erwartete Zahl von Fehlversuchen: n−kk
Beispiel 7.1 Sei k = ε · n fur eine Konstante ε > 0. Sei δ > 0 gegeben.
Pr(≥ l Fehlversuche) =(
kn
)l= εl < δ fur l > log1/ε(1/δ).
Zahlenbeispiele:
ε = 12, δ = 2−20(≈ 1
1Mio) Dann reichen ≈ 20 Versuche mit Wahrscheinlichkeit 1− 1
1Mioaus.
Eine einfache Anwendung:
Eingabe: Ein Programm Q mit Eingaben aus Z, R oder Q. Wir wissen: Q wertet ein (unsnicht bekanntes!) Polynom p : R→ R aus. Wir wissen: p hat Grad ≤ d.Ausgabe: Wahrheitswert von “p ≡ 0”?Test(Q)(1) index← 0(2) while index < l(3) Wahle zufalliges x ∈ {1, . . . , 2d}.(4) Starte Q mit Eingabe x.(5) if Q berechnet Wert 6= 0 then return p 6≡ 0(6) index← index + 1(7) return p ≡ 0
Aufwand: O(l) + l· “Zeit fur Q” (wir sagen: l Runden)Was berechnet Test?Falls p ≡ 0 ist, gibt es die korrekte Losung aus.
14. Oktober 2008, Version 0.6

7.1 Grundbegriffe zu probabilistischen Algorithmen 58
Behauptung 7.2 Falls p 6≡ 0 ist, liefert Test die falsche Antwort nur mit Wahrschein-
lichkeit hochstens(
12
)l.
Beweis: Falls p 6≡ 0 ist, hat p hochstens d Nullstellen. Da wir x ∈ {1, . . . , 2d} zufalligwahlen, erwischen wir mit obigem Spiel l Dosen (die l Versuche) und k = ε · n Pralinen(die Versuche, in denen wir eine Nicht-Nullstelle finden) fur ε ≤ 1
2. 2
Wir haben also einen Algorithmus mit einer festen Laufzeit (bei fester Eingabe) vorliegen,der allerdings mit kleiner Wahrscheinlichkeit eine falsche Ausgabe erzeugt, ein sogenannterMonte Carlo Algorithmus.
Eine Variante:
Eingabe: Ein Algorithmus Q, der ein Polynom p 6≡ 0 vom Grad d berechnet.Ausgabe: x mit p(x) 6= 0Las-Vegas-Sucher()(1) repeat(2) wahle x zufallig aus {1, . . . , 2d}(3) if p(x) 6= 0 then x gefunden(4) until x gefunden(5) return x
Dieser Algorithmus liefert immer das korrekte Ergebnis, falls er anhalt. Allerdings ist nun
die Laufzeit T eine Zufallsvariable. Pr(T > l) = Pr(≥ l Fehlversuche) ≤(
12
)lErwartete Laufzeit: E(T ) = 2Algorithmen, die immer (vorausgesetzt sie halten) ein korrektes Ergebnis liefern, derenLaufzeit aber eine Zufallsvariable ist, heißen Las Vegas Algorithmen.(Ein weiteres bekanntes Beispiel fur einen Las Vegas Algorithmus ist der randomisierteQuicksort Algorithmus.)
7.1 Grundbegriffe zu probabilistischen Algorithmen
Deterministische Algorithmen zeichnen sich dadurch aus, dass Algorithmus und Ein-gabe die Rechnung (und damit ihre Lange und ihre Ausgabe) eindeutig festlegen.Nichtdeterministische Algorithmen erlauben dagegen bei fester Eingabe verschiedeneRechnungen mit verschiedenen Langen und verschiedenen Ergebnissen. Wenn wir uns vor-stellen, dass wir nichtdeterministische Algorithmen so abarbeiten, dass wir jeweils zufalligeine der moglichen Nachfolgekonfigurationen auswahlen, haben wir einen randomisiertenAlgorithmus.Ein randomisierter Algorithmus A ist ein Algorithmus, in dem wir zusatzlich erlau-ben, dass in einem Schritt von einer (im Algorithmus definierten) Menge M ein Elementzufallig, gleichverteilt erzeugt wird.Beispiel: M{0, 1}, M = {0, . . . , k}, M = (0, 1).
14. Oktober 2008, Version 0.6

7.1 Grundbegriffe zu probabilistischen Algorithmen 59
Im Falle von M = {0, 1} sprechen wir haufig von “Munzwurf” (coin flip). Ein sol-cher Algorithmus kann nun abhangig von den Ergebnissen der Zufallschritte verschiede-ne Rechnungen ausfuhren. Jede Rechnung R taucht mit einer Wahrscheinlichkeit Pr(R)auf. Pr(R) ist dabei wie folgt definiert. Falls auf der Rechnung die Zufallsergebnissea1 ∈M1, a2 ∈M2, as ∈Ms auftauchen, ist Pr(R) = 1
|M1| · . . . ·1
|Ms| .
Klar: Falls C die Menge aller Rechnungen von A gestartet mit x ist, ist∑
R∈C Pr(R) = 1,d.h. wir haben eine Wahrscheinlichkeitsverteilung auf den Rechnungen aus C. Da dieRechnungen verschieden lang sind, haben wir kein deterministisches Maß fur die Laufzeit,wir konnen aber die erwartete Laufzeit angeben. |R| bezeichne die Lange der Rechnung R.Erwartete Laufzeit von A gestartet mit x :ETA(x)=∑
R∈C
Pr(R) · |R|
Erwartete Laufzeit im worst case:ETA(n) = maxx,|x|≤nETA(x)Zuverlassigkeit der Laufzeitschranke:Wir wollen wissen: Wie sicher ist es, dass die Laufzeit T nicht wesentlich uber der Erwar-tungszeit liegt?Mogliche Maße:
• Varianz angeben
• Pr(TA(x) ≤ (1 + d)ETA(x)) ist klein. (siehe spater)
Was berechnet A?
1. Las Vegas Algorithmen:Jede endliche Rechnung von A gestartet mit x liefert das gleiche Ergebnis f(x), d.h.A macht keine Fehler. (Die Laufzeit ist weiterhin eine Zufallsvariable)
2. Monte Carlo Algorithmen:A darf Fehler machen. Wir mussen naturlich nun Einschrankungen an die Fehlermachen: A berechnet f mit Fehler ε, falls fur jede Eingabe x gilt:
Pr(A berechnet nicht f(x)) < ε
Fur Spracherkennung, d.h. f(x) ∈ {0, 1}, (Sprache L = f−1(1)) unterscheiden wirzwei Typen:Einseitiger Fehlerx ∈ L⇒ Pr(A sagt “x 6∈ L”) < εx 6∈ L⇒ A berechnet immer richtige Losung(Fur ε = 1 haben wir nichtdeterministische Algorithmen definiert)Zweiseitiger Fehler:x ∈ L⇒ Pr(A sagt “x 6∈ L”) < εx 6∈ L⇒ Pr(A sagt “x ∈ L”) < ε.
14. Oktober 2008, Version 0.6

7.1 Grundbegriffe zu probabilistischen Algorithmen 60
Nun macht es keinen Sinn, ε ≥ 12
zu erlauben, da dann immer der triviale Algorithmus“Werfe Munze, gebe Ergebnis des Munzwurfs aus” funktioniert.Der Einfachheit halber (und oBdA, s.u.) gehen wir immer von ε ≤ 1
4aus.
3. AmplifikationWie robust sind randomisierte Algorithmen gegenuber
• Wechsel von erwarteter Laufzeit zu worst case Laufzeit und
• Veranderung der Fehlerwahrscheinlichkeit?
worst case ↔ erwartete Laufzeit
Fur Las Vegas Algorithmen sind diese Maße deutlich unterschiedlich, sonst konnten wir siedeterministisch machen. Fur Monte Carlo Algorithmen sieht das anders aus:
Lemma 7.3 Sei A ein Monte Carlo Algorithmus fur die Sprache L mit Fehlerwahrschein-lichkeit ε und ETA(n) = t(n). Sei δ > 0 so, dass ε+δ < 1 bzw. < 1
2bei zweiseitigem Fehler.
Dann gibt es einen Monte Carlo Algorithmus A∗ fur L mit Fehlerwahrscheinlichkeit ε + δund worst case Laufzeit 1
δt(n).
Beweis: A∗ entsteht aus A, indem wir alle Rechnungen der Lange > 1δ
t(n) nach 1δ
t(n)Schritten abbrechen und irgendetwas ausgeben. A∗ hat naturlich worst case Laufzeit ≤1δt(n). Was passiert mit der Fehlerwahrscheinlichkeit?
Die abgeschnittenen Rechnungen zusammen haben nur Wahrscheinlichkeit ≤ δ, denn sonstware die erwartete Zeit > δ ·
(1δ
)t(n) = t(n). Im schlimmsten Fall waren es lauter korrekte
Rechnungen, die durch das Abschneiden fehlerhaft wurden. Aber auch dann erhohen siedie Fehlerwahrscheinlichkeit um hochstens δ. 2
Anderung der Fehlerwahrscheinlichkeit
Was passiert mit der Laufzeit von Monte Carlo Algorithmen, wenn wir die Fehlerwahr-scheinlichkeit ε verandern?Bei einseitigem Fehler ist das sehr einfach zu analysieren: Wir lassen einen solchen Al-gorithmus mit Fehlerwahrscheinlichkeit ε bei Eingabe x l-mal unabhangig von einanderlaufen, und verwerfen x nur dann, wenn es in allen Versuchen verworfen wird.
Lemma 7.4 Sei A ein Monte Carlo Algorithmus mit worst case Laufzeit t(n) und ein-seitiger Fehlerwahrscheinlichkeit ε. Dann hat der oben beschriebene Algorithmus A∗ worstcase Laufzeit l · t(n) + O(l) und Fehlerwahrscheinlichkeit εl.
Beweis: A∗ macht sicherlich genau wie A keine Fehler, falls x 6∈ L. Sonst verwirft er nur,wenn jeder der l unabhangigen Versuche einen Fehler macht. Dieses geschieht pro Versuchmit Wahrscheinlichkeit ε, als l-mal nur mit Wahrscheinlichkeit εl. 2
14. Oktober 2008, Version 0.6

7.1 Grundbegriffe zu probabilistischen Algorithmen 61
Beispiel 7.5 Falls A Fehlerwahrscheinlichkeit 12
und polynomielle Laufzeit nr hat, konnenwir die Fehlerwahrscheinlichkeit auf 1
2nl , l beliebig, reduzieren und noch polynomielle Lauf-
zeit O(nr+l) behalten.( 1
2n ≈ 11Mio
fur n = 20 !!!)
Konnen wir fur 2-seitigen Fehler eine ahnlichen Trick machen? Ja!Wir lassen den Algorithmus A mit worst case Laufzeit t(n) und Fehlerwahrscheinlichkeitε < 1
4wieder l mal laufen, und akzeptieren, falls mehr als die Halfte der Versuche akzep-
tieren (majority vote).
Lemma 7.6 A sei Monte Carlo Algorithmus fur L mit worst case Laufzeit t(n) und 2-seitiger Fehlerwahrscheinlichkeit ε ≤ 1
4. Dann hat obiger Algorithmus A∗ fur L die Laufzeit
l · t(n) + O(l) und Fehlerwahrscheinlichkeit (4ε)l/2.
Beweis: Pr(A∗ ist bei Eingabe x ≥ l/2 mal fehlerhaft) ≤(
ll/2
)· εl/2 ≤ 2lεl/2 = (4ε)l/2 2
Beispiel 7.7 Wir erzielen einen ahnlichen Effekt bei polynomiellen Algorithmen wie schonvorher fur einseitige Fehler gezeigt.
7.1.1 Randomisierte Komplexitatsklassen
RP = {L : ∃ polynomiellen Monte Carlo Algorithmus fur L mit einseitigem Fehler < 12}.
(12
konnte auch durch 12poly(n) ersetzt werden, siehe oben.)
BPP = {L : ∃ polynomiellen Monte Carlo Algorithmus fur L mit zweiseitigem Fehler< 1
4}.
(14
ist das gleiche wie 12poly(n) .)
PP = {L : ∃ polynomiellen Monte Carlo Algorithmus fur L mit zweiseitigem Fehler < 12}.
ZPP = {L : Es gibt polynomiellen Las Vegas Algorithmus fur L}.ZPP, RP und BPP sind von praktischem Interesse, weil sie Algorithmen mit sehr kleinen,vernachlassigbaren Fehlerwahrscheinlichkeiten behandeln.
Spannende offene Probleme in der Komplexitatstheorie
(i) RP = coRP ??
(ii) RP ⊆ NP ∩ coNP? (wurde aus (i) folgen, da coRP ⊆ coNP )
(iii) BPP ⊆ NP ?
Eine einfache Charakterisierung fur ZPP :Es gilt ZPP = RP ∩ coRP(Beweis: Ubung)
14. Oktober 2008, Version 0.6

7.2 Einige grundlegende randomisierte Algorithmen 62
7.2 Einige grundlegende randomisierte Algorithmen
7.2.1 Verifikation von Polynom-Identitaten und Anwendungen
Wir haben schon am Eingangsbeispiel gesehen, wie man einfach testen kann, ob ein Po-lynom p : Z → Z identisch Null ist (bzw.: ob zwei Polynome p, q : Z → Z identisch sind;teste p − q ≡ 0), indem man p nur an wenigen, zufallig gewahlten Stellen auswertet. Wirzeigen nun ein ahnliches Resultat fur Polynome in mehreren Variablen.
Satz 7.8 (Schwarz-Zippel)Sei F ein Korper, p ∈ F(x1, . . . , xn) ein Polynom vom Grad d, S ⊆ F eine endliche Menge.Falls r1, . . . , rn ∈ S unabhangig, zufallig, gewahlt sind, gilt:
Pr(p(r1, . . . , rn) = 0 | p 6≡ 0) ≤ d
|S|.
Beweis: Induktion nach n.n = 1: Dann hat p hochstens d Nullstellen, schlimmstenfalls alle in S. Somit wird Nullstellemit Wahrscheinlichkeit ≤ d
|S| gezogen.
n > 1 : Schreibe p : Fn → F als p(x1, . . . , xn) =d∑
i=0
xi1 · pi(x2, . . . , xn).
Dann hat pi nur n− 1 Variablen und Grad ≤ d− i. Sei k maximal mit pk 6≡ 0. (k existiert,da p 6≡ 0). Fur zufallige r2, . . . , rn ∈ S gilt nach Induktionsvoraussetzung:(i) Pr(pk(r2, . . . , rn) = 0) ≤ d−k
|S| .
Sei nun p 6≡ 0 und k, pk wie oben. Betrachte nun festes r2, . . . , rn mit pk(r2, . . . , rn) 6= 0.Das Polynom q(x1) = p(x1, r2, . . . , rn) hat Grad k und eine Variable. Bei zufalliger Wahlvon r1 ∈ S ist also Pr(q(r1) = 0) ≤ k
|S| .Insbesondere folgt:(ii) Pr(p(r1, . . . , rn) = 0 | pk(r2, . . . , rn) 6= 0) ≤ k
|S| .
Beachte: Fur Ereignisse E1, E2 gilt Pr(E1) ≤ Pr(E1|ε2) + Pr(E2)).Also gilt der Satz wegen (i) und (ii). 2
7.2.2 Perfekte Matchings in Bipartite Graphen
G = (U, V,E) ist ein bipartiter Graph mit Knotenmenge U ∪ V (U ∩ V = ∅), falls alleKanten zwischen U und V verlaufen. Ein Matching in G ist ein Subgraph vom Grad 1. Ineinem perfekten Matching ist jeder Knoten inzident zu einer Matchingkante.Frage: Wie entscheiden wir, ob ein bipartiter Graph ein perfektes Matching enthalt?Variante 1: Flußalgorithmen → Zeit O(m
√n).
Variante 2:
Satz 7.9 (Edmonds)A sei die n× n Matrix, die aus G = (U, V,E) entsteht durch
14. Oktober 2008, Version 0.6

7.2 Einige grundlegende randomisierte Algorithmen 63
Aij =
{xij (ui, vj) ∈ E
0 sonst.
Betrachte Polynom Q(x1,1, . . . , xn,n) := det(A).G hat ein perfektes Matching ⇔ Q 6≡ 0.
Beweis: det(A) =∑
Π∈Sn
sgn(Π) · A1,Π(1) · . . . · An,Π(n)
Jedes perfekte Matching konnen wir durch eine Permutation Π ∈ Sn beschreiben, es enthaltdie Kanten (ui, vΠ(i)), i = 1, . . . , n. Genau die Π ∈ Sn die ein Matching beschreiben, leisteneinen Beitrag zu obigem Polynom, d.h.
det(A) =∑Π∈Sn
Π Matching
sgn(Π) · A1,Π(1) · . . . · An,Π(n)
Falls mindestens ein Matching existiert, ist mindestens ein Summand ungleich Null. Dajeder Sumand durch ein anderes Produkt von Variablen bestimmt ist, ist dann Q 6≡ 0
2
Q ist Polynom von Grad n. Falls wir also zufallig r1, . . . , rn ∈ {1, . . . , k · n} wahlen undtesten, ob Q(r1, . . . , rn) = 0 ist, gilt: Pr(Q(r1, . . . , rn) = 0 | q 6≡ 0) ≤ 1
k.
Satz 7.10 Obiger Monte Carlo Algorithmus mit einseitigem Fehler < 1k
entscheidet, obein bipartiter Graph ein perfektes Matching enthalt.
Wir bemerken, dass dieser Algorithmus zu den auf Flußtechniken basierenden nicht kon-kurenzfahig ist, da er eine Determinante ausrechnen muß (Zeit = Zeit fur Matrixmultipli-kation = n2.376 (Coppersmith/Winograd). Der deterministische Algorithmus benotigt zwarfur dichte Graphen Zeit O(n2.5), ist in der Praxis aber viel schneller. Der randomisierteAlgorithmus ist jedoch einfach parallelisierbar.
7.2.3 Perfekte Matchings in beliebigen Graphen
G = (V, E) sei nun beliebiger ungerichteter Graph V = {1, . . . , n}.
Satz 7.11 (Tutte)Betrachte zu G folgende n×n Matrix A. Zu jeder Kante e = (i, j), i < j, sei eine Variablexi,j assoziert. Die Matrix A hat dann Eintrage:
Ai,j =
0 {i, j} 6∈ E
xi,j i < j, {i, j} ∈ E
−xj,i i > j, {i, j} ∈ E
G hat perfektes Matching ⇔ detA 6≡ O.
14. Oktober 2008, Version 0.6

7.2 Einige grundlegende randomisierte Algorithmen 64
Beweis: Ubung. 2
Analog zu Satz 7.3 erhalten wir:
Satz 7.12 Falls wir ,,det(A(r1, . . . , rn)) = 0” fur zufallige r, . . . , rn ∈ {1, . . . , k ·n} testen,erhalten wir einen Monte Carlo Algorithmus mit einseitigem Fehler < 1
k, der entscheidet,
ob G ein perfektes Matching enthalt.
7.2.4 Effiziente Tests fur “p(x) = 0”
Obige Verfahren basiern auf der Auswertung von Straight Line Programmen, die Polynomebeschreiben. Wir haben bisher hierfur als Laufzeit die Zahl der auszufuhrenden Operatio-nen betrachtet. Da diese Operationen aber Multiplikationen enthalten, konnen wir in kurzerZeit sehr lange Operanden erhalten. Z.B. konnen wir 22t
in t Schritten berechnen (t-fachiteriertes Quadrieren).
Bemerkung 7.13 Sei A ∈Mn,n({−s, . . . , s}). Dann gilt |det(A)| ≤ (√
(n) · s)n.
In unserem obigen Verfahren haben wir Determinaten fur Eintrage ≈ k ·n ausgewertet, alsokonnen (tatsachlich) Werte der Große nΘ(n), also Zahlen mit binarer Lange Θ(n log n) als(Zwischen)- Ergebnis auftauchen. Wir werden sehen, daß es auch reicht, mit nur O(log(n))langen (Zwischen-) Ergebnissen zu arbeiten.
Lemma 7.14 Die Zahl der verschiedenen Primteiler einer Zahl k ist hochstens log(k).
Beweis: Primteiler sind ≥ 2, das Produkt der verschiedenen Primteiler von k ist ≤ k. 2
Lemma 7.15 Sei k > 0, p prim, k nicht Vielfaches von p. Dann ist k mod p 6= 0.
Satz 7.16 Sei S ein Straight Line Programm, in dem nur Konstanten a, |a| ≤ k, auftau-chen, der Lange t. S berechne Polynom Q. Sei x ∈ Zn und |x|∞ ≤ l.Sei p zufallig gewahlte Primzahl. p ≤ R′ = s · (2t log(k · l)).Dann gilt:Falls Q(x) 6= 0 ist, ist Q(x) mod p 6= 0 mit Wahrscheinlichkeit ≥ (1− 1
s).
Beweis: Es gilt: |Q(x)| ≤ k2t ·l2t. Somit hat |Q(x)| hochstens R = log(k2t ·l2t
) = 2t ·log(k ·l)viele Primteiler. In {1, . . . , R′) sind aber mindestens s · R viele Primzahlen. Also folgt:Mit Wahrscheinlichkeit ≤ 1
swird Primteiler p von Q(x) ausgewahlt. Deshalb wird mit
Wahrscheinlichkeit ≤ 1s
das Ergebnis Q(x) mod p = 0 berechnet. 2
Dieser Algorithmus arbeitet mit Operanden der Lange ≈ t, anstatt 2t!! (Auswertung derSLP nutzt nun Arithmetik im Korper Zp.)Speziell fur Determinatenberechnung reicht das nicht. Aber da wissen wir:Q(x) ≤ (
√ns)n, also R′ ≈ log(s(
√ns)n) ≈ n log n reicht. Also haben Operanden Lange
hochstens log(R′) ≈ log(n).
14. Oktober 2008, Version 0.6

7.2 Einige grundlegende randomisierte Algorithmen 65
7.2.5 Quicksort
Input S, |S| = n
1. Wahle zufalliges x ∈ S (Splitelement)
2. Vergleiche jedes y ∈ S mit x, bilde S1 = {y ∈ S, y < x}, S2 = {y ∈ S, y > x}.
3. Sortiere Rekursiv S1 und S2.Ausgabe: Sortiertes S1, x, sortiertes S2.
Erwartete Zahl von Vergleichen?Beachte: Zwei Elemente x, y werden hochstens einmal verglichen, namlich wenn eins vonihnen als Splitelement genutzt wird, und das andere in der zu splittenden Menge ist.S(i) sei das Element mit Rang i aus S. Fur i < j sei Xij die Zufallsvariable
Xij =
{1 S(i)und S(j) werden verglichen
0 sonst
Erwartete Zahl von Vergleichen:
E(n∑
i=1
∑j>i
Xij) =∑∑
E(Xij).
Sei pij die Wahrscheinlichkeit, dass S(i) und S(j) verglichen werden, d.h. pij = Pr(Xij = 1)
⇒ E(Xij) = pij · 1 + (1− pij) · 0 = pij
Wir mussen pij bestimmen. Betrachte Rechnung von Quicksort bis eine Partition
S ′ = {S(a), . . . , S(b)} a ≤ i, b ≥ j
erreicht ist, und im nachsten Schritt ein Split-Element S(r) mit i ≤ r ≤ j gewahlt wird(also im nachsten Schritt S(i) und S(j) separiert werden).Wann wird S(i) mit S(j) verglichen?Kann nur in diesem Schritt passieren, und zwar genau dann, wenn r = i oder r = j ist.
14. Oktober 2008, Version 0.6

7.2 Einige grundlegende randomisierte Algorithmen 66
Somit gilt:
pij =2
j − i + 1
Also folgt :E(# Vergleiche ) =n−1∑i=1
∑j>i
2
j − i + 1
=n−1∑i=1
n−i+1∑k=2
2
k
≤ 2n−1∑i=1
n∑k=2
1
k
= 2(n− 1) · (Hn − 1)
≤ 2(n− 1) ln(n)
Hn – Harmonische Zahl (Hn ≤ ln(n) + 1)
Satz 7.17 Quicksort benotigt eine erwartete Anzahl von ≤ 2(n− 1)ln(n) viele Vergleiche.
Ein anderer Beweis: Sei T (n) die erwartete Anzahl Vergleiche von n Zahlen zu sortieren.Dann gilt: T (1) = 0, und fur n > 1:
T (n) =1
n
n∑r=1
[T (r − 1) + T (n− r)] + (n− 1)
Wir erhalten durch Losen der Rekursion das gleiche Ergebnis. 2
14. Oktober 2008, Version 0.6

67
8 Ein randomisiertes Worterbuch: Skip-Listen
Der abstrakte Datentyp ,,Worterbuch” verwaltet eine Teilmenge S einer geordneten Menge(z.B. N) so, dass effizient die Operationen Search, Delete und Insert unterstutzt werden.
Aus dem Grundstudium sind weitere Datenstrukturen wie rot-schwarz Baume, AVL-Baume oder 2-3-Baume bekannt, die jeweils O(n) Platz und worst case Zeit O(log(n))pro Operation benotigen (n = |S|). Die Datenstrukturen werden in der Praxis haufig be-nutzt, ihre Implementierung ist jedoch sehr aufwendig.
Wir stellen nun eine relativ neue, randomisierte Datenstruktur fur Worterbucher vor, diesehr einfach ist, und erwartete Laufzeit O(log n) pro Operation aufweist. Sie hat in denletzten Jahren begonnen, auch in der Praxis immer haufiger eingesetzt zu werden, da siesich auch dort als sehr effizient erweist, und sehr einfach zu implementieren ist.
Eine Skipliste fur Elemente X = {x1 < ... < xn} besteht aus linearen Listen L0, L1, ...,Lh. Jede Liste verwaltet eine Teilmenge Xi von X in aufsteigend sortierter Reihenfolge.
Welches Element in welchen Listen vertreten ist, wird durch die Hohen h(xi) ≥ 1 derElemente bestimmt: xi ist in den Listen L0, ..., Lh(xi)−1 gespeichert.
Insbesondere gilt also: X0 = X, X0 ⊇ X1 ⊇ ... ⊇ Xh.
Beispiel:
−∞
L0
L1
L2
L3
-
-5 -
-
-
8- 10 -
-
-
14- 16 -
-
-
-
21
-
-25
-
-
-
-
∞
Eine Skipliste fur X = {5, 8, 10, 14, 16, 21, 25} mit h = 4, h(5) = 2, h(8) = 3, h(10) = 1,h(14) = 3, h(16) = 1, h(21) = 4, h(25) = 2.
Search(x):
i← h− 1, Left← −∞,”gefunden“ = false
Solange i ≥ 0 und”nicht gefunden“:
Suche in Li, startend in Left, bis zuerst ein
y ≥ x gefunden ist.
Falls x = y, dann”gefunden“ = true; gebe x aus.
sonst: Left→ Prev(y); i← i− 1./* Falls x ∈ X gilt, ist x ≥ Left. */
Falls”gefunden“ = false, gebe Fehlermeldung aus.
14. Oktober 2008, Version 0.6

68
Wegen des Kommentars ist die Suche offensichtlich korrekt.Beispiele:
Fur Search(10) wird folgendes durchlaufen:In L3: −∞, 21In L2: −∞, 8, 14In L1: 8, 14In L0: 8, 10
Fur Search(9) wurden die gleichen Elemente durchlaufen, allerdings dann eine Fehlermel-dung ausgegeben.Fur alle x ∈ (5, 8) werden genau die gleichen Elemente durchlaufen, danach wird dieFehlermeldung ausgegeben.Insert(x):
Wir mussen entscheiden, in welche Listen L0, ..., Lh(x)−1 x eingefugt wird, d.h. wir mussenh(x) berechnen.Hierfur benutzen wir den Zufallszahlengenerator: Wir simulieren
”Munzwurfe“, d.h. benut-
zen einen Zufallszahlengenerator, der uns (Folgen von unabhangigen) Werte(n) aus {0, 1}liefert. Dabei liefert er jeweils eine 0 mit Wahrscheinlichkeit 1
2. Wir bestimmen h(x) als die
Anzahl der Munzwurfe, bis das erste Mal eine 1 erscheint.Die Wahrscheinlichkeit fur Hohe h ist also gleich der Wahrscheinlichkeit, dass zuerst h− 1mal 0, und dann eine 1 auftritt. Also ist die Wahrscheinlichkeit (1
2)h. Damit gilt fur die
erwartete Hohe E(h):
E(h) = P (h = 1) · 1 + P (h = 2) · 2 + ...
=∞∑
h=1
h ·(
1
2
)h
= 2
Wir fugen nun x ein, indem wir zuerst Search(x) durchfuhren und uns in den ListenLh(x)−1, ..., L0 die Position speichern, wo x hingehort. Falls x bereits in X ist, aktualisierenwir nur sein Datenfeld. Sonst fugen wir x in Lh(x)−1, ..., L0 ein. Da wir uns die Positionengemerkt haben, kostet Einfugen pro Liste konstante Zeit. Also benotigt Insert(x) ZeitO(Zeit fur Search(x)).Delete(x):
Wir starten wieder mit Search(x). Falls wir x in Lj finden, ist j = h(x)−1 und wir streichenx in Lh(x)−1, ..., L0. Da wir mit der Position von x in Lh(x)−1 auch seine Positionen in denanderen Listen kennen, sind die Kosten pro Streichen aus einer linearen Liste konstant,somit sind die Gesamtkosten O((Zeit fur Search(x)) + h(x)).Beachte: Diese Kosten sind hochstens die Kosten fur Search(z) fur ein z ∈ (xi, xi+1), wobeix = xi ist. (Also ist z nicht in X, und sein Suchweg ist zuerst der gleiche wie der fur x,geht dann aber bis zu L0 herunter.)Somit reicht es, die Laufzeitanalyse fur Search(z) fur ein z /∈ X durchzufuhren.
14. Oktober 2008, Version 0.6

69
Lemma 8.1 a) Die erwartete Hohe H(n) einer Skip-Liste fur n Elemente istO(log(n)).
b) Die erwartete Zahl von Zeigern in einer Skip-Liste mit n Elementen ist hochstens2n + O(log(n)).
zu a) In X0 sind alle Elemente. In X1 ist jedes Element aus X0 mit Wahrscheinlichkeit 12,
also erwarten wir hier 12n Elemente. In X2 ist jedes Element aus X1 mit Wahrscheinlichkeit
12, also erwarten wir hier 1
2·(
12n)
= 14n Elemente.
Allgemein: In Li erwarten wir 12i ·n Elemente. In Lblog(n)c+2 erwarten wir damit weniger als
1, also null Elemente. Also ist H(n) ≤ blog(n)c+ 1.zu b) Wir haben schon gesehen, dass die erwartete Hohe eines Elements 2 ist. Somit ist dieerwartete Zahl von Zeigern, die aus Elementen heraus zeigen ebenfalls 2. Je ein weitererZeiger ist fur jede der O(log(n)) Listen am Anfang notig.
Satz 8.2 Eine Skip-Liste fur n Elemente hat erwartete Große O(n) und erwartete Zeitpro Operation O(log(n)).
Beweis: Wie oben gesagt, reicht es eine erfolglose Suche nach einem z /∈ X zu analysieren.Wir nutzen eine sehr elegante Beweismethode, der Ruckwartsanalyse. D.h. wir schauenuns die Suche ruckwarts an:Am Ende ist in L0 die Lucke xi, xi+1 gefunden, in die z hineingehort. Wie viele Elementehaben wir in L0 dafur anschauen mussen? In L1 haben wir zwei aufeinander folgendeElemente a und b gefunden, mit a < z < b.Naturlich sind a, b auch in L0, und wir suchen in L0 hochstens alle Elemente y ∈ X0 mita ≤ y ≤ b.Beachte: Jedes solche y ist mit Wahrscheinlichkeit 1
2auch in L1! Somit erwarten wir, dass
in L0 im Durchschnitt hochstens zwei Elemente zwischen a und b liegen, wir also nurerwartete 4 Elemente in L0 durchsuchen. Analoges gilt fur alle anderen Levels. Also sinddie erwarteten Kosten fur die Suche nach z
4 ·H(n) = O(log(n)).
Die Schranke fur die Große folgt direkt aus Teil b) des Lemmas. 2
14. Oktober 2008, Version 0.6

70
9 Berechnung minimaler Schnitte in Graphen
Wir betrachten einen gewichteten Graphen G = (V, E, w), w : E → N. Ein Schnitt in Gist eine Menge S ⊆ E mit der Eigenschaft, dass (V, E \ S) nicht zusammenhangend ist.Wir wollen nun in G einen minimalen Schnitt, d.h. einen Schnitt mit minimalem Gewichtberechnen.
9.1 Ein sehr einfacher Algorithmus
Eine Kontraktion einer Kante e von G identifiziert die beiden Endpunkte a, b von e zueinem Punkt c, d.h. die Kante zwischen a und b verschwindet, Kanten (i, a) und (i, b)werden zu einer Kante (i, c) mit Gewicht w(i, a)+w(i, b). Durch eine Kontraktion wird dieKnotenmenge von G um eins verkleinert.
MinCut()(1) w(E) =
∑e∈E w(e)
(2) for i = 1 to n− 2
(3) wahle zufallige Kante e von G mit Pr[e] = w(e)w(E)
(4) Kontrahiere e(5) G← kontrahierter Graph(6) w(E)← w(E)− w(e)(7) /∗ Nun hat G hat nur noch zwei Knoten a, b ∗/(8) Gebe w(a, b) aus.
Behauptung 9.1 G′ gehe aus G durch eine Kontraktion hervor. Dann ist der MinCutvon G′ nicht kleiner als der von G.
Beweis: Betrachte Cut S in G′. Wenn man die Kontraktion ruckgangig macht, dann istder der Cut auch ein Cut in G. 2
Daraus ergibt sich, dass der obrige Algorithmus einen Cut in G liefert. Wir konnen denCut berechnen, indem wir Schritt fur Schritt die Kontraktionen ruckgangig machen unduns die so wieder entstehenden Kanten aus (a, b) merken.
Frage: Mit welcher Wahrscheinlichkeit ist dieser ein MinCut von G?
Lemma 9.2 Es sei C ein fester MinCut von G.
Pr(Algorithmus erzeugt C) ≥ 2
n(n− 1)
Beweis: Sei k = w(C). Dann ist w(E) ≥ k2· n, denn sonst gabe es eine Knoten, deren
inzidente Kanten ein Gewicht kleiner k haben. Dieses ergabe somit einen kleineren Schnitt.Es gilt: Der Algorithmus erzeugt C ⇔ Kanten aus C werden nie kontrahiert.
14. Oktober 2008, Version 0.6

9.1 Ein sehr einfacher Algorithmus 71
Sei G′ = (V ′, E ′, w′) der Graph nach einer Kontraktion. εi bezeichne das Ereignis, dass ineiner Runde i (1 ≤ i ≤ n− 2) keine Kante aus C gewahlt wird.
Pr(ε1) = 1− w(C)
w(E)
≥ 1− kk2· n
= 1− 2
n
Pr(ε2|ε1) = 1− w′(C ′)
w′(E ′)
≥ 1− kk2· (n− 1)
= 1− 2
n− 1
Pr
(εi|
i−1⋂j=1
εj
)= 1− 2
n− i + 1
Daraus folgt:
Pr(C uberlebt) = Pr
(n−2⋂i=1
εi
)= Pr(εi) · Pr(ε2|ε1) · Pr(ε3|ε1 ∧ ε2) · · · · · Pr(εn−2|ε1 ∧ · · · ∧ εn−3)
≥n−2∏i=1
(1− 2
n− i + 1
)
=n−2∏i=1
n− i− 1
n− i + 1
=n− 2
n· n− 3
n− 1· n− 4
n− 2· · · · · 3
5· 24· 13
=2
n(n− 1)
2
MinCut kann in O(n2) ausgefuhrt werden. Die Erfolgswahrscheinlichkeit ist naturlich nichtzufriedenstellend.Aber: Fuhre den Algorithmus t · n(n−1)
2oft aus und wahle den kleinsten so erhaltenen Cut
als Ergebnis aus.
Pr(Cut ist nicht MinCut) =
(1− 2
n(n− 1)
)t·n(n−1)2
≤ e−t
14. Oktober 2008, Version 0.6

9.1 Ein sehr einfacher Algorithmus 72
Satz 9.3 Obiger Algorithmus kann in Zeit O (n4 · t) mit Fehlerwahrscheinlichkeit kleinere−t einen MinCut berechnen.
Bemerkung 9.4 Varianten dieses Algorithmus laufen in Zeit O (t · n2 log(n)2) und sinddamit schneller als alle auf Flußalgorithmen basierenden deterministischen Verfahren!
14. Oktober 2008, Version 0.6