Embed Size (px)
Citation preview

Grundlagen von Support Vector Maschinen und
Anwendungen in der Bildverarbeitung
Jan Eichhorn
Max-Planck-Institut fur biologische Kybernetik
72076 Tubingen

Danksagung
• Olivier Bousquet und Bernhard Scholkopf (slides)
• Wolf Kienzle (Demo)
September 10, 2004, page 1 of 33

Ubersicht
• Grundlagen von Support Vector Maschinen
– Motivation aus Statistischer Lerntheorie
– Lineare Klassifizierer – warum großer Margin?
– Formulierung der Support Vector Maschine
– Der Kern-Trick
• Anwendungen in der Bildverarbeitung
– Kern-Funktionen fur lokale Deskriptoren
– Separable Filter zur Beschleunigung von SVMs in der
Gesichtserkennung
September 10, 2004, page 2 of 33
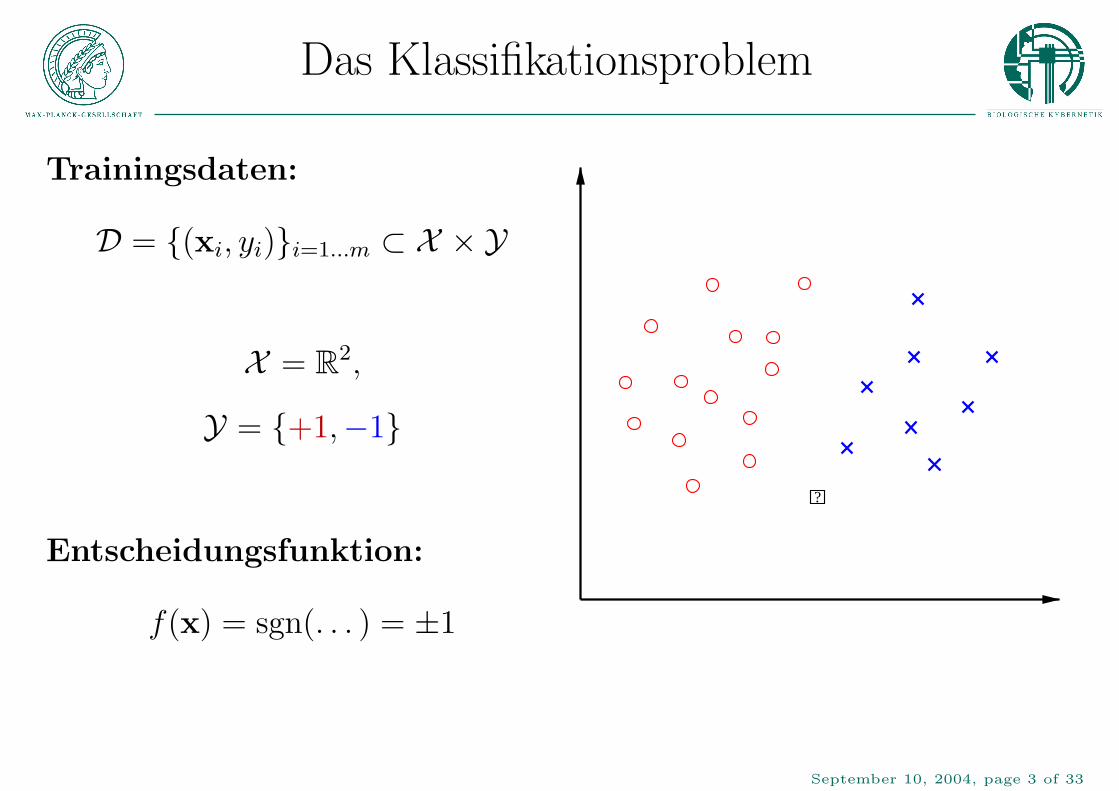
Das Klassifikationsproblem
Trainingsdaten:
?
D = {(xi, yi)}i=1...m ⊂ X × Y
X = R2,
Y = {+1,−1}
Entscheidungsfunktion:
f(x) = sgn(. . . ) = ±1
September 10, 2004, page 3 of 33

Das Lernproblem
Gegeben: Daten D = {(xi, yi)}i=1...m ⊂ X × YAnnahme: Datenpunkte unabhangig und gleichverteilt nach
unbekannter Verteilung: (xi, yi) ∼ P(x, y)
Ziel: Schatze Entscheidungsfunktion f ∈ F so, dass das Risiko
R[f ] minimal ist.
R[f ] =
∫
X×Y
l(f(x), y) dP(x, y)
l(f(x), y) ist die Verlustfunktion fur die Vorhersage f(x) wenn der
wahre Wert y ist.
September 10, 2004, page 4 of 33

Empirische Risiko-Minimierung
• Wahres Risiko R[f ] ist nicht berechenbar, da P(x, y) unbekannt
• Man muss aus den Daten D lernen ⇒ Induktionsprinzip
• Empirisches Risiko aus den Daten geschatzt:
Rmemp[f ] =
1
m
m∑
i=1
l(yi, f(xi))
⇒ Empirische Risiko-Minimierung: finde fm so dass
fm = argminf∈F
Rmemp[f ]
• Wie gut approximiert Rmemp[f ] das Wahre Risiko R[f ]?
September 10, 2004, page 5 of 33

No free lunch-Theorem
Betr. zwei Falle:
1. F enthalt nur eine einzige Funktion
Gesetz der Großen Zahlen ⇒ Rmemp[f ]
m→∞−→ R[f ]
2. F = {±1}X enthalt alle Funktionen:
Betr. zwei Mengen mit m Punkten:
Dtrain,Dtest ⊂ X × {±1}, Dtrain ∩ Dtest = ∅
Zu jedem f ∈ F gibt es ein f ∗ ∈ F so dass:
f ∗(xi) = f(xi), ∀xi ∈ Dtrain aber f ∗(xj) 6= f(xj), ∀xj ∈ Dtest
Auf Dtrain sind f und f ∗ ununterscheidbar, liefern jedoch
entgegengesetzte Resultate auf Dtest.
September 10, 2004, page 6 of 33

Einschrankung der Funktionenklasse
Die Funktionenklasse muss eingeschrankt werden, um erfolgreich lernen
zu konnen.
• Statistische Lerntheorie beschrankt die Kapazitat der
Funktionenklasse (z.B. VC-Dimension)
• Bayesianische Lerntheorie nimmt eine
a priori -Wahrscheinlichkeitsverteilung der Funktionen im
Funktionenraum an
• Heuristisch: Der Algorithmus benutzt implizit eine bestimmte
Funktionenklasse (Nearest Neighbour) oder es wird eine
Regularisierung vorgenommen (early stopping in N.N.,
Ridge-Regression).
September 10, 2004, page 7 of 33

Die Vapnik-Chervonenkis-Dimension
• Die Menge X = {xi}i=1...m kann auf max. 2m Arten in zwei
Klassen aufgeteilt werden. Wenn Funktionen f ∈ F alle
Aufteilungen realisieren konnen, sagt man F “zertrummert” X .
• F hat die VC-Dimension h, wenn F eine Menge von h Punkten
“zertrummern” kann, es aber keine Konfiguration von h+ 1
Punkten gibt, die F “zertrummern” kann.
• Gibt es kein solches h so ist V C(F) =∞
test
Vapnik und Chervonenkis, 1968, 1971
September 10, 2004, page 8 of 33

Gleichmaßige Konvergenz
Das empirische Risiko konvergiert gleichmaßig (uber alle f ∈ F)
gegen das wahre Risiko genau dann wenn VC-Dimension endlich.
limm→∞
P
(
supf∈F
(
|Rmemp[f ]−R[f ]|
)
> ε
)
= 0 ⇔ V C(F) <∞
Wenn h = V C(F) < m dann gilt mit Wahrscheinlichkeit 1− δ:
R[f ] < Rmemp[f ] + φ (h,m, δ)
φ (h,m, δ) =
√
1
m
(
h
(
ln2m
h+ 1
)
+ ln4
δ
)
∼√
h
m
⇒ Beim Lernen die VC-Dimension kontrollieren!!
September 10, 2004, page 9 of 33
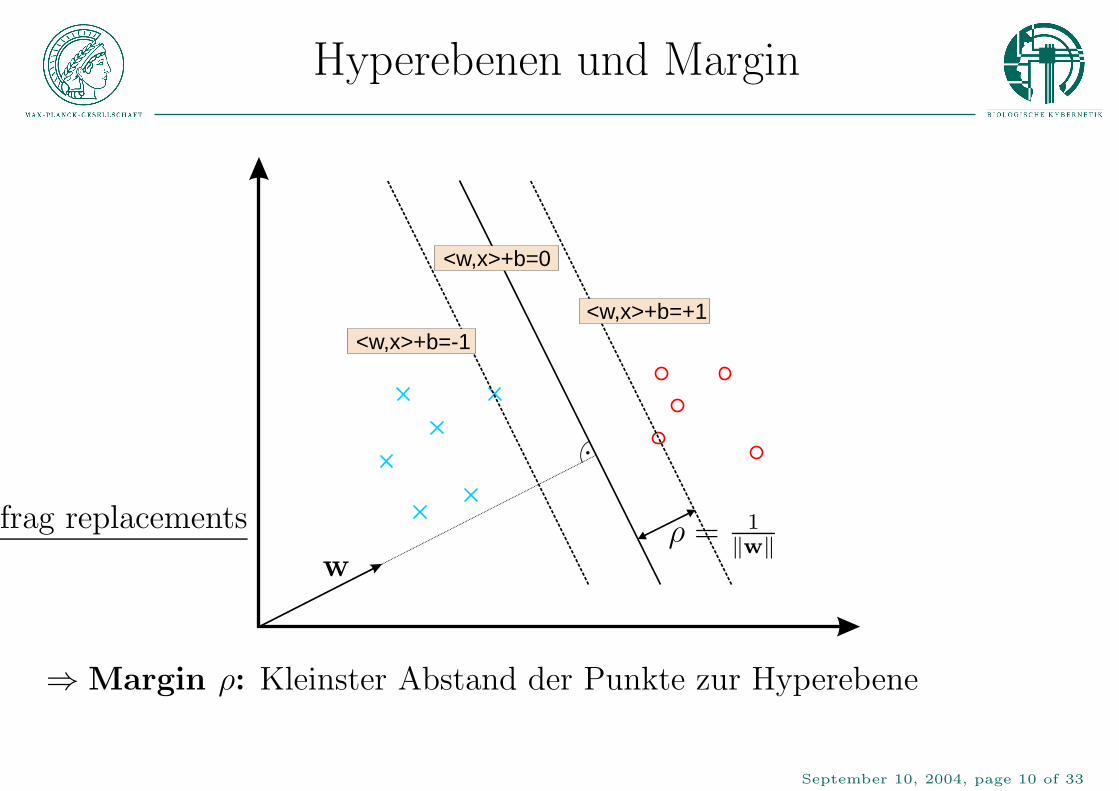
Hyperebenen und Margin
<w,x>+b=+1<w,x>+b=-1
<w,x>+b=0
PSfrag replacements
wρ = 1
‖w‖
⇒Margin ρ: Kleinster Abstand der Punkte zur Hyperebene
September 10, 2004, page 10 of 33

Lineare Klassifizierer
Entscheidungsfunktion:
?
PSfrag replacements
c+c−c
w
x − c
x
f(x) = sgn (〈w, x〉+ b)
Beispiel: Prototype-Klassifizierer
f(x) = sgn (〈c+ − c−, x− c〉)
also
w = c+ − c−, b = −〈w, c〉
September 10, 2004, page 11 of 33
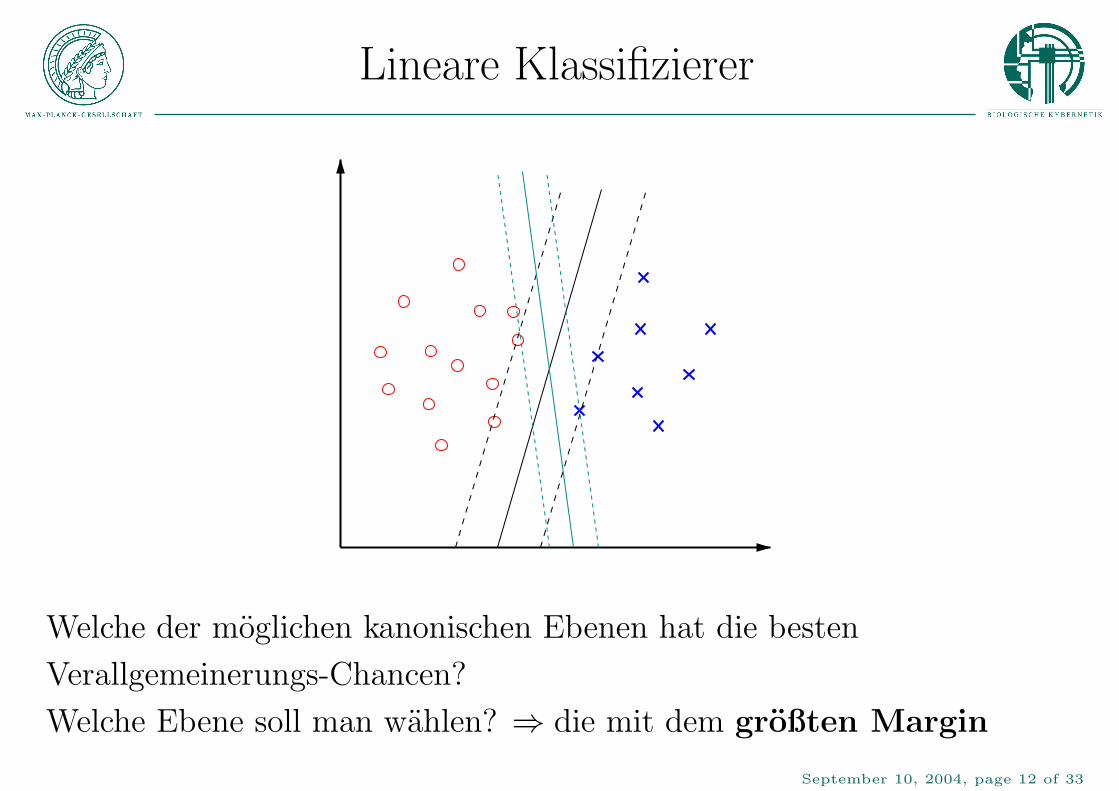
Lineare Klassifizierer
Welche der moglichen kanonischen Ebenen hat die besten
Verallgemeinerungs-Chancen?
Welche Ebene soll man wahlen? ⇒ die mit dem großten Margin
September 10, 2004, page 12 of 33

Warum Large Margin Klassifizierer?
Satz [Vapnik, 1979]: Betrachte Hyperebenen 〈w, x〉 = 0 wobei w
so normiert ist, dass diese in kanonischer Form bzgl. einer Menge von
Punkten X∗ = {x1, . . . ,xr} sind, d.h.,
mini=1,...,r
| 〈w, xi〉 | = 1.
Die Menge der auf X∗ definierten Entscheidungsfunktionen
fw(x) = sgn 〈w, x〉 hat eine VC-Dimension
h ≤ R2
ρ2
Hierbei ist R der Radius der kleinsten Kugel um den Ursprung, die X∗
enthalt.
September 10, 2004, page 13 of 33
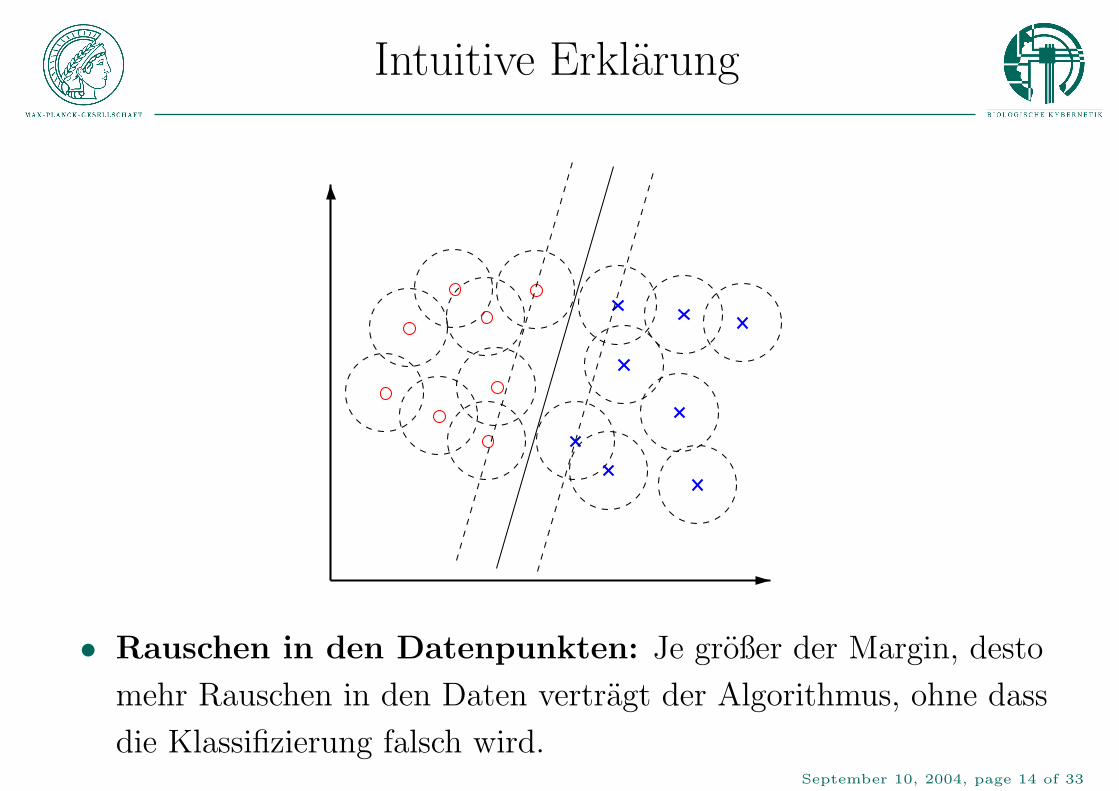
Intuitive Erklarung
• Rauschen in den Datenpunkten: Je großer der Margin, desto
mehr Rauschen in den Daten vertragt der Algorithmus, ohne dass
die Klassifizierung falsch wird.September 10, 2004, page 14 of 33

Die Support Vector Maschine
Formulierung des Optimierungsproblems fur großtmoglichen Margin
(bedenke: ρ ∼ 1/‖w‖)minw,b
‖w‖2
unter den Nebenbedingungen
yi(〈w, xi〉+ b) ≥ 1, ∀ i = 1 . . .m
D.h., die Trainingsdaten werden korrekt separiert.
September 10, 2004, page 15 of 33

Die Lagrange-Funktion
Einfuhrung von Lagrange-Multiplikatoren αi ≥ 0 liefert die
Lagrange-Funktion:
L(w, b,α) =1
2‖w‖2 −
m∑
i=1
αi[ yi(〈w, xi〉+ b)− 1]
L(w, b,α) wird minimiert bzgl. der primaren Variablen w und b und
maximiert bzgl. der dualen Variablen αi.
September 10, 2004, page 16 of 33

Die duale Formulierung
Einsetzen der KKT-Bedingungen in L(w, b,α) liefert das duale
Problem:
maxα
W (α) =m∑
i=1
αi −1
2
m∑
i,j=1
αiαjyiyj 〈xi, xj〉
unter den Nebenbedingungen:
αi ≥ 0, ∀i = 1 . . .m, undm∑
i=1
αiyi = 0.
⇒ Konvexes quadratisches Optimierungsproblem
(d.h. globales Optimum erreichbar)
September 10, 2004, page 17 of 33

Support Vektoren
w =m∑
i=1
αiyixi
wobei ∀ i = 1 . . .m entweder
yi · [〈w, xi〉+ b] > 1 =⇒ αi = 0 −→ xi irrelevant
oder
yi · [〈w, xi〉+ b] = 1 (auf dem Margin) −→ xi “Support Vector”
Die Losung wird bestimmt durch die Datenpunkte auf dem Margin.
f(x) = sgn (〈x, w〉+ b)
= sgn
(
m∑
i=1
αiyi〈x, xi〉+ b
)
.
September 10, 2004, page 18 of 33

Der Kern-Trick
• Erlaubt lineare Algorithmen auf nicht linear separierbare Probleme
anzuwenden durch effiziente Berechnung einer (nicht-linearen)
Merkmalstransformation.
September 10, 2004, page 19 of 33
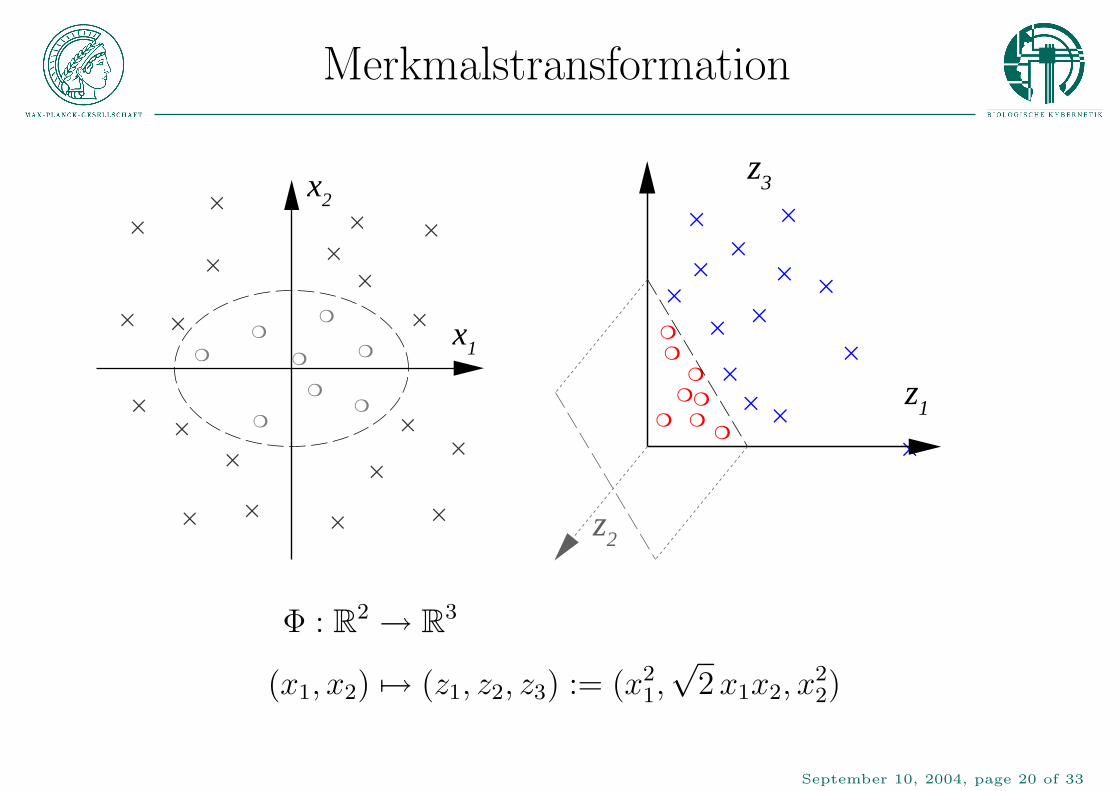
Merkmalstransformation
❍
❍
❍
❍
❍
❍
❍
❍
✕
✕
✕
✕
✕
✕
✕
✕
✕
✕
✕✕
✕
✕
✕
✕
✕
✕
✕
✕
x1
x2
❍❍
❍❍
❍
❍
❍
❍
✕
✕
✕
✕
✕
✕
✕
✕
✕
✕
✕
✕
✕
z1
z3
✕
z2
Φ : R2 → R3
(x1, x2) 7→ (z1, z2, z3) := (x21,√2x1x2, x
22)
September 10, 2004, page 20 of 33

Merkmalsraum
Fur nicht linear separierbare Probleme konnen in einem
Vorverarbeitungsschritt geeignete Merkmale konstruiert werden (z.B.
Pixel-Korrelationen in Bildern).
Vorverarbeitung der Daten mit:
Φ : X → Hx 7→ Φ(x)
Der lineare Klassifizierer kann jetzt auf den neuen Merkmalen arbeiten.
September 10, 2004, page 21 of 33

Der Kern-Trick in der SVM
Die Zielfunktion
maxα
W (α) =m∑
i=1
αi −1
2
m∑
i,j=1
αiαjyiyj〈Φ(xi), Φ(xj)〉
und die Entscheidungsfunktion
f(x) = sgn(
∑m
i=1αiyi〈Φ(x), Φ(xi)〉+ b
)
.
verwenden nur Skalarprodukte der Daten.
Das Skalarprodukt im Merkmalsraum kann durch eine Kernfunktion
k(x,x′) = 〈Φ(x), Φ(x′)〉
ausgedruckt werden.
September 10, 2004, page 22 of 33

Welche Kerne sind erlaubt?
Fur X 6= ∅ sind folgende Aussagen aquivalent:
• k ist positiv definit (pd), d.h.
– fur eine beliebige Menge von Punkten x1, . . . ,xm ∈ X und
– fur alle a1, . . . , am ∈ R
gilt:a>Ka =
∑
i,j
aiajKij ≥ 0, wobei Kij := k(xi, xj)
• Es gibt eine Funktion Φ : X → H in einen Hilbertraum H so dass
k(x, x′) = 〈Φ(x), Φ(x′)〉
H ist ein sogenannter reproducing kernel Hilbert space (RKHS).
September 10, 2004, page 23 of 33

Kern-Trick — Zusammenfassung
• Jeder Algorithmus, der nur Skalarprodukte verwendet, kann den
Kern-Trick benutzen
⇒ Große Vielfalt kernelisierter Standardalgorithmen (z.B.
Kernel-Perceptron, Kernel-Fisher-Diskriminante, Kernel-PCA,
Kernel-CCA).
• Man kann den Kern als ein nichtlineares Ahnlichkeitsmaß
interpretieren.
• Daher braucht X kein Vektorraum zu sein (∃ Kerne auf Graphen,
Text etc.). Die Geometrie wird durch die Kernfunktion induziert.
September 10, 2004, page 24 of 33

Beispiel: Gausscher Kern
k(x, x′) =1√2πσ
exp
(
−‖x− x′‖22σ2
)
• σ kontrolliert die Lokalitat der Daten
demo
September 10, 2004, page 25 of 33

Weiterfuhrende Ansatze
• C-SVM und µ-SVM fur nicht separierbare Probleme
• Support Vektor Regression
• One-Class-SVM zur Identifikation von Ausreißern
• Reduced-set-Methoden zur Beschleunigung (s. Anwendung)
• Andere Large-Margin-Klassifizierer (z.B. Boosting) und
Kernel-Maschinen
September 10, 2004, page 26 of 33

Anwendungen in der Bildverarbeitung
• SVM fur Objekt-Kategorisierung, Reprasentation der Bilder durch
lokale Deskriptoren ⇒ Kernfunktion fur Mengen
• SVM in der Gesichtserkennung, Kaskade von Klassifizierern,
Beschleunigung des ersten Layers durch separable Filter
September 10, 2004, page 27 of 33

Objekt-Kategorisierung mit SVM
September 10, 2004, page 28 of 33

Lokale Deskriptoren fur Bilder
Wie?
1. Interest Point Detector findet markante Punkte
2. In lokaler Umgebung wird eine Bildcharakteristik berechnet
(z.B. Ausschnitt, Gradientenhistogramm etc.)
Warum?
• Je nach Konstruktion - Invariant unter Translation, Rotation,
Skalierung, Anderung von Kontrast, Helligkeit etc.
• Sehr erfolgreich in Objektidentifizierung (D. Lowe)
September 10, 2004, page 29 of 33
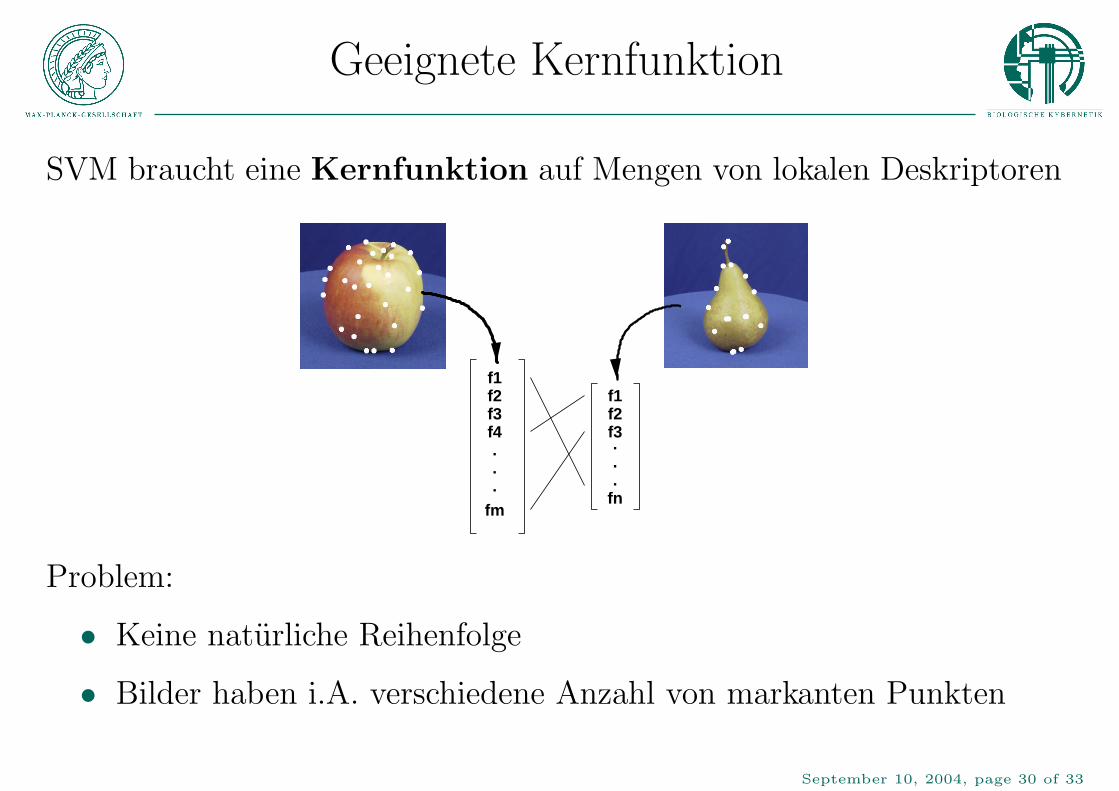
Geeignete Kernfunktion
SVM braucht eine Kernfunktion auf Mengen von lokalen Deskriptoren
f1f2f3f4
fm...
.
.
.
f1f2f3
fn
Problem:
• Keine naturliche Reihenfolge
• Bilder haben i.A. verschiedene Anzahl von markanten Punkten
September 10, 2004, page 30 of 33

Bisherige Ansatze
• Wallraven et al.a: Berechne Mittelwert des Abstandes zum jeweils
ahnlichsten Deskriptor
⇒ Vergleichen einzelne Deskriptoren
• Kondor und Jebarab: Berechnen die Ahnlichkeit zweier
Verteilungen
⇒ Vergleichen suffiziente Statistiken
a C. Wallraven et al, Recognition with Local Features: the Kernel Recipe, Proc. of ICCV’03b R. Kondor and T. Jebara, A Kernel between Sets of Vectors, Proceedings of the ICML, 2003
September 10, 2004, page 31 of 33

”A Kernel between Sets of Vectors”
Bhattacharyya-Kern fur Wahrscheinlichkeitsverteilungen:
K(p, p′) =
∫
√
p(x)√
p′(x) dx
• Geschlossener Ausdruck fur p ∼ N (µ,Σ)
• Mehr Variabilitat durch Merkmalstranformation:
x ∼ N (µ,Σ)Φ−→ Φ(x) ∼ N (µ, Σ)
⇒ effizient berechenbar durch Kern-Trick
September 10, 2004, page 32 of 33

Literatur
References[1] B. E. Boser, I. M. Guyon, and V. Vapnik. A training algorithm for optimal margin classifiers.
In D. Haussler, editor, Proceedings of the 5th Annual ACM Workshop on Computational
Learning Theory, pages 144–152, Pittsburgh, PA, July 1992. ACM Press.
[2] V. N. Vapnik. Statistical Learning Theory. Wiley, New York, 1998.
[3] V. N. Vapnik. The Nature of Statistical Learning Theory. Statistics for Engineering and
Information Science. Springer Verlag, New York, 2nd edition, 2000.
[4] B. Scholkopf and A. J. Smola. Learning with Kernels. MIT Press, Cambridge, MA, 2002.
[5] N. Cristianini and J. Shawe-Taylor. An Introduction to Support Vector Machines. Cambridge
University Press, 2000.
[6] A. J. Smola, P. L. Bartlett, B. Scholkopf, and D. Schuurmans. Advances in Large Margin
Classifiers. MIT Press, Cambridge, MA, 2000.
[7] E. T. Jaynes. Probability Theory - The Logic of Science. Cambridge University Press,
Cambridge, U.K., 2003.
[8] D. J. C. MacKay. Information Theory, Inference, and Learning Algorithms. Cambridge
University Press, Cambridge, UK, 2003.
September 10, 2004, page 33 of 33









![Der Mensch Muss Müssen Können - · PDF file•Sinkend (U-Boot) ... Microsoft PowerPoint - darm_mensch_muessen_obstipation_pp_vortrag.ppt [Kompatibilitätsmodus] Author: Jürg Eichhorn](https://img.pdfslide.org/doc/110x75/5abe79787f8b9a3a428cf806/der-mensch-muss-mssen-knnen-sinkend-u-boot-microsoft-powerpoint-darmmenschmuessenobstipationppvortragppt.jpg)



![Der Mensch Muss Müssen Können - · PDF file•Sinkend (U-Boot) ... Microsoft PowerPoint - ernaehrung_essvortrag_3_leaky-gut_pp.ppt [Kompatibilitätsmodus] Author: Jürg Eichhorn](https://img.pdfslide.org/doc/110x75/5abe79787f8b9a3a428cf7fb/der-mensch-muss-mssen-knnen-sinkend-u-boot-microsoft-powerpoint-ernaehrungessvortrag3leaky-gutppppt.jpg)















